
Kraków, 10 maja 2001
Referat z przedmiotu
Administracja Systemami Komputerowymi
HTTPD
konfiguracja, uruchamianie modu
łów, PHP,
CGI, suexec, proxy,
WYDZIAŁ ELEKTROTECHNIKI, AUTOMATYKI,
INFORMATYKI I ELEKTRONIKI
KATEDRA IFORMATYKI
KIERUNEK INFORMATYKA
Wykonawcy:
Łukasz Hołody
Marcin Jaromin
Marcin Jarząb

HTTPD
Daemon HTTP (HyperText Transfer Protocol) zwany częściej WebSerwerem pozwala na
udostępnianie plików w Internecie przy użyciu bardzo popularnych stron www
(WorldWideWeb). Obecnie systemy UNIXowe zostały zdominowane przez Apache'a
(
) , który jest praktycznie jedynym używanym demonem HTTP, dlatego na
jego przykładzie przedstawimy proces instalacji, konfiguracji oraz dołączania i odłączania
modułów.
Odpowiednikiem Apache'a na platformę Microsoft Windows jest MS IIS (Internet
Information Services).
Istnieją również Web serwery napisane w Javie np.: Jigsaw -oficjalny webserver W3C (World
Wide Web Consorcium). Są one "przenośne" i mogą być uruchamiane na każdym systemie
operacyjnym wyposażonym w maszynę wirtualną Javy.
Obszerne porównanie WebSerwerów można znaleźć na stronie
WebServer Compare
.
porównanie WebSerwerów
(mirror WebServerCompare)
techniczny opis Apache'e
(mirror WebServerCompare)
Apache - krótki opis
Apache, serwer www przeznaczony na platformę Unix jak i Windows NT (ta druga nie
oferuje takich możliwości jak pod unixem). Ten darmowy serwer można bez problemów
samodzielnie zainstalować i skonfigurować, przy odrobinie wysiłku. Instalując serwer
możemy w zależności od potrzeb dodawać lub usuwać moduły. Stwarza to możliwość
tworzenia samemu modułów, które później będzie wykorzystywał serwer.
Instalacja
Instalację Apache'a możemy wykonać poprzez skompilowanie kodów źródłowych lub
wykorzystanie przygotowanych dla danego systemu operacyjnego binariów.
Kompilację wykonuje sie identycznie jak w przypadku innych aplikacji w systemach
UNIXowych przy wykorzystaniu narzędzia make. Makefile'e tworzomy przy użyciu skryptu
konfiguracyjnego configure, któremu podajemy parametry konfiguracyjne serwera (ścieżki
konfiguracyjne, listę modułów do wkompilowania, ścieżka wynikowa skompilowanej
aplikacji, etc.). Tutaj możemy dokonać wstępnej (podstawowej) konfiguracji Apache'a. Pełną
listę parametrów otrzymamy po podaniu opcji --help (
configure --help
).
Uruchamianie serwera
usr/local/etc/apache/src/httpd -f /usr/local/etc/apache/conf/httpd.conf
Serwer uruchamiamy poprzez uruchomienie httpd. Jeżeli chcemy, aby WebServer uruchamiał
się przy każdym starcie komputera (servera) to musimy jego uruchamianie dołączyć do
plików startowych serwera, na którym jest uruchamiamy Apache'a.

Przy uruchamianiu Apache'a możemy zdefiniować kilka parametrów, np. podanie innej niż
domyślna ścieżki do pliku konfiguracyjnego httpd.conf. Wszystkie opcje możemy zobaczyć
poprzez wywołanie Apache'a z opcją -h (
httpd -h
).
Zatrzymywanie serwera
Serwer httpd możemy zatrzymać poprzez wysłanie do niego sygnału TERM.
kill -TERM `cat /usr/local/etc/httpd/logs/httpd.pid`
Restartowanie serwera
Czasami możemy chcieć zrestartować serwer po zmianie konfiguracji, ale zależy nam na
zachowaniu statystyk serwera.
Służy do tego sygnał USR1.
Konfiguracja
Konfiguracja Apache'a odbywa się poprzez dyrektywy, które są wpisywane w tekstowym
pliku konfiguracyjnym httpd.conf.
Ze względów historycznych istnieją czasami dwa dodatkowe pliki konfiguracyjne: srm.conf i
access.conf.
srm.conf zawiera dyrektywy zarządzania zasobami i przestrzeniami nazw (namespace)
access.conf zawiera informacje o kontroli dostępu do katalogów i plików.
Można nie używać tych plików dodając powyższą konfigurację do httpd.conf i dodając do
niego poniższe dyrektywy (systemy UNIXowe):
AccessConfig /dev/null
ResourceConfig /dev/null
Nie będziemy tutaj przedstawiać kompletnej listy parametrów możliwych do skonfigurowania
w Apache'u, gdyż wymagałoby to przytaczania całego instrukcji, przedstawimy tylko
podstawowe parametry konfiguracyjne.
Należą do nich:
ServerType
ServerRoot
-
ścieżka do głównego katalogu serwera, w którym
znajduj
ą się pliki konfiguracyjne i logi serwera
PidFile
- okre
śla ścieżkę do pliku z PID procesu serwera
Timeout
- czas po jakim serwer wysy
ła timeout
KeepAlive
- pozwala na sta
łe połączenia (obsługujące więcej niż
jedno
żądanie)
KeepAliveTimeout
- czas timeoutu przy sta
łych połączenia
MinSpareServers
- minimalna ilo
ść procesów serwera
MaxSpareServers
- maksymalna ilo
ść procesów serwera
StartServers
- inicjalizajcyjna (przy starcie) ilo
ść procesów serwera
MaxClients
- maksymalna ilo
ść jednoczesnych połączeń
MaxRequestsPerChild
- maksymalna ilo
ść żądań od jednego klienta
Port
- port na którym dzia
ła serwer
User
- u
żytkownik, z którego ma być uruchamiany serwer

Group
- grupa, z której ma by
ć uruchamiany serwer
ServerAdmin
- adres e-mail administratora systemu
DocumentRoot
- folder, z którego s
ą udostępniane strony WWW na
serwerze
Konfiguracja plików z logami serwera
ErrorLog
-
LogLevel
-
CustomLog
-
Uruchamianie modułów
Moduły mogą być wkompilowane bezpośrednio w httpd lub mogą być skompilowane
oddzielnie i podłączane do serwera www poprzez dyrektywy jeżeli tylko pozwala na to
konfiguracja serwera (podstawowy moduł Windows: experymentalny moduł Unix).
Moduł Core jest podstawowym modułem Apache'a. Dyrektywy z tego modułu są zawsze
dostępne i służą do podstawowej konfiguracji WebServera przybliżonej w poprzednim
punkcie.
Do uruchamiania modułu wkompilowanego w serwer używa się dyrektywy AddModule.
Jeżeli natomiast chcemy uruchomić moduł z zewnętrznego pliku binarnego to
wykorzystujemy dyrektywę LoadModule.
Dyrektywa LoadModule nie jest dostępne w podstawowym module Core, dostarczana jest w
module mod_sp (podstawowy moduł Windows, eksperymentalny moduł Unix).
PHP
Wprowadzenie
PHP czyli Hypertext Preprocessor jest językiem skryptowym działającym po stronie
serwera i zagnieżdżonym w kodzie HTML. Tak więc cały kod php umieszczony jest
pomiędzy kodem html, a wykonywany na serwerze. Znakomicie nadaje się do zbierania
danych z formularzy, generowania dynamicznie zmianiających się stron www, operowanie na
cookies (ciasteczkach) oraz przedstawiania i operacji na bazach danych. Ponadto PHP ma
wsparcie dla innych protokołów sieciowych np. pop3
Instalacja (kompilacja)
Kod źródlowy oraz binarne dystrybucje na niektóre platformy (w tym Windows),
można znaleźć na stronie http://www.php.net. Polski mirror tej strony znajduje się pod
adresem http://pl.php.net.
PHP możemy skompilować na dwa sposoby: pierwszy, statyczny, na stałe wbudowany
w serwer www (w naszym wypadku w apache) i dynamiczny jako moduł ładowany przez
serwer www. Znacznie korzystniejszym rozwiązaniem jest drugi sposób, gdyż pozwala na
lepszą kontrolę nad PHP i przy kompilacji nowej wersji PHP nie jest wymagana rekompilacja
serwera Apache.

Dynamiczne kompilowanie PHP4 dla Apacha
Potrzebujemy do tego zainstalowanego serwera Apache’a. Ważne jest aby Apache był
skompilowany z modułami http_core.c i mod_so.c dlatego też nie należy ich wyłączać przy
konfiguracji.
Na początku należy skonfigurować PHP poleceniem:
./configure –with-pgsql –with-apxs=/usr/local/apache/bin/apxs
oczywiście –with-pgsql dodajmy tylko wtedy gdy chcemy mieć wsparcie PHP dla
PostgreSQL’a. Dla innych baz także są odpowiednie opcje (pełna lista jest na
Po skonfigurowaniu PHP należy je zkompilować:
make
make install
Kolejnym krokiem jest konfiguracja Apache’a. W tym celu do pliku httpd.conf
dodajemy następujące linie:
LoadModule php4_module libexec/libphp4.so
AddModule mod_php4.c
AddType application/x-httpd-php.php
I to już wszystko. Oczywiście należy jeszcze zrestartować Apache’a.
Statyczne kompilowanie PHP4 z Apache
Na początku musimy skompilować PHP ze wsparciem dla Apache’a.
./configure --with-pgsql --with-apache=sciezka/do/zrodel/apache --enable-track-vars
make
make install
Skompilowaliśmy PHP jak moduł, który teraz dodamy do Apache’a.
./configure –activate-module=src/modules/php4/libphp4.a
make
make install
Plik libphp4.a nie istnieje, ale zostanie automatycznie utworzony.
Kopiujemy plik php.ini-dist
cp php.ini-dist /usr/local/lib/php.ini
Ostatnim krokiem jest edycja pliku konfiguracyjnego Apache’a – httpd.conf.
Dopisujemy w nim jedną linię:
AddType application/x-httpd-php .php
Na koniec powinniśmy oczywiście zrestartować serwer Apache.
Linki
o
•

o
•
o
•
CGI
Wprowadzenie
Jeśli mamy już zainstalowany serwer WWW (np. Apache) chcielibyśmy mieć troszkę
większe możliwości niż tylko wyświetlanie statycznych stron HTML’owych. Możemy
poszerzyć usługi naszego serwera np. o możliwość korzystania z CGI.
Zasadę współpracy serwera WWW z programem CGI obrazuje przedstawiony obok
rysunek.
Użytkownik odwołuje się do skryptu CGI za pośrednictwem przeglądarki WWW w
sposób analogiczny, jak do zwykłego statycznego dokumentu HTML - np. klikając na
odsyłacz na stronie WWW. Serwer WWW rozpoznaje, ze adres nie oznacza zwykłego
statycznego pliku, lecz skrypt, i uruchamia wskazany program, przekazując mu ewentualne
informacje otrzymane z przeglądarki (np. w przypadku, gdy skrypt został wywołany w
wyniku wypełnienia formularza na stronie WWW). Program wykonuje jakieś działanie (np.
dopisuje wpis użytkownika do przechowywanej na serwerze księgi gości), a następnie tworzy
dokument wyjściowy, który zostanie przez serwer odesłany przeglądarce użytkownika.
Dokument ten ma najczęściej postać strony w języku HTML, ale nie jest to obowiązkowe -
np. popularne na stronach WWW liczniki odwiedzin są przykładem skryptów wysyłających
obrazy graficzne w formacie GIF.
Technika CGI nie jest związana z żadnym konkretnym językiem programowania.
Skryptem CGI może być dowolny plik wykonywalny, który czyta dane ze standardowego
wejścia i wypisuje wyniki na standardowe wyjście (w przypadku serwerów pracujących w
systemie Windows program taki powinien być napisany jako tzw. aplikacja konsolowa). Plik
ten powinien być oznaczony jako wykonywalny w normalnie przyjęty w danym systemie
operacyjnym sposób (np. poprzez rozszerzenie .EXE w systemie Windows).
Instalacja / konfiguracja
Aby to mieć możliwość korzystania z CGI należy jedynie przekonfigurować trochę
Apache’a.
Wszelkich niezbędnych wpisów będziemy dokonywać w pliku srm.conf znajdującym
się w podkatalogu conf głównego katalogu serwera Apache (katalog ten określamy przy
instalacji; przy standardowej instalacji ze źródeł jest to /usr/local/etc/httpd)
Na początku sprawimy aby serwer w ogóle obsługiwał CGI.
W pliku /usr/local/apache/httpd.conf odkomentowujemy (znakiem komentarza jest tu
‘#’) lub wpisujemy jeśli nie istnieje następującą linię.
AddHandler cgi-script .cgi
Dla umożliwienia natomiast używania wstawek SSI niezbędne będą poniższe dwa
polecenia (analogicznie jak poprzednie, zwykle są już one w pliku - trzeba tylko usunąć znaki
"#" przed nimi):

AddType text/html .shtml
AddHandler server-parsed .shtml
Następnie należy dodać alias cgi, aby zamiast ścieżki
Odnajdujemy wiersz zaczynający się od polecenia ScriptAlias
przykładowo, wiersz ten może mieć postać:
ScriptAlias /cgi-bin/ /usr/local/etc/httpd/cgi-bin/
Wiersz ten definiuje katalog /cgi-bin, przeznaczony do umieszczania skryptów, oraz
jego rzeczywistą lokalizację na dysku (w tym przypadku /usr/local/etc/httpd/cgi-bin).
Możemy zmienić tę lokalizację; możemy także dodać dodatkowe katalogi przeznaczone dla
skryptów dopisując kolejne polecenia ScriptAlias w następnych wierszach. Przez wydanie
takiego polecenia będziemy się mogli odwoływać do naszego katalogu np. poprzez
http://127.0.0.1/cgi-bin/.
Natomiast drugim wartym zainteresowania plikiem jest plik access.conf, w którym
możemy określić, w których katalogach wolno uruchamiać skrypty CGI. W pliku tym
znajdziemy zwykle jedną lub kilka konstrukcji następującej postaci:
<Directory /
ścieżka/dostępu/do/katalogu>
...
Options - lista opcji
...
</Directory>
na przykład:
<Directory /usr/local/etc/httpd/htdocs>
Order deny,allow
Allow from all
Options Indexes FollowSymLinks ExecCGI
AllowOverride None
</Directory>
Obecność w wierszu Options napisu "ExecCGI" oznacza zezwolenie na uruchamianie w
danym katalogu skryptów CGI, zaś "Includes" - na stosowanie SSI. Można też spotkać się z
formą "Options All", która zawiera w sobie m.in. obydwa te uprawnienia.
W zależności od potrzeb, możemy modyfikować wiersze Options istniejące w pliku lub
dopisywać całkowicie nowe fragmenty <Directory ...> ... </Directory> dla katalogów, w
których chcemy odblokować możliwość korzystania z CGI lub SSI.
Należy pamiętać, że po każdej zmianie w plikach konfiguracyjnych musimy
zrestartować program Apache, aby zmiany zostały zauważone przez serwer.
To już wszystko. Teraz należy sprawdzić czy na naszym serwerze rzeczywiście
wywołują się skrypty CGI. Aby to zrobić można napisać proste skrypty wyświetlające np.
informacje o systemie.
skrypt Test-CGI
#!/bin/sh
# disable filename globbing
set -f
echo Content-type: text/plain
echo
echo CGI/1.0 test script report:
echo
echo argc is $#. argv is "$*".
echo
echo SERVER_SOFTWARE = $SERVER_SOFTWARE
echo SERVER_NAME = $SERVER_NAME

echo GATEWAY_INTERFACE = $GATEWAY_INTERFACE
echo SERVER_PROTOCOL = $SERVER_PROTOCOL
echo SERVER_PORT = $SERVER_PORT
echo REQUEST_METHOD = $REQUEST_METHOD
echo HTTP_ACCEPT = "$HTTP_ACCEPT"
echo PATH_INFO = "$PATH_INFO"
echo PATH_TRANSLATED = "$PATH_TRANSLATED"
echo SCRIPT_NAME = "$SCRIPT_NAME"
echo QUERY_STRING = "$QUERY_STRING"
echo REMOTE_HOST = $REMOTE_HOST
echo REMOTE_ADDR = $REMOTE_ADDR
echo REMOTE_USER = $REMOTE_USER
echo AUTH_TYPE = $AUTH_TYPE
echo CONTENT_TYPE = $CONTENT_TYPE
echo CONTENT_LENGTH = $CONTENT_LENGTH
skrypt PrintENV
#!/usr/bin/perl
print "Content-type: text/html\n\n";
while (($key, $val) = each %ENV) {
print "$key = $val\n";
}
Skrypty te umieszczamy w katalogu cgi-bin, nadajemy prawa dostępu na 755 (chmod
755), uruchamiamy porzeglądarkę i wpisujemy http://127.0.0.1/cgi-bin/printenv. Jeśli
wyświetlą się informacje o naszym systemie – to wszystko działa.
Linki
• •
SetUserID Execution
Wstęp - SUID2
Program typu SUID (set-UID) oznacza, że uruchomienie danego programu powoduje
przyznanie uruchamiającemu praw właściciela programu. Technika ta jest wykorzystywana
między innymi przy programie
passwd
, który ma właściciela
root'a
i jest programem typu
SUID. Dzięki temu w trakcie uruchomienia programu
passwd
mamy możliwość pisania do
pliku
/etc/passwd
, który normalnie ma tą możliwość zablokowaną. Aby programowi nadać
cechę SUID'a należy mu ustawić bit SUID czyli ósemkowo 4000. Tak samo sprawa
przedstawia się z programami SGID, tyle że przy nich otrzymujemy prawa danej grupy, do
której należy ten program. Bit SGID ustawia się podając ósemkowo 2000.
Choć programy tego typu dają wiele dobrego, można dostać większe uprawnienia na
czas uruchomienia takiego programu, to jednak są też potencjalnym zagrożeniem dla systemu.
Jeśliby na przykład stworzyć shell typu SUID z konta
root'a
i nadać mu prawa do
uruchamiania dla wszystkich, to każdy mógłby dostać przywileje superużytkownika
uruchamiając tego shella. Można to zrobić następującymi dwoma komendami (mając dostęp
do terminala
root'a
):
# cp /bin/sh /tmp
# chmod 4777 /tmp/sh
W ten sposób w katalogu
/tmp
powstanie kopia shella
sh
typu SUID, dająca się
uruchomić przez każdego użytkownika. Czyli każdy może być teraz
root'em
w tym
systemie. Należy więc uważać aby takie wypadki nie miały miejsca, gdyż są poważnym

zagrożeniem dla całęgo systemu. Jednym z rozwiązań tego problemu jest zamontowanie
partycji jako
nosuid
, wtedy nie możliwe jest ustawienie bit SUID dla plików znajdujących
się na niej. Szczególnie należy uważać na systemy plików, które są podmontowywane z
zewnątrz w czasie działania systemu, np. stacje dyskietek czy zdalne systemy plików
udostępnione przez NFS. Takie systemu należy montować w następujący sposób:
# /etc/mount -o nosuid remote_host:/dir /home/dir
w ten sposób unikamy działania programów SUID zainstalowanych na podłączanym dysku.
Bez tej możliwości łatwo możnaby stworzyć na dyskietce SUID'ową wersję shella, następnie
zamontować tą dyskietkę w systemie i uzyskać prawa
root'a
w tym systemie.
Przykładem popularnego programu SUID jest
write
, program ten na czas
wykonywania się także dostaje prawa
root'a
, dzięki czemu jest możliwe pisanie do terminali
innych użytkowników co jest w reguły zabronione.
Następnym problemem występującym przy programach typu SUID jest ich bezpieczne
pisanie. Zasadniczo należy unikać pisania takich programów (a już na pewno niedopuszczalne
jest pisanie skryptów SUID). Czasem jednak zachodzi taka potrzeba i musimy mieć program
typu SUID. Należy wtedy pamiętać w kilku podstawowych w tym przypadku zasadach
bezpieczeństwa, gdyż zagrożenie ze strony błędnie napisanego programu typu SUID jest
olbrzymie (szczególnie jeśli ma on mieć
root'a
jako właściciela):
Pod żadnym pozorem nie należy pisać skryptów SUID. Skrypt taki można przerwać lub
zawiesić otrzymując prawa właściciela.
Nie należy używać SUID'ów do uzyskania dostępu do niedostępnych plików, do tego
celu służą grupy, lepiej jest utworzyć taką i przypisać tam potrzebnych użytkowników.
Jeśli program potrzebuje wykonać pewne funkcje jako superużytkownik, ale ogólnie nie
potrzebuje
uprawnień
SUID,
należy
rozważyć
możliwość
umieszczenia
części
uprzywilejowanej w osobnym programie i (bezpieczne) połączenie obu tych programów.
Nie należy korzystać w programie z domyślnej ścieżki dostępu do plików, lepiej
podawać zawsze bezwzględną ścieżkę.
Począwszy od Apache’a 1.2 została wprowadzona funkcja suEXEC, która dostarcza
możliwość uruchomienia skryptów CGI i SSI pod innym user ID niż to które zadało pytanie
do serwera WWW.
Konfiguracja i instalacja
Aby skonfigurować suEXEC możemy posłużyć się następującymi opcjami:
--enable-suexec
Ta opcja włącza suEXEC. Co najmniej jedna z opcji typu –suexec-xxxxx musi być połączona z
opisywaną opcją.
--suexec-caller=UID
Użytkownik pod którym Apache jest uruchomiony.
--suexec-docroot=DIR
Wszystki pliki wykonywalne z tego katalogu będą wykonywane przez
suEXEC.
--suexec-logfile=FILE
Definiuje plik do którego będą zapisywane wszystkie logi
--suexec-userdir=DIR

Definiuje katalog (podkatalog katalogu domowego użytkownika), w którym wszystkie
programy będą uruchamiane przez suEXEC.
--suexec-uidmin=UID
Definiuje najmniejszy UID (ID użytkownika) z jakim programy mogą być
uruchamiane przez suEXEC. Standardowa wartość to 100.
--suexec-gidmin=GID
Definiuje najmniejszy GID (ID grupy) z jakim programy mogą być
uruchamiane przez suEXEC.
--suexec-safepath=PATH
Definiuje ścieżkę to pass to CGI executables. Standardowa wartość to
/usr/local/bin:/usr/bin:/bin
Przykładowa konfiguracja funkcji suEXEC może wyglądać następująco:
$ ./configure --prefix=/path/to/apache \
--enable-suexec \
--suexec-caller=www \
--suexec-userdir=.www \
--suexec-docroot=/path/to/root/dir \
--suexec-logfile=/path/to/logdir/suexec_log \
--suexec-uidmin=1000 \
--suexec-gidmin=1000 \
--suexec-safepath="/bin:/usr/bin"
Teraz pozostało nam już tylko skompilowac i zainstalowac funkcję suEXEC:
make
make install
Włączanie i wyłączanie suEXEC
Podczas uruchamiania serwera, Apache szuka binariów suEXEC w swojej ścieżce
(standardowo jest to /usr/local/apache/sbin/suexec). Po ich znalezieniu zostanie wyświetlony
komunikat:
suEXEC mechanism enabled (wrapper: /path/to/suexec)
Aby wyłączyć funkcję suEXEC należy sunąć binaria ze ścieżek Apache’a i
zrestartować serwer.
Serwery proxy
Serwery WWW proxy są używane w celu przyspieszenia dostępu do innych serwerów www a
także jako element bezpieczeństwa. Poniższe omówienie skupia się na wersji darmowej takiego serwera
jakim jest Squid. Jego dodatkowymi zaletami jest
•
wydajność,
•
duże możliwości konfiguracyjne
•
obsługa protokołu ICP, który jest protokołem komunikacyjnym pomiędzy
serwerami proxy WWW
•
wsparcie dla FTP oraz Gophera

•
definiowanie dostępu czyli mechanizm ACL
•
wsparcie dla protokołu SSL
Serwer Squid może pracować w trzech trybach: http-accelerator w celu zwiększenia
wydajności serwera WWW, normalny tryb accelerator gdy chcemy przyspieszyć
dostęp do innych serwerów WWW oraz w trybie hierarchicznym w takim przypadku
mamy do czynienia z wieloma serwerami proxy, które komunikują się ze sobą za
pomocą protokołu ICP.
Poniższe omówienie skupi się na konfiguracji dla wszystkich trzech powyższych
przypadków.
Konfiguracja
Plikiem konfiguracyjnym dla serwera Squid jest squid.conf.
Poniższa konfiguracja uwzględnia przypadek gdy Squid pracuje w trybie
http-accelerator. W tym trybie jeśli serwer WWW pracuje na tej samej maszynie co
Squid to konieczne jest ustawienie innego numeru portu dla demona http. W przypadku
serwera Apache wystarczy odpowiedni wpis w pliku httpd.conf przez zmianę opcji
Port 80 na Port 81.
http_port 80
icp_port 0
acl QUERY urlpath_regex cgi-bin \?
no_cache deny QUERY
cache_mem 16 MB
cache_dir ufs /cache 200 16 256
emulate_httpd_log on
redirect_rewrites_host_header off
acl all src 0.0.0.0/0.0.0.0
http_access allow all
cache_mgr admin@anonymous.com
cache_effective_user squid
cache_effective_group squid
httpd_accel_host 208.164.186.3
httpd_accel_port 80
log_icp_queries off
buffered_logs on
•
http_port 80 opcja wskazuje na port na jakim ma nasłuchiwać Squid przez co
serwer „występuje” w roli serwera WWW
•
icp_port opcja wskazuje na jakim porcie squid będzie odbierał pakiety ICP od
sąsiednich serwerów cache, w przypadku gdy wartość jest ustawiona na 0 opcja
ta jest wyłączona ze względów na wydajność, ponieważ serwer nie pracuje w
środowisku Muilti-level Web Caching.
•
acl QUERY urlpath_regex cgi-bin \? and no_cache deny QUERY nakazuje aby
obiekty znajdujące się w katalogach CGI nie były uwzględniane przy
cachowaniu
•
cache_mem 16 MB wskazuje na ilość pamięci RAM jaka ma być użyta w
przypadku cachowania obiektów typu hot, in-transit, negative-cached

•
cache_dir ufs /cache 200 16 256 opcje w kolejności oznaczają typ struktury
katalogów(ufs), katalog w jakim mają być przechowywane dane(/cache), ilość
miejsca na dysku dla tego katalogu(200 MB) oraz liczbę katalogów kolejno na
poziome 1 i 2 każdego katalogów, odpowiednio jest to 16 i 256.
•
emulate_httpd_log on format pliku z logami będzie miał taką postać jak w
przypadku serwera Apache
•
redirect_rewrites_host_header off opcja ta jest wyłączona aby Squid nie
nadpisywał żadnych informacji w nagłówkach które są przekierowywane do
prawdziwego serwera WWW
•
acl all src 0.0.0.0/0.0.0.0 and http_access allow all mamy tu do czynienia z
definicją listy dostępu na podstawie adresu źródłowego, w tym przypadku dostęp
naszego serwera nie jest ograniczony(ponieważ na zewnątrz jest widziany jako
serwer WWW)
•
cache_mgr admin definiuje adres emailowy administratora serwera Squid
•
cache_effective_user squid and cache_effective_group squid wskazuje na
UID/GID użytkownika pod którym będzie się uruchamiał serwer
•
httpd_accel_host 208.164.186.3 and httpd_accel_port 80 tutaj są informacje na
jakiej maszynie i jakim porcie nasłuchuje „prawdziwy” serwer WWW
•
log_icp_queries off wyłącza logowanie na temat wymiany komunikatów typu ICP pomiędzy
róznymi serwerami
•
buffered_logs on przyspiesza zapis logów
W przypadku gdy chcemy aby nasz serwer pracował w trybie cache powyższa
konfiguracja wymaga niewielkich zmian. Dodatkowo można jeszcze uwzględnić co
może być przeglądane, a także tryb w jakim ma pracować; czy ma pracować jako
samodzielny serwer czy też w hierarchii serwerów Squid.
http_port 8080
icp_port 0
acl QUERY urlpath_regex cgi-bin \?
no_cache deny QUERY
cache_mem 16 MB
cache_dir ufs /cache 200 16 256
redirect_rewrites_host_header off
acl localnet src 192.168.1.0/255.255.255.0
acl localhost src 127.0.0.1/255.255.255.255
acl all src 0.0.0.0/0.0.0.0
http_access allow localnet
http_access allow localhost
http_access deny all
cache_mgr admin@anonymous.com
cache_effective_user squid
cache_effective_group squid
log_icp_queries off
buffered_logs on
Różnice w tej konfiguracji głównie odnoszą się do definicji kontroli dostępu
ACL, opcje te pozwalają na definicje jakie hosty mają prawo dostępu do naszego
serwera, jakie dokumenty mogą być cachowane etc.
Powyższa konfiguracja pozwala na dostęp tylko klientom z sieci lokalnej i tylko na
określonych portach czyli dostęp mają klienci których adres źródłowy jest w klasie
C(192.168.1.0/24) oraz „localhost”.
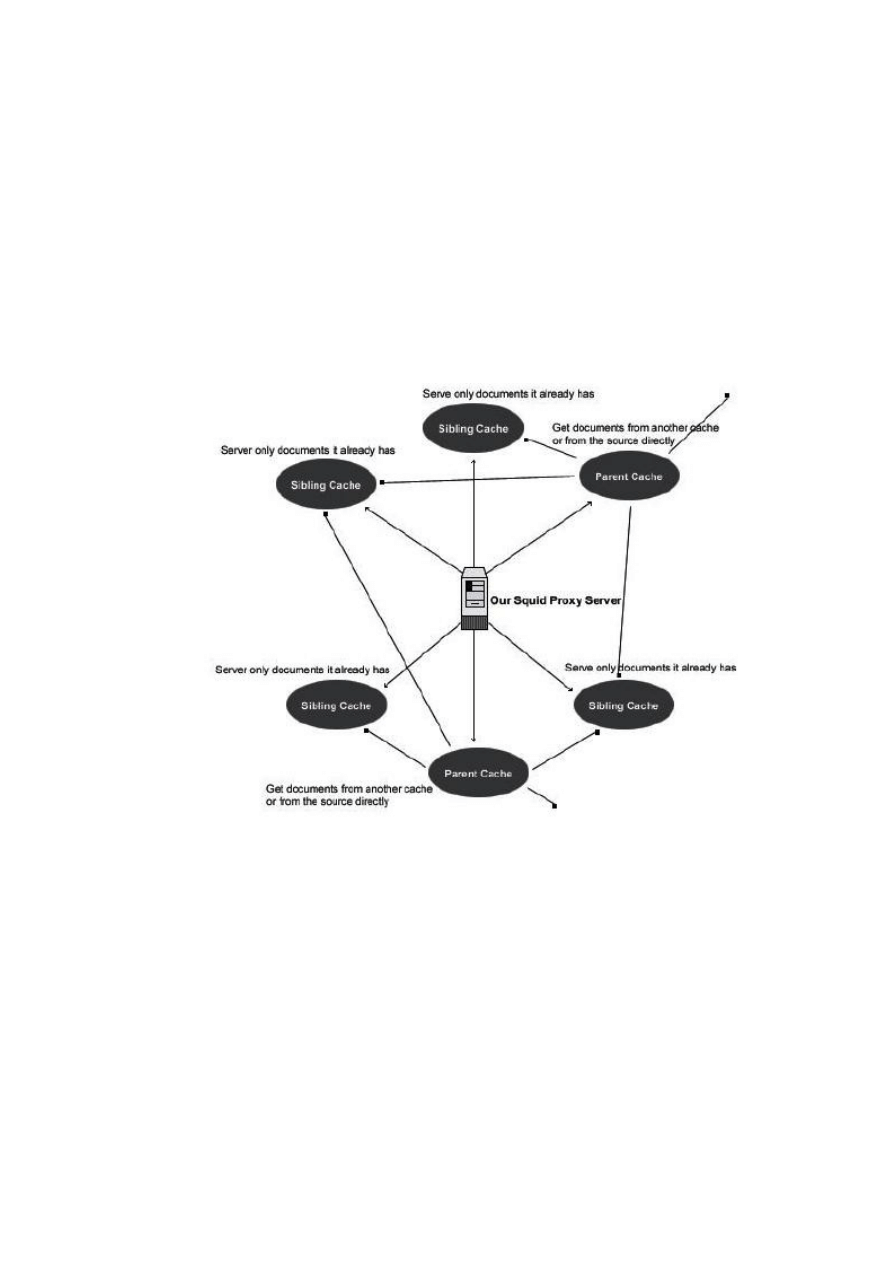
Klaster serwerów proxy
Interesującym rozwiązaniem jest konfiguracja serwerów w taki sposób, aby ze
sobą współpracowały np. jeden serwer mógłby udostępniać dokumenty, które już ma w
pamięci, natomiast następny mógłby bezpośrednio się odwoływać do serwera zdalnego.
Serwer, który odwołuje się bezpośrednio tym przypadku serwer taki jest tzw. parent
proxy
Dobrym pomysłem aby uniknąć dużego ruchu w sieci jest posiadania paru
serwerów, które serwują dokument już znajdujące w pamięci oraz mniejszą liczbę
parent proxy.
Automatyczna konfiguracja przegl
ądarki:
Aby nasza przeglądarka używała proxy trzeba ją o tym poinformować poprzez
odpowiednie ustawienia jakimi są adres IP oraz port na jakim uruchomiony jest serwer proxy.
Dla części użytkowników znajomość ta może być kłopotliwa i tutaj pomocne może być
rozwiązanie oparte na tzw. skrypcie automatycznej konfiguracji, który może być
udostępniony bezpośrednio na serwerze WWW i automatycznie ściągany przy każdym starcie
klienta. Jako standard jest przyjęte że plik taki powinien mieć rozszerzenie .pac, dodatkowo
także jeśli to konieczne trzeba także zdefiniować odpowiedni mime-type dla tego pliku, czyli
w pliku konfiguracyjnym mime.types apache umieścić
application/x-ns-proxy-autoconfig pac

Sam plik napisany jest przy użyciu składni Java-Scriptu, gdzie definiuje się funkcję
dwuargumentową FindProxyForURL(url, host)
function FindProxyForURL(url, host) {
// dla domen lokalnych nie używaj proxy
if dnsDomainIs(host, "mydomain.example")
return "DIRECT";
// w przeciwnym razie użyj proxy z opcją fail-over
return "PROXY cache.mydomain.example:3128; DIRECT";
}
Jeśli w odpowiedzi zawarty jest średnik oznacza to opcję fail-over czyli w przypadku
gdy proxy cache.mydomain.example z jakiś powodów nie działa wtedy klient wykona
bezpośrednie połączenie.
Inne pożyteczne funkcje:
•
dnsDomainIs(host,".mydomain.example”) – używana aby sprawdzić czy host
przekazany jako pierwszy argument należy do domeny określonej przez drugi
argument
•
isInNet(host, "192.168.0.0", "255.255.0.0") – czy host należy do podsieci
•
isPlainHostName(host )- sprawdza czy nazwa host’a jest FQDN
•
url.substring(begin,end)- zwraca podstring
if (url.substring(0, 5) == "http:" ||
url.substring(0, 4) == "ftp:"||
url.substring(0, 7) == "gopher:")
return "PROXY cache.is.co.za:8080; DIRECT";
else
return "DIRECT";
Wirtualne serwery WWW
Zagadnienie wirtualnych serwerów WWW odnosi się do przypadku gdy jeden serwer
obsługuje wiele domen lub wiele adresów IP. Dla przykładu firma może używać dwóch
różnych domen
oraz
obsługiwanych przez jeden
serwer oraz innej zawartości.
Apache był jednym z pierwszych serwerów który obsługiwał wirtualny hosting z zależności
od IP lub nazwy kanonicznej.
1. Hosty wirtualne w oparciu o IP
W tym rozwiązaniu wymagane jest aby każdy host miał osobny numer IP, poprzez odpowiednią
liczbę interfejsów lub wykorzystanie wirtualnej adresacji jednego interfejsu jakim jest IPAliasing.
Przy takiej architekturze konfiguracja Apache może być przeprowadzona w dwojaki sposób tzn:
•
uruchomienie odpowiedniej ilości serwerów, każdy z nich obsługiwałby jedno odpowiadające mu
IP – rozwiązanie to jest pomocne w przypadku gdy potrzebne jest ograniczenie dostępu do danych
do jednej z domen. W takim przypadku każdy z serwerów musi być uruchomiony z różnymi
opcjami User, Group, Listen i ServerRoot.
•
konfiguracja demona w taki sposób aby nasłuchiwał na wielu interfejsach w sposób określony
przez informacje zawarte w plikach konfiguracyjnych.
Drugie rozwiązanie jest bardziej odpowiednie jeśli chodzi o wydajność ponieważ mamy
uruchomiony jeden proces z większą liczbą wątków.

Konfiguracja wymaga użycia dyrektywy VirtualHost wraz z opcjami
ServerAdmi
n,
ServerNam
e,
DocumentRoo
t,
ErrorLog
i
TransferLog
lub
CustomLog np.:
Poniżej zostanie omówiony przykład konfiguracji obsługującej interfejsy o adresie
(111.22.33.44 i 111.22.33.55). Domena
dla server.domain.tld i odpowiada adresowi 111.22.33.44, natomiast
jest skojarzona z adresem 111.22.33.55.
Port 80
ServerName server.domain.tld
<VirtualHost 111.22.33.44>
DocumentRoot /www/domain
ServerName www.domain.tld
...
</VirtualHost>
<VirtualHost 111.22.33.55>
DocumentRoot /www/otherdomain
ServerName www.otherdomain.tld
...
</VirtualHost>
wPrzy takiej konfiguracji główny serwer(server.domain.tld) nie będzie obsługiwał
żadnych połączeń z wyjątkiem tych które będą pochodziły od localhosta, ponieważ
wszystkie adresy IP naszej maszyny są użyte przy definicji hostów wirtualnych.
2. Hosty wirtualne w oparciu o nazwę
Takie rozwiązanie ma miejsce w przypadku gdy pojedynczemu adresowi IP odpowiadają
jakieś nazwy kanoniczne (CNAME). Obsługa hostów wirtualnych w oparciu o nazwę
wykorzystuje możliwości protokołu HTTP/1.1. Dodatkową różnicą jest konieczność
użycia dyrektywy
NameVirtualHost
która określa adres interfejsu używanego do
obsługi nazw kanonicznych.
Dla przykładu zostanie przedstawiony przypadek kiedy to adresowi 111.22.33.44
odpowiadają dwie nazwy domen
NameVirtualHost 111.22.33.44
<VirtualHost 111.22.33.44>
ServerName www.domain.tld
DocumentRoot /www/domain
</VirtualHost>
<VirtualHost 111.22.33.44>
ServerName www.otherdomain.tld
DocumentRoot /www/otherdomain
</VirtualHost>
Ważną rzeczą która należy podkreślić jest to, że adres wyspecyfikowany w dyrektywie
NameVirtualHost
będzie obsługiwał jedynie te domeny, które są określone przez
dyrektywę
VirtualHost
. Tak więc gdy przyjdzie request do
on obsłużony chyba że zostanie on umieszczony w sekcji
VirtualHost
. Innymi słowy
sekcja ta musi określać każdą domenę, która ma być obsługiwana przez dany serwer.

W przypadku gdy chcemy aby nasz serwer wirtualny obsługiwał więcej niż jedną nazwę i
te nazwy odnoszą się do tego samego numeru IP należy zastosować dyrektywę
ServerAlias
wewn
ątrz
VirtualHost
.
ServerAlias domain.tld *.domain.tld
Przy określaniu pasujących nazw można używać znaków * oraz ?
Rozwiązanie takie jest także wymagane gdy użytkownicy nie stosują nazw FQDN
tylko same nazwy kanoniczne bez wyspecyfikowania domeny do której należy dana
maszyna np. www zamiast
Dyrektywy konfiguracyjne:
•
<VirtualHost></VirtualHost> używana przy definicji pojedynczego hosta
wirtualnego, w jej kontekście są umieszczane inne dyrektywy definiujące sposób
pracy danego serwera. Każda dyrektywa <VirtualHost> musi się odnosić do
innego IP, nazwy hosta i numeru portu. Przy konfiguracji może być użyty
parametr _default_ który odnosi się do dowolnego IP, który nie jest bezpośrednio
określony, w szczególności odnosi się to do „głównego serwera”. Dodatkowo w
tym przypadku można też wyspecyfikować port(:port), domyślnie opcja ta odnosi
się do dowolnego portu na danym interfejsie. Przykład:
<VirtualHost _default_:*>
DocumentRoot /www/default
...
</VirtualHost>
•
NameVirtualHost wymagana w przypadku definiowania serwerów wirtualnych w
oparciu o nazwy domen i odnosi się do adresu IP na którym są obsługiwane
domeny, jeśli istnieje wiele domen na różnych interfejsach ich określenie musi być
zrobione za pomocą dyrektywy NameVirtualHost.
•
ServerName ustala nazwę serwera, używana w przypadku odpowiedzi serwera
do klienta
•
ServerAlias używana przy definiowaniu domen wirtualnych, ustala nazwę
alternatywną(wzór) jaka może być stosowana w przypadku odwołania do serwera
Dns i apache:
Jeśli podczas parsowania pliku konfiguracyjnego apache musi odwoływać się do
DNS’u może to być powodem problemów np. podczas jego startu, który może się nie
powieść w wyniku czego nasz serwer nie będzie działał.
Dla przykładu można przytoczyć konfigurację
:
<VirtualHost www.abc.dom>
ServerAdmin webgirl@abc.dom
DocumentRoot /www/abc
</VirtualHost>

tutaj apache musi się odwołać do dns’u w celu ustalenia adresu IP
,
jeśli w momencie parsowania dns jest niedostępny wtedy ta domena wirtualna będzie
nieobsługiwana, a od wersji apacha 1.2 serwer nawet nie wystartuje.
Podobna sytuacja ma miejsce w przypadku gdy definiujemy domenę wirtualną w
oparciu o IP
<VirtualHost 10.10.1.10>
ServerAdmin webgirl@abc.dom
DocumentRoot /www/abc
</VirtualHost>
gdzie apache musi się odwołać do revers dns’u aby ustalić nazwę serwera,
aczkolwiek w tym przypadku można tego uniknąć poprzez dyrektywę ServerName
czyli:
<VirtualHost 10.10.1.10>
ServerName www.abc.com
ServerAdmin webgirl@abc.dom
DocumentRoot /www/abc
</VirtualHost>
Inna możliwość to odpowiednia konfiguracja resolvera nazw czyli odpowiedni
wpis do /etc/hosts oraz /etc/host.conf.
Wyszukiwarka
Podobne podstrony:
HTTPD, J FORMS, Tworzenie formularzy HTML, mechanizm CGI
HTTPD, J HTTPD, httpd apache_1.0.3
httpd 1
httpd 3
httpd 2
więcej podobnych podstron