1. Wstęp
Literatura
Dodatek
Wstęp
Wprowadzenie
Pierwsze komputery i języki programowania sięgają lat 50-tych naszego stulecia. Od tamtego czasu informatyka rozwija się bardzo szybko. Nowe technologie wytwarzania procesorów, nowe rozwiązania w budowie różnych podzespołów, nowe trendy w informatyce sprawiają, że ta dziedzina staje się coraz ważniejsza i bliższa każdemu człowiekowi. Rozpęd z jakim komputery ogarnęły świat przerósł wszelkie oczekiwania. Informatyka funkcjonuje w prawie każdej dziedzinie nauki.
Nowe badania, symulacje, testy przeprowadzane są przy użyciu komputerów. Tak ważna dziedzina jak medycyna większość nowych badań, a także nowych metod leczenia (dokonywanie operacji i zabiegów) opiera na informatyce.
Jednak każda dziedzina nauki, przemysłu ma zupełnie inne problemy i trudno te rzeczy ze sobą powiązać. Dlatego ciągle powstają nowe kierunki rozwoju w informatyce. Jednym z nich jest na pewno programowanie równoległe i rozproszone, a co z tym się wiąże to problem przetwarzania coraz większej ilości informacji w „rozsądnym czasie”, przyspieszenie działania algorytmów i programów, bardziej optymalne i równomierne rozłożenie obciążenia w całej sieci, wykonywanie jednego zadania przez grupę procesorów, komputerów. Problem ten dotyczy każdej dziedziny.
Zagadnienie przyspieszenia i poprawy pracy systemu jest zadaniem bardzo ważnym. W tym celu ciągle powstają i są rozwijane języki do programowania współbieżnego i rozproszonego. Programowanie równoległe wiąże się z szeregiem problemów. Część z nich została lepiej lub gorzej rozwiązana.
Cel pracy
Celem pracy było zbadanie i ocena działania programów napisanych w języku CC++ przeznaczonym do programowania współbieżnego i rozproszonego. Zaimplementowane algorytmy zostały przetestowane pod kątem poprawności wyników i szybkości działania.
Wyniki zostały porównane z wersją sekwencyjną napisaną w C++, a jeden z programów w CC++ z programem napisanym pod systemem PVM (ang. Parallel Virtual Machine) przeznaczonym do programowania równoległego i rozproszonego. Na tej podstawie została wydana ocena przydatności języka CC++, a także ogólnie języków do programowania współbieżnego i rozproszonego.
Testy przeprowadzono na komputerze Cray CS 6400 zainstalowanym w Centralnym Ośrodku Informatyki Politechniki Warszawskiej.
Organizacja pracy
Rozdział pierwszy ma charakter wstępny.
Rozdział drugi przedstawia definicje, podstawowe informacje i zagadnienia z dziedziny programowania równoległego i rozproszonego. Omówiono kilka języków współbieżnych z podaniem kluczowych informacji o każdym z nich. Wymieniono i opisano biblioteki do programowania równoległego. Komputery równoległe w tym Cray opisane zostały na końcu rozdziału.
Rozdział trzeci przedstawia język CC++. Wymienione zostały systemy operacyjne dla CC++ oraz kompilatory C++ zgodne z kodem generowanym przez preprocesor CC++. Omówiono główne idee oraz nowe instrukcje języka CC++ wraz z przykładami. Przedstawiony został krótki sposób instalacji programu CC++ oraz podany adres serwera z pełną dokumentacją i programem instalacyjnym.
Rozdział czwarty omawia sposoby i narzędzia do śledzenia wątków. Przedstawia programy do mierzenia obciążenia zarówno całego systemu, jak też każdego procesora osobno. Na podstawie tych narzędzi wykonane zostały testy zaimplementowanych algorytmów i pomiary obciążenia systemu.
Rozdział piąty wymienia napisane programy. Szczegółowo omówiono poszczególne algorytmy uzasadniając ich użycie oraz przedstawiono fragmenty kodu, które zostały zrównoleglone.
Rozdział szósty zawiera całą procedurę testowania opisanych algorytmów. Przedstawia modyfikacje kodu w celu przyspieszenia wykonania się programu oraz rezultaty zmian. Wykresy, pomiary i wnioski prezentują cechy i ocenę języka CC++.
Rozdział siódmy zawiera podsumowanie i wnioski końcowe.
Podstawowe definicje i zagadnienia
Program
Program jest to plik wykonywalny, utworzony zazwyczaj przy użyciu programu łączącego i znajdujący się w pamięci dyskowej. Jedynym sposobem spowodowania wykonania się programu przez system Unix jest wywołanie funkcji systemowej exec.
Proces
Proces powstaje w momencie, gdy program wykonywany jest przez system operacyjny. Każdy proces ma przydzielony przez system pewien obszar pamięci. Pamięć podzielona jest na kilka części:
tekst - pamięć zawierająca rozkazy maszynowe, które są wykonywane przez program.
dane - pamięć zawierająca dane programu.
sterta - pamięć przeznaczona na dane do dynamicznego przydzielania podczas wykonywania się procesu.
stos - pamięć przeznaczona do przechowywania adresów powrotu funkcji oraz danych potrzebnych dla tych funkcji.
Każdy proces otrzymuje od procesora(-ów) pewne zasoby potrzebne do wykonywania się procesu.
Wątek
Różnica między procesem a wątkiem polega przede wszystkim na sposobie wykorzystywania dostępnych zasobów. Proces w zależności od potrzeby może mieć utworzonych kilka wątków. Wątki korzystają z pamięci procesu. Wątki procesu mogą wykonywać się współbieżnie. Wątki mogą być synchroniczne lub asynchroniczne. Wątki synchroniczne same przekazują sobie sterowanie, natomiast przy asynchronicznych synchronizacja musi być oprogramowana.
Program współbieżny (równoległy)
Program współbieżny składa się z procesów, które wzajemnie komunikują się i synchronizują w sposób określony przez programistę. Typowym przykładem programu współbieżnego jest system operacyjny, który składa się z wielu procesów współpracujących ze sobą i obsługujących różne zasoby systemu.
Program rozproszony
Program rozproszony ma takie samo znaczenie jak program współbieżny, jednak tego terminu używa się w przypadku sieci komputerowych i systemów rozproszonych. W takich przypadkach jedynym sposobem wymiany informacji między procesami jest wysłanie komunikatu, natomiast w programie współbieżnym procesy mogą komunikować się przez zmienne globalne.
Semafor
Semafor używany jest do synchronizacji procesów . Na semaforze można wykonywać tylko dwie operacje:
podniesienie semafora
opuszczenie semafora
Dzięki tym operacjom semafor umożliwia wstrzymywanie i wznawianie procesów.
Monitor
Monitor jest to zbiór zmiennych oraz procedur i funkcji, które działają na tych zmiennych. Podstawową cechą monitora jest fakt, że wykonanie procedury lub funkcji monitora jest sekcją krytyczną wykonującego go procesu. Oznacza to, że tylko jeden spośród współbieżnie działających procesów może wykonywać procedurę monitora. Oprócz tego istnieje możliwość wstrzymywania i wznawiania procesów wewnątrz procedury monitora.
Sekcja krytyczna
Sekcja krytyczna zapewnia, że w danej chwili tylko jeden spośród współbieżnie działających procesów może wykonywać instrukcje objęte jej zasięgiem.
Komputery równoległe
Wprowadzenie
Komputery równoległe są to maszyny wieloprocesorowe wyposażone w specjalne szyny danych do szybkiego przekazywania informacji między procesorami. W zależności od ilości procesorów projektowana jest cała struktura połączeń pomiędzy nimi. Opracowywane są mechanizmy komunikacji zarówno pomiędzy poszczególnymi procesorami, jak także pomiędzy pamięcią wspólną i pamięcią lokalną (ang. cache) każdego procesora.
Odświeżanie buforów każdego procesora, podział zadania między procesory, automatyczne przekazywanie części zadania do mniej obciążonego procesora, badanie obciążenia każdego procesora, informowanie innych procesorów o zakończeniu zadania, przekazywanie danych między sobą to zadania, które muszą być rozwiązane podczas projektowania takiego komputera. Minimalizuje się ilość potrzebnych zapisów i odczytów zarówno z pamięci dyskowej, jak i globalnej (wspólnej pamięci dzielonej).
Rozbudowa takiego systemu o jeden procesor wiąże się często z przebudową całej struktury. Podwojenie ilości procesorów nie oznacza przyspieszenia pracy dwukrotnie.
Komputer wieloprocesorowy dużo czasu traci na komunikację i synchronizację między procesorami, procesami oraz pamięcią zarówno lokalną, jak globalną.
Pod zaprojektowaną architekturę komputera równoległego powstają specjalnie opracowane systemy operacyjne potrafiące maksymalnie wykorzystać moc takiego komputera. Systemy takie wyposażone są w biblioteki procedur i funkcji do obsługi wszystkich urządzeń i mechanizmów komputera. Biblioteki umożliwiają zarządzanie procesorami, pamięcią, komunikacją. Dopiero pod gotowe biblioteki i systemy operacyjne opracowywane są języki do programowania równoległego.
Programista pisząc program na maszynę równoległą musi znać mniej lub bardziej dokładnie specyfikację i budowę całego systemu w zależności od tego jakie mechanizmy będzie chciał sam oprogramować.
Podstawowe informacje o komputerze Cray CS 6400
Architektura typu SMP (symetryczna, równoległa), aktualnie 16 procesorów SuperSPARC+ (z możliwością rozbudowy do 64).
Pamięć operacyjna 768 MB (z możliwością rozbudowy do 16 GB).
Pamięć dyskowa około 84 GB (z możliwością rozbudowy do 2 TB).
System operacyjny Solaris 2.5 z rozszerzeniami firmy Cray Research.
Całkowita zgodność binarna z programami napisanymi dla stacji roboczych SUN. Każdy program skompilowany na stacji roboczej SUN z procesorem SuperSPARC może być bez rekompilacji uruchomiony na CS 6400. Większość programów skompilowanych na CS 6400 może być bez rekompilacji uruchomiona na stacjach roboczych SUN.
Przedstawiony komputer znajduje się na Politechnice Warszawskiej w COI (Centralny Ośrodek Informatyki). Na nim zostały przetestowane programy równoległe i sekwencyjne opisane w tej pracy.
Języki równoległe
Wprowadzenie
Języki równoległe zyskały uznanie i są coraz częściej stosowane w sieciach komputerowych, systemach rozproszonych, komputerach jedno i wieloprocesorowych. Mechanizmy do tworzenia nowych procesów, komunikacji między procesami, synchronizacji procesów stały się bardzo wygodne podczas programowania. Umożliwienie programowania równoległego ułatwiło programowanie w systemach rozproszonych, a także spowodowało powstanie wielu nowych algorytmów uwzględniających i wykorzystujących równoległe wykonywanie się pewnych zadań.
Wiele zagadnień i algorytmów wymagających dużej mocy obliczeniowej komputerów stara się rozbić na mniejsze części i w ten sposób wykorzystać moc obliczeniową kilku komputerów lub procesorów. Wiąże się to z nowymi trudnościami takimi jak wspólny dostęp do danych, integralność danych, odświeżanie buforów z danymi w sieciach rozległych, przekazywanie dużych ilości informacji. Ułatwienie oprogramowania komunikacji między procesami powoduje większą przejrzystość i czytelność programów, a także powoduje większą niezawodność i skuteczność.
Przedstawione poniższe języki do programowania współbieżnego mają długą historię. Problemy i nowe potrzeby dotyczące programowania równoległego są ciągle aktualne, a przykładem jest język CC++, który powstał dopiero na początku lat 90-tych.
Język Pascal_C
Pascal_C powstał w Instytucie Informatyki Uniwersytetu Warszawskiego. Język ten został wzbogacony o dwie instrukcje wykonania współbieżnego cobegin, coend oraz możliwość deklarowania monitorów i procesów w taki sam sposób jak deklaruje się procedury i funkcje.
Język Concurrent Pascal
Concurrent Pascal został rozszerzony o mechanizmy programowania współbieżnego. Można definiować specjalne typy: monitorowy i procesowy. W języku został zdefiniowany typ kolejkowy (ang. queue). Na zmiennych tego typu można wykonywać operacje czekania (ang. delay, wait), wznawiania (ang. continue, signal) oraz funkcję do sprawdzania czy kolejka jest pusta (ang. empty).
Język Pascal Plus
Podstawowym pojęciem w Pascal Plus jest koperta (ang. envelope). Koperta ma podobne znaczenie jak monitor tzn. można w niej deklarować zmienne, procedury i funkcje z tą różnicą, że nie ma ograniczenia na ilość procesów współbieżnych korzystających jednocześnie z jej procedur.
Język Modula 2
Język Modula 2 zaprojektowany został przez Wirth'a jako rozszerzenie języka Pascal. Kluczowym elementem jest pojęcie modułu. W module mogą być deklarowane zmienne, procedury, funkcje. Moduł Processes służy do programowania współbieżnego. Zawiera procedurę do tworzenia i uruchamiania nowego procesu, a także typ SIGNAL. Na zmiennych typu SIGNAL zdefiniowane są operacje czekania (ang. wait), wysłania komunikatu (ang. send), zainicjowania (ang. init). Dzięki priorytetom, które są nadawane modułowi, moduł może pełnić funkcję monitora.
Język Modula 3
Język Modula 3 powstał na podstawie Modula 2 i Modula 2+. Zrezygnowano tutaj z procesów na rzecz wątków. Główną zaletą wątków jest wspólna przestrzeń adresowa. Każdy wątek ma dostęp do wszystkich danych procesu, co nie powoduje dużych narzutów czasowych podczas tworzenia nowego wątku. Wadą jest., że wszystkie operacje na zmiennych wymagają synchronizacji.
Omawiany język CC++ w głównej mierze opiera się także tylko na wątkach.
Biblioteki do programowania równoległego
Wprowadzenie
Biblioteki do programowania współbieżnego mogą być dołączane do programów napisanych w językach C, Fortran, rzadziej C++. Procedury zawarte w tych bibliotekach pozwalają tworzyć programy równoległe.
PVM (ang. Parallel Virtual Machine)
PVM jest to zbiór bibliotek i narzędzi do programowania równoległego i rozproszonego. System PVM traktuje sieć z różnymi komputerami jako jedną maszynę. W ten sposób potrafi wykorzystać wszystkie dostępne komputery jedno i wieloprocesorowe do równoległego i rozproszonego przetwarzania. Biblioteki PVM dostępne są w trzech językach C, C++ i Fortran. PVM działa pod systemem Unix, Windows.
System PVM składa się z dwóch części. Pierwsza jest to demon pvmd3, który lokuje się na każdym dostępnym komputerze w sieci. W ten sposób buduje on jedną wirtualną maszynę. Drugą częścią systemu jest biblioteka funkcji PVM. Zawiera ona pełen zestaw procedur potrzebnych do tworzenia procesów, zarządzania i komunikowania się z nimi oraz konfigurowania maszyny wirtualnej.
Zarządzanie procesami na poziomie PVM wygląda podobnie jak w systemie Unix tzn. są grupy procesów, są procesy macierzyste i procesy potomne i każdy z nich ma unikalny identyfikator. A zatem możliwe jest usuwanie grupy, jak i pojedynczych procesów.
MPI (ang. Multiprocess Interface)
System MPI działa podobnie jak PVM. PVM stosowane jest głównie do łączenia systemów rozproszonych. MPI używamy pisząc program na maszynę wieloprocesorową.
BLAS (ang. Basic Linear Algebra Subprograms)
Biblioteka procedur matematycznych BLAS przeznaczona jest do operacji numerycznych w algebrze liniowej. Biblioteka składa się z trzech części. Pierwszy zbiór procedur przeznaczony jest do działań na obiektach wektor-wektor. Drugi na obiektach macierz-wektor. Natomiast trzeci na obiektach macierz-macierz. Ten trzeci zbiór często jest wykorzystywany w algorytmach działających na macierzach.
Biblioteka dopuszcza cztery typy danych, na których wykonuje obliczenia:
dane rzeczywiste pojedynczej precyzji
dane rzeczywiste podwójnej precyzji
dane zespolone pojedynczej precyzji
dane zespolone podwójnej precyzji
Wszystkie procedury BLAS pisane były z myślą o kompilatorze FORTRAN, jednak przy pewnym wysiłku można je uruchamiać także z C. Przystosowane zostały do wykorzystania mechanizmów równoległych i maszyn wieloprocesorowych. Pozwalają wykorzystać komputery równoległe bez zagłębiania się w tajniki tworzenia wątków i procesów. Procedury BLAS są napisane tak, aby w maksymalny sposób wykorzystać możliwość równoległego wykonywania algorytmów numerycznych.
Język CC++
Historia
Język CC++ (ang. Compositional C++) powstał na uczelni Caltech. Został stworzony przez członków Compositional Systems Research Group. Prace nad językiem częściowo finansowane były przez NSERC. Ostatnia wersja CC++ 0.4 powstała w roku 1995. Na tej wersji oparte zostały badania i testy.
Wprowadzenie
Język CC++ jest rozszerzeniem języka C++ o kilka dodatkowych dyrektyw i bibliotekę funkcji do programowania równoległego i rozproszonego. Oznacza to, że przed przystąpieniem do kompilacji w C++, pewne dyrektywy z języka CC++ muszą najpierw zostać przetłumaczone na kod zgodny z C++. Dlatego kod źródłowy musi zostać przeanalizowany przez preprocesor CC++, a następnie skompilowany przez C++. Po tych dwóch operacjach otrzymujemy plik wynikowy EXE.
Systemy operacyjne dla CC++
Język CC++ został zaimplementowany pod następującymi systemami operacyjnymi:
Solaris 2.3 and 2.4
AIX 3.2.5
SunOS 4.1.3
HP/UX 9.05
Kompilatory zgodne z CC++
Preprocesor języka CC++ może generować kod dla następujących kompilatorów:
Solaris 2.3 and 2.4
kompilator sunCC SC3.0.1 (zalecany przez autorów)
kompilator gcc 2.6.3 oraz biblioteka libg++ 2.6.2
AIX 3.2.5
kompilator xlC (IBM AIX XL C++ Compiler/6000)
kompilator C Set++
SunOS 4.1.3
kompilator gcc 2.6.3 oraz biblioteka libg++ 2.6.2
HP/UX 9.05
kompilator HP-C++ 3.5
Każdy ze wspomnianych systemów operacyjnych musi mieć dodatkowo zainstalowany pakiet do obsługi wątków (ang. threads package).
Nowe instrukcje i słowa kluczowe w CC++
Język CC++ dostarcza kilka nowych słów kluczowych. Są to tak naprawdę dyrektywy, ponieważ CC++ jest prekompilatorem do C++. Nowe instrukcje pozwalają w łatwy sposób tworzyć nowe wątki i procesy, wykonywać niektóre operacje równolegle, wykorzystywać do wykonania części zadań dodatkowe dostępne procesory i komputery w sieci.
Lista instrukcji z opisem i przykładami:
Instrukcja par.
Instrukcje ujęte w bloku par będą wykonywane równolegle. Oznacza to, że dla każdego wyrażenia z tego bloku zostanie stworzony oddzielny wątek, który wykona dane wyrażenie. Jeśli jakieś wyrażenia z bloku par zostaną ujęte w klamry {..}, to dla nich zostanie stworzony jeden wątek. Pierwsza instrukcja po bloku par zostanie wykonana dopiero po zakończeniu działania wszystkich stworzonych wątków. W bloku par nie można umieszczać następujących instrukcji: goto, break, continue, return.
Przykład:
Instrukcje z bloku par zostaną wykonane równolegle. Dlatego nie wiadomo, które z dwóch przypisań wykona się jako pierwsze. Jednak efekt końcowy w tym przypadku będzie prawidłowy.
Schemat wykonania instrukcji par:
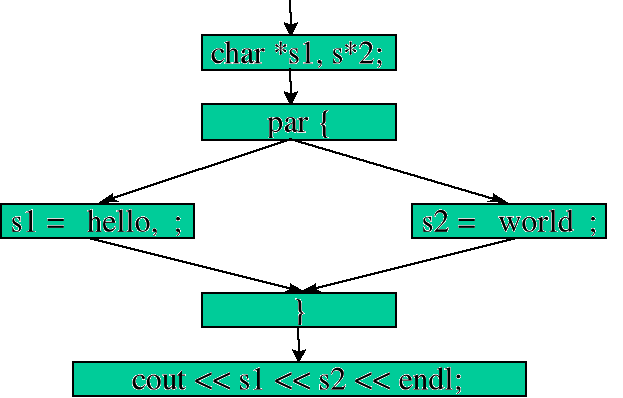
Gdyby zamiast zmiennych s1 i s2 była tylko jedna zmienna, do której chcielibyśmy zapisać zarówno jedno, jak i drugie słowo, to efekt końcowy mógłby być zupełnie inny. Wiąże się to z naruszeniem zasady dostępu (sekcja krytyczna). W dalszej części zostanie wyjaśnione jak do tego nie dopuścić.
Następujący program jest przykładem naruszającym zasadę dostępu do danych oraz budzący wątpliwości co do wyników zmiennych po bloku par:
Nie wiadomo czy najpierw wykona się przypisanie wartości zmiennym „b” i „c”, czy obliczenie wartości zmiennych „a” i „d”.
Fragment programu naruszający zasadę definiowania i zasięgu zmiennej:
W powyższym przykładzie zostaną utworzone dwa wątki. Jednak zmienna zdefiniowana w jednym wątku nie będzie widoczna (dostępna) w drugim. Zmienna „i” jest zmienną lokalną.
Instrukcja parfor.
Wszystkie iteracje z pętli parfor odbywają się równolegle. Wiąże się z tym szereg ograniczeń m.in. ilość iteracji musi być znana z góry i nie można jej zmienić w trakcie wykonywania się jednej z nich. Po drugie trzeba być bardzo ostrożnym, aby nie naruszyć zasad dostępu do danych. Dodatkowo nie mogą być używane takie instrukcje jak goto, break, continue, return.
Przykład:

Przypisanie wartości do kolejnych elementów tablicy zostanie wykonane równolegle.
Schemat wykonania instrukcji parfor:
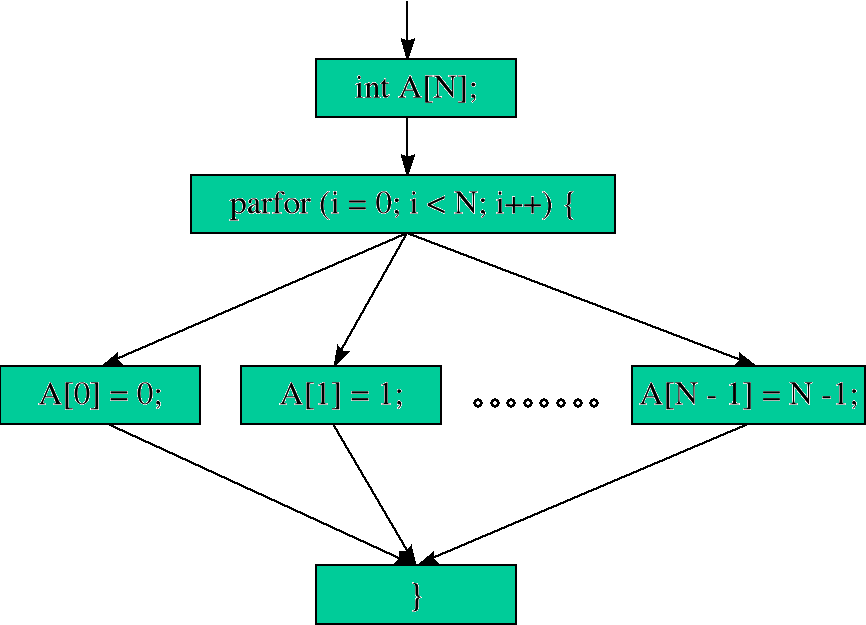
Instrukcja spawn.
Instrukcja spawn uruchamia funkcję w nowym niezależnym wątku. Oznacza to, że synchronizacja między wywołaniem tej funkcji a czekaniem na pełne wykonanie się musi być zrealizowana przez program. CC++ umożliwia czekanie na zakończenie działania takiego wątku. Typowym rozwiązaniem w takim przypadku jest skorzystanie z własności zmiennych typu sync.
Używając instrukcji spawn należy pamiętać o kilku rzeczach:
wywoływane funkcje instrukcją spawn nie mogą zwracać żadnej wartości
synchronizacja musi zostać oprogramowana przez programistę (czekanie na zakończenie wykonywania się funkcji wywołanej instrukcją spawn)
uważnie przemyśleć przekazywanie wszelkich referencji zmiennych lub wskaźników jako argumentów funkcji
Przykład 1:
Przykład 2:

Słowo kluczowe sync.
Typ sync służy do synchronizacji procesów. Zmienna typu sync ma podobne własności jak zmienna typu const w C++. W obu przypadkach zmiennym takim można tylko raz przypisać wartość. Można to zrobić w momencie deklaracji zmiennej lub w trakcie wykonywania się programu. Dopóki zmiennej typu sync nie zostanie przypisana wartość, dopóty wszelkie czynności związane z odczytem, porównywaniem, itd. zostają zawieszone (zaczną być wykonywane dopiero po przypisaniu wartości tej zmiennej).
Przykład:
Jeśli zmienne a, b, c, d nie byłyby dodatkowo typu sync końcowe wyniki tych czterech operacji mogłyby być zupełnie inne, np. przez nieprawidłową kolejność wykonania się tych instrukcji (dodawanie dwóch zmiennych zanim zostanie im przypisana sensowna wartość).
Schemat wykonania się programu wykorzystującego zmienne typu sync:
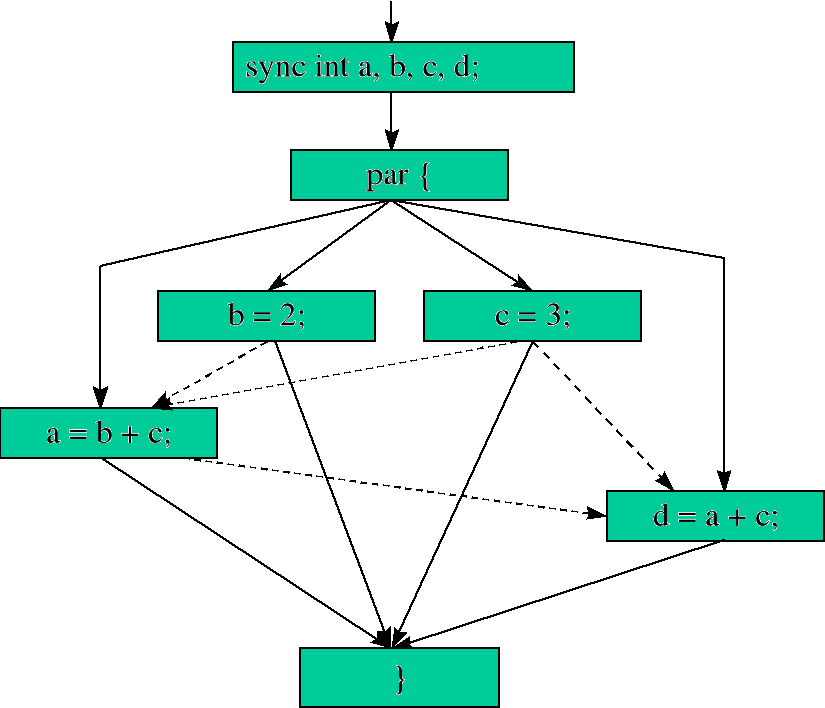
Funkcje z dyrektywą atomic.
Funkcje z dyrektywą atomic oznaczają, że będą wykonywane sekwencyjnie. Konsekwencją tego żadne dwie funkcje typu atomic nie mogą być wykonywane jednocześnie. Funkcji tych używa się w sekcjach krytycznych. Funkcje typu atomic mogą być deklarowane tylko jako metody klasy.
Przykład:
Celem przestawionego programu jest znalezienie wartości minimalnej w tablicy A[]. Wyszukiwanie i przypisywanie wartości minimalnej mogło być wykonywane równolegle, ponieważ funkcja check klasy Min została zadeklarowana jako atomic. Ze względu na własność dyrektywy atomic, kolejne wywołania funkcji check zostaną wykonane sekwencyjnie.
Schemat działania programu z dyrektywą atomic:
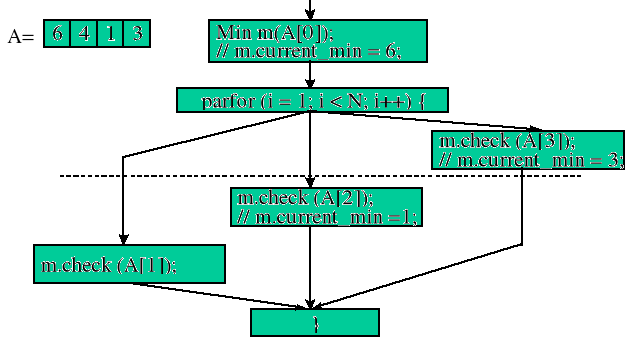
Obiekt processor object.
Dotychczas omówiono instrukcje par, parfor, spawn, które działały w ten sposób, że tworzyły wątki mające dostęp do wspólnego obszaru pamięci. Oznaczało to, że komunikacja i wymiana danych między takimi wątkami niczym nie różniła się od programu z jednym wątkiem, ponieważ zmienne były dostępne i widoczne w ten sam sposób z każdego wątku. Jednak, aby zapobiec nieoczekiwanym sytuacjom należało synchronizować dostęp do danych przez zmienne typu sync lub funkcje o typie atomic.
Obiekt processor object różni się tym, że po pierwsze ma odrębną pamięć, a po drugie dostęp do danych tego obiektu jest znacznie kosztowniejszy. Obiekty te używane są w programowaniu rozproszonym. Obiekt taki może zostać uruchomiony na innej maszynie. Stąd dostęp do danych i przesyłanie ich jest czasochłonne. Typ proc_t definiuje obiekt processor object. Podczas definicji należy podać nazwę pliku wykonywalnego oraz miejsce (nazwę serwera), gdzie obiekt (program) zostanie uruchomiony.
Przykład z obiektem processor object (składa się z trzech plików):
Następnie kompilujemy pliki cc++:
Wywołanie programu dist_Hello.out:
W wyniku wywołania dist_Hello.out uruchomione zostaną trzy obiekty (procesy) Greeter na następujących maszynach: dwa na Cray1 i jeden na Cray2.
Słowo kluczowe global.
W CC++ są dwa typy wskaźników: globalne i lokalne. Wskaźniki globalne (typ global) mogą odwoływać się do danych z innych obiektów processor object., natomiast lokalne tylko do danych obiektu procesora, w którym zostały utworzone. Dostęp do danych przez wskaźniki globalne jest dużo kosztowniejszy.
Wskaźniki globalne deklarowane są przez dodanie słowa kluczowego global np.
int *global gpint; // wskaźnik globalny na zmienną typu integer
int * *global gppint; // wskaźnik globalny do wskaźnika lokalnego na zmienną typu
integerC *global gpC; // wskaźnik globalny na zmienną typu C
Globalne wskaźniki mogą wskazywać na typy proste (tzn. int, double, char) i struktury definiowane przez użytkownika. Wskaźniki takie nie mogą wskazywać na funkcje.
Mechanizm wywoływania funkcji z danego obiektu, pobrania lub ustawienia wartości atrybutu odbywa się na zasadzie mechanizmu RPC (ang. Remote Procedure Call). Po stronie zdalnej tworzony jest nowy wątek zarządzający całym przebiegiem operacji. Jeśli wywoływana funkcja zwraca wartość, to wynik przekazywany jest z powrotem. Wątek kończy działanie wraz z zakończeniem się funkcji.
Schemat wywołania funkcji przez mechanizm RPC:
Funkcje do wysyłania i odbierania danych z obiektów processor object.
Każdy typ danej, która jest wysyłana lub odbierana z obiektu processor object musi mieć zdefiniowane operatory do transferu tego typu. Funkcje takie są automatycznie wywoływane w razie potrzeby. W CC++ są już zdefiniowane funkcje dla wszystkich typów prostych, a także do kilku dodatkowych typów m.in. do klas CCArray, VectorDouble zaimplementowanych w CC++.
Funkcja CCVoid& operator<<(CCVoid&, const TYPE& obj_in)definiuje jak typ TYPE powinien być spakowany przed przesłaniem do innego obiektu processor object. Natomiast funkcja CCVoid& operator>>(CCVoid&, const TYPE& obj_out) definiuje jak typ TYPE powinien być rozpakowany po odebraniu z innego obiektu processor object.
Programista może zaimplementować powyższe operatory dla typów danych przez niego zdefiniowanych np. dla klas, struktur. Operatory takie będą automatycznie użyte podczas transferu danych o typach prostych i złożonych.
Podsumowanie nowych instrukcji w CC++
Opisane instrukcje są tylko pewnym podzbiorem języka CC++. Jednak już one wyraźnie wskazują na duże możliwości tego języka. Okazały się bardzo wygodne i skuteczne w programowaniu równoległym i rozproszonym.
Nowe mechanizmy wykorzystano w algorytmach opartych na macierzach i w sortowaniu. Warto spróbować wykorzystać je w innego typu algorytmach np. w przetwarzaniu dużej ilości rekordów w bazie danych i próbie przyspieszenia i zoptymalizowania algorytmu.
Przedstawione instrukcje i przykłady zostały zaczerpnięte z dokumentacji do języka CC++. Szczegółowe dane odnośnie języka CC++ znajdują się w plikach na serwerze ftp://ftp.compbio.caltech.edu w katalogu cc++/docs.
Instalacja prekompilatora CC++
Skompilowane wersje programu CC++, kod źródłowy programu CC++ oraz dokumentacja znajdują się na serwerze ftp://ftp.compbio.caltech.edu. Na wskazany serwer należy zalogować się jako użytkownik anonymous podając jako hasło własny adres e-mail.
Translator CC++ można zainstalować na dwa sposoby:
1) Korzystając ze skompilowanej wersji programu CC++
W zależności od systemu operacyjnego i używanego w nim kompilatora kodu C++ wybieramy odpowiedni plik z serwera ftp://ftp.compbio.caltech.edu z katalogu pub/CC++/v0.4/prebuilts.
Wybrany plik należy rozpakować w wybranym lub utworzonym przez nas katalogu.
Po rozpakowaniu należy uruchomić skrypt ./bin/setup-cc++.
Po wykonaniu powyższych instrukcji kompilator CC++ znajduje się w katalogu ./bin pod nazwą cc++.
W katalogach ./bin i ./lib znajdują się też programy do śledzenia procesów i wątków. Oprócz nich są tam skrypty, biblioteki oraz pliki konfiguracyjne. Każdy plik z podanych katalogów (łącznie z cc++) należy przejrzeć i w razie potrzeby ustawić prawidłowe ścieżki (np. ścieżkę do kompilatora CC i jego plików nagłówkowych, ścieżkę do cc++).
Należy stworzyć nowy katalog np. /usr/local/scratch.
W katalogu scratch należy utworzyć katalog build.
Następnie w katalogu scratch rozpakować i roztarować cc++.tar.gz oraz nexus.tar.gz.
Po wykonaniu tych instrukcji w katalogu scratch powinny być następujące podkatalogi: build, cc++ oraz nexus.
Przechodzimy do katalogu build i uruchamiamy skrypt /usr/local/scratch/cc++/configure -prefix=/usr/local.
Po wykonaniu się tej operacji przechodzimy do katalogu build i uruchamiamy kompilację kodu źródłowego CC++ (instrukcja make).
Metody śledzenia i analizy programów na serwerze Cray
Wprowadzenie
Tha - narzędzie do analizy wątków
Programy do debagowania: ddd, gdb, dbx
Opis algorytmów
Wprowadzenie
Sortowanie parzysto-nieparzyste
Posortuj rekurencyjnie dwie połówki A i B.
Utwórz posortowaną listę C przez scalenie elementów o numerach nieparzystych z obu list.
Utwórz posortowaną listę D przez scalenie elementów o numerach parzystych z obu list.
Odłóż na listę wynikową pierwszy element z listy C, po czym kolejno zdejmuj pierwsze elementy z list C i D porównując je i przekazując do listy wynikowej w ustalonym porządku.
Wynikowa lista będzie posortowana!
Sortowanie QuickSort
Przenieś elementy mniejsze od x na lewą stronę.
Przenieś elementy większe od x na prawą stronę.
Posortuj rekurencyjnie elementy mniejsze od x .
Posortuj rekurencyjnie elementy większe od x.
Algorytm Strassen'a mnożenia macierzy
równoległe obliczanie macierzy Pi
równoległe obliczanie macierzy Cij
częściowo zrównoleglone operacje mnożenia, dodawania, odejmowania
wszystkie powyższe modyfikacje zachodzą dla macierzy, których wymiar jest większy od pewnej ustalonej granicy równoległości. Jeśli w trakcie wywołań rekurencyjnych przekazana macierz ma wymiar mniejszy od ustalonej granicy, to wszystkie operacje wykonują się sekwencyjnie.
Testy i porównania opisanych algorytmów
Wprowadzenie
Testy algorytmu - sortowanie QuickSort
Wyniki czasowe algorytmu QuickSort - tabela.
Uwagi i wnioski po testach algorytmu QuickSort.
Podczas pomiarów czasu wykonania się programu sortowania stwierdzono, że przy algorytmie sekwencyjnym wykorzystywany był zawsze tylko jeden procesor. W czasie sortowania jego obciążenie wahało się w granicach 95 ÷ 100%. W tym czasie system zużywał 0 ÷ 1% jego zasobów, a więc zwykle całe zasoby danego procesora wykorzystywane były przez program.
W algorytmie równoległym sytuacja wyglądała identycznie, jeśli w ścieżce wywołania programu nie został podany parametr odpowiadający za ilość wątków wykonywanych jednocześnie. Standardowa wartość tego parametru wynosiła 1 i wtedy program równoległy wykonywał się w tym samym lub dłuższym czasie co jego wersja sekwencyjna. Program równoległy mógł wykonywać się dłużej, ponieważ tworzył i obsługiwał wiele wątków, które wykonywane były jeden po drugim.
Algorytm równoległy działał znacznie szybciej przy podaniu podczas wywołania programu parametru równoległości (ang. concurrency_level) odpowiedzialnego za maksymalną ilość wątków wykonywanych jednocześnie.
Optymalna ilość wątków wykonywanych jednocześnie (parametr concurrency_level) zależna była od szeregu czynników: ogólnej liczby elementów do sortowania, stopnia nie uporządkowania elementów, wolnych zasobów maszyny, ilości procesorów, ilości pamięci operacyjnej i dyskowej, a także od podanej wartości granicznej liczby elementów, poniżej której wykonanie równoległe było wolniejsze od sekwencyjnego.
Testy algorytmu przeprowadzone zostały przy różnym obciążeniu systemu. Na podstawie tabeli (punkt 6.2.1) można dostrzec różnice w szybkości wykonania się algorytmów w wersji sekwencyjnej i równoległej.
Bardzo łatwo zaobserwować różnice w czasie wykonania się programu równoległego przy różnym obciążeniu maszyny. Przy obciążeniu maszyny na poziomie 6 ÷ 7 (tylko jeden procesor był obciążony, a pozostałe piętnaście były w 100% wolne) programy równoległe wykonywały się znacznie szybciej.
Program równoległy potrafił obciążyć wszystkie procesory na poziomie 98 ÷ 100%.
Wersja sekwencyjna okazała się mniej wrażliwa na obciążenie systemu, ponieważ zawsze wykorzystywała maksymalnie jeden procesor.
Przy sortowaniu elementów odwrotnie posortowanych złożoność algorytmu wynosiła dokładnie O(nlogn). Podział elementów tablicy na dwie części odbywał się zawsze względem środkowego elementu, a więc każda z dwóch części po podziale była połową tablicy.
Im większa liczba elementów do sortowania, tym stosunek czasu wykonania się algorytmu sekwencyjnego do równoległego wzrastał na korzyść wersji równoległej.
Czasy wykonania się algorytmu sekwencyjnego dla 10 milionów losowych elementów są mało optymistyczne z czasami wykonania się algorytmu w wersji równoległej.
W zależności od ilości elementów do sortowania czas wykonania się algorytmu równoległego w porównaniu z sekwencyjnym był od 5 do 13 razy krótszy.
kolumna CPU oznacza numer procesora (procesory numerowane są od 0 do 15)
kolumna migr oznacza ilość wątków przekazanych do innych procesorów w ciągu czasu t (w tym wypadku były to 3 sekundy)
kolumna usr wyznacza obciążenie procesora przez programy użytkowników (%)
kolumna sys wyznacza obciążenie procesora przez programy lub operacje systemowe (%)
kolumna idl wyznacza wolne zasoby procesora (%)
kolumna usr wyznacza obciążenie całej maszyny (wszystkich procesorów) przez programy użytkowników (%)
kolumna sys wyznacza obciążenie maszyny przez programy lub operacje systemowe (%)
kolumna idl wyznacza wolne zasoby maszyny (%)
Analiza plików śladowych QuickSort przy użyciu programu tha.
ilość elementów = 262 144
wybór elementów = losowy
wartość graniczna = 20 000
poziom równoległości = 20
Mutex Wait Time - łączny czas, kiedy wątek (wątki) był „uśpiony” (ang. suspended) czekając na dostęp do dzielonych zasobów.
Join Wait Time - łączny czas, w którym obiekt był „uśpiony” w funkcji thr_join() czekając na zakończenie innego wątku.
Semaphore Wait Time - łączny czas, w którym obiekt był „uśpiony” czekając na semafor.
Condition Variable Wait Time - łączny czas, w którym obiekt był „uśpiony” czekając na zdarzenie (sygnał) od zmiennej warunkowej (ang. condition variable).
RW Read Lock Wait - łączny czas, kiedy obiekt był „uśpiony” czekając na zablokowanie zasobów do odczytu.
Total Sync Wait Time - łączny czas pięciu powyższych statystyk plus szóstej RW Write Lock Wait (łączny czas, kiedy obiekt był „uśpiony” czekając na zablokowanie zasobów do zapisu).
CPU Time - wykorzystanie procesora (procesorów)
Wall Clock Time - mierzy czas od momentu kiedy obiekt zostaje utworzony do momentu kiedy zostaje zniszczony. Różnica między CPU Time polega na tym, że statystyka Wall Clock Time mierzy czas nawet w sytuacji kiedy obiekt jest „uśpiony” i nie zajmuje zasobów procesora.
Total Sync Wait Time - wyjaśniony przy opisie statystyki synchronizacji wątków.
Testy algorytmu sortowania parzysto-nieparzystego.
Wyniki czasowe algorytmu sortowania parzysto-nieparzystego - tabela.
Kompilując źródła programu CC++
W przypadku tej pracy kompilator zainstalowany został z plików binarnych (pierwszy sposób instalacji).
Opisana instrukcja instalacji zawiera tylko podstawowe informacje. Szczegółowe dane odnośnie instalacji CC++, wymagań sprzętowych znajdują się na serwerze ftp://ftp.compbio.caltech.edu w pliku cc++/docs/Configuration.
Narzędzia do śledzenia i analizy programów służą do śledzenia (ang. debugging) i pomiaru czasu wykonania się poszczególnych części programu. Przede wszystkim ułatwiają szukanie ewentualnych błędów, a także pozwalają ocenić szybkość i skuteczność zastosowanych mechanizmów. Można badać całkowity czas wykonania się programu, czas potrzebny na utworzenie nowego wątku, czas wykorzystany na synchronizację wątków, czas potrzebny na synchronizację dostępu do danych, czas jaki pochłonęły operacje na semaforach, itd.
Narzędzia te okazują się tym bardziej pomocne, im więcej jest użytej techniki programowania równoległego. Omówione niżej narzędzia zostały wykorzystane w tej pracy do badania i analizy zaimplementowanych algorytmów.
Program tha (ang. Thread Analyzer) posiada interfejs graficzny i służy do przeglądania plików śladowych wygenerowanych przez program, który ma być analizowany. Aby pliki śladowe mogły się wygenerować, program należy skompilować i zlinkować z opcją -Ztha. Po uruchomieniu programu wykonywalnego, na dysku powstanie katalog z plikami śladowymi uruchomionego programu. W plikach zapisywane są informacje o czasach i zasobach procesora(ów) użytych na wykonanie się programu i jego wątków.
Na podstawie danych z plików śladowych program tha przedstawia wykresy i zestawienia ze statystyką czasową dotyczącą używanych semaforów, wątków, operacji odczytu i zapisu. Można w ten sposób odczytać czas, jaki wątek użył czekając na zwolnienie semafora lub ile bajtów zostało przesłanych w ciągu jednej sekundy. Analizując pomiary można znaleźć „wąskie gardła” programu i wyeliminować je.
Programy ddd, gdb, dbx przydatne są do lokalizowania błędów w programach. Umożliwiają śledzenie programów na poziomie pojedynczych instrukcji i procedur. Potrafią analizować plik core i w ten sposób odtworzyć stan programu, w którym ten plik został wygenerowany. Podając plik źródłowy programu i identyfikator procesu (ang. pid) można również śledzić programy, które się wykonują.
Wybrane i zaimplementowane algorytmy miały na celu sprawdzić po pierwsze poprawność działania języka CC++ a w szczególności jego nowych mechanizmów do programowania równoległego, po drugie porównać szybkość zaimplementowanych w nim algorytmów równoległych z tymi samymi algorytmami, ale zaimplementowanymi sekwencyjnie w C++, po trzecie pokazać jakie problemy należy rozważyć przy programowaniu w CC++, a także pozwoliły wyciągnąć wnioski co do ograniczeń jakie niesie ze sobą programowanie równoległe.
Podczas testowania zbadano w jaki sposób i w jakim stopniu obciążana była maszyna wieloprocesorowa przez program. Każdy w algorytmów został przetestowany na mniejszej i większej ilości elementów, a także przy większym i mniejszym obciążeniu maszyny.
Sortowanie parzysto-nieparzyste polega na sortowaniu i scalaniu posortowanych elementów listy. Sortowanie to odbywa się przez rekurencyjne posortowanie dwóch połówek w ten sposób, że najpierw z obydwu połówek wybierane są elementy o indeksach nieparzystych, z których utworzona zostaje nowa posortowana lista. Te same kroki wykonywane są dla elementów o indeksach parzystych.
Po wykonaniu tych czynności, następuje scalanie obydwu nowych, posortowanych list w jedną w ten sposób, że wiadomo, iż pierwszy element z listy utworzonej z elementów o indeksach nieparzystych ma najmniejszą wartość, natomiast ostatni element z listy utworzonej z elementów o indeksach parzystych ma największą wartość tzn. te dwa elementy mają już wyznaczone właściwe miejsce w posortowanej liście wynikowej. Pozostałe elementy są umieszczane w tablicy wynikowej w ten sposób, że zdejmujemy kolejno po jednym elemencie z obydwu list i przekazujemy do listy wynikowej najpierw mniejszy, a później większy. Po scaleniu wynikowa lista jest już posortowana!
Algorytm:
W algorytmie wyraźnie widać, że wszystkie operacje wykonywane dla obydwu połówek mogą odbywać się jednocześnie. Jednak niektórych z nich nie warto wykonywać równolegle, ponieważ są zbyt krótkie, więc nieopłacalna byłaby zamiana z wykonania sekwencyjnego na równoległe. Jeśli ilość elementów spada poniżej pewnej granicy, to wtedy także warto wykonać dane zadanie sekwencyjnie. Inicjacja, komunikacja, a w końcowej fazie usunięcie każdego utworzonego wątku zajmuje pewien czas. Dlatego podczas implementacji należy rozważyć słuszność wykonywania pewnych operacji równolegle.
Skrócony kod głównej procedury sortowania parzysto-nieparzystego:
W algorytmie wykorzystano instrukcję par, aby sortowanie i scalanie odbywało się równolegle. W ostatnich liniach procedury sortuj można było zamiast instrukcji for użyć parfor, ponieważ brane tam są kolejno po dwa elementy listy i w razie potrzeby zamieniane miejscami. Takie operacje można wykonać jednocześnie (złożoność O(1)), ale zarządzanie powstałymi wątkami zajęłoby znacznie więcej czasu niż wykonanie tej operacji sekwencyjnie.
Przykład sortowania parzysto-nieparzystego dla 8 elementów:
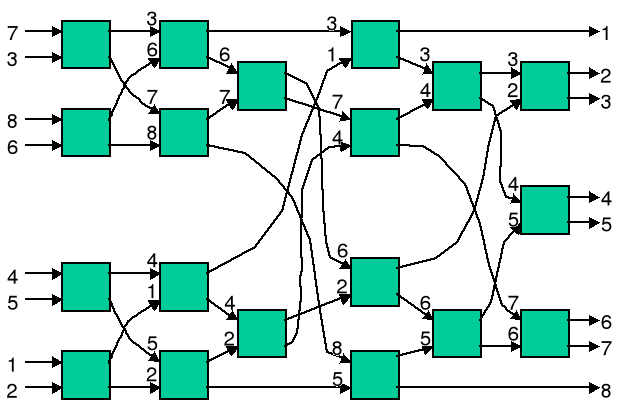
Sortowanie szybkie QuickSort uważane jest za jedno z najpopularniejszych algorytmów sortowania. Średnia złożoność czasowa wynosi O(nlogn). Pesymistyczna złożoność czasowa wynosi O(n2).
Algorytm sortowania polega na wybraniu dowolnego elementu z listy do posortowania i względem jego przeniesienia wszystkich elementów mniejszych od niego na lewą (prawą) stronę od niego, a większych lub równych jemu na prawą (lewą) stronę. Następnie powyższe czynności wykonuje się dla obydwu powstałych części.
Algorytm:
Oto krótki kod głównej procedury sortowania QuickSort:
Ponieważ sortowanie połówek wykonywane jest niezależnie, uznano, że warto zaimplementować ten algorytm w CC++ i wykorzystać mechanizm do równoległego wykonywania sortowania obydwu połówek. W tym celu wykorzystano zmienne typu sync do synchronizacji wątków wywoływanych klauzulą spawn.
Zamiast takiego rozwiązania można było użyć instrukcji par i za pomocą jej równolegle uruchamiać sortowanie dla obydwu części. Jednak ze względu na sytuacje, kiedy jedna z części może być jedno lub kilku elementowa, natomiast druga zawierać prawie wszystkie elementy do sortowania, proces inicjacji dwóch nowych wątków niepotrzebnie zużywałby czas dla dwóch części zamiast tylko dla jednej. Dlatego zastosowane rozwiązanie powinno być bardziej optymalne.
Algorytm Strassen'a opiera się na metodzie „dziel i zwyciężaj” tzn. zadanie mnożenia dwóch macierzy możemy podzielić na podzadania, które wykonają mnożenia na podmacierzach.
Do wykonania jest zadanie pomnożenia macierzy C = A * B, gdzie A, B, C są macierzami o wymiarach 2N x 2N. Każdą z macierzy dzielimy na 4 bloki:
Tak więc każda z macierzy Aij, Bij, Cij jest wymiaru N x N.
Standardowe mnożenie macierzy odbywa się w ten sposób:
C11 = A11* B11 + A12 * B21
C12 = A11* B12 + A12 * B22
C21 = A21* B11 + A22 * B21
C22 = A21* B12 + A22 * B22
W tym sposobie mamy 8 mnożeń macierzy - O(N3) i 4 dodawania macierzy - O(N2).
Algorytm Strassen'a polega na tym, aby zadanie podzielić na jeszcze mniejsze podmacierze i obliczać tymczasowe macierze Pi.
P1 = (A11 + A22) * (B11 + B22)
P2 = (A21 + A22) * B11
P3 = A11 * (B12 - B22)
P4 = A22 * (B21 - B11)
P5 = (A11 + A12) * B22
P6 = (A21 - A11) * (B11 + B12)
P7 = (A12 - A22) * (B21 + B22)
Macierze Cij obliczane są na podstawie macierzy Pi.
C11 = P1 + P4 - P5 + P7
C12 = P3 + P5
C21 = P2 + P4
C22 = P1 + P3 - P2 + P6
W tym sposobie mamy 7 mnożeń macierzy i 18 dodawań. Ponieważ algorytm jest rekurencyjny, to 7 mnożeń macierzy N x N zamieniane jest na 49 mnożeń macierzy N/2 x N/2 itd.
W algorytmie wyraźnie widać, że można wykorzystać programowanie równoległe. Zrównoleglone zostały następujące operacje:
Każdy z opisanych algorytmów został przetestowany na komputerze Cray CS 6400. Algorytmy testowane były w dwóch wersjach: równoległej i sekwencyjnej. Każdy z nich uruchomiony był przynajmniej kilkadziesiąt razy przy różnym obciążeniu maszyny i z różnymi parametrami. Na podstawie testów i wyników została wydana ocena języka CC++.
Testy algorytmu QuickSort przeprowadzono w wersjach sekwencyjnej i równoległej. W obydwu przypadkach algorytmy uruchamiane były z tymi samymi parametrami i przy tym samym obciążeniu maszyny. Ilość elementów do sortowania wahała się w granicach od 262 144 do 10 000 000 elementów (od 218 do 107 ≈ 223). Elementy do sortowania były losowane lub odwrotnie uporządkowane.
Podczas sortowania elementów losowych do wyboru elementu dowolnego brane były pod uwagę zawsze trzy elementy (w skrajnych przypadkach tylko dwa - tablica dwuelementowa). Z wybranych elementów wybierany był średni co do wartości i względem jego odbywał się podział elementów w tablicy na dwie części.
Podczas sortowania elementów odwrotnie posortowanych, podział elementów na dwie części odbywał się na podstawie porównania ze środkowym elementem tablicy.
Obciążenie maszyny (%) |
Ilość elementów |
Wybór elementów |
Rodzaj algorytmu |
Czas sortowania (s) |
25 ÷ 30 % |
262 144 (218) |
losowy |
równoległy |
1s (100%) |
|
|
|
sekwencyjny |
4 ÷7s (50% ÷ 40%) |
|
|
odwrotny do sort. |
równoległy |
1s (100%) |
|
|
|
sekwencyjny |
3 ÷4s (70% ÷ 30%) |
|
524 288 (219) |
losowy |
równoległy |
1 ÷ 2s (50% ÷ 50%) |
|
|
|
sekwencyjny |
8 ÷ 15s (50% ÷ 30%) |
|
|
odwrotny do sort. |
równoległy |
1 ÷ 2s (50% ÷ 30%) |
|
|
|
sekwencyjny |
6 ÷ 9s (5% ÷ 50%) |
|
2 097 152 (221) |
losowy |
równoległy |
6 ÷ 8s (15% ÷ 15%) |
|
|
|
sekwencyjny |
54s ÷1m. 19s (30% ÷ 60%) |
|
|
odwrotny do sort. |
równoległy |
3 ÷ 5s (25% ÷ 15%) |
|
|
|
sekwencyjny |
24s ÷25s (50% ÷ 50%) |
|
10 000 000 (107) |
losowy |
równoległy |
49 ÷ 52s (15% ÷ 30%) |
|
|
|
sekwencyjny |
8m.21s ÷12m 43s (25% ÷ 15%) |
|
|
odwrotny do sort. |
równoległy |
17 ÷ 20s (40% ÷ 30%) |
|
|
|
sekwencyjny |
2m. 3 ÷ 3m. 1s (40% ÷ 60%) |
6 ÷ 7% |
10 000 000 (107) |
losowy |
równoległy |
47s ÷50s (60% ÷ 10%) |
|
|
|
sekwencyjny |
8m. 23s ÷12m.3s (45% ÷ 45%) |
|
|
odwrotny do sort. |
równoległy |
16s ÷ 18s (15% ÷ 50%) |
|
|
|
sekwencyjny |
2m. 3s ÷ 3m.1s (40% ÷ 60%) |
Rys. 6.1. Zestawienie przyspieszenia w wykonaniu się algorytmu równoległego do sekwencyjnego. Wykres na podstawie tabeli 6.2.1 z wynikami czasowymi dla losowo wybranych elementów do sortowania przy obciążeniu maszyny na poziomie 25 ÷ 30%.
Rys. 6.2. Obciążenie poszczególnych procesorów przed uruchomieniem sortowania w wersji równoległej.
Rys. 6.3. Obciążenie poszczególnych procesorów podczas wykonywania algorytmu równoległego z optymalnymi parametrami: wartość graniczna, poziom równoległości.
Rys. 6.4. Obciążenie poszczególnych procesorów podczas wykonywania algorytmu równoległego z błędnie dobranymi parametrami: wartość graniczna, poziom równoległości.
Opis najważniejszych kolumn z Rys. 6.2, Rys. 6.3, Rys. 6.4 :
Na rysunkach Rys. 6.2, Rys. 6.3, Rys. 6.4 przedstawiono obciążenie poszczególnych procesorów przed i po wykonaniu zadania. Na Rys. 6.2 wyraźnie widać, że przed rozpoczęciem zadania 9 procesorów w 100% miało wolne zasoby (kolumna idl), natomiast 7 pozostałych było w 100% obciążonych (zarówno przez programy użytkownika - kolumna usr, jak i operacje systemowe - kolumna sys).
Na Rys. 6.3 kolumna idl z wolnymi zasobami procesorów jest „wyzerowana”. Oznacza to, że każdy z 16 procesorów jest obciążony w 100%. Obciążenie jest prawie w całości wykorzystywane przez programy użytkowników (w większości przez program równoległy QuickSort). System pochłaniał przeciętnie 1 ÷ 3% zasobów każdego procesora. W tym wypadku obciążenie każdego procesora przez system wiązało się z obsługą komunikacji i synchronizacji poszczególnych wątków programu QuickSort, a także pozostałych programów użytkowników. Wątki programu QuickSort obciążyły przynajmniej 9 wolnych przed uruchomieniem programu procesorów (można sądzić, że nawet wszystkie procesory).
Czas procesora pochłaniany przez system przedstawiono na Rys. 6.4 (kolumna sys). Program równoległy został celowo uruchomiony ze złymi parametrami. Wartość graniczna, poniżej której program sekwencyjny wykonuje się znacznie szybciej została celowo zaniżona, a parametr poziomu równoległości (ang. concurrency_level) został znacznie zawyżony. Te dwa parametry wpłynęły bardzo negatywnie na przebieg i czas wykonania się programu. System pochłaniał prawie połowę zasobów każdego procesora. Takie zachowanie się systemu było spowodowane nadmierną ilością wątków, które musiały zostać obsłużone. Więcej czasu kosztowała synchronizacja i przekazywanie zadania pomiędzy poszczególne wątki, niż czas wykorzystany na samo sortowanie.
O tym, że zostały podane błędne parametry świadczy również kolumna migr, w której zliczane są wątki przesłane z danego procesora do innych. Kolumna ta zawierała dużo wyższe wartości niż w przypadku tej samej kolumny z Rys. 6.3. System, aby zapewnić jednakowy czas pracy (tyle samo zasobów) każdego wątku musiał cały czas przekazywać sterowanie różnym wątkom. Kolumna migr była przynajmniej o jeden rząd wielkości wyższa niż w przypadku Rys. 6.3 z optymalnymi parametrami wartości granicznej i poziomu równoległości.
Podając nie przemyślane wartości wyżej wymienionych dwóch parametrów można doprowadzić do „zapchania systemu” i przerwania wykonania się programu. Każdy system operacyjny ma ograniczone zasoby. Jeśliby nawet takie zadanie wykonało się pomyślnie, to czas mógłby być znacznie dłuższy od wersji sekwencyjnej.
Rys. 6.5. Obciążenie maszyny przed i po zakończeniu wykonywania się algorytmu równoległego.
Opis najważniejszych kolumn z Rys. 6.5:
Na Rys. 6.5 można zauważyć, że system przez około 48 sekund był całkowicie obciążony. Obciążenie takie w głównej mierze spowodowane było przez QuickSort w wersji równoległej. Do programu zostały przekazane odpowiednie parametry wejściowe m.in. wartość graniczna i poziom równoległości. Obciążenie procesorów przez system wahało się na poziomie 1 ÷ 3%. Takie samo obciążenie procesorów przez system było także przed uruchomieniem programu QuickSort.
Pliki śladowe programu można wygenerować dodając podczas kompilacji i linkowania opcję -Ztha. Program QuickSort w wersji równoległej został skompilowany i zlinkowany z tą opcją i uruchomiony z następującymi parametrami:
Co prawda optymalna wartość graniczna dla 262 144 elementów była na poziomie 10 000, ale nie ma to większego znaczenia dla takiej ilości elementów. Zawyżona wartość graniczna podana została w celu ograniczenia całkowitej liczby wątków generowanych przez program.
Im większa ilość wątków tym dłużej generują się pliki śladowe, a program tha ma trudności z wczytaniem i wyświetlaniem wszytkich wątków.
Poniżej zostały przedstawione i omówione wykresy z programu tha.
Rys. 6.6. Ogólny obraz wątków programu QuickSort.
Trudno powiedzieć, dlaczego w takiej kolejności zostały wyświetlone wątki. Na początku kolejność jest zachowana później numery wątków są pomieszane.
Rys. 6.7. Całkowity czas wykorzystany na synchronizację przez wątek nr 0.
Rys. 6.8. Całkowity czas wykorzystany na synchronizację przez wątek nr 5.
Rys. 6.9. Całkowity czas wykorzystany na synchronizację przez wątek nr 20.
Rys. 6.10. Całkowity czas wykorzystany na synchronizację wszystkich wątków.
Znaczenie poszczególnych linii z wykresów Rys. 6.7, Rys. 6.8, Rys. 6.9, Rys. 6.10:
Wykres przedstawiający całkowity czas na synchronizację wątków (Rys. 6.10) ma na osi pionowej podziałkę procentową z wartościami większymi niż 100%. Takie przedstawienie wykresu wynika z faktu, że program składał się łącznie z 22 wątków i każdy z nich mógł mieć wartości z przedziału 0 ÷ 100%. Łączne dane ze wszystkich wątków są sumowane i nie są podawane w skali 0 ÷ 100%, tylko w skali od 0 do maksymalnej procentowej wartości uzyskanej po zsumowaniu. Dlatego Rys. 6.10 na osi pionowej ma przedział od 0 do 1600%.
Przebieg pracy każdego z przedstawionych wątków Rys. 6.7, Rys. 6.8, Rys. 6.9 jest zupełnie inny. Wynika to przede wszystkim z faktu, że wątki nie były tworzone w tym samym czasie, a także każdy z nich miał większą lub mniejszą część tablicy do posortowania i w trakcie swojej pracy zarządzał różną ilością stworzonych przez siebie wątków.
W programie QuickSort dzielonym zasobem pośród wszystkie wątki była tablica z elementami do sortowania. Jak widać na Rys. 6.10 całkowity czas na synchronizację dostępu wątków do danych (ang. Mutex Wait Time) kształtował się na poziomie około 200%, a całkowity czas wykorzystany na synchronizację (ang. Total Sync Wait Time) wynosił średnio 1000 ÷ 1100% (maksymalnie 1400%).
Na wykresach i w tabelach ze statystyką nie pojawiają się wartości dotyczące Join Wait Time, Semaphore Wait Time, RW Read Lock Wait. Program QuickSort zaimplementowany w CC++ nie używał semaforów, nie blokował pamięci do odczytu. Zamiast semaforów program używał zmiennych typu Mutex (ang. Mutual exclusion), które zachowują się jak semafory binarne.
W programie QuickSort do synchronizacji wątków użyte zostały zmienne typu sync. Zmienne tego typu miały za zadanie powiadomić wątek nadrzędny o zakończeniu pracy wątka podrzędnego. Wątek nadrzędny tworzył nowy wątek i wywoływał w nim rekurencyjnie procedurę QuickSort do posortowania jednej z części tablicy. Następnie wątek nadrzędny czekał na zakończenie pracy wątka podrzędnego. Jeśli każda z obu części tablicy miała do posortowania więcej elementów niż podana wartość graniczna, to wątek nadrzędny tworzył dla każdej z nich nowy i czekał na wykonanie zadania przez oba wątki. Czekanie polegało na otrzymaniu sygnału od zmiennych typu sync.
Na Rys. 6.10 linia przedstawiająca Condition Variable Wait Time przyczyniła się w głównej mierze do całkowitego czasu zużytego na synchronizację. W CC++ zmienne typu sync zaimplementowane zostały jako Condition Variable Wait Time.
Rys. 6.11. Wykres dla wątku nr 0: a) wykorzystanie CPU (linia czerwona), b) całkowity wykorzystany czas (linia zielona), c) całkowity czas wykorzystany na synchronizację (linia żółta).
Rys. 6.12. Wykres dla wątku nr 5: a) wykorzystanie CPU (linia czerwona), b) całkowity wykorzystany czas (linia zielona), c) całkowity czas wykorzystany na synchronizację (linia żółta).
Rys. 6.13. Wykres dla wątku nr 20: a) wykorzystanie CPU (linia czerwona), b) całkowity wykorzystany czas (linia zielona), c) całkowity czas wykorzystany na synchronizację (linia żółta).
Rys. 6.14. Wykres dla całego programu (wszystkich wątków): a) wykorzystanie CPU (linia czerwona), b) całkowity wykorzystany czas (linia zielona), c) całkowity czas wykorzystany na synchronizację (linia żółta).
Znaczenie poszczególnych linii z wykresów Rys. 6.11, Rys. 6.12, Rys. 6.13, Rys. 6.14:
Z analizy obciążenia maszyny mierzonego programami sar i mpstat wynikało, że program tylko przez krótki moment obciążył wszystkie procesory. Obciążenie to trwało około 4 sekund i nie było maksymalne. Program QuickSort dla 262 144 elementów wykonywał się standardowo około 1s, jednak z opcją generowania plików śladowych jego wykonywanie wzrosło do 20s. Dlatego obciążenie procesora (ang. CPU Time) w maksymalnym punkcie wynosiło tylko 800 ÷ 900%, chociaż mogło być na poziomie dwa razy większym.
Testy algorytmu sortowania parzysto-nieparzystego przeprowadzone zostały dla wersji sekwencyjnej i równoległej. Ilość elementów do sortowania była znacznie mniejsza niż w przypadku algorytmu QuickSort: od 32 768 do 262 144 elementów (od 215 do 218). Elementy do sortowania były losowane lub odwrotnie uporządkowane.
Złożoność czasowa algorytmu sortowania parzysto-nieparzystego wynosiła O(nlogn). Algorytm działał podobnie jak QuickSort tzn. tablicę z elementami do sortowania dzielił na dwie części z tą różnicą, że nie był to podział względem wybranego elementu, tylko podział względem indeksu w tablicy. Elementy o indeksach parzystych były jedną połową, a o indeksach nieparzystych drugą.
Zaletą tego algorytmu jest jednak mała wrażliwość na stopień nie uporządkowania elementów. Złożoność algorytmu QuickSort bez optymalizacji w przypadku elementów odwrotnie posortowanych, byłaby znacznie większa (wynosiłaby O(n2)) od złożoności algorytmu sortowania parzysto-nieparzystego.
Obciążenie maszyny (%) |
Ilość elementów |
Wybór elementów |
Rodzaj algorytmu |
Czas sortowania (s) |
6 ÷ 7% |
32768 (215) |
losowy |
równoległy |
3s ÷ 5s (35% ÷ 10%) |
|
|
|
sekwencyjny |
39s ÷ 55s (55% ÷ 45%) |
|
|
odwrotny do sort. |
równoległy |
3s ÷ 4s (65% ÷ 35%) |
|
|
|
sekwencyjny |
39s ÷ 54s (45% ÷ 55%) |
|
65 536 (216) |
losowy |
równoległy |
11 ÷ 12s (90%÷10%) |
|
|
|
sekwencyjny |
2m. 6s ÷2m. 54s (70% ÷ 30%) |
|
|
odwrotny do sort. |
równoległy |
11 ÷ 12s (95% ÷ 5%) |
|
|
|
sekwencyjny |
2m. 4s ÷3m.s (60% ÷ 40%) |
|
262 144 (218) |
losowy |
równoległy |
1m. 44s ÷ 1m.46s (40% ÷ 40%) |
|
|
|
sekwencyjny |
24m44s÷31m.5s (70% ÷ 30%) |
|
|
odwrotny do sort. |
równoległy |
1m. 44s ÷1m. 46s (40% ÷ 40%) |
|
|
|
sekwencyjny |
31m55s ÷33m27s (50% ÷ 50%) |
30 ÷ 35 % |
32768 (215) |
losowy |
równoległy |
4s ÷ 5s (30% ÷ 70%) |
|
|
|
sekwencyjny |
41s ÷ 56s (60% ÷ 40%) |
|
|
odwrotny do sort. |
równoległy |
4s ÷ 5s (30% ÷ 70%) |
|
|
|
sekwencyjny |
41s ÷ 56s (25% ÷ 60%) |
|
65 536 (216) |
losowy |
równoległy |
13 ÷ 14s (50%÷50%) |
|
|
|
sekwencyjny |
2m. 9s ÷2m. 57s (70% ÷ 30%) |
|
|
odwrotny do sort. |
równoległy |
13 ÷ 14s (40% ÷ 60%) |
|
|
|
sekwencyjny |
2m. 8s ÷3m. 2s (60% ÷ 40%) |
|
262 144 (218) |
losowy |
równoległy |
1m. 54s ÷ 1m.56s (40% ÷ 40%) |
|
|
|
sekwencyjny |
24m54s÷31m.33s (70% ÷ 30%) |
|
|
odwrotny do sort. |
równoległy |
1m. 55s ÷ 2m. (50% ÷ 30%) |
|
|
|
sekwencyjny |
32m15s ÷33m43s (50% ÷ 50%) |
Rys. 6.15. Zestawienie przyspieszenia wykonania się algorytmu równoległego do sekwencyjnego. Wykres na podstawie tabeli 6.3.1 z wynikami czasowymi dla losowo wybranych elementów do sortowania przy obciążeniu maszyny na poziomie 6 ÷ 7%.
Wyszukiwarka