
Krótkie opracowanie zagadnień
z Architektury Komputerów.
Autorzy:
Fanknastich
Brovar
Niniejsze opracowanie jest oparte prawie w całości na książce prof. Janusza Biernata „Architektura Komputerów” -
wiele fragmentów zostało żywcem skopiowane z książki i dotyczy zagadnień wymienionych przez profesora pod koniec
pierwszego wykładu. Powstało ono jako „efekt uboczny” naszej nauki do egzaminu i postanowiliśmy się nim podzielić –
mamy nadzieję, że komuś będzie pomocne. Jako że egzamin już wkrótce: powodzenia i niech Bóg ma nas w swojej opiece.
1. Obsługa przerwań – priorytety, identyfikacja źródła
Priorytety:
High
-naruszenie bezpieczeństwa błąd sprzętu
Medium
-krytyczne ze względu na czas obsługi (transmisja danych).
Low
-Obnizenie przepustowosci systemu, albo obsluga zdarzen, ktorych waznosc okresla user.
Aby synchronizowac procesy i hierachiwizowac przerwania niezbedna jest kontrola mozliwosci zgoszenia.
Maskowanie polega na blokowaniu przerwan danej klasy, lub lepiej odkladaniu ich na pozniej. H nie mogą byc
maskowane
Przer. Precyzyjne- Z miekkich powodow. można rozpoczac obluge po wykonaniu zadania.
Przer. Nieprecyzyjne- Z krytycznych powodow. obsluga rozpoczyna sie odrazu (to chyba po prostu
prior High)
Identyfikacja
Tryb odpytywania-czasochlonny, uzywany tylko dla obslugi duzych ilosci urzadzen, ale można zastapic ukl.
Wektoryzacja-Nie angazuje procesora. Można wykonac jako ustanowienie lancucha przerwan, co wyklucza
biezaca zmiane priorytetow. (wektoryzacja=automatyczne identyfikowanie)
Lancuch blokujacy-nie można obsluzyc L przerwania gdy wyzsze jest w trakcie obslugi.
Lancuch nieblokujacy-nie blokuje nizszych przerwan
Rozstrzyganie konfliktów jest wspomagne sprzetowo przez sterownik przerwan.
Sterownik. Zgloszenie zadania obslugi->Rzgloszen->Rmaski->Kontroler prior<->Robslugi<->Rwektorow
Robslugi wysyla IRQ, Rwektorow otrzymuje INTA.
APIC-sterownik rozsyla zgloszenia miedzy procesory (wieleprockow).Dolaczony do procesora za pomoca 2 linii
PIC 0/1 oraz linii synchronizacji lokalnej.
Obsluga przerwania krytycznego-korzysta z pamieci przyslonietej w celu unikniecia wyrzucania z procka procesu
który spowodowal blad.
2. Ochrona procesu – zagrożenia, komunikacja
Zagrozenia
Mozliwosc uzyskania dostepu do tablicy procesow co moze skutkowac zniszczeniem systemu.
Ochrona powinna zapewniac:
-bezpieczenstwo systemu (zapobiegac zwisom powodowanym przez procesy
uzytkownikow)
-prywatność procesów- blokować dostęp nieupoważnionego procesu do innych procesów.
Ochrona
Ochrona zasobow
-zapobieganie naruszaniu spojnosci systemu
-reagowanie na ingerencje w mechanizm ochrony
-wykrywanie bledow i atakow
-rozpoznanie i neutralizacja skutkow ingerencji
-uniewaznianie dziala ingerujacych w mechanizm ochrony
Ochrona zasobow na poziomie architektury maszyny rzeczywistej
-w przestrzeni kodow – uniemozliwanie wykon. instr. uprzywilejowanych w procesie uzytkownika
-w przestrzeni operandow – wykluczenie wykonania w trybie uzytkownika operacji uzywajacych
zastrzezonych operandow.
-w przestrzeni danych – przypisanie kazdej danej znacznika. Sprzeczne z klasyczna konc. pamieci.
Ochrona Pamieci
Jednolite reguly dostepu: zakaz/zezwolenie + tryp r-w-x
-pamięć jednozakresowa – proces otrzymuje wyłącznie przydział
własnej pamięci, niedostępnej dla innych procesów, co wyklucza uzycie wspólnych
danych i komunikację przez pamięć
Alternatywne prawa dostępu do zasobów pamięci
-pamięć dwuzakresowa – jeden z obszarów jest współdzielony
i dostępny dla wszystkich procesów, drugi jest obszarem własnym procesu,
niedostępnym dla innych procesów, wszystkie obszary są separowane
Selektywne prawa dostępu do zasobów pamięci
-pamięć wielozakresowa – cała pamięć jest podzielona na N
rozłącznych obszarów , kazdy proces uzyskuje prawo dostępu do
pewnego podzbioru tych obszarów

-furtki – deskryptory w tablicach dostępu (część kontekstu procesu)
3. Obsługa i procesy wejścia i wyjścia
–
Procesy we/wy
Sterowniki urzadzen sa chronione bo uzywane przez rozne procesy. Funkcje obslugi we/wy – osobne procesy na
poziomie nadzoru.
-Proces obslugi we/wy:
-program wykonywany przez procesor
-program wykonywany przez sterownik
-Jesli część obslugi I/O wykonywana przez stery stanowi niezalezny proces to zaleznie od poziomu
synchronizacji z procesem wywolujacym wyrozniamy:
-bezposrednie I/O, funkcje sterów przejmuje procesor (testowaanie statusu urzadzenia i nadzor
wykonania polecenia)
-nakladane I/O – obsluga w trybie przerwan precyzyjnych wymaga mocnej synchronizacj
-autonomiczne I/O – obsluga w trybie DMA (bezposredni dostęp do pamieci) prawie nie wymaga
synchronizacji.
4. Obsługa wyjątków – klasyfikacja, wymagania
–
Wyjatek
Zdarzenie sygnalizujace wystapienie stanu niesprawnosci kompa. Wymaga natychmiastowej obslugi.
Powodowany przez błedy programowe i sprzętowe
–
Techniki
-Unikanie uszkodzen- zwyczajne testowanie sprzetu i programu oraz tworzenie ich tak aby uniknac bledow
łagodzenia
krytycznyc
-Tolerowanie uszkodzen- wprowadzanie do systemu nadmiaru sprzetu or czasu or informacji. Wymaga
natychmiastowego wykrycia buga i automatycznego usuniecia badz zamaskowania, co umozliwia dalsza prace
procesu bez wstrzymania.
–
Obsluga/fazy
Wykrycie bledu -> diagnostyka -> ew. Naprawa -> definicja strat -> przywrocenie systemu
Obsluga wyjatkow sprzetowych (programowe to wiadomo) polega na wprowadzeniu nadmiarow w postaci:
- redundancji statycznej – maskowanie, polega na nadmiarowym kodowaniu badz powielaniu
modulow i glosowaniu wynikow. (np. TMR)
- redundancji dynamicznej – automatyczne wylaczanie modulow zapasowych badz obnizenie
przepustowosci systemu.
- redundancji czasowej – ponawianie operacji, albo wykonanie tego samego algorytmu dwoma
sposobami.
Redundancja statyczna i czasowa eliminuja bledy przemijajace, dynamiczna i statyczna bledy trwale.
–
Hierarchia
Reset procka -> blad sprzetu -> zle wykonanie instrukcji -> monitorowanie procesu -> f. Systemowa ->
przerwanie zewnetrzne.
5. Zarządzanie pamięcią – cele, mechanizmy, wspomaganie na poziomie architektury
–
Cele
-Przydzial zasobow pamieci
-Ochrona zasobow pamieci
-Współdzielenie zasobów pamięci
-Przemieszczanie zasobów pamięci
-Przeźroczysta organizacja pamięci fizycznej i logicznej
-relacje logiczne niewrazliwe na zarzadzanie
-elastyczne powiazanie struktur logicznych i fizycznych
–
Mechanizmy
Stronicowanie, Segmentowanie, Segmentowanie stronicowe
6. Wirtualna i rzeczywista przestrzeń adresowa; adres wirtualny, adres logiczny i fizyczny
Uzyskanie dostępu do danej wymaga wskazania jej lokalizacji w przestrzeni adresowej (swoistej mapie pamięci możliwej do zaadresowania
przez proces). Ze względu na sposób adresowania wyróżnia się:
- rejestry robocze
- pamięć główną
- przestrzeń sterowania
- stos
- przestrzeń peryferiów albo wejścia-wyjścia
Adres (identyfikator danej) jest wyznaczany zgodnie z trybem adresowania. Symbolicznym identyfikatorem danej jest jej nazwa. Daną w
obszarze stosu adresuje wskaźnik szczytu stosu. Adres logiczny identyfikuje obiekty w strukturze programu (przestrzeni logicznej). Adres
fizyczny – w przestrzeni rzeczywistej (fizycznej). Przestrzenie adresowe są separowane – zapewnia jednoznaczność adresowania. Separacja
przestrzeni adresowych wyklucza możliwość jednoczesnego wskazania różnych danych lub dostępu do danej w różnych obszarach
adresowych. Wyjątkiem jest implementacja stosu programowego w pamięci głównej.

W Intel x86 jest wydzielona przestrzeń adresowa stosu zmiennoprzecinkowego (8 lokacji 80bitowych) – skutek implementacji osobnych
rozkazów arytmetyki zmiennoprzecinkowej.
Użycie danej wymaga wytworzenia jej adresu fizycznego (rzeczywistego). Adres fizyczny jest wynikiem przekształcenia przypisanego adresu
logicznego, opisującego logiczne relacje zmiennych w strukturach danych. Sposób przekształcenia składowych adresu logicznego w adres
liniowy opisuje tryb adresowania. Jeśli fizyczna przestrzeń pamięci jest mniejsza od przestrzeni logicznej, to adres liniowy podlega
dodatkowej translacji, w przeciwnym przypadku jest tożsamy z adresem fizycznym. W procesach wykonywanych współbieżnie każdej
zmiennej zostaje nadany unikatowy adres wirtualny, zawierający identyfikator procesu oraz lokalny adres logiczny zmiennej. Zamianę adresu
wykonuje układ zarządzania pamięcią.
Adresowanie wirtualne – zerwanie sztywnych powiązań między adresami logicznymi a fizycznymi – umożliwia przypisanie różnym
strukturom tych samych obszarów pamięci fizycznej oraz używanie adresów logicznych z zakresu spoza dostępnej pamięci fizycznej. Adres
wirtualny – odwzorowanie logicznej struktury programu i jej powiązanie z procesem. Układ zarządzania pamięcią MMU dokonuje translacji
adresów wirtualnych na adresy rzeczywiste (rys 7.11, strona 142). Jeśli obiekt nie jest dostępny w pamięci głównej (ze względu na
ograniczony rozmiar), to następuje jego pobranie z pamięci wtórnej, z miejsca wskazywanego przez adres zewnętrzny. Rozróżnienie
adresowania pamięci głównej i wtórnej musi być dla procesu przeźroczyste (wykonywane na poziomie zarządzania procesami).
Uruchomienie przesyłania bloków danych pomiędzy pamięcią główną i wtórną jest realizowane jako obsługa błędu braku jednostki –
następuje też sprawdzenie uprawnień dostępu oraz aktualizacja tablic systemowych opisujących relację odwzorowania bloków. Regularność i
spójność logicznych struktur programu umożliwia ograniczenie translacji do adresów bloków danych (zamiast poszczególnych bajtów).
Część adresu danej, zwana przemieszczeniem (displacement, offset), określająca lokalizację względem początku adresowanego bloku nie jest
przekształcana.
Najprostszym mechanizmem translacji adresu wirtualnego jest relokacja – polega na sumowaniu adresu logicznego i wektora relokacji.
Wyklucza dzielenie zasobów pamięci, bo dla procesu jest dany jeden wektor relokacji.
7. Stronicowanie – adres wirtualny, tablice stron
Stronicowanie służy jednoczesnej ochronie i dzieleniu zasobów. Adres wirtualny jest dwuskładnikowy. Część adresu jest wskaźnikiem opisu
adresu rzeczywistego umieszczonego w tablicy opisów. Tablica ta jest częścią kontekstu pamięci procesu i powinna być stale dostępna w
pamięci głównej. Ze względu na duży rozmiar stosuje się tablice wielopoziomowe.
W stronicowaniu pamięci cały obszar pamięci rzeczywistej tworzą rozłączne bloki o identycznym rozmiarze, zwane stronami. Typowym
rozmiarem strony jest obecnie 4kB przy zastosowaniu 32bitowych adresów rzeczywistych. Alternatywne rozwiązania dopuszczają integrację
stron w bloki o rozmiarze
k
2
lub tylko wybór innego rozmiaru strony. Pozwala to uprościć translację adresów w spójnych obszarach pamięci
wirtualnej.
Niższa część adresu wirtualnego jest adresem względnym w obszarze strony (rys 7.14, strona 145) i nie podlega translacji. Każda strona
rozpoczyna się na granicy adresów podzielnej przez rozmiar strony (
S
2
) , więc numer strony rzeczywistej jest jednocześnie bardziej
znaczącą częścią adresu obiektu umieszczonego na stronie. Adres rzeczywisty jest więc złożeniem adresu strony i adresu na stronie (adres
strony jest wielokrotnością
S
2
, adres na stronie nie może przekraczać
S
2
).
W stronicowaniu nie ma znaczenia logiczna struktura programu, a tylko fizyczna struktura pamięci głównej, ochrona i dzielenie zasobów są
realizowane na poziomie bloków pamięci (stron). Główną wadą stronicowania jest konieczność pamiętania osobnego opisu dla każdej strony
wirtualnej, co z uwagi na bardzo dużą liczbę stron wirtualnych wymaga użycia dużego obszaru pamięci wirtualnej do zapamiętania
odwzorowań (tablica stron). Drugą wadą jest wewnętrzna fragmentacja pamięci (średnio pół strony na jeden proces jest nieużywane).
Mniejszy rozmiar strony obniża straty, ale powoduje wzrost rozmiaru tablicy stron. Szybkość wyszukiwania zależy od rozmiaru tablicy, więc
konieczny jest kompromis.
Nie dotyczy bezpośrednio zagadnienia, ale chyba jest ważne:
Jednym ze sposobów przyśpieszenia translacji adresu jest hierarchiczna organizacja tablic. Przy m-bitowym wirtualnym numerze strony i n-
poziomowej strukturze tablic wystarczy zapamiętać n tablic o wielkości
p
2
słów, gdzie p=m/n. Na przykład, gdy strona ma rozmiar 4kB
(2^12), a adresy wirtualne są 32 bitowe, trzeba pamiętać 2^20=1 048 576 deskryptorów, a każdy z nich musi zawierać minimum 4 bajty.
8. Bufor antycypacji (TLB), odwrócone tablice stron.
Bufor TLB (bufor ostatnio wykonanych translacji, bufor antycypacji translacji, translation look-aside buffers) – sposób przyspieszenia
translacji adresu, którego skuteczność wynika z zasady lokalności. TLB jest rodzajem pamięci adresowanej zawartością (CAM) zwanej też
pamięcią skojarzeniową i jest umieszczony w układzie adresowym procesora. Translacja adresu jest wynikiem skojarzenia adresu
wirtualnego, umieszczonego w TLB, z adresem wirtualnym w programie. Jeśli skojarzenie nastąpi, to z bufora pobierany jest rzeczywisty
numer strony (adres segmentu przy segmentacji). Porównanie jest dokonywane jednocześnie z każdym wzorcem w buforze. Jeśli TLB nie
zawiera poszukiwanego wzorca, to nastąpi jego aktualizacja w trybie obsługi wyjątku (więc czasochłonne). Istotny jest dobór rozmiaru bufora
– aby mógł pomieścić wzorce należące do zbioru roboczego procesu oraz aby jego przeładowanie było szybkie. Bufory są zwykle 2 lub
4drożne, co umożliwia jednoczesną identyfikację 2 lub 4 wzorców. (rys 7.17, strona 149)
Sposobem zmniejszania rozmiaru tablicy stron jest użycie odwróconej tablicy stron. Zawiera ona jeden opis dla każdej strony rzeczywistej.
Opis ten obejmuje znacznik strony i adres strony wirtualnej. Znacznik (hash value) jest tworzony na podstawie wirtualnego adresu strony za
pomocą funkcji mieszającej. Jest konieczna weryfikacja konwersji, ponieważ jest możliwe wytworzenie identycznych znaczników dla

różnych adresów wirtualnych. Właściwy wybór funkcji mieszającej sprawia, że czas wyszukiwania opisu w odwróconej tablicy jest mało
zależny od liczby stron rzeczywistych i nie przekracza kilku powiązań. Problemem jest duża liczba opisów (zależna od rozmiaru pamięci
fizycznej), więc metoda jest rzadko stosowana. Jeśli liczba stron jest duża, lepszym rozwiązaniem jest bufor TLB. Rys7.18, strona 150.
9. Segmentacja – segment wirtualny i rzeczywisty, translacja adresu, deskryptory (opisy segmentów)
W segmentacji cały obszar pamięci rzeczywistej jest podzielony na bloki zwane segmentami, o rozmiarach odpowiadających logicznym
strukturom danych programu, definiowanych w przestrzeni adresów wirtualnych.
Translacja adresu polega na przekodowaniu wirtualnego identyfikatora spójnego bloku logicznego (VS – segment wirtualny) na adres bazowy
segmentu rzeczywistego (RS – segment rzeczywisty) za pomocą tablicy opisu segmentów (deskryptorów). Drugą częścią adresu wirtualnego
jest adres względny (relokacja) w obszarze segmentu. Adres bazowy segmentu może być dowolny, więc adres obiektu w pamięci rzeczywistej
jest obliczany przez zsumowanie adresu bazowego i relokacji (inaczej niż w stronicowaniu).
Występuje fragmentacja zewnętrzna – wskutek zmiennych rozmiarów segmentów powstają dziury. W celu ich likwidacji musi nastąpić
przesunięcie segmentów.
O rozmiarach tablicy deskryptorów było przy okazji zagadnienia 7.
10. Strategie przydziału stron i segmentów
Aby uniknąć wymiany pamięci podczas przełączania procesów jednemu procesowi jest przydzielana tylko część adresowalnego obszaru
pamięci głównej zwana partycją. Obszar nie musi być spójny. Jeśli rozmiar pamięci udostępnionej procesom jest mniejszy od sumy potrzeb,
konieczna jest wymiana bloków. Rozmiary partycji są różne dla różnych procesów.
Rozmiar bloku pamięci przydzielonej procesowi może być stały lub zmienny w czasie życia procesu.
Partycja stała – łatwa implementacja, nieefektywność przy dużej zmienności lokalności czasowej i przestrzennej
Partycja zmienna – większa elastyczność, trudna implementacja.
Przydział spójnych partycji jest podobny do przydziału pamięci segmentowanej. Wskutek różnej wielkości partycji spójnych następuje
fragmentacja – tworzą się obszary niewykorzystane, dziury. Choć lista dziur jest aktualizowana, to wskutek ich tworzenia może dojść do
stanu, w którym nie można uruchomić nowego procesu, mimo że suma dziur jest większa od zapotrzebowania procesu na pamięć (rys 7.19,
strona 151).
Najprostszy algorytm (komasacji dziur) polega na przesuwaniu partycji w jednym kierunku (w górę lub w dół pamięci). Nie jest skuteczny ze
względu na to, że relokacja partycji jest czasochłonna. Lepsze wyniki daje uwzględnianie rozmieszczenia dziur i dostosowanie kierunku
relokacji partycji do zapotrzebowania.
Najczęściej stosowane metody przydziału to:
BF – najlepsze wpasowanie (Best-Fit): lista dziur jest uporządkowana wg rosnących rozmiarów dziur, segment umieszcza się w
pierwszej o rozmiarze wystarczającym, kolejność adresów jest przypadkowa. W krótkim czasie prowadzi do powstania w pamięci
wielu bezużytecznych małych dziur.
WF – najgorsze wpasowanie (Worst Fit) : lista tworzona w kolejnośći malejących rozmiarów dziur, segment umieszcza się w
pierwszej dziurze o rozmiarze wystarczającym, kolejność adresów jest przypadkowa.
FF – pierwsze wpasowanie (First Fit): lista dziur uporządkowana wg rosnących adresów, segment trafia do pierwszej dziury o
wystarczającym rozmiarze, przeszukiwanie może być wznawiane od miejsca zakończenia poprzedniego wyszukiwania lub zawsze od
początku. Wadą jest kumulacja dziur o małym rozmiarze na początku listy, co wydłuża czas wyszukiwania
BB – wpasowanie binarne (binary Buddy, binarny koleś): tworzone są listy dziur o rozmiarach <
p
ip
ip
+
2
,
2
) {przedział lewostronnie
domknięty}, wpasowanie segmentu następuje metodą FF w obrębie listy odpowiadającej rozmiarowi segmentu zaokrąglonemu w górę
do całkowitej potęgi dwójki, kolejność adresów na liście jest liniowa.
11. Partycje i strategie wymiany stron – zbiór roboczy, zasada lokalności
Definicja partycji była w pytaniu 10.
Lokalność czasowa oznacza tendencję do powtarzania odwołań, realizowanych w niedawnej przeszłości (pętle, referencje do danych w
tablicy). Lokalność przestrzenna oznacza tendencję do odwołań do obiektów w obszarze adresowym obejmującym obiekty, które były już
użyte w programie (blok kolejnych rozkazów w programie, elementy regularnej struktury danych, tablice translacji adresów).
Zbiór bloków danych, do których zrealizowano h ostatnich odwołań przed chwilą t nazywa się zbiorem roboczym W(t,h). Rozmiar zbioru
roboczego rośnie asymptotycznie ze wzrostem h i można go dobrze przybliżyć funkcją wykładniczą S(t,h)~=P[1-exp(-h/h0)] {P- pamięć
programu}.
W systemach wieloprocesowych przepustowość początkowo rośnie ze wzrostem liczby procesów aktywnych, osiąga maksimum dla pewnej
liczby procesów max, potem gwałtownie spada (rys 7.12, s 144).

Układy szeregowania procesów i zarządzania pamięcią powinny stosować zasadę:
Nie wymieniaj bloku, który jest częścią zbioru roboczego aktywnego procesu i nie uaktywniaj procesu, którego zbiór roboczy nie mieści się w
całości w pamięci głównej.
Nie spełnienie w/w zasady prowadzi do konieczności częstego przywracania wymienionego bloku lub do wyjątków braku bloku.
Rozmiar partycji powinien być nie mniejszy niż rozmiar zbioru roboczego. Spełnienie tego warunku nie gwarantuje jednak obecności w
pamięci każdej potrzebnej strony i dlatego potrzebne są wymiany stron. Dla partycji stałych stosowanymi strategiami są:
- losowa – nadaje się do użycia wyłącznie w środowisku o niewielkiej lokalności (np. duże bazy danych)
- FIFO (first In first out) – kolejka stron do wymiany jest ustawiana w kolejności ich umieszczania w pamięci; nie uwzględnia
intensywności używania stron
- LRU (last recently used) – wymienia się stronę najdawniej używaną, wymaga użycia etykiet czasowych, niezbędna jest indeksacja
kolejności referencji
Optymalną strategią (MIN) jest wymiana bloku, który będzie użyty najpóźniej. Wymaga to jednak antycypacji kolejności wymian i nie jest
stosowane.
Dla stronicowanych partycji zmiennych stosuje się dwie strategie wymiany:
- WS – globalną – wymiana całego zbioru roboczego
- PFF – stosownie do częstości błędu braku strony (page fault frequency)
Miarą efektywności jest częstość występowania błędu braku strony.
12. Protokoły magistrali i arbitraż magistrali
Magistrala to zespół linii oraz układów przełączających służących do przesyłania sygnałów między połączonymi urządzeniami. W
komputerach jest rodzajem "autostrady", którą dane przenoszą się pomiędzy poszczególnymi elementami komputera. Magistrala jest
elementem, który sprawia, że system komputerowy staje się określoną całością. Magistrala składa się z:
•
•
szyny kontrolnej
•
szyny rdzeniowej
protokół – Reguła transakcji na danej magistrali. Obejmuje sposób przesyłania i relacje czasowe sygnałów sterujących, niezbędnych dla
poprawnego przebiegu transakcji. Typowa sekwencja zdarzeń czasowych -> rys 8.3, Str 169.
Protokoły:
1. Protokół synchroniczny – chwile pojawienia się zdarzeń (impulsów gotowości, potwierdzeń) ustalane są w relacji do impulsów
taktujących (CLK), niezależnie od szybkości działania nadajnika i odbiornika. Szybkość przesyłania jest teoretycznie największa,
jednak dostosowana do najwolniejszego urządzenia. Stosowane przy urządzeniach o tej samej szybkości.
2. Protokół asynchroniczny
a) Przesłania niepowiązane – ustalony czas trwania sygnałów gotowości i potwierdzenia lub błędu, zależne od szybkości
odbiornika opóźnienie potwierdzenia i zależne od szybkości nadajnika opóźnienie zakończenia. Może wystąpić zbyt
szybkie usunięcie danych z magistrali lub zbyt wczesne rozpoczęcie kolejnego transferu.
b) Przesłania częściowo powiązane – wysłanie nowych danych wymaga wcześniejszego wygaszenia sygnału gotowości, co
jest możliwe dopiero po uaktywnieniu sygnału potwierdzenia. Nadajnik nie otrzymuje potwierdzenia odbioru – wciąż
możliwość zmiany danych podczas trwania sygnału potwierdzenia
c) Protokół z potwierdzeniem – kasowanie sygnału gotowości (DR) po uaktywnieniu sygnału akceptacji (DA) lub błędu
(DE) (przednim zboczem sygnału) i kasowanie sygnału DA/DE zboczem tylnym sygnału DR. Nowy transfer może się
rozpocząć dopiero po wygaszeniu DA/DE. W komunikacji z jednym odbiornikiem protokół jest realizowany jako
czterozboczowy.
d) Sześciozboczowe przesyłanie z potwierdzeniem – stosowane podczas transmisji do wielu odbiorników. Używa się
dodatkowego sygnału ogólnej gotowości RDY (iloczyn logiczny gotowości poszczególnych odbiorników).
Problem arbitrażu żądań dostępu pojawia się w systemach, w których wiele urządzeń może pełnić funkcję zarządcy magistrali (bus master).
Rozstrzyganie konfliktów może być statyczne, zgodne z ustalonym harmonogramem, lub dynamiczne, na podstawie priorytetów zgłoszeń lub
wg zasady uczciwości, przy której priorytety są jednakowe. Stosowany jest też arbitraż mieszany.
W arbitrażu statycznym każdemu zarządcy przyznawany jest kwant czasu, nawet jeśli nie wykonuje on transmisji. Wadą tego rozwiązania jest
konieczność wykonywaniua transakcji pozornych, prowadzących do strat czasu, zaletą jest prostota.
Arbitraż dynamiczny:
- oparty na ważności żądania
- zasada uczciwości – blokada kolejnego zgłoszenia, dopóki nie zostaną obsłużone inne żądania o tym samym priorytecie

- rotacja karuzelowa (round-robin)
Trzy metody przekazywania dostępu:
- na żądanie
- po wykonaniu operacji
- odblokowujące (pre-emption)
Występują trzy rodzaje błędów:
- błędy adresowania
- błędy danych
- błędy arbitrażu
13. Hierarchia pamięci – organizacja, budowa, obsługa
Hierarcha pamięci:
1. rejestry procesora – czas dostępu 0,25-1ns, rozmiar 128-1024B, duży pobór mocy
2. pamięć główna – czas dostępu 10-50ns, rozmiar 256MB-4GB, mały pobór mocy
3. pamięć wtórna – czas dostępu 1-10ms, rozmiar >400GB, bardzo mały pobór mocy
4. archiwum – ponad 500 GB, bardzo mały pobór mocy
Organizacja pamięci głównej:
Jest zwykle zbudowana z wielu modułów, ich selekcja wymaga zastosowania układów dekodujących, do zapewnienia bezkonfliktowego
dostępu do modułów używa się układów buforujących. Sposób sterowania wpływa na szybkość dostępu do danych.
Pamięć główna jest wykonana jako dynamiczna i ma strukturę modułową. W pamięciach typu SIMM moduł zawiera 8+1 układów o
organizacji bitowej (
N
2
x 1), gdzie N jest liczbą bitów adresu w module. Dodatkowy układ zawiera bity parzystości. Moduł DIMM tworzą
dwa moduły SIMM. Adresowanie następuje przez wybór modułu i wszystkich układów zawierających adres wskazanego bajtu (rys. 9.10,
strona 188). Moduły mogą być organizowane w banki. Zalecanym trybem dostępu jest dostęp seryjny RAS-CAS-CAS – czas dostępu do
pierwszego bitu rządka w module SIMM jest sumą czasu wytworzenia stabilnego adresu rządka, odczytu rządka i opóźnienia strobu CAS w
celu odczytu. Dostęp do kolejnego bitu trwa już tylko 1 cykl. W pamięciach DDR odczyty bitów rządka synchronizują oba zbocza impulsu
zegarowego, co podwaja gęstość odczytu.
W modułach o strukturze bajtowej
N
2
x (8+1) dane wskazane kolejnymi adresami są umieszczone w kolejnych blokach albo lokacjach bloku.
W strukturze typu przeplot bloków niższe bity wskazują blok, a wybór słowa następuje za pomocą bitów wyższych. W strukturze typu
przeplot słów słowo w bloku wskazują niższe bity adresu fizycznego, podczas gdy wyższe bity identyfikują blok. Możliwy jest jednoczesny
dostęp do różnych bloków.
14. Zasada lokalności i jej zastosowania
Definicja zasady lokalności była w opisie zagadnienia 11.
Z zasady lokalności wynika koncepcja pamięci podręcznej (cache) – pamięci położonej bardzo blisko procesora (w sensie czasu dostępu),
przechowującej kopie aktualnie wykonywanego fragmentu programu.
15. Pamięć skojarzeniowa
Zwana też pamięcią asocjacyjną lub adresowalną przez zawartość (CAM) jest układem, który w odpowiedzi na pobudzenie wzorcem
sygnalizuje trafienie, jeśli którekolwiek słowo jest zgodne ze wzorcem, albo chybienie w przeciwnym wypadku. Zgodność może być
weryfikowana na wszystkich pozycjach słowa lub na pozycjach istotnych, wskazanych zawartością rejestru maski (rys 9.8, str 186). Jedno ze
słów zgodnych, wybrane wg kryterium selekcji (pierwsze zgodne, ostatnie zgodne, zawierające tylko „0” lub tylko „1” na pozycjach
maskowanych) przez układ rozstrzygania zgodności (MMR) może być skopiowane do bufora wyjściowego.
Pamięć skojarzeniowa wytwarza wiele wyjść po pobudzeniu. Słowa w pamięci asocjacyjnej mogą być zmieniane, jednak z powodu braku
wejść adresowych ich modyfikacja może być wykonywana albo sekwencyjnie, albo poprzez wymianę zbędnych wzorców na podstawie
rozstrzygnięcia MMR.
Może być typu ROM, lecz takie rozwiązanie jest nieelastyczne. Słowo maski wzorca może być stałe dla sekwencji dostępów (skojarzeń), lub
być zmieniane po każdym dostępie.
16. Pamięć podręczna – organizacja, charakterystyki
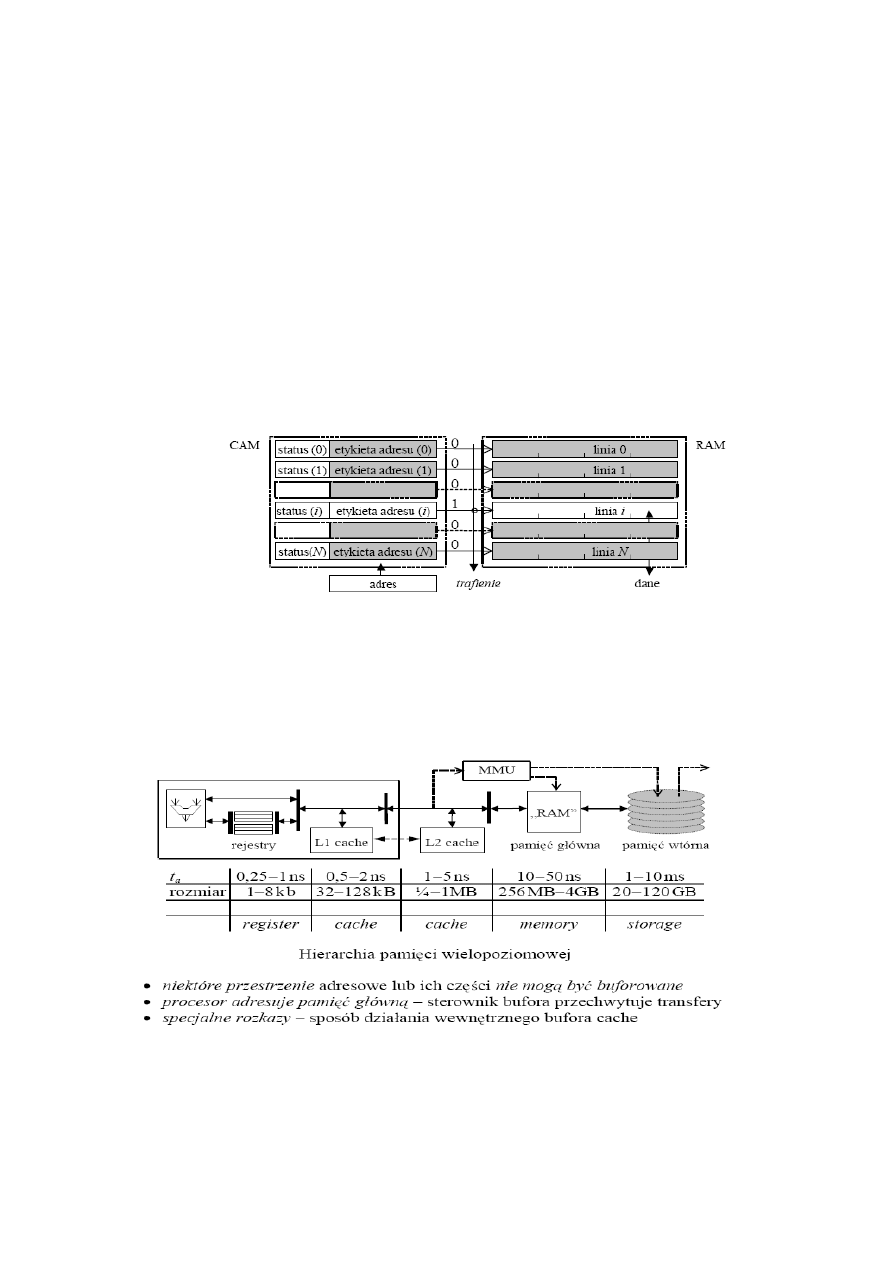
–
Pamiec
Z powodu lokalnosci odwolan do pamieci, tworzy sie przy procesorze bufor kopii danych z pamieci aktualnie
Podreczna
pracujacego procesu.
–
Organizacja
Konieczne jest etykietowanie stworzonych kopii pamięci w buforze w celu ich identyfikacji.
-Identyfikatorem danej w pamieci glownej jest jej adres – adres ten stanowi etykiete identyfikacyjna kopii w
buforze keszu.
-Odwzorowanie w buforze osobnych słów jest sprzeczne z zasada lokalnosci przestrzennej (dane powinny byc
lokowane w buforze wraz z ich otoczeniem). Jedna lokacja w buforze zawiera wiele slow.
-Jednorodna struktura ulatwia identyfikacje, upraszcza i przyspiesza dostep. (Ustalony rozmiar pojedynczej linii
w buforze, co znacznie upraszcza uklad)
-Linia – jednostka wymiany danych (zlozona z ustalonej liczby slow) miedzy buforem a pamiecia glowna
-Rozmiar lokacji zawier 2
k
słów/bajtów (linia wymiany)
-Przestrzen adresowa procesora = suma rozlacznych linii
-Identyfikatorem w pamieci moze byc skrocony adres (k-bitow)
Stworzenie keszu wymaga rozbudowy układu sterowania, bo trzeba przechwytywac transmisje z/do pamieci
glownej. Bufor powinien byc na tyle duzy aby pomiescic zbior roboczy jednego procesu, a wszystko po to zeby
zapobiec ciaglej wymianie danych ktore sie nie mieszcza.
-czas wyszukiwania w buforze log
2
N gdzie N to liczba linii.
–
Wielopoziom
Pamiec inkluzywna (hierarchiczna)
-lokalizacja danej znajdujacej sie w L1 dostepna w L2
-bufor L1 zawiera kopie nietorych danych z L2 (linie w L1 moga byc zaaktualizowane)
-aktualne dane dostepna tylko na najnizszym poziomie(L2)
Pamiec nieinkluzywna (separowana)
-zadna lokalizacja danej L1 nie jest dostepna w L2
-dostep do L1 krotszy niz do L2
-w L2 sa dane usuniete z L1
–
Charakterystyki
-Wieksza liczba linii N – lepsza lokalnosc czasowa
-Wiekszy rozmiar linii s– lepsza przestrzenna
-Dla danej pojemnosci, przy zwiekszeniu rozmiaru linii nastepuje wzrost czasu (proporcjonalny do liczby
transferow) w razie chybienia
17. Bufory zapisu
–
Chybienie
-Tryb WT, wymaga transferu do poziomu wyzszego. Bez uprzedzajacego kopiowania (NAOW) nie powoduje
Żądania
strat czasu, dopoki bufor nie zostanie przepelniony.
Zapisu
-Tryb CB, uprzedzajace kopiowanie (AOW) wymaga blokady zaisu i powoduje niezgodnosc kopii po
odblokowaiu.
-Tryb CB, kopiowanie odlozeone (NAOW) do chybienia w razie odczytu lub koljnego zapisu nie pwooduje strat
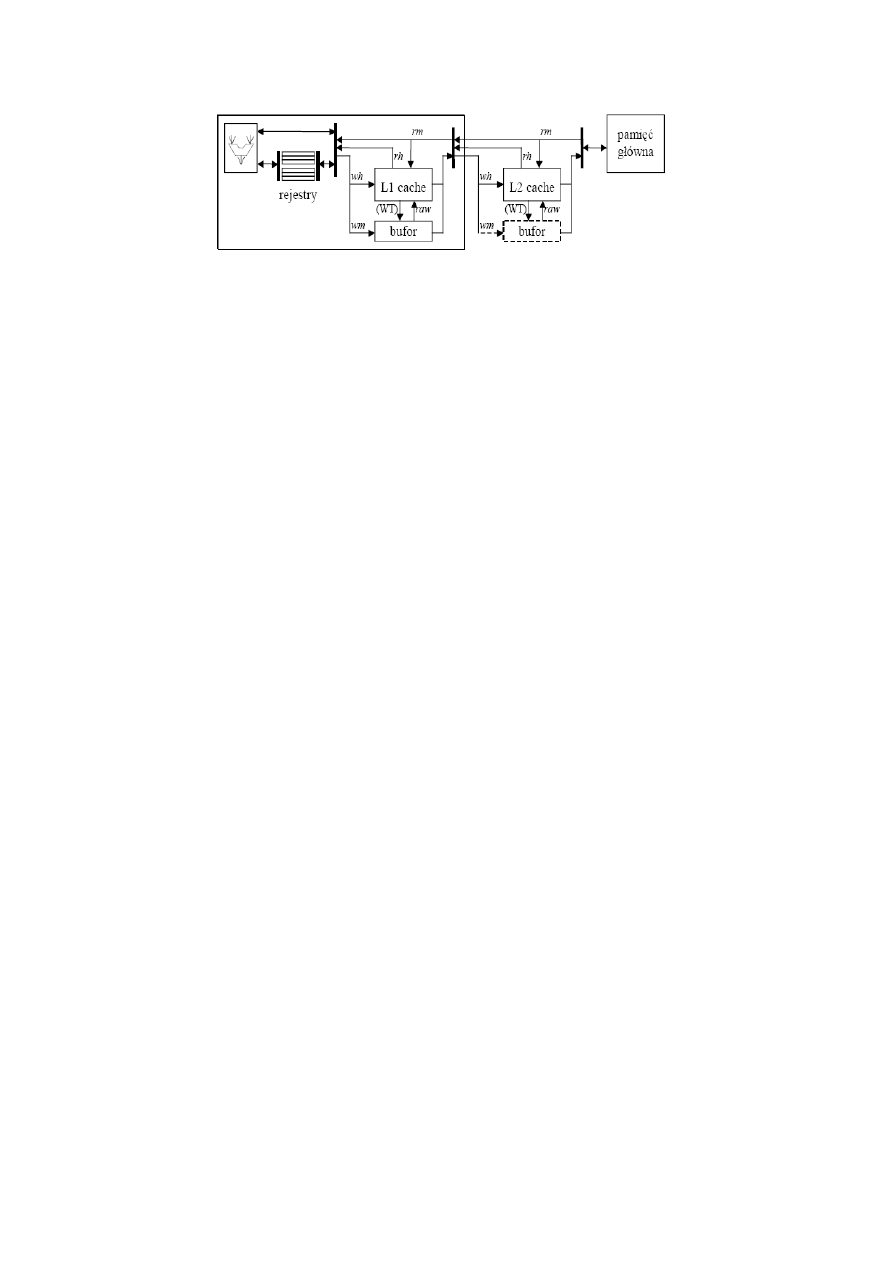
jesli zapis jest buforowany.
–
Bufor zapisu
pamięc FIFO (zachowanie koolejnosci zapisow). Jesli bufor sie przepelni to nastepuje blokada do momentu
zwolnienia sie miejsca.
18. Działania w pamięci podręcznej (wypełnianie,...)
–
Działania
Dzialania sluza utrzymaniu spojnosci danych
-Uniewaznienie linii zawierajacej dane przypadkowe
-Przed pierwszym wypelnieniem
-Przy zewnetrznej zmianie oryginalu w pamiecy glownej
-Przelaczenie procesu
-Wypełnianie linii nową zawartością
-Chybienie podczs odczytu badz (jesli AOW) podczas zapisu
-Wymiana linii w razie braku miejsca w buforze
-Chybienie podczs odczytu badz (jesli AOW) podczas zapisu (tak samo)
-Zapis w obszarze skopiowanej linii (rozbieznosc kopii z orginalem)
-Trafienie podczas zapisu
-Zapis skrośny [jednoczesny] (WT) modyfikuje kopie w buf. Wyzszego poziomu
-Zapis lokalny [zwrotny] (WB/WC) w kopii lokalnej opozniony zapis do bufora
wyzszego poziomu podczas kasowania linii
-Zapis omijający wykonywany do pamieci glownej z uniewaznieniem linii trafionej
-Chybienie podczas zapisu – zapis do pamieci glownej badz bufora wyzszego poziomu (NAOW)
lub wypelnianie i zapis AOW.
-Odczyt danej
-Trafienie podczas odczytu
19. Strategie aktualizacji pamięci podręcznej
–
Strategie
Wybor strategii ma wplyw na szybkosc wykonywania program.
-Strategie wypełniania pamięci podręcznej, obejmuja zasady odwzorowania linii pamieci glownej w pamieci
podrecznej.
-losowe-zbior linii w zbior lokacjii linii
-bezposrednie-podzbior linii w lini elokacji
-blokowo-skojarzeniowe-podzbior linii w podzbior linii
-Strategie pobierania linii z pamieci glownej, obejmujace reguly podejmowania decyzji o wypelnianiu linii.
-pobranie wymuszone – uaktywniane chybieniem
-pobranie uprzedzajace – na podstawie prognozy dostepu
-Strategie wymiany linii w pamieci podrecznej i metody aktualizacji ich statusu
-losowa- dowolnie (skuteczne przy odwzorowaniu losowym)
-kolejkowa- kolejnosc wymiany jest zgodna z kolejnoscia wypelniania
-LRU- wymieniana linia najdawniej uzywana (skuteczne przy blokowo-skojarzeniowym)
Do tego trzeba znac odwzorowania AK-A 19
20. Antycypowane pobieranie linii, strategie wymiany
–
Atcp. Pob. Linii
Antycypacja jednostopniowa - (OBL) Jest to najprostsza prognoza zapotrzebowania.Z zasady lokalności
przestrzennej sluszne jest branie nastepnej linii jesli wzieto poprzednia.
Pobranie uprzedzajace mozna wykonac jako:
-wymuszone (inicjowane podczas kazdej proby dostepu do lnii) – pobierana nastepna linia jesli nie ma jej w buf.
-implikowane chybieniem – jesli nastepuje wypelnienie linii to pobierana jest tez nastepna
-markowane – realizowane tylko przy pierwszym odwolaniu do danej linii (odnotowane w etykiecie linii)
Pobrania antycypowane trudno zrealizowac w buforze skojarzeniowym, w maja niewielka skutecznosc w buforze
z odwzorowaniem bezposrednim, w wielodroznym nie wprowadzaja dodatkowych opoznien (tzn ze tu pasuja
najlepiej?)
–
Str. Wymiany linii
Algorytm wymiany:
-losowy – only w buforach asocjacyjnych
-ryzyko usuniecia potrzbnej linii p2
-K
(K – liczba lokacji w buforze)
-FIFO – usuwana linia najdawniej alokowana
-liczba bitow historii log2S (S- liczba lokacji w podzbiorze)
-ryzyko usuniecia potrzbnej linii p2
-S
-LRU – wymieniana linia najdawniej uzyta
-oba podpunkty jak powyzej ale (S-1)log2S
Aktualizacja bufora podczas przelaczania zadan.
-bufor ciepły – czesc bufora nie jest wymieniana
-bufor zimny – uniewaznienie calego bufora
21. Spójność pamięci podręcznej – model MESI
Niezbędnym warunkiem poprawnej współpracy procesora z pamięcią podręczną jest zapewnienie spójności pamięci podręcznej (cache
coherency), czyli zgodności kopii danych w niej umieszczonych z oryginałami w pamięci głównej lub zapewnienie bieżącej dostępności
statusu każdej linii pamięci podręcznej.
Jeśli aktualizacja następuje w trybie zapisu lokalnego, to po wypełnieniu linia mogła być modyfikowana wskutek zapisu. Należy więc
odróżnić dwa stany ważności – linia zgodna („conforming”, clear, C, czysta) z oryginałem i linia zamazana (dirty, D, „brudna”).
MESI jest szeroko używanym protokołem zapewniania spójności pamięci, został wprowadzony w procesorach Pentium. Każda linia pamięci
podręcznej jest oznaczona jednym z czterech stanów:
M – Modified – zmodyfikowany: Linia jest obecna tylko w obecnym cache, i jest „brudna” - została zmodyfikowana w stosunku do
oryginału w pamięci głównej. Należy przepisać dane z powrotem do pamięci głównej przed kolejnym odczytaniem (już niepoprawnego)
stanu pamięci głównej.
E – Exclusive – unikatowy: Linia jest obecna tylko w obecnym cache, ale jest „czysta”
S – Shared – współdzielona: Linia może być zapisana w innych pamięciach cache w systemie
I – Invalid – unieważniona: Linia jest nieprawidłowa.
Cache może zapewnić odczyt w każdym stanie poza I. Unieważniona linia musi zostać pobrana by umożliwić odczyt.
Zapis może być wykonany tylko w stanie M lub E. W stanie S najpierw należy najpierw unieważnić wszystkie kopie w pamięciach
podręcznych. Jest to zazwyczaj osiągane poprzez operację Read For Ownership (RFO).
Cache może pozbyć się linii w stanie innym niż M, poprzez zmianę jej stanu na I. M musi zostać najpierw przepisane do pamięci głównej.
Stany M i E są zawsze prawidłowe – odpowiadają stanowi faktycznemu. Stan S może być niedokładny – jeśli inny CPU pozbywa się linii, a
omawiany CPU staje się jej jedynym „właścicielem”, jej stan nie zostaje przemianowany na E.
(Autorskie, wolne tłumaczenie z angielskiej wikipedii, hasło MESI).
22. Przetwarzanie potokowe – koncepcja, wymagania
W maszynach ściśle sekwencyjnych (np. Procesory I i II generacji) zarówno instrukcje tworzące program, jak też ich poszczególne etapy, sa
wykonywane kolejno, a czas wykonania programu jest sumą czasów wykonywania instrukcji. Ułatwia to synchronizację zadań, lecz
powoduje straty czasu procesora, bezczynnego podczas cykli dostępu do pamięci.
W przetwarzaniu potokowym instrukcje są wykonywane kolejno lub współbieżnie. Poszczególne etapy instrukcji są natomiast wykonywane
jednocześnie. Dzięki temu minimalizowane są straty czasu procesora.
Niezależnie od sposobu przetwarzania programu czas jego wykonania jest proporcjonalny do czasu cyklu procesora Tc i zależy od liczby
wykonań instrukcji i-go typu
I
i
oraz średniej liczby cykli
C
i
potrzebnych na wykonanie takiej instrukcji:
t
p
=
T
c
I
i
C
i
W systemach wielowątkowych realizujących jednocześnie wiele procesów, czas wykonania programu zależy również od organizacji
przetwarzania tych procesów. Rzeczywiste skrócenie czasu przetwarzania wymaga zwiększenia liczby procesorów.
Jeżeli każdy etap (fetch, decode, execute, write) wykonania rozkazu angażuje inny blok funkcjonalny procesora, to w czasie jego
wykonywania inne bloki są bezczynne. Jeśli kolejne etapy będą odseparowane, to jest możliwe jednoczesne wykonanie różnych etapów
kolejnych rozkazów (rys 10.1, strona 216), co umożliwi wytwarzanie wyniku raz na cykl, nie raz na kilka cykli.
Przetwarzanie superskalarne. Przetwarzanie można przyspieszyć, umożliwiając współbieżne wykonanie różnych rozkazów w powielonych
potokach. Skuteczność tego przetwarzania ograniczają zależności funkcjonalne między kolejnymi rozkazami, które uniemożliwiają ich
jednoczesne niezależne wykonanie. Skutecznym rozwiązaniem problemu jest dynamiczne tworzenie kodu integrującego kilka rozkazów
podczas kompilacji. Tworzenie takich multirozkazów jest istotą koncepcji architektury VLIW.
Z drugiej strony, skoro czas wykonania najdłuższego etapu ogranicza częstość wytwarzania wyników można przypuszczać, że podział etapu
na fazy umożliwi wzrost szybkości przetwarzania. W takim superpotoku liczba podetapów cyklu, zwana głębokością potoku, nie może być
dowolnie duża, bo każdy wprowadza dodatkowe opóźnienie wskutek konieczności separacji etapów.
Przy częstych zakłóceniach potoku może się zdarzyć, że czas przetwarzania potokowego będzie porównywalny z czasem sekwencyjnego

wykonania instrukcji.
1. W każdym cyklu musi być zwiększany licznik rozkazów, w fazie F(etch) lub wcześniej
2. W każdym cyklu konieczne jest pobieranie kolejnej instrukcji
3. W każdym cyklu potrzebne jest pobieranie nowych danych
4. transfery danych z i do pamięci mogą wystąpić jednocześnie co wymaga rozdzielenia buforów odczytu i zapisu danych
5. potrzebne jest zastosowanie rejestrów zatrzaskowych do przechowania danych, które mogą być potrzebne do wykonania kolejnej
instrukcji.
23. Wydajność i przepustowość potoku
Wydajnością przetwarzania nazywa się stosunek liczby zakończonych instrukcji do liczby cykli, w których to nastąpiło. Wydajność
nominalną potoku określa osiągalna liczba wyników tworzonych w cyklu. W potoku i superpotoku jest ona równa 1, w potoku
superskalarnym >=2. Faktyczna wydajność jest zawsze mniejsza od nominalnej.
Zgodnie z podstawową definicją wydajność dowolnego potoku można określić jako odwrotność średniej liczby cykli potrzebnych na
zakończenie instrukcji:
P= p[1−b−r rd bn]
−
1
gdzie:
p – wydajność nominalna, n – głębokość potoku (liczba etapów cyklu rozkazu), b – częstość rozgałęzień wstrzymujących potok (opóźnienie n
cykli), d – liczba cykli opóźnienia z powodu konfliktu danych (d>=1), r- częstość konfliktów danych (r<<b).
Przepustowość potoku to średnia liczba instrukcji ukończonych w jednostce czasu, zależy od wydajności i czasu trwania najdłuższego etapu.
Czas trwania etapu obejmuje opóźnienie, które wnoszą separujące bufory oraz asynchronizm zegara taktującego. Czynniki te obniżają
przepustowość i ograniczają zwiększanie głębokości potoku. Uwzględniwszy straty czasu, przepustowość potoku można obliczyć jako:
G=P [1k tC ]
−
1
[
s
−
1
]
24. Organizacja potoku statycznego i dynamicznego
Potok statyczny jest najbardziej restrykcyjną formą potoku – nie można przeskoczyć żadnego etapu i w szczególnych okolicznościach
konieczne jest nieaktywne oczekiwanie na dokończenie etapu poprzedniego. W potoku statycznym każdy konflikt powoduje przestój.
W potoku dynamicznym możliwe jest ominięcie etapów przetwarzania nie związanych bezpośrednio z wykonaniem. W najprostszym
przypadku polega to na bezpośrednim przekazaniu wyniku działania do miejsca gdzie jest potrzebny, bez oczekiwania na koniec zapisu.
–
Potok dynamiczny I rodzaju: kolejność dekodowania i zapisów do pamięci musi być zgodna z z kolejnością pobierania instrukcji. Jeśli
częstość działań load lub store jest niewielka (przy wystarczającej liczbie rejestrów) to efektywność takiego potoku jest tylko nieco
większa niż potoku statycznego
–
Potok dynamiczny II rodzaju: jest zachowana tylko kolejność dekodowania. Jeśli między kolejnymi instrukcjami nie ma zależności
funkcjonalnych, to inne etapy nie są wykonywane kolejno.
–
Potok dynamiczny III rodzaju: dekodowanie odbywa się w takiej kolejności, aby instrukcja aktualnie dekodowana była niezależna od
tych, których dekodowania jeszcze nie zakończono.
25. Konflikty przetwarzania w potoku i przestoje
–
Konflikt sterowania – zakłócenie sekwencji przetwarzania wskutek rozgałęzienia
–
Konflikt danych – jednoczesne zapotrzebowania na to samo źródło danych
–
Konflikt strukturalny – jednoczesne żądania dostępu do unikatowego zasobu.
Konflikty prowadzą do przestojów potoku (interlocks). Wpływ konfliktów na opóźnienie potoku zależy od rodzaju konfliktu, architektury i
organizacji procesora oraz konstrukcji jego bloków funkcjonalnych. Najbardziej niekorzystny jest konflikt sterowania, spowodowany
rozgałęzieniem. Wznowienie jest możliwe tylko po użyciu warunku i pobraniu instrukcji docelowej skoku.
Konflikty sterowania i czasy przestojów przez nie generowanych:
t
IF
, t
DF
- czas upływający od początku cyklu rozkazowego do zakończenia etapów pobrania kodu lub danych w potoku bez blokad
(wskutek konfliktów),
t
CC
- czas od początku cyklu rozkazowego do wytworzenia warunku przez instrukcję wcześniejszą. Wyróżnić
można trzy przypadki:
1) rozgałęzienie warunkowe niewykonane – dekodowanie już pobranej instrukcji następującej po instrukcji rozgałęzienia odbywa się
dopiero po wytworzeniu warunku
t
bnt
=
max 0, t
CC
−
t
IF
−
1
2) rozgałęzienie warunkowe wykonane – instrukcja może być dekodowana dopiero po pobraniu, ale nie przed wytworzeniem warunku
t
bt
=
t
DF
−
t
IF
max0, t
CC
−
t
DF
3) rozgałęzienie bezwarunkowe – instrukcja docelowa może być dekodowana dopiero po jej pobraniu
t
bu
=
t
DF
−
t
IF
Powodem konfliktu danych może być:

a) zależność adresowa – obliczenie adresu wymaga operandu, którego wartość wytwarza poprzednia instrukcja w trybie WR
t
da
=
t
WR
−
t
AG
b) zależność danych – wykonanie instrukcji wymaga operandu wytwarzanego przez poprzednią instrukcję
t
dd
=
t
WR
−
t
DF
26. Prognoza rozgałęzień – kolejka rozkazów, prognoza statyczna i dynamiczna
–
Prognoza
Na podstawie prognozy rozgalezienia mozna minimalizowac konflikty sterowania. Aby prognoza skutecznie
wplywala na przepustowosc potoku nalezy wczesniej rozpoznac rogalezienia.
Uklad prognozy rozgalezien musi byc ziwazany z kolejka rozkazow.
–
Statyczna
Prognoza oparta na regułach statystycznych
Podstawa jej dzialania jest rozpoznanie kierunku skoku na podstawie kodu rozkazu. Polega na regule
statystycznej zwanej PRAWEM 90/50. (90% ze rozgalezienie do tylu i 50% ze do przodu)
–
Dynamiczna
Prognoza oparta na historii przetwarzania
Oparta na analizie szansy wykonania rozgalezienia na podstawie historii jego wykoniania. Ma pierwszenstwo nad
prognoza statyczna.
27. Konflikty strukturalne
–
Konflikt strukt.
Nazywany tez konfliktem zasobu lub dostepu. Przejawia sie jako:
-konflikt dostepu do keszu, spowodowany żądaniem dostepu do dwoch linii jednoczesnie pochodzacym z jednej
badz z roznych faz potoku.
-konflikt wydluzonego dostepu do pamieci wskutek chybienia
-konflikt dostepu do pliku rejestrow, spowodowany jednoczesnymi żądaniami uzycia rejestrow pliku
-konflik przedluzonego wykonania instrukcji zlozonej
Minimalizacja konfliktow wiaze sie z kosztem czasu i pamieci.
- Usuwanie
-Konflikt dostepu do danych w pliku mozna zlagodzic realizujac wieloportowy uklad dostepu do rejestrow.
Umozliwia to jednoczesne uzywanie roznych rejestrow do zapisu i odczytu. (Wielomagistralowy dostep do pliku)
-Konflikt wydluzonego dostepu do pamieci na skutek chybienia podczas odczytu, moze byc zlagodzony jedynie
przez antycypowanie pobierania linii. Skutki chybienia podczas zapisu mozna lagodzic poprzez dostosowanie
bufora zapisu.
-Konflikt przedluzonego wykonania mozna lagodzic przez niekolejne wykonywanie dzialan
-Konflikt jednoczesnych żądań dostepu do 2 linii mozna usunac przez uzycie pamieci wieloportowej.
28. Przemianowanie rejestrów
–
Przemianowanie rej.
Jest metodą radzenia sobie z konflikatmi antyzaleznosci i zaleznosci wyjsciowej przez powielanie zasobow.
Uzycie innego fizycznego rejestru w rozkazie zapobiega antyzaleznosci w innym rozkazie oraz zaleznosci
wyjsciowej w pierwszym.
-zależność RAR (odczyt po odczycie) moze spowodowac konflikt jesli dozwolone jest jednoczesne przekazanie
do wykonana kilku instrukcji.(np potok superskalarny). Sprawe moze rozwiazac przemianowanie.
-konflikt typu WAR (zapis po odczycie) moze byc skutkiem wykonania instrukcji czasochlonnej. Mozna usunac
przemmianowaniem rejestrow.
29. Stacje rezerwacyjne i buforowanie instrukcji
–
Stacja rezerw.
Problem-ograniczenie technologii potokowej przez wykonywanie instrukcji w kolejnosci zapisanej w programie
Lagodzenie – niekolejne wykonanie instrukcji
Zmiana kolejności rozkazow moze odbywac sie w rytmie naplywu rozkazow lub gotowosci danych.
-Pierwsza metoda poleg ana notowaniu stanu kolejnych instrukcji w buforze STACJI
REZERWACYJNEJ i ich rozsylaniu do jednostek wykonawczych jesli dostepne sa argumenty.
-W 2 metodzie kazda jednostka funkcjonalna ma wlasny bufor. Gdy jest miejsca w lokalnej stacji
rezerwacyjnej instrukcja jest tam przeslana wraz z kopiami lub adresami danych i wtedy czeka na
wykonanie poki argumenty nie beda dostepne.
Szeregowanie zgodnie z naplywem instrukcji:
-Procesor ma pojedyncza stacje rezerwacyjna (buf. Wyjsciowy). Jesli bufor jest zajety, bo trwa
jeszcze wykanie instrukcji wczesniej przekazanych to nastepuje blokada rozsylania. Stacja
rezerwacyjna zawiera tablice stanu operacyjnego instrukcji biezacych oraz tablice notowan dla
rejestrów.
Szeregowanie zgodnie z napływem danych:
-(Alg. Tamasulo) Dostarczenie do stacji rezerwacyjnej wartosci danych. Wszelkie transfery danych
nastepuja przez wsplna magistrale co pozwala na tworzene kopii danych jednoczesnie w wielu
buforach. Zapis do rejestru zrodlowego jest mozliwy jesli wszystkie potrzebne kopie dostarczono
do stacji rezerwacyjnych. Jesli zrodlo danych jest niedostepne do bufora zostaje wyslany adres a
bufor przechodzi w tryb podgladania magistrali.
-Roznice w stosunku do schematu poprzedniego:
-stacja rezerwacyjna osobna dla kazdej jednostki funkcjonalnej.
Wydanie instrukcji jest mozliwe tylko jesli we wlasciwej stacji rezerwacyjnej jest wolne miejsce.
30. Komputer z programem zintegrowanym – definicja pamięci, rola licznika rozkazów
–
Liznik rozkazow
Jest to uklad wytwarzajacy adres kolejnego rozkazu podczas wykonywania rozkazu poprzedniego. Umozliwia
sterowanie przebiegiem programu. Sterowanie wymaga mozliwosci decyzji sciezki przetwarzania zaleznie od

wyniku poprzednich dzialan. Wymaga to jawnego wskazania lokacji nastepnego rozkazu. Sluza do tego celu
specjalne rozkazy jak roznego rodzaju dżampy czy rozgalezienia, powodujace wymuszenie nowej zawartosci
licznika rozkazow.
–
Pamiec
Zasady organizacji pamięci:
-Informacja przechowywana w komórkach o jednakowym rozmiarze. Kazda komorka zawiera
jednostke informacji zwana slowem.
-Znaczenie slow nie jest przypisane ich tresci. Sposob przechowywania danych i instrukcji jest
identyczny.
-Interpretacja slowa zalezy od stanu maszyny w chwili pobrania go z pamieci.
-Komorki tworzas zbior uporzadkowany. Kazdemu slowu mozna przypisac unikatowy adres.
-Zawartosc komorki pamieci moze zmienic tylko procesor.
31. Architektura listy rozkazów – struktura kodu, koncepcja architektury RISC
–
Arch list. Rozkazow
Program jest sekwencja polecen ktore przekazane jednostce sterujacej powoduja wykonanie przez komputer
kolejnych dzialan. Struktura opisu maszyny wirtualnej (software) jest warstwowa i miedzy poziomem aplikacji a
poziomem architektury listy rozkazow obejmuje takie typowe warstwy jak:
-system operacyjny
-jezyk asm
-jezyk algorytmiczny
-jezyk makropolecen
–
Struktura kodu
Obligatoryjnym elementem skladni programu jest mnemonik (MNEMONIK{arg1}{,arg2}{,arg3}) czyli
symboliczna nazwa dzialania ktora jest akronimem lub skrotem slowa z jezyka angielskiego.
Uzywanych jest kilka standardow notacji rozkazow i zapisu programu w jezyku asm.
Intel:
MNEMONIK{{typ PTR}Destination}{,{typ PTR}Source}
Motor Ola:
MNEMONIK{.rozmiar}{Source}{,Destination}
Ogolnie RISC:
MNEMONIK{.rozmiar}{arg 1}{,arg2}{wynik}
Klasyfikuje sie instrukcje wedlug ilosci argumentow jako: bezadresowa, jednoadresowe, poltoradresowa i
wieloadresowe. Pozwala to okreslic rodzaj architektury.
STRUKTURA KODU MASZYNOWEGO AK-3.pdf PIERWSZE DWIE STRONY.
–
RISC
W architekrurze RISC pojemny plik rejestrow pozwala ograniczyc komunikacje procka z pamiecia, a szybsze
wykonanie rozkazow prostych kompensuje brak zlozonych rozkazow i trybow adresowania. Bufor pamieci
podrecznej pozwala tez skrocic czas dostepu do pamieci. Współcześnie istotą architektury RISC jest rozsądne
projektowanie listy rozkazów, którego wyrazem jest jednolita struktura kodów rozkazów, łatwość dekodowania i
wykonania oraz przystosowanie do wymagań kompilatorów. (Archotektura rejestrowa L/S jest typowa dla RISC)
32. Architektura procesora – R/M, R+M, L/S
–
Arch. Proc.
Okresla ogolne zasady przetwarzania dnych w komputerze. W polaczeniu z architektura pamieci tworzy
architekture maszyny rzeczywistej.
Zasadnicze elementy architektury procesora:
-jednostka centralna (kontrolujaca)
-zawiera rejestr rozkazow IR – przechowywanie kodu pobranego z pamieci glownej
-dekoder (z ukladem sterowania) – wytwarza sygnaly sterujace dzialaniem jednostek
procesora i jego wsp. Z pamiecia.
-licznik rozkazow PC
-rejestr stanu SR – pamieta biezacy stan procesora
-jednostka wykonawcza i adresowa tworzace laczne sciezki przeplywu danych.
EU
-zawiera jednostke arytmetyczno-logiczna ALU
-bufor pamieci MBR
-plik rejestrow roboczych R
MU
-zawiera uklad wytwarzania adresu MAG
-plik rejestrow MAR
-rejestr wskaznika stosu SP
Informacja o poprawnosci wyniku operacji jest zapisywana przez ALU do rejestru warunkow (CR).
ALU jest zwyczajowo dzielone na jednostke stalo i zmiennoprzecinkowa. Jednostki te uzywaja roznych
rejestrow.
Cztery glowne rodzaje architektury procka:
-akumulatorowa AC – Jeden argument operacji musi byc umieszczony w wyroznionym rejestrze procka, w
ktorym jest tez zapamietany wynik operacji. Poniewaz mozna w nim podwojnie wykorzystac ten
rejestr nosi on nazwe akumulatora. Drugi argument pobrany z pamieci idzie do MBR,
niedostepnym dla programu.

-rejestr-pamiec R/M – cechuje ja umieszczenie przynajmniej jednego argumentu w rejestrze procka. Drugi jest
pobierany z innego rejestru procesora lub z pamieci, tam tez zostaje umieszczony wynik. Miejsce
przechowywania drugiego argumentu pelni funkcje uogulnionego akumulatora.
-uniwersalna R+M – zarowno argumenty jak zrodlowe operacji jak tez wynik sa umieszczone w rejestrach procka
lub w pamieci. Konieczne jest uzycie MBR, niezbednych podczas wykonania operacji z wiecej niz
jednym argumentem pochadzacym z pamieci.
-rejestrowa L/S (GPR) – kazdy rejestr dostepny dla uzytkownika jest rejestrem ogolnego przeznaczenia. Moze
byc uzyty jako rejestr argumentu badz adresowy. Argumenty dzialan sa umieszczane zawsze w
rejestrach. Wytworzenie adresu wykonuje albo jednostka stało albo zmiennoprzecinkowa.
33. Adresowanie danych – rozdzielczość adresowania
–
Adresowanie
W architekturze klasycznej pamiec jest uporzadkowanym zbiorem komorek.Kazda komorka zawiera jednostke
informacji zwana slowem. Jesli rozmiar jakiejs informacji przekracza rozmiar slowa to musi byc ona
umieszczona w kilku komorkach pamieci. I tutaj powstaej problem kolejnosci w jakiej powinno sie to robic i jak
je indeksowac. Stosowane sa dwie konwencje:
Big Endian
wazniejszy nizszy koncowy wyzszy – slowo zawierajace bardziej znaczaca czesc informacji ma
nizszy numer porzadkowy (adres)
Litte Endian
wazniejszy wyzszy koncowy nizszy – slwoo zawierajace mniej znaczaca czesc informacji ma
nizszy numer porzadkowy (adres)
W Intelu x86 obowiazuje LE a w PowerPC BE. Natomiast w motoroli bajty wedlug BE a bity LE.
–
Rozdzielczosc
Rozdzielczosc adresowania jest to rozmiar najmniejszej adresowanej jednostki danych w pamieci. Rozdzielczosc
adresowania danych jest najczesciej bajtowa, a rozdzielczosc adresowania kodu zgodna z rozmiarem slowa
maszynowego (2 lub 4 bajty). Rozdzielczosc absolutna czyli dostep do pojedynczych bitow w slowie jest cechą
wyjątkowa .
Standardowym rozmiarem kodu jest slowo maszynowe. Szerokosc magistrali danych procka powinna umozliwic
przeslanie jedngo lub wielokrotnosci slowa maszynowego. (Przy wielokrotnosci pojawia sie problem
wpasowania slowa)
Wpasowanie natomiast (aby bylo ekonomiczne i umozliwialo dostep do danej w jednym cyklu pamieci) powinno
nastepwac tak aby umieszczac slowo pod adresem podzielnym przez jego rozmiar.
34. Separacja logiczna i fizyczna przestrzeni adresowych
–
Separacja
Separacja przestrzeni adresowych powinna wykluczyc mozliwosc jednoczesnego wskazania roznych danych lub
dostepu do danej w roznych obszarach adresowych.
Fizyczna – osobne uklady dla roznych przestrzeni adresowych. Rozroznianie na podstawie rodzaju wartosci
wskaznika lokacji. Sa z tym zwiazane dwie architektury.
-Harwardzka
-pamiec programu
-pamiec danych
-rejestry urzadzen
-Klasyczna
-komorki pamieci (pamiec ogolnie)
-rejestry urzadzen
Logiczna – oznacza przypisanie instrukcjom lub grupom instrukcji osobnych przestrzeni adresowych.
-przestrzen sterowania – ochrona sterowania
-przestrzen peryferiow – rozdzial umowny
-niezalezna od separacji fizycznej (Motorola)
-opcjonalna – mozliwe jednolite adresowanie (intel “in” “out”)
-niepotrzbena w RISC (“load” “store”)
35. Adresowanie bezpośrednie i pośrednie
ZDECYDOWANIE POLECAM RZUCIC OKIEM NA AK-5.PD OD STRONY 10
–
Bezposrednie
Wskaznik adresu jest zawsze pojedynczy i jest nim albo nazwa rejestru albo adres liniowy danej pamieci.
–
Posrednie
Jesli chociaz jedna ze skladowych wskaznika adresu jest okreslona przez wskazanie loakcji (rejestru lub slowa w
pamieci) w ktorej umieszczono wartosc tej skladowej.
Adresowanie zeroelementowe – jest adresowaniem bezposrednim, w ktorym adres jest niejawny.
-zwarte – jeden lub wszystkie operandy sa domniemanye przez skojarzenie z funkcja
wykonywanego rozkazu. (wystepuje: architektura akumulatorowa,stosowa)

-natycnmiastowe – wzgledne wobec licznika rozkazow w ktorym slowa kodu danej
stanowiarozszerzenie kodu rozkazu.
-blyskawiczne – skrocony kod danej stanowi czesc slowa kodu operacyjnego. (RISC)
Adresowanie jednoelementowe – lokalizacja argumentu okresla jeden jawnie podany wskaznik.
-Adresowanie jednoelementowe posrednie
Jest zawsze adresowaniem bezwzglednym.
-bezwsgledne posrednie – w slowie rozszerzenia kodu rozkazu podany jest adres korki pamieci
zawierajacej adres danej.
-rejestrowe posrednie – adres danej jest umieszczony w rejestrze identyfikowanym w slowie rozk.
-rej. Posrednie zmodyfikowane – adres w rejestrze jest automatycznie zmniejszany przed uzyciem
lub zwiekszany po uzyciu.
-Adresowanie jednoelementowe bezposrednie
-bezwzgledne – Skrocony adres danej umieszcza sie w polu slowa kodu rozkazu lub pelny adres
jest slowem rozszerzenia kodu.
Rejestrowe bezposrednie – Argument jest umieszczony we wskazanym rejestrze identyfikowanym
w slowie kodu rozkazu
Adresowanie wieloelementowe – jest zawsze adresowaniem posrednim i najczesciej jest interpretowane jako
adresowani ewzgledne. Wskaznk adresu jest wyznaczany jako funkcja skladowych adresu. Ktorymi są:
-baza – adres odniesienia umieszczony w rejestrze procesora
-przemieszczenie bazy – stala adresowa, w adresowaniu dwupoziomowym dodawana do bazy,
stanowiaca osobne slowo rozszerzenia kodu rozkazu.
-indeks – umieszczony w rej. Procesora wraz z mniznikiem skali wskazanym w slowie lub slowach
rozszerzenia kodu.
-relokacja – stala dodawana do wyznaczonego adresu stanowiaca osobne rozszerzenia kodu
rozkazu.
Adresowanie wieloelementowe jednopoziomowe posrednie – suma skladowych adresu wyznacza lokacje danej w
pamieci.
Adresowanie wieloelementowe wielopoziomowe bezposrednie – niektore skladowe adresu sa uzyte do wskazania
lokacji w pamieci zawierajacej adres odniesienia ktory zsumowany z pozostalymi skladowymi okresla adres
danej.
35. Adresowanie bezpośrednie i pośrednie
W adresowaniu bezpośrednim wskaźnik adresu jest zawsze pojedynczy i jest nim albo nazwa rejestru, albo adres liniowy danej w pamięci.
Wyróżnia się adresowanie zeroelementowe (zwarte – jeden lub wszystkie operandy domniemane, natychmiastowe – względne wobec licznika
rozkazów, błyskawiczne – skrócony kod danej stanowi część słowa kodu operacyjnego), i jednoelementowe bezpośrednie.
Adresowanie pośrednie – mówimy o nim, jeśli chociaż jedna ze składowych wskaźnika adresu jest określona przez wskazanie lokacji
(rejestru lub słowa w pamięci), w której umieszczono wartość tej składowej. Wyróżniamy Adresowanie jednoelementowe pośrednie,
wieloelementowe jedno- i dwupoziomowe.
Tryb adresowania jest specyficzny dla każdej danej.
36. Hierarchia i charakterystyka działań podstawowych
Kryterium klasyfikacji działań są wspólne cechy ich wykonania. Według ogólnych cech przetwarzania można wyróżnić następujące funkcje:
a) obsługę danych:
–
kopiowanie danych – najmniej skomplikowane działanie, powoduje utworzenie kopii informacji źródłowej w miejscu docelowym i
nieodwracalne zamazanie znajdujących się tam wcześniej danych.
–
przekształcenie formatu – działania na polach bitowych i systematyczne przemieszczenia łańcucha bitów – otwartego (przesunięcia) lub
zamkniętego (rotacje)
–
przekształcenie kodu – mogą być wykonane algorytmicznie jako wstawianie lub kopiowanie bitów lub przez tablicę przekodowań i mogą
być nieodwracalne (jeśli funkcja kodująca nie jest wzajemnie jednoznaczna). Obejmują: konwersje formatów zmiennoprzecinkowych,
rozszerzenia formatów zmiennoprzecinkowych, upakowanie kodu i rozpakowanie kodu skompresowanego, tworzenie kodów znaków w
ASCII lub Unicode, upakowanie i rozpakowanie kodu BCD.
b) działania na danych:
–
działania logicznego – wykonywane na pojedynczych bitach, więc mogą być wykonywane jednocześnie na wszystkich bitach słowa
maszynowego
–
(skalarne) działania arytmetyczne – oprócz wyniku obliczonego są wytwarzane atrybuty jego poprawności, zwykle jako kody warunków
lub flagi. Atrybuty są też nazywane wynikiem wyznaczonym. Stosowana jest automatyczna sygnalizacja błędu jako wyjątku (np.
Dzielenia przez 0). W PowerPC możliwe jest sterowanie wytwarzaniem atrybutów.
–
wektorowe działania arytmetyczne
Wykonanie każdego działania wymaga pobrania danych i przechowania wyniku. Przetwarzanie inne niż kopiowanie wymaga rozpakowania
informacji (identyfikacji specyficznych pól bitowych) i dekodowania w celu wytworzenia argumentów. Etapy mogą być pominięte, gdy
struktura informacji jest jednorodna. Patrz: rys 3.8, strona 41.
Możliwe jest skonstruowanie komputera jednorozkazowego, z rozkazem o dwóch funkcjach: odejmowania i skoku warunkowego, np.
„odejmij i skocz, gdy różnica >0”.

37. Struktury danych systemowych – stos i kolejka
Większość danych systemowych jest tworzonych dynamicznie podczas wykonania programu. Aby zapewnić jednolitość i elastyczność
odwzorowania danych, muszą być one odpowiednio zorganizowane. Typowe schematy to:
a) stos – bufor typu LIFO (Last In First Out). Do lokalizacji (adresowania) danych w rejonie stosu wystarczy jeden identyfikator, zwany
wskaźnikiem stosu. Odpowiednio do rodzaju operacji (złożenie na stos, pobranie ze stosu) i rozmiaru danych, działanie na stosie powoduje
zmniejszenie lub zwiększeniew wartości wskaźnijka. Stos może być implementowany w przestrzeni adresowej pamięci, lecz wtedy czas
dostępu do danych na nim umieszcoznych jest dłuższy. Rozmiar stosu jest ograniczony, więc może nastąpić jego przepełnienie lub
wyczerpanie. Wskaźnik szczytu stosu jest pamiętany w specjalnym rejestrze procesora, co umożliwia automatyczne adresowanie w obszarze
stosu.
b) kolejka – bufor typu FIFO (First In First Out). Adresowanie wymaga użycia 2 wskaźników: początku, identyfikującego kolejną daną
możliwa do pobrania, oraz końca, identyfikującego miejsce w buforze, do którego można przesłać kolejną daną. Dołączenie do kolejki
powoduje wzrost wartości wskaźnika końca, a opuszczenie kolejki jego zmniejszenie lub odwrotnie. Stosowana jest w szeregowaniu zadań
np. W postaci bufora rozkazów do bieżącego wykonania.
38. Typy i formaty danych, charakterystyka
Grupy danych:
I) kody rozkazów – zawierają informację określającą rodzaj operacji i identyfikatory argumentów tej operacji. Zwykle na bardziej
znaczących pozycjach kodowany jest rodzaj lub klasa operacji, kolejne pola identyfikują argumenty, bity pozostałe zawierają informacje
dodatkowe. Uzyskanie pełnej jednolitości kodowania rozkazów wymaga pełnej ortogonalności rodzajów działań oraz trybów
adresowania. W praktyce cecha ta jest zachowana tylko w grupach rozkazów, czego skutkiem są różne formaty kodu. Skutkiem braku
ortogonalności jest niepełne wykorzystanie przestrzeni kodowej, określonej rozmiarem słowa maszynowego (32bit dla współczesnych
procesorów)
II) dane systemowe – bezpieczna realizacja obsługi wyjątków czy przerwań wymaga automatycznego tworzenia danych systemowych
zwanych kontekstem. Dane systemowe mają ustaloną strukturę zdefiniowaną na poziomie architektury, aby zapewnić jednolite i
powtarzalne wykonanie niezbędnych czynności obsługi zdarzeń w otoczeniu procesora. Typowe schematy organizacji struktur danych to
stos (LIFO) i kolejka (FIFO)
III) dane użytkowe – najbardziej różnorodne, definiowane przez projektanta algorytmu. Trzy zasadnicze grupy danych:
1) skalarne:
a) jakościowe lub wyliczenia, indeksujące cechy, np. Logiczne (boolean), Znakowe (char), Opisowe (descriptive)
b) dyskretne:
–
porządkowe, często utożsamiane z naturalnymi
–
całkowite (integer)
–
stałoprzecinkowe (fixed-point) lub ułamkowe (fractional)
c) pseudorzeczywiste lub ciągłe:
–
zmiennoprzecinkowe (fixed-point)
–
logarytmiczne
2) strukturalne – definiują zorganizowane zbiory danych innych typów
a) zestawy – nieuporządkowane
b) wektory i tablice – uporządkowane
c) rekordy – uporządkowane złożenia danych dowolnych typów
3) wskaźnikowe – definiują dane lokalizujące obiekt. Występują jako operandy w trybach adresowania. Występują jako skalarne (w liniowej
przestrzeni adresowej) lub strukturalne (wektorowe – umożliwiające elastyczne adresowanie bezpośrednie lub deskryptorowe –
umożliwiające elastyczne adresowanie bezpośrednie)
39. Arytmetyka stałoprzecinkowa – zasady, szybkość i poprawność działań, wykrywanie nadmiaru
Zasady dodawania/odejmowania/mnożenia/dzielenia/pierwiastkowania wszyscy znają z Arytmetyki, nie podejmuję się tutaj tłumaczyć:P
Szczegóły – strona 80.
W dodawaniu lub odejmowaniu stałoprzecinkowym w systemie naturalnym wyjściowe przeniesienie c jest sygnałem poprawności wyniku
wytworzonego na k pozycjach. Obliczona wartość S jest poprawna, jeśli c=0. Jeśli c=1, to S przekracza zakres reprezentacji i mówimy, że
wystąpił nadmiar. Wynik da się poprawnie zapisać na k+1 pozycjach.
Poprawny iloczyn da się zawsze zapisać w rozmiarze równym sumie liczby pozycji mnożnej i mnożnika.
Wynik dzielenia jest zawsze przybliżony.
Podstawowym kryterium oceny jakości układów arytmetyki jest ich szybkkość. Przyspieszenie dodawania dwu liczb bez nadmiaru w
systemie pozycyjnym jest możliwe albo przez skrócenie czasu propagacji przeniesień albo przez wyeliminowanie propagacji przeniesień. Oba
rozwiązania są porównywalne i pozwalają na uzyskanie szybkości dodawania bliskiej teoretycznie osiągalnej – logn.
40. Dodawanie i odejmowanie wielokrotnej precyzji – realizacja programowa.
Przełamanie ograniczeń rozmiaru w językach programowania jest trudne i wymaga dokładnej znajomości specyfiki danej implementacji.

Inaczej jest na poziomie maszyny rzeczywistej i języka asemblerowego, gdzie programista ma dostęp do wszystkich tych zasobów procesora,
które umożliwiają pełną konktrolę przebiegu działań. Możliwości wynikają z właściwości pozycyjnych reprezentacji liczb i dostępu do
wszystkich bitów wyniku.
n-pozycyjne (n>k) dodawanie lub odejmowanie można wykonać przez sekwencyjne wykonanie działań k-pozycyjnych, w których
zapamiętane przeniesienie wyjściowe w kroku poprzednim będzie użyte jako przeniesienie wejściowe w kroku następnym. Aby możliwa była
jego realizacja programowa, procesor musi dysponować rozkazem odejmowania z przeniesieniem.
Wyszukiwarka
Podobne podstrony:
opracowanie pytan id 338374 Nieznany
Nhip opracowanie pytan id 31802 Nieznany
Opracowanie pytan 3 id 338376 Nieznany
opracowania Ekologia id 794643 Nieznany
Opracowanie Hoffmanna id 338261 Nieznany
opracowanie antropologia id 338 Nieznany
Opracowanie Metrologia 2 id 338 Nieznany
opracowanko histogram id 338711 Nieznany
Opracowanie klp id 338270 Nieznany
Opracowanie seminaria id 338435 Nieznany
opracowanie lewkowicz id 338277 Nieznany
dod opracowanie wynikow id 1386 Nieznany
opracowanie cw5 id 338131 Nieznany
OpracowanieUOOPby wpiana7 id 33 Nieznany
OPRACOWANE ODPOWIEDZI id 337615 Nieznany
MOJE OPRACOWANIE wersja C id 30 Nieznany
Opracowanie pytan 5 id 338378 Nieznany
opracowane pytania 2 id 337625 Nieznany
opracowanie metrologia id 33828 Nieznany
więcej podobnych podstron