
Procesor i techniki
przyspieszania jego pracy
Wyższa Szkoła Biznesu
Architektura i organizacja
komputerów
Studia dzienne
Wykład 11

Zmieniają się szczegóły
konstrukcyjne, zasada pracy
wciąż ta sama
Każdy
z
systemów
komputerowych
posiada
centralny
ośrodek
zarządzania,
którym
jest
procesor.
Nowoczesne osiągnięcia w dziedzinie technologii
produkcji układów scalonych pozwalają na budowę
coraz „potężniejszych” mikroprocesorów.
Jednak bez względu na zmieniające się elementy
takie jak: szerokość magistral, częstotliwość pracy,
czy wielkość zintegrowanej w układzie pamięci
podręcznej;
pierwotna
zasada
działania
mikroprocesorów pozostaje (przynajmniej na razie)
bez zmian.

Nowe procesory, nowe
aplikacje,
a rynek
Konstrukcja komputera PC podlega stałej ewolucji,
wymuszonej przez wymagania nakładane ze strony
współczesnego oprogramowania.
„Pamięciożerne”
aplikacje
i
rozszerzenia
multimedialne są w stanie zniwelować każdą
sprzętową inwestycję.
Rynek
przyjmuje
z
wdzięcznością
nowe
opracowania
procesorów,
gdyż
brak
kompatybilności z poprzednimi modelami zmusza
do wymiany płyt głównych (i innych podzespołów) i
stanowi dźwignię napędową do nowych zakupów.
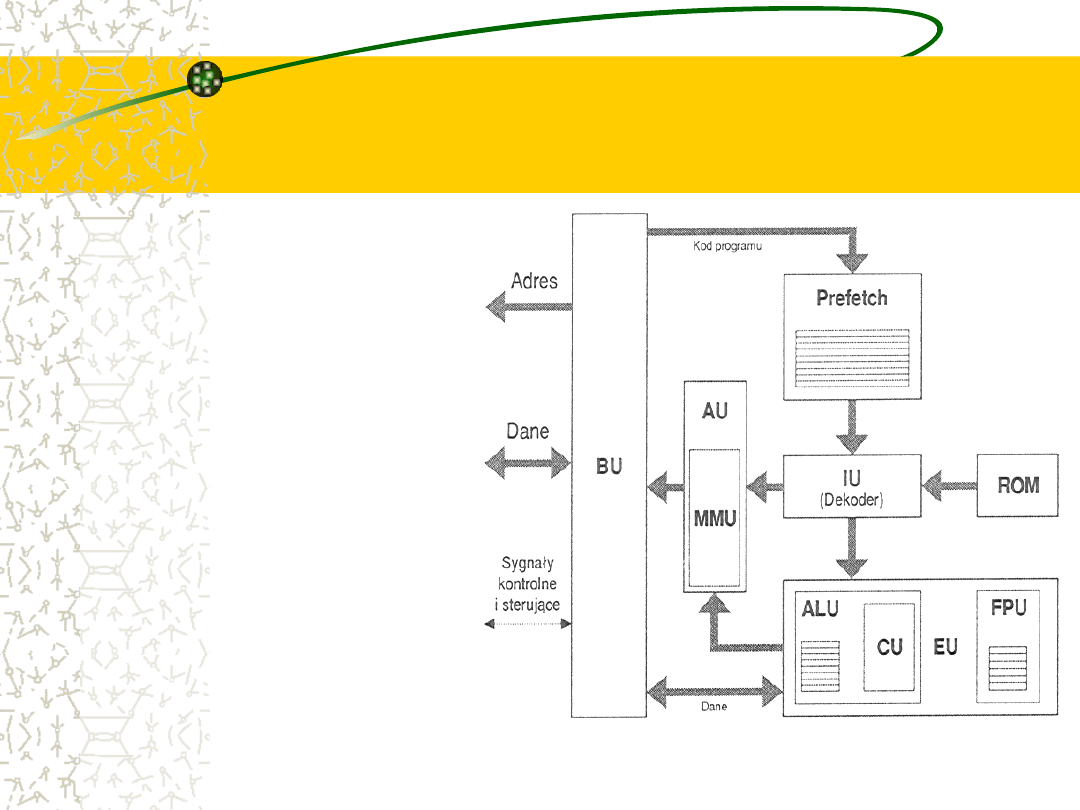
Podstawowe bloki
funkcjonalne
mikroprocesora
Niezależnie od
częstotliwości
taktującej i
charakterystycznych
dla danej firmy
rozwiązań
indywidualnych każdy z
procesorów można
przedstawić jako zespół
współpracujących ze
sobą bloków
funkcjonalnych.

Komunikacja z pamięcią
Architektura komputera PC zakłada bardzo silną
więź mikroprocesora z pamięcią operacyjną. W
niej bowiem przechowywane są dane i rozkazy.,
tam też odsyła się wyniki obliczeń.
Za
współpracę
z
pamięcią
odpowiada
wyizolowany blok komunikacyjny (Bus Unit, BU).
Połączenie jest realizowane zwykle w postaci dwu
odseparowanych magistral (jedna dla danych i
kodu, druga dla adresów),
Zarządzanie ruchem na magistralach gwarantują
dodatkowe sygnały sterujące.

Dekodowanie rozkazów
Konieczność zapewnienia płynnego funkcjonowania
procesora wymaga, by dane do wykonania (kod
programu) pobierane były w większych porcjach i
gromadzone w kolejce, gdzie oczekują na wykonanie.
Każdy ze spoczywających tu bajtów stanowi pewną
zakodowaną informację o koniecznych do wykonania
operacjach. Odtworzenie tej informacji odbywa się w
bloku dekodera (Instruction Unit, IU).
Praca tego układu jest często wspomagana przez
obszerną podręczną pamięć stałą (ROM), w której
zawarty jest słownik tłumaczący przyjmowane kody
rozkazowe na sekwencje ukrywających się pod nimi
operacji.

Jednostka wykonawcza
(EU=CU+ALU+FPU)
Rozkodowane instrukcje przekazywane są do układu
wykonawczego (Execution Unit, EU), gdzie realizowana
jest operacja określona danym kodem rozkazowym.
Znaczna cześć obecnie używanych rozkazów pracuje na
liczbach stałoprzecinkowych (Integer) i podlega obróbce w
module arytmetyczno logicznym (Arithmetic-Logic Unit ,
ALU) sterowanego z bloku kontrolnego (Control Unit, CU).
Jeśli
jednak
rozkaz
dotyczył
obiektów
zmiennoprzecinkowych
jego
realizacja
w
stałoprzecinkowych układach logicznych zajęłaby zbyt
wiele czasu. W takim wypadku przekazuje się go do
wyspecjalizowanej
jednostki
zmiennoprzecinkowej
(Floating Point Unit, FPU).

Jednostka adresowania
Rozkazy posługują się zwykle pewnymi argumentami
(parametry funkcji, np. składniki przy dodawaniu),
które również trzeba pobrać z pamięci operacyjnej.
Często wymaga się również, aby wynik operacji
przesłany został pod określony adres.
Obsługę tego rodzaju życzeń realizuje jednostka
adresowania (Addressing Unit, AU).
Względy
natury
technicznej
(stronicowanie
i
segmentacja) powodują, iż dostęp do pamięci
operacyjnej
wymaga
pewnych
dodatkowych
nakładów, których realizacji poświęca się jednostkę
zarządzania pamięcią (Memory Management Unit).

RISC
Termin RISC (Reduced Instruction Set Computer)
zrodził się w toku prac nad projektem 801 firmy IBM
i oznaczał tendencję do ograniczania listy rozkazów
procesora do niewielu błyskawicznie wykonywanych
instrukcji.
Realizacja każdej z nich była wynikiem odwołania się
do wyspecjalizowanego obwodu elektronicznego,
który nie tracił czasu na tłumaczenie rozkazu.
Rozpisanie algorytmu wykonywanego programu,
który przecież składał się z operacji dużo bardziej
skomplikowanych niż przepisanie danych z rejestru
do rejestru, należało do kompilatora.

Wysoka prędkość
przetwarzania RISC wymaga
dużej przepustowości
magistrali
Warto zwrócić uwagę, że system taki wyzwala ogromne
obciążenie magistrali pamięciowej – kod przetłumaczony
przez kompilator znajduje się przecież w pamięci
operacyjnej i każdy z elementarnych „klocków” musi
zostać pobrany przez procesor.
Prędkość przetwarzania jest bardzo duża i taka też musi
być przepustowość magistrali.
Problem ten rozwiązuje się współcześnie przez
zastosowanie szybkich pamięci podręcznych (L1 i L2).
Spore uproszczenie konstrukcji typu RISC zawdzięcza się
stałej (zazwyczaj) długości wszystkich mikrorozkazów.

CISC
Odmienny punkt widzenia reprezentuje CISC
(Complex Instruction Set Computer) dominująca w
rodzinach x86 Intela i 680xx Motoroli.
Procesory budowane według tej zasady biorą na
siebie coraz większe zadania.
Pobierany z pamięci pojedynczy rozkaz wywołuje
szereg
kompleksowych
działań
.
Czas
opracowywania takiego polecenia może dochodzić
nawet do kilkudziesięciu cykli zegarowych.
Kod programu jest bardzo zwarty, a proces jego
transportu do procesora znacznie mniej krytyczny.

Obecnie trudno zazwyczaj
powiedzieć czy procesor jest
CISC czy RISC
Jakkolwiek oba pojęcia definiowały początkowo kategorie
przeciwstawne, to obecnie coraz trudniej jednoznacznie
przypisać dany procesor do jednej z nich, a ostry podział
traci sens.
Współczesne procesory (AMD od K6 po Athlon XP i Intel
Pentium PRO – Pentium 4) chociaż same zaliczają się do
grupy CISC (akceptują na swoim wejściu złożone instrukcje
x86) to wyposażone są w dekoder tłumaczący je na
wewnętrzny kod mikroprocesora. Jądro tych konstrukcji
pracuje zatem w trybie RISC (RISC kernel).
Uznawany za członka rodziny RISC procesor PowerPC 601
może z kolei poszczycić się chyba zbyt nadmierną (jak na
zredukowaną) listą rozkazów (samych rozgałęzień jest ponad
150).

Linia produkcyjna –
sposób na zwiększenie
przepustowości
Niezależnie od tego czy mamy do czynienia z układem RISC czy
CISC każdy procesor można porównać do zakładu produkcyjnego,
który z dostarczonych materiałów (dane w pamięci) wytwarza wg
określonego algorytmu (kod programu) pewien określony produkt
wyjściowy (inny, wynikowy stan danych).
Analogia ta pozwala na sięgnięcie do jednego z bardziej
rewolucyjnych
pomysłów
racjonalizatorskich
–
taśmy
produkcyjnej.
Wprowadzona w zakładach Forda idea podzielenia cyklu
produkcyjnego na wiele małych i szybkich operacji wydaje się
pozornie bezużyteczna: czas pracy nad produktem nie ulega
przecież zmianie (może się nawet wydłużyć jeśli szwankują
połączenia pomiędzy poszczególnymi etapami).
Nie o czas tu jednak chodzi lecz o zwiększenie
przepustowości.

Przetwarzanie potokowe
(Pipeline)
Przeniesienie powyższej idei na grunt architektury
mikroprocesorów odbyło się po raz pierwszy w 1960r.
podczas
prac
nad
projektem
IBM
7030;
mikroprocesory skorzystały z tego pomysłu 20 lat
później.
Charakterystyczny
jest
podział
pracy
nad
pojedynczym rozkazem na wyraźnie zarysowane fazy.
Symboliczna taśma produkcyjna nazywana jest tutaj
potokiem przetwarzającym (Pipeline, Pipe), a jej
poszczególne punkty stopniami (Pipeline Stages).

Potok wykonuje jednocześnie
wiele rozkazów, a jego pracę
usprawniają kolejki
Potok pracuje jednocześnie nad kilkoma rozkazami, a każdy z
nich znajduje się w innej fazie wykonania. Chociaż czas
przetwarzania każdego z nich wynosi wielokrotność okresu
zegara taktującego, to w każdym jego cyklu taśmę opuszcza
kompletny produkt finalny (podobnie jak w fabryce
samochodów – mimo, że co minutę zjeżdża z niej gotowy
samochód, czas montażu może wynosić wiele godzin).
Połączenia pomiędzy poszczególnymi stacjami mogą być
elastyczne, co pozwala na zmniejszenie dyscypliny całej
taśmy. Czas przebywania rozkazu w poszczególnych
stopniach zależy często od czynników zewnętrznych i ścisłe
przestrzeganie reżimu czasowego nie zawsze jest możliwe.
W punktach krytycznych montowane są więc małe magazyny
pośrednie (bufory) nazywane też kolejkami (Queue).
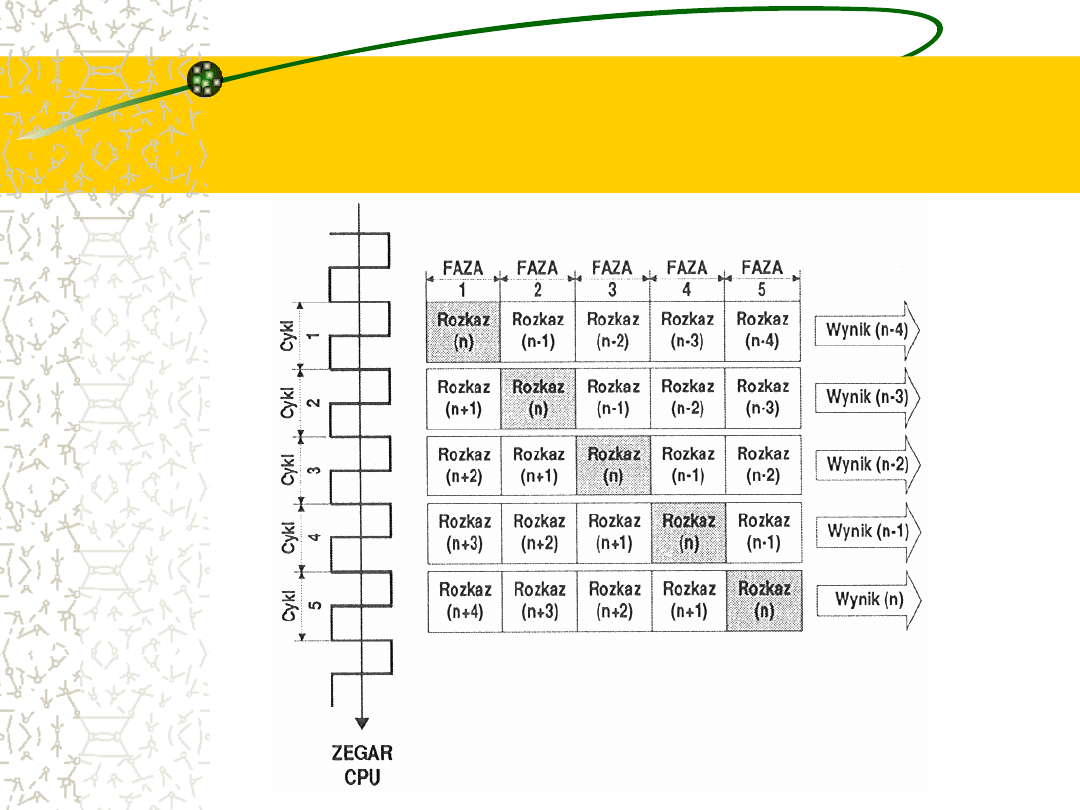
Idea potokowego
przetwarzania danych

Głębokość potoku
Stopień rozdrobnienia takiej linii produkcyjnej (ilość
stopni) nazywany jest głębokością potoku.
Wielkość ta ma fundamentalne znaczenie dla kluczowych
parametrów procesora.
Rozbicie procesu produkcyjnego na bardzo wiele małych
operacji pozwala na ich przyspieszenie (dwaj robotnicy
przykręcający po jednym kole pracują szybciej niż jeden,
który miał zamontować dwa). W przeniesieniu na grunt
architektury procesora oznacza to możliwość zwiększenia
częstotliwości taktującej i ogólnej wydajności.
Poszczególne stacje mogą nawet pracować szybciej niż
wynika to z wymiaru zewnętrznego zegara (Super-
Pipeline).

Ewentualne błędy w
przetwarzaniu potoku
drastycznie ograniczają
wydajność
Model powyższy nie bierze pod uwagę sytuacji
awaryjnych i analogia do taśmy produkcyjnej nie
znajduje tutaj pełnego zastosowania.
Międzystopniowa kontrola jakości dla taśmy
produkcyjnej może odrzucić wadliwy wyrób na
dowolnym etapie przetwarzania, a obywa się to
bez większej szkody dla całej taśmy.
Inaczej jest w przypadku procesorów. Stwierdzenie
błędu (na przykład opracowywana właśnie
instrukcja miała zrealizować dzielnie przez zero)
oznacza konieczność oczyszczenia całego potoku.

Ograniczenia długości
potoków
Punkt, w którym taka sytuacja została
rozpoznana znajduje się z natury rzeczy
daleko od wejścia (średnio tym dalej im
dłuższy jest potok).
Dodatkowym czynnikiem ograniczającym
wzrost wydajności wraz z rozdrobnieniem
potoku
są
wzajemne
uzależnienia
pomiędzy instrukcjami oraz konflikty w
wykorzystywaniu zasobów zewnętrznych.

Schemat przetwarzania
potokowego
Procesory wyposażone w potok pracują nad
kolejnymi rozkazami według ściśle określonego
schematu. Przetwarzana instrukcja przesuwa się
wzdłuż linii produkcyjnej zaliczając kolejne etapy.
Niezależnie
od
różnic
w
architekturze
poszczególnych modeli procesorów, należą do
nich zawsze cztery podstawowe czynności:
pobranie,
dekodowanie,
wykonanie
i
zakończenie.
Każda z tych operacji może być rozpisana na
kilka czynności bardziej elementarnych.

Faza pierwsza: pobranie
(Prefetch, PF)
Zakładamy obecność kodu w kolejce
rozkazowej procesora.
Zapełnienie tej kolejki odbywa się poprzez
ściąganie do pamięci podręcznej L1.
Jeśli rozkaz znajduje się w pamięci
operacyjnej uruchamiana jest procedura
zapełniania linijki pamięci podręcznej L1, z
ewentualnym uwzględnieniem pośredniej
pamięci L2.

Faza druga: dekodowanie
(Decode, DE)
W
pierwszej
części
tej
fazy
analizowany jest kod operacyjny
instrukcji i jeśli to konieczne separuje
się przedrostki i argumenty.
W drugiej części oblicza się adres
efektywny
argumentów
(jeśli
występują).

Faza trzecia: wykonanie
(Execute, EX)
W tej fazie następuje fizyczny dostęp
do
pamięci
w
celu
pobrania
ewentualnych argumentów rozkazu
oraz
operacje
na
argumentach
określone kodem instrukcji.

Faza czwarta:zakończenie
i zapisanie wyników (Write
Back, WB)
Wyniki operacji wykonanej w fazie EX
umieszczony jest w miejscu określonym w
kodzie rozkazowym (rejestry procesora lub
pamięć).
Na
zakończenie
przywracany
jest
stan
początkowy wewnętrznych (niewidocznych dla
użytkownika i programisty) układów procesora
oraz ustawiane są pewne bity sygnalizujące
stany charakterystyczne dla zakończonej
właśnie operacji (znaczniki, słowa stanu, itp.)

Przykład: wykonanie
rozkazu dodawania
Przyjrzyjmy się bliżej etapom wykonywania rozkazu:
add ax, [bx] ;
dodaj zawartość rejestru AX do
zawartości komórki, której adres
znajdziesz w
BX; wynik prześlij do AX
Faza PF: Pobranie kodu instrukcji
Faza DE: Określenie czynności do wykonania,
obliczenie
adresu
efektywnego
dla
drugiego
argumentu (16*DS)+BX
Faza EX: Dostęp do komórki pamięci o obliczonym
adresie, operacja dodawania do AX.
Faza WB. Umieszczenie wyniku w AX, ustawienie flag.

Nie tylko zegar
Wzrost mocy obliczeniowej mierzy się ilością operacji
wykonanych w jednostce czasu.
Zwiększenie częstotliwości taktującej (skrócenie czasu
trwania pojedynczego cyklu jest najbardziej oczywistym
czynnikiem gwarantującym wzrost wydajności (pod
warunkiem, iż nadążają za tym wzrostem również układy
otaczające procesor, głównie systemy pamięciowe).
Istnieją jednak również inne metody zwiększania
wydajności procesorów. Jeśli trzymać się analogii do
zakładu produkcyjnego, to ogromne możliwości drzemią
zawsze we właściwej organizacji pracy i różnych
„drobnych usprawnieniach”.

Techniki przyspieszania
W świecie mikroprocesorów należą do nich
między innymi:
techniki superskalarne,
przemianowywanie rejestrów,
przepowiadanie rozgałęzień
i odpowiednie (zoptymalizowana pod
kątem konstrukcji wewnętrzne j danego
procesora) przygotowanie kodu.

Techniki superskalarne
Jeśli nie można zwiększyć wydajności pojedynczej linii
produkcyjnej należy wybudować drugą. Tak zbudowany
procesor nosi nazwę superskalarnego.
Uruchomienie dodatkowych, równoległych linii produkcyjnych
gwarantuje oczywiście zwielokrotnienie produkcji. Model taki
nie sprawdza się jednak na gruncie mikroprocesorów.
Strumień rozkazów do wykonania naszpikowany jest
wzajemnymi uzależnieniami i jest pełen punktów rozgałęzień.
Ponadto pracujące równolegle taśmy produkcyjne procesora
(potoki) nie stanowią niezależnych obiektów (gdyż korzystają z
wielu wspólnych zasobów (choćby z rejestrów) .
Przy
zbyt
wielkiej
liczbie
kanałów
zwielokrotniona
(teoretycznie) moc jest trawiona przez wewnętrzny system
komunikacji międzypotokowej.

FPU- dodatkowy potok
Zdecydowana większość procesorów na rynku posiada
równoległe kanały przetwarzające dane typu Integer.
Jednostka zmiennoprzecinkowa (FPU) została już
stosunkowo dawno wydzielona z właściwej struktury
logicznej i ma swoje własne życie wewnętrzne.
Możemy ją traktować jako dodatkowy równoległy
potok przeznaczony do wykonywania operacji
zmiennoprzecinkowych.
Z napływającego do procesora strumienia danych
odławiane są te, które operują na danych
zmiennoprzecinkowych i kierowane są do właściwego
im potoku.

Potoki mogą pracować
synchronicznie bądź
asynchronicznie
To, który z rozkazów wykonywany jest przez poszczególne
potoki stanowi wynik pracy rozdzielacza.
Istniejące reguły rozdziału wynikają głównie z drobnych
różnic w budowie wewnętrznej poszczególnych potoków
ora wymogów synchronizacji potoków.
Możliwość
niezależnego
(asynchronicznego)
doprowadzania
do
końca
instrukcji
równocześnie
zapoczątkowanych w dwu potokach (Out of Order
Completion, ReOrder Buffer - ROB ) jest cechą tylko
niektórych procesorów. Wprowadzenie tego rodzaju
mechanizmów wymaga bowiem zastosowania śledzenia
kodu we wszystkich potokach wykonawczych (analiza
prowadzona jest pod kątem zależności między danymi).
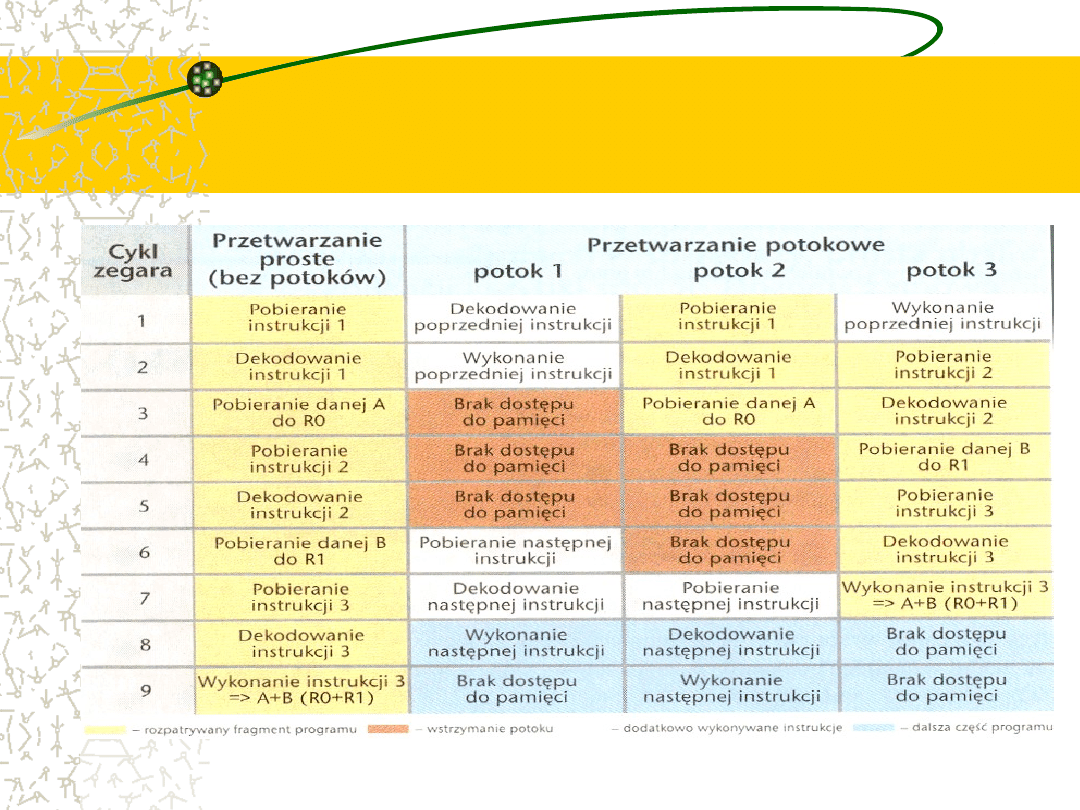
Przetwarzanie proste i
superskalarne na przykładzie
dodawania

Czasem superskalarność nic
nie daje
Nie zawsze poprzez równoległe przetwarzanie
da się cokolwiek przyspieszyć. Rozkazy
odwołujące się do tych samych lokalizacji w
pamięci lub oceniające status procesora nie
mogą być wcześniej wykonywane niż to wynika
z naturalnego położenia w sekwencji kodu.
Najczęstsza przyczyna uzależnień leży jednak
w
zazębieniach
powstałych
skutkiem
odwoływania
się
do
tych
samych
programowych rejestrów procesora.

Przykład uzależnienia
instrukcji
Przykładowy ciąg instrukcji asemblera:
move bx, ax;
do pierwszego potoku
add ax, cx; do drugiego potoku
Prowadzi do uzależnienia od rejestru AX.
Przepisanie stanu CX do AX w drugiej z instrukcji
nie
może
być
wykonane
wcześniej
niż
zakończenie realizacji odczytu AX z pierwszej
pary.
Jeszcze większa kłopoty generowała by próba
jednoczesnego zapisu rejestru przez różne potoki.

Przemianowywanie
rejestrów
Prostym sposobem wyjścia z opresji jest tymczasowe
podstawienie rejestru pomocniczego, tak by nie
zamazywać wartości zapisanej jako wcześniejsza
i\lub stosowanie wielokrotnych portów odczytu
rejestrów.
Technika ta nazywa się przemianowywaniem
rejestrów (Register Renaming).
Różne procesory posługują się tą techniką w różny
sposób i w mniejszym lub większym zakresie. W
najprostszej formie procesor wyposaża się w zestaw
dodatkowych rejestrów.
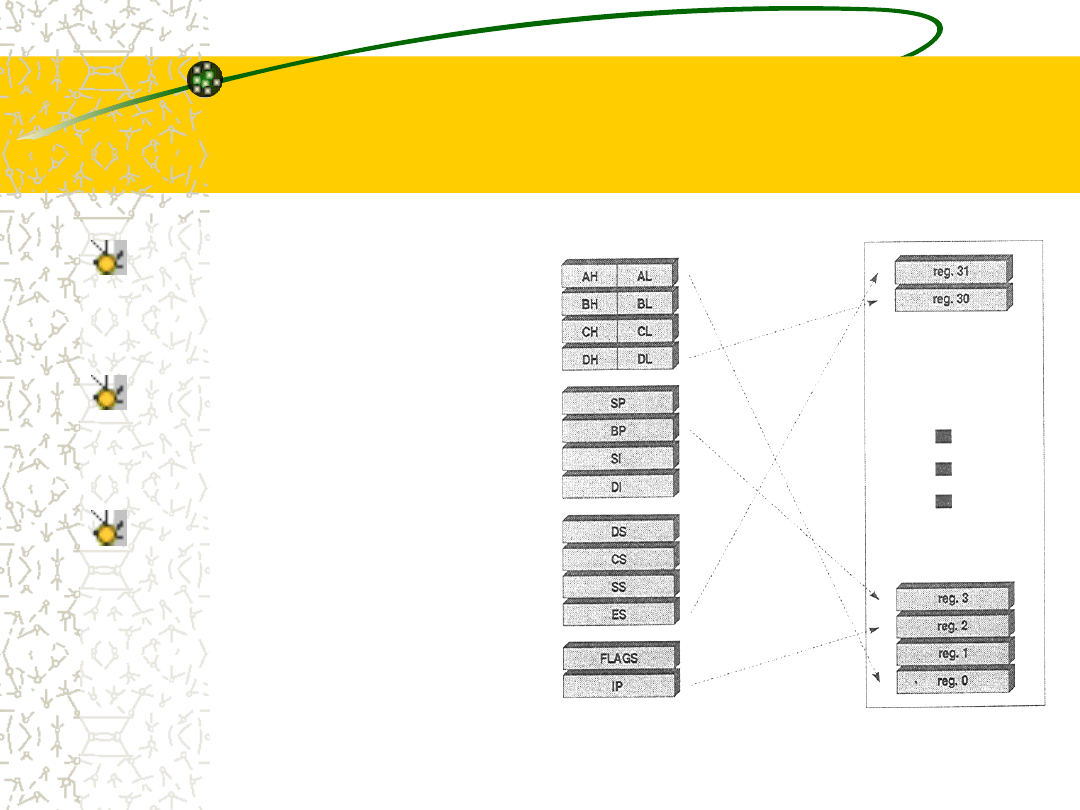
Idea przemianowywania
rejestrów
W razie napotkania pary
powodującej
uzależnienie
np. move bx, ax
add ax, cx
Układ sterowania dokonuje
szybkiego
podstawienia
AX→Reg0,
BX→Reg1,
CX→Reg2.
Jeśli
dokonać
teraz
przemianowania AX →Reg3
to
bez
trudu
można
wykonać operacje:
Reg1:=Reg0||
Reg3:=Reg2+Reg0

Kłopoty z rozgałęzieniami
Wykorzystanie pełnej mocy obliczeniowej procesorów
wyposażonych w potoki przetwarzania wymaga stałego
zasilania instrukcjami.
Program, którego realizacja przebiega kolejno od jednej
instrukcji do następnej nie stwarza w tym zakresie
żadnych problemów.
Również bezwarunkowe skoki typu go to mają jasno
określony punkt docelowy.
Kłopoty pojawiają się w momencie napotkania instrukcji
rozgałęzienia, kiedy dalsza realizacja programu może w
zależności
od
spełnienia
określonych
warunków
przebiegać sekwencyjnie dalej lub też przemieścić się do
odległego obszaru kodu.

Złe rozpoznanie prowadzi
do konieczności
opróżnienia potoku
Mimo iż nie wiadomo, która z instrukcji będzie wykonana
jako następna po problematycznej if potok musi zostać
czymś napełniony.
Problem przybiera na sile wraz ze wzrostem długości
potoku (coraz więcej operacji tkwi już głęboko w systemie
przetwarzania choć nie do końca wiadomo czy słusznie.
Ostateczne rozstrzygnięcie warunku odbywa się w
najlepszym razie w okolicach środka potoku. Może się więc
zdarzyć, iż wszystko co jest za instrukcją warunkową
trzeba będzie usunąć, co zajmuje od kilku do kilkunastu
cykli zegarowych.
Jest to oczywiście z punktu widzenia wydajności ogromna
strata czasu.

Również system
pobierania instrukcji musi
wiedzieć „co dalej ?”
Dodatkowe
opóźnienia
mogą
powstawać
w
systemach pobierania rozkazów zwłaszcza w
procesorach RISC. Dekodery tych procesorów
rozkładające instukcje x86 na drobne mikrooperacje
też muszą pracować z dużą wydajnością.
Oczekują więc nieprzerwanego dopływu materiału od
układów współpracy z pamięcią podręczną i
magistralami.
Od systemu pobierania kolejnych instrukcji x86 czy
to z przeznaczeniem na rozkład na mikrokroki (RISC)
czy też bezpośrednio do wykonania wymaga się
również orientacji w zamiarach programu.

Rozwiązania problemu
rozgałęzień
Dalszy bieg programu można z
większym
lub
mniejszym
prawdopodobieństwem przewidywać
(Branch Prediction)
W przypadku u rozgałęzienia podąża
się na wszelki wypadek w obydwu
kierunkach
(Multiple
Path
of
Execution).

Zalety i wady obu
rozwiązań
Prawdopodobieństwo trafnego przewidzenia jest zawsze
mniejsze od jedności;Wybranie tej drogi (Speculative
Execution) niesie za sobą sporą komplikację systemu.
Wyniki poszczególnych operacji muszą lądować w
dodatkowych buforach pośrednich, bo nie wolno niczego
zmieniać w świecie poza procesorem (zapis do pamięci
wywołany sekwencją programu, która nie miała być nigdy
wykonana miałby „katastrofalne skutki”).
Prowadzenie programu kilkoma równoległymi drogami
prowadzi do ogromnej komplikacji sprzętowej. Powieleniu
muszą ulec nie tylko jednostki wykonawcze, ale i dekodery
oraz
systemy
pamięci
podręcznej.
Wielokrotne
zagnieżdżenie warunków szybko upora się z każdą ilością
zasobów sprzętowych.

A jednak przepowiadanie
Współczesne procesory korzystają zwykle z techniki
przepowiadania
biegu
programu,
a
stopień
zaawansowania i komplikacji stosowanych systemów
odpowiada z grubsza uzyskiwanym wynikom.
Podstawową strukturą informacyjną tych układów jest
tablica BTB (Branch Tager Buffer). Jest to szybka
pamięć podręczna grupująca zwykle 128-1024 rekordy.
Każdy wiersz zawiera w sobie informację o jednym z
punktów rozgałęzienia programu. BTB to w najprostszej
formie zestaw adresów instrukcji skoków i adresów tych
skoków; dodatkowo pamiętane są status linijki oraz bity
historii (opisujące zachowanie się instrukcji).
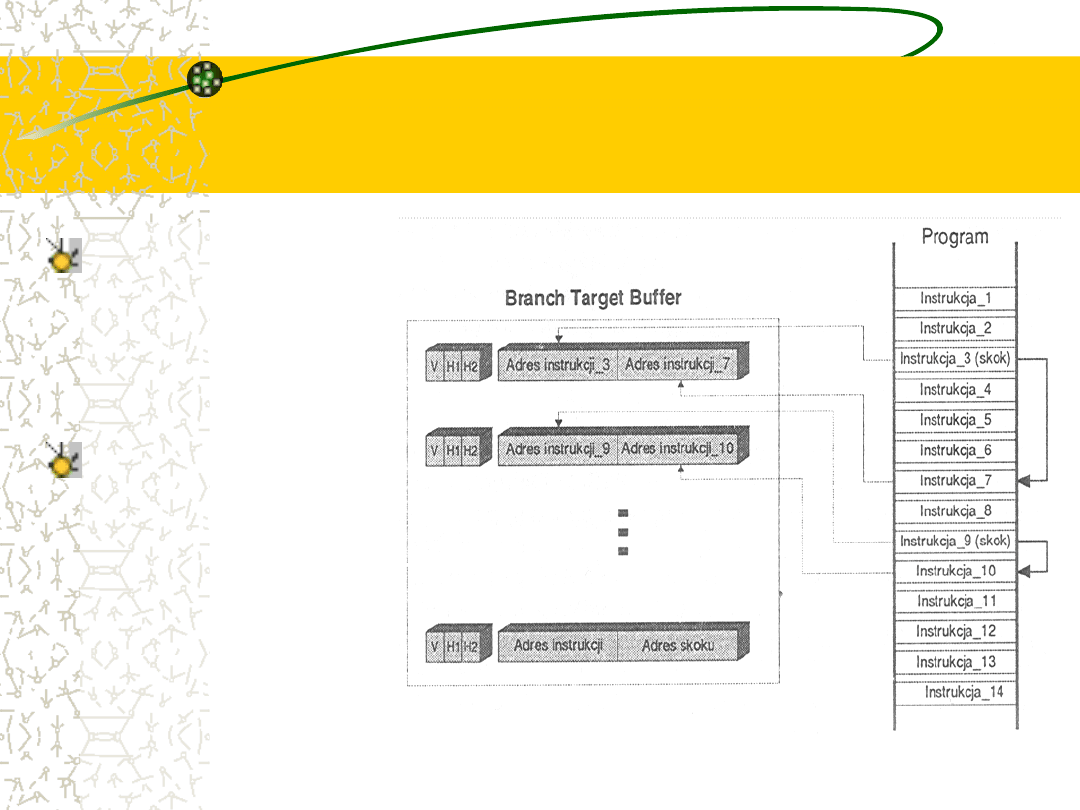
Struktura BTB
W tablicy umieszczane
są tylko te instrukcje,
które już się wykonały,
tzn.
takie
których
zachowanie
zostało
zaobserwowane
i
udokumentowane.
System
nadzorujący
pobieranie
kolejnych
rozkazów może więc w
wypadku
napotkania
rozgałęzienia zwrócić
się do tabeli BTB z
zapytaniem o dalszy
przebieg programu.

Metoda statyczna
Stosowany jest zwykle jeden bit, a
jego
ustawianie
odbywa
się
stosunkowo wcześnie bo w fazie
kompilacji.
Faktyczny
przebieg
programu nie jest już w stanie nic
zmienić.
Metoda szybka i tania, ale mało
skuteczna.

Metody dynamiczne
Metody tej grupy opierają się na jednym lub dwu bitach,
którymi manipuluje się w fazie wykonania programu.
Jednym z możliwych punktów podejścia jest przyjęcie
założenia o powtarzalności przebiegu. Każdemu
rozgałęzieniu towarzyszy wtedy bit, który jest ustawiany
na 1 jeśli nastąpił skok. Proste przejście przez
rozwidlenie kwitowane jest jego zerowaniem. Jeśli
ponownie znajdziemy się w punkcie. Takiego rozwidlenia
typowany jest wynik zgodny z ostatnim zachowaniem.
Bardziej rozbudowana logika cechuje układy dwubitowe.
Możliwe są 4 sygnatury: mocne bądź słabe założenie
braku skoku i słabe bądź mocne założenie skoku.

Logika działania
systemów z dwoma
bitami historii
Punktem wyjściowym algorytmu jest założenie, że wszystkie
rozgałęzienia napotkane po raz pierwszy nie prowadzą do skoków. Póki
program działa zgodnie z przepowiednią stan historii się utrzymuje.
Jeśli dojdzie do skoku mamy pierwsze niepowodzenie , a system
zmienia stan sygnatury na: słabe założenie skoku, i nadal zakłada, że
skoki nie będą miały miejsca.
Następna ocena dokonywana jest w czasie następnego przejścia. Jeśli
skok się nie powtórzył przechodzimy do stanu początkowego w
przeciwnym razie instrukcja opatrywana jest sygnaturą mocnego
założenia skoku.
Pozostaje w tym stanie do czasu pierwszej pomyłki, wówczas osłabia
założenie, ale dalej wykonuje skoki.
Z tego stanu zależnie od następnego rozgałęzienia może przejść do
stanu mocnego założenia skoku bądź jego braku w zależności od
trafienia.

Optymalizacja kodu
Jeżeli dobrze pozna się szczegóły
konstrukcyjne konkretnego procesora
można próbować tak pisać program
(już w fazie doboru algorytmu i
podejścia do problemu, a potem na
etapie kompilacji) by wykorzystać
mocne strony konstrukcji, a ominąć
jej słabe punkty.

Literatura
Piotr Metzenger, Adam Jełowiecki
„Anatomia PC” wyd. V, Helion,
Gliwice 1999
Marcin Bieńkowski „Czarna magia
procesora” Chip 2/2002 str. 62;
(szukaj w bazie artykułów)
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
Wyszukiwarka
Podobne podstrony:
Architektura i organizacja komuterów W9 Procesor
Architektura i organizacja komuterów W5 Pamięć wewnętrzna
Architektura i organizacja komuterów W3 Działanie komput
Architektura i organizacja komuterów W1 Co to jest i skąd to się wzięło
Architektura i organizacja komuterów W6 Pamięć zewnętrzna
Architektura i organizacja komuterów W4 Połączenia magistralowe
Architektura i organizacja komuterów W4 Połączenia magis
Architektura i organizacja komuterów W7 Wejście Wyjście
Architektura i organizacja komuterów W3 Działanie komputera
Architektura i organizacja komuterów W9 Wspieranie systemu operacyjnego
Architektura i organizacja komuterów W7 Pamięć zewnętrzn
Architektura i organizacja komuterów W8 Wejście Wyjście
Architektura i organizacja komuterów W6 Pamięć wewnętrzn
Architektura i organizacja komuterów W1 i 2 Co to jest i skąd to się wzięło
Architektura i organizacja komuterów W2 Ewolucja i wydaj
Architektura i organizacja komuterów W5 Pamięć wewnętrzna
Struktura organizacyjna cz 2 11 10
Podstawy organizacji ściąga (11)
więcej podobnych podstron