Ogólna charakterystyka sztucznej inteligencji
Co to jest sztuczna inteligencja?
W książce tej opisane są wybrane metody i techniki należące do dziedziny, której nazwa (popularna i powszechnie dziś stosowana w profesjonalnym piśmiennictwie) wciąż budzi różne wątpliwości i emocje. Wiele osób odrzuca samą możliwość istnienia czegoś takiego, jak inteligencja której można by przypisać określenie „sztuczna”. Twierdzą oni, że inteligentny może być tylko człowiek, zaś komputer może automatycznie odtwarzać zaprogramowane przez człowieka reguły działania, które przy zewnętrznej obserwacji sprawiają wrażenie zachowania inteligentnego, są jednak w istocie antytezą inteligencji, gdyż ta ostatnia powinna być twórcza, a nie odtwórcza.
Na temat tego, czy maszyna może (czy też nie może) być inteligentna spisano już wiele dzieł filozoficznych oraz metodologicznych, z których jednak bardzo niewiele wynika. Dlatego my w tej książce do kwestii sztucznej inteligencji podchodzić będziemy wyłącznie narzędziowo, rozumiejąc ją w taki sposób, żeby mieć z tego pojęcia pożytek praktyczny, pozostawiając dyskusję temat ontologicznego statusu sztucznej inteligencji filozofom. Dla uporządkowania dalszych rozważań kilka definicji bardzo się jednak przyda, dlatego spróbujemy przynajmniej w trybie roboczym ustalić, co to jest sztuczna inteligencja?
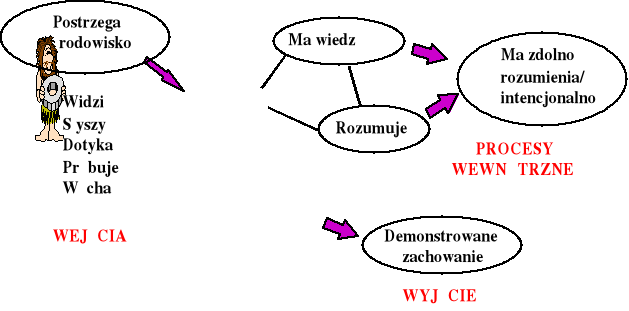
Rys. 2. Istota inteligentna i jej główne atrybuty (źródło: opracowanie własne na podstawie rysunku z wykładu prof. Haliny Kwaśnickiej z Politechniki Wrocławskiej)
Niewątpliwie człowiek jest inteligentny. Składają się na to liczne składniki jego percepcji, jego zdolności rozumowania oraz jego zachowania, przedstawiona na rysunku 2. Czy jednak w każdym jego działaniu czynnik inteligencji ma swój istotny udział? Czy świadczy o naszej inteligencji na przykład to, że usłyszawszy od naszego sąsiada powitanie „dzień dobry” odpowiemy tym samym pozdrowieniem? A jeśli na nasze powitanie odpowie komputer, to czy obdarzymy go mianem inteligentnego? Co to jest inteligencja? Czym jest sztuczna inteligencja? Jakie problemy są rozważane na jej gruncie? Kiedy powstała sztuczna inteligencja? Czym się ona zajmuje? Tych zagadnień dotyczy ten rozdział.
Słownik języka polskiego definiuje pojęcie inteligencji następująco:
inteligencja to zdolność rozumienia otaczających sytuacji i znajdowania na nie właściwych, celowych reakcji.
Z kolei Wielka Internetowa Encyklopedia Multimedialna określa inteligencję jako:
zespół zdolności umysłowych umożliwiających jednostce korzystanie z nabytej wiedzy przy rozwiązywaniu nowych problemów i racjonalnym zachowaniu w różnych sytuacjach życiowych.
Inteligencję definiuje też Internetowa encyklopedia PWN:
Inteligencja to cecha umysłu warunkująca sprawność czynności poznawczych, takich jak myślenie, rozwiązywanie problemów; od inteligencji zależy sprawne korzystanie z nabytej wiedzy, a także skuteczne zachowanie się wobec nowych sytuacji i zadań.
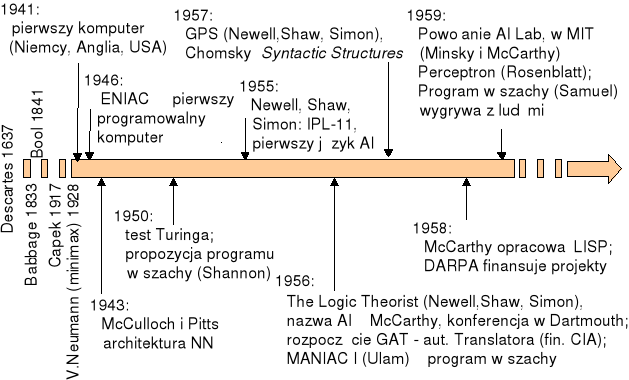
Rys. 3. Ważniejsze fakty związane z początkami sztucznej inteligencji do 1960 roku (źródło: opracowanie własne na podstawie rysunku z wykładu prof. Haliny Kwaśnickiej z Politechniki Wrocławskiej)
Czy zdefiniowana w ten sposób inteligencja jest cechą właściwą tylko człowiekowi? Aby odpowiedzieć na to pytanie zastanówmy się, czy komputer może rozumować, rozwiązywać problemy, uczyć się, właściwie reagować w nowych, nieznanych mu wcześniej, sytuacjach? Okazuje się, że często tak! Czy zatem komputer może być inteligentny, czy można mówić o inteligencji maszyn, o sztucznej inteligencji? Kiedyś, konkretnie pod koniec lat 40., gdy powstawały pierwsze komputery, samo postawienie takiego pytania budziło oburzenie. Jak można maszynie przypisywać atrybut tak nierozerwalnie związany z człowiekiem, jak inteligencja?! Dzisiaj o maszynach i o ich możliwościach wiemy o wiele więcej i dlatego dla nas odpowiedź jest oczywista: Tak, można (a nawet trzeba) mówić o sztucznej inteligencji. Spróbujmy prześledzić, jak do tego doszło (patrz rysunek 3).
Pojęcie sztucznej inteligencji zrodziło się w 1956 roku. Wówczas to John McCarthy - profesor matematyki na uniwersytecie w Dartmouth College w New Hampshire (Stany Zjednoczone), zorganizował seminarium wakacyjne, w trakcie którego uczestnicy zastanawiali się, jakie aspekty działalności ludzkiej mogą zostać zastąpione przez komputer. Tam właśnie po raz pierwszy użyto terminu „sztuczna inteligencja” obejmującego działalność zmierzającą do konstruowania urządzeń i programów zdolnych do wykonywania zadań, które - gdyby były rozwiązywane przez człowieka - wymagałyby zaangażowania jego inteligencji (autorem tej definicji był inny uczestnik wspomnianego spotkania - Marvin Minsky).
Rys. 4. Ważniejsze fakty związane z wczesnym etapem rozwoju sztucznej inteligencji (źródło: opracowanie własne na podstawie rysunku z wykładu prof. Haliny Kwaśnickiej z Politechniki Wrocławskiej)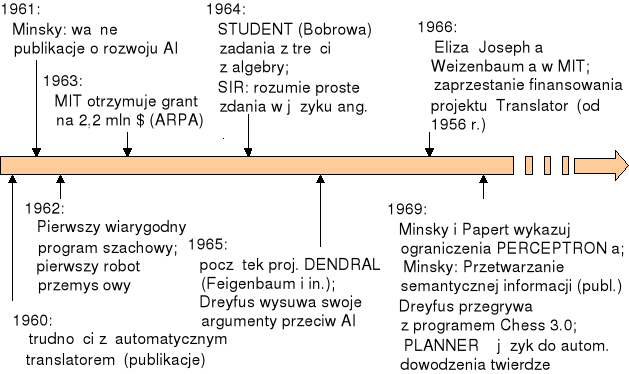
Potem sprawy potoczyły się z szybkością lawiny (patrz rysunki: 4, 5, 6 i 7). Skoro zgodzono się, że komputer może konkurować z ludzkim mózgiem - to zaczęto szturmować kolejne obszary, w których monopol ludzkiego myślenia zdawał się szczególnie łatwy do zakwestionowania. Zaczęły powstawać programy dowodzące twierdzenia matematyczne, grające w różne gry, rozwiązujące łamigłówki, rozpoznające obrazy, kojarzące fakty, prowadzące konwersacje w języku naturalnym itd. Sztuczna inteligencja przeszła ze sfery mitu do sfery praktyki. Departament Obrony USA w wydawanym czasopiśmie Software Technology Strategy w grudniu 1991 roku definiuje sztuczną inteligencję jako:
gałąź informatyki zajmującą się rozwojem technologii pozwalającej komputerom na rozwiązywanie problemów (lub wspomaganie człowieka w tym procesie) przy wykorzystaniu metod wnioskowania i zgromadzonej w systemie wiedzy.
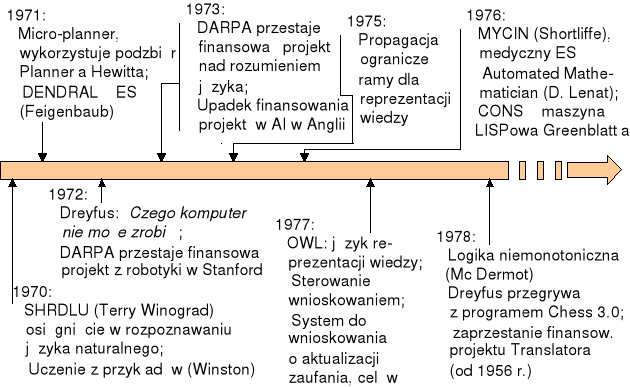
Rys. 5. Lata 70. to „złoty okres” najszybszego rozwoju sztucznej inteligencji i najśmielszych nadziei z nią wiązanych (źródło: opracowanie własne na podstawie rysunku z wykładu prof. Haliny Kwaśnickiej z Politechniki Wrocławskiej)
Włodzisław Duch, jeden z największych polskich autorytetów w dziedzinie sztucznej inteligencji definiuje ją w następujący sposób:
Sztuczna inteligencja to dziedzina nauki zajmująca się rozwiązywaniem zagadnień efektywnie niealgorytmizowalnych w oparciu o modelowanie wiedzy.
Halina Kwaśnicka, prowadząca badania nad zagadnieniami sztucznej inteligencji w Politechnice Wrocławskiej stwierdza, że sztuczna inteligencja to:
rozwiązywanie problemów sposobami wzorowanymi na naturalnych działaniach i procesach poznawczych człowieka za pomocą symulujących je programów komputerowych.
Wszystkie przytoczone definicje wskazują na podstawowe cechy sztucznej inteligencji:
jest to gałąź informatyki,
zajmująca się konstruowaniem rozwiązań programowych i sprzętowych,
pozwalających na gromadzenie wiedzy,
i jej wykorzystanie w celu dostarczania rozwiązań nietrywialnych problemów.
Wymienione powyżej „nietrywialne problemy” obejmują obecnie między innymi: automatyczne wnioskowanie, porozumiewanie się przy użyciu języków naturalnych, rozgrywanie gier logicznych (np. w szachy), tworzenie systemów ekspertowych i wiele innych dziedzin.
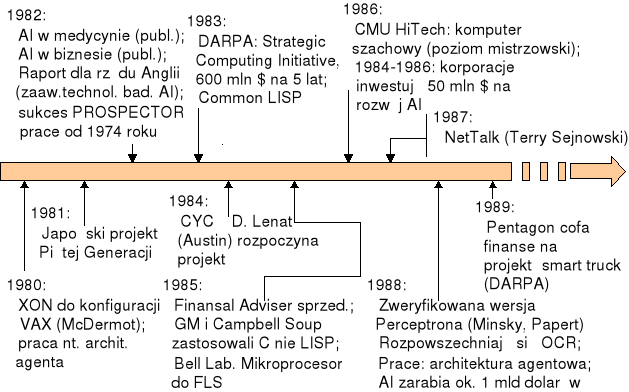
Rys. 6. Lata 80. to okres pierwszych skutecznych zastosowań praktycznych sztucznej inteligencji (źródło: opracowanie własne na podstawie rysunku z wykładu prof. Haliny Kwaśnickiej z Politechniki Wrocławskiej)
Pod koniec XX wieku (w latach 90.) w dziedzinie sztucznej inteligencji ukształtowała się ciekawa sytuacja, nieco podobna do tej, z jaką mieliśmy do czynienia w astronautyce po wylądowaniu Człowieka na Księżycu. Osiągnięty sukces zamiast inspirować do dalszych wysiłków - paradoksalnie spowodował zblazowanie i znudzenie, co zaowocowało gwałtownym wyhamowaniem bardzo obiecującego rozwoju. W sztucznej inteligencji w latach 90. wydarzyło się coś podobnego: Z jednej strony zanotowano liczne sukcesy, zwłaszcza w zastosowaniach praktycznych. Jednym ze źródeł tych sukcesów był fakt szerokiego stosowania w sztucznej inteligencji metod opartych na biologicznych źródłach inspiracji (na przykład wyjątkowo chętnie i często stosowano sieci neuronowe i algorytmy genetyczne). Zanotowano spektakularny sukces, jakim była wygrana programu Deep Blue w meczu szachowym z arcymistrzem Garri Kasparowem. Równocześnie jednak zaznaczył się trend do dzielenia jednolitej dotychczas sztucznej inteligencji na działy oraz kierunki, które zaczęły się rozwijać niezależnie, dając początek zjawisku nazywanemu czasem „diasporą sztucznej inteligencji”. Fakt ten ma duży wpływ na obraz sztucznej inteligencji obserwowany aktualnie - zarówno w obszarze badań naukowych, jak i w dziedzinie zastosowań.
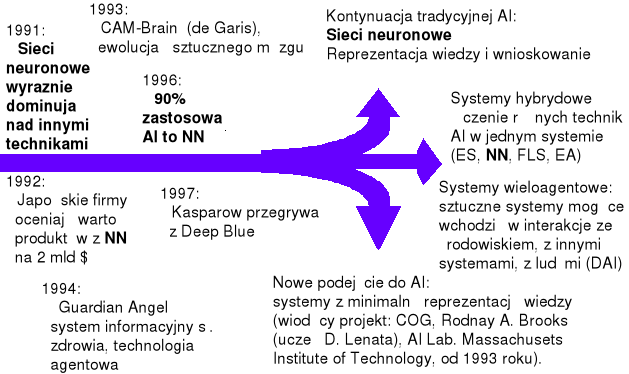
Rys. 7. Lata 90. to początek „diaspory” sztucznej inteligencji - z jednolitej początkowo dziedziny wyodrębniają się niezależne nurty, które mają ze sobą coraz mniej wspólnego
(źródło: opracowanie własne na podstawie rysunku z wykładu prof. Haliny Kwaśnickiej z Politechniki Wrocławskiej)
Chociaż, jak wyżej wspomniano, nazwę „sztuczna inteligencja” zaproponował Marvin Minsky, to jednak powszechnie za ojca sztucznej inteligencji uważany jest matematyk angielski Alan Turing (1912 - 1954). Badacz ten w prowadzonych przez siebie pracach badawczych (na przełomie lat 40. i 50.) rozważał możliwość samodzielnego nabywania wiedzy przez komputery i prowadzenia przez nie indukcyjnego a także dedukcyjnego rozumowania. Turing był przekonany, że komputer będzie można uznać za myślący, jeśli będzie on w stanie prowadzić rozmowę z użytkownikiem w języku naturalnym w sposób taki, że sztuczna tożsamość rozmówcy będzie dla człowieka niezauważalna. W 1950 roku zaproponował on nawet formalną procedurę badawczą (tzw. test Turinga) pozwalającą sprawdzić empirycznie, czy komputer posiada zdolność do myślenia. Test ten zakładał, że zamknięty w pokoju człowiek ma możliwość komunikowania się za pośrednictwem konsoli z innymi podmiotami, których jednak nie może bezpośrednio obserwować. Ów człowiek - przystępując do konwersacji - nie wie, czy jego partnerem w rozmowie będzie inny człowiek, czy komputer. Jeśli nasz zamknięty w pokoju rozmówca po dłuższej wymianie zdań i opinii będzie przekonany, że rozmawiał z człowiekiem, a w rzeczywistości będzie prowadzić rozmowę z komputerem, to będzie można uznać, że komputer ów posiadł inteligencję właściwą człowiekowi (patrz rysunek 8). Warto stwierdzić, że do tej pory żaden komputer nie przeszedł pomyślnie testu zaproponowanego przez Turinga, chociaż niektóre z programów prowadzących dialog w języku naturalnym (np. tzw. talk-boty ulokowane w różnych miejscach w Internecie) są bliskie tego ideału.
Rys. 8. Schemat „Testu Turinga”. (źródło: opracowanie własne na podstawie rysunku z wykładu prof. Haliny Kwaśnickiej z Politechniki Wrocławskiej)
Wyraźnie widoczne w teście Turinga utożsamianie jednej tylko umiejętności (prowadzenia rozmowy) z faktem posiadania inteligencji wywołało wiele dyskusji. Amerykański filozof John Searle, zbudował konstrukcję myślową wskazującą, że maszyna można jedynie mechanicznie przetwarzać język naturalny, nie może go jednak zrozumieć. Jego rozumowanie znane jest pod nazwą Argumentu chińskiego pokoju. Przedstawia on człowieka zamkniętego w pokoju i komunikującego się z otoczeniem za pomocą wymiany kartek z napisami (patrz rysunek 9). Człowiek ten z założenia nie zna języka chińskiego, lecz jest wyposażony w niezwykle szczegółową instrukcję, zwierającą wszelkie możliwe reguły (opisane w języku angielskim) czysto mechanicznego stosowania znaków alfabetu chińskiego do tworzenia wypowiedzi w tym języku. Wyposażony w taka wiedzę ów człowiek odpowiada na przedstawione mu na piśmie w języku chińskim pytania w taki sposób, że pytający (rodowity Chińczyk) ma wrażenie, iż koresponduje z kimś znającym jego język, chociaż w rzeczywistości zamknięty w pokoju osobnik nie rozumie ani znaków zawierających stawiane mu pytania, ani znaków, które sam wypisuje (zgodnie z regułami posiadanej instrukcji) jako odpowiedzi. Searle wskazuje, że w tym przypadku następuje jedynie żonglowanie symbolami którego wynikiem jest przetwarzanie języka, ale znając stan umysłu i świadomości działającego podmiotu (zamkniętego w pokoju człowieka) możemy być całkowicie pewni, że nie można mówić o zrozumieniu języka. Przedstawiona sytuacja jest obrazem aspirującego do inteligencji programu komputerowego - pokój to komputer, człowiek to procesor realizujący program, zaś czytane i przetwarzane zdania to dane wejściowe i wyjściowe. Searle dochodzi do wniosku, że program komputerowy nigdy nie zrozumie zdań w języku naturalnym. Dopuszcza możliwość, że komputer przejdzie przez test Turinga, ale podkreśla, że nie będzie to oznaczało, że program posiada cechy właściwe człowiekowi - gdyż program nie rozumie, nie ma świadomości, lecz jedynie automatycznie realizuje zlecone mu instrukcje.
Rys. 9. Koncepcja „Chińskiego Pokoju”, zaproponowana przez Searle'a, służąca do kwestionowania idei „Testu Turinga” (źródło: opracowanie własne na podstawie rysunku z wykładu prof. Haliny Kwaśnickiej z Politechniki Wrocławskiej)

Do twórców sztucznej inteligencji zaliczyć należy również Norberta Wienera (1894 - 1964), amerykańskiego matematyka (pochodzenia żydowskiego; jego ojciec, Leo ukończył studia w Warszawie, później przebywał w różnych krajach europejskich, aż ostatecznie osiedlił się w Stanach Zjednoczonych), twórcę cybernetyki. W 1948 roku opublikował on pracę Cybernetyka czyli sterowanie i komunikacja w zwierzęciu i maszynie (Cybernetics, or control and communication in the animal and the machine). Słowo cybernetyka pochodzi od greckiego słowa kybernētes, gdzie oznacza sternika lub zarządcę. Jako ciekawostkę warto odnotować mało znany fakt, że w odniesieniu do sterowania lub zarządzania termin cybernetyka został użyty wiele lat przed ukazanie się książki Wienera, konkretnie w roku 1843 przez polskiego filozofa Bronisława Trentowskiego, autora książki Stosunek filozofii do cybernetyki, czyli sztuki rządzenia narodem.
Jednym z filarów stosowanych na gruncie sztucznej inteligencji metod rozwiązywania problemów jest teoria gier. Jednym z jej twórców był John von Neumann (1903 - 1957), wybitny Amerykanin węgierskiego pochodzenia, który przyczynił się nie tylko do rozwoju teorii gier i sztucznej inteligencji (jest między twórcą strategii minimaksowej), ale również wypracował koncepcję architektury logicznej współczesnych komputerów (tzw. maszyna von Neumanna). Przyczynił się on również do rozwoju potęgi militarnej Stanów Zjednoczonych, zwłaszcza w zakresie zastosowań energii atomowej.
Za szczególnie interesujące należy uznać prace zmierzające do przekształcenia komputera w sztuczny mózg. Początki były bardzo obiecujące. W 1943 roku dwaj uczeni amerykańscy: W. S. McCulloch i W. H. Pitts przedstawili pierwszy matematyczny model neuronu, podstawowej komórki stanowiącej główny element strukturalny mózgu. Ich prace stanowiły początek badań nad sztucznymi sieciami neuronowymi będącymi dzisiaj zarówno formalnymi modelami struktur mózgowych, jak i praktycznymi narzędziami informatycznymi wykorzystywanymi do rozwiązywania wielu problemów związanych z opisem występujących w świecie rzeczywistym prawidłowości, związanych z klasyfikacją zjawisk, ich kojarzeniem czy prognozowaniem.
Problemy związane z budową sztucznego mózgu były również tematem dociekań naukowych wspomnianego już powyżej Johna von Neumanna. Prowadząc prace nad zwiększeniem możliwości komputerów studiował on neurologię oraz psychiatrię, wierząc, że komputer może pracować w sposób naśladujący pracę ludzkiego mózgu. Swoje przemyślenia w tym zakresie zawarł w książce Maszyna matematyczna a mózg ludzki (The Computer and the Brain). Niestety, swojego dzieła nie ukończył. Zmarł z powodu choroby nowotworowej kości w 1957 roku.
Zasadniczym celem konstruowania systemów sztucznej inteligencji było i jest rozwiązywanie różnych praktycznych problemów. Ten nurt badań zapoczątkowali Allan Newell i Herbert Simon, którzy postawili sobie za cel prac utworzenie programu służącego do rozwiązywania dowolnych problemów. W założeniach twórców program ten (nazwany GPS od General Problem Solver) mógł rozwiązywać zagadnienia z dowolnej dziedziny, jeśli tylko zostały we właściwy sposób opisane. Chcieli oni osiągnąć swój cel próbując skonstruować program, który w swoim działania naśladowałby zachodzące u człowieka procesy rozumowania, odkrywania wiedzy i podejmowania decyzji. Po blisko dziesięciu latach pracy musieli się przyznać do porażki: będący efektem ich prac był system GPS nigdy nie rozwiązał żadnego problemu.
Dokonując przeglądu badaczy zaliczanych do twórców sztucznej inteligencji należy choćby w bardzo skrótowy sposób przedstawić dokonania wspomnianych już badaczy: John'a McCarthy'ego oraz Marvina Minsky'ego. Lista dokonać John'a McCarthy'ego jest długa: jest to jeden z bardziej produktywnych twórców sztucznej inteligencji, twórca języka programowania Lisp (jest to język należący do podstawowych narzędzi wykorzystywanych przez badaczy z zakresu sztucznej inteligencji, pozwalający na wykonywanie operacji na abstrakcyjnych symbolach, a nie tylko na konkretnych wartościach liczbowych), badacz formalnych metod dowodzenia poprawności programów komputerowych itp.. Natomiast zainteresowania badawcze Marvin'a Minsky'ego skupiają się wokół problematyki reprezentacji wiedzy, sieci neuronowych oraz robotyki.
Zagadnienia rozważane na gruncie sztucznej inteligencji
Zamieszczony powyżej przegląd definicji pojęcia sztucznej inteligencji pozwala się domyślać, że podstawowe problemy rozważane na jej gruncie związane będą z realizacją procesów pozyskiwania, gromadzenia i przetwarzania wiedzy. Wiedza musi być przy tym odróżniona od informacji, których gromadzenie przetwarzanie w systemach komputerowych jest oczywiste i łatwe. Wiedza składa się z wiadomości, czyli odpowiednio spreparowanych informacji, cechą wiedzy jest jednak to, że kolekcji wiadomości, będących jej budulcem, nadana jest odpowiednia struktura (współzależności i powiązań nazywanych obecnie w sieciach semantycznych ontologią) oraz to, że posiadanie wiedzy wiąże się zawsze z możliwością jej wykorzystania przy rozwiązywaniu problemów decyzyjnych, podczas gdy same informacje w rozwiązywaniu czegokolwiek bezpośrednio nie pomagają.
Pozyskiwanie wiedzy
Jak wskazano w zakończeniu poprzedniego punktu, warunkiem koniecznym do rozwiązywania przez system komputerowy złożonych problemów jest wyposażenie go w wiedzę (rozumianą jako ogół informacji i ich powiązań, dotyczących zwykle pewnej, ściśle określonej dziedziny). Można mówić o dwóch sposobach zasilenia systemów sztucznej inteligencji w wiedzę. Pierwsza metoda zakłada, że człowiek przekazuje systemowi posiadaną przez siebie wiedzę. Drugi sposób zakłada, że systemowi prezentowane są różnorodne przykłady, z których wyciąga on użyteczne informacje, które następnie są uogólniane i tworzą wiedzę przydatną w rozwiązywaniu problemów także znacząco odmiennych od tych, które prezentowano w ramach przykładów (taka metoda pozyskiwania wiedzy określana jest często uczeniem się systemu).
Wybór pierwszej z wymienionych metody pozyskiwania wiedzy zakłada, że do systemu przekazywana jest wiedza uzyskana bezpośrednio od człowieka pełniącego rolę eksperta w danej dziedzinie. Realizacja takiego procesu wymaga:
precyzyjnego określenia dziedziny wiedzy uwzględnionej w systemie - ze względu na ogrom wiedzy możliwe jest tylko tworzenie systemów dziedzinowych, a nie takich, które zostałyby wyposażone w ogół wiedzy na każdy możliwy temat,
zebrania, selekcji, weryfikacji i doboru faktów prezentowanych systemowi,
określenia sposobu prezentacji wiedzy - zwykle program komputerowy nie jest w stanie zrozumieć przekazu formułowanego w języku naturalnym (a w takiej postaci najchętniej wyraża swoją wiedzę zapytywany ekspert), dlatego też konieczne jest opracowanie formalnych reguł reprezentowania wiedzy w takiej formie, by nie uronić niczego z mądrości eksperta, a jednocześnie pozwolić komputerowi na efektywne korzystanie z niej w sformalizowanych procedurach automatycznego wnioskowania,
zaprojektowania takiego sposobu komunikowania się człowieka z systemem, by system mógł poprawnie reagować na zapytania użytkownika, mające z reguły mało sformalizowaną i nieprecyzyjną postać, a także by odpowiedź systemu była dla użytkownika zrozumiała i przydatna bez konieczności odwoływania się do skomplikowanej interpretacji.
Duża liczba problemów pojawiających się w trakcie akwizycji wiedzy wymaga, aby praca człowieka-eksperta (będącego dawcą wiedzy) wspomagana była przez specjalistę pomagającego mu w przekazaniu tej wiedzy systemowi komputerowemu. Specjalista taki nazywany jest zwykle inżynierem wiedzy. Praca inżyniera wiedzy polega na uzyskaniu wiedzy od eksperta (głównie w drodze wywiadu lub specjalnej ankiety), zakodowaniu jej w postaci użytecznej dla komputera i wprowadzeniu wiedzy do systemu.
Drugi sposób pozyskiwania wiedzy polega na samodzielnym uczeniu się systemu. W tym przypadku odpowiednio skonstruowana procedura analizuje prezentowane przykłady, na które składać się mogą (zależnie od dziedziny zastosowań) rozmaite fakty, informacje, obserwacje itp.. Maszyna rejestruje te przykłady w swojej pamięci (w zależności od stosowanej techniki uczenia odbywa się to w różny sposób), następnie je uogólnia, generalizuje, eliminuje występujące w przykładach sprzeczności lub niedomówienia, a wreszcie przekształca w wiedzę dotyczącą rozpatrywanego wycinka rozważanej rzeczywistości w taki sposób, by była to wiedza operatywna przy rozwiązywaniu praktycznych problemów. Taki sposób pozyskiwania wiedzy jest bardzo obiecujący, gdyż pozwala systemowi sztucznej inteligencji samodzielnie odkryć wiedzę, co może być dokonane na przykład poprzez analizę baz i hurtowni danych (jest to tak zwane drążenie lub przekopywanie danych /ang. data mining/). Uczenie maszyn jest techniką wygodną, gdyż nie wymaga ciągłych konsultacji z ekspertem, a także pozwala na łatwą aktualizację wiedzy (poprzez prezentację nowych faktów - tzw. douczanie systemu).
Gromadzenie wiedzy
Wiedza przekazane do systemu (pochodząca od eksperta lub pozyskana w wyniku uczenia się) powinna być we właściwy sposób gromadzona w bazie wiedzy. Dokonując choćby bardzo powierzchownego przeglądu opisywanych w literaturze metod gromadzenia wiedzy można dostrzec olbrzymią różnorodność stosowanych rozwiązań. Warto w tym miejscu dokonać krótkiego przeglądu najczęściej wymienianych rozwiązań:
Regułowe bazy wiedzy. Stosowanie tego sposoby reprezentacji wiedzy sprowadza się do utworzenia bazy wiedzy składającej się z szeregu stwierdzeń, pozwalających na scharakteryzowanie obiektów (stwierdzenia te przyjmują postać trójki: {obiekt, cecha, wartość} i pozwalają na określenie wartości cech charakteryzujących rozpatrywane obiekty) oraz reguł pozwalających na późniejsze przetwarzanie zgromadzonej wiedzy w celu automatycznego wyciągania wniosków z określonych przesłanek (reguły te przyjmują najczęściej postać jeżeli ... to ... i funkcjonują w sposób zbliżony do instrukcji warunkowej występującej w językach programowania);
Ramowa reprezentacja wiedzy. Rama jest strukturą danych służącą do opisu rozpatrywanych obiektów. Rama jest strukturą złożoną - składa się z elementów składowych zwanych klatkami albo szczelinami (ang. slots). Klatki służą do przechowywania opisu różnych aspektów obiektu reprezentowanego przez ramę. Klatka również jest strukturą złożoną i składa się z faset pozwalających na określenie wartości poszczególnych cech obiektu. Dopuszcza się umieszczania w fasetach wartości typu prostego (np. liczb, ciągów znaków) jak również wartości złożonych - na przykład opisanych za pomocą innych ram. Istotną cechą ramowej reprezentacji wiedzy jest jej hierarchiczny charakter, przejawiający się w definiowaniu zależności hierarchicznych pomiędzy poszczególnymi ramami. Taka struktura pozwala na dziedziczenie cech ram - przodków przez ramy potomne (np. rama bank spółdzielczy może zostać zdefiniowany jako potomek ramy bank).
Bazy wiedzy oparte na sieciach semantycznych. Jest to model asocjacyjny, pozwalający przede wszystkim na uwypuklenie powiązań pomiędzy gromadzonymi faktami. Inspirację dla twórców tego sposobu gromadzenia wiedzy stanowił mózg ludzki, w którym także (jak wynika z psychologii) przechowywane są powiązane ze sobą fakty. Podobne rozwiązanie przyjęto w sieciach semantycznych, w których do opisu wiedzy stosuje się grafy. Węzły grafu reprezentują fakty, zaś jego krawędzie opisują powiązania pomiędzy faktami. Analiza danych opisanych za pomocą sieci polega w głównej mierze na „wędrówce” po grafie - przechodząc po krawędzi łączącej dwa węzły (fakty) poznajemy rodzaj wiążącej je relacji. Rozwiązania wypracowane przy tworzeniu sieci semantycznych łączone są często z osiągnięciami reprezentacji ramowej - w takim hybrydowym rozwiązaniu węzłami sieci są ramy, a krawędzie wskazują na relacje pomiędzy ramami.
Modelowe ujęcie wiedzy. Takie rozwiązanie zakłada, że wiedza opisana zostanie za pomocą pewnych modeli (najlepiej matematycznych, chociaż bywają reprezentacje modelowe odwołujące się do ujęć innych niż matematyczne). Ujęcie modelowe jest szczególnie przydatne do reprezentacji istniejących powiązań pomiędzy rozpatrywanymi obiektami lub pojęciami. Można wskazać na dwa podstawowe rodzaje modeli.
Pierwszą grupę stanowią modele reprezentujące istniejące prawa. Opisują one zależności istniejące pomiędzy badanymi zjawiskami. Prawo takie wyrażane jest najczęściej za pomocą równania lub zespołu równań.
Drugim rodzajem modeli są modele adaptacyjne. Są one konstruowane w procesie uczenia na podstawie danych procesowych i reprezentują wiedzę pozyskaną poprzez drążenie danych. Modele tego typu mogą przyjmować mogą postać równania, zestawu równań, sztucznej sieci neuronowej lub drzewa decyzyjnego.Tekstowe bazy wiedzy. W tym przypadku wiedza opisywana jest w wybranym języku naturalnym. Taki sposób gromadzenia wiedzy jest bardzo dogodny, gdyż pozwala na bezpośrednie umieszczenie w systemie wiedzy pozyskanej od eksperta w postaci czytelnej dla każdego człowieka, a więc łatwo weryfikowalnej. Tekstowy sposób gromadzenia i reprezentacji wiedzy nie wymaga czasochłonnego i często kłopotliwego przekształcania pozyskanej wiedzy od postaci językowej (w jakiej ją zgromadzono) do postaci wymaganej przez przyjęty sposób jej reprezentacji. Z uwagi na niski stopień sformalizowania stwierdzeń formułowanych w językach naturalnych tekstowe bazy wiedzy są stosunkowo trudne do eksploatacji w trakcie dalszego ich wykorzystywania (np. przeszukiwania lub wnioskowania). Tekstowe bazy wiedzy są jednak szczególnie dogodnym sposobem opisu pewnego typu danych, które bardzo trudno jest przekształcić do postaci bardziej formalnej, co implikuje między innymi stosowanie ich jako rozwiązań z wyboru dla wszelkich baz wiadomości prawnych i organizacyjnych. Mają one także duże znaczenie w systemach budowanych na potrzeby nauk społecznych i humanistycznych.
Przetwarzanie wiedzy
Najistotniejszym etapem pracy każdego systemu sztucznej inteligencji jest zastąpienie lub wspomożenie człowieka w procesie decyzyjnym. Realizacja tego etapu może polegać na doradztwie to znaczy może opierać się jedynie na udzielaniu przez system odpowiedzi na formułowane przez użytkownika zapytania, czasem jednak system może całkowicie zastępować człowieka przy podjęciu decyzji rozwiązującej postawiony problem. Zastosowania systemów sztucznej inteligencji mogą polegać także czasem na zaawansowanym przekształceniu informacji (w celu ułatwienia decyzji poprzez oddzielenie faktów istotnych od nieistotnych) lub też mogą polegać na uzasadnieniu (lub krytykowaniu czy wręcz odrzucaniu) sformułowanej przez człowieka hipotezy. W zależności od celu oraz od przyjętego sposobu reprezentacji wiedzy swoje zadanie system może realizować na wiele sposobów. Zostaną one teraz krótko scharakteryzowane.
Wnioskowanie
Ważnym elementem funkcjonowania większości systemów sztucznej inteligencji jest automatyczne wnioskowanie, czyli zespół działań pozwalających na analizowanie dostępnych faktów za pomocą przyjętych reguł prowadzone w celu uzyskania nowych faktów.
Klasyczne metody wnioskowania wywodzą się bezpośrednio z logiki formalnej, a dokładniej mówiąc z jej dwóch działów zwanych rachunkiem zdań (za jego twórcę uważa się niemieckiego logika Gottloba Frege /1948 - 1925/) oraz rachunkiem predykatów. Można wyróżnić trzy podstawowe metody wnioskowania. Są to:
wnioskowanie do przodu - Polega ono na tym, że przetwarzając dostępne fakty za pomocą dostępnych reguł generuje się nowe fakty. Jeśli celem postępowania jest weryfikacja postawionej hipotezy, to przedstawiony proces realizuje się aż do momentu uzyskania stwierdzenia zgodnego z hipotezą (co potwierdza jej prawdziwość) lub do chwili stwierdzenia, że na podstawie dostępnej wiedzy (faktów i reguł ich przekształcania) nie jest możliwe potwierdzenie postawionej hipotezy (co na ogół jest równoważne z jej falsyfikacją).
wnioskowanie do tyłu - we wnioskowaniu od tyłu kierunek poszukiwań jest przeciwny do wyżej opisanego. Jeśli wnioskowanie ma na celu potwierdzenie prawdziwości postawionej hipotezy, to proces rozumowania rozpoczyna się od analizy oczekiwanego stwierdzenia końcowego. W posiadanej bazie reguł wyszukiwane są wszystkie te, z których może wypływać wniosek zgodny z weryfikowaną hipotezą. Jeśli przesłanki tych reguł są zawarte w zbiorze posiadanych faktów, to hipotezę można uznać za prawdziwą. Jeśli nie, to w kolejnym kroku próbuje się dowieść prawdziwości nowych przesłanek. Proces wnioskowania kończy się sukcesem, gdy uda się wykazać, że przesłankami (bezpośrednimi bądź pośrednimi) dla weryfikowanego stwierdzenia są dostępne fakty. Wnioskowanie wstecz może być efektywniejsze obliczeniowo od wnioskowania w przód (omówionego wcześniej), ponieważ w większości zadań, które trzeba rozwiązywać, mamy duży zbiór przesłanek i tylko jeden pożądany (oczekiwany) wniosek. Przy wnioskowaniu w przód trzeba zbadać (teoretycznie) wszystkie drogi wychodzące ze wszystkich dostępnych przesłanek w celu znalezienia wśród nich tej drogi, która wiedzie do pożądanej tezy końcowej (lub do jej zaprzeczenia). Natomiast przy wnioskowaniu wstecz pierwszy krok procesu poszukiwania jest zdeterminowany przez pożądany (oczekiwany) cel, a wzrost liczby kombinacji na drodze od wniosku do przesłanek (które go mogą potwierdzić lub wykazać jego fałszywość) jest znacznie wolniejszy od typowej „eksplozji kombinatorycznej” koniecznych do zbadania wariantów, która wyłania się przy wnioskowaniu wprost.
Wnioskowanie wstecz jest w technikach sztucznej inteligencji stosowane rzadziej, niż by to wynikało z logicznego rozważenia wyliczonych wyżej przesłanek, ponieważ dla człowieka wnioskowanie wstecz jest psychologicznie trudniejsze, a metody sztucznej inteligencji są często tworzone jako modele procesów myślowych stosowanych w określonych sytuacjach przez człowieka. Jednak z racjonalnego punktu widzenia taka dyskryminacja jest bezsensowna, ponieważ komputer z równą łatwością wykorzystuje zarówno w przód jak i wstecz wszelkie posiadane w bazie wiedzy relacje, przeto wnioskowanie wstecz realizowane automatycznie nie jest wcale trudniejsze, niż popularne i intuicyjnie bardziej oczywiste wnioskowanie w przód.wnioskowanie mieszane - strategia wnioskowania mieszanego polega na łącznym stosowaniu techniki rozumowania do przodu i do tyłu. Zastosowany algorytm powinien dokonywać wyboru najlepszego dla rozważanego problemu podejścia i podejmować decyzję o zmianie stosowanej techniki.
Wymienione metody przeprowadzania rozumowania przez system sztucznej inteligencji mają bardzo rozległy obszar zastosowań. Stanowią one o sile systemów ekspertowych, gdyż pozwalają na konstruowanie użytecznych odpowiedzi na dowolne zadawane przez użytkowników pytania, w tym także na pytania, których brzmienie było niemożliwe do przewidzenia w momencie tworzenia systemu. Zaprezentowanie przez system odpowiedzi może być wzbogacone (na życzenie użytkownika) uzasadnieniem, w którym pokazuje się, jak znaleziono podany przez komputer wniosek wraz ze wskazanymi wszystkimi przesłankami pobranymi w tym celu z bazy faktów oraz ze szczegółowym opisem sposobu przeprowadzenia wnioskowania. Takie uzasadnienie w dużym stopniu uwiarygodnia odpowiedź systemu, a w określonych sytuacjach może także przyczynić się do wykrycia i do eliminacji odpowiedzi błędnej, jeśli użytkownik wykryje w uzasadnieniu fakt albo regułę, które w danej konkretnej sytuacji nie powinny były być zastosowane.
Metody wnioskowania używane są obecnie do tworzenia dróg rozumowania na dowolne tematy, warto jednak wspomnieć, że pierwotnie powstały one w celu stworzenia systemów automatycznego dowodzenia twierdzeń matematycznych. Zadanie komputera w tych pracach (których początki sięgają lat 70.) polegało na rozstrzygnięciu, czy przedstawione twierdzenie matematyczne jest prawdziwe, czy też nie. W przypadku pozytywnej odpowiedzi system komputerowy powinien był przedstawić dowód twierdzenia. W zależności od przyjętego sposobu wnioskowania procedura dowodzenia polegała na przekształcaniu weryfikowanego twierdzenia aż do momentu otrzymania aksjomatów lub też na przekształcaniu aksjomatów w sposób prowadzący do uzyskania analizowanego twierdzenia. Powodzenie realizowanych przekształceń świadczy o prawdziwości twierdzenia, natomiast niepowodzenie nie zawsze odpowiadało sytuacji braku prawdziwości twierdzenia. Pierwszym systemem funkcjonującym w ten sposób był Logic Theorist. Twórcami programu byli Simon, Newell i Shaw. Program powstał w 1956 roku. Bazując na kilku aksjomatach i kilku regułach był w stanie dowieść 38 twierdzeń dotyczących rachunku zdań spośród 52 zawartych w pracy Principia Mathemathica Whitheada i Russela.
Wspomniane powyżej metody wnioskowania oparte są na logice dwuwartościowej, uznającej istnienie dwóch stanów (tak - nie, prawda - fałsz) i nie dającej możliwości reprezentowania stanów pośrednich (typu: „raczej mało prawdopodobne” albo „to jest częściowo prawda”). Taką możliwość dała wprowadzona przez Lofti Zadeha nowatorska koncepcja wnioskowania rozmytego, pozwalająca na prowadzenie rozumowania w oparciu o nieprecyzyjne (nieostre, rozmyte) fakty - znane z codziennej praktyki.
Systemy wspomagania decyzji
Zasadniczym celem tego typu systemów jest wypracowywanie przez system decyzji właściwej dla zaistniałej sytuacji. W niektórych zastosowaniach decyzja wypracowana przez system jest niezwłocznie (bez przeanalizowania jej przez człowieka) przekazywana do realizacji. W innych zastosowaniach niezbędne jest zaakceptowanie wypracowanej przez system decyzji przez znającego problem człowieka. Do bardzo spektakularnych zastosowań systemów wspomagających procesy decyzyjne należą programy grające w rozmaite gry. Jeśli gry te są logiczne (np. szachy, warcaby) to programy komputerowe potrafią grać w nie na mistrzowskim poziomie. Systemy tego typu mają charakter zabawek, jednak po odpowiednim przedefiniowaniu zasad i reguł mogą być one stosowane na szeroką skalę na przykład w wojskowości a także mogą się okazać użyteczne w zastosowaniach ekonomicznych. Do najbardziej znanych ich zastosowań należy zaliczyć programy przygotowujące projekty decyzji kredytowych, wspomagające bankowca (człowieka) w podejmowaniu trudnych i ryzykownych decyzji inwestycyjnych na rynkach kapitałowych. Komputer może w takich przypadkach skutecznie doradzać, co należy uczynić w aktualnej sytuacji, by prowadzić swój biznes w sposób zgodny z założoną długofalową strategią. Podobną rolę odgrywają systemy poszukujące optymalnego sposobu alokacji posiadanych zasobów w wielu innych zastosowaniach (nie tylko na rynku kapitałowym).
Możliwość zastosowania komputerów przy rozwiązywaniu lub wspomaganiu problemów decyzyjnych wymaga opracowania właściwych algorytmów postępowania, co jest możliwe dzięki badaniom prowadzonym przez badaczy zajmujących się bardzo różnorodnymi gałęziami nauki. Filary tej grupy metod sztucznej inteligencji to:
teoria gier - powstały w latach trzydziestych XX wieku dział matematyki (za twórców uznaje się Johna von Neumanna i Oskara Morgensterna), zajmujący się wypracowywaniem i badaniem różnych strategii postępowania stosowanych przez uczestników rozgrywki (która jest swoistym modelem sytuacji wymagającej podjęcia decyzji). Teoria gier znajduje duże zastosowanie w praktyce. W ekonomii służy do opisu zjawisk rynkowych, w informatyce opisuje sytuacje powstające przy ubieganiu się procesów o wspólne zasoby. Jest wykorzystywana do opisu zjawisk społecznych i do interpretacji procesów biologicznych.
Teoria gier osiągnęła tak wysoki stopień efektywności, ponieważ odnosi się ona do sytuacji wysoce sformalizowanych. Każdy uczestnik gry, wykonując swój ruch, realizuje przyjętą przez siebie strategię postępowania. Wykonujący swój ruch gracz chce osiągnąć najlepszą dla siebie sytuację zarówno doraźnie, jak i długofalowo. Taka optymalizacja jest możliwa, ponieważ do oceny jakości ruchu służy jednoznacznie obliczalna funkcja wypłaty, pozwalająca na precyzyjne wyznaczenie zysku osiąganego poprzez wykonanie danego posunięcia. Wystarczy więc, gdy w trakcie gry uczestnik dąży do jego maksymalizacji.
Typowa gra jest sytuacją konfliktową - ruch korzystny dla jednego gracza pociąga za sobą straty drugiego gracza. Jeśli korzyść jednego gracza jest równa stracie ponoszonej przez drugiego uczestnika, to mówimy o grze o sumie zerowej; w przeciwnym przypadku rozpatrywana jest gra o sumie niezerowej. To właśnie teoria gier i jej osiągnięcia pozwoli w 1997 roku na stworzenia oprogramowania pozwalającego komputerowi Deep Blue (firmy IBM) na odniesienie zwycięstwa w pojedynku szachowym z arcymistrzem szachowym Garrim Kasparowem.badania operacyjne - jest to dziedzina wiedzy zajmująca się wypracowywaniem metod podejmowania racjonalnych decyzji. Metody te dostosowane są do sytuacji, w której wiedza opisana jest za pomocą modelu matematycznego, zaś jakość decyzji można wyrazić za pomocą funkcji celu. W takiej sytuacji podjęcie decyzji sprowadza się do problemu minimalizacji lub maksymalizacji funkcji celu przy jednoczesnym zachowaniu warunków ograniczających i/lub warunków brzegowych. Najważniejsze obszary zastosowań badań operacyjnych to optymalna alokacja zasobów i harmonogramowanie prac.
modelowanie statystyczne - modele statystyczne mogą opisywać różne aspekty rzeczywistości. Są one wykorzystywane do opisu zależności (modele regresyjne), definiują reguły klasyfikacji obiektów, pozwalają na badanie i opis struktury zbiorowości obiektów, służą do modelowania i prognozowania szeregów czasowych itp.. W każdym z wymienionych przypadków model statystyczny może stanowić zasadniczy element systemu wspomagającego decyzje.
sieci neuronowe - należą do zaawansowanych modeli matematyczno - statystycznych typu „czarna skrzynka” (model naśladuje zachowanie systemu, nie musi natomiast odwzorowywać jego struktury ani funkcjonujących w systemie zależności przyczynowo-skutkowych). Sieci neuronowe są pod wieloma względami podobne do niektórych wcześniej omówionych metod, posiadają jednak szereg specyficznych cech uzasadniających ich odrębne traktowania. Ważne jest, że są to modele adaptacyjne, w których reguły działania konstruowane są w wyniku procesu uczenia. Są one przystosowane do opisu zjawisk złożonych, o nieznanych a priori charakterystykach. Stanowią zarówno narzędzie prezentacji wiedzy pozyskanej w trakcie uczenia, jak i pozwalają na jej późniejsze wykorzystanie poprzez uogólnianie (generalizację) wyuczonych reguł. Neuronowe systemy decyzyjne wykorzystywane mogą być w zagadnieniach decyzyjnych z zakresu inwestowania, do oceny sytuacji ekonomicznej, do estymowania zdolności kredytowej, do prognozowania wielu zjawisk ekonomicznych i społecznych, a także do jakościowej analizy złożonych wielowymiarowych zbiorów danych.
algorytmy ewolucyjne - stanowią bardzo interesującą grupę metod zaprojektowanych z myślą o podejmowaniu optymalnych decyzji przy braku możliwości zastosowania metod ukierunkowanej (np. gradientowej) optymalizacji. Podstawowym założeniem ich funkcjonowania jest upodobnienie procesu poszukiwania optymalnej decyzji do zachodzących w świecie rzeczywistym procesów ewolucyjnych, zakładających stopniowe przystosowywanie się osobników do wymogów środowiska poprzez realizację zasady doboru naturalnego. Stosowanie metod ewolucyjnych wymaga przyjęcia specyficznego sposobu reprezentacji wiedzy o problemie decyzyjnym. W tym celu stosowane są wektory binarne - tak zwane chromosomy, które podlegają przekształceniom opisanym za pomocą operatów genetycznych - głównie selekcji, krzyżowania i mutacji. Kierunek zachodzących zmian jest wytyczany za pomocą funkcji przystosowania, oceniającej zachodzące zmiany w populacji chromosomów i decydującej o przeżyciu najlepszych „osobników”. Informacje o możliwych zastosowaniach podejścia ewolucyjnego wskazują na jego wielkie możliwości: Zastosowania dla tej techniki obliczeniowej to między innymi procesy inwestycyjne, alokacja zasobów, poszukiwanie optymalnych modeli statystycznych i neuronowych, dobór zmiennych właściwych do opisu badanych zjawisk.
Algorytmy ewolucyjne sprawdzają się dobrze przy zadaniach o dużym stopniu złożoności, wymagają jednak dużych mocy obliczeniowych. Nakład pracy i środków niezbędnych do ich realizacji (przede wszystkim czasu i mocy obliczeniowej komputera) raczej nie uzasadnia ich stosowania w przypadku prób rozwiązania prostych zadań.
Przetwarzanie języka naturalnego
Stosowanie języków naturalnych jest podstawowym sposobem zapewnienia komunikacji międzyludzkiej. Fakt ten uzasadnia olbrzymie wysiłki badaczy podejmowane w celu zastosowania tego sposobu porozumiewania się także do realizacji komunikacji na linii człowiek - komputer. Możliwość stosowania języka naturalnego jako narzędzia gromadzenia wiedzy, formułowania zapytań, wydawania poleceń wpłynęłaby na zakres zastosowań systemów komputerów i uproszczenie sposobów ich wykorzystania. Cele badaczy zajmujących się komputerową analizą języka naturalnego związane są również z zapewnieniem możliwości automatycznego tłumaczenia tekstów oraz żywej mowy pomiędzy różnymi językami naturalnymi, a także wiążą się z analizą zasobów tekstowych czy też z rozumieniem i generowaniem mowy ludzkiej.
Autorem pionierskich prac z zakresu analizy języków naturalnych jest wybitny lingwista Noam Avram Chomsky (ur. 1928), który był przekonany o istnieniu ogólnych reguł gramatycznych pozwalających na stworzenie takiego matematycznego (formalnego) modelu, który umożliwi rozumienie i tworzenie poprawnych zdań w języku naturalnym. W rozumieniu Chomsky'ego gramatyka to zbiór symboli i zbiór reguł określających sposób ich przetwarzania. Zgodnie z jego podejściem można wyróżnić cztery rodzaje gramatyk, przy czym gramatyki języków naturalnych uznał za najbardziej złożone. Mimo ogromnych osiągnięć lingwistyki formalnej (widocznych np. w technikach kompilacji wykorzystywanych przy programowaniu komputerów) wydaje się, że bogactwo języków naturalnych nadal wymyka się ograniczeniom nakładanym przez ich formalny opis.
Prace Chomsky'ego kontynuowane były przez wielu badaczy. Wspomnieć tu należy o osiągnięciach Josepha Weizenbauma, twórcy programu ELIZA, posiadającego umiejętność prowadzenia rozmowy (za pośrednictwem klawiatury i monitora) na pozornie dowolny temat. Program ELIZA stał się pierwowzorem dla wielu dalszych prac zmierzających do utworzenia jeszcze doskonalszych narzędzi rozumiejących, a przynajmniej inteligentnie przetwarzających mowę ludzką. Programy tego typu wzbudzają również obecnie wielkie zainteresowanie i poddawane są ciągłemu doskonaleniu między innymi w kontekście wyzwań tworzonych przez korzystanie z Internetu. Żaden z nich nie przeszedł jednak sprawdzianu zaproponowanego w teście Turinga, choć w nieodległej przyszłości cel ten może zostać osiągnięty.
Jednym z celów badań zmierzających do umożliwienia zrozumienia języka ludzkiego jest stworzenie systemów automatycznego tłumaczenia. Początkowo systemy automatycznego tłumaczenia bazowały na wspomnianych wyżej gramatykach formalnych. Prace w tym zakresie zapoczątkowane zostały pod koniec lat czterdziestych dwudziestego wieku w Stanach Zjednoczonych. W roku 1954 na uniwersytecie Georgetown zaprezentowano opracowany wspólnie z firmą IBM system tłumaczący zdania z języka rosyjskiego na angielski operujący bardzo ubogim słownikiem i tylko kilkoma regułami gramatycznymi). Możliwości tego pierwszego systemu były niewielkie, ale jego powstanie było ogromnym impulsem do prowadzenia dalszych prac. Wielki optymizm i zaangażowanie nie pozwoliły jednak na przezwyciężenie wszystkich problemów związanych z automatyczną translacją. W roku 1966 opracowany został na zlecenie rządu Stanów Zjednoczonych raport, którego autorzy uznali dokonania w dziedzinie automatycznego tłumaczenia za niewielkie i nie dające nadziei na ich zastosowania w praktyce. Wydanie takiej opinii przerwało dalsze badania w USA na około 10 lat. Badania takie były jednak kontynuowane w Kanadzie, Europie Zachodniej i krajach Azji Dalekowschodniej. W ich wyniku w latach siedemdziesiątych pojawiły się systemy uwzględniające możliwość tłumaczenia pomiędzy językiem angielskim, francuskim, hiszpańskim czy japońskim.
W latach osiemdziesiątych dyskusja dotycząca możliwości zastosowania komputerów do automatycznego tłumaczenia tekstów przybrała wymiar filozoficzny. John Searle, filozof amerykański, buduje konstrukcję myślową (przedstawioną w początkowej części bieżącego rozdziału) wskazującą, że maszyna może jedynie przetwarzać język naturalny, natomiast nigdy go nie zrozumie.
Mimo pesymistycznej (z punktu widzenia zwolenników sztucznej inteligencji) wymowy rozumowania Searle'a na początku lat dziewięćdziesiątych nastąpił wyraźny przełom. Był on związany z wyraźną zmianą podejścia do translacji maszynowej. Badacze doszli do wniosku, że prawidłowych rezultatów tłumaczenia nie można osiągnąć stosując tłumaczenie bezpośrednie (wyraz po wyrazie). Nie sprawdziło się również stosowanie zaawansowanych modeli formalnych. Natomiast coraz bardziej obiecującą metodą okazało się tłumaczenie oparte na przykładach, bazujące na dużej bazie danych zawierającej przykłady równoważnych większych form językowych, w szczególności całych zdań w dwóch językach (oczywiście tłumaczonych za pomocą tłumacza - człowieka). Tłumaczenie takie, polegające na odszukaniu w bazie zdań zbliżonych do tłumaczonego i przetłumaczeniu w sposób analogiczny do wzorców zawartych w bazie okazało się bardziej skuteczne i jest dziś dosyć chętnie stosowane. Taka metoda tłumaczenia wymaga jednak zaangażowania dużych mocy obliczeniowych.
Z przetwarzaniem języka naturalnego związany jest również problem generowania mowy ludzkiej przez komputer. Prace nad metodami generowania mowy prowadzone są od lat sześćdziesiątych. Rola komputera sprowadza się tu do generowania kolejnych dźwięków składających się na wypowiedź. Podstawową, najmniejszą słyszalną częścią wypowiedź jest fonem. Program służący do syntezy mowy w trakcie swojej pracy generuje kolejne fonemy, a także zapewnia płynne przejścia pomiędzy nimi (tak zwane transjenty) maksymalnie zbliżone do tych, z jakimi mamy do czynienia przy naturalnej artykulacji. Liczba fonemów występujących w języku naturalnym jest stosunkowo nieduża (w języku polskim nie przekracza pięćdziesięciu). Fonemy mogą być generowane automatycznie przez komputer (na podstawie ich matematycznego opisu) lub są wyodrębnianie z nagranych wcześniej wypowiedzi lektora - człowieka. Ta druga metoda daje lepsze rezultaty, gdyż generowana w ten sposób mowa brzmi bardziej naturalnie, ale problemy z zapewnieniem płynnych przejść między fonemami są w tym przypadku znacznie trudniejsze.
Ponieważ w trakcie tworzenia wypowiedzi z nagranych wzorców fonemów tak wiele problemów sprawia właściwe przejście z jednego fonemu do drugiego, a niedopasowane fonemy powodują, że wypowiedź ma charakter sztuczny i czasami trudny do zrozumienia, przeto w celu rozwiązania tego problemu w generatorze przechowuje się czasem nie tylko wzorce poszczególnych fonemów, ale również wzorce wszystkich możliwych ich par (pary fonemów zwane są difonami).
Przy generowania mowy trudnym problem jest również zapewnienie właściwego brzmienia wypowiedzi (akcent, intonacja). Zagadnienia brzmieniowe danego języka są określane mianem jego prozodii. Prace nad prawidłową strukturą prozodyczną mowy syntetycznej są nadal prowadzone i są jeszcze dalekie od ostatecznego zakończenia. Można wskazać na wiele, różnorodnych zastosowań metod generowania mowy - komunikacja z systemem, nauka języków obcych, książki dla niewidomych, dostęp do zasobów tekstowych poprzez narzędzia komunikacji głosowej i wiele innych.
Języki sztucznej inteligencji
Elementem ułatwiającym tworzenie aplikacji z dziedziny sztucznej inteligencji jest stosowanie specjalizowanych w tym zakresie języków programowania. Pierwszym (i do dzisiaj bardzo popularnym) językiem sztucznej inteligencji był język Lisp. Jego nazwa wywodzi się od List Processing i wskazuje na powiązanie z listami, które są w tym języku podstawową, złożoną strukturą danych. Lisp ukierunkowany jest na zastosowanie rekurencji. Specyficzny jest również sposób zapisu wyrażeń w tym języku, gdyż wykorzystywana jest tak zwana Odwrotna Notacja Polska - wygodna dla komputera, ale stosunkowo mało czytelna. Lisp posiada szereg narzędzi do realizacji obliczeń symbolicznych - dostępne w nim mechanizmy pozwalają na przekształcanie wyrażeń, czy nawet definicji fragmentów programów przyjmujących postać funkcji. Z punktu widzenia sztucznej inteligencji szczególnie istotna jest możliwość dynamicznego generowania przez program kodu innych fragmentów aplikacji. Ta cecha języka Lisp sprawiła, że stał się podstawowym narzędziem programowania genetycznego, polegającego na zastosowanie algorytmów genetycznych do poszukiwania optymalnej postaci programu. Przeprowadzana optymalizacja genetyczna ma na celu ocenę różnych wersji programu i skonstruowanie tej najlepszej. Cechy języka Lisp sprawiają, że jest idealnym narzędziem do opisu tego typu postępowania.
Drugim sztandarowym językiem programowania sztucznej inteligencji jest Prolog. Jest językiem pozwalającym na tzw. programowanie logiczne lub programowanie w logice (Prolog = Programming in Logic). Język powstał w 1972 roku. Do jego twórców zalicza się między innymi Roberta Kowalskiego, Anglika polskiego pochodzenia. Język Prolog ma charakter języka deklaratywnego, co oznacza, że program zawiera wyłącznie opis wyodrębnionego fragmentu rzeczywistości (jest to tzw. bazy wiedzy zawierająca opis faktów oraz opis stwierdzeń powiązanych z analizowaną dziedziną). Natomiast pogram nie zawiera klasycznego i znanego z innych języków programowania opisu przetwarzania zgromadzonych danych. Chcąc skorzystać z utworzonej bazy wiedzy należy sformułować odpowiednie zapytanie, na które odpowiedź generowana jest poprzez analizę zgromadzonej bazy wiedzy i wykorzystanie wbudowanych w język mechanizmów wnioskowania.
Kolejnym językiem sztucznej inteligencji jest Clips. Podobnie jak Prolog jest językiem deklaratywnym. Jego podstawowe zadanie związane jest z tworzeniem systemów ekspertowych. Program definiuje bazę wiedzy (fakty i reguły), a w trakcie generowania odpowiedzi na pytania formułowane przez użytkownika wykorzystywany jest mechanizm wnioskowania w przód.
Tego ściśle technicznego terminu nie należy mylić z pojęciem ontologii jako dziedziny filozofii, odnoszącej się do teorii bytu.
Próby przezwyciężenia tego ostatniego ograniczenia, to znaczy próby wyposażenia komputera w wiedzę „ogólną” (na przykład wiedzę o procesach i zjawiskach codziennego życia) nie powiodły się, gdyż wiedza ta jest bardzo obszerna, a ponadto bardzo źle ustrukturalizowana.
Jak wiadomo w matematyce „od zawsze” istniały twierdzenia, których prawdziwość wydawała się wysoce prawdopodobna (nikt nie potrafił podać tzw. kontrprzykładu), a jednak formalnego dowodu nie potrafiono podać przez całe dziesięciolecia. Klasycznym przykładem jest tu tak zwane „wielkie twierdzenie Fermata”, którego dowodu bezskutecznie poszukiwano przez ponad czterysta lat, aż wreszcie dowiedziono je ... za pomocą komputera.
27
Wyszukiwarka
Podobne podstrony:
Wersja do oddania, Rozdzial 5 - Drzewa decyzyjne, Rozdział III
Wersja do oddania, Rozdzial 7 - Badanie asocjacji i sekwencji, Rozdział III
Wersja do oddania, Rozdzial 4 - Algorytmy genetyczne, Rozdział III
Wersja do oddania, Rozdzial 2 - Systemy ekspertowe, Systemy ekspertowe
Wersja do oddania, Rozdzial 3 - Sieci neuronowe, Rozdział III
Wersja do oddania, Strona tytulowa
Wersja do oddania, Spis treści
Wersja do oddania, Literatura
36, Rozdział I Ogólna charakterystyka korytarzy transportowych
Wersja do oddania, Wstep, Wprowadzenie
wprowadzenie do sztucznej inteligencji-wyk łady (10 str), Administracja, Administracja, Administracj
2009-10-13 Wstęp do SI [w 01], Sztuczna inteligencja
opracowanie 2013, Studia, Informatyka, Semestr IV, Wstęp do sztucznej inteligencji
Barok ogólna charakterystyka, Przydatne do szkoły, barok
Tutorial do zadania z SI numer 4, WAT, semestr III, Sztuczna inteligencja
2009-10-13 Wstęp do SI [w 02], Sztuczna inteligencja
DO WYDRUKOWANIA, Sztuczna inteligencja
Do nauki, Studia, ZiIP, SEMESTR IV, Metody sztucznej inteligencji
więcej podobnych podstron