
BAZY DANYCH – egzamin eksternistyczny
--------------------------------------------------------------------------------------------------------------------------------------
Zestaw 1
1. Omów role administratora danych.
2. Omów metody uwierzytelniania oparte nie na metodach hasel
3. Co to sa klasy?.
--------------------------------------------------------------------------------------------------------------------------------------
Zestaw 2
1. Zasady projektowania baz danych.
2. Co to sa obiekty wielotypowe?
3. Omów problemy zwiazane z niezaleznoscia danych.
--------------------------------------------------------------------------------------------------------------------------------------
Zestaw 3
1. Omów role administratora danych.
2. Omów problemy zwiazane z wielowersyjnoscia obiektów
3. Omów typy jezyków stosowanych w modelu relacyjnym.
--------------------------------------------------------------------------------------------------------------------------------------
Zestaw 4
1. Omów zaleznosci wykorzystywane w modelu relacyjnym.
2. Omów
role redundancji w bazach danych.
3. Omów etapy rozwoju baz danych.

--------------------------------------------------------------------------------------------------------------------------------------
Zestaw 5
1. Omów operacje algebry relacji.
2. Omów metody klasyczne (tradycyjne) szyfrowania.
3. Omów klasyfikacje systemów rozproszonych.
--------------------------------------------------------------------------------------------------------------------------------------
ODPOWIEDZI
Zestaw 1
AD. 1
1. Tworzenie pierwotnego opisu struktury bazy danych i sposobu odwzorowania go w
plikach fizycznych bazy danych.
2. Udzielanie uzytkownikom zezwolen na korzystanie z bazy danych lub jej
fragmentów.
3. Modyfikacja opisów bazy danych lub jego zwiazków z fizyczna organizacja bazy
danych, gdy wnioski z jej eksploatacji wskaza , ze inna organizacja bylaby bardziej
efektywna.
4. Wykonywanie archiwalnych kopii bazy danych i przywracanie jej poprawnego
(pierwotnego) stanu po uszkodzeniu powstalych na skutek awarii lub
nieprawidlowego uzycia sprzetu lub oprogramowania.
Administrator systemu baz danych to zespól ludzi. Musi znac biegle organizacje baz danych, ale nie
musi znac zawartosci baz danych.
Pelni on bardzo wazna funkcje podczas tworzenia i uzytkowania baz danych. Jest odpowiedzialny za:
•
Skonstruowanie schematu pojeciowego zewnetrznego
•
Okreslenie organizacji fizycznej danych i metod dostepu do danych
•
Definiowanie procedur zapewniajacych dobry poziom niezawodnosci systemu.
Administrator musi miec swobode zmiany struktury pamieci lub strategii dostepu bez koniecznosci
modyfikowania programów uzytkowych.
Jest on odpowiedzialny za:
1. decyduje jakie informacje beda utrzymywane w bazie danych
2. ustala jakie dane powinny byc reprezentowane w bazie danych i okresla cechy tej reprezentacji
oraz odpowiednie odwzorowanie miedzy struktura pamieci a schematem pojeciowym
3. utrzymuje kontakt z uzytkownikiem w celu zapewnienia dostepu do danych
4. definiuje procedury badania legalnosci i poprawnosci
5. definiuje i realizuje odpowiednia strategie odtwarzania
6. musi zapewnic wydajnosc najlepsza dla zakladu oraz odpowiednie dostosowanie systemu do
zmieniajacych sie wymagan.
AD. 2
Identyfikator to niepowtarzalna nazwa lub numer nadany obiektowi. Uwierzytelnianie to sprawdzenie,
czy osoba lub obiekt jest tym, za kogo sie podaje; procedura upowazniania bada, czy osoba ta lub
obiekt ma prawo do chronionego zasobu. Wszystko to jest brane pod uwage w celu podjecia decyzji o
udzieleniu dostepu. Identyfikator podaje tylko niepotwierdzona tozsamosc. Numery identyfikacyjne
powinny w miare mozliwosci uzywac cyfr kontrolnych lub stosowac inne metody samokontroli, by
zminimalizowac szanse blednej identyfikacji. Identyfikatory sa niezbedne dla rozliczen i upowazniania,

ale nie moga byc uzywane bez dodatkowego uwierzytelniania, jesli jest potrzebny w systemie stopien
bezpieczenstwa. Uwierzytelnienie zwykle jest dokonywane jednorazowo, ale w instalacjach o duzym
stopniu bezpieczenstwa moze byc wymagana okresowa lub stala weryfikacja. Dla uwierzytelniania
tozsamosci uzytkowników komputery uzywaja hasel lub innych metod dialogowych. Z punktu widzenia
uzytkownika znacznie wazniejsze sa czynniki takie jak: liczba znaków do wprowadzenia, wysilek
umyslowy i sposób postepowania w wypadku popelnienia bledu przy wpisywaniu.
Metoda pytan i odpowiedzi - system otrzymuje zbiór odpowiedzi na m.-standardowych i n-
dostarczonych przez uzytkownika pytan. System przy kazdej próbie rozpoczecia sesji przez
uzytkownika zadaje z posród tych pytan niektóre (wybrane przypadkowo). Trzeba na nie wszystkie
poprawnie odpowiedziec. Pytania dobiera sie tak, by uzytkownik tylko znal odpowiedzi a nie musial je
zapisywac. Wyrózniamy pytania systemowe i pytania uzytkownika.
1 etap – pytania systemowe, to wspólna lista dla wszystkich uzytkowników, a gdy odpowiedzi do tego
rodzaju pytan sa poprawne to przechodzimy dalej
2 etap – pytania do danego uzytkownika
- w kazdej sesji po poprawnej serii odpowiedzi uzytkownik moze dokonac korekty do pytan
uzytkownika.
Uwierzytelnianie tozsamosci systemów - hasla moga byc stosowane takze do uwierzytelniania
tozsamosci systemów np. w sieciach. Do uwierzytelniania systemów mozna wykorzystywac szyfry.
Uzytkownik po podaniu hasla troche czeka, gdyz terminal podaje swoje dane identyfikujace do
jednostki centralnej systemu.
Procedura uwierzytelniania - system moze zadac od uzytkownika uwierzytelniania w postaci
poprawnego wykonania jakiegos algorytmu. Nazywane jest to czesto procedura przywitania - ma
wyzszy stopien bezpieczenstwa, ale jest bardziej czasochlonne i zmudne i wymaga operacji
myslowych.
Jednak jest to metoda odporna na podglady i podsluch na liniach komunikacyjnych.
Np.
X
tn(X)
1312
4
4752
86
5472
76
1111
0 itd.
Gdzie X – losowa liczba podana przez komputer
tn(X) – wartosc wyliczona przez uzytkownika na podstawie algorytmu.
Procedury uzytkownika - niektóre systemy dopuszczaja wykonanie dostarczonych przez uzytkownika
procedur przed wejsciem do systemu. Zaraz po przeslaniu pierwszego wiersza z terminalu system
przekazuje sterowanie tej procedurze. Po zakonczeniu tej procedury system wywoluje wlasna kontrole
bezpieczenstwa.
Fizyczne metody uwierzytelniania - inne metody uwierzytelniania niz programowe sprawdzaja czy
uzytkownik posiada jakis przedmiot lub czy charakteryzuje sie jakas cecha fizyczna np. odciski palców,
karty magnetyczne, zamki z kluczami itp.
Dzialania w wyniku odmowy udzielenia dostepu - dziennik systemu i zwloka czasowa przy zle
wprowadzonej odpowiedzi, oraz ilosc prób wejscia do systemu.
AD. 3
Co to jest obiektowa baza danych:
1. jest to system , który umozliwia zarzadzanie baza danych, zorientowany obiektowo
2. jest to system, który dziedziczy wszystkie zasadnicze cechy technologii obiektowej (istnienie
zlozonych obiektów, tozsamosc obiektów, enkapsulacja danych i procedur, dziedziczenie,
funkcje polimorficzne, rozszerzalnosc o nowe typy danych ) i baz danych (trwalosc danych,
oddzielenie fizycznego i logicznego poziomu danych, zarzadzanie wielodostepem, odtwarzanie
spójnego stanu danych po awariach, zapytania ad hoc, zarzadzanie transakcjami, i in.)

Co to jest obiektowy model danych:
Jest to model danych, w którym wykorzystano cechy obiektowosci, tj. pojecie klasy,
enkapsulacja, mechanizm identyfikacji obiektów, dziedziczenie, przeciazanie funkcji i pózne wiazanie
Co to jest obiekt:
Obiekt jest podstawowym pojeciem dla obiektowosci. Obiekt reprezentuje soba konkretny
pojedynczy byt (ksiazke, osobe, samochód) charakteryzowany przez opis stanu (atrybuty obiektu) i
zachowania tego bytu (metody obiektu). Opis ten jest realizowany przy uzyciu klasy.
Co to jest klasa i obiekty klasy:
•
Klasa jest zbiorem obiektów o jednakowej strukturze wewnetrznej (atrybutach i metodach). O
obiektach w tym rozumieniu mówi sie ze sa obiektami pewnej klasy. Opis stanu obiektów klasy
realizowany jest za pomoca atrybutu natomiast opis zachowania sie obiektów za pomoca metod
(procedur i operacji), które mozna wykonywac dla obiektów tej klasy.
•
Klasa moze byc rozumiana jako pewien opisywany typ
•
Klasa jest obiektem – wtedy nalezy okreslic sposób opisu takiego obiektu, którego jest klasa,
nalezy wyodrebnic specyficzne cechy obiektu (nazwa, liczba obiektów w klasie, metoda
dodaj/usun, atrybut z tej klasy)
Atrybuty:
Wartosci atrybutów (wartosci proste interpretowane na dwa sposoby)
•
Takie, które nie maja swojego opisu, maja tylko wartosc
•
Takie, które moga byc interpretowane jak inne dane, majace swoja nazwe i wartosc.
Atrybuty klasy (wlasciwe dla obiektów, które sa klasa):
•
Wyliczalne
•
Domyslne
Atrybuty obiektu:
•
Proste (wartosci rozumiane sa w sposób prosty, o.b.d. nie rózni sie od relacyjnej b.d.)
•
Zlozone
Atrybuty referencyjne – ich wartosci wskazuja na inne obiekty. Maja to do siebie, ze powstaja
nowe zjawiska, moga powodowac powstanie cykli, jezeli powstal obiekt kompozytowy (moze byc
okreslany na zasadzie silnego lub slabego powiazania). Silne powiazanie – wynikajace z semantyki
danych. Slabe powiazanie – nie wynika z pow. semantycznego)
Czy róznia sie pojecia obiektu, klasy oraz obiektów klasy dla obiektowych baz danych od tych samych
pojec dla popularnych obiektowych jezyków programowania:
Pojecia te sa z reguly zgodne dla o.b.d. i dla obiektowych jezyków programowania (np. C++,
Smalltalk, itp.). Róznice moga byc spowodowane tym, iz pojecia te nie zawsze rozumiane sa
jednakowo w róznych jezykach programowania a nawet w róznych podejsciach do obiektowych baz
danych.
Jakie elementy skladaja sie na standardowy opis klasy:
Sa to nastepujace elementy:
•
nazwa klasy
•
cechy (atrybuty) klasy (wspólne dla wszystkich)
•
opis statycznej struktury obiektów nalezacych do klasy: zbiór atrybutów opisujacych obiekty
tej klasy
•
opis dynamicznych zachowan obiektów: zbiór definicji metod (metody dzialan na atrybuty
obiektu)
Co to jest enkapsulacja:
Pelna e. mamy wtedy, gdy wszystkie atrybuty mozna traktowac jako atr.
wirtualne,
bowiem wtedy dostep do wszystkich atrybutów odbywa sie tylko za posrednictwem metod. Zapewnia
ona, ze wewnetrzna struktura i funkcjonowanie danego obiektu sa dla innych obiektów niewidoczne
(information hiding).
Koncepcja enkapsulacji (hermetyzacji) wywodzi sie z potrzeby rozdzielenia deklaracji i implementacji
operacji oraz z potrzeby strukturyzacji programu poprzez jego podzial na funkcjonalnie niezalezne
moduly.
Samo pojecie wywodzi sie z obiektowych jezyków programowania i odwoluje sie do pojecia
abstrakcyjnych typów danych. W tym podejsciu rozrózniamy: deklaracje danej struktury i jej definicje.
W czesci deklaracyjnej wyszczególnia sie zestaw operacji, jakie moga byc wykonywane na danym
obiekcie – dla uzytkownika jest to jedyna widoczna czesc obiektu. Czesc definicyjna sklada sie z
definicji danych, czyli atrybutów i definicji procedur – metod.

Pojecie enkapsulacji dla baz danych ma podobne znaczenie.
Jaka jest koncepcja enkapsulacji w obiektowych bazach danych:
Przy zachowaniu pelnej enkapsulacji uzytkownicy maja dostep do danych, czy to dla
wyszukania czy dla modyfikacji tylko poprzez operacje zdefiniowane dla danego typu obiektu. Taki
model enkapsulacji zapewnia rodzaj logicznej niezaleznosci danych. Nie zawsze korzystna jest pelna
niewidocznosc danych dla uzytkownika – czasami przy formulowaniu zapytan odwolujacych sie
bezposrednio do atrybutów potrzebna jest ta mozliwosc. Wiekszosc systemów obiektowych baz
danych daje mozliwosc dostepu do atrybutów, sluza do tego systemowe operacje czytania i
modyfikacji atrybutów. Innym problemem jest tworzenie metod dla obiektów odwolujacych sie do
wartosci atrybutów innych obiektów. W przypadku pelnej enkapsulacji jest to niemozliwe. Rozwiazanie
wzieto z obiektowych jezyków programowania i wprowadzono typ friend (zaprzyjazniony), dzieki temu
metody nalezace do danego obiektu moga odwolywac sie do wartosci atrybutów obiektu nalezacego
do typu friend.
Zestaw 2
AD. 1
W projektowaniu BD nalezy szczególna uwage zwrócic na takie ich zorganizowanie, by mogly miec jak
najwieksze zastosowanie oraz by sposób wykorzystania mógl byc zmieniony szybko i latwo. Aby
zapewnic elastycznosc w uzywaniu danych trzeba miec na uwadze :
1. dane powinny byc niezalezne od programów, które z nich korzystaja.
2. zadawanie pytan i przeszukiwanie BD powinno wyeliminowac pisanie programów w
konwencjonalnych jezykach.
Aby dobrze zaprojektowac BD nalezy wyszczególnic wszystkie dane jakimi operujemy i dokonac
powiazan miedzy nimi.
System przy projektowaniu powinien spelniac warunki:
1. projektant systemu BD powinien byc jawny. Powinny byc nawet ujawnione rodzaje ubezpieczen,
ale bez odpowiednich kluczy, algorytmów rozwiazujacych.
2. System powinien byc latwy w obsludze tzn. akceptowalnosc.
3. Projekt powinien w pelni uczestniczyc w calkowitym posrednictwie miedzy danymi, a
uzytkownikiem.
4. Projekt powinien przydzielac jak najmniejsze prawa uzytkownikom, a dopiero administrator moze
miec mozliwosc nadawania wiekszych praw lub odebrania ich.
Programista projektujacy BD powinien bardzo dobrze znac zastosowanie bazy i znac srodowisko dla
której tworzy baze danych. Przy projektowaniu BD nalezy uwzglednic wszystkie cechy BD opisane w
pytaniu 3.
Schematy przyszlosciowe-które korzystajac ze slownika danych opisywalyby struktury danych nie
wystepujace jeszcze w systemie. Schematy inteligentne-tak potrafia wykorzystac powiazania miedzy
danymi, ze wiedza wszystko na temat znaczenia lub tresci danego powiazania. Musimy wiedziec jaki
model BD wybrac: relacyjny, hierarchiczny czy sieciowy.
Aby dobrze zrobic BD nalezy wyspecyfikowac wszystkie dane jakimi operujemy i dokonac powiazan
miedzy nimi-jest to najwazniejsze. Nalezy sie dobrze orientowac w powiazaniach danych.
W systemie 3 kryteria zabezpieczen powinny byc zaimplementowane -patrz pytanie 22.
Projekt powinien zakladac udzielanie uzytkownikom przywilejów i dokladac ich, a nie odejmowac,
mimo to system musi umiec sprawnie reagowac na zadania nieprzewidziane.
Powinien byc otwarty na modyfikacje tj. aktualizacje, dopisywanie nowych danych jak i mechanizmy
rozbudowy do BD.
Ø Projektowanie BD rozpoczyna sie od stworzenia schematów zewnetrznych dla poszczególnych
uzytkowników.
Ø Powstale schematy laczymy nastepnie tworzac model konceptualny BD.

Musimy dokonac wyboru co do typu organizacji danych pomiedzy modelem: sieciowym,
hierarchicznym i relacyjnym.
Ø Nalezy zaprojektowac system zarzadzania BD, który bedzie posredniczyl w dialogu czlowiek-
nabywca.
System zarzadzania powinien tworzyc proste i przejrzyste schematy dla poszczególnych
programistów oraz powinien zapewniac niezaleznosc fizyczna i logiczna danych i programów.
System powinien zapewnic minimalna redundancje, integralnosc i poufnosc danych.
Systemy powinny przyjmowac dane wprowadzone jeszcze przed ich instalacja tzn. sprzezenie z
przeszloscia i przyszloscia.
Dane wprowadzone do systemu beda przechowywane w rózny sposób.
♦
Na poczatku nastepuje wstepna selekcja encji i zwiazków
♦
Nastepnie wykrycie zwiazków wielokrotnych i ich natury.
♦
Po czym model jest racjonalizowany oraz wyliczane sa atrybuty
♦
Ostatni krok przygotowania bazy danych to ustalenie klucza glównego .
Kluczem relacji nazywamy taki zbiór atrybutów tej relacji, których kombinacje wartosci jednoznacznie
identyfikuja kazda krotke tej relacji i którego zaden podzbiór wlasciwy nie ma tej wlasnosci.
Klucz glówny-jednoznacznie wyróznia obiekty.
Klucz kandydujacy- zbiór atrybutów o wlasnosciach klucza glównego.
Zasady rysowania schematu danych:
1. Laczenie danych elem. w grupy powinno byc przejrzyste.
2. Z schematu powinno wynikac, które nazwy sa nazwami danych elementarnych, rekordów, pól,
schematów itd.
3. Nie wolno duplikowac nazw.
4. Nalezy wyróznic klucze glówne, klucze wtórne, gdy sa waznym elementem schematu.
5. Ze schematu powinno wynikac, które powiazania sa proste, a które zlozone oraz podac ich nazwy,
jesli istnieja .
6. Jesli powiazania maja nalezy je przedstawic w schemacie( wnikniecie w nature danych).
Wyszukac wszystkie wystapienia SLUCHACZ rozpoczynajac od pierwszego sluchacza dla wystapienia
segmentu OFERTA znalezionego w KURSIE, w którym wartoscia pola LOKALIZACJA jest Polska.
GU KURS
OFERTA (LOKALIZACJA=‘POLSKA’)
SLUCHACZ
NS GN SLUCHACZ
go to NS
Usunac oferte kursu M23 z data 13 sierpien 1983.
GHU KURS (KURS# =‘M23’)
OFERTA (DATA=‘830813’)
DLET
Przeszukiwanie drzewa binarnego:
- wzdluzne KAB
- poprzeczne AKB
- wsteczne ABK
Podejscie hierarchiczne
- mozna przedstawic graficznie za pomoca drzewa
- rekord moze nie miec rekordu podrzednego (pusty zbiór wystapien rekordu podrzednego)
- wierzcholek drzewa - rekord glówny
- moze istniec dowolna liczba rekordów podrzednych i dowolna liczba poziomów podrzednosci
- zaden rekord podrzedny nie moze istniec bez nadrzednego
- podejscie hierarchiczne pozwala na naturalne modelowanie rzeczywistosci, której odpowiadaja
struktury hierarchiczne
- asymetria jest glówna wada podejscia hierarchicznego, gdyz niepotrzebnie komplikuje zagadnienie
Operacje:
Wprowadz - bez uzycia specjalnego rekordu pustego (nadrzednego) nie mozne wprowadzic rekordu,
który w hierarchii jest podrzedny.
Usun - problem powstaje wówczas, gdy usuwamy jedyne wystapienie rekordu X (który jest ogniwem
posrednim) w calej bazie danych, to tracimy informacje o rekordzie podrzednym.

Aktualizuj - chcac zaktualizowac inf. o rekordzie musimy przeszukac cala baze danych i zaktualizowac
wszystkie wystapienia tego rekordu. W przeciwnym razie moga pojawic sie sprzecznosci.
1. Zaleznosc funkcjonalna: atrybut b jest funkcjonalnie zalezny od atrybutu a wtedy i tylko wtedy
gdy, kazdej wartosci atrybutu a odpowiada okreslona wartosc atrybutu b.
2. Pelna zaleznosc funkcjonalna: atrybut b jest w pelni funkcjonalnie zalezny od atrybutu a wtedy i
tylko wtedy gdy, jest funkcjonalnie zalezny od tego atrybutu i nie zalezy od zadnego podzbioru
tego atrybutu
3. Zaleznosc tranzytywna: równolegla zaleznosc od tego samego atrybutu.
4. Zaleznosc wielowartosciowa: jest uogólnieniem zaleznosci funkcjonalnej; wystepuje gdy wartosc
jednego atrybutu determinuje zbiór wartosci drugiego atrybutu.
5. Zaleznosc polaczeniowa: wystepuje w relacji R wtedy i tylko wtedy gdy, po dekompozycji relacji
oraz po nastepnym jej zlozeniu otrzymujemy ta sama relacje R.
Model relacyjny dostarcza tylko jednego sposobu reprezentowania danych. Jest nim dwuwymiarowa
tablica, nazwana relacja.
Zasady jakim podlegaja relacje CODD’A:
1. kazdy element tablicy reprezentuje jedna elementarna dana.
2. Elementy jednej kolumny naleza do zbioru wartosci prostych.
3. Kazdej kolumnie przyporzadkowana jest jedna nazwa.
4. W tablicy nie moga wystapic dwa identyczne wiersze.
5. Kolejnosc wystepowania kolumn i wierszy w tablicy nie jest istotna.
Relacja : dowolny podzbiór iloczynu kartezjanskiego.
Atrybuty – kolumny tabeli
Krotki – wiersze tabeli
Stopien tabeli – liczba kolumn w tabeli
Liczebnosc tabeli – liczba wierszy w tabeli
Klucz glówny –
Klucz kandynujacy –
Klucz obcy –
Zaleznosci mówia o zwiazkach miedzy atrybutami.
AD. 2
Problem obiektów wielotypowych odnosi sie do pojecia dziedziczenia wielokrotnego. Dziedziczenie
wielokrotne rózni sie tym od dziedziczenia pojedynczego tym, ze klasa moze dziedziczyc atrybuty
i metody od wiecej niz jednej nadklasy.
Przyklad:
Pojazd
Predkosc ekspolatac
masa
Pojazd wodny
wypornsc
predkosc
Pojazd ladowy
ciezar
predkosc
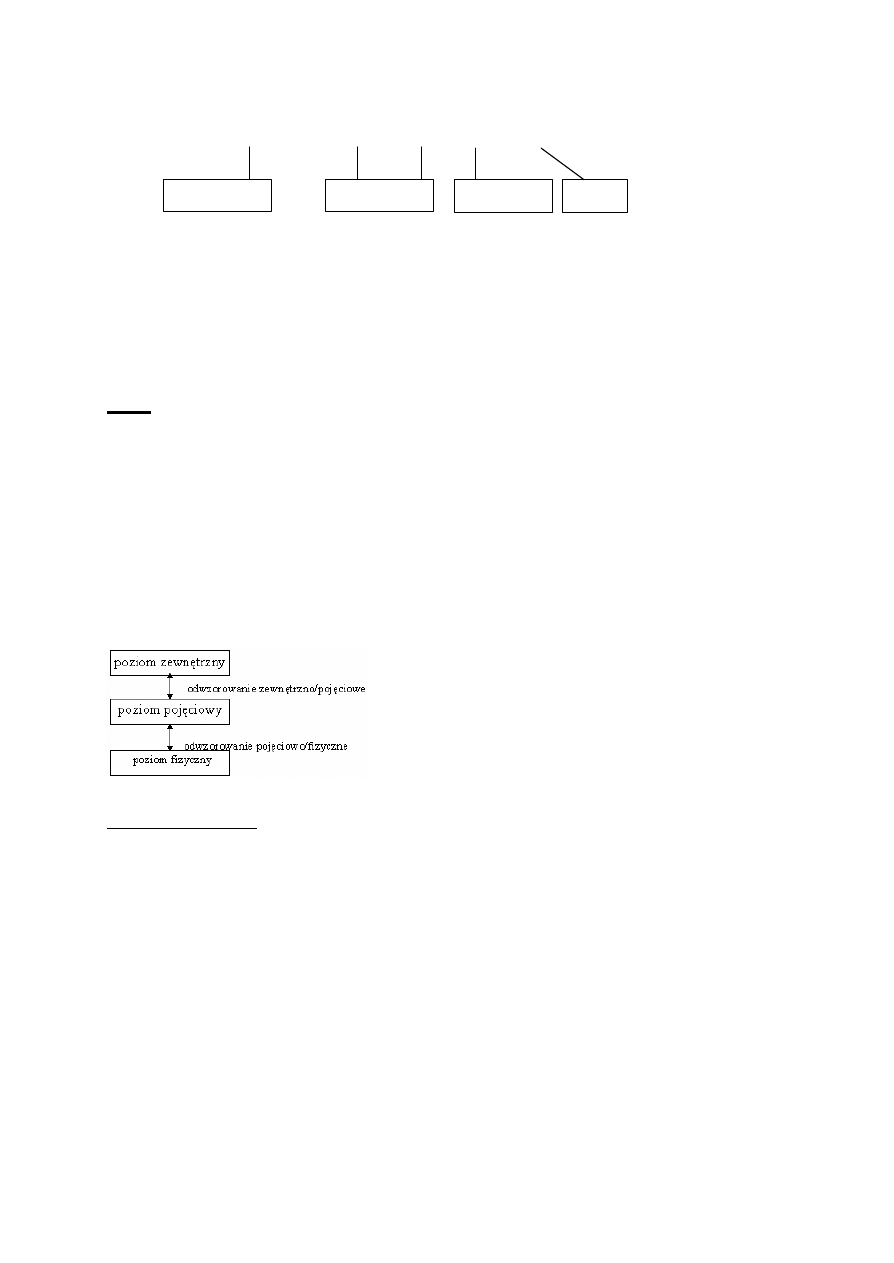
W naszym przykladzie istnieje obiekt amfibia który dziedziczy atrybuty i metody ze swoich nadklas
(pojazd ladowy i pojazd wodny). Do tego obiektu moga byc dodawane nowe zestawy nie istniejacych
atrybutów oraz metod.
Dziedziczenie wielokrotne jest modelem wilce kontrowersyjnym ze wzgledu na mozliwosc powstania
konfliktów nazw. W naszym przypadku jest to atrybut predkosc, który moze byc podawany w
kilometrach na godzine lub w wezlach.
AD. 3
Podstawowym celem baz danych jest zapewnienie niezaleznosci danych, czyli: odpornosc programów
uzytkowych na zmiany struktury pamieci i strategii dostepu. Rozrózniamy 2 typy niezaleznosci danych:
•
logiczna-zmiany w strukturze logicznej bazy danych nie wywoluja zmian w strukturze fizycznej
oprogramowania.
•
fizyczna-zmiany w strukturze fizycznej baz danych nie wywoluja zmian w
strukturze logicznej bazy.
Niezaleznosc fizyczna wyraza sie w tym, ze w wyniku zmian struktury pamieci zmienia sie jedynie
definicja odwzorowania miedzy poziomem pojeciowym a poziomem fizycznym.
Niezaleznosc logiczna wyraza sie tym, ze w wyniku zmian na poziomie pojeciowym zmienia sie tylko
definicja odwzorowania miedzy poziomem pojeciowym a poziomem zewnetrznym - umozliwia to
zachowanie programów uzytkowych w nie zmienionej postaci.
Reprezentacja danych:
- poziom pojeciowy - jest on abstrakcyjnym, lecz wiernym opisem pewnego wycinka rzeczywistosci.
- poziom wewnetrzny - okresla sposoby organizacji danych w pamieci zewnetrznej.
- poziom zewnetrzny - odnosi sie do sposobu w jaki dane sa widziane przez poszczególne grupy
uzytkowników.
W strukture logiczna programu uzytkowego wladowuje sie informacje dotyczace organizacji danych w
pamieciach zewnetrznych. Jezeli jakis zbiór bedzie pamietany w postaci indeksowo-sekwencyjnej, to
ukladajac program uzytkowy nalezy uwzglednic istnienie indeksu (a nawet w pewnych momentach od
niego zalezec). Zmiana zbioru indeksowo-sekwencyjnego na zbiór o adresowaniu metoda mieszajaca
moze okazac sie niewykonalna w programie uzytkowym.
Rózne programy uzytkowe wymagaja róznego spojrzenia na te same dane. Np. jezeli istnialy
programy uzytkowe A i B i kazdy z nich mial wlasny zbiór danych zawierajacych pole „konto”, ale w
programie A zapisuje sie je w postaci dwójkowej, a w programie B w postaci dziesietnej, to
zintegrowanie tych zbiorów bedzie mozliwe wtedy i tylko wtedy, gdy oprogramowanie baz danych
wykona wszystkie niezbedne przeksztalcenia wybranej postaci pamietania danych do postaci
wymaganej przez kazdy z programów uzytkowych A i B. Jest to przyklad istniejacej w bazach danych
róznicy miedzy spojrzeniem autora programu uzytkowego na dane, a sposobem ich fizycznego zapisu.
rower
samochód
statek
amfibia
Musi istniec mozliwosc zmiany struktury pamieci (lub strategii dostepu) w wyniku udostepnienia
nowych typów nosników pamieciowych, wprowadzania nowych standardów itp. bez koniecznosci
modyfikowania istniejacych programów uzytkowych. Zmiany w nich pochlaniaja duzo czasu (ok. 25%
czasu pracy), a jest to strata szczególnie wartosciowych zasobów przedsiebiorstwa. (Mozna by go
przeznaczyc na pisanie nowych programów). Niezaleznosc danych jest podstawowym skladnikiem
cechujacym bazy danych, a mianowicie „sprzezeniem z przyszloscia”, poniewaz nie mozna dokladnie
okreslic kierunku rozwoju zastosowan pamietanych danych.
Schemat kanoniczny jest próba opisu wewnetrznych wlasciwosci danych. Jezeli system zarzadzania BD
korzysta z niego, który nie zmienia sie bez wzgledu na rodzaj zastosowanego sprzetu,
oprogramowania czy fizycznej struktury danych, to mozna mówic o prawdziwej niezaleznosci danych.
W praktyce nie stosuje sie go. Schemat kanoniczny ??? jest jako model danych, przedstawiajacy
wewnetrzna strukture danych. Tym samym niezalezny jest od poszczególnych dziedzin stosowania
danych, jak równiez od mechanizmów zwiazanych z oprogramowaniem lub sprzetem, które to
wykorzystywane sa do reprezentowania oraz zachowywania danych.
Statyczna i dynamiczna niezaleznosc danych: O wiazaniu dynamicznym mówimy, gdy wiazanie
wystepuje w momencie wyszukiwania danych. Schemat lub fizyczna organizacja moze byc wtedy
modyfikowana w dowolnym momencie - daje ono dynamiczna niezaleznosc danych. Statyczna
niezaleznosc danych wymaga, aby przeprowadzenie zmian w schemacie ogólnym, podschemacie lub
fizycznej reprezentacji, zakonczylo sie zanim dowolny program uzytkowy uzywajacy tych danych
zostanie wykonany. Mamy 3 rodzaje danych:
1. Dane zagregowane? - tresc danej majacej nazwe definiuje sie tylko raz . Kazdy programista
odwolujacy sie do okreslonej danej musi zakladac te sama tresc tej danej.
2. Dane elementarne - definiuje sie tylko raz. Programista odwolujacy sie do tych danych musi
zakladac te sama ich tresc. Z tego samego zbioru danych elementarnych moga byc utworzone rózne
rekordy lub segmenty.
3. Dane subelementarne - tresci tych danych, majacych nazwe, moga byc rózne w róznych
programach uzytkowych. I tak np. jeden program moze odwolywac sie do siedmiocyfrowych, a inny
do osmiocyfrowych danych elementarnych (patrz przyklad wyzej).
SCHEMAT - wskazanie wszystkich danych wraz z ich powiazaniami w bazie danych.
PODSCHEMAT - fragment, który interesuje dane osoby operujace na danych np. ksiegowy,
personalny.
Zestaw 3
AD. 1
1. Tworzenie pierwotnego opisu struktury bazy danych i sposobu odwzorowania go w plikach
fizycznych bazy danych.
2. Udzielanie uzytkownikom zezwolen na korzystanie z bazy danych lub jej fragmentów.
3. Modyfikacja opisów bazy danych lub jego zwiazków z fizyczna organizacja bazy danych, gdy
wnioski z jej eksploatacji wskaza , ze inna organizacja bylaby bardziej efektywna.
4. Wykonywanie archiwalnych kopii bazy danych i przywracanie jej poprawnego (pierwotnego)
stanu po uszkodzeniu powstalych na skutek awarii lub nieprawidlowego uzycia sprzetu lub
oprogramowania.
Administrator systemu baz danych to zespól ludzi. Musi znac biegle organizacje baz danych, ale nie
musi znac zawartosci baz danych.
Pelni on bardzo wazna funkcje podczas tworzenia i uzytkowania baz danych. Jest odpowiedzialny za:
•
Skonstruowanie schematu pojeciowego zewnetrznego
•
Okreslenie organizacji fizycznej danych i metod dostepu do danych
•
Definiowanie procedur zapewniajacych dobry poziom niezawodnosci systemu.
Administrator musi miec swobode zmiany struktury pamieci lub strategii dostepu bez koniecznosci
modyfikowania programów uzytkowych.
Jest on odpowiedzialny za:
1. decyduje jakie informacje beda utrzymywane w bazie danych
2. ustala jakie dane powinny byc reprezentowane w bazie danych i okresla cechy tej
reprezentacji oraz odpowiednie odwzorowanie miedzy struktura pamieci a schematem
pojeciowym
3. utrzymuje kontakt z uzytkownikiem w celu zapewnienia dostepu do danych
4. definiuje procedury badania legalnosci i poprawnosci
5. definiuje i realizuje odpowiednia strategie odtwarzania
6. musi zapewnic wydajnosc najlepsza dla zakladu oraz odpowiednie dostosowanie systemu do
zmieniajacych sie wymagan.
AD. 2
PROBLEM WIELOWERSYJNOSCI OBIEKTÓW
Wielowersyjnosc obiektów ma na celu odwzorowanie poszczególnych cykli powstawania
jakiegos tworu (np. w programie, po wykonaniu czegos mozna wracac do poszczególnych wersji,
kazda z nich jakos sie zazebia w sensie historycznym).
Wprowadzenie wersji obiektu moze tez byc korzystne w aplikacjach, w których konieczne jest
stosowanie dlugotrwalych transakcji, zamykajacych dostep do obiektu, dla innych uzytkowników. W
standardowych systemach zarzadzania baza danych zmodyfikowanie wartosci atrybutów obiektów
powoduje utrate poprzednich danych. W bardziej wyrafinowanych aplikacjach, zwlaszcza w takich,
gdzie baza danych wykorzystywana jest do wspomagania projektowania rozmaitych produktów bardzo
uzyteczne byloby przechowywanie poprzednich wersji obiektów.
Zwykle powstanie nowej wersji jest decyzja projektanta, który akceptuje naniesienie zmiany.
Przy zarzadzaniu wersjami obiektu poslugujemy sie dwoma podstawowymi pojeciami: pochodzenie
wersji i historia wersji. Nowa wersja pochodzi od pewnej wersji poprzedniej. Kazda kolejna wersja
powstaje w wyniku modyfikacji dokonanej w jakims odcinku czasowym, wersji poprzedniej, a ta
wywodzi sie z kolei z jakiejs wersji pierwotnej. Przedstawienie pochodzenia poszczególnych wersji
obiektów dostarcza historia wersji.
Do czego jest potrzebna wielowersyjnosc w systemach obiektowych:
Wprowadzenie wielowersyjnosci pozwala na zachowanie poprzednich danych, jest to
konieczne w systemach, w których stosowane sa dlugotrwale transakcje, zamykajace dostep do
obiektu dla innych uzytkowników.
Co rozumiemy pod pojeciem wersji obiektu:
Przez wersje obiektu rozumiemy semantycznie znaczacy rzut obiektu, dokonany w pewnym
momencie czasowym. Semantycznie znaczacy oznacza, ze nie kazda modyfikacja obiektu tworzy jego
nowa wersje.
Co to jest historia pochodzenia wersji i historia wersji:
Nowa wersja pochodzi od pewnej wersji poprzedniej; kazda kolejna wersja powstaje w wyniku
modyfikacji wersji poprzedniej, a ta wywodzi sie z jakiejs wersji pierwotnej.
Przedstawienie pochodzenia poszczególnych wersji obiektów dostarcza historie wersji. Graficzna
reprezentacja historii moze byc drzewo – wezly drzewa odpowiadaja poszczególnym wersjom. Od
danej wersji moze pochodzic kilka równoleglych wersji – mówimy wtedy o alternatywach wersji.
Wersja obiektu kompozytowego moze skladac sie z poszczególnych wersji jego obiektów skladowych.
Co to jest konfiguracja obiektu:
Konfiguracja obiektu okresla zwiazek miedzy wersjami obiektu kompozytowego a wersjami
kazdego z obiektów skladowych danego obiektu. Konfiguracje obiektów moze tworzyc uzytkownik, tu
system musi udostepniac uzytkownikowi odpowiednie narzedzia umozliwiajace sprawne i spójne
tworzenie nowych konfiguracji obiektów, lub system automatycznie tworzy konfiguracje z tym, ze
uzytkownik okresla sposób tworzenia takich konfiguracji – ustawia odpowiednie opcje systemu.
Czy jest mozliwe przechowywanie w obiektowych bazach danych informacji multimedialnych:
W systemach obiektowych baz danych dazy sie do wprowadzenia obiektów przechowujacych
dane graficzne, obrazy, zdjecia. Mozliwe jest dolaczanie do obiektów zawierajacych informacje
tekstowa.
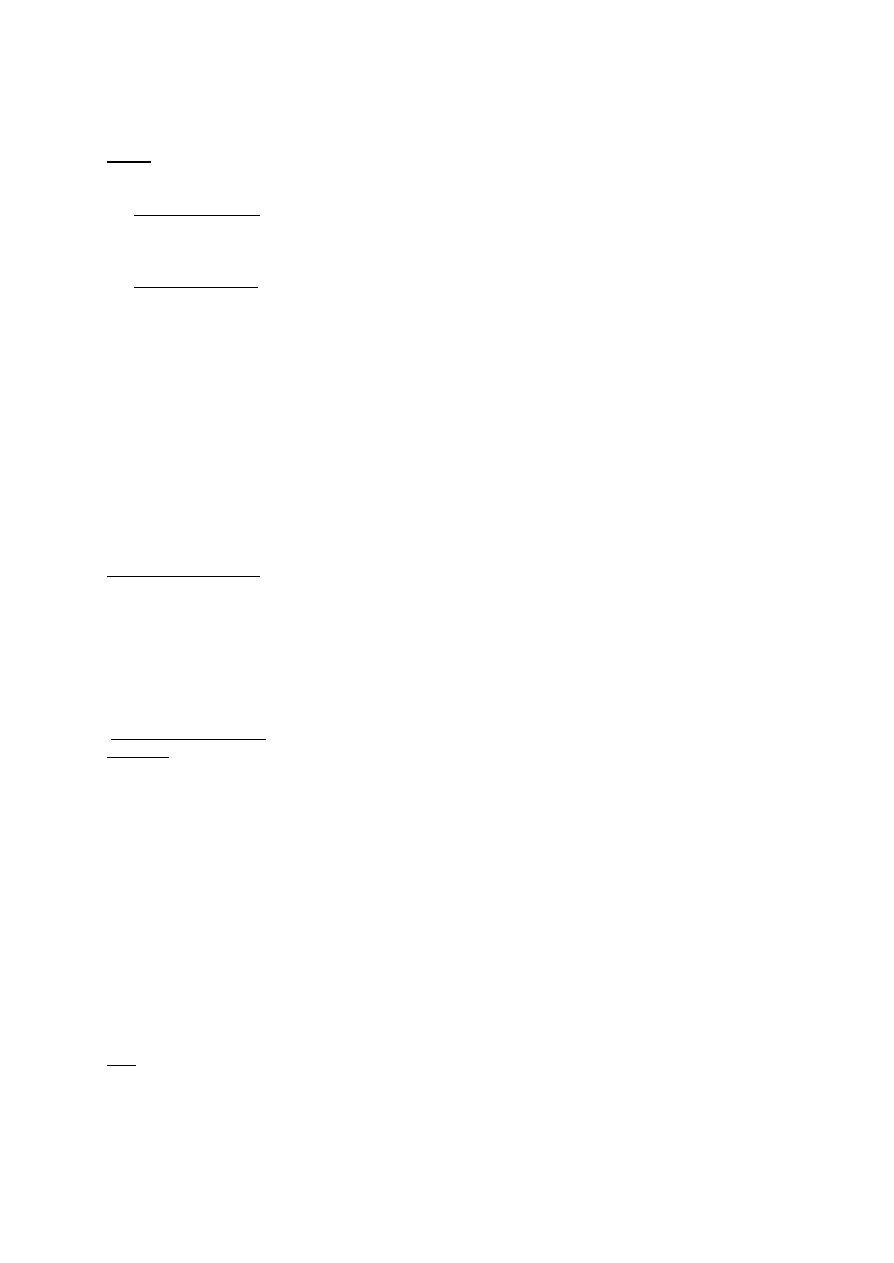
AD. 3
W modelu relacyjnym stosowane sa dwa rodzaje jezyków sztucznych: algebraiczny i predykatowy.
•
Jezyk algebraiczny: Podstawa tego jezyka stanowi zalozenie mówiace o tym, ze informacje, która
chcemy wybrac z bazy danych mozna wyrazic w postaci relacji, powstalej w wyniku wykonywania
operacji jedna po drugiej.
Jezyk ten jest oparty na relacjach algebraicznych, które moga byc wykonywane na relacjach.
•
Jezyk predykatowy: Opiera sie na rachunków predykatów.
Do podstawowych symboli naleza:
1. nawiasy: ( , )
2. symbole zmiennych ( x, y, z ) i stalych ( a, b, c )
3. symbole funkcji ( male litery )
4. symbole predykatów ( duze litery )
5. operatory: negacja,
6. kwantyfikatory: ogólny, szczególowy
Predykat definiuje sie opierajac na pojeciach ze zbioru X i zmiennej przyjmujacej wartosci ze
zbioru X.
Predykat P(x) jest funkcja zdaniowa, która staje sie zdaniem, gdy w miejsce zmiennej x
podstawimy dowolna wartosc ze zbioru X. Okreslenie wartosci logicznej polega na
przyporzadkowaniu jednej z dwóch wartosci: „prawda” lub „falsz”.
W modelu relacyjnym stosuje sie dwa typy jezyków sztucznych. Mianowicie : jezyk algebraiczny oraz
jezyki predykatowe.
JEZYK ALGEBRAICZNY : Podstawe jezyka algebraicznego stanowi zalozenie mówiace o tym, ze
informacja, która chcemy wybrac z bazy danych, daje sie wyrazic w postaci relacji powstalej w wyniku
wykonania szeregu operacji jedna po drugiej, których argumentami sa relacje istniejace w BD.
Operacje jezyka algebraicznego - patrz pytania nr.18.
W jezyku algebraicznym w skladni operacji, które zdefiniowalismy, uwzglednialismy zawsze nazwy
atrybutów relacji. Mozna przyporzadkowac poszczególnym nazwa atryb. relacji numery kolumn w
tablicy relacji, przy zalozeniu, ze jest to przyporzadkowanie wzajemnie jednoznaczne. Nie wszystkie
operatory sa proste tzn. daja sie przedstawic za pomoca innych operatorów. Jest to zamierzone, gdyz
chodzi o ulatwienie uzytkownikowi formulowania zadan kierowanych do systemu BD.
JEZYKI PREDYKATOWE opieraja sie na rachunku predykatów pierwszego rzedu.
Predykat definiuje sie opierajac na pojeciach zbioru X i zmiennej x przyjmujacej wartosci z X. Predykat
P(x) jest funkcja zdaniowa, która staje sie zdaniem, gdy w miejsce zmiennej x podstawimy dowolna
wartosc ze zbioru X. Okreslenie wartosci logicznej predykatu polega na przyporzadkowaniu mu jednej
z dwóch wartosci: prawda lub falsz. 1-argumentowy predykat P(x).
Wieloargumentowy P(x
1
,x
2
,...,x
n
) x
1
∈
X
1
, x
2
∈
X
2
, ... , x
n
∈
X
n
.
•
JEZYK PRZEDMIOTOWY :
→
def. predykatu. Zmienna wolna tzn. nie zwiazana zadnym
kwantyfikatorem. Zmienna zamknieta to zwiazana kwantyfikatorem. Pytanie zamkniete
odpowiada formule zamknietej. Pytanie otwarte odpowiada formule otwartej. Jesli P jest
symbolem
predykatu n-argumentowego,a t
1
,t
2
,..,t
n
sa termami, to P(t
1
,t
2
,...,t
n
) jest formula atomowa.
•
RACHUNEK PREDYKATÓW O ZMIENNYCH KROTKOWYCH (tez jezyki predykatowe -odmiana) :
zmienne odpowiadaja krotkom relacji.
•
RACHUNEK PREDYKATÓW O ZMIENNYCH ATRYBUTOWYCH : zasady zgodne jak przy
konstruowaniu formuly. Wyjatek : zmienne wyrazen przyjmuja wartosci z dziedzin zwiazanych z
poszczególnymi atrybutami relacji..
Jezyki te sa jezykami kwerend stanowiacych podstawe okreslonych jezyków manipulowania danymi
opracowanych dla konkretnych systemów relacyjnych.
Ad1. Przykladem jezyka opartego na algebrze relacji jest jezyk ISBL. W jezyku tym podajemy
kolejnosc operacji, a wiec mówimy w jaki sposób uzyskac dana informacje. Jest to jezyk proceduralny.
Odpowiedniosc operatorów i argumentów alg.relacji jest nastepujaca : R
∪
S
→
R
+
S; R
−
S
→
R
−
S; R
∩
S
→
R
•
S; R S
→
R
.
S;
δ
F
(R)
→
R
:
F;
Π
A1,...,An
(R)
→
R
%
A
1
,...,A
n

Zestaw 4
AD. 1
1. Zaleznosc funkcjonalna: atrybut b jest funkcjonalnie zalezny od atrybutu a wtedy i tylko wtedy
gdy, kazdej wartosci atrybutu a odpowiada okreslona wartosc atrybutu b.
2. Pelna zaleznosc funkcjonalna: atrybut b jest w pelni funkcjonalnie zalezny od atrybutu a
wtedy i tylko wtedy gdy, jest funkcjonalnie zalezny od tego atrybutu i nie zalezy od zadnego
podzbioru tego atrybutu
3. Zaleznosc tranzytywna: równolegla zaleznosc od tego samego atrybutu.
4. Zaleznosc wielowartosciowa: jest uogólnieniem zaleznosci funkcjonalnej; wystepuje gdy
wartosc jednego atrybutu determinuje zbiór wartosci drugiego atrybutu.
5. Zaleznosc polaczeniowa: wystepuje w relacji R wtedy i tylko wtedy gdy, po dekompozycji
relacji oraz po nastepnym jej zlozeniu otrzymujemy ta sama relacje R.
Model relacyjny dostarcza tylko jednego sposobu reprezentowania danych. Jest nim dwuwymiarowa
tablica, nazwana relacja.
Zasady jakim podlegaja relacje CODD’A:
1. kazdy element tablicy reprezentuje jedna elementarna dana.
2. Elementy jednej kolumny naleza do zbioru wartosci prostych.
3. Kazdej kolumnie przyporzadkowana jest jedna nazwa.
4. W tablicy nie moga wystapic dwa identyczne wiersze.
5. Kolejnosc wystepowania kolumn i wierszy w tablicy nie jest istotna.
Relacja : dowolny podzbiór iloczynu kartezjanskiego.
Atrybuty – kolumny tabeli
Krotki – wiersze tabeli
Stopien tabeli – liczba kolumn w tabeli
Liczebnosc tabeli – liczba wierszy w tabeli
Klucz glówny –
Klucz kandynujacy –
Klucz obcy –
Zaleznosci mówia o zwiazkach miedzy atrybutami.
AD. 2
Redundancja (nadmiar): to powielanie sie danych, gdy wystepuja wielokrotnie w systemie.
Rola redundancji:
WADY:
1. zwieksza zajetosc pamieci
2. wymaga wiekszej niz jednej operacji aktualizacji, czyli wymusza dluzszy czas aktualizacji
3. grozi utrata integralnosci
4. system moze dostarczac informacje sprzeczne, poniewaz kopie danych moga znajdowac sie w
róznych miejscach; nalezy wyeliminowac nadmiarowe dane wszedzie tam gdzie jest to mozliwe i
opcjonalne, gdy redundancja istnieje nalezy ustalic i zapisac jedna wersje danych oraz ustalic
powiazanie miedzy nimi; calkowite zlikwidowanie redundancji nie zawsze jest pozadane.
5. zwieksza koszty zwiazane z pamietaniem duplikatów
ZALETY:
1. przyspiesza wyszukiwanie informacji
2. prostsze adresowanie

3. lepszy dostep do danych
4. powtarzanie rekordów by umozliwic odtworzenie w czasie awarii
Braku redundancji w bazie danych i posiadania przez nia wielu niepozadanych cech nie da sie
pogodzic, lepiej wiec uzywac terminu redundancja kontrolowana ( minimalna ) i przyjac, ze w dobrze
zaprojektowanej bazie danych wyeliminowano redundancje szkodliwa ( niekontrolowana ).
Wady redundancji niekontrolowanej:
- wielokrotne przeprowadzanie aktualizacji
- rózne kopie, rózne etapy uaktualnien, tj. system moze udostepniac sprzeczne informacje.
Celem organizacji bazy danych powinno byc wyeliminowanie nadmiarowych danych wszedzie tam
gdzie jest to opcjonalne oraz kontrolowanie naruszania zgodnosci danych powodowanej tym
zjawiskiem.
AD. 3
ETAP 1: Oprogramowanie obsluguje (wykonuje) tylko proste operacje wej/wy. Fizyczna struktura
danych taka sama jak logiczna struktura pliku. W programach uzytkowych uwzgledniono organizacje
danych w postaci prostych plików seryjnych. Nie istnieje niezaleznosc danych. Zmiana struktury
danych lub urzadzen pamieciowych stwarza koniecznosc ponownego pisania, kompilowania i
testowania programów uzytkowych. Aktualizacja pliku polega na utworzeniu nowego pliku
zawierajacego zaktualizowane dane. Jest jednoczesnie zachowany plik stary, a takze jego poprzednik
itd. Prowadzi to do powstania kilku generacji tego samego pliku. Wiekszosc plików uzywano tylko raz.
Bardzo wysoki poziom redundancji.
ETAP 2: Mozliwy jest bezposredni dostep do rekordów (ale nie pól). Logiczna organizacja pliku rózni
sie od fizycznej, ale zaleznosci miedzy nimi sa proste. Jednostki pamieci moga sie zmieniac bez
koniecznosci zmieniania programów uzytkowych. Struktury danych najczesciej seryjne indeksowo-
sekwencyjne lub o prostym dostepie bezposrednim. Nie korzysta sie z wyszukiwania wielokluczowego.
Mozna uzywac srodków zabezpieczania danych. Duza redundancja miedzy innymi dlatego ze istnieje
tendencja organizowania i optymalizacji danych dla jednego zastosowania. Oprogramowanie
umozliwilo zmiane fizycznego rozmieszczenia danych bez potrzeby zmiany ich obrazu logicznego, pod
warunkiem, ze zostana w tej samej postaci zawartosci rekordów i ogólnej struktury pliku.
ETAP 3: Z tych samych plików fizycznych (danych) otrzymac mozna wiele róznych plików logicznych a
dostep do jednej i tej samej danej ze strony róznych zastosowan moze odbywac sie w rózny sposób.
Prowadzi to do skomplikowania struktur danych. Oprogramowanie umozliwia zmniejszenie
redundancji. Elementy danych sa wspólne dla wielu zastosowan. Wyeliminowanie redundancji ulatwia
zachowanie zgodnosci danych. Fizyczna organizacja pamieci jest niezalezna od programów
uzytkowych. Mozna ja zmieniac w celu zwiekszenia efektywnosci BD (baz danych) bez koniecznosci
modyfikacji programów uzytkowych. Dane adresowane sa na poziomie pól lub grup. Mozna stosowac
wyszukiwanie wielokluczowe.
ETAP 4: Oprogramowanie zapewnia logiczna i fizyczna niezaleznosc danych, dopuszczajac istnienie
globalnego opisu logicznego danych niezaleznie od pewnych zmian w obrazie danych programisty,
zastosowan lub ich rozmieszczenia fizycznego. Przewidziane sa srodki zapewnienia niezaleznosci
danych. BD moze rozwijac sie bez wiekszych kosztów. Srodki przewidziane dla administratora BD
pozwalaja mu pelnic funkcje kontrolera i straznika danych oraz zapewnic taka ich organizacje, która
bedzie najlepsza dla wszystkich uzytkowników. Zapewnione sa zachowania tajnosci, bezpieczenstwa i
integralnosci danych. W niektórych systemach sa pliki odwrócone umozliwiajace szybkie wyszukiwanie
danych z bazy. BD konstruowana jest z mysla o zapewnieniu odpowiedzi na nieprzewidziane rodzaje
pytan. Oprogramowanie dostarcza jezyk opisu danych administratorowi BD, jezyk komend
programiscie i jezyk zapytan uzytkownikowi.
Podsumowanie:
ETAP1: Proste pliki danych
•
Seryjna organizacja plików
•
Fizyczna struktura danych równa logicznej strukturze danych
•
Przetwarzanie wsadowe
•
Brak dostepu w real
•
Wiele kopii
•
Obsluga operacji wej / wyj
•
Zmiany struktury danych ponowne pisanie programów
•
Duza redundancja
ETAP2: Metody dostepu do plików
•
Bezposredni dostep do rekordów
•
Przetwarzanie wsadowe bezposrednie lub real.
•
Fizyczna organizacja plików rózna od logicznej organizacji plików
•
Jednostki pamieci zmieniane bez zmian programów uzytkowych
•
Struktura seryjna, indeks – sekwencyjny
•
Brak wyszukiwan wielokluczowych
•
Duza redundancja
•
Srodki zabezpieczen danych
ETAP3: Wczesne systemy baz danych
•
Wiele plików logicznych z jednego pliku fizycznego
•
Rózny dostep do tych samych danych
•
Mala redundancja
⇒
Duza zgodnosc danych
•
Elementy danych wspólne dla wielu zastosowan
•
Fizyczna organizacja niezalezna od programów uzytkowych
•
Wyszukiwanie wielokluczowe
•
Adresacja
→
poziom pól lub grup
ETAP3: Wymagania
→
nowoczesne systemy baz danych
•
Logiczna, fizyczna niezaleznosc danych
•
Ciagly rozwój
→
male koszty
•
Kontrola danych (najlepsza organizacja administracyjna)
•
Procedury tajnosci (bezpieczenstwo, integralnosc)
•
Odpowiedzi na nieprzewidziane zapytania
•
Jezyk wysokiego poziomu
•
Zapewnione srodowisko przemieszczenia danych
Zestaw 5
AD. 1

JEZYKI ZADAN
Jedna z grup jezyków umozliwia kierowanie zadan do systemu:
♦
Jezyk rachunku krotek (jezyk alfa, który zawiera kwantyfikatory, operatory relacji i operatory
logiczne )
♦
Jezyk opary o szablony (SQL )
♦
Jezyk oparty na algebrze relacji
Algebra relacji jest zbiorem operacji wysokiego poziomu wyszukiwania na relacjach. Jezyk oparty o
algebre relacji to jezyk, którego elementami sa relacje i wynik tez jest relacja. Kazdy z tych elementów
definiuje sie przy pomocy specjalnych operatorów. Algebra relacji sklada sie z dwóch grup operacji:
♦
Tradycyjne dzialania na zbiorach (suma, przeciecie, róznica)
♦
Specjalne operacje relacyjne (wyboru, rzutu, laczenia, dzielenia)
Mamy dwie relacje R i Q, t jest krotka relacji,
α
(t)=X, czyli zbiór atrybutów bedacy schematem
opisujacym krotke,
α
(R)=Y, czyli zbiór atrybutów bedacych schematem relacji.
1. Operacje dwuargumentowe to: suma, zlaczenie, iloczyn kartezjanski, róznica
2. Operacje jednoargumentowe to: uzupelnienie, projekcja, antyprojekcja, selekcja.
•
Suma : uwzglednia wszystkie wiersze z obu zbiorów lub tabel; bierze dwie zgodne relacje jako
swoje argumenty i produkuje jedna relacje wynikowa;
zgodne relacje to tabele, które maja ta sama strukture, te same kolumny na tych samych
dziedzinach
R
∪
Q={ t: t
∈
R
∪
t
∈
Q}
α
(t)=X ,
α
(R)=X ,
α
(Q)=X
•
Róznica:
R MI Q= { t: t
∈
R
∩
t
∉
Q }
α
(t)=
α
(R)=
α
(Q)=X
•
Projekcja: to wybieranie fragmentu relacji takiego, który jest sprecyzowany w warunku
rzutowania.
π
y
(R)= {t[y]:t
∈
R } Y
⊆
α
(R)
•
Selekcja: to operator, który bierze jedna relacje i produkuje w wyniku jedna relacje; to
„pozioma maszyna do ciecia”, która wydobywa z wejsciowej relacji wiersze, które pasuja do
podanego warunku i przekazuje je do relacji wynikowej.
δ
E
(R)= { t
∈
R: E(t)=true }
•
Przeciecie relacji zgodnych: uwzglednia w tabeli wynikowej tylko wiersze wspólne dla obu
tabel.
R IN Q= { t: t
∈
R
∩
t
∈
Q}
α
(t)=X,
α
(R)=X,
α
(Q)=X
•
Polaczenie:
R Q= { t:
α
(t)= X
∪
Y
∩
t[X]
∈
R
∩
t[Y]
∈
Q }
X=
α
(R) ; Y=
α
(Q)
Byly to jezyki zadan, które umozliwiaja manipulowanie danymi ( grupa DML).
Grupa druga DDL , to jezyki które maja pomóc w tworzeniu baz danych.
AD. 2
Do szyfrowania metodami klasycznymi zaliczamy szyfry i kody tradycyjne. Róznica pomiedzy
kodowaniem, a szyfrowaniem jest plynna i nie ma bezposredniej granicy pomiedzy nimi. Do
tradycyjnych metod szyfrowania zaliczamy: szyfry podstawieniowe i przestawieniowe np. szyfr Cezara
oraz szyfry monoalfabetyczne i polialfabetyczne. Kryptografia pozwala znakomicie podniesc
bezpieczenstwo komunikacji w sieciach i bezpieczenstwo danych w urzadzeniach wymiennych pamieci
zewnetrznych. Szyfrowanie jest kodowaniem danych dla ukrycia informacji. Szyfry przeksztalcaja tekst
otwarty, dzialaja na tekscie otwartym zmiennej dlugosci. Kody dzialaja na jednostkach
lingwistycznych.
SZYFR CEZARA: szczególny przypadek szyfru podstawienia monoalfabetycznego. Jest to prosty szyfr
gdzie kazdy znak P tekstu otwartego jest zastepowany przez odpowiadajaca mu liczbe
β
(P.) (
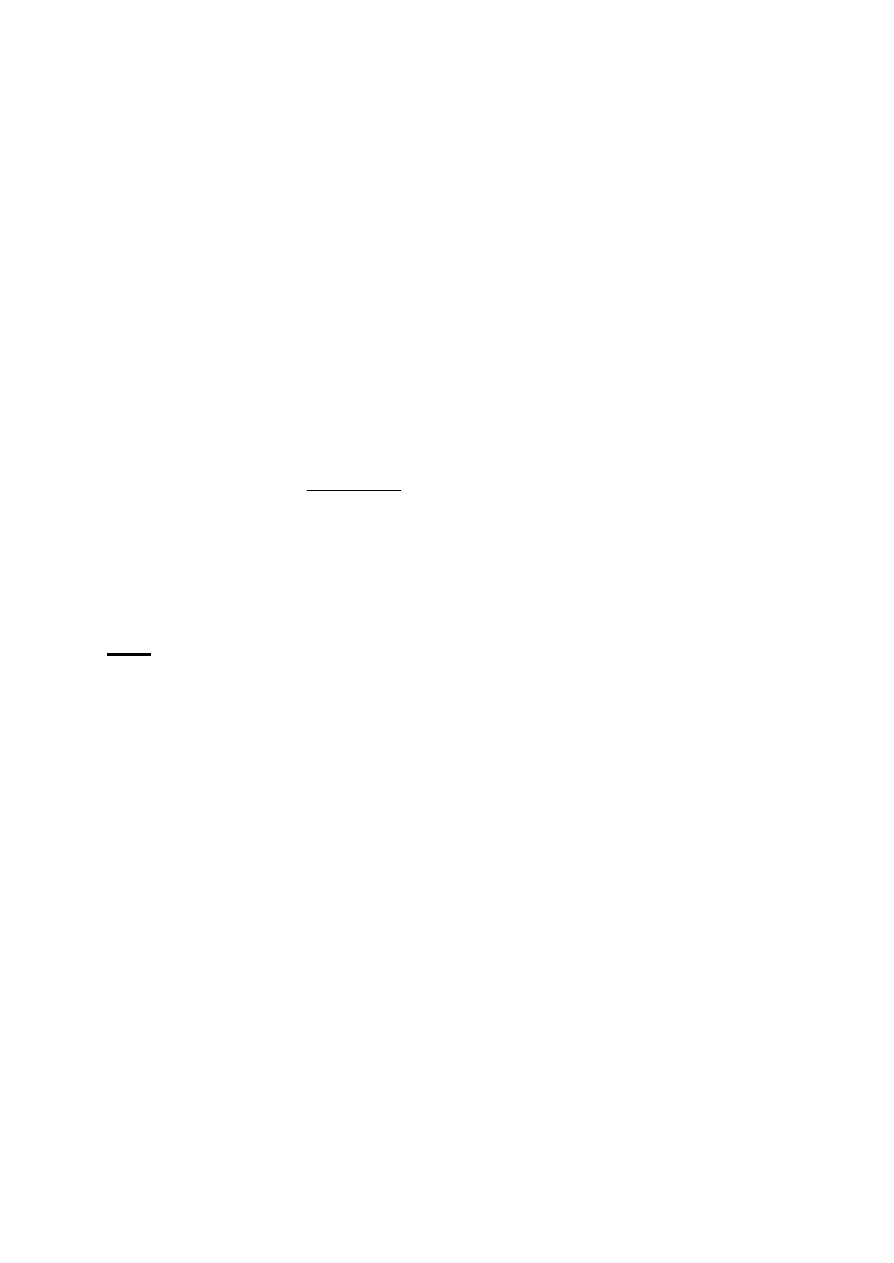
odpowiadajacej nr litery w alfabecie). Nastepnie otrzymujemy numery liter zaszyfrowanych na
podstawie równania:
γ
(P)=
β
(P)+2(mod27)
Wartosci sa nastepniezamieniane na odpowiadajace im litery i w ten sposób otrzymujemy tekst
zaszyfrowany.
W podstawieniach monoalfabetycznych kazdy symbol tekstu otwartego jest zastepowany jednym lub
kilkoma symbolami ( ). Rozszyfrowanie poprzez analize czestosci wystepowania liter danego jezyka.
Ogólny wzór na podstawienie : C=(aP+s)*mod K ,gdzie a-czynnik dziesiatkowania, s- czynnik
przesuniecia, K- liczba znaków alfabetu, P.-nr litery w alfabecie.
POLIALFABETYCZNE: proste podstawienie polialfabetyczne sekwencyjnie i cyklicznie zmienia uzywane
alfabety. Kodujemy podobnie jak w szyfrach monoalfabetycznych jednak co litera zmieniamy alfabet
(czyli wartosc o ile przesuwamy) co utrudnia dekodowanie przy pomoca analizy czestosci. Szyfry
homofoniczne sa to polialfabetyczne szyfry podstawieniowe dajace rózne czestosci wystepowania
zaszyfrowanych znaków- nie mozna go zlamac za pomoca analizy czestosci .Jeden znak alfabetu -
kilka róznych znaków.
PRZESTAWIENIA :szyfry przestawiajace z jakas regula znaki teks tu otwartego.
SZYFRY ZLOZONE: zastosowano tu ciag szyfrów np. zmiany okresów przeksztalcen polialfabetycznych.
ANALIZA CZESTOSCI : indeks koincydencji :
Szyfry ,dla których IC przekracza 0,066 dla angielskiego sa podstawieniami monoalfabetycznymi.
Gdy 0,052<=IC<=0,066 to 2 alfabetyczne podstawienie.
Analiza czestosci jest liczbowym przedstawieniem wystepowania danej litery w tekscie danego jezyka .
AD. 3
KLASYFIKACJA SYSTEMÓW ROZPROSZONYCH
System rozproszony:
Jest to zbiór systemów baz danych, które z punktu widzenia aplikacji tworza jeden system.
Kazda baza danych generowana jest przez swój serwer.
Cztery typy systemów rozproszonych:
1. Technologia klient-serwer: System rozproszonych baz danych rózni sie od technologii klient-
serwer tym, ze w klient-serwer wystepuje rozproszenie funkcji, a w sys. Rozproszonym
delokacja danych
klient – broker – serwer } 3 poziomy
?
posrednik
2. Jednorodne systemy baz danych: Jednorodna struktura danych i jednorodna struktura sys.
zarzadzania
3. Niejednorodne: Poszczególne fragmenty sys. moga byc rózne i np. sys. zarzadzania moze byc
inny niz w pozostalych systemach
4. Federacyjny system baz danych: System, w którym wystepuje „autonomia podsystemów”.
System zarzadzania nadzorujacy pewien podsystem decyduje, które beda integrowane z
danymi innych podsystemów (z podsystemu beda widoczne tylko niektóre dane)
Podzial rozproszonych systemów zarzadzania ze wzgledu na funkcje danych:
f
i
- liczba wystapien i-tej litery w tekscie zaszyfr.
N- liczba liter tekstu
zaszyfrowanego.
(
)
(
)
N
N
f
f
IC
z
A
i
i
i
*
1
1
−
−
=
∑
=

1. Homogoniczne: operuja na jednorodnych bazach danych:
•
Autonomiczne – maja duzy stopien autonomii
•
Nieautonomiczne – calkowicie podlegaja sys. zarzadzania rozproszona baza danych
2. Heterogoniczne: dzialaja na sys. niejednorodnych, federacyjnych:
•
Integrowane poprzez sys.
1. niefederacyjne
2. federacyjne
•
integrowane poprzez ramki
W heterogenicznych musza istniec translatory, które dokonuja translacji z kazdej postaci do
kazdej innej postaci jaka moze byc w systemie. Wieksza swoboda, ale jesli mamy n-
podsystemów to potrzebowalibysmy n – 1 translatorów.
Translacja ma jedna postac ustalona (postac kanoniczna). 2n translatorów (dla
dwukierunkowej)
Wyszukiwarka
Podobne podstrony:
Bazy danych zestawy 1 5
odp zestaw e, Politechnika Śląska MT MiBM, Semestr III, Bazy danych
BD gr D, Studia, Bazy danych, Wszystkie zestawy na BD
Zestaw A, Politechnika Śląska MT MiBM, Semestr III, Bazy danych
Zestawienie funkcji modułu mysqli odczytujących dane, bazy danych
BD gr B, POLITECHNIKA ŚLĄSKA Wydział Mechaniczny-Technologiczny - MiBM POLSL, Semestr 3, StudiaIII c
1 Tworzenie bazy danychid 10005 ppt
bazy danych II
Bazy danych
Podstawy Informatyki Wykład XIX Bazy danych
Bazy Danych1
eksploracja lab03, Lista sprawozdaniowych bazy danych
bazy danych druga id 81754 Nieznany (2)
bazy danych odpowiedzi
więcej podobnych podstron