
7
Matematyka dyskretna
Zbigniew Doma ski
Instytut Matematyki i Informatyki, Politechnika Cz stochowska
Elementy teorii kodowania.
Wprowadzenie.
Przedyskutujemy niektóre aspekty kodowania informacji. Jednym ze znanych
kodów jest kod ASCII. W kodzie tym ka dy symbol jest kodowany za pomoc słowa
binarnego o długo ci 8. Istotn cech kodu ASCII, jak i wielu innych kodów, jest to,
e ka dy symbol ma kod o tej samej długo ci (tzw. fixed length character code). Ma
to swoje plusy i minusy.
• Plusem jest to, e nie potrzeba adnego specjalnego symbolu do oddzielania
symboli w informacji. Dzi ki temu łatwo jest odkodowa informacj .
• Minus to fakt, e cz sto powtarzaj ce si symbole maj kod o takiej samej
długo ci jak wyst puj ce rzadko. Jest to wi c strata czasu i przestrzeni w procesie
kodowania i odkodowywania.
Powstała wi c idea u ywania kodów o zmiennej długo ci charakterów, tzn.
symbolom cz sto wyst puj cym przypisuje si krótkie charaktery, za tym o małej
cz sto ci odpowiadaj dłu sze charaktery.
O ile nie ma problemu z wyborem mo liwie krótkich charakterów koduj cych to
mo e wyst pi problem z odczytem kodu gdy przy zmiennej długo ci charakterów
trzeba wiedzie gdzie ko czy si kod jakiego symbolu a gdzie zaczyna nast pny.
Przykład.
Mamy zbiór symboli C={a,b,c,d,e,f}. Przypu my, e a oraz b maj
najwi ksz cz sto wyst powania. Mo emy wi c wybra nast puj cy kod:
a – 0, b – 1, c – 00, d – 01, e –10, f –11.
Kod ten jest bardzo „krótki” w tym sensie, e indywidualne symbole s kodowane
przez najkrótsze mo liwe charaktery.
Jak jednak odczyta nast puj c zakodowan informacj : 010011?
Czy „010011” oznacza „abaabb” czy te „dcf”?

8
Mo na problem niejednoznaczno ci odczytu rozwi za wprowadzaj c extra charakter
np. / do oddzielania indywidualnych charakterów. Jednak taki zabieg wydłu a
kodowan informacj .
Istnieje elegancka metoda omini cia niejednoznaczno ci dekodowania. Metoda ta
wykorzystuje tzw. kody prefiksowe.
Słowo
w
jest
prefiksem słowa
u
je li
u
ma posta
wx
u
=
, gdzie
x
jest innym
słowem.
Np. słowo 101 jest prefiksem słowa 1011100.
Widzimy wi c, e problem na tym, e kod dla jednego symbolu jest prefiksem dla
innego. Np. kod dla symbolu a jest prefiksem kodu dla symbolu c. Je li informacja
zaczyna si od 0 to nie wiemy jak j interpretowa .
Kod o tej własno ci, e kod indywidualnego symbolu nie jest prefiksem adnego
innego symbolu nazywamy
kodem prefiksowym.
Przykład.
Rozwa my nast puj cy kod dla zbioru symboli {c,e,o,r,t}:
c – 11, e – 0, o –100, r – 1010, t – 1011.
Jest to kod prefiksowy. Nie ma tu problemu z odczytem informacji. Np.
111001010101001111 (= 11 100 1010 100 11 11) oznacza corrocc.
Naszym celem jest wi c zbudowanie jak najkrótszego kodu prefiksowego.
Potrzebna jest nam znajomo cz sto ci wyst powania symboli w kodowanym
j zyku. Jest to charakterystyka, któr znamy z bada nad j zykiem. Przypisujemy
wi c ka demu symbolowi cz sto
f wzgl dem zbioru symboli.
Np. niech C = {a,b,c,d}. Przypisanie cz sto ci f(a)=2, f(b)=2, f(c)=8, f(d)=5 oznacza,
e w danym j zyku zapisywanym przy pomocy tych 4 symboli na ka de dwa
wyst pienia symbolu a symbol b pojawia si te dwa razy, symbol c 8 razy a symbol
d 5 razy. Tzn. c jest najcz ciej pojawiaj cym si symbolem.
W oparciu o cz sto ci symboli oblicza si wag kodu.

9
Definicja. Niech
}
,
,
,
{
2
1
k
a
a
a
C
=
jest zbiorem symboli za
)
(
,
),
(
),
(
2
1
k
a
f
a
f
a
f
s cz sto ciami tych symboli. Przyjmijmy, e mamy zbiór charakterów koduj cych
poszczególne symbole oraz, e
)
(
,
),
(
),
(
2
1
k
a
l
a
l
a
l
s długo ciami tych charakterów
koduj cych. Wtedy
wag kodu jest
=
=
k
i
i
i
i
a
l
a
f
1
)
(
)
(
.
Przykład . Waga kodu: c – 11, e – 0, o –100, r – 1010, t – 1011 o cz sto ciach
2
)
(
)
(
,
3
)
(
,
9
)
(
,
4
)
(
=
=
=
=
=
t
f
r
f
o
f
e
f
c
f
wynosi:
.
41
4
2
4
2
3
3
1
9
2
4
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
=
⋅
+
⋅
+
⋅
+
⋅
+
⋅
=
⋅
+
⋅
+
⋅
+
⋅
+
⋅
t
l
t
f
r
l
r
f
o
l
o
f
e
l
e
f
c
l
c
f
Im mniejsza waga kodu tym kod jest efektywniejszy. Podamy teraz metod
konstruowania najefektywniejszego kodu prefiksowego. Kod ten został znaleziony
przez D. A. Huffmana z Bell Labs.
D. A. Huffman, „A method for the construction of minimum redundancy codes”,
Proc. IRE
40, 1098-1101 (1952).
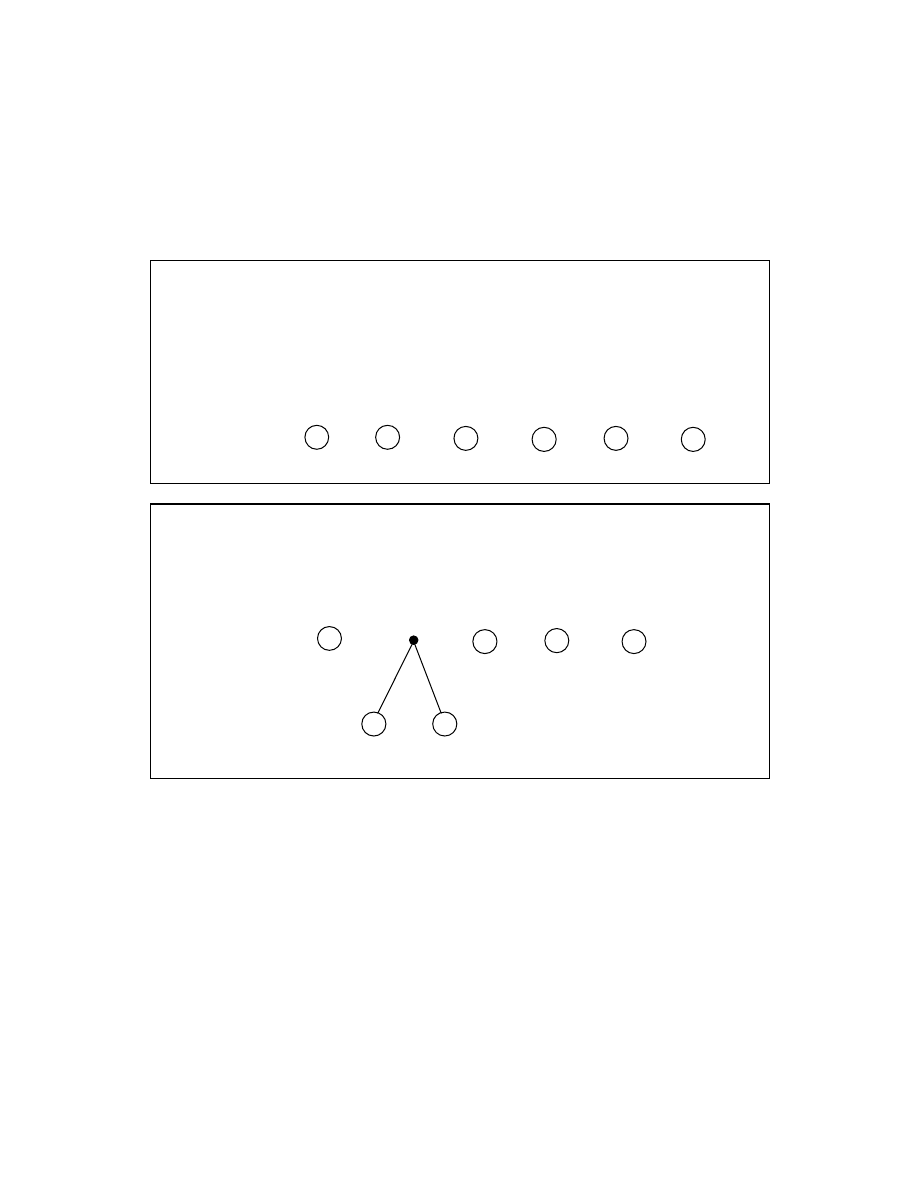
10
Algorytm konstrukcji kodu Huffmana.
Algorytm kreuje drzewo, którego wierzchołki le na s siaduj cych poziomach.
Wierzchołki s etykietowane cz sto ciami wyst powania symboli w u ywanym
j zyku.
Krok
1.
Umie jeden wierzchołek dla ka dego symbolu na najwy szym
poziomie. Oznacz wierzchołki odpowiadaj cymi im symbolami i przypisz im
cz sto ci wyst powania symboli w j zyku. Uporz dkuj wierzchołki wzgl dem
wzrastaj cej cz sto ci.
Krok
2.
Poł cz dwa wierzchołki o najmniejszej cz sto ci do nowego
wierzchołka na poziomie o jeden wy szym. Oznacz ten nowy wierzchołek sum
cz sto ci. Podnie pozostałe wierzchołki o jeden poziom wy ej tak je przestawiaj c
aby zachowane było uporz dkowanie wierzchołków wzgl dem wzrastaj cej cz sto ci.
-
4
+
5
b
7
c
9
d
25
a
32
Poziom
najwy szy
-
4
+
5
b
7
c
9
d
25
a
32
Poziom
najwy szy
9
11
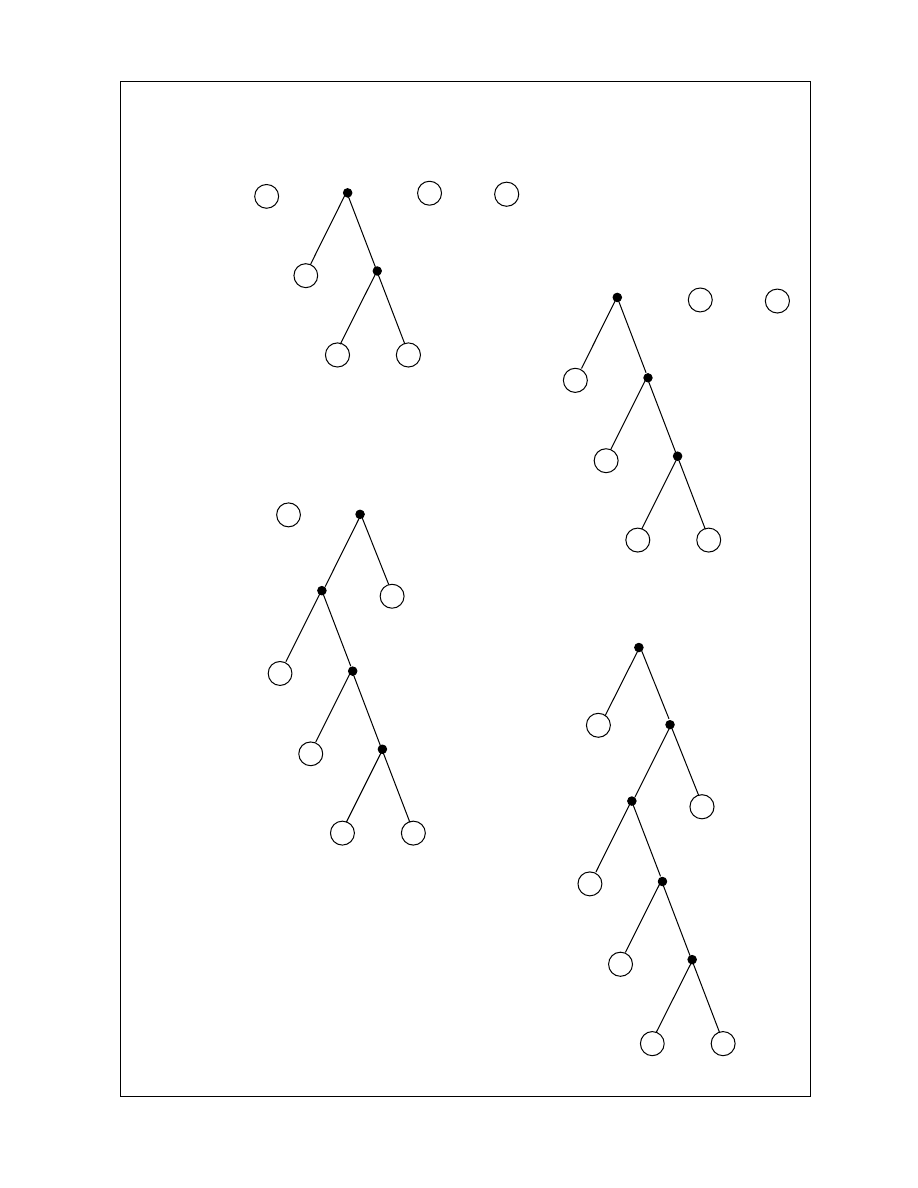
Krok
3.
Powtarzaj Krok 2 tak długo a na najwy szym poziomie zostanie jeden
wierzchołek.
-
4
+
5
b
7
c
9
d
25
a
32
Poziom
najwy szy
9
16
-
4
+
5
b
7
c
9
d
25
a
32
Poziom
najwy szy
9
16
25
-
4
+
5
b
7
c
9
d
25
a
32
Poziom
najwy szy
9
16
25
50
-
4
+
5
b
7
c
9
d
25
a
32
Poziom
najwy szy
9
16
25
50
82
12
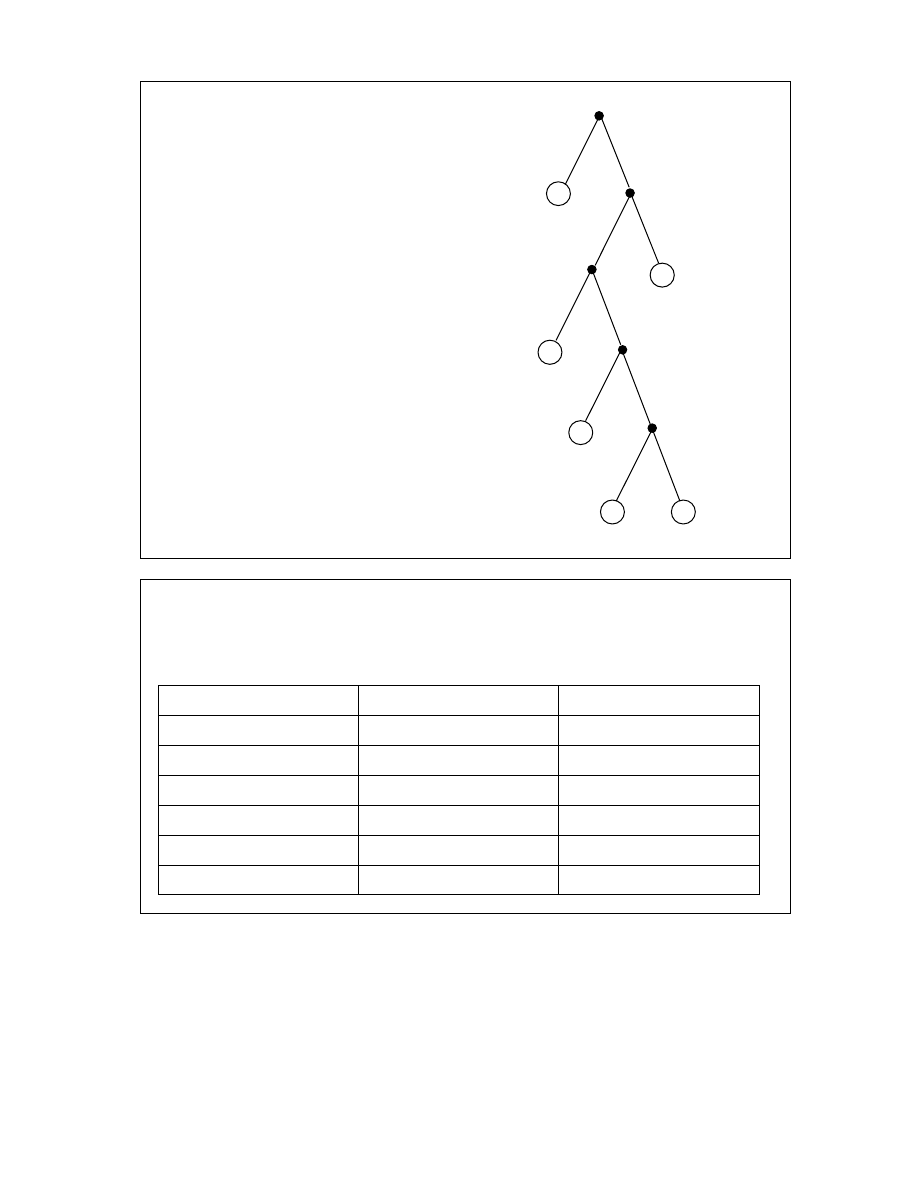
Krok
4.
Usu wszystkie etykiety
cz sto ci oraz oznacz ka d lew
kraw d przez 0 a ka d praw kraw d
przez 1.
Tak otrzymany graf nazywa si drzewem Huffmana.
Krok
5.
Zbuduj tabel kodu. Kod wybranego symbolu otrzymuje si wypisuj c
wszystkie 0 i 1 jakie napotyka si na drodze o pocz tku w wierzchołku drzewa i
ko cu w wierzchołku przypisanemu danemu symbolowi.
Symbol
Cz sto
Kod Huffmana
a
32
0
b
7
1010
c
9
100
d
25
11
+
5
10111
-
4
10110
Jest to kod prefiksowy, ponadto symbole o wysokiej cz sto ci wyst powania maj
krótsze kody ni te o małej cz sto ci. Waga naszego przykładowego kodu wynosi
.
182
5
4
5
5
2
25
3
9
4
7
1
32
=
⋅
+
⋅
+
⋅
+
⋅
+
⋅
+
⋅
Kod Huffmana jest kodem o najmniejszej mo liwej wadze po ród wszystkich kodów
prefiksowych.
-
+
b
c
d
a
0
0
0
0
0
1
1
1
1
1
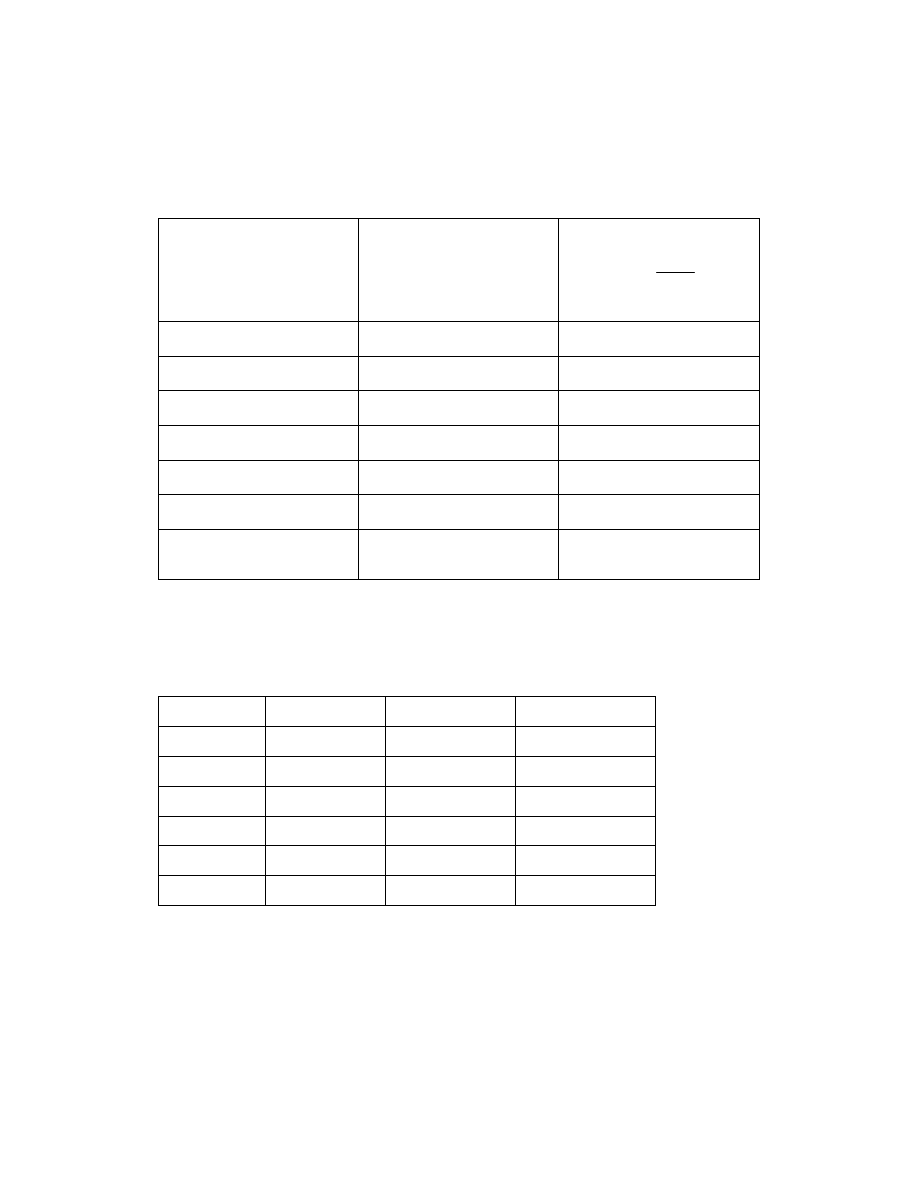
13
Podane w powy szym algorytmie cz sto ci wyst powania symboli mo na zast pi
prawdopodobie stwami pojawienia si poszczególnych symboli. Procedura przej cia
od cz stotliwo ci do prawdopodobie stw jest nast puj ca:
Symbol
Cz sto
i
f
Prawdopodobie stwo
=
=
5
,
1
i
i
i
i
f
f
p
a
32
32/82
b
7
7/82
c
9
9/82
d
25
25/82
+
5
5/82
-
4
4/82
82
5
,
1
=
=
i
i
f
1
5
,
1
=
=
i
i
p
Wyliczymy teraz entropi odpowiadaj c naszemu kodowi i porównamy j z entropi
Shanon’a.
Symbol
p
i
Kod Huffmana
Długo [bits]
a
32/82
0
1
b
7/82
1010
4
c
9/82
100
3
d
25/82
11
2
+
5/82
10111
5
-
4/82
10110
5
1818
,
2
log
2195
.
2
82
/
182
82
/
4
5
82
/
5
5
82
/
25
2
82
/
9
3
82
/
7
4
82
/
32
1
5
,
1
2
=
−
=
=
=
⋅
+
⋅
+
⋅
+
⋅
+
⋅
+
⋅
=
=
i
i
i
SHANON
KOD
p
p
S
S
Kod Huffmana ma najmniejsz entropi spo ród kodów prefiksowych. Warto tej
entropii jest bliska teoretycznej granicy danej warto ci entropii Shanon’a.
Wyszukiwarka
Podobne podstrony:
kod Huffmana
04) Kod genetyczny i białka (wykład 4)
1 kod kresk
kod matlab
Gazeta Wyborcza a kod kulturowy judaizmu
105 - Kod ramki, RAMKI NA CHOMIKA, Miłego dnia
niebieskie 2, ❀KODY RAMEK I INNE, Gotowe tła do rozmówek
54 - Kod ramki, RAMKI NA CHOMIKA, Gotowe kody do małych ramek
140 - Kod ramki
więcej podobnych podstron