Testy:
T - Studenta:
odrzucam
na korzyść hipotezy alternatywnej, parametr strukturalny istotnie wpływa na zmienną objaśnioną y.
brak podstaw do odrzucenia
, możemy sądzić, że parametr strukturalny nieistotnie wpływa na zmienną objaśnioną y.
F - wybór stopnia wielomianu trendu:
brak podstaw do odrzucenia
, nie nastąpił istotny spadek wariancji resztowej - wybieramy trend z niższym stopniem.
odrzucamy
na korzyść hipotezy alternatywnej, nastąpi istotny spadek wariancji resztowej - wybieramy trend z wyższym stopniem.
DW:
reszty losowe, brak autokorelacji składnika losowego rz. I
Gdy
reszty nielosowe, występuje autokorelacja składnika losowego rz. I
Gdy
, wówczas
DW(DW*) > dlu brak podstaw do odrzucenia hipotezy zerowej - autokorelacja składnika losowego rz. I nie występuje
DW(DW*) < dl odrzucam hipoteze zerową na korzyść hipotezy alternatywnej - autokorelacja składnika losowego rz. I występuję
dl < DW(DW*) < du test nie rozstrzyga o autokorelacji składnika losowego rz. I
Test Quenouille'a:
wspólczynnik autokorelacji rzędu
jest nieistotny statystycznie
współczynnik autokorelacji rzędu
jest istotny statystycznie
, t= 1,2,…q
odrzucam hipotezę zerową na korzyść alternatywnej, współczynnik autokorelacji rzędu
jest istotny statystycznie, występuje autokorelacja co najmniej rzędu
.
brak podstaw do odrzucenia hipotezy zerowej, współczynnik autokorelacji rzędu
jest nieistotny statystycznie.
Ljunga-Boxa:
każdy współczynnik autokorelacji od 1 do rzędu p jest nieistotny statystycznie
przynajmniej jeden współczynnik korelacji rzędu od 1 do p jest statystycznie istotny
p)
Q≥Q* odrzucamy hipotezę zerową na korzyść alternatywnej, możemy sadzić, że przynajmniej jeden współczynnik korelacji rzędu od 1 do p jest statystycznie istotny.
Q<Q* brak podstaw do odrzucenia hipotezy zerowej, możemy sądzić, że każdy współczynnik autokorelacji od 1 do rzędu p jest nieistotny statystycznie.
Wnioskowania na podstawie wyników:
testu Durbina-h:
testu CUSUM:
brak zmian w parametrach, parametry stabilne
zmiany w parametrach, parametry niestabilne
Statystyka testu: Harvey-Collier
brak podstaw do odrzucenia hipotezy zerowej - brak zmian w parametrach - parametry stabilne
z empirycznym poziomem błędu p odrzucamy hipotezę zerową na korzyść alternatywnej - występują zmiany w parametrach - parametry niestabilne
testu normalności rozkładu reszt:
składniki losowy ma rozkład normalny
składnik losowy nie ma rozkładu normalnego
Statystyka testu: Chi-kwadrat
brak podstaw do odrzucenia hipotezy zerowej - rozkład reszt posiada cechy rozkładu normalnego
z empirycznym poziomem błędu p odrzucamy hipotezę zerową na korzyść alternatywnej - rozkład reszt nie posiada cech rozkładu normalnego
testów autokorelacji:
brak autokorelacji składnika losowego
autokorelacji składnika losowego
brak podstaw do odrzucenia hipotezy zerowej - brak autokorelacji składnika losowego
z empirycznym poziomem błędu p odrzucamy hipotezę zerową na korzyść alternatywnej - autokorelacja składnika losowego występuje.
3. Model trendu:
Zapisanie otrzymanego modelu: Pt =∑αjtj
Gdzie:
t- zmienna czasowa przyjmująca wartości t=1,2,...,n,
r- stopień wielomianu trendu,
αj- parametry modelu trendu.
W zależności od parametru r, hipotezy modelowe przyjmują postaci:
r = 0 Yt = α0 + ηt,
r = 1 Yt = α0+α1t + ηt
r = 2 Yt =α0+α1t+α2t2 + ηt
r = 3 Yt =α0+α1t + α2t2 +α3t3 + ηt
.
.
.
4. Model sezonowości:
Zapisanie otrzymanego modelu: St = ΣdkQkt
Gdzie:
dk - parametry modelu sezonowości oznaczające o ile wartość zjawiska odchyla się od poziomu średniego, wyłącznie z tytułu wahań sezonowych,
Σdk = 0 - co oznacza, że wahania sezonowe w skali roku wznoszą się wzajemnie,
m - liczba podokresów w roku,
Qkt - zmienna zero-jedynkowa przyjmująca wartość jeden zawsze w okresie gdy (t-k) dzieli się bez reszty przez m i zero w pozostałych okresach,
Qkt= 1 gdy (t-k) dzieli się przez m bez reszty
0 w pozostałych okresach
Hipoteza modelowa:
Model sezonowości kwartalnej ma następującą postać:
St= d1Q1t + d2Q2t + d3Q3t + d4Q4t
Model sezonowości kwartalnej bez stałej:
Yt = d1Q1t + d2Q2t + d3Q3t + d4Q4t + ηt
Model sezonowości kwartalnej ze stałą ma następującą postać:
Yt = α0 + d1Q1t + d2Q2t + d3Q3t + d4Q4t + ηt
Model sezonowości kwartalnej ze stałą i trendem liniowym ma postać:
Yt = α0 + α1t + d1Q1t + d2Q2t + d3Q3t + d4Q4t + ηt
5. Model AR:
Hipoteza modelowa:
Yt = α1Yt-1 + α2Yt-2 + α3Yt-3 + ... + αpYt-p + ξt
Zapis otrzymanego modelu:
Yt = ΣαiYt-i + ξt
Gdzie:
p- rząd autoregresji, czyli maksymalne opóźnienie zmiennej objaśnianej,
α1,α2,α3,...,αp - parametry modelu autoregresyjnego
ξt - proces resztkowy (biały szum)
6. Budowa modelu struktury procesu (hipoteza modelowa, zapisanie otrzymanego modelu),
Eliminacja a posteriori-Metoda selekcji nieistotnych zmiennych typu aposteriori, polega na eliminacji, w pojedynczym kroku jednej najsłabszej zmiennej objaśniającej x i ponowną estymację modelu. Najsłabsza zmienna- wartość statystyki p- największa lub t- najmniejsza.
Jeśli chodzi o konkretny przykład hipotezy i zapisy modelu to w punkcie 7 jest wszystko napisane na konkretnym przykładzie.
7. Procedury budowy modelu zgodnego (kolejne kroki postępowania, hipoteza modelowa, zapisanie modelu końcowego)
Model zgodny
Model zgodny zakłada zgodność harmonicznej struktury procesu objaśnianego z łączną harmoniczną strukturą procesów objaśniających oraz procesu resztowego, który jest niezależny od procesów objaśniających.
Jest to model uwzględniający wewnętrzną strukturę dynamiczną każdego z procesów objaśnianych i objaśniających, przy czym proces resztowy pozostaje białym szumem.
Etapy specyfikacji liniowego modelu zgodnego:
1. Badanie wewnętrznej struktury procesu endogenicznego i procesów egzogenicznych:
- wyodrębnienie trendu,
- wyodrębnienie składnika sezonowego,
- ustalenie rzędów opóźnień poszczególnych procesów (na ogół rzędu autoregresji).
2. Sformułowanie ogólnego modelu zawierającego maksymalny stopień wielomianu trendu
(czyli wybrać trend o największym stopniu, który wyszedł spośród badanych zmiennych), sezonowość oraz maksymalny rząd autoregresji dla każdego procesu.
Hipoteza modelowa: przykład
zmienna |
st.w. trendu |
sezonowość |
autokorelacja |
Rząd AR |
Y |
1 |
+ |
TAK |
2 |
X1 |
1 |
- |
TAK |
1 |
X2 |
1 |
- |
TAK |
1 |
X3 |
2 |
+ |
TAK |
1 |
X4 |
1 |
+ |
TAK |
2 |
Hipoteza na podstawie tabeli
Patrzymy na tabelę- wybieramy największy stopień wielomianu trendu z całej tabeli( w tym wypadku kwadratowy)
Sezonowość- jeżeli występuje chociaż raz to ją uwzględniamy
Autoregresja- 2 opóźnienia na Y dodajemy zmienną objaśniającą X1 i jej 1 opóźnienie
Hipoteza modelowa:
Yt= ℒ0 + ℒ1t + ℒ2 t2 + d1Q1, t +…+ d12Q12,t + ℒ 3Yt-1 + ℒ4Yt-2 + ℒ 5X1,t + ℒ6X1,t-1+ ℒ7X2 t +ℒ8X2, t-1 + ℒ9 X3 t +ℒ10X3, t-1 +ℒ11 X4,t + ℒ12X4,t-1 + ℒ13X4,t-2 + εt
3. Oszacowanie postaci pierwotnej modelu zgodnego uwzględniającej wszystkie wyspecyfikowane składniki.
4. Weryfikacja modelu na podstawie badania istotności zmiennych oraz własności reszt.( Jeśli przy któreś z sezonowości są gwiazdki (*,**,***) to jej w ogóle nie ruszamy. Dokonujemy estymacji innych zmiennych po największym p lub najmniejszym t-Studenta.
Model końcowy:
Yt= a0 + a1t + a2 t2 + d ^1Q*1, t +…+ d^11Q*11,t + a 3Yt-1 + a5X1,t +a8X2, t-1 +a10X3, t-1 +a12X4,t-1+ εt
W miejsce a wstawić konkretne wartości
Yt= -60628,6 + -106,723 t + 4,32117 t2 + -696,280 Q*1, t +…+ 637,569Q*11,t -0,705101Yt-1 + 35,8439 X1,t + 266,884 X2, t-1 + 55,5243X3, t-1 + 2,64454X4,t-1
( nie jestem pewna czy w seznowośći współczynnik wstawia się za d^1 czy za Q*1,t)
5. Następnie robimy prognozy , wyznaczamy błędy ex-post, ex- ante.
6. Interpretacja ocen parametrów strukturalnych oraz ocena dopasowania modelu.
8. Model ARMA(p,q) (zapis, identyfikacja):
Można stosować do modelowania stacjonarnych szeregów czasowych tj. takich, w których występują jedynie wahania losowe wokół średniej lub szeregów niestacjonarnych prowadzących do stacjonarnych.
W przypadku, gdy rzeczywisty proces charakteryzuje się zmienną w czasie wartością średnią, to należy ją usunąć.
Eliminacja trendu i sezonowości powinna nastąpić przed różnicowaniem procesu.
Stosowanie do konstrukcji prognoz modeli ARMA, ARIMA wymaga dysponowania długim szeregiem czasowym (min. 50)
W modelu w którym nie występuję elementy związane ze średnią ruchomą (q=0) model sprowadza się do AR(p) - który estymuje się za pomocą metody KMNK
Jeżeli q
0 estymacja KMNK prowadzi do uzyskania estymatorów asymptotycznie obciążonych - stosujemy tu metodę największej wiarygodności MNW.
Funkcja autokorelacji ACF, funkcja autokorelacji cząstkowej PACF , metodologia Boxa Jenkinsa
AR(p) - ACF maleje wykładniczo lub jest sinusoidą tłumioną
- PACF urywa się po odstępie p
MA(q) - ACF urywa się po odstępie q
- PACF maleje wykładniczo lub jest sinusoidą tłumioną
ARMA(p,q) - ACF i PACF łagodnie zanikają
9. Błędy ex ante (dopuszczalność prognozy)
- informują o spodziewanej wielkości odchyleń rzeczywistych wartości zmiennej prognozowanej od prognoz
Błąd predykcji - błąd bezwzględny
![]()
- wariancja predykcji
![]()
- błąd średni predykcji
Interpretacja -w okresie prognozowanym rzeczywiste wartości zmiennej prognozowanej będą się różnić od wartości prognoz średnio o +/- VT
Względny błąd predykcji
![]()
Interpretacja : ![]()
- prognoza dopuszczalna (Vg*=5-10%)
Błędy ex post (trafność prognozy)
- informują o rzeczywistej różnicy między rzeczywistymi wartościami zmiennej prognozowanej (realizacje) a prognozami
Średni błąd predykcji ME - błąd bezwzględny
![]()
ME>0 prognozy niedoszacowane
ME<0 prognozy przeszacowane
Średni absolutny błąd predykcji MAE
![]()
Błąd średniokwadratowy MSE
![]()
Wyznaczany i analizowany w celu umożliwienia wstępnej oceny, czy wariancja błędu prognozy jest stała, czy zmienia się w czasie.
Pierwiastek błędu średniokwadratowego
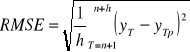
Interpretacja - rzeczywiste wartości zmiennej prognozowanej w okresie prognozowanym różniły się średnio od wyznaczonych prognoz o RMSE
5. Średni błąd procentowy MPE
![]()
![]()
- prognozy trafne
6. Średni absolutny procentowy (względny) błąd prognoz
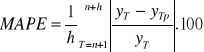
Współczynnik Janusowy
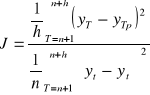
,
J=0 rząd dokładności predykcji jest równy rzędowi dokładności modelu w próbie,
J>1 dezaktualizacja modelu
Współczynnik Theila
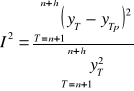
,
![]()
- w okresie prognozowanym przeciętny względny błąd predykcji wyniósł I
I²=
+
+
S -odchylenie standardowe
r - współczynnik korelacji
- obciążoność predykcji
- niedostateczna elastyczność/wahania
- niedostateczna zgodność
10. Prognoza przedziałowa
- przedział liczbowy, w którym z zadanym prawdopodobieństwem zawiera się nieznana wartość zmiennej objaśnianej Y w okresie T.
Założenie! zmienna prognozowana ma rozkład normalny, z prawdopodobieństwem 1-α można sądzić, że rzeczywista wartość zmiennej prognozowanej będzie w przedziale:
![]()
![]()
średni błąd predykcji (miara ex ante) ![]()
![]()
![]()
wartość dystrybuanty rozkładu normalnego odpowiadająca wiarygodności ![]()
, odczytujemy ją z tablic dystrybuanty rozkładu normalnego (dla ![]()
).
11. Ocena wartości prognostycznej modelu ekonometrycznego
Należy zbadać istotność parametrów występujących w modelu za pomocą testu t-Studenta( podpunkt 1). Z wyłączeniem sezonowości przynajmniej jeden parametr musi być istotny.
Miary dopasowania modelu
a) Wariancja resztowa S2(u) i odchylenie standardowe reszt S(u).
Dla regresji Y względem X wariancję resztową określa wzór
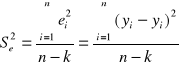
, gdzie
yi - rzeczywista wartość zmiennej objaśnianej
ŷi - wartość teoretyczna zmiennej objaśnianej (na podstawie modelu)
n - liczebność próby
k - liczba szacowanych parametrów modelu
Odchylenie standardowe reszt jest to pierwiastek kwadratowy z wariancji resztowej, S(x)=√S2(x). Odchylenie to informuje, że wartości empiryczne zmiennej objaśnianej yi różnią się od wartości teoretycznej ŷi , otrzymanych na podstawie modelu regresji, średnio o +/- S(x). Odchylenie standardowe reszt jest miarą bezwzględną( absolutną), wyrażoną w takich jednostkach, w jakich jest wyrażona zmienna objaśniająca.
b) Współczynnik zmienności losowej
![]()
gdzie:
![]()
- średnia arytmetyczna empirycznych wartości zmiennej objaśnianej
Współczynnik ten informuje, jaki procent dniej arytmetycznej zmiennej objaśnianej sanowi odchylenie standardowe reszt. Jeżeli współczynnik zmienności nie przekracza założonej z góry wartości granicznej, Vu ≤ V*, przy czym V* ustala się maksymalnie na poziomie 15%, to odchylenie wartości empirycznych zmiennej objaśnianej od jej wartości teoretycznych można uznać za niewielkie. Świadczy to również o dobrym dopasowaniu modelu do danych empirycznych.
c) współczynnik determinacji:
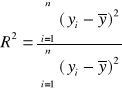
gdzie:
yi - rzeczywista wartość zmiennej objaśnianej
ŷi - wartość teoretyczna zmiennej objaśnianej (na podstawie modelu)
![]()
- średnia arytmetyczna empirycznych wartości zmiennej objaśnianej
Współczynnik determinacji R2 informuje o tym jaka część całkowitej zmienności (zmian) zmiennej objaśnianej została wyjaśniona przez oszacowany model regresji ( lub inaczej przez zmiany zmiennej objaśniającej). Jeżeli R2 przekracza pewną wielkość graniczną przyjętą z góry, R2≥ R2g, przy czym R2g ustalane jest umownie( np. R2g=85%), to można uznać, że stopień dopasowania modelu do danych empirycznych jest wysoki.
d) współczynnik zbieżności
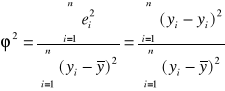
Współczynnik zbieżności
informuje o tym, jaka część całkowitej zmienności( zmian) zmiennej objaśnianej nie została wyjaśniona przez zmiany zmiennej objaśniającej występującej w modelu regresji. Im niższa jest wartość
( bliższa zeru), tym dopasowanie modelu do danych empirycznych jest lepsze.
Własności reszt- testy autokorelacji, test normalność rozkładu reszt ( podpunkt 2)
Stabilność ocen parametrów- test CUSUM ( podpunkt 2)
12. Założenia predykcji na podstawie modelu ekonometrycznego
Sformułowanie prognozy wymaga wykonania wielu kroków, często specyficznych dla danego zadania, niemniej jednak układający się w pewien ogólny schemat, którego schemat ułatwia i poprawia organizację procesu prognostycznego.
W procesie prognozowania, występuje dwóch partnerów: odbiorca prognozy, czyli: odbiorca prognozy, czyli osoba zlecająca wykonanie prognozy, oraz prognosta, czyli wykonawca prognozy.
Etapy predykcji:
Sformułowanie zadania prognostycznego
W tym etapie należy okeślić obiekt, zjawisko, zmienne, które mają podlegać prognozowaniu, cel wyznaczania prognozy, wymagania co do dopuszczalności i horyzontu prognozy.
Główną role odgrywa odbiorca, prognosta jest konsultantem pomagającym w precyzowaniu ustaleń. Predykcja w określeniu zadania prognostycznego jest niezwykle ważna, ponieważ na tym etapie ustala się zakres działań prognosty, a więc praktycznie decyduje się o postaci wyniku, jaki ma być uzyskany.
Podanie przesłanek prognostycznych
Sformułowanie przesłanek wymaga współpracy obu partnerów procesu prognozowania, przy czym prognosta odgrywa rolę podstawową, gdyż zdaje odbiorcy pytania o realia zjawiska prognozowanego i konfrontuje z nim swoje opinie, uzyskane w wyniku studiów literaturowych dotyczących teorii i dotychczasowych badań zjawiska, a także opinie z innych źródeł. Efektem tych prac są hipotezy o czynnikach kształtujących zjawisko, deklaracja prognosty co do postawy wobec przyszłości zjawiska oraz określenie zbioru danych potrzebnych do sporządzenia prognozy i zebranie tych danych.
Wybór metody prognozowania
Wybór metody prognozowania jest konsekwencją zaakceptowanych przesłanek prognostycznych. Wybór metod zależy również od rodzaju posiadanych danych.
Wyznaczenie prognozy
Czynność ta powinna przebiegać zgodnie z ogólnym schematem wybranych metod, a gdy to nie jest możliwe, należy w opisie postępowania ująć wszelkie podjęte decyzje. Samo sformułowanie prognozy powinno odpowiadać określeniu zadania prognostycznego.
Ocena dopuszczalności prognozy
Ocena dopuszczalności musi być podana w sposób zgodny z żądaniem odbiorcy w pierwszym etapie.
Weryfikacja prognozy
Weryfikacja polega na określeniu trafności prognozy za pomocą któregoś błędu prognozy ex post, gdy prognoza dotyczyła zmiennej ilościowej, lub na porównaniu prognozowanego stanu zmiennej jakościowej ze stanem zweryfikowanym. Gdy prognoza okazała się trafna, prognosta analizuje słuszność swego postępowania. Jeśli nie, to prognosta dąży do określenia przyczyn swego błędu
13. Modele adaptacyjne
Metoda średniej ruchomej
- wygładzenie szeregu czasowego (metoda mechaniczna) -zastąpienie rzeczywistych wartości szeregu średnimi arytmetycznymi
Założenia :
- poziom wartości zmiennej prognozowanej prawie stały, z niewielkimi odchyleniami losowymi (wahania przypadkowe)
- brak tendencji rozwojowej , wahań sezonowych i cyklicznych
k- stała wygładzania, czyli liczba wyrazów średniej ruchomej (k=10-15 dla danych dziennych, k=3-5 dla miesięcznych)
k=1 - model naiwny, yTp = yt-1
Do wyznaczenia liczby wyrazów średniej ruchomej używa się średni kwadratowy błąd prognozy ex post ( wyraża odchylenia prognoz wygasłych od wartości zmiennej prognozowanej):
![]()
, delta = √MSE
n- liczba wyrazów szeregu czasowego zmiennej prognozowanej
Prognozy :
yTp =
Model Browna (prosty model wygładzania wykładniczego)
Założenia :
- prawie stały poziom zmiennej prognozowanej, wahania przypadkowe
Prognozy:
y*t = αyt-1 + (1-α)y*t-1 , gdzie α
(0;1], α- parametr wygładzania
lub y*t=y*t-1 + αqt-1 , gdzie qt-1=yt-1-y*t-1
y*1=y1
Model Holta
Założenia :
- występuje trend i wahania przypadkowe
Ft-1 = αyt-1 + (1-α)(Ft-2 + Tt-2) ,α,β
[0;1]
Tt-1 = β(Ft-1- Ft-2) + (1-β)Tt-2
F t-1 = wygładzona wartość zmiennej prognozowanej na okres t-1 ; F1=y1
Tt-1 = wygładzona wartość przyrostu trendu na okres t-1 ; T1= y2-y1
Prognoza :
Y*t = Fn + (t-n)Tn , gdy t>n (gdy wychodzimy poza próbę) ; y*1=y1
MIN- średni kwadratowy błąd prognoz wygasłych
Model Wintersa
Założenia :
- występuje trend, wahania sezonowe i wahania przypadkowe
Wersja addytywna (amplituda wahań stała, taka sama)
Ft-1 = α(yt-1 - St-1-r) + (1-α)(Ft-2 + Tt-2) , α,β,γ
[0;1]
Tt-1 = β(Ft-1 - Ft-2) + (1-β)Tt-2
St-1 = γ(yt-1 - Ft-1) + (1-γ)St-1-r
F- ocena wartości średniej ;F1=y1 -średnia z wartości w pierwszym cyklu
T- ocena przyrostu trendu ;T1=y2-y1 - różnica średnich wyznaczonych dla drugiego i pierwszego okresu cyklu
S- ocena wskaźnika sezonowości; średnia różnic odpowiadających tej samej fazie cyklu wartości zmiennej prognozowanej i wygładzonych wartości trendu
r- długość cyklu sezonowego (np.dla danych miesięcznych r=12)
Prognoza:
y*t = Fn+ (t-n)Tn + St-r
MIN- średni kwadratowy błąd prognoz wygasłych
Wersja multiplikatywna (amplituda wahań zmienia się z okresu na okres)
Ft-1 = α
+ (1-α)(Ft-2 + Tt-2)
Tt-1 = β(Ft-1-Ft-2) + (1-β)Tt-2
St-1 = γ
+ (1-γ)St-1-r
Prognoza:
y*t = (Fn + (t-n)Tn)St-r
MIN- średni kwadratowy błąd prognoz wygasłych
Model trendu pełzającego
Założenia:
- nieregularne zmiany w trendzie
k - stała wygładzania (k<n ustalana arbitralnie)
Etap I - szacowanie parametrów liniowych trendu
d(t)≤ j ≤ g(t), gdzie
d(t) = {1 t=1,2,…,k
t-k+1 t=k+1,…,n
g(t) = { t t=1,2,…,n-k+1
n-k+1 t=n-k+2,…,n.
Etap II - ustalenie średniej wartości wygładzonych wartości teoretycznych z liniowych modeli trendu
t =
Prognozy :
- przyrosty funkcji trendu
t+1 =
t+1 -
t
- średnia w przyrostów
=
wt+1
- wagi harmoniczne realizujące postulat powtarzania informacji
=
; t = 1,…, n-1.
Etap III - odchylenie standardowe przyrostów trendu pełzającego
sw = [
)2 ]0,5
Etap IV - ekstrapolacja trendu
y*τ =
n + (τ - n)
Etap V - przedział prognozy- konstrukcja
P {y*τ - uτsw ≤ yτ ≤ y*τ + uτsw}= p , gdzie uτ = u
, n< τ ≤ 2n-1.
14. Modele wielorównaniowe
- Postać strukturalna : yt = Ayt + Byt-1 + Cxt + ut
yt = (I-A)-1Byt-1 + (I-A)-1Cxt + (I-A)-1ut (postać zredukowana)
yt = P2yt-1 + P1xt + P0ut
- Mnożniki bezpośrednie i pośrednie
M0 = P1 (mnożnik bezpośredni)
M1 = P2M0 (mnożniki pośrednie)
M2 = P2M1
M3 = P2M2 itd.
- Mnożniki skumulowane
S0 = M0
S1 = M0 + M1 = S0 + M1
S2 = M0 + M1 + M2 = S1 + M2
S3 = S2 + M3 itd.
Interpretacje (przykłady)
- mnożniki bezpośrednie - mnożnik y1 wzgl. x1 =0,002 - wzrost x1 o jednostkę przyniesie wzrost y1 o 0,002
- mnożniki pośrednie - mnożnik y1 wzgl. x1(-1) = 0,01 - wzrost x1 o jeden okres wcześniej spowoduje wzrost y1 o 0,01 .
- mnożniki skumulowane - S2- wzrost x1 o jednostkę przez dwa kolejne okresy skończywszy na okresie bieżącym spowoduje wzrost y1 o 0,004
- S3- wzrost x1 o jednostkę przez trzy kolejne okresy skończywszy na okresie bieżącym spowoduje spadek y2 o 0,012
- PROGNOZOWANIE ( z wykorzystaniem skryptu)
Dane równania współzależne :
Pt =β12Zt + α10 + α11Pt-1 + αIt-1 + ε1t
Zt = β21Pt + α20 + α22It +α23It-1 + α24t + ε2t
# specyfikacja modelu
system name=model1
equation produk 0 zatrud produk_1 inwest_1
equation zatrud 0 produk inwest inwest_1 time
endog produkt zatrud
instr const produk_1 inwest inwest_1 time
end system
#estymacja modelu
estimate model1 method=tsls (tsls= 2MNK)
Prognozowanie
# próba (początek skryptu!)
smpl 1962 1980
# specyfikacja
# estymacja
# okres prognozy
smpl 1981 1985
# wyznaczenie prognoz
fcast --dynamic
Symulacje
# pełen zakres danych (na początku skryptu!)
smpl 1962 1985
# specyfikacja
# estymacja
# krok 1 - rozwiązanie bazowe
fcast --dynamic
matrix Z0=$fcast
# krok 2 - impuls/zaburzenie
genr inwest[1964]=inwest[1964]+1
# krok 3 - rozwiązanie zakłócone
fcast --dynamic
matrix Z1=$fcast
# krok 4 - wyznaczenie mnożników
matrix M=Z1-Z0 (mnożniki bezpośrednie i pośrednie)
matrix S=cum(M) (mnożniki skumulowane)
# krok 5 - wydruk
print M S
# powrót do pierwotnych danych
genr inwest[1964]=inwest[1964]-1
Wyszukiwarka
Podobne podstrony:
MSG DEFINICJE, ►► UMK TORUŃ - wydziały w Toruniu, ►► Ekonomia, Międzynarodowe stosunki gospodarcze
ekonomia-INFLACJA, ►► UMK TORUŃ - wydziały w Toruniu, ► Wydział politologii i studiów międzynarodowy
MSG DEFINICJE, ►► UMK TORUŃ - wydziały w Toruniu, ►► Ekonomia, Międzynarodowe stosunki gospodarcze
hydrobiologia 30.11.2011, ►► UMK TORUŃ - wydziały w Toruniu, ► WYDZIAŁ Biologii, WYDZIAŁ Chemii, Bio
Z poprawna polszczyzną - 2 etap, ►► UMK TORUŃ - wydziały w Toruniu, ►► Filologia polska, Stylistyka
Kancelaria Krakowska, ►► UMK TORUŃ - wydziały w Toruniu, ►► Archiwistyka, Rozwój form
opracowane zagadnienia na egzamin, ►► UMK TORUŃ - wydziały w Toruniu, ►► Socjologia, Praca socjalna,
Postepowanie-sadowo-administracyjne, ►► UMK TORUŃ - wydziały w Toruniu, ► WYDZIAŁ Prawa i Administra
kultura jezyka polskiego cz.2, ►► UMK TORUŃ - wydziały w Toruniu, ►► Filologia polska, Kultura jezyk
DEFINICJA DOKTRYNALNA PAPIERU WARTOŚCIOWEGO, ►► UMK TORUŃ - wydziały w Toruniu, ► WYDZIAŁ Prawa i Ad
Kultura jezyka II rok, ►► UMK TORUŃ - wydziały w Toruniu, ►► Filologia polska, Kultura jezyka - Izab
sciaga prawo st, ►► UMK TORUŃ - wydziały w Toruniu, ►► Finanse i rachunkowość (FiR), Prawo
raport ćw 5, ►► UMK TORUŃ - wydziały w Toruniu, ► WYDZIAŁ Biologii, WYDZIAŁ Chemii, Biotechnologia U
Zad2, ►► UMK TORUŃ - wydziały w Toruniu, ►► Socjologia, Praca socjalna, Polityka społeczna, ćwiczeni
Typy dokumentacji, ►► UMK TORUŃ - wydziały w Toruniu, ►► Archiwistyka, Metodyka kształtowania zasobu
kultura jezyka polskiego, ►► UMK TORUŃ - wydziały w Toruniu, ►► Filologia polska, Kultura jezyka - I
więcej podobnych podstron