definicja hurtowni danych
wykład:
Hurtownia danych to jest dziedzinowo zorientowana baza danych organizacja, ktora potrafi polaczyc inforamcje z wielu modelli danych wykorzystywanych w roznych aplikacjach pracujacych na roznych platformach sprzetowych.
Podstawowymi cechami informacji przechowywanych w systemie typu hurtownia danych sa:
separacja - od systemow operacyjnych, ale wypelnianie informacjami pochodzacymi z tych systemow
integracja - inforamcja jest zintegrowana na bazie modelu danych organizacji
zorientowanie dziedzinowe - informacja jest ustrukturyzowana dziedzinowo (tematycznie)
znakowanie czasem- kazda inforamcja posiada znacznik czasu
niezmiennosc - zmiany moga byc dokonywane tylko globalnie tzn wszyscy uzytkownicy widza te same dane
przystepnosc - latwosc uzytkowania dla uzytkownikow nie bedacych specjalistami komputerowymi
Hurtownia danych zostala wymyslona na poczatku lat 90, jako wsparcie do wspomagania decyzji na wyzszych poziomach (analiza, kontrola dzialania firmy, wspomaganie zarzadzaniem firmy).
From Wikipedia
Hurtownia danych (ang. data warehouse) rodzaj bazy danych, która jest zorganizowana i zoptymalizowana pod kątem pewnego wycinka rzeczywistości. Hurtownia danych jest wyższym szczeblem abstrakcji niż zwykła relacyjna baza danych (choć do jej tworzenia używane są także podobne technologie). W skład hurtowni wchodzą zbiory danych zorientowanych tematycznie (np. hurtownia danych klientów). Dane te często pochodzą z wielu źródeł, są one zintegrowane i przeznaczone wyłącznie do odczytu.
W praktyce hurtownie są bazami danych integrującymi wszystkie pozostałe systemy bazodanowe w firmie. Ta integracja polega na cyklicznym zasilaniu hurtowni danymi systemów produkcyjnych (może być tych baz lub systemów dużo i mogą być rozproszone).
Architektura bazy hurtowni jest zorientowana na optymalizację szybkości wyszukiwania i jak najefektywniejszą analizę zawartości. Stąd bywa, że hurtownie danych nie są realizowane za pomocą relacyjnych baz danych, gdyż takie bazy ustępują szybkością innym rozwiązaniom.
W zależności od rodzaju hurtowni dane w jej rekordach mogą być zagregowane lub zawierać nawet informacje szczątkowe. W praktyce oznacza to, że pewne dane w hurtowni nie są przechowywane w postaci rozdrobnionej a tylko jako ich suma.
Użytkownicy końcowi hurtowni, czyli najczęściej zarząd firmy, korzystają z danych hurtowni poprzez różne systemy wyszukiwania danych (np. OLAP - Online Analitical Procesing).
architektura hurtowni danych /10. modele architektoniczne w hurtowni danych
ogolna architektura logiczna systemu typu hurtownia danych
przyklad: hurtownia danych dla marketingu
dane marktingowe
hurtownia danych informacje marketingowe
dane operacyjne
architektura referencyjna
Archiktektura hurtowni danych
Information data data data operational sytemy
delivery warehouse staging access DBS zewnetrzne
prosta hurtownia danych
pc data operational pc
warehouse DBS
zcentralizowana hurtownia danych
pc data data data operational pc
warehouse staging access DBS
rozproszona hurtownia danych
pc data data operational pc
warehouse access DBS

Źródłem danych dla hurtowni danych może być baza operacyjna, zewnętrzna baza danych, pliki oraz dane dostarczone przez firmy zajmujące się tego typu działalnością.
W części źródłowej, integracji oraz w hurtowni danych znajdują się dane, nie przedstawiające większej wartości bez odpowiedniego ich uporządkowania.
Z wyżej wymienionych danych w wyniku przekształcania powstaje informacja - będąca czytelnym dla odbiorcy obrazem bazy danych.
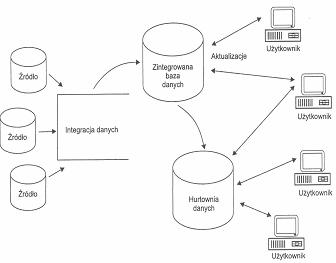
Aby do analiz bazujących na przeszłości dołączyć działania teraźniejsze, można zastosować architekturę hurtowni danych alternatywną względem przedstawionej na rysunku 1. W proponowanym rozwiązaniu dane są wydzielane z systemów źródłowych i wprowadzane do zintegrowanej bazy danych. Informacje znajdujące się w zintegrowanej bazie danych są niezmienne. Inne dane źródłowe są dodawane do bazy danych poprzez aplikację umożliwiającą modyfikację. Taka implementacja (rysunek 4) umożliwia wykonywanie: raportów, zestawień, symulacji bazujących na danych z przeszłości i pozwala na przeprowadzanie symulacji w zależności od zamodelowania teraźniejszości.
typy rozwiazan ktore mozna spotkac - olap
a) ROLAP (Relational). Cechy: zbudowane w relacyjnej bazie danych, wielka objętość danych(TB), złożone struktury danych, problemy z wydajnością, łatwa modyfikacja danych, potrzeba stworzenia kopii bazy do celów analitycznych, niedoskonałość SQL, stosowane dla centralnych hurtowni Opis Typowym sposobem przechowywania kostek danych jest schemat gwiazdy, płatka śniegu, konstelacji faktów Agregacja danych odbywa się w hurtowni danych lub na bieżąco. Architektura ta cechuje się wykonaniem operacji transformowanych na zapytanie SQL, dostępem do danych sumarycznych jak i do danych szczegółowych, szerokim zakresem realizacji zapytań wyspecyfikowanych jak i ad hoc. Najistotniejszym zastrzeżeniem do architektury ROLAP jest niska wydajność zapytań i długi czas oczekiwania na odpowiedź. Jednak wydajność nie jest jedynym kryterium oceny efektywności architektury OLAP. System DSS ma bowiem głównie zapewnić podejmowanie racjonalnych decyzji. Użytkownicy wykorzystujący zapytania ad hoc zgadzają się na niską wydajność w zamian za możliwość zadawania jednostkowych, nieoczekiwanych zapytań do danych szczegółowych w ogromnym zbiorze danych.
b) MOLAP(Multidimensional) Cechy: zoptymalizowane struktury danych - duża wydajność analizy wielowymiarowej, specjalne serwery wielowymiarowe, mniejsze objętości danych(GB), naturalna reprezentacja struktur wielowymiarowych, modyfikacje danych kosztowne, stosowane często dla składnic danych(nie radzą sobie z tb danych) Opis architektura ta opiera się na wielowymiarowych tablicach zawierających dane zagregowane (wg różnych hierarchii i wymiarów - w postaci kostki) gotowe do zaawansowanych analiz tak by użytkownik mógł otrzymać wymagany widok danych
c) HOLAP(HYBRID) Cechy: współdziałające bazy: relacyjna i wielowymiarowa, włącznie rozwiązań molap do relacyjnego dbms Opis: relacyjna baza danych jako źródło danych; najczęściej przetwarzane informacje w wielowarstwowej bazie, minusy są dziedziczone z obu rozwiązań, wydajność większa od ROLAP lecz nie dorównuje MOLAP, HOLAP jest przyśpieszaczem ROLAP.
techniki data mining
eksploracja danych- proces poszukiwania nowych, nietrywialnych i użytecznych wzorców w zbiorach danych. Proces ten składa się z trzech zasadniczych etapów: (1) wstępnej eksploracji, (2) budowania modelu (z określaniem wzorców) oraz oceny i weryfikacji oraz (3) wdrożenia i stosowania modeli (ang. deployment) dla nowych danych, w celu uzyskania przewidywanych wartości lub klasyfikacji.
Zadania ogólne data miningu: klasyfikacja, grupowanie, odkrywanie zależności, analiza sekwencji
techniki data miningu: drzewa decyzyjne, sieci neuronowe, metody statystyczne(regresja), metody uczenia maszynowego, metody ewolucyjne, logika rozmyta, zbiory przybliżone.
narzędzia: Oracle data miner, IBM inteligent miner, SAS Enterprise miner
data mining grupuje rozne techniki sluzace pozyskiwaniu wiedzy z duzych zbiorow danych najczesciej zgromadzonych w postaci duzych klasycznych baz danych. Wsrod technik wykorzystywanych w systemach z data mining mozna wyroznic nastepujace metody:
- wyszukiwanie zaleznosci typu jezeli A to B
- generalizacja obiektow
- metod- klasyfikacja obiegow
y statystyczne
Zastosowania data minigu:
Handel detaliczny:
- identyfikacja wzorców zachowań konsumentów
-znajdowanie zależności pomiędzy charakterystykami demograficznymi kupujących
-przewidywanie, którzy klienci odpowiedzą na wysłaną do nich ofertę
Bankowość:
- detekcja wzorców defraudacyjnego wykorzystywania kart kredytowych
- identyfikacja lojalnych klientów
- wyszukiwanie klientów, którzy mogą zmienić typ karty kredytowej
-określenie wydatków poszczególnych użytkowników kart kredytowych
Ubezpieczenia
- identyfikacja zachować ryzykownych klientów
- wyszukiwanie potencjalnych klientów
Transport
- analiza wzorców załadunków
- analiza dróg dystrybucji miedzy hurtowniami
Medycyna:
- charakterystyki zachowań pacjentów w celu prognozy wizyt
- identyfikacja zakończonych sukcesem terapii różnych chorób
Metodologie data mitingu:
Jednym z modeli data mining jest CRISP (Cross-Industry Standard Process for data mining) zaproponowany w połowie lat dziewięćdziesiątych przez europejskie konsorcjum przedsiębiorstw, jako powszechnie dostępny standard dla procesu data mining. Model ten postuluje następujący ciąg etapów projektu data mining (raczej nie budzą one większych kontrowersji):
Innym podejściem jest metodyka Sześć Sigma (Six Sigma) . Jest to dobrze zorganizowana, bazująca na danych strategia unikania wad i problemów z jakością we wszystkich rodzajach produkcji i usług, zarządzaniu i innej działalności biznesowej. Metodyka Sześć Sigma staje się ostatnio coraz bardziej popularna (ze względu na wiele udany wdrożeń) w USA i na całym świecie. Zaleca ona następujące etapy (tzw. DMAIC):
Definiowanie. Ta faza obejmuje określenie celu i zakresu projektu oraz identyfikację problemów, których rozwiązanie jest wymagane do osiągnięcia wyższego poziomu sigma.
Pomiar. Celem tego etapu metodyki Sześć Sigma jest zebranie informacji o aktualnej sytuacji, uzyskanie wstępnych danych o wydajności procesów i identyfikacja problemów.
Analiza. Celem etapu Analiza jest rozpoznanie przyczyn problemów z jakością i potwierdzenie ich wpływu za pomocą analizy danych.
Udoskonalenie. Na tym etapie strategii Sześć Sigma wdrażane są rozwiązania problemów (przyczyn głównych) zidentyfikowanych na etapie Analizy.
Kontrola. Celem tego etapu jest ocena i monitorowanie wyników poprzedniej fazy (Udoskonalenie).
Wywodzą się one z tradycji doskonalenia jakości i sterowania procesami i szczególnie dobrze nadają się do zastosowania w produkcji i świadczeniu usług.
Inna metodyka (w istocie do pewnego stopnia podobna do Sześć Sigma) to zaproponowana przez SAS Institute strategia SEMMA.
Skupia się ona bardziej na technicznych aspektach projektów data mining.
SEMMA wg dr Chudziaka:
Próbkowanie->eksploracja->manipulacja->modelowanie->ocena
Próbkowanie-redukcja czasu obliczeń; bazy danych poddawane są procesowi data miting są rzędu GB i wciąż rosną
Eksploracja - wizualna lub analityczna analiza w celu znalezienia punktu startu
Manipulacja - uzupełnianie/modyfikacja danych wejściowych
Modelowanie - modelowanie statystyczne z wkorzystaniem innych metod algorytmów decyzyjnych
Ocena - zakończenie lub kolejna iteracja; postawienie nowych pytań
Wszystkie te modele dotyczą sposobu korzystania z metodyki data mining przez organizację, "przekształcania danych na wiedzę", tego jak zaangażować kluczowe osoby (właścicieli, zarząd) w proces data i jak udostępnić wiedzę, w takiej postaci, aby łatwo było podejmować na jej podstawie decyzje.
Niektóre aplikacje data mining zostały zaprojektowane i udokumentowane, tak aby spełniać wymogi jednej z tych strategii.
Predykcyjny data mining (predictive data mining).
Termin ten oznacza analizy, których celem jest uzyskanie modelu (statystycznego lub sieci neuronowych) przeznaczonego do przewidywania wartości pewnych cech. Przykładowo celem projektu data mining może być wykrycie tych transakcji dokonywanych kartą kredytową, które mają duże prawdopodobieństwo nadużycia. Inne, niepredykcyjne projekty data mining, mają charakter eksploracyjny (np. identyfikacja segmentów klientów) i wykorzystują metody eksploracyjne np. drążenie danych i statystyki opisowe. Innym celem data mining może być redukcja danych (tzn. przekształcenie wielkiego zbioru w postać nadającą się do percepcji).
Kryteria wyboru systemu dla data mining:
- jak wiele przykładów/próbek może być jednocześnie przetwarzanych?
- jak wiele przetwarzania wstępnego jest niezbędne?
- czy system umożliwia użytkownikowi testowanie hipotez czy też proces jest tylko bottom-up?
- co jest rezultatem działania systemu- reguły, modele, drzewa decyzyjne czy liczby?
- jak łatwo jest zmodyfikować model gdy dostępne są nowe informacje/dane?
- jak dużo wysiłku/doświadczenia niezbędne jest do efektywnego wykorzystania danego systemu?
Przydatny link:
http://www.statsoft.pl/textbook/stathome_stat.html?http%3A%2F%2Fwww.statsoft.pl%2Ftextbook%2Fstdatmin.html
Eksploracja danych w procesie odkrywania wiedzy
w bazach danych (KDD)
1. Czyszczenie danych (data cleaning) - usuwanie zanieczyszczeń i
niespójności w danych.
2. Integracja danych (data integration) - łączenie danych pochodzących
z różnorodnych źródeł.
3. Selekcja danych (data selection) - wybieranie tych danych z bazy
danych, które są istotne dla zadań analizy.
4. Transformacja danych (data transformation) - przekształcanie i
konsolidowanie danych do postaci przydatnej dla eksploracji, na
przykład ich sumowanie i/lub agregowanie (np. w hurtowni danych).
5. Eksploracja danych (data mining) - stosowanie „inteligentnych” metod
w celu odkrycia istotnych zależności zwanych wzorcami (patterns).
6. Ocena wzorców (pattern evaluation) - identyfikacja naprawdę
interesujących wzorców w oparciu o pewne miary ważności.
7. Reprezentacja wiedzy (knowledge presentation) - przedstawienie
odkrytej wiedzy użytkownikowi za pomocą technik wizualizacji i
reprezentacji wiedzy.
Znaczenie eksploracji danych
1. Wynikiem eksploracji danych powinno być odkrycie
interesującej wiedzy, regularności i uzyskanie informacji
na wysokim poziomie ogólności, która może być
prezentowana z różnych punktów widzenia.
2. Odkryta wiedza powinna być użyteczna dla podejmowania
decyzji, sterowania procesami, zarządzania informacją a
także do udzielania odpowiedzi na różne zapytania.
3. Eksploracja danych może być przeprowadzana na każdym
rodzaju repozytorium danych: relacyjnych bazach danych,
hurtowniach danych, bazach transakcji, plikach, sieci
WWW, przestrzennych bazach danych, bazach
multimedialnych, arkuszach kalkulacyjnych, strumieniach
danych, itp. itd.
jakie mozemy znlezc aplikacje na poziomie wspo. Decyzji
oltp - systemy transakcyjne / on-line transaction systems
mis - systemy wspomagajace zarzadzanie / management inforamtion systems
dss - systemy wspomagania podejmowania decyzji
eis - systemy informacyjne kierownictwa
olap - systemy do interakcyjnej analizy
ess - executive support systems
pms - portfolio management system
iris - industrial relations information
isspa - interactive support system for policy analysis
ims - interactive marketing system
OLTP(on-line transaction systems)- systemy transakcyjne, główne zadanie to gromadzenie danych, typowe operacje to duża liczba niewielkich transakcji modyfikujących dane, operacje zapisu i odczytu- interaktywne i wsadowe. W systemach OLTP klient współpracuje z serwerem transakcji zamiast z serwerem bazy danych.
Termin OLTP w szerokim rozumieniu oznacza przetwarzanie transakcyjne, polegające na bieżącej obsłudze transakcji wprowadzanych przez użytkowników z klawiatury stacji roboczej, czytników kart płatniczych itp.
Zaawansowane OLTP posiada odpowiednie środowisko systemowe zapewniające niezawodną wysoką wydajność obsługi intensywnego strumienia transakcji napływających od dużej liczby współbieżnych użytkowników pracujących w rozproszeniu geograficznym (poprzez sieć rozległą). W skład środowiska wchodzi monitor transakcyjny, np. Tuxedo, ACMS,CICS, Encina, /T, TopEnd, Microsoft Transaction Server - Viper). Monitor transakcyjny funkcjonować może jako przedprocesor front-end w stosunku do komputerów mainframe lub serwerów unixowych. W standardzie Unixa SVR4 na środowisko to składają się m.i. systemy plików ViFS (Veritas Journalizing File System) i VxFS (Veritas Commercial Fille System) oraz system zarządzania i obsługi pamięci masowych VxVM (Veritas Disk Manager).
Transakcje obsługiwane przez OLTP powinny spełniać wymagania ACID (Atomicity, Consistency, Isolation, Durability ). Atomicity (atomowość) oznacza, że wszystkie akcje składające się na transakcję muszą być wykonance w całości (w przeciwnym razie następuje powrót do stanu poprzedzającego transakcję. Consistency (spójnośc) polega na tym, że każda transakcja pozostawia system w poprawnym stanie. Izolacja oznacza izolowanie transakcji od siebie podczas współbieżnej realizacji. Durability (trwałość) jest cechą oznaczającą, iż efekty transakcji są trwałe. Atrybutem OLTP opatrywane są operacyjne bazy danych.
Systemy OLTP ukierunkowane są na operacje aktualizacji określane skrótem CRUD (Create, Replace, Update, Delete), podczas których odczytywana jest niewielka liczba rekordów (wierszy tablicy) np. przy transakcji bankowej aktualizowane jest saldo na rachunku klienta, historia transakcji na rachunku oraz pozycja klienta.
MIS (management inforamtion systems) - system komputerowy wspomagający zarządzanie, przeznaczony dla biznesu i innych organizacji, który zbiera i analizuje dane ze wszystkich wydziałów, po czym dostarcza je jednostkom zarządzającym w uporządkowanej formie i z aktualną informacją, np. w postaci raportów finansowych, analizy magazynowej itp.
DSS - systemy wspomagania podejmowania decyzji - system informatyczny, który dostarcza informacje w danej dziedzinie przy wykorzystaniu analitycznych modeli decyzyjnych z dostępem do baz danych w celu wspomagania decydentów w skutecznym działaniu w kompleksowym i źle ustrukturyzowanym środowisku.
EIS(Executive Information Systems)- systemy informacyjne kierownictwa, informatyczne systemy wspomagające podejmowanie decyzji przez naczelne kierownictwo przedsiębiorstw i instytucji. Systemy te określa się niekiedy jako: bieżące przetwarzanie analityczne (OLAP), narzędzia analizy wielowymiarowej (MDA —Multidimensional Analysis), eksploracja danych (DM —Data Mining) lub IA —Inteligent Agents.
W szerokiej interpretacji oznacza technologię bezpośredniej i interaktywnej obsługi kierownictwa w zakresie informacji składowanych poza systemami obsługi operacyjnej. W wąskiej interpretacji oznacza technologię obsługi zapytań i prezentacji informacji dla kadry zarządzającej.. Wprowadzono go zapewne w celu odróżnienia od tradycyjnych systemów MIS (Management Information System) opartych na wykorzystaniu transakcyjnych baz danych. Pierwsze aplikacje opatrywane etykietą EIS uruchamiane były przez firmy IRI (pakiet Express), Comshare i Pilot (Command Center).
OLAP - systemy do interakcyjnej analizy, patrz pytanie nr 3.
przyklady zastosowan hurtowni danych
przetworzenie organizacji w bardziej zorientowana na klienta
szybsze reagowaie na zmiany sytuacji na rynku, analiza i kontrolowanie / monitorowanie dzialan firmy / kierunkow dzialan firmy, wspomaganie zarzadzaniem firmy
uspojnienie sposobu obserwowania wnetrza i zewnetrza organizacji w procesach podejmowania decyzji
stworzenie jednolitego wielowymiarowego magazynu danych analitycznych
stworzenie dziedzinowych systemmow umozliwiajacych budowanie systemow modelujacych, symulujacych oraz wizualizujacych dane
marketing
architektura cmr
informatyka
inne...
Hurtownie danych mogą służyć do wielu celów, ale wykorzystuje się je zazwyczaj na 3 podstawowych poziomach:
1) raportowanie i analizy statystycznie (systemy typu On Line Analitical Processing)
2) systemy typu Business Inteligence służące do bardziej złożonych analiz, wykorzystujące metody matematyczne i ekonomiczne
3) systemy Data Mining'owe, które tym różnią się od powyższych dwóch, że dostajemy w nich zależności, których nie możemy z góry przewidzieć. Są one najbardziej skomplikowane z tych 3 możliwości wykorzystania HD.
HD mogą być zastosowane wszędzie tam, gdzie:
- mamy do czynienia z dużymi ilościami danych
- chcemy usprawnić analizę działalności firmy
- chcemy zredukować liczbę zatrudnianych pracowników na rzecz wdrożenia technologii
- chcemy być konkurencyjni
- jest wiele rozposzonych źródeł danych dotyczących jednej dziedziny
Obszary, w których może być przykładowo użyta HD:
1) koncerny informatyczne
- zarządzanie wielkimi projektami informatycznymi
- zbieranie danych o pracownikach
- zbieranie danych o potencjalnych konsumentach i ich potrzebach ze źródeł zewnętrznych (ankiety, dane uzyskiwane na zamównie etc... )
2) koncerny telekomunikacyjne / handel detaliczny
- jakie produkty/promocje gdzie się sprzedają?
- zależności pomiędzy sprzedawanymi produktami
- ustalanie profili klientów (DM)
3) ubezpieczenia
- identyfikacja zachowań ryzykowanych klientów (DM)
- wyszukiwanie potencjalnych klientów (DM)
4) bankowość
- określenie wydatków poszczególnych grup użytkowników (DM)
- kontrola wykorzystania kart kredytowych
5) transport
- analiza wzorców załadunków (DM)
- analiza dróg dystrybucji między hurtowniami (DM)
6) medycyna
- analizowanie informacji o terapiach - sukces/porażka i wysnuwanie wniosków co do właściwych metod leczenia (DM)
- charakterystyki zachowań pacjentów w celu prognozy wizyt (DM)
*(DM) == (Data Mining)
To te ciekawsze - raportować można przecież wszystko.
Zastosowanie HD można podzielić jeszcze w inny sposób - ze względu na typ HD, która ma być wybudowana. Typ determinuje tym samym jej przeznaczenie.
Podział na hurtownie:
1) korporacyjne
2) departamentowe
3) funkcjonalne (marketing, finanse, zarządzenie zasobami, produkcja etc.)
4) działów
5) specjalizowane (do konkretnego zagadnienia)
6) osobiste (np. dla sponsora albo prezesa zarządu)
etl - na pewno cos z tego obszaru bedzie;
cos na temat transfomracji w hrutowni danych
transformacja danych obejmuje przetwarzanie danych do postaci wymaganej w hurtowni dancyh. Transformacja ta obejmuje nastepujace procedury / czynnosci:
integracja danych
walidacja danych
czyszczenie danych
redukcja danych
wzbogacanie
denormalizacja
steplowanie znacznikiem czasowm
Organizacja danych w strukturze wielowymiarowej nie jest jedynym wyróżnikiem hurtowni danych. Ważnym elementem tych systemów są procedury ekstrakcji, czyszczenia, transformacji i ładowania danych do bazy (ang. Extract, Transformation, Load - ETL). Procedury ekstrakcji danych z systemów OLTP uruchamiane są w czasie minimalnego obciążenia tych systemów. Dane wyekstrahowane są następnie weryfikowane względem reguł i danych słownikowych przechowywanych w repozytorium metadanych, przekształcane do pożądanej w hurtowni postaci i następnie ładowane do bazy. Dzięki procedurom ETL dane w hurtowni charakteryzują się wysoką jakością, przewyższającą znacznie jakość danych systemów OLTP. Za prosty przykład niech posłuży deduplikacja - procedura usuwająca powtórzenia danych: w systemach OLTP panowie Jan Kowalski i Jan Piotr Kowalski mogą być różnymi klientami, mimo iż mieszkają pod tym samym adresem, w hurtowni (dzięki procesowi deduplikacji) zostaną zidentyfikowani jako ta sama osoba umożliwiając tym samym rzeczywistą analizę zachowań klienta. Zauważmy, że prowadzenie ekstrakcji danych z systemów transakcyjnych w godzinach nocnych oraz umieszczenie hurtowni danych na oddzielnym serwerze odciążyło systemy OLTP umożliwiając efektywne ich wykorzystanie do zadań im dedykowanych.
ETL
Dane zgromadzone w hurtowni powinny być wysokiej jakości, czyli powinny zawierać informacje przydatne do wykorzystania w działalności przedsiębiorstwa. Proces przygotowania, przekształcania i przenoszenia informacji ze źródeł pierwotnych do hurtowni danych został nazwany ekstrakcją danych. Pełna nazwa tego procesu to proces ekstrakcji, transformacji i ładowania (ang. Extraction, Transformation, Load; ETL) albo proces ekstrakcji, transformacji i integracji (ang. Extraction, Transformation, Integration; ETI). Mimo iż problem ekstrakcji wydaje się błahy, to w rzeczywistości poprawne zaprojektowanie procesu ekstrakcji może zabrać sporą część czasu przeznaczoną na zbudowanie hurtowni danych.
Ekstrakcja danych jest jednym z etapów tworzenia hurtowni. Poszczególne kroki ekstrakcji wykonywane są zarówno na początkowym etapie rozwoju hurtowni danych, jak i przy dodawaniu nowych źródeł do istniejącego systemu. Aby jednak rozpocząć przenoszenie danych należy mieć już dokładnie zdefiniowane wymagania stawiane przed tworzonym systemem i zaprojektowaną strukturę fizyczną docelowego systemu. Dodatkowo należy wziąć pod uwagę posiadany sprzęt i oprogramowanie, gdyż ekstrakcja jest procesem silnie obciążającym systemy komputerowe. Brak odpowiedniej infrastruktury technicznej może doprowadzić do sytuacji, w której wykonanie procesu ETL będzie zbyt długotrwałe.
Ekstrakcja danych jest procesem, od którego zależy, co znajdzie się w systemie końcowym. Pierwszym krokiem ekstrakcji jest pozyskanie danych źródłowych. Etap ten koncentruje się na znaczeniu danych i polega na zidentyfikowaniu plików źródłowych pomocnych przy spełnianiu wymagań postawionych przed docelowym systemem. Zazwyczaj wymagania użytkowników są większe, niż jest to możliwe do uzyskania, co zdecydowanie utrudnia wydobycie odpowiednich informacji, zwłaszcza gdy wymagane dane są niedostępne albo niekompletne. Mając już zdefiniowane systemy źródłowe można przystąpić do wydobywania danych z tych systemów. Rzadko zdarza się, aby informacje źródłowe idealnie pasowały do struktury hurtowni danych, dlatego też konieczne jest dokonanie ich konwersji do wspólnego formatu.
Celowe wydaje się wprowadzenie obszaru pośredniego pomiędzy transakcyjnymi systemami źródłowymi a bazą hurtowni danych (rys. 1.). W obszarze tym dane są przygotowywane i przetwarzane, a następnie przenoszone do właściwej hurtowni danych. Obszar pośredni to miejsce, gdzie dane są czyszczone, agregowane, transformowane oraz gdzie kontrolowana jest ich poprawność. Wprowadzenie obszaru pośredniego umożliwia dokonywanie wielokrotnych operacji na tych samych danych, a dodatkowo może on być zlokalizowany na wielu maszynach, dzięki czemu możemy uzyskać równoległe przetwarzanie danych.
W obszarze pośrednim dane podlegają czyszczeniu w celu poprawienia ich jakości. Operacja ta polega na wykrywaniu i usuwaniu błędów i niespójności. Problem jakości danych występują głównie przy scalaniu informacji pochodzących z wielu różnych źródeł, chociaż występują również przy przetwarzaniu danych z jednego źródła. Kontrola jakości danych może polegać na przykład na sprawdzaniu poprawności odpowiednich wartości. Istnieją również takie sytuacje, które są trudne do wykrycia. Można do nich zaliczyć problemy związane z niekonsekwentnym używaniem skrótów, błędami literowymi czy też wielokrotnym wpisaniem informacji dotyczących tego samego faktu. Błędy powinny być poprawione w obszarze pośrednim, zanim trafią na stałe do hurtowni. Należy również poprawić informacje zawarte w systemach źródłowych, aby przy kolejnych procesach ekstrakcji uniknąć czyszczenia tych samych danych.
Poza czyszczeniem danych, w obszarze pośrednim dokonuje się jeszcze transformacji i agregacji danych. Transformacje danych związane są często z konsolidacją informacji pochodzących z różnych systemów rozproszonych geograficznie. Przykładowo mogą one dotyczyć ujednolicenia jednostek wag czy też przeliczania wartości różnych walut. Przykładem transformacji może też być nadanie danym unikalnych identyfikatorów, konwersja pomiędzy różnymi stronami kodowymi czy też zabiegi czysto estetyczne, polegające np. na kapitalizacji pierwszych liter w imionach i nazwiskach. Głównym celem stosowania agregacji jest przyspieszenie wykonywania zapytań przez hurtownię danych. Etap ten również jest wykonywany podczas procesu ekstrakcji, gdyż mamy tutaj dostęp do wszelkich niezbędnych informacji.
Kolejnym problemem jest sposób ładowania przetworzonych informacji. W przypadku relacyjnych hurtowni danych na pierwszy plan wysuwają się narzuty czasowe związane z przetwarzaniem transakcyjnym. Dlatego w rozwiązaniach korzystających z architektury ROLAP zalecane jest wykorzystywanie programów do masowego wprowadzania danych.
problemy zwiazane z wdrozeniami w hurtowni danych
Specyfika wdrazania hurtowni danych polega na:
koniecznosc operowania z wieloma zrodlami danych wewnetrznych i zewnetrznych
praca z bardzo duzym wolumenem danych
praca z wieloma wlascicielami zrodel informacji (semantyka, syntaktyka pozyskiwanej informacji)
praca z wieloma odbiorcami informacji (selekcja informacji)
strategiczne znaczenie informacji przechowywanych i przetwarzanych w hurtowni danych
Projektowanie i wdrażanie hurtowni danych jest procesem bardzo złożonym. W związku z tym w trakcie wdrażania mogą wystąpić następujące problemy:
OGÓLNIE
=======
- bezpieczeństwo - im większej grupie dajemy dostęp, tym mamy większy problem z zachowaniem bezpieczeństwa danych
- zbyt duży czas odświeżania / ładownia danych -> mniej czasu na inne operacje (np analityczne)
- problem skalowalności
- rozminięcie się z oczekiwaniami użytkowników - jeśli długo pracowali tylko na zwykłym systemie raportującym, to mogli nie umieć wyobrazić sobie czego tak naprawdę potrzebują
- brak odpowiedniej kadry pracowniczej, która ma pracować na hurtowni danych (dopóki ktoś nie będzie umiał czegoś konkretnego z niej wyciągnąć to jest bezużyteczna)
- potrzeba walidacji danych, które w systemach produkcyjnych nie są walidowane
- brak grupy pracowników, która rozumie logikę firmy i jest w stanie sprawnie asystować przy czyszczeniu danych (niektóre dane mogą być od razu odrzucone, ale ktoś musi o tym wiedzieć)
- granulacja danych, która nie spełnia oczekiwań użytkowników
- niedoszacowanie kosztów wdrożenia
- problemy, które przez lata były nie zauważone wypłyną, bo zacznie się porządna walidacja danych, a na poziomie baz produkcyjnych była bardzo kiepska, w związku z czym trzeba będzie podejmować decyzję czy naprawiać źródło czy dobrze filtrować
SZCZEGÓŁOWO
===========
Stosuje się trzy metody projektowania i budowania hurtowni danych:
1) back-to-front design / TOP-DOWN (najpierw projektowanie i modelowanie HD, a potem Data Martów na tej podstawie)
- w data martach są dane wyliczane
2) front-to-back data sourcing / BOTTOM-UP (najpierw poszczególne Data Marty, a później na podstawie założeń HD)
- data martach są dane atomowe i wyliczane
3) hybrid - połączenie 1 i 2 jednocześnie.
Każda z powyższych metod może być przyczyną różnych problemów wdrożeniowych:
ad 1)
- większe koszty i dłuższy czas przygotowania
- może się okazać, że Data Marty, które otrzymaliśmy nie zgadzają się z oczekiwaniami użytkowników
ad 2)
- jeśli okaże się, że jednak jakieś Data Marty powinny być połączone, mimo tego co wskazał na początku użytkownik, to bardzo trudno jest to szybko wykonać po wdrożeniu
- Data Marty korzystają również z danych atomowych, więc trzeba kontrolować na poziomie użytkowników czy wszystko z Data Martami jest ok - brak takiej możliwości na poziomie samej HD
ad 3)
- nieścisłości pomiędzy wymaganiami na Data Marty i samą HD mogą wyjść dopiero przy wdrożeniu
przyklady dostawocow rozwiazan w hurotwni danych
business objects
cognos
microsoft
oracle
sap
hyperion
sybase
Sas
1.Oracle:
baza danych: Oracle database 10g
narzędzie do obsługi hurtowni: Oracle Warehouse Builder
2.SAP
SAP's Business Information Warehouse
3.COGNOS
ETL:Cognos DecisionStream
Cognos 8 Business Intelligence is the only BI product to deliver the complete range of BI capabilities: reporting, analysis, scorecarding, dashboards, business event management as well as data integration, on a single, proven architecture. Cognos 8 BI also delivers powerful search functionality for both BI and Enterprise Search.
4.BUSINESSOBJECTS
BusinessObjects XI
BusinessObjects Enterprise is a business intelligence (BI) platform that powers the management and secure deployment of specialized end-user tools for reporting, query and analysis, performance management, and analytic applications on a proven, scalable, and open-services-oriented architecture.
5.SAS
NetWeaver Business Intelligence (SAP NW BI), a component of the SAP NetWeaver platform, is a powerful tool for the identification, integration, and analysis of disparate business data from heterogeneous sources.
The SAS Enterprise Intelligence Platform extends the value of your existing systems while setting the stage for new levels of enterprise intelligence not previously possible. It includes the following components:
SAS Data Integration provides prebuilt, high-performance capabilities for data connectivity, data quality, ETL (extract, transform and load), data migration, data synchronization and data federation.
SAS Intelligence Storage is a dedicated solution that efficiently stores and disseminates information for business intelligence and analytic requirements, offering relational and OLAP storage options from the same foundational inputs.
SAS Analytic Intelligence is an integrated environment for predictive and descriptive modeling, forecasting, optimization, simulation, experimental design and more. SAS Analytic Intelligence leverages existing data and infrastructures to support effective decision making and integration into business intelligence environments.
SAS Business Intelligence delivers a set of BI capabilities that enable different types of users to surface meaningful intelligence from consistent, companywide data.
6.HYPERION
Hyperion System 9 BI+
Hyperion System 9 BI+™ (BI+) is the industry's most comprehensive BI platform that supports all types of reporting and analysis through a personalized, intuitive and interactive thin client workspace.
Hyperion System 9 Applications+™ (Applications+) is a modular suite of integrated financial management applications for managers, analysts, and executives who need to gain visibility into performance, improve forecast accuracy, and respond to changing market conditions.
Hyperion System 9 Foundation Services™ (Foundation Services) make it easy to manage, scale, and deploy BPM across all your departments, applications, business units, and locations.
7.SYBASE
Sybase oferuje trzy bazy danych: SQL Anywhere Studio, Adaptive Server Enterprise, Sybase IQ. Każda baza danych zostałą zoptymalizowana do innych zastosowań.
SQL Anywhere Studio - zintegrowany zestaw produktów do projektowania i udostępniania danych dla stacjonarnych, przenośnych i wbudowanych systemów bazodanowych. Najważniejszym elementem jest w pełni relacyjna baza danych Adaptive Server Anywhere, zoptymalizowana pod względem efektywności użytkowania.
Adaptive Server Enterprise - to wysoko wydajny system zarządzania relacyjnymi bazami danych w heterogenicznych środowiskach informatycznych dużych korporacji. Umożliwia obsługę internetowych portali informacyjnych, transakcji rozproszonych, XML i WebServices, zapewniając przy tym wysoką dostępność danych.
Sybase IQ - serwer analityczny, zoptymalizowany do obsługi hurtowni danych i aplikacji wspierających podejmowanie decyzji. Umożliwia wykonywanie zapytań do bazy danych do 100 razy szybciej niż systemy tradycyjne. Zapewnia wsparcie dla standardu XML.
Enterprise Connect - produkty połączeń i dostępu do baz danych to rozwiązania Sybase dla systemów o strukturze heterogenicznej. Umożliwiają dostęp i przenoszenie danych niezależnie od ich lokalizacji i postaci, zarządzanie środowiskiem rozproszonym, budowanie aplikacji za pomocą dowolnych narzędzi programistycznych.
Replication Server - serwer replikacyjny przeznaczony do tworzenia wysoko wydajnych systemów rozproszonych w czasie rzeczywistym. Synchronizuje dane znajdujące się na różnych serwerach bazodanowymi i systemach e-biznesowych, mogących znajdować się w odległych od siebie miejscach.
8.MICROSOFT
Microsoft SQL Server 2005 to kompletna platforma Business Intelligence (BI) zapewniająca infrastrukturę oraz oprogramowanie serwerowe do tworzenia:
Kompleksowych hurtowni danych, łatwych w obsłudze i o wysokiej efektywności kosztowej;
Elastycznych systemów raportowania i analiz, które mniejsze przedsiębiorstwa bądź departamenty dużych przedsiębiorstw mogą łatwo zbudować, i którymi mogą bez problemów zarządzać;
Systemów dostarczających dane analityczne do użytkowników merytorycznych.
Systemów analitycznych i Data Mining działających w układzie zamkniętym
Osadzonych systemów rozszerzających zasięg rozwiązań Business Intelligence.
Narzędzia:
•Analysis Services
•Data Mining
•Integration Services
•Reporting Services
•Report builder
proces wdrozenia
logiczny projekt bazy danych
inicjalizacja systemu
instalacja oprogramowania laczacego podsystem dss ze zrodlami informacji
projekt fizyczny baz danych
trymowanie systemu
konstrukcja aplikacji
analiza, definicja, przygotowanie i wspomaganie decyzji DW
testowanie
Logiczny projekt bazy danych - jest to model abstrakcyjny, konceptualny. Przedstawiony w postaci encji i atrybutów. Podstawowe schematy logiczne to:
Schemat gwiazdy: centralna tabela faktów połączona ze zdenormalizowanymi tabelami wymiarów poprzez klucze główne i obce. Zalety to prostota struktury oraz duża efektywność zapytań (niewielka ilość połączeń tabel). Wady to długi czas ładowania danych do tabel spowodowany denormalizacją.
Schemat płatka śniegu: centralna tabela faktów połączona z normalizowanymi tabelami wymiarów. Zalety to łatwość modyfikacji struktury i krótki czas ładowania danych. Wady to spadek wydajności zapytań w porównaniu do schematu gwiazdy ze względu na dużą ilość połączeń.
Konstelacja faktów: schemat stanowiący kombinację schematów gwiazd współdzielących niektóre wymiary. Różne tabele faktów mogą odwoływać się do różnych poziomów danego wymiaru
Inicjalizacja systemu
Instalacja oprogramowania łączącego podsystem DSS ze źródłami informacji
Projekt fizyczny baz danych
Wybór sposobu składowania danych
Formaty danych
Strategie partycjonowania:
Partycjonowanie zakresowe - rozdział rekordów pomiędzy partycje odbywa się według przynależności wartości kolumny-klucza do predefiniowanych przedziałów
Partycjonowanie haszowe - rozdział rekordów odbywa się według wartości funkcji haszowej (modulo) wyliczanej dla kolumny-klucza
Partycjonowanie wg listy - rozdział rekordów odbywa się według przynależności wartości kolumny klucza do predefiniowanych list wartości
Partycjonowanie dwupoziomowe zakresowo-haszowe - rozdział rekordów na partycje wg zakresów, a następnie na subpartycje wg wartości funkcji haszowej
Partycjonowanie dwupoziomowe zakresowo-listowe - rozdział rekordów na partycje wg zakresów, a następnie na subpartycje wg przynależności do list wartości
Wybór indeksów
Wybór materializowanych perspektyw
Trymowanie systemu - polega na usunięciu określonej części dolnych i górnych wartości atrybutu. Metoda wstępnego przetwarzania danych.
Konstrukcja aplikacji
Analiza, definicja, przygotowanie i wspomaganie operacji DW
Testowanie
APB-1 -mierzenie wydajności serwera OLAP. Wykonywanie operacji na bazie danych opartych na najczęstszych operacjach biznesowych:
Masowe wprowadzanie danych z wewnętrznych i zewnętrznych źródeł danych
Przyrostowe wprowadzanie danych z systemów operacyjnych
Agregacja danych z poziomu wejściowego w górę hierarchii
Obliczanie nowych danych w oparciu o modele biznesowe
Analiza szeregów czasowych
Zapytanie o wysokim stopniu złożoności
Eksploracja w dół
Zapytania ad hoc
Wielokrotne sesje bezpośrednie
Just In time - ocena zdolności dostarczenia użytkownikowi aktualnych informacji.
Testy AQM - miara ta reprezentuje liczbę zapytań analitycznych przetworzonych w ciągu minuty włączając w to wprowadzanie danych i obliczenia. Sprawdza wydajność wprowadzania danych, wydajności wykonywania obliczeń oraz wydajności realizacji zapytań.
modelowanie procesow w hurtowni danych
jasno okreslone role i zakresy poszczegolnych aktorow w danym procesie. Trudno utworzyc taki model bo malo kto pamieta ze dziala w jakims procesie ( subiektywne obserwowanie swiata) , procesy bywaja dlugie bo dyskutuje sie o rolach ludzi na przyszlosc.
-przeplywy danych: jakie dane przeplywaja pomiedzy poszczegolnymi procesami biznesowymi
- modelowanie przeplywow meta danych: ktore elementy nalezy zdefiniowac w ktorym momencie projektowania hurtowni danych
Elementy informatyzacji firmy:
OPISANIE/ZDEFINIOWANIE wymagań biznesowych,
STWORZENIE wymagań informacyjnych,
specyfikacja niezbędnych systemów/aplikacji.
Modele organizacji
Modele danych (obiekty występujące w danej organizacji),
Modele funkcjonalne (np. podzial funkcjonalny: marketing, sprzedaz),
Modele procesowe (np. proces sprzedazy).
Integracja danych organizacji
Pozioma (wszystkich elem. Pojedynczej aplikacji),
Pionowa (aplikacja ma być spojna z wymaganiami biznesowymi calej firmy),
Integracja całości organizacji,
Projektowanie procesow biznesowych(Business process reengineering) (modelowanie transformacji rozwiazan )/ Projektowanie procesow zmian - możliwość etapowego wdrazania, droga przyrostow, aby firma dala rade przejść przez proces.
DW w kontekście modelu organizacji - wymagania biznesowe.
Informatyzacja dazy do SOA (sernice oriented architecture) - udostępniania serwisow userom i innym aplikacjom.
Techniki modelowania organizacji:
(szczególnie sa to techniki modelowania procesow biznesowych organizacji) - ten model może być wykorzystany podczas tworzenia systemow/aplikacji dla tej organizacji.
Identyfikacja obiektow,
Diagramy relacji obiektow,
Identyfikacja elementarnych procesow,
Analiza cyklu zycia obiektow,
Analiza zdarzen,
Diagramy związków,
Analiza krytycznych czynnikow sukcesu,
Analiza SWOT:
Strengths - silne strony,
Weaknesses - słabe strony,
Opportunities - szanse, możliwości,
Threats - zagrożenia.
Analiza potrzebnych informacji,
Ocena istniejacych systemow,
Modele firmy typu “blue-print” dla danego sektora <- model “vanilla”, generyczny, wstepny.
Modele łańcuchów wartości firmy lub jej czesci <- rozne moduly dla roznych celow,
Modele miernikow efektywności procesow (balance scorecard ) - hierarchia ważności miernikow i ich udzialu w decyzjach i raportach.
Lancuch wartości M. Portera
Modeluje podstawowe procesy firmy. Powinno się je caly czas ulepszac, również z wykorzystaniem technologii inf.
Lancuch:
Marketing Zakupy Logistyka Produkcja Sprzedaz Dystrybucja
Lancuch procesow pomocniczych:
Zarzadzanie zasobami ludzkimi
Przetwarzanie transakcji
Raportowanie i kontrola
Podejmowanie decyzji
Pomiary wydajności, benchmarking
Systemy inf. Powinny wspierac wszystkie te procesy na poziomach operacyjnym, taktycznym i strategicznym.
Przykład struktur organizacyjnych: podzial funkcyjny:
Zarząd
Marketing
Operacje
Finanse
…
…
Przykład modelu danych - model ER (standardowy diagram ER łączący obiekty z przedsiębiorstwa)
Stosowany jest także model przepływu danych (DFP)
Narzędzia modelowania danych:
Erwin(ER Windows),
Sterling Software COOL,
System Architekt,
Power Designer,
DBArtisan,
VISIO.
modelowanie danych
- modelowanie danych jest szczegolnie istotne w aplikacjach o duzym zakresie informacyjnym
- podstawowe techniki sluzace do tworzenia modeli biznesowych sa identyczne oraz niezalezne od aplikacji
- fizyczny model jest bardzo zdeterminowany wymaganiami analitycznymi
- w szczegolnosci znormalizowane modele relacyjne nie spelniaja wymagan wydajnosciowych, stad specjalizowane struktury danych czesto redundantne
- w modelowaniu dla zastosowan analitycznych wykorzystywane sa roznego rodzaju modele wielowymiarowe: gwiazdy, galaktyki etc.
- trzy podstawowe modele: biznesowy, logiczny oraz fizyczny (wewnetrzny)
MOLAP:
Dane przechowywane w wielowymiarowych kostkach, a nie w relacyjnych BD.
model umożliwia doskonałą wydajność zapytań
obliczenia są pregenerowane podczas tworzenia kostki
kostki mogą być tworzone z danych o ograniczonej liczbie wymiarów, ze względu na pregenerowane obliczenia (przy wymiarach > 10 MOLAP zazwyczaj nie wyrabia)
Relacyjna implementacja modelu (ROLAP):
Schematy logiczne:
schemat gwiazdy
schemat płatka śniegu
konstelacja faktów
Schemat gwiazdy:
centralna tabela faktów
wymiary zdenormalizowane
tabela faktów połączona z tabelami wymiarów poprzez klucze obce
uproszczony schemat płatka śniegu
Charakterystyka:
prosta struktura
duża efektywność zapytań ze względu na niewielką liczbę złączeń
duży czas ładowania danych do tabel wymiarów ze względu na denormalizację
struktura dominująca w hurtowniach danych
Schemat płatka śniegu:
centralna tabela faktów
wymiary znormalizowane
Charakterystyka:
spadek wydajności zapytań w porównaniu ze schematem gwiazdy ze względu na większą ilość złączeń (wymiary znormalizowane, składające się z kilku tabel, np. sklepy ->miejscowosci -> regiony)
struktura łatwiejsza w modyfikacji
krótszy czas ładowania danych do tabel wymiarów
mniej popularna niż gwiazda - efektywność zapytań jest ważniejsza niż szybkość ładowania danych
Konstelacja faktów:
różne tabele faktów mogą odwoływać się do różnych poziomów danego wymiaru
FAKT_1------- MIESIAC -------- ROK ----------- FAKT_2
Tabela faktów:
przeważnie kolumny numeryczne (można np agregować)
wieloatrybutowy klucz główny z kluczy obcych do tabel wymiarów
zwykle zawiera 90% danych umieszczonych w schemacie
szybki przyrost danych
Tabele wymiarów:
zawierają dane statyczne (informacje o klientach, produktach etc)
zawierają atrybuty opisowe (ciągi znaków)
Data Marts
PC
Aplikacje
transakcyjne
Hurtownia danych
Agregaty
danych
Dane i
systemy
zrodlowe
Ekstrakcja i
integracja
danych
Operacyjne BD,
posrednie skladnice
do raportowania, aby
odciazyc hurtownie
centralna i
zsynchronizowac
dane
transformacja
Hurtownia
danych
Aplikacje
Analiza wielowymiarowa
OLAP
DW
DW
DW
obszar pośredni
źródło
źródło
hurtownia danych
Rys. 1. Ekstrakcja danych z wykorzystaniem obszaru pośredniego
Wyszukiwarka