
Wydawnictwo Helion
ul. Kociuszki 1c
44-100 Gliwice
tel. 032 230 98 63
e-mail: helion@helion.pl
Perl. Mistrzostwo
w programowaniu
Autor: Brian d foy
T³umaczenie: Grzegorz Werner
ISBN: 978-83-246-1374-8
Tytu³ orygina³u:
Mastering Perl
Format: B5, stron: 304
Profesjonalne programowanie na mistrzowskim poziomie
Jak wykrywaæ b³êdy, których Perl nie raportuje?
Jak pisaæ programy jako modu³y?
Jak ledziæ dzia³anie programu za pomoc¹ Log4perl?
Perl jest jêzykiem o szerokim zastosowaniu, mo¿na go skompilowaæ na prawie
wszystkich architekturach i systemach operacyjnych. Wszechstronnoæ Perla pozwala
na programowanie w ró¿nych modelach: proceduralnym, funkcyjnym czy obiektowym.
Jest doskona³ym narzêdziem do analizy plików tekstowych oraz tworzenia raportów,
aplikacji, modu³ów i programów. Umo¿liwia powi¹zanie systemów i struktur danych,
których wspó³praca nie by³a przewidywana w momencie projektowania. Twórcy Perla
twierdz¹, ¿e jêzyk ten sprawia, i¿ rzeczy ³atwe pozostaj¹ ³atwymi, a trudne staj¹ siê
mo¿liwe do wykonania.
Perl. Mistrzostwo w programowaniu
to wyj¹tkowa ksi¹¿ka pomagaj¹ca
w samodzielnej nauce, przeznaczona dla programistów, którzy u¿ywali ju¿ Perla i znaj¹
jego podstawy. Pod¹¿aj¹c za radami z tego przewodnika, nauczysz siê definiowaæ
procedury i odwracaæ zwyk³y model programowania proceduralnego. Bêdziesz wiedzia³,
jak zapisywaæ dane, aby wykorzystaæ je w innym programie, a tak¿e jak poprawiaæ kod
bez modyfikowania pierwotnego kodu ród³owego. Dowiesz siê tak¿e, jak u¿ywaæ
operacji na bitach oraz wektorów bitowych do efektywnego przechowywania danych.
Czytaj¹c
Perl. Mistrzostwo w programowaniu
, zmierzasz prost¹ drog¹ do mistrzostwa.
Tworzenie i zastêpowanie nazwanych procedur
Modyfikowanie i rozszerzanie modu³ów
Konfigurowanie programów Perla
Rejestrowanie b³êdów i innych informacji
Utrwalanie danych
Praca z formatem Pod
Tworzenie podklas modu³u Pod::Simple
Operatory bitowe
Przechowywanie ³añcuchów bitowych
Testowanie programu
Do³¹cz do klasy mistrzów twórz profesjonalne programy w Perlu!

3
Spis tre
ļci
Przedmowa ....................................................................................................................9
Wst
ýp ............................................................................................................................11
Struktura ksiñĔki
11
Konwencje uĔywane w ksiñĔce
13
Przykäadowy kod
13
Podziökowania
13
1. Wprowadzenie: jak zosta
ë mistrzem? ........................................................................ 15
Co to znaczy byè mistrzem?
16
Kto powinien przeczytaè tö ksiñĔkö?
17
Jak czytaè tö ksiñĔkö?
17
Co naleĔy wiedzieè zawczasu?
17
Co opisano w tej ksiñĔce?
18
Czego nie opisano w tej ksiñĔce?
18
2. Zaawansowane wyra
żenia regularne ........................................................................ 19
Referencje do wyraĔeþ regularnych
19
Grupy nieprzechwytujñce, (?:WZORZEC)
24
Czytelne wyraĔenia regularne, /x i (?#...)
25
Dopasowywanie globalne
27
Patrzenie w przód i w tyä
30
Odszyfrowywanie wyraĔeþ regularnych
36
Koþcowe myĈli
38
Podsumowanie
39
Dalsza lektura
39
3. Bezpieczne techniki programowania ......................................................................... 41
Zäe dane mogñ zepsuè dzieþ
41
Kontrola skaĔeþ
42
OdkaĔanie danych
47

4
_ Spis tre
ļci
Listowe postacie wywoäaþ system i exec
50
Podsumowanie
53
Dalsza lektura
53
4. Debugowanie Perla .....................................................................................................55
Zanim stracimy czas
55
Najlepszy debuger na Ĉwiecie
56
perl5db.pl
66
Alternatywne debugery
66
Inne debugery
70
Podsumowanie
72
Dalsza lektura
73
5. Profilowanie Perla ....................................................................................................... 75
Znajdowanie winowajcy
75
Ogólne podejĈcie
78
Profilowanie DBI
80
Devel::DProf
87
Pisanie wäasnego profilera
89
Profilowanie zestawów testowych
90
Podsumowanie
91
Dalsza lektura
92
6. Testowanie wydajno
ļci Perla .....................................................................................93
Teoria testowania wydajnoĈci
93
Mierzenie czasu
94
Porównywanie kodu
97
Nie wyäñczaè myĈlenia
98
ZuĔycie pamiöci
103
Narzödzie perlbench
107
Podsumowanie
109
Dalsza lektura
109
7. Czyszczenie Perla ....................................................................................................... 111
Dobry styl
111
perltidy
112
Dekodowanie
113
Perl::Critic
117
Podsumowanie
121
Dalsza lektura
121

Spis tre
ļci _
5
8. Tablice symboli i typegloby ....................................................................................... 123
Zmienne pakietowe i leksykalne
123
Tablica symboli
126
Podsumowanie
132
Dalsza lektura
133
9. Procedury dynamiczne .............................................................................................. 135
Procedury jako dane
135
Tworzenie i zastöpowanie nazwanych procedur
138
Referencje symboliczne
140
Iterowanie po listach procedur
141
Przetwarzanie potokowe
143
Listy metod
144
Procedury jako argumenty
144
Metody wczytywane automatycznie
148
Asocjacje jako obiekty
149
AutoSplit
150
Podsumowanie
151
Dalsza lektura
151
10. Modyfikowanie i rozszerzanie modu
ĥów ................................................................ 153
Wybór wäaĈciwego rozwiñzania
153
Zastöpowanie czöĈci moduäu
156
Tworzenie podklas
158
Owijanie procedur
162
Podsumowanie
164
Dalsza lektura
164
11. Konfigurowanie programów Perla ........................................................................... 165
Czego nie naleĔy robiè?
165
Lepsze sposoby
167
Opcje wiersza polecenia
170
Pliki konfiguracyjne
176
Skrypty o róĔnych nazwach
179
Programy interaktywne i nieinteraktywne
180
Moduä Config
181
Podsumowanie
182
Dalsza lektura
182

6
_ Spis tre
ļci
12. Wykrywanie i zg
ĥaszanie bĥýdów ............................................................................. 183
Podstawowe informacje o bäödach Perla
183
Raportowanie bäödów moduäu
188
Wyjñtki
191
Podsumowanie
197
Dalsza lektura
197
13. Rejestrowanie zdarze
ħ ............................................................................................. 199
Rejestrowanie bäödów i innych informacji
199
Log4perl
200
Podsumowanie
205
Dalsza lektura
206
14. Utrwalanie danych ....................................................................................................207
Päaskie pliki
207
Storable
215
Pliki DBM
219
Podsumowanie
221
Dalsza lektura
221
15. Praca z formatem Pod ...............................................................................................223
Format Pod
223
Täumaczenie formatu Pod
224
Testowanie dokumentacji Pod
231
Podsumowanie
233
Dalsza lektura
234
16. Praca z bitami ............................................................................................................235
Liczby binarne
235
Operatory bitowe
237
Wektory bitowe
243
Funkcja vec
244
ćledzenie stanów
249
Podsumowanie
250
Dalsza lektura
250
17. Magia zmiennych zwi
ézanych .................................................................................. 251
Wyglñdajñ jak zwykäe zmienne
251
Na poziomie uĔytkownika
252
Za kulisami
253
Skalary
254
Tablice
258

Spis tre
ļci _
7
Asocjacje
266
Uchwyty plików
268
Podsumowanie
270
Dalsza lektura
270
18. Modu
ĥy jako programy ...............................................................................................271
NajwaĔniejsza rzecz
271
Krok wstecz
272
Kto woäa?
272
Testowanie programu
273
Rozpowszechnianie programu
279
Podsumowanie
280
Dalsza lektura
280
A Dalsza lektura ............................................................................................................ 281
B Przewodnik briana po rozwi
ézywaniu problemów z Perlem .................................283
Skorowidz ..................................................................................................................289

19
ROZDZIA
Ĥ 2.
Zaawansowane wyra
żenia regularne
WyraĔenia regularne stanowiñ klucz do przetwarzania tekstu w Perlu i z pewnoĈciñ sñ jednñ
z funkcji, dziöki którym Perl zyskaä tak duĔñ popularnoĈè. Wszyscy programiĈci Perla przecho-
dzñ fazö, w której próbujñ pisaè wszystkie programy jako wyraĔenia regularne, a jeĈli to im nie
wystarcza — jako jedno wyraĔenie regularne. WyraĔenia regularne Perla majñ wiöcej moĔli-
woĈci, niĔ mogö — i chcö — tu zaprezentowaè, wiöc omówiö te zaawansowane funkcje, które
uwaĔam za najbardziej uĔyteczne i o których kaĔdy programista Perla powinien wiedzieè bez
zaglñdania do perlre (rozdziaäu dokumentacji poĈwiöconego wyraĔeniom regularnym).
Referencje do wyra
żeħ regularnych
Kiedy piszö jakiĈ program, nie muszö zawczasu znaè wszystkich wzorców. Perl pozwala mi in-
terpolowaè wyraĔenia regularne w zmiennych. Mogö zakodowaè te wartoĈci „na sztywno”,
pobraè je z danych dostarczonych przez uĔytkownika albo uzyskaè w dowolny inny sposób. Oto
króciutki program Perla, który dziaäa podobnie jak
grep
. Pobiera pierwszy argument wiersza
polecenia i uĔywa go jako wyraĔenia regularnego w instrukcji
while
. Nie ma w tym nic szczegól-
nego (na razie); pokazaliĈmy, jak to robiè, w ksiñĔce Perl. Wprowadzenie. Mogö uĔyè äaþcucha
w zmiennej
$regex
jako wyraĔenia regularnego, a Perl skompiluje je, kiedy zinterpoluje äaþcuch
w operatorze dopasowania
1
:
#!/usr/bin/perl
# perl-grep.pl
my $regex = shift @ARGV;
print "Wyra
šenie regularne to [$regex]\n";
while( <> )
{
print if m/$regex/;
}
Mogö uruchomiè ten program z poziomu wiersza poleceþ, aby poszukaè wzorca w plikach.
W poniĔszym przykäadzie szukam wzorca
new
we wszystkich programach Perla znajdujñcych
siö w bieĔñcym katalogu:
1
Od wersji 5.6 Perla, jeĈli äaþcuch siö nie zmienia, wyraĔenie nie jest kompilowane ponownie. W starszych
wersjach trzeba byäo uĔyè opcji /o, aby uzyskaè takie dziaäanie. MoĔna nadal uĔywaè opcji /o, aby wskazaè,
Ĕe wzorzec nie powinien byè rekompilowany nawet wtedy, gdy äaþcuch siö zmieni.

20
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
% perl-grep.pl new *.pl
Wyra
šenie regularne to [new]
my $regexp = Regexp::English->new
my $graph = GraphViz::Regex->new($regex);
[ qr/\G(\n)/, "newline" ],
{ ( $1, "newline char" ) }
print YAPE::Regex::Explain->new( $ARGV[0] )->explain;
Co siö stanie, jeĈli podam nieprawidäowe wyraĔenie regularne? Wypróbujö to na wyraĔeniu, które
ma nawias otwierajñcy, ale nie ma zamykajñcego:
$ ./perl-grep.pl "(perl" *.pl
Wyra
šenie regularne to [(perl]
Unmatched ( in regex; marked by <-- HERE in m/( <-- HERE perl/
at ./perl-grep.pl line 10, <> line 1.
Kiedy interpolujö wyraĔenie regularne w operatorze dopasowania, Perl kompiluje wyraĔenie
i natychmiast zgäasza bäñd, przerywajñc dziaäanie programu. Aby tego uniknñè, muszö skompi-
lowaè wyraĔenie, zanim spróbujö go uĔyè.
qr//
to operator przytaczania wyraĔeþ regularnych, który zapisuje wyraĔenie w skalarze (do-
kumentacjö tego operatora moĔna znaleĒè na stronie perlop). Operator
qr//
kompiluje wzorzec,
aby byä gotowy do uĔycia, kiedy zinterpolujö
$regex
w operatorze dopasowania. Aby wychwy-
ciè bäñd, umieszczam
qr//
w bloku operatora
eval
, choè w tym przypadku i tak przerywam
dziaäanie programu instrukcjñ
die
:
#!/usr/bin/perl
# perl-grep2.pl
my $pattern = shift @ARGV;
my $regex = eval { qr/$pattern/ };
die "Sprawd
ş swój wzorzec! $@" if $@;
while( <> )
{
print if m/$regex/;
}
WyraĔenie regularne w zmiennej
$regex
ma wszystkie cechy operatora dopasowania, w tym
odwoäania wsteczne i zmienne pamiöciowe. PoniĔszy wzorzec wyszukuje sekwencjö trzech
znaków, w której pierwszy i trzeci znak sñ takie same, a Ĕaden nie jest znakiem odstöpu. Dane
wejĈciowe to tekstowa wersja strony dokumentacji perl, którñ uzyskujö za pomocñ polecenia
perldoc -t
:
% perldoc -t perl | perl-grep2.pl "\b(\S)\S\1\b"
perl583delta Perl changes in version 5.8.3
perl582delta Perl changes in version 5.8.2
perl581delta Perl changes in version 5.8.1
perl58delta Perl changes in version 5.8.0
perl573delta Perl changes in version 5.7.3
perl572delta Perl changes in version 5.7.2
perl571delta Perl changes in version 5.7.1
perl570delta Perl changes in version 5.7.0
perl561delta Perl changes in version 5.6.1
http://www.perl.com/ the Perl Home Page
http://www.cpan.org/ the Comprehensive Perl Archive
http://www.perl.org/ Perl Mongers (Perl user groups)

Referencje do wyra
żeħ regularnych
_
21
Nie jest zbyt äatwo (przynajmniej mnie) stwierdziè na pierwszy rzut oka, co Perl dopasowaä, wiöc
mogö wprowadziè pewnñ zmianö w programie
grep
. Zmienna
$&
przechowuje dopasowanñ
czöĈè äaþcucha:
#!/usr/bin/perl
# perl-grep3.pl
my $pattern = shift @ARGV;
my $regex = eval { qr/$pattern/ };
die "Sprawd
ş swój wzorzec! $@" if $@;
while( <> )
{
print "$_\t\tdopasowano >>>$&<<<\n" if m/$regex/;
}
Teraz widzö, Ĕe moje wyraĔenie regularne dopasowuje kropkö, znak i kolejnñ kropkö, jak w
.8.
:
% perldoc -t perl | perl-grep3.pl "\b(\S)\S\1\b"
perl587delta Perl changes in version 5.8.7
dopasowano >>>.8.<<<
perl586delta Perl changes in version 5.8.6
dopasowano >>>.8.<<<
perl585delta Perl changes in version 5.8.5
dopasowano >>>.8.<<<
Tak dla zabawy, jak sprawdziè, co zostaäo dopasowane w kaĔdej grupie pamiöciowej, czyli
zmienne
$1
,
$2
itd.? Mógäbym spróbowaè wyĈwietliè ich zawartoĈè bez wzglödu na to, czy mam
zwiñzane z nimi grupy przechwytywania, czy nie, ale ile jest takich zmiennych? Perl to „wie”,
poniewaĔ Ĉledzi dopasowywanie w specjalnych tablicach
@a-
i
@a+
, które przechowujñ prze-
suniöcia odpowiednio poczñtku i koþca kaĔdego dopasowania. Oznacza to, Ĕe dla dopasowanego
äaþcucha w
$_
liczba grup pamiöciowych jest równa ostatniemu indeksowi tablicy
@a-
lub
@a+
(majñ one takñ samñ däugoĈè). Pierwszy element w kaĔdej z nich dotyczy dopasowanej czöĈci
äaþcucha (a zatem
$&
), a nastöpny element, o indeksie
1
, dotyczy zmiennej
$1
itd. aĔ do koþca
tablicy. WartoĈè w
$1
jest taka sama jak w poniĔszym wywoäaniu
substr
:
my $one = substr(
$_, #
áaĔcuch
$-[1], # pocz
ątkowa pozycja $1
$+[1] - $-[1] # d
áugoĞü $1 (nie koĔcowa pozycja!)
);
Aby wyĈwietliè zmienne pamiöciowe, wystarczy przetworzyè w pötli indeksy tablicy
@-
:
#!/usr/bin/perl
# perl-grep4.pl
my $pattern = shift @ARGV;
my $regex = eval { qr/$pattern/ };
die "Sprawd
ş swój wzorzec! $@" if $@;
while( <> )
{
if( m/$regex/ )
{
print "$_";
print "\t\t\$&: ",

22
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
substr( $_, $-[$i], $+[$i] - $-[$i] ),
"\n";
foreach my $i ( 1 .. $#- )
{
print "\t\t\$$i: ",
substr( $_, $-[$i], $+[$i] - $-[$i] ),
"\n";
}
}
}
Teraz mogö zobaczyè dopasowanñ czöĈè äaþcucha, a takĔe dopasowania podrzödne:
% perldoc -t perl | perl-grep4.pl "\b(\S)\S\1\b"
perl587delta Perl changes in version 5.8.7
$&: .8.
$1: .
JeĈli dodam do wzorca wiöcej dopasowaþ podrzödnych, nie bödö musiaä niczego zmieniaè, aby
zobaczyè dodatkowe dopasowania:
% perldoc -t perl | perl-grep4.pl "\b(\S)(\S)\1\b"
perl587delta Perl changes in version 5.8.7
$&: .8.
$1: .
$2: 8
(?imsx-imsx:WZORZEC)
A gdybym chciaä, Ĕeby mój program
grep
robiä coĈ bardziej skomplikowanego, na przykäad
wyszukiwaä äaþcuchy bez uwzglödniania wielkoĈci liter? Aby uĔyè mojego programu do wy-
szukania ciñgu „Perl” lub „perl”, mogö uĔyè kilku sposobów, z których Ĕaden nie wymaga wiök-
szego wysiäku:
% perl-grep.pl "[pP]erl"
% perl-grep.pl "(p|P)erl"
Gdybym chciaä ignorowaè wielkoĈè liter w caäym wzorcu, miaäbym znacznie wiöcej pracy, a to
mi siö nie podoba. W przypadku operatora dopasowania wystarczyäoby dodaè na koþcu opcjö
/i
:
print if m/$regex/i;
Mógäbym to zrobiè równieĔ w przypadku operatora
qr//
, choè wówczas wszystkie wzorce prze-
staäyby rozróĔniaè wielkoĈè liter:
my $regex = qr/$pattern/i;
Aby tego uniknñè, mogö okreĈliè opcje dopasowywania wewnñtrz wzorca. Specjalna sekwencja
(?imsx)
pozwala wäñczyè wybrane opcje. JeĈli chcö ignorowaè wielkoĈè liter, mogö uĔyè
(?i)
wewnñtrz wzorca. Ignorowanie wielkoĈci liter bödzie obowiñzywaè w czöĈci wzorca nastöpujñcej
po
(?i)
(albo do koþca tekstu w nawiasie):
% perl-grep.pl "(?i)perl"
Ogólnie rzecz biorñc, mogö wäñczaè opcje dla czöĈci wzorca, okreĈlajñc te, które sñ mi potrzebne,
w nawiasie okrñgäym, ewentualnie razem z czöĈciñ wzorca, której dotyczñ, jak pokazano
w tabeli 2.1.

Referencje do wyra
żeħ regularnych
_
23
Tabela 2.1. Opcje u
Ĕywane w sekwencji (?opcje:WZORZEC)
Wpleciona opcja
Opis
($i:WZORZEC)
Ignorowanie wielko
ļci liter
($m:WZORZEC)
Wielowierszowy tryb dopasowywania
($s:WZORZEC)
Kropka (
.
) dopasowuje znak nowego wiersza
($x:WZORZEC)
Tryb wyja
ļniania (od ang. eXplain)
Opcje moĔna nawet grupowaè:
(?si:WZORZEC) Kropka dopasowuje nowy wiersz, ignorowanie wielko
Ğci liter
JeĈli poprzedzö opcjö znakiem zapytania, wyäñczö jñ w danej grupie:
(?-s:PATTERN) Kropka nie dopasowuje nowego wiersza
Jest to przydatne szczególnie wtedy, kiedy otrzymujö wzorzec z wiersza polecenia. W rzeczywi-
stoĈci, kiedy uĔywam operatora
qr//
w celu utworzenia wyraĔenia regularnego, opcje te sñ
ustawiane automatycznie. Zmieniö program tak, aby wyĈwietlaä wyraĔenie regularne po utwo-
rzeniu go przez operator
qr//
, ale przed uĔyciem:
#!/usr/bin/perl
# perl-grep3.pl
my $pattern = shift @ARGV;
my $regex = eval { qr/$pattern/ };
die "Sprawd
ş swój wzorzec! $@" if $@;
print "Wyra
šenie regularne ---> $regex\n";
while( <> )
{
print if m/$regex/;
}
Kiedy wyĈwietlam wyraĔenie regularne, widzö, Ĕe poczñtkowo wszystkie opcje sñ w nim wyäñ-
czone. W tekstowej wersji wyraĔenia regularnego znajduje siö ciñg
(?-OPCJE:WZORZEC)
, który
wyäñcza wszystkie opcje:
% perl-grep3.pl "perl"
Wyra
šenie regularne ---> (?-xism:perl)
Kiedy wäñczam ignorowanie wielkoĈci liter, wynikowy äaþcuch wyglñda nieco dziwnie: wyäñcza
opcjö
i
, aby za chwilö wäñczyè jñ ponownie:
% perl-grep3.pl "(?i)perl"
Wyra
šenie regularne ---> (?-xism:(?i)perl)
WyraĔenie regularne Perla majñ wiele podobnych sekwencji w nawiasie okrñgäym, a kilka z nich
pokaĔö w dalszej czöĈci rozdziaäu. KaĔda zaczyna siö od nawiasu otwierajñcego, po którym nastö-
pujñ pewne znaki okreĈlajñce Ĕñdanñ operacjö. Ich peänñ listö moĔna znaleĒè na stronie perlre.
Referencje jako argumenty
PoniewaĔ referencje sñ skalarami, mogö uĔywaè skompilowanego wyraĔenia regularnego tak jak
kaĔdego innego skalara, na przykäad zapisaè go w tablicy lub asocjacji albo przekazaè jako ar-
gument procedury. Na przykäad moduä
Test::More
ma funkcjö
like
, która przyjmuje wyraĔenie
regularne jako drugi argument. Mogö porównaè äaþcuch z wyraĔeniem regularnym i otrzymaè
bardziej szczegóäowe wyniki, jeĈli äaþcuch nie zostanie dopasowany:

24
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
use Test::More 'no_plan';
my $string = "Kolejny programista Perla,";
like( $string, qr/(\S+) haker/, "Co to za haker!" );
PoniewaĔ w äaþcuchu
$string
wystöpuje wyraz
programista
zamiast
haker
, test koþczy siö
niepowodzeniem. Wyniki zawierajñ äaþcuch, oczekiwanñ wartoĈè oraz wyraĔenie regularne,
którego spróbowaäem uĔyè:
not ok 1 - Co to za haker!
1..1
# Failed test 'Co to za haker!'
# 'Kolejny programista Perla,'
# doesn't match '(?-xism:(\S+) haker)'
# Looks like you failed 1 test of 1.
Funkcja
like
nie musi robiè niczego specjalnego, aby przyjñè wyraĔenie regularne jako argu-
ment, choè sprawdza typ referencji
2
, zanim zacznie odprawiaè swoje czary:
if( ref $regex eq 'Regexp' ) { ... }
PoniewaĔ
$regex
jest po prostu referencjñ (typu
Regexp
), mogö wykonywaè na niej róĔne operacje
„referencyjne”, na przykäad uĔyè funkcji
isa
do sprawdzenia typu albo pobraè typ za pomocñ
ref
:
print "Mam wyra
šenie regularne!\n" if $regex->isa( 'Regexp' );
print "Typ referencji to ", ref( $regex ), "\n";
Grupy nieprzechwytuj
éce, (?:WZORZEC)
Nawiasy okrñgäe w wyraĔeniach regularnych nie muszñ wyzwalaè zapisywania dopasowanych
czöĈci wzorca w pamiöci. MoĔna ich uĔyè wyäñcznie do grupowania przez zastosowanie spe-
cjalnej sekwencji
(?:WZORZEC)
. Dziöki temu w grupach przechwytujñcych nie pojawiajñ siö
niepoĔñdane dane.
PrzypuĈèmy, Ĕe chcö dopasowywaè imiona po obu stronach spójników
i
albo
lub
. W tablicy
@array
mam kilka äaþcuchów z takimi parami imion. Spójnik moĔe siö zmieniaè, wiöc w wyra-
Ĕeniu regularnym uĔywam alternacji
i|lub
. Problemem jest pierwszeþstwo operatorów. Alterna-
cja ma wyĔsze pierwszeþstwo niĔ sekwencja, wiöc aby wzorzec zadziaäaä, muszö umieĈciè
alternacjö w nawiasie okrñgäym,
(\S+) (i|lub) (\S+)
:
#!/usr/bin/perl
my @strings = (
"Fred i Barney",
"Jacek lub Agatka",
"Fred i Ginger",
);
foreach my $string ( @strings )
{
# $string =~ m/(\S+) i|lub (\S+)/; # nie dzia
áa
$string =~ m/(\S+) (i|lub) (\S+)/;
print "\$1: $1\n\$2: $2\n\$3: $3\n";
print "-" x 10, "\n";
}
2
W rzeczywistoĈci dzieje siö to w metodzie
maybe_regex
klasy
Test::Builder.

Czytelne wyra
żenia regularne, /x i (?#...)
_
25
Wyniki pokazujñ niepoĔñdanñ konsekwencjö grupowania alternacji: czöĈè äaþcucha umieszczona
w nawiasie pojawia siö wĈród zmiennych pamiöciowych jako
$2
(tabela 2.2). Jest to skutek
uboczny.
Tabela 2.2. Niepo
Ĕñdane przechwytywanie dopasowaþ
Bez grupowania i|lub
Z grupowaniem i|lub
$1: Fred
$2:
$3:
----------
$1:
$2: Agatka
$3:
----------
$1: Fred
$2:
$3:
----------
$1: Fred
$2: i
$3: Barney
----------
$1: Jacek
$2: lub
$3: Agatka
----------
$1: Fred
$2: i
$3: Ginger
----------
UĔycie nawiasów rozwiñzaäo problemy z pierwszeþstwem, ale teraz mam dodatkowñ zmiennñ
pamiöciowñ, która wchodzi mi w drogö, kiedy zmieniam program tak, aby uĔywaä dopasowania
w kontekĈcie listy. Wszystkie zmienne pamiöciowe, äñcznie ze spójnikami, pojawiajñ siö w tablicy
@names
:
# Dodatkowy element!
my @names = ( $string =~ m/(\S+) (i|lub) (\S+)/ );
Chcö po prostu grupowaè elementy bez ich zapamiötywania. Zamiast zwykäych nawiasów, któ-
rych uĔywaäem do tej pory, dodajö
?:
zaraz za nawiasem otwierajñcym grupö, przez co otrzy-
mujö nawias nieprzechwytujñcy. Zamiast
(i|lub)
mam teraz
(?:i|lub)
. Ta postaè nie wyzwala
zmiennych pamiöciowych i nie zmienia ich numerowania. Mogö stosowaè kwantyfikatory, tak
samo jak w zwykäych nawiasach. Teraz w tablicy
@names
nie pojawiajñ siö dodatkowe elementy:
# Teraz tylko imiona
my @names = ( $string =~ m/(\S+) (?:i|lub) (\S+)/ );
Czytelne wyra
żenia regularne, /x i (?#...)
WyraĔenia regularne majñ zasäuĔonñ reputacjö maäo czytelnych. Sñ pisane w zwiözäym jözyku,
który uĔywa bardzo ograniczonej liczby znaków do reprezentowania praktycznie nieskoþczenie
wielu moĔliwoĈci, i to liczñc tylko te elementy, których wiökszoĈè programistów uĔywa na co dzieþ.
Na szczöĈcie Perl daje mi moĔliwoĈè znacznego zwiökszenia czytelnoĈci wyraĔeþ regularnych.
Wystarczy trochö odpowiedniego formatowania, a inni (albo ja sam kilka tygodni póĒniej) bödñ
mogli äatwo stwierdziè, co próbujö dopasowaè. WspomnieliĈmy o tym krótko w ksiñĔce Perl.
Wprowadzenie, ale jest to tak dobry pomysä, Ĕe zamierzam omówiè go dokäadniej. Opisuje to
równieĔ Damian Conway w ksiñĔce Perl. Najlepsze rozwiñzania (Helion).

26
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
Kiedy dodajö opcjö
/x
do operatora dopasowania albo podstawienia, Perl ignoruje dosäowne
odstöpy we wzorcu. Oznacza to, Ĕe mogö rozdzieliè czöĈci wyraĔenia, aby uäatwiè ich identyfi-
kacjö. Moduä
HTTP::Date
napisany przez Gislego Aasa dokonuje analizy skäadniowej daty, wy-
próbowujñc kilka róĔnych wyraĔeþ regularnych. Oto jedno z jego wyraĔeþ, zmodyfikowane tak,
aby mieĈciäo siö w jednym wierszu (tutaj zawiniöte w celu dopasowania do strony):
/^(\d\d?)(?:\s+|[-\/])(\w+)(?:\s+|[-\/])
´(\d+)(?:(?:\s+|:)(\d\d?):(\d\d)(?::(\d\d))
´?)?\s*([-+]?\d{2,4}|(?![APap][Mm]\b)[A-Za-z]+)?\s*(?:\(\w+\))?\s*$/
Szybko: czy ktoĈ potrafi powiedzieè, który z licznych formatów daty dopasowuje to wyraĔenie?
Ja teĔ nie. Na szczöĈcie Gisle uĔyä opcji
/x
, aby podzieliè wyraĔenie na czöĈci, i dodaä komentarze,
które informujñ, do czego säuĔy kaĔda czöĈè. Dziöki opcji
/x
Perl ignoruje odstöpy oraz perlow-
skie komentarze wewnñtrz wyraĔenia. Oto rzeczywisty kod Gislego, który jest znacznie bardziej
zrozumiaäy:
/^
(\d\d?) # dzie
Ĕ
(?:\s+|[-\/])
(\w+) # miesi
ąc
(?:\s+|[-\/])
(\d+) # rok
(?:
(?:\s+|:) # separator przed czasem
(\d\d?):(\d\d) # godzina: minuta
(?::(\d\d))? # opcjonalne sekundy
)? # opcjonalny zegar
\s*
([-+]?\d{2,4}|(?![APap][Mm]\b)[A-Za-z]+)? # strefa czasowa
\s*
(?:\(\w+\))? # reprezentacja ASCII strefy czasowej w nawiasie
\s*$
/x
Kiedy uĔywam opcji
/x
w celu dopasowania odstöpu, muszö okreĈliè go jawnie — albo za pomocñ
symbolu
\s
, który pasuje do dowolnego odstöpu (
\f\r\n\t
), albo za pomocñ odpowiedniej se-
kwencji ósemkowej lub szesnastkowej, na przykäad
\040
lub
\x20
dla dosäownej spacji
3
. Po-
dobnie, jeĈli potrzebujö dosäownego hasha (
#
), muszö poprzedziè go ukoĈnikiem odwrotnym:
\#
.
Nie muszö uĔywaè opcji
/x
, aby umieszczaè komentarze w wyraĔeniach regularnych. Mogö to
zrobiè równieĔ za pomocñ sekwencji
(?#KOMENTARZ)
, choè prawdopodobnie wyraĔenie nie stanie
siö przez to bardziej czytelne. Mogö objaĈniè czöĈci äaþcucha tuĔ obok reprezentujñcych ich czöĈci
wzorca. Choè jednak moĔna uĔywaè sekwencji
(?#)
, nie znaczy to jeszcze, Ĕe naleĔy to robiè. My-
Ĉlö, Ĕe wzorce sñ znacznie czytelniejsze, kiedy uĔywa siö opcji
/x
:
$isbn = '0-596-10206-2';
$isbn =~ m/(\d+)(?#kraj)-(\d+)(?#wydawca)-(\d+)(?#pozycja)-([\dX])/i;
print <<"HERE";
Kod kraju: $1
Kod wydawcy: $2
Pozycja: $3
Suma kontrolna: $4
HERE
3
Mogö równieĔ poprzedziè dosäownñ spacjö znakiem \, ale poniewaĔ spacji nie widaè, wolö uĔywaè czegoĈ,
co jest widoczne, na przykäad \x20.

Dopasowywanie globalne
_
27
Dopasowywanie globalne
W ksiñĔce Perl. Wprowadzenie wspomnieliĈmy o opcji
/g
, której moĔna uĔyè w celu dokonania
wszystkich moĔliwych podstawieþ. Jak siö okazuje, ma ona równieĔ inne zastosowania. MoĔna
uĔyè jej w poäñczeniu z operatorem dopasowania, a wówczas dziaäa inaczej w kontekĈcie ska-
larnym i w kontekĈcie listy. StwierdziliĈmy, Ĕe operator dopasowania zwraca
true
, jeĈli zdoäa
dopasowaè wzorzec, a
false
w przeciwnym przypadku. To prawda (przecieĔ byĈmy nie käamali!),
ale nie jest to po prostu wartoĈè logiczna. Opcja
/g
jest najbardziej przydatna w kontekĈcie listy.
Operator dopasowania zwraca wówczas wszystkie zapamiötane dopasowania:
$_ = "Kolejny haker Perla,";
my @words = /(\S+)/g; # "Kolejny" "haker" "Perla,"
Choè w wyraĔeniu mam tylko jeden nawias pamiöciowy, znajduje on tyle dopasowaþ, ile siö da.
Po udanym dopasowaniu Perl zaczyna od miejsca, w którym skoþczyä, i próbuje jeszcze raz.
Powiem o tym wiöcej za chwilö. Czösto trafiam na zbliĔony idiom Perla, w którym nie chodzi
o rzeczywiste dopasowania, ale o ich liczbö:
my $word_count = () = /(\S+)/g;
Wykorzystano tu maäo znanñ, ale waĔnñ zasadö: wynikiem operacji przypisania listy jest liczba
elementów listy znajdujñcej siö po prawej stronie. W tym przypadku jest to liczba elementów
zwracanych przez operator dopasowania. Dziaäa to tylko w kontekĈcie listy, czyli w przypadku
przypisywania jednej listy do drugiej. Dlatego potrzebny jest dodatkowy nawias
()
.
W kontekĈcie skalarnym opcja
/g
wykonuje dodatkowñ pracö, o której nie wspomniano w po-
przednich ksiñĔkach. Po udanym dopasowaniu Perl zapamiötuje pozycjö w äaþcuchu, a kiedy
znów porównuje ten sam äaþcuch z wzorcem, zaczyna od miejsca, w którym skoþczyä poprzednio.
Zwraca wynik jednego zastosowania wzorca do äaþcucha:
$_ = "Kolejny haker Perla,";
my @words = /(\S+)/g; # "Kolejny" "haker" "Perla,"
while( /(\S+)/g ) # kontekst skalarny
{
print "Nast
Ăpne sĪowo to '$1'\n";
}
Kiedy ponownie dopasowujö ten sam äaþcuch, Perl zwraca nastöpne dopasowanie:
Nast
Ăpne sĪowo to 'Kolejny'
Nast
Ăpne sĪowo to 'haker'
Nast
Ăpne sĪowo to 'Perla,'
Mogö nawet sprawdzaè pozycjö dopasowywania w miarö przetwarzania äaþcucha. Wbudowany
operator
pos()
zwraca pozycjö dopasowywania dla podanego äaþcucha (domyĈlne dla
$_
). Po-
zycja w kaĔdym äaþcuchu jest Ĉledzona oddzielnie. Pierwsza pozycja w äaþcuchu to
0
, wiöc
pos()
zwraca
undef
, jeĈli nie znajdzie dopasowania i pozycja zostanie zresetowana. Dziaäa to tylko
w przypadku uĔycia opcji
/g
(inaczej stosowanie operatora
pos()
nie miaäoby sensu):
$_ = "Kolejny haker Perla,";
my $pos = pos( $_ ); # to samo co pos()
print "Jestem w pozycji [$pos]\n"; # undef
/(Kolejny)/g;
$pos = pos();
print "[$1] ko
Ĭczy siĂ w pozycji $pos\n"; # 7

28
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
Kiedy dopasowywanie zawodzi, Perl resetuje wartoĈè
pos()
na
undef
. JeĈli bödö kontynuowaä
dopasowywanie, zacznö ponownie od poczñtku äaþcucha (moĔe to doprowadziè do nieskoþ-
czonej pötli):
my( $third word ) = /(Java)/g;
print "Nast
Ăpna pozycja to " . pos() . "\n";
Na marginesie: bardzo nie lubiö takich instrukcji
, w których operator konkatenacji jest uĔy-
wany w celu doäñczenia wyniku wywoäania funkcji do danych wyjĈciowych. Perl nie oferuje
specjalnego sposobu interpolowania wywoäaþ funkcji, wiöc konieczne jest maäe oszustwo. Wy-
woäujö funkcjö w konstruktorze tablicy anonimowej
[ ... ]
i natychmiast wyäuskujö jñ przez
umieszczenie w bloku
@{ ... }
4
:
print "Nast
Ăpna pozycja to @{ [ pos( $line ) ] }\n";
Operator
pos()
moĔe byè równieĔ l-wartoĈciñ, przez co programiĈci rozumiejñ, Ĕe mogö uĔywaè
go po lewej stronie przypisania i zmieniaè jego wartoĈè. Dziöki temu mogö skäoniè operator
dopasowania, aby zaczñä od wybranego przeze mnie miejsca. Kiedy dopasujö pierwsze säowo
w
$line
, pozycja dopasowywania znajduje siö gdzieĈ za poczñtkiem äaþcucha. Nastöpnie uĔy-
wam funkcji
index
, aby znaleĒè nastöpnñ literö
h
za bieĔñcñ pozycjñ dopasowywania. Kiedy
znajdö przesuniöcie tej litery
h
, przypisujö je do
pos($line)
, aby nastöpne dopasowywanie
rozpoczöäo siö od tej pozycji
5
:
my $line = "Oto kolejny haker wyra
šeĬ regularnych,";
$line =~ /(\S+)/g;
print "Pierwsze s
Īowo to $1\n";
print "Nast
Ăpna pozycja to @{ [ pos( $line ) ] }\n";
pos( $line ) = index( $line, 'h', pos( $line) );
$line =~ /(\S+)/g;
print "Nast
Ăpne sĪowo to $1\n";
print "Nast
Ăpna pozycja to @{ [ pos( $line ) ] }\n";
Kotwice dopasowywania globalnego
Dotychczas kolejne dopasowania mogäy „päywaè”, to znaczy dopasowywanie mogäo zaczynaè
siö od dowolnego miejsca za pozycjñ poczñtkowñ. Aby zakotwiczyè nastöpne dopasowanie do-
käadnie tam, gdzie skoþczyäem poprzednie, uĔywam kotwicy
\G
. Dziaäa ona tak samo jak kotwica
poczñtku äaþcucha
^
, ale wskazuje bieĔñcñ pozycjö dopasowywania. JeĈli dopasowywanie za-
wiedzie, Perl resetuje
pos()
i znów wracam do poczñtku äaþcucha.
W poniĔszym przykäadzie zakotwiczam wzorzec za pomocñ
\G
. Nastöpnie uĔywam nawiasów
nieprzechwytujñcych, aby zgrupowaè opcjonalne odstöpy,
\s*
, oraz wzorzec säowa,
\w+
. UĔy-
wam teĔ opcji
/x
, aby podzieliè wyraĔenie na czöĈci i zwiökszyè jego czytelnoĈè. Program znajduje
tylko cztery pierwsze säowa, poniewaĔ nie moĔe dopasowaè przecinka (nie ma go w klasie
\w
)
po säowie
regularnych
. PoniewaĔ nastöpne dopasowanie musi zaczynaè siö tam, gdzie skoþ-
4
Tego samego triku moĔna uĔyè do interpolowania wywoäaþ funkcji w äaþcuchu:
print "Wynik to: @{ [ funk-
cja (@argumenty) ] }".
5
Od t
äumacza: aby ten przykäad zadziaäaä poprawnie (podobnie jak inne, w których wystöpujñ polskie litery), nale-
Ĕy uĔyè opcji
-CS
(wielkie litery) programu perl oraz pragmy
use utf8
; w tekĈcie programu, na przykäad:
#!/usr/bin/perl -CS
use utf8;

Dopasowywanie globalne
_
29
czyäem poprzednie, a jedynñ rzeczñ, jakñ da siö dopasowaè, sñ znaki odstöpu albo säów, nie mogö
przejĈè dalej. Nastöpne dopasowanie zawodzi i Perl ustawia pozycjö dopasowywania na po-
czñtek
$line
:
my $line = "Kolejny haker wyra
šeĬ regularnych, haker Perla,";
while( $line =~ / \G (?: \s* (\w+) ) /xg )
{
print "Znaleziono s
Īowo '$1'\n";
print "Bie
šîca pozycja to @{ [ pos( $line ) ] }\n";
}
MoĔna jednak zapobiec resetowaniu pozycji dopasowywania przez Perl. W tym celu naleĔy
uĔyè opcji
/c
, która po prostu wskazuje, Ĕe pozycja nie powinna byè resetowana po nieudanym
dopasowaniu. Mogö bezkarnie wypróbowaè jakiĈ wzorzec; jeĈli to siö nie uda, mogö spróbowaè
czegoĈ innego w tej samej pozycji. Ta funkcja to skaner leksykalny dla ubogich. Oto bardzo
uproszczony parser zdaþ:
my $line = "Kolejny haker wyra
šeĬ regularnych, haker Perla; to chyba wszystko!\n";
while( 1 )
{
my( $found, $type )= do {
if( $line =~ /\G(\w+)/igc )
{ ( $1, "s
Īowo" ) }
elsif( $line =~ /\G (\n) /xgc )
{ ( $1, "znak nowego wiersza" ) }
elsif( $line =~ /\G (\s+) /xgc )
{ ( $1, "znak odst
Ăpu" ) }
elsif( $line =~ /\G ( [[:punct:]] ) /xgc )
{ ( $1, "znak interpunkcyjny" ) }
else
{ last; () }
};
print "Znaleziono $type [$found]\n";
}
Przyjrzyjmy siö dokäadniej temu przykäadowi. A gdybym chciaä dodaè wiöcej elementów do
dopasowania? Musiaäbym dopisaè kolejnñ gaäñĒ struktury decyzyjnej. Nie podoba mi siö to.
Wielokrotnie powtarzam strukturö kodu, która robi to samo: dopasowuje coĈ, a nastöpnie zwraca
$1
i opis. Zmieniö zatem kod tak, aby usunñè powtarzajñcñ siö strukturö. WyraĔenia regularne
mogö zapisaè w tablicy
@items
. UĔywam pokazanego wczeĈniej operatora przytoczenia
qr//
i ustawiam wyraĔenia regularne w takiej kolejnoĈci, w jakiej majñ byè wypróbowywane. Pötla
foreach
przetwarza je kolejno, aĔ znajdzie takie, które pasuje, a wówczas wypisuje komunikat
zäoĔony z opisu oraz zawartoĈci zmiennej
$1
. JeĈli zechcö dodaè wiöcej leksemów, po prostu
uzupeäniö tablicö
@items
:
#!/usr/bin/perl
use strict;
use warnings;
my $line = "Kolejny haker wyra
šeĬ regularnych, haker Perla; to chyba wszystko!\n";
my @items = (
[ qr/\G(\w+)/i, "s
Īowo" ],
[ qr/\G(\n)/, "znak nowego wiersza" ],
[ qr/\G(\s+)/, "znak odst
Ăpu" ],
[ qr/\G([[:punct:]])/, "znak interpunkcyjny" ],
);

30
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
LOOP: while( 1 )
{
MATCH: foreach my $item ( @items )
{
my( $regex, $description ) = @$item;
my( $type, $found );
next unless $line =~ /$regex/gc;
print "Znaleziono $description [$1]\n";
last LOOP if $1 eq "\n";
next LOOP;
}
}
Zobaczmy, co dzieje siö w tym przykäadowym programie. Wszystkie dopasowania wymagajñ
opcji
/gc
, wiöc umieszczam te opcje w pötli
foreach
. WyraĔenie dopasowujñce säowa wymaga
jednak równieĔ opcji
/i
. Nie mogö dodaè jej do operatora dopasowania, poniewaĔ w przy-
szäoĈci mogñ pojawiè siö nowe gaäözie, w których byäaby niepoĔñdana. Dodajö zatem asercjö
/i
do odpowiedniego wyraĔenia regularnego w tablicy
@items
, wäñczajñc ignorowanie wielkoĈci
liter tylko w tym wyraĔeniu. Gdybym chciaä zachowaè eleganckie formatowanie z wczeĈniejszych
przykäadów, mógäbym zastosowaè sekwencjö
(?ix)
. Nawiasem mówiñc, jeĈli wiökszoĈè wy-
raĔeþ regularnych powinna ignorowaè wielkoĈè liter, mogö dodaè opcjö
/i
do operatora do-
pasowania, a nastöpnie wyäñczyè jñ za pomocñ opcji
(?-i)
w odpowiednich wyraĔeniach.
Patrzenie w przód i w ty
ĥ
Operatory patrzenia (ang. lookarounds) to arbitralne kotwice w wyraĔeniach regularnych. Kilka
kotwic, takich jak
^
,
$
oraz
\b
, omówiliĈmy w ksiñĔce Perl. Wprowadzenie, a przed chwilñ poka-
zaäem kotwicö
\G
. Za pomocñ operatora patrzenia mogö opisaè mojñ wäasnñ kotwicö za pomocñ
wyraĔenia regularnego — podobnie jak inne kotwice, nie liczy siö ono jako czöĈè wzorca ani nie
pochäania znaków äaþcucha. OkreĈla warunek, który musi byè speäniony, ale nie wchodzi
w skäad czöĈci äaþcucha dopasowywanej przez ogólny wzorzec.
Operatory patrzenia majñ dwa rodzaje: operatory patrzenia w przód (ang. lookaheads), które
sprawdzajñ pewien warunek tuĔ za bieĔñcñ pozycjñ dopasowywania, oraz operatory patrzenia
w tyä (ang. lookbehinds), które sprawdzajñ pewien warunek tuĔ przed bieĔñcñ pozycjñ dopaso-
wywania. Wydaje siö to proste, ale äatwo o zäe zastosowanie tych reguä. Trzeba przypomnieè
sobie, Ĕe operator zakotwicza siö w bieĔñcej pozycji dopasowywania, a nastöpnie ustaliè, której
strony dotyczy.
Zarówno operatory patrzenia w przód, jak i patrzenia w tyä majñ dwie odmiany: pozytywnñ
i negatywnñ. Odmiana pozytywna potwierdza, Ĕe dany wzorzec pasuje, a odmiana negatywna
— Ĕe nie pasuje. Bez wzglödu zastosowany operator patrzenia trzeba pamiötaè, Ĕe dotyczy
on bieĔñcej pozycji dopasowywania, a nie jakiegoĈ innego miejsca w äaþcuchu.
Asercje z patrzeniem w przód, (?=WZORZEC) i (?!WZORZEC)
Asercje z patrzeniem w przód pozwalajñ mi zerknñè na czöĈè äaþcucha znajdujñcñ siö tuĔ za bie-
Ĕñcñ pozycjñ dopasowywania. Asercja nie pochäania czöĈci äaþcucha, a jeĈli siö powiedzie, dopa-
sowywanie jest kontynuowane tuĔ za bieĔñcñ pozycjñ.
Patrzenie w przód i w ty
ĥ
_
31
Pozytywne asercje z patrzeniem w przód
W ksiñĔce Perl. Wprowadzenie zamieĈciliĈmy èwiczenie polegajñce na sprawdzaniu, czy w danym
wierszu wystöpuje zarówno säowo „Fred”, jak i „Wilma”, bez wzglödu na ich kolejnoĈè. Chodziäo
o to, aby pokazaè poczñtkujñcym programistom Perla, Ĕe dwa wyraĔenia regularne mogñ byè
prostsze od jednego. Jednym z rozwiñzaþ jest powtórzenie äaþcuchów
Wilma
i
Fred
w alternacji
i wypróbowanie obu kolejnoĈci. Drugim — podzielenie ich na dwa wyraĔenia regularne:
#/usr/bin/perl
# fred-and-wilma.pl
$_ = "Nadchodz
î Wilma i Fred!";
print "Pasuje: $_" if /Fred.*Wilma|Wilma.*Fred/;
print "Pasuje: $_" if /Fred/ && /Wilma/;
Mogö równieĔ utworzyè proste, pojedyncze wyraĔenie regularne z pozytywnñ asercjñ patrzenia
w przód oznaczonñ przez
(?=WZORZEC)
. Ta asercja nie pochäania tekstu w äaþcuchu, ale jeĈli nie
jest speäniona, to caäe wyraĔenie nie zostanie dopasowane. W tym przykäadzie w pozytywnej
asercji uĔywam wzorca
.*Wilma
. Wzorzec ten musi zostaè znaleziony tuĔ za bieĔñcñ pozycjñ
dopasowywania:
$_ = "Nadchodz
î Wilma i Fred!";
print "Pasuje: $_" if /(?=.*Wilma).*Fred/;
UmieĈciäem asercjö na poczñtku wzorca, co oznacza, Ĕe musi byè speäniona na poczñtku äaþcucha.
Mówiñc ĈciĈlej, na poczñtku äaþcucha musi zostaè dopasowana dowolna liczba znaków (z wyjñt-
kiem znaku nowego wiersza), po którym nastöpuje ciñg
Wilma
. JeĈli to siö powiedzie, reszta
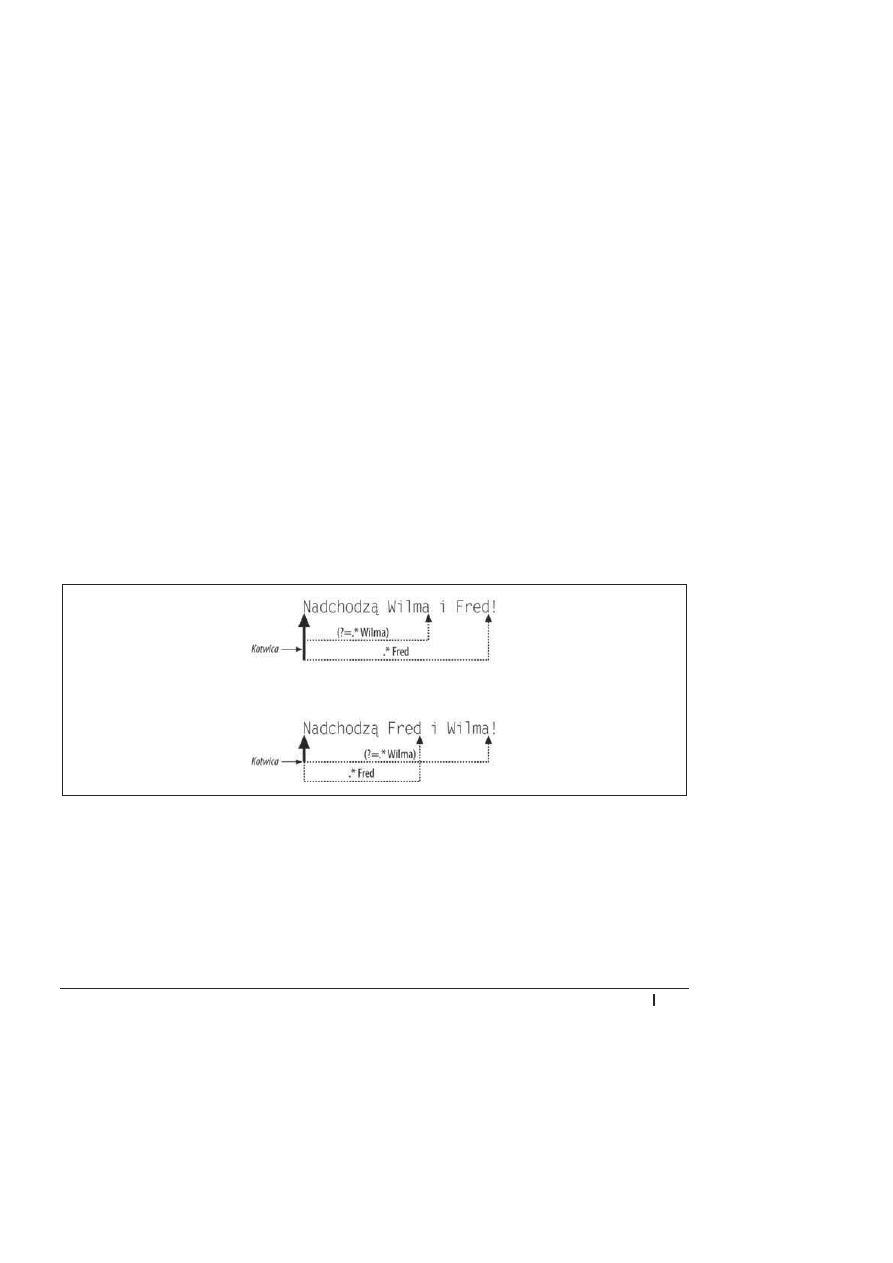
wzorca zostanie zakotwiczona w pozycji asercji (na poczñtku äaþcucha). Na rysunku 2.1 po-
kazano dwa sposoby dziaäania tego wzorca zaleĔne od kolejnoĈci ciñgów
Fred
i
Wilma
w bada-
nym äaþcuchu. Ciñg
.*Wilma
zakotwicza siö tam, gdzie rozpoczöäo siö jego dopasowywanie.
Elastyczny symbol
.*
, który moĔe dopasowaè dowolnñ liczbö znaków innych niĔ znak nowego
wiersza, powoduje zatem zakotwiczenie wzorca na poczñtku äaþcucha.
Rysunek 2.1. Asercja z patrzeniem w przód (?=.*Wilma) zakotwicza wzorzec na pocz
ñtku äaþcucha
ãatwiej jednak zrozumieè operatory patrzenia przez zbadanie przykäadów, w których nie dzia-
äajñ. Zmieniö nieco wzorzec, usuwajñc
.*
z asercji. Poczñtkowo wydaje siö, Ĕe bödzie dziaäaä,
ale zawodzi, kiedy zmieniö kolejnoĈè ciñgów
Fred
i
Wilma
:
$_ = "Nadchodz
î Wilma i Fred!";
print "Pasuje: $_" if /(?=Wilma).*Fred/;
$_ = "Nadchodz
î Fred i Wilma!";
print "Pasuje: $_" if /(?=Wilma).*Fred/;
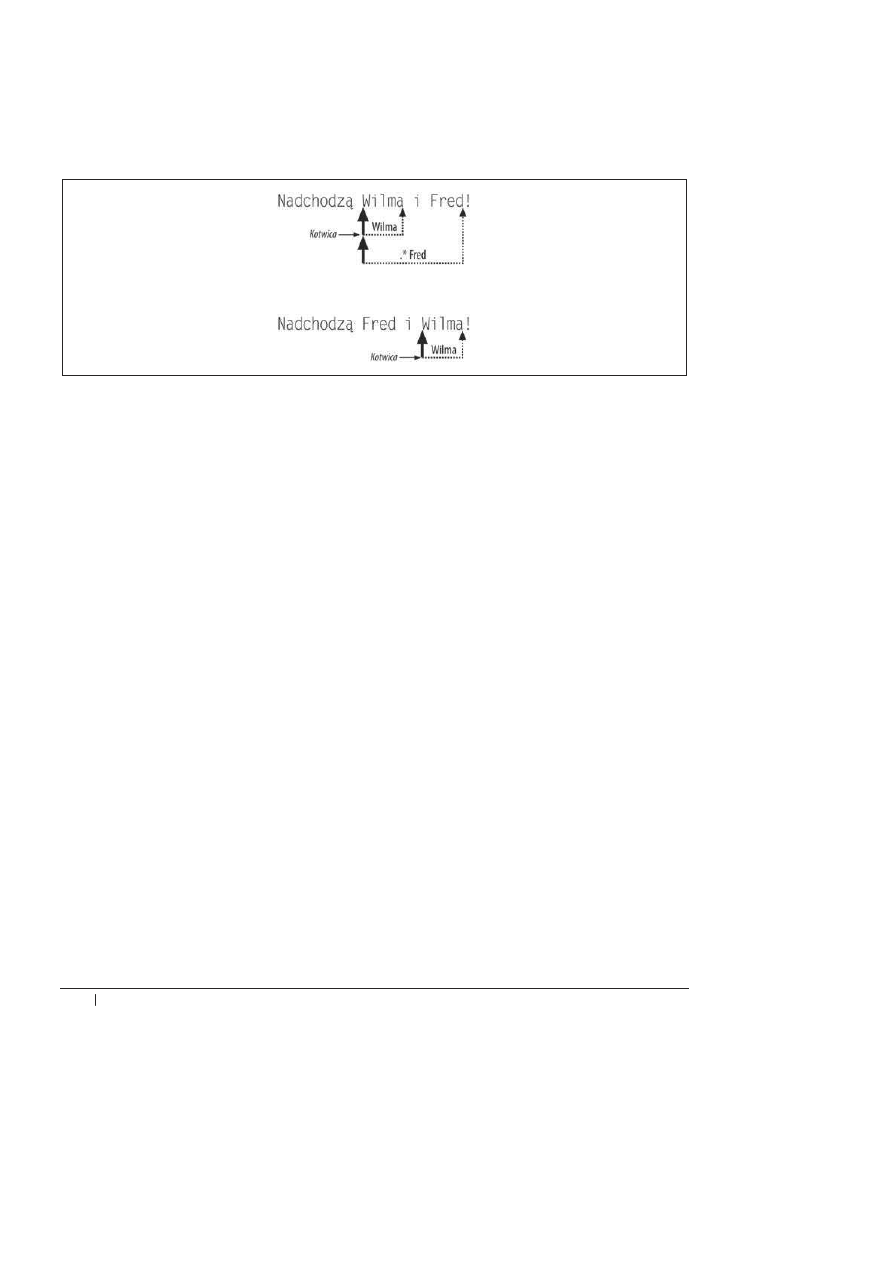
32
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
Na rysunku 2.2 pokazano, co siö dzieje. W pierwszym przypadku operator patrzenia zako-
twicza wzorzec na poczñtku ciñgu
Wilma
. Perl wypróbowaä asercjö na poczñtku äaþcucha,
ustaliä, Ĕe nie jest speäniona, po czym przesunñä siö o jednñ pozycjö w przód i spróbowaä jesz-
cze raz. Robiä to dopóty, dopóki nie dotarä do ciñgu
Wilma
. Kiedy pomyĈlnie dopasowaä ten
ciñg, ustawiä kotwicö. Reszta wzorca musi zaczynaè siö od tej pozycji.
Rysunek 2.2. Asercja z patrzeniem w przód (?=Wilma) zakotwicza wzorzec na ci
ñgu Wilma
W pierwszym przypadku da siö dopasowaè ciñg
.*Fred
od pozycji kotwicy, poniewaĔ nastö-
puje on po ciñgu
Wilma
. W drugim przypadku przedstawionym na rysunku 2.2 Perl postöpuje
podobnie. Wypróbowuje asercjö na poczñtku äaþcucha, ustala, Ĕe nie jest speäniona, po czym prze-
suwa siö o jednñ pozycjö w przód. Asercjö uda siö dopasowaè dopiero po miniöciu ciñgu
Fred
.
Reszta wzorca musi zaczynaè siö od kotwicy, wiöc nie da siö jej dopasowaè.
PoniewaĔ asercje z patrzeniem w przód nie pochäaniajñ czöĈci äaþcucha, mogö uĔywaè ich we
wzorcach
split
, kiedy nie chcö odrzucaè dopasowanych czöĈci wzorca. W poniĔszym przy-
käadzie chcö wydzieliè säowa z äaþcucha zapisanego w notacji „wielbäñdziej”. ãaþcuch trzeba
podzieliè na czöĈci zaczynajñce siö od wielkiej litery. Chcö jednak zachowaè poczñtkowñ literö,
wiöc uĔywam asercji z patrzeniem w przód zamiast ciñgu pochäaniajñcego znaki. RóĔni siö to od
trybu zachowywania separatorów, poniewaĔ wzorzec podziaäu w istocie nie jest separatorem,
lecz po prostu kotwicñ:
my @words = split /(?=[A-Z])/, '
ĩaĬcuchWNotacjiWielbĪîdziej';
print join '_', map { lc } @words; #
áaĔcuch_w_notacji_wielbáądziej
Negatywne asercje z patrzeniem w przód
PrzypuĈèmy, Ĕe chcö znaleĒè wiersze wejĈciowe, które zawierajñ ciñg
Perl
, ale tylko pod warun-
kiem, Ĕe nie jest to
Perl6
albo
Perl 6
. Próbujö uĔyè zanegowanej klasy znakowej, która ma
gwarantowaè, Ĕe zaraz za literñ
l
w ciñgu
Perl
nie pojawi siö cyfra
6
. UĔywam teĔ kotwic
granicy säów
\b
, poniewaĔ nie chcö dopasowywaè ciñgu
Perl
wewnñtrz innych säów, takich jak
„BioPerl” lub „PerlPoint”:
#!/usr/bin/perl
# not-perl6.pl
print "Wypróbowuj
Ă zanegowanî klasĂ znakowî:\n";
while( <> )
{
print if /\bPerl[^6]\b/; #
}

Patrzenie w przód i w ty
ĥ
_
33
Wypróbujö ten wzorzec na przykäadowych danych:
# Przyk
áadowe dane
Najpierw by
Ī Perl 5, a potem Perl6.
W ci
îgu Perl 6 jest spacja.
Po prostu mówi
Ă "Perl".
To jest wiersz j
Ăzyka Perl 5
Perl 5 to bie
šîca wersja.
Kolejny haker j
Ăzyka Perl 5,
Na ko
Ĭcu jest Perl
PerlPoint to PowerPoint
BioPerl jest genetyczny
Nie dziaäa on prawidäowo dla wszystkich wierszy. Znajduje tylko cztery wiersze, w których wy-
stöpuje ciñg
Perl
bez nastöpujñcej po nim cyfry
6
, a takĔe wiersz, w którym miödzy
Perl
a
6
jest
spacja:
Wypróbowuj
Ă zanegowanî klasĂ znakowî:
Najpierw by
Ī Perl 5, a potem Perl6.
W ci
îgu Perl 6 jest spacja.
To jest wiersz j
Ăzyka Perl 5
Perl 5 to bie
šîca wersja.
Kolejny haker j
Ăzyka Perl 5,
Wzorzec nie dziaäa, poniewaĔ po literze
l
w
Perl
musi wystöpowaè znak, a w dodatku okre-
Ĉliäem granicö säowa. JeĈli po literze
l
wystöpuje znak nienaleĔñcy do klasy znaków säów, taki
jak cudzysäów w
Po prostu mówi
Ă "Perl"
, granica säowa nie zostanie dopasowana. JeĈli usunö
koþcowe
\b
, zostanie dopasowany ciñg
PerlPoint
. Nie spróbowaäem nawet obsäuĔyè przypadku,
w którym miödzy
Perl
a
6
wystöpuje spacja. Do tego bödö potrzebowaä czegoĈ znacznie lepszego.
Okazuje siö, Ĕe mogö to zrobiè bardzo äatwo za pomocñ negatywnej asercji patrzenia w przód.
Nie chcö dopasowywaè znaku po
l
, a poniewaĔ asercja nie dopasowuje znaków, jest wäaĈci-
wym narzödziem do tego celu. Po prostu chcö powiedzieè, Ĕe jeĈli cokolwiek nastöpuje po ciñgu
Perl
, to nie moĔe byè to cyfra
6
, nawet jeĈli jest przed niñ jakiĈ odstöp. Negatywna asercja
z patrzeniem w przód ma postaè
(?!WZORZEC)
. Aby rozwiñzaè problem, jako wzorca uĔywam
\s?6
, co oznacza opcjonalny odstöp, po którym nastöpuje
6
:
print "Wypróbowuj
Ă negatywnî asercjĂ z patrzeniem w przód:\n";
while( <> )
{
print if /\bPerl(?!\s?6)\b/; # lub /\bPerl[^6]/
}
Teraz w wynikach pojawiajñ siö wszystkie wäaĈciwe wiersze:
Wypróbowuj
Ă negatywnî asercjĂ z patrzeniem w przód:
Najpierw by
Ī Perl 5, a potem Perl 6.
Po prostu mówi
Ă "Perl".
To jest wiersz j
Ăzyka Perl 5
Perl 5 to bie
šîca wersja.
Kolejny haker j
Ăzyka Perl 5,
Na ko
Ĭcu jest Perl
NaleĔy pamiötaè, Ĕe
(?!WZORZEC)
to asercja z patrzeniem w przód, wiöc wyszukuje wzorzec za
bieĔñcñ pozycjñ dopasowywania. WäaĈnie dlatego pokazany niĔej wzorzec zostaje dopasowany.
TuĔ przed literñ
b
w
bar
asercja sprawdza, czy dalej nie nastöpuje
foo
. PoniewaĔ dalej nastöpuje
bar
, a nie
foo
, wzorzec pasuje. Wiele osób bäödnie sñdzi, Ĕe poniĔszy wzorzec oznacza, Ĕe
przed ciñgiem
foo
nie moĔe wystöpowaè
bar
, ale oba sñ dopasowywane od tej samej pozycji,
wiöc oba warunki sñ speänione:

34
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
if( 'foobar' =~ /(?!foo)bar/ )
{
print "Pasuje! Nie o to mi chodzi
Īo!\n";
}
else
{
print "Nie pasuje! Hura!\n";
}
Asercje z patrzeniem w ty
ĥ, (?<!WZORZEC) i (?<=WZORZEC)
Zamiast przyglñdaè siö czöĈci äaþcucha, która dopiero ma nastñpiè, mogö spojrzeè w tyä i spraw-
dziè tö czöĈè, która zostaäa juĔ przetworzona przez mechanizm wyraĔeþ regularnych. Ze wzglödu
na szczegóäy implementacyjne Perla asercje z patrzeniem w tyä muszñ mieè staäñ däugoĈè, wiöc
nie moĔna stosowaè w nich kwantyfikatorów o zmiennej däugoĈci.
Teraz mogö spróbowaè dopasowaè ciñg
bar
, który nie nastöpuje po
foo
. W poprzednim rozdziale
nie mogäem uĔyè negatywnej asercji z patrzeniem w przód, poniewaĔ sprawdza ona nastöpujñcñ
dalej czöĈè äaþcucha. Negatywna asercja z patrzeniem w tyä, oznaczana przez
(?<!WZORZEC)
,
sprawdza poprzedniñ czöĈè äaþcucha. WäaĈnie tego mi potrzeba. Teraz otrzymujö prawidäowñ
odpowiedĒ:
#!/usr/bin/perl
# correct-foobar.pl
if( 'foobar' =~ /(?<!foo)bar/ )
{
print "Pasuje! Nie o to mi chodzi
Īo!\n";
}
else
{
print "Nie pasuje! Hura!\n";
}
PoniewaĔ mechanizm wyraĔeþ regularnych przetworzyä czöĈè äaþcucha, zanim dotarä do
bar
,
moja asercja z patrzeniem w tyä nie moĔe byè wzorcem o zmiennej däugoĈci. Nie mogö uĔywaè
kwantyfikatorów, poniewaĔ mechanizm nie cofnie siö, aby dopasowaè asercjö. Nie bödö mógä
wiöc sprawdziè zmiennej liczby liter
o
w
foooo
:
'foooobar' =~ /(?<!fo+)bar/;
JeĈli spróbujö to zrobiè, otrzymam komunikat o bäödzie. Choè stwierdza on tylko, Ĕe funkcja jest
niezaimplementowana, nie warto czekaè ze wstrzymanym oddechem, aĔ to siö zmieni:
Variable length lookbehind not implemented in regex...
Pozytywna asercja z patrzeniem w tyä równieĔ sprawdza poprzedniñ czöĈè äaþcucha, ale jej wzo-
rzec musi pasowaè. Asercje te wykorzystujö tylko w podstawieniach w poäñczeniu z innñ asercjñ.
Kiedy uĔywam zarówno asercji z patrzeniem w tyä, jak i z patrzeniem w przód, niektóre pod-
stawienia stajñ siö bardziej czytelne.
Na przykäad kiedy pisaäem tö ksiñĔkö, uĔywaäem róĔnych odmian säów z äñcznikiem, poniewaĔ
nie umiaäem zdecydowaè, która jest wäaĈciwa. Czy pisze siö
builtin
czy
built-in
? W zaleĔnoĈci
od nastroju wybieraäem jednñ albo drugñ wersjö
6
.
6
Wydawnictwo O’Reilly czösto ma do czynienia z tym problemem, wiöc udostöpnia listö säów z zalecanñ pisowniñ,
ale nie znaczy to jeszcze, Ĕe tacy autorzy jak ja jñ czytajñ: http://www.oreilly.com/oreilly/author/stylesheet.html.

Patrzenie w przód i w ty
ĥ
_
35
Musiaäem jakoĈ poradziè sobie z wäasnñ niekonsekwencjñ. Znam czöĈè säowa po lewej stronie
äñcznika oraz czöĈè po prawej stronie. Tam, gdzie spotykajñ siö czöĈci, powinien byè äñcznik. Po
chwili zastanowienia äatwo dojĈè do wniosku, Ĕe operatory patrzenia bödñ tu wprost idealne:
chcö umieĈciè coĈ w okreĈlonej pozycji i wiem, co powinno znajdowaè siö naokoäo. Oto przykäa-
dowy program, który uĔywa pozytywnej asercji z patrzeniem w tyä, aby sprawdziè tekst po
lewej stronie, i pozytywnej asercji z patrzeniem w przód, aby sprawdziè tekst po prawej. Wyra-
Ĕenie jest dopasowywane tylko wtedy, gdy te dwie strony siö spotykajñ, co oznacza, Ĕe wykryto
brakujñcy äñcznik. Kiedy dokonujö podstawienia, umieszczam äñcznik w pozycji dopasowania i
nie muszö siö martwiè o konkretny tekst:
@hyphenated = qw( built-in );
foreach my $word ( @hyphenated )
{
my( $front, $back ) = split /-/, $word;
$text =~ s/(?<=$front)(?=$back)/-/g;
}
JeĈli ten przykäad nie jest wystarczajñco skomplikowany, spróbujmy czegoĈ innego. UĔyjmy ope-
ratorów patrzenia, aby dodaè spacje do liczb. Jeffrey Friedl zamieĈciä w ksiñĔce WyraĔenia regu-
larne przykäadowy wzorzec, który dodaje spacje do liczby obywateli Stanów Zjednoczonych
7
:
$pop = 302799312; # dane z 6 wrze
Ğnia 2007
# Z ksi
ąĪki Jeffreya Friedla
$pop =~ s/(?<=\d)(?=(?:\d\d\d)+$)/ /g;
Wzorzec ten dziaäa — do pewnego stopnia. Pozytywne patrzenie w tyä
(?<=\d)
próbuje dopa-
sowaè liczbö, a pozytywne patrzenie w przód
(?=(?:\d\d\d)+$)
znajduje grupy trzech cyfr aĔ
do koþca äaþcucha. Nie dziaäa to jednak w przypadku liczb zmiennopozycyjnych, na przykäad
kwot pieniöĔnych. Mój broker Ĉledzi kursy akcji z dokäadnoĈciñ do czterech miejsc po przecinku.
Kiedy próbujö takiego podstawienia, nie otrzymujö spacji po lewej stronie przecinka dziesiötnego,
za to pojawia siö ona po przecinku. Dzieje siö tak ze wzglödu na kotwicö koþca äaþcucha:
$money = '1234,5678';
$money =~ s/(?<=\d)(?=(?:\d\d\d)+$)/ /g; # 1234,5 678
Mogö nieco zmodyfikowaè ten wzorzec. Zamiast kotwicy koþca äaþcucha uĔyjö granicy säowa
\b
. MoĔe to wydawaè siö dziwne, ale pamiötajmy, Ĕe cyfry sñ znakami säów. Dziöki temu
otrzymujö spacjö po lewej stronie przecinka, ale nadal nie pozbyäem siö tej po prawej:
$money = '1234,5678';
$money =~ s/(?<=\d)(?=(?:\d\d\d)+\b)/ /g; # 1234.5 678
W pierwszej czöĈè wyraĔenia regularnego tak naprawdö powinienem uĔyè patrzenia w tyä, aby
dopasowaè cyfrö, ale nie wtedy, gdy poprzedza jñ przecinek dziesiötny. To jest opis negatywnego
patrzenia w tyä,
(?<!\,\d)
. PoniewaĔ wszystkie operatory patrzenia dopasowujñ wzorce od tej
samej pozycji, nie ma znaczenia, Ĕe niektóre siö nakäadajñ, pod warunkiem Ĕe robiñ to, co chcö:
$money = '1234,5678';
$money =~ s/(?<!\,\d)(?<=\d)(?=(?:\d\d\d)+\b)/ /g; # 1234,5678
7
Biuro Spisu LudnoĈci Stanów Zjednoczonych prowadzi „zegar populacji”, wiöc ci, którzy czytajñ ksiñĔkö däugo
po jej wydaniu, mogñ znaleĒè aktualnñ liczbö pod adresem http://www.census.gov/main/www/popclock.html.

36
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
To dziaäa! A szkoda, bo potrzebowaäem wymówki, Ĕeby dodaè do wzorca negatywne patrzenie
w przód. WyraĔenie jest teraz doĈè skomplikowane, wiöc dodam opcjö
/x
, aby praktykowaè to,
czego nauczam:
$money =~ s/
(?<!\,\d) # inne znaki ni
Ī przecinek-cyfra tuĪ przed pozycją
(?<=\d) # cyfra tu
Ī przed pozycją
# <--- BIE
ĩĄCA POZYCJA DOPASOWYWANIA
(?= # ta grupa tu
Ī za pozycją
(?:\d\d\d)+ # jedna lub wi
Ċcej grup záoĪonych z trzech cyfr
\b # granica s
áowa (lewa strona przecinka lub koniec áaĔcucha)
)
/ /xg;
Odszyfrowywanie wyra
żeħ regularnych
Kiedy próbujö zrozumieè, o co chodzi w jakimĈ wyraĔeniu regularnym — znalezionym w czy-
imĈ kodzie albo napisanym przez mnie (czasem dawno temu) — mogö wäñczyè tryb debugowania
wyraĔeþ regularnych
8
. Opcja
-D
wäñcza opcje debugowania interpretera Perla (nie programu, jak
w rozdziale 4.). Opcja ta przyjmuje seriö liter lub liczb, które okreĈlajñ, co naleĔy wäñczyè. Opcja
-Dr
wäñcza debugowanie analizy skäadniowej oraz wykonywania wyraĔeþ regularnych.
Do zbadania wyraĔenia regularnego wykorzystam krótki program. Pierwszym argumentem
bödzie äaþcuch, a drugim wyraĔenie regularne. Zapiszö ten program pod nazwñ explain-regex:
#!/usr/bin/perl
$ARGV[0] =~ /$ARGV[1]/;
Kiedy uruchomiö ten program z äaþcuchem Oto kolejny haker Perla, oraz wzorcem
Oto kolejny
haker (\S+),
, zobaczö dwie podstawowe sekcje wyników, które sñ opisane dokäadnie w doku-
mentacji perldebguts. Perl najpierw kompiluje wyraĔenie regularne, a wyniki opcji
-Dr
pokazujñ,
w jaki sposób przeprowadzono jego analizö skäadniowñ. Widaè wözäy wyraĔenia, takie jak
EXACT
i
NSPACE
, a takĔe optymalizacje w rodzaju
anchored "Oto kolejny haker "
. Nastöpnie
Perl próbuje dopasowaè docelowy äaþcuch i pokazuje postöpy. To sporo informacji, ale dziöki
nim dowiadujö siö dokäadnie, co robi Perl:
$ perl -Dr explain-regex 'Oto kolejny haker Perla,' 'Oto kolejny haker (\S+),'
Omitting $` $& $' support.
EXECUTING...
Compiling REx `Oto kolejny haker (\S+),'
size 15 Got 124 bytes for offset annotations.
first at 1
rarest char , at 0
rarest char j at 8
1: EXACT <Oto kolejny haker >(7)
7: OPEN1(9)
9: PLUS(11)
10: NSPACE(0)
11: CLOSE1(13)
8
Tryb debugowania wyraĔeþ regularnych wymaga interpretera Perla skompilowanego z opcjñ
-DDEBUGGING
.
Opcje kompilacyjne interpretera moĔna wyĈwietliè za pomocñ polecenia
perl -V
.

Odszyfrowywanie wyra
żeħ regularnych
_
37
13: EXACT <,>(15)
15: END(0)
anchored "Oto kolejny haker " at 0 floating "," at 19..2147483647 (checking anchored)
´minlen 20
Offsets: [15]
1[18] 0[0] 0[0] 0[0] 0[0] 0[0] 19[1] 0[0] 22[1] 20[2] 23[1] 0[0] 24[1] 0[0] 25[0]
Guessing start of match, REx "Oto kolejny haker (\S+)," against
´"Oto kolejny haker Perla,"...
Found anchored substr "Oto kolejny haker " at offset 0...
Found floating substr "," at offset 23...
Guessed: match at offset 0
Matching REx "Oto kolejny haker (\S+)," against "Oto kolejny haker Perla,"
Setting an EVAL scope, savestack=3
0 <> <Oto kolejny > | 1: EXACT <Oto kolejny haker >
18 <haker > <Perla,> | 7: OPEN1
18 <haker > <Perla,> | 9: PLUS
NSPACE can match 6 times out of 2147483647...
Setting an EVAL scope, savestack=3
23 <haker Perla> <,> | 11: CLOSE1
23 <haker Perla> <,> | 13: EXACT <,>
24 <haker Perla,> <> | 15: END
Match successful!
Freeing REx: `"Oto kolejny haker (\\S+),"'
Pragma
re
Perla ma tryb debugowania, który nie wymaga interpretera skompilowanego z opcjñ
-DDEBUGGING
. Instrukcja
use re 'debug'
dotyczy caäego programu; nie ma zasiögu leksykalnego,
jak wiökszoĈè pragm. Zmodyfikujö poprzedni program tak, aby uĔywaä pragmy
re
zamiast
opcji wiersza polecenia:
#!/usr/bin/perl
use re 'debug';
$ARGV[0] =~ /$ARGV[1]/;
Nie muszö modyfikowaè program w celu uĔycia pragmy
re
, poniewaĔ mogö jñ wäñczyè z po-
ziomu wiersza poleceþ:
$ perl -Mre=debug explain-regex 'Oto kolejny haker Perla,' 'Oto kolejny haker (\S+),'
Kiedy uruchomiö ten program w pokazany wyĔej sposób, otrzymam niemal dokäadnie te same
wyniki, co w poprzednim przykäadzie z opcjñ
-Dr
.
Moduä
YAPE::Regex::Explain
, choè nieco stary, potrafi objaĈniè wyraĔenie regularne w zwy-
käym jözyku angielskim. Dokonuje analizy skäadniowej wyraĔenia i wyjaĈnia, co robi kaĔda jego
czöĈè. Nie potrafi wyjaĈniè semantyki wyraĔenia, ale nie moĔna mieè wszystkiego. Za pomocñ
prostego programu mogö objaĈniaè wyraĔenia podane w wierszu poleceþ:
#!/usr/bin/perl
use YAPE::Regex::Explain;
print YAPE::Regex::Explain->new( $ARGV[0] )->explain;
Kiedy uruchamiam program nawet z krótkim, prostym wyraĔeniem, otrzymujö obszerne wyniki:
$ perl yape-explain 'Oto kolejny haker (\S+),'
The regular expression:
(?-imsx:Oto kolejny haker (\S+),)
matches as follows:

38
_
Rozdzia
ĥ 2. Zaawansowane wyrażenia regularne
NODE EXPLANATION
----------------------------------------------------------------------
(?-imsx: group, but do not capture (case-sensitive)
(with ^ and $ matching normally) (with . not
matching \n) (matching whitespace and #
normally):
----------------------------------------------------------------------
Oto kolejny haker 'Oto kolejny haker '
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
\S+ non-whitespace (all but \n, \r, \t, \f,
and " ") (1 or more times (matching the
most amount possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
, ','
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
Ko
ħcowe myļli
Dotaräem niemal do koþca rozdziaäu, ale wyraĔenia regularne majñ znacznie wiöcej funkcji,
które wydajñ mi siö przydatne. Czytelnicy mogñ potraktowaè ten podrozdziaä jako krótki prze-
wodnik po funkcjach, które mogñ przestudiowaè samodzielnie.
Nie muszö ograniczaè siö do prostych klas znakowych, takich jak
\w
(znaki säów),
\d
(cyfry) oraz
inne sekwencje ukoĈnikowe. Mogö równieĔ uĔywaè klas znakowych POSIX. Umieszczam je
w nawiasie kwadratowym z dwukropkiem po obu stronach nazwy:
print "Znalaz
Īem znak alfabetyczny!\n" if $string =~ m/[:alpha:]/;
print "Znalaz
Īem cyfrĂ szesnastkowî!\n" if $string =~ m/[:xdigit:]/;
Aby zanegowaè te klasy, uĔywam daszka (
^
) po pierwszym dwukropku:
print "Nie znalaz
Īem znaków alfabetycznych!\n" if $string =~ m/[:^alpha:]/;
print "Nie znalaz
Īem spacji!\n" if $string =~ m/[:^space:]/;
Mogö uzyskaè ten sam efekt przez podanie nazwanej wäaĈciwoĈci. Sekwencja
\p{Nazwa}
(maäa
litera
p
) doäñcza znaki odpowiadajñce nazwanej wäaĈciwoĈci, a sekwencja
\P{Nazwa}
(wielka
litera
P
} jest jej dopeänieniem:
print "Znalaz
Īem znak ASCII!\n" if $string =~ m/\p{IsASCII}/;
print "Znalaz
Īem znak kontrolny!\n" if $string =~ m/\p{IsCntrl}/;
print "Nie znalaz
Īem znaków interpunkcyjnych!\n" if $string =~ m/\P{IsPunct}/;
print "Nie znalaz
Īem wielkich liter!\n" if $string =~ m/\P{IsUpper}/;
Moduä
Regexp::Common
zawiera przetestowane i sprawdzone wyraĔenia regularne dla popular-
nych wzorców, takich jak adresy WWW, liczby, kody pocztowe, a nawet przekleþstwa. Oferuje
wielopoziomowñ tablicö asocjacyjnñ
%RE
, której wartoĈciami sñ wyraĔenia regularne. JeĈli komuĈ
to nie pasuje, moĔe skorzystaè z interfejsu funkcyjnego:
use Regexp::Common;
print "Znalaz
Īem liczbĂ rzeczywistî\n" if $string =~ /$RE{num}{real}/;
print "Znalaza
Īem liczbĂ rzeczywistî\n" if $string =~ RE_num_real;
Wyszukiwarka
Podobne podstrony:
więcej podobnych podstron