Co oznacza termin dystrybuanta. Narysuj dystrybuantę rozkładu normalnego wystandaryzowanego.
Dystrybuantą zmiennej losowej X nazywamy funkcję F(x) określoną na zbiorze liczb rzeczywistych jako:
F(x) = P.(X ≤ x)
Z definicji tej wynika, że zmienna losowa X przyjmuje wartość nie większą od wartości argumentu. ( Dystrybuanta w punkcie x, to prawdopodobieństwo, że zmienna losowa przyjmie wartości mniejsze bądź równe x)
Jaka jest definicja i własność standaryzacji.
Definicja standaryzacji mówi, że jeśli mamy zmienną X to żeby jakikolwiek jej pomiar wystandaryzować należy odjąć od tego pomiaru średnią i podzielić przez odchylenie standardowe, tzn. ile odchyleń standardowych mieści się w różnicy ![]()
.
Wynik ten może być dodatni lub ujemny. Znak pokazuje nam czy wynik ten leży poniżej, czy powyżej średniej, zatem ![]()
to nie tylko liczba odchyleń standardowych od średniej, ale także kierunek odchylenia (większy lub mniejszy od średniej)
Własności standaryzacji:
Z własności miar rozproszenia wynika, że skoro odchylnie standardowe zmiennej X równe jest s, to odchylenie standardowe zmiennej X - x (X minus stała) równe jest także s.
Z postaci wzoru bezpośrednio wynika, że średnia arytmetyczna zmiennej z równa jest 0.
Wyniki standardowe stosuje się w celu porównania pomiarów otrzymywanych po użyciu różnych procedur n tego samego badanego, bądź badanych między sobą.
Dlaczego odchylenie standardowe statystyki nazywa się błędem standardowym.
Odchylenie standardowe statystyki nazywa się błędem standardowym, ponieważ błąd standardowy jest właśnie odchyleniem standardowym rozkładu z próby tej statystyki. Jest to błąd mierzący stopień zmienności statystyki.
Ile wynosi błąd standardowy średniej arytmetycznej i dla czego.
Błąd standardowy średniej arytmetycznej równy jest odchyleniu standardowemu tej średniej w rozkładzie z próby. Na podstawie centralnego twierdzenia granicznego, można stwierdzić, że rozkład średniej próby x dąży do rozkładu normalnego ze średnią μ i wariancją δ![]()
/n. Jeśli zatem wariancja średniej arytmetycznej w rozkładzie z próby równa się δ![]()
/n, a odchylenie standardowe średniej arytmetycznej w rozkładzie z próby równa się![]()
Oblicz prawdopodobieństwo zrealizowania się wartości zmiennej losowej o rozkładzie normalnym z przedziału <μ;μ+25>
P.(x1≤ x ≤ x ) = φ (z2) - φ (z1) = φ(z) - φ(o) - 0,9772-0,5 = 0,4772
x1 = μ → z1 = μ - μ![]()
x2 = μ + 25 →![]()
Estymuj przedziałowo μ, gdy x = 40; s=5; n=225
P.![]()
P.(40- 1,96![]()
P. (39,354 ≤ μ ≤ 40,646) = 0,95
Narysuj rozkład t-studenta i podaj jego definicję.
Rozkłady pola t - Studenta zmiennej t są to spłaszczone rozkłady normalne po wystandaryzowaniu. Spłaszczenie jest tym większe im mniejsza wartość próby.
ile znasz błędów wnioskowania. jakie jest ich źródło. jak od siebie zależą.
I° - polega na odrzuceniu hipotezy H0, będącej przypuszczeniem prawdopodobnym. Jest to błąd I rodzaju, równy wielkością poziomowi istotności α. Wywodzi się z probabilistycznego charakteru teorii. Ponieważ badań dokonujemy na poziomie próby, musimy przyjąć jakąś wielkość błędu o jaką zakładamy, że możemy się pomylić. Jest on więc wyznaczany subiektywnie przez badacza.
II° - polega na nie odrzuceniu hipotezy H0, będącej przypuszczeniem fałszywym. Jest to błąd II rodzaje, jest wielkością β. Wywodzi się z czysto logicznego błędu wnioskowania. Prawdopodobieństwo popełnienia tego błędu jest większe, w przypadku małych prób. Zależność między tymi błędami polega na tym, że jeśli będziemy chcieli zmniejszyć błąd α, to zwiększymy tym samym błąd β. Jedynym sposobem zmniejszenia jednocześnie obu tych błędów, jest zwiększenie liczebności prób. Również postawienie hipotezy H1 ,w formie kierunkowej, a idący za tym sposób testowania jej testem jednostronnym, zmniejsza błąd β.
Co to jest obszar krytyczny testu.
Obszar krytyczny (w kolejnych rozkładach z próby) jest to przedział wartości tej statystyki odpowiadający poziomowi istotności.
Co to jest test statystyczny.
Test statystyczny jest to sposób sprawdzający, weryfikujący hipotezę zerową. Jest zdeterminowany postacią hipotezy alternatywnej.
JAKI JEST STATUS HIPOTEZY ZEROWEJ WE WNIOSKOWANIU STATYSTYCZNYM I JAKA JEST JEJ DEFINICJA. (dopisać def.)
Hipoteza zerowa jest weryfikowana przy założonej decyzji odnośnie postępowania po jej ewentualnym odrzuceniu. Sposób sprawdzania hipotezy zbiorowej jest zdetrminowany przez postać hipotezy alternatywnej. Hipotezę zerową weryfikuje się testem statystycznym dwustronnym lub jednostronnym. Hipotezę zerową można przyjąć lub odrzucić z określonym p.-em.
Przedstaw schemat wnioskowania statystycznego.
Procedury wnioskowania statystycznego wprowadzają porządek do wszelkich naszych prób wyciągania wniosków, które wykraczają poza obserwacje dokonywane na poszczególnych próbkach.
Pytania na jakie można odpowiedzieć dzięki wnioskowaniu statystycznemu:
czy uzyskana próbka wyników jest rzeczywiście reprezentatywna dla pewnej okreslonej populacji
czy otrzymana różnica między średnimi różnych próbek jest dostatecznie duża, aby móc wyciągnąć wniosek, że próbki te są prawdopodobnie pobrane z różnych populacji
czy zróżnicowanie wyników między grupami, które podano różnym oddziaływaniom eksperymentalnym, jest większe niż rozrzut wyników w obrębie każdej z tych grup.
Z jaką pewnością przyjmuje się hipotezę zerową. Podaj definicję hipotez rozważanych w trakcie wnioskowania.
Hipotezę zerowa przyjmuje się z pewnością 1 - alfa, np. jeżeli zakładamy, że alfa = 0,05, to hipotezę zerową przyjmujemy z pewnościa 0,95.
W trakcie wnioskownia rozważamy hipotezy: zerową, alternatywną; różnościowe bądź kierunkowe.
Hipoteza różnościowa ma postać : μ1: μ1 ≠ μ2 i mówi o różnym μ1 i μ2.
Hipoteza kierunkowa ma postać μ1 : μ1 > μ2 i mówi, że μ1 jest większe od μ2.
Jakie znasz skale pomiarowe.
Skala stosunkowa (ilorazowa) - stanowi najwyższy poziom pomiaru. Skala ta posiada wszelkie właściwości niżej wymienionych skal , i tę właściwość, że jej początkiem jest zero bezwzględne.
Skala przedziałowa - zwana także interwałową posiada wszystkie właściwości skal nominalnych i porządkowych, a ponadto i tę iż ma równe jednostki. Oznacza to, że jednostkowe różnice wyników reprezentują równej wielkości różnice tej cechy, którą mierzymy. Przedziały są równe na całej skali.
Skala porządkowa - pomiar na tej skali nie tylko odróżnia daną osobę od pozostałych, lecz także mówi nam, czy dana osoba posiada mierzoną cechę w większym lub mniejszym stopniu.
Skala nominalna - jest najniższym poziomem pomiaru. Liczby stosuje się tu tylko dla odróżnienia jednej osoby lub grupy od innej.Liczby te nie reprezentują ilości czegokolwiek.Istotą pomiaru na skali nominalnej jest klasyfikacja jakościowa.
Co oznacza termin „rozkład z próby statystycznej”.
Rozkład z próby statystyki jest to rozkład prawdopodobieństwa estymatora tej statystyki, opisujący zmienność statystyki w zbiorze powtarzanych prób.
Ile stopni swobody ma wariancja i dlaczego.
Wariancja ma n-1 stopnia swobody: ![]()
Spośród n odchyleń podniesionych do kwadratu, tylko n-1 może się swobodnie zmieniać. Wariancja ma n-1 stopni swobody.
![]()
Spośród n odchyleń podniesionych do kwadratu, tylko n-1 może się swobodnie zmieniać, dzięki dzieleniu przez n-1, a nie przez n. Estymator δ![]()
nie jest obciążony, tzn. nie wykazuje systematycznej jedynki do tego by być większym bądź mniejszym niż δ![]()
.
Podaj definicję kwartyli. Jaki jest związek mediany z kwartylami.
Kwartyle - jednostki dzielące liczbę osób na 4 równo liczące grupy, każda po 25% ogólnej liczb osób. Mediana to 2 kwartyl?
Narysuj wystandaryzowany rozkład normalny i wypisz jego własności.
Na odcinku 2 odchyleń powierzchnia pola zajmuje 95,5% całej powierzchni pola, a na odcinku 3 odchyleń 99,7% powierzchni całego pola. α=0, δ2=1
Co znaczy termin wartość krytyczna testu statystycznego.
Wartość krytyczna testu statystycznego stanowi granica przedziału ufności:
![]()
Jak jest definicja statystyki t-studenta i przy jakich założeniach można ją stosować.
![]()
zmienna x musi być przynajmniej ze skali przedziałowej;
xn(α, δ2); próba losowa n-elementowa; α - określone prawoskośnie H0:μ=μ0 H1:μ≠μ0
Jaką interpretacje mają wartości znanych statystyk t-studenta.
Gdy |t|>tαf ⇒ H0- hipotezę zerową odrzucamy z prawem 1-α, przyjmując alternatywną.
Gdy |t|<tαf ⇒ H0+ nie ma podstaw do odrzucenia hipotezy zerowej. f=n-1
NARYSUJ ROZKŁAD STATYSTYKI F-FISHERA I PODAJ JEJ DEFINICJĘ.
Służy on do badania homogeniczności wariancji. Aby go zastosować, musimy mieć dwie próby losowe, niezależne.
F= ≈ ≥ 1
s1 2 - wariancja większa ze stopniami swobody f1 = n1 - 1
s22 - wariancja mniejsza ze stopniami swobody f 2 = n2 - 1
F > Fα, f1, f2 ⇒ H0-
F ≤ Fα, f1, f2 ⇒ H0+
postaw hipotezy stosowane przy weryfikowaniu homogeniczności wariancji dwu populacji. czy mogą mieć postać alternatywną.
H0 : δ12 = δ2 2=δ
H1 : δ12 > δ2 2
H1 zawsze musi mieć taką postać.
kiedy w próbkach mówi się „próby niezależne”, a kiedy „próby zależne”. czy rozróżnienie to wpływa na sposób testowania hipotezy zerowej.
Próby niezależne stanowią dwa rozłączne zbiory osób (w skład jednej próby wchodzą inne osoby niż do drugiej próby). Jedne pomiar nie może wpływać na drugi.
Próby zależne są to próby losowe z jednego zbioru osób (osoby te, mogą powtarzać się w jednej i w drugiej próbie). Jeden pomiar wpływa na drugi.
Rozróżnienie to wpływa na sposób testowania hipotezy zerowej.
POUKŁADAĆ TE WZORY
Próby niezależne. Postać statystyki testu t =
H0 : μ1 = μ2
H1 : μ1 ≠ μ2
Próby zależne. Postać statystyki testu t = ⋅ √n
H0 : μ1 = μ2
H1 : μ1 - μ2
D- różnica z populacji
Czy lepiej jest stosować test jednostronny czy dwustronny. Wyjaśnij na rysunku.
t alfa
t alfa'
t alfa'<t alfa→ granica przedziału ufności dla testu jednostronnego jest mniejsza niż granica przedziału ufności dla testu dwustronnego. W związku z tym jest mniejsze prawdopodobieństwo popelnienia błędu wnioskowania: II rzędu, czyli przyjęcie hipotezy fałszywej. Lepiej jest stosować test jednostronny.
Ile stopni swobody ma statystyka t-studenta przy badaniu, Czy Próba „Pochodzi Z Konkretnej Populacji”.
Statystyka t - studenta ma n-1 stopni swobody przy badaniu.
Podaj definicję znanych miar rozproszenia.
Miary rozproszenia (jak rozproszyły się na osi nasze wartości zmiennej) to rozstęp, wariancja i odchylenia standardowe. Te charakterystyki mówią nam czy próbka rozłożyła się na całej skali, czy też dostaliśmy mało wartości ze skali, ale jest dużo frekwencji.
Rozstęp - estymator tego parametru mówi na ilu jednostkach skali rozrzuciły się wartości zmiennej.
Wariancja - to przeciętna kwadratowa odległość wszystkich pomiarów od średniej arytmetycznej.
Odchylenia standardowe - przeciętna odległość pomiarów od średniej arytmetycznej.
Przytocz i wyjaśnij centralnie twierdzenie graniczne i wniosek z tego twierdzenia.
Centralne twierdzenie graniczne - mówi nam o zbieżności sumy niezależnych zmiennych losowych do rozkładu normalnego. Jeżeli z populacji w której zmienna losowa X ma dowolny rozkład prawdopodobieństwa ze średnią μ i wariancją δ![]()
losujemy kolejno próby losowe o coraz większej liczbie elementów n, to wraz ze wzrostem liczby losowań rozkład estymatora μ, czyli rozkład średniej z próby,![]()
dąży do rozkładu normalnego ze średnią równą μ i wariancją δ![]()
/n
Podaj podstawową własność średniej arytmetycznej. Która z miar: średni arytmetyczna, czy mediana jest „bardziej czuła” pomiary leżące daleko względem pozostałych.
Średnia arytmetyczna jest punktem równowagi odległości wszystkich pomiarów mniejszych od średniej i wszystkich większych.
![]()
(suma odchyleń wszystkich pomiarów od średniej arytmetycznej równa jest zero).
NA POMIARY LEŻĄCE DALEKO WZGLĘDEM POZOSTAŁYCH JEST BARDZIEJ CZUŁA ...............
WYMIEŃ ZAŁOŻENIA NIEZBĘDNE DO UŻYCIA METODY T-STUDENTA PRZY TESTOWANIU HIPOTEZY O RÓWNOŚCI ŚREDNICH DWU POPULACJI NIEZALEŻNYCH.
Od ilu elementów próbę nazywa się „dużą” i dlaczego.
Próbę nazywa się dużą od 130 elementów, ponieważ przy n = 130 rozkład
t - Studenta zbliża się do wystandaryzowanego rozkładu normalnego N (0,1)
Ile stopni swobody ma test t-Studenta dla dwu populacji niezależnych i dlaczego?
Test t-studenta dla dwu populacji niezależnych ilość stopni swobody wynosi: f = n1+n2-2
Uzasadnienie:
Zakładamy:
zmienna X mierzalna (skala przynajmniej przedziałowa)
-zmienna ma rozkład normalny w 1 populacji: N(μ1, ,δ1)
zmienna ma rozkład normalny w 2 populacji: N(μ2,δ2)
2 próby losowe o liczebności n1, n2
postać statystyki t-studenta dla dwu populacji niezależnych:![]()
; (μ1-μ2)=0 , a więc 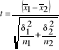
jeśli wariancje sa homogeniczne: δ12=δ22=δ(w populacji)
zatem δ2≈s2.
Gdy założenie to jest spełnione, wariancję należy oszacować tworząc estymator łączny z odchyleń dwu prób s1 i s2
![]()
![]()
, a ponieważ ![]()
![]()
zatem liczba stopni swobody dla 2 populacji niezależnych: f=n1+n2-1
Kiedy rozkład z próby statystycznej F jest bardziej smukły dla próby dużej, czy małej. Przedstaw to na rysunki.
![]()
, ponieważ δ2 ≈s2 , zatem z definicji wariancji ![]()
gdy liczebność próby jest duża to wariancja maleje, zaś gdy liczebność próby maleje to wariancja rośnie. Zatem statystyka F też maleje, a więc rozkład statystyki F jest bardziej smukły, gdy próba jest duża.
Kiedy błąd wnioskowania zależny jest od decyzji badacza.
Od decyzji badacza zależny jest błąd wnioskowania I rodzaju (α), czyli odmiana hipotezy .........
To badacz bowiem z góry ustala wielkość α
Czy jeżeli wariancje dwu populacji niezależnych są heterogeniczne, to stopnie swobody testu t-studenta rosną czy maleją względem stopni swobody testy t-studenta przy wariancji homogenicznej?
Dla wariancji heterogenicznych dla dwu prób niezależnych stopnie swobody testu t-studenta maleją względem stopni swobody przy wariancji homogenicznej.
Czy termin „statystyka” oznacza to samo co termin „estymator parametru”.
Tak.
Dlaczego używa się wyników wystandaryzowanych zamiast zwykłych pomiarów wartości zmiennych.
Wynik wystandaryzowany w odróżnieniu od zwykłych pomiarów wartości zmiennych pozwala na interpretację wyniku pojedynczej osoby w kontekście
przeciętnego wyniku grupy. Możemy powiedzieć o ile odchyleń standardowych od średniej leży wynik danej osoby.
Kiedy trzy zmienne miary tendencji centylowej rozkładu prawdopodobieństwa zmiennej są sobie równe.
Trzy znane miary tendencji centralnej: modalna, mediana i wartość oczekiwana są równe gdy I miara skośności = 0. Rozkład prawdopodobieństwa może być wtedy symetryczny.
W jakiej kolejności ustawią się mediana, średnia arytmetyczna i medialna w rozkładzie prawo skośnym, a jak w lewo skośnym.
Rozkład prawo skośny
m<me<x x
k > 0
Rozkład lewo skośny
X <me<m x
k < 0
Ile wynosi „z” gdy Φ(z)=0,975, a ile, gdy Φ(z)=0,995.
Φ(z)=0,975 z=1,96
Φ(z)=0,995 z=2,58
Narysuj rozkład normalny z duża wariancją i z małą wariancją. Jaki jest drugi parametr (poza wariancją) rozkładu normalnego.
x= 4 μ = 7 x = 10 x
Drugim parametrem rozkładu normalnego jest wartość oczekiwana μ.
Ile prób należy wylosować posługując się planem badań właściwym dla analizy wariancji jednoczynnikowej, a ile przy dwuczynnikowej (dla populacji niezależnych)
W analizie jednoczynnikowej losujemy k-prób (tyle ile jest poziomów), poziomów, w przykładzie k=4 czyli cztery poziomy
W analizie 2 czynnikowej k - poziomów czynnika A; l - poziomów czynnika B; W przykładzie: 4 poziomy czynnika 1; 5 poziomy czynnika 2.
k⋅l - ilość prób 4⋅5=20, iloczyn poziomów czynnika 1 i czynnika 2
Przedstaw założenia dwuczynnikowej analizy wariancji (dla populacji niezależnych).
Dwuczynnikowa analiza wariacji przyjmuje następujące założenia:
Y - skala przedziałowa;
próby niezależne, losowe, równoliczne;
liczba prób równa iloczynowi poziomów obydwu czynników: k⋅l;
licznik elementów wszystkich prób: n=k⋅l⋅m
Y ma rozkład normalny w całej populacji Y-N (μ,δ2) oraz w populacjach wyznaczonych przez poziomy czynników: Y~N (μi,δi2), i=1,...,k; Y~N (μj,δj2), j=1,...,l
Wariancje wszystkich rozważanych populacji są homogeniczne δ2ij=δ2i⋅δ2j=δ2
Założenia o homogeniczności należy bezwzględnie zweryfikować testem Bartletta
Przykład:
W analizie 2 czynnikowej (rys) k - poziomów czynnika A; l - poziomów czynnika B. W przykładzie: 4 poziomy czynnika 1; 5 poziomy czynnika 2.
k⋅l - ilość prób 4⋅5=20, iloczyn poziomów czynnika 1 i czynnika 2
Ile i jakiej postaci hipotezy zerowe testuje się w analizie wariancji (dla populacji niezależnych).
Ogólna hipotez jest: L=2c-1 (c- liczba czynników)
W jednoczynnikowej jednowymiarowej analizie wariancji dla populacji niezależnych wygląda to tak:
H0:αi=0 αi=μi-μ≠0
H1:~H0 i=1,...,k
W dwuczynnikowej:
H0:αi=0
H1:~H0 i=1,...,k brak efektów głównych czynnika A
H0:βj=0
H1:~H0 j=1,...,k brak efektów głównych czynnika B
H0:(αβ)ij=0 αi=μi-μ≠0
H1:~H0 i;j=1,...,k brak efektów interakcji.
Jakie są podstawy teoretycznie konstrukcji statystyki f w analizie wariancji.
Iloraz 2 różnych oszacowań wariancji w populacji jest statystyką F-Fischera.
![]()
m - identyczna liczebność każdej próby.
Mianownik δ2 II
Wariancje we wszystkich populacjach muszą być homogeniczne: δ21=δ22=...=δ2k=δ2
Gdy założenie to jest spełnione wariancje w populacji można szacować estymatorem łącznym wariancji z k-próby ![]()
jest to zmienność wewnątrz grupowa niewyjaśniona wpływem czynnika.
Licznik δ2II
Jeżeli H0 jest prawdziwa, rozkład normalny i próby są równoliczne, to na podstawie wniosku z centralnego twierdzenia granicznego można oszacować wariancje w populacji. Rozrzut średnich grupowych jest właśnie szacunkiem z tych wariancji. ![]()
estymator wariancji średnich równy jest:
![]()
jest to zmienność międzygrupowa wyjaśniona wpływem czynnika. Jeżeli czynnik nie działa to te 2 oszacowania wariancji są sobie równe, więc statystyka F=1. Jeżeli czynnik działa to licznik przeważa mianownik, więc F>1
Czym różni się pojecie efektu głównego (działania czynnikowe) od pojęcia kontrastu I rzędu.
Efekt główny działania i-tego poziomu czynnika kontrolowanego A zmiennej x jest to różnica między wartością oczekiwaną na i-tym poziomie a wartością oczekiwaną w całej populacji. αi=μi-μ≠0
Kontrast I rzędu jest to różnica między efektami głównymi działania czynnika na różnych poziomach, czyli różnica między wartościami oczekiwanymi na 2 różnych poziomach αi-αi` =μi-μi` i≠i`
Co oznacza termin „kontrast parametrów II rzędu”.
Kontrasty parametrów II rzędu oblicza się, kiedy mamy 2 czynniki kontrolowane: A i B według wzoru:
[(αβ)ij-(αβ)ij`]-[(αβ)i`j-(αβ)i`j]=(μij-μij`)-(μi`j-μi`j)
i=i`, j=j`
(αβ)ij - interakcja i-tego poziomu czynnika A z j-tym poziomem czynnika B
(αβ)i`j` - interakcja i`-tego poziomu czynnika A z j`-tym poziomem czynnika B
μij |
1 |
2 |
3 |
4 |
μi |
1 |
20 |
40 |
30 |
50 |
35 |
2 |
30 |
40 |
40 |
30 |
35 |
3 |
50 |
30 |
20 |
40 |
35 |
4 |
40 |
50 |
30 |
20 |
35 |
μj |
35 |
40 |
30 |
35 |
μ=35 |
[-(αβ)11-(αβ)12]-[-(αβ)21-(αβ)22]=(μ11-μ12)-(μ21-μ22)=(20-40)-(30-40)
=-(-20)-(-10)=-10
Ile efektów głównych a ile interakcyjnych należy oszacować w dwuczynnikowej analizie wariancji.
W dwuczynnikowej analizie wariacji szacujemy:
k - liczba poziomów pierwszego czynnika;
l - liczba poziomów drugiego czynnika.
Czyli efektów głównych jest k+l, a efektów interakcyjnych k⋅l
Ile stopni swobody maja wariancje z liczebników a ile z mianowników statystyki F w wieloczynnikowej ANOVA`ie
Przy weryfikacji hipotezy o działaniu efektu głównego wariancje z liczników maja tyle stopni swobody ile poziomów czynnika kontrolowanego minus,
np.:
H0:αi=0 i=1,2,....,k f=k-1
H0:βi=0 i=1,2.....,k f=l-1
Przy weryfikacji hipotezy o działaniu efektu interakcyjnego wariancja z licznika ma (k-1)(l-1) stopni swobody, np.
H0:(αβ)ij=0 i=1,2.....,k; j=1,2....,k f=(k-1)(l-1)
Wariancje z mianowników mają f=n-kl stroni swobody, gdzie n - liczba poziomów, k - liczba poziomów jednego czynnik, l - liczba poziomów drugiego czynnika.
Ile kontrastów II rzędu należy oszacować w dwuczynnikowej ANOVA`ie. Dlaczego?
![]()
k - liczba poziomów czynnika A,
l - liczba poziomów czynnika B.
Aby obliczyć 1 kontrast II rzędu należy wziąć 4 średnie: μij, μi`j, μij`, μi`j`, czyli spośród k poziomów wybieram 2: μi, μi` oraz spośród l poziomów 2: μj, μj` Stąd liczba możliwych kombinacji wynosi:
![]()
Podaj przykład rozkładu średnich (w dwuczynnikowym planie badawczym) przy którym:
Brak efektów głównych działania obydwu czynników lecz istnieją efekty interakcyjne,
Istnieją efekty główne obydwu czynników, ale brak interakcji,
Istnieją efekty główne jednego czynnika, brak efektów głównych drugiego czynnika oraz brak interakcji,
Istnieją efekty główne jednego czynnika, brak efektów głównych drugiego czynnika oraz istnieją efekty interakcyjne obydwu czynników.
Brak efektów głównych działania obydwu czynników lecz istnieją efekty interakcyjne:
μij |
1 |
2 |
μi |
1 |
12 |
8 |
10 |
2 |
8 |
12 |
10 |
μj |
10 |
10 |
μ=10 |
αβ11=12-10-10+10=2
αβ12=8-10-10+12=-2
αβ21=8-10-10+10=-2
αβ22=12-10-10+10=2
są interakcje (αβ)ij≠0
α1=10-10=0
α2=10-10=0
β1=10-10=0
β2=10-10=0
brak efektu głównego bo α1, α2, β1, β2 = 0
Istnieją efekty główne obydwu czynników, ale brak interakcji:
μij |
1 |
2 |
μi |
1 |
3 |
7 |
|
2 |
4 |
8 |
|
μj |
|
|
μ=5,5 |
αβ11=3-5-3,5+5,5=0
αβ12=7-5-7,5+5,5=0
αβ21=4-6-3,5+5,5=0
αβ22=8-6-7,5+5,5=0
brak interakcje (αβ)ij=0
α1=5-5,5=-0,5
α2=6-5,5=0,5
β1=3,5-5,5=-2
β2=7,5-5,5=2
jest efekt główny bo α1, α2, β1, β2 ≠ 0
Istnieją efekty główne jednego czynnika, brak efektów głównych drugiego czynnika oraz brak interakcji
μij |
1 |
2 |
μi |
1 |
40 |
60 |
|
2 |
40 |
60 |
|
μj |
|
|
n= |
αβ11=40-50-40+50=0
αβ12=60-50-60+50=0
αβ21=40-50-40+50=0
αβ22=60-50-60+50=0
brak interakcji (αβ)ij=0
α1=50-50=0
α2=50-50=0
β1=40-50=-10
β2=60-10=50
brak efektu głównego bo α1, α2,=0
jest efekt główny bo β1, β2 ≠ 0
Istnieją efekty główne jednego czynnika, brak efektów głównych drugiego czynnika oraz istnieją efekty interakcyjne obydwu czynników:
μij |
1 |
2 |
μi |
1 |
40 |
60 |
50 |
2 |
20 |
80 |
50 |
μj |
30 |
70 |
μ=50 |
αβ11=40-50-30+50=10
αβ12=60-50-70+50=-10
αβ21=20-50-30+50=-10
αβ22=80-50-70+50=10
jest interakcja bo (αβ)ij≠0
α1=50-50=0
α2=50-50=0
β1=30-50=-20
β2=70-50=20
brak efektu głównego bo α1, α2, = 0
jest efekt główny bo β1, β2 ≠ 0
Jak wygląda rozkład z próby statystyki F stosowanej w ANOVA`ie. Jakie założenia musi być bezwzględnie przestrzegane aby rozkład ten nie „odkształcił się”
Aby rozkład nie odkształcił się musi być identyczna liczebność każdej z prób.
Co znaczy termin „reszta regresji”
Reszta regresji to licznik części zmienności objaśnianej Y nie wyjaśnionej zmienną objaśniającą.
![]()
yi - wynik osoby
![]()
i - wynik przewidy-
wany zgodnie z modelem regresji liniowej.
Jakie wartości przyjmuje współczynnik korelacji liniowej r-Pearsona i od czego to zależy?
Współczynnik korelacji r-Pearsona jest to współczynnik liniowej siły związku X i Y
![]()
Przyjmuje wartości <-1, 1>
Im związek X i Y jest silniejszy, tym wartość bezwzględna r-Pearsona jest większa. Jeżeli związek jest dodatni - r przyjmuje wartości dodatnie; jeżeli ujemne - r przyjmuje wartości ujemne.
r=0 - brak związku między X i Y,
r=1 - istnieje idealny, maksymalny związek dodatni X i Y,
r=-1 - istnieje dokonały, maksymalny związek ujemny X iY.
Jakie założenie musi być spełnione, aby można było stosować prosta regresję liniową (przy analizie danych)
X - skala przedziałowa (przynajmniej),
Y - skala przedziałowa (przynajmniej),
X - ma rozkład normalny dla każdej wartości Y
Y - ma rozkład normalny dla każdej X
Rozkłady te maja identyczne wariancje,
Średnie rozkładów leżą na jednej prostej,
Dużą próba,
H0:ρ=0
H1: ρ<0 lub ρ>0
Jakie właściwości ma współczynnik korelacji liniowej w sytuacji przeskalowywania zmiennych.
Współczynnik korelacji r-Pearsona jest niezmiennikiem przekształceń liniowych tzn.:
X`=ax+b
Y`=cy+d ⇒ ryx=ry`x`, gdy a⋅c>0
Co stanie się ze współczynnikiem determinacji, gdy wartości współczynnika zwiększą dwukrotnie. Czy wtedy jedne zmienne wyjaśnią dwa razy więcej zmienności drugiej.
r2 - współczynnik determinacji
r - współczynnik korelacji
jeśli rx2 r1=2r, to (r1)2=(2r)2=4r2
Zmienna nie wyjaśnia 2x więcej, ale 4x więcej zmienności drugiej.
Jaka jest definicja współczynnika korelacji cząstkowej i jakie przyjmuje wartości.
Współczynnik korelacji cząstkowej I rzędu
Współczynnik korelacji cząstkowej jest to korelacja między dwoma zbiorami reszt, czyli błędów oszacowania x1 na podstawie x3 oraz x2. jest to część korelacji, jaka pozostaje po wyeliminowaniu trzeciej zmiennej r12.3 przyjmuje wartości <-l, l>. Wartość ta może być mniejsza, równa lub większa od wartości współczynnika korelacji całkowitej między zmiennymi.
Jak wygląda rozkład z próby r12, a jak r12,3...k gdy H0 jest prawdziwe, opisz i narysuj.
t=n-k, czyli im więcej zmiennych, tym mniej stopni swobody przy ustalonym n, czyli wykres jest bardziej plaski.
Przedział ufności dal r12.3...k jest większy, czyli trudniej odrzucić H0, a więc trudniej popełnić błąd II rzędu (przyjęcie hipotezy fałszywej)
P
CZY MOŻNA WYZNACZYĆ RÓWNANIE REGRESJI DLA POPULACJI. UZASADNIJ.
Jeżeli r12=0,9 natomiast r13=0,8 to związek między r23 nie może być mniejszy od jakiej liczby?
r12=0,9 →r=0,81 wartość wyjaśniana
1-0,81=0,19 wartość niewyjaśniana między zmiennymi 1i2
r13 =0,8 ~ r2=0,64
r2/23min =0,64-0,19=0,45
r - współczynnik korelacji
r2 - współczynnik determinacji
r2/23 = 0,45
r23 = √0,45
Odpowiedz: Związek między r23 nie może być mniejszy od √0,45
Mianownik korelacji cząstkowej jest dodatni mniejszy od 1, zatem zwiększa wartość całego ułamka, zatem 3 r 12.3 > r 12 Załóżmy, że r 12 jest ujemne r 13 i r 23 są tych samych znaków; lic~ korelacji cząstkowej = -r 12 -r 13 r 23 ;wartość bezwzględna licznika korelacji cząstkowej jest większa od wartości bezwzględnej korelacji całkowitej. rl3=O lub r23=0, zatem licznik korelacji cząstkowej = licznik korelacji całkowitej.
Załóżmy, że r12=0
Bez względu na to, jakich znaków są r13 i r23 (gdy r13≠0 i r23≠O) r12.3 będzie zawsze większy od r12
Podaj definicję współczynnika alienacji.
wspó³czynnik alienacji jest to czźę zrI1iennoci zmiennej objanianej, nie wyjaniana przez zmienn¹ objaniaj¹c¹ 0≤1-r²≤1 - wspó³czynnik alienacji.
Czy tworząc model regresji liniowej dla zmiennych wystandaryzowanych uzyska się identyczne oszacowania współczynników regresji jak dla zmiennych nie wystandaryzowanych? Uzasadnij na przykładzie regresji prostej.
Tworząc model regresji liniowej dla zmiennych wystandaryzowanych nie
zawsze uzyska się identyczne szacowania współczynników regresji jak dla
zmiennych nie wystandaryzowanych.
a, b - współczynnik regresji dla zmiennych nie wystandaryzowanych:
a' , b' - współczynnik regresji dla zmiennych wystandaryzowanych
Dla zmiennych wystandaryzowanych średnia równa się), a odchylenie
standardowe równa się 1, więc:
a'= 0
czyb=b'
Czy związek liniowy zmiennych wystandaryzowanych ma taką samą, czy inna wartość niż związek zmiennych niewystandaryzowanych. Uzasadnij.
Związek liniowy zmiennych wystandaryzowanych ma taką samą wartość jak
związek zmiennych nie wystandaryzowanych
r - współczynnik liniowej siły zmienny nie wystandaryzowanych
r' - współczynnik liniowej siły zmiennych wystandaryzowanych
Dla zmiennych wystandaryzowanych średnia o, a odchylenie standardowe 1
WIĘC:
r=r'
Podaj definicje współczynnika alienacji
Współczynnik alienacji jest to część zmienności zmiennej objaśnianej, nie wyjaśniana przez zmienną obiasniającą 0≤1-r2≤1 - współczynnik alienacji.
Podaj przykład rzeczywistych badań, z których dane można byłoby przewidzieć zgodnie z modelem regresji wielomianowej.
Przewidywanie zagadnień z modelu regresji wielokrotnej
Zadanie z modelu regresji wielokrotnej można przewidywać: powodzenie u mężczyzn kobiet w przedziale wieku <20, 35> lat (mierzone w ilości randek w miesiącu) na podstawie długości uch nóg i obwodu biustów.
X1 - zmienna zależna objaśniana (powodzenie u mężczyzn kobiet w wieku 10-35 lat);
X2 - zamienna objaśniająca (długość nóg);
X3 - zmienna objaśniająca (obwód biustu)
Przytocz strukturę wyniku zakładanej w dwuczynnikowej ANOVA'ie oraz strukturę wyniku zakładanej w regresji liniowej trzech zmiennych. Czy równania te zależą od tej samej klasy funkcji?
Struktura cZYl1lriku w dwuczynnikowej ANOVA'ie wygląda tak:
Struktura wyniku w regresji liniowej 3 zmiennych wygląda tak:
Jaka zmienna ma rozkład prawdopodobieństwa χ2 (chi-kwadrat). Narysuj przykładowo taki rozkład, podaj jego parametry.
Rozkład prawdopodobieństwa χ2 ma zmienną ![]()
![]()
k - liczba stopni swobody
Przykład:
k=5 10
μ=k=5 10
m=k-2=3 8
δ2=2⋅k=10 20
m=3 m=8
JAKIE ZNASZ MIARY SIŁY WSPÓŁWYSTĘPOWANIA KATEGORII ZMIENNYCH NOMINALNYCH. JAKIE PRZYJMUJĄ WARTOŚCI. ZAPREZENTUJ JE.
Która z miar kontyngencji musi być używana w wersji skorygowanej, a której nie trzeba korygować. Uzasadnij.
W wersji skorygowanej musi być używana miara kontyngencji C-Pearsona:
![]()
Ponieważ nigdy nie osiągnie jedności.
Jaka jest maksymalna wartość statystyki chi-kwadrat w przypadku tabeli 2x2, a jaka w przypadku tabeli kxk, k≥3. Czy wartość maksymalna x2 dla tabeli kxl musi być większa w przypadku k≠l (względem k=l)
Maksymalna wartość statystyki hi-kwadrat:
1) tabela 2x2
χ2max=n
2) tabela kxk; k≥3
χ2max=(k-1)n
χ2max dla tabeli kxl nie może być większe od χ2 dla tabeli kxk
Przedstaw przykładowy rozkład frekwencji dwu zmiennych nominalnych z czterema kategoriami wartości, przy którym wartości statystyki chi-kwadrat byłyby maksymalne.
fij |
a |
b |
Σ |
1 |
20 |
0 |
20 |
2 |
0 |
20 |
30 |
Σ |
20 |
30 |
n=50 |

Jak przebiega algorytm weryfikowania hipotezy o normalnym rozkładzie zmiennej dla testu chi-kwadrat?
Ho: rozkład x jest normalny
H1 ~ Ho
1. x - mierzalna uciąglona: Wprowadza się dodatkową klasę wartości <-∞,☻>,gdzie☻to wartość najmniejsza uzyskana w badaniu, np. 0. lub od niej mniejsze (zależne od rozpiętości klasy h) Podobliie wprowadza się klasę <☻, ∞>. Obydwie klasy maja frekwencje empiryczna równą 0;
2. Oblicza się x i s zmiennej (ze wzoru dla danych sklasyfikowanych);
3. Standaryzuje się główne granice wszystkich klas;
4. Z tabel dystrybuanty rozkładu normalnego odnajduje się jej wartości dla wyznaczonych "z-tów". Znajduje się prawdopodobieństwo dla wartości x z danej klasy (różnica Фdla górnej i dolnej granicy po wystandaryzowaniu)
5, Prawdopodobieństwo przyporządkowane klasami, Л wartoњci x zamienia się na frekwencje skale liniowe posługując się szacunkiem:
gdzie li to liczebność próby;
f = kˉ ³
X²
Czy algorytm weryfikowania hipotezy o normalnym rozkładzie zmiennej może mieć wpływ na decyzję o jej odrzuceniu?
Algorytm weryfikowania H o normalnym rozkładzie zmiennych może mieć wpływ na decyzje o jej odrzuceniu, bo decyzja zależy od klasyfikacji: gdy zbyt
wąskie lub zbyt szerokie klasy to wtedy istnieje rozbieżność od rozkładu normalnego.
Jakie warunki muszą spełniać fi i fe aby(przy badaniu normalności rozkładu zmiennej) mogła być użyta statystyka chi-kwadrat?
Aby mog³a byę uæyta statystka chi-kwadrat (x²) naleæy: Uwzglźdnię tylko te klasy, których frekwencje s¹ wiźksze od 1 fei> 1, i= 1 ,. . .,k Ponadto musi byę co najmniej 1/5 klas spośród wyznaczonych, może zawierać foi<5. w przeciwnym razie łączy się w klasy.
Jaka zmienna ma rozk³ad prawdopodobieństwa x²( chi-kwadrat).
Narysuj przyk³adowo taki rozk³ad, podaj jego parametry.
Rozkład prawdopodobieństwa r ma zmienną
k - liczba stoplii swobody
przykład:
k=5 10
.u=k=5 10
m=k-2=3 8
δ²=2*k=10 20
JAK OKREŚLONA JEST MIARA SIŁY ZALEŻNOŚCI DLA DWÓCH SKAL PORZĄDKOWYCH. JAKIE PRZYJMUJE WARTOŚCI. ZINTERPRETUJ JE.
Dlaczego przy występowaniu rang wiązanych dwu zmiennych rangowych naleæy korzystaę szacuj¹c si³ź ich zaleænoci z tzw. "poprawki na wźz³y". Czy poprawka na wźz³y zwiźksza, czy zmniejsza wartoę tau-kwadrat (T²)
Przy występowaniu rang związanych należy kontrolować i poprawiać na węzły, ponieważ kolejność tych samych wartości, w zakresie zmiennych x jest arbitralna, w związku z czym kolejność odpowiadających mu wartości zmiennych y też jest przypadkowa.
Narysuj rozk³ad prawdopodobieństwa tau-kwadrat (T²) gdy hipoteza zerowa jest prawdziwa: dla duæej i ma³ej próby. Kiedy moc testu jest większa.
Moc testu jest większa dla małych prób:
Jaki rozkład ma statystyka chi-kwadrat w teście chi-kwadrat i ile ma stopni swobody. Uzasadnij.
Rozważmy populację o średniej μ wariancji δ² i rozk³adzie normalnym wyników Y. Wynik standardowy z tej populacji równy jest Z=(Y-μ)/δ. Takie wyniki standardowe majΉ oczywicie rozk³ad normalny. Moæemy jednak pos³ugiwaę siź kwadratami wyników standardowych z tej populacji. Taki wynik ma postaę z² = ( y-μ)²/δ² Jeli elementy z tej populacji pobieramy po jednym naraz, to rozk³ad liczebnoci z² bździe rozk³adem x²z 1 stopniem swobody. Czyli po prostu, jeli z² jest wynikiem standardowym o rozk³adzie normalnym, to z bździe mieę rozk³ad x² z 1 stopniem swobody .Znaczy to, Ze przy 1 stopniu swobody z =√x². Wartoci krytyczne x² dla istotnoci na poziomie 0,05 i 0;01 przy df=1 wynosz¹ 3,84 i 6,64. Odpowiadaj¹ce im wartoci z otrzymane z rozk³adu normalnego wynosz¹ 1,96= √3,84 i 2,58=√6,64. Jeæeli elementy z populacji pobieramy po dwa naraz, to rozk³ad z1²+ z2² bździe rozk³adem x² z 2 stopniami swobody. Jeli elementy z populacji pobieramy po trzy naraz to rozk³ad z1²+z2²+z3² bździe rozk³adem x²z 3 stopniami swobody. Ogólnie rzecz bior¹c, przy próbach o liczebnoci N wielkoę suma Zi² ma rozk³ad z N stopniami swobody.
Rozkład chi-kwadrat dla 5-procentowych obszarów krytycznych i dla różnych stopni swobody. Wartość chi-kwadrat jest zawsze dodatnia, co wynika z podnoszenia do kwadratu różnic między wartościami zaobserwowanymi a oczekiwanymi. Może przyjmować wartości od 0 do nieskończoności. Prawa strona krzywej jest asymptotyczna do odciętej. Przy 1 stopniu swobody krzywa jest asymptotyczna zarówno do rzędnej jak i do odciętej .
JAKIE ZNASZ MIARY SIŁ WSPÓŁWYSTĘPOWANIA KATEGORII ZMIENNYCH NOMINALNYCH? JAKIE PRZYJMUJĄ WARTOŚCI ZINTERPRETUJ JE.
która z miar kontyngencji musi być używana w wersji skorygowanej, a której nie trzeba korygować. Uzasadnij.
W wersji skorygowanej musi być zużywana miara kontyngencji C-Pearsona:
Jaka. jest maksymalna wartość statystyki. chi-kwadrat w przypadku tabeli 2x2, a jaka w przypadku tabeli k x k, k≤3. Czy wartoę maksymalna x² dla tabeli k x l musi byę wiźksza w przypadku k≠1 (wzglźdem k=1).
Maksymalna wartość statystyki hi-kwadrat:
l) tabela 2x2; x²max=n
2) tabela kxk; k≥3 ; x²max=(k -l )n
x² max dla tabeli kxl nie moæe byę Wiźksze od x² dla tabeli kxk
Przedstaw przykładowy rozpad frekwencji dwu zmiennych nominalnych z czterema kategoriami wartości, przy którym wartości statystyki chi-kwadrat byłyby maksymalne.
JAK BADA SIĘ ZALEŻNOŚĆ DWÓCH ZMIENNYCH PRZY B. MAŁYM ROZMIARZE PRÓBY? OPISZ TEST. PRZEDSTAW KRYTERIUM DECYZYJNE BADACZA.
δ12 s1 2
δ2 2 s22
x1 - x2
√ δ12/n1 + δ22/n2
xD - μD
sD
-t alfa t alfa
przedział ufności
1
2
3
4
1
2
3
4
5
μ
μ1
μ2
μ3
μ4
Rys 1
1
2
3
4
1
2
3
4
5
P
1
α
F
-1
1
r
αr12
αr12.3...k
P
χ2