Materiały z wykładów ze statystyki z zadaniem
8. NIEPARAMETRYCZNE TESTY ISTOTNOŚCI
Test zgodności
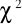
Nieparametryczne testy istotności, w których weryfikowana hipoteza dotycząca rozkładu badanej cechy w populacji generalnej nie precyzuje wartości parametrów tego rozkładu, można ogólnie podzielić na dwie grupy. Pierwsza grupa to tzw. testy zgodności, a druga, bardzo liczna, to testy dla hipotezy, że dwie próby pochodzą z jednej populacji (czyli że dwie populacje mają ten sam rozkład.) Jednym z najstarszych testów statystycznych jest test zgodności ![]()
. Nazwa jego pochodzi stąd, że statystyka, jakiej używa się przy weryfikacji hipotezy o zgodności próby wyników z rozkładem populacji, ma rozkład asymptotyczny ![]()
.
Test zgodności ![]()
pozwala na sprawdzenie hipotezy, że populacja ma określony typ rozkładu (tj. określoną postać funkcyjną dystrybuanty). W teście zgodności ![]()
próba musi być duża.
Model
Populacja generalna ma dowolny rozkład o dystrybuancie należącej do pewnego zbioru ![]()
rozkładów o określonym typie postaci funkcyjnej dystrybuanty. Z populacji tej wylosowano niezależnie dużą próbę (n co najmniej kilkadziesiąt), której wyniki podzielono na r rozłącznych klas o liczebnościach ni w każdej klasie, przy czym ![]()
. Otrzymano w ten sposób tzw. rozklad empiryczny. Na podstawie wyników tej próby należy sprawdzić hipotezę Ha, że populacja generalna ma rozkład typu ![]()
, tzn. Ho : F(x) ![]()
S2, gdzie F(x) jest dystrybuantą rozkładu populacji.
Test istotności, zwany testem zgodności, dla tej hipotezy jest następujący. Z hipotetycznego rozkładu typu ![]()
obliczamy dla każdej z r klas wartości badanej cechy X prawdopodobieństwa pi, że zmienna losowa X o rozkładzie ![]()
przyjmie wartości należące do klasy o numerze i (i=1, 2, ..., r). Z kolei mnożąc pi przez liczebność całej próby n otrzymuje się liczebności teoretyczne npi , które powinny były wystąpić w klasie i, gdyby populacja miała rozkład typu ![]()
, tzn. gdyby hipoteza Ho była prawdziwa. Ze wszystkich liczebności empirycznych ni oraz hipotetycznych npi wyznacza się następnie wartość statystyki
(2.1) 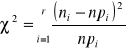
która przy założeniu prawdziwości hipotezy Ho ma rozkład asymptotyczny ![]()
o r-1 stopniach swobody lub o r-k-1 stopniach swobody, gdy z próby szacowano k parametrów rozkładu ![]()
metodą największej wiarygodności.
PRZYKŁAD1
W oddziale położniczym szpitala miejskiego w Bydgoszczy otrzymano dane statystyki płci urodzonych niemowląt za rok 2010.
Na łączną liczbę 2176 porodów urodziło się 1126 chłopców i 1050 dziewczynek. Zweryfikować hipotezę czy uzyskane proporcje liczby chłopców i dziewczynek przeczą teorii, że rozkład płci u potomstwa jest jak 0,5 : 0,5. Czyli 2176:2 = 1088 ni - npi = 38
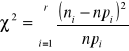
= (38x38):1126+(38x38):1050=1,375+1,282= 2,657
Ponieważ wartość krytyczna Z tablicy rozkładu ![]()
dla 1stopni swobody i dla przyjętego poziomu istotności α=0,05 odczytujemy wartość krytyczną ![]()
=3,991, to oznacza, że .
Przykład 2
Losowa próba n=200 niezależnych obserwacji miesięcznych wydatków na żywność rodzin 3-osobowych dała następujący rozkład tych wydatków (w tys. zł):
Wydatki |
Liczba rodzin |
1,0-1,4 1,4-1,8 1,8-2,2 2,2-2,6 2,6-3,0 |
15 45 70 50 20 |
Należy na poziomie istotności α=0,05 zweryfikować hipotezę, że rozkład wydatków na żywność jest normalny.
Rozwiązanie
Z treści zadania wynika, że nie są sprecyzowane parametry rozkładu hipotetycznego, stawiamy zatem hipotezę Ho : F(x)![]()
, gdzie ![]()
jest klasą wszystkich dystrybuant normalnych. Hipotezę tę weryfikujemy za pomocą testu ![]()
. Dwa parametry rozkładu, średnią m i odchylenie standardowe ![]()
, szacujemy z próby za pomocą estymatorów uzyskanych metodą największej wiarygodności i uzyskujemy wartości ![]()
=2,0 tys. zł oraz s=0,43 tys. zł. Dalsze obliczenia w teście ![]()
wygodnie jest przeprowadzić tabelarycznie, przy czym niech ui oznacza standaryzowaną (tj. ui= =(xi-![]()
)/s) wartość prawego końca przedziału klasowego, a F(ui) wartość dystrybuanty rozkładu N(0, 1) w punkcie ui. Mamy
xi |
ni |
ui |
F(ui) |
pi |
npi |
(F-f) x(F-f) |
|
1,4 1,8 2,2 2,6 3,0 |
15 45 70 50 20 |
-1,39 -0,46 +0,46 1,39 - |
0,082 0,323 0,667 0,918 - |
0,082 0,241 0,354 0,241 0,082 |
16,4 48,2 70,8 48,2 16,4 |
1,96 10,24 0,64 3,24 12,96 |
0,12 0,21 0,01 0,07 0,79 |
|
200 |
|
|
1,000 |
200,0 |
|
1,20 |
Zwróćmy przy tym uwagę, że prawdopodobieństwo dla ostatniego przedziału wyznaczamy jako 1- F(1,39). Otrzymaliśmy więc wartość statystyki ![]()
=1,20: Odpowiednia liczba stopni swobody wynosi 5-2-1=2. Z tablicy rozkładu ![]()
dla 2 stopni swobody i dla przyjętego poziomu istotności α=0,05 odczytujemy wartość krytyczną ![]()
=5,991.
Ponieważ
![]()
nie ma podstaw do odrzucenia hipotezy H0, że rozkład miesięcznych wydatków na żywność w populacji rodzin 3-osobowych jest normalny.
Przykład 2
Zbadano 300 losowo wybranych 5-sekundowych odcinków czasowych pracy pewnej centrali telefonicznej i otrzymano następujący empiryczny rozkład liczby zgłoszeń:
Liczba zgłoszeń |
Liczba odcinków |
0 1 2 3 4 5 |
50 100 80 40 20 10 |
Na poziomie istotności α=0,05 należy zweryfikować hipotezę, że rozkład liczby zgłoszeń w tej centrali jest rozkładem Poissona.
Rozwiązanie
Z treści zadania wynika, że nie jest sprecyzowany parametr ![]()
rozkładu Poissona, stawiamy więc hipotezę H0 : F(x)![]()
,gdzie F(x) jest dystrybuantą rozkładu liczby zgłoszeń, a ![]()
klasą wszystkich rozkładów Poissona. Parametr ![]()
szacujemy z próby za pomocą jego estymatora uzyskanego metodą największej wiarygodności, którym jest średnia z próby ![]()
. Otrzymujemy ![]()
=1,7. Przyjmując za ![]()
tę wartość, z tablicy rozkładu Poissona odczytujemy prawdopodobieństwa pi dla każdej kolejnej liczby zgłoszeń i przeprowadzamy tabelarycznie dalsze obliczenia w celu uzyskania wartości statystyki ![]()
.
Mamy
xi |
ni |
pi |
npi |
|
|
0 1 2 3 4 5 |
50 100 80 40 20 10 |
0,183 0,311 0,264 0,150 0,064 0,028 |
54,9 93,3 79,2 45,0 19,2 8,4 |
24,01 44,89 0,64 25,00 0,64 2,56 |
0,44 0,48 0,01 0,55 0,03 0,30 |
|
300 |
1,000 |
300,0 |
|
1,81 |
Z obliczeń otrzymaliśmy wartość statystyki ![]()
=1,81, a dla przyjętego poziomu istotności α=0,05 i dla 6-1-1 =4 stopni swobody odczytana z tablicy rozkładu ![]()
krytyczna wartość wynosi ![]()
=9,488. Ponieważ ![]()
=1,81 < 9,488 =![]()
, więc nie ma podstaw do odrzucenia hipotezy, że rozkład liczby zgłoszeń w tej centrali telefonicznej jest rozkładem Poissona.
Test niezależności
Często stosowany w praktyce test niezależności ![]()
jest testem istotności pozwalającym na sprawdzenie, czy dwie badane cechy (niekoniecznie mierzalne) są niezależne. Test ten oparty jest na tej samej statystyce co test zgodności ![]()
, z tym że hipotetycznymi prawdopodobieństwami są oszacowane z próby prawdopodobieństwa otrzymania równocześnie określonej wartości (czy kategorii jakościowej) cechy X oraz Y, przy założeniu niezależności tych cech. Sporządza się zatem odpowiednią tablicę kombinowaną dla dwu cech, zwaną tablicy niezależności, która po wypełnieniu daje macierz liczebności empirycznych. Nakłada się na nią macierz liczebności teoretycznych, obliczonych przy założeniu niezależności cech znajdujących się w główce i w boczku. Porównanie elementów obu macierzy, czego dokonuje się przez zastosowanie statystyki ![]()
, daje odpowiedź, czy można odrzucić hipotezę o niezależności cech na skutek wystąpienia zbyt dużych różnic liczebności empirycznych i teoretycznych.
Model
Z populacji tej wylosowano niezależnie dużą próbę o liczebności n elementów. Wyniki próby klasyfikujemy w kombinowaną tablicę niezależności o r wierszach i s kolumnach. Poniższe wzory reprezentują liczebności brzegowe. Zachodzą zatem równości
(2.2) ![]()
![]()
(2.3) ![]()
Z elementów macierzy liczebności empirycznych [nij] oraz elementów macierzy liczebności teoretycznych [npij] konstruujemy statystykę
(2.4) 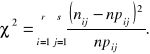
Statystyka ta ma przy założeniu prawdziwości hipotezy H0 o niezależności cech, asymptotyczny rozkład ![]()
z (r-1)(s-1) stopniami swobody.
Przykład
W celu stwierdzenia, czy podanie chorym na pewną chorobę nowego leku przynosi poprawę w ich stanie zdrowia, wylosowano dwie grupy pacjentów w jednakowym stopniu chorych na tę chorobę i jednej grupie o liczebności 120 podawano nowy lek, a druga grupa o liczebności 80 pacjentów otrzymała tradycyjne leki. Po pewnym czasie stwierdzono zestawione w tablicy liczebności chorych w poszczególnych kategoriach stanu zdrowia. Na poziomie istotności a=0,001 zweryfikować hipotezę, że nowy lek istotnie poprawia stan zdrowia pacjentów.
Leczeni |
Stan zdrowia po leczeniu |
||
|
Bez poprawy |
Wyraźna poprawa |
Całkowite wyzdrowienie |
badanym lekiem |
20 39 |
40 36 |
60 45 |
tradycyjnie |
45 26 |
20 24 |
15 30 |
65 60 75 200
Występujące w badaniach wyniki (f empiryczne) reprezentujące badania empiryczne pozwalają wyznaczyć na podstawie proporcji wartości liczebności teoretycznych, które powinniśmy otrzymać gdy badany czynnik nie wpływałby na wyniki leczenia co pozwala wyliczyć F teoretyczne - czyli liczebność teoretyczną .
X:65 =120:200 X:65=80:200 X:75=120:200
X11 = 65x120/200 = 39 X21 = 65x80/200=26 X13 75x120:200=45
Pozostałe wartości teoretyczne możemy obliczyć z różnic bądź proporcji
Jeżeli częstotliwość empiryczną oznaczymy przez f, a teoretyczną obliczoną z proporcji - przez F, to wartość chi kwadrat obliczamy wg następującego wzoru:
χ2 = (F11-f11)x(F11-f11 )/F11 + +(F23 -f23 )x(F23 -f23 )/F23
χ2o= (39-20)x19/39 + (26-45)x(-19) + (36-40)x(-4) + (24-20)x4 +
+(45-60)x(-15) + (30-15)x15 = 9,2 +13,88 + 0,44 + 0,66 + 5 + 7,5=
= 36,66.
Ponieważ liczba stopni swobody n' = (2-1)x(3-1) = 2 to χ2 0,001=13,815.
Przy χ2o = 36,66 to na poziomie istotności α0,001 odrzucamy hipotezę zerową, co oznacza, że zastosowanie nowego leku decyduje o wynikach leczenia.Rozwiązanie
W inny sposób możemy wykonać obliczenia następująco:
Obliczenia w tekście ![]()
niezależności rozpoczynamy od obliczeń liczebności brzegowych ni. i n.j oraz oszacowania prawdopodobieństw brzegowych pi. i p.j. Przyjmując następnie założenie o niezależności cech obliczamy prawdopodobieństwa teoretyczne pij= pi.p.j. Wyniki obliczeń prawdopodobieństw pij zamieszczone są w prawym górnym rogu każdej kratki. Mnożąc te prawdopodobieństwa przez n=200 otrzymujemy dla każdej kratki liczebności teoretyczne npij, które umieszczono w dolnym lewym rogu. Zauważyć przy tym trzeba, że ze względu na konieczność bilansowania się elementów w wierszach i kolumnach obliczenia przeprowadzamy tylko dla tylu kratek, ile wynosi liczba stopni swobody, tzn. (r-1)(s-1)=(2-1)(3-1)=2, a pozostałe elementy zarówno macierzy [pij] jak i [npij] wyznaczamy z wartości brzegowych.
Leczeni |
Stan zdrowia po leczeniu |
||||||||||
|
Bez poprawy |
Wyraźna poprawa |
Całkowite wyzdrowienie |
ni. |
pi. |
||||||
Badanym lekiem |
|
0,195 |
|
0,180 |
|
0,225 |
120 |
0,60 |
|||
|
20 |
40 |
60 |
|
|
||||||
|
-39 |
|
36 |
|
45 |
|
|
|
|||
Tradycyjnie |
|
0,130 |
|
0,120 |
|
0,150 |
80 |
0,40 |
|||
|
45 |
20 |
15 |
|
|
||||||
|
26 |
|
24 |
|
30 |
|
|
|
|||
n.j |
65 |
60 |
75 |
200 |
|
||||||
p.j |
0,325 |
0,300 |
0,375 |
|
1,00 |
||||||
PRZYKŁAD MARKETINGOWY- 1
W dużej sieci handlowej wprowadzano do sprzedaży trzy nowe asortymenty produktów spożywczych, stosując trzy różne metody promocji stosowane równolegle w trzech podobnych obiektach handlowych. Z systemu informacji handlowej hipermarketu uzyskiwano dane o liczbie klientów kupujących poszczególne asortymenty wyrobów oraz odpowiadające im wartości sprzedaży.
Należy zweryfikować hipotezę zerową o braku zależności pomiędzy stosowanymi metodami promocji a liczbą klientów dokonujących zakupy wprowadzanych do sprzedaży nowych wyrobów.
W poniższej tabeli zamieszczono wyniki dotyczące liczby osób kupujących poszczególne produkty w tyś osób na tydzień
Asort/ met. pro |
Metoda1 |
Metoda2 |
Metoda3 |
Produkt 1
|
3,5 |
6,7 |
7,8 18 |
Produkt 2
|
11,4 |
8,9 |
12,5 32,8 |
Produkt 3
|
5,8 |
5,0 |
8,9 19,7 |
Σ 20,7 20,6 29,2 70,5
F11 =5,3 F12 = 5,26 F13 = 7,46 F21 = 9,63 F22 =9,58 F23 = 13,6
F31 = 5,78 F32 = 5,76 F33 =8,16
X = 0,61 +0,39+0,02+0,33+0,05+0,09+0,00+0,1+0,07=1,66
Ponieważ ![]()
α0,05 = 9,488 przy l. st. Sw. = (3-1)x(3-1) = 4 < od χ2o = 1.66
To nie ma podstaw do odrzuceni hipotezy zerowej. Oznacza to że porównywane metody promocji nie różnią się istotnie we wpływie na liczbę klientów hipermarketu kupujących dany produkt w okresie tygodnia.
Przykład Marketingowy 2
W ramach trzech kanałów dystrybucji dokonywano działań reklamowo promocyjnych o podobnym poziomie nakładów i dokonywano oceny przyrostu wartości sprzedaży w kolejnych czterech tygodniach. Badanie miało na celu zidentyfikowanie kanału dystrybucji o najwyższym poziomie efektywności reagowania na zastosowane metody reklamy, które kontynuowałoby w przyszłości w tym sektorze.
Wyniki przyrostu sprzedaży w poszczególnych kanałach dystrybucji zestawiono w poniższej tabeli.
Zestawienie przyrostu sprzedaży w kanałach dystrybucji w tyś zł
Tydz sp\ kanały dyst |
I kan dyst |
II kan. dyst |
III kan. dyst |
Σ |
I tydz |
3,2 3,37 |
4,4 4,6 |
5,5 5,13 |
13,1 |
II tydz |
5,4 4,89 |
6,5 6,67 |
7,1 7,44 |
19,0 |
III tydz |
3,7 4,14 |
5,9 5,5 |
6,5 6,46 |
16,1 |
IV tydz |
6,3 6.32 |
8,6 8.67 |
9,7 9,61 |
24,6 |
Σ |
18,6 |
25,4 |
28,8 |
72,3 |
F11 =18,6x13,1/72,3 =3,37
Ponieważ różnice F teoret i f emp. Nie przekracają 0,5, to nie celowe jest obliczanie ![]()
o przy wartości krytycznej dla l zt sw 4 równe 9,488
Zadanie domowe
Zestawienie przyrostu sprzedaży w kanałach dystrybucji w tyś zł
Tydz sp\ kanały dyst |
I kan dyst |
II kan. dyst |
III kan. dyst |
Σ |
I tydz |
8,8 |
17,5 |
20,1 |
|
II tydz |
6,2 |
14,3 |
16,3 |
|
III tydz |
5,1 |
12,5 |
18,2 |
|
IV tydz |
3,6 |
10,5 |
14,1 |
|
Σ |
|
|
|
|
WYKONAĆ OBLICZENIA I ZINTERPRETOWAĆ WYNIKI
Wyszukiwarka