
Konspekt nr 6 z laboratoriów „Statystyka i rachunek prawdopodobieństwa”
1
Wybrane zagadnienia z weryfikacji hipotez statystycznych
1. Wprowadzenie
Badania niewyczerpujące (częściowe) nie dają podstaw do formułowania stanowczych
(stuprocentowych) stwierdzeń dotyczących obserwowanych zmiennych losowych. Można
natomiast, na podstawie
tych badań, wysuwać pewne przypuszczenia w odniesieniu do nie-
znanej
bliżej klasy rozkładu zmiennej losowej, jak również – przy znanym rozkładzie – w
odniesieniu do nieznanych wartości parametrów rozkładu. Przypuszczenia te nazywane są
hipotezami statystycznymi
. Hipotezy dotyczące parametrów nazywane są hipotezami parame-
trycznymi,
natomiast hipotezy dotyczące klasy rozkładu – a więc postaci funkcji opisującej
rozkład zmiennej losowej, ale bez odwoływania się do liczbowych wartości parametrów –
nazywamy hipotezami nieparametrycznymi.
W celu pełniejszego zrozumienia problemu rozważmy następujący przykład.
PRZYKŁAD 1.
(a)
W fabryce pracuje urządzenie do produkcji pewnych detali. W celu sprawdzenia jaki procent wyro-
bów produkowanych pr
zez to urządzenie jest wadliwych, trzeba wylosować pewną liczbę detali i
zbadać, ile z nich spełnia przyjęte normy jakości. Jeśli wylosowano n detali i spośród nich jest n
w
wadliwych, to stosunek n do n
w
jest oceną prawdopodobieństwa wyprodukowania wadliwego deta-
lu przez badane urządzenie.
(b)
Wyobraźmy sobie teraz, że ta sama fabryka kupuje nowe urządzenie do produkcji tych samych de-
tali i że producent zapewnia, że średnio tylko 1 na 100 (n
w
/n = 0.01) wyprodukowanych detali jest
wadliwych
. Aby to sprawdzić losuje się np. n = 500 detali wyprodukowanych na tym urządzeniu
i
bada ich jakość. Załóżmy, że n
w
= 20 nie spełnia norm jakości (n
w
/n = 0.05). Czy na podstawie ta-
kiego wyniku badań można by obalić zapewnienia producenta urządzenia?
W punkcie (a)
zadanie sprowadza się do oceny (estymacji)
pewnego parametru, w punk-
cie
do podjęcia lub odrzucenia zapewnienia producenta, że prawdopodobieństwo wypro-
dukowania braku nie jest większe od 0.01, a więc do zweryfikowania hipotezy.
Procedury służące do sprawdzania (weryfikowania) owych hipotez noszą nazwę testów
statystycznych.
Postępowanie weryfikacyjne rozpoczyna się od sformułowania hipotezy ze-
rowej H
0
oraz jednej lub kilku hipotez alternatywnych H
1
. Hipotez
ę zerową formułuje się w
ten sposób, by orzekała brak różnic lub ogólniej – brak wpływu badanego czynnika doświad-
czalnego na obserwowany parametr. Jeśli przez Q oznaczymy nieznaną wartość badanego
parametru
0
wartość tego samego parametru uzyskaną w do-
świadczeniu, to hipoteza zerowa wygląda w następujący sposób
0
0
:
Q
Q
H
=
(1).
Zapisana w taki sposób hipoteza zerowa jest hipotezą prostą. Wysuwamy mianowicie
przypuszczenie, że parametr Q ma wartość Q
0
.
Hipoteza zerowa może być również hipotezą złożoną w postaci
0
0
:
Q
Q
H
≤
(2)
albo
I
Podstawowe zagadnienia z estymacji parametrów statystycznych zostały omówione w poprzednim konspek-
cie.
II
W niektórych podręcznikach można znaleźć oznaczenie hipotezy zerowej przez H, a hipotezy alternatywnej
przez K.
III
Tym parametrem może być przykładowo: wartość średnia, wariancja, parametr λ w rozkładzie Poissona itp.

Konspekt nr 6 z laboratoriów „Statystyka i rachunek prawdopodobieństwa”
2
0
0
:
Q
Q
H
≥
(3).
Hipotezy alternatywne formułuje się następująco
0
1
:
Q
Q
H
≠
(4),
0
1
:
Q
Q
H
>
(5),
0
1
:
Q
Q
H
<
(6).
Są to hipotezy złożone. Każda z nich może być alternatywną hipotezą wobec hipotezy ze-
rowej postaci (1)
. Alternatywą hipotezy zerowej (2) jest hipoteza (5), natomiast hipoteza (6)
jest alternatywą hipotezy zerowej (3).
Przy tak sformułowanych hipotezach zerowych i alternatywnych procedura weryfikacyjna
przebiega według podanego poniżej schematu:
− Ze populacji generalnej Z, w której określona jest zmienna losowa X, pobiera się
n-
elementową próbę losową.
− Na podstawie zbioru realizacji X
n
oblicza się wartość G(X
n
) statystyki
−
Na podstawie rozkładu prawdopodobieństwa statystyki G wyznacza się przedział (ob-
szar) krytyczny W
k
, taki
że prawdopodobieństwo tego, iż wartość funkcji G(X
n
) trafi do
obszaru krytycznego, przy założeniu, że Q = Q
0
, wynosi
α. Co zapisuje się następująco
G
, będącej
sprawdzianem hipotezy zerowej. Statystykę G wybiera się odpowiednio do treści wery-
fikowanej hipotezy.
(
)
α
=
=
∈
0
|
)
(
P
Q
Q
W
X
G
k
n
(7).
Prawdopodobieństwo α jest dowolnie małe, ale różne od zera i nazywane jest pozio-
mem istotności testu. Zazwyczaj przyjmuje się wartości α = 0.05 albo α = 0.01.
W prz
ypadku hipotez zerowych złożonych typu (2) i (3) mamy
(
)
α
=
≤
∈
0
|
)
(
P
Q
Q
W
X
G
k
n
(8),
(
)
α
=
≥
∈
0
|
)
(
P
Q
Q
W
X
G
k
n
(9).
−
Jeśli uzyskana z doświadczenia wartość G(X
n
) spełnia warunek
k
n
W
X
G
∈
)
(
(10),
to sprawdzaną hipotezę zerową odrzuca się na korzyść alternatywnej. Decyzja taka jest
realizacją poglądu opartego na doświadczeniu, że zdarzenia mało prawdopodobne za-
chodzą rzadko. Jeśli więc wystąpiło zdarzenie, które – przy założeniu prawdziwości
H
0
–
praktycznie nie powinno zajść, to kwestionujemy słuszność przyjętego założenia,
odrzucając H
0
.
−
Jeśli natomiast
k
n
W
X
G
∉
)
(
(11),
to nie ma podstaw do odrzucenia weryfikowanej hipotezy zerowej.
Weryfikując daną hipotezę statystyczną H
0
, na podstawie wyników próby losowej, pono-
simy zawsze pewne ryzyko podjęcia błędnej decyzji. Wynika to stąd, że na podstawie próbki
IV
Dla przypomnienia – statystyka jest to dowolna funkcja, której dziedziną są wartości zmiennej losowej. W
tym przypadku dziedziną funkcji G jest zbiór realizacji X
n
uzyskany w próbie losowej.
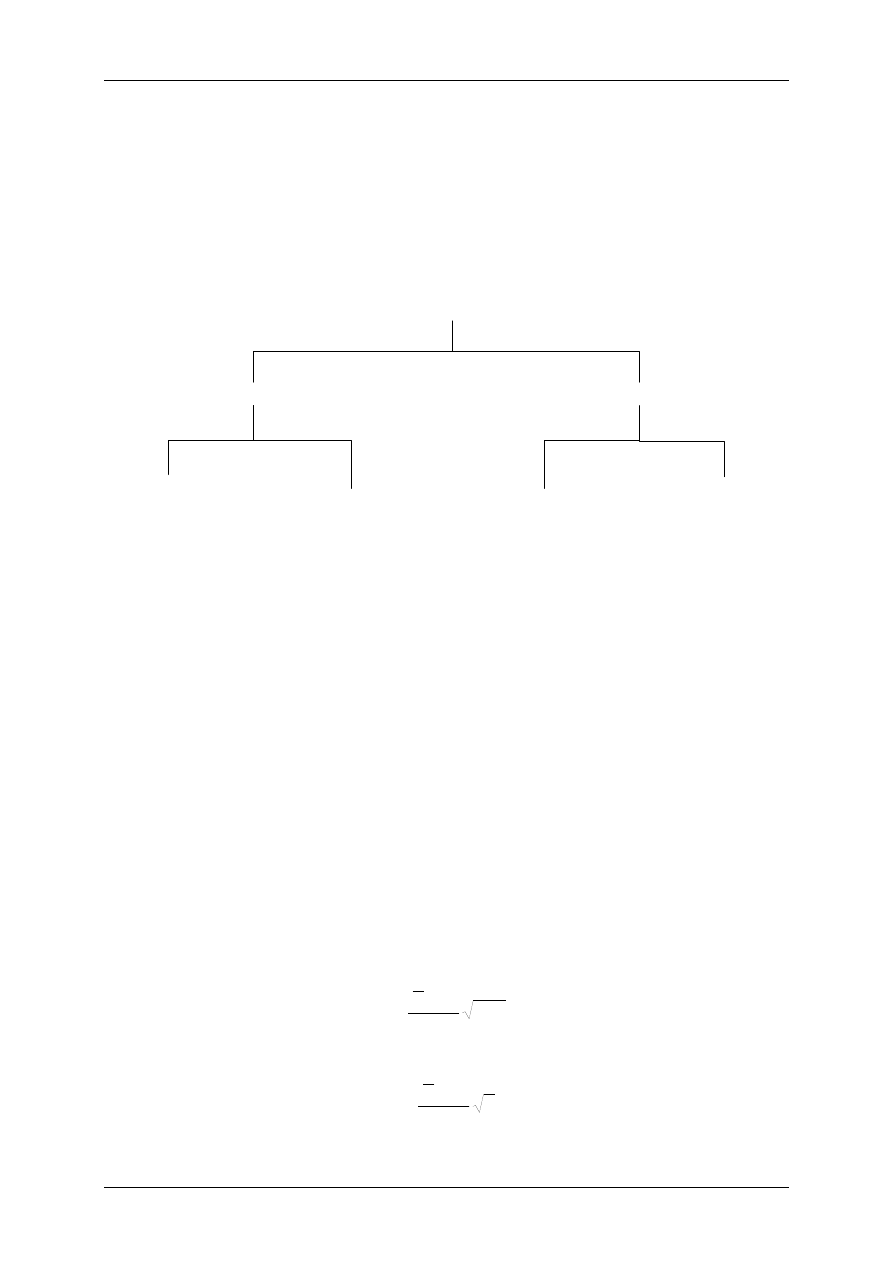
Konspekt nr 6 z laboratoriów „Statystyka i rachunek prawdopodobieństwa”
3
nigdy nie mamy całkowitej informacji o populacji, z której pobrana została próba. W związku
z tym możemy więc podjąć decyzję poprawną, albo popełnić jeden z dwóch błędów:
a)
możemy odrzucić weryfikowaną hipotezę H
0
wtedy, gdy jest ona w rzeczywistości
prawdziwa (popełniamy wtedy błąd pierwszego rodzaju),
b) lub
możemy przyjąć weryfikowaną hipotezę H
0
jako prawdziwą, podczas gdy jest
ona w rzeczywistości fałszywa, czyli prawdziwa jest hipoteza alternatywna H
1
(popełniamy wtedy błąd drugiego rodzaju).
Istotę tych błędów można też zilustrować za pomocą diagramu przedstawionego na rys. 1.
Rys. 1
. Błędy popełniane przy weryfikacji hipotez statystycznych
Prawdopodobieństwo popełnienia błędu pierwszego rodzaju wynosi α. Jest ono znane
a priori
(założone z góry) na etapie tworzenia przedziału krytycznego W
k
. Natomiast, aby
określić prawdopodobieństwo popełnienia błędu drugiego rodzaju, trzeba wprowadzić dodat-
kowe założenia co do postaci hipotez alternatywnych. My nie będziemy zajmować się obli-
czeniem tego prawdopodobieństwa. Należy jedynie wiedzieć, że im mniejsze prawdopodo-
bieństwo popełnienia błędu pierwszego rodzaju, tym większe jest prawdopodobieństwo po-
pełnienia błędu drugiego rodzaju. Gdybyśmy założyli prawdopodobieństwo popełnienia błędu
pierw
szego rodzaju jako równe 0 (tzn. jeśli niezależnie od wyników eksperymentu zawsze
będziemy przyjmować hipotezę H
0
), to prawdopodobieństwo popełnienia błędu drugiego ro-
dzaju jest równe 1 (wtedy nigdy nie odrzucimy hipotezy H
0
, gdy jest fałszywa). Dla ustalone-
go poziomu istotności testu α prawdopodobieństwo popełnienia błędu drugiego rodzaju male-
je wraz ze wzrostem
liczności próbki losowej. Oznacza to, że im większa próba losowa, tym
częściej będziemy odrzucać hipotezę H
0
, gdy jest ona nieprawdziwa.
2.
Weryfikacja hipotezy dotyczącej wartości przeciętnej w rozkładzie normalnym
Jeśli wariancja (σ
2
) obserwowanej zmiennej losowej X
o rozkładzie normalnym nie jest
znana, to do weryfikacji hipotez zerowych (1) – (3)
wykorzystuje się test t-Studenta. W przy-
padku gdy wariancję σ
2
szacuje się za pomocą statystyki S
2
, sprawdzian hipotezy zerowej ma
postać
1
0
0
,
−
µ
−
=
ν
n
S
X
T
(12).
Jeśli natomiast wariancję σ
2
szacuje się za pomocą statystyki S
*2
, to wówczas
n
S
X
T
*
0
0
,
µ
−
=
ν
(13).
Hipoteza zerowa H
0
Przyjąć
Odrzucić
Decyzja
Decyzja
Decyzja
prawidłowa
Błąd II rodzaju
Błąd I rodzaju
Decyzja
prawidłowa
H
0
prawdziwa
w rzeczywistości
H
0
fałszywa
w rzeczywistości
H
0
prawdziwa
w rzeczywistości
H
0
fałszywa
w rzeczywistości
Konspekt nr 6 z laboratoriów „Statystyka i rachunek prawdopodobieństwa”
4
Zmienna losowa T
ν,0
ma roz
kład Studenta o ν = n – 1 stopniach swobody.
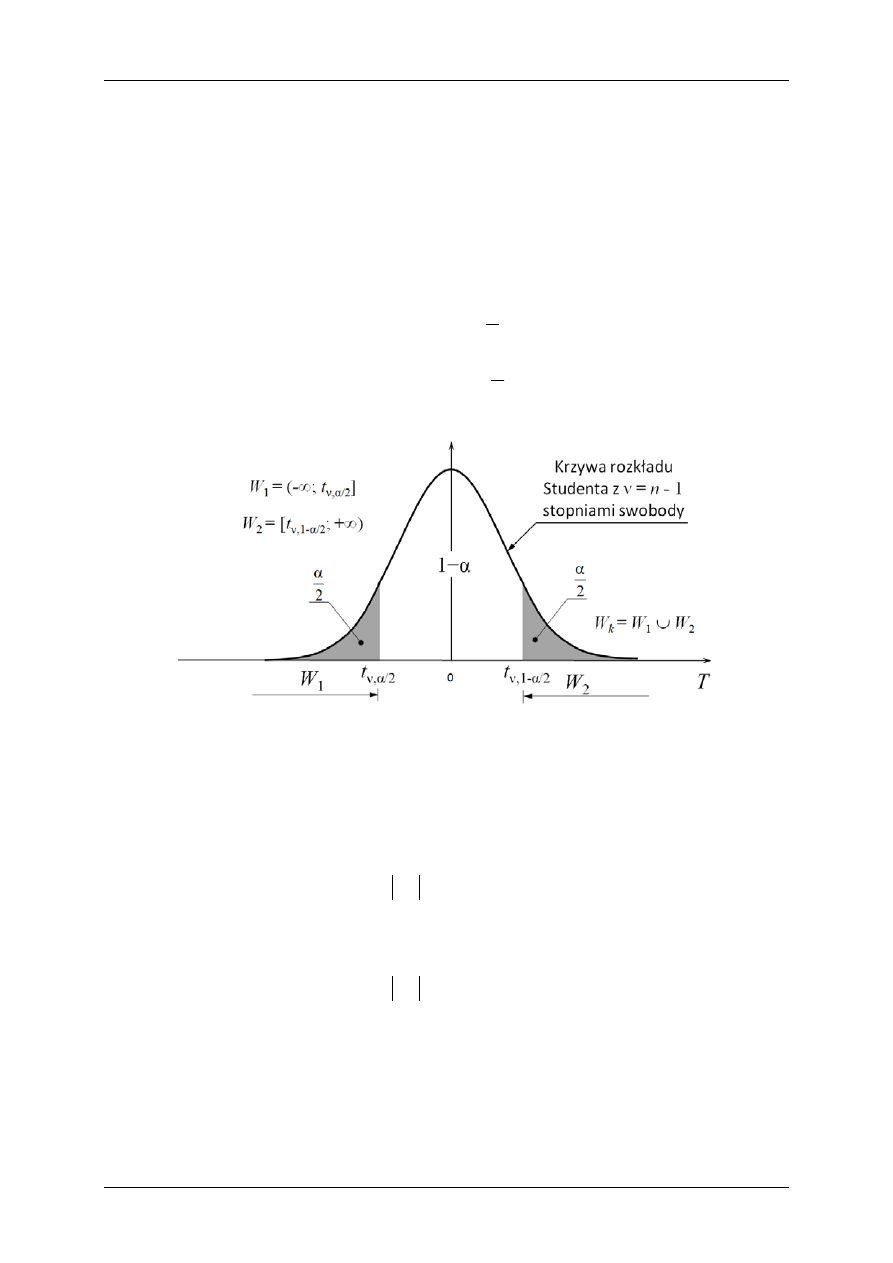
Jeśli hipoteza zerowa ma postać (1) i jest weryfikowana wobec hipotezy alternatywnej (4)
to test jest dwustronny. W takim przypadku obszar krytyczny, przedstawiony na rys. 2, ma
po
stać
)
;
[
]
;
(
2
/
1
,
2
/
,
+∞
∪
−∞
=
α
−
ν
α
ν
t
t
W
k
(14),
przy czym wartości t
ν,α/2
< 0 i t
ν,1-α/2
> 0
są odpowiednio: kwantylem dolnym i górnym rozkła-
du Studenta,
a ich wartości wyznacza się w taki sposób, aby
(
)
2
P
2
/
,
0
,
α
=
≤
α
ν
ν
t
T
(15),
(
)
2
P
2
/
1
,
0
,
α
=
≥
α
−
ν
ν
t
T
(16).
Rys. 2. Konstrukcja zbioru krytycznego (dwustronnego) testu do weryfikacji hipotezy H
0
:
μ = μ
0
przeciw hipotezie alternatywnej H
1
:
μ ≠ μ
0
dla poziomu istotności testu α
Ponieważ |t
ν,α/2
| = t
ν,1-α/2
, zatem w przypadku testu dwustronnego mamy następujące reguły
decyzyjne:
−
jeśli wartość T
ν,0
wyliczona ze wzoru (12) albo (13)
spełnia nierówność
2
/
1
,
0
,
α
−
ν
ν
≥ t
T
(17),
to odrzucamy hipotezę zerową na korzyść hipotezy alternatywnej,
−
jeśli natomiast
2
/
1
,
0
,
α
−
ν
ν
< t
T
(18),
to nie ma podstaw do odrzucenia weryfikowanej hipotezy zerowej.
PRZYKŁAD 1. W pewnym zakładzie pracy, gdzie w sposób ciągły pracuje agregat służący do pakowania
bentonitu w worki, p
obrano w sposób losowy 10 takich worków, a następnie zwarzono je. Uzyskano następujące
wyniki w kg: 1.06; 0.98; 1.01; 0.99; 1.00; 0.98; 1.03; 1.08; 0.96; 1.02. Na podstawie uzyskanych wyników
sprawdzić, czy zadana na początku pracy wartość nominalna masy pojedynczego worka wynosi μ
0
= 1.00 kg.
Przy
jąć poziom istotności testu α = 0.01.
Konspekt nr 6 z laboratoriów „Statystyka i rachunek prawdopodobieństwa”
5
Ponieważ agregat pracuje w sposób ciągły a próba losowa liczy tylko 10 worków to taką próbkę będziemy
traktować jako małą. W związku z tym do testu będziemy używać statystyki (13).
Stawiamy hipotezę zerową orzekającą, że agregat nadal pakuje bentonit w worki o średniej masie równej
1.00 kg. Hipotezę tą zapisujemy następująco: H
0
:
μ = μ
0
. Hipotezą alternatywna orzekać będzie, że automat
rozregulował się, czyli H
1
:
μ ≠ μ
0
. Wartość μ szacujemy obliczając średnią arytmetyczną z wyników próby
losowej
01
.
1
10
1
=
=
=
µ
∑
=
i
i
X
X
.
Wartość statystyki S
*
wyliczamy w następujący sposób (patrz wzór 12 w poprzednim konspekcie)
(
)
04
.
0
01
.
1
1
1
10
1
2
2
*
*
=
−
−
=
=
∑
=
i
i
X
n
S
S
.
Tą samą wartość można uzyskać stosując funkcje Excela o nazwie ODCH.STANDARDOWE.
Wyliczamy wartość statystyki (13)
8582
.
0
10
04
.
0
00
.
1
01
.
1
*
0
0
,
=
−
=
µ
−
=
ν
n
S
X
T
.
Wartość kwantylu t
ν,1-α/2
liczymy korzystając z funkcji Excala ROZKŁAD.T.ODW o następującej składni:
Prawdopodobieństwo =
α = 0.01 (nie należy wpisywać 1 – α/2); stopnie_swobody = ν = n – 1 = 9, otrzymując
t
ν,1-α/2
= 3.2498.
Ponieważ zgodnie z nierównością (18) |T
ν,0
= 0.8582| < t
ν,1-α/2
= 3.2498 to nie ma podstaw do odrzucenia hi-
potezy zerowej. Inaczej możemy powiedzieć, że z prawdopodobieństwem 1 – α agregat nadal pakuje worki
o nominalnej masie 1.00 kg.
Gdy hipoteza (5)
jest alternatywą wobec hipotezy zerowej (2), to test jest jednostronny
(prawostronny). W takim przypadku obszar krytyczny (rys. 3
) wygląda następująco
)
;
[
1
,
+∞
=
α
−
ν
t
W
k
(19),
przy czym
(
)
α
=
≥
α
−
ν
ν
1
,
0
,
P
t
T
(20),
gdzie t
ν,1-α/2
> 0.
Dla testu prawostronnego reguły decyzyjne są następujące:
−
jeśli wartość T
ν,0
wyliczona ze wzoru (12) albo (13)
spełnia nierówność
α
−
ν
ν
≥
1
,
0
,
t
T
(21),
to odrzuca się hipotezę zerową na korzyść hipotezy alternatywnej,
−
jeśli natomiast
α
−
ν
ν
<
1
,
0
,
t
T
(22),
to nie ma podstaw do odrzucenia weryfikowanej hipotezy zerowej.
Test lewostronny występuje w przypadku weryfikowaniu hipotezy zerowej (3) wobec hi-
potezy alternatywnej (6). Obszar krytyczny
dla testu lewostronnego wygląda następująco (rys.
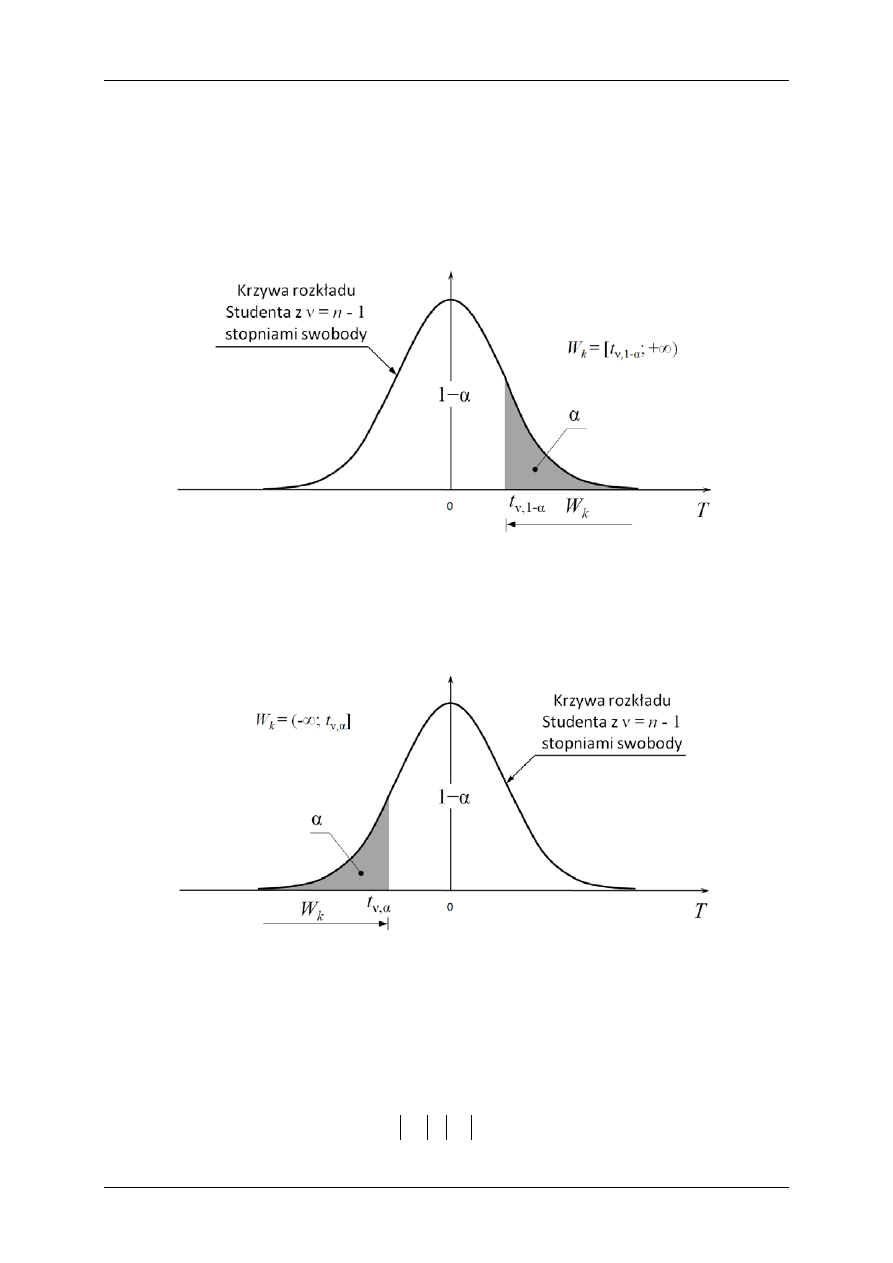
Konspekt nr 6 z laboratoriów „Statystyka i rachunek prawdopodobieństwa”
6
]
;
(
,
α
ν
−∞
=
t
W
k
(23),
przy czym
(
)
α
=
≤
α
ν
ν
,
0
,
P
t
T
(24),
gdzie t
ν,α
< 0.
Rys. 3. Konstrukcja zbioru krytycznego (prawostronnego) testu do weryfikacji hipotezy H
0
:
μ ≤ μ
0
przeciw hipotezie alternatywnej H
1
:
μ > μ
0
dla poziomu istotności testu α
Rys. 4. Konstrukcja zbioru krytycznego (lewostronnego) testu do weryfikacji hipotezy H
0
:
μ ≥ μ
0
przeciw hipotezie alternatywnej H
1
:
μ < μ
0
dla poziomu istotności testu α
Regu
ły decyzyjne dla testu lewostronnego są analogiczne jak dla testu prawo i dwustron-
nego. Decyzje podejmuje si
ę następująco:
−
jeśli wartość T
ν,0
wyliczona ze wzoru (12) albo (13)
spełnia nierówność
α
ν
ν
≥
,
0
,
t
T
(25)

Konspekt nr 6 z laboratoriów „Statystyka i rachunek prawdopodobieństwa”
7
to odrzuca się hipotezę zerową na korzyść hipotezy alternatywnej,
−
jeśli natomiast
α
ν
ν
<
,
0
,
t
T
(26),
to nie ma podstaw do odrzucenia weryfikowanej hipotezy zerowej.
Aby obliczy
ć wartość kwantyli t
ν,α
oraz t
ν,1-α
przy pomocy funkcji Excela o nazwie
ROZKŁAD.T.ODW jako argument Prawdopodobieństwo nale
ży wskazać wartość 2∙α.
LITERATURA
W. Krysicki, J. Bartos, W. Dysza, K. Królikowska, M. Wasilewska: Rachunek prawdopo-
dobieństwa i statystyka matematyczna w zadaniach. Wydawnictwo Naukowe PWN, Warsza-
wa 2005.
A. Iwasiewicz, A. Paszek: Statystyka z elementami statystycznych metod monitorowania
procesów. Wydawnictwo Akademii Ekonomicznej w Krakowie, Kraków 2004.
W. Kordecki:
Rachunek prawdopodobieństwa i statystyka matematyczny. Oficyna Wy-
dawnicza GiS, Wrocław 2003.
Document Outline
- Wybrane zagadnienia z weryfikacji hipotez statystycznych
- 1. Wprowadzenie
- 2. Weryfikacja hipotezy dotyczącej wartości przeciętnej w rozkładzie normalnym
Wyszukiwarka
Podobne podstrony:
Konspekt nr 5 na cw 6 id 245644 Nieznany
Konspekt nr 3 na cw 4 id 245635 Nieznany
Konspekt nr 2 na cw 3 id 245634 Nieznany
konspekt nr 1 na cw 2 id 245631 Nieznany
Dok cw nr 12 RPiS id 139083 Nieznany
MD cw 1 id 290131 Nieznany
cw 9 id 122181 Nieznany
Cwiczenia nr 10 (z 14) id 98678 Nieznany
cw 5 id 121769 Nieznany
28 04 2013 cw id 31908 Nieznany
Cw 8 id 97501 Nieznany
Cwiczenia nr 13 RPiS id 124686 Nieznany
więcej podobnych podstron