Rodzaje badań statystycznych
Wyróżnia się badania :
Pełne ( całkowite )
Częściowe
Badania pełne i częściowe mogą być :
Ciągłe ( np. rejestracja urodzeń, zgonów, małżeństw, itp. )
Okresowe ( np. spisy ludności , rolne, przemysłu )
Doraźne ( np. klęsk żywiołowych )
Wśród badań częściowych wyróżnia się :
Badania reprezentacyjne ( są bardzo wartościowe, bo pozwalają z dużym prawdopodobieństwem uogólnić wyniki uzyskane ze zbiorowości próbnej na całą populację generalną, są tańsze od badań całkowitych).
Badania monograficzne ( obejmują obserwację grupy społecznej, wsi , miasta , przykładem badania monograficznego jest badanie warunków życia ludności w mieście Rzeszowie w pewnym momencie lub w okresie)
Badania ankietowe ( dość często wykorzystywana metoda badań , sprowadza się głównie do zbierania informacji pierwotnych, ważnym problemem jest wykształcenie umiejętności dobrego opracowania ankiety, zestaw pytań w kwestionariuszy ankietowym powinien być umiejętnie sformułowany.
W Polsce badaniami ankietowymi zajmują się takie instytucje jak : OBOP, CBOS, PPENTOR oraz inne ośrodki naukowe.
Procedury dobru próby
W badaniach statystycznych w praktyce posługujemy się próbą . Próba mała gdy ![]()
, gdy n>30 to mamy do czynienia z próbą dużą .
Od próby wymaga się , aby była reprezentatywna. Na reprezentatywność próby mają wpływ dwa czynniki :
Sposób doboru próby
Liczebność próby
Wyróżnia się dwie procedury doboru próby :
Dobór celowy ( sprowadza się do tego , że o wyborze jednostek decyduje badacz, opierając się na merytorycznej znajomości problematyki badawczej, próba ta nie podlega prawu wielkich liczb )
Dobór losowy ( zgodny jest z zasadami doboru według metody reprezentacyjnej, umożliwia zastosowanie metod statystyki matematycznej do wnioskowania, próba ma charakter losowy, gdy każda jednostka populacji z jednakowym prawdopodobieństwem różnym od zera może się w niej znaleźć. Wyodrębniona próba podlega działaniu prawa wielkich liczb, co oznacza że wraz ze wzrostem liczebności próby losowej (n) rośnie stopień jej reprezentatywności )
Przed pobraniem próby ważne jest określenie jednostki losowania Indywidualna jednostka losowania pokrywa się z jednostką badania, a zespołową jednostką losowania , gdy nie pokrywa się z jednostką badania ( np. losuje się mieszkania a bada się ich osoby w nich zameldowane ).
Losowanie próby określa się jako operat losowania , przez który rozumie się wykaz jednostek uwzględnionych przy losowaniu z możliwością ich identyfikacji Na przykład , takim operatem losowania dla populacji mieszkańców Rzeszowa jest spis ( ponumerowany) wszystkich mieszkańców tego miasta.
Sposób postępowania przy doborze próby losowej określa się mianem schematu losowania. Podstawowe schematy losowania to:
losowanie indywidualne
losowanie nieograniczone ze zwracaniem ( zwane inaczej niezależnym lub zwrotnym )
losowanie nieograniczone bez zwracania ( inaczej określane jako zależne )
losowanie warstwowe
losowanie systematyczne
losowanie grupowe
Klasyfikacja cech statystycznych
Cechy statystyczne można podzielić na:
ilościowe ( mierzalne, kwantytatywne ) - można je zmierzyć i wyrazić za pomocą odpowiednich jednostek fizycznych ( np. kg, m, szt, t )
jakościowe ( kwalitatywne) - zwykle są określane słownie np. płeć, standard mieszkania, pochodzenie społeczne, rodzaj kredytu itp.
Cechy ilościowe określa się jako zmienne, które można podzielić na :
skokowe ( dyskretne )
ciągłe
Cecha skokowa przyjmuje skończony i przeliczalny zbiór wartości na danej skali liczbowej , przy czym jest to najczęściej zbiór liczb całkowitych nieujemnych ( np. liczba dzieci w rodzinie , liczba usterek w konkretnym produkcie , wielkość gospodarstwa domowego itp. )
Cecha ciągła przyjmuje wszystkie liczby rzeczywiste z określonego przedziału liczbowego < a , b > , przy czym liczba miejsc po przecinku jest uzależniona od dokładności pomiarów ( np. wiek , płaca, wzrost, plon pszenicy itp. )
Występuje również podział cech na :
stałe ( własności wspólne dla wszystkich jednostek statystycznych danej zbiorowości statystycznej
zmienne ( własności , dzięki którym poszczególne jednostki różnią się między sobą, przy czym dokładny stopień zmienności poszczególnych cech jest możliwy lub niemożliwy do określenia )
Dla potrzeb pomiaru cech stosuje się cztery rodzaje skal : nominalną , porządkową, interwałową i ilorazową .
Skala nominalna - skala stosująca wyłącznie opis słowny dla potrzeb identyfikacji jednostki. Np. kobieta i mężczyzna . Nie są możliwe działania arytmetyczne na danych opisanych na skali nominalnej.
Skala porządkowa - służąca do porządkowania danych. Na przykład ranking szkół wyższych z punktu widzenia ich atrakcyjności.
Skala interwałowa - skala mająca własności skali porządkowej, gdyż możliwe jest porządkowanie jednostek statystycznych opisanych w tej skali , a jednocześnie jest możliwe określenie interwału ( przedziału ) liczbowego, w którym zawierają się obserwacje.
Skala ilorazowa - skala ma cechy skali interwałowej, a ponadto iloraz ma tutaj określoną interpretację. Dane opisane w skali ilorazowej przyjmują zawsze wartości liczbowe, np. waga itp.
Szeregi statystyczne
Materiał liczbowy , otrzymany w wyniku przeprowadzonej obserwacji statystycznej lub pomiaru, po opracowaniu i pogrupowaniu nazywamy szeregiem strukturalnym, charakteryzuje on zbiorowość statystyczną pod względem wyróżnionej cechy jakościowej i ilościowej.
Wyróżnia się dwa typy grupowania : grupowanie typologiczne ( według cechy jakościowej ) oraz grupowanie wariancyjne ( według cechy ilościowej )
Szeregiem szczegółowym prostym nazywamy uporządkowany nierosnąco lub niemalejąco ciąg wartości badanej zmiennej. Oznaczmy symbolem X badaną zmienną , symbolem xi ( i=1,2,...,n) wartość tej zmiennej odpowiadającą i-tej jednostce statystycznej. Załóżmy, że badano n jednostek statystycznych. Ciąg wartości tej zmiennej ;
x1 , x2, ..., xn
określa się szeregiem szczegółowym prostym, jeśli w powyższym ciągu każdy następny element nie jest mniejszy od poprzedniego.
Przykład 1.
Załóżmy , że w pewnej miejscowości poddano obserwacji 16 rodzin ze względu na liczbę dzieci i otrzymano następujące wyniki :
0,1,1,2,2,3,3,3,4,4,4,5,5,6,6,7
Powyższy ciąg wartości jest uporządkowany niemalejąco, jest więc szeregiem szczegółowym prostym. W tym przypadku jednostką statystyczną jest rodzina, a cechą liczba dzieci w rodzinie
Wśród szeregów strukturalnych cechy ilościowej wyróżnia się szereg szczegółowy ważony oraz rozdzielczy.
Szereg szczegółowy ważony
Załóżmy, że wśród danych zawartych w szeregu szczegółowym prostym wyróżniono k różnych wartości. Następnie grupujemy jednostki statystyczne odpowiadające jednakowym wartościom cechy. Postępując w ten sposób otrzymujemy wyniki, które można zaprezentować w poniższej tablicy
Tab. 1 Wyniki grupowania statystycznego
Wartości cechy xi |
Liczebność f i |
Częstość względna fi / n |
x1 x2 . . . xk |
f1 f2 . . . fk |
f1 / n f2 / n . . . fk / n |
Razem |
|
|
Źródło; opracowanie włane
Druga i trzecia kolumna tej tablicy charakteryzuje strukturę zbiorowości n- elementowej pod względem cechy X. Symbolem fi oznaczamy liczbę jednostek statystycznych , dla których wartość cechy przyjęła wartość xi ( i = 1,2,...,n). Wartość tę nazywamy liczebnością. Trzecia kolumna zawiera wielkości zwane liczebnościami względnymi lub frakcjami. Suma tych wielkości jest równa 1. Mnożąc te wielkości przez 100, otrzymujemy częstości w procentach . Częstości względne są wielkościami niemianowanymi. Mogą być wykorzystane do porównań struktur zbiorowości różniących się liczebnościami. Liczebności lub częstości zawarte w przedostatniej i ostatniej kolumnie tej tablicy charakteryzują rozkład elementów zbiorowości pod względem danej cechy , lub rozkład cechy.
Szereg rozdzielczy
Obszar zmienności wartości cech dzielimy na rozłączne przedziały w postaci ![]()
dla i=1,2,...,k. Są to przedziały prawostronnie otwarte. Jednostki statystyczne , których wartości cechy przedstawia szereg szczegółowy prosty grupujemy wykorzystując przedziały, które nazywać będziemy przedziałami klasowymi lub klasami. Wyniki grupowania zawiera poniższa tablica
Tab.2 Wyniki grupowania statystycznego
Przedział klasowy |
Liczebność
|
środek przedziału klasowego
|
Częstość względna
|
. . .
|
. . .
|
. . .
|
. . .
|
Razem |
|
|
|
Źródło: Opracowanie własne
Wartość środkową oblicza się według następującej formuły :
![]()
( i=1,2,...,k)
Przy budowie szeregu rozdzielczego należy sobie odpowiedzieć na następujące pytania :
czy długości przedziałów mają być jednakowe ?
na ile klas należy podzielić obszar zmienności ?
W praktyce badań statystycznych wygodnie jest, gdy przedziały klasowe są jednakowej długości. W przypadku , gdy przedziały nie są jednakowej długości, do opisu struktury zbiorowości wykorzystać należy tzw. gęstość liczebności, definiowaną za pomocą następującego wzoru :
![]()
( i=1,2,...,n )
gdzie w mianowniku mamy długość i-tego przedziału, w liczniku zaś odpowiadającą mu liczebność.
W badaniach statystycznych brak jest jednoznacznych kryteriów umożliwiających w sposób jednoznaczny odpowiedzieć na pytanie o liczbę klas w szeregu rozdzielczym.
J. Spława Neyman zalecał przy tworzeniu szeregów rozdzielczych podział obszaru zmienności na około 10 - 20 klas, w zależności od liczebności zbiorowości.
Oznaczmy symbolem „ h „ długość przedziału klasowego. Załóżmy, że wszystkie przedziały mają mieć równą długość. W tym przypadku najczęściej zaleca się, aby długość przedziału obliczać za pomocą następującej formuły :
![]()
( i=1,...,n)
gdzie : w liczniku jest zakres zmienności wartości cechy, w mianowniku zaś liczba wymaganych klas.
Jeśli decydujemy się na budowę przedziałów klasowych , to narażamy się na pewną stratę informacji dotyczących pojedynczych wyników. Im większa jest rozpiętość przedziału klasowego, tym ta strata może być bardziej dotkliwa.
Przedziały klasowe zapisuje się zazwyczaj z dokładnością do przyjętej jednostki pomiarowej. Można budować rozkłady ( szeregi ) z przedziałami klasowymi domkniętymi lub otwartymi.
Rozstęp wynosi R= Xmax - Xmin . Rozstęp charakteryzuje jedynie wstępnie dyspersję badanego rozkładu.
Odchylenie ćwiartkowe wyrażone jest następującym wzorem :
![]()
Najpierw należy obliczyć kwartyl trzeci i kwartyl pierwszy.
Grupy dochodów miesięcznych na gospodarstwo domowe |
Liczba kobiet W % |
Szereg skumulowany |
0,5 - 1,0 |
0,9 |
0,9 |
1,0 - 1,5 |
4,0 |
4,9 |
1,5 - 2,0 |
8,8 |
13,7 |
2,0 - 3,0 |
21,5 |
35,2 Q1 |
3,0 - 4,0 |
23,5 |
58,7 Q2 |
4,0 - 5,0 |
20,3 |
79,0 Q3 |
5,0 - 6,0 |
10,8 |
89,8 |
6,0 - 7,0 |
5,2 |
95,0 |
7,0 - 8,0 |
2,8 |
97,8 |
8,0 - 9,0 |
2,2 |
100,0 |
Wzory:
![]()
![]()
![]()
![]()
Odchylenie ćwiartkowe wynosi :
![]()
Oznacza to , że średnio miesięczne dochody kobiet różnią się od mediany o ![]()
tyś. zł.
Mediana dla badanego rozkładu wynosi :
![]()
Współczynnik zmienności ( względna miara dyspersji )wynosi:
![]()
![]()
Oznacza to , że 31,32 % mediany dochodów kobiet stanowi odchylenie standardowe.
Wyznaczenie dominanty według wzoru :
![]()
![]()
Podstawowym miernikiem asymetrii jest różnica między średnią arytmetyczną a dominantą, czyli :
![]()
Znak „ - „ przy wartości miernika oznacza asymetrię lewostronną , znak „+” asymetrię prawostronną.
W rozpatrywanym przykładzie mamy do czynienia z asymetrią prawostronną , co oznacza , że przewaga liczebności występuje w przedziałach klasowych poniżej średniej arytmetycznej.
O sile i kierunku symetrii mówią współczynniki asymetrii. Współczynnik asymetrii Pearsona wyznacza się według formuły :
![]()
![]()
Współczynnik asymetrii wykazuje skośność prawostronną.
Gdy rozkład jest symetryczny to , Vs = 0
Gdy rozkład jest asymetryczny - prawostronny., to Vs > 0
Gdy rozkład jest asymetryczny - lewostronny , to Vs < 0
Współczynników asymetrii jest kilka, a zastosowanie ich jest uzależnione od charakteru badanego szeregu i możliwości wyliczenia poszczególnych parametrów.
Miarą asymetrii jest również współczynnik skośności obliczony na podstawie dominanty i mediany, według wzoru :
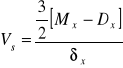
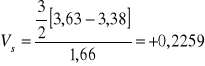
Miarą asymetrii może być także moment trzeci centralny. Dla rozkładu przedziałowego ma on postać następującą:
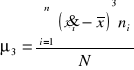
Tablica pomocnicza do wyznaczenia momentu trzeciego centralnego
|
|
|
|
0,75 |
0,9 |
-3,063 |
-25,863 |
1,25 |
4,0 |
-2,563 |
-67,344 |
1,75 |
8,8 |
-2,063 |
-77,263 |
2,50 |
21,5 |
-1,313 |
-48,665 |
3,50 |
23,5 |
-0.313 |
-0,720 |
4,50 |
20,3 |
0,687 |
6,581 |
5,50 |
10,8 |
1,687 |
51,851 |
6,50 |
5,2 |
2,687 |
100,879 |
7,50 |
2,8 |
3,687 |
140,336 |
8,50 |
2,2 |
4,687 |
226,519 |
Razem |
100 |
|
306,313 |
Dla badanego szeregu moment trzeci centralny wynosi :
![]()
Moment trzeci centralny można również zapisać w postaci momentów zwykłych w sposób następujący:
![]()
gdzie :
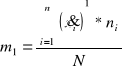
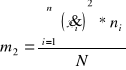
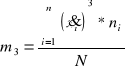
Dla szeregu wynoszą odpowiednio :
![]()
![]()
![]()
wobec tego otrzymujemy :
![]()
Miarą względną asymetrii jest następująca formuła :
![]()
Dla rozpatrywanego szeregu wynosi :
![]()
Rozkład ma asymetrię prawostronną o natężeniu 0,66.
Dla szeregów dokładnie symetrycznych m3=0. W przypadku asymetrii prawostronnej m3 > 0, lewostronnej zaś m3 < 0.
Przykład 3.
Zbiór województw , w którym cechą badania była ich powierzchnia, został opisany przy użyciu podstawowych charakterystyk liczbowych tj średniej arytmetycznej, która wynosi 6,286 tyś. km2 oraz odchylenia standardowego ,które jest równe 2, 138 tyś, km2.W celu dokładniejszego opisu rozkładu tej zbiorowości należy wyznaczyć miary koncentracji.
Powierzchnia W tyś. km2 |
Liczba Wojewódz. |
|
|
|
1-3 |
1 |
2 |
-4,286 |
337,449405 |
3-5 |
14 |
4 |
-2,286 |
382,325213 |
5-7 |
18 |
6 |
-0,286 |
0,12043 |
7-9 |
10 |
8 |
1,714 |
86,306453 |
9-11 |
5 |
10 |
3,714 |
951,344040 |
11-13 |
1 |
12 |
5,714 |
1066,009178 |
|
49 |
|
|
2823,554720 |
![]()
![]()
Względna miara koncentracji to stosunek momentu centralnego czwartego rzędu przez odchylenie standardowe do potęgi czwartej, czyli :
![]()
Im wyższa wartość K , tym bardziej wysmukła jest krzywa liczebności , co wskazuje na tendencję do skupienia się jednostek wokół średniej. Małe wartości wskazują na spłaszczenie krzywej rozkładu , a zatem słabą koncentrację. Zakłada się ,że dla rozkładu normalnego K=3, dla bardziej od niego spłaszczonego K < 3 oraz dla wysmukłego K > 3. W związku z powyższym skonstruowany współczynnik koncentracji o postaci :
![]()
przyjmuje wartość zero, jeżeli rozkład ma kształt normalny ,Ku > 0 , jeżeli rozkład jest bardziej wysmukły, oraz Ku < 0 , gdy rozkład jest spłaszczony w stosunku do rozkładu normalnego.
![]()
Koncentracja w porównaniu z krzywą normalną jest słabsza, a zatem rozkład jest spłaszczony.
Inną miarą koncentracji jest współczynnik koncentracji Lorenca. Zjawisko koncentracji może być rozważane jako nierównomierny podział ogólnej sumy wartości zmiennej x pomiędzy poszczególne jednostki zbiorowości statystycznej. Ma to miejsce przy badaniu dochodów, koncentracji produkcji, gęstości zaludnienia, rozmieszczenia bogactw naturalnych itp. Tak rozumiana koncentracja jest zwykle przedstawiana i mierzona za pomocą krzywej koncentracji Lorenza. Kształt krzywej określa natężenie koncentracji. Współczynnik koncentracji Lorenza ( KL ) można wyrazić za pomocą wzoru:
![]()
gdzie :
a - pole zawarte między linią równomiernego podziału a krzywą Lorenza
b - pole pod krzywą Lorenza
a+b - pole trójkąta
Wyznaczenie pola a nie jest łatwe. Częściej wyznaczamy przybliżoną wartość pola b, budując w tym celu w układzie współrzędnych prostokąty o podstawie równej wskaźnikowi struktury dla liczby jednostek znajdujących się w przedziale, a wysokość jest średnią ze skumulowanych wartości wskaźników struktury wielkości badanego zjawiska grupy badanej i poprzedniej. Obliczenie powierzchni pola b można opisać następującym wzorem:
![]()
gdzie :
skum.Wi - kolejne skumulowane wartości wskaźników struktury wielkości badanego zjawiska
![]()
- kolejne wartośći wskaźników struktury dla liczby badanych jednostek
Współczynnik ten jest względną miarą koncentracji zjawiska. W praktyce zawiera się ![]()
Przykład 4.
Struktura zatrudnienia w badanych firmach została scharakteryzowana za pomocą następujących liczb zawartych w poniższej tablicy. Należy określić stopień koncentracji zatrudnienia w badanych firmach w 1995 roku .
Liczba zatrudnionych pracowników w badanych firmach |
Firmy w % |
Zatrudnienie w % |
do 4 |
37,7 |
1,0 |
5 - 10 |
20,5 |
2,0 |
11-15 |
7,2 |
1,3 |
16 - 50 |
17,4 |
7,0 |
51 -100 |
7,0 |
6,8 |
101 - 200 |
4,3 |
8,2 |
201 - 500 |
3,1 |
13,2 |
501 -1000 |
1,5 |
14,3 |
1001 - 2000 |
0,7 |
13,7 |
2001 - 5000 |
0,4 |
17,7 |
5001 i więcej |
0,2 |
14,8 |
|
100 |
100 |
Źródło: Dane umowne
Tablica pomocnicza do wyznaczenia do wyznaczenia współczynnika Lorenza
Firmy w %
|
Zatrudnienie w %
|
Skum.
|
Skum.
|
|
|
37,7 |
1,0 |
37,7 |
1,0 |
(1+0)/2=0,5 |
0.5*37,7=18,85 |
20,5 |
2,0 |
58,2 |
3,0 |
( 3,0+1,0)/2=2,0 |
2,0*20,5=41,00 |
7,2 |
1,3 |
65,4 |
4,3 |
( 4,3+3,0)/2=3,65 |
3,65*7,2=26,28 |
17,4 |
7,0 |
82,8 |
11,3 |
( 11,3 + 4,3 ) /2=7,80 |
7,80*17,4=135,72 |
7,0 |
6,8 |
89,8 |
18,1 |
14,7 |
102,90 |
4,3 |
8,2 |
94,1 |
26,3 |
22,20 |
95,46 |
3,1 |
13,2 |
97,2 |
39,5 |
32,90 |
101,99 |
1,5 |
14,3 |
98,7 |
53,8 |
46,65 |
69,975 |
0,7 |
13,7 |
99,4 |
67,5 |
60,65 |
42,455 |
0,4 |
17,7 |
99,8 |
85,2 |
76,35 |
30,54 |
0,2 |
14,8 |
100,0 |
100,0 |
92,80 |
18,52 |
100 |
100 |
|
|
|
683,69 |
Źródło: Obliczenia własne
Obliczona powierzchnia b wynosi 683,69, wobec tego współczynnik koncentracji wynosi:
Pole trójkąta ( a + b)=5000, wobec tego
![]()
Oznacza to dość wysoką koncentrację badanego zjawiska.
Inną miarą koncentracji jest współczynnik koncentracji Lorenza. Może być on wykorzystywany do badań w zakresie koncentracji własności ziemskiej, bogactw naturalnych czy kapitału. Punktem wyjścia do ilościowego badania koncentracji jest ustalenie, w jaki sposób rozkłada się ogólna suma wartości badanej cechy na poszczególne jednostki zbiorowości statystycznej.
Do oceny stopnia natężenia tak rozumianej koncentracji stosuje się krzywą koncentracji lub krzywą Lorenza. Kształt linii łamanej określa natężenie koncentracji Jeżeli na każdą jednostkę zbiorowości przypada taka sama część ogólnej sumy wartości cechy , to zamiast krzywej koncentracji otrzymamy linię prostą przechodzącą przez początek układu współrzędnych pod kątem γ=45 w stosunku do osi odciętych. Jest to tzw. Linia równomiernego rozkładu wartości cechy dla poszczególnych jednostek zbiorowości.
Stosunek pola zawartego między krzywą koncentracji a linią równomiernego rozkładu do ogólnego pola trójkąta nosi nazwę współczynnika koncentracji Lorenza.Można go wyznaczyć w sposób następujący:
![]()
gdzie :
a - powierzchnia pola zawartego między krzywą koncentracji a linią równomiernego rozkładu
b - powierzchnia pola leżącego pod krzywą koncentracji
Współczynnik ten zawiera się w przedziale [ 0, 1 ]. Procedurę wyznaczania współczynnika przedstawimy na przykładzi
Przykład 4.Na podstawie danych dotyczących osób pobierających renty z tytułu niezdolności do pracy według wysokości świadczeń we wrześniu 1997 roku należy ocenić stopień koncentracji wysokości świadczeń z ubezpieczenia społecznego.
Obliczenia pomocnicze do wyznaczenia współczynnika koncentracji.
Wysokość Świadczenia Brutto Z ubezp.społ.
|
Liczba Pobier. Renty Z tytuł.niezd. Do pracy ni |
Łączna Wysok. Świadcz. Brutto
|
Odsetki Liczby Pobier. Renty
|
Odsetki Łączn. Wysok. Świadcz.
|
Skum.
|
Skum.
|
Pole figury b |
400-450 |
255,6 |
108 630,0 |
0,159 |
0,101 |
0,159 |
0,101 |
0.0080 |
450-500 |
387,5 |
184 062,5 |
0,241 |
0,172 |
0,400 |
0,273 |
0.0451 |
500-550 |
191,0 |
100 275,0 |
0,119 |
0,093 |
0,518 |
0,366 |
0.0379 |
550 -600 |
142,6 |
81 955,0 |
0,089 |
0,076 |
0,607 |
0,443 |
0,0359 |
600-650 |
104,9 |
65 562,5 |
0,065 |
0,061 |
0,672 |
0,504 |
0,0309 |
650-700 |
88,8 |
59 940,0 |
0,055 |
0,056 |
0,727 |
0,560 |
0,0294 |
700-750 |
61,9 |
44 877,5 |
0,038 |
0,042 |
0,766 |
0,602 |
0,0223 |
750-800 |
48,4 |
37 510,0 |
0.030 |
0,035 |
0,796 |
0,636 |
0,0186 |
800-900 |
72,6 |
62 710,0 |
0,0,45 |
0,058 |
0,841 |
0,694 |
0,0300 |
900-1 000 |
48,4 |
45 980,0 |
0,030 |
0,043 |
0,871 |
0,737 |
0,0215 |
1 000 - 1 100 |
40,3 |
42 315,0 |
0,025 |
0,039 |
0,896 |
0,776 |
0,0190 |
1 100 - 1 200 |
29,6 |
34 040,0 |
0,018 |
0,032 |
0,915 |
0,808 |
0,0146 |
1 200 - 1 300 |
29,6 |
37 000,0 |
0,018 |
0,034 |
0,933 |
0,843 |
0,0152 |
1 300 - 1 400 |
29,6 |
39 960,0 |
0,018 |
0,037 |
0,952 |
0,880 |
0,0158 |
1 400 - 1 500 |
16,1 |
23 345,0 |
0,010 |
0,022 |
0,962 |
0,902 |
0,0089 |
1 500 - 1 600 |
10,7 |
16 585,0 |
0,007 |
0,015 |
0,968 |
0,917 |
0,0060 |
1 600 - 1 700 |
5,6 |
9 240,0 |
0,003 |
0,009 |
0,972 |
0,926 |
0,0032 |
1 700 - 1 800 |
45,6 |
79 800,0 |
0,028 |
0,074 |
1,000 |
1,000 |
0,0273 |
Ogółem |
1 608,8 |
1 072 828,5 |
1,000 |
1,000 |
|
|
0,3896 |
Zaliaś A. : Metody statystyczne. PWE, Warszawa, s.75.
Pole figury b pod krzywą Lorenza , można w przybliżeniu wyznaczyć w sposób następujący:
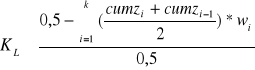
gdzie :
cum zi - względna wartość szeregu skumulowanego obliczonego w sposób następujący
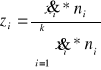
wi - liczebności względne obliczone następująco: ![]()
, przy czym ![]()
W naszym przykładzie mamy :
![]()
a=0,5-0,3896=0,1104
![]()
Uzyskany wynik wskazuje na słaby stopień koncentracji, co odpowiada równomiernemu podziałowi łącznej wysokości świadczenia brutto z ubezpieczenia społecznego między pobierających renty z tytułu niezdolności do pracy.
Rachunek prawdopodobieństwa
Krótki rys historyczny
Podstawowe wiadomości o zdarzeniach
Pojęcie prawdopodobieństwa
Podstawowe twierdzenia rachunku prawdopodobieństwa
!. Krotki rys historyczny
Rachunek prawdopodobieństwa jest dziedziną matematyki. Z rachunkiem prawdopodobieństwa związane są takie nazwiska francuskich matematyków jak : B.Pascal ( 1623 - 1662 ) i P. Fermat ( 1601 - 1661 ).
Duży wkład w rozwój tej dyscypliny przypisuje się również szwajcarskiemu matematykowi J. Bernoulliemu ( 1654 - 1705.W pracy „ Traktat o sztuce przewidywania „ można znaleźć podstawowe twierdzenia rachunku prawdopodobieństwa zwane „ prawem wielkich liczb „. Wielkie zasługi w rozwój teorii prawdopodobieństwa położył również P.S. Laplace ( 1749 - 1705 ) oraz K.F. Gauss ( 1777 - 1855 ). Gauss uważany jest za twórcę teorii błędów obserwacji i metody najmniejszych kwadratów. Na uwagę zasługuje nazwisko S.D. Poissona ( 1781 -1840 ), francuskiego matematyka , którego imieniem został nazwany jeden z najważniejszych rozkładów statystycznych.
Studiując historię rachunku prawdopodobieństwa ważne wydaje się wymienienie prac członka Petersburskiej Akademii Nauk , szwajcara z pochodzenia , L. Eulera ( 1707 - 1783) Całki Eulera nazywa się tzw. Funkcją gamma i funkcją beta. Funkcje te mają duże zastosowanie w statystyce matematycznej.
Za twórcę rosyjskiej szkoły probabilistycznej uznać należy P. Czejbyszewa (1821 - 1894) Wybitni matematycy radzieccy, A. Kołmogorow, N. Smirnow i inni stworzyli radziecką szkołę teorii prawdopodobieństwa, która należy do czołowych w świecie.
Osiągnięcia współczesnej probabilistyki w Polsce są związane z imieniem profesora Uniwersytetu Wrocławskiego H.Steinhausa i jego uczniów.
Zmienna losowa jest to zmienna, która przyjmuje różne wartości liczbowe, wyznaczone przez los.
Zmienną losową można traktować jako pewną funkcję określoną na przestrzeni próby związanej z eksperymentem. Przyporządkowanie prawdopodobieństw różnym możliwym wartością zmiennej losowej, czyli „probabilistyczne prawo rządzące zmienną losową „ nazywamy rozkładem prawdopodobieństwa zmiennej losowej.
Zmienna losowa może być :
Skokowa ( dyskretna )
Ciągła
Zmienna losowa jest skokowa ( dyskretna ), gdy może przyjmować wartości ze zbioru najwyżej przeliczalnego.
Zmienna losowa ciągła może przyjmować wartości z dowolnego przedziału liczbowego. Możliwe wartości takiej zmiennej tworzą zbiór nieprzeliczalnie nieskończony.
Rozkładem prawdopodobieństw zmiennej losowej skokowej, zwanym też funkcją rozkładu masy prawdopodobieństwa jest tablica, wzór lub wykres, który przyporządkowuje prawdopodobieństwa każdej możliwej wartości zmiennej.
Zmienne losowe będziemy oznaczać dużymi literami, najczęściej literą X, chociaż mogą być użyte inne litery. Małych liter będziemy używać do oznaczenia poszczególnych wartości przybieranych przez zmienne losowe. Zapis P(X=x) oznacza prawdopodobieństwo, że zmienna losowa X przyjmuje pewną określoną wartość x. Na przykład zapis P(X=5)=0,2 oznacza, że prawdopodobieństwo , iż zmienna losowa X przyjmuje wartość 5 jest równe 0,2. Można używać skróconych zapisów, np. P(5)=0,2
Rozkład prawdopodobieństwa skokowej zmiennej losowej X spełnia następujące warunki
![]()
dla wszystkich wartości x ( 1 )
![]()
( 2 )
Przykład 1. Załóżmy, że w poniższym zestawieniu wymieniono możliwe liczby ogłoszeń zamieszczonych dziennie w gazecie i odpowiadające im prawdopodobieństwa
X |
0 |
1 |
2 |
3 |
4 |
5 |
P(X) |
0,1 |
0,2 |
0,3 |
0,2 |
0,1 |
0,1 |
Jest to rozkład prawdopodobieństw zmiennej losowej X. Można zauważyć, że wszystkie prawdopodobieństwa są nieujemne i sumują się do jedności. Zmienne losowa nie przyjmuje wartości większych od 5, co oznacza, że nie zamieszcza się nigdy więcej niż 5 ogłoszeń dziennie. Prawdopodobieństwo zamieszczenia dwóch ogłoszeń wynosi 0,3, a trzech ogłoszeń - 0,2.Powstaje pytanie , skąd się biorą prawdopodobieństwa
Redakcja gazety codziennie rejestruje liczbę zamieszczonych ogłoszeń. Częstości z jakimi pojawiają się w długim szeregu dni różne liczby ogłoszeń ,łatwo obliczyć z tych rejestrów. Częstości te uznajemy za prawdopodobieństwa ukazania się odpowiednich liczb zamieszczonych ogłoszeń.
W innych sytuacjach prawdopodobieństwa można wyprowadzić z pewnych teoretycznych rozważań. Takie rozkłady są tablicowane i można je znaleźć w każdym podręczniku statystyki.
Dystrybuanty ( skumulowane funkcje rozkładu )
Skumulowaną funkcją rozkładu ( dystrybuantą ) skokowej zmiennej losowej X jest funkcja
![]()
( 3 )
Dla przykładu 1 dystrybuanta liczby ogłoszeń zamieszczonych dziennie w gazecie wynosi
x |
0 |
1 |
2 |
3 |
4 |
5 |
P(x) |
0,1 |
0,2 |
0,3 |
0,2 |
0,1 |
0,1 |
F(x) |
0,1 |
0,3 |
0,6 |
0,8 |
0,9 |
1,0 |
Należy zauważyć, że każda wartość F(x) jest sumą wszystkich wartości P(i) dla i mniejszych lub równych x. Na przykład ![]()
Oczekiwana wartość i odchylenie standardowe zmiennej losowej
Oczekiwana wartość skokowej zmiennej losowej X jest równa sumie wszystkich możliwych wartości tej zmiennej mnożonych przez ich prawdopodobieństwa
![]()
( 4 )
Wykorzystując dane z przykładu 1 wyznaczamy oczekiwaną liczbę ogłoszeń w gazecie ( zgodnie z wzorem 4 )
Obliczenie oczekiwanej ( średniej ) liczby ogłoszeń w gazecie
x |
P(x) |
X P(x) |
0 |
0,1 |
0 |
1 |
0,2 |
0,2 |
2 |
0,3 |
0,6 |
3 |
0,2 |
0,6 |
4 |
0,1 |
0,4 |
5 |
0,1 |
0,5 |
|
1,0 |
3,3 |
Z tablicy wynika, że ![]()
. Możemy powiedzieć, że przeciętnie dzienne zamieszcza się 2,3 ogłoszenia.
Oczekiwana wartość funkcji skokowej zmiennej losowej h(x) jest :
![]()
( 5 )
Przykład 2. Miesięczna sprzedaż pewnego produktu charakteryzuje rozkład prawdopodobieństwa podany w poniższej tablicy.
Sprzedaż |
5000 |
6000 |
7000 |
8000 |
9000 |
|
P(x) |
0,2 |
0,3 |
0,2 |
0,2 |
0,1 |
1,0 |
Przypuśćmy, że firma ponosi stały miesięczny koszt produkcji równy 8000 $ i że na każdej wyprodukowanej jednostce zarabia 2 $. Jaki jest miesięczny oczekiwany zysk firmy ?
Funkcja zysku ze sprzedaży produktu jest dla firmy funkcja h(x)=2x - 8000.
Tablica pomocnicza do wyznaczenia oczekiwanego zysku
x |
h(x) |
P(x) |
h(x)P(x) |
5 000 |
2 000 |
0,2 |
400 |
6 000 |
4 000 |
0,3 |
1 200 |
7 000 |
6 000 |
0,2 |
1 200 |
8 000 |
8 000 |
0,2 |
1 600 |
9 000 |
10 000 |
0,1 |
1 000 |
|
|
|
5 400 = E[h(x)] |
W przypadku liniowej funkcji zmiennej losowej, obliczenie oczekiwanej wartości funkcji h(x) można uprościć, korzystając ze wzoru na oczekiwaną wartość funkcji zmiennej losowej.
Oczekiwana wartość liniowej funkcji zmiennej losowej :
E(a X +b) = a E(x)+b ( 6 )
Gdzie a i b są ustalonymi liczbami. W rozpatrywanym przykładzie 2 mamy ;
E [ h (x)] = E[2x - 8 000 ] = 2 E (x) - 8 000 = 2 * 6 700 - 8 000 = 5 400 $ .
Wariancja i odchylenie standardowe zmiennej losowej
Wariancja zmiennej losowej jest oczekiwana wartość kwadratu odchylenia tej zmiennej od jej średniej . Pojęcie to jest podobne do pojęcia wariancji w zbiorze wyników obserwacji ( w próbie lub populacji ) .
Wariancją skokowej zmiennej losowej X jest : ![]()
( 7)
Dla przykładu 1 mamy :
x |
P(x) |
|
|
|
0 |
0,1 |
-2,3 |
5,29 |
0,529 |
1 |
0,2 |
-1,3 |
1,69 |
0,338 |
2 |
0,3 |
-0,3 |
0,09 |
0,027 |
3 |
0,2 |
0,7 |
0,49 |
0,098 |
4 |
0,1 |
1,7 |
2,89 |
0,289 |
5 |
0,1 |
2,7 |
7,29 |
0,729 |
|
|
|
|
2,01 |
![]()
Wygodny do stosowania wzór obliczania wariancji zmiennej losowej :
![]()
( 8 )
Zgodnie z wzorem (8) wyznaczamy dla przykładu 1 wariancję liczby ogłoszeń w gazecie.
Obliczenia pomocnicze
X |
P(X) |
X P(X) |
X2P(X) |
0 |
0,10 |
0 |
0 |
1 |
0,20 |
0,20 |
0,20 |
2 |
0,30 |
0,60 |
1,20 |
3 |
0,20 |
0,60 |
1,80 |
4 |
0,10 |
0,40 |
1,60 |
5 |
0,10 |
0,50 |
2,50 |
|
1,00 |
2,30 |
7,30 |
![]()
Dla zmiennych losowych standardowe odchylenie określamy jako dodatni pierwiastek kwadratowy z wariancji . Standardowe odchylenie zmiennej losowej wyraża się wzorem:
![]()
( 9 )
W rozpatrywanym przykładzie 1 wynosi ![]()
Wariancję liniowej funkcji zmiennej losowej ![]()
wyznaczyć można z następującego wzoru :
![]()
( 10 )
gdzie a i b są ustalonymi liczbami.
Wariancja jako średnie kwadratowe odchylenie wartości zmiennej losowej od jej wartości średniej jest miarą rozproszenia możliwych wartości zmiennej. Wariancja daje wyobrażenie o zmienności a tym samym o niepewności związanej z przyszłymi wartościami zmiennej, które mogą tym bardziej odbiegać od przeciętnej, im wyższa jest wariancja.
Posługiwanie się odchyleniem standardowym często jest wygodniejsze z tego powodu, że wariancja jest wielkością „kwadratową” Odchylenie standardowe jest łatwiejsze do interpretacji z punktu widzenia ekonomicznego. Na przykład : standardowe odchylenie stopy przychodu z określonej lokaty kapitału powszechnie jest uznawane za miarę ryzyka związanego z tą lokatą.
Twierdzenie Czebyszewa
Znajomość odchylenia standardowego pozwala wyznaczyć granice, w których możliwe wartości zmiennej losowej mieszczą się z pewnym określonym prawdopodobieństwem. Granice te wyznacza twierdzenie Czebyszewa . Twierdzenie to powiada, że dla dowolnej liczby k większej od jedności prawdopodobieństwo, że wartość zmiennej losowej odchyla się od wartości o mniej niż o k odchyleń standardowych, jest nie mniejsze niż 1 - 1/k2.
Możemy to twierdzenie zapisać następująco : dla dowolnej zmiennej losowej o średniej ![]()
i odchyleniu standardowym ![]()
oraz dla dowolnej liczby ![]()
:
![]()
![]()
( 11 )
Wybrane rozkłady zmiennej losowej skokowej
Podstawowymi rozkładami zmiennej losowej skokowej są:
Rozkład jednopunktowy
Rozkład dwupunktowy
Rozkład dwumianowy ( Bernoulliego )
Rozkład Poissona
Rozkład jednopunktowy
Zmienna losowa X przyjmuje tylko jedną wartość x1 z prawdopodobieństwem równym 1, czyli :
![]()
( 12 )
Łatwo wykazać , że
![]()
, ![]()
Dystrybuanta F(x) w tym przypadku ma postać :
F(x)= { 0 dla ![]()
{ 1 dla ![]()
( 13 )
Rozkład dwupunktowy
Mówimy, że zmienna losowa X podlega rozkładowi X podlega rozkładowi dwupunktowemu, jeśli zbiór wartości { x1 , x2 } jest dwuelementowy , przy czym :
P(X=x1)=q ( 14 )
P(X=x2)=p ( 15 )
oraz p+q=1
Szczególnym przypadkiem rozkładu dwu - punktowego jest tzw. Rozkład zero - jedynkowy , gzie przyjmuje się, że x1 = 0 oraz x2 = 1 .
Mamy więc :
P(X=0)=q ( 16 )
P(X=1)=1 ( 17 )
Przy czym p + q = 1 , skąd q = 1 - p
Podstawowe charakterystyki liczbowe zmiennej podlegającej rozkładowi zero - jedynkowemu:
E(X)=p ( 18 )
![]()
( 19 )
Dystrybuanta w tym przypadku ma postać następującą :
F(x) = { 0 dla ![]()
{ 1 - p dla ![]()
{ 1 dla x > 1
Rozkład dwumianowy
Przypuśćmy, że wykonujemy n niezależnych doświadczeń ( np. rzucamy 10 razy kostką do gry albo wykonujemy 7 rzutów monetą itp. ). Przyjmujemy, że każde z tych doświadczeń może zakończyć się sukcesem albo porażką, przy czym prawdopodobieństwo wystąpienia sukcesu w każdym z wykonywanych doświadczeń jest takie samo i wynosi ![]()
.
Zmienną losową definiujemy jako liczbę sukcesów uzyskanych przy wykonywaniu n doświadczeń.
Dwumianowy rozkład prawdopodobieństwa :
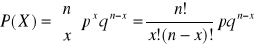
( 20 )
gdzie p jest prawdopodobieństwem sukcesu w jednym doświadczeniu, q=1-p, z kolei n jest liczbą doświadczeń, a x jest liczbą sukcesów .
Rozkład zdefiniowany wzorem ( 20 ) jest rozkładem dwumianowym lub rozkładem Bernoulliego. Nazwa pochodzi od matematyka Jacquesa Bernoulliego ( 1654 - 1705 ). Doświadczenia Bernoulliego to ciągi identycznych doświadczeń spełniających nastęoujące warunki :
Są dwa możliwe wyniki każdego doświadczenia, nazwane sukcesem lub porażką. Wyniki te wykluczają się i dopełniają.
Prawdopodobieństwo sukcesu oznaczone przez p, pozostaje takie samo od doświadczenia do doświadczenia. Prawdopodobieństwo porażki, oznaczone przez q, równe jest 1-p
Doświadczenia są od siebie niezależne. Znaczy to , że wynik któregokolwiek doświadczenia nie ma wpływu na wyniki pozostałych doświadczeń .
Średnia, wariancja i kształt rozkładu dwumianowego
Średnia rozkładu dwumianowego jest to iloczyn liczby doświadczeń n i prawdopodobieństwa sukcesu w pojedynczym doświadczeniu p.
Wariancja jest iloczynem liczby doświadczeń n , wartości p oraz q . Prawdziwe są poniższe wzory :
Średnia rozkładu dwumianowego :
![]()
( 21 )
Wariancja rozkładu dwumianowego :
![]()
( 22 )
Odchylenie standardowe rozkładu dwumianowego :
![]()
( 23 )
Kształt rozkładu prawdopodobieństwa dwumianowej zmiennej losowej jest symetryczny przy p=1/2. Rozkład jest skośny prawostronnie przy p < ½ , a lewostronnie przy p > ½ gdy liczba doświadczeń n jest niewielka.
Dwumianowy rozkład prawdopodobieństwa jest jednym z najpowszechniej stosowanych rozkładów w badaniach statystycznych.
Rozkład Poissona
Rozkład Poissona jest wygodny do scharakteryzowania zmiennej losowej będącej liczbą zajść pewnego zdarzenia w określonym przedziale czasu . Taką zmienną jest liczba awarii urządzenia przemysłowego w ciągu tygodnia, liczba wypadków samochodowych w ciągu miesiąca, itp. Rozkład Poissona jest też dobrym przybliżeniem rozkładu dwumianowego, gdy liczba doświadczeń n jest duża ( ![]()
, a prawdopodobieństwo „ sukcesu „ ( zajścia interesującego nas zdarzenia ) jest niewielkie ( ![]()
.
Rozkład Poissona:
![]()
dla x= 0,1,2,3,..., (24 )
gdzie ![]()
jest średnią rozkładu ( i równocześnie jego wariancji ), ![]()
jest podstawą logarytmów naturalnych ( ![]()
)
Przykłady
Przykład 1. Klientami sklepu spożywczego są kobiety i mężczyźni > Na podstawie wcześniejszych badań wiadomo ,że prawdopodobieństwo zakupu żywności przez kobietę w tym sklepie wynosi 0,6 .
Co jest zmienną losową ?
Wyznaczyć wartość oczekiwaną i wariancję badanej zmiennej losowej ?
Rozwiązanie :
a) ) Zmienną losową jest płeć klienta. Przyjmuje ona wartość 1 w przypadku kobiet oraz 0 , gdy do sklepu wchodzi mężczyzna. Jest to przykład zmiennej zero - jedynkowej .
b) ![]()
oraz ![]()
Przykład 2.
Sprzedawca pewnego dobra trwałego użytku kontaktuje się z 8 potencjalnymi klientami dziennie. Z wcześniejszych doświadczeń wiadomo , że prawdopodobieństwo zakupu tego dobra przez potencjalnego klienta wynosi 0,10.
jakie jest prawdopodobieństwo tego, że sprzedawca przeprowadzi dokładnie 2 transakcje sprzedaży dziennie ?
Jaki odsetek stanowić będą dni, w których sprzedawca nie dokona żadnej transakcji sprzedaży ?
Jakiej średniej liczby sprzedanych dóbr trwałego użytku dziennie może się spodziewać sprzedawca ?
Rozwiązanie :
Korzystając ze wzoru na prawdopodobieństwo w rozkładzie dwumianowym mamy :
![]()
Zamiast przeprowadzania dość skomplikowanych obliczeń można również skorzystać z tablic rozkładu dwumianowego odczytując ( ![]()
dla n=8, k=2, p=0,1
Wobec tego mamy :
![]()
b) ![]()
zatem 43 % ogółu dni roboczych stanowią takie dni , kiedy nie zostanie dokonana żadna transakcja sprzedaży.
c) ![]()
Przykład 3.
Wadliwość produkcji pewnego przedsiębiorstwa wynosi 3%. Z gotowych wyrobów znajdujących się w magazynie sprzedano 40 sztuk.
Jakiej średniej liczby braków można się spodziewać w sprzedanej partii towarów
Jakie jest prawdopodobieństwo , że dokładnie 5 sztuk wadliwych znajdzie się w sprzedanej partii towarów
Rozwiązanie :
a) ![]()
b) ![]()
( por. tablicę w rozkładzie Poissona , dla ![]()
; ![]()
)
Inne podejście opiera się na rachunku dystrybuant. Korzystamy z tablic dystrybuanty w tym rozkładzie i mamy :
![]()
Zmienna losowa ciągła i jej rozkłady
Zmienna losowa ciągła , funkcja gęstości, dystrybuanta, podstawowe charakterystyki
Rozkłady zmiennej losowej ciągłej
Rozkład normalny
Rozkład logarytmiczno - normalny
Rozkład chi - kwadrat
Rozkład Studenta
Rozkład Fishera - Snedecora
Inne ( np. rozkład serii, rozkład Darbina - Watsona
Zmienna losowa ciągła jest to taka zmienna , która przyjmuje wszystkie wartości z pewnego określonego przedziału liczbowego.
Dla zmiennej losowej ciągłej pojawia się pojęcie funkcji gęstości. Funkcja gęstości jest to przedziałami ciągła funkcja f(x), dzięki której można określić prawdopodobieństwo tego, że zmienna losowa x znajdzie się w określonym przedziale.
Funkcja gęstości spełnia następujące warunki :
![]()
( 1)
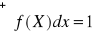
(2)
Funkcja gęstości może być interpretowana jako podstawa do liczbowych ustaleń „ średniej gęstości prawdopodobieństwa z otoczenia punktu, zwanego środkiem przedziału klasowego”.
Dystrybuanta dla zmiennej losowej ciągłej określana jest jako prawdopodobieństwo tego, że zmienna losowa przyjmie wartości mniejsze lub równe xi
![]()
( 3 )
Dystrybuanta dla zmiennej losowej ciągłej jest całką z określoną górną granicą x , zapisaną w sposób następujący :
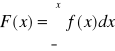
( 4 )
Dla prawdopodobieństwa w przedziale ( x1 ; x2 ) należy stosować formułę :
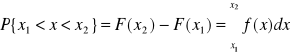
( 5)
Wartość oczekiwana zmiennej losowej ciągłej wyraża się następującym wzorem :
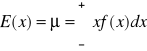
(6)
Wariancja zmiennej losowej ciągłej jest wyznaczona zgodnie z formułą :
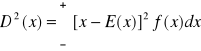
(7)
Odchylenie standardowe zmiennej losowej ciągłej dane jest wzorem :
![]()
(8)
Rozkłady zmiennej losowej ciągłej
Rozkład normalny
Rozkład normalny wiąże się z nazwiskiem matematyka K.F. Gaussa ( 1777 - 1855 ) i bywa najczęściej określany jako rozkład Gaussa. Rozkład normalny to jeden z najważniejszych rozkładów zmiennej losowej ciągłej. Odgrywa on w zastosowaniach statystyki ogromną rolę. Mówimy , że zmienna losowa x ma rozkład normalny z parametrami ![]()
i ![]()
, co zapisujemy ![]()
lub ![]()
, jeśli jej funkcja gęstości jest określona następującym wzorem :
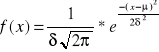
, dla ![]()
( 9)
gdzie :
![]()
![]()
![]()
![]()
Krzywa gęstości prawdopodobieństwa rozkładu normalnego ma następujące własności :
Krzywa normalna jest krzywą w kształcie dzwonu, symetryczną względem prostej przechodzącej przez punkt
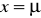
, co znaczy, że jest spełniona równość :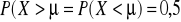
. Oś rzędnych jest oczywiście osią symetrii krzywej.Obszar ograniczony wykresem funkcji f(x) i osią odciętych ma pole równe jedności.
Funkcja gęstości prawdopodobieństwa rozkładu normalnego osiąga maksimum w punkcie
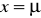
. Obliczając pochodną funkcji (9) i przyrównując ją do 0 , sprawdzamy łatwo, że wartość maksymalna tej funkcji gęstości wynosi :
![]()
4.Krzywa gęstości prawdopodobieństwa rozkładu normalnego ma 2 punkty przegięcia, położone symetrycznie względem osi rzędnych , o odciętych ![]()
, w których krzywa z wklęsłej przechodzi w wypukłą lub odwrotnie.
Parametr ![]()
rozkładu normalnego jest to średnia rozkładu czyli miara położenia. Mówi o tym , gdzie leży centrum rozkładu na osi liczbowej. Ponieważ krzywa gęstości normalnej jest symetryczna i ma jeden szczyt , w środku ,średnia ![]()
jest równocześnie medianą i dominantą rozkładu prawdopodobieństwa. Inaczej mówiąc, ![]()
jest też punktem, w którym gęstość jest największa i który dzieli pole pod krzywą gęstości na połowy, z których każda ma miarę ½.Standardowe odchylenie jest miarą zmienności , czyli rozproszenia zmiennej. Gdy standardowe odchylenie jest duże, wykres funkcji gęstości jest „ szeroki „ , ale za to „ płaski „( Całe pole pod krzywą musi mieć miarę równą 1 ). Gdy standardowe odchylenie jest małe, wykres funkcji gęstości jest „ wąski „ ale „ wysoki „
Na uwagę zasługują także następujące własności rozkładu normalnego :
W analizach szczególnie ważna jest reguła trzech odchyleń standardowych zwana także reguła 3 sigm, której prawdopodobieństwo jest bardzo wysokie i praktycznie wynosi 1. Jest ona wykorzystywana w badaniach empirycznych w celu eliminacji obserwacji nietypowych, nie przystających do pozostałych ( wątpliwych , rzadkich , odstających , ekstremalnych ) , co do których istnieją przypuszczenia , że pochodzą z innej zbiorowości. Za wątpliwe uznaje się takie obserwacje , których wartość różni się od średniej o więcej niż 3 odchylenia standardowe.
Rozkład normalny standaryzowany
Rozkład normalny z wartością oczekiwaną ![]()
i odchyleniem standardowym ![]()
, czyli ![]()
, określony za pomocą formuły :
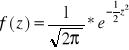
( 10 )
Każdy rozkład normalny ![]()
może być transformowany do rozkładu normalnego ![]()
poprzez procedurę standaryzacji zmiennej X do Z. Czasami zamiast Z stosuje się literę U ( unormowana ). Zmienna losowa standaryzowana wyraża się wzorem :
![]()
( 11 )
Procedura standaryzacji ma swoje uzasadnienie w tym, że tylko rozkład normalny standaryzowany jest stablicowany. Najczęściej korzysta się z tablic dystrybuanty .
Przykład 1.
Załóżmy , że mamy 100 pojedynczych wyników pomiarów pewnej wielkości. Efekty obserwacji pogrupowano , a wyniki w postaci szeregu rozdzielczego przedziałowego podano w poniższej tablicy. Zachodzi przypuszczenie , że rozkład liczby wszystkich pomiarów ma rozkład normalny .
Tab.1. Szereg rozdzielczy wyników pomiaru pewnej wielkości ( w mm)
Wyniki pomiarów
|
Liczba wyników
|
|
|
79-81 |
1 |
80 |
80 |
81-83 |
4 |
82 |
328 |
83-85 |
9 |
84 |
756 |
85-87 |
15 |
86 |
1 290 |
87-89 |
24 |
88 |
2 112 |
89-91 |
21 |
90 |
1 890 |
91-93 |
13 |
92 |
1 196 |
93-95 |
9 |
94 |
846 |
95-97 |
3 |
96 |
288 |
97-99 |
1 |
98 |
98 |
|
100 |
|
8 884 |
Źródło : A. Zeliaś : Metody statystyczne . PWE, Warszawa 2000 s. 221-222.
Parametry rozkładu normalnego ![]()
i ![]()
szacujemy na podstawie wyników zamieszczonych w powyższej tablicy ( tab.1 ) i otrzymujemy :![]()
i ![]()
. Pozostałe obliczenia potrzebne do ustalenia , czy jest to rozkład normalny, znajdują się w poniższej tablicy :
|
|
|
|
|
|
80 |
1 |
-2,73466 |
0,009606 |
0.59 |
0,41 |
82 |
4 |
-2,11596 |
0,042166 |
2,61 |
1,39 |
84 |
9 |
-1,49726 |
0,129518 |
8,01 |
0,99 |
86 |
15 |
-0,87855 |
0,270864 |
16,76 |
-1,76 |
88 |
24 |
-0,25985 |
0,385683 |
23,86 |
0,14 |
90 |
21 |
0,35885 |
0,373911 |
23,13 |
-2,73 |
92 |
13 |
0,97755 |
0,246809 |
15,27 |
-2,27 |
94 |
9 |
1,59625 |
0,112704 |
6,97 |
2,03 |
96 |
3 |
2,21495 |
0,034710 |
2,15 |
0,85 |
98 |
1 |
2,83365 |
0,007274 |
0,45 |
0,55 |
|
100 |
|
|
99,8 |
|
Z uwagi na to , że różnice między rozkładem empirycznym a teoretycznym , czyli ![]()
od i= 1,2,...,10 są względnie duże , to nie można przyjąć , że rozkład liczby wyników pomiarów nie jest rozkładem normalnym.
Rozkład chi - kwadrat
Rozkład chi - kwadrat ![]()
) został opracowany przez statystyków A. Abbego ( 1863 ), H. Helmerta ( 1875 ) , K. Pearsona ( 1900
Zakładając , że X1, X2 , ..., Xk są niezależnymi zmiennymi losowymi o rozkładzie normalnym o parametrach ![]()
i ![]()
, zmienna losowa ![]()
określona w sposób następujący :
![]()
( 12 )
ma rozkład ![]()
z k „ liczbą stopni swobody „
Zmienna losowa o rozkładzie chi- kwadrat przyjmuje wartości dodatnie , a jej rozkład zależy od liczby stopni swobody k . Dla małych wartości k jest to rozkład silnie asymetryczny , w miarę wzrostu k asymetria jest coraz mniejsza. Liczbę stopni swobody k wyznaczamy najczęściej w sposób następujący :
![]()
lub
![]()
gdzie :
n - liczebność próby
p - liczba szacowanych parametrów z próby
Liczba stopni swobody jest równa liczbie wszystkich parametrów ( która nie musi być równa liczbie wyników obserwacji ) pomniejszonej o liczbę wszystkich ograniczeń narzuconych na te parametry . Ograniczeniem jest każda wielkość , która zostaje obliczona na podstawie tych samych pomiarów
Wartość oczekiwana w rozkładzie ![]()
wyraża się następującą formułą :
![]()
( 13 )
Wariancja w rozkładzie ![]()
jest wyrażona formułą :
![]()
( 14 )
Odchylenie standardowe w rozkładzie ![]()
to :
![]()
( 15 )
Dla uproszczenia zapisów można się posługiwać formułą :
![]()
, co oznacza ,że ![]()
ma rozkład o k stopniach swobody . Rozkład ![]()
jest rozkładem asymetrycznym, przy czym wraz ze wzrostem k rozkład ten staje się coraz bardziej zbliżony do symetrycznego, a dla k>30 zachodzi zależność :
![]()
( 16 )
Oznacza to , że wraz ze wzrostem k ( powyżej 30 ) rozkład ![]()
przechodzi w rozkład asymptotycznie normalny o tych samych parametrach ![]()
i ![]()
.
Rozkład t - Studenta
Jest to ważny rozkład , który jest stosowany głównie do małych próbek . Rozkład t - Studenta ( pseudonim angielskiego statystyka W. Gosseta ) jest rozkładem symetrycznym względem prostej x=0, a jego kształt jest bardzo zbliżony do rozkładu normalnego standaryzowanego ( jest nieco bardziej spłaszczony ).
Jeżeli Z :N(0;1) i ![]()
są niezależnymi zmiennymi losowymi , to zmienna ![]()
ma rozkład t- Studenta o k stopniach swobody .
Wartość oczekiwana w rozkładzie t- Studenta ma postać następującą:
![]()
dla ![]()
( 17 )
Wariancja w rozkładzie t- Studenta ma postać następującą:
![]()
dla ![]()
( 18 )
Odchylenie standardowe w rozkładzie t- Studenta ma postać następującą :
![]()
dla ![]()
( 19 )
Dla k >30 zmienna o rozkładzie t- Studenta ma rozkład zbliżony do rozkładu normalnego standaryzowanego [ N : ( 0 , 1 ) ]
Dla różnych wartości k i różnych prawdopodobieństw α stablicowane są wartości ![]()
takie , dla których spełniona jest zależność ![]()
dla ![]()
stopni swobody.
Rozkład F - Snedecora
Jeżeli zmienne ![]()
i ![]()
są zmiennymi niezależnymi i mają rozkłady ![]()
o ![]()
i ![]()
stopniach swobody , to zmienna losowa ![]()
ma rozkład F - Snedecora :
![]()
( 20 )
gdzie ![]()
i ![]()
są stopniami swobody .
Wartość oczekiwana w rozkładzie F wyraża się następującą formułą :
![]()
dla ![]()
( 21 )
Wariancja w rozkładzie F wyraża się następującym wzorem :
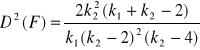
dla ![]()
( 22 )
W zależności od ![]()
i ![]()
stablicowano wartości zmiennej losowej ![]()
, w taki sposób , że dla danych wartości prawdopodobieństw α zależność ![]()
Dobór próby i rozkłady z próby
Estymacja punktowa i przedziałowa
We wnioskowaniu statystycznym - na podstawie znanej próby losowej , opisujemy za pomocą statystyk nieznaną populację, z której została pobrana próba.
Parametry populacji ( np. średnia , odchylenie standardowe ) szacujemy korzystając ze statystyk z próby . Gdy statystyka z próby jest wykorzystywana do oszacowania parametru populacji , nazywa się estymatorem tego parametru.
Estymatorem parametru populacji jest statystyka z próby używana do oszacowania tego parametru. Oceną lub szacunkiem parametru jest konkretna wartość liczbowa estymatora z danej próby Jeżeli jako ocenę ( szacunek ) podajemy jedną wartość liczbową, nazywamy ją oceną punktową ( szacunkiem punktowym ) parametru populacji.
Średnia z próby , jest statystyką używaną jako estymator średniej w populacji. Odchylenie standardowe z próby , służy jako estymator odchylenia standardowego w populacji. Oprócz tych statystyk występują również inne np. częstość ( frakcja ).
Frakcją ( częstością ) w populacji p , jest liczba elementów populacji należących do pewnej kategorii , którą się interesujemy, podzieloną przez liczbę wszystkich elementów populacji .
Frakcja ( częstość ) w próbie wyraża się następującą formułą :
![]()
( 1 )
gdzie x jest liczbą elementów próby , które należą do interesującej nas kategorii , a n jest liczebnością próby.
Pobieranie próby losowej
Aby otrzymać próbę losową z całej populacji , powinniśmy dysponować wykazem wszystkich elementów populacji . Taki wykaz nazywa się operatem losowania . Operat losowania pozwala wybierać elementy z populacji przez losowe generowanie numerów elementów, które znajdują się w próbie. Przypuśćmy, że chcemy pobrać prostą 100- elementową próbę losową z populacji 7 000 ludzi. Sporządzamy wykaz tych 7 000 ludzi i każdemu przypisujemy numer identyfikacyjny. Mamy wykaz 7 000 numerów, które tworzą operat losowania. Następnie generujemy na komputerze lub w jakiś inny sposób 100 liczb losowych o wartościach od 1 do 7 000 . Taka procedura daje każdemu ze 100 ludzi tę samą szansę znalezienia się w próbie .
Do generowania liczb losowych może być użyty komputer lub tablica liczb losowych.
Rozkład statystyki z próby jest rozkładem prawdopodobieństwa wszystkich możliwych wartości, jaka ta statystyka może przyjąć, jeżeli obliczamy je na podstawie badania losowych prób o tych samych rozmiarach, pobranych z określonej populacji.
Rozkład średniej z próby , ![]()
, to rozkład prawdopodobieństwa wszystkich wartości , jakie może przybrać losowa zmienna ![]()
, gdy próba o liczebności n jest pobierana z określonej populacji .
Centralne twierdzenie graniczne - jeżeli pobieramy próbę z populacji o średniej ![]()
i skończonym odchyleniu standardowym ![]()
, to rozkład średniej z próby , ![]()
, dąży do rozkładu normalnego o średniej ![]()
i odchyleniu standardowym ![]()
, gdy liczebność próby wzrasta nieograniczenie , czyli , dla „ dostatecznie dużych n „ : ![]()
Centralne twierdzenie graniczne zasługuje na uwagę , ponieważ stwierdza zmierzanie rozkładu średniej z próby do rozkładu normalnego , niezależnie od rozkładu populacji, z której pochodzi próba.
Trzy główne aspekty centralnego twierdzenia granicznego
Jeżeli liczebność próby jest dostatecznie duża , to rozkład średniej z próby ,
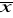
, jest normalnyOczekiwaną wartością średniej
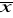
jest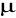
Odchyleniem standardowym średniej
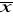
jest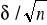
Historia centralnego twierdzenia granicznego jest związana z rozkładem normalnym jako rozkładem granicznym rozkładu dwumianowego, gdy n rośnie nieograniczenie.
Aby wykorzystać centralne twierdzenie graniczne, powinniśmy znać standardowe odchylenie w populacji, ![]()
. Gdy ![]()
nie jest znane, trzeba się posłużyć jego estymatorem z próby , S. W takim przypadku rozkład standaryzowanej statystyki jest następujący :
![]()
( 2 )
gdzie S zastępuje nieznane ![]()
i nie jest standaryzownym rozkładem normalnym.
Jeśli rozkład w populacji jest normalny, to statystyka określona wzorem ( 2 ) ma rozkład t - Studenta o n-1 stopniach swobody .
Centralne twierdzenie graniczne dla przypadku pobierania próby do oszacowania frakcji elementów danej kategorii populacji , p jest sformułowane następująco :
Gdy liczebność próby n wzrasta , to rozkład frakcji z próby , ![]()
, zbliża się do rozkładu normalnego o średniej p o odchyleniu standardowym ![]()
Z centralnego twierdzenia granicznego wynika , iż rozkład średniej z próby i rozkład frakcji z próby zbliżają się do rozkładu normalnego , gdy wzrasta liczebność próby .
Estymatory i ich własności
Estymator jest nieobciążony , jeżeli jego wartość oczekiwana jest równa parametrowi populacji , do oszacowania którego służy. Np. Średnia z próby jest nieobciążonym estymatorem średniej z populacji .
Systematyczne odchylanie się wartości estymatora od szacowanego parametru nazywa się obciążeniem estymatora .
Estymator jest efektywny , jeżeli ma niewielką wariancję ( a tym samym niewielkie odchylenie standardowe )
Estymator jest zgodny , jeżeli prawdopodobieństwo , że jego wartość będzie bliska wartości szacowanego parametru , wzrasta wraz ze wzrostem liczebności próby .
Estymator jest dostateczny , jeżeli wykorzystuje wszystkie informacje o szacowanym parametrze , które są zawarte w danych ( w próbie )
Przykład 1.
W wylosowanych 9 punktach sprzedaży w pewnym mieście w określonym dniu zbadano cenę produktu A i otrzymano następujące rezultaty :
Punkt sprzedaży |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Cena w zł za 1 szt. ( xi) |
1,15 |
1,18 |
1,16 |
1,20 |
1,12 |
1,19 |
1,17 |
1,15 |
1,14 |
Źródło : Dane umowne.
Korzystając z procedury estymacji punktowej , należy oszacować
przeciętną cenę produktu A za 1 szt. W określonym dniu w całej zbiorowości ( miasto )
odchylenie standardowe ceny produktu A w określonym dniu w badanym mieście
Ad 1. Wiedząc ,że estymacja punktowa sprowadza się do znalezienia jednej wartości mogącej służyć do oszacowania nieznanej średniej ceny produktu A w całym mieście zadanie sprowadza się do znalezienia średniej arytmetycznej na podstawie próby (![]()
. Miara ta jest najbardziej użytecznym estymatorem średniej zbiorowości generalnej , gdyż ma własność nieobciążoności i zgodności oraz jest relatywnie bardziej efektywna od innych średnich ( mediany czy dominanty )
![]()
, co oznacza ,że w badanym mieście średnia cena jednej sztuki produktu A wynosi 1,16 zl.
Ad.2. Zadanie sprowadza się , do obliczenia odchylenia standardowego ceny produktu na podstawie wyników próby
xi |
1,15 |
1,18 |
1,16 |
1,20 |
1,20 |
1,19 |
1,17 |
1,15 |
1,14 |
|
|
-0,01 |
0,02 |
0,00 |
0,04 |
-0,04 |
0,03 |
0,01 |
-0,01 |
-0,02 |
|
|
0.0001 |
0,0004 |
0,0000 |
0,0016 |
0,0016 |
0,0009 |
0,0001 |
0,0001 |
0,0004 |
0.0052 |
Źródło : Obliczenia własne
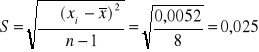
zł
Należy zauważyć , że wzór na estymator S różni się od klasycznego wzoru na odchylenie standardowe ![]()
, które wyznacza się w całej zbiorowości ( lub na podstawie wyników pochodzących z dużej próby ) według formuły :
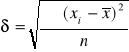
Odchylenie standardowe ceny produktu A w badanym mieście wynosiło 0,025 zł . Oznacza to , że cena w poszczególnych punktach sprzedaży różniła się od średniego poziomu , przeciętnie rzecz biorąc , o ![]()
zł.
Przykład 2.
W pewnej firmie w sposób losowy wybrano 15 rozmów telefonicznych, zbadano długość ich trwania oraz ustalono , czy są to rozmowy lokalne czy też zamiejscowe . Poniższa tablica prezentuje zebrane na ten temat informacje :
Kolejny numer rozmowy |
Czas trwania ( w min ) |
Rodzaj rozmów telefonicznej |
1 |
2 |
miejscowa |
2 |
12 |
zamiejscowa |
3 |
10 |
miejscowa |
4 |
3 |
miejscowa |
5 |
5 |
zamiejscowa |
6 |
6 |
miejscowa |
7 |
3 |
miejscowa |
8 |
5 |
miejscowa |
9 |
8 |
miejscowa |
10 |
4 |
miejscowa |
11 |
5 |
miejscowa |
12 |
4 |
miejscowa |
13 |
5 |
miejscowa |
14 |
4 |
miejscowa |
15 |
9 |
zamiejscowa |
Należy :
Oszacować przeciętny czas trwania wszystkich rozmów telefonicznych w tej firmie
Oszacować odchylenie standardowe czasu trwania wszystkich rozmów telefonicznych w tej firmie
Oszacować odsetek ( procent ) rozmów zamiejscowych wśród ogółu rozmów telefonicznych przeprowadzonych w tej firmie
Wyznaczyć błąd standardowy odsetka rozmów zamiejscowych wśród ogółu rozmów telefonicznych przeprowadzonych w tej firmie
Ad.1. ![]()
, co oznacza że przeciętny czas trwania wszystkich rozmów telefonicznych w tej firmie wynosi 5,67 min.
Ad.2. 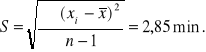
, co oznacza , że odchylenie standardowe czasu
trwania wszystkich rozmów telefonicznych w tej firmie wynosi 2,85 min ( o tyle różni się , średnio biorąc , czas trwania poszczególnych rozmów od przeciętnej rozmowy ).
Ad.3. ![]()
, co oznacza ,że rozmowy zamiejscowe stanowią 20 % ogółu wszystkich rozmów telefonicznych przeprowadzonych w tej firmie.
Ad.4. ![]()
Błąd standardowy odsetka rozmów zamiejscowych w tej firmie wynosi 10,3 %.
Estymacja przedziałowa parametrów
Estymacja przedziałowa określonego parametru z populacji generalnej polega na konstrukcji pewnego przedziału liczbowego ( na podstawie wyników z próby losowej pobieranej ze zbiorowości generalnej ) , o którym można powiedzieć ,że z przyjętym z góry prawdopodobieństwem pokryje wartość estymowanego parametru. Przedział taki nazywamy przedziałem ufności Neymana , natomiast prawdopodobieństwo , że przedział ten -będący zmienną losową - pokryje nieznany parametr, nazywamy współczynnikiem ufności i oznaczamy symbolem 1 - α. Poziomy współczynników ufności najczęściej przyjmowane są jako : 0,90;0,95 ;0,99.
Przedziałem ufności nazywamy przedział liczbowy, o którym przypuszczamy , że mieści się w nim nieznany parametr populacji . Z przedziałem tym związana jest miara ufności ( pewności ) , że ten przedział naprawdę zawiera interesujący nas parametr , zwana poziomem ufności
Na sposób konstrukcji przedziału ufności ma wpływ liczebność próby losowej . W zależności od rodzaju szacowanego parametru i liczebności próby można wyróżnić kilka przedziałów ufności, których sposób konstruowania zostanie przedstawiony na modelowych przykładach .
Model I. Populacja generalna ma rozkład normalny ![]()
. Wartość średnia ![]()
jest nieznana , odchylenie standardowe w populacji jest znane. Z populacji tej pobrano próbę o liczebności n elementów , wylosowanych niezależnie . Wówczas przedział ufności dla średniej ![]()
populacji otrzymuje się ze wzoru :
![]()
gdzie :
![]()
- średnia arytmetyczna obliczona z próby
![]()
poziom zmiennej standaryzowanej odczytany z tablic rozkładu normalnego N(0,1) przy przyjętym z góry współczynniku ufności
![]()
- nadzieja matematyczna w populacji generalnej
![]()
- odchylenie standardowe w populacji generalnej
![]()
- liczebność próby
Przykład 1. Wybraną w sposób losowy 625 - osobową grupę sportowców zbadano pod względem czasu poświęconego na trening w miesiącu otrzymując : ![]()
i ![]()
Wiadomo przy tym ,że czas poświęcony na trening posiada rozkład normalny . Oszacować metodą przedziałową średni miesięczny czas treningu dla ogółu sportowców przyjmując współczynnik ufności 0,95.Dla przyjętego współczynnika ufności 1-α=0,95 mamy ![]()
. Przedział ufności jest następujący :
![]()
Ostatecznie otrzymujemy :
![]()
Otrzymany wynik interpretujemy następująco : przedział liczbowy od 69,216 godzin do 70,784 godzin jest jednym z tych wszystkich możliwych do otrzymania przedziałów, które z prawdopodobieństwem 0,95 pokrywają szacowany średni czas poświęcony miesięcznie na trening przez ogół sportowców .Oznacza to , że gdybyśmy wielokrotnie powtarzali powyższe postępowanie , to średnio biorąc w 95 przypadkach na 100 otrzymywalibyśmy przedziały dobre ( tzn. pokrywające średni czas poświęcony miesięcznie na trening przez ogół sportowców ) zaś w pozostałych przypadkach - złe .
Model II. Populacja generalna ma rozkład ![]()
. Nieznana jest zarówno wartość średnia ![]()
, jak i odchylenie standardowe ![]()
w populacji . Z populacji tej wylosowano niezależnie małą próbę o liczebności n elementów. Przedział ufności dla średniej ![]()
populacji otrzymuje się wówczas według wzoru :
![]()
lub według wzoru równoważnego
![]()
gdzie ![]()
oznacza średnią arytmetyczną obliczoną z próby , s i ![]()
są odchyleniami standardowymi z próby obliczonymi według wzorów :
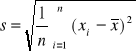
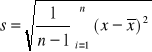
Wartość ![]()
oznacza wartość zmiennej t - Studenta odczytaną z tablicy tego rozkładu dla n-1 stopni swobody w taki sposób , by dla danego z góry prawdopodobieństwa 1 - α była spełniona relacja ![]()
.
Model III. Populacja generalna ma rozkład ![]()
bądź dowolny inny rozkład o średniej ![]()
i skończonej wariancji ![]()
( nieznanej ). Z populacji tej pobrano do próby n niezależnych obserwacji , przy czym liczebność próby jest dużą ( co najmniej kilka dziesiątków ) . Wtedy przedział ufności dla średniej ![]()
populacji wyznaczamy ze wzoru jak w modelu I , z tą tylko różnicą , że zamiast ![]()
we wzorze tym używamy odchyleń standardowych ![]()
lub ![]()
obliczonych z próby. Ze względu na dużą próbę wyniki jej grupuje się w szereg rozdzielczy o r klasach i wtedy wygodnie jest obliczać ![]()
oraz s według wzorów:
![]()
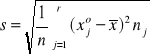
gdzie ![]()
oznacza środek poszczególnego przedziału klasowego, a ![]()
jego liczebność. Gdy liczba ![]()
przedziałów klasowych jest mała , tzn. gdy długość ![]()
każdego przedziału klasowego jest duża , obliczając z powyższego wzoru wartość ![]()
należy stosować , tzw. poprawkę grupowania , tj. odjąć od ![]()
liczbę ![]()
, a dopiero potem wyciągnąć pierwiastek.
Uwaga : Wzory na przedziały ufności dla średniej ![]()
w modelu I i II są wyznaczone w oparciu o dokładny rozkład statystyki ![]()
, natomiast w modelu III w oparciu o jej rozkład graniczny ( z dużej próby ). Ponadto , podczas gdy przedziały ufności otrzymane w oparciu o rozkład normalny mają przy ustalonym n stałą długość , to przedziały ufności otrzymane w oparciu o rozkład Studenta mają w różnych próbach , oprócz końców również zmienną długość.
Współczynnik ufności 1-α przyjmuje się subiektywnie, jako dowolnie duże, bliskie 1 , prawdopodobieństwo. Jest ono miarą zaufania do prawidłowego szacunku . Ponieważ duży współczynnik ufności daje szerszy przedział, nie należy więc bez potrzeby przyjmować tego współczynnika zbyt wysokiego. Zwykle przyjmuje się współczynniki ufności 1-α wynoszące 0,90 ; 0,95 ( najczęściej ), wreszcie 0,99 lub 0,999 w badaniach gdzie ryzyko pomyłki jest małe.
Przykład 2 . Wytrzymałość pewnego materiału budowlanego jest zmienną losową o rozkładzie normalnym ![]()
. W celu oszacowania nieznanej średniej ![]()
wytrzymałości tego materiału dokonano pomiarów wytrzymałości na n=5 wylosowanych niezależnie sztukach tego materiału . Wyniki pomiarów były następujące ( w kg/cm2 ) : 20,4 ; 19,6 ; 22,1 ; 20,8 ; 21,1. Przyjmując współczynnik ufności 1-α = 0,99 należy zbudować przedział ufności dla średniej wytrzymałości ![]()
tego materiału.
Rozwiązanie :
Z treści zadania wynika , że ze względu na nieznajomość odchylenia standardowego ![]()
oraz małą próbę mamy do czynienia z przedziałem ufności zbudowanym o rozkład t Studenta , czyli :
![]()
Należy najpierw obliczyć z próby wartości ![]()
oraz ![]()
.
Obliczenia pomocnicze znajdują się w poniższej tablicy
Wyniki pomiaru
wytrzymałości |
|
|
20,4 |
0,4 |
0,16 |
19,6 |
1,2 |
0,44 |
22,1 |
1,3 |
1,69 |
20,8 |
0 |
0 |
21,1 |
0,3 |
0,09 |
104,0 |
|
3,38 |
Otrzymujemy :
![]()
kg / cm2 , ![]()
kg / cm2
Następnie z tablic rozkładu Studenta dla 1-α=0,99 ( czyli dla α=0,01 ) oraz dla n-1 =4 stopni swobody odczytujemy wartość ![]()
. Podstawiając do wzoru na przedział ufności otrzymujemy :
![]()
czyli
![]()
Możemy powiedzieć ,że przedział liczbowy o końcach 18,9 i 22,7 kg/cm2 z ufnością 0,99 pokrywa nieznaną średnią wytrzymałość tego materiału.
Przykład 3 . Załóżmy , że chcemy oszacować średni staż pracy pracowników zatrudnionych w pewnej firmie przy produkcji wyrobów . Za pomocą schematu losowania nieograniczonego niezależnego , wylosowano z populacji tych pracowników próbę liczącą n=100 osób i otrzymano następujące wyniki badania tego stażu pracy w latach ( wyniki pogrupowano w szereg rozdzielczy ):
Staż pracy w latach xj |
Liczba pracowników nj |
0-2 |
4 |
2-4 |
10 |
4-6 |
55 |
6-8 |
25 |
8-10 |
6 |
Przyjmując współczynnik ufności 1-α =0,90 , zbudować przedział ufności dla średniego stażu pracy badanej populacji pracowników .
Rozwiązanie Z treści zadania wynika , że ze względu na dużą próbę mamy do czynienia z modelem III. Przedział ufności dla średniej ![]()
populacji należy zbudować w oparciu o rozkład normalny , według wzoru :
![]()
przyjmując zamiast ![]()
wartość jego zgodnego estymatora s z próby . Obliczenia do wyznaczenia ![]()
i ![]()
znajdują się w poniższej tablicy :
|
|
|
|
|
|
0-2 |
4 |
1 |
4 |
19,36 |
77,44 |
2-4 |
10 |
3 |
30 |
5,76 |
57,60 |
4-6 |
55 |
5 |
275 |
0,16 |
8,80 |
6-8 |
25 |
7 |
175 |
2,56 |
64,00 |
8-10 |
6 |
9 |
54 |
12,96 |
77,76 |
|
100 |
|
538 |
|
285,60 |
![]()
Wobec tego otrzymujemy :
![]()
![]()
, ![]()
Ze względu na małą liczbę przedziałów ( h=2 lata ) należy zastosować poprawkę na grupowanie , tzn. od ![]()
odjąć ![]()
. Zatem ![]()
. Następnie z tablicy rozkładu normalnego N(0,1) odczytujemy wartość ![]()
Dla 1-α =0,90 ( tzn. dla α=0,1 ) odczytujemy ,że ![]()
. Otrzymujemy następujący przedział ufności dla średniego stażu pracy : ![]()
czyli ![]()
. Zatem przedział liczbowy o końcach 5,1 i 5,7 obejmuje z ufnością 0,90 prawdziwą średnią ![]()
stażu pracy w badanej populacji pracowników w badanej firmie.
Przedział ufności dla wskaźnika struktury
Podstawowym parametrem populacji , szacowanym w przypadku badań statystycznych ze względu na cechę niemierzalną ( jakościową ) jest frakcja , prawdopodobieństwo ( lub po przemnożeniu przez 100 - procent ) elementów wyróżnionych w populacji , zwana też wskaźnikiem struktury w populacji .
Zagadnienie sprowadza się do budowy przedziału liczbowego , który z określonym , z góry zadanym prawdopodobieństwem ( współczynnikiem ufności ), będzie zawierał nieznaną wartość odsetka ( wskaźnika struktury, częstości względnej lub procentu ) zbiorowości generalnej .
Ważnym warunkiem jest duża próba , n>100 , a nawet n>120. W zastosowaniach statystyki warunek ten jest znacznie łagodniejszy n>30. Jednak im większa próba tym lepsze wyniki.
Gdy n jest małe ( n<30), wówczas korzysta się z dokładnego rozkładu estymatora ![]()
, jakim jest rozkład dwumianowy ze średnią ![]()
i odchyleniem standardowym ![]()
.
Jeżeli n jest duże ( n>100 ) , a ![]()
jest małym ułamkiem ![]()
, to można przyjąć , że estymator ![]()
ma rozkład asymptotycznie normalny o parametrach ![]()
a statystyka 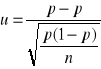
ma asymptotyczny rozkład normalny zero - jedynkowy N(0,1).
Przedział ufności dla parametru p wyraża się wzorem :
![]()
Przykład 4. Pewna firma reklamowa pragnie sprawdzić wyniki kampanii reklamowej towaru A. W tym celu przeprowadziła ankietę wśród 400 osób kupujących ten towar . Okazało się ,że 150 osób do kupna towaru nakłoniła reklama. Przyjmując poziom ufności 1-α = 0,95 , ocenić metodą przedziałową odsetek osób , które zaczęły kupować towar A w wyniku przeprowadzonej kampanii reklamowej .
Rozwiązanie
Zakładając , że losowanie osób do próby było niezależne, możemy przyjąć , że rozkład osób kupujących towar A na skutek przeprowadzonej kampanii reklamowej wśród 400 wybranych do badania jest dwumianowy o nieznanym parametrze p. Próba jest duża ( n>30 ) , a zatem przedział ufności możemy wyznaczyć na podstawie powyższego wzoru:
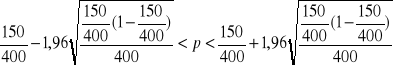
Ostatecznie przedział ten ma postać :
![]()
Można stwierdzić ,że przedział [ 32, 8 % , 42,2 % ] z prawdopodobieństwem 1-α=0,95 obejmuje procent osób kupujących towar A w wyniku przeprowadzonej kampanii reklamowej.
Przedział ufności dla wariancji i odchylenia standardowego
Przedział ufności dla wariancji ![]()
w populacji generalnej można wyznaczyć , gdy cecha X charakteryzująca zbiorowość ma rozkład ![]()
, przy czym parametry ![]()
są nieznane. Na podstawie próby losowej pochodzącej z tej populacji budujemy przedział ufności dla nieznanej wariancji ![]()
, przyjmując współczynnik ufności 1-α .Estymatorem parametru ![]()
jest wariancja z próby ![]()
![]()
określona wzorem :
![]()
.
Przedział ufności dla ![]()
może być zbudowany na podstawie rozkładu statystyki ![]()
, która ma rozkład chi - kwadrat o v=n-1 stopniach swobody. Dla przyjętego współczynnika ufności 1-α można znaleźć dwie wartości ![]()
i ![]()
, które można zapisać jako :
![]()
oraz ![]()
Przedział ufności dla wariancji ![]()
określony jest wzorem :
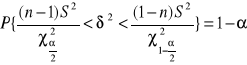
Przedział ufności dla odchylenia standardowego można wyrazić wzorem :
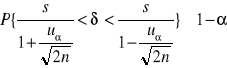
Przykład 4 .Wylosowano 10 banków , które mają swoje centrale lub odziały na Podkarpaciu Oprocentowanie rocznych lokat złotowych w tych bankach w styczniu 2001 roku wynosiło : 10,9 ; 10,75 ; 11,25 ; 12,30 ; 11,25 ; 9,0 ; 11,3 ; 10,75; 12,25 ;11,2.
Zakładając , że oprocentowanie rocznych lokat ma rozkład normalny, oszacować przedziałowo zróżnicowanie oprocentowania tych lokat we wszystkich bankach działających na Podkarpaciu. Przyjmując poziom ufności 1-α=0,96 , należy zbudować przedział ufności dla wariancji przy znajomości parametrów wyznaczonych z małej próby ( n=10 ). Wykorzystanie zostanie wzór na wariancję o następującej postaci :
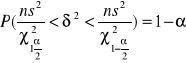
Wyznaczymy wariancję ![]()
, a następnie z tablic rozkładu ![]()
odczytujemy dla n-1=9 stopni swobody oraz dla ![]()
i ![]()
wartości ![]()
i ![]()
. Tablica pomocnicza do wyznaczenia ![]()
|
|
|
10,9 |
-0,195 |
0,038025 |
10,75 |
-0,345 |
0,119025 |
11,25 |
0,155 |
0,024025 |
12,30 |
1,205 |
1,452025 |
11,25 |
0,155 |
0,024025 |
9,0 |
-2,095 |
4,389025 |
11,3 |
0,205 |
0,042025 |
10,75 |
-0,345 |
0,119025 |
12,25 |
1,155 |
1,334025 |
11,2 |
0,105 |
0,011025 |
|
|
7,55222 |
![]()
![]()
Przedział ufności ma postać następującą :
![]()
![]()
Przedział liczbowy ( 0,384 ; 2,982 ) obejmuje z prawdopodobieństwem 1-α =0,96 nieznaną wariancję oprocentowania rocznych lokat złotowych wszystkich banków działających na Podkarpaciu.
Weryfikacja hipotez statystycznych
Hipoteza statystyczna jest założeniem badawczym , sformułowanym przez użytkownika, które dotyczy:
poziomu nieznanych parametrów w populacji generalnej ( hipotezy parametryczne )
kształtu rozkładów teoretycznych dla obserwowanych zmiennych losowych ( hipotezy nieparametryczne )
Złożenia badawcze , zwane parametrycznymi lub nieparametrycznymi hipotezami statystycznymi są formułowane w równoległych i nierozłącznych postaciach, a mianowicie jako :
hipoteza zerowa (
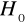
), przez którą należy rozumieć sformułowanie założenia o braku jakiejkolwiek różnicy pomiędzy ocenami z prób losowych a parametrami lub rozkładami w populacji generalnejhipotezy alternatywne (
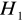
) , które są wszystkimi pozostałymi i możliwymi założeniami, poza sformułowaną hipotezą zerową
Hipotezy alternatywne mogą być sformułowane względem hipotezy zerowej
dwustronnie i wtedy
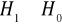
lewostronnie i wtedy
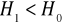
prawostronnie i wtedy
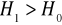
Stopień sformułowania hipotezy alternatywnej względem hipotezy zerowej ma wpływ na stopień jednoznaczności podejmowanych decyzji weryfikacyjnych.
Metody weryfikacji hipotez są skierowane wyłącznie na sprawdzenie hipotez zerowych.
Hipotezy zerowe , decyzje weryfikacyjne oraz błędy i ich prawdopodobieństwa
Hipoteza zerowa ( H0) |
Odrzucenie H0 |
Przyjęcie H0 |
Prawdziwa |
Błąd I - rodzaju (BI) P(BI) =α , 0<α<1 |
Decyzja bezbłędna |
Fałszywa |
Decyzja bezbłędna |
Błąd II rodzaju ( BII)
P(BII )=β , β |
Błąd I rodzaju polega na odrzuceniu sądu prawdziwego , a ryzyko popełnienia błędu mierzone prawdopodobieństwem nazywa się poziomem istotności i wynosi α.
Przyjęcie hipotezy, gdy w rzeczywistości jest ona fałszywa, prowadzi do błędu II rodzaju, a ryzyko popełnienia błędu wynosi β.
Prawdopodobieństwo 1-β nazywa się mocą test i jest miarą ryzyka odrzucenia sprawdzanej hipotezy, a więc H0 , gdy prawdziwa jest H1.
W praktyce dąży się do minimalizacji obydwu błędów. Nie jest to możliwe, bo dla danej liczebności próby n ,zmniejszenie α spowoduje wzrost β. Okazuje się ,że nie można zbudować testu ( reguły postępowania ) , który dla danego n minimalizowałby jednocześnie α i β. Ponieważ ustalenie α jest łatwiejsze , obszar krytyczny K powinien być tak ustalony, aby prawdopodobieństwo zdarzenia
Weryfikacja hipotez statystycznych
Podstawowe pojęcia
Hipoteza statystyczna - Założenie dotyczące wartości parametru lub rodzaju rozkładu zmiennej w zbiorowości generalnej.
Hipoteza zerowa ( H0 ) - Hipoteza formułowana często w testach istotności w taki sposób , aby na podstawie wyników próby mogła być odrzucona ( wbrew zdrowemu rozsądkowi ), tak aby można było ją łatwo odrzucić. Na przykład stawiamy ![]()
( hipoteza prosta ) . Częściej jednak chodzi o zapis ![]()
lub ![]()
( hipotezy złożone ).
Hipoteza alternatywna ( H1 ) - Hipoteza odnośnie której przypuszczamy , że jest prawdziwa ( zgodnie ze zdrowym rozsądkiem ). Jeżeli H0 zostanie odrzucona , wówczas przyjmujemy H1, w przeciwnym przypadku nie mamy podstaw do stwierdzenia , że hipoteza alternatywna jest prawdziwa, np. dla nieznanej średniej zbiorowości generalnej .
Błąd I rodzaju (α) - Jeśli hipoteza zerowa w rzeczywistości jest prawdziwa ( choć tego nie wiemy ) , ale na podstawie wyników hipotezę tę odrzucamy, to popełniamy błąd I rodzaju .
Błąd II rodzaju (β) - Jeśli hipoteza zerowa w rzeczywistości jest fałszywa ( choć tego nie wiemy ), ale na podstawie wyników z próby nie mamy podstaw do jej odrzucenia ( co w praktyce oznacza jej akceptację , czyli przyjęcie ) to wówczas popełniamy błąd II rodzaju.
Sprawdzian testu ( statystyka testu ) - zmienna losowa o określonym rozkładzie z próby ( najczęściej normalnym , t-Studenta lub chi - kwadrat ), której wartość wpada lub nie do obszaru odrzucenia hipotezy zerowej ( H0 ) , w zależności od tego , jaka będzie krytyczna wartość testu .
Wartość krytyczna testu - Wartość zmiennej losowej o określonym rozkładzie ( najczęściej normalnym , t- Studenta lub chi - kwadrat ) , która przy danym α ( poziomie istotności ) jest porównywalna z wartością statystyki testu dla potrzeb ustalenia , czy H0 może być odrzucona czy też nie .
Zbiór krytyczny - Zbiór takich wartości sprawdzianu testu , które przemawiają za odrzuceniem H0.
Poziom istotności - Maksymalne prawdopodobieństwo popełnienia błędu I rodzaju , na które godzi się badacz przeprowadzający test statystyczny .Zazwyczaj jest ono małe i przyjmuje wartości 0,01 ; 0,02 ; 0,05 ; lub 0,10 .
Test jednostronny - Sytuacja , w której zbiór krytyczny hipotezy zerowej znajduje się tylko na lewo lub tylko na prawo od wartości oczekiwanej danej zmiennej losowej. Zbiór krytyczny testu usytuowany jest zatem po jednej stronie wartości oczekiwanej.
Test dwustronny - Sytuacja , w której zbiór krytyczny hipotezy zerowej umieszczony jest symetrycznie na lewo i na prawo od wartości oczekiwanej danej statystyki testu.
Wybór rodzaju testu - Zbiór krytyczny testu , jeśli to możliwe, powinno się wyznaczyć w taki sposób , aby przy ustalonym prawdopodobieństwie popełnienia błędu I rodzaju minimalizować prawdopodobieństwo β ( popełnienia błędu II rodzaju ).
Moc testu - Prawdopodobieństwo odrzucenia hipotezy zerowej H0 , gdy hipoteza alternatywna H1 jest prawdziwa. Moc testu oznaczony jest przez M=1-β.
Wykres mocy testu - wykres prawdopodobieństwa odrzucenia hipotezy zerowej dla wszystkich możliwych wartości nieznanego parametru zbiorowości generalnej.
Wartość p - minimalna wartość α , dla której H0 może być odrzucona na podstawie wyników próby Hipoteza zerowa powinna być odrzucona tylko wtedy , gdy wartość p jest mniejsza od przyjętego dla danego testu poziomu istotności ( H0 odrzucamy , gdy wartość p < α ) . Wartość p często jest nazywana obserwowalnym poziomem istotności . Jest to miara oceniająca , na ile wyniki z próby skłaniają do założenia prawdziwości hipotezy zerowej. Im mniejsze p , tym jest to mniej prawdopodobne.
Uwaga ! - Komputerowy poziom istotności lub poziom prawdopodobieństwa jest w pakiecie Statistica oznaczony jako p. Jeżeli α>p , to na danym poziomie α odrzucamy hipotezę zerową , natomiast gdy α < p , to na danym poziomie istotności α nie ma podstaw do odrzucenia hipotezy zerowej.
Hipoteza parametryczna - założenie odnoszące się do nieznanego poziomu parametru ( parametrów ) zbiorowości generalnej.
Hipoteza nieparametryczna - założenia odnoszące się do nieznanej postaci rozkładu zmiennej losowej w zbiorowości generalnej ( czasami dotyczy to równań nieznanych wartości parametrów tego rozkładu ).
Standardowa procedura testu istotności - jest to sposób weryfikacji hipotezy statystycznej składający się z następujących po sobie czynności :
przyjęcie określonego poziomu istotności α
sformułowanie hipotezy zerowej H0
sformułowanie hipotezy alternatywnej ( w zależności od H1 test może być jednostronny lub dwustronny )
ustalenie sprawdzianu testu ( statystyki ) i jego wartości na podstawie dostępnych informacji o zbiorowości generalnej i próbie
odczytanie wartości krytycznej sprawdzianu testu ( głównie z tablic rozkładu normalnego , t- Studenta lub chi - kwadrat ) przy danym poziomie α i informacjach pochodzących z próby losowej
ustalenie obszaru odrzucenia ( krytycznego ) H0 przy danym α ( obszar ten może być jednostronny lub dwustronny )
podjęcie decyzji o odrzuceniu lub brak podstaw do odrzucenia hipotezy zerowej ( na podstawie porównania wartości statystyki testu z wartością krytyczną )
porównanie wartości p z α
Test dla wartości średniej
Załóżmy , że cecha X posiada w populacji rozkład N(![]()
) i parametry tego rozkładu nie są znane. W postępowaniu weryfikacyjnym ![]()
, gdy nieznana jest wartość drugiego parametru , tzn. ![]()
, należy wyróżnić dwa przypadki :
wykorzystuje się statystykę Zn , której dokładny rozkład w określonych warunkach jest znany. W tym przypadku mamy do czynienia z małą próbą.
wykorzystuje się statystykę Zn, której znany jest rozkład graniczny ( asymptotyczny ). Przypadek ten dotyczy dużych prób , tzn. gdy

W przypadku pierwszym - formułujemy hipotezy : ![]()
wobec ![]()
( albo ![]()
, albo ![]()
)
Pobieramy próbę losową prostą liczącą n jednostek. Jeżeli próba jest mała , w praktyce n<30 , to do weryfikacji hipotezy H0 , wykorzystuje się statystykę :
![]()
Statystyka t ma rozkład t- Studenta o v=n-1 stopniach swobody wtedy , gdy prawdziwa jest hipoteza zerowa . W celu podjęcia decyzji względem H0, z tablic rozkładu t- Studenta odczytujemy wartość krytyczną tα,v spełniającą warunek:
![]()
gdzie : ![]()
- ustalony z góry poziom istotności
Zbiór wartości ![]()
jest obszarem ( zbiorem ) krytycznym. Wiadomo, że dla danego α, n , Zn zbiór krytyczny K określa także postać hipotezy alternatywnej . Jeżeli hipoteza konkurencyjna jest postaci :
![]()
, to obszar krytyczny wyznaczony z równości ![]()
natomiast dla hipotezy ![]()
, zbiór krytyczny określa równość ![]()
W każdym rozważanym przypadku liczba stopni swobody v wynosi n-1 . Jeżeli obliczona wartość statystyki testu t znajdzie się w zbiorze krytycznym K , to hipotezę H0 odrzucamy z prawdopodobieństwem α i przyjmujemy hipotezę alternatywną. Gdy stwierdzimy, że wartość statystyki testu nie znajduje się w obszarze krytycznym ( jej wartość należy do zbioru dopuszczalnego ), wstrzymamy się od podjęcia decyzji mówiąc, że nie ma podstaw do odrzucenia H0 na poziomie istotności α .
Test dla dwóch średnich
Rozważane są dwie zbiorowości , każda ze względu na pewną wybraną zmienną X. Zakłada się , że badana cecha w każdej z tych zbiorowości ma rozkład normalny odpowiednio o parametrach ![]()
- w pierwszej zbiorowości oraz ![]()
- w drugiej zbiorowości. W celu sprawdzenia hipotezy : ![]()
wobec ![]()
( może być ![]()
lub ![]()
) pobiera się niezależnie z każdej z tych zbiorowości próby proste o liczebności odpowiednio równej n1 i n2. Jeżeli ![]()
, to dla zweryfikowania ![]()
wykorzystuje się statystykę :
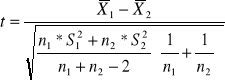
Statystyka ta ma rozkład t- Studenta o ![]()
stopniach swobody wówczas, gdy prawdziwa jest H0 oraz wariancje badanej zmiennej w obu populacjach są równe (![]()
)
W przypadku gdy ![]()
, w celu weryfikacji rozważanej H0 wykorzystuje się statystykę o następującej postaci :
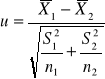
Statystyka ta ma graniczny rozkład normalny , czyli opierając się na rozkładzie N(0,1) określa się krytyczny i dopuszczalny zbiór wartości rozważanej statystyki.
Test dla wariancji
Chcemy sprawdzić hipotezę , że wariancja w populacji , w której badana cecha ma rozkład normalny N( ![]()
), jest równe liczbie ![]()
. Najczęściej w praktyce hipoteza konkurencyjna ( alternatywna ) głosi , że wariancja jest większa od ![]()
. Sformułowane hipotezy możemy zapisać następująco : ![]()
wobec ![]()
.
W celu sprawdzenia hipotezy ![]()
pobieramy próbę prostą losową liczącą n jednostek i wykorzystujemy statystykę o postaci :
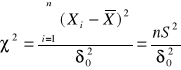
Statystyka ![]()
ma rozkład ![]()
( chi - kwadrat ) o v=n-1 stopniach swobody, gdy prawdziwa jest H0. Zbiór wartości krytycznych testu wyznacza się z relacji ![]()
Jeżeli wartość statystyki testu znajdzie się w obszarze krytycznym ![]()
to z prawdopodobieństwem ![]()
odrzucamy hipotezę ![]()
. W przeciwnym wypadku wstrzymujemy się od podjęcia decyzji.
W przypadku , gdy rozważana jest duża próba, to wykorzystuje się statystykę u Fishera o postaci : ![]()
. Statystyka ta ma graniczny rozkład N ( 0,1 ) wówczas , gdy prawdziwa jest H0.
Test dla dwóch wariancji
Badamy dwie populacje o rozkładzie normalnym N(![]()
i ![]()
. Żaden z tych parametrów nie jest znany. Należy sprawdzić hipotezę ![]()
wobec hipotezy alternatywnej ![]()
.
Do weryfikacji hipotezy ![]()
, że wariancje w obu populacjach są identyczne , używa się wariancji ![]()
oraz ![]()
obliczanych z dwóch niezależnych prób prostych o liczebności , odpowiednio ,![]()
oraz ![]()
.
Jeżeli prawdziwa jest hipoteza zerowa , tzn. ![]()
, to zmienna 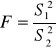
ma rozkład F-Snedecora ( lub krótko rozkład F ) z ![]()
oraz ![]()
stopniami swobody, przy czym ![]()
i ![]()
są estymatorami wariancji z niezależnych prób prostych pobranych ze zbiorowości o rozkładzie normalnym. Relacja wyznaczająca prawostronny obszar krytyczny jest postaci ![]()
, gdzie wartość krytyczną ![]()
odczytujemy z tablic rozkładu F-Snedecora , dla ![]()
i ![]()
stopni swobody. Jeżeli powyższa relacja jest spełniona , należy hipotezę ![]()
odrzucić . W przeciwnym przypadku nie ma podstaw do odrzucenia ![]()
o identyczności wariancji w obu populacjach.
Gdy sprawdzeniu podlega hipoteza ![]()
wobec ![]()
, wówczas statystykę F oblicza się , umieszczając w liczniku większą z wariancji z obu prób, nawet jeśli pochodzi ona z populacji oznaczonej numerem 2 .
Test dla wskaźnika struktury
Niech populacja generalna ma rozkład dwupunktowy z parametrem p oznaczającym prawdopodobieństwo , że badana zmienna X w populacji przyjmie wyróżnioną wartość. Parametr p ( )<p<1 ) można interpretować jako frakcję elementów populacji mających tę wartość określaną często w literaturze wskaźnikiem struktury w populacji.
Załóżmy dalej , że dla takiej populacji chcemy zweryfikować hipotezę zerową , że parametr p w populacji ma określoną wartość ![]()
. Hipoteza zerowa jest postaci ![]()
Sprawdzianem tej hipotezy jest wskaźnik struktury z dużej próby n -elementowej ![]()
zdefiniowany jako :
![]()
( 1 )
gdzie m oznacza liczbę wyróżnionych elementów w próbie i jest realizacją zmiennej losowej X o rozkładzie dwupunktowym.
Statystyka ( 1 ) ma asymptotyczny ( graniczny ) rozkład normalny 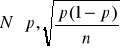
. Jeżeli hipoteza zerowa jest prawdziwa , tzn. jeśli ![]()
, to wskaźnik struktury z próby ma asymptotyczny rozkład normalny 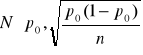
i statystyka :
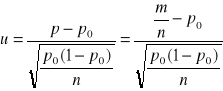
ma asymptotyczny ( w przybliżeniu ) rozkład normalny N( 0,1 ), przy czym m oznacza liczbę jednostek o wyróżnionej wartości cechy w n - elementowej próbie . Obszar krytyczny w tym teście jest określony relacją ![]()
, gdzie ![]()
jest poziomem istotności , a ![]()
- wartością krytyczną.
Sposób weryfikacji przebiega w podobny sposób jak poprzednio. Można konstruować również jednostronne obszary krytyczne w zależności od sformułowania hipotezy alternatywnej.
Test dla dwóch wskaźników struktury
Niech badana cecha X w dwóch populacjach ma rozkład dwupunktowy z parametrami ![]()
i ![]()
. Formułujemy hipotezę , że oba te parametry są identyczne . Hipotezę zerową możemy zapisać w sposób następujący :![]()
a hipotezę alternatywną ![]()
albo ![]()
lub ![]()
. W celu weryfikacji hipotezy zerowej z obu populacji wylosowano próby proste o liczebności ![]()
jednostek. Niech ![]()
oraz ![]()
oznaczają wskaźniki struktury odpowiednio z pierwszej i drugiej próby . Różnica tych wskaźników struktury ma asymptotyczny rozkład :
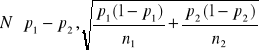
Jeśli prawdziwa jest hipoteza zerowa (![]()
), to statystyka :
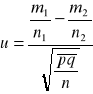
ma rozkład asymptotycznie normalny N ( 0,1 ) , We wzorze tym ![]()
i ![]()
są liczebnościami odpowiednio próby pierwszej i drugiej , ![]()
i ![]()
są liczbą elementów wyróżnionych odpowiednio w próbie pierwszej i drugiej , natomiast :
![]()
, ![]()
, ![]()
Parametryczne testy istotności - Przykłady
test dla wartości średniej
Przykład 1. W celu sprawdzenia opinii, że średnie spożycie masła w czerwcu 2001 roku w rodzinach dwuosobowych wynosiło 1 kg , wybrano 300 rodzin dwuosobowych. Na podstawie uzyskanych informacji obliczono ![]()
kg oraz ![]()
kg . Przyjmijmy, że spożycie masła w populacji badanych rodzin ma skończoną wariancję i średnią . Sprawdźmy zatem ![]()
wobec ![]()
Na podstawie charakterystyk z próby należy obliczyć wartość statystyki u , która wynosi :
![]()
Ustalając α =0,05 , odczytujemy z tablic dystrybuanty rozkładu normalnego ![]()
, przy czym ![]()
spełnia relację ![]()
. Ponieważ wartość 16,3268 znalazła się w zbiorze krytycznym , sprawdzaną hipotezę ![]()
należy odrzucić na poziomie istotności α=0,05 . Przyjmujemy więc ![]()
głoszącą , że przeciętne spożycie masła w czerwcu 1992 roku w populacji badanych rodzin różniło się od wartości hipotetycznej wynoszącej 1 kg.
test dla dwóch średnich
Przykład 2. W celu sprawdzenia przypuszczenia , że dzienne wydatki na pieczywo na osobę w rodzinach trzyosobowych w Rzeszowie są takie same jak w Łańcucie . Wylosowano z Rzeszowa 12 rodzin , a z Łańcuta 6. Zebrano odpowiednie informacje o wydatkach na pieczywo w listopadzie 2001 roku . Na podstawie zebranych danych obliczono dla :
Rzeszowa ![]()
zł ![]()
zł
Łańcuta ![]()
zł ![]()
zł
Przyjmuje się , że dzienne wydatki na pieczywo na osobę w rodzinach trzyosobowych w Rzeszowie i Łańcucie mają rozkład normalny o takiej samej wariancji.
Hipoteza zerowa jest następująca :
![]()
a alternatywna ![]()
Obliczona wartość statystyki zgodnie z wzorem 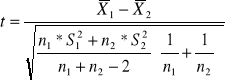
wynosi t=0,796284. Z tablic rozkładu t-Studenta dla v=12 + 6 -2 stopni swobody i przyjętego poziomu istotności α=0,05 , wartość krytyczna ![]()
. Zatem nie ma podstaw do odrzucenia H0 głoszącej , że średnie dzienne wydatki na pieczywo na osobę w rodzinach trzyosobowych Rzeszowa i Łańcuta są równe.
Test dla wskaźnika struktury - Przykład 3. W celu sprawdzenia przypuszczenia , że 30 % dorosłych ludzi w Polsce popiera obecne reformy , wybrano losowo 1200 dorosłych osób i zapytano je o akceptację aktualnych reform. Wśród wylosowanych 362 osoby wyraziły poparcie dla reform. Czy uzyskane wyniki potwierdzają nasze przypuszczenie ? Aby udzielić odpowiedzi na pytanie , formułujemy następujące hipotezy : ![]()
![]()
oraz ![]()
, a następnie obliczamy wartość statystyki u , zgodnie z wzorem 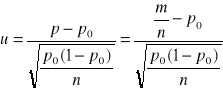
, i otrzymujemy :
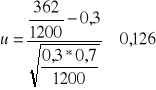
Przyjmując ![]()
, odczytujemy z tablic rozkładu normalnego wartość krytyczną ![]()
. Ponieważ wartość u =0,126 znajduje się w obszarze dopuszczalnym , nie mamy podstaw od odrzucenia sądu , że 30 % dorosłych osób w Polsce popiera aktualne reformy ( na poziomie istotności α=0,06 )
Testy nieparametryczne
Sprawdzanie hipotezy na podstawie testu zgodności ![]()
Populacja generalna ma dowolny rozkład o dystrybuancie należącej do zbioru rozkładów o określonym typie postaci funkcyjnej dystrybuanty. Mogą to być dystrybuanty typu ciągłego i skokowego. Z populacji tej losujemy niezależnie dużą próbę , a wyniki losowania dzielimy na r rozłącznych klas o liczebności ni w każdej klasie , przy czym ![]()
Podział na klasy tworzy tzw. Rozkład empiryczny . Na podstawie wyników próby stawiamy hipotezę , że dystrybuanta populacji należy do klasy określonych dystrybuant, którą będziemy oznaczać przez Ω ; tzn. ![]()
, gdzie F ( x ) jest dystrybuantą rozkładu populacji. Porównanie dystrybuanty F ( x) z dystrybuantą empiryczną daje możliwość weryfikacji postawionej hipotezy. Test zgodności dla tej hipotezy jest następujący : z hipotetycznego rozkładu należącego do poszczególnych klas wartości badanej cechy x prawdopodobieństwa pi, że zmienna losowa x o rozkładzie Ω przyjmie wartości należące do klasy o numerze i ( i=1,2,3,...,m ) . Z kolei mnożąc pi przez liczebność całej próby , otrzymujemy liczebności teoretyczne ![]()
, które wystąpią w poszczególnych klasach , jeżeli postawiona hipoteza H0 jest prawdziwa. Statystyką weryfikującą H0 jest hipoteza ![]()
:
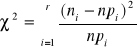
która ma przy słuszności założenia H0 rozkład asymptotyczny ![]()
o r-1 stopniach swobody , lub r-1-k stopniach swobody ( r - jest liczbą klas , k - liczbą parametrów , które wyznaczamy dla funkcji należącej do ![]()
). Obszar krytyczny w tym teście buduje się prawostronnie w oparciu o rozkład statystyki ![]()
. Z tablic rozkładu , dla ustalonego z góry poziomu istotności α , odczytujemy wartość krytyczną ![]()
, by zachodziło ![]()
. Jeżeli ![]()
, to H0 należy odrzucić , jeżeli ![]()
, to nie ma podstaw do odrzucenia hipotezy.
Przykład 4 Losowa próba n=200 niezależnych obserwacji miesięcznych wydatków na żywność rodzin trzyosobowych dała następujący rozkład tych wydatków ( w tys. zł)
Wydatki |
Liczba rodzin |
1,0 - 1,4 |
15 |
1,4 - 1,8 |
45 |
1,8 - 2,2 |
70 |
2,2 - 2,6 |
50 |
2,6 - 3,0 |
20 |
Na poziomie istotności α=0,05 należy zweryfikować hipotezę ,że rozkład wydatków jest normalny.
Rozwiązanie Stawiamy hipotezę ![]()
, gdzie ![]()
jest klasą wszystkich dystrybuant normalnych. Dwa parametry rozkładu tej dystrybuanty , średnią ![]()
i odchylenie standardowe ![]()
, szacujemy z próby za pomocą estymatorów ![]()
tys. zł . , s=0,43 tys. zł - są one potrzebne do standaryzacji . Pozostałe obliczenia znajduję się w tablicy
xi |
ni |
ui |
F(ui) |
pi |
npi |
(ni-npi)2 |
(ni-npi)2/npi |
1,4 |
15 |
-1,39 |
0,082 |
0,082 |
16,4 |
1,96 |
0,12 |
1,8 |
45 |
-1,46 |
0,323 |
0,241 |
48,2 |
10,24 |
0,21 |
2,2 |
70 |
0,46 |
0,677 |
0,354 |
70,8 |
0,64 |
0,01 |
2,6 |
50 |
1,39 |
0,918 |
0,241 |
48,2 |
3,24 |
0,07 |
3,0 |
20 |
2,32 |
1,00 |
0,082 |
16,4 |
12,96 |
0,79 |
|
200 |
|
|
1,000 |
200 |
|
1,20 |
Odpowiednia liczba stopni swobody wynosi 5-1-2=2. Z tablic rozkładu ![]()
dla dwóch stopni swobody i dla przyjętego poziomu istotności α=0,05 odczytujemy wartość krytyczną ![]()
. Mamy ![]()
, nie ma podstaw do odrzucenia hipotezy , że rozkład miesięcznych wydatków w populacji rodzin trzyosobowych jest normalny.
Test zgodności λ- Kołmogorowa
Test zgodności Kołmogorowa jest mniej pracochłonny niż test ![]()
, ale mniej wszechstronny. Stosuje się go jedynie do weryfikacji hipotez , że populacja ma rozkład ciągły .W teście tym porównuje się dystrybuantę empiryczną z hipotetyczną. Na podstawie analizy różnic między wymienionymi dystrybuantami buduje się statystykę : ![]()
gdzie ![]()
Z tablic λ- Kołmogorowa , dla odpowiednich α, wartości λ, które wykorzystujemy do konstrukcji obszaru krytycznego .
Test λ- Kołmogorowa służy do weryfikacji następujących hipotez :
pewna wylosowana próba zmiennej losowej ma rozkład ciągły o dystrybuancie
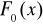
; na podstawie wyników tej próby należy zweryfikować hipotezę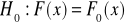
, gdzie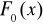
jest hipotetyczną i ciągłą dystrybuantą ,na podstawie dwu losowo pobranych prób sprawdzić hipotezę , że obie próby pochodzą z tej samej populacji , tzn. hipotezę
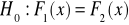
Test istotności dla hipotezy ![]()
jest następujący :
Wyniki próby porządkujemy według rosnącej kolejności zmiennej xi z odpowiadającymi jej liczebnościami ni
Wyznaczamy dla każdego xi wartość empirycznej dystrybuanty
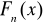
, gdzie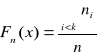
Z rozkładu hipotetycznego wyznaczamy dla każdej wartości xi wartość hipotetycznej dystrybuanty F (x)
Obliczamy bezwzględną wartość różnicy
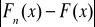
, tzn. różnicę między dystrybuantą empiryczną a hipotetycznąObliczamy wartość statystyki :
![]()
oraz wartość statystyki :
![]()
Dla ustalonego poziomu istotności α budujemy obszar krytyczny statystyki λ i weryfikujemy hipotezę .
Przykład 5 Zbadano losowo wybranych studentów ze względu na wysokość wydatków przeznaczonych na sport i turystykę w skali rocznej i otrzymano następujące wyniki ( w setkach zł )
Wydatki |
Liczba studentów |
29,5 - 30 ,5 |
12 |
30,5 - 31,5 |
23 |
31,5 - 32,5 |
35 |
32,5 - 33,5 |
62 |
33,5 - 34,5 |
44 |
34,5 - 35,5 |
18 |
35,5 - 36,5 |
6 |
Na poziomie istotności α=0,05 zweryfikować hipotezę , że rozkład wydatków na sport i turystykę w grupie studentów jest rozkładem normalnym.
Rozwiązanie : Weryfikujemy hipotezę ![]()
gdzie ![]()
jest dystrybuantą rozkładu normalnego ![]()
) . Z próby obliczamy oszacowania obu parametrów rozkładu normalnego , otrzymując ![]()
oraz ![]()
. Ponieważ próba jest duża , wartości te przyjmujemy jako estymatory ![]()
i ![]()
. Obliczenia konieczne do znalezienia wartości empirycznej i teoretycznej dystrybuanty zostały zamieszczone w poniższej tablicy
xj |
uj |
F(uj ) = F(x) |
nj |
|
Fn(x) |
|
30 ,5 |
-1,71 |
0,044 |
12 |
12 |
0,060 |
0,016 |
31,5 |
-1,00 |
0,159 |
23 |
35 |
0,175 |
0,016 |
32,5 |
-0,29 |
0,386 |
35 |
70 |
0,350 |
0,036 |
33,5 |
0,43 |
0,666 |
62 |
132 |
0,660 |
0,006 |
34,5 |
1,14 |
0,873 |
44 |
176 |
0,880 |
0,007 |
35,5 |
1,86 |
0,969 |
18 |
194 |
0,970 |
0,001 |
36,5 |
2,57 |
0,005 |
6 |
200 |
1,00 |
0,005 |
Otrzymaliśmy zatem D=0,036 . Ponieważ ![]()
wartość empiryczna statystyki λ - Kołmogorowa wynosi 0,509. Z tablicy rozkładu λ- Kołmogorowa ( granicznego ) odczytujemy dla przyjętego poziomu istotności 0,05 krytyczną wartość , która wynosi 1,358. . Nie ma podstaw do odrzucenia hipotezy zerowej , że rozkład wydatków jest rozkładem normalnym .
Analiza korelacji i regresji .
Korelacja jest to współzależność , czyli wzajemne oddziaływanie lub współwystępowanie dwóch zjawisk lub cech tej samej zbiorowości .
Celem analizy współzależności jest stwierdzenie , czy między badanymi zmiennymi zachodzą jakieś zależności , jaka jest ich siła , kształt i kierunek.
Współzależność między zmiennymi może być :
funkcyjna
stochastyczna ( probabilistyczna)
Zależność funkcyjna - określonej wartości jednej zmiennej ( X - niezależnej - objaśniającej ) , odpowiada jedna i tylko jedna wartość drugiej zmiennej ( Y - zależna -objaśniana ). Zależność funkcyjna ( dokładna ) występuje w naukach przyrodniczych , natomiast w naukach społecznych mamy do czynienia z zależnością stochastyczną .
Zależność stochastyczna ( probabilistyczna ) - wraz ze zmianą jednej zmiennej , zmienia się rozkład prawdopodobieństwa drugiej zmiennej . Szczególnym przypadkiem tej zależności jest zależność korelacyjna ( statystyczna ) Polega na tym , że określonym wartościom jednej zmiennej odpowiadają ściśle określone średnie wartości drugiej zmiennej .
Statystyczny opis współzależności może mieć :
Formę tabelaryczną ( szeregi lub tablice )
Graficzną ( diagram korelacyjny )
Parametryczną w postaci odpowiedniej charakterystyki liczbowej.
Badanie współzależności dwóch cech ilościowych ( mierzalnych ) można przeprowadzić za pomocą tzw. analizy regresji prostej , która służy do określenia relacji między zmienną zależną i zmienną niezależną ( lub odwrotnie ) .
Korelacja między cechami mierzalnymi nosi nazwę kontyngencji , a tablice prezentujące takie dane noszą nazwę tablic kontyngencyjnych . Dla potrzeb wykazania zależności w tablicach kontygencyjnych stosuje się test niezależności ![]()
. Test niezależności ![]()
, znajduje zastosowanie zarówno dla korelacji cech mierzalnych jak i niemierzalnych .
Jeśli zbiorowość jest liczna , to wyniki obserwacji dwóch cech grupujemy w tablicy kombinowanej zwanej tablicą korelacyjną .
Tablica przedstawia rozkład dwuwymiarowy czyli łączy rozkład zbiorowości według dwóch cech .
Y=yj
X=xi |
y1 |
y2 |
… |
yj |
… |
yl |
ni . |
x1 |
n11 |
n12 |
... |
n 1 j |
... |
n1 l |
n 1 . |
x2 |
n21 |
n22 |
... |
n2 j |
... |
n 2 l |
n 2 . |
. . . |
. . . |
. . . |
... ... ... |
. . . |
... ... ... |
. . . |
. . . |
xi |
ni1 |
ni2 |
... |
nij |
... |
nil |
ni . |
. . . |
. . . |
. . . |
... ... ... |
. . . |
... ... ... |
. . . |
. . . |
xk |
nk1 |
nk 2 |
... |
nk j |
... |
nk l |
nk . |
n . j |
n . 1 |
n . 2 |
... |
n . j |
... |
n . l |
n |
W boczku tablicy znajdują się warianty cechy X=xi ( i = 1,2,...,k ), w główce tablicy znajdują się warianty cechy Y=yj ( j= 1,2, ..., l ). W polach na przecięciu wierszy i kolumn są umieszczone liczebności nij , oznaczające liczbę jednostek badanej zbiorowości posiadających i-ty wariant cechy X oraz j-ty wariant cechy Y. Suma liczebności zapisana w ostatnim wierszu ( n . j ) odnosi się do wariantów cechy Y , natomiast suma w ostatniej kolumnie ( n i . ) dotyczy wariantów cechy X.
Zachodzi równość : ![]()
, gdzie ![]()
oznacza ogólną liczebność badanej zbiorowości .
W tablicy korelacyjnej wyróżniamy rozkłady brzegowe i rozkłady warunkowe.
Rozkłady brzegowe pokazują rozłożenie obserwacji ( liczebności ) oddzielnie dla każdej z obu cech . W ostatniej kolumnie znajduje się rozkład brzegowy zmiennej X , natomiast w ostatnim wierszu - rozkład brzegowy zmiennej Y. Podstawowymi charakterystykami tych rozkładów są średnie arytmetyczne i wariancje , które obliczamy jako parametry ważone według wzorów :
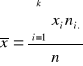
, 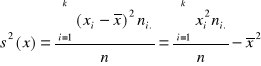
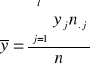
, 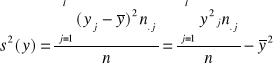
Rozkłady warunkowe pokazują rozłożenie liczebności przy wartościach jednej cechy pod warunkiem , że druga przyjmie określoną wartość . W poszczególnych kolumnach mieszczą się zatem rozkłady warunkowe cechy X , co zapisujemy X ( Y = yj ), natomiast w poszczególnych wierszach znajdują się rozkłady warunkowe Y , czyli Y ( X = xi ).
Średnie i wariancje rozkładów warunkowych X ( Y = yj ) obliczamy dla poszczególnych kolumn ( j= 1, 2 ,..., l ) jako :
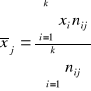
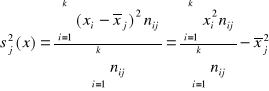
gdzie :
![]()
- wartość cechy X lub środki przedziałów
![]()
- liczebności zawarte w j-tej kolumnie
Średnie i wariancje rozkładów warunkowych Y ( X = xi ) obliczamy dla poszczególnych wierszy ( i=1,2,...,k ) jako :
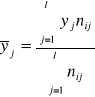
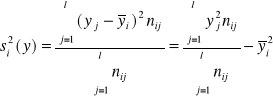
gdzie : ![]()
- wartości cechy Y lub środki przedziałów ;
![]()
- liczebności zawarte w i- tym wierszu
Średnie i wariancje rozkładów warunkowych pozwalają określić rodzaj związku między badanymi zmiennymi. Rodzaje związku między zmiennymi to :
Niezależność stochastyczna między zmienny istnieje wtedy , gdy zmieniającym się wartościom jednej cechy towarzyszą takie same rozkłady warunkowe drugiej cechy , co wyraża się równością parametrów rozkładów warunkowych cechy X i cechy Y.
Związek stochastyczny między zmiennymi istnieje wtedy , gdy zmieniającym się wartością jednej cechy towarzyszą istotnie różne rozkłady warunkowe drugiej cechy .
Związek korelacyjny ( statystyczny ),- związek korelacyjny istnieje , jeżeli zmieniającym się wartościom jednej cechy towarzyszą zmiany średnich warunkowych drugiej.
Jeżeli zmiany te mają zgodny kierunek , tzn. rosnącym wartościom jednej cechy odpowiada wzrost średnich warunkowych drugiej cechy , mamy do czynienia z korelacją dodatnią , natomiast gdy rosnącym wartościom cechy odpowiadają malejące średnie warunkowe drugiej cechy , mówimy o korelacji ujemnej.
Przykład 1. W zbiorowości studentów II roku kierunku Informatyka i Ekonometria AE w Katowicach , którzy przystąpili do egzaminu ze statystyki w czerwcu 2001 roku i odnotowano dwie cechy :
ocenę na egzaminie ze statystyki
liczbę punktów otrzymanych na egzaminie z matematyki
Wyniki obserwacji pogrupowano i zamieszczono w poniższej tablicy
Liczba punktów z matematyki xi |
Ocena ze statystyki yj |
Razem n i . |
||||
|
2 |
3 |
4 |
5 |
|
|
20 - 24 |
1 |
6 |
2 |
- |
9 |
|
25 - 29 |
2 |
12 |
6 |
- |
20 |
|
30 - 34 |
- |
9 |
10 |
2 |
21 |
|
35 - 39 |
- |
6 |
5 |
2 |
13 |
|
40 - 44 |
- |
- |
4 |
1 |
5 |
|
Razem n . j |
3 |
33 |
27 |
5 |
68 |
|
Tablica przedstawia łączny rozkład liczby punktów z matematyki (X) i ocen ze statystyki (Y), czyli rozkład dwuwymiarowy. W ostatniej kolumnie znajduje się rozkład brzegowy punktów , czyli liczebności studentów ( n i . ) przyporządkowane poszczególnym klasom cechy X=xi . W ostatnim wierszu znajduje się rozkład brzegowy ocen ze statystyki , czyli liczebności studentów ( n . j ) przyporządkowane poszczególnym ocenom (Y=yj ) .
W kolumnach tablicy zawarte są rozkłady warunkowe liczby punktów X(Y=yj ) tzn. przy założeniu , że student otrzymał konkretną oceną. W wierszach znajdują się rozkłady warunkowe ocen Y(X=xi ) tzn. przy założeniu , że liczba punktów mieściła się w wyodrębnionej klasie .
Należy ustalić , czy badane zmienne są stochastycznie zależne ?
Średnie warunkowe ocen ze statystyki : ![]()
; ![]()
; ![]()
; ![]()
; ![]()
Wariancje warunkowe ocen ze statystyki : ![]()
; ![]()
; ![]()
; ![]()
; ![]()
Średnie warunkowe punktów z matematyki : ![]()
; ![]()
; ![]()
; ![]()
Wariancje warunkowe punktów z matematyki : ![]()
; ![]()
; ![]()
; ![]()
Analiza rozkładów warunkowych ocen ze statystyki wykazała , że zarówno średnie tych rozkładów , jak i wariancje różnią się między sobą . Taką samą prawidłowość stwierdzamy , analizując rozkłady warunkowe liczby punktów z matematyki . A zatem obie badane zmienne są stochastycznie zależne .
Obserwując zmiany średnich warunkowych jednej i drugiej cechy możemy stwierdzić , że między nimi istnieje związek korelacyjny dodatni , bowiem wzrost wartości jednej cechy łączy się ze zwiększeniem średnich warunkowych drugiej cechy.
Gdy związek badanych cech jest liniowy , to miarą współzależności jest współczynnik korelacji liniowej Pearsona . Jest on ilorazem miary łącznego zróżnicowania obu cech tzw. kowariancji , oraz iloczynu odchyleń standardowych każdej z cech.
![]()
Kowariancja jest średnią arytmetyczną iloczynem odchyleń wartości zmiennych X i Y ich średnich , co zapiszemy dla danych w szeregach :
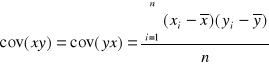
dla danych w tablicy
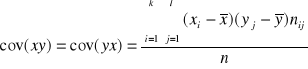
Kowariancja pokazuje jedynie kierunek współzależności ( korelacja dodatnia , ujemna ) . Porównanie jej do iloczynu odchyleń standardowych daje miernik unormowany , przyjmujący wartości z przedziału < -1; +1>. Znak współczynnika korelacji informuje o kierunku związku, natomiast wartość bezwzględna o jego sile , a zatem :
r(xy) = -1 - oznacza , że między cechami istnieje związek funkcyjny ujemny
-1 < r(xy ) <0 - oznacza , że między cechami istnieje związek korelacyjny ujemny
r( xy ) = 0 - oznacza , że cechy są niezależne ( brak związku )
0 < r ( xy ) < 1 - oznacza , że między cechami istnieje związek korelacyjny dodatni
r ( xy ) = 1 - świadczy o istnieniu związku funkcyjnego dodatniego
Współczynnik Pearsona oblicza się według różnie przekształconych wzorów . Przy obliczeniach dokonanych na podstawie szeregów najczęściej stosowane są poniższe wzory :
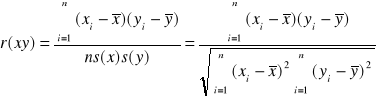
gdzie :
![]()
- zaobserwowane wartości cechy X
![]()
- zaobserwowane wartości cechy Y
![]()
- kolejne pary obserwacji
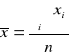
, 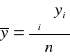
- średnie arytmetyczne
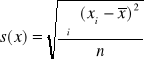
, 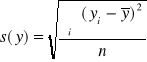
- odchylenia standardowe
Niekiedy wygodnie jest korzystać ze wzoru o postaci :
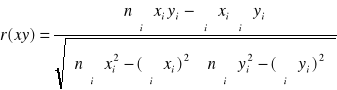
Współczynnik korelacji podniesiony do kwadratu ![]()
nazywa się współczynnikiem determinacji , informuje on , jaka część zmienności jednej z cech jest wyjaśniana kształtowaniem się drugiej cechy . Z kolei dopełnienie tego współczynnika do jedności tzw. współczynnik indeterminacji ![]()
jest interpretowany jako ta część zmienności jednej z cech , która nie jest wyjaśniana przez drugą , a zatem może być spowodowana czynnikami nie ujętymi w badaniu .
Współczynnik korelacji Pearsona jest symetryczny ![]()
, czyli przy jego obliczeniu nie ma potrzeby rozstrzygać , która cecha jest przyczyną , a która skutkiem . Jeżeli chcemy interpretować współczynnik determinacji , musimy zwracać uwagę na to , jakie powiązanie cech jest logicznie uzasadnione .
Dla danych pogrupowanych w tablicy korelacyjnej współczynnik korelacji obliczamy jako parametr ważony liczebnościami rozkładów warunkowych ( ni j ) . Wzór ma postać następującą :
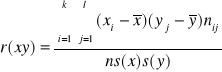
gdzie :
![]()
- wartość cechy X ( i= 1,2,...,k )
![]()
- wartość cechy Y ( j= 1,2, ..., l )
W analizie współzależności ważnym zagadnieniem jest rozstrzygnięcie , czy korelacja stwierdzona w próbie ma także miejsce w populacji , z której pobrano próbę . W ocenie tego faktu może pomóc test istotności współczynnika korelacji Pearsona .
Założenia testu :
Badane zmienne ( X,Y ) populacji generalnej mają dwuwymiarowy rozkład normalny o nieznanym współczynniku korelacji ![]()
. Z populacji tej wylosowano n - elementową próbę na podstawie której obliczono współczynnik korelacji ![]()
.
Weryfikacja hipotezy zerowej :
![]()
Wobec hipotezy alternatywnej :
![]()
lub ![]()
, ![]()
Do weryfikacji hipotezy stosujemy :
test 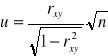
dla ![]()
lub test 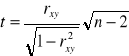
dla n < 122
Przy założeniu prawdziwości hipotezy zerowej omawiane statystyki mają odpowiednio rozkład normalny N(0,1 ) oraz rozkład t- Studenta 0 n-1 stopniach swobody.
Funkcja regresji - to narzędzie do badania mechanizmu powiązań między zmiennymi . Funkcja regresji to analityczny wyraz przyporządkowania średnich wartości zmiennej zależnej konkretnym wartością zmiennej niezależnej . Wybór postaci analitycznej nie jest problemem łatwym .Wyboru postaci analitycznej dokonujemy :
na podstawie wstępnej analizy materiału statystycznego
wykresy rozrzutu
na podstawie źródeł poza statystycznych
Do opisu w sposób syntetyczny współzależności wykorzystuje się odpowiednie funkcje , które należy dopasować do smugi punktów przedstawionej na diagramie korelacyjnym . W praktyce przyjmuje się , że jeśli smuga punktów układa się wzdłuż linii prostej , to dopasowujemy do niej funkcję liniową , którą oznaczymy symbolem :
![]()
( 1 )
Współczynniki regresji szacuje się za pomocą metody najmniejszych kwadratów. MNK polega na takim oszacowaniu parametrów funkcji ( 1 ) , by dla danych z próby był spełniony warunek :
![]()
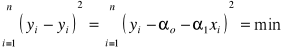
gdzie :
![]()
- oznaczają wartości empiryczne zmiennej Y
![]()
- oznaczają wartości teoretyczne wyznaczone na podstawie równania ( 1 )
Istotą MNK jest taki wybór wartości ![]()
i ![]()
dla których funkcja kryterium osiąga minimum. W tym celu obliczamy odpowiednie pochodne cząstkowe względem argumentów i przyrównujemy je do zera , a mianowicie :
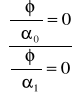
( 2 )
Uwzględniając wprowadzone oznaczenia , układ równań (2) zapiszemy w postaci :
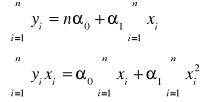
( 3 )
Układ równań (3) nazywa się układem równań normalnych . Rozwiązując układ równań można otrzymać wzory na wartość ![]()
i ![]()
.
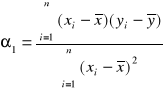
![]()
Między współczynnikiem regresji a wartością wprowadzonego współczynnika korelacji istnieje ścisła zależność . Przekształcając odpowiednio wzór na obliczanie współczynnika ![]()
otrzymamy :
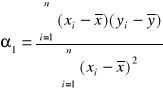
=![]()
Okazuje się , że współczynnik korelacji jest ściśle związany ze współczynnikiem liniowej funkcji regresji i dlatego nazywa się go liniowym współczynnikiem korelacji .
Oceny parametrów a0 i a1 są to estymatory nieobciążone i zgodne parametrów ![]()
i ![]()
.
Przedziały ufności dla parametrów regresji są następujące \:
Dla parametru ![]()
![]()
Dla parametru ![]()
![]()
gdzie :
![]()
, ![]()
- estymatory parametrów ![]()
i ![]()
![]()
- ocena standardowego błędu estymatora ![]()
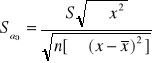
![]()
- ocena standardowego błędu estymatora ![]()
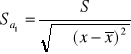
![]()
- nieobciążony estymator wariancji składnika losowego, dany wzorem 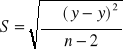
![]()
- wartość statystyki t- Studenta odczytana z tablic rozkładu Studenta przy danym poziomie istotności i stopniach swobody
Gdy próba jest większa od 30 czyli n>30 , wówczas przedziały ufności dla parametrów regresji są następujące :
Dla parametru ![]()
![]()
Dla parametru ![]()
![]()
gdzie :
![]()
- odczytuje się z tablic dystrybuanty rozkładu normalnego
pozostałe oznaczenia jak wyżej
Test hipotezy o zachodzeniu liniowego związku między X a Y
![]()
![]()
Sprawdzianem zachodzenia liniowego związku między zmiennymi X i Y :
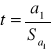
gdzie : ![]()
- jest oceną ( estymatorem ) współczynnika kierunkowego linii regresji
![]()
- jest oceną standardowego błędu estymatora ![]()
Jeśli hipoteza zerowa jest prawdziwa to sprawdzian ma rozkład t o n-2 stopniach swobody . Sprawdzian t jest szczególnym przypadkiem sprawdzianu :
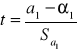
Jest on zbudowany zgodnie ze schematem : ocena parametru - hipotetyczna wartość parametru / ocena standardowego błędu estymatora .
test ze statystyki - odpowiedź -a
Zad. 1. Czy opis statystyczny oraz wnioskowanie statystyczne losowej próby krajów europejskich rozpatrywanych ze względu na rozmiary zadłużenia w 2001 roku dotyczą tej samej zbiorowości statystycznej
tak
nie
i tak i nie
trudno powiedzieć
Zad.2. W odpowiedzi na pytanie „ dlaczego korzystamy z Internetu „ Katedra Marketingu AE w Katowicach uzyskała m.in. następujące dane statystyczne : poszukiwanie informacji na własne potrzeby ( 80 %), komunikacja z innymi (75 % ), edukacja ( 58%), rozrywka (58,6%), praca/biznes ( 44,3 % ), zdobywanie informacji o produktach (40,5%), sposób spędzania wolnego czasu (37,5%), zakupy (9,2%). Czy liczby podane (w procentach) to :
częstości empiryczne
prawdopodobieństwa
miary opisowe
indywidualne dane statystyczne
Zad. 3. Który z aksjomatów A.N. Kołmogorowa jest pewnikiem tego, że prawdopodobieństwo zdarzenia niemożliwego jest równe zero:
pierwszy
drugi
trzeci
żaden
Zad.4. Poniższe dane dotyczą zatłoczenia ( liczby pieszych) w słynnych alejach handlowych w 13 wybranych miastach w dzień powszedni ( wtorek ) oraz dzień weekendowy ( sobota ) :
Lp. |
Nazwa miasta |
Liczba pieszych wtorek |
Liczba pieszych sobota |
1 |
Bruksela |
3792 |
3871 |
2 |
Genewa |
3182 |
3633 |
3 |
Hongkong |
10424 |
8752 |
4 |
Londyn |
8789 |
9239 |
5 |
Madryt |
4280 |
5250 |
6 |
Moskwa |
4289 |
1712 |
7 |
Nowy Jork |
7028 |
4586 |
8 |
Paryż |
10692 |
5511 |
9 |
Szanghaj |
2456 |
4104 |
10 |
Sydney |
6380 |
11890 |
11 |
Tokio |
6393 |
5067 |
12 |
Warszawa |
11892 |
14351 |
13 |
Zurych |
4672 |
5549 |
Czy pozycyjna asymetria rozkładu zatłoczenia w badanych miastach była w dzień powszedni i w sobotę taka sama oraz dodatnia :
nie ; tak
tak ; tak
tak, nie;
nie , nie ?
Zad. 5. Dla 52 wylosowanych gmin pewnego województwa zbadano rozmiary bezrobocia i uzyskano , że w 1999 roku średnia stopa bezrobocia wynosiła 8,2 % , z przeciętnym zróżnicowaniem 3,3 %. Czy precyzja na podstawie uzyskanych danych i przy 1- α = 0,95 , oszacowanego przeciętnego poziomu stopy bezrobocia dla całego województwa pozwala na wnioskowanie :
bezpieczne
nie w pełni bezpieczne
zdecydowanie niebezpieczne
trudno powiedzieć ?
Zad.6. Na reprezentatywnej próbie losowej 1167 dorosłych Polaków na początku 2000 roku COBS przeprowadził sondaż opinii dotyczący zabezpieczenia finansowego na przyszłość. Uzyskano 35 % pozytywnych odpowiedzi. Z jakim względnym błędem precyzji, przy
1-α = 90 , można by uogólnić ten wynik na całą populację dorosłych Polaków i ile należałoby osób wylosować do następnego badania , aby błąd precyzji nie przekroczył 3 %.
6,5 % ; 678
5,6 %; 876
0,65 % ; 76
0,065 % ; 927 ?
Zad. 7.Wpłaty 11 polskich banków ( w mln zł ) przeznaczone dla klientów upadłego Banku Staropolskiego były następujące : [ 136,4 114,7 33,5 28,5 26,7 26,0 23,6 21,7 18,6 16,7 16 ,7 ]. W oparciu o te dane, przyjmując poziom istotności α=0,01, stwierdzić , czy przypuszczenie o przeciętnym przekazie wśród wszystkich banków w wysokości 30,0 mln zł należy :
nie odrzucić
odrzucić
przyjąć
brak decyzji ?
Zad.8. Firma budując nowy obiekt, musi przewidzieć miejsca na parkingu dla pojazdów pracowników i gości. Wśród 200 pracowników stwierdzono, że 150 z nich przyjeżdża do pracy samochodem. Przyjmując poziom istotności 0,05 sprawdzić przypuszczenie, że parking dla pracowników powinien stanowić 65 % powierzchni parkingowej . Czy decyzja taka byłaby :
jednoznaczna
niejednoznaczna
jednoznaczna, ale ...
niejednoznaczna , ale ... ?
Zad. 9. W związku ze zróżnicowaniem opinii o celowości budowy rożnej wielkości supermarketów zbadano zależność pomiędzy wielkością zakupów w średnich i dużych domach handlowych. Otrzymano m.in. informacje o średnim tygodniowym zakupie przeciętnego klienta :
w średnich supermarketach 200 zł , przy przeciętnym zróżnicowaniu bezwzględnym 50 zł,
w dużym 220 zł z przeciętnym zróżnicowaniem 200 zł
W pierwszym przypadku zbadano 1000 klientów, w drugim 3000 osób. Czy badaną zależność należy określić jako :
niewielką
umiarkowaną
wysoką
bardzo wysoką ?
Zad.10. W 1999 roku w porównaniu z 1998 r wartość eksportu dwóch towarów wzrosła o 50 mln zł. W omawianym okresie cena towaru I wzrosła o 8 % , a towaru II o 10 % . O ile przeciętnie wzrósł eksport z tytułu wzrostu cen, jeżeli w 1998 roku eksport towaru I osiągnął wartość 60 mln zł , a towaru II 80 mln zł :
9,1 %
10,91 %
109,1%
1% ?
Wyszukiwarka