Wysoko wydajne MySQL.
Optymalizacja, archiwizacja,
replikacja. Wydanie II
Autor: Baron Schwartz, Peter Zaitsev, Vadim Tkachenko,
Jeremy D. Zawodny, Arjen Lentz, Derek J. Balling
T³umaczenie: Robert Górczyñski
ISBN: 978-83-246-2055-5
Tytu³ orygina³u:
High Performance MySQL:
Optimization, Backups, Replication, and More, 2nd edition
Format: 168x237, stron: 712
Poznaj zaawansowane techniki i nieznane mo¿liwoœci MySQL!
•
Jak za pomoc¹ MySQL budowaæ szybkie i niezawodne systemy?
•
Jak przeprowadzaæ testy wydajnoœci?
•
Jak optymalizowaæ zaawansowane funkcje zapytañ?
MySQL jest ci¹gle udoskonalanym i rozbudowywanym oprogramowaniem. Stale
zwiêksza siê tak¿e liczba jego u¿ytkowników, wœród których nie brak wielkich
korporacji. Wynika to z niezawodnoœci i ogromnej, wci¹¿ rosn¹cej wydajnoœci tego
systemu zarz¹dzania. MySQL sprawdza siê tak¿e w bardzo wymagaj¹cych
œrodowiskach, na przyk³ad aplikacjach sieciowych, ze wzglêdu na du¿¹ elastycznoœæ
i mo¿liwoœci, takie jak zdolnoœæ wczytywania silników magazynu danych jako
rozszerzeñ w trakcie dzia³ania bazy.
Ksi¹¿ka
„
Wysoko wydajne MySQL. Optymalizacja, archiwizacja, replikacja. Wydanie II
”
szczegó³owo prezentuje zaawansowane techniki, dziêki którym mo¿na w pe³ni
wykorzystaæ ca³y potencja³, drzemi¹cy w MySQL. Omówiono w niej praktyczne,
bezpieczne i pozwalaj¹ce na osi¹gniêcie du¿ej wydajnoœci sposoby skalowania
aplikacji. Z tego przewodnika dowiesz siê, w jaki sposób projektowaæ schematy,
indeksy i zapytania. Poznasz tak¿e zaawansowane funkcje MySQL, pozwalaj¹ce na
uzyskanie maksymalnej wydajnoœci. Nauczysz siê tak dostrajaæ serwer MySQL, system
operacyjny oraz osprzêt komputerowy, aby wykorzystywaæ pe³niê ich mo¿liwoœci.
•
Architektura MySQL
•
Testy wydajnoœci i profilowanie
•
Optymalizacja schematu i indeksowanie
•
Optymalizacja wydajnoœci zapytañ
•
Przechowywanie kodu
•
Umieszczanie komentarzy w kodzie sk³adowym
•
Konfiguracja serwera
•
Dostrajanie i optymalizacja wyszukiwania pe³notekstowego
•
Skalowalnoœæ i wysoka dostêpnoœæ
•
WydajnoϾ aplikacji
•
Kopia zapasowa i odzyskiwanie
•
Interfejs SQL dla poleceñ spreparowanych
•
Bezpieczeñstwo
Twórz doskonale dostrojone aplikacje MySQL

3
Spis tre
ļci
Przedmowa .................................................................................................................... 7
Wprowadzenie ..............................................................................................................9
1. Architektura MySQL .................................................................................................... 19
Architektura logiczna MySQL
19
Kontrola wspóäbieĔnoĈci
22
Transakcje
24
Mechanizm Multiversion Concurrency Control
31
Silniki magazynu danych w MySQL
32
2. Okre
ļlanie wéskich gardeĥ: testy wydajnoļci i profilowanie .................................... 51
Dlaczego warto przeprowadziè testy wydajnoĈci?
52
Strategie przeprowadzania testów wydajnoĈci
53
Taktyki przeprowadzania testów wydajnoĈci
56
Narzödzia do przeprowadzania testów wydajnoĈci
61
Przykäadowe testy wydajnoĈci
64
Profilowanie
73
Profilowanie systemu operacyjnego
95
3. Optymalizacja schematu i indeksowanie ...................................................................99
Wybór optymalnego rodzaju danych
100
Podstawy indeksowania
115
Strategie indeksowania w celu osiñgniöcia maksymalnej wydajnoĈci
125
Studium przypadku z zakresu indeksowania
150
Obsäuga indeksu oraz tabeli
155
Uwagi dotyczñce silników magazynowania danych
168

4
_
Spis tre
ļci
4. Optymalizacja wydajno
ļci zapytaħ ...........................................................................171
Podstawy powolnych zapytaþ: optymalizacja dostöpu do danych
171
Sposoby restrukturyzacji zapytaþ
176
Podstawy wykonywania zapytaþ
179
Ograniczenia optymalizatora zapytaþ MySQL
198
Optymalizacja okreĈlonego rodzaju zapytaþ
207
Zmienne zdefiniowane przez uĔytkownika
217
5. Zaawansowane funkcje MySQL ................................................................................223
Bufor zapytaþ MySQL
223
Przechowywanie kodu wewnñtrz MySQL
236
Funkcje zdefiniowane przez uĔytkownika
248
System kodowania znaków i kolejnoĈè sortowania
255
Ograniczenia klucza zewnötrznego
270
Tabele Merge i partycjonowane
271
Transakcje rozproszone (XA)
280
6. Optymalizacja konfiguracji serwera .........................................................................283
Podstawy konfiguracji
284
Skäadnia, zasiög oraz dynamizm
285
Ogólne dostrajanie
289
Dostrajanie zachowania operacji I/O w MySQL
299
Dostosowanie wspóäbieĔnoĈci MySQL
314
7. Optymalizacja systemu operacyjnego i osprz
ýtu ....................................................325
Co ogranicza wydajnoĈè MySQL?
326
W jaki sposób wybraè procesor dla MySQL?
326
Wybór osprzötu komputerowego dla serwera podlegäego
337
Optymalizacja wydajnoĈci macierzy RAID
338
Urzñdzenia Storage Area Network oraz Network Attached Storage
345
UĔywanie woluminów skäadajñcych siö z wielu dysków
347
Stan systemu operacyjnego
356
8. Replikacja ...................................................................................................................363
Ogólny opis replikacji
363
Konfiguracja replikacji
367
Szczegóäy kryjñce siö za replikacjñ
375
Topologie replikacji
382
Replikacja i planowanie pojemnoĈci
397
Administracja replikacjñ i jej obsäuga
399
Problemy zwiñzane z replikacjñ i sposoby ich rozwiñzywania
409
Jak szybka jest replikacja?
428

Spis tre
ļci
_
5
9. Skalowalno
ļë i wysoka dostýpnoļë .......................................................................... 431
Terminologia
432
SkalowalnoĈè MySQL
434
Wysoka dostöpnoĈè
469
10. Optymalizacja na poziomie aplikacji ........................................................................479
Ogólny opis wydajnoĈci aplikacji
479
Kwestie zwiñzane z serwerem WWW
482
11. Kopia zapasowa i odzyskiwanie ...............................................................................495
Ogólny opis
496
Wady i zalety rozwiñzania
500
Zarzñdzanie kopiñ zapasowñ binarnych dzienników zdarzeþ i jej tworzenie
510
Tworzenie kopii zapasowej danych
512
Odzyskiwanie z kopii zapasowej
523
SzybkoĈè tworzenia kopii zapasowej i odzyskiwania
535
Narzödzia säuĔñce do obsäugi kopii zapasowej
536
Kopie zapasowe za pomocñ skryptów
543
12. Bezpiecze
ħstwo .........................................................................................................547
Terminologia
547
Podstawy dotyczñce kont
548
Bezpieczeþstwo systemu operacyjnego
566
Bezpieczeþstwo sieciowe
567
Szyfrowanie danych
575
MySQL w Ĉrodowisku chroot
579
13. Stan serwera MySQL ................................................................................................. 581
Zmienne systemowe
581
SHOW STATUS
582
SHOW INNODB STATUS
589
SHOW PROCESSLIST
602
SHOW MUTEX STATUS
603
Stan replikacji
604
INFORMATION_SCHEMA
605
14. Narz
ýdzia zapewniajéce wysoké wydajnoļë ...........................................................607
Narzödzia interfejsu
607
Narzödzia monitorowania
609
Narzödzia analizy
619
Narzödzia MySQL
622
đródäa dalszych informacji
625

6
_
Spis tre
ļci
A Przesy
ĥanie dużych plików ........................................................................................627
B U
żywanie polecenia EXPLAIN ................................................................................... 631
C U
żywanie silnika Sphinx w MySQL ...........................................................................647
D Usuwanie b
ĥýdów w blokadach ................................................................................675
Skorowidz ..................................................................................................................685

171
ROZDZIA
Ĥ 4.
Optymalizacja wydajno
ļci zapytaħ
W poprzednim rozdziale przeanalizowano sposoby optymalizacji schematu, która jest jed-
nym z niezbödnych warunków osiñgniöcia wysokiej wydajnoĈci. Jednak praca jedynie nad
schematem nie wystarczy — trzeba równieĔ prawidäowo zaprojektowaè zapytania. JeĔeli za-
pytania okaĔñ siö niewäaĈciwie przygotowane, nawet najlepiej zaprojektowany schemat bazy
nie bödzie dziaäaä wydajnie.
Optymalizacja zapytania, optymalizacja indeksu oraz optymalizacja schematu idñ röka w rökö.
Wraz z nabywaniem doĈwiadczenia w tworzeniu zapytaþ MySQL czytelnik odkryje takĔe,
jak projektowaè schematy pozwalajñce na efektywnñ obsäugö zapytaþ. Podobnie zdobyta
wiedza z zakresu projektowania zoptymalizowanych schematów wpäynie na rodzaj zapytaþ.
Ten proces wymaga czasu, dlatego teĔ autorzy zachöcajñ, aby powróciè do rozdziaäów bieĔñ-
cego i poprzedniego po zdobyciu wiökszej wiedzy.
Rozdziaä ten rozpoczyna siö od ogólnych rozwaĔaþ dotyczñcych projektowania zapytaþ — omó-
wione sñ tu elementy, na które powinno siö zwróciè uwagö w pierwszej kolejnoĈci, jeĈli zapyta-
nia nie dziaäajñ zgodnie z oczekiwaniami. Nastöpnie nieco dokäadniej zostanñ przedstawione
zagadnienia dotyczñce optymalizacji zapytaþ oraz wewnötrznego dziaäania serwera. Autorzy za-
demonstrujñ, jak moĔna poznaè sposób wykonywania okreĈlonego zapytania przez MySQL, a takĔe
zmieniè plan wykonywania zapytania. Wreszcie zostanñ przedstawione fragmenty zapytaþ,
w których MySQL nie przeprowadza zbyt dobrej optymalizacji. Czytelnik pozna równieĔ wzorce
optymalizacji pomagajñce MySQL w znacznie efektywniejszym wykonywaniu zapytaþ.
Celem autorów jest pomoc czytelnikowi w dokäadnym zrozumieniu sposobu, w jaki MySQL
faktycznie wykonuje zapytania. Pozwoli to na zorientowanie siö, co jest efektywne lub nieefek-
tywne, umoĔliwi wykorzystanie zalet bazy danych MySQL oraz uäatwi unikanie jej säabych stron.
Podstawy powolnych zapyta
ħ:
optymalizacja dost
ýpu do danych
Najbardziej podstawowym powodem säabej wydajnoĈci zapytania jest fakt, Ĕe obejmuje ono
zbyt duĔñ iloĈè danych. Niektóre zapytania po prostu muszñ dokäadnie przebadaè ogromnñ
iloĈè danych, wiöc w takich przypadkach niewiele moĔna zrobiè. Jednak to nietypowa sytu-
acja, wiökszoĈè bäödnych zapytaþ moĔna zmodyfikowaè, aby uzyskiwaäy dostöp do mniejszej
iloĈci danych. Autorzy odkryli, Ĕe uĔyteczne jest analizowanie zapytaþ o säabej wydajnoĈci
przy zastosowaniu dwóch kroków. Oto one.

172
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
1.
OkreĈlenie, czy aplikacja pobiera wiöcej danych, niĔ potrzebuje. Zazwyczaj oznacza to
uzyskanie dostöpu do zbyt wielu rekordów, ale moĔe równieĔ polegaè na uzyskiwaniu
dostöpu do zbyt wielu kolumn.
2.
OkreĈlenie, czy serwer MySQL analizuje wiöcej rekordów, niĔ potrzebuje.
Czy zapytanie bazy danych obejmuje dane, które s
é niepotrzebne?
Niektóre zapytania dotyczñ wiökszej iloĈci danych niĔ potrzeba, póĒniej czöĈè danych i tak
jest odrzucana. Wymaga to dodatkowej pracy ze strony serwera MySQL, zwiöksza obciñĔenie
sieci
1
, a takĔe zuĔywa pamiöè i zasoby procesora serwera aplikacji.
PoniĔej przedstawiono kilka typowych bäödów.
Pobieranie liczby rekordów wi
ökszej, niĔ to konieczne
NajczöĈciej popeänianym bäödem jest przyjöcie zaäoĔenia, Ĕe MySQL dostarcza wyniki na
Ĕñdanie, a nie generuje peänego zbioru wynikowego i zwraca go. Autorzy czösto spotykali siö
z tym bäödem w aplikacjach zaprojektowanych przez osoby znajñce zagadnienia zwiñzane
z systemami baz danych. ProgramiĈci ci uĔywali technik, takich jak wydawanie poleceþ
SELECT
zwracajñcych wiele rekordów, a nastöpnie pobierajñcych pierwsze N rekordów
i zamykajñcych zbiór wynikowy (np. pobranie stu ostatnich artykuäów dla witryny in-
formacyjnej, podczas gdy na stronie gäównej byäo wyĈwietlanych tylko dziesiöè z nich).
Tacy programiĈci sñdzñ, Ĕe baza danych MySQL dostarczy im dziesiöè rekordów, a na-
stöpnie zakoþczy wykonywanie zapytania. W rzeczywistoĈci MySQL generuje peäny
zbiór wynikowy. Biblioteka klienta pobiera wszystkie dane i odrzuca wiökszoĈè. Najlepszym
rozwiñzaniem jest dodanie do zapytania klauzuli
LIMIT
.
Pobieranie wszystkich kolumn ze z
äñczenia wielu tabel
JeĔeli programista chce pobraè wszystkich aktorów wystöpujñcych w filmie Academy Dinosaur,
nie naleĔy tworzyè zapytania w nastöpujñcy sposób:
mysql> SELECT * FROM sakila.actor
-> INNER JOIN sakila.film_actor USING(actor_id)
-> INNER JOIN sakila.film USING(film_id)
-> WHERE sakila.film.title = 'Academy Dinosaur';
PowyĔsze zapytanie zwróci wszystkie kolumny z wszystkich trzech tabel. W zamian trzeba
utworzyè nastöpujñce zapytanie:
mysql> SELECT sakila.actor.* FROM sakila.actor...;
Pobieranie wszystkich kolumn
Zawsze warto podejrzliwie spojrzeè na zapytania typu
SELECT *
. Czy naprawdö potrzebne
sñ wszystkie kolumny? Prawdopodobnie nie. Pobieranie wszystkich kolumn uniemoĔliwia
optymalizacjö w postaci np. zastosowania indeksu pokrywajñcego, a ponadto zwiöksza
obciñĔenie serwera wynikajñce z wykonywania operacji I/O, wiökszego zuĔycia pamiöci
i mocy obliczeniowej procesora.
Niektórzy administratorzy baz danych z wymienionych powyĔej powodów w ogóle
uniemoĔliwiajñ wykonywanie poleceþ
SELECT *
. Takie rozwiñzanie ogranicza równieĔ
ryzyko wystñpienia problemów, gdy ktokolwiek zmieni listö kolumn tabeli.
1
ObciñĔenie sieci ma jeszcze powaĔniejsze znaczenie, jeĔeli aplikacja znajduje siö na serwerze innym od samego
serwera MySQL. Jednak transfer danych miödzy MySQL i aplikacjñ nie jest bez znaczenia nawet wtedy, kiedy
i MySQL, i aplikacja znajdujñ siö na tym samym serwerze.

Podstawy powolnych zapyta
ħ: optymalizacja dostýpu do danych
_ 173
OczywiĈcie, zapytanie pobierajñce iloĈè danych wiökszñ, niĔ faktycznie potrzeba, nie zawsze
bödzie zäe. W wielu analizowanych przypadkach programiĈci twierdzili, Ĕe takie marno-
trawne podejĈcie upraszcza proces projektowania, a takĔe pozwala na uĔywanie tego samego
fragmentu kodu w wiöcej niĔ tylko jednym miejscu. To doĈè rozsñdne powody, przynajmniej
tak däugo, jak däugo programista jest Ĉwiadom kosztów mierzonych wydajnoĈciñ. Pobieranie
wiökszej iloĈci danych, niĔ w rzeczywistoĈci potrzeba, moĔe byè uĔyteczne takĔe w przypadku
stosowania w aplikacji pewnego rodzaju buforowania lub po uwzglödnieniu innych korzyĈci.
Pobieranie i buforowanie peänych obiektów moĔe byè bardziej wskazane niĔ wykonywanie
wielu oddzielnych zapytaþ, które pobierajñ jedynie fragmenty obiektu.
Czy MySQL analizuje zbyt du
żé iloļë danych?
Po upewnieniu siö, Ĕe zapytania pobierajñ jedynie potrzebne dane, moĔna zajñè siö zapytania-
mi, które podczas generowania wyniku analizujñ zbyt wiele danych. W bazie danych MySQL
najprostsze metody oceny kosztu zapytania to:
x
czas wykonywania zapytania,
x
liczba przeanalizowanych rekordów,
x
liczba zwróconych rekordów.
ēadna z wymienionych miar nie jest doskonaäym sposobem pomiaru kosztu zapytania, ale
w przybliĔeniu okreĈlajñ one iloĈè danych, do których MySQL musi wewnötrznie uzyskaè
dostöp, aby wykonaè zapytanie. W przybliĔeniu podajñ takĔe szybkoĈè wykonywania zapytania.
Wszystkie trzy wymienione miary sñ rejestrowane w dzienniku wolnych zapytaþ. Dlatego
teĔ przejrzenie tego dziennika jest jednym z najlepszych sposobów wykrycia zapytaþ, które
analizujñ zbyt wiele danych.
Czas wykonywania zapytania
Jak wspomniano w rozdziale 2., standardowa funkcja rejestrowania wolnych zapytaþ w MySQL 5.0
oraz wczeĈniejszych wersjach posiada wiele ograniczeþ, m.in. brakuje obsäugi bardziej szcze-
góäowego poziomu rejestrowania. Na szczöĈcie, istniejñ poprawki pozwalajñce na rejestrowa-
nie i analizowanie wolnych zapytaþ z dokäadnoĈciñ wyraĔanñ w mikrosekundach. Poprawki
wprowadzono w MySQL 5.1, ale moĔna je zastosowaè we wczeĈniejszych wersjach serwera,
jeĈli trzeba. NaleĔy pamiötaè, aby nie käaĈè zbyt duĔego nacisku na czas wykonywania za-
pytania. Warto traktowaè go jak miarö obiektywnñ, która nie zachowuje spójnoĈci w róĔnych
warunkach obciñĔenia. Inne czynniki — takie jak blokady silnika magazynu danych (blokady
tabeli i rekordów), wysoki poziom wspóäbieĔnoĈci i uĔywany osprzöt komputerowy — rów-
nieĔ mogñ mieè istotny wpäyw na czas wykonywania zapytania. Miara ta bödzie uĔyteczna
podczas wyszukiwania zapytaþ, które najbardziej wpäywajñ na czas udzielenia odpowiedzi
przez aplikacjö i najbardziej obciñĔajñ serwer, ale nie odpowie na pytanie, czy rzeczywisty
czas udzielenia odpowiedzi jest rozsñdny dla zapytania o podanym stopniu zäoĔonoĈci.
(Czas wykonywania zapytania moĔe byè zarówno symptomem, jak i Ēródäem problemów,
i nie zawsze jest oczywiste, z którym przypadkiem mamy do czynienia).

174
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Rekordy przeanalizowane i rekordy zwrócone
Podczas analizowania zapytaþ warto pochyliè siö nad liczbñ rekordów sprawdzanych przez
zapytanie, poniewaĔ dziöki temu moĔna poznaè efektywnoĈè zapytaþ w wyszukiwaniu po-
trzebnych danych. Jednak, podobnie jak w przypadku czasu wykonywania zapytania, nie
jest to doskonaäa miara w trakcie wyszukiwania bäödnych zapytaþ. Nie wszystkie operacje
dostöpu do rekordów sñ takie same. Krótsze rekordy pozwalajñ na szybszy dostöp, a pobie-
ranie rekordów z pamiöci jest znacznie szybsze niĔ ich odczytywanie z dysku twardego.
W idealnej sytuacji liczba przeanalizowanych rekordów powinna byè równa liczbie zwróco-
nych rekordów, ale w praktyce rzadko ma to miejsce. Przykäadowo podczas budowania re-
kordów w operacjach zäñczeþ w celu wygenerowania kaĔdego rekordu zbioru wynikowego
serwer musi uzyskaè dostöp do wielu innych rekordów. Wspóäczynnik liczby rekordów prze-
analizowanych do liczby rekordów zwróconych zwykle jest maäy — powiedzmy miödzy 1:1
i 10:1 — ale czasami moĔe byè wiökszy o rzñd wielkoĈci.
Rekordy przeanalizowane i rodzaje dost
ýpu do danych
Podczas zastanawiania siö nad kosztem zapytania trzeba rozwaĔyè takĔe koszt zwiñzany ze
znalezieniem pojedynczego rekordu w tabeli. Baza danych moĔe uĔywaè wiele metod dostöpu
pozwalajñcych na odszukanie i zwrócenie rekordu. Niektóre z nich wymagajñ przeanalizo-
wania wielu rekordów, podczas gdy inne mogñ mieè moĔliwoĈè wygenerowania wyniku bez
potrzeby analizowania jakiegokolwiek rekordu.
Rodzaj metody (lub metod) dostöpu jest wyĈwietlany w kolumnie
type
danych wyjĈciowych
polecenia
EXPLAIN
. Zakres stosowanych rodzajów dostöpu obejmuje zarówno peäne skano-
wanie tabeli, jak i skanowanie indeksu, a takĔe skanowanie zakresu, wyszukiwanie unikal-
nego indeksu oraz staäych. KaĔda z nich jest szybsza od poprzedniej, poniewaĔ wymaga od-
czytu mniejszej iloĈci danych. Czytelnik nie musi uczyè siö na pamiöè metod dostöpu, ale
powinien zrozumieè ogólnñ koncepcjö skanowania tabeli, skanowania indeksu, dostöpu do
zakresu oraz dostöpu do pojedynczej wartoĈci.
JeĔeli uĔywana metoda dostöpu jest nieodpowiednia, wówczas najlepszym sposobem roz-
wiñzania problemu zwykle bödzie dodanie wäaĈciwego indeksu. Szczegóäowe omówienie in-
deksów przedstawiono w poprzednim rozdziale. Teraz widaè, dlaczego indeksy sñ tak waĔne
podczas optymalizacji zapytaþ. Indeksy pozwalajñ bazie danych MySQL na wyszukiwanie
rekordów za pomocñ efektywniejszych metod dostöpu, które analizujñ mniejszñ iloĈè danych.
Warto np. spojrzeè na proste zapytanie do przykäadowej bazy danych
Sakila
:
mysql> SELECT * FROM sakila.film_actor WHERE film_id = 1;
PowyĔsze zapytanie zwróci dziesiöè rekordów, a polecenie
EXPLAIN
pokazuje, Ĕe w celu wy-
konania zapytania MySQL stosuje metodö dostöpu
ref
wzglödem indeksu
idx_fk_film
:
mysql> EXPLAIN SELECT * FROM sakila.film_actor WHERE film_id = 1\G
*************************** Rekord 1. ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: ref
possible_keys: idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: const
rows: 10
Extra:

Podstawy powolnych zapyta
ħ: optymalizacja dostýpu do danych
_ 175
Dane wyjĈciowe polecenia
EXPLAIN
pokazujñ, Ĕe baza danych MySQL oszacowaäa na dziesiöè
liczbö rekordów, do których musi uzyskaè dostöp. Innymi säowy, optymalizator wiedziaä,
Ĕe wybrana metoda dostöpu jest wystarczajñca w celu efektywnego wykonania zapytania.
Co siö stanie, jeĔeli dla zapytania nie zostanie znaleziony odpowiedni indeks? Serwer MySQL
moĔe wykorzystaè mniej optymalnñ metodö dostöpu, o czym moĔna siö przekonaè, usuwajñc
indeks i ponownie wydajñc to samo polecenie:
mysql> ALTER TABLE sakila.film_actor DROP FOREIGN KEY fk_film_actor_film;
mysql> ALTER TABLE sakila.film_actor DROP KEY idx_fk_film_id;
mysql> EXPLAIN SELECT * FROM sakila.film_actor WHERE film_id = 1\G
*************************** Rekord 1. ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 5073
Extra: Using where
Zgodnie z przewidywaniami, metoda dostöpu zostaäa zmieniona na peäne skanowanie tabeli
(
ALL
) i baza danych MySQL oszacowaäa, Ĕe musi przeanalizowaè 5073 rekordy, aby wykonaè
zapytanie. Ciñg tekstowy „Using where” w kolumnie
Extra
wskazuje, Ĕe serwer MySQL uĔywa
klauzuli
WHERE
do odrzucenia rekordów po ich odczytaniu przez silnik magazynu danych.
Ogólnie rzecz biorñc, MySQL moĔe zastosowaè klauzulö
WHERE
na trzy wymienione niĔej
sposoby, od najlepszego do najgorszego.
x
Zastosowanie warunków w operacji przeszukiwania indeksu w celu wyeliminowania
niepasujñcych rekordów. To zachodzi na poziomie silnika magazynu danych.
x
UĔycie indeksu pokrywajñcego (ciñg tekstowy „Using index” w kolumnie
Extra
) w celu
unikniöcia bezpoĈredniego dostöpu do rekordu i odfiltrowanie niepasujñcych rekordów
po pobraniu kaĔdego wyniku z indeksu. To zachodzi na poziomie serwera, ale nie wymaga
odczytywania rekordów z tabeli.
x
Pobranie rekordów z tabeli, a nastöpnie odfiltrowanie niepasujñcych (ciñg tekstowy „Using
where” w kolumnie
Extra
). To zachodzi na poziomie serwera i wymaga, aby serwer od-
czytaä rekordy z tabeli przed rozpoczöciem ich filtrowania.
PowyĔszy przykäad pokazuje wiöc, jak waĔne jest tworzenie wäaĈciwych indeksów. Dobre
indeksy pomagajñ zapytaniom w wyborze lepszej metody dostöpu, a tym samym powodujñ
analizowanie jedynie potrzebnych rekordów. Jednak dodanie indeksu nie zawsze oznacza, Ĕe
baza danych MySQL uzyska dostöp i zwróci tö samñ liczbö rekordów. PoniĔej jako przykäad
przedstawiono zapytanie uĔywajñce funkcji agregujñcej
COUNT()
2
:
mysql> SELECT actor_id, COUNT(*) FROM sakila.film_actor GROUP BY actor_id;
PowyĔsze zapytanie zwróci jedynie 200 rekordów, ale w celu zbudowania zbioru wynikowe-
go musi ich odczytaè tysiñce. W takim zapytaniu indeks nie zredukuje liczby analizowanych
rekordów.
2
Wiöcej informacji na ten temat przedstawiono w podrozdziale „Optymalizacja zapytaþ COUNT()”, znajdujñcym
siö w dalszej czöĈci rozdziaäu.

176
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Niestety, baza danych MySQL nie wskaĔe programiĈcie liczby rekordów, do których uzy-
skaäa dostöp podczas budowy zbioru wynikowego, informuje jedynie o ogólnej liczbie rekor-
dów, z których skorzystaäa. Wiele tych rekordów mogäoby zostaè wyeliminowanych za po-
mocñ klauzuli
WHERE
, a tym samym nie braäoby udziaäu w budowaniu zbioru wynikowego.
W poprzednim przykäadzie po usuniöciu indeksu z tabeli
sakila.film_actor
zapytanie
sprawdzaäo kaĔdy rekord tabeli, a klauzula
WHERE
odrzuciäa wszystkie, poza dziesiöcioma.
A wiöc pozostawione dziesiöè rekordów utworzyäo zbiór wynikowy. Zrozumienie, ile rekor-
dów serwer przeanalizuje i ile faktycznie zostanie uĔytych do zbudowania zbioru wyniko-
wego, wymaga umiejötnoĈci wyciñgania wniosków z zapytania.
JeĔeli programista stwierdzi, Ĕe w celu zbudowania zbioru wynikowego obejmujñcego wzglöd-
nie maäñ liczbö rekordów jest analizowana duĔa liczba rekordów, wówczas moĔna wypró-
bowaè bardziej zaawansowane techniki, czyli:
x
uĔycie indeksów pokrywajñcych przechowujñcych dane, wtedy silnik magazynu danych
nie musi pobieraè peänych rekordów (indeksy pokrywajñce zostaäy omówione w po-
przednim rozdziale),
x
zmianö schematu; moĔna np. zastosowaè tabele podsumowaþ (omówione w poprzednim
rozdziale),
x
przepisanie skomplikowanego zapytania, aby optymalizator MySQL mógä wykonaè je
w sposób optymalny (temat ten zostaä przedstawiony w dalszej czöĈci rozdziaäu).
Sposoby restrukturyzacji zapyta
ħ
Podczas optymalizacji problematycznych zapytaþ celem powinno byè odnalezienie alterna-
tywnych sposobów otrzymania poĔñdanego wyniku — choè niekoniecznie oznacza to otrzy-
manie takiego samego wyniku z bazy danych MySQL. Czasami zapytania udaje przeksztaäciè
siö tak, aby uzyskaè jeszcze lepszñ wydajnoĈè. Jednak warto takĔe rozwaĔyè napisanie zapy-
tania od nowa w celu otrzymania innych wyników, jeĈli przyniesie to znaczñce korzyĈci
w zakresie wydajnoĈci. Byè moĔe programista bödzie mógä ostatecznie wykonaè to samo
zadanie poprzez zmianö zarówno kodu aplikacji, jak i zapytania. W podrozdziale zostanñ
przedstawione techniki, które mogñ pomóc w restrukturyzacji szerokiego zakresu zapytaþ,
a takĔe przykäady, kiedy moĔna zastosowaè kaĔdñ z omówionych technik.
Zapytanie skomplikowane kontra wiele mniejszych
Oto jedno z najwaĔniejszych pytaþ dotyczñcych projektu: „Czy bardziej poĔñdane jest
podzielenie zapytania skomplikowanego na kilka prostszych?”. Tradycyjne podejĈcie do
projektu bazy danych käadzie nacisk na wykonanie maksymalnej iloĈci pracy za pomocñ mi-
nimalnej moĔliwej liczby zapytaþ. Takie podejĈcie byäo w przeszäoĈci uznawane za lepsze
z powodu kosztu komunikacji sieciowej oraz obciñĔenia na etapie przetwarzania zapytania
i optymalizacji.
Jednak rada ta nie zawsze jest wäaĈciwa w przypadku bazy danych MySQL, poniewaĔ zo-
staäa ona zaprojektowana w celu efektywnej obsäugi operacji nawiñzywania i zamykania po-
äñczenia oraz szybkiego udzielania odpowiedzi na maäe i proste zapytania. Nowoczesne sieci
sñ równieĔ znacznie szybsze niĔ w przeszäoĈci, co zmniejsza ich opóĒnienie. Serwer MySQL

Sposoby restrukturyzacji zapyta
ħ
_
177
moĔe wykonywaè ponad 50000 prostych zapytaþ na sekundö, korzystajñc z przeciötnego
osprzötu komputerowego, oraz ponad 2000 zapytaþ na sekundö poprzez pojedynczy port
sieciowy o przepustowoĈci gigabitu. Dlatego teĔ wykonywanie wielu zapytaþ niekoniecznie
musi byè zäym rozwiñzaniem.
Czas udzielenia odpowiedzi poprzez sieè nadal jest stosunkowo däugi w porównaniu do
liczby rekordów, które MySQL moĔe wewnötrznie przekazywaè w ciñgu sekundy. Wymie-
nionñ liczbö szacuje siö na milion w ciñgu sekundy w przypadku danych znajdujñcych siö
w pamiöci. Zatem nadal dobrym pomysäem jest stosowanie minimalnej liczby zapytaþ po-
zwalajñcej na wykonanie zadania. Jednak czasami zapytanie moĔe byè bardziej efektywne po
rozäoĔeniu na czöĈci i wykonaniu kilku prostych zapytaþ zamiast jednego zäoĔonego. Nie
naleĔy siö obawiaè tego rodzaju sytuacji, najlepiej oceniè koszty, a nastöpnie wybraè strategiö
wymagajñcñ mniejszego nakäadu pracy. Przykäady takiej techniki zostanñ zaprezentowane
w dalszej czöĈci rozdziaäu.
Majñc to na uwadze, warto pamiötaè, Ĕe uĔywanie zbyt wielu zapytaþ jest bäödem czösto po-
peänianym w projekcie aplikacji. Przykäadowo niektóre aplikacje wykonujñ dziesiöè zapytaþ
pobierajñcych pojedynczy rekord danych z tabeli, zamiast uĔyè jednego pobierajñcego dziesiöè
rekordów. Autorzy spotkali siö z aplikacjami pobierajñcymi oddzielnie kaĔdñ kolumnö, czyli
wykonujñcymi wielokrotne zapytania do kaĔdego rekordu!
Podzia
ĥ zapytania
Innym sposobem podziaäu zapytania jest technika „dziel i rzñdĒ”, w zasadzie oznaczajñca to
samo, ale przeprowadzana w mniejszych „fragmentach”, które kaĔdorazowo wpäywajñ na
mniejszñ liczbö rekordów.
Usuwanie starych danych to doskonaäy przykäad. Okresowe zadania czyszczñce mogñ mieè
do usuniöcia caäkiem sporñ iloĈè danych, a wykonanie tego za pomocñ jednego ogromnego
zapytania moĔe na bardzo däugi czas zablokowaè duĔñ iloĈè rekordów, zapeäniè dziennik
zdarzeþ transakcji, zuĔyè wszystkie dostöpne zasoby oraz zablokowaè maäe zapytania, któ-
rych wykonywanie nie powinno byè przerywane. Podziaä zapytania
DELETE
i uĔycie zapytaþ
o Ĉredniej wielkoĈci moĔe znaczñco wpäynñè na zwiökszenie wydajnoĈci oraz zredukowaè
opóĒnienie podczas replikacji tego zapytania. Przykäadowo zamiast wykonywania przedsta-
wionego poniĔej monolitycznego zapytania:
mysql> DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH);
warto wykonaè poniĔszy pseudokod:
rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH)
LIMIT 10000")
} while rows_affected > 0
Usuniöcie jednorazowo dziesiöciu tysiöcy rekordów jest zazwyczaj na tyle duĔym zadaniem,
aby spowodowaè efektywne wykonanie kaĔdego zapytania, i jednoczeĈnie na tyle krótkim, aby
zminimalizowaè jego wpäyw na serwer
3
(silniki magazynu danych obsäugujñce transakcje mogñ
osiñgnñè lepszñ wydajnoĈè podczas wykonywania mniejszych zapytaþ). Dobrym rozwiñzaniem
3
Narzödzie mk-archiver z pakietu Maatkit bardzo äatwo wykonuje takie zadania.

178
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
moĔe byè równieĔ zastosowanie pewnego rodzaju przerwy miödzy poleceniami
DELETE
.
W ten sposób nastöpuje rozäoĔenie obciñĔenia w czasie oraz zredukowanie okresu czasu,
przez który sñ naäoĔone blokady.
Podzia
ĥ zĥéczeħ
Wiele witryn internetowych o wysokiej wydajnoĈci stosuje podziaä zäñczeþ, który polega na
rozdzieleniu jednego zäñczenia obejmujñcego wiele tabel na kilka zapytaþ obejmujñcych jednñ
tabelö, a nastöpnie wykonaniu zäñczenia w aplikacji. I tak zamiast poniĔszego zapytania:
mysql> SELECT * FROM tag
-> JOIN tag_post ON tag_post.tag_id=tag.id
-> JOIN post ON tag_post.post_id=post.id
-> WHERE tag.tag='mysql';
moĔna wykonaè nastöpujñce:
mysql> SELECT * FROM tag WHERE tag='mysql';
mysql> SELECT * FROM tag_post WHERE tag_id=1234;
mysql> SELECT * FROM post WHERE post.id in (123,456,567,9098,8904);
Na pierwszy rzut oka wyglñda to na marnotrawstwo, poniewaĔ zwiökszono liczbö zapytaþ
bez otrzymania innych wyników. Jednak tego rodzaju restrukturyzacja moĔe w rzeczywistoĈci
przynieĈè wyraĒne korzyĈci w zakresie wydajnoĈci.
x
Buforowanie moĔe byè efektywniejsze. Wiele aplikacji buforuje „obiekty”, które mapujñ
bezpoĈrednio do tabel. W przedstawionym powyĔej przykäadzie aplikacja pominie
pierwsze zapytanie, jeĔeli obiekt ze znacznikiem
mysql
jest juĔ buforowany. JeĔeli w bu-
forze znajdñ siö posty o wartoĈci identyfikatora
id
wynoszñcej 123, 567 lub 9098, wtedy
moĔna usunñè je z listy
IN()
. Bufor zapytania takĔe moĔe skorzystaè na takiej strategii.
JeĈli czöstym zmianom ulega tylko jedna tabela, podziaä zäñczenia moĔe zredukowaè
liczbö nieprawidäowoĈci w buforze.
x
W tabelach MyISAM wykonywanie jednego zapytania na tabelö znacznie efektywniej
stosuje blokady tabel: zapytania blokujñ tabele po kolei i na wzglödnie krótki okres czasu,
zamiast jednoczeĈnie zablokowaè wszystkie na däuĔszy okres czasu.
x
Przeprowadzanie zäñczeþ w aplikacji znacznie uäatwia skalowalnoĈè bazy danych poprzez
umieszczenie tabel w róĔnych serwerach.
x
Same zapytania równieĔ mogñ byè efektywniejsze. W powyĔszym przykäadzie uĔycie listy
IN()
zamiast zäñczenia pozwala serwerowi MySQL na sortowanie identyfikatorów rekor-
dów i bardziej optymalne pobieranie rekordów, niĔ byäoby to moĔliwe za pomocñ zäñczenia.
Zostanie to szczegóäowo omówione w dalszej czöĈci rozdziaäu.
x
Istnieje moĔliwoĈè zmniejszenia liczby nadmiarowych operacji dostöpu do rekordów. Prze-
prowadzenie zäñczenia w aplikacji oznacza, Ĕe kaĔdy rekord jest pobierany tylko jednokrot-
nie, podczas gdy zäñczenie w zapytaniu w zasadzie jest denormalizacjñ, która moĔe wymagaè
wielokrotnego dostöpu do tych samych danych. Z tego samego powodu restrukturyzacja
taka moĔe teĔ zredukowaè ogólny poziom ruchu sieciowego oraz zuĔycie pamiöci.
x
W pewnej mierze technikö tö moĔna potraktowaè jako röcznñ implementacjö zäñczenia
typu hash zamiast algorytmu zagnieĔdĔonych pötli uĔywanych przez MySQL do prze-
prowadzenia zäñczenia. Takie zäñczenie typu hash moĔe byè efektywniejsze. (Strategie
zäñczeþ w MySQL zostaäy przeanalizowane w dalszej czöĈci rozdziaäu).
Podstawy wykonywania zapyta
ħ
_ 179
Podsumowanie. Kiedy przeprowadzanie z
ĥéczeħ w aplikacji
mo
że byë efektywniejsze?
Przeprowadzanie zäñczeþ w aplikacji moĔe byè efektywniejsze, gdy:
x
buforowana i ponownie uĔywana jest duĔa iloĈè danych z poprzednich zapytaþ,
x
uĔywanych jest wiele tabel MyISAM,
x
dane sñ rozproszone na wielu serwerach,
x
w ogromnych tabelach zäñczenia sñ zastöpowane listami
IN()
,
x
zäñczenie odwoäuje siö wielokrotnie do tej samej tabeli.
Podstawy wykonywania zapyta
ħ
JeĔeli programiĈcie zaleĔy na osiñgniöciu wysokiej wydajnoĈci dziaäania serwera MySQL,
jednñ z najlepszych inwestycji bödzie poznanie sposobów, w jakie MySQL optymalizuje i wy-
konuje zapytania. Po zrozumieniu tego zagadnienia wiökszoĈè procesów optymalizacji za-
pytania stanie siö po prostu kwestiñ wyciñgania odpowiednich wniosków, a sama optymali-
zacja zapytania okaĔe siö procesem logicznym.
W poniĔszej analizie autorzy zakäadajñ, Ĕe czytelnik zapoznaä siö z rozdziaäem 2.,
w którym przedstawiono m.in. silniki wykonywania zapytaþ w MySQL i podstawy
ich dziaäania.
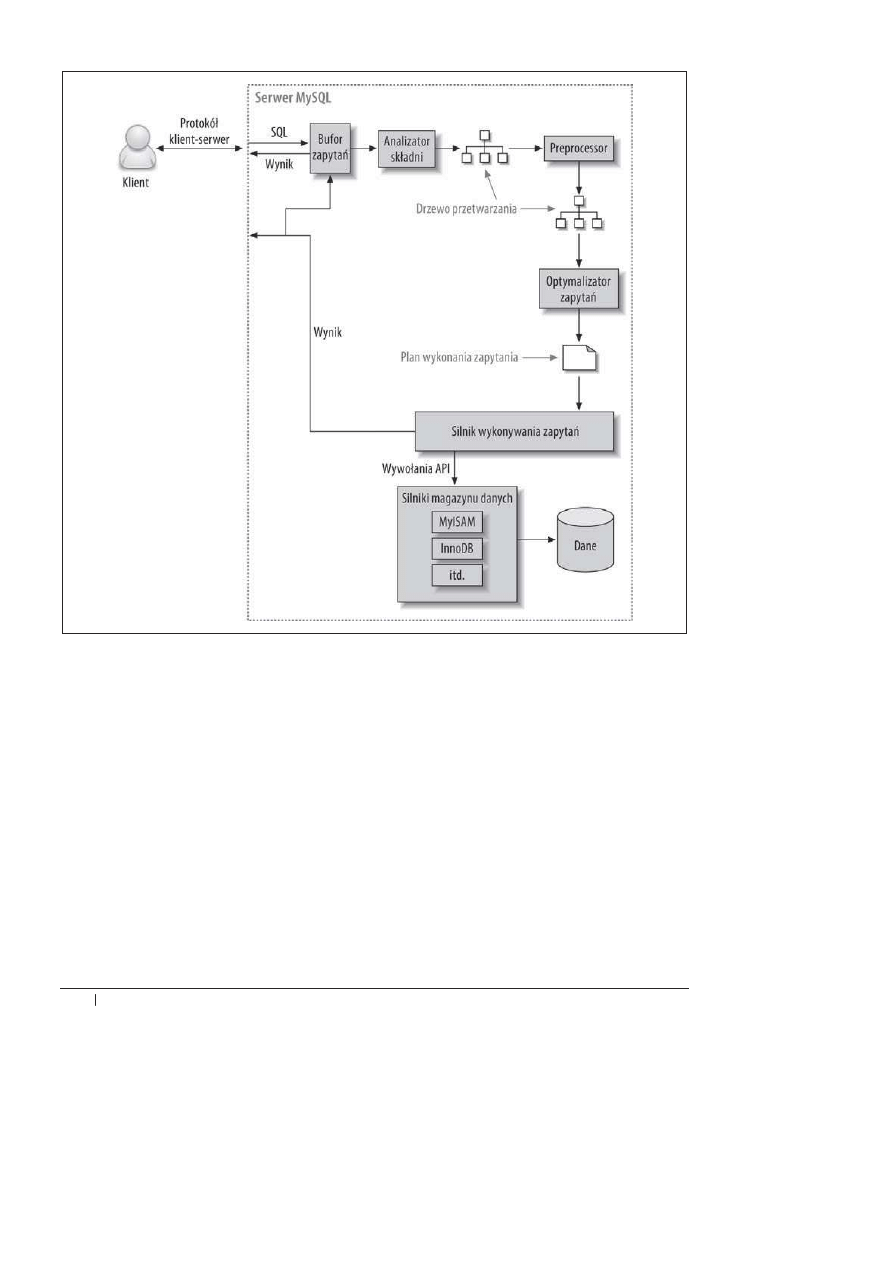
Na rysunku 4.1 pokazano ogólny sposób wykonywania zapytaþ przez MySQL.
Korzystajñc z rysunku, moĔna zilustrowaè procesy zachodzñce po wysäaniu zapytania do
MySQL.
1.
Klient wysyäa polecenie SQL do serwera.
2.
Serwer sprawdza bufor zapytaþ. JeĔeli dane zapytanie znajduje siö w buforze, wyniki sñ
pobierane z bufora. W przeciwnym razie polecenie SQL zostaje przekazane do kolejnego
kroku.
3.
Serwer analizuje, przetwarza i optymalizuje SQL na postaè planu wykonania zapytania.
4.
Silnik wykonywania zapytaþ realizuje plan poprzez wykonanie wywoäaþ do API silnika
magazynu danych.
5.
Serwer zwraca klientowi wyniki zapytania.
KaĔdy z powyĔszych kroków wiñĔe siö z pewnym poziomem zäoĔonoĈci, co bödzie przeana-
lizowane w kolejnych podrozdziaäach. Ponadto zostanñ przedstawione stany, w których za-
pytanie znajduje siö podczas realizacji poszczególnych kroków. Proces optymalizacji zapytania
jest szczególnie zäoĔony i jednoczeĈnie najwaĔniejszy do zrozumienia.
180
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Rysunek 4.1. Ogólny sposób wykonywania zapytania w MySQL
Protokó
ĥ klient-serwer MySQL
ChociaĔ nie jest konieczne zrozumienie wewnötrznych szczegóäów protokoäu klient-serwer
MySQL, jednak trzeba zrozumieè jego dziaäanie na wysokim poziomie. Protokóä jest póädu-
pleksowy, co oznacza, Ĕe w danej chwili serwer MySQL moĔe albo wysyäaè, albo odbieraè
komunikaty, ale nie jedno i drugie jednoczeĈnie. Oznacza to takĔe brak moĔliwoĈci skrócenia
komunikatu.
Protokóä powoduje, Ĕe komunikacja MySQL jest prosta i szybka, ale równoczeĈnie na pewne
sposoby jñ ogranicza. Z tego powodu brakuje kontroli przepäywu — kiedy jedna strona wyĈle
komunikat, druga strona musi pobraè caäy komunikat, zanim bödzie mogäa udzieliè odpo-
wiedzi. Przypomina to grö polegajñcñ na rzucaniu piäki miödzy uczestnikami: w danej chwili
tylko jeden gracz ma piäkö, a wiöc inny gracz nie moĔe rzuciè piäkñ (wysäaè komunikatu),
zanim faktycznie jej nie otrzyma.

Podstawy wykonywania zapyta
ħ
_
181
Klient wysyäa zapytanie do serwera jako pojedynczy pakiet danych. To jest powód, dla któ-
rego konfiguracja zmiennej
max_packet_size
ma tak istotne znaczenie, gdy wykonywane sñ
ogromne zapytania
4
. Po wysäaniu zapytania przez klienta piäka nie znajduje siö juĔ po jego
stronie i moĔe jedynie czekaè na otrzymanie wyników.
Natomiast odpowiedĒ udzielana przez serwer, w przeciwieþstwie do zapytania, zwykle
skäada siö z wielu pakietów danych. Kiedy serwer udzieli odpowiedzi, klient musi otrzymaè
ca
äy zbiór wynikowy. Nie moĔe pobraè kilku rekordów, a nastöpnie poprosiè serwer o za-
przestanie wysyäania pozostaäych. JeĔeli klientowi potrzebne jest jedynie kilka pierwszych
rekordów ze zbioru wynikowego, to albo moĔe poczekaè na otrzymanie wszystkich pakietów
wysäanych przez serwer i odrzuè niepotrzebne, albo w sposób nieelegancki zerwaè poäñczenie.
ēadna z wymienionych moĔliwoĈci nie jest dobrym rozwiñzaniem i to kolejny powód, dla
którego odpowiednie klauzule
LIMIT
majñ tak istotne znaczenie.
Oto inny sposób przedstawienia tego procesu: kiedy klient pobiera rekordy z serwera, wtedy
sñdzi, Ĕe je wyciñga. Jednak w rzeczywistoĈci to serwer MySQL wypycha rekordy podczas ich
generowania. Klient jest jedynie odbiorcñ wypchniötych rekordów, nie ma moĔliwoĈci naka-
zania serwerowi, aby zaprzestaä wysyäania rekordów. UĔywajñc innego porównania, moĔna
powiedzieè, Ĕe „klient pije z wöĔa straĔackiego”. (Tak, to jest pojöcie techniczne).
WiökszoĈè bibliotek nawiñzujñcych poäñczenie z bazñ danych MySQL pozwala na pobranie
caäego zbioru wynikowego i jego buforowanie w pamiöci albo pobieranie poszczególnych
rekordów, gdy bödñ potrzebne. Zazwyczaj zachowaniem domyĈlnym jest pobranie caäego
zbioru wynikowego i buforowanie go w pamiöci. To jest bardzo waĔne, poniewaĔ dopóki
wszystkie rekordy nie zostanñ dostarczone, dopóty serwer MySQL nie zwolni blokad oraz
innych zasobów wymaganych przez dane zapytanie. Zapytanie bödzie znajdowaäo siö w stanie
„Sending data” (stany zostanñ omówione w kolejnym podrozdziale zatytuäowanym „Stany
zapytania”). Kiedy biblioteka klienta jednorazowo pobierze wszystkie rekordy, wtedy redukuje
iloĈè pracy wykonywanñ przez serwer: tzn. serwer moĔe zakoþczyè wykonywanie zapytania
i przeprowadziè czyszczenie po nim tak szybko, jak to moĔliwe.
WiökszoĈè bibliotek klienckich pozwala na traktowanie zbioru wynikowego tak, jakby byä pobie-
rany z serwera. Jednak w rzeczywistoĈci rekordy sñ pobierane z bufora w pamiöci biblioteki.
W wiökszoĈci sytuacji takie rozwiñzanie sprawdza siö doskonale, ale nie jest odpowiednie dla
ogromnych zbiorów wynikowych, poniewaĔ ich pobranie zabiera duĔo czasu oraz wymaga du-
Ĕych iloĈci pamiöci. Poprzez zakazanie bibliotece buforowania wyniku moĔna uĔyè mniejszej ilo-
Ĉci pamiöci oraz szybciej rozpoczñè pracö ze zbiorem wynikowym. Wadñ takiego rozwiñzania sñ
blokady oraz inne zasoby serwera otwarte w czasie, kiedy aplikacja wspóädziaäa z bibliotekñ
5
.
Warto spojrzeè na przykäad w jözyku PHP. W poniĔszym kodzie pokazano, w jaki sposób
najczöĈciej nastöpuje wykonanie zapytania MySQL z poziomu PHP:
<?php
$link = mysql_connect('localhost', 'user', 'p4ssword');
$result = mysql_query('SELECT * FROM HUGE_TABLE', $link);
while ($row = mysql_fetch_array($result)) {
// Dowolny kod przetwarzaj
ący wyniki zapytania.
}
?>
4
JeĔeli zapytanie bödzie zbyt duĔe, serwer odmówi przyjöcia kolejnych danych i nastñpi wygenerowanie bäödu.
5
Rozwiñzaniem problemu moĔe byè opcja
SQL_BUFFER_RESULT
, która zostanie przedstawiona w dalszej czöĈci
rozdziaäu.

182
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Kod wydaje siö wskazywaè, Ĕe w pötli
while
rekordy sñ pobierane jedynie wtedy, gdy sñ
potrzebne. Jednak w rzeczywistoĈci za pomocñ wywoäania funkcji
mysql_query()
kod po-
biera caäy zbiór wynikowy i umieszcza go w buforze. Pötla
while
po prostu przechodzi przez
poszczególne elementy bufora. Natomiast poniĔszy kod w ogóle nie buforuje wyników, po-
niewaĔ zamiast funkcji
mysql_query()
uĔywa funkcji
mysql_unbuffered_query()
:
<?php
$link = mysql_connect('localhost', 'user', 'p4ssword');
$result = mysql_unbuffered_query('SELECT * FROM HUGE_TABLE', $link);
while ($row = mysql_fetch_array($result)) {
// Dowolny kod przetwarzaj
ący wyniki zapytania.
}
?>
Jözyki programowania oferujñ róĔne sposoby unikniöcia buforowania. Przykäadowo sterownik
Perla
DBD:mysql
wymaga uĔycia atrybutu
mysql_use_result
w bibliotece jözyka C po stronie
klienta (atrybutem domyĈlnym jest
mysql_buffer_result
). PoniĔej przedstawiono przykäad:
#!/usr/bin/perl
use DBI;
my $dbh = DBI->connect('DBI:mysql:;host=localhost', 'user', 'p4ssword');
my $sth = $dbh->prepare('SELECT * FROM HUGE_TABLE', { mysql_use_result => 1 });
$sth->execute();
while (my $row = $sth->fetchrow_array()) {
# Dowolny kod przetwarzaj
ący wyniki zapytania.
}
Warto zwróciè uwagö, Ĕe wywoäanie funkcji
prepare()
zakäada uĔycie wyniku zamiast jego
buforowania. MoĔna to równieĔ okreĈliè podczas nawiñzywania poäñczenia, które spowoduje,
Ĕe Ĕadne polecenie nie bödzie buforowane:
my $dbh = DBI->connect('DBI:mysql:;mysql_use_result=1', 'user', 'p4ssword');
Stany zapytania
KaĔde poäñczenie MySQL, czyli wñtek, posiada stan wskazujñcy to, co dzieje siö z nim w da-
nej chwili. Istnieje kilka sposobów sprawdzenia tego stanu, ale najäatwiejszym pozostaje uĔy-
cie polecenia
SHOW FULL PROCESSLIST
(stan jest wyĈwietlany w kolumnie
Command
). Wraz
z postöpem realizacji zapytania, czyli przechodzeniem przez cykl Ĕyciowy, stan zmienia siö
wielokrotnie, a samych stanów sñ dziesiñtki. Podröcznik uĔytkownika MySQL jest odpo-
wiednim Ēródäem informacji o wszystkich stanach, ale poniĔej przedstawiono kilka z nich
wraz z objaĈnieniem znaczenia.
Sleep
Wñtek oczekuje na nowe zapytanie od klienta.
Query
Wñtek albo wykonuje zapytanie, albo odsyäa klientowi wyniki danego zapytania.
Locked
Wñtek oczekuje na naäoĔenie blokady tabeli na poziomie serwera. Blokady, które sñ
implementowane przez silnik magazynu danych, np. blokady rekordów w InnoDB, nie
powodujñ przejĈcia wñtku w stan
Locked
.
Analyzing
oraz
statistics
Wñtek sprawdza dane statystyczne silnika magazynu danych oraz optymalizuje zapytanie.

Podstawy wykonywania zapyta
ħ
_ 183
Copying to tmp table [on disk]
Wñtek przetwarza zapytanie oraz kopiuje wyniki do tabeli tymczasowej, prawdopodob-
nie ze wzglödu na klauzulö
GROUP BY
, w celu posortowania lub speänienia klauzuli
UNION
.
JeĔeli nazwa stanu koþczy siö ciñgiem tekstowym „on disk”, wtedy MySQL konwertuje
tabelö znajdujñcñ siö w pamiöci na tabelö zapisanñ na dysku twardym.
Sorting result
Wñtek sortuje zbiór wynikowy.
Sending data
Ten stan moĔe mieè kilka znaczeþ: wñtek moĔe przesyäaè dane miödzy stanami zapytania,
generowaè zbiór wynikowy bñdĒ zwracaè klientowi zbiór wynikowy.
Przydatna jest znajomoĈè przynajmniej podstawowych stanów zapytania, aby moĔna byäo
zäapaè sens „po czyjej stronie jest piäka”, czyli zapytanie. W przypadku bardzo obciñĔonych
serwerów moĔna zaobserwowaè, Ĕe niecodzienne lub zazwyczaj krótkotrwaäe stany, np.
statistics
, zaczynajñ zabieraè znaczñce iloĈci czasu. Zwykle wskazuje to pewne nie-
prawidäowoĈci.
Bufor zapytania
Przed rozpoczöciem przetwarzania zapytania MySQL sprawdza, czy dane zapytanie znajduje
siö w buforze zapytaþ, o ile zostaä wäñczony. Operacja ta jest wyszukiwaniem typu hash,
w którym ma znaczenie wielkoĈè liter. JeĔeli zapytanie róĔni siö od zapytania znalezionego
w buforze nawet tylko o pojedynczy bajt, nie zostanie dopasowane i proces przetwarzania
zapytania przejdzie do kolejnego etapu.
JeĔeli MySQL znajdzie dopasowanie w buforze zapytaþ, wówczas przed zwróceniem bufo-
rowanych wyników musi sprawdziè uprawnienia. Ta czynnoĈè jest moĔliwa bez przetwarza-
nia zapytania, poniewaĔ MySQL wraz z buforowanym zapytaniem przechowuje tabelö
informacyjnñ. Gdy uprawnienia sñ w porzñdku, MySQL pobiera z bufora przechowywany
wynik zapytania i wysyäa go klientowi, pomijajñc pozostaäe etapy procesu wykonywania za-
pytania. To zapytanie nigdy nie bödzie przetworzone, zoptymalizowane bñdĒ wykonane.
Wiöcej informacji na temat bufora zapytaþ znajduje siö w rozdziale 5.
Proces optymalizacji zapytania
Kolejny krok w cyklu Ĕyciowym zapytania powoduje zmianö zapytania SQL na postaè planu
wykonywania przeznaczonñ dla silnika wykonywania zapytaþ. Krok ten ma kilka etapów
poĈrednich: analizowanie, przetwarzanie oraz optymalizacjö. Bäödy (np. bäödy skäadni) mogñ
byè zgäoszone w dowolnym miejscu tego procesu. Autorzy w tym miejscu nie próbujñ udo-
kumentowaè wnötrza bazy danych MySQL, a wiöc pozwolñ sobie na pewnñ swobodö, np.
opisywanie etapów oddzielnie, nawet jeĈli czösto sñ ze sobñ äñczone w caäoĈè bñdĒ czöĈciowo,
ze wzglödu na wydajnoĈè. Celem autorów jest po prostu pomoc czytelnikowi w zrozumieniu,
jak MySQL wykonuje zapytania oraz jak moĔna utworzyè lepsze.

184
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Analizator sk
ĥadni i preprocesor
Na poczñtek analizator MySQL dzieli zapytanie na tokeny i na ich podstawie buduje „drzewo
analizy”. W celu interpretacji i weryfikacji zapytania analizator wykorzystuje gramatykö SQL
bazy danych MySQL. Ten etap gwarantuje, Ĕe tokeny w zapytaniu sñ prawidäowe i znajdujñ
siö we wäaĈciwej kolejnoĈci. Ponadto nastöpuje sprawdzenie pod kñtem wystöpowania bäödów,
takich jak ciñgi tekstowe ujöte w cudzysäów, które nie zostaäy prawidäowo zakoþczone.
Nastöpnie preprocesor weryfikuje otrzymane drzewo analizy pod kñtem dodatkowej seman-
tyki, której analizator nie mógä zastosowaè. Przykäadowo preprocesor sprawdza istnienie
tabel i kolumn, a takĔe nazwy i aliasy, aby upewniè siö, Ĕe odniesienie nie sñ dwuznaczne.
Kolejny etap to weryfikacja uprawnieþ przez preprocesor. CzynnoĈè zwykle jest bardzo
szybka, chyba Ĕe serwer posiada ogromnñ liczbö uprawnieþ. (Wiöcej informacji na temat
uprawnieþ i bezpieczeþstwa znajduje siö w rozdziale 12.).
Optymalizator zapytania
Na tym etapie drzewo analizy jest poprawne i przygotowane do tego, aby optymalizator prze-
ksztaäciä je na postaè planu wykonywania zapytania. Zapytanie czösto moĔe byè wykonywane
na wiele róĔnych sposobów, generujñc takie same wyniki. Zadaniem optymalizatora jest znale-
zienie najlepszej opcji.
Baza danych MySQL stosuje optymalizator kosztowy, co oznacza, Ĕe optymalizator próbuje
przewidzieè koszt róĔnych wariantów planu wykonania i wybraè najtaþszy. Jednostkñ kosztu
jest odczytanie pojedynczej, losowo wybranej strony danych o wielkoĈci czterech kilobajtów.
Istnieje moĔliwoĈè sprawdzenia oszacowanego przez optymalizator kosztu zapytania prze-
znaczonego do wykonania poprzez wyĈwietlenie wartoĈci zmiennej
Last_query_cost
:
mysql> SELECT SQL_NO_CACHE COUNT(*) FROM sakila.film_actor;
+----------+
| count(*) |
+----------+
| 5462 |
+----------+
mysql> SHOW STATUS LIKE 'last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 1040.599000 |
+-----------------+-------------+
PowyĔszy wynik oznacza, Ĕe optymalizator oszacowaä liczbö losowo odczytywanych stron
danych koniecznych do wykonania zapytania na 1040. Wynik jest obliczany na podstawie
danych statystycznych: liczby stron w tabeli bñdĒ indeksie, liczebnoĈci (liczby odmiennych
wartoĈci) indeksów, däugoĈci rekordów i kluczy oraz rozproszenia klucza. W trakcie obliczeþ
optymalizator nie bierze pod uwagö wpäywu jakiegokolwiek mechanizmu buforowania —
zakäada, Ĕe kaĔdy odczyt bödzie skutkowaä operacjñ I/O na dysku twardym.
Z wielu podanych niĔej powodów optymalizator nie zawsze wybiera najlepszy plan.
x
Dane statystyczne mogñ byè bäödne. Serwer polega na danych statystycznych dostarczanych
przez silnik magazynu danych, a one mogñ znajdowaè siö w zakresie od ĈciĈle dokäadnych
aĔ do zupeänie niedokäadnych. Przykäadowo silnik InnoDB nie zawiera dokäadnych danych
statystycznych na temat liczby rekordów w tabeli, co jest zwiñzane z jego architekturñ MVCC.

Podstawy wykonywania zapyta
ħ
_ 185
x
Koszt metryczny nie zawsze dokäadnie odpowiada rzeczywistemu kosztowi wykonania
zapytania. Dlatego teĔ nawet wtedy, kiedy dane statystyczne sñ dokäadne, wykonanie
zapytania moĔe byè mniej lub bardziej kosztowne, niĔ wynika to z obliczeþ MySQL. W nie-
których sytuacjach plan odczytujñcy wiökszñ liczbö stron moĔe faktycznie byè taþszy, np.
gdy odczyt danych jest ciñgäy, poniewaĔ wtedy operacje I/O na dysku sñ szybsze, lub jeĈli
odczytywane strony zostaäy wczeĈniej buforowane w pamiöci.
x
Znaczenie optymalnoĈci dla MySQL nie musi pokrywaè siö z oczekiwaniami programisty.
Programista prawdopodobnie dñĔy do osiñgniöcia krótszego czasu wykonania zapytania,
ale MySQL w rzeczywistoĈci nie rozumie pojöcia „krótsze”. Rozumie jednak pojöcie
„koszt” i, jak wczeĈniej pokazano, oszacowanie kosztu nie zawsze jest naukñ Ĉcisäñ.
x
MySQL nie bierze pod uwagö innych zapytaþ wykonywanych w tym samym czasie, co
jednak ma wpäyw na szybkoĈè wykonywania danego zapytania.
x
MySQL nie zawsze wykorzystuje optymalizacjö na podstawie kosztu. Czasami po prostu
stosuje siö do reguä, np. takiej: „JeĈli w zapytaniu znajduje siö klauzula
MATCH()
dopasowania
peänotekstowego, uĔyj indeksu
FULLTEXT
, o ile taki istnieje”. Serwer wykona to nawet
wtedy, kiedy szybszym rozwiñzaniem bödzie uĔycie innego indeksu oraz zapytanie
innego rodzaju niĔ
FULLTEXT
, zawierajñce klauzulö
WHERE
.
x
Optymalizator nie bierze pod uwagö kosztów operacji pozostajñcych poza jego kontrolñ, ta-
kich jak wykonanie procedur skäadowanych lub funkcji zdefiniowanych przez uĔytkownika.
x
W dalszej czöĈci rozdziaäu zostanie pokazane, Ĕe optymalizator nie zawsze oszacowuje kaĔdy
moĔliwy plan wykonywania, a wiöc istnieje niebezpieczeþstwo pominiöcia planu optymalnego.
Optymalizator MySQL to bardzo skomplikowany fragment oprogramowania, który uĔywa
wielu optymalizacji w celu przeksztaäcenia zapytania na postaè planu wykonywania. Istniejñ
dwa rodzaje optymalizacji: statyczna i dynamiczna. Optymalizacja statyczna moĔe byè przepro-
wadzona po prostu przez badanie drzewa analizy. Przykäadowo optymalizator moĔe prze-
ksztaäciè klauzulö
WHERE
na odpowiadajñcñ jej innñ formö za pomocñ reguä algebraicznych.
Optymalizacja statyczna dotyczy wartoĈci niezaleĔnych, np. wartoĈci staäej w klauzuli
WHERE
.
Ten rodzaj optymalizacji moĔe byè przeprowadzony jednokrotnie i pozostanie waĔny nawet
wtedy, kiedy zapytanie zostanie ponownie wykonane z uĔyciem innych wartoĈci. Optymali-
zacjö tö moĔna traktowaè jak „optymalizacjö w trakcie kompilacji”.
Optymalizacja dynamiczna, w przeciwieþstwie do optymalizacji statycznej, bazuje na kontek-
Ĉcie i moĔe zaleĔeè od wielu czynników, takich jak wartoĈè w klauzuli
WHERE
lub liczba re-
kordów w indeksie. Ten rodzaj optymalizacji musi byè przeprowadzany w trakcie kaĔdego
wykonywania zapytania. Optymalizacjö tö moĔna wiöc traktowaè jako „optymalizacjö w trakcie
wykonywania zapytania”.
RóĔnica miödzy nimi jest istotna podczas wykonywania przygotowanych poleceþ lub proce-
dur skäadowanych. Optymalizacjö statycznñ MySQL moĔe przeprowadziè tylko jednokrotnie,
ale optymalizacjö dynamicznñ musi powtarzaè w trakcie kaĔdego wykonywania zapytania.
Czasami zdarza siö równieĔ, Ĕe MySQL ponownie optymalizuje zapytanie juĔ w trakcie jego
wykonywania
6
.
6
Przykäadowo sprawdzenie zakresu planu wykonywania ponownie okreĈla indeksy dla kaĔdego rekordu zäñ-
czenia (
JOIN
). Ten plan wykonywania moĔna zobaczyè, szukajñc ciñgu tekstowego „range checked for each
record” w kolumnie
Extra
danych wyjĈciowych polecenia
EXPLAIN
. Taki plan zapytania zwiöksza takĔe
o jednostkö wartoĈè zmiennej serwera o nazwie
Select_full_range_join
.

186
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
PoniĔej przedstawiono kilka rodzajów optymalizacji, które MySQL moĔe przeprowadziè.
Zmiana kolejno
Ĉci zäñczeþ
Tabele nie zawsze muszñ byè zäñczone w kolejnoĈci wskazanej w zapytaniu. OkreĈlenie
najlepszej kolejnoĈè zäñczeþ jest bardzo waĔnym rodzajem optymalizacji. Temat ten zostaä
dokäadnie omówiony w podrozdziale „Optymalizator zäñczeþ”, w tym rozdziale.
Konwersja klauzuli
OUTER JOIN
na
INNER JOIN
Klauzula
OUTER JOIN
niekoniecznie musi byè wykonana jako
OUTER JOIN
. Pewne czyn-
niki, np. klauzula
WHERE
i schemat tabeli, mogñ w rzeczywistoĈci powodowaè, Ĕe klauzula
OUTER
JOIN
bödzie odpowiadaäa klauzuli
INNER JOIN
. Baza danych MySQL rozpoznaje
takie sytuacje i przepisuje zäñczenie, co pozwala na zmianö ustawieþ.
Zastosowanie algebraicznych odpowiedników regu
ä
MySQL stosuje przeksztaäcenia algebraiczne w celu uproszczenia wyraĔeþ i sprowadze-
nia ich do postaci kanonicznej. Baza danych moĔe równieĔ zredukowaè zmienne, elimi-
nujñc niemoĔliwe do zastosowania ograniczenia oraz warunki w postaci zdefiniowanych
staäych. Przykäadowo wyraĔenie
(5=5 AND a>5)
zostanie zredukowane do zwykäego
a>5
.
Podobnie
(a<b ANB b=c) AND a=5
stanie siö wyraĔeniem
b>5 AND b=c AND a=5
. Te reguäy
sñ bardzo uĔyteczne podczas tworzenia zapytaþ warunkowych, które zostanñ omówione
w dalszej czöĈci rozdziaäu.
Optymalizacja funkcji
COUNT()
,
MIN()
oraz
MAX()
Indeksy i kolumny akceptujñce wartoĈè
NULL
bardzo czösto mogñ pomóc serwerowi
MySQL w optymalizacji tych wyraĔeþ. Aby np. odnaleĒè wartoĈè minimalnñ kolumny
wysuniötej najbardziej na lewo w indeksie B-Tree, MySQL moĔe po prostu zaĔñdaè
pierwszego rekordu indeksu. To moĔe nastñpiè nawet na etapie optymalizacji zapytania,
a otrzymanñ wartoĈè serwer moĔe potraktowaè jako staäñ dla pozostaäej czöĈci zapytania.
Podobnie w celu znalezienia wartoĈci maksymalnej w indeksie typu B-tree, serwer od-
czytuje ostatni rekord. JeĔeli serwer stosuje takñ optymalizacjö, wówczas w danych wyj-
Ĉciowych polecenia
EXPLAIN
znajdzie siö ciñg tekstowy „Select tables optimized away”.
Dosäownie oznacza to, Ĕe optymalizator usunñä tabelö z planu wykonywania i zastñpiä jñ
zmiennñ.
Ponadto zapytania
COUNT(*)
bez klauzuli
WHERE
czösto mogñ byè optymalizowane
w pewnych silnikach magazynu danych (np. MyISAM, który przez caäy czas przechowuje
dokäadnñ liczbö rekordów tabeli). Wiöcej informacji na ten temat przedstawiono w podroz-
dziale „Optymalizacja zapytaþ COUNT()”, znajdujñcym siö w dalszej czöĈci rozdziaäu.
Okre
Ĉlanie i redukowanie wyraĔeþ staäych
Kiedy MySQL wykryje, Ĕe wyraĔenie moĔe zostaè zredukowane na postaè staäej, wtedy
taka operacja bödzie przeprowadzona w trakcie optymalizacji. Przykäadowo zmienna
zdefiniowana przez uĔytkownika moĔe byè skonwertowana na postaè staäej, jeĈli nie ulega
zmianie w zapytaniu. WyraĔenia arytmetyczne to kolejny przykäad.
Prawdopodobnie najwiökszym zaskoczeniem jest fakt, Ĕe na etapie optymalizacji nawet
wyraĔenie uwaĔane za zapytanie moĔe byè zredukowane na postaè staäej. Jednym z przy-
käadów jest funkcja
MIN()
w indeksie. MoĔna to nawet rozciñgnñè na wyszukiwanie staäej
w kluczu podstawowym lub unikalnym indeksie. JeĔeli w takim indeksie klauzula
WHERE
stosuje warunek w postaci staäej, wówczas optymizator „wie”, Ĕe MySQL moĔe wyszu-
kaè wartoĈè na poczñtku zapytania. WartoĈè ta bödzie traktowana jako staäa w pozostaäej
czöĈci zapytania:

Podstawy wykonywania zapyta
ħ
_ 187
mysql> EXPLAIN SELECT film.film_id, film_actor.actor_id
-> FROM sakila.film
-> INNER JOIN sakila.film_actor USING(film_id)
-> WHERE film.film_id = 1;
+----+-------------+------------+-------+----------------+-------+------+
| id | select_type | table | type | key | ref | rows |
+----+-------------+------------+-------+----------------+-------+------+
| 1 | SIMPLE | film | const | PRIMARY | const | 1 |
| 1 | SIMPLE | film_actor | ref | idx_fk_film_id | const | 10 |
+----+-------------+------------+-------+----------------+-------+------+
PowyĔsze zapytanie MySQL wykonuje w dwóch krokach, które odpowiadajñ dwóm
rekordom danych wyjĈciowych. Pierwszym krokiem jest odszukanie poĔñdanego rekordu
w tabeli
film
. Optymalizator MySQL wie, Ĕe to jest tylko jeden rekord, poniewaĔ ko-
lumna
film_id
jest kluczem podstawowym. Poza tym, w trakcie optymalizacji zapytania
indeks zostaä juĔ sprawdzony, aby przekonaè siö, ile rekordów bödzie zwróconych.
PoniewaĔ optymalizator znaä iloĈè (wartoĈè w klauzuli
WHERE
) uĔywanñ w zapytaniu, typ
ref
tej tabeli wynosi
const
.
W drugim kroku MySQL traktuje kolumnö
film_id
z rekordu znalezionego w pierwszym
kroku jako znanñ iloĈè. Optymalizator moĔe przyjñè takie zaäoĔenie, poniewaĔ wiadomo,
Ĕe gdy zapytanie dotrze do drugiego kroku, otrzyma wszystkie wartoĈci z poprzedniego
kroku. Warto zwróciè uwagö, Ĕe typ
ref
tabeli
film_actor
wynosi
const
, podobnie jak
dla tabeli
film
.
Innñ sytuacjñ, w której moĔna spotkaè siö z zastosowaniem warunku w postaci staäej, jest
propagowanie wartoĈci niebödñcej staäñ z jednego miejsca do innego, jeĔeli wystöpujñ
klauzule
WHERE
,
USING
lub
ON
powodujñce, Ĕe wartoĈci sñ równe. W omawianym przy-
padku optymalizator przyjmuje, Ĕe klauzula
USING
wymusza, aby kolumna
film_id
miaäa takñ samñ wartoĈè w kaĔdym miejscu zapytania — musi byè równa wartoĈci staäej
podanej w klauzuli
WHERE
.
Indeksy pokrywaj
ñce
Aby uniknñè odczytywania danych rekordów, MySQL moĔe czasami uĔyè indeksu,
ale indeks musi zawieraè wszystkie kolumny wymagane przez zapytanie. Szczegóäowe
omówienie indeksów pokrywajñcych przedstawiono w rozdziale 3.
Optymalizacja podzapytania
Baza danych MySQL moĔe skonwertowaè niektóre rodzaje podzapytaþ na bardziej
efektywne, alternatywne formy, redukujñc je do wyszukiwaþ indeksu zamiast oddzielnych
zapytaþ.
Wcze
Ĉniejsze zakoþczenie zapytania
MySQL moĔe zakoþczyè przetwarzanie zapytania (lub etapu w zapytaniu), gdy tylko zo-
stanie speänione zapytanie albo jego etap. Oczywistym przykäadem jest klauzula
LIMIT
,
choè istnieje równieĔ kilka innych rodzajów wczeĈniejszego zakoþczenia zapytania. JeĔeli
np. MySQL odkryje warunek niemoĔliwy do speänienia, moĔe przerwaè wykonywanie
caäego zapytania. Taka sytuacja zachodzi w poniĔszym zapytaniu:
mysql> EXPLAIN SELECT film.film_id FROM sakila.film WHERE film_id = -1;
+----+...+-----------------------------------------------------+
| id |...| Extra |
+----+...+-----------------------------------------------------+
| 1 |...| Impossible WHERE noticed after reading const tables |
+----+...+-----------------------------------------------------+

188
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Zapytanie zostaäo przerwane na etapie optymalizacji, ale w niektórych sytuacjach
MySQL moĔe przerwaè wykonywanie zapytania równieĔ wczeĈniej. Serwer moĔe wyko-
rzystaè ten rodzaj optymalizacji, kiedy silnik wykonywania zapytaþ stwierdzi, Ĕe musi
pobraè zupeänie inne wartoĈci lub wymagana wartoĈè nie istnieje. Przedstawione poniĔej
przykäadowe zapytanie ma wyszukaè wszystkie filmy, w których nie ma aktorów
7
:
mysql> SELECT film.film_id
-> FROM sakila.film
-> LEFT OUTER JOIN sakila.film_actor USING(film_id)
-> WHERE film_actor.film_id IS NULL;
PowyĔsze zapytanie powoduje odrzucenie filmów, w których wystöpujñ aktorzy. W kaĔdym
filmie moĔe wystöpowaè wielu aktorów, ale tuĔ po znalezieniu aktora nastöpuje prze-
rwanie przetwarzania bieĔñcego filmu i przejĈcie do nastöpnego. Dzieje siö tak, poniewaĔ
klauzula
WHERE
to informacja dla optymalizatora, Ĕe ma uniemoĔliwiè wyĈwietlenie filmów,
w których wystöpujñ aktorzy. Podobny rodzaj optymalizacji, czyli „wartoĈè odmiennñ
lub nieistniejñcñ”, moĔna zastosowaè w okreĈlonych rodzajach zapytaþ
DISTINCT
,
NOT
EXISTS()
oraz
LEFT JOIN
.
Propagowanie równo
Ĉci
Baza danych MySQL rozpoznaje, kiedy zapytanie zawiera dwie kolumny, które sñ jedna-
kowe — np. w warunku
JOIN
— i propaguje uĔycie klauzuli
WHERE
na takich kolumnach.
Warto spojrzeè na poniĔsze przykäadowe zapytanie:
mysql> SELECT film.film_id
-> FROM sakila.film
-> INNER JOIN sakila.film_actor USING(film_id)
-> WHERE film.film_id > 500;
Serwer MySQL przyjmuje, Ĕe klauzula
WHERE
ma zastosowanie nie tylko wzglödem tabeli
film
, ale równieĔ tabeli
film_actor
, poniewaĔ uĔycie klauzuli
USING
wymusiäo dopa-
sowanie tych dwóch kolumn.
JeĔeli byäby zastosowany inny serwer bazy danych, niewykonujñcy takiej czynnoĈci, pro-
gramista mógäby zostaè zachöcony do „udzielenia pomocy optymalizatorowi” poprzez
röczne podanie klauzuli
WHERE
dla obu tabel, np. w taki sposób:
... WHERE film.film_id > 500 AND film_actor.film_id > 500
W bazie danych MySQL jest to niepotrzebne. Taka modyfikacja powoduje, Ĕe zapytania
stajñ siö trudniejsze w obsäudze.
Porównania list IN()
W wielu serwerach baz danych
IN()
to po prostu synonim wielu klauzul
OR
, poniewaĔ
pod wzglödem logicznym obie konstrukcje sñ odpowiednikami. Nie dotyczy to bazy danych
MySQL, która sortuje wartoĈci w liĈcie
IN()
oraz stosuje szybkie wyszukiwanie binarne
w celu okreĈlenia, czy dana wartoĈè znajduje siö na liĈcie. Jest to O(log n) w wielkoĈci listy,
podczas gdy odpowiednik serii klauzul
OR
to O(n) w wielkoĈci listy (np. wyszukiwanie
przeprowadzane jest znacznie wolniej w przypadku ogromnych list).
7
Autorzy zgadzajñ siö, Ĕe film bez aktorów jest czymĈ dziwnym. Jednak przykäadowa baza danych Sakila
„twierdzi”, Ĕe w filmie Slacker Liaisons nie wystöpujñ aktorzy. W opisie filmu moĔna przeczytaè „Dynamiczna
opowieĈè o rekinie i studencie, który musi spotkaè krokodyla w staroĔytnych Chinach”.

Podstawy wykonywania zapyta
ħ
_ 189
Przedstawiona powyĔej lista jest ĔaäoĈnie niekompletna, poniewaĔ MySQL moĔe przeprowadziè
znacznie wiöcej rodzajów optymalizacji, niĔ zmieĈciäoby siö w caäym rozdziale. Lista powin-
na jednak pokazaè stopieþ zäoĔonoĈci optymalizatora oraz trafnoĈè podejmowanych przez
niego decyzji. JeĔeli czytelnik miaäby zapamiötaè tylko jedno z przedstawionej analizy, po-
winno to byè zdanie: Nie warto próbowaè byè sprytniejszym od optymalizatora. Taka próba moĔe
po prostu zakoþczyè siö klöskñ bñdĒ znacznym zwiökszeniem stopniem skomplikowania
zapytaþ, które nie przyniesie Ĕadnych korzyĈci, a same zapytania stanñ siö trudniejsze w ob-
säudze. Ogólnie rzecz biorñc, zadanie optymalizacji lepiej pozostawiè optymalizatorowi.
OczywiĈcie, nadal istniejñ sytuacje, w których optymalizator nie zapewni najlepszych wyników.
Czasami programista ma wiedzö na temat danych, której nie ma optymalizator, np. wie, Ĕe
gwarancja ich poprawnoĈci wynika z logiki aplikacji. Ponadto czasami optymalizator po prostu
nie ma niezbödnej funkcjonalnoĈci, np. indeksów typu hash. Z kolei w innych przypadkach,
jak juĔ wspomniano, wskutek oszacowanych przez niego kosztów preferowany bödzie plan
wykonywania, który okaĔe siö kosztowniejszy niĔ inne moĔliwoĈci.
JeĔeli programista jest przekonany, Ĕe optymalizator nie wykonuje dobrze swojego zadania,
i wie dlaczego, moĔe spróbowaè mu pomóc. Niektóre dostöpne moĔliwoĈci obejmujñ dodanie
wskazówki do zapytania, ponowne napisanie zapytania, przeprojektowanie schematu lub
dodanie indeksów.
Dane statystyczne dotycz
éce tabeli i indeksu
Warto przypomnieè sobie róĔne warstwy w architekturze serwera MySQL, które zostaäy po-
kazane na rysunku 1.1. Warstwa serwera zawierajñca optymalizator zapytaþ nie przechowuje
danych statystycznych dotyczñcych danych i indeksów. To jest zadanie dla silników magazynu
danych, poniewaĔ kaĔdy silnik moĔe przechowywaè róĔne dane statystyczne (lub obsäugi-
waè je w odmienny sposób). Niektóre silniki, np. Archive, w ogóle nie przechowujñ danych
statystycznych!
PoniewaĔ serwer nie przechowuje danych statystycznych, optymalizator zapytaþ MySQL
musi uzyskaè od silnika dane statystyczne dotyczñce tabel, które znajdujñ siö w zapytaniu.
Silnik moĔe dostarczyè optymalizatorowi dane statystyczne, takie jak liczba stron w tabeli
lub indeksie, liczebnoĈè tabel i indeksów, däugoĈè rekordów i kluczy oraz informacje o roz-
proszeniu klucza. Otrzymane dane statystyczne optymizator moĔe wykorzystaè podczas wyboru
najlepszego planu wykonania zapytania. W kolejnych podrozdziaäach pokazano, jak dane te
wpäywajñ na decyzje podejmowane przez optymalizator.
Strategia MySQL w trakcie wykonywania z
ĥéczeħ
Baza danych MySQL uĔywa pojöcia „zäñczenie” w znacznie szerszym kontekĈcie, niĔ moĔna
siö spodziewaè. Ogólnie rzecz ujmujñc, baza traktuje jak zäñczenie kaĔde zapytanie — nie tylko
zapytanie dopasowujñce rekordy z dwóch tabel, ale wszystkie zapytania (äñcznie z podzapy-
taniami, a nawet zapytaniami
SELECT
wzglödem pojedynczej tabeli). W konsekwencji bardzo
waĔne jest, aby dokäadnie zrozumieè, w jaki sposób serwer MySQL wykonuje zäñczenia.
Warto rozwaĔyè przykäad zapytania
UNION
. Serwer MySQL wykonuje klauzulö
UNION
jako
seriö zapytaþ, których wyniki sñ umieszczane w tabeli tymczasowej, a nastöpnie ponownie
z niej odczytywane. Wedäug MySQL kaĔde poszczególne zapytanie jest zäñczeniem — po-
dobnie jak akt odczytania ich z wynikowej tabeli tymczasowej.

190
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Na tym etapie strategia wykonywania zäñczeþ przez MySQL jest prosta: kaĔde zäñczenie jest
traktowane jak zagnieĔdĔona pötla zäñczenia. Oznacza to, Ĕe baza danych MySQL wykonuje
pötlö w celu wyszukania rekordu w tabeli, a nastöpnie wykonuje zagnieĔdĔonñ tabelö, szu-
kajñc dopasowania rekordu w kolejnej tabeli. Proces jest kontynuowany aĔ do chwili znale-
zienia dopasowania rekordu w kaĔdej tabeli zäñczenia. Nastöpnym krokiem jest zbudowanie
i zwrócenie rekordu z kolumn wymienionych na liĈcie polecenia
SELECT
. Baza próbuje zbu-
dowaè kolejny rekord poprzez znalezienie nastöpnych dopasowanych rekordów w ostatniej
tabeli. JeĔeli Ĕaden nie zostanie znaleziony, wówczas baza wraca tñ samñ drogñ do poprzed-
niej tabeli, szukajñc w niej kolejnych rekordów. Powrót trwa aĔ do chwili znalezienia do-
pasowanego rekordu w dowolnej tabeli. Wówczas nastöpuje wyszukiwanie dopasowania
w kolejnej tabeli itd.
8
Proces wyszukiwania rekordów, sprawdzania kolejnej tabeli, a nastöpnie powrotu moĔe zostaè
zapisany w postaci zagnieĔdĔonych pötli w planie wykonywania — stñd nazwa „zäñczenia
zagnieĔdĔonych pötli”. Warto spojrzeè na poniĔsze proste zapytanie:
mysql> SELECT tbl1.col1, tbl2.col2
-> FROM tbl1 INNER JOIN tbl2 USING(col3)
-> WHERE tbl1.col1 IN(5,6);
Przy zaäoĔeniu, Ĕe baza danych MySQL zadecyduje o zäñczeniu tabel w kolejnoĈci przedsta-
wionej w zapytaniu, w poniĔszym pseudokodzie pokazano, jak baza danych MySQL mogäaby
wykonaè to zapytanie:
outer_iter = iterator over tbl1 where col1 IN(5,6)
outer_row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3 = outer_row.col3
inner_row = inner_iter.next
while inner_row
output [outer_row.col1, inner_row.col2]
inner_row = inner_iter.next
end
outer_row = outer_iter.next
end
PowyĔszy plan wykonania ma zastosowanie zarówno do prostego zapytania pojedynczej tabeli,
jak i zapytania obejmujñcego wiele tabel. Dlatego teĔ nawet zapytania do pojedynczej tabeli
mogñ byè uznawane za zäñczenia — zäñczenia w pojedynczych tabelach sñ prostymi opera-
cjami, które skäadajñ siö na bardziej zäoĔone zäñczenia. Obsäugiwane sñ równieĔ klauzule
OUTER JOIN
. Przykäadowo zapytanie moĔna zmieniè na nastöpujñcñ postaè:
mysql> SELECT tbl1.col1, tbl2.col2
-> FROM tbl1 LEFT OUTER JOIN tbl2 USING(col3)
-> WHERE tbl1.col1 IN(5,6);
PoniĔej znajduje siö odpowiadajñcy mu pseudokod, w którym zmienione fragmenty zostaäy
pogrubione:
outer_iter = iterator over tbl1 where col1 IN(5,6)
outer_row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3 = outer_row.col3
inner_row = inner_iter.next
if inner_row
8
Jak to zostaäo pokazane w dalszej czöĈci rozdziaäu, wykonywanie zapytania MySQL nie jest takie proste. Istnieje
wiele róĔnych optymalizacji komplikujñcych ten proces.
Podstawy wykonywania zapyta
ħ
_
191
while inner_row
output [outer_row.col1, inner_row.col2]
inner_row = inner_iter.next
end
else
output [outer_row.col1, NULL]
end
outer_row = outer_iter.next
end
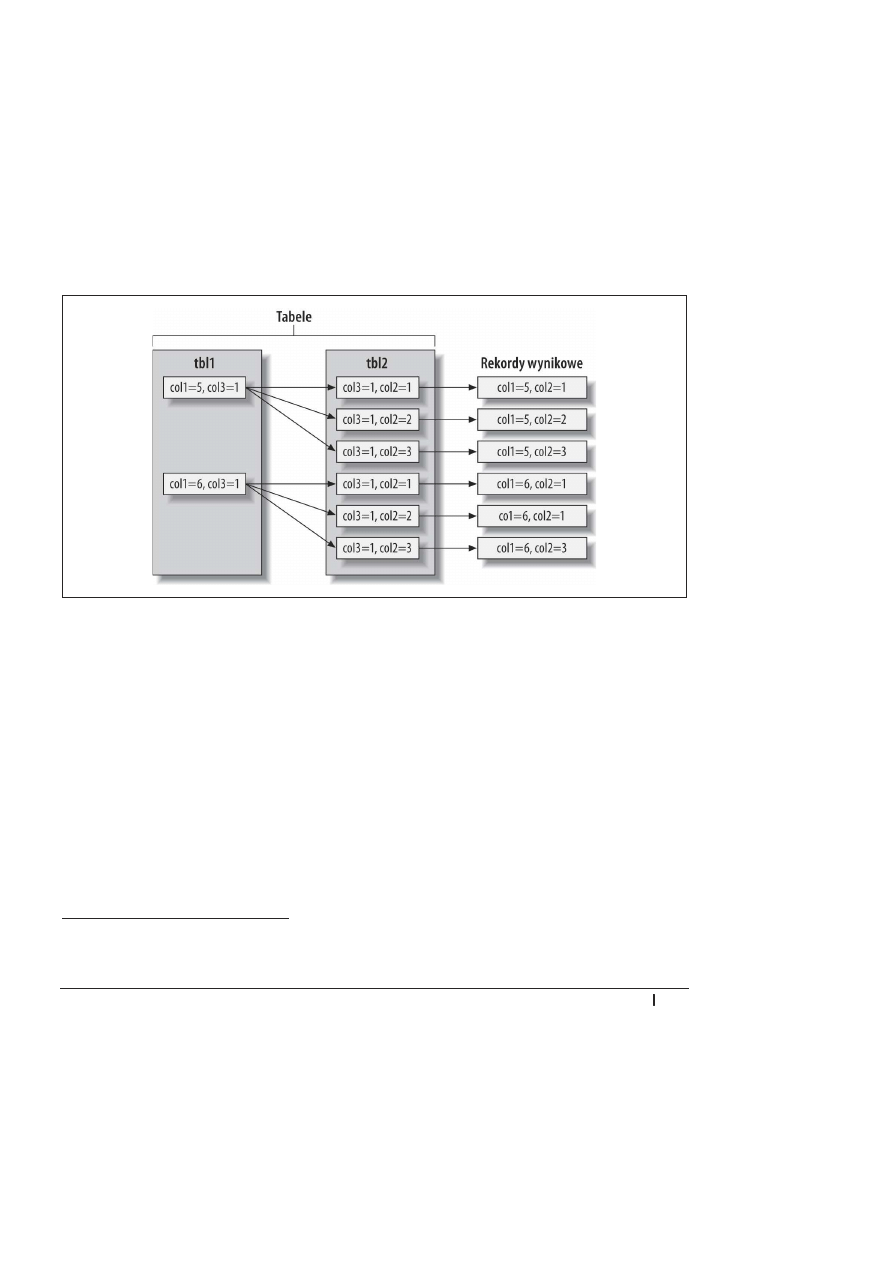
Innym sposobem wizualizacji planu wykonania zapytania jest uĔycie tego, co osoby zajmujñ-
ce siö optymalizacjñ nazywajñ „wykres swim-lane”. Na rysunku 4.2 pokazano wykres swim-
lane dotyczñcy poczñtkowego zapytania
INNER JOIN
. Wykres odczytuje siö od lewej do prawej
strony, od góry do doäu.
Rysunek 4.2. Wykres swim-lane pokazuj
ñcy pobieranie rekordów za pomocñ zäñczenia
W zasadzie serwer MySQL wykonuje kaĔdy rodzaj zapytania w taki sam sposób. Przykäa-
dowo podzapytania w klauzuli
FROM
sñ wykonywane w pierwszej kolejnoĈci, a ich wyniki
zostajñ umieszczone w tabeli tymczasowej
9
. Nastöpnie tabela tymczasowa jest traktowana jak
zwykäa tabela (stñd nazwa „tabela pochodna”). W zapytaniach
UNION
baza danych MySQL
takĔe stosuje tabele tymczasowe, a wszystkie zapytania
RIGHT OUTER JOIN
sñ przepisywane
na ich odpowiedniki
LEFT OUTER JOIN
. W skrócie mówiñc, MySQL zmusza kaĔdy rodzaj za-
pytania do „wpasowania siö” w przedstawiony plan wykonywania.
Jednak niemoĔliwe jest wykonanie w ten sposób kaĔdego poprawnego zapytania SQL. Przy-
käadowo zapytanie
FULL OUTER JOIN
nie moĔe byè wykonane za pomocñ zagnieĔdĔonych
pötli oraz powracania po dotarciu do tabeli, w której nie znaleziono dopasowanych rekordów,
poniewaĔ zapytanie moĔe rozpoczynaè siö od tabeli nieposiadajñcej pasujñcych rekordów.
To wyjaĈnia, dlaczego MySQL nie obsäuguje zapytaþ
FULL OUTER JOIN
. Nadal wszystkie po-
zostaäe zapytania mogñ byè wykonywane za pomocñ zagnieĔdĔonych pötli, ale wynik takich
operacji jest opäakany. Wiöcej informacji na ten temat znajduje siö w dalszej czöĈci rozdziaäu.
9
W tabeli tymczasowej nie ma indeksów i naleĔy o tym pamiötaè podczas tworzenia skomplikowanych zäñczeþ
wzglödem podzapytaþ w klauzuli
FROM
. Dotyczy to równieĔ zapytaþ
UNION
.
192
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Plan wykonywania
Baza danych MySQL nie generuje kodu bajtowego w celu wykonania zapytania, co ma miejsce
w wielu innych bazach danych. Plan wykonania zapytania w rzeczywistoĈci jest drzewem
instrukcji, które silnik wykonywania zapytania realizuje w celu otrzymania wyniku zapytania.
Plan ostateczny zawiera iloĈè informacji wystarczajñcñ do zrekonstruowania poczñtkowego
zapytania. JeĔeli zapytanie jest wykonywane z uĔyciem polecenia
EXPLAIN EXTENDED
poprze-
dzonego przez
SHOW WARNINGS
, wówczas moĔna zobaczyè zrekonstruowane zapytanie
10
.
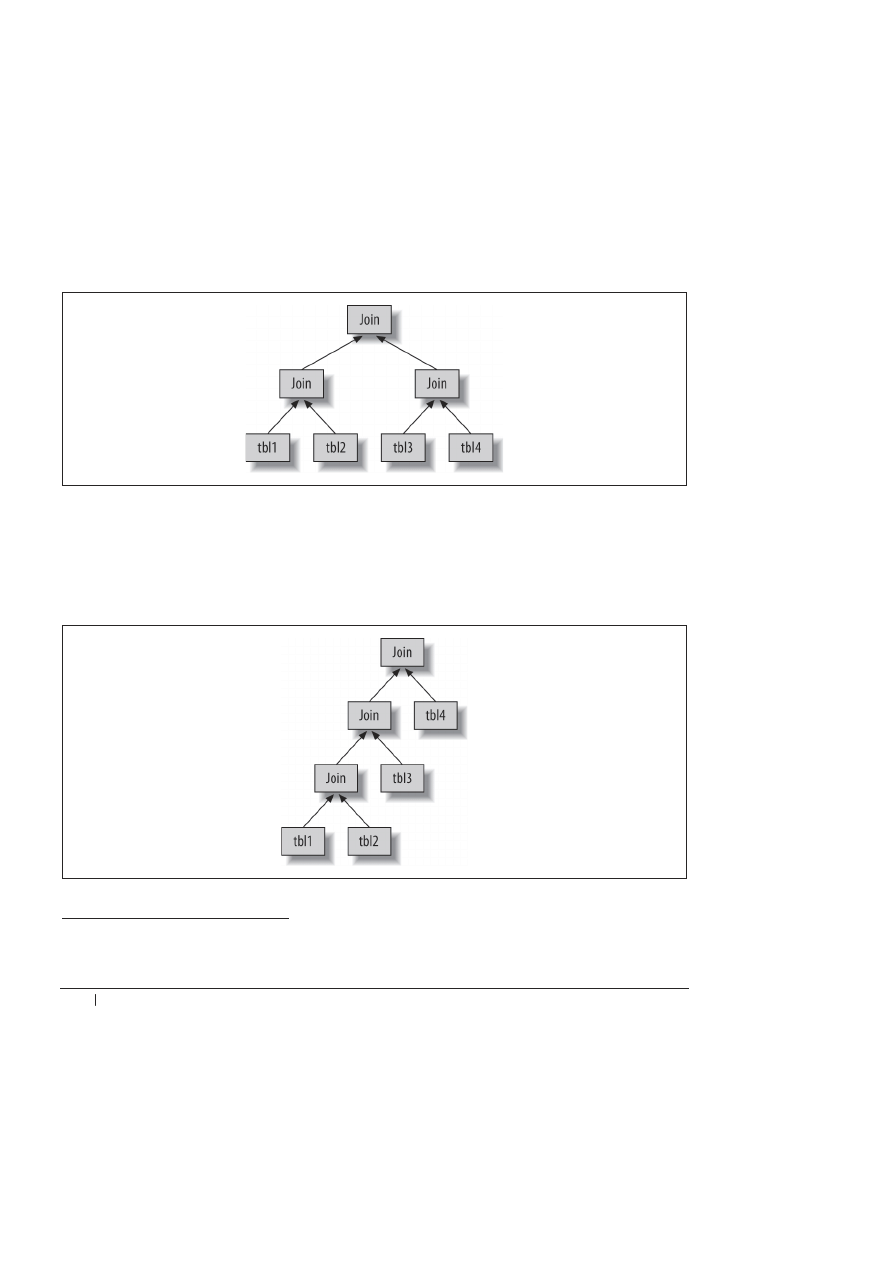
KaĔde zapytanie obejmujñce wiöcej niĔ jednñ tabelö moĔe zostaè przedstawione jako drzewo.
Przykäadowo zapytanie obejmujñce operacjö zäñczenia czterech tabel moĔna wykonaè tak, jak
pokazano na rysunku 4.3.
Rysunek 4.3. Jeden ze sposobów przeprowadzenia operacji z
äñczenia na wielu tabelach
Naukowcy nazywajñ je drzewem zrównowaĔonym. Jednak nie jest to sposób, w jaki MySQL
wykonuje zapytanie. Jak wspomniano w poprzednim podpunkcie, baza danych MySQL zawsze
rozpoczyna wykonywanie zapytania od jednej tabeli i wyszukuje pasujñce rekordy w kolejnej.
Dlatego teĔ plan wykonywania zapytania w MySQL zawsze przybiera postaè drzewa lewo-
stronnie zagnie
ĔdĔonego, co pokazano na rysunku 4.4.
Rysunek 4.4. Sposób przeprowadzania przez MySQL z
äñczeþ obejmujñcych wiele tabel
10
Serwer generuje dane wyjĈciowe na podstawie planu wykonania zapytania. Dlatego teĔ znajduje siö w nich
taka sama semantyka jak w zapytaniu poczñtkowym, ale niekoniecznie ten sam tekst.

Podstawy wykonywania zapyta
ħ
_ 193
Optymalizator z
ĥéczeħ
NajwaĔniejszñ czöĈciñ optymalizatora zapytaþ MySQL jest optymalizator zäñczeþ, który decy-
duje o najlepszej kolejnoĈci wykonywania zapytaþ obejmujñcych wiele tabel. Zazwyczaj ope-
racje zäñczeþ tabel moĔna przeprowadziè w odmiennej kolejnoĈci, wciñĔ otrzymujñc te same
wyniki. Optymalizator zäñczeþ oszacowuje koszt róĔnych planów, a nastöpnie stara siö wybraè
najtaþszy i dajñcy te same wyniki.
PoniĔej przedstawiono zapytanie, którego tabele mogñ zostaè zäñczone w róĔnej kolejnoĈci
bez zmiany otrzymanych wyników:
mysql> SELECT film.film_id, film.title, film.release_year, actor.actor_id,
-> actor.first_name, actor.last_name
-> FROM sakila.film
-> INNER JOIN sakila.film_actor USING(film_id)
-> INNER JOIN sakila.actor USING(actor_id);
Czytelnik prawdopodobnie myĈli o kilku róĔnych planach wykonania zapytania. Przykäa-
dowo baza danych MySQL mogäaby rozpoczñè od tabeli
film
, uĔyè indeksu obejmujñcego
kolumny
film_id
i
film_actor
w celu wyszukania wartoĈci
actor_id
, a nastöpnie znaleĒè re-
kordy w kluczu podstawowym tabeli
actor
. Takie rozwiñzanie byäoby efektywne, nieprawdaĔ?
Warto wiöc uĔyè polecenia
EXPLAIN
i przekonaè siö, w jaki sposób baza danych MySQL wy-
konuje to zapytanie:
*************************** Rekord 1. ***************************
id: 1
select_type: SIMPLE
table: actor
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200
Extra:
*************************** Rekord 2. ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 2
ref: sakila.actor.actor_id
rows: 1
Extra: Using index
*************************** Rekord 3. ***************************
id: 1
select_type: SIMPLE
table: film
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: sakila.film_actor.film_id
rows: 1
Extra:

194
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Jak widaè, to nieco odmienny plan od zasugerowanego w poprzednim akapicie. Baza danych
MySQL rozpoczyna od tabeli
actor
(wiemy o tym, poniewaĔ zostaäa wyĈwietlona w pierw-
szej grupie danych wyjĈciowych polecenia
EXPLAIN
), a nastöpnie porusza siö w odwrotnej
kolejnoĈci. Czy takie rozwiñzanie naprawdö jest efektywne? Warto to sprawdziè. Säowo klu-
czowe
STRAIGHT_JOIN
wymusza przeprowadzanie operacji zäñczeþ w kolejnoĈci okreĈlonej
przez zapytanie. PoniĔej przedstawiono dane wyjĈciowe polecenia
EXPLAIN
dla zmodyfiko-
wanego zapytania:
mysql> EXPLAIN SELECT STRAIGHT_JOIN film.film_id...\G
*************************** Rekord 1. ***************************
id: 1
select_type: SIMPLE
table: film
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 951
Extra:
*************************** Rekord 2. ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: sakila.film.film_id
rows: 1
Extra: Using index
*************************** Rekord 3. ***************************
id: 1
select_type: SIMPLE
table: actor
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: sakila.film_actor.actor_id
rows: 1
Extra:
To pokazuje, dlaczego MySQL stosuje odwrotnñ kolejnoĈè zäñczeþ: dziöki temu serwer musi
przeanalizowaè mniejszñ iloĈè rekordów w pierwszej tabeli
11
. W obu przypadkach moĔliwe
jest przeprowadzenie szybkich wyszukiwaþ indeksu w tabelach drugiej i trzeciej. RóĔnica
dotyczy liczby wymienionych wyszukiwaþ indeksu, które muszñ zostaè wykonane.
x
UĔycie tabeli
film
jako pierwszej wymaga 951 prób w tabelach
film_actor
i
actor
, po
jednej dla kaĔdego rekordu w pierwszej tabeli.
x
JeĔeli serwer jako pierwszñ skanuje tabelö
actor
, w kolejnych tabelach bödzie musiaä
wykonaè tylko okoäo dwustu wyszukiwaþ indeksu.
11
A mówiñc dokäadniej, baza danych MySQL nie próbuje zredukowaè liczby odczytywanych rekordów. Zamiast
tego próbuje przeprowadziè optymalizacjö pozwalajñcñ na odczyt mniejszej liczby stron. Liczba rekordów
czösto moĔe w przybliĔeniu podaè koszt zapytania.

Podstawy wykonywania zapyta
ħ
_ 195
Innymi säowy, odwrotna kolejnoĈè wykonywania zäñczeþ bödzie wymagaäa mniejszej liczby
operacji powrotów oraz ponownego odczytu. Aby dwukrotnie sprawdziè wybór optymalizatora,
autorzy wykonali dwie wersje zapytania i sprawdzili wartoĈè zmiennej
Last_query_cost
dla
kaĔdego z nich. Oszacowany koszt zmodyfikowanego zapytania wyniósä 241, podczas gdy
oszacowany koszt zapytania wymuszajñcego zachowanie kolejnoĈci zäñczeþ wyniósä 1154.
To prosty przykäad na to, jak optymalizator zäñczeþ w MySQL moĔe zmieniè kolejnoĈè operacji
w zapytaniu, aby jego wykonanie staäo siö taþsze. Zmiana kolejnoĈci operacji zäñczeþ zwykle
jest bardzo efektywnñ formñ optymalizacji. Zdarzajñ siö sytuacje, w których optymalizator
nie wybiera optymalnego planu, ale wówczas moĔna uĔyè säowa kluczowego
STRAIGHT_JOIN
oraz napisaè zapytanie w kolejnoĈci uznawanej przez programistö za najlepszñ. Takie sytu-
acje jednak wystöpujñ bardzo rzadko. W wiökszoĈci przypadków optymalizator zäñczeþ wy-
grywa z czäowiekiem.
Optymalizator zäñczeþ próbuje zbudowaè drzewo planu wykonania zapytania o najniĔszym
moĔliwym do zaakceptowania koszcie. Kiedy bödzie to moĔliwe, analizuje wszystkie poten-
cjalne kombinacje poddrzew, a rozpoczyna od wszystkich planów obejmujñcych jednñ tabelö.
Niestety, operacja zäñczeþ n tabel bödzie miaäa n! (silnia) kombinacji kolejnoĈci zäñczeþ do
przeanalizowania. Wspóäczynnik ten nosi nazwö przestrzeni przeszukiwana dla wszystkich
moĔliwych planów zapytania i zwiöksza siö bardzo szybko. Zäñczenie dziesiöciu tabel moĔe
byè przeprowadzone na maksymalnie 3628800 róĔnych sposobów! Kiedy przestrzeþ prze-
szukiwania za bardzo siö rozrasta, wtedy optymalizacja zapytania moĔe wymagaè zbyt duĔej
iloĈci czasu. Serwer zatrzymuje wiöc wykonywanie peänej analizy. W zamian stosuje skróty,
np. szukanie „zachäanne”, kiedy liczba tabel przekroczy wartoĈè granicznñ ustalonñ przez
zmiennñ
optimizer_search_depth
.
Baza danych MySQL dysponuje zgromadzonymi w czasie lat badaþ i eksperymentów wieloma
algorytmami heurystycznymi, które sñ uĔywane do przyĈpieszenia dziaäania fazy optymalizacji.
Wprawdzie jest to korzystne, ale równoczeĈnie oznacza, Ĕe serwer MySQL moĔe (sporadycznie)
pominñè plan optymalny i wybraè nieco mniej optymalny, poniewaĔ nie bödzie próbowaä
przeanalizowaè kaĔdego moĔliwego do wykonania planu.
Zdarzajñ siö sytuacje, gdy zmiana kolejnoĈci w zapytaniu jest niemoĔliwa. Optymalizator
zäñczeþ moĔe wykorzystaè ten fakt do zmniejszenia przestrzeni przeszukiwania poprzez eli-
minacjö okreĈlonych rozwiñzaþ. Klauzula
LEFT JOIN
jest dobrym przykäadem, poniewaĔ skäa-
da siö ze skorelowanych podzapytaþ (wiöcej informacji na ten temat znajduje siö w dalszej
czöĈci rozdziaäu). WiñĔe siö to z faktem, Ĕe wyniki jednej tabeli zaleĔñ od danych otrzymanych
z innej. Tego rodzaju zaleĔnoĈci pomagajñ optymalizatorowi zäñczeþ w redukcji przeszukiwanej
przestrzeni poprzez eliminacjö pewnego rodzaju rozwiñzaþ.
Optymalizacja sortowania
Sortowanie wyników moĔe byè kosztownñ operacjñ, stñd czösto moĔna poprawiè wydajnoĈè
poprzez unikanie sortowania bñdĒ sortowanie mniejszej liczby rekordów.
Wykorzystanie indeksów podczas sortowania zostaäo przedstawione w rozdziale 3. Kiedy
baza danych MySQL nie moĔe uĔyè indeksu w celu zbudowania posortowanego wyniku,
wówczas samodzielnie musi posortowaè rekordy. Operacjö moĔna przeprowadziè w pamiöci
lub na dysku twardym, ale proces zawsze nosi nazwö sortowania pliku, nawet jeĈli w rzeczy-
wistoĈci nie uĔywa pliku.

196
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
JeĔeli wartoĈci przeznaczone do sortowania mieszczñ siö w buforze sortowania, MySQL
moĔe przeprowadziè sortowanie caäkowicie w pamiöci za pomocñ szybkiego sortowania. JeĈli
MySQL nie moĔe wykonaè sortowania w pamiöci, wtedy operacja jest przeprowadzana na
dysku poprzez sortowanie wartoĈci fragmentami. Proces wykorzystuje szybkie sortowanie
w celu posortowania kaĔdego fragmentu, a kaĔdy posortowany fragment jest doäñczany
do wyniku.
Istniejñ dwa algorytmy sortowania pliku.
Dwuprzebiegowy (stary)
Odczytuje wskaĒniki rekordów oraz kolumny
ORDER BY
, sortuje je, a nastöpnie skanuje
posortowanñ listö i ponownie odczytuje rekordy w celu utworzenia danych wyjĈciowych.
Algorytm dwuprzebiegowy moĔe byè bardzo kosztowny, poniewaĔ rekordy sñ odczy-
tywane z tabeli dwukrotnie, a drugi odczyt powoduje wykonanie duĔej iloĈci losowych
operacji I/O. Proces jest szczególnie kosztowny w silniku MyISAM, który do pobrania
kaĔdego rekordu uĔywa wywoäaþ systemowych (poniewaĔ MyISAM polega na buforze
systemu operacyjnego przechowujñcego dane). Jednak w trakcie sortowania przechowy-
wana jest minimalna iloĈè danych. Tak wiöc rekordy sñ sortowane caäkowicie w pamiöci,
a przechowywanie mniejszej iloĈci danych i ponowny odczyt rekordów w celu wygene-
rowania wyniku koþcowego moĔe okazaè siö taþszym rozwiñzaniem.
Jednoprzebiegowy (nowy)
Odczytuje wszystkie kolumny wymagane przez zapytanie, sortuje je wedäug kolumn
ORDER BY
, a nastöpnie skanuje posortowanñ listö i wyĈwietla dane wyjĈciowe wskaza-
nych kolumn.
Ten algorytm sortowania jest dostöpny jedynie w MySQL 4.1 i nowszych. MoĔe byè
znacznie efektywniejszy zwäaszcza dla ogromnych zbiorów danych opierajñcych siö na
operacjach I/O, poniewaĔ unika dwukrotnego odczytywania rekordów z tabel i zastö-
puje losowe operacje I/O bardziej ciñgäymi operacjami I/O. Jednak potencjalnie moĔe
uĔywaè duĔej iloĈci miejsca, poniewaĔ przechowuje wszystkie poĔñdane kolumny z kaĔ-
dego rekordu, a nie tylko kolumny wymagane do posortowania rekordów. Oznacza to,
Ĕe mniejsza iloĈè zbiorów elementów zmieĈci siö w buforze sortowania, a samo sortowanie
pliku bödzie musiaäo wykonaè wiöcej operacji äñczenia wyników sortowania.
MySQL moĔe na potrzeby sortowania pliku wykorzystywaè znacznie wiöcej przestrzeni
tymczasowej, niĔ moĔna przypuszczaè, bo przy sortowaniu kaĔdego zbioru elementów alo-
kuje rekord o staäej däugoĈci. Te rekordy sñ na tyle olbrzymie, aby pomieĈciè najwiökszy
moĔliwy zbiór danych, äñcznie z kaĔdñ kolumnñ
VARCHAR
o peänej däugoĈci. Ponadto podczas
stosowania kodowania UTF-8 serwer MySQL alokuje trzy bajty dla kaĔdego znaku. Autorzy
spotkali siö z kiepsko zoptymalizowanymi schematami, które powodowaäy, Ĕe przestrzeþ
tymczasowa uĔywana podczas sortowania byäa wielokrotnie wiöksza niĔ wielkoĈè caäej tabeli
na dysku twardym.
Podczas sortowania zäñczeþ baza danych MySQL moĔe w trakcie wykonywania zapytania
przeprowadziè sortowanie pliku na dwóch etapach. JeĔeli klauzula
ORDER BY
odnosi siö je-
dynie do kolumn w pierwszej tabeli zäñczenia, MySQL moĔe przeprowadziè sortowanie tej
tabeli, a nastöpnie wykonaè operacjö zäñczenia. W takim przypadku dane wyjĈciowe polecenia
EXPLAIN
zawierajñ w kolumnie
Extra
ciñg tekstowy „Using filesort”. W przeciwnym razie
baza danych MySQL musi przechowywaè wynik zapytania w tabeli tymczasowej, a nastöpnie
Podstawy wykonywania zapyta
ħ
_ 197
przeprowadziè na niej sortowanie pliku po zakoþczeniu operacji zäñczenia. W takim przy-
padku dane wyjĈciowe polecenia
EXPLAIN
zawierajñ w kolumnie
Extra
ciñg tekstowy „Using
temporary; Using filesort”. JeĔeli w zapytaniu znajduje siö klauzula
LIMIT
, bödzie zastoso-
wana po operacji sortowania pliku, a wiöc tabela tymczasowa moĔe byè ogromna, natomiast
operacja sortowania pliku bardzo kosztowna.
Wiöcej informacji na temat dostrajania serwera pod kñtem sortowania pliku oraz wpäywu
uĔywanego przez serwer algorytmu przedstawiono w rozdziale 6., w podrozdziale „Opty-
malizacja sortowania pliku”.
Silnik wykonywania zapyta
ħ
W wyniku etapu analizy i optymalizacji powstaje plan wykonania zapytania, który silnik
wykonywania zapytaþ MySQL stosuje w celu przetworzenia zapytania. Plan jest strukturñ
danych, a nie wykonywalnym kodem bajtowym, jak ma to miejsce w wielu innych bazach
danych.
Faza wykonania zapytania, w przeciwieþstwie do fazy optymalizacji, zwykle nie jest tak
skomplikowana: MySQL po prostu podñĔa za instrukcjami znajdujñcymi siö w planie wyko-
nania zapytania. WiökszoĈè operacji w planie polega na wywoäaniu metod zaimplemento-
wanych przez interfejs silnika magazynu danych, znany równieĔ pod nazwñ API procedury
obs
äugi. KaĔda tabela w zapytaniu jest przedstawiana jako egzemplarz procedury obsäugi.
JeĔeli np. tabela wystöpuje w zapytaniu trzykrotnie, serwer utworzy trzy egzemplarze pro-
cedury obsäugi. ChociaĔ nie byäo to eksponowane wczeĈniej, trzeba powiedzieè, Ĕe MySQL
w rzeczywistoĈci tworzy egzemplarze procedury obsäugi wczeĈniej, w fazie optymalizacji.
Optymalizator wykorzystuje je w celu pobrania informacji dotyczñcych tabel, np. nazw kolumn
oraz danych statystycznych indeksu.
Interfejs silnika magazynu danych ma duĔñ liczbö funkcji, ale do wykonania wiökszoĈci zapytaþ
wymaga jedynie okoäo dziesiöciu operacji typu „bloku budulcowego”. Przykäadowo istnieje
operacja säuĔñca do odczytania pierwszego rekordu z indeksu oraz inna operacja do od-
czytania kolejnego rekordu z indeksu. To wystarczy w zapytaniu, które przeprowadza ska-
nowanie indeksu. Taka uproszczona metoda wykonywania zapytania jest moĔliwa dziöki
architekturze silnika magazynu danych MySQL, ale jednoczeĈnie nak
äada pewne ograniczenia
w zakresie optymalizacji, co zostaäo opisane wczeĈniej.
Nie wszystko jest operacjñ procedury obsäugi. Przykäadowo to serwer zarzñdza blo-
kadami tabel. Procedura obsäugi moĔe implementowaè wäasne blokowanie niĔszego
poziomu, tak jak w przypadku InnoDB i jego blokowania na poziomie rekordu, ale
to nie zastöpuje wäasnej implementacji blokowania znajdujñcej siö w serwerze. Jak
wyjaĈniono w rozdziale 1., wszystko, co jest wspóädzielone przez wszystkie silniki
magazynu danych, zostaäo zaimplementowane w serwerze, np. funkcje daty i godziny,
widoki i wyzwalacze.
W celu wykonania zapytania serwer po prostu powtarza instrukcje aĔ do chwili, gdy nie bödzie
kolejnych rekordów do przeanalizowania.

198
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Zwrot klientowi wyników zapytania
Ostatnim krokiem w trakcie wykonywania zapytania jest zwrot wyników klientowi. Nawet
zapytania niezwracajñce zbioru wynikowego teĔ udzielajñ klientowi odpowiedzi, która za-
wiera informacje o zapytaniu, np. o liczbie rekordów, których dotyczyäo zapytanie.
JeĔeli zapytanie moĔna buforowaè, na tym etapie baza danych MySQL umieĈci jego wyniki
w buforze zapytania.
Serwer generuje i wysyäa wyniki w sposób przyrostowy. Warto w tym miejscu przypomnieè
sobie omówionñ wczeĈniej metodö wielu zäñczeþ. Kiedy baza danych MySQL przetworzy
ostatniñ tabelö i z powodzeniem wygeneruje rekord, moĔe i powinna wysäaè ten rekord
klientowi. Takie rozwiñzanie niesie ze sobñ dwie korzyĈci: umoĔliwia serwerowi unikniöcie
koniecznoĈci przechowywania rekordu w pamiöci oraz oznacza, Ĕe klient bödzie otrzymywaä
wyniki tak szybko, jak to moĔliwe
12
.
Ograniczenia optymalizatora zapyta
ħ MySQL
PodejĈcie MySQL, okreĈlane mianem „wszystko jest zäñczeniem zagnieĔdĔonych pötli”, sto-
sowane podczas wykonywania zapytaþ nie jest idealnym rozwiñzaniem optymalizacji kaĔ-
dego rodzaju zapytaþ. Na szczöĈcie, istnieje tylko niewielka liczba sytuacji, w których optyma-
lizator zapytaþ MySQL siö nie sprawdza. Zazwyczaj moĔliwe jest wówczas ponowne napisanie
zapytaþ, aby dziaäaäy znacznie efektywniej.
Informacje przedstawione w tym podrozdziale majñ zastosowanie do wersji serwera
MySQL dostöpnych w trakcie pisania ksiñĔki, czyli do wersji 5.1 MySQL. Niektóre
z omówionych zapytaþ prawdopodobnie zostanñ zäagodzone lub caäkowicie usuniöte
w przyszäych wersjach serwera. CzöĈè zostaäa juĔ poprawiona i umieszczona w wersjach,
które nie sñ jeszcze oficjalnie dostöpne. W kodzie Ēródäowym MySQL 6 wprowadzono
pewnñ liczbö optymalizacji podzapytaþ, a nad wieloma kolejnymi trwajñ prace.
Podzapytania skorelowane
MySQL czasami kiepsko optymalizuje podzapytania. Najtrudniej poddajñ siö optymalizacji
podzapytania
IN()
w klauzuli
WHERE
. Przeanalizujmy przykäadowe zapytanie majñce za za-
danie znalezienie wszystkich filmów w tabeli
sakila.film
bazy danych
Sakila
, w których
wystöpuje aktorka Penelope Guiness (
actor_id=1
). Naturalne wydaje siö utworzenie nastö-
pujñcego podzapytania:
mysql> SELECT * FROM sakila.film
-> WHERE film_id IN(
-> SELECT film_id FROM sakila.film_actor WHERE actor_id = 1);
12
JeĔeli trzeba, programista moĔe wpäynñè na takie zachowanie bazy danych, stosujñc wskazówkö zwiñzanñ
z
SQL_BUFFER_RESULT
. Wiöcej informacji na ten temat przedstawiono w podrozdziale „Wskazówki dotyczñce
optymalizatora zapytaþ”, znajdujñcym siö w dalszej czöĈci rozdziaäu.

Ograniczenia optymalizatora zapyta
ħ MySQL
_ 199
Kuszñce wydaje siö zaäoĔenie, Ĕe baza danych MySQL wykona powyĔsze zapytanie na odwrót,
poprzez wyszukanie listy wartoĈci
actor_id
i zastosowanie ich w liĈcie
IN()
. WczeĈniej
wspomniano, Ĕe lista
IN()
w zasadzie jest bardzo szybka, a wiöc moĔna spodziewaè siö, Ĕe
zapytanie zostanie zoptymalizowane np. w nastöpujñcy sposób:
-- SELECT GROUP_CONCAT(film_id) FROM sakila.film_actor WHERE actor_id = 1;
-- Result: 1,23,25,106,140,166,277,361,438,499,506,509,605,635,749,832,939,970,980
SELECT * FROM sakila.film
WHERE film_id
IN(1,23,25,106,140,166,277,361,438,499,506,509,605,635,749,832,939,970,980);
Niestety, mamy do czynienia z sytuacjñ odwrotnñ. MySQL próbuje „pomóc” podzapytaniu
poprzez wepchniöcie do niego korelacji z zewnötrznej tabeli, Ĕeby efektywniej mogäo wyszu-
kiwaè rekordy. Nowo napisane zapytanie jest wiöc nastöpujñce:
SELECT * FROM sakila.film
WHERE EXISTS (
SELECT * FROM sakila.film_actor WHERE actor_id = 1
AND film_actor.film_id = film.film_id);
Po powyĔszej modyfikacji podzapytanie wymaga kolumny
film_id
z zewnötrznej tabeli
film
i nie moĔe byè wykonane w pierwszej kolejnoĈci. Dane wyjĈciowe polecenia
EXPLAIN
przedstawiajñ wynik jako
DEPENDENT SUBQUERY
(moĔna wykonaè polecenie
EXPLAIN EXTENDED
w celu dokäadnego zobaczenia, jak zapytanie zostaäo napisane na nowo):
mysql> EXPLAIN SELECT * FROM sakila.film ...;
+----+--------------------+------------+--------+------------------------+
| id | select_type | table | type | possible_keys |
+----+--------------------+------------+--------+------------------------+
| 1 | PRIMARY | film | ALL | NULL |
| 2 | DEPENDENT SUBQUERY | film_actor | eq_ref | PRIMARY,idx_fk_film_id |
+----+--------------------+------------+--------+------------------------+
Zgodnie z danymi wyjĈciowymi polecenia
EXPLAIN
, baza danych MySQL przeprowadzi
skanowanie tabeli
film
i wykona podzapytanie wzglödem kaĔdego znalezionego rekordu.
W przypadku maäej tabeli nie przeäoĔy siö to na zbyt duĔe obniĔenie wydajnoĈci, ale jeĈli
zewnötrzna tabela bödzie ogromna, spadek wydajnoĈè bödzie katastrofalny. Na szczöĈcie,
nowe zapytanie moĔna bardzo äatwo napisaè, np. z uĔyciem klauzuli
JOIN
:
mysql> SELECT film.* FROM sakila.film
-> INNER JOIN sakila.film_actor USING(film_id)
-> WHERE actor_id = 1;
Innym dobrym rozwiñzaniem optymalizacyjnym jest röczne wygenerowanie listy
IN()
poprzez
wykonanie podzapytania jako oddzielnego zapytania z funkcjñ
GROUP_CONCAT()
. Czasami
bödzie to szybsze rozwiñzanie niĔ uĔycie klauzuli
JOIN
.
Baza danych MySQL byäa mocno krytykowana za ten szczególny rodzaj planu wykonywania
podzapytania. ChociaĔ niewñtpliwie wymaga on poprawienia, krytycy czösto mylili dwa
róĔne elementy: kolejnoĈè wykonywania oraz buforowanie. Wykonanie zapytania na odwrót
jest jednñ z form jego optymalizacji, natomiast buforowanie wyniku zapytania to inna forma.
Samodzielne ponowne napisanie zapytania daje kontrolö nad obydwoma aspektami. Przy-
szäe wersje MySQL powinny zapewniaè lepszñ optymalizacjö tego rodzaju zapytaþ, choè nie
jest to zadanie äatwe do wykonania. Wystöpujñ znacznie gorsze przypadki zwiñzane z do-
wolnym planem wykonania zapytania, äñcznie z zastosowaniem odwrotnego planu wykona-
nia zapytania, o którym sñdzi siö, Ĕe bödzie prostszy do optymalizacji.

200 _
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Kiedy podzapytanie skorelowanie jest dobre?
Baza danych MySQL nie zawsze bäödnie optymalizuje podzapytania skorelowane. JeĔeli
czytelnik usäyszy poradö, aby zawsze ich unikaè, nie naleĔy jej säuchaè! W zamian warto
przeprowadziè testy wydajnoĈci i samodzielnie podjñè decyzjö. W niektórych sytuacjach
podzapytanie skorelowane jest caäkiem rozsñdnym lub nawet optymalnym sposobem otrzy-
mania wyniku. Warto spojrzeè na poniĔszy przykäad:
mysql> EXPLAIN SELECT film_id, language_id FROM sakila.film
-> WHERE NOT EXISTS(
-> SELECT * FROM sakila.film_actor
-> WHERE film_actor.film_id = film.film_id
->)\G
*************************** Rekord 1. ***************************
id: 1
select_type: PRIMARY
table: film
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 951
Extra: Using where
*************************** Rekord 2. ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: film_actor
type: ref
possible_keys: idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: film.film_id
rows: 2
Extra: Using where; Using index
Standardowñ poradñ dla takiego zapytania jest zastosowanie w nim klauzuli
LEFT OUTER
JOIN
zamiast uĔycia podzapytania. Teoretycznie, baza danych MySQL powinna zastosowaè
w obu przypadkach taki sam plan wykonania zapytania. Warto to sprawdziè:
mysql> EXPLAIN SELECT film.film_id, film.language_id
-> FROM sakila.film
-> LEFT OUTER JOIN sakila.film_actor USING(film_id)
-> WHERE film_actor.film_id IS NULL\G
*************************** Rekord 1. ***************************
id: 1
select_type: SIMPLE
table: film
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 951
Extra:
*************************** Rekord 2. ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: ref

Ograniczenia optymalizatora zapyta
ħ MySQL
_ 201
possible_keys: idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: sakila.film.film_id
rows: 2
Extra: Using where; Using index; Not exists
Plany sñ niemal identyczne, ale wystöpujñ miödzy nimi pewne róĔnice.
x
Zapytanie
SELECT
wzglödem tabeli
film_actor
jest rodzaju
DEPENDENT SUBQUERY
w jed-
nym zapytaniu, natomiast
SIMPLE
— w drugim. RóĔnica po prostu odzwierciedla skäadniö,
poniewaĔ pierwsze zapytanie uĔywa podzapytania, a drugie nie. Pod wzglödem operacji
procedury obsäugi nie ma miödzy nimi zbyt duĔej róĔnicy.
x
W kolumnie
Extra
drugiego zapytania tabela
film
nie jest opisana ciñgiem tekstowym
„Using where”. To nie ma znaczenia: klauzula
USING
uĔyta w drugim zapytaniu i tak
oznacza to samo, co klauzula
WHERE
.
x
W kolumnie
Extra
drugiego zapytania tabela
film_actor
jest opisana ciñgiem tekstowym
„Not exists”. To jest przykäad dziaäania algorytmu wczesnego zakoþczenia zapytania
omówionego we wczeĈniejszej czöĈci rozdziaäu. Oznacza to, Ĕe baza danych MySQL
chciaäa uĔyè nieistniejñcej optymalizacji w celu unikniöcia odczytu wiöcej niĔ jednego rekordu
z indeksu
idx_fk_film
tabeli
film_actor
. Odpowiada to funkcji
NOT EXISTS()
skorelo-
wanego podzapytania, poniewaĔ zatrzymuje przetwarzanie bieĔñcego rekordu tuĔ po
znalezieniu dopasowania.
Tak wiöc teoretycznie MySQL wykona powyĔsze zapytania niemal identycznie. W rzeczywi-
stoĈci przeprowadzenie testów wydajnoĈci to jedyny sposób stwierdzenia, które z wymie-
nionych rozwiñzaþ jest szybsze. Autorzy przeprowadzili testy wydajnoĈci na obu zapyta-
niach, korzystajñc ze standardowych ustawieþ. Wyniki zostaäy przedstawione w tabeli 4.1.
Tabela 4.1. Zapytanie NOT EXISTS kontra LEFT OUTER JOIN
Zapytanie
Wynik w liczbie zapyta
ħ na sekundý (QPS)
podzapytanie
NOT EXISTS
360 QPS
LEFT OUTER JOIN
425 QPS
A zatem podzapytanie jest nieco wolniejsze!
Jednak nie zawsze tak bywa. Zdarzajñ siö sytuacje, gdy podzapytanie moĔe byè szybsze.
Przykäadowo moĔe sprawdzaè siö doskonale, kiedy trzeba bödzie po prostu wskazaè rekordy
z jednej tabeli dopasowane do rekordów w drugiej. ChociaĔ brzmi to jak doskonaäy opis zäñ-
czenia, nie zawsze jest nim. Przedstawione poniĔej zäñczenie zaprojektowane w celu wyszukania
kaĔdego filmu, w którym wystöpuje aktor, zwróci powielone rekordy, poniewaĔ w niektórych
filmach wystöpuje wielu aktorów:
mysql> SELECT film.film_id FROM sakila.film
-> INNER JOIN sakila.film_actor USING(film_id);
Aby wyeliminowaè powielone rekordy, trzeba uĔyè klauzul
DISTINCT
lub
GROUP BY
:
mysql> SELECT DISTINCT film.film_id FROM sakila.film
-> INNER JOIN sakila.film_actor USING(film_id);

202
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Czy to naprawdö jest próba przyĈpieszenia zapytania i czy wynika z kodu SQL? Operator
EXISTS
wyraĔa logicznñ koncepcjö „ma dopasowanie”, bez tworzenia powielajñcych siö rekor-
dów, oraz unika operacji
GROUP BY
lub
DISTINCT
, które mogäyby wymagaè tabeli tymczasowej.
PoniĔej przedstawiono nowo napisane zapytanie zawierajñce podzapytanie zamiast zäñczenia:
mysql> SELECT film_id FROM sakila.film
-> WHERE EXISTS(SELECT * FROM sakila.film_actor
-> WHERE film.film_id = film_actor.film_id);
TakĔe w tym przypadku autorzy przeprowadzili testy wydajnoĈci sprawdzajñce obie strategie.
Wyniki zostaäy przedstawione w tabeli 4.2.
Tabela 4.2. Zapytanie EXISTS kontra INNER JOIN
Zapytanie
Wynik w liczbie zapyta
ħ na sekundý (QPS)
INNER JOIN
185 QPS
podzapytanie
EXISTS
325 QPS
PowyĔszy przykäad pokazuje, Ĕe podzapytanie zostaäo wykonane szybciej niĔ operacja zäñczenia.
Ten däugi przykäad zostaä zaprezentowany w celu ilustracji dwóch aspektów. Po pierwsze,
nie naleĔy zwaĔaè na kategoryczne porady dotyczñce podzapytaþ. Po drugie, trzeba prze-
prowadzaè testy wydajnoĈci majñce na celu potwierdzenie zaäoĔeþ dotyczñcych planów za-
pytania i szybkoĈci ich wykonywania.
Ograniczenia klauzuli UNION
Baza danych MySQL moĔe czasami „wciñgnñè” do Ĉrodka warunki z zewnötrznej klauzuli
UNION
,
gdzie bödñ mogäy zostaè uĔyte w celu ograniczenia liczby wyników lub wäñczenia dodatkowych
optymalizacji.
JeĔeli programista sñdzi, Ĕe dowolne z poszczególnych zapytaþ poäñczonych klauzulñ
UNION
moĔe odnieĈè korzyĈci z uĔycia klauzuli
LIMIT
lub stanie siö podmiotem dziaäania klauzuli
ORDER BY
po poäñczeniu z innymi zapytaniami, wówczas klauzulö
LIMIT
trzeba umieĈciè we-
wnñtrz kaĔdej czöĈci konstrukcji
UNION
. JeĔeli np. dwie ogromne tabele sñ powiñzane klauzulñ
UNION
, a wynik zostaje ograniczony do dwudziestu rekordów za pomocñ klauzuli
LIMIT
,
wtedy baza danych MySQL bödzie przechowywaäa obie ogromne tabele w tabeli tymczasowej,
a nastöpnie pobierze z niej dwadzieĈcia rekordów. MoĔna uniknñè takiej sytuacji poprzez
umieszczenie klauzuli
LIMIT
wewnñtrz kaĔdego zapytania tworzñcego konstrukcjö
UNION
.
Optymalizacja po
ĥéczonych indeksów
Wprowadzone w MySQL 5.0 algorytmy äñczenia indeksów pozwalajñ bazie danych MySQL
na uĔywanie w zapytaniu wiöcej niĔ tylko jednego indeksu na tabelö. WczeĈniejsze wersje
MySQL mogäy uĔywaè tylko pojedynczego indeksu. Dlatego teĔ kiedy pojedynczy indeks nie
byä wystarczajñco dobry, aby poradziè sobie z wszystkimi ograniczeniami w klauzuli
WHERE
, baza
danych MySQL czösto wybieraäa opcjö skanowania tabeli. Przykäadowo tabela
film_actor
ma indeks obejmujñcy kolumnö
film_id
oraz indeks obejmujñcy kolumnö
actor_id
, ale Ĕaden
z nich nie jest dobrym wyborem dla dwóch warunków klauzuli
WHERE
w poniĔszym zapytaniu:
mysql> SELECT film_id, actor_id FROM sakila.film_actor
-> WHERE actor_id = 1 OR film_id = 1;

Ograniczenia optymalizatora zapyta
ħ MySQL
_ 203
We wczeĈniejszych wersjach MySQL powyĔsze zapytanie spowodowaäoby skanowanie tabeli,
o ile nie zostaäoby napisane od nowa w postaci dwóch zapytaþ poäñczonych klauzulñ
UNION
:
mysql> SELECT film_id, actor_id FROM sakila.film_actor WHERE actor_id = 1
-> UNION ALL
-> SELECT film_id, actor_id FROM sakila.film_actor WHERE film_id = 1
-> AND actor_id <> 1;
Jednak w bazie danych MySQL 5.0 i nowszych zapytanie to moĔe uĔyè obu indeksów rów-
noczeĈnie, skanujñc je i äñczñc wyniki. Istniejñ trzy odmiany algorytmu: unia dla warunków
OR
,
czöĈè wspólna dla warunków
AND
oraz unia czöĈci wspólnych dla poäñczenia dwóch wymie-
nionych. Przedstawione poniĔej zapytanie uĔywa unii operacji skanowania dwóch indeksów,
co moĔna zobaczyè podczas analizy kolumny
Extra
:
mysql> EXPLAIN SELECT film_id, actor_id FROM sakila.film_actor
-> WHERE actor_id = 1 OR film_id = 1\G
*************************** Rekord 1. ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: index_merge
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY,idx_fk_film_id
key_len: 2,2
ref: NULL
rows: 29
Extra: Using union(PRIMARY,idx_fk_film_id); Using where
Baza danych MySQL moĔe wykorzystaè tö technikö w skomplikowanych klauzulach
WHERE
.
Dlatego teĔ w niektórych zapytaniach kolumna
Extra
bödzie wyĈwietlaäa zagnieĔdĔone ope-
racje. Mechanizm zazwyczaj dziaäa bardzo dobrze, ale czasami przeprowadzane przez algorytm
buforowanie, sortowanie i operacje äñczenia uĔywajñ duĔej iloĈci zasobów procesora i pamiöci.
Dotyczy to zwäaszcza sytuacji, gdy nie wszystkie indeksy zapewniajñ wysoki poziom selek-
tywnoĈci, a wiöc równoczesne skanowanie zwraca duĔñ iloĈè rekordów poddawanych opera-
cji äñczenia. Warto sobie w tym miejscu przypomnieè, Ĕe optymalizator nie wlicza tego do
kosztu — po prostu optymalizuje liczbö losowych odczytów stron. W ten sposób koszt za-
pytania jest „niedoszacowany” i wykonanie takiego zapytania moĔe byè wolniejsze niĔ zwy-
käe skanowanie tabeli. Ogromne zuĔycie zasobów pamiöci i mocy obliczeniowej procesora
moĔe mieè takĔe wpäyw na równoczeĈnie wykonywane inne zapytania, ale efekt ten nie bödzie
widoczny, kiedy zapytanie jest wykonywane w izolacji. To kolejny powód skäaniajñcy do
projektowania realistycznych testów wydajnoĈci.
JeĔeli zapytanie jest wykonywane znacznie wolniej z powodu tego ograniczenia optymalizatora,
moĔna sobie poradziè, wyäñczajñc okreĈlone indeksy za pomocñ polecenia
IGNORE INDEX
lub
po prostu wracajñc do starej taktyki z uĔyciem klauzuli
UNION
.
Szerzenie równo
ļci
W niektórych przypadkach szerzenie równoĈci moĔe nieĈè ze sobñ nieoczekiwane koszty.
Przykäadowo warto rozwaĔyè ogromnñ listö
IN()
obejmujñcñ kolumnö, która wg informacji
optymalizatora bödzie równa okreĈlonym kolumnom w innych tabelach z powodu klauzul
WHERE
,
ON
lub
USING
ustanawiajñcych równoĈè kolumn wobec siebie.

204 _
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Optymalizator bödzie „wspóädzieliä” listö poprzez skopiowanie jej do odpowiednich kolumn
we wszystkich powiñzanych tabelach. Zwykle jest to pomocne, poniewaĔ daje optymalizato-
rowi zapytaþ oraz silnikowi wykonywania wiöcej moĔliwoĈci w zakresie miejsca faktycznego
przeprowadzenia sprawdzenia listy
IN()
. Kiedy jednak lista jest ogromna, skutkiem moĔe
byè mniej efektywna optymalizacja i wolniejsze wykonanie zapytania. W trakcie pisania tej
ksiñĔki nie byäo dostöpne Ĕadne wbudowane w bazö rozwiñzanie pozwalajñce na ominiöcie
tego problemu — w takim przypadku trzeba po prostu zmodyfikowaè kod Ēródäowy. (Problem
jednak nie wystöpuje u wiökszoĈci uĔytkowników).
Wykonywanie równoleg
ĥe
Baza danych MySQL nie potrafi wykonywaè pojedynczego zapytania równoczeĈnie na wielu
procesorach. Taka funkcja jest oferowana przez niektóre serwery baz danych, ale nie przez
MySQL. Autorzy wspominajñ, aby nie poĈwiöcaè zbyt duĔej iloĈci czasu na próbö odkrycia,
jak w MySQL uzyskaè wykonywanie zapytania równoczeĈnie na wielu procesorach.
Z
ĥéczenia typu hash
Podczas pisania ksiñĔki baza danych MySQL nie przeprowadzaäa prawdziwych zäñczeþ typu
hash — wszystko pozostaje zäñczeniem w postaci zagnieĔdĔonej pötli. Jednak zäñczenia typu
hash moĔna emulowaè za pomocñ indeksów typu hash. JeĔeli uĔywany silnik magazynu da-
nych jest inny niĔ Memory, trzeba takĔe emulowaè indeksy typu hash. Wiöcej informacji
na ten temat przedstawiono w sekcji „Budowa wäasnych indeksów typu hash”, znajdujñcej
siö w rozdziale 3.
Lu
Śne skanowanie indeksu
Baza danych MySQL znana jest z tego, Ĕe nie umoĔliwia przeprowadzenia luĒnego skano-
wania indeksu, które polega na skanowaniu nieprzylegajñcych do siebie zakresów indeksu.
Ogólnie rzecz biorñc, skanowanie indeksu w MySQL wymaga zdefiniowania punktu poczñt-
kowego oraz koþcowego w indeksie nawet wtedy, jeĈli kilka nieprzylegajñcych do siebie
rekordów w Ĉrodku jest naprawdö poĔñdanych w danym zapytaniu. Baza danych MySQL
bödzie skanowaäa caäy zakres rekordów wewnñtrz zdefiniowanych punktów koþcowych.
Przykäad pomoĔe w zilustrowaniu tego problemu. Zakäadamy, Ĕe tabela zawiera indeks
obejmujñcy kolumny
(a, b)
, a programista chce wykonaè poniĔsze zapytanie:
mysql> SELECT ... FROM tbl WHERE b BETWEEN 2 AND 3;
PoniewaĔ indeks rozpoczyna siö od kolumny
a
, ale klauzula
WHERE
zapytania nie zawiera
kolumny
a
, baza danych MySQL przeprowadzi skanowanie tabeli oraz za pomocñ klauzuli
WHERE
wyeliminuje nieprzylegajñce do siebie rekordy, co pokazano na rysunku 4.5.
Bardzo äatwo moĔna dostrzec, Ĕe istniejñ szybsze sposoby wykonania tego zapytania. Struktura
indeksu (ale nie API silnika magazynu danych MySQL) pozwala na wyszukanie poczñtku
kaĔdego zakresu wartoĈci, skanowanie aĔ do koþca zakresu, a nastöpnie przejĈcie na poczñtek
kolejnego zakresu. Na rysunku 4.6 pokazano, jak taka strategia mogäaby wyglñdaè, gdyby
zostaäa zaimplementowana w MySQL.
Ograniczenia optymalizatora zapyta
ħ MySQL
_ 205
Rysunek 4.5. Baza danych MySQL skanuje ca
äñ tabelö w celu wyszukania rekordów
Rysunek 4.6. Lu
Ēne skanowanie indeksu, którego MySQL aktualnie nie wykonuje, byäoby efektywniejszym
sposobem wykonania omawianego zapytania

206 _
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Warto zwróciè uwagö na brak klauzuli
WHERE
, która staäa siö zbödna, poniewaĔ sam indeks
pozwala na pomijanie niepotrzebnych rekordów. (Przypominamy ponownie, Ĕe baza danych
MySQL nie ma jeszcze takich moĔliwoĈci).
Jest to, co prawda, uproszczony przykäad i przedstawione zapytanie moĔna äatwo zoptyma-
lizowaè poprzez dodanie innego indeksu. Jednak istnieje wiele sytuacji, gdy dodanie innego
indeksu nie stanowi rozwiñzania. Jednym z takich przypadków jest zapytanie, które zawiera
warunek zakresu wzglödem pierwszej kolumny indeksu oraz warunek równoĈci wzglödem
drugiej kolumny indeksu.
Poczñwszy od MySQL w wersji 5.0, operacja luĒnego skanowania indeksu jest moĔliwa w pew-
nych ĈciĈle okreĈlonych sytuacjach, np. w zapytaniach wyszukujñcych wartoĈci maksymalnñ
i minimalnñ w zgrupowanym zapytaniu:
mysql> EXPLAIN SELECT actor_id, MAX(film_id)
-> FROM sakila.film_actor
-> GROUP BY actor_id\G
*************************** Rekord 1. ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: range
possible_keys: NULL
key: PRIMARY
key_len: 2
ref: NULL
rows: 396
Extra: Using index for group-by
Informacja „Using index for group-by” wyĈwietlona w danych wyjĈciowych polecenia
EXPLAIN
wskazuje na zastosowanie luĒnego skanowania indeksu. To jest dobry rodzaj optymalizacji
w tym specjalnym przypadku, ale równoczeĈnie nie jest to ogólnego przeznaczenia luĒne
skanowanie indeksu. Lepiej byäoby, gdyby informacja miaäa postaè „loose index probe”.
Dopóki baza danych MySQL nie bödzie obsäugiwaäa ogólnego przeznaczenia luĒnego ska-
nowania indeksu, obejĈciem problemu jest zastosowanie staäej bñdĒ listy staäych dla pierw-
szych kolumn indeksu. W zaprezentowanym w poprzednim rozdziale studium przypadku
indeksowania przedstawiono kilka przykäadów osiñgniöcia dobrej wydajnoĈci za pomocñ takich
zapytaþ.
Funkcje MIN() i MAX()
Baza danych MySQL nie moĔe zbyt dobrze zoptymalizowaè pewnych zapytaþ wykorzystu-
jñcych funkcje
MIN()
lub
MAX()
. Oto przykäad takiego zapytania:
mysql> SELECT MIN(actor_id) FROM sakila.actor WHERE first_name = 'PENELOPE';
PoniewaĔ nie ma indeksu obejmujñcego kolumnö
first_name
, powyĔsze zapytanie spowoduje
przeprowadzenie skanowania tabeli. JeĔeli MySQL skanuje klucz podstawowy, teoretycznie
moĔe zatrzymaè skanowanie po odczytaniu pierwszego dopasowanego rekordu, gdyĔ klucz
podstawowy jest w kolejnoĈci ĈciĈle rosnñcej i kaĔdy nastöpny rekord bödzie miaä wiökszñ
wartoĈè
actor_id
. Jednak w omawianym przypadku MySQL przeskanuje caäñ tabelö, o czym
moĔna siö przekonaè po sprofilowaniu zapytania. Rozwiñzaniem problemu jest usuniöcie
funkcji
MIN()
i napisanie zapytania z uĔyciem klauzuli
LIMIT
, np. nastöpujñco:
mysql> SELECT actor_id FROM sakila.actor USE INDEX(PRIMARY)
-> WHERE first_name = 'PENELOPE' LIMIT 1;

Optymalizacja okre
ļlonego rodzaju zapytaħ
_ 207
Taka strategia bardzo czösto dziaäa doskonale w innej sytuacji, kiedy baza danych MySQL
wybraäa skanowanie wiökszej liczby rekordów niĔ potrzeba. PuryĈci mogñ uznaè, Ĕe tego
rodzaju zapytanie oznacza brak zrozumienia SQL. Z reguäy programista informuje serwer,
co chce uzyskaè, a serwer okreĈla, jak pobraè te dane. W omawianym zapytaniu programista
informuje serwer MySQL, jak wykonaè dane zapytanie. Dlatego teĔ z zapytania nie wynika
jasno, Ĕe szukane dane to wartoĈè minimalna. To prawda, ale czasami trzeba poĈwiöciè zasady
w imiö uzyskania wiökszej wydajnoĈci.
Równoczesne wykonywanie polece
ħ SELECT i UPDATE w tej samej tabeli
Baza danych MySQL nie pozwala na wykonywanie polecenia
SELECT
wzglödem tabeli, na
której jednoczeĈnie jest wykonywane polecenie
UPDATE
. Naprawdö nie jest to ograniczenie
wynikajñce z optymalizatora, ale wiedza o sposobie wykonywania zapytaþ przez MySQL
moĔe pomóc w obejĈciu tego problemu. PoniĔej przedstawiono przykäad niedozwolonego
zapytania, mimo Ĕe jest standardowym kodem SQL. Zapytanie powoduje uaktualnienie kaĔdego
rekordu liczbñ podobnych rekordów znajdujñcych siö w tabeli:
mysql> UPDATE tbl AS outer_tbl
-> SET cnt = (
-> SELECT count(*) FROM tbl AS inner_tbl
-> WHERE inner_tbl.type = outer_tbl.type
-> );
ERROR 1093 (HY000): You can't specify target table 'outer_tbl' for update in FROM
clause
Aby obejĈè to ograniczenie, moĔna wykorzystaè tabelö pochodnñ, poniewaĔ MySQL potrak-
tuje jñ jak tabelö tymczasowñ. W ten sposób faktycznie zostanñ wykonane dwa zapytania:
pierwsze to
SELECT
w podzapytaniu, drugie obejmuje wiele tabel
UPDATE
z poäñczonymi wy-
nikami tabeli oraz podzapytania. Podzapytanie bödzie otwieraäo i zamykaäo tabelö przed
otworzeniem jej przez zewnötrzne zapytanie
UPDATE
, a wiöc caäe zapytanie bödzie mogäo
zostaè wykonane:
mysql> UPDATE tbl
-> INNER JOIN(
-> SELECT type, count(*) AS cnt
-> FROM tbl
-> GROUP BY type
-> ) AS der USING(type)
-> SET tbl.cnt = der.cnt;
Optymalizacja okre
ļlonego rodzaju zapytaħ
W podrozdziale zostanñ przedstawione wskazówki dotyczñce optymalizacji okreĈlonego ro-
dzaju zapytaþ. WiökszoĈè tych zagadnieþ zostaäa szczegóäowo omówiona w innych czöĈciach
ksiñĔki, ale autorzy chcieli utworzyè listö najczöĈciej spotykanych problemów optymalizacji,
do której moĔna äatwo powracaè.
WiökszoĈè wskazówek przedstawionych w podrozdziale jest uzaleĔniona od wersji serwera
i moĔe byè nieaktualna w przyszäych wersjach MySQL. Nie ma Ĕadnego powodu, aby pew-
nego dnia sam serwer nie uzyskaä moĔliwoĈci przeprowadzania niektórych bñdĒ wszystkich
z wymienionych optymalizacji.

208 _
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
Optymalizacja zapyta
ħ COUNT()
Funkcja agregujñca
COUNT()
i sposób optymalizacji zapytaþ wykorzystujñcych tö funkcjö to
prawdopodobnie jeden z dziesiöciu najbardziej niezrozumiaäych tematów w MySQL. Liczba
bäödnych informacji na ten temat, które autorzy znaleĒli w Internecie, jest wiöksza, niĔ moĔna
sñdziè.
Przed zagäöbieniem siö w zagadnienia optymalizacji bardzo waĔne jest zrozumienie, jak dziaäa
funkcja
COUNT()
.
Jakie jest dzia
ĥanie funkcji COUNT()?
COUNT()
to funkcja specjalna dziaäajñca na dwa odmienne sposoby: zlicza wartoĈci oraz rekordy.
WartoĈè jest wyraĔeniem innym niĔ
NULL
(poniewaĔ
NULL
oznacza brak wartoĈci). JeĔeli
w nawiasie zostanie podana nazwa kolumny lub inne wyraĔenie, funkcja
COUNT()
obliczy, ile
razy podane wyraĔenie ma wartoĈè. Dla wielu osób bödzie to bardzo mylñce, co po czöĈci
wynika z faktu, Ĕe same wartoĈci
NULL
sñ mylñce. JeĔeli czytelnik musi nauczyè siö, jak dziaäa
SQL, warto siögnñè pod dobrñ ksiñĔkö omawiajñcñ podstawy SQL. (Internet niekoniecznie jest
dobrym Ēródäem informacji na ten temat).
Inna forma funkcji
COUNT()
po prostu oblicza liczbö rekordów w wyniku. Jest to sposób dziaäania
bazy danych MySQL, kiedy wie, Ĕe wyraĔenie umieszczone w nawiasie nigdy nie bödzie
NULL
.
Najbardziej oczywistym przykäadem jest polecenie
COUNT(*)
bödñce specjalnñ formñ funkcji
COUNT()
. Nie powoduje ona rozszerzenia znaku wieloznacznego
*
na peänñ listö kolumn w tabeli,
jak moĔna by tego oczekiwaè. Zamiast tego caäkowicie ignoruje kolumny i zlicza rekordy.
Jednym z najczöĈciej popeänianych bäödów jest podawanie w nawiasie nazw kolumn, kiedy
programista chce, aby funkcja zliczyäa rekordy. Gdy trzeba obliczyè liczbö rekordów w wy-
niku, wtedy zawsze naleĔy uĔyè funkcji
COUNT(*)
. Taka postaè jasno wskazuje intencje pro-
gramisty i pozwala uniknñè kiepskiej wydajnoĈci.
Mity dotycz
éce MyISAM
Czösto popeänianym bäödem jest przeĈwiadczenie, Ĕe silnik MyISAM jest wyjñtkowo szybki
podczas wykonywania zapytaþ
COUNT()
. Wprawdzie jest szybki, ale tylko w wyjñtkowej
sytuacji: kiedy stosujemy funkcjö
COUNT(*)
bez klauzuli
WHERE
, która po prostu zlicza liczbö
rekordów w caäej tabeli. Baza danych MySQL moĔe zoptymalizowaè to zapytanie, poniewaĔ
silnik magazynu danych zawsze otrzymuje informacjö, ile rekordów znajduje siö w tabeli.
JeĔeli w MySQL okreĈlono, Ĕe
col
nigdy nie przyjmie wartoĈci
NULL
, wówczas moĔna rów-
nieĔ zoptymalizowaè wyraĔenie
COUNT(col)
poprzez wewnötrznñ konwersjö wyraĔenia
na
COUNT(*)
.
Silnik MyISAM nie ma Ĕadnych magicznych optymalizacji dotyczñcych zliczania rekordów,
kiedy zapytanie uĔywa klauzuli
WHERE
lub dla bardziej ogólnych przypadków zliczania
wartoĈci zamiast rekordów. W okreĈlonym zapytaniu moĔe dziaäaè szybciej niĔ inne silniki
magazynu danych, ale nie musi. Wszystko zaleĔy od wielu czynników.

Optymalizacja okre
ļlonego rodzaju zapytaħ
_ 209
Prosta optymalizacja
Czasami moĔna wykorzystaè zalety optymalizacji MyISAM w postaci
COUNT(*)
do zliczenia
wszystkiego, z wyjñtkiem maäej liczby rekordów, które zostaäy doskonale zindeksowane.
W przedstawionym poniĔej przykäadzie uĔyto standardowej bazy danych
World
w celu po-
kazania, jak moĔna efektywnie znaleĒè liczbö miast, których identyfikator
ID
jest wiökszy niĔ
5
.
Takie zapytanie moĔna zapisaè nastöpujñco:
mysql> SELECT COUNT(*) FROM world.City WHERE ID > 5;
JeĔeli powyĔsze zapytanie zostanie sprofilowane za pomocñ polecenia
SHOW STATUS
, moĔna
przekonaè siö, Ĕe zapytanie przeskanowaäo 4079 rekordów. Po odwróceniu warunków i odjöciu
liczby miast, których identyfikator
ID
ma wartoĈè mniejszñ lub równñ
5
od ogólnej liczby
miast, liczba analizowanych rekordów spada do piöciu:
mysql> SELECT (SELECT COUNT(*) FROM world.City) - COUNT(*)
-> FROM world.City WHERE ID <= 5;
PowyĔsza wersja zapytania odczytuje mniejszñ iloĈè rekordów, poniewaĔ w trakcie fazy opty-
malizacji podzapytanie jest zamieniane na staäñ, o czym moĔna przekonaè siö, przeglñdajñc
dane wyjĈciowe polecenia
EXPLAIN
:
+----+-------------+-------+...+------+------------------------------+
| id | select_type | table |...| rows | Extra |
+----+-------------+-------+...+------+------------------------------+
| 1 | PRIMARY | City |...| 6 | Using where; Using index |
| 2 | SUBQUERY | NULL |...| NULL | Select tables optimized away |
+----+-------------+-------+...+------+------------------------------+
Czösto pojawiajñce siö pytanie na listach dyskusyjnych i kanaäach IRC dotyczy tego, jak po-
braè liczbö odmiennych wartoĈci w tej samej kolumnie za pomocñ tylko jednego zapytania,
ograniczajñc w ten sposób ogólnñ liczbö wymaganych zapytaþ. ZaäóĔmy np., Ĕe programista
chce utworzyè pojedyncze zapytanie, które zlicza iloĈè elementów w kilku kolorach. Nie
moĔna uĔyè klauzuli
OR
(np.
SELECT COUNT(color = 'blue' OR color = 'red') FROM
items;
), poniewaĔ programista nie chce oddzieliè róĔnych liczników od odmiennych kolo-
rów. Kolorów nie moĔna takĔe umieĈciè w klauzuli
WHERE
(np.
SELECT COUNT(*) FROM items
WHERE color = 'blue' AND color = 'red';
), poniewaĔ kolory sñ wzajemnie wykluczajñce siö.
PoniĔej przedstawiono zapytanie rozwiñzujñce ten problem:
mysql> SELECT SUM(IF(color = 'blue', 1, 0)) AS blue,
SUM(IF(color = 'red', 1, 0)) ->AS red FROM items;
PoniĔej znajduje siö kolejne rozwiñzanie przedstawionego problemu, ale zamiast funkcji
SUM()
zastosowano w zapytaniu funkcjö
COUNT()
, przy upewnieniu siö, Ĕe wyraĔenie nie bödzie
miaäo wartoĈci, kiedy kryteria bödñ faäszywe:
mysql> SELECT COUNT(color = 'blue' OR NULL) AS blue, COUNT(color = 'red' OR NULL)
-> AS red FROM items;
Bardziej skomplikowana optymalizacja
Ogólnie rzecz biorñc, zapytania
COUNT()
sñ trudne do optymalizacji, poniewaĔ z reguäy
muszñ obliczaè duĔñ liczbö rekordów (np. dostöp do ogromnej iloĈci danych). Jedynñ innñ
opcjñ jest optymalizacja wewnñtrz samego serwera MySQL, tak aby uĔywaä indeksu pokry-
wajñcego. Takie rozwiñzanie przedstawiono w rozdziale 3. JeĔeli i to okaĔe siö niewystarczajñce,
trzeba bödzie wprowadziè zmiany w architekturze aplikacji. Warto rozwaĔyè uĔycie tabel

210
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
podsumowania (równieĔ omówione w rozdziale 3.) oraz zewnötrzny system buforowania,
taki jak memcached. Czytelnik prawdopodobnie stanie przed dobrze znanym dylematem:
„szybko, dobrze i prosto — wybierz dwa dowolne”.
Optymalizacja zapyta
ħ typu JOIN
Temat ten jest w rzeczywistoĈci poruszany w caäej ksiñĔce, ale w tym miejscu autorzy uwa-
Ĕajñ za stosowne, by wspomnieè o kilku aspektach.
x
NaleĔy siö upewniè, Ĕe indeksy obejmujñ kolumny uĔywane w klauzulach
ON
lub
USING
.
Wiöcej informacji na temat indeksowania przedstawiono w podrozdziale „Podstawy in-
deksowania”, znajdujñcym siö w rozdziale 3. Podczas dodawania indeksów warto roz-
waĔyè uĔycie kolejnoĈci stosowanej w zäñczeniach. JeĔeli za pomocñ kolumny
c
zäñczane
sñ tabele
A
i
B
, a optymalizator postanowi o zäñczeniu tabel w kolejnoĈci
B, A
, wówczas
nie trzeba indeksowaè kolumny w tabeli
B
. NieuĔywane indeksy stanowiñ dodatkowe
obciñĔenie. Ogólnie rzecz biorñc, indeksy warto dodaè jedynie do drugiej tabeli i zasto-
sowaè przy tym kolejnoĈè uĔytñ w zäñczeniu, o ile indeksy nie sñ potrzebne do jeszcze
innych zadaþ.
x
Warto podjñè próbö upewnienia siö, Ĕe kaĔde wyraĔenie
GROUP BY
i
ORDER BY
odnosi siö
do kolumn z pojedynczej tabeli. W ten sposób baza danych MySQL bödzie mogäa spró-
bowaè uĔycia indeksu podczas wykonywania tej operacji.
x
NaleĔy zachowaè ostroĔnoĈè podczas uaktualniania serwera MySQL, poniewaĔ skäadnia
zäñczeþ, kolejnoĈè operatorów oraz inne zachowania mogäy ulec zmianie. Czasami to, co
byäo zwykäym zäñczeniem, moĔe staè siö innym produktem, innym rodzajem zäñczenia
zwracajñcym odmienne wyniki bñdĒ nawet juĔ niewäaĈciwñ skäadniñ.
Optymalizacja podzapyta
ħ
NajwaĔniejszñ wskazówkñ dotyczñcñ podzapytaþ, jakiej moĔna udzieliè, jest zalecenie, aby
— gdy tylko jest to moĔliwe — stosowaè zäñczenia, przynajmniej w bieĔñcych wersjach MySQL.
Temat zostaä dokäadnie omówiony na poczñtku rozdziaäu.
Podzapytania sñ przedmiotem intensywnych prac zespoäu zajmujñcego siö optymalizatorem.
Dlatego teĔ przyszäe wersje MySQL mogñ posiadaè wiöcej moĔliwoĈci w zakresie optymali-
zacji podzapytaþ. Dopiero wówczas okaĔe siö, które optymalizacje znajdñ siö w wersji final-
nej oraz jakñ przyniosñ róĔnicö. Udzielona w tym miejscu wskazówka, Ĕe „warto stosowaè
zäñczenia”, nie musi byè aktualna w przyszäoĈci. Wraz z upäywem czasu serwer staje siö coraz
„sprytniejszy” i sytuacje, w których programista musi wskazywaè sposób rozwiñzania danego
problemu zamiast oczekiwanych wyników, bödñ coraz rzadsze.
Optymalizacja zapyta
ħ typu GROUP BY i DISTINCT
W wielu przypadkach baza danych MySQL optymalizuje te dwa rodzaje zapytaþ bardzo po-
dobnie. W rzeczywistoĈci, kiedy trzeba, podczas procesu optymalizacji po prostu przepro-
wadza wewnötrznñ konwersjö miödzy nimi. Dla obu rodzajów zapytaþ bardzo korzystne sñ
indeksy, a wiöc bödzie to najwaĔniejsza droga prowadzñca do ich optymalizacji.

Optymalizacja okre
ļlonego rodzaju zapytaħ
_
211
Kiedy nie moĔna uĔyè indeksów, MySQL ma dwa rodzaje strategii stosowania
GROUP BY
:
albo uĔycie tabeli tymczasowej, albo sortowanie plików w celu wykonania grupowania. KaĔda
z tych strategii jest efektywna w okreĈlonych zapytaniach. Za pomocñ
SQL_BIG_RESULT
oraz
SQL_SMALL_RESULT
moĔna wymusiè na optymalizatorze wybór danej metody.
JeĔeli trzeba zgrupowaè zäñczenie poprzez wartoĈè pochodzñcñ z przeszukiwanej tabeli, wtedy
zwykle efektywniejszym sposobem grupowania jest przeszukanie identyfikatora tabeli
zamiast wartoĈci. Przedstawione jako przykäad poniĔsze zapytanie nie jest tak efektywne, jak
mogäoby byè:
mysql> SELECT actor.first_name, actor.last_name, COUNT(*)
-> FROM sakila.film_actor
-> INNER JOIN sakila.actor USING(actor_id)
-> GROUP BY actor.first_name, actor.last_name;
Zapytanie bödzie efektywniejsze po zapisaniu w postaci:
mysql> SELECT actor.first_name, actor.last_name, COUNT(*)
-> FROM sakila.film_actor
-> INNER JOIN sakila.actor USING(actor_id)
-> GROUP BY film_actor.actor_id;
Grupowanie pod wzglödem kolumny
actor.actor_id
moĔe byè efektywniejsze niĔ grupo-
wanie pod wzglödem kolumny
film_actor.actor_id
. NaleĔy przeprowadziè profilowanie
i (lub) testy wydajnoĈci, aby zobaczyè, jak to wyglñda dla uĔywanych danych.
Zapytanie wykorzystuje fakt, Ĕe imiö i nazwisko aktora jest uzaleĔnione od wartoĈci pola
actor_id
, a wiöc zwróci te same wyniki. Jednak nie zawsze bödzie moĔliwe beztroskie wy-
branie niezgrupowanych kolumn i otrzymanie tych samych wyników. Opcja konfiguracyjna
serwera o nazwie
SQL_MODE
moĔe nawet uniemoĔliwiaè taki krok. Alternatywñ jest uĔycie
funkcji
MIN()
lub
MAX()
kiedy wiadomo, Ĕe wartoĈci w grupie bödñ odmienne, poniewaĔ
zaleĔñ od zgrupowanych kolumn. Ewentualnie, jeĈli nie ma znaczenia, która wartoĈè bödzie
otrzymana, moĔna wykonaè zapytanie:
mysql> SELECT MIN(actor.first_name), MAX(actor.last_name), ...;
PuryĈci mogñ spieraè siö, Ĕe grupowanie nastñpiäo wzglödem niewäaĈciwego elementu, i bödñ
mieli racjö. NiepoĔñdane funkcje
MIN()
lub
MAX()
sñ znakiem, Ĕe struktura zapytania jest
niewäaĈciwa. Jednak czasami jedynym celem jest to, aby serwer MySQL wykonywaä zapytanie
SQL tak szybko, jak to moĔliwe. PuryĈci bödñ usatysfakcjonowani po zapisaniu powyĔszego
zapytania w nastöpujñcej postaci:
mysql> SELECT actor.first_name, actor.last_name, c.cnt
-> FROM sakila.actor
-> INNER JOIN (
-> SELECT actor_id, COUNT(*) AS cnt
-> FROM sakila.film_actor
-> GROUP BY actor_id
-> ) AS c USING(actor_id) ;
Czasami koszt utworzenia i wypeänienia tabeli tymczasowej wymaganej przez podzapytanie
jest bardzo wysoki w porównaniu z kosztem lekkiego wypaczenia teorii relacyjnoĈci. NaleĔy
pamiötaè, Ĕe tabela tymczasowa utworzona przez podzapytanie nie ma indeksów.
Ogólnie rzecz biorñc, kiepskim pomysäem jest wybór niezgrupowanych kolumn w zgrupo-
wanym zapytaniu, poniewaĔ wyniki bödñ niedeterministyczne oraz äatwo mogñ ulec zmia-
nie, jeĈli nastñpi modyfikacja indeksu bñdĒ optymalizator zadecyduje o uĔyciu odmiennej

212
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
strategii. WiökszoĈè tego rodzaju zapytaþ, z którymi spotkali siö autorzy, byäo czystym przy-
padkiem (poniewaĔ serwer nie zgäaszaä zastrzeĔeþ) lub wynikiem lenistwa, a nie celowym
projektem dotyczñcym optymalizacji. Znacznie lepiej zachowaè jasnoĈè. Autorzy zalecajñ
ustawienie zmiennej konfiguracyjnej serwera o nazwie
SQL_MODE
w taki sposób, aby zawieraäa
ONLY_FULL_GROUP_BY
. Dziöki temu serwer wyĈwietli komunikat bäödu i nie pozwoli progra-
miĈcie na utworzenie bäödnego zapytania.
Baza danych MySQL automatycznie ustala kolejnoĈè zgrupowanych zapytaþ, uwzglödniajñc
kolumny w klauzuli
GROUP BY
, o ile programista wyraĒnie nie zastosuje klauzuli
ORDER BY
.
JeĔeli programista nie przykäada wagi do kolejnoĈci i zauwaĔy zastosowanie operacji sorto-
wania pliku, moĔe uĔyè klauzuli
ORDER BY NULL
wyäñczajñcej automatyczne sortowanie.
Po klauzuli
GROUP BY
moĔna takĔe dodaè opcjonalne säowa kluczowe
DESC
lub
ASC
powodujñce
uäoĔenie wyników w poĔñdanym kierunku wzglödem kolumn klauzuli.
Optymalizacja zapyta
ħ typu GROUP BY WITH ROLLUP
Pewnñ odmianñ zgrupowanych zapytaþ jest nakazanie bazie danych MySQL przeprowadze-
nia superagregacji wewnñtrz wyników. W tym celu moĔna wykorzystaè klauzulö
WITH ROLLUP
,
ale takie rozwiñzanie moĔe nie zapewniè tak dobrej optymalizacji, jakiej oczekuje programista.
Za pomocñ polecenia
EXPLAIN
warto sprawdziè przyjötñ przez serwer metodö wykonania,
zwracajñc uwagö na to, czy grupowanie zostaäo przeprowadzone za pomocñ operacji sortowa-
nia pliku czy uĔycia tabeli tymczasowej. Warto równieĔ usunñè klauzulö
WITH ROLLUP
i zoba-
czyè, czy zostanie wykorzystana taka sama metoda grupowania. Istnieje moĔliwoĈè wymuszenia
uĔycia wskazanej metody grupowania poprzez zastosowanie wskazówek przedstawionych
we wczeĈniejszej czöĈci rozdziaäu.
Czasami przeprowadzenie superagregacji w aplikacji jest duĔo bardziej efektywnym rozwiñ-
zaniem, nawet jeĈli oznacza koniecznoĈè pobrania z serwera znacznie wiökszej liczby rekordów.
W klauzuli
FROM
moĔna takĔe zastosowaè zagnieĔdĔone podzapytanie lub uĔyè tabeli tym-
czasowej przechowujñcej wyniki poĈrednie.
Najlepszym rozwiñzaniem moĔe byè przeniesienie funkcjonalnoĈci
WITH ROLLUP
do kodu
aplikacji.
Optymalizacja zapyta
ħ typu LIMIT i OFFSET
Zapytania z klauzulami
LIMIT
i
OFFSET
sñ czösto stosowane w systemach implementujñcych
stronicowanie niemal zawsze w poäñczeniu z klauzulñ
ORDER BY
. Pomocne bödzie posiadanie
indeksu obsäugujñcego tö kolejnoĈè, poniewaĔ w przeciwnym razie serwer bödzie musiaä
wykonaè duĔñ liczbö operacji sortowania pliku.
Czöstym problemem jest wysoka wartoĈè przesuniöcia. JeĔeli zapytanie ma postaè
LIMIT
10000, 20
, wygeneruje 10020 rekordów, a nastöpnie odrzuci pierwsze 10000, co jest bardzo
kosztowne. Przy zaäoĔeniu, Ĕe wszystkie strony sñ uĔywane z podobnñ czöstotliwoĈciñ, za-
pytanie bödzie przeciötnie skanowaäo poäowö tabeli. W celu optymalizacji takich zapytaþ
moĔna albo ograniczyè liczbö stron wyĈwietlanych w widoku stronicowania, albo spowodowaè,
by wysoka wartoĈè przesuniöcia byäa znacznie bardziej efektywna.

Optymalizacja okre
ļlonego rodzaju zapytaħ
_ 213
Jednñ z prostych technik poprawy wydajnoĈci jest przeprowadzanie przesuniöcia w indeksie
pokrywajñcym zamiast na peänych rekordach. PóĒniej wynik moĔna poäñczyè z peänymi
rekordami i pobraè dodatkowe wymagane kolumny. Takie rozwiñzanie jest znacznie bardziej
efektywne. Warto przeanalizowaè poniĔsze zapytanie:
mysql> SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5;
JeĔeli tabela bödzie ogromna, wówczas lepsza postaè powyĔszego zapytania jest nastöpujñca:
mysql> SELECT film.film_id, film.description
-> FROM sakila.film
-> INNER JOIN (
-> SELECT film_id FROM sakila.film
-> ORDER BY title LIMIT 50, 5
-> ) AS lim USING(film_id);
Takie rozwiñzanie sprawdza siö, pozwala bowiem serwerowi na analizö tak maäej iloĈci
danych, jaka jest moĔliwa w indeksie, bez koniecznoĈci uzyskania dostöpu do rekordów.
Nastöpnie, po znalezieniu poĔñdanych rekordów przeprowadzane jest zäñczenie z peänñ tabelñ
w celu pobrania innych kolumn rekordów. Podobna technika ma zastosowanie w przypadku
zäñczeþ z klauzulami
LIMIT
.
Czasami moĔna równieĔ skonwertowaè ograniczenie na postaè zapytania pozycyjnego, które
serwer moĔe wykonaè jako skanowanie pewnego zakresu indeksu. Przykäadowo po wcze-
Ĉniejszym przeliczeniu i zindeksowaniu kolumny
position
zapytanie moĔna napisaè na nowo
w takiej postaci:
mysql> SELECT film_id, description FROM sakila.film
-> WHERE position BETWEEN 50 AND 54 ORDER BY position;
Ranking danych powoduje powstanie tego samego problemu, ale zapytania zwykle dokäadajñ
jeszcze klauzulö
GROUP BY
. Niemal na pewno programista bödzie musiaä wczeĈniej obliczyè
i przechowywaè ranking danych.
JeĔeli naprawdö trzeba zoptymalizowaè system stronicowania, prawdopodobnie naleĔy za-
stosowaè przygotowane wczeĈniej podsumowania. Alternatywñ jest uĔycie zäñczeþ wzglödem
nadmiarowych tabel, które bödñ zawieraäy jedynie klucz podstawowy oraz kolumny wymagane
przez klauzulö
ORDER BY
. MoĔna takĔe uĔyè mechanizmu Sphinx. Wiöcej informacji na jego
temat znajduje siö w dodatku C.
Optymalizacja za pomoc
é opcji SQL_CALC_FOUND_ROWS
Innñ powszechnie stosowanñ technikñ wyĈwietlania stronicowanych wyników jest dodanie
opcji
SQL_CALC_FOUND_ROWS
do zapytania z klauzulñ
LIMIT
. W ten sposób bödzie wiadomo,
ile rekordów zostaäoby zwróconych, gdyby w zapytaniu nie byäo klauzuli
LIMIT
. MoĔna od-
nieĈè wraĔenie, Ĕe to pewnego rodzaju „magia”, kiedy serwer przewiduje liczbö rekordów,
które mógäby znaleĒè. Niestety, serwer tego nie robi, tzn. nie potrafi obliczyè liczby rekor-
dów, których faktycznie nie znajduje. Wymieniona opcja po prostu nakazuje serwerowi wy-
generowanie i odrzucenie pozostaäej czöĈci zbioru wynikowego, zamiast zakoþczyè dziaäanie
po znalezieniu poĔñdanej liczby rekordów. Dziaäanie to jest bardzo kosztowne.
Lepszym rozwiñzaniem jest konwersja programu stronicowania na äñcze „nastöpny”. Przy
zaäoĔeniu, Ĕe na stronie znajdzie siö dwadzieĈcia wyników wyszukiwania, zapytanie powinno
ograniczyè za pomocñ klauzuli
LIMIT
liczbö rekordów do 21, a nastöpnie wyĈwietliè jedynie 20.

214
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
JeĔeli w zbiorze wynikowym znajduje siö 21. rekord, oznacza on obecnoĈè kolejnej strony, a tym
samym moĔliwoĈè wygenerowania äñcza „nastöpny”.
Inna moĔliwoĈè to pobranie i buforowanie wiökszej liczby rekordów niĔ potrzeba — po-
wiedzmy 1000 — a nastöpnie pobieranie ich z bufora i umieszczanie na kolejnych stronach.
Ta strategia pozwala aplikacji „wiedzieè”, jak duĔy jest zbiór wynikowy. JeĔeli bödzie mniej-
szy niĔ 1000 rekordów, wówczas aplikacja moĔe obliczyè, ile powinna wygenerowaè äñczy.
Natomiast dla wiökszego zbioru wynikowego moĔe po prostu wyĈwietliè komunikat „Znale-
ziono ponad 1000 wyników”. Obie opisane strategie sñ znacznie efektywniejsze od nieustan-
nego generowania caäego zbioru wynikowego i odrzucania jego wiökszoĈci.
JeĈli nie moĔna uĔyè powyĔszych strategii, zastosowanie oddzielnego zapytania
COUNT(*)
w celu
okreĈlenia liczby rekordów moĔe byè szybsze niĔ wykorzystanie opcji
SQL_CALC_FOUND_ROWS
,
o ile moĔliwe jest uĔycie indeksu pokrywajñcego.
Optymalizacja klauzuli UNION
Baza danych MySQL zawsze wykonuje zapytania
UNION
poprzez utworzenie tabeli tymcza-
sowej i umieszczenie w niej wyników operacji
UNION
. Serwer MySQL nie potrafi zastosowaè
na zapytaniach
UNION
tak wielu optymalizacji, ilu mógäby uĔyè programista. Dlatego teĔ mo-
Ĕe siö zdarzyè, Ĕe bödzie trzeba udzieliè optymalizatorowi pomocy i röczne „wciñgnñè” klau-
zule
WHERE
,
LIMIT
,
ORDER BY
oraz inne warunki (np. kopiujñc je z zewnötrznego zapytania do
kaĔdego zapytania
SELECT
w konstrukcji
UNION
).
Zawsze trzeba uĔywaè klauzuli
UNION ALL
, chyba Ĕe nie jest wymagane usuniöcie przez ser-
wer powielajñcych siö rekordów. JeĔeli säowo kluczowe
ALL
zostanie pominiöte, MySQL do-
äñczy do tabeli tymczasowej opcjö
distinct
, która powoduje uĔywanie peänych rekordów
w celu ustalenia unikalnoĈci. To jest kosztowne. NaleĔy mieè na uwadze, Ĕe säowo kluczowe
ALL
nie powoduje wyeliminowania tabeli tymczasowej. Baza danych MySQL zawsze bödzie
umieszczaäa wyniki w tabeli tymczasowej, a nastöpnie ponownie je odczytywaäa, nawet jeĈli
nie bödzie to naprawdö konieczne (np. kiedy wyniki mogäyby zostaè bezpoĈrednio zwrócone
klientowi).
Opcje dotycz
éce optymalizatora zapytaħ
W bazie danych MySQL umieszczono kilka opcji optymalizatora, które moĔna wykorzystaè
w celu nadzorowania planu wykonywania zapytania, jeĈli programista nie jest zadowolony
z wyborów dokonanych przez optymalizator MySQL. PoniĔej przedstawiono opcje oraz
wskazano sytuacje, w których korzystne jest ich uĔycie. Odpowiedniñ opcjö naleĔy umieĈciè
w modyfikowanym zapytaniu; bödzie efektywna tylko w tym konkretnym zapytaniu. Skäad-
niö kaĔdej opcji moĔna znaleĒè w podröczniku uĔytkownika MySQL. Niektóre z nich sñ zde-
cydowanie powiñzane z wersjñ serwera bazy danych. Oto dostöpne opcje.
HIGH_PRIORITY
oraz
LOW_PRIORITY
Opcje informujñ MySQL, w jaki sposób ustalaè priorytet polecenia wzglödem innych poleceþ,
które próbujñ uzyskaè dostöp do tych samych tabel.
Opcja
HIGH_PRIORITY
informuje MySQL, Ĕe polecenia
SELECT
majñ byè wykonywane
przed wszelkimi innymi poleceniami, które mogñ oczekiwaè na moĔliwoĈè naäoĔenia
blokad, czyli chcñ zmodyfikowaè dane. W efekcie polecenia
SELECT
zostanñ umieszczone

Optymalizacja okre
ļlonego rodzaju zapytaħ
_ 215
na poczñtku kolejki, zamiast oczekiwaè na swojñ kolej. Ten modyfikator moĔna równieĔ
zastosowaè wzglödem poleceþ
INSERT
, co po prostu spowoduje zniwelowanie efektu
globalnego ustawienia serwera o nazwie
LOW_PRIORITY
.
Opcja
LOW_PRIORITY
jest przeciwieþstwem poprzedniej: powoduje umieszczenie polece-
nia na samym koþcu kolejki oczekiwania, jeĈli, oczywiĈcie, sñ inne polecenia, które chcñ
uzyskaè dostöp do tabel — nawet gdy inne polecenia zostaäy wydane póĒniej. Przypomi-
na to nadmiernie uprzejmñ osobö stojñcñ przed drzwiami restauracji: dopóki ktokolwiek
inny bödzie czekaä przed restauracjñ, uprzejma osoba bödzie przymieraäa gäodem. Opcjö tö
moĔna zastosowaè wzglödem poleceþ
SELECT
,
INSERT
,
UPDATE
,
REPLACE
oraz
DELETE
.
Opcje sñ efektywne w silnikach magazynu danych obsäugujñcych blokowanie na poziomie
tabeli, ale nigdy nie powinno siö ich stosowaè w InnoDB bñdĒ innych silnikach zapew-
niajñcych bardziej szczegóäowñ kontrolö blokowania i wspóäbieĔnoĈci. NaleĔy zachowaè
szczególnñ ostroĔnoĈè podczas uĔywania ich w silniku MyISAM, poniewaĔ mogñ wyäñ-
czyè moĔliwoĈè przeprowadzania operacji jednoczesnego wstawiania danych, a tym samym
znacznie zmniejszyè wydajnoĈè.
Czösto opcje
HIGH_PRIORITY
oraz
LOW_PRIORITY
sñ Ēródäem pewnego zamieszania. Nie
powodujñ zarezerwowania dla zapytaþ wiökszej bñdĒ mniejszej iloĈci zasobów, aby „pra-
cowaäy ciöĔej” lub „nie pracowaäy tak ciöĔko”. Wymienione opcje po prostu wpäywajñ na
sposób kolejkowania przez serwer zapytaþ, które oczekujñ na uzyskanie dostöpu do tabeli.
DELAYED
Opcja jest przeznaczona do uĔywania z poleceniami
INSERT
i
REPLACE
. Pozwala polece-
niu na natychmiastowe zwrócenie danych oraz umieszczenie wstawianych rekordów
w buforze, a nastöpnie wstawienie ich razem do tabeli, gdy tylko bödzie dostöpna. Taka
opcja jest najbardziej uĔyteczna podczas rejestrowania zdarzeþ oraz w podobnych apli-
kacjach, w których trzeba wstawiè duĔe iloĈci rekordów bez wstrzymywania klienta oraz
bez powodowania operacji I/O w przypadku kaĔdego zapytania. Istnieje kilka ograni-
czeþ zwiñzanych z tñ opcjñ, np. opóĒnione operacje wstawiania nie sñ zaimplementowane
we wszystkich silnikach magazynu danych. Poza tym, funkcja
LAST_INSERT_ID()
nie dziaäa
z opóĒnionymi operacjami wstawiania.
STRAIGHT_JOIN
Opcja ta pojawia siö albo tuĔ za säowem kluczowym
SELECT
w poleceniu
SELECT
, albo
miödzy dwiema äñczonymi tabelami w kaĔdym innym poleceniu. Pierwszy sposób uĔy-
cia wymusza, aby wszystkie tabele w zapytaniu byäy zäñczane z zachowaniem kolejnoĈci
ich przedstawienia w zapytaniu. Drugi sposób wymusza zachowanie kolejnoĈci podczas
zäñczenia dwóch tabel, miödzy którymi znajduje siö ta opcja.
Opcja
STRAIGHT_JOIN
jest uĔyteczna, w sytuacji kiedy baza danych MySQL nie wybiera
dobrej kolejnoĈci zäñczenia lub optymalizator wymaga duĔej iloĈci czasu na podjöcie de-
cyzji dotyczñcej stosowanej kolejnoĈci zäñczenia. W tym drugim przypadku wñtek spödza
duĔo czasu w stanie „Statistics”, a dodanie wymienionej opcji powoduje ograniczenie
optymalizatorowi przestrzeni wyszukiwania.
KolejnoĈè wybranñ przez optymalizator moĔna poznaè za pomocñ danych wyjĈciowych pole-
cenia
EXPLAIN
. NaleĔy napisaè nowe zapytanie w tej kolejnoĈci i dodaè opcjö
STRAIGHT_JOIN
.
Jest to bardzo dobry pomysä, przynajmniej tak däugo, jak däugo ustalona kolejnoĈè nie
skutkuje kiepskñ wydajnoĈciñ w niektórych klauzulach
WHERE
. Jednak po uaktualnieniu
serwera MySQL naleĔy ponownie przejrzeè takie polecenia, poniewaĔ mogñ pojawiè siö
nowe rodzaje optymalizacji, które bödñ uniewaĔniane przez opcjö
STRAIGHT_JOIN
.

216
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
SQL_SMALL_RESULT
oraz
SQL_BIG_RESULT
Opcje te sñ przeznaczone dla poleceþ
SELECT
. Informujñ optymalizator, jak i kiedy uĔywaè
tabel tymczasowych oraz sortowaè zapytania
GROUP BY
i
DISTINCT
. Opcja
SQL_SMALL_RESULT
informuje optymalizator, Ĕe zbiór wynikowy bödzie maäy i moĔe zostaè umieszczony
w zindeksowanej tabeli tymczasowej w celu unikniöcia sortowania dla grupowania. Z kolei
opcja
SQL_BIG_RESULT
wskazuje, Ĕe zbiór wynikowy bödzie ogromny i lepszym rozwiñ-
zaniem jest uĔycie tabel tymczasowych na dysku wraz z sortowaniem.
SQL_BUFFER_RESULT
Opcja ta nakazuje optymalizatorowi umieszczenie wyników w tabeli tymczasowej oraz
zwolnienie blokad tabeli tak wczeĈnie, jak tylko bödzie to moĔliwe. To zupeänie inna
opcja od buforowania po stronie klienta, przedstawionego w podrozdziale „Protokóä
klient-serwer MySQL”, we wczeĈniejszej czöĈci rozdziaäu. Buforowanie po stronie serwera
moĔe byè bardzo uĔyteczne, kiedy nie jest stosowane buforowanie po stronie klienta,
pozwala bowiem uniknñè zuĔywania ogromnych iloĈci pamiöci po stronie klienta i nadal
powoduje bardzo szybkie zwalnianie blokad. Jednak oznacza równieĔ wykorzystanie
pamiöci serwera zamiast klienta.
SQL_CACHE
oraz
SQL_NO_CACHE
Opcje te informujñ serwer, Ĕe dane zapytanie jest lub nie jest kandydatem do buforowania
w buforze zapytaþ. Szczegóäowe informacje na temat uĔywania tych opcji zostaäy przed-
stawione w nastöpnym rozdziale.
SQL_CALC_FOUND_ROWS
Opcja nakazuje MySQL obliczenie peänego zbioru wynikowego, gdy stosowana jest klauzula
LIMIT
, choè zwracane bödñ jedynie rekordy wskazane przez tö klauzulö. Za pomocñ funkcji
FOUND_ROWS()
istnieje moĔliwoĈè pobrania caäkowitej liczby znalezionych rekordów. (Warto
powróciè do podrozdziaäu „Optymalizacja za pomocñ opcji SQL_CALC_FOUND_ROWS”
we wczeĈniejszej czöĈci rozdziaäy, aby przypomnieè sobie, dlaczego nie powinno uĔywaè siö
tej opcji).
FOR UPDATE
oraz
LOCK IN SHARE MODE
Opcje nadzorujñ blokady w poleceniach
SELECT
, ale jedynie w przypadku silników ma-
gazynu danych obsäugujñcych blokowanie na poziomie rekordu. Wymienione opcje po-
zwalajñ na naäoĔenie blokad na dopasowanych rekordach. Taka moĔliwoĈè moĔe byè
uĔyteczna, gdy programista chce zablokowaè rekordy, o których wiadomo, Ĕe bödñ póĒniej
uaktualniane, ewentualnie wtedy, kiedy chce uniknñè eskalacji blokad i po prostu nakäadaè
blokady na wyäñcznoĈè tak szybko, jak bödzie to moĔliwe.
Opcje nie sñ potrzebne w zapytaniach
INSERT ... SELECT
, które w MySQL 5.0 domyĈlnie
umieszczajñ blokady odczytu na rekordach Ēródäowych. (Istnieje moĔliwoĈè wyäñczenia
takiego zachowania, ale nie jest to dobry pomysä — wyjaĈnienie znajduje siö w rozdziaäach
8. i 11.). Baza danych MySQL 5.1 moĔe znieĈè to ograniczenie w pewnych warunkach.
W czasie pisania tej ksiñĔki jedynie silnik InnoDB obsäugiwaä te opcje i byäo jeszcze zbyt
wczeĈnie, aby stwierdziè, czy inne silniki magazynu danych oferujñce blokady na pozio-
mie rekordu bödñ w przyszäoĈci je obsäugiwaäy. Podczas uĔywania opcji w InnoDB naleĔy
zachowaè ostroĔnoĈè, poniewaĔ mogñ doprowadziè do wyäñczenia pewnych optymaliza-
cji, np. stosowania indeksu pokrywajñcego. Silnik InnoDB nie moĔe zablokowaè rekor-
dów na wyäñcznoĈè bez uzyskania dostöpu do klucza podstawowego, który jest miejscem
rekordu przechowujñcym informacje dotyczñce wersji.

Zmienne zdefiniowane przez u
żytkownika
_ 217
USE INDEX
,
IGNORE INDEX
oraz
FORCE INDEX
Opcje informujñ optymalizator, które indeksy majñ byè uĔywane bñdĒ ignorowane pod-
czas wyszukiwania rekordów w tabeli (np. w trakcie decydowania o kolejnoĈci zäñcze-
nia). W bazie danych MySQL 5.0 i wczeĈniejszych wymienione opcje nie wpäywajñ na to,
które indeksy bödñ stosowane przez serwer podczas operacji sortowania i grupowania.
W MySQL 5.1 skäadnia moĔe pobieraè opcjonalnñ klauzulö
FOR ORDER BY
lub
FOR GROUP BY
.
Opcja
FORCE INDEX
jest taka sama jak
USE INDEX
, ale informuje optymalizator, Ĕe skano-
wanie tabeli jest wyjñtkowo kosztowne w porównaniu ze skanowaniem indeksu, nawet
jeĈli indeks nie jest zbyt uĔyteczny. Opcje moĔna zastosowaè, kiedy programista uwaĔa,
Ĕe optymalizator wybiera niewäaĈciwy indeks bñdĒ z jakiegokolwiek powodu majñ byè
wykorzystane zalety päynñce z uĔycia indeksu, np. jawne ustalenie kolejnoĈci bez uĔycia
klauzuli
ORDER BY
. Przykäad takiego rozwiñzania pokazano w podrozdziale „Optymali-
zacja zapytaþ typu LIMIT i OFFSET”, we wczeĈniejszej czöĈci rozdziaäu, podczas omawiania
efektywnego pobierania wartoĈci minimalnej za pomocñ klauzuli
LIMIT
.
W bazie danych MySQL 5.0 i nowszych wystöpujñ jeszcze pewne zmienne systemowe, które
majñ wpäyw na dziaäanie optymalizatora. Oto one.
optimizer_search_depth
Zmienna wskazuje optymalizatorowi, w jaki sposób wyczerpujñco analizowaè plany
czöĈciowe. JeĔeli wykonywanie zapytania w stanie „Statistics” zabiera bardzo duĔo czasu,
moĔna spróbowaè obniĔyè wartoĈè tej zmiennej.
optimizer_prune_level
Zmienna, domyĈlnie wäñczona, pozwala optymalizatorowi na pomijanie okreĈlonych
planów na podstawie liczby przeanalizowanych rekordów.
Obie opisane zmienne nadzorujñ skracanie dziaäania optymalizatora. Takie skróty sñ cenne
pod wzglödem wydajnoĈci w skomplikowanych zapytaniach, ale mogñ spowodowaè, Ĕe
serwer „przeoczy” optymalne plany w imiö efektywnoĈci. To jest powód, dla którego zmiana
tych opcji czasami ma sens.
Zmienne zdefiniowane przez u
żytkownika
Bardzo äatwo zapomnieè o zmiennych zdefiniowanych przez uĔytkownika w MySQL, ale mogñ
one stanowiè technikö o potöĔnych moĔliwoĈciach, säuĔñcñ do tworzenia efektywnych zapytaþ.
Zmienne takie dziaäajñ szczególnie dobrze w przypadku zapytaþ odnoszñcych korzyĈci z poäñ-
czenia logik proceduralnej i relacyjnej. Czysto relacyjne zapytania traktujñ wszystko jak nie-
uporzñdkowane zbiory, którymi serwer w pewien sposób manipuluje, wszystkimi jednoczeĈnie.
Baza danych MySQL stosuje nieco bardziej pragmatyczne podejĈcie. MoĔna to uznaè za wadö,
ale równoczeĈnie moĔe okazaè siö zaletñ, gdy programista nauczy siö korzystaè z tej moĔliwoĈci.
A zmienne zdefiniowane przez uĔytkownika mogñ dodatkowo pomóc.
Zmienne zdefiniowane przez uĔytkownika sñ tymczasowymi magazynami dla wartoĈci, które
bödñ zachowane aĔ do zakoþczenia poäñczenia z serwerem. Definicja zmiennej polega po
prostu na przypisaniu jej warto
Ĉci za pomocñ poleceþ
SET
lub
SELECT
13
.
13
W niektórych sytuacjach przypisanie moĔna wykonaè za pomocñ zwykäego znaku równoĈci (
=
). Autorzy
uwaĔajñ jednak, Ĕe lepiej unikaè dwuznacznoĈci i zawsze stosowaè wyraĔenie
:=
.

218
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
mysql> SET @one := 1;
mysql> SET @min_actor := (SELECT MIN(actor_id) FROM sakila.actor);
mysql> SET @last_week := CURRENT_DATE-INTERVAL 1 WEEK;
Zmiennñ moĔna zastosowaè w miejsce wyraĔenia, np.:
mysql> SELECT ... WHERE col <= @last_week;
Zanim zostanñ przedstawione zalety zmiennych zdefiniowanych przez uĔytkownika, warto
spojrzeè na pewne ich cechy i wady, aby przekonaè siö, kiedy nie moĔna z nich skorzystaè.
x
UniemoĔliwiajñ buforowanie zapytania.
x
Nie moĔna ich uĔyè w sytuacji, gdy wymagany jest literaä bñdĒ identyfikator, np. nazwa
tabeli lub kolumny albo w klauzuli
LIMIT
.
x
Zmienne te sñ przywiñzane do poäñczenia, a wiöc nie moĔna ich uĔyè w trakcie komuni-
kacji miödzy poäñczeniami.
x
JeĔeli stosowana jest pula poäñczeþ bñdĒ trwaäe poäñczenie, mogñ spowodowaè oddzia-
äywanie na siebie pozornie wyizolowanych fragmentów kodu.
x
W wersjach wczeĈniejszych niĔ MySQL 5.0 rozróĔniajñ wielkoĈè liter. NaleĔy wiöc zachowaè
ostroĔnoĈè i wystrzegaè siö problemów zwiñzanych ze zgodnoĈciñ kodu.
x
Nie moĔna jawnie zadeklarowaè rodzaju zmiennej, a punkt, w którym wybierany jest rodzaj
dla niezdefiniowanej zmiennej, jest odmienny w róĔnych wersjach MySQL. Najlepszym
wyjĈciem jest poczñtkowe przypisanie wartoĈci
0
zmiennym, które majñ byè uĔywane
z liczbami caäkowitymi,
0.0
dla liczb zmiennoprzecinkowych oraz
''
(pusty ciñg tekstowy)
dla ciñgów tekstowych. Rodzaj zmiennej ulega zmianie po przypisaniu jej wartoĈci.
Ustalanie typu zmiennej zdefiniowanej przez uĔytkownika jest w serwerze MySQL prze-
prowadzane dynamicznie.
x
W niektórych sytuacjach optymalizator moĔe pozbyè siö zmiennych, uniemoĔliwiajñc im
wykonanie zadaþ zaplanowanych przez programistö.
x
KolejnoĈè przypisania (a wröcz godzina przypisania) moĔe byè niedeterministyczna i za-
leĔeè od planu wykonania zapytania wybranego przez optymalizator. Jak czytelnik prze-
kona siö w dalszej czöĈci rozdziaäu, wyniki mogñ byè bardzo mylñce.
x
Operator przypisania
:=
ma niĔsze pierwszeþstwo od wszelkich pozostaäych operatorów.
NaleĔy wiöc zachowaè szczególnñ ostroĔnoĈè i stosowaè nawiasy, jasno okreĈlajñc kolejnoĈè.
x
Niezdefiniowane zmienne nie powodujñ wygenerowania bäödu skäadni. Bardzo äatwo
popeäniè bäñd, nawet nie zdajñc sobie z tego sprawy.
Jednñ z najwaĔniejszych funkcji zmiennych jest fakt, Ĕe zmiennej moĔna przypisaè wartoĈè,
a nastöpnie zastosowaè wartoĈè otrzymanñ w wyniku operacji przypisania. Innymi säowy,
przypisanie jest L-wartoĈciñ. PoniĔej przedstawiono przykäad jednoczesnego obliczenia i wy-
Ĉwietlenia „liczby rekordów” dla danego zapytania:
mysql> SET @rownum := 0;
mysql> SELECT actor_id, @rownum := @rownum + 1 AS rownum
-> FROM sakila.actor LIMIT 3;
+----------+--------+
| actor_id | rownum |
+----------+--------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+----------+--------+

Zmienne zdefiniowane przez u
żytkownika
_ 219
Przedstawiony przykäad zdecydowanie nie jest interesujñcy, poniewaĔ pokazuje, Ĕe powielono
klucz podstawowy tabeli. Jednak wciñĔ ma swoje zastosowanie: jednym z nich jest ranking.
W kolejnym przykäadzie zaprezentowano zapytanie zwracajñce dziesiöciu aktorów, którzy
wystñpili w najwiökszej liczbie filmów. UĔyta zostanie kolumna rankingu nadajñca aktorowi
tö samñ pozycjö, jeĈli zostaä zaangaĔowany. Trzeba rozpoczñè od zapytania wyszukujñcego
aktorów oraz liczbö filmów, w których wystñpili:
mysql> SELECT actor_id, COUNT(*) as cnt
-> FROM sakila.film_actor
-> GROUP BY actor_id
-> ORDER BY cnt DESC
-> LIMIT 10;
+----------+-----+
| actor_id | cnt |
+----------+-----+
| 107 | 42 |
| 102 | 41 |
| 198 | 40 |
| 181 | 39 |
| 23 | 37 |
| 81 | 36 |
| 106 | 35 |
| 60 | 35 |
| 13 | 35 |
| 158 | 35 |
+----------+-----+
Nastöpnie naleĔy dodaè ranking, który powinien byè taki sam dla wszystkich aktorów
wystöpujñcych w 35 filmach. W tym celu zostanñ uĔyte trzy zmienne: pierwsza Ĉledzñca bieĔñcñ
pozycjö w rankingu, druga przechowujñca poprzedniñ liczbö filmów, w których wystñpiä
aktor, oraz trzecia przechowujñca bieĔñcñ liczbö filmów, w których wystñpiä aktor. Pozycja
w rankingu zostanie zmieniona wraz ze zmianñ liczby filmów, w których zaangaĔowano danego
aktora. PoniĔej przedstawiono pierwsze podejĈcie do utworzenia takiego zapytania:
mysql> SET @curr_cnt := 0, @prev_cnt := 0, @rank := 0;
mysql> SELECT actor_id,
-> @curr_cnt := COUNT(*) AS cnt,
-> @rank := IF(@prev_cnt <> @curr_cnt, @rank + 1, @rank) AS rank,
-> @prev_cnt := @curr_cnt AS dummy
-> FROM sakila.film_actor
-> GROUP BY actor_id
-> ORDER BY cnt DESC
-> LIMIT 10;
+----------+-----+------+-------+
| actor_id | cnt | rank | dummy |
+----------+-----+------+-------+
| 107 | 42 | 0 | 0 |
| 102 | 41 | 0 | 0 |
...
Ups! Zarówno ranking, jak i licznik nigdy nie przekraczajñ wartoĈci zero. Dlaczego tak siö staäo?
Nie moĔliwe jest udzielenie jednej odpowiedzi na takie pytanie. Problem moĔe byè bardzo
prosty i sprowadzaè siö do bäödnie zapisanej nazwy zmiennej (w tym przypadku jednak tak
nie jest) lub nieco bardziej skomplikowany. W omawianym przykäadzie dane wyjĈciowe po-
lecenia
EXPLAIN
pokazujñ, Ĕe uĔywana jest tabela tymczasowa oraz sortowanie pliku. Dlatego
teĔ zmienne sñ obliczane w zupeänie innym czasie, niĔ jest to oczekiwane.
Jest to ten rodzaj tajemniczego zachowania, którego moĔna czösto doĈwiadczyè w MySQL
podczas uĔywania zmiennych zdefiniowanych przez uĔytkownika. Usuwanie takich bäödów

220
_
Rozdzia
ĥ 4. Optymalizacja wydajnoļci zapytaħ
moĔe byè trudne, ale naprawdö opäacalne. Utworzenie rankingu w MySQL zwykle wymaga
algorytmu równania kwadratowego, np. zliczania róĔnych aktorów, którzy wystöpowali
w wiökszej liczbie filmów. Rozwiñzanie z uĔyciem zmiennej zdefiniowanej przez uĔytkownika
moĔe byè algorytmem liniowym — caäkiem spore usprawnienie.
W omawianym przypadku äatwym rozwiñzaniem jest dodanie do zapytania innego poziomu
tabel tymczasowych za pomocñ podzapytania w klauzuli
FROM
:
mysql> SET @curr_cnt := 0, @prev_cnt := 0, @rank := 0;
-> SELECT actor_id,
-> @curr_cnt := cnt AS cnt,
-> @rank := IF(@prev_cnt <> @curr_cnt, @rank + 1, @rank) AS rank,
-> @prev_cnt := @curr_cnt AS dummy
-> FROM (
-> SELECT actor_id, COUNT(*) AS cnt
-> FROM sakila.film_actor
-> GROUP BY actor_id
-> ORDER BY cnt DESC
-> LIMIT 10
-> ) as der;
+----------+-----+------+-------+
| actor_id | cnt | rank | dummy |
+----------+-----+------+-------+
| 107 | 42 | 1 | 42 |
| 102 | 41 | 2 | 41 |
| 198 | 40 | 3 | 40 |
| 181 | 39 | 4 | 39 |
| 23 | 37 | 5 | 37 |
| 81 | 36 | 6 | 36 |
| 106 | 35 | 7 | 35 |
| 60 | 35 | 7 | 35 |
| 13 | 35 | 7 | 35 |
| 158 | 35 | 7 | 35 |
+----------+-----+------+-------+
WiökszoĈè problemów dotyczñcych zmiennych zdefiniowanych przez uĔytkownika wiñĔe siö
z przypisywaniem im wartoĈci i odczytywaniem ich na róĔnych etapach zapytania. Przykäa-
dowo przewidywalnie nie bödzie dziaäaäo przypisanie zmiennej w poleceniu
SELECT
a od-
czytanie w klauzuli
WHERE
. Wydaje siö, Ĕe przedstawione poniĔej zapytanie zwróci po prostu
jeden rekord, ale to bäödne wyobraĔenie:
mysql> SET @rownum := 0;
mysql> SELECT actor_id, @rownum := @rownum + 1 AS cnt
-> FROM sakila.actor
-> WHERE @rownum <= 1;
+----------+------+
| actor_id | cnt |
+----------+------+
| 1 | 1 |
| 2 | 2 |
+----------+------+
Wynika to z faktu, Ĕe polecenia
WHERE
i
SELECT
znajdujñ siö na róĔnych etapach procesu wy-
konywania zapytania. Stanie siö to bardziej oczywiste po dodaniu kolejnego etapu wykony-
wania zapytania przez doäñczenie klauzuli
ORDER BY
:
mysql> SET @rownum := 0;
mysql> SELECT actor_id, @rownum := @rownum + 1 AS cnt
-> FROM sakila.actor
-> WHERE @rownum <= 1
-> ORDER BY first_name;
Wyszukiwarka
Podobne podstrony:
Wysoko wydajne MySQL Optymalizacja, archiwizacja, replikacja Wydanie II
informatyka wysoko wydajny postgresql 9 0 gregory smith ebook
PHP i MySQL Tworzenie sklepow internetowych Wydanie II
PHP, MySQL i Apache dla kazdego Wydanie II
PHP, MySQL i Apache dla kazdego Wydanie II
PHP i MySQL Tworzenie sklepow internetowych Wydanie II
PHP i MySQL Tworzenie sklepow internetowych Wydanie II phmts2
PHP MySQL i Apache dla kazdego Wydanie II pmsadk
PHP i MySQL Tworzenie sklepow internetowych Wydanie II
PHP MySQL i Apache dla kazdego Wydanie II pmsadk
PHP MySQL i Apache dla kazdego Wydanie II pmsadk
więcej podobnych podstron