Podstawowe pojęcia prognozowania i symulacji na podstawie modeli ekonometrycznych. Weryfikacja modeli.
SPIS TREŚCI
0. Bibliografia.
1. Przedmiot „Symulacja i prognozowanie”. Symulacja historyczna. Prognoza ex post. Prognoza ex ante.
2. Zadanie symulacji i prognozowania ekonometrycznego. Liniowy model. Metoda najmniejszych kwadratów. Prognozy na podstawie liniowego modelu.
3. Weryfikacja modelów ekonometrycznych.
4. Błędy prognoz. Prognozy warunkowe.
0. Bibliografia.
1. S.Bartasiewicz. Ekonometria. - Warszawa. Państwowe Wydawnictwo Ekonomiczne. 1976.
2. A.Welfe. Ekonometria. - Warszawa. Państwowe Wydawnictwo Ekonomiczne. 1995.
3. W.Radzikowski. Matematyczne techniki zarządzania. - Warszawa. Państwowe Wydawnictwo Ekonomiczne. 1980.
4. Z.Czerwiński, B.Guzik. Prognozowanie ekonometryczne. - Warszawa. Państwowe Wydawnictwo Ekonomiczne. 1980.
5. J.W.Gajda. Wielorównaniowe modele ekonometriczne. Estymacja - symulacja - sterowanie. - Warszawa. Państwowe Wydawnictwo Ekonomiczne. 1988.
6. J.Buga, W.Grabowski, J.Greń i inny. Ekonometria i badania operacyjne. - Warszawa. Państwowe Wydawnictwo Naukowe. 1980.
7. T.H.Naylor. Modelowanie cyfrowe systemów ekonomycznych. - Warszawa. Państwowe Wydawnictwo Ekonomiczne. 1975.
8. W.Charemza, D.Deadman. Nowa ekonometria. - Warszawa. Państwowe Wydawnictwo Ekonomiczne. 1997.
9. Tomasz Szapiro i inni. Decyzje menedżerskie z Excelem. - Warszawa. Państwowe Wydawnictwo Ekonomiczne. 2000.
10. Prognozowanie gospodarcze. Metody i zastosowania. \ Red. Nuk. Maria Cieśliak. - Warszawa. Państwowe Wydawnictwo Ekonomiczne. 1999.
1. Przedmiot „Symulacja i prognozowanie”. Symulacja historyczna. Prognoza ex post. Prognoza ex ante.
W ekonometrii jednym z głównych zadań jest badane procesów ekonomicznych i wytwarzanie teorii rozwoju tych procesów. Każda teoria, która powstała na gruncie nauk przyrodniczych lub społecznych, powinna być zdolna do tłumaczenia istniejących i przewidywania przyszłych zdarzeń.
Rozdział ekonometrii symulacja i prognozowanie zajmuje się sprawdzeniem modelów ekonometrycznych i prognozowaniem na ich podstawie rozwoju zjawisk ekonomicznych.
Definicja. Symulacja ekonomiczna jest naśladowanie za pomocą ekonometrycznego modelu rzeczywistego ekonomicznego procesu lub efektu albo odtwarzanie układu istniejącego w rzeczywistości ekonomicznej.
Istota symulacji polega na naśladowaniu rzeczywistości w sposób ekwiwalentny ze względu na wybrany cel lub etap analizy (badania). Ekwiwalentność oznacza w tym przypadku jednoznacznie zdefiniowane związki między wybranymi cechami rzeczywistości ekonomicznej a elementami modelu ekonometrycznego przybliżającego tę rzeczywistość.
W symulacji i prognozowanie stosuje się różne modele, spośród których wyróżniamy trzy typy:
1. Model symulacyjny służący do naśladowania (identyfikacji) procesu lub układu. Znany jest stan wejść i wyjść systemu (np. empirycznie), natomiast nie jest znany formalny opis procesów zachodzących w systemie lub stanu systemu. Model takiego typu wykorzystuje się do sprawdzenia prawdziwości hipotez co do stanu systemu lub procesów w nim zachodzących.
2. Model symulacyjny służący do badania systemu wprost. Znany jest stan wejść systemu i formalny opis stanu systemu lub procesów w nim zachodzących, natomiast nie jest znany stan wyjść systemu. Model takiego typu wykorzystuje się do naśladowania efektów np. decyzji.
3. Model symulacyjny służący do naśladowania optymalnego sterowania. Znany jest stan wyjść systemu i formalny opis stanu systemu lub procesów w nim zachodzących, natomiast nie jest znany stan wejść systemu. Model takiego typu wykorzystuje się do kierowania programowanego ekonomicznym systemem.
W praktyce stosuje się również modele symulacyjne będące kombinacją modeli tych trzech typów.
Zwykle będziemy wykorzystywać modeli zbliżony do drugiego typu.
Wszystkie ekonometryczne modele symulacyjne składają się z układu równań, w których występują określone zmienne.
Zmienne dzielą się na objaśniane (zależne) i objaśniające (niezależne).
Zmienne można podzielić na endogeniczne i egzogeniczne. Endogeniczne zmienne - to są wszystkie objaśniane. Niektóre z nich mogą występować w innych funkcjach modelu jako objaśniające. Egzogeniczne zmienne - to są zmienne, które występują w modelu jedyne w roli objaśniających.
W symulacji i prognozowanie często wykorzystuję się modeli, w których istnieje zależność od czasu (modele tendencji rozwojowej).
Symulacji dokonuje się dla kolejnych okresów, w wyniku czego dla wszystkich zmiennych modelu otrzymuje się ciągi wartości liczbowych, który zwane ścieżkami rozwojowymi (lub czasowymi w zależności od rodzaju zmiennych).
W wąskim sensie za symulacje (prognozą ex post) procesów ekonomicznych rozumie się badanie modelu w zakresach zmiennych objaśniających, a prognozowaniem (symulacja historyczna lub prognoza ex ante) procesów ekonomicznych rozumie się badania modelu poza zakresami zmiennych objaśniających.
W tym przypadku dostępność danych, dotyczących zmiennych objaśniających, zależy od długości i struktury występujących opóźnień oraz charakteru zjawisk. Najczęściej dane te są wyznaczone tylko z pewnym prawdopodobieństwem, wówczas otrzymana prognoza nosi nazwę warunkowej (względem zmiennych objaśniających).
Wartości zmiennych objaśniających są znane, sama prognoza może być porównana z wartościami zaobserwowanymi.
Terminy „symulacja historyczna”, „prognoza ex post”, „prognoza ex ante” zwykle wykorzystuje się dla modelów, w których zmienną objaśniającą jest czas.
Schemat typów symulacji i prognozowania dla szeregów czasowych jest na rys 1.1.
Symulacja historyczna Prognoza ex post Prognoza ex ante
t* to t** t1 t***
to , t1 - interwał czasowy (okres czasowy), na podstawie którego rozwiązany model;
t* , t** , t*** - odpowiednie punkty prognozowania w przeszłości, teraźniejszości i przyszłości.
Rysunek 1.1.
Dzięki prognozom można ustrzec się przed skutkami przyszłych zdarzeń, można im zapobiegać, a także próbować wpływać na ich bieg. Współcześnie prognozy ekonometryczne są w wielu krajach rutynowo wykorzystywane przez parlamenty, polityków, duże przedsiębiorstwa i wszędzie tam, gdzie podejmowane są strategiczne decyzje planistyczne.
Metody symulacji i prognozowania wykorzystują najczęściej dwa rodzaje modeli: szeregów czasowych lub ekonometryczne. Te pierwsze próbują opisać badane zjawisko za pomocą pewnej funkcji trendu, z uwzględnieniem sezonowości, cykliczności oraz stochastycznego charakteru procesu, ale bez wnikania w ekonomiczne mechanizmy, które go kształtują. Metody oparte na modelach ekonometrycznych, dla odmiany, biorą pod uwagę całą wiedzę o związkach zachodzących pomiędzy poszczególnymi zmiennymi i z tego powodu są nazywane metodami opartymi na modelach przyczynowo-skutkowych.
2. Zadanie symulacji i prognozowania ekonometrycznego. Liniowy model. Metoda najmniejszych kwadratów. Prognozy na podstawie liniowego modelu.
Przypominamy, że rozwiązanie modeli ekonometrycznych składa się z następujących etapów:
1. Zbiór i uporządkowane danych, specyfikacja zmiennych.
2. Analiza danych i konstrukcja modelu.
3. Estymacja parametrów strukturalnych modelu.
4. Weryfikacja modelu.
5. Zastosowanie modelu.
Na ostatnim etapie, gdzie odbywać się sprawdzenie i zastosowanie modeli, często potrzebuje się rozwiązanie modelu dla konkretnych warunków. Modeli ekonometryczne przedstawią sobą w ogólnym przypadku równania (lub układy równań), za pomocom których badane są prowadzenie zmiennych objaśnianych w zależności od zmiennych objaśniających.
Przy badaniach modelów ekonometrycznych możliwe określenie nie tylko zmiennych objaśnianych w zależności od wiadomych zmiennych objaśniających, ale i odwrotne, określenie zmiennych objaśniających dla ustalonych zmiennych objaśnianych, symulacja zjawisk ekonomicznych. Takiego rodzaju badania potrzebują umiejętności rozwiązania równań lub układów równań.
Te zadania są mogą być bardzo skomplikowanymi problemami, który potrzebują specjalnych metod numerycznych.
Samy prosty model to są linowy model.
Rozpatrzymy liniowy model ekonometryczny z jednej zmiennej objaśniającej postaci
Y = + X + (1.1)
gdzie X - zmienną objaśniającą,
, - parametry strukturalne modelu,
N(0, σ2) - zmienną losową (składnik losowy). Ostatnie oznacza:
- wartość oczekiwana składnika losowego równa się zero
E() = 0 (1.2)
- wariancja (dyspersja) składnika losowego modelu dąży do stałą σ2 i ma rozkład normalny (składnik losowy jest homoskedastyczny)
D( )=σ2 (1.3)
Funkcja
Y' = + X (1.4)
nazywa się funkcją regresji.
Na podstawie (1.4) możliwe obliczyć wartości teoretyczne Y' modelu (1.1).
Na praktyce zmienna objaśniająca X ma dyskretny szereg (dane) x1, x2, ..., xj, ... xn. , a zmienna objaśniana Y odpowiednie obserwacji y1, y2, ..., yj, ... yn.
Metoda najmniejszych kwadratów (MNK) polega na wyznaczeniu takich estymatorów a0, a1 modelu, aby dla danych n obserwacji (xi, yi) suma kwadratów odchyleń od funkcje regresji Y' była najmniejszej:
F(a0, a1)=![]()
(1.5)
Wtedy możliwe obliczyć tylko estymatory parametrów modelu według formuł
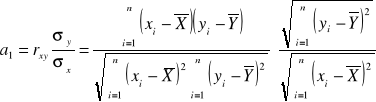
(1.6)
![]()
(1.7)
gdzie
![]()
jest współczynnik korelacji (Pearsona) pomiędzy zmiennymi ![]()
i ![]()
;
![]()
są odchylenia standardowy odpowiednie zmiennych ![]()
i ![]()
.
![]()
- średnie dla zmiennych Y i X.
Estymatorem wariancje σ składnika losowego będzie
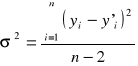
(1.8)
Wariancje parametrów modelu
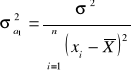
(1.9)
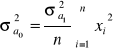
(1.10)
Przedziały ufności dla parametrów , modelu
![]()
(1.11)
![]()
(1.12)
gdzie t jest wartość krytyczna statystyki t-Studenta o (n-2) stopniach swobody i poziome istotności (zwykle ,, co odpowiada prawdopodobieństwu 95%).
Dla prognozowania w punkcie xi, gdzie xi może mieć wartość w zakresach [x1 xn] (prognoza ex post) lub za przedziałami [x1 xn] (symulacja historyczna, prognoza ex ante) potrzebnie wykorzystać funkcją regresji (1.4) i sprawdzić błędy prognozy.
Analogiczne można prognozować na podstawie liniowego modelu wielu (m) zmiennych objaśniających.
Y' = + X+ X+ ... + mXm+ (1.13)
Ten model w postaci macierzowej będzie zapisany
Y = X + (1.13a)
Funkcja regresji ma postać
Y' = X (1.14)
gdzie 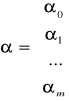
- wektor parametrów strukturalnych modelu, 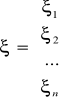
- wektor składników losowych modelu, 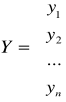
- wektor danych zmiennej objaśnianej, 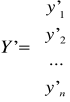
- wektor wartości teoretycznych, 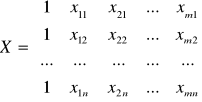
- macierz danych zmiennych objaśniających, m - ilość zmiennych objaśniających, n - ilość danych.
Wtedy estymatory parametrów modelu można obliczyć według wzoru:
![]()
(1.15)
gdzie B=(XTX)-1 - macierz odwrotna, nazywana macierzą wariancji - kowariancji, XT - macierz transponowana.
Estymatorem wariancje σ składnika losowego będzie
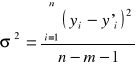
(1.16)
Wariancje parametrów modelu
![]()
, i=0,1,2,...m (1.17)
bii - element głównej przekątnej macierzy B=(XTX)-1.
Przedziały ufności dla parametrów i (i=0,1,2,...m) modelu
![]()
, i=0,1,2,...m (1.18)
3. Weryfikacja modelów ekonometrycznych.
Dla tego, że by wykorzystać model dla prognozowania, potrzebnie jego zweryfikować.
Zwykle prowadzone się następujący badania (minimum):
1. badanie dopuszczalności modelu.
2. badanie istotności parametrów strukturalnych modelu.
3. badanie wartości oczekiwanej składnika losowego.
4. badanie normalności rozkładu składnika losowego.
5. badanie autokorelacji składnika losowego.
6. badanie stacjonarności składnika losowego.
Na tym etapie musimy odpowiedzieć na zasadnicze pytania:
czy model opierający się na danych empirycznych w wystarczającym stopniu jest dopasowany do nich;
czy bierzemy pod uwagę wszystkie czynniki wpływające na zmienne objaśniane i czy wpływ tych czynników na zmienną objaśnianą jest istotny;
czy spełnione są złożenia przyjęte dla naszego modelu;
w jakim stopniu wyniki badań wykorzystujących nasze dane empiryczne możemy przenieść na inne obserwacje.
Etap weryfikacji jak i każde badanie zawiera w sobie elementy sztuki, które nie możemy opisać przez algorytm. Jego można podzielić na dwie części. Pierwsza część to jest sprawdzenie statystycznej istotności oszacowanych parametrów i sprawdzeniem tego na ile ostro są spełnione początkowe ograniczenia. W drugiej części badamy stabilność tych ocen, to na ile dobrze zachowują się wartości teoretyczne po za próbka, czy udało się nam wydzielić systematyczną komponentu badanej zależności i czy możemy wykorzystać model do prognozy. Z punktu widzenia matematyki niema żadnych problem w tym, żeby obliczyć ciągłą prostą do której należą wszystkie obserwacje. Wtedy będziemy mieli model z zerowymi resztami i współczynnikiem determinacji równym jedynce. Ale to będzie oznaczało, że my wytłumaczyli przez model to co w ogóle niemożliwe wytłumaczyć losowy komponent zjawiska. Zrozumiało, że taki model nie nadaje się do prognozowania.
Zapiszemy założenia metody najmniejszych kwadratów, które gwarantują efektywność tej metody:
Losowy charakter składnika losowego
. Poszczególne zakłócenia
mają losowy charakter.Zerowa średnia wartość
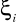
i niezależność jej od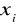
. Każde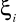
ma zerową wartość oczekiwaną niezależnie od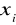
.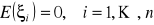
.Zmienne objaśniające
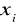
są z góry znane i nie są wzajemnie zależne pomiędzy sobą.Brak autokorelacji. Wartości
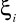
mają niezależne rozkłady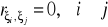
.Homoscedastyczność. Stałość wariancji
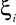
i niezależność jej od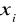
.Normalność. Rozkład
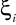
jest normalny.
3.1. badanie dopuszczalności modelu.
Najprostsze charakterystyki które wykorzystują się dla szacunku stopnia dopasowania modelu do danych wartości empirycznych to są współczynniki determinacji, zbieżności i zmienności. Dla liniowego modelu
![]()
. (1.19)
W analizie regresyjnej wykorzystuje się trzy sumy kwadratów:
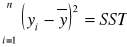
- zmienność całkowita (suma kwadratów odchyleń wartości empirycznych próby od średniej);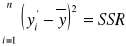
- zmienność objaśniona (suma kwadratów odchyleń wartości teoretycznych od średniej);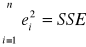
- zmienność nie objaśniona (suma kwadratów reszt).
Łatwo udowodnić, że zmienność całkowita jest sumą zmienności objaśnionej i zmienności nie objaśnionej:
![]()
. (1.20)
W ostatniej równości wykorzystaliśmy to, że ![]()
i ![]()
. Podzielmy stronami wzór (1.20) przez zmienność całkowitą. Mamy:
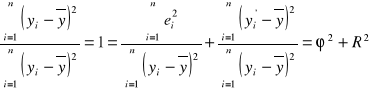
, (1.21)
gdzie ![]()
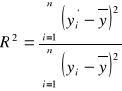
nazywa się współczynnik determinacji, (1.22)
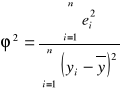
nazywa się współczynnik zbieżności. (1.22)
Biorąc pod uwagę (1.21) łatwo stwierdzić, że wartości współczynników determinacji i zbieżności należą do przedziału ![]()
. Współczynnik determinacji mówi o tym, jaka część całkowitej zmienności wytłumaczona jest przez model. Wartość współczynnika determinacji jest tym bliżej jedynki, im wartości teoretyczne są bliżej linii regresji i tym jest bliżej zera, im więcej rozproszenie punktów (xi, yi) lub kształt chmury punktów (xi, yi) nie odpowiada prostej. Jednocześnie współczynnik zbieżności mówi o tym, jaka część całkowitej zmienności nie jest wytłumaczona przez model. Zwykle w ekonomii warunek dopuszczalności modelu stosuje się jako
![]()
(1.23)
Kolejną charakterystyką dopasowania modelu będzie zmodyfikowany współczynnik zbieżności skorelowany współczynnik zbieżności ![]()
. Ten współczynnik obliczamy wtedy, gdy potrzebujemy porównać modele zawierające różne ilości zmiennych objaśniających i ilość obserwacji. Skorelowany współczynnik zbieżności wyeliminuje tą zależność wprowadzeniem współczynnika ![]()
:
![]()
- skorelowany współczynnik zbieżności (1.24)
i odpowiednio
![]()
- skorelowany współczynnik determinacji. (1.25)
Skorelowany współczynnik determinacji może przyjąć ujemną wartość i wtedy nie może być zinterpretowany w kategoriach zmienności objaśnionej i nie objaśnionej.
Wykorzystanie współczynników determinacji i zbieżności wymaga zastosowanie metody najmniejszych kwadratów, ale i w przypadku innych metod estymacji gdy nie ma możliwości wykorzystania innych miar dopasowania również dopuszczalne jest zastosowanie tych współczynników.
Następną charakterystyką jest współczynnik zmienności modelu:
![]()
(1.26)
gdzie ![]()
jest estymator odchylenia standardowego składnika losowego modelu;
![]()
jest średnia wartości empirycznych modelu.
Współczynnik zmienności mówi o wyrazistości modelu. To znaczy, że jesteśmy raczej zdecydowani prognozować na podstawie modelu z mniejszym współczynnikiem zmienności. Praktycznie kolejność działań jest następna. Określamy, jaki najwyższy procent ![]()
ma stanowić ![]()
do ![]()
. Zwykłe za ![]()
przyjmujemy wartość nie większą za 15%. Jeżeli otrzymane w doświadczeniu ![]()
to model uznajemy za nie dość wyrazisty, a jeżeli ![]()
, to przyjmujemy model.
W zastosowaniach istotne jest porównanie wpływu na zmienną objaśnianą poszczególnych zmiennych objaśniających. Biorąc pod uwagę różne jednostki mierzenia i przedziały do których należą wartości zmiennych, najpierw musimy unormować zmienne objaśniające. Unormowania możemy rozumieć jako proces przekształcenia zmiennych w wyniku którego one będą przejmować wartości z jednego przedziału i mieć jedne jednostki mierzenia. Mamy
![]()
.
Więc
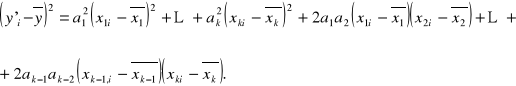
Ostatecznie mamy:
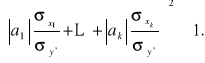
Wartości 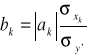
należą do jednego przedziału i nie mają jednostek mierzenia. Im większe są one, tym większy wpływ na zmienną objaśnianą ma zmienna ![]()
.
3.2. badanie istotności parametrów strukturalnych modelu.
Kolejnym badaniem, które charakteryzuje związek pomiędzy zmienną objaśnianą a zmiennymi objaśniającymi to jest badanie istotności parametrów modelu. Badanie to polega na sprawdzeniu, czy wartość parametru istotnie różni się od zera dla poziomu istotności ![]()
(prawdopodobieństwo błędu). Za hipotezę zerową przyjmujemy hipotezę równości zeru parametrowi:
![]()
.
Dla sprawdzenia tej hipotezy obliczamy statystykę
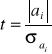
, (1.27)
gdzie ![]()
jest wartością i-go parametru modelu,![]()
jest odchyleniem standardowym i-go parametru modelu (i=0,1, ... m) , obliczonego, na przykład na podstawie wzoru (1.17). Faktycznie (1.17) jest standaryzacją zmiennej ![]()
, dla której przypuszczamy wartość oczekiwaną zero i odchylenie standardowe ![]()
. Z powyższego wynika, że Statystyka (1.17) ma rozkład t-Studenta o n-k-1 stopniach swobody, gdzie n - ilość obserwacji, k - ilość zmiennych objaśniających w modelu. Z tabeli rozkład t-Studenta odczytujemy wartość krytyczną statystyki ![]()
dla poziomu istotności ![]()
i n-m-1 stopni swobody. Jeżeli zachodzi nierówność
![]()
,
to przyjmujemy hipotezę zerową (parametr ![]()
przyznajemy nieistotnym). Najczęściej po takim wniosku decydujemy się na wyeliminowanie odpowiedniej zmiennej i ponownemu oszacowaniu parametrów modelu lub powtórzeniu badania na ustalenie zmiennych objaśniających (na przykład badanie Hellwiga). Druga możliwość to jest zmniejszenie ![]()
. Biorąc pod uwagę to, że w mianowniku odchylenia standardowego reszt znajduje się (n-m-1), możemy to osiągnąć zmniejszając ilość szacowanych parametrów, tj. wyeliminujemy niektóre zmienne objaśniające lub wolny wyraz (przechodzimy do nowych zmiennych, które są odchyleniami od średnich wartości). Zwiększenie n ogólne nie daje zmniejszenia ![]()
(razem ze wzrostem n rośnie licznik), ale nowe obserwacje dostarczają nową informację o modelu i to czasami też poprawia sprawy. Jeżeli
![]()
odrzucamy hipotezę zerową (parametr ![]()
przyznajemy istotnym).
3.3. badanie wartości oczekiwanej składnika losowego.
Badanie to polega na sprawdzeniu, czy wartość oczekiwana składnika losowego istotnie różni się od zera dla poziomu istotności ![]()
(prawdopodobieństwo błędu). Za hipotezę zerową przyjmujemy hipotezę równości zeru parametrowi:
![]()
.
Dla sprawdzenia tej hipotezy obliczamy ![]()
średnia dla reszt i 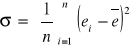
- odchylenie standardowe dla reszt. Wtedy statystyka
![]()
ma rozkład Studenta o (n-2) stopniach swobody. Z tabeli rozkładu t-Studenta odczytujemy wartość krytyczną statystyki ![]()
dla poziomu istotności ![]()
i n-2 stopni swobody. Jeżeli zachodzi nierówność
![]()
,
to przyjmujemy hipotezę zerową (wartość oczekiwana składnika losowego statystycznie nie różnie się od zera). Po takim wniosku prowadzimy następny badania modelu.
Jeżeli
![]()
,
to odrzucamy hipotezę zerową - wartość oczekiwana składnika losowego statystycznie różnię się od zera, a to nie odpowiada założeniom metody najmniejszych kwadratów. Najczęściej po takim wniosku decydujemy się na wyeliminowanie postaci modelu i poszukiwania innej, która odpowiada warunkom metody.
3.4. badanie normalności rozkładu składnika losowego.
W tym kroku procedury weryfikacyjnej chodzi o sprawdzenie czy reszty modelu podlegają prawu rozkładu normalnego. Dla tego wykorzystujemy testy nieparametryczne (zgodności), które określają stopień zgodności rozkładu empirycznego (rozkładu reszt) z rozkładem teoretycznym.
Od razu zauważymy, że estymatory obliczone metodą najmniejszych kwadratów mają dobre właściwości nawet przy braku normalnego rozkładu. To oznacza, że dokładność ogólnie przyjętych statystycznych testów nie jest zbyt wrażliwa na odchylenia od normalnego rozkładu. Natomiast normalny rozkład składnika losowego jest potrzebny dla dowodu tego, że możemy wykorzystać dla sprawdzenia t - Studenta, F i ![]()
statystyki.
Bardzo często dla badania rozkładu normalnego stosuje się test ![]()
. Jednym z podstawowych testów dla badania normalności rozkładu składnika losowego jest test Kolmogorowa ( - test). On stosuje się dla dowolnych próbek. Modyfikacja tego testu dla małych próbek (ilość danych ![]()
) jest test Hellwiga.
Stosując test zgodności Hellwiga postępujemy następująco.
Przeprowadza się standaryzację reszt modelu
![]()
,
gdzie ![]()
, ![]()
- ilość obserwacji modelu, 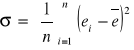
- odchylenie standardowe.
Wartości
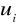
porządkujemy rosnąco tak, żeby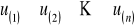
.Dla wartości
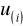
oblicza się dystrybuantę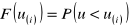
.Odcinek
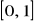
dzieli się na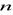
części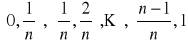
tzw. cel.Wyznacza się ilość pustych cel K do których nie trafiła żadna wartość
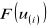
.Z tablic testu zgodności Hellwiga dla przyjętego poziomu istotności
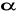
oraz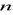
obserwacji odczytuje się krytyczną ilość pustych cel K1., K2.Hipotezę zerową o normalności rozkładu reszt modelu przyjmujemy jeżeli
K1. * K * K2 . Natomiast jeżeli K. < K1 lub K2 < K przyjmujemy hipotezę alternatywną reszty modelu nie podlegającą prawom rozkładu normalnego.
3.5. badanie autokorelacji składnika losowego.
Regresywne modele, które są uzależnione od czasu prawie zawsze mają w tym lub innym stopniu autokorelacje zakłóceń (składnika losowego). Po - pierwsze prawie wszystkie procesy rzeczywistości nawet takie jak strajki, wojny, susze itd. mają okresy lub zmienne nie wzięte pod uwagę w modelu mają wpływ okresowy. Po - drugie metody zebrania danych zawierają elementy zgładzające, które dostarczają informację średnią o badanym zjawisku. Więc powstaje pytanie na ile jest istotna korelacja reszt i czy musimy zmienić model, żeby dokładniej opisywał zjawisko lub przyjąć hipotezą zerową taką, że autokorelacji nie ma. Za miernik liniowej autokorelacji zwykło biorą
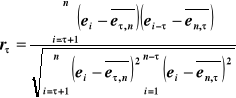
współczynnik autokorelacji![]()
-go rzędu. (1.28)
gdzie ![]()
jest średnia ostatnich ![]()
reszt modelu,
![]()
jest średnia pierwszych ![]()
reszt modelu.
Niestety, z powodu braku rozkładów współczynników autokorelacji, które są bardzo skomplikowane nie możemy wykorzystać (1.28) jako statystyki. Dla tego w celu weryfikacji istotności współczynnika autokorelacji pierwszego rzędu wykorzystamy test Durbina - Watsona, za pomocą którego sprawdza się hipoteza zerowa, głoszącą, że nie występuję autokorelacja reszt
![]()
,
wobec hipotez alternatywnych: występuję ujemna autokorelacja
![]()
albo występuję dodatnia autokorelacja
![]()
.
Sprawdzeniem hipotezy przy ![]()
jest statystyka
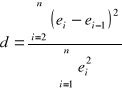
. (1.29)
Wartości krytyczne tej statystyki ![]()
i ![]()
odczytują się z tablic Durbina - Watsona dla pozioma istotności ![]()
oraz ![]()
i ![]()
stopni swobody (![]()
- liczba obserwacji, ![]()
- liczba zmiennych objaśniających w modelu).
Zauważymy, że w dużych próbkach wartości ![]()
i ![]()
są w przybliżeniu równe oraz ![]()
. Więc dla (1.29) możemy zapisać
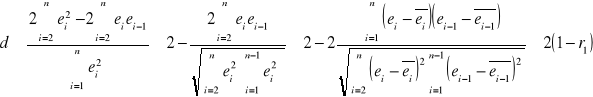
. (1.30)
Biorąc pod uwagę to, że ![]()
i (8.21) mamy
![]()
. (1.31)
W odróżnieniu od innych statystyk dla ![]()
krytyczny brzeg przyjęcia zerowej hipotezy i nie przyjęcie alternatywna hipotezy nie są równe. Więc mamy pięć przedziałów pokazanych niżej w tabeli
Wartość
|
|
|
|
|
|
|
Odrzucamy hipotezę zerową,; przyjmujemy alternatywną hipotezę o istnieniu dodatniej autokorelacji |
Hipotezę zerową nie przyjmuje się i nie odrzuca się |
Przyjmujemy hipotezę zerową |
Hipotezę zerową nie przyjmuje się i nie odrzuca się |
Odrzucamy hipotezę zerową,; przyjmujemy alternatywną hipotezę o istnieniu ujemnej autokorelacji |
Więc mamy:
jeśli ![]()
i ![]()
, to przyjmujemy hipotezę zerową;
![]()
, to odrzucamy hipotezę zerową,; przyjmujemy alternatywną hipotezę o istnieniu dodatniej autokorelacji;
![]()
, to nie można podjąć żadnej decyzji;
jeśli ![]()
i ![]()
, to przyjmujemy hipotezę zerową;
![]()
, to odrzucamy hipotezę zerową,; przyjmujemy alternatywną hipotezę o istnieniu ujemnej autokorelacji;
![]()
, to nie można podjąć żadnej decyzji.
Autokorelacji pokazuje nieadekwatność co najmniej części modelu. Wtedy metoda najmniejszych kwadratów nie dozwala obliczyć efektywne estymatory parametrów, na przykład w przypadku dodatniej autokorelacji wartości estymatorów odchyleń standardowych parametrów okazują się zaniżone. Jedno z możliwych rozwiązań to jest badanie zależności reszt od innych zmiennych i jeżeli ich wpływ nie okazuje się istotny wtedy możemy przyjąć hipotezę o zależności błędów od czasu.
3.6. badanie stacjonarności składnika losowego.
Stacjonarność składnika losowego modelu oznacza niezależność jego od czasu. Jeżeli składnik losowy jest stacjonarny, to możemy wnioskować, że model nie zmienia się na długim okresie czasu, i to pozwala być pewnym, że prognozie można zaufać dla długiego okresu czasu. Test prowadzimy w prowadzimy w następującej kolejności:
1. Obliczamy współczynnik korelacji re,t pomiędzy resztami ei a czasem ti:
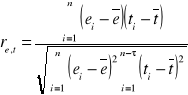
2. Za hipotezę zerową (stacjonarności) przyjmujemy hipotezę równości zeru współczynnika korelacji re,t:
![]()
.
3. Dla sprawdzenia tej hipotezy obliczamy statystykę
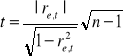
Ona ma rozkład Studenta o (n-1) stopniach swobody. Z tabeli rozkładu t-Studenta odczytujemy wartość krytyczną statystyki ![]()
dla poziomu istotności ![]()
i n-1 stopni swobody. Jeżeli zachodzi nierówność
![]()
,
to przyjmujemy hipotezę zerową (składnik losowy jest stacjonarny). Po takim wniosku prowadzimy następny badania modelu.
Jeżeli
![]()
,
to odrzucamy hipotezę zerową - składnik losowy nie jest stacjonarny. Wtedy badamy model dalej, ale pamiętamy, że dla prognozowania dla długich okresów czasu on jest nieprzydatny.
4. Błędy prognoz. Prognozy warunkowe.
Definicja. Wiarygodnością prognozy będziemy nazywać minimalne wartość prawdopodobieństwa prawidłowości sądu potrzebną do uznania tego sądu za prognozą statystyczną.
Definicja. Dokładnością prognozy będziemy nazywać przedział prognozy, który odpowiada wiarogodności.
Z tych definicji wynika następująca procedura prognozowania:
1. Założenie a priori prawdopodobieństwa prawidłowości naszego sądu, czyli wiarygodność prognozy (zwykle =0,05).
2. Oszacowanie wartości zmiennej prognozowanej Y* w okresie prognozowania.
3. Ustalenie przedziału dla wartości zmiennej prognozowanej w okresie prognozowania [Yd*, Yg*],
gdzie Yd*, Yg* odpowiednie dolna i górna granica przedziału w okresie prognozowania
Zauważymy, że wiarogodność prognozy powinna być bliska jedności, przykładowo możemy wymienić, że wiarogodność prognozy powinna być z reguły nie mniejsza niż 0,8.
Podstawowa różnica pomiędzy procesem estymacji parametrów a prognozowaniem polega na tym, że wyniki prognoz weryfikuje rozwój zdarzeń, prawdziwe zaś parametry zawsze są nie obserwowalny i ich wartości nie mogą być porównany z tymi, które zostały oszacowany.
Definicja. Różnica pomiędzy rzeczywistą wartością Yn+1 i jej prognozą Y*=Y'n+1 nazywa się błędem prognozy:
Błąd prognozy ma rozkład normalny, bo jest liniowa kombinacja zmiennych o rozkładzie normalnym. Wartość oczekiwania błędu prognozy równa się zeru.
Ze względu losowości zmiennych objaśniających Xi, i=1,2,...m, prognozy dzielimy na prognozy bezwarunkowe (zmienne Xi, i=1,2,...m są stałe) i prognozy warunkowe (zmienne Xi, i=1,2,...m są losowe)
Dokonamy prognozę w punkcie xn+1, gdy xn+1 jest ustalone.
Prognoza punktowa dla liniowego modelu
Y* = + Xn+1
lub
Y* = + Xn+ X n+ ... + mXm n
Wariancja zmiennej objaśnianej w punkcie prognozowania jest
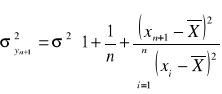
(1.32)
dla modelu (1.1) i
![]()
, (1.33)
(gdzie xn+1 - wiersz danych dla prognozowania) dla modelu (1.13).
Z analizy (1.32), (1.33) wynika, że wariancja błędu prognozy
1. maleje wraz z wzrostem liczebności próby n;
2. maleje ze wzrostem wariancji σ w próbie zmiennej objaśniającej;
3. rośnie, gdy wzrasta rozpiętość ![]()
pomiędzy wartością zmiennej objaśniającej w okresie prognozy i jej średnią wartością w próbie.
Wtedy prognoza przedziałowa
![]()
, ![]()
(1.34)
Definicja. Prognozą statystyczną (warunkową) nazywa się prognoza, prawidłowość której jest zdarzeniem losowym, przy czym prawdopodobieństwo tego zdarzenia jest znane i wystarczająco duże dla celów praktycznych.
Dokonamy prognozę w punkcie xn+1, gdy xn+1 jest losowe. Zdefiniujemy, że
x = xst + x,
gdzie xst - stała cześć zmiennej x, x - składnik losowy zmiennej x. Dla jego spełnione warunki
1. Zerowa średnia wartość x i niezależność jej od innych zmiennych.
2. Brak autokorelacji. Wartości x mają niezależne rozkłady.
3. Normalność. Rozkład x jest normalny i wariancja σx2: N(0, σx2).
Prognoza punktowa dla liniowego modelu szacowana według wzorów
Y* = + Xn+1
lub
Y* = + Xn+ X n+ ... + mXm n
Wariancja zmiennej objaśnianej w punkcie prognozowania jest
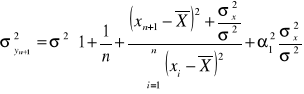
(1.35)
dla modelu (1.1) i
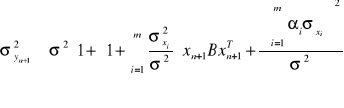
, (1.36)
(gdzie xn+1 - wiersz danych dla prognozowania) dla modelu (1.13).
Z analizy (1.35), (1.36) wynika, że wariancja błędu prognozy
1. maleje wraz z wzrostem liczebności próby n;
2. maleje ze wzrostem wariancji σ w próbie zmiennej objaśniającej;
3. rośnie, gdy wzrasta rozpiętość ![]()
pomiędzy wartością zmiennej objaśniającej w okresie prognozy i jej średnią wartością w próbie.
4. rośnie ze wzrostem parametrów strukturalnych modelu i.
Z (1.35), (1.36) widać, że błąd prognozy warunkowej jest zawsze większy niż błąd odpowiedniej prognozy bezwarunkowej.
Analogicznie prognoza przedziałowa
![]()
, ![]()
(1.37)
Praca pochodzi z serwisu www.e-sciagi.pl
Wyszukiwarka
Podobne podstrony:
podstawowe pojęcia prognozowania i symulacji na podstawie mo
8 wnioskowanie na podstawie modelu ekonometrycznego prognozowanie ekonometryczne
MP Wykład 7A Prognozowanie na podstawie modelu ekonometrycznego
WEiP (5 Prognozowanie na podstawie modeli ekonometrycznych 2010)
WEiP (4 Prognozowanie na podstawie modeli ekonometrycznych 2011)
8 wnioskowanie na podstawie modelu ekonometrycznego prognozowanie ekonometryczne
POJECIA PODSTAWOWE PROGNOZOWANIE I SYMULACJE
Prognozowanie na podstawie modelu ekonometrycznego
5 Prognozowanie na podstawie modelu ekonometrycznego zadaniaid 26868
TEST na egzamin z rozwiazaniami, ● STUDIA EKONOMICZNO-MENEDŻERSKIE (SGH i UW), prognozowanie i symul
Rodowód, przedmiot?dań i podstawowe pojęcia statystyczne Uwagi na temat organizacji?dań stat
podstawowe pojęcia użyte w ustawach dotyczących zamówień pub, Ekonomia
PODSTAWOWE POJECIA definicje cyklu, Prawo, Wstęp do ekonomii i przedsiębiorczości, MAKROEKONOMIA
budżet - pojęcia podstawowe, biznes, ekonomia + marketing i zarządzanie
podstawowe pojęcia użyte w ustawach dotyczących zamówień pub, Ekonomia, ekonomia
więcej podobnych podstron