
Wydawnictwo Helion
ul. Chopina 6
44-100 Gliwice
tel. (32)230-98-63
IDZ DO
IDZ DO
KATALOG KSI¥¯EK
KATALOG KSI¥¯EK
TWÓJ KOSZYK
TWÓJ KOSZYK
CENNIK I INFORMACJE
CENNIK I INFORMACJE
CZYTELNIA
CZYTELNIA
Projektowanie baz
danych XML.
Vademecum profesjonalisty
Autor: Mark Graves
T³umaczenie: Tomasz ¯mijewski
ISBN: 83-7197-667-4
Tytu³ orygina³u:
Format: B5, stron: 498
„Projektowanie baz danych XML. Vademecum profesjonalisty” — to obszerny
podrêcznik do nauki baz danych XML, wykorzystywanych w Internecie oraz baz
stanowi¹cych czêæ wiêkszych systemów.
Jeli dysponujesz gotow¹ baz¹ danych obs³uguj¹c¹ XML, to dziêki tej ksi¹¿ce poznasz
szczegó³owe techniki, w pe³ni wykorzystuj¹ce tê bazê. Jeli natomiast korzystasz
z klasycznych relacyjnych baz danych, nauczysz siê tworzyæ aplikacje
z wykorzystaniem XML. Zainteresowani tworzeniem baz danych XML „od zera”,
dowiedz¹ siê jak w pe³ni wykorzystaæ dostêpne narzêdzia.
Dodatkowo autor omawia:
•
Najwa¿niejsze techniki projektowe baz danych, systemów obs³uguj¹cych te bazy
oraz aplikacji XML
•
Przechowywanie danych XML w bazach obiektowych, relacyjnych i opartych
na
plikach p³askich
•
Zaawansowane techniki modelowania danych XML
•
Zapytania kierowane do baz danych XML (uwagi praktyczne, techniki stosowania
JDBC oraz podstawy teoretyczne)
•
Sposób korzystania z sieciowych baz danych XML za pomoc¹ jêzyka XSL
i
jêzyka Java
•
Architekturê baz danych XML i specjalizowane indeksy
•
W³¹czanie baz danych XML do wiêkszych systemów
•
Bazy danych XML i ich zastosowanie w nauce
„Projektowanie baz danych XML. Vademecum profesjonalisty” to podstawowe ród³o
informacji dla projektantów i programistów baz danych, twórców aplikacji XML,
projektantów systemów oraz kierowników projektów — szczególnie w rodowiskach
o specyficznych wymaganiach.

5RKUVTGħEK
1.1. XML................................................................................................................................16
1.1.1. Czym jest XML? ..................................................................................................16
1.1.2. Skąd się wziął XML? ...........................................................................................19
1.1.3. Czemu akurat XML? ............................................................................................19
1.2. Systemy baz danych........................................................................................................22
1.2.1. Czym jest baza danych? .......................................................................................22
1.2.2. Czym jest baza danych XML?..............................................................................24
1.2.3. Czemu używać baz danych XML?.......................................................................25
1.3. Bazy danych dostępne w Sieci........................................................................................26
1.3.1. Baza danych w plikach płaskich...........................................................................26
1.3.2. Systemy zarządzania relacyjnymi bazami danych ...............................................29
1.3.3. Systemy zarządzania bazami danych XML..........................................................30
1.4. Aplikacje .........................................................................................................................31
1.5. Dodatkowe informacje....................................................................................................32
1.5.1. Czasopisma...........................................................................................................32
1.5.2. Witryny ogólne .....................................................................................................32
1.5.3. Portale XML .........................................................................................................33
1.5.4. Narzędzia XML ....................................................................................................33
1.5.5. XSL.......................................................................................................................33
1.5.6. Dokumenty W3C..................................................................................................33
1.5.7. Przykłady specyfikacji XML w konkretnych dziedzinach...................................34
1.5.8. Więcej informacji o XML ....................................................................................34
2.1. Projektowanie bazy danych ............................................................................................35
2.2. Modelowanie koncepcyjne .............................................................................................38
2.2.1. Model koncepcyjny w formie grafów ..................................................................38
2.2.2. Proces modelowania koncepcyjnego za pomocą grafu ........................................42
2.2.3. Modelowanie koncepcyjne ...................................................................................46
2.2.4. Model koncepcyjny XML ....................................................................................51
2.3. Modelowanie logiczne ....................................................................................................53
2.3.1. Diagram encji i relacji ..........................................................................................53
2.3.2. Schemat relacyjny.................................................................................................54
2.3.3. Model obiektowy..................................................................................................55
2.3.4. Schemat logiczny XML........................................................................................59
2.4. Modelowanie fizyczne ....................................................................................................61
2.4.1. Schemat fizyczny XML........................................................................................62
2.4.2. Przetwarzanie danych a przetwarzanie dokumentów...........................................65
2.4.3. Przenoszenie danych.............................................................................................67
2.4.4. Atrybuty czy podelementy?..................................................................................68
2.5. Bibliografia .....................................................................................................................71

6
Projektowanie baz danych XML. Vademecum profesjonalisty
3.1. Typy danych ...................................................................................................................73
3.1.1. XML Schema........................................................................................................74
3.1.2. Wprowadzanie strukturalnych typów danych ......................................................75
3.1.3. Aplikacje sterowane schematem ..........................................................................76
3.2. Systemy zarządzania bazami danych..............................................................................79
3.3. Standardy XML ..............................................................................................................80
3.3.1. XML Schema (XSDL) .........................................................................................83
3.3.2. XSL.......................................................................................................................83
3.3.3. Łącza, wskaźniki i ścieżki XML ..........................................................................83
3.3.4. XML Query ..........................................................................................................84
3.3.5. Przestrzenie nazw XML .......................................................................................84
3.3.6. DOM.....................................................................................................................85
3.4. Bazy danych XML..........................................................................................................85
3.4.1. Schemat koncepcyjny ...........................................................................................86
3.4.2. Zadania .................................................................................................................87
3.4.3. Operacje................................................................................................................88
3.5. Modelowanie danych ......................................................................................................89
3.5.1. Istniejące modele danych......................................................................................91
3.5.2. Prosty model danych XML ..................................................................................94
3.5.3. Model danych XML zgodny ze specyfikacją W3C..............................................98
3.5.4. Relacyjny model danych XML ............................................................................99
3.5.5. Model danych XML oparty na węzłach .............................................................106
3.5.6. Model danych XML zbudowany na podstawie krawędzi ..................................110
3.5.7. Ogólny model danych XML...............................................................................113
3.6. Bibliografia ...................................................................................................................118
4.1. Funkcje przechowywania danych .................................................................................121
4.1.1. Baza danych oparta na plikach płaskich.............................................................121
4.1.2. Obiektowa baza danych......................................................................................124
4.1.3. Relacyjna baza danych .......................................................................................130
4.2. Drobnoziarnisty schemat relacyjny ..............................................................................130
4.2.1. Projekt logiczny..................................................................................................131
4.2.2. Projekt fizyczny..................................................................................................134
4.2.3. Przykłady ............................................................................................................139
4.2.4. Implementacja ....................................................................................................142
4.3. Gruboziarnisty schemat relacyjny ................................................................................165
4.4. Schemat relacyjny o średniej granulacji .......................................................................166
4.4.1. Punkty podziału ..................................................................................................167
4.4.2. Projekt bazy danych............................................................................................168
4.4.3. Implementacja ....................................................................................................170
4.5. Uwagi praktyczne .........................................................................................................180
!" #
5.1. Architektura systemu ....................................................................................................181
5.1.1. Klient-serwer ......................................................................................................183
5.1.2. Architektura trzywarstwowa...............................................................................185
5.2. Serwer sieciowy XML ..................................................................................................186
5.2.1. Możliwości implementacji .................................................................................186
5.2.2. Dostęp klienta .....................................................................................................188
5.2.3. Ładowanie danych..............................................................................................189
5.2.4. Generacja XML ..................................................................................................202
5.3. Relacyjny serwer danych ..............................................................................................202
5.3.1. Żądania adresu URL...........................................................................................204
5.3.2. Tworzenie zapytań SQL .....................................................................................205

5RKUVTGħ EK
7
5.3.3. Formatowanie wyników jako XML ...................................................................206
5.3.4. Pobieranie danych słownikowych ......................................................................207
5.3.5. Implementacja ....................................................................................................210
5.4. Serwer danych XML.....................................................................................................232
5.4.1. Implementacja ....................................................................................................235
5.5. Hybrydowy serwer łączący technologię relacyjną i XML ...........................................252
5.5.1. Implementacja ....................................................................................................253
$
%!& '
6.1. Przegląd dostępnych rozwiązań....................................................................................259
6.2. Adaptery do baz danych ...............................................................................................260
6.2.1. Narzędzia warstwy pośredniej............................................................................261
6.2.2. Komercyjne relacyjne bazy danych....................................................................261
6.2.3. Narzędzia do obsługi zapytań.............................................................................262
6.3. Systemy zarządzania bazami danych............................................................................262
6.4. Serwery danych XML...................................................................................................263
6.4.1. dbXML ...............................................................................................................263
6.4.2. eXcelon...............................................................................................................263
6.4.3. Tamino................................................................................................................263
6.5. Serwery dokumentów XML .........................................................................................263
6.6. Zasoby i witryny ...........................................................................................................264
()&*!! $
7.1. Przegląd ........................................................................................................................267
7.2. Interfejsy użytkownika XSL .........................................................................................268
7.2.1. Arkusze stylów XSL...........................................................................................268
7.2.2. Prezentacja danych XML jako tabeli..................................................................269
7.2.3. Prezentacja fragmentów XML jako kolejnych rekordów...................................275
7.2.4. Prezentacja identyfikatorów elementów zastępczych jako hiperłączy...............276
7.2.5. Zmiana formatowania w zależności od treści.....................................................280
7.3. Formy prezentacji wykorzystujące technologię Java ...................................................284
7.3.1. Budowa klienta ...................................................................................................284
7.3.2. Przykład z drzewem............................................................................................287
7.4. Aplikacje prototypowe..................................................................................................293
#
+ ''
8.1. Rodzaje zapytań ............................................................................................................299
8.2. Reprezentacja................................................................................................................302
8.2.1. Dokumenty opisujące strukturę a dane opisujące relacje...................................302
8.2.2. Reprezentacje wykorzystujące węzły a reprezentacje
wykorzystujące krawędzie.................................................................................303
8.2.3. Reprezentacja łączy ............................................................................................305
8.2.4. Łącza XML zapisywane jako krawędzie............................................................307
8.2.5. Zapisywanie łączy ..............................................................................................308
8.3. Mechanizmy obsługi zapytań .......................................................................................310
8.3.1. Zapytania według ścieżki ...................................................................................310
8.3.2. Zapytania według drzewa...................................................................................313
8.4. Zapytania wykorzystujące grafy ...................................................................................314
8.4.1. Model danych korzystający z grafów.................................................................315
8.4.2. Wzorce korzystające z grafów............................................................................316
8.4.3. Wizualizacja .......................................................................................................318
8.4.4. Implementacja SQL............................................................................................319
8.4.5. Algorytm zapytań według grafu .........................................................................340
8.5. Narzędzia do tworzenia raportów .................................................................................345
8.5.1. Użycie XSL do zapytań według ścieżek ............................................................345
8.5.2. Zapytania według grafu ......................................................................................347

8Projektowanie baz danych XML. Vademecum profesjonalisty
'
(! '
9.1. Wprowadzenie ..............................................................................................................349
9.2. Struktury danych elementów ........................................................................................350
9.3. Strategie indeksowania .................................................................................................350
9.3.1. Brak indeksowania .............................................................................................351
9.3.2. Pełne indeksowanie ............................................................................................351
9.3.3. Indeksowanie częściowe.....................................................................................355
9.3.4. Indeksowanie związków między dokumentami .................................................358
9.4. Identyfikacja dokumentu ..............................................................................................360
9.5. Metody przeszukiwania ................................................................................................362
, (-& $
10.1. System notatek ............................................................................................................365
10.2. Podstawy biologii .......................................................................................................366
10.3. Wymagania użytkownika ...........................................................................................367
10.4. Model koncepcyjny.....................................................................................................368
10.5. Opis aplikacji ..............................................................................................................371
10.5.1. Klient ................................................................................................................371
10.5.2. Warstwa pośrednia ...........................................................................................378
10.6. Ograniczenia i rozszerzenia ........................................................................................403
10.7. Uwagi praktyczne .......................................................................................................404
10.8. Skalowanie..................................................................................................................404
10.8.1. Zarządzanie transakcjami .................................................................................404
10.8.2. Bezpieczeństwo ................................................................................................405
10.8.3. Odzyskiwanie danych.......................................................................................405
10.8.4. Optymalizacja...................................................................................................406
.! /01 ,
A.1. Domyślne ustawienia systemowe ................................................................................407
A.2. Połączenie z relacyjną bazą danych .............................................................................409
A.3. Wyniki działania serwleta............................................................................................415
A.4. Interaktywny interfejs dostępu.....................................................................................417
.!2
% 3 '
.!4 356%478,9:-
Rekomendacja W3C, 2 maja 2001 r. ...................................................................................423
Spis treści .............................................................................................................................424
1. Wprowadzenie .................................................................................................................425
2. Podstawowe pojęcia: Zamówienie...................................................................................426
2.1. Schemat opisujący zamówienia.............................................................................427
2.2. Definicje typów złożonych, deklaracje elementów i atrybutów............................429
2.3. Typy proste ............................................................................................................433
2.4. Definicje typów anonimowych..............................................................................438
2.5. Treść elementów....................................................................................................439
2.6. Adnotacje...............................................................................................................442
2.7. Tworzenie modeli zawartości................................................................................443
2.8. Grupy atrybutów....................................................................................................444
2.9. Wartości Nil...........................................................................................................446
3. Zagadnienia zaawansowane I: Przestrzenie nazw, schematy i kwalifikacja ...................447
3.1. Docelowe przestrzenie nazw i niekwalifikowane elementy i atrybuty lokalne.....447
3.2. Kwalifikowane deklaracje lokalne ........................................................................449
3.3. Deklaracje globalne a deklaracje lokalne ..............................................................452
3.4. Niezadeklarowane docelowe przestrzenie nazw ...................................................453

5RKUVTGħ EK
9
4. Zagadnienia zaawansowane II: Zamówienie międzynarodowe ......................................453
4.1. Schemat w szeregu dokumentów ..........................................................................454
4.2. Wyprowadzanie typów przez rozszerzenie ...........................................................457
4.3. Użycie typów pochodnych w dokumentach..........................................................457
4.4. Wyprowadzanie typów złożonych przez ograniczanie .........................................458
4.5. Przedefiniowywanie typów i grup.........................................................................460
4.6. Grupy podstawienia...............................................................................................462
4.7. Elementy i typy abstrakcyjne ................................................................................463
4.8. Kontrolowanie tworzenia i użycia typów pochodnych .........................................464
5. Zagadnienia zaawansowane III: Raport kwartalny..........................................................466
5.1. Wymuszanie niepowtarzalności ............................................................................468
5.2. Definiowanie kluczy i wskaźników.......................................................................469
5.3. Reguły w XML Schema a atrybut ID XML 1.0 ....................................................469
5.4. Importowanie typów..............................................................................................469
5.5. Dowolny element, dowolny atrybut ......................................................................472
5.6. schemaLocation.....................................................................................................475
5.7. Zgodność ze schematem........................................................................................476
A. Podziękowania ................................................................................................................478
B. Typy proste i ich fazy......................................................................................................478
C. Użycie encji.....................................................................................................................478
D. Wyrażenia regularne .......................................................................................................480
E. Indeks ..............................................................................................................................481
%! #

Rozdział 5.
Język XML świetnie nadaje się do wymiany danych, dlatego też często wykorzystujemy
go w komunikacji między systemami. Pojęcia „architektura systemu baz danych” uży-
wamy w odniesieniu do sposobu, w jaki aplikacje i użytkownicy korzystają z danych oraz
zarządzają nimi. W przypadku baz danych XML użytkownicy i aplikacje muszą załado-
wać dane do bazy, przekształcić je na dokumenty XML, pobrać XML z bazy i powiązać
dane relacyjne z kodem XML. Architektura systemu baz danych może być typu klient-
serwer — wtedy aplikacja klienta współpracuje bezpośrednio z bazą danych albo może
to być struktura trzywarstwowa, w której między klientem a bazą danych pojawia się
dodatkowo serwer.
Architektura systemu to sposób funkcjonowania systemu i jego poszczególnych modułów.
Każdy moduł jest komponentem systemu i realizuje powiązane ze sobą funkcje. Dobrą
architekturę systemu tworzy się przez odpowiednie pogrupowanie wymagań funkcjonal-
nych w moduły i łączenie modułów w system, który spełnia wszystkie założone zadania.
Definiując architekturę systemu, należy odpowiedzieć na następujące pytania:
Ile jest modułów?
Jak są ze sobą powiązane? (Czy liniowo, czy w drzewo albo graf?)
Na czym polega ich działanie? Czyli jakie są funkcje poszczególnych modułów?
Z systemami spotykamy się wszędzie — poznawanie większości dziedzin naukowych
wiąże się ze studiowaniem konkretnych systemów. Fizyka bryły sztywnej opisuje, jak
należące do systemu obiekty oddziałują na siebie, a w przypadku biologii dokładnie anali-
zuje się systemy o „organicznej” naturze. Inżynieria polega na tworzeniu złożonych sys-
temów o założonych funkcjach. W budownictwie przez termin „architektura” rozumie
się projekt budynku, jego wygląd i sposób funkcjonowania.
Architektura systemu to obszerne zagadnienie związane z projektowaniem komponentów,
które współpracując ze sobą, realizują całościowe zadania. W tej książce będziemy mówić
o architekcie systemu, którego zadanie polega na zaprojektowaniu deterministycznych
komponentów programowych baz danych XML.

182
Projektowanie baz danych XML. Vademecum profesjonalisty
Duże systemy zwykle mają hierarchiczną budowę: większe podsystemy zawierają mniejsze,
a te z kolei tworzone są z jeszcze mniejszych podsystemów, i tak dalej, aż do pakietów,
które zawierają podstawowe składniki programów, czyli klasy obiektów, funkcje i proce-
dury. W tym rozdziale zajmiemy się abstrakcyjnymi aspektami projektowania i podziałem
pracy na różne maszyny dostępne w Sieci.
Pierwsze systemy baz danych były monolityczne. Obsługiwała je jedna stacja robocza.
Użytkownicy korzystali z systemu za pomocą prostych terminali lub kart perforowanych.
Z czasem, kiedy stacje robocze zaczęły mieć coraz większą moc obliczeniową, część
obliczeń i funkcji została wydzielona z monolitycznego systemu i przeniesiona na stacje
robocze (klientów), w architekturze klient-serwer. Podsystem klienta przeprowadzał for-
matowanie i proste przetwarzanie, zaś serwer zarządzał większością danych. W miarę
jak powiększały się bazy danych i włączano je do systemów korporacyjnych, konieczne
stało się zastosowanie architektury trzywarstwowej. Dzięki zastosowaniu odrębnego
serwera uproszczono dostęp klientów do wielu baz danych. Warstwa pośrednia umoż-
liwiła aplikacjom klienta łączenie się z wieloma bazami danych przez jednolity interfejs.
Jednocześnie projektanci starali się znaleźć odpowiednie miejsce dla reguł biznesowych,
które opisują zasady użycia danych. Przetwarzanie reguł mogło przecież „zatkać” serwer
lub wymagało powtórzenia tych operacji na stacjach klientów, szczególnie w dużych
systemach, w których wiele aplikacji przetwarza reguły. Jeśli reguły biznesowe znajdowały
się w warstwie pośredniej, to różne aplikacje, nie troszcząc się o wydajność czy utrzyma-
nie serwera baz danych, mogły z nich korzystać. Wzrost liczby baz danych i aplikacji
przyczynia się do tego, że konieczne staje się stosowanie dodatkowych warstw pośred-
nich, a co z tym związane — zmiana architektury trzywarstwowej na wielowarstwową.
Sieciowy system baz danych zawiera — jako jeden ze swoich modułów — serwer sieciowy.
Do komunikacji między poszczególnymi warstwami używa się protokołu nośnego sieci,
na przykład
. Sieciowy system baz danych może mieć architekturę klient-serwer,
architekturę trzywarstwową lub wielowarstwową. Najczęściej stosuje się rozwiązanie
trzywarstwowe — w takim wypadku baza danych wysyła dane do serwera sieciowego.
Jeśli bierzemy pod uwagę architekturę wielowarstwową, to wiele baz danych i serwerów
aplikacji wysyła dane do jednego lub wielu serwerów sieciowych, które następnie przeka-
zują dane klientom. Języka XML można użyć do komunikacji pomiędzy komponentami
struktury wielowarstwowej. Można również zastosować układ klient-serwer — zwykle
serwer sieciowy jest wtedy wbudowany w bazę danych.
Jedną z zalet sieciowych baz danych jest uproszczenie aplikacji przez zastosowanie
przeglądarek sieciowych obsługujących aplety Javy. W przypadku apletów kod języka
Java jest przenoszony przez Sieć w chwili kiedy jest wywoływany, zaś przeglądarka za-
pewnia podstawowe formatowanie danych, obsługę formularzy i prostych języków skrypto-
wych; jej możliwości mogą być rozszerzone przez zastosowanie apletów. Chęć poprawienia
przepustowości i uruchamiania coraz bardziej złożonych aplikacji w coraz mniejszych
systemach powoduje, że funkcje, które były dostępne w aplikacjach klienta, są wykony-
wane na serwerach lub w warstwach pośrednich (mówimy wtedy o aplikacjach „cienkiego
klienta”). I tak na przykład aplety Javy mogą sięgać do bazy danych za pośrednictwem
połączenia JDBC, zamiast stosować natywne sterowniki. Aplety mogą też korzystać
z udostępnianych w pośredniej warstwie programów analitycznych, zamiast lokalnie
wykonywać wszystkie obliczenia.

4Q\F\KC đ
Architektura systemu baz danych
183
Dobrze opracowaną architekturę systemu rozpoznaje się po tym, że odpowiednie funkcje
umieszczono w odpowiednich modułach. Wyboru można dokonać na podstawie różnych
kryteriów, na przykład takich jak unikanie zależności od stosowanych technologii lub
określenie zależności pojęć w opisywanej dziedzinie. Takie niefunkcjonalne wymagania
to podstawowe kryteria stosowane w początkowych etapach projektowania. Zdefiniowanie
odpowiednich kryteriów warunkuje dobrą architekturę systemu, jest też podstawą udanego
projektu. W niektórych sytuacjach w doborze kryteriów mogą pomóc następujące pytania:
Czy funkcje baz danych powinny być wydzielone jako odrębny moduł, by
ułatwić uruchamianie systemu w różnych środowiskach?
Czy w całym systemie będzie można zastosować technologię jednej firmy?
Czy system powinien być niezależny od dostawcy oprogramowania warstwy
pośredniej?
Czy interfejs użytkownika ma przyjmować schemat bazy danych
(minimalizowanie wpływu częstych zmian opisywanej dziedziny)?
Czy, z uwagi na duże ilości danych, należy ograniczać ilość przesyłanych
informacji z bazy danych?
Czy — by spełnić wymogi bezpieczeństwa — kontrola dostępu do danych
powinna być wydzielona jako odrębny moduł?
Najważniejsza jest równowaga między podstawowymi wymaganiami, tak aby zanadto
nie ograniczać systemu. Elastyczność i spełnianie precyzyjnych wymagań to sprzeczne
oczekiwania wobec systemu. Proces rozszerzania możliwości systemu często jest hamo-
wany przez jego realne uwarunkowania. W oprogramowaniu ważnym dla działania przed-
siębiorstwa dużo pracy wkłada się w tworzenie architektury dopasowanej do konkretnych
wymagań i pozwalającej wykorzystywać dostępne zasoby. W przypadku szybko tworzo-
nych systemów architekturze poświęca się niewiele uwagi. Wielu autorów skryptów Perl
czy CGI łączy instrukcje języków SQL z generacją HTML i specyficznymi dla danej
dziedziny regułami biznesowymi, w efekcie w szybkim tempie tworzą sprawnie działający
system. Niestety, trudności wiążą się z utrzymaniem takiego systemu, a wzrastają przy
każdej zmianie schematu bazy danych, przeglądarki i rozszerzaniu reguł biznesowych.
Przetwarzanie XML może się odbywać na serwerze baz danych. Baza danych XML lub
program generujący XML mogą być włączone do innego serwera baz danych. (Rozwią-
zania, które oferują komercyjne relacyjne bazy danych opiszemy w punkcie 6.2.2). Poza
tym można tak modyfikować kod serwera, aby zwracał kod HTML. By uzyskać taki efekt,
należy skorzystać z darmowego serwera relacyjnej bazy danych, na przykład mysql, który
potrafi generować XML. Inny sposób polega na dodaniu do obiektowej bazy danych obiek-
tów obsługujących XML (tę metodę wykorzystano w systemie eXcelon; opis można znaleźć
w punkcie 4.1.2). W tym punkcie zajmiemy się kilkoma prostymi metodami generowania
XML z relacyjnego serwera baz danych. W końcowej części tego rozdziału opiszemy
serwery baz danych, które charakteryzuje trzywarstwowa architektura i które można włą-
czać do serwerów baz danych, korzystających z języków programowania takich jak Java.

184
Projektowanie baz danych XML. Vademecum profesjonalisty
XML można generować bezpośrednio w instrukcji SQL. Jeśli mamy tabelę
z kolum-
nami:
,
i
(jak w bazie danych Oracle
), to kod z wydruku 5.1
wygeneruje dokument XML. Aby stworzyć dokument XML, należy otoczyć dane znacz-
nikiem
. Istnieje jeszcze jeden warunek, który powinien zostać spełniony,
byśmy mogli osiągnąć cel — serwer lub aplikacja klienta powinny obsługiwać funkcje
agregujące, tak jak to pokazuje wydruk 5.2. Wprawdzie nie jest to rozwiązanie zbyt ogólne,
ale stosując SQL, można w prosty sposób generować kod XML z relacyjnej bazy danych.
Co ważne, w przypadku prostych zastosowań może to być wygodne.
Kod SQL generujący fragment tabeli wydziałów przykładowej bazy danych Scott/Tiger
Skrypt generujący dokument XML dla tabeli wydziałów przykładowej bazy danych Scott/Tiger
!
"#$%&'
%&'
Jeśli uniezależnimy się od konkretnych kolumn, to otrzymamy bardziej uniwersalne rozwią-
zanie. Na serwerze można stworzyć funkcję, która wartości kolumny otoczy znacznikami,
których nazwy są nazwą kolumny, wiersze — nazwą tabeli, a dokument — elementem
.
Rekord relacyjnej tabeli można przekształcić w pojedynczy element, a wartości zapisy-
wać w atrybutach tego elementu, można też stworzyć element z podelementami. Zapis
rekordów jako atrybutów jest prostszy, ale użycie podelementów — bardziej uniwersalne.
Kiedy korzystamy z podelementów, możemy zastosować sekcje CDATA do zapisywania
znaków zastrzeżonych. Atrybuty mogą przechowywać informacje o formatowaniu, można
je zastąpić kompletniejszymi danymi ze wskaźnikami kluczy obcych. Różnice między
zastosowaniem atrybutów i elementów opisano w punkcie 2.4.4.
Pseudokod, za pomocą którego można przekształcić rekordy tabeli w atrybuty, podano
w wydruku 5.3, zaś ten, za pomocą którego przekształca się rekordy na elementy z po-
delementami, przedstawia wydruk 5.4. Wielu sprzedawców baz danych proponuje takie
rozwiązania, w których wyniki zapytania przekształcane są na dokumenty XML. Pro-
pozycje firm IBM, Oracle i Microsoft opisano w rozdziale 6.
Procedura zapisu danych z relacyjnej tabeli jako atrybutów XML
#()*+,#-.
!
(
#(
##

4Q\F\KC đ
Architektura systemu baz danych
185
Procedura zapisu danych z relacyjnej tabeli jako podelementów
#()*+%%-.
!
(
#(
#
#
#
Niektóre przykłady kodu Java zaprezentowane w dalszej części tego rozdziału uruchomią
się w systemie o architekturze dwuwarstwowej, która pozwala rozwijać klucze obce,
pobierać pojedyncze rekordy oraz narzucać warunki na zapytania. Przetwarzanie XML
bezpośrednio na serwerze baz danych, z właściwą mu architekturą klient-serwer, ma
kluczowe znaczenie dla wydajności w dużych zbiorach danych. Jednak oprogramowanie
jest opisywane jedynie w architekturze trzywarstwowej, gdyż wtedy wymogi związane ze
znajomością różnych procesów i ich działaniem są mniejsze niż w przypadku architektury
dwuwarstwowej. Jeśli trzeba skorzystać z systemu o architekturze klient-serwer, to funkcjo-
nalność warstwy pośredniej i serwera z systemu o architekturze trzywarstwowej można ze
sobą połączyć, tworząc serwer odpowiedni dla modelu opartego na strukturze dwuwar-
stwowej. Zdarza się, że nawet jeśli przetwarzanie odbywa się na serwerze, to i tak mogą wy-
stąpić problemy z komunikacją między jądrem bazy danych a rozszerzeniami obsługujący-
mi XML — w przypadku struktury trzywarstwowej łatwiej można poprawić wydajność.
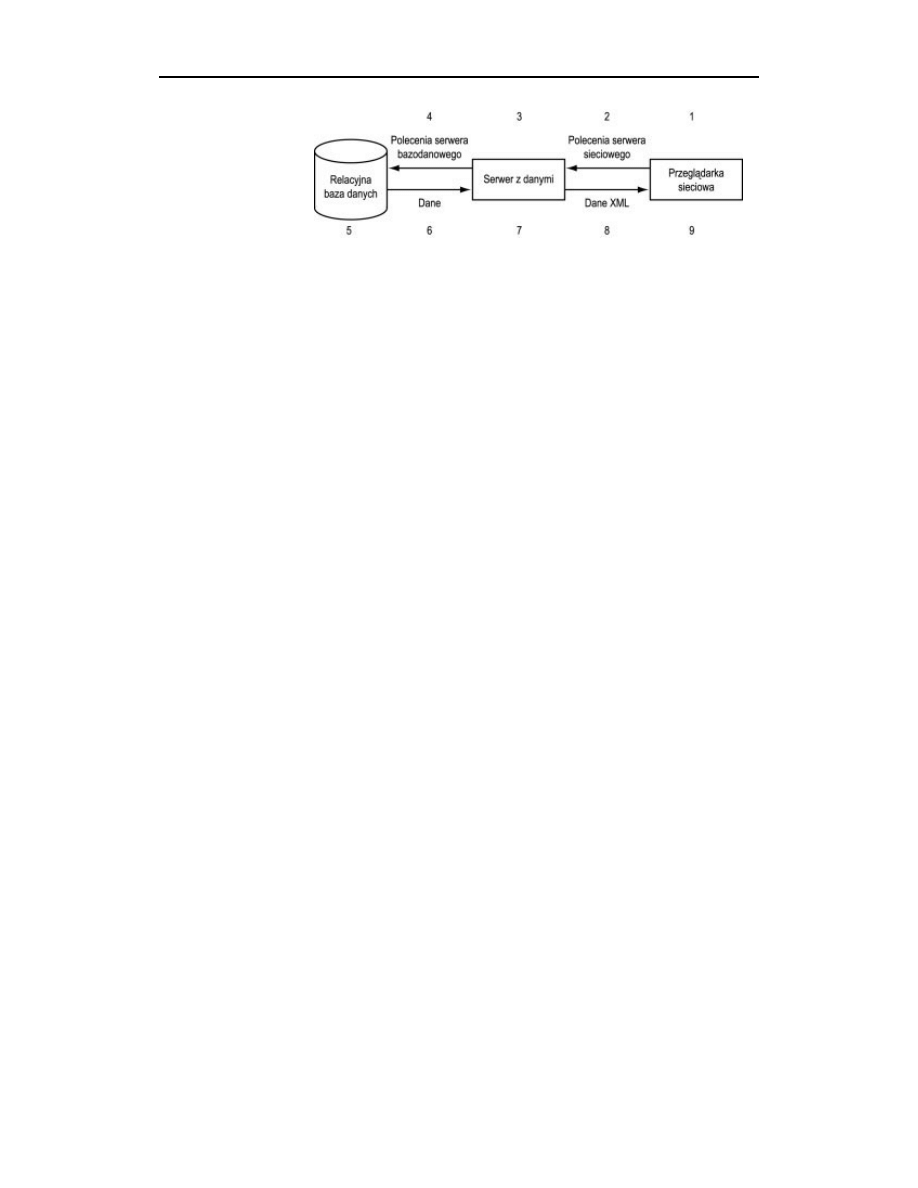
Prostą trzywarstwową architekturę sieciowego systemu baz danych pokazano na rysun-
ku 5.1. System ten składa się z trzech modułów:
DBMS — realizuje funkcje bazy danych i umożliwia dostęp do bazy.
Można zastosować relacyjną, obiektową bazę danych, bazę danych XML
lub system plików.
Warstwa pośrednia — zawiera serwer sieciowy, który może korzystać z bazy
danych i udostępniać te dane klientowi. Można zastosować zwykły serwer
sieciowy, serwer sieciowy ze skryptami CGI, serwer z serwletami, serwer z JSP,
komercyjne oprogramowanie warstwy pośredniej z dostępem do baz danych
lub serwer aplikacji.

186
Projektowanie baz danych XML. Vademecum profesjonalisty
Trzywarstwowa
architektura
sieciowego systemu
baz danych
Klient — zawiera interfejs użytkownika, który pozwala korzystać z funkcji
warstwy pośredniej. Klient może być też inną aplikacją. Zwykle rolę tę pełni
przeglądarka, aplet Javy lub aplikacja napisana w języku Java.
W różnorodny sposób można określać zawartość poszczególnych modułw i sposób ich
łączenia. Protokołem komunikacyjnym z klientem może być TCP/IP, HTML lub XML,
przenoszone przez HTTP lub CORBA. Komunikacja między bazą danych lub warstwą
pośrednią może się odbywać za pomocą JDBC lub CORBA. Zwykle wybór jednej tech-
niki komunikacji wpływa na inne decyzje.
Oczywiście, zawsze można zastosować inne typy architektury i inne techniki. Niezależnie
od dokonanego wyboru, projektując system, warto i należy zadać kilka pytań, między
innymi:
W jaki sposób dane są ładowane do bazy danych?
Za pomocą jakich zapytań dane będą pobierane z bazy?
W którym module jest generowny XML?
W którym module odbywa się przetwarzanie XML?
Serwer XML umożliwia sieciowy dostęp do bazy danych. Obsługuje takie operacje baz
danych, jak: przechowywanie, pobieranie, aktualizowanie dokumentów. Baza danych
może opierać się na dowolnym modelu danych, ale dane pobierane zawsze mają postać
XML. Kiedy serwer danych ładuje dane do bazy innej niż XML, może przyjmować dane
w formie XML lub w formacie odpowiednim dla konkretnej bazy.
W następnym punkcie opiszemy niektóre możliwości implementacji, zaś w punkcie 5.2.2
sposób, w jaki można sięgać do danych na serwerze. W punktach 5.2.3 i 5.3 przedstawimy
kolejno zapisywanie danych z bazy relacyjnej jako XML i odczyt tych danych. W punk-
cie 5.4 — pobieranie i odczyt danych XML z serwera bazy danych XML, zaś w punkcie 5.5
— pobieranie danych relacyjnych i XML ze wspólnego serwera.
Serwer danych XML można stworzyć „od zera”, na przykład modyfikując serwer sieciowy
albo korzystając z serwera sieciowego z obsługą CGI, z serwera sieciowego z obsługą
serwletów, z obsługą JSP, można także wykorzystać serwer aplikacji lub po prostu kupić
gotowy system. Jeśli tworzymy serwer danych XML „od zera”, to należy pamietać, że
serwer sieciowy jest podstawą, na której tworzy się funkcje dostępu do danych, funkcje

4Q\F\KC đ
Architektura systemu baz danych
187
formatowania XML i zwracania odpowiedzi zgodniez podanymi adresami URL. Gotowy
serwer sieciowy (na przykład niewielki, darmowy serwer) można zmodyfikować lub
rozszerzyć o funkcje dostępu do bazy danych, formatowanie XML i odpowiadanie na
żądania w formie adresów URL. W przypadku używania serwera z obsługą CGI, ser-
wletów lub serwera aplikacji trzeba zrobić to samo. Korzystanie z serwera aplikacji ma
jedną zaletę, serwery te posiadają wbudowaną funkcję połączeń z bazą danych. Dobry
system komercyjny zazwyczaj od razu dysponuje wszystkimi potrzebnymi funkcjami.
Do serwera danych można dodać funkcje, które wykonują określone zadania przed zwró-
ceniem, wprowadzeniem lub zmodyfikowaniem danych XML w bazie. Na przykład
niektóre zapytania mogą wymagać agregacji lub wyliczeń statystycznych. W przypadku
wprowadzania danych i ich modyfikowania konieczne może być sprawdzenie poprawności
danych lub reguł biznesowych. Warto o tym pamiętać, zanim wybierzemy serwer danych.
Najlepszym rozwiązaniem jest, oczywiście, komercyjny serwer danych XML, gdyż spełnia
wszystkie wymagania. Warto także rozważyć możliwość zakupu serwera aplikacji, który
można łatwo połączyć ze środowiskiem projektowym (jeśli spełnia nasze wymagania)
i który posiada odpowiednie funkcje baz danych. Wadą niektórych serwerów aplikacji
jest to, że często projektanci są ograniczani przez dostępne interfejsy użytkownika lub
niestandardową metodę łączenia się z bazą danych — wymaga to od nich dodatkowego
wysiłku. Jednak tworzenie od początku pakietu łączności z bazą danych (na przykład
opartego na JDBC) jest trudnym zadaniem i w przypadku dużych aplikacji komercyjnych
należy to uznać za ostateczność (chyba że postawiliśmy sobie za cel stworzenie serwera
danych XML — wtedy, oczywiście, rzecz jest warta zachodu). Pakiety łączności z bazą
danych w przypadku małych aplikacji mogą być proste. Wystarczy otwarcie połączenia
z bazą danych, wykonanie transakcji i zamknięcie połączenia. Taki prosty pakiet opisano
w dodatku A. Jednak wykonanie pakietów łączności z bazą danych staje się dużo bardziej
odpowiedzialnym zsadaniem, kiedy trzeba utrzymywać połączenia dla wielu transakcji
przeprowadzanych z różnych kont, dbać o wydajność (wymaga to zarządzania połącze-
niami, czasem rozłączania się) i bezpieczeństwo połączeń.
Ważną decyzją związaną z implementacją serwera danych jest wybór języka programo-
wania.
Jeśli do stworzenia serwera danych używamy Javy, serwer sieciowy powinien obsługiwać
serwlety. Komunikacja bazy danych z serwerem sieciowym może mieć formę „cienkiego
klienta” lub „grubego klienta”. Wybór jednego z tych rozwiązań zależy od możliwości
bazy danych. W przypadku „grubego klienta” cała aplikacja ma bezpośredni dostęp do
bazy. W przypadku „cienkiego klienta” serwer sieciowy może sięgać do bazy danych za
pomocą odpowiedniego protokołu, który zwykle nie obsługuje specjalnych funkcji bazy.
Połączenie z bazą „cienkiego klienta” można zrealizować jako bezpośrednie, zapisane
w języku C z obudową w języku Java. Rozwiązanie „cienkiego klienta” zwykle realizuje
się za pomocą JDBC (ODBC zrealizowane w Javie), czyli standardowego mechanizmu
dostępu do danych w bazach relacyjnych, typowego dla większości (a może nawet dla
wszystkich) baz danych. Niektóre bazy danych oferują także bezpośrednie połączenie
Javy oparte na JDBC lub innym protokole. Porównanie tych dwóch rozwiązań: „cienkiego
klienta” i „grubego klienta” można znaleźć w każdej dobrej książce o JDBC. „Gruby klient”
może być wydajniejszy. W tym rozdziale skorzystamy z JDBC („cienki klient”), gdyż
jest to rozwiązanie ogólne, dostępne w większości baz danych — zwykle wystarczające.

188
Projektowanie baz danych XML. Vademecum profesjonalisty
Alternatywa dla Javy to użycie języka skryptowego Tcl/Tk. Ma on kilka zalet: łatwo można
go rozszerzać, bez trudu można go łączyć z językiem C i różnymi pakietami oprogramo-
wania. Niestety, nie jest tak popularny jak Java czy JavaScript, ale warto się zastanowić
nad tym wyborem, szczególnie jeśli Tcl/Tk jest dostępny w używanym systemie. Język
Tcl/Tk świetnie nadaje się do tworzenia prototypów, gdyż nie są uwzględniane typy danych,
a struktury danych są elastyczne, poza tym język ten dysponuje wieloma wbudowanymi
możliwościami. W Sieci są dostępne rozszerzenia łączności z bazami Oracle, Sybase i in-
nymi, istnieją darmowe serwery HTTPD dostępne wraz z kodem źródłowym, w tym jeden
autorstwa Scriptics. Znane są jeszcze lepsze serwery sieciowe i aplikacje napisane w Tcl/Tk,
w tym serwer działający na stronie AOL, którego zaletą jest wbudowana łączność z bazami
danych. Wadą jest mała popularność Tcl/Tk, co wpływa na utrudnienia w dostępie do
pomocy i mniejszą liczbę darmowych pakietów, skromniejsze możliwości i wolniejszą
reakcję na pojawiające się nowinki techniczne. Jednak ci, którzy znają Tcl/Tk, mogą
w kilka dni stworzyć dobrze działający serwer danych XML, korzystając z darmowych
komponentów. Jest to świetna metoda tworzenia prototypu takiego serwera.
Inne języki skryptowe to Perl i Python. Perl zawiera mnóstwo modułów obsługujących
CGI i umożliwia łączność z bazami danych. Coraz większa grupa programistów korzysta
z tego języka, gdyż umożliwia programowanie obiektowe oraz posiada sprawne algorytmy.
Osoby, które chciałyby zbudować serwer danych XML oparty na relacyjnej bazie danych,
a nie mają dostępu do bazy komercyjnej, mogą skorzystać z darmowej bazy mysql, która
jest obsługiwana w wielu językach skryptowych.
Kiedy używamy sieciowego serwera danych, aplikacje klienckie uzyskują do niego dostęp
za pomocą adresu URL. Adres ten może zawierać większość informacji, a nawet wszyst-
kie, które są potrzebne, by mieć dostęp do danych, zaś dane zapisywane w bazie mogą
być wysyłane metodą POST. Jeśli chcielibyśmy mieć dostęp do danych z serwera XML,
trzeba zastanowić się nad takimi zagadnieniami:
W jaki sposób zyskamy dostęp do serwera sieciowego?
Jak należy podawać adres URL, aby umożliwić dostęp do bazy danych?
Jakie są najważniejsze wyzwania projektowe?
Należy użyć jednego adresu URL czy wielu?
Jakie warunki decydują o konstrukcji adresu URL?
Oto sposoby, możliwości tworzenia adresu URL:
Jeden adres URL, wszystkie informacje przekazywane są metodą POST
pojedynczego dokumentu.
Jeden adres URL, większość informacji przekazywana jest metodą POST
i jako parametry GET.
Różne adresy URL, które spełniają różne funkcje.

4Q\F\KC đ
Architektura systemu baz danych
189
Wszystkie dane i polecenia mogą być umieszczane w dokumencie, a następnie przesyłane
pod jednym adresem URL. Zaletą takiego rozwiązania jest przenoszenie wszystkich danych
jako XML (dzięki czemu rozwiązanie jest zgodne z innymi metodami). Wada to koniecz-
ność parsowania dokumentów (przynajmniej wstępnego), zanim zostanie podjęta decyzja,
które dane mają być wysłane. Jeśli na przykład można wprowadzić nowe dane lub zak-
tualizować istniejące, to wybór odpowiedniej operacji może wymagać częściowego przy-
najmniej parsowania dokumentu. Przekazywanie częściowo sparsowanego strumienia
danych innemu parserowi jest trudne, o ile w ogóle możliwe. Jednak takie rozwiązanie
jest przydatne, kiedy można od razu przeanalizować cały dokument. Użycie pojedyn-
czego dokumentu to optymalne rozwiązanie, kiedy z serwerem danych XML współpra-
cuje wiele aplikacji.
Kiedy użytkownicy kontaktują się z serwerem danych XML za pośrednictwem stron
sieciowych i formularzy HTML, łatwiejsze jest przekazywanie danych metodami POST
i GET. Jest to najlepsze rozwiązanie, kiedy mamy do czynienia z niewielkim zbiorem
poleceń i niewielką ilością strukturalnych danych. Jeśli na przykład należy przeglądać
dane i zadawać zapytania za pośrednictwem prostych formularzy, parametry można prze-
kazywać w wierszu adresu. W tej książce postąpimy najlepiej jak potrafimy — z peda-
gogicznego punktu widzenia — użyjemy metod POST/GET, dane strukturalne przekażemy
jako XML, podając kod XML jako część adresu URL.
Zastosowanie odrębnych adresów URL i przypisanie ich do innej funkcji lub jednego
adresu i wskazywanie funkcji w parametrach to kwestia stylu programowania, choć
w zależności od stosowanych technik programistycznych jedno z tych rozwiązań może
być prostsze w implementacji.
Adresy URL można podawać w przeglądarce sieciowej, w formularzu HTML, z apletu,
aplikacji, ze skryptu CGI lub w jakikolwiek inny sposób zapisany w HTTP.
!"##
Załadowanie danych XML do istniejącej bazy relacyjnej (lub obiektowej) stanowi po-
dwójne wyzwanie: semantyczne i techniczne. Pierwsze polega na odwzorowaniu semantyki
XML, czyli przekształceniu danych XML w relacje — na przykład elementu
w tabelę
. Kiedy dokument XML jest projektowany z myślą o istniejącej bazie
relacyjnej, odwzorowania powinny być proste. W dokumencie XML mogą wystąpić takie
znaczniki, którym nie odpowiadają żadne obiekty bazy; dane tego rodzaju można pominąć
lub należy tak zmodyfikować bazę, aby je uwzględnić.
Trudność odwzorowywania dokumentów XML w relacje pojawia się, kiedy semantyka
XML i relacyjnej bazy danych częściowo się pokrywa. Na przykład dane XML, które
pochodzą z jednego systemu, mogą zawierać informacje o pracownikach zatrudnionych
etatowo, tymczasowo i na umowę zlecenia, zaś w bazie relacyjnej wszystkim tym gru-
pom pracowników mogą odpowiadać odrębne relacje. W zasadzie problem jest podobny
do tego, który wiąże się z łączeniem wielu baz danych. W takiej sytuacji przydają się
doświadczenia związane z dużymi bazami danych oraz scalaniem różnych baz, szcze-
gólnie jeśli bazy oparte były na różnych modelach danych.
Drugi rodzaj problemu, techniczny — to sposób odwzorowania hierarchicznych danych
XML, przekształcenia ich na płaskie relacje. Chodzi o to, żekiedy dojdzie do odwzoro-
wania, zapis danych w formie relacji wymaga „spłaszczenia” danych.

190
Projektowanie baz danych XML. Vademecum profesjonalisty
W przypadku przechowywania danych XML w gotowej bazie relacyjnej lub obiektowej
mogą się przydać cztery wymienione rozwiązania.
Specjalny skrypt — to najprostszy, choć najmniej ogólny sposób. Polega na stworzeniu
specjalnego programu, który odczyta i sparsuje dokument XML, a następnie wstawi dane
do odpowiednich tabel.
Ograniczenie struktury — dokument XML można przekształcić (na przykład za pomocą
XSLT) w strukturę podobną do relacji bazy danych. Elementy zagnieżdżone można za-
stąpić wartościami odpowiednich identyfikatorów, zaś ich treść umieścić w innej czę-
ści dokumentu, która zostanie utworzona później. Połączenie elementu „rodzica” z elemen-
tem w nim zagnieżdżonym dokonuje się przez klucz obcy lub tabelę łączącą w relacyjnej
bazie danych. W wydruku 5.5 mikromatryca podłoży z zagnieżdżonymi informacjami
o genach może być zastąpiona dwoma zbiorami płaskich rekordów, gdzie podłoża będą od-
woływały się do genów, korzystając z identyfikatora. Przykłady doświadczeń z mikro-
matrycą są podobne do opisanych w punkcie 2.3.3 eksperymentów hybrydyzacji na filtrze,
ale przy okazji mierzona jest także liczba genów, które połączyły się z DNA matrycy.
Zagnieżdżone rekordy przeznaczone do załadowania
!
$$
,
$
/01
2%3021&4%5%6,71%'%5,/8
(9:;&<05/%6,/01&6050(9
$==$
$
$$
,>
$
412?
1%/%5@A,4&+4;71&/%;50
(9B026;%+,5;%(9
$==$
$
Tworzenie połączeń — w czasie ładowania można sprawdzać na przykład format danych
poprzez proste zapytania. Ułatwia to ładowanie tabel mających klucze obce.

4Q\F\KC đ
Architektura systemu baz danych
191
Przekształcenia — jeśli używamy bazy danych opartej na innym modelu danych niż XML,
dobrym pomysłem może być przekształcenie XML. Kiedy rolę klienta pełni użytkownik,
a nie inna aplikacja, właściwe będzie sformatowanie danych jako XML, zanim zostaną
załadowane do bazy, szczególnie w przypadku interaktywnego procesu wprowadzania
lub edycji danych, gdy drobne poprawki pojawiają się na zmianę z zapytaniami. Dużym
atutem stosowanego w takich systemach XML jest realizacja zapytań. Istnieją różne
techniki, za pomocą których można tworzyć dane i korzystać z formularzy do edycji.
W niektórych sytuacjach, aby załadować dane XML do bazy relacyjnej, można użyć ogól-
nego narzędzia. Warunkiem jest, żeby preprocesor mógł przekształcać hierarchiczne dane
XML w płaskie relacje. Jedna z możliwości to zastosowanie arkuszy stylów XSL do prze-
kształcenia specyficznej postaci XML na ogólną postać rekordów, które można załadować
za pomocą aplikacji języka Java. Jeśli jednak danych jest dużo, konieczne może być za-
stosowanie mechanizmu, który nie będzie przetwarzał danych w pamięci — na przykład
użycie parsera SAX (opisanego w dodatku B).
Aplikacja ładująca dane może być samodzielnym programem lub znajduje się na serwerze,
co pozwala przesłać dane XML do serwera HTTP i ładować do bazy. Poprzez Sieć dane
można ładować na dwa sposoby: przez dokument XML lub metodami HTTP — POST/GET.
Informacje o bazie danych i transakcjach można podać w parametrach POST/GET lub
w dokumencie XML. Dokument ten może zawierać informacje potrzebne do załadowania
danych w formie elementów lub atrybutów, zaś ładowane dane mogą być jednym z ele-
mentów dokumentu. Użycie dokumentu XML jest ogólniejszą metodą ładowania danych
generowanych przez aplikację, ale użycie metod POST/GET pozwala wprowadzać dane
ręcznie w formularzach HTML.
Parametrów POST można użyć do przekazania informacji o ładowaniu danych, elemen-
tów oraz atrybutów. W przypadku elementu płaskiego parametry są wyliczane według
nazwy. Struktury hierarchiczne są bardziej skomplikowane, ale można je tworzyć, wyko-
rzystując hierarchię nazw. W takiej hierarchii podelementy elementu głównego są wyliczane
według nazw, z kolei ich podelementy są nazywane przez połączenie ich nazw z nazwami
„rodziców” (z użyciem separatora).
Innym problemem, związanym ze stosowaniem formularzy HTML do przekazywania
informacji w parametrach, jest to, że niektóre parametry mogą być potrzebne aplikacji.
Na przykład formularz może ustawiać zmienną
, konto bazy danych i punkt wejścia
(nazwę tabeli lub klasę obiektu). Można postępować na cztery sposoby: jednoznacznie
identyfikować zmienne aplikacji, jednoznacznie identyfikować zmienne użytkownika,
jednoznacznie identyfikować jedne i drugie lub w ogóle się tym nie przejmować. Nazwy
zmiennych identyfikuje się, stosując przedrostki, na przykład
,
,
!
,
lub
.
By uprościć tworzenie formularza, można umieszczać polecenia XML w wartościach
parametrów. Jeśli na przykład konieczne jest utworzenie niepowtarzalnego identyfikatora,
można użyć polecenia nakazującego utworzyć taki identyfikator w trakcie ładowania, na
przykład
" #"$% "%
.

192
Projektowanie baz danych XML. Vademecum profesjonalisty
!
Dokumenty XML, które chcemy załadować, mogą pochodzić z innej aplikacji, źródła
zewnętrznego (bazy danych, zwykłego pliku) lub z formularza. Jednym ze sposobów
utworzenia dokumentu XML na podstawie danych z formularza jest wykorzystanie
skryptu lub programu formatującego dane z formularza HTML jako XML. Można też
użyć apletu języka Java. Dokładniej temat ten omówimy w rozdziale 7.
Autor napisał w języku Java program ładujący dane do bazy relacyjnej,
&
. Wydruk 5.6
pokazuje kod źródłowy
&
. Aplikacja ładuje dane XML w dwóch etapach:
Pierwszy polega na przekształceniu danych XML za pomocą arkuszy XSL
na dokument XML, składający się ze znaczników
&
i
'&
, które odpowiadają
ładowanym tabelom oraz metadanych opisujących ładowanie danych. Na przykład
dokument z wydruku 5.7 można przekształcić za pomocą arkusza stylów
na dokument XML
&
(zobacz wydruk 5.8). Arkusze stylów zostaną
dokładniej omówione w rozdziale 7., ale prosty arkusz, który w przykładzie
z mikromatrycą przekształca geny, przedstawia wydruk 5.9.
Drugi etap to ładowanie danych
&'&
do bazy za pomocą parsera SAX.
Dokument XML
&'&
, nazywany dokumentem
&
, składa się
z elementów
&
i
'&
, a także metadanych, które spełniają następujące
zadania:
Wskazują, w której tabeli powinien być umieszczony dany rekord. Rekordy
przeznaczone do różnych tabel mogą się przeplatać w dokumencie. Poza tym
rekord przeznaczony do jednej tabeli może być zagnieżdżony w rekordzie
ładowanym do innej tabeli. Upraszcza to generację dokumentu XML
&
.
Informują o tym, czy rekord zagnieżdżony ma być załadowany przed,
czy za rekordem, w którym jest zagnieżdżony. Wpływa to na większą
elastyczność definiowania, zwłaszcza w przypadku rekordów, które można
zdefiniować w arkuszu XSL bez względu na klucz obcy. Na przykład
w dokumencie XML pracownik może zawierać wydział, w którym dana osoba
pracuje, tak samo wydział może zawierać listę zatrudnionych w nim osób.
W trakcie ładowania rekord niezależny może zostać utworzony jako pierwszy,
potem mogą być tworzone rekordy zależne, bez względu na to który rekord
jest zagnieżdżonym, a który elementem otaczającym.
Wskazują, że wartość pola powinna być użyta do generacji wartości
przez generator sekwencji w bazie danych.
Wskazują, że wartość pola ma być pobrana z generatora sekwencji bazy danych.
Tak więc rekord zależny może odwoływać się do niepowtarzalnego identyfikatora
wygenerowanego dla rekordu nadrzędnego.
Wskazują, że białe znaki powinny być z wartości odrzucone bądź znormalizowane.
Wskazują, że wartość powinna być identyfikatorem rekordu w innej tabeli,
której dana kolumna ma wartość równą polu elementu. Pozwala to tworzyć
klucze obce na podstawie identyfikatorów generowanych przez bazę danych,
zaś klucze alternatywne lub kolumny o niepowtarzalnych wartościach mogą
być używane przy wprowadzaniu i ładowaniu danych.

4Q\F\KC đ
Architektura systemu baz danych
193
Kod Java programu ładującego dane XML, rLoad
CCCCCCCCCCCCCCCCCCCCCCCCC+)*+ DCCCCCCCCCCCCCCCCCCCCCCC
E$ ( F
CC
C4GH(EG#DI)*+9DDJ99
C
$ CF
$ 7'9F
2&*7F
$ (K 2#F
D ;&%F
( # CF
#+)*+L
#&2:2:#F
#+)*+-.L
#-.F
M
#&2:$&2:-.L
-2:#.L
9L
2:(&2:-(A2:@,-$$N>O ! ! ..F
2: -.F
M-D " <P+%.L
<E/-.F
M
M
#2:F
M
#-D $ <$QR$.L
/#D((SED#DI9EDT
-$ $.L
<9 -)*++U(9$9DEDE$# .F
M
-(+)*+-.. -$Q!R.F
M
#-<$'.L
<$@ <,)7F
9L
77'9 E7-@.F
3:(A2:@+3-.F
2#3-.F
%3-.F
9L
-'.F
M-<,)%.L
<E/-.F
M-;&%.L
<E/-.F
M
M-@5'#%.L
<E/-.F
M-;$,%.L
<E/-.F
M-;%.L
<E/-.F
M
M

194
Projektowanie baz danych XML. Vademecum profesjonalisty
#&2:-&2:(V#.L
+)*+ 2:(V#F
M
M
CCCCCCCCCCCCCCCCCCCCCCCCC1 DCCCCCCCCCCCCCCCCCCCCCCC
E$ ( F
CC
C6(DEJ
C
D $ CF
( # 12:F
#1L
#<$F
<$:#5:##F
<$:#V#:##F
<$:##"B:##F
<$:##"':##F
#<#"!F
<#"F
9F
#1-.L
#-.F
M
#'%-<$#.L
-$'V#:#-. $-.!.L
$'V#:#-. -W.F
M
<#"F
$'V#:#-. -#.F
M
#'5-<$.L
-$'5:#-. $-.!.L
$'5:#-. -W.F
M
$'5:#-. -.F
M
#'<#"-<$#.L
-$<#"B:#-. $-.!.L
$<#"B:#-. -,52.F
$<#"':#-. -W.F
M
JGG(E#J($
# &--. .F
-X.L
$<#"B:#-. -:YZ2[#[XJ9.F
#F
M
<$# #$-!W.F
<$## #$-[.F
#H(
#<#"[[F
'%-"[;$ <$-#<#".[ .F
<#"#F
$<#"B:#-. -"[;$ <$-#<#".[ [#[.F
$<#"':#-. -["[;$ <$-#<#"..F
M

4Q\F\KC đ
Architektura systemu baz danych
195
#'V#-<$#.L
-<#"#.L
('<#"
$<#"B:#-. -[#[.F
<#"F
#F
M
-$'V#:#-. $-.!.L
$'V#:#-. -W.F
M
BJJ9&(J#DG\#DEJT
$'V#:#-. -[#[.F
M
$29-.L
#9F
M
<$:#$'5:#-.L
-5:##.L
5:#(<$:#-.F
M
#5:#F
M
<$:#$'V#:#-.L
-V#:##.L
V#:#(<$:#-.F
M
#V#:#F
M
#1$'1-.L
#(1-.F
M
#<$$<P+;<$-.L
<$:##(<$:#-.F
# -.F
# -[$/-.[.F
# --[$'5:#-.[..F
-#<#"!.L
# -.F
# -$'V#:#-..F
# -[$<#"':#-..F
# -([$<#"B:#-..F
ML
# -#.F
# --[$'V#:#-.[..F
M
## <$-.F
M
<$:#$<#"':#-.L
-#"':##.L
#"':#(<$:#-.F
M
##"':#F
M
<$:#$<#"B:#-.L
-#"B:##.L
#"B:#(<$:#-.F
M

196
Projektowanie baz danych XML. Vademecum profesjonalisty
##"B:#F
M
#<$$/-.L
#F
M
#-.L
<9 # -$<P+;<$-..F
9L
-+)*+ $&2:-. #8-$<P+;<$-..!.L
<9 # - JJGG.F
ML
<9 # - JJGG.F
M
M-D " <P+%.L
<E/-.F
<9 # - JJGG.F
M
M
29-(V#.L
9(V#F
M
'5:#-<$:#(V#.L
5:#(V#F
M
'V#:#-<$:#(V#.L
V#:#(V#F
M
<#"':#-<$:#(V#.L
#"':#(V#F
M
<#"B:#-<$:#(V#.L
#"B:#(V#F
M
#/-<$(V#.L
(V#F
M
M
CCCCCCCCCCCCCCCCCCCCCCCCCA2:@+3 DCCCCCCCCCCCCCCCCCCCCCCC
E$ ( F
CC
CY(9)*+9DDJ99
C
$ CF
D # CF
#A2:@+3$ 3:L
1#1#F
<E<E#F
VV#F
'F
%9#F
(&!F
B3;/%<7,@%]&7]5&5%!F
B3;/%<7,@%]&7]/1;*F
B3;/%<7,@%]&7]1%*&V%>F
#A2:@+3-.L
#-.F
M

4Q\F\KC đ
Architektura systemu baz danych
197
#-QRWW$.L
%9F
-'.L
(-(&.L
B3;/%<7,@%]&7]/1;*U
#1 'V#-<$ #&-WW
$. -..F
EF
B3;/%<7,@%]&7]1%*&V%U
<$:#(<$:#-.F
-F[$F[[.L
-@ B-QR..L
-QR.F
M
M
#1 'V#- <$-..F
EF
#U
##5&5%UJJ9(^##(JEH(
#1 'V#-<$ #&-WW
$. -..F
M
M
M
#%-<$.L
'F
- "#;$@-..L
1-.F
#F
M
- "#;$@-..L
'-.F
#F
M
M
'-.L
-'__%9.L
#1 'V#-.F
M
M
1-.L
-$@#1-. $29-..L
$7V-. %-$@#1-..F
@#1-#.F
#F
M
$@#1-. -.F
@#1-#.F
-$7V-. %9-..L
D(H`9EE\(9W(T#E#D9
E9H`
%#$7V-. -.F
(- *%-..L
--1. %-.. -.F
M
$7V-. ,%-.F
M
M

198
Projektowanie baz danych XML. Vademecum profesjonalisty
1$@#1-.L
##1F
M
D # V$7V-.L
-V#.L
V(D # V-.F
M
#VF
M
D # <E$1<E-.L
-<E#.L
<E(D # <E-.F
M
#<EF
M
@#1-1(V#.L
-(V##.L
#1
-$1<E-. 9-..L
#1#F
ML
#1-1.$1<E-. -.F
M
#F
M
-$@#1-.#.L
$1<E-. #-$@#1-..F
M
#1(V#F
M
7V-D # V(V#.L
V(V#F
M
1<E-D # <E(V#.L
<E(V#F
M
#%-<$W,#++.L
<9 # -.F
'F
(&B3;/%<7,@%]&7]5&5%F
- "#;$@-..L
1-+.F
#F
M
- "#;$@-..L
'-+.F
#F
M
M
'-,#++.L
-#1#.L
<9 # -BEJ[+ <$-..F
M
'#F
%9#F
-!F+ $+$-.F[[.L

4Q\F\KC đ
Architektura systemu baz danych
199
-+ $5-. "#;$@-..L
#1 '5-+ $V#-..F
M
-+ $5-. "#;$@-"#X$..L
#1 '%-+ $V#-.[ 5V.F
'F
M
-+ $5-. "#;$@-"#X#..L
#1 '%-+ $V#-.[ @#V.F
'F
M
-+ $5-. "#;$@-E9..L
#1 '<#"-+ $V#-..F
M
-+ $5-. "#;$@-(..L
-+ $V#-. "#;$@-..L
(&B3;/%<7,@%]&7]5&5%F
M
-+ $V#-. "#;$@-..L
(&B3;/%<7,@%]&7]/1;*F
M
-+ $V#-. "#;$@-..L
(&B3;/%<7,@%]&7]1%*&V%F
M
M
M
M
1-,#++.L
@#1-1 $'1-..F
-!F+ $+$-.F[[.L
-+ $5-. "#;$@-..L
#1 /-+ $V#-..F
M
-+ $5-. "#;$@-9..L
-+ $V#-. "#;$@-..L
#1 29-#.F
M
M
M
M
M
Przykład wprowadzanych danych
!
]#
$!!!$
,
$aK$JG(E
]]
!

200
Projektowanie baz danych XML. Vademecum profesjonalisty
#X! ab#
]#
]#
$!!!$
,>
$:1@,$JG(E
]]
!
#K >a#
]#
]#
$!!!$
,K
$7E$JG(E
]]
!
#> c#
]#
Rekordy zagnieżdżone do ładowania z wartościami zapytań do bazy danych
!
1&&/
]#
"#X$]#]
"#X$]
$!!!
,
$E9$ aK
"#X$]
]
!
#X! ab
]#
"#X$]#]
"#X$]
$!!!$
,>

4Q\F\KC đ
Architektura systemu baz danych
201
$E9$ :1@,
"#X#]
!
#K >a
1&&/
Arkusz XSL przekształcający dane XML z przykładu na XML rLoad
!
XX,E#J9H(G#DI9$XX
U9 !UU((( (K $???)<+/
U##
U
U9XC
U
U
1&&/
U9XC
1&&/
U
U$
4%5%
"#X$$]
U9XNC
U9X
U
UN
U#X
U
UN
U#X
U
UN(9
(9
U#X
U
UN$
$
U#X
U
U9
Implementacja w języku Java składa się z trzech klas: głównej klasy
&(
, klasy
)* &+ &
używanej z parserem SAX oraz klasy
,&
, zawierającej informacje
dotyczące wszystkich ładowanych rekordów. Metoda
klasy
&(
pobiera plik
XML
&
jako dane wejściowe i wywołuje metodę
, tworzącą obiekt parsera SAX

202
Projektowanie baz danych XML. Vademecum profesjonalisty
z procedurą obsługi
)* &+ &
.
)* &+ &
tworzy obiekt
,&
i wypełnia
w miarę parsowania jego pola. Jeśli element XML
&
wymaga więcej niż jednego
rekordu relacyjnego, tworzonych jest odpowiednio wiele obiektów
,&
.
$%&'
Istnieje kilka sposobów generowania dokumentów XML na podstawie danych z relacyjnej
bazy danych. Przedstawimy pięć możliwości:
Dokument XML można wygenerować na podstawie danych z tabeli relacyjnej bazy
danych. Tabela jest formatowana jako dokument XML, zaś kluczy obcych używa
się do określenia hierarchii elementów dokumentu. Nazwy typów elementów to nazwy
tabeli i kolumn. Takie rozwiązanie przydaje się do przeglądania danych z bazy.
To rozwiązanie jest podobne do poprzedniego: o strukturze dokumentu decyduje
struktura bazy danych, ale możliwe jest też użycie widoków (perspektyw).
Każdy widok jest zamieniany na dokument XML. Dzięki temu tworzenie
dokumentów jest bardziej elastyczne, gdyż struktura dokumentu nie zależy
bezpośrednio od postaci tabel. Hierarchię elementów określają klucze obce
i (lub) relacje jawnie określające, które wartości i jak mają być rozwijane.
Dokumenty można tworzyć na podstawie formułowanych ad hoc zapytań. Hierarchia
elementów nadal zależy od struktury bazy danych (i ewentualnie widoków).
Szablon dokumentu można zdefiniować, podając jego części w formie zapytań.
Zapytania są wykonywane i przekształcane na XML jak poprzednio, ale wyniki
wielu zapytań są zbierane w jednym dokumencie.
Można podać zapytanie z podzapytaniami, wtedy strukturę dokumentu określa
struktura zapytań. Takie rozwiązanie sprawdza się tylko wtedy, gdy generacja
XML odbywa się bezpośrednio w maszynie bazy danych.
Rozwiązania wymienione w punktach od a) do c) są wykorzystywane w oprogramowaniu,
o którym mówi punkt 5.3. Rozwiązanie d) może być przydatne, kiedy generacja XML
jest powiązana z serwerem sieciowym obsługującym generację dokumentów po stronie
serwera, jak Java Server Pages (JSP).
Sterownik relacyjnej bazy danych udostępnia dane z relacyjnego DBMS w XML. Do bazy
danych kierowane jest zapytanie, po czym wyniki z bazy są formatowane jako XML.
W punkcie 6.2 opisano zastosowanie rozwiązań komercyjnych. Relacyjny serwer danych
jest sterownikiem bazy danych wraz z serwerem sieciowym.
Podstawowy schemat pracy użytkownika, żądającego raportu XML z relacyjnej bazy
danych przez przeglądarkę sieciową, wygląda następująco (rysunek 5.2):
Użytkownik podaje w przeglądarce sieciowej w formie adresu URL zapytanie
do relacyjnej bazy danych.
Przeglądarka przesyła żądanie adresu URL do serwera danych.
4Q\F\KC đ
Architektura systemu baz danych
203
Przetwarzanie
żądania użytkownika
w trzywarstwowej
strukturze relacyjnego
serwera danych
Serwer danych analizuje żądanie URL i tworzy zapytanie SQL.
Serwer danych przekazuje zapytanie SQL do serwera baz danych.
Serwer baz danych wykonuje zapytanie.
Serwer baz danych zwraca do serwera danych wyniki zapytania w formie
tabelarycznej.
Serwer danych formatuje wyniki jako XML.
Serwer danych zwraca dane w postaci XML do przeglądarki.
Przeglądarka sieciowa parsuje dane XML i wyświetla je.
Jeśli arkusz stylów został użyty, konieczne jest pobranie i przeanalizowanie w przeglą-
darce także arkusza.
Jeśli chcemy stworzyć relacyjny serwer danych, powinniśmy odpowiedzieć na wiele
pytań, między innymi:
Czy oprócz tabel przewidujemy wyświetlanie danych z widoków?
Czy dane będą aktualizowane, czy są przeznaczone tylko do odczytu?
Czy użytkownik może wybierać jednocześnie dane z wielu tabel?
Jak obsługiwane są złączenia?
Jak złożone mogą być odwzorowania relacji na strukturę XML?
Czy mają być obsługiwane (może specjalnie) tabele pomocnicze lub tabele
złączające?
Czy wiązania będą analizowane przez klucze obce? Do ilu poziomów?
Jak są obsługiwane cykliczne powiązania kluczy obcych?
Jak są obsługiwane powiązania między tabelami?
Co pozwalają zrealizować zapytania?
Jak dużo danych ma być zwracanych? Duże porcje czy niewielkie fragmenty?
Na te pytania trzeba było odpowiedzieć, opracowując relacyjny serwer danych w języku
Java, rServe (opisano go szczegółowo w punkcie 5.3.5). Przykładowe dane dotyczące
bazy danych mikromatrycy pokazano na rysunku 5.3. Przykład sformatowano, korzy-
stając z arkusza stylów opisanego w rozdziale 7. Warto zauważyć, że niektóre kolumny to
hiperłącza, za którymi kryją się kolejne dane generowane przez rServe.

204
Projektowanie baz danych XML. Vademecum profesjonalisty
Przykład danych
z rServe z bazy
danych mikromatryc
!()##*+'
API do relacyjnego serwera danych można zrealizować jako żądania URL. Zanim zaj-
miemy się szczegółami rServe, opiszemy takie API.
rServe umożliwia korzystanie z danych tylko do odczytu za pośrednictwem adresu URL.
Serwlet jest wywoływany z parametrami takimi, jak: nazwa tabeli, ograniczenia na ko-
lumny, konto w relacyjnej bazie danych. Alternatywna implementacja umożliwiałaby
podawanie instrukcji SQL w adresie URL. Oto przykłady adresów URL dla rServe:
http://127.0.0.1/servlets/com.xweave.xmldb.rserve.XMLServlet?tablename=company
— pobiera wszystkie rekordy z tabeli
-
.
http://127.0.0.1/servlets/com.xweave.xmldb.rserve.XMLServlet?tablename=company
&stylesheet=/ss/generic1.xsl — pobiera wszystkie rekordy z tabeli
-
,
następnie formatuje dane według arkusza stylów /ss/generic1.xsl.
http://127.0.0.1/servlets/com.xweave.xmldb.rserve.XMLServlet?tablename=company
&id=12 — pobiera z tabeli
-
rekord o identyfikatorze 12.
http://127.0.0.1/servlets/com.xweave.xmldb.rserve.XMLServlet?tablename=company
&stylesheet=/ss/generic1.xsl&name=Acme — pobiera z tabeli
-
rekord,
który w kolumnie
ma wartość „
”, następnie otrzymane dane zwraca,
stosując arkusz stylów /ss/generic1.xsl.

4Q\F\KC đ
Architektura systemu baz danych
205
Adres URL składa się z trzech zasadniczych części: adresu bazowego, arkusza stylów
i zapytania. Adres wskazuje serwlet (lub skrypt CGI), obsługujący dane. W naszym wy-
padku jest to adres serwletu rServe zainstalowany na dowolnym komputerze wskazywa-
nym przez adres (w tym wypadku skorzystaliśmy z adresu IP 127.0.0.1 zarezerwowanego
dla serwera lokalnego, localhost). Opcjonalny wskaźnik arkusza stylów informuje, gdzie
znajduje się arkusz XSL używany przez przeglądarkę do przekształcenia XML na HTML.
Arkusz i zapytanie mogą występować w dowolnej kolejności.
Baza adresu może wyglądać następująco:
http://127.0.0.1/servlets/com.xweave.xmldb.rserve.XMLServlet?
http://mojkomputer/servlets/com.xweave.xmldb.rserve.XMLServlet?
Na końcu pojawia się znak zapytania.
Adres arkusza stylów przybiera postać
-$./!
. Arkusz może zo-
stać pominięty, wtedy zostanie użyty domyślny arkusz przeglądarki. Zwykle powoduje
to pokazanie tekstu i znaczników dokumentu XML.
Zapytanie składa się z nazwy tabeli i nazw kolumn, poszczególne pary wartości rozdzie-
lane są znakiem
0
.
Do pobrania wszystkich rekordów z tabeli używa się zapytania
$
, gdzie
to nazwa pokazywanej tabeli. Do pobrania konkretnego rekordu używa się zapisu
$ 0&$&
. Częścią zapytania może być nazwa dowolnej kolumny.
Dodatkowo serwer danych umożliwia podanie konta DBMS w postaci pary nazwa-wartość,
$1 23 4
. Korzystając z adresu URL, można sięgnąć do dowolnej
bazy danych dostępnej na serwerze DBMS, na przykład
U>O ! ! ( )*+<_9
$ _$N&1@+
Tworząc adres URL, należy zwrócić uwagę na kilka rzeczy. Jeśli używamy formularzy
HTML, to nazwy takie jak
wypełniane są automatycznie. Parametr
jest
pomijany przez serwer danych. W adresie URL znaki specjalne są kodowane w ASCII
jako kody szesnastkowe lub zastępowane innymi znakami, na przykład
zapisuje się
jako
567
, a spację jako
8
. Ostatecznie adres URL może tak wyglądać:
U>O ! ! ( )*+<_9
d>'d>'$ _,_<#'[9
A oto rozwinięcie takiego adresu:
U>O ! ! ( )*+<_9
$ _,
!,-./'
Relacyjny serwer używa parametrów adresu URL do tworzenia instrukcji SQL. Na przy-
kład żądanie pobrania zawartości tabeli tworzy się, używając parametru
9:
w szablonie:
CJ(

206
Projektowanie baz danych XML. Vademecum profesjonalisty
Bardziej złożone zapytania można tworzyć stopniowo, dodając ograniczenia na wartości
kolumn we frazie
:
, żądania uporządkowania we frazie
&#-
oraz podając kolumny
do wyświetlenia we frazie
. W efekcie uzyskuje się następujące zapytania SQL:
E#9J(
((#E
9ED^S
Dużą część instrukcji SQL można zakodować w adresie URL, choć warunki podawane
we frazie
:
wymagają nieco więcej pracy. Nazwa musi być oddzielona od wartości
znakiem równości, dlatego inne operacje można zakodować przez podanie wartości
i operatora, na przykład:
_>Kc_"#9>!_ -"#9H(>!.
_>Kc_"#9>!_ -"#9DJ>!.
_>Kc_"#9>!_ -"#9DJI`H(>!.
!!01&'
Dane relacyjne można formatować jako XML, używając nazw tabel i kolumn tabel do
sterowania tworzeniem nazw elementów (i ewentualnie nazw atrybutów). Informacje
zawarte w kluczach głównych i obcych służą do definiowania struktury dokumentu. Trud-
ności przysparza fakt, że w nazwach kolumn można używać znaków specjalnych, których
nie można stosować w nazwach elementów XML. Drugi problem wiąże się z tym, że
klucze obce mogą tworzyć cykle (w ten sposób może dojść do utworzenia pętli nieskoń-
czonej). Cykl powstaje, kiedy klucz obcy odwołuje się do innej tabeli, do innego klucza
obcego, który znowuż odwołuje się do klucza obcego z pierwszej tabeli. W takim cyklu
może istnieć więcej kluczy i tabel pośrednich. Rozwiązaniem jest zapamiętywanie kolej-
nych tabel lub ograniczanie liczby kluczy obcych.
Formatowanie wyników zapytania przebiega następująco:
Wypisanie nagłówka dokumentu.
Wypisanie znacznika początkowego elementu głównego.
Jeśli nazwy kolumn używane są jako nazwy typów elementów, to pobranie
ich z metadanych.
Przeglądanie kolejnych rekordów relacyjnych.
Wypisanie znacznika początkowego relacji (na przykład nazwy tabeli,
pojęcia ogólniejszego jako „rekord” lub innego tekstu).
Iteracja realizowana po kolejnych kolumnach rekordu.
Jeśli wartością danej kolumny jest napis, umieszcza się go między
znacznikiem początkowym i końcowym.
Jeśli kolumna zawiera klucz obcy, można ewentualnie wypisać
rekursywnie kolumny rekordu, który wskazuje dany klucz.
Wpisanie znacznika końcowego relacji.
Wypisanie znacznika końcowego elementu głównego.

4Q\F\KC đ
Architektura systemu baz danych
207
Podany algorytm może nie znaleźć zastosowania w dużych bazach danych, gdyż wymaga
wykonywania wielu zapytań. Poza tym klucze obce pobierane są w kolejnych krokach
(powstaje w ten sposób wiele poziomów drzewa dokumentu). Kiedy pobierane klucze obce
są takie same jak wcześniejsze, powtarzane są te same zapytania. Algorytm nie pozwala
skorzystać z informacji strukturalnych relacyjnej bazy danych, na przykład informacji
o kluczach obcych. Można byłoby ich użyć do tworzenia zapytań pobierających w jednym
zapytaniu informacje z wielu wierszy (lub wielu tabel). Dzięki temu w jednym zapytaniu
można pobierać informacje do wielu elementów.
!$23#4
Komercyjne relacyjne systemy baz danych zawierają informacje o tabelach systemowych,
które mogą się przydać przy tworzeniu serwera danych. Na przykład klucz główny stanowi
źródło jednoznacznego indeksu rekordów. Można go używać do identyfikowania poszcze-
gólnych rekordów. Klucze obce wskazują klucze główne innych relacji. Można ich użyć
do łączenia elementu z jego podelementami. Jeśli na przykład klucz obcy tabeli
9 1
wskazuje klucz główny tabeli
1
, to dokument XML, który pokazuje dane z tabeli
zamówień, może uwzględniać dane klienta jako podelement. W większości relacyjnych baz
danych informacje o kluczach głównych i obcych są zapisywane w tabelach systemowych.
Zapytania SQL mogą pobrać te informacje na potrzeby serwera danych.
Klucze obce można wykorzystać do wypisywania danych relacyjnych jako drzewa XML.
Wartość kolumny lub wartości kolumn mogą zawierać wartości klucza głównego innej
relacji. Klucz główny jednoznacznie identyfikuje rekord danej relacji, zaś klucz obcy
można zastąpić treścią wskazywanego rekordu.
Dane z relacyjnej bazy danych można przekształcić na XML w formie drzewa. Korzystając
z relacji „rodzic”-„dziecko” w bazie danych, tworzy się analogiczną relację w drzewie XML.
Relacje takie w relacyjnej bazie danych są zwykle kodowane za pomocą kluczy obcych.
Ostrzeżenie dla projektantów baz danych: Terminy „rodzic”-„dziecko” wywołują pewne
nieporozumienie. W projekcie relacyjnym zależność „rodzic”-„dziecko” podlega analizie,
tak więc „dziecko” zależy od informacji „rodzica”. W drzewach „dzieci” składają się na
„rodzica”, więc to „rodzic” zależy od „dzieci”. Wobec tego relacja „rodzic”-„dziecko”
w teorii relacji ma znaczenie dokładnie odwrotne niż relacja „rodzic”-„dziecko” w drzewie
XML. Na przykład jeśli w relacyjnej bazie danych rejestruje się przynależność pracowni-
ków do wydziałów, wydziały będą relacją „rodzicem”, zaś relacja pracowników będzie
„dzieckiem”. W przypadku formatowania danych jako XML bezpośrednio na podstawie
relacji pracowników, element opisujący pracownika będzie „rodzicem” i będzie miał
element wydziału jako swoje „dziecko” (rysunek 5.4.).
Porównanie relacji
„rodzic”-„dziecko”
w teorii relacyjnej
i drzewach XML
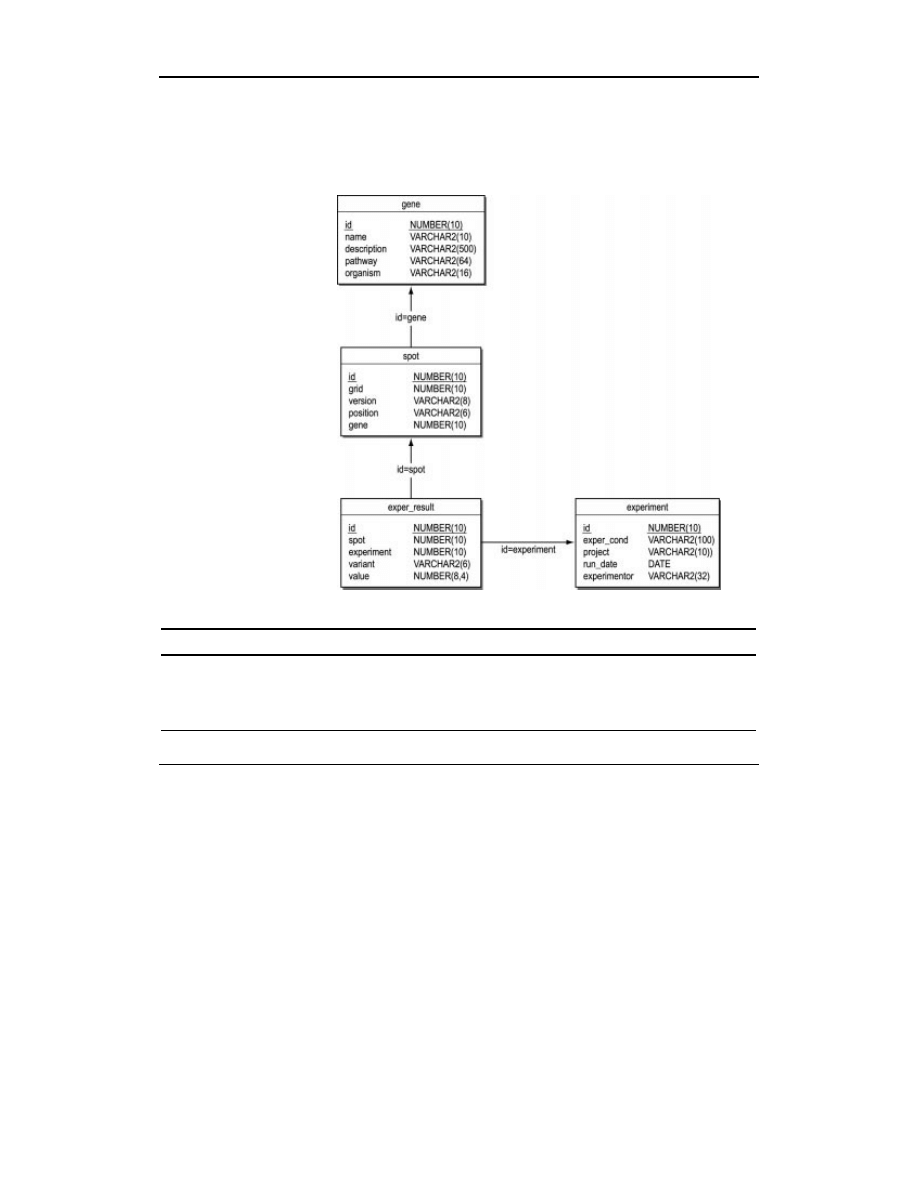
208
Projektowanie baz danych XML. Vademecum profesjonalisty
Schemat relacyjny doświadczenia z mikromatrycą (zobacz rysunek 5.5) ma klucze obce
opisane w tabeli 5.1. Za pomocą tych kluczy obcych można wygenerować kod XML,
który prezentuje wydruk 5.10. Klucze obce z tabeli 5.1 są analizowane w celu stworzenia
elementów zagnieżdżonych.
Relacyjny schemat
bazy danych
mikromatryc
Klucze obce bazy danych mikromatryc
Tabela „dziecko”
Kolumna „dziecko”
Tabela „rodzic”
Kolumna „rodzic”
SPOT
GENE
GENE
ID
EXPER_RESULT
SPOT
SPOT
ID
EXPER_RESULT
EXPERIMENT
EXPERIMENT
ID
Przykład — wynik działania rServe uzyskany z bazy danych mikromatryc
!
%)7%1]1%<8+/e>Oc
<7&/
<7&/!?c
41;241;2
V%1<;&5
7&<;/;&5?a7&<;/;&5
4%5%
4%5%!?c
5,*%7,f5,*%
2%<@1;7/;&5f;5,6,:;,Yf&B,F7&6B,+,85;f5Zg+;@650@3*8/,@A;,+',2%<@1;7/;&5

4Q\F\KC đ
Architektura systemu baz danych
209
7,/3B,01%7+;f,@A,25,7,/3B,0
&14,5;<*
4%5%
4%5%
<7&/
<7&/
%)7%1;*%5/
%)7%1;*%5/!
%)7%1]@&52%)7%1]@&52
71&A%@/%;<%571&A%@/
185]2,/%
%)7%1;*%5/&1
%)7%1;*%5/
%)7%1;*%5/
V,1;,5/!V,1;,5/
V,+8%X! !V,+8%
%)7%1]1%<8+/
W bazie danych Oracle można użyć kodu z wydruku 5.11, aby pobierać z tabel systemo-
wych informacje o kluczach obcych. Na przykład w tabeli 5.2 pokazano klucze obce
relacyjnego systemu przechowywania danych XML o strukturze drobnoziarnistej (roz-
dział 4.). Kod SQL z wydruku 5.12 wykonuje analogiczne zadania w bazie DB2.
Kod SQL pozwala pobrać informacje o kluczach obcych z bazy danych Oracle
]]W
#]]#W
]]W
#]]#
9 ]W
9 ]]#W
9 ]]#
( ]91
] ]
]] ]
( (
]( (
Kod SQL pozwala pobrać informacje o kluczach obcych z bazy danych DB2
]W
]#W
]W
]#
9 W
9 E9#W
9 E9#
(
E9
" "

210
Projektowanie baz danych XML. Vademecum profesjonalisty
Klucze obce relacyjnego systemu przechowywania danych XML
Tabela „dziecko”
Kolumna „dziecko”
Tabela „rodzic”
Kolumna „rodzic”
XDB_ATTR
DOC_ID
XDB_DOC
DOC_ID
XDB_CHILD
DOC_ID
XDB_DOC
DOC_ID
XDB_ELE
DOC_ID
XDB_DOC
DOC_ID
XDB_STR
DOC_ID
XDB_DOC
DOC_ID
XDB_TEXT
DOC_ID
XDB_DOC
DOC_ID
XDB_ATTR
DOC_ID
XDB_ELE
DOC_ID
XDB_CHILD
DOC_ID
XDB_ELE
DOC_ID
XDB_DOC
DOC_ID
XDB_ELE
DOC_ID
XDB_STR
DOC_ID
XDB_ELE
DOC_ID
XDB_TEXT
DOC_ID
XDB_ELE
DOC_ID
XDB_ATTR
ELE_ID
XDB_ELE
ELE_ID
XDB_CHILD
ELE_ID
XDB_ELE
ELE_ID
XDB_DOC
ROOT
XDB_ELE
ELE_ID
XDB_STR
ELE_ID
XDB_ELE
ELE_ID
XDB_TEXT
ELE_ID
XDB_ELE
ELE_ID
!5
Kod języka Java, stanowiący implementację relacyjnego serwera danych rServe, pokazuje
wydruk 5.13. Diagram klas przedstawiono na rysunku 5.6.
Kod Java relacyjnego serwera danych rServe
CCCCCCCCCCCCCCCCCCCCCCCCC2 DCCCCCCCCCCCCCCCCCCCCCCC
E$ ( F
( # &##F
#2')*+L
CC
Cf#E2
C
#2-.L
#-.F
M
#2-;##W&####.L
#-#W##.F
M
M
CCCCCCCCCCCCCCCCCCCCCCCCC')*+ DCCCCCCCCCCCCCCCCCCCCCCC
E$ ( F
D " CF
D # CF
4Q\F\KC
đ
Architektura systemu baz danych
211
4[UWPGM
Diagram klas UML
relacyjnego serwera
danych rServe

212
Projektowanie baz danych XML. Vademecum profesjonalisty
!"#
$$%!"#&
'()
()
"*+$,*)
"*+$-*)
(.)*+./0
%!"#/0&
$/0
1
%!"#/'20&
$/0
$'(/0
$(/0
1
$$3./.$$($$2(2(0&
+()$$+(/0
4(5)$$4(/0
/5$',$/6-.7#89."8600&
5$-9/0
1
/5$',$/6'*600&
5$'/0
1
/5$',$/6.,,-600&
$$$./0
1
/5$',$/6*8:-;600&
$"*3/'$'/00
1
/5$',$/6+8:+-.+(600&
$+.$/0
1
/5$',$/64<8+=(-+600&
5$,$(/0
1
/5$',$/6(-=#8(;88-600&
$$$((3/0
1
/5$',$/6(<7"'-600&
1
/5$',$/6+*8+7=600&
5$/0
1
5,$/20
1

4Q\F\KC đ
Architektura systemu baz danych
213
"*+$,,*/0&
/*))0&
*)"*+$,/'(/00
1
*
1
"$>?$.
@(
(*./0&
.
1
''(/0&
/())0&
$'(/'/*./000
1
(
1
(/0&
/())0&
$(//00
1
(
1
"*+$--*/0&
/*))0&
*)"*+$-/'(/00
1
*
1
$/($AB0&
/$3CD0&
($/6%!"#E FGCHI60
1
/%!"#/00*/$AJB0
1
$'(/'?0&
3$()?
1
$(/?0&
3$()?
1
*/.$$($$0&
&
(/0/6CK$)L6DJL6KI60
/$$((3/0M)0&
(/0/6CKE$$3)L6$L63)L66N
$$((3/0N6L6KI60
1
(/0/6CI60
-/$$2D0
(/0/6CI60
13/880&
($/68E6N8"$$/00
1
1

214
Projektowanie baz danych XML. Vademecum profesjonalisty
*/(90&
*/9220
1
*/(92(,92(0&
.$$($$).$$(/0
4(5)4(/92,920
+()+(/0
$$$4(/50
$$$+(/0
*/$$0
1
-/.$$($$230&
&
4(5)$$4(/0
+()$$+(/0
(
(9)5-9/0<,$/0
/89/0))0&
)9
1$&
)89/0
1
()5'/0
(,9)-*/0'9/90
+$($()'(/0*/$$230
/$())0&
(/0/6C$)L67 3L6
)L66N'(/0,./0N6L65)L66N5N6L6I60
1
+$("**)$("*/0
,$)*,,/0
(AB#)(A,$NDB
,9)OD
/)DC),$NN0&
#AB)*,#/0
/#AB5$',$/,900
(>$HF2>,9$$
,9)
1
?,3AB)?A,$NDB
/)DC),$NN0
,3AB)?/0
(')
+$)$(/0
+P)$
(+AB)(A,$NDB
3/+$0&
F$>$+$(
/)DC),$NN0&
+AB)$((/0
1
+> $>2$(>$>$H
+$)$(/0
/,9))OD0&
(/0/6C6NN6I60
1$&

4Q\F\KC đ
Architektura systemu baz danych
215
/+$0&
')$((/,90
1$&
')
1
<E >FGF3>
>2 G >6'*6!"#
$>FEPQG $
>$2HG F>
(/0/6C6NN66N,9N6)6NR6RN
+A,9BNR6RN6I60
1
/,9M)ODSS+A,9B5$/'00&
$3$3
+P)
/)DC),$NN0&
>$>3
,3AB8/+AB0
$Q
?/2#AB2+AB2$$23ND0
1
3/+P0&
>+$$(
F2F $$FF$>
$G
/)DC),$NN0&
+AB)$((/0
1
$Q >3
/)DC),$NN0&
/+ABM)SSM,3AB$/+AB00&
,3AB8/+AB0
?/2#AB2+AB2$$23
ND0
1
1
>$(2>$H$>
+$)$(/0
/+$0&
')$((/,90
+P)+A,9B5$/'0
1$&
QF$>$2$
> T>
')
+P)$
1
1
>,3
/)DC),$NN0
,3AB.8$/0
1$&
$>$>
/)DC),$NN0&
/)),90
?/2#AB2+AB2$$23ND0
1

216
Projektowanie baz danych XML. Vademecum profesjonalisty
1
(/0/6C6NN6I60
1
13/(4#880&
($/6P E6N8"$$/00
1
1
?/(92(92(2.$$($$2
30&
/))0&
(/0/6C6N9N6I60
1
(/0/6C6N9N6I60
($),*/0+$/9290
(9),*/0'9/9290
/$))UU9))0&
(/0/0
1$&
/3I$$+(/0"*3/00&
(/0/6C)L66N$N6L660
/9M)0&
(/0/6)L66N9#,$/0N6L6
)L66NN6L660
1
(/0/6I60
1$&
.$$($$).$$(/0
$$$4(/4(/$29200
$$$+(/$$+(/00
$$$./$$./00
-/$$230
1
1
(/0/6C6N9N6IL60
1
1
'
$
:>>>3
$5
$$'&
+*7
(.)6$@DVWJJDEDXVDE+,#6
+*7..)
'/0&
$/0
/Y*7,./.00
1
'/+*7.0&
$/0
/0
1

4Q\F\KC đ
Architektura systemu baz danych
217
'/(0&
$/0
/Y*7,./00
1
'/,0&
$/0
/0
1
+*7.,./0&
.
1
+$(*/.$$($$230&
/.))UU
M../05$',$/$$./000
/$$./0M)0
$./$$./00
4(5)$$4(/0
()5-9/0
()5'/0
(,9)5',9/0
($)5,$(/0
($)$$+(/0+.$/0
(3)
/$M)0
3)$
/M)0&
/,9))0&
H>
($/6*E,96N0
,9)66
1
3),9N6)6N
1
()66
/5/0M)0&
)6+*8+7=6N5/0
1
/3))0&
$4/6$6N$N66NN2
30
1$&
$4/6$6N$N66NN636N
3N230
1
1
+$(*/(230&
$4/6$6N230
1
+$(*/(2(230&
/))0*/230
$4/6$6NN63)6N230
1
+*7+*7/0&
1
/+*7.0&
&
)+*7,/0
/0

218
Projektowanie baz danych XML. Vademecum profesjonalisty
13/(4#80&
( -/0
1
1
/,0&
&
)+*7,/0
/0
13/(4#80&
( -/0
1
1
+$($4/(5230&
//+*7,0+*7/00*/5230
1
$./($0&
/$))0
$
:G$H F>T>3
+*7/0$/0
+*7
&
)+*7,/0
+*7.)Y*7,./$0
.)
/0
)
13/(4#80&
( -/0
$
1
1
1
!"#(
$
(7$
$3
$
$$!"#($(7$&
!"#(/0&
$/0
1
$$+5$/;(+5$52;(+$$$03$
(82'8&
(()$/$0
8)5:9$/0
()
.$$($$).$$(/0
3/3$"8$/00&
)/(08/0
%!"#$3./$$225:/00
1

4Q\F\KC đ
Architektura systemu baz danych
219
/$$4(/0-9/0))0&
/67$$+5$E>EL6N
5:3-$/00
1
/6Z6N$$4(/0(/00
%!"#)%!"#/0
$(/(/00
//(0(/00$/$/$00
//(0(/00/0/6;PVMMM60
*/$$0
/$0
1
1
(:8,'%',.-'9(
.$$(
$
[$$$H>32>
$$.$$(&
()
4(5()
+(()
($(3)
.$$(/0&
$/0
1
(./0&
1
4(4(/0&
/5())0
5()4(/0
5(
1
+(+(/0&
/())0
()+(/0
(
1
(((3/0&
$(3
1
$./(?0&
3$)?
1
$4(/4(?0&
3$5()?
1
$+(/+(?0&
3$()?
1
$((3/(?0&
3$$(3)?
1
1

220
Projektowanie baz danych XML. Vademecum profesjonalisty
4(
$
Z>
$$4(&
(9)
()
($()
?$(?)
()
(,9)
4(/0&
$/0
1
4(/(90&
3$/0
$-9/90
1
4(/(92(,92(0&
3$/0
$-9/90
$'/0
$',9/,90
1
,$/,$($0&
,$(?/08/$0
1
,$/(2(0&
,$($),$(/20
,$/$0
1
?,$(?/0&
/$(?))0
$(?)?/D0
$(?
1
(,$(/0&
(7)(7/0
/$(M)0&
/$(0
1
8),$(?/0$/0
,$($)
3/3$"8$/00&
/3/0IJ0
/6.9*60
$)/,$(08/0
/$(/00
1
/3/0IJ0
(/0
1

4Q\F\KC đ
Architektura systemu baz danych
221
('/0&
1
(',9/0&
,9
1
(/0&
1
(-9/0&
9
1
$,$(/(?0&
3$$()?
1
$'/(?0&
3$)?
1
$',9/(?0&
3$,9)?
1
$/(?0&
/?3./J0))ROR0&
?)?$$/D0N6*8(,6
1
3$)?
1
$-9/(?0&
3$9)?
1
((/0&
-9/0N6E6N',9/0N6)6N'/0N6E6N
,$(/0
1
1
,$(
$
Z >>3
$$,$(&
(9)
()
()6)6
5?)
,$(/0&
$/0
1
,$(/(92(0&
3$/0
$%9/90
$?/0
1
(%9/0&
9
1

222
Projektowanie baz danych XML. Vademecum profesjonalisty
(/0&
1
(?/0&
1
$%9/(?0&
3$9)?
1
$/(?0&
3$)?
1
$?/(?0&
33D)?3./J0
>C2I2C)2I)2M)>
/3D))RCRUU3D))RIRUU3D))RMR0&
33V)?3./D0
/3V))R)R0&
$/(/3D0N6)60
?)?$$/V0
1$&
$/(/3D00
?)?$$/D0
1
>HR@R
/?3./J0))R@R0&
3$5?)$
?)?$$/D0
1
1$/3D))R\RUU?3./?3/0OD0))R\R0&
Q$>>$H T>R\R2$#'[8
$/6#'[860
1$/3D))RRUU?3./?3/0OD0))RR0&
Q$>>$H T>RR2$#'[8
*>H $$>$H>> <+#>$
> RR> R\R
$/6#'[860
/3D))RR0&
?)6\6N?$$/D0
1
/?3./?3/0OD0))RR0&
?)?$$/J2?3/0OD0N6\6
1
1$/3D))R@R0&
3$5?)$
?)?$$/D0
1
3$)?
1
((/0&
/3$5?0&
&
'$'/?/00
QG '2>>$
%9/0N66N/0N66N?/0
13/9%80&
QGF'2>>$
1
%9/0N66N/0N66N6R6N?/0N6R6

4Q\F\KC đ
Architektura systemu baz danych
223
1$&
%9/0N66N/0N66N?/0
1
1
1
+(
$
:
$$+(&
*3)J
*3)D
(.$)66
(9)
+(/0&
$/0
1
(89/0&
9
1
"*3/0&
*3
1
(+.$/0&
.$
1
$89/(?0&
3$9)?
1
$"*3/?0&
3$*3)?
1
$+.$/(?0&
3$.$)?
1
1
"8-.*.98
"*+$-
$
$5
Z33
$$"*+$-$;$3&
$"*+$-'$)
([4)
$(-.7#8]'9%]-.7#8)6!*7]+(]-.7]'9%6
"*+$-/,0&
$/,0
1

224
Projektowanie baz danych XML. Vademecum profesjonalisty
"*+$-/,2%0&
$/,2%0
1
"*+$-/'0&
$/0
///+*7,0+*7/000
1
:[/(2(90&
/0$'9/90
1
$$/(0&
$/<,$/00M)
1
"*+-/(0&
"*+-)/"*+-0$/<,$/00
/))0&
)"*+-/0
/20
1
1
('9/(0&
()/0'9/0
/M)0&
1
)/RR0
()
/M)OD0&
$2
)$$/J20
)$$/ND0
)/0'9/0
/M)0&
1
1
/$P3/6]?600&
)/$$/3/0OD00'9/0
/M)0&
1
1
)/6]?]60
/M)OD0&
)/$$/J200'9/0
/M)0&
1
1
1
(:[4/+*70&
+*7,)//+*7,00
G2$>G
/$,$/00&
Q2>$$

4Q\F\KC đ
Architektura systemu baz danych
225
($/69>6N./00
1
(>>>3
($$),/0,$$/09/0
/$$/660M)OD0&
:[4/0
1
/$$/6V60M)OD0&
:[4*7V/0
1
1
(:[4*7V/0&
(7)(7/0
/6$3]260
/63]260
/6]260
/6]60
/6$$$260
/6$$ $260
/6$$ $60
/63$)$60
/6 )$60
/6$3)$360
/6$3)$360
/6$5)$560
(/0
1
(:[4/0&
(7)(7/0
<EQ]$$>> >
H>F3F > >$H
F32>$ G>"F
>>G2$$$]$$$]$]$$
/6$]260
/6]60
/6$$]$$260
/6$$]$]$60
/63$])R:R60
/6$])$]60
/6)60
(/0
1
/+*70&
+$($
+$("**
(
: >3>$$3
&
$)*/:[4/00
*)$"*/0
,$)*,,/0
3/$/00&
)$(/D0

226
Projektowanie baz danych XML. Vademecum profesjonalisty
/$$/00&
>
>$$2$
$$ >
:[/20
1$&
:[/2$(/V00
1
1
3$/0
13/880&
($/6P E6N8"$$/00
1
YQ$H$ $ > >32
$>
&
(5()6$6N-.7#8]'9%]-.7#8
$)4/5(0
*)$"*/0
,$)*,,/0
3/$/00&
:[/$(/D02$(/V00
1
13/-380&
Q$ > 2H
1
1
/0&
8)3$ $/0
(
"*+-
3/3$"8$/00&
)/(08/0
)/"*+-0/ 0
($/ N6L6N'9/00
1
1
/(20&
$/<,$/020
1
$:[4/(?0&
3$[4)?
1
1
"*+-
$
+ 3>3
$$"*+-&
(9
"*+-/0&
$/0
1

4Q\F\KC đ
Architektura systemu baz danych
227
('9/0&
9
1
$'9/(?0&
3$9)?
1
((/0&
6/6N'9/0N606
1
1
"*+$,
$
$5
Z3 3
$$"*+$,$;$3&
$"*+$,'$)
([4)
$(,#<"9]'9%]-.7#8)6!*7]+(],#]'9%6
"*+$,/,0&
$/,0
1
"*+$,/,2%0&
$/,2%0
1
"*+$,/'0&
$/0
///+*7,0+*7/000
1
+$/(2(2(2(0&
/20$+$/20
1
$$/(2(0&
/<,$/0N66N<,$/00M)
1
"*+,/(2(0&
"*+,)/"*+,0
/<,$/0N66N<,$/00
/))0&
)"*+,/0
/220
1
1
(%[4/+*70&
+*7,)//+*7,00
G 2$>G
/$,$/00&
2$
($/6+$$6N./00
1

228
Projektowanie baz danych XML. Vademecum profesjonalisty
(>>> >3
($$),/0,$$/09/0
/$$/660M)OD0&
%[4/0
1
/$$/6V60M)OD0&
%[4*7V/0
1
1
(%[4*7V/0&
(7)(7/0
/6$3]260
/63]260
/6]260
/6]60
/6$$$260
/6$$ $260
/6$$ $60
/63$)$60
/6 )$60
/6$3)$360
/6$3)$360
/6$5)$560
(/0
1
(%[4/0&
(7)(7/0
<EQ]$$>> >
H>F3F > >$H
F32>$ G>"F
>>G2$$$]$$$]$]$$
/6$]3]260
/6]3]260
/6]]260
/6]]60
/6$$]$$260
/6$$]$]$260
/6$$]$]$60
/63$])R+R60
/6$])$]60
/6]$])$]60
/6)60
/6])60
/6$)$60
/6])R'*R60
(/0
1
('9/(2(0&
()/20'9/0
/M)0&
1
1
(+$/(2(0&
()/20+$/0
/M)0&

4Q\F\KC đ
Architektura systemu baz danych
229
1
)/RR0
()
/M)OD0&
>F 2
)$$/J20
)$$/ND0
)/20+$/0
/M)0&
/M)0&
N66N
1
1
1
/$P3/6]?600&
)/$$/3/0OD020+$/0
/M)0&
/M)0&
N66N
1
1
1
)/6]?]60
/M)OD0&
)/$$/J2020+$/0
/M)0&
/M)0&
N66N
1
1
1
1
/+*70&
+$($
+$("**
(2
:>$$3 >3
&
$)*/%[4/00
*)$"*/0
,$)*,,/0
3/$/00&
)$(/D0
)$(/V0
/$$/200&
>
>$$2$H
>
+$/2220
1$&
+$/22$(/^02$(/_00
1
1

230
Projektowanie baz danych XML. Vademecum profesjonalisty
3$/0
13/880&
($/6P E6N8"$$/00
1
YQ$H$ $ > >>323
&
(5()6$6N,#<"9]'9%]-.7#8
$)4/5(0
*)$"*/0
,$)*,,/0
3/$/00&
+$/$(/D02$(/V02$(/^02
$(/_00
1
13/-380&
$ > 2H
1
1
/0&
8)3$ $/0
(
"*+,
3/3$"8$/00&
)/(08/0
)/"*+,0/ 0
($/ N6L6N+$/0N6L6N'9/00
1
1
/(2(20&
/<,$/0N66N<,$/020
1
$%[4/(?0&
3$[4)?
1
1
"*+,
$
+ 3 33
$$"*+,&
(9
(9
"*+,/0&
$/0
1
('9/0&
9
1
(+$/0&
9
1
(-9/0&
9
1

4Q\F\KC đ
Architektura systemu baz danych
231
$'9/(?0&
3$9)?
1
$+$/(2(0&
3$9)
3$9)
1
$-9/(?0&
3$9)?
1
((/0&
+$/0N6/6N'9/0N606
1
1
Główna klasa rServe,
, przekształca dane relacyjne ze źródła wskazanego przez klasę
i zapisuje dane do strumienia wskazanego przez klasę
. Informacje o zapytaniu,
koncie i formatowaniu danych pobierane są przez klasę kontener
i jej klasy
pomocnicze,
oraz
. Klasa
zawiera warunki umieszczane
we frazie
zapytania SQL, klasa pomocnicza
jest używana do zapisa-
nia poszczególnych warunków. Klasa
formatuje zapytanie SQL, przy czym do forma-
towania frazy
używa się klasy
. Poza tym klasa
komunikuje się z rela-
cyjną bazą danych (za pomocą kolejnej klasy pomocniczej z com.xweave.xmldb.util.rdb,
opisanej w dodatku A).
Zapytanie wykonywane jest przez utworzenie obiektu
i przekazanie go me-
todzie
klasy
. Metoda
zapisuje nagłówek dokumentu i znacz-
nik początkowy oraz końcowy elementu głównego, wywołuje metodę
. Ta
metoda z kolei realizuje algorytm opisany w punkcie 5.3.3. Do pobrania danych z bazy
używany jest obiekt
(przechowywany w polu
), zaś obiekt
(z pola
) generuje sformatowany kod XML. Metoda
używa metody
do wypisania kolejnych danych, ta ostatnia może rekursywnie wywoływać
metodę
w przypadku odwoływania się do innych tabel przez klucze obce.
Każda instancja klasy
zawiera opis kluczy głównych jednej tabeli.
Wszystkie instancje składają się na repozytorium metadanych tabel, które jest inicjali-
zowane przy pierwszej próbie dostępu do danych.
jest tablicą
asocjacyjną, zawierającą jako wartości obiekty
, a jako klucze nazwy
tabel i kolumn kluczy głównych. Każdy obiekt
zawiera nazwę tabeli
i nazwę pola klucza głównego, wskazywanych w kluczu. Istnieje też metoda JDBC, której
używa się, by sięgać do systemowej tabeli kluczy głównych w celu inicjalizacji. My nie
używaliśmy jej, tak by przedstawiane rozwiązanie można było łatwiej zastosować w połą-
czeniu z innymi protokołami.
Informacje o kluczach obcych zapisywane są w obiektach klasy
.
to tablica asocjacyjna zawierająca jako wartości obiekty
!
, a jako klucze nazwy kluczy obcych używanych do przechodzenia do po-
zostałych danych. Każdy obiekt
zawiera nazwę tabeli i nazwę kolumny
klucza głównego wskazywanej przez klucz obcy.

232
Projektowanie baz danych XML. Vademecum profesjonalisty
!
Serwer danych XML łączy funkcje bazy danych XML i serwera sieciowego. Użytkow-
nicy i aplikacje, sięgając do danych za pośrednictwem serwera danych XML, korzystają
z interfejsu sieciowego.
W tym punkcie przedstawimy jako przykład serwer danych XML xServe, który pozwala
zapisywać, edytować i wyszukiwać dane z bazy danych XML za pomocą mechanizmów
relacyjnych (zgodnie z zasadami opisanymi w rozdziale 4.). Serwer ten realizuje model
danych scharakteryzowany w rozdziale 3. i udostępnia API przez adres URL, podobnie
jak relacyjny serwer danych opisany w poprzednim punkcie.
Oprócz operacji na dokumentach (opisane w rozdziale 3.) są dostępne analogiczne operacje
dotyczące fragmentów dokumentów (odpowiadają poszczególnym elementom z doku-
mentu). Możliwe więc jest pobieranie, usuwanie i aktualizowanie elementów.
Na przykładzie tego konkretnego serwera danych XML zaprezentowano niektóre funk-
cje oferowane przez system baz danych XML dostępny w Sieci. Wprawdzie rozwiąza-
nie to należy traktować jako prosty prototyp, jednak można go używać do zapisywania
i pobierania dokumentów XML lub zapisywania danych zorientowanych hierarchicznie.
Przykład ten posłużył także do pokazania sposobu tworzenia systemu baz danych XML
i realizacji niektórych funkcji w praktyce.
Serwer xServe „rozumie” następujące polecenia:
Zapisanie dokumentu spod podanego adresu URL.
Pobranie dokumentu lub jego fragmentu z bazy danych.
Pobranie dokumentu jako fragmentu lub dowolnego fragmentu jako całego
dokumentu. W ten sposób na podstawie innych dokumentów i ich fragmentów
można tworzyć nowe dokumenty.
Aktualizacja dokumentu przez zastąpienie jego fragmentu innym dokumentem
lub jego fragmentem spod podanego adresu URL (można użyć także adresu xServe).
Dołączenie fragmentu XML spod wskazanego adresu URL do danego fragmentu.
Usunięcie dokumentu lub jego fragmentu z bazy danych.
Przydatne mogłyby być inne polecenia, na przykład zmiana kolejności elementów w doku-
mencie, wyszukiwanie dokumentów według podanych warunków lub realizacja innych
operacji opisanych w rozdziale 3.
Stronę główną xServe pokazano na rysunku 5.7, jej kod źródłowy HTML zawiera wy-
druk 5.14. Za pomocą formularza HTML tworzy się adresy URL, sięgające do bazy danych
XML. Oto przykłady adresów URL:
http://127.0.0.1/servlets/com.xweave.xmldb.xserve.XMLServlet?list=1
http://127.0.0.1/servlets/com.xweave.xmldb.xserve.XMLServlet?store=http://127.
0.0.1/temp1.xml
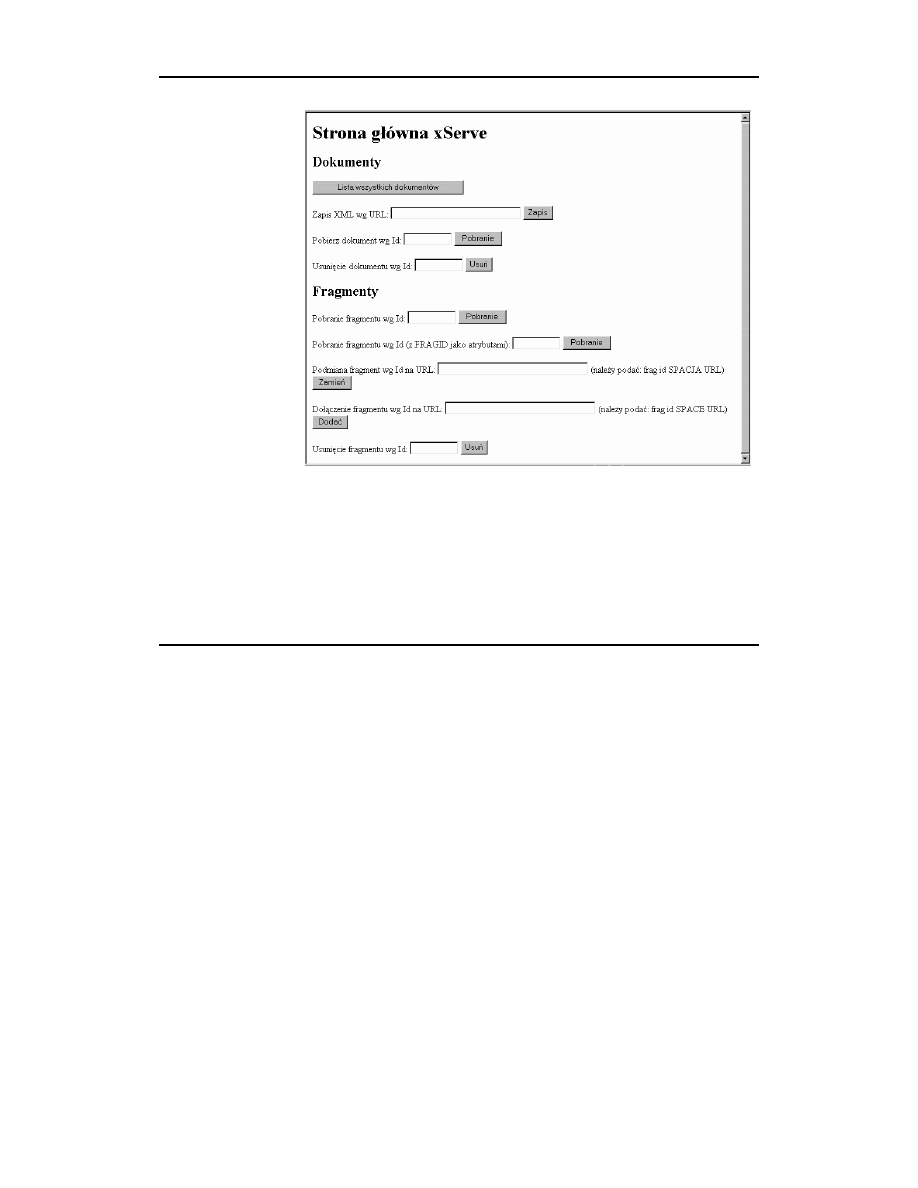
4Q\F\KC đ
Architektura systemu baz danych
233
Strona główna
xServe
http://127.0.0.1/servlets/com.xweave.xmldb.xserve.XMLServlet?store=D:\Temp\
cancer.xml
http://127.0.0.1/servlets/com.xweave.xmldb.xserve.XMLServlet?getfragdoc=7.1
http://127.0.0.1/servlets/com.xweave.xmldb.xserve.XMLServlet?appendfrag=7.1
+ http://127.0.0.1/servlets/com.xweave.xmldb.xserve.XMLServlet?retrieve=4
http://127.0.0.1/servlets/com.xweave.xmldb.xserve.XMLServlet?deletefrag=1.2
Strona główna xServe
C3I
C3I
C3O5)6,O-6)636I
CI((CI
C3I
CI
C3DI((C3DI
C3VI* C3VI
C)63EDVWJJDE`J`J$$!"#(6
3)68-6I
C)636)6$6)6D6I
CIC)6$6)66)6#$$>$ 3 6I
CI
C)63EDVWJJDE`J`J$$!"#(6
3)68-6I
CIZ$!"#<+#E
C)66)6$6$>)^JI

234
Projektowanie baz danych XML. Vademecum profesjonalisty
C)6$6)66)6Z$6I
CI
C)63EDVWJJDE`J`J$$!"#(6
3)68-6I
CI:> 'E
C)66)66$>)DJI
C)6$6)66)6:6I
CI
C)63EDVWJJDE`J`J$$!"#(6
3)68-6I
CI<$H 'E
C)66)66$>)DJI
C)6$6)66)6<$T6I
CI
C3VI%C3VI
C)63EDVWJJDE`J`J$$!"#(6
3)68-6I
CI:'E
C)66)66$>)DJI
C)6$6)66)6:6I
CI
C)63EDVWJJDE`J`J$$!"#(6
3)68-6I
CI:'/>%+.'* 0E
C)66)66$>)DJI
C)6$6)66)6:6I
CI
C)63EDVWJJDE`J`J$$!"#(6
3)68-6I
CI:'<+#E
C)66)6$6$>)^XI
/FGE(:.,Y.<+#0
C)6$6)66)6ZT6I
CI
C)63EDVWJJDE`J`J$$!"#(6
3)68-6I
CI*>'<+#E
C)66)66$>)^XI
/FGE(:.,8<+#0
C)6$6)66)6*G6I
CI
C)63EDVWJJDE`J`J$$!"#(6
3)68-6I
CI<$H'E
C)66)66$>)DJI
C)6$6)66)6<$T6I
CI
CI
C3I

4Q\F\KC đ
Architektura systemu baz danych
235
+ORNGOGPVCELC
Kod języka Java, stanowiący implementację relacyjnego serwera danych xServe, pokazuje
wydruk 5.15. Diagram klas pokazano na rysunku 5.8.
Kod Java serwera danych XML xServe
*
$
*$$3!"#>F>$$
$$*$*&
*%%)
.%%)
+%%)
*/0&
$/0
1
*>!"#C'IC'IC$IC%I
%/(0&
('2'2%
)/RR0
$)/RR0
/$))OD0&
$
1
/))OD0&
')$$/J2$0
')6D6
1$&
')$$/J20
')$$/ND2$0
1
%)$$/$ND0
3$%</'2'2%0
1
*>C'IC'I
%/(2(%0&
('2'
)/RR0
/))OD0&
')
')6D6
1$&
')$$/J20
')$$/ND0
1
236
Projektowanie baz danych XML. Vademecum profesjonalisty
4[UWPGM
Diagram klas UML
serwera danych
XML xServe

4Q\F\KC đ
Architektura systemu baz danych
237
!"!"
##$%%%
&
'$
!"!"
##%%%
&
'
()*+,!"!"
##%&
%
-.//
--01&
-
-212
&
-#3
-#41
()*+,!"!"
##%%&
##'%%5&
67289$:'82&
55
67289$:'8.72&
. 2!;5-<213<2;"2
55
672%9$:'82&
5
672'==9>:'82&
5
6729+9$9:'82&
5

238
Projektowanie baz danych XML. Vademecum profesjonalisty
67289$:'8.72&
. 2!;5-<213<2;"2
?9
55
?9
'5
=##@AB,
#''&
--&
- ':#.
=##@(
#&
--&
- :#.
=##@,B
#::&
--&
- ::#.
C)*+ !"!"!"!"
##%&
%
-.//
-.//
--01&
--01&
-#3
-212
&
-#3
-#41
-#41

4Q\F\KC đ
Architektura systemu baz danych
239
C)*+ !"!"
##%%&
%
-.//
--01&
-
-212
&
-#3
-#41
CB)*+ !"!"
##$%%%
$&
:$$
CB)*+ !"!"
##%%%
&
:
% )*+,!"!"
##5%&
%
-.//
--01&
-
-212
&
-#3
-#41
5
% )*+,!"!"
##5%%&
)*+%5D5
@ 5#5
D55
D55

240
Projektowanie baz danych XML. Vademecum profesjonalisty
D5
D5
5#%5.
D #,EE
#)*+%5 5#%5F&
G@)*+%5
#)*+%5&
#5:6H%5:66H%5:
%59D5.9&
%5.%-.
9-6=>
%5-
#-
#. %5.
#:#'% 5#)#'
#
*9&
-%9
5-6=
292442245
#'5
#:#'%--&
2FAB :6I, B DJI<24
6=$
.
=.+979>'
'D5
@ 5#5
5#
5##:F
5#.
D56
=E
#.*=
K
D5.9
=AB, #,E
#'7&
#'&

4Q\F\KC đ
Architektura systemu baz danych
241
#':F#&
#
#':F#.&
#
= @)*+,B%'),D@
I,!7"*%#EL(E JM7+'%%='$H
##$%$%%&
%7- 5#=7
E&
=-=E@=7
HF
:#--&
&
- NF7'H:#
H
9H
E&
+H>224422422
NF7'H
NF7'H
% D5%:$
%')9&
. %
%@$
.9&
%@$
7>9&
%@$
'9&
%@$
9&
%@$
= @)*+,B%'),D@
I,!7"*%#EL(E JM7+'%%='$H
##%%%&
%7- 5#=7
E&
=-=E@=7
HF
:#--&
&
- NF7'H:#

242
Projektowanie baz danych XML. Vademecum profesjonalisty
H
9H
E&
+H>
NF7'H
NF7'H
%')9&
. %
%@$
.9&
%@$
7>9&
%@$
'9&
%@$
9&
%@$
D5
@ 5#5
5#
5##:F
5#.
D56
D5
=(
#7&
G@
#&
#:F#&
#
#:F#.&
#
57%%%%
# %O+9&
%F#- %F
#22
#224#422
#2 P-24
#2P-24
#2P-24
#9#%

4Q\F\KC đ
Architektura systemu baz danych
243
?E,#,EED2,2
59%% %O+9&
%F#
2,2
,,EBD@J2,2
#- %F
#2PP2
#2247H+P$'F+9422
#2 P-24
#2P-24
:%-:##%
#: -
# ,E@ ,E(@D, #E
@BL, @
Q5- Q
: &
,B,B@ A@
-%1
"5,&
5%,
59' 7%R%K
: -
@DE2,2
9-5
7
%7
*9&
-79
--&
7-7>
76729+92&
@E E A9
9
7672%$:2&
7,A%$:#$9)$,,NF7
7%$:P$'F+9
7672$9)$2&
7,A%$:#$9)$,,NF7
7$9)$P$'F+9
&
@,#AE@E#,EE
(,#D2,2
#- %F
#22
#2247H+P$'F+9422
#2 P-24
#2P-24
#9#%
(E#S
#- %F
#22

244
Projektowanie baz danych XML. Vademecum profesjonalisty
#224'$$:P$'F+9422
#2 P-24
#2P-24
#9#%
(
#- %F
#22
#2249+9P$'F+9422
#2 P-24
#2P-24
#9#%
##%%&
=, , B,,AE@ ,E@
@@ , E E@@,DD
@E
#-
E&
(D2,@2,#
%F#- %F
#22
#2247H+P$'F+9422
#2 P-24
#2P-24
#9#%
(
9
%O+9&
-
%@$
:D5
@ 5#5
5#
5#
5##
D56
=E
#.*=
K
D5.9
= DB #,E
#:7&
G@:
#:&

4Q\F\KC đ
Architektura systemu baz danych
245
G@:
T# 5##:F
#::F#&
#
G@:
T# 5##:F
T 5#.
#::F#.&
#
= @)*+,B%'),D@
I,!7"*%#EL(E JM7+'%%='$H
##$%$%%&
%7- 5#=7
E&
=-=E@=7
HF
:#--&
&
- NF7:H:#
H
9H
E&
+H
>224422422
NF7:H
NF7:H
% D5%:$
%')9&
. %
%@$
.9&
%@$
7>9&
%@$
'9&
%@$
9&
%@$
= @)*+,B%'),D@
I,!7"*%#EL(E JM7+'%%='$H

246
Projektowanie baz danych XML. Vademecum profesjonalisty
##%%%&
%7- 5#=7
E&
=-=E@=7
HF
:#--&
&
- NF7:H:#
H
9H
E&
+H>
NF7:H
NF7:H
%')9&
. %
%@$
.9&
%@$
7>9&
%@$
'9&
%@$
9&
%@$
=E#A,,U%')
NF7+HD5
@ 5#5
5#
5##
D56%O+9
=#A%')@SME NF7,A #,EE
##NF7+HNF7+H&
%-
#NF7+H 5##:F#&
#
#%&
#%&

4Q\F\KC đ
Architektura systemu baz danych
247
=#(E@, E@S ,E
#>7%6E&
#(E@,.
E&
D56:%%-:#6E
%--&
#AB ,E
D,@AE (DE EDB@
92>M #,#,EEE@I24
6E
%
%-%%1
--&
#
1
&
41
%O+9&
%@$
D,@AE (DE EDB@
92>M #,#,EE I246E
=#E@@,,D#,#,EE
#5&
%-
#(7
%F#- %F
#2P2
#9+9P$'F+9
#2 P-24
7->7#%
#(7
#- %F
#2P2
#'$$:P$'F+9
#2 P-24
7->7#%
#(7
#- %F
#2P2
#7H+P$'F+9
#2 P-24
#2P/%$://$9)$/2
7->7#%
#5% Q&
- Q
D,D,@S ,B@@)*+

248
Projektowanie baz danych XML. Vademecum profesjonalisty
#5&
NF7'HD5
@ 5#5
5#
5##
D56%O+9
=#A%')@,EDB,NF7 #,
#NF7'HNF7+H&
#NF7'H:F#&
#
.#AE#S B,,D2,2
#59%'#++&
9F8I%E
,, E
9-79
%
%>-
--&
-2>++2
&
-
%F#
%
--&
AS E#(@
-
#(@
#- %F
#22
#7H+P$'F+9
#2 P-24
#2P-24
E&
D56:%%-:##%
%--&
#AB ,E
D,@AE (DE EDB@
92>M #>),#,EI24
42244224#%
%
%-%%1
--&
#
>-212

4Q\F\KC đ
Architektura systemu baz danych
249
&
>-%5.41
%O+9&
%@$
D,@AE (DE EDB@
92>M #>),#,EI24
42244224#%
,EB ,
79%97Q
-79
#- %F
#22
#2249+9P$'F+9422
#2PPP2
#252
#2244224
4224
4224
2/2442/2
#9#%
,,2,@2
#- %F
#22
#2247H+P$'F+9422
#2PPPP2
#252
#2244224422
--&
AS E
#>
&
#7
#2242/9+9/24422
V#9#%&
92>M @,D #,D<2,@<2I24
42244
2244224#%
$ ,,S ,,SEE#S
-3!++44&
#- %F
#22
#224'$$:P$'F+9422
#2PPP52
#252
#2244224
'7Q4224
4224
2/24+>42/24
2/24+Q42/2
#9#%

250
Projektowanie baz danych XML. Vademecum profesjonalisty
NF7:HD5
@ 5#5
5#
5##
D56%O+9
=#A%')@SME NF7,B #,
#NF7:HNF7+H&
G@NF7:HT# 5##:F
#NF7:H:F#&
#
.#AE#S B,,D2,2
#59%'#++&
9F8I%E
,, E
9-79
%
%>-
--&
-2>++2
&
-
%F#
%
--&
, ,E
79
-79
#E@2,2
#- %F
#2P2
#9+9P$'F+9
#2 P-24
#2P-24
-:##%
--&
D,@AE (DE EDB@
92>M #2,2,#,EI24
42244224#%
#@
#- %F
#22
#7H+P$'F+9
#2 P-24
#2P-24
#2P-24
>-:##%
>--&
D,@AE (DE EDB@
92>M #>),#,EEI24

4Q\F\KC đ
Architektura systemu baz danych
251
42244224#%
(EDD2,2
, ME
7- :#
V7&
D,@AE (DE EDB@
92>M (,#,EEI24
42244224#%
&
AS E,
79%97Q
-79
,EB ,
#- %F
#22
#2249+9P$'F+9422
#2PPP2
#252
#2244224
4224
4224
2/2442/2
#9#%
,D2,2
#- %F
#22
#2247H+P$'F+9422
#2PPPP2
#252
#2244224422
--&
AS E
#>
&
#7
#2242/9+9/24422
#9#%
$ ,,S ,,SEE#S
-3!++44&
#- %F
#22
#224'$$:P$'F+9422
#2PPP52
#252
#2244224
'7Q4224
4224
2/24+>42/24
2/24+Q42/2
#9#%

252
Projektowanie baz danych XML. Vademecum profesjonalisty
Klasa główna
xServe,
, jest subklasą klasy
z drobnoziarnistego systemu prze-
chowywania danych opisanego w punkcie 4.2.4. Klasa
zawiera pola dla każdej klasy
implementującej polecenia serwera danych i wykonuje polecenia, korzystając z metody
. Każde polecenie jest subklasą. Każde polecenie jest podklasą klasy abs-
trakcyjnej
, zawierającą obiekt
, łączący się z bazą danych oraz obiekt
,
wypisujący sformatowane dane do odpowiedniego strumienia.
i
— zostały
opisane w dodatku A. Polecenia
xServe pozwalają pobierać, dodawać i podmieniać zarówno
fragmenty dokumentu, jak też pobierać, zapisywać i usuwać dokumenty.
Do dodawania i podmiany fragmentów używa się procedury obsługi parsera SAX. Parser
ten został opisany w dodatku B. Klasa abstrakcyjna
pobiera naj-
większy indeks „dziecka”, elementu zagnieżdżonego i atrybutów, dzięki czemu podczas
wstawiania danych będą tworzone odpowiednie, niepowtarzalne identyfikatory.
korzysta z polecenia
, by usunąć stary element i wstawić
w jego miejsce nowy fragment XML.
wstawia fragment XML po ostat-
nim elemencie zagnieżdżonym. Oba polecenia wstawiają dane podobnie jak polecenie
ładowania dokumentu
w drobnoziarnistym, relacyjnym systemie prze-
chowywania danych.
"
#$$%& $
Opisane w poprzednich punktach dwa serwery danych: relacyjny i XML sprawdzają się
w różnych sytuacjach, jednak równie przydatny jest system hybrydowy, obsługujący
zapytania kierowane do obydu serwerów. Hybrydowy serwer danych pozwala sięgać
zarówno do danych w postaci relacyjnej, jak i do danych XML. Dane mogą być prze-
chowywane w układzie najbardziej dla nich odpowiednim. Taki hybrydowy serwer po-
zwala, w pewnym stopniu, łączyć dane z różnych modeli danych — tworzone są połącze-
nia między strukturami danych stanowiącymi podstawę obydwu sposobów przechowywania
danych. Na przykład dokument XML może udostępniać element odpowiadający zapytaniu
relacyjnemu. Kiedy pobierany jest dokument XML, może zostać wykonane zapytanie
relacyjne i jego wyniki mogą być włączone do strumienia danych. Analogicznie wartości
z kolumn relacyjnej bazy danych mogą wskazywać dokumenty lub ich fragmenty w bazie
danych XML, zaś dane XML mogą być łączone z danymi relacyjnymi pobranymi i sfor-
matowanymi jako XML. Dzięki temu można połączyć wydajność modelu relacyjnego
z elastycznością modelu XML.
Serwer hybrydowy można stworzyć w architekturze wielowarstwowej z dwóch serwerów:
klasycznego serwera relacyjnego i serwera danych XML. Serwer hybrydowy przekazuje
żądania adresu URL do obu serwerów danych i łączy otrzymane dokumenty (możliwe
jest też wykorzystanie innych protokołów niż HTTP).
Zapewne byłoby łatwiej stworzyć nowy serwer danych w architekturze trzywarstwowej,
aby sięgać do serwera relacyjnego i serwera XML. Upraszcza to strukturę systemu, ale
wiąże się z tym, że serwer XML i serwer relacyjny powinny być dostępne w ramach tej
samej aplikacji. Jako że aplikacje
xServe i rServe mogą współistnieć, system hybrydowy
—
xrServe — może przekazywać polecenia bezpośrednio do odpowiednich klas. Archi-
tektura wielowarstwowa byłaby podobna do trzywarstwowej, z tym że istniałyby dodatkowe
procesy formatowania, wysyłania i pobierania danych z dwóch odrębnych serwerów.

4Q\F\KC đ
Architektura systemu baz danych
253
W tej samej strukturze można umieścić dodatkowe funkcje. Dobrze byłoby na przykład
umożliwić w dokumencie XML lub tabeli relacyjnej dostęp do zewnętrznych adresów
URL. Inny element dostępowy może oferować informacje pozwalające sięgnąć do zasobu
z plików lub URL (jak pliki XML).
+ORNGOGPVCELC
Serwer hybrydowy jest rozwinięciem serwera danych XML, który przedstawiliśmy w po-
przednim punkcie. Operacje serwera danych XML są dziedziczone, aby uniknąć powtórzeń.
Operacje serwera relacyjnego są przekazywane odrębnym instancjom. W trakcie parso-
wania adresu URL tworzony jest obiekt
na dane zapytania. Następnie wy-
woływana jest metoda
, aby przekazać polecenia odpowiedniej instancji:
obiektowi
xServe lub obiektowi z pola
rServe. Jako że jedyną obsługiwaną
operacją jest wypisanie fragmentu XML z dowolnego źródła, kod jest dość prosty.
Kod Java dla serwera hybrydowego
xrServe pokazuje wydruk 5.16, a diagram klas UML
zawiera rysunek 5.9.
Kod Java hybrydowego serwera danych relacje-XML
D5
@ 5#5
5#
5##
5#5
5#5
DE#E EED0)*+
# 5#5&
5#5:-
#&
#5''%%%5&
672$'F+9>'*92&
$#5
6722&
5
672.7*9>$2&
5
672'77$2&
'5

254
Projektowanie baz danych XML. Vademecum profesjonalisty
Diagram klas
hybrydowego
serwera danych
łączącego technologię
relacyjną i XML
672%$W+9%H99$2&
%E%5
672.7H9'9:2&
H5
6728>.:92XX672%F*$2&
(S
>, EMB,EEDD#,E
OE%75
# 5#5:&
:--&
:- 5#5
:
#5: 5#5 Q&
:- Q
## ''%&
V-&
,@
5#-
..
HV-&
. 2!;5-<213<2;"2
%E%V-&
. 2!;IEE-<2<2-<224
%E%42<2;"2

4Q\F\KC đ
Architektura systemu baz danych
255
V-&
,
&
,A@
$#V-&
,#
5#5-:
.%.
5#5OE%6E-OE%
5#5'%-
5#5'%
OE%6E
''
%E%V-&
%E%%E%
6E$#>$#
,
C:.FYILD@AS @@
V-&
,DE,@
6E
OEV-&
,,E
6E7%OE
, E E@,AD#
B ME
,@,EAS
H--&
$#3
&
&
#@D
'%D5
@ 5#5
D5
5#5OE%
%E@D(
#'%&
#%-
#%#-

256
Projektowanie baz danych XML. Vademecum profesjonalisty
#%-
#%6E-
#%- 5#)#'
#%E%-
#%H-
#OE%6E%-
#'%&
#%'&
#%H&
H
#%&
#%&
#%OE&
6E
#OE%OE%&
6E%--
6E%- OE%
6E%
#%%E%&
E%
#%$#&
#
#5'% Q&
- Q
#5H% Q&
H- Q
#5% Q&
- Q
#5% Q&
- Q
#5OE% Q&
6E- Q
#5OE%OE% Q&
6E%- Q
#5%E%% Q&
E%- Q
#5$#% Q&

4Q\F\KC đ
Architektura systemu baz danych
257
#- Q
)*+%5D5
@ 5#5
D55
D55
D5
D5
5#%5.
D #,EE
#)*+%5 5#%5F&
#)*+%5&
#5:6H%5:66H%5:
%59D5.9&
%5.%-.
9-6=>
%5-
#-
#. %5.
#:#'%255T1RZ331I1[R1I.:7+2
'%- '%
*9&
-%9
5-6=
22442245
#'5
'V-&
#:#'%'
#:#'%--&
2FAB :6IAU(I<24
6=$
# '
.
Wyszukiwarka
Podobne podstrony:
Projektowanie baz danych XML Vademecum profesjonalisty pxmlvp 2
Projektowanie baz danych XML Vademecum profesjonalisty pxmlvp
Projektowanie Baz Danych Xml Vademecum Profesjonalisty [XML]
Projektowanie baz danych XML Vademecum profesjonalisty 2
Projektowanie Baz Danych Xml Vademecum Profesjonalisty [XML]
Projektowanie Baz Danych Xml Vademecum Profesjonalisty R 5 Architektura Systemu Baz Danych
Projektowanie baz danych XML Vademecum profesjonalisty
Access 2002 Projektowanie baz danych Ksiega eksperta ac22ke
Projektowanie baz danych
Projektowanie baz danych Wykłady Sem 5, pbd 2006.01.07 wykład03, Podstawy projektowania
access zaawansowane projektowanie baz danych, SPIS TREŚCI
access zaawansowane projektowanie baz danych, SPIS TREŚCI
Projektowanie baz danych
Access 2002 Projektowanie baz danych Ksiega eksperta ac22ke
r03-01, ## Documents ##, XML Vademecum profesjonalisty
r05-01, ## Documents ##, XML Vademecum profesjonalisty
Projektowanie baz danych Wykłady Sem 5, pbd 2005.10.02 wykład01, Każda dyscyplina naukowa posiada sw
r04-01, ## Documents ##, XML Vademecum profesjonalisty
r07-01, ## Documents ##, XML Vademecum profesjonalisty
więcej podobnych podstron