Piotr Szpryngier
1
Piotr Szpryngier
1
Architektury Komputerów i Systemy
Operacyjne
Podstawowe definicje,
system operacyjny i maszyna wirtualna, systemy wbudowane
Piotr Szpryngier
piotrs@eti.pg.gda.pl

Piotr Szpryngier
2
Piotr Szpryngier
2
Plan i literatura
•
1. Klasyfikacja modeli przetwarzania
•
2. Systemy operacyjne – zadania i funkcje.
•
3. Proces, zarządzanie procesami, usługi SO.
•
4. Mechanizmy koordynacji procesów.
•
5. Charakterystyka systemów czasu rzeczywistego i systemów
wbudowanych.
•
6. Jądro systemu real-time, opis procesu, funkcje jądra.
•
7. Przykład systemu czasu rzeczywistego – węzeł radiowej sieci
teleinformatycznej.
•
Silberschatz A., Peterson J.L., Galvin P.B., Podstawy systemów
operacyjnych, WNT 1998.
•
Ben-Ari M., Podstawy programowania wspó
łbieżnego i rozproszonego, WNT
1996.

Piotr Szpryngier
3
Piotr Szpryngier
3
Podstawowe pojęcia z architektury systemów
komputerowych
program = algorytm + dane
przetwarzanie = użytkownik + komputer + program
modele przetwarzania = przetwarzanie + zarządzanie +
komunikacja
organizacja = <język, poziom, maszyna wirtualna>
architektura = implementacja modelu przetwarzania:
konfiguracja sprzętu i oprogramowania
model przetwarzania – sposób wykonywania zadań i usług w
systemie
architektura systemu – sposób implementacji modelu
przetwarzania
konfiguracja systemu – własności sprzętu i oprogramowania

Piotr Szpryngier
4
Piotr Szpryngier
4
Typy architektur
Układu,
Zespołu układów, np. procesora,
Komputera, stacji roboczej,
Grupy komputerów – klaster dla przetwarzania równoległego lub
gridowego, serwery sieciowe, serwery aplikacji dla przetwarzania
rozproszonego, rozproszone usługi,
Internet jako środowisko rozproszonych usług i przetwarzania
zespołowego. Usługi: bezpośrednie, zdalne, grupowe.
Aplikacja rozproszona – taka, której wymagania mogą być spełnione
przez wiele fizycznych komputerów, dane mogą być przechowywane
w wielu lokalizacjach, a funkcjonalność nie jest w żaden sposób
ograniczona przez topologie implementacji.

Piotr Szpryngier
5
Piotr Szpryngier
5
Typy przetwarzania
Obecnie obok klasycznego modelu MCC (Machine Centric Computing)
wyróżnia się 2 inne modele: HCC (Human Centric Computing) i SCC (Service
Centric Computing).
MCC:
Scentralizowane (pojedynczy komputer osobisty, mainframe i przetwarzanie
wsadowe)
Współbieżne (Wiele procesów na jednym komputerze, które mogą ze sobą
współpracować, a także rywalizować); Dwa rodzaje podziału czasu procesora
(może być więcej procesorów, ale jeden wspólny SO):
•
ze stałym podziałem czasu lub
•
sterowane priorytetami procesów i zdarzeniami - programy procesów wykonują się
„równolegle”, współdzieląc zasoby (procesor, pamięć, komunikacja).
Wieloprogramowe (
kilka programów wykonywanych sekwencyjne naprzemiennie
na tym samym komputerze. O przekazaniu całości zasobów komputera innemu
programowi decyduje aktualnie wykonywany program)

Piotr Szpryngier
6
Piotr Szpryngier
6
Typy przetwarzania
Wieloprocesorowe (ze wspólną pamięcią, z pamięcia rozproszoną)
Rozproszone:
RMI, RPC
Message passing, PVM
CORBA
Przetwarzanie agentowe
Przetwarzanie gridowe
HCC (przetwarzanie zespołowe, częściowo usługowe)
SCC (Web Services, Cloud Computing) – rozproszone! Wyróżnia się trzy typy
przetwarzania w chmurze (Cloud Computing – nowszy typ SOA):
SaaS (Software as a Service) – usługi w postaci narzędzi
programistycznych są dostępne na żądanie klienta,
PaaS (Platform as a Service) – usługi w postaci narzędzi do budowy
własnych aplikacji i platformy do ich wdrożenia,
IaaS (Infrastructure as a Service) – usługi w postaci udostępnienia
maszyn wirtualnych z systemami operacyjnymi

Piotr Szpryngier
7
Piotr Szpryngier
7
Przetwarzanie rozproszone
Zalety:
możliwość uzyskania większej wydajności, poprzez dodanie
nowych węzłów – elastyczność i skalowalność;
komunikowanie się ze sobą procesów zapewnia
współdzielenie pewnych, zgromadzonych przez siebie,
informacji, dzięki zlokalizowaniu i zarządzaniu w jednym
miejscu uzyskujemy logiczną spójność;
w przypadku awarii jednego z procesów, bądź węzłów,
pozostała część systemu nadal pracuje, a co najważniejsze,
istnieje możliwość odzyskania utraconych danych, np.
poprzez mechanizmy replikacji, checkpointing, itp.

Piotr Szpryngier
8
Piotr Szpryngier
8
Przetwarzanie rozproszone
Wady:
aplikacje rozproszone mogą być nieco trudniejsze do
zaprojektowania i implementacji, gdyż są one zazwyczaj
bardziej złożone.
do prawidłowej współpracy procesów, należy zapewnić im
odpowiednie niezawodne mechanizmy komunikacji. Z
samym procesem komunikacji oraz wydajnością wiążą się
dwie podstawowe metryki: czasy opóźnień oraz
przepustowość.
synchronizacja jest wymagana w przypadku, kiedy pewien
proces może rozpocząć swoje działanie po zakończeniu
otrzymania danych od innego procesu.

Piotr Szpryngier
9
Piotr Szpryngier
9
Przetwarzanie rozproszone
RPC (remote procedure call) jest wywołaniem funkcji, która rezyduje w
odległym systemie. Wygląda jak zwykłe wywołanie funkcji i zapewnia:
Niezależność lokalizacji (transparency),
Wygodę użytkowania (zgodność ze standardami programowania).
message passing -
za pomocą przesyłanych komunikatów,
Ale mamy dodatkowe kłopoty:
Jak aplikacja dowie się, że wywoływana funkcja jest gdzieś indziej?
Identyfikacja lokalizacji – wymaga znajomości położenia serwera;
Wzrost podatności na awarie, gdy zdalna funkcja nie jest dostępna,
Niemożność zrównoważenia obciążeń
Brak wyróżnienia ważności – najważniejsi klienci mogą zostać pominięci
w obsłudze – straty biznesowe
Reakcja na chwilowe silne przeciążenia – wymaga dodatkowych
zabiegów

Piotr Szpryngier
10
Piotr Szpryngier
10
Przetwarzanie rozproszone
Najprostszy model przetwarzania rozproszonego – klient-serwer
W Internecie: klient to przeglądarka, a serwer to najczęściej
serwer www wykonujący żądania klienta;
Po stronie serwera są wykonywane nast. aplikacje:
Moduły kodu HTML
Skrypty (CGI, PHP, .., itp.)
Serwlety (skompilowane aplikacje Javy)
Po stronie klienta (przeglądarki) są wykonywane:
Aplety (aplikacje w języku Java) w tzw. piaskownicy –
środowisko Javy
Skrypty umieszczone w ciele dokumentu HTML
Piotr Szpryngier
11
Piotr Szpryngier
11
Przetwarzanie rozproszone
Wykonywanepostronieserwera
ang.server-side scripting
CGI (Perl,C,
Shell... etc.)
Moduły
serwera HTTP
Um
ieszczonewciele
dokum
entu HTML
(PHP, ASP-VBS)
Jaktradycyjne CGI
(m
od_perl/Apache)
Aplety
(Java,Activex,
Flash)
Skryptyum
ieszczonew
cieledokum
entu HTML
(JavaScript)
Wykonywanepostronieklienta
ang.client-side scripting
Servlety
(Java)
Aplikacje W
W
W
A
plikacje W
W
W

Piotr Szpryngier
12
Piotr Szpryngier
12
Przetwarzanie rozproszone
Message passing jest jednym z najstarszych paradygmatów dla
programowania równoległego, w szczególności dla systemów z
rozproszoną pamięcią, gdzie komunikacja odbywa się wyłącznie za
pomocą przesyłanych komunikatów. Dwie podstawowe metody:
wysyłanie i
odbiór (
send
/
receive
).
Problemy:
buforowanie, blokowanie, niezawodność komunikacji,
niskopoziomowe podejście: zadania do wykonania oraz dane
wejściowe muszą zostać w sposób jawny rozdzielone na procesy
ustalone adresy – transfer via gniazdka
zagrożenie powstawania zakleszczeń w przypadku komunikacji
blokującej

Piotr Szpryngier
13
Piotr Szpryngier
13
Przetwarzanie rozproszone - gridowe
Rozproszone maszyny lub klastry tworzą tzw. siatkę - traktowaną
jako pojedyncze, ujednolicone źródło obliczeniowe - zintegrowane
środowisko obliczeniowe. Broker – pośrednik – daje dostęp do
zasobów, rozwiązuje konflikty, np. poprzez kolejkowanie.
Grid udostępnia usługi:
Obliczeniowe
Działanie na źródłach danych (bezpieczny dostęp, zarządzanie
rozproszonymi danymi)
Informacyjne – wydobywanie wiedzy, eksploracja danych,
prezentacja
Cechy: Zdolność równoległych obliczeń, wirtualna współpraca przy
użyciu wirtualnych zasobów, dostęp do dodatkowych źródeł danych i
usług, równoważenie zasobów, niezawodność, zarządzanie.

Piotr Szpryngier
14
Piotr Szpryngier
14
Przetwarzanie gridowe
Różnorodność obszarów i autonomia
– zasoby siatki są
geograficznie
rozproszone
pomiędzy
różnymi
obszarami
zastosowań i należą do różnych organizacji.
Heterogeniczność
– Grid łączy różnorodne zasoby, które mogą
obejmować szeroki zakres technologii.
Skalowalność
– mimo, iż Grid nie wpływa bezpośrednio na wzrost
skalowalności, to w niektórych przypadkach (przy bardzo dużej
ilości zintegrowanych zasobów) pojawia się problem obniżenia
wydajności ze wzrostem wielkości siatki Grid.
Dynamiczność i zdolność adaptacyjna
– w modelu Grid awaria jest
raczej regułą, niż wyjątkiem. W przypadku wielu zasobów siatki,
prawdopodobieństwo wystąpienia awarii w jednym z nich jest
dosyć wysokie. Aplikacje oraz menadżerzy zasobów muszą być
przygotowani do wystąpienia takich awarii i w sposób dynamiczny
przydzielać, bądź zwalniać kolejne zasoby siatki.

Piotr Szpryngier
15
Piotr Szpryngier
15
Przetwarzanie agentowe
Dokładny opis agenta stanowi właśnie jego implementacja,
która jest zależna od platformy, na której będzie pracował
Mamy agenty mobilne, agenty słabe i silne.
Mają cztery zasadnicze cechy, gdzie każda zależna jest w
mniejszym lub większym stopniu od wykonywanego zadania:
Autonomiczność
– posiadają zdolność niezależnego
działania, aby osiągnąć zamierzone cele.
Proaktywne
– posiadają zdolność przejęcia inicjatywy, aby
osiągnąć zamierzone cele.
Zdolność współpracy
– mogą współpracować ze sobą.
Zdolność oddziaływania
– mogą reagować na zmiany w
środowisku ich działania.

Piotr Szpryngier
16
Piotr Szpryngier
16
Przetwarzanie agentowe
dwa typy oddziaływania agentów:
obserwacja, zmieniająca informacje posiadane przez agenta
na temat środowiska, nie powodując jednak zmian stanu
tego środowiska.
przeprowadzanie działań, które mogą już zmieniać globalny
stan
środowiska,
ale
nie
zmieniają
informacji
przechowywanych przez agenta.
dwa typy komunikacji z innymi agentami:
komunikacja wychodząca, czyli zdolność do nawiązania
współpracy z drugim agentem oraz
komunikacja przychodząca, czyli zdolność odbierania
informacji od innego agenta.

Piotr Szpryngier
17
Piotr Szpryngier
17
Przetwarzanie agentowe
Modele współpracy agentów:
Środowisko i modele agenta
– każdy agent może tworzyć i
przechowywać informacje o środowisku (modelu) zewnętrznym,
bazując na obserwacji tego środowiska, informacji posiadanych
przez innych agentów jak i na własnej podstawowej wiedzy na
temat danego środowiska.
Model własny i historia
– niekiedy agenty mogą tworzyć i
przechowywać informacje na temat swoich własnych cech
charakterystycznych, stanu wewnętrznego oraz zachowania.
Cele i plany
– agent prezentuje, generuje i używa jawnych celów i
jego własnych planów działania.
Koncepcja grupy
– poza koncepcjami indywidualnymi, agenty
często są w stanie tworzyć pewne grupy, w których istnieje
możliwość wzajemnej współpracy.

Piotr Szpryngier
18
Piotr Szpryngier
18
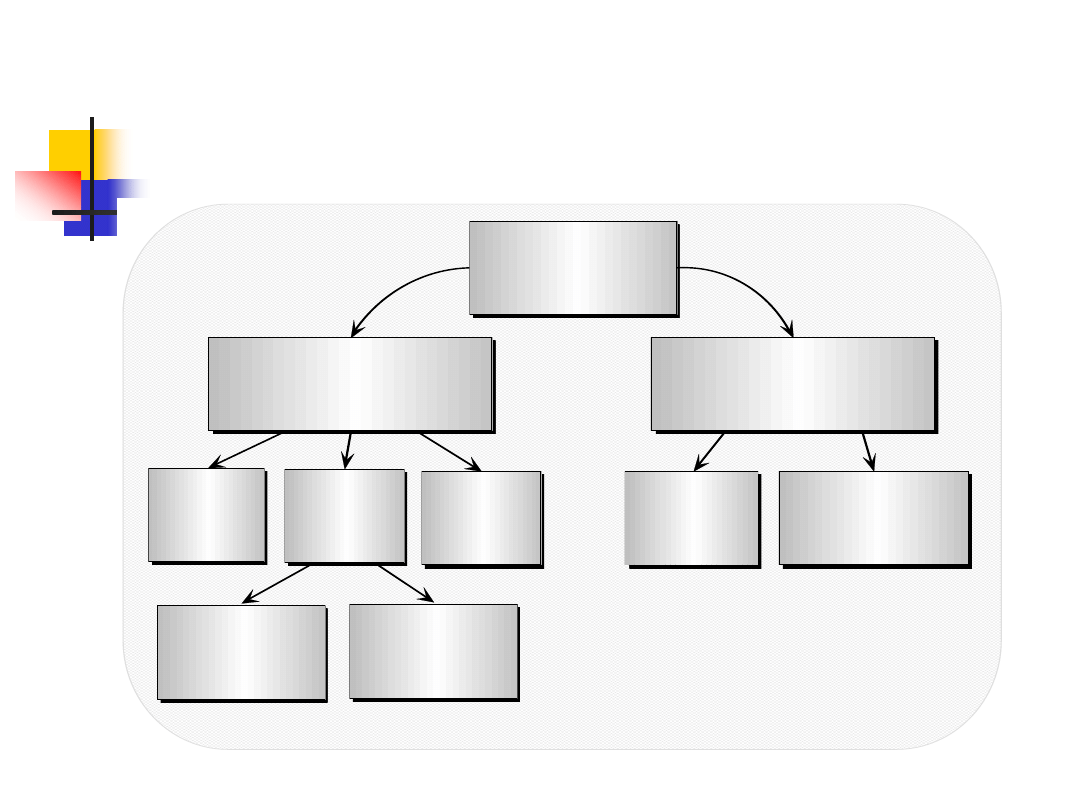
Rozproszone aplikacje wielowarstwowe
Struktura:
Pierwszą warstwę stanowi warstwa prezentacji (GUI). Jest ona
odpowiedzialna za zbieranie informacji od użytkownika, przesyłanie ich
do warstwy logiki biznesowej oraz sytuacji odwrotnej, czyli odbieranie
wyników i prezentacja ich użytkownikowi.
Drugą warstwą jest warstwa logiki biznesowej, która definiuje zbiór
usług, które udostępniane są przez serwer. Jest to niewątpliwie
warstwa najtrudniejsza do zaimplementowania, ze względu na jej dużą
złożoność i nieraz brak odpowiednich narzędzi do jej właściwego
zaprojektowania. W warstwie tej należy zadbać o takie kwestie jak:
skalowalność, współbieżność oraz bezpieczeństwo.
Ostatnią warstwą jest warstwa danych. Odpowiedzialna jest za
przechowywanie, dostarczanie, utrzymywanie oraz integrację danych.
Cechy: skalowalność, łatwość rozbudowy

Piotr Szpryngier
19
Piotr Szpryngier
19
Rozproszone aplikacje wielowarstwowe
W aplikacjach webowych klient oczekuje uniwersalnego
interfejsu, którym jest przeglądarka sieciowa. Warstwa
biznesowa:
1.
przyjmuje żądania klienta,
2.
odbiera informacje pochodzące z wewnętrznych systemów,
3.
przetwarza dane i
4.
przekazuje wyniki z powrotem do klienta.
Cechy warstwy biznesowej:
Serwery aplikacji mieszczące się w tej warstwie, mają za zadanie
obsługiwanie przychodzących żądań klientów jak i łączenie się z
innymi systemami wewnętrznymi, np. serwerami pocztowymi
(MS Exchange), baz danych (np. MySQL, Oracle), itp.
Piotr Szpryngier
20
Piotr Szpryngier
20
Rozproszone aplikacje wielowarstwowe

Piotr Szpryngier
21
Piotr Szpryngier
21
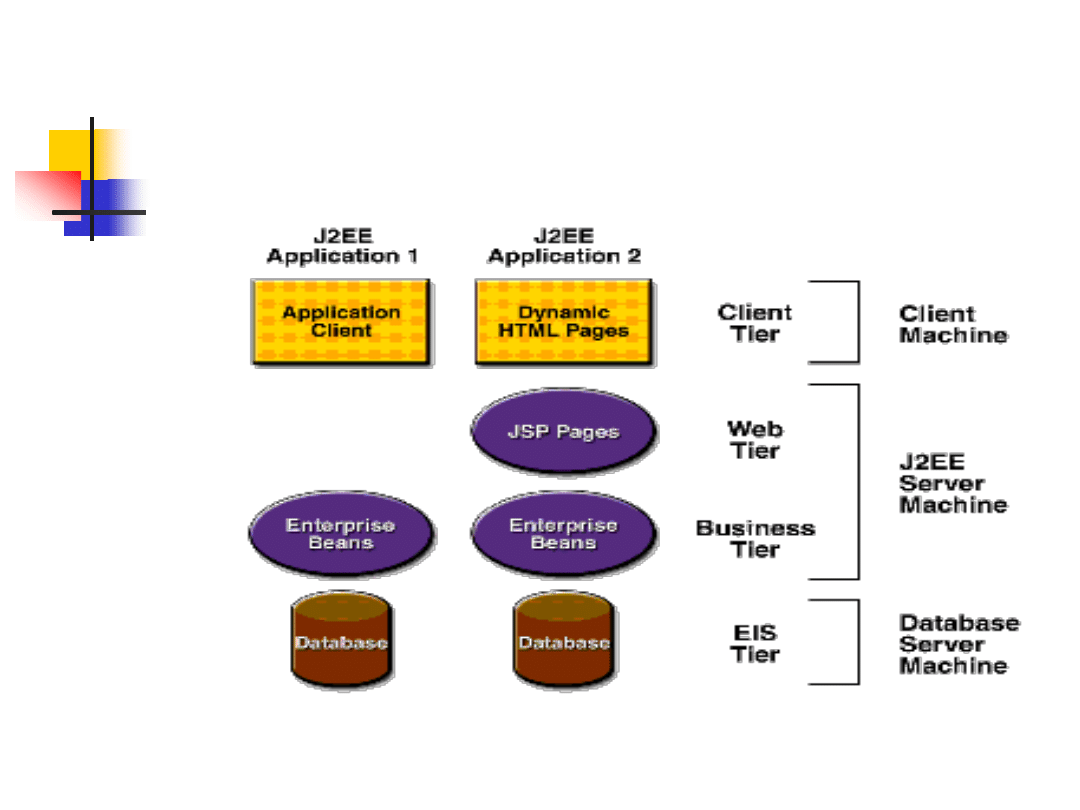
Rozproszone aplikacje wielowarstwowe
Mamy trzy rodzaje ziaren EJB:
Session Beans
(stanowe i bezstanowe) – utrzymują czasowe połączenie z
klientem. Po zakończeniu procesu wykonywania przez klienta, zarówno ziarno
sesji jak i dane zostają utracone. Ziarna sesyjne:
-
Stanowe – (ang. Stateful) –
podczas trwania sesji, ziarna te zachowują
swój stan, który może zmieniać się z kolejnymi wywołaniami metod obiektu.
-
Bezstanowe – (ang. Stateless)
– nie przechowują one stanu obiektu po
zakończeniu obsługi żądania. Ziarna te mogą być wykorzystywane przez
wiele aplikacji, zwiększając tym samy przepustowość i podnosząc
wydajność.
Entity Beans
– reprezentują dane w postaci rekordu z bazy danych, które
utrzymywane są w sposób trwały. Jeżeli klient przerwie wykonywanie lub
serwer zostanie wyłączony, odpowiednie usługi zapewniają wcześniejsze
zachowanie danych.
Message-driven Bean
– łączą cechy ziaren sesji oraz usług JMS (Java Message
Service), pozwalając komponentom biznesowym na asynchroniczne odbieranie
komunikatów JMS.

Piotr Szpryngier
22
Piotr Szpryngier
22
Rozproszone aplikacje – Web Services
Dzięki XML powstało wiele innych standardów, z których
najważniejsze dla omawianych usług internetowych to: SOAP
(ang. Simple Object Access Protocol - obecnie nie zaleca się tak
rozwijać tego skrótu, gdyż ma on teraz o wiele szersze
zastosowanie), WSDL (ang. Web Services Description
Language) i UDDI (ang. Universal Description, Discovery, and
Integration). Przewagą standardów opartych na XML jest ich
prostota oraz naturalna niezależność sprzętowo-platformowa.
Usługi sieciowe (Web Services) można przedstawić jako
technologię która umożliwia szeroko pojętym użytkownikom
komunikację i współpracę w oparciu o istniejącą infrastrukturę
Internetu głównie w paradygmacie RPC.
Architektura SOA (ang. Service Oriented Architecture) opiera się
na znanych standardach (TCP/IP, HTTP, XML) i nowszych dot.
usług sieciowych (WSDL, SOAP, UDDI).

Piotr Szpryngier
23
Piotr Szpryngier
23
Web Services
Funkcjonowanie
usług sieciowych opiera się na trzech głównych
składnikach:
SOAP - prosty
protokół komunikacji,
WSDL - interfejs
usługi zapisany na tyle szczegółowo, aby użytkownik na
jego podstawie
mógł stworzyć aplikację kliencką,
UDDI - mechanizm rejestracji
umożliwiający opisanie usługi, przedstawienie
tego opisu aplikacjom i odnalezienie poszukiwanej
usługi użytkownikowi.
Język XML (ang. eXtensible Markup Language) był tworzony z myślą o
definiowaniu nowych formatów dokumentów dla WWW.
WSDL (Web Services Description Languade)- interfejs usługi zapisany na
tyle szczegółowo, aby użytkownik na jego podstawie mógł stworzyć
aplikację kliencką.
SOAP to protokół zapewniający standardowy mechanizm opakowywania
danych w wiadomości.
UDDI (ang. Universal Discovery Description and Integration) to forma
ks
iążki telefonicznej dla usług internetowych.

Piotr Szpryngier
24
Piotr Szpryngier
24
Platformy i narzędzia informatyczne
3 grupy narzędzi programistycznych
platformy
programistyczne
wspomaganie
zarz
ądzania
zapewnianie
jako
ści
aplikacje
u
żytkowe
systemy
operacyjne
testowanie i
uruchamianie
narz
ędzia
wspomagaj
ące
projektowanie
narz
ędzia
konfigurowania i
inicjalizowania
pakiety
pomiarowe
wytwarzanie
złożonych
systemów
informatycznych
pakiety
wspomagania
administrowania
zintegrowane
systemy oceny

Piotr Szpryngier
25
Piotr Szpryngier
25
Systemy operacyjne - definicje
definicja SO (bottom-up): program zarządzający zasobami systemu
komputerowego.
definicja SO (top-down): maszyna wirtualna lub wygodny interfejs
użytkownika.
definicja komercyjna: Podstawowe oprogramowanie dostarczane
przez producenta.
cel działania SO: efektywne wykorzystanie zasobów systemu.
Zasób systemowy to: pamięć, czas procesora, kontrola medium
komunikacyjnego logicznego/fizycznego.
Proces = (program, procesor, pamięć) – każde uruchomione zadanie
Proces wykonuje się niezależnie od innych programów -procesów.
Ubiega się i współzawodniczy o zasoby systemu. Korzysta z funkcji
jądra SO.
terminologia: jednocześnie (w tej samej chwili) a równocześnie (w tym
samym przedziale czasu).
Piotr Szpryngier
26
Piotr Szpryngier
26
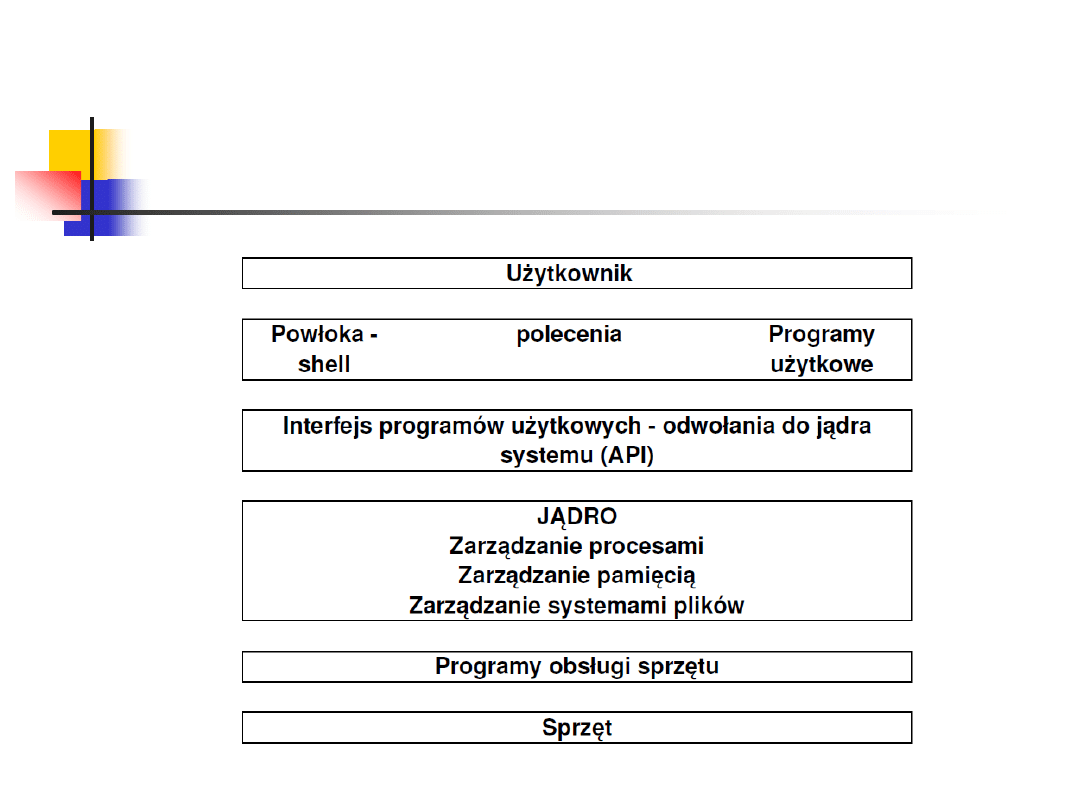
Warstwowa struktura systemu operacyjnego

Piotr Szpryngier
27
Piotr Szpryngier
27
System operacyjny - definicje
Dalsze definicje:
Zorganizowany zespół programów (systemów), które pełnią rolę
pośredniczącą między sprzętem a użytkownikami, dostarczającą
użytkownikom zestaw środków ułatwiających projektowanie,
kodowanie, uruchamianie i eksploatację programów oraz w tym
samym czasie sterują przydziałem zasobów w celu zapewnienia
efektywnego działania.
definicja komercyjna: Podstawowe oprogramowanie
dostarczane przez producenta.
Inne określenie: Oprogramowanie jądra (zawsze aktywne)

Piotr Szpryngier
28
Piotr Szpryngier
28
System operacyjny – model warstwowy - cechy
Powszechnie stosowanym modelem statycznym systemu operacyjnego jest
struktura warstwowa, w której warstwy niższe oferują pewne funkcje i
usługi warstwom niższym.
Najniższą warstwę SO stanowią programy niskiego poziomu obsługi sprzętu
(sterowniki), często wbudowane do pamięci stałej (BIOS).
Jądro (ang. kernel), składające się ze zbioru funkcji i tablic systemowych.
Głównym zadaniem jądra jest dostarczenie narzędzi do zarządzania procesami,
zarządzania pamięcią i zarządzania systemem plików.
Kolejna warstwa to narzędzia do odwoływania się do systemu operacyjnego z
wnętrza programów, a więc tzw. interfejs programów użytkowych (ang.
Application Program Interface - API). Korzystają z niego również programy
systemowe, jak np. programy powłok.
Pomiędzy warstwą API i użytkownikiem ulokowano w modelu warstwowym
w/w programy powłok, programy poleceń systemowych i programy
użytkowe jako narzędzia bezpośrednio wykorzystywane przez użytkownika.
W tej warstwie pracują też tzw. procesy jądra (SO).

Piotr Szpryngier
29
Piotr Szpryngier
29
System operacyjny – model warstwowy - uwagi
Z modelem warstwowym związana jest koncepcja hierarchii
maszyn wirtualnych, tworzących abstrakcyjny ciąg modeli
systemów komputerowych. Każda kolejna warstwa wzbogaca
sprzęt o nowe własności, dając ciekawe implikacje w przypadku
systemów wielozadaniowych (różne maszyny dla różnych
zadań).
Ze względu na potrzebę przenośności oprogramowania
użytkowego istotne jest korzystanie z mechanizmów
systemowych na określonym poziomie, np. wyłącznie za
pośrednictwem odwołań API (w wielu systemach operacyjnych,
w tym w UNIXie, jest to jedyna możliwość uzyskania usług od
procesów systemowych).

Piotr Szpryngier
30
30
Zadania systemu operacyjnego
Zarządzanie procesami (własnymi i użytkowników),
Zarządzanie pamięcią operacyjną,
Zarządzanie pamięcią pomocniczą (dyskową, taśmową, FLASH,
CD, itp..),
Zarządzanie plikami,
Zarządzanie systemem wejścia/wyjścia,
Zarządzanie systemem ochrony (autoryzacja, autentyczność i
wiarygodność, kontrola dostępu),
Zarządzanie komunikacją sieciową (obsługa),
System interpretacji poleceń (shell – powłoka).
UWAGA: zadania są wykonywane permanentnie przez cały czas
życia SO

Piotr Szpryngier
31
Piotr Szpryngier
31
Usługi systemu operacyjnego
Wykonanie programu użytkownika,
Operacje wejścia/wyjścia,
Operacje na plikach i systemach plików,
Komunikacja sieciowa i międzyprocesowa,
Wykrywanie błędów – diagnostyka systemowa,
Przydział zasobów,
Rozliczanie (auditing),
Ochrona i kontrola dostępu (authorisation&AC),
Wiarygodna komunikacja (authentication).
UWAGA: usługi (funkcje) są wykonywane przez SO na życzenie
użytkownika lub aplikacji (procesu) wykonywanego w jego
imieniu.

Piotr Szpryngier
32
Opis procesu w systemie operacyjnym
Piotr Szpryngier
32

Piotr Szpryngier
33
Opis procesu w systemie operacyjnym
Każdy uruchomiony proces zajmuje jedną pozycję (strukturę-tablicę) w
tablicy opisu procesów. Możliwe są różne podejścia:
Tablica tablic w obszarze zarządzanym przez SO (pamięć ciągła,
niestronicowana),
Mieszane - tablica opisu i dodatkowy opis wraz ze stosem i stertą połączone z
kodem programu.
Każdy proces ma typowe atrybuty takie jak: identyfikator (numer), stan,
priorytet, id właściciela, miejsce w kolejce (kolejkach), ograniczenia
pamięci. Mogą występować inne argumenty takie jak np. id procesu-
rodzica, wykaz zajętych zasobów (semafory, muteksy, strefy krytyczne,
pliki, itp.)
Podstawowe stany procesu to: gotowy (czeka na dostęp do procesora),
aktywny (ma właśnie procesor i działa), czekający (na jakieś zdarzenie,
np. zwolnienie muteksu), zawieszony (czeka na upłynięcie jakiegoś
wskazanego czasu). Tych stanów może być więcej.
Piotr Szpryngier
33

Piotr Szpryngier
34
Zarządzanie procesami w systemie operacyjnym
1.
Utworzenie procesu (przydzielenie pamięci, pobranie chociaż
jednego bloku kodu programu, wpis do tablicy opisu procesów,
umieszczenie w kolejce oczekiwania na procesor - planowanie) i
zakończenie procesu (zabranie zasobów, usunięcie wpisu w tablicy
opisu, przekazanie kodu diagnostycznego procesowi-rodzicowi);
2.
Zatrzymanie procesu (zmiana stanu procesu, wpisanie do którejś z
kolejek – co najmniej jednej, wznowienie innego zadania) i
wznowienie działania procesu (zmiana stanu procesu, wypisanie z
kolejek – co najmniej jednej – i wpisanie do kolejki zadań gotowych -
planowanie);
3.
Dostarczanie mechanizmów synchronizacji i komunikacji procesów;
4.
Dostarczanie mechanizmów obsługi blokad i przeciwdziałanie nim.
Piotr Szpryngier
34

Piotr Szpryngier
35
Zarządzanie procesami w systemie operacyjnym
Mamy procesy samodzielne (niezależne) i współpracujące.
Działanie każdego procesu można powielić, a także można
wstrzymywać i wznawiać.
Niezależne procesy nie mogą wpływać bezpośrednio na
działanie innych procesów, ani nie podlegają wpływom innych
procesów. Działanie procesu niezależnego jest zdeterminowane
jedynie wartością parametrów i danych wejściowych.
Jedynym sposobem organizacji współpracy procesów zależnych
od siebie to protokoły wzajemnej komunikacji bądź
synchronizacji. Jego stan jest dzielony z innymi procesami. Nie
można przewidzieć wyniku działania!!! (bo może zależeć od
względnej kolejności wykonania i efektu działania innych
procesów).
Piotr Szpryngier
35

Piotr Szpryngier
36
Zarządzanie procesami w systemie operacyjnym –
planowanie zadań
Cel: optymalizacja wykorzystania zasobów poprzez wyrównanie
ró
żnic w prędkości działania.
Sposó
b realizacji: organizacja kolejek zadań i zarządzanie nimi.
Kolejkami zarządza planista (scheduler) długoterminowy (nie
zawsze istnieje) i krótkoterminowy. Kolejki:
Zada
ń aktywnych czekających na procesor,
Dost
ępu do urządzeń we/wy (inna dla każdego urządzenia),
Oczekiwania na up
łynięcie zadanego czasu (zawieszenie),
Oczekiwania na sygnał lub komunikat lub zakończenie pracy
procesu-potomka.
Kolejka to struktura danych
– posiada:
Nagłówek kolejki,
Ogon (koniec) kolejki.

Piotr Szpryngier
37
Zarządzanie procesami w systemie operacyjnym –
planowanie zadań
Odpowiednie pola w tablicy opisu procesu, wskazuj
ące na stan i
przypisanie procesu do kolejek (proces mo
że być umieszczony w co
najwyżej dwóch jednocześnie, w tym w jednej kolejce czasowej) służą
do zarz
ądzania procesami przez planistów.
Planista krótkoterminowy przydziela procesor jednemu z procesów
b
ędących w kolejce aktywnych procesów. Gdy ta kolejka jest pusta,
działa tzw. proces tła.
Program realizujący przydział (dispatcher) dokonuje:
Prze
łączenia kontekstu (zmiana procesu aktywnego, a dotychczasowy
aktywny wpisuje do którejś z kolejek, a jego ślad do tablicy opisu),
Prze
łączenia do trybu użytkownika,
Za
ładowanie PC (licznik rozkazów) adresem miejsca wznowienia
programu (przekazanie procesora nowemu aktywnemu procesowi).

Piotr Szpryngier
38
Zarządzanie procesami w systemie operacyjnym –
algorytmy planowania zadań
FCFS (First Come - First Served).
Sposób realizacji - kolejka FIFO (First
In - First Out). Wada -
średni czas oczekiwania na procesor może być
bardzo długi
SJF (Shortest Job First) -
najpierw najkrótsze zadanie (szacowany czas
realizacji). Stosowany we wst
ępnej fazie. Gdy kolejne fazy realizacji
procesów mają zbliżone czasy trwania, to wówczas przechodzimy do
modelu FCFS.
Sposób realizacji: porządkowanie kolejki zadań
gotowych.
Zaleta: optymalny czas oczekiwania.
Wada: trudność określenia czasu realizacji w kolejnych fazach realizacji
zadań (np. po zakończeniu operacji we/wy). Stosuje się różne oszacowania,
najczęściej tzw. średnie wykładnicze czasu wykonania poprzednich faz.
Algorytm SJF może być wywłaszczający lub niewywłaszczający.
SJF jest algorytmem priorytetowym z priorytetem odwrotnie zależnym
od wielkości czasu przewidywanej następnej fazy wykonania.

Piotr Szpryngier
39
Zarządzanie procesami w systemie operacyjnym –
algorytmy planowania zadań
Planowanie priorytetowe -
SJF to szczególny przypadek tego bardziej
ogólnego modelu. Algorytm planowania priorytetowego może być
wywłaszczający lub niewywłaszczający.
Założenie: każdy proces ma przypisany pewien priorytet.
Zasada działania: procesor otrzymuje proces o najwyższym priorytecie. Jeśli są
równe, to reguła FCFS.
Planowanie rotacyjne (round-robin) - specjalnie zaprojektowany dla
systemów z podziałem czasu.
Założenie: Procesy wykonują się przez określony z góry, zdefiniowany dla
systemu kwant (odcinek) czasu.
Realizacja: Kolejka procesów to kolejka cykliczna (ostatni proces wskazuje jako
na nast
ępny na pierwszy proces). Procesy gotowe wstawiane do kolejki
zgodnie z regu
łą FIFO. Nowe procesy są wstawiane na koniec kolejki. Po
zako
ńczeniu fazy wykonania następuje przełączenie kontekstu, proces wędruje
na koniec kolejki i pobierany jest pierwszy z pocz
ątku kolejki.

Piotr Szpryngier
40
Zarządzanie procesami w systemie operacyjnym –
algorytmy planowania zadań
Planowanie rotacyjne (round-robin)- cd
Faza wykonania może być krótsza niż jeden kwant wtedy, kiedy
proces zwolni procesor lub zakończy działanie.
Ocena:
średni czas cyklu przetwarzania zależy od kwantu
czasu.
Wada: Trudno optymalnie dobrać kwant czasu. Gdy jest za
duży, to planowanie rotacyjne przekształca się w model FCFS.
Gdy jest za mały, to wydłuża się średni czas przetwarzania ze
względu na narzut czasu na organizację przełączania procesów.

Piotr Szpryngier
41
Zarządzanie procesami w systemie operacyjnym –
algorytmy planowania zadań
Wielopoziomowe planowanie kolejek - stosowane wtedy,
kiedy mo
żna procesy przypisać do różnych grup (klas)
wykonania, np. procesy pierwszoplanowe i procesy
drugoplanowe (wsadowe).
Przykładowa hierarchia może wyglądać następująco:
Procesy systemowe,
Procesy interakcyjne,
Procesy wsadowe,
Programy studenckie.
Dla ka
żdej grupy można zastosować inną metodę (algorytm)
przydzia
łu procesora.
Do rozs
ądzania sporów pomiędzy kolejkami stosujemy
wyw
łaszczające planowanie stało-priorytetowe.

Piotr Szpryngier
42
Zarządzanie procesami w systemie operacyjnym –
algorytmy planowania zadań
Wielopoziomowe planowanie kolejek ze sprz
ężeniem
zwrotnym - to wielopoziomowe planowanie kolejek z
uwzgl
ędnieniem możliwości przemieszczania procesów pomiędzy
kolejkami.
Proces jest przypisywany na stałe do kolejki w chwili wprowadzania
do systemu. W miar
ę postępu w swoich obliczeniach proces może
migrowa
ć do kolejek o ograniczonym (niższym) priorytecie. Z kolei
procesy bardzo d
ługo czekające na uruchomienie mogą otrzymać
procesor szybciej.
Parametry takiego modelu to:
Liczba kolejek,
Algorytm planowania dla ka
żdej kolejki,
Metody zastosowane do podj
ęcia decyzji o zmianie priorytetu lub
zmianie kolejki procesów,
Metoda okre
ślenia kolejki do której trafi proces.

Piotr Szpryngier
43
Zarządzanie procesami w systemie operacyjnym –
algorytmy planowania zadań
Planowanie wieloprocesorowe
Rozró
żniamy 2 rodzaje systemów wieloprocesorowych:
homogeniczne - wszystkie procesory jednakowe i
heterogeniczne - przynajmniej jeden procesor inny.
Rodzaje przydziału:
Ładowanie dzielone - każdy procesor ma własną kolejkę.
Ładowanie wspólne - gdy jednakowe procesory - wspólna kolejka
procesów gotowych do wszystkich procesorów.
Niekiedy jeden z procesorów nie wykonuje innych zadań, a
spe
łnia jedynie rolę planisty - wieloprzetwarzanie asymetryczne.

Piotr Szpryngier
44
Koordynowanie działania procesów
Stosowanie: przetwarzanie wspó
łbieżne - podstawa systemów
wielozadaniowych, ale komunikaty są też wykorzystywane w
systemach rozproszonych.
Klasyczne problemy synchronizacji:
Producent - konsument (ci) - problem ograniczonego buforowania.
Problem typu dost
ępu do zasobów współdzielonych - problem
czytelników i pisarzy.
Problem posilaj
ących się filozofów - powstawanie blokad i
przeciwdziałanie blokadom (deadlocks).
Mechanizmy
koordynacji działania procesów:
Sprz
ętowe – przerwania,
Niskiego poziomu (j
ądro systemu poprzez API): sygnały, potoki;
Programowe na poziome SO lub wy
żej:
semafory, sekcje krytyczne
monitory, komunikaty.

Piotr Szpryngier
45
Koordynowanie działania procesów
Konstrukcje programistyczne służące do realizacji
synchronizacji: semafory, strefy krytyczne, komunikaty,
semafory.
Semafor: zmienna globalna o wartościach całkowitych –
działanie sprowadza się do wskaźnika (flagi) sygnalizującej
dostępność (dostępny, gdy wartość >0). Operacje na
semaforze: czekaj(s), sygnalizuj(s) mają charakter atomowy,
tzn. nie mogą być przerwane w żadnej sytuacji. Inne nazwy
tych operacji: zajmij(s), zwolnij(s).
Pseudokod obrazujący użycie operacji semaforowych:
czekaj(S): while S 0 do nic;
//próba zajęcia
S := S
– 1;
// tu dostaliśmy się
sygnalizuj(S): S := S + 1;
//zwolnienie

Piotr Szpryngier
46
Koordynowanie działania procesów - semafory
Semafory s
łużą m.in. do budowy sekcji krytycznej
wykorzystywanej przez wiele procesów:
Sekcja krytyczna zapewnia wy
łączność korzystania z danych i
kodu zawartego w tej sekcji.
Jest strzeżona przez semafor
binarny (mutex). Nazwa pochodzi od mutual exclusion.
Przykład implementacji sekcji krytycznej:
Ka
żdy proces zawiera następujący fragment kodu źródłowego:
repeat
czekaj(S);
sekcja krytyczna
//jesteśmy wewnątrz sekcji krytycznej
sygnalizuj(S);
// wyjście z sekcji
reszta kodu procesu
until false;

Piotr Szpryngier
47
Zarządzanie procesami – blokady i ich unikanie
Blokada – stan w jakim znajduje się część procesów w systemie,
nie mogąc kontynuować działania, bowiem przetrzymując jakiś
zasób potrzebny innemu procesowi, nie mogą otrzymać innego
potrzebnego do dalszej pracy, a przetrzymywanego przez ten
właśnie inny proces.
Blokada powstanie, gdy jednocze
śnie są spełnione następujące
4 warunki:
Wzajemne wy
łączanie - przynajmniej jeden zasób musi być
niepodzielny,
Przetrzymywanie i oczekiwanie na inny zasób,
Brak wyw
łaszczeń zasobów,
Czekanie cykliczne - procesy czekaj
ą na zasoby wzajemnie
przetrzymywane.

Piotr Szpryngier
48
Zarządzanie procesami – zapobieganie blokadom
Unikanie blokad:
1.
Warunek wzajemnego wyłączania musi być spełniony w stosunku
do zasobów niepodzielnych, a w przypadku pozostałych zasobów
należy dążyć do wyeliminowania tego warunku.
2.
Aby przetrzymywanie i oczekiwanie
nie powodowało blokad, należy
ograniczyć liczbę przetrzymywanych (posiadanych) zasobów do
najwyżej jednego. Inny sposób to przydzielanie zasobów
zgrupowanych (podczas akcji atomowej - nierozdzielnie).
3.
Aby zapewnić, że przydzielane zasoby ulegną wywłaszczeniu,
używamy różnych protokołów.
4.
Aby czekanie cykliczne
nigdy nie nastąpiło, należy uporządkować
typy zasobów i wymagać, by ubiegać się o nie w porządku np.
wzrastającej numeracji.

Piotr Szpryngier
49
Zarządzanie procesami – unikanie blokad
Unikanie blokad -
takie sterowanie pracą systemu, by zawsze był on
w tzw. stanie bezpiecznym
. Sprowadza się to do wykrywania pętli
podczas realizacji zamó
wień na zasoby i wymuszanie czekania bez
posiadania żadnych zasobów.
Istniej
ą także algorytmy służące do wykrywania i usuwania blokad.
Wychodzenie z blokady - sposoby:
Zako
ńczenie procesu,
Zaniechanie (cofni
ęcie obliczeń do początku) wszystkich procesów
uwik
łanych w blokady,
Usuwanie procesów pojedynczo a
ż do chwili wyeliminowania pętli
blokady,
Wywłaszczenie zasobów (trudności: wybór ofiary, wycofanie i
wznowie
nie działania)

Piotr Szpryngier
50
Zarządzanie pamięcią główną (operacyjną)
Zarządzanie pamięcią:
dynamiczne ładowanie programów w postaci kodu relokowalnego,
przydzielanie i odbieranie bloków pamięci, przemieszczanie w pamięci,
planowanie długoterminowe przydzielania pamięci, usuwanie fragmentacji
pamięci;
dynamiczne łączenie z bibliotekami,
stosowanie nakładek (wymiennych fragmentów programu),
Zarządzanie pamięcią wirtualną (mechanizm stronicowania).
Stronicowanie (sprzętowe) - pamięć fizyczną dzielimy na bloki zwane
ramkami. Ramki mają stały rozmiar. Pamięć logiczna również jest
podzielona na bloki tego samego rozmiaru, zwane stronami. Ka
żdy adres
fizyczny wygenerowany przez procesor dzieli si
ę na dwie części: numer
strony s
i odległość na stronie o (offset). Numery stron tworzą ciągłą
sekwencj
ę liczb od 0, natomiast w tablicy stron są one indeksem do
wyszukania lokalizacji rzeczywistej ramki w pami
ęci fizycznej.

Piotr Szpryngier
51
Zarządzanie pamięcią główną (operacyjną)
Segmentacja –
schemat zarządzania pamięcią urzeczywistniający
sposó
b widzenia pamięci przez użytkownika. Przestrzeń adresów
logicznych jest zbiorem segmentów. Ka
żdy segment ma nazwę i
długość. Adres określa nazwę segmentu i odległość (przesunięcie)
wewn
ątrz segmentu.
Wiele kompilatorów wytwarza odr
ębne segmenty dla zmiennych
globalnych, stosu lokalnego, kodu programu (mo
że być ich wiele) i
danych oraz zmiennych lokalnych.
Przyk
ład: procesory x86 stosują segmentację jako schemat
zarz
ądzania pamięcią. Mamy segmenty kodu (CODE), danych
(DATA) i stosu (STACK).

Piotr Szpryngier
52
Zarządzanie pamięcią główną (operacyjną)
Pamięć wirtualna to technika, która umożliwia równoczesne
(wspó
łbieżne) wykonywanie wielu procesów mimo tego, że nie
są one w całości przechowywane w pamięci. Polega ona na
„wydłużeniu” obszaru pamięci operacyjnej o dowolnej wielkości
obszar pamięci dyskowej (pomocniczej). W efekcie otrzymujemy
tzw. pamięć logiczną (taką jaka jest widziana przez
użytkownika). Realizacja - najczęściej jako stronicowanie na
żądanie, ale jest możliwe wykonanie w systemie segmentacji.
Zalety: mo
żna nie ograniczać wielkości kodu programu –
uproszczenie programowania i likwidacja stosowania nakładek,
a także można w PAO umieścić więcej programów i będą one
ładować się szybciej.
Wady: trudna implementacja,
przy dużej nadprogramowości
mo
że obniżyć wydajność systemu.

Piotr Szpryngier
53
Zarządzanie pamięcią pomocniczą (najczęściej dyskową)
Struktura fizyczna:
Talerze + głowice,
Talerz jest podzielony na ścieżki i sektory,
Ścieżki tworzą tzw. cylindry,
Sektory tworzą tzw. bloki fizyczne danych o stałym rozmiarze (w bajtach)
Tablica bloków dyskowych jest
najczęściej traktowana przez SO jako
ciągły obszar adresowany następująco:
b = k + s (j + i t), gdzie:
b - adres (numer) bloku
k - numer sektora
s - liczba sektoró
w na ścieżce
t -
liczba ścieżek w cylindrze
j - numer powierzchni
i - numer cylindra

Piotr Szpryngier
54
Zarządzanie pamięcią pomocniczą (najczęściej dyskową)
i zarządzanie plikami
Zarządzanie pamięcią pomocniczą:
zarządzanie wolnymi obszarami (blokami),
przydzielanie pamięci (bloków) procesom (rodzaje przydziału: ciągły,
listowy, indeksowy).
planowanie przydziałów obszarów (porcji) pamięci dyskowej –
związane z aktualnym położeniem głowicy odczytu/zapisu.
Zarządzanie plikami:
tworzenie i usuwanie plików i katalogów,
dostarczanie podstawowych operacji do manipulowania plikami i
katalogami,
odwzorowywanie plików na obszary (porcje) pamięci pomocniczej ,
składowanie plików w archiwach.

Piotr Szpryngier
55
Systemy czasu rzeczywistego i systemy wbudowane
Real-Time Systems reagują na zdarzenia w obrębie określonego
limitu czasu. Rozróżniamy systemy czasu rzeczywistego:
rygorystyczne i
systemy łagodne.
Systemy wbudowane są nazywane czasem systemami
dedykowanymi - pracują bez udziału ludzi (np. w rakietach,
stacjach kosmicznych, samochodach, urządzeniach wszelkiego
typu). Cechy:
brak pamięci zewnętrznej,
całkowity brak lub bardzo znikomy interfejs użytkownika,
ograniczony znacznie pod względem liczby wykaz realizowanych
zadań i udostępnianych usług.

Piotr Szpryngier
56
Wyszukiwarka
Podobne podstrony:
AKiSO lab1 id 53765 Nieznany
AKiSO lab3 id 53767 Nieznany
AKiSO lab2 id 53766 Nieznany
AKiSO lab6 id 53769 Nieznany
AKiSO lab5 id 53768 Nieznany (2)
Plany3 rok PS S id 362021 Nieznany
AKiSO lab1 id 53765 Nieznany
AKiSO lab3 id 53767 Nieznany
Oceny z PS 27 01 id 329690 Nieznany
Abolicja podatkowa id 50334 Nieznany (2)
4 LIDER MENEDZER id 37733 Nieznany (2)
katechezy MB id 233498 Nieznany
metro sciaga id 296943 Nieznany
perf id 354744 Nieznany
interbase id 92028 Nieznany
Mbaku id 289860 Nieznany
Probiotyki antybiotyki id 66316 Nieznany
miedziowanie cz 2 id 113259 Nieznany
LTC1729 id 273494 Nieznany
więcej podobnych podstron