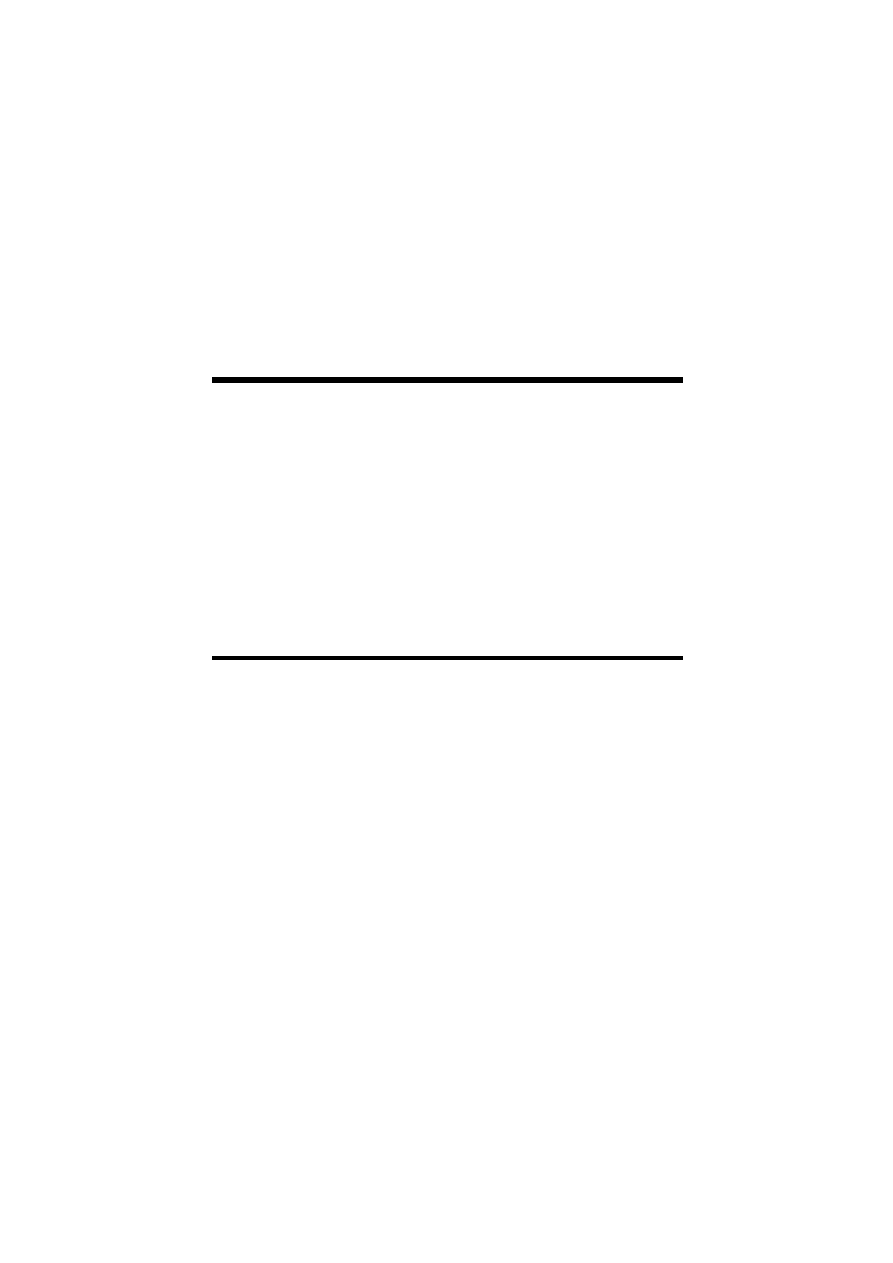
Rozdział 27
Windows NT Server jako serwer
baz danych
W bieżącym rozdziale zajmować się będziemy tematem
wykorzystania serwerów NT - jako podstawy dla systemów
zarządzania bazami danych, opracowywanych przez zdalnych
klientów. Napisano już wiele książek (w USA), poświęconych
różnorodnym systemom zarządzania bazami danych dla Windows
NT . W naszych rozważaniach pominiemy aspekt administrowania
baz danych, tworzenia aplikacji itp, ograniczając się do zależności
pomiędzy popularnymi systemami zarządzania bazami danych
(takimi jak Oracle, Microsoft SQL Server czy też Microsoft
Access's Jet) a Windows NT .
Bazy danych a Windows NT
Mogłoby się wydawać, że stworzenie systemu zarządzania
obszernymi bazami danych, działającego w oparciu o sprzęt klasy
PC, o cechach, którymi charakteryzują się systemy przeznaczone
do pracy w środowisku UNIX-a, jest zadaniem bardzo trudnym.
Jednak już po bliższym zapoznaniu się z Windows NT , dojdziemy
do wniosku, że pozwala on na zarządzanie nawet dużymi bazami
danych w rozsądny sposób. Zauważymy z pewnością, że np.
opracowywanie dokumentów pod kontrolą NT Server trwa
wyraźnie dłużej, niż w
NT Workstation (działających na
komputerach o takich samych parametrach). Różne są po prostu,
przyjęte w obu tych systemach założenia. Podobnie jak i inne
wielodostępne systemy zarządzania bazami danych, serwer NT - do
zapisywania i przeszukiwania informacji zawartej w bazach danych -
wykorzystuje szereg procesów uruchamianych w tle, czego nie robi
stacja robocza NT . W NT Server część dostępnego czasu procesora
przeznaczana jest dla procesów obsługujących bazy danych. Należy
o tym pamiętać przy podejmowaniu decyzji o zakupie platformy,
w oparciu o którą realizować będziemy planowane zadania.

1104
Rozdział 27
Systemy zarządzania bazami danych
Często zdarza się, iż w
sytuacji wystąpienia jakichkolwiek
problemów w pracy systemów obsługi baz danych, administratorzy
tych baz dopatrują się ich źródeł w złym funkcjonowaniu serwera
i systemu operacyjnego. Z kolei administratorzy systemu twierdzą,
że powodem zakłóceń są systemy obsługi baz danych same w sobie.
Spróbujemy tutaj odpowiedzieć na pytanie, jak można tego rodzaju
konfliktów unikać.
Poniżej przedstawiliśmy systemy zarządzania bazami danych,
działających na serwerze NT , z podziałem wg ich architektury:
!
przetwarzanie typu klient/serwer vs host/terminal,
!
bezpośredni dostęp do plików vs dostęp do danych
z wykorzystaniem procesów uruchamianych w tle,
!
rozproszone bazy danych,
!
powielane bazy danych.
Pierwsze z
wymienionych powyżej zagadnień dotyczy
przetwarzania typu kilent/serwer. Najprościej mówiąc, w takiej
architekturze aplikacje funkcjonują z wykorzystaniem kilku (dwóch
lub więcej) komputerów. Przeciwnym - w stosunku do kilent/serwer
- jest przetwarzanie typu host/terminal (rysunek 27.1).
Windows NT Server jako serwer baz danych
1105
W ujęciu historycznym jako pierwsze zastosowanie znalazło
przetwarzanie typu host/terminal. Wykorzystywany jest tutaj -
w
centralnym, zazwyczaj dużym komputerze - kontroler
pozwalający na podłączenie wielu terminali. Zwykle są to bardzo
proste terminale z
niewielką ilością pamięci, praktycznie
pozbawione możliwości przetwarzania danych. Ich zadanie
sprowadza się do wyświetlania informacji w postaci przekazanej
przez komputer centralny.
W przetwarzaniu typu klient/serwer, praca zostaje podzielona
pomiędzy kilka komputerów, z których każdy charakteryzuje się
odpowiednimi możliwościami. Użytkownicy systemu pracują
bezpośrednio na stacjach roboczych, których zadaniem jest
wyświetlanie informacji i być może (w pewnym stopniu) analiza
i przetwarzanie danych. Z kolei stacje robocze wykorzystują serwer
jako źródło danych i
narzędzie do transmisji. Oczywiście
przedstawiony tutaj opis jest bardzo uproszczony. Istnieje wiele
różnych typów konfiguracji klient/serwer. Różnią się one między
sobą przede wszystkim tym, w jaki sposób zadania są rozdzielane
pomiędzy klientem a serwerem. Jedynym, na stałe przydzielonym
zadaniem jest, dla klienta - wyświetlanie informacji, a dla serwera -
udostępnianie danych. Produkty dostępne dziś na rynku możemy
(pomijając niewielkie różnice) podzielić na dwie grupy: typu
Us er Inte rfa c e
Host/Term inal
C lie nt/Se rver
Us er Inte rfa c e
Pre se nta tion L ogic
Pre se nta tion L ogic
Applic a tion L ogic
Applic a tion L ogic
Da ta R eq L ogic
Da ta R eq & Re sults
Da ta Inte grity L ogic
Da ta Inte grity L ogic
Physic al Da ta Mgm t
Physic al Da ta Mgm t
Rys. 27.1.
Przetwarzanie
typu
host/terminal vs
klient/serwer.
1106
Rozdział 27
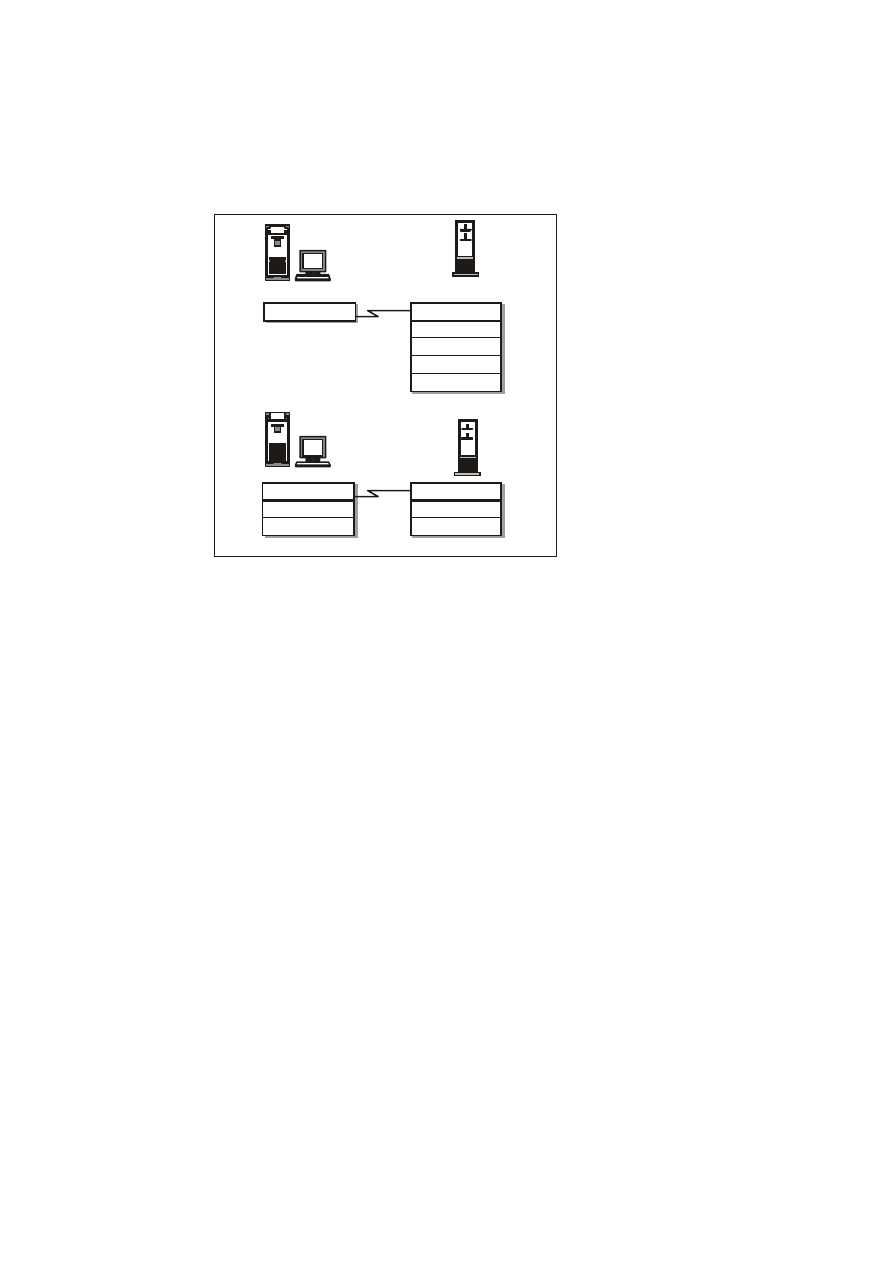
klient/serwer o architekturze dwuwęzłowej oraz te, o architekturze
trójwęzłowej. Rys. 27.2 ilustruje jedynie podstawowe różnice
pomiędzy wymienionymi architekturami.
W przypadku architektury dwuwęzłowej przetwarzanie danych dla
celów komercyjnych wykonywane jest zarówno przez stację
roboczą użytkownika, jak i serwer baz danych. Jednakże w takim
układzie, uruchomienie wielu skomplikowanych procesów
przetwarzania danych przez użytkowników, może prowadzić do
przeciążenia komputerów. Może się bowiem zdarzyć, że
pojedynczy serwer NT będzie zmuszony do obsługi wielu (nawet
setek) użytkowników w
tym samym czasie. Niejednokrotnie
wymagany jest przy tym wysoki stopień koordynacji pomiędzy
osobami wykorzystującymi te same aplikacje. Z pomocą mógłby
nam tutaj przyjść dodatkowy serwer, którego jedynym obszarem
działania byłaby logika komercyjnego przetwarzania danych.
Mógłby on - w
celu koordynacji działań oraz odciążenia
pozostałych komputerów - współdziałać zarówno z klientami, jak i
z bazami danych.
Większość instalacji systemu Windows NT pracuje w oparciu
o strukturę klient/serwer. Jakkolwiek można korzystać
z dobrodziejstw funkcji terminala w systemie NT , jednak - z uwagi
na wbudowane weń funkcje sieciowe (NetBEUI, T CP/IP, IPX/SPX,
opisane w rozdziale 7) - stwarza nam możliwość swobodnej
komunikacji pomiędzy procesami klienta i serwera. Pozwala to np.
na uruchamianie interfejsu użytkownika bezpośrednio na stacji
roboczej NT , w czasie realizacji programu zarządzającego bazami
danych na serwerze NT . Logika przetwarzania danych może zostać
K lie nt
K lie nt
S erw e r
P rze tw a rz anie
danyc h
S erw e r
baz dan yc h
S erw e r
a pl ikac ji
D wuw ę zł ow a archit ektura
klie nt/se rwe r
Trójw ę złow a archi tekt ura
klie nt/se rwe r
Rys. 27.2. Dwu-
i trójwęzłowa
architektura typu
klient/serwer.

Windows NT Server jako serwer baz danych
1107
podzielona pomiędzy klienta a serwer, zgodnie z nakreślonymi
wymaganiami, czy też nawet zainstalowana na dodatkowym
serwerze aplikacji (który również może działać pod kontrolą NT ).
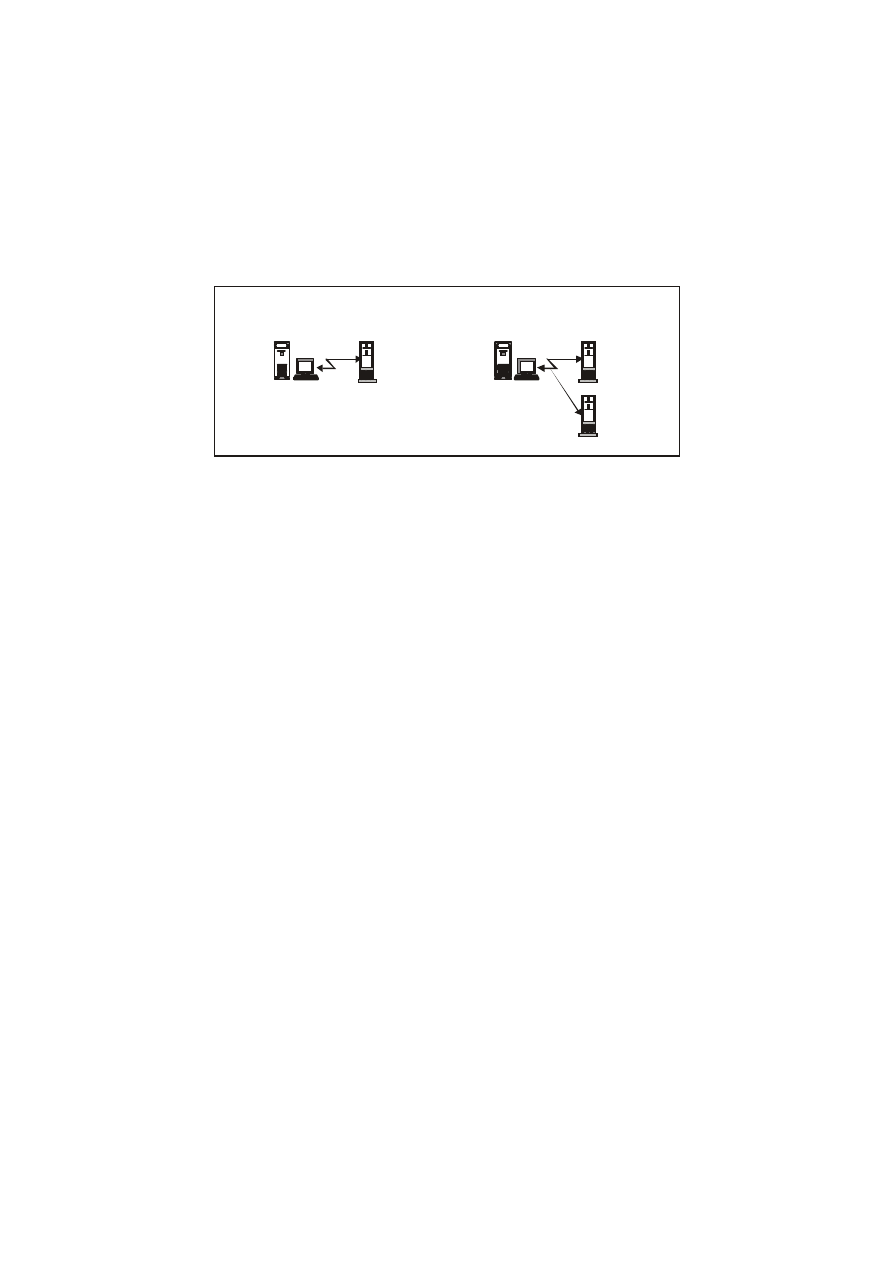
W pewnym sensie, system Microsoft-u kojarzyć się nam może
z produktem Sun Microsystems w świecie UNIXa - tj. z zestawem,
połączonych siecią urządzeń do przetwarzania, realizującym
potrzeby użytkowników. T aką sieć urządzeń można sobie
wyobrazić jako "wirtualny komputer", tak jak to przedstawiono na
rysunku 27.3.
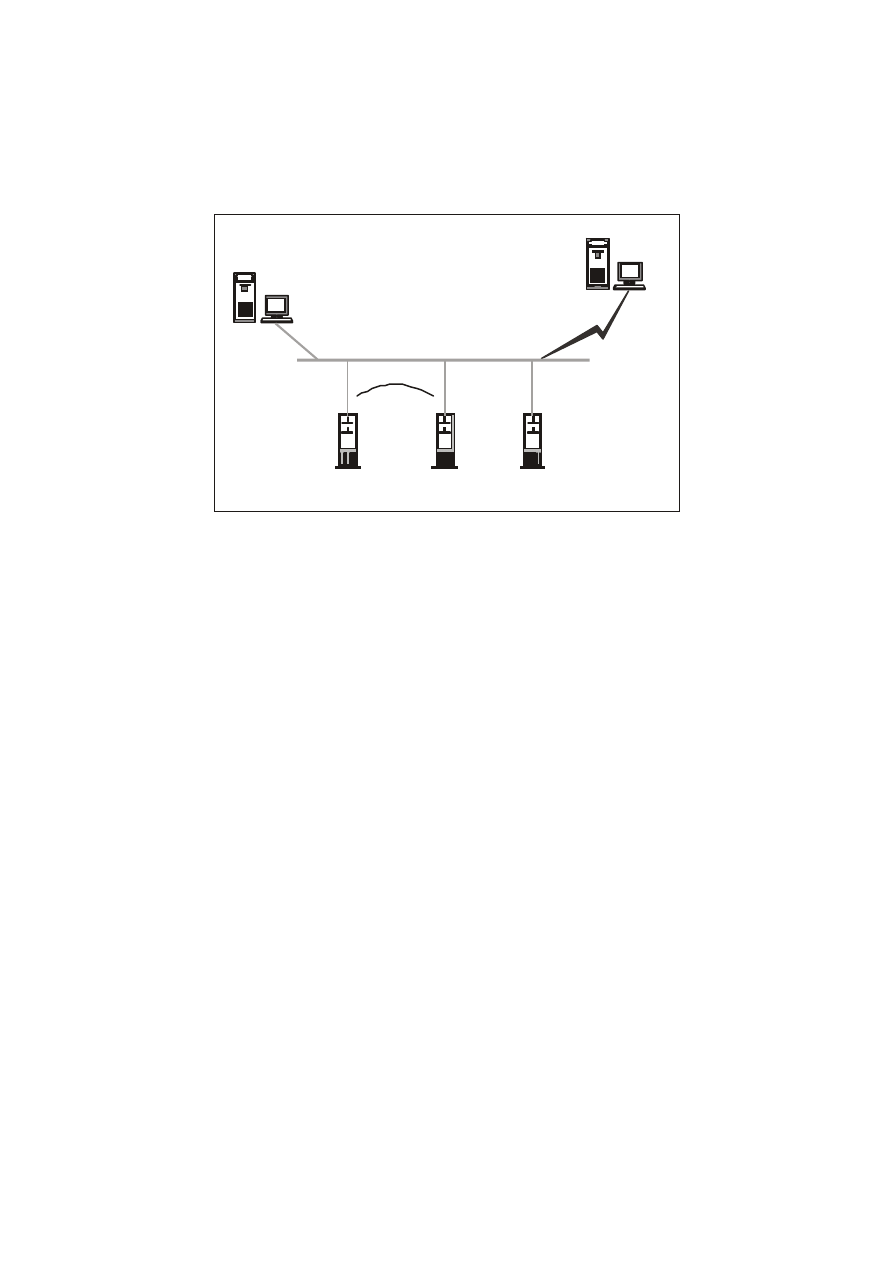
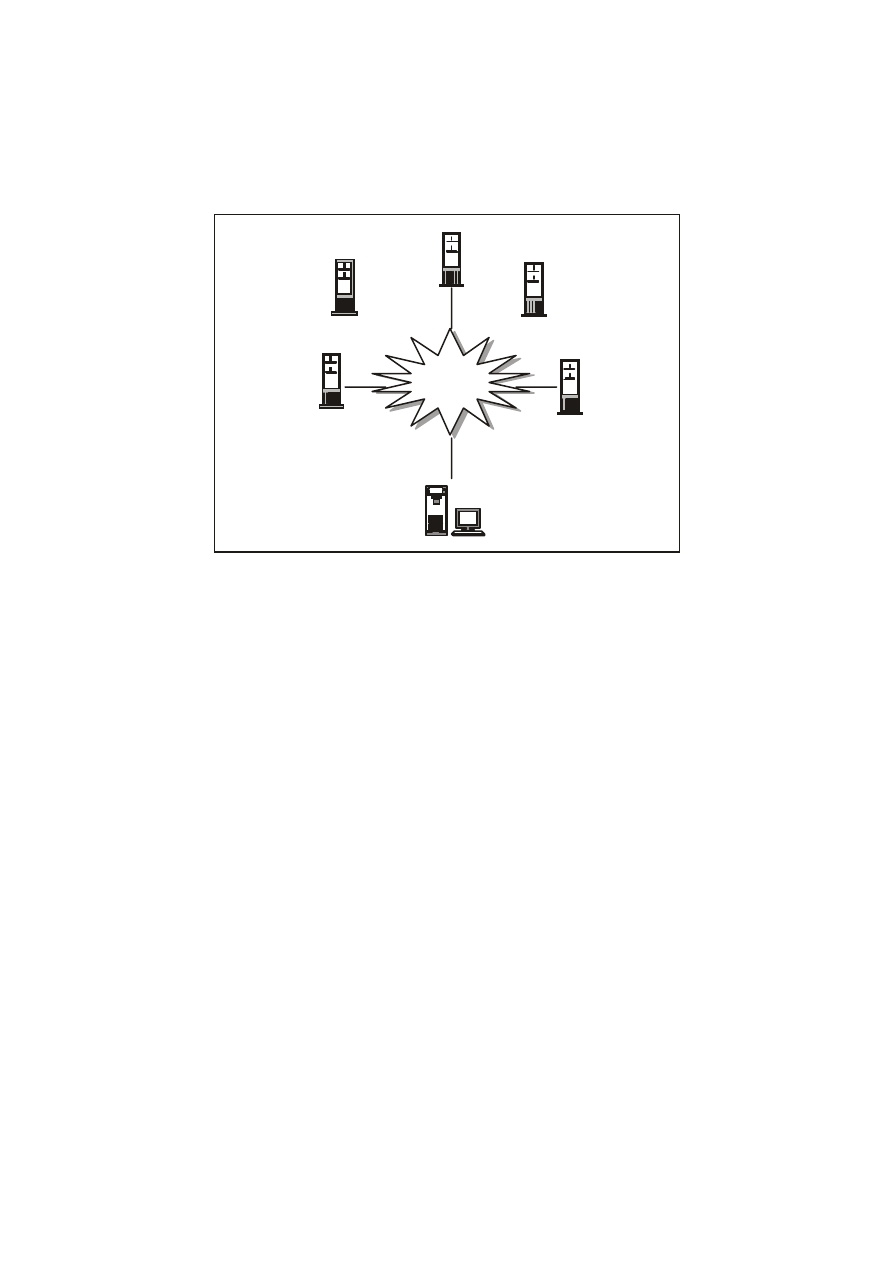
Przyjrzyjmy się teraz problemom towarzyszącym projektowaniu
rzeczywistych systemów komputerowych. Oczywiście, często
najlepszym, możliwym do implementacji rozwiązaniem będzie
architektura typu klient/serwer. Jednakże i w takim przypadku
musimy zadać sobie dwa podstawowe pytania (rysunek 27.4):
!
W jaki sposób zamierzamy zapewnić łączność ze zdalnymi
jednostkami, pracującymi w ramach naszej jednostki (sieci)?
!
Jak sprzęgniemy ze sobą różnorodne bazy danych dostępne
w
naszej jednostce (sieci), by umożliwić uzyskiwania
całościowego obrazu danych w nich przechowywanych?
Klient
Ser wer
baz danych
Ser wer
aplikacji
Rys. 27.3. System
komputerów
połączonych
siecią, czyli
„wirtualny
komputer".
1108
Rozdział 27
Musimy zdawać sobie sprawę, iż jak długo będziemy prowadzili
transmisje na odległości rzędu dziesiątek metrów, trudności i koszty
będą relatywnie niewielkie. Nie można jednak tego samego
powiedzieć w odniesieniu do transmisji dalekosiężnych (nawet do
tysięcy kilometrów). Zwłaszcza, gdy mamy do czynienia z dużą
liczbą użytkowników, z których każdy transmituje ogromne ilości
danych. W tym miejscu nie sposób nie wspomnieć o Internecie.
Jego strukturę można sobie wyobrazić jako zbiór lokalnych sieci,
utworzonych przede wszystkim na potrzeby ich lokalnych
użytkowników, do których możemy uzyskać dostęp, wykorzystując
te same narzędzia co do komunikacji lokalnej (rysunek 27.5). T aka
sieć może stanowić tanią metodę transferu informacji. Windows
NT - obsługując protokół T CP/IP - otwiera przed nami wrota
Internetu. Obecna wersja serwera NT udostępnia wiele z usług
związanych z tą siecią. Niestety wykorzystanie sieci Internet jako
podstawowego, a
zarazem ogólnodostępnego narzędzia do
przekazywania danych, wiąże się z pewnym ryzykiem. Po pierwsze
- nie mamy żadnych gwarancji, że przesyłana przez nas informacja
nie jest przechwytywana przez osoby niepowołane. Ponadto, przy
narastającej lawinowo liczbie użytkowników, sieć ta może ulec
(czasami już ulega) przeciążeniu. Niemniej jednak Internet wciąż
stanowi znakomitą drogę przesyłania informacji.
K lie nt
K lie nt
Link
Zdal ne
połą cz eni e
S erw e r
baz dan yc h
S erw e r
baz dan yc h
S erw e r
a pl ikac ji
Rys. 27.4.
Problemy
napotykane przy
implementacjach
struktur
klient/serwer.
Windows NT Server jako serwer baz danych
1109
Kolejny aspekt w projektowaniu sieci komputerowych wiąże się
z potrzebą integracji informacji pochodzących z różnych źródeł.
Oczywiście, dysponując dostępem do sieci komputerowej
ogarniającej swoim zasięgiem całe jednostki organizacyjne, ich
pracownicy traktować ją będą jako podstawowe źródło informacji.
T aka sieć pozwala na wyeliminowanie całej masy dokumentów
krążących zazwyczaj w ramach poszczególnych organizacji. Dzieje
się tak tym bardziej, że informacja w formie elektronicznej jest
przeważnie znacznie łatwiejsza do analizy i ewentualnego dalszego
przetworzenia niż jej "papierowy" odpowiednik.
W odpowiedzi na potrzeby zgłaszane przez użytkowników, na
rynku pojawiły się produkty do obsługi rozproszonych baz danych.
Odnosi się to także do Windows NT , który pozwala - w celu
stworzenia środowiska komputerowego o dużych możliwościach
operacyjnych - na połączenie szeregu relatywnie małych serwerów
NT . Do głównych części składowych rozproszonych baz danych
zaliczyć możemy:
!
interfejsy pozwalające na wykorzystanie możliwości transmisji
danych systemu operacyjnego,
!
narzędzia klienta i serwera, pozwalające na dostęp do wielu baz
danych w tym samym czasie,
Internet
G rupy dyskusyj ne
S yst emy poc zty
e lektronic zne j
Wymia na da nych,
z akupy itp.
P liki
danyc h
Informa cja
ogólnodostę pna
Rys. 27.5.
Poglądowy
schemat
ilustrujący ideę
Internetu.

1110
Rozdział 27
!
bramy do łączenia systemów zarządzania bazami danych,
pochodzących od różnych producentów, w
sposób
niezauważalny dla użytkownika,
!
systemy zarządzania bazami danych, pozwalające na pracę przy
opóźnieniach czasowych (pojawiających się we współpracy
z systemami zdalnymi),
!
wydajne systemy transmisji danych pomiędzy różnymi
komputerami i stacjami roboczymi użytkowników.
Z
uwagi na fakt, iż integralną częścią Windows NT jest
oprogramowanie sieciowe, pozwala on na efektywną komunikację
pomiędzy aplikacjami (włączając systemy zarządzania bazami
danych), a także na wykorzystanie ich możliwości do pracy w sieci.
Co więcej - wielozadaniowość NT umożliwia uruchamianie
różnorodnych procesów w
tle, zarządzających komunikacją
w trakcie regularnej pracy użytkownika.
Pora teraz na pytanie - jakie korzyści płyną z zastosowania
rozproszonych baz danych?. Ich podstawową cechę stanowi
możliwość wykorzystania powielanych baz danych. Wyobraźmy
sobie sytuację, gdy pracując w swojej lokalnej, nieobciążonej sieci,
pragniemy informacji składowanej w
bazie danych, dostępnej
w innej sieci. Sieć ta charakteryzuje się ponadto ogromnym
obciążeniem w ciągu dnia i nikłym w nocy. Zamiast każdorazowo
oczekiwać na połączenie z bazą danych, co przy obciążonej sieci
może być naprawdę czasochłonne, lepiej byłoby przechowywać u
siebie (w sieci lokalnej) kopię wspominanej bazy danych, która
będzie uaktualniana każdej nocy w sposób automatyczny. T akie
rozwiązanie jest oczywiście możliwe wtedy, gdy informacja
przechowywana w bazie danych nie zmienia się zbyt dynamicznie.
W
omawianym przypadku zadaniem systemu jest troska
o synchronizację, weryfikację i
aktualizację wszystkich tabel
w bazach i przechowywanych w nich danych.
Po zapoznaniu się z zasadami leżącymi u podstaw systemów
zarządzania bazami danych przejdziemy do omówienia wzajemnych
zależności pomiędzy systemami - operacyjnym i zarządzania
bazami danych.

Windows NT Server jako serwer baz danych
1111
System operacyjny a system zarządzania bazami
danych
Na potrzeby bieżącego rozdziału podzieliliśmy istniejące zależności
pomiędzy systemem operacyjnym a systemem zarządzania bazami
danych na następujące grupy:
!
dzielone (współużytkowane) obszary pamięci serwera,
!
procesy serwera uruchamiane w tle,
!
możliwości składowania danych na dysku serwera,
!
możliwości wykonywania operacji wejścia/wyjścia serwera,
!
możliwości komunikacji sieciowej,
!
możliwości transmisji danych poprzez sieć.
Poznanie zasady wykorzystania dzielonych obszarów pamięci
serwera warunkuje zrozumienie różnic pomiędzy funkcjami
współużytkowania plików i drukowania sieciowego w systemie NT ,
a systemami zarządzania bazami danych. Większość tych ostatnich
- dla maksymalnych prędkości pracy - wykorzystuje ogromne
obszary pamięci. Niestety nie zawsze mamy możliwość składowania
całej niezbędnej informacji bezpośrednio w pamięci. Pewna jej część
musi pozostać w
plikach dyskowych, a
jak wiadomo, nawet
w przypadku nowoczesnych napędów dyskowych, czas dostępu do
danych na nich składowanych jest - w porównaniu z dostępem do
danych przechowywanych w pamięci - o kilka rzędów większy. Stąd
właśnie koncepcja przechowywania w pamięci tej informacji, która
jest wykorzystywana częściej, oraz wykorzystania pamięci do
przechowywania danych odczytywanych z plików dyskowych Rys.
27.6 przedstawia przykład eksploatowania pamięci przez system
Oracle. Jak widać procesy użytkownika komunikują się
bezpośrednio jedynie z obszarami w pamięci komputera, podczas
gdy zadaniem procesów działających w tle jest przenoszenie danych
z
plików dyskowych do pamięci. W
przypadku dobrze
zaprojektowanych systemów zarządzania bazami danych, są one
(dane) umieszczane w pamięci, zanim użytkownik będzie chciał
z nich skorzystać. Niestety, takie rozwiązanie często wiąże się
z zakupem dużych ilości układów pamięci operacyjnej (może to
stanowić poważny problem, zwłaszcza w
przypadku platform
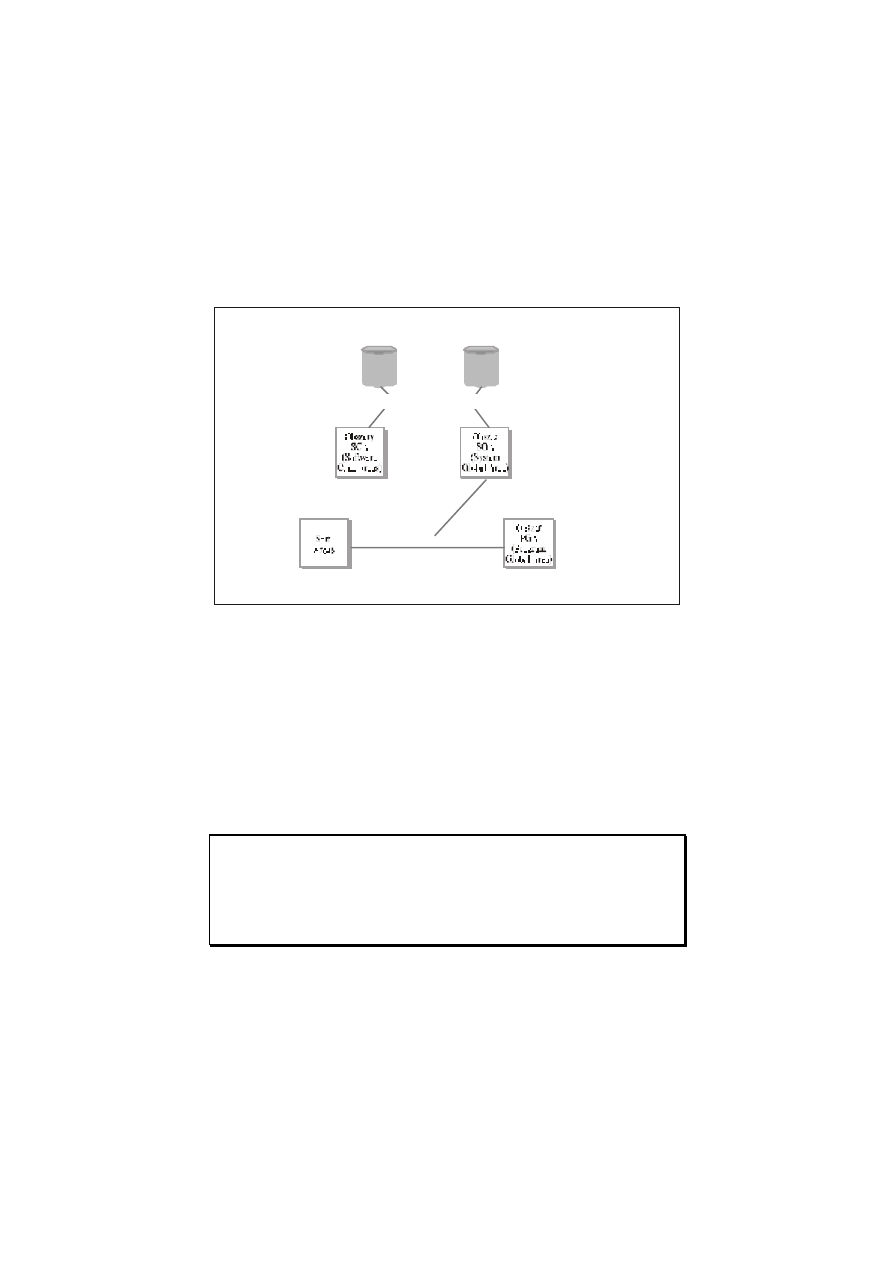
1112
Rozdział 27
bazujących na produktach Intela. Wprawdzie sam NT jest w stanie
obsłużyć obszar pamięci do 4 GB, jednak z reguły w komputerach
z procesorami Intela dopuszczalna wielkość pamięci nie przekracza
128 MB).
Przy analizie wymagań stawianych przez system zarządzania
bazami danych należy rozpatrzyć zarówno jego wymagania
w odniesieniu do ilości pamięci, jak i możliwości jakimi dysponuje
system komputerowy. Należy zdawać sobie sprawę z faktu, że
przeważnie bazy danych rozrastają się w ogromnym tempie,
i dlatego niejednokrotnie warto zapewnić sobie pewien nadmiar
zainstalowanej pamięci. Dodajmy tu jeszcze, że przy ocenie stopnia
wykorzystania zasobów systemu komputerowego pomocnym może
być Performance Monitor (opisany w rozdziale 19).
Uwaga: W przypadku wykorzystania całej dostępnej w danym
komputerze pamięci, system operacyjny zaczyna składować dane
i aplikacje na twardym dysku, wydatnie redukując wydajność
pracy. W
takich sytuacjach powinniśmy zamknąć sesję
nieaktywnych aplikacji.
W naszych rozważaniach związanych z systemami zarządzania
bazami danych przejdziemy teraz do procesów uruchamianych
w tle. W większości takich systemów właśnie one ponoszą
odpowiedzialność za umieszczanie z wyprzedzeniem w pamięci
P liki dyskow e
U żytkow nic y
P roc esy rea liz ow ane w tl e
Rys. 27.6.
W spółużytkowani
e obszarów
pamięci w bazie
danych.
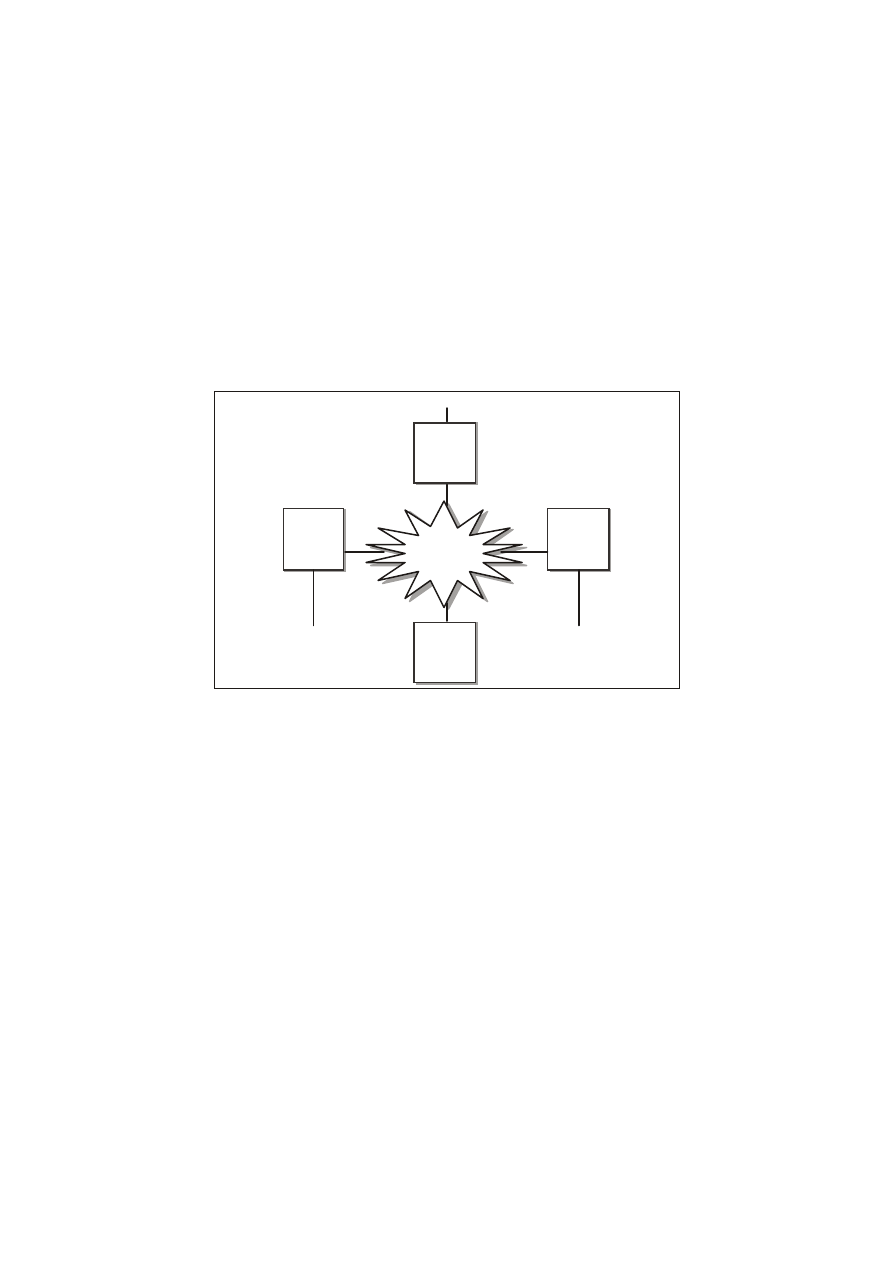
Windows NT Server jako serwer baz danych
1113
operacyjnej komputera danych wymaganych przez użytkownika.
Warunkują one także uaktualnianie plików dyskowych,
w
odpowiedzi na jego ingerencje w
pamięci (rysunek 27.7).
Niektóre z tych procesów wykorzystywane są do obsługi żądań
użytkowników. W nowoczesnych systemach zarządzania bazami
danych rola użytkownika ogranicza się zazwyczaj do określenia
rodzaju zadania (jakie chce, aby zostało wykonane). Metoda
realizacji zadania leży w gestii samego systemu.
Pomimo iż NT jest w dużym stopniu "samokonfigurującym się "
systemem operacyjnym, ingerencja administratora jest często
pożądana. Po pierwsze - istnieje zestaw procesów i wątków, które
mogą być uruchomione bezpośrednio przez administratora (co bywa
pomocne zwłaszcza w większych systemach, z wielomo równolegle
realizowanymi aplikacjami). Po drugie - często przydzielenie
dodatkowych procesów do wykonywania pewnych zadań zwiększa
wydatnie wydajność całego systemu. Wówczas wydajność całego
systemu jest funkcją wydajności najsłabszego ogniwa w łańcuchu
procesów tworzących system. Stąd istotne jest tutaj wyznaczenie
takiego (najsłabszego) miejsca, i przydzielenie do jego obsługi
dodatkowych zasobów.
Przyjrzyjmy się teraz bliżej systemom składowania danych na
dysku (rysunek 27.8). T ypowe systemy baz danych wymagają dużo
End Users
User
Service
Processes
Memory
Area s
Log
Writers
Data
Writers
Data
Files
Log
Files
Orac le
Monitors
Rys. 27.7. Usługi
działające w tle
w systemie baz
danych.
1114
Rozdział 27
większych obszarów pamięci dyskowej niż inne aplikacje. Warto
więc zastanowić się tutaj nad wielkością, wymaganej przez
planowane zadanie, pamięci dyskowej. Powinniśmy także
rozpatrzyć fizyczne konfiguracje sytemu dysków twardych.
Niejednokrotnie, zwłaszcza serwery klasy PC, dopuszczają istotnie
ograniczoną liczbę dysków. W
takich sytuacjach jedynym
sposobem na rozszerzenie możliwości składowania danych jest
zastąpienie starszych napędów o mniejszej pojemności, większymi.
W systemach zarządzania bazami danych, poniższe komponenty
wykazują znaczne wymagania względem przestrzeni na dysku:
!
oprogramowanie systemu zarządzania bazami danych, samo
w sobie (którego wielkość może dochodzić nawet do kilkuset
MB),
!
pliki rejestracji i składowania systemu zarządzania bazami
danych (które mogą zawierać wiele przydatnych informacji;
należy jednak pamiętać o okresowym ich usuwaniu),
!
aplikacje pisane przez użytkownika (jak np. logika
przetwarzania danych w aplikacjach serwera dla trójwęzłowej
architektury klient/serwer),
!
dodatkowa przestrzeń w pliku wymiany, którą może zwiększyć
efektywność pracy z bazą danych.
Memory
Area s
Background
Processes
Data
Files
Control
Files
Alert
Log
Redo
Log
Files
Archive
Log
Files
Trace
Files
Rys. 27.8. System
składowania
danych na dysku.

Windows NT Server jako serwer baz danych
1115
Dodatkowej przestrzeni dyskowej możemy również potrzebować
przy zmianie sposobu organizacji naszego systemu (lub konfiguracji
dysków).
Analizując system składowania danych na dysku, oprócz wielkości
dostępnych urządzeń dyskowych, powinniśmy rozważyć szybkość
wykonywania operacji wejścia/wyjścia przy zapisie/odczycie danych
składowanych na dyskach. Dotyczy to przede wszystkim systemów
NT , tworzonych w oparciu o produkty Intela. Podczas gdy wiele
systemów UNIX-owych bazuje na bardzo szybkich kontrolerach
i napędach dyskowych SCSI, wiele serwerów „intelowych”
dysponuje dużo wolniejszymi podsystemami transferu danych.
Częstokroć, właśnie szybkość transmisji danych z dysku limituje
szybkość działania systemu obsługi baz danych. Dlatego też należy
pamiętać o kilku kluczowych sprawach, warunkujących przyjęcie
optymalnych rozwiązań (rysunek 27.9). Mamy tutaj na myśli:
!
możliwości i
konfigurację wykorzystywanych napędów
dyskowych i
ich kontrolerów. Przede wszystkim należy
pamiętać, że własności zastosowanych kontrolerów mogą być
diametralnie różne. Dla przykładu kontroler SCSI-2 jest dwa
razy szybszy od kontrolera SCSI, a także od kontrolerów IDE,
tradycyjnie instalowanych w sprzęcie klasy PC. Do tego,
wymienione kontrolery współpracują z magistralami różnych
typów (np. magistrala PCI jest dużo szybsza od ISA, stosowanej
w komputerach PC). Stąd odpowiednie rozmieszczenie plików
danych na dyskach (dane częściej wykorzystywane na dyskach
szybszych) może znacznie poprawić wydajność całego systemu.
!
sposób rozdziału możliwości przesyłania danych pomiędzy
system baz danych a innymi aplikacjami. Należy unikać sytuacji,
w których pliki intensywnie wykorzystywane przez system
zarządzania bazami danych są umieszczone na tych samych
napędach, co te, często wykorzystywane przez inne aplikacje.
T akie przypadki z pewnością prowadzić będą bezpośrednio do
przeciążenia niektórych dysków w
systemie i
spadku jego
wydajności.
!
fragmentację plików na dysku. Częste dodawanie informacji do
plików dyskowych, tworzenie nowych, usuwanie istniejących,
prowadzi do fragmentacji zapisu plików (rysunek 27.10).
W
efekcie odczytanie czy też zapisanie pliku wymaga
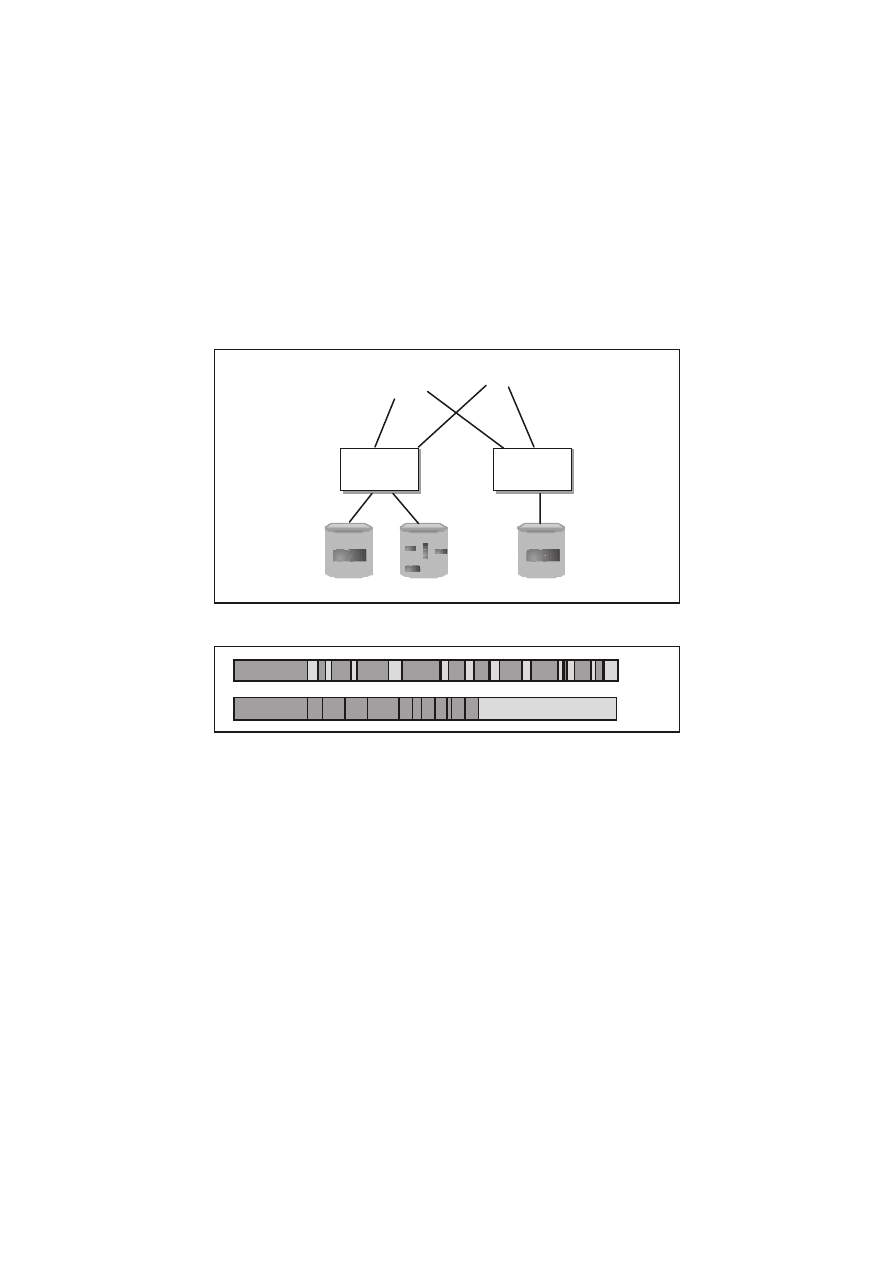
1116
Rozdział 27
wielokrotnej zmiany pozycji głowicy dysku, ponownie redukując
wydajności systemu. Niestety NT 4.0 nie dysponuje
wbudowanym narzędziem do porządkowania danych na dysku (w
przeciwieństwie np. do Windows 95). Pozostają nam jedynie
zewnętrzne narzędzia do ich porządkowania, czy też
wykorzystanie systemu plików NT FS.
Następnym punkt na liście zależności pomiędzy systemem
operacyjnym a systemem zarządzania bazami danych wiąże się
z komunikacją sieciową. Zazwyczaj, system NT samodzielnie
zarządza komunikacją pomiędzy poszczególnymi procesami
używanymi do uzyskiwania dostępu do serwerów baz danych, do
serwerów innych aplikacji, czy w końcu do stacji roboczych.
Aczkolwiek i w tym przypadku istnieją czynniki, na które możemy
mieć wpływ, bezpośrednio oddziałujące na wydajność systemu.
A mianowicie:
!
rodzaj zastosowanej karty sieciowej. Podobnie jak przy
napędach dyskowych i tutaj parametry poszczególnych kart
sieciowych mogą się znacznie różnić. Niektóre z nich mogą
System zarządzania bazą
danych DMS
Inne aplikacje
Kontroler
dysku
Kontroler
dysku
Rys. 27.9.
Transmisja
danych w systemie
komputerowym.
Large, Free Extent
Rys. 27.10.
Przykład
fragmentacji
dysku.

Windows NT Server jako serwer baz danych
1117
pracować nawet kilkakrotnie szybciej niż inne, nawet w sieci
tego samego typu.
!
rodzaj zastosowanego protokołu do obsługi komunikacji
pomiędzy klientem a serwerem. Istnieją protokoły (jak np.
T CP/IP), zaprojektowane do obsługi większych systemów,
skuteczniejsze przy nałożonych systemowi wysokich
wymaganiach.
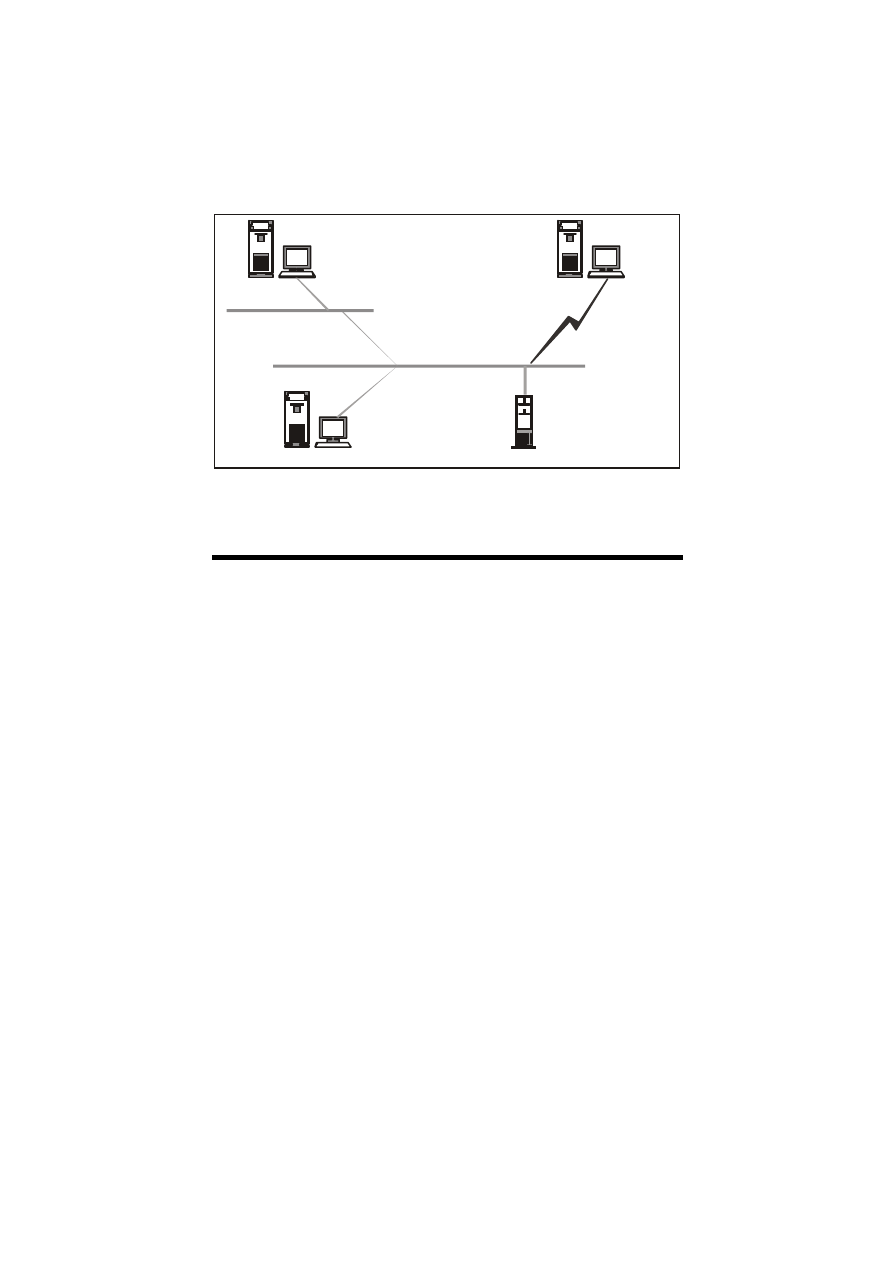
Pora zająć się teraz problemem transmisji danych poprzez sieć.
Charakterystyka tej transmisji często pozostaje poza naszym
wpływem. Pomimo tego, warto poznać sposoby wykorzystania
sieci i jej topologię - aby mieć możliwość ustalenia, czy to właśnie
nie tempo transmisji danych w sieci limituje możliwości naszego
systemu. Rys. 27.11 ilustruje przykładową strukturę sieci
komputerowej. Schemat sieci komputerowej, w której pracujemy
może być bardzo pomocny przy ustaleniu źródła ewentualnych
zakłóceń. W takich sytuacjach należy w
pierwszej kolejności
ustalić, czy:
!
pojawiający się problem dotyczy pojedynczego użytkownika,
pewnej ich grupy, czy też wszystkich użytkowników danej sieci.
Zazwyczaj określenie zasięgu awarii pozwala na jednoznaczne
ustalenie jej źródła - bez względu na to czy wynika ona
z przeciążenia poprawnie funkcjonującej sieci o
małej
przepustowości, czy też awarii sieci nieobciążonej.
!
zakłócenia mają charakter przypadkowy czy też regularny.
W przypadku problemów pojawiających się regularnie, ich
źródłem może być fakt okresowego przeciążania sieci - gdy np.
pewni użytkownicy przesyłający znaczne pakiety danych siecią
w tym samym czasie. Rozwiązaniem może być odpowiedni
harmonogram wykorzystania sieci, z
zobowiązaniem
poszczególnych grup użytkowników do transferu danych
o określonych porach.
1118
Rozdział 27
System Oracle w Windows NT
W pracy z systemami zarządzania bazami danych powinniśmy znać
oferowane przez nie możliwości. Dzięki temu będziemy mogli
sprawnie wykonywać zamierzone zadania, a także wybrać system
zarządzania bazami danych, odpowiedni dla ich (tych zadań)
realizacji. T rzeba pamiętać, że systemy zarządzania bazami danych
różnią się zarówno pod względem jakości dostarczanych usług (np.
jedne są szybsze niż inne) jak i ich ilości (jedne oferują narzędzia do
wspomagania podejmowania decyzji, a inne nie). Zajmiemy się
teraz najpopularniejszymi systemami zarządzania bazami danych.
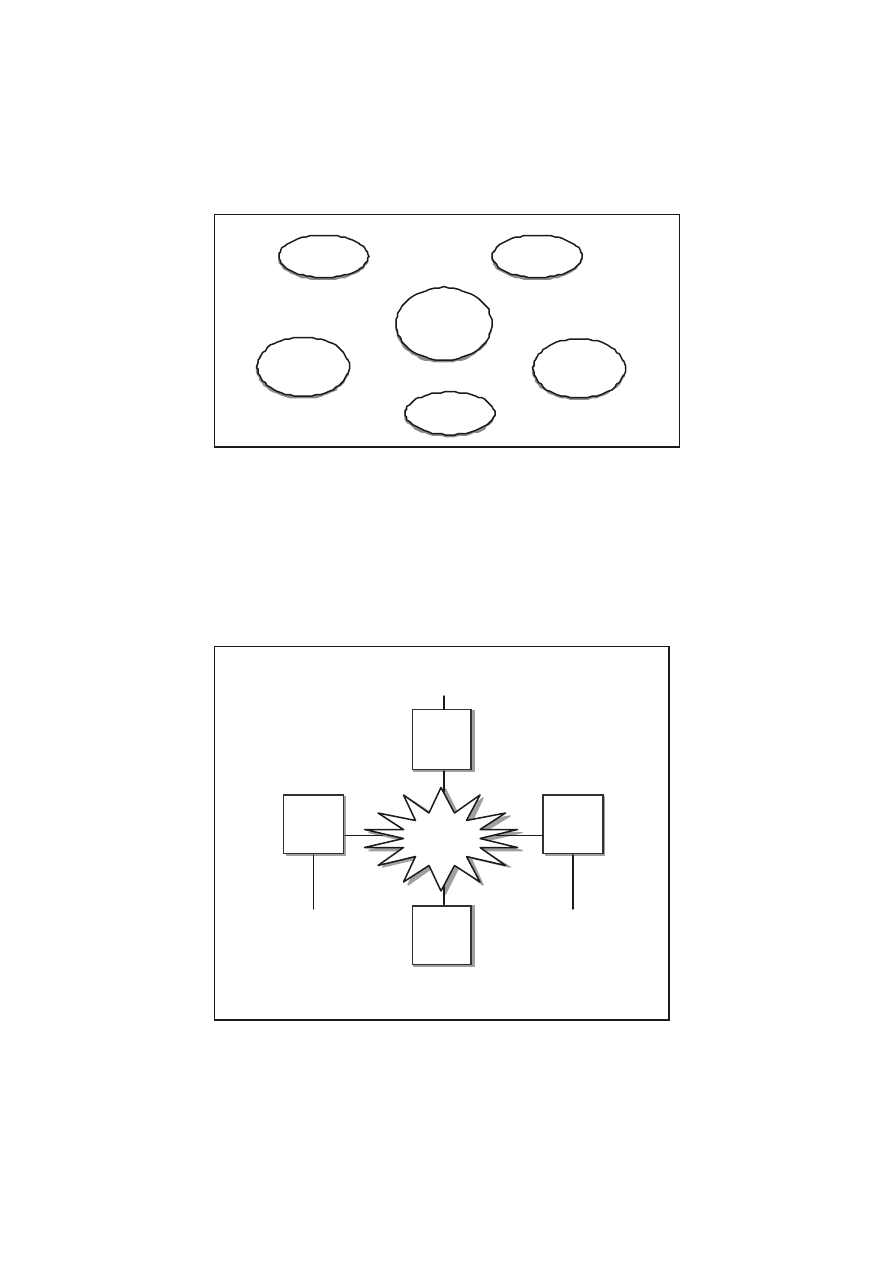
Pierwszym z nich, zajmującym najsilniejszą pozycję na rynku, jest
Oracle. Znajduje on zastosowanie zarówno na dużych maszynach,
jak i komputerach osobistych, funkcjonujących pod nadzorem
Windows 3.1. Pod pojęciem Oracle kryje się szeroka rodzina
produktów, począwszy od systemu zarządzania bazami danych,
służącego do tworzenia aplikacji, po gotowe aplikacje - jak np.
systemy finansowe i produkcyjne (rysunek 27.12).
Klient
Klient
Klient
Połącz enie zdalne
Serwer a plikacji
LAN pie rwsze piętro
LAN drugie piętro
Rys. 27.11.
Przykład
struktury lokalnej
sieci
komputerowej.
Windows NT Server jako serwer baz danych
1119
System zarządzania bazami danych stanowi część składową
systemów komputerowych, wyznaczającą przeważnie największe
wymagania administratorom. T aki system składa się zazwyczaj
z kilku obszarów pamięci (przeznaczonych do różnych celów,
o wielkości zmienianej dynamicznie przez DBA), szeregu procesów
działających w tle (jako usługi dla poszczególnych sesji systemu baz
danych pod NT ) oraz plików danych (rysunek 27.13).
Orac le
CASE
Aplikacje
przemysłowe
System zarządzania
bazami danych
Orac le
Interfe jsy
programistyczne
Orac le
Produkty innych
firm
Oprogramowanie
narzędziowe
Orac le 'a
Rys. 27.12.
Rodzina
produktów
Oracle.
End Users
User
Service
Processes
Memory
Areas
Log
Writers
Data
Writers
Data
Files
Log
Files
Oracle
Monitors
Rys. 27.13.
Podstawowa
struktura systemu
Oracle.

1120
Rozdział 27
Dla jasności naszych rozważań wprowadziliśmy kilka
podstawowych definicji, a mianowicie:
!
O racle Instance: Zestaw procesów realizowanych w tle (w
terminologii NT stanowią one pojedynczą usługę), które
pośredniczą w
wymianie danych pomiędzy bazą danych
a plikami z danymi.
!
Baza danych O racle: Zestaw plików z danymi oraz plików
pomocniczych, zawierających dane wymagane przez
użytkownika.
!
Alert Log (plik rejestacji sytuacji alarmowych): Plik
zawierający informację o
wszystkich podejmowanych
działaniach (uruchomieniach i
zatrzymaniach działania
programu, powstających problemach itp.) w ramach jednego
Oracle Instance. Stanowi on bezcenną pomoc (jego położenie
jest ustalane w
pliku startowym systemu Oracle) przy
wystąpieniu jakichkolwiek problemów.
!
Trace Files (pliki śledzenia): Plik tworzony w
chwili
wystąpienia zakłóceń w pracy systemu, opisujący czynności
podjęte w tym momencie oraz przyczyny je powodujące.
!
SQ L*Net: Narzędzie z
rodziny Oracle, przeznaczone do
komunikacji z
podrzędnym oprogramowaniem sieciowym
(takim jak T CP/IP). Pośredniczy ono zarówno pomiędzy
aplikacjami a
oprogramowaniem sieciowym klienta, jak
i oprogramowaniem sieciowym hosta a bazą danych. Ważna jest
tutaj zgodność wersji narzędzi używanych przez wszystkie
komunikujące się ze sobą jednostki. Podobne wymaganie stawia
się przed opcjami stosowanego protokołu. SQL*Net w wersji 2
posiada zbiory zawierające informację o
konfiguracji sieci
(TNSNAMES.ORA, SQLNET.ORA oraz
LISTENER.ORA
), które muszą zostać utworzone przez DBA
i umieszczone na wszystkich systemach, które się ze sobą łączą
z wykorzystaniem programu SQL*Net.
!
O dbiornik SQ L*Net (SQ L*Net Listner): Usługa NT ,
łącząca ze sobą usługi transportowe (takie jak T CP/IP) i procesy
poszczególnych baz danych. Musi zostać uruchomiona
równocześnie z każdą usługą obsługującą bazę danych - by
umożliwić start Oracle Instance.

Windows NT Server jako serwer baz danych
1121
!
SQ L*DBA: Jedno ze starszych narzędzi, wciąż stosowane
w wersji 7.1 systemu Oracle. Stanowi interfejs użytkownika,
wyposażony w linię komend i rozwijalne menu, pozwalający na
prace administracyjne związane z bazami danych.
!
Instance Manager: Narzędzie wyposażone w
graficzny
interfejs użytkownika, pozwalające na uruchamianie,
zatrzymywanie oraz badanie aktualnego stanu realizowanych
Oracle Instance. Ze względu na częste wykorzystanie tego
programu warto umieścić na pulpicie roboczym jego ikonę
startową. Należy dodać, że przy każdorazowym uruchamianiu
czy zatrzymywaniu Oracle Instance, potrzebna jest znajomość
specjalnego hasła dostępu (ustalanego przez administratora baz
danych).
!
SQ L*Plus: Prosty interfejs z linią komend, pozwalający na
dostęp do danych zawartych w
bazach systemu Oracle
(rekomendowany osobom znającym język SQL).
!
O racle Navigator: Jedno z nowszych narzędzi systemu Oracle,
udostępnione wraz z systemem Windows 95. Pozwala na zdalne
(poprzez sieć) przeglądanie różnych baz danych i tabularyczną
wizualizację danych w nich zawartych, z wykorzystaniem tabel
systemu Oracle. Wygodne narzędzie do przeglądania zawartości
baz danych, a także sprawdzania dostępu do nich.
Pora teraz na kilka wskazówek, dotyczących pracy z systemem
Oracle w środowisku Windows NT :
!
Jeśli wykorzystujemy w
naszym systemie zestaw zasobów
Windows NT wraz z systemem Oracle RDBMS w wersji 7.1
powinniśmy przyjrzeć się narzędziu SRVANY i
zapoznać
z dołączoną do niego dokumentacją. Pozwala ono na
automatyczne uruchamianie systemu Oracle w chwili startu
Windows NT . Sam Oracle umożliwia wykonywanie usług do
obsługi baz danych (Instance zgodnie z powyżej wprowadzonym
nazewnictwem) oraz usług SQL*Net, ale nie otwiera ogólnego
dostępu do baz danych. Aby to uczynić, należy użyć programu
Instance Manager, SQL*DBA lub jednego z innych narzędzi
systemu Oracle. Jednakże, aby tego nie robić każdorazowo
„ręcznie”, można wykorzystać SRVANY - do automatycznej
realizacji komend umieszczonych w
pliku wsadowym

1122
Rozdział 27
(szczegółowy opis sposobu tworzenia wspomnianego pliku
zawarty jest w dokumentacji systemu Oracle; ponieważ jest on
zależny od wersji systemu nie będziemy tutaj go przytaczać).
Doprowadzi to do wykonania skryptu w
języku SQL
z wykorzystaniem narzędzia SQL*DBA. Skrypt ten łączy się
z bazą danych Oracle i wydaje komendę uruchamiającą bazę
danych. Omawiane czynności nie muszą być wykonywane, gdy
korzystamy z
wersji 7.2 systemu Oracle RDBMS,
udostępniającego własne narzędzie do automatycznego
uruchamiania.
!
W pracy z siecią Ethernet należy raczej wykorzystywać
SQL*Net z protokołem T CP/IP, co pozwala - w porównaniu
z
wykorzystaniem NetBEUI - na uzyskiwanie znacznie
szybszych i bardziej niezawodnych połączeń.
!
Wiele obszarów pamięci przydzielanych jest systemowi Oracle
tylko wtedy, gdy będą wykorzystywane. Stąd 32MB pamięci
operacyjnej, zupełnie zadowalające do pracy kilku
użytkowników, nie będzie wystarczające dla ich większej liczby,
gdyż wówczas część wykorzystywanej informacji musiała by być
przechowywana na dysku, wydatnie zmniejszając tempo pracy
systemu Oracle.
!
W pracy z wersją 7.1 systemu Oracle należy pamiętać, że
niektóre z dostępnych tutaj narzędzi, jak np. SQL*DBA czy
Instance Manager, są 32-bitowe, inne natomiast - 16-bitowe.
Większość z 16 bitowych narzędzi, takich jak SQL*Plus czy do
importu i
eksportu danych, wymagają wcześniejszego
zainstalowania na serwerze NT programu SQL*Net, i
to
zarówno w środowisku Windows, jak i Windows NT . Wynika to
z faktu, iż większość aplikacji Oracle to programy 16-bitowe.
Bazy danych w systemie Oracle są 32-bitowe, przez co zachodzi
konieczność wykorzystania usługi udostępnianej przez SQL*Net,
konwersji pomiędzy słowami 32 bitowymi a 16 bitowymi.
W takiej sytuacji należy także pamiętać o umieszczeniu plików
konfiguracyjnych sieci w kartotekach zarządzania siecią systemu
Windows i Windows NT . Dodajmy, że narzędzia z wersji 7.2
systemu Oracle nie wymagają przeprowadzania opisanych
operacji.

Windows NT Server jako serwer baz danych
1123
Serwer Microsoft SQL w Windows NT
Innym systemem zarządzania bazami danych, będącym produktem
własnym Microsoftu, jest Serwer Microsoft SQL. Istnieje
przynajmniej kilka powodów, dla których warto mu poświęcić
uwagę:
!
system ten jest bazą danych powiązaną z i stanowiącą podstawę
dla kilku innych produktów z rodziny Microsoft BackOffice (jak
np. dla serwera zarządzania systemami, opisanych w rozdziale
26),
!
stanowi on relatywnie tanią bazę danych, przeznaczoną do pracy
w środowisku serwera Windows NT ,
!
jest składowym elementem pakietu Microsoft BackOffice,
oferowanym w
ramach subskrypcji Microsoft Developer
Network Level 3 - stąd wykorzystywany jest w produktach
niezależnych producentów.
Przyjrzyjmy się teraz serwerowi SQL Microsoftu i omawianym
wcześniej Oracle - pod kątem podobieństw i różnic. W kontekście
architektury oba produkty są do siebie podobne (przynajmniej
z punktu widzenia administratora systemu operacyjnego). Rys.
27.14 ilustruje schematycznie architekturę serwera SQL
Microsoftu. Wśród części składowych serwera można wyróżnić trzy
części o znaczeniu kluczowym, występujące w większości systemów
zarządzania bazami danych: obszary pamięci współużytkowanej,
procesy uruchamiane w tle oraz pliki dyskowe do przechowywania
danych.
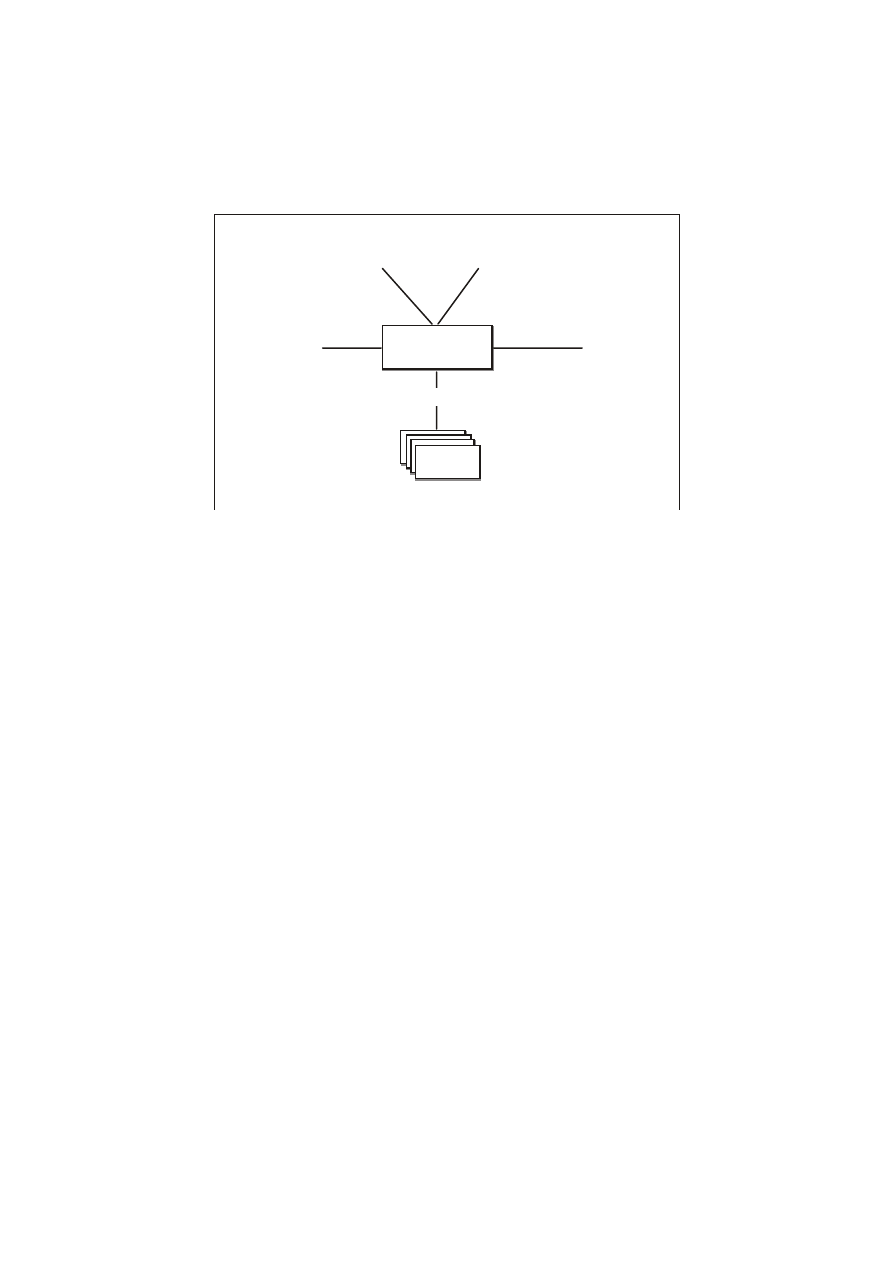
1124
Rozdział 27
Wśród podstawowych terminów związanych z serwerem SQL, jak
i samymi bazami danych, można wyróżnić:
!
Baza danych: Zestaw danych, tabel i
innych logicznie
powiązanych ze sobą obiektów (takich jak widoki i indeksy)
spełniających jedno, wspólne zadanie i przechowywanych razem
na urządzeniu bazy danych (zobacz: urządzenie).
!
Urządzenie (device): Plik dyskowy systemu Windows NT ,
służący do przechowywania danych z baz danych. Jedna baza
danych może wykorzystywać więcej niż jedno urządzenie. Serwer
SQL definiuje dwa rodzaje urządzeń: urządzenia baz danych,
służące do przechowywania baz danych, oraz urządzenia
składujące, wykorzystywane do tworzenia kopii zapasowych baz
danych.
!
SQ L Server Engine: Usługa umożliwiająca dostęp do baz
danych i
urządzeń w
systemie serwera SQL. Może być
optymalizowana pod kątem liczby wykorzystywanych przez nią
wątków.
!
Program wykonawczy SQ L (SQ L Executive): Usługa
pozwalająca użytkownikom na uzyskiwanie odpowiedzi od
systemu, na zarządzanie zadaniami i zdarzeniami.
!
SQ L Enterprise Manager: Narzędzie wykorzystywane do
zarządzania serwerami i bazami danych. Umożliwia ono, poprzez
udostępniany użytkownikowi interfejs graficzny, wykonywanie
SQL Serve r
Engine
SQL Serve r
Executive
SQL Enterprise
Manager
Performance
Monitor
SQL
Database
Devices
Rys. 27.14.
Architektura
serwera SQL
Microsoftu.

Windows NT Server jako serwer baz danych
1125
różnorodnych zadań związanych z zarządzaniem serwerem SQL,
włączając w to zarządzanie bazami danych, obiektami w bazach
danych (tabelami) oraz planowanie zdarzeń.
!
ISQ L/w: prosty interfejs wyposażony w
linię komend,
pozwalający na wywołanie kilku narzędzi z
interfejsem
graficznym, wykorzystywany do pracy z serwerem SQL (jest on
odpowiednikiem programu SQL*Plus z systemu Oracle).
!
SQ L Performance Monitor: pakiet zintegrowany z Windows
NT Performance Monitor, umożliwiający monitorowanie pracy
serwera SQL, w sposób podobny do monitorowania innych
zasobów NT . Został on szczegółowo omówiony w rozdziale 19.
Na zakończenie podzielimy się uwagami, związanymi
z wykorzystywaniem serwera SQL Microsoftu:
!
Instalacja serwera SQL Microsoft zajmuje około godziny.
W tym czasie, oprócz fizycznego zapisu programu na dysku,
dokonywane są pewne zabiegi konfigurujące system oraz
zestawiane wstępne bazy danych. Po wykonaniu instalacji, przed
pierwszym uruchomieniem serwera SQL, należy zrestarować
komputer.
!
Nie zapominajmy o
monitorowaniu wydajności systemu.
Zazwyczaj pozwala to na bezproblemowe ustalenie przyczyn
ewentualnego jej wydajności.
!
Dobrze jest, gdy w przypadku wykorzystywania wielu napędów
dyskowych, na wszystkich z nich urządzenia baz danych (pliki)
przechowywane są w
takich samych katalogach (np.
\dbdata\production
). T aki sposób postępowania z reguły
ułatwia rozbudowę systemu, jak również rozwiązywanie
ewentualnych problemów.
Microsoft Access's Jet Database Engine
w Windows NT
Rozważmy teraz koncepcję wykorzystania prostego pliku z bazą
danych, przechowywanego na serwerze, w
celu spełnienia
najnowszych wymagań stawianych systemom zarządzania bazami
danych. Ich poprzednicy (jak np. dBASE, funkcjonujący na

1126
Rozdział 27
serwerze dostępnym z kilku stanowisk połączonych siecią), byli
wyposażeni w prymitywny mechanizm kontroli dostępu do danych
(zapobiegający nadpisywaniu zmian, dokonywanych przez jednych
użytkowników systemu baz danych, zapisami innych osób w tym
samym czasie). W większości przypadków mechanizm ten stanowił
wystarczające zabezpieczenie przed ewentualnymi kłopotami.
W
podobnym celu - w
odniesieniu do omawianego systemu
zarządzania bazami danych - może zostać wykorzystany Microsoft
Access Jet Database Engine (dostępny obecnie zarówno z poziomu
Visual C++, Visual Basic'a jak i programu Microsoft Query).
Decydując się na takie rozwiązanie, powinniśmy zapewnić miejsce
we współużytkowanym katalogu z
plikami baz danych (w
przypadku Microsoft Access, pliki z rozszerzeniem
.
mdb
). Aby
uzyskać dostęp do danych, znajdujących się w tych plikach, należy
się posłużyć aplikacją lub też narzędziem dostępu (takie jak MS
Query), stosującym zestaw narzędzi ODBC (Open Database
Connectivity). W
trakcie tworzenia źródła danych ODBC,
wystarczy wybrać (w oknie wyboru pliku) plik z rozszerzeniem
.
mdb
- by uzyskać dostęp do danych w nim zamieszczonych. T aka
procedura nie zapewnia wprawdzie rozbudowanego systemu
rejestracji wydarzeń, odzyskiwania czy kontroli dostępu, jest za to
prosta w realizacji i odpowiada wymaganiom wielu użytkowników.
ODBC i OLE
W naszych rozważaniach doszliśmy - w kontekście pracy z bazami
danych w systemie klient/serwer - do zagadnienia związanego
z oprogramowaniem
pośredniczącym.
Oprogramowanie
pośredniczące umożliwia po prostu aplikacjom wykorzystanie
narzędzi związanych z
dostępem do sieci komputerowej,
oferowanych przez system operacyjny. Pewne utrudnienie wynika
tutaj z faktu, iż zazwyczaj każda baza danych może stosować
różniące się między sobą zestawy oprogramowania pośredniczącego
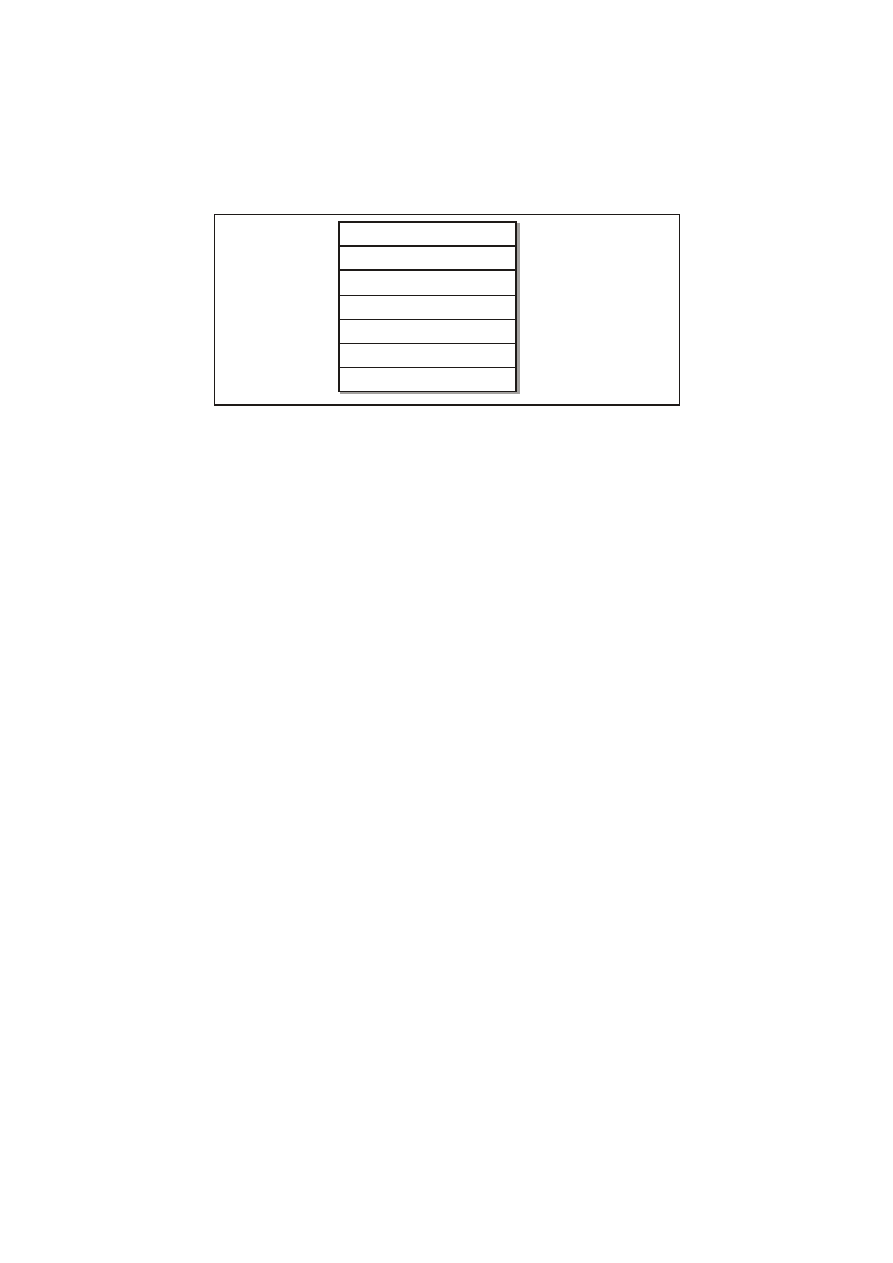
(do tego pochodzące od różnych producentów). Rys. 27.15 ilustruje
poziomy obsługiwane przez oprogramowanie pośredniczące
w systemie baz danych.
Windows NT Server jako serwer baz danych
1127
T ypowe oprogramowanie pośredniczące możemy podzielić na dwie
warstwy: górną i dolną. Warstwa górna jest odpowiedzialna za
łączność z bazami danych, jak też aplikacjami. Zadaniem warstwy
dolnej jest zaś łączność ze sterownikami sieci. W systemie Oracle
zadania obu warstw wykonywane są przez program SQL*Net.
Jednakże, tworząc aplikacje pod Visual C++ - w celu ich połączenia
z SQL*Net - trzeba wykorzystać mechanizm podobny do ODBC.
Dodajmy, że istnieją sterowniki ODBC dla systemu Oracle (takie
jak Openlink), umożliwiające zintegrowanie oprogramowania
pośredniczącego obu warstw w jednym pakiecie.
Rozwiązaniem alternatywnym do mechanizmu ODBC jest,
zaproponowany przez Microsoft, OLE 2 (Object Linking and
Embedding). Wspomnieć należy tutaj jeszcze o, również
opracowanym przez Microsoft, mechaniźmie DAO (Database
Access Objects), czyli obiektach dostępu do baz danych.
Jak widać więc, mamy do dyspozycji przynajmniej kilka narzędzi,
pozwalających na wymianę informacji pomiędzy elementami
tworzonego i wykorzystywanego przez nas systemu. Oczywiście nie
wszystkie charakteryzują się identycznymi funkcjami. Dlatego też
warto przyjrzeć się możliwościom poszczególnych narzędzi
i zastanowić nad ich przydatnością przy realizacji naszego zadania.
Dzięki temu nie będziemy musieli przechodzić w trakcie pracy -
z aktualnie wykorzystywanych na inne.
Aplikacja i bazy danych
Oprogramowanie pośre dnie wyższ e
Oprogramowanie pośre dnie niższe
Protokół transmisji
Format transmisji
Interfe js fizyczny
Sieciowy system transmisji
Rys. 27.15.
Oprogramowanie
pośredniczące
a dostęp do baz
danych.
Wyszukiwarka
Podobne podstrony:
28 Rozdziae 27 id 31977 Nieznany (2)
27 28 ROZ w sprawie ksiazki Nieznany (2)
27 rozdzial 26 mjtwzr7c54hzzud5 Niez
22 Rozdzial 21 KP4Q5YBIEV5DBSVC Nieznany (2)
09 08 Rozdzielnice budowlane RB Nieznany (2)
17 rozdzial 16 fq3zy7m2bu2oan6t Nieznany (2)
Kanicki Systemy Rozdzial 10 id Nieznany
24 rozdzial 23 wjv3mksbkbdm37qy Nieznany
28 Ustawa o dochodach jednostek Nieznany (2)
13 Rozdziae 12id 14782 Nieznany (2)
16 rozdzial 15 EJCDLTJY3F3I2FKL Nieznany (2)
14 rozdzial 13 w2pa42u4da5r3dcm Nieznany (2)
16 rozdzial 15 zpgg3d2etikxyjv3 Nieznany
02 rozdzial 01 t4p4wqyl4oclhuae Nieznany (2)
więcej podobnych podstron