Minimalne kryteria jakości, które powinny być spełnione przez poszczególne elementy systemu
1 Komponenty systemów informacji geograficznej
Bazując na definicji GIS, sformułowanej przez Gaździckiego (2001), systemy informacji geograficznej i przestrzennej składają się z:
- sprzętu komputerowego,
-oprogramowania
- danych,
- procedur do zarządzania i analizowania danych,
- ludzi.
Sprzęt komputerowy i oprogramowanie to niezbędne środki techniczne do funkcjonowania GIS. Wobec różnorodności wymagań klientów oraz dostępnych pakietów oprogramowania systemy informacji geograficznej można budować bazując na dowolnym sprzęcie komputerowym, począwszy od komputerów przenośnych poprzez stacjonarne komputery personalne, stacje robocze, a także komputery o dużej mocy obliczeniowej. Projektując system informacji geograficznej należy dostosować sprzęt do specyfiki realizowanych zadań, a szczególnie czasochłonnych przetworzeń danych przestrzennych i zgodnie z tym wybrać odpowiedni procesor, szybki i pojemny dysk, zasoby pamięci RAM, monitor oraz urządzenia peryferyjne do wprowadzenia i wyprowadzania danych takie jak skaner, ploter czy drukarka.
Oprogramowanie systemowe, narzędziowe i aplikacyjne pełni rolę integratora wszystkich elementów systemu. Posiada funkcje do wprowadzania danych, wstępnego ich przetwarzania (m.in. konwersje formatów), przechowywania, zarządzania bazą danych, narzędzia do analiz i wizualizacji ulanych przestrzennych oraz graficzny interfejs użytkownika umożliwiający korzystanie z funkcji systemu. Wybór oprogramowania narzędziowego GIS wpływa na sposób rozwiązania określonego zadania. Stosownie do dokonanego wyboru mamy w rezultacie do dyspozycji większe lub mniejsze możliwości funkcjonalne systemu.
Dane stanowią najważniejszy element systemu. Podstawowymi cechami gwarantującymi wysoką jakość danych przestrzennych jest: dokładność, aktualność, wiarygodność i kompletność. O tych własnościach danych bardziej szczegółowo w dalszej części pracy. Ponieważ proces gromadzenia szczegółowych danych jest nadzwyczaj czasochłonny, kosztowny i złożony pod względem techniczno-organizacyjnym, zatem w systemie informacji geograficznej należy gromadzić jedynie dane niezbędne, pozwalające uzyskać określone wyniki w możliwie krótkim czasie i minimalnym koszcie. Opracowując koncepcję systemu oraz projektując strukturę bazy należy kierować się zasadą pragmatyzmu, potrzebami przyszłych użytkowników systemu oraz dostępnością danych źródłowych.
Dane przechowywane są w bazie danych. Baza danych to nie tylko zbiór danych, ale również system zarządzania bazą danych (SZBD), który jest zorganizowanym zbiorem narzędzi umożliwiającym dostęp do danych i zarządzanie nimi. Bazy danych GIS mają swoją odrębność związaną z przechowywaniem danych przestrzennych.
Ludzie są bardzo istotnym komponentem systemów informacji geograficznej. Oni system planują, wdrażają, użytkują oraz podejmują decyzje w oparciu o dane zgromadzone w systemie. Sukces czy też niepowodzenie wdrożenia GIS w dużo większym stopniu zależy od czynnika ludzkiego" niż od środków technicznych. W większości instytucji wdrażaniu GIS towarzyszą zmiany organizacyjne. Zaakceptowanie tych zmian, sprawne zarządzanie systemu i wykorzystanie GIS w procesie podejmowania decyzji to podstawowe czynniki gwarantujące sukces przy wdrażaniu GIS.
2 Normy ISO w zakresie jakości danych geograficznych
Jakość danych geograficznych jest zagadnieniem na tyle ważnym, ze zajęły się nimi międzynarodowe organizacje normalizacyjne. Wśród norm ISO az trzy dokumenty podejmują temat jakości danych geograficznych. Należą do nich norma ISO 19113 Geographic information - Quality principles (ISO 2002a), norma ISO 19114 Geographic information - Quality evaluation procedures (ISO 2002b) oraz opracowywany dokument ISO/AWI 19138 Geographic information - Data quality measures (ISO 2002c). Pierwsza z wymienionych norm ustanawia model oraz zasady zapisu jakości danych geograficznych, w drugiej został zdefiniowany proces identyfikacji i oceny potrzeb informacyjnych w zakresie jakości oraz procedury oceny jakości danych geograficznych. Natomiast dokument ISO/AWI 19138 ma zaowocować Specyfikacją Techniczną uzupełniającą zakres normy ISO 19114. Wszystkie trzy dokumenty tworzą spójny zbiór wytycznych przeznaczonych do opisu oceny jakości danych geograficznych oraz procesu oceny jakości. Powiązania między dokumentami normatywnymi w zakresie jakości zostały pokazane na rysunku 1. Analizując rozwiązania normatywne ISO w zakresie jakości, Kmiecik (2004) stwierdziła, że normy ISO regulują problematykę jakości danych geograficznych w sześciu aspektach:
(1) organizacji opisu jakości,
(2) procesu ustalania i oceny modelu jakości dla danych geograficznych,
(3) procedur oceny jakości geodanych,
(4) metod oceny jakości geodanych,
(5) miar jakości,
(6) zapisu jakości zbiorów geodanych.
Jakość danych geograficznych powinna być zapisana bezpośrednio w metadanych oraz w raporcie zewnętrznym zdefiniowanym w normie ISO 19114.
stosuje zapis procedury
oceny jakości
wykorzystuje model jakości
implementuje opisany
proces oceny jakości danych
powołuje się na miary
jakości danych
powołuje się na miary
jakości danych
wykorzystuje model jakości
Rysunek 1. Powiązania między dokumentami ISO dotyczącymi jakości danych geograficznych (Kmiecik 2004)
Jak widać na rysunku 2, ocena jakości danych geograficznych rozpoczyna się od identyfikacji potrzeb informacyjnych użytkowników, czyli określenia elementów i podelementów niezbędnych do oceny jakości danych i zakresu ich zastosowań. Następnie dla każdego podelementu należy ustalić miary jakości w taki sposób, aby najlepiej oszacować ilościowo jakość danych geograficznych. W kolejnym kroku wybieramy metodę oceny jakości. Ustalenie wyników jakości następuje na podstawie zbiorczego zestawienia wartości miar jakości. Procedurę oceny jakości danych geograficznych kończy określenie stopnia zgodności wyników z zakładanym poziomem jakości.
3 Ocena jakości danych geograficznych
Do oceny jakości danych geograficznych niezbędna jest znajomość:
- kompletności,
- spójności logicznej,
- dokładności położenia,
- dokładności czasu,
- dokładności tematycznej.
Kompletność oznacza stosunek danych zgromadzonych w systemie do danych, które powinny być zgromadzone i dotyczy zarówno obszaru, jak i szczegółowości bazy danych. Brak obiektów lub ich atrybutów określa się jako pominięcie.
zbiory danych
specyfikacja zbioru
lub wymagania
użytkowników
etap 1
etap 2
identyfikacja miar jakości danych
etap 3
etap 4
etap 5
Rysunek.2. Pięcioetapowy proces oceny jakości danych geograficznych zdefiniowany w normie ISO 19114 (ISO 2002b)
Nadmiar danych spowodowany np. podwójną digitalizacją nazywany bywa przeładowaniem. Kompletność wyrażana jest najczęściej w procentach. Spójność logiczna dotyczy wzajemnej zgodności między danymi zgromadzonymi w bazie a wartościami zdefiniowanymi w modelu danych. Spójność może odnosić się do semantyki (zasad zdefiniowanych w schemacie pojęciowym), dziedziny (przynależności wartości do uprzednio zdefiniowanej dziedziny), topologii (zgodności z zasadami topologicznymi) i formatu. Dokładność położenia może być określana w sposób bezwzględny poprzez podanie błędu położenia, w sposób względny lub też w stosunku do siatki. Dokładność czasu odnosi się do dokładności pomiaru czasu, aktualności oraz spójności danych dotyczących czasu (np. zachowanie sekwencji zdarzeń). Dokładność tematyczna dotyczy atrybutów danych ilościowych, jakościowych i poprawności klasyfikacji.
3.1 Dokładność położenia
Pod terminem dokładność położenia rozumie się dokładność określania współrzędnych punktów lub lokalizacji piksela w przypadku danych rastrowych. Dokładność oznacza bliskość wartości odniesienia, niekiedy przyjmowanej za prawdziwą. Dokładność położenia określa się poprzez podanie wielkości błędu, czyli różnicy pomiędzy daną wartością a odpowiadającą jej wartością odniesienia. Najczęściej jako miarę dokładności przejmujemy błąd średni kwadratowy. Dla prawdziwej wartości odniesienia błąd ten wyraża się wzorem (1):
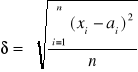
(1)
gdzie: δ - błąd rzeczywisty, xi - wartość obserwowana,
a - wartość rzeczywista, n - liczba obserwacji.
Najczęściej wartość rzeczywista jest nieznana i wówczas posługujemy się błędem średnim, który definiowany jest jako różnica pomiędzy wartością zmierzoną a wartością oczekiwaną i dla n obserwacji wyraża się wzorem (2):
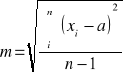
(2)
gdzie: m - błąd średni
xi - wartość obserwowana
a - wartość oczekiwana
n - liczba obserwacji
Jeśli mamy do czynienia z wartościami niejednakowo dokładnymi, to przy obliczaniu błędu musimy uwzględnić wagi p charakteryzujące dokładności poszczególnych wartości. Wzór na błąd średni przyjmuje wówczas postać (3):
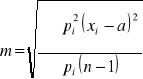
(3)
Prawdopodobieństwo pojawienia się błędu średniego w przedziale [-m, +m] jest równe polu zawartemu pod krzywą Gaussa o odciętych -mi +mi wynosi 0.683, w przedziale
[ -2m, +2m] wynosi 0.956 i w przedziale [-3m, +3m] wynosi 0.997. Trzykrotny błąd średni nazywany jest błędem granicznym.
W zagadnieniach pomiarowych często używamy błędu względnego. Błąd względny jest to ułamek, w którego liczniku znajduje się absolutna wartość błędu popełnionego przy pomiarze, a w mianowniku wartość wielkości mierzonej. Dla wygody wartość licznika ułamka sprowadzamy do jedności. Np. jeśli pomierzono odcinek o długości 150 m i popełniono przy tym pomiarze błąd 5 cm, to błąd względny tego pomiaru wynosi:
![]()
.
Do najważniejszych zalet błędu względnego Leśniok (1979) zalicza: prostotę i szybkość wyznaczania oraz możność porównania dokładności różnych wartości.
Dokładność położenia obiektów zapisana w bazie danych systemu informacji geograficznej jest ściśle uzależniona od dokładności materiałów źródłowych. Dane pozyskiwane w wyniku digitalizacji map charakteryzuj ą się zwykle niższą dokładnością niż sama mapa, ponieważ w wyniku digitalizacji wprowadzamy dodatkowe błędy. W przypadku map topograficznych średni błąd położenia szczegółów sytuacyjnych nie powinien przekraczać 0,6 mm w skali mapy. Dokładność położenia obiektu na mapie zarówno w postaci analogowej, jak i numerycznej związana jest ze skalą mapy (0,6 mm w skali mapy w przypadku mapy w skali 1:1000 to 0,6 m w terenie; 1:10000 - 6 m; a 1:100000 - 60 m). Dla opracowań wielkoskalowych wymagania dokładnościowe dotyczące położenia obiektów są wyższe niż dla średnio i małoskalowych. Należy pamiętać, że powiększenie obrazu bazy na ekranie monitora nie zwiększa dokładności wyświetlanych danych.
3.2 Dokładność tematyczna
Dokładność tematyczna danych geograficznych określana jest przez liczbę atrybutów i dokładność określenia ich wartości. W zależności od tego, czy dane mają charakter ilościowy czy jakościowy, inaczej będziemy określać ich dokładność. Znacznie łatwiej określić dokładność danych ilościowych o wartościach wyrażanych w skali interwałowej lub bezwzględnej, np. szerokość drogi podawana jest z dokładnością l m, temperatura powietrza z dokładnością 1°C. W przypadku danych jakościowych ocena dokładności jest trudna i złożona, albowiem składa się na nią wiele elementów. Baza danych geograficznych stanowi model wycinka rzeczywistości. Model ten opisuje wybrane zagadnienia z pewnym przybliżeniem. Dokładność tego opisu zależy od wielu czynników takich jak: przyjęty stopień szczegółowości danych, klasyfikacja obiektów, dopuszczalna w projekcie swoboda interpretacji danych w aspekcie przestrzennym i tematycznym, błędy operatorskie popełnione przy identyfikacji i wprowadzaniu obiektów itp. Czynniki wpływające na zmniejszenie dokładności danych nie mogą być całkowicie wyeliminowane, a jedynie ograniczone do określonego poziomu przez stosowanie ustalonych procedur kontrolnych stosowanych w trakcie tworzenia bazy. Najczęściej dokładność danych jakościowych, będących wynikiem interpretacji (klasyfikacji) ocenia się przez porównanie wyników klasyfikacji z danymi pochodzącymi z innych źródeł przyjętych jako dane referencyjne. Wobec braku danych referencyjnych dopuszcza się powtórną interpretację tego samego obszaru. Wyniki klasyfikacji porównuje się z danymi referencyjnymi i rezultat przedstawia w macierzy przejść. W kolumnach macierzy (tab. 1) zapisujemy wyniki (np. powierzchnie, liczby obiektów) otrzymane na podstawie zbioru referencyjnego, a w wierszach wartości otrzymane w procesie klasyfikacji. Na głównej przekątnej znajdują się tylko wartości reprezentujące pokrywające się (zgodne) wydzielenia. Jeśli zbiór danych byłby bezbłędny, to w tabeli przejść pojawiłyby się tylko wartości na głównej przekątnej. Wszystkie pozostałe wielkości świadczą o błędach, opuszczeniu lub wprowadzeniu nadmiernej liczby obiektów.
Poprawność klasyfikacji zbioru geodanych określa się poprzez obliczenie procentowego udziału sumy obiektów (lub ich powierzchni) zapisanych w zbiorze do całkowitej liczby obiektów. Macierz przejść pozwala także na określenie tzw. dokładności producenta i użytkownika dla poszczególnych klas. Dokładność producenta, obliczana jako stosunek obiektów prawidłowo przypisanych do danej klasy do wszystkich obiektów występujących w tej klasie, mówi nam o tym, jak dokładnie świat rzeczywisty został zapisany w systemie GIS i jakie jest prawdopodobieństwo faktu, że obiekt rzeczywisty nie został zarejestrowany w bazie danych. Dokładność użytkownika obliczamy poprzez podzielenie liczby obiektów prawidłowo przypisanych
Tabela 1. Macierz przejść
Dane referencyjne
|
Zabudowa
|
Grunty rolne |
Lasy
|
Woda
|
Suma
|
Dokładność użytkownika |
Zabudowa
|
68
|
7 |
3
|
0
|
78
|
87.2%
|
Grunty rolne |
12 |
112 |
15 |
10 |
149 |
75.2% |
Lasy
|
3
|
9
|
89
|
0
|
101
|
88.1%
|
Woda
|
0
|
2
|
5
|
56
|
63
|
88.9%
|
Suma
|
83
|
130
|
112
|
66
|
391
|
|
Dokładność producenta |
81.9% |
86.2% |
79.5% |
84.8% |
|
|
Dokładność całkowita
|
84%
|
|
||||
do danej klasy do wszystkich obiektów przypisanych do tej klasy. Wielkość ta wyraża wiarygodność bazy informując jednocześnie o tym, ile obiektów o innej charakterystyce zostało błędnie przypisanych do danej klasy.
Często do oceny poprawności klasyfikacji stosuje się współczynnik zgodności ![]()
(kappa) (Cohena). Współczynnik ten jest miarą zgodności pomiędzy atrybutami dwóch różnych zbiorów danych i wyraża względne odchylenie zaistniałych zmian. Jest on szeroko wykorzystywany do oceny dokładności klasyfikacji treści obrazów satelitarnych. Dokładność klasyfikacji określa się poprzez porównanie zgodności wyniku klasyfikacji obrazu ze zbiorem referencyjnym, traktowanym jako wolny od błędów. Zbiór referencyjny mogą stanowić mapy, pomiary terenowe lub inne niezależnie przeprowadzone klasyfikacje. W celu obliczenia wartości współczynnika ![]()
(kappa) należy przedstawić wyniki klasyfikacji i danych referencyjnych w postaci macierzy przejść, obliczyć zgodność obserwowaną (po) i zgodność oczekiwaną (pc). Współczynnik zgodności kappa oblicza się ze wzoru (4):
![]()
(4)
gdzie:
po oznacza zgodność obserwowaną,
pc - zgodność oczekiwaną.
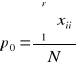
(5)
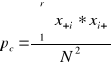
(6)
N - liczba obserwacji
r - liczba wierszy i kolumn w macierzy przejść,
xii - wartość zapisana w kolumnie i oraz wierszu i,
x+i- suma wartości w wierszu i
x i+ - suma wartości w kolumnie i
Dla wartości zapisanych w tabeli 1 zgodność obserwowana wynosi po = 0.831, zgodność oczekiwana pc = 0.27, a wartość współczynnika k = 0.768.
Z dokładnością często mylona jest precyzja. Precyzja dotyczy zapisu danych, czyli liczby znaków zapisanych w komputerze. Należy pamiętać, że nawet dane niedokładne mogą być zapisane z dużą precyzją. Jeśli odbiornik GPS pozwala na zmierzenie współrzędnych punktów z dokładnością 10 m, to zapisanie tych współrzędnych w komputerze z precyzją l mm nie zwiększy dokładności danych. W takim przypadku o dokładności świadczą tylko cyfry znaczące, czyli w powyższym przypadku są to cyfry dziesiątek.
Często wśród użytkowników GIS spotyka się opinię, że dane zapisane w postaci numerycznej są dokładniejsze niż dane zapisane w formie analogowej (np. na mapie papierowej). Wynika to z większej precyzji zapisu danych związanej z cyfrowym przetwarzaniem, przez wielu mylonych z dokładnością. Dokładność danych przechowywanych w bazach danych geograficznych zależy przede wszystkim od dokładności danych wejściowych oraz od wykonanych przetworzeń.
3.3 Szczegółowość
Szczegółowość określa, jaki najmniejszy lub najniższy w hierarchii obiekt jest zapisany w bazie, np. szczegółowość bazy o drogach określa droga najniższej kategorii, może to być droga gminna, lokalna, a w przypadku baz bardzo szczegółowych nawet ścieżka. W odniesieniu do danych zapisanych w postaci rastrowej zamiast terminu szczegółowość używamy określania rozdzielczość przestrzenna. Rozdzielczość przestrzenna wyrażana wielkością piksela (komórki rastra) określa najmniejszy rozróżnialny obiekt w bazie. Jeśli rozdzielczość obrazu rastrowego wynosi 10 m, to wszystkie obiekty terenowe o rozmiarach mniejszych niż 10 m nie zostaną zapisane w bazie.
Szczegółowość z reguły związana jest z dokładnością. Bazy o dużej dokładności najczęściej są bardzo szczegółowe, co oznacza, że przechowywane jest w nich dużo małych obiektów o dokładnie określonych granicach. Wraz ze zmniejszaniem się dokładności spada zazwyczaj szczegółowość bazy danych, liczba obiektów zostaje zmniejszona, a ich granice prowadzone są z mniejszą dokładnością. Proces zmniejszania szczegółowości bazy nosi nazwę generalizacji.
3.4 Aktualność
Bardzo istotną informacją z punktu widzenia jakości danych geograficznych jest aktualność danych, czyli ich zgodność ze stanem faktycznym. Zmiany zawartości bazy danych geograficznych są ściśle związane z ciągłymi zmianami zachodzącymi w terenie, a wynikającymi najczęściej z budowy nowych dróg, osiedli, zakładów przemysłowych lub ich likwidacji, regulacji wód, zmian charakteru użytków rolnych itd. Nowe obiekty w terenie zmieniają zasadniczo zawartość bazy danych geograficznych i im szybciej zachodzą zmiany, tym szybciej „starzeją" się bazy danych. Innymi czynnikami wpływającymi na dezaktualizację geodanych są zmiany nazewnictwa lub granic administracyjnych.
Zakres treści bazy jest związany z jej szczegółowością i dokładnością, a więc i szybkość „starzenia" się bazy ma związek z jej szczegółowością i dokładnością. Starzenie się bazy danych geograficznych następuje tym szybciej, im większa jest jej szczegółowość i dokładność. Według Dzikiewicza (1971) największym zmianom ulegają tereny zabudowane, drogi i użytkowanie gruntów. Osiedla i obiekty przemysłowe są rozbudowywane. Przy przejmowaniu gruntów pod użytkowanie przemysłowe lub w przypadku powstawania nowych zbiorników wodnych ulegają likwidacji miejscowości. Drogi są ulepszane, zatem zmieniają swoją kategorię, budowane są nowe drogi, niektóre szlaki komunikacyjne jak stare linie kolejowe ulegają likwidacji. Zmianom ulega również rodzaj użytkowania gruntów: wycinane są lasy, a tereny przeznaczone są do wykorzystania rolniczego lub pod budowę osiedli i dróg, w innych miejscach następują dolesienia; w lesie ulega często zmianie podział gospodarczy i gatunek drzewostanu; łąki zmieniają swój zasięg, często są osuszane i zamieniane na pola uprawne. Koryta większych rzek zmieniają przy regulacji swój bieg, na terenach podmokłych powstaje sieć rowów melioracyjnych. Formy terenu zasadniczo nie ulegają zmianom, zachodzą jednak rzadkie przypadki zmian, np. przy eksploatacji złóż mineralnych (kopalnie odkrywkowe), gdy powstają wysokie hałdy lub głębokie wykopy oraz przy rozległych budowach dróg i kolei, gdy teren ulega wyrównaniu.
Aktualizacja oznacza zespół czynności mających na celu doprowadzenie bazy danych geograficznych do zgodności ze stanem w terenie. Aktualizacja polega na wprowadzeniu do bazy nowych obiektów i/lub ich atrybutów lub usunięciu z bazy obiektów już nie istniejących w świecie rzeczywistym. Obiekty nieaktualne powinny być zapisywane automatycznie w „historii" bazy danych.
Aktualizację bazy danych geograficznych wykonuje się na podstawie danych zawartych w urzędowych bazach krajowego systemu informacji o terenie, materiałów kartograficznych (mapa topograficzna w skali 1:10000), materiałów fotogrametrycznych (zdjęcia lotnicze, zdjęcia satelitarne), danych geodezyjnych (np. mapy zasadniczej, ewidencji gruntów i budynków, ewidencji sieci uzbrojenia terenu), danych statystycznych i innych materiałów opisowych oraz wyników uzyskanych z wywiadów terenowych i pomiarów uzupełniających. Do aktualizacji mogą być wykorzystane pomiary terenowe oraz takie materiały pomocnicze jak mapy tematyczne, dane statystyczne, plany miast, informatory turystyczne i inne.
Aktualizacja może być przeprowadzana na bieżąco lub okresowo. Aktualizacja bieżąca polega na wprowadzaniu zmian tuż po ich powstaniu, natomiast aktualizacja okresowa - na wprowadzeniu zmian i uzupełnień do bazy danych w ustalonych odstępach czasu. W wielu systemach dane aktualizowane są na bieżąco (np. ewidencja gruntów i budynków lub ewidencja sieci uzbrojenia technicznego terenu) lub raz w roku (np. rejestr TERYT, Państwowy Rejestr Granic), chociaż spotyka się również systemy, w których aktualizacja odbywa się w cyklu pięcio- lub dziesięcioletnim (np. Baza Danych Ogólnogeograficznych, baza CORINE Land Cover).
Rodzaj aktualizacji bazy danych geograficznych oraz jej częstotliwość w przypadku aktualizacji okresowej uzależnia się od szczegółowości danych oraz tempa zmian zachodzących w terenie i potrzeb gospodarczych danego regionu.. Według instrukcji GUGiK (2001) dla terenów o wysokim stopniu zainwestowania (aglomeracje miejskie, tereny przemysłowe itp.) przewiduje się pięcioletni okres aktualizacji, a dla terenów rolnych i leśnych dziesięcioletni. Okresy te w zależności od występujących potrzeb mogą ulec przedłużeniu lub skróceniu.
3.5 Wiarygodność
Wiarygodność danych geograficznych oznacza zgodność pomiędzy stanem faktycznym a daną reprezentującą ten stan w systemie, innymi słowy jest to stopień zaufania do informacji, jaką możemy uzyskać z systemu. Wiarygodność odnosi się do produktu końcowego i wyrażana jest najczęściej w procentach.
Za najbardziej wiarygodne dane geograficzne uważa się dane otrzymane w wyniku pomiarów terenowych oraz dane pochodzące z urzędowych rejestrów, ewidencji i baz danych, następnie dane otrzymane z map. Informacja pozyskiwana z map została wcześniej przetworzona i zredagowana. Z jednej strony obarczona jest pewnymi ograniczeniami, z drugiej zaś przystosowana do łatwej percepcji. Najbardziej zmienna jest wiarygodność danych interpretowanych, pozyskiwanych między innymi ze zdjęć lotniczych lub obrazów satelitarnych. W tym przypadku stopień wiarygodności zależy od zakresu tematycznego bazy, materiałów źródłowych oraz przyjętej technologii pozyskiwania danych. Oczywiście im mniejsza szczegółowość i dokładność pozyskiwanych danych, tym większa ich wiarygodność.
Załóżmy, że tworzymy bazę danych o pokryciu terenu w Polsce. Materiał źródłowy stanowią wielospektralne obrazy satelitarne o rozdzielczości przestrzennej 30 m. W bazie znajdują się obiekty o minimalnej powierzchni 25 ha zaklasyfikowane do jednej z czterech kategorii: tereny zabudowane, tereny rolnicze, lasy, wody. Poprawność takiej klasyfikacji będzie bardzo wysoka, ponieważ wydzielenie na obrazie satelitarnym wieloboków o minimalnej powierzchni 25 ha i przypisanie im powyższych kategorii nie sprawia trudności. Prawdopodobieństwo popełnienia błędów przy klasyfikacji, w tym błędów o charakterze systematycznym jest niewielkie, stąd poprawność klasyfikacji może wynosić 98%. Zatem i wiarygodność tej bazy jest wysoka. Gdybyśmy, dysponując tymi samymi materiałami, chcieli zwiększyć zakres tematyczny bazy danych i podzielić tereny zabudowane na mieszkalne, przemysłowe i handlowe, tereny rolne na użytki orne, łąki i sady, lasy na iglaste, liściaste i mieszane, to zdecydowanie wzrosłaby trudność interpretacji poszczególnych kategorii. Wzrosłaby tym samym liczba popełnianych błędów i zmalałaby poprawność klasyfikacji. Tak rozbudowana klasyfikacja pozwala na uzyskanie poprawności najwyżej 85%. Co oznacza, że na każde 100 zweryfikowanych punktów w co najmniej 85 przypadkach kategoria pokrycia terenu zapisana w bazie danych zgadza się z rzeczywistym pokryciem terenu. Wiarygodność tego zbioru jest wobec tego mniejsza.
4. Rozprzestrzenianie się błędów
W trakcie wykonywania obliczeń matematycznych i operacji przestrzennych błędy, jakim obarczone są dane wejściowe, przenoszą się na wyniki przetworzeń. Błąd pomiaru współrzędnych x, y, z punktu wpływa na dokładność jego lokalizacji. Idąc dalej, ma wpływ na dokładność określenia wysokości w numerycznym modelu powierzchni terenu (NMT) oraz na dokładność wszystkich analiz, dla których danymi wejściowymi jest NMT takich, jak: analiza widoczności terenu, określenie nachylenia i ekspozycji stoków.
Rozprzestrzenianie się błędów dotyczy wszystkich operacji przestrzennych, w tym transformacji, interpolacji, generalizacji, klasyfikacji, analiz typu over-lay. Błędy w danych wejściowych powodują, że w wyniku otrzymujemy zbędne obiekty lub niedokładne wartości atrybutów. Do zbędnych obiektów należą tzw. slivery, czyli poligony szczątkowe. Slivery powstają w wyniku nakładania warstw tematycznych, w których przechowywane są obiekty mające w terenie wspólną granicę, np. granica obiektu z warstwy A jest jednocześnie granicą obiektu z warstwy B. Jeśli w bazie danych geograficznych w obu warstwach granica ta jest zdefiniowana przez zbiór punktów o różnych współrzędnych w warstwie A i B, to w wyniku analiz typu overlay powstaną poligony szczątkowe. Podany przykład został zilustrowany na rysunku 3.
Poligony szczątkowe (silvery)
Rysunek 3. Poligony szczątkowe (silvery)
Błąd, jakim obarczony jest wynik analiz, można wyznaczyć na podstawie prawa przenoszenia się błędów średnich Gaussa. Dla zmiennych niezależnych (l1, l2,...,ln) określonych odpowiednio z błędami mi, m2, mn błąd funkcji F(l1,l2,...,ln) możemy określić według wzoru:
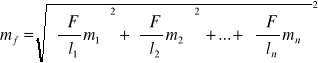
(7)
![]()
Błąd średni funkcji obserwacji m jest równy pierwiastkowi z sumy kwadratów pochodnych cząstkowych pomnożonych przez odpowiadające im średnie błędy zmiennych niezależnych. W twierdzeniu tym przyjęto założenie, że funkcja F jest aproksymowana w punkcie szeregami Taylora, z których dla obliczeń bierzemy tylko pierwszy wyraz przyjmując założenie, że następne są zbyt małe.
W celu zminimalizowania liczby błędów w danych geograficznych należy wykorzystywać tylko dane udokumentowane i pochodzące ze znanych źródeł.
Słownik
topologia (topo- + gr. lógos `nauka') mat. dział badający te własności figur, które nie ulegają zmianom przy różnego rodzaju przekształceniach, np. przy wyginaniu lub kurczeniu się.
Topologia, dział matematyki badający własności zbiorów punktów nie ulegających zmianom w przekształceniach będących
. Z punktu widzenia topologii zbiory, które można przekształcić w siebie za pomocą homeomorfizmu, są sobie równoważne (np. okrąg i kwadrat, ale nie dwa kwadraty i prostokąt).
8
ISO 19114
ISO 19113
ISO 19138
określenie zgodności
ustalenie wyniku oceny
jakości danych
wybór i zastosowanie metody oceny jakości
zakładany poziom
jakości danych
identyfikacja potrzeb informacyjnych elementy, podelementy, zakresy
raport wyniku oceny jakości
(elementy jakości o charakterze ilościowym)
raport wyniku porównania
jakości zakładanej
z jakością uzyskaną
Wyszukiwarka
Podobne podstrony:
Odwzorowanie elementow powierzchni elipsoidy, AGH, II ROK, Kartografia I
Interpretacje pojęcia kartografii, AGH, II ROK, Kartografia I
Hodograf, AGH, II ROK, Kartografia I
wyróżniki jakości całe, dietetyka II rok, analiza i ocena jakości żywności
test bdanych, AGH, II ROK, Bazy Danych
2. WODA W PRZYRODZIE - OCENA JAKOŚCI, Budownictwo, chemia, II semestr
budiwnictwo, AGH, II ROK, Budownictwo i Inżynieria
STAT.KONTR.JAKOŚCI, Mechatronika AGH IMIR, rok 2, Metrologia sprawozdania, inncyh
7Wyznaczanie stałej dodawania dalmierza elektrooptycznego, AGH, II ROK, ETP
ekspertyza, AGH, II ROK, Podstawy Prawa
1 Ćwiczenia, AGH, II rok, Hydrogeologia, Hydrogeologia
ETP zaliczenie, AGH, II ROK, ETP
Tematy seminariów z Analizy i oceny jakości żywności Dietetyka II rok, Dietetyka 2 Rok, Analiza
OWI, AGH, II ROK, I SEMESTR
więcej podobnych podstron