
Zarządzanie pamięcią operacyjną
Zbyszko Królikowski - Instytut Informatyki PP
Literatura
Tanenbaum A., Modern Operating Systems, Prentice-Hall Icor., 1992.
Silberschatz, P.B. Galvin, Operating System Concepts, Addison-Wesley Pub. Comp., 1994.
,
Tanenbaum A., Operating Systems: Design and Implementation, Prentice-Hall Intern. Editions, 1995.
Silberschatz, J.L. Peterson, P.B. Galvin, Podstawy systemów operacyjnych, WNT, W-wa, 1993.
Z. Królikowski, M. Sajkowski, UNIX dla początkujących i zaawansowanych, Wyd. Nakom, 1995.
Gościński, Distributed Operating Systems, Addison-Wesley Pub. Comp., 1992.
Funkcje modułów zarządzania pamięcią operacyjną
Funkcje:
Utrzymywanie informacji o aktualnym stanie pamięci (przydzielonej i wolnej)
Określanie polityki przydziału pamięci do procesów (którym procesom przydzielić, ile przydzielić i które obszary)
Realizacja przydziału pamięci do procesów (określone obszary są fizycznie przydzielane a systemowe struktury danych (...)
Zwalnianie obszaru pamięci (...)
Wiązanie adresów (ang. address binding)
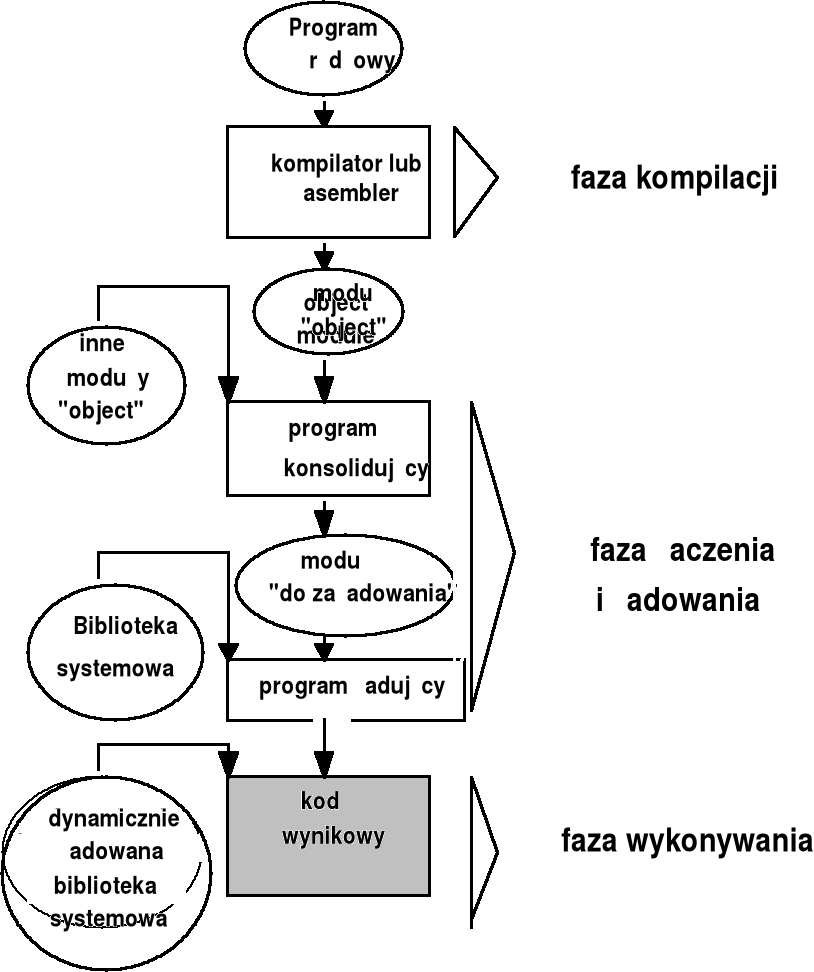
Wiązanie adresów - cd.
Podczas faz kompilacji, ładowania i wykonywania reprezentacja adresów może ulegać zmianie.
W programie źródłowym adresy są wyrażone w sposób symboliczny (np. X=X+1)
Kompilator wiąże te adresy z adresami względnymi (relokowalnymi - kod względny, relokowany) np. 14 bajtów od początku modułu
Rozwiązania z przeszłości: program konsolidujący (ładujący) wiąże dalej te adresy względne z adresami bezwzględnymi (kod bezwzględny) np. 70014.
Zmiana reprezentacji adresów jest nazywana wiązaniem adresów - każde wiązanie adresów jest odwzorowaniem jednej przestrzeni adresowej w inną. Teoretycznie, wiązanie przestrzeni adresowej z przestrzenią pamięci może być wykonywane na każdym z etapów realizacji programu.
Każde wiązanie adresów jest odwzorowaniem jednej przestrzeni adresowej w inną.
Faza kompilacji:
Faza kompilacji (compile time)
- jeżeli podczas kompilacji wiadomo, gdzie proces będzie rezydował w pamięci, wówczas może być wygenerowany kod (adres) bezwzględny - wystarczy znajomość miejsca, od którego zaczyna się obszar przeznaczony dla danego programu;
- rozwiązanie to jest tylko możliwe dla wybranych organizacji pamięci, tj. przydział jednego spójnego obszaru lub przydział stref stałych;
- jeśli lokalizacja programu ulegnie zmianie, niezbędna jest rekompilacja programu .Wiązanie adresów - cd.
Faza łączenia i ładowania:
Faza ładowania (load time)
- jeśli nie wiadomo, gdzie program będzie umiejscowiony w pamięci to kompilator musi generować kod relokowalny (relocatable);
- ostateczne określanie (wiązanie) adresów jest realizowane dopiero na etapie ładowania (rozwiązanie bardziej elastyczne).Wiązanie adresów - cd.
Faza wykonywania:
Faza wykonywania (run time)
- jeśli proces może być przemieszczany z jednego miejsca w pamięci w inne podczas swojego wykonywania, to wiązanie adresów powinno być realizowane dopiero na etapie wykonywania instrukcji programu.
adresy programu wynikowego podlegają dynamicznej transformacji (w trakcie wykonywnania instrukcji programu) i dlatego lokację tego typu nazywa się lokacją dynamiczną
moduły relokowalne programu są łączone razem (..).Wiązanie adresów - cd.
Lokacja statyczna (faza kompilacji lub ładowania)
dla adresów wygenerowanych podczas kompilacji programu, system operacyjny musi dodać odpowiednią wartość związaną z adresem obszaru, w którym program powinien „operować”
zadania programu konsolidującego
problem ochrony pamięci - dwa rejestry graniczne chroniące obszar programu; proces nie może odwoływać się do adresów pamięci spoza obszaru „opisanego” przez te rejestry
Lokacja dynamiczna (faza wykonywania)
Wspomaganie sprzętowe: rejestr relokacji lub rejestry base i limit
Intel 80386 i wzwyż: rejestry base i limit (rejestry deskryptorowe)
Wiązanie adresów - rejestry relokacja dynamicznej

Wymiatanie (ang. swapping)
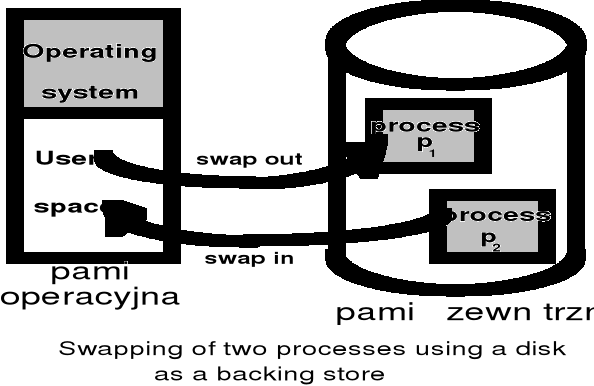
Wymiatanie (ang. swapping)
Dwie klasy organizacji pamięci: z wymiataniem i bez wymiatania
Cel wymiatania: zwiększenie liczby zadań, które jednocześnie mogą być przetwarzane w systemie (zwiększenie stopnia wieloprogramowości) . Stosowane w powiązaniu z rotacyjnym (Round Robin) i priorytetowym algorytmem szeregowania przydziału procesora
Związek z zastosowaną techniką wiązania adresów:
jeśli wiązanie adresów jest wykonywane w fazie kompilacji lub ładowania do pamięci operacyjnej, to proces wymieciony musi powrócić w to samo miejsce pamięci, w którym przebywał
jeśli wiązanie jest wykonywane w fazie wykonywania, to proces wymieciony może być sprowadzony do innego obszaru pamięci
Wada: Czas przełączania kontekstu w systemie w którym stosuje się wymiatanie jest stosunkowo długi
Wniosek: aby wykorzystanie procesora mogło być wydajne, czas wykonywania (np. kwant czasu w algorytmie rotacyjnym) każdego procesu powinien być porównywalny z czasem wymiany . Wymianie nie mogą podlegać procesy bezczynne, w szczególności nie można wymiatać procesów, które czekają na zakończenie operacji we/wy
Problem: Jeśli z pamięci zostałby wymieciony proces P1 oczekujący na wykonanie operacji we/wy i zastąpiony procesem P2, to operacja we/wy procesu P1 mogłaby usiłować użyć pamięci należącej obecnie do procesu P2.
Rozwiązanie:
nigdy nie wymiatać procesów, w którym trwają operacje we/wy
wykonywać operacje we/wy tylko za pośrednictwem buforów systemowych
W praktyce wymiatanie stosuje się gdy przekroczona jest pewna wartość progowa ( pozostaje wolne 15 - 20 % pamięci ) .W UNIX-ie decyzję o wymiataniu podejmuje proces 1 - „swapper”
Organizacje pamięci
Jeden spójny obszar
Strefy statyczne i dynamiczne
Stronicowanie
Segmentacja
Segmentacja ze stronicowaniem
Przydział jednego, spójnego obszaru
Najprostszy schemat organizacji pamięci
Najczęściej stosuje się kompilatory generujące kod relokowalny, tzn. wiązanie adresów opóźnia się do czasu ładowania
Wada: statyczna wartość adresu bazowego podczas wykonywania programu - adres bazowy może być zmieniany tylko wtedy, gdy nie jest wykonywany żaden program użytkownika
Problem z kodem przejściowym systemu operacyjnego
W celu umożliwienia dynamicznych zmian rozmiaru systemu operacyjnego można:
załadować program do pamięci górnej
dokonać wiązania adresów dopiero w fazie wykonywania
Najprostsza organizacja pamięci umożliwiająca realizację systemu wieloprogramowego
Wada:
Zastosowanie:
metoda statycznego podziału na strefy - gdy znane są rozmiary zadań (np. w systemach wsadowych) IBM OS/360 PC-8086
metoda dynamicznego podziału na strefy PC-80286
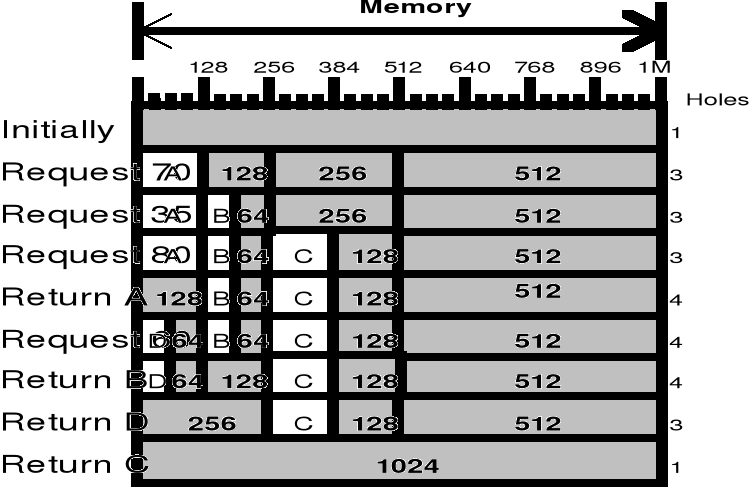
Dwie podstawowe struktury danych opisujące "dziury" - tj. wolne miejsca w pamięci:
Dynamiczny przydział pamięci - "Jak na podstawie struktury opisującej dziury w pamięci spełnić żądanie przydziału obszaru pamięci o rozmiarze n jednostek alokacji (np. 1B)"
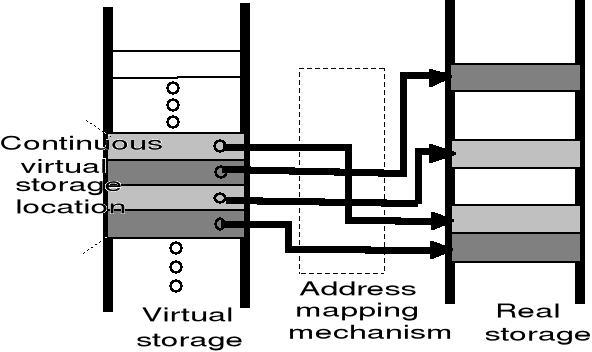
Stosując odpowiednią metodę odwzorowania, dowolną stronę można umieścić w dowolnej ramce (strony aktywne) - użytkownik „nie widzi” wpływu tego odwzorowania na przestrzeń adresową swojego zadania
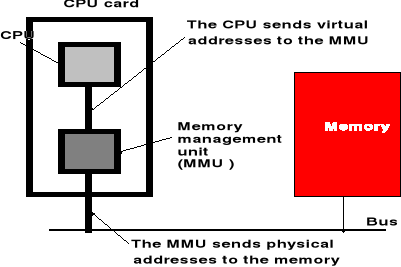
Adresy wirtualne (logiczne) zanim trafią na szynę adresową procesora są przekształcane przez jednostkę zarządzania pamięcią - MMU (Memory Management Unit)
Sprzęt dokonujący odwzorowania z przestrzeni adresowej w przestrzeń pamięci korzysta ze struktur danych opisujących to odwzorowanie, tj. tablic stron.
Odwzorowanie adresów musi być bardzo szybkie
Tablica stron jako zestaw szybkich rejestrów logicznych
Tablica stron w pamięci asocjacyjnej i pamięci operacyjnej
Proste, ale kosztowne rozwiązanie stosowane w latach `60, `70 w maszynach klasy mainframe
Numer strony jest indeksem do tablicy szybkich rejestrów logicznych
Gdy proces jest tworzony, to system operacyjny ładuje do tych rejestrów zawartość tablicy stron z pamięci operacyjnej - dalsze odwołania następują do tych rejestrów
Ograniczony zakres stosowania ze wzgl. na wysokie koszty takiego rozwiązania
Tablica stron w całości jest przechowywana w pamięci operacyjnej
Adres początkowy obszaru zajmowanego przez tablicę stron jest wskazywany przez rejestr bazowy tablicy stron - PTBR
Przy zmianie kontekstu procesu wymieniana jest zawartość tego rejestru - wskazuje on wówczas początek tablicy stron nowego procesu
Wada: Dla każdej wykonywanej instrukcji musi być wykonywana co najmniej jedna dodatkowa operacja dostępu do pamięci operacyjnej w celu odczytania odpowiednich zapisów w tablicy stron
Problem lokalności odwołań:
Sprzęt klasy PC - po raz pierwszy Intel 80386
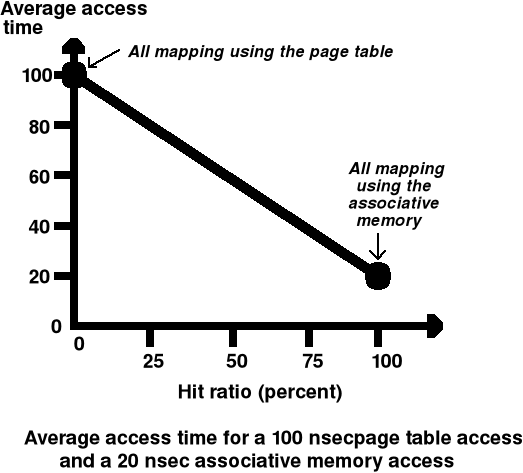
Załóżmy, że dostęp do tab. stron w pamięci operacyjnej wymaga 100 nanosekund, a dostęp do pamięci asocjacyjnej 20 nanosekund
Jeśli współczynnik trafień wynosi 90% to średni czas dostępu do tablic stron będzie wynosił 0.9*20ns+0.1*100ns = 28ns
Wykonanie instrukcji maszynowej, która unieważnia (zeruje) bity ważności stron w pamięci asocjacyjnej przed zapisem dla nowego procesu - najprostsze rozwiązanie
Wydzielenie w pamięci asocjacyjnej pola, w którym przechowuje się identyfikator procesu oraz dołożenie dodatkowego rejestru wewnętrznego, w którym przechowywany jest identyfikator bieżącego procesu - zapisy w pamięci asocjacyjnej nie dotyczące bieżącego procesu są ignorowane - obecnie najczęściej stosowane
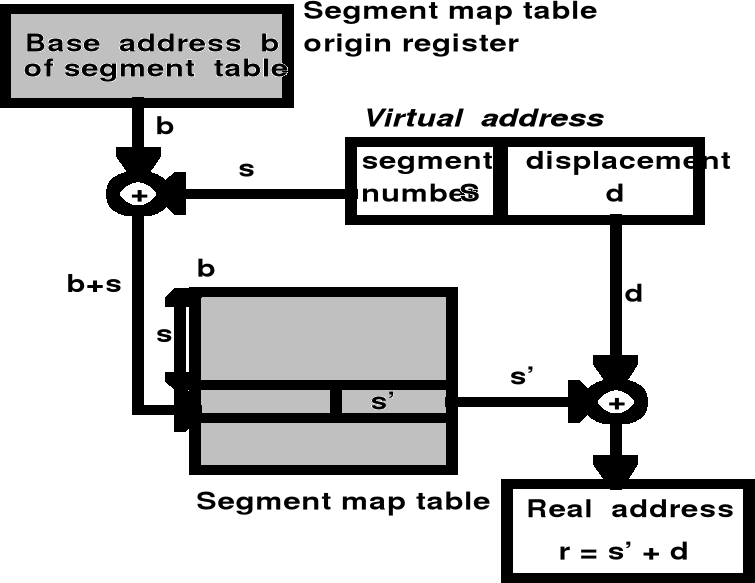
Jeden zapis w odwróconej tablicy stron odpowiada ramce pamięci fizycznej i zawiera adres wirtualny strony przechowywanej w tej ramce wraz z informacją o procesie, który jest właścicielem tej strony
W systemie istnieje tylko jedna odwrócona tablica stron (np. IBM System 38, IBM RISC System 6000, IBM RT, Hewlett Packard Spectrum)
Schemat translacji adresu - patrz następna folia
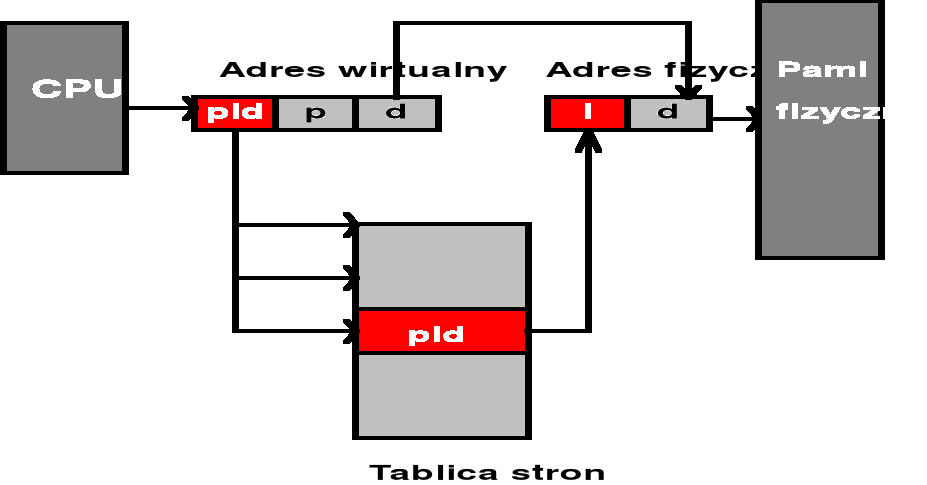
Adres wirtualny: <proces_id, numer_strony, offset>
Część adresu wirtualnego tj. <proces_id, numer_strony> stanowi wzorzec przeszukiwania odwróconej tablicy stron
Jeśli w tablicy zostanie znaleziony zapis zgodny z wzorcem, to generowany jest adres fizyczny <i, offset>
Odwrócona tablica stron nie zawiera informacji niezbędnych do obsługi błędu strony - konieczne jest i tak przechowywanie konwencjonalnych tablic stron dla każdego procesu - są one jednak wykorzystywane rzadko
Odwrócone tablice stron są implementowane z wykorzystaniem pamięci asocjacyjnej
Można osiągnąć ponad stu procentowe wykorzystanie pamięci operacyjnej
Suma wielkości wszystkich przestrzeni adresowych zadań wykonywanych w trybie wieloprogramowym może przekraczać wielkość fizycznej pamięci operacyjnej
Podstawa: odrzucenie wymagania, aby cała przestrzeń adresowa zadania znajdowała się naraz w pamięci operacyjnej i ograniczenie do umieszczenia tam jedynie jej części (wyst. 1 strona <- (nie tylko stronnicowanie, także segmentacja))
oddzielenie wirtualnej przestrzeni adresowej od przestrzeni pamięci fizycznej
stronnicowanie lub segmentacja przestrzeni adresowej
mechanizm odwzorowania adresów (MMU, tablice stron)
odpowiednie moduły systemu operacyjnego obsługujące wymianę części zadań pomiędzy pamięcią operacyjną i dyskową
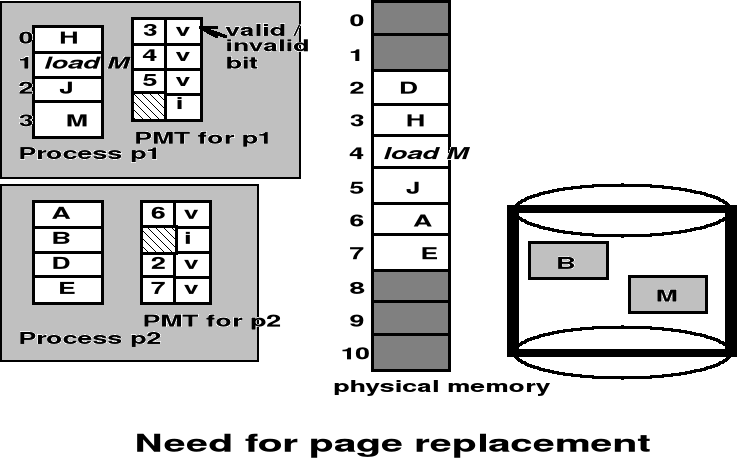
Procesy wykonują się poprawnie (przy założeniach przedstawionych wcześniej) dopóki odwołują się do informacji na stronach znajdujących się w pamięci operacyjnej (ustawiony bit valid)
Jeśli odwołanie do pamięci dotyczy strony, której nie ma w pamięci operacyjnej (invalid), a znajduje się na dysku, to generowny jest błąd strony (przerwanie programowe)
System operacyjny musi przetworzyć to przerwanie, ładując odpowiednią stronę z dysku do pamięci operacyjnej oraz odpowiednio korygując zapisy w tablicy stron - daną stronę „załadowano na żądanie”
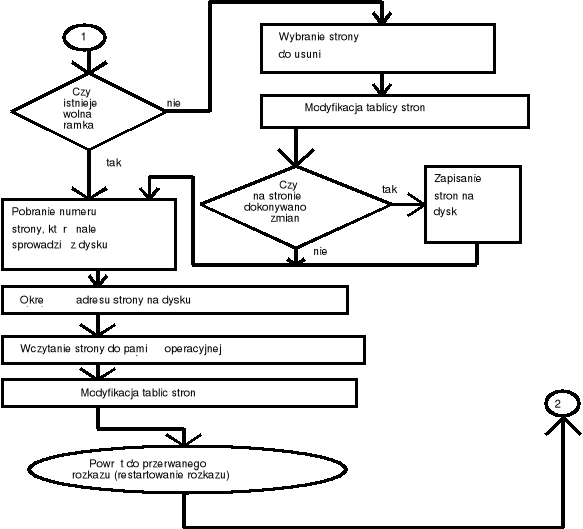
Sprawdzenie w odpowiedniej tablicy systemowej (blok kontrolny procesu) czy nie nastąpiło odwołanie do niedozwolonego obszaru pamięci; jeśli tak to proces jest kończony.
Jeśli odwołanie do pamięci było prawidłowe i danej strony nie ma w pamięci operacyjnej musi zostać sprowadzona z dysku.
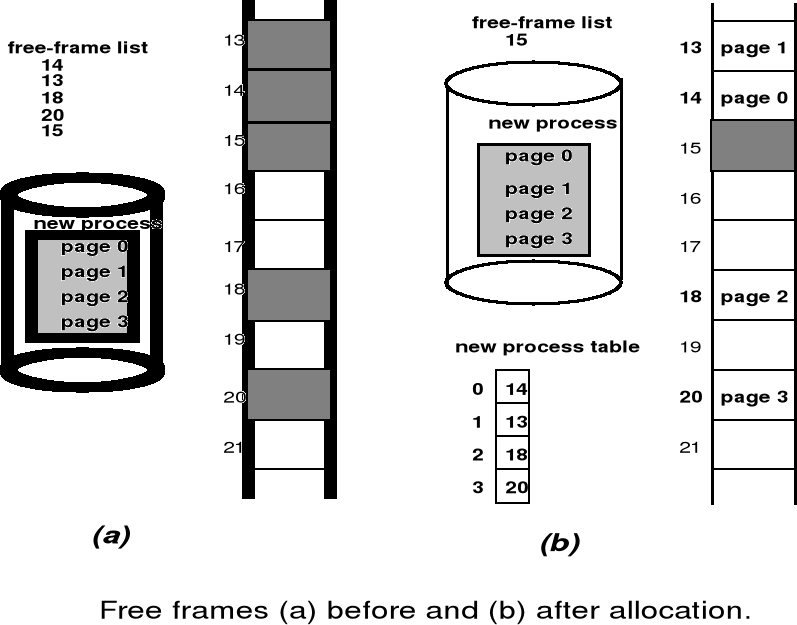
Znalezienie wolnej ramki z odpowiedniej listy.
Wykonanie operacji odczytu strony z dysku i załadowanie jej do wybranej ramki.
Aktualizacja tablicy stron (oznaczenie strony jako ważnej - valid) i tablicy procesów.
Restartowanie instrukcji, która spowodowała błąd strony.
W celu zrestartowania instrukcji, system operacyjny musi określić, gdzie znajduje się pierwszy bajt instrukcji, której wykonanie zostało przerwane
Wartość licznika rozkazów podczas błędu strony zależy od tego, przy którym operandzie instrukcji błąd wystąpił oraz od sposobu implementacji mikrokodu procesora (dla technologii CISC)
Przykład: instrukcja która musi być restartowana
Instrukcja wymaga wykonania trzech operacji dostępu do pamięci - od słowa kodu instrukcji i dwóch operandów - w zależności od tego, które z tyh trzech odwołań powoduje błąd strony, licznik rozkazów może mieć wartość 1000, 1002, 1004
Często system operacyjny nie miał możliwości stwierdzenia gdzie zaczyna się instrukcja, która powinna być restartowana
Problem ten jest znacznie bardziej złożony - zwiększenie licznika rozkazów może być wykonane przed odwołaniem do pamięci lub po wykonaniu tej operacji
Przy wystąpieniu błędu strony „brakująca” strona musi być sprowadzona z dysku - adres danej strony na dysku, tzw. adres plikowy jest przechowywany w odpowiedniej tablicy systemowej
Wirtualizacja pamięci - zwiększenie stopnia wieloprogramowości i efektywności systemu. Jednak czy zawsze ?
Wirtualizacja pamięci może spowodować wzrost obciążenia systemu dodatkowymi transmisjami z/do pamięci dyskowej, wynikającymi z wymiany stron
W skrajnie niekorzystnym przypadku dochodzi do tzw. migotania stron (ang. thrashing) - zjawisko to charakteryzuje się na tyle częstym zachodzeniem sytuacji, w której bezpośrednio po usunięciu danej strony z pamięci operacyjnej następuje dowołanie się do niej i w konsekwencji ponowne jej sprowadzenie - na tyle częstym, że system traci prawie cały czas na wymianę stron, co praktycznie oznacza jego blokadę
Algorytm łatwy w implementacji - za każdym razem gdy nowa strona jest sprowadzana z dysku, to identyfikujący ją numer zostaje umieszczony w kolejce (lista łączona) zorganizowanej wg zasady FIFO
Usuwana jest strona znajdująca się na pierwszym miejscu na liście
Jeśli strona, która ma być usunięta była modyfikowana w pamięci operacyjnej, to przed jej usunięciem musi być zapisana na dysk (dla uspójnienia obu kopii strony) - nie tylko dla FIFO
Jeśli bit R (reference), to jest bit pokazujący czy do strony były odwołania, jest równy 0, tzn. że jest to strona zarówno „stara” jak i nieużywana, to strona może być usunięta
Jeśli bit R = 1 to wówczas bit ten jest zerowany, odpowiednia strona jest przesuwana na koniec listy FIFO - strona uzyskuje drugą szansę
Jeśli do wszystkich stron były odwołania, algorytm ten przekształca się w FIFO w „czystej” postaci
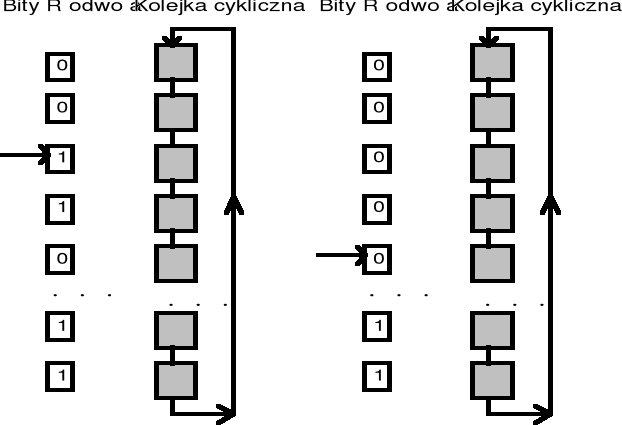
Algorytm ten od algorytmu Drugiej Szansy różni się tylko implementacją - identyfikatory stron są utrzymywane na liście cyklicznej, a „wskazówka zegara” pokazuje stronę najstarszą
Jeżeli bit R = 0 to strona jest usuwana, a na jej miejsce wstawiana nowa i wskazówka zegara jest przesuwana o jedną pozycję wprzód
Jeśli bit R =1 to wówczas bit ten jest zerowany, a wskazówka zegara jest przesuwana na następną stronę - proces ten jest powtarzany, aż zostanie znaleziona strona z bitem R = 0
Algorytm ten jest oparty o obserwację, że strona ostatnio wykorzystywana prawdopodobnie będzie używana dalej i konsekwentnie, strona ostatnio nie wykorzystywana nie będzie używana również w przyszłości
Implementacje algorytmu LRU
Rejestr wieku (ang. aging register) - sprzęt jest wyposażony w 64-bitowy licznik, który jest automatycznie powiększany po każdej instrukcji
w tablicy stron musi być wydzielone pole (wskaźnik do tablicy systemowej) do którego jest przepisywana wartość tego licznika po każdym odwołaniu do pamięci dotyczącym określonej strony - to właśnie pole jest nazywane rejestrem wieku
gdy występuje błąd strony, to badane są wszystkie rejestry wieku w tablicy stron i wybierana jest strona, której wartość tego rejestru jest najmniejsza - jest to strona najmniej ostatnio używana
macierz n x n bitów dla maszyny z n ramkami - patrz następna folia
Znacznie łatwiej może dokonać konsolidacji procedur, z których każda rozpoczyna się od adresu 0 - wywołanie procedury stanowiącej segment n, wykorzystuje wówczas 2-częściowy adres (n, 0) - od słowa 0 segmentu n
Adres to nazwa segmentu i przesunięcie wewnątrz segmentu - dla uproszczenia implementacji zamiast nazw używa się numerów segmentów
Ponieważ każdy segment stanowi pełną logiczną jednostkę odpowiadającą postrzeganiu pamięci przez użytkownika, dla każdego z segmentów można zastosować inny rodzaj ochrony
Każdy segment może być załadowany w dowolne miejsce pamięci - niezbędny jest więc mechanizm odwzorowania adresów
zamiast traktować każdy segment jako pojedynczy ciągły obiekt można go podzielić na strony
manipulując fizycznie stronami zamiast całymi segmentami unika się problemu fragmentacji pamięci
rozwiązanie powszechnie stosowane w sprzęcie mikrokomputerowym - wspomagane sprzętowo np. w rodzinie procesorów Intel począwszy od 80386
tablice stron związane z poszczególnymi segmentami
W procesorach Intel pamięć wirtualna jest dodatkowo wspomagana sprzętowo przez:
tablicę LDT (ang. Local Descriptor Table) lokalnych deskryptorów - każdy proces ma własną tablicę LDT; opisuje ona segmenty lokalne programu
tablicę GDT (ang. Global Descriptor Table) globalnych deskryptorów - opisuje segmenty dzielone; jest tylko jedna taka tablica w systemie
Każdy zapis w tablicy LDT/GDT składa się z 8 bajtów i zawiera szczegółowe informacje o określonym segmencie (w tym początek segmentu i jego długość)
Aby wykonać operację dostępu do segmentu wpierw do jednego z sześciu rejestrów segmentowych jest ładowany selektor segmentu
Selektor stanowi wskaźnik do tablicy LDT (lub GDT) i jest liczbą 16-bitową
Podczas wykonywania rejestr CS utrzymuje selektor segmentu kodu programu, a DS segmentu danych
Maszyna jest wyposażona w 6 rejestrów segmentowych (6 segmentów procesu może być adresowanych jednocześnie) oraz sześć 8-bajtowych rejestrów mikroprogramowych w których są przechowywane odpowiednie deskryptory
Selektor z odpowiedniego rejestru segmentowego wskazuje na odpowiedni zapis w tablicy deskryptorów LDT (GDT)
31czy dana strona
znajduje się w pamięci
USER PROGRAM |
|
KOD PRZEJŚCIOWY |
SYSTEM OPERACYJNY |
Przydział jednego, spójnego obszaru - cd.
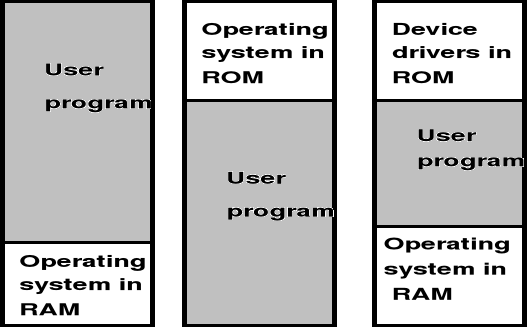
Three ways of organizing memory with an operating system and one user process.
Przydział jednego, spójnego obszaru - cd.
Podział pamięci na strefy statyczne i dynamiczne (ang. Multiprogramming with Fixed and Variable Partition)
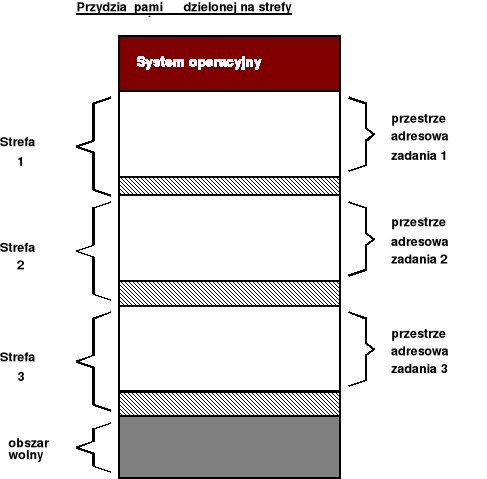
Podział pamięci na strefy statyczne i dynamiczne - cd.
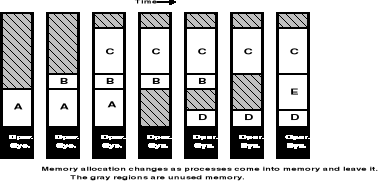
Podział pamięci na strefy statyczne i dynamiczne - cd.
Podział pamięci na strefy statyczne i dynamiczne - cd.
Podział pamięci na strefy statyczne i dynamiczne - cd.
Fragmentacja pamięci: zewnętrzna i wewnętrzna
Rozwiązanie: scalanie pamięci (ang. memory compaction) ze wzgl. oszczędnościowych może być wykonywane tylko w przypadku gdy stosowana jest metoda dynamicznego wiązania adresów przy odpowiednim wspomaganiu sprzętowym
Podział pamięci na strefy statyczne i dynamiczne - cd.
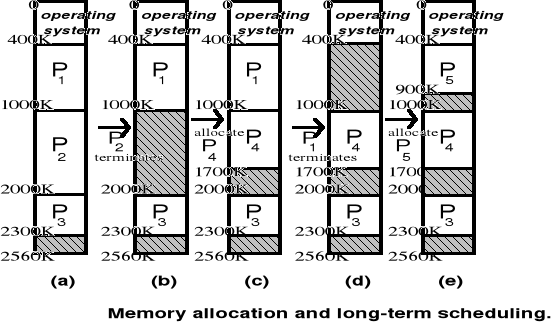
Podział pamięci na strefy statyczne i dynamiczne - Scalanie (kompresja) pamięci
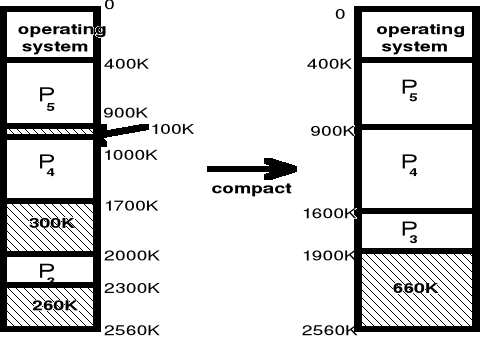
Podział pamięci na strefy statyczne i dynamiczne - Scalanie pamięci - cd. Różne sposoby.
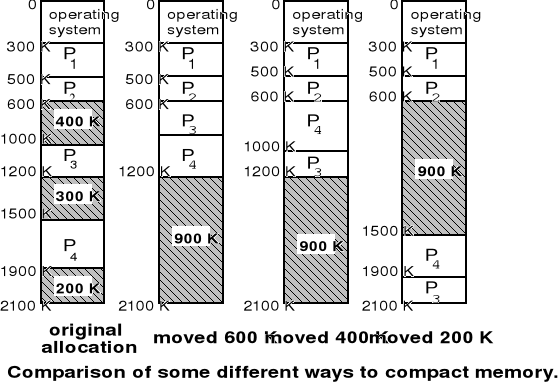
Podział pamięci na strefy statyczne i dynamiczne - cd.
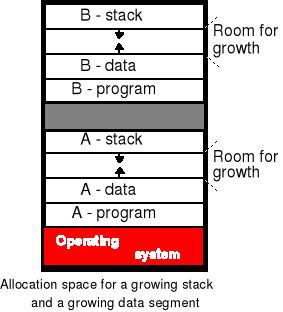
Dynamiczna zmiana obszaru pamięci zajmowanego przez proces - UNIX
Algorytmy alokacji pamięci - Wyszukiwanie wolnych miejsc w pamięci
- mapa bitowa - z jednostką alokacji pamięci jest związany 1 bit na mapie bitowej
- lista łączona - "dziury" są połączone wskaźnikami
Wyszukiwanie wolnych miejsc w pamięci - wykorzystywane struktury danych
The buddy system (pączkowanie). The horizontal axis represents memory addresses. The number are the sizes of unallocated blocks of memory in K. The letters represent allocated blocks of memory. Szybki ale następuje fragmentacja wewnętrzna i zewnętrzna, rozważany tylko teoretycznie.
Stronicowanie pamięci - założenia
Przestrzeń adresowa procesu jest dzielona na równe części nazywane stronami, pamięć fizyczna natomiast jest podzielona na części tej samej wielkości nazywane ramkami stron.
Stronicowanie pamięci - odwzorowanie przestrzeni adresowej w przestrzeń pamięci
Stronicowanie pamięci - wspomaganie sprzętowe odwzorowania przestrzeni adresowej w przestrzeń pamięci
po raz pierwszy w 80386 (32-bit)
Stronicowanie pamięci - odwzorowanie przestrzeni adresowej w przestrzeń pamięci - tablica stron
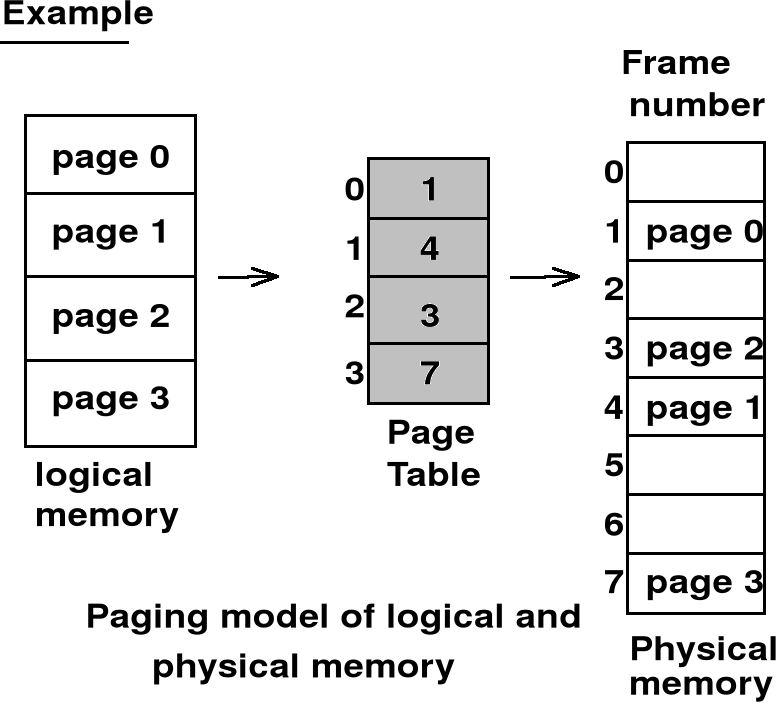
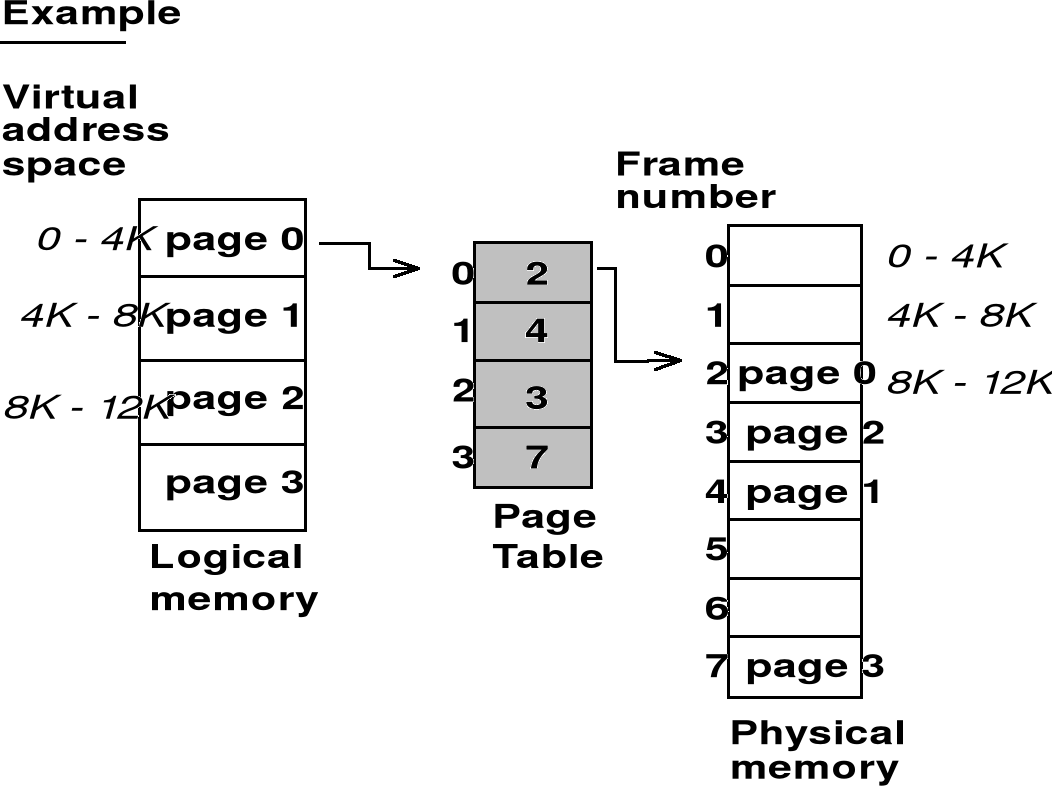
Stronicowanie pamięci - odwzorowanie przestrzeni adresowej w przestrzeń pamięci - przykład
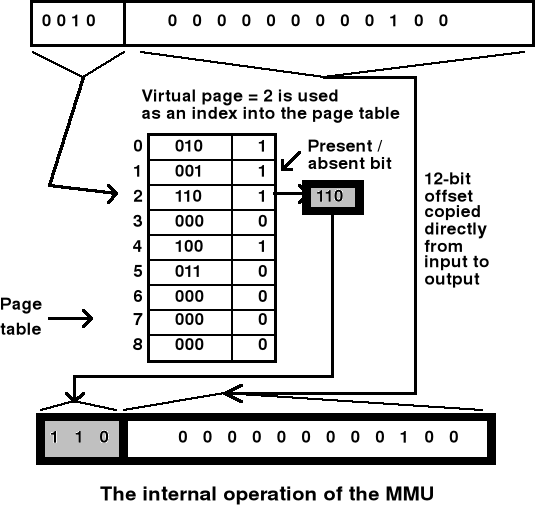
Stronicowanie pamięci - odwzorowanie przestrzeni adresowej w przestrzeń pamięci - przykład
Stronicowanie pamięci - strony współdzielone
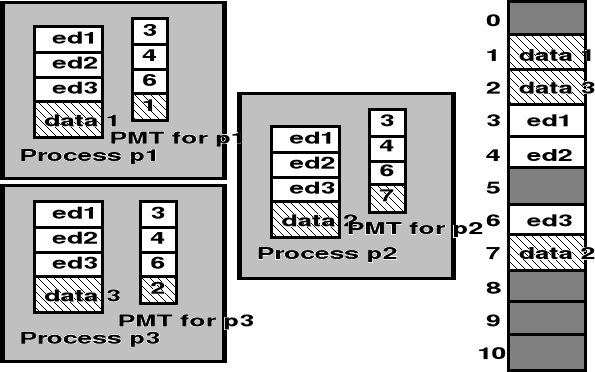
PMT - Page Management Table, ed - edytor
Tablice stron - opis strony
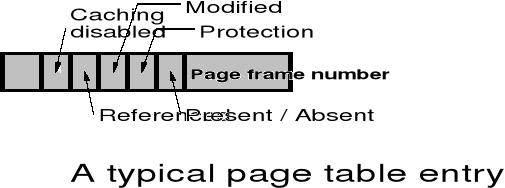
Tablice stron - opis strony
Typowy zapis w tablicy stron - 32 bity
Znaczenie poszczególnych pól:
Protection: określa dozwolony sposób dostępu do strony (3 bity: zapis, odczyt, wykonywanie)
Modified ustawiane automatycznie przez MMU jeśli na stronie były wykonywane operacje zapisu
Referenced ustawiane automatycznie jeśli następuje odwołanie do strony
Caching Disabled pozwala na zablokowanie mechanizmu buforowania (ważne przy operacjach we/wy)
Tablice stron - problemy implementacyjne
2. Tablice stron mogą być bardzo duże
Ad 1.)
Typowa instrukcja składa się z dwóch części: kodu i argumentów i może w niej nastąpić nawet kilka odwołań do pamięci . Każde odwołanie do pamięci wiąże się z odwołaniem do pamięci stron. Aby mechanizm odwzorowywania adresów nie stał się wąskim gardłem systemu, to operacja przeglądania tablicy stron powinna być wykonana w ciągu kilku nanosekund.
Ad 2.)
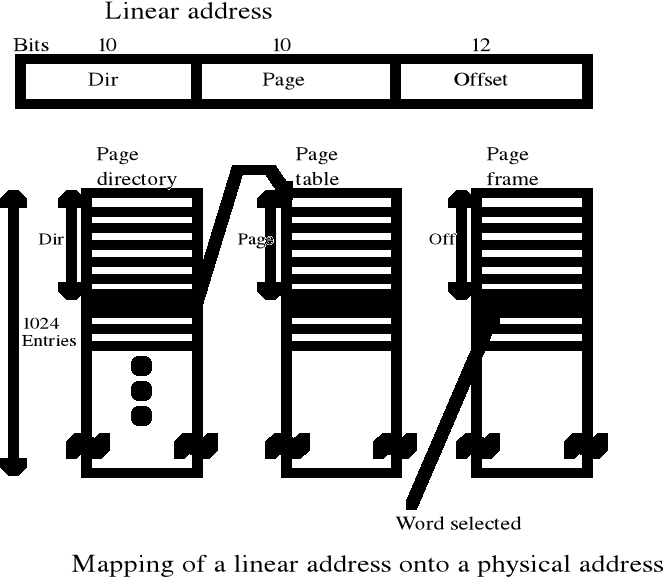
Współczesne komputery wykorzystują adresy 32-bitowe. Przy rozmiarze strony 4KB otrzymujemy 1M stron wirtualnej pamięci adresowej. Tablica stron każdego procesu miałaby milion wierszy, tj. około 4MB
adres:
20 bit - page |
12 bit - offset |
Implementacje tablic stron
(rozwiązanie pierwotnie stosowane w maszynach klasy mainframe - lata `60, `70) .
2.Tablica stron w pamięci operacyjnej + rejestr bazowy tablicy stron
Implementacje tablic stron + schemat translacji adresu (1)
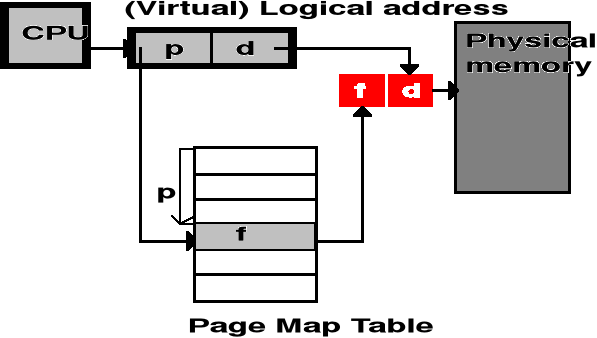
Implementacje tablic stron (1)
Implementacje tablic stron + schemat translacji adresu (2)
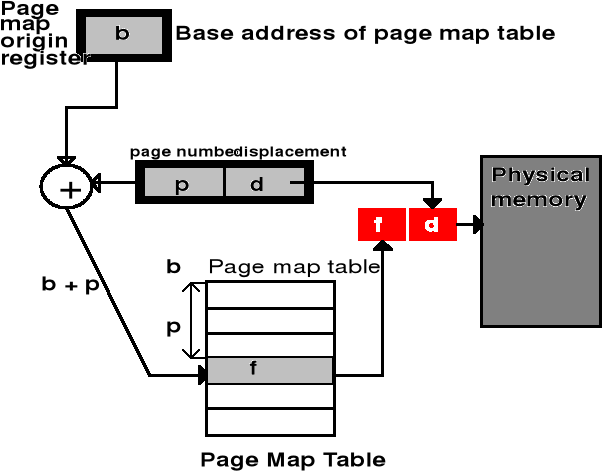
Implementacje tablic stron (2)
Implementacje tablic stron (3) - pamięć asocjacyjna
Geneza:
W przypadku większości programów widać tendencję do odwoływania się do małej liczby tych samych stron - oznacza to, że tylko mała liczba zapisów stron jest zazwyczaj odczytywana. Opłaca się przechowywać te właśnie zapisy z tablicy stron w osobnej, szybkiej pamięci - pamięci asocjacyjnej (ang. associative memory, translation lookaside buffer)
szybkość
rozmiar
Implementacje tablic stron (3) - pamięć asocjacyjna
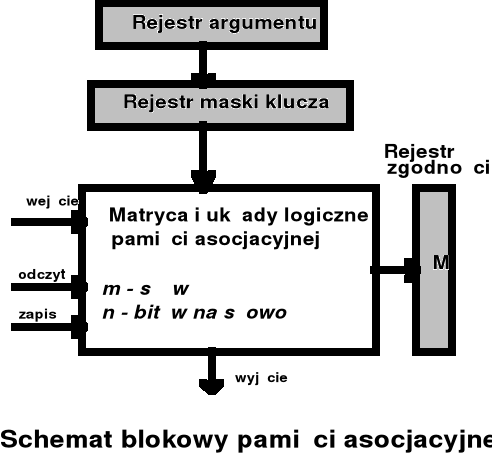
Implementacje tablic stron (3) - pamięć asocjacyjna
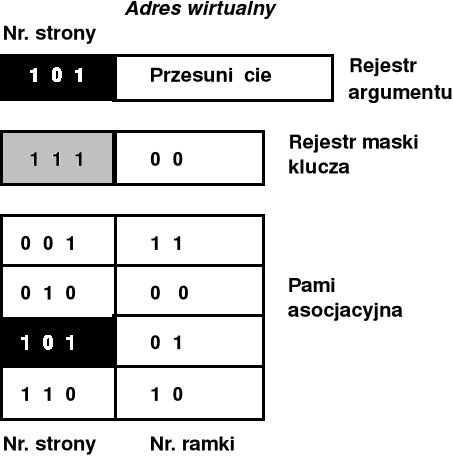
Implementacje tablic stron (3) - schemat translacji adresu (pamięć asocjacyjna)
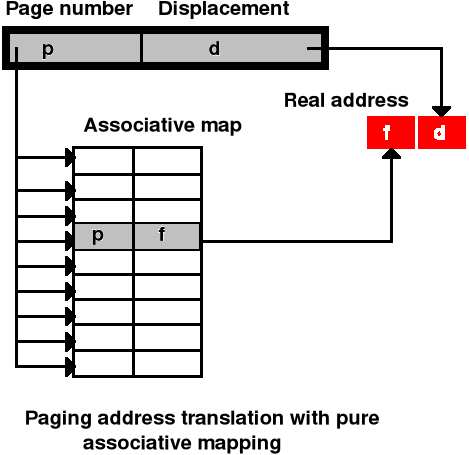
Implementacje tablic stron (3) - schemat translacji adresu (pamięć asocjacyjna) - cd.
Implementacje tablic stron (3) - pamięć asocjacyjna - współczynnik trafień (ang. hit ratio)
Implementacje tablic stron (3) - pamięć asocjacyjna
Hit ratio jest to stosunek liczby odwołań do pamięci realizowanych na podstawie pamięci asocjacyjnej do ogólnej liczby odwołań do pamięci
Im wyższy współczynnik trafień tym wyższa sprawność mechanizmu stronicowania - hit ratio = 100% oznacza, że wszystkie odwołania do pamięci są obsługiwane z wykorzystaniem pamięci asocjacyjnej . Zazwyczaj 97-98 % .
Przykład:
Implementacje tablic stron (3) - Funkcjonowanie pamięci asocjacyjnej w systemie wieloprogramowym
Problem: W systemie wieloprogramowym każdy proces ma własną tablicę stron - gdy uruchamiany jest nowy proces, to nie może on wykorzystywać zapisów w pamięci asocjacyjnej, które należały do poprzedniego procesu
Rozwiązania:
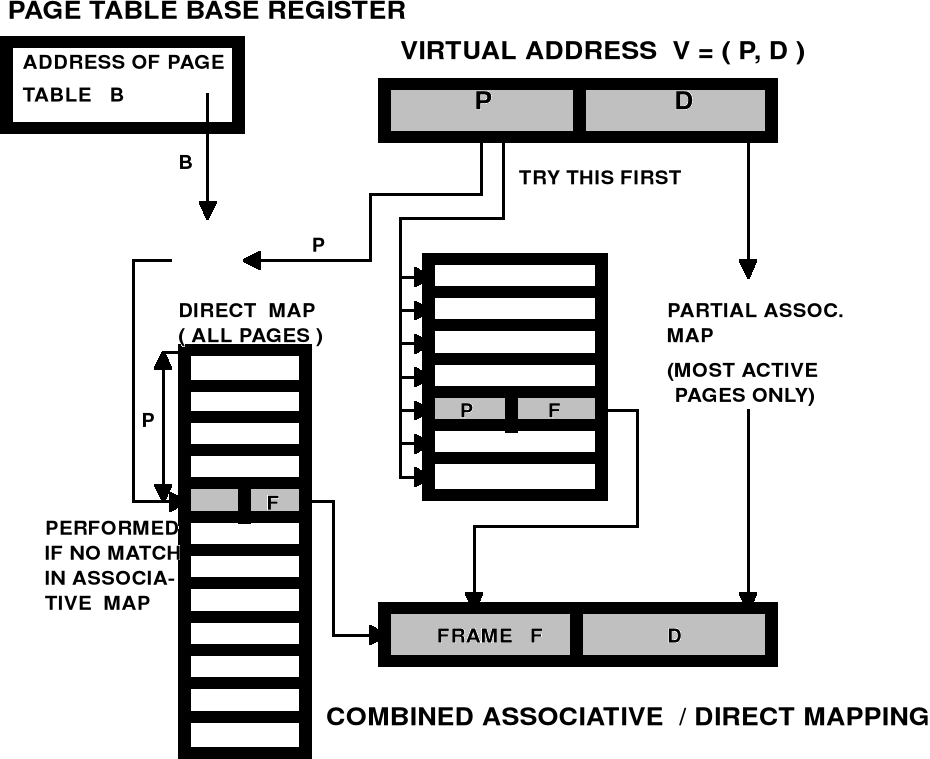
Problemy implementacji tablic stron - Wielopoziomowe tablice stron
Wielopoziomowe tablice stron - SUN Sparc np. Solaris
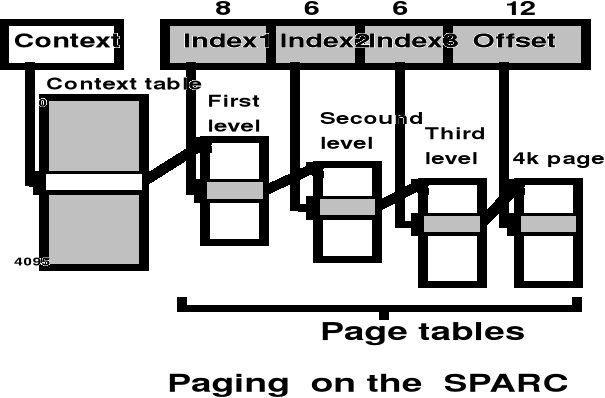
Odwrócone tablice stron
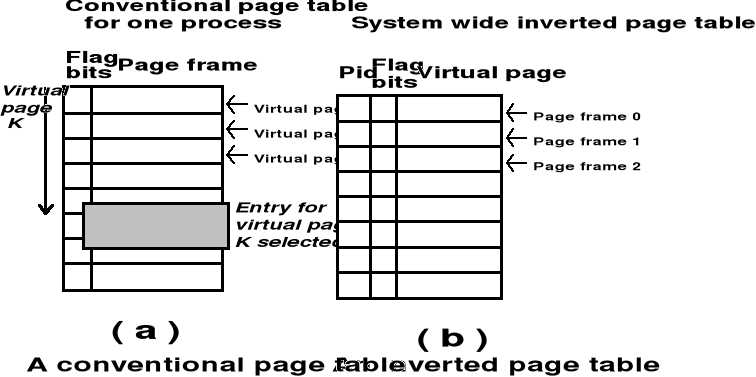
Odwrócone tablice stron
Odwrócone tablice stron - Schemat translacji adresu
Pamięć wirtualna - założenia
Podstawowe założenia:
Pamięć wirtualna
Pamięć wirtualna - Błąd strony
Definicja błędu strony:
Błąd strony - ilustracja
Schemat obsługi błędu strony
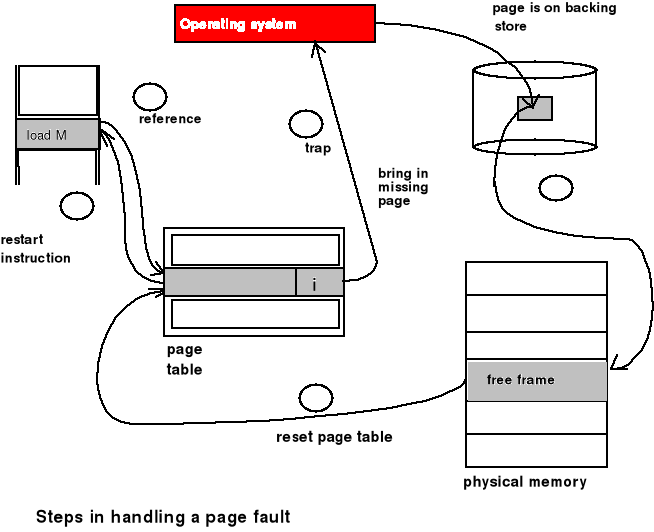
Obsługa błędu strony
Etapy obsługi błędu strony:
Problem restartowania zadań przy wystąpieniu błędu strony - przykład
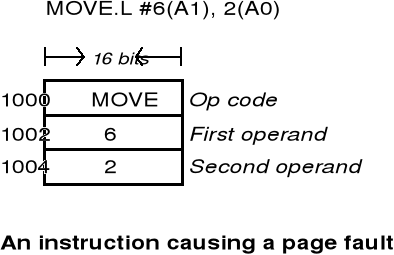
The Motorola 68000 instruction: MOVE.L #6(A1),2(A0) is 6 bytes
Rozwiązanie: Wprowadzenie dodatkowego rejestru, do którego kopiowany jest licznik rozkazów tuż przed rozpoczęciem cyklu rozkazowego instrukcji
Błąd strony - podsumowanie (1)
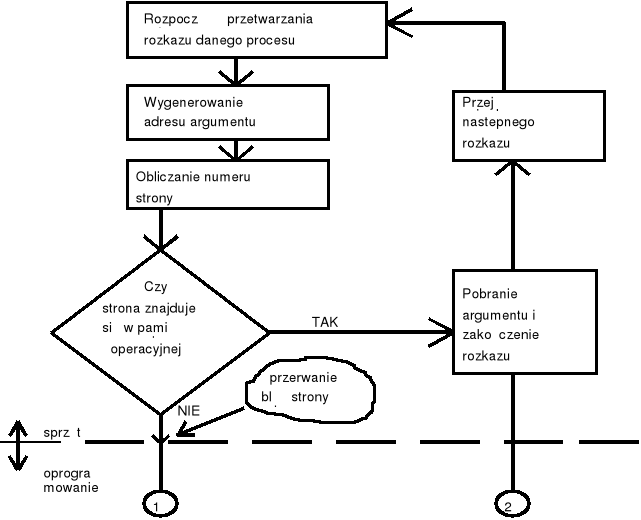
Błąd strony - podsumowanie (2)
Problemy pamięci wirtualnej
W kontekście pamięci wirtualnej można wyróżnić trzy podstawowe grupy problemów:
Problemy sprowadzania (ang. fetch) - „Którą stronę i kiedy należy sprowadzić do pamięci operacyjne”
Problemy umieszczania (ang. placement) - polega na wyborze wolnego bloku ze zbioru wolnych bloków (blok czyli strona lub segment)
- praktycznie nie istnieje w przypadku pamięci stronnicowanej
- ma znaczenie w systemie z segmentowaną pamięcią wirtualną
Problemy wymiany (usuwania) (ang. replacement) - polega na wyborze, która strona i kiedy powinna zostać usunięta z pamięci operacyjnej w celu utworzenia wolnego miejsca dla strony sprowadzanej
Problemy wymiany stron
Algorytmy wymiany stron
FIFO (First In First Out)
Gdy trzeba załadować nową stronę, to jest usuwana strona najdłużej przebywająca w pamięci
Algorytmy wymiany stron - cd.
FIFO - “Drugiej Szansy” (ang. Second Chance)
Algorytmy wymiany stron - cd.
FIFO - “Drugiej Szansy
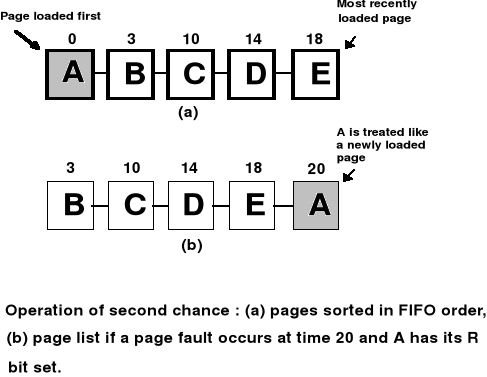
Algorytmy wymiany stron - cd.
FIFO - “Zegarowy” (ang. Clock Page Replacement)
Algorytmy wymiany stron - cd.
FIFO - “Zegarowy” (ang. Clock Page Replacement)
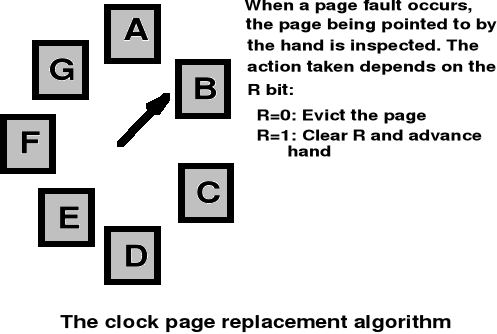
Algorytmy wymiany stron - cd.
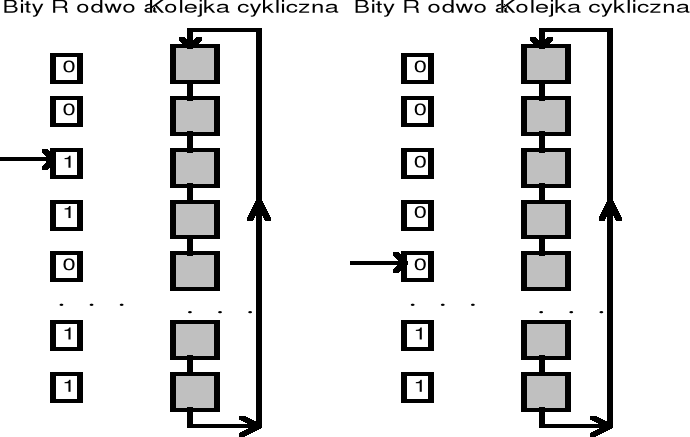
FIFO - “Zegarowy” - Implementacja
Algorytmy wymiany stron - cd.
LRU (Least Recently Used) - Usuwanie strony najmniej ostatnio używanej
( na razie rozwiązanie rzadko stosowane , najczęściej stosowane - FIFO drugiej szansy lub LRU z rejestrem wieku
Algorytmy wymiany stron - cd.
LRU - jedna z implementacji
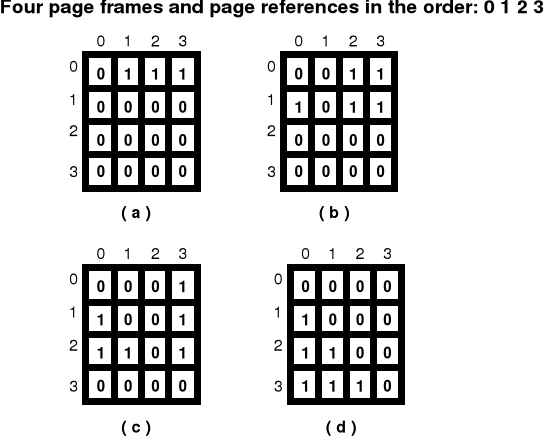
Algorytmy wymiany stron - cd.
NUR (Not-Recently Used) - Usuwanie strony ostatnio nie używanej
Znany również jako algorytm Rozszerzony Drugiej Szansy (ang. Enhanced Second Chance) (Macintosh)
Wykorzystuje się bity R i M. z tablicy stron
R bit - odwołanie do strony (page referenced) ; M bit - modyfikacja strony (page modified)
W przypadku wystąpienia błędu strony i konieczności usunięcia strony, system operacyjny poszukuje strony - kandydatki do usunięcia - spośród 4 następujących grup stron określonych na podstawie zawartości bitów R i M
Grupa 1: bez odwołań, bez modyfikacji,
Grupa 2: bez odwołań, z modyfikacjami, (?)
Grupa 3: z odwołaniami, bez modyfikacji,
Grupa 4: z odwołaniami, z modyfikacjami,
Algorytmy wymiany stron - cd.
LFU (Least Frequently Used) - Usuwanie strony najrzadziej używanej
Algorytm ten usuwa te strony do których odwołania pojawiają się z najmniejszą częstotliwością
W przypadku tego algorytmu ze szczególną ostrością pojawia się niebezpieczeństwo migotania stron
Dlaczego ?
Najmniejszą częstość odwołań ma strona ostatnio sprowadzona z dysku,
( była użyta tylko raz !!! ) , przy sprowadzaniu nowej tamta może zostać usunięta - RYZYKO
Zarządzanie przestrzenią do wymiatania na dysku
Obszar do wymiatania (ang. swap area)
Jest tworzony w momencie startowania systemu. Obszar do wymiatania jest zarządzany jako lista wolnych porcji. ( porcja - obszar strony ).
Z każdym procesem jest związany jest adres dyskowy (przechowywany w tablicy procesów) obszaru swap tego procesu
Obliczenie adresu w celu zapisania strony na dysk polega na dodaniu do adresu początkowego obszaru SWAP procesu, przesunięcie określonego na podstawie adresu wirtualnego
Stosowane są dwa rozwiązania inicjacji obszaru do wymiatania:
W obu rozwiązaniach na dysku w obszarze SWAP AREA jest przydzielana porcja równa rozmiarowi procesu
I rozwiązanie: Skopiowanie całego obrazu procesu do obszaru SWAP i sprowadzenie odpowiednich stron w miarę potrzeb ukierunkowane na zwiększenie stopnia wieloprogramowości
II rozwiązanie: Załadowanie całego procesu do pamięci operacyjnej i wymiatanie stron jeśli zachodzi taka potrzeba ukierunkowane na eliminację błędu stron
Problem: Rozmiar procesu może „rosnąć” podczas jego wykonywania
Rozwiązanie: Rezerwowanie osobnych obszarów do wymiatania dla tekstu programu, danych i stosu
Segmentacja pamięci
Pamięć wirtualna ze stronicowaniem na żądanie - przykład pamięci jedno-wymiarowej:
Adresy wirtualne zaczynają się od 0 i w sposób ciągły narastają aż do pewnej wartości maksymalnej
Rozwiązanie często pożądane:
Wiele odseparowanych wirtualnych przestrzeni adresowych - przykład procesu kompilacji (nast. strona)
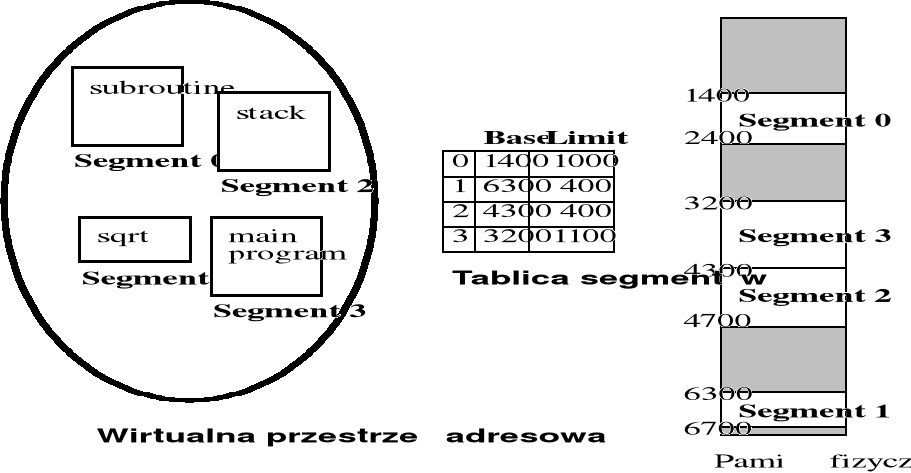
Segmentacja pamięci - proces kompilacji
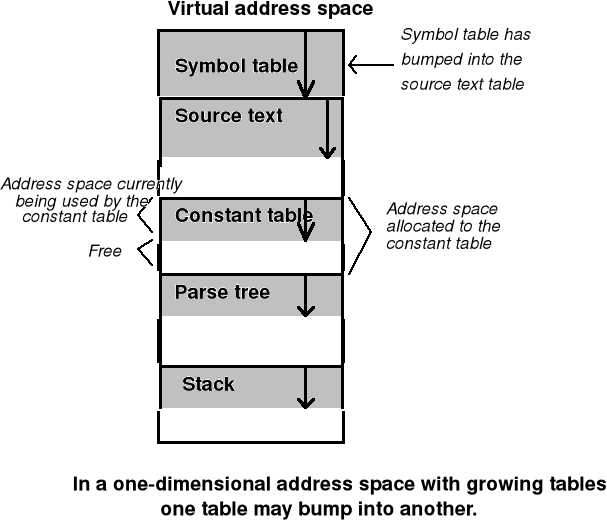
Segmentacja pamięci - założenia
Wiele całkowicie niezależnych przestrzeni adresowych nazywanych segmentami
Segmentacja jest metodą zarządzania pamięcią, która odpowiada widzeniu przez użytkownika (programistę)
Segmentacja pamięci - założenia
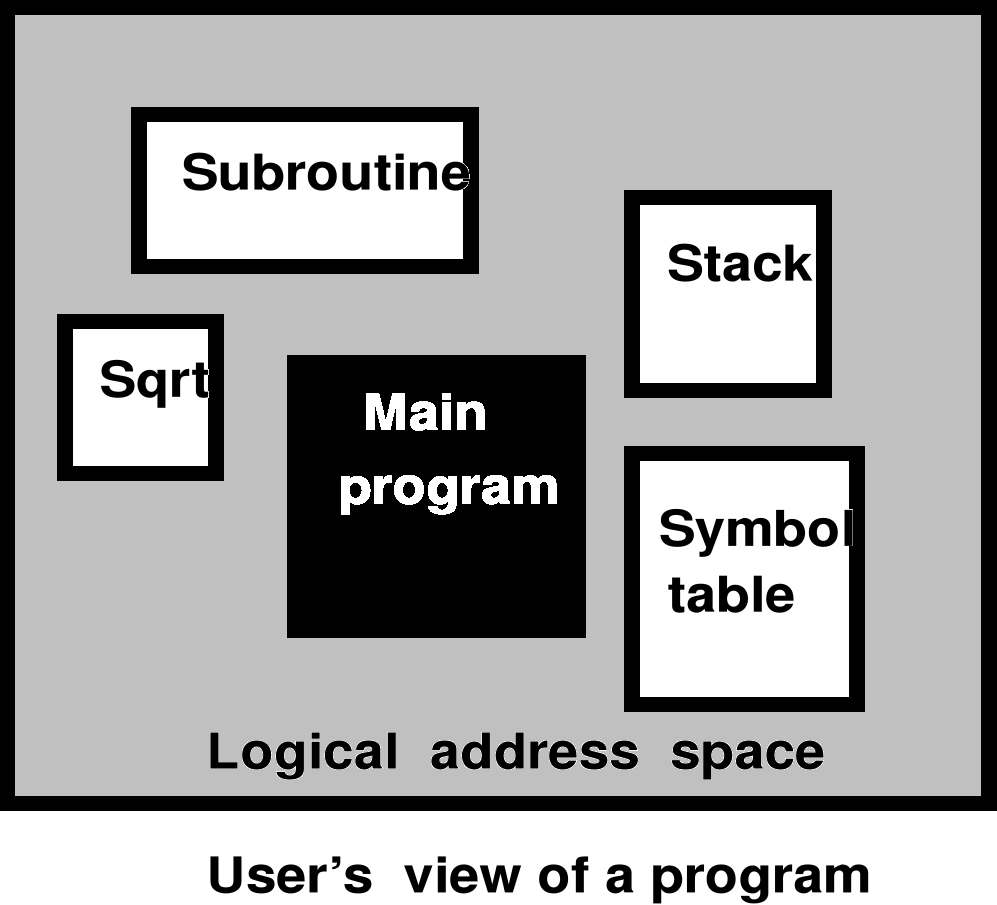
Segmentacja pamięci - założenia
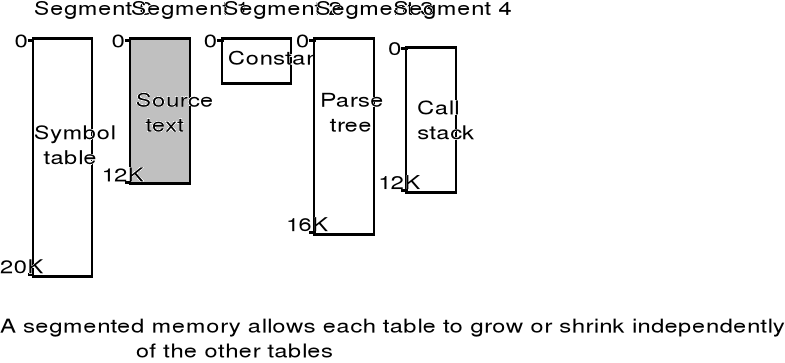
Każdy segment stanowi liniową sekwencję adresów, rozpoczynającą się od 0 do pewnej wartości maksymalnej. Segmenty mogą mieć różną długość, zmienną podczas wykonywania - zmiana rozmiaru jednego segmentu nie ma wpływu na inne.
Porównanie segmnetacji i stronicowania
Problemy Paging Segment.
Czy programista musi być świadom jaka technika jest wykorzystywana ? (Organizacja pamięci odpowiada organizacji programu) |
No |
Yes |
Ile liniowych przestrzeni adresowych ? |
1 |
Many |
Czy przestrzeń adresowa przekracza rozmiar pamięci fizycznej ? |
Yes |
Yes |
Czy moduły tekstu programu i danych są rozróżniane i osobno chronione ? |
No |
Yes |
Czy łatwa jest obsługa tablic, których rozmiary ulegają zmianie w trakcie realizacji procesu ? |
No |
Yes |
Czy możliwe jest współdzielenie programów (danych) ? |
Yes |
Yes |
Segmentacja pamięci - założenia cd.
Logiczna przestrzeń adresowa jest zbiorem segmentów - każdy segment ma własną nazwę i długość
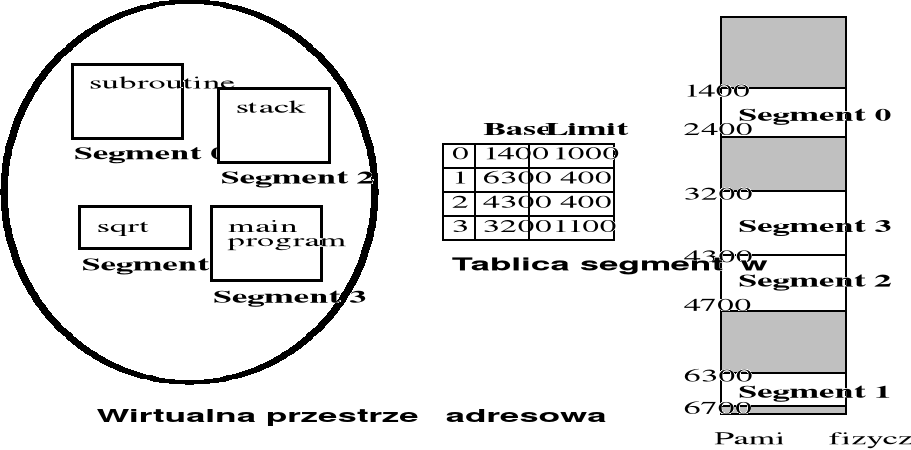
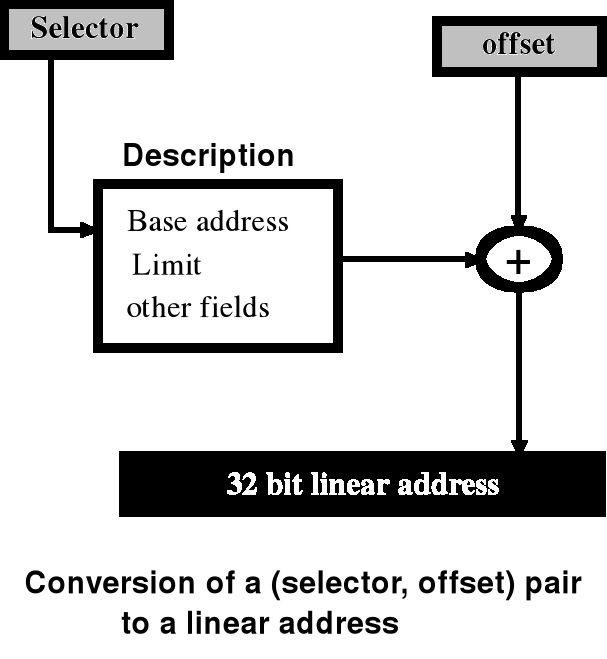
Odwzorowanie adresów w pamięci segmentowanej
Zmiana dwuczęściowego adresu logicznego na adres liniowy w pamięci fizycznej jest realizowana dynamicznie podczas wykonywania rozkazu, na podstawie tablicy segmentów.
Schemat translacji adresów i ochrona pamięci
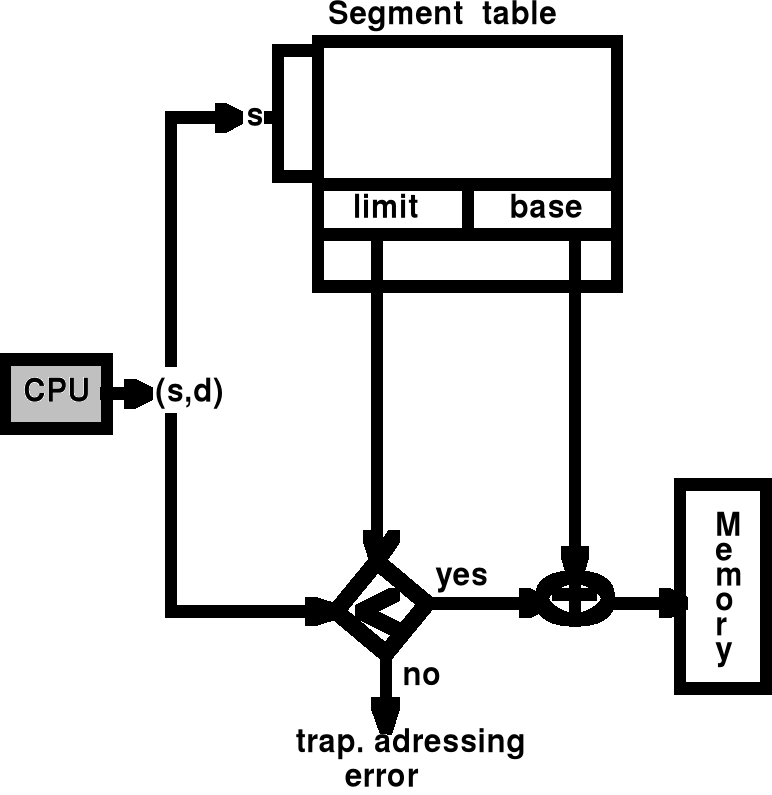
Schemat translacji adresów - cd.
Dzielenie segmentów
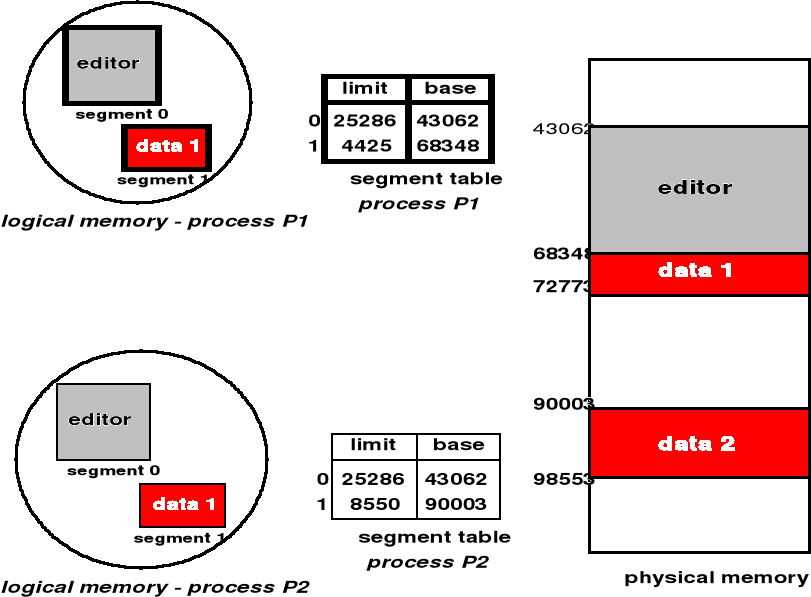
Segmenty mogą być wykorzystywane wspólnie; mogą być jednostką wymiatania na dysk
Może również dojść do fragmentacji
Segmantacja ze stronicowaniem na żądanie
Połączenie mechanizmów segmentacji i stronicowania - sposób na wykorzystanie zalet segmentacji i usunięcia jej wad tj. fragmentacji zewnętrznej pamięci
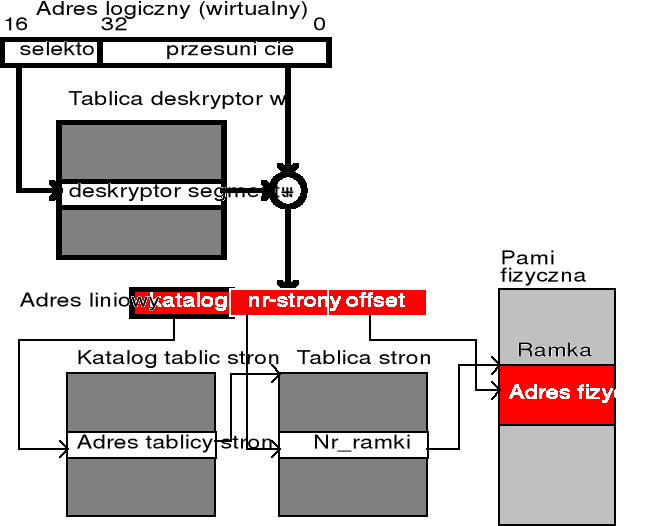
Segmantacja ze stronicowaniem na żądanie - schemat translacji adresu
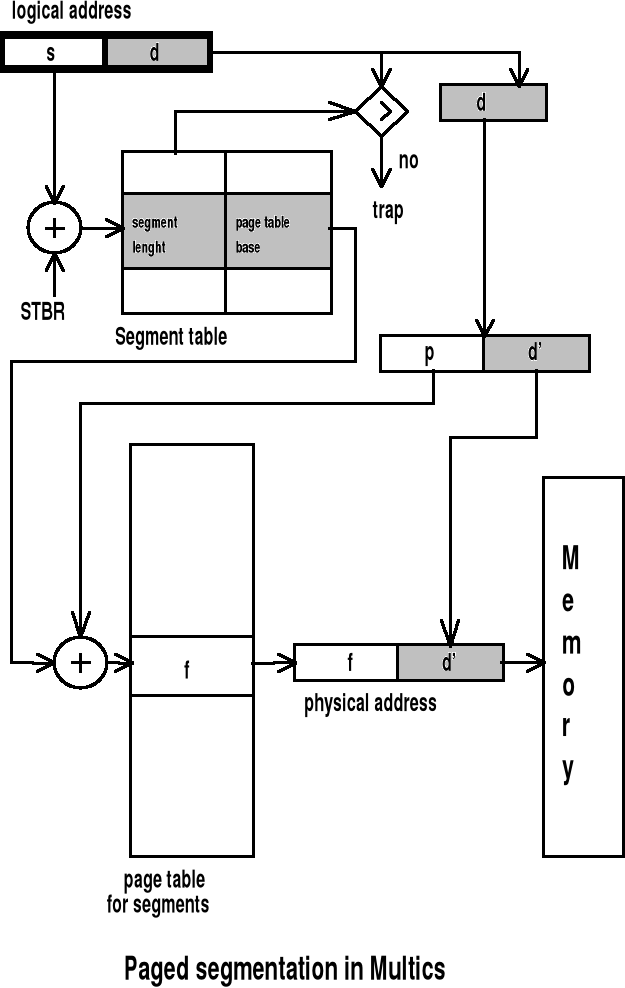
Segmentacja ze stronicowniem w procesorach Intel (OS/2 - 32 bit, Windows NT)
Segmentacja ze stronicowniem w procesorach Intel - cd.
Adres logiczny jest parą (selektor, offset), gdzie selektor jest liczbą 16-bitową. Tylko 13 bitów (a nie 16) jest wykorzystane...
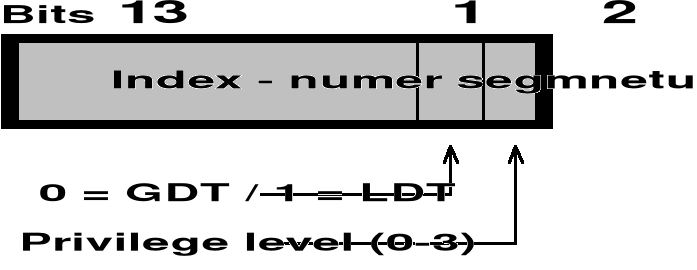
Offset jest liczbą 32-bitową i określa lokalizację danego bajtu wewnątrz segmentu. MAX=2^(13+32)=32 TB
Segmentacja ze stronicowniem w procesorach Intel - cd.
ADRES BAZOWY SEGMENTU | DŁUGOŚĆ SEGMENTU
Razem 8 bajtów Base
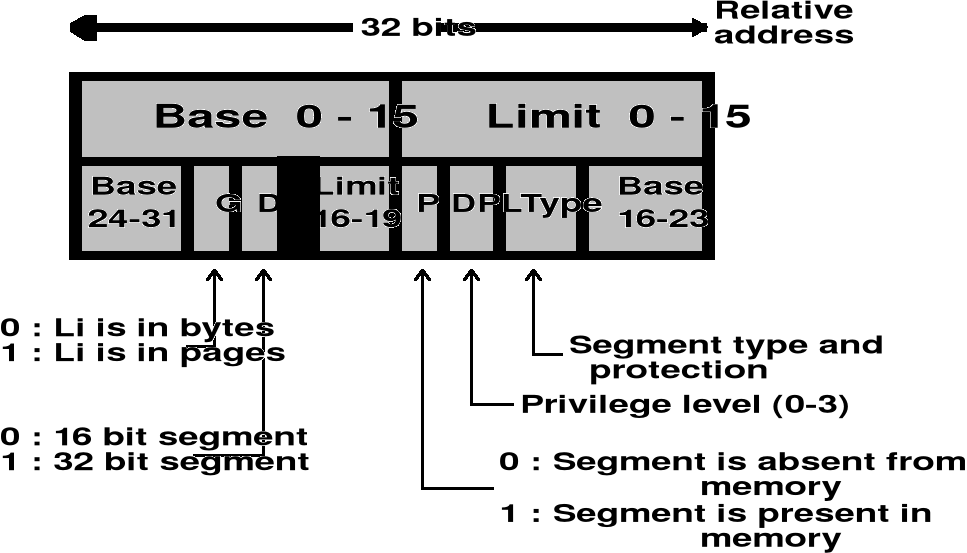
386 Code segment descriptor | Li=1 włączony mechanizm stronnicowania | MAX=2^20=1mln stron
Segmentacja ze stronicowniem w procesorach Intel - cd.
Obliczanie adresu liniowego i fizycznego:
(jeśli brak stronnicowania to adres liniowy = adres fizyczny)
Segmentacja ze stronicowniem w procesorach Intel - cd. Dodatkowo patrz str. 102
Segmentacja ze stronicowniem w procesorach Intel - cd.
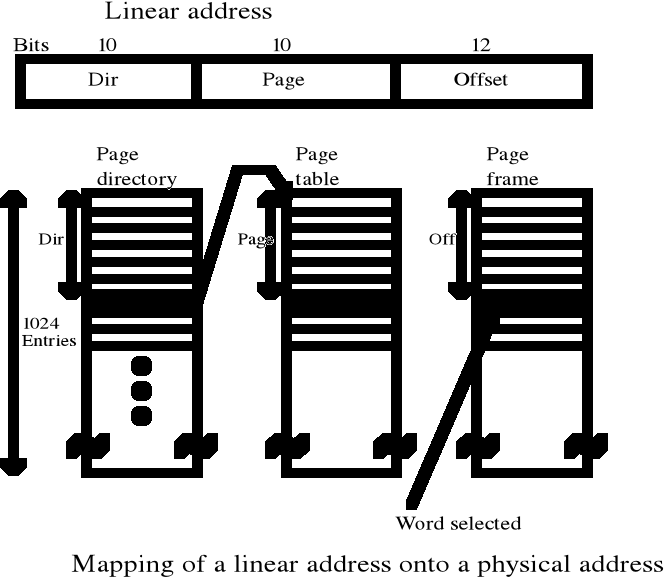
Segmentacja ze stronicowniem w procesorach Intel - cd.
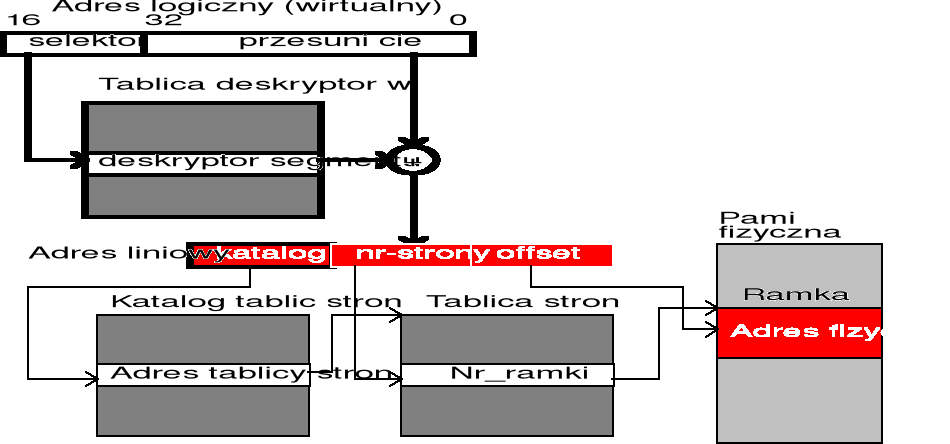
Zarządzanie pamięcią w systemie UNIX
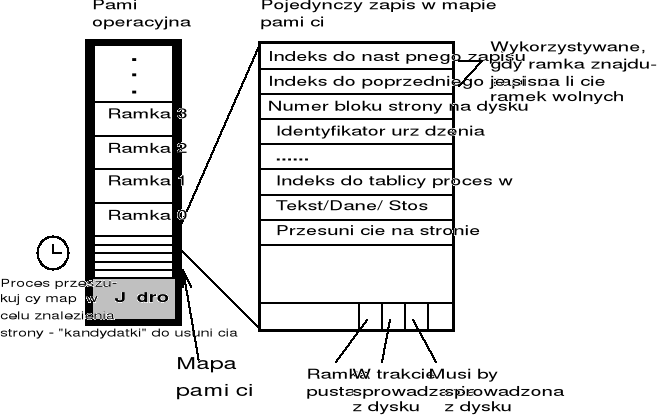
Strona dodatkowa - schemat dla str. 98
Adres logiczny
Zbyszko Królikowski - Systemy operacyjne - Zarządzanie pamięcią operacyjną 29
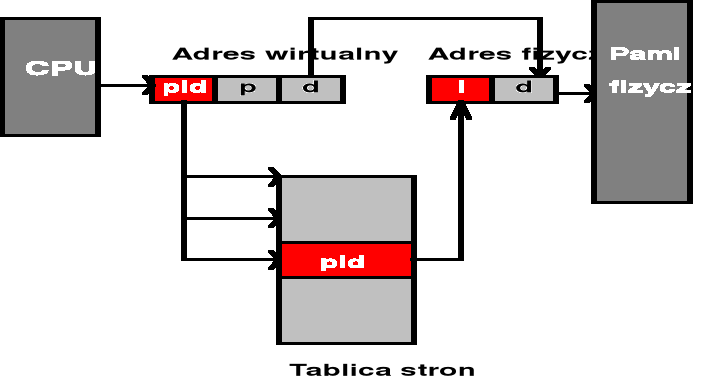
Czasowe usuwanie na dysk określonych procesów (lub ich fragmentów - np. stronnicowanie) znajdujących się w pamięci operacyjnej
(jednostka stronnicowania)
Schemat translacji adresu - tablica stron w PAO + rejestr bazowy tablicy stron
pam
asocjacyjna
cache
PAO
pam zewnętrzne
nr strony
s - segment
d - displacement
(przeniesienie)
p - page
(strona (w segmencie))
f - frame (ramka)
nr strony w segmencie
nr ramki
0 0
0 1 ? <-po wyzerowniu bitów odwołań do stron
1 0 po pewnym czasie bity R są zerowane dla
1 1 wszystkich stron ( bitów M nie można
R M zerować !!! )
im mniej jedynek tym starsza strona
wybierana jest strona w której wierszu jest
najmniej jedynek
jeśli następuje odwołanie do k-tej strony wtedy wszystkie bity w k-tym wierszu są ustawiane na 1, a w k-tej kolumnie na 0
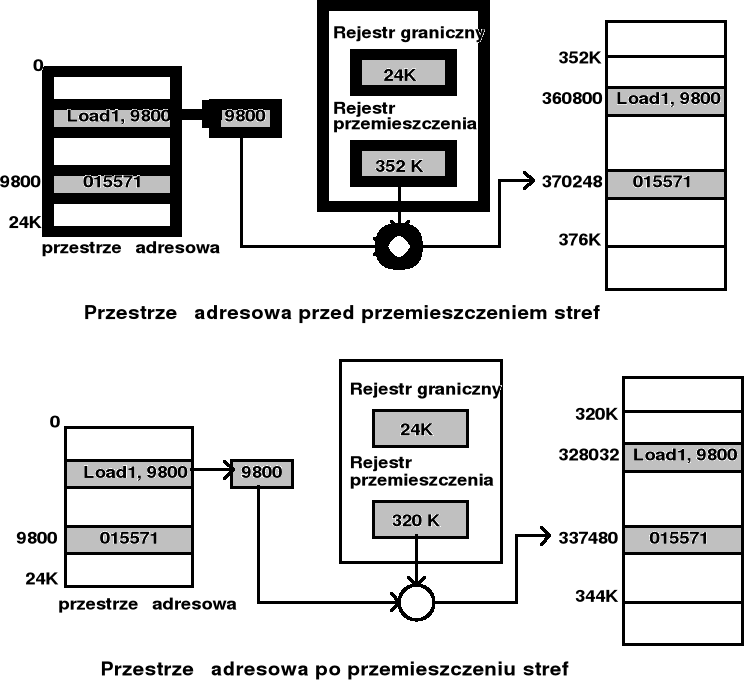
sprawdzenie poprawności długości segmentu
rej. bez tab. segm.
Przesunięcie (OFFS)
rzadko stosowane
nr segmentu
(SEG)
przemieszczenie
selektor

Najprostszy schemat organizacji pamięci - MS-DOS - polega na podziale przestrzeni pamięci na dwie części: jednej dla użytkownika i jednej dla systemu operacyjnego.
Najprostszy schemat organizacji pamięci umożliwia realizację systemu wieloprogramowego (wielozadaniowego)
//// - fragmentacja wewnętrzna
Strefy stałe mogą mieć równe lub różne rozmiary - każda strefa może zawierać dokładnie jeden proces.
STREFA ≠ SEGMENT
Strefy dynamiczne - o zmiennym rozmiarze, dostosowanym do rozmiaru procesu
//// - fragmentacja zewnętrzna
Fragmentacja:
- zewnętrzna - pozostają niewykorzystane wolne strefy, gdyż są za małe na potrzeby procesów zgłaszanych do systemu
- wewnętrzna - część strefy pozostaje niewykorzystana przez realizowany w niej proces
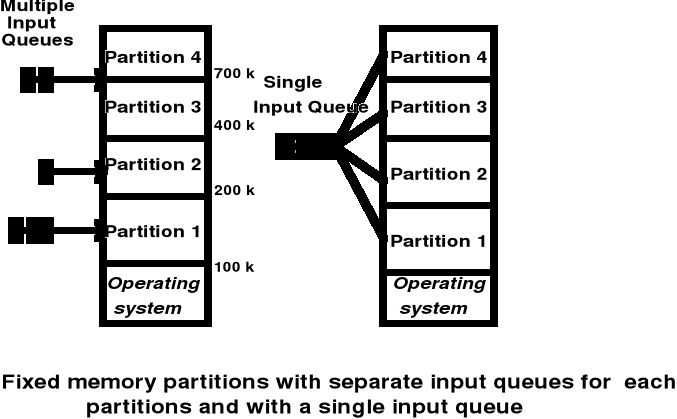
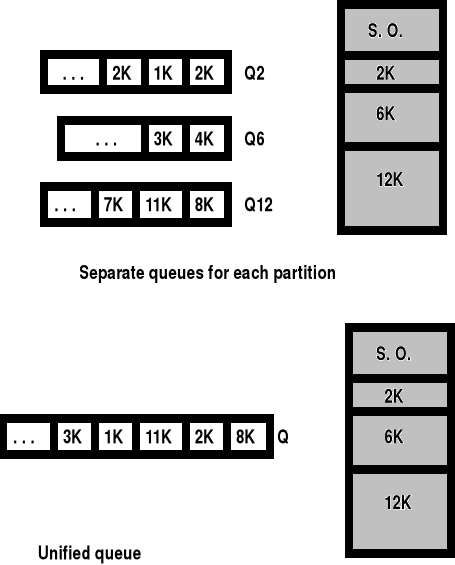
W przypadku stref stałych przydział pamięci może być realizowany z pojedynczą lub wielokrotną kolejką zadań oczekujących na wprowadzenie do pamięci.
Wada rozwiązania przydziału stref stałych z pojedynczą kolejką zadań oczekujących na wprowadzenie do pamięci - przykład
Scalanie pamięci (kompresja) - przykład
Wymaga przesunięcia 600K
Scalanie
może być
procesem
czasochłonnym
Scalanie pamięci - wykorzystanie rejestru przemieszczenia ( rej. bazowego )
Present / absent
( valid / invalid ) bit
(szczelina)
Jednostka alokacji pamięci
mapa bitowa
lista łączona
P = Proces
H = Hole (dziura, wolny obszar)
nr strony | nr ramki
tablice stron
4 bity
(w tym przypadku)
- numer strony
tablica
stron
numer ramki
przesunięcie
adres fizyczny
Jeśli nr strony jest 4bit, to jaki jest rozmiar dopuszczalnej przestrzeni adresowej procesu ?
2^3=8 8*4kB=32kB
12bit przesunięcie pozwala zaadresować 4096 bajtów wewnątrz strony - narzuca to rozmiar strony (4kB)
Kod współuzywany
(ang. reentrant code)
1 edytor jest współdzielony a nie
uruchamiany 3 razy
Każdy proces może mieć inną tablicę
Przesłania pewien obszar
Wskazanie zgodnego wiersza
Przepuszcza tylko 3 najbardziej znaczące bity
(adresowana zawartością)
katalog stron
tablica kontekstowa procesu (z id procesu i rejestrem roboczym)
Uporządkowana wg numerów ramek
Taka tablica jest JEDNA w systemie, przechowywana w pamięci asocjacyjnej
nr ramki
PMT = Page Map Table
tablice deskryptorów
translacja adresu w segmencie
adres liniowy
stronnicowanie włączone
stronnicowanie wyłączone
translacja adresu na stronę
tablice stron
adres fizyczny
Częste odwoływanie się do tego samego miejsca w pamięci ( np. pętla - ciągle te same instrukcje , ciągłe operacje na tych samych danych ) - podobnie jak pamięć
cache
Operacje przeszukiwania są wykonywane w 1
Cyklu - są to operacje równoległe - operacja dostępu daje od razu adres
Ponieważ znaleziona strona będzie dalej wykorzystywana - opłaca się przepisać ją do pamięci asocjacyjnej aby przy następnych odwołaniach do niej przyspieszyć je
Proces kompilacji może trwać długo ( trzeba przebudowywać
tablice stron gdy jedna najdzie
na drugą )
Wyszukiwarka