OPRACOWANIE MATERIAŁU STATYSTYCZNEGO
&
TABLICE STATYSTYCZNE
OPRACOWANIE MATERIAŁU STATYSTYCZNEGO
Obejmuje dwie zasadnicze czynności: grupowanie i zliczanie.
GRUPOWANIE polega na wyodrębnianiu jednorodnych lub względnie jednorodnych części obejmujących jednostki o takich samych lub zbliżonych właściwościach. O przynależności do określonej grupy decyduje cel badania. Zaleca się jednak korzystanie z dwóch kryteriów:
jednostki zaliczane do jednej grupy nie powinny być (z punktu widzenia badanej cechy) zbyt zróżnicowane;
liczba grup nie powinna być zbyt duża.
Wyróżnia się dwa podstawowe rodzaje grupowania: typologiczne i wariacyjne.
Celem grupowania typologicznego (np. wg cech przestrzennych, rzeczowych czy czasowych) jest wyodrębnienie różnych jakościowo grup. Niekiedy grupowanie ma charakter naturalny - grupowanie wg płci, często jednak osoba prowadząca badanie może sama zdecydować na ile i jakich grup podzielić daną zbiorowość.
Grupowanie wariacyjne opiera się na cesze ilościowej i polega na łączeniu w klasy jednostek statystycznych o takich samych lub zbliżonych wartościach cech.
Jednolity system grupowania nazywa się klasyfikacją.
Dzielenie materiału statystycznego wg jednej cechy nosi nazwę grupowania prostego (np. podział zbiorowości wg płci). Grupowanie na podstawie kilku cech wzajemnie ze sobą powiązanych i uzupełniających się to grupowanie złożone (np. podział wg stażu pracy).
Ćwiczenie 1.
Dokonaj grupowania ludności Polski wg stanu cywilnego.
(Na podstawie obecnie obowiązującego stanu prawnego bez uwzględniania podziału na płci.)
Ćwiczenie 2.
Dokonaj grupowania przedstawionej poniżej zbiorowości przyjmując, że celem badania jest ustalenie udziału poszczególnych branż w podatkach uzyskiwanych przez państwo X w roku Y2K (handel itp.). Dane w milionach zieleńców.
przewóz krów na duże odległości 234; destylarnie 60; sklepy samoobsługowe 2,8; hipermarkety 20; produkcja młotków 14;sklepy odzieżowe 15; teleportacja i telekineza w firmach państwowych 31; sklepy on-line 0,02; handel bazarowy45; fabryki kowadeł 23; teleportacja i telekineza w firmach prywatnych 421; rafinerie 60; taksówki 46; sklepy osiedlowe 35; handel walizkowy 1.
ZLICZANIE danych odbywa się w rozmaity sposób - od ręcznego do komputerowego.
TABLICE STATYSTYCZNE
Wykorzystywane są do prezentacji danych uporządkowanych wg określonego kryterium. Stanowią one główną formę prezentacji danych liczbowych, dlatego też powinny spełniać określone wymogi dotyczące budowy - formalne oraz merytoryczne.
Z formalnego punktu widzenia tablica powinna zawierać:
Część liczbową (tabela właściwa);
Część opisową:
tytuł tablicy;
nazwy wierszy (boczek);
nazwy kolumn (główka);
źródła danych, ewentualne uwagi wyjaśniające (np. legenda użytych znaków graficznych)
Obowiązuje zasada bezwzględnego wypełniania wszystkich kolumn i wierszy tablicy.
Jeżeli wszystkie pola nie mogą być wypełnione liczbami stosuje się odpowiednie znaki umowne:
oznacza, że dane zjawisko nie występuje;
oznacza, że zjawisko występuje, ale w jednostkach mniejszych niż pół jednostki miary przyjętej w tablicy;
. (kropka) oznacza zupełny brak informacji lub brak informacji wiarygodnych;
x oznacza, że danej rubryki nie można wypełnić ze względu na układ tablicy;
* (gwiazdka) stawiana jest w tablicy obok liczby, dla zaznaczenia, że została ona zmieniona w stosunku do poprzednio publikowanej;
„w tym” (napis) oznacza, ze nie podaje się wszystkich składników sumy ogólnej.
Ćwiczenie 3.
Wykorzystaj wyniki uzyskane w ćwiczeniu 2 do obliczenia % udziału poszczególnych branż w dochodach państwa X. Wyniki (2 i 3) przedstaw w formie tabeli statystycznej.
OPISOWA ANALIZA ZJAWISK MASOWYCH
Wstęp
Analiza struktury zmierza do wydobycia na jaw charakterystycznych właściwości zbiorowości i porównania ich z inną zbiorowością. Każde badanie, które w efekcie ma dać wszechstronną ocenę zjawiska i doprowadzić do konstruktywnych wniosków, musi mieć swój punkt odniesienia w czasie albo przestrzeni.
Badając np. rozwój gospodarczy w regionie X nie będziemy w stanie prawidłowo ocenić poziomu rozwoju w tym regionie bez znajomości rozmiarów tego samego zjawiska w innym regionie lub tym samym regionie, ale w poprzednich okresach.
W badaniach statystycznych dosyć często zachodzi konieczność przeprowadzenia dwóch typów porównań:
Dwóch (lub więcej) różnych zbiorowości - pod względem tej samej cechy (np. struktura zgonów według wieku mężczyzn w Polsce w roku 2002);
Rozkładu dwóch (lub więcej) cech w tej samej zbiorowości (np. struktura urodzeń żywych według kolejności urodzenia dziecka i wieku matki w Polsce w roku 2002).
W sytuacjach, w których badanie struktury zbiorowości statystycznej prowadzone jest z punktu widzenia cech mierzalnych, wszechstronną analizę można prowadzić przy wykorzystaniu następujących miar statystycznych:
miar średnich (miar poziomu wartości zmiennej, miar położenia, przeciętnych) służących do określania tej wartości zmiennej opisanej przez rozkład, wokół której skupiają się wszystkie pozostałe wartości zmiennej;
miar rozproszenia (zmienności, zróżnicowania, dyspersji) służących do badania stopnia zróżnicowania wartości zmiennej;
miar asymetrii (skośności) służących do badania kierunku zróżnicowania wartości zmiennej;
miar koncentracji służących do badania stopnia nierównomierności rozkładu ogólnej sumy wartości zmiennej pomiędzy poszczególne jednostki zbiorowości lub analizy stopnia skupienia poszczególnych jednostek wokół średniej.
Miary średnie
Dzielą się na dwie grupy: średnie klasyczne i pozycyjne. Do średnich klasycznych należą: średnia arytmetyczna, średnia harmoniczna oraz średnia geometryczna. Najczęściej wykorzystywanymi średnimi pozycyjnymi są: dominanta (wartość najczęstsza) oraz kwantyle. Wśród kwantyli wyróżniamy - kwartyle (dzielące zbiorowość na cztery części), kwintyle (pięć części), decyle (dziesięć części) oraz centyle [percentyle] (sto części).
Średnie klasyczne są obliczane na podstawie wszystkich wartości szeregu. Średnie pozycyjne są wartościami konkretnych wyrazów szeregu (pozycji) wyróżniających się pod pewnym względem. Obie grupy wzajemnie się uzupełniają, każda opisuje poziom wartości zmiennej z innego punktu widzenia.
Średnia arytmetyczna
Średnią arytmetyczną nazywamy sumę wartości zmiennej wszystkich jednostek badanej zbiorowości podzieloną przez liczbę tych jednostek.
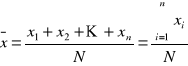
![]()
- symbol średniej arytmetycznej;
xi - warianty cechy mierzalnej;
N - liczebność badanej zbirowości.
Średnią określoną powyższym wzorem nazywa się średnią arytmetyczną nieważoną.
Jeżeli warianty średniej występują z różną częstotliwością, to oblicza się średnią arytmetyczną ważoną. Wagami są liczebności odpowiadające poszczególnym wariantom. Z tego typu sytuacją mamy do czynienia w szeregach rozdzielczych i przedziałowych.
Średnią arytmetyczną z szeregów przedziałowych oblicza się następująco:
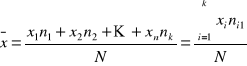
![]()
(n=1,2,…,k) - liczebność jednostek odpowiadająca poszczególnym wariantom zmiennej;
N - suma tych liczebności
(Σ - suma)
W szeregach rozdzielczych przedziałowych wartości zmiennej w każdej klasie nie są jednoznacznie określone, ale mieszczą się w pewnym przedziale. Dlatego też w celu obliczenia średniej arytmetycznej w przypadku tego typu szeregów należy wcześniej wyznaczyć środki przedziałów. Środki przedziałów otrzymuje się jako średnią arytmetyczną dolnej i górnej granicy każdej klasy. Oznacza się ją symbolem ![]()
.
Wzór na średnią arytmetyczną z szeregu rozdzielczego przedziałowego:
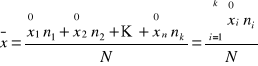
Jeżeli w obliczeniach możemy wykorzystać wyłącznie procentowe wskaźniki struktury (odsetki całości) ![]()
to wzór wygląda następująco:
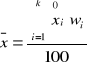
gdzie
![]()
Ćwiczenie 1
Tab. 1 Wyniki badań testowych dotyczących wiedzy teoretycznej ze statystyki
Wiedza ze statystyki (w punktach)
|
Liczba studentów
|
Obliczenia pomocnicze |
|||
|
|
|
|
|
|
20-30 30-40 40-50 50-60 60-70 70-80 |
2 10 7 9 12 10 |
25 35 45 55 65 75 |
50 350 315 495 780 750 |
4,0 20,0 14,0 18,0 24,0 20,0 |
100,0 700,0 630,0 990,0 1560,0 1500,0 |
Razem |
50 |
x |
2740 |
100,0 |
5480,0 |
![]()
- środek klasy
![]()
- odsetek ogółu
Oblicz średnią arytmetyczną.
Metoda 1:
„Za pomocą szeregu rozdzielczego przedziałowego”
![]()
Metoda 2:
„Za pomocą procentowych wskaźników struktury”
![]()
Wyniki są równoważne, ponieważ wartość średniej arytmetycznej nie zależy od liczebności poszczególnych klas, ale od proporcji między nimi.
Jeżeli znamy średnie arytmetyczne dla pewnych grup, a chcemy obliczyć średnią arytmetyczną dla wszystkich grup łącznie korzystamy ze wzoru:
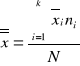
gdzie:
![]()
- średnia ze średnich;
![]()
- średnia arytmetyczna i-tej grupy;
![]()
- suma liczebności grupy;
Średnia arytmetyczna jest miarą prawidłową tylko w odniesieniu do zbiorowości jednorodnych, o niewielkim stopniu zróżnicowania wartości zmiennej. W miarę wzrostu asymetrii i zróżnicowania rozkładu, a także w rozkładach bimodalnych i wielomodalnych średnia arytmetyczna traci swoje znaczenie. Nie można jej obliczyć dla szeregu o otwartych przedziałach, jeżeli przedziały te mają duże liczebności. (Przyjmuje się, że otwarte przedziały klasowe przedziały można zamykać, jeżeli liczba jednostek w tych przedziałach nie przekracza 5% liczebności zbiorowości.)
Jeżeli wartości zmiennej podane są w jednostkach względnych, np. km/godz, kg/osobę, wagi zaś w jednostkach liczników tych jednostek względnych (prędkość pojazdu - zmienna: km/godz.; waga: w km; gęstość zaludnienia - zmienna: w osobach/km2, waga: w osobach; spożycie artykułu X na 1 osobę - zmienna: w litrach, waga: na osobę), to stosuje się średnią harmoniczną.
Średnia harmoniczna jest odwrotnością średniej arytmetycznej z odwrotności wartości zmiennych.
W przypadku szeregów wyliczających oblicza się ją ze wzoru:
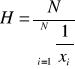
gdzie:
H - symbol średniej harmonicznej.
Dla obliczenia średniej harmonicznej z szeregów rozdzielczych (punktowych lub przedziałowych) zachodzi konieczność zastosowania wag (uwzględnienia liczebności). Stosuje się wzór:
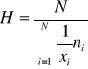
Dla szeregów rozdzielczych przedziałowych średnią harmoniczną obliczamy według powyższego wzoru, z tym, że konkretne warianty cechy (xi) zastępujemy środkami przedziałów (![]()
).
Ćwiczenie 2
Gęstość zaludnienia w dwu 100-tysięcznych miastach wynosi odpowiednio 300 osób/km2 i 900 osób km2. Oblicz przeciętną gęstość zaludnienia.
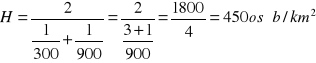
Stosując średnią arytmetyczną dla obliczenia powyższego zadania otrzymalibyśmy:
![]()
CO NIE JEST PRAWDĄ!
Każde z miast zajmuje odpowiednio:
100 000 : 300 osób km2 = 333,33 km2
100 000 : 900 osób km2 = 111,11 km2
Z czego wynika, że oba miasta zajmują powierzchnię - 444,44 km2.
Wobec tego średnia gęstość zaludnienia w tych miastach wynosi:
200 000 osób : 444,44 km2 = 450 osób/km2.
Ten sam rezultat uzyskamy wzór na średnią harmoniczną dla szeregów rozdzielczych punktowych:
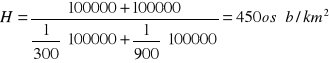
Jeżeli zachodzi konieczność zbadania średniego tempa zmian zjawiska, stosuje się średnią geometryczną. (Więcej na ten temat przy analizie dynamiki zjawisk).
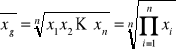
gdzie:
![]()
- symbol średniej geometrycznej;
![]()
- znak iloczynu
ŚREDNIE POZYCYJNE
Dominantą (modalna, wartość najczęstsza) nazywamy taką wartość zmiennej, która w danym rozkładzie empirycznym występuje najczęściej. (Wynika z tego, że dominantę można wyznaczyć tylko w rozkładach jednomodalnych).
W szeregach wyliczających i rozdzielczych punktowych dominanta jest wartością cechy, której odpowiada największa liczebność.
W szeregach rozdzielczych przedziałowych bezpośrednio można określić tylko przedział, w którym znajduje się dominanta - jest to przedział o największej liczebności. Konkretną wartość liczbową należącą do tego przedziału, która jest dominantą wyznacza się w następujący sposób:
![]()
gdzie:
![]()
- symbol dominanty;
![]()
- dolna granica klasy, w której znajduje się dominanta;
![]()
- liczebność przedziału dominanty;
![]()
- liczebność przedziału poprzedzającego przedział dominanty;
![]()
- liczebność przedziału następującego po przedziale dominanty;
![]()
- interwał, czyli rozpiętość przedziału dominanty.
Z szeregów rozdzielczych przedziałowych dominantę można wyznaczyć metodą rachunkową (patrz wyżej) lub graficzną.
Ćwiczenie 3.
Na podstawie tabeli wyznacz dominantę danego szeregu.
Tab. Rozwody w Polsce w 1977 r. wg wieku kobiet w momencie wniesienia powództwa.
Wiek kobiet (w latach) |
Liczba kobiet |
Odsetek kobiet |
Do 19 20-24 25-29 30-34 35-39 40-49 50 i więcej |
314 6979 11440 6391 5412 8450 4200 |
0,7 16,2 26,2 14,8 12,5 19,6 9,7 |
![]()
Wartość będzie identyczna, jeżeli do obliczeń wykorzystamy odsetki zamiast liczebności absolutnych.
![]()
Metoda graficzna sprowadza się do wykonania wykresu z trzech przedziałów klasowych: przedziału, w którym znajduje się dominanta oraz dwóch sąsiednich. Z górnej podstawy najwyższego prostokąta wyznaczamy dwie przekątne łączące najbliżej położone punkty górnych podstaw sąsiednich prostokątów. Następnie z punkty ich przecięcia wyznaczamy prostopadłą do osi odciętych (x).
Jeżeli liczebności przedziałów sąsiednich są jednakowe, to dominanta jest równa środkowi klasy dominującej.
Wyznaczanie dominanty jest możliwe wówczas, gdy szereg spełnia następujące warunki:
rozkład empiryczny ma jeden ośrodek dominujący (rozkład jednomodalny);
asymetria układu jest umiarkowana;
przedział w którym występuje dominanta oraz dwa sąsiednie z nim przedziały mają jednakowe rozpiętości.
Kwantyle, są to najogólniej rzecz ujmując wartości cechy badanej jednostki, które definiują ją na określone części - pod względem liczby jednostek. Części te mogą być równe lub pozostawać do siebie w określonych proporcjach. Szeregi, w których wyznacza się kwartyle musza być uporządkowane według malejących lub rosnących wartości cechy. Do najczęściej używanych kwantyli zaliczamy: kwartyle, a w przypadku badania struktury zbiorowości o dużej liczbie jednostek - decyle i centyle.
Wśród kwartyli wyróżniamy: kwartyl pierwszy (dolny), drugi (mediana lub wartość środkowa) oraz trzeci (górny). Każdy z kwartyli dzieli zbiorowość na dwie części pod względem liczebności.
kwartyl pierwszy - dzieli zbiorowość uporządkowaną na dwie części w ten sposób, że 25% jednostek na wartości cechy niższe i 75% wyższe od kwartyla pierwszego;
kwartyl drugi - dzieli zbiorowość uporządkowaną na dwie części w ten sposób, że 50% jednostek na wartości cechy niższe i 50% wyższe od mediany;
kwartyl trzeci - dzieli zbiorowość uporządkowaną na dwie części w ten sposób, że 75% jednostek na wartości cechy niższe i 25% wyższe od kwartyla trzeciego.
W przypadku szeregów wyliczających składających się z reguły z niewielkiej liczby jednostek medianę oblicza się najczęściej ze wzoru:
![]()
gdy N jest nieparzyste
![]()
gdy N jest parzyste
gdzie:
![]()
- symbol mediany.
Obliczanie mediany z szeregu rozdzielczego punktowego sprowadza się do wskazania jednostki środkowej i odczytania wariantu cechy odpowiadającego tej jednostce. Odnalezienie środkowej jednostki ułatwia skumulowanie liczebności. Kumulacja polega na kolejnym narastającym sumowaniu liczebności dotyczących poszczególnych wariantów cechy.
W przypadku szeregów rozdzielczych przedziałowych kwartyle wyznacza się metodą graficzną lub rachunkową. W metodzie rachunkowej stosuje się następujące wzory:
Kwartyl pierwszy:
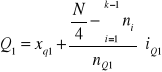
;
Kwartyl drugi:
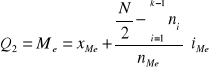
;
Kwartyl trzeci:
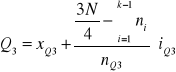
gdzie:
![]()
- symbole kwartyli;
![]()
- granice przedziałów, w których znajdują się odpowiednio: kwartyl pierwszy, drugi (mediana) i trzeci;
N - ogólna liczebność danej zbiorowości;
![]()
- suma liczebności od klasy pierwszej do tej, w której znajdują się odpowiednio: kwartyl pierwszy, drugi (mediana) i trzeci;
![]()
- liczebności przedziałów, w których, w których znajdują się odpowiednio: kwartyl pierwszy, drugi (mediana) i trzeci;
![]()
- interwały (rozpiętość) przedziałów, w których znajdują się odpowiednio: kwartyl pierwszy, drugi (mediana) i trzeci;
Ćwiczenie 4
Na podstawie tabeli wyznacz kwartyle szeregu.
Tab. Wiek kobiet zawierających związek małżeński w Polsce w 1977 r.
Wiek kobiet |
Liczba kobiet
|
Odsetek kobiet
|
Skumulowane częstości względne |
do 19 20-24 25-29 30-34 35-39 40-49 50-59 60 i więcej |
68 694 184 088 43 239 10 127 4 925 7 251 4 586 3 277 |
21,1 56,4 13,3 3,1 1,5 2,2 1,4 1,0 |
21,1 77,5 90,8 93,9 95,4 97,6 99,0 100,0 |
Ogółem |
326 277 |
100,0 |
x |
Źródło: M. Sobczyk, Statystyka, PWN, W-wa 1991, s.41
Pierwszą czynnością jest kumulacja liczebności (absolutnych bądź odsetków). Następnie wyznaczamy pozycję poszczególnych kwartyli w szeregu, tzn. ![]()
. Wykorzystując skumulowane częstości względne otrzymujemy:
![]()
Na tej podstawie obliczamy wartości kwartyli:
![]()
![]()
![]()
(21,1 - jest to suma liczebności od klasy pierwszej do tej, w której znajdują się odpowiednie kwartyle)
Kwartyle są dogodnymi parametrami w analizie struktury. Mogą być wykorzystane w przypadkach, w których nie jest możliwe obliczenie z danego szeregu średniej arytmetycznej (otwarte przedziały klasowe, ekstremalne wartości), a także dominanty (nierówne rozpiętości przedziałów, silna asymetria rozkładu.
Decyle i centyle (percentyle) wyznacza się podobnie jak kwartyle. Decyle dzielą zbiorowość na 10 części - 5 decyl to mediana. Centyle zaś na 100 części - 50 centyl jest medianą.
Średnia arytmetyczna, dominanta i mediana, jako miary tendencji centralnej, są powiązane ze sobą odpowiednimi zależnościami - równość lub nierówność (w zależności od typu rozkładu) [więcej na ten temat w dziale miary asymetrii ;-)] W przypadku rozkładu umiarkowanie niesymetrycznego zachodzi między nimi następujący związek:
![]()
; (wzór Pearsona)
Na postawie tego wzoru można wyznaczyć średnią znając dwie pozostałe zmienne. Po przekształceniach możemy na jego podstawie obliczyć dominantę - znając średnią arytmetyczną i medianę.
![]()
Miary zmienności
Wartości średnie nie dają wyczerpującej charakterystyki struktury zbiorowości. Przede wszystkim nie informują o stopniu zmienności (dyspersji) badanej cechy. Dyspersją nazywamy zróżnicowanie jednostek zbiorowości ze względu na wartość badanej cechy. Siłę dyspersji oceniamy za pomocą pozycyjnych i klasycznych miar zmienności. Do miar klasycznych zaliczamy: odchylenie przeciętne, wariancję, odchylenie standardowe oraz współczynnik zmienności (w zależności od techniki obliczania może być również pozycyjną miarą dyspersji)
Odchylenie przeciętne określa, o ile wszystkie jednostki danej zbiorowości różnią się średnio ze względu na wartość zmiennej od średniej arytmetycznej tej zmiennej. Odchylenie przeciętne jest średnią arytmetyczną bezwzględnych wartość (modułów) odchyleń wartości cechy od jej średniej arytmetycznej. Oblicza się je wg wzoru:
dla szeregu wyliczającego:
![]()
dla szeregu rozdzielczego punktowego:
![]()
dla szeregu rozdzielczego przedziałowego:
![]()
Ćwiczenie 5
Oblicz odchylenie przeciętne dla podanego szeregu
Tab. Nauczyciele szkół średnich w miejscowości Z wg stażu pracy
Staż pracy (w latach) |
Liczba
|
Obliczenie pomocnicze |
|||
|
|
|
|
|
|
0-5 5-10 10-15 15-20 20-25 25-30 30-35 |
4 7 10 15 8 4 2 |
2,5 7,5 12,5 17,5 22,5 27,5 32,5 |
10,0 52,5 125,0 262,5 180,0 110,0 65,0 |
13,6 8,6 3,6 1,4 6,4 11,4 16,4 |
54,4 60,2 36,0 21,0 51,2 45,6 32,8 |
Ogółem |
50 |
x |
805,0 |
x |
301,2 |
Źródło: M. Sobczyk, Statystyka, PWN, W-wa 1991, s.45.
Najpierw należy obliczyć średni staż pracy:
![]()
Wynik podstawiamy do wzoru:
![]()
Otrzymany wynik oznacza, że przeciętne zróżnicowanie badanej zbiorowości nauczycieli ze względu na staż pracy wynosi ![]()
6 lat.
Wariancja jest to średnia arytmetyczna z kwadratów odchyleń poszczególnych wartości cechy od średniej arytmetycznej całej zbiorowości.
Dla szeregu wyliczającego oblicza się ją wg wzoru:
![]()
Dla szeregu rozdzielczego punktowego:
![]()
Dla szeregu rozdzielczego przedziałowego:
![]()
Ćwiczenie 6
Oblicz wariancję z podanego szeregu.
Tab. Zgony niemowląt na wsi wg wieku w Polsce w 1977 r.
Wiek zmarłych
|
Liczba
|
Obliczenie pomocnicze |
||||
|
|
|
|
|
|
|
0-6 7-13 14-20 21-27 28-29 |
3 186 623 336 243 74 |
3,0 10,0 17,0 24,0 28,5 |
9 558 6 230 5 712 5 832 2 109 |
-3,6 3,4 10,4 17,4 21,9 |
12,96 11,56 108,16 302,76 479,61 |
41 290,56 7 201,88 36 341,76 73 570,68 35 491,14 |
Ogółem |
4 462 |
x |
29 441 |
x |
x |
193 896,02 |
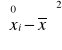
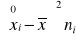
Źródło: M. Sobczyk, Statystyka, PWN, W-wa 1991, s.47.
Najpierw należy obliczyć średnią arytmetyczną:
![]()
Następnie podstawiamy do wzoru:
![]()
Wariancja, jako suma kwadratów dzielona przez liczbę dodatnią jest zawsze wielkością dodatnią i mianowaną. Mianem wariancji jest kwadrat jednostki fizycznej, w jakiej mierzona jest badana cecha.
Im zbiorowość jest bardziej zróżnicowana tym wyższa jest wartość wariancji
Wariancja obliczona na podstawie szeregów rozdzielczych przedziałowych jest wielkością zawyżoną. Powoduje to fakt, że do obliczeń wykorzystuje się środki przedziałów klasowych, a nie średnie arytmetyczne z poszczególnych klas.
Wariancja jest wielkością kwadratową. Aby uzyskać miarę zróżnicowania o postaci liniowej (o mianie zgodnym z mianem badanej cechy), wyciągamy pierwiastek kwadratowy. W wyniku pierwiastkowania otrzymujemy tzw. odchylenie standardowe.
Odchylenie standardowe jest pierwiastkiem kwadratowym z wariancji.
![]()
Odchylenie standardowe określa o ile wszystkie jednostki danej zbiorowości różnią się średnio od średniej arytmetycznej badanej zmiennej. Dla poszczególnych rodzajów szeregów korzystamy z odpowiednich wzorów na wariancję, a następnie wyciągamy pierwiastek kwadratowy z wariancji.
Możemy je wykorzystać do konstrukcji typowego obszaru zmienności badanej cechy. W obszarze tym mieści się około 2/3 wszystkich jednostek badanej zbiorowości statystycznej. Typowy obszar zmienności określa wzór:
![]()
Pomiędzy odchyleniami: przeciętnym a standardowym obliczonym z tego samego szeregu zachodzi relacja:
![]()
Omówione powyżej miary dyspersji są miarami bezwzględnymi, gdyż wyrażamy je w takich samych jednostkach jak wartości badanej zmiennej. Nie pozwala to na porównywanie zmienności cech o różnych mianach. Ponadto nie można porównywać pod względem tej samej cechy dwóch (lub kilku) zbiorowości będących na różnym poziomie, określonym np. średnią arytmetyczną czy medianą. Z tego powodu w analizie dyspersji stosuje się względną miarę zróżnicowania - współczynnik zmienności.
Współczynnik zmienności jest ilorazem bezwzględnej miary dyspersji i odpowiednich wartości średnich. Jest on wyrażany w procentach. Ponieważ w analizie rozkładu zmienności cech korzystamy z różnych miar zróżnicowania i różnych przeciętnych, współczynnik zmienności można obliczyć kilkoma metodami:
1)
![]()
;
2)
![]()
Są to tzw. klasyczne współczynniki zmienności.
3)
![]()
;
4)
![]()
Są to tzw. pozycyjne współczynniki zmienności.
Współczynniki zmienności informują o sile dyspersji.
Ich duże wartości liczbowe świadczą o niejednorodności zbiorowości.
Ćwiczenie 9
Zastosuj współczynnik zmienności dla analizy dyspersji dochodów w podanych niżej hotelach A, B i C:
Średnie miesięczny wpływy:
![]()
![]()
![]()
.
Odchylenia standardowe wartości sprzedanych usług wynosiły:
![]()
![]()
![]()
.
Z uwagi na duże różnice w średnim poziomie wpływów w poszczególnych hotelach należy zastosować wzór 1.
Po podstawieniu danych otrzymujemy:
Dla hotelu A: ![]()
;
Dla hotelu B: ![]()
;
Dla hotelu C: ![]()
.
Z powyższego wynika, że największe względne zróżnicowanie miesięcznych wpływów miało miejsce w hotelu B, a najmniejsze w hotelu A.
SŁOWNICZEK:
![]()
- symbol średniej arytmetycznej;
xi - warianty cechy mierzalnej;
N - liczebność badanej zbiorowości;
N - suma liczebności (szeregi przedziałowe);
![]()
- środek przedziału;
![]()
- procentowy wskaźnik udziału (odsetki);
H - symbol średniej harmonicznej;
![]()
- symbol dominanty;
![]()
- dolna granica klasy, w której znajduje się dominanta;
![]()
- liczebność przedziału dominanty;
![]()
- liczebność przedziału poprzedzającego przedział dominanty;
![]()
- liczebność przedziału następującego po przedziale dominanty;
![]()
- interwał, czyli rozpiętość przedziału dominanty;
![]()
- symbol mediany;
![]()
- symbole kwartyli;
![]()
- granice przedziałów, w których znajdują się odpowiednio: kwartyl pierwszy, drugi (mediana) i trzeci;
N - ogólna liczebność danej zbiorowości;
![]()
- suma liczebności od klasy pierwszej do tej, w której znajdują się odpowiednio: kwartyl pierwszy, drugi (mediana) i trzeci;
![]()
- liczebności przedziałów, w których, w których znajdują się odpowiednio: kwartyl pierwszy, drugi (mediana) i trzeci;
![]()
- interwały (rozpiętość) przedziałów, w których znajdują się odpowiednio: kwartyl pierwszy, drugi (mediana) i trzeci;
d - symbol odchylenia przeciętnego;
![]()
- symbol wariancji;
s - symbol odchylenia standardowego;
V - symbol współczynnika zmienności.
Wyszukiwarka