Wykład IV
Rodzaje i zadania
systemów operacyjnych
Podstawy informatyki
Semestr I Transport
Semestr II Elektrotechnika

O czym będzie ?
Prześledzimy
rozwój
systemów
operacyjnych od pierwszych ręcznych
systemów
aż
po
obecne,
wieloprogramowe systemy z podziałem
czasu. Zrozumienie przyczyn rozwoju
systemów operacyjnych pozwoli nam
ocenić, co robi system operacyjny i w
jaki sposób.

O czym będzie ?
cd.
Aby zrozumieć, czym są systemy operacyjne, musimy
najpierw dowiedzieć się, jak one powstawały.
Dlatego też poznamy rozwój systemów operacyjnych od
pierwszych systemów bezpośrednich aż po obecne,
wieloprogramowe systemy z podziałem czasu.
Poznając kolejne stadia ich rozwoju, będziemy mogli
zobaczyć ewolucję współtworzących je elementów, które
powstawały jako naturalne rozwiązania problemów
pojawiających
się
we
wczesnych
systemach
komputerowych.
Zrozumienie przyczyn, które wyznaczyły rozwój systemów
operacyjnych, da nam pojęcie o tym, jakie zadania
wykonuje system operacyjny i w jaki sposób.

Wprowadzenie
System operacyjny jest programem, który
działa jako pośrednik między użytkownikiem
komputera a sprzętem komputerowym.
Zadaniem systemu operacyjnego jest tworzenie
środowiska,
w
którym
użytkownik
może
wykonywać programy.
Podstawowym celem systemu operacyjnego jest
zatem spowodowanie, aby system komputerowy
był wygodny w użyciu.
Drugim celem jest wydajna eksploatacja sprzętu
komputerowego.
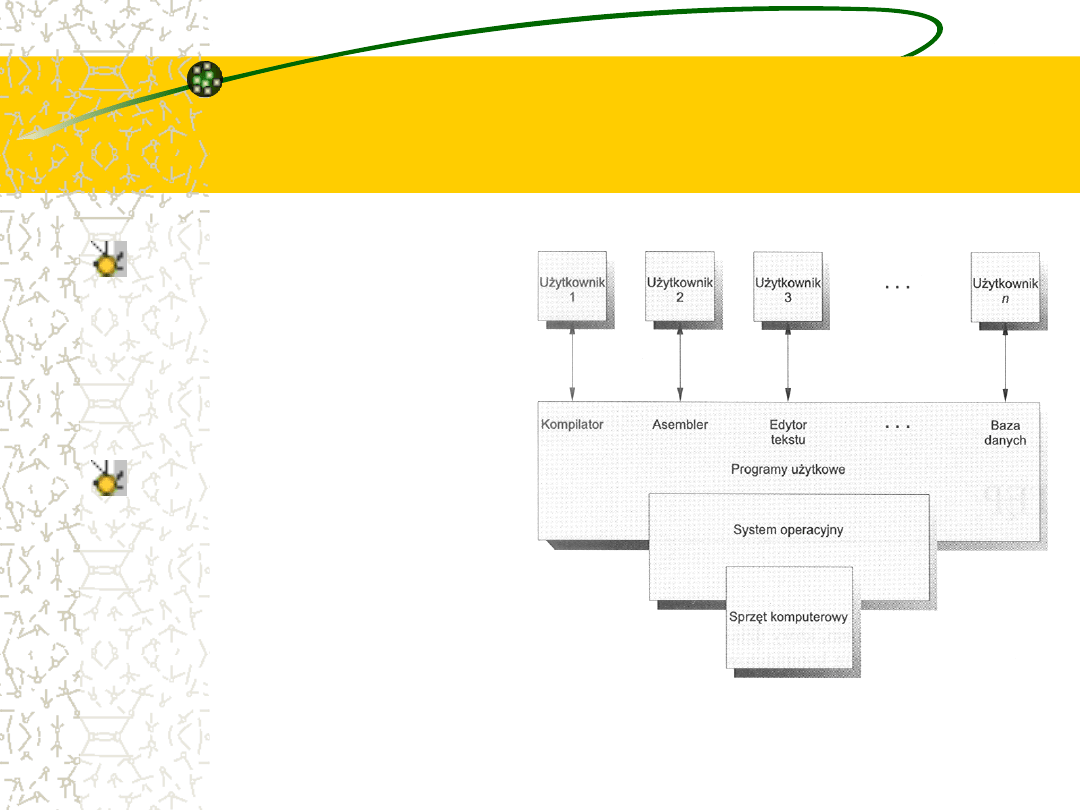
Abstrakcyjne wyobrażenie
elementów systemu
komputerowego
System operacyjny
(ang.
operating
system) jest ważną
częścią prawie każdego
systemu
komputerowego.
System komputerowy
można
z
grubsza
podzielić
na
cztery
części: sprzęt, system
operacyjny, programy
użytkowe
i
użytkowników

System operacyjny to
nadzorca
i koordynator
Sprzęt (ang. hardware), czyli: procesor - zwany też jednostką
centralną (ang. central processing unit - CPU), pamięć i
urządzenia wejścia - wyjścia, to podstawowe zasoby systemu
komputerowego.
Programy użytkowe (aplikacje) - kompilatory, systemy baz
danych, gry komputerowe lub programy handlowe - określają
sposoby użycia tych zasobów do rozwiązania zadań stawianych
przez użytkowników.
Zazwyczaj istnieje wielu różnych użytkowników (ludzie, maszyny,
inne komputery) zmagających się z rozwiązywaniem różnych
zadań. Odpowiednio do rozmaitych potrzeb może istnieć wiele
różnych programów użytkowych.
System operacyjny nadzoruje i koordynuje posługiwanie się
sprzętem przez różne programy użytkowe, które pracują na
zlecenie różnych użytkowników.

System operacyjny tworzy
środowisko pracy dla innych
programów
System operacyjny jest podobny do rządu.
W skład systemu komputerowego wchodzą: sprzęt,
oprogramowanie i dane. System operacyjny
dostarcza środków do właściwego użycia tych
zasobów w działającym systemie komputerowym.
Podobnie jak rząd, system operacyjny nie wykonuje
sam żadnej użytecznej funkcji. Po prostu tworzy
środowisko (ang. environment), w którym inne
programy mogą wykonywać pożyteczne prace.

System operacyjny –
alokator zasobów
Możemy uważać system operacyjny za dystrybutora zasobów
(alokator zasobów; ang. resource allocator).
System komputerowy ma wiele zasobów (sprzęt i
oprogramowanie), które mogą być potrzebne do rozwiązania
zadania: czas procesora, obszar w pamięci operacyjnej lub w
pamięci plików, urządzenia wejścia - wyjścia itd.
System operacyjny spełni funkcję zarządcy owych dóbr i
przydziela je poszczególnym programom i użytkownikom
wówczas, gdy są one nieodzowne do wykonywania zadań.
Ponieważ często może dochodzić do konfliktów przy
zamawianiu zasobów, system operacyjny musi decydować o
przydziale zasobów poszczególnym zamawiającym, mając na
względzie wydajne i harmonijne działanie całego systemu
komputerowego.

System operacyjny jest
programem sterującym
Nieco inne spojrzenie na system operacyjny jest
związane z zapotrzebowaniem na sterowanie
rozmaitymi urządzeniami wejścia - wyjścia i
programami użytkownika.
System operacyjny jest programem sterującym
(ang. control program).
Program
sterujący
nadzoruje
działanie
programów użytkownika, przeciwdziała błędom i
zapobiega niewłaściwemu użyciu komputera.
Zajmuje
się
zwłaszcza
obsługiwaniem
i
kontrolowaniem pracy urządzeń wejścia - wyjścia.

System operacyjny realizuje
wspólne operacje na potrzeby
programów użytkowych
Nie ma wszakże w pełni adekwatnej definicji systemu
operacyjnego.
Istnienie systemów operacyjnych jest uzasadnione tym, że
umożliwiają one rozsądne rozwiązywanie problemu kreowania
użytecznego systemu obliczeniowego.
Podstawowym celem systemów komputerowych jest wykonywanie
programów użytkownika i ułatwianie rozwiązywania stawianych
przez użytkownika problemów. Do spełnienia tego celu konstruuje
się sprzęt komputerowy. Ponieważ posługiwanie się samym
sprzętem nie jest szczególnie wygodne, opracowuje się programy
użytkowe.
Rozmaite programy wymagają pewnych wspólnych operacji, takich
jak sterowanie pracą urządzeń wejścia - wyjścia. Wspólne funkcje
sterowania i przydzielania zasobów gromadzi się zatem w jednym
fragmencie oprogramowania - systemie operacyjnym.

Nie jest jasno określone co
powinno wchodzić w skład
systemu operacyjnego
Nie ma również uniwersalnie akceptowanej definicji tego, co jest, a
co nie jest częścią systemu operacyjnego. Przyjmuje się w
uproszczeniu, że należy wziąć pod uwagę to wszystko, co
dostawca wysyła w odpowiedzi na nasze zamówienie na „system
operacyjny”.
Jednakże w zależności od rodzaju systemu zapotrzebowanie na
pamięć oraz oferowane właściwości bywają bardzo zróżnicowane.
Istnieją systemy zajmujące mniej niż 1 MB pamięci, a jednocześnie
nie wyposażone nawet w pełnoekranowy edytor, podczas gdy inne
wymagają setek megabajtów pamięci oraz zawierają takie
udogodnienia jak korektory pisowni i całe „systemy okien”.
Częściej spotykamy definicję, że system operacyjny jest to ten
program, który działa w komputerze nieustannie (nazywany
zazwyczaj jądrem), podczas gdy wszystkie inne są programami
użytkowymi.

Wygoda i wydajność
często są ze sobą
sprzeczne
Najważniejszym celem systemu operacyjnego jest wygoda
użytkownika. Systemy operacyjne istnieją, ponieważ
przyjmuje się, że łatwiej z nimi niż bez nich korzystać z
komputerów. Widać to szczególnie wyraźnie wówczas, gdy
przyjrzymy się systemom operacyjnym małych komputerów
osobistych.
Celem drugorzędnym jest efektywne działanie systemu
komputerowego. Ten cel jest szczególnie ważny w
rozbudowanych, wielodostępnych systemach z podziałem
czasu. Systemy tego rodzaju są zazwyczaj kosztowne, jest
więc pożądane, aby były maksymalnie wydajne.
Te dwa cele - wygoda i wydajność - są nieraz ze sobą
sprzeczne. W przeszłości osiągnięcie wydajności było często
przedkładane nad wygodę.

Sposób pracy w
pierwszych komputerach
Pierwsze komputery były wielkimi (fizycznie) maszynami
obsługiwanymi
za
pośrednictwem
konsoli.
Popularnymi
urządzeniami wejściowymi były czytniki kart i przewijaki taśm.
Na wyjściu najczęściej można było spotkać drukarki wierszowe,
przewijaki taśm i perforatory kart.
Użytkownicy takich systemów nie współpracowali bezpośrednio
z
systemem
komputerowym.
Przeciwnie,
użytkownik
przygotowywał zadanie, które składało się z programu, danych i
pewnych, charakteryzujących zadanie informacji sterujących
(karty sterujące), po czym przedkładał to wszystko operatorowi
komputera. Zadanie znajdowało się zazwyczaj na kartach
perforowanych. W późniejszym czasie (po minutach, godzinach
lub dniach) pojawiały się informacje wyjściowe zawierające
wyniki działania programu, a niekiedy obraz jego pamięci - jeśli
działanie programu zakończyło się błędem.
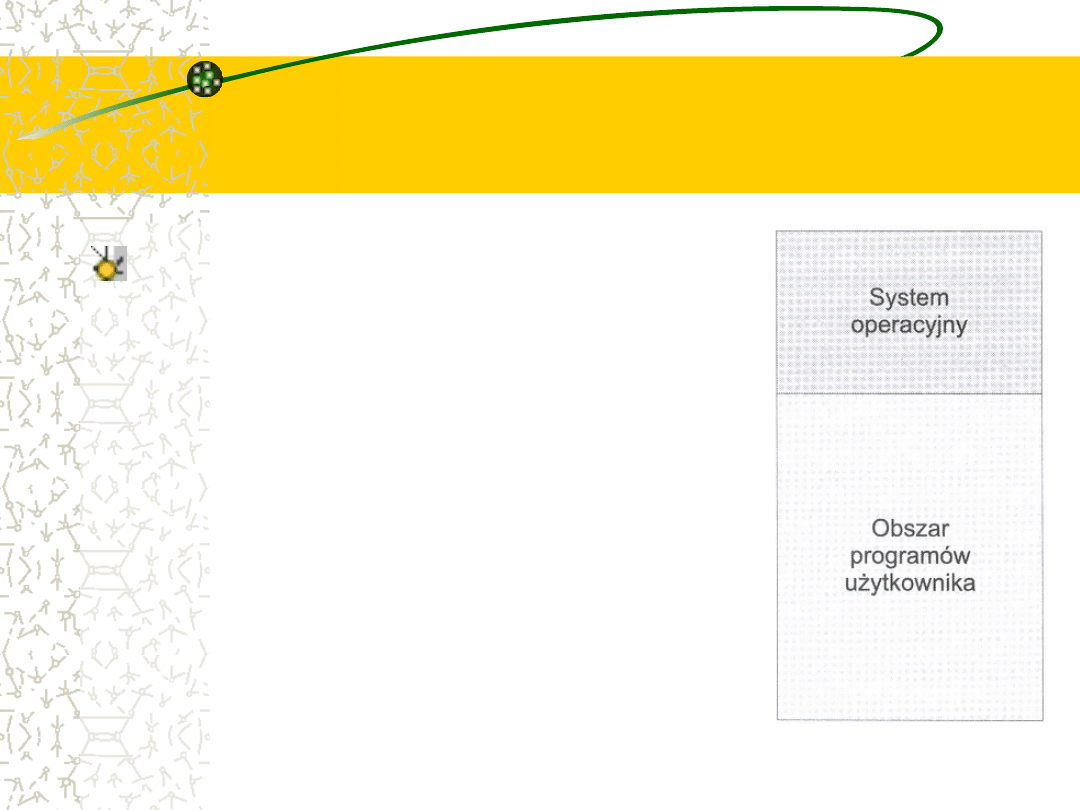
Wygląd pamięci
operacyjnej prostego
systemu wsadowego
Systemy
operacyjne
tych
pierwszych komputerów były
zupełnie proste. Podstawowym
ich
obowiązkiem
było
automatyczne przekazywanie
sterowania od jednego zadania
do
następnego.
System
operacyjny rezydował na stałe
w pamięci operacyjnej

Wsadowe wykonywanie
zadań
Aby przyspieszyć przetwarzanie, zadania o podobnych
wymaganiach grupowano razem i wykonywano w komputerze
w formie tzw. wsadu (ang. batch).
Programiści zostawiali zatem programy operatorowi. Operator
sortował je w grupy o podobnych wymaganiach i z chwilą, gdy
komputer stawał się dostępny, przekazywał po-szczególne
pakiety zadań do wykonania. Informacje wyprowadzane przez
każde z zadań rozsyłano odpowiednim autorom programów.
Po zakończeniu zadania jego wyniki są zazwyczaj drukowane
(np. na drukarce wierszowej). Wyróżniającą cechą systemu
wsadowego jest brak bezpośredniego nadzoru ze strony
użytkownika podczas wykonywania zadania. Zadania są
przygotowywane i przedkładane. Wyniki pojawiają się po
jakimś czasie.

Przy takiej organizacji
pracy procesor zbyt
często leniuchuje
W takim środowisku wykonywania
programów
jednostka
centralna
często pozostawała bezczynna.
Przyczyna tych przestojów wynikała z
szybkości działania mechanicznych
urządzeń wejścia - wyjścia, które z
natury są powolniejsze od urządzeń
elektronicznych.

Rozwiązanie przyniosło
zastosowanie dysków
Pomocne okazało się tutaj wprowadzenie technologii dyskowej.
Zamiast czytać karty za pomocą czytnika wprost do pamięci,
a następnie przetwarzać zadanie, karty z czytnika kart są
czytane bezpośrednio na dysk.
Rozmieszczenie obrazów kart jest zapisywane w tablicy
przechowywanej przez system operacyjny.
Podczas wykonywania zadania zamówienia na dane
wejściowe z czytnika kart są realizowane przez czytanie z
dysku.
Podobnie, gdy zadanie zamówi wyprowadzenie wiersza na
drukarkę, wówczas dany wiersz będzie skopiowany do bufora
systemowego i zapisany na dysku. Po zakończeniu zadania
wyniki są rzeczywiście drukowane.
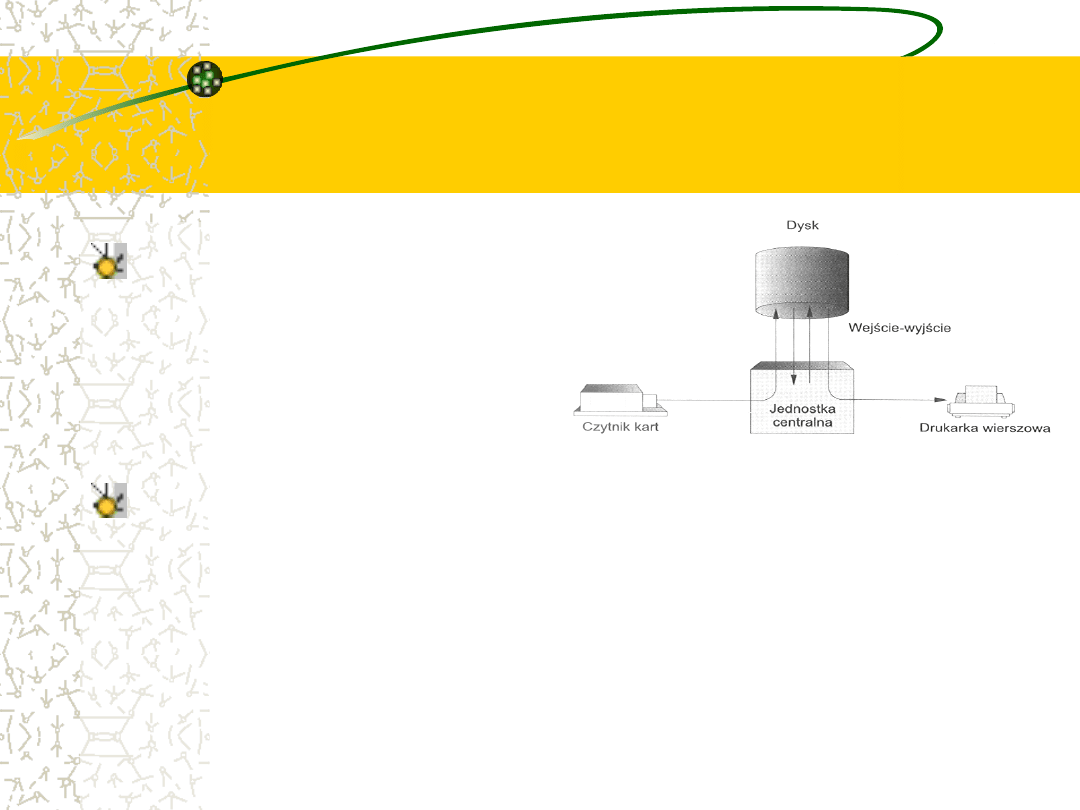
Spooling
Tej
metodzie
przetwarzania
nadano
nazwę
spooling,
którą
utworzono
jako
skrót
określenia
„simultaneous
peripheral
operation
on-line”
(jednoczesna, bezpośrednia praca urządzeń).
Spooling w istocie polega na tym, że używa się
dysku jako olbrzymiego bufora do czytania z
maksymalnym
wyprzedzeniem
z
urządzeń
wejściowych oraz do przechowywania plików
wyjściowych do czasu, aż urządzenia wyjściowe
będą w stanieje przyjąć.

Co daje spooling ?
Spooling umożliwia nakładanie w czasie operacji wejścia -
wyjścia jednego zadania na obliczenia innych zadań. Nawet
w prostym systemie procedura spooler może czytać dane
jednego zadania i równocześnie drukować wyniki innego. W
tym samym czasie może być wykonywane jeszcze inne
zadanie (lub zadania), które czyta swoje „karty” z dysku i
również na dysku „drukuje” wiersze swoich wyników.
Spooling wywarł bezpośredni, dobroczynny wpływ na
zachowanie systemu. Kosztem pewnego obszaru pamięci na
dysku i niewielu tablic procesor mógł wykonywać obliczenia
jednego zadania równocześnie z operacjami wejścia - wyjścia
dla innych zadań. Dzięki spoolingowi stało się możliwe
utrzymywanie zarówno procesora, jak i urządzeń wejścia -
wyjścia w znacznie większej aktywności.

Pula zadań
daje możliwość ich
szeregowania
Ze spoolingiem jest związana bardzo ważna struktura danych -
pula zadań (ang. job pool).
Spooling powoduje, że pewna liczba zadań jest zawczasu czytana
na dysk, gdzie czeka gotowa do wykonania. Dzięki istnieniu puli
zadań na dysku system operacyjny może tak wybierać następne
zadania do wykonania, aby zwiększyć wykorzystanie jednostki
centralnej.
Przy zadaniach nadchodzących wprost z kart lub nawet z taśmy
magnetycznej nie ma możliwości wykonywania zadań w
dowolnym porządku. Zadania muszą być wykonane po kolei w
myśl zasady: pierwsze nadeszło - pierwsze zostanie obsłużone
(FIFO).
Gdy kilka zadań znajdzie się na urządzeniu o dostępie
bezpośrednim - jak dysk, wówczas staje się możliwe planowanie
zadań (szeregowanie zadań; ang. job scheduling).

Wieloprogramowanie –
sposób na zapewnienie
procesorowi aktywności
Najważniejszym aspektem planowania zadań jest
możliwość wieloprogramowania.
Praca pośrednia (ang. off-line operation) oraz
spooling umożliwiający nakładanie operacji wejścia
- wyjścia mają ograniczenia. Jeden użytkownik na
ogół nie zdoła utrzymać cały czas w aktywności
procesora lub urządzeń wejścia - wyjścia.
Dzięki
wieloprogramowaniu
zwiększa
się
wykorzystanie procesora wskutek takiej organizacji
zadań, aby procesor miał zawsze któreś z nich do
wykonania.
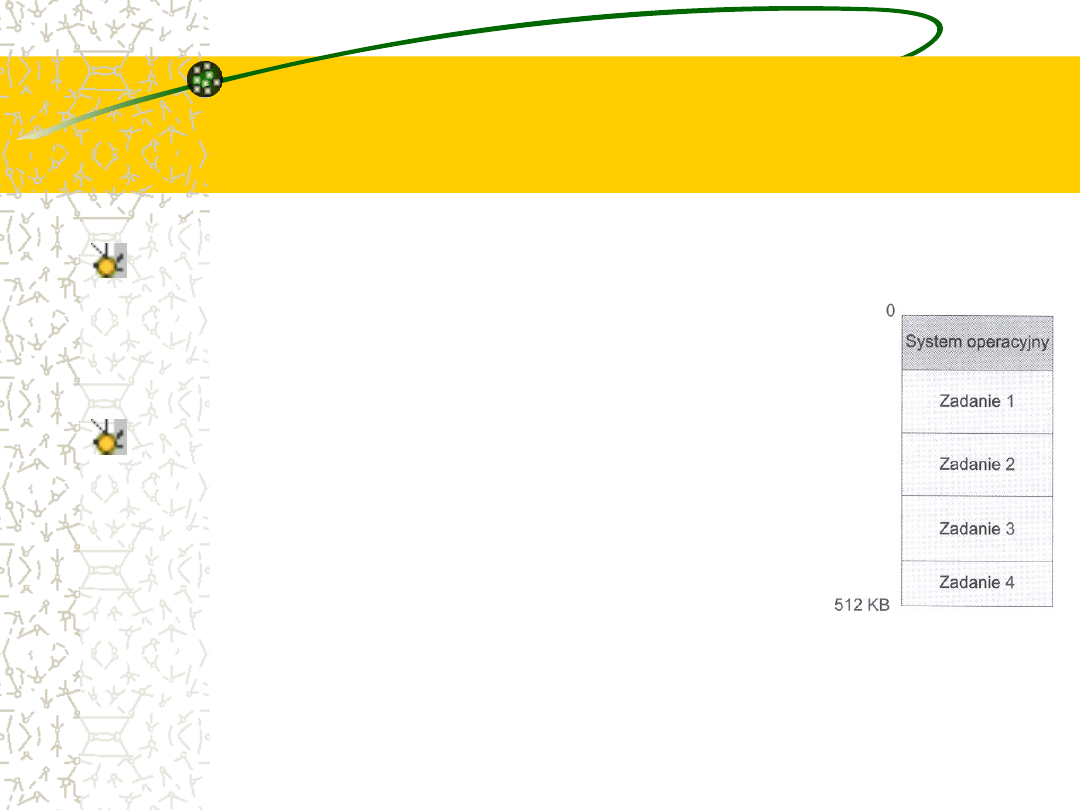
Wygląd pamięci w
systemie
wieloprogramowym
Idea
wieloprogramownia
jest
następująca. W tym samym czasie
system operacyjny przechowuje w
pamięci kilka zadań (rys.)
Ten zbiór zadań jest podzbiorem zadań
zgromadzonych w puli zadań (gdyż
liczba
zadań,
które
można
jednocześnie
przechowywać
w
pamięci operacyjnej, jest na ogół
znacznie mniejsza niż liczba zadań,
którą może pomieścić pula).

Sposób pracy systemu
wieloprogramowego
System operacyjny pobiera któreś z zadań do pamięci i
rozpoczyna jego wykonywanie.
Prędzej czy później zadanie to może zacząć oczekiwać na
jakąś usługę, na przykład na zakończenie operacji wejścia
- wyjścia.
W systemie jednoprogramowym jednostka centralna
musiałaby wówczas przejść w stan bezczynności.
W systemie wieloprogramowym można po prostu przejść
do wykonywania innego zadania itd. Po jakimś czasie
pierwsze zadanie skończy oczekiwanie i otrzyma z
powrotem dostęp do procesora.
Dopóki są jakieś zadania do wykonania, dopóty jednostka
centralna nie jest bezczynna.

Podobnie bywa w życiu
Takie postępowanie jest typowe dla zwyczajnych
sytuacji życiowych.
Adwokat nie prowadzi na ogół sprawy tylko jednego
klienta. Przeciwnie - sprawy kilku klientów toczą się w
tym samym czasie. Kiedy jeden pozew czeka na
rozprawę lub sporządzenie maszynopisów, wtedy
adwokat może pracować nad innym przypadkiem.
Przy wystarczającej liczbie klientów adwokat nigdy się
nie nudzi.
Bezczynni adwokaci mają skłonności do zostawania
politykami, toteż utrzymywanie adwokatów w ciągłym
zatrudnieniu ma pewne społeczne znaczenie.

System wieloprogramowy
podejmuje część decyzji za
użytkowników
Wieloprogramowanie jest pierwszym przypadkiem, w
którym system operacyjny musi decydować za
użytkowników.
Wieloprogramowane systemy operacyjne są więc dość
skomplikowane. Wszystkie zadania wchodzące do
systemu trafiają do puli zadań. Pula ta składa się ze
wszystkich procesów pozostających w pamięci masowej i
czekających na przydział pamięci operacyjnej.
Jeżeli kilka zadań jest gotowych do wprowadzenia do
pamięci operacyjnej, lecz brakuje dla wszystkich
miejsca, to system musi wybierać spośród nich.
Podejmowanie takich decyzji jest planowaniem zadań
(szeregowaniem zadań).

Zadania systemu
operacyjnego związane z
pracą wspólbieżną
Wybrawszy któreś z zadań z puli, system wprowadza je do
pamięci operacyjnej w celu wykonania. Przechowywanie
wielu programów w pamięci w tym samym czasie wymaga
jakiegoś zarządzania pamięcią.
Ponadto, jeżeli kilka zadań jest gotowych do działania w
tym samym czasie, to system musi wybrać któreś z nich.
Tego rodzaju decyzje są planowaniem przydziału procesora
(ang. CPU scheduling).
Ze współbieżnego wykonywania wielu zadań wynika też
potrzeba
ograniczania
możliwości
ich
wzajemnego
zaburzania we wszystkich stadiach pobytu w systemie
operacyjnym: w czasie planowania procesów, przydzielania
pamięci dyskowej i zarządzania pamięci operacyjną.

Wady systemów
wsadowych
Z punktu widzenia użytkownika system wsadowy jest jednak
trochę kłopotliwy. Ponieważ użytkownik nie może ingerować w
zadanie podczas jego wykonywania, musi przygotować karty
sterujące na okoliczność wszystkich możliwych zdarzeń.
W zadaniu wykonywanym krok po kroku następne kroki mogą
zależeć od wcześniejszych wyników. Na przykład uruchomienie
programu może zależeć od powodzenia fazy kompilacji. Trudno
przewidzieć, co należy robić we wszystkich przypadkach.
Inną wadą jest konieczność statycznego testowania programów
na podstawie ich migawkowych obrazów pamięci. Programista nie
może na bieżąco zmieniać programu w celu zaobserwowania jego
zachowań.
Długi
czas
obiegu
zadania
wyklucza
eksperymentowanie z programem. (I na odwrót - sytuacja taka
może powodować zwiększenie dyscypliny przy pisaniu i
testowaniu programu).

Podział czasu
Podział
czasu
(inaczej
wielozadaniowość; ang. multitasking)
stanowi
logiczne
rozszerzenie
wieloprogramowości.
Procesor wykonuje na przemian wiele
różnych zadań, przy czym przełączenia
następują tak często, że użytkownicy
mogą współdziałać z każdym programem
podczas jego wykonania.

Interakcyjny system
komputerowy
Interakcyjny lub bezpośredni (ang. hands-on)
system komputerowy umożliwia bezpośredni dialog
użytkownika z systemem.
Użytkownik
wydaje
bezpośrednio
instrukcje
systemowi operacyjnemu lub programowi i otrzymuje
natychmiastowe odpowiedzi. Po wykonaniu jednego
polecenia
system
szuka
następnej
„instrukcji
sterującej”.
Użytkownik wydaje polecenie, czeka na odpowiedź i o
kolejnym poleceniu decyduje na podstawie wyników
poprzedniego polecenia. Użytkownik może łatwo
eksperymentować i natychmiast oglądać rezultaty.

System plików
Aby użytkownicy mogli wygodnie korzystać zarówno z
danych, jak i z oprogramowania, powinien mieć
bezpośredni dostęp do systemu plików (ang. on-line file
system).
Plik (ang. file) jest zestawem powiązanych informacji,
zdefiniowanym przez jego twórcę. Z grubsza biorąc, w
plikach pamięta się programy (zarówno w postaci
źródłowej, jak i wynikowej) oraz dane. Pliki danych mogą
zawierać liczby, teksty lub mieszane dane alfanumeryczne.
Pliki mogą mieć układ swobodny, jak w plikach tekstowych,
lub precyzyjnie określony format. Mówiąc ogólnie, plik jest
ciągiem bitów, bajtów, wierszy lub rekordów, których
znaczenie jest określone przez jego twórcę i użytkownika.

Organizacja systemu
plików
System operacyjny urzeczywistnia abstrakcyjną
koncepcję pliku, zarządzając takimi urządzeniami
pamięci masowych jak taśmy, napędy i dyski.
Zazwyczaj pliki są zorganizowane w logiczne
niepodzielne
grupy,
czyli
katalogi
(ang.
directories), ułatwiające ich odnajdywanie i
wykonywanie na nich działań.
Ponieważ
do
plików
ma
dostęp
wielu
użytkowników, jest pożądane, by istniał nadzór
nad tym, kto i w jaki sposób z nich korzysta.

Systemy wsadowe i
interakcyjne
Systemy wsadowe są odpowiednie dla wielkich
zadań, których wykonanie nie wymaga stałego
bezpośredniego dozoru. Użytkownik może przedłożyć
zadanie i przyjść później po wyniki; nie ma powodu,
aby czekał na nie podczas wykonywania zadania.
Zadania interakcyjne składają się z wielu krótkich
działań, w których rezultaty kolejnych poleceń mogą
być nieprzewidywalne. Czas odpowiedzi (ang.
response time) powinien więc być krótki - co
najwyżej rzędu sekund. Systemy interakcyjne mają
zastosowanie tam, gdzie oczekuje się szybkich
odpowiedzi.

Procesy
Wprowadzenie systemów z podziałem czasu (ang. time-sharing
systems)
umożliwiło
interakcyjne
użytkowanie
systemu
komputerowego po umiarkowanych kosztach.
W systemie operacyjnym z podziałem czasu zastosowano
planowanie przydziału procesora i wieloprogramowość, aby
zapewnić każdemu użytkownikowi możliwość korzystania z małej
porcji dzielonego czasu pracy komputera.
Każdy użytkownik ma przynajmniej jeden oddzielny program w
pamięci. Załadowany do pamięci operacyjnej i wykonywany w niej
program przyjęto nazywać procesem (ang. process).
Wykonywanie procesu trwa zwykle niedługo i albo się kończy, albo
powoduje zapotrzebowanie na operację wejścia - wyjścia. Zamiast
pozwalać procesorowi na bezczynność, system operacyjny w
takich przypadkach angażuje go błyskawicznie do wykonywania
programu innego użytkownika.

System operacyjny
z podziałem czasu
System operacyjny z podziałem czasu sprawia, że
wielu użytkowników dzieli (ang. share) równocześnie
jeden komputer.
Ponieważ pojedyncze działania lub polecenia w
systemie z podziałem czasu trwają krótko, każdemu
użytkownikowi wystarcza mały przydział czasu
jednostki centralnej.
Dzięki błyskawicznym przełączeniom systemu od
jednego użytkownika do drugiego, każdy z nich
odnosi
wrażenie,
że
dysponuje
własnym
komputerem, choć w rzeczywistości jeden komputer
jest dzielony pomiędzy wielu użytkowników.

Praca z podziałem czasu i
przetwarzanie wsadowe
Ideę podziału czasu zaprezentowano już w 1960 r., lecz ze
względu na trudności i koszty budowy systemy z podziałem czasu
pojawiły się dopiero we wczesnych latach siedemdziesiątych.
W miarę wzrostu popularności podziału czasu konstruktorzy
systemów zaczęli łączyć systemy wsadowe z systemami z
podziałem czasu. Wiele systemów komputerowych, które
pierwotnie zaprojektowano z myślą o użytkowaniu w trybie
wsadowym, zostało zmodyfikowanych w celu umożliwienia pracy
z podziałem czasu.
W tym samym okresie systemy z podziałem czasu wzbogacano
często o podsystemy wsadowe.
Obecnie większość systemów umożliwia zarówno przetwarzanie
wsadowe, jak i podział czasu, chociaż w ich podstawowych
założeniach i sposobie użycia zwykle przeważa jeden z tych
typów pracy.

Pamięć wirtualna
Systemy operacyjne z podziałem czasu są jeszcze bardziej
złożone niż wieloprogramowe systemy operacyjne.
Tak jak w wieloprogramowości, w pamięci operacyjnej
należy przechowywać jednocześnie wiele zadań, które
potrzebują pewnych form zarządzania pamięcią i ochrony.
Aby zagwarantować akceptowalny czas odpowiedzi,
zadania z pamięci operacyjnej trzeba niekiedy odsyłać na
dysk i wprowadzać do niej z powrotem. Dysk staje się
zapleczem dla pamięci głównej komputera.
Popularną metodą osiągania tego celu jest pamięć
wirtualna
(ang.
virtual
memory),
czyli
technika
umożliwiająca wykonywanie zadania nie mieszczącego się
w całości w pamięci operacyjnej.

Zalety pamięci wirtualnej
Najbardziej
widoczną
zaletą
takiego
rozwiązania jest umożliwienie wykonania
programów większych niż pamięć fizyczna.
Ponadto powstaje tu abstrakcja pamięci
głównej w postaci wielkiej, jednolitej tablicy,
oddzielająca pamięć logiczną - oglądaną
przez użytkownika - od pamięci fizycznej.
Uwalnia to programistów od zajmowania się
ograniczeniami pamięciowymi.

Co muszą zapewniać systemy
wieloprogramowe i systemy z
podziałem czasu ?
Systemy z podziałem czasu muszą też dostarczać
bezpośrednio dostępnego systemu plików.
System plików rezyduje w zbiorze dysków, należy więc
także zapewnić zarządzanie dyskami.
Systemy z podziałem czasu muszą też umożliwiać
działania współbieżne, a to wymaga przemyślanych
metod przydziału procesora.
Aby zagwarantować porządek wykonywanych działań, w
systemie muszą istnieć mechanizmy synchronizowania
zadań oraz komunikacji między nimi; system musi
również zapewniać, że zadania nie będą się zakleszczać ,
nieustannie wzajemnie na siebie czekając.

Pojawia się PC
Zmniejszanie się cen sprzętu spowodowało możliwość
zbudowania systemu komputerowego przeznaczonego
dla indywidualnych użytkowników.
Ten rodzaj systemów komputerowych zwykło się nazywać
komputerami osobistymi (ang. personal computers - PC).
Oczywiście, zmieniły się urządzenia wejścia - wyjścia;
pojawiły się nowoczesne klawiatury i monitory, szybkie
drukarki laserowe i atramentowe, skanery i joysticki.
Komputery
osobiste
pojawiły
się
w
latach
siedemdziesiątych. Są to mikrokomputery, zdecydowanie
mniejsze i tańsze od systemów komputerów głównych
(ang. mainframe).

Nie od razu PC były
wielozadaniowe,
wielostanowiskowe, ...
W pierwszym dziesięcioleciu rozwoju komputerów osobistych
stosowane w nich jednostki centralne były pozbawione cech
potrzebnych
do
ochrony
systemu
operacyjnego
przed
programami użytkowymi. Systemy operacyjne komputerów
osobistych nie były więc ani wielostanowiskowe, ani
wielozadaniowe.
Jednakże cele tych systemów zmieniły się z upływem czasu -
zamiast maksymalizowania wykorzystania procesora i urządzeń
zewnętrznych położono w nich nacisk na maksimum wygody
użytkowania i szybkości kontaktu z użytkownikiem.
Do systemów takich zalicza się komputery PC pracujące pod
nadzorem systemu MS Windows i systemu Apple MacOS,
Pojawiają się mniej lub bardziej udane próby wprowadzenia
szeregu innych systemów operacyjnych: OS/2, BeOS, Linux,
Lindows
.

Następuje migracja z
dużych na małe
W systemach operacyjnych mikrokomputerów skorzystano z
różnych wzorów sprawdzonych podczas rozwoju systemów
operacyjnych dla dużych komputerów.
W mikrokomputerach od samego początku zaadaptowano
technikę opracowaną dla większych systemów operacyjnych.
Jednak taniość sprzętu mikrokomputerowego sprawia, że
może on być użytkowany przez indywidualne osoby, a
wykorzystanie procesora przestaje mieć doniosłe znaczenie.
W związku z tym pewne rozwiązania uzyskane przy
tworzeniu systemów operacyjnych dla dużych komputerów
mogą być nieodpowiednie dla systemów mniejszych. Na
przykład ochrona plików w komputerach osobistych może
okazać się zbędna.
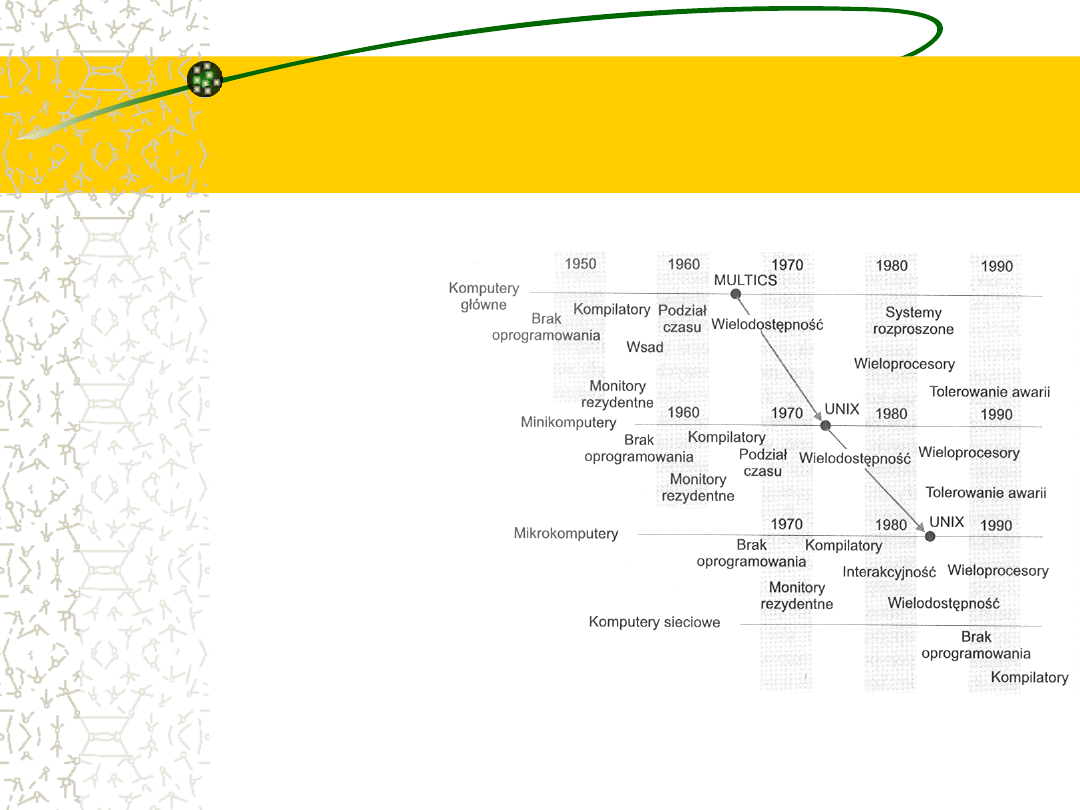
Wędrówka cech i
koncepcji systemów
operacyjnych
Po przeanalizowaniu
systemów operacyjnych
dla dużych komputerów i
dla mikrokomputerów
okazało się, że w istocie
te cechy, które były w
swoim czasie dostępne
tylko w komputerach
głównych, zaadaptowano
też w mikrokomputerach.
Te same koncepcje
okazują się odpowiednie
dla rozmaitych klas
komputerów:
komputerów głównych,
minikomputerów i
mikrokomputerów (rys.)

MULTICS protoplasta wielu
systemów
Dobrym
przykładem
przenoszenia
koncepcji
systemów
operacyjnych jest system operacyjny MULTICS. System ten
opracowano w latach 1965-1970 w MIT jako narzędzie obliczeniowe.
Działał na dużym, złożonym komputerze głównym GE 645.
Wiele pomysłów wprowadzonych do systemu MULTICS zastosowano
następnie w firmie Bell Labs przy projektowaniu systemu UNIX.
System operacyjny UNIX powstał około 1970 r., pierwotnie dla
minikomputera PDP-11.
Około 1980 r. rozwiązania rodem z systemu UNIX stały się bazą dla
uniksopodobnych systemów operacyjnych przeznaczonych dla
systemów mikrokomputerowych i pojawiły się w późniejszych
systemach operacyjnych, takich jak MS Windows NT, IBM OS/2 i
MacOS. W ten sposób pomysły zastosowane w wielkich systemach
komputerowych przeniknęły z czasem do mikrokomputerów.

Systemy
wieloprocesorowe
Dzisiejsze
systemy
są
w
większości
jednoprocesorowe, tzn. mają tylko jedną, główną
jednostkę centralną.
Obserwuje się jednakże zainteresowanie systemami
wieloprocesorowymi
(ang.
multiprocessor
systems).
W systemach tego rodzaju pewna liczba procesorów
ściśle współpracuje ze sobą, dzieląc szynę komputera,
zegar, a czasami pamięć i urządzenia zewnętrzne.
Systemy takie nazywa się ściśle powiązanymi (ang.
tightly coupled).

Systemy
wieloprocesorowe
zwiększają przepustowość
Istnieje kilka powodów uzasadniających budowanie takich
systemów. Jednym z argumentów jest zwiększenie
przepustowości (ang. throughput).
Zwiększając liczbę procesorów, możemy oczekiwać, że
większą ilość pracy da się wykonać w krótszym czasie.
Jednak współczynnik przyspieszenia przy n procesorach nie
wynosi n, lecz jest od n mniejszy. Kiedy kilka procesorów
współpracuje przy wykonaniu jednego zadania, wtedy traci się
pewną część czasu na utrzymywanie właściwego działania
wszystkich części. Ten nakład w połączeniu z rywalizacją o
zasoby dzielone powoduje zmniejszenie oczekiwanego zysku z
zastosowania dodatkowych procesorów.
Analogicznie, grupa współpracujących ze sobą n programistów
nie powoduje n-krotnego wzrostu wydajności pracy.

Systemy
wieloprocesorowe
wykorzystują wspólne
zasoby
Oszczędności, jakie można uzyskać, stosując
wieloprocesory w porównaniu z wykorzystaniem
wielu pojedynczych systemów, wynikają także z
możliwości wspólnego użytkowania przez nie
urządzeń
zewnętrznych,
zamykania
ich
we
wspólnych obudowach i zasilania ze wspólnego
źródła.
Jeśli kilka programów ma działać na tym samym
zbiorze danych, to taniej jest zapamiętać dane na
jednym dysku i pozwolić na korzystanie z nich
wszystkim procesorom, aniżeli rozmieszczać liczne
ich kopie na lokalnych dyskach wielu komputerów.

Łagodna degradacja
Innym argumentem na rzecz systemów wieloprocesorowych jest
to, że zwiększają one niezawodność.
Umiejętne rozdzielenie zadań między pewną liczbą procesorów
powoduje, że awaria jednego procesora nie za-trzymuje systemu,
tylko go spowalnia.
Gdy mamy dziesięć procesorów i jeden ulegnie awarii, wówczas
pozostałe procesory muszą przejąć i podzielić między siebie
pracę uszkodzonego procesora. Dzięki temu cały system bę-dzie
pracował tylko o 10% wolniej i nie grozi mu całkowite załamanie.
Zdolność kontynuowania usług na poziomie proporcjonalnym do
ilości ocalałego sprzętu jest nazywana łagodną degradacją
(ang. graceful degradation). Systemy przystosowane do łagodnej
degradacji są również zwane systemami tolerującymi awarie
(ang. fault-tolerant).

Wieloprzetwarzanie
symetryczne i
asymetryczne
Obecnie w systemach wieloprocesorowych używa się
najczęściej modelu wieloprzetwarzania symetrycznego
(ang. symmetric multiprocessing), w którym na każdym
procesorze działa identyczna kopia systemu operacyjnego.
Kopie te komunikują się ze sobą w zależności od potrzeb.
W
niektórych
systemach
zastosowano
wieloprzetwarzanie asymetryczne (ang. asymmetric
multiprocessing) polegające na tym, że każdy procesor ma
przypisane inne zadanie. Systemem takim zawiaduje
procesor główny. Inne procesory albo czekają na instrukcje
od procesora głównego, albo zajmują się swoimi uprzednio
określonymi zadaniami. Procesor główny planuje i
przydziela prace procesorom podporządkowanym.

Wersja Encore systemu UNIX -
przykład systemu
z wieloprzetwarzaniem
symetrycznym
Komputer ten tak skonfigurowany, że umożliwia
działanie wielkiej liczby procesorów, z których
każdy pracuje pod nadzorem kopii systemu UNIX.
Zaletą tego modelu jest to, iż równocześnie może
pracować wiele procesów (N procesów na N
egzemplarzach
jednostki
centralnej)
bez
pogarszania działania całego systemu.
Należy jednak zadbać o takie wykonanie operacji
wejścia - wyjścia, aby dane docierały do
właściwych procesorów.

Procesory na zapleczu
Spadek cen mikroprocesorów i zwiększenie ich możliwości
powodują
przerzucanie
wielu
funkcji
systemowych
na
podporządkowany
systemowi
operacyjnemu
sprzęt
mikroprocesorowy, czyli jego zaplecze (ang. back-ends).
Na przykład można obecnie z łatwością dodać do systemu
mikroprocesor wyposażony we własną pamięć i przeznaczony do
zarządzania dyskami. Mikroprocesor taki może przyjmować
polecenia od procesora głównego i realizować własną kolejkę
dyskową i algorytm planowania. Rozwiązanie to uwalnia procesor
główny od zajmowania się planowaniem operacji dyskowych.
Komputery PC zawierają wmontowany w klawiaturę mikro-
procesor zamieniający uderzenia klawiszy na kody gotowe do
przesłania
do
procesora.
Tego
rodzaju
zastosowania
mikroprocesorów rozpowszechniły się do tego stopnia, że nie
uważa się ich już za wieloprzetwarzanie.

Systemy rozproszone
W tworzonych ostatnio systemach komputerowych daje
się zauważyć tendencja do rozdzielania obliczeń między
wiele procesorów.
W porównaniu ze ściśle powiązanymi systemami,
(omówionymi wcześniej), procesory te nie dzielą pamięci
ani zegara. Każdy procesor ma natomiast własną pamięć
lokalną.
Procesory komunikują się za pomocą różnych linii
komunikacyjnych, na przykład szybkich szyn danych lub
sieci komputerowych.
Systemy
takie
nazywają
się
zazwyczaj
luźno
powiązanymi (ang. loosely coupled) lub rozproszonymi
(ang. distributed systems).

Stanowiska, węzły,
komputery...
Procesory w systemach rozproszonych mogą się
różnić pod względem rozmiaru i przeznaczenia.
Mogą wśród nich być małe mikroprocesory, stacje
robocze, minikomputery i wielkie systemy
komputerowe ogólnego przeznaczenia.
Na określenie tych procesorów używa się różnych
nazw, takich jak: stanowiska (ang. sites), węzły
(ang. nodes), komputery itp. - zależnie od
kontekstu, w którym się o nich mówi.

Podział zasobów
Po połączeniu ze sobą różnych stanowisk (o różnych
możliwościach) użytkownik jednego stanowiska może
korzystać z zasobów dostępnych na innym.
Na przykład użytkownik węzła A może korzystać z drukarki
laserowej zainstalowanej w węźle B. Użytkownik węzła B
może w tym samym czasie mieć dostęp do pliku
znajdującego w A.
Mówiąc ogólnie, podział zasobów w systemie rozproszonym
tworzy mechanizmy dzielonego dostępu do plików w węzłach
zdalnych, przetwarzania informacji w rozproszonych bazach
danych, drukowania plików w węzłach zdalnych, zdalnego
użytkowania specjalizowanych urządzeń sprzętowych (np.
odznaczających
się
wielką
szybkością
procesorów
tablicowych) i wykonywania innych operacji.

Przyspieszenie obliczeń
Jeśli pewne obliczenie da się rozłożyć na zbiór
obliczeń cząstkowych, które można wykonywać
współbieżnie, to system rozproszony umożliwia
przydzielenie tych obliczeń do poszczególnych
stanowisk i współbieżne ich wykonanie.
Ponadto, jeżeli pewne stanowisko jest w danej
chwili przeciążone zadaniami, to część z nich
można przenieść do innego, mniej obciążonego
stanowiska. Takie przemieszczanie zadań nazywa
się dzieleniem obciążeń (ang. load sharing).

Niezawodność
W przypadku awarii jednego stanowiska w systemie
rozproszonym pozostałe mogą kontynuować pracę.
Jeżeli system składa się z dużych, autonomicznych instalacji
(tzn. komputerów ogólnego przeznaczenia), to awaria jednego
z nich nie wpływa na działanie pozostałych.
Natomiast gdy system składa się z małych maszyn, z których
każda odpowiada za jakąś istotną funkcję (np. za wykonywanie
operacji wejścia - wyjścia z końcówek konwersacyjnych lub za
system plików), wówczas z powodu jednego błędu może zostać
wstrzymane działanie całego systemu.
Ogólnie można powiedzieć, że istnienie w systemie
wystarczającego zapasu (zarówno sprzętu, jak i danych)
sprawia, że system może pracować nawet po uszkodzeniu
pewnej liczby jego węzłów (stanowisk).

Komunikacja
Istnieje wiele sytuacji, w których programy muszą
wymieniać dane między sobą w ramach jednego
systemu.
Przykładem tego są systemy okien, w których często
dzieli się dane lub wymienia je między terminalami.
Wzajemne połączenie węzłów za pomocą komputerowej
sieci komunikacyjnej umożliwia procesom w różnych
węzłach wymianę informacji.
Użytkownicy
sieci
mogą
przesyłać
pliki
lub
kontaktować się ze sobą za pomocy poczty
elektronicznej
(ang.
electronic
mail).
Przesyłki
pocztowe mogą być nadawane do użytkowników tego
samego węzła lub do użytkowników innych węzłów.

Systemy czasu
rzeczywistego
Jeszcze innym rodzajem specjalizowanego systemu
operacyjnego jest system czasu rzeczywistego
(ang. real-time).
System czasu rzeczywistego jest stosowany tam,
gdzie istnieją surowe wymagania na czas wykonania
operacji lub przepływu danych, dlatego używa się go
często jako sterownika w urządzeniu o ściśle
określonym celu.
Czujniki dostarczają dane do komputera. Komputer
musi analizować te dane i w zależności od sytuacji
tak regulować działanie kontrolowanego obiektu, aby
zmieniły się wskazania wejściowe czujników.

Przykłady RTS
Przykładami systemów czasu rzeczywistego są
systemy
nadzorowania
eksperymentów
naukowych, obrazowania badań medycznych,
sterowania
procesami
przemysłowymi
i
niektóre systemy wizualizacji.
Można tu podać również takie przykłady, jak
elektroniczny sterownik wtrysku paliwa do
silników samochodowych, sterowniki urządzeń
gospodarstwa domowego, a także sterowniki
stosowane w różnych rodzajach broni.

RTS mają ścisłe
ograniczenia czasowe
System operacyjny czasu rzeczywistego ma
ściśle
zdefiniowane,
stałe
ograniczenia
czasowe. Przetwarzanie danych musi się
zakończyć przed upływem określonego czasu,
w przeciwnym razie system nie spełnia
wymagań.
Na przykład poinstruowanie robota, aby
zatrzymał ruch ramienia już po zgnieceniu
samochodu, który właśnie montował, mija się z
celem.

Rygorystyczny RTS
(ang. hard real-time system)
Gwarantuje terminowe wypełnianie krytycznych zadań.
Osiągnięcie tego celu wymaga ograniczenia wszystkich
opóźnień w systemie, poczynając od odzyskiwania
przechowywanych danych, a kończąc na czasie
zużywanym przez system na wypełnienie dowolnego
zamówienia.
Takie ograniczenia czasu wpływają na dobór środków, w
które są wyposażane rygorystyczne systemy czasu
rzeczywistego. Wszelkiego rodzaju pamięć pomocnicza
jest na ogół bardzo mała albo nie występuje wcale.
Wszystkie dane są przechowywane w pamięci o krótkim
czasie dostępu lub w pamięci, z której można je tylko
pobierać (ang. read-only memory - ROM).

Ograniczenia czasowe
wpływają na cechy
systemu
Systemy te nie mają również większości
cech
nowoczesnych
systemów
operacyjnych, które oddalają użytkownika
od sprzętu, zwiększając niepewność
odnośnie do ilości czasu zużywanego
przez operacje.
Na przykład prawie nie spotyka się w
systemach czasu rzeczywistego pamięci
wirtualnej.

Łagodny system czasu
rzeczywistego (ang. soft real-
time system)
To system, w którym krytyczne zadanie do obsługi w
czasie rzeczywistym otrzymuje pierwszeństwo przed
innymi zadaniami i zachowuje je aż do swojego
zakończenia.
Podobnie jak w rygorystycznym systemie czasu
rzeczywistego opóźnienia muszą być ograniczone -
zadanie
czasu
rzeczywistego
nie
może
w
nieskończoność czekać na usługi jądra.
Użyteczność łagodnych systemów czasu rzeczywistego
jest bardziej ograniczona niż systemów rygorystycznych.
Ponieważ nie zapewniają one nieprzekraczalnych
terminów, zastosowanie ich w przemyśle i robotyce jest
ryzykowne.

Podsumowanie
Przedstawiliśmy logikę rozwoju systemów
operacyjnych, która wyrażała się przez
dodawanie do sprzętu jednostki centralnej
udogodnień
warunkujących
uzyskanie
funkcjonalności nowoczesnych systemów
operacyjnych.
Ów trend można obserwować dzisiaj w
ewolucji komputerów osobistych, których
niedrogi sprzęt jest wciąż ulepszany, przez co
zwiększają się ich możliwości.
Więcej informacji można znaleźć w:
A. Silberschatz, P. Galvin: Podstawy
systemów
operacyjnych,
WNT,
Warszawa 2001
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
- Slide 60
- Slide 61
- Slide 62
- Slide 63
Wyszukiwarka
Podobne podstrony:
Podstawy Informatyki Wykład V Struktury systemów komputerowych
z1 SO na 28.05.11 w2 ze skryptami, Informatyka, SEMESTR IV, Systemu Operacujne
Sem II Transport, Podstawy Informatyki Wykład XXII i XXIII Operacje plikowe
Podstawy Informatyki Wykład V Struktury systemów komputerowych
Podstawy Informatyki Wykład XVIII Operacje plikowe
Sem II Transport, Podstawy Informatyki Wykład XXI Object Pascal Komponenty
Podstawy Informatyki Wykład XIX Bazy danych
Rafał Polak 12k2 lab8, Inżynieria Oprogramowania - Informatyka, Semestr III, Systemy Operacyjne, Spr
Rafał Polak 12k2 lab9, Inżynieria Oprogramowania - Informatyka, Semestr III, Systemy Operacyjne, Spr
Zagadnienia egzamin podstawy informatyki, Elektronika i Telekomunikacja, z PENDRIVE, Politechnika -
Podstawy informatyki, wykład 7
Sem II Transport, Podstawy Informatyki Wykład XIV i XV Object Pascal Funkcje i procedury
Podstawy Informatyki Wykład VI Reprezentacja informacji w komputerze
Podstawy Informatyki Wykład XI Object Pascal Podstawy programowania w Object Pascalu
Podstawy informatyki, wykład 1
więcej podobnych podstron