Dr Marzenna Zakrzewska
Instytut Psychologii UAM
ANALIZA WARIANCJI I ANALIZA REGRESJI WIELOKROTNEJ – TOŻSAMOŚĆ MODELI
Na ćwiczeniach przy omawianiu jednoczynnikowej analizy wariancji posłużyliśmy się przykładem zaczerpniętym z książki Brzezińskiego i Stachowskiego (1984)1. Przypomnijmy go w skrócie.
Otóż w pewnym fikcyjnym eksperymencie badającym wpływ wielkości kąta widzenia na czas spostrzegania bodźca otrzymano następujące wyniki (tabela ze strony 38):
|
Poziomy czynnika A |
|||
|
a1 (900) |
a2 (1800) |
a3 (2700) |
a4 (3600) |
|
21 |
30 |
33 |
42 |
|
23 |
29 |
28 |
32 |
|
21 |
21 |
29 |
39 |
|
15 |
22 |
33 |
35 |
|
20 |
31 |
30 |
41 |
|
25 |
28 |
27 |
38 |
|
27 |
26 |
25 |
37 |
|
16 |
25 |
29 |
40 |
|
22 |
27 |
25 |
39 |
|
17 |
31 |
26 |
38 |
Symbole a1, a2, a3 oraz a4 oznaczają cztery różne kąty widzenia w stopniach, zaś czasy spostrzegania bodźca wyrażono w sekundach pomnożonych przez 102.
Mamy tu więc cztery równoliczne (n=10) grupy osób badanych. Każda z grup wykonywała zadanie (badani naciskali przycisk, gdy spostrzegli bodziec świetlny) w różnych warunkach eksperymentalnych (różne wielkości kąta widzenia). Problem badawczy, jaki starał się rozwiązać eksperymentator można sformułować następująco:
Czy czas spostrzegania bodźca zależy od kąta widzenia?
Taki problem badawczy można analizować odwołując się:
- albo do modelu analizy wariancji (ANOVA)
- albo do modelu analizy regresji wielokrotnej (MCR)
Po zastosowaniu obu modeli otrzymamy takie same wyniki, a więc sformułujemy takie same wnioski.
Przyjrzyjmy się więc, jak za pomocą pakietu statystycznego SPSS poradzić sobie w obu wyżej wymienionych modelach z weryfikacją hipotezy, która brzmi:
Czas spostrzegania bodźca zależy od kąta widzenia.
I. MODEL ANALIZY WARIANCJI
Najpierw zajmijmy się modelem analizy wariancji. Pokażemy, jak wprowadzić dane do SPSS-a, jak uruchomić w pakiecie odpowiednie procedury i jak zinterpretować uzyskany wydruk.
1. Wprowadzenie danych
Dane do jednoczynnikowej analizy wariancji powinny zostać wprowadzone w dwóch kolumnach.
Pierwsza z nich może zostać nazwana „grupa”. Kolejne liczby (od 1 do 4), które pojawiły się w tej kolumnie oznaczają numer grupy eksperymentalnej. Osoby oznaczone liczbą „1” to osoby, którym przyporządkowano kąt widzenia o wielkości 900, osobom oznaczonym liczbą „2” przyporządkowano kąt 1800, oznaczonym liczbą „3” kąt 2700, zaś oznaczonym liczbą „4” kąt 3600. Wykorzystanym tu liczbom można rzecz jasna przypisać etykiety, takie jak na przykład 900, 1800, 2700 i 3600 lub a1, a2, a3 oraz a4. Druga zmienna zawiera czas spostrzegania bodźca dla każdej osoby badanej i może zostać na przykład nazwana „czas”. Opisany tutaj sposób zapisania danych w pakiecie SPSS ilustruje poniższa tabela:
|
|
Grupa |
czas |
|
1 |
1 |
21 |
|
2 |
1 |
23 |
|
3 |
1 |
21 |
|
4 |
1 |
15 |
|
5 |
1 |
20 |
|
6 |
1 |
25 |
|
7 |
1 |
27 |
|
8 |
1 |
16 |
|
9 |
1 |
22 |
|
10 |
1 |
17 |
|
11 |
2 |
30 |
|
12 |
2 |
29 |
|
13 |
2 |
21 |
|
14 |
2 |
22 |
|
15 |
2 |
31 |
|
16 |
2 |
28 |
|
17 |
2 |
26 |
|
18 |
2 |
25 |
|
19 |
2 |
27 |
|
20 |
2 |
31 |
|
21 |
3 |
33 |
|
22 |
3 |
28 |
|
23 |
3 |
29 |
|
24 |
3 |
33 |
|
25 |
3 |
30 |
|
26 |
3 |
27 |
|
27 |
3 |
25 |
|
28 |
3 |
29 |
|
29 |
3 |
25 |
|
30 |
3 |
26 |
|
31 |
4 |
42 |
|
32 |
4 |
32 |
|
33 |
4 |
39 |
|
34 |
4 |
35 |
|
35 |
4 |
41 |
|
36 |
4 |
38 |
|
37 |
4 |
37 |
|
38 |
4 |
40 |
|
39 |
4 |
39 |
|
40 |
4 |
38 |
2. Uruchomienie jednoczynnikowej analizy wariancji w pakiecie SPSS
Aby uruchomić analizę wariancji należy wybrać następujące elementy w menu SPSS-a:
- Analiza → Ogólny model liniowy → Jednej zmiennej…
- do okienka Zmienna zależna przenosimy zmienną „czas”
- do okienka Czynniki stałe przenosimy zmienną „grupa”
- naciskamy przycisk Opcje i wybieramy Statystyki opisowe oraz Oceny wielko≈õci efektu
- naciskamy przycisk Post hoc, przenosimy zmienną „grupa” z okienka Czynniki do okienka Testy post hoc dla i wybieramy Tukey
- naciskamy przycisk Wykresy i przenosimy zmienną „grupa” z okienka Czynniki do okienka Oś pozioma
Po klikniƒôciu przycisku OK otrzymamy nastƒôpujƒÖcy wydruk:
Analiza wariancji jednej zmiennej (UNIANOVA)
Czynniki miƒôdzyobiektowe
|
|
Etykieta warto≈õci |
N |
|
|
grupa (czynnik) |
1,00 |
a1 |
10 |
|
2,00 |
a2 |
10 |
|
|
3,00 |
a3 |
10 |
|
|
4,00 |
a4 |
10 |
|
Statystyki opisowe
Zmienna zależna: czas (zm. zależna)
|
grupa (czynnik) |
≈örednia |
Odchylenie standardowe |
N |
|
a1 |
20,7000 |
3,86005 |
10 |
|
a2 |
27,0000 |
3,52767 |
10 |
|
a3 |
28,5000 |
2,91548 |
10 |
|
a4 |
38,1000 |
2,92309 |
10 |
|
Ogółem |
28,5750 |
7,07429 |
40 |
Testy efektów międzyobiektowych
Zmienna zależna: czas (zm. zależna)
|
Źródło zmienności |
Typ III sumy kwadratów |
df |
≈öredni kwadrat |
F |
Istotność |
Czastkowe Eta kwadrat |
|
Model skorygowany |
1552,275(a) |
3 |
517,425 |
46,627 |
,000 |
,795 |
|
Stała |
32661,225 |
1 |
32661,225 |
2943,189 |
,000 |
,988 |
|
grupa |
1552,275 |
3 |
517,425 |
46,627 |
,000 |
,795 |
|
Błąd |
399,500 |
36 |
11,097 |
|
|
|
|
Ogółem |
34613,000 |
40 |
|
|
|
|
|
Ogółem skorygowane |
1951,775 |
39 |
|
|
|
|
a R kwadrat = ,795 (Skorygowane R kwadrat = ,778)
Testy post hoc
grupa (czynnik)
Porównania wielokrotne
Zmienna zależna: czas (zm. zależna)
Test Tukey'a HSD
|
(I) grupa (czynnik) |
(J) grupa (czynnik) |
Różnica średnich (I-J) |
Błąd standardowy |
Istotność |
95% przedział ufności |
|
|
Dolna granica |
Górna granica |
|||||
|
a1 |
a2 |
-6,3000(*) |
1,48978 |
,001 |
-10,3123 |
-2,2877 |
|
a3 |
-7,8000(*) |
1,48978 |
,000 |
-11,8123 |
-3,7877 |
|
|
a4 |
-17,4000(*) |
1,48978 |
,000 |
-21,4123 |
-13,3877 |
|
|
a2 |
a1 |
6,3000(*) |
1,48978 |
,001 |
2,2877 |
10,3123 |
|
a3 |
-1,5000 |
1,48978 |
,746 |
-5,5123 |
2,5123 |
|
|
a4 |
-11,1000(*) |
1,48978 |
,000 |
-15,1123 |
-7,0877 |
|
|
a3 |
a1 |
7,8000(*) |
1,48978 |
,000 |
3,7877 |
11,8123 |
|
a2 |
1,5000 |
1,48978 |
,746 |
-2,5123 |
5,5123 |
|
|
a4 |
-9,6000(*) |
1,48978 |
,000 |
-13,6123 |
-5,5877 |
|
|
a4 |
a1 |
17,4000(*) |
1,48978 |
,000 |
13,3877 |
21,4123 |
|
a2 |
11,1000(*) |
1,48978 |
,000 |
7,0877 |
15,1123 |
|
|
a3 |
9,6000(*) |
1,48978 |
,000 |
5,5877 |
13,6123 |
|
W oparciu o ≈õrednie obserwowane.
* Różnica średnich jest istotna na poziomie ,05.
Grupy jednorodne
czas (zm. zależna)
Test Tukey'a HSD
|
grupa (czynnik) |
N |
Grupy |
||
|
1 |
2 |
3 |
||
|
A1 |
10 |
20,7000 |
|
|
|
A2 |
10 |
|
27,0000 |
|
|
A3 |
10 |
|
28,5000 |
|
|
A4 |
10 |
|
|
38,1000 |
|
Istotność |
|
1,000 |
,746 |
1,000 |
Przedstawione są średnie grupowe dla grup jednorodnych. W oparciu o Typ III sumy kwadratów. Składnikiem błędów jest Średni kwadrat (Błąd) = 11,097.
a Użyto średniej harmonicznej wielkości próby = 10,000
b Alfa = ,05.
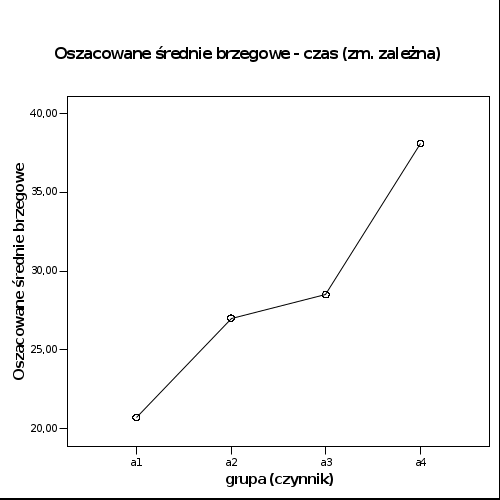
Wykresy profili
3. Interpretacja wydruku
Analiza wariancji jest techniką różnicową, dlatego też weryfikuje hipotezy o różnicach pomiędzy grupami. Hipoteza zerowa do naszego przykładu powinna więc zostać sformułowana następująco:
Grupy osób badanych różniące się kątem widzenia różnią się czasem spostrzegania bodźca.
(co oczywiście w tym kontekście oznacza, że od kąta widzenia zależy czas spostrzegania bodźca).
Bardziej formalnie
hipotezę tę można wyrazić w sposób następujący:
 [brak
zróżnicowania (= wariancji) pomiędzy grupami]
[brak
zróżnicowania (= wariancji) pomiędzy grupami]
Testu weryfikującego tę hipotezę szukamy w tabeli zatytułowanej „Testy efektów międzyobiektowych” w wierszu dla zmiennej „grupa”. Efekt tego testu można podsumować następująco: F=46,627; dfgrupa=3; dfbłąd=36; p<0,001. Wynika z niego, że mamy podstawy do odrzucenia hipotezy zerowej o braku różnic pomiędzy grupami na rzecz hipotezy alternatywnej. Taki wniosek statystyczny oznacza, że mamy do czynienia ze zróżnicowaniem pomiędzy analizowanymi grupami.
Średnie i odchylenia standardowe dla czasu potrzebnego do spostrzeżenia bodźca świetlnego dla każdej z czterech badanych grup eksperymentalnych odnajdziemy w tabeli zatytułowanej „Statystyki opisowe”. Dodatkową wizualizacją różnic pomiędzy średnimi dla czterech grup jest diagram zatytułowany „Wykresy profili”. Możemy się przekonać, że najniższą średnią osiągnęła grupa a1, najwyższą grupa a4, a średnie grup a2 i a3 są większe od a1 i mniejsze od a4, ale niewiele się od siebie różnią. Czy więc wszystkie cztery grupy badanych różnią się pomiędzy sobą? Odpowiedź na to pytanie znajdziemy w tabeli zatytułowanej „Testy post hoc” (kolumna z /nagłówkiem „Istotność”).
- różnica pomiędzy grupą a1 i a2 jest istotna statystycznie (p=0,001)
- różnica pomiędzy grupą a1 i a3 jest istotna statystycznie (p<0,001)
- różnica pomiędzy grupą a1 i a4 jest istotna statystycznie (p<0,001)
- różnica pomiędzy grupą a2 i a3 jest nieistotna statystycznie (p=0,746)
- różnica pomiędzy grupą a2 i a4 jest istotna statystycznie (p<0,001)
- różnica pomiędzy grupą a3 i a4 jest istotna statystycznie (p<0,001)
Tak więc grupy a2 oraz a3 od siebie się nie różnią, ale mają czas spostrzegania bodźca dłuższy niż grupa a1 i krótszy niż grupa a4.
Wyniki eksperymentu potwierdzają więc hipotezę o zależności czasu spostrzegania bodźca od kąta widzenia. Sprawdźmy jeszcze, jaki procent wariancji zmiennej zależnej można wytłumaczyć wpływem zmiennej niezależnej (tu: czynnika). Na wydruku analizy wariancji wartość ta pojawia się w dwóch miejscach:
Pod tabelą „Testy efektów międzyobiektowych” mamy podaną wartość R-kwadrat=0,759. Ta wartość pomnożona razy 100% da nam procent wariancji zmiennej zależnej tłumaczony przez wszystkie wykorzystane zmienne niezależne (=czynniki)
W tabeli „Testy efektów międzyobiektowych”, w kolumnie „cząstkowe Eta kwadrat” mamy te samą wartość równą 0,759. Ta wartość pomnożona razy 100% da nam procent wariancji zmiennej zależnej tłumaczony przez pojedynczą zmienną niezależną (=czynnik)
W przypadku jednoczynnikowej analizy wariancji R-kwadrat i cząstkowe Eta kwadrat dla czynnika będą rzecz jasna tą samą wartością. Dodajmy jeszcze, że w analizie wariancji wskaźnik eta-kwadrat liczymy dzieląc SSgrupa przez SSogółem skorygowane [1552,275/1951,775=0,759].
Interpretację możemy wiec zakończyć wnioskiem, że kąt widzenia tłumaczy 75,9 procenta wariancji czasu spostrzegania bodźca.
II. MODEL ANALIZY REGRESJI
Spróbujmy teraz te same wyniki zanalizować w modelu regresji wielokrotnej.
W analizie wariancji czynnik (=zmienna niezależna) zawsze – bez względu na swoją naturę – jest traktowany jak zmienna jakościowa. Jeżeli w analizie regresji pojawi się jakościowa zmienna niezależna, to należy ją zakodować.
Jeżeli nasza zmienna niezależna nazwana „grupa” zostałaby wprowadzona do równania regresji w nie zmienionej formie, to użyte w pliku liczby zostałyby potraktowane tak, jakby wyrażały jednostki na skali co najmniej interwałowej (osoba z grupy a2 miałaby o dwie jednostki niższy wynik od osoby z grupy a4).
Prześledźmy więc najpierw sposób kodowania zmiennej jakościowej za pomocą SPSS-a a następnie wydruk analizy regresji, do której wprowadzimy tę zakodowaną zmienną. Skupimy się na dwóch najbardziej rozpowszechnionych systemach, które nazwane zostały kodowaniem zero-jedynkowym i kodowaniem quasi-eksperymentalnym.
A. KODOWANIE ZERO-JEDYNKOWE
1. Kodowanie zero-jedynkowe zmiennej jako≈õciowej
Jak pisze profesor Brzeziński (s. 371) „Objaśnię teraz, na czym polega zabieg kodowania zero-jedynkowego (ang. dummy coding) p-kategorialnej zmiennej jakościowej. Kodowanie polega na utworzeniu m (gdzie m = p – 1) nowych zmiennych (wektorów) instrumentalnych. Te nowe zmienne powstają w ten sposób, że osobom z danej i-tej kategorii (i-tej grupy porównawczej) przypisujemy jedynki, a osobom z pozostałych kategorii przypisujemy zera. Ostatnia kategoria p (p-ta grupa porównawcza) reprezentowana jest we wszystkich m wektorach przez same zera.”2
Dla naszych danych oznacza to, że dla czterech kategorii zmiennej niezależnej (cztery grupy osób badanych) będziemy musieli utworzyć trzy wektory instrumentalne (T1, T2 i T3).
- osoby z grupy a1 na wektorze T1 będą miały jedynki, a na pozostałych wektorach zera (T1=1 T2=0 i T3=0)
- osoby z grupy a2 na wektorze T2 będą miały jedynki, a na pozostałych wektorach zera (T1=0 T2=1 i T3=0)
- osoby z grupy a3 na wektorze T3 będą miały jedynki, a na pozostałych wektorach zera (T1=0 T2=0 i T3=1)
- osoby z grupy a4 na wszystkich trzech wektorach będą miały zera (T1=0 T2=0 i T3=0)
W ten sposób cztery grupy będą odróżnialne jedynie wtedy, gdy weźmiemy pod uwagę wszystkie trzy zmienne instrumentalne równocześnie:
- grupa a1 – sekwencja 1 0 0
- grupa a2 – sekwencja 0 1 0
- grupa a3 – sekwencja 0 0 1
- grupa a4 – sekwencja 0 0 0
Aby zakodować naszą zmienną jakościową (stworzyć trzy nowe zmienne instrumentalne) należy wybrać następujące elementy w menu SPSS-a:
1. Najpierw tworzymy pierwszą zmienną instrumentalną (T1) na której tylko grupa a1 ma „1”, a reszta „0”
- Analiza → Przekształcenia → Oblicz wartości…
- do okienka Zmienna wynikowa wpisujemy nazwę nowego wektora: „T1”
- do okienka Wyrażenie numeryczne wpisujemy liczbę „1”
- naciskamy przycisk Jeżeli i zaznaczamy opcję Uwzględnij, jeśli obserwacja spełnia warunek
- przenosimy z listy zmiennych do podświetlonego już teraz okienka zmienną „grupa” i korzystając z klawiatury w oknie dialogowym albo z klawiatury komputera dopisujemy warunek logiczny „= 1”
- naciskamy przycisk Dalej oraz OK
SPSS dopisze do pliku nową zmienną o nazwie „T1” i osobom z grupy a1 przypisze na niej jedynki. Pozostałe osoby będą miały na tej zmiennej brakujące wartości (puste kratki).
2. Następnie tworzymy drugą zmienną instrumentalną (T2) na której tylko grupa a2 ma „1”, a reszta „0”.
- Analiza → Przekształcenia → Oblicz wartości…
- do okienka Zmienna wynikowa wpisujemy nazwę nowego wektora: „T2”
- do okienka Wyrażenie numeryczne wpisujemy liczbę „1”
- naciskamy przycisk Jeżeli i zaznaczamy opcję Uwzględnij, jeśli obserwacja spełnia warunek
- przenosimy z listy zmiennych do podświetlonego już teraz okienka zmienną „grupa” i korzystając z klawiatury w oknie dialogowym albo z klawiatury komputera dopisujemy warunek logiczny „= 2”
- naciskamy przycisk Dalej oraz OK
SPSS dopisze do pliku następną zmienną, tym razem o nazwie „T2” i osobom z grupy a2 przypisze na niej jedynki. Pozostałe osoby będą miały na tej zmiennej brakujące wartości (puste kratki).
3. Teraz tworzymy trzecią zmienną instrumentalną (T3) na której tylko grupa a3 ma „1”, a reszta „0”.
- Analiza → Przekształcenia → Oblicz wartości…
- do okienka Zmienna wynikowa wpisujemy nazwę nowego wektora: „T3”
- do okienka Wyrażenie numeryczne wpisujemy liczbę „1”
- naciskamy przycisk Jeżeli i zaznaczamy opcję Uwzględnij, jeśli obserwacja spełnia warunek
- przenosimy z listy zmiennych do podświetlonego już teraz okienka zmienną „grupa” i korzystając z klawiatury w oknie dialogowym albo z klawiatury komputera dopisujemy warunek logiczny „= 3”
- naciskamy przycisk Dalej oraz OK
SPSS dopisze do pliku następną zmienną, tym razem o nazwie „T3” i osobom z grupy a3 przypisze na niej jedynki. Pozostałe osoby będą miały na tej zmiennej brakujące wartości (puste kratki).
4. Teraz trzeba wypełnić wartościami „0” wszystkie puste kratki dla zmiennych T1, T2 i T3.
- Analiza → Przekształcenia → Rekoduj → Na te same zmienne…
- do okienka Zmienne numeryczne przenosimy nowe zmienne: „T1, T2 i T3”
- naciskamy przycisk Wartości źródłowe i wynikowe
- w lewej części okna dialogowego zatytułowanej Wartości źródłowe zaznaczamy opcję Systemowy brak danych
- w prawej części okna dialogowego zatytułowanej Wartości wynikowe zaznaczamy opcję Wartość i do pustego okienka wpisujemy liczbę „0”
- naciskamy przyciski Dodaj, Dalej oraz OK
SPSS uzupełni zerami wszystkie brakujące dane (puste kratki) w zmiennych T1, T2 i T3.
Efekt wyżej przedstawionych przekształceń ilustruje poniższa tabela:
|
|
Grupa |
czas |
T1 |
T2 |
T3 |
|
1 |
1 |
21 |
1 |
0 |
0 |
|
2 |
1 |
23 |
1 |
0 |
0 |
|
3 |
1 |
21 |
1 |
0 |
0 |
|
4 |
1 |
15 |
1 |
0 |
0 |
|
5 |
1 |
20 |
1 |
0 |
0 |
|
6 |
1 |
25 |
1 |
0 |
0 |
|
7 |
1 |
27 |
1 |
0 |
0 |
|
8 |
1 |
16 |
1 |
0 |
0 |
|
9 |
1 |
22 |
1 |
0 |
0 |
|
10 |
1 |
17 |
1 |
0 |
0 |
|
11 |
2 |
30 |
0 |
1 |
0 |
|
12 |
2 |
29 |
0 |
1 |
0 |
|
13 |
2 |
21 |
0 |
1 |
0 |
|
14 |
2 |
22 |
0 |
1 |
0 |
|
15 |
2 |
31 |
0 |
1 |
0 |
|
16 |
2 |
28 |
0 |
1 |
0 |
|
17 |
2 |
26 |
0 |
1 |
0 |
|
18 |
2 |
25 |
0 |
1 |
0 |
|
19 |
2 |
27 |
0 |
1 |
0 |
|
20 |
2 |
31 |
0 |
1 |
0 |
|
21 |
3 |
33 |
0 |
0 |
1 |
|
22 |
3 |
28 |
0 |
0 |
1 |
|
23 |
3 |
29 |
0 |
0 |
1 |
|
24 |
3 |
33 |
0 |
0 |
1 |
|
25 |
3 |
30 |
0 |
0 |
1 |
|
26 |
3 |
27 |
0 |
0 |
1 |
|
27 |
3 |
25 |
0 |
0 |
1 |
|
28 |
3 |
29 |
0 |
0 |
1 |
|
29 |
3 |
25 |
0 |
0 |
1 |
|
30 |
3 |
26 |
0 |
0 |
1 |
|
31 |
4 |
42 |
0 |
0 |
0 |
|
32 |
4 |
32 |
0 |
0 |
0 |
|
33 |
4 |
39 |
0 |
0 |
0 |
|
34 |
4 |
35 |
0 |
0 |
0 |
|
35 |
4 |
41 |
0 |
0 |
0 |
|
36 |
4 |
38 |
0 |
0 |
0 |
|
37 |
4 |
37 |
0 |
0 |
0 |
|
38 |
4 |
40 |
0 |
0 |
0 |
|
39 |
4 |
39 |
0 |
0 |
0 |
|
40 |
4 |
38 |
0 |
0 |
0 |
2. Uruchomienie analizy regresji w pakiecie SPSS
Aby uruchomić analizę regresji należy wybrać następujące elementy w menu SPSS-a:
- Analiza → Regresja → Liniowa…
- do okienka Zmienna zależna przenosimy zmienną „czas”
- do okienka Zmienne niezależne przenosimy wektory instrumentalne „T1, T2 i T3”
- upewnijmy się, że w okienku Metoda znajduje się „Metoda wprowadzania” (zaznaczana domyślnie)
Po klikniƒôciu przycisku OK otrzymamy nastƒôpujƒÖcy wydruk:
Regresja
Zmienne wprowadzone/usuniƒôte(b)
|
Model |
Zmienne wprowadzone |
Zmienne usuniƒôte |
Metoda |
|
1 |
T3 - (1) grupa a3, T2 - (1) grupa a2, T1 - (1) grupa a1(a) |
. |
Wprowadzanie |
a Wszystkie wyspecyfikowane zmienne zostały wprowadzone.
b Zmienna zależna: czas (zm. zależna)
Model - Podsumowanie
|
Model |
R |
R-kwadrat |
Skorygowane R-kwadrat |
Błąd standardowy oszacowania |
|
1 |
,892(a) |
,795 |
,778 |
3,33125 |
a Predyktory: (Stała), T3 - (1) grupa a3, T2 - (1) grupa a2, T1 - (1) grupa a1
Analiza wariancji(b)
|
Model |
|
Suma kwadratów |
df |
≈öredni kwadrat |
F |
Istotność |
|
1 |
Regresja |
1552,275 |
3 |
517,425 |
46,627 |
,000(a) |
|
Reszta |
399,500 |
36 |
11,097 |
|
|
|
|
Ogółem |
1951,775 |
39 |
|
|
|
a Predyktory: (Stała), T3 - (1) grupa a3, T2 - (1) grupa a2, T1 - (1) grupa a1
b Zmienna zależna: czas (zm. zależna)
Współczynniki(a)
|
Model |
|
Współczynniki niestandaryzowane |
Współczynniki standaryzowane |
t |
Istotność |
|
|
B |
Błąd standardowy |
Beta |
||||
|
1 |
(Stała) |
38,100 |
1,053 |
|
36,167 |
,000 |
|
T1 - (1) grupa a1 |
-17,400 |
1,490 |
-1,079 |
-11,680 |
,000 |
|
|
T2 - (1) grupa a2 |
-11,100 |
1,490 |
-,688 |
-7,451 |
,000 |
|
|
T3 - (1) grupa a3 |
-9,600 |
1,490 |
-,595 |
-6,444 |
,000 |
|
a Zmienna zależna: czas (zm. zależna)
3. Interpretacja wydruku
Analiza regresji jest techniką zależnościową, dlatego też weryfikuje hipotezy o zależnościach pomiędzy zmiennymi. Hipoteza zerowa do naszego przykładu powinna więc zostać sformułowana następująco:
Brak zwiƒÖzku pomiƒôdzy kƒÖtem widzenia i czasem spostrzegania bod≈∫ca.
(co oczywiście oznacza, że ludzie przy różnych kątach widzenia różnią się czasem spostrzegania bodźca).
Ponieważ nasze trzy zmienne instrumentalne tworzą de facto jedną zmienną jakościową (zakodowaną), nie będą nas interesowały związki pomiędzy pojedynczymi wektorami (T1, T2 oraz T3) i zmienną zależną. Ogólny wskaźnik R-kwadrat informuje nas o tym, ile wariancji zmiennej zależnej (czasu spostrzegania bodźca) wyjaśnia zmienna niezależna (kąt widzenia).
Wskaźnik R-kwadrat znajdziemy w tabeli „Model – Podsumowanie”. Jego wartość wynosi 0,795, a to oznacza, że zmienna zależna tłumaczy 79,5% wariancji zmiennej zależnej. Porównajmy tę wartość ze wskaźnikiem R-kwadrat lub Eta-kwadrat z analizy wariancji. Są one identyczne.
Porównajmy teraz zawartość tabel:
- „Testy efektów międzyobiektowych” z wydruku analizy wariancji (wiersze: „grupa”, „błąd” oraz „ogółem skorygowane”)
- „Analiza wariancji” z wydruku analizy regresji
Zawierają one dokładnie te same liczby. Nic w tym dziwnego, ponieważ – jak staramy się wykazać – model analizy wariancji i model analizy regresji są tożsame.
- Test F w analizie wariancji testuje, czy wariancja zmiennej zależnej (=czas spostrzegania bodźca) wyjaśniona przez czynnik (zmienną niezależną = kąt widzenia) jest większa od tej wariancji, której ten czynnik nie wyjaśnia (tzw. wariancji błędu)
- Test F w analizie regresji testuje, czy wariancja zmiennej zależnej (=czas spostrzegania bodźca) wyjaśniona przez zmienną niezależną (kąt widzenia) jest większa od tej wariancji, której ta zmienna nie wyjaśnia (tzw. wariancja resztowa) – jest to test istotności wartości R-kwadrat
Nic więc w tym dziwnego, że obie tabele zawierają te same wartości. Wynik tego testu (F=46,627; dfregresja=3; dfreszta=36; p<0,001) wskazuje, ze odrzucamy hipotezę zerową o braku związku pomiędzy zmienną zależną (czasem spostrzegania bodźca) i zmienną niezależną (kątem widzenia). Wnioski z analizy wariancji i z analizy regresji nie różnią się.
Żeby do końca zrozumieć tożsamość obu omawianych modeli warto jeszcze zwrócić uwagę na równanie regresji. W analizowanym przypadku owo równanie przyjmie następującą postać:
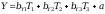
Z tabeli „Współczynniki” możemy odczytać wartości współczynników b (w tabeli kolumna z nagłówkiem „B”) i uzupełnić równanie. Liczba znajdująca się w wierszu „(stała)” i w kolumnie „B” to wartość współczynnika a w równaniu regresji. Nasze równanie będzie więc miało postać:
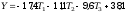
Co te współczynniki oznaczają? Jak je interpretować? Żeby je można było sensownie interpretować trzeba pamiętać o tym, że przy kodowaniu zero-jedynkowym zawsze jedna z analizowanych grup zostanie potraktowana jako grupa odniesienia, do której będziemy porównywać wszystkie pozostałe. Może to być dowolna grupa. My jednak musimy dokonać jej wyboru już na etapie kodowania zmiennej jakościowej. Będzie to bowiem zawsze ta grupa, która ma na wszystkich zmiennych instrumentalnych zera. W naszym przypadku grupą referencyjną stała się grupa a4, bo ona właśnie charakteryzuje się sekwencją 0, 0, 0 na wektorach T1, T2 oraz T3.
Wracając do interpretacji współczynników regresji:
- współczynnik a zawsze jest równy średniej dla grupy referencyjnej (tu a4) = 38,1
- współczynnik bY1 jest równy różnicy pomiędzy średnią grupy, która na wektorze T1 ma jedynki (tu a1) i średnią grupy referencyjnej (tu a4), czyli 20,7 – 38,1 = - 17,4
- współczynnik bY2 jest równy różnicy pomiędzy średnią grupy, która na wektorze T2 ma jedynki (tu a2) i średnią grupy referencyjnej (tu a4), czyli 27,0 – 38,1 = - 11,1
- współczynnik bY3 jest równy różnicy pomiędzy średnią grupy, która na wektorze T3 ma jedynki (tu a3) i średnią grupy referencyjnej (tu a4), czyli 28,5 – 38,1 = - 9,6
Testy t zamieszczone w tabeli „Współczynniki” w wierszach dla każdej z trzech zmiennych instrumentalnych testują po prostu, czy te różnice są istotne statystycznie. I tak:
- różnica pomiędzy grupą a1 i grupą a4 jest istotna statystycznie (t=-11,680; p<0,001)
- różnica pomiędzy grupą a2 i grupą a4 jest istotna statystycznie (t=-7,451; p<0,001)
- różnica pomiędzy grupą a3 i grupą a4 jest istotna statystycznie (t=-6,444; p<0,001)
Grupa referencyjna (a4) ma więc wyższą średnią od wszystkich pozostałych. Taki sam wynik uzyskaliśmy w analizie wariancji.
4. Wybór innej grupy jako grupy referencyjnej
Jeżeli wybierzemy inną grupę jako grupę odniesienia, to zmieni się nam tylko (i to nie w całości) tabela „Współczynniki”.. Zakodujmy zmienną jakościową raz jeszcze. Tym razem jednak zera na wszystkich zmiennych instrumentalnych przypiszmy grupie a3, zaś jedynki na trzecim wektorze grupie a4. Efekt takiego kodowania zawiera poniższa tabela (wektory T1a, T2a i T3a).
|
|
Grupa |
czas |
T1 |
T2 |
T3 |
T1a |
T2a |
T3a |
|
1 |
1 |
21 |
1 |
0 |
0 |
1 |
0 |
0 |
|
2 |
1 |
23 |
1 |
0 |
0 |
1 |
0 |
0 |
|
3 |
1 |
21 |
1 |
0 |
0 |
1 |
0 |
0 |
|
4 |
1 |
15 |
1 |
0 |
0 |
1 |
0 |
0 |
|
5 |
1 |
20 |
1 |
0 |
0 |
1 |
0 |
0 |
|
6 |
1 |
25 |
1 |
0 |
0 |
1 |
0 |
0 |
|
7 |
1 |
27 |
1 |
0 |
0 |
1 |
0 |
0 |
|
8 |
1 |
16 |
1 |
0 |
0 |
1 |
0 |
0 |
|
9 |
1 |
22 |
1 |
0 |
0 |
1 |
0 |
0 |
|
10 |
1 |
17 |
1 |
0 |
0 |
1 |
0 |
0 |
|
11 |
2 |
30 |
0 |
1 |
0 |
0 |
1 |
0 |
|
12 |
2 |
29 |
0 |
1 |
0 |
0 |
1 |
0 |
|
13 |
2 |
21 |
0 |
1 |
0 |
0 |
1 |
0 |
|
14 |
2 |
22 |
0 |
1 |
0 |
0 |
1 |
0 |
|
15 |
2 |
31 |
0 |
1 |
0 |
0 |
1 |
0 |
|
16 |
2 |
28 |
0 |
1 |
0 |
0 |
1 |
0 |
|
17 |
2 |
26 |
0 |
1 |
0 |
0 |
1 |
0 |
|
18 |
2 |
25 |
0 |
1 |
0 |
0 |
1 |
0 |
|
19 |
2 |
27 |
0 |
1 |
0 |
0 |
1 |
0 |
|
20 |
2 |
31 |
0 |
1 |
0 |
0 |
1 |
0 |
|
21 |
3 |
33 |
0 |
0 |
1 |
0 |
0 |
0 |
|
22 |
3 |
28 |
0 |
0 |
1 |
0 |
0 |
0 |
|
23 |
3 |
29 |
0 |
0 |
1 |
0 |
0 |
0 |
|
24 |
3 |
33 |
0 |
0 |
1 |
0 |
0 |
0 |
|
25 |
3 |
30 |
0 |
0 |
1 |
0 |
0 |
0 |
|
26 |
3 |
27 |
0 |
0 |
1 |
0 |
0 |
0 |
|
27 |
3 |
25 |
0 |
0 |
1 |
0 |
0 |
0 |
|
28 |
3 |
29 |
0 |
0 |
1 |
0 |
0 |
0 |
|
29 |
3 |
25 |
0 |
0 |
1 |
0 |
0 |
0 |
|
30 |
3 |
26 |
0 |
0 |
1 |
0 |
0 |
0 |
|
31 |
4 |
42 |
0 |
0 |
0 |
0 |
0 |
1 |
|
32 |
4 |
32 |
0 |
0 |
0 |
0 |
0 |
1 |
|
33 |
4 |
39 |
0 |
0 |
0 |
0 |
0 |
1 |
|
34 |
4 |
35 |
0 |
0 |
0 |
0 |
0 |
1 |
|
35 |
4 |
41 |
0 |
0 |
0 |
0 |
0 |
1 |
|
36 |
4 |
38 |
0 |
0 |
0 |
0 |
0 |
1 |
|
37 |
4 |
37 |
0 |
0 |
0 |
0 |
0 |
1 |
|
38 |
4 |
40 |
0 |
0 |
0 |
0 |
0 |
1 |
|
39 |
4 |
39 |
0 |
0 |
0 |
0 |
0 |
1 |
|
40 |
4 |
38 |
0 |
0 |
0 |
0 |
0 |
1 |
Niżej przedstawiono wydruk analizy regresji, w której jako zmiennych niezależnych użyto wektorów T1a, T2a i T3a:
Regresja
Zmienne wprowadzone/usuniƒôte(b)
|
Model |
Zmienne wprowadzone |
Zmienne usuniƒôte |
Metoda |
|
1 |
T3a - (1) grupa a4, T2a - (1) grupa a2, T1a - (1) grupa a1(a) |
. |
Wprowadzanie |
a Wszystkie wyspecyfikowane zmienne zostały wprowadzone.
b Zmienna zależna: czas (zm. zależna)
Model - Podsumowanie
|
Model |
R |
R-kwadrat |
Skorygowane R-kwadrat |
Błąd standardowy oszacowania |
|
1 |
,892(a) |
,795 |
,778 |
3,33125 |
a Predyktory: (Stała), T3a - (1) grupa a4, T2a - (1) grupa a2, T1a - (1) grupa a1
Analiza wariancji(b)
|
Model |
|
Suma kwadratów |
df |
≈öredni kwadrat |
F |
Istotność |
|
1 |
Regresja |
1552,275 |
3 |
517,425 |
46,627 |
,000(a) |
|
Reszta |
399,500 |
36 |
11,097 |
|
|
|
|
Ogółem |
1951,775 |
39 |
|
|
|
a Predyktory: (Stała), T3a - (1) grupa a4, T2a - (1) grupa a2, T1a - (1) grupa a1
b Zmienna zależna: czas (zm. zależna)
Współczynniki(a)
|
Model |
|
Współczynniki niestandaryzowane |
Współczynniki standaryzowane |
t |
Istotność |
|
|
B |
Błąd standardowy |
Beta |
||||
|
1 |
(Stała) |
28,500 |
1,053 |
|
27,054 |
,000 |
|
T1a - (1) grupa a1 |
-7,800 |
1,490 |
-,484 |
-5,236 |
,000 |
|
|
T2a - (1) grupa a2 |
-1,500 |
1,490 |
-,093 |
-1,007 |
,321 |
|
|
T3a - (1) grupa a4 |
9,600 |
1,490 |
,595 |
6,444 |
,000 |
|
a Zmienna zależna: czas (zm. zależna)
Nasze równanie będzie teraz miało postać:
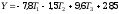
- współczynnik a jest równy średniej dla grupy referencyjnej (tu a3) = 28,5
- współczynnik bY1 jest równy różnicy pomiędzy średnią grupy, która na wektorze T1a ma jedynki (tu a1) i średnią grupy referencyjnej (tu a3), czyli 20,7 – 28,5 = - 7,8
- współczynnik bY2 jest równy różnicy pomiędzy średnią grupy, która na wektorze T2a ma jedynki (tu a2) i średnią grupy referencyjnej (tu a3), czyli 27,0 – 28,5 = - 1,5
- współczynnik bY3 jest równy różnicy pomiędzy średnią grupy, która na wektorze T3a ma jedynki (tu a4) i średnią grupy referencyjnej (tu a3), czyli 38,1 – 28,5 = 9,6
I interpretacja testów t:
- różnica pomiędzy grupą a1 i grupą a3 jest istotna statystycznie (t=-5,236; p<0,001)
- różnica pomiędzy grupą a2 i grupą a3 nie jest istotna statystycznie (t=-1,007; p=0,321)
- różnica pomiędzy grupą a4 i grupą a3 jest istotna statystycznie (t=-6,444; p<0,001)
Grupa referencyjna (a3) ma więc wyższą średnią od a1, niższą od a4 i nie różni się od a2. Taki sam wynik uzyskaliśmy w analizie wariancji.
B. KODOWANIE QUASI-EKSPERYMENTALNE
1. Kodowanie quasi-eksperymantalne zmiennej jako≈õciowej
Profesor Brzeziński pisze też że(s. 379)3: „Czytelnik, który opanował już zasady kodowania zero-jedynkowego, bez trudu poradzi sobie z kodowaniem quasi-eksperymentalnym. Różnica między obydwoma systemami kodowania – w sensie technicznym – sprowadza się do tego, że w kodowaniu zero-jedynkowym osobom z ostatniej grupy (p-tej) przypisano we wszystkich m wektorach instrumentalnych same zera, natomiast w kodowaniu tu omawianym miejsce zer zajmują współczynniki „–1.”
Dla naszych danych oznacza to, że dla czterech kategorii zmiennej niezależnej (cztery grupy osób badanych) będziemy musieli znowu utworzyć trzy wektory instrumentalne (T1, T2 i T3). Teraz jednak
- osoby z grupy a1 na wektorze T1 będą miały jedynki, a na pozostałych wektorach zera (T1=1 T2=0 i T3=0)
- osoby z grupy a2 na wektorze T2 będą miały jedynki, a na pozostałych wektorach zera (T1=0 T2=1 i T3=0)
- osoby z grupy a3 na wektorze T3 będą miały jedynki, a na pozostałych wektorach zera (T1=0 T2=0 i T3=1)
- ale osoby z grupy a4 na wszystkich trzech wektorach będą miały nie zera, ale wartości –1 (T1=–1 T2=–1 i T3=–1)
I tu znowu wszystkie grupy (tym razem jednak za wyjątkiem ostatniej) będą odróżnialne jedynie wtedy, gdy weźmiemy pod uwagę wszystkie trzy zmienne instrumentalne równocześnie:
- grupa a1 – sekwencja 1 0 0
- grupa a2 – sekwencja 0 1 0
- grupa a3 – sekwencja 0 0 1
- grupa a4 – sekwencja –1 –1 –1
Aby zakodować naszą zmienną jakościową w systemie quasi-eksperymentalnym przećwiczymy inny, alternatywny sposób tworzenia zmiennych instrumentalnych w pakiecie SPSS. Tym razem posłużymy się opcją Rekoduj zmienne. W menu należy wybrać następujące polecenia:
1. Najpierw tworzymy pierwszą zmienną instrumentalną (T1) na której grupa a1 ma „1”, grupa a4 ma „–1”, zaś reszta „0”.
- Analiza → Przekształcenia → Rekoduj → Na inne zmienne…
- do okienka Zmienna źrodłowa → wynikowa: przenosimy z obok wydrukowanej listy zmienną „grupa”, a do okienka zatytułowanego Zmienna wynikowa wpisujemy nazwę nowego wektora: „T1” i naciskamy przycisk Zmień. W wyniku tej operacji w okienku Zmienna źródłowa → wynikowa: pojawi się wpis: „grupa → T1”. Oznacza on, że cztery różne wartości wpisanej do pliku zmiennej „grupa” zostaną przekodowane na wartości na nowo utworzonej zmiennej o nazwie T1.
- następnie naciskamy przycisk Wartości źródłowe i wynikowe i pojawia się tabela, która podzielona jest na dwie części zatytułowane: Wartość źródłowa oraz Wartość wynikowa
- do okienka zatytułowanego Wartość po stronie Wartość źródłowa wpisujemy liczbę „1”, i do okienka o tej samej nazwie po stronie Wartość wynikowa wpisujemy liczbę „1” i naciskamy przycisk Dodaj. W wyniku tej operacji w okienku Źródłowa → Wynikowa pojawi się wpis „1 → 1”. Oznacza on, że wszystkie osoby z grupy a1 (oznaczone w zmiennej „grupa” liczbą 1) w wektorze T1 będą miały jedynki.
- do okienka zatytułowanego Wartość po stronie Wartość źródłowa wpisujemy teraz liczbę „2”, a do okienka o tej samej nazwie po stronie Wartość wynikowa wpisujemy liczbę „0” i naciskamy przycisk Dodaj. W wyniku tej operacji w okienku Źródłowa → Wynikowa pojawi się kolejny wpis: „2 → 0”. Oznacza on, że wszystkie osoby z grupy a2 (oznaczone w zmiennej „grupa” liczbą 2) w wektorze T1 będą miały zera.
- z kolei do okienka zatytułowanego Wartość po stronie Wartość źródłowa wpisujemy liczbę „3”, a do okienka o tej samej nazwie po stronie Wartość wynikowa wpisujemy liczbę „0” i naciskamy przycisk Dodaj. W wyniku tej operacji w okienku Źródłowa → Wynikowa pojawi się trzeci wpis: „3 → 0”. Oznacza on oczywiście, że wszystkie osoby z grupy a3 (oznaczone w zmiennej „grupa” liczbą 3) w wektorze T1 również będą miały zera.
- na koniec do okienka zatytułowanego Wartość po stronie Wartość źródłowa wpisujemy liczbę „4”, a do okienka o tej samej nazwie po stronie Wartość wynikowa wpisujemy liczbę „–1” i naciskamy przycisk Dodaj. W wyniku tej operacji w okienku Źródłowa → Wynikowa pojawi się ostatni wpis: „4 → –1”. Oznacza on, że wszystkie osoby z grupy a4 (oznaczone w zmiennej „grupa” liczbą 4) w wektorze T1 będą miały wpisane wartości „–1”.
- teraz naciskamy po kolei przyciski Dalej oraz OK
SPSS dopisze do pliku nową zmienną o nazwie „T1” i osobom z grupy a1 przypisze na niej jedynki, osobom z grupy a4 wartości „–1”, zaś osoby z grup a2 oraz a3 będą miały na tej zmiennej przypisane zera.
2. Następnie tworzymy drugą zmienną instrumentalną (T2) na której grupa a2 ma „1”, grupa a4 ma „–1”, zaś reszta „0”.
- Analiza → Przekształcenia → Rekoduj → Na inne zmienne…
- do okienka Zmienna źrodłowa → wynikowa: znowu przenosimy z obok wydrukowanej listy zmienną „grupa”, a do okienka zatytułowanego Zmienna wynikowa wpisujemy nazwę kolejnego wektora: „T2” i naciskamy przycisk Zmień. W wyniku tej operacji w okienku Zmienna źródłowa → wynikowa: pojawi się wpis: „grupa → T2”. Oznacza on, że cztery różne wartości wpisanej do pliku zmiennej „grupa” zostaną przekodowane na wartości drugiej zmiennej instrumentalnej o nazwie T2.
- naciskamy przycisk Wartości źródłowe i wynikowe i w tabeli, która pojawi się w wyniku wybrania tej opcji wpisujemy kolejno do okienka Wartość w częściach zatytułowanych: Wartość źródłowa oraz Wartość wynikowa:
- liczby „1” i „0” i naciskamy przycisk Dodaj. Wpis „1 → 0” w okienku Źródłowa → Wynikowa oznacza, że wszystkie osoby z grupy a1 w wektorze T2 będą miały zera.
- liczby „2” i „1” i naciskamy przycisk Dodaj. Wpis „2 → 1” w okienku Źródłowa → Wynikowa oznacza, że wszystkie osoby z grupy a2 w wektorze T2 będą miały jedynki.
- liczby „3” i „0” i naciskamy przycisk Dodaj. Wpis „3 → 0” w okienku Źródłowa → Wynikowa oznacza, że wszystkie osoby z grupy a3 w wektorze T2 będą miały zera.
- liczby „4” i „–1” i naciskamy przycisk Dodaj. Wpis „4 → –1” w okienku Źródłowa → Wynikowa oznacza, że wszystkie osoby z grupy a4 w wektorze T2 będą miały wpisane wartości –1.
Po naciśnięciu przycisków Dalej oraz OK. SPSS dopisze do pliku nową zmienną o nazwie „T2” i osobom z grupy a2 przypisze na niej jedynki, osobom z grupy a4 wartości „–1”, zaś osoby z grup a1 oraz a3 będą miały na tej zmiennej przypisane zera.
3. Teraz tworzymy trzecią zmienną instrumentalną (T3) na której grupa a3 ma „1”, grupa a4 ma „–1”, zaś reszta „0”.
- Analiza → Przekształcenia → Rekoduj → Na inne zmienne…
- i znowu do okienka Zmienna źrodłowa → wynikowa: znowu przenosimy z obok wydrukowanej listy zmienną „grupa”, a do okienka zatytułowanego Zmienna wynikowa wpisujemy nazwę ostatniego wektora instrumentalnego: „T3” i naciskamy przycisk Zmień. W wyniku tej operacji w okienku Zmienna źródłowa → wynikowa: pojawi się wpis: „grupa → T3”. Oznacza on, że cztery różne wartości wpisanej do pliku zmiennej „grupa” zostaną przekodowane na wartości drugiej zmiennej instrumentalnej o nazwie T3.
- postępując analogicznie do sposobu opisanego w dwóch wyżej opisanych punktach naciskamy przycisk Wartości źródłowe i wynikowe i wpisujemy kolejno do okienek Wartość w częściach zatytułowanych: Wartość źródłowa oraz Wartość wynikowa:
- liczby „1” i „0” i naciskamy przycisk Dodaj. Wpis „1 → 0” w okienku Źródłowa → Wynikowa oznacza, że wszystkie osoby z grupy a1 w wektorze T3 będą miały zera.
- liczby „2” i „0” i naciskamy przycisk Dodaj. Wpis „2 → 0” w okienku Źródłowa → Wynikowa oznacza, że wszystkie osoby z grupy a2 w wektorze T3 będą miały zera.
- liczby „3” i „1” i naciskamy przycisk Dodaj. Wpis „3 → 1” w okienku Źródłowa → Wynikowa oznacza, że wszystkie osoby z grupy a3 w wektorze T3 będą miały jedynki.
- liczby „4” i „–1” i naciskamy przycisk Dodaj. Wpis „4 → –1” w okienku Źródłowa → Wynikowa oznacza, że wszystkie osoby z grupy a4 w wektorze T3 będą miały wpisane wartości –1.
Po naciśnięciu przycisków Dalej oraz OK. SPSS dopisze do pliku nową zmienną o nazwie „T3” i osobom z grupy a3 przypisze na niej jedynki, osobom z grupy a4 wartości „–1”, zaś osoby z grup a1 oraz a3 będą miały na tej zmiennej przypisane zera.
Efekt wyżej przedstawionych przekształceń ilustruje poniższa tabela:
|
|
Grupa |
czas |
T1 |
T2 |
T3 |
|
1 |
1 |
21 |
1 |
0 |
0 |
|
2 |
1 |
23 |
1 |
0 |
0 |
|
3 |
1 |
21 |
1 |
0 |
0 |
|
4 |
1 |
15 |
1 |
0 |
0 |
|
5 |
1 |
20 |
1 |
0 |
0 |
|
6 |
1 |
25 |
1 |
0 |
0 |
|
7 |
1 |
27 |
1 |
0 |
0 |
|
8 |
1 |
16 |
1 |
0 |
0 |
|
9 |
1 |
22 |
1 |
0 |
0 |
|
10 |
1 |
17 |
1 |
0 |
0 |
|
11 |
2 |
30 |
0 |
1 |
0 |
|
12 |
2 |
29 |
0 |
1 |
0 |
|
13 |
2 |
21 |
0 |
1 |
0 |
|
14 |
2 |
22 |
0 |
1 |
0 |
|
15 |
2 |
31 |
0 |
1 |
0 |
|
16 |
2 |
28 |
0 |
1 |
0 |
|
17 |
2 |
26 |
0 |
1 |
0 |
|
18 |
2 |
25 |
0 |
1 |
0 |
|
19 |
2 |
27 |
0 |
1 |
0 |
|
20 |
2 |
31 |
0 |
1 |
0 |
|
21 |
3 |
33 |
0 |
0 |
1 |
|
22 |
3 |
28 |
0 |
0 |
1 |
|
23 |
3 |
29 |
0 |
0 |
1 |
|
24 |
3 |
33 |
0 |
0 |
1 |
|
25 |
3 |
30 |
0 |
0 |
1 |
|
26 |
3 |
27 |
0 |
0 |
1 |
|
27 |
3 |
25 |
0 |
0 |
1 |
|
28 |
3 |
29 |
0 |
0 |
1 |
|
29 |
3 |
25 |
0 |
0 |
1 |
|
30 |
3 |
26 |
0 |
0 |
1 |
|
31 |
4 |
42 |
–1 |
–1 |
–1 |
|
32 |
4 |
32 |
–1 |
–1 |
–1 |
|
33 |
4 |
39 |
–1 |
–1 |
–1 |
|
34 |
4 |
35 |
–1 |
–1 |
–1 |
|
35 |
4 |
41 |
–1 |
–1 |
–1 |
|
36 |
4 |
38 |
–1 |
–1 |
–1 |
|
37 |
4 |
37 |
–1 |
–1 |
–1 |
|
38 |
4 |
40 |
–1 |
–1 |
–1 |
|
39 |
4 |
39 |
–1 |
–1 |
–1 |
|
40 |
4 |
38 |
–1 |
–1 |
–1 |
2. Uruchomienie analizy regresji w pakiecie SPSS
Przypomnijmy, że aby uruchomić analizę regresji w pakiecie SPSS należy – jak już pokazywaliśmy omawiając kodowanie zero-jedynkowe - wybrać następujące elementy z menu:
- Analiza → Regresja → Liniowa…
- do okienka Zmienna zależna przenosimy zmienną „czas”
- do okienka Zmienne niezależne przenosimy wektory instrumentalne „T1, T2 i T3”
- upewnijmy się, że w okienku Metoda znajduje się „Metoda wprowadzania” (zaznaczana domyślnie)
Po klikniƒôciu przycisku OK otrzymamy nastƒôpujƒÖcy wydruk:
Regresja
Zmienne wprowadzone/usuniƒôte(b)
|
Model |
Zmienne wprowadzone |
Zmienne usuniƒôte |
Metoda |
|
1 |
T3, T2, T1(a) |
. |
Wprowadzanie |
a Wszystkie wyspecyfikowane zmienne zostały wprowadzone.
b Zmienna zależna: czas
Model - Podsumowanie
|
Model |
R |
R-kwadrat |
Skorygowane R-kwadrat |
Błąd standardowy oszacowania |
|
1 |
,892(a) |
,795 |
,778 |
3,33125 |
a Predyktory: (Stała), T3, T2, T1
Analiza wariancji(b)
|
Model |
|
Suma kwadratów |
df |
≈öredni kwadrat |
F |
Istotność |
|
1 |
Regresja |
1552,275 |
3 |
517,425 |
46,627 |
,000(a) |
|
Reszta |
399,500 |
36 |
11,097 |
|
|
|
|
Ogółem |
1951,775 |
39 |
|
|
|
a Predyktory: (Stała), T3, T2, T1
b Zmienna zależna: czas
Współczynniki(a)
|
Model |
|
Współczynniki niestandaryzowane |
Współczynniki standaryzowane |
t |
Istotność |
|||
|
B |
Błąd standardowy |
Beta |
||||||
|
1 |
(Stała) |
28,575 |
,527 |
|
54,251 |
,000 |
||
|
T1 |
-7,875 |
,912 |
-,797 |
-8,632 |
,000 |
|||
|
T2 |
-1,575 |
,912 |
-,159 |
-1,726 |
,093 |
|||
|
T3 |
-,075 |
,912 |
-,008 |
-,082 |
,935 |
|||
a Zmienna zależna: czas
3. Interpretacja wydruku
Jeżeli porównamy dwa wydruki:
dla analizy regresji z wykorzystaniem zmiennej jako≈õciowej zakodowanej w systemie zero-jedynkowym (punkt A2)
dla analizy regresji z wykorzystaniem zmiennej jako≈õciowej zakodowanej w systemie quasi-eksperymentalnym (punkt B2)
to okaże się, że różnią się one wyłącznie wartościami zamieszczonymi w ostatniej tabeli zatytułowanej „Współczynniki”. Stąd też znaczenie i interpretacja wartości wskaźnika R-kwadrat oraz wyniku testu F są w obu przypadkach identyczne (oraz zgodne z efektem analizy wariancji przeprowadzonej dla tych samych danych)
Cóż więc zmienia w interpretacji zależności pomiędzy zmienną zależną (czas) oraz niezależną zmienną jakościową (grupa) zabieg kodowania quasi-eksperymentalnego? Otóż zmieni on interpretację nadawaną cząstkowym współczynnikom a oraz b w równaniu regresji. Teraz przyjmie ono inną niż w przypadku kodowania zero-jedynkowego postać:
- wzór ogólny dla trzech wektorów instrumentalnych:
- równanie regresji dla zmiennej jakościowej w systemie kodowania zero-jedynkowego (punkt A2 – gdzie grupa a4 zakodowana została za pomocą sekwencji: 0, 0, 0)

- równanie regresji dla zmiennej jakościowej w systemie kodowania quasi-eksperymntalnego (punkt B2 – gdzie grupa a4 zakodowana została za pomocą sekwencji: –1, –1, –1):
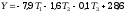
Równanie regresji policzone dla tych samych danych raz zakodowanych w systemie zero-jedynkowym, a raz w systemie quasi-eksperymentalnym zawiera inne współczynniki. Jak więc interpretować poszczególne współczynniki regresji z powyższego równania? Otóż:
- współczynnik a to po prostu średnia ogólna zmiennej zależnej (równa 28,6)
- współczynnik bY1 to odchylenie od średniej ogólnej średniej tej grupy, która na wektorze instrumentalnym T1 ma jedynki (20,7 – 28,6 = – 7,9)
- współczynnik bY2 to odchylenie od średniej ogólnej średniej tej grupy, która ma jedynki na wektorze instrumentalnym T2 (27,0 – 28,6 = – 1,6)
- zaś współczynnik bY3 to odchylenie od średniej ogólnej średniej tej grupy, która z kolei na wektorze instrumentalnym T3 ma jedynki (28,5 – 28,6 = – 0,1).
Aby zrozumieć, co z tego wynika, wróćmy na moment do modelu analizy wariancji.
3a. Raz jeszcze o analizie wariancji
Przypomnijmy, że w jednoczynnikowej analizie wariancji strukturę wyniku pojedynczej osoby badanej można wyrazić w sposób następujący:
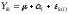
Co oznaczają kolejne symbole w wyżej przedstawionym równaniu? Otóż:
Yik – to wynik konkretnej osoby badanej (osoby k z grupy i). I tak na przykład wyrażenie Y24 oznacza wynik 4-tej osoby z 2-giej grupy porównawczej)
μ – średni wynik zmiennej Y w populacji
αi – efekt oddziaływania i-tego poziomu czynnika A na zmienną zależną Y (i-ty poziom czynnika, to mówiąc inaczej grupa porównawcza, do której należy osoba badana)
εk(i) – błąd eksperymentalny (czyli zmienność Y wywołana przez wszystkie te źródła, które nie są czynnikiem A)
Ponieważ mówimy tu o efektach populacyjnych (używamy greckiego alfabetu) powinniśmy się teraz zastanowić nad tym, w jaki sposób są one szacowane na podstawie wartości uzyskanych w próbie.
oszacowaniem średniej dla zmiennej zależnej w populacji (μ) jest średnia tej zmiennej w próbie,
oszacowaniem efektu oddziaływania i-tego poziomu czynnika A w populacji (αi) jest odchylenie średniej odpowiadającej i-temu poziomowi czynnika w próbie od średniej ogólnej w tejże próbie (efekt będzie tym większy, im bardziej średnia grupowa będzie się różniła od średniej ogólnej),
zaś oszacowaniem efektu błędu eksperymentalnego w populacji (αi) jest odchylenie wyniku osoby badanej od średniej odpowiadającej i-temu poziomowi czynnika (tj. od średniej tej grupy, do której należy osoba badana).
Prześledźmy teraz kolejny przykład, który pomoże w zrozumieniu tożsamości obu omawianych modeli.
|
grupa (czynnik) |
≈örednia |
Odchylenie standardowe |
N |
|
a1 |
20,7000 |
3,86005 |
10 |
|
a2 |
27,0000 |
3,52767 |
10 |
|
a3 |
28,5000 |
2,91548 |
10 |
|
a4 |
38,1000 |
2,92309 |
10 |
|
Ogółem |
28,5750 |
7,07429 |
40 |
Wyżej zamieszczona tabela przypomina średnie dla każdej z czterech grup eksperymentalnych oraz średnią dla całej próby złożonej z 40 osób badanych.
(1) Czas reakcji osoby numer 7 z pierwszej grupy porównawczej (a1) wynosi 27 sek x 102 i możemy go opisać w następujący sposób:
|
Parametr populacyjny |
Oszacowanie parametru populacyjnego |
Obliczenia |
W przybliżeniu |
|
μ |
Średnia ogólna |
+ 28,575 |
+ 28,6 |
|
αi |
Średnia grupowa – średnia ogólna |
20,700 – 28,575 = – 7,875 |
– 7,9 |
|
εk(i) |
Wynik osoby badanej – średnia grupowa |
27,000 – 20,700 = + 6,300 |
+ 6,3 |
|
|
|
Suma (Y17) |
27,0 |
(2) Czas reakcji osoby numer 4 z drugiej grupy porównawczej (a2) wynosi 22 sek x 102 i możemy go opisać tak::
|
Parametr populacyjny |
Oszacowanie parametru populacyjnego |
Obliczenia |
W przybliżeniu |
|
μ |
Średnia ogólna |
+ 28,575 |
+ 28,6 |
|
αi |
Średnia grupowa – średnia ogólna |
27,000 – 28,575 = – 1,575 |
– 1,6 |
|
εk(i) |
Wynik osoby badanej – średnia grupowa |
22,000 – 27,000 = – 5,000 |
– 5,0 |
|
|
|
Suma (Y24) |
22,0 |
(3) Czas reakcji osoby numer 9 z trzeciej grupy porównawczej (a3) wynosi 25 sek x 102 i możemy go opisać następująco::
|
Parametr populacyjny |
Oszacowanie parametru populacyjnego |
Obliczenia |
W przybliżeniu |
|
μ |
Średnia ogólna |
+ 28,575 |
+ 28,6 |
|
αi |
Średnia grupowa – średnia ogólna |
28,500 – 28,575 = – 0,075 |
– 0,1 |
|
εk(i) |
Wynik osoby badanej – średnia grupowa |
25,000 – 28,500 = – 3,500 |
– 3,5 |
|
|
|
Suma (Y39) |
25,0 |
(4) Czas reakcji osoby numer 1 z czwartej grupy porównawczej (a4) wynosi 42 sek x 102 i możemy go opisać tak::
|
Parametr populacyjny |
Oszacowanie parametru Populacyjnego |
Obliczenia |
W przybliżeniu |
|
μ |
Średnia ogólna |
+ 28,575 |
+ 28,6 |
|
αi |
Średnia grupowa – średnia ogólna |
38,100 – 28,575 = + 9,525 |
+ 9,5 |
|
εk(i) |
Wynik osoby badanej – średnia grupowa |
42,000 – 38,100 = + 3,900 |
+ 3,9 |
|
|
|
Suma (Y41) |
42,0 |
3b. I znowu analiza regresji
Wróćmy do równania regresji, które uzyskaliśmy po zakodowaniu zmiennej jakościowej w systemie quasi-eksperymentalnym (punkt B2):
i odnieśmy je do wyróżnionych pogrubioną czcionką wierszy zawartych w tabelach [od (1) do (4)] w punkcie 3a:
ad (1) Efekt oddziaływania i-tego poziomu czynnika dla osoby numer 7 z pierwszej grupy porównawczej (a1) wynosi – 7,9. Współczynnik regresji bY1 dla wektora instrumentalnego T1 (na którym grupie a1 przypisano jedynki) również wynosi – 7,9.
ad (2) Efekt oddziaływania i-tego poziomu czynnika dla osoby numer 4 z drugiej grupy porównawczej (a2) wynosi – 1,6. Współczynnik regresji bY2 dla wektora instrumentalnego T2 (na którym grupie a2 przypisano jedynki) również wynosi – 1,6.
ad (3) Efekt oddziaływania i-tego poziomu czynnika dla osoby numer 9 z trzeciej grupy porównawczej (a3) wynosi – 0,1. Współczynnik regresji bY3 dla wektora instrumentalnego T3 (na którym grupie a3 przypisano jedynki) również wynosi – 0,1.
ad (4) Efekt oddziaływania i-tego poziomu czynnika dla osoby numer 1 z czwartej grupy porównawczej (a4) wynosi + 9,5. Tego efektu nie znajdziemy wprost w równaniu regresji. Wrócimy do niego za moment.
Wszystko, co napisano powyżej można podsumować następująco:
- współczynniki zapisane przy kolejnych zmiennych instrumentalnych (od T1 do T3) w równaniu regresji są tożsame z oceną efektów kolejnych poziomów czynnika (od a1 do a3) w modelu analizy wariancji.
Jak zatem w analizie regresji wyznaczyć efekt ostatniego poziomu czynnika (a4)? Musimy się tutaj odwołać do właściwości średniej arytmetycznej. Kiedy w modelu analizy wariancji szukamy efektów działania poszczególnych poziomów czynnika, liczymy odchylenia kolejnych średnich grupowych od średniej ogólnej (patrz tabele od 1 do 4 w punkcie 3a). Im większe będą te odchylenia, tym większy efekt działania czynnika. Jedną z właściwości średniej arytmetycznej jest ta, że suma odchyleń poszczególnych wyników od tego wskaźnika wynosi zero (ponieważ średnia arytmetyczna jest środkiem ciężkości dla wyników, a co za tym idzie – równoważy wszystkie wartości, które są od niej mniejsze oraz większe). Dlatego tez suma efektów wszystkich poziomów czynnika musi być równa zero. Dlatego też:
|
Efekt pierwszego poziomu czynnika |
α1 |
równa się – 7,9 |
|
Efekt drugiego poziomu czynnika |
α2 |
równa się – 1,6 |
|
Efekt trzeciego poziomu czynnika |
α3 |
równa się – 0,1 |
|
Suma efektów od α1 do α3 równa się – 9,6 |
||
Jeżeli (korzystając z właściwości średnie arytmetycznej) suma odchyleń poszczególnych wyników od średniej równa się zero:
α1 + α2 + α3 + α4 = 0
to:
α4 = – (α1 + α2 + α3)
Dlatego:
α4 = – ( – 7,9 – 1,6 – 0,1)
α4 = + 9,6 [patrz tabela (4) punkt 3.a].
Oszacowaliśmy w ten sposób efekt czwartego poziomu czynnika A (a4).
Na zakończenie zapytajmy jeszcze o to, co oznacza test istotności poszczególnych współczynników b w tabeli o nazwie „Współczynniki” (którą raz jeszcze przytaczamy poniżej) na wydruku z analizy regresji
Współczynniki(a)
|
Model |
|
Współczynniki niestandaryzowane |
Współczynniki standaryzowane |
t |
Istotność |
|||
|
B |
Błąd standardowy |
Beta |
||||||
|
1 |
(Stała) |
28,575 |
,527 |
|
54,251 |
,000 |
||
|
T1 |
-7,875 |
,912 |
-,797 |
-8,632 |
,000 |
|||
|
T2 |
-1,575 |
,912 |
-,159 |
-1,726 |
,093 |
|||
|
T3 |
-,075 |
,912 |
-,008 |
-,082 |
,935 |
|||
a Zmienna zależna: czas
Przypomnijmy, że w przypadku kodowania zero-jedynkowego testy t zamieszczone w tej tabeli dla każdej z trzech zmiennych instrumentalnych testują po prostu, czy różnica pomiędzy średnim wynikiem dla tej grupy osób badanych, która na danym wektorze instrumentalnym ma jedynki oraz średnim wynikiem grupy referencyjnej (zakodowanej za pomocą sekwencji złożonej z samych zer) jest istotna. Dzieje się tak, ponieważ kolejne współczynniki b w równaniu regresji są po prostu tymi różnicami.
W systemie kodowania quasi-eksperymentalnego współczynniki b interpretowane są inaczej. Są to odchylenia kolejnych średnich grupowych (poza średnią tej grupy, która zakodowana została za pomocą sekwencji złożonej z wartości „–1”) od średniej ogólnej. Dlatego też testy t zamieszczone w powyższej tabeli testują istotność takiego właśnie efektu. Okazało się, że:
- średnia grupy a1 istotnie statystycznie różni się od średniej ogólnej (t= – 8,632; p<0,001)
- średnia grupy a2 nie różni się istotnie statystycznie od średniej ogólnej (t= – 1,726; p=0,093)
- średnia grupy a3 nie różni się istotnie statystycznie od średniej ogólnej (t= – 0,082; p=0,935)
Ujemny znak przy współczynnikach b (oraz oczywiście przy statystykach t) oznacza, że wszystkie wyżej wymienione średnie grupowe są niższe od średniej ogólnej. Średnia dla grupy a1 jest najniższa i istotnie różni się od średniej ogólnej. Średnie dla grup a2 oraz a3 są wyższe od średniej grupy a1 (mniej się odchylają), od średniej ogólnej się nie różnią,
Gdybyśmy teraz zmienili sposób kodowania i inną grupę (a1, a2 lub a3) oznaczylibyśmy sekwencją wartości „–1”, to okazałoby się, że różnica pomiędzy średnią grupy a4 i średnią ogólną jest istotna statystycznie, a współczynnik b byłby dodatni. Oznacza to, że wynik ten jest istotnie wyższy od średniej ogólnej.
1 Brzeziński, J., Stachowski, R. (1984). Zastosowanie analizy wariancji w eksperymentalnych badaniach psychologicznych (wyd. 2). Warszawa: PWN.
2 Brzeziński, J. (1996). Metodologia badań psychologicznych. Warszawa: Wyd. Nauk. PWN.
3 Brzeziński, J. (1996). Metodologia badań psychologicznych. Warszawa: Wyd. Nauk. PWN.
Wyszukiwarka