Katedra Baz Danych
Dawid Borek
nr albumu s3188/M
Synchronizacja i replikacja danych,
z zastosowanie do studiów internetowych PJWSTK.
Praca napisana pod kierunkiem
Prof. dr Lecha Banachowskiego
WARSZAWA 2004
Wstęp.
Nieustanny rozwój ludzkości generuje ogromną ilość informacji. Wiek XIX i XX były nazywane złotymi wiekami rozwoju i nauki, zaś wiek XXI nazywany jest wiekiem informacji.
Każde nowe osiągniecie ludzkości, wynalazek, nowe prawo naukowe traktujemy jako nową informację, która jeszcze dokładniej opisuje nasz świat i pozwala lepiej go zrozumieć. Właśnie dzięki natychmiastowej wiedzy na temat najnowszych osiągnięć ludzkości, jesteśmy w stanie tak szybko i właściwie reagować na zmiany, które nie zawsze blisko nas zachodzą. To dzięki Internetowi - ogromnej bazie danych - możemy natychmiast korzystać z wiedzy innych ludzi. Nigdy jeszcze w historii ludzkości nie mieliśmy tak wielkich możliwości. Jednak problem pojawia się, kiedy informacji jest za dużo i nie jesteśmy w stanie przyswoić wszystkich danych dotyczących poszukiwanych informacji. Powód jest prosty - informacji jest za wiele, są mało konkretne, lub są one zbyt obszerne, często zdarza się tak, że dostępne informacje w momencie swojej publikacji są już przestarzałe. Dlatego ważne dla funkcjonowania ludzkości dane są cenniejsze niż wszelkie bogactwa, to one opisują nasze życie i wytyczają nowe szlaki w naszym rozwoju.
Nie jest możliwe wypisanie wszystkich kluczowych informacji potrzebnych ludzkości. Każdy człowiek potrzebuje do swojej pracy, rozwoju, informacji na dany, konkretny temat.
Dlatego coraz częściej spotykamy się z handlem informacją, sprzedawaniem konkretnych danych.
Dzisiejszy świat nie istniałby bez informacji, które zmieniają się cały czas. Przykładem mogą być notowania giełdowe, kursy walut, wiadomości kluczowe dla działania instytucji, itp..
Te i wiele innych newralgicznych informacji musimy posiadać a co najważniejsze musimy posiadać je jak najbardziej aktualne. W wielu przypadkach nie możemy pozwolić sobie na używanie danych, co do których nie jesteśmy pewni, że są aktualne i konkretne.
I tu właśnie przychodzą na z pomocą ogromne bazy danych, które cały czas ewoluują, setki tysięcy ludzi pracują tylko nad tym, aby dane te były trafne i aktualne, a informacje jakie niosą konkretne. Dane, które są kluczowe musza być dostępne w każdym miejscu na ziemi i w każdej chwili.
Dlatego tak ważne jest ich poprawne rozpropagowywanie, natychmiastowe kopiowanie ich do węzłów, z których będą dostępne dla wszystkich, którzy chcą je otrzymać. Same dane są nic nie warte, jeśli nie można z nich skorzystać, wiec najważniejsze jest udostępnienie ich zainteresowanym ludziom.
Informacje bez konkretnego przeznaczenia nie są wykorzystywane i tracą swoja wartość, więc tak ważne jest, aby informacja zawsze była dostępna i aktualna.
Do tego właśnie celu służy replikacja, dzięki tej funkcji dostajemy możliwość dowolnego kopiowania danych ze źródła posiadającego aktualne dane, dzięki czemu możemy na bieżąco wiedzieć, co dzieje się w około nas.
Dzięki zastosowaniu replikacji informacje zostają przesłane do dowolnej ilości subskrybentów (serwerów podległych), dzięki czemu dostęp do nich staje się szybszy i łatwiejszy.
Funkcjonowanie wielu dziedzin życia jest zależne od sprawnego przepływu danych. Dzięki ciągłości i niezawodności w przepływie informacji mogliśmy wyprzedzić setki lat ewolucji, zyskaliśmy ogromna wygodę i bezpieczeństwo.
Głównym celem mojej pracy jest zaprojektowanie systemu replikacji i synchronizacji danych dla bazy danych EDU@PJWSTK. System Studiów Internetowych EDU@PJWSTK jest przeznaczony do prowadzenia nauczania przez Internet. Wraz z powstaniem nowych placówek naszej uczelni w Polsce jak i w Europie istnieje potrzeba zaprojektowania systemu wymiany danych pomiędzy różnymi filiami szkoły. Praca moja ma na celu analizę danych EDU@PJWSTK oraz przedstawienie konkretnych rozwiązań, które w przyszłości mogą zostać zrealizowane.
W pracy przedstawię najważniejsze zagadnienia związane z dystrybucją danych bazy EDU@PJWSTK. Praca będzie miała na celu przedstawienie procesu synchronizacji danych z jednego lub wielu źródeł. Wskaże jak ważne jest właściwe zarządzanie danymi, kiedy i jak należy uaktualniać informacje. Będę starał się przedstawić przypadki, w których natychmiastowe aktualizowanie danych jest niezbędne dla poprawnego działania systemu, jak również takie przypadki, kiedy dane z wielu źródeł będą scalane i aktualizowane w jednym centralnym głównym źródle. W pracy pokaże jak ważna może być pojedyncza zmiana informacji dla utrzymania spójności złożonego systemu. Wskaże dane, które są newralgiczne i które nie mogą zostać przekłamane jak i takie, których zmiana nie ma skutku natychmiastowego w całym systemie.
Replikacja jest to proces kopiowania i utrzymywania obiektów (np. tabel) w połączonych bazach danych, tworzących jedno środowisko.
W pracy przedstawię różne typy środowisk replikacji (replikacja transakcyjna, replikacja, migawkowa, replikacja scalająca), przebieg propagacji zmian, obiekty wspomagające replikację, a także metody wykrywania i rozwiązywania konfliktów replikacji.
1.Opis dziedziny i problemu.
Głównym problemem mojej pracy jest analiza danych bazy danych EDU@PJWSTK i na podstawie przeprowadzonej analizy dobór odpowiedniej metody replikacji i synchronizacji danych.
Baza danych EDU@PJWSTK jest integralną częścią systemu Studiów Internetowych Polsko-Japońskiej Wyższej Szkoły Technik Komputerowych w Warszawie. Ten nowatorski system Studiów Internetowych EDU@PJWSTK daje studentom możliwość uczenia się w dowolnym momencie, całą dobę, 7 dni w tygodniu, przez cały semestr. Umożliwia studentom pozyskiwanie informacji potrzebnych w celach nauki, oferuje możliwość przeprowadzania testów, egzaminów, kontaktu z wykładowcami, wymiany informacji pomiędzy studentami oraz wiele innych . System EDU@PJWSTK przygotowany jest z myślą o ludziach którzy nie mogą pozwolić sobie na normalny system studiowania.
Sercem systemu EDU@PJWSTK jest baza danych w której zapisane są wszystkie informacje odnośnie działania systemu, studentów zarejestrowanych w systemie, wyników ich nauki oraz materiałów z których powinni korzystać. System posiada wiele funkcji przydatnych wykładowcom do analizy pracy studentów. Szersze informacje na temat danych w systemie EDU@PJWSTK przedstawię w rozdziale.
Wraz z powstaniem nowych fili Polsko-Japońskiej Wyższej Szkoły Technik Komputerowych zaistniała potrzeba synchronizacji i replikacji danych z różnych źródeł do centrali uczelni w Warszawie. W kolejnych rozdziałach przedstawię dokładnie zasadę działania systemu replikacji danych jak również wskaże argumenty przemawiające za konkretnymi rozwiązaniami replikacji i synchronizacji danych.
Replikacja i synchronizacja danych to procesy których nie da się wdrożyć nie wykonując analizy danych dla których będą przeprowadzane. Proces replikowania danych jest autonomiczną sprawą każdej bazy danych. To jakie dane i w jakim środowisku te dane działają ma podstawowe znaczenia na proces konfiguracji replikacji. Synchronizacja danych jest zaś procesem wymagającym bardzo dokładnej analizy danych, odpowiednia analiza danych w tym przypadku jest kluczową sprawą.
Nie można założyć że odpowiedni proces replikacji bądź synchronizacji danych będzie właściwy nie wykonując testów i pomiarów, jak również nie biorąc pod uwagę zagrożeń które mogą wyniknąć z niewłaściwego doboru metody propagacji danych do innych źródeł.
Moja praca jest pewnym rozpoczęciem problemu replikacji danych, gdyż proces replikacji i synchronizacji danych ewoluuje wraz ze zmianą bądź rozszerzeniem bazy danych o nowe funkcje. Replikacja zmienia się również jeśli zachodzi potrzeba zmiany środowiska w jakim pracują dane bądź zastosowań danych.
System EDU@PJWSTK jest cały czas poszerzany o nowe funkcje, moduły. Polsko-Japońska Wyższa Szkoła Technik Komputerowych tworzy nowe filie. Program nauczania studentów też zmienia się co jakiś czas. Te zmiany będą powodować ciągłą ewolucje systemów replikacji i synchronizacji danych, które w przyszłości będą tworzone dla potrzeb naszej uczelni.
Praca moja jest więc tylko wstępem, fundamentem na którym w przyszłości może powstać skomplikowany system wymiany informacji, który będzie obejmował kilka europejskich stolic.
Replikacja danych.
W sposób bardziej zrozumiały można przestawić replikację jako lustrzane odbicie pewnych wartości w dowolnym innym miejscu. Replikowane dane zachowują podstawowe wartości ACID. Mówiąc o replikacji mamy na myśli kopiowanie pewnego zbioru danych z pewnego miejsca czyli źródła, do miejsca docelowego. Źródłem danych może być pojedyncza tabela, baza lub wiele baz danych, to samo tyczy się miejsca docelowego, które nazywamy repliką.
Replikację danych najczęściej wykorzystuje się w systemach rozproszonych baz danych, gdzie z jednego zdalnego węzła kopiuje się dane do innych zdalnych węzłów. Celem replikacji w tych systemach jest, po pierwsze, skrócenie czasu dostępu do danych. W tym przypadku uniezależniamy się od przepustowości i aktualnego obciążenia sieci, oraz od wydajności zdalnych węzłów i ich aktualnego obciążenia. Po drugie, dzięki replikacji uniezależniamy się od czasowej niedostępności węzłów i awarii sieci.
Wadą replikacji jest konieczność uaktualniania repliki w przypadku zmian w tabelach źródłowych. Taki proces uaktualniania będę również nazywał synchronizacją (ang. synchronization) lub odświeżaniem (ang. refreshing) repliki.
Replikacja wymaga utrzymywania połączeń pomiędzy węzłami. Węzeł kontaktuje się z innymi węzłami przy pomocy specjalnego obiektu schematu, noszącego nazwę łącznika bazy danych.
W większości opracowań podstawowa definicja replikacji przedstawiana jest jako model dystrybucji danych „przechowaj i wyślij”, czyli dane wprowadzone w jednym miejscu są automatycznie przesyłane dalej.
Rysunek 3.1. Schemat „przechowaj i wyślij”.
Zastosowanie replikacji i synchronizacji.
Replikacja i synchronizacja jest problemem bardzo złożonym i ciężko jest zdefiniować jej wszystkie zastosowania. Jednakże można przedstawić podstawowe, szablonowe zastosowania tych technik w informatyce. W literaturze dotyczącej replikacji danych można wyróżnić trzy podstawowe zastosowania replikacji i synchronizacji danych. Rozwiązania te przedstawiam jako pojedyncze problemy, chociaż mogą one być zastosowane wszystkie naraz lub jako kombinacja poszczególnych rozwiązań w zależności od środowiska replikacji i potrzeb.
Wyróżniamy trzy podstawowe zastosowania replikacji:
Dostarczanie danych do różnych miejsc w sieci w celu ograniczenia ruchu, obciążenia i niepotrzebnego ładowania danych na pojedynczy (najczęściej główny) serwer.
Rysunek 4.1. Przykład zastosowania replikacji 1.
Rozsyłanie danych do wielu serwerów w celu zwiększenia stopnia niezawodności i decentralizacji lub partycjonowania danych.
Rysunek 4.2. Przykład zastosowania replikacji 2.
Przesyłanie wszystkich danych do serwera pełniącego role zapasowego (backup) w celu zastąpienia serwera podstawowego podczas awarii.
Rysunek 4.3. Przykład zastosowania replikacji 3.
Role serwera w środowisku replikacji danych.
SQL Server może pełnić jedną z trzech ról w środowisku replikacji:
Publikator
Publikator jest to serwer na którym przechowywana jest publikacja lub publikacje które zamierzamy rozpropagować. Publikacją nazywamy bazę danych, która została udostępniona do replikacji.
Dystrybutor
Dystrybutor jest to serwer na którym została zlokalizowana baza danych przeznaczona do dystrybucji. Jest serwerem dystrybucyjny. Może być zlokalizowany na serwerze publikacji lub na innym serwerze typu „stand alone”. Baza dystrybutora zawiera wszystkie zmienione dane które oczekują na rozpropagowanie. Dystrybutor może obsługiwać wiele publikatorów i rozsyłać dane do wielu subskrybentów. Jest głównym serwerem w środowisku replikacji.
Subskrybent
Subskrybent jest serwerem przechowywującym całą lub fragment publikowanej bazy danych. Serwer dystrybucyjny przesyła wszystkie zmiany zachodzące w publikowanej bazie do kopii tej bazy utrzymywanej na subskrybencie lub subskrybentach.
W Microsoft SQL Server 2000 subskrybent jest w stanie wprowadzać zmiany w danych które otrzymuje po czym odesłać je do publikatora. Subskrybent taki jest nazywany również „modyfikującym subskrybentem”, którego jednak nie możemy uważać za publikatora.
Te trzy podstawowe role serwera współpracują ze sobą wymieniając dane. Dane takie nazywamy publikacjami lub artykułami.
Replikowane dane.
Używając mechanizmów replikacji i synchronizacji MS SQL Server możemy publikować dane z tabel, obiektów bazy, wyniki działania procedur zapamiętanych, obiekty schematu bazy, indeksy, wyzwalacze.
W pracy replikowane dane będę nazywał publikacją, która jest podstawową jednostką publikowanych danych.
Publikacja jest to zbiór złożony z jednego lub kilku artykułów.
Artykuł jest to pojedyncza tabela przeznaczona do replikacji lub przefiltrowany zbiór jej wierszy albo kolumn.
Pojedyncza baza danych może zawierać więcej niż jedną publikację. MS SQL automatycznie aktualizuje wszystkie artykuły w publikacji w tym samym czasie, dane te są zsynchronizowane, niezależnie od tego czy planujemy je replikować teraz czy w późniejszym czasie. Takie działanie zapobiega replikowaniu danych różnych danych na serwery mające posiadać taką samą replikę. Można sobie wyobrazić, że dwa serwery pobierają dane z tej samej publikacji w różnym czasie. Serwer pierwszy pobiera publikacje o 2 godziny wcześniej niż drugi. Jednak dane które pobrały te serwery są zsynchronizowane względem siebie. Dzięki możliwości zablokowania aktualizacji publikacji do czasu replikacji do wszystkich subskrybentów, dane na wszystkich subskrybentach są zsynchronizowane. Istnieje oczywiście możliwość natychmiastowej aktualizacji publikacji jednak stosuje się ją w konkretnych przypadkach o których w dalszej części pracy.
Filtrowanie danych.
Publikacja składa się z artykułów, artykuły zaś z konkretnych danych. Istnieje wiele sposobów na stworzenie artykułów. Najprostszą jest opublikowanie wszystkich wierszy i kolumn danej tabeli. Jednak w bazie danych EDU@PJWSTK istnieją dane podlegające szczególnej ochronie tj. dane osobowe, oceny, numery indeksów, itd. Dlatego podczas replikowania tabel zawierających takie dane możemy wykluczyć ich replikowanie do konkretnych subskrybentów za pomocą zastosowania filtrów. Innym przykładem zastosowania filtrów dla bazy danych EDU@PJWSTK jest publikacja danych dotyczących tylko konkretnego regionu np. fili uczelni na Ukrainie.
W niektórych opracowaniach można spotkać się z terminami fragmentacji poziomej i pionowej, która zamiennie występuje z terminem filtrowania danych.
W Microsoft SQL Server 2000 wyróżniamy dwa rodzaje filtrowania, fragmentacji:
poziome (horizontal) - dotyczy wierszy tabeli
pionowe (vertical) - dotyczy kolumn tabeli
Filtrowanie poziome i pionowe możemy stosować jako połączenie obu sposobów filtracji.
Istnieją również możliwość używania filtrów złączeniowych lub dynamicznych.
Filtry złączeniowe pozwalają na wybieranie konkretnych informacji z kilku tabel.
DOPISAC
Jak wcześniej wspomniałem publikować możemy również zapamiętane procedury. Dzięki takiej opcji możemy przesłać do subskrybenta dane i nakazać mu wykonanie odpowiedniej procedury. Mówimy tu o publikacji „wykonania procedury zapamiętanej”. Po przez zastosowanie tej metody zyskujemy ogromne zmniejszenie liczby przenoszonych przez sieć poleceń SQL, ponieważ procedura wykonywana jest na serwerze subskrybenta. Trzeba jednak pamiętać o tym aby „przeniesiona procedura” wykonała się identycznie jak na publikatorze.
Środowiska replikacji.
W zależności od potrzeb, wymagań można przyjąć jedno z kilku środowisk replikacji:
Centralny publikator.
Centralny subskrybent.
Centralny publikator ze zdalnym dystrybutorem.
Publikujący subskrybent.
Wiele publikatorów lub subskrybentów.
Subskrybent wprowadzający zmiany.
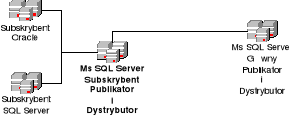
Centralny publikator.
Podstawowym środowiskiem replikacji według Microsoftu jest model centralnego publikatora, rysunek 6.1. Jest to pojedynczy serwer Microsoft SQL Server, który pełni rolę publikatora oraz jest jednocześnie dystrybutorem, może posiadać wiele różnych subskrybentów np. MS SQL Server 2000, MS SQL Server 7.0, Oracle, IBM DB2, Sybase.
Rysunek 6.1 Centralny publikator.
Środowisko centralnego publikatora można stosować w następujących sytuacjach:
Tworzenie kopii bazy danych do szybkiego generowania raportów (klasyczne rozwiązanie).
Publikowanie informacji nadrzędnych, takich jak listy studentów czy aktualnych ocen, do innych miejsc w sieci.
Pielęgnowanie zdalnych kopii baz OLTP, które mogą być użyte przez zdalne serwery w razie przerw komunikacyjnych.
Pielęgnowanie kopii zapasowej bazy OLTP, która może być użyta podczas awarii głównego serwera.
Microsoft zastrzega, że nie wolno wykorzystywać tego środowiska jeśli:
Zmiany na serwerze OLTP dotyczą więcej niż 10% ogólnej liczby danych.
Jeśli pamięć, CPU, dyski twarde na serwerze są wykorzystywane w więcej niż 70%
Jeżeli nie jest to serwer typu „stand alone” czyli nie jest dedykowany tylko do działania jako serwer SZBD.
W takim przypadku należy wybrać jedno z pozostałych rozwiązań.
Centralny publikator ze zdalnym dystrybutorem.
Środowisko centralnego publikatora ze zdalnym dystrybutorem, rysunek 6.2, nie różni się znacząco od środowiska centralnego publikatora, jedyną różnicą jest to że serwer dystrybucyjny znajduje się na oddzielnym komputerze. Dzięki czemu publikator zostaje odciążony i nie prowadzi zadań dystrybucyjnych. Zastosowanie to ma również duże znaczenie w sytuacji kiedy mamy wiele publikatorów gdyż mogą one wykorzystywać jeden dystrybutor. Głównym wymaganiem dotyczącym tego środowiska jest zapewnienie dystrybutorowi szybkiego i niezawodnego łącza. Dzięki zastosowaniu zdalnego dystrybutora, możemy zastosować większą liczbę subskrybentów i publikatorów. Zdalny dystrybutor może być umiejscowiony w dowolnym miejscu (np. w centrum kraju, lub Europy) oczywiście jeśli pozwala na to przepustowość łączy.
Rysunek 6.2 Centralny publikator ze zdalnym dystrybutorem.
Zastosowanie środowiska centralnego publikatora ze zdalnym dystrybutorem może być użyte w identycznych sytuacjach jak dla środowiska centralnego publikatora. Koszty tego rozwiązania będą wyższe o cenę dodatkowego serwera dystrybucyjnego lecz obciążenia publikatora będą minimalne.
Microsoft zapewnia, że jeżeli aktywność serwera OLTP wynosi dziennie więcej niż 10% i zasoby publikatora są wykorzystywane w znacznym stopniu to zastosowanie tego środowiska powinno się sprawdzić.
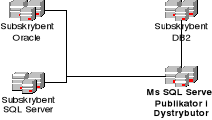
Publikujący subskrybent.
W środowisku publikującego subskrybenta, rysunek 6.3, serwer publikujący spełnia jednocześnie rolę dystrybutora dla pojedynczego subskrybenta. Subskrybent ten publikuje otrzymane dane do innych subskrybentów. Przedstawione środowisko nie wykorzystuje opcji zdalnej dystrybucji, lecz spełnia jej wszystkie warunki. Środowisko takie sprawdza się najlepiej w sytuacji, kiedy połączenia pomiędzy serwerem publikującym a odbiorcami mają małą przepustowość lub ich utrzymanie jest kosztowne. Zamiast wielu łącz utrzymywane jest jedno do publikującego subskrybenta znajdującego się na tyle blisko potencjalnych odbiorców, że mogą oni zostać przyłączeni do niego poprzez szybszą i tańszą sieć lokalną. Środowisko to można również z powodzeniem stosować używając szyfrowanego, bezpiecznego łącza do filii szkoły a dalej dzięki zastosowaniu sieci LAN przesyłać do konkretnych subskrybentów.
Rysunek 6.3 Publikujący subskrybent.
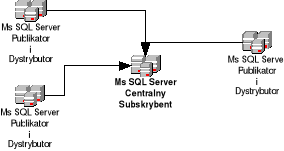
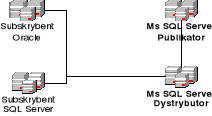
Centralny subskrybent.
W środowisku centralnego subskrybenta, rysunek 6.4, wiele serwerów publikujących replikuje dane do pojedynczego, centralnego subskrybenta. Model ten wspiera koncepcje utrzymywania centralnej bazy danych i jest najbardziej adekwatnym środowiskiem do zastosowania w przyszłym modelu EDU@PJWSKT. Przykładem może być zastosowanie centralnej bazy danych w PJWSTK w Warszawie i konsolidowanie danych pochodzących z różnych placówek uczelni. W tej sytuacji pojedyncza tabela np. studenci jest przesyłana przez wielu nadawców, zatem przed jej scaleniem trzeba będzie poczynić pewne kroki zapobiegające nakładaniu się danych, jak choćby filtrowanie według kryterium regionu.
Rysunek 6.4 Centralny subskrybent.
6.5 Wiele publikatorów lub wiele subskrybentów.
W środowisku wiele publikatorów i subskrybentów, rysunek 6.5, pojedyncza tabela (np. studenci) jest wspólna i może być modyfikowana przez każdy z serwerów. Każdy z nich jest publikatorem określonego zbioru rekordów, a jednocześnie subskrybentem całej tabeli. Inaczej mówiąc, każdy serwer posiada dostęp do aktualnej tabeli i prawo wprowadzania zmian w pewnej jej części. Przed zastosowaniem tego scenariusza należy upewnić się, czy zmiany wprowadzane przez poszczególne serwery mają charakter lokalny. Przykład zastosowania to lokalne przetwarzanie ocen studentów. Kontrolę lokalności wprowadzanych zmian może zapewnić wykorzystywanie procedur zapamiętanych, ograniczonych widoków lub kontrola zakresu.
Rysunek 6.5 Wiele publikatorów lub wiele subskrybentów.
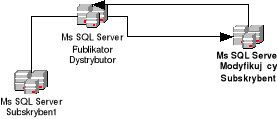
6.6 Modyfikujący subskrybent.
SQL Server 2000 dzięki zastosowaniu wbudowanych mechanizmów subskrybent ma możliwość wprowadzenia zmian w subskrybowanej tabeli oraz ich automatyczne przesłanie z powrotem do publikatora jako zmiany natychmiastowe lub kolejkowane. Model ten wykorzystuje proces dwustopniowego zatwierdzania zmian na serwerze publikującym.
Dwu fazowe zatwierdzenie wykorzystuje protokół 2PC (Two-Phase Commit). Polega ono na tym, że serwer chcący wprowadzić zmiany w swoich danych zgłasza chęć modyfikacji do innych serwerów z którymi wymienia dane. Po otrzymaniu sygnału gotowości do modyfikacji serwery otrzymują dane które muszą wprowadzić. Serwer główny który zażądał zmiany danych czeka na serwery aby wysłały potwierdzenia zmiany danych, jeśli od wszystkich serwerów otrzyma sygnał o zatwierdzeniu transakcji (commit) wtedy zmodyfikuje swoje dane. Jeśli chociaż jeden z serwerów zwróci błąd wszystkie transakcje zostają zerwane. System ten gwarantuje bardzo dużą spójność wszystkich połączonych baz danych. Wadą jest to że jeden serwer który ulegnie awarii blokuje wszystkie z nim połączone.
Modyfikacje są replikowane do wszystkich subskrybentów, z wyjątkiem tego, który je wprowadził.
Rysunek 6.6 Modyfikujący subskrybent.
Zmiany natychmiastowe są rozsyłane do subskrybentów po zatwierdzeniu ich przez serwer publikujący. Subskrybenci muszą być połączeni do niego na stałe on-line przez niezawodne łącze.
Zmiany kolejkowane są przechowywane w kolejce zmian na czas odłączania od publikatora. Przy ponownym połączeniu są do niego przesyłane. Metoda ta wykorzystuje kolejkę SQL Server 2000 i Queue Leader Agent lub Microsoft Message Queuing.
Dzięki zastosowaniu obu tych metod przesyłania zmian pozwala subskrybentowi wykorzystywać modyfikacje natychmiastowe, a przełączać się do trybu kolejkowego w wypadku braku połączenia. Po przywróceniu połączenia i poróżnieniu bufora kolejki subskrybent może przejść do trybu natychmiastowego.
Typy replikacji
W SQL Server 2000 istnieją trzy rodzaje replikacji:
migawkowa (snapshot)
transakcyjna (transactional)
scalająca (merge)
Rysunek 7.1 Typy replikacji
Każdy z rodzajów replikacji odnosi się do pojedynczej publikacji. Jednak możliwe jest stosowanie różnych kombinacji tych metod dla pojedynczej bazy danych.
Replikacja migawkowa jest najprostszym typem replikacji. Tworzy ona obraz (migawkę) wszystkich tabel przeznaczonych do publikacji i wysyła je w całości do subskrybentów. Wadą tego rozwiązania jest to, że każda nowa migawka jest tworzona w całości od początku, replikacja migawkowa nie analizuje wprowadzonych zmian. Trzeba również zauważyć, że każdy rodzaj replikacji zaczyna się od stworzenia pojedynczej migawki i rozpropagowania jej do subskrybentów. Ten typ replikacji wymaga dużej przepustowości sieci gdyż rozmiary przesyłanej migawki mogą być znaczne. Replikację tą możemy stosować w przypadkach niezbyt dużych tabel w których subskrybenci nie będą wprowadzać zmian, oraz kiedy częstotliwość replikacji danych nie musi być bardzo częsta (raz na dzień lub rzadziej).
Wadą replikacji migawkowej jest to że baza subskrybenta jest aktualna tylko do momentu pobrania migawki, wszelkie zmiany u dystrybutora które następują po zrobieniu migawki będą aktualne po sporządzeniu następnej.
Zastosowanie - systemy nie wymagające natychmiastowych aktualizacji danych np. replika książki telefonicznej, replika pracowników uczelni.
Replikacja transakcyjna polega na śledzeniu i przechwytywaniu przez SQL Server wszelkich zmian typu INSERT, UPDATE, DELETE i zachowywaniu ich w dystrybucyjnej bazie danych. Polecenia typu CREATE będą aktywne dopiero po zatwierdzeniu ich jako artykuły publikacji! Zmiany z dystrybucyjnej bazy danych są natychmiast przesyłane do subskrybentów z zachowaniem kolejności wprowadzenia. Dzięki stałemu śledzeniu zmian w dzienniku transakcji SQL Server umożliwia publikowanie za pomocą replikacji transakcyjnej tabel, widoków, procedur przechowywanych. Jak już wcześniej wspomniałem rozpoczęcie działania replikacji transakcyjnej powoduje stworzenie migawki publikacji i zapisaniu jej na dystrybutorze. Od tego momentu SQL Server zajmuje się tylko analizą dziennika transakcji. Czynności te wykonywane są bardzo efektywnie i nie jest potrzebne odczytywanie zawartości tabel źródłowych, oczywiści pomijając stworzenie początkowej migawki danych. Liczba przenoszonych danych w replikacji transakcyjnej jest minimalna w porównaniu z replikacją migawkową. Wprowadzenie zmian powoduje automatyczne przeniesienie ich do odbiorców prawie w tym samym czasie. Standardowe środowisko replikacji transakcyjnej polega na wprowadzaniu zmian tylko na jednym głównym publikatorze co eliminuje konflikty. Stosowanie replikacji transakcyjnej pozwala na uzyskanie tak zwanej luźnej lub opóźnionej spójności transakcyjnej. Dane wprowadzone na publikatorze mają pewne opóźnienie, gdyż proces ten nie przebiega w tym samym czasie na publikatorze i subskrybencie. Jednakże opóźnienie takie nie przekracza zazwyczaj minuty. Możemy więc mówić o synchronizacji danych z niewielkim opóźnieniem. O pełnej synchronizacji danych opisze w dalszej części pracy.
Zalety replikacji transakcyjnej sprawiają, że jest to najczęściej używany typ replikacji.
Wadą replikacji transakcyjnej jest generowanie ciągłego ruchu danych we wszystkich węzłach sieci.
Zastosowanie tej replikacji to systemy wymagające natychmiastowej walidacji danych np. systemy bankowe, sprzedaży, aukcyjnie (dane newralgiczne).
Replikacja scalająca jest najtrudniejszym, najbardziej skomplikowanym typem replikacji. Daje ona możliwość autonomicznych zmian replikowanych danych nie tylko na publikatorze lecz również na każdym subskrybencie. Wprowadzone modyfikacje są scalane i rozsyłane do wszystkich zainteresowanych subskrypcją stron, co umożliwia utrzymywanie w każdej bazie prawie identycznych danych. Podczas tworzenia tej replikacji do wszystkich publikowanych tabel dodawana jest kolumna typu ROWGUIDCOL, która służy do identyfikacji wierszy w kopiach tabeli. Podczas działania replikacji scalającej często występują konflikty, dlatego wymaga ona stałego nadzoru lub specjalnie zaprojektowanych mechanizmów rozwiązywania konfliktów. W czasie rozstrzygania konfliktów stroną uprzywilejowaną jest zawsze publikator oczywiście jeśli nie ustali się tego inaczej.
Zalety replikacji scalającej to możliwość synchronizacji wielu systemów, zapobieganie zakleszczeniom (deadlock). Tworzy w każdej replikowanej tabeli kolumnę zawierającą niepowtarzalny identyfikator wiersza co pozwala na efektywne śledzenie i uaktualnianie zmian.
Wadą jest duże wykorzystanie łącza, opóźnienia w aktualizacji danych (konfigurowalne), większe zużycie zasobów SZBD.
Zastosowanie - systemy rozproszone wymagające synchronizacji np. systemy bankowe, systemy firm o wielu filiach, systemy hurtowni, magazynów.
Subskrypcja - metody realizacji.
Rozważając pojecie subskrypcji czyli przesyłania publikowanych danych, możemy rozróżnić dwa przypadki realizowania przesyłu danych:
Wysyłanie danych przez dystrybutor.
Pobieranie danych z dystrybutora.
Na ogół te dwa przypadki nie są brane pod uwagę podczas projektowania replikacji, jednak mają one duże znaczenie w procesie replikacji danych.
W pierwszym przypadku, gdy dane zostają wysyłane do subskrybentów, mówimy o tak zwanej subskrypcji wymuszonej (push subscription). Subskrypcja taka jest w pełni zarządzana przez dystrybutor. Główną zaletą tego rozwiązania jest centralne administrowanie tego procesu po stronie publikatora oraz to, że wiele subskrybentów odbiera dane w tym samym czasie co zmniejsza znacznie ruch w sieci.
W przypadku pobierania danych przez subskrybenta mówimy o tak zwanej subskrypcji żądanej (pull subscription), subskrypcja taka jest zawsze realizowana po stronie odbiorcy (subskrybenta). Główną zaletą tego rozwiązania jest możliwość wyboru publikacji oraz czasu jej odbioru przez administratora serwera subskrypcji. Metoda ta jest zalecana gdy publikacje otrzymywane są okresowo i wtedy kiedy administrator tego zażąda.
Rozważając metody subskrypcji trzeba wspomnieć o możliwości zdefiniowania subskrypcji anonimowej. Jest to szczególny przypadek subskrypcji w którym nie definiujemy odbiorców. W normalnym przypadku wszystkie informacje o subskrybentach włącznie z danymi o wydajności są utrzymywane na serwerze dystrybucyjnym. Jeżeli zdecydujemy się na ten rodzaj subskrypcji cała odpowiedzialność za inicjalizowanie i utrzymywanie transmisji zostanie przeniesiona na subskrybenty.
Subskrypcje anonimową można wykorzystać w przypadkach:
Publikacji danych w Internecie.
Dużej liczby odbiorców.
Przeniesienia odpowiedzialności za utrzymywanie i zarządzanie danymi na subskrybentów.
Odbiorcy anonimowi spełniają wszystkie zasady subskrypcji żądanej.
Synchronizacja danych.
W systemach wymagających stałej aktualizacji danych takich jak systemy bankowe, giełda itp. dane muszą być ciągle zsynchronizowane. Zsynchronizowanie takie nazywamy jednoczesną spójnością transakcyjną (immediate transactional consistency), znane jako bliska spójność w poprzednich wersjach SQL Server.
SQL Server implementuje dystrybucje danych w jednoczesnej spójności transakcyjnej jako proces z dwufazowym zatwierdzaniem (two-phase commit), 2PC. Rozwiązanie to daje pewność że transakcje są zatwierdzone bądź wycofane jednocześnie na obu serwerach. Problemem podczas wprowadzania systemu jednoczesnej spójności transakcyjnej jest wymóg posiadania sieci o bardzo dużej przepustowości i rozwiązanie to może okazać się nieodpowiednie dla dużych środowisk z wieloma serwerami, właśnie z powodu możliwości wystąpienia okresowych problemów z siecią.
W systemach takich jak EDU@PJWSTK 100% synchronizacja danych we wszystkich węzłach nie jest sprawą kluczową. Dane powinny być aktualne lecz nie muszą następować natychmiast na wszystkich serwerach. Dlatego dla systemu EDU@PJWSTK możemy zastosować replikację danych zapewniającą opóźnioną spójność transakcyjną (latent transactional consistency). W poprzednich wersjach zwaną jako luźna spójność.
Opóźniona spójność transakcyjna realizowana przez replikację danych pozwala na aktualizację danych we wszystkich serwerach, lecz proces ten nie będzie przebiegał jednocześnie. W wyniku działania replikacji dane w węzłach są wystarczająco zgodne w czasie (Real-enough time data).
Na opóźnienie to składa się analiza danych przez publikator, czas przesyłu danych do dystrybutora, czas przesyłu danych z dystrybutora do subskrybenta oraz analiza danych przez subskrybenta. W części pracy poświęconej analizie danych EDU@PJWSTK podaje wartość opóźnienia danych, jako zaszło pomiędzy publikacją danych a wprowadzeniu ich na subskrybencie.
9 Agenci replikacji.
Proces replikacji w SQL Serwerze zarządzany jest przez kilka rodzajów agentów replikacji. Odpowiedni agent replikacji jest uruchamiany w celu zrealizowania konkretnego działania. Aby otrzymać dostęp do agentów replikacji potrzebne jest wcześniejsze skonfigurowanie SQL Server jako publikator lub dystrybutor.
9.1 Agent odczytu dziennika transakcji (Log Leader Agent).
Agent odczytu dziennika transakcji jest odpowiedzialny za przesłanie do bazy dystrybucyjnej przeznaczonych do publikacji transakcji bazy publikowanej.
Każda publikowana baza danych, wykorzystująca replikację transakcyjną posiada swojego agenta odczytu dziennika transakcji uruchomionego na serwerze dystrybucyjnym.
Po zakończeniu wstępnej synchronizacji agent odczytu dziennika transakcji rozpoczyna przesyłanie transakcji z serwera publikacyjnego do dystrybucyjnego.
Dziennik transakcji służy do automatycznego odzyskiwania danych jak również wykorzystywany jest do replikowania danych.
Agent analizuje dziennik transakcji publikowanej bazy i w przypadku znalezienia zmian w dzienniku odczytuje je i automatycznie przekształca na polecenia SQL odpowiadające zmianom. Utworzone polecenia zostają zapisane na serwerze dystrybucyjnym gdzie oczekują na dystrybucję do subskrybentów.
Ponieważ replikacja wykorzystuje dziennik transakcji, wprowadzono kilka zmian w sposobie jego funkcjonowania. Podczas standardowej pracy każda zakończona lub wycofana transakcja zostaje oznaczona jako nieaktywna. W czasie replikacji zakończone transakcje nie są oznaczane jako nieaktywne do czasu przesłania ich do serwera dystrybucyjnego.
Największa zmiana w dzienniku transakcji zachodzi gdy włączymy opcję obcinania w punkcie kontrolnym. Opcja Truncate Log On Checz Point powoduje skracanie dziennika transakcji przy napotkaniu punktu kontrolnego. W zależności od szybkości działania serwera obcinanie może zachodzić co kilkanaście sekund. W takiej sytuacji dziennik transakcji składa się tylko z „nieaktywnych” transakcji czyli takich które nie zostały jeszcze przesłane do dystrybutora. Opcja ta jest bardzo przydatna gdy replikowany system realizuje bardzo wiele transakcji a rozmiary dziennika rosły by do dużych rozmiarów.
9.2 Agent migawki (Snapshot Agent).
Agent migawki jest odpowiedzialny za przygotowanie schematy, wstępnych plików publikowanych tabel i procedur zapamiętanych, przechowywanie migawki na serwerze dystrybucyjnym oraz zapis statusu operacji w bazie dystrybucyjnej. Każda publikacja obsługiwana jest przez własnego agenta publikacji uruchomionego na serwerze dystrybucyjnym.
Agent migawki ma duże znaczenie gdyż podczas rozpoczęcia pracy synchronizuje bazy tworząc identyczną kopie publikowanej bazy na subskrybencie. Proces ten zwany synchronizacją początkową przeprowadzany jest tylko jeden raz, gdy publikacja otrzymuje nowego subskrybenta.
Kiedy inny serwer zgłasza subskrypcję publikacji, przeprowadzana jest kolejna synchronizacja. Po jej rozpoczęciu kopia schematu tabeli jest przenoszona do pliku z rozszerzeniem .SCH. Plik ten zawiera wszystkie informacje niezbędne do utworzenia tabeli i jej indeksów. Następnie wykonywana jest i zapisywana do pliku z rozszerzeniem .BCP kopia danych synchronizowanej tabeli. Plik BCP jest typu masowego kopiowania. Oba pliki *.SCH i *.BCP przechowywane są na dystrybutorze.
Po rozpoczęciu procesu synchronizacji gdy pliki danych są już utworzone, wszystkie zmiany są zapisywane w bazie dystrybucyjnej lecz do zakończenia synchronizacji nie są replikowane do baz danych subskrybentów.
Rozpoczynający się proces synchronizacji dotyczy wybranej grupy subskrybentów. Wszystkie serwery, które odebrały modyfikacje schematu są pomijane a otrzymują ją oczekujące. Po ponownym utworzeniu schematów i danych wszystkie transakcje przechowywane na serwerze dystrybucyjnym są wysyłane do odbiorców.
W czasie konfigurowania subskrypcji istnieje możliwość ręcznego załadowania do serwera migawki początkowanej. Czynność ta określana jest jako ręczna synchronizacja. Dla wyjątkowo dużych baz danych często prostsze jest wykonanie kopii bazy na nośniku i ręczne załadowanie jej kopii do serwera subskrypcyjnego. W czasie takiego ładowanie migawki SQL Server zakłada że bazy są zsynchronizowane i automatycznie rozpoczyna transmisję zmienionych danych.
9.3 Agent dystrybucji (Distribution Agent)
Agent dystrybucji zajmuje się przesyłaniem transakcji i migawek z dystrybucyjnej bazy danych do subskrybentów. Zostaje on utworzony po zdefiniowaniu subskrypcji wymuszonej.
Subskrypcje nie skonfigurowane do bezpośredniej synchronizacji wykorzystują agenta dystrybucji uruchomionego na serwerze dystrybucyjnym. Subskrypcje żądane, migawkowe lub transakcyjne posiadają agenta dystrybucji na serwerze subskrypcyjnym. Publikacje scalające nie mają agenta dystrybucji i wykorzystują agenta scalającego.
W replikacji transakcyjnej transakcje są przenoszone do dystrybucyjnej bazy danych skąd w zależności od konfiguracji serwera agent dystrybucji przesyła je do subskrybentów lub pobiera z bazy dystrybucyjnej.
Wszystkie zmiany wprowadzone w danych serwera publikacyjnego są rozsyłane do odbiorców w porządku w jakim zostały wprowadzone.
9.4 Agent scalający (Merge Agent)
Agent scalający służy do ustalania i przesyłania zmian danych które zaszły od czasu wykonania migawki początkowej. Każda publikacja scalająca posiada własnego agenta scalającego, który łączy się z serwerem publikacyjnym i subskrypcyjnym, po czym wykonuje odpowiednie modyfikacje danych po obu stronach.
Podczas działania replikacji scalającej mogą występować konflikty kiedy te same wiersze zostaną zmodyfikowane w tym samym czasie. W SQL Server 2000 istnieją specjalne skrypty nazywane analizatorami konfliktów (conflict resolver). Analizator konfliktów powinien być zdolny do rozwiązania każdej, nawet najbardziej złożonej sytuacji konfliktowej. Następnie agent odwraca cały proces, pobierając zmiany z serwera publikacyjnego. Subskrypcja wymuszona wykorzystuje agenta scalającego uruchomionego na serwerze publikacyjnym, podczas gdy żądana agenta działającego na serwerze subskrypcyjnym. Migawki i publikacje transakcyjne nie używają agenta scalającego.
Projektowanie replikacji.
Replikacja nie jest procesem w którym możemy zastosować istniejące szablony, nie da się skonstruować doskonałego systemu replikacji danych i stosować go dla wszystkich przypadków. To jakie wymagania stawia się replikacji określają wybór metody replikacji i sposób jej konfiguracji. Samo zdefiniowanie wymagań dotyczących replikacji danych może okazać się bardzo trudnym procesem, nie zawsze możemy przewidzieć wszystkie potrzeby lub zagrożenia podczas samego procesu projektowania replikacji. Dlatego w większości przypadków projektuje się model najbardziej odpowiadający potrzebom biznesowym i wdraża się takie system w celach testowych. Dopiero po sprawdzeniu działania replikacji w praktyce może zagwarantować, że zaprojektowany i wdrożony system replikacji będzie sprawnie działał i sprosta potrzebom biznesowym.
W każdym przypadku w którym rozpoczynamy projektowanie replikacji danych musimy odpowiedzieć sobie na kilka podstawowych pytań decydujących o podjęciu dobrej decyzji projektowej. Ja postaram się odpowiedzieć na te pytania opierając się na informacjach dotyczących nowego systemu EDU@PJWSTK:
Jaka jest liczba abonentów (stron) procesu.
PJWSTK w Warszawie
PJWSTK w Bytomiu
PJWSTK w Kijowie
PJWSTK w Bratysławie
Kto utrzymuje główne dane.
Dane będą utrzymywane przez główny serwer znajdujący się w PJWSTK w Warszawie. Jednakże każdy z serwerów będzie posiadał dane dotyczące swojego konkretnego regionu.
Jakie może być opóźnienie danych.
Przyjmijmy, że największe opóźnienie danych może wynieść jeden dzień. Jednak tworząc jednorodny moduł TESTOWY lub przyjmując że wszystkie serwery będą miały możliwość prowadzenia testów dla studentów z dowolnego regionu opóźnienie powinno być jak najmniejsze lub należy zadbać o wprowadzenie pełnej spójności transakcyjnej we wszystkich węzłach.
Jak strony korzystają z danych. (czytanie, zapis, modyfikacja, usuwanie).
Przyjmuję, że każda ze stron będzie posiadać swoją autonomię odnośnie wszystkich operacji na danych dotyczących jej regionu.
Ile komputerów będzie współpracować dla jednej strony.
Zakładając najkorzystniejsze rozwiązanie przyjmę, że każda ze stron posiada tylko 1 publikator i 1 dystrybutor danych i 1 centralny subskrybent.
Jaka jest moc obliczeniowa (CPU, pamięć, przestrzeń dysków) dla tych komputerów (dla strony).
Przyjmijmy, że każdy z komputerów będących serwerami uczestniczącymi w procesie replikacji będzie posiadał wystarczające zasoby dla sprawnego przeprowadzenia procesu replikacji danych.
Jaka jest sieć i jej przepustowość dla każdej ze stron.
Zakładam że nowo powstałe placówki PJWSTK będą posiadać łącza internetowe co najmniej 1Mbit/sek. co w pełni zaspokoi potrzeby replikacji danych.
Jaki jest sposób dostępu do informacji (LAN, Internet, dial-in czy inny).
Wszystkie placówki naszej uczelni będą posiadać stałe łącza internetowe aktywne 24 godziny na dobę.
Jakie typy baz danych będą posiadać strony.
Wszystkie serwery uczestniczące w procesie replikacji danych będą używały systemów zarządzania bazami danych typu MS SQL Server 2000 lub Oracle.
Najczęściej 95% projektu replikacji możemy przewidzieć przed rozpoczęciem testowania już wdrożonego systemu jednak te 5% które nie udało się przewidzieć będzie sprawiać najwięcej problemów. To właśnie te 5% sprawia że replikacja jest inna w każdym środowisku w którym działa
9. EDU@PJWSTK.
EDU@PJWSTK jest bazą danych przeznaczoną dla systemu Studiów Internetowych w Polsko Japońskiej Wyższej Szkole Technik Komputerowych. Z myślą o poszerzeniu działalności szkoły o kilka nowych placówek pojawił się problem scentralizowania, synchronizacji danych ze wszystkich fili szkoły w jednym głównym serwerze. Rozważania moje będą dotyczyć głównie danych jakie znajdują się w bazie i ich analizą pod kontem przyszłego scentralizowania. Będę starał przedstawić konkretne rozwiązania najbardziej adekwatne dla powstania takiego systemu.
Do celów analizy danych w mojej pracy dostałem kopie bazy danych EDU@PJWSTK odpowiednio przygotowaną (brak danych osobowych oraz różnych tabel pochodzących z innych modułów). W pracy skupię się na analizie danych pochodzących z dwóch głównych modułów. Podstawowym pierwotnym modelem bazy EDU@PJWSTK był model zaprezentowany na schemacie, schemat 1, w późniejszym czasie został on rozszerzony o moduł TESTOWY. Całościowy schemat bazy umieszczam jako załącznik do pracy, załącznik numer 1.
Baza danych którą zainstalowałem na swoim komputerze w celach testowych to:
Nazwa |
Rozmiar |
Tabele |
Perspektywy |
Procedury |
edukacja |
237.56 MB |
76 |
5 |
402 |
W celu uzyskania bardziej dokładnych informacji na temat bazy danych EDU@PJWSTK po zainstalowaniu jej na serwerze można użyć polecenia sp_spaceused w SQL Query Analyzer, które zwraca dwie tabelki dodatkowych informacji o zainstalowanej bazie.
Nazwa |
Rozmiar |
Niezapisana przestrzeń |
edukacja |
237.56 MB |
7.23 MB |
Zarezerwowana przestrzeń |
Dane |
Rozmiar indexu |
Nieużywane |
16592 KB |
8056 KB |
7488 KB |
1048 KB |
Na schemacie widać pierwotną wersję bazy EDU@PJWSTK jest to główna baza, która została rozszerzona o kilka innych modułów. Ja w swojej pracy będę analizował dane pochodzące tylko z tego schematu i modułu TESTOWEGO. Analiza tego modelu danych będzie pomocna do opracowania technik replikacji innych modułów które powstały bądź są w trakcie tworzenia. Moduły EDU oraz TESTOWY są najważniejszymi w całej strukturze EDU@PJWSTK, oraz posiadają najważniejsze dane związane z działaniem systemu Studiów Internetowych. Pełną listę tabel z modułów EDU i TESTOWEGO przedstawiam w tabeli.
Podstawą więc jest zaprojektowanie systemu replikacji dla tych dwóch modułów które są sercem systemu EDU@PJWSTK. Pełen schemat bazy danych EDU@PJWSTK zamieszczam w dodatkach do pracy gdyż zajmuje on bardzo wielki format i nie można przedstawić go w sposób inny niż jako diagram wygenerowany z SQL Server Enterpise Manager.
Schemat 1. Schemat pierwotny EDU@PJWSTK.
W tabeli przedstawiam tylko te relacje które mają znaczący wpływ na działanie systemu EDU@PJWSTK oraz pochodzą z dwóch głównych modułów EDU i TESTOWEGO. Kolumna „Jak często zmieniają się dane w tabeli” wywnioskowana jest na zasadzie zmian jakie zachodzą w bazie danych. Zmiany te są uśrednione i mogą odbiegać od rzeczywistych w niektórych przypadkach. Ilość wierszy podana jest dla zobrazowania wielkości tabel oraz zachodzących w nich zmian.
Niestety wraz z bazą nie dostałem żadnych logów bazy danych, które mógłbym poddać analizie. Baza nie posiadała logów przydatnych mojej analizie. Informacje o zmianie danych pochodzą z obserwacji administratora bazy EDU@PJWSTK, oraz odpowiadają rzeczywistym zmianom jakie powinny zachodzić w sprawnie działającym systemie.
Określenie zachodzenia zmian „Codziennie” oznacza zmianę danych raz lub wiele razy dziennie.
„Na początku lub końcu semestru” oznacza zachodzenie zmian tylko w czasie rozpoczęcia lub zakończenia semestru, zmiany te mogą zachodzić raz lub wiele razy dziennie w tym okresie.
Można zaobserwować, że czas zmiany określony jako „Codziennie” informuje nas, że dane te mogą zostać zmienione w każdej chwili. Dla przykładu rozważmy tabele „Notatka”, która może zmienić się codziennie lecz jej zmiana od dwóch lat działania modułu TESTOWY mogła nastąpić kilka lub kilkanaście razy biorąc pod uwagę fakt, że tabela ta zawiera tylko 8 wierszy.
W tabeli na pomarańczowo zaznaczyłem tabele należące do modułu pierwotnego EDU.
Na niebiesko zaznaczone są tabele kluczowe dla działania modułu TESTOWEGO, na czarno pozostały tabele które należą do modułu testowego lecz nie są kluczowe dla działania systemu.
Nazwa tabeli. |
Jak często zmieniają się dane w tabeli. |
Ilość wierszy. |
Asystent |
Na początku i końcu semestru. |
120 |
FAQ |
Raz na tydzień lub częściej. |
10 |
FolderObszaru |
Codziennie ! |
69 |
Forumdyskusyjne |
Codziennie ! |
495 |
Gosc |
Na początku lub końcu semestru. |
31 |
Kalendarz |
Co tydzień. |
50 |
Kurs |
Codziennie. |
63 |
Materialdydaktyczny |
Codziennie |
481 |
Materialobszaru |
Codziennie. |
934 |
Modul |
Raz na semestr lub rzadziej. |
17 |
Modul_kursu |
Na początku semestru. |
843 |
Notatka |
Codziennie. |
8 |
Obejrzal |
Codziennie. |
6153 |
Ocena |
Codziennie. |
4293 |
OcenaEgzamin |
Pod koniec semestru - codziennie. |
0 |
OcenaKoncowa |
Pod koniec semestru - codziennie. |
351 |
OcenaZa |
Codziennie. |
239 |
Odnosnik |
Codziennie. |
93 |
Odpowiedzi |
Codziennie |
9029 |
Opcja |
Codziennie. |
2002 |
Osoba |
Na początku semestru. |
596 |
Podrecznik |
Na początku semestru. |
62 |
Podrecznik_kursu |
Na początku semestru. |
48 |
Program |
Rzadko. |
10 |
Pytanie |
Codziennie. |
754 |
Rejestraktywnosci |
Codziennie. |
55985 |
Rejestrmodulow |
Codziennie |
45223 |
Student |
Codziennie. |
576 |
StudentKursu |
Codziennie. |
363 |
StudentProgramu |
Codziennie. |
204 |
TablicaOgloszen |
Codziennie. |
448 |
Test |
Codziennie |
115 |
Tabela 1. Lista głównych tabel modułów EDU i TESTOWEGO.
Mając zainstalowaną na serwerze bazę danych EDU@PJWSTK możemy przystąpić do analizy tabel.
Stosując poniższy skrypt w SQL Query Analyzer możemy uzyskać informacje na temat wielkości tabel, ilości wierszy, rozmiarów indeksów.
use edukacja
go
DECLARE @pagesizeKB int
SELECT @pagesizeKB = low / 1024 FROM master.dbo.spt_values
WHERE number = 1 AND type = 'E'
SELECT
table_name = OBJECT_NAME(o.id),
rows = i1.rowcnt,
reservedKB = (ISNULL(SUM(i1.reserved), 0) + ISNULL(SUM(i2.reserved), 0)) * @pagesizeKB,
dataKB = (ISNULL(SUM(i1.dpages), 0) + ISNULL(SUM(i2.used), 0)) * @pagesizeKB,
index_sizeKB = ((ISNULL(SUM(i1.used), 0) + ISNULL(SUM(i2.used), 0))
- (ISNULL(SUM(i1.dpages), 0) + ISNULL(SUM(i2.used), 0))) * @pagesizeKB,
unusedKB = ((ISNULL(SUM(i1.reserved), 0) + ISNULL(SUM(i2.reserved), 0))
- (ISNULL(SUM(i1.used), 0) + ISNULL(SUM(i2.used), 0))) * @pagesizeKB
FROM sysobjects o
LEFT OUTER JOIN sysindexes i1 ON i1.id = o.id AND i1.indid < 2
LEFT OUTER JOIN sysindexes i2 ON i2.id = o.id AND i2.indid = 255
WHERE OBJECTPROPERTY(o.id, N'IsUserTable') = 1 --same as: o.xtype = %af_src_str_2
OR (OBJECTPROPERTY(o.id, N'IsView') = 1 AND OBJECTPROPERTY(o.id, N'IsIndexed') = 1)
GROUP BY o.id, i1.rowcnt
ORDER BY 3 DESC
Go
Użycie powyższego skryptu powoduje zwrócenie poniższej tabeli przez SQL Server Query Analyzer. Tabelę prezentuje w niezmienionej postaci. Tabele posegregowane są według kolumny `Zarezerwowane KB'.
Nazwa |
Liczba wierszy |
Zarezerwowane KB |
Rozmiar KB |
Rozmiar Indeksu KB |
Nieużywane KB |
RejestrAktywnosci |
55985 |
4536 |
1616 |
2672 |
248 |
RejestrModulow |
45223 |
3440 |
1352 |
1880 |
208 |
Odpowiedz |
9029 |
768 |
488 |
272 |
8 |
Obejrzal |
6153 |
448 |
144 |
240 |
64 |
ForumDyskusyjne |
495 |
328 |
248 |
80 |
0 |
Ocena |
4293 |
320 |
144 |
160 |
16 |
Pytanie |
754 |
296 |
208 |
48 |
40 |
MaterialObszaru |
934 |
288 |
176 |
112 |
0 |
TablicaOgloszen |
448 |
272 |
192 |
48 |
32 |
czesc_lekcji |
233 |
248 |
176 |
24 |
48 |
Opcja |
2002 |
240 |
128 |
64 |
48 |
MaterialDydaktyczny |
481 |
144 |
72 |
32 |
40 |
Kurs |
63 |
112 |
64 |
48 |
0 |
Modul_Kursu |
843 |
104 |
24 |
80 |
0 |
dtproperties |
7 |
104 |
80 |
24 |
0 |
cwiczenie_odp |
388 |
88 |
64 |
24 |
0 |
przyklad |
104 |
88 |
80 |
8 |
0 |
Osoba |
596 |
80 |
64 |
16 |
0 |
Notatka |
8 |
80 |
32 |
48 |
0 |
PodrecznikKursu |
48 |
80 |
32 |
48 |
0 |
sysschemaarticles |
375 |
72 |
48 |
24 |
0 |
StudentKursu |
363 |
64 |
24 |
40 |
0 |
OcenaKoncowa |
351 |
64 |
16 |
48 |
0 |
StudentProgramu |
204 |
64 |
24 |
40 |
0 |
Student |
576 |
64 |
16 |
48 |
0 |
Kalendarz |
50 |
64 |
32 |
32 |
0 |
lekcja |
40 |
64 |
40 |
24 |
0 |
FAQ |
10 |
64 |
32 |
32 |
0 |
sysarticles |
56 |
56 |
32 |
24 |
0 |
cwiczenie_pyt |
105 |
56 |
32 |
24 |
0 |
Asystent |
120 |
56 |
8 |
48 |
0 |
Odnosnik |
97 |
56 |
8 |
48 |
0 |
Forum_Osoby_Grupy |
128 |
48 |
40 |
8 |
0 |
OcenaZa |
236 |
48 |
16 |
32 |
0 |
lesson_wizyty |
42 |
48 |
24 |
24 |
0 |
Forum_Wiadomosci |
10 |
48 |
32 |
16 |
0 |
dzial |
9 |
48 |
24 |
24 |
0 |
syspublications |
1 |
48 |
8 |
40 |
0 |
ustawienia |
2 |
40 |
16 |
24 |
0 |
wyniki_student |
51 |
40 |
16 |
24 |
0 |
FolderObszaru |
69 |
40 |
8 |
32 |
0 |
Test |
115 |
40 |
8 |
32 |
0 |
cwiczenie_odp_student |
419 |
32 |
24 |
8 |
0 |
typy_odpowiedzi |
2 |
32 |
8 |
24 |
0 |
Sekcja |
2 |
24 |
8 |
16 |
0 |
Forum_Tagi |
2 |
24 |
8 |
16 |
0 |
Forum_Profile |
3 |
24 |
8 |
16 |
0 |
Element |
4 |
24 |
8 |
16 |
0 |
El |
1 |
24 |
8 |
16 |
0 |
Modul |
17 |
24 |
8 |
16 |
0 |
Gosc |
31 |
24 |
16 |
8 |
0 |
Forum_Schematy |
6 |
24 |
8 |
16 |
0 |
Program |
10 |
24 |
8 |
16 |
0 |
Forum_Wiadomosci_ Przeczytane |
14 |
24 |
8 |
16 |
0 |
Podrecznik |
62 |
24 |
8 |
16 |
0 |
Forum_Grupy |
130 |
24 |
8 |
16 |
0 |
mgr |
1 |
16 |
8 |
8 |
0 |
Forum_Grupy_Tagi |
4 |
16 |
8 |
8 |
0 |
Spec |
1 |
16 |
8 |
8 |
0 |
OcenaEgzamin |
0 |
0 |
0 |
0 |
0 |
syssubscriptions |
0 |
0 |
0 |
0 |
0 |
sysarticleupdates |
0 |
0 |
0 |
0 |
0 |
MSpub_identity_range |
0 |
0 |
0 |
0 |
0 |
systranschemas |
0 |
0 |
0 |
0 |
0 |
SUMA |
131806 |
13656 |
6048 |
6856 |
752 |
Testowanie replikacji danych.
Do testowania replikacji używałem dwóch komputerów. Pierwszy pełnił rolę publikatora/dystrybutora, drugi zaś subskrybenta, inaczej mówiąc zastosowałem środowisko centralnego publikatora. W tym środowisku przetestowałem wszystkie trzy metody replikacji danych.
Publikator/Dystrybutor: Procesor AMD Athlon 1.2 GHz, 384MB RAM, system Microsoft Windows Server 2003 Enterprise Edition, Microsoft SQL Server 2000 Enterprise Edition.
Subskrybent: Procesor Pentium III 550 MHz, 256 MB RAM, system Microsoft Windows 2000 Professional, Microsoft SQL Server 2000 Developer Edition.
Poniżej przedstawiam kilka kroków, od których należy zacząć przygotowania do replikacji danych, kroki te muszą być spełnione aby replikacja powiodła się:
Pierwszym krokiem jaki należy uczynić jest stworzenie konta z uprawnieniami administratora, na którym uruchomiony będzie SQL Server 2000 oczywiście o ile takiego nie posiadamy. Tylko użytkownik z uprawnieniami administratora może zarządzać i konfigurować replikację.
Trzeba się upewnić że SQL Server Agent uruchamia się automatycznie wraz z SQL Server.
Konto na którym działa SQL Server musi posiadać stały dostęp do zaufanej sieci jest to bardzo ważne gdyż podczas działania replikacji subskrybent lub dystrybutor muszą być widoczni. W innym razie wszystkie operacje związane z propagacją danych zostaną przejęte przez Queque Reader Agent w celu rozesłania ich w późniejszym terminie lub w przypadku replikacji scalającej działanie serwera może zostać wstrzymane z powodu konfliktów.
Powinniśmy się upewnić czy mamy wystarczającą ilość miejsca dla stworzenia dystrybucyjnej bazy danych. Krok ten należy pominąć jeśli dystrybutor będzie osobnym serwerem typu „stand alone”.
Należy zapewnić odpowiednią ilość miejsca na stworzenie bazy danych publikatora.
Musimy pamiętać że nie możemy replikować samych tabel zawierających więzy referencyjne, gdzie wartości klucza obcego muszą występować jako wartości powiązanego z nim klucza głównego. Jeśli taki problem wystąpi należy replikować wszystkie powiązane tabele.
Należy zdefiniować serwer dystrybucyjny lub subskrybenta jako serwer zdalny, w zakładce Security/Remote Server
Przebieg procesu testowania.
Mając zainstalowany na dwóch komputerach MS SQL Server oraz wgraną na publikator bazę danych EDU@PJWSTK, można zacząć przygotowania do pierwszej replikacji danych.
Aby replikacja mogła sprawnie działać należy ustawić zaufane połączenie (trustem connection) pomiędzy serwerami.
Stworzenie zaufanego połączenia polega na właściwym ustawieniu praw użytkownika którego będziemy używać do łączenia się bazami dystrybutora lub subskrybenta.
Dlatego należy zdefiniować na serwerach do których będziemy się łączyć użytkowników używających autentykacji SQL Server o ile serwery te nie działają w jednej domenie Windows. Ważne jest aby użytkownik którego będziemy używać posiadał uprawnienia sysadmin.
Dodałem użytkownika systemowego „sa” a na subskrybencie oraz ustawiłem mu ważne hasło.
Na publikatorze można w łatwy sposób sprawdzić czy serwery będą działać rejestrując nowy SQL Server, opcja New SQL Server Registration. Po wpisaniu adresu serwera zdalnego oraz wprowadzeniu poprawnej nazwy użytkownika i hasła, nowy serwer powinien być widoczny.
W celu dodania zdalnego serwera na stałe do listy zdalnych serwerów należy zdefiniować jego udział w zakładce Security/Remote Server należy dodać nowy serwer w moim przypadku - SUBSKRYBENT.
Remote Servers 1
Powyższy rysunek pokazuje zakładkę Security/Remote Servers w której widać trzy pozycje:
COMPAQ jest lokalnym serwerem publikatorem
Repl_distirbutor jest serwerem dystrybucyjnym uruchomionym na lokalnym komputerze. Wpis ten dodaje się samoczynnie jeśli zdefiniujemy lokalny komputera jako dystrybutor.
SUBSKRYBENT\SQL2000 jest serwerem subskrypcyjnym uruchomionym na osobnym, zdalnym komputerze.
Większość potrzebnych funkcji odnośnie stworzenia procesu replikacji znajdziemy w menu Tools/Replication.
Rysunek 2. Menu Replikacji.
Pierwszym krokiem, który powinniśmy wykonać jest stworzenie bazy dystrybucyjnej. W tym celu wybieramy opcję Configure Publishing, Subscribers, and Distribution.
W momencie wybrania opcji konfiguracji publikacji, subskrybentów i dystrybutorów uruchamia się kreator procesu konfiguracji.
MS SQL Server zaczyna konfigurację replikacji od stworzenia dystrybutora danych czyli „serca” całego procesu. Na rysunku poniżej możemy zobaczyć opcję wyboru dystrybutora. Standardowo zaznaczona jest opcja czyniąca komputer lokalny jako dystrybutor, lecz możemy sami zdefiniować zdalny komputer do celów dystrybucji. Jak widać w oknie jako nieaktywny, wyświetlony jest komputer zdalny SUBSKRYBENT\SQL2000, który jest dodany do listy zdalnych serwerów (Security/Remote Servers). Za pomocą opcji Add Server możemy dodać inny komputer zdalny.
Ja wybrałem opcję czyniącą z lokalnego komputera publikatora i dystrybutora danych.
Po wybraniu dystrybutora musimy ustalić czy chcemy aby SQL Server użył standardowych opcji konfiguracji czy sami ustalimy wszystkie parametry.
Po wyborze standardowych ustawień kreator pominie następne dwa kroki. Ja jednak wybieram opcje ręcznej konfiguracji parametrów replikacji.
Kolejnym krokiem jest zdefiniowanie dystrybucyjnej bazy danych. W tym przypadku musimy wybrać nazwę bazy danych oraz jej lokalizację na dysku twardym.
W celu zmniejszenia obciążenia związanego z pracą dystrybucyjnej bazy danych powinniśmy zdefiniować położenia dystrybucyjnej bazy danych na innym dysku twardym niż publikacja. Ja niestety na komputerze na którym prowadzę testy nie posiadam drugiego dysku twardego.
Następnie zostaniemy poproszeni o zdefiniowanie publikatorów, którzy będą przesyłać dane do serwera dystrybucji. Krok ten jest już tworzony na dystrybutorze. W tym przypadku na komputerze lokalnym, jednak jeśli istnieje potrzeba stworzenia centralnego dystrybutora jako osobny komputer musi on mieć połączenie ze wszystkimi publikatorami jako zdalne serwery. Microsoft sugeruje aby pojedynczy dystrybutor nie posiadał więcej jak 16 różnych publikatorów. Tyle też instancji baz danych można utrzymywać na jednym SQL Server 2000.
W moim przypadku jako publikator wybrałem serwer lokalny COMPAQ. Oczywiście możemy dodać innych aktywnych publikatorów.
Po zdefiniowaniu publikatorów musimy zdefiniować jakie bazy danych będą publikowane. W tej instancji SQL Server 2000 oprócz standardowych baz dołączonych do serwera posiadam tylko jedną bazę danych EDU@PJWSTK o nazwie edukacja.
Włączenie publikowania bazy danych spowoduje stworzenie kopii tej bazy na dystrybutorze. W celu wykonania replikacji migawkowej lub transakcyjnej musimy zaznaczyć opcję Trans do jeśli planujemy używać replikacji scalającej powinniśmy wybrać opcję Merge ponieważ publikowana baza danych będzie musiała zostać rozszerzona o specjalne kolumny ROWGUIDCOL.
Ostatnim krokiem jaki należy wykonać jest zdefiniowanie subskrybentów.
W przypadku testowania replikacji subskrybentem jest zdalny komputer.
Serwer SUBSKRYBENT\SQL2000 na którym zainstalowany jest MS SQL Server 2000 Developer Edition.
W celu dodania subskrypcji do serwerów innego typu niż SQL Server musimy zakończyć pracę kreatora i dodać je później ręcznie jako zdalne serwery i włączyć w proces subskrypcji.
Po kliknięciu przycisku Dalej następuje stworzenie dystrybucyjnej bazy danych, dystrybutora, dodanie publikatorów, subskrybentów oraz udostępnienie publikowanej bazy danych.
Po wykonaniu wszystkich kroków kreatora Konfiguracji publikatora, subskrybenta i dystrybutora możemy przejść do konfigurowania procesu replikacji danych. W tym celu musimy uruchomić polecenie Create and Manage publications w menu Tool/Replication.
W oknie które pojawi się po wybraniu opcji stworzenia publikacji wybieramy bazę danych, którą chcemy replikować.
Po wybraniu bazy danych będącej publikacją i wciśnięciu przycisku Create Publication, kreator wyświetli okno z zapytaniem czy chcemy używać opcji zawansowanych.
Ja wybrałem opcje zaawansowane co spowodowało pojawienie się okna dotyczącego wyboru bazy danych
W moim przypadku wybieram bazę „edukacja”.
Po wybraniu bazy publikacji przechodzimy do wyboru rodzaju replikacji rys 7.1 Typy replikacji, w którym możemy wybrać jedną z trzech metod propagacji danych. Ja wybieram opcję replikacji migawkowej (snapshot replication).
Dalszy wybór ma na celu określenie typu subskrybenta, który będzie odbierał dane z naszej publikacji. Standardowo możemy wybrać subskrybentów używających serwery MS SQL Server 2000 i 7.0 oraz inne typy subskrybentów takie jak Oracle, MS Access, Sybase, IBM DB2. Istnieje możliwość ręcznego zdefiniowania innych typów subskrybentów.
Po wybraniu rodzaju subskrybentów przechodzimy do fazy definiowania danych które będą tworzyć publikacje czyli artykułów publikacji.
Automatycznie wyświetlona zostaje zawartość bazy danych wcześniej ustalonej jako baza danych publikacji.
Do wyboru mamy wszystkie tabele, zapamiętane procedury i perspektywy publikowanej bazy. W lewym oknie widzimy dwa pola wyboru Show i Publish All. W celu dołączenia wszystkich tabel do publikacji wystarczy zaznaczyć pole Publish All
Możemy użyć wszystkich tabel, zapamiętanych procedur i perspektyw do stworzenia migawki zaznaczając pola Publish All dla trzech typów danych. Ja jednak zacznę od stworzenia migawki samych tabel.
W następnym kroku zostaniemy poproszeni o nadanie nazwy bazie danych którą będziemy używać jako bazę danych publikacji. Ja pozostawiłem nazwę bazy niezmienioną „edukacja”. Kreator w kolejnym kroku zapyta czy chcemy zastosować filtrowanie lub zezwolić na anonimową subskrypcje publikowanych danych. W przypadku bazy danych EDU@PJWSTK nie definiowałem filtrowania.
Po zdefiniowaniu opcji filtrowania i anonimowej subskrypcji możemy ustalić częstość z jaką następować będzie replikacja danych. Możemy dowolnie zdefiniować co jaki czas ma zachodzić wymiana danych (co godzinę, co dzień).
Kreator zakończy działanie tworząc publikację bazy danych. Można zauważyć, że stworzonych zostało 56 artykułów publikowanej bazy. W 56 artykułach publikacji zamieszczone są wszystkie tabele bazy danych EDU@PJWSTK.
Do testowania wydajności replikowania danych używał będę procedur zapamiętanych które standardowo występują w SQL Server. Analizował informacje, które zostają generowane przez monitory replikacji, jak również posługiwał się Monitorem Wydajności Systemu na którym analizował będę wykorzystanie mocy procesora i wielkość używanej pamięci.
Standardowe procedury, których można używać do testowania replikacji możemy uruchamiać w SQL Query Analyzer. Są to następujące procedury:
sp_helppublication - pokazuje informacje o serwerze publikującym
sp_subscriberinfo - pokazuje informacje o serwerze subskrybenta
sp_helpartice - informacje o definicja artykułów
sp_helpdistributor - informacje o dystrybutorze
sp_helpsubscription -informacje o subskrypcji
sp_replcounters - pokazuje aktywność aktualnej sesji repliakcyjnej
sp_publication_validation - wskazuje liczbę wierszy publikacji subskrybentów
Pierwszym krokiem który należy wykonać jest stworzenie subskrybowanej bazy na subskrybencie. Stworzyłem bazę danych „edukacja”.
Do replikacji zaznaczyłem tylko same tabele bazy EDU@PJWSTK
Jak widzieliśmy na rysunku publikacja samych tabel składa się z 56 artykułów.
Migawka zawierająca 56 artykułów na publikatorze została wygenerowana i replikowana migawkowo 3 razy, w tabeli poniżej przedstawiam wyniki, które uzyskałem używając monitora transakcji oraz monitora wydajności.
Artykuły |
Czas stworzenia migawki (sek) |
Czas całej operacji (min) |
Ilość transakcji / komend |
Opóźnienie (ms) |
Ilość dostarczanych komend (cmd/sek) |
Maks użycie procesor (%) / pamięć (MB) |
56 |
28 |
1,26 |
1/171 |
59,656 |
17,9400 |
63 / 97 |
56 |
27 |
1,23 |
1/171 |
40,365 |
17,0000 |
52 /110 |
56 |
29 |
1,31 |
1/171 |
28,700 |
17,0700 |
55 / 107 |
Opis kolumn:
Artykuły - (articles) liczba artykułów publikacji.
Czas stworzenia migawki (duration) - czas potrzebny agentowi migawki do stworzenia migawki zawierającej wszystkie artykuły publikacji.
Czas całej operacji (duration) - całkowity czas działania agenta dystrybucji potrzebny do analizy danych i dostarczenia ich subskrybentowi.
Ilość transakcji / komend (#trans / #cmd) - ilość transakcji dostarczonych do subskrybenta / ilość komend dostarczonych do subskrybenta.
Opóźnienie (latency) - jest to opóźnienie liczone od dostarczenia transakcji na dystrybutor do przesłania ich na dystrybutor.
Ilość dostarczonych komend (delivery rate) - stosunek dostarczonych komend do czasu działania agenta dystrybucji.
Jak łatwo zauważyć wartość w kolumnach „artykuły” oraz „ilość transakcji / komend” jest stała. Spowodowane to jest używaniem tych samych danych podczas testu.
W pierwszym teście opóźnienie było o ponad 20 sekund większe niż w pozostałych przypadkach mogło to być spowodowane uruchamianiem odpowiednich funkcji na subskrybencie.
Następnie przetestowałem działanie replikacji na pojedynczej tabeli. Na publikatorze stworzyłem migawkę zawierającą tylko jedną tabele, jeden artykuł RejestrAktywności największą tabele w bazie.
Nazwa |
Liczba wierszy |
Zarezerwowane KB |
Rozmiar KB |
Rozmiar Indeksu KB |
Nieużywane KB |
RejestrAktywnosci |
55985 |
4536 |
1616 |
2672 |
248 |
Stworzenie migawki z tego artykułu zajęło tylko maksymalnie 2 sekundy. Wybrałem opcję natychmiastowego synchronizowania serwerów po skończeniu tworzenia migawki. Inicjalizacja SQL Server Agent oraz przesłanie i zarejestrowanie danych do subskrybenta trwało nieco ponad minutę. Migawka RejestrAktywności składała się z 1 transakcji i 6 komend. Opóźnienie pomiędzy danymi wyniosło maksymalnie 33,850 sekundy. Należy zauważyć, że tak jak w poprzednim przypadku podczas pierwszego testu opóźnienie było największe.
Obciążenie zasobów dystrybutora było niewielkie. Największe użycie mocy procesora wyniosło 15% a wzrost użycia pamięci zwiększył się do 115 MB.
Artykuły |
Czas stworzenia migawki (sek) |
Czas całej operacji (min) |
Ilość transakcji / komend |
Opóźnienie (ms) |
Ilość dostarczanych komend (cmd/sek) |
Maks użycie procesor (%) / pamięć (MB) |
1 |
1 |
1,11 |
1/6 |
33850 |
1,0000 |
14 / 113 |
1 |
2 |
1,06 |
1/6 |
15733 |
1,0000 |
15 /115 |
1 |
1 |
1,06 |
1/6 |
11463 |
1,0000 |
12 / 111 |
Publikacja zajmująca same procedury zapamiętane składa się z 372 artykułów. Podczas tworzenia migawki użycie mocy procesora przez 2 sekundy wynosiło 100%.
Podczas testowania replikacji procedur zapamiętanych wystąpił błąd!
Procedury dotyczące tabeli FAQ zawierają odnośniki dotyczące tabel, których nie posiadam i posiadają błąd (odwołania do nie istniejących kolumn w tabeli).
Testowanie przenoszenia procedur zapamiętanych zacząłem więc od przetestowanie procedur odnoszących się do tabeli
Artykuły |
Czas stworzenia migawki (sek) |
Czas całej operacji (min) |
Ilość transakcji / komend |
Opóźnienie (ms) |
Ilość dostarczanych komend (cmd/sek) |
Maks użycie procesor (%) / pamięć (MB) |
88 |
17 |
1/30 |
1/179 |
27560 |
5966,0000 |
32 / 84 |
88 |
18 |
1/30 |
1/179 |
86976 |
5966,0000 |
30 /81 |
88 |
17 |
1/20 |
1/179 |
9813 |
5966,0000 |
36 / 89 |
Bardzo ciekawe wyniki uzyskałem testując przenoszenie procedur zapamiętanych. Jak wynika z tabeli generacja publikacji trwała średnio 8 razy dłużej niż przesłanie procedur do subskrybenta. Wynika to z tego że SQL Server przesyła procedury zapamiętane w swojej pierwotnej postaci dlatego jeśli chcemy używać skomplikowanych filtrów możemy użyć z procedury zapamiętanej która bardzo szybko zostanie przeniesiona na subskrybenta a dopiero na nim wykonana.
Opóźnienie wynosiło w krytycznym wypadku ponad 86976 a minimalne niecałe 10 sekund.
Wykorzystanie zasobów procesora było minimalne w porównaniu z poprzednimi testami replikacji.
Czas przesyłu procedur zapamiętanych wahał się pomiędzy 2 lub 3 sekundami więc jest to bardzo niewielki czas w porównaniu z przenoszeniem pojedynczych tabel (niezależnie od ich wielkości).
Stworzenie migawki z publikacji zawierającej 431 artykułów na komputerze testowym COMPAQ zajęło 2 minuty i 33 sekundy.
Microsoft SQL Server 2000.
Pracę swoją przeprowadzę na systemie zarządzania bazą danych MS SQL Server 2000. Jest to system na którym aktualnie działa baza danych naszej uczelni. MS SQL Server 2000, dzięki swojej wydajności, skalowalności, łatwości zarządzania, a także łatwości tworzenia aplikacji, jest serwerem bazodanowym polecanym dla wielu typów aplikacji, wśród których warto wymienić produkty typu:
Customer Relationship Management (CRM),
Business Intelligence (BI),
Enterprise Resource Planning (ERP).
dobrze współpracuje z aplikacjami przeznaczonymi dla Internetu.
Przedstawię kilka cech charakteryzujących Microsoft SQL Server:
zaprojektowany dla Internetu,
bezpieczeństwo,
analiza dużych ilości danych oparta na interfejsie internetowym,
kompletne rozwiązanie dla hurtowni danych,
uproszczone zarządzanie,
integracja z usługami katalogowymi, skalowalność, dostępność.
MS SQL Serwer 2000 działa w środowisku rozproszonym i posiada rozbudowane narzędzia, które wspierają i realizują podstawowe zadania zarządzania taką architekturą.
Rozproszone partycje, możliwości rozdzielania obciążenia na różne serwery. Zwiększanie stopnia skalowalności w wyniku zwiększania liczby serwerów.
Możliwość automatycznej synchronizacji baz danych na zapasowych serwerach bez względu na to, jak daleko się od siebie znajdują.
Możliwość zainstalowania baz danych przejmujących zadania w razie awarii. Bazy danych mogą zostać przejęte przez dowolny funkcjonujący węzeł z grupy czterech komputerów.
Zarządzanie klasterem z przejmowaniem zadań po awarii. Możliwość przeinstalowania lub przekonstruowania dowolnego węzła z klastera obsługującego przejmowanie zadań bez negatywnego wpływu na pozostałe węzły. Łatwe konfigurowanie przejmowania zadań na potrzeby replikacji i rozproszonych partycji.
Tworzenie indeksów perspektyw w celu zwiększenia wydajności obsługi istniejących kwerend bez konieczności przeprogramowywania. Przyspieszenie analiz i tworzenia raportów wykorzystujących perspektywy złożone.
Szybkie sporządzanie kopii zapasowych z minimalnym wpływem na działanie serwera - wystarczy jedynie kopiować strony, na których wystąpiły zmiany. Bezproblemowe tworzenie kopii zapasowych, praktycznie bez negatywnego wpływu na pracę serwera. Szybkie odtwarzanie danych i tworzenie serwerów zapasowych.
Kreator kopiowania bazy danych, który pozwala na przenoszenie oraz kopiowanie bazy danych i obiektów między serwerami.
Bibliografia.
William R. Stanek „Microsoft SQL Serwer 2000 Vademecum Administratora” - Microsoft Press 2001.
Kalen Delaney “Microsoft SQL Serwer 2000” - Wydawnictwo RM 2002.
“Understanading SQL Server 7.0 Replication” - dokumentacja MSsql Server.
Sean Nolan, Tom Huguelet “Microsoft SQL Server 7.0 Data Warehousing Training” - Microsoft Press.
Rebecca M. Riordan “Microsoft SQL Serwer 2000 Programowanie” - Wydawnictwo RM.
Marlene Theriault, Rachel Carmichael, James Viscusi “Oracle9i. Administrowanie bazami danych od podstaw” - Wydawnictwo Helion 2003.
Ray Ranking, Paul Jansen, Paul Bertucci „Microsoft SQL Server 2000 Księga Eksperta” - Wydawnictwo Helion 2003.
Kevin Looney, Marlene Theriault „Oracle9i. Podręcznik administratora baz danych” - Wydawnictwo Helion 2003.
Robert Wrembel, Bartosz Bębel „Oracle. Projektowanie rozproszonych baz danych” - Wydawnictwo Helion 2003.
Michał Lentner „Oracle 9i. Kompletny podręcznik użytkownika” Wydawnictwo Polsko-Japońskiej Wyższej Szkoły Technik Komputerowych 2002.
Ed Whalen, Mitchell Schroeter „Oracle. Optymalizacja wydajności” - Wydawnictwo Helion 2003.
BD
Przechowaj dane
Replika z częścią danych.
Podstawowa baza danych. Wszystkie dane.
Główna baza danych EDU@PJWSTK.
Baza danych w Polsce.
Baza danych na Ukrainie.
Podstawowy serwer.
Zapasowy (backup).
Prześlij dane.
BD
BD
BD
BD
BD
BD
BD
BD
BD
BD

Wyszukiwarka