
77. Modelowanie bazy danych – rodzaje połączeń
relacyjnych, pojęcie klucza obcego.
Przy modelowaniu bazy danych możemy wyróżnić następujące typy
połączeń relacyjnych:
•
jeden do wielu,
•
jeden do jednego,
•
wiele do wielu.
Relacja jeden do wielu
Załóżmy, że mamy dane różnych dostawców i każdy z nich w jednym
czasie dostarcza pewne różne produkty. Rozwiązanie polegające na
umieszczeniu tych informacji w jednej tabeli posiada wiele wad:
•
należałoby utworzyć osobne kolumny dla wszystkich możliwych do
dostarczenia produktów i ich stanu magazynowego – struktura
tabeli byłaby przez to bardzo rozbudowana,
•
brak oszczędności miejsca – dostawca A miałby puste wartości dla
produktów, które są dostarczane przez innych dostawców,
•
problemy przy ewentualnej modyfikacji struktury tabeli – w
przypadku, gdy asortyment ulegnie poszerzeniu należałoby do
tabeli dodać kolejne kolumny i dla każdego istniejącego już wiersza
zapewnić prawidłowe wartości.
Rozwiązaniem powyższych problemów jest zastosowanie relacji jeden-
do-wielu. Charakteryzuje się ona tym, że dla każdego rekordu jednej
tabeli może istnieć wiele rekordów w drugiej tabeli pozostającej z nią w
związku. Relacja jeden-do-wielu jest realizowana poprzez utworzenie
atrybutu w encji po stronie wiele, aby umieścić w nim klucz encji
znajdującej się po stronie jeden. Tak utworzony atrybut encji po stronie
wiele nosi nazwę klucza obcego ponieważ jest on głównym kluczem w
innej tabeli. Relacja jeden do wielu jest najczęściej wykorzystywanym
typem połączenia w relacyjnych baza danych.
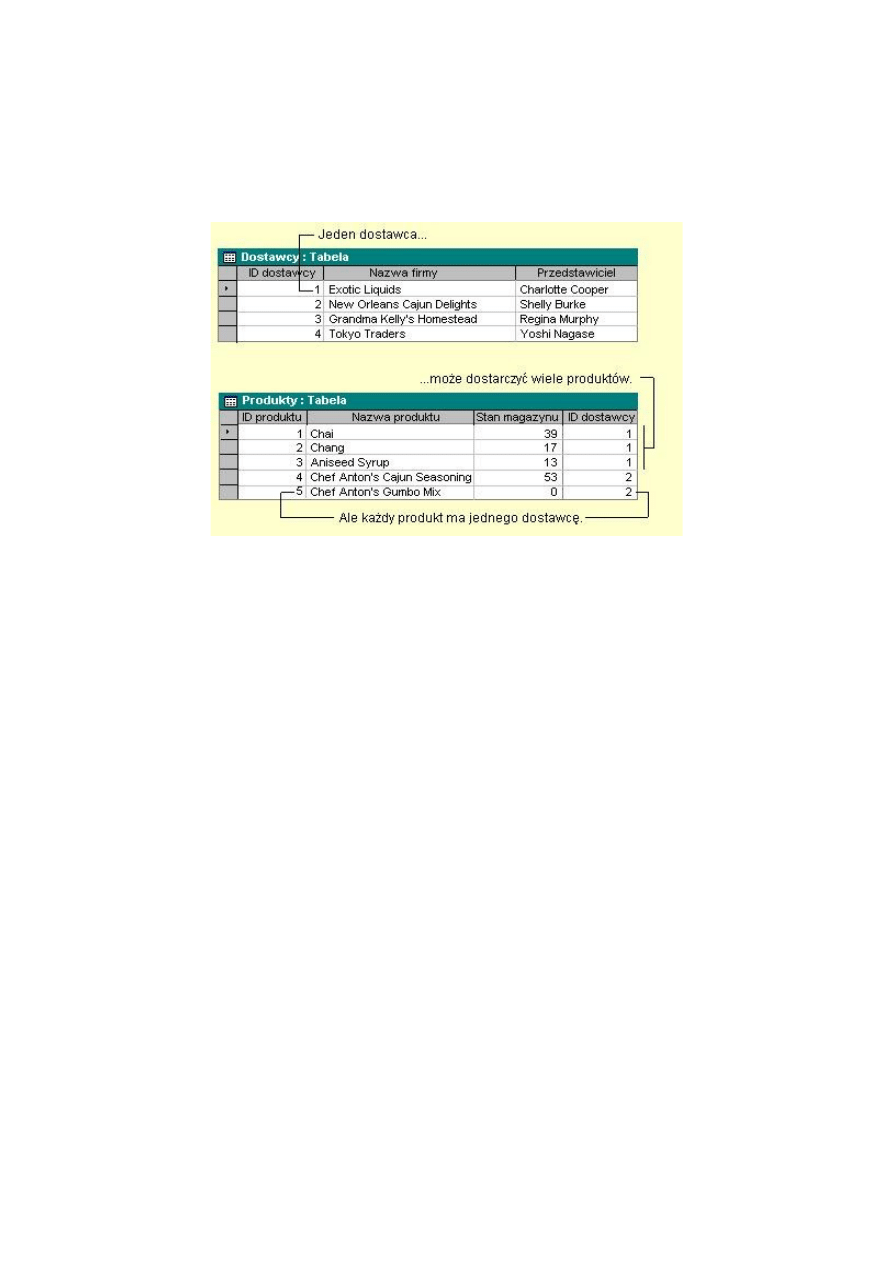
Poniżej prezentacja przykładowej struktura tabel dla omawianego
wcześniej przypadku dostawców i produktów po zastosowaniu relacji
jeden-do-wielu.
Relacja je
d
e
n
do jednego
Charakteryzuje się tym ,że dla każdej instancji jednej z dwóch encji
istnieje dokładnie jedna instancja drugiej encji pozostająca z nią w
równoważnym związku np. czek i opłata ( opłata jest realizowana za
pomocą jednego czeku i za pomocą jednego czeku można zrealizować
tylko jedną opłatę). Ten typ relacji spotyka się rzadko, ponieważ
większość informacji powiązanych w ten sposób byłoby zawartych w
jednej tabeli. Relacji jeden-do-jednego można używać do podziału tabeli z
wieloma polami, do odizolowania części tabeli ze względów
bezpieczeństwa, albo do przechowania informacji odnoszącej się tylko do
podzbioru tabeli głównej. Na przykład, można by utworzyć tabelę do
wyszukiwania pracowników uczestniczących w rozgrywkach piłkarskich.
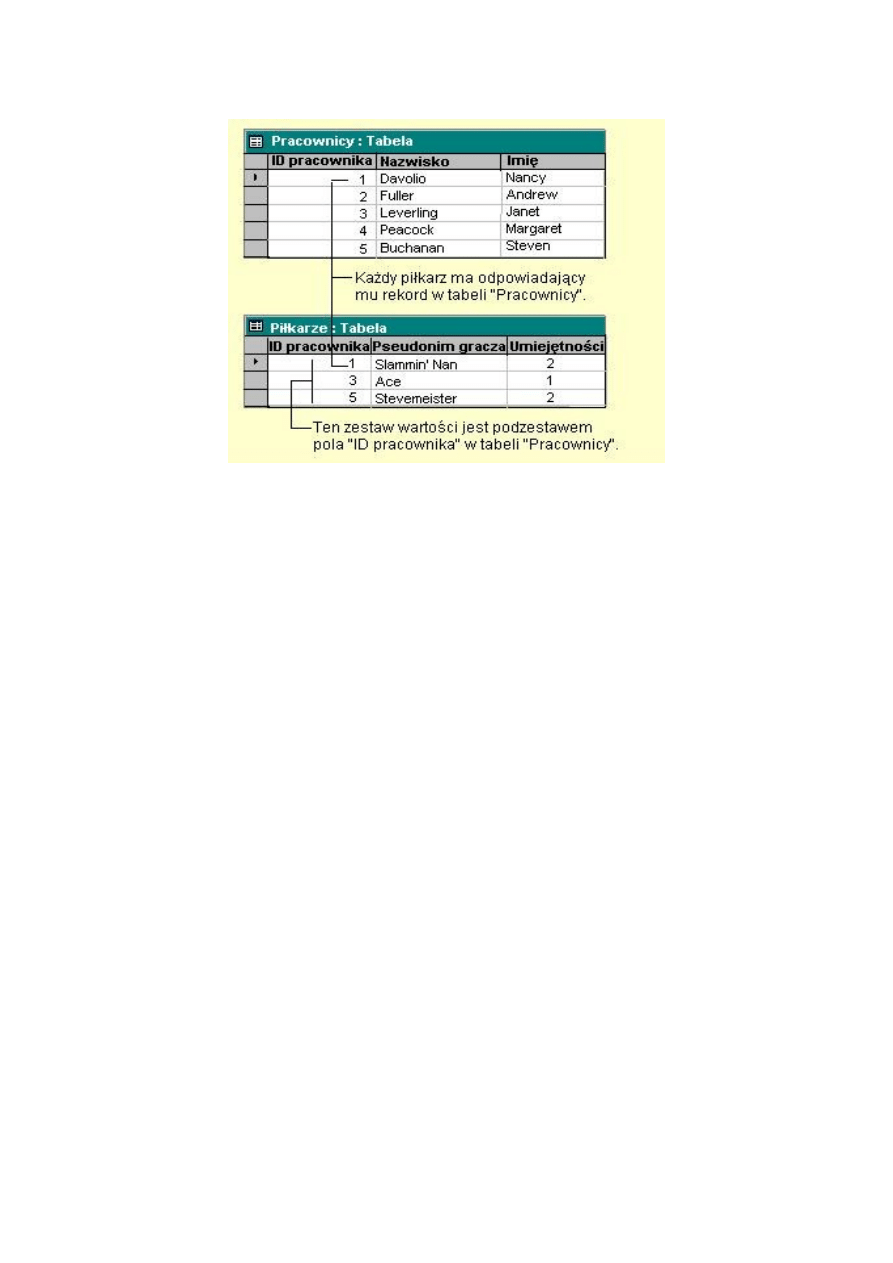
Relacja wiele do wielu
W relacji wiele-do-wielu, rekord w tabeli A może mieć wiele
dopasowanych do niego rekordów z tabeli B i tak samo rekord w tabeli B
może mieć wiele dopasowanych do niego rekordów z tabeli A. Jest to
możliwe tylko przez zdefiniowanie trzeciej tabeli (nazywanej tabelą łącza
lub tabelą przejściową), której klucz podstawowy składa się z dwóch pól -
kluczy obcych z tabel A i B. Relacja wiele-do-wielu jest definiowana jako
dwie relacje jeden-do-wielu z trzecią tabelą. Na przykład, tabele
"Zamówienia" i "Produkty" są powiązane relacją wiele-do-wielu
zdefiniowaną przez utworzenie dwóch relacji jeden-do-wielu z tabelą
"Opisy zamówień".
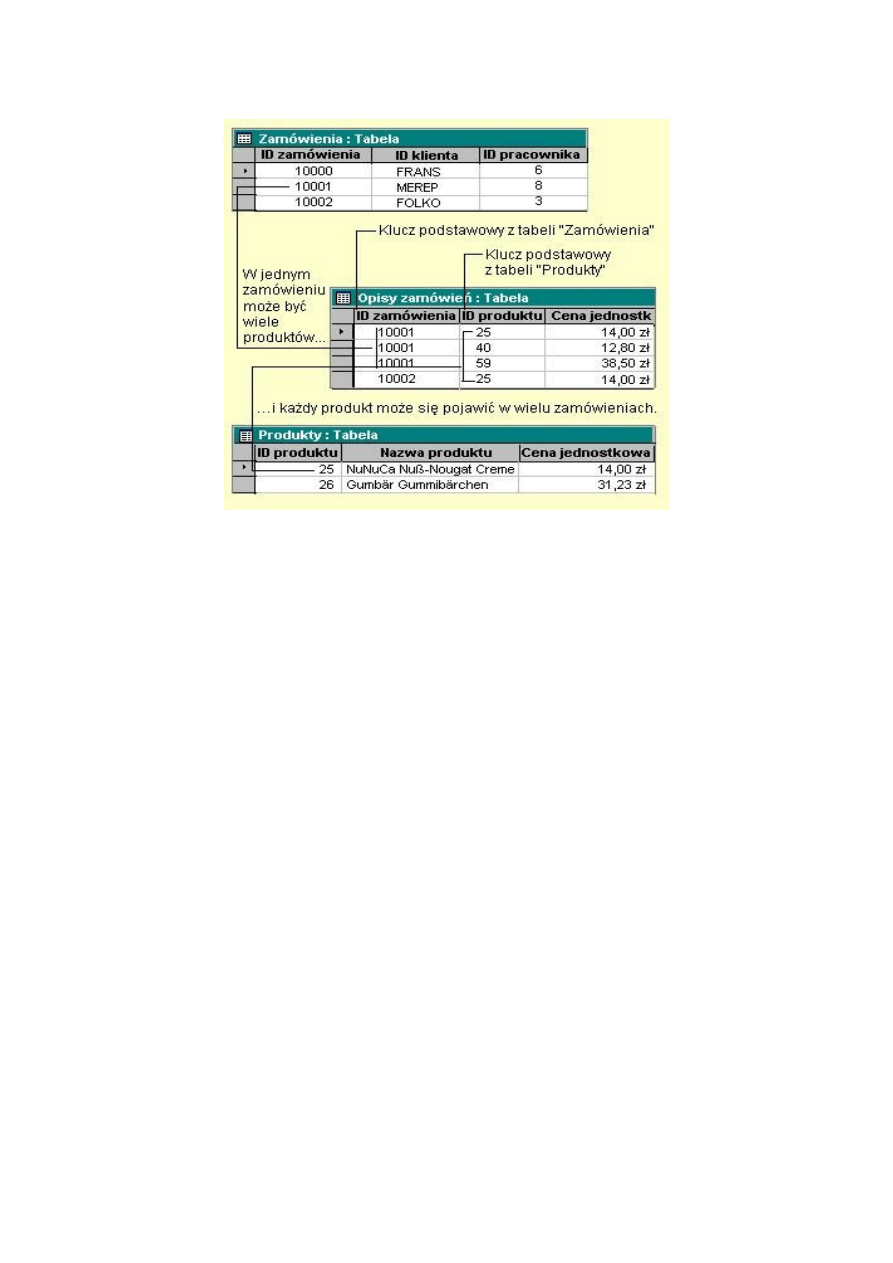
Klucz obcy (Foreign Key)
Klucz główny (Primary Key), to kolumna lub zbiór kolumn, które w
sposób unikalny definiują
wiersz
w danej tabeli.
Klucz obcy jest kolumną lub zbiorem kolumn, który jest kluczem
głównym w innej tabeli. Można powiedzieć, że klucz obcy jest kopią
klucza głównego z innej tabeli. Asocjacja jest utworzona pomiędzy
tabelami poprzez zaznaczenie, iż wartość z jednej tabeli, w której jest
kluczem obcym, jest powiązana z wartością z innej tabeli, gdzie jest
kluczem głównym. Ważne jest to, iż wartość klucza obcego nie może
istnieć bez powiązania z kluczem głównym. Korzystając z przykładu dla
relacji wiele-do-wielu: w tabeli Opisy zamówień mamy pole ID produktu,
które jest kluczem głównym w tabeli
Produkty
, w związku z czym nie
możemy wpisać w nie wartości, która nie istnieje w tabeli Produkty. Silnik
bazy danych nie zezwoli, aby wstawić wartość klucza obcego, który nie
posiada odnośnika na klucz główny.

78. Pojęcie indeksu – rodzaje i zastosowania
Podczas wykonywania polecenia SELECT serwer bazodanowy musi
wykonać wiele różnych operacji: wybieranie danych, sortowanie wyników
itd. W przypadku operacji na tabelach posiadających duże ilości danych,
bardzo ważną rolę zaczyna odgrywać optymalizacja wszelkiego rodzaju
wyszukiwania oraz sortowania. Rekordy ułożone są w tabeli w takiej
kolejności, w jakiej zostały dodane. Oznacza to, że jeżeli spróbujemy
wykonać wyszukiwanie względem jakiegoś określonego kryterium, serwer
musi przejrzeć całą zawartość tabeli i wyodrębnić rekordy odpowiadające
zadanym kryteriom. Im większa ilość danych, tym dłuższy będzie czas
potrzebny na wykonanie tej operacji.
Rozwiązaniem mającym za zadanie przyspieszyć przeszukiwanie bazy
danych są indeksy. Indeks nałożony na pole A jest kopią zawartości tego
pola, tyle że posortowaną i odpowiednio ułożoną.
Podział indeksów:
•
ze względu na strukturę:
•
B-drzewa – stosowany w relacyjnych bazach danych, definiuje się
go dla atrybutów o dużej selektywności, nie przechowuje
informacji o wartościach pustych, niski koszt pojedynczej
modyfikacji, wysoki dla grupy rekordów,
•
bitmapowe – stosowany w systemach OLAP (np. hurtownie
danych), definiowany dla atrybutów o małej selektywności,
przechowuje informacje o wartościach pustych
•
ze względu na liczbę atrybutów indeksowych w kluczu:
•
indeksy zwykłe – klucz indeksu zawiera jeden atrybut relacji,
•
indeksy złożone – klucz indeksu zawiera więcej niż jeden atrybut
relacji, zakłada je się na atrybutach często występujących razem
w klauzuli WHERE zapytań lub na atrybutach często
odczytywanych wspólnie przez wiele zapytań,

•
ze względu na unikalność wartości klucza:
•
indeksy unikalne - gwarantują, że w relacji nie będzie dwóch
rekordów z tą samą wartością atrybutu indeksowego (atrybutów
indeksowych w przypadku indeksu złożonego)
•
indeksy nieunikalne – relacja może zawierać rekordy z tą samą
wartością atrybutu indeksowego.
•
ze względu na kolejność wartości klucza:
•
indeksy zwykłe
•
indeksy odwrócone - wartości w kluczu indeksowym składowane
są w postaci odwróconej,
•
ze względu na sposób składowania:
•
indeksy nieskompresowane
•
indeksy skompresowane,
•
ze względu na zastosowania:
•
indeksy funkcyjne
•
bitmapowe indeksy połączeniowe.
Komendy do tworzenia indeksów mogą się różnić w zależności od
używanej bazy danych. Poniżej zaprezentowano przykłady dla przypadku
bazy MySQL.
Tworzenie indeksów (zwykłego i unikalnego) podczas tworzenia tabeli:
CREATE TABLE nazwa_tabeli (
kolumna1 INT,
kolumna2 INT,
UNIQUE indeks_unikalny (kolumna1),
INDEX indeks_zwykly (kolumna2)
)
Tworzenie indeksów w istniejącej tabeli:
ALTER TABLE nazwa_tabeli

ADD UNIQUE indeks_unikalny (kolumna1),
ADD INDEX indeks_zwykly (kolumna2)
Tworzenie indeksów w istniejącej tabeli (inna wersja; komenda tworzy
tylko jeden indeks na raz, zatem należy wydać dwie komendy):
CREATE UNIQUE INDEX indeks_unikalny ON nazwa_tabeli (kolumna1)
CREATE INDEX indeks_zwykly ON nazwa_tabeli (kolumna2)
W pojedynczej tabeli może istnieć wiele indeksów. Istnieje także
możliwość utworzenia indeksów na kilku kolumnach jednocześnie.
Dwa indeksy, każdy na jednej kolumnie:
CREATE INDEX indeks_imie ON osoby (imie)
CREATE INDEX indeks_nazw ON osoby (nazwisko)
Jeden indeks nałożony na dwie kolumny jednocześnie (indeks złożony):
CREATE INDEX indeks_imie_nazw ON osoby (imie, nazwisko)
Pomiędzy dwoma powyższymi indeksami istnieje zasadnicza różnica,
która objawia się w momencie gdy zapytanie wybierające dane posiada
warunki odwołujące się do kilku kolumn z indeksami. Na przykład można
użyć takiego zapytania:
SELECT * FROM osoby WHERE imie='Jan' AND nazwisko='Kowalski'
W przypadku gdy tabela posiada dwa indeksy, każdy na pojedynczej
kolumnie, baza danych wykona to zapytanie następująco:
1. Wyszuka wszystkie rekordy gdzie imie = Jan;
2. Wyszuka wszystkie rekordy gdzie nazwisko = Kowalski;
3. Obliczy część wspólną zbiorów rekordów z pierwszego i drugiego
kroku, i zwróci ją jako wynik zapytania.
Natomiast w przypadku gdy na tabeli jest nałożony indeks na
kolumnach (imie, nazwisko), baza danych może wyszukać potrzebne dane
w jednym kroku, równocześnie sprawdzając wartości w polach imie i
nazwisko.
Warto także wiedzieć, iż indeks nałożony na kilku kolumnach zostanie
użyty nie tylko gdy warunek zawiera wszystkie kolumny indeksu, ale

również dla warunków zawierających dowolną ilość kolumn z lewej strony
indeksu. Np. indeks na kolumnach (imie, nazwisko, miejscowosc) zostanie
użyty dla następujących kombinacji kolumn występujących w warunku
wyszukiwania:
•
imie, nazwisko, miejscowosc
•
imie, nazwisko
•
imie
Kolejność warunków nie ma tu żadnego znaczenia - baza danych sama
je sobie odpowiednio przestawi aby pasowały do indeksu.
Jeżeli przewidujemy że będziemy używać zapytań wyszukujących tylko
po imieniu, tylko po nazwisku, lub po imieniu i nazwisku, możemy
stworzyć następujące indeksy, aby obsłużyć wszystkie przypadki:
CREATE INDEX indeks_imie_nazw ON osoby (imie, nazwisko)
CREATE INDEX indeks_nazw ON osoby (nazwisko)
Podsumowując indeksy stosuje się:
•
by szybko wyszukać rekordy spełniające warunek WHERE
•
by wyeliminować brane pod uwagę rekordy. Jeśli istnieje warunek
na kilka indeksów wybierany jest indeks który zwraca najmniejszą
liczbę rekordów.
•
by wyszukać rekordy z innych tabel przy wykonywaniu połączeń
tabel (JOIN).
•
by wyszukać wartości MIN() lub MAX() dla poszczególnych tabel.
•
by posortować lub pogrupować tabelę.
Wady:
•
każdy indeks zajmuje pewną ilość miejsca na dysku, zatem nie
warto tworzyć indeksów na każdej kolumnie w bazie. Zamiast tego
należy przeanalizować zapytania które są wykonywane, i na
podstawie tego podjąć decyzję gdzie i jakie indeksy utworzyć.

•
indeks spowalnia wstawianie, usuwanie i zmiany wartości w
indeksowanych kolumnach, ponieważ jego zawartość musi ulec
zmianie w momencie zmiany zawartości tabeli.

79. Podstawowe konstrukcje języka SQL
Podstawowe funkcje języka SQL:
SELECT
Służy do wyszukiwania wierszy w jednej lub więcej tabel lub widoków.
Najczęściej stosuje się w połączeniu z kluczami:
•
DISTINCT – zostaną zwrócone tylko różne wartości,
•
WHERE - warunek wyszukiwania,
•
GROUP BY - warunek grupowania,
•
HAVING - warunek wyszukiwania,
•
ORDER BY - warunek porządkowania.
Składnia:
SELECT [DISTINCT] kolumna
FROM nazwa_tabeli
[WHERE warunek]
[GROUP BY kolumna]
[HAVING warunek]
[ORDER BY kolumna]
INSERT
Służy do wstawiania jednego lub więcej rekordów to jednej tabeli.
Składnia:
INSERT INTO tabela
VALUES (wartości tabeli)
UPDATE
Służy do zmiany danych w jednym lub więcej rekordów, bez lub pod
warunkiem.
Składnia:

UPDATE nazwa_tabeli
SET nazwa_kolumny = wartość
[WHERE warunek]
MERGE
Służy do wstawienia nowych rekordów lub zmiany już istniejących,
bez lub pod warunkiem.
Składnia:
MERGE INTO nazwa_tabeli
USING nazwa_tabeli
ON warunek
WHEN MATCHED THEN UPDATE SET nazwa_kolumny = wartość
WHEN NOT MATCHED THEN INSERT nazwa_kolumny
VALUES (wartości);
DELETE
Służy do usunięcia jednego lub więcej rekordów z tabeli, bez lub pod
warunkiem.
Składnia:
DELETE FROM nazwa_tabeli [WHERE warunek]
JOIN
Służy do łączenia rekordów z dwóch tabel w relacyjnej bazie danych i
stworzenia nowej, tymczasowej tabeli. Istnieją trzy typy połączeń: INNER,
OUTER i CROSS.
Składnia:
SELECT nazwa_kolumny_1 FROM nazwa_tabeli_1 JOIN
nazwa_tabeli_2 ON nazwa_tabeli_1.nazwa_kolumny_1 =
nazwa_tabeli_2.nazwa_kolumny_2
UNION
Służy do połączenia dwóch rezultatów zapytań w jedną tabelę.
Obydwa zapytania muszą mieć równą ilość pól i typów danych.

Jakiekolwiek duplikaty w zwróconym wyniku są usuwane, chyba, że użyta
jest opcja UNION ALL.
Składnia:
SELECT nazwa_kolumny_1 FROM nazwa_tabeli_1 UNION
SELECT nazwa_kolumny_2 FROM nazwa_tabeli_2
CREATE
Służy do tworzenia obiektów w środowisku bazodanowym – większość
środowisk pozwala na tworzenie tabel, indeksów, użytkowników i baz
danych.
Składnia:
CREATE obiekt …
DROP
Służy do usuwania obiektu ze środowiska bazodanowego – typ obiektu
zależy od danego środowiska.
Składnia:
DROP obiekt …

Źródła:
•
http://web.pertus.com.pl/~stanley/access_pigulka/Relacje.htm
•
webmastera.com/artykuly/bazy_danych/optymalizacja_bazy_danych.php
•
Document Outline
- 77. Modelowanie bazy danych – rodzaje połączeń relacyjnych, pojęcie klucza obcego.
- 78. Pojęcie indeksu – rodzaje i zastosowania
- 79. Podstawowe konstrukcje języka SQL
- Źródła:
- http://web.pertus.com.pl/~stanley/access_pigulka/Relacje.htm
- http://www.poradnik-webmastera.com/artykuly/bazy_danych/optymalizacja_bazy_danych.php
- http://www.cs.put.poznan.pl/bbebel/sbd_2/18Indeksy.pdf
Wyszukiwarka
Podobne podstrony:
78 79 id 46015 Nieznany
piel 38 1 14 79 id 356923 Nieznany
77 Uzasadnic cos 3 id 45973 Nieznany (2)
79 2 id 46035 Nieznany
78 Przymiotniki 1 id 46008 Nieznany (2)
79 id 45533 Nieznany (2)
piel 38 1 14 79 id 356923 Nieznany
77 Uzasadnic cos 3 id 45973 Nieznany (2)
77 id 45963 Nieznany (2)
IV CR 216 77 id 220956 Nieznany
Lista 69 78 id 269926 Nieznany
78 Nw 02 Co i jak kleic id 4601 Nieznany
III CZP 79 11 id 210290 Nieznany
Anamnesis70 4 str 73 78 id 6215 Nieznany (2)
MARPOL 73 78 id 280987 Nieznany
79 Przymiotniki 2 id 46038 Nieznany (2)
69 78 id 44542 Nieznany (2)
79 Nw 12 Lamiglowka id 46043 Nieznany (2)
więcej podobnych podstron