ANALIZA OBRAZÓW CYFROWYCH
I SYGNAŁU MOWY (cz. 2)
TREŚĆ PRZEDMIOTU
|
Tematyka |
wykł. |
lab. |
Wytwarzanie mowy. Charakterystyka sygnału mowy, reprezentacja czasowa i częstotliwościowa |
2 |
2 |
|
Modelowanie sygnału mowy. Ukryte modele Markowa. |
2 |
2 |
|
Rozpoznawanie mowy i mówcy |
2 |
2 |
|
Synteza mowy |
2 |
2 |
Temat 1:
Wytwarzanie i percepcja sygnału mowy
Komunikacja pomiędzy człowiekiem operatorem i maszyną upodabnia się - w sensie zakresu, charakteru i tematyki - do komunikacji pomiędzy ludźmi.
Sygnał mowy jest najszybszym i najbardziej naturalnym sposobem porozumiewania się między ludźmi.
Cechy komunikowania się za pomocą sygnału mowy:
szybkość działania,
brak związania operatora z pulpitem, manipulatorem czy klawiaturą,
możliwość sprawnego działania w trudnych warunkach,
naturalność i wygoda (bez treningu i przyuczenia).
Sygnał mowy zwiększa komfort pracy operatora, wpływając na jej jakość.
Rola wejścia głosowego będzie rosła wraz z rozwojem technologii w automatyce i robotyce.
Przy komunikacji w przeciwną stronę (wyjście głosowe) nie jest to tak oczywiste - człowiek dużo efektywniej posługuje się wzrokiem, najszybciej i najwięcej analizuje oczyma.
Synteza mowy znajduje zastosowanie tam, gdzie nie może być wykorzystany wzrok: w komunikacji z ludźmi niewidzącymi lub przy przekazywaniu informacji za pomocą telefonu.
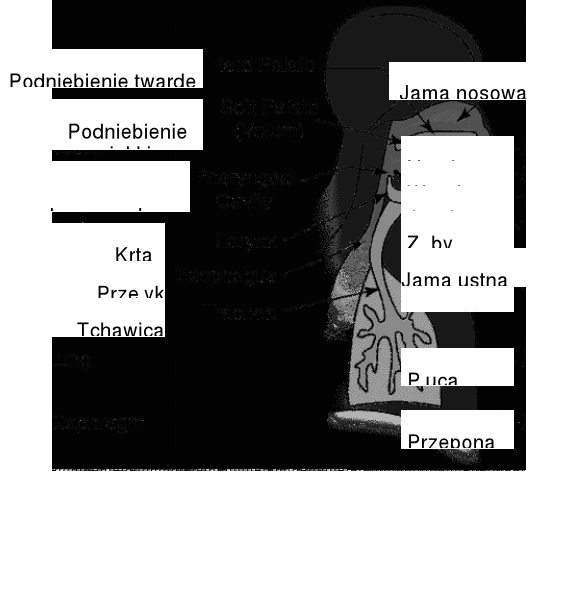
Wytwarzanie mowy
System głosowy człowieka

Schemat funkcjonalny systemu głosowego

Proces wytwarzania dźwięków mowy:
płuca wypełnione powietrzem,
skurcz klatki piersiowej przetacza powietrze z płuc do tchawicy - ilość powietrza określa amplitudę dźwięku,
tchawica przenosi powietrze do traktu głosowego (wokalnego); struny głosowe oddzielają tchawicę od traktu wokalnego,
trakt wokalny:
składa się z gardła, ust i nosa,
kształt i rozmiar traktu wokalnego zmienia się przez zmianę pozycji języka, zębów i ust,
kształt traktu głosowego determinuje typ dźwięku mowy.
Dwa zasadnicze składniki wytwarzania mowy:
Pobudzenie - tworzy dźwięk przez wprawienie powietrza w szybki ruch.
Trakt głosowy - kształtuje dźwięk.
Ad 1. Pobudzenie: trzy podstawowe postaci
wibracje strun głosowych (dźwięczność):
struny głosowe składają się z wiązadła i mięśni, które nimi sterują; otwór umożliwiający przepływ powietrza przez struny głosowe nazywa się głośnią.
Dwa sposoby działania strun głosowych:
wibrowanie:
struny napięte, ściśnięte razem - brak przepływu powietrza
ciśnienie powietrza z płuc wymusza otwarcie strun
miejscowe ciśnienie zmniejsza się - struny zamykają się
cykl powtarza się
Częstotliwość cyklu zamykania/otwierania strun głosowych jest podstawową częstotliwością wytworzonego dźwięku (wysokość głosu).
Wibracje wytwarzają ton podstawowy (krtaniowy, ang. pitch)
Ton krtaniowy odznacza się bogatym widmem, w którym harmoniczne są tłumione w przybliżeniu o 12 dB na oktawę, ale mimo tego są wyraźnie widoczne nawet harmoniczne o częstotliwości 30-krotnie wyższej od częstotliwości podstawowej, zależnej od okresu drgań strun głosowych.
Ton podstawowy zmienia swoją częstotliwość wpływając na intonację wypowiedzi i melodykę głosu. Zakres tych zmian zależy od płci, wieku i cech osobniczych i jest ograniczony. Częstotliwość podstawowa i jej modulacja są cechami umożliwiającymi identyfikację osoby mówiącej.
Im dłuższe struny głosowe tym niższy głos
Typowe częstotliwości cyklu:
mężczyźni: ok. 125 Hz; kobiety: ok. 250 Hz
Im bardziej napięta struna głosowa tym wyższy głos i tym krótszy okres
brak wibracji: oddychanie
Mowa różni się od oddychania tym, że w pewnym punkcie na drodze wprawia się powietrze w szybki ruch lub wibracje.
turbulentny przepływ powietrza (tarcie):
źródło szumu
pobudzenie powstaje przez przepływ powietrza przez zwężenie w pewnym punkcie traktu głosowego (\f\: górne zęby i dolna warga)
połączone tarcie i dźwięczność( \w\: górne zęby i dolne wargi połączone z dźwięcznością)
przypadek szczególny: \h\ - częściowo zamknięte struny głosowe, sztywne, bez periodycznego przepływu powietrza
plozja:
zamknięcie w pewnym miejscu traktu głosowego a następnie uwolnienie powietrza - \p\: zamknięte wargi
plozja może być połączona z wibracją strun głosowych: dźwięczność i plozja; \b\ - zamknięte wargi i dźwięczność.
Ad 2) Trakt głosowy
Prosty (uproszczony) model: jednorodna rura
zamknięta od strony głośni, otwarta od strony ust,
posiada częstotliwości rezonansowe (np. 500, 1500, 2500 Hz)
Ponieważ kanał głosowy jest rezonatorem akustycznym, można go opisać za pomocą częstotliwości, dla których jego częstotliwościowa charakterystyka amplitudowa posiada maksima zwane formantami.
Te częstotliwości rezonansowe nazywane są częstotliwościami formantowymi.
Można pokazać, że trakt głosowy modelowany jako jednorodna rura może być opisany za pomocą transmitancji posiadającej wyłącznie bieguny.
W terminach teorii sterowania: pobudzenie - wejście ![]()
,
trakt głosowy - transmitancja ![]()
sygnał mowy (mowa) - wyjście ![]()
Kształt widma sygnału określany jest przez charakterystykę częstotliwościową ![]()
lub ![]()
.
W modelu uproszczonym głosek dźwięcznych sygnał wejściowy jest sekwencją impulsów o okresie ![]()
- tzw. ton krtaniowy lub podstawowy. W efekcie w widmie sygnału mowy występują kształtowane przez trakt głosowy (charakterystykę częstotliwościową)
prążki odległe o ![]()
Hz.
W rzeczywistości system głosowy różni się od rury jednorodnej:
w trakcie głosowym: straty przez ściany, odbicia od warg, promieniowanie ust
w pobudzeniu: w kształcie impulsów tonu krtaniowego
Braki modelu:
głoski nosowe: jednorodna rura z bocznym odgałęzieniem
![]()
ma zera - zwykle jedno zero w zakresie 1-2 kHz
głoski szczelinowe, plozyjne: rury z przodu i z tyłu ze źródłem pobudzenia między nimi wprowadzają zera (mogą nie wystąpić rezonanse lub rezonanse mogą być ukryte przez zera).
Przyjmuje się zazwyczaj, że systemy analizy mowy są filtrami wyłącznie biegunowymi, identycznymi dla wszystkich dźwięków mowy.
Znacząca część energii:
dla sygnałów dźwięcznych: do 4 kHz
dla sygnałów szumowych i plozyjnych: do 8-10 kHz
Na rysunku pokazano model artykulacji sygnału mowy.
Podczas artykulacji mowy:
włączane są generatory tonu podstawowego i szumu (na przemian lub łącznie - zależnie od wymawianej głoski),
regulowane są parametry generatorów,
zmieniana jest transmitancja filtru modelującego trakt głosowy (co odpowiada zmianom kształtu toru głosowego),
zmienia się impedancja emisji (promieniowania) mowy.
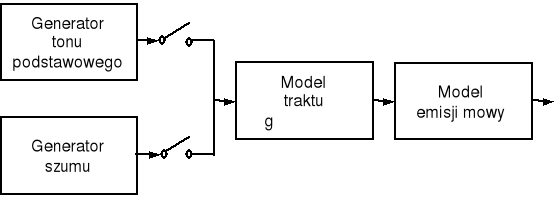
W porównaniu z prawie biernym procesem generacji drgań głosowych (tonu krtaniowego), proces formowania dźwięków w trakcie głosowym jest aktywnie sterowany przez mięśnie krtani i kontrolowany przez układ nerwowy. Intonacja i modulacja głosu również umożliwiają identyfikację mówcy.
Wynikowe widmo określonej głoski dźwięcznej powstaje jako nałożenie charakterystyki częstotliwościowej traktu głosowego na widmo tonu krtaniowego. W rezultacie powstaje widmo o kształcie zależnym od konfiguracji narządów mowy w chwili artykulacji danej głoski, odmienne dla każdej głoski i umożliwiające jej identyfikację.
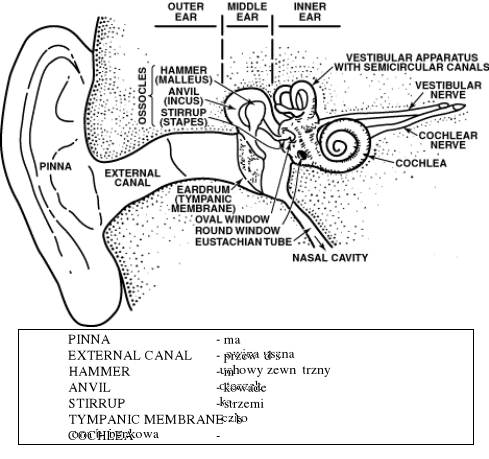
System percepcji mowy
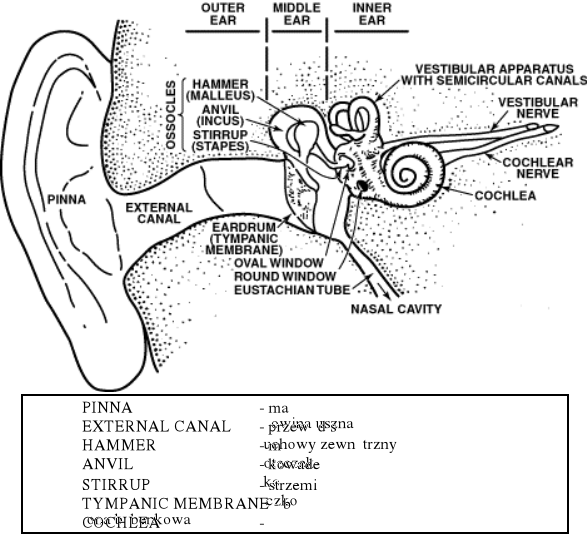
Schemat ucha człowieka
Ucho zewnętrzne: zbiera dźwięki
wzmacnia fale dźwiękowe o pewnych częstotliwościach
drgania powietrza są przekształcane na drgania błony bębenkowej
Ucho środkowe: drgania błony bębenkowej są przekształcane na oscylacje cieczy w uchu wewnętrznym
wzmocnienie 15:1
Ucho wewnętrzne:
ślimak: przekształca drgania mechaniczne na impulsy nerwowe
zakończenia nerwów: przenoszą impulsy nerwowe do mózgu.
Punkt największych drgań ślimaka (a właściwie błony podstawnej) zależy od częstotliwości dźwięku
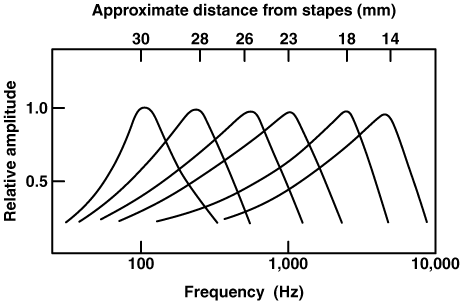
Ruchy błony podstawnej powodują zgięcia włosków w ślimaku i wytwarzają impulsy elektryczne w nerwie(3000 włosków w ślimaku, 30 000 włókien nerwowych)
Percepcja dźwięku jest możliwa dzięki następującym jego cechom:
głośności, będącej miarą mocy czy intensywności,
wysokości, określanej przez częstotliwość składowej podstawowej,
barwie (inna nazwa: tembr) - jest to podstawowe wrażenie dźwiękowe, pozwalające odróżnić od siebie dźwięki o jednakowej wysokości i głośności, określane przez zawartość harmonicznych, umożliwiające odróżnienie brzmienia głosów ludzkich lub instrumentów.
Tembr dźwięku jest zdeterminowany przez kształt fali dźwiękowej. Jednak ze względu na to, że ucho ludzkie jest niewrażliwe na fazę sygnału, taki sam tembr może posiadać wiele różnych fal dźwiękowych.
Przykład
![]()
![]()
Charakterystyka ucha -
logarytmiczna w dziedzinie częstotliwości
taka sama ilość informacji przenoszona jest w oktawach:
50 - 100 Hz i 10 - 20 kHz
(oktawa jest zakresem częstotliwości, którego górna granica jest dwukrotnie większa niż dolna).
Człowiek słyszy dźwięki z zakresu 10 oktaw
Naturalnie brzmiąca mowa wymaga pasma ok. 3.2 kHz
Zakres częstotliwości jest zredukowany do 16% (3.2 z 20 kHz) - sygnał wciąż zawiera 80% informacji dźwięku oryginalnego (8 z 10 oktaw)
Ucho jest przyzwyczajone do słuchania częstotliwości podstawowej wzbogaconej harmonicznymi: złożenie dźwięków sinusoidalnych o częstotliwościach 1 i 3 kHz brzmi naturalnie i przyjemnie, a dla częstotliwości 1 i 3.1 kHz brzmi nieprzyjemnie.
W celu realizowania prostszych i tańszych systemów automatycznego rozpoznawania mowy, wydobywa się i opisuje cechy, zakłócenia i deformacje sygnału mowy, których ucho człowieka nie rejestruje i nie analizuje.
W szczególności dotyczy to następujących problemów.
1. Można ograniczyć pasmo sygnału mowy, tzn. wyciąć fragmenty widma poniżej 300 Hz i powyżej 3500 Hz. Nie prowadzi to do zauważalnego obniżenia zrozumiałości sygnału mowy. Wystarczający dla wielu zastosowań poziom zrozumiałości można osiągnąć przy paśmie o szerokości 1000 Hz wokół tzw. środka widma sygnału mowy równego w przybliżeniu 1750 Hz.
2. Rozdzielczość częstotliwościowa słuchu jest ograniczona. Oznacza to maskowanie równocześnie występujących dźwięków o bliskich częstotliwościach. Można traktować ucho jako zestaw filtrów pasmowych o szerokości pasm odpowiadających tzw. pasmom krytycznym. Szerokość tych pasm wzrasta wraz ze wzrostem częstotliwości środkowej filtru. Przyjmuje się zwykle, że w zakresie dolnych częstotliwości do około 800 Hz szerokość wynosi 50 - 100 Hz, a dla częstotliwości wyższych rośnie w przybliżeniu logarytmicznie i osiąga przy f=8000 Hz wartość 500 - 1800 Hz. Powyższe dane dotyczą słyszenia jednousznego, przy słyszeniu dwuusznym pasma krytyczne są węższe i stanowią około 50% podanych wartości.
3. Precyzja w określaniu częstotliwości maksimum widma sygnału zależy od wartości tej częstotliwości. Dla częstotliwości sygnału 700 Hz ucho lokalizuje maksimum z dokładnością 10 Hz, a dla f=2000 Hz - z dokładnością 20 Hz. Formantowa struktura wielu głosek (występowanie jednego lub więcej maksimów w widmie głoski) ma związek z tą własnością.
4. Zmienna jest rozdzielczość amplitudowa słuchu. W pobliżu częstotliwości formantowych dostrzegalne zmiany poziomu głośności wynoszą około 3 dB, a dla słabych dźwięków - 6 dB.
5. Wykrywanie krótkotrwałych zmian poziomu sygnału jest utrudnione. Z powodu dużej stałej czasowej narządu słuchu (20 - 30 ms przy narastaniu i 200 - 250 ms przy opadaniu natężenia sygnału) nie są wykrywane zmiany głośności mniejsze niż 100 dB/s i trwające krócej niż 20 ms.
Reprezentacja sygnału mowy w dziedzinie
czasu i częstotliwości
Fizyka sygnału mowy
Dźwięk to fala podłużna
Pomiarom podlega:
- zmiana ciśnienia dźwięku, czyli amplituda dźwięku
- moc (intensywność) - zmienia się jak kwadrat ciśnienia
Siła dźwięku wyraża się w skali logarytmicznej
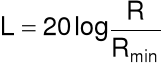
[dB]
gdzie:
![]()
- zmiana ciśnienia wywołana przez mierzony dźwięk
![]()
- najmniejsza zmiana ciśnienia wytwarzająca słyszalny dźwięk (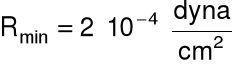
)
lub
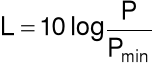
[dB]
gdzie:
![]()
- moc mierzonego dźwięku
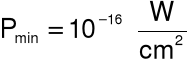
- moc najsłabszego dźwięku słyszalnego przez ucho.
Normalna rozmowa -60dB
szept - 46 dB; krzyk - 86 dB; 140dB - ból
Ucho ludzkie: od ok. 20 Hz do ok. 20 kHz
najbardziej wrażliwe: z zakresu 1 - 4 kHz
Tworzenie cyfrowego systemu dźwiękowego wymaga odpowiedzi na dwa pytania: jak dobrze ma brzmieć oraz jaka powinna być prędkość przesyłania danych.
Wyróżnia się trzy kategorie systemów akustycznych:
muzyka o wysokiej wierności - najważniejsza jest jakość dźwięku,
komunikacja telefoniczna - wymaga naturalnie brzmiącej mowy i małej prędkości przesyłania danych,
mowa skompresowana - najważniejsza jest mała prędkość przesyłania danych, pewne pogorszenie jakości dźwięku może być dopuszczalne.
Techniki stosowane w procesie akwizycji sygnału analogowego w postaci cyfrowej:
kodowanie PCM, DPCM, ADPCM,
kwantyzacja logarytmiczna,
kodowanie LPC (umożliwia redukcję objętości przesyłanej informacji przez usunięcie jej redundancji, w szczególności wykorzystuje się do tego standardy LPC10 i CELP, uzyskując prędkość 2-6 kbitów/s),
kompresja sygnału.
Microsoft:
ogólna strukturę plików dźwiękowych w środowisku Windows - standard RIFF (Resource Interchange File Format), zwykle z rozszerzeniem .wav.
Multimedia
odtwarzacze: Windows Media Player, Sound Player (odtwarza nie tylko pliki dźwiękowe)
Najbardziej popularne formaty dźwiękowe: .wav, .mid, .mp3, .asf, .wma, .ra.
Sygnał mowy w dziedzinie czasu
Sygnał analogowy:
napięcie na wyjściu mikrofonu,
proporcjonalne do zmian ciśnienia powietrza;
Sygnał cyfrowy:
próbki sygnału analogowego,
konwersja A/C (ang. A/D);
Dwie operacje konwersji A/D:
próbkowanie
kwantyzacja
Próbkowanie
Przekształca zmienną niezależną z ciągłej na dyskretną w czasie
Oznaczenia:
![]()
- częstotliwość próbkowania
![]()
- okres próbkowania
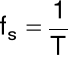
![]()
- częstotliwość najwyższej składowej widma sygnału
Zasada próbkowania:
dowolny sygnał analogowy jest dokładnie określony przez równoodległe próbki
dostarczane z częstotliwością ![]()
Twierdzenie Nyquista:
aby nie utracić informacji zawartej w sygnale ciągłym (odtworzyć go z sygnału cyfrowego) należy przebieg próbkować z częstotliwością przynajmniej dwukrotnie większą od częstotliwości najwyższej harmonicznej zawartej w tym sygnale.
Ciąg próbek sygnału nie określa jednoznacznie (bez dodatkowych informacji) ciągłego w czasie sygnału.
Przykład
![]()
![]()
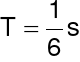
ale te same punkty mogą reprezentować inny przebieg
![]()
![]()
Ogólnie:
![]()
![]()
- dowolna liczba całkowita
Gdy nie jest spełniony warunek ![]()
(undersampling)
powstaje zjawisko aliasingu
Składowe dla 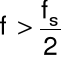
są obserwowane jako składowe dla
![]()
.
Fałszywa składowa jest dodawana do prawdziwej składowej
Przykład
Załóżmy ![]()
6 kHz
Sygnał zawiera składową o częstotliwości 4 kHz
Składowa o częstotliwości 4 kHz dodana zostanie do wartości składowej 2 kHz
antyaliasing:
- zagwarantować, że w sygnale nie ma składowych powyżej zadanej częstotliwości: należy przepuścić sygnał przez filtr dolnoprzepustowy o częstotliwości odcięcia równej tej zadanej,
- zakres słyszalności: 20 - 20.000 Hz: częstotliwość odcięcia filtru antyaliasingowego jest 20 kHz, po filtrze występuje konwerter AD o częstotliwości próbkowania 40 kHz
- dla dźwięków mowy stosuje się filtr antyaliasingowy o częstotliwości odcięcia 4 kHz, po którym występuje konwerter o częstotliwości próbkowania 8 kHz
Przetwornik A/D należy poprzedzić dolnoprzepustowym filtrem, wtedy w sygnale nie będzie składowych o 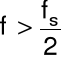
Techniki wieloczęstotliwościowe
prosty dolnoprzepustowy filtr analogowy typu RC
próbkowanie z częstotliwością 64 kHz
sygnał zawiera głos z zakresu (100 Hz - 3 kHz), ale też niepożądane dźwięki z zakresu (3 - 32 kHz)
programowe usunięcie niepotrzebnych składowych za pomocą dolnoprzepustowego filtru cyfrowego
zmiana okresu próbkowania przez usunięcie każdych 7 z 8 próbek (decymacja)
Wynik jest taki sam jak otrzymany za pomocą złożonego filtru analogowego i próbkowaniu 8 kHz.
mowa wysokiej jakości: ![]()
20 kHz
zapisanie i odtworzenie dowolnego dźwięku, który może usłyszeć człowiek: ![]()
44,1 kHz
w magnetofonach cyfrowych (DAT): ![]()
48 kHz
dla mowy telefonicznej (300Hz - 3200Hz) ![]()
6,4 kHz;
przyjmuje się 8 kHz
Kwantyzacja
Przekształca zmienną zależną (np. napięcie) z ciągłej na dyskretną
Kwantyzacja dodaje błąd losowy do sygnału:
rozkład równomierny w zakresie [-½ ½]LSB
wartość średnia=0,
odchylenie standardowe=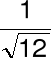
LSB (LSB - least significant bit)
Przykład
Kwantyzator dodaje do sygnału zakłócenie losowe o odchyleniu standardowym:
8-bitowy:
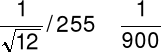
pełnej skali wartości
12-bitowy:
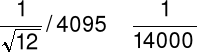
pełnej skali wartości
16-bitowy:
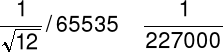
pełnej skali wartości
Liczba bitów określa dokładność danych
Ma sens zdanie: zwiększono dokładność pomiarów z 8 do 12 bitów
Decyzja o liczbie bitów dla próbki zależy od:
- wielkości zakłóceń już obecnych w sygnale analogowym
- wielkości zakłóceń dopuszczalnych w sygnale cyfrowym
Stosunek sygnał - zakłócenie
(ang. signal to noise ratio, SNR)
Definicja:
moc sygnału
moc błędu kwantyzacji
Najczęściej: kwantyzacja równomierna
n - liczba bitów reprezentacji próbki
wtedy
SNR=6n -7,2 [dB]
czyli
wzrost o 1 bit reprezentacji powoduje wzrost SNR o 6 dB
20 bitów wystarczy, aby pokryć cały zakres słyszalności
120 dB (od progu słyszenia do progu bólu),
gdy ten zakres ma być zapisany na n bitach, wtedy
20 log102n=120,
stąd
n=120/(20 log102) = 20
Skutki dla mowy:
Nie ma sensu, aby SNR dla błędów kwantowania był większy niż SNR dla zakłóceń tła:
dla mowy telefonicznej: ~40 dB, czyli 7 bitów (stosuje się 8 bitów) n=40/(20 log102) = 6,7
dla mowy wysokiej jakości: 60-70 dB - 11 lub 12 bitów
n=70/(20 log102) = 11,7
wzmacnia się sygnał przed kwantyzacją - aby wykorzystać cały zakres amplitudy zapewniany przez b bitów
W systemach wyłącznie głosowych:
redukuje się również dokładność segmentowania z 16 do 12 bitów na próbkę
8 bitów na próbkę: krok kwantyzacji nie jest równy - companding
Dla częstotliwości próbkowania 8 kHz oraz dokładności segmentowania 8 bitów/próbkę, prędkość przesyłania danych jest 64 kbitów/s - mowa wymaga mniej niż 10% danych niezbędnych przy przesyłaniu muzyki hi-fi.
Reprezentacja sygnału mowy w czasie
Charakterystyki mowy - proces wytwarzania i percepcji mowy
Wytwarzanie mowy: model źródło-filtr.
Źródło (sygnał wymuszenia):
pseudookresowy ciąg impulsów dla głosek dźwięcznych: samogłosek, spółgłosek płynnych, spółgłosek nosowych, głoski niesylabicznej j, głoski drżącej r;
szum biały dla bezdźwięcznych głosek: trących, zwartych i zwarto-trących;
suma powyższych wymuszeń dla dźwięcznych głosek trących, zwartych, zwarto-trących.
Filtr (trakt głosowy) - filtr o skończonej odpowiedzi impulsowej
Sygnał mowy: splot wymuszenia i odpowiedzi impulsowej filtru
Proces percepcji: nieliniowy (logarytmiczny) analizator widma mowy
Założenie podstawowe:
sygnał mowy quasi-stacjonarny w krótkim (ok. 10 ms) okresie czasu
Najczęściej wykorzystywana charakterystyka:
widmo częstotliwościowe - charakterystyka amplitudowa - FFT dla segmentu (ramki) sygnału mowy.
Dla sekwencji próbek sygnału mowy ![]()
Energia sygnału (krótkookresowa)
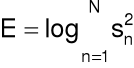
przed wykonaniem na próbkach jakiejkolwiek operacji
Sygnał mowy podczas emisji przez usta jest tłumiony około 6 dB na oktawę.
Stosuje się dla wysokich częstotliwości kompensację przez zastosowanie preemfazy pierwszego rzędu:
![]()
,
![]()
- współczynnik preemfazy
(najczęściej z zakresu 0,95 do 1,0).
Sygnał ![]()
o zerowej wartości średniej:
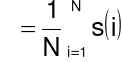
![]()
dla ![]()
Wartość największa M:
![]()
Liczba przejść przez zero PPZ:
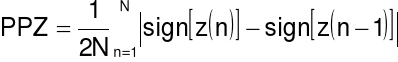
gdzie:
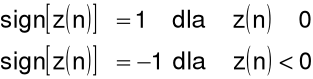
Wykrywanie sygnału mowy - ciszy np. za pomocą energii i przejść przez zero
Analiza autokorelacyjna (krótkookresowa)
Przebiegi mowy powtarzają się w przybliżeniu (nie dokładnie) w każdym cyklu głośni. Okres powtórzeń, czyli częstotliwość podstawową, można wyznaczyć za pomocą funkcji autokorelacji, która jest iloczynem sygnału i jego opóźnionej wersji:
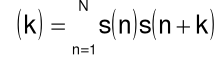
gdzie k jest opóźnieniem
W praktyce, szczególnie ze względu na niestacjonarność sygnałów mowy, należy ograniczyć zakres sumowania do N punktów dla zdigitalizowanych przebiegów sygnałów mowy. Wydzielenie segmentu może być zrealizowane za pomocą okna.
Dla funkcji okresowych w funkcji autokorelacji wystąpi wiele szczytów (lokalnych maksimów) odpowiadających okresowi i jego wielokrotności. Dla sygnału mowy szczyty pojawią się dla częstotliwości pobudzenia i jego kolejnych harmonicznych.
Wobec tego funkcja autokorelacji może być stosowana do estymacji częstotliwości podstawowej przebiegów sygnału mowy oraz do określania jego dźwięczności lub bezdźwięczności (przebieg przypadkowy da płaską funkcję autokorelacji).
Reprezentacja sygnału mowy w dziedzinie częstotliwości
Najważniejszym narzędziem przetwarzania sygnałów cyfrowych jest dyskretne przekształcenie Fouriera (ang. Discrete Fourier Transform, DFT).
Jean Baptiste Joseph Fourier (1768-1830) - Institut de France - protest Joseph Louis Lagrange i zgoda Pierre Simon de Laplace - efekt Gibbsa.
DFT wyznacza rozkład zadanego sygnału na sygnały sinusoidalne, zatem jest procedurą wykorzystywaną do wyznaczenia zawartości harmonicznej (częstotliwościowej) sygnału dyskretnego.
Dla sygnałów dyskretnych jest to rozkład dokładny matematycznie.
Dlaczego stosuje się rozkład na składowe sinusoidalne, a nie na przykład na sygnały prostokątne czy trójkątne?
Ostatecznym celem dekompozycji jest uproszczenie i głębsze zrozumienie działań związanych z przetwarzaniem sygnałów. Składowe sinusoidalne są prostsze niż sygnał oryginalny, ponieważ odpowiedzią układów liniowych na sygnał sinusoidalny jest również sygnał sinusoidalny, który ma tę samą częstotliwość, a różni się tylko amplitudą i fazą. Taką własność mają wyłącznie sygnały sinusoidalne.
W zależności od typu sygnału w czasie (ciągłe czy dyskretne, okresowe czy nieokresowe) wyróżnia się cztery kategorie przekształceń (transformat) Fouriera:
dla sygnałów ciągłych okresowych - szeregi Fouriera (ang. Fourier series);
dla sygnałów ciągłych nieokresowych - przekształcenie Fouriera (ang. Fourier transform);
dla sygnałów dyskretnych okresowych - (dyskretny szereg Fouriera) dyskretne przekształcenie Fouriera (ang. discrete Fourier transform, DFT);
dla sygnałów dyskretnych nieokresowych - przekształcenie Fouriera dla sygnałów o czasie dyskretnym (ang. discrete time Fourier transform, DTFT).
Zakłada się, ze wszystkie sygnały trwają w czasie od ![]()
do ![]()
.
Oznacza to, że sygnały o skończonej długości traktuje się jak sygnały nieskończone. Na przykład dla sygnału dyskretnego o długości N próbek przyjmuje się, że:
próbki na lewo (do

) i na prawo (do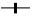
) od sygnału mają wartości zerowe - wtedy sygnał jest dyskretny i nieokresowy;sygnał nieskończony powstanie przez powielenie sygnału skończonego - wtedy powstanie sygnał dyskretny i okresowy (z okresem N).
W cyfrowym przetwarzaniu sygnałów wykorzystywane jest dyskretne przekształcenie Fouriera (DFT), czyli założono, że sygnał analizowany jest dyskretny i okresowy (oczywiście również nieskończony).
Czy to istotne, że sygnał dyskretny zadany N próbkami jest traktowany jako sygnał nieskończony okresowy o okresie N
Czyli, że zamiast:
N-punktowy sygnał jest syntezowany z N-punktowych sinusoid
jest:
nieskończony sygnał okresowy jest syntezowany z nieskończonych sinusoid.
Zwykle nie ma to znaczenia, ale czasami ma (pewne własności DFT są niezrozumiałe, gdy sygnały są widziane jako skończone i stają się jasne, gdy uwzględni się ich okresową naturę).
Oś odciętych wykresu w dziedzinie częstotliwości może przyjmować jedną z czterech postaci:
oznaczana „m” i indeksowana liczbami całkowitymi z zakresu
(numery składowych sinusoidalnych);oznaczana „f” i indeksowana liczbami rzeczywistymi z zakresu
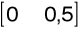
(krotność częstotliwości próbkowania sygnału - ponieważ składowymi sinusoidalnymi mogą być wyłącznie sygnały o częstotliwościach między zerem i połową częstotliwości próbkowania, zwanej częstotliwością Nyquista); spełniona jest zależność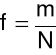
;oznaczana „

” (pulsacja mierzona w rad/s) i indeksowana liczbami rzeczywistymi z zakresu
;oznaczana
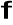
i indeksowana wartościami częstotliwości (fizycznych) w analizowanym sygnale (np. gdy analizowany sygnał był próbkowany z częstotliwością 8 kHz, oś odciętych w dziedzinie częstotliwości etykietowana jest liczbami z zakresu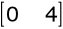
kHz).
Niewystarczająca rozdzielczość częstotliwościowa widma
(proporcjonalna do liczby próbek w segmencie)
dla typowych częstotliwości próbkowania (8 - 16 kHz)
10 ms segmentu sygnału
Rozsądna rozdzielczość:
sygnał o długości 25 - 30 ms (czyli ok. 250 próbek)
Można pogodzić powyższe sprzeczne wymagania:
analiza sygnału wydzielonego przez nakładające się ramki.
Sygnał mowy - sekwencja ramek - z ramki pojedyncza obserwacja
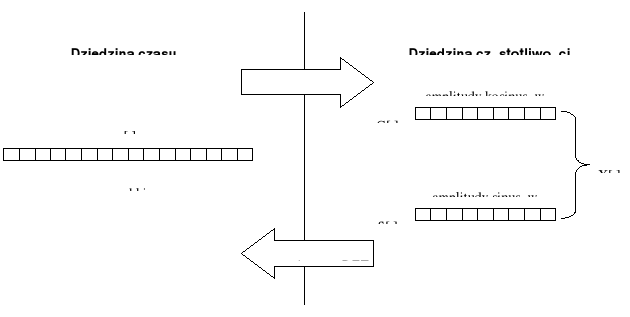
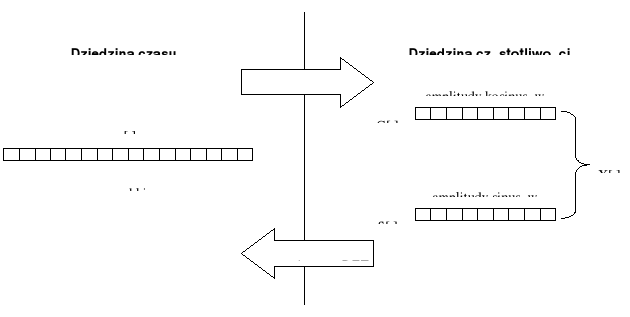
Analiza częstotliwościowa (analiza Fouriera)
Transformata Fouriera
Synteza
sygnał ciągły w czasie, (zespolony), nieokresowy (impuls)
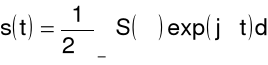
widmo ciągłe, zespolone, nieokresowe
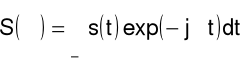
Szereg Fouriera
Synteza
sygnał ciągły w czasie, (zespolony), okresowy
(o okresie T)
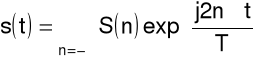
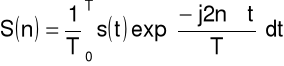
Transformata Fouriera sygnału czasu dyskretnego (okres próbkowania ![]()
)
Synteza
sygnał: dyskretny w czasie, (zespolony), nieokresowy
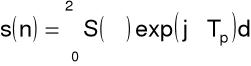
Analiza
widmo: ciągłe, zespolone, okresowe
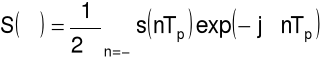
Dyskretny szereg Fouriera
Synteza
sygnał: dyskretny w czasie, (zespolony), okresowy
(N próbek w okresie T),
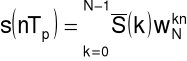
gdzie
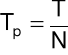
oraz 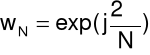
Analiza
widmo: dyskretne, zespolone, okresowe
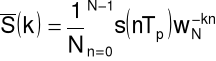
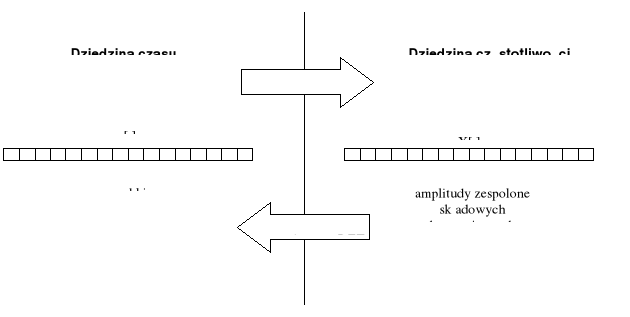
Dyskretna transformata Fouriera
Synteza
sygnał: dyskretny w czasie, (zespolony), okresowy
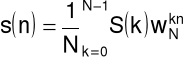
Analiza
widmo: dyskretne, zespolone, okresowe
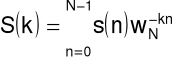
Praktycznie:
z dyskretnego sygnału pobiera się sekwencję (segment) N próbek - mnożenie przez okno prostokątne - to wprowadza nieciągłości na brzegach okna, które zniekształcają widmo przez dodanie fałszywych składowych o wysokich częstotliwościach.
lepsza technika: mnożenie przez okno wygładzające (trójkątne, gaussowskie, o kształcie kosinusowym, np. Hanninga, Hamminga; wszystkie dają bardzo podobny efekt).
widmo wyrażane jest za pomocą liczb zespolonych. Zwykle pożądana jest znajomość energii przenoszonej przez każdą składową harmoniczną - wyznacza się widmo mocy
![]()
[dB],
gdzie a i b są składową rzeczywistą i urojoną widma zespolonego.
ucho ludzkie jest nieczułe na zmianę fazy sygnału - widmo fazowe jest zwykle nie wykorzystywane.
zmienność sygnału mowy wymaga, aby analizowany segment był nie dłuższy niż 10 ms.
rozdzielczość częstotliwościowa wyznaczanego widma wymaga ok. 250 punktów, czyli dla
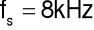
oznacza to, że segment powinien mieć długość ok. 30 ms.do efektywnego wyznaczania dyskretnej transformaty Fouriera (zamiast
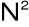
operacji mnożenia i dodawania, potrzebuje
) wykorzystuje się algorytm Cooleya - Tukeya (1965), zw. szybkim przekształceniem Fouriera (FFT), który wymaga, aby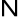
było potęgą dwójki.
13
8
18
3
31
3

Wyszukiwarka