

Ws ze chnica Popołudniowa
Optymalizacja zapytań SQL
mgr inż. Andrzej Pta sznik
prof. dr hab. Maciej M Sysło
Ze szyt dydaktyczny opracowany w ramach projektu edukacyjne go
— ponadre gionalny program rozwijania kompe tencji
uczniów szkół ponadgimna zjalnych w zakresie technologii
informacyjno-komunikacyjnych (ICT).
Warszawska Wyżs za Szkoła Informa tyki
ul. Lewartowskie go 17, 00 -169 Wars zawa
Projekt graficzny: FRYCZ I WICHA
Wars zawa 2009
Copyright © Wars za wska Wyżs za Szkoła Informatyki 2009
Publikacja nie jes t prze znaczona do sprze da ży.
Warszawska Wyższa Szkoła Informatyki
aptaszni@wwsi.edu.pl

< 4 >
Informa tyka +
Wykład zapoznaje słuchaczy z problematyką wydajnoś ci i optymalizacji zapyta ń SQL. Omówiona zos tanie fi-
zyczna organiza cja przechowywania danych i wprowadzone zos taną pojęcia indeksów zgrupowanych i nie -
zgrupowanych. Zapre zentowane zos taną przykłady planów wykonania zapytań generowa ne przez optymali-
zator SQL. Na ba zie przykła du omówione zos taną problemy wyboru s trategii wykonania za pytania w zależno-
ś ci od zawartości tabel i zdefiniowanych indeksów. Wprowadzone zos tanie pojecie s tatys tyk indeks ów i omó-
wione będzie ich znaczenie przy wyborze s trate gii realiza cji zapytania .
1. Wprowadzenie............................................................................................................................................... 5
2 . Metody optymalizacji wydajności bazy danych ............................................................................................ 5
3. Fizyczna organizacja danych w SQL Se rver 2008 .......................................................................................... 6
4 . Plany wykonania zapytania ......................................................................................................................... 12
5. Stat yst yki
............................................................................................................................................... 13
6. Optymalizacja przykładowego zapytania ................................................................................................... 13
7. Narzę dzia wspomagające optymalizację ..................................................................................................... 15
Literatura
............................................................................................................................................... 16
> Optymalizacja zapyta ń SQL
< 5 >
W ka żdym projekcie informatycznym, wykorzys tującym relacyjne ba zy danych, prędzej czy później pojawia
się problem zwią za ny z wydajnością . Jeś li „prę dzej” oznacza „przed wdrożeniem”, to nie jes t jes zcze tak źle.
Można wtedy podjąć decyzje wią żące się z dokonywaniem zmian w projekcie bazy da nych i nie będą one się
wiązać z konie cznością dbania o już is tniejące dane. Gors zym wariantem jes t praca na „żywym organizmie”.
Nie doś ć, że możliwoś ci modyfikacji są ograniczone, to jes zcze trzeba s tarać się nie zakłócać normalnej pra-
cy użytkowników. Gdy dodamy do tego pres ję czas u i s tres – pojawia się obra z pracy nie do poza zdros zcze -
nia. W ka żdym jednak przypadku is totne jes t, żeby wiedzie ć, jakie kroki podjąć, co sprawdzić, na co zwrócić
szcze gólną uwagę, jakich narzędzi użyć i w jaki spos ób aby osią gną ć cel – wzros t wydajnoś ci ba zy danych do
akceptowalnego poziomu. Może nam się wydawać, że takie problemy dotyczą tylko dużych projektów i ba z
danych, wię c nie ma się co martwić na zapas . Bardzo s zybko je dnak można natrafić na podobne problemy na-
we t w pros tych aplikacjach.
W ramach niniejs ze go wykładu pos taramy się przeds tawić pods tawy wiedzy potrzebnej do poruszania
się w dziedzinie zagadnień zwią zanych z wydajnoś cią ba z danych, a dokła dniej – zapytań na nich wykony-
wanych. Zanim zaczniemy jednak wkraczać do problematyki optymalizacji zapytań SQL, pos taramy s ię odpo-
wiedzie ć na pytanie: A po co w ogóle optymalizować? Odpowie dź na to pytanie nie jes t wbre w pozorom taka
oczywis ta . Niejako przy oka zji zaprezentowany zos tanie też ogólny model optymalizacji wyda jności s tosowa-
ny w praktyce przy realizacji zadań zwią zanych z zapewnieniem wyma gane go poziomu wydajności ba zy da-
nych.
W ś wiecie s ys temów informatycznych i komputerów od wielu la t utrzymuje się s tały trend wzros tu mocy ob-
liczeniowej, pojemnoś ci pamięci operacyjnej, pojemności i szybkoś ci dys ków twardych itp. W związku z tym,
jeśli mamy do czynienia ze zbyt niską wydajnoś cią ba zy da nych, to pierws zym pomysłem może być rozbudo-
wa s ys temu od strony sprzętowej – a nuż, ten dodatkowy procesor lub 4 GB pamię ci doda dzą ba zie s krzyde ł.
Nies tety nie zaws ze to działa, lub przewidywane koszty rozbudowy są zdecydowa nie nieakceptowalne. Osią -
gnię ty efekt może także nie być zbyt długotrwa ły i po kolejnym miesiącu uzupe łniania danych w ba zie wraca -
my do punktu wyjś cia – działa za wolno!.
W takiej s ytuacji warto zrobić to, od czego tak naprawdę należa ło zaczą ć – przeanalizowa ć bazę da-
nych pod kątem możliwoś ci optymaliza cji jej wydajnoś ci. Oka zuje się , że tą drogą można osią gnąć bardzo do-
bre re zulta ty. Nies tety wymaga to zna cznej wiedzy i umiejętnoś ci, a także s porej dozy wyczucia, którego ot
tak nie da się nauczyć. Is tnieją sprawdzone w praktyce podejś cia (modele) optymalizacji wydajnoś ci ba z da-
nych, lecz ich rola polega raczej na wyznaczeniu ogólnych ram i sekwencji czynności, których wykonanie na -
leży wziąć pod uwagę przy prowadzeniu optymalizacji, niż na dos tarczeniu gotowej recepty. Proces optymali-
zacji wydajnoś ci we dług przyję tego prze z na s modelu składa się z kilku obs zarów:
■
Struktura (projekt) bazy danych
■
Optymalizacja zapytań
■
Indeks y
■
Blokady
■
Tuning serwera
Całoś ć modelu jes t przeds tawiona na diagramie na rys. 1.
Kolejność realizacji zadań powinna przebiegać od dołu dia gramu do góry. Podobnie, liczba możliwych do
os iągnięcia usprawnień je st tym większa , im niżej znajdujemy się na diagramie. Sekwencja ta nie jes t przy-
pa dkowa i wzajemne zale żnoś ci pomiędzy blokami powodują , że założona kolejnoś ć realizacji umożliwia uzy-
skanie najleps zych efektów najmniejszym kos ztem. W ramach wykładu skupimy s ię na wyróżnionych blokach
– optymalizacji zapytań i indeks ach.
Pierws zym i najistotniejs zym zadaniem jes t jednak optymalizacja s truktury ba zy danych. Osiąga się ją
zwykle poprze z normalizację (doprowadzenie do trzeciej pos taci normalnej). Taka pos tać cechuje się większą
liczbą tabel, króts zymi rekordami w tabelach, mniejs zą podatnoś cią na blokowanie, łatwiejszym tworzeniem
zapytań ba zujących na zbiorach itp. Czas poś więcony na tym e tapie zwraca się bardzo szybko, podobnie jak
błędy tu pope łnione okrutnie mszczą s ię przy da ls zych próbach optymalizacji wydajnoś ci.

< 6 >
Informa tyka +
Bardzo istotną rzeczą jes t pamiętanie o tym, że baza nie is tnieje s ama dla siebie. Z reguły współpracuje z ja-
ką ś aplikacją lub aplikacjami. Jakiekolwiek modyfikacje s truktury bazy danych mogą wią zać się z konie czno-
ś cią wprowadzania modyfikacji kodu aplikacji, a to nie jes t już tak miłe. Z tego względu zalecane jes t podej-
ś cie zakładające utworzenie w bazie danych „wars twy abs trakcji danych”, której rola polega na odcię ciu apli-
kacji od szczegółów struktury ba zy danych. Zwykle realizowane jes t to za pomocą widoków, procedur s kła -
dowanych, czy funkcji użytkownika. Aplikacje „widzą” i korzystają tylko z tych obiektów nie kontaktując się
be zpośrednio z tabelami. Dzięki temu, w przypadku modyfikowania s truktury bazy, można ukryć ten fakt
przed aplikacjami – wys tarczy zmodyfikować kod procedury czy widoku, aby pas owa ł do nowej s truktury ta -
bel, a aplikacje jak z nich korzys ta ły tak będą korzys tać – zupe łnie nie ś wiadome , że dane pobierane wcze -
śniej z dwóch tabel obecnie są rozrzucone po pięciu ta belach.
Kolejnym etapem jes t optymalizacja zapytań. Głównym za gadnieniem je st tu oderwanie się od starych
nawyków pis ania zapytań iteracyjnych (częs to korzys tając z kursorów) na rzecz zapytań ba zujących na zbio-
ra ch. Są one bardziej wydajne oraz ła twiej skalowa lne. Indeks y łączą s ię z poprzednim etapem pe łniąc rolę
pomos tu pomię dzy zapytaniem a danymi. Dobrze napis ane zapytania z odpowiednio dobranymi indeks ami
potrafią czynić cuda , a z drugiej s trony żaden indeks nie naprawi kardynalnych błędów w zapytaniach czy
s trukturze danych. Z kolei kwes tie blokad wią żą się nierozerwalnie z korzys taniem z ba zy prze z wielu użyt-
kowników jednocze śnie. Częs to zdarza się, że pozornie wydajnie działająca ba za s zybko traci wigor przy ko-
lejnych je dnocześnie pracujących użytkownikach. Jakiekolwiek próby na tym poziomie nie dadzą nic, je żeli na
poprzednich etapach przeoczyliśmy jakieś problemy.
Os tatni poziom to wspominane już wcześniej „rozszerzanie” serwera . Zwiększanie mocy procesora -
(ów), iloś ci pamięci czy s zybkości i pojemnoś ci dysków umożliwiają os iągnięcie s zybkiego efektu wzros tu wy-
dajnoś ci. Nie pomoże to jednak w przypadku b łędów pope łnionych na poprzednich etapach i efekt końcowy
może być mizerny, szczególnie wziąws zy pod uwagę kos zty.
Skoro przekonaliśmy się już co do konieczności zwrócenia uwagi na zagadnienia w ramach optymalizowania wy-
dajności, to możemy przejść do rzeczy i rozpocząć zgłębianie tej dziedziny. Nie uda się nam to w żaden sposób, je-
śli nie zrozumiemy mechanizmów le żących u podstaw działania SQL Servera. Jednym z is totnych zagadnień jest
tu sposób, w jaki dane są fizycznie przechowywane w bazie danych. Gdy myślimy o tabeli, to od razu przedstawia-
my sobie coś na ks ztałt zbioru wierszy składających się z kolumn zawierających dane różnego typu (patrz rys. 2).
Rysunek 1.
Model proces u optyma lizacji
> Optymalizacja zapyta ń SQL
< 7 >
Rysunek 2.
Tabela w ba zie danych
Nie za s tana wiamy s ię, jak te dane s ą przechowywane fizycznie na dysku, ani jaki wpływ na wydajnoś ć mogą
mieć na sze decyzje podjęte przy projektowaniu tabeli. Warto jednak zadać s obie nieco trudu i zapoznać się
z fizycznym spos obem przechowywania danych w ba zie. Zrozumienie pods taw ułatwi później zrozumienie,
dlaczego w takiej czy innej s ytuacji wykonanie zapytania czy modyfikacji danych trwa tak długo.
Najmniejs zą jednos tką prze chowywania danych jes t w SQL Serverze s trona (ang. pa ge). Jes t to 8 KB blok skła-
dający się z nagłówka i 8060 ba jtów na dane z wiers za (lub wierszy). Przy za łożeniu, że wiersz tabeli musi się
zmieś cić na stronie ja sno widać, że maks ymalny rozmiar wiersza to 8060 bajtów. Trochę mało? Niekoniecz-
nie. Częś ć danych o rozmia rze przekraczającym 8KB jes t zapis ywa na na innych stronach, a w s amym wiers zu
umies zczany jes t tylko wska źnik do pierws zej z tych s tron. SQL Server rozróżnia 9 rodzajów s tron przechowu-
jących informacje o rozmaitym znaczeniu:
■
Strony danych (da ta) zawierają wszystkie dane z wiersza , z wyją tkiem kolumn typów: te xt, ntext, image,
nvarchar(ma x), varchar(ma x), varbinary(ma x), xml.
■
Je żeli wiers z nie mieś ci się w limicie długoś ci 8060 bajtów, to najdłuższa z kolumn jes t przenos zona do tzw.
strony przepełnienia (s trona danych), a w jej miejs cu w wierszu zos taje 24 bajtowy wska źnik.
■
Strony indeks ów (inde x) zawierają pos zczególne wpis y indeksu. W ich przypadku is totny jes t limit długoś ci
klucza indeksu – 900 bajtów.
■
Strony obiektów BLOB/ CLOB (Binary/ Character Large Object) (te xt/ image) służą do przechowywania danych
o rozmiarze do 2 GB.
■
Strony GAM, SGAM i IAM – wrócimy do nich w dals zej czę ści wykładu, gdy poznamy kolejne poję cia
dotyczą ce fizycznego przechowywania danych.
Wymieniliśmy tylko 6 rodzajów s tron, żeby niepotrzebnie nie komplikować dals zych rozwa żań. Dla uporząd-
kowania warto wspomnieć o pozos tałych trzech: Page Free Space, Bulk Changed Map, Differential Cha nged
Map. Pierws za za wiera informacje o zaalokowanych s tronach i wolnym miejs cu na nich. Pozos ta łe dwa rodza -
je są wykorzys tywane do oznacza nia danych zmodyfikowanych w ramach operacji typu bulk ora z do oznacza-
nia zmian od os ta tnio wykonanej kopii zapa sowej.
Pods tawową je dnos tką alokacji nie jes t jednak w SQL Serverze s trona, tylko zbiór ośmiu s tron zwany
obs zarem (ang. e xtent) – patrz rys. 3.
Rysunek 3.
Obszar
< 8 >
Informa tyka +
Jes t tak ze względu na fakt, iż 8 KB to trochę za mało jak na operacje w s ys temie plików, a 64 KB to akura t jed-
nos tka alokacji w s ystemie plików NTFS. Obs zary mogą za wierać s trony nale żące do jednego obiektu (tabe -
li czy indeksu) – nazywamy je wtedy je dnolit ymi (uniform), lub do wielu obiektów – s tają się wtedy obs zara -
mi mies zanymi (mixed ). Je żeli SQL Server alokuje miejs ce na nowe dane , to najmniejszą jednostką je st wła -
śnie obs zar.
Je żeli ta bela nie zawiera ża dnego indeksu, to jej dane tworzą s tertę – nieuporządkowaną lis tę s tron nale żą -
cych do tej tabeli. Ws zelkie opera cje wys zukiwania na s tercie odbywają s ię wolno, gdyż wymagają za ws ze
prze jrzenia ws zys tkich s tron. Inaczej w żaden sposób s erwer nie je s t w s tanie s twierdzić, czy np. odnala zł
już ws zys tkie wiersze za wierające dane klientów o na zwisku Kowals ki. Stertę można wyobra zić s obie jak na
rys . 4.
Rysunek 4.
Przykładowa s terta
Dodatkowo tabela może zos tać podzielona na partycje (względy wydajnoś ciowe – zrównoleglenie operacji
wejś cia/ wyjścia). W takim przypadku ka żda z partycji zawiera wła sną s tertę. Wszys tkie ra zem tworzą zbiór
danych tabeli (rys . 5).
Rysunek 5.
Tabela, partycje , s terty
Gdy SQL Server a lokuje miejsce w plikach ba zy da nych, wype łnia je obs zarami, które wstępnie s ą oznaczo-
ne jako wolne. Podobnie ws zystkie s trony w obs zara ch s ą oznaczone jako pus te. W jaki sposób przechowy-
> Optymalizacja zapyta ń SQL
< 9 >
wane s ą informacje na temat te go, czy dany obs zar lub s trona są wolne lub nale żą do jakiegoś obiektu? Służą
do tego s pe cjalne strony – GAM, SGAM i IAM. Zawierają one informacje o zaję tości pos zczególnych obs zarów
w pos taci map bitowych (GAM, SGAM) lub o przyna leżności obszarów do obiektów (tabel, indeks ów) – IAM.
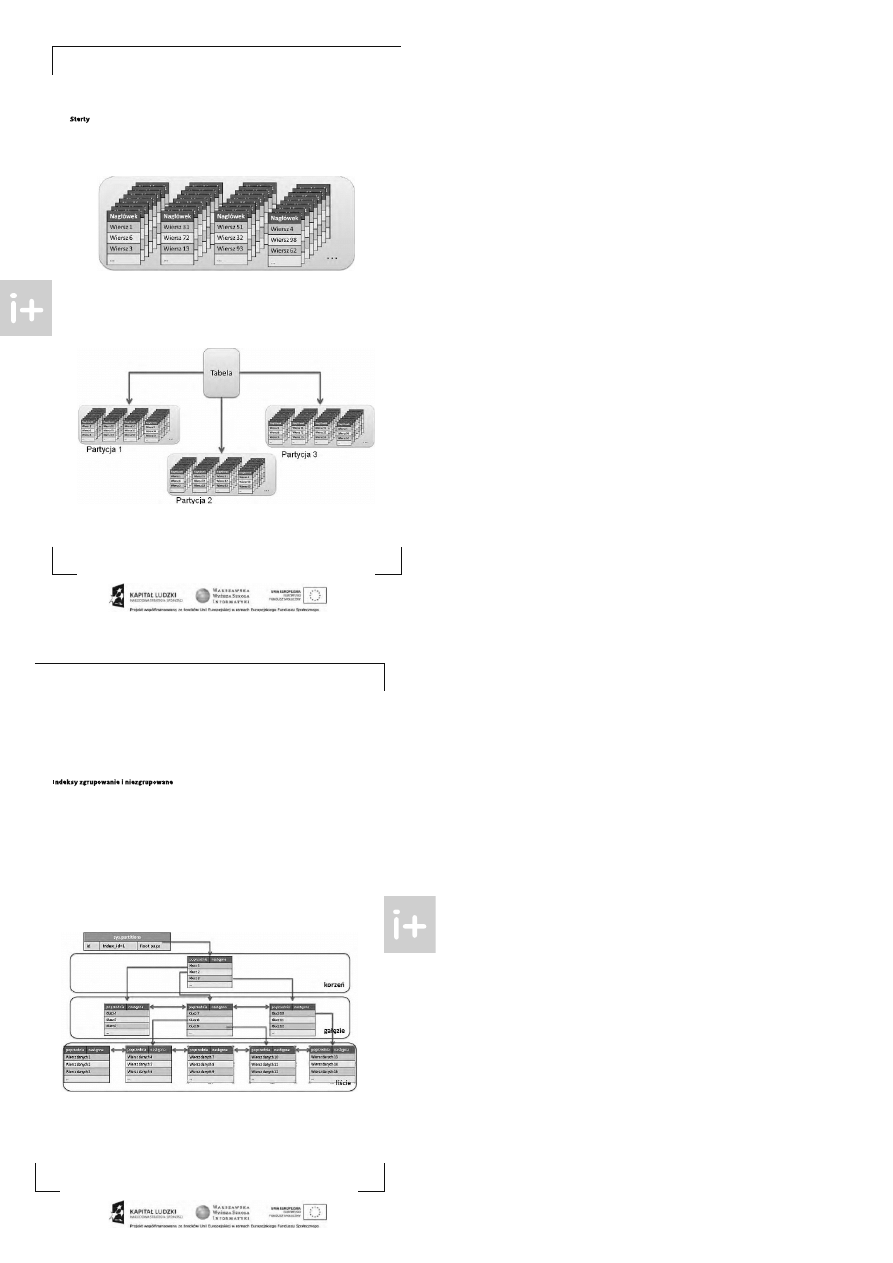
Kluczem do uzyskania dos tępu do danych z tabeli jes t możliwoś ć dostania się do strony IAM tej tabeli. Infor-
macje na temat lokalizacji s tron IAM dla poszcze gólnych obiektów znajdują się we wpisa ch w tabelach s ys -
temowych. Jako, że nie zaleca się „grzebania” be zpośrednio w tych tabelach, zos ta ły udos tępnione specjal-
ne widoki, które za wierają potrzebne nam da ne. W przypadku s tron IAM jes t to widok s ys.partitions. Wpis y
w nim zawarte składają s ię m.in. z kolumny inde x_id okreś lającej rodzaj obiektu (s terta , indeks zgrupowa-
ny, indeks niezgrupowany, obiekty LOB), kolumn okreś lających id obiektu i partycji ora z wska źnika do s tro-
ny IAM obiektu.
Poznaliś my już w zarysie sposób przechowywania danych w ta beli, dla której nie s tworzono indeksów. Ce -
chą charakterys tyczną był fakt nieuporządkowania s tron i wierszy nale żących do je dnej ta beli, co wymus za ło
przy ka żdej operacji wys zukiwania danych w tabeli przes zukanie wszystkich wiers zy. Taka operacja nosi na -
zwę skanowania tabeli (ang. table scan). Jes t ona bardzo kos ztowna (w s ensie za s obów) i wymaga częs tego
sięgania do danych z dysku, tym częściej im więcej danych znajduje się w tabeli. Taki mechanizm jes t skrajnie
nieefektywny, wię c muszą is tnieć jakieś inne, bardziej efektywne mechanizmy wys zukiwania. Rzeczywiś cie
is tnieją – s ą to indeks y, wys tępujące w dwóch pods tawowych wariantach jako indeks y: zgrupowane (ang.
clustered ) i nie zgrupowane (ang. nonclustered )
Indeks zgrupowany ma pos tać drzewa zrównowa żonego (B-tree). Na poziomie korzenia i gałę zi znaj-
dują s ię s trony indeksu zawierające kolejne wartoś ci klucza indeksu uporzą dkowane rosnąco. Na poziomie
liści znajdują się podobnie uporządkowane s trony z danymi tabeli. To wła śnie jes t ce chą charakterys tyczną
indeksu zgrupowanego – powoduje on fizyczne uporządkowanie wiers zy w tabeli, ros nąco we dług wartoś ci
klucza indeksu (wska zanej kolumny lub kolumn). Z tego względu oczywiste jes t ogra niczenie do jednego in-
deksu zgrupowanego dla tabeli.
Rysunek 6.
Indeks zgrupowany
Specyfika indeksu zgrupowanego polega na fizycznym porządkowaniu danych z tabeli we dług wartoś ci klu-
cza indeksu. W związku z tym ja sne jes t, że indeks ten będzie szczególnie przydatny przy zapytaniach operu-
jących na zakres ach danych, grupujących dane, ora z korzys tających z danych z wielu kolumn. W takich przy-
pa dkach indeks zgrupowany zapewnia znaczny wzrost wydajności w s tosunku do s terty lub indeksu niezgru-
powane go.
< 10 >
Informa tyka +
Is totna rzeczą przy podejmowaniu decyzji o utworzeniu indeksu zgrupowa nego jes t wybranie wła ś ci-
wej kolumny (kolumn). Długoś ć klucza powinna być jak najmniejs za , co umożliwia zmies zczenie więks zej ilo-
ś ci wpis ów indeksu na je dnej s tronie , co z kolei przenosi się na zmniejs zenie liczby s tron całoś ci indeksu
i w efekcie mniej operacji wejścia/ wyjś cia do wykonania przez s erwer. Żeby indeks zgrupowany korzys tnie
wpływał na wydajnoś ć przy dodawaniu nowych wierszy do mocno wykorzys tywanej tabeli, klucz powinien
przyjmować dla kolejnych wpisów wartości ros nące (zwykle s tosowana jes t tu kolumna z cechą IDENTITY). In-
deks daje duży zysk wydajnoś ci, gdy jego klucz jes t możliwie wysoko s elektywny (co oznacza mniejs zą liczbę
kluczy o tej samej wartości – duplikatów). Is totny je st także fakt, że kolumny klucza indeksu zgrupowanego
nie powinny być raczej modyfikowane, gdyż pociąga to za s obą konie czność modyfikowania nie tylko s tron
indeksu ale także p orządkowania s tron danych.
Indeks y zgrupowane nie wyczerpują możliwości budowania tego typu s truktur w SQL Serverze 2008.
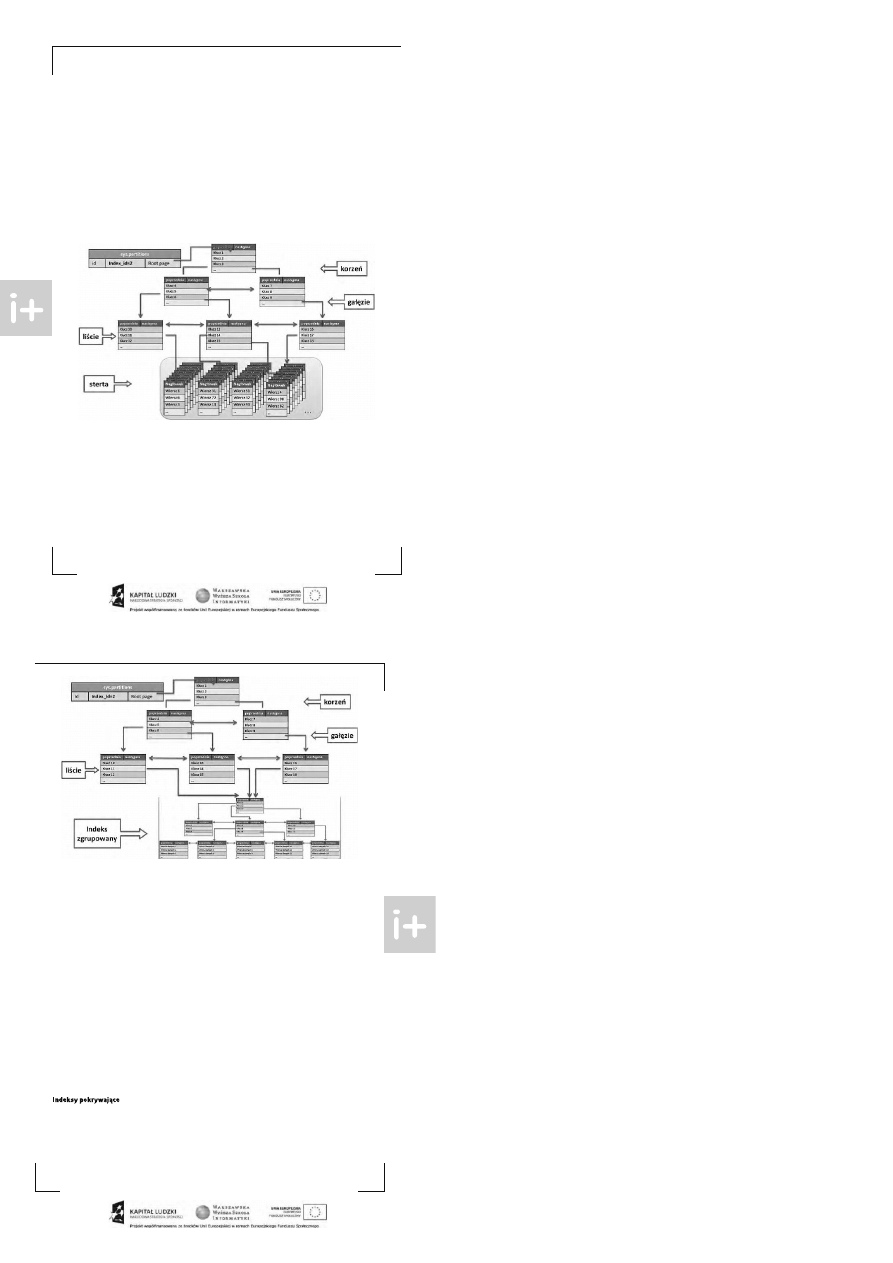
Drugim typem indeks ów s ą indeks y niezgrupowane. Ich budowa odbiega nieco od budowy indeksu zgrupo-
wanego, a do tego indeks y niezgrupowane mogą być tworzone w oparciu o s tertę lub is tniejący indeks zgru-
powany. Dla jednej tabeli można utworzyć do 248 indeks ów niezgrupowanych. Indeks nie zgrupowany różni
się od zgrupowanego przede ws zys tkim tym, że w s wojej s trukturze na poziomie liś ci ma także s trony indek-
su (a nie s trony danych).
W przypadku budowania indeksu nie zgrupowanego na s tercie, s trony te oprócz wartoś ci klucza indek-
su za wierają wska źniki do konkretnych s tron na s tercie, które dopiero zawierają odpowiednie dane.
Rysunek 7.
Indeks y nie zgrupowane – s terty w liściach
Indeks y nie zgrupowane mają strukturę zbliżoną do zgrupowanych. Za s adnicza różnica pole ga na zawartości
liś ci indeksu. O ile indeks y zgrupowane mają w tym miejscu s trony da nych, to indeks y nie zgrupowa ne – s tro-
ny indeksu. Strony te zależnie od wariantu indeksu nie zgrupowanego zawierają oprócz klucza różne informa -
cje. Indeks y niezgrupowane mogą być tworzone w oparciu o stertę. Jes t to możliwe tylko w przypadku, gdy ta -
bela nie ma indeksu zgrupowane go. W takim przypadku liś cie indeksu zawierają wska źniki do konkretnych
s tron na stercie.
Indeks niezgrupowany tworzony na tabeli zawierającej już indeks zgrupowany, jes t tworzony nie co ina -
czej. Korzeń, ga łę zie i liś cie zawierają s trony indeksu, ale liście zamia s t wska źników do s tron na s tercie zawie -
ra ją wartoś ci klucza indeksu zgrupowane go. Ka żde wys zukanie w oparciu o indeks nie zgrupowany, po doj-
ś ciu do poziomu liś ci, zaczyna dals ze przetwarzanie od korzenia indeks u zgrupowanego (wys zukiwany jes t
klucz za warty w liś ciu).
> Optymalizacja zapyta ń SQL
< 11 >
Rysunek 8.
Indeks y niezgrupowane – indeks y zgrupowane w liściach
W przypadku budowania indeksów niezgrupowa nych, s zczególnie na dużych ta belach, warto dobrze zapla-
nować tę czynnoś ć, s zcze gólnie gdy planowane jes t te ż utworzenie indeksu zgrupowanego. Niewzię cie tego
pod uwagę może powodować koniecznoś ć przebudowywania indeksów niezgrupowanych w zwią zku z doda -
niem lub usunięciem indeks u zgrupowanego.
W sporym upros zczeniu rola indeksów sprowadza się do ograniczenia liczby operacji wejś cia/ wyjś cia
niezbędnych do realiza cji zapytania. SQL Server nie odczytuje pos zcze gólnych obs zarów potrzebnych do re -
alizacji zapytania z dys ku za ka żdym ra zem. Zawiera rozbudowany bufor pamięci podręcznej, do której trafia -
ją kolejne odczytywane z dysku obs zary. Ze wzglę du na ograniczony rozmiar bufora , s trony nieużywane lub
używane rzadziej s ą za s tępowane tymi, z których zapytania korzys tają częś ciej.
Przy korzys taniu z indeksów niezgrupowanych is tnieje jes zcze jedna możliwoś ć dals zego ogranicza-
nia liczby operacji wejś cia/ wyjś cia . Polega ona na tym, że do indeks u (dokładnie do s tron liś ci indeksu) do-
dawane s ą dodatkowe kolumny. Je żeli liś cie indeksu niezgrupowane go za wierają ws zys tkie kolumny zwra -
cane przez zapytanie, to nie ma w ogóle koniecznoś ci sięgania do s tron z danymi. W takim przypadku mamy
do czynienia z tak zwanym indekse m pokrywającym. Dodawanie kolumn do indeks u niezgrupowane go może
polegać na dodawaniu kolejnych kolumn do klucza (występuje tu ograniczenie do 16 kolumn w kluczu i 900
bajtów długoś ci klucza), albo na dodawaniu kolumn „niekluczowych” do indeks u (nie wliczają s ię one do dłu-
gości klucza). Trzeba jednak pamiętać, że tworzenie indeks ów pokrywających dla kolejnych zapytań nie pro-
wadzi do niczego dobrego, gdyż po pierws ze rośnie ilość danych (wartoś ci kolumn s ą prze cież kopiowane do
stron indeksu), a po drugie dra s tycznie s pada wydajnoś ć modyfikowania danych (pocią ga za s obą konie cz-
ność naniesienia zmian we ws zys tkich indeksach).
Żeby zademonstrować s posób działania indeks ów pokrywających, załóżmy na stępującą s ytuację. W ba zie
is tnieje tabela zawierająca dane klientów. W jej s kład wchodzi kilka kolumn: ID, Na zwisko, Imie, Email, Da-
ta Os ta tnie goZamowienia . Na tabeli zos ta ł s tworzony indeks zgrupowany na kolumnie ID, oraz indeks nie -
zgrupowany na kolumnie Na zwisko. Jeżeli w takim przypadku realizowane będzie zapytanie, które co praw-
da w klauzuli WHERE zawiera warunek tylko dla kolumny na zwisko (zawartej w indeksie niezgrupowanym),
ale na liś cie kolumn wyjściowych zawiera także inne kolumny (w na szym przypadku kolumna Email), to in-
deks niezgrupowany nie zos tanie wykorzys tany, gdyż wartoś ci kolumn spoza indeksu mus zą zos tać pobrane
ze s tron danych. Zapyta nie zos tanie zrealizowane poprzez s kanowanie indeksu zgrupowanego. Jeżeli usunie -

< 12 >
Informa tyka +
my z lis ty kolumn wyjściowych kolumnę Email i wykonamy zapytanie ponownie, to tym ra zem indeks nie zgru-
powany oka że się przydatny i zos tanie na nim wykonana operacja wys zukiwania w indeksie (ang. index seek).
Będzie ona mniej kosztowna od skanowania indeksu zgrupowane go, gdyż nie wymaga dos tępu do s tron da -
nych. Żeby osiągnąć ten s am efekt z kolumną email na liś cie wyjś ciowej należy dodać ją do indeksu nie zgru-
powanego (jako częś ć klucza lub nie). Po takiej modyfika cji os iągniemy za łożony cel – zapytanie zos tanie zre -
alizowane z wykorzys taniem operacji wyszukiwania w indeksie niezgrupowanym.
Mechanizm indeks ów pokrywających wygląda bardzo fajnie i nie jes t trudny w zas tos owaniu. Jes t je d-
nak druga s trona medalu. Zwykle zapytań je st więcej niż jedno i zwracają więcej kolumn. Rozbudowywanie
indeksów (zarówno ich liczba, jak i liczba kolumn w nich zawartych) prowadzi do znacznego wzros tu rozmiaru
ba zy danych ora z spadku wydajności przy modyfikowaniu danych z tej tabeli. W skrajnych przypadka ch two-
rzymy prze cież kopie poszcze gólnych wiers zy na s tronach indeksu, a co za tym idzie iloś ć operacji wejś cia/
wyjścia s taje się zbliżona do tej potrzebnej do skanowania tabeli czy indeksu zgrupowanego.
Gdy zlecamy serwerowi wykonanie zapytania rozpoczyna się dość złożony proces prowadzący do określenia spo-
sobu realizacji zapytania. Zależnie od kons trukcji s amego zapytania, rozmiarów tabel, istniejących indeksów, sta-
tys tyk itp. serwer tworzy kilka planów wykonania zapytania. Następnie spośród nich wybierany jes t ten, który ce-
chuje się najniższym kosztem wykonania (wyrażanym przez kos zt operacji wejścia/ wyjścia ora z czasu procesora).
Tak wybrany plan jes t na stępnie kompilowany (przetwarzany na postać gotową do wykonania przez silnik bazo-
danowy) i przechowywany w buforze w razie gdyby mógłby się przydać przy kolejnym wykonaniu podobnego za-
pytania. W ramach tego punktu zajmiemy się nieco dokładniej proces em wykonania zapytania przez SQL Server.
Cały proces , przebie gający od momentu przeka zania zapytania do wykonania do odebrania jego rezul-
tatów, jes t dość złożony i może s tanowić temat niejednego wykładu. Pos taramy się choć z grubsza za s ygna -
lizować najis totniejs ze etapy tego procesu.
■
Pars owanie zapytania – polega na zweryfikowaniu składni polecenia , wychwyceniu błę dów
i nieprawidłowoś ci w jego s trukturze. Je żeli takie błędy nie występują , to efektem pars owania je st tak zwane
drzewo zapytania (pos tać przeznaczona do dals zej obróbki).
■
Standaryzacja zapytania . Na tym etapie drzewo zapytania jes t doprowadzane do pos taci s tandardowej
– us uwana jest e wentualna nadmiarowość, s tandaryzowana jes t postać podzapytań itp. Efektem tego etapu
jes t us tandaryzowane drze wo zapytania .
■
Optymalizacja zapytania . Pole ga na wygenerowaniu kilku planów wykonania zapytania ora z
przeprowa dzeniu ich analizy kos ztowej zakończonej wybraniem najtańs zego planu wykonania .
■
Kompilacja polega na przetłumaczeniu wybranego planu wykonania do postaci kodu wykonywalnego przez
silnik ba zodanowy.
■
Określenie metod fizycznego dos tępu do danych (skanowanie tabel, skanowanie indeksów, wys zukiwanie
w indeks ach itp.).
Proce s optymalizacji zapytania skła da się z kilku etapów. W ich skład wchodzą: analizowanie zapytania pod
ką tem kryteriów wys zukiwania i złączeń, dobranie indeks ów mogących wspomóc wykonanie zapytania , ora z
okreś lenie spos obów realizacji złą czeń. W ramach realizacji pos zczególnych etapów optymalizator zapytań
może korzys tać z istniejących statys tyk indeksów, generować je dla wybranych indeks ów lub wręcz tworzyć
nowe indeks y na potrzeby wykonania zapytania. Efektem te go procesu jes t plan wykonania o najniżs zym
kos zcie , który jes t na s tępnie przekazywany do kompilacji i wykonania. Plan wykonania dla zapytania moż-
na podejrze ć w formie teks towej, XML bą dź zbioru wiers zy. Realizuje się to za pomocą us tawienia na „ON”
je dnej z opcji SHOWPLAN_TEXT, SHOWPLAN_XML, SHOWPLAN_ALL. SQL Server, a wła ściwie na rzędzie SQL
Server Management Studio, umożliwia podejrzenie graficznej repre zentacji planu wykonania dla zapytania
Opcja prezentacji graficznej postaci planu wykonania dla za pytania jes t dos tępna w dwóch warian-
tach: Estima ted Execution Plan oraz Actual Execution Plan. Pierws zy z nich polega na wygenerowaniu planu
wykonania dla zapytania be z jego wykonywania. Powoduje to, że czę ść informacji w planie wykonania jes t
s zacunkowa lub jej brakuje (np. liczba wierszy poddanych operacjom, liczba wą tków zaanga żowanych w wy-
konanie itp.). Zaletą tego wariantu jes t na pewno s zybkoś ć dzia łania . Jes t to s zczególnie odczuwalne przy za -
pytaniach, które wykonują s ię dłużej niż kilkanaś cie s ekund.
> Optymalizacja zapyta ń SQL
< 13 >
Drugi wariant za wiera pe łne dane na temat wykonania zapytania . Jes t on zaws ze wiarygodny i mamy
gwarancję, że dokładnie tak zos tało wykonane zapytanie. W praktyce lepiej jes t pracować z faktycznymi pla-
nami wykona nia, chyba , że cza s potrzebny ich uzys kanie je st przes zkodą .
Na diagramach reprezentujących plany wykonania zapytań może zna jdować się kilkadziesią t różnych
s ymboli graficznych reprezentujących różne opera tory (logiczne i fizyczne) ora z przebie g wykonania zapyta-
nia. Nie spos ób omówić ich choćby pobieżnie w ramach tego wykładu.
Wśród całej gamy informacji wyś wietlanych w s zczegółach wybranego operatora, dla nas najistotniejs ze są
te, związane z kosztem wykonania danego etapu. W dalszych przykładach będziemy się na nich opierać prezentu-
jąc zmiany kosztu wykonania zapytania w zależności od podjętych kroków przy optymalizacji zapytania.
Sam fakt is tnienia takiego czy innego indeks u nie powoduje , że od ra zu s taje się on kandydatem do skorzy-
stania w ramach realizacji zapytania. W trakcie optymalizacji zapytania potrzebne s ą dodatkowe informacje
na tema t indeksów – s tat yst yki indeksów. Sens owność skorzystania z indeksu można ocenić tylko w połą -
czeniu z informacjami o liczbie wierszy w tabeli ora z o rozkładzie wystąpień pos zczególnych wartoś ci lub za -
kresów wartości w danych za wartych w kolumnie. Przykładowo mamy tabele klientów, w której 80% klientów
nos i na zwis ko Kowalski, a je dynie dwóch Nowak. Na pods ta wie s amego faktu is tnienia indeksu na kolumnie
nazwisko trudno oce nić czy sens ownie jes t go wykorzystać przy wys zukiwaniu Kowalskich lub Nowaków. Po
przejrzeniu s ta tys tyk może oka zać s ię, że dla Kowalskiego nie ma co zaprzątać s obie głowy indeksami, nato-
mias t w przypadku Nowaka może to znacznie poprawić wydajnoś ć.
Jako, że dane zawarte w tabelach zwykle się zmieniają (pojawiają się nowe, istniejące są modyfikowane lub
usuwane), is totne jest także aktualizowanie statys tyk. Optymalizator zapytań podejmujący decyzje na pods tawie
nieaktualnych s tatystyk działa jak pilot samolotu, któremu przyrządy pokładowe pokazują wskazania sprzed 5 mi-
nut. Skutki mogą być opłakane. Z tego powodu, jeżeli mamy do czynienia z s ytuacja, gdy do tej pory zapytanie wy-
konywało się zadowalająco s zybko, a nagle wydajność spadła, pierwszym krokiem do wykonania jest właśnie uak-
tualnienie s tatystyk. Warto o tym pamiętać, bo może to nam os zczędzić sporo czasu.
Przejdźmy tera z do kilku przykładów wykonywania zapytań przy różnych kombinacjach is tniejących indek-
sów. Za ka żdym ra zem spróbujemy przyjrzeć się kos ztom wykonania zapytania i szcze gółom przyję tych pla-
nów wykonania Na kolejnych przykładach pos taramy się zademons trować wp ływ indeks ów na plan wykona -
nia zapytania i jego ca łkowity koszt. Zapytania będą dotyczyły tabeli Klienci (rys. 9), w której nie ma żadne -
go indeksu.
Rysunek 9.
Przykładowa tabela – Klienci
Z te go powodu można przewidywać, że operacją wykorzys taną do realiza cji zapyta nia będzie skanowanie ta -
beli. Przykładowe zapytanie ma pos tać:

< 14 >
Informa tyka +
Po dwukrotnym wykonaniu zapytania uzyskaliśmy re zultaty, jak na rys . 10.
Rysunek 10.
Efekty wykonania przykładowego zapytania
Zgodnie z oczekiwaniami, do realizacji zapytania zos ta ła wykorzys tana operacja skanowania ta beli. Przy
pierws zym wykonaniu konieczne było pobranie s tron danych z dysku (liczba fizycznych odczytów więks za
od 0). Ka żde nas tępne wykonanie korzys ta już ze s tron umie szczonych w pamięci cache, czego przejawem
jes t zerowa wartoś ć fizycznych odczytów. Całkowity kos zt zapytania realizowanego według te go planu jes t
równy 2,1385.
Pierws zym etapem na s zych działań je st utworzenie indeks u zgrupowanego na kolumnie ID. Nie przy-
czyni się to w znaczącym stopniu do zwiększenia wydajności, a le spowoduje zmianę planu wykonania . Skoro
utworzenie indeks u zgrupowane go powoduje fizyczne uporządkowanie s tron danych (i likwidacje s terty), to
plan wykonania powinien zawierać wykona nie innej operacji niż skanowanie tabeli. Po wykonaniu zapytania
s twierdzamy, że faktycznie tak je st – patrz rys . 11.
Rysunek 11.
Efekty wykonania przykładowego zapytania po utworzeniu indeksu zgrupowanego
Tym ra zem s erwer skorzys ta ł z opera cji skanowania indeksu zgrupowanego. Nie jes t to żaden skok wydajno-
ś ciowy, bo i tak przejrza ne muszą być ws zys tkie s trony da nych, gdyż na sze kryterium wys zukiwania nie jes t
kolumną zawartą w indeksie.
Rozpocznijmy te ra z działania ukierunkowane na obniżenie kos ztów re aliza cji za pyta nia . Pierws zy
pomysł – s twórzmy inde ks nie zgrupowany na kolumnie na zwis ko, która jes t wykorzys t ywana jako kry-
terium wys zukiwa nia. Powinno to spowodować wykorzys tanie te go indeks u do wys zukania wiers zy z na -
> Optymalizacja zapyta ń SQL
< 15 >
zwis ka mi z okreś lone go przez na s zakre su. Nie s te ty po wykonaniu zapyta nia doznaliś my rozczarowa nia
– pa trz rys . 12.
Rysunek 12.
Efekt utworzenia indeks u niezgrupowanego
Plan wykonania się nie zmienił! Dlaczego? Z powodu umies zczenia na liś cie kolumn wyjściowych kolumny
Imie. Optymalizator zapytań s twierdził, że mimo is tnienia indeksu nie zgrupowanego na kolumnie po której
wys zukujemy, nie warto z niego korzys tać, gdyż i tak trzeba sięgnąć do stron danych, żeby pobrać wartoś ci
kolumny Imie. Z tego powodu plan wykonania nie uległ zmianie.
Skoro przemyśleliśmy już mechanizm działania zapytania i role indeksu, doprowa dźmy sprawę do koń-
ca. Usuńmy is tnieją cy indeks nie zgrupowany, utwórzmy go na nowo z dodaną kolumną Imie. Po wykonaniu
zapytania po raz kolejny, oka zuje się, że tym razem indeks zos tał wykorzys tany – pa trz rys . 13.
Rysunek 13.
Przykład wykorzys tania indeksu
Odpowiednie wiers ze s pełniające kryteria wys zukiwania zos tały zlokalizowane bardzo ła two dzięki indekso-
wi niezgrupowanemu. Dodatkowo nie było koniecznoś ci się ga nia do stron danych, gdyż indeks zawierał tak-
że kolumnę Imie , która była potrzebna do realizacji zapytania. Efekt jes t widoczny. Koszt realizacji zapytania
spadł z 2,1385 do 0,0453!
Po zakończeniu „walki” z optymalizacją pros tego zapytania przez utworzenie odpowiednich indeksów
można zdać sobie sprawę, iż wykonywanie tego typu operacji na prawdziwych ba zach danych jes t proces em
złożonym i żmudnym. Do tego często nie da się pogodzić ze s obą wydajności dwóch lub więcej zapytań, bo
każda poprawa wydajnoś ci w jednym psuje wydajność drugiego. Dodatkowo ka żdy kolejny indeks to dodatko-
wy problem z jego utrzymaniem oraz więcej czynności do wykonania przy modyfikacji danych. Jak sobie z tym
radzić? Nie ma jednej sprawdzonej i zaws ze działającej recepty. Są pewne podejś cia umożliwiające realizację
czynnoś ci w określonym porządku co może się przyczynić do uniknięcia błędów lub ułatwienia wychwycenia
typowych problemów. Zawsze jednak optymalizowanie wydajności pozostanie po części s ztuką :-).
Przy optymalizowaniu zapytań trzeba brać pod uwagę wiele czynników. Jeś li dodać do tego pracę z wieloma
zapytaniami, to szybko wyłania się obra z ogromu pracy do wykonania. Na szczęś cie is tnieją narzę dzia , które
mogą choć trochę ws pomóc na s ze wys iłki. Narzędzie Databa s e Engine Tuning Advis or jes t w s tanie wygene -
rować i wykonać wiele czynnoś ci prowadzących do podniesienia wydajności ba zy danych. Proces ten jes t re -
alizowany rzecz jasna w kontekś cie konkretnych zapytań, gdyż nie ma możliwoś ci optymalizowania pod ką-
tem dowolnych zapytań.

< 16 >
Informa tyka +
Punktem wejścia do procesu automa tycznej optymalizacji jes t okre ślenie zapytań, które s ą wykony-
wane na ba zie wraz z określeniem częs totliwości ich wykonywania . Najłatwiej zrobić to w ramach monitoro-
wania działania aplikacji. Za pomocą narzędzia SQL Profiler można zebrać tzw. ślad za wierający informacje
o ws zystkich wykonywanych na ba zie zapytaniach. Plik z takimi informacjami może s tanowić dane wejś cio-
we dla Databa se Engine Tuning Advis ora . Na ich pods ta wie narzędzie jes t w s tanie określić zapytania naj-
is totniejs ze dla funkcjonowania aplikacji i skupić s ię na optymalizowaniu pod ich kątem. Narzędzie za wiera
wiele opcji umożliwiających s terowanie proces em optymaliza cji. Można na przykład określić zbiór mechani-
zmów, które mają być wykorzystane do zwiększenia wydajnoś ci (indeks y, widoki indeks owane itp.). Można
również okre ślić, czy opt ymalizacja ma pozos tawić is tniejące indeks y be z zmia n, czy „zaora ć” je i zaplano-
wa ć ws zys tkie od począ tku.
Rezultatem pracy narzędzia jes t lis ta poleceń do wykonania na ba zie danych (służą one do tworzenia
zaplanowanych indeksów, usuwania niepotrzebnych itp.). To co jes t is totne, to przeds ta wiony przez narzę -
dzie plan z reguły przyczynia się do podnie sienia wydajności. Częs to można na tym zakończyć dals ze prace.
Jeśli je dna k mamy więcej pomysłów na zwięks zenie wydajności, to wynik prac narzędzia zaws ze można trak-
tować jako dobry punkt wyjś cia do dals zej analizy prowadzonej już „rę cznie”.
W ramach tego wykładu zaledwie rozpoczęliśmy omawianie zaga dnień zwią zanych z optymalizacją za -
pytań i optymalizacją wydajności SQL Servera jako taką . Celem było przeds tawienie pewnych pods tawowych
zagadnień i mechanizmów nie zbędnych do zrozumienia pods tawowych za s ad rządzących w dziedzinie spo-
s obów realizacji zapytań przez SQL Server
1. Ben-Gan I., Kollar L., Sarka D., MS SQL Server 2005 od środka . Zapytania w języku T-SQL, APN PROMISE, War-
s zawa 2006
2. Delany K., MS SQL Server 2005 od środka . Dostrajanie i optymalizacja zapytań, APN PROMISE, Warsza wa
2008
3. Rizzo T., Machanic A., De wson R., Walters R., Sack J., Skin J., SQL Server 2005, WNT, Wars zawa 2008
4. Vieira R., SQL Server 20 05. Programowanie. Od Podsta w, Helion, Gliwice 2007
Nota tki
< 17 >

< 18 > Notatki
Informa tyka +
Nota tki
< 19 >

W projekcie
, poza wykładami i warsztatami,
przewidziano następujące działania:
■
24-godzinne kursy dla uczniów w ramach modułów tematycznych
■
24-godzinne kurs y metodyczne dla nauczycieli, przygotowujące
do pracy z uczniem zdolnym
■
nagrania 60 wykładów informatycznych, prowadzonych
przez wybitnych specjalistów i nauczycieli akademickich
■
konkursy dla uczniów, trzy w ciągu roku
■
udział uczniów w pracach kół naukowych
■
udział uczniów w konferencjach naukowych
■
obozy wypoczynkowo-naukowe.
Szczegółowe informacje znajdują się na stronie projektu
Wyszukiwarka
Podobne podstrony:
OKLADKA Przeglad podstawowych algorytmow indd przeglad podstawowych algorytmow
OKLADKI Jak wnioskuja maszyny indd jak wnioskuja maszyny
Optymalizacja zapytań w SQL
Optymalizacja zapytań SQL
rozne, SBD zapytania sql PL, I
rozne, SBD zapytania sql PL, I
Zapytania SQL, powtórzenie materiału
Zapytania w jezyku SQL ref 3
Zapytania SQL PL, pjwstk PJLinka.pl, SBD
helion%2c+o%27reilly+ +optymalizacja+oracle+sql+ +leksykon+kieszonkowy 5VYAOTMKBEMJVIKMQWPLPR26MA5UX
Zapytania SQL, Szkoła, MS SQL
zapytania SQL, PJWSTK, 0sem, SBD
Wykorzystanie błędów w zapytaniach sql, DZIAŁ IT, Doc HACK
Zapytania SQL, I
Optymalizacja Oracle SQL Leksykon kieszonkowy oporsq
zapytania SQL
więcej podobnych podstron