Systemy plików
Zbyszko Królikowski - Instytut Informatyki PP
Literatura
Tanenbaum A., Modern Operating Systems, Prentice-Hall Icor., 1992.
Silberschatz, P.B. Galvin, Operating System Concepts, Addison-Wesley Pub. Comp., 1994.
Tanenbaum A., Operating Systems: Design and Implementation, Prentice-Hall Intern. Editions, 1995.
Silberschatz, J.L. Peterson, P.B. Galvin, Podstawy systemów operacyjnych, WNT, W-wa, 1993.
Królikowski, M. Sajkowski, UNIX dla początkujących i zaawansowanych, Wyd. Nakom, 1995.
Gościński, Distributed Operating Systems, Addison-Wesley Pub. Comp., 1992.
Systemy operacyjny - znaczenie tej problematyki
Praktyczne znaczenie wiedzy z zakresu systemów operacyjnych wynika z następujących spostrzeżeń:
Wybór systemu operacyjnego jest jedną z najważniejszych decyzji przy wyborze całego systemu komputerowego
Użytkownik w wielu przypadkach operuje bezpośrednio na funkcjach realizowanych przez systemy operacyjne
Wiele koncepcji i technik wyrastających i związanych z systemami operacyjnymi ma znaczenie uniwersalne
Wybrane problemy organizacji systemów komputerowych
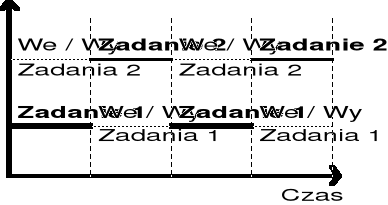
Systemy wielozadaniowe pracujące w trybie z podziałem czasu procesora

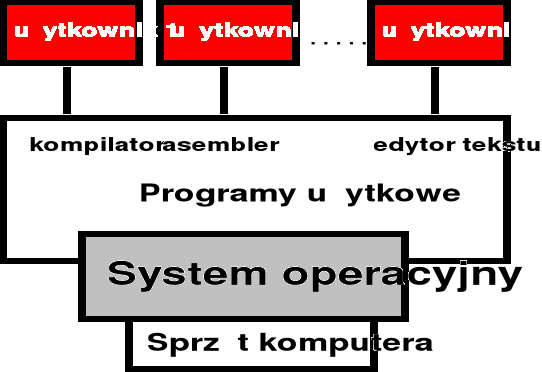
Struktura oprogramowania i jego związek ze sprzętem
System operacyjny - definicje
Przez system operacyjny rozumiemy oprogramowanie zarządzające zasobami sprzętowymi i programowymi systemu komputerowego, które pozwala użytkownikom na wspólne, wygodne i efektywne wykorzystywanie tych zasobów.
Abraham Silberschatz: „System operacyjny jest programem, który działa jako pośrednik między użytkownikiem komputera a sprzętem komputerowym. Zadaniem systemu operacyjnego jest tworzenie środowiska, w którym użytkownik może wykonywać programy w sposób wygodny i wydajny”
Andrew Tanenbaum: „System operacyjny jest warstwą oprogramowania operującą bezpośrednio na sprzęcie, której celem jest zarządzanie zasobami systemu komputerowego i stworzenie użytkownikowi środowiska łatwiejszego do zrozumienia i wykorzystania”
Funkcje systemu operacyjnego
Problem: W interesie każdego zadania przedłożonego do wykonania w systemie leży efektywność jego wykonania - w systemie wielo-zadaniowym powstaje więc problem zarządzania przydziałem zasobów do zadań,
Sprzęt komputerowy jest jedynie potencjalnie zdolny do wykonywania zadań,
Powstaje więc konieczność istnienia pośrednictwa pomiędzy sprzętem systemu komputerowego a zadaniami użytkowników, którego funkcjami byłyby:
1. zarządzanie (optymalizacja wykorzystania) zasobami, a tym samym optymalizacja działania całego systemu komputerowego,
2. rozwiązywanie konfliktów powstających podczas współubiegania się różnych zadań o zasoby systemu.
Są to właśnie podstawowe funkcje systemu operacyjnego.
Funkcje systemu operacyjnego - cd.
System operacyjny realizuje miedzy innymi następujące funkcje:
definiuje interfejs użytkownika,
przydziela zasoby użytkownikowi,
umożliwia użytkownikom bezpieczne współdzielenie zasobów (danych),
planuje (szereguje) przydział zasobów,
realizuje obsługę urządzeń wejścia / wyjścia (I/O),
gwarantuje obsługę podstawowych błędów,
zapewnia stan odtwarzania po błędzie,
chroni zasoby własne użytkowników przed nieautoryzowanym dostępem.
Pojęcia podstawowe
Zasoby
Zasoby komputerowe to obiekty dzielone (ang. shared) (współdzielone, współużywalne) przez użytkowników i system operacyjny.
Tradycyjnie wyróżnia się zasoby sprzętowe (procesory, urządzenia we/wy, pamięci) oraz programowe (pliki, programy i dane).
Zarządzanie zasobami w systemie wielozadaniowym polega na takim ich rozdzielaniu pomiędzy użytkowników, aby każdy z nich miał wrażenie, że pracuje na własnym komputerze.
Użytkownik, zadanie, proces
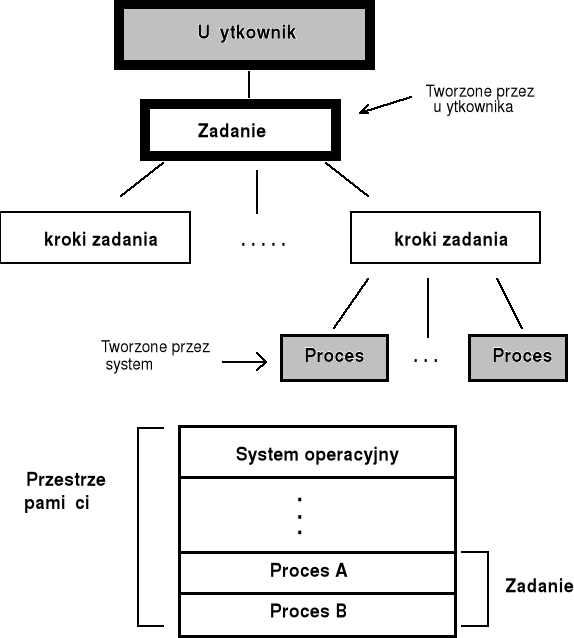
Pojęcia podstawowe - cd.
Przez użytkownika będziemy rozumieli ogólnie każdego, kto wymaga realizacji pewnych zadań przez system operacyjny.
Pracą (ang. job) jest zbiór akcji niezbędnych do realizacji określonego zadania - pracę tworzy przykładowo sekwencja: kompilacja, załadowanie i wykonanie.
Proces jest najmniejszą jednostką (?) aktywności, która może się ubiegać się o zasoby systemu komputerowego
Pojęcia podstawowe - cd.
Proces odpowiada programowi, ale jest obiektem aktywnym, któremu przydzielono zasoby komputerowe takie jak: pamięć operacyjna i procesor. System operacyjny przekształcając program w proces tworzy pewne pomocnicze struktury danych, wykorzystywane do zarządzania procesami (jak np. opis przydzielonych zasobów, stan procesu, itd.)
Proces sekwencyjny jest to realizacja programu sekwencyjnego lub też wstrzymana realizacja w oczekiwaniu na zdarzenie które umożliwi jego kontynuację.
Dwa procesy sekwencyjne są współbieżne, jeżeli wykonywanie jednego z nich zaczyna się po rozpoczęciu, ale przed zakończeniem wykonywania drugiego.
Pojęcia podstawowe - cd.
Przestrzeń adresowa i przestrzeń pamięci
Adresy, których używa programista w swoim programie nazywamy adresami wirtualnymi (logicznymi), a zbiór tych adresów przestrzenią adresową.
Adresy rzeczywistych komórek pamięci operacyjnej nazywamy adresami fizycznymi, a ich zbiór przestrzenią pamięci.
W systemach wyposażonych w mechanizm pamięci wirtualnej, przestrzeń adresowa jest większa niż przestrzeń pamięci.
Pojęcia podstawowe - cd.
W celu zagwarantowania ochrony dostępu do zasobów, system operacyjny korzysta z instrukcji dostępnych tylko dla niego, tj. instrukcji uprzywilejowanych. Specjalny sprzęt sprawdza każdorazowo czy instrukcja uprzywilejowana może być wykonana. W celu realizacji tego zadania wyróżnia się zazwyczaj dwa tryby pracy systemu komputerowego:
tryb użytkownika (ang. user mode)
tryb systemowy (jądra) (ang. system mode)
Instrukcje uprzywilejowane są wykonywane tylko gdy system (procesor) jest w trybie systemowym. Zmiana trybu pracy procesora z trybu „user” na tryb „system” może odbywać się jedynie za pośrednictwem systemu operacyjnego
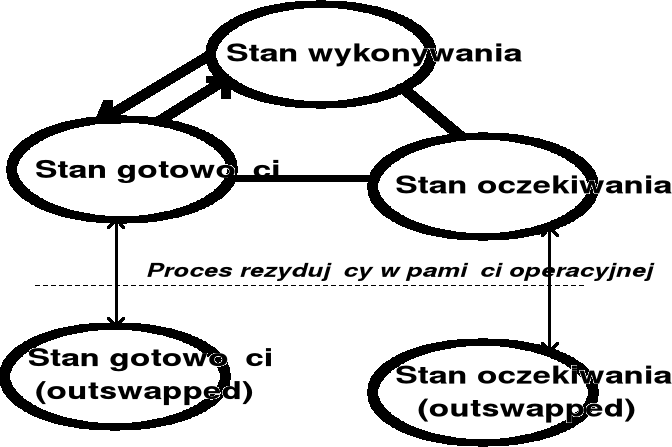
Uproszczony model stanów procesu
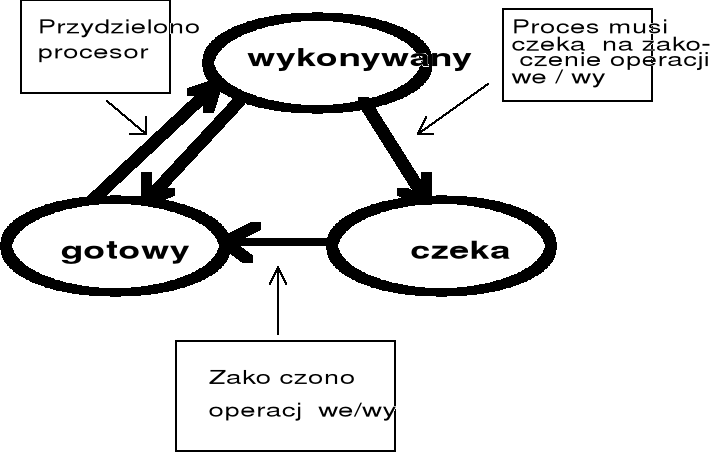
Model stanów procesu

Model stanów procesu - cd.
Wprowadzenie (ang. hold) - praca użytkownika jest przetworzona do formatu stosowanego w danym systemie, ale żadne zasoby nie są jeszcze przydzielone, oprócz ewentualnie plików.
Stan gotowości (ang. ready) - procesowi skojarzonemu z pracą przydzielone są wszystkie zasoby systemu komputerowego z wyjątkiem procesora - proces czeka zatem na przydział ostatniego, istotnego zasobu.
Stan wykonywania (ang. run / execute) - w stanie tym proces ma przydzielony procesor i jest wykonywany.
Stan zawieszenia / oczekiwania (ang. suspend / wait) - w stanie tym proces oczekuje na zdarzenie (ang. event), np. zakończenie wcześniej zainicjowanej operacji wejścia / wyjścia lub na przydział dodatkowych zasobów.
Zakończenie - jest to stan, w którym proces zakończył definitywnie wykonywanie i wszystkie przydzielone mu zasoby zostały zwolnione.
Uproszczony model stanów procesu w systemie VAX / VMS
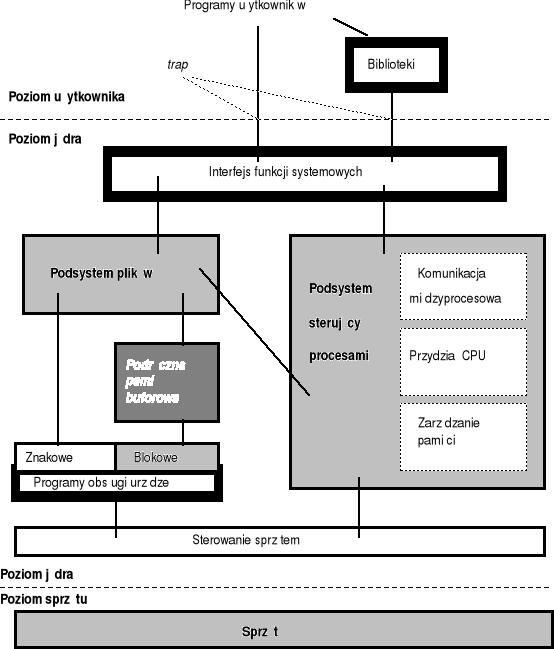
Systemy monolityczne
Systemy monolityczne ( tylko systemy czasu rzeczywistego )
Tutaj, system operacyjny jest zbiorem procedur, przy czym każda z nich może wywoływać dowolną inną gdy tylko istnieje taka potrzeba.
Każda z procedur musi mieć dobrze zdefiniowany interfejs przekazywania parametrów i wyników do innych procedur.
W celu konstrukcji aktualnej aplikacji systemu operacyjnego należy skompilować zbiór odpowiednich procedur, połączyć je razem, tworząc potrzebną wersję systemu.
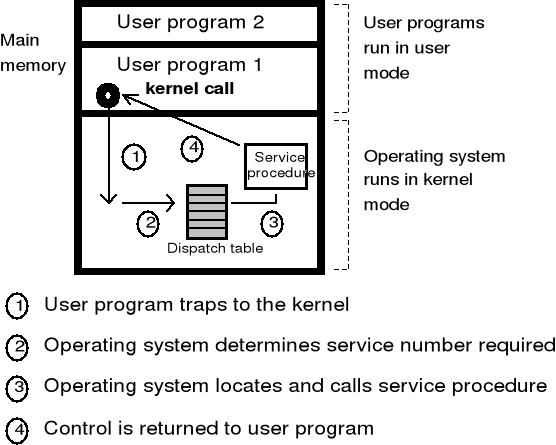
Struktura wydzielona ⇒ jądro
kernel call = funkcja systemowa
pułapka - przerwane programowe
tryb użytkownika - user mode
tryb systemowy - kernel mode
Funkcje jądra
Najważniejszą częścią systemu operacyjnego jest jądro, którego funkcjami między innymi są:
tworzenie i usuwanie procesów z systemu,
planowanie przydziału procesora (szeregowanie procesów), zarządzanie pamięcią i urządzeniami we / wy dla potrzeb procesów,
synchronizacja akcji wykonywanych przez procesy,
obsługa komunikacji pomiędzy procesami.
message passing - przekazywanie informacji między procesami
Systemy o strukturze wielopoziomowej (hierarchicznej)
Jest to struktura, która w prosty sposób zapewnia modularność systemu.
System jest podzielony na kilka poziomów, przy czym każdy z nich jest budowany na szczycie poprzedniego.
Każdy poziom składa się ze zbioru procedur i struktur danych, które mogą być wywoływane z poziomów wyższych - dany poziom może wykorzystywać funkcje i usługi oferowane przez poziomy niższe.
Przykład: users (poziom 4) -> poz.3 -> poz.2 -> poz.1 -> sprzęt (poz.0)
Korzystanie z funkcji (usług) niższego poziomu: 2->1 3->2 ale nie 3->1 !
Standard OSI/ISO to 7 warstw.
Systemy o strukturze wielopoziomowej (hierarchicznej) - cd.
Struktura przykładowa:
Poziom 6: programy użytkowe
Poziom 5: interpreter poleceń systemowych (powłoka, shell)
Poziom 4: zarządzanie pamięcią wirtualną
Poziom 3: zarządzanie procesami i przydziałem procesora
Poziom 2: zarządzanie urządzeniami we / wy
Poziom 1: moduły obsługi urządzeń i procedury obsługi przerwań
Poziom 0: sprzęt Nie ma systemów o czystej postaci wielopoziomowej lub monopolitycznej.
Struktura wielopoziomowa MS - DOS
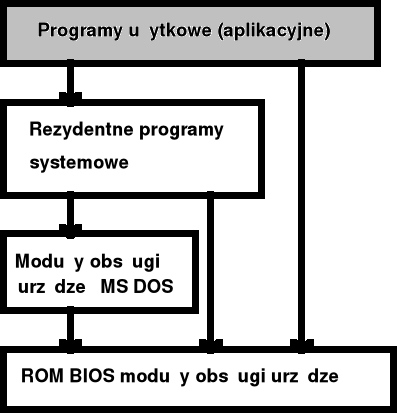
W MS-DOS brak utrzymania hierarchii.
Przykładowa struktura systemu UNIX

Metoda mieszana np. jądro systemowe - wiele modułów.
Dwa złącza - z użytkownikiem i funkcji systemowych.
Systemy o strukturze klient - serwer
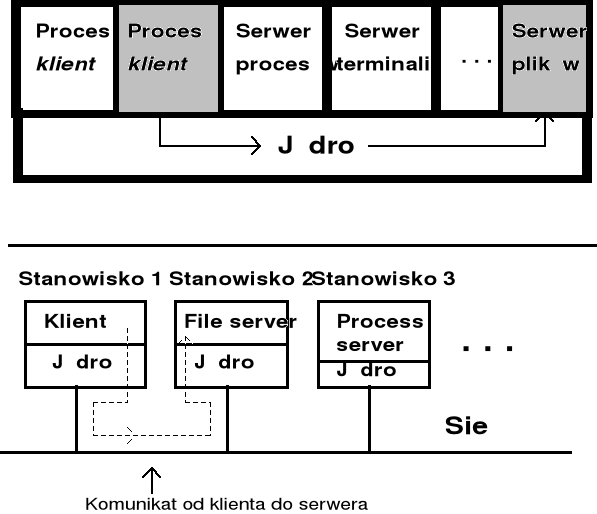
System rozproszony - każdy ma kopię mikrojądra.
Systemy o strukturze klient - serwer - cd.
Najnowsza tendencja w konstrukcji systemów operacyjnych - maksymalne przesuwanie części kodu systemu operacyjnego na wyższe poziom, tj. do procesów użytkowników, pozostawiając minimalne jądro systemu (ang. mikro-kernel).
Serwery (moduły świadczące usługi) zazwyczaj pracują w trybie użytkownika i nie mają bezpośredniego dostępu do sprzętu - zwiększa to bezpieczeństwo systemu.
Struktura systemu polega na jego podziale na moduły, które spełniają pewne wyodrębnione zadania - moduły nie są rozmieszczone w warstwach.
Moduły komunikują się z wykorzystaniem mechanizmu przesyłania komunikatów (ang. message passing) (w tym przesyłanie wyników) - program obsługi komunikatów jest głównym składnikiem mikrojądra systemu.
Moduł wysyłający początkowy komunikat jest nazywany klientem, a moduł odbierający serwerem - moduł może zmienić status, tzn. serwer może stać się klientem, jeśli wymaga tego zlecona mu do wykonania usługa.
Przesunięcie oprogramowania na poziom wyżej, a jądro jest małe - mikrojądro. Proces klienta i serwera plików mają te same prawa. Komunikacja modułów przez mikrojądro.
Systemy plików
Zarządzanie plikami - jeden z najważniejszych aspektów systemu operacyjnego z punktu widzenia użytkownika.
W systemie komputerowym informacja może być przechowywana w różnych postaciach fizycznych
Plik: - aby system komp. był wygodny w użyciu , sys. op. tworzy jednolity
obraz pamiętanej informacji - niezależną od właściwości fiz. urządzeń
pamięciowych jednostkę logiczną informacji - plik.
System plików składa się z dwóch wyraźnie wyodrębnionych części:
- zbiór faktycznych plików
struktura katalogowa - zawierająca informacje o wszystkich plikach
Czym jest plik ?
Plik jest zbiorem powiązanych ze sobą informacji określonych przez jego twórcę. .
Plik jest ciągiem bitów, bajtów, wierszy lub rekordów, których znaczenie określa twórca pliku i jego użytkownik.
Najczęściej pliki reprezentują programy (zarówno w postaci źródłowej jak i wynikowej) oraz dane. Pliki danych mogą być liczbowe, literowe, alfanumeryczne lub binarne. Pliki mogą mieć format swobodny, jak np. pliki tekstowe, lub ściśle określony.
Pojęcie pliku jest zatem bardzo ogólne.
Plik ma nazwę, za której pomocą można się do niego odwoływać. Ma również inne atrybuty (cechy), jak typ, czas założenia, nazwę właściciela, rozmiar itp.
Plik = strumień, ciąg bajtów
Organizacje plików w systemach operacyjnych
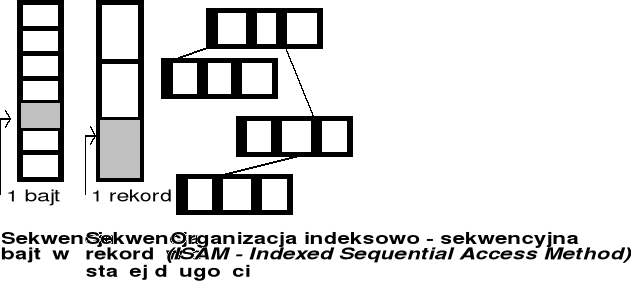
Organizacje plików w systemach operacyjnych
Sekwencja (strumień) bajtów - UNIX (plik jest ciągiem znaków zakończonym znakiem EOF (ang. End-Of-File)
EOF = CTRL-D ( UNIX )
Sesja użytkownika = PLIK
Chcąc odczytać 16-ty bajt, trzeba wczytać całe 512B do pamięci oper.
Read(16) -> HDD -> 512B -> PAO
każdy bajt może być indywidualnie adresowany przez przesunięcie( offset ) w stosunku do początku pliku
rekordem logicznym ( najmniejszą jednostką informacji ) jest 1 bajt
system plików automatycznie upakowuje bajty do bloków dyskowych ,
które mogą mieć rozmiar 1 lub kilku sektorów na dysku .wszystkie dyskowe operacje we/wy operują jednostką którą jest blok
( rekord fiz. ) - rozmiar bloku nie musi być zgodny z rekordem logicznym
Organizacje plików - cd.
Sekwencja rekordów - rekord logiczny składa się z kilku lub kilkudziesięciu bajtów i może mieć stałą, ściśle określoną długość lub zmienną długość
Organizacja indeksowo - sekwencyjna (ISAM) - IBM
Bardzo często w systemach baz danych.
ISAM - pogrupowanie rekordów tematycznie w BLOKI.
SQL - 4GL - 4th generation language
przeznaczona dla b. dużych plików
wykorzystywana jest dodatkowa struktura - indeks
ISAM zakłada istnienie małego indeksu głównego , który wskazuje na
blok dyskowy zawierający indeksy wtórne ( adresy bloków dyskowych )
plik jest posortowany wg. określonego klucza głównego ( np. nazwisk ) - indeks
jest tworzony na bazie tego klucza
Metody dostępu do plików
1. Dostęp sekwencyjny
(read next, write next)

Read( ,0,512)
zawartość pliku przetwarzana po kolei - porcja za porcją
operacja read czyta następną porcję pliku i automatycznie przesuwa wskaźnik
pozycji w kierunku końca pliku.
- podobnie jest wykonywana write ( należy rozróżnić nadpisywanie danych i
zapis na końcu pliku ).
Metody dostępu do plików - cd.
2. Dostęp bezpośredni (swobodny)
(read n, write n)
gdzie n jest numerem rekordu logicznego
PLIK - ciąg ponumerowanych rekordów logicznych
n - numer rekordu
plik jest traktowany jako ciąg ponumerowanych rekordów logicznych ( najczęściej bajtów ) - metoda pozwala na czytanie lub zapisywanie dowolnych porcji pliku )
nie ma żadnych ograniczeń odnośnie kolejności operacji czytania i pisania w pliku ).
- nr. rekordu logicznego przekazywany przez użytkownika w poleceniu read/write
jest numerem względnym tego rekordu ( względem początku pliku ).
Metody dostępu do plików - cd.
3. Dostęp z wykorzystaniem indeksów
Założenia dostępu bezpośredniego oraz INDEKS PLIKU. Wskaźniki do konkretnych bloków dyskowych. Aby znaleźć konkretny blok, należy przeszukać INDEKS. Nazwisko -> nr bloku -> adres bloku dyskowego -> nr cylindra,ścieżki, talerza ...
- rozszerzenie metody dostępu bezpośredniego z wykorzystaniem dodatkowej
struktury danych -indeksów pliku
- indeks zawiera wskaźniki do odpowiednich bloków dyskowych .

Typy plików
Problem projektowy: w jakim stopniu system operacyjny powinien znać, rozpoznawać i ingerować w typy plików.
Dwa podejścia:
System operacyjny rozpoznaje typy plików -rozróżnianie typu pliku najczęściej polega na wprowadzeniu odpowiedniego rozszerzenia w nazwie pliku np. file.pas, file.obj, file.bin
Zalety:
System operacyjny, na podstawie typu pliku, nie dopuści do wydrukowania
programu wynikowego w postaci binarnej
Możliwość zagwarantowania, że użytkownik będzie zawsze wykonywać
aktualną wersję pliku wynikowego
Typy plików - cd
System operacyjny rozpoznaje typy plików - cd.
Wady:
Zwiększenie rozmiaru systemu operacyjnego
Problemy w przypadku nowych zastosowań wymagających struktur informacji (typów plików) nie obsługiwanych przez dany system operacyjny
W systemie operacyjnym nie wyróżnia się typów plików - w takim przypadku, każdy program użytkowy oraz funkcje systemowe muszą zawierać własny kod interpretujący plik wejściowy odpowiednio do jego struktury
Zmierzanie do tego: pliki | katalogi | pliki specjalne (~systemowe~)
JĄDRO nie rozróżnia, odpowiednie moduły MUSZĄ TO ROBIĆ.
Format pliku wykonywalnego w systemie UNIX

Program wykonywalny: |Tekst|Stos|-> szczelina <-|Dane|
Funkcje systemowe operujące na plikach
CREATE
W różnych systemach operacyjnych dostępne są różne operacje przeznaczone do przechowywania danych w plikach i do manipulowania tymi danymi. Poniżej przedstawiono zestaw najczęściej spotykanych operacji (funkcji systemowych) na plikach.
Funkcje systemowe operujące na plikach - cd.
CREATE -cd.
UNIX:
CREATE. Plik jest tworzony, lecz pozostaje pusty. Celem tej funkcji jest „zaanonsowanie”, że plik został utworzony i wstępne nadanie mu pewnych atrybutów. Do utworzenia pliku są niezbędne dwa kroki. Po pierwsze, na dysku musi zostać znalezione miejsce na plik. Po drugie, w katalogu należy utworzyć pozycję opisującą nowy plik.
Funkcje systemowe operujące na plikach - cd.
DELETE
DELETE. Jeśli plik nie jest już dalej potrzebny, należy go usunąć aby zwolnić miejsce na dysku. W celu usunięcia pliku odnajduje się jego nazwę w katalogu, zwalnia całą przestrzeń na dysku zajmowaną przez plik i likwiduje daną pozycję w katalogu.
OPEN
OPEN. Przed użyciem pliku proces musi ten plik otworzyć. Celem funkcji OPEN jest pozwolenie systemowi na odczytanie atrybutów pliku oraz listy adresowej jego bloków dyskowych. Informacje te są przepisywane do pamięci operacyjnej, aby przyśpieszyć wszystkie kolejne operacje wykonywane na tym pliku. Niektóre systemy niejawnie otwierają plik przy pierwszym do niego odwołaniu, jednak większość systemów wymaga jawnego otwierania plików przez programistę za pomocą funkcji OPEN, która powinna być wywołana przy pierwszym użyciu pliku. Operacja otwierania pliku pobiera nazwę pliku, przegląda katalog i kopiuje odpowiednią pozycję w katalogu do tablicy otwartych plików.
Funkcje systemowe operujące na plikach - cd.
OPEN - cd.
Natępnie do procesu jest przekazywany wskaźnik do pozycji opisującej plik w tablicy otwartych plików. Wszystkie następne operacje we / wy używają tego wskaźnika zamiast faktycznej nazwy pliku, dzięki czemu unika się dalszych przeszukiwań katalogu.
Funkcje systemowe operujące na plikach - cd.
CLOSE
CLOSE. Gdy wszystkie operacje na pliku zostaną zakończone, to jego atrybuty i adresy bloków dyskowych nie są już potrzebne, i plik powinien zostać zamknięty aby zwolnić obszar w odpowiednich tablicach systemowych. Gdy plik jest zamykany jego opisy w tablicy otwartych plików są usuwane.
Funkcje systemowe operujące na plikach - cd.
READ
READ. Funkcja ta realizuje operacje odczytu danych pamiętanych w pliku. Wykorzystywany jest przy tym wskaźnik bieżącej pozycji w pliku (ang. current file position). Zarówno operacje czytania, jak i pisania posługują się tym samym wskaźnikiem. Zazwyczaj czytane bajty pliku są wskazywane przez ten wskaźnik. Proces wywołujący tą funkcję musi musi podać specyfikację liczby bloków, które mają być odczytane, oraz zabezpieczyć bufor dla ich przechowywania.
Funkcje systemowe operujące na plikach - cd.
WRITE
WRITE. Funkcja ta realizuje operacje zapisu, zazwyczaj wykorzystując przy tym wskaźnik bieżącej pozycji w pliku. Jeśli wskaźnik ten znajduje sie na końcu pliku, to jego rozmiar rośnie. Jeśli wskaźnik znajduje się w środku pliku, to istniejące dane są nadpisywane.
Funkcje systemowe operujące na plikach - cd.
READ / WRITE
??????????????
APPEND. Jest to ograniczone postać funkcji WRITE. Funkcja ta może dopisywać dane tylko na końcu pliku. Systemy które zabezpieczają tylko minimalny zbiór funkcji systemowych, tej funkcji nie posiadają. Jednakże czynności realizowane przez tę funkcję mogą być wykonane w inny sposób.
Tablica struktury pliku - tworzona w programie (jednocześnie kilka procesów otwiera jeden plik)
ID_UŻYTKOWNIKA |
ID_PROCESU |
ID_bajtu_na_którym_operuje |
... |
A |
120 |
... |
B |
0 |
... |
... |
... |
Funkcje systemowe operujące na plikach - cd.
SEEK
SEEK. W celu umożliwienia bezpośredniego dostępu do pliku, konieczne jest jakaś metoda określania z jakiego miejsca pliku pobierać dane. Powszechnie stosowanym rozwiązaniem jest funkcja SEEK, która przesuwa wskaźnik bieżącej pozycji w pliku, wskazując to miejsce w pliku. Po wykonaniu tej funkcji dane można z tego miejsca odczytać lub zapisać.
GET ATTRIBUTES. Procesy często muszą odczytywać atrybuty pliku aby wykonać swoją „pracę”. Przykładem może być tutaj UNIX-owy program make, wykorzystywany do zarządzania wspólny projektami programistycznymi. Program make bada czas i datę modyfikacji plików źródłowych i wynikowych, i wykonuje rekompilację programów nieaktualnych.
Atrybuty plików
Field |
Meaning |
Protection |
Who can access the file and in what way |
Password |
Password needed to access the file |
Owner |
Current owner |
Read-only flag |
0 for read/write, 1 for read only |
Hidden flag |
0 for normal, 1 for do not display in listings |
System flag |
0 for normal file, 1 for system file |
Archive flag |
0 has been backed up, 1 for needs to be backed up |
ASCII/binary flag |
0 for ASCII file, 1 for binary file |
Random access flag |
0 for sequential access only, 1 for random access |
Atrybuty plików - cd.
Field |
Meaning |
Temporary flag |
0 for normal, 1 for delete on process exit |
Lock flag |
0 for unlocked, nonzero for locked |
Record length |
Number of bytes in a record |
Key length |
Number of bytes in the key field |
Creation time |
Date and time file was created |
Time of last access |
Date and time file was last accessed |
Time of last change |
Date and time file was last changed |
Current size |
Number of bytes in the file |
Maximum size |
Maximum size file may grow to |
Katalogi
W niektórych systemach można wyróżnić dwie oddzielne struktury katalogów:
katalog urządzenia (ang. device directory) - pamiętany na każdym urządzeniu fizycznym - opisuje wszystkie pliki tam pamiętane,
katalog plików (ang. file directory) - jest logiczną organizacją plików na wszystkich urządzeniach, widzianą przez użytkownika
katalogi utrzymuje się dla określenia sposobu dostępu do pliku,
w wielu systemach katalogi są same w sobie plikami,
katalog zawiera określoną liczbę pozycji - po jednej na plik,
Budowa katalogu w różnych systemach
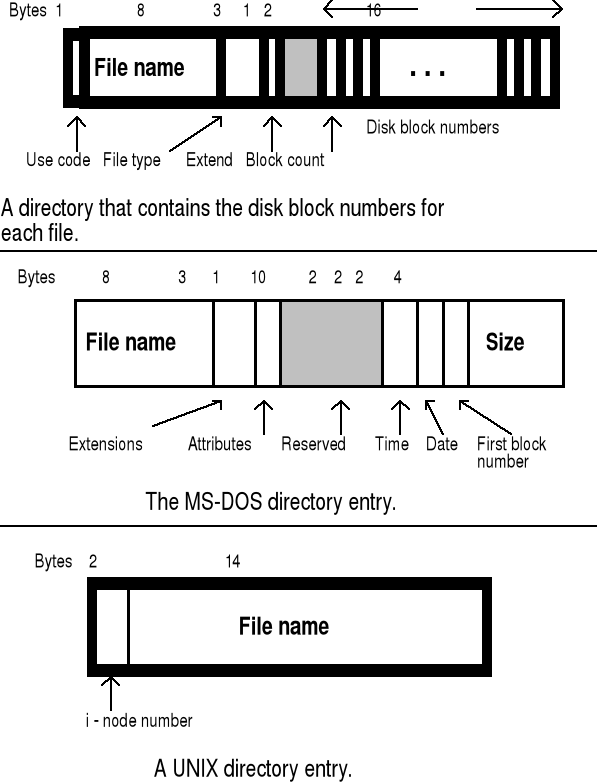
rys1 - CP/M rys2 - MS-DOS rys3 - UNIX
Organizacje struktury katalogowej
W prostych systemach utrzymuje się jeden katalog dla wszystkich plików wszystkich użytkowników, tzw. katalog jednopoziomowy, lub katalog dwupoziomowy - główny katalog plików systemu i katalogi plików użytkowników,
W systemach wielodostępnych stosuje się katalogi hierarchiczne o strukturze drzewa

Hierarchiczna struktura katalogów - UNIX
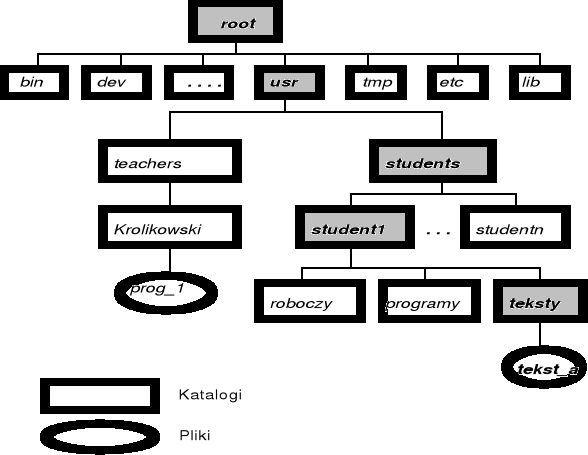
Organizacja struktury katalogowej - cd.
W drzewie katalogów wyróżnia się katalog - korzeń (główny).
Katalog (lub podkatalog) zawiera zbiór plików i (lub) podkatalogów - wszystkie katalogi mają taką samą budowę wewnętrzną.
Podczas pracy z systemem użytkownik dysponuje katalogiem bieżącym (inaczej - roboczym); w większości systemów jest on oznaczany kropką ( . ), natomiast katalog nadrzędny w stosunku do niego - dwiema kropkami( .. ).
Każdy plik w systemie ma jednoznaczną tzw. nazwę ścieżki (lub inaczej nazwę ścieżkową). Nazwa ścieżki jest ścieżką dostępu od katalogu korzenia, przez wszystkie katalogi pośrednie, aż do określonego pliku. Nazwy ścieżek mogą być:
bezwzględne (inaczej absolutne)
względne (inaczej relatywne)
W systemie UNIX, przy rejestrowaniu nazwy użytkownika w systemie zostaje z nią związany katalog osobisty (ang. home directory) danego użytkownika. Katalog ten staje się katalogiem bieżącym w chwili rozpoczynania przez użytkownika sesji przy terminalu.
Ścieżki dostępu
Pliki nie umieszczone w żadnym podkatalogu bieżącego katalogu użytkownika można znaleźć rozpoczynając przeszukiwanie od katalogu pierwotnego, tj. od korzenia drzewa katalogów. Katalog pierwotny jest jedynym katalogiem bez nazwy.
Na przykład, jeśli katalogiem bieżącym jest katalog student1, to plik tekst_a może być identyfikowany na kilka sposobów:
student1/teksty/tekst_a - od katalogu bieżącego,
. /student1/teksty/tekst_a - od katalogu bieżącego (kropka użyta jako nazwa pliku odnosi się do katalogu bieżącego),
/usr/students/student1/teksty/tekst_a - od korzenia.
Jeśli katalogiem bieżącym jest w danym momencie katalog student1, a ma być wydane polecenie dostępu do pliku prog_1 w katalogu krolikowski, to powinno ono zawierać argument:
../../teachers/krolikowski/prog_1
przy czym dwie kropki (..) wskazują katalog nadrzędny (tutaj powtórzone dwa razy wskazują na katalog usr) i z niego rozpocznie się poszukiwanie pliku prog_1 przez katalogi teachers i krolikowski.
Lokalizacja bloków dyskowych pliku w systemie UNIX
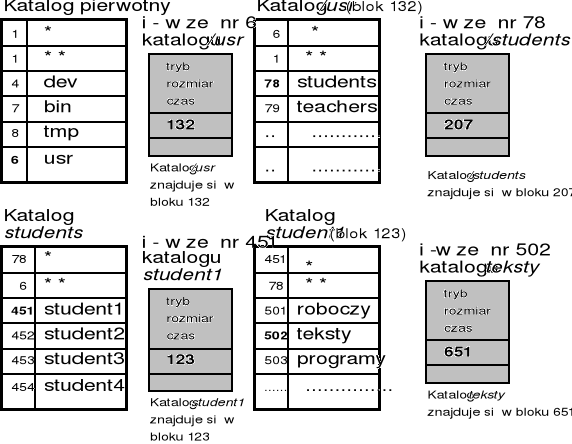
Parametr polecenia - ścieżka dostępu: /usr/students/student1/teksty/tekst_a
1 -> 2 -> 3 i-węzły (512B)
Katalogi o strukturze acyklicznego grafu skierowanego - pliki współdzielone
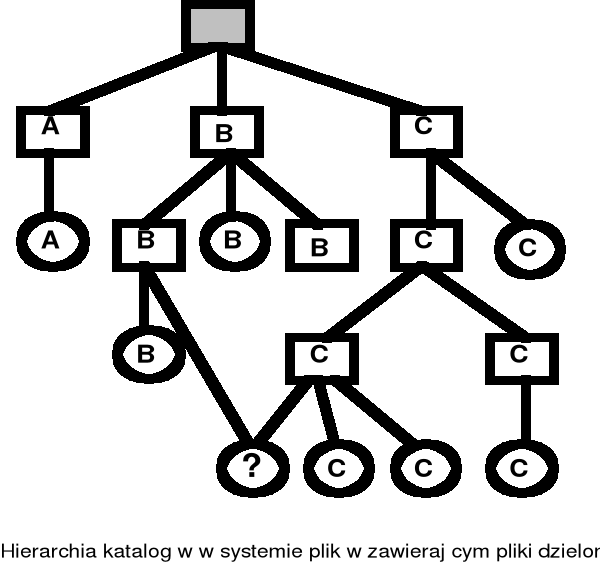
? - to nie są kopie tego samego pliku, to jest współdzielenie. Pliki takie są backup'owane 2 razy (rozróżnienie tylko przez nowe programy). Po odtworzeniu 2 osobne kopie pliku a nie 1 współdzielony. Graf skier. bez cykli!
Katalogi o strukturze acyklicznego grafu skierowanego - pliki współdzielone - cd.
Dzielenie (współdzielenie) plików umożliwiają katalogi o strukturze grafu skierowanego (bez cykli) (ang. directed acyclic graph - DAG)
Problem dowiązywania (dołączania) plików:
dowiązanie „twarde” - dokonanie odpowie-dniego wpisu do katalogu użytkownika, który przyłącza się do danego pliku,
UNIX: Link -opcja - tworzy nowy zapis w katalogu wykorzystując i-node istniejącego pliku,
rozwiązanie stosowane w systemach, w których katalog zawiera adresy bloków dyskowych pliku,
dowiązanie „miękkie” (symboliczne) (ang. symbolic linking) - system tworzy nowy plik, typu LINK, i wprowadza zapis o nim do katalogu użytkownika - plik typu LINK zawiera tylko ścieżkę dostępu do pliku dowiązanego
Pliki dzielone - dowiązywanie
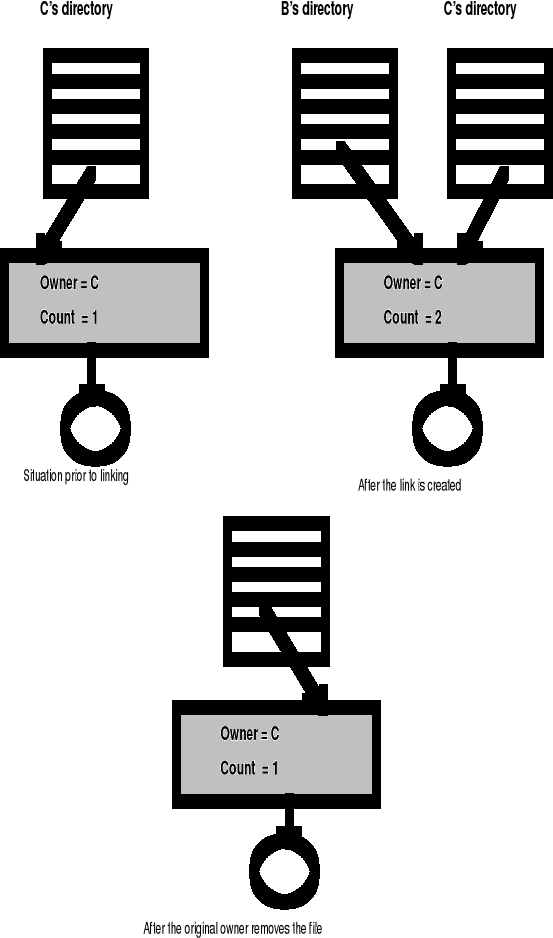
Pliki dzielone - dowiązywanie - cd.
Problemy:
Dowiązanie „twarde”:
Właściciel pliku (C) usuwa plik. Co się może zdarzyć w systemie ?
count=2 więc 2 dowiązania. B dowiązał się. C (właściciel) chce usunąć plik. B w ogóle nie może usunąć (nie jest właścicielem). Jeśli (przy dowiązaniach twardych) COUNT>1 to NIE MOŻNA SKASOWAĆ - najpierw skasować dowiązanie !
Rozwiązanie:
Dowiązanie symboliczne:
?
Przy dowiązaniu miękkim katalog ma przynajmniej 2 odnośniki, plik przynajmniej 1.
Przy obu rodzajach dowiązań mogą pojawiać się problemy przy składowaniu systemu plików na taśmę i jego odtwarzaniu - tworzone są wielokrotne kopie plików a nie dowiązania
System plików - UNIX

Montowanie systemu plików
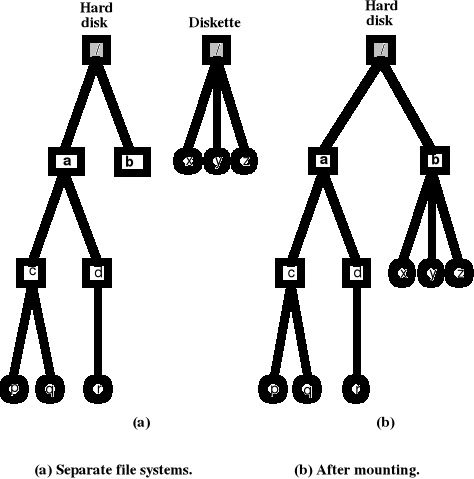
Budowa systemu plików - UNIX
Dany logiczny system plików jest ciągiem bloków ponumerowanych kolejno 0 ... n, przy czym kolejne bloki stanowią:
blok 0 (ang. boot block) (zarezerwowany dla programu ładującego system),
blok nadrzędny (ang. super block),
lista tzw. i-węzłów plików (ang. i-node list),
bloki danych,
obszar do wymiatania programów (ang. swapping space).
W bloku nadrzędnym zawarte są następujące informacje o systemie plików:
rozmiar w blokach,
nazwa urządzenia logicznego,
nazwa systemu plików,
rozmiar listy węzłów plików,
wskaźnik na pierwszy element listy wolnych bloków,
wskaźnik na pierwszy element listy węzłów plików,
data ostatniej modyfikacji,
data ostatniego dostępu,
rozmiar bloku.
Tablice systemowe systemu plików - UNIX
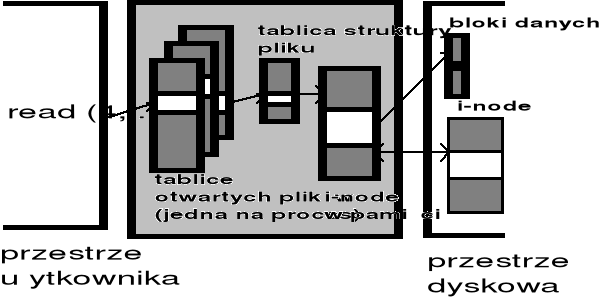
Pliki specjalne systemu UNIX
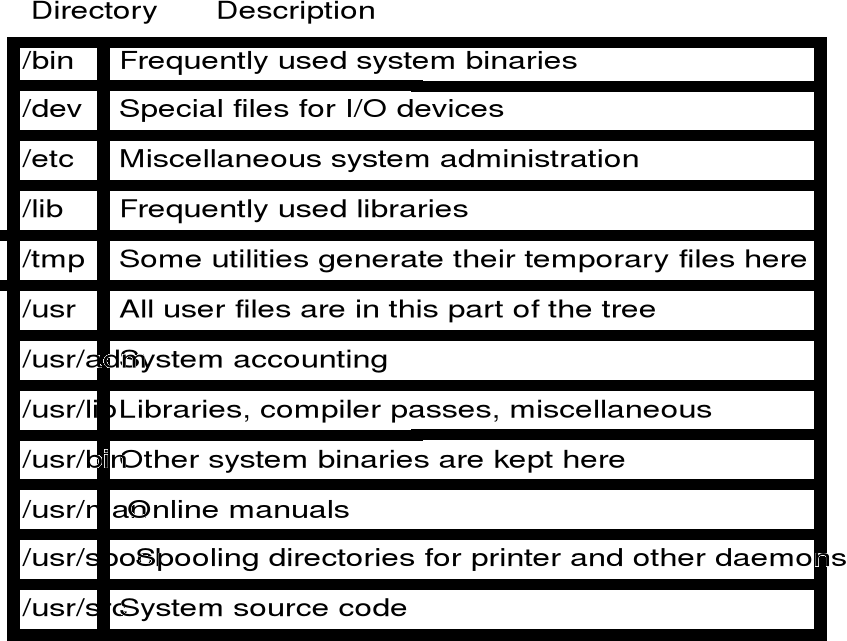
Pliki specjalne reprezentujące urządzenia zgrupowane są w katalogu /dev. Wpisane są w nim pliki pseudourządzeń i urządzeń rzeczywistych. Do pseudourządzeń należą między innymi:
/dev/console - konsola systemowa, na którą wyprowadzane są komunikaty systemowe,
/dev/kmem - odwzorowanie wirtualnej pamięci operacyjnej,
/dev/swap - urządzenie logiczne reprezentujące obszar, do którego są wymiatane programy z pamięci operacyjnej,
/dev/tty - wirtualny terminal, z którego został zainicjowany proces.
Urządzenia rzeczywiste to:
/dev/fdn - stacja dysków elastycznych,
/dev/hdn - stacja dysków twardych,
/dev/lp - drukarka,
/dev/mtn - stacja taśm magnetycznych.
Standardowe katalogi - Unix
Zarządzanie przestrzenią na dysku - Budżet dyskowy użytkownika
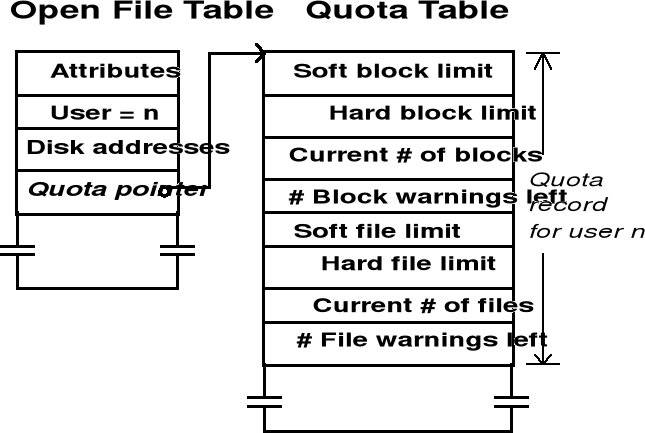
Budżet dyskowy użytkownika
Mechanizm „dyscyplinowania” użytkowników przed nadmiernym wykorzystywaniem przestrzeni na dysku
Gdy proces otwiera plik, atrybuty i adresy dyskowe bloków pliku są przepisywane do tablicy otwartych plików - pomiędzy tymi atrybutami znajduje się wskaźnik do tablicy budżetu dyskowego użytkownika (właściciela) pliku
Każdy wzrost rozmiaru pliku powoduje zwiększenie liczby bloków obciążających konto użytkownika - liczba ta jest porównywana z tzw. „miękkim” i „twardym” limitem
Limit twardy nie może być przekroczony - próba dostępu przy przekroczonym limicie jest traktowana jako błąd (podobnie w przypadku liczby plików)
Limit miękki może być przekroczony - wyświetlany jest komunikat - ostrzeżenie
Administrator określa maksymalną liczbę takich ostrzeżeń jakie mogą być wysłane do użytkownika - po ich zignorowaniu system zachowuje się tak, jakby został przekroczony limit twardy.
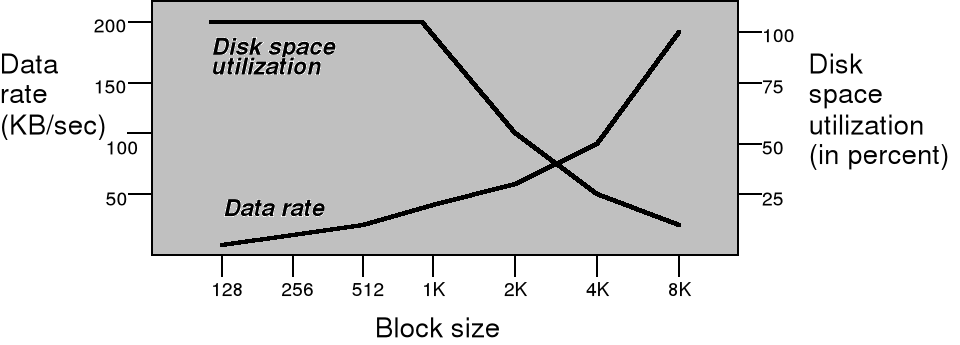
Problem rozmiaru bloku dyskowego
Problem: Jaki rozmiar bloku dyskowego dobrać w danym systemie ?
Organizacja dysku: sektor, ścieżka, cylinder ?
System z pamięcią stronicowaną: rozmiar strony ?
Najczęściej stosowane obecnie rozmiary bloków:
512 B, 1kB, 4 kB
program_użytkownika -> (np. 4kB) -> ramki -> (swp) -> HDD
Wykorzystanie przestrzeni na dysku a szybkość dostępu i rozmiar bloku
Zarządzanie obszarami wolnymi na dysku Mapa bitowa
Każdy blok jest reprezentowany przez jeden bit (0 - jeśli blok jest wolny). Rozważmy dysk na którym wolne są następujące bloki:
2, 3, 4, 5, 8, 9, 10, 11, 12, 13, 17, 18, 25, 26, 27.

Lista łączona bloków wolnych
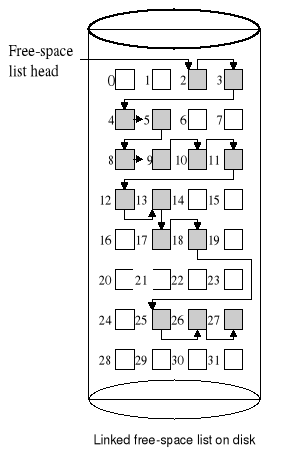
Lista łączona bloków wolnych - cd.
Grupowanie ( obecnie nie stosowane )
pamiętanie adresów n bloków wolnych w pierwszym bloku wolnym
ostatni blok z tej grupy zawiera wskaźnik na kolejną grupę wolnych bloków
zaleta - adresy dużej liczby wolnych bloków mogą być szybko znalezione
Zliczanie ( stosowane najczęściej )
wykorzystanie faktu, że najczęściej pliki są alokowane i zwalniane w zestawie n przylegających do siebie bloków
zamiast utzrymywać listę n wolnych bloków (adresy tych bloków), wystarczy przechowywać adres pierwszego wolnego bloku i licznik pokazujący liczbę przylegających do niego bloków wolnych
przydatne gdy stosowana jest alokacja ciągła
Metody alokacji plików na dysku
Problem:
Jak alokować (przydzielać) przestrzeń na dysku do plików, tak aby była ona wykorzystywana maksymalnie efektywnie i dostęp do plików był możliwie jak najszybszy ?
Metody alokacji przestrzeni dyskowej:
ciągła (ang. contignous)
łączona (ang. linked)
indeksowa (ang. indexed)
Z reguły obecnie stosuje się kombinacje tych metod lub różne metody dla plików o różnych rozmiarach
Alokacja ciągła (ang. Contignous Allocation)
Założenie: Każdy plik zajmuje zbiór ciągły adresów na dysku
Zalety:
dostęp do bloku b+1 po bloku b nie wymaga ruchu głowic (lub minimalnego bo bloki do siebie przylegają ) - operacji najbardziej czasochłonnej
liczba operacji przeszukiwania (ang. seek) dysku jest minimalna
możliwy jest zarówno dostęp sekwencyjny jak i losowy ( tak samo efektywny )
Wady:
problemy ze znalezieniem obszaru wolnego na dysku dla nowego pliku
fragmentacja zewnętrzna (ang. external fragmentation) - poszatkowanie
na obszary wolne i używane . Na dysku mogą powstać obszary na tyle małe , że
nie można do nich zapisać plików o najczęściej występujących rozmiarach.problem określenia przewidywanego rozmiaru pliku
Alokacja ciągła
Plik |
Początek |
Długość |
count |
0 |
2 |
tr |
14 |
3 |
19 |
6 |
|
list |
28 |
4 |
f |
6 |
2 |
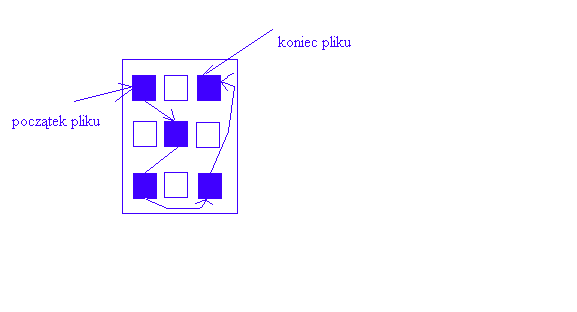
Alokacja łączona (ang. Linked Allocation)
Alokacja łączona (ang. Linked Allocation)
Założenia:
Plik jest listą łączoną bloków dyskowych - blok może być przechowywany w dowolnym miejscu na dysku
Katalog zawiera wskaźnik (ang. pointer) do pierwszego i ostatniego bloku pliku
Zalety:
brak fragmentacji zewnętrznej
nie ma potrzeby deklarowania rozmiaru pliku w momencie jego tworzenia
Wady:
możliwość efektywnego tylko dostępu sekwencyjnego do plików
problemy jeśli zostanie utracony wskaźnik do bloku
Alokacja łączona - Tablica FAT
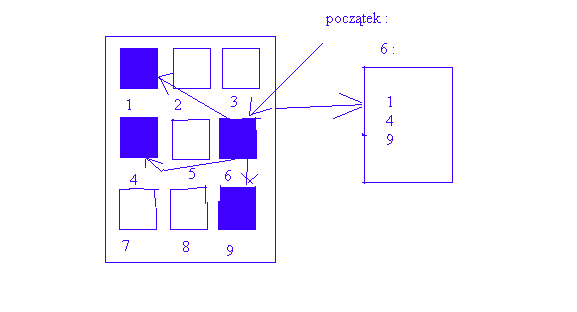
Alokacja indeksowa (ang. Indexed Allocation)
Alokacja indeksowa (ang. Indexed Allocation)
Założenia:
przeniesienie wszystkich wskaźników do bloków dyskowych do bloku indeksów
każdy plik ma swój własny blok indeksów, który jest jednym z bloków dyskowych
i - ty zapis w bloku indeksów wskazuje na i - ty blok pliku
Zalety:
możliwość efektywnego wykonywania dostępu bezpośredniego
łatwe dodawanie nowych bloków do pliku
brak fragmentacji zewn.
Wady:
marnotrawienie przestrzeni na dysku w przypadku małych plików ( fragmentacja
wewn. - w blokach związanych z plikiem powstają obszary niewykorzystane )
Jeśli nie starcza 1 blok - lista łączona bloków indeksowych ( dla dużych plików ) .
Dla plików o dużych rozmiarach najczęściej stosuje się alokację indeksową , dla
Plików o małych rozmiarach - alokację ciągłą .
Szeregowanie ruchu głowic
Problem: bardzo duża dysproporcja pomiędzy szybkością procesora a szybkością obsługi operacji dyskowych;
Rozwiązanie: dodanie nawet kilku tysięcy instrukcji do kodu systemu operacyjnego w celu zaoszczędzenia kilku ruchów głowic
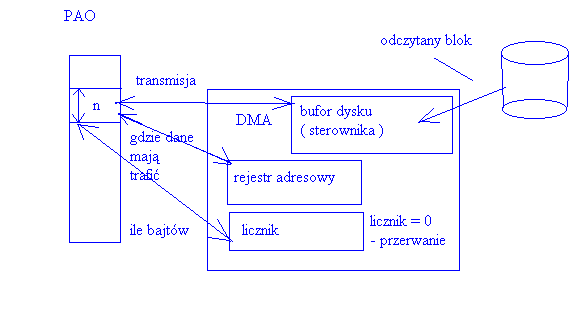
Sumaryczny czas obsługi operacji dyskowych:
czas wyszukania (ang. seek time) - czas przesunięcia głowicy nad odpowiednią ścieżkę lub cylinder
czas opóźnienia (ang. latency time) - czas oczekiwania aż określony blok znajdzie się pod głowicą
czas transmisji (ang. transfer time) - czas transmisji przeczytanego bloku do pamięci operacyjnej
Szeregowanie ruchu głowic - budowa sterownika dysku :
Algorytm FCFS szeregowania ruchu głowic
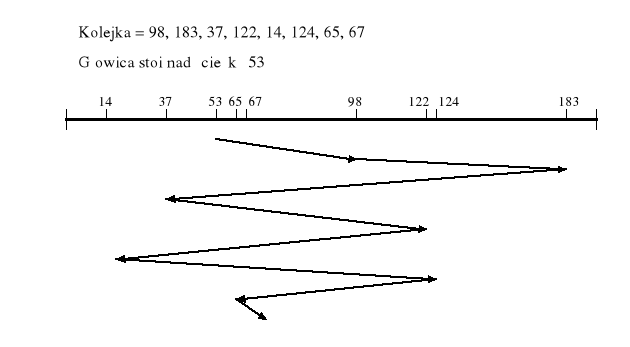
First Come First Served (= FIFO) długi czas , nie ma faworyzacji
Algorytm „Najpierw najkrótszy skok” (ang.SSTF disk scheduling)

Shortest Seek Time First - rzadko stosowany
Algorytm SCAN - „windowy” (ang. SCAN disk scheduling)
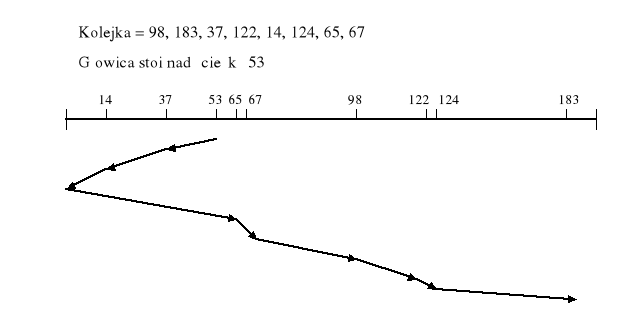
wersja najprostsza najczęściej stosowany
Algorytm C-LOOK (w grupie algorytmów windowych)
Gdy głowica przesuwa się tylko w jedną stronę
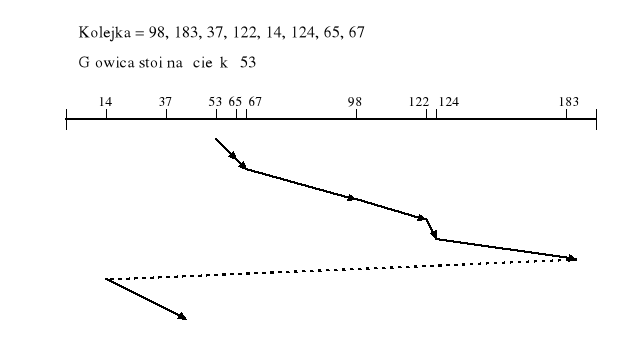
.... - szybki „ruch jałowy”
Algorytmy windowe - najlepsze , zwłaszcza dla systemów mocno
obciążonych ( gdy jest dużo żądań dysku ) .
- wybór algorytmu zależy też od rodzaju alokacji - gdy stosowana jest
alokacja ciągła - nie ma aż takiego znaczenia
Wielopoziomowa struktura systemu plików
Application programs
⇓
Logical File System (logiczny system plików)- analiza nazwy ścieżkowej z wykorzystaniem struktury katalogowej
⇓
File Organization Module (moduł organizacji pliku)- dysponując informacją o metodzie alokacji plików, ich położeniu na dysku, oraz żądaniu użytkownika (read (n-ty bajt), generuje adresy bloków dyskowych
⇓
Basic File System (podstawowy system plików)- nadzoruje wykonywanie operacji dyskowych (zapis i odczyt)
⇓
I/O Control - sterowanie operacjami we/wy (procedury obsługi urządzeń, procedury obsługi przerwań)
⇓
Devices - obsługa urządzeń i sterowników
Niezawodność systemu plików
Zarządzanie blokami uszkodzonymi (ang. Bad Block Management)
Dwa rozwiązania problemu bloków uszkodzonych:
Sprzętowe: przypisanie uszkodzonego sektora do listy bloków „złych”; podczas inicjacji sterownika czytana jest lista bloków uszkodzonych, są one zastępowane blokami zapasowymi, przy zapamiętaniu tego odwzorowania na liście bloków wolnych
Programowe: utworzenie pliku, który zawiera wszystkie uszkodzone bloki, bloki te są usuwane z listy bloków wolnych (problemy przy składowaniu plików).
Obecnie - problem drugorzędny ze względu na jakość dysków .
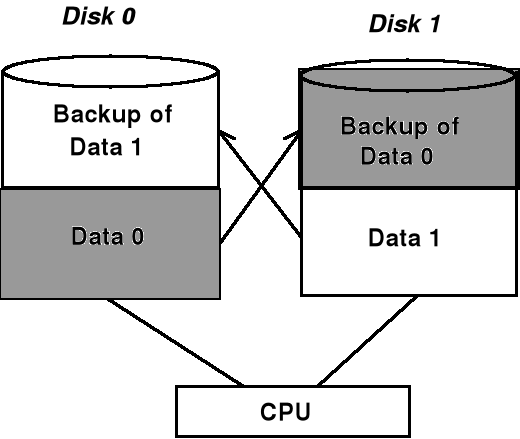
Niezawodność systemu plików - Backups
System dysków „zwierciadlanego” odbicia (ang. Disk Mirroring System)
Niezawodność systemu plików - Backups -cd.
Problem: zniszczenie systemu plików stanowi często większą szkodę niż zniszczenie całego komputera
Rozwiązanie: składowanie systemu plików na taśmę.
Jak ?
1. Okresowe składowanie systemu plików (np. raz na 2 tygodnie)
Wady:
utworzenie pliku, który zawiera wszystkie uszkodzone bloki, bloki te są usuwane z listy bloków wolnych (problemy przy składowaniu plików)
podczas składowania system musi pracować w trybie jednego użytkownika
bardzo czasochłonne ( ze względu na nośnik - taśmę ) .
2. Składowanie okresowe (np. raz w miesiącu) oraz składowanie przyrostowe (ang. incremental dump)
konieczna znajomość daty ostatniego składowania i daty ostatniej modyfikacji pliku
bity archiwizacji (MS-DOS) - jeśli 1 - plik / katalog ( wraz z jego plikami ) był modyfikowany
Spójność systemu plików

Stany systemu plików: (a) spójny (b) brakujące bloki (c) powtarzające się bloki na liście bloków wolnych (d) powtarzające się bloki danych
Sprawdzanie spójności systemu plików - UNIX
Po co ? Kiedy ?
brak spójności systemu plików - pogorszenie efektywności systemu
Jak ?
wprowadzenie systemu w stan pracy jednego użytkownika,
odłączenie (unmount) badanego systemu plików,
program fsck
Etapy pracy programu fsck obejmują sprawdzanie:
bloków i ich rozmiarów,
ścieżek dostępu,
połączeń,
zgodności licznika łączników do pliku dla każdego zapisu w katalogu,
listy bloków wolnych,
odtwarzanie listy bloków wolnych.
Sprawność systemu plików
Problem:
Operacja dostępu do danych w pliku wymaga ich sprowadzenia do pamięci operacyjnej, gdzie proces może je testować, zmieniać, po czym zażądać ponownego ich zapisania do systemu plików.
Czytanie i pisanie bezpośrednio z/na dysk podczas wszystkich operacji dostępu do plików jest niemożliwe ze wzgl. na to, że czas reakcji i przepustowość systemu byłyby bardzo niskie (mała szybkość transmisji dyskowych)
Rozwiązanie:
Minimalizacja dostępów do dysku przez utrzymywanie puli wewn. buforów zwanych podręczną pamięcią buforową (buffer cache) które zawierają dane z ostatnio używanych bloków dyskowych.
Uwaga ! Podręczna pamięć buforowa jest strukturą programową, której nie należy mylić ze sprzętowymi pamięciami podręcznymi (procesora i dysków), które przyśpieszają odwołania do pamięci.
Sprawność systemu plików - buforowanie
Zasady buforowania
Bloki dyskowe aktualnie wykorzystywane są utrzymywane w pamięci buffer cache - dane w jednym buforze odpowiadają danym z logicznego bloku dyskowego
obsługa żądania odczytu bloku polega najpierw na sprawdzeniu czy dany blok znajduje się w pamięci buffer cache
jeśli blok nie znajduje się w pamięci buffer cache jest czytany z dysku do tej pamięci, i następnie kopiowany w odpowiednie miejsce w pamięci głównej
dane zapisywane na dysk są również zapamiętywane w pamięci buforowej, by były tam dostępne dla ewentualnych kolejnych operacji odczytu
jądro próbuje minimalizować częstość zapisów dyskowych, starając się stwierdzić, czy dane na pewno muszą być zapisane, czy też są to dane przejściowe
specjalizowane algorytmy jądra zlecają modułowi zarządzającemu podręczną pamięcią buforową sprowadzanie danych z wyprzedzeniem oraz opóźnianie ich zapisu w celu zwiększenia skutków buforowania
Zasady buforowania
Wykonywanie operacji read i write
Operacje dostępu do danych, które może zawierać program są następujące:
read(X) - czyta daną jednostkę X pamiętaną w pliku (bazie danych) i podstawia ją pod zmienną w programie
write(X) - zapisuje wartość zmiennej X programu do jednostki danych X w pliku (bazie danych)
Wykonanie polecenia read (X) składa się z następujących kroków:
Znajdź adres bloku dyskowego, który zawiera jednostkę X
Przekopiuj zawartość tego bloku do bufora w pamięci głównej (jeśli blok się tam jeszcze nie znajduje)
Przekopiuj jednostkę X z bufora do zmiennej programowej X
Zasady buforowania
Wykonywanie operacji read i write
Wykonanie polecenia write (X) składa się z następujących kroków:
Znajdź adres bloku dysk. zawierającego jednostkę X
Przekopiuj zawartość tego bloku do bufora w pamięci głównej (jeśli ten blok się tam jeszcze nie znajduje)
Przepisz jednostkę X ze zmiennej programowej X do właściwej lokalizacji w buforze
Zapisz na dysk uaktualniony blok z bufora (albo w trybie natychmiastowym, albo z opóźnieniem)
Przykład 1:
T1: read(X); T2: read(X);
X := X - N; X := X + M;
write(X); write(X);
read(y);
Y := Y + N;
write(Y);
Zasady buforowania - cd.
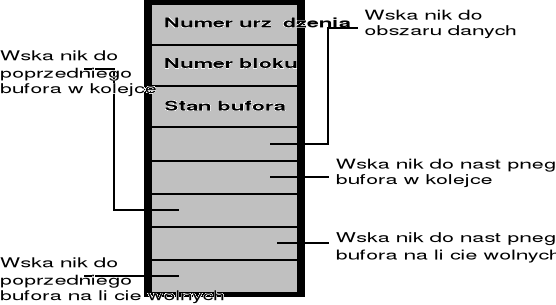
Obszar buforowy ma postać listy łączonej - do zarządzania wykorzystujemy same nagłówki
Zasady buforowania - cd.
Stan bufora jest kombinacją następujących warunków:
bufor ma właśnie założoną blokadę
bufor zawiera aktualne dane
jadro musi zapisać zawartość bufora na dysk przed ponownym przydzieleniem bufora - w trybie zapisu opóźnionego (ang. delayed-write)
jądro właśnie czyta dane do bufora z dysku lub zapisuje jego zawartość na dysk
proces właśnie czeka na zwolnienie bufora
Algorytm zarządzania pulą buforów - LRU
Jądro umieszcza dane w puli buforów zgodnie z algorytmem LRU (ang. Least Recently Used) - najdłużej nieużywany.
Oznacza to, że po przydzieleniu bufora na potrzeby bloku dyskowego nie można użyć tego bufora do przechowywania innego bloku dopóty, dopóki wcześniej nie zostaną użyte wszystkie pozostałe bufory
Zasady buforowania - cd.
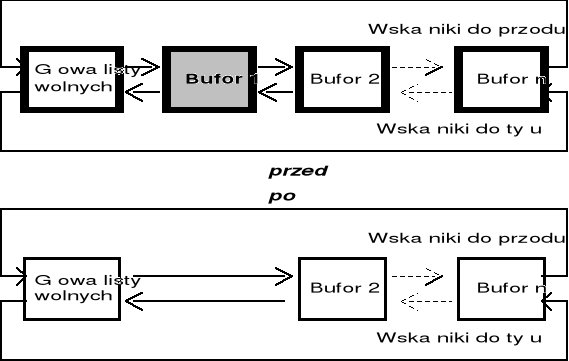
Algorytmy zapisu / odczytu
Moduły jądra przewidują zapotrzebowanie na kolejne bloki dyskowe, gdy proces czyta plik sekwencyjnie - jest to realizowane w następujących krokach:
proces wysyła żądanie odczytania pierwszego bloku
jeśli bloku nie ma w pamięci buforowej, to jądro wywołuje procedurę obsługi dysku z poleceniem zaszeregowania żądania odczytu
procedura obsługi dysku powiadamia sterownik dysku, że chce czytać dane
sterownik przesyła dane do bufora i po zakończeniu operacji we/wy generuje przerwanie
procedura obsługi przerwań dyskowych „budzi śpiący” proces - zawartość bloku dyskowego jest już w buforze
operacje te są wykonywane w trybie synchronicznym - proces inicjujący „śpi” oczekując na przerwanie
Algorytmy zapisu / odczytu - cd.
Czytanie bloku z wyprzedzeniem (ang. block read-ahead) jest wykonywane w celu poprawy wydajności - blok, który może być za chwilę potrzebny będzie już w pamięci buforowej (! problem metody alokacji)
Czytanie bloku z wyprzedzeniem jest realizowane w trybie asynchronicznym, w następujących krokach:
jeśli drugiego bloku nie ma w pamięci buforowej, to jądro zleca procedurze obsługi dysku jego wczytanie w trybie asynchronicznym
proces znajduje się w stanie zawieszenia (śpi) w oczekiwaniu na zakończenie czytania pierwszego bloku
po obudzeniu procesu zdejmowana jest blokada z bufora - proces nie interesuje się, kiedy zakończy się czytanie drugiego bloku
wreszcie gdy drugi blok znajdzie sie w buforze, sterownik dysku zgłosi przerwanie, i procedura obsługi przerwania rozpozna, że ta operacja we/wy była wykonywana w trybie asynchronicznym i zdejmie blokadę z bufora
Algorytmy zapisu / odczytu - cd.
Algorytm zapisu zawartości bufora do bloku dyskowego:
jądro informuje podprogram obsługi dysku, że ma bufor, którego zawartość należy zapisać - blok jest wstawiany do kolejki
jeśli zapis jest synchroniczny, to wołający proces „zasypia” w oczekiwaniu na zakończenie we/wy, i po obudzeniu zwolni bufor
jeśli zapis jest asynchroniczny, to jądro inicjuje zapis na dysk, lecz nie czeka na jego zakończenie - bufor zostanie zwolniony po zakończeniu we/wy
w trybie asynchronicznym są zapisywane bloki ważne z punktu widzenia spójności systemu, np. bloki i-węzłów
Algorytmy zapisu / odczytu - zapis opóźniony
Zapis opóźniony - sytuacja, kiedy jądro nie zapisuje danych na dysk natychmiast po ich modyfikacji
Jeśli wykonywany jest zapis opóźniony, to bufor jest oznaczany, zwalniany i działania w systemie są kontynuowane bez szeregowania żądania we/wy
Jądro zapisuje ten blok dopiero gdy inny proces uzyska przydział tego bufora na inny blok
W tym czasie może się zdarzyć, że proces „sięgnie” ponownie do bloku zanim bufor zostanie zapisany na dysk - jeśli proces zmodyfikuje zawartość bufora, to jądro uniknie jednej operacji dyskowej
Zapis opóźniony jest realizowany w trybie asynchronicznym
Sprawność systemu plików - cd.
1. Problem zapisu na dysk bloków ważnych z punktu widzenia spójności systemu plików:
UNIX: daemon systemowy - proces drugoplanowy update, funkcja systemowa SYNC
MS-DOS: zapis modyfikowanego bloku na dysk tak szybko jak jest to możliwe - metoda write-through cache
________________________________________
2. Alokacja i - węzlów w systemie UNIX
Jeśli bloki i - węzlów będą umiejscowione na krawędzi dysku to średni czas dostępu do nich będzie równy połowie najdłuższego skoku głowicy (rys(a)).
Sprawność systemu plików - cd.

Dostęp do bloków pliku wymaga wykonania operacji dostępu do bloku i-węzła i następnie do bloków pliku. Można ten średni czas skrócić umiejscawiając i-węzły w połowie talerza dysku (rys (b)).
Powered by ZAK & his C64
_______________________________________________________________________
Systemy plików Zbyszko Królikowski 31
_______________________________________________________________________
Systemy plików Zbyszko Królikowski 121
Struktura i - węzła
Rozmiar pliku
Typ pliku i prawa dostępu
Liczba łączników do pliku
Identyfikator właściciela
Identyfikator grupy
Data utworzenia pliku
...
Data ostat.operacji dostępu
10 bezpośrednich wskaźników bloków
danych
Data ostatniej modyfikacji
Wskaźnik adresowy
pojedynczy pośredni
Wskaźnik adresowy
podwójny pośredni
Wskaźnik adresowy
potrójny pośredni
niebezpieczne
2->1
0->1
missing block
OK
Liczniki poprawne gdy np. dla blok1 in use=1
free=0 lub odwrotnie
Wyszukiwarka