
14. KOMUNIKACJA MIĘDZYPROCESOWA W SYSTEMIE OPERACYJNYM
UNIX
Poniższa seria slajdów jest w trakcie opracowywania.
W systemie Unix istnieje wiele środków komunikacji międzyprocesowej - zarówno
przeznaczonych
do komunikacji między procesami na tym samym komputerze (zaprojektowanych
glownie w AT&T),
jak i przeznaczonych do komunikacji w sieci komputerowej (gniazda BSD
zaprojektowane
w Berkeley). Wszystkie te środki dostępne są w postaci struktur danych i
obsługujących je funkcji
systemowych w interfejsie programisty w języku C. Najprostsze środki, takie jak
przekazanie kodu
zakończenia procesu potomnego procesowi rodzicielskiemu, współdzielenie
plików oraz łącza
(nazwane i nienazwane) dostępne są również poprzez polecenia powłoki (shella).

Proste mechanizmy koordynacji procesów w shellu:
1) polecenia exit i wait
exit liczba - kończy działanie procesu i przesyła jednobajtową liczbę
(kod wyjścia)
do jego procesu rodzicielskiego
wait praca - powoduje zawieszenie procesu w oczekiwaniu na
zakończenie jego procesu
potomnego i odbiera jego kod wyjścia
2) polecenia kill i trap
kill sygnał praca - powoduje wysłanie sygnału do procesu (z tej samej
grupy)
trap komenda sygnał - powoduje przechwycenie przysłanego sygnału (jeśli to
możliwe)
i wykonanie komendy

3) łącza nienazwane (bezimienne)
komenda1 | komenda2 | ... | komendan - potok
(może być utworzony przy założeniu, że komendy korzystają ze standardowego
wejścia/wyjścia)
4) łącza nazwane (kolejki FIFO)
mkfifo nazwa (lub mknod nazwa p) - tworzy kolejkę FIFO
Zapis/odczyt oraz usunięcie odbywają się dla kolejki FIFO tak samo, jak dla
zwykłego pliku
(mogą to robić wszystkie procesy, które mają odpowiednie prawa dostępu do
kolejki). Musi
zachodzić synchronizacja operacji zapisu i odczytu.
Uwaga.
1) Łącza są realizowane jako bufory plików i mają ograniczoną pojemność. Mogą
być widziane jako
„pliki nietrwałe” - odczyt porcji informacji z łącza usuwa ją jednocześnie z
łącza.
2) Łącza nazwane są uwidocznione w systemie plików jako szczególny rodzaj
plików (o wielkości 0).
Łącza nienazwane nie są uwidocznione (istnieją tylko w czasie wykonywania
potoku).

Funkcje operujące na identyfikatorach.
Każdy proces poza procesem o numerze 0 powstaje wskutek utworzenia przez
inny proces. Numery
procesów są liczbami naturalnymi przydzielanymi rosnąco modulo rozmiar
tablicy procesów (zwykle
32 K) z pominięciem numerów aktualnie używanych. Każdy proces pamięta swój
PID i PPID, ale
nie zapamiętuje w sposób automatyczny identyfikatorów tworzonych potomków
(programista może
spowodować przechowywanie ich w zmiennych). Jeśli proces kończy działanie
wcześniej, niż jego
(niektóre) procesy potomne, wszystkie procesy potomne otrzymują PPID=1 (jest
to PID procesu Init)
i kontynuują działanie.
int getpid(void); - zwraca PID procesu
int getppid(void); - zwraca PPID procesu
int getpgrp(void); - zwraca PGRP procesu
int setpgrp(void); - odłącza proces od dotychczasowej grupy i
ustanawia go przywódcą
nowej grupy (PGRP = PID)
Uwaga. Istnieją też odpowiednie funkcje dla identyfikatorów użytkowników i ich
grup.

Funkcje związane z tworzeniem i kończeniem procesów.
Tworzenie nowego procesu:
int fork(void); zwraca -1 w przypadku niepowodzenia (na przykład brak
zasobów)
zwraca 0 utworzonemu procesowi potomnemu
zwraca PID utworzonego potomka procesowi
rodzicielskiemu
Wykonanie funkcji fork przez jądro systemu wiąże się z szeregiem
skomplikowanych czynności
(przydział zasobów, wpisanie do tablicy procesów, kopiowanie środowiska itp.) i
jest czasochłonne.
Segment instrukcji nie jest kopiowany, segment danych jest zwykle kopiowany
dopiero w przypadku
próby dokonania zapisu przez nowy proces.

Zamiana kontekstu procesu:
Funkcja systemowa exec ma sześć interfejsów w języku C (różniących się
sposobem przekazywania
parametrów i zmiennych środowiska). Jej zadaniem jest zamiana kontekstu
procesu (przy zachowaniu
tożsamości procesu), to jest spowodowanie, żeby proces zaczął wykonywać inny
program.
int execl (char ścieżka, char arg0, char arg1, ... , char argn, NULL);
ścieżka - pełna nazwa ścieżkowa pliku z nowym programem;
arg0 - powtórzona sama nazwa pliku z nowym programem;
arg1 ... argn - lista parametrów dla nowego programu zakończona znakiem
pustym (NULL).
int execv (char ścieżka, char argv [ ] );
int execle (...);
int execve (...);
int execlp (...);
int execvp (...);
Funkcje fork i exec zazwyczaj współpracują ze sobą.

Kończenie wykonywania procesu:
void exit (int kod);
Kończy działanie procesu, wysyła sygnał do procesu rodzicielskiego oraz
jednobajtowy kod wyjścia.
Oczekiwanie na zakończenie działania potomka:
int wait (int wsk);
Zawiesza proces w oczekiwaniu na zakończenie któregokolwiek procesu
potomnego. Zwraca PID
zakończonego potomka lub -1 w przypadku błędu. wsk zwraca dwa bajty:
- jeśli prawy bajt ma wartość 0, to lewy bajt zwraca kod wyjścia potomka;
- jeśli prawy bajt ma wartość niezerową, to określa, jaki sygnał spowodował
zakończenie potomka,
oraz czy nastąpił zrzut pamięci do pliku core.
Uwaga. Obecnie istnieje też funkcja pozwalająca czekać na zakończenie
określonego potomka.

Funkcje związane z operowaniem na sygnałach.
Wysłanie sygnału:
int kill (int pid, int sig);
Umożliwia wysłanie określonego sygnału do określonego procesu / grupy
procesów.
Przechwycenie sygnału:
void (signal (int sig, void (func) (int))) (int);
Umożliwia przechwycenie określonego sygnału (jeśli to możliwe) i wykonanie
wskazanej funkcji
obsługi.
Polecenia shella kill i trap są obudowami funkcji systemowych kill i signal.
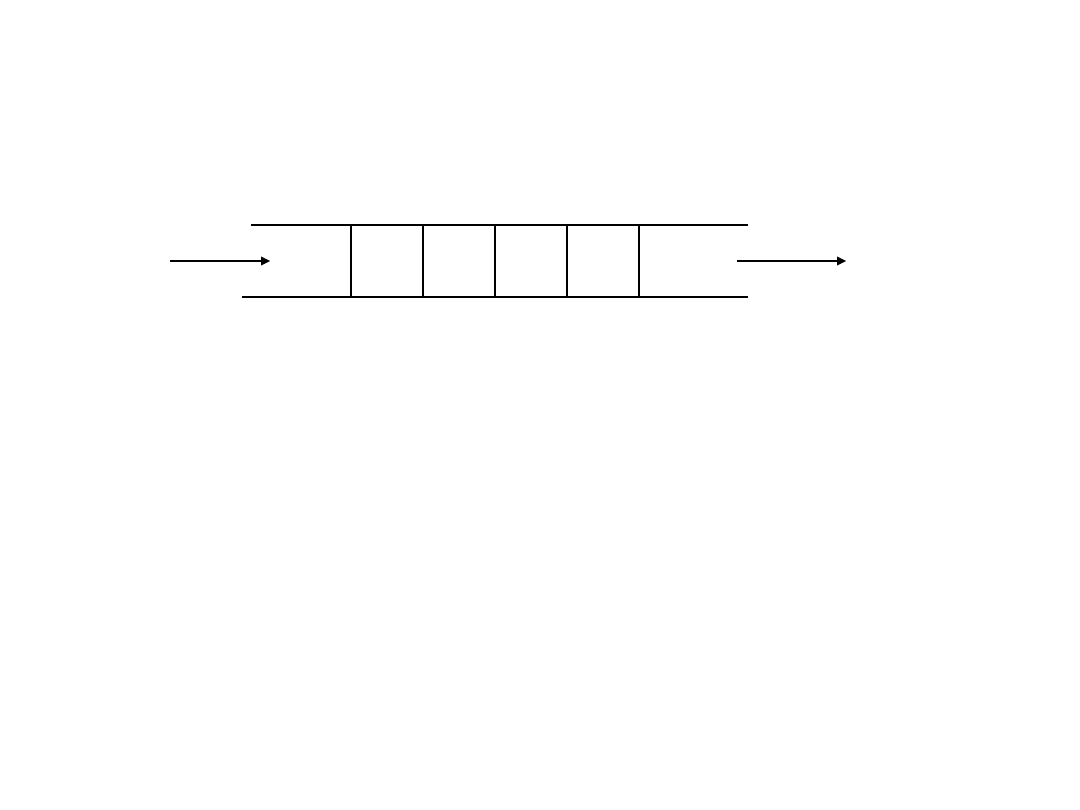
Funkcje związane z operowaniem na łączach nienazwanych.
Pierwotnie łącza nienazwane mogły być używane jedynie jako jednokierunkowe:
P Q
zapis
odczyt
kolejka prosta
Funkcja tworząca łącze:
int pipe (int fd [2] );
fd [0] - deskryptor pliku służący do odczytu z łącza
fd [1] - deskryptor pliku służący do zapisu do łącza
Do zapisów / odczytów stosujemy funkcje systemowe write i read (są
wykonywane niepodzielnie).
Łącze ma pojemność zależną od ustawień systemowych (co najmniej pół KB,
zazwyczaj 4 KB).
Zazwyczaj bezpośrednio po wywołaniu funkcji pipe wywoływana jest funkcja
fork (proces potomny
dziedziczy deskryptory plików), a następnie, w zależności od zamierzonego
kierunku przesyłania,
zamykane są niepotrzebne deskryptory (po jednym w każdym procesie).
...
pipe (fd);
if (fork ( ) = = 0) fd [1] fd
[1]
{
close (fd [0] );
...
} fd [0] łącze fd
[0]
else
{ proces
proces
close (fd [1] ); potomny
rodzicielski
...
}

Główną wadą łącz nienazwanych jest to, że mogą łączyć tylko procesy
spokrewnione (zazwyczaj
pary rodzic - potomek, ale mogą też być dziadek - wnuk, dwóch potomków itp.).
W nowszych wersjach Unixa łącza są implementowane jako dwukierunkowe
(full
duplex)
.
W starszych mogły być tylko jednokierunkowe
(half-duplex)
- chcąc uzyskać
łączność
dwukierunkową należało skorzystać z dwóch par deskryptorów i dwukrotnie
wywołać funkcję pipe.
Uwaga.
1) W przypadku próby odczytu z pustego łącza lub próby zapisu do pełnego łącza
procesy są czasowo
zawieszane.
2) W przypadku łącz dwukierunkowych może być potrzebna synchronizacja
operacji zapisu i odczytu
po obu stronach łącza (na przykład za pomocą semaforów).
3) Na zakończenie działania programu należy pozamykać wszystkie otwarte
deskryptory.

Funkcje związane z operowaniem na łączach nazwanych (FIFO).
Łącza nazwane są uwidoczniane w systemie plików jako specjalny rodzaj plików o
zerowym
rozmiarze. Mogą być tworzone i usuwane zarówno w programach, jak i przy użyciu
komend shella.
Z łączami nazwanymi mogą współpracować dowolne procesy (niekoniecznie
spokrewnione), które
posiadają odpowiednie prawa dostępu.
Funkcja tworząca kolejkę FIFO:
int mknod (const char ścieżka, int tryb);
ścieżka - pełna nazwa ścieżkowa kolejki FIFO
tryb - słowo trybu, którego bity informują między innymi o prawach dostępu do
kolejki
Przed użyciem łącze nazwane musi być otwarte (open), a przed zakończeniem
wykonywania programu
zamknięte (close) przez każdy proces współpracujący z łączem. Jest wymuszona
synchronizacja
otwarcia łącza do zapisu i otwarcia łącza do odczytu przez dwa procesy chcące
korzystać z łącza.
Samo korzystanie z łącza wygląda podobnie, jak w przypadku łącz nienazwanych
(funkcje write i read).
11. PAKIET IPC
Narzędzia z pakietu IPC
(InterProcess Communication)
służą do koordynacji
procesów wykonywa-
nych na jednym komputerze (nie są przeznaczone do komunikacji sieciowej). W
skład tego pakietu
wchodzą biblioteki funkcji obsługujących kolejki komunikatów
(message
queue)
, pamięć dzieloną
(shared memory)
i semafory
(semaphore)
. Z wszystkimi trzema rodzajami
obiektów związane są
odpowiednie struktury danych tworzone przez jądro systemu, do których dostęp
jest możliwy jedynie
poprzez wywoływanie przeznaczonych do tego funkcji systemowych.
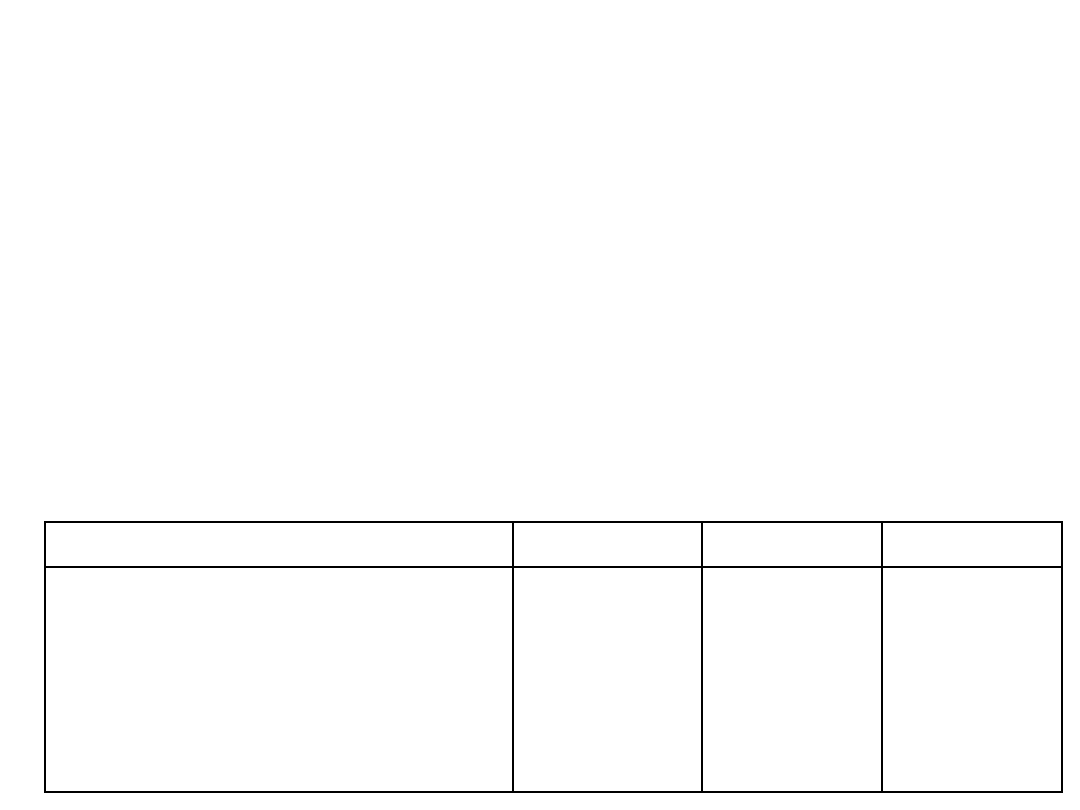
Zestawienie głównych funkcji pakietu IPC (wg W.R. Stevensa):
Kolejki komun. Semafory
Pamięć dziel.
Plik nagłówkowy < sys/msg.h > <
sys/sem.h> < sys/shm.h>
Funkcja systemowa tworzenia lub otwierania msgget semget
shmget
Funkcja systemowa operacji sterujących msgctl semctl
shmctl
Funkcje systemowe przesyłania msgsnd semop
shmat
msgrcv
shmdt

Ze względu na to, że struktury kontrolne obiektów pakietu IPC są przechowywane
w jądrze systemu
i mogą być widoczne dla wszystkich procesów, muszą mieć klucze unikalne w
obrębie całego systemu.
Zalecane jest stosowanie funkcji ftok generującej unikalne klucze na podstawie
ścieżek dostępu do
plików z programami wykonywanymi przez procesy tworzące obiekty pakietu IPC.
Dopuszczalny
zakres kluczy zależy od ustawień systemowych - odpowiada mu typ key_t
zdefiniowany w nagłówku
< sys/types.h >.
Kolejki komunikatów
Kolejki komunikatów nie są kolejkami prostymi (komunikaty mogą być z nich
wybierane w innej
kolejności, niż zostały umieszczone). Komunikaty posiadają pewną strukturę (nie
są tylko ciągami
bajtów, jak w przypadku łącz):
struct msgbuf { long mtype ;
char mtext[1] ; }
Uwaga. Typ char zawartości komunikatu jest zdefiniowany tylko pro forma - może
być rzutowany.

int msgget (key_t klucz, int flagi);
Zwraca: identyfikator kolejki w przypadku sukcesu ;
-1 w przypadku błędu.
Flagi określają prawa dostępu, oraz czy ma być zwrócony błąd, jeśli kolejka o
danym kluczu już istnieje.
Działanie: tworzy kolejkę o podanym kluczu, jeśli taka kolejka jeszcze nie istnieje.
int msgsnd (int ident, struct msgbuf kom, int rozmiar, int flagi) ;
Zwraca: 0 w przypadku sukcesu ;
-1 w przypadku błędu.
ident - identyfikator kolejki (zwrócony przez msgget)
kom - wskaźnik do struktury przechowującej typ komunikatu i sam komunikat
(bufora komunikatu)
rozmiar - rozmiar komunikatu „netto” (nie licząc typu)
flagi - 0 lub IPC_NOWAIT (decydują, czy w sytuacji przepełnienia kolejki proces ma
być zawieszony)
Działanie: wstawia komunikat wraz z podanym typem na koniec kolejki.

int msgrcv (int ident; struct msgbuf kom, int rozmiar, long mtype, int flagi);
Zwraca: liczbę faktycznie pobranych bajtów z kolejki w przypadku sukcesu ;
-1 w przypadku błędu.
ident - identyfikator kolejki
kom - wskaźnik do bufora komunikatu
rozmiar - rozmiar struktury komunikatu (nie licząc typu)
mtype - typ komunikatu, jaki chcemy pobrać z kolejki (może być 0)
flagi - można ustawić IPC_NOWAIT i / lub MSG_NOERROR (powoduje
odpowiednie zachowanie,
jeśli komunikat jest większy, niż przewiduje rozmiar)
Działanie: pobiera z kolejki najdawniej wstawiony komunikat o danym typie (jeśli
istnieje), zaś
jeśli został podany typ 0, pobiera najdawniej wstawiony komunikat (o
dowolnym typie).

int msgctl (int ident, int polecenie, struct msgqid_ds struktura);
Zwraca: 0 w przypadku sukcesu ;
-1 w przypadku błędu.
ident - identyfikator kolejki
polecenie - kod czynności do wykonania na strukturze kontrolnej kolejki
struktura - wskaźnik do bufora struktury kontrolnej
Działanie: może wykonywać mnóstwo różnych czynności (w tym również takich,
które mogą
pozbawić programistę kontroli nad kolejką) - zmieniać prawa dostępu,
odczytywać
informacje o ostatnio wykonanej operacji na kolejce itp. Najczęściej jest
wykorzystywana
do usunięcia kolejki:
msgctl (ident, IPC_RMID, 0);
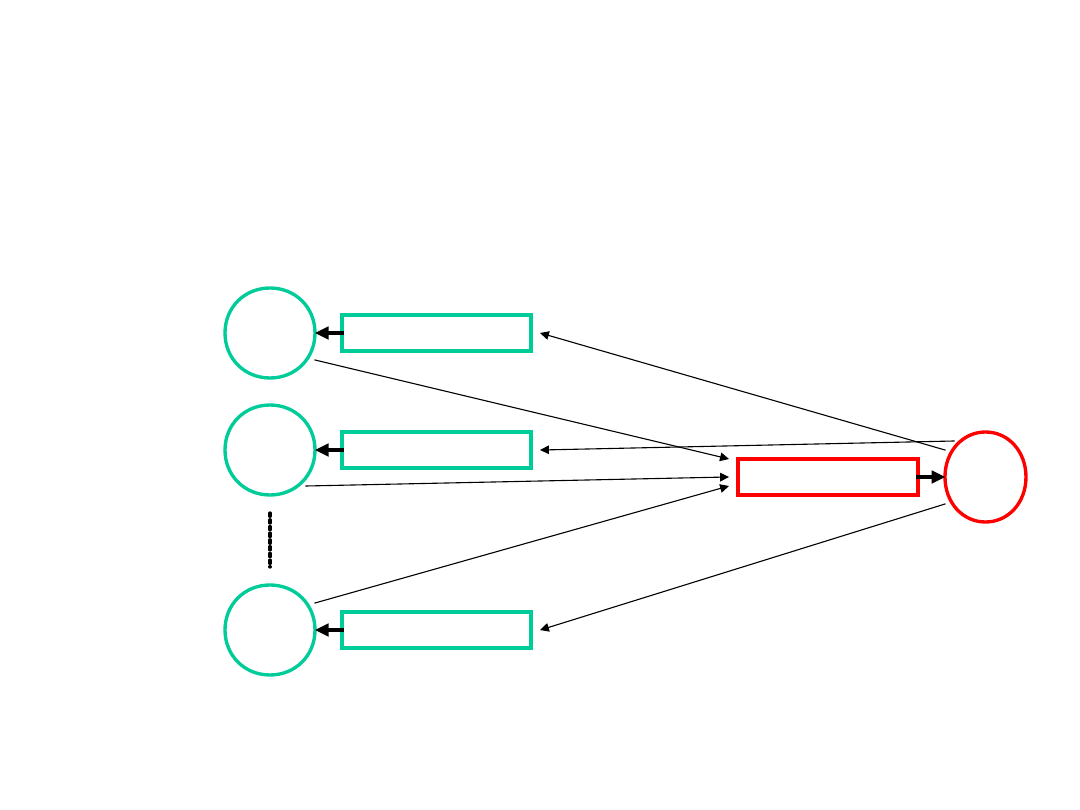
Kolejki komunikatów są narzędziem bardziej skomplikowanym w użyciu, a
jednocześnie oferującym
bogatsze możliwości, niż kolejki FIFO. W typowym zastosowaniu - implementacji
par programów
typu klient / serwer - stosując kolejki FIFO musimy otworzyć oddzielną kolejkę dla
serwera i oddzielne
dla wszystkich klientów (gdyż nie ma możliwości testowania danych
umieszczonych w jednej kolejce
dla wielu odbiorców).
klient 1
kolejka
klienta 1
Dane od klientów powinny na początku zawierać informację o swojej długości oraz
adres zwrotny
(to jest adres kolejki odbiorczej klienta).
serw
er
kolejka
serwera
klient
2
kolejka klienta
2
klient
n
kolejka
klienta n
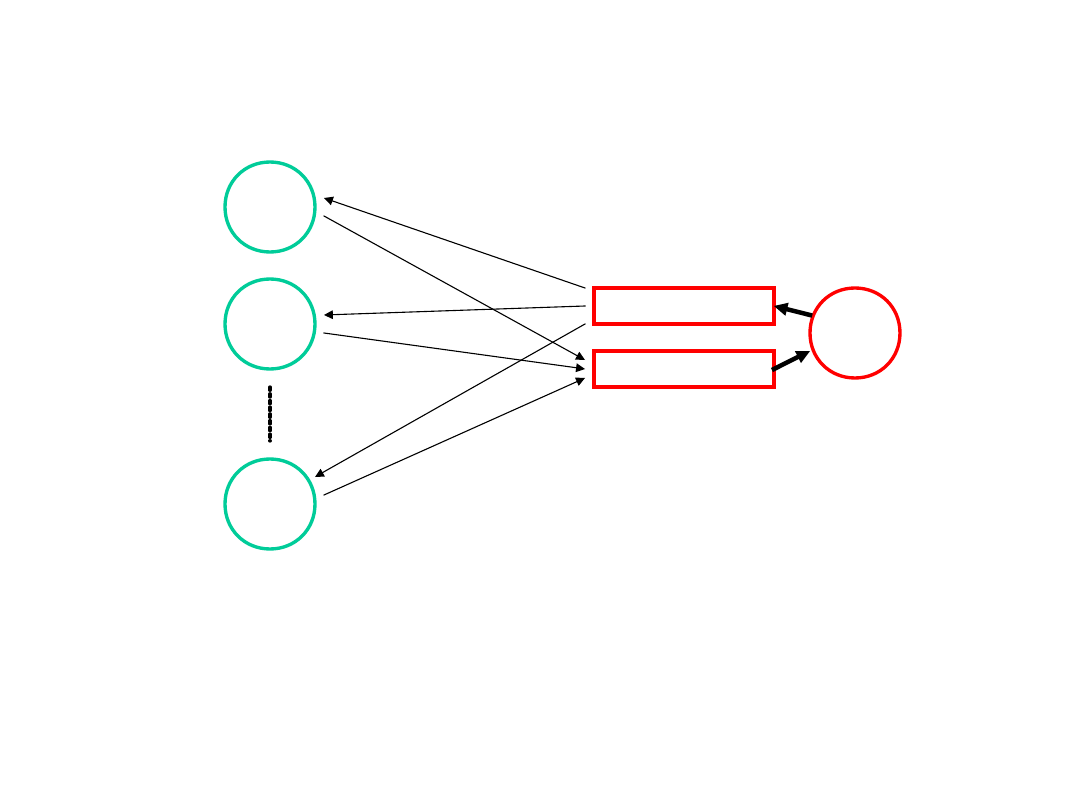
W przypadku stosowania kolejek komunikatów wystarczają dwie takie kolejki
(związane z serwerem),
gdyż umożliwiają demultipleksowanie odpowiedzi serwera do różnych klientów.
serwe
r
odpowiedzi
pytania
Klienci muszą mieć unikalne adresy kodowane jako typy komunikatów.
Odpowiedzi serwera są
opatrywane tymi samymi typami, jakie miały przysyłane przez klientów pytania -
klienci mogą je
selektywnie wybierać z kolejki zwrotnej.
Uwaga. Jest również możliwe rozwiązanie przy użyciu tylko jednej kolejki (dla
pytań i odpowiedzi).
klient
1
klient
2
klient
n

Pamięć dzielona
Poza własnym segmentem danych przydzielonym w momencie utworzenia,
proces może mieć
przydzielony dynamicznie (w trakcie wykonywania) jeden lub więcej segmentów
pamięci z ogólnych
zasobów systemowych. Takie segmenty są dołączane do przestrzeni adresowej
procesu i można na
nich operować bezpośrednio (na przykład wykonując operacje przypisania). Jeśli
programista ustanowi
odpowiednie prawa dostępu, segmenty takie mogą być niezależnie przydzielane
wielu procesom
jednocześnie. Komunikowanie się przez pamięć dzieloną jest zdecydowanie
najszybszym sposobem
komunikowania się procesów (choć najtrudniejszym do synchronizacji).
Uwaga.
1) Podobnie jak w przypadku plików i dowiązań do nich, segment pamięci
dzielonej jest zwracany do
puli wolnych zasobów systemowych dopiero wtedy, gdy ostatni z użytkujących
go procesów
zrzeknie się jego dalszego używania (odłączy go od swojej przestrzeni
adresowej).
2) Nie ma możliwości operowania w segmencie pamięci dzielonej inaczej, niż za
pomocą zmiennych
dynamicznych (wskaźników). W gruncie rzeczy segmenty pamięci dzielonej są
widziane przez
programy jako dodatkowe (współdzielone) sterty.

3) Jeden i ten sam segment pamięci dzielonej może być dołączony do przestrzeni
adresowej procesu
w wielu różnych miejscach. W ten sposób możemy dysponować wieloma
kopiami jednej i tej
samej zmiennej, zmiana wartości jednej kopii jest natychmiast widoczna w
pozostałych miejscach.
4) Proces potomny dziedziczy utworzony (i przyłączony) segment pamięci
dzielonej.
int shmget (key_t klucz, int rozmiar, int flagi);
Zwraca: identyfikator segmentu w przypadku sukcesu;
-1 w przypadku błędu.
klucz, flagi - pełnią podobną rolę, jak dla kolejek komunikatów
rozmiar - rozmiar tworzonego segmentu w bajtach (argument nieistotny, jeśli
segment już istnieje)
Działanie: tworzy nową pozycję w tablicy segmentów, jeśli segment wcześniej nie
istniał.

int shmat (int ident, char adres, int flagi);
Zwraca: wskaźnik do miejsca, gdzie rzeczywiście został dołączony segment, w
przypadku sukcesu;
-1 w przypadku błędu.
ident - identyfikator segmentu (zwrócony przez funkcję shmget)
adres - wskaźnik do miejsca, gdzie programista proponuje dołączyć segment
(może być 0)
flagi - rozmaite role ( na przykład mogą nakazać dołączenie segmentu tylko do
odczytu)
Działanie: dołącza segment (i zwiększa jego licznik dowiązań o 1) pod podanym
adresem (w miarę
możności) jeśli adres jest większy od 0, zaś pod adresem wybranym
przez system, jeśli
podany adres jest równy 0 (najczęściej stosowane i najbardziej
zalecane postępowanie).

int shmdt (char *adres);
Zwraca: 0 w przypadku sukcesu;
-1 w przypadku błędu.
adres - adres, pod którym był dołączony (przez funkcję shmat) segment pamięci
dzielonej
Działanie: segment jest odłączany od przestrzeni adresowej procesu, a jego licznik
dowiązań zmniej-
szany o 1. Jeżeli stan licznika dowiązań zmniejszył się w wyniku tego do
0, a segment był
oznaczony do usunięcia, w tym momencie następuje jego usunięcie z
tablicy segmentów.

int shmctl (int ident, int polecenie, struct shmid_ds struktura);
Zwraca: 0 w przypadku sukcesu;
-1 w przypadku błędu.
ident - identyfikator segmentu (zwrócony przez funkcję shmget)
polecenie - kod polecenia do wykonania na strukturze zarządzającej segmentem
struktura - wskaźnik do bufora struktury zarządzającej segmentem
Działanie: podobnie, jak w przypadku kolejek komunikatów, może wykonywać
wiele różnych
czynności, a najczęsciej wykonywaną jest oznaczenie segmentu do
usunięcia:
shmctl (ident, IPC_RMID, 0);
Uwaga. Zalecane jest odłączenie segmentu (wykonanie funkcji shmdt) przed
oznaczeniem segmentu
do usunięcia.
Semafory
Semafory są uważane za najbardziej skomplikowane w użyciu obiekty pakietu
IPC. Ich najbardziej
typowym zastosowaniem jest synchronizacja dostępu różnych procesów do
zmiennych w pamięci
dzielonej. Semafory zaimplementowane w pakiecie IPC są podobne do
semaforów Agerwali.
Występują nie jako pojedyncze obiekty, ale jako elementy tablic semaforów, na
których można
wykonywać jednocześnie (niepodzielne) operacje. Maksymalny rozmiar tablicy
semaforów zależy od
ustawień systemowych. Zakres wartości przyjmowanych przez pojedynczy
semafor jest zakresem
wartości typu ushort (czyli od 0 do 255).
0 1 2 3
n-1
sem. 0 sem. 1 sem. 2 sem. 3
sem. n-1

int semget (key_t klucz, int liczbasem, int flagi);
Zwraca: identyfikator tablicy semaforów w przypadku sukcesu;
-1 w przypadku błędu.
klucz, flagi - jak dla kolejek komunikatów i pamięci dzielonej
liczbasem - liczba semaforów w tablicy (argument nieistotny, jeśli tablica już
istnieje)
Działanie: tworzy nową tablicę semaforów, jeśli wcześniej nie istniała.

int semop (int ident, struct sembuf oper, unsigned liczbaoper);
gdzie struct sembuf
{ ushort sem_num; numer semafora w tablicy
short sem_op; operacja na semaforze
short sem_flg; } flagi operacji
Zwraca: 0 w przypadku sukcesu;
-1 w przypadku błędu.
ident - identyfikator tablicy semaforów (zwrócony przez funkcję semget)
oper - wskaźnik do początku tablicy operacji (tablicy struktur sembuf)
liczbaoper - liczba elementów w tablicy wskazywanej przez oper
Działanie: system wykonuje niepodzielnie wszystkie operacje nakazane w tablicy
struktur wskazywanej
przez oper - albo nie wykonuje żadnej, jeśli choć jedna z nich jest w danej chwili
niemożliwa.

Pojedyncza operacja na pojedynczym semaforze wygląda następująco:
- jeżeli wartość sem_op jest dodatnia, wartość semafora zwiększa się o nią
(zatem, w przeciwieństwie
do tego, co jest podane w klasycznej definicji semafora, wartość semafora może
wzrosnąć o więcej,
niż 1), a jednocześnie jest budzona odpowiednia liczba procesów śpiących pod
tym semaforem (jeśli
są takie);
- jeżeli wartość sem_op jest ujemna, wartość semafora odpowiednio się
zmniejsza, jeśli to możliwe,
a jeśli niemożliwe, zmniejszenie nie jest wykonywane, a proces albo zasypia
czekając na zaistnienie
takiej możliwości, albo od razu następuje powrót z funkcji z błędem (w
zależności od ustawienia
flagi IPC_NOWAIT);
- jeżeli wartość sem_op wynosi zero, proces zasypia, jeśli wartość semafora nie
jest zerem (lub wraca
od razu z błędem, jeśli jest ustawiona flaga IPC_NOWAIT) i budzi się dopiero po
osiągnięciu
wartości zero przez semafor.

int semctl (int ident, int numer, int polecenie, union semun argument);
gdzie union semun
{ int val; do ustawienia wartości pojedynczego
semafora
struct semid_ds buf; bufor struktury zarządzającej tablicą
semaforów
ushort array; wskaźnik do tablicy ustawień
wartości całej tablicy sem.
struct seminfo __buf; specyficzne dla Linuxa, używane przez
void __pad; } jądro systemu operacyjnego
Zwraca: liczbę dodatnią będącą wynikiem wykonania polecenia - w przypadku
sukcesu
-1 w przypadku błędu
ident - identyfikator tablicy semaforów (zwrócony przez funkcję semget)
numer - numer semafora w tablicy (istotny w przypadku, gdy polecenie dotyczy
pojedynczego semafora)
polecenie - kod polecenia do wykonania
argument - argument jednego z typów wchodzących w skład unii, zależnego od
polecenia

Działanie: może wykonywać mnóstwo różnych czynności (najwięcej z wszystkich
funkcji IPC) na
pojedynczych semaforach, na całej ich tablicy lub na strukturze
zarządzającej. Najczęściej
używanymi poleceniami są:
IPC_RMID usunięcie tablicy semaforów
GETALL odczytanie wartości wszystkich semaforów w
tablicy
SETALL nadanie wartości wszystkim semaforom w
tablicy
GETVAL odczytanie wartości pojedynczego semafora
SETVAL nadanie wartości pojedynczemu semaforowi
Uwaga. Operacje nadania lub odczytania wartości semaforów nie wiążą się z
możliwością wstrzymania
procesu wykonującego daną operację.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
Wyszukiwarka
Podobne podstrony:
Systop2
Systop11
Systop13
Systop8
Systop3
Systop5
Systop10
Systop1
Systop9
Systop7
Systop2
Systop12
SystOper
więcej podobnych podstron