
Katedra
Podstaw
Konstrukcji
Maszyn
Wydział
Mechaniczny
Technologiczny
Politechnika
Śląska
ul. Konarskiego 18a
44-100 Gliwice
tel. 237 1467
fax 237 1360
http://kpkm.polsl.pl
Metody sztucznej
inteligencji
Pozyskiwanie wiedzy
Rok akademicki 20
10/11
Opracował: dr inż. K. Ciupke
Gliwice 2009-11-23
- 1/8 -

1. Cel ćwiczenia
Celem ćwiczenia jest zapoznanie się z zagadnieniami pozyskiwania wiedzy z baz
danych i nabycie praktycznych umiejętności zarówno w zakresie pozyskiwania
wiedzy jak i jej oceny.
2. Wprowadzenie
Wiedza, którą następnie może być użyta w systemach sztucznej inteligencji, może
być pozyskiwana z dwóch głównych źródeł:
• od specjalistów z danej dziedziny (bezpośrednio lub pośrednio poprzez np.
publikacje)
• z baz danych.
Pozyskiwanie wiedzy od specjalistów nastręcza wiele różnorakich problemów, m.in.:
• jest
czasochłonne,
• jest
mało efektywne,
• nie bez znaczenia jest również niechęć specjalistów do dzielenia się swoją
wiedzą.
Dlatego też bazy danych stały się przedmiotem zainteresowania jako źródło
potencjalnej wiedzy.
Jedną z często stosowanych form pozyskiwanej wiedzy są tzw. klasyfikatory, czyli
wiedza (w postaci np. reguł lub drzew decyzyjnych) pozwalająca na
przyporządkowanie analizowanych danych do określonych klas (np.
przyporządkowanie rośliny do odpowiedniego gatunku na podstawie opisujących ją
danych).
Innym sposobem pozyskiwania wiedzy z baz danych jest odkrywanie zależności
funkcyjnych pomiędzy danymi w bazie danych. Zagadnienie to nie jest jednak
przedmiotem niniejszego laboratorium.
3. Przykładowe zadanie
Wzięto pod uwagę trzy, trudne do rozróżnienia, gatunki irysów:
• setosa,
• versicolor,
• virginica,
Dokonano pomiarów wybranych cech kwiatów tych roślin, mierząc długość i
szerokość kielichów oraz długość i szerokość płatków. W sumie zmierzono kwiaty
150 roślin, po 50 z każdego gatunku. Zadanie polega na pozyskaniu wiedzy,
pozwalającej na rozróżnienie poszczególnych gatunków na podstawie wartości
badanych cech.
3.1. Drzewa decyzyjne
Jedną z form zapisu wiedzy są drzewa decyzyjne. Istnieją algorytmy pozwalające na
pozyskiwanie wiedzy i zapisanie jej w postaci drzew. Przykładowe drzewo decyzyjne
pozyskane dla danych opisanych w rozdziale 3 przedstawia rys. 1.
Gliwice 2009-11-23
- 2/8 -
Z przedstawionego drzewa wynika, że klasyfikacja odbywa się w pierwszej kolejności
na podstawie szerokości płatka. Jeżeli szerokość ta jest mniejsza bądź równa
0,6
mm to kwiat należy zaklasyfikować do gatunku setosa (w przypadku
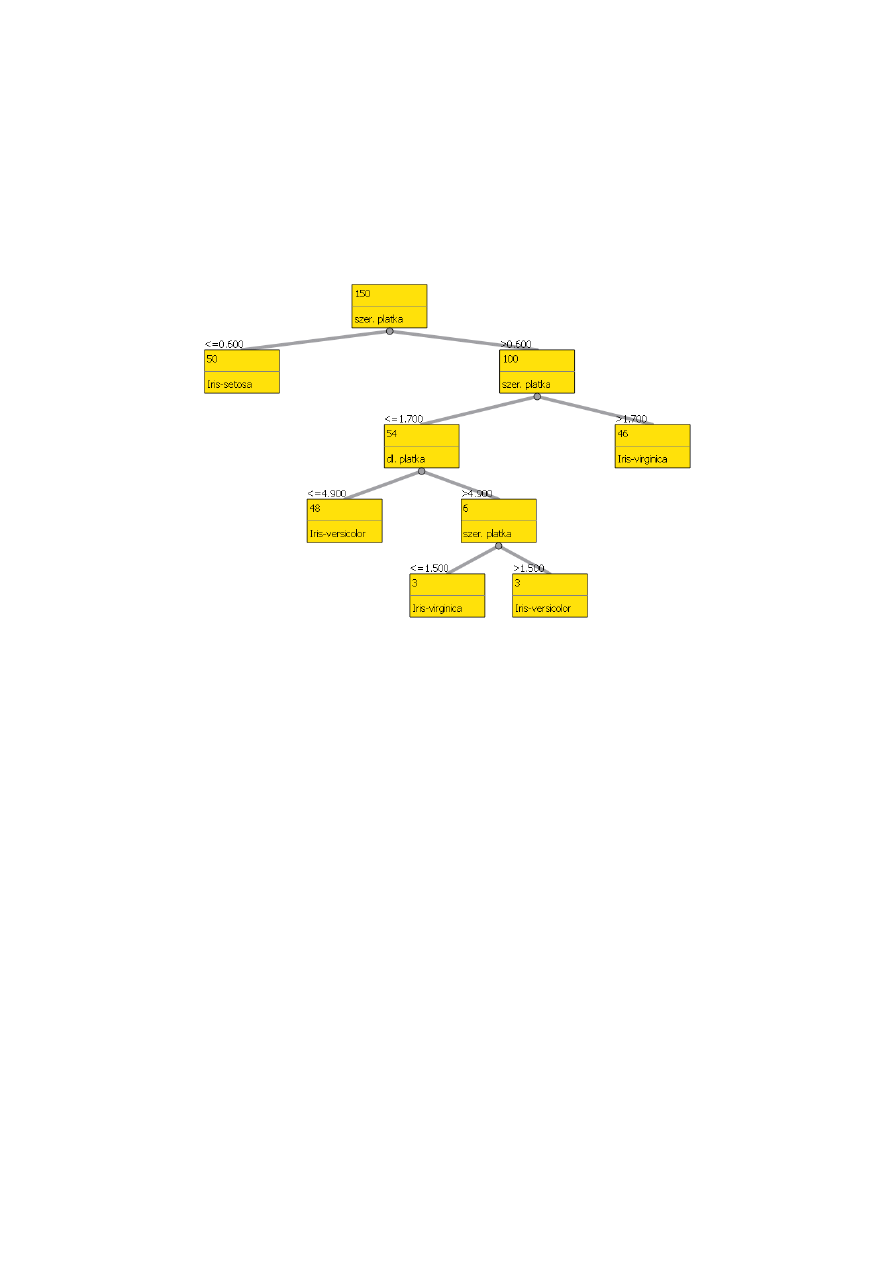
analizowanych danych 50 przypadków zostało tak właśnie zaklasyfikowanych).
Jeżeli natomiast szerokość płatka jest większa od 1,7 mm to mamy do czynienia
z gatunkiem virginica. W przypadku, gdy szerokość płatka jest mniejsza bądź równa
1,7 mm, wówczas dalsza klasyfikacja jest możliwa dopiero po określeniu długości
płatka (jeżeli długość płatka <= 4,9 mm to kwiat należy do gatunku versicolor - 48
przypadków z bazy sklasyfikowano w ten sposób) W przypadku, gdy długość płatka
byłaby większa od 4,9 mm należy znowu wziąć pod uwagę szerokość płatka i na tej
podstawie dokonać klasyfikacji pozostałych 6 przypadków.
Rys. 1. Przykładowe drzewo decyzyjne
3.2. Reguły
Inną formą zapisu wiedzy są reguły. Ogólna postać reguły jest następująca:
Jeżeli przesłanka to konkluzja
część warunkowa
część decyzyjna
Jest to postać reguły prostej. Reguła złożona natomiast to taka, której część
warunkowa składa się z kilku przesłanek, np.:
Jeżeli przesłanka1 i przesłanka2 to konkluzja
Podobnie jak w przypadku drzew decyzyjnych, istnieją metody pozyskiwania wiedzy
z danych, pozwalające na generowanie wiedzy w postaci reguł. Jak można łatwo
zauważyć, opisując drzewo decyzyjne posłużono się już formą reguły:
Jeżeli szerokość płatka <= 0.6 to gatunek setosa
Jeżeli szerokość płatka > 0.6 i szerokość płatka < 1.7 i
długość płatka <= 4.9 to gatunek versicolor
Gliwice 2009-11-23
- 3/8 -
W istocie, obydwie formy zapisu są sobie równoważne, tzn. każde drzewo decyzyjne
da się zapisać w postaci reguł i odwrotnie.
4. Przykład pozyskiwania wiedzy
Zastosowane oprogramowanie:
Orange 2.0b for Windows (GNU General Public License) dostępne na stronie
4.1. Pozyskiwanie wiedzy w postaci drzewa decyzyjnego
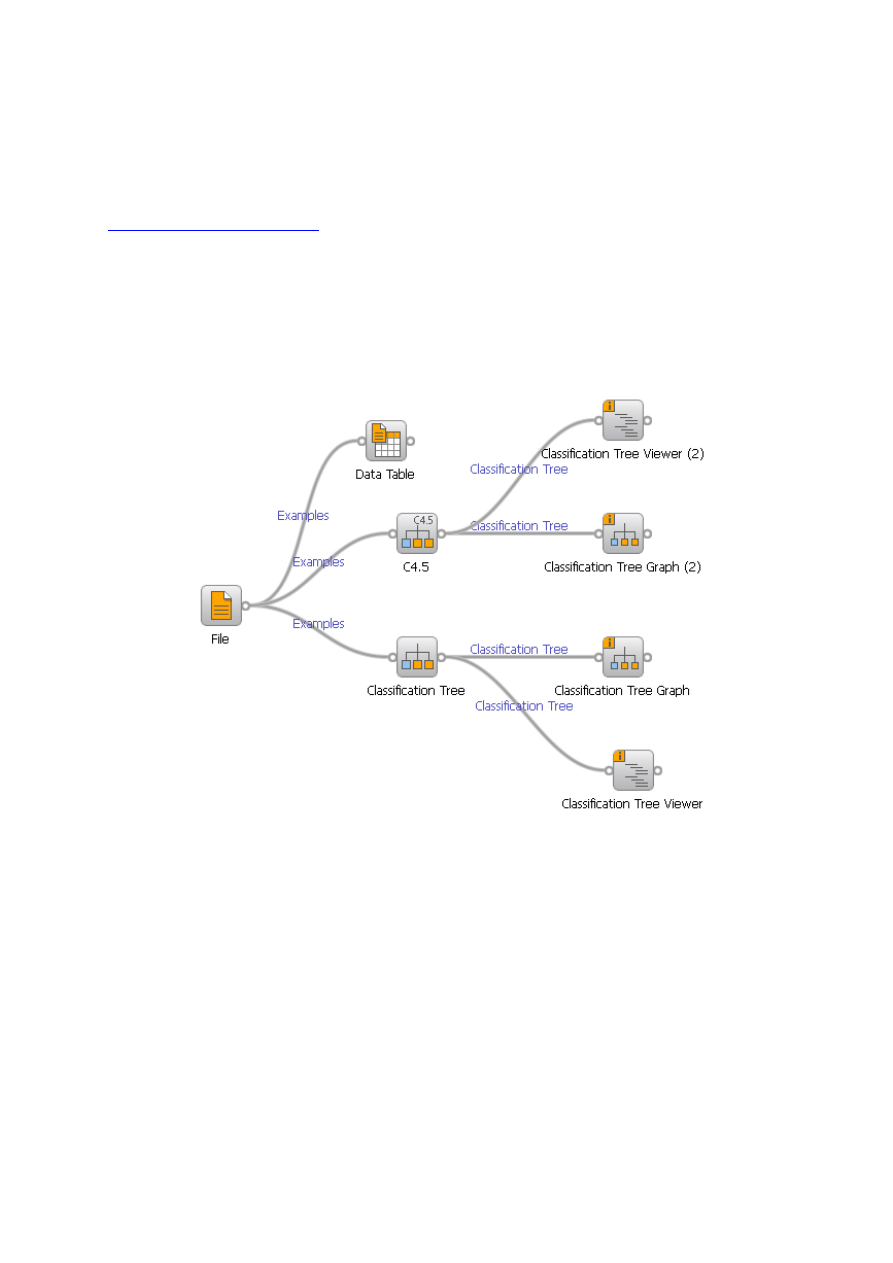
W systemie Orange zaimplementowano dwa algorytmy generowania drzew
decyzyjnych: algorytm Classification Tree oraz C4.5 [2]. Sposób tworzenia drzew
decyzyjnych w systemie Orange oraz ich wizualizacji przedstawiono na rys. 2.
Drzewa przedstawiono w postaci graficznej jak i w postaci tekstowej.
Rys. 2. Przykład tworzenia i wizualizacji drzew decyzyjnych.
4.2. Pozyskiwanie wiedzy w postaci reguł
Algorytmy pozyskiwania reguł różnią się od algorytmów tworzenia drzew
decyzyjnych, stąd też wiedza pozyskana w postaci reguł i drzew decyzyjnych może
się w niektórych przypadkach różnić.
Reguły, podobnie jak drzewa decyzyjne, można pozyskiwać z danych stosując różne
algorytmy. W systemie Orange zaimplementowany jest algorytm CN2 [1].
Przykład zastosowania algorytmu pozyskiwania reguł i ich prezentacji pokazano na
rys. 3.
Gliwice 2009-11-23
- 4/8 -

Rys. 3. Przykład pozyskiwania wiedzy w postaci reguł
5. Ocena wiedzy
Istotnym zagadnieniem w przypadku pozyskiwania wiedzy jest jej ocena. Mając do
czynienia z wiedzą zapisaną w postaci klasyfikatorów, możemy oceniać tzw.
sprawność klasyfikacji. Im jest ona wyższa, tym pozyskana wiedza jest „lepsza”.
Sprawność klasyfikatora wyznaczana jest na podstawie oceny poprawności działania
(klasyfikacji) utworzonego klasyfikatora. Proces ten nosi nazwę testowania
klasyfikatora. Klasyfikator ma za zadanie sklasyfikować przypadki, które nie były
uwzględniane w procesie jego pozyskiwania, a których poprawna klasyfikacja jest
znana. Wówczas wyznaczając iloraz liczby poprawnie sklasyfikowanych przypadków
do liczby wszystkich przypadków testowych uzyskuje się sprawność klasyfikacji.
Przyjmijmy następujące oznaczenia:
• cały zbiór dostępnych danych nazywamy zbiorem danych uczących – U,
• zbiór danych zastosowanych do tworzenia klasyfikatora nazywamy zbiorem
danych trenujących – L,
• zbiór danych użytych do testowania określamy mianem danych testowych – T.
W praktyce stosowanych jest kilka sposobów testowania klasyfikatorów:
1. losowy podział zbioru U na dwa rozłączne podzbiory T
∪L (ang. random
sampling
) przy czym wielkość zbiorów określana jest procentowo np. 70%
przypadków w zbiorze L, pozostałe w T,
2. podział zbioru U na k podzbiorów U={U
1
, U
2
,…, U
k
), wówczas
L=U\U
i
, T=U
i
∀i=(1,…,k) (ang. cross-validation); najczęściej , operację
tworzenia klasyfikatora i jego testowania dokonywana jest k-krotnie a
uzyskane wyniki są uśredniane,
3. ze zbioru U usuwany jest jeden przypadek u
i
(L=U\ u
i
), tworzony jest
klasyfikator, a zbiór testowy jest zbiorem jednoelementowy L={u
i
} (ang. leave-
one-out
); operacje powtarzana jest n-krotnie, gdzie n=|U| określa liczność
zbioru U.
Do oceny pozyskanej wiedzy, w systemie Orange przewidziany jest widget Test
Lerners
(por. rys. 4). Uzyskane uśrednione wyniki można przedstawić np. w postaci
tzw. macierzy pomyłek (ang. confusion matrix) – rys. 5, w której prezentowane są
liczby przypadków poprawnie i błędnie sklasyfikowanych, z podziałem na
poszczególne klasy.
Gliwice 2009-11-23
- 5/8 -
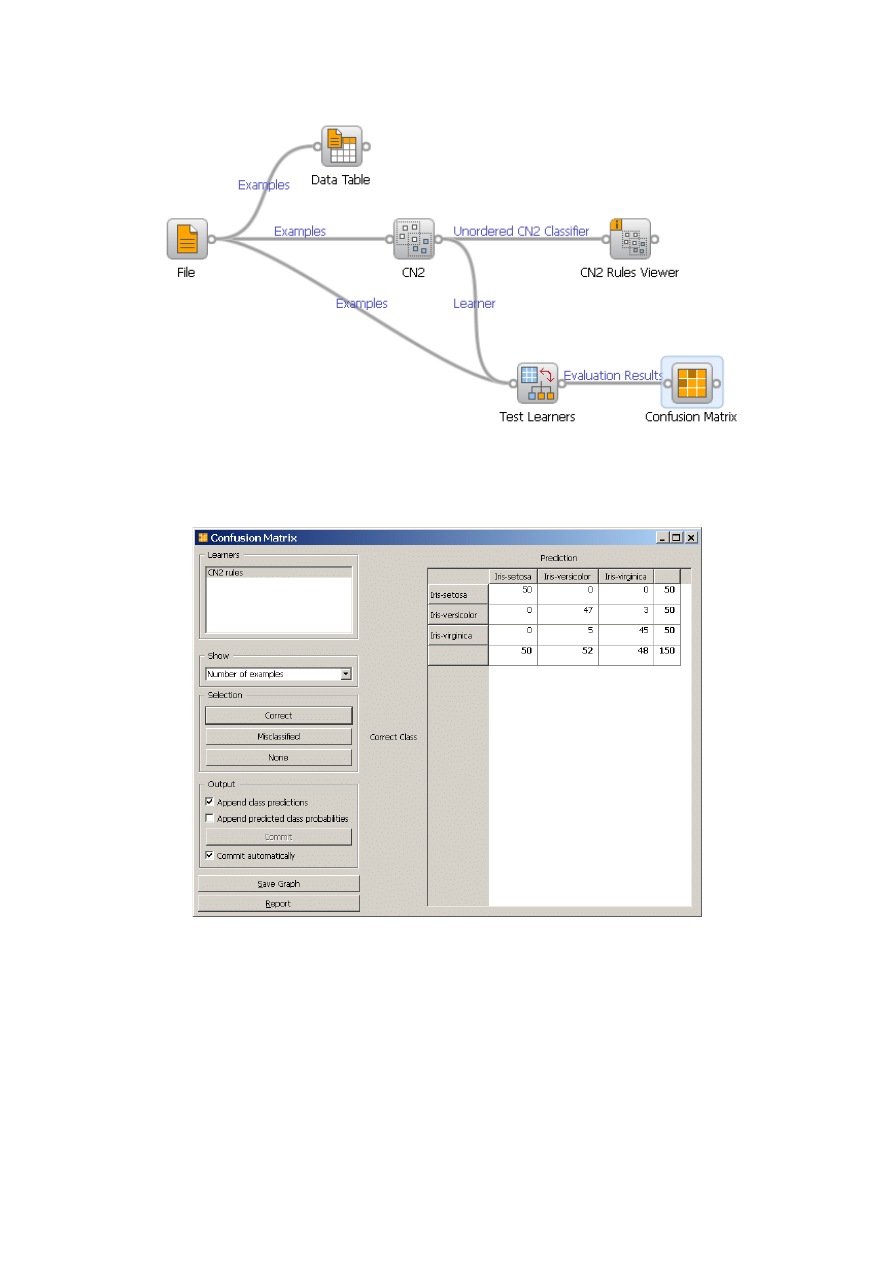
Rys. 4. Schemat pozyskiwania wiedzy w postaci reguł i drzew decyzyjnych oraz
sposób prezentacji wyników jej oceny
Rys. 5. Macierz pomyłek
Szczegółowe wyniki dotyczące np. dokładności klasyfikacji (sprawności
klasyfikatora) można znaleźć w informacjach podawanych przez widget Test lerners
(por. rys. 6).
Gliwice 2009-11-23
- 6/8 -
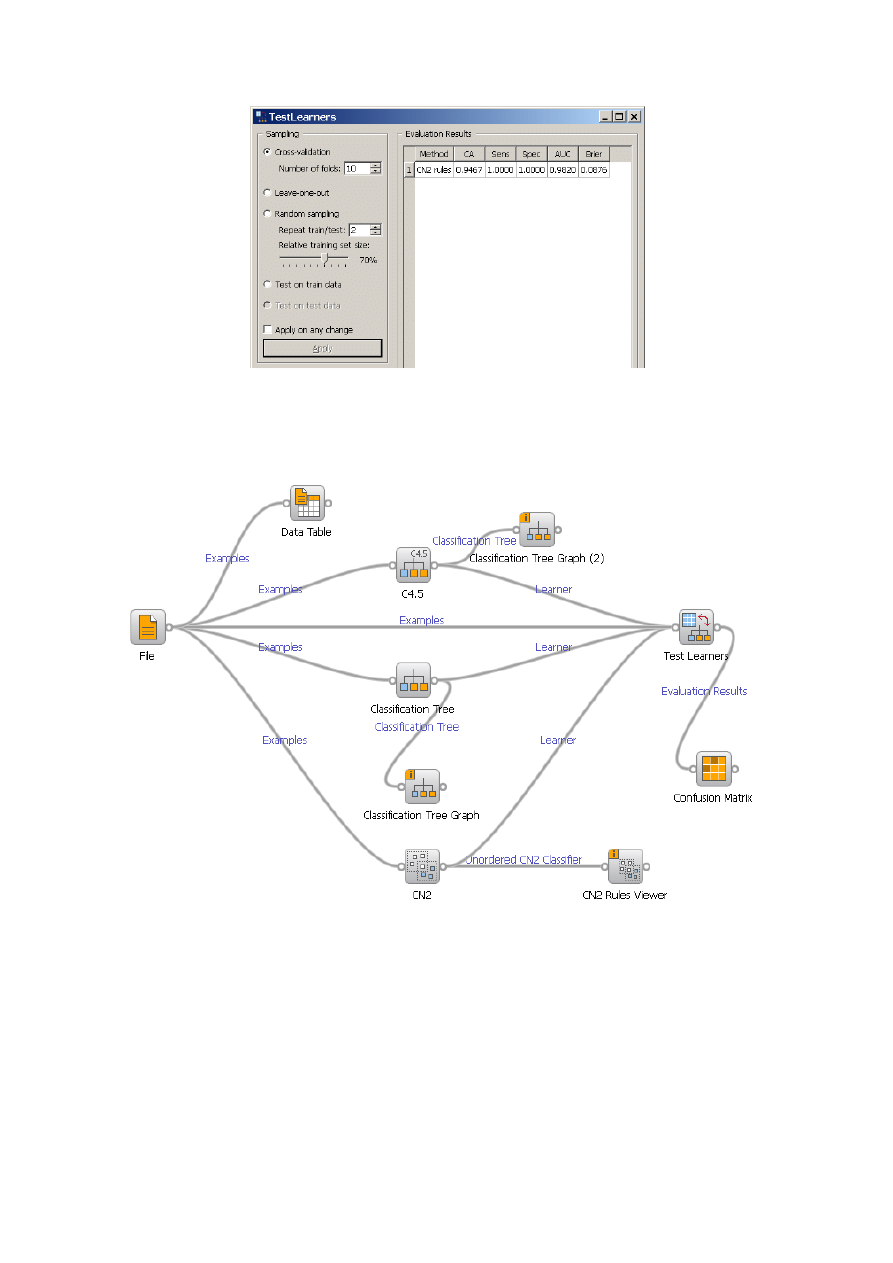
Rys. 6. Wyniki podawane przez widget Test lerners
Na jednym schemacie można zastosować kilka metod pozyskiwania wiedzy i jej
oceny, co pokazano na rys. 7.
Rys. 7. Przykład zastosowania kilku metod pozyskiwania wiedzy jednocześnie
Dane stosowane w procesie pozyskiwania wiedzy możemy wstępnie przetworzyć,
m.in. poddać procesowi dyskretyzacji (zamienić dane ciągłe na dane dyskretne) i/lub
wybrać cechy, które będą uwzględniane w procesie pozyskiwania wiedzy. Przykłady
tego typu działań w systemie Orange przedstawia rys. 8.
Gliwice 2009-11-23
- 7/8 -
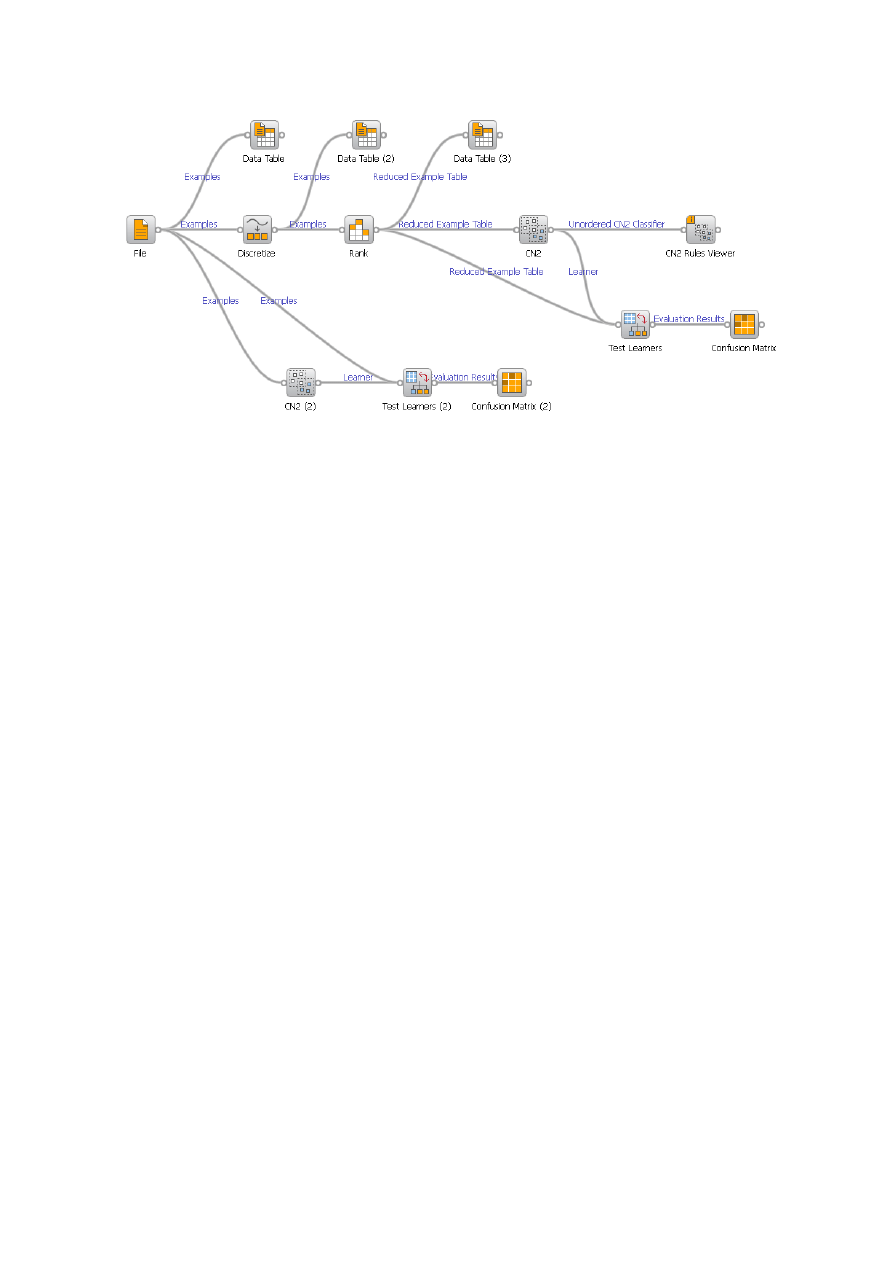
Rys. 8. Proces pozyskiwania wiedzy uwzględniający dyskretyzację wartości i
selekcję cech
6. Zadania do wykonania
1. Opracować schemat pozyskiwania wiedzy w postaci reguł.
2. Wczytać wskazane przez prowadzącego dane.
3. Pozyskać wiedzę w postaci reguł klasyfikacji.
4. Uzupełnić schemat tak, by możliwe było testowanie klasyfikatora metodą
cross-validation
dla k=10.
5. Przetestować klasyfikator i przeanalizować uzyskane wyniki.
6. Uzupełnić schemat w sposób pozwalający na pozyskiwanie wiedzy w postaci
drzew decyzyjnych stosując dwa różne algorytmy generowania drzew.
7. Wygenerować drzewa decyzyjne i porównać je ze sobą.
8. Przetestować pozyskane klasyfikatory i przeanalizować uzyskane wyniki.
9. Przeanalizować wyniki klasyfikacji dla różnych metod testowania
klasyfikatorów.
10. Dokonać dyskretyzacji danych.
11. Pozyskać wiedzę dla danych dyskretnych i ocenić jakość pozyskanej wiedzy.
12. Ograniczyć liczbę uwzględnianych cech.
13. Pozyskać wiedzę dla ograniczonych danych i ocenić jakość pozyskanej
wiedzy.
14. Przeanalizować uzyskane wyniki.
15. Wskazać metodę dzięki której pozyskano „najlepszą” wiedzę.
16. Opracować sprawozdanie obejmujące wyniki i wnioski wynikające ze
wszystkich opisanych wyżej punktów.
Literatura
[1] Clark P., Niblett T. The CN2 induction algorithm. Machine Learning, 3(4): 261–
283, 1989.
Gliwice 2009-11-23
- 8/8 -
[2] Quinlan, J. R. C4.5: Programs for Machine Learning. Morgan Kaufmann
Publishers, 1993.
Document Outline
Wyszukiwarka
Podobne podstrony:
PozyskiwanieWiedzy id 380685 Nieznany
lab4 opr id 259824 Nieznany
lab4 10 id 259714 Nieznany
BD 1st 2 4 lab4 tresc 1 1 id 81 Nieznany (2)
lab4 miernictwo id 259817 Nieznany
Lab4 NZEE id 259822 Nieznany
PozyskiwanieWiedzy id 380685 Nieznany
lab4(1) 3 id 259842 Nieznany
Instrukcja Lab4 id 216877 Nieznany
Lab4 id 257948 Nieznany
ECE3204 D2013 Lab4 id 149958 Nieznany
lab4 moje zad04 id 750844 Nieznany
pozysk miodu id 380664 Nieznany
Podstawy Robotyki lab4 id 36833 Nieznany
Abolicja podatkowa id 50334 Nieznany (2)
4 LIDER MENEDZER id 37733 Nieznany (2)
katechezy MB id 233498 Nieznany
metro sciaga id 296943 Nieznany
więcej podobnych podstron