
Prof. dr hab. inż. S. Wiak
1
Systemy Baz
Systemy Baz
Danych
Danych
(cz. 1.0)
(cz. 1.0)
Prof. dr hab.
Prof. dr hab.
inż
inż
. Sławomir Wiak
. Sławomir Wiak

Prof. dr hab. inż. S. Wiak
2
BAZY DANYCH
BAZY DANYCH
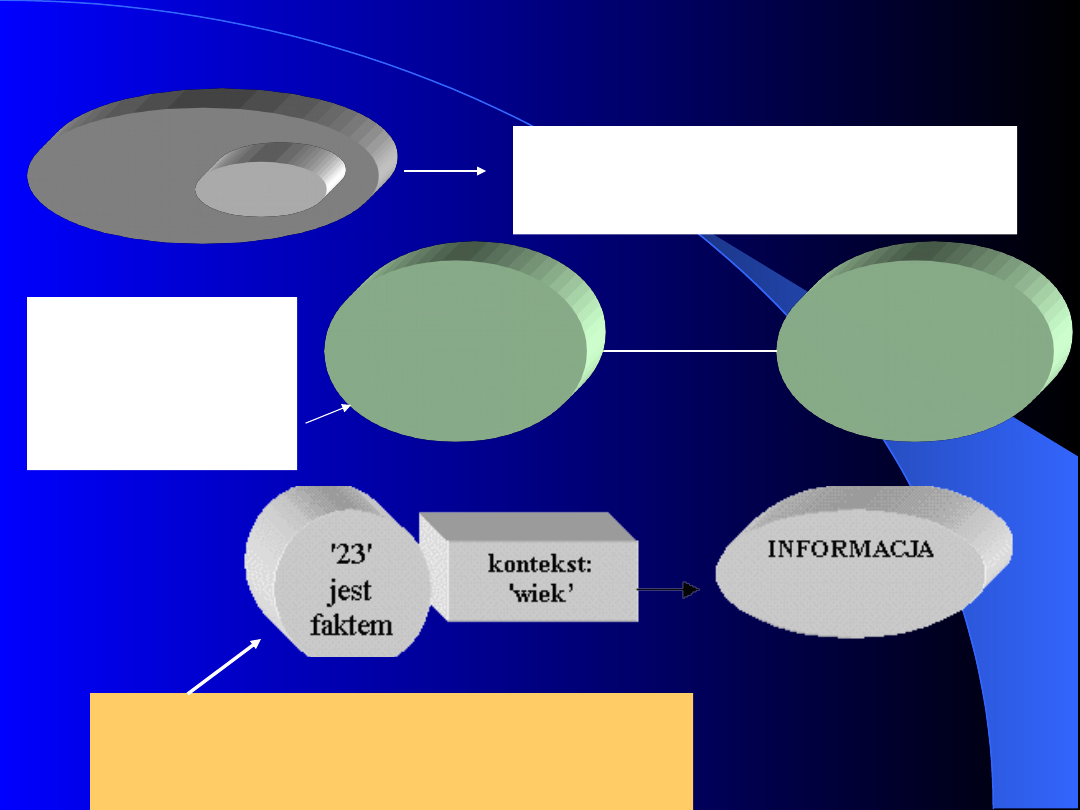
Baza danych jest modelem pewnego aspektu rzeczywistości
danej organizacji. Tę rzeczywistość nazywamy
obszarem
analizy (OA) (ang. universe of discourse, w skrócie
UR).
Bazę danych możemy uważać za zbiór danych, których
zadaniem jest reprezentowanie pewnego OA. Dane to fakty.
Dana, jednostka danych, jest jednym symbolem lub zbiorem
symboli, którego używamy, aby reprezentować jakąś „rzecz”.
Dane w bazie danych są traktowane jako trwałe. Przez trwałość
rozumiemy, że dane są przechowywane przez pewien czas.
Ten czas nie musi być bardzo długi. Termin „trwałość” jest
używany do rozróżnienia bardziej trwałych danych od
danych, które są tymczasowe.
Baza danych składa się z dwóch części:
intensjonalnej i
ekstensjonalnej.
Część intensjonalna bazy danych jest
zbiorem definicji, które opisują strukturę danych bazy
danych.
Część ekstensjonalna bazy danych jest łącznym
zbiorem danych w bazie danych.
Część intensjonalną bazy
danych nazywamy schematem bazy danych. Tworzenie
schematu bazy danych nazywamy projektowaniem bazy
danych.

Prof. dr hab. inż. S. Wiak
3
Bazy danych charakteryzują się
Bazy danych charakteryzują się
czterema podstawowymi
czterema podstawowymi
własnościami:
własnościami:
Niezależność aplikacji i danych.
Abstrakcyjna reprezentacja danych.
Różnorodność
sposobów
widzenia
danych.
Fizyczna i logiczna niezależność danych.
Prof. dr hab. inż. S. Wiak
4
Bazy danych jako maszyny abstrakcyjne
Bazy danych jako maszyny abstrakcyjne
OA
Klasa: Moduł
- liczba
zapisanych
studentów
Klasa:
Studenci
- nazwisko
- imię
- adres
Rzeczy istotne
dla naszego OA
to obiekty
nazywane
klasami
Zinterpretowane dane to informacje.
Natomiast informacja to dane z
przypisaną im
semantyką (znaczeniem).
Baza danych jest modelem
pewnego aspektu
rzeczywistości (OA)

Prof. dr hab. inż. S. Wiak
5
W pewnym uproszczeniu przez bazę danych rozumiemy
uporządkowany zbiór danych, a przez system bazy
danych – bazę danych wraz z oprogramowaniem
umożliwiającym operowanie na niej. Baza danych jest
przechowywana
na
nośnikach
komputerowych.
Precyzując definicję bazy danych można powiedzieć, że
baza danych jest abstrakcyjnym, informatycznym
modelem wybranego fragmentu rzeczywistości (ten
fragment rzeczywistości bywa nazywany miniświatem).
Fragment rzeczywistości może być rozumiany jako:
rzeczywistość fizyczna – taka, którą postrzegamy
naszymi organami percepcji
rzeczywistość konceptualna – istniejąca najczęściej w
wyobraźni pewnych osób; przykładem tej rzeczywistości
może być projekt nowego samolotu firmy Boeing, który
istnieje tylko w wyobraźni konstruktorów.

Prof. dr hab. inż. S. Wiak
6
Poprawne
(z punktu widzenia człowieka) operowanie na
bazie danych wiąże się z właściwą interpretacją danych,
które zostały w niej zapisane. W związku z tym
konieczny jest opis semantyki (znaczenia) danych,
przechowywanych w bazie.
System bazy danych
służy więc do modelowania
rzeczywistości (fragmentu). W systemach baz danych
rzeczywistość opisuje się za pomocą modelu danych.
Przez model danych rozumiemy zbiór abstrakcyjnych
pojęć umożliwiających reprezentację określonych
własności tego świata.
Zbiór pojęć
użyty do opisu własności tego konkretnego
fragmentu świata rzeczywistego, istotnych z punktu
widzenia danego zastosowania tworzy schemat bazy
danych.
Baza danych jest modelem logicznie spójnym
służącym
określonemu celowi. W związku z tym baza danych nie
może (nie powinna) przyjąć stanu, który nie jest nigdy
osiągalny w modelowanej rzeczywistości.

Prof. dr hab. inż. S. Wiak
7
Można więc powiedzieć, że każda baza danych posiada
:
o
źródło danych
o
użytkowników
o
związki z reprezentowaną rzeczywistością.
Baza danych
to dane i tzw. schemat bazy danych
.
Dane
opisują cechy (własności) modelowanych obiektów
. Nie jest
jednak możliwa ich interpretacja bez użycia schematu.
Schemat jest opisem struktury (formatu)
przechowywanych
danych oraz wzajemnych powiązań między nimi.
System
System
Z
Z
arządzania
arządzania
B
B
azą
azą
D
D
anych
anych
(SZBD)
(SZBD)
System Zarządzania Bazą Danych DBMS (Database
Management System) jest to zestaw programów
umożliwiających tworzenie i eksploatację bazy danych.
System zarządzania bazą danych jest oprogramowaniem
ogólnego przeznaczenia. System bazy danych składa się z
bazy danych, systemu zarządzania bazą danych i
ewentualnie z zestawu aplikacji
wspomagających
pracę poszczególnych grup użytkowników.

Prof. dr hab. inż. S. Wiak
8
Czego oczekuje się od systemu DBMS:
1.
Umożliwienia użytkownikowi
utworzenia nowej bazy
danych i określenia jej schematu (logicznej struktury
danych)
za
pomocą
specjalizowanego
języka
definiowania danych (data-definition language).
2.
Udostępnienia użytkownikowi
możliwości tworzenia
zapytań (query) o dane oraz aktualizowania danych, za
pomocą odpowiedniego języka nazywanego językiem
zapytać (query language).
3.
Zapewnienia możliwości
przechowywania ogromnej
ilości danych przechowywanej przez długi czas
chroniąc je przed przypadkowym, lub niepowołanym
dostępem, a także umożliwiając efektywny dostęp do
danych z poziomu języka zapytań i operacji na danych.
4.
Sterowania jednoczesnym
dostępem do danych przez
wielu użytkowników, z zapewnieniem bezkolizyjności
oraz ochrony danych przed przypadkowym
uszkodzeniem.
Prof. dr hab. inż. S. Wiak
9
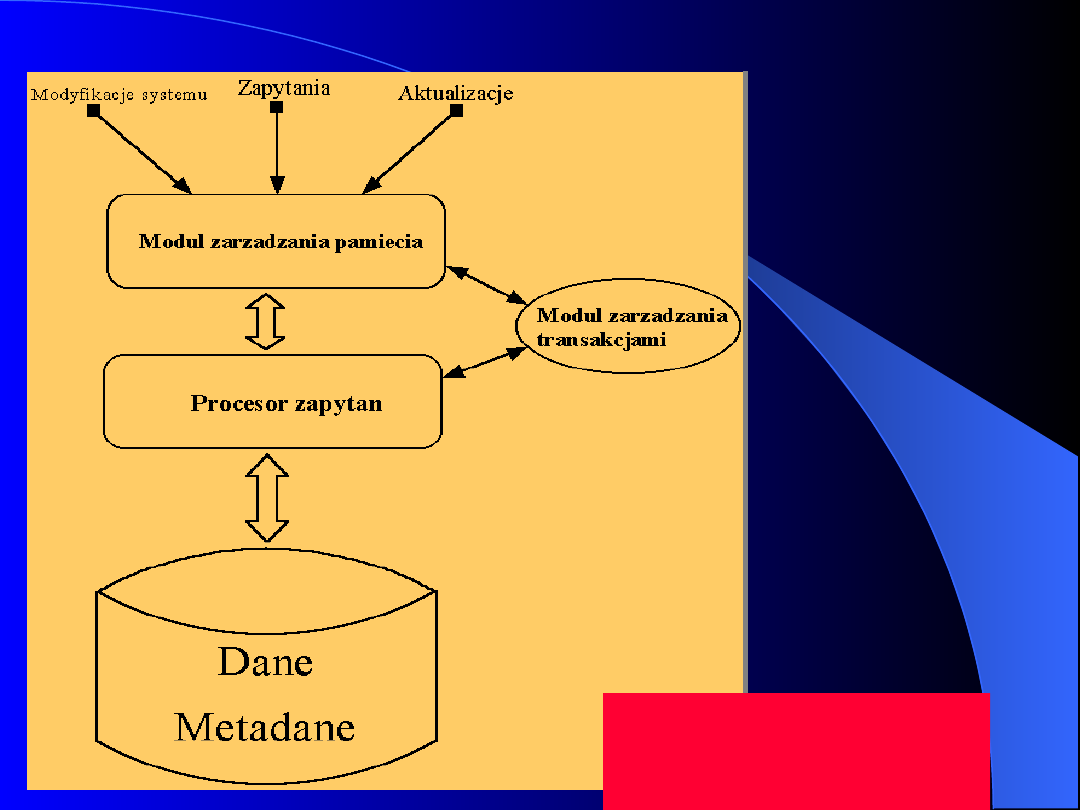
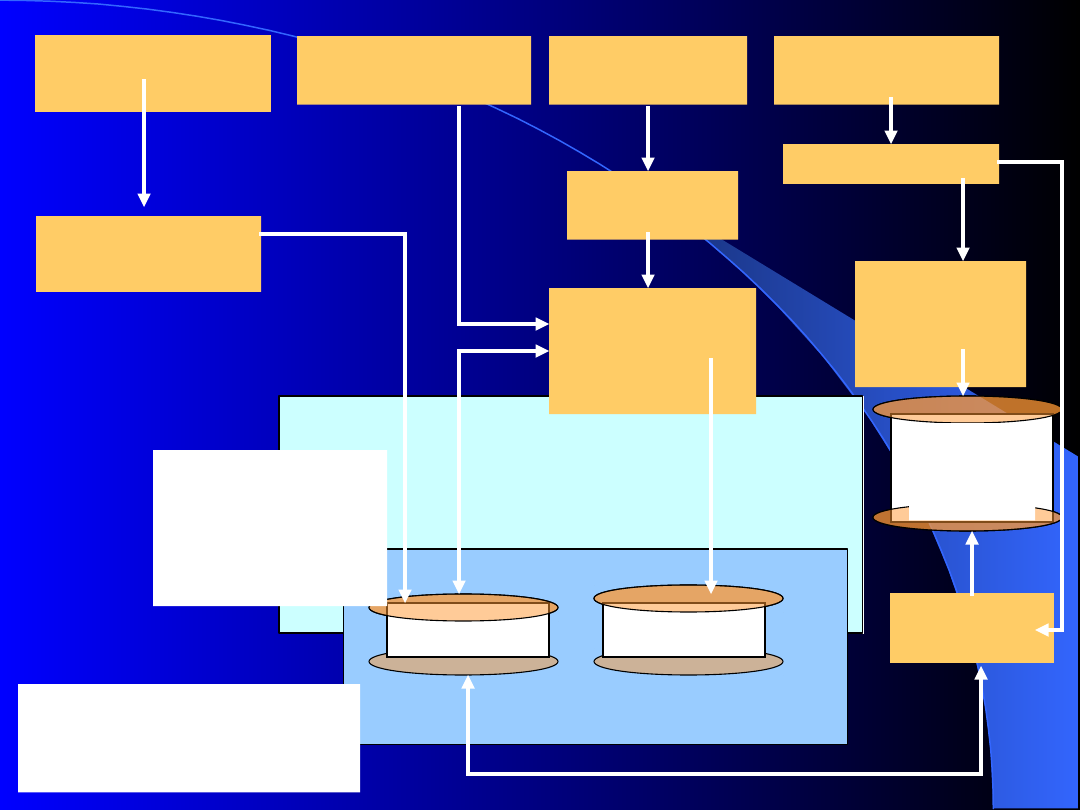
Architektura systemu DBMS
Schemat
architektury systemu
DBMS
Prof. dr hab. inż. S. Wiak
10
Sch
em
at b
azy
dan
ych
Baz
a da
nyc
h
System bazy
danych
modu³ zarz¹dzania
dostêpem do bazy danych
SZBD
modu³ zarz¹dzania
transakcjami
transkacje

Prof. dr hab. inż. S. Wiak
11
Na samym dole widzimy
element reprezentujący miejsce
składowania danych
. Zauważmy, że ten element służy nie
tylko do zapisu danych, ale także
metadanych
, które
opisują strukturę danych. Na przykład, jeśli rozważany
DBMS jest relacyjny, to metadane obejmują nazwy relacji,
nazwy atrybutów relacji i typy poszczególnych atrybutów (
np. całkowity lub znakowy ).
Często system DBMS
obsługuje
indeksy
danych.
Indeks jest
taką strukturą danych
, która pomaga w szybkim
odnajdywaniu właściwych danych, a posługuje się przy
tym ich wartościami; najbardziej popularny przykład
indeksu umożliwia odnalezienie właściwej krotki relacji,
mającej zadane wartości pewnych atrybutów. Na przykład
relacja obejmująca numery kont i bilans może mieć indeks
założony na numerach kont, wówczas odnalezienie bilansu
konta o podanym numerze odbywa się błyskawicznie.
Indeksy są przechowywane razem z danymi, a informacja
o tym, który atrybut ma założone indeksy, należy do
metadanych
.

Prof. dr hab. inż. S. Wiak
12
Na rysunku można także dostrzec moduł zarządzania pamięcią,
który
ma za zadanie wybierać właściwe dane z pamięci i w razie potrzeby
dostosować je do wymagań modułów z wyższych poziomów
systemu.
Moduł zarządzania pamięcią składa się z dwóch części
:
modułu
zarządzania buforami
oraz
modułu zarządzania plikami
.
1.
Moduł zarządzania plikami
przechowuje dane o miejscu
zapisania plików na dysku i na polecenie modułu zarządzania
buforami przesyła zawartość bloku lub bloków, gdzie jest
zapamiętany żądany plik.
2.
Moduł
zarządzania
buforami
obsługuje
pamięć
operacyjną. Moduł zarządzania plikami przekazuje bloki
danych z dysku, a moduł zarządzania buforami wybiera w
pamięci operacyjnej strony, które zostaną przydzielone dla
wybranych bloków. Blok z dysku może być przez chwile
przechowywany w pamięci operacyjnej, ale musi zostać
przesłany z powrotem na dysk, gdy tylko pojawi się potrzeba
zapisania w to miejsce pamięci innego bloku. Powrót bloku na
dysk może nastąpić również w wyniku żądania modułu obsługi
transakcji.

Prof. dr hab. inż. S. Wiak
13
Widać tam także składową, którą nazwaliśmy procesorem
zapytań, mimo, że taka nazwa może wprowadzać w
błąd, bowiem obsługuje on nie tylko zapytania, ale
również aktualizacje danych oraz metadanych. Jego
zadanie polega na znalezieniu najlepszego sposobu
wykonania zadanych operacji i na wydaniu poleceń do
modułu zarządzania pamięcią, który je wykona.
Typowy DBMS stwarza użytkownikowi sposobność łączenia
jednego lub więcej zapytań, bądź modyfikacji, w
transakcję, która stanowi nieformalną grupę operacji
przeznaczonych do wykonania razem w jednym ciągu,
jako duża operacja jednostkowa.

Prof. dr hab. inż. S. Wiak
14
Moduł zarządzania transakcjami odpowiada za spójność systemu.
Musi on gwarantować
, że
kilka jednocześnie przetwarzanych zapytań
nie będzie sobie nawzajem przeszkadzać
oraz, że
żadne dane nie
zostaną utracone
, nawet jeśli nastąpi awaria systemu. W tym celu
dokumentuje wszystkie operacje, tzn. rozpoczęcie każdej transakcji,
zmiany w bazie danych dokonane przez transakcje oraz zakończenie
transakcji. Zapis taki nazywa się
logiem
. Log jest przechowywany w
pamięci stałej, tzn. na nośniku danych jakim jest dysk, który zapewni
przetrwanie danych w przypadku awarii zasilania.
Zasadnicze przetwarzanie transakcji odbywa się w pamięci
operacyjnej, ale dane o przebiegu jej wykonania są natychmiast
zapisywane na dysku. A więc log wszystkich operacji jest ważnym
czynnikiem zapewniającym systemowi trwałość. Moduł zarządzania
transakcjami współdziała z modułem obsługi zapytań, ponieważ musi
mieć dostęp do szczegółów dotyczących tych danych, na których
przetwarza się bieżące zapytanie. Może się zdarzyć, że część
przetwarzania będzie musiała zostać opóźniona, aby nie powstał
konflikt.
Prof. dr hab. inż. S. Wiak
15
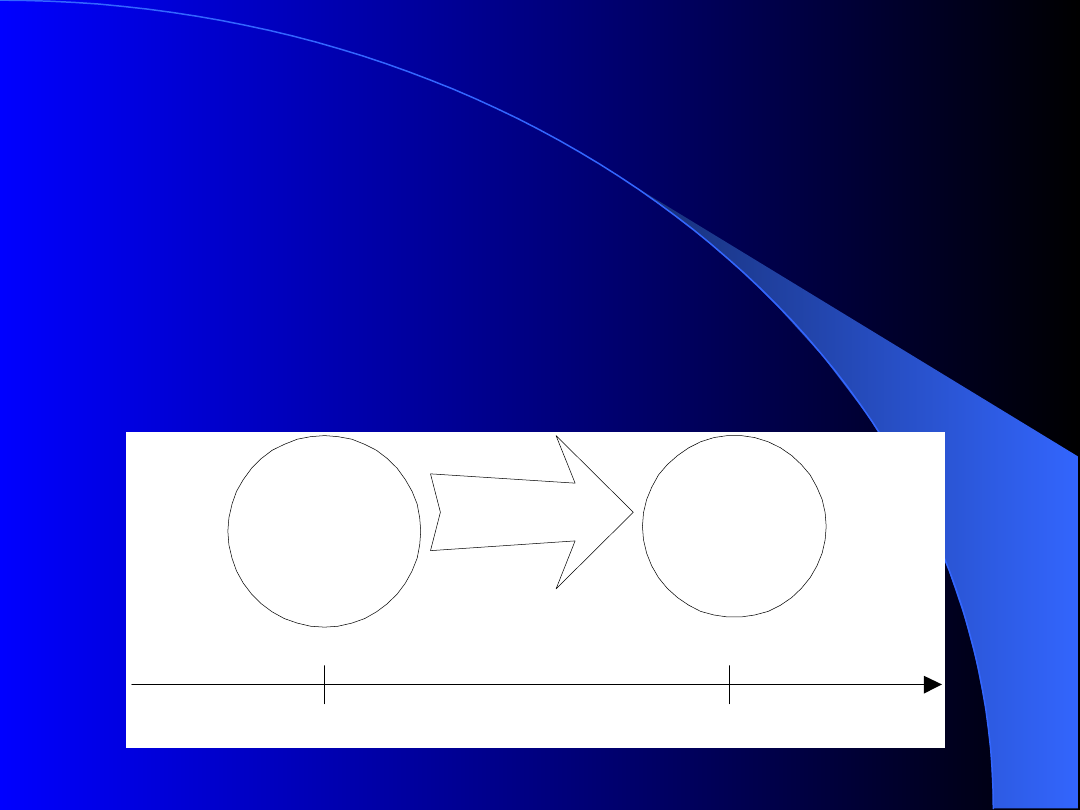
Transakcja jest atomową jednostką pracy, taką że
baza danych jest w stanie spójnym (tj.
zgodnym z modelowanym miniświatem) przed i
po zakończeniu transakcji. Inaczej mówiąc, jeśli
dana transakcja jest wykonana poprawnie,
zmiany, które wprowadziła, będą pamiętane w
bazie danych. W przeciwnym przypadku,
wszystkie zmiany wprowadzone przez
transakcje będą anulowane ( wycofane).
Stan spójny
S1
Stan spójny
S2
transakcja
czas
t1
t2

Prof. dr hab. inż. S. Wiak
16
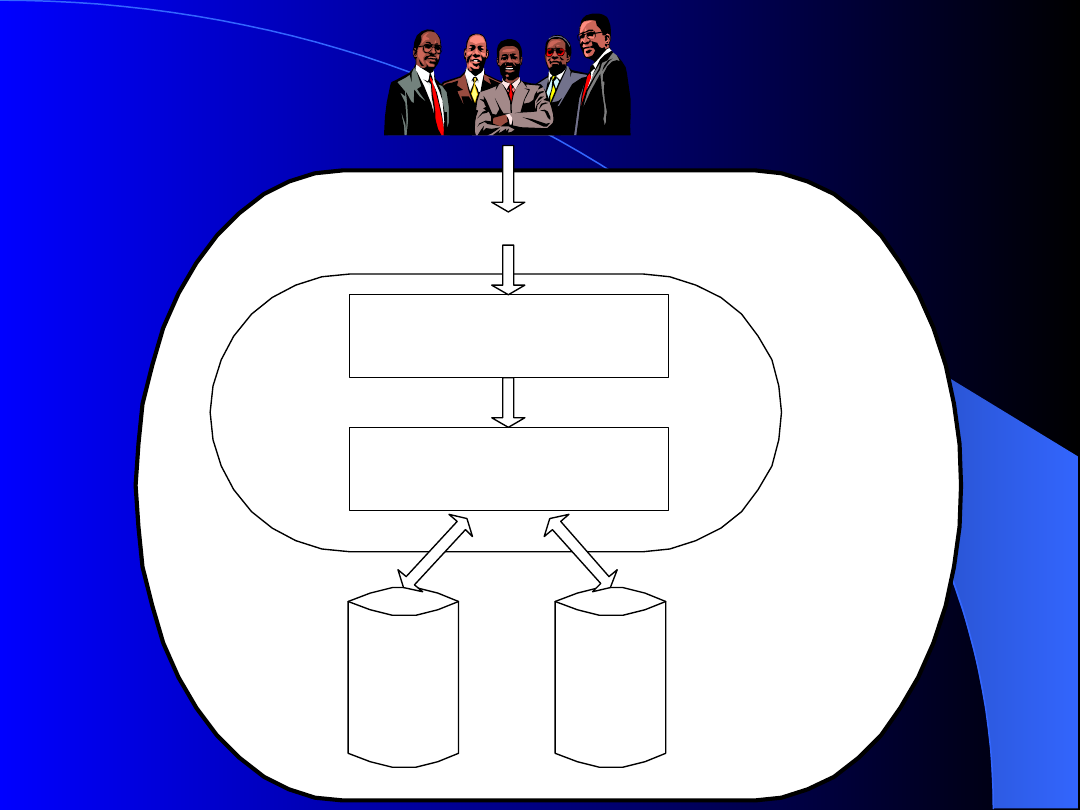
U góry rysunku można zobaczyć trzy rodzaje wejść
do systemu DBMS:
1.
Zapytania. Są to zapytania o dane. Mogą one być
sformułowane dwojako:
Poprzez interfejs zapytań bezpośrednich. Na przykład
relacyjny DBMS umożliwia wprowadzenie zapytań w SQL,
które są następnie przekazywane do modułu
przetwarzania danych, który z kolei tworzy odpowiedź
Poprzez interfejsy programów użytkowych. Typowy DBMS
umożliwia programiście tworzenie programu użytkowego,
który poprzez wywołania procedur DBMS tworzy zapytania
do bazy danych. Na przykład agent posługujący się
systemem rezerwacji lotniczych uruchamia program
użytkowy, który tworzy zapytanie bazy danych dotyczące
dostępności rejsów. Zapytania mogą być formułowane
dzięki specjalizowanemu interfejsowi, który na ogół składa
się z formularzy z pustymi polami, przeznaczonymi do
wypełnienia konkretnymi danymi, np. nazwą miasta,
terminem itp.. nie można w ten sposób zadać zupełnie
dowolnego pytania, ale jest znacznie łatwiej sformułować
zupełnie typowe zapytanie poprzez taki interfejs, niż
formułować zapytanie bezpośrednio w języku SQL

Prof. dr hab. inż. S. Wiak
17
2.
Aktualizacje. Są to operacje zmiany
danych. Tak jak w przypadku zapytań
można je wprowadzić do systemu poprzez
interfejsy zapytań bezpośrednich lub
poprzez interfejsy programów użytkowych.
3.
Modyfikacje schematu. Polecenia tego
rodzaju wydaje specjalnie uprawniona
osoba nazywana administratorem bazy
danych, której wolno zmieniać schemat
bazy danych i tworzyć nowe bazy danych.
Na przykład, jeśli agencje rządowe wezwą
banki do udokumentowania wypłaty
odsetek zgodnie z numerami ubezpieczenia
społecznego klientów, to bank może
zażądać dodania do relacji opisującej
klientów nowego atrybutu o nazwie np.
nrUbezpieczenia
.

Prof. dr hab. inż. S. Wiak
18
Funkcje systemu zarządzania bazą
Funkcje systemu zarządzania bazą
danych
danych
przechowywanie danych w co wchodzi
tworzenie i utrzymywanie struktur danych,
zapewnianie
mechanizmów
bezpieczeństwa i prywatności,
umożliwianie
równoczesnego,
kontrolowanego korzystania z bazy
danych wielu użytkownikom,
umożliwianie wprowadzania i ładowania
danych,
umożliwianie wydobywania i operowania
na przechowywanych danych,

Prof. dr hab. inż. S. Wiak
19
zapewnianie integralności rekordów
bazy danych,
udostępnianie wydajnych mechanizmów
indeksowania pozwalających na szybkie
przeszukiwanie i odnajdywanie
interesujących nas danych,
zapewnianie ochrony przechowywanych
danych przed ewentualną utratą, na
skutek przyczyn niekoniecznie zależnych
od człowieka, za pomocą metod
tworzenia kopii bezpieczeństwa i
procedur odtwarzania

Prof. dr hab. inż. S. Wiak
20
Języki stosowane w bazach danych
Języki, które stosuje się do projektowania i
wypełniania bazy danych można podzielić na
cztery różne grupy:
język definiowania danych
(
Data Definition Language
– DDL
), który umożliwia definiowanie struktury
danych przechowywanych w bazie, czyli tworzenie
schematu implementacyjnego
język manipulowania danymi
(
Data Manipulation
Language – DML
), który umożliwia wypełnienie,
modyfikowanie i usuwanie informacji z bazy danych
język sterowania danymi
(
Data Control Language –
DCL
), który umożliwia sterowania transakcjami (np.
zatwierdzanie lub wycofywanie)
język zapytań
(
Query Language
), który umożliwia
pobieranie z bazy informacji zgodnych z podanymi
warunkami

Prof. dr hab. inż. S. Wiak
21
Jądro systemu zarządzania bazą danych
Jądro systemu zarządzania bazą danych
Funkcje jądra
S
ystemu
Z
arządzania
B
azą
D
anych
(SZBD) określają następujące kategorie
działań:
Organizacja plików.
Mechanizmy dostępu.
Zarządzanie transakcjami: kontrola współbieżności i
spójności.
Zarządzanie słownikami.
Zarządzanie zapytaniami.
Sporządzanie kopii zapasowych (ang. backup) i
odtwarzanie.
Prof. dr hab. inż. S. Wiak
22
Katalog
Katalog
System
operacyjn
y
Menedżer
danych
Bazy
danych
Katalo
g
*współbieżność
*Kopie
zapasowe
*odtwarzanie
Instrukcje
DLL
Kompilator
DLL
Uprzywilejowa
ne instrukcje
Zapytania
użytkownika
Programy
użytkowe
prekompilator
Kompilator
języka
gospodarz
a
Katalog
Przechow
y-wane
transakcj
e
Kompilato
r DML
Procesor
zapytań
Procesor
czasu
rzeczywisteg
o
Składniki typowego
systemu zarządzania
bazą danych (SZBD)

Prof. dr hab. inż. S. Wiak
23
Organizacja plików dotyczy
Organizacja plików dotyczy sposobu, w jaki układa się dane
w fizycznych urządzeniach przechowywania danych, z
których
najważniejszymi
są
urządzenia
dyskowe.
Organizacje
plików
i
dostępów
są
wewnętrznie
powiązane. Poniżej zostaną omówione dwa główne typy
plików systemu relacyjnego: pliki sekwencyjne i
pliki
haszowane
.
Podstawową postacią organizacji
Podstawową postacią organizacji plików sekwencyjnych jest
plik nieuporządkowany. W tej postaci pliku rekordy są
ustawiane w pliku w porządku ich wstawiania.
Wstawianie do pliku nieuporządkowanego jest bardzo
proste.
Wyszukanie
rekordu
wymaga
natomiast
liniowego przeszukania całego pliku, rekord po rekordzie.
Dlatego do pliku o N rekordach średnio trzeba będzie
przeszukać N/2 rekordów.

Prof. dr hab. inż. S. Wiak
24
Z tego powodu większość systemów stara się
utrzymywać pewną postać sekwencyjnej
organizacji pliku. W sekwencyjnym pliku
uporządkowanym rekordy są
uporządkowane według wartości jednego
lub więcej pól. W praktyce dotyczy to
zazwyczaj
klucza głównego pliku.
klucza głównego pliku.
Ogólnie rzecz biorąc, oznacza to, że chociaż
wstawianie wiąże się z większą ilością
przetwarzania niż w przypadku pliku
nieuporządkowanego, wyszukiwanie może
być zrealizowane za pomocą bardziej
efektywnych algorytmów dostępu. Jednym z
najbardziej znanych algorytmów jest
algorytm wyszukiwania binarnego, którego
działanie polega na ciągłym zmniejszaniu
obszaru wyszukiwania o połowę.

Prof. dr hab. inż. S. Wiak
25
Klucz główny
to jedna lub więcej kolumn
tabeli, w których wartości jednoznacznie
identyfikują każdy wiersz tabeli.
Pliki haszowane
dostarczają bardzo szybkiego
dostępu
do
rekordów
na
podstawie
określonego kryterium. Plik haszowany musi
być zadeklarowany za pomocą tak zwanego
klucza haszowania
.
To oznacza, że w pliku
może być tylko jeden porządek haszowania
.
Wstawianie rekordu do pliku haszowanego
oznacza, że klucz rekordu jest przekazywany
do funkcji haszującej. Funkcja haszująca
tłumaczy logiczną wartość klucza na fizyczną
wartość klucza – względny adres bloku.

Prof. dr hab. inż. S. Wiak
26
Powyżej zostały omówione pewne
mechanizmy dostępu, które są
wewnętrznie powiązane z leżącą u ich
podstaw organizacją plików. Dlatego, na
przykład, dostęp sekwencyjny jest
możliwy dla plików sekwencyjnych, a
dostęp haszowany – dla plików
haszowanych
. Poniżej zostanie
omówiony mechanizm dostępu, który
jest dodawany do bazy danych, aby
usprawnić jej działanie bez wpływu na
strukturę przechowywania danych –
indeks.

Prof. dr hab. inż. S. Wiak
27
Podstawowa
idea
indeksu
polega
na
zastosowaniu dodatkowego pliku o dwóch
polach
, dodawanego do systemu baz
danych. Pierwsze pole indeksu zawiera
posortowaną listę logicznych wartości
kluczy, drugie pole – listę adresów bloków
dla wartości kluczy. Główny problem
polega na utrzymaniu odpowiednio małego
indeksu, tak aby mógł być przechowywany
w
pamięci
głównej.
Na
indeksie
wykonujemy
przetwarzanie
używając
algorytmu,
takiego
jak
wyszukiwanie
binarne.
Wyszukiwanie
binarne
jest
szybkim
algorytmem
przeszukiwania
posortowanej listy wartości kluczy.

Prof. dr hab. inż. S. Wiak
28
W praktyce większość indeksów w
SZBD
jest
implementowana za pomocą pewnych postaci
B-drzew. Termin B-drzewo jest skrótem od
„drzewo wyważone” i oznacza hierarchiczną
strukturę danych.
W
systemie
baz
danych
z
wieloma
użytkownikami
transakcjami
nazywamy
procedury, które wprowadzają zmiany do bazy
danych lub które wyszukują dane w bazie
danych.
Transakcja może być zdefiniowana
jako logiczna jednostka pracy. Każda
transakcja
powinna
mieć
właściwości:
niepodzielność, spójność, izolacji i trwałości
(czasami używany skrót to ACID):
Niepodzielność.
Skoro transakcja składa się ze
zbioru akcji, menedżer transakcji powinien zapewnić,
że albo cała transakcja zostanie wykonana, albo w
ogóle nic.

Prof. dr hab. inż. S. Wiak
29
Spójność.
Wszystkie transakcje muszą zachowywać
spójność i integralność bazy danych. Operacje
wykonywane na przykład przez transakcję
modyfikującą nie powinny pozostawiać bazy
danych w stanie niespójnym lub niepoprawnym
Izolacja.
Jeżeli transakcja modyfikuje dzielone
dane, to te dane mogą być tymczasowo niespójne.
Takie dane muszą być niedostępne dla innych
transakcji dopóty, dopóki transakcja nie zakończy
ich używać. Menedżer transakcji musi dostarczać
iluzji, że dana transakcja działa w izolacji od innych
transakcji.
Trwałość.
Gdy transakcja kończy się, wówczas
zmiany dokonane przez nią powinny zostać w pełni
utrwalone. To znaczy, nawet w wypadku awarii
sprzętu lub oprogramowania powinny one zostać
zachowane.

Prof. dr hab. inż. S. Wiak
30
Modele danych
Każda baza danych, a także każdy SZBD
muszą się stosować do zasad określonego
modelu danych. W literaturze baz danych
termin modelu danych używany jest w
odniesieniu do architektury danych oraz
zintegrowanego
zbioru
wymagań
w
odniesieniu do danych. Model danych w
sensie architektury danych jest zbiorem
ogólnych zasad posługiwania się danymi.
Rozróżniamy
trzy
generacje
architektonicznych modeli danych:
Proste modele danych. W tym podejściu
obiekty są reprezentowane za pomocą struktury
rekordów zgrupowanych w strukturach plików.

Prof. dr hab. inż. S. Wiak
31
Klasyczne modele danych
. Są to hierarchiczne,
sieciowe
i
relacyjne
modele
danych.
Hierarchiczny model danych jest rozszerzeniem
opisanego wyżej modelu prostego natomiast
sieciowy model jest rozszerzeniem podejścia
hierarchicznego. Relacyjny model danych jest
następcą
modeli
hierarchicznego
oraz
sieciowego.
Semantyczne modele danych
. Głównym
problemem związanym z klasycznymi modelami
danych, jest to, że zachowują one podstawową
orientację opartą na rekordach. Semantyczne
modele danych próbują dostarczyć bardziej
znaczących sposobów reprezentowania
znaczenia informacji, niż jest to możliwie przy
modelach klasycznych. Pod wieloma względami
obiektowy model danych może być uważany za
semantyczny model danych.

Prof. dr hab. inż. S. Wiak
32
Model danych jako projekt rozumiany jest
jako zintegrowany, niezależny od
implementacji zbiór wymagań dotyczący
danych dla pewnej aplikacji. Mówimy więc
o modelu danych do przetwarzania
zamówień, modelu danych do księgowania
rachunków itp.

Prof. dr hab. inż. S. Wiak
33
Podstawowym
celem
baz
danych
jest
zapewnienie niezależności danych, czyli:
odporność programów użytkowych na zmiany
struktury
pamięci
i
strategii
dostępu.
Rozróżniamy 2 typy niezależności danych:
1
Fizyczna niezależność danych
oznacza, że
rozmieszczenie fizyczne i organizacja danych
mogą być zmieniane bez zmiany programów
użytkowych jak i globalnej struktury logicznej
danych. Niezależność fizyczna wyraża się w
tym, że w wyniku zmian struktury pamięci
zmienia się jedynie definicja odwzorowania
między poziomem pojęciowym a poziomem
fizycznym.

Prof. dr hab. inż. S. Wiak
34
2
Logiczna niezależność danych
oznacza,
że globalna struktura logiczna danych
może
być
zmieniana
bez
zmiany
programów użytkowych (zmiany nie
mogą oczywiście usunąć danych, z
których
te
programy
korzystają).
Niezależność logiczna wyraża się tym, że
w wyniku zmian na poziomie pojęciowym
zmienia się tylko definicja odwzorowania
między
poziomem
pojęciowym
a
poziomem zewnętrznym - umożliwia
zachowanie programów użytkowych w
nie zmienionej postaci.

Prof. dr hab. inż. S. Wiak
35
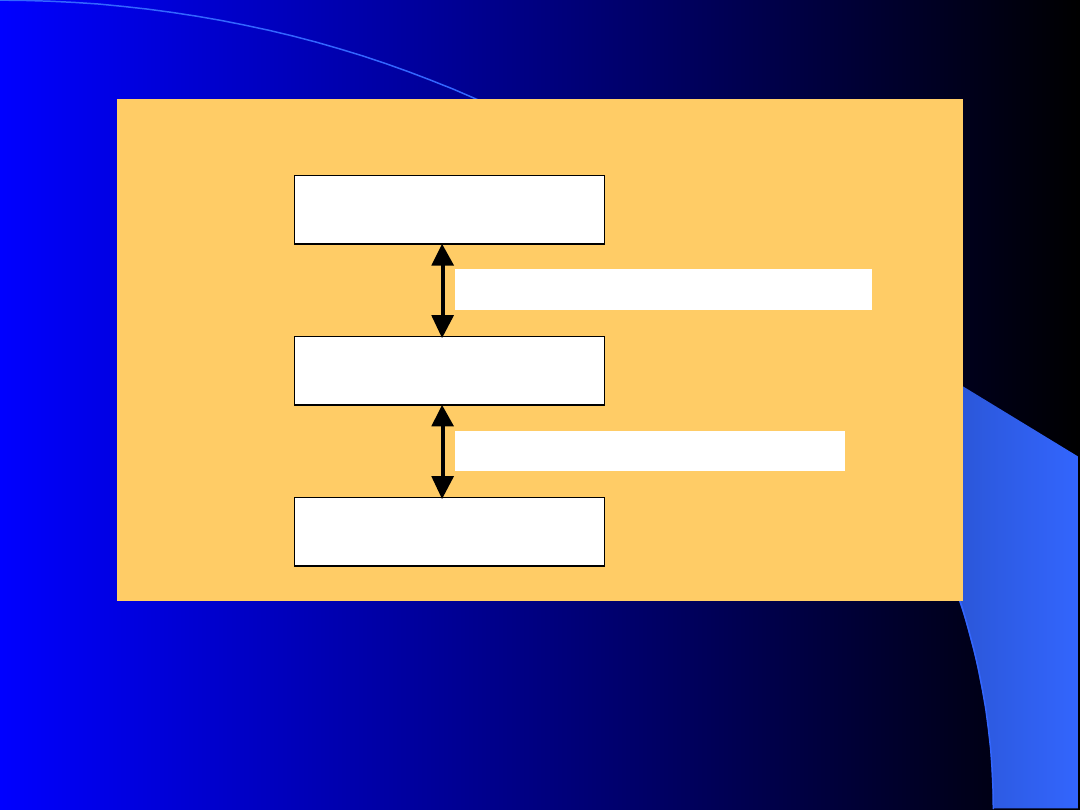
Reprezentacja danych:
poziom pojęciowy - jest on abstrakcyjnym, lecz
wiernym
opisem
pewnego
wycinka
rzeczywistości.
poziom
wewnętrzny
-
określa
sposoby
organizacji danych w pamięci zewnętrznej.
poziom zewnętrzny - odnosi się do sposobu w
jaki dane są widziane przez poszczególne grupy
użytkowników.
Schemat
kanoniczny
jest
próbą
opisu
wewnętrznych
właściwości
danych.
Jeżeli
System Zarządzania Bazą Danych korzysta z
niego, który nie zmienia się bez względu na
rodzaj
zastosowanego
sprzętu,
oprogramowania
czy
fizycznej
struktury
danych, to można mówić o prawdziwej
niezależności danych. W praktyce nie stosuje
się go.
Prof. dr hab. inż. S. Wiak
36
poziom zewnętrzny
poziom pojęciowy
poziom fizyczny
odwzorowanie zewnętrzno-pojęciowe
odwzorowanie pojęciowo-fizyczne

Prof. dr hab. inż. S. Wiak
37
Schemat kanoniczny jest jako model danych,
przedstawiający
wewnętrzną
strukturę
danych. Tym samym niezależny jest od
poszczególnych dziedzin stosowania danych,
jak również od mechanizmów związanych z
oprogramowaniem lub sprzętem, które to
wykorzystywane są do reprezentowania oraz
zachowywania danych.
Statyczna i dynamiczna niezależność danych
:
o wiązaniu dynamicznym mówimy w trakcie
wyszukiwania danych. Schemat lub fizyczna
organizacja może być wtedy modyfikowana w
dowolnym momencie -
daje ono dynamiczną
niezależność danych
.
Statyczna niezależność
danych wymaga aby przeprowadzenie zmian w
schemacie ogólnym, podschemacie lub fizycznej
reprezentacji, zakończyło się zanim dowolny program
użytkowy używający tych danych zostanie wykonany.

Prof. dr hab. inż. S. Wiak
38
Mamy trzy rodzaje danych:
1.
Dane zagregowane
- treść danej mającej
nazwę definiuje się tylko raz. Każdy
programista odwołujący się do określonej
danej musi zakładać tę samą treść tej
danej.
2.
Dane elementarne
- definiuje się tylko raz.
Programista odwołujący się do tych danych
musi zakładać tę samą ich treść. Z tego
samego zbioru danych elementarnych mogą
być utworzone różne rekordy lub segmenty.
3.
Dane subelementarne
- treści tych danych,
mających nazwę, mogą być różne w różnych
programach użytkowych. I tak np. jeden
program może odwoływać się do
siedmiocyfrowych, a inny do
ośmiocyfrowych danych elementarnych.

Prof. dr hab. inż. S. Wiak
39
Historyczny przegl
Historyczny przegl
ą
ą
d baz danych
d baz danych
ARCHITEKTURA DWUWARSTWOWA
W myśl tej koncepcji systemy oparte na tej
architekturze podzielono na dwie części. Z
jednej strony została wydzielona pewna
część systemu (inaczej mówiąc proces)
odpowiedzialna za przechowywanie danych
i zachowanie ich pełnej spójności.
Z drugiej strony wydzielono pewne aplikacje
czy procesy , które pobierają dane od
użytkownika wyświetlają je i przetwarzają ,
a następnie albo przesyłają je do serwera w
celu zapamiętania, albo generują pewne
zapytania w celu uzyskania konkretnych
informacji z komputera-serwera.

Prof. dr hab. inż. S. Wiak
40
W ten sposób cały proces przetwarzania
danych mamy podzielony na dwie części. Z
jednej strony mamy serwer, który
przechowuje dane, ale potrafi także je
wyszukiwać z przechowywanej bazy na
podstawie zapytań poszczególnych
komputerów (klientów), a z drugiej strony
mamy aplikacje klienta, które tak naprawdę
nic nie muszą wiedzieć o fizycznej
strukturze danych przechowywanych na
serwerze o sposobie ich zarządzania o
liczbie użytkowników, a muszą jedynie
umieć wysłać zapytanie do bazy ,
wyświetlić informacje na ekranie lub wysłać
do serwera polecenie aktualizujące dane.

Prof. dr hab. inż. S. Wiak
41
Architektura klient/serwer
Architektura klient/serwer
Przesłanką architektury klient/serwer
jest podział
wykonywania zadań pomiędzy kilka procesorów
znajdujacych się w sieci. Każdy procesor jest
dedykowany do określonego zbioru zadań, które
jest w stanie wykonywać najefektywniej, co w
rezultacie daje zwiększenie wydajności i
skuteczności systemu jako całości.
Rozdzielenie wykonywania zadań
pomiędzy
procesory jest dokonywane poprzez
protokół
usług
: jeden procesor, klient, zleca pewną
usługę drugiemu procesorowi zwanym
serwerem, który ma tę usługę zrealizować.
Najbardziej powszechną implementacją
architektury klient/serwer
jest odseparowanie
części aplikacji będącej interfejsem użytkownika
od części odpowiedzialnej za dostęp do danych.

Prof. dr hab. inż. S. Wiak
42
Typowym rozwiązaniem jest oczywiście kilka
komputerów pracujących w sieci. W takiej
konfiguracji mamy komputer (często jest to
maszyna unixowa) wyposażony w serwer
bazy danych, czyli pewne oprogramowanie
umożliwiające przechowywanie i
zarządzanie danymi.
Z drugiej strony mamy aplikacje klienta,
posadowioną najczęściej w środowisku
graficznym typu Windows, realizującą
komunikację z użytkownikiem tzn.
prezentującą dane, pozwalającą
wprowadzać i uaktualniać informację
zadawać nietypowe zapytania dotyczące
pogrupowanych informacji
przechowywanych na serwerze.

Prof. dr hab. inż. S. Wiak
43
Zastosowanie środowiska graficznego
znacznie wzbogaciło możliwości
prezentacyjne, a jednocześnie
pozwoliło na bardziej naturalną
komunikację z użytkownikiem
z wykorzystaniem wykresów, map
cyfrowych, a także z wykorzystaniem
rozwiązań multimedialnych, co
pozwala na przechowywanie w bazie
danych obrazów i dźwięków.

Prof. dr hab. inż. S. Wiak
44
Jaka jest zatem różnica między tym rozwiązaniem
a innymi architekturami?.
Zasadniczym
elementem
jest fakt , że w przypadku
architektury klient/serwer mamy do czynienia z
równolegle działającymi dwoma programami
(pakietami programów) czy procesami. Jeden z
nich realizuje usługi na żądania drugiego
procesu. Użycie sformułowania proces jest
właściwsze w tym przypadku od użycia słowa
program gdyż zauważmy, że do tej pory nie
stawialiśmy żadnych wymagań na ilość
komputerów użytych do realizacji tej koncepcji.
Okazuje się, że
system o architekturze
klient/serwer
można usadowić na jednym
komputerze, a odbywa się to poprzez możliwość
przełączania procesorów. Jest to jednak
rozwiązanie nietypowe.

Prof. dr hab. inż. S. Wiak
45
ZALETY I WADY
Tworząc system klient/serwer musimy
zastanowić się nad tym co zyskujemy, a co
tracimy wybierając taką właśnie architekturę.
Zyskujemy przede wszystkim dużą
elastyczność całego systemu, gdyż możemy
pracować z różnymi środowiskami graficznymi
równocześnie, możemy operować danymi w
sposób spójny a jednocześnie niezależny od
ich bieżącej struktury.
Zarządzając z kolei
samym serwerem danych jesteśmy
uniezależnieni od konkretnych użytkowników
,
od problemów związanych ze wspólnym
dostępem, a co za tym idzie możemy
skoncentrować się na samej strukturze
informacji, na strukturach biznesowych, na
współbieżności i efektywności.

Prof. dr hab. inż. S. Wiak
46
Pomimo bardzo istotnych i wymiernych
korzyści wybór tej technologii nie
odbywa się nigdy bez strat. Po pierwsze
stopień komplikacji jest dużo większy niż
pojedynczy pakiet programów
przystosowany do pracy na komputerach
pracujących w jakiejkolwiek sieci.
Musimy przy pisaniu programów
zapewniać mechanizmy kontroli
spójności, wielodostępu, co przy
rozległych systemach nie jest sprawą
trywialną. Po drugie pisząc aplikacje
klienckie musimy zapewnić ich właściwe
komunikowanie się z serwerem bazy
danych.

Prof. dr hab. inż. S. Wiak
47
Aplikacja kliencka nie ma
bezpośredniego dostępu do danych
elementarnych, a jedynie za pomocą
specjalnego języka (najczęściej jest to
SQL) komunikuje się z serwerem
zadając pytania, nanosząc pewne
poprawki.
Przy architekturze
klient/serwer musimy także pamiętać
o
odpowiednich połączeniach
sieciowych - o pewnych standardach,
czyli zapewnieniu prawidłowego
porozumiewania się komputerów z
różnymi systemami.

Prof. dr hab. inż. S. Wiak
48
W architekturze klient/serwer zakłada się,
że poszczególne komponenty środowiska
mogą pochodzić od różnych dostawców.
Wynika , to ze specjalizacji firm
produkujących poszczególne komponenty
systemów informatycznych. Jeżeli jakaś
firma specjalizuje się w środowisku
graficznym, to niekoniecznie musi być
najlepsza w produkcji serwerów baz
danych i odwrotnie. Stąd celowym jest
dobieranie najlepszych w swojej klasie
produktów, aby tworzyć najlepsze
systemy. Samo wybieranie komponentów
jest poważnym problemem, gdyż musimy
pamiętać o tym, że później te najlepsze
produkty muszą ze sobą uzgodnić pewien
standard wymiany informacji.

Prof. dr hab. inż. S. Wiak
49
Na poziomie serwera bazy danych
najczęściej takim standardem jest język
SQL, chociaż pomimo przyjętych
pewnych norm każdy z serwerów
operuje pewnymi rozszerzeniami. Nie
korzystanie z tych rozszerzeń powoduje
, że tracimy pewną możliwość, która
jest zaimplementowana bardzo
wydajnie i decyduje o wyższości danego
serwera nad innym. Korzystanie z tych
rozszerzeń powoduje często mniejszą
skalowalność i przenośność aplikacji jak
w przypadku korzystania ze
standardowego SQL.

Prof. dr hab. inż. S. Wiak
50
KOMUNIKACJA
KOMUNIKACJA
Innym zagadnieniem jest sposób
przekazywania danych. Sam SQL nie
oferuje określonych standardów, a jest
kwestią samego łącza. Powstaje problem
jak spowodować, aby aplikacja kliencka
pracująca w systemie Windows mogła
wymieniać dane z serwerem baz danych.
Jednym z rozwiązań jest standard zwany
ODBC, który zapewnia jednolity sposób
wymiany danych pomiędzy aplikacją
kliencką i aplikacją serwera. Obejmuje on
nie tylko sam format zapytań i format ich
przekazywania, ale również sposób
odbierania otrzymanych danych
i określania statusu czyli wyniku
wykonywanych operacji bazodanowych.

Prof. dr hab. inż. S. Wiak
51
Powoduje to z jednej strony, że aplikacje
przestrzegające standard "rozumieją" się
i właściwie razem funkcjonują.
Rozwiązanie to ma tę wadę, że aplikacje
przystosowując się do standardu często
muszą rezygnować ze swoich
oryginalnych rozwiązań, często bardzo
wydajnych i pożytecznych. Tak więc
zdarza się, że standard ODBC w pewnych
sytuacjach nie jest najwydajniejszym
sposobem połączenia z bazą danych.

Prof. dr hab. inż. S. Wiak
52
Dlatego właśnie producenci środowisk
tworzenia aplikacji klienckich bardzo
często dostarczają w ramach swoich
produktów
specjalne
dedykowane
sterowniki (połączenia) do niektórych
serwerów baz danych. Zaznaczyć jednak
należy,
że
taki
sterownik
jest
przeznaczony tylko do jednej konkretnej
bazy danych i z żadną inną się nie
komunikuje. Przejście na inny system
baz danych wymaga najczęściej wymiany
sterownika, ale istnieje groźba, że jeżeli
takiego sterownika nie ma to nie
możemy w sposób bezpośredni dokonać
modyfikacji systemu.

Prof. dr hab. inż. S. Wiak
53
ROZWARSTWIENIE
Środowisko
klient/serwer
z jednej strony
elastyczne i wydajne ma swoje ograniczenia.
Okazuje się, że tworzenie bardzo dużych
systemów, gdzie aplikacja kliencka musi
realizować bardzo dużo funkcji, w których
mamy do czynienia nie z jednym ale z
wieloma serwerami danych rozproszonymi
między oddziałami danej organizacji zaczyna
nastręczać pewne trudności. Wiąże się to
z tym, że musimy zapewnić zarówno
wydajność wykonywania pewnych operacji,
jak i spójność danych. Z kolei
rozbudowywanie aplikacji klienckiej
powoduje ich ogromną czasami złożoność i
wysoki stopień komplikacji przez co
zwiększają się jej wymagania sprzętowe

Prof. dr hab. inż. S. Wiak
54
W związku z tym pojawiła się tendencja do
wydzielania pewnych płaszczyzn
przetwarzania. Jeżeli przyjrzymy się
strukturze informacji w organizacji czy
firmie, to okaże się, że możemy tę
informację podzielić na pewne warstwy
.
Z jednej strony mamy samą
strukturę
informacji
, czyli fizycznie rzecz ujmując
strukturę bazy
danych
- strukturę
tablic, strukturę rekordów, listę pól, typy
wartości jakie mogą przyjmować dane.

Prof. dr hab. inż. S. Wiak
55
Na tą strukturę nakłada się
warstwa
tzw. reguł biznesowych
.
Są to pewne
zależności pomiędzy danymi właściwe
dla konkretnej organizacji lub właściwe
w danym okresie istnienia organizacji.
Taką regułą może być np. algorytm
naliczania oprocentowania dla
kredytów, sposób udzielania zniżek na
bilety lotnicze itd. Są to więc pewne
algorytmy postępowania nie związane w
sposób bezpośredni z danymi, ale ich
sprecyzowanie jest konieczne dla
prawidłowego funkcjonowania firmy.

Prof. dr hab. inż. S. Wiak
56
Trzecia warstwa
to tzw.
warstwa
prezentacyjna
określająca sposób
wprowadzania i wyświetlania danych.
Określa ona np. czy pewne dane
przedstawiamy w postaci listy, czy pól
do wprowadzania, czy dana ma mieć
strukturę dzień-miesiąc-rok, czy też
rok-miesiąc-dzień, czy jak klikniemy
myszą na nazwisku klienta to
wyświetlą się informacje o operacjach
przeprowadzonych na jego koncie itp.

Prof. dr hab. inż. S. Wiak
57
Widać
z
tego,
że
sama struktura
informacji
narzuca
nam
podejście
wielowarstwowe do tworzenia systemu
informatycznego.
Wyraźnie wyłoniła się
pewna warstwa,
która nie dotyczy ani samej struktury
informacji ani sposobu jej prezentacji,
natomiast dotyczy reguł zarządzania tą
informacją.
Powstała wobec tego idea, która zakłada
umieszczenie tychże reguł biznesowych
w odpowiednim miejscu, czy też na
odpowiedniej płaszczyźnie architektury
klient/serwer.

Prof. dr hab. inż. S. Wiak
58
W przypadku
typowej architektury
klient/serwer
mamy do czynienia
z
architekturą dwuwarstwową
(warstwa
klienta i warstwa serwera); reguły
biznesowe najczęściej są umieszczane w
aplikacji klienckiej.
Reguły, że na każde zamówienie musi być
jedna faktura, a każda faktura musi być
w trzech kopiach itp. umieszczono w
aplikacji klienta. Zmiana tych reguł
powodowała, że trzeba było wymieniać
wszystkie aplikacje klienckie bez
możliwości równoległego
funkcjonowania starej i nowej wersji.

Prof. dr hab. inż. S. Wiak
59
Z drugiej strony mając serwer bazy
danych i funkcjonujące aplikacje
stajemy przed problemem tworzenia
nowych aplikacji tworzących czy
gromadzących nowe informacje w
oparciu o bazę danych.
Co zatem zrobić, aby te nowe aplikacje
nie zaburzyły już istniejących w
systemie? Jak zrobić, aby system
uchował spójność ze starymi
aplikacjami, a jednocześnie prawidłowo
funkcjonowały nowe?

Prof. dr hab. inż. S. Wiak
60
NOWE ROZWIĄZANIA - ARCHITEKTURA
DWU I PÓŁ WARSTWOWA
Powstała idea przeniesienia pewnej warstwy
funkcjonalnej, czyli sposobów zarządzania i
przetwarzania
informacjami
na
stronę
serwera tak, aby aplikacje klienckie dostały
jedynie pewną listę funkcji, operacji, żądań
jakie mogą realizować, a nie miały
bezpośredniego dostępu do danych. Takie
umieszczenie po stronie serwera było
możliwe dzięki temu, że wiele serwerów baz
danych wyposażono w mechanizm zwany
procedurami
wbudowanymi
i
trigerami,
czyli
pewnymi
procedurami,
które
uruchamiają
się
automatycznie
przy
zachodzeniu pewnych zjawisk
.

Prof. dr hab. inż. S. Wiak
61
Trigery
powodują np., że przy zmianie
pewnych danych inne się uaktualniają; gdy
usuwamy
z
naszej
bazy
informacje
o kliencie, to chcemy usunąć wszystkie
zamówienia jakie on złożył itd. Procedury
te powinny uruchamiać się automatycznie,
bez ingerencji użytkownika.
W takiej architekturze mamy zatem do
czynienia z
aplikacją kliencką
, która
nie
odwołuje
się
bezpośrednio
do
bazy
danych
, ale jedynie wywołuje pewne
operacje w serwerze danych, który bądź
udostępnia pewne dane bądź realizuje
wywołane procedury bazodanowe.

Prof. dr hab. inż. S. Wiak
62
Drugim
elementem
są
zaimplementowane
w bazie
danych
reguły
biznesowe
wspólne
dla
wszystkich
aplikacji
klienckich.
Wymiana takiej reguły powoduje, że
sposób funkcjonowania aplikacji klienta
zmieni
się
dla
każdego
klienta
jednocześnie.
Taką aplikację z warstwą
kliencką
i warstwą
serwera
bazy
danych, który nie ogranicza się tylko do
przechowywania danych, ale również
realizuje funkcje biznesowe nazywamy
często
architekturą
dwu
i
pół
warstwową.

Prof. dr hab. inż. S. Wiak
63
NOWE TRENDY – ARCHITEKTURA
NOWE TRENDY – ARCHITEKTURA
TRÓJWARSTWOWA
TRÓJWARSTWOWA
Jednak istnieją pewne wady tej architektury.
Język procedur wbudowanych i trigerów
jest dość skomplikowany, a najczęściej jest
to "dialekt" języka SQL z pewnymi
rozszerzeniami dotyczącymi przetwarzania
instrukcji strukturalnych. Niestety każdy
producent serwerów baz danych lansuje
nieco odmienny format tego języka i
trudno znaleźć dwie identyczne pod tym
względem bazy danych.

Prof. dr hab. inż. S. Wiak
64
Stąd też istnieje groźba przepisywania od
nowa procedur w przypadku zmiany
serwera bazy danych. Nie jest to
szczególnie
skomplikowane,
gdyż
większość
procedur
ma
podobne
mechanizmy ale różnią się składnią.
Ponadto często reguły biznesowe są
bardziej skomplikowane niż te podane
jako przykłady i do ich realizacji nie
zawsze najodpowiedniejszy jest język
procedur
wbudowanych
serwera.
Wygodniejsze okazują się języki trzeciej
generacji.

Prof. dr hab. inż. S. Wiak
65
Stąd istnieje potrzeba wprowadzania kodu poza
strukturą serwera bazy danych. Rodzi się
więc pojęcie trzeciej warstwy, warstwy która
byłaby niezależna zarówno od serwera jak też
od aplikacji klienckiej, a która odpowiadałaby
za przetwarzanie funkcjonalne samej
informacji.
W
ten
sposób
aplikacja
kliencka
nie
komunikowałaby się z bazą danych, a nawet
nie musiałaby wiedzieć o jego istnieniu, a
komunikowałaby się jedynie z pewnym
komputerem, na którym zainstalowany byłby;
tzw. serwer aplikacji.
Wykonywałby on
procedury na żądanie aplikacji klienckiej, a
one odwoływałyby się do bazy danych.
Mógłby on także oprócz odwoływania się do
bazy
samodzielnie
realizować
pewne
operacje.

Prof. dr hab. inż. S. Wiak
66
Mógłby on dokonywać pewnych obliczeń
numerycznych,
a
nawet
inicjować
realizowanie
pewnych
operacji
bazodanowych na kilku serwerach baz
danych jednocześnie.
Warstwa aplikacyjna
jest wtedy odpowiedzialna za spójność
danych posadowionych na kilku serwerach
oraz za to, aby aplikacja kliencka nie
"wnikała"
w
to
gdzie
fizycznie
posadowione są dane, do których się
odwołuje.
W ten sposób warstwa środkowa
(aplikacyjna)
stanowiłaby
odrębną
płaszczyznę programową w architekturze
klient/serwer,
z
własnym
językiem
(środowiskiem) programistycznym.

Prof. dr hab. inż. S. Wiak
67
Widać więc, że w łatwy sposób
posługując
się
architekturą
klient/serwer
możemy przeskalować
swoje
myślenie
od
poziomu
prostego
systemu
do
modelu
trójwarstwowego,
za
pomocą
którego tworzymy duże systemy
informatyczne.
W
architekturze
trójwarstwowej
istnieje
szereg
standardów
komunikowania
się
między
warstwami.

Prof. dr hab. inż. S. Wiak
68
Tak jak mechanizm ODBC stosowany
jest
w
architekturze
dwuwarstwowej, tak tu możemy
mówić o standardzie RPC, czyli
zdalnym wywoływaniu procedur. Jest
to
jeden
ze
standardów
przetwarzania rozproszonego, kiedy
aplikacja
kliencka
wywołując
procedurę przekazuje parametry i
inicjuje wykonanie procedury na
innym komputerze,
który z kolei
wykonując pewne obliczenia zwraca
wyniki do procedury, która wywołała
je z aplikacji klienckiej.

Prof. dr hab. inż. S. Wiak
69
Modele systemów zarządzania
Modele systemów zarządzania
bazami danych
bazami danych
(modele baz
(modele baz
danych)
danych)
Hierarchiczny
Obiektowy
Relacyjny
Sieciowy

Prof. dr hab. inż. S. Wiak
70
Hierarchiczny model danych
Hierarchiczny model danych został opracowany w
wyniku analizy istniejących implementacji.
Model ten używa
dwóch struktur
, którymi są:
typy rekordów i związki nadrzędny-podrzędny
.
Typ rekordów jest nazwany strukturą danych,
złożoną ze zbioru nazwanych pól. Każde pole
jest używane do przechowywania prostego
atrybutu i jest mu przyporządkowany typ
danych.
Powiązanie nadrzędny-podrzędny jest związkiem
jeden-do-wiele
między dwoma typami
rekordów.
Mówimy, że typ rekordu po
stronie jeden związku jest nadrzędnym
typem rekordu; rekord po stronie wiele
jest podrzędnym typem rekordu
.

Prof. dr hab. inż. S. Wiak
71
A więc, schemat hierarchiczny jest złożony z
wielu typów rekordów, powiązanych ze
sobą za pomocą związków nadrzędny-
podrzędny. Zauważmy, że schemat ten ma
wiele podobieństw do relacyjnego modelu
danych. Zasadniczymi różnicami są:
o
Struktury
danych
są
inne
:
w
hierarchicznym modelu danych mamy typy
rekordów; w relacyjnym modelu mamy
relacje i związki.
o
Związki są inaczej implementowane
; w
hierarchicznym modelu danych przez
powiązania
nadrzędny-podrzędny;
w
relacyjnym modelu danych przez klucze
obce.

Prof. dr hab. inż. S. Wiak
72
W hierarchicznym modelu
danych operowanie danymi
jest wykonywane przez wbudowane funkcje dostępu
do baz danych w wybranym języku programowania
(tak zwanym języku gospodarza).
Istnieje wiele wewnętrznych
więzów integralności w
modelu hierarchicznym, które są zawsze obecne,
gdy tworzymy schemat hierarchiczny.
Przykładami
Przykładami
takich więzów są:
takich więzów są:
Nie mogą istnieć żadne wystąpienia rekordów, z
wyjątkiem
rekordu
korzenia
(najwyższego
w
hierarchii),
bez
powiązania
z
odpowiednim
wystąpieniem rekordu nadrzędnego. Oznacza to, że:
-
Nie można wstawić rekordu
podrzędnego dopóty,
dopóki nie zostanie powiązany z rekordem
nadrzędnym.
-
Usunięcie rekordu nadrzędnego
powoduje
automatyczne usunięcie wszystkich powiązanych z
nim rekordów podrzędnych.

Prof. dr hab. inż. S. Wiak
73
Jeżeli podrzędny typ rekordu ma
związane dwa
lub więcej nadrzędnych typów
rekordów, to
rekord podrzędny musi zostać
powielony dla
każdego rekordu nadrzędnego
.
W hierarchicznym modelu bazy danych
(
HMBD
) dane mają strukturę, którą
można
przedstawić
jako
odwrócone
drzewo.
Jedna
z
tabel
pełni
rolę
„korzenia” drzewa, a pozostałe mają
postać „gałęzi” biorących swój początek w
korzeniu. Rysunek przedstawia diagram
struktury
HMBD
.
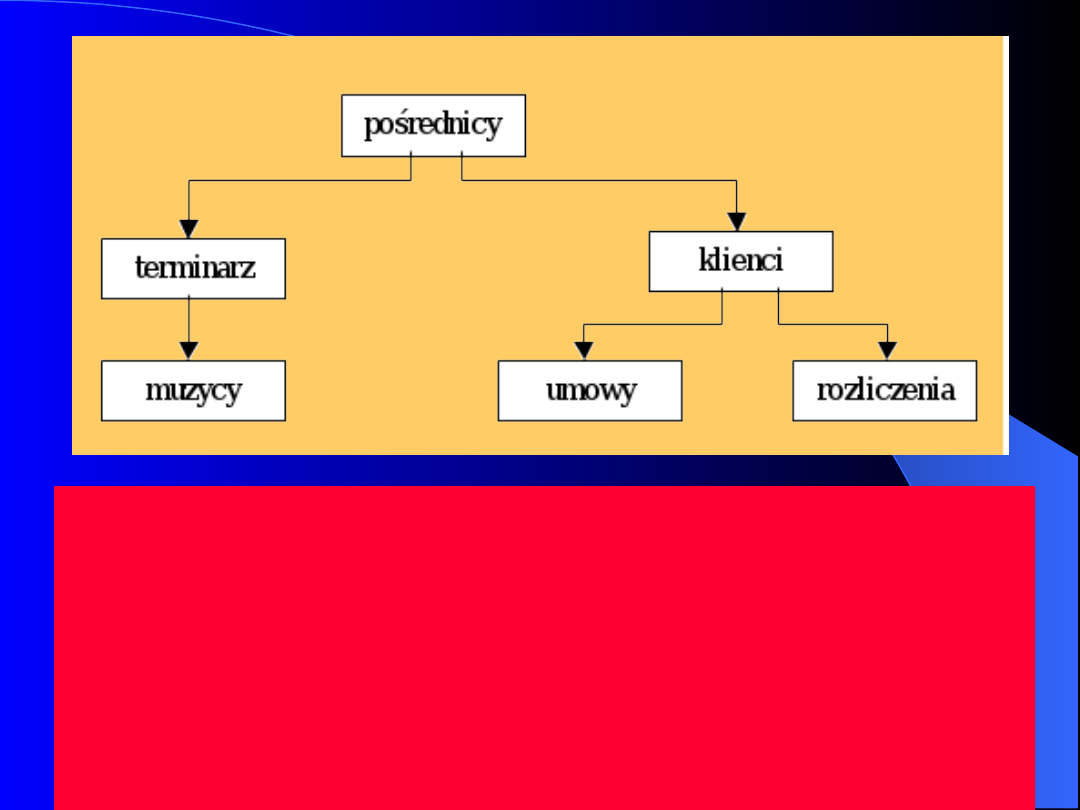
Prof. dr hab. inż. S. Wiak
74
Diagram modelu hierarchicznego. (Baza
danych pośredników. W przykładzie każdy
pośrednik pracuje dla kilku muzyków i ma
pewną liczbę klientów, którzy zamawiają u
niego obsługę muzyczną różnych imprez.
Klient zawiera umowę z muzykiem przez
pośrednika i u tego właśnie pośrednika uiszcza
należność za usługę.).
Prof. dr hab. inż. S. Wiak
75
W hierarchicznym modelu bazy danych dane mają
strukturę odwróconego drzewa, podobnie jak
struktura drzewa katalogowego w systemie
DOS® czy Windows®. W modelu tym tabela
nadrzędna powiązana jest z wieloma tabelami
podrzędnymi,
natomiast
jedna
tabela
podrzędna powiązana może być tylko z jedną
tabelą nadrzędną. Na przykład:
Schemat
hierarchicznego
modelu bazy danych

Prof. dr hab. inż. S. Wiak
76
Relacje w HMBD
są reprezentowane w kategoriach
„
ojciec/syn”.
Oznacza to, że tabela nadrzędna
(ojciec) może być powiązana z wieloma tabelami
podrzędnymi (syn), lecz pojedyncza tabela
podrzędna może mieć tylko jedną tabelę
nadrzędną. Aby uzyskać dostęp do danych w
modelu hierarchicznym, użytkownik zaczyna od
korzenia i przedziera się przez całe drzewo
danych, aż do interesującego go miejsca.
Oznacza to, że użytkownik musi dobrze znać
strukturę bazy danych.
Zaletami tego modelu
danych jest szybkie
przywoływanie
potrzebnych
danych
oraz
automatycznie
wbudowana
integralność
odwołań.
Największym problemem
modelu hierarchicznego
jest nadmiarowość danych ze względu na
niezdolność do obsługi złożonych relacji.

Prof. dr hab. inż. S. Wiak
77
Hierarchiczny
model
danych
był
z
powodzeniem stosowany w systemach
zapisu taśmowego, wykorzystywanych w
komputerach
typu
„
mainframe”
do
późnych lat siedemdziesiątych, i zdobył
dużą popularność w firmach polegających
na tych systemach.
Pomimo tego, że
HMBD
zapewniał szybki,
bezpośredni
dostęp
do
danych
i
znajdował zastosowanie w rozwiązaniu
wielu problemów, narastała potrzeba
wprowadzenia nowego modelu danych
nie wymagającego wprowadzania tak
dużej
nadmiarowości
danych
zaburzających integralność bazy.

Prof. dr hab. inż. S. Wiak
78
Obiektowy model danych
Pod
koniec
lat
osiemdziesiątych
zapowiadano, że systemy baz danych
mające za podstawę obiektowy model
danych, istotnie różny od relacyjnego
modelu
danych,
prześcigną
systemy
relacyjnych baz danych w połowie lat
dziewięćdziesiątych. Chociaż tak się nie
stało, nie ma wątpliwości, że modele
obiektowe wywierają wpływ na rozwój
systemów
informatycznych.
Dowodem
tego może być fakt, że wielu producentów
relacyjnych
SZBD
zaczyna
oferować
modele obiektowe i twierdzi, że
SQL 3
zwraca się w kierunku
obiektowości.

Prof. dr hab. inż. S. Wiak
79
We współczesnej informatyce
pojęcie
obiektowości
ma
wiele
różnych
znaczeń. Termin ten był po raz pierwszy
zastosowany w odniesieniu do grupy
języków programowania wywodzących
się z języka będącego odkryciem
pochodzenia
skandynawskiego,
znanego jako
Simula
. Język
Simula
był
pierwszym językiem, który wprowadził
pojęcie struktur danych i procedur.

Prof. dr hab. inż. S. Wiak
80
Dopiero
niedawno
zastosowano
obiektowość
w dziedzinie baz danych.
Główną
różnicą
między
obiektowymi
językami programowania a bazami danych
jest to, że obiektowe bazy danych
wymagają istnienia trwałych obiektów.
W obiektowych językach programowania
obiekty istnieją tylko przez krótki czas
przy wykonywaniu programu.
W obiektowych bazach danych obiekty
pozostają zapisane w pamięci pomocniczej
przed i po wykonaniu programów
.

Prof. dr hab. inż. S. Wiak
81
Często stwierdza się,
że model relacyjny był
odpowiedni dla zastosowań tradycyjnych takich
jak
zastosowania
bankowe,
ale
jest
nieadekwatny dla nowoczesnych zastosowań w
takich dziedzinach jak np. CAD (Computer Aided
Design).
Zważywszy
na
wyposażenie
współczesnych systemów relacyjnych w takie
cechy jak możliwość pracy z multimediami,
możliwość umieszczania dowolnie długich ciągów
znaków zmiennej długości itp., teoretycznie nie
ma przeszkód w zaimplementowaniu dowolnego
zastosowania różnych dziedzin.
Istotną zaletą modelu obiektowego jest
wyższy poziom abstrakcji
, który umożliwia
zaprojektowanie i zaprogramowanie tej samej
aplikacji
w
sposób
bardziej
elastyczny,
konsekwentny i jednolity.

Prof. dr hab. inż. S. Wiak
82
Model obiektowy dotyczy głównie
struktur
danych przechowywanych w obiektowej
bazie
danych.
Wyznacza
on
bazę
intelektualną i pojęciową określającą
budowę
struktur
danych
oraz
komunikację pomiędzy ludźmi.
Filarami, na których opiera się każdy
model obiektowy są pojęcia: złożone
obiekty, tożsamość, powiązania, klasy i
typy, hierarchia (lub inna struktura)
dziedziczenia,
metody,
komunikaty,
hermetyzacja,
przesłanianie,
polimorfizm.

Prof. dr hab. inż. S. Wiak
83
Celem nadrzędnym obiektowości
jest lepsze
dopasowanie modeli pojęciowych i modeli
relacyjnych
systemów
do
wrodzonych
instynktów,
własności
psychologicznych,
mentalnych
mechanizmów
percepcji
i
rozumienia świata.
Obiekt jest pakietem danych i procedur
. Dane są
trzymane w atrybutach obiektu. Procedury są
definiowane za pomocą metod obiektu. Metody
są
uaktywniane
przez
komunikaty
przekazywane między obiektami.
Obiektowy model danych powinien
dostarczać
środków do realizacji tożsamości obiektów. Jest
to możliwość rozróżnienia dwóch obiektów o
tych samych cechach.

Prof. dr hab. inż. S. Wiak
84
Relacyjny model danych jest modelem
danych zorientowanym na wartości
. Nie
wprowadza
możliwości
przyporządkowania
jednoznacznego
identyfikatora każdemu obiektowi w
bazie danych.
Dlatego
dwie
identyczne
krotki
w
relacyjnym modelu danych wskazują na
ten sam obiekt. Dwa identyczne rekordy
w
obiektowej
bazie
danych
mogą
odwoływać
się
do
dwóch
różnych
obiektów
dzięki
wprowadzeniu
jednoznacznego
identyfikatora
generowanego przez system.

Prof. dr hab. inż. S. Wiak
85
Wszystkie obiekty
muszą mieć własność hermetyzacji.
Jest to proces umieszczania danych i procesu w
jednym opakowaniu w ramach zdefiniowanego
interfejsu i udostępniania go z zewnątrz w sposób
kontrolowany przez ten interfejs. Hermetyzacja
przejmuje się niejawnie w definicję obiektu, ponieważ
wszystkie
operacje
na
obiektach
muszą
być
wykonywane przez zdefiniowane procedury dołączone
do obiektów.
Klasa
obiektów
jest
zgrupowaniem
podobnych
obiektów. Używamy jej do określenia wspólnych dla
grupy obiektów atrybutów, metod i związków.
Obiekty są więc instancjami pewnej klasy. Mają one
te same atrybuty i metody. Innymi słowy, klasy
obiektów definiują schemat bazy danych – główny
temat dziedziny projektowania baz. Obiekty definiują
zawartość bazy danych – główny temat dziedziny
implementacji baz danych.

Prof. dr hab. inż. S. Wiak
86
Tak więc bazy danych zastosowano w nowych
dziedzinach, formułując nowe, wymagania
związane z
zarządzaniem danymi.
Przykładami takich wymagań są:
Dane
niejednorodne
(nonhomogeneous
data).
Tradycyjne modele danych operują na
jednorodnych
zbiorach
obiektów,
charakteryzujących się niewielką liczbą typów
i dużą liczbą wystąpień każdego typu
. Nowe
zastosowania baz danych wymagają natomiast
różnorodnej
kolekcji
projektowanych
obiektów, które
charakteryzuje duża liczba
typów oraz stosunkowo mała liczba wystąpień
każdego typu.

Prof. dr hab. inż. S. Wiak
87
Długie łańcuchy znakowe o zmiennej
długości (variable length & long strings).
Zapis informacji multimedialnej w postaci
cyfrowej zawiera długie łańcuchy znakowe,
przy czym długość tych łańcuchów jest
zmienna. Tradycyjne bazy danych głównie
pracują
na
formatowanych
liczbach,
krótkich
łańcuchach
i
rekordach
o
ustalonym formacie.
Obiekty
złożone
(complex
objects).
Cechują się one hierarchiczną strukturą
danych. Często muszą być traktowane jako
niepodzielne
jednostki
danych,
mieć
charakter abstrakcyjny. Konwencjonalne
modele danych nie zapewniają takiego
poziomu abstrakcji.

Prof. dr hab. inż. S. Wiak
88
Wielowersyjność (version control).
W wielu
współczesnych zastosowaniach potrzebne jest
zachowanie poprzednich lub alternatywnych
wersji obiektu dla prześledzenia historii
procesu (back tracking) lub jego odtworzenia
(recovering).
Tradycyjne
bazy
danych
reprezentują dane aktualne; stare wersje
danych nie są zachowywane lub nie są
bezpośrednio dostępne dla użytkownika.
Ewolucja schematu (scheme evolution).
Bazy
danych wspomagające projektowanie, z reguły
podlegają modyfikacji schematu, w miarę
ewoluowania projektowanych przedmiotów.
Schemat w konwencjonalnych bazach danych
nie podlega tak szybkim zmianom.

Prof. dr hab. inż. S. Wiak
89
Obiekty
równoważne
(equivalent
objects).
Projektowany obiekt można
rozpatrywać
z
różnych
punktów
widzenia, co odpowiada istnieniu w bazie
danych jego różnych reprezentacji. W
przypadku zmiany wprowadzonej do
jednej reprezentacji obiektu, system
zarządzania bazą powinien dokonać
odpowiednich zmian we wszystkich
pozostałych
reprezentacjach
danego
obiektu. Tradycyjne bazy danych nie
mają mechanizmów do modelowania
semantyki obiektów równoważnych.

Prof. dr hab. inż. S. Wiak
90
Długie
transakcje
(long
transactions).
Transakcja jest sekwencją operacji zapisywania i
odczytu, która nie narusza integralności bazy
danych.
W
tradycyjnych
bazach
danych
transakcje są zazwyczaj krótkie i dotyczą
jednego rekordu lub określonej grupy rekordów.
Inna sytuacja powstaje w bazach danych
wspomagających projektowanie. Projektowanie i
testowanie
jednego
obiektu
może
trwać
tygodnie przed ostatecznym wprowadzeniem
tego obiektu do bazy danych. Dlatego w
przypadku odrzucenia danej wersji projektu,
system zarządzania bazą danych powinien być
zdolny do przywrócenia odpowiednio wczesnego
stanu transakcji, by można było iteracyjnie
powtórzyć dany etap projektowania.

Prof. dr hab. inż. S. Wiak
91
Tradycyjne
modele
danych,
w
tym
najbardziej popularny model relacyjny, nie
były w stanie sprostać lub w efektywny
sposób spełniać tych wymagań. Dlatego
też, w drugiej połowie lat 80-tych,
popularność w systemach informatycznych
zyskuje podejście obiektowe.
Szczególne znaczenie w rozwoju systemów
obiektowych
ma
dynamiczny
rozwój
języków
programowania
opartych
na
pojęciu obiektu. Początku tego trendu w
programowaniu należy szukać w latach
powstania języka Simula (1966 r.) oraz
jego
następcy
-
języka
Smalltalk.
Większość obecnych obiektowych baz
danych używa języka C++ (1980 r.) jako
podstawę opisu języka baz danych.

Prof. dr hab. inż. S. Wiak
92
Powstaje więc kilka kierunków rozwoju baz
danych.
Po pierwsze
Po pierwsze
– dalszy rozwój systemów
opartych o relacyjny model danych
.
Prawdopodobnie będzie jeszcze długo w
powszechnym użyciu, ze względu na:
ich obecne bardzo duże rozpowszechnienie,
zaufanie
jakim
cieszą
się
wśród
użytkowników,
doprowadzoną do perfekcji technologię
dotyczącą w szczególności ochrony danych
i optymalizacji zapytań,
prostotę i elastyczność relacyjnego modelu
danych
.

Prof. dr hab. inż. S. Wiak
93
Drugi kierunek
Drugi kierunek
rozwoju baz danych to
obiektowo – relacyjne bazy danych.
Ich twórcy
starają się zachować jak najwięcej z modelu
relacyjnego (aby wykorzystać osiągnięcia relacyjnych
baz danych), a jednocześnie wprowadzać pewne
aspekty obiektowe. Przedstawicielem tego kierunku
jest standard SQL3.
Trzecim
kierunkiem
Trzecim
kierunkiem
rozwoju,
najbardziej
obiecującym, to obiektowe bazy danych.
Standardem takich baz jest
ODMG (Object
Database Management Group),
organizacja
skupiająca firmy tworzące obiektowe bazy danych.
ODMG stworzyła standardy takich baz, najnowszą z
wersji jest ODMG 2.0. Elementami tego standardu
są:
ODL (Object Definition Language
– Język
definiujący
obiekty),
OQL
(Object
Query
Language
– Obiektowy język zapytań) oraz tzw.
wiązania do trzech języków programowania: C++,
Smalltalk i Java.

Prof. dr hab. inż. S. Wiak
94
Relacyjny model bazy danych (RMBD)
Twórcą relacyjnego modelu danych jest E. F.
Codd. W 1970 roku opublikował pracę, która
położyła
fundament
pod
najbardziej
ze
współczesnych modeli danych. Od 1968 do
1988 r. Codd opublikował ponad 30 prac na
temat relacyjnego modelu danych. Codd
powołuje się na trzy problemy, którym
poświęca
swoją
teoretyczną
pracę.
Po
pierwsze, twierdzi, że wcześniejsze modele
danych traktowały dane w niezdyscyplinowany
sposób.
Jego model, przy użyciu ścisłych
narzędzi matematycznych, zwłaszcza teorii
zbiorów, wprowadza zdyscyplinowany sposób
posługiwania się danymi
.

Prof. dr hab. inż. S. Wiak
95
Codd oczekiwał, że w wyniku stosowania
ścisłych metod zostaną osiągnięte dwie
podstawowe korzyści.
Po pierwsze
,
zostanie
poprawiony
możliwy
do
uzyskania
poziom niezależności między
programami a danymi
.
Po drugie
,
wzrośnie
wydajność
tworzenia
oprogramowania.

Prof. dr hab. inż. S. Wiak
96
Zgodnie z teorią model danych w relacyjnych
bazach
danych
składa
się
z trzech
podstawowych elementów:
Relacyjnych struktur danych
Operatorów
relacyjnych
umożliwiających
tworzenie, przeszukiwanie i modyfikację bazy
danych
Więzów integralności jawnie lub niejawnie
określających wartości danych
Podstawową strukturą danych jest relacja
będąca podzbiorem iloczynu kartezjańskiego
dwóch wybranych zbiorów reprezentujących
dopuszczalne wartości. W bazach danych
relacja przedstawiana jest w postaci tabeli.
Relacja jest zbiorem krotek posiadających taką
samą strukturę, lecz różne wartości.

Prof. dr hab. inż. S. Wiak
97
Każda
krotka
odpowiada
jednemu
wierszowi tablicy. Każda krotka posiada
co najmniej jeden atrybut odpowiadający
pojedynczej kolumnie tablicy. Każda
relacja (tablica) posiada następujące
własności:
krotki (wiersze) są unikalne
atrybuty (kolumny) są unikalne
kolejność krotek (wierszy) nie ma
znaczenia
kolejność atrybutów (kolumn) nie ma
znaczenia
wartości atrybutów (pól) są atomowe

Prof. dr hab. inż. S. Wiak
98
Przykład tabeli wraz z jej
elementami

Prof. dr hab. inż. S. Wiak
99
Dokumentacja
systemów
zarządzania
bazami danych posługuje się najczęściej
terminologią tabela, wiersz i kolumna, a
nie terminologią relacyjną. Wynika to z
tego, że operacje na relacjach są
opisywane za pomocą matematycznych
operacji na zbiorach i relacjach, które są
ścisłe,
ale
trudno
zrozumiałe
dla
przeciętnego użytkownika. Natomiast
posługiwanie się tabelami, wierszami i
kolumnami jest mniej formalne i ścisłe,
ale bardziej przejrzyste. W dalszej części
będzie stosowana zarówno jedna jak i
druga terminologia.

Prof. dr hab. inż. S. Wiak
100
Tabela może reprezentować:
zbiór encji wraz z atrybutami
zbiór powiązań pomiędzy encjami wraz z
ich atrybutami
zbiór encji wraz z atrybutami i ich
powiązania z innymi encjami (wraz z
atrybutami)
Każdy wiersz w tabeli reprezentuje pojedynczą
encję
,
powiązanie lub encję wraz z
powiązaniami
.
W tabeli nie powinny powtarzać
się dwa identyczne wiersze - zabezpieczenie
przed tym powtórzeniem jest realizowane
poprzez pola kluczowe.
Wiersze w odróżnieniu
od kolumn są dynamiczne - działanie bazy
danych polega na dopisywaniu, modyfikacji i
usuwaniu wierszy.

Prof. dr hab. inż. S. Wiak
101
W przypadku projektowania tabeli w bazie
danych należy stosować się do następujących
wskazówek:
Używaj nazw opisowych do nazwania kolumn
tabeli. Kolumny nie powinny mieć znaczenia
ukrytego, ani reprezentować kilku atrybutów
(złożonych w pojedynczą wartość).
Bądź konsekwentny w stosowaniu liczby
pojedynczej lub mnogiej przy nazywaniu tabeli.
Twórz tylko te kolumny, które są niezbędne do
opisania modelowanej encji lub powiązania -
tabele z mniejszą ilością kolumn są łatwiejsze
w użyciu.
Utwórz kolumnę pól kluczowych dla każdej
tabeli.
Unikaj powtarzania informacji w bazie danych
(normalizacja).

Prof. dr hab. inż. S. Wiak
102
Baza danych jest faktycznie zbiorem struktur danych
służących do organizowania i przechowywania
danych. W każdym modelu danych i w
konsekwencji w każdym
SZBD (SZBD - System
Zarządzania Bazą Danych)
musimy mieć do
dyspozycji zbiór reguł określających
wykorzystanie takich struktur danych w
aplikacjach baz danych. Tworząc definicję danych
używamy wewnętrznych struktur danych z myślą
o konkretnym zadaniu.
Jest tylko jedna struktura danych w relacyjnym
modelu danych – relacja
. W związku z tym, że
pojęcie relacji jest matematyczną konstrukcją,
relacja jest tabelą, dla której jest spełniony
następujący zbiór zasad:
1.
Każda relacja w bazie
danych ma jednoznaczną
nazwę. Według Codda dwuwymiarowa tabela jest
matematycznym zbiorem, a matematyczne zbiory
muszą być nazywane jednoznacznie.

Prof. dr hab. inż. S. Wiak
103
2.
Każda kolumna
w relacji ma jednoznaczną
nazwę w ramach jednej relacji. Każda
kolumna relacji jest również zbiorem i dlatego
powinna być jednoznacznie nazwana.
3.
Wszystkie wartości
w kolumnie muszą być
tego samego typu. Wynika to z punktu 2.
4.
Porządek kolumn
w relacji nie jest istotny.
Schemat relacji – lista nazw jej kolumn – jest
również matematycznym zbiorem. Elementy
zbioru nie są uporządkowane.
5.
Każdy wiersz
w relacji musi być różny. Innymi
słowy, powtórzenia wierszy nie są dozwolone
w relacji.
6.
Porządek wierszy
nie jest istotny. Skoro
zawartość relacji jest zbiorem, to nie powinno
być określonego porządku wierszy relacji
.

Prof. dr hab. inż. S. Wiak
104
7.
Każde
pole
leżące
na
przecięciu
kolumny/wiersza w relacji powinno zawierać
wartość atomową. To znaczy, zbiór wartości
nie jest dozwolony na jednym polu relacji.
W swojej pracy na
oznaczenie elementów
swojego
modelu
danych
Codd
użył
terminologii matematycznej.
Kolumny tabeli
to były atrybuty. Wiersze tabeli to były
krotki.
Liczba kolumn w tabeli to stopień
tabeli. Liczba wierszy w tabeli to liczebność
tabeli.
Każda relacja musi mieć klucz główny
. Dzięki
temu możemy zapewnić, aby wiersze nie
powtarzały się w relacji. Klucz główny to
jedna lub więcej kolumn tabeli, w których
wartości jednoznacznie identyfikują każdy
wiersz tabeli.

Prof. dr hab. inż. S. Wiak
105
Klucze obce
są sposobem łączenia danych
przechowywanych w różnych tabelach. Klucz obcy
jest kolumną lub grupą kolumn tabeli, która
czerpie swoje wartości z tej samej dziedziny co
klucz główny tabeli powiązanej z nią w bazie
danych.
W systemach relacyjnych
wprowadzono
specjalną wartość, aby wskazać niepełną
lub nieznaną informację – wartość
null
. Ta
wartość, różna od zera i spacji, jest
szczególnie użyteczna przy powiązaniu
kluczy głównego i obcego. Pojęcie wartości
null nie jest jednak do końca akceptowane.
Codd utrzymuje, że wprowadzenie wartości
null do systemu relacyjnego zmienia
konwencjonalną logikę dwuwartościową
(prawda, fałsz) na logikę trójwartościową
(prawa, fałsz, nieznane).

Prof. dr hab. inż. S. Wiak
106
Schemat relacji jest to zbiór
R = {A
1 ,
A
2 ,.......,
A
n
}
gdzie
A
1 ,
A
2
, ..., A
n
są atrybutami
( nazwami kolumn ).
Każdemu atrybutowi przyporządkowana jest
dziedzina
DOM ( A),
czyli zbiór
dopuszczalnych wartości.
Dziedziną relacji o schemacie
R = {A
1 ,
A
2 ,.......,
A
n
}
nazywamy sumę dziedzin wszystkich
atrybutów relacji:
DOM ( R) = DOM ( A1)
DOM ( A2) ...DOM ( An)

Prof. dr hab. inż. S. Wiak
107
Relacja o schemacie
R = {A
1 ,
A
2 ,.......,
A
n
}
jest to skończony zbiór
r = { t
1
, t
2
, ... ,
t
m
}
odwzorowań
t
i
: R DOM ( R)
takich, że dla
każdego
j, 1<= j <= n , t
i
( A
j
) DOM
( A
j
)
Każde takie odwzorowanie nazywa się
krotką (lub wierszem).
krotką (lub wierszem).
Krotka
odpowiada wierszowi w tabeli.

Prof. dr hab. inż. S. Wiak
108
System zarządzania relacyjną bazą danych, w
skrócie SZRBD
, to program wykorzystywany
do tworzenia i modyfikowania relacyjnych
baz danych. Służy również do generowana
aplikacji,
z
której
będzie
korzystał
użytkownik gotowej bazy.
Oczywiście jakość danego SZRBD zależy od
stopnia, w jakim implementuje on relacyjny
model logiczny. Nawet „prawdziwe” SZRBD
niekiedy diametralnie odbiegają od siebie w
tej kwestii, a pełnej implementacji
RMBD
nadal nie udało się nikomu osiągnąć. Mimo
to
obecne
SZRBD
są
potężniejsze
i
wszechstronniejsze niż kiedykolwiek.

Prof. dr hab. inż. S. Wiak
109
RMBD relacyjny model baz danych
. Po
raz pierwszy zaprezentowany przez dr
E.F. Codda w lipcu 1970 roku w pracy
Relacyjny model logiczny dla dużych
banków. Model został stworzony w
oparciu o dwie gałęzie matematyki
teorię mnogości i rachunek predykatów
pierwszego rzędu.

Prof. dr hab. inż. S. Wiak
110
Systemy zarządzania relacyjnymi
bazami danych
były wytwarzane przez sporą liczbę producentów
oprogramowania
od
wczesnych
lat
siedemdziesiątych. Programy te działały na
różnych platformach sprzętowych i pod różnymi
systemami operacyjnymi. Istnieją implementacje
SZRBD na praktycznie dowolny komputer.
Przez pewien czas po stworzeniu modelu relacyjnego
SZRBD
były pisane tylko na komputery
mainframe
.
Dwoma
takimi
programami, napisanymi
we
wczesnych latach siedemdziesiątych, były System
R,
opracowany
przez
IBM
w
laboratorium
badawczym w San Jose, oraz INGRES (
interaktywny
System Obsługi Grafiki; ang. Interactive Graphics
Retrieval System
), powstały na Uniwersytecie
Berkeley. Oba te systemy przysłużyły się znacząco
do upowszechnienia modelu relacyjnego.

Prof. dr hab. inż. S. Wiak
111
W miarę jak zalety
RMBD
stawały się coraz
wyraźniejsze,
wiele
organizacji
zaczęło
powoli przechodzić z modeli hierarchicznych
i sieciowych na model relacyjny, stwarzając
tym samym popyt na lepsze i większe
programy SZRBD. Lata osiemdziesiąte były
okresem burzliwego rozwoju komercyjnych
systemów zarządzania dla komputerów
mainframe
, jak np.
Oracle korporacji Oracle,
czy DB2 IBM.

Prof. dr hab. inż. S. Wiak
112
We wczesnych latach osiemdziesiątych do
powszechnego użytku zaczęły wchodzić
komputery osobiste, a razem z nimi,
przeznaczone dla nich, SZRBD. Niektóre z
wcześniejszych programów, jak
dBase
firmy Ashton-Tate czy FoxPro z Fox
Software
,
były
jedynie
prostymi
systemami
zarządzania
danymi,
zapisanymi
w
plikach.
Historia
prawdziwych SZRBD dla komputerów PC
rozpoczęła się wraz z wejściem na rynek
programów
R:BASE firmy Microrim oraz
Paradox firmy Ansa Software
. Każdy z tych
produktów przyczynił się do udostępniania
użytkownikom
komputerów
domowych
możliwości uprzednio zarezerwowanych
dla systemów mainframe.

Prof. dr hab. inż. S. Wiak
113
W miarę jak coraz więcej użytkowników
wchodziło w kontakt z bazami danych, po
koniec lat osiemdziesiątych i na początku
dziewięćdziesiątych potrzeba szerszego
udostępnienia danych gromadzonych w
owych bazach stała się pilna.
Pomysł
centralnie ulokowanej bazy dostępnej dla
dowolnej liczby użytkowników wydawał
się bardzo kuszący.
Poza zwiększeniem
szybkości
systemu,
przechowywanie
danych w jednym miejscu znacznie
ułatwiłoby
ich
obsługę
i
ochronę.
Producenci oprogramowania baz danych
odpowiedzieli na to zapotrzebowanie,
opracowując system
SZRBD typu klient-
serwer
.

Prof. dr hab. inż. S. Wiak
114
W tym typie SZRBD
dane znajdują się w
centralnym komputerze, nazywanym
serwerem
bazy danych
, a użytkownicy uzyskują do nich
dostęp, wykorzystując aplikacje zainstalowane
w ich własnych komputerach PC, nazywanych
klientami bazy danych
.
Serwer „troszczy się” zarówno o integralność
bazy, jak i o ich bezpieczeństwo, umożliwiając
stworzenie wielu różnych aplikacji-klientów,
których
zastosowanie
nie
wyklucza
się
nawzajem
i
nie
zagraża
danym
przechowywanym na serwerze. Zarówno sama
baza danych, jak i obsługujące ją aplikacje są
nadzorowane przez
oprogramowanie SZRBD
typu klient-serwer.

Prof. dr hab. inż. S. Wiak
115
Bazy
danych typu
klient-serwer
są
obecnie
szeroko
wykorzystywane
przy obsłudze dużych ilości danych
współdzielonych
przez
wielu
użytkowników.
Najnowsze systemy
zarządzania
takimi bazami to między
innymi:
Microsoft SQL Serwer
firmy
Microsoft,
Oracle 7
Cooperative
Server korporacji Oracle czy
Sybase
System 11 SQL Server
firmy
Sybase
.

Prof. dr hab. inż. S. Wiak
116
Systemy zarządzania
relacyjnymi bazami danych
mają za sobą długą historię, a rola odgrywana
przez nie w obsłudze danych zarówno w dużych,
jak i małych organizacjach jest trudna do
przecenienia. Należy oczekiwać, że w niedługiej
przyszłości wpływ tych programów na nasze
życie ulegnie dalszemu zwiększeniu na skutek
integracji ich możliwości z architekturą sieci
Internet.
Model
został
oparty
na
dwóch
gałęziach
matematyki – teorii mnogości i rachunku
predykatów pierwszego rzędu
. W
RMBD
dane
przechowywane są w tabelach. Każda tabela
składa się z rekordów oraz pól. Fizyczna
kolejność pól i rekordów w tabeli jest całkowicie
bez znaczenia. Każdy rekord jest wyróżniany
przez jedno pole zawierające unikatową wartość.
Te dwie cechy RMBD umożliwiają trwanie danych
niezależnie od sposobu, w jaki przechowuje je
komputer.

Prof. dr hab. inż. S. Wiak
117
Użytkownik nie musi zatem znać fizycznego
położenia rekordu, który chce odczytać. To
odróżnia relacyjny model danych od modelu
hierarchicznego
i
sieciowego,
gdzie
użytkownik musiał opanować strukturę bazy
danych, by móc odczytać interesujące go
dane. Rysunek przedstawia diagram modelu
RMBD.
Relacje w RMBD można podzielić na trzy grupy:
jeden – do – jednego,
jeden – do – wielu
wiele – do – wielu.
Każde dwie tabele, między którymi istnieje
relacja, są ze sobą jawnie powiązane,
ponieważ dzielone przez nie pola zawierają
odpowiadające sobie wartości.
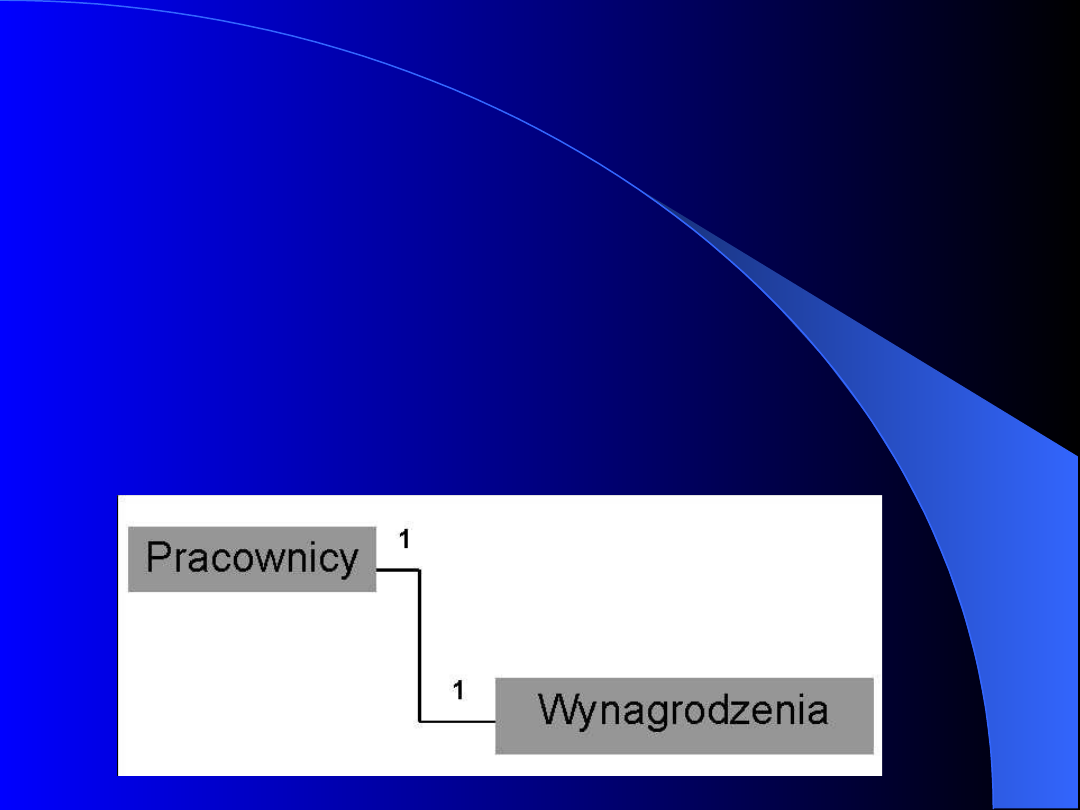
Prof. dr hab. inż. S. Wiak
118
1 – 1
- jeden do jednego - relacja ta nazywana jest
związkiem jednoznacznym. W związku tym
jednemu rekordowi z pierwszej tabeli może
odpowiadać tylko jeden rekord z drugiej tabeli i
odwrotnie - jednemu rekordowi z tabeli drugiej
może odpowiadać tylko jeden rekord z tabeli
pierwszej. Jest to rzadko spotykany typ relacji,
gdyż większość informacji powiązanych w ten
sposób byłoby zawartych w jednej tabeli, na
Rysunku przedstawiona została relacja
1–1
dla
tabel
Pracownicy i Wynagrodzenia.
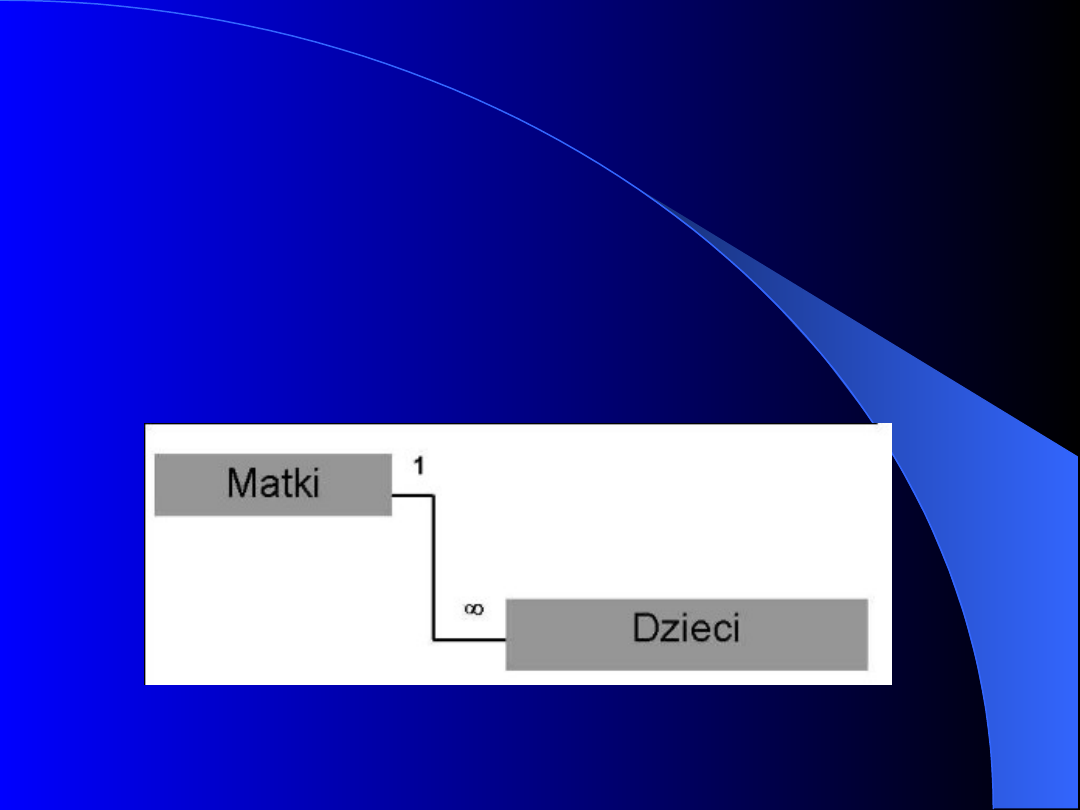
Prof. dr hab. inż. S. Wiak
119
1 – ∞
- jeden do wielu - relacja najczęściej
spotykana w bazach danych. W relacji tej
jednemu rekordowi z tabeli pierwszej może
odpowiadać wiele rekordów z tabeli drugiej,
natomiast jednemu rekordowi z tabeli drugiej
może odpowiadać tylko jeden rekord z tabeli
pierwszej,
na
przykład
relacja
pomiędzy
tabelami
MATKI i DZIECI
(Rys. poniżej), gdzie
jedna matka może mieć wiele dzieci, natomiast
jedno dziecko może mieć tylko jedną matkę.

Prof. dr hab. inż. S. Wiak
120
∞ – ∞
- wiele do wielu - jest to tzw. związek
wieloznaczny. W relacji takiej jednemu rekordowi z
pierwszej tabeli może odpowiadać jeden lub więcej
rekordów z tabeli drugiej i odwrotnie – jednemu
rekordowi z drugiej tabeli może odpowiadać jeden
lub wiele rekordów z tabeli pierwszej. Stworzenie
relacji
wiele-do-wielu
jest trudne, a ponadto wiąże
się
z
wprowadzeniem
dużej
ilości
danych
powtarzających
się,
a
operacje
związane
z
modyfikowaniem,
usuwaniem
czy
wstawianiem
danych sprawiają duże kłopoty. Przykładem takiej
relacji jest Rys. nastepny. Mamy tu tabelę
STUDENCI
oraz tabelę
WYKŁADY
. Występuje tu relacja
wiele-do-
wielu
, ponieważ wiele studentów może chodzić na
wiele wykładów. W praktyce relacje takie zastępuje
się dwiema relacjami
1 – ∞
, z wykorzystaniem relacji pośredniczącej (Rys.
poniżej). Tabela taka składa się z kopii kluczy
podstawowych obu tabel.
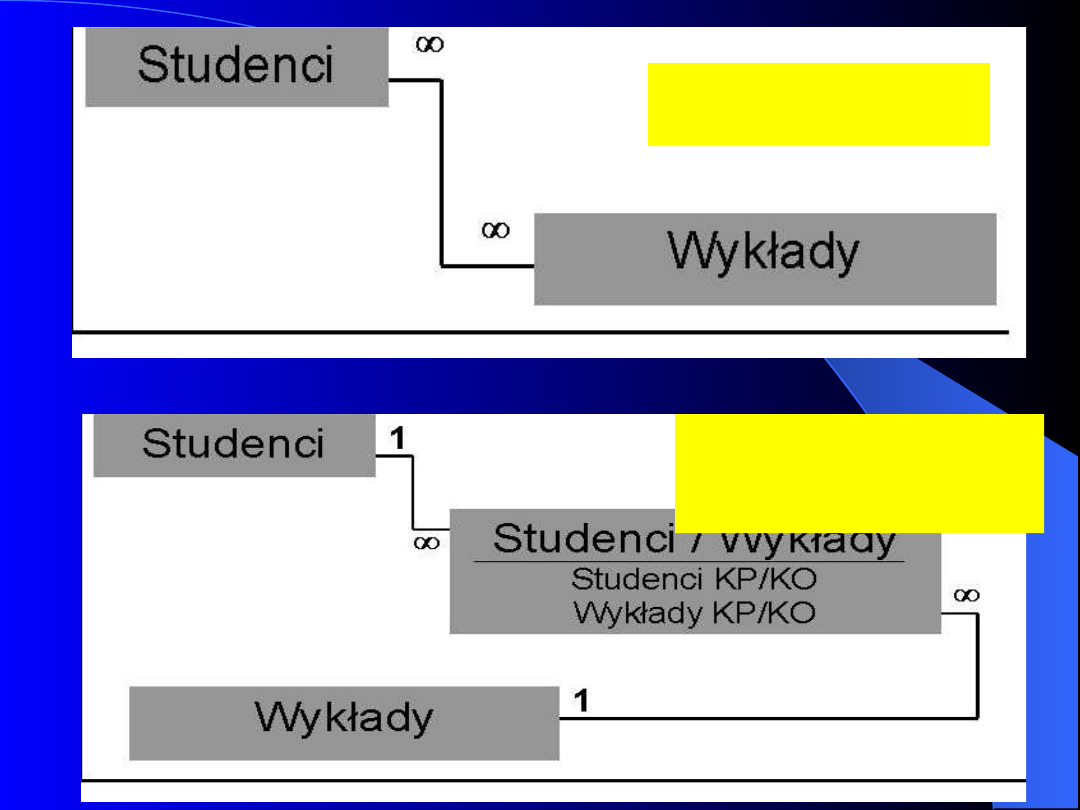
Prof. dr hab. inż. S. Wiak
121
Przykład relacji ∞–
∞
Przykład relacji ∞–∞
z tabelą
pośredniczącą
Prof. dr hab. inż. S. Wiak
122
pośrednicy
gatunki/muzycy
muzycy
klienci
rozliczenia
gatunki
muzyczne
Diagram relacyjnego modelu logicznego. (Każdy
pośrednik pracuje dla kilku muzyków i ma
pewną liczbę klientów. Ponadto klienci i muzycy
są ze sobą powiązani przez tabelę umów,
ponieważ klient może zatrudnić dowolną liczbę
muzyków, a każdy muzyk może grać dla wielu
różnych klientów. Oprócz tego każdy muzyk
reprezentuje jeden lub więcej gatunków muzyki,
co odzwierciedla tabela „gatunki/muzycy”)

Prof. dr hab. inż. S. Wiak
123
Jeżeli użytkownik wie, jakie relacje występują
między poszczególnymi tabelami w bazie
danych, może czerpać z niej informacje na
niemal nieograniczoną ilość sposobów,
kojarząc ze sobą dane z bezpośrednio lub
pośrednio powiązanych tabel.
W
RMBD dostęp do danych uzyskuje się,
podając nazwę interesującego nas pola oraz
tabeli, do której należy
. Jednym ze
sposobów jest wykorzystanie strukturalnego
języka zapytań SQL (ang. Structured Query
Language).
SQL
jest
standardowym
językiem używanym do wprowadzania,
modyfikowania
oraz
odczytywania
informacji z bazy danych.

Prof. dr hab. inż. S. Wiak
124
Relacyjny model logiczny bazy danych
posiada wiele zalet. Najważniejsze z
nich to:
Wielopoziomowa
integralność
danych.
Integralność na poziomie pól zapewnia
dokładność
wprowadzania
danych,
integralność na poziomie tabel uniemożliwia
powtarzanie się tego samego rekordu i
pozostawienie
nie
wypełnionych
pól
wchodzących w skład klucza podstawowego,
integralność na poziomie relacji gwarantuje
odpowiednie ich zdefiniowanie, a reguły
integralności kontrolują poprawność danych
z punktu widzenia tematu bazy danych.

Prof. dr hab. inż. S. Wiak
125
Logiczna i fizyczna niezależność od
aplikacji
bazodanowych
.
Zarówno
zmiany
wprowadzane
przez
użytkownika do projektu logicznego,
jak i modyfikacje sposobów fizycznej
implementacji
bazy
przez
producentów oprogramowania mają
znikomy wpływ na działanie aplikacji
obsługującej tę bazę.

Prof. dr hab. inż. S. Wiak
126
Zagwarantowana
dokładność
i
poprawność danych
. Dane są poprawne i
dokładne
dzięki
wprowadzeniu
wielopoziomowej integralności.
Łatwy dostęp do danych.
Dane można w
prosty sposób odczytywać z pojedynczej
tabeli lub z całej grupy powiązanych
tabel.
Te zalety czynią RMBD użytecznym we
wszystkich
sytuacjach
wymagających
gromadzenia i przechowywania danych.
Obecnie jest on najbardziej popularnym
wśród wszystkich modeli baz danych.

Prof. dr hab. inż. S. Wiak
127
Jeszcze do niedawna za
główną wadę RMBD
uważany był fakt, że oparte na nim aplikacje
działały bardzo powoli. Nie była to jednak
wina samego modelu, lecz technologii
wykorzystywanej w czasach kiedy powstawał.
Dostępna wówczas moc obliczeniowa, pamięć
operacyjna i masowa nie wystarczały do
pełnego zaspokojenia potrzeb producentów
oprogramowania obsługującego RMBD.
Postęp w mikroelektronice i w inżynierii
oprogramowania zepchnęły problem mocy
obliczeniowej na dalszy plan i umożliwiły
producentom
oprogramowania
pełną
implementację relacyjnego modelu bazy
danych.

Prof. dr hab. inż. S. Wiak
128
Algebra relacyjna
Algebra relacyjna
jest
zbiorem ośmiu
zbiorem ośmiu
operatorów
operatorów. Każdy operator bierze
jedną lub więcej relacji jako argument
i produkuje jedną relację jako wynik.
Trzema głównymi operatorami
algebry
relacyjnej są:
selekcja
(ograniczenie),
rzut
(projekcja) i
złączenie
. Dzięki tym
trzem operatorom możemy wykonać
większość
operacji
na
danych
wymaganych od systemu relacyjnego.
Istnieją również dodatkowe operatory -
iloczyn, suma, przecięcie, różnica i
iloraz.

Prof. dr hab. inż. S. Wiak
129
Selekcja.
Selekcja jest operatorem, który
bierze jedną relację jako swój argument i
produkuje w wyniku jedną relację.
Selekcja może być uważana za “poziomą
maszynę do cięcia", gdyż wydobywa z
wejściowej relacji wiersze, które pasują
do podanego warunku, i przekazuje je do
relacji wynikowej.
Operator selekcji ma składnię:
RESTRICT <nazwa tabeli>
[WHERE
<warunek>]
<tabela
wynikowa>
np.:
RESTRICT Studenci WHERE Wiek >=
18
Poborowi

Prof. dr hab. inż. S. Wiak
130
Rzut.
Operator rzutu bierze jedną
relację jako swój argument i
produkuje jedną relację
wynikową. Rzut jest “pionową
maszyną do cięcia”
Operator projekcji ma składnię:
PROJECT <nazwa tabeli>
[<lista
kolumn>]
<tabela
wynikowa>
np.:
PROJECT Studenci (Nazwisko)
Lista

Prof. dr hab. inż. S. Wiak
131
Suma.
Suma
()
jest operatorem,
który bierze dwie zgodne relacje jako
swoje argumenty i produkuje jedną
relację
wynikową.
Zgodne,
czyli
tabele
mają
te
same
kolumny
określone
na
tych
samych
dziedzinach (uwzględnia wszystkie
wiersze z obu tabel w tabeli
wynikowej).
Operator sumy ma składnię:
<tabela 1> UNION <tabela 2>
<tabela wynikowa>

Prof. dr hab. inż. S. Wiak
132
Przecięcie.
Przecięcie
()
ma
działanie przeciwne działaniu sumy
(uwzględnia w tabeli wynikowej
tylko wiersze wspólne dla obu
tabel).
Operator przecięcia ma składnię:
<tabela 1> INTERSECTION <tabela
2> <tabela wynikowa>

Prof. dr hab. inż. S. Wiak
133
Złączenie.
Złączenia oparte są na relacyjnym
operatorze iloczynu kartezjańskiego
(),
to znaczy z dwóch relacji będących
argumentami złączenia produkowana
jest jedna relacja wynikowa będąca
wszystkimi możliwymi kombinacjami
wierszy z wejściowych tabel.
Operator iloczynu kartezjańskiego ma
składnię:
PRODUCT <tabela 1> WITH <tabela 2>
<tabela wynikowa>

Prof. dr hab. inż. S. Wiak
134
Rozróżnia się:
Równozłączenie,
które jest iloczynem
kartezjańskim po którym wykonywana
jest selekcja. Onacza to, iż łączy się dwie
tabele, ale tylko dla wierszy, w których
wartości w kolumnach złączenia są takie
same. Kolumnami złączenia może być
klucz główny jednej tabeli i klucz obcy
drugiej tabeli.
Składnia równozłączenia jest następująca:
EQUIJOIN <tabela 1> WITH <tabela 2>
<tabela wynikowa>

Prof. dr hab. inż. S. Wiak
135
Złączenie naturalne
, które jest iloczynem
kartezjańskim po którym wykonywana jest
selekcja oraz rzut, w którym nie bierze się pod
uwagę kolumn złączenia.
Składnia złączenia naturalnego jest następująca:
JOIN <tabela 1> WITH <tabela 2> <tabela
wynikowa>
Może jeszcze istnieć
złączenie zewnętrzne
, w
którym brane są pod uwagę wszystkie wiersze
z
jednej
(złączenie
lewostronne
lub
prawostronne) lub obu relacji (złączenie
obustronne), bez względu na to czy mają swoje
odpowiedniki.

Prof. dr hab. inż. S. Wiak
136
Różnica
W wypadku tego operatora
(-)
istotna
jest
kolejność
określania
argumentów.
Produkuje on te wiersze, które są w pierwszej
tabeli i jednocześnie nie będące w tabeli
drugiej.
Operator różnicy ma składnię:
<tabela 1> DIFFERENCE <tabela 2> <tabela
wynikowa>
Algebra relacyjna jest
proceduralnym językiem
zapytań, ponieważ ma własności domknięcia
,
to
znaczy
wynik
zastosowania
jednego
operatora relacyjnego może być przekazany
jako
argument
wejściowy
kolejnemu
operatorowi relacyjnemu. W związku z tym
dowolny ciąg instrukcji algebraicznych można
zastąpić jednym wyrażeniem zagnieżdżonym.

Prof. dr hab. inż. S. Wiak
137
Operacje dynamiczne na relacjach
Istnieją trzy podstawowe operacje dynamiczne
potrzebne
do
wspomagania
działań
wyszukiwania:
wstawianie (INSERT)
usuwanie (DELETE)
modyfikacja (UPDATE)
INSERT
(<wartość>,<wartość>,...)
INTO
<nazwa
tabeli>
DELETE
<nazwa tabeli>
WITH
<warunek>
UPDATE
<nazwa tabeli>
WHERE
<warunek>
SET
<nazwa kolumny> = <wartość>
Podczas modyfikacji trzeba uważać, żeby nie
naruszyć
żadnych
więzów
integralności
określonych w schemacie relacji.

Prof. dr hab. inż. S. Wiak
138
Integralność danych
Mówimy
, że baza danych ma właściwość
integralności, kiedy istnieje odpowiedniość
między faktami przechowywanymi w bazie
danych a światem rzeczywistym modelowanym
przez tą bazę. Tą właśnie integralność
zapewniają reguły integralności, które można
podzielić na dwa rodzaje:
integralność encji
oraz
integralność referencyjną
.
Integralność encji
dotyczy kluczy głównych.
Mówi ona, że każda tabela musi mieć klucz
główny i, że kolumna lub kolumny wybrane
jako klucz główny powinny być jednoznaczne i
nie zawierać wartości null.
Wynika stąd, że w
tabeli są zabronione powtórzenia wierszy.

Prof. dr hab. inż. S. Wiak
139
Integralność referencyjna
dotyczy kluczy
obcych. Mówi ona, że wartość klucza obcego
może się znajdować tylko w jednym z dwóch
stanów.
Wartość klucza obcego
odwołuje się do wartości
klucza głównego w tabeli w bazie danych.
Czasami wartość klucza obcego może być null,
co oznacza że nie ma związku między
reprezentowanymi obiektami w bazie danych
albo że ten związek jest nieznany.
Utrzymywanie integralności referencyjnej
,
oprócz określenia czy klucz obcy jest null czy
nie, obejmuje również określenie
więzów
propagacji
. Mówią one co powinno się stać z
powiązaną tabelą, gdy modyfikujemy wiersz
lub wiersze w tabeli docelowej.

Prof. dr hab. inż. S. Wiak
140
Są trzy możliwości
Są trzy możliwości, które określają co się
będzie działo z docelowymi i powiązanymi
krotkami dla każdego związku między
tabelami w naszej bazie:
Ograniczone
usuwanie
(Restricted).
Podejście ostrożne – nie dopuszcza do
usuwania
rekordu
nadrzędnego,
jeśli
istnieją rekordy podrzędne.
Kaskadowe
usuwanie
(Cascades).
Podejście ufne – przy usuwaniu rekordu
nadrzędnego
usuwa
także
rekordy
podrzędne.
Izolowane usuwanie
(Isolated). Podejście
wyważone
–
usuwa
jedynie
rekord
nadrzędny.

Prof. dr hab. inż. S. Wiak
141
Oprócz wewnętrznej integralności
bazy danych można do schematu
relacji
dodać
dodatkową
integralność
,
przez
dołączenie
ciągu definicji więzów, zapisanych
w
postaci
wyrażeń
algebry
relacyjnej
lub
rachunku
relacyjnego
. Najczęściej stosuje się
do tego zagnieżdżone wyrażenia
algebry relacyjnej.

Prof. dr hab. inż. S. Wiak
142
Modelowanie danych
Modelowanie danych
Diagramy
związków
encji
encji
(ang.
entity
relationship diagramming
; nazywa się je
również
diagramami
ER
)
są
metodą
modelowania danych. Obrazują podstawowe
składniki bazy danych i związki między nimi w
trakcie jej projektowania.
Diagram ER jest często nazywany semantycznym
modelem danych. Słowo model wskazuje, że ze
świata rzeczywistego będziemy pobierać tylko
te dane, które są istotne dla tworzenia systemu
komputerowego.
Semantyczny charakter diagramu ER wiąże się z
uwzględnianiem
znaczenia
składników
diagramu.

Prof. dr hab. inż. S. Wiak
143
W przypadku diagramu ER,
encje są zazwyczaj
opisywane
rzeczownikami
,
atrybuty-
przymiotnikami i rzeczownikami,
a
związki -
czasownikami
. Ponieważ encje są powiązane
ze sobą za pomocą związków, jakie tworzą,
znaczenie każdej z nich wynika z jej
kontekstu, tak jak znaczenie wyrazu w zdaniu
z kontekstu, w jakim został użyty.
Pierwsza próba utworzenia modelu danych
polega
na
rozpatrzeniu
pomysłów
i
zorientowaniu
się,
jak
różne
elementy
informacji mają się względem siebie. Kolejne
modyfikacje
diagramu
ER
umożliwiają
ulepszanie projektu do chwili, aż będzie
możliwe utworzenie z niego bazy danych.
Semantyczne
modelowanie
danych
daje
sposobność przedstawiania i modyfikowania
projektu.

Prof. dr hab. inż. S. Wiak
144
Diagramy związków encji
Encja to zbiór obiektów
, istniejących
niezależnie i jednoznacznie zdefiniowanych,
które mogą być reprezentowane za pomocą
jednakowej struktury.
Termin encja
używany
jest zarówno w znaczeniu
typ encji
, czyli
zbiór encji o tych samych własnościach, jak
i
instancja encji
, czyli konkretny egzemplarz
encji. W diagramie ER encje o podobnej
strukturze są grupowane w zbiory, którym
nadaje się nazwy. Nazwy te są umieszczane
na diagramie i reprezentują wiele instancji
modelowanych obiektów, z których każdy
ma identyczną strukturę rekordu.
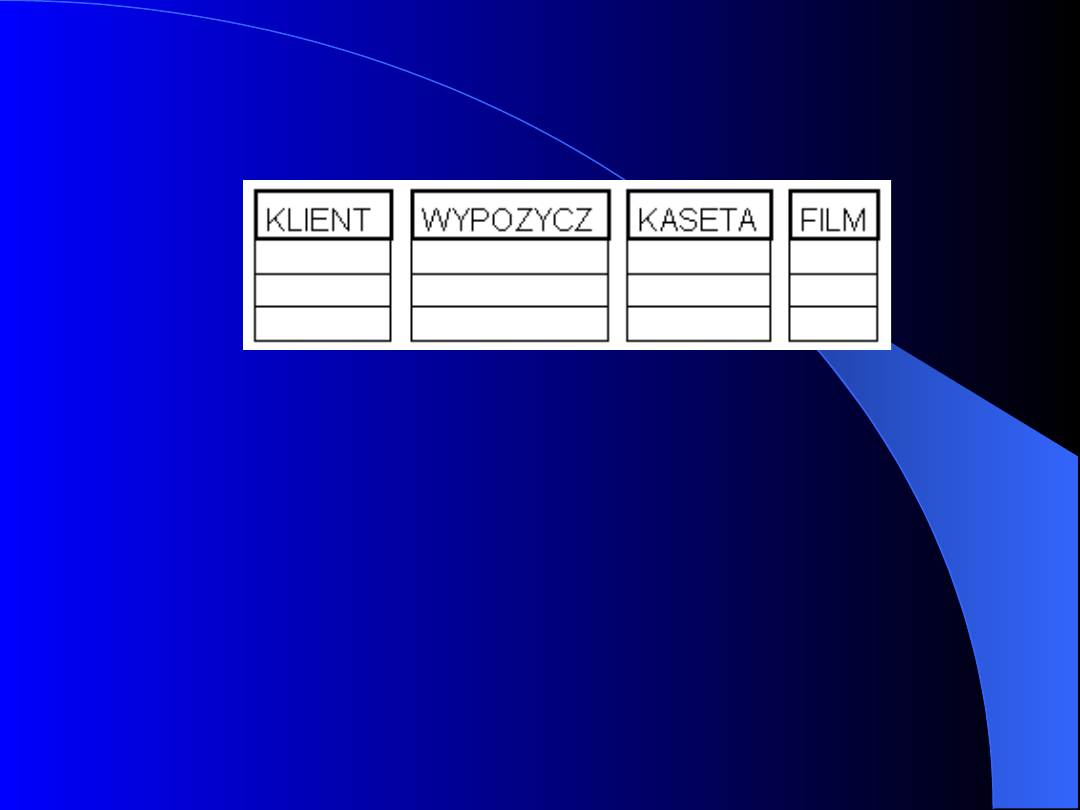
Prof. dr hab. inż. S. Wiak
145
Przykładowo, encjami w diagramie
przedstawionym na rysunku będą
KLIENT,
WYPOZYCZ, KASETA, FILM.
Przykład systemu pozwalającego na
zapisywanie informacji o wypożyczonych
kasetach video
Po opracowaniu diagramu, nazw encji używa się
w relacyjnej bazie danych jako nazw tabel.
Encje
powiązane
są
związkami
oraz
scharakteryzowane pewną liczbą właściwości
lub atrybutów.

Prof. dr hab. inż. S. Wiak
146
Atrybuty
zawierają
opisy cech encji
. Z powodów
związanych z samą strukturą relacyjnych baz
danych, ich typ musi być liczbą całkowitą, liczbą
rzeczywistą, datą, wartością logiczną, itd.
Poniższy rysunek przedstawia
encję KLIENT
z
zestawionymi wszystkimi jego atrybutami,
takimi jak numer klienta, jego imię, nazwisko,
data urodzenia, nazwa ulicy, numer telefonu,
numer dowodu, data zapisu oraz miejsce
przewidziane na wprowadzenie dodatkowych
uwag o kliencie.
Atrybuty stają się nazwami kolumn
w tabelach
odpowiadających encjom, gdy diagram zostaje
przetłumaczony na relacyjną bazę danych.
Czasami trudno jest podjąć decyzję,
czy coś jest
encją, czy atrybutem, np. KLIENT może być
atrybutem encji FIRMA

Prof. dr hab. inż. S. Wiak
147
Przykładowa encja
KLIENT z jej atrybutami
Ogólna zasada w takim przypadku polega na
rozpoznaniu, co ma być przechowywane i czy jest
do tego potrzebna cała nowa encja, czy też
wystarczy tylko atrybut w pewnej encji.
Z
atrybutem jest zawsze związana tylko jego
wartość
,
podczas gdy z encją można związać cały
zbiór informacji.

Prof. dr hab. inż. S. Wiak
148
Dwie encje można często połączyć w jedną, gdy
różnią się tylko kilkoma atrybutami. Przy takim
połączeniu niektóre instancje encji nie mają
przypisanych wartości do niektórych swoich
atrybutów.
Istnieje specjalna wartość używana w
takich przypadkach, która nazywa się wartością
pustą (oznaczana przez null), różna od spacji czy
zera.
Oznacza ona wartość albo nieznaną albo
niestosowaną w danej sytuacji.
Połączenie dwóch podobnych rodzajów encji w
jedną ma uzasadnienie wtedy, kiedy dzięki temu
zostaje uproszczony model i baza danych. Trzeba
pamiętać, że im więcej encji, tym bardziej
skomplikowany system. Za uproszczenie modelu
płaci się zwykle zwiększoną pamięcią, jak
również
utratą
zdolności
odróżnienia
rzeczywiście różnych encji.

Prof. dr hab. inż. S. Wiak
149
Ten konflikt między kosztem, a prostotą jest
bardzo
trudny
do
pogodzenia
podczas
projektowania systemu, ponieważ zależy w
dużej mierze od sposobu użycia danych po
zainstalowaniu systemu dla użytkowników. Jest
to jedno z zagadnień, z którymi projektanci
bazy danych mają najwięcej kłopotów.
Należy pamiętać, że wartością każdego atrybutu
musi być wartość prostego typu danych
, aby
można było bezpośrednio przejść od diagramu
do relacyjnej bazy danych. W przypadku
związania z encją zbioru wartości, zbiór ten
musi być reprezentowany jako osobna encja.
Atrybuty mogą opisywać dana encję lub
reprezentować związki danej encji z innymi.

Prof. dr hab. inż. S. Wiak
150
Klucz
jest to atrybut lub zbiór atrybutów
dla danego typu encji, których wartości
jednoznacznie identyfikują każdą instancję
encji. W składa klucza mogą wchodzić
atrybuty określające związki danej encji z
innymi.
Na diagramie atrybuty klucza
mogą być zaznaczane przez umieszczenie
gwiazdki lub pogrubione.
W początkowej fazie tworzenia modelu
danych
nie
należy
stosować
tzw.
atrybutów wyliczanych
. Są to atrybuty
definiowane za pomocą innych atrybutów,
np. wiek na podstawie daty urodzenia.

Prof. dr hab. inż. S. Wiak
151
Związki zachodzące pomiędzy encjami
Związek jest to uporządkowana lista encji, w
której
poszczególne
encje
mogą
występować wielokrotnie. Związki określają
wzajemne
relacje
między
zbiorami
egzemplarzy encji, wchodzących w skład
związku. Taka relację nazywa się
instancją
związku
. Związek można formalnie zapisać
przy użyciu notacji relacyjnej, jako:
Z(E
1
,....,E
n
)
Przykładowo, klient może dokonywać
wielokrotnie wypożyczenia kaset - każdemu
więc klientowi jest przyporządkowany zbiór
kaset. Na rysunku poniżej słowo
WYPOŻYCZA, umieszczone w ramce,
symbolizuje związek między encjami.
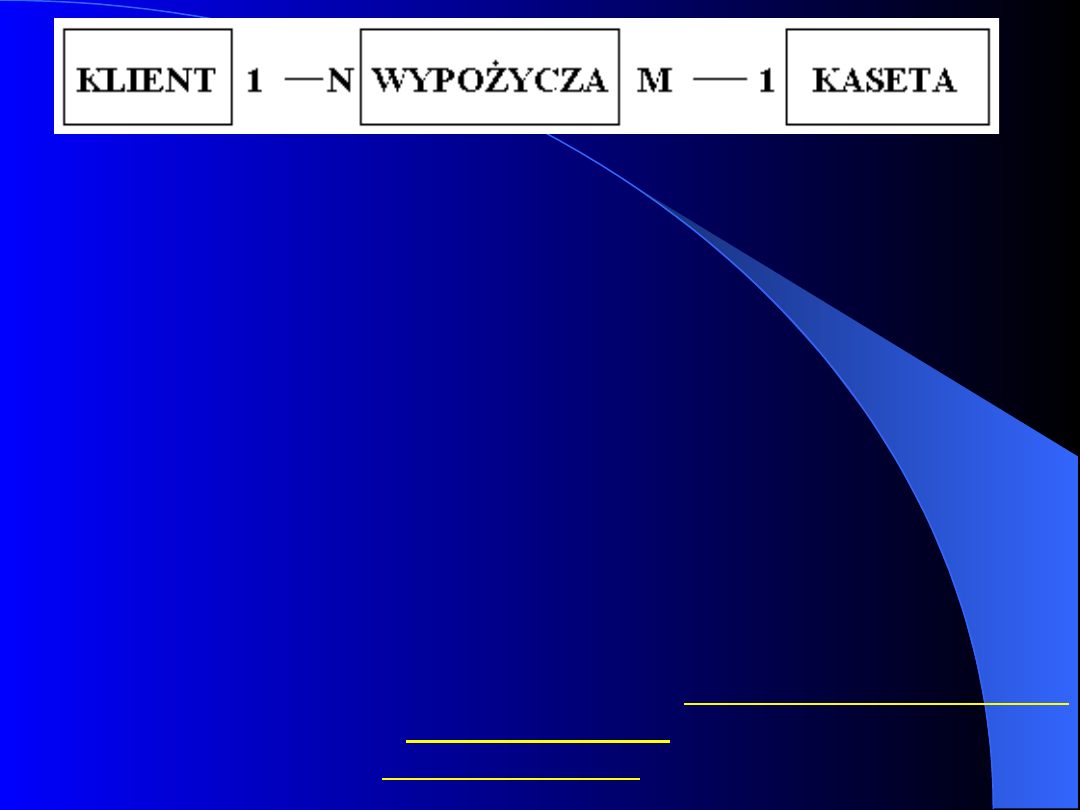
Prof. dr hab. inż. S. Wiak
152
Przykładowe związki między encjami Klient i Kaseta
Związek WYPOŻYCZA ma przyporządkowaną literę N
po stronie KLIENT, a literę M po stronie KASETA.
Oznaczenie to określa liczebność związku i wskazuje
(w tym przypadku), że każdy KLIENT mógł
wypożyczyć dowolną liczbę KASET oraz, że każda z
KASET może zostać wypożyczona kilkakrotnie dla
różnych klientów. Mamy więc tu do czynienia ze
związkiem wieloznacznym.
Większość związków to związki binarne, czyli
dwuargumentowe, reprezentowane przez linię
łączącą dwie encje. Rozróżnia się następujące
rodzaje związków binarnych:
jedno-jednoznaczne
(jeden do jeden),
jednoznaczne
(wiele do jeden lub
jeden do wiele) i
wieloznaczne
(wiele do wiele).

Prof. dr hab. inż. S. Wiak
153
Związki jedno-jednoznaczne
(jeden do jednego)
Związki jedno - jednoznaczne charakteryzują się
tym, że dla każdej instancji jednej z dwóch
encji istnieje dokładnie jedna instancja
drugiej encji, pozostająca z nią w rozważanym
związku.
Związki jedno - jednoznaczne
rzadko
występują w bazach danych, ponieważ istnieje
tendencja, aby łączyć takie pary encji w
jedną.
Aby rozpoznać tego typu związek, należy
sprawdzić, czy dla każdej instancji jednej encji
istnieje dokładnie jedna instancja encji po
przeciwnej stronie związku, a następnie to
samo powtórzyć dla drugiej. Przykładem tego
typu związku mógłby być związek pomiędzy
KLIENT a jego numerem identyfikacji PESEL,
gdyby on występował w oddzielnej encji.

Prof. dr hab. inż. S. Wiak
154
Związki jednoznaczne
(jeden do wielu, lub wiele
do jednego)
Związki
jednoznaczne
są
najczęściej
spotykanymi związkami w typowych bazach
danych. Dzieje się tak dlatego, ponieważ
związek wieloznaczny można prawie zawsze
uprościć, zamieniając go na dwa związki
jednoznaczne.
Jednoznaczne związki są realizowane przez
utworzenie atrybutu encji po stronie
wieloznacznej (tzn. etykietowanej przez N),
aby umieścić w nim klucz encji znajdującej się
po stronie jednoznacznej (tzn. etykietowanej
przez 1). Jednoznaczne związki są zawsze
reprezentowane powiązaniem przez wartość
klucza obcego w tabeli odpowiadającej encji
po stronie wiele związku i klucza głównego w
tabeli odpowiadającej encji po stronie jeden.

Prof. dr hab. inż. S. Wiak
155
Związki wieloznaczne
(wiele do
wielu)
Związki wieloznaczne - przed zastąpieniem
ich dwoma związkami jednoznacznymi -
są bardzo powszechne w bazach danych.
Encje KLIENT i KASETA na przykład są
powiązane związkiem WYPOZYCZ na
przedstawionym
wcześniej
rysunku.
Litery N i M
po obu stronach związku na
tym rysunku oznaczają, że każdy klient
może wypożyczyć wiele kaset. Po drugiej
stronie związku, każda kaseta będzie
wybrana przez wiele osób.

Prof. dr hab. inż. S. Wiak
156
W praktyce, związki wieloznaczne sprawiają
kłopot w relacyjnych bazach danych, ponieważ
przy tłumaczeniu modelu do relacyjnej bazy
danych atrybut używany do połączenia encji,
tzn. klucz obcy, musi zawierać listę wartości
dla każdej powiązanej instancji w innej encji.
W naszym przykładzie - dla każdego klienta
trzeba przechowywać listę kaset i podobnie,
dla każdej kasety trzeba przechowywać listę
klientów, którzy ją oglądali.
Wieloznaczny związek może być łatwo usunięty z
modelu przez utworzenie nowej encji i
zastąpienie wieloznacznego związku dwoma
jednoznacznymi związkami.

Prof. dr hab. inż. S. Wiak
157
Ta nowa encja spełnia funkcję pośrednika dla
instancji obu encji i ponieważ używa dwóch
związków
jednoznacznych,
łatwo
ją
przekształcić na dwa klucze obce w nowej
encji. Jeżeli do naszego przykładu dodamy
encję WYPOZYCZ, to każdy klient będzie miał
przypisaną listę wypożyczeń, a każda KASETA
będzie związana z kolei ze swoją listą klientów.
Specyficznym rodzajem związku jest związek
rekurencyjny, zachodzący między tymi samymi
encjami,
np.:
Element urządzenia jest częścią elementu
urządzenia
.

Prof. dr hab. inż. S. Wiak
158
W przypadku związków encji o większej niż dwa
liczbie argumentów, należy je przekształcić na
binarne związki jednoznaczne, korzystając z
następujących reguł:
*
Dla każdego związku o liczbie argumentów
większej niż dwa
Z(E
1
,..,E
n
)
n>2
wprowadza
się nową encję
E
0
oraz
n
jednoznacznych
związków binarnych
Z
1
(E
0
,E
1
)
łączących nową
encję ze starymi. Klucz encji
E
0
jest sumą
kluczy encji
E
1
,...,E
n
.
Dla każdego wieloznacznego związku binarnego
Z(E
1
,E
2
)
wprowadza się
nową encję
E
0
oraz
2
związki jednoznaczne
Z
1
(E
0
,E
1
)
oraz
Z
2
(E
0
,E
2
)
łączące nowy zbiór encji ze starymi. Klucz
encji
E
0
jest sumą kluczy encji
E
1
oraz
E
2
.

Prof. dr hab. inż. S. Wiak
159
Przedstawianie związków na diagramach
Bardzo
istotnym
zagadnieniem
jest
przedstawienie na diagramach związków
encji ich typów. Można spotkać się w
literaturze
z
kilkoma
sposobami
oznaczeń. W dużej mierze sposób
oznaczania jest często uzależniony od
posiadanych przez wprowadzającego je
autora
narzędzi
umożliwiających
przedstawienie ich graficzne.
Przykładem takiego oznaczania mogą być
rysunki zamieszczone poniżej. Związek
jedno- jednoznaczny (typu 1:1- poziomy
odcinek łączący encję A i B).
Przykład związku
jednojednoznaczn
ego
Prof. dr hab. inż. S. Wiak
160
Związek wieloznaczny (typu N:M. wiele do
wielu - poziomy odcinek zakończony grotami
z obydwu stron).
Przykład związku wieloznacznego
Związki jednoznaczne (typu 1:N jeden do wielu
oraz typu N:1 wiele do jednego - poziome
odcinki zakończone z jednej strony grotem
od strony N).
Przykład związków jednoznacznych

Prof. dr hab. inż. S. Wiak
161
Przekształcenie diagramów E-R w schematy
relacyjne
Przy
przekształcaniu
diagramów
ER
w
schematy relacyjne obowiązują następujące
zasady:
Dla każdej encji diagramu tworzona jest
tabela, przy czym zalecane jest, aby nazwę
encji zmienić na liczbę mnogą
Identyfikujący
atrybut
encji
staje
się
kluczem głównym tabeli
Pozostałe
atrybuty
encji
stają
się
niegłównymi atrybutami tabeli,
Dla każdego związku jeden do wiele klucz
główny tabeli strony jeden linii związku
wstawiamy do tabeli strony wiele linii
związku,

Prof. dr hab. inż. S. Wiak
162
Opcjonalność na stronie
wiele
linii
związku
określa,
czy
klucz
obcy
reprezentujący związek może być null,
czy nie. Jeśli strona
wiele
jest wymagana,
to klucz obcy nie może być null.
Istniejące związki
wiele do wiele
musza
być wcześniej rozłożone na jeden do
wiele, natomiast związki
jeden do jeden
można zrealizować umieszczając atrybuty
obu encji tego związku w jednej tabeli.
Związek rekurencyjny
jeden do wiele
przekształca się w jedna tabelę z kluczem
obcym, którego wartościami są wartości
klucza głównego. Związek rekurencyjny
wiele do wiele
należy najpierw rozłożyć
na związki
jeden do wiele.

Prof. dr hab. inż. S. Wiak
163
Modelowanie danych przy pomocy narzędzia
CASE - ErWin
Do modelowania danych, obok stosowanych
diagramów związków encji, w postaci
zbliżonej
do
diagramów
opisujących
schematy baz danych, można stosować tzw.
narzędzia
CASE
o nazwie
ErWin
firmy
Logic
Works
. Według konwencji ErWin,
nazwa
tabeli jest zapisywana nad ramką
. Atrybuty
encji
są
podzielone
na
atrybuty
identyfikujące
, to znaczy wchodzące w skład
klucza, oraz
atrybuty nieidentyfikujące
, to
znaczy nie wchodzące w skład klucza. Obie
części rozdzielone są pozioma kreską.

Prof. dr hab. inż. S. Wiak
164
Tabela według konwencji ErWin
Związek między dwiema encjami jest
reprezentowany za pomocą linii, których
położenie ErWin sam rozplanowuje na
diagramie, umieszczając po stronie
wiele
czarne kółko
.
Dla związku jednoznacznego ErWin sam
wstawia identyfikator encji po stronie
jeden
do encji po stronie
wiele
i oznacza
go jako (FK) – klucz obcy (Foreign Key)
Prof. dr hab. inż. S. Wiak
165
Diagram związku identyfikującego encji w konwencji
ErWin
Przy związku
jedno-jednoznacznym
czarne kółko
oznacza stronę związku, do którego przechodzi
identyfikator z drugiej strony związku, oraz pojawia
się literka
Z
oznaczająca
zero
lub
jeden
, to znaczy,
że każdy Nauczyciel należy do Pracowników, a
każdy Pracownik jest Nauczycielem lub nim nie
jest. ErWin rozróżnia encje niezależne i zależne,
oraz związki identyfikujące i nieidentyfikujące.
Pracownicy
ID_Pracownika
IMIE
NAZWISKO
DATA_URODZ
Nauczyciele
ID_Pracownika (FK)
Z
Z

Prof. dr hab. inż. S. Wiak
166
Encja
niezależna
jest
to
encja,
której
jednoznaczny identyfikator składa się wyłącznie
z atrybutów opisujących encje, a więc nie
zawiera atrybutu oznaczonego przez (FK). Jest
ona rysowana jako ramka o ostrych rogach.
Encja zależna
jest to encja, której jednoznaczny
identyfikator zawiera co najmniej jeden atrybut
opisujący związek, a więc zawiera atrybut
oznaczony przez (FK). Jest ona rysowana jako
ramka o zaokrąglonych rogach.
Związek
identyfikujący
jest
to
związek
jednoznaczny,
który
wchodzi
w
skład
jednoznacznego identyfikatora encji po swojej
stronie wiele. Jest oznaczany linią ciągłą.
Związek nieidentyfikujący
jest to związek
jednoznaczny, który nie wchodzi w skład
jednoznacznego identyfikatora encji po swojej
stronie wiele. Jest oznaczany linią przerywaną.

Prof. dr hab. inż. S. Wiak
167
Diagram związku nieidentyfikującego encji w konwencji
ErWin
Związki wieloznaczne muszą być reprezentowane za
pomocą encji asocjacyjnych i odpowiednich par
związków
jednoznacznych
identyfikujących
encje
asocjacyjne, np. związek wieloznaczny pomiędzy
pracownikami i zajęciami (rysunek poniżej) należy
zastąpić dwoma związkami jednoznacznymi:
Pracownik otrzymuje Przydział
Przydział dotyczy Zajęć (rys.następny):
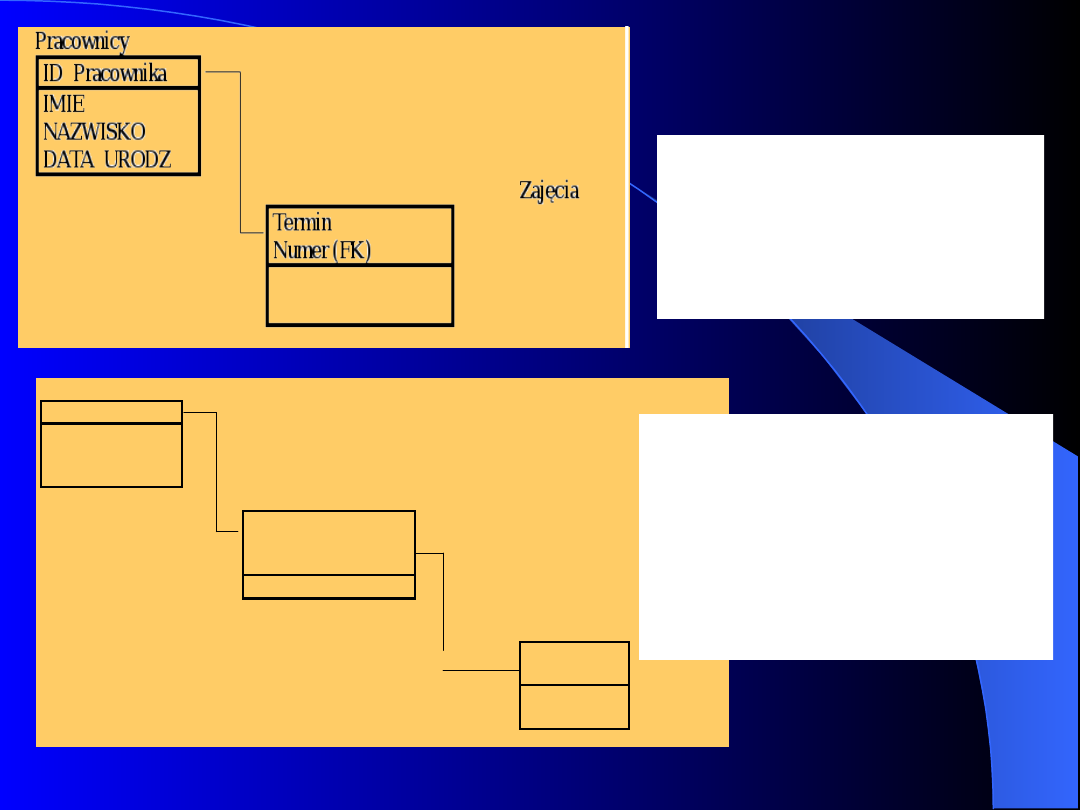
Prof. dr hab. inż. S. Wiak
168
Pracownicy
ID_Pracownika
IMIE
NAZWISKO
DATA_URODZ
Przydziały
Termin(FK)
Numer (FK)
ID_Pracownika (FK)
Zajęcia
Termin
Numer (FK)
Diagram związku
wieloznacznego
encji w konwencji
ErWin
Diagram związku
wieloznacznego encji
zastąpionego
związkami
jednoznacznymi
w konwencji ErWin

Prof. dr hab. inż. S. Wiak
169
Związki nieidentyfikujące dzielą się na dwa
rodzaje, w zależności od tego, czy encja po
stronie
wiele
jest
egzystencjonalnie
zależna
od encji po stronie
jeden
, czy też nie.
Encja po stronie
wiele
jest
egzystencjonalnie
zależna
od encji po stronie
jeden
jeśli dla
każdej instancji encji po stronie
wiele
jest
zawsze określona powiązana z nią
związkiem instancja encji po stronie
jeden
.
W przeciwnym przypadku encję po stronie
wiele
związku nazywamy
egzystencjonalnie
niezależną
od encji po stronie jeden.
Oznacza się to przy pomocy pustego rombu
stawianego przy encji po stronie jeden.

Prof. dr hab. inż. S. Wiak
170
Jeśli przyjmiemy, że w związku nieidentyfikującym
przedstawionym na rysunku powyżej każdy
Samochód
ma przypisany
Nr_modelu
, to encja
Samochody
jest egzystencjonalnie zależna od
encji Typy samochodów, jeśli nie (np. samochód
jest składakiem), to jest ona egzystencjonalnie
niezależna od encji
Typy samochodów
i w takim
przypadku wartością klucza obcego
Nr_modelu
(FK)
w encji po stronie
wiele
może być NULL
Diagramy w konwencji ErWin pozwalaja na
wskazanie atrybutów, na których w bazie danych
ma byc założony indeks unikatowy lub zwykły.
Klucz alternatywny
to dowolny klucz encji, który
nie
został
wybrany
jako
klucz
główny.
Oznaczany jest przez (AKn), gdzie n – kolejny
numer klucza alternatywnego. Może to być np.
Cena, o ile ceny samochodów nie powtarzają
się.

Prof. dr hab. inż. S. Wiak
171
Pozycja inwersji
to dowolny zbiór atrybutów,
względem wartości których będzie następowało
wyszukiwanie instancji. Oznacza się ją jako
(IEn), gdzie n – kolejny numer pozycji inwersji.
Może to być np.
Pojemność silnika.
Przy przekształcaniu diagramu z binarnymi
związkami jednoznacznymi w schemat relacyjnej
bazy danych, każdą encję zamieniamy na tabelę,
której kolumnami są:
wszystkie atrybuty opisujące bezpośrednio daną
encję,
dla każdego binarnego związku jednoznacznego
w encji po stronie
wiele
związku uwzględniamy
atrybuty (oznaczone jako (FK)) tworzące klucz
główny encji po stronie
jeden
związku. Niektóre
z tych atrybutów (identyfikujące) dodajemy do
klucza
głównego
encji
–
może
to
być
postępowanie rekurencyjne.

Prof. dr hab. inż. S. Wiak
172
Związki jedno-jednoznaczne służą często do
budowy
hierarchii
encji,
to
znaczy
do
hierarchicznego grupowania encji mających
wspólne cechy, przy czym na szczycie hierarchii
jest encja najbardziej ogólna, a na dole –
najbardziej konkretne. Każda podkategoria
dziedziczy własności od swojej nadkategorii.
Podział na podkategorie odbywa się przez
wskazanie atrybutu zwanego wyróżnikiem
kategorii. Są dwa rodzaje związku podkategorii:
pełny
, w którym każdy obiekt nadkategorii jest
suma obiektów rozłącznych podkategorii, czyli
należy do dokładnie jednej podkategorii
(oznaczane jako kółko i dwie kreski poziome),
niepełny
, w którym obiekt nadkategorii może
nie należeć do żadnej podkategorii, ale jesli
należy to tylko do jednej (ozn. jako kółko i
jedna kreska pozioma).

Prof. dr hab. inż. S. Wiak
173
Nie wszystkie związki
jedno-jednoznaczne
, ze
względu na występujące rozłączności, można
zdefiniować
za
pomocą
związków
podkategorii.
Związkom można przyporządkować nazwy lub
określenia,
pisane
na
diagramie.
W
przypadku, gdy ta sama para encji połączona
jest dwoma związkami, można kluczom obcym
nadać dwie różne nazwy, zwane
rolami w
związku
.
W programie ErWin można również określać
więzy spójności, w tym więzy referencyjne,
związane z wykonywaniem instrukcji INSERT,
UPDATE, DELETE, w sytuacji, gdy istnieją
związki między encjami, przy czym jest sześć
możliwości (3 operacje oraz dwie strony
związku – PARENT, czyli strona jeden, oraz
CHILD czyli strona wiele).

Prof. dr hab. inż. S. Wiak
174
ErWin jako narzędzie CASE posiada
zestaw
narzędzi
ułatwiających
tworzenie
diagramów
związków
encji,
zawierających
takie
narzędzia jak encja, związek itp. Po
wybraniu
encji
lub
związku,
prawym klawiszem myszy można
otworzyć
okna
dialogowe
obejmujące podstawowe własności
encji, określania więzów spójności,
własności
związku
i
więzów
spójności referencyjnej.

Prof. dr hab. inż. S. Wiak
175
Ponadto
program
ErWin
może
wygenerować gotowy schemat bazy
danych w jednym z wielu systemów
zarządzania bazą danych (wybranym
w menu Server/Targed Server), oraz
można bezpośrednio połączyć się z
systemem bazy danych Oracle,
Access lub SQL Server i utworzyć w
nim
bazę
danych
(menu
Tasks/Forward Engineer), a także
wrócić do diagramu ErWin (menu
Tasks/Reverse Engineer).

Prof. dr hab. inż. S. Wiak
176
Zatwierdzanie zmian w bazie danych
Instrukcje
INSERT, DELETE, UPDATE
nie
dokonują same trwałych zmian w bazie
danych. Aby zmiany wprowadzone przez
nie utrwalić, należy wykonać instrukcję
COMMIT
.
Można
również
zrezygnować
z
wprowadzania zmian do bazy danych,
wycofując je za pomocą instrukcji
ROLLBACK
.

Prof. dr hab. inż. S. Wiak
177
Normalizacja
W swojej pracy na temat relacyjnego modelu
danych E.F Codd sformułował pewne reguły
projektowania relacyjnych baz danych. Te
reguły zostały pierwotnie wyrażone jako
trzy
postacie normalne: pierwsza postać normalna,
druga postać normalna i trzecia postać
normalna.
Proces kolejnego przekształcania
projektu bazy danych przez te trzy postacie
normalne jest znany jako normalizacja.
W połowie lat siedemdziesiątych spostrzeżono
pewne braki w trzeciej postaci normalnej i
zdefiniowano mocniejszą postać normalną,
znaną jako postać normalna Boyce’a – Codda
.
Później Fagin przedstawił
czwartą postać
normalną
(1977), a w roku 1979
piątą postać
normalną
.

Prof. dr hab. inż. S. Wiak
178
Normalizacja jest procesem identyfikowania
logicznych związków między elementami
bazy i projektowania bazy danych, która
będzie reprezentowała takie związki, by nie
posiadała ona cech niepożądanych takich jak
redundancja (powtarzanie się danych) oraz
anomalii istnienia, wstawiania, usuwania i
modyfikowania danych. Normalizacja składa
się z następujących etapów:
Zebrania zbioru danych,
Przekształcenie nieznormalizowanego zbioru
danych w tabele w pierwszej postaci
normalnej,
Przekształcenie tabel z pierwszej postaci
normalnej w drugą postać normalną,

Prof. dr hab. inż. S. Wiak
179
Przekształcenie tabel z drugiej postaci
normalnej w trzecią postać normalną; jeśli
jeszcze w tej postaci występują anomalie
danych, to należy:
Przekształcić trzecią postać normalną w
czwartą postać normalną,
Przekształcić czwartą postać normalną w
piątą postać normalną.
Relacja jest w pierwszej postaci normalnej
(1NF),
wtedy i tylko wtedy, gdy każdy
atrybut niekluczowy jest funkcyjnie zależny
od klucza głównego. Wartości atrybutów
muszą
być
elementarne
tzn.
są
to
pojedyncze wartości określonego typu, a
nie zbiory wartości.

Prof. dr hab. inż. S. Wiak
180
Pierwsza postać normalna jest konieczna aby,
tabelę można było nazwać relacją. Większość
systemów baz danych nie ma możliwości
zbudowania tabel nie będących w pierwszej
postaci normalnej.
Relacja jest w drugiej postaci normalnej (2NF),
wtedy i tylko wtedy, gdy jest w 1NF i każdy
atrybut niekluczowy (nie należący do żadnego
klucza) jest w pełni funkcyjnie zależny od
klucza głównego. W celu sprowadzenia relacji
do drugiej postaci normalnej, należy podzielić
ją na takie relacje, których wszystkie atrybuty
będą w pełni funkcjonalnie zależne od kluczy.
Należy zauważyć, że relacja będąca w
pierwszej postaci normalnej, jest równocześnie
w drugiej postaci normalnej, jeśli wszystkie jej
klucze potencjalne są kluczami prostymi.

Prof. dr hab. inż. S. Wiak
181
Dana relacja jest w trzeciej postaci
normalnej (3NF),
wtedy i tylko wtedy, jeśli
jest ona w drugiej postaci normalnej i każdy
jej atrybut niekluczowy (nie wchodzący w
skład żadnego klucza potencjalnego) jest
bezpośrednio zależny (a nie przechodnio
funkcjonalnie zależny) od klucza głównego.
Aby przejść z drugiej postaci normalnej do
trzeciej
postaci
normalnej
usuwamy
zależności przechodnie między danymi. Aby
to zrobić, w każdej tabeli, dla każdej pary
niekluczowych
elementów
danych
sprawdzamy, czy wartość pola A zależy od
wartości pola B. Jeśli tak, to przenosimy
powiązane elementy do oddzielnej tabeli.
Podział relacji ilustruje rysunek.
Prof. dr hab. inż. S. Wiak
182
Podział relacji w trzeciej postaci normalnej
Istota procesu normalizacji polega na tym,
że:
Wszystkie elementy danych w tabeli muszą
całkowicie
zależeć od
całego klucza
.
W tabeli nie mogą wystąpić
powtarzające
się
grupy danych,
W tabeli nie powinny występować
zależności przechodnie
między danymi.

Prof. dr hab. inż. S. Wiak
183
Proces
przekształcania
nieznormalizowanego
zbioru danych w pełni znormalizowaną bazę
danych
(w
trzeciej
postaci
normalnej)
nazywamy
procesem rozkładu odwracalnego
.
Przy każdym kolejnym przekształceniu dzielimy
strukturę danych na coraz więcej tabel
(poprzez rzutowanie), bez straty podstawowych
związków między elementami danych, a więc z
możliwością odwrócenia operacji rozkładu.
Metoda rozkładu wymaga, aby cały zbiór danych
był w pełni określony, zanim rozpocznie się
proces ciągu rzutów, a ponadto, dla każdego
zbioru danych proces ten jest czasochłonny i
podatny na błędy. Metodą alternatywną do
normalizacji jest
metoda diagramów zależności.

Prof. dr hab. inż. S. Wiak
184
Diagramy
zależności
są
graficznym
podejściem,
polegającym
na
procesie
akomodacji, w celu utworzenia logicznego
schematu bazy danych.
Główną zaletą metody diagramów zależności
jest to, że określa mechanizm przyrostowego
projektowania bazy danych, a więc nie jest
konieczny
pełny
zbiór
danych
przy
rozpoczęciu procesu projektowania, a w
trakcie trwania procesu można dodawać
nowe elementy danych, dopóki wszystkie
zależności nie będą w pełni udokumentowane
(zdeterminowane).
Elementy danych rysuje się na diagramie w
postaci owali lub kółek, natomiast zależności
w postaci strzałek .
Prof. dr hab. inż. S. Wiak
185
Diagram zależności funkcyjnej
Rozróżniamy
zależności funkcyjne
, łączące
determinujący
element
danych
z
elementem zależnym (relacja jeden do
jednego), oraz zależności niefunkcyjne.
Mówimy, że element danych B jest
niefunkcyjnie zależny od elementu danych
A, jeżeli dla każdej wartości elementu
danych A istnieje ograniczony zbiór
wartości elementu danych B (relacja
jeden do wiele).
Diagram
zależności
niefunkcyjnej

Prof. dr hab. inż. S. Wiak
186
Zależności niefunkcyjne lub wielowartościowe
oznaczamy strzałkami z dwoma grotami,
skierowanymi
jak
poprzednio,
od
determinującego
elementu
danych
do
zależnego.
Zależności
między
dwoma
elementami danych można rysować tylko w
jedną stronę, przy czym zależność może być
funkcyjna
(jednowartościowa)
w
jednym
kierunku, ale wielowartościowa w drugim
kierunku. W takich przypadkach należy zawsze
wybrać kierunek zależności funkcyjnej. Przy
zależnościach funkcyjnych lub niefunkcyjnych
w obu kierunkach, kierunek nie gra roli.
Mogą również istnieć
zależności przechodnie
, to
znaczy takie, w których A determinuje B, B
determinuje C, ale A determinuje również C.
Należy je uprościć do łańcucha: A do B oraz B
do C
Prof. dr hab. inż. S. Wiak
187
Diagram zależności przechodniej
Czasami
do
zdeterminowania
jakiegoś
elementu
danych
potrzeba
kilku
elementów. Taką grupę determinujących
elementów
nazywamy
złożonym
związkiem
determinującym
.
Zależność
funkcyjną rysuje się od najbardziej
zewnętrznego owalu.
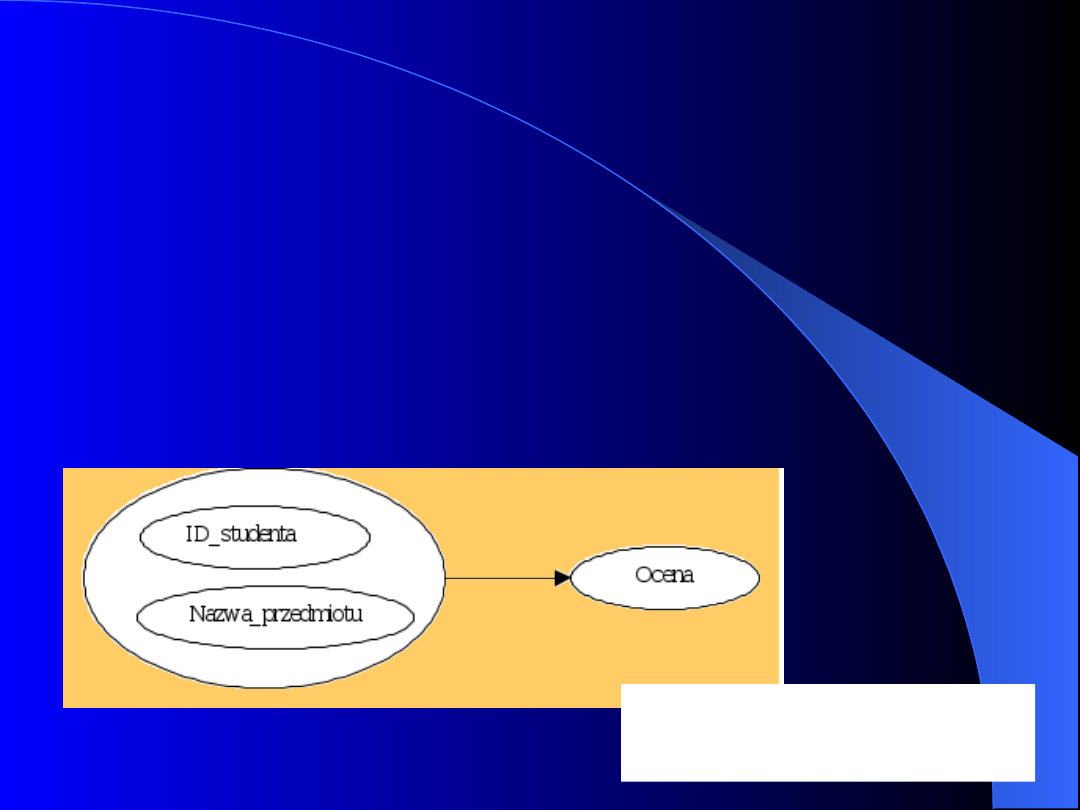
Prof. dr hab. inż. S. Wiak
188
Proces przekształcania diagramu zależności
w zbiór struktur tabel lub schemat
relacyjny nazywamy akomodacją, przy
czym obowiązują tu reguły Boyce’a -
Codda:
Każdy funkcyjnie determinujący element
staje się kluczem głównym tabeli
Wszystkie bezpośrednio zależne od niego
elementy danych stają się niegłównymi
atrybutami tabeli
Diagram
zależności złożonej

Prof. dr hab. inż. S. Wiak
189
Diagram zależności może służyć do identyfikacji
kluczy kandydujących. Klucz kandydujący jest to
element danych, który może pełnić funkcję klucza
głównego.
W
diagramie
zależności
klucze
kandydujące
są
reprezentowane
przez
determinujące elementy danych.
Relacja jest w postaci normalnej Boyce’a-Codda, gdy
każdy funkcyjnie determinujący element staje się
kluczem kandydującym, z których jeden pełni
funkcje klucza głównego.
Najważniejszymi z postaci normalnych są trzecia
postać normalna oraz postać normalna Boyce’a –
Codda.
Trzecią postać normalną da się uzyskać dla
dowolnego schematu bazy danych nie tracąc, ani
własności zachowywania zależności, ani własności
odwracalności. Schemat może być w trzeciej
postaci normalnej i nie mieć postaci normalnej
Boyce’a – Codda. Każdy schemat w postaci
normalnej Boyce’a – Codda jest natomiast w
trzeciej postaci normalnej.

Prof. dr hab. inż. S. Wiak
190
Zależności niefunkcyjne przekształcamy
stosując regułę, że każdy niefunkcyjny,
determinujący element danych staje się
częścią klucza głównego tabeli, to znaczy,
klucz
główny
tworzony
jest
z
determinującego
elementu
danych
i
zależnych elementów danych wchodzących w
skład związku niefunkcyjnego
Pierwsza, druga i trzecia postać normalna
dotyczy zależności funkcyjnych.
Pierwsza
postać
normalna
dotyczy
powtarzających się grup, to znaczy, jeśli
zależności funkcyjne dokumentują związki
jeden do wiele między danymi, to są one
jawną reprezentacja powtarzających się
grup.

Prof. dr hab. inż. S. Wiak
191
Druga postać normalna dotyczy zależności od
części klucza, to znaczy wydobywane są
zależności funkcyjne z klucza złożonego.
Trzecia postać normalna dotyczy zależności
przechodnich między danymi, to znaczy
identyfikowane są determinujące elementy
wśród niegłównych atrybutów tabeli.
Oprócz tego istnieje jeszcze czwarta i piąta
postać normalna dotyczące związków
niefunkcyjnych.
Dana relacja R jest w czwartej postaci
normalnej
wtedy i tylko wtedy, gdy jest w
trzeciej postaci normalnej i wielowartościowa
zależność zbioru Y od X pociąga za sobą
funkcjonalną zależność wszystkich atrybutów
tej relacji od X.

Prof. dr hab. inż. S. Wiak
192
Jak wynika z definicji relacja, która zawiera
trywialną
wielowartościową
zależność
funkcjonalną jest w czwartej postaci normalnej.
Stąd
wniosek,
że
relację
zawierającą
nietrywialną
wielowartościową
zależność
funkcjonalną należy podzielić na takie relacje,
które będą zawierać tylko zależności trywialne.
Dana relacja R jest w piątej postaci normalnej
wtedy i tylko wtedy, gdy jest w czwartej postaci
normalnej i jeżeli nie istnieje jej rozkład
odwracalny na zbiór mniejszych tabel.
Wynika z tego, że w celu doprowadzenia pewnej
relacji do piątej postaci normalnej konieczne
jest podzielenie jej na takie relacje, które
spełniać będą podany wyżej warunek. Piąta
postać normalna dotyczy powiązanych ze sobą
zależności
wielowartościowych,
zwanych
również zależnościami złączenia.

Prof. dr hab. inż. S. Wiak
193
W
większości
przypadków
po
znormalizowaniu bazy danych przychodzi
kolej na przeanalizowanie odwrotnej
operacji,
polegającej
na
łączeniu
niektórych znormalizowanych tabel w
celu przyspieszenia dostępu do danych.
Ponieważ operacja łączenia tabel w bazie
danych jest jedną z najwolniejszych
operacji przeprowadzanych w bazie,
projektantowi zależy na zbudowaniu
schematu o najmniejszej liczbie złączeń i
jednocześnie znormalizowanej.

Prof. dr hab. inż. S. Wiak
194
Normalizację przeprowadzamy w następujących krokach:
1) Zbierz zbiór danych.
2) Przekształć nieznormalizowany zbiór danych w tabele w
pierwszej postaci normalnej.
3) Przekształć tabele z pierwszej postaci normalnej w drugą
postać normalną.
4) Przekształć tabele z drugiej postaci normalnej w trzecią
postać normalną.
Niekiedy w trzeciej postaci normalnej występują
wciąż pewne anomalie danych. W takich
wypadkach musimy wykonać dalsze kroki:
5) Przekształcić trzecią postać normalną w czwartą postać
normalną
6) Przekształcić czwartą postać normalną w piątą postać
normalną
.
ETAPY NORMALIZACJI
ETAPY NORMALIZACJI
Prof. dr hab. inż. S. Wiak
195
nazwa_modułu
nr_pr
ac
nazwa_
prac
nr_stud
enta
nazwisko_stu
denta
ocena
typ_oc
eny
Systemy relacyjne baz
danych
234
Davies
T
34698
37798
34888
Smith S
Jones S
Patel P
B3
B1
B2
B1
B3
cwk1
ck2
ck1
ck1
cwk2
Projektowanie
relacyjnych baz danych
234
Davies
T
34698
34888
Smith S
Smith S
B2
B2
cwk1
cwk1
Dedukcyjne bazy danych
345
Evans R
34668
Smith J
A1
egz
Moduł
Poniższa tabela jest nieznormalizowanym zbiorem
danych. Przyglądając się jej widzimy ,że nr_studenta,
nazwisko_studenta, ocena, i typ_oceny powtarzają się
względem
atrybutu
nazwa_modułu.
Atrybuty
nr_studenta, nazwisko_studenta, ocena i typ_oceny nie
są funkcyjnie zależne od wybranego przez nas klucz
głównego. Natomiast atrybuty nr_prac i nazwisko_prac,
są zależne.
NIEZNORMALIZOWANY ZBIOR DANYCH
NIEZNORMALIZOWANY ZBIOR DANYCH
Prof. dr hab. inż. S. Wiak
196
nazwa_modułu
nr_student
a
nazwisko_stud
enta
ocena
typ_oceny
Systemy relacyjne baz danych
34698
Smith S
B3
cwk1
Systemy relacyjne baz danych
34698
Smith S
B1
cwk2
Systemy relacyjne baz danych
37798
Jones S
B2
cwk1
Systemy relacyjne baz danych
34888
Patel P
B1
cwk1
Systemy relacyjne baz danych
34888
Patel P
B3
cwk2
Projektowanie relacyjnych baz
danych
34698
Smith S
B2
cwk1
Projektowanie relacyjnych baz
danych
34888
Smith S
B3
cwk1
Dedukcyjne bazy danych
34668
Smith J
A1
egz
nazwa_modułu
nr_p
rac
nazw_pr
ac
Systemy relacyjne baz danych
234
Davies
T
Projektowanie relacyjnych
baz danych
234
Davies
T
Projektowanie relacyjnych
baz danych
234
Davies
T
Dedukcyjne bazy danych
345
Evans R
Moduły
Zaliczenia
Relacja jest pierwszej postaci normalnej (1NF) wtedy i
tylko wtedy, gdy każdy atrybut niekluczowy jest
funkcyjnie zależny od klucz głównego.
Oznacza to konieczność utworzenia dwóch tabel: jednej
dla funkcyjnie zależnych atrybutów i drugiej dla
funkcyjni niezależnych atrybutów.
PIERWSZA POSTAC NORMALNA
PIERWSZA POSTAC NORMALNA
Przykła
d

Prof. dr hab. inż. S. Wiak
197
Relacja jest drugiej postaci normalnej (2NF) wtedy i tylko wtedy, gdy jest w 1NF i każdy
atrybut niekluczowy (nie należący do żadnego klucza) jest w pełni funkcyjnie zależny od klucz
głównego,
nazwa_modułu
nr_pra
c
nazw_prac
Systemy relacyjne baz danych
234
Davies T
Projektowanie relacyjnych baz
danych
234
Davies T
Projektowanie relacyjnych baz
danych
234
Davies T
Dedukcyjne bazy danych
345
Evans R
Moduły
nazwa_modułu
nr_stude
nta
ocena
typ_oceny
Systemy relacyjne baz danych
34698
B3
cwk1
Systemy relacyjne baz danych
34698
B1
cwk2
Systemy relacyjne baz danych
37798
B2
cwk1
Systemy relacyjne baz danych
34888
B1
cwk1
Systemy relacyjne baz danych
34888
B3
cwk2
Projektowanie relacyjnych baz
danych
34698
B2
cwk1
Projektowanie relacyjnych baz
danych
34888
B3
cwk1
Dedukcyjne bazy danych
34668
A1
egz
nr_student
a
nazwisko_studen
ta
34698
Smith S
34698
Smith S
37798
Jones S
34888
Patel P
34888
Patel P
34698
Smith S
34888
Smith S
34668
Smith J
Zaliczenia
Studenci
Aby przejść z pierwszej postaci normalnej do drugiej postaci
normalnej, usuwamy zależności od części klucza. Wiąże się to ze
zbadaniem tych tabel, które mają klucze złożone i dla każdego
niekluczowego elementu danych tabeli z postawieniem pytania, czy ten
element nie jest czasem jednoznacznie identyfikowalny przez część
klucz złożonego.
DRUGA POSTAĆ NORMALNA
DRUGA POSTAĆ NORMALNA
Przykła
d

Prof. dr hab. inż. S. Wiak
198
nazwa_modułu
nr_pra
c
Systemy relacyjne baz danych
234
Projektowanie relacyjnych baz
danych
234
Projektowanie relacyjnych baz
danych
234
Dedukcyjne bazy danych
345
Moduły
nr_pra
c
nazw_prac
234
Davies T
234
Davies T
234
Davies T
345
Evans R
Wykładowcy
nazwa_modułu
nr_student
a
ocena
typ_oce
ny
Systemy relacyjne baz danych
34698
B3
cwk1
Systemy relacyjne baz danych
34698
B1
cwk2
Systemy relacyjne baz danych
37798
B2
cwk1
Systemy relacyjne baz danych
34888
B1
cwk1
Systemy relacyjne baz danych
34888
B3
cwk2
Projektowanie relacyjnych baz
danych
34698
B2
cwk1
Projektowanie relacyjnych baz
danych
34888
B3
cwk1
Dedukcyjne bazy danych
34668
A1
egz
nr_student
a1
nazwisko_student
a
34698
Smith S
34698
Smith S
37798
Jones S
34888
Patel P
34888
Patel P
34698
Smith S
34888
Smith S
34668
Smith J
Zaliczenia
Studenci
Relacja jest w trzeciej postaci normalnej (3NF) wtedy i tylko wtedy, gdy jest w 2NF i każdy
niekluczowy atrybut jest bezpośrednio zależny (a nie przechodnio zależny) od klucz głównego.
Aby przejść z drugiej postaci normalnej do trzeciej postaci normalnej, usuwamy tak zwane
zależności przechodnie między danymi. Aby to zrobić, rozważmy każdą tabelę i dla każdej pary
niekluczowych elementów danych zadajemy pytanie, czy wartość pola A zależy od wartości pola B
lub odwrotnie? Jeżeli tak to przenosimy powiązane elementy danych do oddzielnej tabeli.
TRZECIA POSTAĆ NORMALNA
TRZECIA POSTAĆ NORMALNA
Przykła
d
Prof. dr hab. inż. S. Wiak
199
nazwa_modułu
nr_pra
c
nazwa_pr
ac
Systemy relacyjne baz danych
234
Davies T
Projektowanie relacyjnych
baz danych
234
Davies T
Projektowanie relacyjnych
baz danych
234
Davies T
Dedukcyjne bazy danych
345
Evans R
nazwa_modułu
nr_studen
ta
nazwisko_stud
enta
ocena
typ_oce
ny
Systemy relacyjne baz danych
34698
Smith S
B3
cwk1
Systemy relacyjne baz danych
34698
Smith S
B1
cwk2
Systemy relacyjne baz danych
37798
Jones S
B2
cwk1
Systemy relacyjne baz danych
34888
Patel P
B1
cwk1
Systemy relacyjne baz danych
34888
Patel P
B3
cwk2
Projektowanie relacyjnych
baz danych
34698
Smith S
B2
cwk1
Projektowanie relacyjnych
baz danych
34888
Smith S
B3
cwk1
Dedukcyjne bazy danych
34668
Smith J
A1
egz
nazwa_modułu
nr_pra
c
nazwa_prac
Systemy relacyjne baz danych
234
Davies T
Projektowanie relacyjnych
baz danych
234
Davies T
Projektowanie relacyjnych
baz danych
234
Davies T
Dedukcyjne bazy danych
345
Evans R
nazwa_modułu
nr_studen
ta
ocena
typ_oce
ny
Systemy relacyjne baz danych
34698
B3
cwk1
Systemy relacyjne baz danych
34698
B1
cwk2
Systemy relacyjne baz danych
37798
B2
cwk1
Systemy relacyjne baz danych
34888
B1
cwk1
Systemy relacyjne baz danych
34888
B3
cwk2
Projektowanie relacyjnych
baz danych
34698
B2
cwk1
Projektowanie relacyjnych
baz danych
34888
B3
cwk1
Dedukcyjne bazy danych
34668
A1
egz
nr_studen
ta
nazwisko_stud
enta
34698
Smith S
34698
Smith S
37798
Jones S
34888
Patel P
34888
Patel P
34698
Smith S
34888
Smith S
34668
Smith J
nazwa_modułu
nr_pra
c
Systemy relacyjne baz danych
234
Projektowanie relacyjnych
baz danych
234
Projektowanie relacyjnych
baz danych
234
Dedukcyjne bazy danych
345
nr_prac
nazwa_pr
ac
234
Davies T
234
Davies T
234
Davies T
345
Evans R
nazwa_modułu
nr_student
a
ocena
typ_oceny
Systemy relacyjne baz danych
34698
B3
cwk1
Systemy relacyjne baz danych
34698
B1
cwk2
Systemy relacyjne baz danych
37798
B2
cwk1
Systemy relacyjne baz danych
34888
B1
cwk1
Systemy relacyjne baz danych
34888
B3
cwk2
Projektowanie relacyjnych
baz danych
34698
B2
cwk1
Projektowanie relacyjnych
baz danych
34888
B3
cwk1
Dedukcyjne bazy danych
34668
A1
egz
nr_studenta1
nazwisko_stud
enta
34698
Smith S
34698
Smith S
37798
Jones S
34888
Patel P
34888
Patel P
34698
Smith S
34888
Smith S
34668
Smith J
Moduły
Zaliczenia
Studenci
Moduły
Zaliczenia
Moduły
Zaliczenia
Studenci
Wykładowcy
1NF
2NF
3NF
Prof. dr hab. inż. S. Wiak
200
Aby przejść z trzeciej postaci normalnej do czwartej, szukamy tabel,
które
zawierają
dwie
lub
więcej
niezależnych
zależności
wielowartościowych. Które na szczęście występują występują rzadziej
niż zależności od części klucza lub zależności przechodnie. Poniższa
tabela zawiera dane na temat umiejętności i znajomości języków
pracowników. Jeżeli jednak chcemy dodać ograniczenie, takie aby
posiadanie umiejętności i znajomość języków nie były ze sobą
związane.W czwartej postaci normalnej te dwa związki nie mogą być
reprezentowane w jednej tabeli. Tak więc występowanie dwóch
niezależnych zależności wielowartościowych oznacza, że musimy
podzielić tabelę na dwie.
nr_pracown
ika
umiejętności
język
0122443
Pisanie na
maszynie
Angielsk
i
0122443
Pisanie na
maszynie
Francusk
i
0122443
Dyktowanie
Angielsk
i
0221133
Pisanie na
maszynie
Niemiec
ki
0221133
Dyktowanie
Francusk
i
0332222
Pisanie na
maszynie
Francusk
i
0332222
Pisanie na
maszynie
Angielsk
i
Pracownicy
nr_pracown
ika
język
0122443
Angielsk
i
0122443
Francusk
i
0122443
Angielsk
i
0221133
Niemiec
ki
0221133
Francusk
i
0332222
Francusk
i
0332222
Angielsk
i
Języki
Umiejętności
nr_pracown
ika
umiejętności
0122443
Pisanie na
maszynie
0122443
Pisanie na
maszynie
0122443
Dyktowanie
0221133
Pisanie na
maszynie
0221133
Dyktowanie
0332222
Pisanie na
maszynie
0332222
Pisanie na
maszynie
CZWARTA POSTAĆ NORMALNA
CZWARTA POSTAĆ NORMALNA
Prof. dr hab. inż. S. Wiak
201
Tabela w czwartej postaci normalnej jest w piątej postaci
normalnej, jeżeli nie istnieje jej rozkład odwracalny na
zbiór mniejszych tabel.
W poniższej tabeli nie można dokonać rozkładu
struktury, ponieważ, chociaż chociaż dealer Jones
sprzedaje samochody osobowe firmy Ford i furgonetki
firmy Vauxhall, nie sprzedaje furgonetek firmy Ford ani
samochodów osobowych firmy Vauxhall. Piąta postać
normalna dotyczy powiązanych między sobą zależności
wielowartościowych,
nazywanych
też
zależnościami
złączeń.
dealer
firma
pojazd
Jones
Ford
Samochód_osobo
wy
Jones
Vauxhall Furgonetka
Smith
Ford
Furgonetka
Smith
Vauxhall Samochód_osobo
wy
Punkt
y
PIĄTA POSTAĆ NORMALNA
PIĄTA POSTAĆ NORMALNA

Prof. dr hab. inż. S. Wiak
202
Projektowanie relacyjnych baz danych
Proces projektowania baz danych składa się
z trzech faz:
analizy wymagań
,
modelowania danych
i
normalizacji
.
Faza analizy wymagań
zakłada wgłębienie
się w sposób funkcjonowania obsługiwanej
organizacji, przeprowadzenie rozmów z jej
pracownikami i kierownictwem, w celu
dokonania
oceny
aktualnie
wykorzystywanego systemu i poczynienia
prognoz na przyszłość oraz dokonanie
całościowej
oceny
wymagań
informacyjnych organizacji.

Prof. dr hab. inż. S. Wiak
203
Faza modelowania danych
polega na
tworzeniu „zrębów struktury” nowej
bazy danych. Pomocne stają się tu takie
metody
modelowania
danych,
jak
tworzenie tzw.
diagramów związków
encji
(ang.
entity
relationship
diagramming
; nazywa się je również
diagramami ER),
analiza zależności
semantycznych, czy analiza obiektowa
.
Każda z tych metod stanowi sposób
wizualnej
reprezentacji
różnych
aspektów projektowanej struktury, jak
tabel czy relacji oraz ich cech i
atrybutów.

Prof. dr hab. inż. S. Wiak
204
W skład
modelowania danych wchodzi
również
definiowanie pól
i przypisywanie
ich odpowiednim tabelom,
przypisanie
tabelom
kluczy
podstawowych,
wprowadzenie
kolejnych
poziomów
integralności danych oraz
zdefiniowanie
poszczególnych
relacji
za
pomocą
odpowiednich kluczy obcych
.
Kiedy podstawowe struktury tabel są już
gotowe, a relacje zostały zdefiniowane
zgodnie z przyjętym modelem danych,
baza danych jest gotowa do przejścia
przez fazę normalizacji.

Prof. dr hab. inż. S. Wiak
205
Normalizacja jest procesem
, w którym
następuje rozkład dużych tabel na
mniejsze,
w
celu
wyeliminowania
redundantnych i powtarzających się
danych
oraz
uniknięcia
problemów
związanych
z
wstawianiem,
modyfikowaniem i usuwaniem rekordów.
Podczas fazy normalizacji sprawdza się
zgodność
struktur
bazy
danych
z
postaciami normalnymi oraz poddaje się
je poprawkom, jeśli zgodność ta nie jest
zachowana.

Prof. dr hab. inż. S. Wiak
206
Postać normalna to zestaw kryteriów, które
musi spełniać dana tabela, aby mogła być
uznana za poprawną i nie przyczyniała się
do powstawania błędów. Istnieje kilka
różnych postaci normalnych; każda z nich
związana jest z eliminowaniem pewnego
typu problemów.
Obecnie stosowane postacie normalne to:
pierwsza postać normalna, druga postać
normalna,
trzecia
postać
normalna,
czwarta postać normalna, piąta postać
normalna, postać normalna Boyce'a-
Codda
oraz
postać
normalna
klucza/domeny.

Prof. dr hab. inż. S. Wiak
207
Analiza wymagań
Formułowanie
definicji
celu
i
założeń
wstępnych
Pierwszą fazą tworzenia projektu bazy danych
jest
zdefiniowanie
celu
oraz
założeń
wstępnych. „Definicja celu” mówi, po co
projektujemy bazę danych, oraz co stanowi
punkt odniesienia dla jej twórcy.
Określając
cel, jakiemu ma służyć baza danych,
ułatwiamy tworzenie właściwego projektu i
umożliwiamy przechowywanie w gotowej
bazie właściwych danych.
Oprócz definicji
celu
na
tym
etapie
należy
również
sformułować założenia wstępne. Są to
wymagania, jakie powinny spełniać dane
przechowywane w bazie.

Prof. dr hab. inż. S. Wiak
208
Warunki te powinny uzupełniać definicję
celu
i
pomagać
w
tworzeniu
poszczególnych elementów bazy danych.
Istnieją
dwie oddzielne grupy ludzi
, którzy
mają wpływ na definicję celu i założeń
wstępnych.
Pierwsza z nich, składająca się z twórcy bazy
danych,
właściciela
lub
dyrektora
organizacji, której baza ta ma służyć, oraz
członków kierownictwa tejże organizacji,
jest odpowiedzialna za definicję celu.
Druga, złożona z twórcy bazy, kierownictwa
organizacji oraz przyszłych użytkowników
bazy, powinna zająć się sformułowaniem
założeń wstępnych.

Prof. dr hab. inż. S. Wiak
209
Analiza istniejącej bazy danych
Drugą fazą procesu projektowania jest
analiza istniejącej bazy danych, jeśli
takowa istnieje. W zależności od
organizacji, będzie to zazwyczaj baza
„spadkowa” lub baza tradycyjna.
Stara baza danych, użytkowana od
wielu lat, to baza „spadkowa”
(czasem
nazywana
bazą
odziedziczoną).
Z
kolei
baza
tradycyjna to luźny zbiór formularzy,
teczek, notatek i tym podobnych.

Prof. dr hab. inż. S. Wiak
210
Niezależnie od typu i stanu
istniejącej bazy danych, dokładne
przyjrzenie
się
jej
strukturze
udzieli
cennych
informacji
na
temat sposobu wykorzystywania
danych
przez
organizację.
Co
więcej, analiza ta pozwoli na
zrozumienie sposobu, w jaki dane
są gromadzone i prezentowane
użytkownikom.

Prof. dr hab. inż. S. Wiak
211
Tworzenie struktur danych
Tworzenie struktur danych jest trzecim
etapem procesu projektowania bazy.
Należy zdefiniować tabele i pola,
wskazać pola kluczowe oraz określić
atrybuty każdego z pól.
Tabele są pierwszą strukturą, jaką
należy zaprojektować. Tematy, którym
mają one być poświęcone, wynikają z
założeń wstępnych, zdefiniowanych w
pierwszej fazie procesu projektowania
oraz z wymagań informacyjnych,
ustalonych w fazie drugiej.

Prof. dr hab. inż. S. Wiak
212
Po
ustaleniu
odpowiednich
tematów, należy dla każdego z nich
utworzyć
tabelę,
a
następnie
przypisać wszystkie pola z listy
sporządzonej
pod
koniec
ostatniego etapu do odpowiednich
tabel.

Prof. dr hab. inż. S. Wiak
213
Po zakończeniu tej czynności należy
przeanalizować każdą tabelę i upewnić
się,
że reprezentuje ona tylko jeden temat
i nie zawiera powtarzających się pól
.
Następnie należy przeanalizować każde
pole z osobna. Jeśli stwierdzono, że
któreś z nich jest wielowartościowe lub
segmentowe, trzeba je rozbić tak, aby
wszystkie
pola
w
tabeli
zawierały
pojedyncze wartości.
Pole nie reprezentujące tematu danej
tabeli powinno zostać przesunięte do
innej, bardziej odpowiedniej tabeli lub
zostać usunięte z bazy.

Prof. dr hab. inż. S. Wiak
214
Na
koniec
należy
zdefiniować
klucze
podstawowe
,
które
będą
jednoznacznie
identyfikować
każdy
rekord
w
poszczególnych tabelach.
Ostatnim krokiem tego etapu jest definiowanie
atrybutów dla każdego pola w bazie danych.
Należy powtórnie przeprowadzić rozmowy z
pracownikami i kierownictwem organizacji w
celu ustalenia odpowiednich atrybutów dla
poszczególnych pól.
Po
zakończeniu
tej
procedury
trzeba
zdefiniować
i
udokumentować
atrybuty
każdego pola.

Prof. dr hab. inż. S. Wiak
215
Definiowanie relacji
W
czwartej
fazie
procesu
projektowania należy zdefiniować
relacje
między
poszczególnymi
tabelami.
Znowu
więc
trzeba
przeprowadzić
rozmowy
z
użytkownikami
bazy,
określić
istniejące relacje, ustalić ich cechy
oraz zagwarantować integralność
na poziomie relacji.

Prof. dr hab. inż. S. Wiak
216
Współpraca
użytkowników
przy
określaniu relacji jest niesłychanie
pomocna,
ponieważ
najprawdopodobniej projektantowi
nie są znane wszystkie aspekty
funkcjonowania danej organizacji.
Większość jej pracowników ma jednak
dobre wyobrażenie o danych, na
których operuje, i może z łatwością
wskazać ewentualne relacje.

Prof. dr hab. inż. S. Wiak
217
Kiedy relacje zostaną już ustalone, należy
określić ich cechy. W zależności od typu
danej relacji wchodzące w jej skład tabele
trzeba połączyć, korzystając albo z klucza
podstawowego, albo z tabeli łączącej.
Następnym
krokiem
powinno
być
zdefiniowanie typu i stopnia uczestnictwa
tabel w poszczególnych relacjach; w
większości przypadków cechy te będą w
prosty sposób wynikać z rodzaju danych
przechowywanych w każdej z tych tabel,
czasami jednak trzeba będzie odwołać się
do reguł integralności.

Prof. dr hab. inż. S. Wiak
218
Wprowadzenie reguł integralności
Wprowadzenie reguł integralności
jest
piątym
etapem
procesu
projektowania bazy danych.
Twórca
bazy
danych
powinien
przeprowadzić
rozmowy
z
jej
przyszłymi użytkownikami, ustalić
ograniczenia, jakim mają podlegać
dane,
zdefiniować
reguły
integralności
oraz
wprowadzić
tabele walidacji.

Prof. dr hab. inż. S. Wiak
219
Sposób w jaki dana organizacja
wykorzystuje swoje dane, dyktuje
wiele
ograniczeń,
które
będą
musiały
zostać
uwzględnione
podczas tworzenia bazy danych.
Rozmowy
z
pracownikami
i
kierownictwem
pomogą
ustalić
wymagania, które powinny być
spełniane przez dane oraz ich
struktury.
Pełną
listę
tych
wymagań można traktować jako
zestaw reguł integralności
.

Prof. dr hab. inż. S. Wiak
220
Następnie
należy
zdefiniować
i
zaimplementować
tabele walidacji
, o
ile tylko okażą się one przydatne we
wprowadzaniu reguł integralności.
Na przykład jeżeli niektóre pola
mogą
przyjmować
tylko
kilka
różnych wartości zdefiniowanych na
podstawie wymagań użytkownika,
tabele
walidacji
pomogą
w
zagwarantowaniu, że rzeczywiste
wartości
tych
pól
odpowiadają
wartościom dozwolonym.

Prof. dr hab. inż. S. Wiak
221
Ważne staje się tu wprowadzenie
poziomu
integralności
danych,
opartego na regułach integralności,
ponieważ odnosi się on bezpośrednio
do sposobu, w jaki dana organizacja
wykorzystuje dane zawarte w bazie.
Wraz z ekspansją tej organizacji jej
wymagania
informacyjne
będą
ulegać zmianie, a w ślad za nimi
również reguły integralności.
Ustalanie reguł integralności jest
procesem ciągłym.

Prof. dr hab. inż. S. Wiak
222
Definiowanie perspektyw
Definiowanie perspektyw to szósta faza
procesu
tworzenia bazy danych. Jeszcze raz
koniecznym staje się skonsultowanie z
pracownikami i kierownictwem organizacji i
zdefiniowanie odpowiednich perspektyw w
oparciu
o
przedstawione
przez
nich
wymagania.
Trzeba ustalić żądane metody prezentowania
danych
użytkownikom
bazy.
Niektórzy
pracownicy będą wymagali specjalnych
sposobów wizualizacji, w zależności od
wykonywanych
przez
siebie
zadań.
Przykładowo, pewne osoby mogą chcieć
odczytywać dane z kilku tabel jednocześnie;
innym
wystarczy
odwoływanie
się
do
pojedynczych tabel.

Prof. dr hab. inż. S. Wiak
223
Kiedy określi się wymagane sposoby
prezentowania
danych,
należy
je
zdefiniować formalnie, jako perspektywy.
Każda perspektywa składa się z pól
należących do jednej lub większej liczby
tabel.
Po zdefiniowaniu wszystkich perspektyw
trzeba
jeszcze
odpowiednio
dobrać
parametry każdej z nich tak, aby zwracały
one tylko żądane rekordy.

Prof. dr hab. inż. S. Wiak
224
Kontrola integralności danych
Siódmą i ostatnią fazy procesu
projektowania
bazy danych jest kontrola struktury bazy
pod kątem integralności zawartych w niej
danych.
Przede wszystkim należy przyjrzeć się każdej
tabeli z osobna i upewnić się, że spełnia ona
odpowiednie kryteria poprawności; należy
też sprawdzić w ten sposób każde z
należących do niej pól.
Wszelkie nieścisłości i problemy powinny być
teraz
rozstrzygnięte
i
usunięte.
Po
wprowadzeniu
odpowiednich
poprawek
należy sprawdzić integralność na poziomie
tabel.

Prof. dr hab. inż. S. Wiak
225
Następnie
trzeba
przejrzeć
atrybuty
wszystkich pól w bazie, wprowadzając
konieczne
poprawki
i
sprawdzając
integralność na poziomie pól. To pozwoli
upewnić się, że integralność wprowadzona na
wcześniejszych etapach projektowania bazy
została zachowana.
Należy sprawdzić poprawność każdej z relacji
oraz jej typ
, jak również rodzaj i stopień
uczestnictwa wszystkich tabel w relacjach, w
których
skład
wchodzą.
Należy
przeanalizować integralność na poziomie
relacji, upewniając się, że współdzielone pola
zawierają odpowiednie wartości oraz że
wprowadzanie, modyfikowanie i usuwanie
danych z powiązanych tabel nie sprawia
żadnych problemów.

Prof. dr hab. inż. S. Wiak
226
Na koniec trzeba ponownie przejrzeć listę
reguł integralności, potwierdzając zgodność
ograniczeń nakładanych przez nie na bazę
danych
z
ustalonymi
wcześniej
wymaganiami. Jeśli podczas późniejszych
faz procesu projektowania zauważono by
konieczność wprowadzenia dodatkowych
ograniczeń, należy je uwzględnić jako
dodatkowe reguły integralności i dopisać do
istniejącej listy.
Po zakończeniu procesu projektowania bazy
danych struktura utworzonej bazy będzie
gotowa do zaimplementowania w programie
SZRBD.
Po zaimplementowaniu bazy danych
ostatnim etapem przed jej wdrożeniem do
użytku
jest
przeprowadzenie
fazy
testowania.

Prof. dr hab. inż. S. Wiak
227
Fizyczne projektowanie relacyjnej bazy
danych
Fizyczne projektowanie relacyjnej bazy danych
można podzielić na następujące etapy:
Opracowanie
modelu
danych
dla
planowanego
systemu
bazy
danych,
z
wykorzystaniem
metody
modelowania
danych,
Oszacowanie
średniej i maksymalnej liczby
instancji
dla każdej encji. Maksymalna liczba
instancji pozwala określić wielkość pamięci
dyskowej potrzebnej na wszystkie tabele bazy
danych, natomiast średnia liczba instancji
pozwala ocenić możliwości modelu co do
spełnienia wymagań dotyczących dostępu do
danych.

Prof. dr hab. inż. S. Wiak
228
Przeprowadzenie
analizy użycia
, polegającej na
zidentyfikowaniu
podstawowych
rodzajów
transakcji wymaganych w systemie bazy danych.
Transakcje są to ciągi operacji wstawiania,
modyfikowania, wyszukiwania, przemieszczania
i usuwania. Szybkość wykonywania operacji
modyfikowania i wyszukiwania zależy od
zmienności pliku.
Zmienność encji
lub
pliku
określana jest jako różnica między średnią a
maksymalną liczbą instancji obliczoną dla encji.
Stworzenie
struktur dostępu
do danych.
Właściwości dostępu do danych w pliku zależą
od rozmiaru i zmienności pliku.

Prof. dr hab. inż. S. Wiak
229
Przeprowadzenie
analizy integralności
,
poprzez
udokumentowanie
więzów
integralności encji, referencyjnych więzów
integralności oraz więzów dziedziny. Każda
aplikacja wymaga zazwyczaj dodatkowych
więzów;
więzów
przejścia
,
dokumentujących przejście z jednego
stanu bazy danych w drugi, lub
więzów
statycznych
,
wiążących
się
ze
sprawdzeniem,
że
transakcja
nie
spowoduje przejście bazy danych w stan
niepoprawny.
Zdefiniowanie
wydajności
dostępu
i
wydajności modyfikowania
, które na ogół
są sprzeczne. Wydajność zależy istotnie od
aplikacji. W celu poprawienia wydajności
wykorzystywane są następujące opcje:

Prof. dr hab. inż. S. Wiak
230
i.
Tworzenie
mechanizmów
dostępu
związanych z przechowywaniem.
Do
przechowywania
danych
w
pamięci
pomocniczej
wykorzystywana
jest
sekwencyjność, haszowanie i klastry.
Dostęp sekwencyjny
zalecany jest dla
małych tabel, średnich i dużych – jeśli
dostęp musi być uzyskany do więcej niż
20% wierszy, oraz dowolnych tabel, gdy
dostęp następuje przez zapytania o niskim
priorytecie, lub realizowane za pomocą
przetwarzania
wsadowego.
Pliki
haszowane
są budowane zwykle na
kluczach głównych i stosowane jako
główna ścieżka dostępu do pliku.
Klastry
są tworzone, aby ułatwić wykonywanie z
góry ustalonych operacji złączeń danych.

Prof. dr hab. inż. S. Wiak
231
ii.
Dodawanie
indeksów
.
Indeks
jest
mechanizmem poprawienia szybkości
dostępu do danych bez zmiany struktury
ich przechowywania. Rozróżniamy dwa
typy indeksów: główny i wtórny. Indeksy
powinno się tworzyć zawsze na kluczach
głównych (indeksy jednoznaczne) i
obcych, a jedynie czasem na innych
elementach danych, gdyż maja one
negatywny
wpływ
na
wydajność
modyfikacji.
Ogólną
zasadą
jest
tworzenie indeksów na średnich i
dużych tabelach w celu ułatwienia
dostępu do małego procentu wierszy w
tabeli.

Prof. dr hab. inż. S. Wiak
232
iii.
Denormalizacja
ma na celu przyśpieszenia
wyszukiwania lub modyfikowania danych.
Wprowadza ona kontrolowana redundancję,
dlatego
powinna
być
stosowana
wyjątkowo, zwłaszcza dla dużych, często
zmienianych plików.
iv.
Implementowanie więzów integralności.
Stosowane są trzy sposoby.
Wewnętrznie
,
to
znaczy,
że
za
pomocą
prostych
mechanizmów można określić integralność
encji,
referencyjną
i
dziedziny.
Proceduralnie
, to znaczy, że więzy są
implementowane
w
językach
trzeciej
generacji,
takich
jak
C
lub
Cobol.
Nieproceduralnie
, to znaczy, że więzy są
utrzymywane niezależnie od programów
użytkowych,
w
centralnym
słowniku
danych.

Prof. dr hab. inż. S. Wiak
233
v.
Wybór i wykorzystanie SZBD
.
Istnieją systemy które kompilują
wszystkie zapytania uruchomione
na bazie danych i przechowują w
postaci gotowej do ponownego
użycia,
oraz
systemy,
które
interpretują zapytania w czasie
ich wykonywania. Wydajność tych
systemów
zależy
od
rodzaju
zapytań.

Prof. dr hab. inż. S. Wiak
234
Sieciowy model danych
Sieciowy model bazy danych (SMBD)
został
stworzony
głównie
w
celu
rozwiązania
problemów
związanych
z
modelem
hierarchicznym. Tak jak w HMBD, strukturę
SMBD można przedstawić jako odwrócone
drzewo. Różnica polega jednak na tym, że w
przypadku SMBD kilka drzew może dzielić ze
sobą gałęzie, a każde drzewo stanowi część
ogólnej struktury bazy danych. Rysunek 2.
przedstawia diagram modelu sieciowego.
Relacje w SMBD
są definiowane przez kolekcje.
Kolekcja jest niejawną konstrukcją łączącą
dwie tabele poprzez przypisanie jednej z nich
roli właściciela, a drugiej – roli członka.
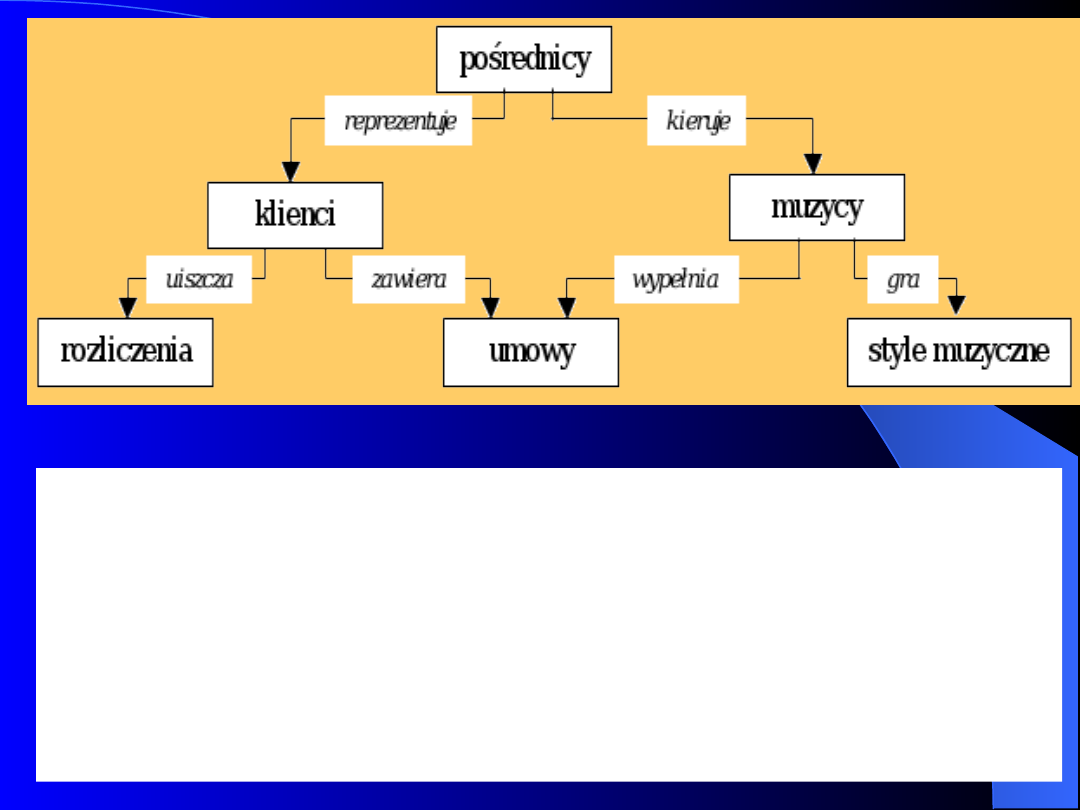
Prof. dr hab. inż. S. Wiak
235
Diagram modelu sieciowego. (Baza danych
pośredników. Każdy pośrednik pracuje dla kilku
muzyków i ma pewną liczbę klientów, którzy
zamawiają u niego obsługę muzyczną różnych
imprez i uiszczają opłaty. Każdy muzyk może
zawrzeć wiele oddzielnych umów i specjalizować
się w wielu różnych gatunkach muzyki.)
Prof. dr hab. inż. S. Wiak
236
Sieciowy model bazy danych ma, podobnie jak
model hierarchiczny, strukturę odwróconego
drzewa z tą różnicą, że w modelu sieciowym
jest możliwe dowolne połączenie pomiędzy
poszczególnymi elementami. Na przykład:
Schemat sieciowego
modelu bazy danych

Prof. dr hab. inż. S. Wiak
237
Kolekcje
umożliwiają
wprowadzenie
relacji jeden – do – wielu, co oznacza, że
w obrębie struktury każdy rekord z
tabeli – właściciela może być powiązany
z dowolną ilością rekordów z tabeli –
członka,
natomiast
pojedynczemu
rekordowi z tabeli – członka może
odpowiadać tylko jeden rekord w tabeli
– właściciela.
Między każdymi dwoma tabelami
można
zdefiniować dowolną liczbę powiązań
(kolekcji),
a
każda
tabela
może
uczestniczyć
w
wielu
różnych
kolekcjach.

Prof. dr hab. inż. S. Wiak
238
W
SMBD dostęp do danych można uzyskać
,
poruszając
się
po
kolekcjach.
W
przeciwieństwie do modelu hierarchicznego,
gdzie poszukiwanie danych należało rozpocząć
od podstaw, w SMBD użytkownik może
rozpocząć od dowolnej tabeli, a następnie
poruszać się w górę lub w dół po tabelach z nią
powiązanych. Zaletą modelu SMBD jest
szybkość, z jaką można odczytywać z niego
dane. Ponadto użytkownik ma możliwość
tworzenia znacznie bardziej złożonych zapytań
niż miało to miejsce w modelu hierarchicznym.
Wadą tego modelu
jest to, że użytkownik musi
mieć dobre wyobrażenie o strukturze używanej
bazy danych. Kolejną wadą jest niemożność
zmiany struktury bazy danych bez ponownego
tworzenia obsługujących ją programów.

Prof. dr hab. inż. S. Wiak
239
Pomimo, że model sieciowy był dużym
postępem w porównaniu z modelem
hierarchicznym to jednak, w miarę
rozwoju
przemysłu
informatycznego,
użytkownicy
chcieli
uzyskiwać
odpowiedzi na coraz bardziej złożone
zapytania, których istniejące struktury
baz danych nie potrafiły obsłużyć.
Odpowiedzią na takie potrzeby stał się
relacyjny model danych.

Prof. dr hab. inż. S. Wiak
240
Interfejs systemu zarządzania bazą danych
Interfejs systemu zarządzania bazą danych
język SQL
język SQL
Do opisu operacji na bazach danych stworzono
specjalny język
SQL (SQL ang. Structured
Query
Language
-
strukturalny
język
zapytań).
Jego składnia i znaczenie jest
określane
odpowiednimi
standardami
międzynarodowymi. Obecnie obowiązuje już
czwarta wersja standardu. Wyrażenia w SQL
są w większości systemów zarządzania
bazami danych (w szczególności w systemach
wykorzystujących
architekturę klient-serwer
)
formą
pośrednią
pomiędzy
programem
użytkowym
klienta
(
tzw.
front-end
)
a
serwerem bazy danych (
tzw.back-end
).
W
języku tym zapisywane są polecenia (tzw.
zapytania) do serwera bazy danych.

Prof. dr hab. inż. S. Wiak
241
SQL
różni
się
od
innych
języków
programowania pod kilkoma względami.
Po
pierwsze,
jest
językiem
nieproceduralnym. Języki takie jak
C lub
COBOL
instruują komputer krok po
kroku jak wykonać dane zadanie.

Prof. dr hab. inż. S. Wiak
242
Natomiast SQL tylko określa, co ma być
zrobione,
sposób
rozwiązania
pozostawiając SZBD (SZBD - System
Zarządzania Bazą Danych). Jest to
zgodne z filozofią relacyjnych baz
danych.
SZBD
jest
jakby
„czarną
skrzynką”, nie musimy się interesować
jak on wykonuje zadanie.
Najważniejszy dla nas jest poprawny wynik. Ten
sposób podejścia upraszcza operacje i pozwala
na dużą elastyczność twórcom baz danych.
Instrukcje SQL-a operują na dowolnie dużych
zbiorach danych. Przetwarzają one cały zbiór
danych,
natomiast
instrukcje
większości
innych języków operują na pojedynczych
danych.

Prof. dr hab. inż. S. Wiak
243
Inną
ważną
cechą
SQL-a
jest
trójwartościowa
logika
(3VL).
W
większości jęzków wyrażenia logiczne
może
być
prawdziwe
(TRUE)
lub
fałszywe (FALSE).

Prof. dr hab. inż. S. Wiak
244
SQL zezwala
na wprowadzenie do
tablic
wartości
NULL
(
nieznana,
nieokreślona
).
Jest
to
znacznik
wpisywany do kolumny w miejsce
brakującej danej (NULL stosujemy
wtedy, gdy nie możemy wpisać do
bazy żadnej wartości, np. „koloru
włosów łysego człowieka”).
Kiedy wartość NULL jest użyta w
porównaniu, wynik nie będzie ani
FALSE, ani TRUE, lecz nieznany
(UNKNOWN).
Jest
to
najbardziej
kontrowersyjny aspekt SQL-a.

Prof. dr hab. inż. S. Wiak
245
Historia SQL-a zaczyna się we
wczesnych
latach
siedemdziesiątych, kiedy firma
IBM
stworzyła
język
SEQUEL
(
Structured
English
Query
Language
)
dla
projektu
badawczego systemów zarządzania
relacyjnymi bazami danych.
Potem ten język przerodził się w
Sequel/2 i w końcu w
SQL
(ang.
Structured
Query
Language
–
strukturalny język zapytań).

Prof. dr hab. inż. S. Wiak
246
Inne
firmy
były
także
zainteresowane
pomysłem
relacyjnych
baz
danych
i
interfejscm SQL.
Relational Software Inc. (znane teraz
jako Oracle Corporation) w 1979 r.
Stworzyło
relacyjną bazę danych
zwaną Oracle
. W 1981 r.
IBM wypuścił na rynek pierwszy
produkt relacyjnej bazy danych
SQL/DS
. (
SQL Data System
).

Prof. dr hab. inż. S. Wiak
247
SQL jest standardem
w systemach
zarządzania bazami danych, takich jak:
Oracle,
INGRES,
Informix,
Sybase,
SQLbase,
Microsoft
SQL
Server,
Paradox,
Access,
Approach
,
w
produktach
IBM-a: DB2 I SQL/DS I
innych
. Poza tym niektóre programy, jak
na przykład: dBase lub Interbase,
oprócz swoich własnych interfejsów
mają także (lub właśnie wprowadzają)
SQL.
SQL służy do komunikowania
się z bazą
danych. Za pomocą samego SQL-a nie
można napisać kompletnego programu.

Prof. dr hab. inż. S. Wiak
248
SQL jest używany na trzy sposoby:
Interakcyjny
lub
samodzielny
SQL
używany jest do wprowadzania lub
wyszukiwania
informacji
do/z
bazy
danych. Jeśli użytkownik poprosi o listę
aktywnych kont w bieżącym miesiącu.
Wynik może być wysyłany na ekran,
skierowany do pliku albo wydrukowany,

Prof. dr hab. inż. S. Wiak
249
Statyczny SQL
jest to stały kod SQL-a
napisany przed wykonaniem programu.
Są dwie wersje statycznego SQL-a. W
zanurzonym SQL-u kod SQL-a znajduje się
w źródłowym programie innego języka.
Większość tych aplikacji jest napisana w
języku
C
lub
COBOL,
natomiast
odwoływania do bazy danych są w SQL-u.
Inna wersja statycznego SQL-a to język
modułowy. W tym przypadku moduły SQL-
a są łączone z modułami kodu innych
języków.

Prof. dr hab. inż. S. Wiak
250
Dynamiczny SQL jest to kod SQL-a
generowany przez aplikację w czasie jej
wykonywania.
Jest
używany
zamiast
statycznego SQL-a, gdy potrzebny kod nie
może
być
określony
podczas
pisania
programu. Ten rodzaj kodu SQL-a jest często
generowany w odpowiedzi na działania
użytkownika za pomocą takich narzędzi jak
np. graficzne języki zapytań.
Język został po raz pierwszy zaimplementowany przez
Oracle w 1979 roku, jednak nie był oficjalnie
uznawany za standard do 1986, kiedy to został
opublikowany częściowo przez
ANSI (American
National Standards Institute) i ISO (International
Standards Organization
). W 1989 zrewidowano
standard SQL-a wprowadzając nowe elementy
zwiększające
integralność
.

Prof. dr hab. inż. S. Wiak
251
Do chwili pojawienia się standardu 86 wiele
programów korzystało już z SQL-a.
Dlatego też ISO dopasowało standard do
istniejącego już na rynku. Zdefiniowano
minimalny standard, dając wolną rękę
twórcom programów SQL-a. W standardzie
całkowicie pominięto pewne potrzebne
funkcje, takie jak usuwanie obiektów i
uprawnień.
Teraz,
w
dobie
scalania
się
świata
komputerowego, twórcy oprogramowania
i użytkownicy chcieliby pracować z
różnymi
systemami
baz
danych
w
jednakowy sposób.

Prof. dr hab. inż. S. Wiak
252
Spowodowało to
żądanie standaryzacji
programów
, co dawniej zależało tylko
od dobrej woli twórców programów. W
dodatku wiele lat korzystania z języka i
badań nad nim doprowadziło do tego,
że wielu twórców chciało wprowadzić
nowe elementy do SQL-a. Dlatego też
powstał nowy standard: SQL 92.
SQL 92 jest nadzbiorem standardu 89
.
Jednym z braków starego standardu
poprawionego
w
SQL-u
92
były
definicje użytkowników, schematów i
sesji. Poprzedni standard pozostawił je
całkowicie uznaniu twórcom systemów.

Prof. dr hab. inż. S. Wiak
253
Instrukcje SQL-a są pogrupowane
według funkcji. Taki podział jest
praktyczny w pewnych sytuacjach. W
standardzie SQL-a najczęściej używa
się trzech grup.
Są to:
Język definicji danych (DDL), który zawiera
wszystkie
instrukcje
do
definiowania
schematów i należących do nich obiektów.
Najważniejsze instrukcje DDL służą do
tworzenia
różnych
obiektów:
CREATE
SCHEMA, CREATE TABLE, CREATE VIEW,
CREATE ASSERTION, CREATE DOMAIN.

Prof. dr hab. inż. S. Wiak
254
Język „manipulowania” danymi (DML)
zawierający
wszystkie
instrukcje
do
przechowywania,
modyfikowania
i
wyszukiwania
danych
w
tablicach.
Najważniejsze
instrukcje
to:
SELECT,
INSERT, UPDATE i DELETE. SELECT jest
używany do formułowania zapytań i
prawdopodobnie jest najbardziej złożoną,
pojedynczą instrukcją w SQL-u. Inne
instrukcje operują na danych w tablicach.
Instrukcje
Sterowania
Danymi,
które
kontrolują
uprawnienia
użytkownika
umożliwiające wykonywanie określonych
akcji na obiektach w bazie danych (często
w standardzie 92 uważa się tę część za
fragment DDL). Podstawowe instrukcje to
GRANT i REVOKE.

Prof. dr hab. inż. S. Wiak
255
Inne kategorie standardu 92 to instrukcje
transakcji, łączenia, sesji, dynamiczne i
diagnostyczne. Głównym praktycznym
znaczeniem podziału na kategorie jest
to, że standard nie pozwala na
mieszanie instrukcji DDL i DML w jednej
transakcji
(grupie
instrukcji,
która
kończy się sukcesem lub porażką jako
całość).

Prof. dr hab. inż. S. Wiak
256
Relacja Internet - bazy danych
Trendy w technologii baz danych.
Ze względu na ogromnie szybki rozwój sieci Internet,
i tego że coraz szersze grupy użytkowników
posiadają takie narzędzie jak przeglądarka WWW,
okazało się, że najłatwiejszym sposobem dotarcia
do klienta, będzie dostosowanie baz danych do
wymogów
języka
hipertekstowego.
Ta
technologia baz danych udostępnianych przez
Internet w najbliższych latach rozwijać się będzie w
następujących kierunkach:
trójwarstwowa architektura klient-serwer -
przesunięcie logiki działania aplikacji z
poziomu
komputera/aplikacji-klienta
lub
serwera na pośredni poziom - poziom
działania modułu transakcyjnego

Prof. dr hab. inż. S. Wiak
257
Universal Data Access
- technologia
firmy Microsoft pozwalająca na dostęp
do wszystkich typów danych poprzez
jeden uniwersalny model obiektów.
Wykorzystuje
ona
nowoczesny
standard dostępu do danych zwany
OLE DB
. Z kolei technologia
ActiveX
Data Objects
(
ADO
) udostępnia zestaw
interfejsów do programowego dostępu
do danych. Te techniki pozwalają na
oddzielenie rezerwuarów danych i
modułów przetwarzających zapytania.
Np. lokalna baza danych jest częścią
całościowej,
ogólnopolskiej
bazy
danych.

Prof. dr hab. inż. S. Wiak
258
Remote Data Services
(
RDS
) i
Active Server
Pages
(
ASP
) - Internet mimo całej swoje
uniwersalności zastosowań stwarza nowe
problemy w dostępie do baz danych, tj. w
braku
ciągłości
połączenia
pomiędzy
klientem i serwerem danych. W związku z
tym powstały dwa modele dostępu do danych
poprzez sieć Internet:
1.
RDS jest to zestaw komponentów które
udostępniają infrastrukturę pozwalającą na
efektywne
przenoszenie
danych
z
komponentów serwerowych mieszczących się
w
pośredniej
warstwie
trójwarstwowego
modelu klient-serwer do poziomu klienta
2.
ASP pozwala serwerom WWW na inteligentne
współdziałanie z użytkownikiem-klientem danych i
dynamiczne budowanie stron HTML w zależności od
potrzeb klienta.

Prof. dr hab. inż. S. Wiak
259
Relacja Internet - bazy danych.
Gwałtowny
rozwój
Internetu
i
masowe
udostępnianie go użytkownikom to jeden z
najważniejszych powodów dla jakich projektanci
baz danych musieli znaleźć drogę udostępniania
swoich zasobów przy pomocy zwykłej internetowej
przeglądarki. Obecnie każdy użytkownik Windows
posiada zainstalowaną przeglądarkę WWW, także
ilość przyłączony komputerów do sieci Internet
nieustannie wzrasta.
Zaprojektowana baza danych musi wiec spełniać
kilka wymogów:
jej interfejs musi być w formacie
HTML
,
rozpoznawanym przez przeglądarki
,
jak i
obciążenie związane z wykonywaniem zapytań do
źródła bazy musi zachodzić po stronie serwera
, a
nie klienta.
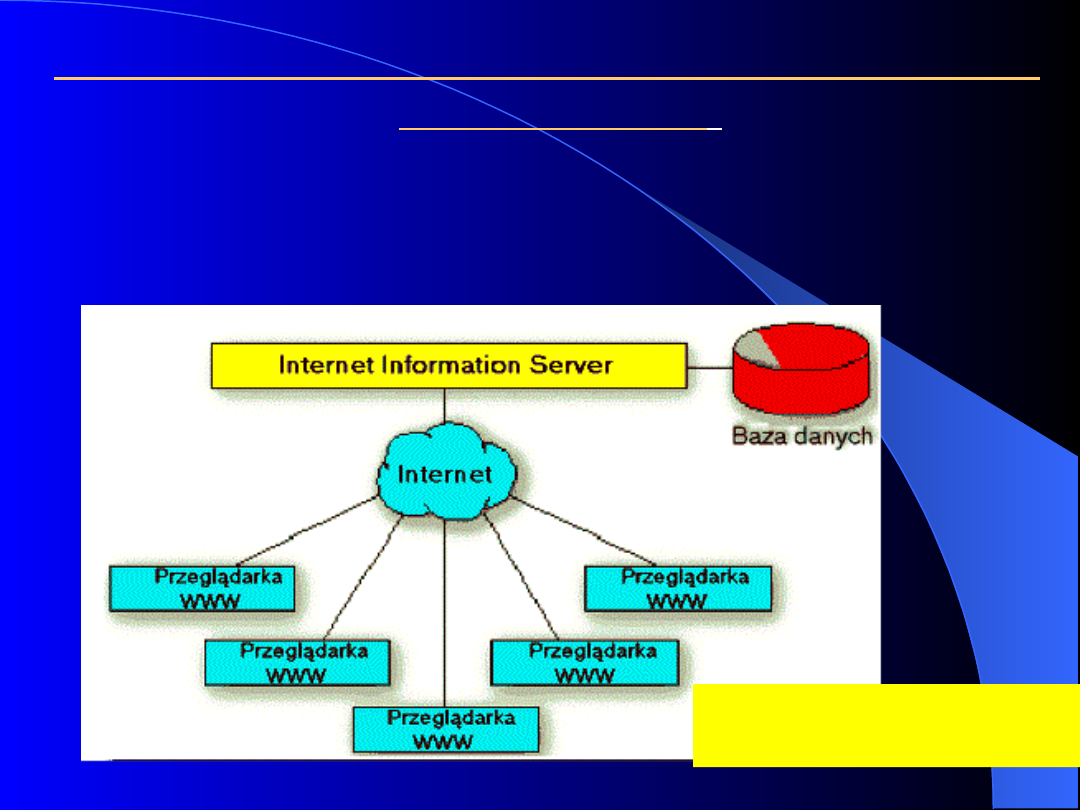
Prof. dr hab. inż. S. Wiak
260
Proces adaptacji danych i ich wizualizacja
w Internecie.
Jak działa program
Internet Database
Connector (IDC
)? -
Sposób w jaki można uzyskać dostęp do bazy
danych w programie
Internet
Information
Server
(IIS)
przedstawia następujący schemat:
Schemat
funkcjonowania IDC

Prof. dr hab. inż. S. Wiak
261
Przeglądarki WWW (takie jak Internet Explorer
lub przeglądarki innych firm, na przykład
Netscape) zgłaszają zadania do serwera
internetowego, używając protokółu
HTTP
.
Serwer internetowy odpowiada dokumentem
sformatowanym w języku
HTML
.
Dostęp do bazy danych jest realizowany przez
składnik
programu
Internet
Information
Serwer (IIS)
o nazwie
Internet Database
Connector (IDC).
Jego plik -
Httpodbc.dll
jest
biblioteką
ISAPI DLL
używającą
ODBC
do
dostępu do baz danych. Różne konfiguracje
połączenia programu
IIS
z bazami danych,
wyżej wymienionych składników przedstawia
rys.
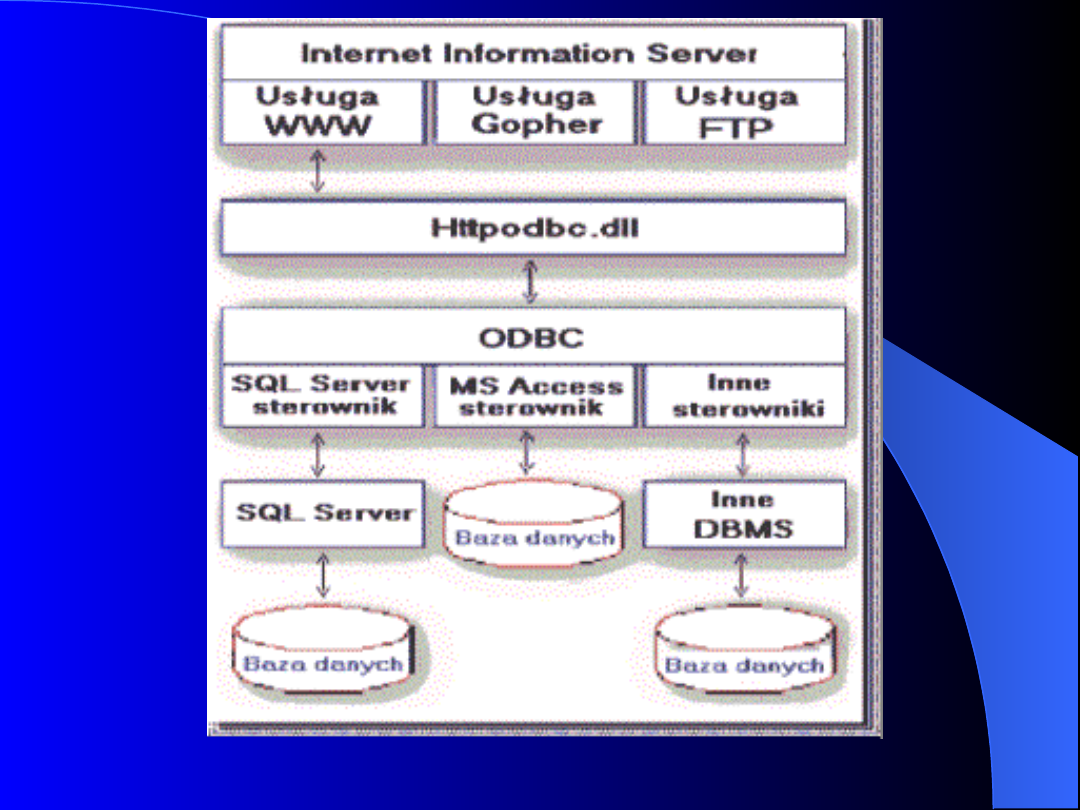
Prof. dr hab. inż. S. Wiak
262

Prof. dr hab. inż. S. Wiak
263
W programie IDC stosowane są dwa typy plików
do kontrolowania sposobu dostępu do bazy
danych oraz sposobu konstruowania wynikowej
strony WWW. Pliki te to pliki programu
Internet
Database Connector (.idc)
i pliki rozszerzeń
HTML (.htx
).
Pliki programu
Internet Database Connector
zawierają informacje konieczne do połączenia
się z odpowiednim źródłem danych
ODBC
i
wykonania instrukcji
SQL
. Plik
IDC
zawiera
także nazwę i lokalizacje pliku rozszerzenia
HTML
.
Plik
rozszerzenia
HTML
jest
szablonem
rzeczywistego dokumentu
HTML
, który jest
zwracany
do
przeglądarki
WWW
po
umieszczeniu w nim informacji przez program
IDC
.
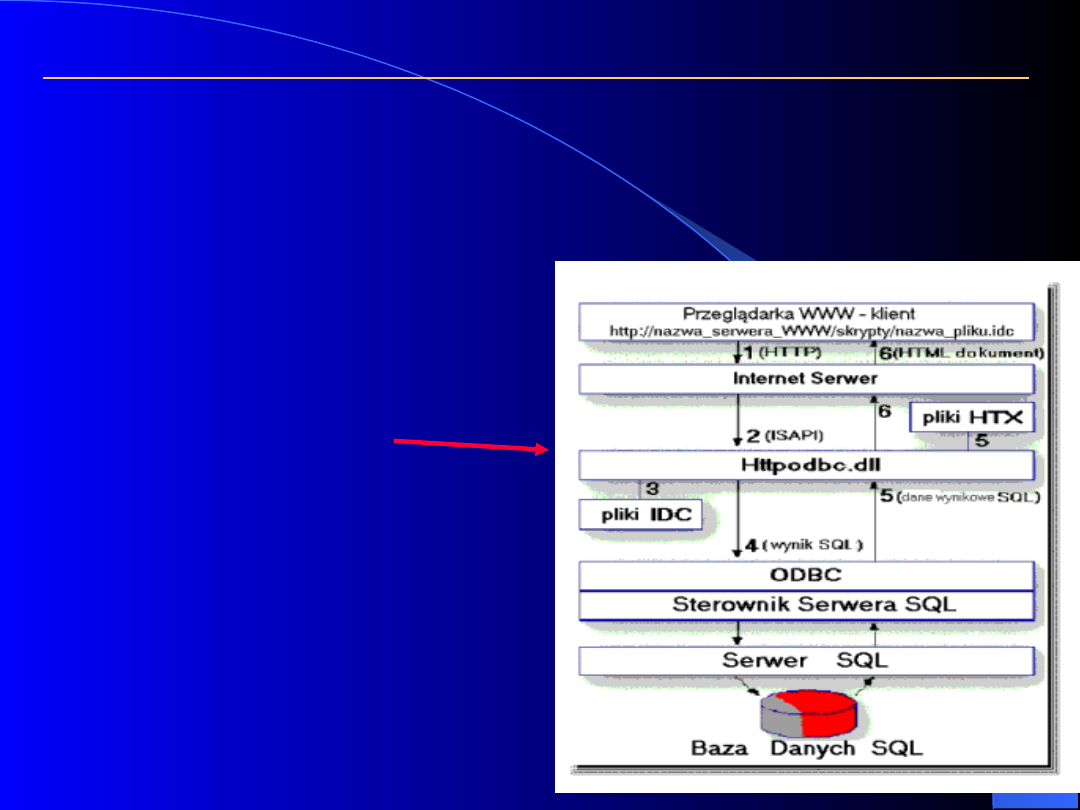
Prof. dr hab. inż. S. Wiak
264
Edycja stron WWW z dostępem do bazy danych.
W celu zapewnienia dostępu do bazy danych SQL
ze strony WWW, należy utworzyć plik
Internet
Database
Connector
(rozszerzenie
nazwy
pliku
.idc)
i
plik
rozszerzenia
HTML
(rozszerzenie nazwy pliku .htx).
Cały proces korzystania
z programu Internet Database
Connector jest wykonywany
w sześciu krokach
pokazanych na rysunku.

Prof. dr hab. inż. S. Wiak
265
Sześć kroków korzystania z
IDC
:
1.
Program
IIS
otrzymuje adres
URL
.
2.
Adres
URL
jest
wysłany
przez
przeglądarkę WWW.
3.
IIS
ładuje plik
Httpodbc.dll
i przekazuje
pozostałe informacje z adresu
URL
.
Pliki
.idc
są mapowane do biblioteki
Httpodbc.dll
.
Jest
ona
ładowana
i
uzyskuje nazwę pliku
Internet Database
Connector
(i inne elementy) z adresu
URL
przekazanego do programu
IIS
.
Httpodbc.dll
czyta plik Internet Database
Connector (
.idc
).

Prof. dr hab. inż. S. Wiak
266
4.
Program
IDC
łączy się ze źródłem
ODBC
i wykonuje
instrukcje
SQL
zawarta w pliku Internet
Database
Connector.
Tworzone jest połączenie
IDC
ze źródłem danych
ODBC
, co polega w tym przykładzie na załadowaniu
sterownika
ODBC
bazy
SQL Server
i połączeniu z
serwerem określonym w definicji źródła danych. Po
utworzeniu połączenia, instrukcja
SQL
z pliku
Internet Database Connector
przesyłana jest do
sterownika
ODBC bazy SQL Server
, który z kolei
przesyła ją do bazy
SQL Server
.
5.
IDC
pobiera dane z bazy danych i scala je z plikiem
rozszerzenia
HTML
.
6.
IDC
przesyła scalony dokument z powrotem do
programu
IIS
, który zwraca go do klienta.
Po scaleniu wszystkich danych w pliku
.htx
, pełny
dokument HTML jest przesyłany z powrotem do
klienta.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
- Slide 60
- Slide 61
- Slide 62
- Slide 63
- Slide 64
- Slide 65
- Slide 66
- Slide 67
- Slide 68
- Slide 69
- Slide 70
- Slide 71
- Slide 72
- Slide 73
- Slide 74
- Slide 75
- Slide 76
- Slide 77
- Slide 78
- Slide 79
- Slide 80
- Slide 81
- Slide 82
- Slide 83
- Slide 84
- Slide 85
- Slide 86
- Slide 87
- Slide 88
- Slide 89
- Slide 90
- Slide 91
- Slide 92
- Slide 93
- Slide 94
- Slide 95
- Slide 96
- Slide 97
- Slide 98
- Slide 99
- Slide 100
- Slide 101
- Slide 102
- Slide 103
- Slide 104
- Slide 105
- Slide 106
- Slide 107
- Slide 108
- Slide 109
- Slide 110
- Slide 111
- Slide 112
- Slide 113
- Slide 114
- Slide 115
- Slide 116
- Slide 117
- Slide 118
- Slide 119
- Slide 120
- Slide 121
- Slide 122
- Slide 123
- Slide 124
- Slide 125
- Slide 126
- Slide 127
- Slide 128
- Slide 129
- Slide 130
- Slide 131
- Slide 132
- Slide 133
- Slide 134
- Slide 135
- Slide 136
- Slide 137
- Slide 138
- Slide 139
- Slide 140
- Slide 141
- Slide 142
- Slide 143
- Slide 144
- Slide 145
- Slide 146
- Slide 147
- Slide 148
- Slide 149
- Slide 150
- Slide 151
- Slide 152
- Slide 153
- Slide 154
- Slide 155
- Slide 156
- Slide 157
- Slide 158
- Slide 159
- Slide 160
- Slide 161
- Slide 162
- Slide 163
- Slide 164
- Slide 165
- Slide 166
- Slide 167
- Slide 168
- Slide 169
- Slide 170
- Slide 171
- Slide 172
- Slide 173
- Slide 174
- Slide 175
- Slide 176
- Slide 177
- Slide 178
- Slide 179
- Slide 180
- Slide 181
- Slide 182
- Slide 183
- Slide 184
- Slide 185
- Slide 186
- Slide 187
- Slide 188
- Slide 189
- Slide 190
- Slide 191
- Slide 192
- Slide 193
- Slide 194
- Slide 195
- Slide 196
- Slide 197
- Slide 198
- Slide 199
- Slide 200
- Slide 201
- Slide 202
- Slide 203
- Slide 204
- Slide 205
- Slide 206
- Slide 207
- Slide 208
- Slide 209
- Slide 210
- Slide 211
- Slide 212
- Slide 213
- Slide 214
- Slide 215
- Slide 216
- Slide 217
- Slide 218
- Slide 219
- Slide 220
- Slide 221
- Slide 222
- Slide 223
- Slide 224
- Slide 225
- Slide 226
- Slide 227
- Slide 228
- Slide 229
- Slide 230
- Slide 231
- Slide 232
- Slide 233
- Slide 234
- Slide 235
- Slide 236
- Slide 237
- Slide 238
- Slide 239
- Slide 240
- Slide 241
- Slide 242
- Slide 243
- Slide 244
- Slide 245
- Slide 246
- Slide 247
- Slide 248
- Slide 249
- Slide 250
- Slide 251
- Slide 252
- Slide 253
- Slide 254
- Slide 255
- Slide 256
- Slide 257
- Slide 258
- Slide 259
- Slide 260
- Slide 261
- Slide 262
- Slide 263
- Slide 264
- Slide 265
- Slide 266
Wyszukiwarka
Podobne podstrony:
Systemy Baz Danych (cz 1 2)
Systemy Baz Danych (cz 1 3)
Systemy Baz Danych (cz 1 2)
SBD wyklad 4, student - informatyka, Systemy Baz Danych
SBD wykład 2, student - informatyka, Systemy Baz Danych
SBD wykład 3, student - informatyka, Systemy Baz Danych
SBD wykład 1, student - informatyka, Systemy Baz Danych
SYSTEM B, student - informatyka, Systemy Baz Danych
R. 6-2 Struktura OBD-przyklad 1, Uczelniane, Semestr 2, Zaawansowane Systemy Baz Danych, WYKŁ [OZaik
Systemy baz danych 10
Wprowadzenie do systemow baz danych wprsys
Systemy baz danych Kompletny podrecznik Wydanie II 2
Wprowadzenie do systemow baz danych wprsys
Systemy baz danych w7
perspektywy w systemach baz danych
Systemy baz danych Kompletny podrecznik Wydanie II
Wprowadzenie do systemow baz danych
więcej podobnych podstron