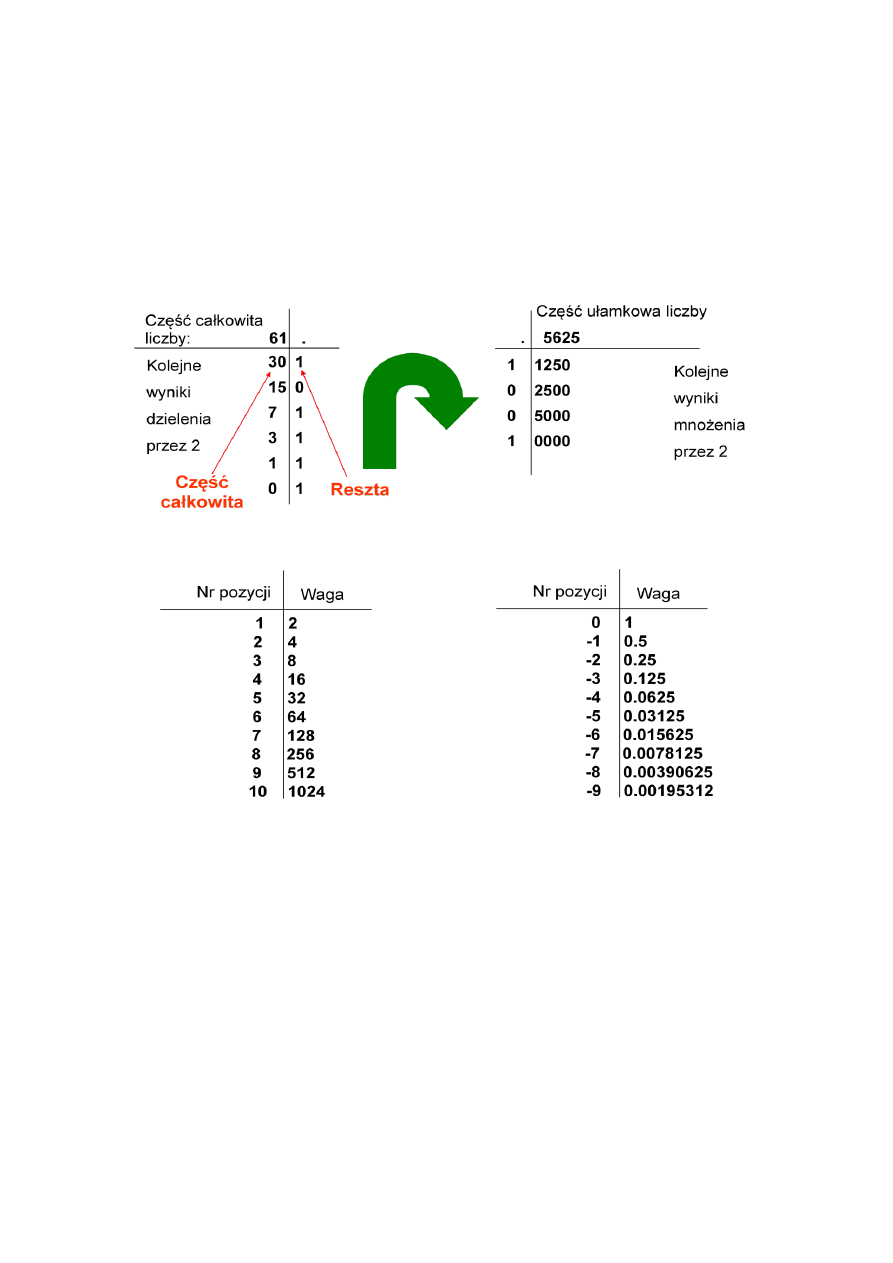
Konwersja liczb
Istotą konwersji liczb jest przekształcenie liczby zapisanej w jednym systemie liczbowym na równoważną jej liczbę zapisaną w
innym systemie liczbowym. Ze względu na to, że wynik konwersji zapisu liczby z dowolnego systemu na binarny jest dłuższy
niż pierwotna postad tej liczby, konwersję do postaci binarnej nazywa się również znajdowaniem rozwinięcia dwójkowego
liczb, zaś jej wynik rozwinięciem dwójkowym liczby poddawanej konwersji.
Prostym sposobem znajdowania rozwinięcia dwójkowego liczby dziesiętnej, czyli przeprowadzania konwersji dziesiętno-
dwójkowej, jest znalezienie:
•
dla części całkowitej - ciągu reszt dzielenia przez dwa, który w odwrotnym porządku daje częśd całkowitą wyniku;
•
dla części ułamkowej - ciągu części całkowitych mnożenia przez dwa.
Znaleźd rozwinięcie dwójkowe liczby 61.5625
61.5625
10
= 11101.1001
2
Znaleźd rozwinięcie dwójkowe liczby 61.5625
1 ∙ 2
5
+ 1 ∙ 2
4
+ 1 ∙ 2
3
+ 1 ∙ 2
2
+ 0 ∙ 2
1
+ 1 ∙ 2
0
= 61
1 ∙ 2
−1
+ 0 ∙ 2
−2
+ 0 ∙ 2
−3
+ 1 ∙ 2
−4
= 0.5625
111101.1001
2
= 61.5625
10

Algebra Boole'a
Fundamentem teoretycznym dla techniki cyfrowej jest algebra Boole'a. Jej podstawy przedstawił
matematyk angielski George Boole w opracowaniu pt. "An Investigation of the Laws of Thought" z 1854 roku. Dzieło to
przeleżało na półkach ponad pół wieku, zanim znalazło zastosowanie w technice do analizy i syntezy układów
przełączających. Jest to nie pierwszy przykład w historii nauki, że dopiero po wielu latach niektóre teorie abstrakcyjne stają
się teoriami o wyraźnie zaznaczonym aplikacyjnym charakterze. Teoria układów logicznych wykorzystuje również pewne
wyniki osiągnięte w XIX wieku w dziedzinie logiki teoretycznej przez takich matematyków jak de'Morgan czy też Polak
Łukasiewicz, który jest twórcą znanego i stosowanego do dziś sposobu zapisu algorytmu, określanego jako tzw. odwrotna
notacja polska.
Algebrą Boole’a B = <B, +,
,
, 0, 1> nazywamy zbiór B zawierający przynajmniej dwa elementy i spełniający
następujące aksjomaty (dla x, y, z
B):
A1: x + 0 = x
A2: x
1 = x
element neutralny
A3: x + (
x) = 1
A4: x
(
x) = 0
uzupełnienie
A5: x + y = y + x
A6: x
y = y
x
przemiennośd
A7: (x + y) + z = x + (y + z)
łącznośd
A8: (x
y)
z = x
(y
z)
łącznośd
A9: x
(y + z) = x
y + x
z
rozdzielnośd
A10: x + y
z = (x + y)
(x + z)
rozdzielnośd
Twierdzenia
T1: x + x = x
T2: x
x = x
idempotentnośd
T3: x + 1 = 1
T4: x
0 = 0
własności „zera” i „jedynki”
T5:
(x + y) = (
x)
(
y)
dualnośd (prawa d'Morgana)
T6:
(x
y) = (
x) + (
y)
dualnośd (prawa d'Morgana)
T7: x + (x
y) = x
T8 x
(x + y) = x
absorpcja
T9:
(
x) = x
inwolucja
Przykłady
B = <B,
,
,
, 0, 1>, gdzie B = {0, 1}
B = <B,
,
,
, F, T>, gdzie B = {T, F}
B = <B,
,
,
, 0, 1>, gdzie B = {F
n
} oraz F
n
- zbiór funkcji boolowskich

Prawo Moore'a
w oryginalnym sformułowaniu mówi, ze ekonomicznie optymalna liczba tranzystorów w układzie
scalonym podwaja sie co 18 miesięcy. To sformułowanie przypisuje sie jednemu z założycieli firmy Intel, Gordonowi
Moore’owi, który tezę taka przedstawił w kwietniu 1965 roku. Istnieje jeszcze inne sformułowanie prawa Moore’a: „moc
obliczeniowa komputerów podwaja sie co 18 miesięcy”. Tak wyrażone prawo jest nawet popularniejsze od oryginalnego
sformułowania.
Zakres znaczenia Termin ten jest też używany do określenia praktycznie dowolnego postępu technologicznego. "Prawo
Moore'a", mówiące że "moc obliczeniowa komputerów podwaja się co 24 miesiące" jest nawet popularniejsze od
oryginalnego prawa Moore'a.
Podobnie (z innym okresem) mówi się o:
stosunku mocy obliczeniowej do kosztu
ilości tranzystorów w stosunku do powierzchni
układu
rozmiarach RAM
pojemności dysków twardych
przepustowości sieci
Nie wszystko jednak podlega tak rozszerzonemu prawu Moore'a: latencja (pamięci, dysków twardych, sieci komputerowych)
spada bardzo powoli, pomimo rosnącej przepustowości. W niewielkim stopniu spadły też ceny typowych komputerów, ich
rozmiar czy pobór mocy.
Granice prawa Moore'a
Jednym z głównych powodów, dzięki któremu ten wykładniczy wzrost jest możliwy, jest stosowanie coraz mniejszych
elementów w procesie fabrykacji. Współcześnie dominują technologie 90, 65 i ostatnio 45 nm, kiedy we wczesnych latach 90.
używano technologii 500 nm. Rozmiary te nie mogą się jednak zmniejszad w nieskooczonośd: w pewnym momencie takie
tranzystory musiałyby byd mniejsze od atomów. Inne istotne ograniczenie wynikają ze skooczoności prędkości światła,
stawiając nieprzekraczalną barierę minimalnego czasu potrzebnego na nawiązanie komunikacji między oddalonymi od siebie
elementami komputerów lub sieci komputerowych.
Ze względu na niemożliwośd zejścia z rozmiarem struktur poniżej rozmiaru atomu prawo to musi kiedyś przestad
obowiązywad. Nie stanie się to nagle, będzie to raczej trwający proces spowalniania polepszania pewnych parametrów, jak
szybkośd czy pojemnośd. Od wielu lat powtarzane zapowiedzi, że czas obowiązywania prawa Moore'a właśnie dobiega kooca,
dotychczas nie spełniały się, aczkolwiek w listopadzie 2006 sam Gordon Moore oświadczył, że według niego za 2–3 lata (w
2008 lub 2009 roku) prawo to przestanie obowiązywad.
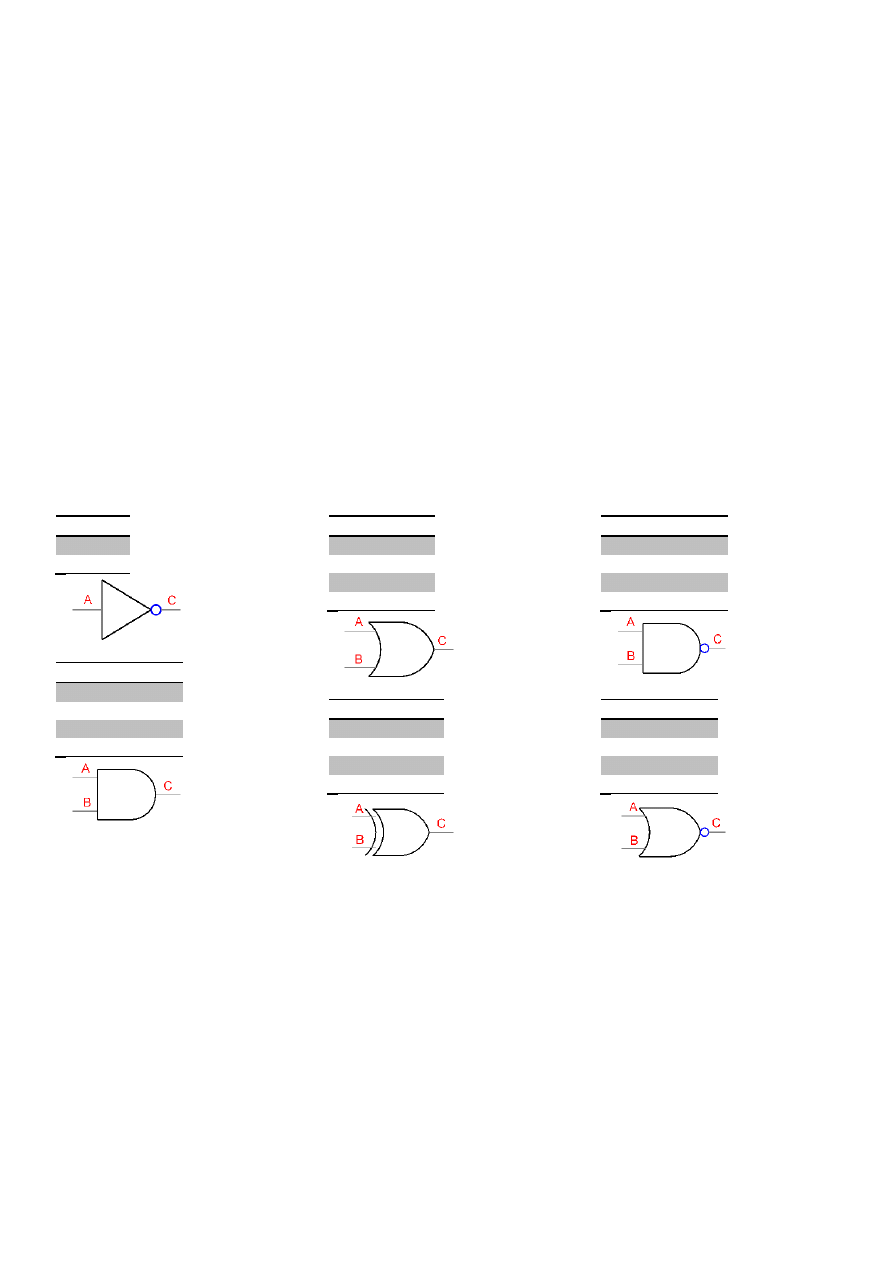
Bramka logiczna
(angielskie logical gate), elementarny układ kombinacyjny mający stałą liczbę wejśd i wyjśd, na
których mogą się pojawiad tylko wartości ze zbioru dwuelementowego ,0, 1-.
W technice cyfrowej wykorzystuje się układy elektron. charakteryzujące się skooczoną liczbą możliwych stanów. Najbardziej
są rozpowszechnione cyfrowe układy dwustanowe, konstrukcyjnie najprostsze, a jednocześnie zapewniające maksymalną
odpornośd na zakłócenia oraz najlepszą rozróżnialnośd przybieranych stanów. Najczęściej stany elektron. układów cyfrowych
są definiowane przez stany ich wyjśd (portów), a fizycznie reprezentowane przez poziomy napięd elektrycznych. Układy
cyfrowe dwustanowe pozwalają na prostą realizację działao algebry Boole’a oraz opartej na niej arytmetyki w zapisie
dwójkowym (binarnym, zero-jedynkowym).
Charakterystyka układów cyfrowych:
L - stan niski - 0 odpowiada napięciu 0-0,4V
H - stan wysoki - 1 odpowiada napięciu 5V
Sygnał cyfrowy charakteryzują dwa stany napięcia:
wysoki poziom VH
niski poziom VL
wysoki oznaczona się jako "1", a poziom niski jako "0". Stąd pochodzi nazwa sygnał cyfrowy.
VH = 1
VL = 0
Stany logiczne na wejściu i wyjściu bramki zawiera tablica prawdy - jest to (najczęściej) tabela, która ukazuje jak przy danych
stanach logicznych ustawionych na wejściach bramki będzie ustawione wyjście bramki.
Istnieje sześd podstawowych bramek logicznych: NOT, AND, OR, XOR, NAND i NOR.
NOT - negacja.
IN NOT
0
1
1
0
AND -iloczyn
In1 In2 AND
0
0
0
0
1
0
1
0
0
1
1
1
OR - suma
In1 In2 OR
0
0
0
0
1
1
1
0
1
1
1
1
XOR - tylko jeden z
In1 In2 XOR
0
0
0
0
1
1
1
0
1
1
1
0
NAND - negacja iloczynu
In1 In2 NAND
0
0
1
0
1
1
1
0
1
1
1
0
NOR - negacja sumy
In1 In2 NOR
0
0
1
0
1
0
1
0
0
1
1
0
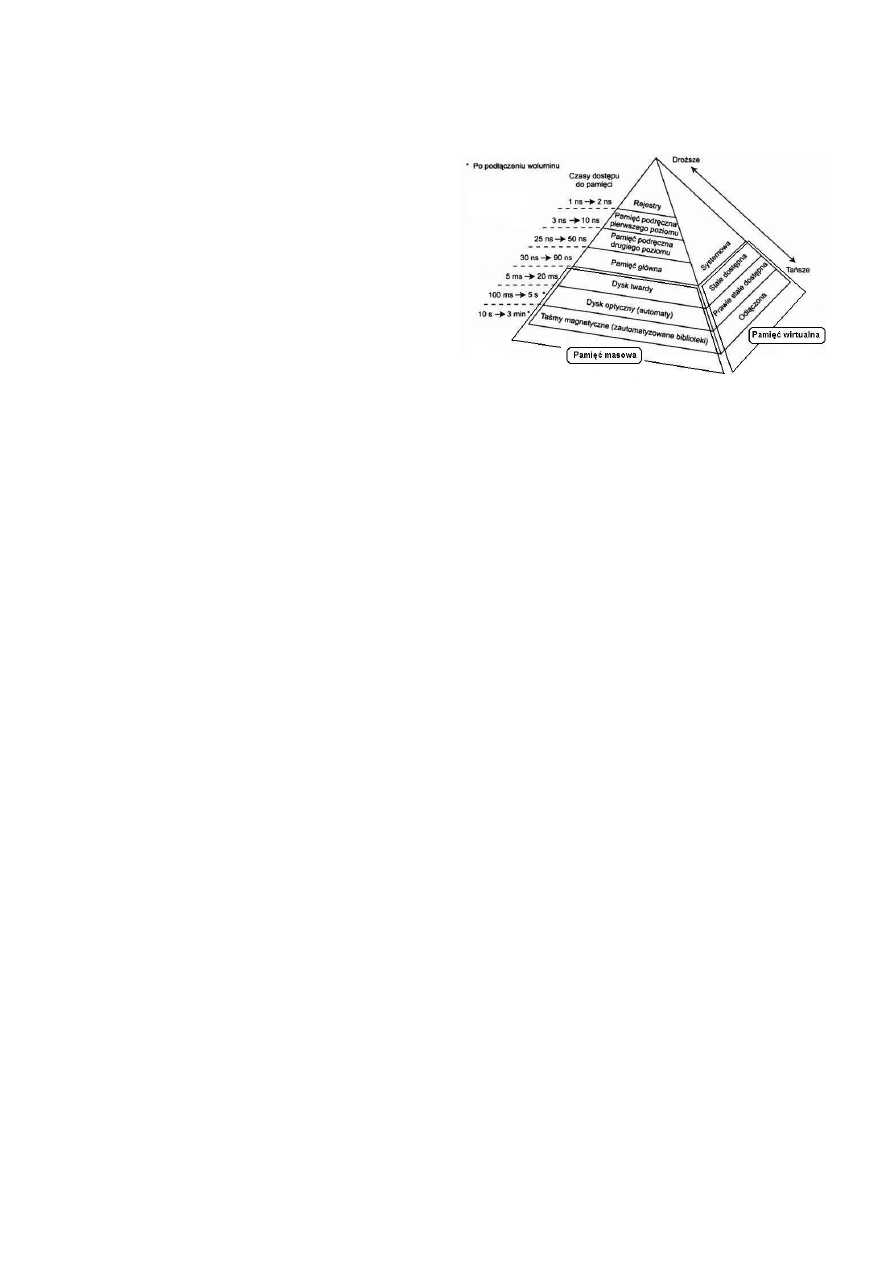
Pamięd komputerowa
to różnego rodzaju urządzenia i bloki funkcjonalne komputera, służące do przechowywania
danych i programów (systemu operacyjnego oraz aplikacji). Potocznie przez "pamięd komputerową" rozumie się samą
pamięd operacyjną.
Hierarchia pamięci opiera się na „oddaleniu” od procesora, gdzie odległośd określa czas dostępu do danych.
1. Rejestry procesora to komórki pamięci o niewielkich
rozmiarach (najczęściej 4/8/16/32/64/128 bitów)
umieszczone wewnątrz procesora i służące do
przechowywania tymczasowych wyników obliczeo,
adresów lokacji w pamięci operacyjnej itd. Większośd
procesorów
przeprowadza
działania
wyłącznie
korzystając z wewnętrznych rejestrów, kopiując do
nich dane z pamięci i po zakooczeniu obliczeo
odsyłając wynik do pamięci.
Rejestry procesora stanowią najwyższy szczebel w
hierarchii pamięci, będąc najszybszym z rodzajów
pamięci komputera, zarazem najdroższą w produkcji,
a co za tym idzie - o najmniejszej pojemności.
Realizowane zazwyczaj za pomocą przerzutników
dwustanowych, z reguły jako tablica rejestrów (blok rejestrów, z ang. register file).
Liczba rejestrów zależy od zastosowania procesora i jest jednym z kryteriów podziału procesorów na klasy
CISC i RISC. Proste mikroprocesory mają tylko jeden rejestr danych zwany akumulatorem, procesory stosowane w
komputerach osobistych - kilkanaście, natomiast procesory w komputerach serwerowych mogą mied ich kilkaset.
2. Cache (pamięd podręczna) to mechanizm, w którym ostatnio pobierane dane dostępne ze źródła o wysokiej latencji
i niższej przepustowości są przechowywane w pamięci o lepszych parametrach.
Cache jest elementem właściwie wszystkich systemów - współczesny procesor ma 2 albo 3 poziomy pamięci cache
oddzielającej go od pamięci RAM. Dostęp do dysku jest buforowany w pamięci RAM, a dokumenty HTTP są
buforowane przez pośredniki HTTP oraz przez przeglądarkę.
Systemy te są tak wydajne dzięki lokalności odwołao - jeśli nastąpiło odwołanie do pewnych danych, jest duża
szansa, że w najbliższej przyszłości będą one potrzebne ponownie. Niektóre systemy cache próbują przewidywad,
które dane będą potrzebne i pobierają je wyprzedzając żądania. Np. cache procesora pobiera dane w pakietach po
kilkadziesiąt czy też więcej bajtów, cache dysku zaś nawet do kolejnych kilkuset kilobajtów czytanego właśnie pliku.
3. Pamięd operacyjna (en. internal memory, Primary storage). Jest to pamięd adresowana i dostępna bezpośrednio
przez procesor, a nie przez urządzenia wejścia-wyjścia procesora. W pamięci tej mogą byd umieszczane rozkazy
(kody operacji) procesora (program) dostępny bezpośrednio przez procesor i stąd nazwa pamięć operacyjna. W
Polsce często pamięd ta jest utożsamiana z pamięcią RAM, chod jest to zawężenie pojęcia, pamięcią operacyjną jest
też pamięd nieulotna (ROM, EPROM i inne jej odmiany) dostępna bezpośrednio przez procesor. Obecnie pamięci
operacyjne są wyłącznie pamięciami elektronicznymi, dawniej używano pamięci ferrytowych.
W obecnych komputerach głównym rodzajem pamięci operacyjnej jest pamięd RAM, wykonana jako układy
elektroniczne, wykorzystywana przez komputer do przechowywania programu i danych podczas jego pracy.
4. Pamięd masowa (ang. mass memory, mass storage) – pamięd trwała, przeznaczona do długotrwałego
przechowywania dużej ilości danych w przeciwieostwie do pamięci RAM i ROM. Pamięd masowa zapisywana jest na
zewnętrznych nośnikach informacji. Nośniki informacji zapisywane i odczytywane są w urządzeniach zwanych
napędami.
Nośniki magnetyczne:
a. dyski stałe - pamięd o dostępie bezpośrednim; nośniki danych zainstalowane w macierzach dyskowych
b. taśmy magnetyczne - pamięd o dostępie sekwencyjnym zapisywana i odczytywana w napędzie taśmowym
Napędy optyczne:
c. CD-ROM
d. płyty DVD
e. płyty Blu-Ray Disk
f. płyty HD DVD
Pamięci półprzewodnikowe (pozbawione części mechanicznych), współpracujące z różnymi złączami
komunikacyjnymi:
g. pamięci USB.
h. karty pamięci
5. Pamięd offline tworzą dane, które są składowane na nośniku poza serwerem. Najbardziej popularnymi pamięciami
offline są nośniki taśm i nośniki optyczne. Chociaż nośniki optyczne stają się coraz bardziej popularne, to nośniki
taśm są stosowane najczęściej. Inną opcją, której można używad, są wirtualne nośniki optyczne. Wirtualnych
nośników optycznych można używad do składowania obrazów wirtualnych na jednostkach dyskowych. Następnie
obrazy takie można kopiowad na dyski CD lub DVD albo rozpowszechniad je przez sied.

Przerwanie
(ang. interrupt) lub żądanie przerwania (IRQ – Interrupt ReQuest) – sygnał powodujący zmianę przepływu
sterowania, niezależnie od aktualnie wykonywanego programu. Pojawienie się przerwania powoduje wstrzymanie aktualnie
wykonywanego programu i wykonanie przez procesor kodu procedury obsługi przerwania (ang. interrupt handler).
Przerwania dzielą się na dwie grupy:
I.
Sprzętowe:
a. Zewnętrzne – sygnał przerwania pochodzi z zewnętrznego układu obsługującego przerwania sprzętowe;
przerwania te służą do komunikacji z urządzeniami zewnętrznymi, np. z klawiaturą, napędami dysków itp.
b. Wewnętrzne, nazywane wyjątkami (ang. exceptions) – zgłaszane przez procesor dla sygnalizowania sytuacji
wyjątkowych (np. dzielenie przez zero); dzielą się na trzy grupy:
i.
faults (niepowodzenie) – sytuacje, w których aktualnie wykonywana instrukcja powoduje błąd; gdy
procesor powraca do wykonywania przerwanego kodu wykonuje tę samą instrukcję która
wywołała wyjątek;
ii.
traps (pułapki) – sytuacja, która nie jest błędem, jej wystąpienie ma na celu wykonanie
określonego kodu; wykorzystywane przede wszystkim w debugerach; gdy procesor powraca do
wykonywania przerwanego kodu, wykonuje następną, po tej która wywołała wyjątek, instrukcję;
iii.
aborts – błędy, których nie można naprawid.
II.
Programowe – z kodu programu wywoływana jest procedura obsługi przerwania; najczęściej wykorzystywane do
komunikacji z systemem operacyjnym, który w procedurze obsługi przerwania (np. w DOS 21h, 2fh, Windows 2fh,
Linux x86 przerwanie 80h) umieszcza kod wywołujący odpowiednie funkcje systemowe w zależności od zawartości
rejestrów ustawionych przez program wywołujący, lub oprogramowaniem wbudowanym jak procedury BIOS lub
firmware.

Układ cyfrowy a analogowe.
Układy cyfrowe to rodzaj układów elektronicznych, w których sygnały napięciowe przyjmują tylko określoną liczbę
poziomów, którym przypisywane są wartości liczbowe. Najczęściej (chod nie zawsze) liczba poziomów napięd jest równa dwa,
a poziomom przypisywane są cyfry 0 i 1, wówczas układy cyfrowe realizują operacje zgodnie z algebrą Boola i z tego powodu
nazywane są też układami logicznymi. Obecnie układy cyfrowe budowane są w oparciu o bramki logiczne realizujące
elementarne operacje znane z algebry Boola: iloczyn logiczny (AND, NAND), sumę logiczną (OR, NOR), negację NOT, różnicę
symetryczną (XOR) itp. Ze względu na stopieo skomplikowania współczesnych układów wykonuje się je w postaci układów
scalonych.
Zalety układów cyfrowych:
Możliwośd bezstratnego kodowania i przesyłania informacji – jest to coś, czego w układach analogowych
operujących na nieskooczonej liczbie poziomów napięd nie sposób zrealizowad.
Zapis i przechowywanie informacji cyfrowej jest prostsze.
Mniejsza wrażliwośd na zakłócenia elektryczne.
Możliwośd tworzenia układów programowalnych, których działanie określa program komputerowy
Wady układów cyfrowych:
Są skomplikowane zarówno na poziomie elektrycznym, jak i logicznym i obecnie ich projektowanie wspomagają
komputery
Chociaż są bardziej odporne na zakłócenia, to wykrywanie przekłamao stanów logicznych, np. pojawienie się liczby
0 zamiast spodziewanej 1, wymaga dodatkowych zabezpieczeo (jak: kod korekcyjny) i też nie zawsze jest możliwe
wykrycie błędu. Jeszcze większy problem stanowi ewentualne odtworzenie oryginalnej informacji.
Sygnał analogowy – sygnał, który może przyjmowad dowolną wartośd z ciągłego przedziału (nieskooczonego lub
ograniczonego zakresem zmienności). Jego wartości mogą zostad określone w każdej chwili czasu, dzięki funkcji
matematycznej opisującej dany sygnał.

Podział procesorów
długośd słowa maszynowego
liczba rdzeni
architektura
przeznaczenie
taktowanie zegara
wielkośd cache
Procesor a system operacyjny
system operacyjny budowany jest z myślą o konkretnej platformie sprzętowej
popularnośd konkretnych procesorów zależy w głównej mierze od tego, jakie systemy operacyjne będą na nich
działad
procesor wpływa przede wszystkim na szybkośd działania systemu operacyjnego
Charakterystyka CISC
Istotą architektury CISC jest to, iż pojedynczy rozkaz mikroprocesora, wykonuje kilka operacji niskiego poziomu, jak na
przykład pobranie z pamięci, operację arytmetyczną i zapisanie do pamięci.
duży zbiór instrukcji
dużo (nieużywanych) trybów adresowania
kody instrukcji o zmiennej długości
wyspecjalizowane rejestry
łatwiejsze kodowanie w językach Asemblerowych
Charakterystyka RISC
Jej podstawowe cechy to:
1. Zredukowana liczba rozkazów do niezbędnego minimum. Ich liczba wynosi kilkadziesiąt, podczas gdy w procesorach
CISC sięga setek. Upraszcza to znacznie dekoder rozkazów.
2. Redukcja trybów adresowania, dzięki czemu kody rozkazów są prostsze, bardziej zunifikowane, co dodatkowo
upraszcza wspomniany wcześniej dekoder rozkazów. Ponadto wprowadzono tryb adresowania, który ogranicza ilośd
przesłao.
3. Ograniczenie komunikacji pomiędzy pamięcią, a procesorem. Przede wszystkim do przesyłania danych pomiędzy
pamięcią, a rejestrami służą dedykowane instrukcje, które zwykle nazywają się load (załaduj z pamięci), oraz store
(zapisz do pamięci); pozostałe instrukcje mogą operowad wyłącznie na rejestrach. Schemat działania na liczbach
znajdujących się w pamięci jest następujący: załaduj daną z pamięci do rejestru, na zawartości rejestru wykonaj
działanie, przepisz wynik z rejestru do pamięci.
4. Zwiększenie liczby rejestrów (np. 32, 192, 256, podczas gdy np. w architekturze x86 jest zaledwie 8 rejestrów), co
również ma wpływ na zmniejszenie liczby odwołao do pamięci.
5. Dzięki przetwarzaniu potokowemu (ang. pipelining) wszystkie rozkazy wykonują się w jednym cyklu maszynowym,
co pozwala na znaczne uproszczenie bloku wykonawczego, a zastosowanie superskalarności także na umożliwienie
równoległego wykonywania rozkazów. Dodatkowo czas reakcji na przerwania jest krótszy.
mała liczba instrukcji
proste tryby adresowania
kod instrukcji mieszczący się w słowie procesora
dużo uniwersalnych rejestrów procesora
jedynie store i load na danych w pamięci
potokowanie
Charakterystyka VLIW
Obecnie procesory VLIW są oparte na architekturze RISC, zazwyczaj z czterema lub maksymalnie ośmioma jednostkami
obliczeniowymi. Po normalnej kompilacji programu, kompilator VLIW porządkuje kod na ścieżki, które wprost nie posiadają
jakichkolwiek zależności. Następnie są one dzielone na cztery lub więcej części (jeden dla każdej jednostki obliczeniowej CPU)
i pakowane razem w większe instrukcje z dodatkową informacją odnośnie jednostki, na której ma byd wykonywana.
Rezultatem tego jest pojedynczy wielki op-code (stąd nazwa "Very Long").
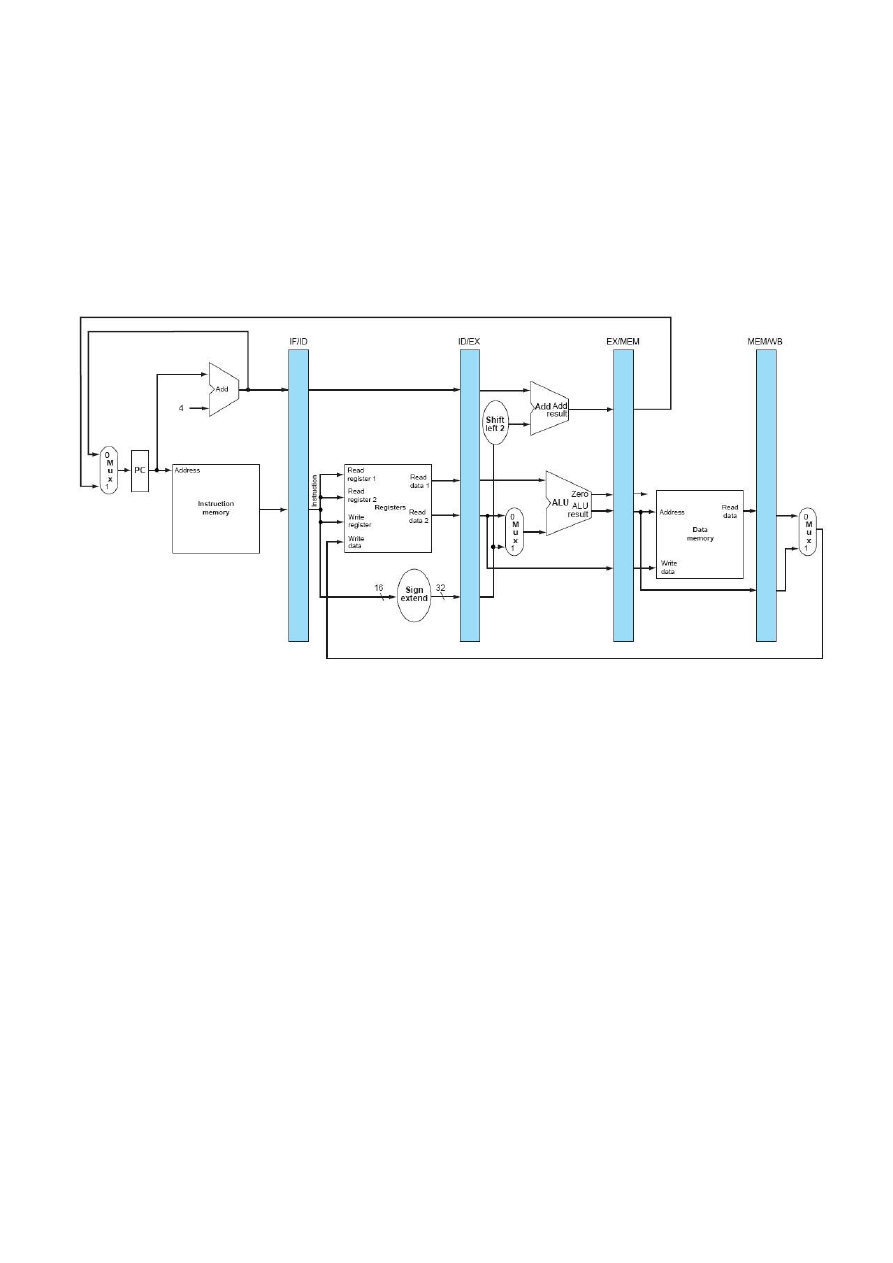
Przetwarzanie potokowe
- sposób przetwarzania rozkazów w procesorach, w którym do przetwarzania
zastosowano potok podzielony na etapy. W przeciwieostwie do klasycznego (sekwencyjnego) sposobu przetwarzania
rozkazów gdzie każdy jest pobierany, dekodowany, wykonywany oddzielnie, w przetwarzaniu potokowym w procesorze
następuje jednoczesne przetwarzanie kliku (zależności od głębokości/ilości etapów potoku) rozkazów jednocześnie. Każdy z
rozkazów znajduje się w danym cyklu maszynowym w innym etapie przetwarzania i dzięki temu wyniki operacji mogą byd
produkowane niemal w każdym cyklu.
Główne etapy przetwarzania potokowego to:
pobranie kodu rozkazu z pamięci
dekodowanie - wytworzenie sygnałów sterujących jednostkami wykonawczymi na podstawie kodu rozkazu
wykonanie - właściwa częśd przetwarzania rozkazu w jednostce wykonawczej
zapis wyniku operacji do pamięci
Podział każdego etapu na podetapy umożliwia skrócenie cyklu, a to z kolei pozwala na dalszy wzrost szybkości przetwarzania.
Taki mechanizm nazywany jest przetwarzaniem superpotokowym superpipelined pipeline. Liczba podetapów cyklów
rozkazów (głębokośd potoku) nie może byd jednak dowolnie duża, bo podział etapu wymaga zwiększenia liczby buforów
separujących, co z kolei powoduje zmniejszenie przepustowości potoku (opóźnienie w układach separujących etapy jest
proporcjonalne do ich liczby i jest skutkiem wzrostu narzutu czasu na cele organizacyjne).
W przetwarzaniu potokowym ze względu na narzuty czasowe na wykonanie każdego etapu rozkazu (opóźnienia buforów) i
koniecznośd wpasowania etapów w ramy czasowe potoku (czas przejścia rozkazu przez etap jest równy czasowi cyklu), czas
wykonania pojedynczego rozkazu jest dłuższy niż w przetwarzaniu sekwencyjnym. Przy częstych zakłóceniach potoku może
się zatem zdarzyd, że czas przetwarzania potokowego będzie porównywalny bądź nawet dłuższy z czasem sekwencyjnego
wykonania instrukcji programu.
Na wydajnośd potoku mają wpływ:
konflikty sterowania - zaburzenie sekwencji przetwarzania przy rozgałęzieniu (np. występuje w momencie
wykonywania rozkazu skoku warunkowego, zależnego od stanu wskaźników ustalanych przez poprzednie, jeszcze
nie zakooczone rozkazy). Zmniejszenie uciążliwości tego konfliktu jest osiągane przez zastosowanie prognozy
rozgałęzieo (skoków). Prognoza może byd statyczna (oparta na analizie/identyfikacji kodu rozkazu i rozpoznawaniu
skoków bezwarunkowych zwykłych lub skoków bezwarunkowych do podprogramu) lub dynamiczna (oparta na
historii przetwarzania – analizie szansy wykonania rozgałęzienia). Straty wywołane przez rozgałęzienia warunkowe
można zmniejszyd metodami programowymi (przyspieszenie chwili wytworzenia warunku przez zmianę sekwencji
rozkazów) lub sprzętowymi (implementacja układów prognozy rozgałęzieo umożliwiających uprzednie przełączanie
strumienia rozkazów zanim rozkaz przejdzie do etapu dekodowania – jest powiązany z buforem/kolejką rozkazów).
konflikty danych - jednoczesne użycie tej samej danej (gdy wynik 2 instrukcji zależy od wartości wytworzonej przez
instrukcję poprzednią). Grupowe przetwarzanie rozkazów (stosowane w procesorach nowszej generacji) umożliwia
usunięcie niektórych konfliktów danych i jednocześnie złagodzenie konfliktów dostępu. Nie zawsze bowiem jest
konieczne zachowanie porządku wykonania rozkazów ustalonego w programie, a zmiana kolejności może
wyeliminowad przestoje związane z konfliktem danych i konfliktem dostępu. Metodą zmniejszania strat wywołanych

konfliktem dostępu jest stosowanie skrótów (bypass) na ścieżkach przepływu danych. Skróty polegają na tworzeniu
bezpośrednich połączeo między stanowiskami etapów wykonania i zapisu wyniku, co umożliwia błyskawiczne
dostarczenie wyniku wytworzonego ale nie zapisanego do jednostki wykonawczej (forwarding). Każdy skrót wymaga
użycia dodatkowego zatrzasku i pary komparatorów do sprawdzenia, czy sąsiednie instrukcje współdzielą zasób.
konflikty zasobów - jednoczesne żądanie dostępu do pamięci lub innego zasobu unikatowego w komputerze (pliku
rejestrowego, jednostki zmiennoprzecinkowej FPU spowodowany długim czasem wykonywania działao
zmiennoprzecinkowych). W celu wyeliminowania konfliktów do pamięci spowodowanych jednoczesnymi żądaniami
pobrania kolejnego rozkazu i przesłania danych, wewnętrzną pamięd podręczną należy rozdzielid na osobne pamięci
danych i pamięci kodu (podobnie jak w architekturze harwardzkiej). Rozwiązanie takie nie jest sprzeczne z modelem
klasycznym, bo pamięd podręczna jest jedynie buforem pamięci głównej, zawierającym kopie oryginalnej informacji
umieszczonej w pamięci głównej lub dane tymczasowe. Takie rozdzielenie umożliwia jednoczesny dostęp do kodu i
danych. Potencjalny konflikt dostępu do jednostki adresowej złagodzi też buforowanie instrukcji, podobnie jak
konflikt przy konieczności zapisu do pamięci głównej można złagodzid przez stosowanie bufora zapisu. Konflikty
dostępu do plików rejestrowych można złagodzid rozbudowując układy dostępu do rejestrów (np. dostęp
wieloportowy, umożliwiający jednoczesne użycie różnych rejestrów pliku).
Metody rozwiązywania zastojów
forwarding
Polega na tym, że wynik działania operacji jest wcześniej dostępny dla wcześniejszych faz przetwarzania. DLX
pokazuje to jako zielone strzałki. Dodanie forwardingu powoduje, że fazy dekodowania instrukcji i wykonania jej
mogą pobierad argumenty nie tylko z rejestrów, ale też z wyjścia.
zmiana kolejności instrukcji – scheduling
Polega na takim ułożeniu instrukcji, aby hazard nie występował. Bardziej efektywne od forwardingu, ale zmusza
programistę do myślenia. Sprzętowo rozwiązywane w ten sposób, że w drażliwych momentach w potoku nop i potok
czeka aż dana się obliczy. Gdy programista poukłada odpowiednio instrukcje, to nie doda się żaden nop, ani nie
będzie używany forwarding.
przenazwanie rejestrów
rozwijanie pętli
Polega na tym, że kod jednej pętli piszemy 2 lub więcej razy tak, aby jedno wykonanie przetworzyło kilka porcji
danych. Wysoko efektywne, mocno zmniejsza ilośd skoków, a tym samym stalli. To z tego powodu RISCe mają tak
dużo rejestrów.
zgadywanie dalszej kolejności rozkazów
optymalizacja kodu
Cache (pamięd podręczna)
to mechanizm, w którym ostatnio pobierane dane dostępne ze źródła o wysokiej
latencji i niższej przepustowości są przechowywane w pamięci o lepszych parametrach.
Cel stosowania pamięci cache w procesorach
Aby określid cel stosowania pamięci podręcznej cache, należy w skrócie omówid zasadę działania mikroprocesora. Jest on
układem cyfrowym taktowanym przez sygnał zegarowy, który realizuje zadany program - ciąg rozkazów umieszczony w
pamięci operacyjnej. Program ma zwykle zadanie przetworzenia określonych danych pobranych z pamięci (lub urządzeo
zewnętrznych), oraz zapisanie wyników ich przetwarzania, też w pamięci (lub przekazanie do urządzeniach zewnętrznych).
Szybkośd wykonywania programu zależy w znacznej mierze od czasu dostępu procesora do układu pamięci operacyjnej. Nie
bez znaczenia jest także pojemnośd pamięci (ile danych można w niej zapisad). Stosowane we współczesnych komputerach
wielozadaniowe systemy operacyjne umożliwiają uruchamianie wielu programów jednocześnie. Dobrze jest więc gdy
procesor ma do dyspozycji dużą pamięd operacyjną RAM. Ważnym czynnikiem pozostaje też koszt zastosowanego układu
pamięci. Naturalnie w przypadku praktycznego systemu musi on byd jak najniższy.
Istnieją wzajemne zależności pomiędzy wszystkimi opisywanymi wyżej parametrami.
mniejszy czas dostępu - większy koszt
większa pojemnośd - większy czas dostępu
Z tego wynika, że nie jest możliwe wyprodukowanie idealnej pamięci o maksymalnie dużej pojemności, a przy tym małym
czasie dostępu i minimalnym koszcie. Możliwe jest budowanie szybkich układów, ale stosunkowo drogich i o małej
pojemności. Istnieją też duże pamięci o małych kosztach w przeliczeniu na bajt, ale cechujące się mniejszą efektywnością w
zakresie czasu dostępu.
We współczesnych procesorach stosuje się rozwiązanie kompromisowe, polegające na zastosowaniu pamięci wewnętrznej
dwupoziomowej. Mikroprocesor wyposaża się we względnie dużą i wolniejszą pamięd główną, oraz w mniejszą, ale szybszą
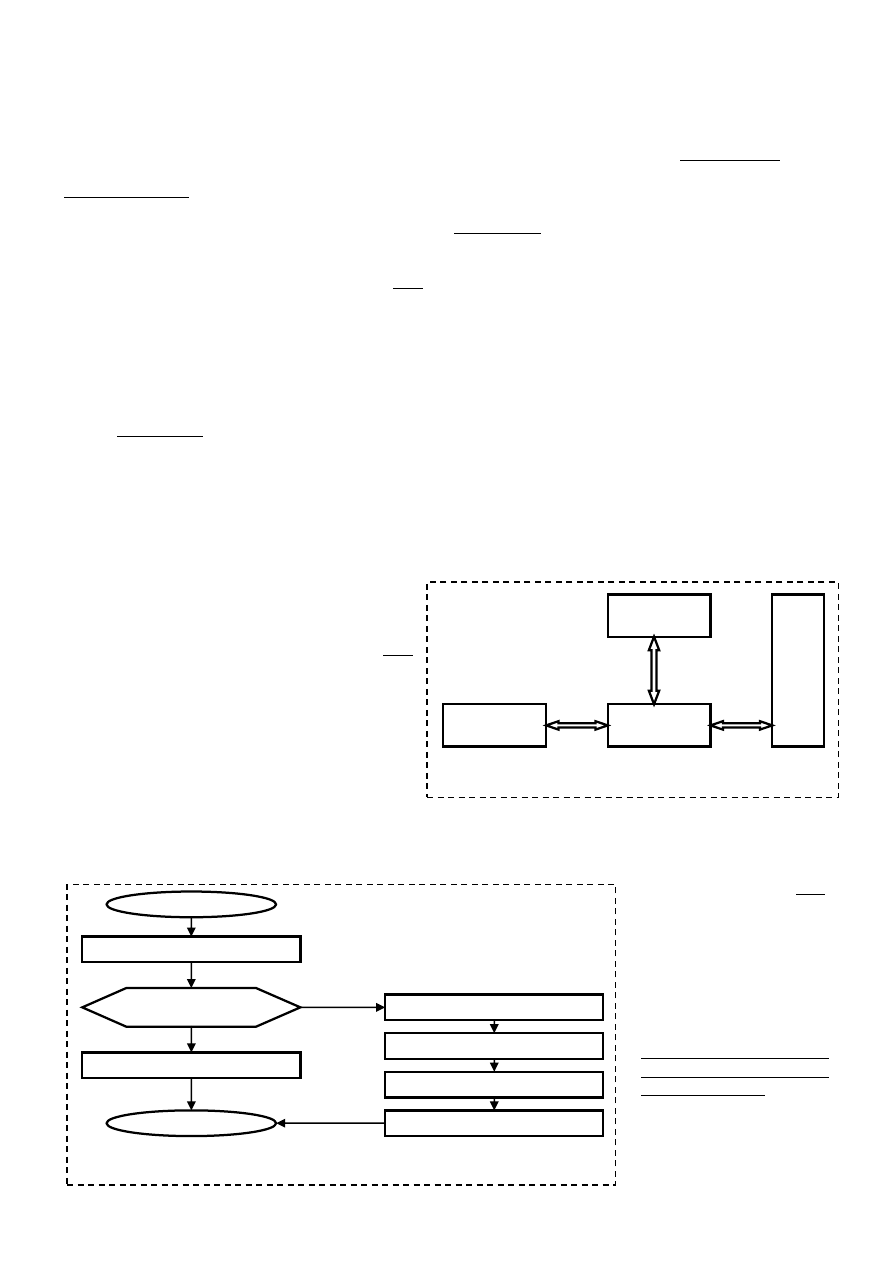
pamięd podręczną cache. Ilustruje to schemat blokowy przedstawiony na rysunku 2. Takie rozwiązanie pozwala na
korzystanie z pamięci o dużej pojemności, jednocześnie możliwe jest umieszczenie najpotrzebniejszych danych, w szybkiej
pamięci podręcznej.
Sprzętowa pamięd podręczna (ang. Cache memory) jest pamięcią typu SRAM (Static Random Access Memory). Układy tej
pamięci są zbudowane z tranzystorów, które trwale przechowują zapisane dane. Pamięd podręczna zawiera kopię części
zawartości pamięci głównej. Gdy procesor zamierza
odczytad słowo z pamięci, najpierw następuje
sprawdzenie, czy słowo to nie znajduje się w pamięci
podręcznej. Jeśli tak, to słowo to jest szybko dostarczane
do procesora. Jeśli nie, to blok pamięci głównej RAM
zawierający określoną liczbę kolejnych słów jest
wczytywany do pamięci podręcznej, a następnie
potrzebne słowo (zawarte w tym bloku) jest dostarczane
do procesora. Następne odwołania do tego samego
słowa i sąsiednich zawartych w przepisanym bloku będą
realizowane już znacznie szybciej.
Organizacja współpracy procesora z takimi pamięciami
wymaga zastosowania dodatkowego układu - kontrolera
cache, który steruje tym procesem.
Efektywnośd stosowania cache zależy w znacznej mierze od sposobu ułożenia kodu programów i danych pobieranych z
pamięci przez mikroprocesory. Zwykle kod i dane nie są "porozrzucane" przypadkowo po całej dostępnej przestrzeni
adresowej w pamięci RAM.
Większośd
odwołao
do
pamięci
w
trakcie
wykonywania
programu
odbywa się przez pewien czas
pracy
mikroprocesora
w
wąskim obszarze. Zjawisko to
jest
określane
mianem
lokalności odniesieo.
Lokalnośd odniesieo można
uzasadnid
intuicyjnie
w
następujący sposób:
Z
wyjątkiem
rozkazów skoku i wywołania
procedury,
realizacja
programów
ma
charakter
sekwencyjny. Tak więc, w
Procesor CPU
Kontroler
CACHE
Pamięd CACHE
P
am
ię
d R
A
M
Rys. 1. Podłączenie cache do procesora.
START
CPU wystawia adres słowa
Sprawdzanie czy blok zawierający
słowo jest w CACHE
Pobranie słowa z CACHE
Wykonanie
Odczyt bloku z pamięci
Wyznaczenie miejsca dla bloku CACHE
Zapis bloku w CACHE
Dostarczenie słowa potrzebnego CPU
NIE
TAK
Rys. 2. Algorytm dostępu procesora do pamięci.

większości przypadków następny rozkaz przewidziany do pobrania z pamięci następuje bezpośrednio po ostatnio
pobranym rozkazie.
Rzadkością jest występowanie w programach długich, nieprzerwanych sekwencji wywołao procedury (procedura
wywołuje procedurę itd.), a potem długiej sekwencji powrotów z procedur. Wymagałoby to ciągłego odwoływania
się do oddalonych od siebie obszarów pamięci głównej, zawierających kody poszczególnych procedur.
Większośd pętli (konstrukcji bardzo często występujących w programach) składa się z małej liczby wielokrotnie
powtarzanych rozkazów. Podczas iteracji następuje kolejne powtarzanie zwartej części programu.
W wielu programach znaczna częśd obliczeo obejmuje przetwarzanie struktur danych, takich jak tablice lub szeregi
rekordów ułożone kolejno w pamięci operacyjnej. Tak, więc procesor pobiera dane zapisane w sposób
uporządkowany w małym jej fragmencie.
Oczywiście w długim czasie wykonywania programu procesor potrzebuje dane rozmieszczone w różnych odległych
miejscach pamięci. Zwykle jednak, po wykonaniu skoku następne odniesienia odbywają się już lokalnie. Przepisanie bloku
kolejnych komórek pamięci do szybkiego układu cache może, więc skutecznie przyspieszyd dostęp do pamięci.
W stosowanych obecnie rozwiązaniach można wyróżnid następujące poziomy pamięci podręcznej.
L1 - (level 1) zintegrowana z procesorem - umieszczona wewnątrz jego struktury.
L2 - (level 2) umieszczona w jednej obudowie układu scalonego mikroprocesora lub na wspólnej płytce hybrydowej
(Pentium II).
L3 - (level 3) występuje w bezpośrednim sąsiedztwie procesora ITANIUM.
Pamięd podręczna najniższego poziomu (L1 – Level 1) jest stosunkowo mała, ale dane w niej zgromadzone są szybko
dostępne dla procesora. W wypadku braku potrzebnych w danym momencie danych (braku trafienia), następuje odwołanie
do pamięci kolejnych, wyższych poziomów. Po ich odczycie następuje przepisanie do niższych poziomów, tak by były szybciej
dostępne w kolejnych odwołaniach. Jeśli dane nie są aktualnie buforowane w cache, następuje odczyt bloku pamięci głównej
RAM, który je zawiera i wymiana zawartości cache. Pamięci niższych poziomów mogą mied mniejszą pojemnośd i byd bardziej
efektywne. Procesor może szybko odczytywad mniejsze porcje danych w jednym cyklu zegara. Wyższe poziomy cache mają
większe pojemności, dzięki czemu odwołania do RAM mogą odbywad się rzadziej. Można też w jednym odczycie przepisad
większą porcję danych z RAM.
Ważnym zagadnieniem, jest podział pamięci podręcznej na oddzielny blok dla kodu programu i oddzielny blok dla danych.
W taki sposób jest podzielona pamięd poziomu L1 procesora ITANIUM - Pamięd cache poziomów L2 i L3 jest już wspólna dla
rozkazów i danych. W wielu (szczególnie starszych) procesorach wykorzystuje się również jednolitą pamięd podręczną
poziomu L1. Takie rozwiązanie też posiada pewne zalety. Poniżej przedstawiono korzyści płynące z zastosowania pamięci
oddzielnej i jednolitej.
Pamięd oddzielna kod i dane
Eliminowana jest rywalizacja o dostęp do pamięci między układem pobierania i dekodowania rozkazów w procesorze, a
jednostką wykonującą w tym samym czasie inne, poprzednio pobrane rozkazy, które mogą wymagad odczytu pewnych
zmiennych z cache. Ma to szczególne znaczenie w przypadku procesorów superskalarnych, w których kilka rozkazów jest
wykonywanych równolegle. Dlatego we współczesnych procesorach poziom pamięci podręcznej L1 jest zawsze dzielony na
blok danych i instrukcji.
Pamięd łączna dla kodu i danych
Poprawia się współczynnik trafieo w tak zorganizowanej pamięci podręcznej, dzięki temu, że naturalnie równoważy się
zapotrzebowanie na przechowywanie rozkazów i danych. Jeśli na przykład program wymaga ciągłego pobierania rozkazów i w
małym stopniu korzysta z danych, dostępna pamięd podręczna zapełni się w większości rozkazami. Oddzielna cache dla
danych w takiej sytuacji pozostałaby niewykorzystana. Drugą zaletą jest to, że upraszcza się układ procesora - łatwiej jest
zrealizowad w jego strukturze jeden bufor pamięci cache niż dwa.
Sposoby dołączania pamięci cache do procesora
Układ cache jest w obecnych procesorach ściśle związany z ich strukturą - właściwie poziom L1 fizycznie stanowi integralną
częśd mikroprocesora. Jednak aby łatwiej było przedstawid zasadę działania i sposoby dostępu procesora do pamięci
podręcznej, ta częśd programu traktuje ją jako oddzielny blok logiczny, dołączony do mikroprocesora, nie zajmując się jej
fizycznym umiejscowieniem. Pisząc o sposobach dołączania, mamy więc na myśli sposób umieszczenia bloku cache na drodze
procesor - pamięd.
Obecnie stosuje się trzy podstawowe sposoby dostępu procesora do pamięci podręcznej:
Procesor odwołuje się do cache wykorzystując magistralę pamięciową. Pamięd podręczna jest podłączona równolegle z
pamięcią operacyjną RAM. W takim układzie częstotliwośd
pracy obu pamięci jest taka sama (komunikacja odbywa się
po wspólnej magistrali), tylko czas dostępu dzięki szybkości
cache może ulec skróceniu. Wykorzystanie tej samej
magistrali nie jest korzystne. Jest ona blokowana przy
każdym dostępie procesora do cache i nie może byd w tym
samym czasie udostępniona innym urządzeniom
Look – Aside (dostęp bezpośredni)
Procesor CPU
Pamięd operacyjna
RAM
Pamięd podręczna
CACHE
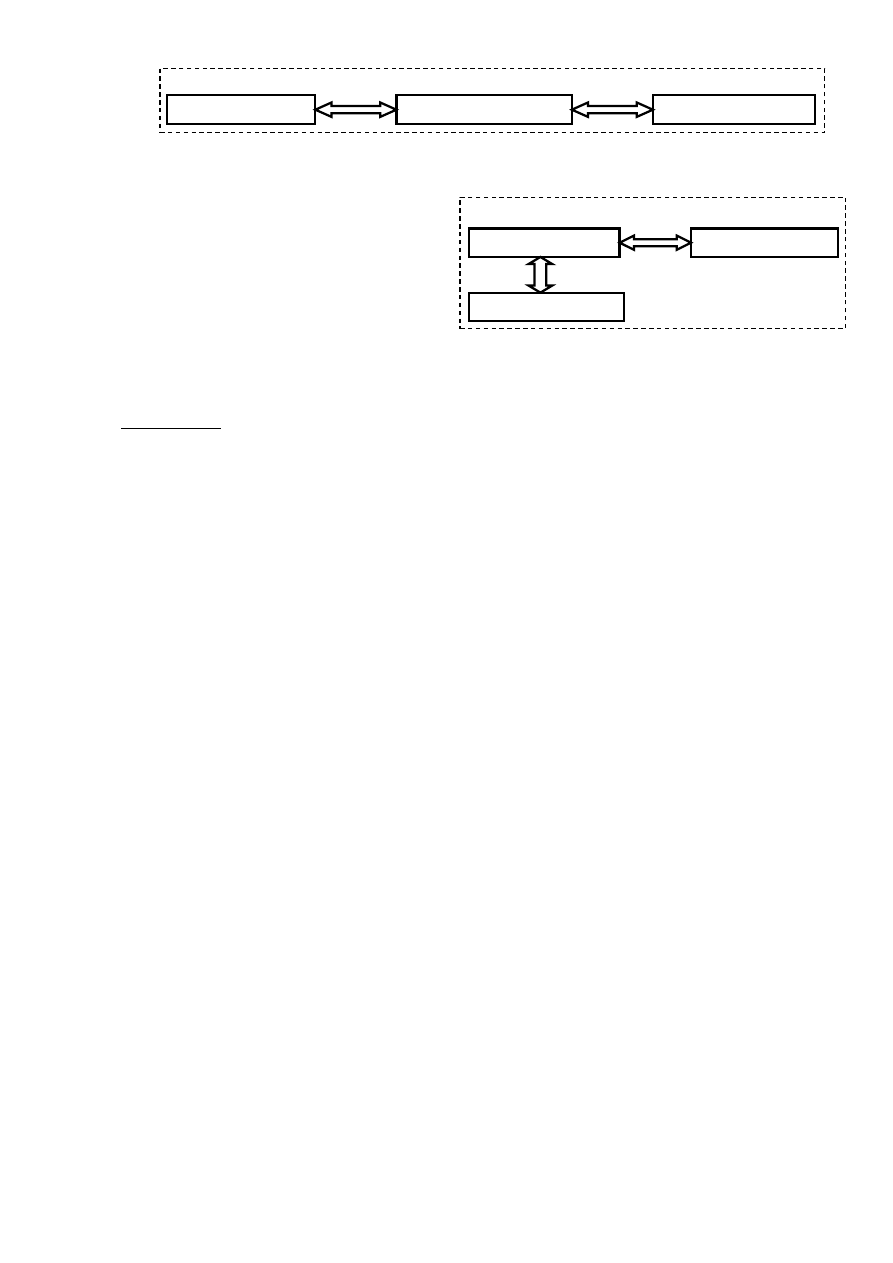
Układ
pamięci
podręcznej
pośredniczy
w dostępie procesora do RAM. Procesor odwołuje się do układu cache, natomiast ten układ jest dołączony przez magistralę
pamięciową do RAM.
Układ pamięci podręcznej jest dołączony do procesora przez
oddzielną magistralę nazywaną BSB (Back Side Bus). Druga
magistrala FSB (Front Side Bus) łączy procesor z pamięcią
główną. W tym układzie częstotliwości obu magistral są
zupełnie niezależne. Możliwe jest też wykorzystanie magistrali
FSB przez inne urządzenia zapisujące do pamięci RAM, w
czasie gdy procesor komunikuje się z cache po BSB.
Budowa i organizacja pamięci podręcznej
Pamięd cache jest zorganizowana w linijki (o rozmiarach 16 lub 32 bajty - 128 lub 256 bitów), w których są przechowywane
informacje pobrane z RAM w postaci słów binarnych. Jedna linijka jest najmniejszą porcją informacji - blokiem danych jaki
układ cache wymienia z pamięcią operacyjną RAM. W różnych linijkach może byd więc zapisana kopia zawartości odległych
bloków z pamięci głównej.
Poniżej opisano budowę 32-bajtowej linijki pamięci podręcznej L1 w procesorze Pentium (rys. 3). W innych procesorach
mogą byd zastosowane trochę inne rozwiązania, jednak ogólna zasada organizacji cache w linijki pozostaje taka sama.
Procesor Pentium posiada oddzielną pamięd podręczną poziomu L1 dla kodu programu (8kB) i oddzielną dla danych (8kB).
Każda z nich jest podzielona na 256 linijek (256 x 32 B = 8kB).
Aby zbiór takich linijek był dla procesora użyteczną strukturą, w której łatwo odszukad potrzebne dane, musi istnied
mechanizm zapisywania i kodowania dodatkowych informacji na temat każdej linijki. Przede wszystkim potrzebna jest
informacja o tym, które fragmenty zawartości pamięci RAM są aktualnie skopiowane w poszczególnych linijkach. Jest to
niezbędne, aby podczas żądania procesora odczytu z pamięci, kontroler cache mógł poprawnie określid czy dane są dostępne
w linijkach, czy trzeba je sprowadzid z RAM. Wszystkie te informacje przechowuje się w katalogu cache (czasem określanym
skrótem TAG-RAM). Jest on częścią pamięci podręcznej, która zawiera rekordy odpowiadające każdej linijce cache. Są w nich
zakodowane informacje na temat danych aktualnie zapisanych w odpowiednich linijkach. Wartości poszczególnych pół tych
rekordów mogą także wskazywad, że dana linijka jest wolna.
Podczas dostępu procesora do cache układy logiczne dzielą przekazywany przez niego adres na następujące części:
Znacznik (20 bitów) jest porównywany ze znacznikiem w katalogu cache. Na podstawie porównania znaczników
określa się, czy potrzebne procesorowi dane są w linijce cache (określanie trafienia).
Wiersz (7 bitów) określa, która pozycja (indeks) w katalogu 1 i katalogu 2 może odwzorowywad potrzebne dane.
Słowo (3 bity) pozwala na określenie, które z ośmiu 32-bitowych słów przechowywanych w linijce zawiera dane
potrzebne procesorowi.
Bajt (2 bity) określa, który bajt w 32- bitowym słowie jest aktualnie potrzebny mikroprocesorowi.
W wypadku braku trafienia, tak zbudowany adres wskazuje blok w pamięci operacyjnej RAM, zawierający potrzebne dane.
Zgodnie z zasadą działania cache, po odczytaniu zawartości bloku z RAM musi ona byd zapisana do pamięci podręcznej. Na
podstawie bitu LRU oraz części adresu (pola wiersz) jest wyznaczana linijka, do której można dokonad zapisu.
Skrót MESI używany do określania bitów w katalogu cache, został utworzony od pierwszych liter angielskich określeo czterech
możliwych stanów linijki (Modified, Exclusive, Schared, Invalid). Na podstawie stanu bitów MESI można także określid, czy
dane w poszczególnych linijkach są także zapisane w innych poziomach pamięci podręcznej. Stan bitów MESI zmienia się
również podczas modyfikacji danych w pamięci. Dotychczas omawiane były jedynie zagadnienia związane ze skróceniem czas
dostępu do danych i rozkazów podczas ich odczytu. Jednak procesor nie tylko odczytuje z pamięci RAM. W trakcie
wykonywania programu musi też tam zapisywad wyniki swoich peracji, modyfikowad pewne zmienne i dane. Niektóre z nich
mogą byd w tym czasie skopiowane także do pamięci podręcznej. Wiąże się z tym koniecznośd zadbania o aktualnośd obu
kopii danych.
Do pamięci operacyjnej oprócz procesora mogą też mied dostęp inne urządzenia. Mogą one zapisywad i odczytywad RAM bez
udziału mikroprocesora. Jeśli dokonają zmiany słowa w RAM, którego kopia aktualnie jest przechowywana w cache, mogą
spowodowad, że procesor posiada w pamięci podręcznej nieaktualne dane. Również gdy procesor w trakcie programu
dokona zmiany danych tylko w cache, inne urządzenia mogą odczytad bezpośrednio z RAM stare błędne wartości. Należy
zaznaczyd, że taka niespójnośd może występowad tylko dla pamięci podręcznej danych. W oddzielnej pamięci podręcznej
kodu programu procesor nie zapisuje swoich wyników, gdyż przechowuje ona jedynie dla niego instrukcje - kolejne rozkazy.
Są różne rozwiązania problemu spójności danych stosowane w różnych procesorach, jednakże generalnie można wyróżnid
dwa sposoby:
Look – Throgh (dostęp „przez”)
ProcesorCPU
Pamięd operacyjna RAM
Pamięd podręczna CACHE
Look – Backside (dostęp od tyłu)
Procesor CPU
Pamięd operacyjna RAM
Pamięd podręczna CACHE
mag. BSB
mag. FSB

Write Trougch (zapis jednoczesny)
W tym sposobie każdy zapis danych wykonywany jest jednocześnie zarówno do pamięci głównej jak i do cache. Każdy zapis
wymaga więc dostępu procesora do pamięci RAM. Również każdy bezpośredni zapis do RAM wykonywany przez inne
urządzenia musi byd monitorowany przez procesor. W ten sposób może on w razie potrzeby uaktualnid zawartośd cache. Jest
to więc najbardziej naturalny sposób, jednak generuje znaczny przepływ danych między pamięciami co powoduje duże
opóźnienia.
Wirte Back (zapis opóźniony)
W tym trybie przy zapisie procesor aktualizuje tylko pamięd podręczną. Jednocześnie dla zmodyfikowanych linijek układ
cache ustawia odpowiednie statusy (na bitach MES). Zawartośd pamięci głównej jest aktualizowana później na żądanie. Może
ono byd wyrażone przez instrukcję programową WBINVO (Write Back and Invalid Data Cache), lub specjalny sterujący sygnał
sprzętowy.
Aktualizacja jest też wyzwalana w wyniku braku trafienia w fazie odczytu z pamięci głównej. Gdy trzeba dokonad wymiany
linijki cache, zawartośd linijki usuwanej mającej status zmodyfikowany (zakodowany na bitach MESI), musi byd koniecznie
zapisana do RAM.
Taka implementacja sposobu utrzymania spójności danych jest bardziej wydajna, minimalizuje ilośd cyklów zapisu do pamięci
głównej. Problemem jest jednak to, że bezpośredni dostęp zewnętrznych modułów wejścia-wyjścia do RAM także powoduje
koniecznośd uaktualniania pamięci cache co może powodowad pewne opóźnienia.
W trakcie wykonywania programu może też nastąpid koniecznośd zapisu danych w obszarach RAM, które nie są aktualnie
skopiowane do pamięci podręcznej. Niektóre procesory w takim wypadku mogą po prostu dokonywad zapisu w RAM z
pominięciem układu cache. W nowszych generacjach procesorów stosuje się mechanizm, w którym zapis danych pociąga za
sobą skopiowanie odpowiedniego bloku RAM do linijki cache, gdzie jest on modyfikowany.
Dzięki temu ewentualny odczyt lub zapis tych samych danych w następnych rozkazach procesora może przebiegad już bez
konieczności odwoływania się do RAM.

Pamięd wirtualna
to mechanizm komputerowy zapewniający procesowi wrażenie pracy w jednym dużym, ciągłym
obszarze pamięci operacyjnej podczas gdy fizycznie może byd ona pofragmentowana, nieciągła i częściowo przechowywana
na urządzeniach pamięci masowej. Systemy korzystające z tej techniki ułatwiają tworzenie rozbudowanych aplikacji oraz
poprawiają wykorzystanie fizycznej pamięci RAM. Często popełnianym błędem jest utożsamianie pamięci wirtualnej z
wykorzystaniem pamięci masowej do rozszerzenia dostępnej pamięci operacyjnej. Rozszerzenie pamięci na dyski twarde w
rzeczywistości jest tylko naturalną konsekwencją zastosowania techniki pamięci wirtualnej, lecz może byd osiągnięte także na
inne sposoby, np. nakładki lub całkowite przenoszenie pamięci procesów na dysk, gdy znajdują się w stanie uśpienia. Pamięd
wirtualna działa na zasadzie przedefiniowania adresów pamięci tak, aby "oszukad" procesy i dad im wrażenie pracy w ciągłej
przestrzeni adresowej.
Obecnie wszystkie systemy operacyjne ogólnego przeznaczenia wykorzystują techniki pamięci wirtualnej dla procesów
uruchamianych w ich obrębie. Wcześniejsze systemy takie, jak DOS, wydania Microsoft Windows*1+ z lat 80. oraz
oprogramowanie komputerów mainframe z lat 60. nie pozwalały pracowad w środowisku z pamięcią wirtualną. Godnymi
odnotowania wyjątkami były komputery Atlas, B5000 oraz Apple Lisa.
Pamięd wirtualna wymaga wykonania pewnych dodatkowych nakładów pracy przy próbie odczytu lub zapisu, dlatego
systemy wbudowane lub szczególnego przeznaczenia, gdzie czas dostępu jest czynnikiem krytycznym i musi byd
przewidywalny, często z niej rezygnują za cenę zmniejszonego determinizmu.
Stronicowana pamięd wirtualna
Prawie wszystkie istniejące obecnie implementacje dzielą wirtualną przestrzeo adresową procesu na strony. Strona jest to
obszar ciągłej pamięci o stałym rozmiarze, zazwyczaj 4 KB. Systemy, gdzie zapotrzebowanie na wielkośd wirtualnej przestrzeni
adresowej jest większe lub dysponujące większymi zasobami pamięci operacyjnej mogą używad stron o większym rozmiarze.
Rzeczywista pamięd operacyjna podzielona jest na ramki, których rozmiar odpowiada wielkości stron. System operacyjny
według uznania może przydzielad ramkom strony pamięci lub pozostawiad je puste.
Tablice stron
Każde odwołanie przez dany proces do wirtualnego adresu pamięci powoduje jego przetłumaczenie na adres
fizyczny przy pomocy tablicy stron. Wpisy w tablicy stron przechowują namiary na ramkę, gdzie aktualnie znajduje
się dana strona lub znacznik informujący, że dana strona znajduje się aktualnie na dysku twardym.
Systemy mogą utrzymywad tylko jedną tablicę stron - wtedy wszystkie procesy pracują we wspólnej wirtualnej
przestrzeni adresowej, przy czym każdy z nich używa innej jej części. Odmiennym podejściem jest utrzymywanie
osobnych tablic stron dla każdego procesu oraz dodatkowej na potrzeby samego systemu operacyjnego. W tym
modelu każdy proces posiada swoją własną, niezależną przestrzeo adresową. Dwa identyczne adresy logiczne
należące do różnych procesów tłumaczone są na inne adresy rzeczywiste, uniemożliwiając tym samym jednemu
procesowi modyfikację danych innego.
Dynamiczne tłumaczenie adresów
Dynamiczne tłumaczenie adresów jest zadaniem głównego procesora. Najczęściej wykonywane jest przez sprzętowy
komponent zwany Memory management unit (ang. układ zarządzania pamięcią) obsługujący każde odwołanie do
pamięci. MMU przeszukuje aktualną tablicę stron w poszukiwaniu ramki zawierającej żądane dane i przekazuje
rzeczywisty adres pozostałym częściom procesora odpowiedzialnym za wykonanie instrukcji. Jeśli MMU stwierdzi, że
dana strona nie znajduje się w pamięci, generuje przerwanie braku strony, które musi zostad obsłużone przez
zarządcę pamięci systemu operacyjnego.
Zarządca pamięci
Ta częśd systemu operacyjnego odpowiada za tworzenie i zarządzanie tablicami stron, a także obsługuje przerwanie
braku strony generowane przez MMU. W przypadku jego wystąpienia zarządca poszukuje wskazanej strony na dysku
twardym (pamięd wymiany), ładuje ją do aktualnie wolnej ramki, uaktualnia tablicę stron i nakazuje MMU ponowne
przetłumaczenie adresu. Ładowanie brakujących stron z dysku jest powolnym procesem, dlatego jeśli system
dysponuje wystarczającą ilością ramek, dąży do minimalizacji wystąpieo błędów braku strony.
Gdy ilośd dostępnej pamięci operacyjnej jest na wyczerpaniu, zarządca może podjąd decyzję o przeniesieniu części
stron z ramek na dysk. Do wyznaczenia niepotrzebnych stron stosowany jest algorytm LRU (Least Recently Used), w
którym na dysk przenoszone są najrzadziej używane strony jako te, których najprawdopodobniej proces będzie
potrzebowad najpóźniej.
Strony krytyczne
Nie wszystkie strony pamięci mogą byd przeniesione do pamięci wymiany. Wśród takich krytycznych stron możemy
wyróżnid:
Procedury obsługi przerwao oparte są na tablicy wskaźników do kodu obsługującego poszczególne rodzaje
przerwao. Gdyby strony przechowujące ten kod mogłyby byd przenoszone do pamięci wymiany, obsługa przerwao
byłaby jeszcze bardziej kłopotliwa, szczególnie że brak strony również sygnalizowany jest przez przerwanie.
Tablice stron same nie podlegają stronicowaniu.

Bufory danych, które muszą byd dostępne dla innych podzespołów komputera, które przeważnie wykorzystują
fizyczne adresowanie.
Krytyczne fragmenty kodu jądra lub aplikacji, gdzie nie można pozwolid na zbyt długie czasy dostępu do pamięci
spowodowane przez brak strony.
Segmentowana pamięd wirtualna
Pamięd wirtualna może byd zrealizowana również w oparciu o techniki segmentowania. Wirtualna przestrzeo adresowa
aplikacji podzielona jest na bloki zmiennej długości zwane segmentami. Adres logiczny składa się z numeru segmentu oraz
przesunięcia w obrębie tego segmentu. Pamięd jest wciąż fizycznie dostępna za pomocą tzw. adresu absolutnego lub
liniowego. Do jego otrzymania, procesor odczytuje deskryptor segmentu z tablicy segmentów. Zawiera on flagę informującą,
czy dany segment znajduje się aktualnie w pamięci czy nie, adres początku segmentu oraz jego długośd. Następnie sprawdza
czy przesunięcie adresu mieści się w granicach segmentu. Jeśli segment nie znajduje się w pamięci, generowane jest
przerwanie powiadamiające system operacyjny o konieczności jego załadowania. W trakcie wczytywania może okazad się
niezbędne przeniesienie innych segmentów na dysk, aby zrobid miejsce dla nowego.
Technikę segmentowanej pamięci wirtualnej wspierał jako dodatkową opcję procesor Intel 80286 będący jednym z przodków
wszystkich procesorów stosowanych we współczesnych komputerach PC, jednak nie była ona wykorzystywana w większości
systemów operacyjnych.
Możliwe jest połączenie segmentacji pamięci ze stronicowaniem poprzez podzielenie każdego segmentu na strony. Systemy
korzystające z tej techniki, np. Multics czy IBM System/38 pamięd wirtualna realizowana jest przez stronicowanie, zaś
segmentacja wprowadza dodatkowy mechanizm ochrony. W procesorach IA-32 oraz Intel 80386 segmenty znajdują się w 32-
bitowej liniowej stronicowanej przestrzeni adresowej: segmenty mogą byd przenoszone z/do przestrzeni adresowej, zaś
strony w obrębie przestrzeni adresowej mogą byd przenoszone z/do pamięci operacyjnej. Korzystają z tego jednak tylko
nieliczne systemy - najczęściej stosowane jest wyłącznie stronicowanie pamięci.
Różnica pomiędzy pamięcią stronicowaną a segmentowaną nie polega wyłącznie na podziale pamięci na porcje o stałym i
zmiennym rozmiarze. W tego typu systemach segmentacja jest często widoczna dla procesów użytkownika, w
przeciwieostwie do przezroczystych stron, które nie wymagają od nich żadnego dodatkowego zaangażowania.
Szamotanie procesów
Mianem szamotania określany jest stan procesu, w którym spędza on więcej czasu na oczekiwaniu na brakujące strony
pamięci niż na faktycznym wykonywaniu obliczeo, co znacząco spowalnia jego działanie. Problem szamotania występuje we
wszystkich implementacjach i objawia się przy zbyt dużym zapotrzebowaniu na pamięd ze strony procesów przy zbyt małej
ilości wolnych ramek. Problem może byd częściowo rozwiązany przez poprawienie jakości programów, lecz na dłuższą metę
jedynym skutecznym lekarstwem jest zainstalowanie większej ilości fizycznej pamięci operacyjnej.

RAM
(ang. Random Access Memory – pamięd o dostępie swobodnym) – podstawowy rodzaj pamięci cyfrowej. Chod nazwa
sugeruje, że oznacza to każdą pamięd o bezpośrednim dostępie do dowolnej komórki pamięci (w przeciwieostwie do pamięci
o dostępie sekwencyjnym, np. rejestrów przesuwających), nazwa ta ze względów historycznych oznacza tylko te rodzaje
pamięci o bezpośrednim dostępie, które mogą byd też zapisywane przez procesor, a wyklucza pamięci ROM (tylko do
odczytu), pomimo iż w ich przypadku również występuje swobodny dostęp do zawartości.
W pamięci RAM przechowywane są aktualnie wykonywane programy i dane dla tych programów oraz wyniki ich pracy.
Zawartośd większości pamięci RAM jest tracona kilka sekund po zaniku napięcia zasilania, niektóre typy wymagają także
odświeżania, dlatego wyniki pracy programów muszą byd zapisane na innym nośniku danych.
Pamięci RAM dzieli się na pamięci statyczne (ang. Static RAM, w skrócie SRAM) oraz pamięci dynamiczne (ang. Dynamic RAM,
w skrócie DRAM). Pamięci statyczne są szybsze od pamięci dynamicznych, które wymagają ponadto częstego odświeżania,
bez którego szybko tracą swoją zawartośd. Pomimo swoich zalet są one jednak dużo droższe i w praktyce używa się pamięci
DRAM.
Pamięd RAM jest stosowana głównie jako pamięd operacyjna komputera, jako pamięd niektórych komponentów (procesorów
specjalizowanych) komputera (np. kart graficznych, dźwiękowych, itp.), jako pamięd danych sterowników
mikroprocesorowych.
SRAM
(ang. Static Random Access Memory), statyczna pamięd o dostępie swobodnym – typ pamięci półprzewodnikowej
stosowanej w komputerach, służy jako pamięd buforująca między pamięcią operacyjną i procesorem.
Słowo "statyczna" oznacza, że pamięd SRAM przechowuje dane tak długo, jak długo włączone jest zasilanie, w odróżnieniu od
pamięci typu DRAM, która wymaga okresowego odświeżania.
Każdy bit przechowywany jest w pamięci SRAM w układzie zbudowanym z czterech tranzystorów, które tworzą przerzutnik,
oraz z dwóch tranzystorów sterujących. Taka struktura umożliwia znacznie szybsze odczytanie bitu niż w pamięci typu DRAM,
oraz w przeciwieostwie do pamięci DRAM nie wymaga odświeżania.
Pamięci SRAM wykorzystywane są w szybkich pamięciach podręcznych cache, gdyż nie wymagają one dużych pojemności
(gęstośd danych w SRAM jest 4 razy mniejsza niż w DRAM), ale prędkośd dostępu jest około 7 razy szybsza od DRAM (1 cykl
SRAM wynosi około 10 ns, natomiast w DRAM około 70 ns). Szybkośd ta dotyczy dostępu swobodnego (czyli kolejne
odczytywane dane są ulokowane pod różnymi adresami), w przypadku odczytu danych z sąsiednich komórek adresowych
szybkośd pamięci SRAM i DRAM jest jednak porównywalna.
DRAM
(ang. Dynamic Random Access Memory) – rodzaj ulotnej pamięci półprzewodnikowej o dostępie swobodnym,
której bity są reprezentowane przez stan naładowania kondensatorów. Poszczególne jej elementy zbudowane są z
tranzystorów MOS, z których jeden pełni funkcję kondensatora, a drugi elementu separującego.
W przeciwieostwie do pamięci statycznych nie wymagają stałego zasilania, a jedynie okresowego odświeżania zawartości (ze
względu na rozładowywanie się kondensatorów). Dzięki takiemu zasilaniu zużywają mniej energii. Jednocześnie pojedyncza
komórka pamięci dynamicznej składa się z mniejszej liczby elementów niż analogiczna komórka pamięci statycznej. Powyższe
cechy pozwalają na większe upakowanie elementów w układach scalonych, co daje efekt w postaci niższych kosztów
produkcji i pozwala na budowę układów pamięci o większych pojemnościach.
Odświeżanie musi następowad w regularnych odstępach czasu oraz bezpośrednio po każdej po operacji odczytu i polega na
ponownym zapisie odczytanej wartości w tych samych komórkach pamięci. Za odświeżanie odpowiedzialne są
specjalizowane układy wspomagające (kontroler pamięci – obecnie najczęściej stanowi on integralną częśd chipsetu) bądź
sam procesor (np. Z80).
Pamięci dynamiczne najczęściej łączone są w dwuwymiarowe tablice adresowane numerem wiersza i kolumny, co pozwala
ograniczyd liczbę wymaganych linii adresowych i przyspiesza sekwencyjny odczyt danych umieszczonych w kolejnych
komórkach tego samego wiersza pamięci.
Pamięci dynamiczne są obecnie szeroko wykorzystywane jako pamięd operacyjna we wszystkich urządzeniach
niespecjalizowanych.

CAS
to skrót od Column Address Strobe (bramkowanie adresu kolumny) lub Column Address Select (wybór adresu
kolumny). Adresy te odnoszą się do kolumny fizycznych komórek pamięci w tablicy kondensatorów używanych w
dynamicznej pamięci RAM (DRAM).
CAS latency
(CL), czyli „czas oczekiwania CAS”, oznacza czas (liczbę cykli zegara) jaki upływa między wysłaniem przez
kontroler pamięci żądania dostępu do określonej kolumny pamięci a odczytaniem danych z tej kolumny na wyprowadzeniach
modułu pamięci.
Im niższa jest wartośd CAS latency (przy takiej samej częstotliwości zegara), tym mniej czasu potrzeba na pobranie danych z
pamięci. Najprościej mówiąc, im krótsze CAS latency, tym lepiej. Czas oczekiwania CAS wpływa bowiem na szybkośd
wykonywania w pamięci operacji, takich jak pobranie kolejnej instrukcji do wykonania przez procesor, operacje
odczytu/zapisu/porównania/przesunięcia bitowego itp. Im dłuższy czas oczekiwania, tym dłużej procesor musi czekad na
reakcję ze strony pamięci. Istnieją różnorodne sposoby na przyśpieszenie działania pamięci, takie jak stosowanie przeplotu
(ang. interleaving; pozwala na rozdzielenie operacji zapisu na kilka banków pamięci), czy też korzystanie z pamięci podręcznej
(ang. cache; umożliwia tymczasowe przechowywanie przetwarzanych danych, a czasem także inteligentną synchronizację z
modułami pamięci).
Zdecydowana większośd producentów pamięci komputerowych podaje parametr CAS latency (CL) w nazwie konkretnego
modelu. Niektórzy podają go bezpośrednio (pisząc np. CL5).

Architektura komputera
– sposób organizacji elementów tworzących komputer. Pojęcie to używane jest dosyd
luźno. Może ono dzielid systemy komputerowe ze względu na wiele czynników, zazwyczaj jednak pod pojęciem architektury
rozumie się organizację połączeo pomiędzy pamięcią, procesorem i urządzeniami wejścia-wyjścia.
Innym, stosowanym potocznie znaczeniem terminu "architektura komputera" jest typ procesora wraz z zestawem jego
instrukcji. Właściwszym określeniem w tym przypadku jest model programowy procesora (ang. ISA – Instruction Set
Architecture).
Taksonomia Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześddziesiątych XX wieku przez
Michaela Flynna, opierająca się na liczbie przetwarzanych strumieni danych i strumieni rozkazów.
W taksonomii tej wyróżnia się cztery grupy:
SISD (Single Instruction, Single Data) - przetwarzany jest jeden strumieo danych przez jeden wykonywany program -
komputery skalarne (sekwencyjne).
SIMD (Single Instruction, Multiple Data) - przetwarzanych jest wiele strumieni danych przez jeden wykonywany program
- tzw. komputery wektorowe.
MISD (Multiple Instruction, Single Data) - wiele równolegle wykonywanych programów przetwarza jednocześnie jeden
wspólny strumieo danych. W zasadzie jedynym zastosowaniem są systemy wykorzystujące redundancję (wielokrotne
wykonywanie tych samych obliczeo) do minimalizacji błędów.
MIMD (Multiple Instruction, Multiple Data) - równolegle wykonywanych jest wiele programów, z których każdy
przetwarza własne strumienie danych - przykładem mogą byd komputery wieloprocesorowe, a także klastry i gridy.
Ze względu na sposób podziału pracy i dostęp procesora do pamięci możemy podzielid architektury na:
SMP (Symmetric Multiprocessing) – symetryczne
ASMP (Asymmetric Multiprocessing) – asymetryczne
NUMA (Non-Uniform Memory Access) – asymetryczne
AMP (Asynchronous Multiprocessing) – asynchroniczne
MPP (Massively Parallel Processors)
Ze względu na sposób organizacji pamięci i wykonywania programu:
architektura von Neumanna
Polega na ścisłym podziale komputera na trzy podstawowe części:
o
procesor (w ramach którego wydzielona bywa częśd sterująca oraz częśd arytmetyczno-logiczna)
o
pamięd komputera (zawierająca dane i sam program)
o
urządzenia wejścia/wyjścia
System komputerowy zbudowany w oparciu o architekturę von Neumanna powinien:
o
mied skooczoną i funkcjonalnie pełną listę rozkazów
o
mied możliwośd wprowadzenia programu do systemu komputerowego poprzez urządzenia zewnętrzne i jego
przechowywanie w pamięci w sposób identyczny jak danych
o
dane i instrukcje w takim systemie powinny byd jednakowo dostępne dla procesora
o
informacja jest tam przetwarzana dzięki sekwencyjnemu odczytywaniu instrukcji z pamięci komputera i
wykonywaniu tych instrukcji w procesorze.
Architektura harwardzka
W odróżnieniu od architektury von Neumanna, pamięd danych programu jest oddzielona od pamięci rozkazów.
Podstawowa architektura komputerów zerowej generacji i początkowa komputerów pierwszej generacji. Prostsza (w
stosunku do architektury von Neumanna) budowa przekłada się na większą szybkośd działania - dlatego ten typ
architektury jest często wykorzystywany w procesorach sygnałowych oraz przy dostępie procesora do pamięci cache.
Separacja pamięci danych od pamięci rozkazów sprawia, że architektura harwardzka jest obecnie powszechnie
stosowana w mikrokomputerach jednoukładowych, w których dane programu są najczęściej zapisane w nieulotnej
pamięci ROM (EPROM/EEPROM), natomiast dla danych tymczasowych wykorzystana jest pamięd RAM (wewnętrzna lub
zewnętrzna).
architektura mieszana
łączy w sobie cechy architektury harwardzkiej i architektury von Neumanna. Oddzielone zostały pamięci danych i
rozkazów, lecz wykorzystują one wspólne magistrale danych i adresową. Architektura niniejsza umożliwia łatwe
przesyłanie danych pomiędzy rozdzielonymi pamięciami.
Wyszukiwarka
Podobne podstrony:
AOK I II
AOK I II
AOK II cojuzbylo doc
L5 I1Y6S1 7, WAT, sem II, aok
Prel II 7 szyny stałe i ruchome
Produkty przeciwwskazane w chorobach jelit II
9 Sieci komputerowe II
W wiatecznym nastroju II
W01(Patomorfologia) II Lek
Mała chirurgia II Sem IV MOD
Analiza czynnikowa II
PKM NOWY W T II 11
Ekonomia II ZACHOWANIA PROEKOLOGICZNE
Asembler ARM przyklady II
S Majka II Oś
Spotkanie z rodzicami II
Wyklad FP II dla studenta
Ocena ryzyka położniczego II
więcej podobnych podstron