Rozdział 10.
Pobieranie danych przy pomocy wyrażenia SELECT
Kiedy w bazie danych są już informacje, nadszedł czas na wytłumaczenie jak pobierać dane z bazy i wykonywać ich modyfikacje w bazie. Niniejszy rozdział rozpoczyna się omówieniem prostego wyrażenia i sposobu pobierania określonych kolumn. Następnie na podstawie prostego wyrażenia SELECT zostaną omówione techniki manipulacji danymi i konwersji danych. Kolejnym zagadnieniem będzie wybieranie informacji z określonych wierszy w tablicy i eliminowanie podwójnych danych. Rozdział kończy się nauką stosowania zaawansowanych zapytań tj. zapytań zagnieżdżonych, łączeń i korelacji danych.
Niniejszy rozdział jest dość długi ale bardzo istotny. SQL jest fundamentalnym językiem używanym prawie we wszystkich systemach zarządzania relacyjnymi bazami danych. Inaczej mówiąc, omówione tutaj wyrażenia mogą być stosowane z niewielkimi modyfikacjami w dowolnej bazie. Na początek omówienie prostego polecenia SELECT.
SQL Server obsługuje zarówno standard ANSI'92 jak i własny Microsoft SQL Server 2000, który w tej książce nazywany jest Transact-SQL (T-SQL).
Proste polecenia SELECT
W celu pobrania informacji z bazy danych można tworzyć zapytania przy pomocy SQL Server Query Analyzer w SQL Server Enterprise Managerze lub poza nim, jak również przy pomocy narzędzia wiersza poleceń osql. Można również używać innych narzędzi, włączając w to program MSQuery i narzędzie SQL Server English Query. Dostępne są również narzędzia innych producentów. W tej książce przykłady będą oparte na aplikacji SQL Server Query Analyzer.
Polecenie SELECT ma trzy podstawowe składniki: SELECT, FROM i WHERE. Podstawowa składnia wygląda następująco:
SELECT column_list
FROM table_list
WHERE search_criteria
Pierwszy wiersz (SELECT) określa kolumny, z których mają być pobrane dane. Warunek FROM określa tablice, z których mają być pobierane kolumny. Warunek WHERE ogranicza ilość wierszy zwracanych przez zapytanie.
Pełna składnia polecenia SELECT przedstawia się następująco:
SELECT [ALL|DISTINCT] [ TOP n [PERCENT] [ WITH TIES]]
select_list
[ INTO new_table ]
[ FROM table_sources]
[ WHERE search_condition]
[ GROUP BY [ALL] group_by_expression [,...n]
[ WITH { CUBE | ROLLUP } ]]
[ HAVING search_condition ]
[ ORDER BY { column_name [ASC | DESC ] } [,...n] ]
[ COMPUTE { { AVG | COUNT | MAX | MIN | SUM } (expression) } [,...n] [ BY expression [,...n] ]
[ FOR BROWSE ] [ OPTION (query_hint [,...n]) ]
Zapytanie SELECT * FROM table_name jest najbardziej podstawowym zapytaniem. Używanie symbolu (*) powoduje pobranie wszystkich kolumn z tablicy. W SQL Serverze, * jest zamieniana na listę wszystkich kolumn tablicy.
W bazie danych pubs można uruchomić następujące zapytanie aby wybrać wszystkie kolumny i wiersze z tablicy employee:
SELECT *
FROM employee
emp_id fname minit lname job_id job_lvl
--------- -------------------- ----- ------------------------------
PMA42628M Paolo M Accorti
PSA89086M Pedro S Afonso
VPA30890F Victoria P Ashworth
H-B39728F Helen Bennett
L-B31947F Lesley Brown
F-C16315M Francisco Chang
[...] [...]
GHT50241M Gary H Thomas
DBT39435M Daniel B Tonini
(43 row(s) affected)
Aby wybrać określone kolumny, należy oddzielić każdą kolumnę przecinkiem (,). Jednak, nie należy umieszczać przecinka po ostatniej kolumnie:
SELECT column_name [, column_name...]
FROM table_name
Następujące zapytanie pobiera imiona, nazwiska i identyfikatory pracowników (ID) dla każdego pracownika z tablicy employee:
SELECT fname, lname, emp_id
FROM employee
fname lname emp_id
------------- -------------- ---------
Paolo Accorti PMA42628M
Pedro Afonso PSA89086M
Victoria Ashworth VPA30890F
Helen Bennett H-B39728F
Lesley Brown L-B31947F
Francisco Chang F-C16315M
[...] [...] [...]
Gary Thomas GHT50241M
Daniel Tonini DBT39435M
(43 row(s) affected)
Kiedy zostaje uruchomione zapytanie SELECT *, kolejność kolumn jest taka sama jak ich kolejność jaka została określona w poleceniu CREATE TABLE. Jeżeli pobiera się kolumny z tablicy, kolejność column_list nie musi być taka sama jak kolejność kolumn w tablicy. Można zmienić kolejność kolumn w wynikach zapytania poprzez inne podanie kolumn w parametrze column_list.
Można zmienić kolejność wyświetlanych kolumn z poprzedniego zapytania. Zwracana jest ta sama informacja, ale wyświetlana jest w innej kolejności kolumn:
SELECT emp_id, lname, fname
FROM employee
emp_id lname fname
------------- -------------- -----------
PMA42628M Accorti Paolo
PSA89086M Afonso Pedro
VPA30890F Ashworth Victoria
H-B39728F Bennett Helen
L-B31947F Brown Lesley
F-C16315M Chang Francisco
[...] [...] [...]
GHT50241M Thomas Gary
DBT39435M Tonini Daniel
(43 row(s) affected)
Zmiana nagłówków kolumn
W wyświetlanych wynikach nagłówki kolumn są nazwami, które zostały użyte w column_list. Aby nie używać nie zawsze zrozumiałych nazw, takich jak lname, fname, można nadać kolumnom bardziej czytelne nagłówki (FirstName i LastName) poprzez wprowadzenie aliasów nagłówków kolumn. Można skorzystać ze składni SQL Server 2000 lub składni American National Standards Institute Structured Query Language (ANSI SQL).
Można stworzyć aliasy kolumn w SQL Serverze na dwa sposoby. Pierwszy sposób skorzysta ze składni SQL Server 2000:
SELECT column_heading = column_name
FROM table_name
Ten przykład używa składni standardu ANSI:
SELECT column_name 'column_heading'
FROM table_name
--> Jeżeli[Author:AK] używany alias zawiera spacje lub jest słowem kluczowym SQL Servera, należy ująć alias w pojedynczy cudzysłów lub nawiasy kwadratowe oznaczające identyfikator SQL Servera. Następujący przykład korzysta ze spacji i nawiasów kwadratowych:
SELECT lname AS 'Last Name', fname AS [First Name]
FROM employee
Następujący przykład używa słowa kluczowego SQL:
SELECT 'count' = Count(*)
--> FROM[Author:AK] employee
Można poprawić wcześniejsze zapytanie używając następującego polecenie SQL Servera 2000:
SELECT EmployeeID = emp_id, LastName = lname, FirstName = fname
FROM employee
Można również zmienić wcześniejsze zapytanie używając ANSI SQL:
SELECT emp_id AS EmployeeID, lname AS LastName, fname AS FirstName
FROM employee
Słowo kluczowe AS nie jest wymagane. Przykładowo, następujące wyrażenie zwraca takie same informacje jak poprzednie zapytanie:
SELECT emp_id EmployeeID, lname LastName, fname FirstName FROM employee
Obydwa zapytania zwracają takie same wyniki:
EmployeeID LastName FirstName
--------------- ------------ -----------
PMA42628M Accorti Paolo
PSA89086M Afonso Pedro
VPA30890F Ashworth Victoria
H-B39728F Bennett Helen
L-B31947F Brown Lesley
F-C16315M Chang Francisco
[...] [...] [...]
GHT50241M Thomas Gary
DBT39435M Tonini Daniel
(43 row(s) affected)
Używanie literałów
Aby wyniki były bardziej czytelne można używać literałów. Literał (stała znakowa)jest ciągiem znaków ujętym w pojedynczy lub podwójny cudzysłów, włączonym do column_list i wyświetlanym jako dodatkowa kolumna w wynikach zapytania. W zbiorze wynikowym, etykieta jest umieszczana w kolumnie obok wartości pobranych z bazy.
Składnia zawierająca wartości literału jest następująca:
SELECT 'literal' [, 'literal'...]
Następujące zapytanie zwraca imię, nazwisko i kolumnę zawierającą ciąg literałów: Employee ID, oraz identyfikator ID dla wszystkich pracowników z tablicy employee:
SELECT fname, lname, 'EmployeeID:', emp_id
FROM employee
FirstName LastName emp_id
-------------------- ------------------------- ---------
Paolo Accorti EmployeeID: PMA42628M
Pedro Afonso EmployeeID: PSA89086M
Victoria Ashworth EmployeeID: VPA30890F
Helen Bennett EmployeeID: H-B39728F
Lesley Brown EmployeeID: L-B31947F
Francisco Chang EmployeeID: F-C16315M
[...] [...] [...]
Gary Thomas EmployeeID: GHT50241M
Daniel Tonini EmployeeID: DBT39435M
(43 row(s) affected)
Manipulacja danymi
Można manipulować danymi w wynikach zapytania aby wyprodukować nowe kolumny, które wyświetlają obliczone dane, nowe wartości ciągów znaków, skonwertowane daty i wiele innych. Można manipulować wynikami zapytań przy pomocy operatorów arytmetycznych, funkcji matematycznych, funkcji znakowych, funkcji daty i czasu oraz funkcji systemowych. Można również skorzystać z funkcji CONVERT aby przekształcić dane jednego typu w inny w celu łatwiejszej manipulacji.
Operatory arytmetyczne
Można używać operatorów arytmetycznych dla następujących typów danych: bigint, int, smallint, tinyint, numeric, decimal, float, real, money i smallmoney. Tabela 10.1. pokazuje operatory arytmetyczne i typy danych jakie mogą być z nimi używane.
Tabela 10.1. Typy danych i operatory arytmetyczne
Typ danych |
Dodawanie + |
Odejmowanie - |
Dzielenie / |
Mnożenie * |
Modulo % |
bigint |
Tak |
Tak |
Tak |
Tak |
Tak |
decimal |
Tak |
Tak |
Tak |
Tak |
Nie |
float |
Tak |
Tak |
Tak |
Tak |
Nie |
int |
Tak |
Tak |
Tak |
Tak |
Tak |
money |
Tak |
Tak |
Tak |
Tak |
Nie |
numeric |
Tak |
Tak |
Tak |
Tak |
Nie |
real |
Tak |
Tak |
Tak |
Tak |
Nie |
smallint |
Tak |
Tak |
Tak |
Tak |
Tak |
smallmoney |
Tak |
Tak |
Tak |
Tak |
Nie |
tinyint |
Tak |
Tak |
Tak |
Tak |
Tak |
Operator pierwszeństwa (Precedence)
W przypadku operatorów logicznych istnieją dwa poziomy pierwszeństwa: pierwszeństwo typu danych i pierwszeństwo operatora.
Pierwszeństwo typu danych używane jest, gdy operacje arytmetyczne są przeprowadzane na różnych typach danych. Kiedy używane są różne typy danych, najmniejszy typ danych jest konwertowany do wyższego typu danych. Przykładowo, jeżeli mnożone są dane typu smallint i int, wynik posiada typ int. Jedyny wyjątek od tej reguły występuje gdy używany jest typ danych money, wtedy wynikiem zawsze są dane typu money.
Pierwszeństwo operatorów jest używane gdy używane są różne operatory. Operatory spełniają normalne reguły, dotyczące pierwszeństwa wykonywania działań, w których operacja modulo jest zawsze wykonywana pierwsza, następnie mnożenie i dzielenie, a później dodawanie i odejmowanie — w kolejności od lewej do prawej strony równania.
W przypadku normalnych operacji arytmetycznych, można zmienić kolejność pierwszeństwa poprzez ujęcie działania w nawiasy zwykłe. Najbardziej zagnieżdżone wyrażenia są wyliczane najpierw. Można również używać nawiasów zwykłych, aby operacje arytmetyczne były bardziej przejrzyste. Przykładowo:
5 + 5 * 5 = 30 (Mnożenie zostanie wykonane najpierw)
ale
(5 + 5) * 5 = 50 (Operacja w nawiasach zostanie wykonana pierwsza)
Zasadniczo, ujmowanie operacji w nawiasy poprawia czytelność i przejrzystość kodu Transact-SQL.
Funkcje matematyczne
Funkcje matematyczne są dostępne do wykonywania operacji na danych matematycznych. Można spowodować zwrócenie danej matematycznej używając następującej składni:
SELECT function_name (parameters)
Tabela 10.2 wymienia funkcje matematyczne z parametrami i wynikami. Przykłady te zawierają takie operacje, jak szukanie wartości bezwzględnej, szukanie wartości funkcji trygonometrycznych, wyliczanie pierwiastków kwadratowych i podnoszenie wartości do potęgi. Tabela 10.3 pokazuje niektóre dodatkowe przykłady.
Tabela 10.2. Funkcje matematyczne
Funkcja |
Wynik |
ABS (numeric_expr) |
Wartość bezwzględna |
ACOS | ASIN | ATAN (float_expr) |
Kąt w radianach, którego wartość cos, sin lub tng jest wartością zmiennoprzecinkową |
ATN2 (float_expr1, float_expr2) |
Kąt w radianach, którego wartość tng jest pomiędzy float_expr1 a float_expr2. |
COS | SIN | COT | TAN(float_expr) |
Cos, sin lub tng kąta (w radianach) |
CEILING(numeric_expr) |
Najmniejsza wartość całkowita, większa lub równa podanej wartości |
DEGREES(numeric_expr) |
Konwersja z radianów do stopni |
EXP(float_expr) |
Wartość wykładnicza podanej wartości. |
FLOOR(numeric_expr) |
Największa liczba całkowita mniejsza lub równa podanej wartości |
LOG(float_expr) |
Logarytm naturalny |
LOG10(float_expr) |
Logarytm o podstawie 10 |
PI() |
Stała 3.141592653589793 |
POWER(numeric_expr,y) |
Wartość numeric_expr podniesiona do potęgi y. |
RADIANS(numeric_expr) |
Konwersja ze stopni do radianów |
RAND([seed]) |
Losowa liczba rzeczywista z przedziału 0 do 1 |
ROUND(numeric_expr,len) |
numeric_expr zaokrąglona do długości określonej przez wartość całkowitą. |
SIGN(numeric_expr) |
Znak dodatni, ujemny lub zero |
SQUARE(float_expr) |
Potęga kwadratowa podanej wartości |
SQRL(float_expr) |
Pierwiastek kwadratowy określonej wartości |
Tabela 10.3. Funkcje matematyczne i ich wyniki
Wyrażenie |
Wynik |
SELECT SQRT(9) |
3.0 |
SELECT ROUND(1234.56, 0) |
1235 |
SELECT ROUND(1234.56, 1) |
1234.60 |
SELECT ROUND($1234.56, 1) |
1,234.60 |
SELECT POWER (2,8) |
256.0 |
SELECT FLOOR (1332.39) |
1332 |
SELECT ABS(-365) |
365 |
W przypadku korzystania z funkcji matematycznych z walutowymi typami danych, należy zawsze poprzedzić wartość walutową znakiem dolara ($). Inaczej, wartość jest traktowana jako wartość numeryczna ze skalą 4.
-->
W[Author:AK]
przypadku korzystania z typu danych float, można otrzymać niespodziewane wyniki korzystając z SQL Server Query Analyzer lub innych narzędzi. Przykładowo, uruchamiając kod:
SELECT ROUND(12.3456789E+5,2)
otrzymuje się
1234567.8899999999
-->
Wynik[Author:AK]
ten jest funkcją open database connectivity (ODBC). SQL Server nadal wykonuje zaokrąglenie, ale definicja typu danych float jest nieścisła i nie zawsze zwraca to, czego oczekiwałby użytkownik. Zasadniczo, lepiej jest unikać typu danych float.
Funkcje ciągu znaków
Podczas pracy z informacjami znakowymi, można używać wielu funkcji znakowych do manipulacji danymi (zobacz tabela 10.4). Ponieważ większość funkcji znakowych operuje jedynie typami danych char, nchar, varchar i nvarchar, inne typy danych muszą być najpierw skonwertowane. Dane znakowe są wynikiem zastosowania następującej składni:
SELECT function_name(parameters)
Tabela 10.4. Funkcje znakowe
Funkcja |
Wynik |
'expression' + 'expression' |
Łączy dwa lub więcej łańcuchów znakowych |
ASCII(char_expr) |
Zwraca wartość ASCII pierwszego znaku z lewej strony |
CHAR(integer_expr) |
Zwraca odpowiednik znakowy wartości kodu ASCII |
CHARINDEX(pattern, expression) |
Zwraca pozycję początkową określonego wzoru |
DIFFERENCE(char_expr1, char_expr2) |
Porównuje dwa łańcuchy znaków i określa ich podobieństwo; zwraca wartość od 0 do 4; 4 oznacza najlepsze dopasowanie |
LEFT(char_expr, integer_expr) |
Zwraca łańcuch znaków rozpoczynający się od lewej i poprzedzający ilość znaków określoną przez integer_expr |
LOWER(char_expr) |
Konwersja na małe litery |
LTRIM(char_expr) |
Zwraca dane bez spacji na początku |
NCHAR(integer_expr) |
Zwraca znak Unicode odpowiadający wartości integer_expr |
PATINDEX('%pattern%', expression) |
Zwraca pozycję pierwszego wystąpienia wzoru w expression. |
QUOTENAME('string1', 'quote_char') |
Zwraca łańcuch Unicode (varchar(129)) z odpowiednimi ograniczeniami poprawności narzuconymi przez SQL Server |
REPLACE('string1', 'string2', 'string3') |
Zastępuje wszelkie wystąpienia łańcucha string2 w łańcuchu string1 przez string3 |
REPLICATE(char_expr, integer_expr) |
Powtarza char_expr ilość razy określoną parametrem integer_expr |
REVERSE(char_expr) |
Zwraca odwrotność łańcucha char_expr |
RIGHT(char_expr, integer_expr) |
Zwraca łańcuch znaków zaczynający się w odległości integer_expr znaków od prawej strony |
RTRIM(char_expr) |
Zwraca dane bez ostatnich spacji |
SOUNDEX(char_expr) |
Zwraca czterocyfrowy (SOUNDEX) kod do określenia podobieństwa dwóch łańcuchów znakowych |
SPACE(integer_expr) |
Zwraca łańcuch spacji o długości integer_expr |
STR(float_expr [, length [, decimal]]) |
Zwraca dane znakowe skonwertowane z danych liczbowych: length oznacza całkowitą długość a decimal jest ilością spacji do prawej strony konwertowanej liczby dziesiętnej |
STUFF(char_expr1, start, length, char_expr2) |
Usuwa z łańcucha char_expr1 ilość znaków określoną przez length rozpoczynając od miejsca start i wkleja do char_expr2 w miejscu start. |
SUBSTRING(expression, start, length) |
Zwraca część łańcucha znakowego lub binarnego |
UNICODE('nchar_string') |
Zwraca wartość całkowitą Unicode pierwszego znaku ciągu 'nchar_string' |
UPPER(char_expr) |
Konwersja na duże litery |
Przykładowo, można korzystając z funkcji znakowych uzyskać kolumnę Name, która jest połączeniem (konkatenacją) kolumn nazwisko, pierwsza litera imienia i identyfikatora EmployeeID:
SELECT lname + ',' + SUBSTRING(fname,1,1) + '.'
AS Name, emp_id AS EmployeeID
FROM employee
Name EmployeeID
-------------------------
Accorti, P. PMA42628M
Afonso, P. PSA89086M
Ashworth, V. PA30890F
Bennett, H. H-B39728F
[...] [...]
Sommer, M. MFS52347M
Thomas, G. GHT50241M
Tonini, D. DBT39435M
(43 row(s) affected)
Tabela 10.5. prezentuje więcej przykładów funkcji znakowych.
Tabela 10.5. Więcej funkcji znakowych
Wyrażenie |
Wynik |
SELECT ASCII('G') |
71 |
SELECT LOWER('ABCDE') |
abcde |
SELECT PATINDEX('%BC%','ABCDE') |
2 |
SELECT RIGHT('ABCED',3) |
CDE |
SELECT REVERSE('ABCDE') |
EDCBA |
Funkcje daty
Przy pomocy funkcji daty można operować na danych typu datetime. Można również używać funkcji daty w liście kolumn (column_list), w klauzuli WHERE lub innych wyrażeniach. Składnia jest następująca:
SELECT date_function(parameters)
Należy umieszczać wartości datetime jako parametry w pojedynczym lub podwójnym cudzysłowiu. Niektóre funkcje korzystają z parametru datepart. W tabeli 10.6. została przedstawiona lista wartości datepart i ich skrótów.
Tabela 10.6. Wartości parametru datepart
datepart |
Skrót |
Wartości |
day |
dd |
1-31 |
day of year |
dy |
1-366 |
hour |
hh |
0-23 |
milisecond |
ms |
0-999 |
minute |
mi |
0-59 |
month |
mm |
1-12 |
quarter |
1-4 |
|
second |
ss |
0-59 |
week |
wk |
0-53 |
weekday |
dw |
1-7 (Sun-Sat) |
year |
yy |
1753-9999 |
Tabela 10.7. pokazuje funkcje daty, parametry tych funkcji i wyniki ich działania. Tabela 10.8. pokazuje niektóre przykłady działania funkcji daty.
Tabela 10.7. Funkcje daty
Funkcja |
Wynik |
DATEADD(datepart, number, date) |
Dodaje ilość (number) jednostek czasu datepart do date |
DATEDIFF(datepart, date1, date2) |
Zwraca ilość jednostek datepart pomiędzy dwoma datami |
DATENAME(datepart, date) |
Zwraca wartość ASCII dla określonej jednostki datepart dla określonej daty (date) |
DATEPART(datepart, date) |
Zwraca wartość całkowitą dla określonej datepart dla daty (date) |
DAY(date) |
Zwraca wartość całkowitą reprezentującą ilość dni |
GETDATE() |
Zwraca bieżącą datę i czas w wewnętrznym formacie |
MONTH(date) |
Zwraca wartość całkowitą reprezentującą miesiąc |
YEAR(date) |
Zwraca wartość całkowitą reprezentującą rok |
Tabela 10.8. Przykłady wykorzystania funkcji daty
Funkcja |
Wynik |
SELECT DATEDIFF(mm, '1/1/00', '12/31/02') |
35 |
SELECT GETDATE() |
Apr 29, 2000 2:10AM |
SELECT DATEADD(mm, 6, '1/1/00') |
Jul 1, 2000 2:10AM |
SELECT DATEADD(mm, -5, '10/6/00') |
May 6, 2000 2:10AM |
Warto się przyjrzeć bardziej złożonemu zapytaniu, które korzysta z wielu różnych elementów omówionych do tej pory:
SELECT emp_id AS EmployeeID, lname + ', ' + SUBSTRING(fname,1,1) +
'.' AS Name,
'Has been employed for ', DATEDIFF(year, hire_date, getdate()), ' years.'
FROM employee
EmployeeID Name
--------------- ------------ ------ ---------------- -----
PMA42628M Accorti, P. Has been employed for 8 years
PSA89086M Afonso, P. Has been employed for 10 years
VPA30890F Ashworth, V. Has been employed for 10 years
H-B39728F Bennett, H. Has been employed for 11 years.
[...] [...] [...]
MFS52347M Sommer, M. Has been employed for 10 years
GHT50241M Thomas, G. Has been employed for 12 years
DBT39435M Tonini, D. Has been employed for 10 years
(43 row(s) affected)
Funkcje systemowe
Można korzystać z kilku wbudowanych funkcji systemowych aby pobierać informacje z tablic systemowych. Aby pobrać dane, należy skorzystać ze składni:
SELECT function_name(parameters)
Można używać funkcji systemowych w liście kolumn (column_list), klauzuli WHERE i wszędzie indziej, gdzie może być używane wyrażenie.
Tabela 10.9. pokazuje niektóre funkcje systemowe, ich parametry i wyniki.
Tabela 10.9. Funkcje systemowe
Funkcja |
Wynik |
COALESCE(expression1, expression2,...expressionN) |
Zwraca pierwsze wyrażenie nie będące wartością NULL |
COL_NAME(table_id, column_id) |
Zwraca nazwę kolumny |
COL_LENGTH('table_name', 'column_name') |
Zwraca długość kolumny |
DATALENGTH('expression') |
Zwraca bieżącą długość wyrażenia dowolnego typu danych |
DB_ID(['database_name']) |
Zwraca ID bazy danych |
DB_NAME([database_id]) |
Zwraca nazwę bazy danych |
GETANSINULL(['database_name']) |
Zwraca domyślną wartość ustawienia dopuszczania przez bazę danych w kolumnach wartości NULL |
HOST_ID() |
Zwraca identyfikator ID stacji roboczej hosta |
HOST_NAME() |
Zwraca nazwę komputera hosta |
IDENT_INCR('table_name') |
Zwraca wartość parametru increment określoną podczas tworzenia kolumny identity |
IDENT_SEED('table_name') |
Zwraca wartość seed określoną podczas tworzenia kolumny identity |
INDEX_COL('table_name', index_id, key_id) |
Zwraca nazwę indeksowanej kolumny |
ISDATE(variable |column_name) |
Sprawdza poprawność formatu daty: zwraca 1 gdy poprawny, w przeciwnym wypadku zwraca 0 |
ISNULL(expression, value) |
Zwraca określoną wartość w miejsce NULL |
ISNUMERIC(variable| column_name) |
Sprawdza poprawność formatu liczbowego: zwraca 1 gdy poprawny, w przeciwnym wypadku zwraca 0 |
NULLIF(expression1, expression2) |
Zwraca NULL jeśli expression1=expression2 |
OBJECT_ID('object_name') |
Zwraca ID obiektu bazy danych |
OBJECT_NAME('object_id') |
Zwraca nazwę obiektu bazy danych |
STATS_DATE(table_id, index_id) |
Zwraca datę ostatniej aktualizacji statystyki indeksu |
SUSER_ID(['server_username']) |
Zwraca ID użytkownika serwera |
SUSER_NAME([server_id]) |
Zwraca nazwę użytkownika serwera |
USER_ID(['username']) |
Zwraca ID użytkownika bazy danych |
USER_NAME([user_id]) |
Zwraca nazwę użytkownika bazy danych |
Następujące zapytanie używa dwóch funkcji systemowych aby uzyskać nazwę drugiej kolumny tablicy employee:
SELECT COL_NAME(OBJECT_ID('employee'),2)
fname
(1 row(s) affected)
Konwersja danych
Ponieważ wiele funkcji wymaga danych w określonym formacie lub typie danych, może zachodzić potrzebna konwersja jednego typu w drugi. Można użyć funkcji CONVERT() lub CAST()aby modyfikować typy danych. Można używać funkcji CONVERT() w dowolnym miejscu gdzie są dozwolone wyrażenia. Składnia tego polecenia jest następująca:
CONVERT(datatype [(length)], expression [, style])
Tabela 10.10. pokazuje parametry stylu skojarzone ze standardem i format danych wyjściowych.
Tabela 10.10. Używanie funkcji CONVERT() dla typu danych DATETIME
Styl bez podawania roku yy |
Styl z podawaniem roku yyyy |
Standard |
Format danych wyjściowych |
--- |
0 lub 100 |
domyślny |
mon dd yyyy hh:mi AM (lub PM) |
1 |
101 |
USA |
mm/dd/yy |
2 |
102 |
ANSI |
yy.mm.dd |
3 |
103 |
Brytyjski/Francuski |
dd/mm/yy |
4 |
104 |
Niemiecki |
dd.mm.yy |
5 |
105 |
Włoski |
dd-mm-yy |
6 |
106 |
--- |
dd mon yy |
7 |
107 |
--- |
mon dd, yy |
8 |
108 |
--- |
hh:mi:ss |
--- |
9 lub 109 |
domyślny + milisekundy |
mon dd, yyyy hh:mi:ss:ms AM (lub PM) |
10 |
110 |
USA |
mm-dd-yy |
11 |
111 |
Japoński |
yy/mm/dd |
12 |
112 |
ISO |
yymmdd |
--- |
12 lub 113 |
domyślny europejski + milisekundy |
dd mon yyyy hh:mi:ss:ms (24h) |
14 |
114 |
--- |
hh:mi:ss:ms (24h) |
Można zastosować następujące zapytanie do konwersji bieżącej daty do łańcucha znaków o długości osiem i stylu danych ANSI:
SELECT CONVERT(CHAR(8),GETDATE(),2)
........
00.07.06
(1 row(s) affected)
SELECT emp_id AS EmployeeID, lname + ', ' + SUBSTRING(fname,1,1) + '.'
AS Name, 'Has been employed for ' + CONVERT(CHAR(2),
(DATEDIFF(year, hire_date, getdate()))) + ' years.'
FROM employee
EmployeeID Name
-------------- -------------- -------------------------------
PMA42628M Accorti, P. Has been employed for 8 years.
PSA89086M Afonso, P. Has been employed for 10 years.
VPA30890F Ashworth, V. Has been employed for 10 years.
H-B39728F Bennett, H. Has been employed for 11 years.
[...] [...] [...]
MFS52347M Sommer, M. Has been employed for 10 years.
GHT50241M Thomas, G. Has been employed for 12 years.
DBT39435M Tonini, D. Has been employed for 10 years.
(43 row(s) affected)
Ten przykład jest oparty na zapytaniu, które było uruchamiane wcześniej w sekcji „Funkcje daty”. W tym przykładzie, ostatnie trzy kolumny są połączone w jedną kolumnę poprzez funkcję CONVERT() i konkatenację łańcuchów znaków.
Wybór wierszy
Zostały omówione różne sposoby pobierania, formatowania i manipulowania kolumnami w zestawie wyników zapytania. Teraz zostanie pokazane jak określać, które wiersze wybrać — w oparciu o warunki wyszukiwania. Można określać warunki zapytania używając klauzuli WHERE w poleceniu SELECT. Warunki wyszukiwania uwzględniają operatory porównania, zakresy, listy, dopasowywanie łańcuchów znaków, nieznane wartości, kombinacje i zaprzeczenia warunków.
Podstawowa składnia zakładająca wybór określonych wierszy wygląda następująco:
SELECT column_list
FROM table_list
WHERE search_conditions
Operatory porównania
Można zaimplementować warunki wyszukiwania przy pomocy operatorów porównania (zobacz tabela 10.11). Można wybierać wiersze przez porównanie wartości kolumny z określonym wyrażeniem lub wartością. Wyrażenia mogą zawierać stałe, nazwy kolumn, funkcje lub zagnieżdżone zapytania. Jeżeli są porównywane dane dwóch różnych typów (jak np.: char i varchar) lub dane typu data i czas (datetime i smalldatetime), należy ująć je w pojedynczy cudzysłów. Akceptowalny jest również podwójny cudzysłów, ale pojedynczy zapewnia zgodność ze standardem ANSI.
Operator |
Opis |
= |
Równy |
> |
Większy |
< |
Mniejszy |
>= |
Większy lub równy |
<= |
Mniejszy lub równy |
<> |
Różny (preferowany) |
!= |
Różny |
!> |
Nie większy niż |
!< |
Nie mniejszy niż |
() |
Kolejność wykonywania (pierwszeństwo) |
Składnia klauzuli WHERE z zastosowaniem operatorów porównania wygląda następująco:
SELECT column_list
FROM table_list
WHERE column_name comparision_operator expression
Następujące zapytanie zwraca identyfikator pracownika ID, nazwisko, imię wszystkich pracowników zatrudnionych przez wydawnictwo z identyfikatorem pub_id o wartości 0877:
SELECT emp_id, lname, fname
FROM employee
WHERE pub_id = '0877'
emp_id lname fname
------------- ------------ ------------
PMA42628M Accorti Paolo
VPA30890F Ashworth Victoria
H-B39728F Bennett Helen
[...] [...] [...]
GHT50241M Gary Thomas
DBT39435M Tonini Daniel
(10 row(s) affected)
W przypadku korzystania z operatorów arytmetycznych połączonych przez operatory logiczne, operatory arytmetyczne są realizowane najpierw. Oczywiście, można zawsze zmienić kolejność wykonywania działań używając nawiasów zwykłych.
Zakresy
Można pobierać wiersze bazując na zakresie wartości przy pomocy słowa kluczowego BETWEEN. Jeżeli zakresy zostały określone w oparciu o znakowe typy danych (jak np. char lub varchar) lub w oparciu o typy daty (datetime lub smalldatetime), należy objąć je pojedynczym cudzysłowem.
Składnia klauzuli WHERE z zastosowaniem porównań jest następująca:
SELECT column_list
FROM table_list
WHERE column_name [NOT] BETWEEN expression AND expression
Następujące zapytanie zwraca nazwisko i ID pracownika dla wszystkich pracowników zatrudnionych pomiędzy 10/1/92 a 12/31/92:
SELECT lname, emp_id
FROM employee
WHERE hire_date BETWEEN '10/1/92' AND '12/31/92'
lname emp_id
----------- ----------
Josephs KFJ64308F
Paolino MAP77183M
(2 row(s) affected)
W tym przykładzie klauzula BETWEEN jest łącznikiem. Oznacza to, że obydwie daty 10/1/92 i 12/31/92 są włączone jako potencjalne daty przyjęcia pracownika. Warto zauważyć, że w klauzuli BETWEEN mniejsza wartość musi wystąpić najpierw.
Listy
Można również pobierać wiersze jedynie z wartościami, które pasują do wartości na liście przy pomocy słowa kluczowego IN. Jeżeli zakresy zostały określone w oparciu o znakowe typy danych (jak np. char lub varchar) lub w oparciu o typy daty (datetime lub smalldatetime), należy objąć je pojedynczym cudzysłowem.
Składnia klauzuli WHERE z zastosowaniem porównań jest następująca:
SELECT column_list
FROM table_list
WHERE column_name [NOT] IN (value_list)
Następujące zapytanie znajduje pracowników, którzy pracują dla publishers z identyfikatorem pub_id 0877 lub 9999:
SELECT emp_id, lname, fname
FROM employee
WHERE pub_id IN ('0877', '9999')
emp_id lname fname
-------------- -------------- -----------
PMA42628M Accorti Paolo
VPA30890F Ashworth Victoria
H-B39728F Bennett Helen
[...] [...] [...]
A-R89858F Roulet Annette
DBT39435M Tonini Daniel
(17 row(s) affected)
Można również wybrać wiersze nie znajdujące się na liście przy pomocy operatora NOT. Przykładowo, aby znaleźć wszystkich pracowników, którzy nie pracowali dla publishers z identyfikatorem pub_id 0877 lub 9999, należy uruchomić następujące zapytanie:
SELECT emp_id, lname, fname
FROM employee
WHERE pub_id NOT IN ('0877', '9999')
emp_id lname fname
--------------- ------------ ---------
PSA89086M Afonso Pedro
F-C16315M Chang Francisco
PTC11962M Cramer Philip
A-C71970F Cruz Aria
AMD15433F Devon Ann
[...] [...] [...]
CGS88322F Schmitt Carine
MAS70474F Smith Margaret
HAS54740M Snyder Howard
MFS52347M Sommer Martin
GHT50241M Thomas Gary
(26 row(s) affected)
Należy używać pozytywnych warunków wyszukiwania jeżeli tylko jest to możliwe. Należy unikać używania operatora NOT ponieważ optymalizator zapytań nie zawsze rozpoznaje negatywne warunki wyszukiwania. Inaczej mówiąc, SQL Server musi włożyć więcej pracy aby zwrócić zestaw wyników, gdy został użyty operator NOT. Można przepisać poprzednie zapytanie używając polecenie BETWEEN i AND.
Łańcuchy znaków
Można pobierać wiersze opierając się na fragmentach łańcuchów znaków przy pomocy słowa kluczowego LIKE. LIKE jest używane z danymi typu char, varchar, nchar, nvarchar, text, datetime i smalldatetime. Można również używać symboli wieloznacznych w formie wyrażeń regularnych.
Składnia klauzuli WHERE z zastosowaniem słowa kluczowego LIKE jest następująca:
SELECT column_list
FROM table_list
WHERE column_name [NOT] LIKE 'string'
Dostępne są następujące symbole wieloznaczne
% Łańcuch zero lub więcej znaków
_ Pojedynczy znak
[] Pojedynczy znak z podanego zakresu
[^] Pojedynczy znak nie należący do podanego zakresu
Kiedy używana jest klauzula LIKE, należy ująć znaki wieloznaczne w pojedynczy cudzysłów.
Można uruchomić następujące zapytanie aby otrzymać title_id i title(tytuł) wszystkich książek ze słowem computer w tytule z tablicy titles:
SELECT title_id, title
FROM titles
WHERE title LIKE '%computer%'
title_id title
-------- -----------------------------------------------------
BU1111 Cooking with Computers: Surreptitious Balance Sheets
BU2075 You Can Combat Computer Stress!
BU7832 Straight Talk About Computers
MC3026 The Psychology of Computer Cooking
PS1372 Computer Phobic AND Non-Phobic Individuals: Behavior Variations
(5 row(s) affected)
Można uruchomić następujące zapytanie aby otrzymać au_id, au_lname i au_fname wszystkich autorów, których nazwiska zaczynają się literą B lub M z tablicy authors. Aby uzyskać nazwiska zaczynające się literą B lub M należy użyć klauzuli LIKE z obydwiema literami w nawiasach kwadratowych:
SELECT au_id, au_lname, au_fname
FROM authors
WHERE au_lname LIKE '[BM]%'
au_id au_lname au_fname
------------- ---------------- --------
409-56-7008 Bennet Abraham
648-92-1872 Blotchet-Halls Reginald
724-80-9391 MacFeather Stearns
893-72-1158 McBadden Heather
(4 row(s) affected)
Nieznane wartości
Wartość NULL nie jest tym samym, co pusty łańcuch znakowy, ani nie jest tym samych co 0, w przypadku danych liczbowych. Wartość NULL występuje gdy do pola nie jest przypisana żadna konkretna wartość. Jest to inny sposób określenia, że wartość NULL jest odpowiednikiem wartości „nieznanej”. NULL zwraca fałsz w przypadku porównania z wartościami pustymi, zerami i innymi wartościami NULL (korzystając z operatorów porównania > lub <). Jak można zatem znaleźć wiersze oparte na wartościach NULL? Można określić wiersze w tablicy zawierające wartości NULL przy pomocy słów kluczowych IS NULL lub NOT NULL.
Składnia klauzuli WHERE z zastosowaniem operatorów IS NULL i NOT NULL jest następująca:
SELECT column_list
FROM table_list
WHERE column_name IS [NOT] NULL
Przykładowo, można uruchomić następujące zapytanie aby znaleźć wszystkie książki, które nie zostały sprzedane:
SELECT title_id, title
FROM titles
WHERE ytd_sales IS NULL
title_id title
------------- ----------------------------------
MC3026 The Psychology of Computer Cooking
PC9999 Net Etiquette
(2 row(s) affected)
Jako kontrast do poprzedniego zapytania, można użyć klauzuli NOT NULL aby znaleźć wszystkie książki, które mają wartość w kolumnie ytd_sales poprzez zapytanie:
SELECT title_id, title
FROM titles
WHERE ytd_sales IS NOT NULL
title_id title
--------- --------------------------------------------------------------
BU1032 The Busy Executive's Database Guide
BU1111 Cooking with Computers: Surreptitious Balance Sheets
BU2075 You Can Combat Computer Stress!
BU7832 Straight Talk About Computers
[...] [...]
TC3218 Onions, Leeks, and Garlic: Cooking Secrets of the Mediterranean
TC4203 Fifty Years in Buckingham Palace Kitchens
TC7777 Sushi, Anyone?
(16 row(s) affected)
Stosowanie złożonych kryteriów do pobierania wierszy
Zostało omówione pobieranie wierszy z tablic przy pomocy określonych wartości, zakresów, list, porównania łańcuchów znaków i nieznanych wartości. Następnie zostanie omówione zastosowanie złożonych kryteriów wyszukiwania do pobierania wierszy.
Można łączyć wiele kryteriów wyszukiwania przy pomocy operatorów AND, OR lub NOT. Używanie AND i OR pozwala na łączenie dwóch lub więcej wyrażeń. AND zwraca wyniki gdy wszystkie warunki są prawdziwe; OR zwraca wyniki gdy dowolny z warunków jest prawdziwy.
Kiedy w klauzuli WHERE używanych jest więcej operatorów logicznych, kolejność wykonywania ma znaczenie. Pierwszeństwo ma operator NOT, następnie AND i OR.
Składnia klauzuli WHERE z zastosowaniem złożonych kryteriów wyszukiwania jest następująca:
SELECT column_list
FROM table_list
WHERE [NOT] expression {AND|OR} [NOT] expression
Zapytanie 1
Przykładowo: Należy pobrać identyfikator tytułu (ID), tytuł i cenę wszystkich książek, które posiadają identyfikator pub_id o wartości 0877 lub słowo computer w tytule oraz te, dla których cena jest podana (czyli NOT NULL).
SELECT title_id, title, price, pub_id
FROM titles
WHERE title LIKE '%computer%' OR pub_id = '0877' AND price IS NOT NULL
title_id title price pub_id
-------- ---------------------------------------------------------------
BU1111 Cooking with Computers: Surreptitious Balance ...11.95 1389
BU2075 You Can Combat Computer Stress! 2.99 736
BU7832 Straight Talk About Computers 19.99 1389
MC2222 Silicon Valley Gastronomic Treats 19.99 877
MC3021 The Gourmet Microwave 2.99 877
MC3026 The Psychology of Computer Cooking NULL 877
PS1372 Computer Phobic AND Non-Phobic Individuals: Be. 21.59 877
TC3218 Onions, Leeks, and Garlic: Cooking Secrets of 20.95 877
TC4203 Fifty Years in Buckingham Palace Kitchens 11.95 877
TC7777 Sushi, Anyone? 14.99 877
(10 row(s) affected)
Zapytanie 2
Teraz należy uruchomić zapytanie ponownie i sprawdzić, czy udało się pozbyć wartości NULL w polu price:
SELECT title_id, title, price, pub_id
FROM titles
WHERE (title LIKE '%computer%' OR pub_id = '0877') AND price IS NOT NULL
title_id title price pub_id
-------------------------------------------------------------------------
BU1111 Cooking with Computers: Surreptitious Balance ... 11.95 1389
BU2075 You Can Combat Computer Stress! 2.99 736
BU7832 Straight Talk About Computers 19.99 1389
MC2222 Silicon Valley Gastronomic Treats 19.99 877
MC3021 The Gourmet Microwave 2.99 877
PS1372 Computer Phobic AND Non-Phobic Individuals: Be... 21.59 877
TC3218 Onions, Leeks, and Garlic: Cooking Secrets of .. 20.95 877
TC4203 Fifty Years in Buckingham Palace Kitchens 11.95 877
TC7777 Sushi, Anyone? 14.99 877
(9 row(s) affected)
Warto zauważyć, że to zapytanie zwraca pożądane wyniki poprzez zmianę kolejności wykonywania operacji.
Eliminacja nadmiarowych informacji
Podczas pobierania określonej informacji z tablicy, można otrzymać powtórzone te same wiersze danych. Można wyeliminować nadmiarowe informacje używając klauzuli DISTINCT w połączeniu ze słowem kluczowym SELECT w zapytaniu. Jeżeli klauzula DISTINCT nie zostanie określona, w wyniku zostaną podane wszystkie wiersze, które spełniają warunki klauzuli WHERE.
Składnia klauzuli DISTINCT jest następująca:
SELECT DISTINCT column_list
FROM table_name
WHERE search_conditions
Odmienność wierszy jest zdeterminowana przez kombinację wszystkich kolumn w column_list. Ponieważ wartości NULL są traktowane jak wartości powtarzające się, zwrócona zostanie tylko jedna wartość NULL.
Tabela 10.12. pokazuje niektóre polecenia SELECT z klauzulą DISTINCT. Zapytanie 1 zwraca stan (w USA) w którym mieszka autor, bez wypisywania wartości powtarzających się. Zapytanie 2 zwraca miasta w których mieszkają autorzy, również bez wypisywania duplikatów. Zapytanie 2 zwraca obszary, będące połączeniem miast i stanów.
Tabela 10.12. Każde z zapytań podaje inny wynik
Zapytanie1 |
Zapytanie2 |
Zapytanie3 |
SELECT DISTINCT state FROM authors |
SELECT DISTINCT city FROM authors |
SELECT DISTINCT city, state FROM authors |
CA |
Ann Arbor |
Ann Arbor, MI |
IN |
Berkeley |
Berkeley, CA |
KS |
Corvallis |
Corvallis, OR |
MD |
Covelo |
Covelo, CA |
MI |
Gary |
Gary, IN |
SELECT DISTINCT city, state FROM authors |
SELECT DISTINCT city FROM authors |
SELECT DISTINCT city, state FROM authors |
OR |
Lawrence |
Lawrence, KS |
TN |
Menlo Park |
Menlo Park, CA |
UT |
Oakland |
Oakland, CA |
|
Palo Alto |
Palo Alto, CA |
|
Rockville |
Rockville, MD |
|
Salt Lake City |
Salt Lake City, UT |
|
San Francisco |
San Francisco, CA |
|
San Jose |
San Jose, CA |
|
Vacaville |
Vacaville, CA |
|
Walnut Creek |
Walnut Creek, CA |
Jeżeli potrzeba pobrać różne miasta w których mieszkają autorzy, dlaczego nie skorzystać z Zapytania2 ponieważ zwraca ono te same nazwy miast co Zapytanie3? Aby odpowiedzieć na to pytanie, przypuśćmy, że dwóch autorów z bazy danych mieszka w Portland. Jeżeli zostanie uruchomione Zapytanie2, zwróci Portland jako jedną z powtórzonych wartości. Jednak, jeden autor mieszka w Portland, Oregon, a drugi w Portland, Maine. W rzeczywistości są to dwie różne lokalizacje. Dlatego, Zapytanie3 będące kombinacją DISTINCT miasta i stanu, zwróci obydwie lokalizacje Portland, Oregon i Portland, Maine.
Warto zauważyć, że wyniki wszystkich trzech zapytań są posortowane. Mogło do tego dojść przez przypadek. Poprzednie wersje SQL Servera najpierw sortowały wartości tak, że pierwsza wartość mogła być porównana z następną co ułatwiało usunięcie powtarzających się wartości. SQL Server 2000 używa bardziej złożonego algorytmu mieszającego aby uzyskać te informacje. Algorytm ten zwiększa prędkość i efektywności, ale może utracić sortowanie. Aby zagwarantować, że dane są posortowane, należy zamieścić w zapytaniu klauzulę ORDER BY.
Teraz należy zwrócić uwagę na Zapytanie3:
SELECT DISTINCT city, state
FROM authors
Wyniki zwracają Portland, OR i Portland, ME:
city state
............ .....
Portland ME
Portland OR
(2 row(s) affected)
Sortowanie danych przy pomocy klauzuli ORDER BY
Można posortować wyniki przy pomocy klauzuli ORDER BY w poleceniu SELECT. Podstawowa składnia z wykorzystaniem klauzuli DISTINCT jest następująca:
SELECT column_list
FROM table_list
[ORDER BY column_name | column_list_number [ASC|DESC]]
Lista ORDER BY może zawierać dowolną liczbę kolumn, pod warunkiem, że nie przekraczają one 900 bajtów. Można również określić nazwy kolumn lub liczbę porządkową kolumny w liście column_list.
Poniższe zapytania zwracają jednakowo posortowane zbiory wyników:
Zapytanie1
SELECT title_id, au_id
FROM titleauthor
ORDER BY title_id, au_id
Zapytanie2
SELECT title_id, au_id
FROM titleauthor
ORDER BY 1, 2
W klauzuli ORDER BY można używać razem nazw kolumn i liczb porządkowych. Można również określić, czy wyniki mają być posortowane w kolejności rosnącej (ASC) czy malejącej (DESC). Jeżeli nie zostanie to określone, domyślnie wyniki sortowane są rosnąco (ASC).
Jeżeli wyniki sortowane są wg kolumny zawierającej wartości NULL i wybrana jest kolejność ASC, wiersze zawierające wartość NULL wyświetlane są na początku.
Kiedy używana jest klauzula ORDER BY, kolejność sortowania ustawiona dla SQL Servera również odgrywa rolę. Domyślną kolejnością sortowania SQL Servera jest kolejność słownikowa z nie rozróżnianiem wielkości liter. Rozróżnianie wielkości liter może mieć wpływ na wyniki kolejności sortowania ponieważ duża litera A nie jest rozpatrywana tak samo jak małe a.
W celu sprawdzenia jaka kolejność sortowania jest aktualnie ustawiona dla serwera, należy uruchomić procedurę składową sp_helpsort.
Nie można stosować klauzuli ORDER BY do kolumn typu text lub image. Jest to prawdą dla danych tekstowych ponieważ są one przechowywane w różnych lokalizacjach w bazie danych i mogą zajmować od 0 do 2GB przestrzeni. SQL Server nie zezwala na sortowanie wg pól o takim rozmiarze. Dane typu image są również przechowywane w osobnych 8KB stronach danych i nie są możliwe do posortowania. Do utworzenia zależnej tablicy przechowującej podsumowanie informacji na temat obrazu i tekstu używany jest obszar roboczy.
Przegląd zagadnień
Następująca sekcja zawiera podsumowanie tego, co zostało powiedziane do tej pory w niniejszym rozdziale.
Zostały omówione fundamentalne zagadnienia pobierania danych przy pomocy polecenia SELECT. Następnie pokazano jak zmienić nazwy nagłówków kolumn i dodać literały znakowe do wyników zapytania używając
SELECT col_name AS new_col_name
aby zmienić nagłówek kolumny oraz
SELECT string_literal, col_name
aby dodać literał znakowy. Kolejnym zagadnieniem były operatory arytmetyczne, funkcje matematyczne, funkcje znakowe i funkcje daty i czasu. Następnie omówiono funkcje systemowe takie jak GETDATE, do późniejszej manipulacji danymi.
Często dane wejściowe nie są wyrażone w odpowiednim formacie i typie danych jakiego należałby użyć. W takim przypadku można skorzystać z polecenia konwersji danych CONVERT aby zmienić dane z jednego typu na inny.
Następnie, kontynuując omawianie możliwości polecenia SELECT, wspomniano o wybieraniu różnych wierszy z bazy poprzez stosowanie operatorów porównania, zakresów, wartości, list i łańcuchów znaków.
Omówiono także jak eliminować wiersze o wartości NULL oraz jak wybierać jedynie nie powtarzające się wiersze danych.
Ostatnia sekcja kończy się omówieniem sortowania wyników przy pomocy klauzuli ORDER BY.
Teraz użytkownik zapozna się z niektórymi zaawansowanymi poleceniami SELECT. Zostaną omówione „zaawansowane własności”, takie jak tworzenie podsumowań przy pomocy funkcji agregujących GROUP BY i HAVING oraz poleceń COMPUTE i COMPUTE BY. Kolejne przedstawione zagadnienie to korelacja danych i wykonywanie podzapytań. Na końcu zostaną omówione niektóre zaawansowane zapytania, które dokonują wyboru danych z więcej niż jednej tablicy.
Pomimo tego, że te zapytania są zaawansowane nie oznacza to wcale, że będą dużo trudniejsze. Wymagają one jedynie trochę więcej praktyki aby nabyć biegłości niż w przypadku omówionych wcześniej prostych poleceń SELECT.
Funkcje agregujące
Funkcje agregujące zwracają podsumowania dla całej tablicy lub dla grup wierszy w tablicy. Funkcje agregujące są normalnie używane z klauzulą GROUP BY oraz w klauzuli HAVING lub column_list. Informacja ta może się wydawać początkowo niejasna. Każda z części zostanie omówiona w swojej podstawowej formie a następnie będą dodawane po jednym dodatkowe elementy. Tabela 10.13 pokazuje funkcje agregujące z ich parametrami i wynikami.
Tabela 10.13. Funkcje agregujące
Funkcja |
Wynik |
AVG([ALL | DISTINCT] column_name) |
Zwraca średnią z wartości wyrażenia numerycznego, z wszystkich kolumn lub z różnych wartości kolumn (distinct) |
COUNT(*) |
Zwraca liczbę wybranych wierszy |
COUNT([ALL | DISTINCT] column_name) |
Zwraca liczbę wartości w wyrażeniu, z wszystkich kolumn lub z różnych wartości kolumn (distinct) |
MAX(column_name) |
Zwraca największą wartość w wyrażeniu |
MIN(column_name) |
Zwraca najmniejszą wartość w wyrażeniu |
STDEV(column_name) |
Zwraca statystyczną standardową pochodną ze wszystkich wartości w nazwie kolumn lub wyrażeniu |
STDEVP(column_name) |
Zwraca statystyczną standardową pochodną dla populacji wszystkich wartości w zadanej nazwie kolumny lub wyrażeniu |
SUM([ALL| DISTINCT] column_name) |
Zwraca sumę wartości w wyrażeniu liczbowym, zarówno ze wszystkich kolumn jak i ze zbioru różnych wartości (distict) |
TOP n [PERCENT] |
Zwraca n najwyższych wartości lub n% wartości z zestawu wynikowego |
VAR(column_name) |
Zwraca statystyczną wariancję wartości podanych w nazwie kolumny lub w wyrażeniu |
VARP(column_name) |
Zwraca statystyczną wariancję populacji wartości wymieniowych w nazwie kolumny lub w wyrażeniu |
Przykładowo, to zapytanie zwraca policzoną ilość wierszy w tablicy employee:
SELECT COUNT(*)
FROM employee
...............
43
(1 row(s) affected)
Zapytanie to wybiera maksymalną wartość znalezioną w kolumnie ytd_sales z tablicy titles:
SELECT MAX(ytd_sales)
FROM titles
...............
22246
(1 row(s) affected)
Natomiast to zapytanie zlicza wszystkie wartości w kolumnie qty w tablicy sales i dodaje je:
SELECT SUM(qty)
FROM sales
...............
493
(1 row(s) affected)
GROUP BY i HAVING
Klauzula GROUP BY grupuje dane podsumowania, które spełniają warunki zawarte w klauzuli WHERE, aby zostały zwrócone w postaci pojedynczych wierszy. Klauzula HAVING ustawia kryterium, determinujące które wiersze zostaną zwrócone przez klauzulę GROUP BY. Przykładowo, można wyszukać, które książki posiadają więcej niż jednego autora a następnie wyświetlić tytuł książki i jej autorów.
Składnia klauzuli GROUP BY i HAVING jest następująca:
SELECT column_list
FROM table_list
WHERE search_criteria
[GROUP BY [ALL] non_aggregate_expression(s)
[HAVING] search_criteria]
Klauzula HAVING przynosi ten sam efekt w klauzuli GROUP BY co klauzula WHERE w poleceniu SELECT. Przykładowo, następujące zapytanie znajduje wszystkie książki, które mają więcej niż jednego autora i zwracają title_id i liczbę autorów dla każdej z książek:
SELECT title_id, count(title_id) AS Number_of_Authors
FROM titleauthor
GROUP BY title_id
HAVING count(title_id) > 1
title_id Number_of_Authors
--------- ---------------
BU1032 2
BU1111 2
MC3021 2
PC8888 2
PS1372 2
PS2091 2
TC7777 3
Klauzula GROUP BY ALL zwraca wszelkie grupowania, uwzględniają te, które nie spełniają warunków klauzuli WHERE.
Aby znaleźć wszystkie książki ze sprzedażą roczną o wartości $4000 lub więcej i pobrać listę wszystkich identyfikatorów tytułów ID, należy uruchomić następujące zapytanie:
SELECT title_id, ytd_sales
FROM titles
WHERE (ytd_sales>=4000)
GROUP BY ALL title_id, ytd_sales
title_id ytd_sales
---------- --------
BU1032 4095
BU1111 3876
BU2075 18722
BU7832 4095
MC2222 2032
MC3021 22246
MC3026 NULL
PC1035 8780
PC8888 4095
PC9999 NULL
PS1372 375
PS2091 2045
PS2106 111
PS3333 4072
PS7777 3336
TC3218 375
TC4203 15096
TC7777 4095
Warto zauważyć, że książki, które nie spełniają kryterium klauzuli WHERE również są pokazane w wyniku zapytania.
Klauzule GROUP BY i HAVING muszą spełniać wymagania zgodności ze standardem ANSI. Jednym z tych wymagań jest to, aby klauzula GROUP BY zawierała wszystkie nie zagregowane kolumny wymienione w części zapytania: SELECT column_list. Innym warunkiem jest to, że kolumny ujęte w warunku HAVING mają zwracać tylko jedną wartość.
COMPUTE i COMPUTE BY
Klauzule COMPUTE i COMPUTE BY tworzą nowe wiersze dotyczące podsumowań i szczegółów danych. Korzystają one z wcześniej omówionych funkcji agregujących. Klauzula COMPUTE zwraca szczegóły wierszy i wiersz zawierający całkowite podsumowanie. Klauzula COMPUTE BY zwraca nowe wiersze podsumowania danych, podobnie jak klauzula GROUP BY, ale zwraca wiersze jako podgrupy z wartością podsumowującą je.
Składnia klauzul COMPUTE i COMPUTE BY jest następująca:
SELECT column_list
FROM table_list
WHERE search_criteria
[COMPUTE] aggregate_expression(s)
[BY] column_list
Następujące przykłady pozwolą porównać działanie klauzuli COMPUTE BY i GROUP BY:
SELECT type, SUM(ytd_sales)
FROM titles
GROUP BY type
type ytd_sales
--------------- ---------
business 30788
mod_cook 24278
popular_comp 12875
psychology 9939
trad_cook 19566
UNDECIDED NULL
W przypadku korzystania z klauzuli COMPUTE BY, należy również dołączyć klauzulę ORDER BY. Gdy klauzula ORDER BY jest następująca
ORDER BY title_id, pub_id, au_id
klauzula COMPUTE BY może mieć następującą postać:
COMPUTE aggregate_function (column_name)
BY title_id, pub_id, au_id
COMPUTE aggregate_function (column_name)
BY title_id, pub_id
COMPUTE aggregate_function (column_name)
BY title_id
Jak widać, kolumny wymienione w klauzuli COMPUTE BY muszą być takie same lub może to być ich podzbiór jak kolumny w klauzuli ORDER BY. Kolejność kolumn w COMPUTE BY musi być taka sama jak kolejność kolumn w ORDER BY i nie można opuszczać kolumn. A teraz warto popatrzeć na wyniki następującego zapytania:
SELECT type, ytd_sales
FROM titles
ORDER BY type
COMPUTE SUM(ytd_sales) BY type
type ytd_sales
----------- ---------
business 4095
business 3876
business 18722
business 4095
sum
===========
30788
type ytd_sales
------------ ---------
mod_cook 2032
mod_cook 22246
sum
===========
24278
type ytd_sales
------------ ---------
popular_comp 8780
popular_comp 4095
popular_comp NULL
sum
===========
12875
type ytd_sales
------------ ----------
psychology 375
psychology 2045
psychology 111
psychology 4072
psychology 3336
sum
===========
9939
type ytd_sales
------------ ---------
trad_cook 375
trad_cook 15096
trad_cook 4095
sum
===========
19566
type ytd_sales
------------ ---------
UNDECIDED NULL
sum
===========
NULL
(24 row(s) affected)
Ponieważ operatory COMPUTE i COMPUTE BY tworzą nowe wiersze zawierające nie relacyjne dane, nie można używać ich z poleceniem SELECT INTO. Również nie można używać tych operatorów z danymi typu text i typu image, ponieważ dane tego typu nie są możliwe do posortowania.
Super aggregates (ROLLUP i CUBE)
Aby stworzyć dodatkowe podsumowujące wiersze, zwane super aggregates, należy skorzystać z operatorów ROLLUP i CUBE. Operatorów tych używa się z klauzulą GROUP BY.
Składnia polecenia SELECT z wykorzystaniem operatorów ROLLUP i CUBE jest następująca:
SELECT column_list
FROM table_list
WHERE search_criteria
[GROUP BY [ALL] nonaggregate_expression(s)
[WITH {ROLLUP | CUBE}]]
Operator ROLLUP jest na ogół używany do utworzenia bieżących średnich lub sum. Dokonuje się tego przez zastosowanie funkcji agregującej w poleceniu SELECT column_list do każdej kolumny w klauzuli GROUP BY idąc od lewej do prawej. Co to oznacza? Najlepiej wyjaśni to przykład:
SELECT type, pub_id,
SUM(ytd_sales) AS ytd_sales
FROM titles
GROUP BY type, pub_id
WITH ROLLUP
type pub_id ytd_sales
------------ ------ ---------
business 736 18722
business 1389 12066
business NULL 30788
mod_cook 877 24278
mod_cook NULL 24278
popular_comp 1389 12875
popular_comp NULL 12875
psychology 736 9564
psychology 877 375
psychology NULL 9939
trad_cook 877 19566
trad_cook NULL 19566
UNDECIDED 877 NULL
UNDECIDED NULL NULL
NULL NULL 97446
(15 row(s) affected)
Operator ROLLUP tworzy dodatkowy wiersz wyjściowy, dla każdego wiersza z tablicy titles dotyczącego pojedynczej wartości type i pub_id. Następnie powoduje wypisanie ytd_sales dla każdego elementu i tworzy dodatkowy wiersz dla każdego typu z informacją podsumowującą. W tym przykładzie, wiersze z wartością NULL w polu pub_id podają sumę wszystkich ytd_sales dla grupy danego typu (np.: business).
Spróbujmy wyjaśnić to inaczej. Tablica titles zawiera dwa wiersze, które mają w kolumnie type wartość business i unikalny pub_id (prawdziwa tablica zawiera w sumie cztery książki typu business, z czego jeden autor (pub_id) napisał trzy z nich, a inny napisał czwartą). Każdy z autorów, piszących książki o biznesie posiada ytd_sales o wartości odpowiednio 18,722 i 12,066.
Operator ROLLUP tworzy pole będące podsumowaniem wszystkich książek typu business (18,722+12,066=30,788). Zapytanie wykonuje takie podsumowanie dla każdej grupy książek danego typu i autorów w tablicy i daje całkowitą sumę (97,446) oznaczoną wartością NULL w kolumnie type i pub_id.
Operator CUBE tworzy wiersze super aggregates przy pomocy każdej możliwej kombinacji kolumn w klauzuli GROUP BY. Podobnie jak operator ROLLUP, operator CUBE tworzy bieżące średnie i sumy ale również wylicza skośne relacje kolumn (cross-reference), aby podać dodatkowe wiersze podsumowujące. Teraz należy rozważyć przykład:
SELECT type, pub_id,
SUM(ytd_sales) AS ytd_sales
FROM titles
GROUP BY type, pub_id
WITH CUBE
type pub_id ytd_sales
------------- -------- ---------
business 736 18722
business 1389 12066
business NULL 30788
mod_cook 877 24278
mod_cook NULL 24278
popular_comp 1389 12875
popular_comp NULL 12875
psychology 736 9564
psychology 877 375
psychology NULL 9939
trad_cook 877 19566
trad_cook NULL 19566
UNDECIDED 877 NULL
UNDECIDED NULL NULL
NULL NULL 97446
NULL 736 28286
NULL 877 44219
NULL 1389 24941
(18 row(s) affected)
Operator CUBE tworzy wiersz w danych wyjściowych dla każdego wiersza w tablicy title z pojedynczym typem (type) i pub_id. W tym przykładzie, wiersze z wartością NULL w polu pub_id wyświetlają sumę wszystkich ytd_sales dla grupy danego typu; wiersze z wartością NULL w kolumnie type podają sumę wszystkich ytd_sales dla grup utworzonych przez dane w kolumnie pub_id.
W przypadku korzystania z ROLLUP lub CUBE w klauzuli GROUP BY występują pewne restrykcje. W klauzuli GROUP BY można podać maksymalnie 10 kolumn, suma rozmiarów tych kolumn nie może przekroczyć 900 bajtów. W tym przypadku nie można także używać klauzuli GROUP BY ALL.
Operatory ROLLUP i CUBE tworzą nowe wiersze relacyjnych danych. Wyniki relacyjne są preferowane w porównaniu z wynikami w dowolnej formie uzyskiwanymi przy pomocy poleceń --> COMPUTE[Author:AK] i COMPUTE BY.
Należy również mieć na uwadze, że nie można używać operatorów ROLLUP i CUBE z danymi typu text i typu image ponieważ nie są one możliwe do posortowania.
Korelacja danych
W następujących sekcjach zostanie omówiona implementacja złączeń, aby otrzymać dane z dwóch lub więcej tablic. Wyniki złączenia zostają przedstawione w postaci pojedynczej tablicy, z kolumnami ze wszystkich tablic określonymi w poleceniu SELECT column_list i spełniającymi kryteria wyszukiwania. Zostanie powiedziane, jak implementować złączenia przy pomocy składni zarówno ANSI jak i SQL Servera, a następnie zostaną omówione różne typy złączeń: złączenia wewnętrzne(inner joins), złączenia zewnętrzne (outer joins) i złączenia własne (self joins).
Implementacja złączeń
Aby połączyć ze sobą tablice, należy porównać jedną lub więcej kolumn z jednej tablicy z kolumnami z innej lub innych tablic. Wyniki porównania tworzą nowe wiersze poprzez połączenie kolumn z polecenia SELECT column_list pochodzących z łączonych tablic, które spełniają warunki połączenia. Podczas łączenia tablic można używać starszej składni SQL '89 ANSI lub nowszej SQL '99 ANSI.
W większości zapytań wyniki będą identyczne przy zastosowaniu dowolnej z tych składni. Różnica wystąpi jedynie wtedy, gdy przeprowadzone jest złączenie zewnętrzne (outer join). W przypadku starej składni SQL '89, kompilator zapytań może po przeanalizowaniu zapytania zdecydować, że zewnętrzne złączenie nie jest potrzebne i wykona proste wewnętrzne złączenie pomiędzy dwoma tablicami. W przypadku nowszego standardu SQL'99 takie sytuacje nie występują.
Składnia złączenia SQL '99 ANSI
Polecenia złączenia dla nowszej składni ANSI występują w klauzuli FROM polecenia SELECT:
SELECT table_name.column_name [, ...]
FROM {table_name [ join_type] JOIN table_name
ON search_criteria} [, ...]
WHERE search_criteria
Klauzula WHERE wybiera te wiersze spośród złączonych wierszy, które mają być zwrócone w wyniku zapytania. Można wybrać trzy typy poleceń złączenia ANSI: INNER JOIN, OUTER JOIN i CROSS JOIN.
Składnia złączenia SQL '89
Pomimo tego, że SQL Server 2000 nadal obsługuje starszą składnię SQL '89, zaleca się korzystanie z nowej składni standardu ANSI:
SELECT table_name.column_name [, ...]
FROM table_list
WHERE table_name.column_name
join_operator table_name.column_name [, ...]
W przypadku korzystanie z wcześniejszych wersji składni, klauzula FROM wymienia tablice, które biorą udział w złączeniu. Klauzula WHERE zawiera kolumny, które mają być złączone i może zawierać dodatkowe kryteria wyszukiwania, które determinują jakie wiersze mają być zwrócone. Operatory złączania (join_operators) w składni SQL Servera są następujące: =, >, <, >=, <=, !> i !<.
Złączenia wewnętrzne (inner joins)
Złączenia łączą dwie tablice opierając się na warunkach złączenia tworzących w wyniku nową tablicę, z wierszami, które spełniają warunki złączenia. Złączenia wewnętrzne tworzą wynikowe informacje, jeżeli znajdą pasujące dane w obydwu tablicach. Najbardziej popularne złączenia wewnętrzne to equijoins i natural joins. W przypadku equijoin, sprawdzane jest czy wartości kolumn są równe. Nadmiarowe kolumny są wyświetlane w zbiorze wynikowym. W przypadku --> natural join[Author:AK] , nadmiarowe kolumny nie są wyświetlane.
Starsze polecenie ANSI
SELECT pub_id, pub_name, pr_info
FROM publishers, pub_info
WHERE publishers.pub_id = pub_info.pub_id
Preferowane polecenie ANSI
SELECT pub_id, pub_name, pr_info
FROM publishers
INNER JOIN pub_info ON publishers.pub_id = pub_info.pub_id
pub_id pub_name pr_info
------ ------------------ ---------------------------------------
736 New Moon Books This is sample text data for New Moon .
877 Binnet & Hardley This is sample text data for Binnet & .
1389 Algodata Infosystems This is sample text data for Algodata .
1622 Five Lakes Publishing This is sample text data for Five Lake.
1756 Ramona Publishers This is sample text data for Ramona ...
9901 GGG&G This is sample text data for GGG&G ...
9952 Scootney Books This is sample text data for Scootney..
9999 Lucerne Publishing This is sample text data for Lucerne ..
(8 row(s) affected)
Złączenia naturalne (Natural Joins)
W przypadku złączeń naturalnych, wartości kolumn są sprawdzane pod względem równości, ale nadmiarowe kolumny są eliminowane ze zbioru wynikowego. W następującym przykładzie, polecenie SELECT wybiera wszystkie kolumny z tablicy publishers i wszystkie kolumny, z wyjątkiem pub_id z tablicy pub_info.
Starsze polecenie ANSI
SELECT publishers.*, pub_info.logo, pub_info.pr_info
FROM publishers, pub_info
WHERE publishers.pub_id = pub_info.pub_id
Preferowane polecenie ANSI
SELECT publishers.*, pub_info.logo, pub_info.pr_info
FROM publishers
INNER JOIN pub_info ON publishers.pub_id = pub_info.pub_id
pub_id pub_name city state country ...
-------- -------------------- ----------- -------------....
736 New Moon Books Boston MA USA......
877 Binnet & Hardley Washington DC USA......
1389 Algodata Infosystems Berkeley CA USA......
1622 Five Lakes Publishing Chicago IL USA.......
1756 Ramona Publishers Dallas TX USA......
9901 GGG&G München NULL Germany..
9952 Scootney Books New York NY USA......
9999 Lucerne Publishing Paris NULL France....
(8 row(s) affected)
Złączenia skośne lub nie ograniczone (cross lub unrestricted joins)
Złączenia skośne i nieograniczone jako wynik zwracają kombinację wszystkich wierszy ze wszystkich tablic w złączeniu. Można utworzyć złączenie skośne lub nieograniczone nie przy użyciu klauzuli WHERE w złączeniu SQL Servera dwóch lub więcej tablic, ale poprzez użycie słowa kluczowego CROSS JOIN dla złączenia ANSI.
Kombinacja wszystkich wierszy ze wszystkich tablic uczestniczących w złączeniu tworzy iloczyn kartezjański. W większości przypadków ten typ zbioru wynikowego jest bezużyteczny dopóki intencją nie było znalezienie wszystkich możliwych kombinacji, tak jak w przypadku jakiegoś typu analizy matematycznej lub statystycznej. Inaczej mówiąc, patrząc na każdą z tablic jak na macierz, przemnażając je przez siebie otrzymuje się nową macierz zawierającą wszystkie kombinacje (zobacz rysunek 10.1). Każdy z wierszy z Tabeli 1 jest dodawany do każdego z wierszy z Tabeli 2. Wynikową liczbę kolumn otrzyma się w wyniku dodania liczby kolumn z obydwóch tabel. Jeżeli pomnoży się ilość wierszy z Tabeli 1 przez ilość wierszy z Tabeli 2, można otrzymać wynikową ilość wierszy jaka zostanie zwrócona przez zapytanie.
Tabele nie mogą być złączone na podstawie kolumny typu text lub image. Można jednak porównać długości kolumn testowych z dwóch tabel przy pomocy klauzuli WHERE, ale nie można porównać faktycznych danych.
Rysunek 10.1 Tworzenie iloczynu kartezjańskiego. |
|
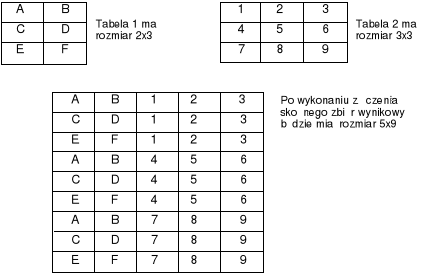
Jako przykład tworzenia iloczynu kartezjańskiego przy pomocy złączenia skośnego lub nieograniczonego, można podać znalezienie listy wszystkich tytułów książek i identyfikatorów ich autorów (ID). W tym celu należy uruchomić następujące zapytanie:
Starsza składnia ANSI
SELECT titles.title, titleauthor.au_id
FROM titles, titleauthor
Preferowana składnia ANSI
SELECT titles.title, titleauthor.au_id
FROM titles CROSS JOIN titleauthor
title au_id
------------------------------------ -----------
The Busy Executive's Database Guide 172-32-1176
The Busy Executive's Database Guide 213-46-8915
[...] [...]
Sushi, Anyone? 998-72-3567
Sushi, Anyone? 998-72-3567
(450 row(s) affected)
W wyniku zapytania zostało zwróconych 450 wierszy, ponieważ było 18 wierszy w tablicy titles i 25 wierszy w tablicy titleauthor. Ponieważ złączenia skośne lub nieograniczone zwracają wszystkie możliwe kombinacje, w wyniku otrzymano 18x25 = 450 wierszy. Nie jest to do końca pożądany rezultat.
Aby uniknąć stosowania nieograniczonego złączenia, należy odjąć 1 od liczby tablic, które mają być łączone, N-1 oznacza potrzebną liczbę klauzul złączeń, gdzie N jest ilością tablic, wykorzystywanych w złączeniu (czyli, w przypadku trzech tablic, 3-1=2, potrzeba dwóch klauzul złączeń). Można zastosować więcej klauzul złączenia jeżeli złączenie oparte jest na kluczu złożonym.
Złączenia zewnętrzne (outer join)
Przy pomocy złączenia zewnętrznego można ograniczyć w zbiorze wynikowym wiersze z jednej tablicy, podczas gdy wiersze z drugiej tablicy nie zostaną ograniczone. Jednym z najpopularniejszych zastosowań złączenia tego typu jest wyszukiwanie „osieroconych rekordów”(orphan records). Operatory złączenia zewnętrznego i słowa kluczowe składni ANSI są następujące:
LEFT OUTER JOIN Zawiera wszystkie wiersze z pierwszej tablicy i jedynie pasujące wiersze z drugiej tabeli
RIGHT OUTER JOIN Zawiera wszystkie wiersze z drugiej tabeli i jedynie pasujące wiersze z pierwszej tabeli
FULL OUTER JOIN Zawiera wszystkie nie pasujące i pasujące wiersze z obydwóch tabel
Przypuśćmy, że istnieje tablica klientów i tablica zamówień. Te dwie tablice są w relacji poprzez pole CustomerID. W przypadku equijoin lub natural join, rekordy rozstaną zwrócone tylko gdy pole CustomerID zostanie dopasowane w obydwóch tablicach. Złączenia zewnętrzne mogą być przydatne do pobierania listy klientów, i jeżeli klient posiada zamówienie, informacje o zamówieniu również zostaną pokazane. Jeżeli klient nie posiada zamówienia, informacja z tablicy zamówień zostanie pokazana jako NULL.
W przypadku zastosowania do tych tablic lewego złączenia zewnętrznego (left outer join) i tablica klientów zostanie podana jako pierwsza, zostaną zwrócone pożądane rezultaty. W przypadku prawego złączenia zewnętrznego (right outer join), w wyniku zostaną pokazane wszystkie zamówienia. Jeżeli zamówienie będzie posiadać CustomerID, który nie pasuje do CustomerID w tablicy klientów, informacja na temat klienta będzie wartością NULL. (Jeżeli w bazie danych zachowywane są reguły integralności danych, nie powinno się nigdy zdarzyć, że zamówienie nie posiada prawidłowego CustomerID. Jeżeli warunki te są zachowane, prawe złączenie zewnętrzne zwróci te same wyniki co equijoin lub natural join — wszystkie zamówienia i klientów, jeżeli tylko wystąpi dopasowanie CustomerID).
Lewe i prawe złączenie zewnętrzne mogą zwracać takie same wyniki, w zależności od kolejności tablic. Przykładowo, podane złączenia zwrócą te same informacje:
Customers.CustomerID *= Orders.CustomerID
oraz
Orders.CustomerID =* Customers.CustomerID
--> W[Author:AK] przypadku SQL Servera w wersji wcześniejszej niż 7.0, można korzystać z następującej składni SQL '89:
*= zawiera wszystkie wiersze z pierwszej tabeli i tylko pasujące wiersze z drugiej tabeli (lewe złączenie zewnętrzne).
=* zawiera wszystkie wiersze z drugiej tabeli i tylko pasujące wiersze z pierwszej tabeli (prawe złączenie zewnętrzne).
Niestety, operatory te nie gwarantują otrzymania prawidłowego wyniku. Problemy mogą wystąpić, gdy pojawiają się wartości NULL. Dlatego, używając złączeń zewnętrznych należy --> zawsze[Author:AK] korzystać z nowszej składni SQL '99 ANSI.
Jeżeli mają zostać znalezione wszystkie tytuły, bez względu na to czy zostały sprzedane jakieś ich kopie, oraz liczba sprzedanych egzemplarzy, należy uruchomić następujące zapytanie, wykorzystujące składnię SQL '99:
SELECT titles.title_id, titles.title, sales.qty
FROM titles LEFT OUTER JOIN sales
ON titles.title_id = sales.title_id
title_id title qty
-------- -------------------------- ------
BU1032 The Busy Executive's D ... 5
BU1032 The Busy Executive's D ... 10
BU1111 Cooking With Computers ... 25
BU2075 You Can Combat Compute ... 35
BU7832 Straight Talk About Co ... 15
MC2222 Silicon Valley Gastron ... 10
MC3021 The Gourmet Microwave 25
[...] [...] [...]
TC4203 Fifty Years in Bucking ... 20
TC7777 Sushi, Anyone? 20
(23 row(s) affected)
Złączenia własne (self join)
Jak sugeruje nazwa, własne złączenia łączą wiersze z tablicy z innymi wierszami z tej samej tablicy. Zapytania porównujące te same informacje są najczęstszym wykorzystaniem złączeń własnych. Przykładowo, jeżeli potrzeba znaleźć wszystkich autorów, którzy mieszkają w tym samym mieście i mają taki sam kod pocztowy, należy porównać miasto i kod pocztowy uruchamiając następujące zapytanie:
Starsza składnia ANSI
SELECT au1.au_fname, au1.au_lname,
au2.au_fname, au2.au_lname,
au1.city, au1.zip
FROM authors au1, authors au2
WHERE au1.city = au2.city
AND au1.zip = au2.zip
AND au1.au_id < au2.au_id
ORDER BY au1.city, au1.zip
Preferowana składnia ANSI
SELECT au1.au_fname, au1.au_lname,
au2.au_fname, au2.au_lname,
au1.city, au1.zip
FROM authors au1
INNER JOIN authors au2 ON au1.city = au2.city
AND au1.zip = au2.zip
WHERE au1.au_id < au2.au_id
ORDER BY au1.city, au1.zip
au_fname au_lname au_fname au_lname city zip
-------- -------- ------- --------- ------------- -----
Cheryl Carson Abraham Bennet Berkeley 94705
Dean Straight Dirk Stringer Oakland 94609
Dean Straight Livia Karsen Oakland 94609
Dirk Stringer Livia Karsen Oakland 94609
Ann Dull Sheryl Hunter Palo Alto 94301
Anne Ringer Albert Ringer Salt Lake City 84152
(6 row(s) affected)
Warto zauważyć, że w przypadku przeprowadzania na tablicy złączenia własnego, zostaje stworzony alias dla nazwy tablicy. Alias ten jest używany aby jedna tablica była logiczne traktowana jako dwie osobne tablice.
Alias tablicy jest przydatny w sytuacji, gdy jest wykonywana operacja złączenia wielu tablic. Alias pozwala na utworzenie bardziej czytelnego i krótszego zapytania, ponieważ występują odniesienia do aliasu tablicy zamiast bezpośrednio do nazwy tablicy.
Podzapytania
Polecenie SELECT zagnieżdżone w innym poleceniu SELECT zwane jest potocznie podzapytaniem. Podzapytania mogą tworzyć takie same wyniki jak operacja złączenia. W kolejnych sekcjach, zostanie omówione stosowanie podzapytań, typy podzapytań, ograniczenia stosowania podzapytań i podzapytania skorelowane.
Stosowanie podzapytań
Polecenie SELECT może być zagnieżdżone w innym poleceniu SELECT, INSERT, UPDATE lub DELETE. Jeżeli podzapytanie zwraca pojedynczą wartość, taką jak wartość zagregowana, może być używane wszędzie tam, gdzie dozwolona jest pojedyncza wartość. Jeżeli podzapytanie zwraca listę, na przykład pojedynczą kolumnę z wieloma wartościami, może być używane jedynie w klauzuli WHERE.
W wielu przypadkach, zamiast podzapytania może być używana operacja złączenia. Jednak, niektóre instancje mogą być obsługiwane jedynie przez podzapytania. W niektórych przypadkach, operacja złączenia daje lepszą wydajność niż podzapytanie, ale zasadniczo, nie ma wielkiej różnicy w wydajności.
Podzapytanie jest zawsze zamknięte w nawiasach zwykłych; chyba, że wykonywane jest podzapytanie skorelowane, zakończone zanim rozpocznie się wykonywanie zapytania zewnętrznego. Podzapytanie może zawierać inne podzapytanie, a to z kolei może zawierać kolejne itd. Oprócz zasobów systemu nie ma praktycznego ograniczenia na ilość podzapytań, jakie mogą być wykonywane w jednym zapytaniu.
Składnia zagnieżdżonego polecenia SELECT jest następująca:
[SELECT [ALL | DISTINCT] subquery_column_list
[FROM table_list]
[WHERE clause]
[GROUP BY clause]
[HAVING clause]
Typy podzapytań
Podzapytanie może zwracać pojedynczą kolumnę lub pojedynczą wartość, tam gdzie może być używane wyrażenie z pojedynczą wartością i może być porównywane przy pomocy operatorów: =, <, >, <=, >=, <>, !> i !<. Może zwracać pojedynczą kolumnę lub wiele wartości, które mogą być używane w liście operatora porównania IN w klauzuli WHERE. Podzapytanie może zwracać również wiele wierszy, które mogą być używane do sprawdzania istnienia wartości przy pomocy słowa kluczowego EXISTS w klauzuli WHERE.
Aby znaleźć wszystkich autorów, którzy mieszkają w tym samym stanie i księgarnie, które sprzedają ich publikacje, należy uruchomić następujące zapytania:
SELECT DISTINCT au_fname, au_lname, state
FROM authors
WHERE state IN
(SELECT state FROM stores)
lub
SELECT DISTINCT au_fname, au_lname, state
FROM authors
WHERE EXISTS
(SELECT * FROM stores
WHERE state = authors.state)
au_fname au_lname state
---------------------- ------------------ ------
Abraham Bennet CA
Akiko Yokomoto CA
Ann Dull CA
Burt Gringlesby CA
[...] [...] [...]
Sheryl Hunter CA
Stearns MacFeather CA
(16 row(s) affected)
Na wykonywanie podzapytań nałożonych jest kilka ograniczeń. Można tworzyć i używać podzapytań przestrzegając następujących reguł:
podzapytanie musi być ujęte w nawiasy zwykłe.
jeżeli podzapytanie jest używane tam, gdzie występuje jedynie pojedyncze wyrażenie, podzapytanie musi zwracać pojedynczą wartość.
Nie może być używane w klauzuli ORDER BY.
Nie może zawierać klauzuli ORDER BY, COMPUTE lub SELECT INTO.
Nie może mieć więcej niż jedną kolumnę w column_list jeżeli jest używane w klauzuli IN.
Musi posiadać polecenie SELECT * jeżeli jest używane w klauzuli EXISTS.
Dane typu text i image nie są dozwolone w liście SELECT (z wyjątkiem używania *).
Nie mogą zawierać klauzuli GROUP BY i HAVING jeżeli są używane z niemodyfikowanymi operatorami porównania (bez słów kluczowych ANY i ALL).
Podzapytania skorelowane
Podzapytania skorelowane odnoszą się do tablicy z zapytania zewnętrznego i określają każdy z wierszy dla zapytania zewnętrznego. W tym aspekcie, podzapytania skorelowane różnią się od normalnych podzapytań, ponieważ zależą one od wartości z zewnętrznego zapytania. Normalne podzapytanie jest wykonywane niezależnie od zapytania zewnętrznego.
W następującym przykładzie, zapytanie używające złączenia jest przedstawione w postaci podzapytania skorelowanego. Obydwa zapytania zwracają tę samą informację. Zapytania wykonują następujące zadanie: Pokaż autorów, którzy mieszkają w tym samym mieście i mają taki sam kod pocztowy.
Przy pomocy JOIN
SELECT au1.au_fname, au1.au_lname,
au2.au_fname, au2.au_lname,
au1.city, au1.zip
FROM authors au1, authors au2
WHERE au1.city = au2.city
AND au1.zip = au2.zip
AND au1.au_id < au2.au_id
ORDER BY au1.city, au1.zip
au_fname au_lname au_fname au_lname city zip
-------- -------- -------- -------- -------------- -----
Cheryl Carson Abraham Bennet Berkeley 94705
Dean Straight Dirk Stringer Oakland 94609
Dean Straight Livia Karsen Oakland 94609
Dirk Stringer Livia Karsen Oakland 94609
Ann Dull Sheryl Hunter Palo Alto 94301
Anne Ringer Albert Ringer Salt Lake City 84152
(6 row(s) affected)
Przy pomocy podzapytania skorelowanego
SELECT au1.au_fname, au1.au_lname, au1.city, au1.zip
FROM authors au1
WHERE zip IN
(SELECT zip
FROM authors au2
WHERE au1.city = au2.city
AND au1.au_id <> au2.au_id)
ORDER BY au1.city, au1.zip
au_fname au_lname city zip
-------- --------- -------------- -----
Abraham Bennet Berkeley 94705
Cheryl Carson Berkeley 94705
Livia Karsen Oakland 94609
Dirk Stringer Oakland 94609
Dean Straight Oakland 94609
Sheryl hunter Palo Alto 94301
Ann Dull Palo Alto 94301
Albert Ringer Salt Lake City 84152
Anne Ringer Salt Lake City 84152
(9 row(s) affected)
Warto zwrócić uwagę, że zostały zwrócone te same dane co poprzednio, są jedynie inaczej sformatowane i bardziej czytelne.
SELECT INTO
Polecenie SELECT INTO pozwala na tworzenie nowej tablicy w oparciu o wyniki zapytania. Nowa tablica jest oparta na kolumnach, które zostały określone w liście polecenia select, tablicach z klauzuli FROM i wierszach, które zostały wybrane przy pomocy klauzuli WHERE. Przy pomocy polecenia SELECT INTO można utworzyć dwa typy tablic: stałą i tymczasową. Składnia polecenia SELECT INTO jest następująca:
SELECT column_list
INTO new_table_name
FROM table_list
WHERE search_criteria
Tworząc tablicę stałą, należy ustawić opcję bazy danych SELECT INTO/BULKCOPY. Używając polecenia SELECT INTO, zostaje zdefiniowana tablica i umieszczone w niej dane bez przechodzenia przez zwykły proces definiowania danych. Nazwa nowej tablicy musi być unikalna w całej bazie danych i musi spełniać warunki konwencji nazewnictwa SQL Servera.
Jeżeli kolumny w column_list w poleceniu SELECT nie maja tytułów, takich jak kolumny wyliczone z funkcji agregujących, kolumny nowej tablicy nie będą miały nazw. Proces ten powoduje dwa problemy:
Nazwy kolumn wewnątrz tablicy muszą być unikalne; dlatego, jeżeli więcej niż jedna kolumna nie ma nagłówka polecenie SELECT INTO nie powiedzie się.
Jeżeli nowa tablica zawiera kolumnę bez nagłówka, jedynym sposobem pobrania tej kolumny jest polecenie SELECT *.
Z tych powodów, dobrze jest tworzyć aliasy kolumn, dla kolumn powstałych w wyniku wyliczeń. Również, ponieważ operacja SELECT INTO nie jest rejestrowana w dzienniku, należy utworzyć kopię bezpieczeństwa bazy danych natychmiast po wykonaniu tej operacji. Można również używać polecenia SELECT INTO do tworzenia tablic tymczasowych.
Można wyróżnić dwa typy tablic tymczasowych:
Lokalna tablica tymczasowa jest dostępna podczas bieżącej sesji użytkownika w SQL Serverze i jest usuwana, gdy sesja jest zakończona. Można tworzyć lokalne tablice tymczasowe poprzedzając nazwę nowej tablicy symbolem #.
Globalna tablica tymczasowa jest dostępna dla wszystkich sesji użytkowników SQL Servera i jest usuwana gdy ostatnia sesja użytkownika, mającego dostęp do tej tablicy jest zawieszana. Można tworzyć globalne tablice tymczasowe poprzedzając nazwę nowej tablicy symbolami ##.
Tablice tymczasowe są umieszczane w bazie danych tempdb. Następujący przykład tworzy tablicę tymczasową zwaną #tmpTitles z listą identyfikatorów tytułów (ID), tytułami i ceną sprzedaży książki:
SELECT title_id, title, price
INTO #tmpTitles
FROM titles
GO
SELECT * FROM #tmpTitles
GO
title_id title Price
-------- -------------------------------------------------- -----
BU1032 The Busy Executive's Database Guide 19.99
BU1111 Cooking with Computers: Surreptitious Balance ... 11.95
BU2075 You Can Combat Computer Stress! 2.99
[...] [...] [...]
TC3218 Onions, Leeks, and Garlic: Cooking Secrets of ... 20.95
TC4203 Fifty Years in Buckingham Palace Kitchens 11.95
TC7777 Sushi, Anyone? 14.99
(18 row(s) affected)
Polecenie SELECT INTO tworzy nową tablicę. Aby dodać wiersz do istniejącej tablicy należy skorzystać z polecenia INSERT lub INSERT INTO. Obydwa polecenia zostaną omówione w kolejnym rozdziale.
Operator UNION
Przy pomocy operatora UNION można łączyć wyniki dwóch lub więcej zapytań w pojedynczy zbiór wynikowy. Domyślnie, powtarzające się wiersze są eliminowane; jednak, można skorzystać z polecenia UNION ze słowem kluczowym ALL, aby zapytania zwróciły wszystkie wiersze, uwzględniając w tym powtarzające się elementy. Składnia operatora UNION jest następująca:
SELECT column_list [INTO clause]
[FROM clause]
[WHERE clause]
[GROUP BY clause]
[HAVING clause]
[ UNION [ALL]
SELECT column_list
[FROM clause]
[WHERE clause]
[GROUP BY clause]
[HAVING clause] ...
[ORDER BY clause]
[COMPUTE clause]
Następujące reguły obowiązują używanie operatora UNION:
Wszystkie listy kolumn (column_list) muszą mieć tę samą ilość kolumn, tę samą kolejność i podobne typy danych.
Jeżeli w jednym z zapytań jest używana klauzula INTO, należy użyć jej w pierwszym zapytaniu.
Można skorzystać z klauzul GROUP BY i HAVING jedynie w indywidualnych zapytaniach.
Klauzule ORDER BY i COMPUTE są dozwolone jedynie na końcu polecenia UNION, w celu zdefiniowania kolejności końcowych wyników lub w celu policzenia wartości podsumowujących.
Nazwy kolumn pochodzą z pierwszej listy SELECT column_list.
Następujący przykład pokazuje zastosowanie operatora UNION do pobrania danych z dwóch różnych zapytań i połączenia dwóch zbiorów wynikowych w jeden:
SELECT title, stor_name, ord_date, qty
FROM titles, sales, stores
WHERE titles.title_id = sales.title_id
AND stores.stor_id = sales.stor_id
UNION
SELECT title, 'No Sales', NULL, NULL
FROM titles
WHERE title_id NOT IN
(SELECT title_id FROM sales)
ORDER BY qty
title stor_name ord_date qty
-----------------------------------------------------------------------
Net Etiquette No Sales NULL NULL
The Psychology of ... No Sales NULL NULL
Is Anger the Enemy? Eric the Read Books 1994-09-13... 3
[...] [...] [...] [...]
Onions, Leeks, and Garlic: ...News & Brews 1992-06-15... 40
Secrets of Silicon Valley Barnum's 1993-05-24... 50
Is Anger the Enemy? Barnum's 1994-09-13... 75
(23 row(s) affected)
2 Część I ♦ Podstawy obsługi systemu WhizBang (Nagłówek strony)
2 P:\Aneta\SQLSER~1\SQLSER~1\r10-1.doc
Początek wskazówki
Koniec wskazówki
Nowa wskazówka
Koniec wskazówki
Poniżej pusty wiersz dla tej samej wskazówki.
Poniżej brak krótkiej partii tekstu. str. 360 "Look at....."
Początek wskazówki
Koniec wskazówki.
Wyszukiwarka
Podobne podstrony:
r13-05, informatyka, SQL Server 2000 dla kazdego
r08-05, informatyka, SQL Server 2000 dla kazdego
R07-05, materiały stare, stare plyty, Programowamie, SQL Server 2000 dla kazdego
microsoft sql server 2000 ksieg Nieznany
R10-05(2), Informacje dot. kompa
Microsoft SQL Server 2000 Księga eksperta
XML i SQL Server 2000 xmlsql
Microsoft SQL Server 2000 Ksiega eksperta
XML i SQL Server 2000 2
XML i SQL Server 2000 xmlsql
Microsoft SQL Server 2000 Ksiega eksperta 2
XML i SQL Server 2000 xmlsql
Microsoft SQL Server 2000 Ksiega eksperta sqlske
XML i SQL Server 2000
XML i SQL Server 2000 2
Microsoft SQL Server 2000 Ksiega eksperta
więcej podobnych podstron