Dr Michał Major
Akademia Ekonomiczna w Krakowie
Klasyczne procedury sekwencyjne i procedury sum skumulowanych
Wprowadzenie
Procedury sum skumulowanych opierają się na sekwencyjnych testach ilorazowych a szerzej na teorii analizy sekwencyjnej. Można powiedzieć o nich, że są procedurami sekwencyjnymi realizowanymi wstecznie. Teoria analizy sekwencyjnej sprowadza się do losowego pobierania pojedynczych lub małych zespołów zbiorowości generalnej, oraz każdorazowym rozstrzyganiu czy zdobyty dotąd zasób informacji pozwala na podjęcie określonej decyzji. Przy sformułowanej hipotezie zerowej H0 i alternatywnej H1 decyzje takie mogą dotyczyć:
- przyjęcia hipotezy H0,
- odrzucenia hipotezy H0 i przyjęcia hipotezy H1
- odłożenia decyzji do czasu pobrania następnej jednostki (próbki n) do próby m.
Próba m jest w tym ujęciu sumą wszystkich próbek n pobieranych w kolejnych krokach k, czyli
m = n1 + n2 +…+nk. (1)
Jeżeli w każdym k -tym przedziale próbkowania liczebność próbki wynosi jeden, to wówczas liczność całej skumulowanej próby wyniesie k (m = k).
Podczas każdego etapu badań obliczana jest wartość sekwencyjnego testu ilorazowego postaci:
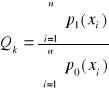
, (2)
gdzie
p1(xi) jest prawdopodobieństwem zdarzenia losowego X = xi, gdy założona jest prawdziwość hipotezy H1,
p0(xi) jest prawdopodobieństwem zdarzenia losowego X = xi, gdy założona jest prawdziwość hipotezy H0,
i sprawdza się czy zachodzi nierówność
A ≤ Qk ≤ B, (3)
gdzie
![]()
, natomiast ![]()
Jeżeli Qk ≤ A to przyjmuje się hipotezę H0 z prawdopodobieństwem błędu niewiększym niż β.
Gdy Qk ≥ B to należy przyjąć hipotezę H1 z prawdopodobieństwem błędu niewiększym niż α.
Natomiast, kiedy A < Qk < B to brak jest podstaw do podjęcia jednej z dwóch wymienionych powyżej decyzji i należy kontynuować badanie.
Załóżmy na początek, że zmienna losowa X ma rozkład normalny o wartości oczekiwanej μ i znanym odchyleniu standardowym σ (X~N( μ,σ)).
Kontrola wartości oczekiwanej
Sekwencyjna kontrola wartości oczekiwanej przy prawostronnym ograniczeniu przedziału tolerancji
Rozpatrywany przypadek dotyczy kontroli wartości oczekiwanej przy prawostronnym ograniczeniu przedziału tolerancji. Przyjmijmy, że obserwowaną charakterystyką z próby jest suma realizacji badanej zmiennej diagnostycznej w kolejnych krokach badania sekwencyjnego. Załóżmy dalej, że w każdym z kroków analizy sekwencyjnej dostępna jest jedna realizacja zmiennej losowej. Charakterystykę taką można określić wzorem:
![]()
(4)
gdzie xi jest realizacją zmiennej diagnostycznej X w kolejnych krokach postępowania sekwencyjnego.
Jeśli wartość oczekiwaną oznaczymy przez μ to wówczas weryfikowana hipoteza zerowa i alternatywna mają postać:
Ho:μ = μo,
H1: μ = μ1,
dla których jest spełniona zależność μo < μ1.
O badanym procesie stochastycznym mówimy, że jest uregulowany, a o wyrobie, że jest zgodny z wymogami jakościowymi, gdy jest spełniona następująca zależność: μ ≤ μo, natomiast gdy μ ≥ μ1 to twierdzi się, że proces jest nieuregulowany a wyrób nie spełnia wymogów jakościowych.
Całość postępowania można zobrazować schematycznie w następujący sposób:
Rys. 1 Zależność pomiędzy μ0 i μ1 przy prawostronnym przedziale tolerancji
Źródło: Oporowanie własne
Jedną z dwóch powyższych decyzji podejmuje się przy założonym ryzyku błędu α i β, gdzie α i β są wartościami rzędu 0.01 czy 0.05 i oznaczają kolejno:
α - prawdopodobieństwo przyjęcia hipotezy H1, gdy prawdziwa jest Ho,
natomiast
β - prawdopodobieństwo przyjęcia hipotezy Ho, gdy prawdziwa jest H1.
Zakładając postępowanie sekwencyjne, ciągłość badanej zmiennej diagnostycznej, oraz fakt, że zmienna ta ma rozkład normalny o parametrach μ i σ budujemy test sekwencyjny następującej postaci:
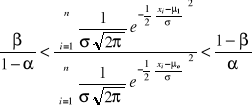
(5)
który jest ilorazem dwóch funkcji wiarygodności sformułowanych dla przypadków gdy μ = μ1 oraz gdy μ = μo.
1- α i 1- β stanowią natomiast dopełnienie α i β i oznaczają :wartość 1- α prawdopodobieństwo przyjęcia hipotezy Ho gdy jest ona prawdziwa, natomiast 1- β- prawdopodobieństwo przyjęcia hipotezy H1 gdy jest ona prawdziwa.
Przekształcając funkcję (5) otrzymujemy:
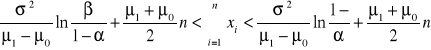
(6)
Mamy więc:
![]()
, (7)
gdzie
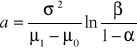
, (8)
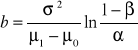
, (9)
![]()
. (10)
Reguły postępowania są następujące:
Jeśli w kolejnym kroku postępowania sekwencyjnego wartość statystyki zn będzie mniejsza lub równa zd,n to wówczas przyjmuję się hipotezę Ho z prawdopodobieństwem błędu niewiększym niż β. Kiedy natomiast zn jest większe lub równe zg,n przyjmowaną hipotezą jest H1 przy ryzyku błędu niewiększym niż α. W sytuacji, gdy żaden z powyższych warunków nie jest spełniony podejmuje się decyzję badać dalej.
Graficznie całość sytuacji przedstawia poniższy rysunek.
Rys. 2 Diagram przeglądowy stosowany w procedurze sekwencyjnej weryfikacji hipotezy H0:μ = μ0, wobec hipotezy H1: μ = μ1.
Źródło: opracowanie własne.
Procedura sum skumulowanych dla wartości oczekiwanej przy prawostronnym ograniczeniu przedziału tolerancji (metoda graficzna)
Konstruując procedurę sum skumulowanych zakłada się, że β = 0. W takiej sytuacji obszar kontynuacji badań łączy się z obszarem przyjęcia hipotezy H0 i obszar decyzji redukuje się do dwóch. Cała technika postępowania opiera się na założeniu, że procedura sum skumulowanych jest klasyczną procedurą sekwencyjną realizowaną wstecznie. Fakt ten zmusza nas do tego, aby w każdym punkcie kończącym sekwencje wykreślać pomocniczy układ współrzędnych obrócony w stosunku do pierwotnego o 180o.
W każdym n- tym kroku postępowania bada się czy zaobserwowana dotychczas sekwencja ![]()
wystarcza do przyjęcia hipotezy H1 (stwierdzenia rozregulowania procesu).
Rys. 3. Zależność pomiędzy klasyczną procedurą a procedurą sum skumulowanych,
Źródło: opracowanie własne
Dla poprawienia wygody tej metody konstruuje się tzw. ruchomą maskownicę, którą przesuwa się na wykresie wraz ze wzrostem długości badanej sekwencji.
Całość rozumowania przedstawia poniższy rysunek.
Rys. 4. Maskownica w schemacie kontrolnym z prawostronnym ograniczeniem przedziału tolerancji.
Źródło: opracowanie własne.
Jak widać maskownica posiada kilka podstawowych parametrów:d, h oraz ϕ będące kątem nachylenia czynnej krawędzi maskownicy do odciętej odwróconego o 180o układu współrzędnych.
Korzystając z twierdzenia, że procedura sum skumulowanych jest klasyczną procedurą kontrolną realizowaną wstecznie, oraz że β = 0 możemy zapisać,
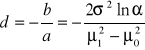
, (11)
![]()
; (12)
![]()
. (13)
Najważniejszą w maskownicy jest tzw. czynna krawędź kontrolna oznaczona na rysunku BC oraz punkt D pokrywający się z ostatnim z punktów obserwowanej sekwencji. Ważną pozostaje również zasada, aby górna krawędź maskownicy DE pozostała równoległa do osi odciętych n.
Reguły postępowania są następujące:
- Jeśli chociaż jeden z punktów w sekwencji z0 . . . zn znajdzie się poniżej czynnej krawędzi(linii) kontrolnej BC wówczas przyjmujemy z ryzykiem błędu niewiększym od α, że prawdziwą hipotezą jest H1.
- Jeśli żaden z punktów sekwencji nie leży poniżej krawędzi BC wówczas przechodzimy do następnego etapu powiększając skumulowaną próbkę o następną wartość xi.
Procedura sum skumulowanych dla wartości oczekiwanej przy prawostronnym ograniczeniu przedziału tolerancji (algorytm numeryczny)
Posługiwanie się maskownicą w wielu przypadkach bywa dość niewygodne, gdy jej parametry wyrażają się dużymi wartościami.
Niedogodność tą można usunąć zastępując klasyczny algorytm graficzny algorytmem numerycznym. Reguły postępowania są tutaj dosyć podobne jak w procedurach shewhartowskich, a parametry, które występują tutaj we wzorach są wyznaczane analogicznie jak w przypadku parametrów maskownicy.
Zakładając, β = 0 statystykę postaci zn można zastąpić statystyką ![]()
, zdefiniowaną następującym wzorem:
![]()
, (14)
gdzie
![]()
Podwójny indeks ij świadczy tutaj o dwustopniowości prowadzonych badań. Indeks j funkcjonuje przez cały okres badań, natomiast indeks i zostaje uruchomiony wówczas, gdy spełniona jest następująca zależność: xj - c > 0. Spełnienie powyższej nierówności jest niezbędnym warunkiem do rozpoczęcia obliczania wartości statystyki (14).
Obliczanie wartości charakterystyki (14) jest kontynuowane tak długo aż nie zostanie spełniony jeden z poniższych warunków:
1o ![]()
, gdzie ![]()
(15)
2o ![]()
(16)
W przypadku, gdy spełniony jest warunek 1o badanie kończy się i przyjmuje się hipotezę alternatywną H1 z ryzykiem błędu niewiększym niż α, natomiast gdy spełniony jest warunek 2o przerywa się obliczanie wartości charakterystyki ![]()
przyporządkowując jednocześnie indeksowi i wartość 0.
Opisany cykl postępowania ilustruje poniższy rysunek.
Rys. 5. Funkcjonowanie algorytmu numerycznego, przy prawostronnym ograniczeniu przedziału tolerancji.
Źródło: opracowanie własne.
Na rysunku tym zaznaczone zostały sekwencje odpowiadające przypadkom 1o i 2o. Dla j = 4, nastąpiło przerwanie wyznaczania statystyki (14) i ponowne wznowienie przy j =7. W okresach dla j = 5 i j = 6 wartość statystyki (14) nie była wyznaczana gdyż:![]()
.
Sekwencyjna kontrola wartości oczekiwanej przy lewostronnym ograniczeniu przedziału tolerancji
Jeżeli przedział tolerancji zmiennej diagnostycznej ograniczony jest lewostronnie, to wówczas weryfikacji poddaje się następujące hipotezy:
Ho:μ = μo
H-1: μ = μ-1
dla których jest spełniona zależność μo > μ-1.
O badanym procesie stochastycznym mówimy, że jest uregulowany, a o wyrobie, że jest zgodny z wymogami jakościowymi, gdy jest spełniona następująca zależność: μ ≥ μo, natomiast gdy μ ≤ μ-1 to twierdzi się, że proces jest nieuregulowany a wyrób nie spełnia wymogów jakościowych.
Podobnie jak przy prawostronnym schemacie kontrolnym obserwowaną charakterystyką z próby jest suma realizacji badanej zmiennej diagnostycznej ![]()
. Podczas klasycznego testu sekwencyjnego w kolejnych krokach monitorowania badanego procesu sprawdza się czy spełniona jest następująca nierówność:
![]()
, (17)
gdzie
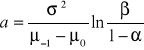
, (18)
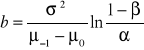
, (19)
![]()
. (20)
Jeśli w kolejnym kroku postępowania sekwencyjnego wartość statystyki zn będzie mniejsza lub równa zd,n to wówczas przyjmuję się hipotezę H-1 z prawdopodobieństwem błędu niewiększym niż α. Kiedy natomiast zn jest większe lub równe zg,n przyjmowaną hipotezą jest Ho przy ryzyku błędu niewiększym niż β. W sytuacji, gdy żaden z powyższych warunków nie jest spełniony podejmuje się decyzję badać dalej. Całość postępowania ilustruje rys. 6.
Rys. 6. Diagram przeglądowy stosowany w procedurze sekwencyjnej weryfikacji hipotezy H0:μ = μ0, wobec hipotezy H-1: μ = μ-1.
Źródło: opracowanie własne.
Sytuacja jest tutaj dokładnie odwrotna do tej jaka była na rys. 2. Duże wartości statystyki zn przemawiają za przyjęciem hipotezy zerowej (H0) , natomiast małe za przyjęciem hipotezy alternatywnej (H-1)
Procedura sum skumulowanych dla wartości oczekiwanej przy lewostronnym ograniczeniu przedziału tolerancji (metoda graficzna)
Podczas wyznaczania parametrów procedury kontrolnej opartej o technikę sum- skumulowanych za punkt wyjścia bierze się teraz równanie dolnej linii kontrolnej zd,n. Postępując analogicznie, jak w sytuacji, gdy przedział tolerancji był ograniczone prawostronnie, wyznacza się parametry maskownicy. Otrzymujemy wówczas:
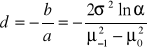
, (21)
![]()
; (22)
![]()
. (23)
Sama maskownica wyglądać będzie nieco inaczej (zob. rys. 7), gdyż rolę czynnej krawędzi pełnić będzie odwrócona o 180o dolna linia kontrolna zd,n.
Rys. 7. Maskownica w schemacie kontrolnym z lewostronnym ograniczeniem przedziału tolerancji.
Źródło: opracowanie własne.
Tak jak poprzednio, najważniejszą w maskownicy jest tzw. czynna krawędź kontrolna oznaczona na rysunku BC oraz punkt D pokrywający się z ostatnim z punktów obserwowanej sekwencji. Ważną pozostaje również zasada, aby krawędź maskownicy CD pozostała równoległa do osi odciętych n.
Reguły postępowania są następujące:
- Jeśli chociaż jeden z punktów w sekwencji z0 . . . zn znajdzie się powyżej czynnej krawędzi(linii) kontrolnej BC wówczas przyjmujemy z ryzykiem błędu niewiększym od α, że prawdziwą hipotezą jest H-1.
- Jeśli żaden z punktów sekwencji nie leży powyżej krawędzi BC wówczas przechodzimy do następnego etapu powiększając skumulowaną próbkę o następną wartość xi.
W praktyce algorytm graficzny (oparty na maskownicy) często zastępuje się algorytmem numerycznym
Procedura sum skumulowanych dla wartości oczekiwanej przy lewostronnym ograniczeniu przedziału tolerancji (algorytm numeryczny)
Reguły postępowania są tutaj następujące. Podobnie jak w przypadku, gdy przedział tolerancji ograniczony był prawostronnie, statystykę postaci zn należy zastąpić statystyką ![]()
zdefiniowaną wzorem (14). Kumulację próby (obliczanie wartości statystyki ![]()
) rozpoczyna się wówczas, gdy kolejna wartość xj (j - indeks bieżący) spełnia nierówność xj < tgϕ i kontynuuje do momentu, gdy spełni się jeden z dwóch poniższych warunków:
1o ![]()
, gdzie ![]()
(24)
2o ![]()
(25)
W przypadku, gdy spełniony jest warunek 1o badanie kończy się i przyjmuje się hipotezę alternatywną H-1 z ryzykiem błędu niewiększym niż α, natomiast, gdy spełniony jest warunek 2o przerywa się obliczanie wartości charakterystyki ![]()
przyporządkowując jednocześnie indeksowi i wartość 0.
Przykładowy przebieg procesu może wyglądać tak jak na rys. 8.
Rys. 8. Funkcjonowanie algorytmu numerycznego, przy lewostronnym ograniczeniu przedziału tolerancji.
Źródło: opracowanie własne.
Innowacją jest to, że linia kontrolna znajduje się tutaj poniżej zera, a sygnał o rozregulowaniu (dla j = 12) jest emitowany, gdy zostanie ona przekroczona in minus. Przekroczenie osi odciętych (n) in plus powoduje natomiast przerwanie kumulacji próby i powrót do śledzenia znaku różnicy xj - tgϕ.
Sekwencyjna kontrola wartości oczekiwanej przy dwustronnym ograniczeniu przedziału tolerancji
W rozważanym przypadku weryfikacji poddawane są następujące hipotezy:
Ho:μ = μo
H1: μ = μ1
H-1: μ = μ-1
przy czym zachodzi następująca nierówność:
μ-1<μo < μ1.
Obserwowany proces należy zakwalifikować jako uregulowany, jeżeli μ = μo, natomiast jeżeli μ ≥ μ1 lub μ ≤ μ-1 to wyrób nie spełnia wymagań jakościowych a proces produkcyjny jest rozregulowany.
Dwustronne procedury kontrolne stanowią kombinację odpowiednich procedur jednostronnych. Diagram przeglądowy stosowany podczas stosowania sekwencyjnej procedury kontrolnej przedstawiono na rys. 9.
Rys. 9. Diagram przeglądowy stosowany w procedurze sekwencyjnej weryfikacji hipotezy H0:μ = μ0, wobec hipotez H1: μ = μ1 i H-1: μ = μ-1.
Źródło: opracowanie własne.
Poszczególne linie kontrolne wyznaczamy według następujących wzorów:
![]()
, (26)
![]()
, (27)
![]()
, (28)
![]()
, (29)
gdzie
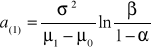
, (30)
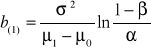
, (31)
![]()
, (32)
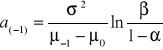
, (33)
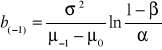
, (34)
![]()
, (35)
Procedura sum skumulowanych dla wartości oczekiwanej przy dwustronnym ograniczeniu przedziału tolerancji (metoda graficzna)
Łącząc obszar przyjęcia H0 z obszarem badać dalej, a następnie odwracając układ o 180o otrzymamy maskownicę przedstawioną na rys.10.
`
Rys. 10. Maskownica przy dwustronnym ograniczeniu przedziału tolerancji.
Źródło: opracowanie własne.
Sposób posługiwania się maskownicą jest analogiczny do wcześniejszych przypadków. Ważne jest aby ostatni punkt w sekwencji pokrył się z punktem D, oraz, żeby odcinek DJ pozostał równoległy do osi dociętych n. Sygnał o rozregulowaniu procesu jest generowany wówczas gdy chociaż jeden z punktów zostanie zamaskowany, tzn. znajdzie się poniżej linii biegnącej przez punkty B i C lub powyżej linii przechodzącej przez punkty E i F. Parametry maskownicy możemy wyznaczyć stosując następujące wzory:
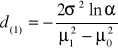
, (36)
![]()
; (37)
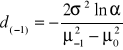
, (38)
![]()
. (39)
Procedura sum skumulowanych dla wartości oczekiwanej przy dwustronnym ograniczeniu przedziału tolerancji (algorytm numeryczny)
Wykorzystując parametry maskownicy można łatwo skonstruować algorytm numeryczny. Stosujemy wówczas statystykę
![]()
, (40)
gdzie
![]()
.
Górna i dolna linia kontrolna wyznaczane są według wzorów:
![]()
(41)
![]()
, (42)
przy czym jeśli α jest ustalona, oraz μ1 -μ0 = μ0 - μ-1, to d(1) = d(-1) oraz ϕ(1) = ϕ(-1).
Przekroczenie in plus lub osiągniecie górnej linii powoduje przyjęcie hipotezy H1, natomiast przekroczenie in minus lub osiągnięcie dolnej linii kontrolnej skutkuje przyjęciem hipotezy H-1.
Kontrola wskaźnika struktury p (frakcji)
Podczas tej analizy zakłada się, że zmienna diagnostyczna X posiada rozkład zero-jedynkowy o nieznanym parametrze p. W trakcie monitorowania procesu zakłada się, że jest on uregulowany, jeżeli prawdziwą pozostaje hipoteza H0: p = p0, natomiast rozregulowany gdy prawdziwą jest hipoteza alternatywna H1: p = p1, przy czym p1 > p0. Tak jak uprzednio w trakcie weryfikacji hipotezy zerowej wykorzystuje się statystykę z próby ![]()
, przy czy xi przyjmuje wartości zero lub jeden (zero, gdy produkt jest zgodny z wymaganiami jakościowymi, jeden gdy produkt jest niezgodny z wymaganiami jakościowymi). Statystykę ![]()
można więc nazwać liczbą wadliwych jednostek produktu w skumulowanej próbie o liczności n. W każdym punkcie badania sprawdza się prawdziwość następującej nierówności.
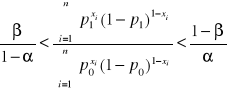
(43)
lub po przekształceniu
![]()
, (44)
gdzie
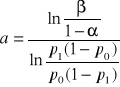
, (45)
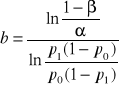
, (46)
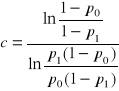
. (47)
W statystycznej kontroli jakości, występujące w powyższych zapisach, p0 traktuje się jako najwyższą dopuszczalną wadliwość, natomiast p1 jako najniższą wadliwość dyskwalifikującą.
Wykres jaki należy narysować stosując klasyczną procedurę sekwencyjną jest analogiczny do wykresu przedstawionego na rys. 2.
Analogicznie można również skonstruować maskownicę lub zbudować algorytm numeryczny.
Parametry maskownicy można wyznaczyć według następujących wzorów:
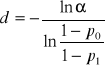
, (48)
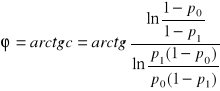
; (49)
W przypadku, gdy stosujemy algorytm numeryczny postępujemy analogicznie do sposobu opisanego powyżej dla wartości oczekiwanej przy prawostronnym ograniczeniu przedziału tolerancji, z tym, że poziom linii kontrolnej wyznaczamy według wzoru:
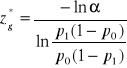
(50)
Stosując algorytm numeryczny możemy również sporządzić rysunek analogiczny do rys. 5.
Kontrola jakości ze względu na zmienne diagnostyczne o rozkładzie Poissona
Weryfikowane hipotezy mają następującą postać:
Ho:λ = λ0
H1: λ = λ1,
gdzie
λ - wartość oczekiwana w rozkładzie Poissona
λ0 - najwyższa dopuszczalna wartość parametru λ,
λ1 najniższa niedopuszczalna wartość parametru λ,
przy czym λ0 < λ1
Badany proces należy zakwalifikować jako uregulowany, jeżeli λ ≤ λ0, natomiast, gdy λ ≥ λ1 badany proces należy uznać za rozregulowany. W statystycznej kontroli jakości parametr λ nazywany jest przeciętną liczbą niezgodności (wad) w jednostce produktu.
Podobnie jak uprzednio postawione hipotezy można zweryfikować stosując klasyczną procedurę sekwencyjną lub procedurę sum-skumulowanych (sum-kum). Podczas klasycznej procedury kontrolnej tak jak poprzednio weryfikuje się czy prawdziwa jest nierówność:
![]()
, (51)
gdzie
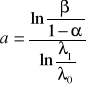
, (52)
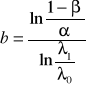
, (53)
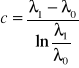
, (54)
Sumy skumulowane zn powstają obecnie przez dodawanie wartości zmiennej X, które oznaczają liczbę wad w jednej sztuce wyrobu.
Kontrolując przeciętną liczbę wad przy zastosowaniu maskownicy należy wyznaczyć jej parametry według następujących wzorów:
![]()
, (55)
![]()
. (56)
W przypadku, gdy stosujemy algorytm numeryczny postępujemy analogicznie jak w przypadku weryfikowaniu wartości oczekiwanej przy prawostronnym ograniczeniu przedziału tolerancji, z tym, że poziom linii kontrolnej wyznaczamy według wzoru:
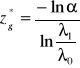
(57)
Literatura:
Podczas pisania opracowania wykorzystano materiały z:
A. Iwasiewicz; Zarządzanie jakością; Wydawnictwo Naukowe PWN; Warszawa-Kraków 1999
A. Iwasiewicz, Z. Paszek; Sekwencyjne metody kontroli jakości; AE w Krakowie; Kraków 1988
A. Iwasiewicz, Z. Paszek; Statystyka z elementami statystycznych metod kontroli jakości; AE w Krakowie; Kraków 2000
M. Major; Sterowanie procesem za pomocą kart kontrolnych sum skumulowanych; w: Materiały z I Krajowej Konferencji Naukowej pt. Materiałoznawstwo, Odlewnictwo, Jakość, Tom III, s. 47-54; Instytut Materiałoznawstwa i Technologii Metali Politechniki Krakowskiej im. T. Kościuszki, Kraków 1997.
Przykłady
Przykład 1
Załóżmy, że w procesie bieżącej kontroli jakości monitorowana jest zmienna diagnostyczna X będąca czasem obsługi pasażerów przy kasie biletowej. Zmienna ta ma rozkład normalny o stałym i znanym odchyleniu standardowym σ = 0,5 min. Załóżmy, że proces obsługi jest uregulowany, jeżeli średni czas obsługi μ ≤ 2 min, natomiast proces obsługi zostanie uznany za rozregulowany, jeżeli μ ≥ 2 min. Należy ocenić przebieg procesu obsługi pasażerów, jeżeli w rezultacie przeprowadzonych badań uzyskano następujące wyniki:
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
n |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
xi |
2,8 |
2,9 |
1,3 |
3,1 |
2,2 |
3,2 |
3 |
3 |
3 |
5 |
W procesie analizy rezultatów załóżmy, że α = β = 0,05.
Formułujemy hipotezy:
H0: μ ≤ μ0 = 2,
H1: μ ≥ μ0 = 3.
Obliczamy parametry a, b i c
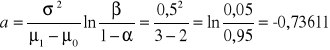
,
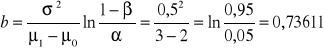
,
![]()
.
Otrzymujemy zatem:
zd,n = -0,73611+2,5n,
zg,n = 0,73611+2,5n,
Wyniki analizy danych empirycznych zestawiono w poniższej tablicy
i |
n |
xi |
zn |
zd,n |
zg,n |
decyzja |
1 |
1 |
2,8 |
2,8 |
1,76389 |
3,23611 |
badać dalej |
2 |
2 |
2,9 |
5,7 |
4,26389 |
5,73611 |
badać dalej |
3 |
3 |
1,3 |
7 |
6,76389 |
8,23611 |
badać dalej |
4 |
4 |
3,1 |
10,1 |
9,26389 |
10,73611 |
badać dalej |
5 |
5 |
2,2 |
12,3 |
11,76389 |
13,23611 |
badać dalej |
6 |
6 |
3,2 |
15,5 |
14,26389 |
15,73611 |
badać dalej |
7 |
7 |
3 |
18,5 |
16,76389 |
18,23611 |
przyjąć H1 |
8 |
8 |
3 |
21,5 |
19,26389 |
20,73611 |
* |
9 |
9 |
3 |
24,5 |
21,76389 |
23,23611 |
* |
10 |
10 |
5 |
29,5 |
24,26389 |
25,73611 |
* |
Z powyższej analizy wynika, że w siódmym kroku postępowania sekwencyjnego, przy liczności próbki skumulowanej n = 7, należy przyjąć hipotezę alternatywną H1 i proces obsługi pasażerów należy uznać za rozregulowany. Prawdopodobieństwo tego, że ocena ta jest fałszywa nie przekracza α = 0,05.
Powtórzmy nasze badanie wykorzystując technikę sum-skumulowanych. Informacje wejściowe zapiszmy teraz następująco:
j |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
xi |
2,8 |
2,9 |
1,3 |
3,1 |
2,2 |
3,2 |
3 |
3 |
3 |
5 |
Obliczmy wartości parametrów d, tgϕ,.
Mamy wówczas
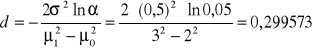
,
![]()
,
Wyznaczamy wartość ![]()
.
Mając te parametry, można przystąpić do analizy danych. W tym celu wykorzystamy poniższą tablicę.
j |
xi |
i |
xji |
n |
|
|
uwagi |
1 |
2,8 |
1 |
2,8 |
1 |
0,3 |
0,3 |
xj>tgϕ (zacząć kumulację) |
2 |
2,9 |
2 |
2,9 |
2 |
0,4 |
0,7 |
kumulować |
3 |
1,3 |
* |
1,3 |
* |
-1,2 |
-0,5 |
|
4 |
3,1 |
1 |
3,1 |
1 |
0,6 |
0,6 |
xj>tgϕ (zacząć kumulację) |
5 |
2,2 |
2 |
2,2 |
2 |
-0,3 |
0,3 |
kumulować |
6 |
3,2 |
3 |
3,2 |
3 |
0,7 |
1 |
|
7 |
3 |
* |
3 |
* |
* |
* |
* |
8 |
3 |
* |
3 |
* |
* |
* |
* |
9 |
3 |
* |
3 |
* |
* |
* |
* |
10 |
5 |
* |
|
* |
* |
* |
* |
Z tablicy tej wynika, że po uwzględnieniu sześciu kolejnych realizacji zmiennej X należy przyjąć hipotezę H1.W procesie analizy, przy j = 3 musieliśmy przerwać rozpoczętą kumulację i powrócić do śledzenia znaku różnicy xj - tgϕ, ponieważ wartość statystyki ![]()
.
Przykład 2
Załóżmy, że w procesie bieżącej kontroli jakości monitorowana jest zmienna diagnostyczna X opisująca jakość śrub wykorzystywanych do montażu elementów trakcji kolejowej. Zmienna ta przyjmuje dwie wartości „0” i „1”, „0” jeżeli śruba ma poprawnie wykonany gwint, na który z łatwością daje się nakręcić nakrętkę, oraz przyjmuje „1”, gdy gwint jest źle wykonany i nakręcenie na śrubę nakrętki jest niemożliwe. Załóżmy, że proces produkcji śrub jest uregulowany, jeżeli frakcja śrub wadliwych p ≤ 0,01 (1%), natomiast proces produkcji zostanie uznany za rozregulowany, jeżeli p ≥ 0,03 (3%). Należy ocenić przebieg procesu produkcji śrub, jeżeli w rezultacie przeprowadzonych badań uzyskano następujące wyniki:
i |
n |
xi |
1 |
1 |
0 |
2 |
2 |
0 |
3 |
3 |
0 |
4 |
4 |
1 |
5 |
5 |
0 |
6 |
6 |
1 |
7 |
7 |
0 |
8 |
8 |
0 |
9 |
9 |
1 |
10 |
10 |
0 |
Należy sprawdzić, czy na podstawie powyższych wyników możliwe jest przyjęcie jednej z dwóch poniższych hipotez
H0: p ≤ p0 = 0,01,
H1: p ≥ p1 = 0,03,
jeżeli α = β = 0,05.
Obliczamy parametry a, b i c
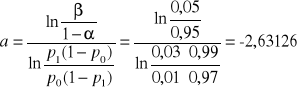
,
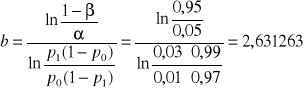
,
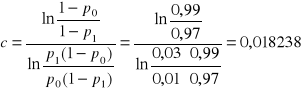
.
Równania linii kontrolnych będą miały postać:
zd,n = -2,63126+0,018238n,
zg,n = 2,631263+0,018238n.
Wyniki analizy danych empirycznych zestawiono w poniższej tablicy
i |
n |
xi |
zn |
zd,n |
zg,n |
decyzja |
1 |
1 |
0 |
0 |
-2,61302 |
2,649501 |
badać dalej |
2 |
2 |
0 |
0 |
-2,59479 |
2,667739 |
badać dalej |
3 |
3 |
0 |
0 |
-2,57655 |
2,685977 |
badać dalej |
4 |
4 |
1 |
1 |
-2,55831 |
2,704216 |
badać dalej |
5 |
5 |
0 |
1 |
-2,54007 |
2,722454 |
badać dalej |
6 |
6 |
1 |
2 |
-2,52183 |
2,740692 |
badać dalej |
7 |
7 |
0 |
2 |
-2,5036 |
2,75893 |
badać dalej |
8 |
8 |
0 |
2 |
-2,48536 |
2,777168 |
badać dalej |
9 |
9 |
1 |
3 |
-2,46712 |
2,795406 |
przyjąć H1 |
10 |
10 |
0 |
3 |
-2,44888 |
2,813644 |
* |
W dziewiątym kroku badania (i = 9) należy przyjąć z prawdopodobieństwem błędu niewiększym niż α = 0,05, hipotezę alternatywną H1 i uznać, że proces produkcji śrub uległ rozregulowaniu.
Wykorzystując te same dane, zestawione w poniższy sposób przeprowadźmy analizę stanu procesu wykorzystując numeryczny algorytm sum skumulowanych.
j |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
xj |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
Obliczmy niezbędne parametry procedury.
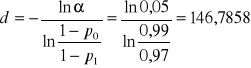
,
![]()
![]()
.
Przebieg analizy danych przedstawiono w poniższej tablicy
j |
xj |
i |
xji |
n |
|
|
uwagi |
1 |
0 |
* |
* |
* |
* |
* |
xj < tgϕ |
2 |
0 |
* |
* |
* |
* |
* |
xj < tgϕ |
3 |
0 |
* |
* |
* |
* |
* |
xj < tgϕ |
4 |
1 |
1 |
1 |
1 |
0,981762 |
0,981762 |
xj > tgϕ (zacząć kumulację) |
5 |
0 |
2 |
0 |
2 |
-0,01824 |
0,963524 |
kumulować |
6 |
1 |
3 |
1 |
3 |
0,981762 |
1,945286 |
kumulować |
7 |
0 |
4 |
0 |
4 |
-0,01824 |
1,927047 |
kumulować |
8 |
0 |
5 |
0 |
5 |
-0,01824 |
1,908809 |
kumulować |
9 |
1 |
6 |
1 |
6 |
0,981762 |
2,890571 |
|
10 |
0 |
* |
* |
* |
* |
* |
|
Z powyższej analizy wynika, że dziewiątym kroku badania, należy przyjąć jako prawdziwą hipotezę H1 i uznać, że proces produkcji śrub uległ rozregulowaniu.
Przykład 3
Załóżmy, że w procesie bieżącej kontroli jakości monitorowana jest zmienna diagnostyczna X opisująca liczbę awarii taboru kolejowego na przeciągu jednego miesiąca. Wyniki badania pochodzące z kolejnych dziewięciu miesięcy prezentuje poniższa tabela.
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
n |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
xi |
0 |
0 |
1 |
0 |
3 |
0 |
2 |
1 |
4 |
Proces użytkowania taboru przebiega w sposób „bezawaryjny”, jeżeli przeciętna liczba awarii w przeciągu jednego miesiąca (λ) nie przekracza 0,5, natomiast proces ten należy poddać regulacji, gdy (λ) jest większe lub równe 1.
Należy sprawdzić, czy na podstawie wyników badań można przyjąć jedną w dwóch poniższych hipotez:
H0: λ ≤ λ0 = 0,5,
H1: λ ≥ λ1 = 1,
jeżeli α = β = 0,05.
Obliczamy parametry linii kontrolnych.
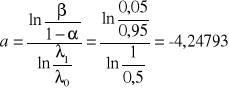
,
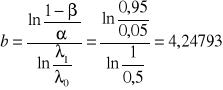
,
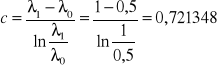
,
Równania linii kontrolnych będą równe odpowiednio:
zd,n = -4,24793+ 0,721348n,
zg,n = 4,24793+ 0,721348n.
Wyniki analizy danych empirycznych zestawiono w poniższej tablicy
i |
n |
xi |
zn |
zd,n |
zg,n |
decyzja |
1 |
1 |
0 |
0 |
-3,52658 |
4,969275 |
badać dalej |
2 |
2 |
0 |
0 |
-2,80523 |
5,690623 |
badać dalej |
3 |
3 |
1 |
1 |
-2,08388 |
6,41197 |
badać dalej |
4 |
4 |
0 |
1 |
-1,36254 |
7,133318 |
badać dalej |
5 |
5 |
3 |
4 |
-0,64119 |
7,854665 |
badać dalej |
6 |
6 |
0 |
4 |
0,080158 |
8,576013 |
badać dalej |
7 |
7 |
2 |
6 |
0,801505 |
9,29736 |
badać dalej |
8 |
8 |
1 |
7 |
1,522853 |
10,01871 |
badać dalej |
9 |
9 |
4 |
11 |
2,2442 |
10,74006 |
przyjąć H1 |
Z powyższych badań wynika, że w okresie 9 (dziewiątym miesiącu badania) należy podjąć działania regulacyjne zmierzające do poprawienia jakości użytkowanego taboru kolejowego.
Wykorzystując te same dane, zestawione w poniższy sposób przeprowadźmy analizę stanu procesu wykorzystując numeryczny algorytm sum skumulowanych.
j |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
xj |
0 |
0 |
1 |
0 |
3 |
0 |
2 |
1 |
4 |
Obliczmy niezbędne parametry procedury.
![]()
,
![]()
(5
![]()
.
Przebieg analizy danych przedstawiono w poniższej tablicy
j |
xj |
i |
xji |
n |
|
|
uwagi |
1 |
0 |
* |
* |
* |
* |
* |
xj < tgϕ |
2 |
0 |
* |
* |
* |
* |
* |
xj < tgϕ |
3 |
1 |
1 |
1 |
1 |
0,278652 |
0,278652 |
xj > tgϕ (zacząć kumulację) |
4 |
0 |
* |
* |
* |
-0,72135 |
-0,4427 |
|
5 |
3 |
1 |
3 |
1 |
2,278652 |
2,278652 |
xj > tgϕ (zacząć kumulację) |
6 |
0 |
2 |
0 |
2 |
-0,72135 |
1,557305 |
kumulować |
7 |
2 |
3 |
2 |
3 |
1,278652 |
2,835957 |
kumulować |
8 |
1 |
4 |
1 |
4 |
0,278652 |
3,11461 |
kumulować |
9 |
4 |
5 |
4 |
5 |
3,278652 |
6,393262 |
|
Z powyższej analizy wynika, że dziewiątym kroku badania (j = 9), należy przyjąć jako prawdziwą hipotezę H1 i uznać, że proces użytkowania taboru nie przebiega płynnie (bez zakłóceń).
Z teoretycznego punktu widzenia można również formułować testy sekwencyjne dla przypadku, gdy przedział tolerancji analizowanej zmiennej X jest ograniczony lewostronnie lub dwustronnie, przy czym jeżeli założymy, że p to wadliwość, to wówczas najczęściej tracą one sens ekonomiczny.
proces uregulowany
proces rozregulowany
obszar decyzji niepewnych
o
1
badać dalej
przyjąć H1
przyjąć H0
n
Zn
Zn
n
n'
![]()
![]()
d
n'
![]()
Zn
n
A
B
C
E
D
F
ϕ
0
h
2 3 4 1 2 3 4 5 6 n
1 2 3 4 1 2 3 4 5 6 i
2 3 4 5 6 7 8 9 10 11 12 j
![]()
![]()
zg,n
zd,n
zd,n
zg,n
Zn
n
przyjąć H-1
przyjąć H0
badać dalej
h
0
ϕ
F
D
E
C
B
A
d
n'
![]()
Zn
n
G
![]()
![]()
2 3 4 5 6 7 8 9 10 11 12 j
1 2 3 4 1 2 3 4 5 6 i
2 3 4 1 2 3 4 5 6 n
0
![]()
![]()
Zn
n
przyjąć H0
przyjąć H-1
badać dalej
badać dalej
przyjąć H1
![]()
![]()
h
0
ϕ(
F
D
E
C
B
A
d(-1)
n'
![]()
Zn
n
G
H
I
d(1)
ϕ(
J
Wyszukiwarka
Podobne podstrony:
Document 4
Document
Autograss documentation
Document (10)
document (2)
Document (51)
C DOCUME~1 GERICOM USTAWI~1 Temp plugtmp 1 plugin lokalizacja przejsc problemy i dobre praktyki rkur
2012 11 22 Document 001
alcatel support document for cable system in cuba
Document 0
Eisenhower Briefing Document, 18 November 1952
document (7)
document (20)
Documentation
ZAPROSZENIE, Documents, IP Zielona gora, mat inf
Podsumowanie pracy Zespołu Informacji Publicznej i Współpracy z innymi za rok 2015, Documents, ip, s
r00-0-spr-spr, ## Documents ##, Debian GNU Linux
New Microsoft Word Document (2)
więcej podobnych podstron