
Autor opracowania: Marek Walesiak
1
PROJEKT A – MODEL LINIOWY
Nazwisko i imię studenta 1: ..........................................
Rok i forma studiów studenta 1: ......
Numer grupy lub specjalność studenta 1: .....
Nazwisko i imię studenta 2: ..........................................
Rok i forma studiów studenta 2: ......
Numer grupy lub specjalność studenta 2: .....
Uwagi dla studentów:
1. Program R należy pobrać ze strony: http://cran.r-project.org/
2. Co najmniej jeden projekt (A, B, C) należy przesłać na e-mail prowadzącego laboratoria
3. Projekty można wykonywać osobiście lub w zespołach dwuosobowych (jakość i estetyka wykonania
oraz liczba zrealizowanych projektów będzie decydować o ocenie z laboratorium dla przedmiotu Eko-
nometria)
4. Liczba obserwacji w projekcie A oraz B musi wynosić co najmniej 13 (trzynaście). Dla projektu C
musi być co najmniej pięć cykli. Dla danych statystycznych należy koniecznie podać źródło. Dane
powinny być aktualne
5. Nie wolno w projektach stosować zmiennych użytych w przykładowych projektach prezentowanych
na laboratoriach
6. Wstępnym warunkiem poprawności projektu A i B jest współczynnik determinacji (
Multiple R-
Squared
) nie mniejszy nić 0,50
7. Wraz z każdym projektem opracowanym w edytorze Word (może też być jego odpowiednik z pakietu
OpenOffice) należy przesłać:
a) pliki danych w formacie csv
b) odpowiednie procedury w programie R
8. Termin przesłania projektu (projektów): 03 stycznia 2012 roku
9. Proszę przesyłać projekty z własnych e-maili podając w e-mailu skład zespołu (imię i nazwisko, rok i
forma studiów, numer grupy lub specjalność)
10. Warunkiem przyjęcia projektu (projektów) jest uzyskanie pozytywnej odpowiedzi od prowadzącego
laboratoria
11. Odpowiedzi na e-maile informujące o akceptacji projektu lub projektów będą przesyłane w ciągu
siedmiu dni od ich nadesłania
12. Projekty, które wykonali inni studenci będą odrzucane
Autor opracowania: Marek Walesiak
2
1. Na podstawie danych statystycznych dotyczących zmiennej objaśnianej y i zmiennej objaśniają-
cej x pochodzących z Rocznika Statystycznego sporządzić wykres korelacyjny i metodą oceny
wzrokowej dobrać postać analityczną modelu ekonometrycznego.
y – plony pszenicy w q z ha w Polsce w latach 1960-1979,
x – zużycie nawozów mineralnych w kg czystego składnika NPK.
Źródło: Rocznik Statystyczny 1980, s. XLII-XLIII (zob. Nowak (2002), Zarys metod ekonometrii, PWN,
Warszawa, s. 39).
a) wprowadzić dane statystyczne do programu EXCEL w następującym układzie:
Plik dane_rys1
Plik dane_rys1a
Plik dane_rys1b
b) zapisać dane w formacie csv na dysku (podać nazwę pliku (odpowiednio): dane_rys1.csv;
dane_rys1a.csv; dane_rys1b.csv)

Autor opracowania: Marek Walesiak
3
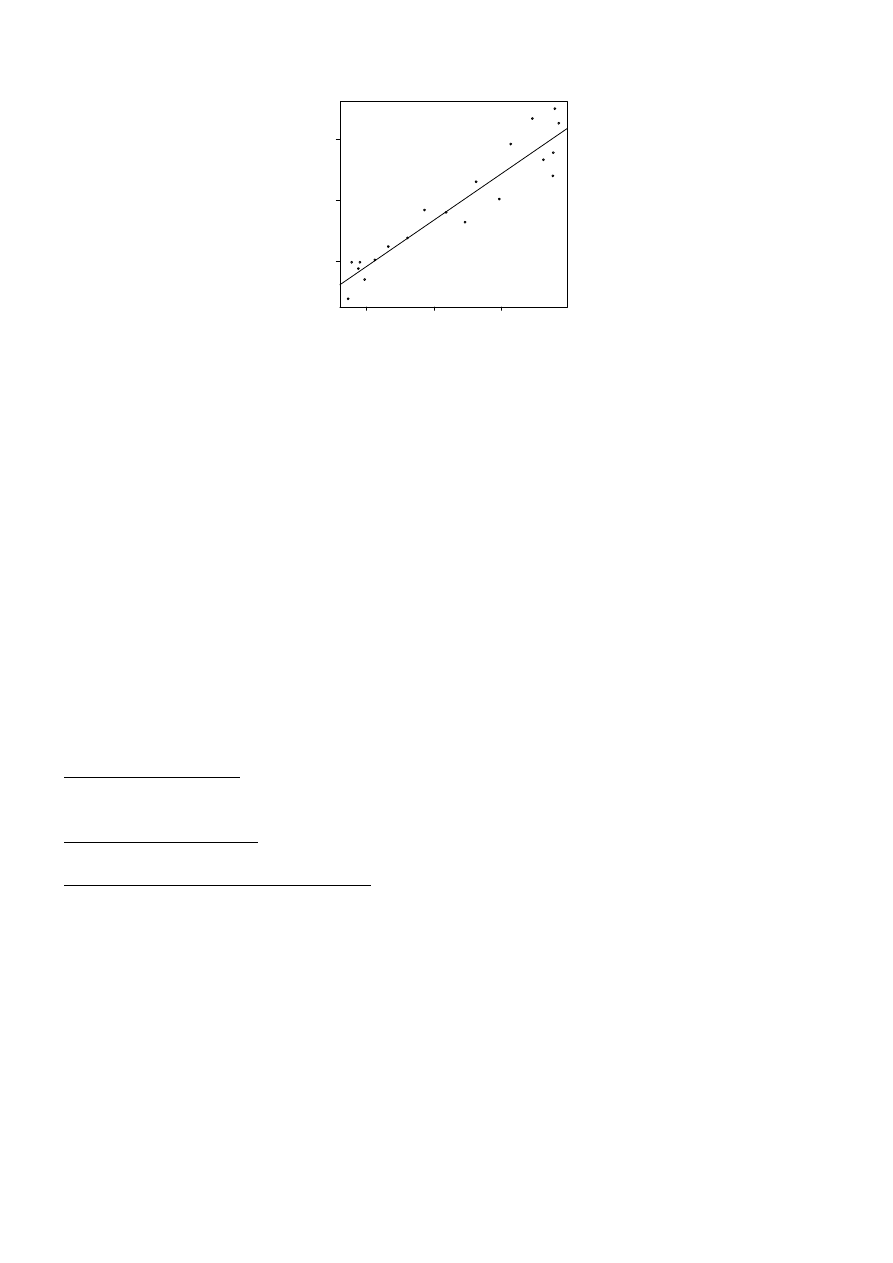
c) sporządzić wykres korelacyjny dla zmiennych y i x na podstawie danych z pliku
dane_rys1.csv (zastosuj w programie R procedurę podaną w pliku Rys_1.r)
50
100
150
20
25
30
x
y
Rys. 1. Związek plonów pszenicy w q z 1 ha (y) ze zużyciem nawozów mineralnych w kg
czystego składnika NPK (x) w Polsce w latach 1960-1979
d) na podstawie oceny wzrokowej rys. 1 z punktu c) dobrano do opisu zależności y od x postać linio-
wą:
x
b
b
y
1
0
ˆ
(1)
2. Wykorzystując w programie R procedurę Estymacja_rys1.r:
a) oszacować metodą najmniejszych kwadratów parametry strukturalne modelu (1). Przedstawić gra-
ficznie dopasowany model do danych. Zapisać postać modelu z oszacowanymi parametrami poda-
jąc w nawiasach pod ocenami estymatorów parametrów ich błędy. Podać interpretację parametrów
strukturalnych oraz błędów estymatorów parametrów strukturalnych,
b) zinterpretować obliczone parametry struktury stochastycznej (standardowy błąd oceny, współczyn-
nik determinacji, skorygowany współczynnik determinacji),
c) wyznaczyć i zinterpretować przedziały ufności dla parametrów strukturalnych,
d) zbudować tablicę analizy wariancji dla modelu regresji prostej,
e) przeprowadzić weryfikację modelu regresji prostej (test Shapiro-Wilka na normalność składnika lo-
sowego, testy t i F istotności współczynników regresji),
f) przeprowadzić predykcję w modelu regresji prostej wewnątrz próby oraz zbudować pasma ufności
predykcji y na podstawie znanego x.
ODPOWIEDZI Z WYKORZYSTANIEM obliczeń w programie R
a) oszacować metodą najmniejszych kwadratów parametry strukturalne modelu (1)
[1] Wyniki estymacji modelu regresji prostej
Call:
lm(formula = y ~ x, data = d, x = TRUE, y = TRUE)
Residuals:
Min 1Q Median 3Q Max
-3,1063 -1,2294 0,1506 0,9316 2,7531
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15,791400 0,789077 20,01 9,53e-14 ***
x 0,075780 0,006124 12,37 3,08e-10 ***
---
Signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘*’ 0,05 ‘.’ 0,1 ‘ ’ 1
Residual standard error: 1,592 on 18 degrees of freedom
Multiple R-Squared: 0.8948, Adjusted R-squared: 0.889
F-statistic: 153.1 on 1 and 18 DF, p-value: 3,077e-10
Autor opracowania: Marek Walesiak
4
a) przedstawić graficznie dopasowany model do danych
50
100
150
20
25
30
x
y
a) zapisać postać modelu z oszacowanymi parametrami podając w nawiasach pod ocenami
estymatorów parametrów ich błędy
x
y
)
006124
,
0
(
)
789077
,
0
(
07578
,
0
7914
,
15
ˆ
(2)
a) podać interpretację parametrów strukturalnych oraz błędów estymatorów parametrów struk-
turalnych
07578
,
0
ˆ
1
b
– wzrost (spadek) zużycia nawozów mineralnych (wartości zmiennej objaśniającej x) o kg
czystego składnika NPK spowoduje wzrost (spadek) plonów pszenicy w q z ha w Polsce (wartości
zmiennej objaśnianej y) średnio o 0,07578 q z ha (q = 100 kg),
7914
,
15
ˆ
0
b
(wyraz wolny) – oznacza w tym przypadku szacowane plony pszenicy w q z ha w Polsce
bez zużycia nawozów mineralnych.
789077
,
0
)
ˆ
(
0
b
S
– szacując parametr
0
b , gdybyśmy mogli wiele razy pobrać próbę z tej samej populacji
generalnej, mylimy się średnio in plus i in minus o 0,789077 (
789077
,
0
7914
,
15
0
b
),
006124
,
0
)
ˆ
(
1
b
S
– szacując parametr
1
b , gdybyśmy mogli wiele razy pobrać próbę z tej samej populacji
generalnej, mylimy się średnio in plus i in minus o 0,006124 (
006124
,
0
07578
,
0
1
b
).
b) zinterpretować obliczone parametry struktury stochastycznej (standardowy błąd oceny,
współczynnik determinacji, skorygowany współczynnik determinacji),
standardowy błąd oceny (Residual standard error: 1,592) – wartości empiryczne zmiennej
objaśnianej (plony pszenicy w q z ha w Polsce) odchylają się od wartości teoretycznych przeciętnie o
1,592 q z ha.
współczynnik determinacji (Multiple R-Squared: 0.8948) – 89,48% zmienności zmiennej obja-
śnianej (plony pszenicy w q z ha w Polsce) zostało wyjaśnionych przez zbudowany model.
skorygowany współczynnik determinacji (Adjusted R-squared: 0.889) – 88,9% wariancji
zmiennej objaśnianej (plony pszenicy w q z ha w Polsce) zostało wyjaśnionych przez zbudowany mo-
del.
c) wyznaczyć i zinterpretować przedziały ufności dla parametrów strukturalnych,
[1] Przedziały ufności dla parametrów
2,5 % 97,5 %
(Intercept) 14,13360953 17,44918997
x 0,06291333 0,08864732
Z prawdopodobieństwem 0,95 przedział
449
,
17
134
,
14
;
pokryje nieznaną wartość parametru
0
b z
modelu
t
t
t
x
b
b
y
1
0
.
Z prawdopodobieństwem 0,95 przedział
089
,
0
063
,
0
;
pokryje nieznaną wartość parametru
1
b z mo-
delu
t
t
t
x
b
b
y
1
0
.
Węższe (szersze) przedziały ufności można uzyskać poprzez zmniejszenie (zwiększenie) poziomu uf-
ności.

Autor opracowania: Marek Walesiak
5
d) zbudować tablicę analizy wariancji dla modelu regresji prostej
[1] Analiza wariancji
Analysis of Variance Table
Response: y
Df Sum Sq Mean Sq F value Pr(>F)
x 1 388,01 388,01 153,1 3,077e-10 ***
Residuals 18 45,62 2,53
---
Signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘*’ 0,05 ‘.’ 0,1 ‘ ’ 1
e) przeprowadzić weryfikację modelu regresji prostej (test Shapiro-Wilka)
[1] Test Shapiro-Wilka na normalność składnika losowego
Shapiro-Wilk normality test
data: model$residuals
W = 0,9798, p-value = 0,9317
Z uwagi na to, że
0,9317
value
p
05
,
0
nie ma podstaw do odrzucenia hipotezy o normalno-
ści rozkładu składnika losowego.
e) przeprowadzić weryfikację modelu regresji prostej (testy t i F istotności współczynników re-
gresji)
Test t
t value Pr(>|t|)
20,01 9,53e-14
12,37 3,08e-10
Z uwagi na to, że dla
0
b
14
53
,
9
05
,
0
e
hipotezę zerową odrzucamy. Oznacza to, że parametr
0
b istotnie różni się od zera.
Z uwagi na to, że dla
1
b
10
08
,
3
05
,
0
e
hipotezę zerową odrzucamy. Oznacza to, że parametr
1
b
istotnie różni się od zera. Zmienna objaśniająca x ma istotny wpływ na zmienną objaśnianą y.
Test F
F-statistic: 153.1 on 1 and 18 DF, p-value: 3,077e-10
Z uwagi na to, że
10
077
,
3
05
,
0
e
hipotezę zerową należy odrzucić. Oznacza to, że parametr
1
b
istotnie różni się od zera. Zmienna objaśniająca x ma istotny wpływ na zmienną objaśnianą y.
f) przeprowadzić predykcję w modelu regresji prostej wewnątrz próby oraz zbudować pasma
ufności predykcji y na podstawie znanego x
[1] Predykcja w modelu regresji prostej
fit lwr upr
1960 18,55738 14,98451 22,13026
1961 18,75441 15,19085 22,31797
1962 19,13331 15,58684 22,67979
1963 19,23940 15,69752 22,78129
1964 19,50464 15,97385 23,03542
1965 20,06541 16,55630 23,57452
1966 20,82321 17,33948 24,30695
1967 21,92203 18,46690 25,37716
1968 22,86928 19,43086 26,30770
1969 24,08934 20,66143 27,51726
1970 25,15785 21,72887 28,58682
1971 25,76409 22,33024 29,19794
1972 27,09025 23,63506 30,54543
1973 27,73438 24,26361 31,20515
1974 28,94686 25,43767 32,45605
1975 29,57584 26,04216 33,10952
1976 30,43974 26,86748 34,01199
1977 30,11388 26,55684 33,67093
1978 30,21239 26,65084 33,77395
1979 30,10630 26,54960 33,66300
fit
– prognoza zmiennej y w próbie
lwr – dolna wartość przedziału ufności dla prognozy
upr – górna wartość przedziału ufności dla prognozy

Autor opracowania: Marek Walesiak
6
[1] Pasma ufności predykcji
50
100
150
20
25
30
x
y
Rys. 2. Pasma ufności predykcji y na podstawie znanego x
(zaznaczone pasma ufności to
)
ˆ
(
ˆ
)
2
(
2
y
SE
t
y
T
, gdzie
)
2
(
2
/
T
t
to statystyka t-Studenta)
[1] Błąd średni predykcji
SE
1960 1,700622
1961 1,696190
1962 1,688056
1963 1,685871
1964 1,680589
1965 1,670270
1966 1,658193
1967 1,644579
1968 1,636624
1969 1,631622
1970 1,632130
1971 1,634447
1972 1,644602
1973 1,652023
1974 1,670309
1975 1,681967
1976 1,700328
1977 1,693088
1978 1,695237
1979 1,692924
[1] Wartość statystyki t
[1] 2,100922
3. Wykorzystując w programie R procedurę Prognoza_rys1.r postaw prognozę poza próbę
[1] Prognoza dla zmiennej Y oraz przedział ufności dla prognozy
fit lwr upr
[1,] 30,94746 27,34994 34,54499
[1] Błąd średni prognozy
1980
1,712355
Prognoza plonów pszenicy w Polsce na rok 1980 wynosi 30,94746 q z 1 ha. Błąd średni predykcji wy-
nosi 1,712355 q z 1 ha. Przedział ufności (poziom ufności
95
,
0
1
) dla prognozy wyznaczony ze
wzoru
)
ˆ
(
ˆ
)
ˆ
(
ˆ
)
18
(
2
05
,
0
1980
1980
)
18
(
2
05
,
0
1980
y
SE
t
y
Y
y
SE
t
y
,
(3)
wynosi
712355
,
1
94746
,
30
712355
,
1
94746
30
1980
2,100922
2,100922
Y
,
5450
,
34
3499
,
27
1980
Y
qt(0.975,18)= 2,100922
wartość statystyki t Studenta.
Wyszukiwarka
Podobne podstrony:
więcej podobnych podstron