
ITPro
™
SERIES
Sponsored by
Backup
and
Recovery
Survival Guide

Contents
Chapter 1: Disaster Prevention: Preparing for the Worst . . . . . . . . . . . . . .
Use these best practices to help your system survive
Kalen Delaney
Chapter 2: Is True Recovery Always Possible? . . . . . . . . . . . . . . . . . . . . . .
By Michael Hotek
Chapter 3: The Best Place for Bulk_Logged . . . . . . . . . . . . . . . . . . . . . . .
Make this misunderstood recovery model work for you
By Kimberly L. Tripp
Chapter 4: Before Disaster Strikes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
A solid backup strategy can save your VLDB
By Kimberly L. Tripp
Chapter 5: All About Restore . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Plan and test your recovery operation now
By Kalen Delaney
i

Restoring WITH RECOVERY and WITH NORECOVERY . . . . . . . . . . . . . . . . . . . . . . . .
ii
Backup and Recovery Survival Guide

1
Brought to you by Neverfail and Windows IT Pro eBooks
Chapter 1
Disaster Prevention:
Preparing for the Worst
Use these best practices to help your system survive
By Kalen Delaney
Many people break the subject of high availability into two parts—disaster prevention and disaster
recovery—and discuss the topic as if every step in a high-availability solution fits neatly into one
arena or the other. However, while planning for this chapter and trying to determine which activities
constitute disaster prevention and which constitute disaster recovery, we found that the line between
the two isn’t a neat one. We also realized that to distinguish between disaster prevention and disaster
recovery, you need a clear definition of “disaster” for your organization.
If you define disaster as something outside the technical realm, such as a flood or earthquake,
then preventing disaster isn’t possible, at least for the IT staff. In such a case, you’d focus on disaster
preparedness. But if you concentrate on disasters directly involving technology, drawing the line
between prevention and recovery is difficult. For example, if you define the loss of your SQL Server
as a disaster, you might implement a clustered SQL Server environment so that a SQL Server on
another machine automatically takes over for the failed server. That failover lets you recover from the
disaster of losing your primary SQL Server. However, most people think of a clustering solution as
disaster prevention.
Similarly, most people think of backup-and-restore strategies as disaster recovery. However, if
you define a disaster as a loss of data and if a complete restore from backups prevents data loss
because of a disastrous event, did the disaster occur, or did you prevent it? Because you need good
backups to perform a complete restore and you have to perform backups before a disaster occurs,
you can think of an effective backup strategy as a disaster-prevention technique.
So what exactly constitutes a disaster? For the purpose of this article, a disaster is a loss of
production data or downtime that causes a loss of productivity. For your own purposes, if you think
a particular event is a disaster for your business, it’s a disaster.
When we distinguish between disaster prevention and disaster recovery, we suggest that
prevention is what you can do before something happens and recovery is what you do after. The
“something” could be an event that’s preventable, such as multiple disk failures, or it could be an
event that’s unpreventable, such as an earthquake. In the latter case, you don’t look for ways to
prevent the event; you look for ways to be prepared and prevent the event from causing an
unacceptable loss of data or productivity.

Strategies for Disaster Prevention
Dealing with disaster takes many forms, but I’ve come up with my top five best practices for disaster
prevention. Adhering to these practices will help you plan and implement a disaster-prevention plan
for your organization.
Make a list of possible disasters.
No matter how ridiculous or improbable an event might seem, if
it could cause downtime or loss of data, list it and think about what you would do if it happened.
Some improbable examples might be a meteor demolishing your entire site or the entire IT staff
coming down with food poisoning at the company picnic. I always put this step first because
keeping these possibilities in mind will help you decide how to carry out each of the other strategies
I suggest.
After planning for—or at least considering—the worst possible disasters and determining what
steps you can take to minimize the risk, evaluate the cost-benefit ratio of taking those steps. If
protecting your data against a catastrophic but low-probability event—such as a meteor strike—
would cost a lot, you might decide to take the risk and not provide specific protection for that event.
Document your decision so that coworkers and successors know that you at least considered the
possibility. However, you might discover that protecting your data against some low-probability
events doesn’t cost much. For example, you might already store database backups in a location
across town, but what would happen if the meteor destroyed the entire town? If your company
already ships regular backups for another system or application to another town, the cost of adding
tapes of your SQL Server backups to that shipment might be negligible. So although the likelihood of
a meteor strike might be small, the cost to save your data if that unlikely event occurs might also be
small.
Also, be sure to plan for the infamous “user error” in your list of possible disasters. User errors
can be the most difficult disasters to prevent and can take the longest to recover from. Users commit
such errors as accidentally deleting data rows, tables, or an entire database. SQL Server makes it easy
for users with high levels of privilege to do lots of damage. Although referential integrity, schema
binding, and triggers can help prevent inadvertent deleting of rows or dropping of tables, SQL Server
provides little protection against dropping an entire database. Unlike in earlier SQL Server releases, in
which the DROP DATABASE command didn’t actually remove the physical files from the file system,
when you drop a database in SQL Server 2000 or 7.0, SQL Server deletes the disk files holding the
data, so the database is really gone.
Users can also create havoc by implementing the wrong procedure. Many procedures have
similar names, and if a typing error causes a user or an application to call the wrong procedure, you
might not notice the damage for some time. You’ll lose more time while you track down the
problem, and even more time before you start correcting the problem and undoing the damage.
Note that ineffective security can foster user errors. Weak or nonexistent passwords, along with
allowing too many users too much privilege, can compromise system and data integrity. Accidental
deletions are also more likely when users have higher permission levels than they need.
2
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

Create effective operational processes.
Document all your planning decisions (including your list
of possible disasters) and recovery procedures, and store copies of the documentation off site.
Remember that high system availability involves people and processes as much as it involves
technology. If you don’t clearly define the processes for disaster prevention and disaster recovery, or
if the people involved don’t understand the processes, all the technology in the world won’t help
you.
After you’ve created operational processes, you need to verify that your processes do what you
need them to do. Make sure your test servers are configured exactly like your production machines—
with the same hardware and the same workload—so that the test machines can accurately predict the
capabilities of the production machines in the event of a disaster. When you run simulations of com-
plete system failure and measure how long a complete system rebuild and restore takes, be sure that
the time the test machines take to complete the operations is an accurate predictor of how long the
operations will take on your production system.
Understand and implement technologies to prevent downtime.
Learn everything you can about
the technologies available to prevent or reduce downtime. Learn about redundant hardware solutions
such as clustering, and investigate companies that offer split-mirror backup technology or other types
of fast backup-and-restore solutions. The only downtime that fast-backup and split-mirroring solutions
need is the time it takes to perform a restore. And with split-mirror backup, the restore happens
almost immediately after an administrator requests it.
Many solutions for avoiding downtime depend on your hard-disk system. The disks are the most
active part of any system—and no system is foolproof. Even if you implement the best RAID system,
the hardware system could still fail and make the entire array unavailable. With RAID, you also need
to remember that fault tolerance might apply to only one drive failure, so you have to consider the
possibility of a second drive failing. Don’t get complacent and think that the chance of a second drive
failing soon after the first is remote. If you purchased all your drives at the same time, the other
drives are the same age as the failed drive and might also be nearing failure. And remember that
even the most redundant drive system won’t protect you against user errors. If a user accidentally
drops a production table, all the redundant drives will reflect that drop. If you don’t know a drive has
failed and you don’t replace the drive before a second failure occurs, you risk complete system
failure. Make sure that you regularly check your logs for a message in the log that tells you a drive
has failed or that you receive automatic notifications when failures occur.
Consider warm-standby solutions.
In solutions that prevent downtime almost completely by using
redundancy, the redundant hardware is called a hot standby. Another solution that isn’t as costly but
provides comparable protection is called a warm standby. Unlike a hot-standby system such as a
clustered SQL Server, a warm standby requires human intervention at the application level to make
the switch from the failed system to the standby system.
The two most common warm-standby solutions are log shipping and replication. A great feature
of both of these solutions is that they can have serendipitous performance benefits. For example, in
some cases, log shipping can provide a second read-only copy of your data that you can use to
off-load some of the reporting work from the production server. And depending on the type of
replication you implement, you can frequently use replication to distribute your entire workload
across more systems so that each system performs more effectively.
Chapter 1 Disaster Prevention: Preparing for the Worst
3
Brought to you by Neverfail and Windows IT Pro eBooks

Plan your backup-and-recovery strategy.
Although you could consider planning a backup-
and-recovery strategy as part of one of the previous best practices, we list this as a separate strategy
because it’s so crucial—even if you do nothing else, you must save the data. If your only manage-
ment experience with SQL Server is through Enterprise Manager, you might think backup is a simple
one-step operation or that once you define a maintenance task, you don’t need to think any more
about it. But if you want to be truly prepared to avoid disastrous loss of data or productivity, you
need to learn all you can about SQL Server’s backup and restore capabilities. SQL Server has three
recovery modes, each of which affects backup and restore operations in different ways. SQL Server
lets you back up the entire database, the transaction log, and individual files or filegroups. In
addition, you can make differential backups of the database that let you back up just the data that
has changed since the last full database backup.
No one solution or plan can provide complete disaster protection for your system, so you need
to put in place people, processes, and technology that combine to give your organization the greatest
possible chance for survival. These suggested practices can give you a place to start planning for the
survival of your organization’s precious data.
4
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

Chapter 2
Is True Recovery Always Possible?
By Kalen Delaney
Despite what some advertisements lead you to believe, when a disaster strikes, you need more than
just a large insurance policy to get things back to normal. And in some cases, you simply can’t bring
a business back to where it was before the disaster.
Mike Hotek, a principal mentor and colleague of mine at Solid Quality Learning, is one of the
world’s leading experts in SQL Server replication and high availability. As a consultant, Hotek works
with companies of all sizes, from Fortune 100 firms to organizations with only a dozen people.
Twelve of Hotek’s client companies were housed in the World Trade Center in New York on
September 11, 2001. Of those 12 companies, seven were destroyed that day. Although some data
might have survived, no people from those companies remained to care about the information.
Survivors from each of the other five companies contacted Hotek for help. The first company
called two days after the attack. Hotek spent only half a day working with that company because
every piece of data the company owned and any information about how to recreate the data was lost
when the World Trade Center towers collapsed. The business didn’t survive. Two of the other four
companies that had survivors were in similar situations—they simply didn’t have anything left with
which to restart their businesses. The remaining two companies have survived—primarily because
they implemented Hotek’s suggestions for disaster prevention and preparedness. Hotek described his
experiences with these surviving businesses.
During the first week after the attacks, Hotek slept at most an hour each night. Despite all the
disaster planning and preparation his clients had done, recovery took weeks of hard work. However,
both companies were minimally functional within a week because of a fortuitous coincidence. Both
companies had ordered new hardware before the attack, so in the week after September 11, they
contacted the hardware vendors and redirected the hardware to the companies’ new locations. Those
preexisting hardware orders became the starting point for their new systems. One company was fully
functional in about 18 days; the other was operating normally in about a month.
The magnitude of this particular disaster made full site recovery different in two ways from other
disasters that require a complete system rebuild. First, because of the widespread devastation, no one
had any idea how fast the system might be back up. No company officers or stockholders were
breathing down the necks of Hotek and the survivors, asking “How much longer?” That the
companies even had survivors was a miracle, so the news that the businesses might be operational
again was beyond anyone’s expectations. So no external pressures forced the companies to hurry
their recovery.
The second reason this recovery was different from typical scenarios was more personal.
Although many disaster-prevention strategy lists specify making sure that more than one person has
all the system passwords and knows where the backups are stored, few people really plan for what
they would do if the entire IT staff was no longer available. Both surviving companies lost most of
their IT staffs, and the remaining people were in shock. Fortunately, in both cases, Hotek also had
Chapter 2 Is True Recovery Always Possible?
5
Brought to you by Neverfail and Windows IT Pro eBooks

most of the necessary information because he’d helped the companies set up their disaster-recovery
plans. For both companies, he was the one person who knew about the technology requirements of
the businesses—which is why he gave up sleep for a while. Although company officers and stock-
holders didn’t expect an immediate recovery, Hotek realized that he needed to help the companies
recover as quickly as possible. He took these six basic steps to get both businesses functioning again:
• Determined what skills were available among the survivors
• Procured funding for recovery efforts
• Found a new site and ordered new hardware for the most crucial systems
• Hired contractors to help rebuild the systems
• Located all the backups and process documents and determined what data was still available
• Got the surviving IT staff and the contractors working
For both companies, part of the recovery effort involved planning a whole new information-
management infrastructure that built in disaster-prevention and recovery strategies, including both
hot- and warm-standby systems. Hotek explained that he became a replication expert because of all
the work he does for disaster preparedness. When he sets up a replicated system, he gains the
immediate benefit of having a distributed, scalable system, and he has a warm standby to turn to if
some systems are lost.
Five years later, both companies are still in business and restaffed, although they are slightly
smaller than they were before September 11. Hotek still works with the companies, performing
checkups and reviews. He still has specific knowledge about their systems that no one else knows
because he designed and implemented those systems. But he believes his role will phase out over
6
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks
Disaster Recovery Means Availability, Too
By Michael Hotek
The goal of high availability is to produce a system that lets an IT department minimize downtime on critical systems.
In other words, high availability is about putting in place the people, processes, and technologies that allow for rapid
rebuilding of a failed component while incurring the least amount of outage. You measure availability with respect to
downtime.
Disaster recovery is a buzzword that’s currently out of favor with IT executives and business decision makers.
But the ultimate goal of disaster recovery and high availability are the same: To put in place people, processes, and
technologies that let you rapidly rebuild a failed component while incurring the least amount of outage. In IT,
disaster recovery is seen as a cost that drains IT budgets with long, complicated processes, but high availability is
recognized as essential to the company’s profit stream. That’s unfortunate, because the words are interchangeable
when you’re talking about keeping systems up and running.
For IT professionals who wish they had the budget to implement robust disaster-recovery plans, the solution is
easy—package disaster recovery as high availability. IT executives reading this article need to understand that you
can leverage every investment you make in disaster recovery into high availability, and vice versa. No matter which
term you use, you’re trying to accomplish the same goal: making data available to users 100 percent of the time.

the next year or so, at which time he plans to turn over his knowledge to in-house IT staff. Today,
both companies have redundant offsite hardware that they can bring in at short notice. They both
have distance clusters 25 miles from their main sites, and they use log shipping to keep the distance
clusters in sync with the main systems. Data-loss exposure is now limited to about 5 minutes.
Ironically, both companies had this level of redundancy in the planning stages before the attacks and
had expected to begin implementation in October 2001.
When asked if he’d learned any lessons about disaster prevention from his experiences after
September 11, Hotek said the most important lesson was that what he’d been telling his clients for
years was true—no scenario is too far-fetched to consider when preparing for disaster. As Hotek
knew all along, the factors that helped the surviving companies get back up and running were
planning, preparation, and perseverance.
Chapter 2 Is True Recovery Always Possible?
7
Brought to you by Neverfail and Windows IT Pro eBooks

Chapter 3
The Best Place for Bulk_Logged
Make this misunderstood recovery model work for you
By Kimberly L. Tripp
In looking at what’s most important for averting disaster, people often get wrapped up in technology.
Although you need to understand the available technologies so that you can make the best choices, a
single technology rarely provides a complete solution. You need to consider many important factors
in building a sound disaster-preparedness strategy, including which database recovery model is best
for your environment. Your choice of recovery model can have a tremendous effect on what data
you can recover after a failure—and the worst time to discover you’ve selected the wrong
recovery-model strategy is in the middle of a disaster.
SQL Server 2000 introduced three database recovery models: Full, Bulk_Logged, and Simple.
Microsoft created these recovery models in large part to better tie together the concepts of logging,
recovery, and performance. However, many DBAs wrongly assume that these recovery models work
just like pre-SQL Server 2000 database options such as SELECT INTO/Bulk Copy and Trunc. Log on
Chkpt. Although there are some similarities between the recovery models and previous database
options, there’s no direct correlation between them. Table 1 lists SQL Server 2000’s recovery models
and debunks the common misunderstandings of how each model compares to earlier database-option
settings.
Table 1: SQL Server 2000 Recovery Models
SQL Server 2000
Recovery Model
Common Incorrect Comparisons with Pre-SQL Server 2000 Database Options
Full
Not the same as if neither database option SELECT INTO/Bulk Copy and Trunc. Log on Chkpt.
is set. Some operations take longer when you use the Full model and require more log space
than not setting either database option in earlier SQL Server releases.
Bulk_Logged
Not the same as setting the SELECT INTO/Bulk Copy option. Although both settings provide
similar performance, Bulk_Logged provides different recovery capabilities.
Simple
Not exactly the same as setting both database options SELECT INTO/Bulk Copy and Trunc. Log
on Chkpt. (although this recovery model provides the closest similarity in function to the earlier
database-option settings).
For example, the Full recovery model isn’t the same as not setting SELECT INTO/Bulk Copy and
Trunc. Log on Chkpt. The Full model logs information in a new and, for some operations, more
extensive way. You might have learned this the hard way as you watched your batch operations
take more time and use more log space than they did in previous releases. But probably the most
misunderstood recovery model is Bulk_Logged, which provides similar performance to setting the
8
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

SELECT INTO/Bulk Copy option but provides different recovery capabilities. Let’s get a clearer picture
of how recovery works with Bulk_Logged, see why you might want to switch between Full and
Bulk_Logged recovery models, then explore a Bulk_Logged vulnerability that you shouldn’t overlook.
Understanding the Bulk_Logged Recovery Model
The Bulk_Logged recovery model, which minimally logs certain operations, allows some operations
to run more efficiently than the Full recovery model, which logs every operation fully. Bulk_ Logged
logs only the extents modified during an operation, keeping the active log small and possibly letting
you have a smaller defined transaction-log size than the Full recovery model allows. To be able to
recover the operation, you need to back up the transaction log immediately upon the completion of
any bulk-logged operation.
When you’re in Bulk_Logged mode, SQL Server backs up the transaction log in two steps.
First—and this is the big difference between using the Bulk_Logged recovery model instead of the
Full recovery model—SQL Server backs up all the extents that the bulk operations modified (I list the
specific commands defined as “bulk” in a moment). Second, SQL Server backs up the transaction log
as it would during a log backup in the Full recovery model. This two-step process is similar in
concept to how a differential backup works, except that with Bulk_Logged, SQL Server backs up
only the extents that the bulk operation changed.
The Bulk_Logged model lets some operations occur quickly and with minimal logging (only a
bitmap of the changed extents is maintained through the operation), but your recovery options are
limited. First, if you perform a bulk operation, the transaction-log backup doesn’t allow point-in-time
recovery during a restore. Second, if the data portion of the database isn’t accessible (because, for
example, the disks failed), a transaction-log backup isn’t possible after a bulk operation. Bulk_Logged
minimally logs the following bulk operations:
• Index creation or rebuilds
• Bulk loading of data (fast load), including (but not limited to) BULK INSERT, Data Transformation
Services (DTS) Bulk Load, and bulk copy program (bcp) operations SELECT INTO operations
when creating permanent tables
• WRITETEXT and UPDATETEXT operations for binary large object (BLOB) manipulation
Consider Switching
Technically, you can still have point-in-time and up-to-the-minute recovery when running in
Bulk_Logged mode, but this is possible only when bulk-logged operations haven’t occurred since the
last transaction-log backup. And the process can be confusing and error-prone. Instead of running in
Bulk_Logged recovery mode all the time, changing between the Full and Bulk_Logged recovery
models as part of your batch processes might be your best strategy. By switching between these
models, you can force transaction-log backups to occur at the most appropriate times, minimizing the
potential for data loss.
You still must perform log backups immediately after a batch operation to ensure that all your
data is recoverable. Consider this time-line scenario:
12:00
A
.
M
.— Transaction-log backup occurs (transaction-log backups occur hourly).
12:10
A
.
M
.— Batch operation begins.
12:20
A
.
M
.— Batch operation completes.
Chapter 3 The Best Place for Bulk_Logged
9
Brought to you by Neverfail and Windows IT Pro eBooks

12:47
A
.
M
.— Database becomes suspect due to drive failure.
12:50
A
.
M
.—You become aware of the suspect database. You try to access the tail of the transaction
log, but you receive the following errors:
Server: Msg 4216, Level 16, State 1, Line 1
Minimally logged operations cannot be backed up when the database is unavailable.
Server: Msg 3013, Level 16, State 1,
Line 1 BACKUP LOG is terminating abnormally.
At 12:50
A
.
M
., all you can do is restore the database and the logs up to 12:00
A
.
M
. If you had
backed up the log at 12:20
A
.
M
., your database would not have been in a bulk-logged state
(regardless of whether or not you were running in the Bulk_Logged recovery model setting). You can
back up the tail of the transaction log when you’re running in Bulk_Logged mode only if no bulk
operations have occurred. By backing up the transaction log immediately after a bulk operation, you
are in effect resetting the bulk-logged state so that transaction-log backups can be performed without
requiring access to the data portion of the database. So if the database hadn’t been in a bulk-logged
state at 12:50
A
.
M
., you would have been able to back up the tail of the transaction log. If the tail of
the log had been accessible, you would have had up-to-the-minute recovery and no data loss.
Instead, you lose all activity since 12:00
A
.
M
.
Let’s take this concept further by looking at another scenario. Let’s say the database becomes
corrupt at 12:15
A
.
M
., in the middle of the batch operation. You know that the tail of the transaction
log isn’t accessible because you’re in the process of a bulk operation in the Bulk_Logged recovery
model. As we just saw, your data loss is everything past 12:00
A
.
M
. But you could have prevented
some—and possibly all—of this data loss. Performing a transaction-log backup at 12:10
A
.
M
., when
the database was accessible (right before the bulk operation began), would have at least brought you
up to 12:10
A
.
M
., the moment before the bulk operation. If the bulk operation were the only
operation occurring from 12:10
A
.
M
. to 12:15
A
.
M
. (when the database became corrupt), you could use
the transaction-log backup to bring the database up to 12:10
A
.
M
. Once recovered to 12:10
A
.
M
., you
could execute the bulk operation again to bring the database up to the time of the failure and
continue it moving forward.
It’s crucial that you back up your transaction log immediately before and after performing a
batch operation. Doing both minimizes the overall potential for data loss in the event of a failure.
Remember that if the database is set to the Bulk_Logged recovery model and you’ve performed a
bulk operation, you cannot back up the tail of the log even if the transaction-log file is accessible. If
you haven’t performed a bulk operation, you can back up the log. Because log backups are possible
in the Bulk_Logged recovery model, some people might consider always running in Bulk_Logged
mode. However, always running in Bulk_Logged mode can be dangerous because you’re no longer
entirely in control of the recovery. Performing bulk operations isn’t necessarily limited to DBAs or sys-
tems administrators. Anyone who owns a table can create or rebuild indexes on their tables, anyone
with Create Table permissions can use SELECT INTO to create a permanent table, and anyone who
has access to text data can manipulate it with WRITETEXT and UPDATETEXT.
Because you don’t control who performs bulk operations or when, it’s important to know and
limit when operations are fully or minimally logged. If you’re responsible for data recovery and your
environment can’t afford data loss, the only way to minimize data loss is by running in the Full
10
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

recovery model and controlling changes through the Bulk_Logged recovery model. And you
should switch to Bulk_Logged only if and when it’s appropriate for your environment. In some
environments, switching might never be appropriate.
If your databases aren’t processing transactions around the clock or if you’re willing to have
work-loss exposure to achieve better performance of your batch operations, you might consider a
temporary change to the Bulk_Logged recovery model. The best practice, if you determine that you
can periodically change to the Bulk_Logged recovery model, is to change recovery models within
batch processes, which usually occur after normal working hours. This practice ensures that the
window of potential work loss is limited to the safest times of the day. When you change to
Bulk_ Logged during the batch operation, perform a log backup before the switch, then change back
to the Full recovery model when the operation is complete, performing a log backup after the switch.
To see how to programmatically and optimally change recovery models during a bulk operation,
download the script DB Alter for Batch Operation.sql by clicking <a href=”http://www.winnetmag
.com/Files/09/39782/39782.zip”>Download the Code.</a>
In addition, you might consider breaking large or complex batch operations into smaller, simpler
batch operations to keep the transaction log from growing excessively large. To minimize the
potential for data loss (because you can’t back up the tail of the log if the database becomes
suspect), consider performing log backups during the batch process and between some steps of the
bulk operations. Breaking down large or complex operations and performing log backups between
the larger steps gives you more recovery options.
A Recovery-Model Test
To see how your choice of recovery model can affect the database’s transaction-log size (the amount
of space required to log the operation), the transaction-log backup size, and the operation’s speed
let’s look at a simple test that uses the SELECT INTO operation to create a new table called
TestTable, based on a table called charge from another database. The charge table has 800,000 rows,
and the data is roughly 40MB in size.
As Table 2 shows, the Simple and Bulk_Logged recovery models seem to provide the same
performance and the same active log size. However, recovery models don’t affect all operations. In a
second test, I performed an UPDATE operation against all 800,000 rows in TestTable. As Table 3
shows, compared to the SELECT INTO operation, the UPDATE operation caused the transaction log
for all three databases to grow significantly to handle the modification, but the UPDATE operation’s
duration and the size of the transaction-log backup (where a transaction-log backup was permitted)
were the same for all the recovery models.
Table 2: Results of SELECT INTO Operation
Database Recovery Model
Duration (Seconds)
Database Transaction-
Transaction-Log Backup Size
Log Size
Simple
8.5
< 4MB
Not allowed
Bulk_Logged
8.5
< 4MB
~40MB
Full
14
~40MB
~40MB
Chapter 3 The Best Place for Bulk_Logged
11
Brought to you by Neverfail and Windows IT Pro eBooks

Table 3: Results of UPDATE Operation
Database Recovery Model
Duration (Seconds)
Database Transaction-
Transaction-Log Backup Size
Log Size
Simple
18
230MB
Not allowed
Bulk_Logged
18
230MB
~54MB
Full
18
230MB
~54MB
In looking at the test results in Tables 2 and 3, you might think that Bulk_Logged is the best
recovery model to use because it seems to allow transaction-log backups and because the operations
affected by recovery models run faster than with the Full recovery model. However, remember that
the transaction log isn’t always available for a transaction-log backup when you’re running the
Bulk_Logged recovery model. If the device on which the data resides isn’t available when SQL Server
attempts a transaction-log backup, SQL Server can’t perform the transaction-log backup, resulting in
data loss. Thus, up-to-the-minute recovery isn’t always possible with Bulk_Logged. Take some time to
get familiar with the different recovery models and their trade-offs and determine out how they affect
speed, logging, and recovery for your production databases.
12
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

Chapter 4
Before Disaster Strikes
A solid backup strategy can save your VLDB
By Kimberly L. Tripp
In the event of a disaster, fast and effective recovery of your database environment is essential. You
must be able to quickly implement your disaster-recovery plan—which must be tested and well
documented before the disaster. A successful disaster-recovery plan lets you recover your database
within your company’s defined acceptable amount of downtime and data loss, if any. Because
backup and restore are important and required parts of any disaster-recovery plan, your
backup/restore strategy should minimize both data loss and downtime. And when your database is
measured in hundreds of gigabytes—or even terabytes—the plan to minimize downtime and restore
quickly becomes even harder to achieve as database size affects recovery times and backup
complexities.
Creating, testing, and maintaining a database environment where little to no data is lost and
downtime is entirely avoided in a disaster is no trivial task. More important, in your quest for high
availability, remember that more than the database can fail. Many SQL Server features—such as
failover clustering, log shipping, and replication—offer high-availability solutions. However, regardless
of the options you choose and the levels of redundancy your hardware provides, you’ll always need
a solid backup strategy. No matter what size the database or the availability requirements, restore is
always an option—and in some cases, such as accidental data modifications or deletions, the only
option—that lets you restore the database to a state before the modification.
Whether you’re recovering from accidental data deletion, hardware failure, natural disaster, or
other unplanned incident, your backup strategy is the foundation of a solid recovery plan. You can
restore backups to different servers or different file locations, and you can easily send them to
geographically dispersed locations either electronically or on removable media. Backups offer the
most options for the lowest cost and require little additional hardware, except maybe backup storage
devices such as tape. But you still need to take time to fully understand all the features and potential
pitfalls to ensure that your backup is as automated as possible and your restore is as fast as possible.
With SQL Server 2000, backup and restore options are easy to automate and combine to create a
flexible, effective recovery path. All backup/restore features are included with all SQL Server 2000
editions and don’t require Enterprise Edition. Moreover, by practicing some of the advanced options I
discuss here, you can minimize downtime and reduce data loss even in the event of total server
failure.
Chapter 4 Before Disaster Strikes
13
Brought to you by Neverfail and Windows IT Pro eBooks

What’s Your Backup Strategy?
On many production servers, the backup and restore strategy is periodic complete database backups
(e.g., weekly) with frequent log backups (e.g., hourly); some shops add occasional differential
backups (e.g., nightly except on the day when full backups occur). The basic strategy is acceptable,
but adding differentials helps minimize downtime by reducing the number of logs you have to apply
to roll forward the database; you need to apply only the full backup, the most recent differential
backup, and the logs since the last differential backup. However, both strategies must use a full
backup as the starting point for a restore.
If you have a very large database (VLDB)—measured in hundreds of gigabytes or even
terabytes—you need to ask yourself a few questions about your backup strategy. How long does
your VLDB take to back up? More importantly, how long does it take to restore? Are these times
acceptable based on your business requirements? Unless your strategy uses storage-assisted backup
such as split-mirror, a restore that uses one of the full-backupbased strategies is likely to take hours.
Even if hours of downtime are acceptable, how much data can you afford to lose? And what’s your
site redundancy strategy—do you use log shipping or do you copy all your log backups to a
secondary site?
SQL Server pauses log backups while a full database backup is running. You could lose a lot of
data if you had a site failure during a full backup. This scenario might sound unlikely, but when your
full database backup is measured in hours, your risk of data loss increases. If your database backup
takes 8 hours to perform, your secondary site could be as much as 8 hours behind at the time of a
failure, resulting in 8 hours of data loss if the backup wasn’t complete or hadn’t copied to the
secondary location. Losing 8 hours of data is unacceptable in most cases. But what if a log backup
could occur while you were performing a different backup? Such an approach would let you ship
changes to another site even while your large backups are occurring. To let logs back up every
minute (a common frequency for minimizing data loss), you might choose not to perform a full
database backup at all. By using a file and filegroup backup strategy, you can completely avoid
performing a full database backup, so log backups will never be paused. This strategy lets a
secondary site’s data stay as close as possible to the primary site’s and minimizes potential data loss.
Some basic backup and restore strategies have few restrictions; for example, a full database
backup has no real restrictions—it can be performed anytime. However, the more advanced file and
filegroup backup strategies have some basic requirements you need to understand. Primarily, you
must perform log backups regularly. Log backups are a crucial component of restore and are
required for recovery if you use the file and filegroup backup strategy. To allow log backups and
thereby minimize your work loss exposure, you must first set the database recovery model to either
Full or Bulk_logged. Because the Simple recovery model doesn’t let you back up the transaction log,
you can’t use this recovery model with the file and filegroup backup strategy.
The second step—optional but beneficial in setting up the file and filegroup strategy—takes some
planning. When you create objects, take time to place your objects strategically within the database.
In most databases and especially in VLDBs, your data will likely vary in the way it’s used. For
example, you’ll probably have some data that’s predominantly read-only and some that’s predomi-
nantly read/write. In some tables, new rows might be read/write to accommodate frequent inserts,
whereas old rows (historical data used mainly for analysis) would be read-only. For other tables, the
14
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

distribution might vary based on corporate policy (for example, price changes are infrequent, so price
information would be predominantly read-only—until price increases were put into effect).
After reviewing the overall usage of your data, you can determine table usage and strategically
place read-only tables (or tables with isolated or batch updates) on one filegroup and read/write
tables on another. Doing so will not only save you time during a restore but can also save money
and time during backups because although the read-only portion of your database might be very
large, it doesn’t need to be backed up as often as the read/write portion.
Additionally, partitioning your larger tables to split read activity from write activity can improve
maintenance performance. Operations such as rebuilding an index take less time on smaller tables.
For example, consider a typical sales table that holds the online sales information for a large
company. Sales for the current month are read/write (which requires frequent index maintenance),
but sales from the previous month or quarter are read-only because they’re used only for analysis
(maintenance occurs only once a month, when the data is moved to the read-only portion of the
database). For tables whose usage differs, consider using separate filegroups for each type of data.
For example, creating four separate filegroups—one for read-only data, one for read/write data, one
for text and image data, and one for extremely large tables—can help when you’re determining your
backup strategies. Not only will you create smaller tables (partitions) that reduce maintenance times,
you’ll add numerous backup and especially restore strategy options that can reduce downtime and
backup costs.
To determine the correct number of filegroups and files for your database, you need to know
your data; the sidebar “Filegroup Usage for VLDBs” contains some recommendations.
Backup by the Numbers
Once you’re using good design and the Full (or Bulk_logged) recovery model, you’re ready to start
taking advantage of the file and filegroup backup strategy. To demonstrate the syntax and exact
usage of this strategy, let’s look at the case study that Figure 1 illustrates. To create the PubsTest data-
base and all the backups in the case study, run the FileFilegroupStrategiesCaseStudy.sql script, which
you can download at http://www.sqlmag.com. You can execute this script in its entirety, but I recom-
mend working through the script slowly to review the syntax and understand the backup strategy.
Chapter 4 Before Disaster Strikes
15
Brought to you by Neverfail and Windows IT Pro eBooks
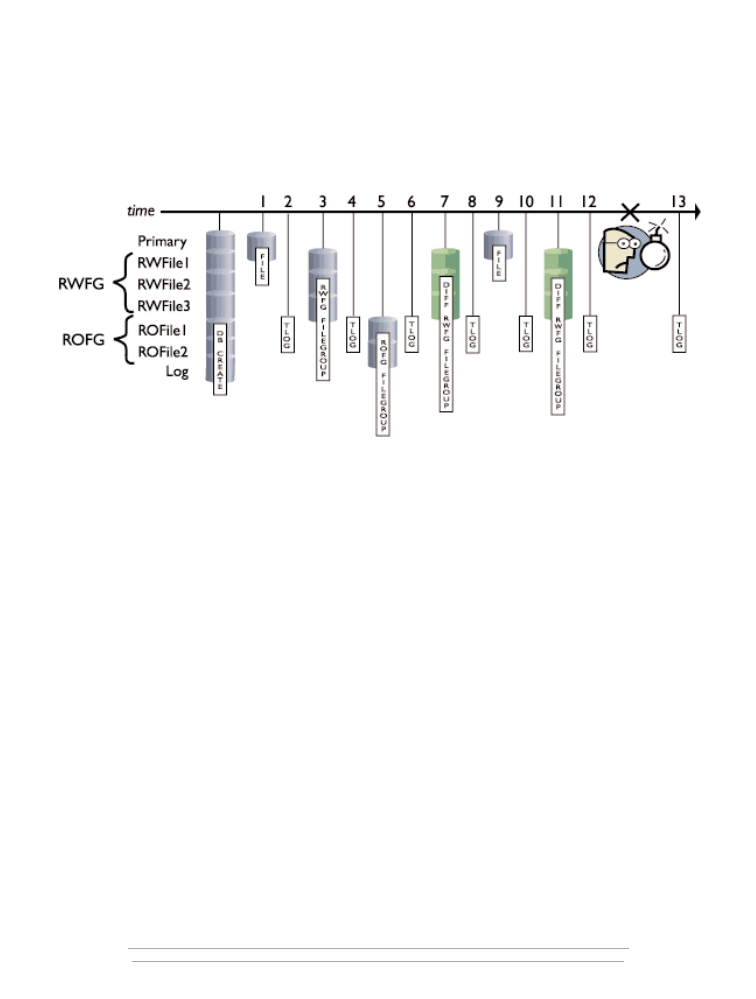
Figure 1
PubsTest Case Study
The case study uses seven files: a primary file, three files in a filegroup named RWFG (used for
read/write data), two files in a filegroup named ROFG (used for read-only data), and one transaction
log file. After creating the PubsTest database, the script modifies data in between several backups.
The diagram lists the backup types from left to right in this sequence (the number corresponds to the
number along the time line):
Full file backup of the primary file
Transaction log backup
Full filegroup backup of the RWFG filegroup
Transaction log backup
Full filegroup backup of the ROFG filegroup
Transaction log backup
Differential filegroup backup of the RWFG filegroup
Transaction log backup
Full file backup of primary file
Transaction log backup
Differential filegroup backup of the RWFG filegroup
Transaction log backup
Final transaction log backup after the disaster
Note that the time line, at number 13, includes a backup after the disaster. When a database
becomes suspect, your first question should be, “Can I back up the tail of the transaction log?” The
tail of the log is the up-to-the-minute information that lets you recover your database from the last
backup until the database became suspect. For backing up the tail of the log, use BACKUP LOG with
the NO_TRUNCATE option.
16
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

When you use the file and filegroup backup strategy, you must make sure that you back up
every file so that you create a complete backup set (all of the database’s data files) and can recreate
the database framework if needed. You can create a backup set either by backing up the files
individually, by backing up filegroups, or by backing up some combination of the two—as long as all
files are backed up at some point. In SQL Server 2000, you can back up any file individually—even
when it’s a member of a filegroup. In SQL Server 7.0, you must back up the entire filegroup; you
can’t separately back up individual files that are members of a filegroup. This change in SQL Server
2000 gives much better backup-and-restore granularity: If an isolated failure occurs, you have to
restore only that file. However, finding the file’s pages in a larger filegroup backup takes more time
than restoring the file from an individual file backup.
The PubsTest case study provides the database framework along with the most recent file backup
for the primary file (backup 9) and backups of the filegroups (backups 3 and 5). The example
recovery scenario involves recovering the entire database. However, one of the biggest benefits of the
file and filegroup backup strategy is the ability to recover quickly when isolated corruption or media
failure occurs. Instead of recovering the whole database or recovering partially from a full database
backup (which is slower because the backup contains the entire database, not just the target file or
filegroup), you can recover just the corrupted file or filegroup.
To recover the entire PubsTest database, you build the database framework, restoring the last full
file and filegroup backups first. To build the example framework, you’d restore backup number 9 to
create the primary file, then backup 3 to create the RWFG filegroup, then backup 5 to create the
ROFG filegroup. Because the database recovery process is incomplete (the database files are all at
different states and still need to be rolled forward to a consistent point), the database is said to be in
a loading state. To continue to apply transaction logs (to get the database files to the same point in
time), use the NORECOVERY option when you restore all file and filegroup backups. This option lets
you restore backups without bringing the database online until it’s recovered. When you’re ready to
bring the database online, you can use the following simple statement:
RESTORE DATABASE dbname WITH RECOVERY
Before you get to that point, you need to roll forward the data to the point in time when the
disaster occurred. To minimize rollforward time, you might have been performing differential backups
in addition to transaction log backups. Differential backups can occur at any level: database, file, or
filegroup. The next step on the road to recovery is to restore the last differential backups of all files
or filegroups. In the case study, you have a differential backup for RWFG at backup number 7 and
again at backup 11. Because differentials contain all changes made since the last full file or filegroup
backup, you need to restore only backup 11. (If the differential backup failed, you could easily use
the next most recent differential backup, so you have some redundancy in your backup strategy.)
Now you have the bulk of the database populated. However, the database is still not ready for
recovery. The files are still at different stages of modification: The primary file is at point in time 9,
RWFG is at 11, and ROFG is at 5. The next step is to roll forward the database by applying the
correct transaction log backups. Watch out—this step can be tricky. To determine the proper
sequence of log backups to apply, you need to first figure out the oldest backup set that you’ve
restored. In the case study, you restored the following:
Chapter 4 Before Disaster Strikes
17
Brought to you by Neverfail and Windows IT Pro eBooks

Backup set number 9 to get the latest full file backup of the primary file
Backup set number 3 to get the latest full filegroup backup of the RWFG filegroup
Backup set number 5 to get the latest full filegroup backup of the ROFG filegroup
Backup set number 11 to get the latest differential of the RWFG filegroup
At this point, the ROFG filegroup is at the earliest point in time—point in time 5. To recover up
to the minute, you need to calculate the minimum effective log to apply. For this, you can use the
information from the backup history. Querying msdb for backup history can help speed the process;
however, msdb might not be available at the time of the failure. If msdb is available, you can query it
directly to gather the information about your database backups. Querying backup history from msdb
can produce quite a bit of information because SQL Server doesn’t automatically clear msdb’s backup
history. Historical information is kept permanently. You might want to periodically clear old informa-
tion from msdb, but make sure to retain one or two complete backup sets of information. To clear
the backup history, you can use the msdb.dbo.sp_delete_database_backuphistory or
msdb.dbo.sp_delete_backuphistory procedures.
If msdb is unavailable, you must gather the backup history by reviewing the header information
directly from your backup devices. To view the header information, use the LOAD HEADERONLY
syntax. Web Listing 1, (http://www.sqlmag.com/Files/09/25915/25915.zip) downloadable from
http:\\www.sqlmag.com, contains some examples of how to use this syntax. LOAD HEADERONLY
requires that the backup devices be online. Bringing all the tape devices online and gathering all of
this information will probably add quite a bit of time to your recovery process. You’ll probably load
some backup devices and inevitably interrogate some of the wrong ones to find the correct set and
the right sequence to restore. To ensure that msdb is always available for querying, see the sidebar
“Msdb Quick Tip” for instructions on resetting msdb to allow transaction log backups and how to
back it up frequently.
In the PubsTest case study, you can review the backup set information by using the query that
Listing 1 shows. Executing this query produces the results that Table 1 shows. These results are fairly
clean because the backups used good naming conventions. I recommend that you have a standard
for backup names and descriptions so that you can more quickly find the correct sequence of
backups to restore. In the case study, I used descriptive names, such as “PubsTest Backup, File =
pubs” and left the backup description option blank. Additionally, the backup history was cleared
before these backups occurred.
LISTING 1: Code to Display the PubsTest Backup Set Information
SELECT *
FROM msdb.dbo.backupset AS s
JOIN msdb.dbo.backupmediafamily AS m
ON s.media_set_id = m.media_set_id
WHERE database_name = 'PubsTest'
ORDER BY 1 ASC
18
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

TABLE 1: PubsTest Case Study with msdb Information
Backup_
Name
Description
First_LSN
Last_LSN
Backup_
Start_Date
Finish_Date
2002-05-22 PubsTest
Backup, NULL
11000000062400001
11000000062600001
2002-05-22
21:31:37.000
File = pubs
21:31:38.000
2002-05-22 PubsTest
Backup, NULL
11000000062400001
11000000267900001
2002-05-22
21:31:39.000
Transaction Log
21:31:39.000
2002-05-22 PubsTest
Backup, NULL
12000000155000001
12000000155900001
2002-05-22
21:31:41.000
FileGroup = RWFG
21:31:41.000
2002-05-22 PubsTest
Backup, NULL
11000000267900001
13000000043600001
2002-05-22
21:31:43.000
Transaction Log
21:31:43.000
2002-05-22 PubsTest
Backup, NULL
13000000248600001
13000000248800001
2002-05-22
21:31:45.000
FileGroup = ROFG
21:31:45.000
2002-05-22 PubsTest
Backup, NULL
13000000043600001
16000000038500001
2002-05-22
21:31:47.000
Transaction Log
21:31:47.000
2002-05-22 PubsTest
Backup, NULL
17000000196200002
17000000196400001
2002-05-22
21:31:49.000
FileGroup
21:31:49.000
DIFFERENTIAL =
RWFG
2002-05-22 PubsTest
Backup, NULL
16000000038500001
18000000084500001
2002-05-22
21:31:51.000
Transaction Log
21:31:51.000
2002-05-22 PubsTest
Backup, NULL
18000000289600001
18000000289800001
2002-05-22
21:31:53.000
File = pubs
21:31:54.000
2002-05-22 PubsTest
Backup, NULL
18000000084500001
19000000177300001
2002-05-22
21:31:56.000
Transaction Log
21:31:56.000
2002-05-22 PubsTest
Backup, NULL
20000000064700002
20000000064900001
2002-05-22
21:31:58.000
FileGroup
21:31:59.000
DIFFERENTIAL =
RWFG
2002-05-22 PubsTest
Backup, NULL
19000000177300001
20000000269800001
2002-05-22
21:32:00.000
Transaction Log
21:32:01.000
Chapter 4 Before Disaster Strikes
19
Brought to you by Neverfail and Windows IT Pro eBooks

Now, the database framework has been restored and you know that ROFG is at the earliest state in
this database’s backup set. To roll the database forward up to the minute of the disaster, you need to
restore the transaction logs in the correct sequence. To determine the correct set of transaction log
backups to restore, you need to find backup 5’s minimum effective log sequence number (LSN), which
the First_LSN column in Table 1 contains. In this case, the minimum effective LSN of backup number 5
is 13000000248600001. To know which logs to restore, find the first transaction log whose minimum
effective LSN is less than this number—backup number 6, in this case. You need to find the next lower
LSN because you’re looking for the transaction log (or logs) that contains the transactional information
of what happened during this backup. Because log backups can occur concurrently with file and file-
group backups, multiple log backups could occur within the time frame of a large file or filegroup
backup. In some cases, the first transaction log to load might be “before” the file or filegroup set you’ve
loaded. So, always review the LSNs to ensure that you have the proper starting point.
To complete the full recovery of this database, you need to apply all transaction logs starting with
backup number 6. In this case, you’d restore backup 6, then 8, then 10, then 12, and finally backup 13
to bring the data up to the minute. For backup number 13 (the last transaction log), you can either use
the RESTORE WITH RECOVERY option to bring the database online or use the NORECOVERY option,
then follow this restore with a RESTORE DATABASE PubsTest WITH RECOVERY statement to recover
the database.
Be Prepared
Recovering the entire database from file and filegroup backups is by far the most complex backup and
restore strategy. This strategy takes the greatest amount of testing to fully understand and requires good
practices such as strong naming conventions and regular backups of msdb to ensure an easy recovery.
But by using this strategy, you can completely recover a database without ever doing a full database
backup or having to pause your log backups. With this strategy, you can selectively choose when to
back up large read-only portions of your database, an approach that can save backup time and money
in backup media. More important, because the log is never paused, your secondary sites (for example,
log-shipping destination sites) will always receive the transaction logs as quickly as possible, which can
drastically reduce data loss in the event of a site failure. For best results, have your most senior DBA
devise the backup plan and the least senior DBA test it.
20
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

Chapter 5
All About Restore
Plan and test your recovery operation now
Kalen Delaney
Restoring a SQL Server database after a disaster is one of the most important jobs of a systems
administrator (sa). But recovery often receives less attention than its companion operation, backup.
Most competent administrators know they need to regularly back up the company’s mission-critical
data. So, to make sure it gets finished—and because making backups is usually a straightforward
operation—they assign the job of backing up to a novice member of the administration team. And
there’s nothing wrong with having novice SQL Server administrators perform backups as long as they
use a consistent procedure.
Restore operations, however, are rarely left to novices. Still, because restoring a database isn’t a
daily operation, a SQL Server administrator might manage databases for years without having to
perform an emergency restore. So on the day that you have to perform a restore after a disaster, the
many subtleties of the restore process can take you by surprise. Unexpected glitches in the restore
can mean that you’re searching SQL Server Books Online (BOL) and the Microsoft Knowledge Base
for solutions to problems while your entire company is waiting for you to make data available. In
addition to being prepared for unexpected problems, you need to test your recovery plan. If you
haven’t already completely tested your recovery operations in a simulated disaster scenario, start
planning such a simulation as soon as you finish reading this article.
In this article, I review various types of backup operations, including full, differential, and
transaction log backups. Then, I discuss basic restore operations and describe what SQL Server does
when it restores your data.
Backup and Restore
Although backup is usually a straightforward operation, you need to understand what happens during
different types of backups so you can plan your restore operations. When you perform a backup,
you’re copying data, the transaction log, or both to another, presumably safe, location. That location
can be a local disk file (which you then copy to tape or other media) or tape. Although you can
copy to a remote disk file, writing to a local file and using the OS file copy operations to move the
file to another machine is usually more efficient. How fast and how completely you can restore
backed-up data depends on the type of backup you’ve made and how well you’ve planned your
restore operation. (For example, you need to plan ahead for how much space your restore will
require, as I explain in the sidebar “Planning the Space for a Restore.”) SQL Server 2000 supports
three main types of backups: full, differential, and log.
Chapter 5 All About Restore
21
Brought to you by Neverfail and Windows IT Pro eBooks

Full backup. A full database backup copies all the pages from a database to a backup device,
which can be a local or network disk file, a local tape drive, or even a named pipe. SQL Server also
copies the portion of the transaction log that was active while the backup was in process.
Differential backup. A differential backup copies only the extents that have changed since the
last full backup. SQL Server 2000 can quickly tell which extents need to be backed up by examining
a special page called the Differential Changed Map (DCM) in each file of the database. A file’s DCM
contains a bit for each extent in the file. Each time you make a full backup, all the bit values revert
to 0. When any page in an extent is changed, the page’s corresponding bit in the DCM page changes
to 1. SQL Server copies the portion of the transaction log that was active during the backup.
Typically, you make several differential backups between full backups, and each differential backup
contains all the changes since the last full backup.
Log backup. A transaction log backup copies all the log records that SQL Server has written
since the last log backup. Even if you’ve made full database backups, a log backup always contains
all the records since the last log backup. Thus, you can restore from any full database backup as long
as you have all the subsequent log backups. However, the exact behavior of the BACKUP LOG
command depends on your database’s recovery-model setting. If the database is using the full
recovery model, the BACKUP LOG command copies the entire contents of the transaction log. In the
bulk_logged recovery model, a transaction log backup copies the contents of the log and all the
extents containing data pages that bulk operations have modified since the last log backup. If the
database is using the simple recovery model, you can’t perform a log backup because the log is
truncated regularly, so no useful information is available. In a typical recovery scenario, an
administrator would make a series of log backups between full database backups, with each log
backup containing only the log records recorded since the last log backup.
SQL Server supports variations on these basic backup types, including file or filegroup backups,
which are useful in environments that use very large databases (VLDBs). The more kinds of backups
you make and the more frequently you make them, the more options you have for restoring a
database quickly and completely. Restore operations, however, involve more work for SQL Server
than backups do. When you perform a complete restore operation, SQL Server must make sure that
the data in the database agrees with the transaction records in the transaction log. The process of
verifying that the data and the log are in agreement is called database recovery.
Restore vs. Recovery
Database recovery and database restore are similar, but they aren’t the same. A complete restore
almost always includes a recovery operation, but recovery doesn’t have to include a restore. Restore
is a manual process of loading backed-up data that an administrator must initiate. Recovery is an
automatic process that can occur at the end of a restore operation and occurs every time an
administrator restarts SQL Server. Although recovery is usually part of a restore operation, the
administrator controls the process, as I discuss later.
During database recovery (either at the end of a restore operation or after a restart), SQL Server
compares the records of transactions in the transaction log with the data in the database. Recovery
performs both redo (roll-forward) and undo (rollback) operations. In a redo operation, SQL Server
examines the log and verifies that each change is already in the database. If a committed transaction
22
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

is recorded in the transaction log but doesn’t exist in the data pages, SQL Server redoes the
transaction. After a redo, SQL Server guarantees that every change that the transaction made has been
applied. If parts of a transaction appear in the database but that transaction was never committed,
SQL Server performs an undo operation to remove the changes that the uncommitted transaction
made. After the entire recovery process is finished, the database and the transaction log are synchro-
nized. All completed transactions recorded in the log appear in the database, and no part of an
uncompleted transaction appears in the database.
Restoring a Damaged Database
If you need to restore a database because of a media failure or because of an error that destroyed or
changed data, you can restore the database to the original SQL Server. To restore a database, you
start by restoring the most recent full backup. If you’re restoring the database because a disk is
damaged, you need to restore the database to a new (undamaged) location. By default, a SQL Server
restore operation creates the database if it doesn’t already exist and uses the same file locations for
the data and log files that the original database used. To verify those file locations, you can run the
following command against the disk or tape backup file:
RESTORE FILELISTONLY FROM <backup device location>
To create the restored database in a different location on the same SQL Server, you must use the
RESTORE DATABASE command’s MOVE option. (BOL contains the complete syntax for the MOVE
option.) If your physical media hasn’t been damaged and you’re restoring only to correct user errors,
you might want to restore a backed-up copy of your database to the same location on disk—right on
top of your current database.
Note that no users can be in the database when you perform this operation. In SQL Server 2000,
you can use the ALTER DATABASE command to change the database status to single-user mode and
disconnect users from the database. (BOL contains complete documentation for ALTER DATABASE.)
However, SQL Server 7.0 has no automatic way to disconnect users from a database. You can run a
script that checks the sysprocesses table for connected users, issue a KILL command for each, then try
to change the database to single-user mode—but you can’t keep new users from logging in during
the process. To try to prevent logins, you can use the OS service manager to put the server in a
pause state, but this pause affects more databases than just the one you want to restore. Also
remember that using Enterprise Manager to inspect your database or perform the restore uses up a
connection to the database, so if you’re in single-user mode, you can’t simultaneously use Query
Analyzer to connect to the database.
Restoring and Renaming a Database
If you want to restore a database and give it a new name, perhaps because you want an identical
copy of a database on the same server, you might need to use the REPLACE option with the
RESTORE DATABASE command. The REPLACE option is necessary when the database name in the
backup files doesn’t match the name of the database you’re specifying in the RESTORE DATABASE
command and the name you’re specifying in the RESTORE command already exists on the SQL
Server. The REPLACE option helps prevent you from accidentally overwriting one database with the
backup of a different database.
Chapter 5 All About Restore
23
Brought to you by Neverfail and Windows IT Pro eBooks

For example, if you have a backup of the Northwind database in a file and you try to restore the
backup into the Pubs database , SQL Server won’t let you perform the restore without the REPLACE
option. However, if you do specify REPLACE, the backed-up data from Northwind will overwrite the
original Pubs data.
You also need the REPLACE option when you use the MOVE option and specify an existing file.
The MOVE option lets you use the RESTORE command to recreate a database in a different physical
location, perhaps on a new, faster disk. However, if the file specified as the destination of the MOVE
option already exists, SQL Server assumes that the existing file belongs to a different database.
Usually, RESTORE DATABASE refuses to overwrite existing files, but REPLACE lets RESTORE
DATABASE overwrite an existing file. You need to be aware of one caveat when you use the
REPLACE option: Usually, the user who is running the RESTORE DATABASE command has to be
only the database owner (DBO). But when you’re using REPLACE, SQL Server behaves as if you’re
creating a new database. The user who is running the RESTORE DATABASE command with the
REPLACE option must have permission to create a database or be in a group that has such
permissions. In my next article, I’ll discuss a few other caveats that also apply to a nonadministrator
DBO running a restore operation with REPLACE.
Restoring WITH RECOVERY and WITH NORECOVERY
The RESTORE DATABASE command does two things: It copies all the data, log, and index pages
from the backup media to the database files, and it applies all the transactions in the backed-up
portion of the log. You must determine whether to tell SQL Server to roll back incomplete
transactions. If you want rollback, you can use the WITH RECOVERY option of the RESTORE
DATABASE command to recover the database. The WITH RECOVERY option rolls back incomplete
transactions and opens the database for use. If you plan to restore subsequent transaction log
backups, and you don’t want to recover the database and have SQL Server perform rollbacks until
after the last transaction log is restored, you won’t need to use the WITH RECOVERY option. The
RESTORE LOG command also lets you specify either WITH RECOVERY or WITH NORECOVERY.
Remember that SQL Server 2000 and 7.0 log backups don’t overlap—each log backup starts
where the previous one ended. Consider a transaction that makes hundreds of updates to one table.
If you back up the log in the middle of the updating and again after the updating is finished, the first
log backup will include the beginning of the transaction and some of the updates, and the second
log backup will include the remainder of the updates and the commit. Suppose you then need to
restore these log backups after restoring the full database. If you choose to restore the first log
backup WITH RECOVERY, SQL Server will roll back the incomplete transaction in the first part of
the log.
If you then try to restore the second log backup, the restore will start in the middle of a
transaction and SQL Server won’t know what the beginning of the transaction did. You can’t recover
transactions that occurred after this large update because their operations might depend on part of
the update that you lost. So, SQL Server won’t let you do any more restoring. The alternative is to run
WITH NORECOVERY, which leaves the transaction incomplete. SQL Server will know that the
database is inconsistent and won’t let any users into the database until you run recovery on it.
So, should you choose WITH RECOVERY or WITH NORECOVERY? If you use the RESTORE
command to restore a database or log backup, the default restore option is WITH RECOVERY. But
generally, you should use the WITH NORECOVERY option for all but the last log restore. If you
24
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks

make a mistake and forget to specify WITH NORECOVERY, you’ll have to restart your restore
operation because the database has now been recovered and incomplete transactions have been
rolled back. However, if you forget to specify WITH RECOVERY for the last log restore, the fix is
simple. Just use the command below to recover the database without specifying any backup device
to restore from:
RESTORE DATABASE <database name> WITH RECOVERY
Incomplete Restore
An incomplete restore is useful if someone accidentally destroys crucial data with an UPDATE or
DELETE command and you want to just restore the database to the point before the data was
destroyed. If you follow the usual restore procedure and apply the entire last transaction log, you’ll
reapply the transaction that damaged your database. But SQL Server 2000 and 7.0 let you restore your
database up to a specific point in time.
The STOPAT option of the RESTORE command lets you specify a point at which to stop
restoring a transaction log. Because each log record includes a datetime value that shows when the
transaction began, SQL Server will stop restoring transactions as soon as it encounters a transaction
that happened after the specified STOPAT time. If the transaction log backup doesn’t contain the
requested time (e.g., the time specified is after the time that the transaction log covers), SQL Server
generates a warning and the database remains unrecovered, as if you’d run RESTORE WITH
NORECOVERY.
In SQL Server 7.0, you can use the STOPAT option only with the RESTORE LOG command. In
SQL Server 2000, you can also use STOPAT with the RESTORE DATABASE command, and STOPAT
includes log records applied after all the database pages were loaded. However, you can’t use
STOPAT when you’re restoring differential backups because most of the work of a differential restore
is replacing data that has changed and no datetime value is associated with the changed pages. In
addition, you can’t use STOPAT with a file or filegroup restore because all the logs must be applied
completely so that the restored file or filegroup is current through the same point in time as the rest
of the files in the database.
Restoring WITH STANDBY
As useful as the STOPAT option can be, it’s not perfect. What happens if you know that data was
destroyed, but you don’t know exactly when it happened? For example, you discover at 5:00 p.m.
that a crucial table was dropped during the day, but you don’t know when. You’d like to restore the
database to a time as close as possible to the time the data was damaged.
In a typical restore, as I mentioned earlier, you have the choice of either specifying WITH
RECOVERY to roll back incomplete transactions or specifying WITH NORECOVERY. If you use WITH
RECOVERY, you can’t restore subsequent log backups, but the database is fully usable. If you run
WITH NORECOVERY, the database might be inconsistent, in which case SQL Server won’t let you
use it.
But what if you had a way to combine the two approaches by restoring one log backup, then
looking at the data before restoring more log backups? Such a combined approach would be
particularly helpful if you’re trying to do a point-in-time recovery but you don’t know what the right
point is.
Chapter 5 All About Restore
25
Brought to you by Neverfail and Windows IT Pro eBooks

SQL Server provides an option called STANDBY that lets you recover the database and still
restore more log backups. If you restore a log backup and specify
WITH STANDBY = ‘<some filename>’
SQL Server rolls back incomplete transactions but keeps a record of the rolled-back work in a
specified file called an undo file. The default suffix for this undo file is .ldf because its structure is just
like the transaction log’s structure, which also uses the .ldf suffix.
The next RESTORE LOG operation reads the contents of the undo file, redoes the operations that
were rolled back, then restores the log backup specified in the RESTORE LOG command. If that
RESTORE LOG command also specifies WITH STANDBY, the restore again rolls back incomplete
transactions but saves a record of those rolled-back transactions. After each RESTORE LOG ... WITH
STANDBY operation, the data is consistent because no half-completed transactions are included in
the database, so users can access the database and read the data. Thus, you can determine after
restoring each log whether a particular change has already taken place. (Keep in mind that you can’t
modify any data if you’ve restored WITH STANDBY—SQL Server generates an error message if you
try. But you can read the data and continue to restore more logs if you want to.) You must restore
the final log WITH RECOVERY (and SQL Server won’t keep an undo file) to make the database fully
usable.
You can use the RESTORE WITH STANDBY option to try to track down the time that data was
damaged, but the process isn’t fun. After you restore a log and discover that it contains the undesired
operation, you have to try to narrow down the time within that span of log records when the
damage occurred. You need to go all the way back to the beginning of the restore process and use
the STOPAT option to stop at some point in the middle of the time that the log backup spans. If you
examine the data and it’s still good, you know the damage happened at a later time; if the damage
already shows up, you know the change happened at an earlier time than the middle of the log
backup. You repeat this bisecting process, stopping either a little later or a little earlier in the log each
26
Backup and Recovery Survival Guide
Brought to you by Neverfail and Windows IT Pro eBooks
Planning the Space for a Restore
Each page in a database has a file number and a page number that uniquely identifies its location in the database.
When you restore a database, the pages keep their original file numbers and page numbers. Consequently, you must
replace the restored database in the same number of files as the original. If your original database contained five data
files, the new database must also have five data files. If the original database used only two data files—one for the
primary file and a 48GB file as the secondary data file, for example—you must use two data files for the restore, and
one of the files must be at least 48GB.
When you plan how many data files to use for your original database, remember that restoring to a smaller
number of physical files than you had originally is easier than restoring to a larger number because you can place
multiple logical files on one physical file, but you can’t place one logical file on multiple physical files. If the original
database had one 48GB file, you can’t restore it to more than one file. However, if you created your original
database in six 8GB files, you can restore to a 48GB physical disk by creating six files on the same disk, you can
restore to two 24GB disks that each contain three files, or you can restore to three 16GB disks.

time. This tedious process can help you recover to a time right before your data was damaged so
that you minimize your data loss.
Partial Restore
SQL Server 2000 lets you perform a partial restore of a database in emergencies. Although the
description and the syntax of a partial restore are similar to those of file and filegroup restores, the
operations are quite different. For restoring file and filegroup backups, you start with a complete
database and replace one or more files or filegroups with previously backed-up versions. (For details
about file and filegroup backups and restores, see the sidebar “Backing Up and Restoring Files and
Filegroups.”) For a partial database restore, you don’t start with a full database. You restore individual
filegroups (including the primary filegroup, which contains all the system tables) to a new location.
Any filegroups you don’t restore no longer exist, and SQL Server refers to them as offline when you
attempt to reference data stored in them.
After a partial restore, you can restore log backups or differential backups to bring the data in the
restored filegroups to a later point in time. A partial restore gives you the option of recovering the
data from a subset of tables after an accidental deletion or modification of table data. You can use
the partially restored database to extract the data from the lost tables, then copy the data back to
your original database.
Prepare for the Extraordinary
You can choose from many options when restoring a database, and you have to remember lots of
details. When your restore operations are successful, they seem easy and straightforward. However, if
you want to do anything unusual with your restore or if the process doesn’t work as you expect,
knowing what SQL Server is doing during the restore process and what SQL Server expects from you
can help prepare you for some of the possible extraordinary circumstances. Start now to develop
your step-by-step recovery plan, and test it to make sure it behaves as expected.
Chapter 5 All About Restore
27
Brought to you by Neverfail and Windows IT Pro eBooks
Wyszukiwarka
Podobne podstrony:
Team USA Preparing for the World Cup
#0892 Preparing for the Busy Season
The American Society for the Prevention of Cruelty
Preparing for Death and Helping the Dying Sangye Khadro
ESL Seminars Preparation Guide For The Test of Spoken Engl
The American Society for the Prevention of Cruelty
The Writing for the Disaster
A software authentication system for the prevention of computer viruses
What Curiosity in the Structure The Hollow Earth in Science by Duane Griffin MS Prepared for From
Preparing for Death and Helping the Dying Sangye Khadro
A Templar Encyclopedia Prepared by Ray V Denslow for the Grand Commandery Knights Templar in Missou
The Challenge of Being Prepared for Tomorrows MalWare Today
(ebook english) TOEFL Preparing Students for the Computer Based Test
#0918 Preparing for a Disaster
Interventions for the prevention of falls in older adults
Honing the Tip of the Spear Developing an Operational Level Intelligence Preparation of the Battlefi
CEN TR 15281 2006 Guidance on Inerting for the Prevention of Explosions
How to prepare for IELTS Speaking
Efficient VLSI architectures for the biorthogonal wavelet transform by filter bank and lifting sc
więcej podobnych podstron