Oracle Database 11g.
Kompendium administratora
Autor:
T³umaczenie: Pawe³ Gonera
ISBN: 978-83-246-2549-9
Tytu³ orygina³u:
Format: 168×237, stron: 1504
Poznaj najbardziej efektywne funkcje najnowszej wersji bazy danych Oracle
• Jak u¿ywaæ nowych funkcji i narzêdzi Oracle 11g?
• Jak uruchamiaæ efektywne zapytania SQL?
• Jak tworzyæ instrukcje PL/SQL?
Baza danych Oracle 11g znacz¹co ró¿ni siê od wczeœniejszych wersji Oracle. Dziêki
nowym funkcjom programiœci i administratorzy baz danych zyskali du¿o wiêksz¹ kontrolê
nad przechowywaniem, przetwarzaniem oraz odczytywaniem danych. Jeœli chcesz
zdobyæ najnowsz¹ specjalistyczn¹ wiedzê z tego zakresu, skorzystaj z przewodnika
Kevina Loneya, œwiatowej s³awy eksperta w dziedzinie projektowania, tworzenia
i dostrajania baz danych Oracle oraz administrowania tymi bazami.
Ksi¹¿ka „Oracle Database 11g. Kompendium administratora” stanowi kompletny,
napisany klarownym jêzykiem i bogaty w niebanalne przyk³ady przewodnik po najnowszej
wersji Oracle. Korzystaj¹c z tego podrêcznika, nauczysz siê wdra¿aæ aktualne
zabezpieczenia, dostrajaæ wydajnoœæ bazy danych, tworzyæ instalacje przetwarzania
siatkowego oraz stosowaæ narzêdzie flashback. Dowiesz siê, jak wykorzystywaæ techniki
stosowane w relacyjnych systemach baz danych i aplikacjach. Poznasz tak¿e
zaawansowane opcje Oracle, takie jak technologia Data Pump, replikacja czy
indeksowanie.
Nieocenion¹ zalet¹ ksi¹¿ki jest dodatek zawieraj¹cy polecenia Oracle, s³owa kluczowe i
funkcje.
• Wybór architektury Oracle 11g
• Planowanie aplikacji systemu Oracle
• Tworzenie tabel, sekwencji, indeksów i kont u¿ytkowników
• Optymalizacja bezpieczeñstwa
• Importowanie i eksportowanie danych
• Unikanie b³êdów ludzkich dziêki technologii flashback
• Optymalizacja dostêpnoœci i skalowalnoœci – Oracle Real Application Clusters
• Wielkie obiekty LOB i zaawansowane funkcje obiektowe
• Zarz¹dzanie zmianami oraz buforowanie wyników
• Tworzenie aplikacji baz danych z u¿yciem Java JDBC i XML
Skorzystaj z wiedzy ekspertów – twórz efektywne relacyjne bazy danych!

Spis tre!ci
5
Spis tre!ci
O autorze ................................................................................................. 21
O wspó"pracownikach ............................................................................... 23
Cz#!$ I Najwa%niejsze poj#cia dotycz&ce bazy danych ....................... 25
Rozdzia" 1. Opcje architektury bazy danych Oracle 11g ............................................... 27
Bazy danych i instancje ...............................................................................................................28
Wn!trze bazy danych ...................................................................................................................29
Przechowywanie danych .......................................................................................................31
Ochrona danych ....................................................................................................................32
Struktury programowe ...........................................................................................................33
Wybór architektury i opcji ...........................................................................................................34
Rozdzia" 2. Instalacja bazy danych Oracle 11g i tworzenie bazy danych ....................... 35
Przegl"d opcji licencji i instalacji ................................................................................................36
U$ycie programu OUI do instalowania komponentów systemu Oracle ......................................37
Rozdzia" 3. Aktualizacja do wersji Oracle 11g ............................................................. 45
Wybór metody aktualizacji ..........................................................................................................46
Przed aktualizacj" ........................................................................................................................47
Uruchamianie narz!dzia do zbierania informacji przed aktualizacj" ...........................................48
Wykorzystanie asystenta aktualizacji bazy danych .....................................................................49
R!czna aktualizacja bezpo%rednia ...............................................................................................50
Wykorzystanie mechanizmów eksportu i importu .......................................................................51
Wersje narz!dzi eksportowania i importowania ....................................................................51
Wykonywanie aktualizacji ....................................................................................................52
Zastosowanie metody z kopiowaniem danych .............................................................................53
Po aktualizacji .............................................................................................................................53
Rozdzia" 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro%enia ... 55
Podej%cie kooperacyjne ...............................................................................................................56
Dane s" wsz!dzie .........................................................................................................................57
J!zyk systemu Oracle ..................................................................................................................58
Tabele ....................................................................................................................................59
Strukturalny j!zyk zapyta& ....................................................................................................59
Proste zapytanie w systemie Oracle ......................................................................................60

6
Oracle Database 11g. Kompendium administratora
Dlaczego system baz danych nazywa si! „relacyjnym”? ......................................................61
Proste przyk*ady ....................................................................................................................63
Zagro$enia ...................................................................................................................................64
Znaczenie nowego podej%cia .......................................................................................................65
Zmiana %rodowisk .................................................................................................................65
Kody, skróty i standardy nazw ..............................................................................................66
Jak zmniejszy+ zamieszanie? .......................................................................................................67
Normalizacja .........................................................................................................................68
Opisowe nazwy tabel i kolumn .............................................................................................72
Dane w j!zyku naturalnym ....................................................................................................74
Stosowanie wielkich liter w nazwach i danych .....................................................................74
Normalizacja nazw ......................................................................................................................75
Czynnik ludzki ............................................................................................................................75
Zadania aplikacji i dane aplikacji ..........................................................................................76
Identyfikacja zada& ...............................................................................................................78
Identyfikacja danych .............................................................................................................80
Model biznesowy .........................................................................................................................82
Wprowadzanie danych ..........................................................................................................82
Zapytania i tworzenie raportów .............................................................................................83
Normalizacja nazw obiektów ......................................................................................................84
Integralno%+ poziom-nazwa ...................................................................................................84
Klucze obce ...........................................................................................................................85
Nazwy w liczbie pojedynczej ................................................................................................85
Zwi!z*o%+ ..............................................................................................................................86
Obiekt o nazwie tezaurus ......................................................................................................86
Inteligentne klucze i warto%ci kolumn .........................................................................................86
Przykazania .................................................................................................................................87
Cz#!$ II SQL i SQL*Plus .................................................................... 89
Rozdzia" 5. Zasadnicze elementy j#zyka SQL .............................................................. 91
Styl ..............................................................................................................................................93
Utworzenie tabeli GAZETA ........................................................................................................93
Zastosowanie j!zyka SQL do wybierania danych z tabel ............................................................94
S*owa kluczowe select, from, where i order by ...........................................................................97
Operatory logiczne i warto%ci ......................................................................................................99
Testy pojedynczych warto%ci ..............................................................................................100
LIKE ...................................................................................................................................103
Proste testy dla list warto%ci ................................................................................................105
:"czenie wyra$e& logicznych ..............................................................................................107
Inne zastosowanie klauzuli where — podzapytania ..................................................................108
Podzapytania zwracaj"ce pojedyncz" warto%+ ....................................................................109
Podzapytania zwracaj"ce listy warto%ci ...............................................................................110
:"czenie tabel ............................................................................................................................111
Tworzenie perspektyw ...............................................................................................................113
Rozszerzanie perspektyw ..........................................................................................................115
Rozdzia" 6. Podstawowe raporty i polecenia programu SQL*Plus ............................... 117
Tworzenie prostego raportu .......................................................................................................119
remark .................................................................................................................................120
set headsep ..........................................................................................................................121
ttitle i btitle ..........................................................................................................................122
column .................................................................................................................................122
break on ...............................................................................................................................123

Spis tre!ci
7
compute avg ........................................................................................................................124
set linesize ...........................................................................................................................125
set pagesize ..........................................................................................................................125
set newpage .........................................................................................................................126
spool ....................................................................................................................................126
/* */ .....................................................................................................................................128
Obja%nienia dotycz"ce nag*ówków kolumn ........................................................................128
Inne w*asno%ci ...........................................................................................................................129
Edytor wierszowy ................................................................................................................129
set pause ..............................................................................................................................132
save .....................................................................................................................................132
store .....................................................................................................................................133
Edycja ..................................................................................................................................133
host ......................................................................................................................................134
Dodawanie polece& programu SQL*Plus ............................................................................135
Odczytywanie ustawie& programu SQL*Plus ...........................................................................135
Klocki ........................................................................................................................................137
Rozdzia" 7. Pobieranie informacji tekstowych i ich modyfikowanie ............................. 139
Typy danych ..............................................................................................................................139
Czym jest ci"g? .........................................................................................................................140
Notacja ......................................................................................................................................140
Konkatenacja (||) ........................................................................................................................143
Wycinanie i wklejanie ci"gów znaków ......................................................................................144
RPAD i LPAD .....................................................................................................................144
LTRIM, RTRIM i TRIM .....................................................................................................145
:"czenie dwóch funkcji .......................................................................................................146
Zastosowanie funkcji TRIM ................................................................................................149
U$ycie dodatkowej funkcji ..................................................................................................149
LOWER, UPPER i INITCAP ..............................................................................................150
LENGTH .............................................................................................................................151
SUBSTR ..............................................................................................................................152
INSTR .................................................................................................................................155
ASCII i CHR .......................................................................................................................159
Zastosowanie klauzul order by oraz where z funkcjami znakowymi .........................................160
SOUNDEX ..........................................................................................................................161
Obs*uga j!zyków narodowych ............................................................................................163
Obs*uga wyra$e& regularnych .............................................................................................163
Podsumowanie ...........................................................................................................................163
Rozdzia" 8. Wyszukiwanie z wykorzystaniem wyra%e( regularnych ............................. 165
Wyszukiwanie w ci"gach znaków .............................................................................................165
REGEXP_SUBSTR ...................................................................................................................167
REGEXP_INSTR ................................................................................................................171
REGEXP_LIKE ..................................................................................................................172
REPLACE i REGEXP_REPLACE .....................................................................................173
REGEXP_COUNT ..............................................................................................................177
Rozdzia" 9. Operacje z danymi numerycznymi ............................................................ 179
Trzy klasy funkcji numerycznych ..............................................................................................179
Notacja ......................................................................................................................................180
Funkcje operuj"ce na pojedynczych warto%ciach ......................................................................180
Dodawanie (+), odejmowanie (–), mno$enie (*) i dzielenie (/) ...........................................181
NULL ..................................................................................................................................182

8
Oracle Database 11g. Kompendium administratora
NVL — zast!powanie warto%ci NULL ...............................................................................182
ABS — warto%+ bezwzgl!dna .............................................................................................184
CEIL ....................................................................................................................................184
FLOOR ................................................................................................................................184
MOD ...................................................................................................................................184
POWER ...............................................................................................................................185
SQRT — pierwiastek kwadratowy ......................................................................................185
EXP, LN i LOG ...................................................................................................................186
ROUND i TRUNC ..............................................................................................................186
SIGN ...................................................................................................................................188
SIN, SINH, COS, COSH, TAN, TANH, ACOS, ATAN, ATAN2 i ASIN .........................188
Funkcje agregacji .......................................................................................................................189
Warto%ci NULL w funkcjach agregacji ...............................................................................189
Przyk*ady funkcji operuj"cych na pojedynczych warto%ciach oraz na grupach warto%ci ....190
AVG, COUNT, MAX, MIN i SUM ....................................................................................191
:"czenie funkcji grupowych z funkcjami operuj"cymi na pojedynczych warto%ciach .......192
STDDEV i VARIANCE .....................................................................................................194
Opcja DISTINCT w funkcjach grupowych .........................................................................194
Funkcje operuj"ce na listach ......................................................................................................195
Wyszukiwanie wierszy za pomoc" funkcji MAX lub MIN .......................................................197
Priorytety dzia*a& i nawiasy .......................................................................................................198
Podsumowanie ...........................................................................................................................199
Rozdzia" 10. Daty — kiedy!, teraz i ró%nice ................................................................ 201
Arytmetyka dat ..........................................................................................................................201
SYSDATE, CURRENT_DATE i SYSTIMESTAMP .........................................................202
Ró$nica pomi!dzy dwiema datami ......................................................................................203
Dodawanie miesi!cy ...........................................................................................................204
Odejmowanie miesi!cy .......................................................................................................204
GREATEST i LEAST .........................................................................................................204
NEXT_DAY .......................................................................................................................205
LAST_DAY ........................................................................................................................207
MONTHS_BETWEEN — liczba miesi!cy dziel"cych dwie daty ......................................207
:"czenie funkcji przetwarzania dat .....................................................................................208
Funkcje ROUND i TRUNC w obliczeniach z wykorzystaniem dat ..........................................208
Formatowanie w funkcjach TO_DATE i TO_CHAR ................................................................209
Najcz!stsze b*!dy funkcji TO_CHAR .................................................................................214
NEW_TIME — prze*"czanie stref czasowych ....................................................................214
Obliczenia z wykorzystaniem funkcji TO_DATE ...............................................................215
Daty w klauzuli where ...............................................................................................................217
Obs*uga wielu stuleci .................................................................................................................218
Zastosowanie funkcji EXTRACT ..............................................................................................219
Zastosowanie typu danych TIMESTAMP .................................................................................220
Rozdzia" 11. Funkcje konwersji i transformacji ............................................................ 223
Podstawowe funkcje konwersji .................................................................................................225
Automatyczna konwersja typów danych .............................................................................227
Ostrze$enie przed automatyczn" konwersj" ........................................................................230
Specjalne funkcje konwersji ......................................................................................................230
Funkcje transformacji ................................................................................................................231
TRANSLATE .....................................................................................................................231
DECODE ............................................................................................................................232
Podsumowanie ...........................................................................................................................233

Spis tre!ci
9
Rozdzia" 12. Grupowanie danych ................................................................................ 235
Zastosowanie klauzul group by i having ...................................................................................235
Dodanie klauzuli order by ...................................................................................................237
Kolejno%+ wykonywania klauzul .........................................................................................238
Perspektywy grup ......................................................................................................................240
Zmiana nazw kolumn za pomoc" aliasów .................................................................................241
Mo$liwo%ci perspektyw grupowych ..........................................................................................242
Zastosowanie klauzuli order by w perspektywach ..............................................................243
Logika klauzuli having ........................................................................................................244
Zastosowanie klauzuli order by z kolumnami i funkcjami grupuj"cymi .............................246
Kolumny z*"cze& .................................................................................................................246
Dodatkowe mo$liwo%ci grupowania ..........................................................................................247
Rozdzia" 13. Kiedy jedno zapytanie zale%y od drugiego ................................................ 249
Zaawansowane podzapytania ....................................................................................................249
Skorelowane podzapytania ..................................................................................................250
Koordynacja testów logicznych ..........................................................................................251
Zastosowanie klauzuli EXISTS oraz jej skorelowanego podzapytania ...............................252
Z*"czenia zewn!trzne ................................................................................................................254
Sk*adnia z*"cze& zewn!trznych w wersjach bazy danych poprzedzaj"cych Oracle9i .........254
Nowa sk*adnia z*"cze& zewn!trznych .................................................................................256
Zast"pienie klauzuli NOT IN zewn!trznym z*"czeniem .....................................................258
Zast"pienie klauzuli NOT IN klauzul" NOT EXISTS .........................................................259
Z*"czenia naturalne i wewn!trzne ..............................................................................................260
UNION, INTERSECT i MINUS ...............................................................................................261
Podzapytania IN ..................................................................................................................264
Ograniczenia stosowania operatorów UNION, INTERSECT i MINUS .............................264
Rozdzia" 14. Zaawansowane mo%liwo!ci ..................................................................... 265
Z*o$one grupowanie ..................................................................................................................265
Tabele tymczasowe ...................................................................................................................267
Zastosowanie funkcji ROLLUP, GROUPING i CUBE .............................................................268
Drzewa rodzinne i klauzula connect by .....................................................................................272
Wykluczanie pojedynczych wierszy i ga*!zi .......................................................................275
Poruszanie si! w kierunku korzeni ......................................................................................276
Podstawowe zasady .............................................................................................................278
Rozdzia" 15. Modyfikowanie danych: insert, update, merge i delete ............................. 281
insert ..........................................................................................................................................281
Wprowadzanie informacji o godzinie ..................................................................................282
insert na podstawie select ....................................................................................................283
Zastosowanie wskazówki APPEND do poprawy wydajno%ci instrukcji insert ...................284
rollback, commit i autocommit ..................................................................................................285
Zastosowanie punktów zapisu .............................................................................................285
Niejawne polecenie commit ................................................................................................287
Automatyczne cofanie .........................................................................................................287
Wprowadzanie danych do wielu tabel .......................................................................................287
delete .........................................................................................................................................291
update ........................................................................................................................................292
Instrukcja update z wbudowan" instrukcj" select ................................................................293
Instrukcja update z warto%ciami NULL ...............................................................................294
Zastosowanie polecenia merge ..................................................................................................295
Obs*uga b*!dów .........................................................................................................................298

10
Oracle Database 11g. Kompendium administratora
Rozdzia" 16. DECODE i CASE: if, then oraz else w j#zyku SQL ..................................... 301
if, then, else ...............................................................................................................................301
Zast!powanie warto%ci przy u$yciu funkcji DECODE ..............................................................304
Funkcja DECODE w innej funkcji DECODE ...........................................................................305
Operatory wi!kszy ni$ i mniejszy ni$ w funkcji DECODE .......................................................309
Funkcja CASE ...........................................................................................................................310
U$ycie operatora PIVOT ...........................................................................................................313
Rozdzia" 17. Tworzenie tabel, perspektyw, indeksów,
klastrów i sekwencji oraz zarz&dzanie nimi .............................................. 317
Tworzenie tabeli ........................................................................................................................317
Szeroko%+ ci"gów znaków i precyzja danych liczbowych ...................................................318
Zaokr"glanie danych podczas wprowadzania do bazy ........................................................321
Ograniczenia w instrukcji create table .................................................................................321
Wyznaczanie indeksowych przestrzeni tabel ......................................................................324
Nazwy ogranicze& ...............................................................................................................325
Usuwanie tabel ..........................................................................................................................326
Uaktualnianie definicji tabel ......................................................................................................326
Regu*y dodawania lub modyfikowania kolumn ..................................................................329
Tworzenie tabel tylko do odczytu .......................................................................................330
Modyfikowanie aktywnie wykorzystywanych tabel ...........................................................330
Tworzenie kolumn wirtualnych ...........................................................................................331
Usuwanie kolumn ................................................................................................................332
Tworzenie tabeli na podstawie innej tabeli ................................................................................333
Tworzenie tabeli o strukturze indeksu .......................................................................................335
Tworzenie perspektyw ...............................................................................................................336
Stabilno%+ perspektywy .......................................................................................................336
Zastosowanie klauzuli order by w perspektywach ..............................................................337
Tworzenie perspektyw tylko do odczytu .............................................................................338
Indeksy ......................................................................................................................................338
Tworzenie indeksów ...........................................................................................................339
Wymuszanie niepowtarzalno%ci ..........................................................................................340
Tworzenie indeksów niepowtarzalnych ..............................................................................340
Tworzenie indeksów bitmapowych .....................................................................................341
Kiedy nale$y tworzy+ indeksy .............................................................................................342
Tworzenie niewidocznych indeksów ...................................................................................342
Ró$norodno%+ danych w kolumnach indeksowanych .........................................................343
Ile indeksów wykorzystywa+ w tabeli .................................................................................344
Lokalizacja indeksów w bazie danych ................................................................................344
Odbudowywanie indeksu ....................................................................................................345
Indeksy tworzone na podstawie funkcji ..............................................................................345
Klastry .......................................................................................................................................346
Sekwencje ..................................................................................................................................348
Rozdzia" 18. Partycjonowanie ..................................................................................... 351
Tworzenie tabeli partycjonowanej .............................................................................................351
Partycjonowanie wed*ug listy ....................................................................................................354
Tworzenie podpartycji ...............................................................................................................354
Tworzenie partycji wed*ug odwo*a& i interwa*ów .....................................................................355
Indeksowanie partycji ................................................................................................................357
Zarz"dzanie tabelami partycjonowanymi ..................................................................................357
Rozdzia" 19. Podstawowe mechanizmy bezpiecze(stwa systemu Oracle ...................... 359
U$ytkownicy, role i uprawnienia ...............................................................................................359
Tworzenie u$ytkownika ......................................................................................................360
Zarz"dzanie has*ami ............................................................................................................361

Spis tre!ci
11
Standardowe role .................................................................................................................365
Polecenie grant ....................................................................................................................366
Odbieranie uprawnie& i ról ..................................................................................................366
Jakie uprawnienia mog" nadawa+ u$ytkownicy? ......................................................................367
Prze*"czanie si! do innego u$ytkownika za pomoc" polecenia connect ..............................369
create synonym ....................................................................................................................372
Wykorzystanie uprawnie&, które nie zosta*y nadane ...........................................................372
Przekazywanie uprawnie& ...................................................................................................372
Tworzenie ról ......................................................................................................................374
Nadawanie uprawnie& do ról ...............................................................................................374
Przypisywanie ról do innych ról ..........................................................................................375
Nadawanie ról u$ytkownikom .............................................................................................375
Definiowanie hase* dla ról ...................................................................................................376
Usuwanie has*a z roli ..........................................................................................................377
W*"czanie i wy*"czanie ról ..................................................................................................377
Odbieranie uprawnie& nadanych rolom ...............................................................................378
Usuwanie roli ......................................................................................................................378
Nadawanie uprawnienia UPDATE do okre%lonych kolumn ...............................................378
Odbieranie uprawnie& do obiektów .....................................................................................379
Zabezpieczenia na poziomie u$ytkownika ..........................................................................379
Nadawanie uprawnie& publicznych .....................................................................................381
Nadawanie uprawnie& do ograniczonych zasobów ...................................................................382
Cz#!$ III Wi#cej ni% podstawy ........................................................... 383
Rozdzia" 20. Zaawansowane w"a!ciwo!ci bezpiecze(stwa
— wirtualne prywatne bazy danych ......................................................... 385
Konfiguracja wst!pna ................................................................................................................386
Tworzenie kontekstu aplikacji ...................................................................................................387
Tworzenie wyzwalacza logowania ............................................................................................388
Tworzenie strategii bezpiecze&stwa ..........................................................................................389
Zastosowanie strategii bezpiecze&stwa do tabel ........................................................................391
Testowanie mechanizmu VPD ..................................................................................................391
Implementacja mechanizmu VPD na poziomie kolumn ............................................................393
Wy*"czanie mechanizmu VPD ..................................................................................................393
Korzystanie z grup strategii .......................................................................................................395
Rozdzia" 21. Zaawansowane w"a!ciwo!ci bezpiecze(stwa
— przezroczyste szyfrowanie danych ....................................................... 397
Przezroczyste szyfrowanie danych w kolumnach ......................................................................397
Konfiguracja ........................................................................................................................398
Dodatkowa konfiguracja baz danych RAC .........................................................................399
Otwieranie i zamykanie portfela ..........................................................................................399
Szyfrowanie i deszyfrowanie kolumn .................................................................................400
Szyfrowanie przestrzeni tabel ....................................................................................................401
Konfiguracja ........................................................................................................................402
Tworzenie zaszyfrowanej przestrzeni tabel .........................................................................403
Rozdzia" 22. Przestrzenie tabel .................................................................................. 405
Przestrzenie tabel a struktura bazy danych ................................................................................405
Zawarto%+ przestrzeni tabel .................................................................................................406
Przestrze& RECYCLEBIN ..................................................................................................408
Przestrzenie tabel tylko do odczytu .....................................................................................409
Przestrzenie tabel nologging ................................................................................................410
Tymczasowe przestrzenie tabel ...........................................................................................410

12
Oracle Database 11g. Kompendium administratora
Przestrzenie tabel dla operacji cofania zarz"dzanych przez system ....................................410
Przestrzenie tabel z du$ymi plikami ....................................................................................411
Szyfrowane przestrzenie tabel .............................................................................................411
Obs*uga opcji flashback ......................................................................................................412
Transportowanie przestrzeni tabel .......................................................................................412
Planowanie wykorzystania przestrzeni tabel .............................................................................413
Oddzielenie tabel aktywnych od tabel statycznych .............................................................413
Oddzielenie indeksów od tabel ............................................................................................413
Oddzielenie du$ych od ma*ych obiektów ............................................................................413
Oddzielenie tabel aplikacji od obiektów podstawowych .....................................................414
Rozdzia" 23. Zastosowanie programu SQL*Loader do "adowania danych ...................... 415
Plik steruj"cy .............................................................................................................................416
:adowanie danych o zmiennej d*ugo%ci ..............................................................................417
Rozpocz!cie *adowania .............................................................................................................418
Rekordy logiczne i fizyczne ......................................................................................................421
Uwagi na temat sk*adni pliku steruj"cego .................................................................................422
Zarz"dzanie *adowaniem danych ...............................................................................................424
Powtarzanie operacji *adowania danych ....................................................................................425
Dostrajanie operacji *adowania danych .....................................................................................426
:adowanie Direct Path ..............................................................................................................428
Dodatkowe w*asno%ci ................................................................................................................429
Rozdzia" 24. Mechanizm eksportu i importu Data Pump .............................................. 431
Tworzenie katalogu ...................................................................................................................431
Opcje mechanizmu Data Pump Export ......................................................................................432
Uruchamianie zadania eksportu mechanizmu Data Pump .........................................................435
Zatrzymywanie dzia*aj"cych zada& i ich wznawianie .........................................................436
Eksportowanie z innej bazy danych ....................................................................................437
Opcje EXCLUDE, INCLUDE i QUERY ............................................................................437
Opcje mechanizmu Data Pump Import ......................................................................................439
Uruchamianie zadania importu mechanizmu Data Pump ..........................................................441
Zatrzymanie dzia*aj"cych zada& i ich wznawianie ..............................................................443
Opcje EXCLUDE, INCLUDE i QUERY ............................................................................443
Przekszta*canie importowanych obiektów ..........................................................................444
Generowanie SQL ...............................................................................................................444
Rozdzia" 25. Zdalny dost#p do danych ........................................................................ 447
:"cza baz danych ......................................................................................................................447
Jak dzia*aj" *"cza baz danych ..............................................................................................447
Zdalne zapytania .................................................................................................................448
Definiowanie synonimów lub perspektyw ..........................................................................449
Zdalne aktualizacje ..............................................................................................................450
Sk*adnia *"cza bazy danych .................................................................................................451
Zastosowanie synonimów w celu uzyskania przezroczystej lokalizacji obiektów .....................454
Pseudokolumna User w perspektywach .....................................................................................456
Rozdzia" 26. Perspektywy zmaterializowane ............................................................... 459
Dzia*anie ....................................................................................................................................459
Wymagane uprawnienia systemowe ..........................................................................................460
Wymagane uprawnienia do tabel ...............................................................................................461
Perspektywy tylko do odczytu a perspektywy z mo$liwo%ci" aktualizacji ................................461
Sk*adnia polecenia create materialized view .............................................................................462
Typy perspektyw zmaterializowanych ................................................................................466
Perspektywy zmaterializowane z kluczami g*ównymi i kolumnami RowID ......................466
Zastosowanie tabel gotowych ..............................................................................................467
Indeksowanie tabel perspektywy zmaterializowanej ...........................................................467

Spis tre!ci
13
Zastosowanie perspektyw zmaterializowanych
do modyfikacji %cie$ek wykonywania zapyta& .......................................................................468
Pakiet DBMS_ADVISOR .........................................................................................................470
Od%wie$anie perspektyw zmaterializowanych ..........................................................................472
Jakiego rodzaju od%wie$anie mo$na wykona+? ...................................................................472
Szybkie od%wie$anie z u$yciem CONSIDER FRESH ........................................................476
Od%wie$anie automatyczne .................................................................................................476
Od%wie$anie r!czne .............................................................................................................477
Polecenie create materialized view log ......................................................................................478
Modyfikowanie zmaterializowanych perspektyw i dzienników ................................................480
Usuwanie zmaterializowanych perspektyw i dzienników .........................................................480
Rozdzia" 27. Zastosowanie pakietu Oracle Text do wyszukiwania ci&gów znaków ........ 483
Wprowadzanie tekstu do bazy danych .......................................................................................483
Zapytania tekstowe i indeksy .....................................................................................................484
Zapytania tekstowe ..............................................................................................................485
Dost!pne wyra$enia w zapytaniach tekstowych ..................................................................486
Dok*adne wyszukiwanie s*ów .............................................................................................487
Dok*adne wyszukiwanie wielu s*ów ...................................................................................488
Wyszukiwanie fraz ..............................................................................................................491
Wyszukiwanie s*ów, które s" blisko siebie .........................................................................492
Zastosowanie wzorców w operacjach wyszukiwania ..........................................................493
Wyszukiwanie s*ów o tym samym rdzeniu .........................................................................494
Wyszukiwanie niedok*adne .................................................................................................494
Wyszukiwanie s*ów o podobnym brzmieniu .......................................................................495
Zastosowanie operatora ABOUT ........................................................................................496
Synchronizacja indeksów ....................................................................................................498
Zestawy indeksów .....................................................................................................................498
Rozdzia" 28. Tabele zewn#trzne .................................................................................. 501
Dost!p do zewn!trznych danych ...............................................................................................501
Tworzenie tabeli zewn!trznej ....................................................................................................502
Opcje tworzenia tabel zewn!trznych ...................................................................................506
:adowanie danych do tabel zewn!trznych w czasie ich tworzenia .....................................511
Modyfikowanie tabel zewn!trznych ..........................................................................................512
Klauzula access parameters .................................................................................................512
Klauzula add column ...........................................................................................................513
Klauzula default directory ...................................................................................................513
Klauzula drop column .........................................................................................................513
Klauzula location .................................................................................................................513
Klauzula modify column .....................................................................................................513
Klauzula parallel .................................................................................................................513
Klauzula project column .....................................................................................................514
Klauzula reject limit ............................................................................................................514
Klauzula rename to ..............................................................................................................514
Ograniczenia, zalety i potencjalne zastosowania tabel zewn!trznych .......................................514
Rozdzia" 29. Zapytania flashback ............................................................................... 517
Przyk*ad czasowego zapytania flashback ..................................................................................518
Zapisywanie danych ..................................................................................................................519
Przyk*ad zapytania flashback z wykorzystaniem numerów SCN ..............................................520
Co zrobi+, je%li zapytanie flashback nie powiedzie si!? ............................................................521
Jaki numer SCN jest przypisany do ka$dego wiersza? ..............................................................522
Zapytania flashback o wersje .....................................................................................................523
Planowanie operacji flashback ..................................................................................................525

14
Oracle Database 11g. Kompendium administratora
Rozdzia" 30. Operacje flashback — tabele i bazy danych ............................................. 527
Polecenie flashback table ...........................................................................................................527
Wymagane uprawnienia ......................................................................................................528
Odtwarzanie usuni!tych tabel ..............................................................................................528
W*"czanie i wy*"czanie kosza .............................................................................................530
Odtwarzanie danych do okre%lonego numeru SCN lub znacznika czasu ............................530
Indeksy i statystyki ..............................................................................................................531
Polecenie flashback database .....................................................................................................532
Rozdzia" 31. Powtarzanie polece( SQL ....................................................................... 537
Konfiguracja wysokiego poziomu .............................................................................................537
Izolacja i *"cza .....................................................................................................................538
Tworzenie katalogu polece& ................................................................................................538
Przechwytywanie polece& .........................................................................................................539
Definiowanie filtrów ...........................................................................................................539
Uruchamianie przechwytywania .........................................................................................540
Zatrzymywanie przechwytywania .......................................................................................541
Eksportowanie danych AWR ..............................................................................................541
Przetwarzanie polece& ...............................................................................................................541
Powtarzanie polece& ..................................................................................................................542
Uruchamianie klientów powtarzania i sterowanie nimi .......................................................543
Inicjowanie i uruchamianie powtarzania .............................................................................543
Eksportowanie danych AWR ..............................................................................................545
Cz#!$ IV PL/SQL .............................................................................. 547
Rozdzia" 32. Wprowadzenie do j#zyka PL/SQL ............................................................ 549
Przegl"d j!zyka PL/SQL ...........................................................................................................549
Sekcja deklaracji ........................................................................................................................550
Sekcja polece& wykonywalnych ................................................................................................553
Logika warunkowa ..............................................................................................................555
P!tle .....................................................................................................................................556
Instrukcje CASE ..................................................................................................................564
Sekcja obs*ugi wyj"tków ...........................................................................................................566
Rozdzia" 33. Aktualizacja dzia"aj&cych aplikacji .......................................................... 569
Bazy danych o wysokiej dost!pno%ci ........................................................................................569
Architektura Oracle Data Guard ..........................................................................................570
Tworzenie konfiguracji zapasowej bazy danych .................................................................572
Zarz"dzanie rolami — prze*"czanie i prze*"czanie awaryjne ..............................................574
Wprowadzanie zmian DDL w sposób nieinwazyjny .................................................................577
Tworzenie kolumn wirtualnych ...........................................................................................577
Modyfikowanie aktywnie wykorzystywanych tabel ...........................................................578
Dodawanie kolumn NOT NULL .........................................................................................579
Reorganizacja obiektów w trybie online .............................................................................579
Usuwanie kolumn ................................................................................................................582
Rozdzia" 34. Wyzwalacze ........................................................................................... 585
Wymagane uprawnienia systemowe ..........................................................................................585
Wymagane uprawnienia do tabel ...............................................................................................586
Typy wyzwalaczy ......................................................................................................................586
Wyzwalacze na poziomie wierszy .......................................................................................586
Wyzwalacze na poziomie instrukcji ....................................................................................586
Wyzwalacze BEFORE i AFTER .........................................................................................587
Wyzwalacz INSTEAD OF ..................................................................................................587

Spis tre!ci
15
Wyzwalacze na poziomie schematu ....................................................................................588
Wyzwalacze na poziomie bazy danych ...............................................................................588
Wyzwalacze z*o$one ...........................................................................................................588
Sk*adnia wyzwalaczy ................................................................................................................588
:"czenie wyzwalaczy typu DML ........................................................................................590
Ustawianie warto%ci we wprowadzanych wierszach ...........................................................592
Utrzymanie zdublowanych danych .....................................................................................593
Dostosowanie obs*ugi b*!dów do indywidualnych potrzeb .................................................594
Wywo*ywanie procedur wewn"trz wyzwalaczy ..................................................................596
Nazwy wyzwalaczy .............................................................................................................597
Tworzenie wyzwalaczy zwi"zanych z operacjami DDL .....................................................597
Wyzwalacze zwi"zane z operacjami na poziomie bazy danych ..........................................602
Tworzenie wyzwalaczy z*o$onych ......................................................................................602
W*"czanie i wy*"czanie wyzwalaczy .........................................................................................604
Zast!powanie wyzwalaczy ........................................................................................................605
Usuwanie wyzwalaczy ..............................................................................................................605
Rozdzia" 35. Procedury, funkcje i pakiety ................................................................... 607
Wymagane uprawnienia systemowe ..........................................................................................608
Wymagane uprawnienia do tabel ...............................................................................................609
Procedury a funkcje ...................................................................................................................610
Procedury a pakiety ...................................................................................................................610
Sk*adnia polecenia create procedure ..........................................................................................610
Sk*adnia polecenia create function ............................................................................................612
Odwo*ywanie si! do zdalnych tabel w procedurach ............................................................614
Procedury diagnostyczne .....................................................................................................615
Tworzenie funkcji u$ytkownika ..........................................................................................616
Dostosowanie obs*ugi b*!dów do indywidualnych potrzeb .................................................618
Nazwy procedur i funkcji ....................................................................................................619
Sk*adnia polecenia create package ............................................................................................620
Przegl"danie kodu ]ród*owego obiektów proceduralnych .........................................................623
Kompilacja procedur, funkcji i pakietów ...................................................................................623
Zast!powanie procedur, funkcji i pakietów ...............................................................................624
Usuwanie procedur, funkcji i pakietów .....................................................................................625
Rozdzia" 36. Wbudowany dynamiczny SQL i pakiet DBMS_SQL .................................... 627
Polecenie EXECUTE IMMEDIATE .........................................................................................627
Zmienne wi"$"ce .......................................................................................................................629
Pakiet DBMS_SQL ...................................................................................................................630
OPEN_CURSOR ................................................................................................................631
PARSE ................................................................................................................................631
BIND_VARIABLE oraz BIND_ARRAY ...........................................................................631
EXECUTE ..........................................................................................................................632
DEFINE_COLUMN ...........................................................................................................632
FETCH_ROWS, EXECUTE_AND_FETCH oraz COLUMN_VALUE ............................633
CLOSE_CURSOR ..............................................................................................................633
Rozdzia" 37. Dostrajanie wydajno!ci PL/SQL .............................................................. 635
Dostrajanie SQL ........................................................................................................................635
Dostrajanie kodu PL/SQL .........................................................................................................636
Zastosowanie pakietu DBMS_PROFILER do identyfikowania problemów .............................637
U$ycie funkcji PL/SQL obs*uguj"cych operacje masowe .........................................................642
forall ....................................................................................................................................642
bulk collect ..........................................................................................................................644

16
Oracle Database 11g. Kompendium administratora
Cz#!$ V Obiektowo-relacyjne bazy danych ........................................ 647
Rozdzia" 38. Implementowanie typów, perspektyw obiektowych i metod ..................... 649
Zasady pracy z abstrakcyjnymi typami danych .........................................................................649
Abstrakcyjne typy danych a bezpiecze&stwo ......................................................................650
Indeksowanie atrybutów abstrakcyjnego typu danych ........................................................653
Implementowanie perspektyw obiektowych ..............................................................................655
Operowanie na danych za po%rednictwem perspektyw obiektowych ..................................658
Wyzwalacz INSTEAD OF ..................................................................................................658
Metody ......................................................................................................................................661
Sk*adnia metod ....................................................................................................................661
Zarz"dzanie metodami ........................................................................................................663
Rozdzia" 39. Kolektory (tabele zagnie%d%one i tablice zmienne) ................................... 665
Tablice zmienne .........................................................................................................................665
Tworzenie tablicy zmiennej ................................................................................................665
Opis tablicy zmiennej ..........................................................................................................666
Wstawianie rekordów do tablicy zmiennej ..........................................................................667
Pobieranie danych z tablic zmiennych ................................................................................669
Tabele zagnie$d$one ..................................................................................................................672
Definiowanie przestrzeni tabel dla tabel zagnie$d$onych ...................................................673
Wstawianie rekordów do tabeli zagnie$d$onej ...................................................................673
Wykonywanie zapyta& do tabel zagnie$d$onych ................................................................675
Dodatkowe funkcje dla tabel zagnie$d$onych i tablic zmiennych .............................................677
Zarz"dzanie tabelami zagnie$d$onymi i tablicami zmiennymi .................................................677
Problemy ze zmienno%ci" charakterystyk kolektorów .........................................................678
Lokalizacja danych ..............................................................................................................679
Rozdzia" 40. Wielkie obiekty (LOB) ............................................................................ 681
Dost!pne typy ............................................................................................................................681
Definiowanie parametrów sk*adowania dla danych LOB ..........................................................683
Zapytania o warto%ci typu LOB .................................................................................................685
Inicjowanie warto%ci ...........................................................................................................687
U$ywanie polecenia insert w podzapytaniach .....................................................................689
Aktualizowanie warto%ci LOB ............................................................................................689
Funkcje obs*ugi ci"gów znaków w typach LOB .................................................................690
Operowanie na warto%ciach LOB za pomoc" pakietu DBMS_LOB ...................................691
Usuwanie obiektów typu LOB ............................................................................................708
Rozdzia" 41. Zaawansowane funkcje obiektowe .......................................................... 709
Obiekty wierszy a obiekty kolumn ............................................................................................709
Tabele obiektowe i identyfikatory OID .....................................................................................710
Wstawianie wierszy do tabel obiektowych ..........................................................................711
Pobieranie danych z tabel obiektowych ..............................................................................712
Aktualizowanie warto%ci i ich usuwanie z tabel obiektowych .............................................712
Funkcja REF ........................................................................................................................713
Funkcja DEREF ..................................................................................................................714
Funkcja VALUE .................................................................................................................717
Nieprawid*owe odwo*ania ...................................................................................................717
Perspektywy obiektowe z odwo*aniami REF ............................................................................718
Przegl"d perspektyw obiektowych ......................................................................................718
Perspektywy obiektowe korzystaj"ce z odwo*a& .................................................................719
Obiektowy j!zyk PL/SQL .........................................................................................................723
Obiekty w bazie danych ............................................................................................................724

Spis tre!ci
17
Cz#!$ VI J#zyk Java w systemie Oracle ............................................. 727
Rozdzia" 42. Wprowadzenie do j#zyka Java ................................................................. 729
Krótkie porównanie j!zyków PL/SQL i Java ............................................................................730
Zaczynamy ................................................................................................................................731
Deklaracje ..................................................................................................................................731
Podstawowe polecenia ...............................................................................................................732
Instrukcje warunkowe .........................................................................................................733
P!tle .....................................................................................................................................737
Obs*uga wyj"tków ...............................................................................................................739
S*owa zastrze$one w Javie ..................................................................................................740
Klasy ..........................................................................................................................................740
Rozdzia" 43. Programowanie z u%yciem JDBC .............................................................. 747
Korzystanie z klas JDBC ...........................................................................................................748
Operacje z wykorzystaniem sterownika JDBC ..........................................................................751
Rozdzia" 44. Procedury sk"adowane w Javie ................................................................ 755
:adowanie klas do bazy danych ................................................................................................757
Korzystanie z klas ......................................................................................................................761
Bezpo%rednie przywo*ywanie procedur sk*adowanych Javy ...............................................764
Wydajno%+ ...........................................................................................................................764
Cz#!$ VII
Przewodniki autostopowicza ................................................................... 767
Rozdzia" 45. Autostopem po s"owniku danych Oracle .................................................. 769
Nazewnictwo .............................................................................................................................770
Nowe perspektywy w systemie Oracle 11g ...............................................................................770
Mapy DICTIONARY (DICT) i DICT_COLUMNS ..................................................................774
Tabele (z kolumnami), perspektywy, synonimy i sekwencje ....................................................776
Katalog — USER_CATALOG (CAT) ................................................................................776
Obiekty — USER_OBJECTS (OBJ) ..................................................................................777
Tabele — USER_TABLES (TABS) ...................................................................................778
Kolumny — USER_TAB_COLUMNS (COLS) .................................................................780
Perspektywy — USER_VIEWS ..........................................................................................781
Synonimy — USER_SYNONYMS (SYN) .........................................................................784
Sekwencje — USER_SEQUENCES (SEQ) ........................................................................784
Kosz — USER_RECYCLEBIN i DBA_RECYCLEBIN ..........................................................785
Ograniczenia i komentarze ........................................................................................................785
Ograniczenia — USER_CONSTRAINTS ..........................................................................785
Kolumny ogranicze& — USER_CONS_COLUMNS ..........................................................787
Wyj"tki ogranicze& — EXCEPTIONS ...............................................................................788
Komentarze do tabel — USER_TAB_COMMENTS .........................................................789
Komentarze do kolumn — USER_COL_COMMENTS .....................................................790
Indeksy i klastry ........................................................................................................................790
Indeksy — USER_INDEXES (IND) ..................................................................................790
Kolumny indeksowane — USER_IND_COLUMNS ..........................................................792
Klastry — USER_CLUSTERS (CLU) ................................................................................793
Kolumny klastrów — USER_CLU_COLUMNS ................................................................794
Abstrakcyjne typy danych i obiekty LOB .................................................................................795
Abstrakcyjne typy danych — USER_TYPES .....................................................................795
Obiekty LOB — USER_LOBS ...........................................................................................797
:"cza bazy danych i perspektywy zmaterializowane ................................................................798
:"cza bazy danych — USER_DB_LINKS .........................................................................798
Perspektywy zmaterializowane ...........................................................................................798
Dzienniki perspektyw zmaterializowanych — USER_MVIEW_LOGS .............................800

18
Oracle Database 11g. Kompendium administratora
Wyzwalacze, procedury, funkcje i pakiety ................................................................................801
Wyzwalacze — USER_TRIGGERS ...................................................................................801
Procedury, funkcje i pakiety — USER_SOURCE ..............................................................802
Wymiary ....................................................................................................................................803
Alokacja i zu$ycie przestrzeni razem z partycjami i podpartycjami ..........................................805
Przestrzenie tabel — USER_TABLESPACES ...................................................................805
Limity dyskowe — USER_TS_QUOTAS ..........................................................................806
Segmenty i obszary — USER_SEGMENTS i USER_EXTENTS ......................................806
Partycje i podpartycje ..........................................................................................................807
Wolna przestrze& — USER_FREE_SPACE .......................................................................809
U$ytkownicy i uprawnienia .......................................................................................................810
U$ytkownicy — USER_USERS .........................................................................................810
Limity zasobów — USER_RESOURCE_LIMITS .............................................................810
Uprawnienia do tabel — USER_TAB_PRIVS ...................................................................811
Uprawnienia do kolumn — USER_COL_PRIVS ...............................................................811
Uprawnienia systemowe — USER_SYS_PRIVS ...............................................................811
Role ...........................................................................................................................................812
Audytowanie .............................................................................................................................813
Inne perspektywy .......................................................................................................................814
Monitorowanie wydajno%ci — dynamiczne perspektywy V$ ...................................................814
CHAINED_ROWS .............................................................................................................815
PLAN_TABLE ...................................................................................................................815
Zale$no%ci mi!dzy obiektami — USER_DEPENDENCIES i IDEPTREE .........................816
Perspektywy dost!pne tylko dla administratora ..................................................................816
Oracle Label Security ..........................................................................................................816
Perspektywy bezpo%redniego *adowania SQL*Loader ........................................................816
Perspektywy obs*ugi globalizacji ........................................................................................817
Biblioteki .............................................................................................................................817
Us*ugi heterogeniczne .........................................................................................................817
Typy indeksowe i operatory ................................................................................................818
Zarysy .................................................................................................................................818
Doradcy ...............................................................................................................................818
Planowanie zada& ................................................................................................................819
Rozdzia" 46. Autostopem po dostrajaniu aplikacji i zapyta( SQL .................................. 821
Nowe mo$liwo%ci dostrajania w Oracle 11g ..............................................................................821
Nowe funkcje dostrajania w Oracle 11g ....................................................................................822
Zalecane praktyki dostrajania aplikacji .....................................................................................823
Wykonujmy jak najmniej operacji ......................................................................................824
Upraszczajmy, co si! da ......................................................................................................827
Przekazujmy bazie potrzebne jej informacje .......................................................................829
Maksymalizujmy przepustowo%+ otoczenia ........................................................................829
Dzielmy i rz"d]my ..............................................................................................................831
Testujmy prawid*owo ..........................................................................................................832
Generowanie i czytanie planów wykonania ...............................................................................835
Polecenie set autotrace on ...................................................................................................835
Polecenie explain plan .........................................................................................................839
Najwa$niejsze operacje spotykane w planach wykonania .........................................................840
TABLE ACCESS FULL .....................................................................................................840
TABLE ACCESS BY INDEX ROWID ..............................................................................841
Powi"zane podpowiedzi ......................................................................................................841
Operacje u$ywaj"ce indeksów ............................................................................................841
Kiedy baza u$ywa indeksów ...............................................................................................843
Operacje na zbiorach danych ...............................................................................................849
Operacje wykonuj"ce z*"czenia ...........................................................................................856

Spis tre!ci
19
Z*"czenia wi!cej ni$ dwóch tabel ........................................................................................856
Przetwarzanie równoleg*e i buforowanie ............................................................................863
Implementowanie zarysów sk*adowanych .................................................................................864
Podsumowanie ...........................................................................................................................866
Rozdzia" 47. Buforowanie wyników SQL oraz buforowanie zapyta( po stronie klienta .... 867
Ustawienia parametrów bazy danych dla bufora wyników SQL ...............................................874
Pakiet DBMS_RESULT_CACHE ............................................................................................875
Perspektywy s*ownikowe bufora wyników SQL .......................................................................876
Dodatkowe informacje na temat bufora wyników SQL .............................................................877
Bufor kliencki Oracle Call Interface (OCI) ...............................................................................877
Ograniczenia buforowania klienckiego Oracle Call Interface (OCI) .........................................878
Rozdzia" 48. Analiza przypadków optymalizacji ............................................................ 879
Przypadek 1. Czekanie, czekanie i jeszcze raz czekanie ............................................................879
Przypadek 2. Mordercze zapytania ............................................................................................883
U$ycie zdarzenia %ladu 10053 .............................................................................................885
Przypadek 3. D*ugotrwa*e zadania wsadowe .............................................................................887
Rozdzia" 49. Zaawansowane opcje architektoniczne
— DB Vault, Content DB oraz Records DB .............................................. 891
Oracle Database Vault ...............................................................................................................891
Nowe koncepcje w Oracle Database Vault ..........................................................................892
Blokowanie Oracle Database Vault .....................................................................................893
W*"czanie Oracle Database Vault .......................................................................................894
Uwagi na temat instalacji Database Vault ...........................................................................895
Oracle Content Database Suite ..................................................................................................899
Repository ...........................................................................................................................899
Zarz"dzanie dokumentami ..................................................................................................900
Bezpiecze&stwo u$ytkowników ..........................................................................................900
Oracle Records Database ...........................................................................................................901
Rozdzia" 50. Opcja Real Application Clusters w systemie Oracle ................................. 905
Przygotowania do instalacji .......................................................................................................905
Instalowanie konfiguracji Real Application Clusters ................................................................906
Sk*adowanie danych ............................................................................................................907
Parametry inicjalizacji .........................................................................................................908
Uruchamianie i zatrzymywanie instancji klastra .......................................................................910
Mechanizm TAF ........................................................................................................................911
Dodawanie w!z*ów i instancji do klastra ...................................................................................914
Rozdzia" 51. Autostopem po administrowaniu baz& danych ......................................... 915
Tworzenie bazy danych .............................................................................................................916
Praca z Oracle Enterprise Manager .....................................................................................916
Uruchamianie i zamykanie bazy danych ...................................................................................917
Zarz"dzanie obszarami pami!ci .................................................................................................918
Plik parametrów ..................................................................................................................920
Zarz"dzanie przestrzeni" dla obiektów ......................................................................................920
Znaczenie klauzuli storage ..................................................................................................921
Segmenty tabel ....................................................................................................................923
Segmenty indeksów .............................................................................................................924
Systemowe zarz"dzanie segmentami wycofania .................................................................924
Segmenty tymczasowe ........................................................................................................925
Wolna przestrze& .................................................................................................................927
Okre%lanie rozmiaru obiektów ............................................................................................927
Monitorowanie przestrzeni tabel wycofania ..............................................................................930

20
Oracle Database 11g. Kompendium administratora
Automatyczne zarz"dzanie sk*adowaniem danych ....................................................................931
Konfiguracja us*ugi ASM ...................................................................................................931
Zarz"dzanie miejscem w segmentach ........................................................................................932
Przenoszenie przestrzeni tabel ...................................................................................................933
Generowanie zbioru przestrzeni przeno%nych .....................................................................933
Do*"czanie zbioru przestrzeni przeno%nych ........................................................................934
Kopie zapasowe .........................................................................................................................935
Data Pump Export i Import .................................................................................................936
Kopie zapasowe offline .......................................................................................................936
Kopie zapasowe online ........................................................................................................937
Mened$er odzyskiwania RMAN .........................................................................................941
Co dalej? ....................................................................................................................................941
Rozdzia" 52. Autostopem po XML w bazach danych Oracle ......................................... 943
Definicje DTD, elementy i atrybuty ..........................................................................................943
Schematy XML .........................................................................................................................947
Wykonywanie polece& SQL na danych XML za pomoc" XSU ................................................949
Polecenia insert, update i delete w XSU ..............................................................................951
XSU i Java ..........................................................................................................................952
Dostosowanie procedur obs*ugi SQL ..................................................................................953
Korzystanie z typu danych XMLType .......................................................................................954
Inne funkcje ...............................................................................................................................956
Cz#!$ VIII Alfabetyczne zestawienie polece( ....................................... 957
Skorowidz ........................................................................................... 1443

Rozdzia 4.
Planowanie aplikacji
systemu Oracle
— sposoby, standardy
i zagro3enia
Aby stworzy! aplikacj" systemu Oracle i szybko oraz efektywnie z niej korzysta!, u#ytkow-
nicy i programi$ci musz% pos&ugiwa! si" wspólnym j"zykiem, a tak#e posiada! g&"bok% wiedz"
zarówno na temat aplikacji biznesowych, jak i narz"dzi systemu Oracle. W poprzednich roz-
dzia&ach zaprezentowano ogólny opis systemu Oracle oraz sposoby jego instalacji i aktuali-
zacji. Teraz, po zainstalowaniu oprogramowania, mo#emy przyst%pi! do tworzenia aplikacji.
Kluczowym elementem w tym przypadku jest $cis&a wspó&praca mened#erów i personelu
technicznego.
Dawniej analitycy systemowi szczegó&owo badali wymagania klienta, a nast"pnie programi-
$ci tworzyli aplikacje, które spe&nia&y te wymagania. Klient dostarcza& jedynie opis procesu,
który aplikacja mia&a usprawni!, oraz testowa& jej dzia&anie.
Dzi"ki najnowszym narz"dziom systemu Oracle mo#na tworzy! aplikacje znacznie lepiej
odpowiadaj%ce potrzebom i przyzwyczajeniom u#ytkowników. Jest to jednak mo#liwe tylko
w przypadku w&a$ciwego rozumienia zagadnie' biznesowych.
Zarówno u#ytkownicy, jak i programi$ci powinni zmierza! do maksymalnego wykorzystania
mo#liwo$ci systemu Oracle. U#ytkownik aplikacji ma wiedz" na temat zagadnie' meryto-
rycznych, której nie posiada programista. Programista rozumie dzia&anie wewn"trznych
funkcji i w&asno$ci systemu Oracle i $rodowiska komputerów, które s% zbyt skomplikowane
dla u#ytkownika. Ale takie obszary wy&%czno$ci wiedzy nie s% liczne. Podczas korzystania
z systemu Oracle u#ytkownicy i programi$ci zwykle poruszaj% si" w obr"bie zagadnie' zna-
nych obu stronom.
Nie jest tajemnic%, #e pracownicy „merytoryczni” i „techniczni” od lat nie darz% si" szcze-
góln% sympati%. Przyczyn% tego stanu s% ró#nice w posiadanej wiedzy, zainteresowaniach

56
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
i zwyczajach, a tak#e inne cele. Nie bez znaczenia jest tak#e poczucie odr"bno$ci, jakie pow-
staje w wyniku fizycznego oddzielenia obu grup. Mówi%c szczerze, te zjawiska nie s% wy&%cz-
nie domen% osób zajmuj%cych si" przetwarzaniem danych. Podobne problemy dotycz% na
przyk&ad pracowników dzia&u ksi"gowo$ci, którzy cz"sto pracuj% na ró#nych pi"trach, w oddziel-
nych budynkach, a nawet w innych miastach. Relacje pomi"dzy cz&onkami fizycznie odizo-
lowanych grup staj% si" formalne, sztywne i dalekie od normalno$ci. Powstaj% sztuczne bariery
i procedury, które jeszcze bardziej pot"guj% syndrom izolacji.
Mo#na by powiedzie!, #e to, co zosta&o napisane powy#ej, jest interesuj%ce dla socjologów.
Dlaczego wi"c przypominamy te informacje przy okazji systemu Oracle?
Poniewa" wdro"enie tego systemu fundamentalnie zmienia natur& zwi'zków zachodz'cych
pomi&dzy pracownikami merytorycznymi a technicznymi. W systemie Oracle nie u"ywa si&
specyficznego j&zyka, który rozumiej' tylko profesjonali/ci. System ten mo#e opanowa! ka#dy
i ka#dy mo#e go u#ywa!. Informacje, wcze$niej wi"zione w systemach komputerowych pod
czujnym okiem ich administratorów, s% teraz dost"pne dla mened#erów, którzy musz% jedynie
wpisa! odpowiednie zapytanie. Ta sytuacja znacz%co zmienia obowi%zuj%ce regu&y gry.
Od momentu wdro#enia systemu Oracle obydwa obozy znacznie lepiej si" rozumiej%, norma-
lizuj%c zachodz%ce pomi"dzy nimi relacje. Dzi"ki temu powstaj% lepsze aplikacje.
Ju# pierwsze wydanie systemu Oracle bazowa&o na zrozumia&ym modelu relacyjnym (który
wkrótce zostanie szczegó&owo omówiony). Osoby, które nie s% programistami, nie maj% pro-
blemów ze zrozumieniem zada' wykonywanych przez system Oracle. Dzi"ki temu jest on
dost"pny w stopniu praktycznie nieograniczonym.
Niektóre osoby nie rozumiej%, jak wa#n% rzecz% jest, aby run"&y przestarza&e i sztuczne bariery
pomi"dzy u#ytkownikami i systemowcami. Z pewno$ci% jednak metoda kooperacyjna korzyst-
nie wp&ywa na jako$! i u#yteczno$! tworzonych aplikacji.
Jednak wielu do$wiadczonych projektantów wpada w pu&apk": pracuj%c z systemem Oracle,
usi&uj% stosowa! metody sprawdzone w systemach poprzedniej generacji. O wielu z nich
powinni zapomnie!, gdy# b"d% nieskuteczne. Niektóre techniki (i ograniczenia), które by&y
sta&ym elementem systemów poprzedniej generacji, teraz nie tylko s% zbyteczne, ale nawet
maj% ujemny wp&yw na dzia&anie aplikacji. W procesie poznawania systemu Oracle nale#y
pozby! si" wi"kszo$ci starych nawyków i bezu#ytecznych metod. Od teraz s% dost"pne nowe
od$wie#aj%ce mo#liwo$ci.
Za&o#eniem tej ksi%#ki jest prezentacja systemu Oracle w sposób jasny i prosty — z wykorzy-
staniem poj"!, które s% zrozumia&e zarówno dla u#ytkowników, jak i programistów. Oma-
wiaj%c system, wskazano przestarza&e i niew&a$ciwe techniki projektowania i zarz%dzania oraz
przedstawiono alternatywne rozwi%zania.
Podej4cie kooperacyjne
Oracle jest obiektowo-relacyjnym systemem baz danych. Relacyjna baza danych to niezwykle
prosty sposób przedstawiania i zarz%dzania danymi wykorzystywanymi w biznesie. Model
relacyjny to nic innego, jak kolekcja tabel danych. Z tabelami wszyscy spotykamy si" na co

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
57
dzie', czytaj%c na przyk&ad raporty o pogodzie lub wyniki sportowe. Wszystko to s% tabele
z wyra2nie zaznaczonymi nag&ówkami kolumn i wierszy. Pomimo swojej prostoty model rela-
cyjny wystarcza do prezentowania nawet bardzo z&o#onych zagadnie'. Obiektowo-relacyjna
baza danych charakteryzuje si" wszystkimi w&asno$ciami relacyjnej bazy danych, a jednocze-
$nie ma cechy modelu obiektowego. Oracle mo#na wykorzysta! zarówno jako relacyjny sys-
tem zarz%dzania baz% danych (RDBMS), jak te# skorzysta! z jego w&asno$ci obiektowych.
Niestety, jedyni ludzie, którym przydaje si" relacyjna baza danych — u#ytkownicy bizne-
sowi — z regu&y najmniej j% rozumiej%. Projektanci aplikacji tworz%cy systemy dla u#ytkowni-
ków biznesowych cz"sto nie potrafi% obja$ni! poj"! modelu relacyjnego w prosty sposób.
Aby by&a mo#liwa wspó&praca, potrzebny jest wspólny j"zyk.
Za chwil" wyja$nimy, czym s% relacyjne bazy danych i w jaki sposób wykorzystuje si" je
w biznesie. Mo#e si" wydawa!, #e materia& ten zainteresuje wy&%cznie „u#ytkowników”. Do$-
wiadczony projektant aplikacji relacyjnych odczuje zapewne pokus" pomini"cia tych frag-
mentów, a ksi%#k" wykorzysta jako dokumentacj" systemu Oracle. Chocia# wi"kszo$! mate-
ria&u z pierwszych rozdzia&ów to zagadnienia elementarne, to jednak projektanci, którzy
po$wi"c% im czas, poznaj% jasn%, spójn% i funkcjonaln% terminologi", u&atwiaj%c% komunikacj"
z u#ytkownikami oraz precyzyjniejsze ustalenie ich wymaga'. Wa#ne jest równie# pozbycie
si" niepotrzebnych i prawdopodobnie nie$wiadomie stosowanych przyzwyczaje' projekto-
wych. Wiele z nich zidentyfikujemy podczas prezentacji modelu relacyjnego. Trzeba sobie
u$wiadomi!, #e nawet mo#liwo$ci tak rozbudowanego systemu, jak Oracle mo#na zniweczy!,
stosuj%c metody w&a$ciwe dla projektów nierelacyjnych.
Gdy u#ytkownik docelowy rozumie podstawowe poj"cia obiektowo-relacyjnych baz danych, mo#e
w spójny sposób przedstawi! wymagania projektantom aplikacji. Pracuj%c w systemie Oracle, jest
w stanie przetwarza! informacje, kontrolowa! raporty i dane oraz niczym prawdziwy ekspert
zarz%dza! w&asno$ciami tworzenia aplikacji i zapyta'. 3wiadomy u#ytkownik, który rozumie
funkcjonowanie aplikacji, z &atwo$ci% zorientuje si&, czy osi%gn"&a ona maksymaln% wydajno$!.
System Oracle uwalnia tak#e programistów od najmniej lubianego przez nich obowi%zku: two-
rzenia raportów. W du#ych firmach niemal 95 % wszystkich prac programistycznych to #%dania
tworzenia nowych raportów. Poniewa# dzi"ki systemowi Oracle u#ytkownicy tworz% raport
w kilka minut, a nie w kilka miesi"cy, spe&nianie takiego obowi%zku staje si" przyjemno$ci%.
Dane s6 wsz7dzie
W bibliotece znajduj% si" informacje o czytelnikach, ksi%#kach i karach za nieterminowy zwrot.
W&a$ciciel kolekcji kart baseballowych zbiera informacje o graczach, notuje daty i wyniki
meczów, interesuje si" warto$ci% kart. W ka#dej firmie musz% by! przechowywane rejestry
z informacjami o klientach, produktach czy cenach. Informacje te okre$la si" jako dane.
Teoretycy cz"sto mówi%, #e dane pozostaj% danymi, dopóki nie zostan% odpowiednio zorga-
nizowane. Wtedy staj% si" informacjami. Je$li przyj%! tak% tez", system Oracle $mia&o mo#na
nazwa! mechanizmem wytwarzania informacji, gdy# bazuj%c na surowych danych, potrafi na
przyk&ad wykonywa! podsumowania lub pomaga identyfikowa! trendy handlowe. Jest to
wiedza, z istnienia której nie zawsze zdajemy sobie spraw". W niniejszej ksi%#ce wyja$nimy,
jak j% uzyskiwa!.
58
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Po opanowaniu podstaw obs&ugi systemu Oracle mo#na wykonywa! obliczenia z danymi, prze-
nosi! je z miejsca na miejsce i modyfikowa!. Takie dzia&ania nazywa si" przetwarzaniem danych.
Rzecz jasna, przetwarza! dane mo#na równie#, wykorzystuj%c o&ówek, kartk" papieru i kalku-
lator, ale w miar" jak rosn% zbiory danych, trzeba si"gn%! po komputery.
System zarz'dzania relacyjnymi bazami danych (ang. Relational Database Management
System — RDBMS) taki, jak Oracle umo#liwia wykonywanie zada' w sposób zrozumia&y
dla u#ytkownika i stosunkowo nieskomplikowany. Mówi%c w uproszczeniu, system Oracle
pozwala wykonywanie trzech operacji pokazanych na rysunku 4.1:
wprowadzanie danych do systemu,
utrzymywanie (przechowywanie) danych,
wyprowadzanie danych i pos&ugiwanie si" nimi.
Rysunek 4.1.
Dane w systemie
Oracle
W systemie Oracle sposób post"powania z danymi mo#na opisa! schematem wprowadzanie-
-utrzymywanie-wyprowadzanie. System dostarcza inteligentnych narz"dzi pozwalaj%cych na
stosowanie wyrafinowanych metod pobierania, edycji, modyfikacji i wprowadzania danych,
zapewnia ich bezpieczne przechowywanie, a tak#e wyprowadzanie, na przyk&ad w celu two-
rzenia raportów.
J7zyk systemu Oracle
Informacje zapisane w systemie Oracle s% przechowywane w tabelach. W podobny sposób s%
prezentowane w gazetach na przyk&ad informacje o pogodzie (rysunek 4.2).
Tabela pokazana na rysunku sk&ada si" czterech kolumn:
Miasto
,
Temperatura
,
Wilgotno*+
i
Warunki
. Zawiera tak#e wiersze dla poszczególnych miast — od Aten do Sydney — oraz
nazw":
POGODA
.
Kolumny, wiersze i nazwa to trzy g&ówne cechy drukowanych tabel. Podobnie jest w przy-
padku tabel z relacyjnych baz danych. Wszyscy z &atwo$ci% rozumiej% poj"cia u#ywane do

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
59
Rysunek 4.2.
Dane w gazetach
cz&sto podawane
s' w tabelach
opisu tabeli w bazie danych, poniewa# takie same poj"cia stosuje si" w #yciu codziennym. Nie
kryje si" w nich #adne specjalne, niezwyk&e czy tajemnicze znaczenie. To, co widzimy, jest tym,
na co wygl%da.
Tabele
W systemie Oracle informacje s% zapisywane w tabelach. Ka#da tabela sk&ada si" z jednej lub
wi"kszej liczby kolumn. Odpowiedni przyk&ad pokazano na rysunku 4.3. Nag&ówki:
Miasto
,
Temperatura
,
Wilgotno*+
i
Warunki
wskazuj%, jaki rodzaj informacji przechowuje si" w kolum-
nach. Informacje s% zapisywane w wierszach (miasto po mie$cie). Ka#dy niepowtarzalny zestaw
danych, na przyk&ad temperatura, wilgotno$! i warunki dla miasta Manchester, jest zapisywany
w osobnym wierszu.
Rysunek 4.3.
Tabela POGODA
w systemie Oracle
Aby produkt by& bardziej dost"pny, firma Oracle unika stosowania specjalistycznej, akademickiej
terminologii. W artyku&ach o relacyjnych bazach danych kolumny czasami okre$la si" jako „atry-
buty”, wiersze jako „krotki”, a tabele jako „encje”. Takie poj"cia s% jednak myl%ce dla u#ytkow-
nika. Cz"sto terminy te s% tylko niepotrzebnymi zamiennikami dla powszechnie zrozumia&ych
nazw z j"zyka ogólnego. Firma Oracle stosuje ogólny j"zyk, a zatem mog% go równie# stosowa!
programi$ci. Trzeba pami"ta!, #e niepotrzebne stosowanie technicznego #argonu stwarza barier"
braku zaufania i niezrozumienia. W tej ksi%#ce, podobnie jak to uczyniono w dokumentacji sys-
temu Oracle, konsekwentnie pos&ugujemy si" poj"ciami „tabele”, „kolumny” i „wiersze”.
Strukturalny j zyk zapyta(
Firma Oracle jako pierwsza zacz"&a stosowa! strukturalny j&zyk zapyta: (ang. Structured
Query Language — SQL). J"zyk ten pozwala u#ytkownikom na samodzielne wydobywanie
informacji z bazy danych. Nie musz% si"ga! po pomoc fachowców, aby sporz%dzi! cho!by naj-
mniejszy raport.

60
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
J"zyk zapyta' systemu Oracle ma swoj% struktur", podobnie jak j"zyk angielski i dowolny
inny j"zyk naturalny. Ma równie# regu&y gramatyczne i sk&adni", ale s% to zasady bardzo proste
i ich zrozumienie nie powinno przysparza! wi"kszych trudno$ci.
J"zyk SQL, którego nazw" wymawia si" jako sequel lub es-ku-el, oferuje, jak wkrótce si"
przekonamy, niezwyk&e wr"cz mo#liwo$ci. Korzystanie z niego nie wymaga #adnego do$wiad-
czenia w programowaniu.
Oto przyk&ad, jak mo#na wykorzystywa! SQL. Gdyby kto$ poprosi& nas, aby$my w tabeli
POGODA
wskazali miasto, gdzie wilgotno$! wynosi 89 %, szybko wymieniliby$my Ateny. Gdyby
kto$ poprosi& nas o wskazanie miast, gdzie temperatura wynios&a 19°C, wymieniliby$my
Chicago i Manchester.
System Oracle jest w stanie odpowiada! na takie pytania niemal równie &atwo. Wystarczy sfor-
mu&owa! proste zapytania. S&owa kluczowe wykorzystywane w zapytaniach to
select
(wybierz),
from
(z),
where
(gdzie) oraz
order by
(uporz%dkuj wed&ug). S% to wskazówki dla systemu
Oracle, które u&atwiaj% mu zrozumienie #%da' i udzielenie poprawnej odpowiedzi.
Proste zapytanie w systemie Oracle
Gdyby w bazie danych Oracle by&a zapisana przyk&adowa tabela
POGODA
, pierwsze zapytanie
przyj"&oby pokazan% poni#ej posta! ($rednik jest informacj% dla systemu, #e nale#y wykona!
zapytanie):
select Miasto from POGODA where Wilgotnosc = 89;
System Oracle odpowiedzia&by na nie w taki sposób:
Miasto
------------
ATENY
Drugie zapytanie przyj"&oby nast"puj%c% posta!:
select Miasto from POGODA where Temperatura = 19;
W przypadku tego zapytania system Oracle odpowiedzia&by tak:
Miasto
-----------
MANCHESTER
CHICAGO
Jak &atwo zauwa#y!, w ka#dym z tych zapyta' wykorzystano s&owa kluczowe
select
,
from
oraz
where
. A co z klauzul%
order by
? Przypu$!my, #e interesuj% nas wszystkie miasta upo-
rz%dkowane wed&ug temperatury. Wystarczy, #e wprowadzimy takie oto zapytanie:
select Miasto, Temperatura from POGODA
order by Temperatura;
— a system Oracle natychmiast odpowie w nast"puj%cy sposób:
Miasto Temperatura
---------- -----------
LIMA 7

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
61
MANCHESTER 19
CHICAGO 19
SYDNEY 21
SPARTA 23
PARYD 27
ATENY 36
System Oracle szybko uporz%dkowa& tabel" od najni#szej do najwy#szej temperatury. W jed-
nym z kolejnych rozdzia&ów dowiemy si", jak okre$li!, czy najpierw maj% by! wy$wietlane
wy#sze, czy ni#sze warto$ci.
Zaprezentowane powy#ej przyk&ady pokazuj%, jak &atwo uzyskuje si" potrzebne informacje
z bazy danych Oracle, w postaci najprzydatniejszej dla u#ytkownika. Mo#na tworzy! skom-
plikowane #%dania o ró#ne dane, ale stosowane metody zawsze b"d% zrozumia&e. Mo#na na
przyk&ad po&%czy! dwa elementarne s&owa kluczowe
where
i
order by
— po to, by wybra!
tylko te miasta, w których temperatura przekracza 26 stopni, oraz wy$wietli! je uporz%dko-
wane wed&ug rosn%cej temperatury. W tym celu nale#y skorzysta! z nast"puj%cego zapytania:
select Miasto, Temperatura from POGODA
where Temperatura > 26
order by Temperatura;
System Oracle natychmiast wy$wietli nast"puj%c% odpowied2:
Miasto Temperatura
---------- -----------
PARYD 27
ATENY 36
Mo#na stworzy! jeszcze dok&adniejsze zapytanie i poprosi! o wy$wietlenie miast, w których
temperatura jest wy#sza ni# 26 stopni, a wilgotno$! mniejsza ni# 70 %:
select Miasto, Temperatura, Wilgotnosc from POGODA
where Temperatura > 26
and Wilgotnosc < 70
order by Temperatura;
— a system Oracle natychmiast odpowie w nast"puj%cy sposób:
Miasto Temperatura Wilgotnosc
------------- ------------ ----------
PARYD 27 62
Dlaczego system baz danych nazywa si „relacyjnym”?
Zwró!my uwag", #e w tabeli
POGODA
wy$wietlaj% si" miasta z kilku pa'stw, przy czym w przy-
padku niektórych pa'stw w tabeli znajduje si" wi"cej ni# jedno miasto. Przypu$!my, #e inte-
resuje nas, w którym pa'stwie le#y okre$lone miasto. W tym celu mo#na utworzy! oddzieln%
tabel"
LOKALIZACJA
zawieraj%c% informacje o zlokalizowaniu miast (rysunek 4.4).
Ka#de miasto z tabeli
POGODA
znajduje si" równie# w tabeli
LOKALIZACJA
. Wystarczy znale2!
interesuj%c% nas nazw" w kolumnie
Miasto
, a wówczas w kolumnie
Panstwo
w tym samym
wierszu znajdziemy nazw" pa'stwa.
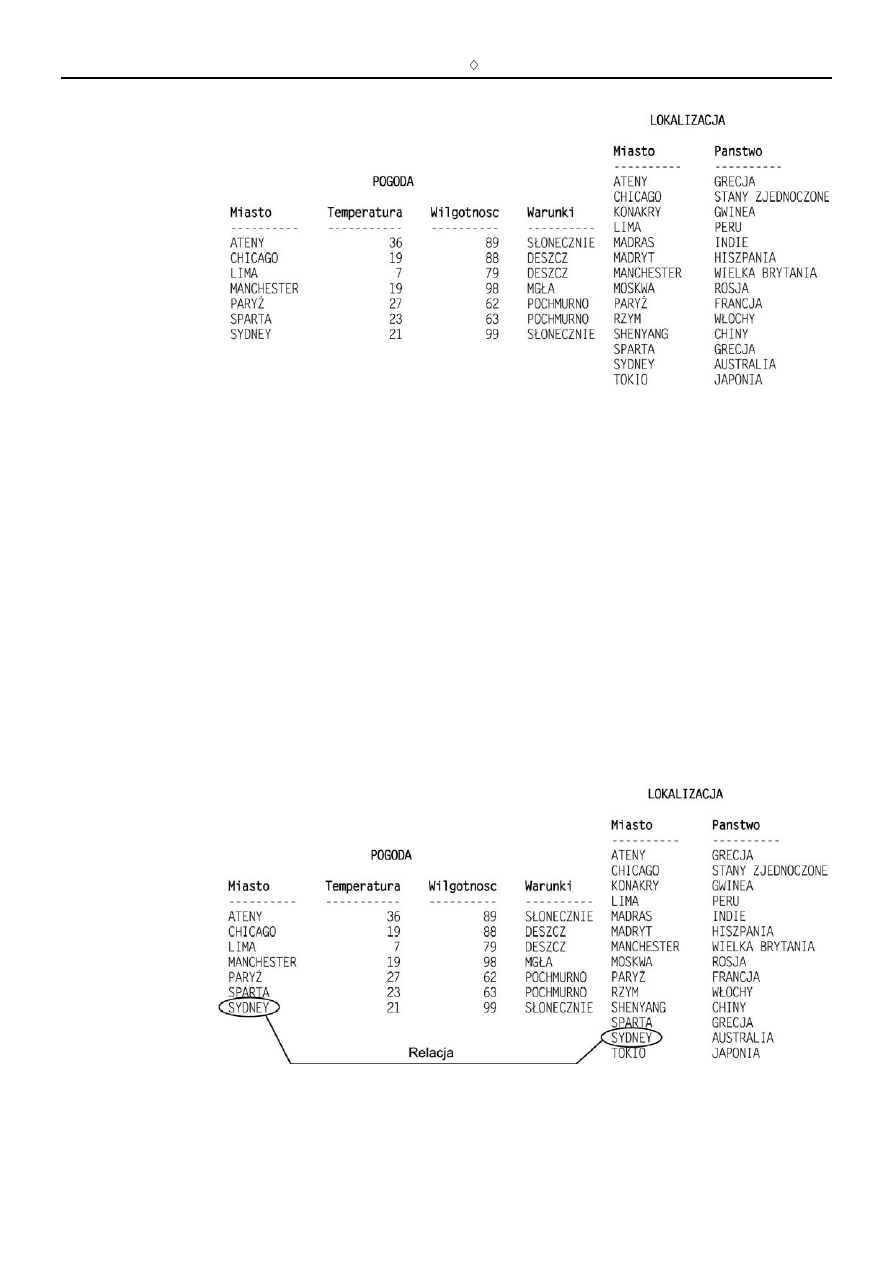
62
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Rysunek 4.4.
Tabele POGODA
i LOKALIZACJA
S% to ca&kowicie odr"bne i niezale#ne od siebie tabele. Ka#da z nich zawiera w&asne infor-
macje zestawione w kolumnach i wierszach. Tabele maj% cz"$! wspóln%: kolumn"
Miasto
. Dla
ka#dej nazwy miasta w tabeli
POGODA
istnieje identyczna nazwa miasta w tabeli
LOKALIZACJA
.
Spróbujmy na przyk&ad dowiedzie! si", jakie temperatury, wilgotno$! i warunki atmosferyczne
panuj% w miastach australijskich. Spójrzmy na obie tabele i odczytajmy z nich te informacje.
W jaki sposób to zrobili$my? W tabeli
LOKALIZACJA
znajduje si" tylko jeden zapis z warto$ci%
AUSTRALIA
w kolumnie
Panstwo
. Obok niego, w tym samym wierszu w kolumnie
Miasto
figu-
ruje nazwa miasta
SYDNEY
. Po znalezieniu nazwy
SYDNEY
w kolumnie
Miasto
tabeli
POGODA
prze-
sun"li$my si" wzd&u# wiersza i znale2li$my warto$ci pól
Temperatura
,
Wilgotnosc
i
Warunki
.
By&y to odpowiednio:
21
,
99
i
SQONECZNIE
.
Nawet je$li tabele s% niezale#ne, z &atwo$ci% mo#na spostrzec, #e s% z sob% powi%zane. Nazwa
miasta w jednej tabeli jest powi'zana (pozostaje w relacji) z nazw% miasta w drugiej (patrz
rysunek 4.5). Relacje pomi"dzy tabelami tworz% podstaw" nazwy relacyjna baza danych
(czasami mówi si" te# o relacyjnym modelu danych).
Rysunek 4.5.
Relacje pomi&dzy
tabelami POGODA
i LOKALIZACJA
Dane zapisuje si" w tabelach, na które sk&adaj% si" kolumny, wiersze i nazwy. Tabele mog% by!
z sob% powi%zane, je$li w ka#dej z nich znajduje si" kolumna o takim samym typie informacji.
To wszystko. Nie ma w tym nic skomplikowanego.
Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
63
Proste przyk&ady
Kiedy zrozumiemy podstawowe zasady rz%dz%ce relacyjnymi bazami danych, wsz"dzie zaczy-
namy widzie! tabele, wiersze i kolumny. Nie oznacza to, #e wcze$niej ich nie widzieli$my,
ale prawdopodobnie nie my$leli$my o nich w taki sposób. W systemie Oracle mo#na zapisa!
wiele tabel i wykorzysta! je do szybkiego uzyskania odpowiedzi na pytania.
Typowy raport kursów akcji w postaci papierowej mo#e wygl%da! tak, jak ten, który zapre-
zentowano na rysunku 4.6. Jest to fragment wydrukowanego g"st% czcionk% alfabetycznego
zestawienia wype&niaj%cego szereg w%skich kolumn na kilku stronach w gazecie. Jakich akcji
sprzedano najwi"cej? Które akcje odnotowa&y najwy#szy procentowy wzrost, a które najwi"kszy
spadek? W systemie Oracle odpowiedzi na te pytania mo#na uzyska! za pomoc% prostych
zapyta'. Jest to dzia&anie o wiele szybsze ni# przeszukiwanie kolumn cyfr w gazecie.
Rysunek 4.6.
Tabela kursów akcji
Na rysunku 4.7 pokazano indeks gazety. Co mo#na znale2! w sekcji F? W jakim porz%dku
b"dziemy czyta! artyku&y, je$li wertujemy gazet" od pocz%tku do ko'ca? W systemie Oracle
odpowiedzi na te pytania mo#na uzyska! z pomoc% prostych zapyta'. Nauczymy si", jak
formu&owa! takie zapytania, a nawet tworzy! tabele do zapisywania informacji.
W przyk&adach u#ytych w tej ksi%#ce wykorzystano dane i obiekty, z którymi cz"sto spotykamy
si" na co dzie' — w pracy i w domu. Dane do wykorzystania w !wiczeniach mo#na znale2!
wsz"dzie. Na kolejnych stronach poka#emy, w jaki sposób wprowadza si" i pobiera dane.
Przyk&ady bazuj% na spotykanych na co dzie' 2ród&ach danych.
Podobnie jak w przypadku ka#dej nowej technologii, nie wolno dostrzega! tylko jej zalet, trzeba
równie# widzie! zagro#enia. Je$li skorzystamy z relacyjnej bazy danych oraz szeregu rozbu-
dowanych i &atwych w u#yciu narz"dzi dostarczanych z systemem Oracle, niebezpiecze'stwo,

64
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Rysunek 4.7.
Tabela danych
o sekcjach w gazecie
#e padniemy ofiar% tej prostoty, stanie si" bardzo realne. Dodajmy do tego w&a$ciwo$ci obiek-
towe i &atwo$! wykorzystania w internecie, a zagro#enia stan% si" jeszcze wi"ksze. W kolejnych
punktach przedstawimy niektóre zagro#enia zwi%zane z korzystaniem z relacyjnych baz danych,
o których powinni pami"ta! zarówno u#ytkownicy, jak i projektanci.
Zagro3enia
Podstawowym zagro#eniem podczas projektowania aplikacji wykorzystuj%cych relacyjne bazy
danych jest… prostota tego zadania. Zrozumienie, czym s% tabele, kolumny i wiersze nie
sprawia k&opotów. Zwi%zki pomi"dzy dwoma tabelami s% &atwe do uchwycenia. Nawet nor-
malizacji — procesu analizy wewn"trznych „normalnych” relacji pomi"dzy poszczególnymi
danymi — mo#na z &atwo$ci% si" nauczy!.
W zwi%zku z tym cz"sto pojawiaj% si" „eksperci”, którzy s% bardzo pewni siebie, ale maj%
niewielkie do$wiadczenie w tworzeniu rzeczywistych aplikacji o wysokiej jako$ci. Gdy w gr"
wchodzi niewielka baza z danymi marketingowymi lub domowy indeks, nie ma to wielkiego
znaczenia. Pope&nione b&"dy ujawni% si" po pewnym czasie. B"dzie to dobra lekcja pozwala-
j%ca na unikni"cie b&"dów w przysz&o$ci. Jednak w przypadku wa#nej aplikacji droga ta w pro-
stej linii prowadzi do katastrofy. Brak do$wiadczenia twórców aplikacji jest cz"sto podawany
w artyku&ach prasowych jako przyczyna niepowodze' wa#nych projektów.
Starsze metody projektowania generalnie s% wolniejsze, poniewa# zadania takie, jak kodo-
wanie, kompilacja, konsolidacja i testowanie zajmuj% wi"cej czasu. Cykl powstawania aplikacji,
w szczególno$ci dla komputerów typu mainframe, cz"sto jest tak #mudny, #e aby unikn%!
opó2nie' zwi%zanych z powtarzaniem pe&nego cyklu z powodu b&"du w kodzie, programi$ci
du#% cz"$! czasu po$wi"caj% na sprawdzanie kodu na papierze.
Narz"dzia czwartej generacji kusz% projektantów, aby natychmiast przekazywa! kod do eks-
ploatacji. Modyfikacje mo#na implementowa! tak szybko, #e testowanie bardzo cz"sto zajmuje
niewiele czasu. Niemal ca&kowite wyeliminowanie etapu sprawdzania przy biurku stwarza
problem. Kiedy znikn%& negatywny bodziec (d&ugotrwa&y cykl), który zach"ca& do sprawdza-
nia przy biurku, znikn"&o tak#e samo sprawdzanie. Wielu programistów wyra#a nast"puj%cy
pogl%d: „Je$li aplikacja nie dzia&a w&a$ciwie, b&%d szybko si" poprawi. Je$li dane ulegn%
uszkodzeniu, mo#na je szybko zaktualizowa!. Je$li metoda oka#e si" niedostatecznie szybka,
dostroi si" j% w locie. Zrealizujmy kolejny punkt harmonogramu i poka#my to, co zrobili$my”.

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
65
Testowanie wa#nego projektu Oracle powinno trwa! d&u#ej ni# testowanie projektu trady-
cyjnego, niezale#nie od tego, czy zarz%dza nim do$wiadczony, czy pocz%tkuj%cy mened#er.
Musi by! tak#e dok&adniejsze. Sprawdzi! nale#y przede wszystkim poprawno$! formularzy
wykorzystywanych do wprowadzania danych, tworzenie raportów, &adowanie danych i uaktu-
alnie', integralno$! i wspó&bie#no$! danych, rozmiary transakcji i pami"ci masowej w warun-
kach maksymalnych obci%#e'.
Poniewa# tworzenie aplikacji za pomoc% narz"dzi systemu Oracle jest niezwykle proste,
aplikacje powstaj% bardzo szybko. Si&% rzeczy czas przeznaczony na testowanie w fazie pro-
jektowania skraca si". Aby zachowa! równowag" i zapewni! odpowiedni% jako$! produktu,
proces planowanego testowania nale#y $wiadomie wyd&u#y!. Cho! zazwyczaj problemu tego
nie dostrzegaj% programi$ci, którzy rozpoczynaj% dopiero swoj% przygod" z systemem Oracle
lub z narz"dziami czwartej generacji, w planie projektu nale#y przewidzie! czas i pieni%dze na
dok&adne przetestowanie projektu.
Znaczenie nowego podej4cia
Wielu z nas z niecierpliwo$ci% oczekuje dnia, kiedy b"dzie mo#na napisa! zapytanie w j"zyku
naturalnym i w ci%gu kilku sekund uzyska! na ekranie odpowied2.
Jeste$my o wiele bli#si osi%gni"cia tego celu, ni# wielu z nas sobie wyobra#a. Czynnikiem
ograniczaj%cym nie jest ju# technika, ale raczej schematy stosowane w projektach aplikacji.
Za pomoc% systemu Oracle mo#na w prosty sposób tworzy! aplikacje pisane w j"zyku zbli-
#onym do naturalnego j"zyka angielskiego, które z &atwo$ci% eksploatuj% niezbyt zaawanso-
wani technicznie u#ytkownicy. W bazie danych Oracle i skojarzonych z ni% narz"dziach tkwi
potencja&, cho! jeszcze stosunkowo niewielu programistów wykorzystuje go w pe&ni.
Podstawowym celem projektanta Oracle powinno by! stworzenie aplikacji zrozumia&ej i &atwej
w obs&udze tak, aby u#ytkownicy bez do$wiadczenia programistycznego potrafili pozyskiwa!
informacje, stawiaj%c proste pytania w j"zyku zbli#onym do naturalnego.
Jak? Po pierwsze, g&ównym celem projektowania jest opracowanie aplikacji, która jest &atwa do
zrozumienia i prosta w u#yciu. Czasami oznacza to intensywniejsze wykorzystanie procesora
lub wi"ksze zu#ycie miejsca na dysku. Nie mo#na jednak przesadza!. Je$li stworzymy apli-
kacj" niezwykle &atw% w u#yciu, ale tak skomplikowan% programistycznie, #e jej piel"gnacja
lub usprawnianie oka#% si" niemo#liwe, pope&nimy równie powa#ny b&%d. Pami"tajmy tak#e,
#e nigdy nie wolno tworzy! inteligentnych programów kosztem wygody u#ytkownika.
Zmiana !rodowisk
Koszty u#ytkowania komputerów liczone jako cena miliona instrukcji na sekund" (MIPS) stale
spadaj% w tempie 20% rocznie. Z kolei koszty si&y roboczej ci%gle wzrastaj%. Oznacza to, #e
wsz"dzie tam, gdzie ludzi mo#na zast%pi! komputerami, uzyskuje si" oszcz"dno$ci finansowe.
W jaki sposób cech" t" uwzgl"dniono w projektowaniu aplikacji? Odpowied2 brzmi: „W jaki$”,
cho! na pewno nie jest to sposób zadowalaj%cy. Prawdziwy post"p przynios&o na przyk&ad

66
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
opracowanie /rodowiska graficznego przez instytut PARC firmy Xerox, a nast"pnie wyko-
rzystanie go w komputerach Macintosh, w przegl%darkach internetowych oraz w innych syste-
mach bazuj%cych na ikonach. 3rodowisko graficzne jest znacznie przyja2niejsze w obs&udze
ni# starsze $rodowiska znakowe. Ludzie, którzy z niego korzystaj%, potrafi% stworzy! w ci%gu
kilku minut to, co wcze$niej zajmowa&o im kilka dni. Post"p w niektórych przypadkach jest
tak wielki, #e ca&kowicie utracili$my obraz tego, jak trudne by&y kiedy$ pewne zadania.
Niestety, wielu projektantów aplikacji nie przyzwyczai&o si" do przyjaznych $rodowisk. Nawet
je$li ich u#ywaj%, powielaj% niew&a$ciwe nawyki.
Kody, skróty i standardy nazw
Problem starych przyzwyczaje' programistycznych staje si" najbardziej widoczny, gdy pro-
jektant musi przeanalizowa! kody, skróty i standardy nazewnictwa. Zwykle uwzgl"dnia
wówczas jedynie potrzeby i konwencje stosowane przez programistów, zapominaj%c o u#yt-
kownikach. Mo#e si" wydawa!, #e jest to suchy i niezbyt interesuj%cy problem, któremu nie
warto po$wi"ca! czasu, ale zaj"cie si" nim oznacza ró#nic" pomi"dzy wielkim sukcesem
a rozwi%zaniem takim sobie; pomi"dzy popraw% wydajno$ci o rz%d wielko$ci a marginalnym
zyskiem; pomi"dzy u#ytkownikami zainteresowanymi i zadowolonymi a zrz"dami n"kaj%cymi
programistów nowymi #%daniami.
Oto, co cz"sto si" zdarza. Dane biznesowe s% rejestrowane w ksi"gach i rejestrach. Wszyst-
kie zdarzenia lub transakcje s% zapisywane wiersz po wierszu w j"zyku naturalnym. W miar"
opracowywania aplikacji, zamiast czytelnych warto$ci wprowadza si" kody (np.
01
zamiast
Konta przychodowe
,
02
zamiast
Konta rozchodowe
itd.). Pracownicy musz% zna! te kody i wpi-
sywa! je w odpowiednio oznaczonych polach formularzy ekranowych. Jest to skrajny przypa-
dek, ale takie rozwi%zania stosuje si" w tysi%cach aplikacji, przez co trudno si" ich nauczy!.
Problem ten najwyra2niej wyst"puje podczas projektowania aplikacji w du#ych, konwencjo-
nalnych systemach typu mainframe. Poniewa# do tej grupy nale#% równie# relacyjne bazy
danych, wykorzystuje si" je jako zamienniki starych metod wprowadzania-wyprowadzania
danych takich, jak metoda VSAM (ang. Virtual Storage Access Method) oraz systemy IMS
(ang. Information Management System). Wielkie mo#liwo$ci relacyjnych baz danych s% niemal
ca&kowicie marnotrawione, je$li s% wykorzystywane w taki sposób.
Dlaczego zamiast j zyka naturalnego stosuje si kody?
Po co w ogóle stosowa! kody? Z regu&y podaje si" dwa uzasadnienia:
kategoria zawiera tak wiele elementów, #e nie mo#na ich sensownie przedstawi!
lub zapami"ta! w j"zyku naturalnym,
dla zaoszcz"dzenia miejsca w komputerze.
Drugi powód to ju# anachronizm. Pami"! operacyjna i masowa by&y niegdy$ tak drogie, a pro-
cesory tak wolne (ich moc obliczeniowa nie dorównywa&a wspó&czesnym nowoczesnym kal-
kulatorom), #e programi$ci musieli stara! si" zapisywa! dane o jak najmniejszej obj"to$ci.

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
67
Liczby przechowywane w postaci numerycznej zajmuj% w pami"ci o po&ow" mniej miejsca ni#
liczby w postaci znakowej, a kody jeszcze bardziej zmniejszaj% wymagania w stosunku do
komputerów.
Poniewa# komputery by&y kiedy$ drogie, programi$ci wsz&dzie musieli stosowa! kody. Takie
techniczne rozwi%zanie problemów ekonomicznych stanowi&o prawdziw% udr"k" dla u#ytkow-
ników. Komputery by&y zbyt wolne i za drogie, aby sprosta! wymaganiom ludzi, a zatem szko-
lono ludzi, aby umieli sprosta! wymaganiom komputerów. To dziwactwo by&o konieczno$ci%.
Ekonomiczne uzasadnienie stosowania kodów znik&o wiele lat temu. Komputery s% teraz wystar-
czaj%co dobre, aby mo#na je by&o przystosowa! do sposobu pracy ludzi, a zw&aszcza do u#ywa-
nia j"zyka naturalnego. Najwy#szy czas, aby tak si" sta&o. A jednak projektanci i programi$ci,
nie zastanawiaj%c si" nad tym zbytnio, w dalszym ci%gu u#ywaj% kodów.
Pierwszy powód mo#na uzna! za istotny, a poza tym cz"$ciej wyst"puje. Wprowadzanie kodów
numerycznych zamiast ci%gów tekstowych (np. tytu&ów ksi%#ek) zwykle jest mniej praco-
ch&onne (o ile oczywi$cie pracownicy s% odpowiednio przeszkoleni), a co za tym idzie ta'sze.
Ale w systemie Oracle stosowanie kodów oznacza po prostu niepe&ne wykorzystanie jego
mo#liwo$ci. System Oracle potrafi pobra! kilka pierwszych znaków tytu&u i automatycznie
uzupe&ni! pozosta&% jego cz"$!. To samo potrafi zrobi! z nazwami produktów, transakcji
(litera „z” mo#e by! automatycznie zast%piona warto$ci% „zakup”, a litera „s” warto$ci%
„sprzeda#”) i innymi danymi w aplikacji. Jest to mo#liwe dzi"ki bardzo rozbudowanemu mecha-
nizmowi dopasowywania wzorców.
Korzy!ci z wprowadzania czytelnych danych
Stosowanie j"zyka naturalnego przynosi jeszcze jedn% korzy$!: niemal ca&kowicie znikaj% b&"dy
w kluczach, poniewa# u#ytkownicy natychmiast widz% wprowadzone przez siebie informacje.
Cyfry nie s% przekszta&cane, nie trzeba wpisywa! #adnych kodów, zatem nie istnieje tu mo#-
liwo$! pope&nienia b&"du. Zmniejsza si" równie# ryzyko, #e u#ytkownicy aplikacji finansowych
strac% pieni%dze z powodu b&"dnie wprowadzonych danych.
Aplikacje staj% si" tak#e bardziej zrozumia&e. Ekrany i raporty zyskuj% czytelny format, który
zast"puje ci%gi tajemniczych liczb i kodów. Odej$cie od kodów na rzecz j"zyka naturalnego ma
olbrzymi i o#ywczy wp&yw na firm" i jej pracowników. Dla u#ytkowników, którzy musieli
si" uczy! kodów, aplikacja bazuj%ca na j"zyku naturalnym oznacza chwil" wytchnienia.
Jak zmniejszy: zamieszanie?
Zwolennicy kodów argumentuj% czasami, #e istnieje zbyt du#a liczba produktów, klientów,
typów transakcji, aby mo#na by&o ka#dej pozycji nada! odr"bn% nazw". Dowodz% równie#,
ile k&opotów sprawiaj% pozycje identyczne b%d2 bardzo podobne (np. trzydziestu klientów
nazywaj%cych si" „Jan Kowalski”). Owszem, zdarza si", #e kategoria zawiera za du#o pozycji,
aby mo#na je by&o &atwo zapami"ta! lub rozró#ni!, ale znacznie cz"$ciej jest to dowód nie-
odpowiedniego podzia&u informacji na kategorie: zbyt wiele niepodobnych do siebie obiektów
umieszcza si" w zbyt obszernej kategorii. Tworzenie aplikacji zorientowanej na j"zyk naturalny
wymaga czasu, w którym u#ytkownicy musz% komunikowa! si" z programistami — trzeba

68
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
zidentyfikowa! informacje biznesowe, zrozumie! naturalne relacje i kategorie, a nast"pnie
uwa#nie skonstruowa! baz" danych i schemat nazw, które w prosty i dok&adny sposób odzwier-
ciedl% rzeczywisto$!.
S% trzy podstawowe etapy wykonywania tych dzia&a':
1)
normalizacja danych,
2)
wybór nazw dla tabel i kolumn w j"zyku naturalnym,
3)
wybór nazw danych.
Ka#dy z tych etapów zostanie omówiony w dalszej cz"$ci rozdzia&u. Naszym celem jest pro-
jektowanie sensownie zorganizowanych aplikacji, zapisanych w tabelach i kolumnach, których
nazwy brzmi% znajomo dla u#ytkownika, gdy# s% zaczerpni"te z codzienno$ci.
Normalizacja
Bie#%ce relacje pomi"dzy krajami, wydzia&ami w firmie albo pomi"dzy u#ytkownikami i pro-
jektantami zazwyczaj s% wynikiem historycznych uwarunkowa'. Poniewa# okoliczno$ci histo-
ryczne dawno min"&y, w efekcie czasami powstaj% relacje, których nie mo#na uwa#a! za
normalne. Mówi%c inaczej, s% one niefunkcjonalne. Zasz&o$ci historyczne równie cz"sto wywie-
raj% wp&yw na sposób zbierania, organizowania i raportowania danych, co oznacza, #e dane
tak#e mog% by! nienormalne lub niefunkcjonalne.
Normalizacja jest procesem tworzenia prawid&owego, normalnego stanu. Poj"cie pochodzi
od &aci'skiego s&owa norma oznaczaj%cego przyrz%d u#ywany przez stolarzy do zapewnienia
k%ta prostego. W geometrii normalna jest lini% prost% przebiegaj%c% pod k%tem prostym do
innej linii prostej. W relacyjnych bazach danych norma tak#e ma specyficzne znaczenie, które
dotyczy przydzielania ró#nych danych (np. nazwisk, adresów lub umiej"tno$ci) do niezale"-
nych grup i definiowania dla nich normalnych lub inaczej mówi%c „prawid&owych” relacji.
Za chwil" zostan% omówione podstawowe zasady normalizacji, dzi"ki czemu u#ytkownicy
b"d% mogli uczestniczy! w procesie projektowania aplikacji lub lepiej zrozumiej% aplikacj",
która zosta&a stworzona wcze$niej. B&"dem by&oby jednak my$lenie, #e proces normalizacji
dotyczy jedynie baz danych lub aplikacji komputerowych. Normalizacja to g&"boka analiza
informacji wykorzystywanych w biznesie oraz relacji zachodz%cych pomi"dzy elementami tych
informacji. Umiej"tno$! ta przydaje si" w ró#nych dziedzinach.
Model logiczny
Jedn% z pierwszych czynno$ci w procesie analizy jest utworzenie modelu logicznego, czyli po
prostu znormalizowanego diagramu danych. Wiedza na temat zasad klasyfikowania danych
jest niezb"dna do zrozumienia modelu, a model jest niezb"dny do stworzenia funkcjonalnej
aplikacji.
W normalizacji wyró#nia si" kilka postaci: najpopularniejsze s% pierwsza, druga i trzecia posta!
normalna, przy czym trzecia reprezentuje stan najbardziej znormalizowany. Istniej% tak#e
postacie czwarta i pi%ta, ale wykraczaj% one poza zakres przedstawionego tu wyk&adu.

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
69
Rozwa#my przypadek z bibliotek%. Ka#da ksi%#ka ma tytu&, wydawc", autora lub autorów oraz
wiele innych charakterystycznych cech. Przyjmijmy, #e dane te pos&u#% do zaprojektowania
dziesi"ciokolumnowej tabeli w systemie Oracle. Tabel" nazwali$my
BIBLIOTECZKA
, a kolum-
nom nadali$my nazwy
Tytul
,
Wydawca
,
Autor1
,
Autor2
,
Autor3
oraz
Kategoria1
,
Kategoria2
,
Kategoria3
,
Ocena
i
OpisOceny
. U#ytkownicy tej tabeli ju# maj% problem: jednej ksi%#ce mo#na
przypisa! tylko trzech autorów lub tylko trzy kategorie.
Co si" stanie, kiedy zmieni si" lista dopuszczalnych kategorii? Kto$ b"dzie musia& przejrze!
wszystkie wiersze tabeli
BIBLIOTECZKA
i poprawi! stare warto$ci. A co si" stanie, je$li jeden
z autorów zmieni nazwisko? Ponownie b"dzie trzeba zmodyfikowa! wszystkie powi%zane
rekordy. A co zrobi!, je$li ksi%#ka ma czterech autorów?
Ka#dy projektant powa#nej bazy danych staje przed problemem sensownego i logicznego
zorganizowania informacji. Nie jest to problem techniczny sensu stricto, wi"c w&a$ciwie nie
powinni$my si" nim zajmowa!, ale przecie# projektant bazy danych musi si" z nim upora! —
musi znormalizowa! dane. Normalizacj" wykonuje si" poprzez stopniow% reorganizacj" danych,
tworz%c grupy podobnych danych, eliminuj%c niefunkcjonalne relacje i buduj%c relacje normalne.
Normalizacja danych
Pierwszym etapem reorganizacji jest sprowadzenie danych do pierwszej postaci normalnej.
Polega to na umieszczeniu danych podobnego typu w oddzielnych tabelach i wyznaczeniu
w ka#dej z nich klucza gDównego — niepowtarzalnej etykiety lub identyfikatora. Proces ten
eliminuje powtarzaj%ce si" grupy danych takie, jak autorzy ksi%#ek w tabeli
BIBLIOTECZKA
.
Zamiast definiowa! tylko trzech autorów ksi%#ki, dane ka#dego autora s% przenoszone do tabeli,
w której ka#demu autorowi odpowiada jeden wiersz (imi", nazwisko i opis). Dzi"ki temu
w tabeli
BIBLIOTECZKA
nie trzeba definiowa! kolumn dla kilku autorów. Jest to lepsze rozwi%za-
nie projektowe, poniewa# umo#liwia przypisanie nieograniczonej liczby autorów do ksi%#ki.
Nast"pn% czynno$ci% jest zdefiniowanie w ka#dej tabeli klucza g&ównego — informacji, która
w niepowtarzalny sposób identyfikuje dane, uniemo#liwia dublowanie si" grup danych i pozwala
na wybranie interesuj%cego nas wiersza. Dla uproszczenia za&ó#my, #e tytu&y ksi%#ek i nazwi-
ska autorów s% niepowtarzalne, a zatem kluczem g&ównym w tabeli
AUTOR
jest kolumna
NazwiskoAutora
.
Podzielili$my ju# tabel"
BIBLIOTECZKA
na dwie tabele:
AUTOR
zawieraj%c% kolumny
Nazwisko
Autora
(klucz g&ówny) i
Uwagi
oraz
BIBLIOTECZKA
, z kluczem g&ównym
Tytul
i kolumnami
Wydawca
,
Kategoria1
,
Kategoria2
,
Kategoria3
,
Ocena
i
OpisOceny
. Trzecia tabela
BIBLIOTECZKA_
AUTOR
definiuje powi%zania. Jednej ksi%#ce mo#na przypisa! wielu autorów, a jeden autor
mo#e napisa! wiele ksi%#ek — jest to zatem relacja wiele do wielu. Relacje i klucze g&ówne
zaprezentowano na rysunku 4.8
Nast"pna czynno$! w procesie normalizacji — doprowadzenie danych do drugiej postaci nor-
malnej — obejmuje wydzielenie danych, które zale#% tylko od cz"$ci klucza. Je$li istniej%
atrybuty, które nie zale#% od ca&ego klucza, nale#y je przenie$! do nowej tabeli. W tym przy-
padku kolumna
OpisOceny
w istocie nie zale#y od kolumny
Tytul
, zale#y natomiast od kolumny
Ocena
i dlatego nale#y j% przenie$! do oddzielnej tabeli.
70
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Rysunek 4.8.
Tabele BIBLIOTECZKA,
AUTOR
i BIBLIOTECZKA_AUTOR
Aby osi%gn%! trzeci% posta! normaln%, nale#y pozby! si" z tabeli wszystkich atrybutów, które
nie zale#% wy&%cznie od klucza g&ównego. W zaprezentowanym przyk&adzie pomi"dzy kate-
goriami zachodz% relacje wzajemne. Nie mo#na wymieni! ksi%#ki jednocze$nie w kategorii
Fikcja
i
Fakty
, a w kategoriach
Doro*li
i
Dzieci
mo#na wymieni! kilka podkategorii. Z tego
powodu informacje o kategoriach nale#y przenie$! do oddzielnej tabeli. Tabele w trzeciej
postaci normalnej przedstawia rysunek 4.9.
Rysunek 4.9.
Tabela BIBLIOTECZKA
i tabele powi'zane
Dane, które osi%gn"&y trzeci% posta! normaln%, z definicji znajduj% si" tak#e w postaciach pierw-
szej i drugiej. W zwi%zku z tym nie trzeba #mudnie przekszta&ca! jednej postaci w drug%.
Wystarczy tak zorganizowa! dane, aby wszystkie kolumny w ka#dej tabeli (oprócz klucza
g&ównego) zale#a&y wy&%cznie od caDego klucza gDównego. Trzeci% posta! normaln% czasami
opisuje si" fraz% „klucz, ca&y klucz i nic innego, tylko klucz”.
Poruszanie si w obr bie danych
Baza danych
BIBLIOTECZKA
jest teraz w trzeciej postaci normalnej. Przyk&adow% zawarto$! tabel
pokazano na rysunku 4.10. Z &atwo$ci% mo#na zauwa#y! relacje pomi"dzy tabelami. Aby
uzyska! informacje o poszczególnych autorach, korzystamy z kluczy. Klucz g&ówny w ka#-
dej tabeli w sposób niepowtarzalny identyfikuje pojedynczy wiersz. Wybierzmy na przyk&ad
autora o nazwisku Stephen Jay Gould, a natychmiast znajdziemy odpowiadaj%cy mu zapis
w tabeli
AUTOR
, poniewa# pole
NazwiskoAutora
jest kluczem g&ównym.

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
71
Rysunek 4.10.
PrzykDadowe dane
z bazy danych
BIBLIOTECZKA
Odszukajmy autork" Harper Lee w kolumnie
NazwiskoAutora
w tabeli
BIBLIOTECZKA_AUTOR
,
a zobaczymy, #e napisa&a ona powie$! ZabiJ drozda. Nast"pnie w tabeli
BIBLIOTECZKA
mo#emy
sprawdzi! wydawc", kategori" i ocen" tej ksi%#ki, a w tabeli
OCENA
— opis oceny.
Je$li szukamy tytu&u ZabiJ drozda w tabeli
BIBLIOTECZKA
, skorzystamy z klucza g&ównego
w tabeli. Aby znale2! autora ksi%#ki, mo#na odwróci! wcze$niejsz% $cie#k" wyszukiwania,
poszukuj%c w tabeli
BIBLIOTECZKA_AUTOR
rekordów, które w kolumnie
Tytul
maj% szukan%
warto$! — kolumna
Tytul
jest kluczem obcym w tabeli
BIBLIOTECZKA_AUTOR
. Je$li klucz g&ówny
tabeli
BIBLIOTECZKA
znajdzie si" w innej tabeli tak, jak to ma miejsce w przypadku tabeli
BIBLIOTECZKA_AUTOR
, nazywa si" go kluczem obcym tej tabeli.

72
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Tabele te maj% bardzo prost% charakterystyk". Istniej% oceny i kategorie, które nie zosta&y
jeszcze u#yte w ksi%#kach w biblioteczce. Poniewa# dane zorganizowano w sposób logiczny,
mo#na przygotowa! kategorie i oceny, do których nie przypisano jeszcze #adnych ksi%#ek.
Jest to sensowny i logiczny sposób organizowania informacji nawet wtedy, gdy „tabele” s%
zapisane w ksi%#ce magazynowej lub na fiszkach przechowywanych w pude&kach. Oczywi$cie
ci%gle czeka nas sporo pracy, aby dane zorganizowane w ten sposób przekszta&ci! w praw-
dziw% baz" danych. Na przyk&ad pole
NazwiskoAutora
mo#na podzieli! na
Imie
i
Nazwisko
.
Przyda&aby si" te# mo#liwo$! wy$wietlenia informacji o tym, kto jest g&ównym autorem ksi%#ki,
a kto na przyk&ad recenzentem.
Ca&y ten proces nazywa si" normalizacj%. Naprawd" nie ma w tym nic specjalnego. Chocia#
dobry projekt aplikacji bazodanowej uwzgl"dnia kilka dodatkowych zagadnie', podstawowe
zasady analizowania „normalnych” relacji pomi"dzy ró#nymi danymi s% tak proste, jak w&a-
$nie opisali$my.
Trzeba jednak pami"ta!, #e normalizacja jest cz"$ci% procesu analizy, a nie projektu. Uzna-
nie, #e znormalizowane tabele modelu logicznego s% projektem rzeczywistej bazy danych to
istotny b&%d. Mylenie procesów analizy i projektowania jest podstawow% przyczyn% niepo-
wodze' powa#nych aplikacji wykorzystuj%cych relacyjne bazy danych, o których pó2niej
mo#na przeczyta! w prasie. Zagadnienia te — z którymi dok&adnie powinni zapozna! si"
programi$ci — zostan% opisane bardziej szczegó&owo w dalszej cz"$ci rozdzia&u.
Opisowe nazwy tabel i kolumn
Po zidentyfikowaniu relacji zachodz%cych pomi"dzy ró#nymi elementami w bazie danych
i odpowiednim posegregowaniu danych, nale#y po$wi"ci! sporo czasu na wybranie nazw dla
tabel i kolumn, w których zostan% umieszczone dane. Zagadnieniu temu cz"sto po$wi"ca si"
zbyt ma&o uwagi. Lekcewa#% je nawet ci, którzy powinni zdawa! sobie spraw" z jego donio-
s&o$ci. Nazwy tabel i kolumn cz"sto s% wybierane bez konsultacji oraz odpowiedniej analizy.
Nieodpowiedni dobór nazw tabel i kolumn ma powa#ne nast"pstwa podczas korzystania
z aplikacji.
Dla przyk&adu rozwa#my tabele pokazane na rysunku 4.10. Nazwy mówi% tu same za siebie.
Nawet u#ytkownik, dla którego problematyka relacyjnych baz danych jest nowa, nie b"dzie mia&
trudno$ci ze zrozumieniem zapytania nast"puj%cej postaci
1
:
select Tytul, Wydawca
from BIBLIOTECZKA
order by Wydawca;
U#ytkownicy rozumiej% zapytanie, poniewa# wszystkie s&owa brzmi% znajomo. Nie s% to jakie$
tajemnicze zakl"cia. Kiedy trzeba zdefiniowa! tabele zawieraj%ce znacznie wi"cej kolumn,
dobranie odpowiednich nazw jest trudniejsze. W takiej sytuacji wystarczy jednak konsekwent-
1
Mowa tu oczywi$cie o u#ytkownikach znaj%cych podstawy j"zyka angielskiego. Jednak nawet ci, którzy
nie znaj% tego j"zyka, zrozumiej% zapytanie, je$li poznaj% znaczenie kilku s&ów: select — wybierz, from — z,
where — gdzie, order by — uporz%dkuj wed&ug — przyp. tDum.

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
73
nie stosowa! kilka regu&. Przeanalizujmy kilka problemów, które cz"sto powstaj% w przy-
padku braku odpowiedniej konwencji nazw. Zastanówmy si", co by si" sta&o, gdyby$my zasto-
sowali takie oto nazwy:
BIBLIOTECZKA B_A AUT KATEGORIE
-------------- ----- ------------ ----------
tytul tytul naz_a kat
wyd naz_a koment p_kat
kat s_kat
oc
Nazwy zastosowane w tej tabeli, mimo #e dziwne, s% niestety do$! powszechne. Zosta&y dobrane
zgodnie z konwencj% (lub brakiem konwencji) wykorzystywan% przez znanych producentów
oprogramowania i programistów.
Poni#ej wymieniono kilka bardziej znanych problemów wyst"puj%cych podczas dobierania nazw.
Stosowanie skrótów bez powodu. W ten sposób zapami"tanie pisowni nazw staje si"
niemal niemo#liwe. Nazwy mog&yby równie dobrze by! kodami, poniewa# u#ytkownicy
i tak musz% ich szuka!.
Niespójne stosowanie skrótów.
Na podstawie nazwy nie mo"na w sposób jednoznaczny okre/liJ przeznaczenia tabeli
lub kolumny. Skróty nie tylko powoduj%, #e zapami"tanie pisowni nazw staje si" trudne,
ale równie# zaciemniaj% natur" danych zapisanych w kolumnie lub tabeli. Co to jest
p_kat
lub
koment
?
Niespójne stosowanie znaków podkre/lenia. Znaków podkre$lenia czasami u#ywa si"
do oddzielania s&ów w nazwie, ale innym razem nie u#ywa si" ich w ogóle. W jaki
sposób zapami"ta! gdzie wstawiono znaki podkre$lenia, a gdzie nie?
Niespójne stosowanie liczby mnogiej.
KATEGORIA
czy
KATEGORIE
?
Komentarz
czy
Komentarze
?
Stosowane reguDy maj' ograniczenia. Je$li nazwa kolumny rozpoczyna si" od pierwszej
litery nazwy tabeli (np. kolumna
Anaz
w tabeli, której nazwa rozpoczyna si" na liter" A),
to co nale#y zrobi!, kiedy innej tabeli trzeba nada! nazw" na liter" A? Czy kolumn"
w tej tabeli równie# nazwiemy
Anaz
? Je$li tak, to dlaczego nie nada! obu kolumnom
nazwy
Nazwisko
?
U#ytkownicy, którzy nadaj% tabelom i kolumnom niew&a$ciwe nazwy, nie s% w stanie w prosty
sposób formu&owa! zapyta'. Zapytania nie maj% intuicyjnego charakteru i znajomego wygl%du
tak, jak w przypadku zapytania do tabeli
BIBLIOTECZKA
, co w znacznym stopniu zmniejsza
u#yteczno$! aplikacji.
Dawniej od programistów wymagano tworzenia nazw sk&adaj%cych si" maksymalnie z o$miu
znaków. W rezultacie nazwy by&y myl%cym zlepkiem liter, cyfr i niewiele mówi%cych skrótów.
Obecnie podobne ograniczenia, wymuszane przez star% technologi", nie maj% ju# zastosowa-
nia. W systemie Oracle nazwy kolumn i tabel mog% mie! rozmiar do 30 znaków. Projektanci
zyskali dzi"ki temu mo#liwo$! tworzenia nazw pe&nych, jednoznacznych i opisowych.
Pami"tajmy zatem, aby w nazwach wystrzega! si" skrótów, liczby mnogiej i nie stosowa!
znaków podkre$lenia (lub stosowa! je konsekwentnie). Unikniemy wówczas myl%cych nazw,

74
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
które obecnie zdarzaj% si" nader cz"sto. Jednocze$nie konwencje nazw musz% by! proste,
zrozumia&e i &atwe do zapami"tania. W pewnym sensie potrzebna jest zatem normalizacja nazw.
W podobny sposób, w jaki analizujemy dane, segregujemy je wed&ug przeznaczenia i w ten
sposób normalizujemy, powinni$my przeanalizowa! standardy nazewnictwa. Bez tego zadanie
utworzenia aplikacji zostanie wykonane niew&a$ciwie.
Dane w j zyku naturalnym
Po przeanalizowaniu konwencji nazw dla tabel i kolumn, trzeba po$wi"ci! uwag" samym danym.
Przecie# od czytelno$ci danych b"dzie zale#e! czytelno$! drukowanego raportu. W przyk&a-
dzie z baz% danych
BIBLIOTECZKA
, warto$ci w kolumnie
Ocena
s% wyra#one za pomoc% kodu,
a
Kategoria
to po&%czenie kilku warto$ci. Czy to dobrze? Je$li zapytamy kogo$ o ksi%#k",
czy chcieliby$my us&ysze!, #e uzyska&a ona ocen"
4
w kategorii
Doro*liFakty
? Dlaczego
mieliby$my pozwala! maszynie, aby wyra#a&a si" nie do$! jasno?
Dzi"ki opisowym informacjom formu&owanie zapyta' staje si" &atwiejsze. Zapytanie powinno
w maksymalny sposób przypomina! zdanie z j"zyka naturalnego:
select Tutul, NazwiskoAutora
from BIBLIOTECZKA_AUTOR;
Stosowanie wielkich liter w nazwach i danych
Nazwy tabel i kolumn s% zapisywane w wewn"trznym s&owniku danych systemu Oracle za
pomoc% wielkich liter. Gdy w zapytaniu nazwy wpiszemy ma&ymi literami, system natych-
miast zmieni ich wielko$!, a nast"pnie przeszuka s&ownik danych. W niektórych systemach
relacyjnych baz danych wielko$! liter ma znaczenie. Je$li u#ytkownik wpisze nazw" kolumny
jako
Zdolnosc
, a w bazie danych kolumna ta wyst"puje jako
zdolnosc
lub
ZDOLNOSC
(w zale#-
no$ci od tego, w jaki sposób zdefiniowano kolumn" podczas tworzenia tabeli), system nie
zrozumie zapytania.
U$ytkownik mo$e wymusi/ na systemie Oracle obs ug6 nazw o mieszanej wielko8ci liter, ale
wówczas tworzenie zapyta< i praca z danymi b6d= trudniejsze. Z tego powodu najlepiej wyko-
rzystywa/ domy8ln= w a8ciwo8/ — stosowanie wielkich liter.
Rozró#nianie wielko$ci liter jest czasami promowane jako zaleta baz danych, dzi"ki której
programi$ci mog% tworzy! ró#ne tabele o podobnych nazwach — jak cho!by
pracownik
,
Pracownik
i
pRAcownik
. Ale w jaki sposób zapami"ta! ró#nice? Taka w&a$ciwo$! jest w istocie
wad%, a nie zalet%. Firma Oracle by&a wystarczaj%co rozs%dna, aby nie wpa$! w t" pu&apk".
Podobnie rzecz si" ma w przypadku danych zapisanych w bazie. Skoro istnieje mo#liwo$!
interakcji z systemem Oracle w taki sposób, #e wielko$! liter w zapytaniach nie ma znaczenia,
to istniej% równie# sposoby wyszukiwania danych, niezale#nie od tego, czy zosta&y zapisane
wielkimi, czy ma&ymi literami. Ale po co wykonywa! niepotrzebne dzia&ania? Poza kilkoma
wyj%tkami, takimi jak teksty prawnicze lub formularze, o wiele &atwiej zapisywa! dane za
pomoc% wielkich liter i tworzy! aplikacje, w których wybrano spójn% wielko$! liter dla danych.

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
75
Dzi"ki temu formu&owanie zapyta' staje si" &atwiejsze, a dane otrzymuj% spójniejszy wygl%d
w raportach. Je$li niektóre dane trzeba zapisa! mieszanymi literami (np. nazwisko i adres na
kopercie), mo#na wywo&a! funkcj" systemu Oracle, która dokona odpowiedniej konwersji.
Uwa#ni czytelnicy dostrzegli zapewne, #e autor ksi%#ki nie przestrzega& dotychczas tej zasady.
Jej stosowanie opó2niano do czasu odpowiedniego wprowadzenia i umieszczenia jej we w&a-
$ciwym kontek$cie. Od tej pory, poza kilkoma uzasadnionymi wyj%tkami, dane w bazie danych
b"d% zapisywane wielkimi literami.
Normalizacja nazw
Na rynku pojawi&o si" kilka narz"dzi umo#liwiaj%cych stosowanie w zapytaniach s&ów j"zyka
naturalnego zamiast dziwnych zestawie'. Dzia&anie tych produktów polega na utworzeniu
logicznej mapy ze s&ów j"zyka naturalnego, trudnych do zapami"tania kodów oraz nazw kolumn
i tabel. Przygotowanie takiego odwzorowania wymaga szczegó&owej analizy, ale po pomy$l-
nym wykonaniu tego zadania interakcja z aplikacj% staje si" o wiele &atwiejsza. Jednak dla-
czegó# by nie zwróci! uwagi na ten problem od pocz%tku? Po co tworzy! dodatkowy pro-
dukt i wykonywa! dodatkow% prac", skoro mo#na unikn%! wi"kszo$ci zamieszania, od razu
nadaj%c odpowiednie nazwy?
Aby zapewni! odpowiedni% wydajno$! aplikacji, czasami niektóre dane s% zapisywane w bazie
w postaci zakodowanej. Kody te nie powinny by! ujawniane u#ytkownikom ani podczas wpro-
wadzania danych, ani podczas ich pobierania. System Oracle umo#liwia ich &atwe ukrywanie.
Je$li przy wprowadzaniu danych trzeba zastosowa! kody, natychmiast wzrasta liczba b&"dów
literowych. Je$li kody wyst"puj% w raportach zamiast powszechnie u#ywanych s&ów, poja-
wiaj% si" b&"dy interpretacji. A kiedy u#ytkownicy chc% utworzy! nowy raport, ich zdolno$!
do szybkiego i dok&adnego wykonania tej czynno$ci jest znacznie ograniczona zarówno za
spraw% kodów, jak i z powodu trudno$ci w zapami"taniu dziwnych nazw kolumn i tabel.
System Oracle daje u#ytkownikom mo#liwo$! pos&ugiwania si" j"zykiem naturalnym w ca&ej
aplikacji. Ignorowanie tej sposobno$ci jest marnotrawieniem mo#liwo$ci systemu Oracle. Je$li
z niej nie skorzystamy, bezsprzecznie powstanie mniej zrozumia&a i ma&o wydajna aplikacja.
Programi$ci maj% obowi%zek skorzystania z okazji. U#ytkownicy powinni si" tego domaga!.
Obie grupy z ca&% pewno$ci% na tym skorzystaj%.
Czynnik ludzki
U#ytkownicy, którzy dopiero rozpoczynaj% przygod" z systemem Oracle, by! mo#e poczuli
ju# ochot", aby przej$! do konkretnych dzia&a'. Jednak sposoby pracy z u#yciem j"zyka SQL
zostan% opisane dopiero w nast"pnym rozdziale. Teraz zajmiemy si" inn% problematyk%: spró-
bujemy przeanalizowa! projekt programistyczny, w którym zamiast skupia! si" na danych,
wzi"to pod uwag" rzeczywiste zadania biznesowe wykonywane przez u#ytkowników doce-
lowych.

76
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Technologie normalizacji danych oraz wspomagana komputerowo in#ynieria oprogramowania
(ang. Computer Aided Software Engineering — CASE) zyska&y tak wielkie znaczenie podczas
projektowania aplikacji relacyjnych, #e koncentracja na danych, zagadnieniach referencyjnej
integralno$ci, kluczach i diagramach tabel sta&a si" prawie obsesj%. Zagadnienia te cz"sto s%
mylone z w&a$ciwym projektem. Przypomnienie, i# jest to tylko analiza, dla wielu stanowi
spore zaskoczenie.
Normalizacja jest analiz', a nie projektowaniem. A w&a$ciwie jest to jedynie cz"$! analizy,
niezb"dna do zrozumienia zasad funkcjonowania danej firmy i stworzenia u#ytecznej aplikacji.
Celem aplikacji jest przede wszystkim wspomaganie dzia&a' przedsi"biorstwa poprzez szybsze
i wydajniejsze wykonywanie zada' biznesowych oraz usprawnienie $rodowiska pracy. Je$li pra-
cownikom damy kontrol" nad informacjami oraz zapewnimy do nich prosty i intuicyjny dost"p,
odpowiedz% wzrostem wydajno$ci. Je$li kontrol" powierzymy obcej grupie, ukryjemy informa-
cje za wrogimi interfejsami — pracownicy b"d% niezadowoleni, a przez to mniej wydajni.
Naszym celem jest zaprezentowanie filozofii dzia&ania, która prowadzi do powstania przyja-
znych i wygodnych aplikacji. Do projektowania struktur danych oraz przep&ywu sterowania
wystarcz% narz"dzia, które znamy i których u#ywamy w codziennej pracy.
Zadania aplikacji i dane aplikacji
Twórcy oprogramowania cz"sto nie po$wi"caj% nale#ytej uwagi identyfikacji zada', których
wykonywanie chc% upro$ci!. Jedn% z przyczyn tego stanu rzeczy jest wysoki poziom z&o#o-
no$ci niektórych projektów, drug% — znacznie cz"$ciej wyst"puj%c% — skupienie si" na danych.
Podczas analizy programi$ci najcz"$ciej zadaj% nast"puj%ce pytania:
Jaki jest rodzaj pobieranych danych?
Jaki jest sposób ich przetwarzania?
Jakie dane powinny by! przedstawiane w raportach?
Pó2niej zadaj% szereg pyta' pomocniczych, poruszaj%c takie zagadnienia, jak formularze do
wprowadzania danych, kody, projekty ekranów, obliczenia, komunikaty, poprawki, raport
audytu, obj"to$! pami"ci masowej, cykl przetwarzania danych, formatowanie raportów, dys-
trybucja i piel"gnacja. S% to bardzo wa#ne zagadnienia. Problem polega na tym, #e wszystkie
koncentruj% si" wy&%cznie na danych.
Profesjonali$ci korzystaj' z danych, ale wykonuj' zadania. Ich wiedza i umiej"tno$ci s% nale-
#ycie zagospodarowane. Z kolei szeregowi urz"dnicy cz"sto jeszcze zajmuj% si" jedynie wpisy-
waniem danych do formularza wej$ciowego. Zatrudnianie ludzi tylko po to, by wprowadzali
dane, w szczególno$ci dane o du#ej obj"to$ci, spójne co do formatu (tak, jak w przypadku for-
mularzy) oraz z ograniczon% ró#norodno$ci%, jest drogie, przestarza&e, a przede wszystkim
antyhumanitarne. Czasy takiego my$lenia ju# przemin"&y, podobnie jak czasy kodów minima-
lizuj%cych ograniczenia maszyn.
Pami"tajmy ponadto, #e rzadko kiedy pracownik, rozpocz%wszy realizacj" zadania, zajmuje
si" nim tak d&ugo, a# je uko'czy. Zwykle wykonuje ró#ne dodatkowe czynno$ci, mniej lub
bardziej wa#ne, ale w jaki$ sposób powi%zane z zadaniem g&ównym. Bywa, #e realizuje je rów-
nolegle — wszystkie naraz.

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
77
Wszystko to ma swoje konsekwencje praktyczne. Projektanci, którzy pracuj% w nowoczesny
sposób, nie koncentruj% si" na danych tak, jak to by&o w przesz&o$ci. Dla nich najwa#niejsze
s% zadania, które z pomoc% aplikacji b"dzie wykonywa! u#ytkownik. Dlaczego $rodowiska
okienkowe odnios&y taki sukces? Poniewa# pozwalaj% u#ytkownikowi na szybk% zmian" reali-
zowanego zadania, a kilka zada' mo#e oczekiwa! na swoj% kolej w stanie aktywno$ci. Takiej
lekcji nie mo#na zmarnowa!. Nale#y wyci%gn%! z niej prawid&owe wnioski.
Identyfikacja zada' aplikacji to przedsi"wzi"cie znacznie ambitniejsze ni# prosta identyfika-
cja i normalizacja danych lub zwyk&e zaprojektowanie ekranów, programów przetwarzaj%-
cych i narz"dzi raportuj%cych. Oznacza ona zrozumienie rzeczywistych potrzeb u#ytkownika
i w efekcie opracowanie aplikacji, która interpretuje zadania, a nie tylko pobiera skojarzone
z nimi dane. Je$li projektant skoncentruje si" na danych, aplikacja zniekszta&ci zadania u#yt-
kowników. Najwi"kszym problemem jest wi"c u$wiadomienie sobie, #e skoncentrowanie si"
na zadaniach jest konieczno$ci%.
W jaki sposób zaprojektowa! aplikacj" ukierunkowan% na zadania, a nie na dane? Najwi"k-
szym problemem jest zrozumienie, #e skupienie si" na zadaniach jest po prostu niezb"dne.
Pozwala to spojrze! na analiz" z nowej perspektywy.
Rozpoczynaj%c proces analizy, najpierw musimy okre$li!, do jakich zada' u#ytkownicy doce-
lowi wykorzystuj% komputery. Jak% us&ug" lub produkt chc% wytworzy!? Jest to podstawowe
i mo#e nawet nieco uproszczone pytanie, ale jak zaraz zobaczymy, zaskakuj%co wielu ludzi
nie potrafi udzieli! na nie przekonuj%cej odpowiedzi. Przedstawiciele licznych bran#, pocz%wszy
od ochrony zdrowia, a na bankach, firmach wysy&kowych i fabrykach sko'czywszy, uwa#aj%,
#e istot% ich pracy jest przetwarzanie danych. Przecie# dane s% wprowadzane do komputerów
i przetwarzane, po czym tworzy si" raporty — czy# nie? Z powodu tej deformacji, któr% nale#y
uzna! za jeszcze jeden przejaw orientacji na dane w projektowaniu systemów, mnóstwo firm
podj"&o prób" wprowadzenia na rynek wyimaginowanego produktu — przetwarzania danych —
z katastrofalnymi, rzecz jasna, skutkami.
Dlatego tak wa#na jest wiedza na temat przeznaczenia aplikacji. Aby projektant zrozumia&,
czym naprawd" zajmuje si" dana dziedzina, do czego s&u#y wytworzony produkt i jakie zadania
s% wykonywane w procesie produkcji, musi mie! otwart% g&ow" i cz"sto intuicyjnie wyczuwa!
przedmiot biznesu.
Równie wa#ne jest, aby u#ytkownicy aplikacji znali j"zyk SQL i orientowali si" w za&o#e-
niach modelu relacyjnego. Zespó& sk&adaj%cy si" z projektantów, którzy rozumiej% potrzeby
u#ytkowników i doceniaj% warto$! zorientowanego na zadania, czytelnego $rodowiska apli-
kacji, oraz z u#ytkowników maj%cych odpowiednie przygotowanie techniczne (np. dzi"ki prze-
czytaniu niniejszej ksi%#ki) z pewno$ci% stworzy bardzo dobry system. Cz&onkowie takiego
zespo&u wzajemnie sprawdzaj% si", mobilizuj% i pomagaj% w realizacji indywidualnych zada'.
Punktem wyj$cia w pracach nad przygotowaniem profesjonalnej aplikacji b"dzie wi"c opra-
cowanie dwóch zbie#nych z sob% dokumentów: jednego z opisem zada', drugiego z opisem
danych. Przygotowuj%c opis zada', u$wiadamiamy sobie sens aplikacji. Opis danych pomaga
w implementacji wizji i zapewnia uwzgl"dnienie wszystkich szczegó&ów i obowi%zuj%cych
zasad.

78
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Identyfikacja zada(
Dokument, który opisuje zadania zwi%zane z prowadzon% dzia&alno$ci%, powstaje w wyniku
wspólnej pracy u#ytkowników docelowych i projektantów aplikacji. Rozpoczyna si" od zwi"-
z&ego opisu tej dzia&alno$ci. Powinno to by! jedno proste zdanie, sk&adaj%ce si" z nie wi"cej
ni# 10 s&ów, pisane w stronie czynnej, bez przecinków i z minimaln% liczb% przymiotników, na
przyk&ad:
Zajmujemy si" sprzeda#% ubezpiecze'.
A nie:
Firma Amalgamated Diversified jest wiod%cym mi"dzynarodowym dostawc% produktów
finansowych w dziedzinie ubezpiecze' zdrowotnych i komunikacyjnych, prowadz%c
w tym zakresie równie# szkolenia i $wiadcz%c us&ugi doradcze.
Istnieje pokusa, aby w pierwszym zdaniu umie$ci! wszelkie szczegó&y dotycz%ce prowadzonej
dzia&alno$ci. Nie nale#y tego robi!. Skrócenie rozwlek&ego opisu do prostego zdania umo#-
liwia skoncentrowanie si" na temacie. Je$li kto$ nie potrafi si" w ten sposób stre$ci!, oznacza
to, #e jeszcze nie zrozumia& istoty prowadzonej dzia&alno$ci.
U&o#enie tego zdania, które inicjuje proces tworzenia dokumentacji, jest wspólnym obowi%z-
kiem projektantów i u#ytkowników. Wspó&pracuj%c, &atwiej znajd% odpowied2 na pytania, czym
zajmuje si" przedsi"biorstwo i w jaki sposób wykonywane s% jego zadania. Jest to cenna wiedza
dla firmy, gdy# w procesie poszukiwania odpowiedzi zidentyfikowanych zostaje wiele zada'
podrz"dnych, jak równie# procedur i regu&, które nie maj% znaczenia lub s% u#ywane margi-
nalnie. Zazwyczaj s% to albo odpryski problemu, który ju# rozwi%zano, albo postulaty mene-
d#erów, które dawno zosta&y za&atwione.
Przekorni twierdz%, #e aby poradzi! sobie z nadmiarem raportów, nale#y zaprzesta! ich two-
rzenia i sprawdzi!, czy ktokolwiek to zauwa#y. W tym przesadnym stwierdzeniu tkwi ziarno
prawdy — przecie# w podobny sposób rozwi%zano problem roku dwutysi"cznego w star-
szych komputerach! Okaza&o si", #e wiele programów nie wymaga&o wprowadzania poprawek
z tego prostego powodu, #e zaprzestano ich u#ywania!
Programista aplikacji, dokumentuj%c zadania firmy, ma prawo zadawa! dociekliwe pytania
i wskazywa! marginalne obszary jej dzia&alno$ci. Nale#y jednak zdawa! sobie spraw", #e pro-
jektant nigdy nie b"dzie tak dobrze rozumia& zada' firmy, jak u#ytkownik docelowy. Istnieje
ró#nica pomi"dzy wykorzystaniem prac projektowych do zracjonalizowania wykonywanych
zada' i zrozumienia ich znaczenia a obra#aniem u#ytkowników poprzez prób" wmówienia im,
#e znamy firm" lepiej ni# oni.
Nale#y poprosi! u#ytkownika o w miar" szczegó&owe przedstawienie celów firmy, a tak#e
zada', które zmierzaj% do ich realizacji. Je$li cele s% niezbyt dobrze umotywowane (np. „zawsze
to robimy w ten sposób” lub „my$l", #e wykorzystuj% to do czego$”), powinna zapali! si"
nam czerwona lampka. Powinni$my powiedzie!, #e nie rozumiemy, i poprosi! o ponowne
wyja$nienia. Je$li odpowied2 w dalszym ci%gu nie jest zadowalaj%ca, nale#y umie$ci! takie
zadanie na oddzielnej li$cie w celu pó2niejszej dok&adnej analizy. Na niektóre z takich pyta'
odpowiedzi udziel% u#ytkownicy lepiej znaj%cy temat, z innymi b"dzie trzeba si" zwróci! do kie-
rownictwa, a wiele zada' wyeliminujemy, poniewa# oka#% si" niepotrzebne. Jednym z dowo-

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
79
dów na dobrze przeprowadzony proces analizy jest usprawnienie istniej%cych procedur. Jest
to niezale#ne od nowej aplikacji komputerowej i generalnie powinno nast%pi! na d&ugo przed
jej zaimplementowaniem.
Ogólny schemat dokumentu opisuj%cego zadania
Dokument opisuj%cy zadania sk&ada si" z trzech sekcji:
zdanie charakteryzuj%ce prowadzon% dzia&alno$! (trzy do dziesi"ciu s&ów),
kilka krótkich zda' opisuj%cych w prostych s&owach g&ówne zadania firmy,
opis zada' szczegó&owych.
Po ka#dej sekcji mo#na umie$ci! krótki, opisowy akapit, je$li jest taka potrzeba, co oczywi-
$cie nie usprawiedliwia lenistwa w d%#eniu do jasno$ci i zwi"z&o$ci. G&ówne zadania zazwy-
czaj numeruje si" jako 1.0, 2.0, 3.0 itd. i opisuje jako zadania poziomu zero. Dla ni#szych
poziomów wykorzystuje si" dodatkowe kropki, na przyk&ad 3.1 oraz 3.1.14. Ka#de zadanie
g&ówne rozpisuje si" na szereg zada: niepodzielnych — takich, które albo trzeba wykona! do
ko'ca, nie przerywaj%c ich realizacji, albo ca&kowicie anulowa!.
Wypisanie czeku jest zadaniem niepodzielnym, ale wpisanie samej kwoty ju# nie. Odebranie
telefonu w imieniu dzia&u obs&ugi klienta nie jest zadaniem niepodzielnym. Odebranie telefonu
i spe&nienie #%da' klienta jest zadaniem niepodzielnym. Zadania niepodzielne musz% mie!
znaczenie, a ich wykonanie musi przynosi! jakie$ rezultaty.
Poziom, na którym zadanie staje si" niepodzielne, zale#y od tre$ci zadania g&ównego. Zadanie
oznaczone jako 3.1.14 mo#e by! niepodzielne, ale równie dobrze mo#e zawiera! kilka dodat-
kowych poziomów podrz"dnych. Niepodzielne mo#e by! zadanie 3.2, ale tak#e 3.1.16.4. Wa#ny
nie jest sam schemat numerowania (który jest po prostu metod% opisu hierarchii zada'), ale
dekompozycja zada' do poziomu niepodzielnego. Dwa zadania w dalszym ci%gu mog% by!
niepodzielne, nawet je$li oka#e si", #e jedno zale#y od drugiego, ale tylko wtedy, kiedy jedno
mo#e zako'czy! si" niezale#nie od drugiego. Je$li dwa zadania zawsze zale#% od siebie, nie
s% to zadania niepodzielne. Prawdziwe zadanie niepodzielne obejmuje oba te zadania.
W przypadku wi"kszo$ci przedsi"wzi"! szybko si" zorientujemy, #e wiele zada' podrz"dnych
mo#na przyporz%dkowa! do dwóch lub wi"kszej liczby zada' z poziomu zero, co niemal
zawsze dowodzi, #e niew&a$ciwie zdefiniowano zadania g&ówne lub dokonano nieodpowied-
niego ich podzia&u. Celem naszych dzia&a' jest przekszta&cenie ka#dego zadania w poj"ciowy
„obiekt”, z dobrze zdefiniowanymi zadaniami i jasno okre$lonymi zasobami niezb"dnymi do
osi%gni"cia celu.
Wnioski wynikaj%ce z dokumentu opisuj%cego zadania
Wniosków jest kilka. Po pierwsze, poniewa# dokument ten jest bardziej zorientowany na zada-
nia ni# na dane, istnieje prawdopodobie'stwo, #e pod wp&ywem zawartych w nim zapisów
zmieni si" sposób projektowania ekranów u#ytkownika. Dokument ma tak#e wp&yw na zasady
pobierania i prezentacji danych oraz na implementacj" systemu pomocy. Gwarantuje, #e prze-
&%czanie pomi"dzy zadaniami nie b"dzie wymaga&o od u#ytkownika zbytniego wysi&ku.

80
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Po drugie, w miar" odkrywania konfliktów pomi"dzy zadaniami podrz"dnymi mo#e zmieni! si"
opis zada' g&ównych. To z kolei wp&ywa na sposób rozumienia zada' przedsi"biorstwa zarówno
przez u#ytkowników, jak i projektantów aplikacji.
Po trzecie, nawet akapity ko'cz%ce sekcje prawdopodobnie ulegn% zmianie. Racjonalizacja,
polegaj%ca w tym przypadku na definiowaniu niepodzielnych zada' i budowaniu wspomnia-
nych przed chwil% poj"ciowych „obiektów”, wymusza usuni"cie niedomówie' i zale#no$ci,
które niepotrzebnie wywieraj% wp&yw na dzia&alno$! firmy.
Tworzenie tego dokumentu nie jest procesem bezproblemowym — trzeba szuka! odpowiedzi na
niewygodne pytania, ponownie definiowa! niew&a$ciwe za&o#enia, #mudnie korygowa! b&"dy.
Ostatecznie jednak jego opracowanie przynosi du#e korzy$ci. Lepiej rozumiemy sens dzia&alno$ci
firmy, potrafimy okre$li! obowi%zuj%ce procedury, mo#emy zaplanowa! automatyzacj" zada'.
Identyfikacja danych
Dokument opisuj%cy zadania oprócz dekompozycji i opisu zada' zawiera równie# omówienie
zasobów koniecznych w ka#dym kroku, szczególnie w odniesieniu do wymaganych danych.
Jest to realizowane metodycznie, krok po kroku, a wynikaj%ce z tej analizy wymagane dane
s% zamieszczane w dokumencie opisu danych. Jest to koncepcyjnie inne podej$cie w porówna-
niu do klasycznego widoku danych. Nie zbieramy wy&%cznie formularzy i zawarto$ci ekranów
u#ywanych przy realizacji zadania i nie zapisujemy tylko znajduj%cych si" tam danych. Zasad-
niczym mankamentem w takim podej$ciu jest nasza tendencja (cho! cz"sto si" do tego nie
przyznajemy) do akceptowania i niepodwa#ania wszystkiego, co jest wydrukowane na papierze.
Definiuj%c ka#de zadanie, okre$lamy zasoby potrzebne do jego realizacji, w tym przede wszyst-
kim dane. Wymagania w zakresie danych uwzgl"dniamy w dokumencie opisu danych. Nie
chodzi tu o opis pól w formularzach i zawartych w nich elementów. Chodzi o rejestr koniecz-
nych danych. Poniewa# o tym, które dane s% konieczne, decyduje tre$! zadania, a nie istnie-
j%ce formularze, niezb"dna staje si" dok&adna analiza tej tre$ci oraz okre$lenie rzeczywistych
wymaga' w zakresie danych. Je$li osoba wykonuj%ca zadanie nie zna zastosowania pola, w które
wprowadza dane, takie pole nale#y umie$ci! na li$cie problemów wymagaj%cych dok&adniej-
szej analizy. Pracuj%c w ten sposób, usuwamy mnóstwo niepotrzebnych danych.
Po zidentyfikowaniu danych nale#y je uwa#nie przeanalizowa!. Szczególn% uwag" powinni$my
zwróci! na kody numeryczne i literowe, które ukrywaj% rzeczywiste informacje za barier%
nieintuicyjnych, niewiele mówi%cych symboli. Poniewa# zawsze budz% podejrzenia, nale#y
do nich podchodzi! z dystansem. W ka#dym przypadku trzeba zada! sobie pytanie, czy okre-
$lony element powinien by! kodem, czy nie. Czasami u#ycie kodów jest por"czne — cho!by
dlatego, #e u&atwia zapami"tywanie. Dla ich stosowania mo#na znale2! równie# inne racjo-
nalne argumenty i sensowne powody. Jednak w gotowym projekcie takie przypadki nie mog%
zdarza! si" cz"sto, a znaczenie kodów powinno by! oczywiste. W przeciwnym razie &atwo si"
pogubimy.
Proces konwersji kodów na warto$ci opisowe to zadanie do$! proste, ale stanowi dodatkow%
prac". W dokumencie opisuj%cym dane kody nale#y poda! wraz z ich znaczeniem uzgodnio-
nym i zatwierdzonym wspólnie przez u#ytkowników i projektantów.

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
81
Projektanci i u#ytkownicy powinni równie# wybra! nazwy grup danych. Nazwy te zostan%
u#yte jako nazwy kolumn w bazie danych i b"d% regularnie stosowane w zapytaniach, a zatem
powinny to by! nazwy opisowe (w miar" mo#liwo$ci bez skrótów, poza powszechnie stoso-
wanymi) i wyra#one w liczbie pojedynczej. Ze wzgl"du na bliski zwi%zek nazwy kolumny
z zapisanymi w niej danymi, oba te elementy nale#y okre$li! jednocze$nie. Przemy$lane nazwy
kolumn znacznie upraszczaj% identyfikacj" charakteru danych.
Dane, które nie s% kodami, tak#e musz% zosta! dok&adnie przeanalizowane. W tym momencie
mo#emy przyj%!, #e wszystkie zidentyfikowane elementy danych s% niezb"dne do wykona-
nia zada' biznesowych, cho! niekoniecznie s% one dobrze zorganizowane. To, co wygl%da na
jeden element danych w istniej%cym zadaniu, mo#e w istocie by! kilkoma elementami, które
wymagaj% rozdzielenia. Dane osobowe, adresy, numery telefonów to popularne przyk&ady
takich danych.
Na przyk&ad w tabeli
AUTOR
imiona by&y po&%czone z nazwiskami. Kolumna
NazwiskoAutora
zawiera&a zarówno imiona, jak i nazwiska, pomimo #e tabela zosta&a doprowadzona do trze-
ciej postaci normalnej. By&by to niezwykle nieudolny sposób zaimplementowania aplikacji,
cho! z technicznego punktu widzenia regu&y normalizacji zosta&y zachowane. Aby aplikacja
pozwala&a na formu&owanie prostych zapyta', kolumn"
NazwiskoAutora
nale#y rozdzieli! na
co najmniej dwie nowe kolumny:
Imie
i
Nazwisko
. Proces wydzielania nowych kategorii, który
prowadzi do poprawy czytelno$ci i wi"kszej funkcjonalno$ci bazy danych, bardzo cz"sto jest
niezale#ny od normalizacji.
Stopie' dekompozycji zale#y od przewidywanego sposobu wykorzystania danych. Istnieje mo#-
liwo$!, #e posuniemy si" za daleko i wprowadzimy kategorie, które cho! sk&adaj% si" z oddziel-
nych elementów, w rzeczywisto$ci nie tworz% dodatkowej warto$ci w systemie. Sposób wyko-
nywania dekompozycji zale#y od aplikacji i rodzaju danych. Nowym grupom danych, które
stan% si" kolumnami, nale#y dobra! odpowiednie nazwy. Trzeba uwa#nie przeanalizowa!
dane, które zostan% w tych kolumnach zapisane. Nazwy nale#y tak#e przypisa! danym tek-
stowym, dla których mo#na wyró#ni! sko'czon% liczb" warto$ci. Nazwy tych kolumn, ich
warto$ci oraz same kody mo#na uzna! za tymczasowe.
Modele danych niepodzielnych
Od tego momentu rozpoczyna si" proces normalizacji, a razem z nim rysowanie modeli danych
niepodzielnych. Istnieje wiele dobrych artyku&ów na ten temat oraz mnóstwo narz"dzi ana-
litycznych i projektowych, które pozwalaj% przyspieszy! proces normalizacji, a zatem w tej
ksi%#ce nie proponujemy jednej metody. Taka propozycja mog&aby raczej zaszkodzi!, ni#
pomóc.
W modelu nale#y uwzgl"dni! ka#d% niepodzieln% transakcj" i oznaczy! numerem zadanie,
którego ta transakcja dotyczy. Nale#y uwzgl"dni! nazwy tabel, klucze g&ówne i obce oraz naj-
wa#niejsze kolumny. Ka#dej znormalizowanej relacji nale#y nada! opisow% nazw" oraz osza-
cowa! liczb" wierszy i transakcji. Ka#demu modelowi towarzyszy dodatkowy arkusz, w którym
zapisano nazwy kolumn z typami danych, zakresem warto$ci oraz tymczasowymi nazwami
tabel, kolumn oraz danych tekstowych w kolumnach.

82
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Biznesowy model danych niepodzielnych
Dokument opisuj%cy dane jest teraz po&%czony z dokumentem opisuj%cym zadania, co tworzy
model biznesowy. Projektanci aplikacji i u#ytkownicy musz% wspólnie go przeanalizowa! w celu
sprawdzenia jego dok&adno$ci i kompletno$ci.
Model biznesowy
W tym momencie powinni posiada! ju# jasn% wizj" przedsi"wzi"cia, realizowanych w nim
zada' i u#ywanych danych. Po wprowadzeniu poprawek oraz zatwierdzeniu modelu bizne-
sowego rozpoczyna si" proces syntezy zada' i danych. W tej fazie nast"puje sortowanie danych,
przydzielanie ich do zada', ostateczne zako'czenie normalizacji oraz przypisanie nazw wszyst-
kim elementom, które ich wymagaj%.
W przypadku rozbudowanych aplikacji zwykle powstaje do$! du#y rysunek. Do&%cza si" do
niego dokumentacj" pomocnicz% uwzgl"dniaj%c% zadania, modele danych (z poprawionymi
nazwami utworzonymi na podstawie kompletnego modelu), list" tabel, nazw kolumn, typów
danych i zawarto$ci. Jedn% z ostatnich czynno$ci jest prze$ledzenie $cie#ek dost"pu do danych
dla ka#dej transakcji w pe&nym modelu biznesowym w celu sprawdzenia, czy wszystkie dane
wymagane przez transakcje mo#na pobiera! lub wprowadza! oraz czy nie przetrwa&y zadania
wprowadzania danych z brakuj%cymi elementami, co mog&oby uniemo#liwi! zachowanie inte-
gralno$ci referencyjnej modelu.
Z wyj%tkiem nadawania nazw poszczególnym tabelom, kolumnom i danym, wszystkie czyn-
no$ci a# do tego momentu by&y elementami analizy, a nie fazami projektowania. Celem tego
etapu by&o w&a$ciwe zrozumienie biznesu i jego komponentów.
Wprowadzanie danych
Model biznesowy koncentruje si" raczej na zadaniach, a nie na tabelach danych. Ekrany
aplikacji projektowanej w oparciu o model biznesowy wspomagaj% t" orientacj", umo#li-
wiaj%c sprawn% obs&ug" zada', a w razie potrzeby prze&%czanie si" mi"dzy nimi. Ekrany te
wygl%daj% i dzia&aj% nieco inaczej ni# ekrany typowe, odwo&uj%ce si" do tabel i wyst"puj%ce
w wielu aplikacjach, ale przyczyniaj% si" do wzrostu skuteczno$ci u#ytkowników oraz pod-
nosz% jako$! ich pracy.
W praktyce oznacza to mo#liwo$! formu&owania zapyta' o warto$ci umieszczone w tabeli
g&ównej dla danego zadania oraz w innych tabelach, aktualizowanych w momencie, kiedy jest
wykonywany dost"p do tabeli g&ównej. Bywa jednak i tak, #e gdy nie okre$lono tabeli g&ównej,
dane mo#na pobra! z kilku powi%zanych z sob% tabel. Wszystkie one zwracaj% (a w razie
potrzeby przyjmuj%) dane w czasie wykonywania zadania.
Interakcja pomi"dzy u#ytkownikiem a komputerem ma znaczenie kluczowe. Ekrany do wpro-
wadzania danych i tworzenia zapyta' powinny by! zorientowane na zadania i pisane w j"zyku

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
83
naturalnym. Wa#n% rol" odgrywaj% tak#e ikony i interfejs graficzny. Ekrany musz% by! zor-
ganizowane w taki sposób, aby komunikacja odbywa&a si" j"zyku, do jakiego s% przyzwycza-
jeni u#ytkownicy.
Zapytania i tworzenie raportów
Jedn% z podstawowych cech, odró#niaj%cych aplikacje relacyjne i j"zyk SQL od aplikacji
tradycyjnych, jest mo#liwo$! &atwego formu&owania indywidualnych zapyta' do obiektów
bazy danych oraz tworzenia w&asnych raportów. Zapytania wpisywane z wiersza polece'
i otrzymywane t% drog% raporty nie wchodz% w sk&ad podstawowego zestawu opracowanego
przez programist" w kodzie aplikacji.
Pozwala na to narz"dzie SQL*Plus. Dzi"ki temu u#ytkownicy i programi$ci systemu Oracle
zyskuj% niezwyk&% kontrol" nad danymi. U#ytkownicy mog% analizowa! informacje, mody-
fikowa! zapytania i wykonywa! je w ci%gu kilku minut oraz tworzy! raporty. Programi$ci s%
zwolnieni z niemi&ego obowi%zku tworzenia nowych raportów.
U#ytkownicy maj% mo#liwo$! wgl%du w dane, przeprowadzenia szczegó&owej ich analizy
i reagowania z szybko$ci% i dok&adno$ci%, jakie jeszcze kilka lat temu by&y nieosi%galne.
Wydajno$! aplikacji znacznie wzrasta, je$li nazwy tabel, kolumn i warto$ci danych s% opisowe,
spada natomiast, je$li w projekcie przyj"to z&% konwencj" nazw oraz u#yto kodów i skrótów.
Czas po$wi"cony na spójne, opisowe nazwanie obiektów w fazie projektowania op&aci si".
Z pewno$ci% u#ytkownicy szybko odczuj% korzy$ci z tego powodu.
Niektórzy projektanci, szczególnie ci niemaj%cy do$wiadczenia w tworzeniu du#ych aplikacji
z wykorzystaniem relacyjnych baz danych, obawiaj% si", #e kiepsko przygotowani u#ytkow-
nicy b"d% pisa! nieefektywne zapytania zu#ywaj%ce olbrzymi% liczb" cykli procesora, co
spowoduje spowolnienie pracy komputera. Do$wiadczenie pokazuje, #e z regu&y nie jest to
prawda. U#ytkownicy szybko si" ucz%, jakie zapytania s% obs&ugiwane sprawnie, a jakie nie.
Co wi"cej, wi"kszo$! dost"pnych dzi$ narz"dzi, s&u#%cych do wyszukiwania danych i tworze-
nia raportów, pozwala oszacowa! ilo$! czasu, jak% zajmie wykonanie zapytania, oraz ograniczy!
dost"p (o okre$lonej porze dnia lub gdy na komputerze zaloguje si" okre$lony u#ytkownik)
do tych zapyta', które spowodowa&yby zu#ycie nieproporcjonalnie du#ej ilo$ci zasobów.
W praktyce #%dania, które u#ytkownicy wpisuj% do wiersza polece', tylko czasami wymykaj%
si" spod kontroli, ale korzy$ci, jakie z nich wynikaj%, znacznie przekraczaj% koszty przetwa-
rzania. Niemal za ka#dym razem, kiedy scedujemy na komputery zadania wykonywane dotych-
czas przez ludzi, osi%gamy oszcz"dno$ci finansowe.
Rzeczywistym celem projektowania jest sprecyzowanie i spe&nienie wymaga' u#ytkowni-
ków biznesowych. Zawsze nale#y stara! si", aby aplikacja by&a jak naj&atwiejsza do zrozu-
mienia i wykorzystania, nawet kosztem zu#ycia procesora lub miejsca na dysku. Nie mo#na
jednak dopu$ci! do tego, aby wewn"trzna z&o#ono$! aplikacji by&a tak du#a, #e jej piel"gnacja
i modyfikacja stan% si" trudne i czasoch&onne.

84
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Normalizacja nazw obiektów
Najlepsze nazwy to nazwy przyjazne w u#ytkowaniu: opisowe, czytelne, &atwe do zapami"ta-
nia, obja$nienia i zastosowania, bez skrótów i kodów. Je$li decydujemy si" w nazwach na
znaki podkre$lenia, stosujmy je w sposób spójny i przemy$lany. W du#ych aplikacjach nazwy
tabel, kolumn i danych cz"sto sk&adaj% si" z wielu s&ów, na przyk&ad
OdwroconeKontoZawieszone
lub
Data_Ostatniego_Zamkniecia_KG
. Na kilku nast"pnych stronach zostanie zaprezentowane
nieco bardziej rygorystyczne podej$cie do nazewnictwa, którego celem jest opracowanie for-
malnego procesu normalizacji nazw obiektów.
Integralno!" poziom-nazwa
W systemie relacyjnej bazy danych obiekty takie, jak bazy danych, w&a$ciciele tabel, tabele,
kolumny i warto$ci danych, s% uporz%dkowane hierarchicznie. W przypadku bardzo du#ych
systemów ró#ne bazy danych mog% zosta! rozmieszczone w ró#nych lokalizacjach. Dla potrzeb
zwi"z&o$ci, wy#sze poziomy zostan% na razie zignorowane, ale to, co tutaj powiemy, ich tak#e
dotyczy.
Ka#dy poziom w hierarchii jest zdefiniowany w ramach poziomu znajduj%cego si" powy#ej.
Obiektom nale#y przypisywa! nazwy odpowiednie dla danego poziomu i unika! stosowania
nazw z innych poziomów. Na przyk&ad w tabeli nie mo#e by! dwóch kolumn o nazwie
Nazwisko
, a konto o nazwie
Jerzy
nie mo#e zawiera! dwóch tabel o nazwie
AUTOR
.
Nie ma obowi%zku, aby wszystkie tabele konta
Jerzy
mia&y nazwy niepowtarzalne w ca&ej
bazie danych. Inni w&a$ciciele tak#e mog% posiada! tabele
AUTOR
. Nawet je$li
Jerzy
ma do
nich dost"p, nie ma mo#liwo$ci pomy&ki, poniewa# tabel" mo#na zidentyfikowa! w sposób
niepowtarzalny, poprzedzaj%c nazw" tabeli prefiksem w postaci imienia jej w&a$ciciela, na
przyk&ad
Dariusz.AUTOR
. Nie by&oby spójno$ci logicznej, gdyby cz"$ci% nazw wszystkich tabel
nale#%cych do Jerzego by&o jego imi", jak na przyk&ad
JERZYAUTOR
,
JERZYBIBLIOTECZKA
itd. Sto-
sowanie takich nazw jest myl%ce, a poza tym umieszczenie w nazwie cz"$ci nazwy nadrz"dnej
niepotrzebnie komplikuje nazewnictwo tabel i w efekcie narusza integralno/J poziom-nazwa.
Zwi"z&o$ci nigdy nie nale#y przedk&ada! nad czytelno$!. W&%czanie fragmentów nazw tabel
do nazw kolumn jest z&% technik%, gdy# narusza logiczn% struktur" poziomów oraz wymagan%
integralno$! poziom-nazwa. Jest to tak#e myl%ce, poniewa# wymaga od u#ytkowników wyszu-
kiwania nazw kolumn niemal za ka#dym razem, kiedy pisz% zapytania. Nazwy obiektów musz%
by! niepowtarzalne w obr"bie poziomu nadrz"dnego, ale u#ywanie nazw spoza w&asnego
poziomu obiektu nie powinno by! dozwolone.
Obs&uga abstrakcyjnych typów danych w systemie Oracle wzmacnia mo#liwo$ci tworzenia
spójnych nazw atrybutów. Na przyk&ad typ danych o nazwie
ADRES_TY
b"dzie charakteryzo-
wa& si" takimi samymi atrybutami za ka#dym razem, kiedy zostanie u#yty. Ka#dy atrybut ma
zdefiniowan% nazw", typ danych i rozmiar, co powoduje, #e implementacja aplikacji w ca&ym
przedsi"biorstwie stanie si" spójniejsza. Jednak wykorzystanie abstrakcyjnych typów danych
w ten sposób wymaga:

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
85
w&a$ciwego zdefiniowania typów danych na pocz%tku procesu projektowania,
aby unikn%! konieczno$ci pó2niejszego ich modyfikowania,
spe&nienia wymaga' sk&adniowych obowi%zuj%cych dla abstrakcyjnych typów danych.
Klucze obce
Jedn% z przeszkód stoj%cych na drodze do stosowania zwi"z&ych nazw kolumn jest wyst"po-
wanie obcych kluczy w tabeli. Czasem si" zdarza, #e kolumna w tabeli, w której wyst"puje
klucz obcy, ma t" sam% nazw", co kolumna klucza obcego w swojej tabeli macierzystej. Nie
by&oby problemu, gdyby mo#na by&o u#y! pe&nej nazwy klucza obcego wraz z nazw% tabeli
macierzystej (np.
BIBLIOTECZKA.Tytul
).
Aby rozwi%za! problem z takimi samymi nazwami, trzeba wykona! jedno z nast"puj%cych
dzia&a':
opracowa! nazw", która obejmuje nazw" tabeli 2ród&owej klucza obcego,
bez wykorzystywania kropki (np. z u#yciem znaku podkre$lenia),
opracowa! nazw", która obejmuje skrót nazwy tabeli 2ród&owej klucza obcego,
opracowa! nazw", która ró#ni si" od nazwy w tabeli 2ród&owej,
zmieni! nazw" kolumny powoduj%cej konflikt.
]adne z tych dzia&a' nie jest szczególnie atrakcyjne, ale je$li zetkniemy si" z tego typu dyle-
matem dotycz%cym nazwy, nale#y wybra! jedno z nich.
Nazwy w liczbie pojedynczej
Obszarem niespójno$ci powoduj%cym sporo zamieszania jest liczba gramatyczna nazw nada-
wanych obiektom. Czy tabela powinna nosi! nazw"
AUTOR
, czy
AUTORZY
? Kolumna ma mie!
nazw"
Nazwisko
czy
Nazwiska
?
Najpierw przeanalizujmy kolumny, które wyst"puj% niemal w ka#dej bazie danych:
Nazwisko
,
Adres
,
Miasto
,
Wojewodztwo
i
KodPocztowy
. Czy — nie licz%c pierwszej kolumny — kiedy-
kolwiek zauwa#yli$my, aby kto$ u#ywa& tych nazw w liczbie mnogiej? Jest niemal oczywiste,
#e nazwy te opisuj% zawarto$! pojedynczego wiersza — rekordu. Pomimo #e relacyjne bazy
danych przetwarzaj% zbiory, podstawow% jednostk% zbioru jest wiersz, a zawarto$! wiersza
dobrze opisuj% nazwy kolumn w liczbie pojedynczej. Czy formularz do wprowadzania danych
osobowych powinien mie! tak% posta!, jak poni#ej?
Nazwiska: ___________________________________________________________
Adresy: _____________________________________________________________
Miasta: _______________________ Województwa:_____ KodyPocztowe:__-___
Czy te# nazwy wy$wietlane na ekranie powinny mie! liczb" pojedyncz%, poniewa# w okre-
$lonym czasie pobieramy jedno nazwisko i jeden adres, ale podczas pisania zapyta' trzeba
poinformowa! u#ytkowników, aby przekszta&cili te nazwy na liczb" mnog%? Konsekwentne
stosowanie nazw kolumn w liczbie pojedynczej jest po prostu bardziej intuicyjne.

86
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Je$li nazwy wszystkich obiektów maj% t" sam% liczb", ani programista, ani u#ytkownik nie
musz% zapami"tywa! dodatkowych regu&. Korzy$ci s% oczywiste. Za&ó#my, #e zdecydowali-
$my o tym, #e wszystkim obiektom nadamy nazwy w liczbie mnogiej. W tym przypadku
pojawi% si" ró#ne ko'cówki w nazwie niemal ka#dego obiektu. Z kolei w nazwie wielowyra-
zowej poszczególne s&owa otrzymaj% ró#ne ko'cówki. Jakie korzy$ci mieliby$my osi%gn%!
z ci%g&ego wpisywania tych dodatkowych liter? Czy#by tak by&o &atwiej? Czy takie nazwy s%
bardziej zrozumia&e? Czy takie nazwy &atwiej zapami"ta!? Oczywi$cie nie.
Z tego powodu najlepiej stosowa! nast"puj%c% zasad": dla wszystkich nazw obiektów zawsze
nale#y u#ywa! liczby pojedynczej. Wyj%tkami mog% by! terminy, które s% powszechnie sto-
sowane w biznesie, takie jak na przyk&ad
Aktywa
.
Zwi z&o!"
Jak wspomniano wcze$niej, zwi"z&o$ci nigdy nie nale#y przedk&ada! nad czytelno$!, ale
w przypadku dwóch jednakowo tre$ciwych, równie &atwych do zapami"tania i opisowych
nazw zawsze nale#y wybra! krótsz%. W czasie projektowania aplikacji warto zaproponowa!
alternatywne nazwy kolumn i tabel grupie u#ytkowników i programistów i wykorzysta! ich
rady w celu wybrania tych propozycji, które s% czytelniejsze. W jaki sposób tworzy! list"
alternatyw? Mo#na skorzysta! z tezaurusa i s&ownika. W zespole projektowym, zajmuj%cym si"
tworzeniem ró#nych aplikacji, ka#dego cz&onka zespo&u nale#y wyposa#y! w tezaurus i s&ownik,
a nast"pnie przypomina! im o konieczno$ci uwa#nego nadawania nazw obiektom.
Obiekt o nazwie tezaurus
Relacyjne bazy danych powinny zawiera! obiekt o nazwie tezaurus, podobnie jak zawieraj%
s&ownik danych. Tezaurus wymusza korzystanie z firmowych standardów nazewniczych
i zapewnia spójne stosowanie nazw i skrótów (je$li s% u#ywane).
Takie standardy czasami wymagaj% u#ywania (równie# spójnego i konsekwentnego!) znaków
podkre$lenia, co u&atwia identyfikacj" poszczególnych elementów z&o#onej nazwy.
W agencjach rz%dowych lub du#ych firmach wprowadzono standardy nazewnictwa obiektów.
Standardy obowi%zuj%ce w du#ych organizacjach w ci%gu lat przenikn"&y do pozosta&ej cz"$ci
komercyjnego rynku i mo#e si" zdarzy!, #e tworz% podstaw" standardów nazewnictwa naszej
firmy. Mog% one na przyk&ad zawiera! wskazówki dotycz%ce stosowania terminów Korporacja
lub Firma. Je$li nie zaadaptowali$my takich standardów nazewnictwa, w celu zachowania
spójno$ci nale#y opracowa! w&asne normy, które uwzgl"dniaj% zarówno standardy bazowe,
jak i wskazówki nakre$lone w tym rozdziale.
Inteligentne klucze i warto4ci kolumn
Nazwa inteligentne klucze jest niezwykle myl%ca, poniewa# sugeruje, #e mamy do czynienia
z czym$ pozytywnym lub godnym uwagi. Trafniejszym okre$leniem móg&by by! termin klucze
przeci'"one. Do tej kategorii cz"sto zalicza si" kody Ksi"gi G&ównej oraz kody produktów

Rozdzia& 4. Planowanie aplikacji systemu Oracle — sposoby, standardy i zagro$enia
87
(dotycz% ich wszystkie trudno$ci charakterystyczne dla innych kodów). Trudno$ci typowe dla
kluczy przeci%#onych dotycz% tak#e kolumn niekluczowych, które zawieraj% wi"cej ni# jeden
element danych.
Typowy przyk&ad przeci%#onego klucza opisano w nast"puj%cym fragmencie: „Pierwszy znak
jest kodem regionu. Kolejne cztery znaki s% numerem katalogowym. Ostatnia cyfra to kod
centrum kosztów, o ile nie mamy do czynienia z cz"$ci% importowan% — w takiej sytuacji na
ko'cu liczby umieszcza si" znacznik /. Je$li nie jest to element wyst"puj%cy w du#ej ilo$ci,
wtedy dla numeru katalogowego s% wykorzystywane tylko trzy cyfry, a kod regionu oznacza
si" symbolem HD”.
W dobrym projekcie relacyjnym wyeliminowanie przeci%#onych kluczy i warto$ci kolumn
ma zasadnicze znaczenie. Zachowanie przeci%#onej struktury stwarza zagro#enie dla relacji
tworzonych na jej podstawie (zazwyczaj dotyczy to obcych kluczy w innych tabelach). Nie-
stety, w wielu firmach przeci%#one klucze s% wykorzystywane od lat i na trwa&e wros&y w jej
zadania. Niektóre zosta&y wdro#one we wcze$niejszych etapach automatyzacji, kiedy u#y-
wano baz danych nieobs&uguj%cych kluczy wielokolumnowych. Inne maj% pod&o#e histo-
ryczne — stosowano je po to, aby krótkiemu kodowi nada! szersze znaczenie i obj%! nim
wi"ksz% liczb" przypadków, ni# pierwotnie planowano. Z wyeliminowaniem przeci%#onych
kluczy mog% by! trudno$ci natury praktycznej, które uniemo#liwiaj% natychmiastowe wykona-
nie tego zadania. Dlatego tworzenie nowej aplikacji relacyjnej staje si" wówczas trudniejsze.
Rozwi%zaniem problemu jest utworzenie nowego zestawu kluczy — zarówno g&ównych, jak
i obcych, które w prawid&owy sposób normalizuj% dane, a nast"pnie upewnienie si", #e dost"p
do tabel jest mo#liwy wy&%cznie za pomoc% tych nowych kluczy. Przeci%#one klucze s% wówczas
utrzymywane jako dodatkowe, niepowtarzalne kolumny tabeli. Dost"p do danych za pomoc%
historycznych metod jest zachowany (np. poprzez wyszukanie przeci%#onego klucza w zapy-
taniu), ale jednocze$nie promuje si" klucze o poprawnej strukturze jako preferowan% metod"
dost"pu. Z czasem, przy odpowiednim szkoleniu, u#ytkownicy przekonaj% si" do nowych
kluczy. Na koniec przeci%#one klucze (lub inne przeci%#one warto$ci kolumn) mo#na po prostu
zamieni! na warto$ci
NULL
lub usun%! z tabeli.
Je$li nie uda si" wyeliminowa! przeci%#onych kluczy i warto$ci z bazy danych, kontrola popraw-
no$ci danych, zapewnienie integralno$ci danych oraz modyfikowanie struktury stan% si" bardzo
trudne i kosztowne.
Przykazania
Omówili$my wszystkie najwa#niejsze zagadnienia wydajnego projektowania. Warto teraz je
podsumowa! w jednym miejscu, st%d tytu& Przykazania (cho! mo#e lepszy by&by tytu& Wska-
zówki). Znaj%c te zalecenia, u#ytkownik mo#e dokona! racjonalnej oceny projektu i skorzy-
sta! z do$wiadcze' innych osób rozwi%zuj%cych podobne problemy. Celem tego podroz-
dzia&u nie jest opisanie cyklu tworzenia oprogramowania, który prawdopodobnie wszyscy
dobrze znaj%, ale raczej udowodnienie twierdzenia, #e projektowanie z odpowiedni% orientacj%
powoduje radykaln% zmian" wygl%du i sposobu korzystania z aplikacji. Uwa#ne post"powa-
nie zgodnie z podanymi wskazówkami pozwala na znacz%c% popraw" wydajno$ci i poziomu
zadowolenia u#ytkowników aplikacji.

88
Cz !" I Najwa$niejsze poj cia dotycz%ce bazy danych
Oto dziesi"! przykaza' w&a$ciwego projektu:
1.
Nie zapominajmy o u#ytkownikach. W&%czajmy ich do zespo&u projektowego i uczmy
modelu relacyjnego i j"zyka SQL.
2.
Nazwy tabel, kolumn, kluczy i danych nadawajmy wspólnie z u#ytkownikami.
Opracujmy tezaurus aplikacji w celu zapewnienia spójno$ci nazw.
3.
Stosujmy opisowe nazwy w liczbie pojedynczej, które maj% znaczenie, s% &atwe
do zapami"tania i krótkie. Wykorzystujmy znaki podkre$lenia konsekwentnie lub wcale.
4.
Nie mieszajmy poziomów nazw.
5.
Unikajmy kodów i skrótów.
6.
Wsz"dzie tam, gdzie to mo#liwe, u#ywajmy kluczy maj%cych znaczenie.
7.
Przeprowad2my dekompozycj" kluczy przeci%#onych.
8.
Podczas analizy i projektowania miejmy na uwadze zadania, a nie tylko dane.
Pami"tajmy, #e normalizacja nie jest cz"$ci% projektu.
9.
Jak najwi"cej zada' zlecajmy komputerom. Op&aca si" po$wi"ci! cykle procesora
i miejsce w pami"ci, aby zyska! &atwo$! u#ytkowania.
10.
Nie ulegajmy pokusie szybkiego projektowania. Po$wi"!my odpowiedni% ilo$! czasu
na analiz", projekt, testowanie i dostrajanie.
Ten rozdzia& celowo poprzedza rozdzia&y opisuj%ce polecenia i funkcje — je$li projekt jest z&y,
aplikacja równie# b"dzie dzia&a&a 2le, niezale#nie od tego, jakich polece' u#yjemy. Funkcjo-
nalno$!, wydajno$!, mo#liwo$ci odtwarzania, bezpiecze'stwo oraz dost"pno$! trzeba odpowied-
nio zaplanowa!. Dobry plan to gwarancja sukcesu.
Wyszukiwarka
Podobne podstrony:
Oracle Database 10g Kompendium administratora or10ka
Oracle Database 11g Podręcznik administratora
Oracle Database 10g Kompendium administratora
Oracle Database 10g Kompendium administratora
Oracle Database 10g Kompendium administratora
więcej podobnych podstron