
ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
Wersja 1.0
Indeksy i transakcje
Spis treści
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 2/20
Informacje o module
Opis modułu
W module tym znajdziesz informacje na temat dostępu fizycznego do
danych oraz optymalizacji dostępu. Poznasz indeksy i ich rodzaje a
następnie dowiesz się jakie operacje wykonywane są na indeksach. Dowiesz
się, że jest to parametr niezbędny do zapewnienia rozsądnych czasów
wyszukiwania informacji. W drugiej części poznasz transakcje, które służą
do zapewnienia spójności bazy danych i mają wpływ na wydajnośd bazy
danych. Dowiesz się, że obsługa transakcji nie jest rzeczą łatwą i wymaga
rozwiązywania wielu trudnych problemów.
Cel modułu
Celem modułu jest zapoznanie słuchacza z podstawowymi mechanizmami
indeksowania oraz struktury pisania transakcji. Zostaną przedstawione
proste przykłady, które mają pokazad mechanizmy obowiązujące w
metodach indeksowania oraz w transakcjach.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
wiedział, na czym polega zasada działania indeksów
potrafił we właściwy sposób dobierad politykę indeksowania
znał zasadę funkcjonowania transakcji
potrafił we właściwy sposób pisad proste transakcje
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
umied stworzyd bazę danych wraz z jej podstawowymi obiektami
(patrz Moduł 4)
znad zaawansowane mechanizmy programowania w języku T-SQL
(patrz Moduł 9)
znad podstawowe mechanizmy bezpieczeostwa (patrz Moduł 11)
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na Rys. 1, przed przystąpieniem
do realizacji tego modułu należy zapoznad się z materiałem zawartym
w module 3, module 8 i module 10
Moduł 7
Dodatek
Moduł 1
Moduł 2
Moduł 3
Moduł 4
Moduł 5
Moduł 6
Moduł 8
Moduł 9
Moduł 10
Moduł 11
Moduł 12
Moduł 13
Rys. 1 Mapa zależności modułu
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 3/20
Przygotowanie teoretyczne
Przykładowy problem
Z bazy danych może korzystad wielu użytkowników. Użytkownicy ci, mogą dysponowad różnymi
prawami dostępu i mają dostęp do różnych obiektów w bazie danych. Głównym ich zadaniem jest
możliwośd przeszukiwania danych oraz modyfikacji danych w niej zawartych według pewnych
reguł, które wcześniej zostały zdefiniowane przez administratora, projektanta i programistę bazy
danych. Zatem podstawowym zadaniem jaki stoi przed osobami odpowiedzialnymi za prawidłowe
funkcjonowanie bazy danych to dobór odpowiedniej polityki indeksowania, która pozwoli na
szybsze przeszukiwanie bazy danych. Jednym z zadao jakie stoi przed administratorem bazy danych
jest optymalizacja bazy danych (tuning bazy danych) między innymi poprzez przebudowę indeksów.
Kolejnym mechanizmem z jakim bardzo często możemy się spotkad to transakcje. Jak wiadomo
zgodnie z definicją są to operacje, które są niepodzielne i muszą byd wykonane w całości. Kolejnym
ważnym zadaniem transakcji jest zapewnienie bazie danych spójności oraz umożliwienie
równoległych operacji na bazie danych. W celu dobrego pisania transakcji potrzebna jest
znajomośd zaawansowanego programowania w języku T-SQL. Transakcje stanowią bardzo ważny
element programowania bazy danych i muszą byd one pisane profesjonalnie. Przykładem transakcji
może byd wypłata pieniędzy z bankomatu, płatnośd kartą debetową itp.
Podstawy teoretyczne
Dostęp fizyczny do danych
Zrozumienie mechanizmu dostępu do danych zapisanych w bazie danych jest bardzo istotne dla
zrozumienia zasad działania indeksów.
Jak wiadomo, dane w bazach danych w sposób trwały są zapisywane na dyskach optycznych,
magnetycznych lub rodzinach nośników o dostępie bezpośrednim, takich jak macierze RAID (z ang.
Redundant Array of Independent Disks). Zasady działania tego typu nośników oraz pojęcia głowicy,
cylindrów, strony danych itp. powinny byd Ci znane z przedmiotu Podstawy Informatyki lub
podobnego.
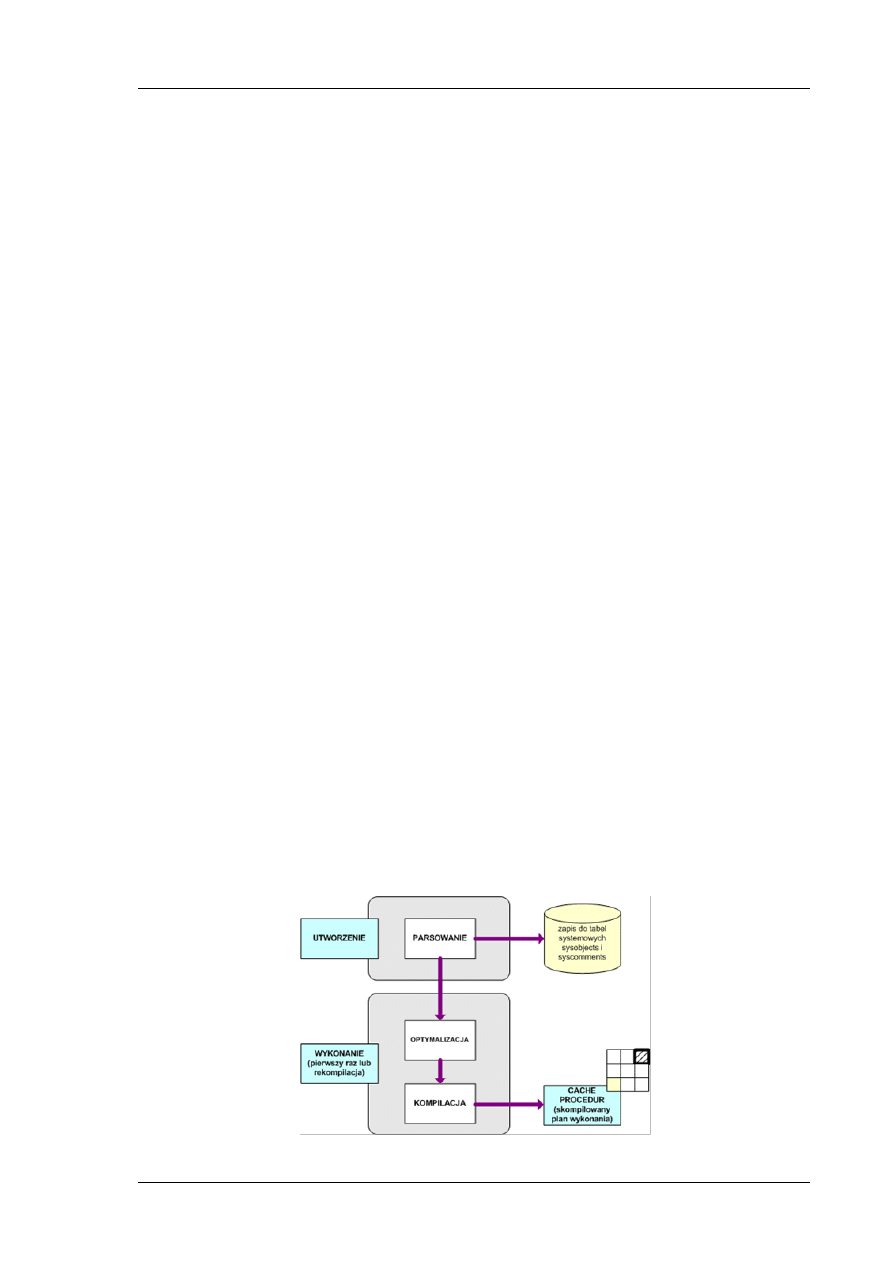
SZBD najczęściej nie zajmuje się fizyczną obsługą dysków. W procesie dostępu do danych biorą
udział:
Menedżer plików – ma odpowiednią wiedzę o strukturze systemu plików i jest
odpowiedzialny za odszukanie odpowiedniego pliku.
Menedżer dysku – ma niezbędną wiedzę na temat fizycznej organizacji dysku i jest
odpowiedzialny za odnalezienie odpowiedniej strony danych.
Schemat łaocucha dostępu do danych pokazany jest na Rys. 2.
Rys. 2 Schemat dostępu do danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 4/20
Optymalizacja dostępu
Zasadniczy czas dostępu do danych bazy to czas odczytu tych danych z dysków. W celu
optymalizacji tego dostępu stosuje się metodę zwaną klastrowaniem.
Klastrowanie polega na dążeniu do utrzymania blisko siebie na dysku rekordów, które są logicznie
powiązane. Taka organizacja danych znacznie przyspiesza dostęp do danych. Aby odczytad dane
powiązane, głowica nie musi wykonywad dużych ruchów, a tym samym maleją czasy wyszukiwania.
Rozróżniamy przy tym dwa rodzaje klastrowania:
Klastrowanie wewnątrzplikowe – polega na grupowaniu rekordów obok siebie wewnątrz
jednego pliku.
Klastrowanie międzyplikowe – polega na umieszczaniu na stronie obok siebie rekordów
pochodzących z więcej niż jednego pliku (tabeli).
Optymalizacja dostępu do danych sprowadza się w zasadzie do odpowiedniego zarządzania
stronami i decydowania, w jaki sposób dane mają byd klastrowane.
Więcej na temat fizycznej struktury danych możesz znaleźd w module 5.
Indeksy i ich zastosowanie
Zastanowimy się teraz nad problemem wyszukiwania danych w tabeli. Na przykład załóżmy, że w
tabeli
Studenci
chcemy znaleźd studenta o nazwisku Nowak.
Tab. 1 Przykładowa tabela bazy studentów
ID
Nazwisko
Imie
Wydzial
1
Olacki
Jan
Elektryczny
2
Babicki
Adam
Mechaniczny
3
Nowak
Jerzy
Elektryczny
1
Adamski
Adam
Elektronika
Wiersze zapisane są w bazie w kolejności ich wpisywania i nie są w szczególny sposób sortowane.
Co robi wobec tego system, kiedy wydajemy polecenie odnalezienia rekordu zawierającego
informacje o Nowaku, np.:
SELECT imie, nazwisko FROM Studenci WHERE Nazwisko = 'Nowak'
System musi przeszukad całą tabelę (skanowanie wszystkich stron danych zawierających dane z
tabeli) i przejrzed wszystkie rekordy tej tabeli, aby mied pewnośd, że odnalazł rekordy zawierające
nazwisko Nowak. Operacja taka jest oczywiście czasochłonna.
Podobnie jest, gdy w książce poszukujemy jakiegoś hasła (na przykład w podręczniku do baz danych
szukamy informacji o indeksach). Aby znaleźd szukaną informację, powinniśmy przeczytad całą
książkę. Na szczęście niektóre książki są wyposażone na koocu w specjalne zestawienie haseł – czyli
w indeks.
Nasze postępowanie przebiega wówczas następująco:
1. Odszukujemy poszukiwane hasło w indeksie, który jest uporządkowany alfabetycznie (co
znacznie ułatwia nam odnalezienie hasła).
2. Odczytujemy w indeksie numer strony, na której hasło to występuje w książce.
3. Otwieramy książkę na odpowiedniej stronie.
4. Przeglądamy stronę w poszukiwaniu naszego hasła.
5. Odczytujemy informacje związane z szukanym hasłem.
Idea działania indeksów w bazie danych jest dokładnie taka sama.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 5/20
Indeks określony na atrybucie A relacji jest mechanizmem, który pozwala na efektywne
wyszukiwanie krotek o ustalonej wartości składowej atrybutu A. Jak więc wyglądałby indeks dla
tabeli Studenci?
Indeks określany jest dla konkretnego pola. Mówimy wówczas, że pole to jest polem
indeksowanym. W wypadku tabeli Studenci możemy jako pole indeksowane wybrad pole
Nazwisko. Wówczas założenie indeksu na tym polu będzie oznaczało założenie przez system
dodatkowej tabeli, w której umieszczone zostaną nazwiska studentów z tabeli Studenci oraz
dostarczy przesłankę, gdzie należy szukad (na której stronie danych) pełnej informacji o danym
studencie. Dodatkowo rekordy w tabeli indeksu zostaną posortowane w kolejności alfabetycznej
nazwisk. Poszukiwanie naszego studenta Nowaka będzie teraz przebiegad znacznie szybciej.
Działanie i rola indeksów polega głównie na przyspieszeniu wyszukiwania rekordów w bazie
danych. Niestety obciążają one dodatkowo system w czasie aktualizacji lub wstawiania danych.
SZBD musi bowiem oprócz umieszczenia rekordu w bazie dokonad też wpisu w tabeli indeksu oraz
ponownie posortowad rekordy tabeli indeksu.
Zalety i wady stosowania indeksów zebrano w Tab. 2.
Tab. 2 Zalety i wady stosowania indeksów
Zalety
Wady
Przyspieszają dostęp do danych
Zajmują miejsce na dysku
Wymuszają unikatowośd wierszy
Zwiększają obciążenie systemu
Niektóre z pól warto jest indeksowad, inne natomiast nie powinny byd nigdy indeksowane.
Warto indeksowad następujące pola:
klucze podstawowe i obce (często są automatycznie indeksowane)
pola, po których często następuje wyszukiwanie
pola, do których dostęp następuje w ustalonej, uporządkowanej kolejności
Nie należy indeksowad:
pól, do których rzadko odwołują się zapytania
pól, które zawierają tylko kilka wartości unikatowych
pól zawierających dane typu image, bit czy obiekt OLE
Indeksy mogą byd zakładane na jednym polu lub na większej liczbie pól jednocześnie.
Rodzaje indeksów
Indeksy można klasyfikowad w różny sposób. My podzielimy indeksy na dwie grupy:
indeksy grupowane (klastrowe)
indeksy niegrupowane (nieklastrowe)
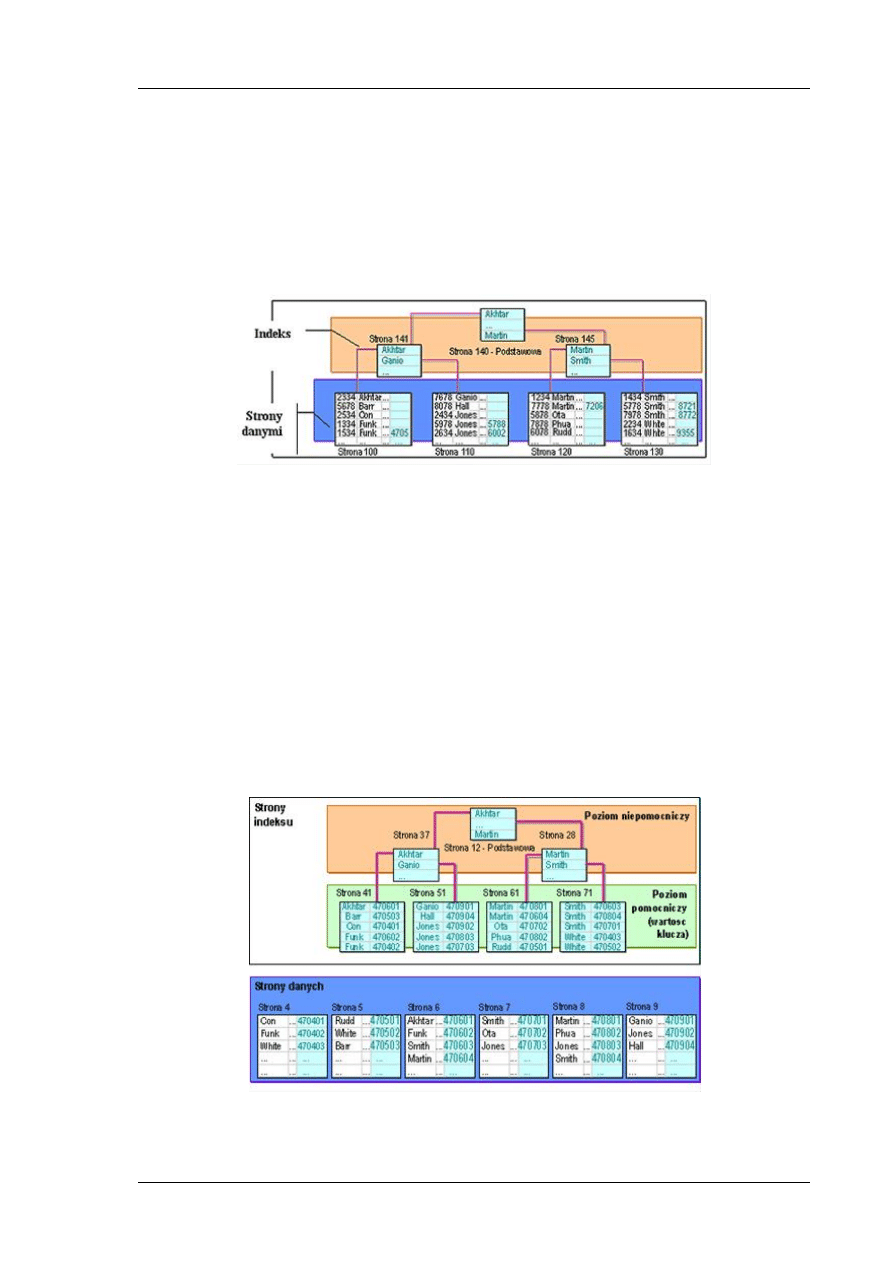
Indeksy grupowane
Indeks grupowany działa na podobnej zasadzie, jak książka telefoniczna. Zawiera strony szybkiego
dostępu do danych (w książce telefonicznej na początku znajduje się alfabetyczny spis mówiący o
tym, na której stronie szukad nazwisk, firm czy instytucji zaczynających się na daną literę alfabetu).
Strony te są ułożone w odwrócone drzewo i przechowują tylko ułożone alfabetycznie wartości
indeksowanego pola oraz wskaźniki do stron znajdujących się w niższej warstwie drzewa.
Na samym dole drzewa znajdują się strony zawierające posortowane wg indeksowanego pola dane
(w książce telefonicznej zawartośd też jest posortowana – wg nazwisk lub nazw firm czy instytucji).
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 6/20
Przeszukiwanie indeksu odbywa się z góry na dół na następującej zasadzie: porównywana jest
szukana wartośd pola indeksowanego z wartościami zapisanymi (i posortowanymi) na stronach
indeksu - jeśli znajdzie się wartośd „większa” od wartości szukanej, wtedy następuje skok jeden
poziom niżej do strony wskazywanej przez ostatnią pozycję (na ostatnio sprawdzanej stronie), która
nie była „większa” od szukanej wartości.
Każda pozycja na stronach zawiera wskaźnik do strony danych jeden poziom niżej w hierarchii
indeksu. Dzięki takiej strukturze przeszukiwane są tylko wybrane strony z danymi, nie zaś wszystkie
strony zawierające dane z wybranej tabeli.
Rys. 3 Indeks grupowany
Indeksy niegrupowane
Indeks niegrupowany działa na podobnej zasadzie, jak indeks w typowej książce (ale nie w
telefonicznej). Indeks niegrupowany budowany jest na stronach danych, które nie są sortowane.
Składa się z co najmniej dwu poziomów: poziomu niepomocniczego i poziomów pomocniczych. Na
stronach poziomu niepomocniczego, podobnie jak w przypadku indeksu grupowanego,
przechowywane są wartości indeksowanego pola ze wskaźnikami do poziomu niżej w drzewie
indeksu.
Strony poziomu pomocniczego zwane też liśdmi i zawierają wskaźniki do konkretnych stron danych
(które nie są posortowane). Wskaźnik taki zawiera następujące dane: ID pliku, numer strony,
numer wiersza na stronie.
Przeszukiwanie indeksu niegrupowanego odbywa się na podobnej zasadzie, jak w indeksie
grupowanym. Po dojściu do poziomu pomocniczego następują skoki do stron danych (do
konkretnych wierszy).
Rys. 4 Indeks niegrupowany

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 7/20
Operacje na indeksach
Indeksy są tworzone najczęściej automatycznie dla kluczy głównych oraz dla pól, dla których ma byd
wymuszona unikatowośd.
Indeksy można też tworzyd dla innych pól korzystając z polecenia języka
SQL CREATE INDEX
.
Poniżej podano przykład utworzenia indeksu grupowanego dla tabeli
Recenzent
dla pola
Nazwisko
.
USE PraceDyplomowe
CREATE CLUSTERED INDEX cl_nazwisko
ON member(nazwisko)
Indeks może też byd zakładany na kilku polach jednocześnie. Poniższy przykład pokazuje sposób
definiowania unikalnego indeksu na polach Nazwisko i Imie jednocześnie:
CREATE UNIQUE INDEX Indeks_Osoba
ON Osoba (Nazwisko, Imie)
Założenie takiego indeksu spowoduje, że będzie możliwe wprowadzenie jedynie unikatowych par
Imie-Nazwisko
.
Transakcje
Transakcja jest ciągiem operacji wykonywanych na bazie, które to operacje są niepodzielne i muszą
byd wykonane w całości. Transakcja jest więc jednostką logiczną operowania na bazie. Podlega ona
kontroli i sterowaniu.
Każda transakcja może składad się z następujących operacji:
czytanie danej x przez transakcje T
zapisanie danej x przez transakcję T
wycofanie transakcji T
zatwierdzenie transakcji T
Transakcje służą do zapewnienia bazie spójności oraz mają umożliwid równoległe operacje na bazie
danych. Jeśli wiele procesów działa jednocześnie na bazie danych, to może łatwo dojśd do utraty
spójności danych, a co za tym idzie do błędów i otrzymywania nieprawdziwych zestawów danych.
Transakcja zabezpiecza również przed częściowym wykonaniem zbioru operacji, które mogą byd
przerwane, na przykład w wyniku awarii. Klasycznym przykładem jest operacja polegająca na
wypłacaniu pieniędzy z bankomatu. W uproszczeniu operacje realizowane w czasie wypłaty
pieniędzy z bankomatu są następujące:
1. Klient wczytuje kartę magnetyczną i jest rozpoznawany.
2. Klient określa sumę wypłaty.
3. Konto klienta jest sprawdzane.
4. Konto jest zmniejszane o sumę wypłaty.
5. Wysyłane jest zlecenie do kasy.
6. Bankomat odlicza sumę i koryguje stan gotówki w bankomacie.
7. Bankomat wypłaca klientowi pieniądze.
Zaistnienie awarii w kroku 5 lub 6 może prowadzid do niezbyt przyjemnej sytuacji dla posiadacza
konta. Transakcje pozwalają na uniknięcie tego typu niespodzianek.
Postulaty AICD
Każda transakcja powinna spełniad cztery postulaty. Są to tak zwane postulaty AICD.
1. Atomowośd (ang. atomicity) – w ramach jednej transakcji wykonują się albo wszystkie
operacje, albo żadna.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 8/20
2. Spójnośd (ang. consistency) – o ile transakcja zastała bazę danych w spójnym stanie, po jej
zakooczeniu stan jest również spójny (w międzyczasie stan może byd chwilowo niespójny).
3. Izolacja (ang. isolation) – transakcja nie wie nic o innych transakcjach i nie musi uwzględniad
ich działania. Czynności wykonane przez daną transakcję są niewidoczne dla innych transakcji
aż do jej zakooczenia.
4. Trwałośd (ang. durability) – po zakooczeniu transakcji jej skutki są na trwale zapamiętane (na
dysku) i nie mogą byd odwrócone przez zdarzenia losowe (np. wyłączenie prądu).
Transakcje w SQL
W języku SQL każda transakcja rozpoczyna się słowem
BEGIN TRANSACTION
, a kooczy operacją
COMMIT
oznaczającą pomyślne zakooczenie transakcji lub operacją
ROLLBACK
oznaczające
odrzucenie transakcji.
Dowolne polecenie
SELECT
,
INSERT
,
UPDATE
,
DELATE
,
CREATE
rozpoczyna transakcję.
Transakcja trwa aż do wydania komendy
COMMIT
(potwierdzającej) lub
ROLLBACK
(zrywającej,
cofającej). Transakcja może objąd dowolną liczbę zdao
SELECT
,
INSERT
,
UPDATE
,
DELATE
,
CREATE
ii
innych.
Stosowanie zamków oraz problem z zakleszczaniem
Zarządzanie transakcjami wymaga zastosowania specjalnego modułu (zwanego modułem planisty)
oraz protokołu zarządzania transakcjami. W celu uniknięcia problemów ze współbieżnym dostępem
stosuje się mechanizmy blokady dostępu do danych (tzw. zamki).
Wyróżniamy dwa typy takich zamków:
Zamek typu X – założenie zamka tego typu całkowicie blokuje dostęp do obiektu dla innych
transakcji.
Zamek typu S – założenie zamka tego typu powoduje, że inne transakcje mogą czytad dane,
ale nie mogą ich modyfikowad.
Najczęściej stosowanym w bazach relacyjnych protokołem zarządzania transakcjami jest protokół
blokowania dwufazowego 2PL (ang. two-phase locking). Reguły pracy protokołu 2PL są
następujące:
1. Jeśli dana operacja pi(x) może byd wykonana, to planista zakłada blokadę na daną x dla
transakcji Ti i operację przekazuje do wykonania. Jeśli natomiast operacja ta nie może byd
wykonana, to umieszcza ją w kolejce.
2. Zdjęcie założonej blokady może nastąpid dopiero wtedy, gdy operacja zostanie wykonana.
3. Jeśli nastąpiło zdjęcie jakiejkolwiek blokady założonej dla transakcji T, to dla tej transakcji nie
można założyd żadnej innej blokady.
Postępując zgodnie z tymi zasadami przebieg wykonania transakcji wymusza dwie fazy obsługi
transakcji. W pierwszej fazie są zakładane blokady, a w drugiej następuje ich zdejmowanie. Faza
druga jest znacznie szybsza od pierwszej.
Rys. 5 Protokół blokowania dwufazowego 2PL
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 9/20
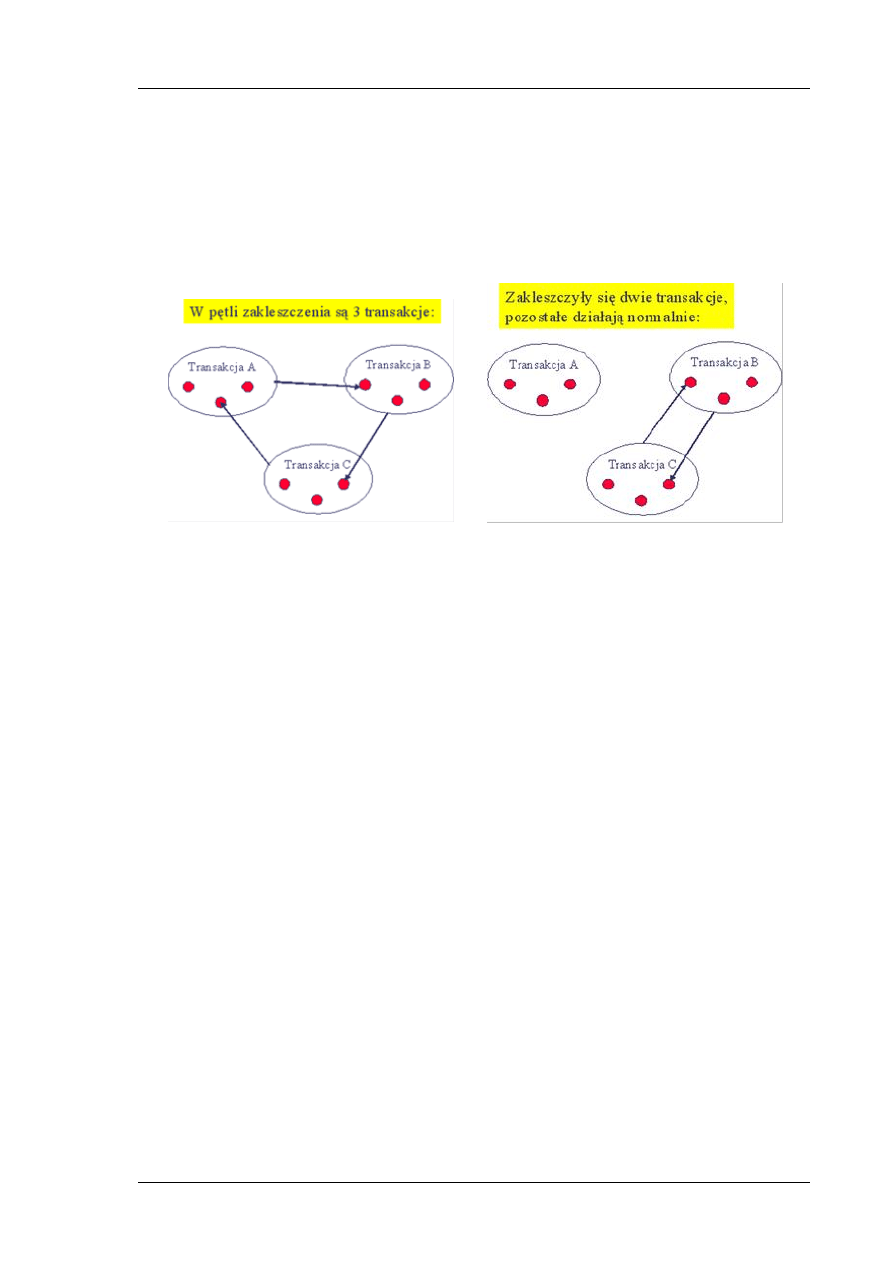
Stosowanie zamków może prowadzid do zjawiska zwanego zakleszczaniem. Zakleszczanie polega na
tym, że transakcje blokują się, oczekując siebie nawzajem. Powodem powstania zakleszczeo jest
koniecznośd oczekiwania na zwolnienie zasobu, do którego dostęp potrzebują.
Weźmy pod uwagę dwie transakcje A i B. Transakcja A blokuje zasób X i żąda dostępu do zasobu Y.
Transakcja B blokuje zasób Y i żąda dostępu do zasobu X. W wyniku tego dochodzi do zakleszczenia
i żadna z transakcji nie może wykonywad swojej akcji.
Inne przykłady zakleszczeo są pokazane na Rys.6.
Rys.6 Zakleszczenie transakcji
Stemple czasowe oraz ziarnistość transakcji
Każda transakcja w momencie startu dostaje unikalny stempel czasowy. Stempel ten jest na tyle
precyzyjny, aby móc po nim rozróżniad transakcje. Żadna zmiana nie jest nanoszona do bazy
danych, transakcja działa na swoich własnych kopiach, aż do potwierdzenia.
Każdy obiekt bazy danych przechowuje dwa stemple czasowe: transakcji, która ostatnio brała
obiekt do czytania i transakcji, która ostatnio brała obiekt do modyfikacji. W momencie
potwierdzenia sprawdza się stemple transakcji oraz wszystkich pobranych przez nią obiektów.
Można dośd łatwo wyprowadzid reguły zgodności, np. jeżeli obiekt był aktualizowany i stempel na
obiekcie do aktualizacji jest taki sam, jak stempel transakcji, to wykonaj, a w przeciwnym razie
należy zerwad i uruchomid od nowa. Jeżeli obiekt był tylko czytany i stempel na obiekcie do
aktualizacji jest starszy niż stempel transakcji, to wykonaj, a w przeciwnym razie należy zerwad i
uruchomid od nowa.
Z problemem zakładania zamków wiąże się również problem ziarnistości. Ziarnistośd oznacza
decyzję, co będzie niepodzielną jednostką, na którą zakłada się blokady. Poziomy ziarnistości mogą
dotyczyd: bazy danych, relacji, rekordu, elementu rekordu, pojedynczego atrybutu, fizycznej strony
pamięci.
Grube ziarna mogą zapewnid znaczny poziom bezpieczeostwa, jednak dają niewielki stopieo
współbieżności procesów. Z kolei małe ziarna wiążą się z dużymi nakładami na zakładanie zamków
oraz ich obsługę.
Przykładowe rozwiązanie
Optymalizacja bazy danych
Bardzo często działająca od jakiegoś czasu baza danych, na której wykonuje się bardzo dużo
operacji zaczyna działad woniej niż podczas pierwszego uruchomienia. Wówczas do głównego
zadania administratora bazy danych należy zoptymalizowanie bazy danych oraz przebudowa
indeksów. Do tego celu może posłużyd nam narzędzie SQL Server Profiler.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 10/20
SQL Server Profiler to potężne chod rzadko wykorzystywane narzędzie do analizy problemów z
wydajnością bazy danych. Wykorzystując Profiler do przechwytywania śladów (traces) aktywności
bazy danych można analizowad wzorce zapytao, aby wykryd problemy z wydajnością nawet przed
ich uwidocznieniem w aplikacjach.
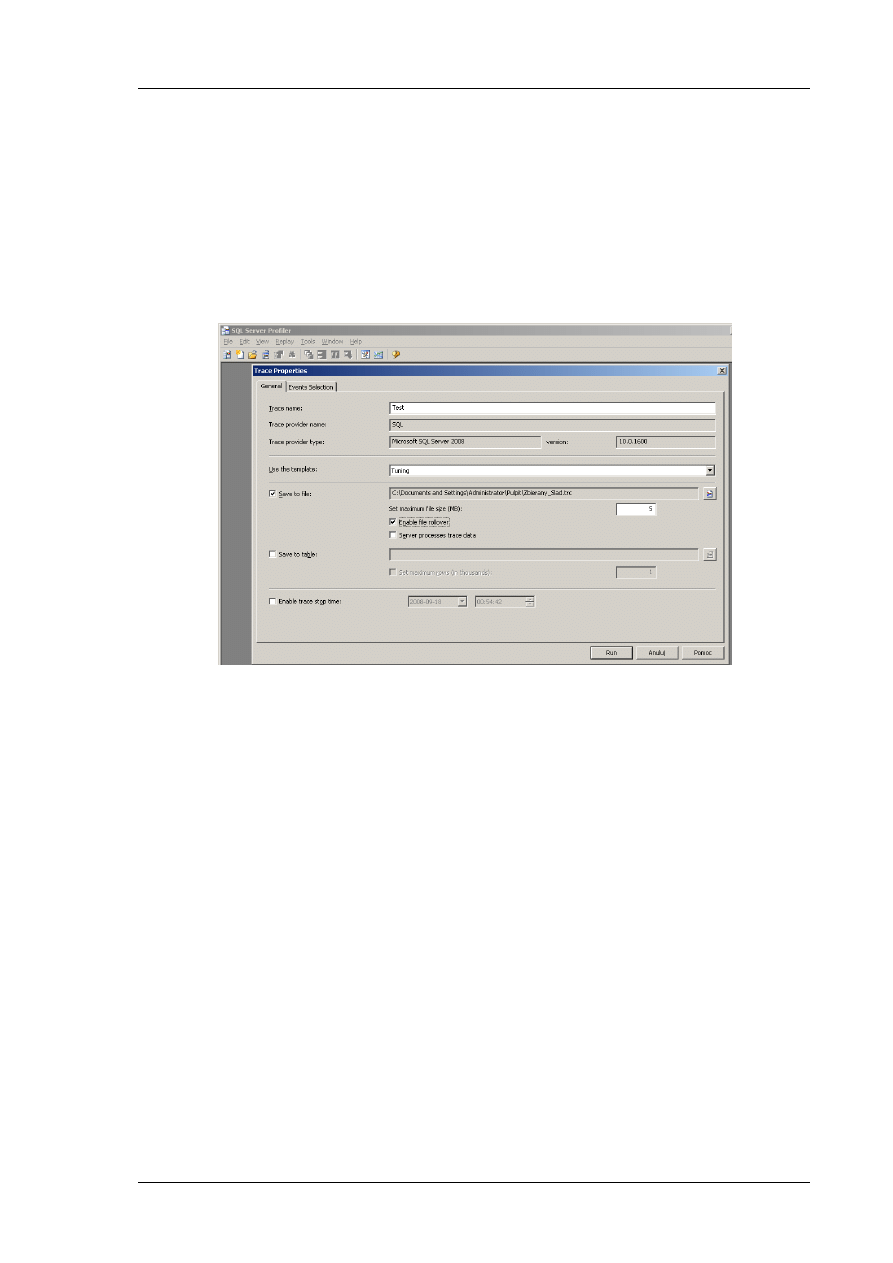
W pierwszym kroku należy zdefiniowad ślad. Wewnątrz silnika bazy danych SQL Server udostępnia
podsystem zdarzeo nazwany SQL Trace, który opiera się na zewnętrznych interfejsie. Interfejs ten
pozwala na wywoływanie SQL Trace z wykorzystaniem różnorodnych parametrów.
SQL Server Profiler uruchamia się z menu SQL Server 2008 Performance Tools. Po jego otworzeniu
należy wybrad
File
a następnie
New Trace
co pokazano na Rysunku 7.
Rys. 7 Definicja sladu
Każdy definiowany ślad musi zostad nazwany (w naszym przykładzie Test). Następnie następuje
wybór wzorca. Istnieje kilka wzorców, które najczęściej są monitorowane. Oczywiście możemy
ustawid pusty wzorzec i sami zdefiniowad opcje. Na Rysunku 7 użyliśmy predefiniowanego wzorca
Tuning bazy danych. Następnie ustawiamy sposób zapisu. Mamy możliwośd zapisu do pliku lub do
tabeli. Zapis do tabeli nie jest polecany gdyż SQL Trace może generowad setki tysięcy wierszy
danych śladu na minutę na obciążonym serwerze.
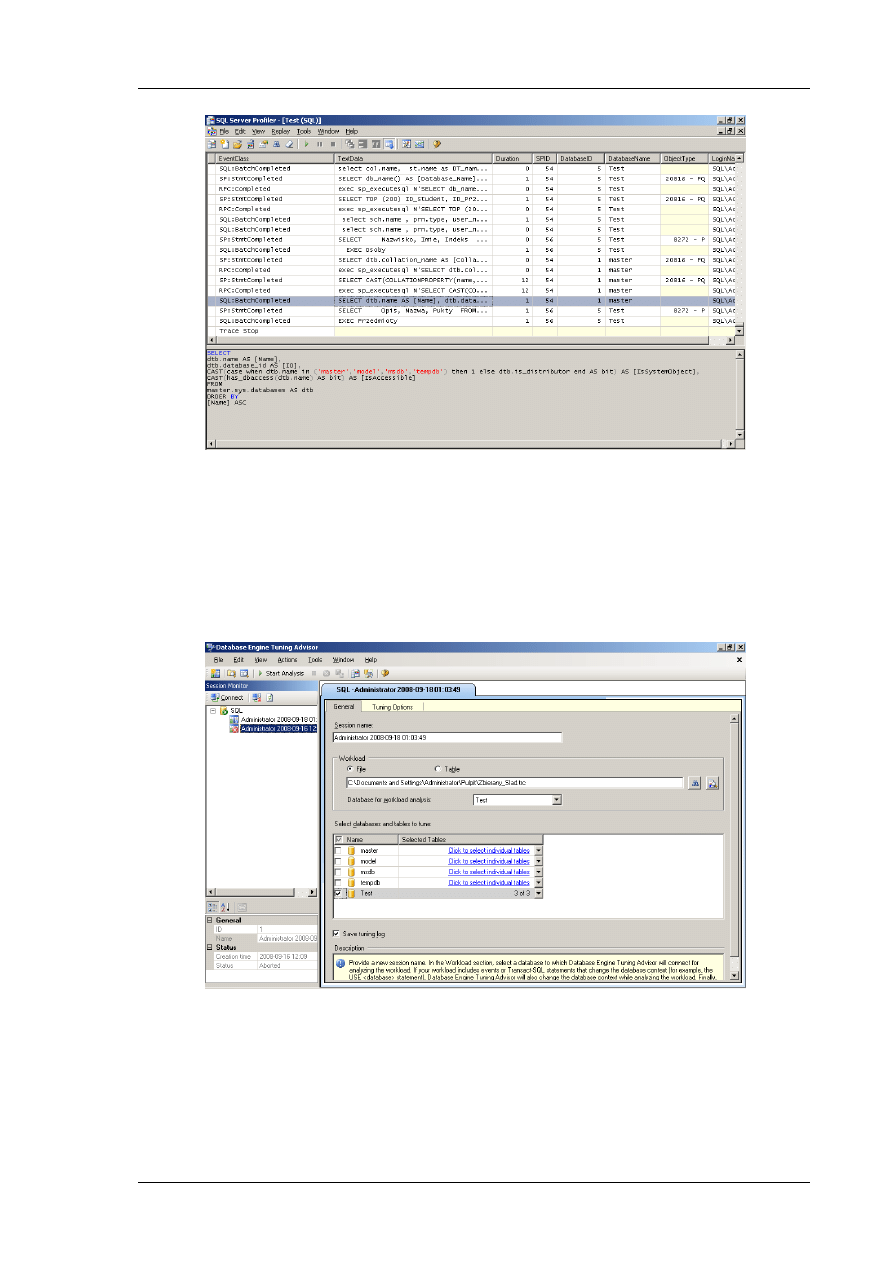
Gdy ślad jest w pełni zdefiniowany należy go tylko uruchomid i zbierad dane. W tym celu należy
kliknąd Run. Wynik działania śladu pokazano na Rysunku 8.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 11/20
Rys. 8 Uruchomienie śladu
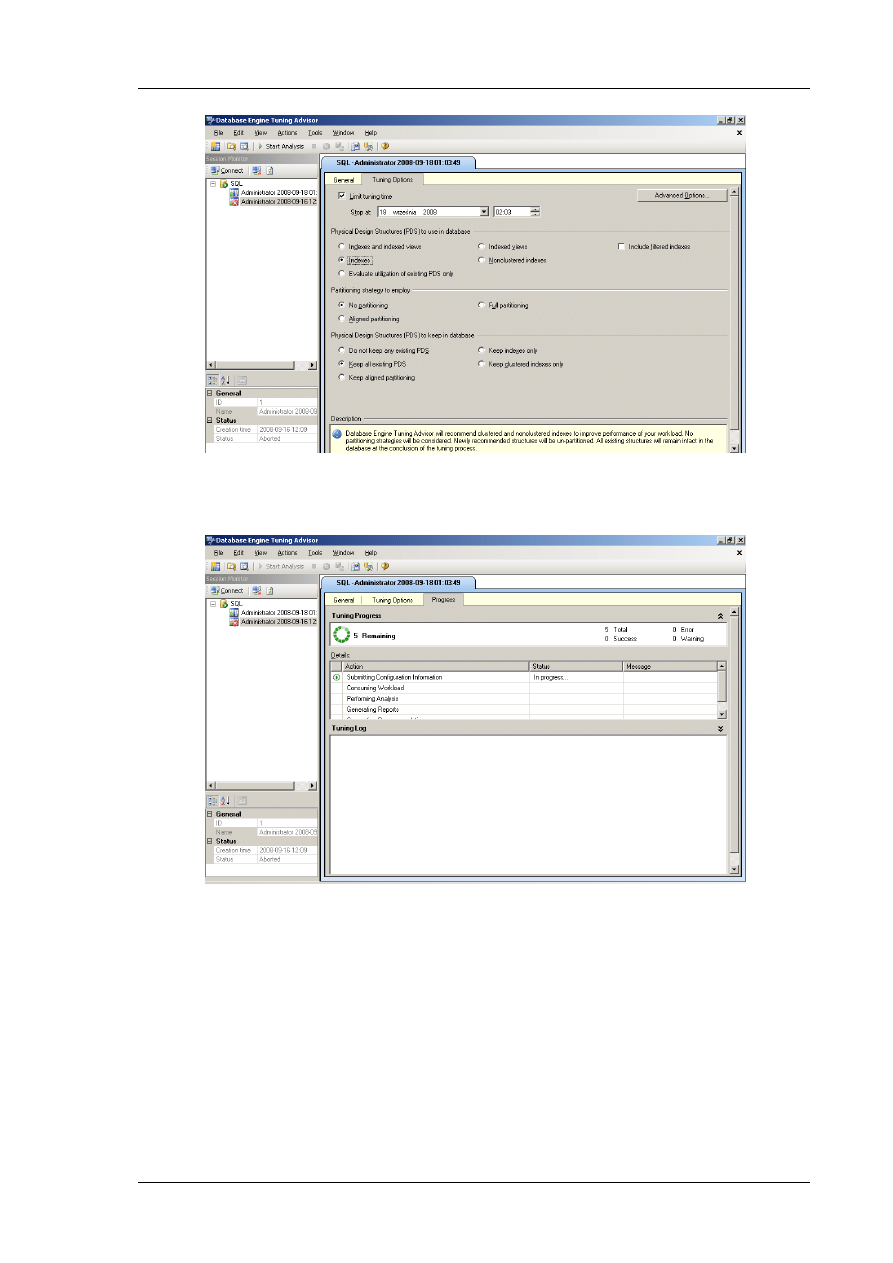
Po zakooczeniu zbierania śladu kolejnym etapem jest użycie narzędzia Database Engine Tuning
Advisor (DTA). Odgrywa ono ważną rolę w ogólnych rozwiązaniach wydajności, pozwalając na
wpływ na optymizator zapytao w celu otrzymania zaleceo dla indeksów, indeksowanych widoków
lub partycji, które mogą zwiększyd wydajnośd.
W celu uruchomienia DTA należy z zakładki Tools wybrad Database Engine Tuning Advisor.
Następnie należy połączyd się z serwerem, wybrad plik obciążający do analizy (ten, do którego
zapisaliśmy zbierany ślad) (Rysunek 9) oraz określid opcje strojenia (Rysunek 10).
Rys. 9 Definiowanie ogólnych opcji strojenia bazy danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 12/20
Rys. 10 Definiowanie strojenia bazy danych
Po skonfigurowaniu opcji strojenia DTA można zacząd analizę klikając Start Analysis co pokazano na
Rysunku 11.
Rys. 11 Strojenie bazy danych
Po wykonaniu analizy otrzymujemy zalecenia na przykład dotyczące przebudowy indeksów, które
możemy zastosowad do naszej bazy danych.
Porady praktyczne
Indeksowanie kolumn
Indeksy powinny byd planowane z myślą o najczęściej wykonywanych w Twojej bazie danych
zapytao
SELECT
z klauzulą
WHERE
. Pierwszym krokiem powinno byd zatem wypisanie
najczęściej wykonywanych zapytao
SELECT
(koniecznie z klauzulą
WHERE
)
MS SQL Server umożliwia utworzenie w tabeli jednego indeksu grupowanego oraz 249
indeksów niegrupowanych. Pojedynczy indeks można założyd na maksymalnie 16 polach. To
jednak tylko maksymalne możliwości serwera. W praktyce w bazach danych OLTP (ang.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 13/20
online transaction processing) nie tworzy się więcej niż 8 do 10 indeksów związanych z
pojedynczą tabelą.
Należy pamiętad, iż nie wszystkie zapytania wykorzystują indeksy. Np. w MS SQL Server
zapytanie:
SELECT imie, nazwisko FROM osoby WHERE nazwisko LIKE '%mar%'
nie wykorzysta indeksu grupowanego na polu nazwisko, ponieważ niemożliwe będzie
porównanie wartości wzorca z wartościami na stronach indeksu.
Indeksy mają kluczowe znaczenie dla optymalizacji wydajności baz danych. Dobrze
zaprojektowane indeksy mogą znacząco poprawid szybkośd operacji przeszukiwania bazy
danych (najczęściej wykonywana operacja i dotyczy największych ilości danych), ale źle
zaplanowane mogą spowodowad efekt odwrotny do pożądanego. Z tego powodu należy
starannie zaplanowad ich strukturę.
Database Engine Tuning Advisor (DTA) to znacznie udoskonalony następca narzędzia Index
Tuning Wizard dostarczonego z wersją SQL Server 2000.
Żeby Database Engine Tuning Advisor (DTA) mógł przeprowadzid optymalizację bazy danych
w oparciu o plik zawierający ślad musi on mied co najmniej 2 MB zebranych danych.
Transakcje
Zakleszczenia są poważnym problemem i mają istotny wpływ na wydajnośd systemu. Walka z
zakleszczeniami może przebiegad według dwu metod:
a) Wykrywanie zakleszczeo i rozrywanie pętli zakleszczenia – Detekcja zakleszczenia
wymaga skonstruowania grafu czekania (ang. wait-for graph) i tranzytywnego domknięcia
tego grafu (złożonośd gorsza niż n * n). Rozrywanie pętli zakleszczenia polega na wybraniu
transakcji "ofiary" uczestniczącej w zakleszczeniu i następnie, jej zerwaniu i uruchomieniu
od nowa. Wybór "ofiary" podlega różnym kryteriom - np. najmłodsza, najmniej
pracochłonna, o niskim priorytecie, itd.
b) Niedopuszczanie do zakleszczeo – Istnieje wiele tego rodzaju metod, np.
Wstępne żądanie zasobów – przed uruchomieniem każda transakcja określa potrzebne
jej zasoby. Nie może później nic więcej żądad. Wada: zgrubne oszacowanie żądanych
zasobów prowadzi do zmniejszenia stopnia współbieżności.
Czekasz-umieraj (ang. wait-die) – jeżeli transakcja próbuje dostad się do zasobu, który jest
zablokowany, to natychmiast jest zrywana i powtarzana od nowa. Metoda może byd
nieskuteczna dla systemów interakcyjnych (użytkownik może się denerwowad
koniecznością dwukrotnego wprowadzania tych samych danych) oraz prowadzi do spadku
efektywności (sporo pracy idzie na marne).
Postulat możliwości odtworzenia stanu systemu sprzed wywołani transakcji w wypadku jej
awarii (wycofania) możliwy jest dzięki m.in. zastosowaniu osobnego dziennika transakcji.
Mogą byd w nim zapisywane wszystkie dane, na których pracuje transakcja lub też tylko dane
różnicowe. Należy jednak pamiętad, że obsługa transakcji wiąże się z dodatkowymi
nakładami i obciążeniem dla systemu.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
rozumiesz mechanizm działania i polityki indeksowania
rozumiesz zasadę działania transakcji
znasz składnię nakładania indeksów na poszczególne pola
rozumiesz sposób działania transakcji
rozumiesz mechanizm zakleszczania transakcji

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 14/20
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1. Kalen Delaney, Microsoft SQL Server 2005: Rozwiązania praktyczne krok po kroku, Microsoft
Press, 2006
W książce autor przedstawia między innymi w jaki sposób należy stosowad
transakcje w celu zapewnienia bezpiecznej współbieżności bazy danych. Pokazuje
jak należy definiowad transakcje w SQL Server oraz jak zarządzad odseparowanymi
transakcjami. W pozycji tej znajdziesz dużo rozwiązao praktycznych.
2. Deren Bieniek, Randy Dyess, Mike Hotek, Javier Loria, Adam Machanic, Antonio Soto, Adolfo
Wiernik, SQL Server 2005 Implemantacja i obsuga, APN Promise, Warsyawa 2006
W książce obszernie przedstawiono zagadnienia związane z tworzeniem indeksów
oraz transakcjami. Znajdziesz tu potrzebne informacje na temat struktury indeksu,
tworzenia indeksów klastrowych i nieklastrowych oraz na temat tworzenia
transakcji. Znajdziesz tutaj również szczegółowe informacje na temat optymalizacji
bazy danych oraz przebudowy indeksów. Książka szczególnie polecana ze względu
na dużą zawartośd dwiczeo laboratoryjnych.
3. Ramez Elmasri, Shamkant B. Navathe, Wprowadzenie do systemów baz danych, Wydawnictwo
Helion, 2005
W książce tej znajdziemy dużo szczegółowych informacji na temat indeksowania
oraz zagadnieo związanych z przetwarzaniem transakcji. Pozycja szczególnie
polecana dla osób pragnących poszerzenie swojej wiedzy z tej tematyki.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 15/20
Laboratorium podstawowe
Problem 1 (czas realizacji 30 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma National Insurance zarządzająca systemem prac dyplomowych na twoim wydziale planuje
rozszerzenie systemu na skalę uczelniana. Zadanie, jakie przed Tobą stoi, to zdefiniowanie nowych
pól indeksowania, zaplanowanie struktury indeksów.
Zadanie
Tok postępowania
1. Lista
najczęściej
wykonywanych
zapytao
Wypisz najczęściej wykonywane zapytania
SELECT
na bazie danych
PraceDyplomowe.
— wyszukujące prace według tytułów
— wyszukujące prace według autorów
— wyszukujące prace według promotorów
— wyszukujące prace według recenzentów
Zastanów się, jakie inne zapytania można stworzyd dla bazy danych
PraceDyplomowe
, które będą zawierały klauzulę WHERE.
2. Wybór pól do
indeksowania
Mając przed sobą listę najczęściej wykonywanych zapytao oraz
strukturę tabel planujemy strukturę indeksów
Kandydatami do indeksowania są kolumny lub kombinacje kolumn,
które:
— narzucają porządek sortowania (indeks grupowy)
— przechowują wartości częściej odczytywane niż modyfikowane
— są wykorzystywane do łączenia (
JOIN
) lub wyszukiwania (
WHERE
)
danych
— przechowują różnorodne wartości
Zastanów się, jakie inne kolumny są dobrymi kandydatami na to żeby
założyd na nie indeks.
3. Nawiązywanie
połączenia z SQL
Server 2008
Uruchom maszynę wirtualną BD2008.
— Jako nazwę użytkownika podaj Administrator.
— Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w MS Virtual PC,
dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008 uruchom
SQL Server Management Studio.
W oknie logowania kliknij Connect.
4. Przygotowanie
tabeli
Z menu głównego wybierz File -> Open -> File
Odszukaj plik C:\Lab08\Indeksy.sql i kliknij Open
Kliknij w menu głównym programu SQL Server Menagement Studio na
Tools -> Customize
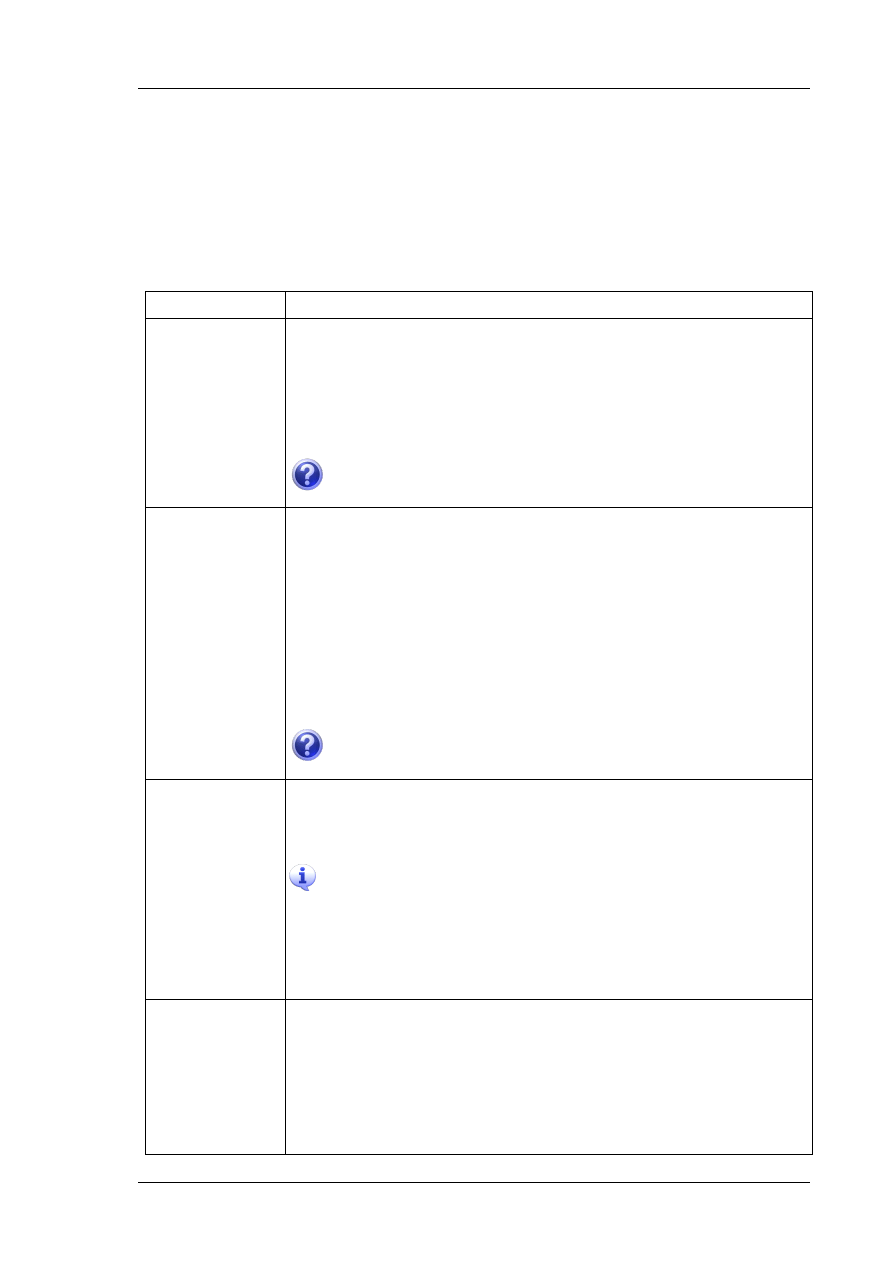
W oknie Customize kliknij przycisk Keybord
W pozycji odpowiadającej kombinacji klawiszy Ctrl+F1 wpisz
sp_helpindex i wciśnij OK. Wynik powyższych operacji pokazano na Rys.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 16/20
Rys. 12 Definicja klawiszy skrótu
Dzięki zdefiniowaniu klawiszy skrótu w porosty sposób będziesz mógł
wywoływad z klawiatury procedurę składowaną sp_helpindex, która
wyświetla informacje o indeksach w wybranej tabeli.
Stwórz kopie tabeli Osoba
-- (2) Tworzymy kopie tabeli Osoba
IF EXISTS (
SELECT name
FROM sysobjects
WHERE name='Osoba_kopia')
DROP TABLE Osoba_kopia
GO
SELECT Imie, Nazwisko, Nr_Indeksu
INTO Osoba_kopia
FROM Osoba
GO
Uruchom zapytanie do tabeli Osoba_kopia:
-- (3) Wyswietl zawartość tabeli Osoba_kopia
SELECT * FROM Osoba_kopia
GO
Podkreśl w edytorze słowo Osoba (nazwa twojej tabeli) i wciśnij
CTRL+F1 lub wykonaj poniższy fragment skryptu. Powinieneś zobaczyd
informację pokazaną na Rys.13
-- (4) zobaczmy indeksy w tabeli
EXEC sp_helpindex Osoba_kopia
GO

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 17/20
Rys. 13 Informacja o indeksach w tabeli Osoba
Zastanów się, dlaczego w wyniku wywołania procedury składowanej
odpowiedzialnej za wyświetlanie informacji o indeksach pojawia się
wpis z indeksem PK_Osoba, skoro żaden indeks nie został założony?
Włącz pomiar statystyk wejścia/wyjścia ilości skanowanych stron
wykonując poniższe polecenie:
-- (5) Wlacz statystyki wejscia/wyjscia ilosci skanowanych stron
SET statistic io on
GO
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (6) wykonajmy proste wyszukiwanie po Nr_Indeksu
-- oraz po nazwisku
SELECT * FROM Osoba
WHERE Nr_Indeksu > 1000 AND Nazwisko = 'K%'
GO
5. Utworzenie
indeksu
Zaznacz i uruchom (F5) poniższy fragment kodu
-- (7) utworzmy indeks niegrupowany
CREATE INDEX index_Osoba ON Osoba(Nazwisko, Nr_Indeksu)
GO
Ponownie podkreśl w edytorze słowo Osoba (nazwa twojej tabeli) i
wciśnij CTRL+F1. Powinieneś zobaczyd informację pokazaną na Rys. 14.
Rys. 14 Informacja o indeksach w tabeli Osoba
6. Testowanie
indeksu
Zaznacz i uruchom (F5) poniższy fragment kodu
-- (6) wykonajmy proste wyszukiwanie po Nr_Indeksu
-- oraz po nazwisku
SELECT * FROM Osoba
WHERE Nr_Indeksu > 1000 AND Nazwisko = 'K%'
GO
Zauważ, iż wynik będzie oczywiście taki sam, ale pojawi się różnica w
statystykach.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 18/20
Problem 2 (czas realizacji 15 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma National Insurance zarządzająca systemem prac dyplomowych na twoim wydziale planuje
rozszerzenie systemu na skalę uczelniana. Zadanie, jakie przed Tobą stoi, to stworzenie transakcji
dla rozwijanej bazy danych.
Zadanie
Tok postępowania
1. Nawiązywanie
połączenia z SQL
Server 2008
Uruchom maszynę wirtualną BD2008.
— Jako nazwę użytkownika podaj Administrator.
— Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w MS Virtual PC,
dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008 uruchom
SQL Server Management Studio.
W oknie logowania kliknij Connect.
2. Przygotowanie
tabeli
Z menu głównego wybierz File -> Open -> File
Odszukaj plik C:\Lab08\Transakcje.sql i kliknij Open
Zaznacz kod, który wyświetla fragment tabeli, oznaczony w komentarzu
(1) i (2).
-- (1) Ustaw sie na bazie danych PraceDyplomowe
USE PraceDyplomowe
GO
-- (2) Wyswietlamy dwa pierwsze rekordy z tabeli Osoba
SELECT *
FROM Osoba
WHERE ID_Osoby IN (1,2)
Zaznacz kod, który próbuje wykonad transakcje
-- (3) Przykladowa transakcja
BEGIN TRANSACTION
BEGIN TRY
UPDATE Osoba
SET Nazwisko = 'Kochan'
WHERE ID_Osoby = 2
UPDATE Osoba
SET Nazwisko = 'Kowalski'
WHERE ID_Osoby = 6
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() as ErrorState,
ERROR_PROCEDURE() as ErrorProcedure,
ERROR_LINE() as ErrorLine,
ERROR_MESSAGE() as ErrorMessage
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION
END CATCH
IF @@TRANCOUNT > 0
COMMIT TRANSACTION
GO
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 19/20
Powyższy kod podejmuje próbę wykonania transakcji złożonej z
dwóch operacji UPDATE. Próba wykonania pierwszej z nich spowoduje
błąd, ponieważ wartości w kolumnie ID_Osoby w tabeli Osoby muszą
byd unikalne, a polecenie próbuje wstawid duplikat wartości 2, która
już istnieje w rekordzie drugim tabeli. Przechwytywanie błędów
odbywa się przy użyciu bloków TRY...CATCH, które poznałeś w module
9.
Zastanów się, jak powinieneś zmodyfikowad powyższą transakcję,
żeby zakooczyła się powodzeniem?

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 20/20
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma zarządzająca bazą AdventureWorks planuje rozszerzenie i modernizację systemu w celu
spełnienia pewnych standardów. W związku z modernizacją systemu bazodanowego, a zatem
zmianą struktury fizycznej bazy danych, najprawdopodobniej będzie musiała nastąpid przebudowa
struktury indeksów. Poza przebudową indeksów będzie musiała zapewne nastąpid modernizacja
istniejących transakcji tak, żeby odpowiadały one nowej strukturze fizycznej przebudowanej bazy
danych.
Zadanie, jakie przed Tobą stoi, to:
1. Podjęcie decyzji, które obiekty w bazie danych pozostaną bez zmian, a które zostaną
zmodyfikowane lub usunięte.
2. Podjęcie decyzji, na które pola opłaca się nałożyd indeks i jakiego typu te indeksy powinny
byd.
3. Podjęcie decyzji, które transakcje należy zmodernizowad i czy nie trzeba będzie dodad
nowych transakcji.
Wyszukiwarka
Podobne podstrony:
ITA 101 Modul 03
ITA 101 Modul 02
ITA 101 Modul 06
ITA 101 Modul 13
ITA 101 Modul 11
ITA 101 Modul 04
ITA 101 Modul 09
ITA 101 Modul Dodatek A
ITA 101 Modul 08
ITA 101 Modul 10
ITA 101 Modul 12
ITA 101 Modul 01
ITA 101 Modul 05
ITA 101 Modul 02 v2
więcej podobnych podstron