
71. Kolejki priorytetowe i metody ich realizacji
Kolejka priorytetowa to struktura danych służąca do przechowywania zbioru S elementów, z których
każdy ma przyporządkowaną wartość, zwaną kluczem.
Kolejka priorytetowa ma zastosowanie tam, gdzie obiekty są pobierane z dynamicznej struktury i
przetwarzane w kolejności od obiektu o najwyższym priorytecie do obiektu o najniższym priorytecie. Przy
czym, w trakcie procesu przetwarzania nowe obiekty mogą być dodawane do kolejki.
Kolejka priorytetowa to jedna z podstawowych abstrakcyjnych struktur danych, wykorzystywana
między innymi w takich zastosowaniach jak:
- algorytm Dijkstry wyznaczania najkrótszych ścieżek w grafach
- algorytm Prima znajdowania minimalnego drzewa rozpinającego
- symulacja sterowana zdarzeniami
- metoda zamiatania w geometrii obliczeniowej
- kodowanie Huffmana
- sortowanie (algorytm Heapsort)
Na kolejce priorytetowej można wykonać następujące operacje:
INSERT(S,x) - wstawia element x do zbioru S. Ta operacja może być zapisana jako S<-S U {x} (x jest
elementem o kluczu z pewnego liniowo uporządkowanego uniwersum)
MAXIMUM(S) - daje w wyniku element S o największym kluczu
EXTRACT-MAX(S) - usuwa i daje w wyniku element S o największym kluczu.
Ten zestaw operacji często rozszerza się o:
DECREASE-KEY(S,x,y): nadaje kluczowi elementu x w zbiorze S nową, mniejszą wartość y
Jeśli struktura danych udostępnia dodatkowo operację łączenia kolejek
MELD(S1,S2): zwraca nową kolejkę, zawierającą wszystkie elementy ze zbiorów S1 i S2
to nazywamy ją złączalną kolejką priorytetową.
Jednym z zastosowań kolejki priorytetowej jest przydzielanie zasobów na komputerze wykonującym
zadanie współbieżnie. W kolejce priorytetowej są zapamiętane zadania, które mają być wykonane, a ich
priorytety względem siebie. Kiedy zadanie kończy się lub zostaje przerwane, zadanie o największym
priorytecie jest wybierane przez EXTRACT-MAX spośród zadań czekających. Nowe zadanie może zostać
dodane do kolejki w dowolnej chwili za pomocą operacji INSERT.
Kolejka priorytetowa może również być użyta jako symulator zdarzeń. Elementami kolejki są
zdarzenia, które należy symulować, każde z przyporządkowanym czasem występowania, który służy jako
klucz. Zdarzenia muszą być symulowane w kolejności ich zajścia, ponieważ symulacja zdarzenia może
spowodować, że inne zdarzenia będą symulowane w przyszłości. W tym zastosowaniu naturalnym
rozwiązaniem jest odwrócenie liniowego porządku kolejki i wykorzystanie operacji MINIMUM i
EXTRACT-MIN w miejsce operacji MAXIMUM i EXTRACT-MAX. Program symulacyjny korzysta w
każdym kroku z operacji EXTRACT-MIN do wybierania zdarzenia, które będzie symulował. Kiedy
zachodzą nowe zdarzenia, zostają one dodane do kolejki za pomocą operacji INSERT.
Najprostszą, choć niezbyt efektywną implementację kolejki priorytetowej stanowi zwykła lista.
Znacznie efektywniejszy jest kopiec binarny (wykorzystywany w algorytmie HeapSort), nie pozwala on
jednak na szybkie łączenie kolejek. Przedstawione na tym wykładzie struktury danych: kopiec dwumianowy
i kopiec Fibonacciego, umożliwiają efektywne wykonywanie wszystkich operacji złączalnej kolejki
priorytetowej.
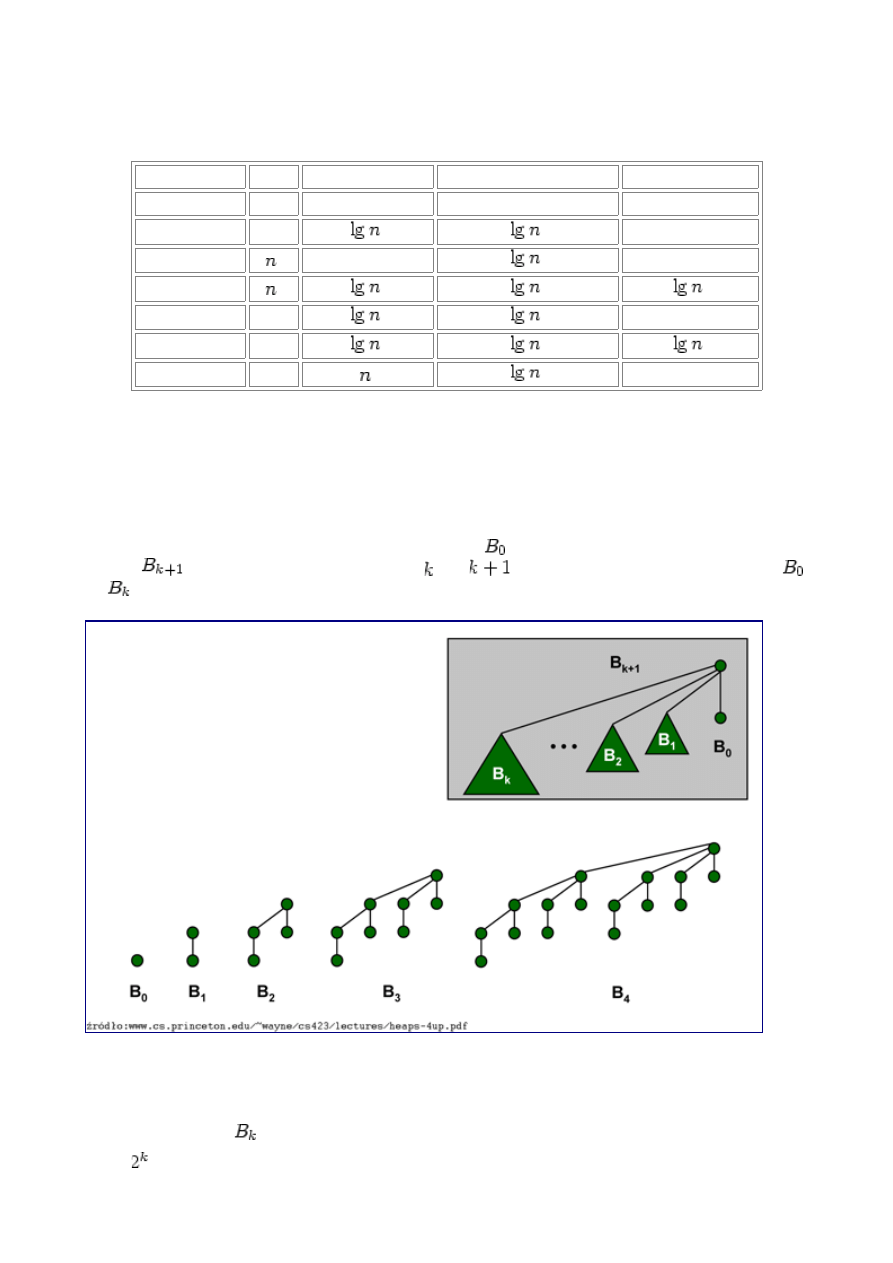
Oto tabela kosztów poszczególnych operacji w wymienionych implementacjach, przy założeniu, że
w kolejce(ach) jest aktualnie n elementów:
Operacja
Lista Kopiec Binarny
Kolejka Dwumianowa
Fibonacciego(*)
MakePQ
1
1
1
1
Insert
1
1
FindMin
1
1
DelMin
DecreaseKey
1
1
Delete
1
Meld
1
1
(*) - koszt zamortyzowany
Uwaga: wyszukiwanie elementu nie należy do zestawu operacji (złączalnej) kolejki priorytetowej,
dlatego w przypadku operacji DecreaseKey i Delete zakładamy, że jako parametr przekazywane jest
dowiązanie do elementu, którego ma dotyczyć operacja.
Drzewa i kolejki dwumianowe
Wynaleziona w roku 1978 przez J. Vuillemina [V] kolejka dwumianowa to kolekcja drzew
dwumianowych o następującej rekurencyjnej definicji:
jest drzewem jednowęzłowym, a korzeń
drzewa
(drzewa dwumianowego stopnia ) ma
synów stanowiących korzenie drzew
,...,
(w tej właśnie kolejności, idąc od prawej do lewej).
{kind=link}
Poniższy lemat dotyczy podstawowych własności drzew dwumianowych:
L
EMAT
[L
EMAT
1]
Drzewo dwumianowe
(a) ma węzłów;

(b) ma wysokość ;
(c) ma dokładnie
węzłów na poziomie , dla
(stąd nazwa 'drzewo dwumianowe');
(d) można otrzymać dołączając do drzewa
drugie drzewo
jako skrajnie lewego syna korzenia.
Kolejka dwumianowa to lista drzew dwumianowych uporządkowana ściśle rosnąco względem
stopni (idąc od prawej do lewej), przy czym każde drzewo spełnia warunek kopca: klucz w ojcu jest
niewiększy niż klucze w synach. Z lematu 1(a) wynika, że w skład kolejki dwumianowej zawierającej
kluczy drzewo wchodzi wtedy i tylko wtedy, gdy -tym bitem rozwinięcia binarnego liczby jest 1; w
szczególności łączna liczba drzew to
.
Operacje na kolejce dwumianowej
Ponieważ z warunku kopca wynika, że w każdym drzewie wchodzącym w skład kolejki element
najmniejszy znajduje się w korzeniu, operacja FindMin wymaga jednokrotnego przejścia listy drzew. Jej
koszt to
dla -elementowej kolejki.
Najważniejszą operacją na kolejce dwumianowej, za pomocą której definiuje się większość
pozostałych, jest Meld (łączenie kolejek).Jej działanie przypomina mechanizm dodawania liczb binarnych,
przy czym sumowaniu jedynek na pozycji w dodawanych liczbach odpowiada łączenie dwóch drzew
dwumianowych stopnia (zobacz lemat 1(d)): korzeń z mniejszym kluczem (w celu zachowania warunku
kopca) zostaje korzeniem wynikowego drzewa
('przeniesienia'), a drugi korzeń zostaje jego skrajnie
prawym synem. Łączenie dwóch kolejek polega na przejściu obydwu list drzew i złączeniu drzew
jednakowych stopni. Jego koszt jest proporcjonalny do sumy długości list.
Operacja Insert (wstawienie węzła) stanowi w zasadzie szczególny przypadek Meld (łączenie z
kolejką jednoelementową).Operacja DelMin(H) polega na znalezieniu i usunięciu z listy H drzewa z
najmniejszym kluczem, odcięciu jego korzenia (ten klucz jest wynikiem całej operacji) i połączeniu listy
jego synów (stanowiącej poprawną kolejkę dwumianową) z H. Łączny koszt to
dla -elementowej
kolejki. Operację DecreaseKey wykonuje się podobnie jak poprawianie kopca binarnego przy wstawianiu
elementu: zmniejszony klucz wędruje w górę swojego drzewa dwumianowego, zamieniając się miejscami z
ojcem dopóty, dopóki nie zostanie odtworzony warunek kopca. W myśl lematu 1(b) maksymalna wysokość
drzewa w -elementowej kolejce to
, więc koszt takiej operacji jest logarytmiczny.Operacja Delete
sprowadza się do przesunięcia klucza, który mamy usunąć, do korzenia (jak w DecreaseKey), a potem
usunięcia tego korzenia (jak w DelMin).
Kopce Fibonacciego
Ta struktura danych, wynaleziona przez Fredmana i Tarjana w roku 1984 [FT], stanowi ulepszenie
kolejki dwumianowej, które pozwala uzyskać stały (w sensie zamortyzowanym) koszt operacji DecreaseKey,
dominującej w algorytmie Dijkstry i jemu pokrewnych. Podstawowy pomysł polega tu na leniwym
wykonywaniu operacji, tzn. odkładaniu pracy związanej z zarządzaniem strukturą danych do momentu,
kiedy jest to naprawdę niezbędne. Podobnie jak kolejka dwumianowa, kopiec Fibonacciego to lista drzew, z
których każde spełnia warunek kopca. Drzewa te nie są już jednak drzewami dwumianowymi (chociaż są im
na tyle bliskie, że mają zbliżone własności) i nie są uporządkowane względem stopni korzeni.
Operacja Meld (łączenie kolejek) to po prostu sklejenie dwóch list drzew, bez prób porządkowania
względem stopni korzeni czy eliminacji powtórzeń. Jej koszt to oczywiście O(1). Tak jak poprzednio, Insert
stanowi szczególny przypadek Meld (łączenie z kolejką jednoelementową). Podczas operacji DelMin
przychodzi czas na wykonanie odkładanej wcześniej pracy. Najpierw usuwany jest korzeń zawierający
najmniejszy klucz, a jego synowie są dołączani do listy korzeni. Następnie odbywa się konsolidacja listy
drzew, mająca na celu doprowadzenie do sytuacji, w której wszystkie korzenie na liście będą miały różne
stopnie. Polega ona na przejściu przez listę korzeni i łączeniu drzew jednakowego stopnia - tak samo, jak
łączyło się drzewa dwumianowe - a przy okazji uaktualnieniu wskaźnika do korzenia zawierającego
najmniejszy klucz. Można ją zrealizować w czasie proporcjonalnym do liczby konsolidowanych drzew, jeśli
skorzystamy z pomocniczej tablicy indeksowanej stopniami korzeni: pod indeksem przechowujemy w niej
wskaźnik do (jedynego) korzenia stopnia w przetworzonej części listy, albo NULL, jeśli w tym fragmencie

listy korzenia o stopniu nie ma.
Oto oszacowanie kosztu zamortyzowanego operacji DelMin: Każdemu drzewu w kopcu
Fibonacciego w chwili jego pojawienia się na liście przypisujemy jednostkę kredytu. Niech oznacza liczbę
drzew w kopcu przed wykonaniem operacji, - stopień korzenia zawierającego najmniejszy klucz, zaś -
liczbę wykonań operacji łączenia drzew. Żeby wykonać Delmin, musimy wykonać pracę proporcjonalną do
. Ponieważ przy każdym połączeniu drzew uwalniana jest jednostka kredytu, uzyskujemy w ten
sposób
jednostek. Jak pokażemy później (Tw. 2), rozmiar drzewa w kopcu Fibonacciego jest
wykładniczy względem stopnia korzenia. Wynika z tego, że po konsolidacji, kiedy wszystkie drzewa w
kopcu będą miały różne stopnie, ich liczba
będzie
, gdzie to rozmiar kopca po
operacji. Tak więc do wykonania koniecznej pracy i utrzymania niezmiennika "jedna jednostka kredytu
związana z każdym drzewem w kopcu" wystarczy
dodatkowych jednostek kredytu - i taki właśnie
jest koszt zamortyzowany operacji DelMin.
Operacja DecreaseKey
mogłaby polegać na zmniejszeniu wartości klucza oraz - o ile został
naruszony warunek kopca - odcięciu poddrzewa o korzeniu i dołączeniu go do listy korzeni. To jednak,
zbyt gwałtownie zmniejszając rozmiary poddrzew, powodowałoby, że twierdzenie 2 nie byłoby prawdziwe, a
nasza analiza operacji DelMin przestałaby działać. Bedziemy zatem odcinać poddrzewa, ale w sposób
kontrolowany: każdy nie będący korzeniem węzeł może stracić co najwyżej jednego syna. Jeśli sytuacja
wymaga odcięcia drugiego syna, to taki węzeł sam zostaje odcięty od swojego ojca (co może oczywiście
spowodować dalsze rekurencyjne odcięcia). Do utrzymywania informacji o stanie węzła wystarcza znacznik
logiczny, który ma wartość TRUE wtedy i tylko wtedy, gdy dany węzeł stracił dokładnie jednego syna od
czasu, kiedy sam stał się synem innego węzła (w wyniku łączenia drzew).
Argumentacja, że koszt zamortyzowany operacji DecreaseKey to
, jest następująca: Oprócz
kredytu przypisywanego do drzew będziemy dodatkowo przypisywać dwie jednostki kredytu każdemu
węzłowi , który traci jednego syna, kosztem kredytu obciążając operację, która spowodowała odcięcie (dla
każdej operacji jest co najwyżej jeden taki węzeł). Kiedy następuje odcięcie drugiego syna (a więc także i
odcięcie samego węzła od ojca), koszt tego zabiegu pokrywa jedna jednostka kredytu, a druga pozostaje
przypisana do nowo wstawionego na listę drzewa o korzeniu (w celu utrzymania niezmiennika "jedna
jednostka kredytu związana z każdym drzewem w kopcu"). Podczas jednej operacji DecreaseKey może
nastąpić cała seria odcięć, ale wszystkie (oprócz być może ostatniego) są już wcześniej z góry opłacone.
Operacja Delete
polega na odcięciu węzła od ojca (o ile nie jest korzeniem) - jak w DecreaseKey -
a następnie usunięciu , będącego teraz korzeniem - jak w DelMin. Koszt zamortyzowany tej operacji to
dla -elementowego kopca.
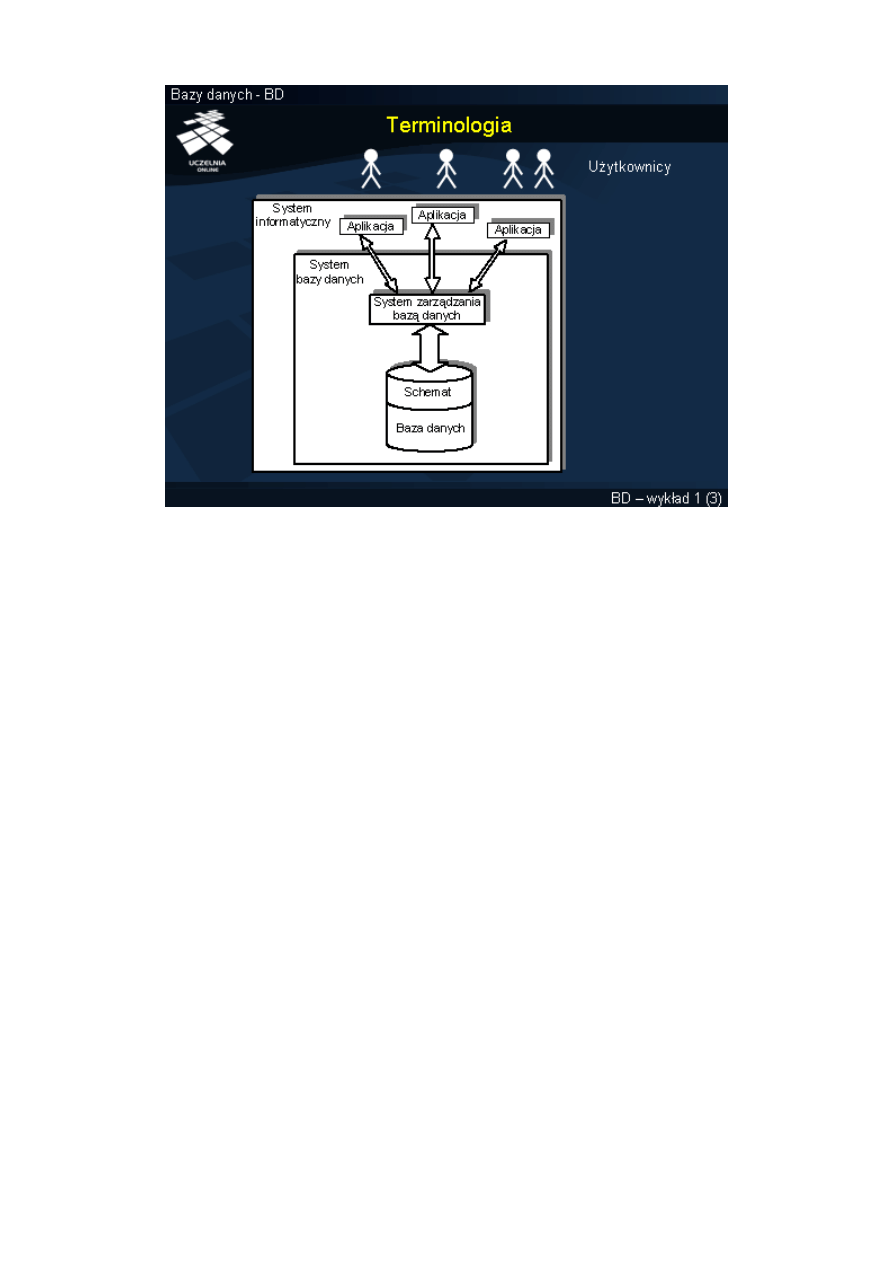
72. Pojęcie bazy danych – funkcje i możliwości.
Baza danych to zbiór informacji zapisanych w ściśle określony sposób w strukturach
odpowiadających założonemu modelowi danych. W potocznym ujęciu obejmuje dane oraz program
komputerowy wyspecjalizowany do gromadzenia i przetwarzania tych danych. Program taki (często zestaw
programów) nazywany jest „Systemem zarządzania bazą danych” (ang. DataBase Management System,
DBMS). W ścisłej nomenklaturze baza danych oznacza zbiór danych, opisujący pewien wybrany fragment
rzeczywistości. Przykładowo bazą danych może być zbiór danych banku na temat klientów, ich rachunków,
operacji na rachunkach, udzielanych kredytach.
Dane w bazie danych posiadają dwie podstawowe cechy. Po pierwsze, odzwierciedlają
rzeczywistość w sposób z nią zgodny (prawidłowy). Po drugie, są zorganizowane w specyficzny sposób,
zgodnie z tzw. modelem danych. Struktura danych i powiązania między nimi są opisane przez tzw. schemat
bazy danych. Z DBMS współpracują programy użytkowników, zwane aplikacjami. Zadaniem tych
programów jest przetwarzanie danych, tj. wstawianie nowych danych, modyfikowanie danych już
istniejących, usuwanie danych nieaktualnych, wyszukiwanie danych.
Charakterystyka baz danych:
Do głównych cech charakteryzujących bazę danych zalicza się: trwałość danych, rozmiar wolumenu
danych i złożoność danych.
Trwałość danych oznacza, że dane przechowywane w bazie danych nie są ulotne. W konsekwencji,
okres przechowywania danych jest ograniczony wyłącznie okresem żywotności nośnika danych. "Czas
życia" danych, po ich zapisaniu do bazy danych jest niezależny od istnienia i działania bądź niedziałania
aplikacji. Trwałość danych jest również niezależna od platformy sprzętowo-programowej.
W ogromnej większości zastosowań, dane zgromadzone w bazie danych nie mieszczą się w pamięci
operacyjnej, więc do ich składowania jest wymagana pamięć zewnętrzna (dyskowa, optyczna, taśmowa).
Tak duże ilości danych nie mogą być przeglądane liniowo ze względu na niewielką efektywność tej techniki.
W konsekwencji konieczne jest wykorzystanie innych zaawansowanych mechanizmów efektywnego dostępu
do danych.
Dane gromadzone w bazie danych często są złożone ze względu na:
- złożoność ich struktur i zależności pomiędzy danymi (np. projekt samochodu, złożony z tysięcy
elementów),
- złożoność semantyczną danych (np. fakt przyznania kredytu mieszkaniowego jest uzależniony od
spełnienia lub niespełnienia wielu wymagań przez petenta).
Ponadto, na dane są często nakładane tzw. ograniczenia integralnościowe gwarantujące, że w bazie
danych pojawią się wyłącznie dane spełniające te ograniczenia. Ograniczenia takie mogą być również bardzo
złożone.
Bazie danych stawia się 6 podstawowych wymagań:
1. Spójność bazy danych jest definiowana jako poprawność danych z punktu widzenia pewnych
przyjętych kryteriów. Definiując spójność wymienia się trzy takie kryteria, tj.:
- wierne odzwierciedlenie danych rzeczywistych - dane przechowywane w bazie danych są takie jak
w świecie rzeczywistym, który ta baza reprezentuje. Przykładowo, w bazie danych dziekanatu są
przechowywane dane tylko tych studentów, którzy kiedykolwiek ukończyli studia i dane tylko studentów
aktualnie studiujących. Innymi słowy, baza ta nie zawiera danych studentów nieistniejących. Ponadto,
zależności między danymi wiernie odzwierciedlają zależności pomiędzy obiektami świata rzeczywistego.
Przykładowo, grupa studencka G1 w bazie danych dziekanatu składa się ze studentów należących do tej
grupy w świecie rzeczywistym. ,
- spełnienie ograniczeń nałożonych przez użytkowników - wszystkie dane w bazie, na które nałożono

pewne ograniczenia integralnościowe muszą te ograniczenia spełniać. Przykładowo, w bazie danych
dziekanatu zdefiniowano ograniczenie na możliwe wartości oceny i określono, zbiór dozwolonych ocen jako
{2, 3, 4, 5}. Oznacza to, że w bazie danych nie pojawi się żadna inna ocena niż dozwolona. ,
- brak anomalii wynikających ze współbieżnego dostępu do danych - w przypadku baz danych, z
których korzysta przynajmniej dwóch użytkowników mogą powstać dane niepoprawne na skutek
równoczesnego modyfikowania tego samego zbioru danych. Baza danych musi być odporna na takie
sytuacje niepoprawne. .
Spójność to również poprawność danych w przypadku awarii sprzętowo-programowych. W sytuacji
wystąpienia awarii, w bazie danych nie mogą powstać dane niepoprawne. Ponadto, żadne dane nie mogą
zostać utracone.
Baza danych powinna być również odporna na przypadkowe błędy użytkowników, np. usunięcie
danych. W takiej sytuacji musi istnieć mechanizm naprawienia błędu, wycofania akcji użytkownika.
2. Drugim wymaganiem stawianym bazie danych jest zapewnienie efektywnego przetwarzania
danych, tj. wstawiania nowych danych, modyfikowania istniejących, usuwania i wyszukiwania danych. W
tym celu koniecznej jest wykorzystywanie efektywnych metod dostępu do danych z wykorzystaniem
specjalizowanych struktur i optymalizacja metod dostępu. Ponadto, program, czy użytkownik korzystający z
bazy danych nie zna fizycznej organizacji danych na nośniku. W związku z tym, optymalizacja dostępu
powinna być realizowana przez wyspecjalizowany moduł programowy i powinna być niewidoczna dla
użytkownika.
3. Trzecim wymaganiem stawianym bazie danych jest poprawne modelowanie świata
rzeczywistego. Oznacza to, że struktura bazy danych musi odzwierciedlać we właściwy/poprawny sposób
obiekty świata rzeczywistego i powiązania pomiędzy tymi obiektami. Przykładowo, jeżeli dealer
samochodowy sprzedaje samochody osobowe i dostawcze w różnych konfiguracjach, to baza danych dla
tego dealera musi umożliwiać przechowywanie danych na temat samochodów i osobowych i dostawczych,
oraz konfiguracji poszczególnych modeli.
Producenci systemów zarządzania bazami danych oferują narzędzia wspomagające procesy
modelowania danych, projektowania bazy danych i transformacje pomiędzy różnymi modelami.
4. Czwartym wymaganiem jest autoryzacja dostępu do danych. Oznacza to, że dostęp do bazy
danych mają tylko jej użytkownicy identyfikowani unikalną nazwą i hasłem. Ponadto, każdy użytkownik
posiada określone uprawnienia w bazie danych.
5. Piątym wymaganiem jest zagwarantowanie możliwości równoczesnej pracy wielu
użytkownikom tej samej bazy danych. Co więcej, użytkownicy ci mogą jednocześnie pracować z tym
samym zbiorem danych. W takim przypadku mogą powstać konflikty w dostępie do danych, gdy jeden
użytkownik modyfikuje zbiór danych, a drugi próbuje ten sam zbiór odczytać lub zmodyfikować. Baza
danych musi zapewnić poprawne rozwiązanie tego typu konfliktów.
6. Szóstym wymaganiem jest wsparcie dla tzw. metadanych. Metadane to najprościej mówiąc dane
o bazie danych. Dane te opisują m.in.: dane przechowywane w bazie, struktury danych, użytkowników i ich
uprawnienia.
Technologie baz danych:
Omówione wymagania odnośnie baz danych są zapewniane w ramach tzw. technologii baz danych.
Oferuje ona m.in. fizyczne struktury i metody dostępu. Do fizycznych struktur wykorzystywanych w bazach
danych zalicza się pliki uporządkowane, pliki haszowe, pliki zgrupowane, indeksy drzewiaste i indeksy
bitmapowe. Do metod dostępu zalicza się: połowienie binarne, haszowanie statyczne i dynamiczne,
algorytmy łączenia, sortowania i grupowania.
Dostęp do danych z wykorzystaniem struktur fizycznych i metod dostępuj jest optymalizowany za
pomocą zaawansowanych technik optymalizacji składniowej i kosztowej.
Ponadto, fizyczna organizacja danych na dysku nie ma wpływu na działanie aplikacji/programów
użytkowników korzystających z bazy danych. Oznacza to, że zmiana fizycznej organizacji danych np. o

klientach banku, po pierwsze, jest niewidoczna dla użytkownika i po drugie, nie wymaga zmiany kodu
aplikacji. Innymi słowy aplikacja działa tak samo dobrze jak poprzednio.
Technologia baz danych oferuje wsparcie dla tzw. przetwarzania transakcyjnego, zapewniającego
spójność całej bazy danych.
W ramach tego przetwarzania każdy dostęp do bazy danych jest realizowany w ramach pewnej
jednostki interakcji, zwanej transakcją. Posiada ona cechy atomowości, spójności, izolacji i trwałości
(problematyka transakcji zostanie omówiona w osobnym wykładzie). Transakcje działające równocześnie w
systemie muszą być synchronizowane za pomocą specjalizowanych algorytmów (2PL, znaczników
czasowych) i stosowania wersji danych.
Zapewnienie spójności danych, np. w przypadku konfliktu transakcji lub awarii sprzętowo-
programowych, często wymaga wycofania zmian w bazie danych. Do tego celu konieczne są dodatkowe
struktury danych, algorytmy i mechanizmy systemowe.
Awaria sprzętowo-programowa nie może spowodować utraty żadnych danych. W celu zapewnienia
tego wymagania stosuje się techniki i systemowe mechanizmy archiwizowania bazy danych i jej odtwarzania
po awarii.
Technologia baz danych oferuje wsparcie dla wielu modeli danych, czyli wielu sposobów
reprezentowania danych. Wyróżnia się tu:
- modele pojęciowe (np. związków-encji, UML),
- modele logiczne (np. relacyjny, obiektowy, obiektowo-relacyjny, semistrukturalny, hierarchiczny,
sieciowy).
Oprócz technik związanych z zarządzaniem danymi, technologia baz danych oferuje narzędzia
programistyczne do budowania aplikacji, modelowania i projektowania bazy danych. Narzędzie te wspierają
uznane metodyki projektowania.
Jak wspomniano wcześniej, jednym z komponentów systemu bazy danych jest tzw. System
Zarządzania Bazą Danych (DBMS). Z technologicznego punktu widzenia jest to moduł programowy,
którego zadaniem jest zarządzanie całą bazą danych oraz realizowanie żądań aplikacji użytkowników.
Podstawowa funkcjonalność DBMS obejmuje:
- wsparcie dla języka bazy danych, który umożliwia m.in. wstawianie, modyfikowanie, usuwanie i
wyszukiwanie danych oraz tworzenie, modyfikowanie i usuwanie struktur danych;
- wsparcie dla struktur danych zapewniających efektywne składowanie i przetwarzanie dużych
wolumenów danych;
- optymalizację dostępu do danych;
- synchronizację współbieżnego dostępu do danych;
- zapewnienie bezpieczeństwa danych w przypadku awarii sprzętowo-programowej;
- autoryzację dostępu do danych;
- wielość interfejsów dostępu do bazy danych.
Model danych.
Obiekty ze świata rzeczywistego są reprezentowane w bazie danych za pomocą tzw. modelu danych.
Wyróżnia się następujące modele danych: hierarchiczny, sieciowy, relacyjny, obiektowy, obiektowo-
relacyjny, semistrukturalny.
Model hierarchiczny i sieciowy nie są już stosowane w nowobudowanych systemach. Obecnie w
bazach danych najczęściej stosuje się model relacyjny, obiektowo-relacyjny lub semistrukturalny.
Każdy model danych definiuje trzy podstawowe elementy, tj. struktury danych, operacje na danych i
ograniczenia intergralnościowe nakładane na dane.
Struktura danych służy do reprezentowania w bazie danych obiektów ze świata rzeczywistego.
Przykładowo, grupa pracowników firmy może być reprezentowana w modelu obiektowym jako klasa, lub w
modelu relacyjnym jako relacja. Poszczególni pracownicy są reprezentowani odpowiednio jako wystąpienia
klasy (w modelu obiektowym) lub krotki relacji (w modelu relacyjnym).
Każdy model danych posiada zbiór predefiniowanych operacji na danych. Przykładowo, w modelu
relacyjnym operacje na danych oferowane przez model to: selekcja, projekcja, połączenie i operacje na
zbiorach.
Ponadto, model danych umożliwia nałożenie ograniczeń integralnościowych na dane

reprezentowane w nim dane. Przykładowo, dla relacji ze slajdu można zdefiniować ograniczenie
integralnościowe zapewniające, że data rozpoczęcia projektu będzie zawsze mniejsza niż data jego
zakończenia.
Interakcja z bazą danych:
Jakakolwiek interakcja programu użytkowego (aplikacji) z bazą danych odbywa się za pomocą
języka SQL. Jest to jedyny sposób komunikowania się aplikacji z bazą danych. SQL jest językiem
deklaratywnym. Oznacza to, że posługując się nim specyfikujemy tylko co chcemy otrzymać. Nie
specyfikujemy sposobu (algorytmu) w jaki ma być zrealizowane zadanie. Przykładem polecenia SQL może
być zapytanie do bazy danych poszukujące informacje o klientach banku z Poznania, którzy w ciągu
ostatniego miesiąca wypłacili z bankomatu łącznie powyżej 8000 PLN. W tym zapytaniu specyfikujemy
tylko jakie dane nas interesują. Sposób ich wyszukania jest automatycznie dobierany przez DBMS.
SQL jest językiem ustandaryzowanym. Jego standardyzacją zajmuje się specjalny międzynarodowy
komitet, w skład którego wchodzą przedstawiciele największych producentów DBMS (IBM, Microsoft,
Oracle). Dotychczas opracowano trzy standardy języka SQL, kolejno rozszerzające jego funkcjonalność.
Standardy te to: SQL-92, SQL-99, SQL-2003.
Producenci systemów komercyjnych i niekomercyjnych starają się implementować przynajmniej
standard SQL-92. Należy jednak pamiętać, że nie ma 100% zgodności implementacji.
Język SQL jest narzędziem dostępu do bazy danych stosowanym głównie przez projektantów
aplikacji, projektantów baz danych i administratorów baz danych. Standardowym sposobem korzystania z
bazy danych przez użytkowników końcowych są aplikacje. Należy jednak pamiętać, że na poziomie
programistycznym aplikacje również komunikują się z bazą danych za pomocą poleceń SQL.
Ze względu na funkcjonalność, wyróżnia się dwa rodzaje aplikacji, tj. formularze i raporty. Aplikację
pierwszego rodzaju należy postrzegać jako elektroniczny formularz (z polami, listami, elementami wyboru)
wypełniany przez użytkownika. Formularze umożliwiają pełną obsługę danych, tj. wstawianie,
modyfikowanie, usuwanie i wyszukiwanie.
Raporty umożliwiają wyłącznie odczytywanie danych z bazy i prezentowanie ich w różnej postaci,
głównie tekstu lub wykresu.
Podział baz danych:
Podziału systemów BD można dokonać w oparciu o kilka kryteriów. Najważniejszymi są:
wykorzystywany model danych, liczba węzłów, czyli liczba baz danych wchodzących w skład systemu i cel
stosowania systemu bd.
Ze względu na model danych SBD dzieli się na: relacyjne, obiektowe, obiektowo-relacyjne,
semistrukturalne, hierarchiczne, sieciowe.
Ze względu na liczbę wykorzystywanych BD, wyróżnia się systemy scenralizowane z jedną bazą
danych i systemy rozproszone z więcej niż jedną bazą wchodzącą w skład systemu.
Ze względu na cel stosowania wyróżnia się bazy danych przetwarzania tranaskcyjnego, BD
przetwarzania analitycznego, wspomagania projektowania, informacji geograficznej, wytwarzania
oprogramowania.
Bazy danych przetwarzania transakcyjnego (OLTP) stosuje się w typowych zastosowaniach
ewidencyjnych, np. w rezerwacji i sprzedaży biletów, w bibliotekach i wypożyczalniach, w systemach
ewidencji ludności, pojazdów, mienia nieruchomego, w bankowości w obsłudze bieżącej, w systemach
handlu internetowego i bankowości elektronicznej. Zastosowania tego typu charakteryzują się ogromną
liczbą jednocześnie działających użytkowników (tysiące, dziesiątki tysięcy). Interakcja pojedynczego
użytkownika z bazą danych jest krótka - kilka kilkanaście sekund.
Bazy danych przetwarzania analitycznego (OLAP) stosuje się w systemach wspomagania
zarządzania. Zastosowania tego typu charakteryzują się niewielką liczbą użytkowników (kilku, kilkunastu)
ale czas interakcji użytkownika z bazą danych jest długi (godziny, dziesiątki godzin).
Bazy danych dla wspomagania projektowania umożliwiają przechowywanie projektów złożonych
obiektów, np. konstrukcji mostów, budynków, schematy urządzeń.
W bazach danych informacji geograficznej przechowuje się zarówno dane tekstowe (np. dane
triangulacyjne, opisy terenu) jak i dane przestrzenne (mapy). Tego typu systemy wymagają zaawansowanych
technik przeszukiwania map i operacji na nich.

Bazy danych służące do wspomagania wytwarzania oprogramowania przechowują wyniki
poszczególnych faz realizacji projektów. Wyniki te są najczęściej reprezentowane w postaci
specjalizowanych modeli (diagramów), obiektów i ich własności, projektów i kodów oprogramowania. Tego
typu systemy, oprócz standardowej funkcjonalności, wspierają wyszukiwanie zależności pomiędzy
obiektami oraz wywodzenie wersji obiektów (np. oprogramowania) i zarządzanie tymi wersjami.
Dostępne DBMS:
Na rynku istnieje wiele komercyjnych systemów BD. Do najpopularniejszych producentów zalicza
się Oracle, IBM, Microsoft i Sybase. Oracle oferuje SZBD o nazwie Oracle 9i, Oracle10g. IBM oferuje
systemy DB2 i Informix(R) Dynamic Server. Microsoft oferuje popularny SQL Server w wersjach 2000 i
2005. Sybase jest producentem systemu Adaptive Server Enterprise i Adaptive Server Anywhere.
Ponadto, dostępne są rozwiązania niekomercyjne, spośród których najpopularniejszymi są MySQL,
PostgreSQL i FireBird.
73. Relacja, atrybuty relacji.
Relacja w bazach danych jest wydzielonym logicznie zbiorem danych, zorganizowanych w formie
tabeli składającej się z wierszy dzielonych na kolumny. Jest to obiekt teoretyczny i nie należy go mylić z jej
graficzną reprezentacją, czy miejscem zajmowanym w pamięci komputera. W zależności od typu bazy
danych wewnętrzna organizacja podziału danych na kolumny i wiersze jest różna i często umowna.
Pojedyncza tabela może być reprezentacją pewnej encji (np. książek, mieszkań, ludzi), relacji
między nimi, albo może stanowić zawartość całej bazy danych. Pojedynczy wiersz tabeli nazywany jest
rekordem i stanowi najczęściej zbiór danych o pojedynczym obiekcie (ew. grupie obiektów).
W relacyjnym modelu baz danych i podobnych, kolumny stanowią zwykle atrybuty jakiegoś obiektu
(np. wielkość, grubość, tytuł, nazwisko) i stąd dane zawarte w kolumnach mają najczęściej jeden określony
typ. Dodatkowo w bazach obsługiwanych przez język SQL kolumnom nadawane są nazwy, także poza
etapem projektowym i nazwy te są unikatowe w obrębie jednej tabeli.
Do identyfikacji wierszy stosuje się klucz główny (ang. primary key), czyli jedna z kolumn lub ich
grupę, których wartości są unikatowe w całej tabeli (dzięki czemu jednoznacznie identyfikują wiersz).
Klucz główny może być:
- ukrytym przed użytkownikami identyfikatorem, który jest nadawany automatycznie przez system
obsługujący bazę danych; w szczególności wiersz może być wówczas identyfikowany poprzez położenie w
zbiorze danych (stosowany zwykle wtedy, gdy wszystkie rekordy mają stała, taką samą wielkość);
- jawnym numerycznym kluczem, wybranym w procesie projektowania bazy dancych, a w trakcie jej
używania automatycznie zwiększanym przez system obsługujący bazę danych;
- jawnym kluczem składającym się z pojedynczej lub wielu kolumn; taka kolumna (kolumny) może
być teoretycznie dowolnego typu, czy to numerycznego, czy tekstowego, czy nawet binarnego, niektóre
systemy bazodanowe narzucają jednak pewne ograniczenia, wynikające z tego, że klucze te są indeksowane.
Rodzaje relacji:
1. Relacja jeden-do-jednego.
Charakteryzuje się tym ,że dla każdej instancji jednej z dwóch encji istnieje dokładnie jedna
instancja drugiej encji pozostająca z nią w równoważnym związku np. czek i opłata ( opłata jest realizowana
za pomocą jednego czeku i za pomocą jedego czeku można zrealizować tylko jedną opłatę).Ten typ relacji
spotyka się rzadko, ponieważ większość informacji powiązanych w ten sposób byłoby zawartych w jednej
tabeli. Relacji jeden-do-jednego można używać do podziału tabeli z wieloma polami, do odizolowania części
tabeli ze względów bezpieczeństwa, albo do przechowania informacji odnoszącej się tylko do podzbioru
tabeli głównej. Na przykład, można by utworzyć tabelę do wyszukiwania pracowników uczestniczących w
rozgrywkach piłkarskich.
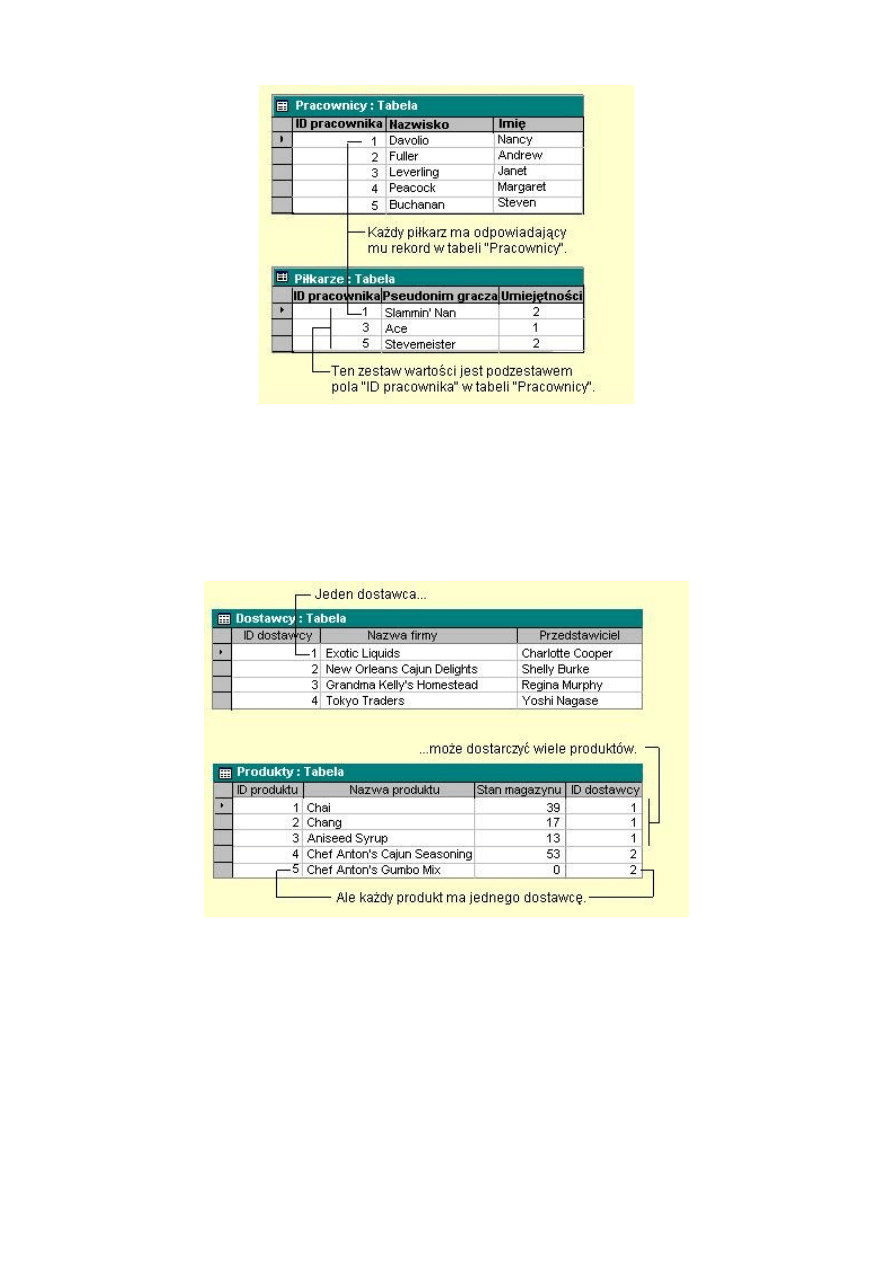
2. Relacja jeden-do-wielu.
Charakteryzuje się tym ,że dla każdej instancji jednej encji istnieje wiele instancji drugiej encji
pozostającej z nią w rozważanym związku. Relacja jeden-do-wielu jest realizowana poprzez utworzenie
atrybutu w encji po stronie wiele aby umieścić w nim klucz encji znajdującej się po stronie jeden. Tak
utworzony atrybut encji po stronie wiele nosi nazwę klucza obcego ponieważ jest on głównym kluczem w
innej tabeli. Relacja jeden-do-wielu jest najbardziej powszechnym typem relacji.
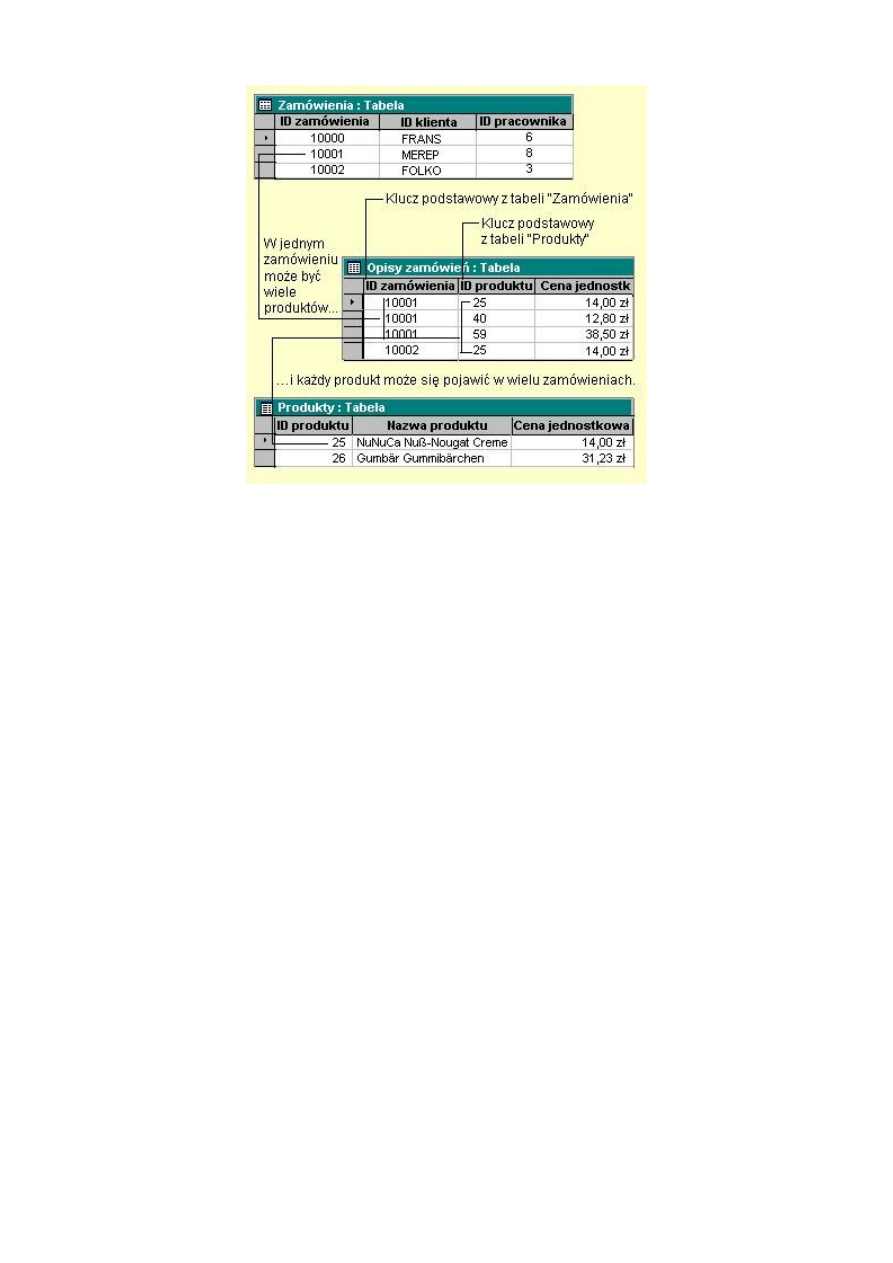
3. Relacja wiele-do-wielu.
W relacji wiele-do-wielu, rekord w tabeli A może mieć wiele dopasowanych do niego rekordów z
tabeli B i tak samo rekord w tabeli B może mieć wiele dopasowanych do niego rekordów z tabeli A. Jest to
możliwe tylko przez zdefiniowanie trzeciej tabeli (nazywanej tabelą łącza), której klucz podstawowy składa
się z dwóch pól - kluczy obcych z tabel A i B. Relacja wiele-do-wielu jest definiowana jako dwie relacje
jeden-do-wielu z trzecią tabelą. Na przykład, tabele "Zamówienia" i "Produkty" są powiązane relacją wiele-
do-wielu zdefiniowaną przez utworzenie dwóch relacji jeden-do-wielu z tabelą "Opisy zamówień".
Wyszukiwarka
Podobne podstrony:
71 72
11 1995 71 72
71 72
71 72
71 72
71 72
71 72
72 73
72, 73
10 1995 72 73
cfps 72 73
71 72
71 72
72 73
page 72 73
71 72
71 72
05 1996 71 72
więcej podobnych podstron