
RYNEK NIERUCHOMOŚCI
dr inż. Radosław Cellmer

Wykład 5
Analiza statystyczna cen nieruchomości
Treść wykładu:
1. Pojęcie zmiennej
2. Opis statystyczny danych rynkowych
3. Analiza zależności między zmiennymi

POJĘCIE ZMIENNEJ
Zmienne są to wielkości, które mierzymy, kontrolujemy lub którymi manipulujemy w
jakiś sposób w trakcie badań.
Przykłady zmiennych wykorzystywanych do analiz rynkowych):
-
cena (np. wyrażona w zł/m
2
)
-
lokalizacja (np. wyrażona w skali atrakcyjności od 1 do 5)
-
powierzchnia (np. wyrażona w m
2
)
-
powierzchnia (np. wyrażona w m
2
)
-
stan techniczny budynku (np. mierzony % stopniem zużycia)
-
stopa kapitalizacji (mierzona %)

ZMIENNE OBJAŚNIANE I ZMIENNE OBJAŚNIAJĄCE
Zmiennymi objaśniającymi (niezależnymi) nazywamy te spośród zmiennych, które wg
założeń są przyczyną występowania określonego poziomu zjawiska (np. cechy fizyczne
nieruchomości, jako czynniki kształtujące ceny)
Zmiennymi objaśnianymi (zależnymi) nazywamy te spośród zmiennych, których
wartości są zdeterminowane przez zmienne objaśniające (np. cena jest uzależniona od
cech fizycznych nieruchomości)
Przykład
Jeżeli przyjmiemy hipotezę, że na ceny lokali wpływa lokalizacja i położenie na piętrze
to cena będzie stanowiła zmienną objaśnianą a lokalizacja i piętro będą stanowiły
zmienne objaśniające
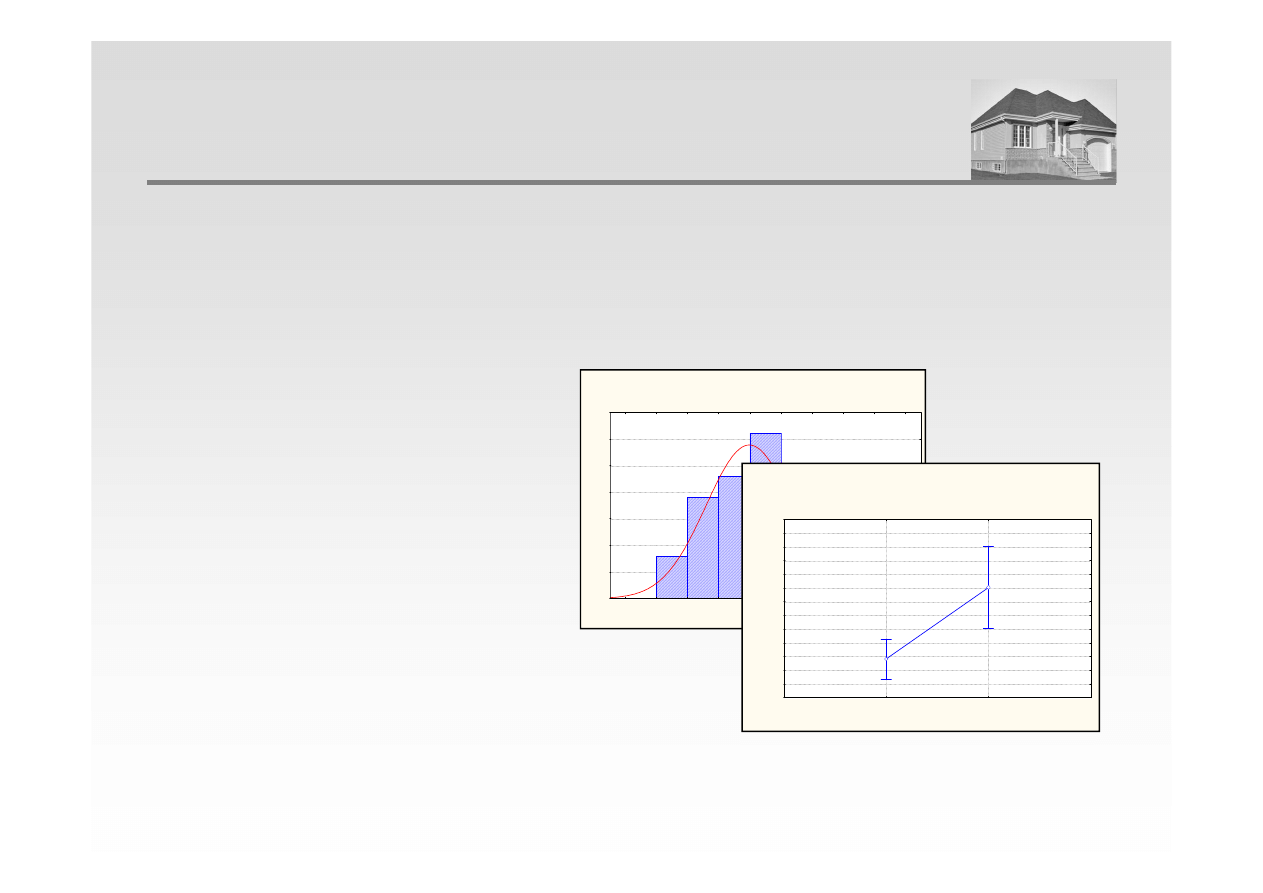
WYBRANE METODY OPISU STATYSTYCZNEGO
•
prezentacja graficzna rozkładu empirycznego
•
miary położenia
•
miary (rozproszenia) dyspersji
•
miary asymetrii
Histogram Cena skorygowana
lokale 12v*100c
Cena skorygowana = 100*500*normal(x; 4481,8; 690,7521)
30
35
2500
3000
3500
4000
4500
5000
5500
6000
6500
7000
Cena skorygowana
0
5
10
15
20
25
L
ic
z
b
a
o
b
s
.
Technologia; Oczekiwane
ś
rednie brzegowe
Bie
żą
cy efekt: F(1, 98)=9,5692, p=,00258
Dekompozycja efektywnych hipotez
Pionowe słupki oznaczaj
ą
0,95 przedziały ufno
ś
ci
0
1
Technologia
4100
4200
4300
4400
4500
4600
4700
4800
4900
5000
5100
5200
5300
5400
C
e
n
a
s
k
o
ry
g
o
w
a
n
a
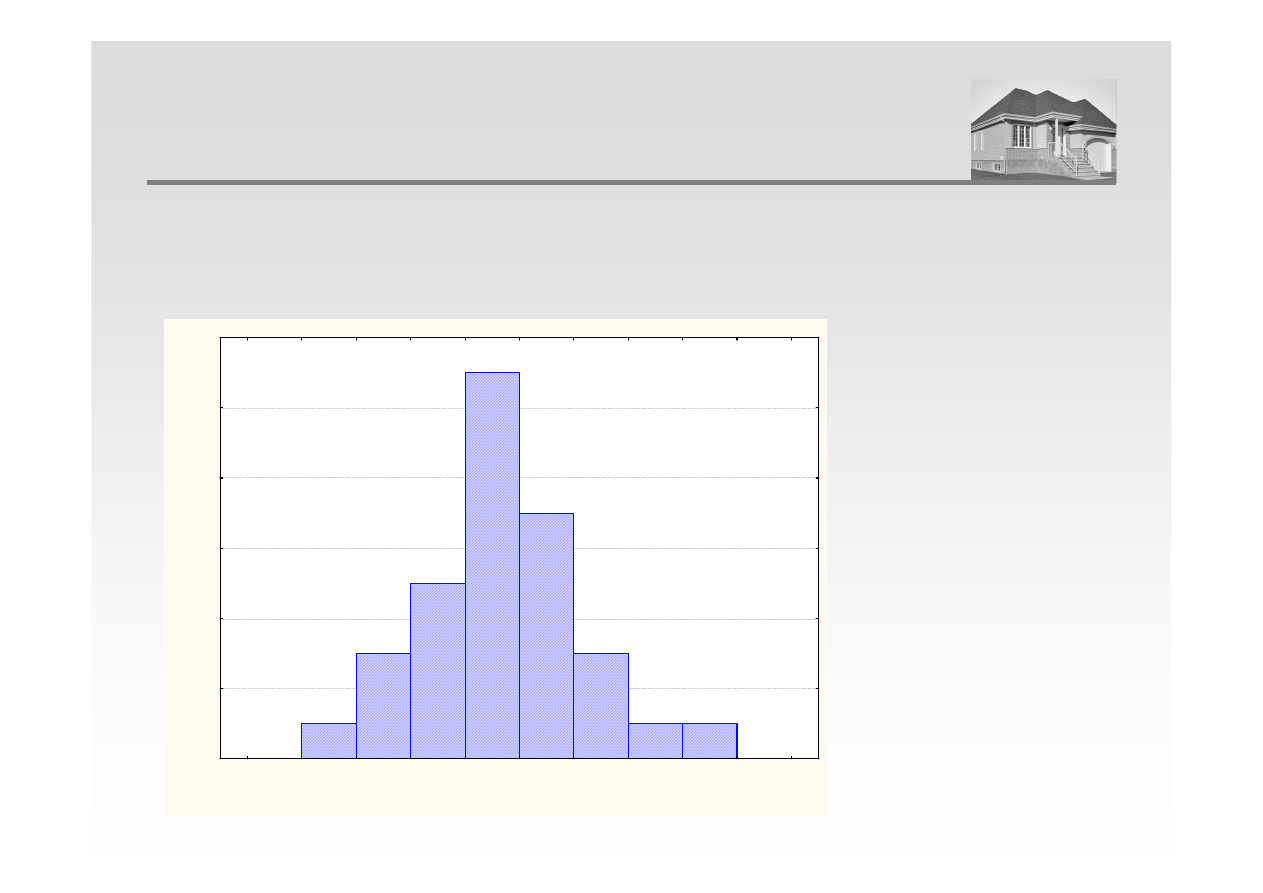
ROZKŁAD EMPIRYCZNY CEN NIERUCHOMOŚCI
Empiryczny rozkład cechy, to przyporządkowanie uszeregowanym rosnąco wartościom
cechy (np. cenom transakcyjnym) odpowiednio zdefiniowanych częstości (lub
prawdopodobieństw) ich występowania.
10
12
4800
4900
5000
5100
5200
5300
5400
5500
5600
5700
5800
Cena
0
2
4
6
8
L
ic
z
b
a
o
b
s
.
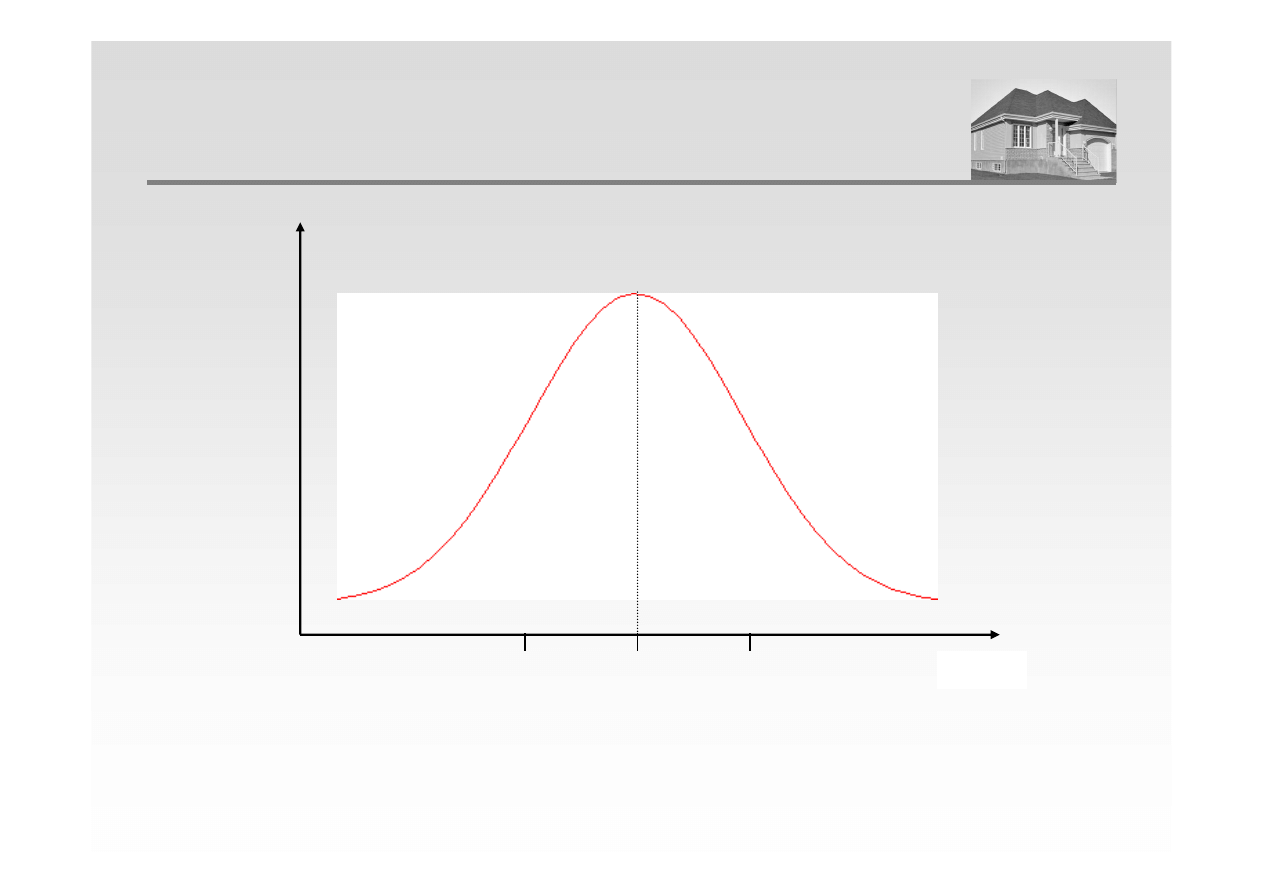
ROZKŁAD NORMALNY (GAUSSA)
f(x)
X
m-
σσσσ
m
m+
σσσσ
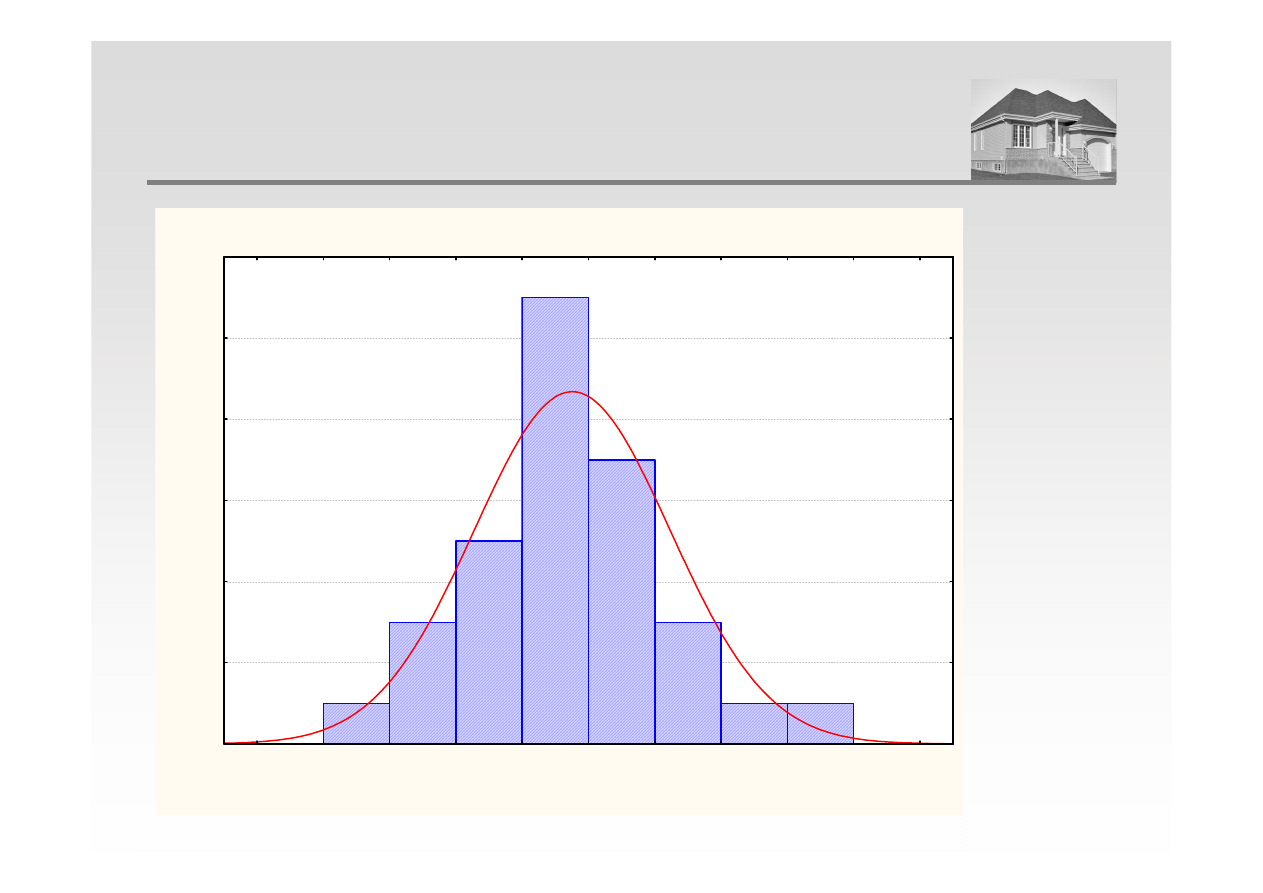
ROZKŁAD EMPIRYCZNY CEN NIERUCHOMOŚCI
Histogram Cena
8
10
12
4800
4900
5000
5100
5200
5300
5400
5500
5600
5700
5800
Cena
0
2
4
6
L
ic
z
b
a
o
b
s
.

OPIS STATYSTYCZNY DANYCH – MIARY POŁOŻENIA
Miary położenia
Służą do wyznaczenia takiej realizacji zmiennej opisanej przez rozkład, wokół której
skupiają się wszystkie pozostałe realizacje
Miary klasyczne
Określane są przy pomocy wszystkich obserwacji
Przykłady:
• średnia arytmetyczna
• średnia arytmetyczna
• średnia geometryczna
• średnia harmoniczna
Miary pozycyjne
Określane są przy pomocy pewnych charakterystycznych obserwacji
Przykłady:
• mediana
• dominanta (moda)
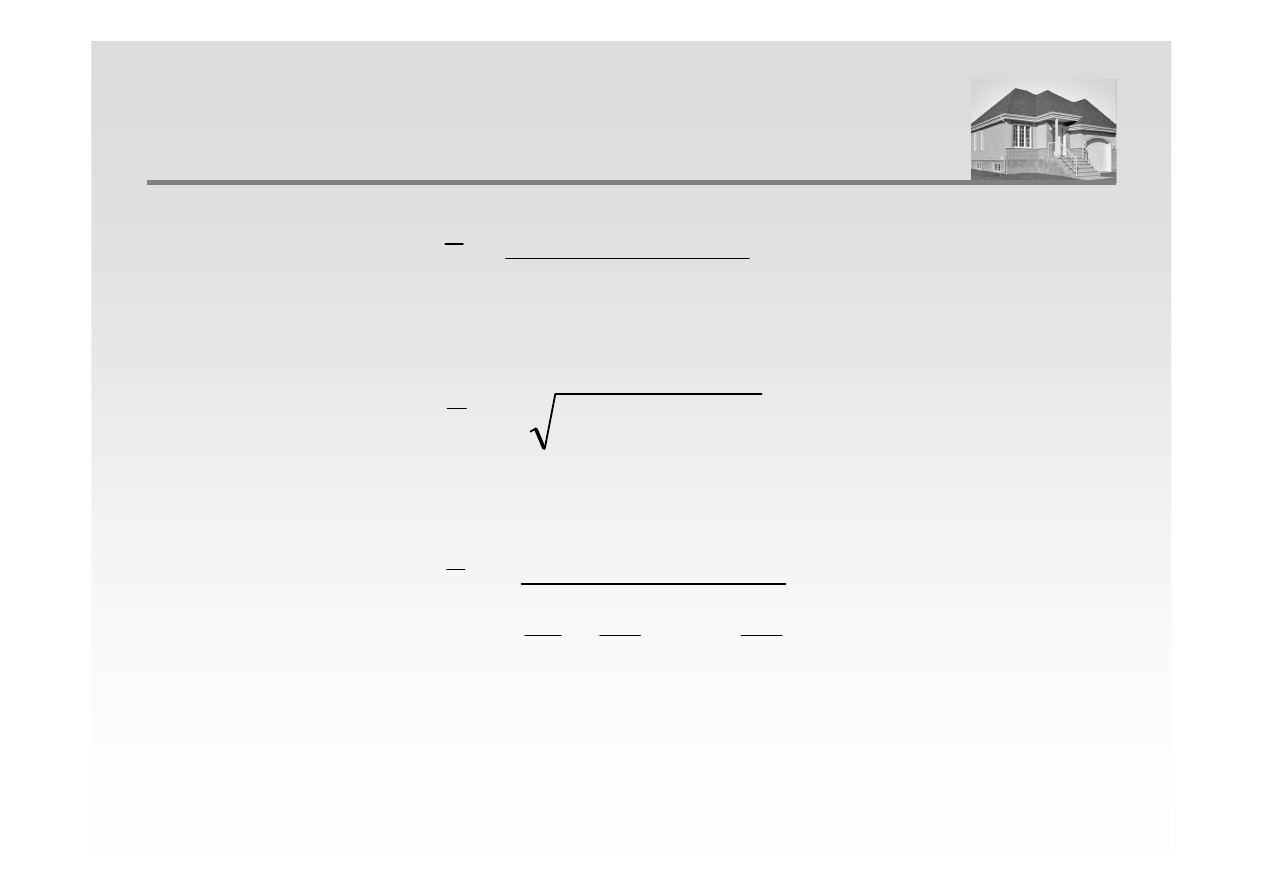
WYBRANIE KLASYCZNE MIARY POŁOŻENIA
Średnia arytmetyczna
Średnia geometryczna
n
x
x
x
x
n
+
+
+
=
...
2
1
n
n
g
x
x
x
x
⋅
⋅
⋅
=
...
2
1
Średnia harmoniczna
n
g
2
1
n
h
x
x
x
n
x
1
...
1
1
2
1
+
+
+
=
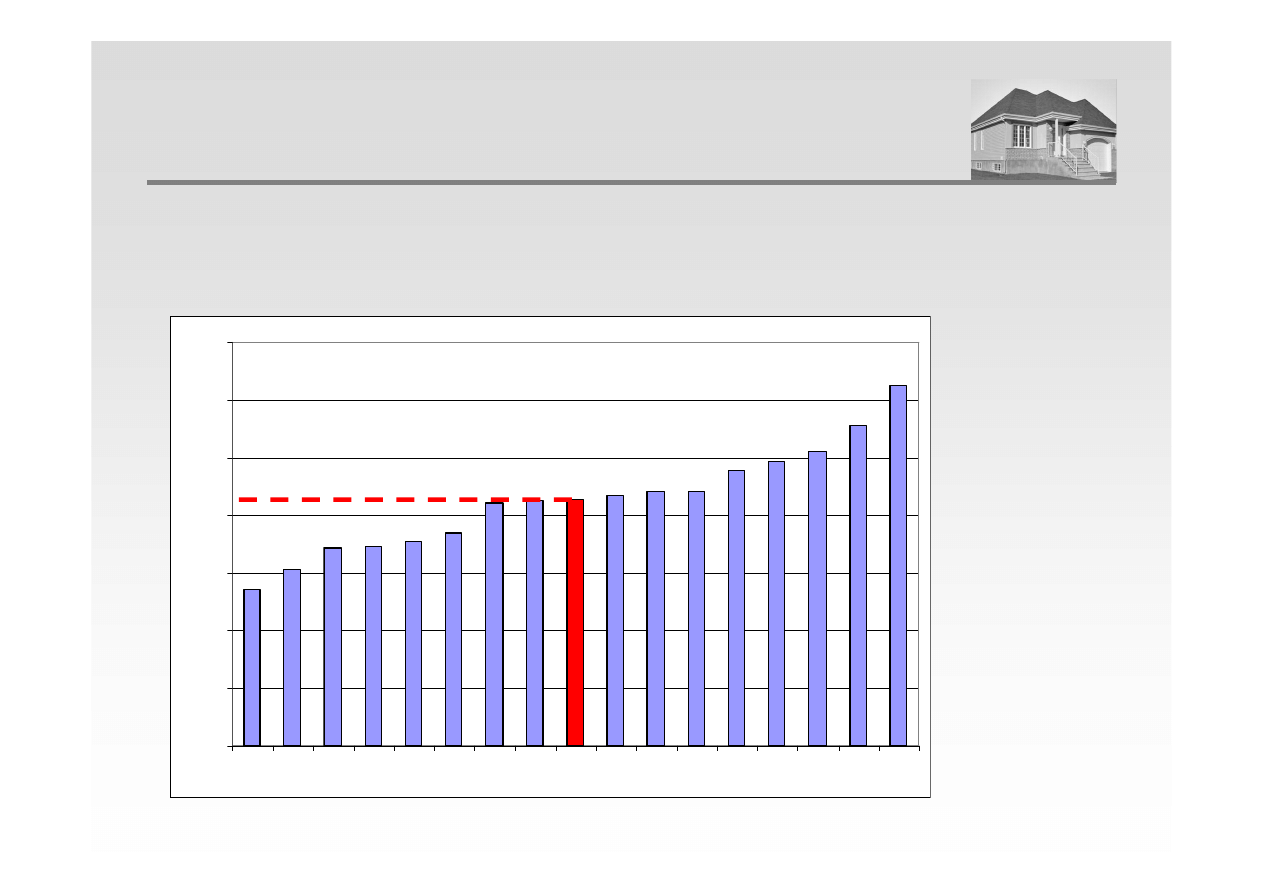
POZYCYJNE MIARY POŁOŻENIA - MEDIANA
Mediana - Jest to taka wartość cechy, że co najmniej połowa jednostek populacji ma wartość
cechy nie większą od niej i równocześnie co najmniej połowa jednostek ma wartość cechy nie
mniejszą od tej wartości
5600
5800
4400
4600
4800
5000
5200
5400
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
m
e
m
e
= 5255,67 zł/m
2
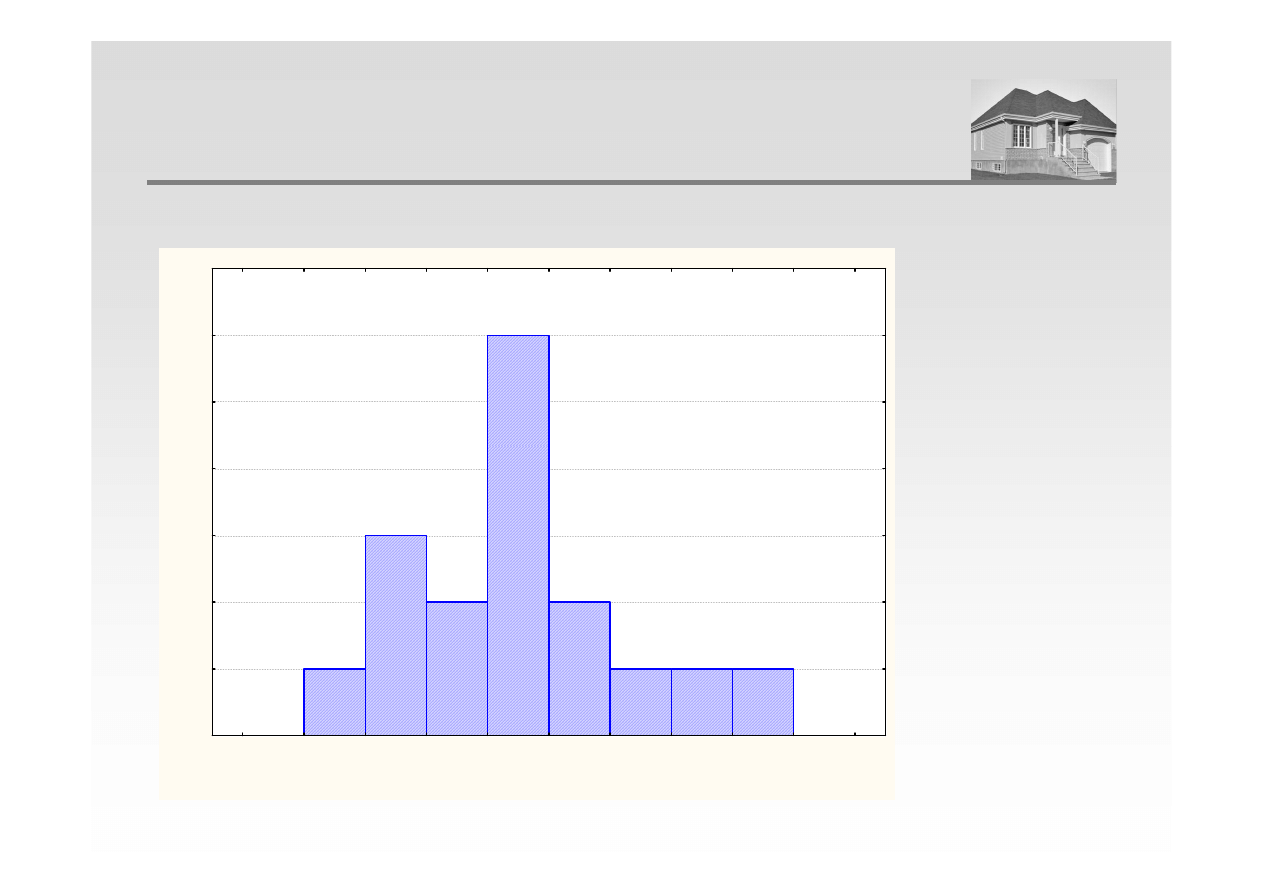
POZYCYJNE MIARY POŁOŻENIA - DOMINANTA
Dominanta - wartość cechy występująca statystycznie najczęściej w danym rozkładzie
5
6
7
4800
4900
5000
5100
5200
5300
5400
5500
5600
5700
5800
Cena
0
1
2
3
4
L
ic
z
b
a
o
b
s
.
d
o
= 5100 zł/m
2

OPIS STATYSTYCZNY DANYCH – MIARY DYSPERSJI
Miary rozproszenia (miary dyspersji)
Służą do badania stopnia zróżnicowania jednostek zbiorowości pod względem badanej
zmiennej
Miary klasyczne
Określane są przy pomocy wszystkich obserwacji
Przykłady:
• wariancja
• wariancja
• odchylenie standardowe
• współczynnik zmienności
Miary pozycyjne
Określane są przy pomocy pewnych charakterystycznych obserwacji
Przykłady:
• kwartyle
• rozstęp ćwiartkowy
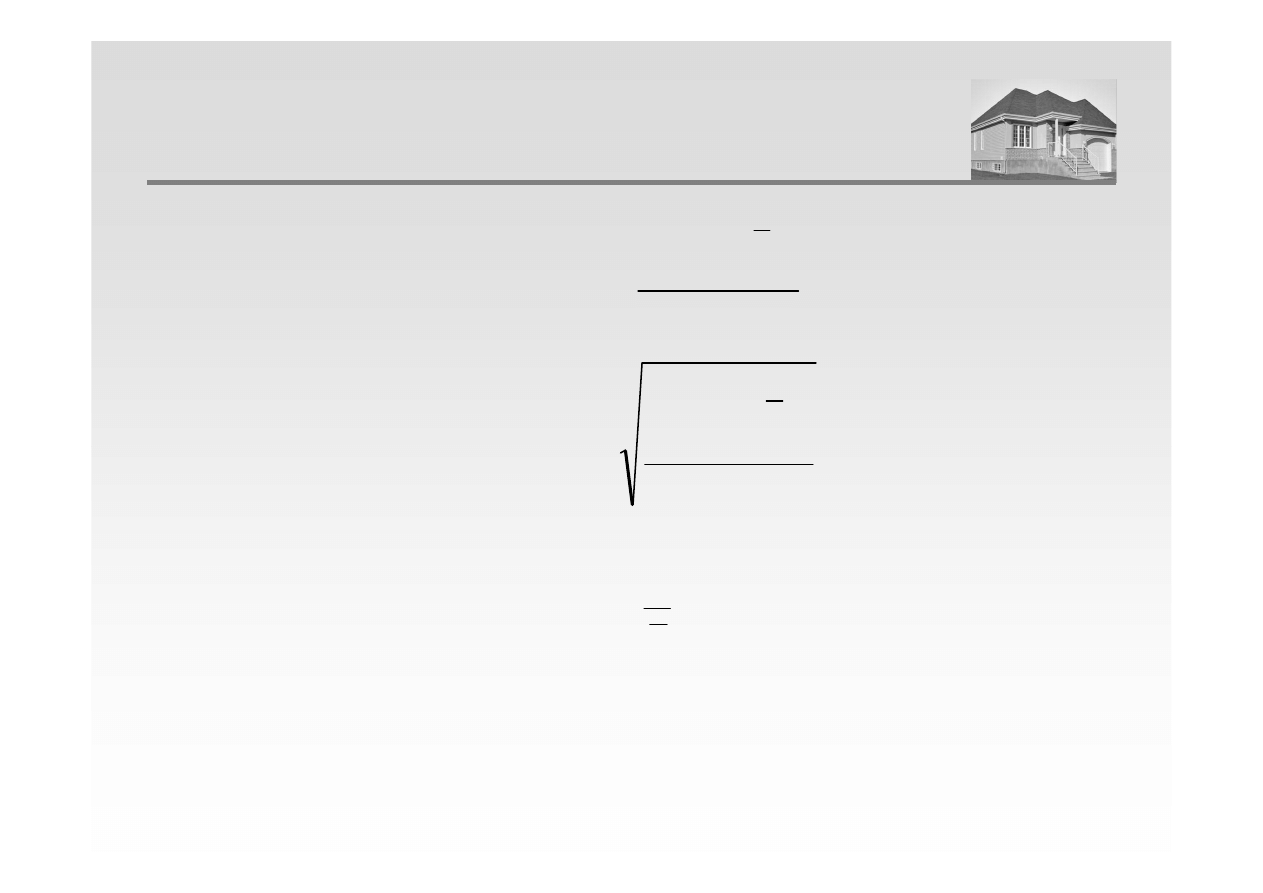
WYBRANE KLASYCZNE MIARY DYSPERSJI
Wariancja
Odchylenie standardowe
(
)
1
1
2
2
−
−
=
∑
=
n
x
x
s
n
i
i
(
)
1
2
−
=
∑
=
x
x
s
n
i
i
Odchylenie standardowe
Współczynnik zmienności
1
1
−
=
=
n
s
i
x
s
V
=
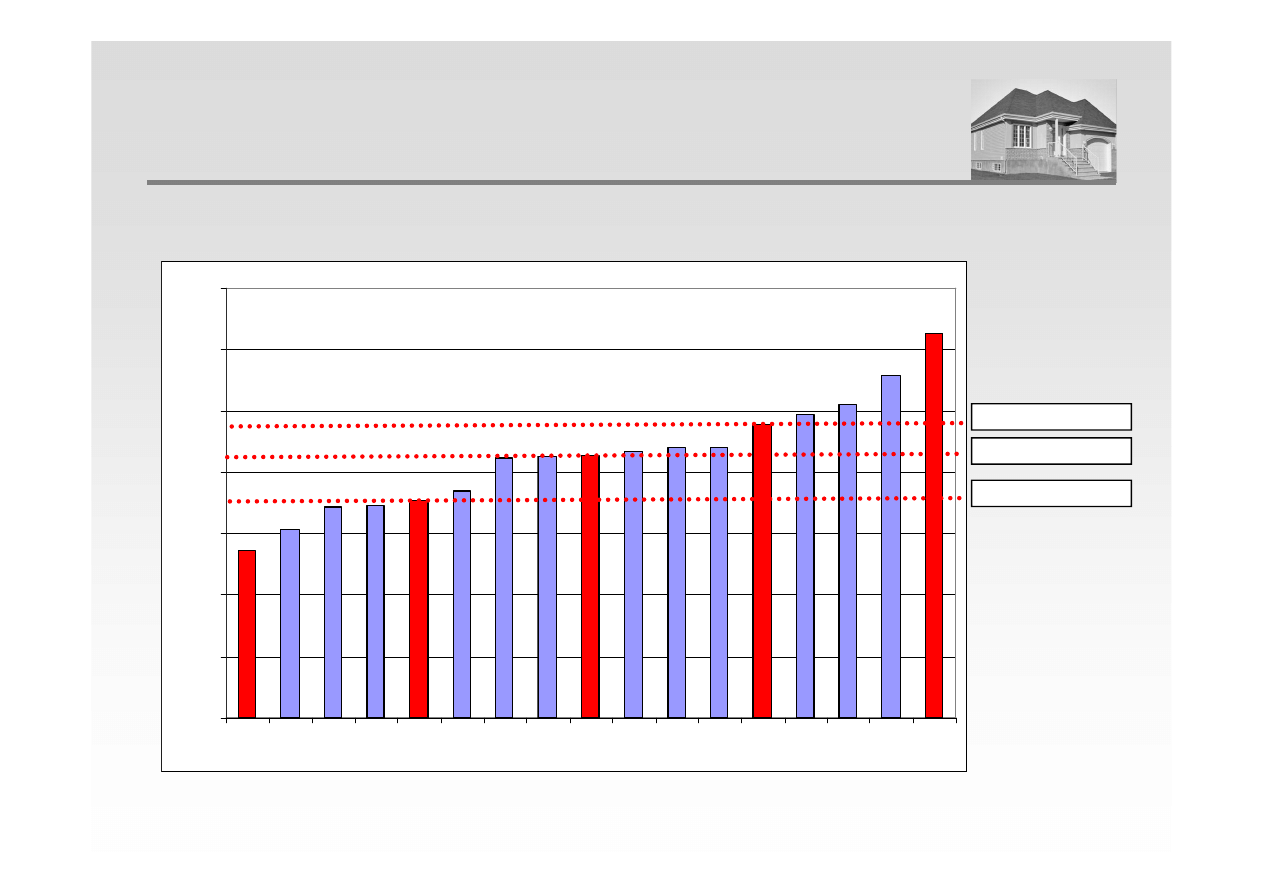
POZYCYJNE MIARY DYSPERSJI - KWARTYLE
5400
5600
5800
Q
3
= 5356,47 zł/m
2
Q = 5255,67 zł/m
2
4400
4600
4800
5000
5200
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Q
1
= 5109,60 zł/m
2
Q
2
= 5255,67 zł/m
2

RELACJE MIĘDZY ZMIENNYMI
Dwie lub więcej zmiennych pozostaje w relacji, jeśli wartości tych zmiennych w
mierzonej próbie rozłożone są w określony, systematyczny sposób.
Każdą relację (zależność) między zmiennymi można scharakteryzować dwiema
własnościami: siłą (lub "wielkością") i istotnością (lub "wiarygodnością") tej relacji
a) siła zależności oznacza możliwość określenia wartości jednej zmiennej na podstawie
a) siła zależności oznacza możliwość określenia wartości jednej zmiennej na podstawie
pomiaru drugiej (w obrębie badanej próbki).
b) istotność zależności dotyczy reprezentatywności wyniku uzyskanego na podstawie
pobranej próbki w odniesieniu do całej badanej populacji.
Nie każda relacja na rynku nieruchomości oznacza związek przyczynowo-skutkowy

ANALIZA RELACJI MIĘDZY CECHAMI NIERUCHOMOŚCI I
CENAMI
Wybrane metody analizy:
•
analiza porównywania parami
•
analiza korelacji
•
analiza regresji
Analiza porównywania parami polega na pogrupowaniu nieruchomości w pary różniące się
jedynie jedną cechą. Średnia różnica cen w każdej parze oznacza wpływ danego czynnika na cenę.
Analiza ta pozwala zmierzyć siłę związku.
Analiza ta pozwala zmierzyć siłę związku.
Analiza korelacji polega na wyznaczeniu współczynnika korelacji i ocenie jego istotności. Analiza
ta pozwala zmierzyć zarówno siłę jak i istotność związku.
Analiza regresji polega na wyznaczeniu zależności funkcyjnej, gdzie cena jako zmienna
objaśniana jest funkcją wybranego czynnika jako zmiennej objaśniającej. Analiza ta pozwala
zmierzyć zarówno siłę, istotność związku, oraz pozwala na podanie jego matematycznej postaci.

KORELACJA
Korelacja jest miarą relacji pomiędzy dwiema lub większą liczbą zmiennych.
Współczynniki korelacji przyjmują wartości z przedziału od -1,00 do +1,00.
Współczynnik korelacji liniowej Pearsona
Określa on stopień wzajemnej proporcjonalności wartości dwóch zmiennych.
Korelacja jest silna, jeśli może być opisana przy pomocy linii prostej (nachylonej
dodatnio lub ujemnie). Linia, o której mowa, nazywa się linią regresji
WSPÓŁCZYNNIK KORELACJI LINIOWEJ PEARSONA
(
)(
)
)
,
cov(
1
−
−
=
∑
=
y
y
x
x
y
x
n
i
i
i
cov (x,y) – kowariancja zmiennych X i Y
S(y)
S(x)
(x,y)
r
⋅
cov
=
S(y) – odchylenie standardowe zmiennej Y
1
)
,
cov(
1
−
=
=
n
y
x
i
( )
(
)
1
1
2
−
−
=
∑
=
n
x
x
x
S
n
i
i
( )
(
)
1
1
2
−
−
=
∑
=
n
y
y
y
S
n
i
i
cov (x,y) – kowariancja zmiennych X i Y
S(x) – odchylenie standardowe zmiennej X
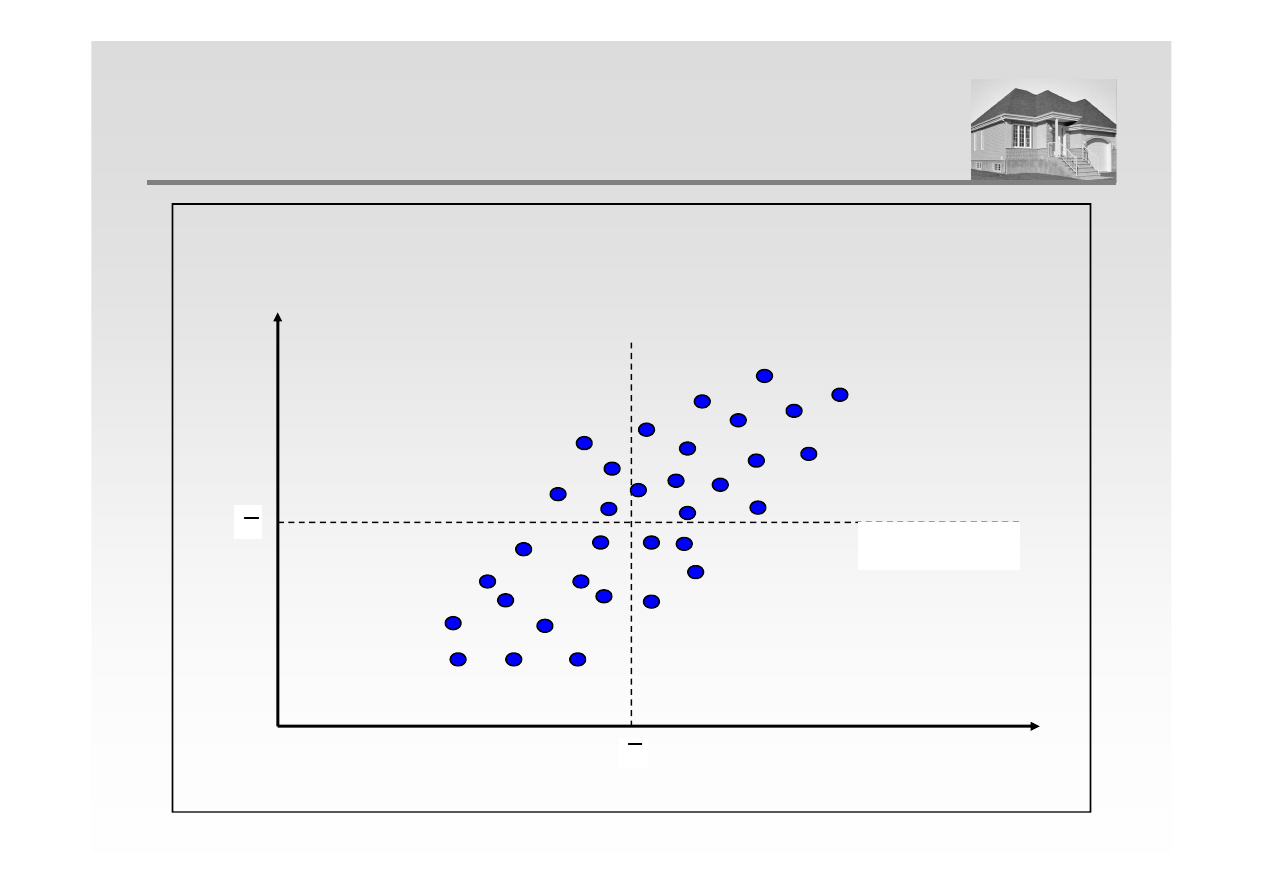
x
i
– x
śr
>
0
y
i
– y
śr
>
0
KORELACJA DODATNIA
x
i
– x
śr
<
0
y
i
– y
śr
<
0
cov (x, y)
>>>>
0
x
y
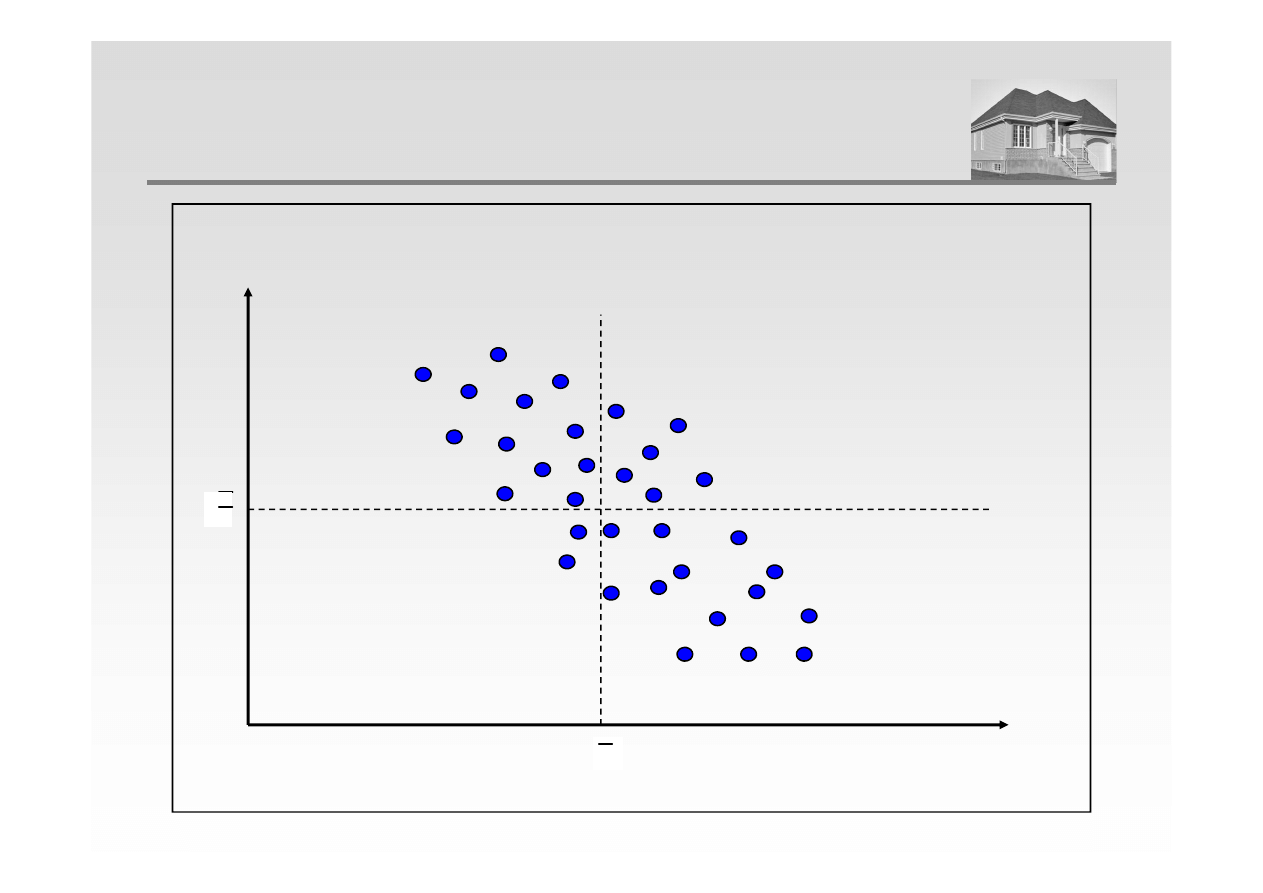
x
i
– x
śr
<
0
y
i
– y
śr
>
0
cov (x, y)
<<<<
0
KORELACJA UJEMNA
y
x
i
– x
śr
>
0
y
i
– y
śr
<
0
cov (x, y)
<<<<
0
x
y
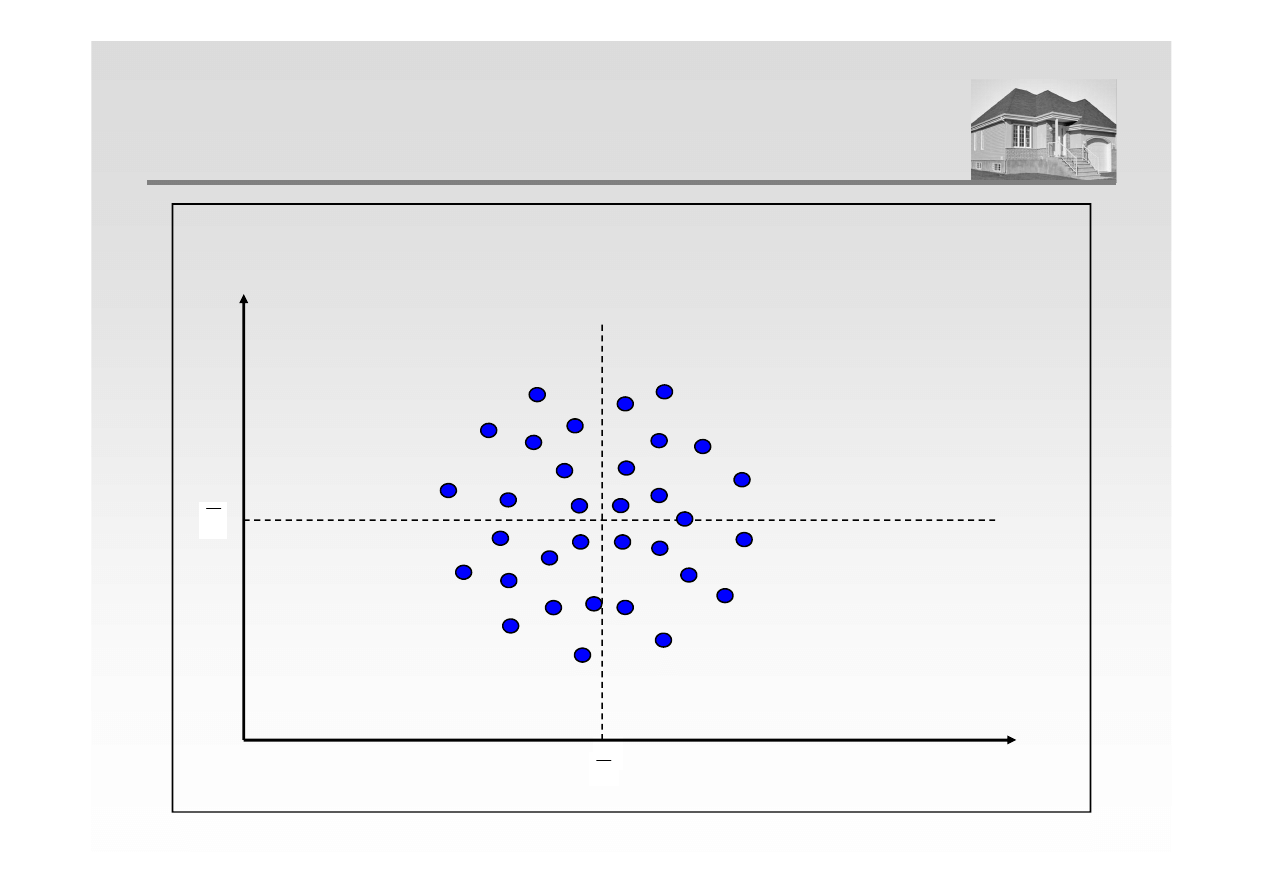
cov (x, y) = 0
BRAK KORELACJI
cov (x, y) = 0
y
x
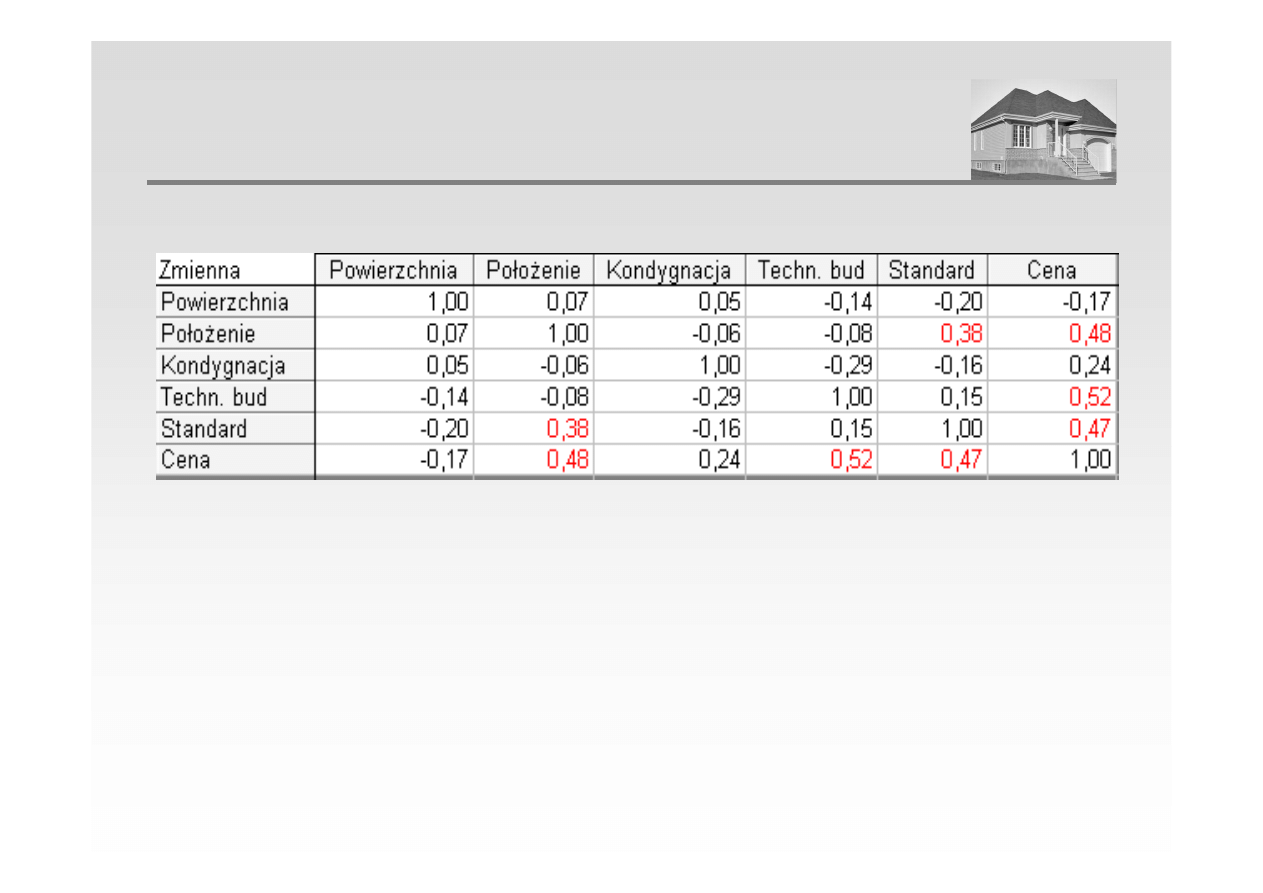
MACIERZ KORELACJI (PRZYKŁAD)
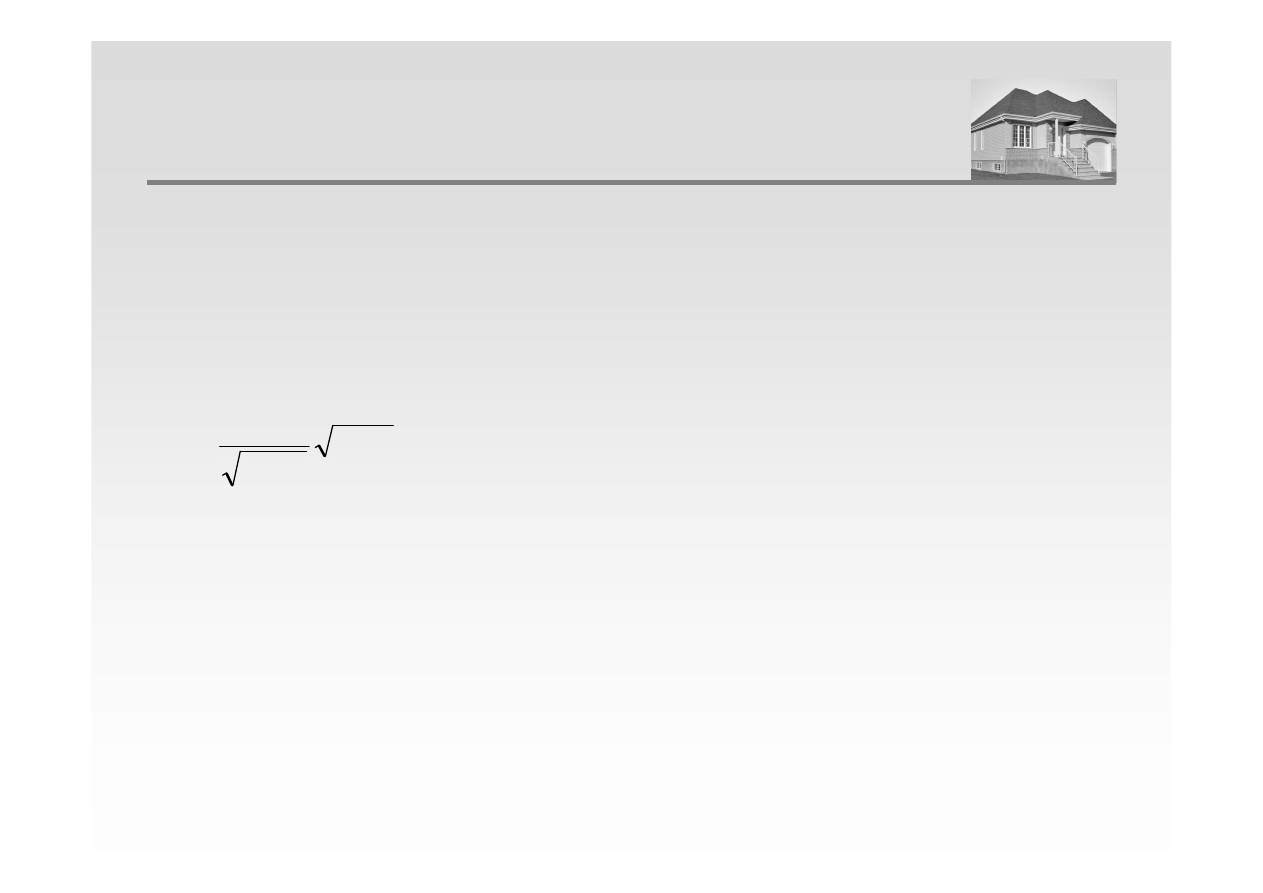
Hipoteza zerowa i hipoteza alternatywna:
H
0
: r
=
0 (wartość współczynnika korelacji jest statystycznie nieistotna)
H
1
: r
≠
0 (wartość współczynnika korelacji jest statystycznie istotna)
2
−
=
n
r
t
Statystyka testu (rozkład t-Studenta):
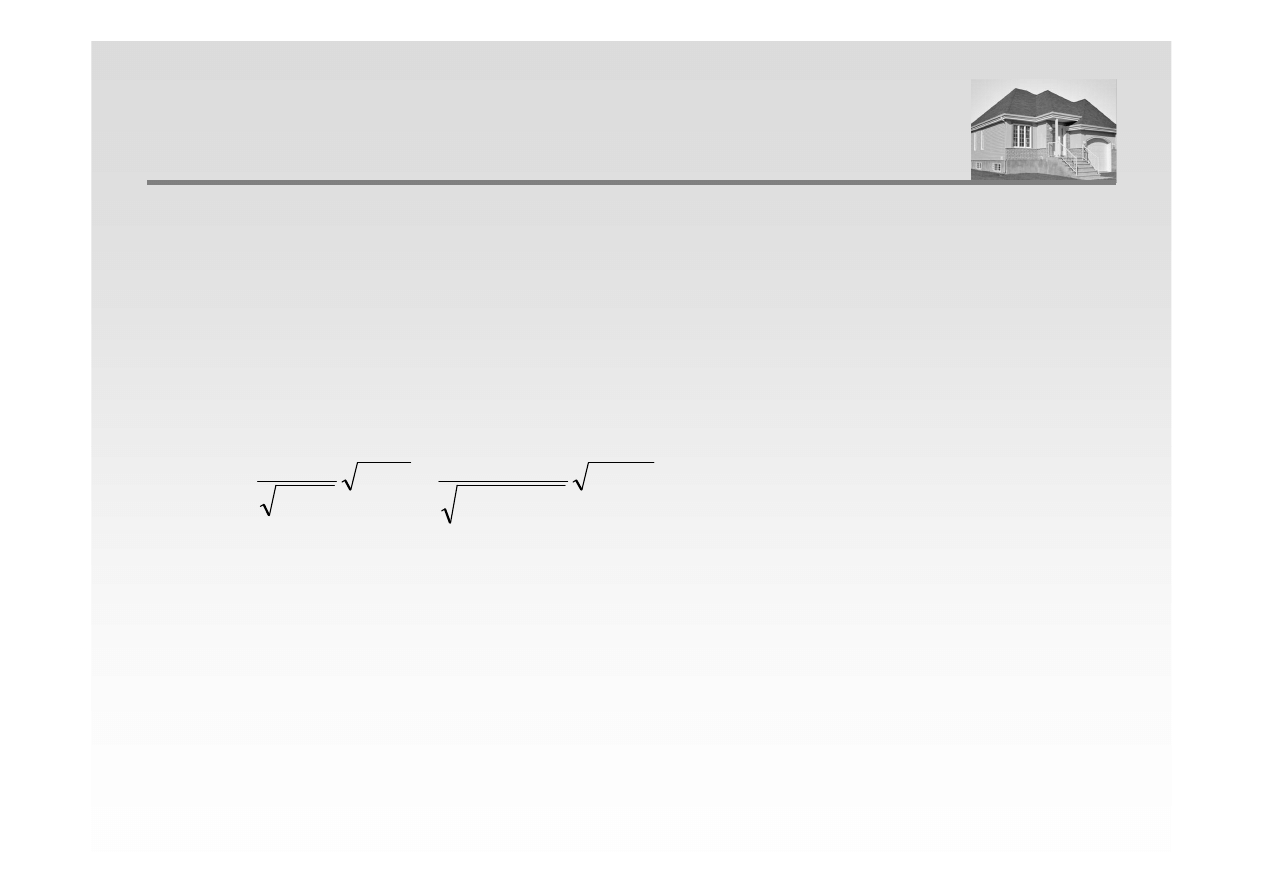
ISTOTNOŚĆ WSPÓŁCZYNNIKA KORELACJI
2
1
2
−
−
=
n
r
t
Jeżeli | t | < t
kryt
oznacza to, że nie ma podstaw do odrzucenia hipotezy zerowej
Jeżeli | t | > t
kryt
oznacza to, że odrzucamy hipotezę zerową na rzecz hipotezy alternatywnej
Na podstawie danych o 50 cenach transakcyjnych lokali mieszkalnych i ich powierzchni zbadano,
czy położenie lokalu na kondygnacji jest istotnym czynnikiem wpływającym na ceny
transakcyjne. W tym celu obliczono wartość współczynnika korelacji, który wyniósł r = 0,24, a
następnie przeprowadzono test istotności współczynnika korelacji.
Przyjmujemy założenie, że błąd, który możemy popełnić wynosi 5% (poziom istotności
α
= 0,05)
Obliczenie empirycznej wartości statystyki t:
ISTOTNOŚĆ WSPÓŁCZYNNIKA KORELACJI (PRZYKŁAD)
(
)
71
,
1
2
50
24
,
0
1
24
,
0
2
1
2
2
=
−
−
=
−
−
=
n
r
r
t
Obliczenie krytycznej wartości statystyki t:
(
)
01
,
2
48
;
05
,
0
=
t
(wielkość tę odczytujemy z tablic rozkładu t-Studenta)
Wartość bezwzględna obliczonej (empirycznej) wartości statystyki t-Studenta nie przekracza
wartości krytycznej. Stąd wniosek, że należy przyjąć hipotezę o nieistotności współczynnika
korelacji. Zależność między ceną i powierzchnia lokalu jest więc statystycznie nieistotna.
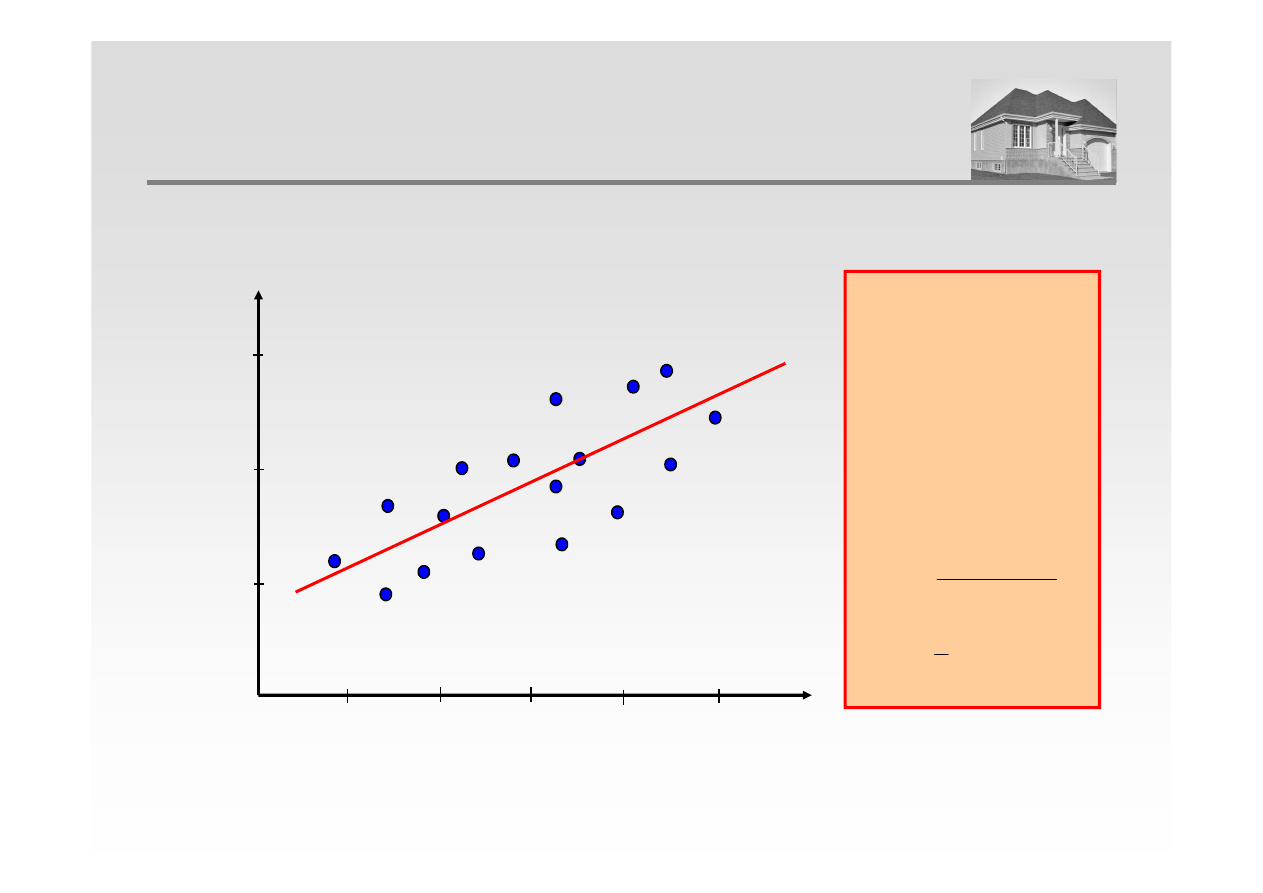
y
30
Równanie prostej:
b
ax
y
+
=
Model regresji:
b
ax
y
+
=
ˆ
REGRESJA LINIOWA
x
1
2
3
4
5
10
20
b
ax
y
+
=
ˆ
)
(
)
,
cov(
2
x
S
y
x
a
=
a
y
b
−
=
gdzie:
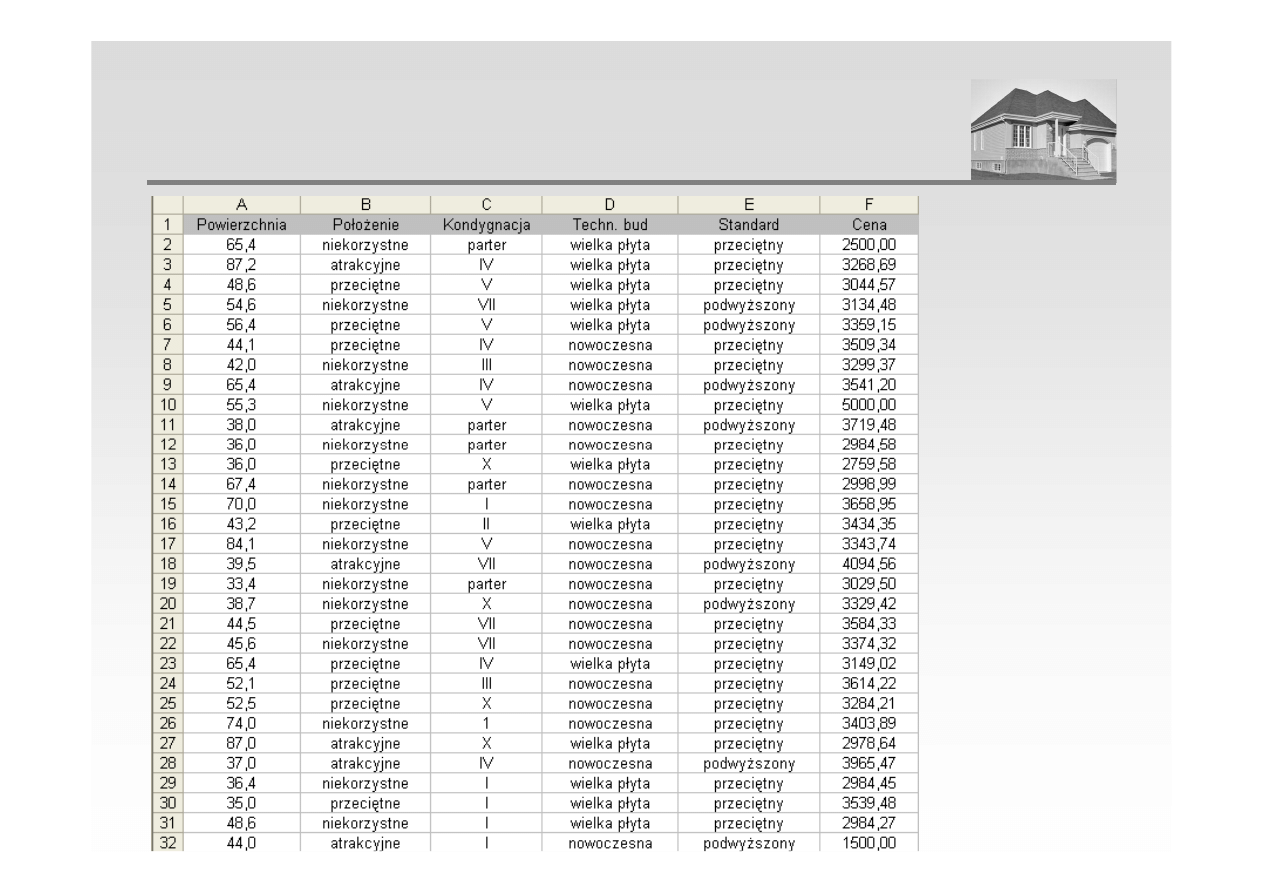
ANALAIZA REGRESJI – PRZYGOTOWANIE DANYCH
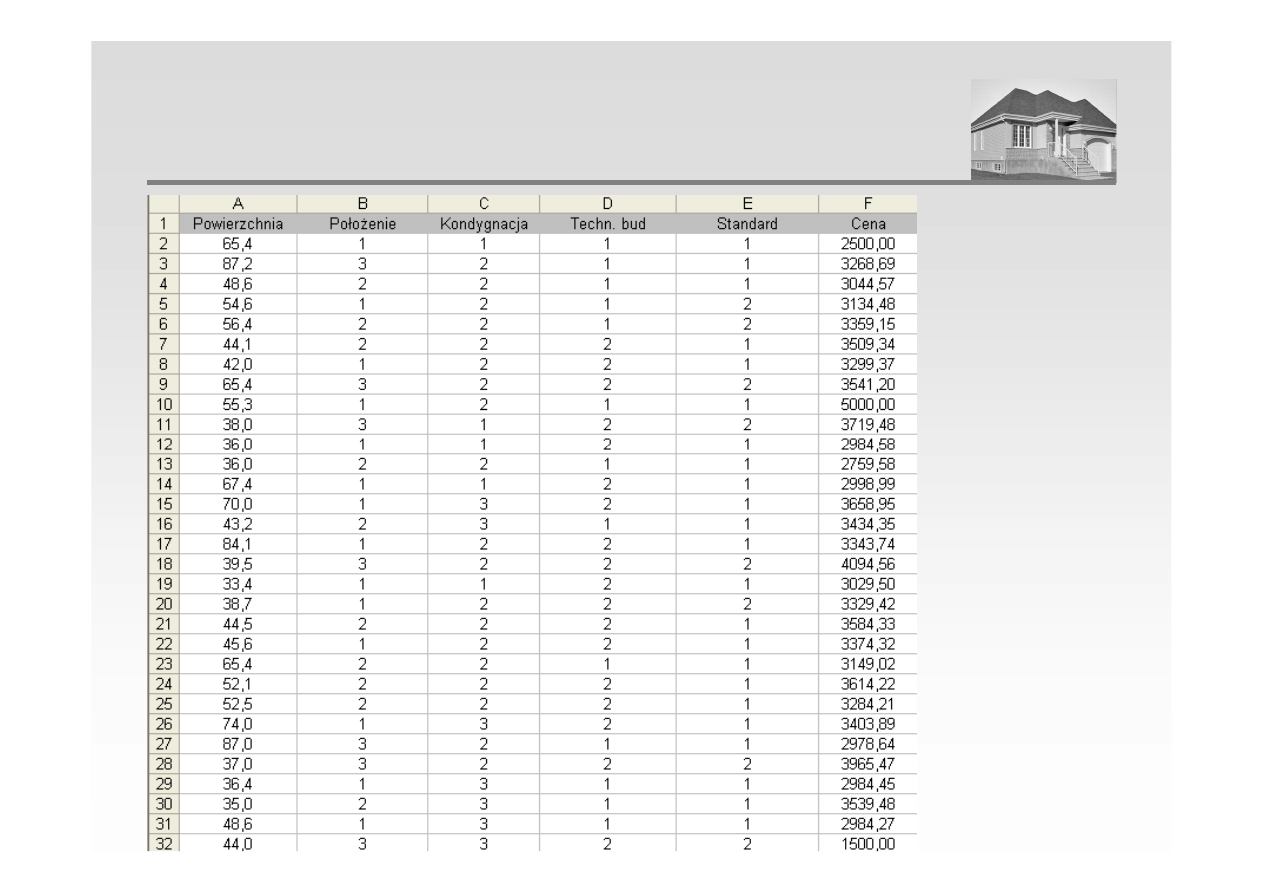
ANALIZA REGRESJI – OPIS DANYCH NA SKALACH LICZBOWYCH
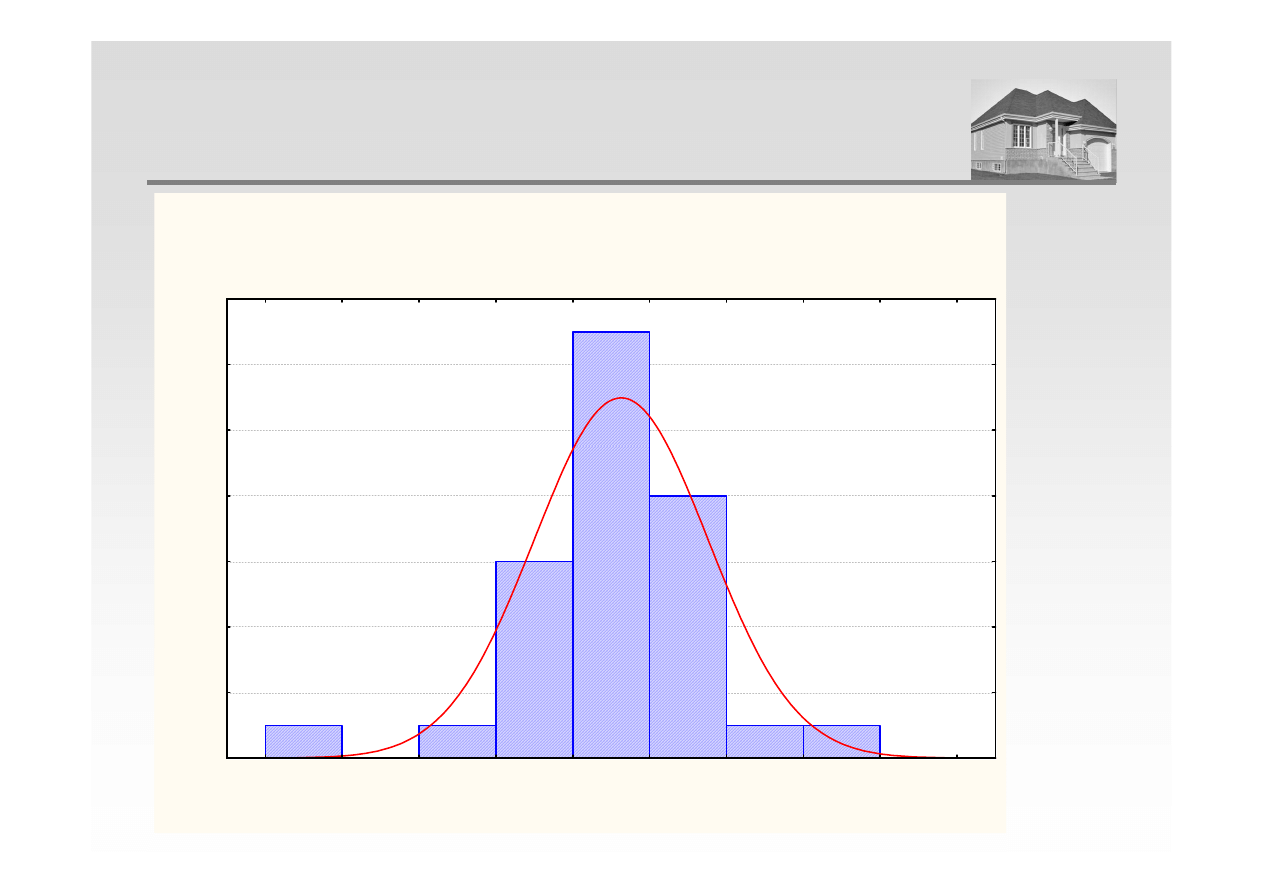
Histogram Cena
Arkusz1 10v*31c
Cena = 31*500*normal(x; 3302,3305; 562,8171)
10
12
14
ANALIZA REGRESJI – HISTOGRAM ROZKŁADU EMPIRYCZNEGO
1000
1500
2000
2500
3000
3500
4000
4500
5000
5500
Cena
0
2
4
6
8
L
ic
z
b
a
o
b
s
.
4000,00
5000,00
6000,00
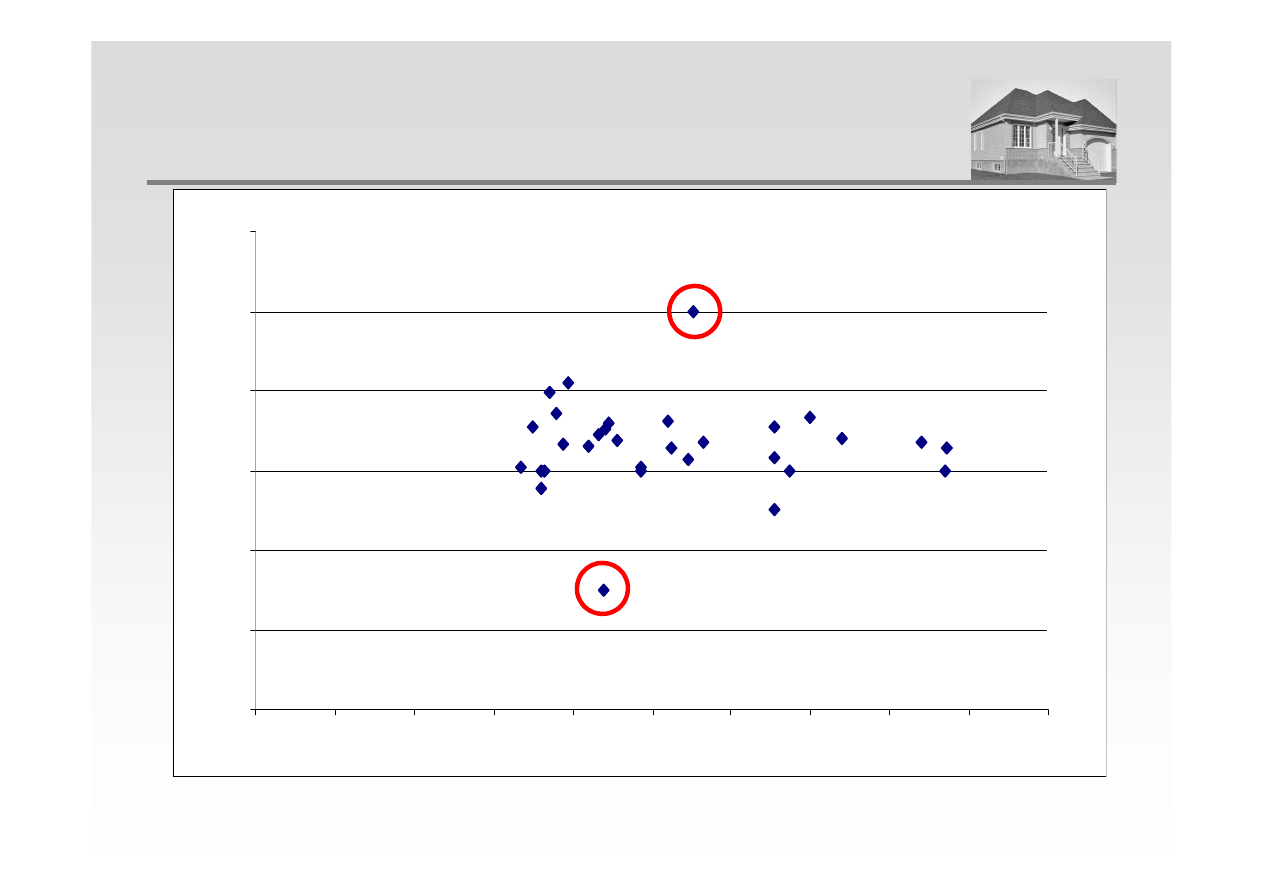
ANALIZA REGRESJI – USUNIĘCIE OBSERWACJI ODSTAJĄCYCH
0,00
1000,00
2000,00
3000,00
0,0
10,0
20,0
30,0
40,0
50,0
60,0
70,0
80,0
90,0
100,0
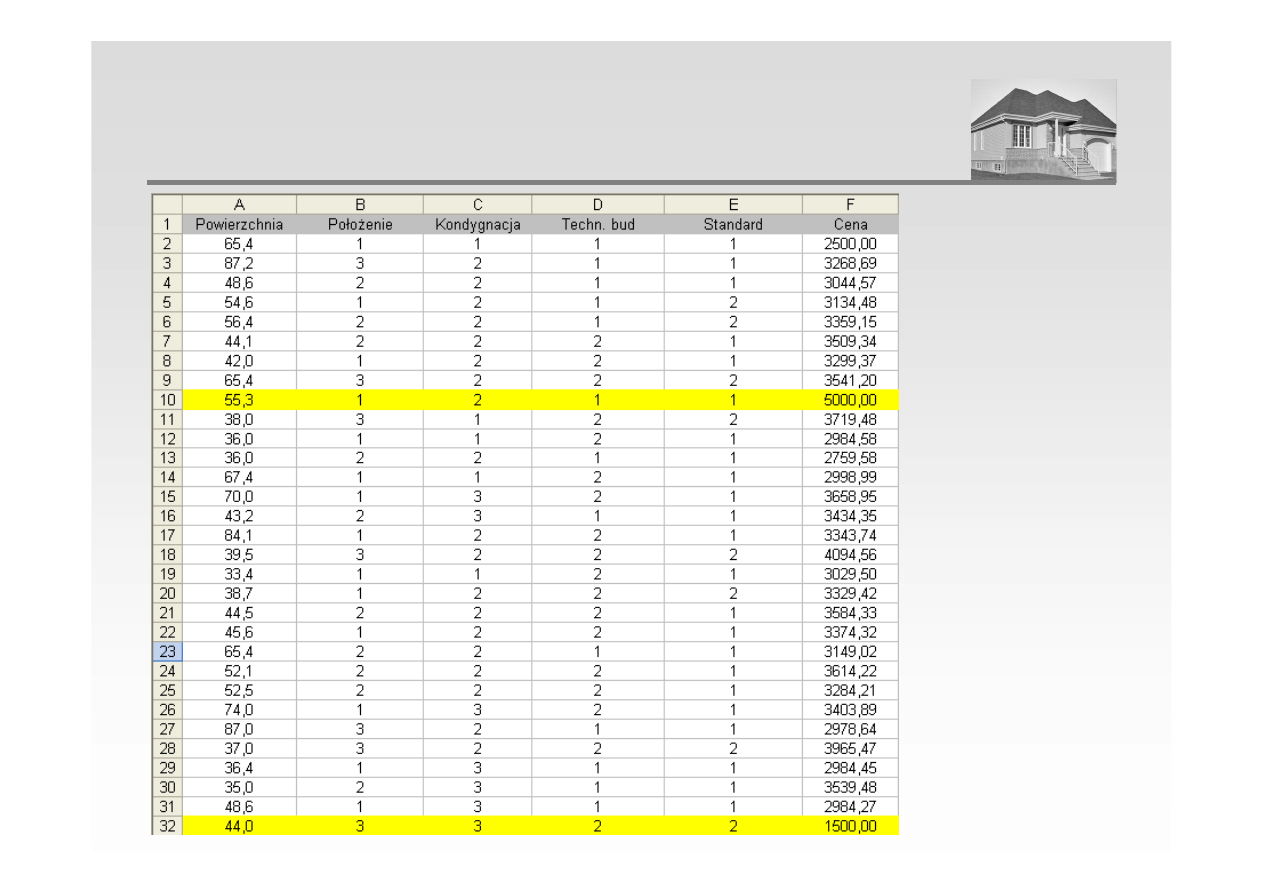
ANALIZA REGRESJI – USUNIĘCIE OBSERWACJI ODSTAJĄCYCH
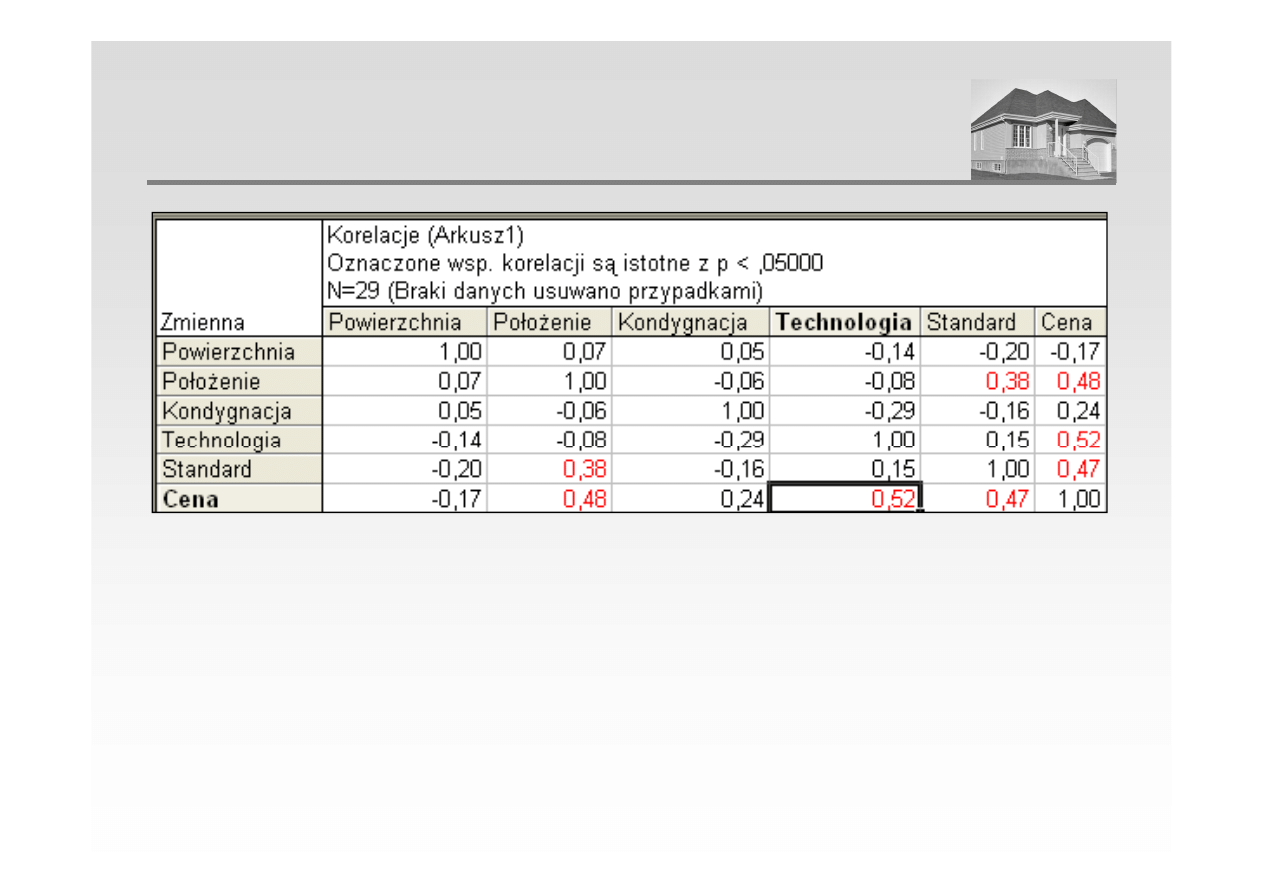
ANALIZA REGRESJI – KORELACJA MIĘDZY ZMIENNYMI
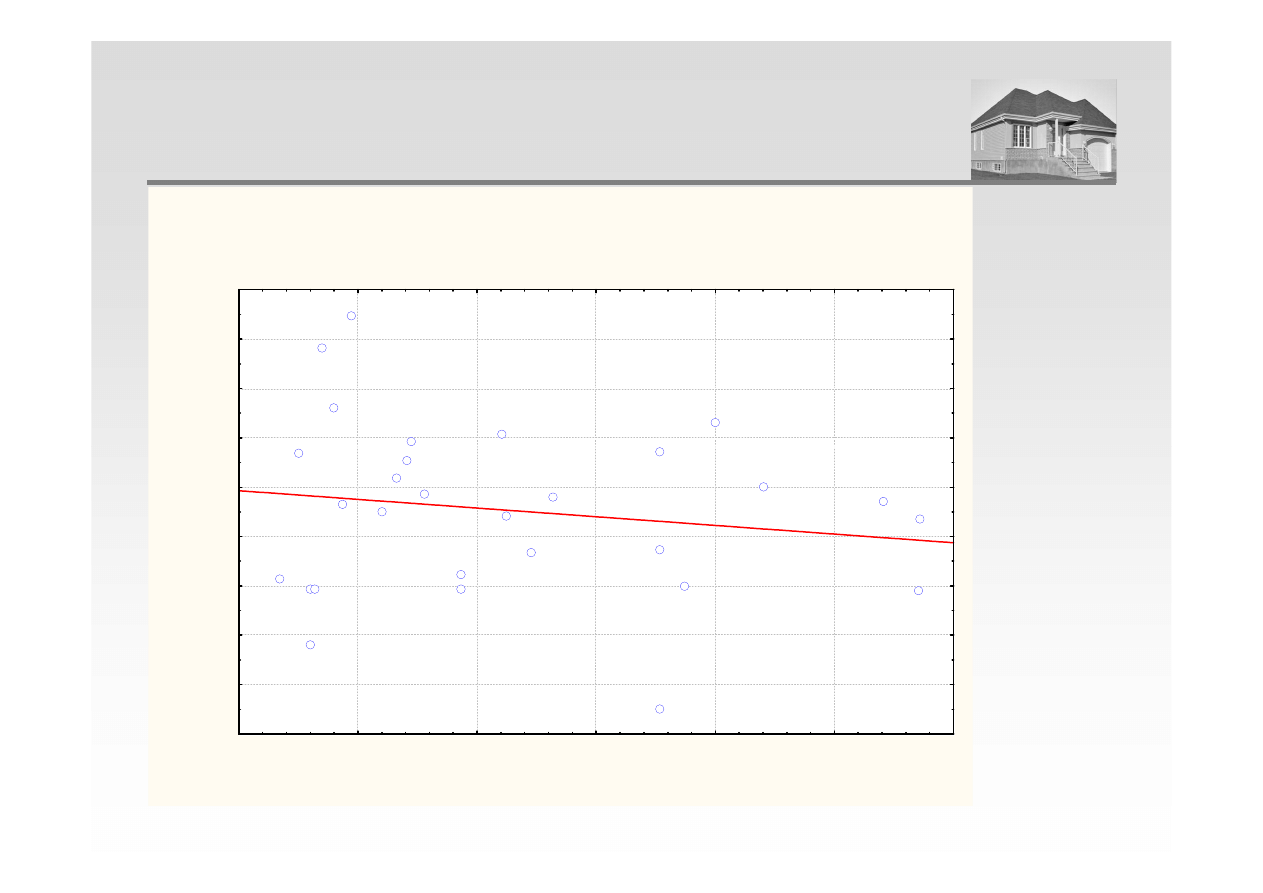
Wykres rozrzutu Cena wzgl
ę
dem Powierzchnia
Arkusz1 10v*29c
Cena = 3491,2353-3,5165*x
3600
3800
4000
4200
ANALIZA REGRESJI – POWIERZCHNIA I CENA
30
40
50
60
70
80
90
Powierzchnia
2400
2600
2800
3000
3200
3400
3600
C
e
n
a
Wykres rozrzutu Cena wzgl
ę
dem Poło
ż
enie
Arkusz1 10v*29c
Cena = 2931,7038+212,8007*x
3600
3800
4000
4200
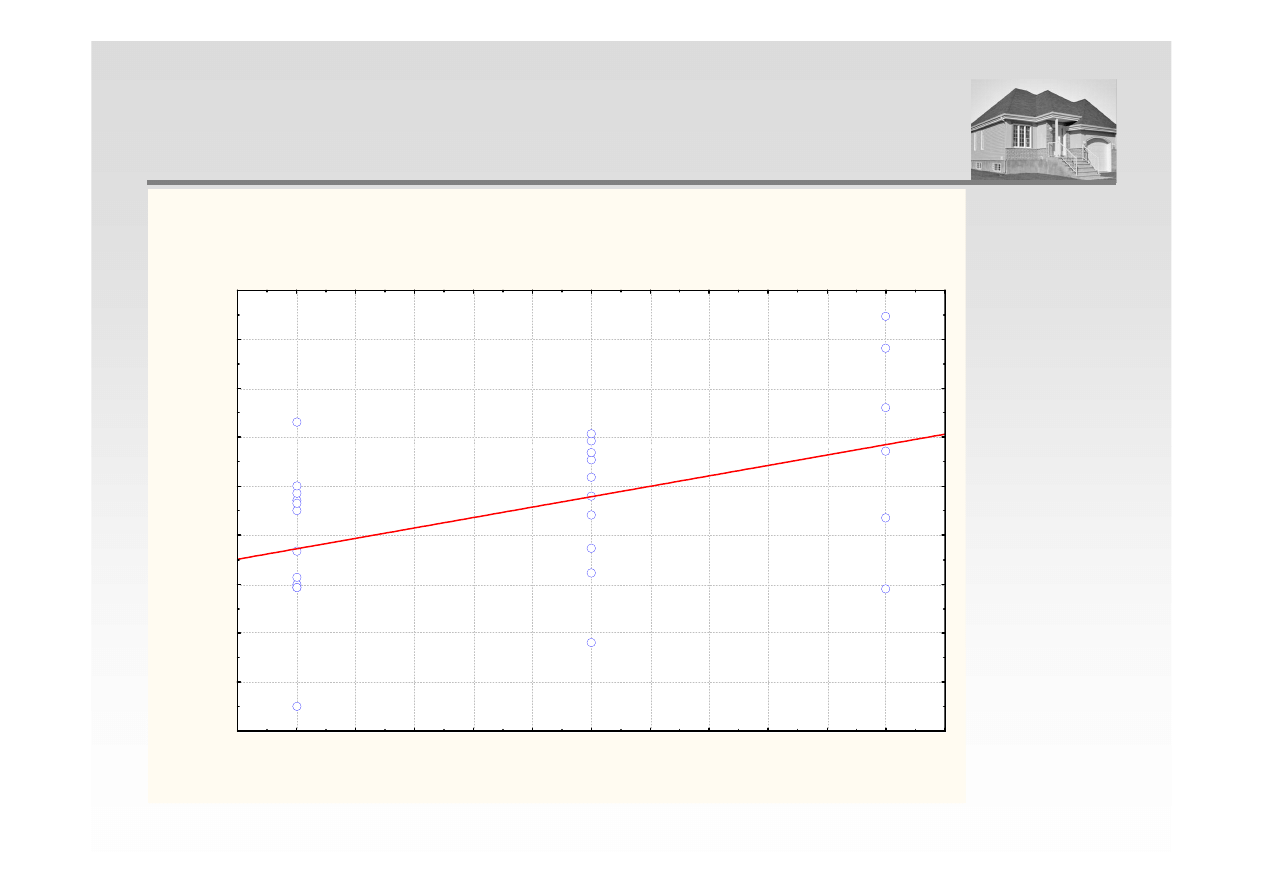
ANALIZA REGRESJI – POŁOŻENIE I CENA
0,8
1,0
1,2
1,4
1,6
1,8
2,0
2,2
2,4
2,6
2,8
3,0
3,2
Poło
ż
enie
2400
2600
2800
3000
3200
3400
C
e
n
a
Wykres rozrzutu Cena wzgl
ę
dem Kondygnacja
Arkusz1 10v*29c
Cena = 3033,777+133,7748*x
3600
3800
4000
4200
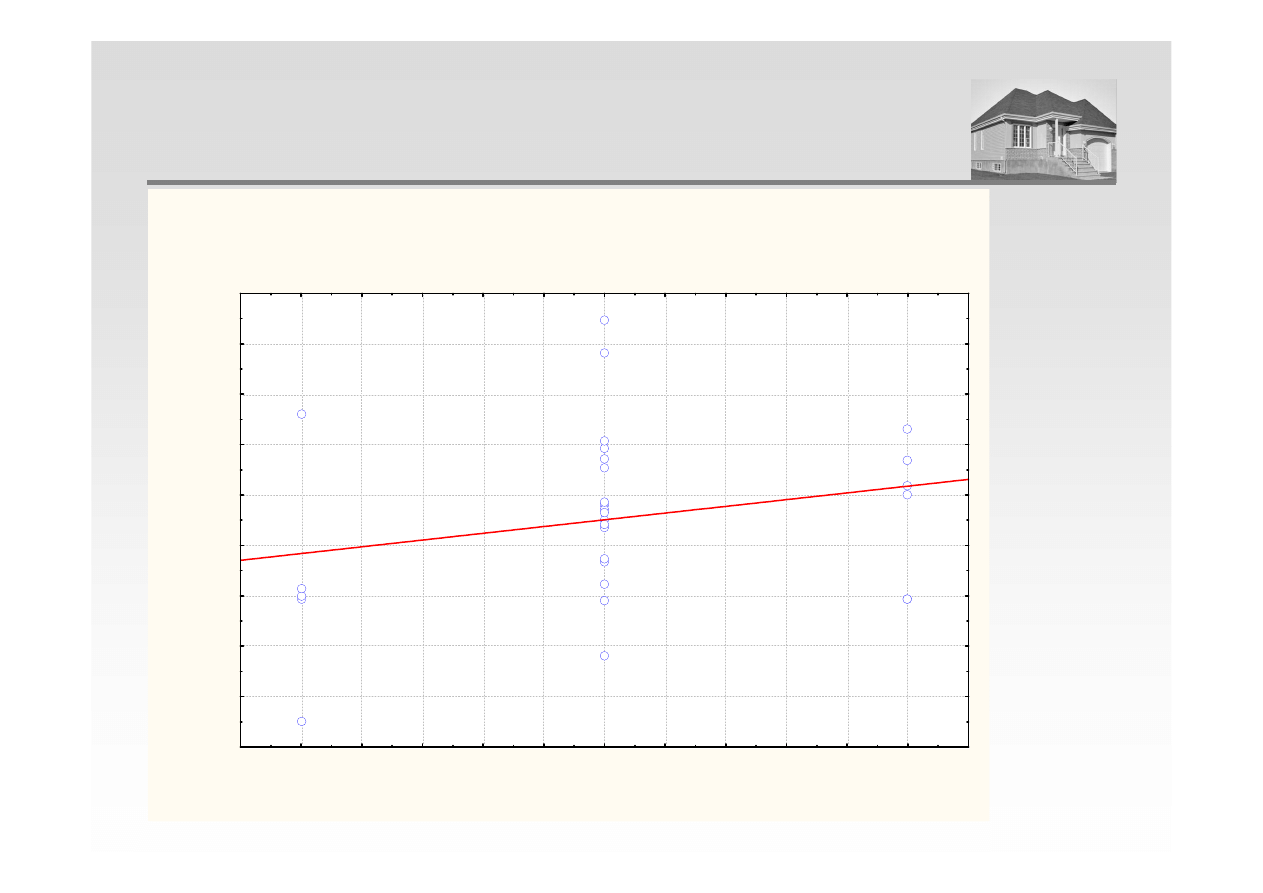
ANALIZA REGRESJI – KONDYGNACJA I CENA
0,8
1,0
1,2
1,4
1,6
1,8
2,0
2,2
2,4
2,6
2,8
3,0
3,2
Kondygnacja
2400
2600
2800
3000
3200
3400
3600
C
e
n
a
Wykres rozrzutu Cena wzgl
ę
dem Technologia
Arkusz1 10v*29c
Cena = 2734,4154+360,3087*x
3600
3800
4000
4200
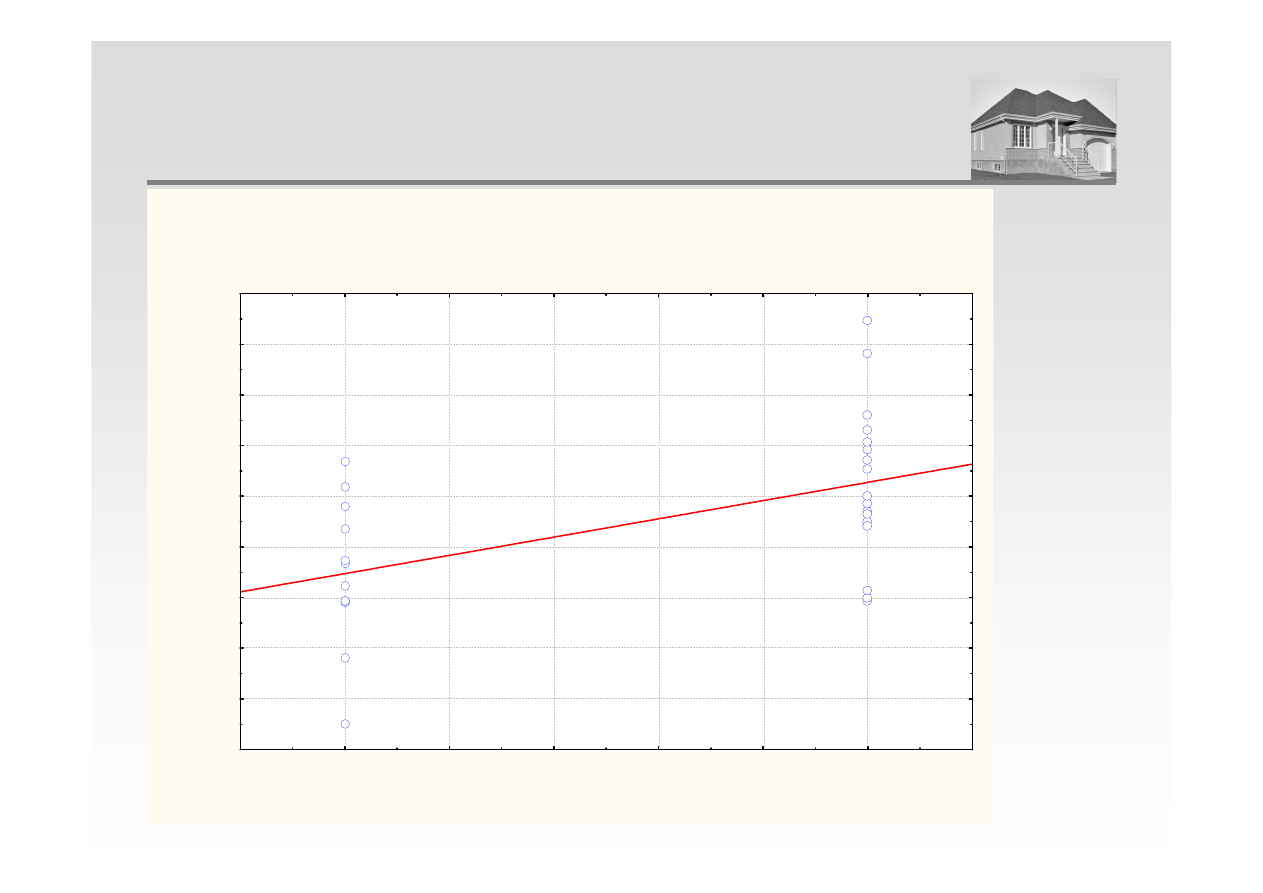
ANALIZA REGRESJI – TECHNOLOGIA I CENA
0,8
1,0
1,2
1,4
1,6
1,8
2,0
2,2
Technologia
2400
2600
2800
3000
3200
3400
3600
C
e
n
a
Wykres rozrzutu Cena wzgl
ę
dem Standard
Arkusz1 10v*29c
Cena = 2837,8973+377,034*x
3600
3800
4000
4200
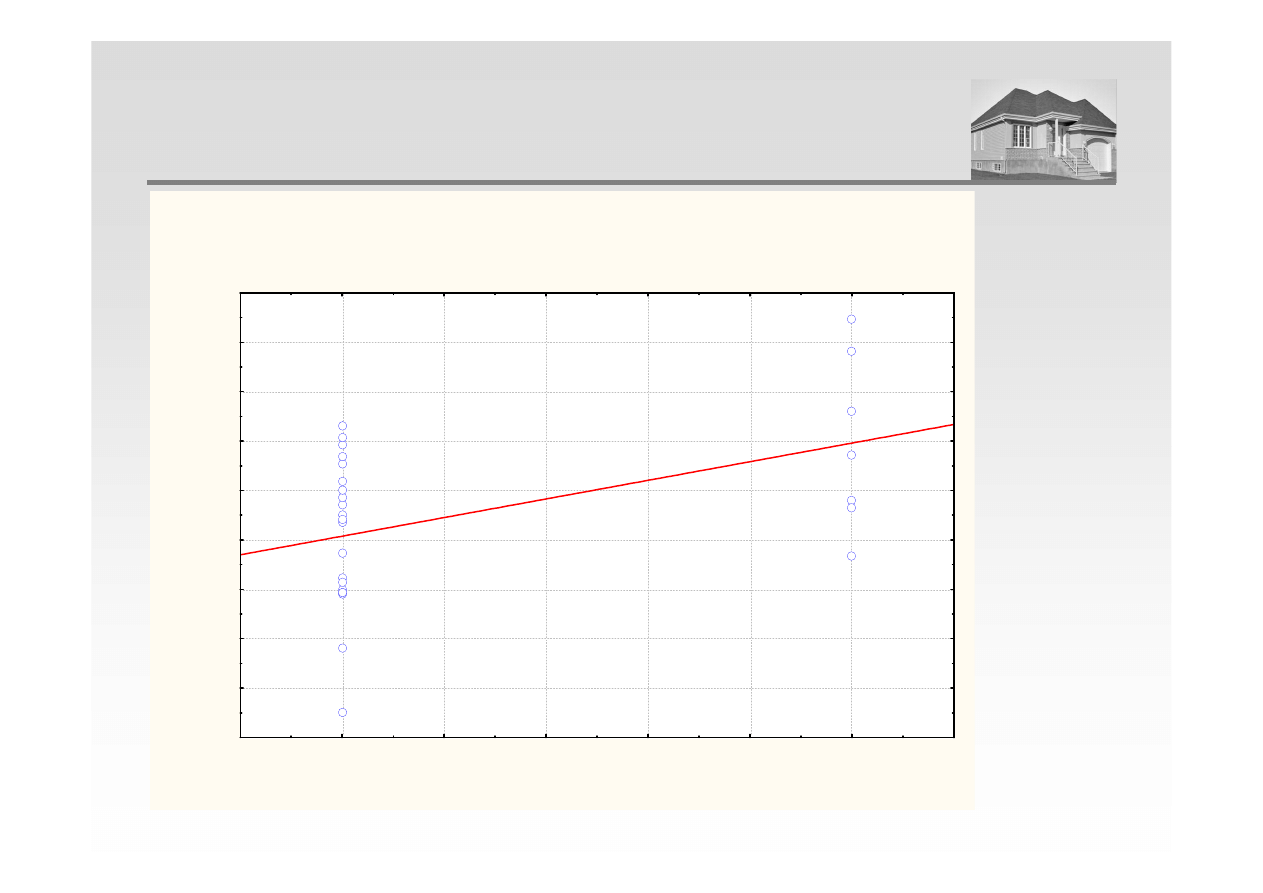
ANALIZA REGRESJI – STANDARD I CENA
0,8
1,0
1,2
1,4
1,6
1,8
2,0
2,2
Standard
2400
2600
2800
3000
3200
3400
3600
C
e
n
a

Równania regresji:
Cena = 3491,24 – 3,52 · Powierzchnia
Cena = 2831,70 + 212,80 · Położenie
Cena = 3033,78 + 133,77 · Kondygnacja
Cena = 2734,41 + 360,31 · Technologia
ANALIZA REGRESJI - PROGNOZOWANIE
Cena = 2734,41 + 360,31 · Technologia
Cena = 2837,90 + 377,03 · Standard

Prognoza ceny jednostkowej dla lokalu o następujących cechach:
Powierzchnia: 50 m2 (50)
Cena (Pow) = 3491,24 – 3,52· 50
= 3315,24 zł
Położenie: przeciętne (2)
Cena (Poł)) = 2831,70 + 212,80 · 2
= 3257,30 zł
Kondygnacja: IV
(2)
Cena (Kon) = 3033,78 + 133,77 · 2
= 3301,32 zł
Technologia: wielka płyta (1)
Cena (Tec) = 2734,41 + 360,31 · 1
= 3094,72 zł
ANALIZA REGRESJI - PROGNOZOWANIE
Technologia: wielka płyta (1)
Cena (Tec) = 2734,41 + 360,31 · 1
= 3094,72 zł
Standard: przeciętny (1)
Cena (Std) = 2837,90 + 377,03 · 1
= 3214,93 zł
Średnia arytmetyczna = 3236,70 zł
Odchylenie std. = 88,60 zł
Wartość lokalu (prognoza ceny) = 3236,70 · 50 = 161 835 zł

Im mniejsza jest wariancja (zmienność, rozproszenie) wartości resztowych
wokół linii regresji w stosunku do zmienności ogólnej, tym lepsza jest jakość
predykcji (prognozy). Jeśli na przykład nie byłoby w ogóle żadnej zależności
pomiędzy zmiennymi X i Y, wówczas stosunek zmienności resztowej Y do
zmienności całkowitej wyniósłby 1,0. Gdyby zaś X i Y były ściśle (w sensie
zależności funkcyjnej) zależne od siebie wtedy zmienność resztowa równałaby
się zero i taki stosunek wyniósłby 0,0.
WSPÓŁCZYNNIK DETERMINACJI
się zero i taki stosunek wyniósłby 0,0.
Współczynnik determinacji (R
2
) posiada następującą interpretację: gdyby, np.
wartość R-kwadrat wynosiła 0,4 wówczas 40% pierwotnej zmienności Y zostało
wytłumaczone przez regresję, a 60% pozostało w zmienności resztowej.
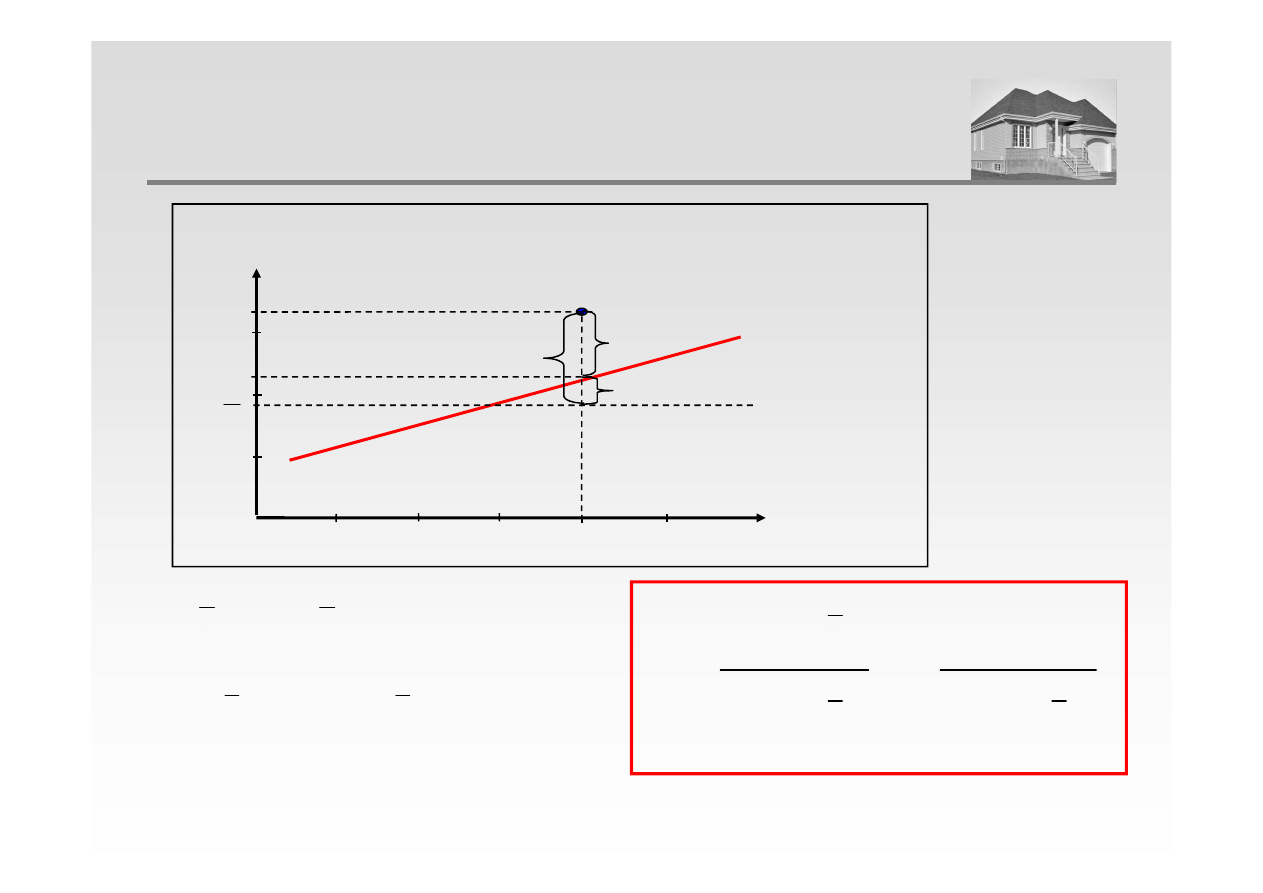
y
odchylenie
całkowite
odchylenie nie wyjaśnione
regresją (reszta)
odchylenie wyjaśnione regresją
i
y
y
i
yˆ
DOKŁADNOŚĆ DOPASOWANIA LINI REGRESJI
x
i
x
(
) (
)
i
i
i
i
y
y
y
y
y
y
ˆ
ˆ
−
+
−
=
−
(
)
(
)
(
)
∑
∑
∑
=
=
=
−
+
−
=
−
n
i
i
i
n
i
i
n
i
i
y
y
y
y
y
y
1
2
1
2
1
2
ˆ
ˆ
(
)
(
)
(
)
(
)
∑
∑
∑
∑
=
=
=
=
−
−
−
=
−
−
=
n
i
i
n
i
i
i
n
i
i
n
i
i
y
y
y
y
y
y
y
y
R
1
2
1
2
1
2
1
2
2
ˆ
1
ˆ
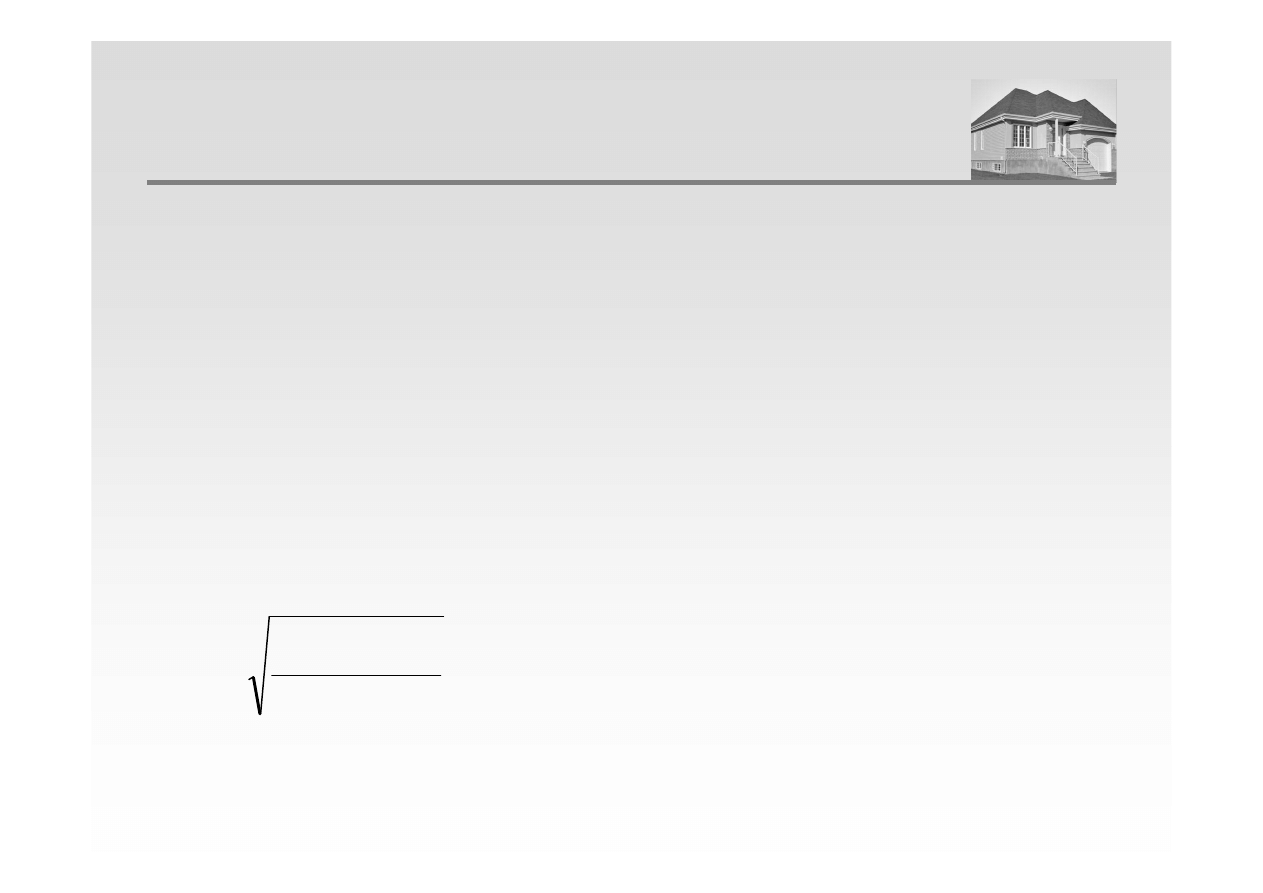
Model liniowy regresji prostej można opisać następującym wzorem:
gdzie „e” oznacza składnik losowy (resztę) modelu.
Pojedynczą resztę oblicza się następująco:
e
b
aX
Y
+
+
=
BŁĄD STANDARDOWY ESTYMACJI
Błąd standardowy estymacji stanowi przeciętne odchylenie reszt obliczone
według wzoru:
Błąd standardowy estymacji stanowi podstawę do określania błędów
predykcji z wykorzystaniem modelu regresji
(
)
2
ˆ
2
−
−
=
∑
n
y
y
S
i
e
i
i
y
y
e
−
=
ˆ
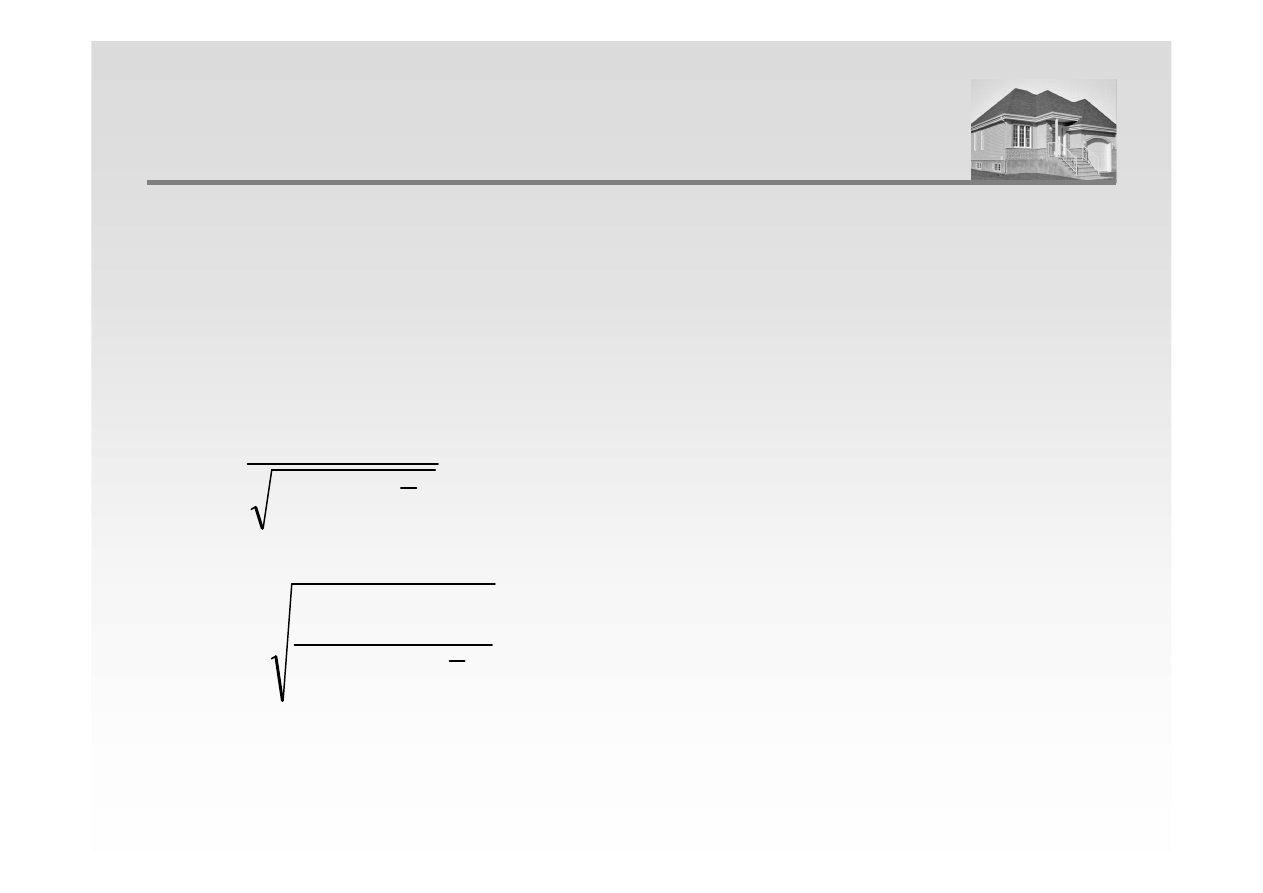
e
b
aX
Y
+
+
=
=
S
S
e
Błędy standardowe parametrów modelu wyznacza się następująco:
BŁĘDY STANDARDOWE PARAMETRÓW „a” I „b”
∑
−
=
2
2
x
n
x
S
S
e
a
(
)
∑
∑
−
=
2
2
2
x
n
x
n
x
S
S
e
b
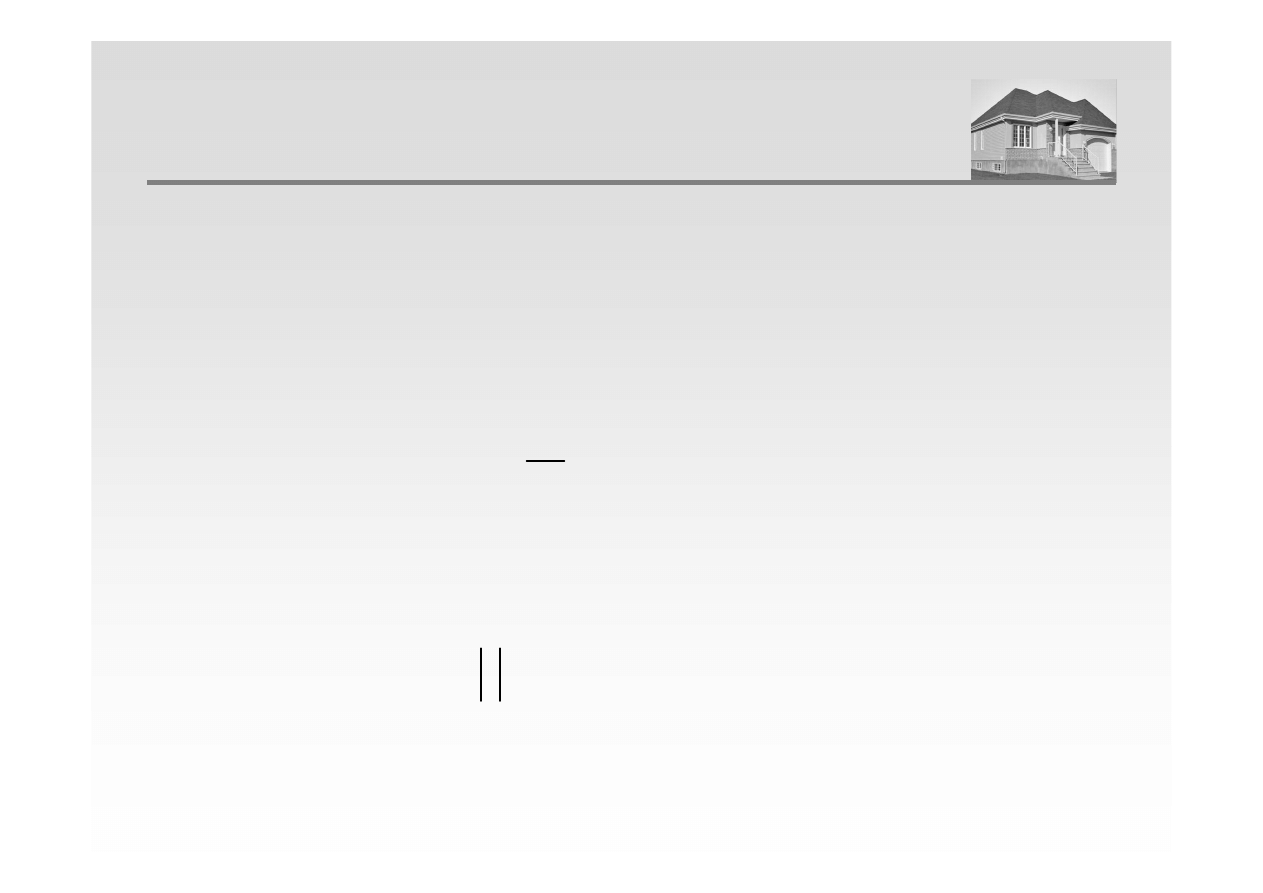
W celu zbadania istotności statystycznej parametru „a” modelu przyjmujemy następujące
hipotezy:
H0: a = 0 (brak jest zależności między badanymi zmiennymi)
H1: a ≠ 0 (istnieje statystyczna zależność)
Test istotności opisany jest następującym wzorem (statystyka t-Studenta):
a
t
=
WERYFIKACJA HIPOTEZY O NIEISTOTNOŚCI PARAMETRÓW
Następnie odczytujemy z tablic rozkładu t-Studenta wartość krytyczną dla poziomu istotności
„alfa” i stopni swobody „n – 2”.
Jeżeli zachodzi nierówność:
to odrzucamy hipotezę zerową na rzecz hipotezy alternatywnej (zależność opisana modelem
jest istotna statystycznie)
a
S
a
t
=
kryt
t
t
>
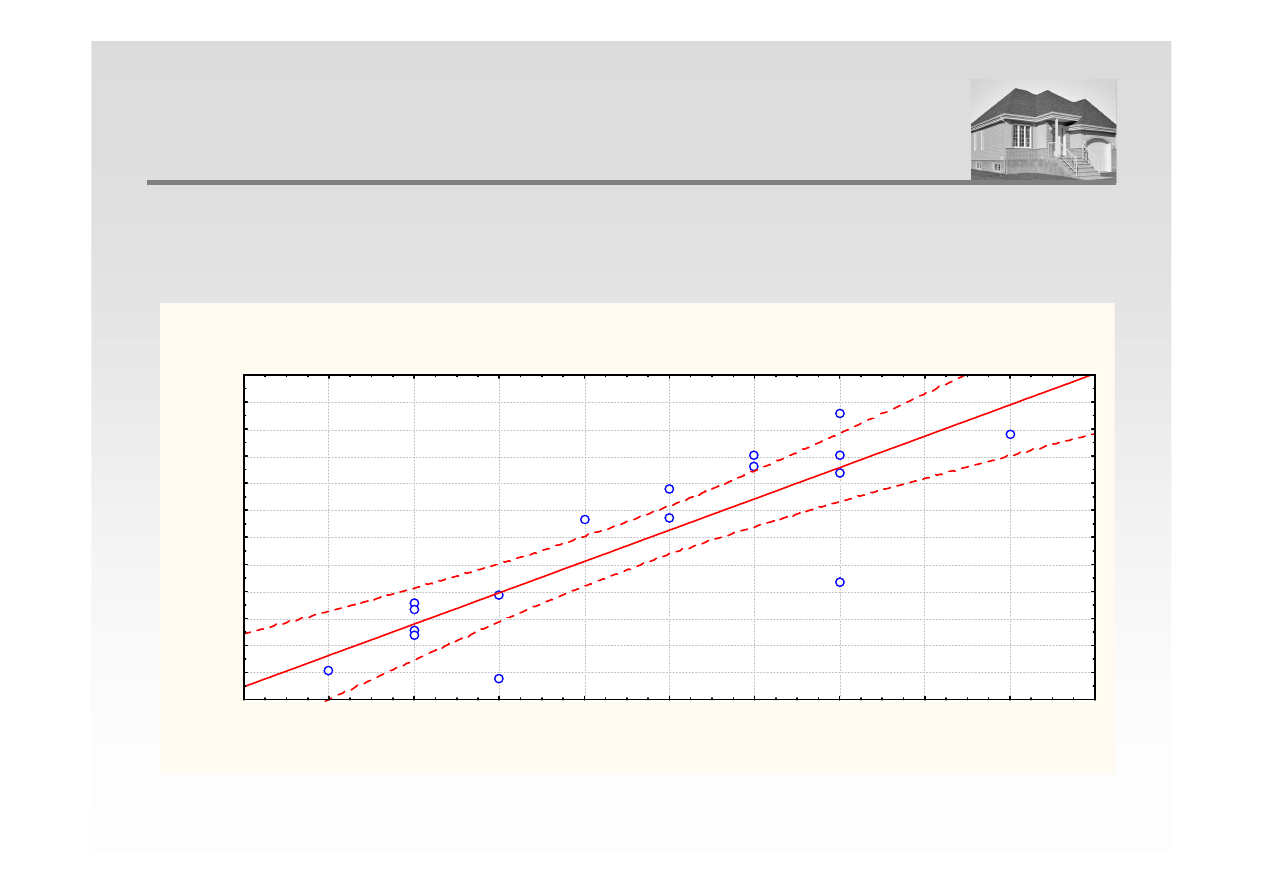
Prognoza jest tym mniej dokładna im mniej obserwacji przyjęto do obliczeń oraz im
dłuższy horyzont prognozy
Wykres rozrzutu (Arkusz2 10v*19c)
Zmn4 = -2,3778+2,3148*x
100
102
104
BŁĄD STANDARDOWY PREDYKCJI
36
37
38
39
40
41
42
43
44
45
46
Zmn1
80
82
84
86
88
90
92
94
96
98
Z
m
n
4
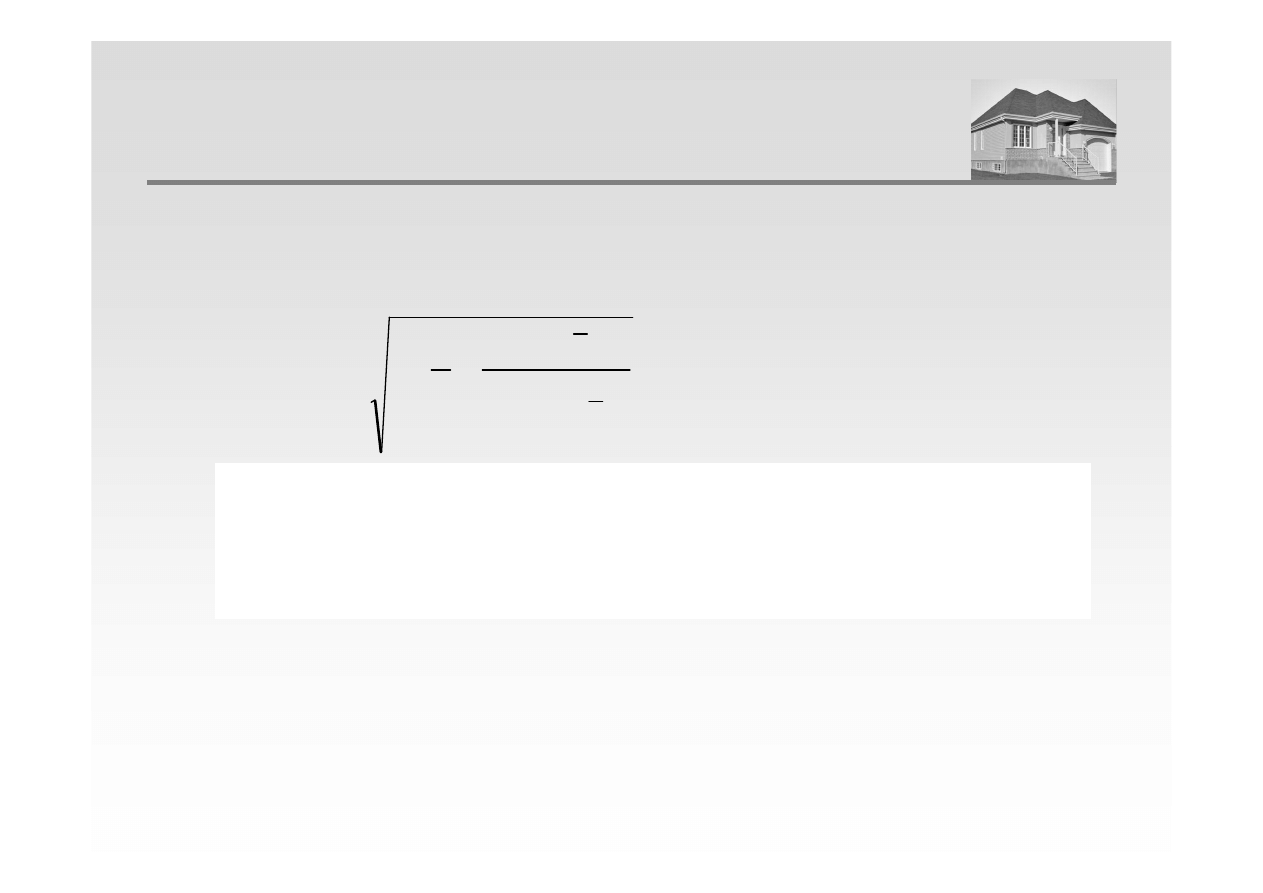
Błąd standardowy prognozy określony jest następującym wzorem:
( )
(
)
(
)
∑
=
−
−
+
+
=
n
i
i
p
e
Xp
x
x
x
x
n
S
Y
S
1
2
2
1
1
BŁĄD STANDARDOWY PREDYKCJI
=
i 1
gdzie:
Se – błąd standardowy estymacji
n - liczba obserwacji
Xp – wartość zmiennej objaśniającej, dla której dokonywana jest prognoza.
Granice przedziału ufności dla prognozowanej wartości:
( )
Xp
n
Xp
Y
S
t
Y
⋅
−
−
2
,
ˆ
α
granica dolna:
( )
Xp
n
Xp
Y
S
t
Y
⋅
+
−
2
,
ˆ
α
granica górna:

X
a
b
Y
⋅
=
a
X
b
Y
log
log
log
+
=
Nie zawsze zależności rynkowe mają charakter liniowy. W przypadku modeli nieliniowych przed
zastosowaniem metody najmniejszych kwadratów dokonujemy transformacji liniowej.
Funkcja wykładnicza:
Funkcja potęgowa:
ESTYMACJA MODELI NIELINIOWYCH
a
X
b
Y
⋅
=
Funkcja potęgowa:
X
a
b
Y
log
log
log
+
=
Funkcja hiperboliczna:
1
−
+
=
aX
b
Y
'
aX
b
Y
+
=
Wyszukiwarka
Podobne podstrony:
05 analiza stat www przeklej pl(1)
03 analiza wycena www przeklej pl
analiza statystyczna www.przeklej.pl, Technik BHP, CKU Technik BHP, CKU, Notatki szkoła CKU (BHP), s
03 analiza wycena www przeklej pl(1)
b pr i ergonomia air 05 www przeklej pl
fizyka www przeklej pl id 17708 Nieznany
phmetria www przeklej pl
06 regresja www przeklej plid 6 Nieznany
inventor modelowanie zespolow www przeklej pl
prob wki www.przeklej.pl, Ratownictwo Medyczne
rozw j teorii literatury wyk zag do egz www przeklej pl
pytania www przeklej pl
hih wyniki kolokwium 21012010 www przeklej pl
referaty na materia oznawstwo www.przeklej.pl, Rok II, laborki z termy
micros atmel www przeklej pl
klucz do skutecznej komunikacji www przeklej pl
ex 2009 2 www przeklej pl
notatka utk www.przeklej.pl, ściągi
więcej podobnych podstron