Struktury systemów operacyjnych
• Składowe systemu.
• Usługi systemu operacyjnego.
• Wywołania systemowe.
• Programy systemowe.
• Struktura systemu.
• Maszyny wirtualne.
• Projektowanie i implementacja systemu.
Składowe systemu operacyjnego
■ Zarządzanie procesami.
■ Zarządzanie pamięcią operacyjną.
■ Zarządzanie plikami.
■ Zarządzanie systemem wejścia-wyjścia.
■ Zarządzanie pamięcią pomocniczą.
■ Praca sieciowa.
■ System ochrony.
■ System interpretacji poleceń.
Zarządzanie procesami
• Proces - program, który jest wykonywany.
Aby wypełnić swoje zadanie, proces potrzebuje pewnych zasobów: czas procesora, pamięć, pliki, urządzenie WE/WY itd.
• System operacyjny jest odpowiedzialny za następujące czynności związane z zarządzaniem procesami:
■ Tworzenie i usuwanie procesów (użytkowych, systemowych);
■ Wstrzymywanie i wznawianie procesów;
■ Dostarczanie mechanizmów do:
Synchronizacji procesów; Komunikacji procesów; Obsługi zakleszczeń.
Zarządzanie pamięcią operacyjną
• Pamięć operacyjna - duża tablica słów lub bajtów, z których każde(y) ma swój adres.
> Jest magazynem szybko dostępnych danych dzielonych przez CPU i urządzenia WE/WY.
> Jest to pamięć ulotna - traci swoją zawartość w przypadku awarii systemu.
• W odniesieniu do zarządzania pamięcią SO jest odpowiedzialny za następujące czynności:
■ Utrzymywanie informacji o tym, które obszary pamięci są aktualnie zajęte i przez kogo;
■ Decydowanie o tym, które procesy mają być załadowane do zwolnionych obszarów pamięci;
■ Przydzielanie (alokacja) i zwalnianie (dealokacja) obszarów pamięci zależnie od potrzeb.
Zarządzanie plikami
Plik (file) - zbiór powiązanych ze sobą informacji zdefiniowanych przez jego twórcę.
W plikach zazwyczaj przechowywane są programy (zarówno w postaci źródłowej, jak i wykonawczej) oraz dane;
Zwykle pliki zorganizowane są w katalogi;
Najczęściej pliki przechowuje się na dyskach i taśmach magnetycznych, dyskach optycznych, obecnie też na dyskach elektronicznych.
W odniesieniu do zarządzania plikami SO jest odpowiedzialny za następujące czynności:
■ Tworzenie i usuwanie plików;
■ Tworzenie i usuwanie katalogów;
■ Dostarczanie elementarnych operacji do manipulowania plikami i katalogami;
■ Odwzorowywanie plików na obszary pamięci pomocniczej;
■ Umieszczanie plików na trwałych nośnikach pamięci.
Zarządzanie systemem WE/WY
Jednym z celów systemu operacyjnego jest ukrywanie przed użytkownikiem (czasem też przed większością samego systemu operacyjnego) szczegółów dotyczących sprzętu, m.in. WE/WY.
> Wiele systemów ma specjalne podsystemy WE/WY..
System WE/WY składa się z:
■ Systemu zarządzania pamięcią: buforowanie, przechowywanie podręczne, spooling;
■ Ogólnego interfejsu do modułów sterujących urządzeń;
■ Modułów sterujących (programów obsługi) dla poszczególnych urządzeń sprzętowych.
Właściwości danego urządzenia zna tylko odpowiadający mu moduł sterujący.
Zarządzanie pamięcią pomocniczą
Ponieważ pamięć operacyjna jest ulotna i za mała by pomieścić wszystkie dane i programy, system komputerowy musi dostarczać pamięć pomocniczą jako zaplecze dla pamięci operacyjnej.
Większość współczesnych systemów komputerowych używa dysków jako podstawowego medium do magazynowania zarówno danych, jak i programów.
System operacyjny odpowiada za następujące czynności związane z zarządzaniem dyskami:
■ Zarządzanie wolnymi obszarami;
■ Alokacja pamięci;
■ Planowanie dostępu do dysku.
Wydajność pamięci pomocniczej może mieć znaczny wpływ na wydajność całego systemu komputerowego (na ogół pamięć ta jest często używana podczas pracy komputera).
Praca sieciowa (systemy rozproszone)
System rozproszony jest zbiorem procesorów, które nie dzielą pamięci, urządzeń zewnętrznych ani zegara - każdy procesor ma swoją lokalną pamięć itd.
Procesory w systemie połączone są za pomocą sieci komunikacyjnej (szybkie szyny danych, linie telefoniczne, łącza bezprzewodowe).
Komunikacja odbywa się przy użyciu protokołu (zbiór reguł używanych przez węzły komunikacyjne przy wymianie informacji).
System rozproszony umożliwia użytkownikowi dostęp do różnych zasobów.
Dostęp do dzielonych zasobów pozwala na:
■ przyspieszanie obliczeń,
■ większą funkcjonalność,
■ zwiększanie dostępności danych;
■ podniesienie niezawodności.
System ochrony
Ochrona - mechanizm nadzorowania dostępu programów, procesów lub użytkowników do zasobów zarówno systemu, jak i użytkowników.
> Każdy wielozadaniowy, wielodostępny i współbieżny system operacyjny musi dostarczać sposoby ochrony procesów przed ich wzajemnym (niepożądanym) oddziaływaniem.
Mechanizm ochrony musi:
■ Rozróżniać między dostępem autoryzowanym a nieautoryzowanym;
■ Określać co i jakiej ma podlegać ochronie;
■ Dostarczać środków do wymuszania zaprowadzonych ustaleń.
System interpretacji poleceń
Wiele poleceń jest przekazywanych do systemu operacyjnego za pomocą instrukcji sterujących (control statements), które dotyczą:
■ tworzenia procesów i zarządzania nimi;
■ obsługi WE/WY;
■ zarządzania pamięcią pomocniczą i operacyjną;
■ dostępu do systemu plików;
■ ochrony;
■ pracy sieciowej (networking).
Program, który czyta i interpretuje instrukcje sterujące nosi różne nazwy:
■ Interpreter wiersza poleceń (command-line interpreter);
■ Powłoka (shell) - np. w systemie UNIX.
Jego zadanie: pobrać następną instrukcję i wykonać ją.
W niektórych systemach jest częścią jądra, w innych (np. MS-DOS, UNIX) jest specjalnym programem, wykonywanym przy rozpoczynaniu zadania lub przy logowaniu się w systemie.
Usługi systemu operacyjnego
Wykonywanie programów - zdolność systemu operacyjnego do ładowania programów do pamięci i ich wykonywania.
Operacje WE/WY - ponieważ program użytkownika nie może bezpośrednio wykonywać operacji WE/WY, system operacyjny musi dostarczać środki do ich wykonywania.
Manipulowanie systemem plików - programy muszą mieć możliwość czytania i pisania w plikach, a także tworzenia i usuwania plików przy użyciu ich nazw.
Komunikacja - wymiana informacji między procesami wykonywanymi albo w tym samym komputerze albo w różnych systemach komputerowych.
> Zaimplementowana za pomocą pamięci dzielonej (shared memory) lub techniki przekazywania komunikatów (message passing).
Wykrywanie błędów - zapewnienie poprawnego przebiegu obliczeń poprzez wykrywanie i obsługę błędów w działaniu CPU i pamięci, w urządzeniach WE/WY lub programach użytkownika.
Dodatkowe funkcje systemu operacyjnego
Istnieje dodatkowy zbiór funkcji systemu operacyjnego przeznaczonych nie do pomagania użytkownikowi, ale do optymalizacji działania samego systemu.
Przydzielanie zasobów - alokacja zasobów do wielu użytkowników i wielu wykonywanych zadań.
Rozliczanie - przechowywanie i śledzenie informacji o tym, którzy użytkownicy i w jakim stopniu korzystają z poszczególnych zasobów.
Ochrona - zapewnienie nadzoru nad wszystkimi dostępami do zasobów systemu. Ważne jest również bezpieczeństwo (security) systemu wobec niepożądanych czynników zewnętrznych.
Wywołania systemowe
Funkcje systemowe, inaczej: wywołania systemowe (system calls) - tworzą interfejs między wykonywanym programem a systemem operacyjnym.
■ Na ogół dostępne jako rozkazy w języku asemblera.
■ Języki, które utworzono aby zastąpić asemblery przy programowaniu systemów operacyjnych dają możliwość bezpośredniego wywołania funkcji systemowych (np. C, C++, Perl).
> Np. wywołania systemu UNIX można wykonywać bezpośrednio z programu w języku C/C++, natomiast w MS Windows XP są one częścią interfejsu programisty aplikacji (application programmer interface -API), dostępnego w kompilatorach dla MS Windows.
Istnieją zasadniczo trzy metody przekazywania parametrów między wykonywanym programem a systemem operacyjnym:
■ Przekazanie parametrów bezpośrednio do rejestrów procesora.
■ Umieszczenie parametrów w tablicy w pamięci i przekazanie jej adresu za pośrednictwem rejestru.
■ Składanie parametrów na stosie za pomocą programu i zdejmowanie
ich stamtąd przez system operacyjny.
Kategorie wywołań systemowych
Nadzorowanie procesów:
> Utworzenie, załadowanie, wykonanie, zakończenie, zaniechanie, określenie atrybutów, ….. procesu; przydział i zwolnienie pamięci itd.
Operacje na plikach:
> Utworzenie, usunięcie, otwarcie, zamknięcie, czytanie, pisanie, określenie/pobranie atrybutów pliku itp.
Operacje na urządzeniach:
> Zamówienie, zwolnienie, logiczne przyłączenie i odłączenie, czytanie, pisanie, określenie/pobranie atrybutów urządzenia itp.
Utrzymywanie informacji:
> Pobranie/ustawienie: czasu, daty, danych systemowych, atrybutów procesu/pliku/urządzenia itp.
Komunikacja:
Utworzenie/usunięcie połączenia komunikacyjnego, nadawanie/odbieranie komunikatów, przekazanie informacji o stanie, przyłączanie/odłączanie urządzeń zdalnych.
Przykłady nadzorowania procesów
Modele komunikacji
Przekazywanie komunikatów - wygodne do wymiany mniejszej
ilości danych w komunikacji międzykomputerowej.Pamięć dzielona - zapewnia maksymalną szybkość i wygodę
komunikacji w obrębie jednego komputera.
Programy systemowe
• Programy systemowe tworzą wygodne środowisko do rozwoju i wykonywania innych programów; można je podzielić na następujące kategorie:
■ Manipulowanie plikami (tworzenie, usuwanie, kopiowanie itd.);
■ Informowanie o stanie systemu (data i czas, wielkość pamięci itp.);
■ Tworzenie i modyfikowanie plików (edytory);
■ Zaplecze języków programowania (kompilatory, asemblery, interpretery popularnych języków, jak C/C++, Java, Perl, ….);
■ Ładowanie i wykonywanie programów (konsolidatory/linkery, programy ładujące i uruchomieniowe, ….);
■ Komunikacja (realizacja mechanizmów połączeń między procesami, użytkownikami, różnymi systemami komputerowymi);
■ Programy aplikacyjne (przeglądarki WWW, arkusze kalkulacyjne, programy przetwarzania tekstu, pakiety graficzne, ….).
• Sposób, w jaki większość użytkowników postrzega system operacyjny, jest określany w większym stopniu przez programy systemowe niż przez funkcje systemowe.
Struktura systemu
MS-DOS - napisany pod kątem osiągnięcia maksymalnej funkcjonalności przy oszczędności miejsca:
■ Brak podziału na moduły;
■ Interfejsy i poziomy funkcjonalne nie są wyraźnie wydzielone.
UNIX - początkowo ograniczany przez cechy sprzętowe miał ograniczoną strukturalizację; składał się z dwu odrębnych części:
♦♦♦ Jądro (kernel):
■ Składa się z wszystkiego poniżej interfejsu funkcji systemowych a powyżej sprzętu;
■ Udostępnia system plików, planowanie przydziału procesora, zarządzanie pamięcią i inne czynności systemu operacyjnego (bardzo wiele możliwości zebranych na jednym poziomie).
♦♦♦ Programy systemowe - korzystają z udostępnianych przez jądro funkcji systemowych dla wykonywania użytecznych działań (np. kompilacja programów, operacje na plikach).
Warstwowa struktura systemu MS-DOS
Struktura systemu UNIX
Struktura warstwowa (Layered Structure
• System operacyjny jest podzielona na warstwy (poziomy).
> Najniższą warstwę (warstwę 0) stanowi sprzęt; najwyższą warstwą (warstwą N) jest interfejs użytkownika.
• Warstwy są tak wybrane, że każda używa funkcji (operacji) i korzysta z usług tylko niżej położonych warstw.
^ Modularność i ukrywanie operacji, danych itd.
Zalety:
S Łatwiejsze uruchamianie i testowanie systemu (warstwa po warstwie, począwszy od najniższej) - upraszcza projektowanie i implementację systemu.
Wady:
S Główna trudność: odpowiednie zdefiniowanie poszczególnych warstw (nie zawsze jest oczywiste co powinna zawierać dana warstwa).
S Mniejsza wydajność (konieczność przechodzenia od warstwy do warstwy).
Warstwa systemu operacyjnego
Struktura warstw systemu OS/2 (IBM)
Mikrojądra
Jądro systemu zredukowane do małego zbioru funkcji rdzeniowych, realizujących jedynie mały zbiór niezbędnych operacji elementarnych - tzw. mikrojądro (microkernel).
Wszystkie mniej ważne operacje przeniesione do programów systemowych lub programów z poziomu użytkownika.
Komunikacja odbywa się między modułami użytkownika przy użyciu metody przekazywania komunikatów.
Zalety:
S System operacyjny łatwiejszy do rozszerzania;
S SO łatwiejszy do przenoszenia na nowe architektury sprzętowe;
S SO bardziej niezawodny (mniej kodu wykonywanego w trybie jądra);
S Większe bezpieczeństwo systemu.
Struktura klient-serwer systemu Microsoft Windows NT
Struktura hybrydowa systemu Apple Macintosh OS X (Darwin)
System OS X ma strukturę hybrydową - środowisko jądra składa się zasadniczo z mikrojądra Mach i jądra BSD.
Struktura systemu z modułami jądra
Stosowanie technik obiektowych przy projektowaniu nowoczesnych systemów operacyjnych prowadzi do tworzenia modularnych jąder.
Jądro takie posiada zbiór rdzeniowych komponent i dynamicznie dołącza dodatkowe usługi albo w trakcie uruchamiania systemu, albo w trakcie jego działania.
Strategia taka oparta jest o dynamicznie łado walne moduły jądra i jest powszechna w nowoczesnych implementacjach systemu UNIX, takich jak Solaris, Linux, Mac OS X.
Np. struktura systemu Solaris jest zorganizowana wokół rdzeniowego jądra z siedmioma typami ładowalnych modułów jądra:
■ Klasy planowania;
■ Systemy plików;
■ Ładowalne wywołania systemowe;
■ Formaty wykonawcze;
■ Moduły STREAMS;
■ Sterowniki urządzeń i szyn;
■ Różnorodne usługi.
Struktura tego typu jest bardziej elastyczna od struktury warstwowej; przypomina strukturę z mikrojądrem, ale jest od niej bardziej wydajna.
Maszyny wirtualne
Maszyna wirtualna (virtual machine) jest logiczną konkluzją podejścia warstwowego; traktuje sprzęt i funkcje systemowe jakby należały do tego samego poziomu - maszyny.
Maszyna wirtualna tworzy interfejs identyczny z podstawowym sprzętem (wirtualna kopia komputera).
SO tworzy złudzenie wielu procesów pracujących na swych własnych procesorach z własną (wirtualną) pamięcią.
Zasoby fizycznego komputera są dzielone w celu utworzenia maszyn wirtualnych.
■ Odpowiednie planowanie przydziału CPU sprawia wrażenie, że każdy użytkownik ma swój własny procesor.
■ Spooling i system plików pozwalają tworzyć wirtualne urządzenia wejścia-wyjścia.
■ Zwykły terminal do pracy z podziałem czasu służy jako wirtualna konsola operatorska.
Modele systemu
Zalety/Wady maszyn wirtualnych
Koncepcja maszyn wirtualnych dostarcza pełną ochronę zasobów systemowych, gdyż każda maszyna wirtualna jest całkowicie odizolowana od innych maszyn wirtualnych.
System maszyn wirtualnych stanowi znakomitą platformę do badań i rozwoju systemów operacyjnych (rozwój systemu operacyjnego dokonuje się na maszynie wirtualnej zamiast na fizycznej maszynie, a zatem nie zaburza normalnego działania systemu).
Koncepcja maszyny wirtualnej jest trudna do implementacji - zrealizowanie dokładnej kopii maszyny bazowej wymaga sporego wysiłku.
Wzajemna izolacja maszyn wirtualnych uniemożliwia bezpośrednie dzielenie zasobów (można wprowadzić komunikację poprzez wirtualną sieć, czy system dzielonych dysków wirtualnych, tzw. minidysków).
Mniejsza wydajność (procesor musi obsługiwać wiele maszyn wirtualnych - przełączanie kontekstu).
Maszyna wirtualna Javy
Kompilator języka Java (Sun Microsystems) wytwarza niezależny od architektury kod pośredni, tzw. bajtokod (bytecode), wykonywany przez wirtualną maszynę Javy (Java Virtual Machine - JVM).
Aby program w języku Java mógł być wykonywany na danej platformie, musi być na niej zainstalowana JVM (na SO, na sprzęcie lub w przeglądarce WWW).
JVM jest specyfikacją abstrakcyjnego komputera; składa się z:
■ Ładowacza klas (class loader);
■ Weryfikatora klas (class verifier);
■ Interpretera działającego w czasie wykonywania (runtime interpreter).
Kompilatory terminowe (Just-In-Time: JIT) - przekształcają bajtokod w język maszynowy danego komputera w celu podniesienia wydajności.
JVM jest implementowana w przeglądarkach internetowych.
JVM jest także realizowana w małym systemie operacyjnym JX, który implementuje ją wprost na sprzęcie.
Urządzenia specjalizowane, np. telefony komórkowe, mogą być oprogramowane za pomocą języka Java (mikroprocesory wykonujące jako rdzenne instrukcje kod pośredni Javy).
Projektowanie systemu
►♦♦ Cele systemu:
1. Cele użytkownika - system operacyjny powinien być wygodny i łatwy w użyciu, łatwy do nauki, niezawodny, bezpieczny i szybki.
2. Cele systemu - system operacyjny powinien być łatwy do zaprojektowania, realizacji i pielęgnowania, a także elastyczny niezawodny, wolny od błędów i wydajny.
Mechanizmy a polityka:
■ Mechanizmy określają jak coś zrobić (np. mechanizmem ochrony procesora jest czasomierz), natomiast polityka decyduje o tym co będzie realizowane w praktyce (np. na jak długo będzie ustawiany czasomierz dla poszczególnych użytkowników).
■ Oddzielenie polityki od mechanizmów jest bardzo ważną zasadą -daje maksimum elastyczności, jeżeli decyzje polityczne mają być później zmieniane (np. systemy z mikrojądrem urzeczywistniają tę zasadę w sposób skrajny, realizując jedynie podstawowy zbiór elementarnych działań składowych; na przeciwnym krańcu są systemy takie jak Windows, gdzie zarówno mechanizmy, jak i polityka są zakodowane w systemie, żeby wymusić jego ogólny wygląd i odbiór).
Procesy i Wątki
Koncepcja procesu. Planowanie procesów. Działania na procesach. Procesy współpracujące. Komunikacja międzyprocesowa.
Wątki:
■ Implementacja wątków.
■ Modele wielowątkowości.
■ Schematy wielowątkowości.
■ Zagadnienia dotyczące wątków.
■ Przykłady implementacji wątków.
Koncepcja procesu
Jak nazwać wszystkie czynności procesora?
System wsadowy: zadania (jobs);
System z podziałem czasu: programy użytkownika (user programs) lub prace (tasks).
Terminy zadanie i proces czasami używane są zamiennie - obecnie preferowany jest termin proces.
Proces - wykonywany program; wykonywanie procesu musi przebiegać sekwencyjnie.
W skład procesu wchodzi:
■ Kod programu (text section);
■ Licznik rozkazów (program counter);
■ Stos procesu (process stack);
■ Sekcja danych (data section).
Stan procesu
Wykonujący się proces zmienia swój stan (state). Każdy proces może się znajdować w jednym z następujących stanów:
■ Nowy: proces został utworzony;
■ Aktywny: są wykonywane instrukcje;
■ Oczekiwanie: proces czeka na wy stąpienie jakiegoś zdarzenia (np. zakończenie operacji WE/WY);
■ Gotowy: proces czeka na przydział procesora;
■ Zakończony: proces zakończył działanie.
W każdej chwili w procesorze tylko jeden proces może być aktywny, ale wiele procesów może być gotowych do działania lub czekających.
Blok kontrolny procesu
Proces jest reprezentowany w systemie przez blok kontrolny procesu (process control block - PCB), który zawiera następujące informacje:
■ Stan procesu: nowy, gotowy, aktywny itd.
■ Licznik rozkazów: wskazuje adres następnego rozkazu do wykonania w procesie.
■ Rejestry procesora: akumulatory, rejestry indeksowe, wskaźniki stosu, rejestry ogólnego przeznaczenia, rejestry przerwań.
■ Informacje o planowaniu przydziału procesora: priorytet procesu, wskaźniki do kolejek porządkujących zamówienia i inne parametry planowania.
■ Informacje o zarządzaniu pamięcią: zawartości rejestrów granicznych, tablice stron lub segmentów.
■ Informacje do rozliczeń: ilość zużytego czasu procesora i czasu rzeczywistego, numery kont, numery procesów itd.
■ Informacje o stanie WE/WY: informacje o urządzeniach WE/WY przydzielonych do procesu, wykaz otwartych plików itd.
Planowanie procesów
Celem planowania procesów jest jak najlepsze wykorzystanie procesora - szczególnie ważne w systemach wieloprogramowych z podziałem czasu.
Kolejki planowania - zbiory procesów czekających na jakieś zdarzenia:
■ Kolejka zadań (job queues): zbiór wszystkich procesów w systemie.
■ Kolejka procesów gotowych (ready queue): zbiór procesów rezydujących w pamięci operacyjnej, gotowych i czekających na wykonanie (ma postać listy powiązanej).
■ Kolejka do urządzenia (device queue): zbiór procesów czekających na konkretne urządzenie WE/WY (każde urządzenie ma własną kolejkę).
> Procesy wędrują między różnymi kolejkami.
Planiści (Schedulers)
Planista (program szeregujący) - program systemowy wybierający procesy z kolejek.
■ Planista długoterminowy (long-term scheduler) lub planista zadań
(job scheduler) - wybiera procesy z puli zadań (zwykle na dyskach) i ładuje do pamięci operacyjnej (do kolejki procesów gotowych).
> Wywoływany jest rzadziej (sekundy, minuty) - może być wolny.
> Nadzoruje stopień wieloprogramowości, tj. liczbę procesów w pamięci (bardzo ważne dla wydajności systemu komputerowego).
■ Planista krótkoterminowy (short-term scheduler) lub planista przydziału procesora (CPU scheduler) - wybiera jeden proces spośród procesów gotowych do wykonania i przydziela mu procesor.
> Wywoływany jest często (milisekundy) - musi być szybki!
Procesy można podzielić na:
■ Procesy ograniczone przez WE/WY - spędzają większość czasu na na wykonywaniu operacji WE/WY, a mniej używają procesora.
■ Procesy ograniczone przez dostęp do procesora - większość czasu spędzają na obliczeniach wykonywanych przez procesor, a tylko sporadycznie korzystają z WE/WY.
Planowanie średnioterminowe
Planista średnioterminowy (mid-term scheduler) -odpowiedzialny za wymianę (swapping) procesów między pamięcią operacyjną a dyskiem - stosowany często w systemach z podziałem czasu.
Przełączanie kontekstu
Przełączanie procesora do innego procesu wymaga przechowania stanu starego procesu i załadowania przechowanego stanu nowego procesu - przełączanie kontekstu (context switch).
Czas przełączania kontekstu jest czystą daniną na rzecz systemu - system nie wykonuje żadnej użytecznej pracy podczas tej czynności.
Wartość czasu przełączania zależy od możliwości sprzętu (zwykle od 1 do 100 mikrosekund).
Niektóre procesory mają po kilka zbiorów rejestrów: przełączanie kontekstu - zmiana wartości wskaźnika do bieżącego zbioru rejestrów.
Przełączanie kontekstu jest nierzadko „wąskim gardłem" w systemach operacyjnych - rozwiązanie: wątki.
Działania na procesach
Tworzenie procesu
• Proces macierzysty (parent process) tworzy procesy potomne (children processes), a te mogą tworzyć dalsze procesy - drzewo procesów.
• Dzielenie zasobów:
■ Proces macierzysty i procesy potomne dzielą wszystkie zasoby.
■ Procesy potomne dzielą podzbiór zasobów procesu macierzystego.
■ Proces macierzysty i potomny nie dzielą żadnych zasobów.
• Wykonywanie:
■ Proces macierzysty i procesy potomne wykonują się współbieżnie.
■ Proces macierzysty czeka na zakończenie procesów potomnych.
• Przestrzeń adresowa:
■ Proces potomny staje się kopią procesu macierzystego (Unix: fork)
■ Proces potomny otrzymuje nowy program (Unix: exec)
Kończenie procesu
Proces wykonuje ostatnią komendę i prosi system operacyjny (poprzez funkcję exit), aby go usunął.
■ Proces może przekazać dane (wyjście) do procesu macierzystego (za pomocą funkcji wait).
■ Wszystkie zasoby procesu zostają odebrane (dealokowane) przez system operacyjny.
Proces macierzysty może zakończyć wykonywanie procesu potomnego (funkcją abort), gdy:
■ Potomek nadużył któregoś z przydzielonych zasobów;
■ Wykonywane przez potomka zadanie stało się zbędne;
■ Proces macierzysty kończy swoje działanie:
S System operacyjny nie pozwala potomkowi na dalsze działanie.
S W wielu systemach następuje kaskadowe kończenie procesów potomnych.
Procesy współpracujące
Proces niezależny (independent) - proces, który nie może oddziaływać z innymi procesami w systemie.
Proces współpracujący (cooperating) - proces, który może wpływać na inne procesy lub inne procesy mogą wpływać na niego (np. przez dzielenie danych).
Zalety współpracy procesów:
© dzielenie informacji (np. plików);
© przyspieszanie obliczeń (podział zadania na podzadania i wykonywanie równoległe - przy wielu procesorach itd.);
© modularność (modularny system z podziałem na osobne procesy);
© wygoda (np. możliwość wykonywania wielu zadań równolegle).
Komunikacja między procesowa
• Komunikacja międzyprocesowa (interprocess communication - IPC) - mechanizm systemu operacyjnego umożliwiający procesom łączność i synchronizację.
• System przekazywania komunikatów (message system) -procesy komunikują się między sobą bez odwoływania się do zmiennych dzielonych.
• Mechanizm IPC dostarcza dwie operacje:
nadaj (komunikat) - rozmiar komunikatu może być stały lub zmienny; odbierz(komunikat)
Jeżeli procesy P i Q chcą się ze sobą komunikować, to muszą:
■ Utworzyć między sobą łącze komunikacyjne (communication link);
■ Wymieniać komunikaty przy użyciu operacji nadaj/odbierz.
Implementacja łącza komunikacyjnego:
■ Fizyczna (np. pamięć dzielona, szyna sprzętowa, sieć);
■ Logiczna (logiczne cechy łącza).
Komunikacja bezpośrednia
W komunikacji bezpośredniej (direct communication) proces musi jawnie nazwać nadawcę lub odbiorcę:
nadaj (P, komunikat) - nadaj komunikat do procesu P; odbierz(Q, komunikat) - odbierz komunikat od procesu Q.
• Własności łącza komunikacyjnego:
■ Łącze jest ustawiane automatycznie (wystarczy aby procesy znały swoje identyfikatory);
■ Łącze dotyczy dokładnie dwóch procesów;
■ Między każdą parą procesów istnieje dokładnie jedno łącze;
■ Łącze może być jednokierunkowe, choć zwykle jest dwukierunkowe.
Wada: ograniczona modularność - zmiana nazwy jednego procesu może pociągać za sobą konieczność zweryfikowania definicji wszystkich innych procesów.
Komunikacja pośrednia
W komunikacji pośredniej (indirect communication) komunikaty są nadawane i odbierane za pomocą skrzynek pocztowych (mailboxes), zwanych także portami (ports).
■ Każda skrzynka pocztowa ma j ednoznaczną identyfikacj ę;
■ Procesy mogą się komunikować tylko wtedy, gdy mają jakąś wspólną skrzynkę pocztową.
Operacje nadawania i odbioru komunikatów:
nadaj (A, komunikat) - nadaj komunikat do skrzynki A; odbierz(A, komunikat) - odbierz komunikat ze skrzynki A.
Własności łącza komunikacyjnego:
■ Łącze między procesami jest ustawiane tylko wtedy, gdy dzielą one jakąś skrzynkę pocztową;
■ Łącze może być związane z więcej niż dwoma procesami;
■ Każda para komunikujących się procesów może mieć wiele łączy;
■ Łącze może być jednokierunkowe lub dwukierunkowe.
Synchronizacja i buforowanie
Synchronizacja
Przekazywanie komunikatów może być:
■ blokujące, czyli synchroniczne;
■ nieblokujące, czyli asynchroniczne.
Operacje nadaj i odbierz mogą być blokujące lub nieblokujące.
Buforowanie
Łącze ma pewną pojemność; komunikaty są w nim ułożone w postaci kolejki. Możliwe pojemności:
■ Pojemność zerowa: maksymalna długość kolejki wynosi 0, czyli nadawca musi czekać aż odbiorca odbierze komunikat (synchronizacja typu rendez-vous).
■ Pojemność ograniczona: kolejka ma skończoną długość n; nadawca musi czekać kiedy kolejka jest pełna (blokowanie).
■ Pojemność nieograniczona: kolejka ma (potencjalnie) nieskończoną długość; nadawca nigdy nie jest opóźniany.
Wątki (Threads)
Wątek (thread), zwany także procesem lekkim (light-weight process - LWP), jest podstawową jednostką wykorzystania CPU -posiada: licznik rozkazów, zbiór rejestrów i obszar stosu.
Wątek dzieli wraz z innymi równorzędnymi wątkami: sekcję kodu, sekcję danych oraz zasoby systemowe (pliki, sygnały) - łącznie nazywa się to zadaniem.
Tradycyjny proces, tzw. ciężki (heavy-weight), jest równoważny zadaniu z jednym wątkiem.
Zadanie nic nie robi, jeśli nie ma w nim ani jednego wątku; wątek może przebiegać dokładnie w jednym zadaniu.
Zalety wątków:
Dzielenie zasobów sprawia, ze przełączanie między wątkami oraz tworzenie wątków jest tanie w porównaniu z procesami ciężkimi.
Oszczędne wykorzystanie zasobów - dzięki ich współużytkowaniu.
Współpraca wielu wątków pozwala zwiększyć przepustowość i poprawić wydajność (np. jeśli jeden wątek jest zablokowany, to może działać inny).
Wykorzystanie architektury wieloprocesorowej (każdy wątek na innym CPU).
Implementacja wątków
• Wątki poziomu użytkownika (user-level threads) - tworzone za pomocą funkcji bibliotecznych; przełączanie między wątkami nie wymaga wzywania systemu operacyjnego (POSIX Pthreads).
> Zalety:
© Szybkie przełączanie między wątkami. © Wydajne obsługiwanie wielu zamówień.
> Wady:
© Przy jedno wątkowym jądrze każde odwołanie wątku poziomu użytkownika do systemu powoduje wstrzymanie całego zadania.
© Nieadekwatny przydział czasu procesora (zadanie wielowątkowe i jednowątkowe mogą dostawać tyle samo kwantów czasu).
• Wątki jądra (kernel threads) - obsługiwane przez jądro systemu (np. systemy Windows XP, Solaris, Tru64 UNIX).
© Zalety: Wydajniejsze planowanie przydziału czasu procesora.
© Wady: Wolniejsze przełączanie wątków - zajmuje się tym jądro (za pomocą przerwań).
• Wątki mieszane - zrealizowane oba rodzaje wątków (Solaris 2).
Modele wielowątkowości
Model „wiele na jeden" (many-to-one):
■ Wiele wątków poziomu użytkownika odwzorowanych na jeden wątek jądra (np. green threads w systemie Solaris 2).
■ Stosowany w systemach nie posiadających wątków jądra.
Model„ jeden na jeden" (one-to-one):
■ Każdy wątek poziomu użytkownika odwzorowany wzajemnie jednoznacznie na jeden wątek jądra.
□ Przykłady: systemy Windows 95/98/NT/2000/XP, OS/2.
Model „wiele na wiele" (many-to-many):
■ Wiele wątków poziomu użytkownika może być odwzorowanych na wiele wątków jądra.
■ Pozwala systemowi operacyjnemu utworzyć dostateczną liczbę wątków jądra.
■ Często występuje poziom pośredni w postaci procesów lekkich (LWP),
będących dla wątków użytkownika czymś w rodzaju wielowątkowych wirtualnych procesorów - z każdym LWP związany jest jeden wątek jądra, natomiast zwykły proces może składać się z jednego lub więcej LWP.
□ Przykłady: systemy Solaris 2, IRIX, HP-UX, Tru64 UNIX.
Zagadnienia dotyczące wątków
Kasowanie wątków (thread cancellation)
■ Kasowanie asynchroniczne - dany wątek kończy natychmiast wątek docelowy (target thread); może być niebezpieczne dla dzielonych zasobów.
■ Kasowanie odroczone - wątek docelowy może okresowo sprawdzać, czy powinien się zakończyć, co daje mu możliwość zakończenia w sposób uporządkowany, np. wątki Pthreads posiadają punkty, w których można je bezpiecznie kasować, tzw. punkty kasowania (cancellation points).
Obsługa sygnałów
> Sygnał (signal) służy w systemach uniksowych do powiadamianiu o wystąpieniu konkretnego zdarzenia (więcej na ten temat na ćwiczeniach).
> Sygnały synchroniczne są dostarczanie do procesu, który wykonał operację powodującą sygnał, natomiast asynchroniczne pochodzą od zdarzeń zewnętrznych.
> Możliwości dostarczania sygnałów do procesów wielowątkowych:
■ Dostarczyć sygnał tylko do tego wątku, do którego się on odnosi.
■ Dostarczyć sygnał do wszystkich wątków w procesie.
■ Dostarczyć sygnał do niektórych wątków (np. tych, które go nie blokują).
■ Przydzielić specjalny wątek do odbierania wszystkich sygnałów do procesu.
> Różne systemy realizują różne możliwości, zależy to też od rodzaju sygnału.
□ System Windows XP nie implementuje jawnie sygnałów, można je emulować za pomocą asynchronicznych wywołań procedur (asynchronous procedure call -APC) - adresowane do konkretnych wątków, możliwość przekazania funkcji.
Zagadnienia dotyczące wątków - c.d.
Pule wątków (thread pools)
Wielo wątko wość jest powszechnie stosowana w serwerach WWW - kiedy taki serwer otrzymuje zamówienie, wtedy tworzy wątek do jego obsługi.
Brak ograniczeń dotyczących wątków może doprowadzić do wyczerpania zasobów systemu, takich jak pamięć lub czas procesora.
S Jednym z rozwiązań jest zastosowanie puli wątków - w chwili uruchomienia proces tworzy pewną liczbę wątków (pulę), które oczekują na zamówienia; kiedy nadchodzi zamówienie, wątek z puli jest budzony przez serwer, a po obsłużeniu zamówienia wraca do puli i czeka na kolejne zlecenie.
© Zwykle łatwiej jest obsłużyć zamówienie za pomocą istniejącego wątku niż tworzyć do tego celu nowy wątek.
© Pula wątków ogranicza liczbę wątków, co chroni przed wyczerpaniem zasobów systemowych, a także spadkiem wydajności systemu.
Dane specyficzne wątku (thread-specific data)
Wątki należące do procesu dzielą jego dane, co jest zaletą wielowątkowości.
W pewnych sytuacjach wątek może potrzebować własnej kopii jakichś danych (np. identyfikator transakcji w wielowątkowych systemach transakcyjnych) - większość bibliotek wątków dostarcza możliwości utrzymywania danych specyficznych wątku (np. Pthreads, Win32, Java).
Przykłady implementacji wątków
P-wątki (Pthreads) - specyfikacja (API) wątków standardu POSIX:
■ Dostępne głównie w systemach uniksowych (np. Linux, Solaris, Mac OS X).
■ MS Windows na ogół ich nie udostępniają, ale można je zainstalować korzystając z oprogramowania shareware.
■ Udostępniane jako biblioteka poziomu użytkownika (więcej na ćwiczeniach) - brak wyraźnych związków między P-wątkami a stowarzyszonymi z nimi wątkami jądra.
Wątki w Windows XP - dostępne poprzez interfejs Win32 API:
■ Aplikacja Windows działa jako osobny proces, który może zawierać jeden lub więcej wątków - stosowane jest odwzorowanie „jeden na jeden".
■ Dostarczana jest także biblioteka włókien (fiber) wg. modelu „wiele na wiele". Wątki Linuxa - od wersji 2.2:
■ Oprócz funkcji systemowej fork do powielania procesów, Linux posiada funkcję systemową clone, która umożliwia tworzenie oddzielnego procesu dzielącego przestrzeń adresową procesu macierzystego (co ma być dzielone określa się za pomocą parametrów funkcji) - taki proces zachowuje się bardzo podobnie jak oddzielny wątek.
■ Linux nie rozróżnia procesów i wątków - przy odnoszeniu się do przepływu sterowania w programie używany jest na ogół terminu zadanie (praca, task).
Wątki Javy - wątki na poziomie języka programowania, realizowane przez JVM, odwzorowanie w wątki jądra zależy od implementacji JVM w danym systemie.
Planowanie przydziału procesora
• Pojęcia podstawowe.
• Kryteria planowania.
• Algorytmy planowania.
• Planowanie wieloprocesorowe.
• Planowanie w czasie rzeczywistym.
• Ocena algorytmów.
Pojęcia podstawowe
Celem wieloprogramowania jest maksymalizowanie wykorzystania CPU przez utrzymywanie w działaniu pewnej liczby procesów (na jednym procesorze wykonywany jest tylko jeden proces, pozostałe czekają na swoją kolej).
Dzięki przełączaniu procesora między różne procesy system operacyjny może zwiększyć wydajność komputera.
Planowanie (scheduling) jest podstawową funkcją systemu operacyjnego - podlega mu użytkowanie prawie wszystkich zasobów komputera.
Planowanie przydziału procesora (CPU scheduling), który jest jednym a podstawowych zasobów komputera, leży u podstaw wieloprogramowych systemów operacyjnych.
Sukces w planowaniu przydziału procesora zależy od obserwowalnej właściwości procesów: cykli działania procesora i oczekiwania na urządzenia WE/WY.
Planista przydziału procesora
Planista przydziału procesora (CPU scheduler) wybiera jeden spośród gotowych do wykonania procesów w pamięci i przydziela mu procesor.
Decyzje o przydziale procesora mogą zapadać kiedy proces:
1. przeszedł od stanu aktywności do stanu czekania;
2. przeszedł od stanu aktywności do stanu gotowości;
3. przeszedł od stanu czekania do stanu gotowości;
4. kończy działanie.
Planowanie, które odbywa się tylko w sytuacjach 1 i 4 jest planowaniem nie wywłaszczającym (nonpreemtive) lub inaczej: szeregowaniem bez wywłaszczania - kandydatem do przydziału procesora musi być nowy proces (np. MS Windows 3.1).
Każdy inny rodzaj planowania jest wywłaszczający (preemtive), zwany też szeregowaniem z wywłaszczaniem; kandydatem do przydziału jest również dany proces (np. UNIX).
> Wymaga wsparcia sprzętowego (np. czasomierz), a także ochrony danych (zwłaszcza danych jądra) i synchronizacji procesów.
Kryteria planowania
Wykorzystanie procesora (CPU utilization) - procesor powinien być możliwie jak najbardziej zajęty.
Przepustowość (throughput) - liczba procesów kończących się w jednostce czasu (np. 10 procesów na sekundę)
Czas cyklu przetwarzania (turnaround time) - czas potrzebny na wykonanie procesu (od momentu pojawienia się procesu w systemie do chwili jego zakończenia).
Czas oczekiwania (waiting time) - suma okresów czasu, które proces spędza czekając w kolejce procesów gotowych.
Czas odpowiedzi (response time) - czas między wysłaniem żądania (złożeniem zamówienia) a pojawieniem się pierwszej odpowiedzi; nie obejmuje czasu potrzebnego na wyprowadzenie odpowiedzi (zależny od urządzenia WY).
Ważne kryterium planowania dla systemów interakcyjnych.
Kryteria optymalizacji
Maksymalne wykorzystanie procesora. Maksymalna przepustowość. Minimalny czas cyklu przetwarzania. Minimalny czas czekania. Minimalny czas odpowiedzi. Najczęściej optymalizuje się miarę średnią.
Czasami bardziej pożądana jest optymalizacja wartości minimalnych lub maksymalnych, np. zmniejszenie maksymalnego czasu odpowiedzi w „sprawiedliwych" systemach interakcyjnych.
Według niektórych analityków w systemach interakcyjnych ważniejsza jest minimalizacja wariancji czasu odpowiedzi niż jego średniej - system z przewidywalnym czasem odpowiedzi może być bardziej pożądany niż system, który ma bardzo zmienny czas odpowiedzi, choć przeciętnie krótszy.
Algorytmy planowania
Algorytm FCFS:
Najprostszy algorytm planowania przydziału procesora -algorytm „pierwszy zgłoszony - pierwszy obsłużony"
(first-come, first-served - FCFS).
> Implementacja za pomocą kolejek FIFO (first-in, first-out).
□ Przykład: Proces Czas trwania fazy [ms]
Pl 24
P2 3
P3 3
■ Przypuśćmy, że procesy nadeszły w kolejności: P1, P2, P3 -diagram Gantta (Gantt chart):
Czas oczekiwania: t1 = 0, t2 = 24, t3 = 27; Średni czas oczekiwania: tś = (0 + 24 + 27)/3 = 17
Przypuśćmy, że procesy nadeszły w kolejności:
P2, P3, P1;
Czas oczekiwania: t1 = 6, t2 = 0, t3 = 3; Średni czas oczekiwania: tś = (6 + 0 + 3)/3 = 3
Znacznie krótszy niż poprzednio!
Efekt konwoju (convoy effect) - procesy krótkie czekają na zwolnienie procesora przez proces długi.
Algorytm FCFS jest niewywłaszczający.
Algorytm FCFS jest kłopotliwy w systemach z podziałem czasu.
Algorytm SJF
Algorytm „najpierw najkrótsze zadanie" (shortest-job-first -SJF) - przydziela CPU procesowi mającemu najkrótszą następną fazę procesora.
Możliwe są dwa schematy:
■ Niewywłaszczający: żaden proces nie jest wywłaszczany podczas wykonywania fazy procesora.
■ Wywłaszczający: bieżący proces jest wywłaszczany przez nowy proces, którego następna faza procesora jest krótsza o pozostałej części fazy procesora bieżącego procesu.
> Schemat ten zwany jest planowaniem „najpierw najkrótszy pozostały czas" (shortest-remaining-time-first - SRTF).
Algorytm SJF jest optymalny - daje minimalny średni czas
oczekiwania dla danego zbioru procesów.
Łatwiejszy do realizacji w planowaniu długoterminowym (np. w systemach wsadowych), trudniejszy w planowaniu krótkoterminowym - brak sposobu na poznanie długości następnej fazy procesora (można jedynie zgadywać).
Planowanie priorytetowe
W algorytmie priorytetowym każdemu procesowi przypisuje się priorytet w postaci pewnej liczby całkowitej - zazwyczaj: im mniejsza liczba tym wyższy priorytet, ale bywa też odwrotnie.
Procesor jest przydzielany procesowi o najwyższym priorytecie.
Priorytety mogą być definiowane wewnętrznie (na podstawie jakichś mierzalnych własności procesu) lub zewnętrznie (ważność procesu, czynniki polityczne itd.).
Algorytm priorytetowy może być wywłaszczający lub niewywłaszczający.
Algorytm SJF jest algorytmem priorytetowym, gdzie priorytetp jest proporcjonalny do przewidywanej długości następnej fazy procesora τ(im krótsza faza tym wyższy priorytet).
Problem: (za)głodzenie (starvation) - procesy o niskim priorytecie mogą nigdy nie zostać dopuszczone do procesora!
Rozwiązanie: postarzanie (aging) procesów - stopniowe podwyższanie priorytetów procesów długo oczekujących.
Planowanie rotacyjne
Algorytm planowania rotacyjnego (round-robin - RR) jest podobny do algorytmu FCFS, ale w celu przełączania procesów dodano w nim wywłaszczanie i cykliczną kolejkę.
Każdy proces dostaje małą jednostkę czasu procesora, tzw. kwant czasu (time quantum) (zwykle 10 do 100 milisekund) - po jej upływie proces jest wywłaszczany i wysyłany na koniec kolejki procesów gotowych, będącą kolejką typu FIFO.
Dla n procesów w kolejce i kwantu czasu q, każdy proces dostaje 1/n czasu procesora porcjami, których wartość nie przekracza q =^> żaden proces nie czeka dłużej niż (n-1)q jednostek czasu.
Długość kwantu czasu:
■ bardzo duża (nieskończona) —→ algorytm FCFS.
■ bardzo mała (np. 1 µs) - dzielenie procesora (processor sharing).
Kwant czasu powinien być długi w porównaniu z czasem przełączania kontekstu, w przeciwnym razie narzut związany z przełączaniem kontekstu jest zbyt wysoki!
> Typowa reguła: 80% faz procesora krótszych od kwantu czasu.
Wielopoziomowe planowanie kolejek
• Kolejka procesów gotowych jest podzielona na osobne kolejki:
1. Procesy pierwszoplanowe (foreground) - interakcyjne;
2. Procesy drugoplanowe (background) - wsadowe.
• Każda kolejka ma swój własny algorytm planujący:
1. Pierwszoplanowa: np. algorytm rotacyjny;
2. Drugoplanowa: np. algorytm FCFS.
• Musi istnieć planowanie między kolejkami:
■ Planowanie stałopriorytetowe z wywłaszczeniem, np.
kolejka pierwszoplanowa ma wyższy priorytet niż drugoplanowa - możliwość zagłodzenia!
■ Przydział porcji czasu procesora dla każdej z kolejek, np. 80% czasu procesora dla kolejki pierwszoplanowej (z planowaniem rotacyjnym), a 20% dla drugoplanowej (z planowaniem FCFS).
Planowanie wielopoziomowych kolejek ze sprzężeniem zwrotnym
W zwykłym algorytmie wielopoziomowego planowania kolejek proces jest na stałe przypisany do określonej kolejki (brak elastyczności).
Planowanie wielopoziomowych kolejek ze sprzężeniem zwrotnym
(multilevel feedback queue) umożliwia przemieszczanie procesów między różnymi kolejkami: proces zużywający dużo czasu procesora zostaje przeniesiony do kolejki o niższym priorytecie i odwrotnie.
Planista wielopoziomowych kolejek ze sprzężeniem zwrotnym jest określony za pomocą następujących parametrów:
■ Liczba kolejek;
■ Algorytm planowania dla każdej kolejki;
■ Metoda użyta do decydowania o awansowaniu procesu do kolejki o wyższym priorytecie;
■ Metoda użyta do decydowania o zdymisjonowaniu procesu do kolejki o niższym priorytecie;
■ Metoda wyznaczająca kolejkę, do której trafia proces potrzebujący obsługi.
Jest to najogólniejszy algorytm planowania przydziału procesora.
Planowanie wieloprocesorowe
W systemach wieloprocesorowych planowanie przydziału CPU jest bardziej skomplikowane.
A. Systemy homogeniczne (identyczne procesory):
■ Dzielenie obciążeń (load sharing) - wszystkie procesy trafiają do jednej kolejki i są przydzielane do dowolnego z dostępnych procesorów.
■ Struktura „master-slave" - jeden procesor pełni funkcję planisty dla pozostałych procesorów.
■ Wieloprzetwarzanie asymetryczne (asymmetric multiprocessing) -jeden procesor (serwer główny) wykonuje planowanie, operacje WE/WY i inne czynności systemowe; pozostałe wykonują tylko kod użytkowy.
B. Systemy heterogeniczne (różne procesory) -planowanie dedykowane dla danego systemu.
Planowanie w czasie rzeczywistym
Rygorystyczne systemy czasu rzeczywistego - do
wypełniania krytycznych zadań w gwarantowanym czasie.
■ Proces jest dostarczany wraz z instrukcją określającą potrzeby czasowe.
■ Na postawie tych danych planista akceptuje proces, zapewniając wykonanie go na czas, lub odrzuca zlecenie jako niewykonalne.
Niemożliwe udzielenie gwarancji wykonania procesu w zadanym czasie w systemach z pamięcią pomocniczą lub wirtualną.
Łagodne systemy czasu rzeczywistego - procesy o decydującym znaczeniu uzyskują priorytet nad innymi procesami:
Planowanie musi być priorytetowe;
Procesy czasu rzeczywistego muszą mieć najwyższy priorytet, a ich priorytety nie mogą maleć z upływem czasu.
Opóźnienie ekspediowania procesów do procesora musi być małe:
o Wstawianie w długotrwałych funkcjach systemowych punktów wywłaszczeń, w których może nastąpić przełączenie kontekstu.
o Możliwość wywłaszczenia całego jądra - potrzebna ochrona danych jądra przy pomocy mechanizmów synchronizacji (np. Solaris 2).
Ocena algorytmów
Modelowanie deterministyczne (deterministic modeling) - przyjmuje konkretne, z góry określone obciążenie robocze systemu i definiuje zachowanie algorytmu dla danego obciążenia (np. dla zbioru procesów o określonych długościach faz procesora porównuje się średnie czasy oczekiwania dla różnych algorytmów). © Jest proste i szybkie, daje dokładne liczby (łatwo porównywalne).
© Wymaga zbyt wiele dokładnej wiedzy i dotyczy zbyt specyficznych sytuacji - nie może być ogólnie użyteczne.
Modele obsługi kolejek (queuing models) - ustala się rozkłady faz procesora i WE/WY, czasów przybywania procesów (np. na podstawie pomiarów) i w oparciu o nie oblicza się średnią przepustowość, wykorzystanie procesora, czas oczekiwania itd. dla różnych algorytmów planowania.
© Potrzebne są pewne założenia (np. uproszczone rozkłady), co może prowadzić do niedokładnych, a czasem nierealistycznych wyników.
Symulacje - komputerowe modelowanie systemu komputerowego (zwykle przy użyciu technik Monte Carlo), np. z użyciem taśm śladów.
> Dostarczają dokładniejszych wyników, ale mogą być kosztowne i czasochłonne. Implementacja - testowanie algorytmu w rzeczywistym systemie.
Planowanie procesów w systemie Linux
• Dwa oddzielne algorytmy planowania procesów:
■ Algorytm z podziałem czasu - do sprawiedliwego planowania z wywłaszczeniami działania wielu procesów.
■ Algorytm dla zadań czasu rzeczywistego, gdzie priorytety bezwzględne są ważniejsze niż sprawiedliwość.
• W skład tożsamości każdego procesu wchodzi klasa planowania, określająca, który z algorytmów ma być użyty dla procesu.
• Dla zwykłych procesów z podziałem czasu stosowany jest algorytm priorytetowy oparty na kredytowaniu:
kredyt = kredyt/2 + priorytet
■ Do wykonania wybierany jest proces o największym kredycie.
■ Kredyt wykonywanego procesu jest obniżany o jedną jednostkę przy każdym przerwaniu zegara - kiedy kredyt spadnie do zera, proces jest zawieszany.
■ Kiedy żaden z procesów gotowych do działania nie ma kredytu, następuje wtórne kredytowanie każdego procesu w systemie (a nie tylko procesów gotowych).
• Dla procesów czasu rzeczywistego realizowane są dwie klasy planowania:
■ Algorytm FCFS;
■ Algorytm RR (rotacyjny).
> Każdy proces posiada priorytet - planista uruchamia ten o najwyższym priorytecie! •" Kod jądra nie może być wywłaszczony przez kod trybu użytkownika!
Planowanie procesów w Windows XP
System Windows XP planuje wątki za pomocą priorytetowego algorytmu wywłaszczaj ącego.
Planista sprawia, że zawsze wykonywany jest wątek o najwyższym priorytecie. Fragment jądra, który zajmuje się planowaniem nazywa się dyspozytorem.
Wątek wybrany przez dyspozytora będzie wykonywany aż do: wywłaszczenia przez wątek o wyższym priorytecie, zakończenia, wyczerpania kwantu czasu lub użycia w nim blokującego wywołania systemowego (np. operacji WE/WY).
Priorytety podzielone są na dwie klasy:
■ Klasa zmienna - priorytety od 1 do 15; priorytet jest zmniejszany przy przerwaniu czasomierza, a zwiększany po zakończeniu czekania (np. na operację WE/WY).
■ Klasa czasu rzeczywistego - priorytety od 16 do 31;
> Istnieje też wątek z priorytetem 0, służący do zarządzania pamięcią.
Z każdym priorytetem związana jest kolejka wątków; jeżeli żaden wątek nie jest gotowy, to wykonywany jest wątek postojowy (idle thread).
Win32 API wyróżnia 6 klas priorytetów, a w obrębie każdej z klas określa 7 priorytetów względnych - są one odpowiednio powiązane z priorytetami liczbowymi jądra; każda klasa posiada odpowiedni priorytet podstawowy.
Ponadto Windows XP rozróżnia proces pierwszoplanowy - aktualnie działający na ekranie, któremu zwiększa kwant czasu (typowo 3-krotnie) i procesy drugoplanowe —→ w celu polepszenia wydajności pracy interakcyjnej.
Synchronizacja procesów
• Podstawy.
• Problem sekcji krytycznej.
• Sprzętowe środki synchronizacji.
• Semafory.
• Klasyczne problemy synchronizacji.
• Regiony krytyczne.
• Monitory.
Podstawy
Proces współpracujący może wpływać na inne procesy w systemie lub podlegać ich oddziaływaniom, np. przez dzielenie danych.
Współbieżny dostęp do danych dzielonych może powodować ich niespójność.
Zachowanie spójności danych dzielonych wymaga mechanizmu zapewniającego uporządkowane wykonywanie współpracujących procesów.
Typowym modelem dla tego rodzaju zagadnień jest problem producenta i konsumenta z ograniczonym buforem.
Problem sekcji krytycznej
Weźmy n procesów rywalizujących o dostęp do wspólnych (dzielonych) danych.
Każdy proces ma segment kodu zwany sekcją krytyczną (critical section), w którym może korzystać ze wspólnych danych.
Problem: Należy zapewnić, że kiedy jeden proces wykonuje sekcję krytyczną, wówczas żaden inny proces nie jest dopuszczany do wykonywania swojej sekcji krytycznej.
Wykonywanie sekcji krytycznej powinno podlegać wzajemnemu wykluczaniu (mutual exclusion).
Struktura typowego procesu
do {
sekcja wejściowa
sekcja krytyczna
sekcja wyjściowa
reszta
} while (1);
Warunki rozwiązania problemu SK
1. Wzajemne wykluczanie: Jeśli jeden proces wykonuje swoją sekcję krytyczną, to żaden inny proces nie działa w sekcji krytycznej.
2. Postęp: Jeżeli żaden proces nie wykonuje swojej sekcji krytycznej oraz istnieją procesy, które chcą wejść do swoich sekcji krytycznych, to tylko procesy nie wykonujące swoich reszt mogą rywalizować o wejście do sekcji krytycznej i
wybór ten nie może być odwlekany w nieskończoność.
3. Ograniczone czekanie: Musi istnieć wartość graniczna
liczby wejść innych procesów do sekcji krytycznych po tym, gdy dany proces zgłosił chęć wejścia do swojej sekcji krytycznej i zanim uzyskał na to pozwolenie.
Zakładamy, że każdy proces jest wykonywany z niezerową szybkością.
Nie robimy założenia co do względnej szybkości n procesów.
Rozwiązania wieloprocesowe
Algorytm piekarni (Bakery algorithm)
Sekcja krytyczna dla n procesów:
• Przed wejściem do sekcji krytycznej proces otrzymuje numer.
• Posiadacz najmniejszego numeru wchodzi do sekcji krytycznej.
• Jeżeli procesy P_i i P_j otrzymały ten sam numer oraz i <j, to P_i będzie obsłużony najpierw.
• Schemat numerowania generuje niemalejące ciągi kolejnych liczb naturalnych, tzn. 1,2,3,3,3,4,5,5, ...
• Notacja: (a,b) < (c,d), jeżeli a < c lub jeżeli a = c i b < d.
• Dzielone zmienne:
bool ean wybi erani e [n] ; → wszystkie zainicjowane na: fal se intnumer[n]; —→ wszystkie zainicjowane na: 0
Sprzętowe środki synchronizacji
• Na jednym procesorze problem sekcji krytycznej można rozwiązać zakazując przerwań w trakcie modyfikacji zmiennej dzielonej.
Np. niepodzielne rozkazy: TestAndSet lub Swap: boolean TestAndSet(boolean &cel){ boolean
zwr = cel;
cel = true;
return zwr;
{
void Swap(boolean &a,boolean &b){
boolean temp = a;
a = b;
b = temp;
}
Semafory
• Semafor (semaphore) - pierwszy mechanizm synchronizacyjny w językach wysokiego poziomu (Dijkstra, 1965):
■ semaphore - abstrakcyjny typ danych;
■ semaphore S ;- zmienna semaforowa o wartościach całkowitych ≥ 0.
• Operacje na semaforze:
■ Opuszczenie (zajęcie) semafora: P (hol. passeren, proberen):
P(S): while (S <= 0) ; /* czekaj */ S—-;
■ Podniesienia (zwolnienie) semafora: V (hol. vrijmaken, verhogen):
V(S): S++; > Operacje te muszą być niepodzielne!
• Powyższy semafor nazywany jest semaforem ogólnym lub liczącym (counting semaphore): S = 0,1,2,...
• Może być też semafor binarny: S = 0,1 (tylko dwie wartości).
• Semafor liczący można zaimplementować przy pomocy semafora binarnego i odwrotnie.
Zakleszczenia i głodzenie
W rozwiązaniach opartych o semafory mogą pojawiać się problemy:
•Zakleszczenie (blokada) (deadlock): Kilka procesów czeka na zdarzenie, które może być spowodowane tylko przez jeden z czekających procesów.
(Za)głodzenie (blokowanie nieskończone) (starvation): Proces nie zostaje wznowiony, mimo iż zdarzenie, na które czeka występuje dowolną ilość razy - za każdym razem, gdy proces ten mógłby być wznowiony wybierany jest inny czekający proces.
Klasyczne problemy synchronizacji
• Wzajemne wykluczanie —→ ćwiczenia.
• Producent-Konsument —→ ćwiczenia.
• Czytelnicy i pisarze:
Dwie grupy procesów: czytelnicy i pisarze konkurują o dostęp do wspólnego zasobu - czytelni. Czytelnik odczytuje informację zgromadzoną w czytelni i może to robić razem z innymi czytelnikami, natomiast pisarz zapisuje nową informację i musi przebywać sam w czytelni. —→ Możliwe rozwiązania:
1. Czytelnik powinien wejść do czytelni najszybciej jak to możliwe. ■^ Możliwość zagłodzenia pisarzy!
2. Pisarz powinien wejść do czytelni najszybciej jak to możliwe. ■^ Możliwość zagłodzenia czytelników!
3. Czytelnicy i pisarze wpuszczani są do czytelni na przemian, np. według kolejności zgłoszeń, przy czym pisarze wchodząpojedynczo, natomiast wchodzący czytelnik może wpuścić do czytelni wszystkich czekających czytelników.
Brak zagłodzenia!
Problem pięciu filozofów
• Pięciu filozofów siedzi przy wspólnym okrągłym stole i myśli. Co jakiś czas filozofowie muszą się posilić. Przed każdym filozofem stoi talerz, a obok talerza widelec. Na środku stołu stoi półmisek z rybą. Rybę należy jeść dwoma widelcami, więc filozof może zacząć jeść tylko gdy będzie miał obok siebie dwa wolne widelce. Po spożyciu posiłku filozof odkłada oba widelce na stół i zatapia się w myśleniu.
> Możliwe rozwiązania:
1. Każdy filozof czeka aż jeden widelec (np. lewy) będzie wolny i podnosi go, a następnie czeka aż będzie wolny drugi widelec i też go podnosi.
■^ Możliwość zakleszczenia - każdy filozof podniesie jeden widelec.
2. Głodny filozof podnosi jednocześnie dwa widelce wtedy gdy są wolne.
■^ Możliwość zagłodzenia -jeżeli któryś z filozofów będzie miał
„żarłocznych" sąsiadów, tak że nigdy dwa widelce obok jego talerza nie będą wolne, to nie będzie mógł jeść i zostanie zagłodzony.
3. Nad procesem jedzenia filozofów czuwa lokaj, który dopuszcza do rywalizacji o widelce tylko czterech filozofów naraz, a ci podnoszą widelce sekwencyjnie.
Regiony krytyczne
Region krytyczny (critical region) - konstrukcja synchronizująca wysokiego poziomu.
Dzielona zmienna v typuT jest zadeklarowana jako:
var v: shared T; Zmienna v jest dostępna tylko w obrębie instrukcji:
region v when B do S; gdzie B jest wyrażeniem boolowskim.
Podczas wykonywania instrukcji S żaden inny proces nie ma dostępu do zmiennej v.
Regiony odwołujące się do tej samej zmiennej v wykluczają się wzajemnie w czasie.
Kiedy proces próbuje wejść do sekcji krytycznej, obliczane jest wyrażenie boolowskie B: jeśli jest ono prawdziwe, to instrukcja S będzie wykonana, w przeciwnym razie proces jest opóźniany aż wyrażenie B stanie się prawdziwe oraz żaden inny proces nie będzie przebywał w regionie związanym ze zmienną v.
Monitory
Monitor - konstrukcja stosowana w językach wysokiego poziomu do synchronizacji; umożliwiająca bezpieczne dzielenie danych abstrakcyjnego typu między współbieżnymi procesami.
Cechy monitora
Procedura zdefiniowana wewnątrz monitora może korzystać tylko ze zmiennych lokalnych monitora i swoich parametrów.
Zmienne lokalne monitora są dostępne tylko za pośrednictwem lokalnych procedur monitora.
Konstrukcja monitora gwarantuje, że w jego wnętrzu może być aktywny tylko jeden proces (sekcja krytyczna).
W celu zwiększenia funkcjonalności monitora wprowadza się dodatkowy mechanizm - warunek (condition):
condition x, y; ← zmienne typu condition;
> Zmienne warunkowe mogą być użyte tylko z operacjami wait i signal:
■ Operacja x. wai t () ; oznacza, że proces ją wywołujący zostaje zawieszony do chwili, gdy inny proces wywoła operację x. si gnal () ;
■ Operacja x. signal (); wznawia dokładnie jeden z zawieszonych procesów -jeżeli nie ma takich procesów, to operacja ta nie ma żadnego efektu. Kolejność wznawiania procesów zależy do implementacji kolejki procesów czekających pod daną zmienną warunkową.
Synchronizacja w MS Windows XP
• W systemie jednoprocesorowym jądro sięgając po jakiś zasób globalny maskuje czasowo przerwania.
• W systemie wieloprocesorowym dostęp do zasobów globalnych chroniony jest przy pomocy wirujących blokad.
• Do synchronizacji wątków poza jądrem służą obiekty dyspozytora
(dispatcher objects).
■ Używając obiektu dyspozytora wątek może korzystać z różnych mechanizmów synchronizacji: zamki (muteksy), semafory, zdarzenia itd.
■ Zdarzenia (events) - mechanizm synchronizacji podobny do zmiennych warunkowych (mogą powiadamiać wątek o spełnieniu żądanego warunku).
• Obiekty dyspozytora mogą znajdować się w stanie sygnalizowania (signaled) lub niesygnalizowania (nonsignaled).
■ Stan sygnalizowania oznacza, że obiekt jest dostępny i wątek nie zablokuje
się przy próbie jego pozyskania.
■ Stan niesygnalizowania wskazuje, że obiekt nie jest dostępny i przy próbie jego pozyskania wątek zostanie zablokowany.
■ Istnieje związek między stanem obiektu dyspozytora a stanem wątku:
sygnalizowany/niesygnalizowany obiekt - wątek w stanie gotowości/czekania.
Synchronizacja w systemie Linux
Jądro Linuxa jest niewywłaszczalne - proces wykonywany w trybie jądra nie może zostać wywłaszczony przez proces o wyższym priorytecie, dzięki czemu nie pojawia się szkodliwa rywalizacja przy dostępie do struktur danych jądra.
W trakcie wykonywania procesu w trybie jądra mogą pojawiać się przerwania.
■ W przypadku krótkich sekcji krytycznych Linux wyłącza przerwania na
czas trwania tych sekcji.
■ Dla dłuższych sekcji krytycznych Linux używa semaforów do ochrony danych jądra.
W systemach wieloprocesorowych dzielone struktury danych jądra chronione są przy pomocy wirujących blokad.
Synchronizacja P-wątków
Interfejs Pthreads API dostarcza muteksów i zmiennych warunkowych jako mechanizmów synchronizacji wątków standardu POSIX.
Wiele systemów implementujących P-wątki dostarcza ponadto semaforów.
Zakleszczenia
Model systemu.
Charakterystyka zakleszczenia.
Metody postępowania z zakleszczeniami.
Zapobieganie zakleszczeniom.
Unikanie zakleszczeń.
Wykrywanie zakleszczenia.
Likwidowanie zakleszczenia.
Mieszane metody postępowania z zakleszczeniami.
Model systemu
System składa się z zasobów: pamięć, cykle procesora, pliki, urządzenia WE/WY itd., o które rywalizują procesy.
Każdy proces korzysta z zasobu według schematu:
1. Zamówienie (żądanie, request) -jeżeli nie może być zrealizowane natychmiast, to proces musi czekać do chwili otrzymania zasobu.
2. Użycie - proces może korzystać z zasobu.
3. Zwolnienie - proces oddaje zasób.
Stan zakleszczenia (blokady; deadlock): każdy proces w zbiorze procesów czeka na zdarzenie, które może być spowodowane tylko przez inny proces z tego samego zbioru (np. zwolnienie zajętego zasobu, na który proces oczekuje).
Charakterystyka zakleszczenia
Zakleszczenie może powstać wtedy, kiedy w systemie spełnione są jednocześnie cztery warunki:
1. Wzajemne wykluczanie: Tylko jeden proces może używać zasobu w tym samym czasie (zasób niepodzielny).
2. Przetrzymywanie i czekanie: Proces mający jeden zasób czeka na przydział dodatkowych zasobów będących w posiadaniu innych procesów.
3. Brak wywłaszczeń: Zasoby nie podlegają wywłaszczaniu.
4. Czekanie cykliczne: Istnieje zbiór czekających procesów {P0,P1,...,Pn}, takich że P0 czeka na zasób przetrzymywany przez P1, P1 czeka na zasób przetrzymywany przez P2, ..., a Pn czeka na zasób przetrzymywany przez P0.
Graf przydziału zasobów - graf skierowany złożony ze zbioru wierzchołków W i zbioru krawędzi K.
■ Zbiór wierzchołków W składa się z dwu podzbiorów: P={P1,...,Pn} -zbiór wszystkich procesów, Z={Z1,...,Zm} - zbiór typów zasobów.
■ Krawędź zamówienia: Pi →Zj; Krawędź przydziału: Zj →Pi.
Metody postępowania z zakleszczeniami
Z problemem zakleszczeń można sobie radzić na trzy różne sposoby:
Zastosować protokół gwarantujący, że system nigdy nie wejdzie w stan zakleszczenia.
Pozwolić systemowi na zakleszczenia, po czym podjąć działania w celu ich usunięcia.
Zlekceważyć problem, udając, że zakleszczenia nigdy się nie pojawią w systemie - stosowane przez większość systemów operacyjnych (m.in. UNIX).
Zapobieganie zakleszczeniom
Zapobiec spełnieniu jednego z warunków koniecznych zakleszczeń:
Wzajemne wykluczanie - konieczne tylko dla zasobów niepodzielnych; nie wymagane dla zasobów podzielnych.
Przetrzymywanie i oczekiwanie - zagwarantować, że kiedy proces żąda zasobu, to nie posiada innych zasobów: np. wymagać by proces zamawiał i dostawał wszystkie swoje zasoby zanim rozpocznie działanie lub zamawiał zasoby gdy nie ma żadnych.
© Słabe wykorzystanie zasobów, możliwość głodzenia procesów.
Brak wywłaszczeń:
■ Jeśli proces będący w posiadaniu pewnych zasobów żąda zasobu, którego nie można natychmiast przydzielić, to musi zwolnić wszystkie posiadane zasoby.
■ Wywłaszczone zasoby są dodawane do listy zasobów, na które proces czeka.
■ Proces zostanie wznowiony tylko wtedy, gdy będzie mógł odzyskać utracone zasoby oraz otrzymać nowo żądane zasoby.
Czekanie cykliczne - wymuszenie całkowitego uporządkowania wszystkich typów zasobów i wymaganie, aby każdy proces zamawiał zasoby w porządku rosnącym ich numeracji.
Unikanie zakleszczeń
> Wymaga informacji a priori o zapotrzebowaniach na zasoby.
• W najprostszym i najbardziej użytecznym modelu wymaga się, aby każdy proces deklarował maksymalną liczbę zasobów każdego typu, których będzie potrzebował.
■ Algorytm unikania zakleszczeń (deadlock avoidance) sprawdza dynamicznie stan przydziały zasobów, by zapewnić, że nigdy nie dojdzie do czekania cyklicznego.
■ Stan przydziału zasobów jest określony przez liczbę dostępnych i przydzielonych zasobów oraz maksymalne zapotrzebowania procesów.
• Kiedy proces żąda dostępnego zasobu, system musi sprawdzić, czy natychmiastowe przydzielenie tego zasobu zachowa system w stanie bezpiecznym.
■ System jest w stanie bezpiecznym, jeżeli istnieje ciąg bezpieczny procesów.
■ Ciąg procesów <P1,P2,...,Pn> jest bezpieczny, jeśli dla każdego Pi jego potencjalne zapotrzebowanie na zasoby można zaspokoić przez aktualnie dostępne zasoby oraz zasoby użytkowane przez wszystkie procesy Pj dlaj < i.
■ System jest w stanie bezpiecznym => brak zakleszczenia!
■ System jest w stanie zagrożenia => 3 możliwość powstania zakleszczenia!
■ Unikanie zakleszczeń - gwarancja, że nigdy nie pojawi się stan zagrożenia!
Algorytmy unikania zakleszczeń
Algorytm grafu przydziału zasobów:
> Dla zasobów, których każdy typ ma pojedynczy egzemplarz.
■ Dodatkowy typ krawędzi: krawędź deklaracji Pi →Zj- wskazuje, że proces Pi może zamówić kiedyś zasób Zj; reprezentowana linią przerywaną.
■ Krawędź deklaracji przechodzi w krawędź zamówienia, gdy proces zamawia zasób.
■ Gdy zasób jest zwalniany krawędź zamówienia przechodzi z powrotem w krawędź deklaracji.
■ Proces musi a priori zadeklarować zapotrzebowanie na potrzebne zasoby.
■ Zamówienie może być spełnione tylko wtedy, gdy nie doprowadzi do powstania cyklu w grafie - koszt szukania cyklu: n^2 (n - liczba procesów).
Algorytm bankiera (banker's algorithm):
Dla zasobów wielokrotnych (tzn. każdy typ może mieć wiele egzemplarzy).
Każdy proces musi zadeklarować maksymalną liczbę egzemplarzy każdego typu, które będą mu potrzebne ( ≤ liczby wszystkich zasobów w systemie).
Kiedy proces zamawia zbiór zasobów, sprawdza się czy ich przydzielenie pozostawi system w stanie bezpiecznym: jeżeli tak - zasoby są przydzielane, jeżeli nie - proces musi poczekać na zwolnienie dostatecznej ilości zasobów.
Koszt sprawdzania stanu bezpiecznego: m ×n^2 (m - ilość typów zasobów).
Wykrywanie zakleszczenia
W systemach nie stosujących zapobiegania zakleszczeniom muszą istnieć:
■ Algorytm wykrywania ewentualnego zakleszczenia;
■ Algorytm likwidowania wykrytego zakleszczenia.
Typy zasobów reprezentowane pojedynczo:
■ Algorytm wykrywania zakleszczeń oparty o graf oczekiwania, który powstaje z grafu przydziału zasobów po usunięciu węzłów reprezentujących zasoby, np. Pi → Pj oznacza, że proces Pi czeka na zasób będący w posiadaniu procesu Pj.
■ Okresowo wykonuje się powyższy algorytm, który szuka cyklu w grafie.
■ Koszt algorytmu (liczba operacji): n^2 (n - liczba wierzchołków grafu).
Typy zasobów reprezentowane wielokrotnie:
■ Algorytm wykrywania zakleszczenia podobny do algorytmu bankiera.
■ Koszt algorytmu: m ×n^2 (m - ilość typów zasobów).
Używanie algorytmu wykrywania zakleszczenia:
Częstość wywoływania algorytmu zależy od tego jak często występują zakleszczenia i ile procesów ulega zakleszczeniu.
Wykonywanie algorytmu w dowolnych chwilach może prowadzić do powstawania wielu cykli i utrudniać wykrywanie sprawcy zakleszczenia.
Likwidowanie zakleszczenia
Zakończenie procesu:
■ Zaniechanie wszystkich zakleszczonych procesów;
■ Usuwanie procesów pojedynczo, aż do wyeliminowania cyklu zakleszczenia. > Jak wybrać proces do zakończenia:
Jaki jest priorytet procesu?
Jak długo proces wykonywał obliczenia i ile czasu potrzebuje do zakończenia?
Ile zasobów i jakiego typu używa proces?
Ile zasobów proces potrzebuje do zakończenia działania?
Ile procesów trzeba będzie zakończyć?
Czy proces jest interakcyjny czy wsadowy?
Wywłaszczanie zasobów:
■ Wybór ofiary: które zasoby/procesy mają być wywłaszczone - minimum kosztów;
■ Wycofanie procesu do pewnego bezpiecznego stanu i późniejsze jego wznowienie z tego stanu - może być trudne!
■ Głodzenie: do roli ofiary może być wybierany wciąż ten sam proces -potrzebne ograniczenie; uwzględnienie liczby wycofań przy ocenie kosztów.
Mieszane metody postępowania z
zakleszczeniami
Połączenie trzech podstawowych metod postępowania z zakleszczeniami:
■ Zapobieganie,
■ Unikanie,
■ Wykrywanie
pozwala na uzyskanie optymalnego podejścia do problemu zakleszczeń dla poszczególnych klas zasobów w systemie.
Podział zasobów na hierarchicznie uporządkowane klasy, np.
■ Zasoby wewnętrzne (bloki kontrolne procesów itp.);
■ Pamięć główna;
■ Zasoby zadania (przydzielane urządzenia i pliki);
■ Wymienny obszar pamięci (pamięć pomocnicza).
Używanie najbardziej odpowiedniej techniki postępowania z zakleszczeniami wewnątrz każdej z klas zasobów.
Zakleszczenia dotyczą zwykle nie więcej niż jednej klasy —→ system mniej (lub wcale nie) narażony na zakleszczenia!
Zarządzanie pamięcią
• Podstawy.
• Wymiana (swapping).
• Przydział ciągły pamięci.
• Stronicowanie.
• Segmentacja.
• Segmentacja ze stronicowaniem.
Podstawy
Pamięć operacyjna lub główna (main memory) jest wielką tablicą oznaczonych adresami słów lub bajtów.
Aby program mógł być wykonywany, musi zostać umieszczony w procesie i wprowadzony do pamięci operacyjnej.
Zbiór procesów czekających na dysku na wprowadzenie do pamięci w celu wykonania tworzy kolejkę wejściową (input queue).
Jeden z procesów zostaje wybrany i załadowany do pamięci; podczas wykonywania pobiera rozkazy i dane z pamięci, a po zakończeniu zwalnia zajmowaną pamięć.
Większość systemów pozwala procesowi użytkownika przebywać w dowolnej części pamięci fizycznej - wpływa to na zakres adresów dostępnych dla procesu.
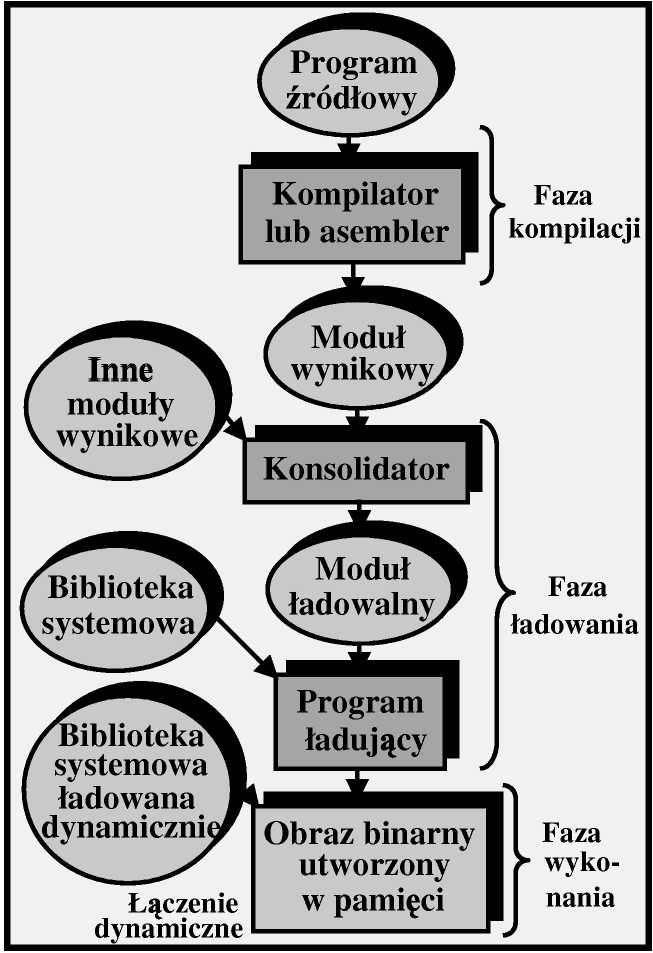
Program użytkownika przechodzi kilka faz zanim zostanie wykonany -podczas tych faz reprezentacja adresów może ulegać zmianie.
W programie źródłowym adresy wyrażone są w sposób symboliczny (np. licznik) - kompilator na ogół wiąże je z adresami względnymi, a konsolidator wiąże dalej te adresy względne z adresami bezwzględnymi.
Wiązanie adresów
Wiązanie rozkazów i danych z
adresami pamięci może być dokonane w dowolnym z trzech kroków:
1. Faza kompilacji: Jeżeli a priori znane jest miejsce, w którym proces będzie przebywał w pamięci, to można wygenerować kod bezwzględny
(absolute code); zmiana położenia kodu w pamięci wymaga jego rekompilacji.
2. Faza ładowania: Jeżeli przyszłe położenie procesu w pamięci nie jest znane podczas kompilacji, to kompilator musi generować kod przemieszczalny (relocatable code); wiązanie adresów następuje w czasie ładowania kodu.
3. Faza wykonania: Jeżeli proces podczas wykonania może być przemieszczany w pamięci, to wiązanie adresów musi być opóźnione do czasu wykonania -wymaga to specjalnego sprzętu (stosowane w większości systemów).
Logiczna i fizyczna przestrzeń adresowa
• Adresy logiczne (wirtualne) - adresy generowane przez CPU.
• Adresy fizyczne - adresy widziane przez jednostkę pamięci.
• Adresy logiczne i fizyczne są:
■ takie same - w schematach wiązania adresów podczas kompilacji i ładowania;
■ różne - w schematach wiązania adresów podczas wykonywania.
• Zbiór wszystkich adresów logicznych generowanych przez program nazywa się logiczną przestrzenią adresową, a zbiór odpowiadających im adresów fizycznych - fizyczną przestrzenią adresową.
• Odwzorowywanie adresów logicznych na fizyczne jest dokonywane przez jednostkę zarządzania pamięcią (memory-management unit - MMU) - jest to urządzenia sprzętowe.
■ Do każdego adresu generowanego przez proces użytkownika w chwili odwołania się do pamięci jest dodawana wartość rejestru przemieszczenia (relocation register).
■ Program użytkownika działa na adresach logicznych, nigdy nie ma do czynienia z rzeczywistymi adresami fizycznymi.
Ładowanie dynamiczne
Przy ładowaniu dynamicznym (dynamic loading) podprogram nie jest wprowadzany do pamięci dopóki nie zostanie wywołany.
Gdy jakiś podprogram chce wywołać inny podprogram, musi sprawdzić czy jest on w pamięci -jeżeli nie, to należy wywołać program łączący i ładujący (relocatable linking loader).
Wszystkie programy przechowywane są na dysku w postaci kodów przemieszczalnych.
Lepsze wykorzystanie pamięci - nieużywany podprogram nie zostanie nigdy załadowany.
Użyteczne, kiedy od czasu do czasu trzeba wykonać duże fragmenty kodu, jak np. podprogramy obsługi błędów.
Nie wymaga specjalnego wsparcia ze strony systemu operacyjnego - użytkownicy są odpowiedzialni za odpowiednie projektowanie programów (system może dostarczać procedury biblioteczne do realizowania ładowania dynamicznego).
Konsolidacja dynamiczna
Konsolidacja statyczna - systemowe biblioteki języków programowania są traktowane jak każdy inny moduł wynikowy i dołączane przez program ładujący do binarnego obrazu programu.
© Marnotrawstwo pamięci operacyjnej oraz przestrzeni dyskowej.
Konsolidacja dynamiczna (dynamic linking) - konsolidacja jest opóźniona do czasu wykonania programu.
■ W miejscu odwołania bibliotecznego w obrazie binarnym znajduje się zakładka (stub) (namiastka procedury) - mały fragment kodu wskazujący jak odnaleźć w pamięci lub załadować z dysku odpowiedni podprogram.
■ Zakładka wprowadza na swoje miejsce adres potrzebnego podprogramu i powoduje jego wykonanie.
■ Wymaga wsparcia ze strony sytemu operacyjnego - sprawdzanie czy podprogram biblioteczny jest w obszarach pamięci procesów oraz zezwalanie by wiele procesów miało dostęp do tych samych adresów pamięci.
© Lepsze wykorzystanie pamięci operacyjnej oraz przestrzeni dyskowej.
© Szczególnie użyteczna dla bibliotek, np. aktualizacja biblioteki nie wymaga ponownej konsolidacji korzystających z niej programów →» biblioteki dzielone (shared libraries).
Wymiana (Swapping)
Proces może być tymczasowo odesłany z pamięci operacyjnej do pamięci pomocniczej, a po jakimś czasie sprowadzony z powrotem w celu kontynuacji wykonywania.
Do wymiany potrzebna jest pamięć pomocnicza (backing store) -jest nią na ogół szybki dysk:
■ Musi być wystarczająco pojemny, aby pomieścić kopie obrazów pamięci wszystkich użytkowników.
■ Musi umożliwiać bezpośredni dostęp do tych obrazów pamięci.
Wytaczanie i wtaczanie (roll-out, roll-in) - wariant wymiany używany w algorytmach planowania priorytetowego, w którym proces o niższym priorytecie jest odsyłany z pamięci po to by proces o wyższym priorytecie mógł zostać załadowany i wykonany.
Główną częścią czasu wymiany jest czas przesyłania, który jest proporcjonalny do ilości wymienianej pamięci.
Obecnie standardowa wymiana stosowana jest rzadko.
Zmodyfikowane wersje wymiany stosowane są w wielu systemach operacyjnych, np. wiele wersji systemu UNIX, MS Windows.
Przydział ciągły pamięci
Pamięć operacyjna jest zwykle podzielona na dwie części:
dla rezydującego systemu operacyjnego - zwykle pamięć dolna;
dla procesów użytkownika - zwykle pamięć górna.
Ochrona pamięci
Do ochrony kodu i danych systemu operacyjnego ze strony procesów
użytkowników oraz tych procesów wzajemnie przed sobą używa się
rejestru przemieszczenia oraz rejestru granicznego.
Rejestr przemieszczenia zawiera wartość najmniejszego adresu fizycznego.
Rejestr graniczny zawiera górny zakres adresów logicznych.
Przydział ciągły pamięci - c.d.
Przydział (alokacja) pamięci:
Dziura (hole) - blok dostępnej pamięci; dziury różnych rozmiarów mogą
być rozproszone po całej pamięci.Kiedy przybywa proces, poszukuje się dla niego odpowiednio obszernej
dziury -jeśli taka zostanie znaleziona, to z niej przydziela się mu pamięć.
Jeżeli nie znajdzie się wystarczająco duża dziura, to proces musi poczekać.System operacyjny przechowuje tablicę z informacjami o przydzielonych
oraz wolnych (dziury) obszarach pamięci.
Dynamiczny przydział pamięci
Jak na podstawie listy wolnych dziur spełnić zamówienie na obszar o rozmiarze n?
Pierwsze dopasowanie (first-fit): Przydziela się pierwszą dziurę o wystarczającej wielkości. Szuka się od początku wykazu dziur lub od miejsca zakończenie ostatniego szukania.
Najlepsze dopasowanie (best-fit): Przydziela się najmniejszą z
dostatecznie dużych dziur. Zapewnia najmniejsze pozostałości, ale wymaga przeszukiwania całej listy.
Najgorsze dopasowanie (worst-fit): Przydziela się największą
dziurę. Wymaga przeszukania całej listy, pozostawia po przydziale największą dziurę (może być bardziej przydatna niż wiele małych).
Symulacje pokazują, że pierwsze dwie strategie są lepsze od trzeciej pod względem zużycia czasu, jak i pamięci (najszybsza jest pierwsza).
Fragmentacj a pamięci
Fragmentacja zewnętrzna (external fragmentation): Suma wolnych obszarów w pamięci wystarcza na spełnienie zamówienia, ale nie tworzą one spójnego obszaru.
Reguła 50 procent - w strategii pierwszego dopasowania z powodu
fragmentacji straty wynoszą zwykle ok. 50% tego co zostało przydzielone.
Fragmentacja wewnętrzna (internal fragmentation): Przydzielona pamięć może być nieco większa niż zamawiana (nie opłaca się trzymać informacji o bardzo małych dziurach) - ten naddatek znajduje się wewnątrz przydzielonego obszaru, ale jest niewykorzystywany.
Fragmentację zewnętrzną można redukować przez upakowanie:
■ Przetasowanie pamięci tak, aby cała wolna pamięć była w jednym bloku.
■ Upakowanie jest możliwe tylko przy dynamicznym wiązaniu adresów
wykonywanym podczas działania procesu.
Algorytm upakowania może być dość kosztowny.
Wybranie optymalnej strategii upakowywania jest dosyć trudne.
Dodatkowe trudności pojawiają się kiedy w systemie występuje wymiana, np. problem przywrócenia procesu o statycznie ustalanych adresach.
Stronicowanie (Paging)
Inne rozwiązanie problemu fragmentacji zewnętrznej - dopuszczenie do nieciągłości logicznej przestrzeni adresowej, tzn. przydzielanie procesowi dowolnych dostępnych miejsc pamięci fizycznej.
• Podział pamięci fizycznej na bloki o stałej długości zwane ramkami (frames); rozmiar zwykle jest potęgą 2, między 512 B a 16 MB.
• Podział pamięci logicznej na bloki takiego samego rozmiaru zwane stronami (pages).
• System utrzymuje informację o wolnych i przydzielonych ramkach w tablicy ramek (a także do jakiego procesu - lub procesów - ramka jest przydzielona).
• Strony uruchamianego procesu przebywające w pamięci pomocniczej są wprowadzane w wolne ramki pamięci operacyjnej (program rozmiaru n stron potrzebuje n ramek - mogą być w dowolnym miejscu pamięci fizycznej).
• Eliminuje się fragmentację zewnętrzną, ale pozostaje fragmentacja wewnętrzna.
• Adres generowany przez procesor składa się z dwóch części:
■ numer strony s (page number) - indeks w tablicy stron; tablica stron zawiera adresy bazowe wszystkich stron w pamięci operacyjnej.
■ odległość na stronie o (page offset) - w połączeniu z adresem bazowym daje adres fizyczny pamięci, który jest wysyłany do jednostki pamięci.
Implementacj a tablicy stron
Tablica stron przechowywana jest w pamięci operacyjnej
(jedynie bardzo małe tablice można przechowywać w rejestrach).
Rejestr bazowy tablicy stron (page-table base register - PTBR) służy do wskazywania położenia tablicy stron.
Rejestr długości tablicy stron (page-table length register -PTLR) służy do podawania rozmiaru tablicy stron.
W takim schemacie każdy dostęp do danych/rozkazów wymaga dwóch kontaktów z pamięcią- dwukrotne spowolnienie dostępu!
Standardowe rozwiązanie powyższego problemu - użycie szybkiej (ale drogiej) pamięci podręcznej zwanej rejestrami asocjacyjnymi lub buforami translacji adresów stron
(translation look-aside buffers - TLBs):
■ Każdy rejestr składa się z dwu części: klucza (znacznika) i wartości.
■ Porównywanie danego obiektu (numeru strony) z kluczami odbywa się równocześnie dla wszystkich kluczy.
■ Jeżeli obiekt zostanie znaleziony, to wynikiem jest odpowiednia wartość -numer ramki; jeżeli nie, to trzeba odwołać się do tablicy stron w pamięci.
Czas dostępu do pamięci, ochrona pamięci
• Efektywny czas dostępu do pamięci:
■ Czas dostępu do pamięci operacyjnej = τ;
■ Współczynnik trafień (hit ratio) stron w rejestrach TLB = α, (0 < a < 1);
■ Czas przeglądania (lookup time) rejestrów TLB = ε×τ, (0 < 8 < 1); > Efektywny czas dostępu (effective access time - EAT):
EAT = α (1 + ε) × τ + (1 - α) (2 + ε) × τ
= (2 + ε - α) ×τ ← α powinno być duże, a ε małe!
Np. procesor Intel 80486: 32 rejestry TLB =^> α = 0.98.
• Ochrona pamięci:
■ Każdej ramce przypisuje się bit ochrony, który określa czy strona jest dostępna do czytania i pisania, czy tylko do czytania.
■ Dodatkowo do każdej pozycji w tablicy stron dołączany jest bit poprawności (valid-invalid bit) mówiący czy strona znajduje się w logicznej przestrzeni adresowej procesu (a więc jest dozwolona), czy nie.
■ Niektóre systemy korzystają ze sprzętowego rejestru długości tablicy stron
(PTLR) wskazującego rozmiar tablicy stron - używa się go w celu sprawdzenia, czy dany adres należy do przedziału dozwolonego dla procesu.
Strony dzielone
> Inną zaletą stronicowania jest możliwość dzielenia wspólnego kodu (np. edytora) przez wiele procesów.
• Kod dzielony:
■ Jedna kopia kodu wznawialnego (reentrant), tzn. takiego, który nie modyfikuje sam siebie, może być współdzielona przez wiele procesów (np. edytory, kompilatory, systemy okien, bazy danych).
■ Kod dzielony musi znajdować się w tej samej pozycji w fizycznej przestrzeni adresowej wszystkich korzystających z niego procesów.
^Trudne do implementacji dla odwróconej tablicy stron!
• Prywatny kod i dane:
■ Każdy proces posiada własną kopię rejestrów i obszar danych prywatnych.
■ Strony prywatnego kodu i danych mogą pojawiać się w dowolnym miejscu w fizycznej przestrzeni adresowej.
Segmentacja
Segmentacja jest schematem zarządzania pamięcią urzeczywistniającym sposób widzenia pamięci przez użytkownika.
Przestrzeń adresów logicznych jest zbiorem segmentów.
■ Segment to jednostka logiczna, taka jak: program główny, procedury, funkcje, metody, obiekty, stosy, wykazy, tablice, zmienne lokalne i globalne itd.
■ Dla ułatwienia implementacji segmenty są ponumerowane. Adres logiczny: <numer_segmentu, odległość>
Tablica segmentów: odwzorowuje dwuwymiarowe adresy logiczne w jednowymiarowe adresy fizyczne. Każda pozycja składa się z dwu części:
■ Baza segmentu - zawiera początkowy adres fizyczny segmentu w pamięci;
■ Granica segmentu - określa długość segmentu. Implementacja tablicy segmentów:
■ Tablica segmentów na ogół przechowywana jest w pamięci.
■ Rejestr bazowy tablicy segmentów (segment-table base register - STBR) wskazuje na tablicę segmentów w pamięci.
■ Rejestr długości tablicy segmentów (segment-table length register - STLR) zawiera liczbę segmentów używanych przez program; numer segmentu s jest dozwolony, jeżeli s < STLR.
Ochrona i wspólne użytkowanie
• Zaletą segmentacji jest powiązanie ochrony pamięci z segmentami (segmenty są określonymi semantycznie porcjami programu, które na ogół powinny być używane w ten sam sposób).
> Z każdą pozycją w tablicy segmentów związane są:
■ Bit poprawności - zero oznacza, ze użycie segmentu jest niedozwolone.
■ Prawa czytania/pisania/wykonywania dla danego segmentu.
• Inną zaletą segmentacji jest dzielenie kodu lub danych:
■ Dzielenie występuje na poziomie całych segmentów, np. kilka procesów może dzielić segmenty zawierające edytor, funkcje biblioteczne itd.
■ Dzielenie segmentów występuje wtedy, gdy wpisy w tablicach różnych procesów wskazują na to samo miejsce w pamięci fizycznej.
■ Dowolna informacja może być dzielona, jeśli została zdefiniowana jako segment.
Fragmentacja
■ Segmenty mają różne długości, zatem przydział pamięci jest zagadnieniem przydziału dynamicznego - na ogół rozwiązywane za pomocą algorytmu pierwszego lub najlepszego dopasowania.
■ Występuje zewnętrzna fragmentacja - zależna od rozmiaru segmentów.
Segmentacja ze stronicowaniem
Możliwe jest połączenie schematów stronicowania i segmentacji. System MULTICS:
■ Rozwiązanie problemu fragmentacji zewnętrznej przez stronicowanie segmentów (strona składa się z 1 K słów).
■ Wpis w tablicy segmentów zawiera nie adres segmentu, lecz adres bazowy tablicy stron tego segmentu.
■ Ponieważ maksymalna liczba segmentów jest spora (262 144), co wymagałoby dużej tablicy segmentów, więc stronicuje się tablicę segmentów.
Procesor Intel 80386 (i późniejsze):
■ Maksymalna liczba segmentów w jednym procesie: 16 K, maksymalny rozmiar segmentu: 4 GB, rozmiar strony: 4 KB.
■ Przestrzeń adresów logicznych podzielona na dwie strefy:
1. Strefa prywatnych segmentów procesu: 8 K segmentów - informacje o niej znajdują się w tablicy lokalnych deskryptorów (local descriptor table, LDT).
2. Strefa segmentów wspólnych dla wszystkich procesów: 8 K segmentów -informacje o niej znajdują się w tablicy globalnych deskryptorów (GDT).
■ Każdy segment jest stronicowany w schemacie stronicowania dwupoziomowego (s1 = 10 bitów, s2 = 10 bitów, o = 12 bitów).
Pamięć wirtualna
Podstawy.
Stronicowanie na żądanie.
Kopiowanie przy zapisie.
Zastępowanie stron.
Algorytmy zastępowania stron.
Przydział ramek.
Szamotanie (migotanie).
Pliki odwzorowywane w pamięci.
Inne kwestie stronicowania.
Przykłady - systemy: Windows XP i Solaris.
Podstawy
Pamięć wirtualna jest techniką, która umożliwia wykonywanie procesów, pomimo że nie są one w całości przechowywane w pamięci operacyjnej. Pozwala stworzyć abstrakcyjną pamięć główną w postaci olbrzymiej, jednolitej tablicy i odseparować pamięć logiczną od pamięci fizycznej.
■ Logiczna przestrzeń adresowa może być większa niż przestrzeń fizyczna.
■ Umożliwia wykonywanie programu, który tylko w części znajduje się w pamięci fizycznej - program nie jest ograniczony wielkością dostępnej pamięci fizycznej (może być od niej większy).
■ Zwiększa wieloprogramowość (więcej procesów może być wykonywanych w tym samym czasie) —→ lepsze wykorzystanie procesora i przepustowość.
■ Pozwala na wydajniejsze tworzenie i wymianę procesów - mniej potrzebnych operacji wejścia-wyjścia.
■ Uwalnia użytkownika od potrzeby znajomości organizacji i ograniczeń pamięci fizycznej —→ ułatwia programowanie.
Pamięć wirtualna jest najczęściej implementowana w formie:
■ Stronicowania na żądanie (demand paging);
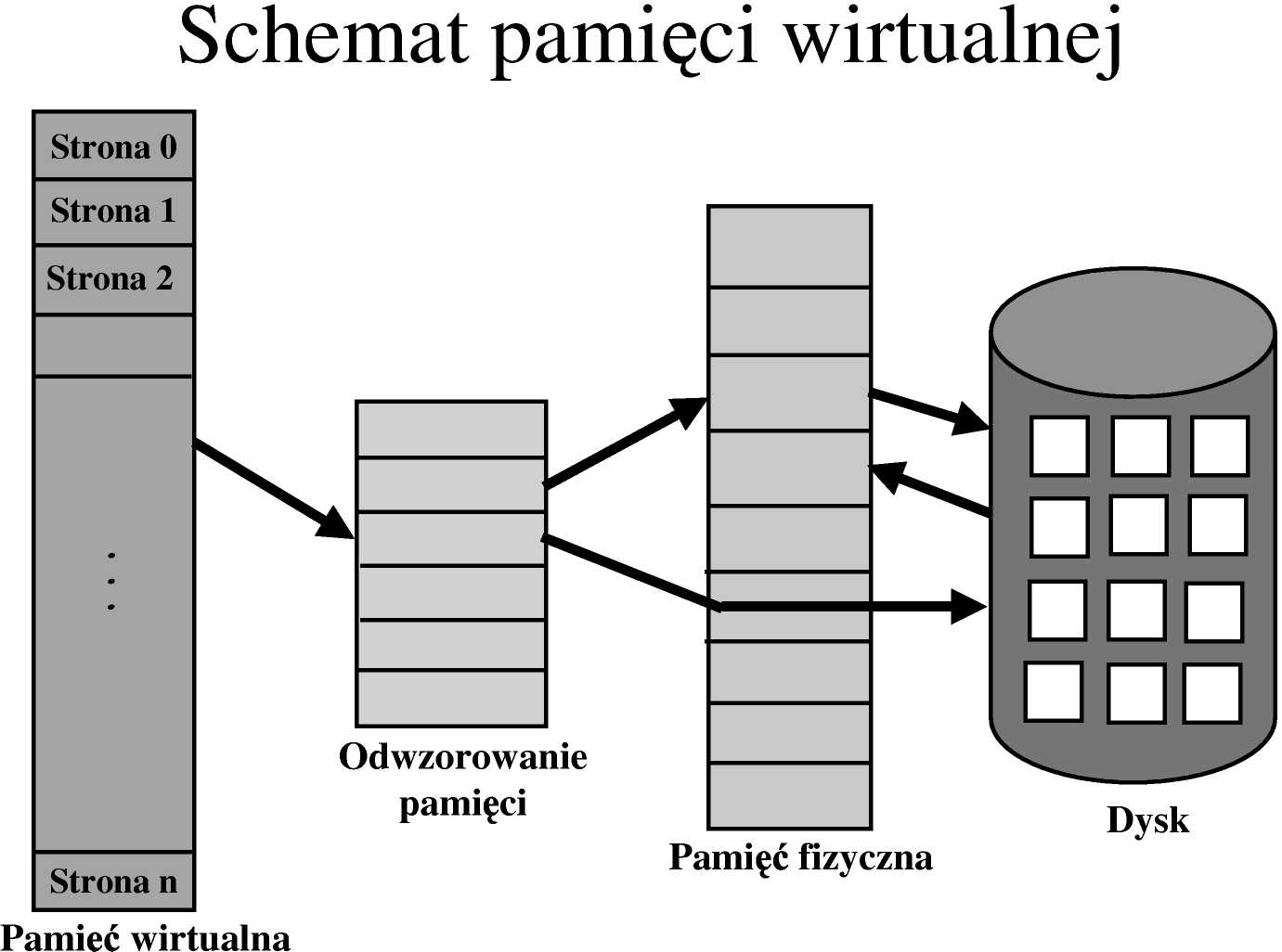
■ Segmentacji na żądanie (demand segmentation) - rzadziej, np. IBM OS/2.
Stronicowanie na żądanie
Procesy podzielone na strony przebywają w pamięci pomocniczej (zwykle dysk).
Strona jest sprowadzana z pamięci pomocniczej do operacyjnej tylko wtedy, kiedy jest potrzebna.
© Mniej operacji WE/WY.
© Mniejsze zapotrzebowanie na pamięć.
© Krótszy czas odpowiedzi.
© Może pracować równocześnie więcej użytkowników.
Strona jest potrzebna kiedy następuje do niej odwołanie.
Z każdą pozycją w tablicy stron związany jest bit poprawności (valid-invalid bit):
■ Wartość = 1: strona dozwolona i znajduje się w pamięci operacyjnej.
■ Wartość = 0: strona niedozwolona albo jest poza pamięcią operacyjną.
Odwołanie do strony z bitem poprawności równym 0 powoduje pułapkę braku strony (page-fault trap), po czym następuje awaryjne przejście do systemu operacyjnego.
Przydział ramek
Minimalna liczba ramek: Istnieje minimalna liczba ramek, które muszą być przydzielone procesowi - zdefiniowana jest przez architekturę logiczną komputera.
> Liczba ramek musi być wystarczająca do pomieszczenia wszystkich stron, do których może odnosić się pojedynczy rozkaz (niektóre rozkazy mogą zawierać wiele poziomów adresowania pośredniego).
Algorytmy przydziału ramek:
■ Przydział równy (equal allocation): Każdy proces dostaje tyle samo ramek, np. Jeżeli mamy 100 ramek i 5 procesów, to dajemy każdemu po 20 ramek.
■ Przydział proporcjonalny (proportional allocation): Każdemu procesowi przydziela się liczbę ramek proporcjonalnie do jego rozmiaru.
■ Przydział priorytetowy (priority allocation): Liczba przydzielanych ramek jest proporcjonalna do priorytetu procesu albo do kombinacji rozmiaru i priorytetu (proces o wyższym priorytecie dostaje więcej ramek).
Globalny lub lokalny przydział ramek:
■ Zastępowanie globalne: Proces może wybierać ramki do zastąpienia ze zbioru wszystkich ramek - jeden proces może odebrać ramkę drugiemu.
■ Zastępowanie lokalne: Proces może wybierać ramki tylko z własnego
zbioru przydzielonych ramek —→ gorsza przepustowość, rzadziej stosowane.
Szamotanie
Jeżeli proces nie ma wystarczającej liczby stron w pamięci operacyjnej, to częstotliwość braków stron będzie wysoka.
Prowadzi to do:
■ Zmniejszenia wykorzystania procesora.
■ Mniejsze wykorzystanie procesora może być sygnałem dla planisty przydziału procesora do zwiększenia wieloprogramowości.
■ Kolejny proces jest dodawany do systemu, co jeszcze zwiększa częstość braków stron.
■ Wykorzystanie procesora jeszcze się zmniejsza, co jest sygnałem dla planisty do dalszego zwiększania wieloprogramowości itd.
■ Powstaje szamotanina - przepustowość systemu gwałtownie spada!
Szamotanie (migotanie) (thrashing) - sytuacja, w której proces jest zajęty głównie wymianą stron (przesyłaniem między dyskiem a pamięcią operacyjną).
Szamotanie powoduje wyraźne zaburzenia wydajności systemu!
Unikanie szamotania
Efekt szamotania można ograniczać za pomocą lokalnego algorytmu
zastępowania -jeżeli jakiś proces się szamoce, to nie powinien zabierać ramek innemu procesowi i doprowadzać go też do szamotania.
Aby zapobiec szamotaniu należy dostarczyć procesowi tyle ramek ile potrzebuje - ale jak się o tym dowiedzieć?
Model strefowy (locality model):
■ Strefa programu - zbiór stron pozostających we wspólnym użyciu.
■ Program składa się z wielu różnych stref, które mogą na siebie zachodzić.
■ W trakcie wykonania proces przechodzi z jednej strefy programu do innej.
■ Aby uniknąć szamotania należy przydzielić procesowi tyle ramek, by mógł w nich pomieścić daną strefę.
Pliki odwzorowywane w pamięci
S Podczas sekwencyjnego przetwarzania pliku na dysku - za pomocą standardowych funkcji systemowych open(), read() i write() - każdy kontakt z plikiem wymaga odwołania do systemu i dostępu do dysku.
> Zamiast tego można skorzystać z metod pamięci wirtualnej i potraktować WE/WY plikowe jak rutynowy dostęp do pamięci.
• Tego typu podejście - zwane odwzorowaniem pliku w pamięci (operacyjnej)
(memory mapping) - polega na logicznym skojarzeniu z plikiem fragmentu pamięci wirtualnej.
■ Odbywa się przez odwzorowanie bloku dyskowego na stronę(y) pamięci.
■ Pierwszy dostęp do pliku odbywa się za pośrednictwem stronicowania na żądanie i skutkuje brakiem strony, co powoduje wczytanie do pamięci porcji pliku o rozmiarze strony (czasem jednorazowo wczytuje się więcej stron).
■ Następne operacje czytania i pisania pliku obsługiwane są jak zwyczajne dostępy do pamięci operacyjnej.
S Zapisy do pamięci niekoniecznie muszą oznaczać zapisy do pliku na dysku! © Prostszy i szybszy kontakt z plikami, łatwe dzielenie części plików przez procesy!
W niektóre systemach odwzorowania w pamięci dokonywane są tylko poprzez specjalne wywołania systemowe, a inne plikowe operacje WE/WY realizowanie są za pomocą standardowych funkcji systemowych.
Np. system Solaris zawsze wykonuje odwzorowanie -jeśli użyto funkcji mmap(), to plik odwzorowywany jest w przestrzeni procesu, jeśli nie, to w przestrzeni jądra.
Inne kwestie stronicowania
Stronicowanie wstępne (prepaging):
> Jednorazowe wprowadzenie do pamięci wszystkich stron, które wiadomo, iż będą potrzebne, np. całego zbioru roboczego.
S Trzeba rozstrzygnąć czy koszt stronicowania wstępnego jest mniejszy niż koszt obsługi odpowiednich braków stron.
Rozmiar strony:
Jaki wybrać rozmiar strony?
Zmniejszanie rozmiaru strony zmniejsza fragmentacje wewnętrzną, ale zwiększa zużycie pamięci na przechowywanie tablic stron.
Zwiększanie rozmiaru strony zmniejsza zużycie pamięci na tablice stron, ale powoduje większą fragmentację wewnętrzną pamięci.
Czas operacji WE/WY potrzebnych do odczytania i zapisania strony składa się z czasu: wyszukiwania, wykrywania i przesyłania. We współczesnych systemach komputerowych szybkość przesyłania jest na ogół znacznie większa od pozostałych dwóch, co przemawia za dużym rozmiarem stron.
Mniejsze strony łatwiej dopasować do stref programu (większa rozdzielczość). Przy większych stronach zmniejsza się liczba braków stron.
Obecnie jest tendencja do zwiększania rozmiarów stron (wzrost szybkości procesorów i pojemności pamięci jest szybszy niż szybkości dysków).
Inne kwestie stronicowania - c.d.
Zasięg TLB:
Współczynnik trafień w buforze TLB podczas tłumaczenia adresów wirtualnych może wpływać znacząco na szybkość dostępu do pamięci.
Zasięg TLB - ilość pamięci dostępnej w buforze, czyli liczba jego pozycji pomnożona przez rozmiar strony.
* Zwiększanie zasięgu TLB - zwiększanie liczby pozycji w buforze lub zwiększanie rozmiaru strony.
2 Niektóre architektury udostępniają strony o różnych rozmiarach, np. system Solaris korzysta ze stron 8 KB i 4 MB - zależnie od potrzeb.
Odwrócona tablica stron:
Odwrócona tablica stron ma po jednej pozycji na każdą ramkę, a indeksowana jest za pomocą pary <PID,numer_strony> - pozwala to zaoszczędzić miejsca w pamięci.
Odwrócona tablica stron nie zawiera jednak pełnych informacji o logicznej przestrzeni adresowej procesu, potrzebnych do obsługi braków stron.
Aby umożliwić stronicowanie na żądanie, dla każdego procesu utrzymuje się zewnętrzną tablicę stron zawierającą informację o położeniu każdej strony wirtualnej procesu. Odwołania do takich tablic występują tylko wskutek braków stron, zatem dostęp do nich nie musi być szybki.
Inne kwestie stronicowania - c.d.
Powiązanie stron z operacjami wejścia-wyjścia:
S Jak pogodzić zastępowanie stron z operacjami WE/WY?
□ Np. proces wysyła zamówienie na operacje WE/WY i zanim te operacje zostaną zrealizowane, system zastępuje jego stronę z buforem inną stroną.
> Stosuje się dwa rozwiązania:
1. Wykonywanie operacji WE/WY za pośrednictwem pamięci systemu.
2. Blokowanie (locking) stron w pamięci do czasu zakończenia operacji WE/WY (każdej ramce przyporządkowuje się bit blokowania) - ryzykowne!
Przetwarzanie w czasie rzeczywistym:
S Proces lub wątek działający w czasie rzeczywistym powinien niezwłocznie otrzymać procesor i działać z minimalnymi opóźnieniami.
> Ponieważ pamięć wirtualna może powodować przestoje w wykonywaniu procesu, dlatego większość systemów czasu rzeczywistego (i systemów wbudowanych) nie posiada pamięci wirtualnej.
□ System Solaris umożliwia zarówno podział czasu, jak i obliczenia w czasie rzeczywistym - proces czasu rzeczywistego ma możliwość powiadamiania systemu o ważnych stronach, a uprzywilejowani użytkownicy mogą blokować strony w pamięci (niebezpieczeństwo nadużycia!).
Pamięć wirtualna w MS Windows XP
1 Pamięć wirtualna jest realizowana przy użyciu stronicowania na żądanie z grupowaniem (clustering) - do pamięci sprowadzana jest nie tylko brakująca strona, ale także pewna liczba stron z jej otoczenia.
1 Zaraz po utworzeniu procesowi przypisuje się minimum i maksimum zbioru
roboczego - w tym zakresie przydziela się procesowi strony w zależności od ilości wolnej pamięci (czasem pozwala się procesowi przekroczyć maksimum).
1 Zarządca pamięci wirtualnej utrzymuje wykaz wolnych ramek, z którym skojarzona jest pewna wartość progowa (threshold value).
1 Gdy ilość wolnej pamięci spada poniżej wartości progowej, zarządca pamięci wirtulanej stosuje taktykę zwaną automatycznym przycinaniem zbioru
roboczego (authomatic working-set trimming) w celu przywrócenia wartości ponadprogowej - procesom, które mają więcej stron niż wynosi ich minimum zbioru roboczego odbierane są strony.
1 Algorytm wyznaczania strony do usunięcia zależy od typu procesora:
■ W jednoprocesorowych systemach x86 Windows XP używa odmiany algorytmu zegarowego.
■ Dla procesorów Alpha i wieloprocesorowych systemów x86 Windows XP stosuje odmianę algorytmu FIFO.
Pamięć wirtualna w systemie Solaris
Z wykazem wolnych stron związany jest parametr lotsfree (tzn. miejsca pod dostatkiem) będący progiem rozpoczynania stronicowania - na ogół wynosi 1/64 rozmiaru pamięci fizycznej.
W ustalonych odstępach czasu jądro sprawdza, czy ilość wolnej pamięci nie jest mniejsza od lotsfree -jeżeli tak, to uruchamiany jest proces wymiatania stron (pageout).
Proces wymiatania stron realizuje odmianę algorytmy drugiej szansy zwaną algorytmem zegara dwuwskazówkowego (two-handed-clock algorithm):
■ Pierwsza wskazówka obiega wszystkie strony pamięci i ustawia ich bity odniesień na0.
■ Po pewnym czasie druga wskazówka sprawdza bity odniesień do stron w pamięci i zwalnia te strony, których bity są dalej równe 0.
Szybkość analizowania stron (scanrate) w powyższym algorytmie jest określona za pomocą kilku parametrów sterujących: od slowscan (wolna analiza) do fastscan (szybka analiza).
Odległość w stronach między wskazówkami zegara jest określona przez parametr handspread.
Jeżeli ilość wolnej pamięci spada poniżej poziomu desfree, to jądro zaczyna wymianę procesów (swapping).
Jeżeli system nie jest w stanie utrzymać ilości wolnej pamięci na poziomie minfree, to wymiatanie jest wołane przy każdym zamówieniu nowej strony.
System plików
Interfejs systemu plików.
Pojęcie pliku. Metody dostępu. Struktura katalogowa.
Montowanie systemu plików.
Dzielenie plików.
Ochrona.
Pojęcie pliku
Plik (file) jest logiczną jednostką magazynowania informacji w pamięci pomocniczej (magnetyczne dyski i taśmy, dyski optyczne).
Plik jest ciągiem bitów, bajtów, wierszy lub rekordów, których znaczenie określa twórca pliku i jego użytkownik.
W pliku można przechowywać różnego rodzaju informacje: programy źródłowe, programy wynikowe, programy wykonywalne, dane liczbowe, teksty, listy płac, obrazy grafiki komputerowej, nagrania dźwiękowe itd.
Za pomocą systemu operacyjnego pliki odwzorowywane są na fizycznych urządzeniach pamięci, które charakteryzują się nieulotnością (nonvolatile devices).
System plików składa się z dwu lub trzech części:
■ Zbiór plików;
■ Struktura katalogów - do organizowania i udostępniania informacji o wszystkich plikach w systemie;
■ W niektórych systemach występują ponadto partycje (strefy) (partitions), służące do wyodrębniania fizycznie lub logicznie wielkich zbiorów katalogów.
Atrybuty pliku
Nazwa - symboliczna nazwa pliku jest jedyną informacją przechowywaną w postaci czytelnej dla człowieka (niektóre systemy rozróżniają wielkie i małe litery, inne zaś nie).
Identyfikator - pole o niepowtarzalnej wartości, zwykle liczbowej; wyodrębnia plik w całym systemie (jest to nazwa pliku w postaci nieczytelnej dla człowieka).
Typ - informacja potrzebna w systemach, w których rozróżnia się typy plików.
Lokacja - wskaźnik do urządzenia i położenia pliku na tym urządzeniu.
Rozmiar - atrybut zawierający bieżący rozmiar pliku (w bajtach, słowach lub blokach); może też zawierać maksymalny dopuszczalny rozmiar pliku.
Ochrona - informacje kontroli dostępu, służące do sprawdzania, kto może plik czytać, zapisywać, wykonywać itd.
Czas, data i identyfikator użytkownika - dane o czasie utworzenia pliku, ostatniej modyfikacji, ostatnim użyciu itp.
Informacje o wszystkich plikach są przechowywane w strukturze katalogowej, która również rezyduje w pamięci pomocniczej.
Operacje plikowe
Tworzenie pliku (create) - niezbędne dwa kroki: (1) znalezienie miejsca na pl oraz (2) utworzenie wpisu pliku w katalogu (nazwa pliku i informacja o jego położeniu w systemie plików).
Zapisywanie pliku (write) - wywołanie odpowiedniej funkcji systemowej i podanie jej nazwy pliku oraz informacji, która ma być zapisana; system musi przechowywać wskaźnik pisania określający miejsce pliku, do którego będzie się odnosić kolejna operacja pisania (musi być uaktualniany podczas każdego pisania).
Czytanie pliku (read) - wywołanie funkcji systemowej, której podaje się nazw pliku oraz miejsce (w pamięci operacyjnej), gdzie należy umieścić następny blok pliku; potrzebny jest wskaźnik czytania. Niektóre systemy utrzymują tylko jeden wskaźnik bieżącego położenia w pliku (current-file-position) - używan zarówno do czytania, jak i pisania (oszczędność miejsca, uproszczenie systemu
Zmiana pozycji w pliku (repositioning) lub przemieszczenie w pliku (seek) -nadanie określonej wartości wskaźnikowi bieżącego położenia w pliku.
Usuwanie pliku (deleting) - zwolnienie całej przestrzeni zajmowanej przez pli i likwidacja danego wpisu katalogowego.
Skracanie pliku (truncating) - ponowne ustalenie zerowej długości pliku przy niezmienionych pozostałych atrybutach.
Mogą też istnieć inne operacje, jak: dopisywanie (appending) na końcu pliku, przemiano wy wanie (renaming) istniejącego pliku itd.
Struktura pliku
Minimalna struktura: plik jako ciąg bajtów lub słów (np. UNIX, MS-DOS); każdy program użytkowy musi posiadać własny kod interpretujący plik wejściowy jako odpowiednią strukturę.
Każdy system operacyjny musi realizować przynajmniej jedną struktur: plik wykonywalny - w celu ładowania i wykonywania programów.
Niektóre systemy realizują pewien zbiór struktur plików zaopatrzonych w zestawy specjalnych operacji do manipulowania takimi plikami (np. DEC VMS, Macintosh OS).
Wewnętrzna struktura pliku:
■ Blok (rekord fizyczny) -jednostka fizycznej pamięci dyskowej; wszystkie bloki są tego samego rozmiaru.
■ Rekord logiczny - logiczna jednostka informacji; rekordy logiczne mogą być różnej długości.
> Często stosuje się upakowywanie (packing) pewnej liczby rekordów logicznych w fizycznych blokach, np. UNIX: rekord logiczny ma długość 1B, a blok fizyczny zwykle 512B.
> Przydział przestrzeni dyskowej w postaci bloków prowadzi do fragmentacji wewnętrznej.
Metody dostępu
Dostęp sekwencyjny (sequential access) - informacje w pliku są przetwarzane sekwencyjnie, jeden rekord za drugim; najpowszechniejszy rodzaj dostępu (np. edytory, kompilatory).
Dostęp bezpośredni (direct access) - plik składa się z rekordów logicznych o stałej długości, które mogą być przetwarzane bez jakiegokolwiek porządku (tzn. bezpośrednio):
Operacje czytania i pisania typu: czytaj n ; pisz n ; gdzie n jest
numerem bloku - zwykle tzw. numerem względnym bloku (relative block
number), tzn. indeksem względem początku pliku.Przy pomocy dostępu bezpośredniego można łatwo symulować dostęp
sekwencyjny; symulacja w drugą stronę jest bardzo nieefektywna.
Dostęp indeksowy (indexed access) - z plikiem związany jest indeks zawierający wskaźniki do bloków pliku; dla dużych plików wprowadza się podwójne indeksowanie, tzn. pierwotny indeks zawiera wskaźniki do wtórnego indeksu.
Struktura katalogowa
Duże zasoby dyskowe często dzieli się na party cj e (strefy) (partition), w niektórych systemach zwane minidyskami lub wolumenami (volumes). Jeden dysk może być podzielony na kilka partycji, ale też kilka dysków może tworzyć jedną party cj ę.
Katalog urządzenia (device directory) zawiera informacje o plikach w danej partycji: nazwy, położenia, rozmiary, typy. Katalog można uważać za tablicę symboli tłumaczącą nazwy plików na ich wpisy katalogowe.
Operacje na katalogu:
Odnajdywanie pliku - znajdowanie plików według ich nazw. Tworzenie pliku - tworzenie plików i dołączanie ich do katalogu. Usuwanie pliku - usuwanie plików z katalogu. Wyprowadzanie katalogu - sporządzanie wykazu plików w katalogu.
Przemiano wy wanie pliku - zmiana nazwy pliku lub jego miejsca w strukturze katalogowej.
Obchód systemu plików - uzyskiwanie dostępu do każdego pliku i katalogu w obrębie struktury katalogowej, regularne zapamiętywanie zawartości i struktury całego systemu plików (kopie zapasowe).
Katalogi jedno- i dwupoziomowe
• Katalog jednopoziomowy - jeden katalog dla wszystkich plików.
• Katalog dwupoziomowy - oddzielny katalog dla każdego użytkownika.
■ Możliwe te same nazwy plików dla różnych użytkowników.
■ Nazwa użytkownika i nazwa pliku definiuje nazwę ścieżki (path name). ® Brak możliwości grupowania plików, użytkowników itd.
Katalogi o strukturach drzewiastych
Własności katalogów drzewiastych
Katalog zawiera zbiór plików lub podkatalogów.
Jeden bit w każdym wpisie katalogowym określa, czy wpis dotyczy pliku (0), czy podkatalogu (1).
Do tworzenia, usuwania, kopiowania, przenoszenia, zmiany katalogów służą specjalne funkcje systemowe.
Podczas normalnej pracy każdy użytkownik ma do dyspozycji katalog bieżący (current directory).
Nazwy ścieżek mogą być:
■ Bezwzględne - biegnie od korzenia aż do danego pliku (podkatalogu).
■ Względne - od bieżącego (lub domowego) katalogu do pliku (podkatalogu).
Użytkownik ma możliwość tworzenia własnych podkatalogów, a tym samym kształtowania struktury własnych plików.
Niektóre systemy pozwalają usuwać tylko puste katalogi (np. MS-DOS), a inne również katalogi z zawartością (np. UNIX: rm).
Użytkownicy mogą mieć dostęp do plików innych użytkowników.
Niektóre systemy pozwalają użytkownikom definiować własne ścieżki przeszukiwań (np. UNIX: zmienna $PATH).
Ochrona
Ochrona (protection) systemu plików przed niewłaściwym dostępem jest jednym z podstawowych zagadnień związanych z przechowywaniem informacji w systemie komputerowym.
Kontroli mogą podlegać następujące operacje:
■ Czytanie - czytanie z pliku.
■ Pisanie - pisanie do pliku lub zapisywanie go na nowo.
■ Wykonywanie - załadowanie pliku do pamięci i wykonanie go.
■ Dopisywanie - zapisywanie danych na końcu pliku.
■ Usuwanie - usuwanie pliku i zwalnianie jego obszaru dyskowego.
■ Opisywanie - wyprowadzenie nazwy i atrybutów pliku.
> Ochronę innych operacji (wyższego poziomu) można zaimplementować za pośrednictwem powyższych operacji.
Kontrolowanie dostępu:
■ Najogólniejsza metoda - skojarzenie z każdym plikiem i katalogiem listy kontroli dostępów (ACL) zawierającego nazwy użytkowników i dozwolone dla nich rodzaje dostępu. © Wysokie koszty utrzymywania i uaktualniania.
■ Efektywniejsza metoda - skojarzenie z każdym plikiem trzech klas użytkowników: właściciel, grupa, wszeświat i przypisywanie praw dostępu (np. czytania, pisania, wykonywania) do każdej z klas (np. system UNIX).
24
Wyszukiwarka
Podobne podstrony:
Systemy operacyjne
5 Systemy Operacyjne 23 11 2010 Zarządzanie procesami
zasady grupy, java, javascript, oprogramowanie biurowe, programowanie, programowanie 2, UTK, systemy
Systemy Operacyjne lab4, Politechnika Wrocławska, Systemy Operacyjne
format[1], Szkoła, Systemy Operacyjnie i sieci komputerowe, systemy, semestr I
System plików, zOthers, Systemy operacyjne i sieci komputerowe
quota, !!!Uczelnia, wsti, materialy, II SEM, systemy operacyjne linux
Rafał Polak 12k2 lab8, Inżynieria Oprogramowania - Informatyka, Semestr III, Systemy Operacyjne, Spr
System operacyjny
01 Systemy Operacyjne ppt
12 wspomaganie systemu operacyjnego pamiec wirtualna
Pytania do egzaminu z Systemow Operacyjnych cz, EdukacjaTEB
W2K3-15-raport, WAT, SEMESTR VII, Systemy operacyjne windows, Systemy operacyjne windows, sow, W2K3-
Pamięci dynamiczne RAM, Szkoła, Systemy Operacyjnie i sieci komputerowe, utk, semestr I
Model ISO-OSI, szkola, systemy operacyjne, klasa 4
dobrucki,systemy operacyjne, Rodzaje pamięci
Organizacja pamięci komputerów, szkola, systemy operacyjne, klasa 1
zadania-egzaminacyjne, Studia WIT - Informatyka, Systemy operacyjne
więcej podobnych podstron