Modelowanie danych
w SQL Server 2005 i 2008.
Przewodnik
Autor: Eric Johnson, Joshua Jones
T³umaczenie: Wojciech Moch
ISBN: 978-83-246-2090-6
to Data Modelling for SQL Server.
Covering SQL Server 2005 and 2008
Format: 168x237, stron: 280
Twórz wydajne modele danych!
•
Jakie techniki modelowania danych warto stosowaæ?
•
Jakie jest znaczenie procesu normalizacji?
•
Jak rozwi¹zaæ typowe problemy w trakcie modelowania?
Model danych jest niezwykle istotnym etapem tworzenia systemu informatycznego,
poniewa¿ rzutuje on bezpoœrednio na wydajnoœæ rozwi¹zania oraz komfort pracy
programisty. Warto zatem poznaæ najlepsze techniki modelowania danych i wszystkie
zwi¹zane z nimi procesy.
Dziêki tej ksi¹¿ce zrozumiesz podstawowe techniki modelowania danych oraz dowiesz
siê, jak gromadziæ wymagania dotycz¹ce modelu. Ponadto zapoznasz siê z elementami
wykorzystywanymi w logicznych i fizycznych modelach danych. Czwarty — niezwykle
istotny — rozdzia³ wprowadzi Ciê w tematykê normalizacji modelu, dziêki czemu
zrozumiesz, jak istotny to proces! W trakcie lektury kolejnych rozdzia³ów nauczysz siê
rozwi¹zywaæ typowe problemy, wystêpuj¹ce w trakcie modelowania, oraz uœwiadomisz
sobie, jak istotn¹ rolê pe³ni¹ w nim indeksy. Pojawiaj¹ce siê tu przyk³ady dotycz¹ bazy
danych SQL Server firmy Microsoft, niew¹tpliwie jednak ksi¹¿ka ta przyda siê równie¿
osobom zwi¹zanym z innymi platformami bazodanowymi.
•
Techniki modelowania danych
•
Elementy wykorzystywane w logicznych modelach danych
•
Elementy wykorzystywane w fizycznych modelach danych
•
Proces normalizacji modelu danych
•
Sposoby efektywnego gromadzenia wymagañ
•
Interpretacja oraz dokumentacja wymagañ
•
Proces tworzenia modelu logicznego
•
Sposób wykorzystania SQL Server w celu stworzenia modelu fizycznego
•
Zastosowanie i znaczenie indeksów
•
Przygotowanie warstwy abstrakcji w SQL Server
•
Rozwi¹zywanie typowych problemów w trakcie procesu modelowania
Dowiedz siê wszystkiego o modelowaniu danych i Twórz wydajne rozwi¹zania!

S
PIS TRECI
Wstp ................................................................................................. 13
O autorach ........................................................................................... 15
Cz I
Teoria modelowania danych ...................................... 17
Rozdzia 1. Przegld technik modelowania danych ..................................... 19
Bazy danych ...................................................................................................... 20
Systemy zarzdzania relacyjnymi bazami danych .............................................21
Dlaczego dobrze zaprojektowany model danych jest tak wany ..................... 22
Spójno danych .............................................................................................22
Skalowalno ..................................................................................................23
Spenianie wymaga biznesowych ...................................................................25
atwe odczytywanie danych ............................................................................26
Poprawianie wydajnoci ..................................................................................28
Proces modelowania danych ............................................................................. 29
Teoria modelowania danych ............................................................................29
Wymagania biznesowe ...................................................................................31
Budowanie modelu logicznego .........................................................................33
Budowanie modelu fizycznego .........................................................................34
Podsumowanie .................................................................................................. 35
Rozdzia 2. Elementy wykorzystane w logicznych modelach danych ............... 37
Encje .................................................................................................................. 37
Atrybuty ............................................................................................................ 38
Typy danych ...................................................................................................39
Klucze gówne i obce ......................................................................................43
Domeny .........................................................................................................44
Atrybuty z pojedyncz wartoci i z wieloma wartociami ................................45
Spójno referencji ............................................................................................ 46
Relacje ............................................................................................................... 47
Typy relacji .....................................................................................................48
Opcje relacji ...................................................................................................52
Liczno .........................................................................................................53

8
S
PIS TRECI
Uywanie podtypów i typów nadrzdnych ....................................................... 54
Definicje podtypów i typów nadrzdnych .........................................................54
Kiedy uywa klastrów podtypów ....................................................................56
Podsumowanie .................................................................................................. 56
Rozdzia 3. Fizyczne elementy modeli danych ............................................ 57
Fizyczne przechowywanie danych .................................................................... 57
Tabele ...........................................................................................................57
Widoki ...........................................................................................................59
Typy danych ...................................................................................................61
Spójno referencji ............................................................................................ 70
Klucze gówne ................................................................................................70
Klucze obce ....................................................................................................74
Ograniczenia ..................................................................................................76
Implementowanie spójnoci referencji .............................................................78
Programowanie ................................................................................................. 81
Procedury skadowane ....................................................................................81
Funkcje uytkownika ......................................................................................82
Wyzwalacze ...................................................................................................83
Integracja z CLR .............................................................................................85
Implementowanie typów nadrzdnych i podtypów ......................................... 85
Tabela typu nadrzdnego ................................................................................86
Tabele podtypów ............................................................................................87
Tabele typu nadrzdnego i podtypów ..............................................................87
Typy nadrzdne i podtypy — podsumowanie ...................................................88
Podsumowanie .................................................................................................. 88
Rozdzia 4. Normalizowanie modelu danych .............................................. 91
Czym jest normalizacja? .................................................................................... 91
Postaci normalne ............................................................................................91
Okrelanie postaci normalnych ......................................................................... 99
Denormalizacja ............................................................................................... 100
Podsumowanie ................................................................................................ 102
Cz II Wymagania biznesowe ........................................... 105
Rozdzia 5. Gromadzenie wymaga ........................................................ 107
Przegld zagadnie zwizanych ze zbieraniem wymaga ............................... 108
Zbieranie wymaga krok po kroku ................................................................. 108
Prowadzenie wywiadów ................................................................................108
Obserwacje ..................................................................................................111
Istniejce procesy i systemy ..........................................................................112
Przypadki uycia ...........................................................................................114

S
PIS TRECI
9
Potrzeby biznesowe ........................................................................................ 120
Szukanie zotego rodka midzy ograniczeniami technicznymi i potrzebami
biznesowymi ................................................................................................... 121
Zbieranie danych uytkowych ........................................................................ 121
Odczyty a zapisy ..........................................................................................121
Wymagania dotyczce przechowywania danych ............................................122
Wymagania transakcyjne .............................................................................123
Podsumowanie ................................................................................................ 124
Rozdzia 6. Interpretowanie wymaga .................................................... 125
Mountain View Music ...................................................................................... 125
Analiza danych na temat wymaga .................................................................. 127
Identyfikowanie uytecznych informacji .........................................................127
Identyfikowanie informacji nadmiarowych .....................................................128
Definiowanie wymaga modelu ...................................................................... 129
Interpretowanie wyników wywiadów .............................................................129
Interpretacja diagramów przepywu ..............................................................134
Interpretowanie istniejcych systemów .........................................................137
Interpretowanie przypadków uycia ..............................................................139
Okrelanie atrybutów ...................................................................................141
Okrelanie regu biznesowych ........................................................................ 143
Definiowanie regu biznesowych ....................................................................145
Liczno .......................................................................................................146
Wymagania wobec danych ...........................................................................146
Dokumentowanie wymaga ........................................................................... 147
Lista encji ....................................................................................................147
Lista atrybutów ............................................................................................147
Lista relacji ..................................................................................................148
Lista regu biznesowych ................................................................................148
Spojrzenie w przyszo — recenzja ............................................................... 148
Dokumentacja projektowa ............................................................................148
Podsumowanie ................................................................................................ 150
Cz III Tworzenie modelu logicznego ................................... 151
Rozdzia 7. Tworzenie modelu logicznego .................................................153
Tworzenie diagramów modelu danych ........................................................... 153
Sugestie dotyczce nazewnictwa ...................................................................153
Standardy notacji .........................................................................................156
Narzdzia do modelowania ...........................................................................159
Wykorzystywanie wymaga do budowania modelu ....................................... 160
Lista encji ....................................................................................................160
Lista atrybutów ............................................................................................164
Dokumentacja relacji ...................................................................................165
Reguy biznesowe .........................................................................................166

10
S
PIS TRECI
Budowanie modelu ......................................................................................... 167
Klucze gówne ..............................................................................................168
Relacje .........................................................................................................169
Domeny .......................................................................................................170
Atrybuty .......................................................................................................170
Podsumowanie ................................................................................................ 172
Rozdzia 8. Typowe problemy przy modelowaniu danych .............................173
Problemy z encjami ......................................................................................... 173
Zbyt mao encji ............................................................................................173
Zbyt wiele encji ............................................................................................176
Problemy z atrybutami .................................................................................... 177
Jeden atrybut zawierajcy róne dane ...........................................................177
Niewaciwe typy danych ..............................................................................179
Problemy z relacjami ....................................................................................... 183
Relacje typu jeden-do-jednego ......................................................................183
Relacje typu wiele-do-wielu ..........................................................................184
Podsumowanie ................................................................................................ 185
Cz IV Tworzenie modelu fizycznego .................................. 187
Rozdzia 9. Tworzenie modelu fizycznego za pomoc serwera SQL Server ........ 189
Nazewnictwo obiektów .................................................................................. 189
Ogólne reguy nazewnictwa ..........................................................................191
Nazywanie tabel ..........................................................................................194
Nazywanie kolumn .......................................................................................195
Nazwy widoków ...........................................................................................195
Nazywanie procedur skadowanych ...............................................................195
Nazywanie funkcji uytkownika ....................................................................196
Nazywanie wyzwalaczy ................................................................................196
Nazywanie indeksów ....................................................................................196
Nazywanie typów danych uytkownika .........................................................197
Nazywanie kluczy gównych i kluczy obcych ..................................................197
Nazywanie ogranicze ..................................................................................197
Tworzenie modelu fizycznego ........................................................................ 198
Modelowanie tabel na podstawie encji ..........................................................198
Uywanie relacji do modelowania kluczy .......................................................208
Modelowanie kolumn za pomoc atrybutów ..................................................209
Implementowanie regu biznesowych w modelu fizycznym ........................... 209
Implementowanie regu biznesowych za pomoc ogranicze ..........................210
Implementowanie regu biznesowych za pomoc wyzwalaczy ........................212
Implementowanie zaawansowanej licznoci ..................................................214
Podsumowanie ................................................................................................ 216

S
PIS TRECI
11
Rozdzia 10. Kilka sów na temat indeksów ............................................... 217
Przegld indeksów .......................................................................................... 217
Czym s indeksy? ..........................................................................................218
Rodzaje ........................................................................................................220
Wymagania dotyczce korzystania z bazy danych .......................................... 226
Odczyty i zapisy ...........................................................................................226
Dane transakcji ............................................................................................228
Okrelanie waciwych indeksów ................................................................... 228
Przegldanie wzorów dostpu do danych .......................................................228
Równowaenie indeksów ..............................................................................229
Indeksy pokrywajce .....................................................................................230
Statystyki indeksów ......................................................................................230
Rozwaania na temat obsugi indeksów ........................................................231
Implementowanie indeksów w serwerze SQL Server .................................... 231
Konwencje nazewnictwa ...............................................................................231
Tworzenie indeksów .....................................................................................232
Grupy plików ................................................................................................233
Konfigurowanie konserwacji indeksów ...........................................................233
Podsumowanie ................................................................................................ 235
Rozdzia 11. Tworzenie warstwy abstrakcji w serwerze SQL Server ................ 237
Czym jest warstwa abstrakcji? ........................................................................ 237
Po co uywa warstwy abstrakcji? .................................................................. 238
Bezpieczestwo ............................................................................................238
Elastyczno i moliwo rozbudowy .............................................................240
Zwizek warstwy abstrakcji z logicznym modelem danych ............................ 241
Zwizek warstwy abstrakcji z programowaniem zorientowanym obiektowo ......241
Implementowanie warstwy abstrakcji ............................................................. 243
Widoki .........................................................................................................243
Procedury skadowane ..................................................................................245
Inne skadniki warstwy abstrakcji ..................................................................248
Podsumowanie ................................................................................................ 248
Cz V
Dodatki ................................................................251
Dodatek A Przykadowy model logiczny .................................................. 253
Dodatek B Przykadowy model fizyczny .................................................. 257
Dodatek C Zarezerwowane sowa serwera SQL Server 2008 ....................... 261
Dodatek D Zalecane standardy nazewnictwa ............................................263
Skorowidz
.........................................................................265

R O Z D Z I A 2
.
E
LEMENTY WYKORZYSTANE
W
LOGICZNYCH MODELACH DANYCH
Prosz sobie wyobrazi, e kto poprosi nas o wybudowanie domu. Jednym z pierw-
szych pyta, jakie w takiej sytuacji naleaoby sobie postawi, jest: „Czy mam wszyst-
kie potrzebne narzdzia i materiay?” Aby na takie pytanie odpowiedzie, potrzebuje-
my projektu tego domu. To wanie z projektu bdziemy w stanie wywnioskowa,
jakie narzdzia i materiay bd niezbdne. Oznacza to, e na pocztek musimy sobie
przygotowa projekt. Jeeli wczeniej tego nie robilimy, to najprawdopodobniej
bdziemy musieli dowiedzie si, jak naley go wykona.
Przygotowany przez nas logiczny model danych, podobnie jak projekt domu,
stanie si podstaw wszystkich prac nad fizyczn baz danych. Oprócz tego logiczny
model danych jest swego rodzaju wysokopoziomowym widokiem na baz danych,
który mona zaprezentowa wszystkim stronom biorcym udzia w projekcie. Z tych
wanie powodów logiczny model danych moe by cakowicie oderwany od technicz-
nych szczegóów zwizanych z konkretnym systemem zarzdzania bazami danych.
Informacje zawarte w modelu logicznym definiuj jedynie sposób, w jaki baza
danych zbudowana na podstawie tego modelu bdzie speniaa biznesowe wymagania
klienta. Zanim jednak przystpimy do konstruowania modelu logicznego, koniecz-
nie musimy pozna wszystkie narzdzia, jakich bdziemy potrzebowali.
W tym rozdziale omówimy obiekty i koncepcje powizane z procesem tworze-
nia logicznego modelu danych. Obiekty te wykorzystamy ponownie w rozdziale 7.,
w którym zaczniemy tworzy model danych dla firmy Mountain View Music. Na
razie opiszemy temat encji oraz atrybutów i zobaczymy, jak mona tworzy relacje
midzy nimi.
Encje
Encje reprezentuj logiczne grupy danych, dlatego w modelu logicznym s najwa-
niejszym elementem, który definiuje sposób zapisu danych w bazie. Typowymi
przykadami encji s klienci, zamówienia lub produkty. Kada encja, która powinna
reprezentowa pojedynczy typ informacji, skada si z caej kolekcji egzemplarzy
tej encji. Egzemplarz (ang. instance) encji jest bardzo podobny do rekordu bazy
danych. W teorii modelowania danych pojcia egzemplarza, rekordu lub wiersza

38
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
s uywane zamiennie. W tej ksice egzemplarz bdzie pojawia si wycznie
w encjach, natomiast rekordy lub wiersze bd elementami fizycznych tabel lub
widoków.
Czsto moemy ulega pokusie traktowania poszczególnych encji jako tabel
(w kocu midzy tabelami a encjami istniej zwykle zwizki typu jeden do jednego),
trzeba jednak pamita, e logiczna encja moe by reprezentowana przez wiele
tabel, a wiele encji moe zosta zgromadzonych w ramach jednej tabeli. Zadaniem
encji jest identyfikacja wszystkich informacji, które bd zapisywane w bazie danych.
Jednym ze sposobów na okrelenie, co mona zakwalifikowa jako encj, jest
mylenie o encjach jak o rzeczownikach. Encje zwykle s obiektami, które mona
opisa za pomoc rzeczownika: zamówieniami, samochodami, trbkami albo telefo-
nami, czyli przedmiotami znanymi nam na co dzie. Waciwe zdefiniowanie encji
na potrzeby modelu jest niezwykle istotne, dlatego to zadanie stanowi zawsze jedn
z wikszych czci procesu projektowania.
Definiujc encje, powinnimy przede wszystkim zajmowa si ich przeznacze-
niem, a dopiero w dalszej kolejnoci zastanawia si nad ich atrybutami i innymi
szczegóami (atrybuty zostan opisane w nastpnym podrozdziale). Wywiady prowa-
dzone z pracownikami firmy i innymi osobami odpowiedzialnymi za jej funkcjonowa-
nie w ramach procesu gromadzenia wymaga biznesowych (bdzie o tym mowa
w rozdziale 5.) pozwol nam okreli najczciej uywane w firmie rzeczowniki,
a co za tym idzie, najistotniejsze encje. Po rozpoczciu projektowania modelu to
wanie z tych notatek bdziemy korzysta do okrelania wszystkich niezbdnych
encji. Musimy przy tym bardzo ostronie przeglda i filtrowa sporzdzone wcze-
niej notatki, tak eby wykorzysta tylko te informacje, które s rzeczywicie istotne
w aktualnym projekcie.
Atrybuty
Kada encja jest opisywana przez pewne szczegóowe informacje, które s wanie
jej atrybutami. Zaómy, e musimy utworzy encj przechowujc wszystkie infor-
macje opisujce kapelusze. Otrzyma ona nazw Kapelusze, a nastpnie bdziemy
mogli okreli, jakie informacje, czyli atrybuty, musimy w niej zachowa: kolor, nazw
producenta, styl, materia itp. W czasie konstruowania modelu definiujemy kolejk
atrybutów, które bd przechowyway te dane w ramach encji. Definicja atrybutu
skada si z jego nazwy, opisu, celu i typu danych (typy danych zostan omówione
w nastpnym podrozdziale).
Naley si przy tym wystrzega dodawania do encji atrybutów, które tak naprawd
powinny by czci innej encji. Typowy bd polega na bezporednim przekszta-
caniu danych z fizycznej dokumentacji, takiej jak wydrukowane arkusze kalkula-
cyjne lub podrczniki, w encje i atrybuty modelu logicznego. Na przykad informacje
na temat klienta s czsto fizycznie czone z informacjami na temat zamówienia.
Mona z tego wysnu bdne zaoenie, e informacje dotyczce klienta, takie jak
adres lub numer telefonu, s atrybutami zamówienia. W rzeczywistoci klient i zamó-
wienie s cakowicie niezalenymi encjami. Zapisanie atrybutów klienta w ramach

A
TRYBUTY
39
encji zamówienia spowoduje niepotrzebne skomplikowanie procesu odczytywania
danych i moe doprowadzi do powstania projektu, który nie bdzie poddawa si
skalowaniu.
Chcc prawidowo modelowa atrybuty encji, musimy pozna kilka najwaniej-
szych poj: typy danych, klucze, domeny i wartoci. W kolejnych podrozdziaach
nieco dokadniej je omówimy.
Typy danych
Oprócz informacji opisowych w definicji atrybutu trzeba poda jeszcze typ danych
(ang. data type). Jak sama nazwa wskazuje, definiuje on typ informacji, jaka bdzie
zapisywana w atrybucie. Na przykad atrybut moe by cigiem znaków, liczb albo
wartoci logiczn typu prawda-fasz.
W modelach logicznych okrelenie typów danych atrybutów nie jest absolutnie
wymagane. Ze wzgldu na to, e typ danych jest okreleniem fizycznego sposobu
zapisu danych, okrelenie typu danych atrybutu nastpuje w czasie tworzenia modelu
fizycznego. Trzeba jednak pamita, e okrelajc typ danych ju w trakcie przy-
gotowywania modelu logicznego, moemy uzyska kilka wanych korzyci:
Zespó tworzcy model fizyczny bdzie dysponowa ju pewnym przewodni-
kiem i nie bdzie musia wyszukiwa informacji w zbiorze wymaga (czasami
moe si to okaza dziaaniem wielokrotnym).
Bdziemy mogli wykry niecisoci powstajce pomidzy encjami przecho-
wujcymi ten sam typ danych (na przykad numer telefonu), i to jeszcze przed
powstaniem modelu fizycznego.
W ramach uatwienia procesu budowania fizycznej bazy danych moemy
zdefiniowa typy danych cile zwizane z uywanym systemem relacyjnych
baz danych. Mona to zrobi tylko wtedy, gdy docelowy system zarzdzania
baz danych bdzie znany jeszcze przed rozpoczciem prac nad modelem.
Wikszo dostpnych programów do modelowania danych pozwala na wybranie
sporód typów danych stosowanego systemu zarzdzania baz danych. Skoro mamy
pracowa z serwerem Microsoft SQL Server, moemy od razu korzysta z typów
danych obsugiwanych przez ten serwer. Przyjrzyjmy si teraz rónym typom danych
stosowanym w modelach logicznych.
Alfanumeryczne
Wszystkie modele danych zawieraj dane alfanumeryczne, czyli dowolne dane
w postaci cigu znaków, niezalenie od tego, czy zawieraj one znaki alfabetu, czy
te cyfry (pod warunkiem e te nie bior udziau w obliczeniach matematycznych).
Przykadami tego typu danych mog by nazwy, adresy albo numery telefonów.
Konkretne typy danych uywane do przechowywania informacji alfanumerycznych
to char, nchar, varchar i nvarchar. Jak mona wywnioskowa z nazw tych typów,
s one przeznaczone do przechowywania znaków, takich jak litery, cyfry i znaki
specjalne.

40
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
Wszystkie te typy danych wymagaj okrelenia ich dugoci. Mówic ogólnie,
dugo definiuje cakowit liczb znaków, jaka moe znale si w danym atrybucie.
Jeeli mamy pewno, e dany atrybut bdzie przechowywa tylko dwuliterowe
skróty nazw pastw, to moemy zdefiniowa go jako char(2). W ten sposób definiuje-
my atrybut jako alfanumeryczne pole mieszczce w sobie dokadnie dwa znaki. Atry-
buty typu char przechowuj dokadnie tyle znaków, ile okrela ich definicja — nie
mniej i nie wicej, niezalenie od tego, ile znaków faktycznie do nich wprowadzono.
Kady zapewne zauway ju, e istniej a cztery rodzaje znakowego typu da-
nych: dwa z przedrostkiem var i dwa z przedrostkiem n (jeden z tych typów zawiera
oba te przedrostki). Pola o zmiennej dugoci s definiowane jako zawierajce nie
wicej znaków, ni zostao to podane w definicji pola. Aby zobrazowa rónic
midzy typami char i varchar, mona poda, e definicja char(10) tworzy pole
o dugoci dziesiciu znaków, nawet jeeli konkretny egzemplarz tego pola bdzie
mia dugo szeciu znaków. W takim przypadku pozostae cztery znaki zostan
automatycznie dopisane. Jeeli ten atrybut zostanie zdefiniowany jako varchar(10),
to w podobnej sytuacji zapisanych zostanie tylko sze znaków.
Przedrostek n oznacza, e znaki bd zapisywane w formacie Unicode. Jest to
midzynarodowa, niezalena od platformy specyfikacja przeznaczona do zapisywania
znaków. Uywanie Unicode’u pozwala na budowanie systemów pracujcych ze
znakami rónych jzyków. Systemy takie mog bez adnych problemów wymienia
midzy sob dane tekstowe, wanie dziki zastosowaniu wspólnej metody zapisu
znaków. Jeeli tylko musimy zapisa znaki wykraczajce poza standardowy zestaw
ASCII konieczne jest zastosowanie Unicode’u.
Podstawow rónic midzy systemami korzystajcymi z Unicode’u a systemami
uywajcymi tylko znaków ASCII jest to, e kady znak Unicode zajmuje dwa bajty,
podczas gdy znaki ASCII zajmuj tylko jeden znak (jeeli s zapisywane dane
o zmiennej dugoci, moe si okaza, e jest potrzebny wicej ni jeden bajt).
Problem z systemami zapisujcymi znaki w jednym bajcie polega na tym, e nie s
one w stanie skutecznie zapisa pewnych znaków, takich jak japoskie znaki Kanji
albo koreaskie znaki Hangul. W tym przypadku trzeba rozway, czy waniejsza jest
wygoda zapisywania danych, czy moe wydajno pracy. Zagadnienie to bdziemy
omawia dokadniej w rozdziale 3. Na razie prosz pamita, e jeeli chcemy prze-
chowywa w bazie pewne typy tekstów, niezbdne moe okaza si uycie znaków
w formacie Unicode.
Numeryczne
Dane numeryczne to dowolne dane, które musz zosta zapisane w postaci licz-
bowej. Na wszystkich typach danych numerycznych moemy wykonywa obliczenia
matematyczne. Wród najogólniejszych typów danych numerycznych znajdziemy
typy cakowite (integer), dziesitne (decimal), walutowe (money), zmiennoprzecin-
kowe (float) i rzeczywiste (real).
Typy cakowite zawsze s zapisywane w postaci liczby cakowitej. Ten typ da-
nych pozwala na zapisywanie liczb dodatnich i ujemnych, a dodatkowo istnieje on
w kilku wielkociach, z których kada pozwala na przechowywanie okrelonego

A
TRYBUTY
41
zakresu wartoci. Typy dziesitne s liczbami o z góry zdefiniowanej wielkoci
i dokadnoci. Wielko typu oznacza w tym przypadku ogóln liczb cyfr, jakie
mona zapisa w danym polu, natomiast dokadno okrela, ile z tych cyfr zostanie
zapisanych po przecinku. Typ walutowy jest przeznaczony do zapisywania wartoci
kwot, a jego dokadno jest uzaleniona od stosowanego wanie systemu zarz-
dzania bazami danych. Typ zmiennoprzecinkowy opisuje liczby zmiennoprzecin-
kowe, a zatem liczby zapisywane z pewnym przyblieniem. Wartoci tego typu s
najczciej zapisywane w notacji naukowej. Dodatkowo moliwe jest zdefiniowanie
liczby bitów, w której maj by przechowywane liczby. Typy rzeczywiste s wa-
ciwie identyczne z typami zmiennoprzecinkowymi, ale typy zmiennoprzecinkowe
umoliwiaj przechowywanie znacznie wikszych liczb.
Podobnie jak w przypadku typów danych alfanumerycznych szczegóowe infor-
macje na temat fizycznego zapisywania danych tych typów zostay przedstawione
w rozdziale 3.
Logiczne
Typy logiczne (boolean) umoliwiaj przechowywanie tylko trzech wartoci: prawdy
(
TRUE
), faszu (
FALSE
) lub zera (
NULL
). Dane przechowywane w polach tego typu s
logiczne, fizycznym typem danych jest jednak jeden bit. Moe on przechowywa
warto 1, 0 lub
NULL
, które mona przetumaczy jako prawd, fasz i nic. Logiczne
typy danych s uywane do przechowywania wyników rónych wyrae logicznych.
Czsto stosowane s te jako przeczniki lub flagi, na przykad wskazujce, e dany
pojazd jest aktualnie niesprawny.
BLOB i CLOB
Nie wszystkie dane przechowywane w bazie danych musz mie posta czyteln
dla uytkownika. Na przykad baza danych zbierajca informacje sklepu interne-
towego oprócz danych opisujcych poszczególne produkty moe równie zawiera
ich obrazy. Binarne dane skadajce si na informacje o obrazie nie nadaj si do
czytania w postaci cigu znaków, ale mog zosta zapisane w bazie danych, tak eby
moga z nich skorzysta aplikacja. Tego rodzaju dane s zwykle nazywane wielkimi
obiektami binarnymi (ang. binary large object — BLOB).
Takie informacje w serwerze SQL Server najczciej s zapisywane za pomoc
nastpujcych typów danych: binary, varbinary i image. Podobnie jak w przypadku
typów znakowych przedrostek var oznacza, e dany atrybut moe przechowywa
wartoci o zmiennej dugoci. W zwizku z tym typ binary definiuje atrybut o staej
wielkoci, przechowujcy dane binarne, a typ varbinary okrela tylko
maksymaln
wielko atrybutu przechowujcego dane binarne. Z kolei typ image okrela, e
atrybut zawiera dane binarne o zmiennej wielkoci, podobne do typu varbinary. Typ
ten daje jednak znacznie wiksze moliwoci przechowywania danych.
Dane znakowe równie mog si pojawia w formach o wiele duszych, ni
przewiduj to typowe typy danych alfanumerycznych, o których mówilimy wcze-
niej. Co zrobi, jeeli w danym atrybucie musimy zapisa tekst dowolnej wielkoci,

42
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
na przykad cay yciorys? W tej sytuacji z pomoc przychodz nam dwa typy wiel-
kich obiektów znakowych (ang. character large object — CLOB), czyli text i ntext. Te
dwa typy danych s przeznaczone do przechowywania duych iloci tekstu w postaci
jednego pola. Podobnie jak byo to w przypadku pozostaych typów znakowych,
przedrostek n oznacza, e tekst w danym atrybucie jest zapisywany w formacie
Unicode. Z tych typów danych naley korzysta wtedy, gdy w ramach jednego atry-
butu encji musimy zapisa naprawd due iloci danych alfanumerycznych.
Data i czas
Niemal kady istniejcy model danych wymaga zastosowania encji zawierajcych
atrybuty opisujce daty lub czas. Pozwalaj one na okrelenie momentu, w którym
wprowadzono zmiany do zamówienia, daty zatrudnienia nowego pracownika albo
zdefiniowanie czasu dostawy towarów. Kady system zarzdzania relacyjnymi ba-
zami danych ma swoj wasn implementacj typów danych pozwalajcych na zapi-
sywanie daty i czasu. W przypadku serwera SQL Server 2008 mamy do dyspozycji
a sze typów danych tego rodzaju. Jest to duy postp w stosunku do poprzednich
wersji tego serwera, które oferoway jedynie dwa typy: datetime i smalldatetime.
Kady z tych typów danych przechowuje informacje na temat daty lub czasu. Ró-
nice wynikaj jedynie z dokadnoci zapisanej daty i zakresu dostpnych wartoci.
Przyjrzyjmy si starszym typom. Typ datetime przechowuje dane dotyczce daty
i czasu z dokadnoci do jednej milisekundy. Zaómy, e do tabeli zawierajcej
kolumn typu datetime wpisujemy dat 12.01.2008 oraz godzin 18.00.
W bazie danych zostanie zapisana warto:
12/01/2008 18:00:00.000
Typ smalldatetime zapisaby t sam warto w postaci:
12/01/2008 18:00
Typ datetime moe przechowywa dowoln dat z zakresu od 1 stycznia 1753
roku do 31 grudnia 9999 roku, a typ smalldatetime pozwala na zapisanie daty z za-
kresu od 1 stycznia 1900 roku do 6 czerwca 2079 roku. Powodem wybrania tych
wanie dat, trzeba przyzna, e do dziwnych, s wymagania zwizane z metodami
zapisu na poziomie dysku twardego oraz z metodami manipulacji na datach w ser-
werze SQL Server.
Jak ju wczeniej wspominalimy, SQL Server 2008 wprowadza cztery nowe typy
danych zwizanych z dat i czasem: date, time, datetime2 i datetimeoffset. Nowe
typy danych przechowuj informacje o dacie i czasie w sposób duo elastyczniejszy
ni poprzednie. Najprostsze s oczywicie typy date i time, poniewa pozwalaj na
zapisanie jedynie daty lub jedynie czasu. Typ datetime2 otrzyma niezbyt dobr
nazw, ale poza tym jest bardzo podobny do typu datetime. Jedyna rónica polega
na tym, e nowy typ danych pozwala na zdefiniowanie dokadnoci zapisywania
uamków sekund od zera do siedmiu miejsc po przecinku. Z kolei typ danych da-
tetimeoffset róni si od typu datetime moliwoci zapisania oprócz daty i czasu

A
TRYBUTY
43
pewnej wartoci przesunicia. Nie musi by ono zwizane z adn stref czasow
ani nawet z czasem Greenwich. Musimy zatem pamita, wzgldem której strefy
czasowej naley je liczy.
Omówilimy ju sporo szczegóów, ale ponownie przypomnimy, e jeszcze du-
szy wywód na temat metod przechowywania informacji w ramach poszczególnych
typów danych znajduje si w rozdziale 3.
W czasie projektowania modelu logicznego moemy ulec pokusie nadawania
atrybutom rónych typów danych. Takie praktyki mog jednak powodowa wiele
problemów podczas dalszych prac. Wikszo programów do modelowania danych
jest w stanie wygenerowa model fizyczny na podstawie modelu logicznego, a zatem
wybranie niewaciwych typów danych w modelu logicznym moe doprowadzi
do nieprawidowoci w modelu fizycznym, szczególnie gdy pracuje nad nim kilka
osób. Naley czsto zaglda do zebranych wymaga biznesowych, tak eby uzyska
pewno, e faktycznie definiujemy atrybuty zgodne z danymi uywanymi w firmie.
Uatwi nam to równie rozmowy na temat modelu danych prowadzone z pracow-
nikami, którzy nie zajmuj si techniczn stron projektu.
Klucze gówne i obce
Klucz gówny (ang. Primary Key — PK) jest atrybutem lub grup atrybutów, która
jednoznacznie identyfikuje kady egzemplarz danej encji. Zawsze musi zawiera
dane i nigdy nie moe by pusty. Jako przykady kluczy gównych mona poda
numery identyfikacyjne pracowników albo numery ISBN ksiek. W czasie tworzenia
modelu musimy pamita o tym, e niemal kada zawarta w nim encja musi mie
klucz gówny, nawet jeeli musimy go utworzy sztucznie za pomoc jakiej liczby.
Jeeli dane nie maj przypisanego klucza gównego, to czsto niezbdne jest
dodanie do tabeli kolumny, która bdzie suya jako taki wanie klucz. Tego rodzaju
klucze nazywane s kluczami zastpczymi. Co prawda, taka praktyka jest ju bardziej
zbliona do fizycznego projektowania bazy danych, ale modelowanie klucza zastp-
czego pozwala na tworzenie relacji na podstawie kluczy gównych. Takie klucze s
zwykle liczbami, których warto jest zwikszana dla kadego wiersza dodawanego
do tabeli. W przypadku serwera SQL Server liczby te nazywane s tosamociami
(ang. Identity).
Inna regua dobrego modelowania mówi, e nie naley uywa opisowych atry-
butów jako kluczy gównych. Na przykad w tabelach opisujcych pracowników
czsto jako klucz gówny jest uywany numer PESEL. Nie jest to dobre rozwizanie
z co najmniej kilku powodów. Po pierwsze, chodzi o wzgldy bezpieczestwa i zacho-
wanie prywatnoci. Wiele kradziey tosamoci dochodzi do skutku wanie dlatego,
e zodziej ma dostp do numeru PESEL ofiary. Po drugie, numery PESEL powinny
by unikatowe, ale nie mona wykluczy sytuacji, w której zostan zmienione.
Po trzecie, moe si okaza, e przyjdzie nam zarejestrowa pracowników za-
granicznych, którzy nie maj numeru PESEL. W takiej sytuacji kuszce moe by
wygenerowanie po prostu sztucznego numeru, ale co bdzie, jeeli zagraniczny
pracownik otrzyma obywatelstwo, a razem z nim wasnym numer PESEL? W takiej

44
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
sytuacji wiersze encji zalenych mog by poczone z prawdziwym lub niepraw-
dziwym numerem PESEL, przez co odczytywanie danych bardzo si skomplikuje,
a co gorsza, w bazie mog pojawi si osierocone wiersze.
Mówic ogólnie, klucz gówny powinien:
by cakowicie unikatowy i absolutnie niezmienny,
skada si z atrybutów, które nigdy nie bd puste,
korzysta z nieznaczcych danych, jeeli tylko jest to moliwe.
Z kluczem gównym jest cile powizany klucz obcy (ang. Foreign Key — FK).
Skadaj si na niego atrybuty dane encji, które bazuj na kluczu (najczciej na
kluczu gównym) innej encji. Przyjrzyjmy si przykadowej encji Pracownik oraz
cakowicie nowej encji Pojazd. Jeeli chcielibymy wiedzie, któremu pracownikowi
przypisano dany samochód, to musielibymy poczy te dwie encje relacj. W takiej
sytuacji w encji Pojazd musi istnie klucz obcy wskazujcy na klucz gówny w tabeli
Pracownik. Najprociej mona to zrealizowa, dodajc do encji Pojazd atrybut
przechowujcy numer pracownika, któremu przypisano dany samochód. Atrybuty
w encji referujcej mog by atrybutami kluczowymi, ale równie niekluczowymi.
Oznacza to, e klucz obcy w encji referujcej moe skada si z tych samych atry-
butów co jej klucz gówny, ale moe zosta zbudowany z cakowicie innego zestawu
atrybutów. Taka kombinacja klucza gównego i klucza obcego pozwala na zachowanie
spójnoci w logicznych relacjach midzy encjami.
Domeny
Zaczynajc budowa model danych, z pewnoci zauwaymy, e w kontekcie danych,
nad którymi pracujemy, pewne encje zawieraj podobne atrybuty. Bardzo czsto ze
wzgldu na spójno informacji cz danych zwizana z funkcjonowaniem aplikacji
lub firmy musi mie tak sam posta we wszystkich encjach. Status, adres, numer
telefonu i adres e-mail s przykadami atrybutów, które najprawdopodobniej bd
musiay mie identyczn posta w wielu encjach. Zamiast mudnie tworzy i ewen-
tualnie modyfikowa te atrybuty w poszczególnych encjach, moemy skorzysta
z domen.
Domena jest definicj atrybutu, która jest przechowywana w ramach modelu
logicznego, ale poza jakkolwiek encj. Jeeli w encji zostanie wykorzystany atrybut
bdcy czci domeny, to domena ta zostanie doczona do encji. Trzeba jednak
pamita, e model danych nie przedstawia widocznej informacji o tym, e dany
atrybut jest czci pewnej domeny. Wikszo narzdzi do modelowania udostpnia
jednak specjaln sekcj lub dokument, taki jak sownik danych, w którym s prze-
chowywane informacje o domenach. Jeeli jakiekolwiek zmiany zostan wprowadzone
do domeny, to wszystkie zwizane z ni atrybuty we wszystkich encjach oraz doku-
mentacja zawierajca dane o domenach zostan odpowiednio dopasowane.
Przyjrzyjmy si na przykad atrybutowi numeru telefonu. Bardzo czsto w mo-
delach logicznych numery telefonów s projektowane jako numery lokalizowane.
W Polsce taki numer jest zwykle zapisywany w postaci trzech cyfr numeru kierun-
kowego, za którymi znajduje si lokalny numer telefonu (XXX-XXXXXXX). Jeeli

A
TRYBUTY
45
w dalszych pracach nad modelem zdecydujemy si zapisywa równie numery
midzynarodowe, a atrybut numeru telefonu znalaz si ju w wielu encjach, to
bdziemy zmuszeni do edytowania wszystkich wystpie tego atrybutu. Jeeli jednak
przygotujemy sobie domen numeru telefonu i dodamy j do wszystkich encji prze-
chowujcych taki numer, to wszelkie zmiany wprowadzane póniej do domeny bd
od razu przenoszone do wszystkich encji w tym modelu.
Czste stosowanie domen pozwala na uniknicie niedogodnoci zwizanych
z maymi rónicami midzy atrybutami przechowujcymi te same dane w rónych
encjach. Praktyka ta pozwala na wymuszenie spójnoci danych i skrócenie czasu
projektowania, nie tylko w okresie pocztkowych prac nad modelem, ale równie
w czasie funkcjonowania bazy danych.
Atrybuty z pojedyncz wartoci
i z wieloma wartociami
Wszystkie omawiane do tej pory atrybuty byy atrybutami z pojedyncz wartoci
(ang. single-valued attributes). Oznacza to, e dla kadego unikatowego elementu
w encji istnieje tylko po jednej wartoci zapisanej w poszczególnych atrybutach.
Niektóre atrybuty mog jednak w sposób naturalny przyjmowa wicej ni jedn
warto. S one nazywane atrybutami z wieloma wartociami (ang. multivalued
attributes). Zidentyfikowanie ich moe by kopotliwe, ale obsuga jest bardzo prosta.
Bardzo typowym przykadem atrybutu z wieloma wartociami jest numer telefonu.
W czasie zapisywania informacji o kliencie najczciej zapisujemy przynajmniej
jeden numer telefonu, ale klienci posiadajcy kilka telefonów z pewnoci nie s
wyjtkami. Moemy zatem doda do encji Klient wiele pól opisujcych numer telefo-
nu i odpowiednio je ponumerowa (na przykad Telefon1, Telefon2 itd.) albo nazwa
zgodnie z rodzajem telefonu (na przykad Dom, Komorka, Biuro). Jest to cakiem
nieze wyjcie, dopóki nie zechcemy zapisa kilku firmowych numerów naszego
klienta. Jest to typowy atrybut z wieloma wartociami, czyli jeden atrybut moe
przechowywa wiele rónych wartoci.
Z pewnoci nie chcemy przechowywa wielu rekordów opisujcych jednego
klienta tylko po to, eby zapisa dodatkowy numer telefonu. Byoby to cakowicie
sprzeczne z ide relacyjnej bazy danych i wprowadzaoby problemy z odczytywa-
niem z niej danych. W zwizku z tym moemy wprowadzi do modelu now encj,
która bdzie przechowywaa numery telefonów i bdzie zwizana relacj z encj
klientów (bazujc na kluczu gównym tej tabeli). Dziki temu zyskamy moliwo
zapisania dowolnej liczby numerów telefonów dla kadego z klientów. Powstaa
encja moe przechowywa wiele rónych wartoci dla kadego klienta, czyli zawiera
tylko dwa atrybuty: unikatowy identyfikator klienta i numer telefonu.
Zastosowanie takiej encji jest jedyn metod na skuteczne rozwizanie problemów
z atrybutami o wielu wartociach. Co wicej, z takiej konstrukcji skorzysta równie
fizyczna implementacja, poniewa bdzie moga wykorzysta techniki wyszukiwania
oferowane przez system zarzdzania baz danych, które pozwalaj na przeszukiwanie
encji zalenej w oderwaniu od encji nadrzdnej.
46
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
Spójno referencji
Jedn z najwaniejszych cech relacyjnej bazy danych jest to, e dane w jednej encji
mog wskazywa na dane w innej encji. Jeeli taka sytuacja ma miejsce, to niemal
zawsze powstaje te wymóg zarzdzania tak relacj. Dane w obu encjach musz
by przecie cakowicie spójne. Koncepcja ta nazywana jest spójnoci referencji
(ang. referential integrity), a w fizycznej implementacji danych jest najczciej re-
alizowana za pomoc obiektów takich jak klucze i ograniczenia. Nie mona jednak
zapomnie, e spójno referencji musi zosta odpowiednio udokumentowana
w modelu logicznym, co gwarantuje przestrzeganie w bazie regu biznesowych
(jak równie spójno zapisanych w niej danych).
Zaómy, e projektujemy baz danych przechowujc informacje na temat
inwentarza biblioteki. W modelu logicznym z pewnoci znajd si encje Autor,
Wydawca i Tytu. Kady autor moe napisa wiele ksiek, ale dana ksika moe
zosta opublikowana tylko przez jednego wydawc. Wydawca moe publikowa wiele
ksiek. Jeeli uytkownik bdzie chcia usun dane autora z bazy, to z pewnoci
zostanie w niej przynajmniej jedna osierocona ksika. Po usuniciu danych wydawcy
równie co najmniej jedna ksika w bazie zostanie osierocona.
W zwizku z tym musimy zdefiniowa te akcje, których wykonanie bdzie
wymuszane za kadym razem, gdy dane bd aktualizowane w ten sposób. Takie
definicje nazywane s wanie spójnoci referencji. Mog one na przykad nakaza
usunicie wszystkich ksiek zwizanych z usuwanym wanie autorem. Moliwe
jest te zdefiniowanie reguy zakazujcej dodania do bazy ksiki, jeeli nie istnieje
w niej jeszcze zapis dotyczcy autora tej ksiki. Nie s to moe najdoskonalsze
przykady, ale dobrze ilustruj konieczno zarzdzania relacjami czcymi poszcze-
gólne encje.
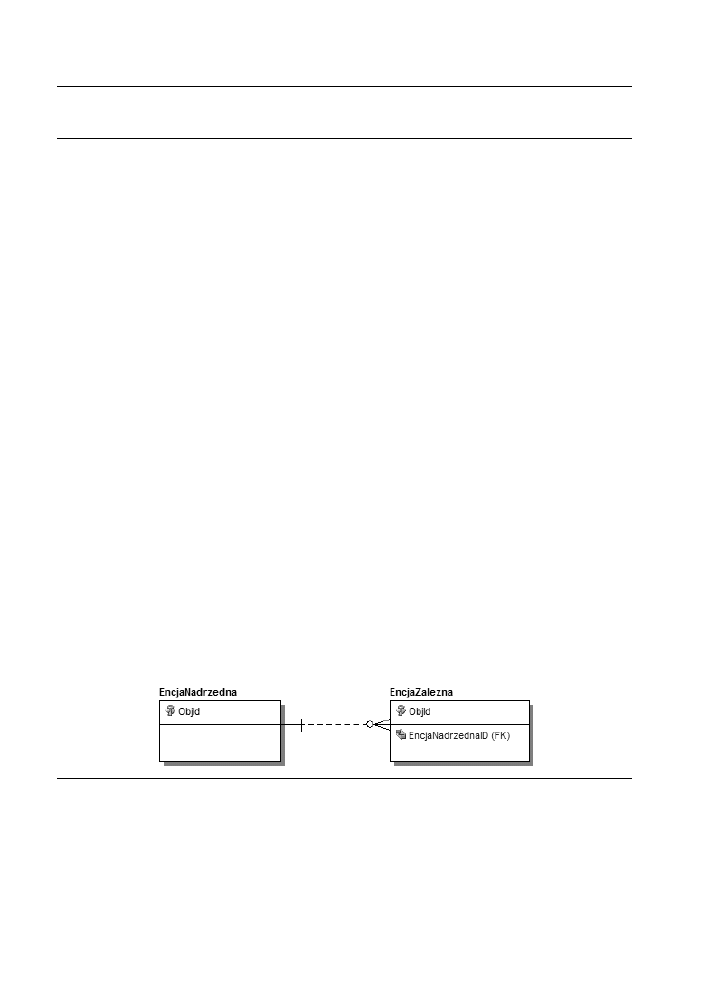
W modelu logicznym spójno referencji jest dokumentowana za pomoc zwiz-
ków tworzonych przez klucze gówne i obce. Kada encja powinna mie atrybut
kluczowy, jednoznacznie identyfikujcy wszystkie zapisane w niej rekordy. Moemy
wykorzysta te klucze do zdefiniowania relacji czcej encj nadrzdn z encj
zalen. Prosz spojrze na rysunek 2.1.
Rysunek 2.1. Klucz gówny i klucz obcy
Przykad przedstawia prost relacj midzy dwoma encjami. Po utworzeniu relacji
moemy w jej definicji poda dowolne ograniczenia akcji zwizanych z manipula-
cjami na danych w encji nadrzdnej i zalenej. Na przykad mona zdefiniowa, e
dowolna próba dopisania danych (
INSERT
) do encji zalenej nie moe si powie,
jeeli w encji nadrzdnej nie istnieje egzemplarz o pasujcym kluczu gównym.

R
ELACJE
47
Mona te okreli, e dowolna operacja usuwania danych (
DELETE
) wykonana na
encji nadrzdnej nie moe si uda, jeeli w encji zalenej istniej jeszcze egzem-
plarze zwizane z usuwanym wierszem w encji nadrzdnej. W tabeli 2.1. zostay
opisane róne opcje, z jakich moemy skorzysta podczas wykonywania akcji na encji
nadrzdnej lub zalenej.
Tabela 2.1. Opcje spójnoci referencji dla relacji
Encja
Akcja
Dostpne akcje
INSERT
Brak: wstawienie nowego egzemplarza nie ma wpywu na encj zalen
UPDATE
Brak: nie ma adnego wpywu na encj zalen i nie powoduje zablokowania
zmian, w wyniku których powstaj niecisoci midzy encj nadrzdn i zalen
Ograniczenie: porównuje dane w kluczu gównym encji nadrzdnej z danymi
w kluczu obcym encji zalenej. Jeeli wartoci te nie s identyczne, to zmiany
s blokowane
Kaskada: kopiuje wszystkie zmiany z klucza gównego encji nadrzdnej do klucza
obcego encji zalenej
Null: podobne do opcji Ograniczenie. Jeeli wartoci nie s identyczne, to klucz
obcy encji zalenej otrzymuje warto NULL, a zmiany w encji nadrzdnej s
wykonywane
Encja
nadrzdna
DELETE
Brak: nie ma adnego wpywu na encj zalen i nie powoduje zablokowania
zmian, w wyniku których powstaj w encji zalenej wiersze osierocone
Ograniczenie: porównuje dane w kluczu gównym encji nadrzdnej z danymi
w kluczu obcym encji zalenej. Jeeli wartoci te nie s identyczne, to zmiany
s blokowane
Kaskada: usuwa wszystkie wiersze encji zalenej, których klucze obce pasuj
do klucza gównego wiersza usuwanego w encji nadrzdnej
Null: podobne do opcji Ograniczenie. Jeeli wartoci nie s identyczne, to klucz
obcy encji zalenej otrzymuje warto NULL, a zmiany w encji nadrzdnej s
wykonywane. Ta opcja powoduje powstanie osieroconych wierszy w encji zalenej
INSERT
Brak: brak ogranicze
Ograniczenie: porównuje dane w kluczu gównym encji nadrzdnej z kluczem
obcym wartoci wstawianej do encji zalenej. Jeeli wartoci te nie s zgodne,
to próba wstawienia danych jest blokowana
UPDATE
Brak: brak ogranicze
Ograniczenie: porównuje dane w kluczu gównym encji nadrzdnej z kluczem
obcym wartoci wstawianej do encji zalenej. Jeeli wartoci te nie s zgodne,
to próba usunicia danych jest blokowana
Encja
zalena
DELETE
Brak: brak ogranicze. Pozwala na usunicie dowolnego wiersza z encji zalenej
Relacje
Pojcie relacyjnej bazy danych implikuje wykorzystanie w bazie relacji. Jeeli nie
wiemy, w jaki sposób dane s z sob powizane, to zastosowanie do ich przechowy-
wania relacyjnej bazy danych nie bdzie si w niczym rónio od przechowywania
wszystkich dokumentów finansowych w jednym worku. Wypenianie rocznego

48
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
zeznania podatkowego moe si w takiej sytuacji okaza prawdziwym koszmarem.
Wszystkie niezbdne informacje mamy pod rk, ale ile czasu zajmie nam wyszu-
kanie ich w tym worku i ostateczne wypenienie dokumentów?
Zalet relacyjnych baz danych jest to, e pozwalaj na wydajne przechowywanie
i odczytywanie danych. Identyfikacja i implementacja waciwych relacji w modelu
logicznym to dwa najwaniejsze kroki w procesie projektowania. Chcc prawido-
wo zidentyfikowa wszystkie relacje, musimy zna wszystkie dostpne moliwoci,
wiedzie, jak je prawidowo rozpoznawa, i podj decyzj o tym, której relacji
naley uy.
Typy relacji
Pod wzgldem logicznym istniej trzy róne relacje czce encje: jeden-do-jednego,
jeden-do-wielu i wiele-do-wielu. Kada z nich opisuje sposób, w jaki dwie encje
zcz si z sob. Naley pamita o tym, e te relacje s tylko relacjami logicznymi.
Ich fizyczna implementacja jest kolejnym krokiem, o którym bdziemy mówi
w rozdziale 9.
Relacje jeden-do-jednego
Relacja jeden-do-jednego czca dwie encje jest ich bezporednim poczeniem,
na co wskazuje jej nazwa. Kady rekord w jednej encji ma dokadnie jeden pasuj-
cy do niego rekord w drugiej encji. Nie mniej i nie wicej. Prosz sobie wyobrazi
dwoje ludzi rzucajcych pik. W tej sytuacji jest dokadnie jeden rzucajcy i jeden
apicy. Moe by tylko jeden rzucajcy i tylko jeden apicy (kto, kto faktycznie
zapa pik).
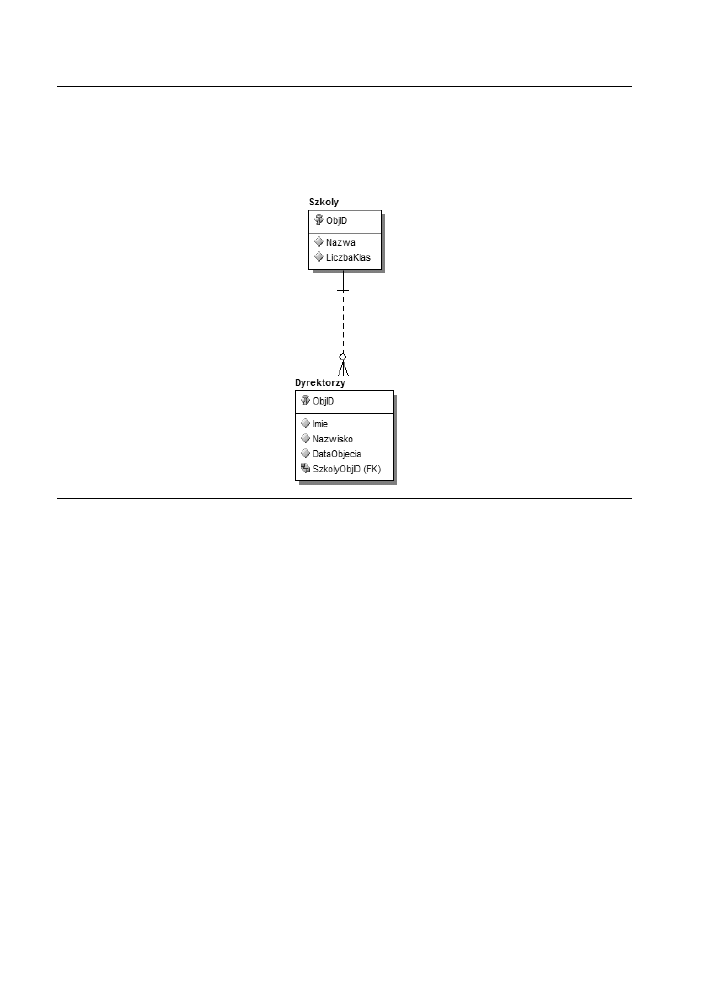
Po co w takim razie wybiera relacj typu jeden-do-jednego? Skoro jeden rekord
w jednej encji jest zwizany z dokadnie jednym rekordem w drugiej encji, to czy
nie lepiej byoby poczy te encje? Prosz spojrze na rysunek 2.2.
Rysunek 2.2. Encja Szkoly
Kada szkoa moe mie tylko jednego dyrektora, a kady dyrektor moe zarz-
dza tylko jedn szko. W tym przykadzie wszystkie atrybuty encji dyrektora s
przechowywane w encji szkoy. To rozwizanie skupia wszystkie informacje w ramach
jednej encji, ale jest bardzo mao elastyczne. Przy kadej zmianie danych szkoy lub
dyrektora konieczne jest odczytanie caego rekordu, a nastpnie jego uaktualnienie.
Oprócz tego szkoa bez dyrektora lub dyrektor bez szkoy bd tworzy rekord
R
ELACJE
49
wypeniony tylko w poowie. Co gorsza, taka konstrukcja powoduje problemy przy
odczytywaniu danych. Jeeli chcielibymy napisa raport zawierajcy informacje
o dyrektorach, to bylibymy zmuszeni do odczytywania równie danych szkó.
A co bdzie, jeeli chcielibymy gromadzi informacje o pracownikach dyrektorów?
W takim przypadku musielibymy powiza pracowników z poczon encj szkó
i dyrektorów, a nie tylko z encj dyrektorów. Prosz si teraz przyjrze rysunkowi 2.3.
Rysunek 2.3. Encje Szkoly i Dyrektorzy
W tym przykadzie mamy ju dwie encje: Szkoly i Dyrektorzy. Kada z nich ma
atrybuty opisujce dany rodzaj obiektu. Oprócz tego w encji Dyrektorzy jest zapisana
referencja na szko, któr dany dyrektor prowadzi, a w encji Szkoly znajdziemy
referencj dyrektora opiekujcego si dan szko. Takie rozwizanie jest duo
bardziej elastyczne, poniewa listy szkó i dyrektorów s zarzdzane cakowicie
niezalenie. Prosz jednak zauway, e encje te czy relacja jeden-do-jednego, która
pozwala na naoenie ogranicze umoliwiajcych utrzymanie spójnoci danych.
Relacje jeden-do-wielu
W najczciej wystpujcych relacjach typu jeden-do-wielu jeden rekord w pierw-
szej encji moe mie zero lub wicej pasujcych rekordów w drugiej encji. Istniej
setki przykadów takich relacji, stosowanych najczciej w ramach czenia danych
nagówkowych z informacjami szczegóowymi. Na przykad zamówienia s czsto
przechowywane jako lista rekordów nagówkowych w jednej encji, druga encja
gromadzi natomiast szczegóowe informacje na temat poszczególnych zamówie.
Takie rozwizanie pozwala na umieszczenie w kadym zamówieniu wielu pozycji
bez koniecznoci tworzenia wielu rekordów zawierajcych te same informacje
wysokiego poziomu, takie jak data zamówienia, dane klienta itp.
50
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
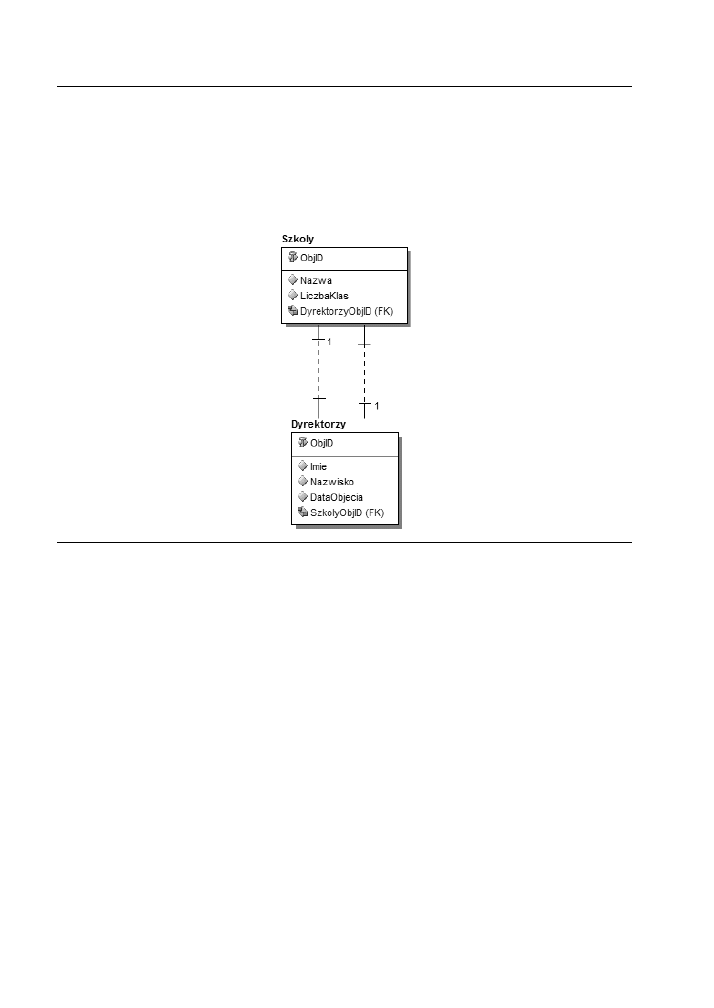
Wrómy do przykadu ze szkoami i dyrektorami. Co si stanie, jeeli pojawi si
zarzdzenie pozwalajce pracowa kilku dyrektorom w jednej szkole? Taka sytuacja
natychmiast tworzy relacj jeden-do-wielu czc encje Dyrektorzy i Szkoly, tak
jak pokazano na rysunku 2.4.
Rysunek 2.4. Encje Szkoly i Dyrektorzy — relacja jeden-do-wielu
Jak wida, taka relacja czca te dwie encje stwarza moliwo powizania kilku
dyrektorów z jedn szko. Jest ona skalowalna, poniewa obie encje mog by
aktualizowane i zarzdzane cakowicie niezalenie od siebie.
Relacje wiele-do-wielu
Sporód wszystkich rodzajów relacji relacje wiele-do-wielu (nazywane równie
relacjami nieokrelonymi) nale do najbardziej skomplikowanych do zidentyfiko-
wania i zaprojektowania. W relacjach wiele-do-wielu rekordy z jednej encji mog
czy si z wieloma rekordami w drugiej encji, a jednoczenie rekordy z drugiej
encji mog wiza si z wieloma rekordami z pierwszej encji. Prosz sobie wyobrazi
czci samochodowe, a w szczególnoci siedzenia montowane w kadym aucie.
W dowolnym samochodzie znajdziemy przynajmniej dwa rodzaje siedze: fotele
dla kierowcy i pasaera oraz du kanap dla pasaerów siedzcych z tyu. Producenci
samochodów niemal zawsze wykorzystuj istniejce siedzenia w kilku modelach
samochodów. Jeli przeoymy te rozwaania na encje, to okae si, e Siedzenie moe
znale si w wielu Samochodach, a kady Samochód moe zawiera wiele Siedze.
Wrómy jednak do naszego przykadu ze szkoami. Co bdzie, jeeli zostanie
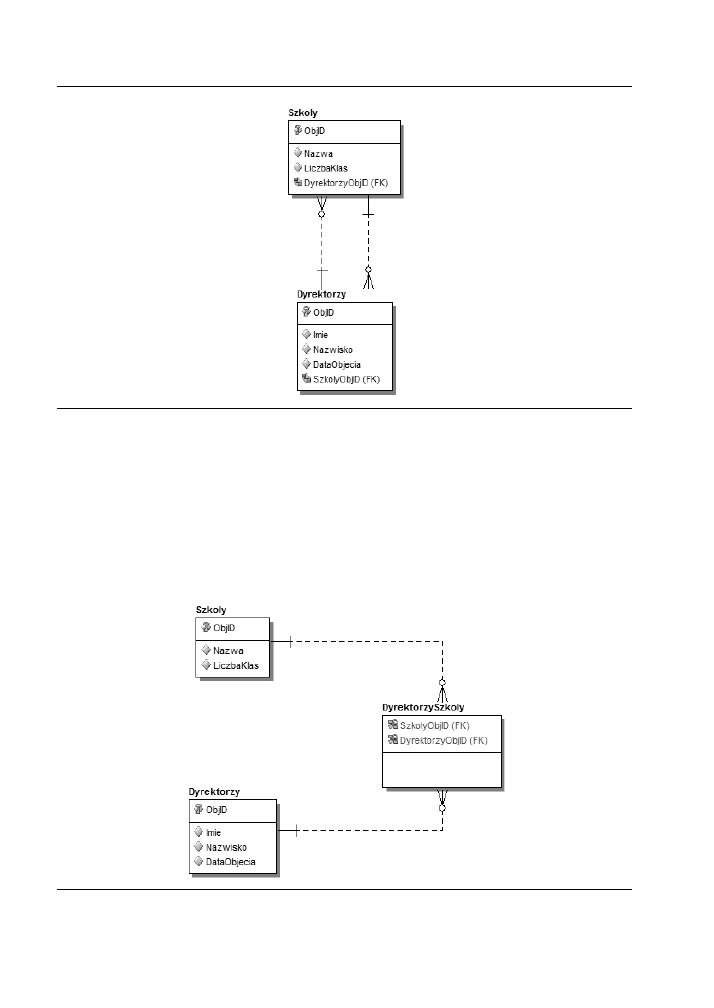
podjta decyzja, e jeden dyrektor moe zarzdza kilkoma szkoami, a jedna szkoa
moe znajdowa si pod opiek kilku dyrektorów? Na rysunku 2.5. przedstawilimy
encje Szkoly i Dyrektorzy zwizane relacjami pozwalajcymi na tworzenie wielu
pocze midzy obiema encjami.
R
ELACJE
51
Rysunek 2.5. Encje Szkoly i Dyrektorzy — relacja wiele-do-wielu
Rozpatrujc t spraw czysto teoretycznie, trzeba powiedzie, e wszystkie relacje
mog istnie tylko midzy dwoma encjami. Pod wzgldem logicznym mamy wic
relacj midzy encjami Szkoly i Dyrektorzy. Pod wzgldem technicznym moemy
zastosowa notacj z dwoma relacjami typu jeden-do-wielu czcymi te encje, ale
skierowanymi przeciwnie. Innym rozwizaniem jest zastosowanie relacji z symbolem
„wiele” umieszczonym po obu jej kocach. Z praktycznego punktu widzenia najwy-
godniej jednak bdzie utworzy trzeci encj obrazujc tak relacj, podobnie jak
zostao to przedstawione na rysunku 2.6.
Rysunek 2.6. Encja Szkoly i Dyrektorzy — relacja wiele-do-wielu z trzeci encj

52
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
Niektórzy stwierdz, e jest to pogwacenie ideau modelu logicznego, który nie
powinien zawiera adnych elementów fizycznej implementacji. Zastosowanie trzeciej
encji czcej encje Szkoly i Dyrektorzy za pomoc ich identyfikatorów jest odwzo-
rowaniem fizycznej implementacji stosowanej wobec wielu relacji typu wiele-do-
wielu. Fizycznie nie jest moliwe odwzorowanie relacji tego typu bez wykorzystania
trzeciej tabeli, nazywanej czasami tabel cznikow (ang. join table). Oznacza to,
e wykorzystanie tej tabeli w modelu logicznym nie jest cile zgodne ze wskazówka-
mi modelowania logicznego. Umieszczenie dodatkowej encji w modelu logicznym
moe jednak uatwia zapamitanie, dlaczego zostaa uyta taka relacja. Bdzie te
pomoc dla przyszych wspópracowników poznajcych dopiero wszystkie relacje
w tym modelu.
Zastosowanie trzeciej encji pozwala ponadto na wprowadzenie dodatkowych
atrybutów opisujcych kady egzemplarz takiej relacji. Na przykad w encji Dyrekto-
rzy_Szkoly mona doda informacj, od kiedy dany dyrektor zajmuje si okrelon
szko. Jeeli istnieje wiele takich kombinacji, to informacja o czasie zajmowania
stanowiska przez dan osob w danej szkole moe by bardzo przydatna.
Relacje typu wiele-do-wielu s stosowane zadziwiajco czsto, ale zawsze naley
podchodzi do nich bardzo ostronie i dokadnie je dokumentowa, tak eby nie
byo adnych nieporozumie w trakcie tworzenia fizycznej implementacji modelu.
Opcje relacji
Skoro znasz ju róne rodzaje relacji, musimy omówi jeszcze opcje, które moemy
definiowa w relacjach poszczególnych typów. Opcje te pozwalaj na dokadniejsze
sterowanie zachowaniem kadej relacji z osobna.
Relacje identyfikujce i nieidentyfikujce
Jeeli klucz gówny encji zalenej wymaga doczenia klucza gównego encji nad-
rzdnej, to znaczy, e relacja czca te encje jest relacj identyfikujc (ang. identi-
fying relation). Wynika to z tego, e unikatowy atrybut encji zalenej wymaga zastoso-
wania wyjtkowego atrybutu encji nadrzdnej, aby jednoznacznie zidentyfikowa
odpowiedni egzemplarz encji. Jeeli takie wymaganie nie istnieje, to relacja jest
definiowana jako nieidentyfikujca (ang. non-identifying relation).
W przypadku relacji identyfikujcej klucz gówny encji nadrzdnej jest faktycznie
jednym z atrybutów skadajcych si na klucz gówny encji zalenej. Oznacza to,
e klucz obcy encji zalenej jest czci lub nawet caoci jej klucza gównego.
W przypadku relacji nieidentyfikujcej klucz gówny encji nadrzdnej jest tylko
niekluczowym atrybutem encji zalenej.
Zaledwie niewielka cz relacji to relacje identyfikujce, poniewa wikszo
encji zalenych moe by referowanych cakowicie niezalenie od encji nadrzdnej.
W relacjach typu wiele-do-wielu s jednak czsto stosowane relacje identyfikujce,
jako e dodatkowa encja wie z sob klucze gówne encji nadrzdnej i zalenej. Na
przykad encja Szkoly_Dyrektorzy z prezentowanego wczeniej rysunku 2.6. zawiera
w caoci klucze gówne encji Szkoly (SzkolyID) i Dyrektorzy (DyrektorzyID).

R
ELACJE
53
Prosz zauway, e jest to typowe w przypadku relacji typu wiele-do-wielu. Klucz
gówny tabeli cznikowej zawsze skada si z kluczy gównych dwóch pozostaych
tabel. Dziki temu, e klucze gówne tabeli nadrzdnej i zalenej s od razu widoczne
w tabeli cznikowej, moemy bez wahania powiedzie, e jest to relacja identyfi-
kujca.
Relacje nieidentyfikujce s zdecydowanie bardziej rozpowszechnione. Mona
je rozpozna po tym, e atrybuty klucza gównego encji nadrzdnej s w encji za-
lenej atrybutami niekluczowymi. Jeeli nie istnieje jaki wany powód do tworzenia
relacji identyfikujcej, to wikszo tworzonych w modelu relacji bdzie relacjami
nieidentyfikujcymi.
Relacje opcjonalne i obowizkowe
Kada relacja w bazie danych musi zosta okrelona jako opcjonalna lub obowiz-
kowa. O relacjach obowizkowych mona myle jak o relacjach typu „musi mie”,
podczas gdy relacje opcjonalne mona okrela jako relacje „moe mie”. Na przykad
jeeli mamy encj Pracownik oraz encj Biuro, to kady pracownik „musi mie” swoje
biuro. Relacja czca te dwie encje opisuje biuro danego pracownika. W takiej sytu-
acji jest tworzona relacja nieidentyfikujca, a poniewa w encji Pracownik nie moemy
wpisa wartoci
NULL
do klucza obcego identyfikujcego biuro, okazuje si, e jest to
równie relacja obowizkowa. Wskazuje ona, e kady pracownik ma przynajmniej
jedno biuro, a nawet jeeli musi pracowa w innych biurach, to jedno z nich trak-
towane jest jako przypisane do niego.
Teraz zajmijmy si sytuacj, w której samochody s przypisywane do pracowników
firmy. Mona j odzwierciedli w modelu danych, czc z sob encje Pracownik
i Samochód. Jak mona si domyli, pracownik „moe mie” samochód, cho wcale
nie musi, co odpowiada definicji relacji opcjonalnej.
Liczno
W przypadku kadej z opisywanych relacji podawalimy jedynie jej ogólny rodzaj:
jeden-do-jednego, jeden-do-wielu lub wiele-do-wielu. Opis takiej relacji zawiera
liczb rekordów w encji nadrzdnej, wizanych z pewn liczb rekordów w encji
zalenej. Chcc dokadniej wymodelowa faktyczn relacj czc te dane, musimy
poda nieco wicej informacji opisujcych te zalenoci — niezbdne jest okrelenie
licznoci (ang. cardinality) danej relacji.
W przypadku relacji jeden-do-jednego jej liczno jest ju z góry narzucona.
Jednoznacznie stwierdzamy, e na kady rekord w encji nadrzdnej moe przypada
dokadnie jeden rekord w encji zalenej. W sposób bardziej opisowy mona powie-
dzie, e na kady rekord w encji nadrzdnej przypada zero lub jeden rekord w encji
zalenej. Jeeli jednak chcemy zaznaczy, e w obu encjach zawsze musi by do-
kadnie jeden rekord, to opis licznoci relacji powinien brzmie: na kady rekord
w encji nadrzdnej przypada dokadnie jeden rekord w encji zalenej. Liczno
relacji typu jeden-do-jednego jest zazwyczaj zapisywana jako
[1:1]
.

54
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
Relacje jeden-do-wielu s definiowane skrótem
[1:M]
, a ich liczno mona opisa
sowami: na kady rekord w encji nadrzdnej przypada jeden lub wicej rekordów
w encji zalenej. Jeeli jednak chcemy dopuci sytuacj, w której w encji zalenej
nie ma rekordów pasujcych do rekordów encji nadrzdnej, to mona zastosowa
inny opis licznoci takiej relacji: na kady rekord w encji nadrzdnej przypada zero
lub wicej rekordów w encji zalenej. W wikszoci relacji waciwsz interpretacj
jest wersja „zero lub wicej”, dlatego w czasie tworzenia modelu naley dokadnie
okreli wariant licznoci.
Relacje typu wiele-do-wielu mona definiowa jako zero lub wicej do zera lub
wicej rekordów. Jak si okazuje, ten rodzaj licznoci jest niemal zawsze odgórnie
przyjmowany za domylny dla tych relacji, cho oczywicie moe zdefiniowa wymóg
istnienia przynajmniej jednego rekordu w kadej z encji. W takim przypadku rela-
cj typu wiele-do-wielu mona zapisa jako
[M:M]
.
W niektórych programach do modelowania danych moliwe jest bardzo dokadne
definiowanie licznoci relacji. Mona na przykad zdefiniowa liczno typu „na
kady rekord w encji nadrzdnej przypada osiem rekordów w encji zalenej”. W ten
sposób mona zdefiniowa osoby bezporednio podporzdkowane kierownikom
(osoby podlegajce danemu menederowi). Firma moe przecie wymaga, aby
pracujcy w niej meneder mia nie mniej ni cztery, ale nie wicej ni dwadziecia
podporzdkowanych sobie bezporednio osób. W takiej sytuacji liczno relacji
mona by opisa jako: przynajmniej cztery, ale nie wicej ni dwadziecia do jed-
nego. Tego rodzaju licznoci wymagaj dokadnego udokumentowania, poniewa
wikszo ludzi przyjmie po prostu ich domyln posta.
Uywanie podtypów i typów nadrzdnych
Definiujc encje, które maj by wykorzystane w modelu danych, od czasu do czasu
moemy wygenerowa tak, która bdzie si skada w caoci z kilku innych. W takiej
sytuacji moemy mie problemy z okreleniem, które atrybuty nale do danej encji
i jakie cz je relacje. Rozwizaniem moe si okaza zastosowanie typów nadrzd-
nych.
Definicje podtypów i typów nadrzdnych
Typ nadrzdny (ang. supertype) jest encj majc wiele encji zalenych, nazywanych
podtypami (ang. subtypes), które opisuj róne warianty tego samego typu nadrzd-
nego. Kolekcja typu nadrzdnego i wszystkich jego podtypów jest czasami nazywana
klastrem podtypów (ang. subtype cluster). Takie klastry pojawiaj si najczciej
przy okazji prac nad pewnymi kategoriami niektórych rzeczy, podobnie jak zostao
to przedstawione na rysunku 2.7.
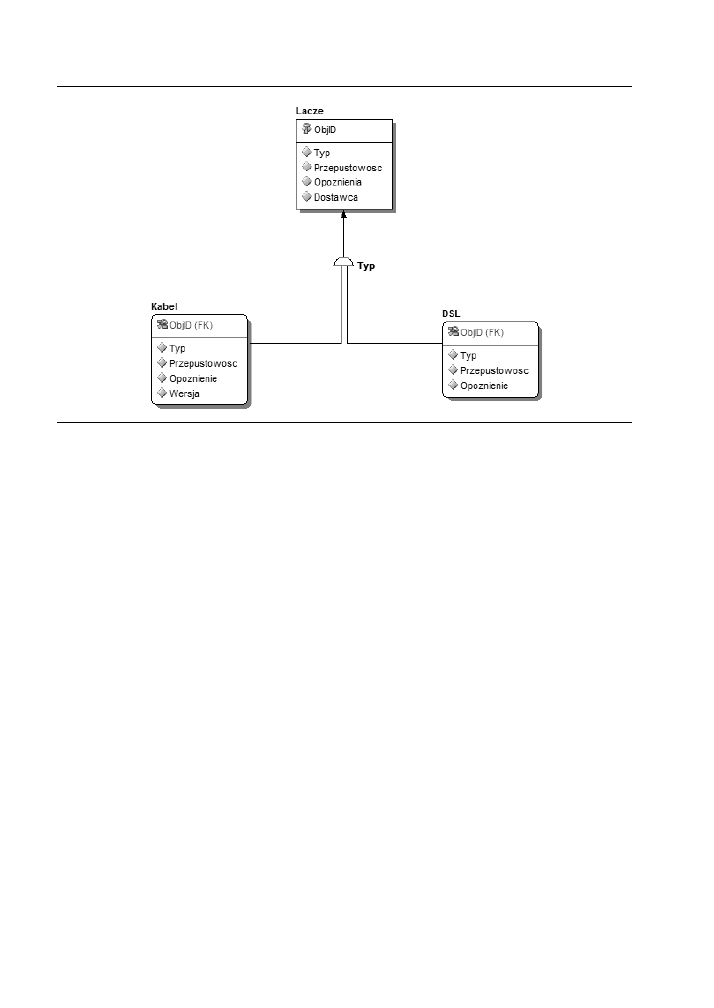
U
YWANIE PODTYPÓW I TYPÓW NADRZDNYCH
55
Rysunek 2.7. Prosty klaster podtypów
Zaómy, e ledzimy informacje na temat produktów zwizanych z dostpem
szerokopasmowym. W tym przykadzie Lacze jest encj z kilkoma atrybutami i klu-
czem gównym. Chcemy jednak, eby róne rodzaje czy byy zapisywane w osob-
nych encjach, poniewa cza kablowe s oferowane klientom prywatnym i komer-
cyjnym, a cza DSL — wycznie klientom prywatnym. Oba rodzaje czy mogyby
by zapisywane w cakowicie niezalenych encjach, ale w ten sposób stracilibymy
cay obraz relacji. W encji Lacze znajduj si atrybuty, których nie znajdziemy
w pozostaych dwóch encjach. Te dwie encje zawieraj natomiast atrybuty, których
próno szuka w encji Lacze. Poza tym przygotowany projekt musi by otwarty, na
wypadek gdybymy w przyszoci chcieli doda kolejne rodzaje czy szerokopa-
smowych bez koniecznoci modyfikowania ju istniejcych.
Chcc rozwiza ten problem, powinnimy przeksztaci encj Lacze w typ
nadrzdny, a encje Kabel i DSL w podtypy. W tym celu najpierw musimy utworzy
encje podtypów i nada im wszystkie niezbdne atrybuty, z wyjtkiem klucza gówne-
go. Nastpnie trzeba przygotowa obowizkow relacj identyfikujc, czc encj
typu nadrzdnego z encjami podtypów. Taka relacja oznacza, e klucz gówny encji
Lacze jest jednoczenie kluczem gównym pozostaych dwóch encji. Na zakoczenie
niezbdne jest jeszcze wybranie dyskryminatora (ang. discriminator), czyli atrybutu
w encji nadrzdnej, którego warto okrela podtyp danego rekordu. Dyskryminato-
rem moe by zarówno atrybut kluczowy, jak i niekluczowy. W tym przykadzie
funkcj t peni atrybut Typ, który moe otrzyma warto
DSL
lub
Kabel
.
Jeeli klaster podtypów zawiera ju wszystkie moliwe podtypy danego typu
nadrzdnego, to mówi si o nim, e jest klastrem kompletnym. Jeeli jednak zawiera
tylko cz moliwych podtypów, to o takim klastrze mówi si, e jest klastrem

56
R
OZDZIA
2. E
LEMENTY WYKORZYSTANE W
LOGICZNYCH MODELACH DANYCH
niekompletnym. Opisy klastra to sprawa zwizana wycznie z dokumentacj, ale
podobnie jak ze wszystkimi innymi elementami tworzenia modelu, prawidowe
dokumentowanie szczegóów moe bardzo uatwi nam prac w przyszoci.
Fizyczna implementacja klastra podtypów jest zawsze zalena od konkretnego
przypadku. Klastry podtypów mog by implementowane w postaci relacji typu
jeden-do-jednego czcych encje i tabele albo w postaci rónych innych kombinacji
tabel i czcych je relacji. Najistotniejszym zagadnieniem, o którym warto pamita,
jest umieszczanie tego samego klucza gównego we wszystkich encjach skadaj-
cych si na klaster, a take zastosowanie prawidowych ogranicze dyskryminatora,
tak eby wszystkie rekordy znalazy si we waciwych tabelach.
Kiedy uywa klastrów podtypów
Niemal kady model danych bdzie zawiera encje, które maj atrybuty, a te z kolei
przechowuj informacje na temat maego podzbioru rekordów znajdujcych si
w encji. Jeeli natkniemy si na tak sytuacj w swoim modelu danych, powinnimy
dokadniej przyjrze si tym atrybutom i sprawdzi, czy nie mona z nich zbudo-
wa klastra podtypów. Nie naley jednak za wszelk cen tworzy relacji budujcych
klaster podtypów. W ten sposób skonstruujemy tylko zagmatwany model danych,
zawierajcy wicej encji, ni faktycznie potrzeba. Co wicej, istnienie nadmiaro-
wych klastrów podtypów bdzie bardzo utrudniao fizyczn implementacj modelu,
prowadzc do powstawania niepotrzebnych tabel i ogranicze. To z kolei moe
przekada si na pogorszenie wydajnoci caej bazy danych i w konsekwencji unie-
moliwia jej prawidow obsug.
Klastry podtypów mog by bardzo przydatnym narzdziem, wprowadzajcym
do modelu danych wysoki poziom elastycznoci. Modelowanie danych za pomoc
tego rodzaju uogólnionej hierarchii umoliwia wprowadzanie w przyszoci rónych
modyfikacji bez koniecznoci poprawiania istniejcych encji, dlatego z pewnoci
warto powici nieco czasu na poszukiwanie zwizków logicznych pozwalajcych
na zastosowanie klastrów podtypów.
Podsumowanie
W niniejszym rozdziale omówilimy narzdzia stosowane podczas tworzenia logiczne-
go modelu danych. Kady model danych skada si z obiektów niezbdnych do prawi-
dowego opisania przechowywanych danych, definicji wszystkich zwizków czcych
poszczególne fragmenty danych oraz istniejcych ogranicze.
Skoro znasz ju wszystkie elementy skadajce si na logiczne modele danych,
moesz zajrze do rozdziau 3., w którym postaramy si agodnie przej od zagadnie
zwizanych z obiektami logicznymi do tych dotyczcych ich fizycznej implementacji.
Póniej wykorzystamy te wszystkie informacje do zbudowania modelu danych dla
firmy Mountain View Music.
Wyszukiwarka
Podobne podstrony:
SQL Server 2005 typy danych
SQL Server 2005 typy danych
An Introduction To Olap In Sql Server 2005
Apress Pro SQL Server 2005 Reporting Services (2006)
Microsoft SQL Server 2005 Nowe mozliwosci
Microsoft SQL Server 2005 Nowe mozliwosci 2
SQL dla SQL Server 2005 Wprowadzenie
SQL Server 2005 Zaawansowane rozwiazania biznesowe 2
SQL Server 2005 Programowanie Od podstaw
więcej podobnych podstron