TCP/IP
TCP/IP - ang. Transmition Control Protocol/Internet Protocol. Jest to zestaw protokołów (ang. protocol suit), na których opiera się Internet, największa pojedyncza sieć świata. Nie oznacza to, że jest to jedyny protokół stosowany w tej sieci, jego użycie jest jednak najpowszechniejsze i nic nie zapowiada zmiany panującej sytuacji.
TCP/IP vs. Model OSI
Model OSI vs. składowe TCP/IP
Warstwa Interfejsu Sieciowego (ang. Network Interface layer) odpowiada warstwom: Fizycznej (ang. Physical layer) oraz Linii (ang. Data Link layer) modelu OSI. Jest odpowiedzialna za transmisję ramek (ang. frame) po medium transmisyjnym.
Architektura Protokołu TCP/IP.
Warstwa Internet (ang. Internet layer) odpowiada warstwie Sieci (ang. Network layer) modelu OSI. Na tym poziomie pakiety poddane zostają enkapsulacji, tworzone są datagramy Internetowe (ang. Internet datagram). Dodatkowo, w warstwie tej uruchamiane są wszystkie algorytmy route'owania (ang. routing algorithms).
Warstwa Transportowa (ang. Transport layer) jest odpowiedzialna za zarządzanie komunikacją orientowaną połączeniowo (ang. connection oriented) oraz bezpołączeniową (ang. connectionless) pomiędzy dwoma host'ami.
Warstwa Aplikacji adresuje aplikacje takie jak Telnet, FTP i SNMP.
Kolejny schemat ilustruje rozmieszczenie protokołów implementacji LM TCP/IP w obrębie zdefiniowanych powyżej warstw TCP/IP.
Schemat x1 ilustruje strukturę protokołu TCP/IP; diagram ten nie jest w żaden sposób wyczerpujący, ukazuje jednak główne protokoły i składowe aplikacji charakterystyczne dla większości komercyjnych pakietów oprogramowania TCP/IP oraz ich wzajemne rozmieszczenie.
----------------------------------------------------- ------
APPLICATION |Telnet|FTP|Gopher|SMTP|HTTP|Finger|POP|DNS|SNMP|RIP| |Ping|
|------+---+------+----+----+------+---+-+-+----+---| |----+-----
TRANSPORT | TCP | UDP | |ICMP|OSPF|
|----------------------------------------+----------+--+----+----+----
INTERNET | IP |ARP|
|----------+-------+----+------+-------+------+-----+-----+------+---|
NETWORK | Ethernet | Token |FDDI| X.25 | Frame | SMDS | ISDN| ATM | SLIP |PPP|
INTERFACE | | Ring | | | Relay | | | | | |
----------------------------------------------------------------------
Sekcje poniżej dostarczą skrótowego opisu każdej z warstw TCP/IP oraz protokołów, które tworzą te warstwy.
Warstwa Interfejsu Sieciowego (ang. The Network Interface Layer)
Protokoły TCP/IP zostały zaprojektowane do operowania na bazie niemalże każdej technologii sieci lokalnej czy rozległej. Pomimo tego, iż w niektórych przypadkach trzeba przeprowadzać pewne dostosowania, wiadomości IP, mogą być transportowane z pomocą wszystkich technologii oznaczonych na schemacie x1.
Dwa z powyższych protokołów pośredniczących (ang. interface protocols) są szczególnie istotne dla TCP/IP. Serial Line Internet Protolol (SLIP — RFC 1055) oraz Point-to-Point Protocol (PPP — RFC 1661), każdy z nich może zostać użyty do zarządzania usługami protokołów warstwy Linii (ang. Data Link Layer) tam, gdzie brak możliwości użycia innych protokołów wzmiankowanej warstwy, jak np. na liniach dzierżawionych lub połączeniach typu dial-up. Większość komercyjnych pakietów oprogramowania dla komputerów PC zawiera implementacje obu tych protokołów. Z pomocą SLIP lub PPP, odległy komputer ma możliwość bezpośredniego połączenia z serwerem i dlatego też połączenia z Internetem dokonywane są raczej z użyciem IP niż przy użyciu do połączenia asynchronicznego. PPP dodatkowo dostarcza jednoczesnej obsługi wielu protokołów na pojedynczym medium transmisyjnym, mechanizmów bezpieczeństwa, oraz ??? ??? (ang. bandwidth allocation).
Warstwa Internet (ang. The Internet Layer)
Protokół Internet (RFC 791), dostarcza usług, które nie są wiernym odpowiednikiem Warstw Sieci OSI. IP zarządza transportem datagramowym (transmisją datagramową), (bezpołączeniową) po sieci. Usługa ta jest czasem określana jako „niegodna zaufania” (zawodna) (ang. unrealiable) ponieważ sieć nie gwarantuje dostarczenia ani też nie informuje systemu docelowego o utracie pakietów z powodu błędów. Datagramy IP zawierają wiadomość, lub jej fragment o rozmiarze do 65,535 bajtów (oktetów). IP nie dostarcza mechanizmów kontroli przepływu (ang. flow control).
ARP
Już wczesne implementacje IP pracowały na komputerach dołączonych do sieci lokalnych (LAN ) Ethernet. Każda transmisja w sieci LAN zawiera adres sieci lokalnej lub MAC (ang. medium access control) źródła i węzła przeznaczenia. Adres MAC ma długość 48-bitów i jest nie-hierarchiczny (ang. non-hierarchical).
Kiedy jakiś host zamierza przesłać datagram do innej maszyny w tej samej sieci, aplikacja-nadawca musi „znać” oba adresy: IP i MAC odbiorcy. Niestety proces IP może nie znać adresu MAC odbiornika. ARP (ang. Adres Resolution Protocol), opisany w RFC 826, zarządza mechanizmem umożliwiającym host'owi określenie adresu MAC odbiornika poprzez adres IP. Proces ten polega na tym, że nadajnik wysyła pakiet ARP w ramce zawierającej adres rozgłoszeniowy (ang. broadcast) MAC; pakiet-rozgłoszenie zawiera adres IP i prośbę o związany z nim adres MAC. Stacja w sieci LAN, która rozpozna swój własny IP prześle odpowiedź. Wiadomość ARP jest przenoszona bezpośrednio poprzez datagram IP.
OSPF i RIP
OSPF i RIP, są to dwa główne protokoły route'ujące połączone z TCP/IP i route'ujące w obrębie poszczególnych domen. Istotne jest dostrzeżenie funkcji protokołów route'ujących. IP, jako protokół Warstwy Sieci, jest odpowiedzialny za route'owanie datagramów. Spełnia to zadanie poprzez sprawdzanie tablicy route'owań. Zadaniem protokołu route'ującego jest wypełnić (ang. populate) tablicę route'owań informacjami, użytecznymi dla protokołu Warstwy Sieci.
Protokół Informacji Route'owań (ang. Routing Information Protocol), opisany w RFC 1058, opisuje jak router'y będę przeprowadzały wymianę informacji zawartych w tablicach route'owań, używając algorytmu wektor-odległościowy (ang. distance-vector). Z pomocą RIP, sąsiadujące route'ry okresowo wymieniają całą zawartość tablic route'owań. RIP używa licznika hop (ang. hop count) jako miary kosztu ścieżki (ang. metric of a path's cost) i ścieżka jest ograniczona do 16 hop'ów.
Niestety, RIP staje się coraz bardziej nieefektywny w Internecie, gdy tymczasem sieć ta utrzymuje szybkie tempo rozwoju. Obecne protokoły route'ujące dla wielu dzisiejszych sieci LAN bazują na UDP, włączając protokoły zaimplementowane w NetWare, AppleTalk, vINES oraz DECnet.
Protokół Open Shortest Path First (OSPF) to algorytm stanu połączenia, który jest o wiele efektywniejszy niż RIP, operuje szybciej, wymaga mniejszej przepustowości łącz i jest bardziej zdatny do obsługi większych sieci. Z pomocą OSPF ruoter'y rozsyłają tylko zmiany w statusie połączenia, nie zaś całe tablice route'owań. OSPF w wersji 2, opisany w RFC 1583, gwałtownie zastępuje RIP w Internecie.
Schemat x2 ukazuje ulokowanie RIP i OSFP w stosunku do IP. Wiadomość RIP jest przenoszona poprzez datagram UDP, który z kolei jest przenoszony w datagramie IP. Wiadomość SOPF jest przenoszona bezpośrednio w datagramie IP.
ICMP
Internetowy Protokół Wiadomości Kontrolnych (ang. Internet Control Message Protocol), opisany w RFC 792, pełni funkcję pomocniczą dla IP, powiadamiając nadawcę datagramów IP o nieprawidłowych zdarzeniach. ICMP może wskazać, dla przykładu, że datagram IP nie może osiągnąć zamierzonego miejsca przeznaczenia, nie może połączyć się do żądanej usługi lub też, że sieć porzuciła datagram z powodu zbyt długiego okresu „życia”. ICMP także dostarcza powrotną informację dla nadawcy, jak przykładowo opóźnienie typu end-to-end dla transmisji datagramowej.
Warstwa Transportowa
(ang. The Transport Layer)
Zestaw protokołów TCP/IP obejmuje dwa protokoły luźno odpowiadające Warstwie Transportowej OSI; te protokoły zwane są: Protokołem Kontroli Transmisji (ang. Transmition Control Protocol — TCP) oraz Protokołem Datagramów Użytkownika (ang. User Datagram Protocol — UDP). Poszczególne aplikacje są powiązane z nimi poprzez identyfikator portu zawarty w wiadomościach TCP/UDP. Identyfikator portu i adres IP razem wspólnie tworzą tzw. Socket . Dobrze znane numery portów przy połączeniach po stronie server'a to np. 20 (FTP), 21 (kontrolny FTP), 23 (Telnet), 25 (SMTP ), 43 (whois ), 70 (Gopher ), 79 (finger ) i 80 (HTTP ).
TCP i UDP
Protokół TCP, opisany w RFC 793, zarządza obsługą wirtualnego połączenia (ang. virtual circuit communication service) poprzez sieć. TCP zawiera zasady formatowania wiadomości, ustanawiania i zrywania pętli wirtualnych, sekwencjonowania, kontroli przepływu, korekty błędów. Większość aplikacji TCP/IP operuje na bazie niezawodnej usługi transportowej zarządzanej przez TCP.
Protokół UDP, opisany w RFC 768, zarządza obsługą datagramów typu end-to-end (transmisja bezpołączeniowa). Niektóre aplikacje, jak np. te które wymagają prostego zapytania i odpowiedzi, mogą skuteczniej odwoływać się do obsługi datagramów oferowanej przez UDP, ponieważ nie ma czasu na ustanawianie i zrywanie wirtualnego połączenia. Podstawową funkcją UDP jest dodawanie numeru portu do adresu IP w celu zabezpieczenia socket'u dla aplikacji.
Warstwa Aplikacji (ang. Applications)
Protokoły Warstwy Aplikacji ukazane na schemacie 2, to przykłady typowych programów usługowych oraz aplikacji TCP/IP.
---------------- ----------------
| Application |<------ end-to-end connection ------>| Application |
|--------------| |--------------|
| TCP |<--------- virtual circuit --------->| TCP |
|--------------| ----------------- |--------------|
| IP |<-- DG -->| IP |<-- DG -->| IP |
|--------------| |-------+-------| |--------------|
| Subnetwork 1 |<-------->|Subnet1|Subnet2|<-------->| Subnetwork 2 |
---------------- --------+-------- ----------------
HOST GATEWAY HOST
Schemat 2. Architektura zestawu protokołów TCP/IP.
Schemat x2 ukazuje zależności pomiędzy różnymi warstwami protokołów TCP/IP. Aplikacje i programy użytkowe rezydują na host'ie lub systemach docelowch transmisji. TCP zarządza niezawodnym połączeniem wirtualnym pomiędzy dwoma hostami. (UDP nie zaznaczone na schemacie zarządza połączeniem datagramowym typu end-to-end w tej warstwie.) IP zarządza obsługą transportu datagramów (DG) poprzez każdą widoczną podsieć, włączając sieci lokalne i rozległe. Leżąca „poniżej” podsieć może zatrudniać prawie każdą popularną technologię sieciową.
Dla określenia urządzenia łączącego dwie podsieci używany jest termin gateway
,urządzenie to zwykle zwane jest router'em w sieciach LAN lub systemem pośredniczącym w środowiskach OSI. W terminologii OSI, gateway wykorzystywany jest do zarządzania konwersją protokołów pomiędzy dwoma sieciami i/lub aplikacjami.
IPv6 — Następna generacja protokołu Internet
Protokół Internet wprowadzany był w obrębie sieci ARPANET w połowie lat 70-tych. Wersja IP będąca obecnie w powszechnym użytku to IPv4, opisana w RFC 791 (Październik 1981). Pomimo tego, że w międzyczasie zaproponowano już kilka rozwiązań kolejnych protokołów (włączając OSI — ang. Open System Interconnection) w miejsce IPv4, żaden z nich nie zdobył wystarczającego uznania, z powodu ogromnej i stale rosnącej bazy IPv4. Niemniej jednak IPv4 nie był przeznaczony dla Internetu w jego obecnej postaci, zarówno w terminologii numerowania hostów, typów aplikacji, jak i w odniesieniu do spraw bezpieczeństwa.
We wczesnych latach 90-tych, IETF (ang. Internet Engeneering Task Force) uznała, że jedyną drogą podołania tym zmianom jest zaprojektowanie nowej wersji IP — jako następcy IPv4. IETF sformowało „Grupę Roboczą następnej generacji (IP)” (ang. IP next generation — Ipng). Celem działań było zdefiniowanie przejściowego protokołu, zapewniającego długo-terminową kompatybilność pomiędzy wersją aktualną IP, a następcami oraz mając na względzie podtrzymanie (ang. support) obecnych i pojawiających się aplikacji IP.
Prace IPng ruszyły w 1991 roku. Ich rezultatem był IP w wersji 6-tej (IPv6), opisany w RFC 1886-1886; te cztery dokumenty oficjalnie wprowadzono do Internet Standards Track w grudniu 1995.
IPv6 został zaprojektowany raczej w formie ewolucyjnej w stosunku do IPv4, z uniknięciem radykalnych zmian. Użyteczne cechy IPv4 zostały przeniesione do specyfikacji IPv6, zmiany pierwotnie pogrupowano w następujące kategorie:
Rozszerzone Możliwości Adresowania
(ang. Expanded Addressing Capabilities). Rozmiar adresu IP jest powiększony z 32 do 128 bitów w IPv6, obsługa znacznie większej liczby węzłów adresowych, więcej poziomów hierarchii adresowania, prostsza auto-konfiguracja adresów dla zdalnych użytkowników. Skalowalność (ang. multicast routing) została udoskonalona poprzez dodanie pola zakresu/dziedziny (ang. scope) do adresów (ang.) multicast . Został także zdefiniowany nowy typ adresu, zwany (ang.) anycast .
Uproszczenie formatu nagłówka
(ang. Header Format Simplification). Niektóre pola nagłówka IPv4 zostały usunięte lub uczynione opcjonalnymi w celu redukcji operacji niezbędnych dla obsługi pakietu oraz ograniczenia kosztu objętości nagłówka IPv6.
Udoskonalona obsługa rozszerzeń i opcji
(ang. Improved Support for Extensions and Options). Niektóre pola nagłówka IPv4 zostały uczynione opcjonalnymi w IPv6. Opcje nagłówka IPv6 są enkodowane (ang. encode) w sposób umożliwiający bardziej efektywne odsyłanie (ang. forwarding), mniej rozciągają limit długości opcji, większą elastyczność wprowadzania nowych opcji w przyszłości.
Możliwość Etykietowania Przepływów
(ang. Flow Labeling Capability). Nowa jakościowo usługa (ang. quality-of-service — QOS), została dodana w celu umożliwienia oznaczania (ang. labeling) pakietów należących do poszczególnych przepływów dla których nadawca prosi o szczególną obsługę (ang. special handling), jak w przypadku usług czasu rzeczywistego (ang. real-time service).
Opcje autentyczności i poufności.
(ang. Authentication and Privacy Capabilities). Rozszerzenia obsługujące opcje bezpieczeństwa jak: autentyczność, integralność i poufność danych, zostały wbudowane w IPv6.
DNS, adresy domenowe
Adresy IP są niezbędne oprogramowaniu sieciowemu do przesyłania pakietów danych, Posługiwanie się nimi jest jednak bardzo niewygodne dla użytkownika. Dlatego obok adresów IP wprowadzono adresy symboliczne albo domenowe. Nie każdy komputer musi mieć taki adres; adresy symboliczne z reguły przypisywane są tylko komputerom udostępniającym w Internecie jakieś usługi, czyli będącym tzw. serwerami. Umożliwia to użytkownikom chcącym z nich skorzystać łatwiejsze wskazanie konkretnego serwera. Komputery będące tylko klientami, to znaczy jedynie korzystające z zasobów informacyjnych serwerów (np. zwykłe domowe PC włączone do Internetu za pośrednictwem modemu) mogą nie mieć nadanych adresów symbolicznych, gdyż nikt „z zewnątrz” nie będzie z nich korzystał. Posiadanie takiego adresu może jednak ułatwić identyfikację naszego komputera przez serwer i np. automatyczne wyświetlanie strony WWW w wersji językowej odpowiedniej dla naszego kraju. Specjalny rodzaj adresów symbolicznych wykorzystywany jest w przypadku komputerów nie przyłączonych bezpośrednio do Internetu, lecz do innych sieci mających możliwość wymiany poczty z Internetem (np. do amatorskiej, modemowej sieci Fido). Komputery te nie mają — z oczywistych przyczyn — adresów IP, jednakże adresy symboliczne umożliwiają zaadresowanie poczty do takiego komputera.
Adres symboliczny jest zapisywany w postaci ciągu nazw, tzw. domen, które rozdzialone są kropkami podobnie jak w przypadku adresu IP. Poszczególne części adresu domenowego nie mają jednak żadnego związku z fragmentami adresu IP, chociażby ze względu na fakt, że o ile adres IP składa się zawsze z czterech części, o tyle adres domenowy może ich mieć różną liczbę - od dwóch do sześciu czy siedmiu. Kilka przykładowych adresów domenowych przedstawiono poniżej:
usctoux1.cto.us.edu.pl
ultra.cto.us.edu.pl
galaxy.uci.agh.edu.pl
morning_star.foxx.pl
ftp.ibm.com
Odwrotnie niż adres IP, adres domenowy czyta się od tyłu. Ostatni jego fragment, tzw. domen najwyższego poziomu (ang. top-level domain) jest z reguły dwuliterowym oznaczeniem kraju (np. .pl, .fi). Jedynie w USA dopuszcza się istnienie adresów bez oznaczenia kraju na końcu. Zamiast kraju, domena najwyższego poziomu opisuje „branżową” przynależność instytucji, do której należy dany komputer (ostatni z przykładowych adresów). Może to być .com — oznaczające firmy komercyjne, .edu — instytucje naukowe i edukacyjne, .gov — instytucje rządowe, .mil — wojskowe, .org — wszelkie organizacje społeczne i inne instytucje typu nonprofit. Istnieją jeszcze dwie domeny top-level, które można spotkać także w adresach komputerów spoza USA: .int — organizacje międzynarodowe nie dające się zlokalizować w konkretnym państwie oraz .net — firmy i organizacje zajmujące się administrowaniem i utrzymywaniem sieci komputerowych.
Ten podział zostanie najprawdopodobniej wkrótce rozszerzony o kolejne domeny top-level, gdyż uważany jest obecnie za przestarzały i nieadekwatny do aktualnego stanu rozwoju Internetu; niektóre domeny (np. .com) stają się zbyt duże, co utrudnia pracę serwerów nazw oraz wywołuje coraz częstsze konflikty między instytucjami chcącymi posiadać tą samą nazwę domenową.
Wzorem USA podział „branżowy” został przyjęty w niektórych innych krajach, gdzie domena „branżowa” została jako przedostatnia, czyli — zgodnie z zasadą czytania adresu od tyłu — bezpośrednio następna po oznaczeniu kraju.
W Europie popularniejszy jest jednak, funkcjonujący w Polsce równolegle ze schematem „branżowym”, inny schemat budowy adresu — „geograficzny”, w którym przedostatni człon adresu określa miasto. Obydwa schematy mają swoich zwolenników i przeciwników.„ branżową”, jak i „geograficzną”, jak np. w adresie garbo.uwasa.fi. Gdzie indziej jeszcze oznaczenia domen „branżowych” są inne niż w USA, np. w Austrii (.ac zamiast .edu; .co zamiast .com). Powoduje to wielką różnorodność adresów symbolicznych.
Następną — idąc od końca — częścią adresu po domenie „branżowej” lub „geograficznej” będzie domena określająca bezpośrednio instytucję - na ogół jej nawa lub skrót nazwy, np. us (Uniwersytet Śląski), wsp (Wyższa Szkoła Pedagogiczna). W obrębie instytucji mogą, ale nie muszą występować kolejne podziały, np. cto (Centrum Techniki Obliczeniowej). dopiero pierwszy człon adresu domenowego jest nazwą komputera np. usctoux1.
Zwyczajowo komputery na których są servery takich usług jak anonimowe FTP, news, gopher, WWW, wyróżniane są charakterystyczną nazwą, odpowiadającą nazwie usługi, aby łatwiej było je odnaleźć. W istocie wszystkie adresy mogą oznaczać ten sam komputer, ponieważ możliwe jest przypisanie do jednego adresu IP kilka adresów domenowych.
DNS
Korzystanie z adresów domenowych jest łatwiejsze dla ludzi, ale oprogramowanie siciowe „rozumie” jedynie adresy IP. Potrzebny jest zatem jakiś sposób „tłumaczenia” adresów symbolicznych na adresy IP. Jako że ich wzajemne przyporządkowanie jest czysto umowne, „tłumaczenia” to może się odbywać tylko na podstawie jakiejś „tabeli”, przechowującej informacje o tym, jakiej nazwie symbolicznej odpowiada jaki adres IP. Ze względu na rozmiary sieci Internet oczywiście niemożliwe jest przechowywanie takiej „tabeli” przez jakikolwiek pojedynczy komputer w sieci, dlatego zastosowano rozwiązanie rozproszone.
W każdej (albo prawie każdej) domenie istniejącej w Internecie jest jeden wyróżniony komputer - tzw. serwer nazw (ang. Domain Name Server), przechowujący wykaz adresów komputerów ze swojej domeny, czasami ewentualnie także sąsiednich nie mających własnych serwerów nazw. Oczywiście serwer nazw nie musi być komputerem wydzielonym wyłącznie do tej funkcji. Jedyny warunek wymagany dla komputera mającego być serwerem nazw to nieprzerwana dostępność w sieci przez 24 godziny na dobę. Każda domena wyższego poziomu (np. obejmująca miasto) również ma swój serwer nazw poszczególnych „poddomen” w obrębie tej domeny (aby zatem utworzyć nową domenę trzeba ją zarejstrować w serwerze nazw domeny nadrzędnej). Np. serwer nazw domeny krakow.pl będzie zawierał nazwy domen wsp.krakow.pl, cyfronet.krakow.pl... itp. i adresy ich serwerów nazw, zaś serwer nazw domeny .pl będzie "pamiętał" adresy serwerów nazw domen krakow.pl, katowice.pl, edu.pl... itd. Na najwyższym poziomie tej hierarchii znajdują się tzw. główne serwery nazw (ang. Root Name Servers) — dla większej sprawności działania jest ich kilka — zwierające informacje o adresach serwerów nazw domen najwyższego poziomu w Internecie (.com, .edu... itp.).
Każdy serwer nazw musi znać adresy serwerów głównych, zaś adres IP jego samego musi być znany wszystkim komputerom w obsługiwanej przezeń domenie.
Gdy zatem użytkownik jakiegoś komputer gdzieś w świecie usiłuje połączyć się np. z komputerem inf.wsp.krakow.pl, jego oprogramowanie sieciowe „pyta” serwer nazw swojej własnej domeny o odpowiedni adres IP. Ten oczywiście zwykle nie zna tego adresu, wysyła zatem najpierw zapytanie do jednego z głównych serwerów o adres DNS dla domeny .pl. Otrzymując ten adres, wysyła tam właśnie pytanie o adres serwera domeny krakow.pl. Ten z kolei jest pytany o adres serwera dla domeny wsp.krakow.pl i wreszcie ten ostatni bezpośrednio o adres komputera inf w jego demonie. Po tej serii zapytań (ang. DNS query) serwer odsyła komputerowi szukany adres IP.
Routing
Routery, łączące poszczególne podsieci, są jednymi z najważniejszych urządzeń w Internecie. To on właśnie wytyczają drogę (ang. route — droga, trasa) pakietów danych między sieciami, zapewniając możliwość połączenia ze sobą dowolnych komputerów, niezależnie od ich fizycznej lokalizacji. Route'r posiada co najmniej dwa przyłącza sieciowe (każde o innym adresie IP), podłączone do różnych sieci: jego zadaniem jest skierowanie danych we właściwą stronę na podstawie adresu docelowego.
Jeżeli komputer o adresie np. 149.156.24.10 wysyła pakiet danych do komputera w tej samej podsieci (np. 149.156.24.15), pakiet ten może być przekazany bezpośrednio — router nie bierze w tym procesie udziału, gdyż pakiety nie wychodzą poza lokalną podsieć (i nie powodują obciążenia reszty Internetu...). Jeżeli jednak zechcemy się połączyć z komputerem spoza swojej podsieci (np. 148.81.18.1), wówczas dane przekazywane są do routera, a poprzez niego do następnej sieci, gdzie — o ile pakiet nie jest adresowany do komputera w tej właśnie sieci — zajmie się nim kolejny router.
Routery „wiedzą” przez który router wiedzie droga do jakich sieci (istnieje wiele metod aby je tego „nauczyć”), stąd też w przypadku gdy dana sieć ma połączenie z kilkoma
innymi (zawiera kilka router'ów), wybierany jest router najbardziej odpowiedni dla docelowej sieci. Router'y potrafią jednak same zmieniać trasę przesyłania pakietów i tworzyć tzw. drogi obejściowe w przypadku np. awarii połączenia — jest to właśnie ta zasadnicza koncepcja, która legła u podstaw APRANET'u, a później Internetu.
Sytuację tą obrazuje rysunek x4 , trzy sieci A, B i C połączone ze sobą na zasadzie każda z każdą. W normalnej sytuacji pakiety wysyłane z sieci A do sieci B przekazywane są połączeniem bezpośrednim poprzez router'y R1 i R3. Jeżeli jednak bezpośrednie połączenie między sieciami A i B ulegnie przerwaniu, pakiety zostaną automatycznie skierowane obejściową trasą poprzez sieć C (router'y R2-R6-R5-R4) - może to nawet zostać nie zauważone przez użytkowników.
TCP/IP
Niniejsze opracowanie przedstawia podstawowe zasady, na których opiera się funkcjonowanie sieci złożonej, będące wynikiem prac wspieranych przez Advanced Research Project Agency (ARPA).
Organizacja ta zaproponowała zbiór standardów określających szczegóły komunikacji między komputerami, a także szczegółów dotyczących łączenia sieci i wyboru trasy w sieci nazwane TCP/IP (od głównych protokołów wchodzących w ich skład).
TCP/IP (Transmission Control Protocol/Internet Protocol) nie jest więc pojedynczym produktem. Jest to uogólniona nazwa całej rodziny protokołów i oprogramowania udostępniającego szereg usług sieciowych.
TCP/IP może zostać wykorzystany w dowolnym zbiorze połączonych ze sobą sieci.
Technika TCP/IP stanowi podstawowe rozwiązanie światowej intersieci - INTERNETU.
Działanie i niezwykle dynamiczny rozwój sieci INTERNET świadczy o sile i przenośności techniki TCP/IP.
Sieć komputerowa jest systemem komunikacyjnym służącym przesyłaniu danych, łączącym dwa lub więcej komputerów i urządzenia peryferyjne. Składa sie z zasobów obliczeniowych i informacyjnych, mediów transmisyjnych i urządzeń sieciowych.
Zapewnienie współdziałania elementów składowych sieci jest złożonym problemem technicznym. W związku z tym stosuje sie model warstwowy, w którym każda warstwa świadczy określony poziom usług: jedna zajmuje się transferem danych, inna pakowaniem/rozpakowaniem komunikatów itd..
Komunikacja pomiędzy komputerami odbywa się zawsze na poziomie odpowiadających sobie warstw. Warstwy komunikują się ze sobą zgodnie z określonymi zasadami nazywanymi protokołem. Rozwiązanie takie ułatwia analizę procesów zachodzących w sieci i w efekcie upraszcza ich projektowanie.
PROTOKOŁY SIECIOWE
Protokołem w sieci komputerowej nazywamy zbiór zasad syntaktycznych i semantycznych sposobu komunikowania się jej elementów funkcjonalnych. Tylko dzięki nim urządzenia tworzące sieć mogą się porozumiewać.
Podstawowym zadaniem protokołu jest identyfikacja procesu, z którym chce się komunikować proces bazowy. Aby było to możliwe konieczne jest podanie sposobu określania właściwego adresata, sposobu rozpoczynania i kończenia transmisji, a także sposobu przesyłania danych.
Przesyłana informacja może być porcjowana - protokół musi umieć odtworzyć informację w postaci pierwotnej. Ponadto informacja może z różnych powodów być przesłana niepoprawnie - protokół musi wykrywać i usuwać powstałe w ten sposób błędy, prosząc nadawcę o ponowną transmisję danej informacji.
Model warstwowy, w którym każda warstwa posługuje się własnym protokołem znacznie upraszcza projektowanie niezwykle skomplikowanego procesu komunikacji sieciowej. Muszą jednak jasno zostać zdefiniowane zasady współpracy tych protokołów. Warstwowy model OSI stanowi przykład takiego opisu, będąc w istocie "protokołem komunikacji między protokołami".
MODEL OSI (Open Systems Interconnection)
Stworzony został przez organizację ISO (International Standard Organization). Jest on zbiorem zasad komunikowania się urządzeń sieciowych. Podzielony jest na siedem warstw, z których każda zbudowana jest na bazie warstwy poprzedniej. Model ten nie określa fizycznej budowy poszczególnych warstw, a koncentruje się na sposobach ich współpracy. Takie podejście do problemu sprawia, że każda warstwa może być implementowana przez producenta na swój sposób, a urządzenia sieciowe od różnych dostawców będą poprawnie współpracować. Poszczególne warstwy sieci stanowią niezależne całości i chociaż nie potrafią wykonywać żadnych widocznych zadań w odosobnieniu od pozostałych warstw, to z programistycznego punktu widzenia są one odrębnymi poziomami.
Warstwy OSI
Komunikacja pomiędzy komputerami odbywa się na poziomie odpowiadających sobie warstw i dla każdej z nich powinien zostać stworzony własny protokół komunikacyjny. W rzeczywistej sieci komputerowej komunikacja odbywa wyłącznie się na poziomie warstwy fizycznej (linia ciągła na rysunku). W tym celu informacja każdorazowo przekazywana jest do sąsiedniej niższej warstwy aż do dotarcia do warstwy fizycznej.
Tak więc pomiędzy wszystkimi warstwami z wyjątkiem fizycznej istnieje komunikacja wirtualna (linie przerywane na rysunku), możliwa dzięki istnieniu połączenia fizycznego.
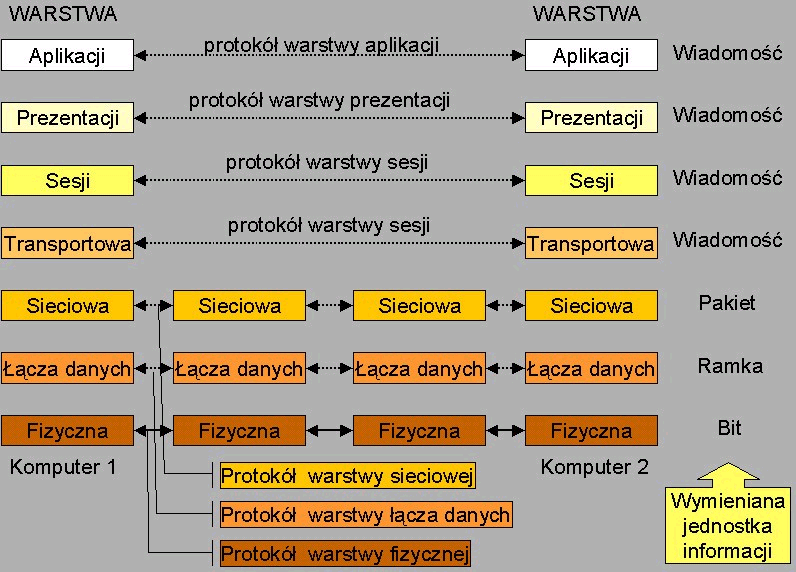
Zadania warstw |
Warstwa fizyczna - odpowiada za transmisje sygnałów w sieci. Realizuje ona konwersje bitów informacji na sygnały, które będą przesyłane w kanale z uwzględnieniem maksymalizacji niezawodności przesyłu. W warstwie fizycznej określa się parametry amplitudowe i czasowe przesyłanego sygnału, fizyczny kształt i rozmiar łączy, znaczenie ich poszczególnych zestyków i wartości napięć na nich występujących, sposoby nawiązywania połączenia i jego rozłączania po zakończeniu transmisji.
Warstwa łącza danych - odpowiedzialna jest za odbiór i konwersję strumienia bitów pochodzących z urządzeń transmisyjnych w taki sposób, aby nie zawierały one błędów. Warstwa ta postrzega dane jako grupy bitów zwane ramkami. Warstwa łącza danych tworzy i rozpoznaje granice ramki. Ramka tworzona jest przez dołączenie do jej początku i końca grupy specjalnych bitów. Kolejnym zadaniem warstwy jest eliminacja zakłóceń, powstałych w trakcie transmisji informacji po kanale łączności. Ramki, które zostały przekazane niepoprawnie, są przesyłane ponownie. Ponadto warstwa łącza danych zapewnia synchronizację szybkości przesyłania danych oraz umożliwia ich przesyłanie w obu kierunkach.
Warstwa sieciowa - steruje działaniem podsieci transportowej. Jej podstawowe zadania to przesyłanie danych pomiędzy węzłami sieci wraz z wyznaczaniem trasy przesyłu, określanie charakterystyk sprzęgu węzeł-komputer obliczeniowy, łączenie bloków informacji w ramki na czas ich przesyłania a następnie stosowny ich podział. W najprostszym przypadku określanie drogi transmisji pakietu informacji odbywa się w oparciu o stałe tablice opisane w sieci. Istnieje również możliwość dynamicznego określania trasy na bazie bieżących obciążeń linii łączności. Stosując drugie rozwiązanie mamy możliwość uniknięcia przeciążeń sieci na trasach, na których pokrywają się drogi wielu pakietów.
Warstwa transportowa - podstawową funkcją tej warstwy jest obsługa danych przyjmowanych z warstwy sesji. Obejmuje ona opcjonalne dzielenie danych na mniejsze jednostki, przekazywanie zblokowanych danych warstwie sieciowej, otwieranie połączenia stosownego typu i prędkości, realizacja przesyłania danych, zamykanie połączenia. Ponadto mechanizmy wbudowane w warstwę transportową pozwalają rozdzielać logicznie szybkie kanały łączności pomiędzy kilka połączeń sieciowych. Możliwe jest także udostępnianie jednego połączenia kilku warstwom sieciowym, co może obniżyć koszty eksploatacji sieci. Celem postawionym przy projektowaniu warstwy transportowej jest zapewnienie pełnej jej niezależności od zmian konstrukcyjnych sprzętu.
Warstwa sesji - określenie parametrów sprzężenia użytkowników realizowane jest za pośrednictwem warstwy sesji. Po nawiązaniu stosownego połączenia warstwa sesji pełni szereg funkcji zarządzających, związanych m. in. Z taryfikacją usług w sieci. W celu otwarcia połączenia pomiędzy komputerami (sesji łączności) poza podaniem stosownych adresów warstwa sprawdza, czy obie warstwy (nadawcy i odbiorcy) mogą otworzyć połączenie. Następnie obie komunikujące się strony muszą wybrać opcje obowiązujące w czasie trwania sesji. Dotyczy to na przykład rodzaju połączenia (simpleks, dupleks) i reakcji warstwy na zerwanie połączenia (rezygnacja, ponowne odtworzenie). Przy projektowaniu warstwy zwraca się uwagę na zapewnienie bezpieczeństwa przesyłanych danych. Przykładowo, jeżeli zostanie przerwane połączenie, którego zadaniem była aktualizacja bazy danych, to w rezultacie tego zawartość bazy może okazać się niespójna. Warstwa sesji musi przeciwdziałać takim sytuacjom.
Warstwa prezentacji - jej zadaniem jest obsługa formatów danych. Odpowiada ona więc za kodowanie i dekodowanie zestawów znaków oraz wybór algorytmów, które do tego będą użyte. Przykładową funkcją realizowaną przez warstwę jest kompresja przesyłanych danych, pozwalająca na zwiększenie szybkości transmisji informacji. Ponadto warstwa udostępnia mechanizmy kodowania danych w celu ich utajniania oraz konwersję kodów w celu zapewnienia ich mobilności.
Warstwa aplikacji - zapewnia programom użytkowym usługi komunikacyjne. Określa ona formaty wymienianych danych i opisuje reakcje systemu na podstawowe operacje komunikacyjne. Warstwa stara się stworzyć wrażenie przezroczystości sieci. Jest to szczególnie ważne w przypadku obsługi rozproszonych baz danych, w których użytkownik nie powinien wiedzieć, gdzie zlokalizowane są wykorzystywane przez niego dane lub gdzie realizowany jest jego proces obliczeniowy.
TCP/IP a model OSI |
Protokół TCP/IP ma również strukturę warstwową i ma do niego zastosowanie większość filozofii modelu OSI. Warstwy TCP/IP różnią się jednak od warstw OSI, o czym się zaraz przekonamy.
Protokoły TCP i IP ustalają zasady komunikacji - opisują szczegóły formatu komunikatów, sposób odpowiadania na otrzymany komunikat, określają jak komputer ma obsługiwać pojawiające się błędy lub inne nienormalne sytuacje.
Umożliwiają one rozpatrywanie zagadnień dotyczących komunikacji niezależnie od sprzętu sieciowego.
Zapewniają szereg popularnych usług dostępnych dla użytkowników:
poczta elektroniczna
przesyłanie plików
praca zdalna
Zadania warstw w TCP/IP |
Warstwa programów użytkowych - na najwyższym poziomie użytkownicy wywołują programy użytkowe, które mają dostęp do usług TCP/IP. Programy użytkowe współpracują z jednym z protokołów na poziomie warstwy transportowej i wysyłają lub odbierają dane w postaci pojedynczych komunikatów lub strumienia bajtów.
Warstwa transportowa - jej podstawowym zadaniem jest zapewnienie komunikacji między jednym programem użytkownika a drugim. Warstwa ta może regulować przepływ informacji. Może też zapewnić pewność przesyłania. W tym celu organizuje wysyłanie przez odbiorcę potwierdzenia otrzymania oraz ponowne wysyłanie utraconych pakietów przez nadawcę.
Warstwa intersieci - odpowiada za obsługę komunikacji jednej maszyny z drugą. Przyjmuje ona pakiety z warstwy transportowej razem z informacjami identyfikującymi maszynę - odbiorcę, kapsułkuje pakiet w datagramie IP, wypełnia jego nagłówek, sprawdza czy wysłać datagram wprost do odbiorcy czy też do routera i przekazuje datagram do interfejsu sieciowego. Warstwa ta zajmuje się także datagramami przychodzącymi, sprawdzając ich poprawność i stwierdzając czy należy je przesłać dalej czy też przetwarzać na miejscu.
Warstwa interfejsu sieciowego - odbiera datagramy IP i przesyła je przez daną sieć.
Adresy IP
Adres IP jest 32-bitową liczbą całkowitą zawierającą informacje o tym do jakiej sieci włączony jest dany komputer, oraz jednoznaczny adres w tej sieci.
Zapisywany jest on w postaci czterech liczb dziesiętnych oddzielonych kropkami, przy czym każda liczba dziesiętna odpowiada 8 bitom adresu IP.
Np. 32-bitowy adres 10000000 00001010 00000010 00011110 jest zapisany jako 128.10.2.30
Adresy IP podzielone są na klasy.
Klasa adresu IP określona jest przez najstarsze bity, przy czym do zidentyfikowania jednej z trzech zasadniczych klas (A, B, C) wystarczą dwa pierwsze bity.
Taki mechanizm adresowania wykorzystują routery, które używają adresu sieci do wyznaczania trasy pakietów.
Klasy adresów IP
Obserwując najstarsze bity adresu można stwierdzić do jakiej klasy należy dany adres, w efekcie można stwierdzić ile bitów będzie adresowalo sieć, ile zaś sam komputer.
Łatwo zauważyć, że adresów klasy A jest niewiele (27=128), ale w każdej z sieci tej klasy może być aż 65535 maszyn.
Klasa B to 214 sieci i 216 komputerów.
W klasie C sieć adresowana jest za pomocą 21 bitów - daje to 221 sieci, ale w każdej z nich może być co najwyżej 28=256 maszyn.
Adres klasy D ma specjalne znaczenie - jest używany w sytuacji gdy ma miejsce jednoczesna transmisja do większej liczby urządzeń.
Jak wspomniano, adresy zamiast w postaci bitowej, zwykle zapisuje się w postaci czterech liczb dziesiętnych. Wówczas podział na klasy wygląda następująco:
Klasa |
Najniższy adres |
Najwyższy adres |
A |
0.1.0.0 |
126.0.0.0 |
B |
128.0.0.0 |
191.255.0.0 |
C |
192.0.1.0 |
223.255.255.0 |
D |
224.0.0.0 |
239.255.255.255 |
E |
240.0.0.0 |
247.255.255.255 |
Przydzielanie adresów sieciowych
W celu zapewnienia jednoznaczności identyfikatorów sieci, wszystkie adresy przydzielane są przez jedną organizację. Zajmuje się tym Internet Network Information Center (INTERNIC). Przydziela ona adresy sieci, zaś adresy maszyn administrator może przydzielać bez potrzeby kontaktowania się z organizacją. Organizacja ta przydziela adresy tym instytucjom, które są lub będą przyłączone do ogólnoświatowej sieci INTERNET. Każda instytucja może sama wziąć odpowiedzialność za ustalenie adresu IP, jeśli nie jest połączona ze światem zewnętrznym. Nie jest to jednak dobre rozwiązanie, gdyż w przyszłości może uniemożliwić współpracę między sieciami i sprawiać trudności przy wymianie oprogramowania z innymi ośrodkami.
Protokół ARP i RARP
Protokół odwzorowania adresów (ARP)
Opisaliśmy już schemat adresowania TCP/IP, w którym każdy komputer ma przypisany 32-bitowy adres jednoznacznie identyfikujący go w sieci.
Jednak dwie maszyny mogą się komunikować tylko wtedy kiedy znają nawzajem swoje adresy fizyczne.
Zachodzi więc potrzeba przekształcenia adresu IP na adres fizyczny tak aby informacja mogła być poprawnie przesyłana.
Problem ten przedstawimy na przykładzie sieci ethernet, w której mamy do czynienia z długim 48-bitowym adresem fizycznym przypisanym w trakcie procesu produkcyjnego urządzeń sieciowych. W efekcie podczas wymiany karty sieciowej w komputerze, zmienia się adres fizyczny maszyny. Ponadto nie ma sposobu na zakodowanie 48-bitowego adresu ethernetowego w 32-bitowym adresie IP.
Przekształcenia adresu IP na adres fizyczny dokonuje protokół odwzorowania adresów ARP (Address Resolution Protocol), który zapewnia dynamiczne odwzorowanie i nie wymaga przechowywania tablicy przekształcania adresowego.
Odwzorowanie adresów i pamięć podręczna
Przedstawiony sposób odwzorowywania adresów ma jednak wady:
Jest zbyt kosztowny aby go używać za każdym razem gdy jakaś maszyna chce przesłać pakiet do innej: przy rozgłaszaniu każda maszyna w sieci musi taki pakiet przetworzyć.
W celu zredukowania kosztów komunikacji komputery używające protokołu ARP przechowują w pamięci podręcznej ostatnio uzyskane powiązania adresu IP z adresem fizycznym, w związku z tym nie muszą ciągle korzystać z protokołu ARP.
Ponadto komputer A wysyłając prośbę o adres fizyczny komputera C od razu dowiązuje informację o swoim adresie fizycznym. Ponieważ prośba ta dociera do wszystkich komputerów w sieci, mogą one umieścić w swoich pamięciach podręcznych informację o adresie fizycznym komputera A.
Jeśli w komputerze zostanie zmieniony adres fizyczny (np. w wyniku zmiany karty sieciowej), to może on bez zapytania o jego adres fizyczny rozgłosić go do innych komputerów, tak aby uaktualniły informacje w swoich pamięciach podręcznych.
Protokół odwrotnego odwzorowania adresów (RARP)
Wiemy już jak maszyna może uzyskać adres fizyczny innego komputera, znając jego adres IP.
Adres IP jest zwykle przechowywany w pamięci zewnętrznej komputera, skąd jest pobierany w trakcie ładowania systemu operacyjnego.
Nasuwa się więc pytanie: jak maszyna nie wyposażona w dysk twardy określa swój adres IP?
Odpowiedź: w sposób przypominający uzyskiwanie adresu fizycznego.
protokół odwrotnego odwzorowania adresów RARP (Reverse Address Resolution Protocol) umożliwia uzyskiwanie adresu IP na podstawie znajomości własnego adresu fizycznego (pobranego z interfejsu sieciowego).
Komputery bez dysku twardego pobierają adres IP z maszyny uprawnionej do świadczenia usług RARP, po przesłaniu zapytania z własnym adresem fizycznym.
Internet Protocol IP
Zasadniczo sieć TCP/IP udostępnia trzy zbiory usług
Najbardziej podstawowa usługa - przenoszenie pakietów bez użycia połączenia nosi nazwę Internet Protocol, a zwykle oznacza się skrótem IP.
Usługa ta jest zdefiniowana jako zawodny (ang. unreliable) system przenoszenia pakietów bez użycia połączenia, tzn. nie ma gwarancji, że przenoszenie zakończy się sukcesem. Każdy pakiet obsługiwany jest niezależnie od innych.
Pakiety z jednego ciągu, wysyłanego z danego komputera do drugiego, mogą podróżować różnymi ścieżkami, niektóre z nich mogą zostać zgubione, inne natomiast dotrą bez problemów.
Pakiet może zostać zagubiony, zduplikowany, zatrzymany, lub dostarczony z błędem, a system nie sprawdzi, że coś takiego zaszło, a także nie powiadomi o tym ani nadawcy, ani odbiorcy.
Protokół IP
Protokół IP zawiera trzy definicje:
Definicję podstawowej jednostki przesyłanych danych, używanej w sieciach TCP/IP. Określa ona dokładny format wszystkich danych przesyłanych przez sieć.
Definicję operacji trasowania, wykonywanej przez oprogramowanie IP, polegającej na wybieraniu trasy, którą będą przesyłane dane.
Zawiera zbiór reguł, które służą do realizacji zawodnego przenoszenia pakietów. Reguły te opisują, w jaki sposób węzły i routery powinny przetwarzać pakiety, jak i kiedy powinny być generowane komunikaty o błędach oraz kiedy pakiety mogą być porzucane.
Datagram IP
Podstawowa jednostka przesyłanych danych nazywana jest datagramem.
Datagram podzielony jest na nagłówek i dane.
Nagłówek datagramu zawiera adres nadawcy i odbiorcy oraz pole typu, które identyfikuje zawartość datagramu.
Datagram przypomina ramkę sieci fizycznej. Różnica polega na tym, że nagłówek ramki zawiera adresy fizyczne, zaś nagłówek datagramu adresy IP (omówione wcześniej).
Ponieważ przetwarzaniem datagramów zajmują się programy, zawartość i format datagramów nie są uwarunkowane sprzętowo.
Opis Datagramu IP
Pole WERSJA (4-bitowe) - zawiera informację o wersji protokołu IP, która była używana przy tworzeniu datagramu. Informacja ta jest wykorzystywana do sprawdzania, czy nadawca, odbiorca i wszystkie routery zgadzają się na format datagramu.
Oprogramowanie IP zawsze sprawdza pole wersji w celu upewnienia się, czy jego format zgadza się ze spodziewanym. Obecna wersja protokołu IP to 4.
Pole DŁUGOŚĆ NAGŁÓWKA (4-bitowe) - zawiera informację o długości nagłówka mierzoną w 32-bitowych słowach.
Pola OPCJE IP i UZUPEŁNIENIE najczęściej nie są wypełnione. Ponieważ długość pozostałych pól nagłówka jest stała, więc nagłówek najczęściej ma długość równą 5 (słów 32-bitowych).
Pole DŁUGOŚĆ CAŁKOWITA (16-bitowe) zawiera, mierzoną w bajtach, długość całego datagramu IP. Rozmiar pola danych można uzyskać przez odjęcie DŁUGOŚCI NAGŁÓWKA od DŁUGOŚCI CAŁKOWITEJ.
Ponieważ pole DŁUGOŚĆ CAŁKOWITA ma 16 bitów długości, maksymalny możliwy rozmiar datagramu IP wynosi 216-1 czyli 65535 bajtów.
Typ obsługi
Pole TYP OBSŁUGI (8-bitowe) określa sposób w jaki powinien być obsłużony datagram. Składa się ono z pięciu podpól.
Podpole PIERWSZEŃSTWO (3-bitowe) zawiera informację o stopniu ważności datagramu, od 0 (normalny stopień ważności) do 7 (sterowanie siecią). Umożliwia to nadawcy wskazanie jak ważny jest dany datagram.
Bity O, S, P określają rodzaj przesyłania, którego wymaga datagram. Ustawienie bitu O - oznacza prośbę o krótkie czasy oczekiwania, S - o przesyłanie szybkimi łączami, P - o dużą pewność przesyłanych danych.
Ponieważ nie ma pewności, że trasa o wskazanych parametrach będzie dostępna, informacje te należy traktować tylko jako podpowiedź dla algorytmów trasowania; jednocześnie wskazanie wszystkich trzech sposobów obsługi na raz, zwykle nie ma sensu. W praktyce większość oprogramowania węzłów i routerów ignoruje pole typ obsługi.
Czas życia TTL
Pole CZAS ŻYCIA TTL (ang. Time To Live) określa jak długo, w sekundach, datagram może pozostawać w systemie sieci. Ten limit czasowy wynosi zwykle od 15 do 30 sekund.
Wymogiem protokołu TCP/IP jest aby każdy router podczas przetwarzania nagłówka datagramu zmniejszał wartość pola CZAS ŻYCIA co najmniej o 1, nawet jeśli rzeczywiste przetwarzanie trwało krócej.
Jeśli jednak router jest przeciążony i czas przetwarzania jest dłuższy wówczas wartość pola CZAS ŻYCIA zmniejsza się o czas faktycznego pozostawania datagramu wewnątrz routera.
Gdy wartość pola maleje do zera router porzuca datagram i wysyła do nadawcy komunikat o błędzie.
Mechanizm ten zapobiega podróżowaniu datagramów w sieci w nieskończoność, np. gdy tablice tras są nieaktualne, a routery wyznaczają datagramom trasy w kółko.
Inne pola nagłówka
Pole PROTOKÓŁ zawiera numer identyfikacyjny protokołu transportowego, dla którego pakiet jest przeznaczony. Numery poszczególnych protokołów transportowych określone są przez Internet Network Information Center (INTERNIC). Najbardziej popularnymi są: ICMP oznaczony numerem 1 oraz TCP oznaczony numerem 6. Pełna lista protokołów obejmuje ok. 50 pozycji i jest dostępna w kilku dokumentach RFC.
Pole SUMA KONTROLNA NAGŁÓWKA służy do sprawdzenia sensowności nagłówka. Obejmuje tylko nagłówek IP i nie dotyczy w żadnym stopniu danych. Zawiera bitową negację sumy obliczonej jako suma kolejnych 16-bitowych półsłów nagłówka. Obliczenie sumy kontrolnej bezpośrednio po otrzymaniu pakietu oraz porównanie jej z wartością zapisaną w niniejszym polu pozwala wykryć większość przekłamań, lecz nie wszystkie: np. nie jest wykrywane zagubienie zerowego półsłowa.
Sumy kontrolne protokołów TCP i UDP obejmują cały pakiet więc przemycenie tego typu błędu jest praktycznie niemożliwe.
Pola adresów
Pola ADRES IP NADAWCY i ADRES IP ODBIORCY zawierają 32-bitowe adresy IP pierwotnego nadawcy i końcowego odbiorcy. (Z wyjątkiem sytuacji gdy datagram zawiera opcje wyznaczania trasy przez nadawcę)
Pole OPCJE IP ma zmienną długość.
Pole UZUPEŁNIENIE zależy od wybranych opcji. Zawiera ono zerowe bity, które mogą być potrzebne do zapewnienia, że nagłówek ma długość, która jest wielokrotnością 32 bitów (ponieważ pole DŁUGOŚĆ NAGŁÓWKA zawiera wartość mierzoną w jednostkach 32-bitowych)
Pole OPCJE IP nie występuje w każdym datagramie - pierwotnym zastosowaniem opcji było ułatwienie testowania i usuwania błędów.
Długość pola OPCJE zmienia się w zależności od tego jakie opcje są wybrane.Niektóre z nich mają długość 1 bajta, inne mają długość zmienną.
Każda opcja składa się kodu opcji długości 1 bajta po którym może się pojawić ciąg bajtów tej opcji.
Opcje IP
Pole OPCJE składa się z trzech części
1 bitowy znacznik kopiuj określa, że opcje maja być przekopiowane do wszystkich fragmentów (wartość 1), bądź tylko do pierwszego (wartość 0).
Bity KLASA OPCJI określają ogólną klasę opcji:
Klasa opcji |
Znaczenie |
0 |
Kontrola datagramów lub sieci |
1 |
Zarezerwowane do przyszłego użytku |
2 |
Poprawianie błędów i pomiary |
3 |
Zarezerwowane do przyszłego użytku |
Klasa opcji |
Numer opcji |
Długość |
Opis |
0 |
0 |
- |
Koniec listy opcji. Używana gdy opcje nie kończą się wraz z końcem nagłówka. |
0 |
1 |
- |
Bez przypisanej funkcji - wypełnienie |
0 |
2 |
11 |
Tajność - używana do zastosowań wojskowych |
0 |
3 |
zmienna |
Swobodne trasowanie wg nadawcy - używana do prowadzenia datagramu określoną ścieżką. |
0 |
7 |
zmienna |
Zapisuj trasę - używana do śledzenia trasy. |
0 |
9 |
zmienna |
Rygorystyczne trasowanie wg nadawcy - używana do ścisłego prowadzenia datagramu. |
2 |
4 |
zmienna |
Intersieciowy datownik - używana do zapisywania czasów wzdłuż ścieżki. |
Routery
Routery łączą sieci fizyczne w intersieć. Każdy router ma fizyczne połączenie z jedną lub więcej sieciami, natomiast zwykły komputer ma zwykle połączenie tylko z jedną siecią fizyczną.
W systemie z wymianą pakietów trasowanie (ang. routing) oznacza proces wyboru ścieżki, po której będą przesyłane pakiety, a router to komputer, który dokonuje tego wyboru.
Wybór optymalnej trasy pakietu jest złożonym problemem, rozwiązywanym na wiele sposobów.
Idealne oprogramowanie trasujące powinno przy wyznaczaniu tras korzystać z takich informacji, jak obciążenie sieci, długość datagramu, czy zawarty w nagłówku datagramu typ obsługi. Jednak przeważająca część oprogramowania trasującego jest znacznie mniej wyrafinowana i wybiera trasy na podstawie ustalonych informacji o najkrótszych ścieżkach.
Rolę routera może pełnić także zwykły komputer z wieloma przyłączeniami do sieci.
Koleje Życia Datagramu
Prześledzimy teraz losy datagramu przy przesyłaniu do pomiędzy maszynami, co pozwoli lepiej zrozumieć jak IP radzi sobie z tym problemem.
Gdy aplikacja ma zamiar wysłać datagram w sieć, wykonuje kilka prostych kroków. Najpierw konstruuje datagram zgodnie z wymogami lokalnej implementacji IP. Zostaje obliczona suma kontrolna dla danych i skonstruowany nagłówek IP. Następnie pierwszy węzeł na drodze wędrówki datagramu określić musi etap następny - inną maszynę w sieci lub router, gdy dane muszą się z sieci wydostać. Jeżeli dane są szczególnie cenne, w nagłówku IP zostaną ustawione odpowiednie opcje. Na koniec datagram jest "posyłany w sieć".
Każdy router otrzymujący datagram wykonuje na nim serię testów. Gdy warstwa sieciowa zdejmie z niego swój nagłówek, warstwa IP weryfikuje sumę kontrolną datagramu. W razie niezgodności datagram jest odrzucany i do węzła-nadawcy kierowany jest komunikat o błędzie. Następnie pole TTL jest odpowiednio zmniejszone i sprawdzane. Jeśli limit czasu jest przekroczony sygnalizowany jest błąd. Po określeniu następnego węzła (na podstawie adresu docelowego) zostaje zapisana nowa wartość TTL i nowa suma kontrolna.
Jeżeli konieczna jest fragmentacja, jest on dzielony na mniejsze datagramy i każdy z nich opatrywany jest nagłówkiem IP. W końcu datagram przekazywany jest z powrotem do warstwy sieciowej. Gdy datagram dotrze do celu zostaje scalony, zdejmowany jest nagłówek IP, odtworzony jest oryginalny komunikat i przesyłany w stronę wyższych warstw.
Kapsułkowanie
Poznajmy teraz pojęcie kapsułkowania (ang. encapsulation).
Jak wiadomo datagramy przemieszczając się od jednej maszyny do drugiej muszą być przenoszone przez sieć fizyczną.
Kapsułkowaniem nazywamy rozwiązanie, w którym jeden datagram przenoszony jest przez jedną ramkę sieciową. Datagram zachowuje się wówczas jak każdy inny komunikat przesyłany z jednej maszyny do innej, tzn. podróżuje w części ramki sieciowej przeznaczonej na dane.
Fragmentacja
W idealnym przypadku cały datagram mieści się w jednej ramce fizycznej. Nie zawsze jednak jest to możliwe.
Dzieje się tak dlatego, że datagram może przemieszczać się przez różne sieci fizyczne. Każda z nich ma ustaloną górną granicę ilości danych, które mogą być przesłane w jednej ramce.
Ten parametr sieci nosi nazwę maksymalnej jednostki transmisyjnej danej sieci (ang. Maximum Transfer Unit - MTU).
Ograniczenie wielkości datagramów, tak aby pasowały do najmniejszego MTU, byłoby nieefektywne w przypadku przechodzenia przez sieci, które mogą przenosić większe ramki.
Jeśli datagram nie mieści się w ramce fizycznej jest dzielony na mniejsze kawałki zwane fragmentami, a proces ten nazywa się fragmentacją. Gdy takie pofragmentowane datagramy dotrą do odbiorcy podlegają procesowi odwrotnemu czyli defragmentacji.
Każdy z fragmentów zawiera nagłówek, w którym jest powielona większość zawartości nagłówka pierwotnego datagramu (z wyjątkiem pola ZNACZNIKI, które wskazuje, że jest to fragment).
Każdy z fragmentów zawiera nagłówek, w którym jest powielona większość zawartości nagłówka pierwotnego datagramu (z wyjątkiem pola ZNACZNIKI, które wskazuje, że jest to fragment).
Kontrola Fragmentacji
Trzy pola nagłówka IDENTYFIKACJA, ZNACZNIKI, PRZESUNIĘCIE FRAGMENTU służą kontroli procesów fragmentacji i składania datagramów.
Pole IDENTYFIKACJA (16-bitowe) zawiera liczbę całkowitą jednoznacznie identyfikującą datagram. Identyfikator jest niezbędny, gdyż zapobiega wymieszaniu się fragmentów pochodzących od różnych datagramów - wszystkie kawałki będące częściami tego samego datagramu posiadają ten sam identyfikator.
Pole ZNACZNIKI (3-bitowe) służy do kontroli fragmentacji. Pierwszy z trzech bitów jest nie używany, nadanie drugiemu wartości 1 oznacza bezwzględny zakaz fragmentacji. Jeśli datagram nie może być przesłany w całości, zostaje odrzucony i sygnalizowany jest błąd. Ostatni z bitów ZNACZNIKÓW umożliwia identyfikację ostatniego kawałka datagramu - ma w nim wartość 0, w pozostałych przypadkach 1.
Pole PRZESUNIĘCIE FRAGMENTU (13-bitowe) zawiera informację, w którym miejscu datagramu umiejscowione są informacje przesyłane w tym kawałku. Jest ono mierzone w jednostkach 64-bajtowych. Umożliwia to poprawne scalenie datagramu - nie istnieje nic w rodzaju kolejnego numeru kawałka w datagramie.
Protokół ICMP
Jak już wiemy oprogramowanie Internet Protocol realizuje zawodne przenoszenie pakietów bez użycia połączenia.
Datagram wędruje od nadawcy przez różne sieci i routery aż do końcowego odbiorcy.
Jeżeli router nie potrafi ani wyznaczyć trasy ani dostarczyć datagramu, albo gdy wykrywa sytuacje mającą wpływ na możliwość dostarczenia datagramu np. Przeciążenie sieci, wyłączenie maszyny docelowej, wyczerpanie się licznika czasu życia datagramu to musi poinformować pierwotnego nadawcę, aby podjął działania w celu uniknięcia skutków tej sytuacji.
Protokół komunikatów kontrolnych internetu ICMP (ang. Internet Control Message Protocol) powstał aby umożliwić routerom oznajmianie o błędach oraz udostępnianie informacji o niespodziewanych sytuacjach.
Chociaż protokół ICMP powstał, aby umożliwić routerom wysyłanie komunikatów to każda maszyna może wysyłać komunikaty ICMP do dowolnej innej.
Protokół ICMP jest traktowany jako wymagana część IP i musi być realizowany przez każdą implementację IP.
Z technicznego punktu widzenia ICMP jest mechanizmem powiadamiania o błędach.
Gdy datagram powoduje błąd, ICMP może jedynie powiadomić pierwotnego nadawcę o przyczynie. Nadawca musi otrzymaną informację przekazać danemu programowi użytkownika, albo podjąć inne działanie mające na celu uporanie się z tym problemem.
Każdy komunikat ICMP ma własny format, ale wszystkie zaczynają się trzema takimi samymi polami:
8-bitowe pole TYP komunikatu identyfikuje komunikat,
8-bitowe pole KOD daje dalsze informacje na temat rodzaju komunikatu,
Pole SUMA KONTROLNA (obliczane podobnie jak suma IP, ale suma kontrolna ICMP odnosi się tylko do komunikatu ICMP).
Oprócz tego komunikaty ICMP oznajmiające o błędach zawsze zawierają nagłówek i pierwsze 64 bity danych datagramu, z którym były problemy.
Określanie ostatecznego adresata
System operacyjny większości komputerów zapewnia wielozadaniowość.
Omówiony mechanizm adresowania i przesyłania datagramów nie rozróżnia użytkowników ani programów użytkowych, do których jest skierowany taki datagram. Zachodzi więc potrzeba rozszerzenia zestawu protokołów o mechanizm, który pozwoli rozróżniać adresy w obrębie pojedynczego komputera.
Adresowanie wprost do konkretnego procesu z wielu powodów nie byłoby dobrym rozwiązaniem; np. ponieważ procesy tworzone i likwidowane są dynamicznie, nadawca ma więc zbyt mało informacji aby wskazać proces na innej maszynie, przeładowanie systemu operacyjnego powoduje zmianę wszystkich procesów itp. W miejsce tego wprowadzono abstrakcyjne punkty docelowe zwane portami protokołów.
Każdy port jest identyfikowany za pomocą dodatniej liczby całkowitej.
Lokalny system operacyjny zapewnia procesom określenie dostępu do portów.
Nadawca musi znać adres IP odbiorcy i numer docelowego portu protokołu na maszynie odbiorcy, komunikat musi ponadto zawierać numer portu nadawcy tak aby proces odbierający komunikat mógł wysłać odpowiedź do nadawcy.
Protokół UDP
W zestawie protokołów TCP/IP protokół datagramów użytkownika UDP (ang. User Datagram Protocol), zapewnia porty protokołów używane do rozróżniania programów wykonywanych na pojedynczej maszynie.
Oprócz wysyłanych danych, każdy komunikat zawiera numer portu odbiorcy i numer portu nadawcy, dzięki czemu oprogramowanie UDP odbiorcy może dostarczyć komunikat do właściwego adresata.
Do przesyłania komunikatów między maszynami UDP używa podstawowego protokołu IP i ma tę samą niepewną, bezpołączeniową semantykę dostarczania datagramów co IP - nie używa potwierdzeń w celu upewnienia się, o dotarciu komunikatów i nie zapewnia kontroli szybkości przesyłania danych między maszynami.
Z tego powodu komunikaty UDP mogą być gubione, duplikowane lub przychodzić w innej kolejności niż były wysłane, ponadto pakiety mogą przychodzić szybciej niż odbiorca może je przetworzyć.
Program użytkowy korzystający z UDP musi na siebie wziąć odpowiedzialność za rozwiązanie problemów niezawodności.
Ponieważ sieci lokalne dają dużą niezawodność i małe opóźnienia wiele programów opartych na UDP dobrze pracuje w sieciach lokalnych, ale może zawodzić w większych intersieciach TCP/IP.
Format komunikatów UDP
Komunikat UDP nazywa się datagramem użytkownika.
Nagłówek datagramu użytkownika składa się z czterech 16-bitowych pól:
Pola PORT NADAWCY i PORT ODBIORCY zawierają 16-bitowe numery portów UDP używane do odnajdywania procesów oczekujących na dany datagram. Pole PORT NADAWCY jest opcjonalne.
Pole DŁUGOŚĆ zawiera wartość odpowiadającą liczbie bajtów datagramu UDP wliczając nagłówek i dane. Minimalna więc wartość tego pola wynosi więc 8, czyli jest długością samego nagłówka.
Pole SUMA KONTROLNA jest opcjonalne. Ponieważ jednak IP nie wylicza sum kontrolnych dla danych, suma kontrolna UDP jest jedyną gwarancją, że dane nie zostały uszkodzone.
Kapsułkowanie UDP
UDP jest pierwszym omówionym tutaj przykładem protokołu transportowego.
Datagram UDP jest przed wysłaniem w sieć, w znany nam już sposób, kapsułkowany w datagram IP.
Nagłówek IP identyfikuje maszynę źródłową i docelową, UDP - identyfikuje porty nadawcy i odbiorcy.
U odbiorcy pakiet dociera do najniższej warstwy oprogramowania sieciowego i wędruje ku coraz wyższym warstwom. Każda z nich usuwa jeden nagłówek, oczekujący proces otrzymuje więc komunikat bez nagłówków.
Zwróćmy uwagę, że datagram UDP otrzymany od IP na maszynie docelowej jest identyczny z tym, który UDP przekazało do IP na maszynie źródłowej.
MULTIPLEKSOWANIE I DEMULTIPLEKSOWANIE |
Protokoły komunikacyjne wykorzystują metody multipleksowania i demultipleksowania na poziomach wszystkich warstw. Przy wysyłaniu komputer nadawcy dołącza do danych dodatkowe bity, które wskazują typ komunikatu, program, który go nadał oraz używane protokoły. Wszystkie komunikaty są umieszczane w przeznaczonych do przesyłania ramkach sieciowych i łączone w strumień pakietów. U odbiorcy zaś te informacje są używane do sterowania przetwarzaniem.
Multipleksowanie i demultipleksowanie pojawia się w prawie wszystkich warstwach protokołów. Przykładowo, gdy interfejs sieciowy zdemultipleksuje ramki i prześle te z nich, które zawierają datagramy IP do modułu IP, oprogramowanie IP wydobędzie z nich datagramy i dalej je zdemultipleksuje w warstwie IP. Aby zdecydować, w jaki sposób obsłużyć datagram, oprogramowanie sprawdza nagłówek datagramu i wybiera na podstawie typu datagramu odpowiednie procedury.
MULTIPLEKSOWANIE I DEMULTIPLEKSOWANIE
Oprogramowanie UDP musi przyjmować datagramy UDP pochodzące od wielu programów użytkowych i przekazywać je warstwie IP w celu przesłania, a także odbierać datagramy UDP nadchodzące od warstwy IP i przekazywać odpowiednim programom użytkowym.
Aby to zrealizować musi multipleksować datagramy UDP tak aby datagramy pochodzące z różnych portów mogły być przekazane do warstwy IP i demultipleksować datagramy przychodzące z warstwy IP tak by skierować je do właściwego portu. Rozróżnienie następuje przy pomocy pola PORT UDP NADAWCY i ODBIORCY.
TRANSMISSION CONTROL PROTOCOL
Do tej pory zajmowaliśmy się usługami zawodnego dostarczania pakietów, bez użycia połączenia, co stanowi podstawę protokołu IP. IP nie troszczy się tak naprawdę o dostarczenie datagramu do adresata, lecz w przypadku odrzucenia datagramu sygnalizuje ten fakt jako błąd maszynie-nadawcy i uznaje sprawę za załatwioną.
Używanie zawodnego dostarczania bez użycia połączenia do przesyłania dużych porcji danych jest więc nużące i wymaga od programistów, aby wbudowywali do każdego programu użytkowego wykrywanie i korekcję błędów.
Teraz zajmiemy się przesyłaniem niezawodnymi strumieniami TCP (ang. Transmission Control Protocol), które istotnie zwiększa funkcjonalność omawianych do tej pory protokołów, biorąc odpowiedzialność za wiarygodne dostarczenie datagramu. Okupione jest to jednak skomplikowaniem protokołu.
Protokół TCP będąc drugą najważniejszą usługą w sieci, wraz z IP dał nazwę całej rodzinie protokołów TCP/IP.
Pomimo związku z protokołem IP - TCP jest protokołem w pełni niezależnym i może zostać zaadaptowany do wykorzystania z innymi systemami dostarczania.
Możliwe jest używanie go zarówno w pojedynczej sieci takiej jak ethernet jak i w skomplikowanej intersieci.
Własności usługi niezawodnego dostarczania
TCP organizuje dwukierunkową współpracę między warstwą IP, a warstwami wyższymi, uwzględniając przy tym wszystkie aspekty priorytetów i bezpieczeństwa. Musi prawidłowo obsłużyć niespodziewane zakończenie aplikacji, do której właśnie wędruje datagram, musi również bezpiecznie izolować warstwy wyższe - w szczególności aplikacje użytkownika - od skutków awarii w warstwie protokołu IP. Scentralizowanie wszystkich tych aspektów w jednej warstwie umożliwia znaczną oszczędność nakładów na projektowanie oprogramowania.
TCP rezyduje w modelu warstwowym powyżej warstwy IP. Warstwa ta jest jednak obecna tylko w tych węzłach sieci, w których odbywa się rzeczywiste przetwarzanie datagramów przez aplikacje, tak więc nie posiadają warstwy TCP na przykład routery, gdyż warstwy powyżej IP nie miałyby tam nic do roboty.
Kanał wirtualny TCP
Rozpatrując TCP z punktu widzenia funkcjonalności można potraktować jego pracę jako ustanowienie kanału wirtualnego realizującego komunikację między "końcówkami" - tak wygląda to z punktu widzenia aplikacji użytkownika.
Rzeczywisty przepływ oczywiście odbywa się poprzez warstwę IP i warstwy niższe.
Realizacja niezawodnego połączenia
Aby zagwarantować, że dane przesyłane z jednej maszyny do drugiej nie są ani tracone, ani duplikowane używa się podstawowej metody znanej jako pozytywne potwierdzanie z retransmisją. Metoda ta wymaga, aby odbiorca komunikował się z nadawcą, wysyłając mu w momencie otrzymania danych komunikat potwierdzenia (ACK). Nadawca zapisuje sobie informację o każdym wysłanym pakiecie i przed wysłaniem następnego czeka na potwierdzenie. Oprócz tego nadawca uruchamia zegar w momencie wysyłania pakietu i wysyła ten pakiet ponownie, gdy minie odpowiedni czas, a potwierdzenie nie nadejdzie.
Idea przesuwających się okien
Poznamy teraz rozwiązanie, które sprawia, że przesyłanie strumieniami jest efektywniejsze. Chodzi o przesuwające się okna (ang. sliding window). Jak wiemy w celu uzyskania niezawodności nadawca wysyła pakiet, a przed wysłaniem następnego oczekuje na potwierdzenie odebrania.
Dane w danym momencie płyną tylko w jednym kierunku i to nawet wtedy, kiedy sieć umożliwia jednoczesną komunikację w obu kierunkach. Ponadto sieć nie będzie używana, kiedy maszyny będą zwlekać z odpowiedziami np. podczas wyliczania sum kontrolnych. Takie rozwiązanie powoduje znaczne marnowanie przepustowości sieci.
Technika przesuwającego się okna lepiej wykorzystuje przepustowość sieci, gdyż umożliwia wysyłanie wielu pakietów przed otrzymaniem potwierdzenia. W rozwiązaniu tym umieszcza się na ciągu pakietów ustalonego rozmiaru okna i przesłanie wszystkich pakietów, które znajdują się w jego obrębie. Mówimy, że pakiet jest niepotwierdzony, jeżeli został wysłany, a nie nadeszło dla niego potwierdzenie. Liczba pakietów niepotwierdzonych w danej chwili jest wyznaczona przez rozmiar okna.
Dla protokołu z przesuwającym się oknem , którego rozmiar jest np. równy 8, nadawca ma możliwość wysłania przed otrzymaniem potwierdzenia do 8 pakietów. Gdy nadawca odbierze potwierdzenie dla pierwszego pakietu, okno przesuwa się i zostaje wysłany następny pakiet. Okno przesuwa się dalej gdy przychodzą kolejne potwierdzenia.
Pakiet dziewiąty może zostać wysłany gdy przyszło potwierdzenie dotyczące pierwszego pakietu. Retransmitowane są tylko te pakiety, dla których nie było potwierdzenia. Oczywiście protokół musi pamiętać, które pakiety zostały potwierdzone i utrzymuje oddzielny zegar dla każdego nie potwierdzonego pakietu. Gdy pakiet zostanie zgubiony lub zostaje przekroczony czas nadawca wysyła ten pakiet jeszcze raz. Poprawa uzyskiwana przy protokołach z przesuwającymi się oknami zależy od rozmiaru okna i szybkości, z jaką sieć akceptuje pakiety. Gdy rozmiar okna wynosi 1, protokół z przesuwającym się oknem jest tym samym, co nasz zwykły protokół z potwierdzaniem. Zwiększając rozmiar okna, możemy w ogóle wyeliminować momenty nieaktywności sieci. Oznacza to, że w sytuacji stabilnej nadawca może przesyłać pakiety tak szybko, jak szybko sieć może je przesyłać. Poniżej pokazano przykład przesyłania trzech pakietów przy użyciu protokołu z przesuwającym się oknem. Istotne jest tutaj, że nadawca może przesłać wszystkie pakiety z okna bez oczekiwania na potwierdzenie.
Segment TCP
Mianem segmentu określa się jednostkową porcję danych przesyłanych między oprogramowaniem TCP na różnych maszynach.
Pola PORT NADAWCY i PORT ODBIORCY zawierają numery portów TCP, które identyfikują programy użytkowe na końcach połączenia.
Pole NUMER PORZĄDKOWY wyznacza pozycję danych segmentu w strumieniu bajtów nadawcy.
Pole NUMER POTWIERDZENIA wyznacza numer oktetu, który nadawca spodziewa się otrzymać w następnej kolejności. Zwróćmy uwagę, że NUMER PORZĄDKOWY odnosi się do strumienia płynącego w tym samym kierunku co segment, zaś NUMER POTWIERDZENIA odnosi się do strumieni płynących w kierunku przeciwnym.
Pole DŁUGOŚĆ NAGŁÓWKA zawiera liczbę całkowitą, która określa długość nagłówka segmentu mierzoną w wielokrotnościach 32 bitów. Jest ono konieczne gdyż pole OPCJE ma zmienną długość.
Pole ZAREZERWOWANE jest pozostawione do wykorzystania w przyszłości.
Ponieważ niektóre segmenty mogą przenosić tylko potwierdzenia, inne dane, inne zaś zawierają prośby o ustanowienie lub zamknięcie połączenia - pole BITY KODU zawiera informację o przeznaczeniu zawartości segmentu.
Przy każdym wysłaniu segmentu oprogramowanie TCP proponuje ile danych może przyjąć, umieszczając rozmiar swojego bufora w polu OKNO.
Porty i połączenia
Protokół TCP umożliwia wielu działającym na jednej maszynie programom użytkowym jednoczesne komunikowanie się oraz rozdziela między programy użytkowe przybywające pakiety TCP. Podobnie jak UDP, TCP używa numerów portów protokołu do identyfikacji w ramach maszyny końcowego odbiorcy. Każdy z portów ma przypisaną małą liczbę całkowitą, która jest używana do jego identyfikacji.
Porty TCP są jednak bardziej złożone, gdyż dany numer nie odpowiada bezpośrednio pojedynczemu obiektowi. TCP działa wykorzystując połączenia, w których obiektami są obwody wirtualne a nie poszczególne porty. Tak więc podstawowym pojęciem TCP jest pojęcie połączenia, a nie portu. Połączenia są identyfikowane przez parę punktów końcowych.
TCP definiuje punkt końcowy jako parę liczb całkowitych (węzeł, port), gdzie węzeł oznacza adres IP węzła, a port jest portem TCP w tym węźle.
Np. punkt końcowy (128.10.2.3, 25) oznacza port 25 maszyny o adresie IP 128.10.2.3.
W efekcie może istnieć połączenie np. pomiędzy:
(18.26.0.36, 1069) oraz (128.10.2.3, 25), w tym samym czasie może też istnieć (128.9.0.32, 1184) oraz (128.10.2.3, 25).
Zwróćmy uwagę, że w związku z tym, że TCP identyfikuje połączenie za pomocą pary punktów końcowych, dany numer portu może być przypisany do wielu połączeń na danej maszynie.
Konfiguracja TCP/IP w UNIX-ie
Konfiguracja większości wersji systemu UNIX, opiera się na kilku plikach konfiguracyjnych wymienionych w tabeli.
W niektórych implementacjach pliki mogą się różnić nazwami, lecz ich znaczenie pozostaje takie samo.
Wymienione pliki są plikami tekstowymi, więc do ich modyfikacji potrzebny jest dowolny edytor tekstowy, operujący w czystym kodzie ASCII.
Nazwa pliku Znaczenie
/etc/hosts Nazwy maszyn w sieci (hostów)
/etc/networks Mnemoniczne nazwy sieci
/etc/services Lista dostępnych usług
/etc/protocols Lista protokołów
/etc/hosts.equiv Lista zaufanych hostów (ang. trusted hosts)
/etc/inetd.conf Lista serwerów uruchamiających program inetd
Przyszłość TCP/IP
Gdy powstawała wersja 4 protokołu IP, 32-bitowy adres wydawał się wystarczający na długie lata rozwoju Internetu; wyczerpanie się adresów (jest ich teoretycznie 232, w praktyce mniej z uwagi na sposób adresowania, istnienie adresów grupowych i zarezerwowanych) traktowano jako coś zupełnie niemożliwego. Rzeczywistość szybko przerosła jednak wyobraźnię. Internet rozrasta się w postępie geometrycznym, ilość przyłączonych hostów podwaja się z każdym rokiem. Groźba wyczerpania się możliwości 32-bitowego adresowania stała się faktem.
W związku z tym pojawiło się kilka propozycji rozwiązania tego problemu. Zaowocowały one pewnym kompromisem będącym punktem wyjścia dla opracowania kolejnej wersji protokołu IP.
Wersja ta znana jest pod roboczą nazwą IP Next Generation (w skrócie IPng) lub IP wersja 6 i znajduje się obecnie w zaawansowanym stadium eksperymentów.
IP Next Generation
Nowy, 128-bitowy system adresowania !!! - przestrzeń adresowa jest tak duża, że nie może być wyczerpana w przewidywalnej przyszłości
Udoskonalona postać nagłówka IP z rozszerzeniami dla aplikacji i opcji
Brak sumy kontrolnej
Nowe pole kontrolne zwane etykietą potoku
Zabezpieczenie przed zjawiskiem tzw. fragmentacji pośredniej (ang. Intermediate fragmentation)
Wbudowane narzędzia kryptograficzne i mechanizmy weryfikacji
Wyszukiwarka
Podobne podstrony:
Model TCP
Protokół TCP IP, R03 5
Protokol TCP IP R08 5 id 834124 Nieznany
Bardzo krótko o TCP IP adresacja w sieciach lokalnych
Protokół TCP IP, R12 5
komunikacja tcp
Protokół TCP IP, R11 5
Bezpieczeństwo protokołów TCP IP oraz IPSec
Protokół TCP IP, R13 5
Protokół UDP,TCP
7 3 1 2 Packet Tracer Simulation Exploration of TCP and UDP Instructions
TCP i UDP
7 2 1 8 Lab Using Wireshark to Observe the TCP 3 Way Handshake
TCP MODEL OSI
Architektura TCP IP
Moduł 6 - Warstwy TCP-IP(1), technik informatyk, soisk utk
Historia i przegl─ůd mo┼╝liwo┼Ťci TCP , Historia i przegląd możliwości TCP/IP
Protokół TCP IP, R09 5
więcej podobnych podstron