Bazy Danych.
Wykład 1.
Prowadzący: Madejewski.
Zakres wykładów:
Podstawowe pojęcia z dziedziny baz danych.
Systemy IDEF0 i modelowanie obiegów danych.
Architektura baz danych (model hierarchiczny, sieciowy i relacyjny).
Projektowanie schematu relacyjnej bazy danych.
Normalizacja.
Podstawy języka SQL.
Zabezpieczenia systemu baz danych.
Literatura:
Tadeusz Pankowski „ Podstawy baz danych” PWN 1992r.
J. Ullman ,,Systemy baz danych” WND 1988r.
Systemy działające na konkretach (na przykładzie firmy zajmującej się wynajmem):
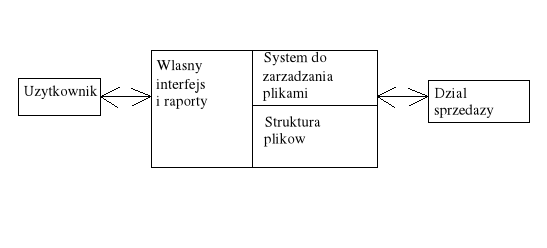
Dział sprzedaży:
nieruchomość do wynajęcia
właściciel nieruchomości
osoba która chce wynająć (nazwisko, rodzaj nieruchomości jaka go interesuje)
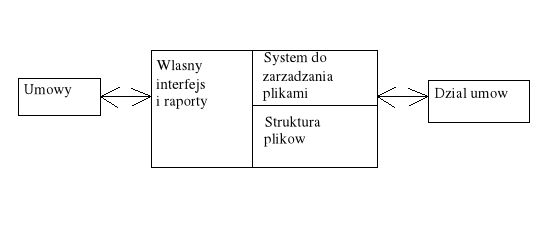
Dział umów:
umowa między wynajmującym (właścicielem)
nieruchomość
wynajmujący (gdzie można go znaleźć)
Są to dwa rozdzielne zbiory danych.
Ograniczenie specjalizowanych aplikacji operujących na dedykowanych strukturach plików:
separacja i izolacja danych - każdy program (aplikacja) operuje na osobnym zestawie danych, dane te są zapisywane w formacie właściwym dla danej aplikacji (tym samym każda aplikacja może korzystać z danych zapisanych w innym formacie), użytkownicy jednej aplikacji nie mają dostępu do danych z których mogą korzystać inne aplikacje
powielanie danych - te same dane przechowywane w wielu miejscach jednocześnie, korzystają z nich różne aplikacje i te same dane mogą być zapisane w różnych formatach, np.: daty, liczby czy łańcuchy tekstowe
struktura danych jest zdefiniowana w aplikacji która z niej korzysta tym samym próba zmiany (rozszerzenia) formatu danych wymaga zmiany aplikacji
celem gromadzenia danych jest wyszukiwanie informacji drogą zapytań; zbiór zapytań w dedykowanych aplikacjach jest zbiorem zamkniętym tym samym próba analizy danych w sposób inny niż zdefiniowane danej aplikacji wymaga zmiany aplikacji
Bazy danych.
Podejście charakterystyczne dla baz danych.
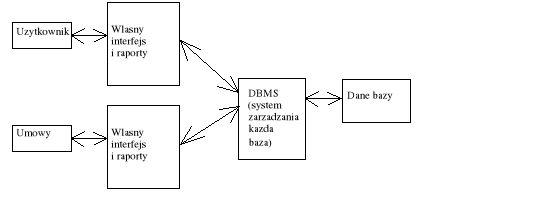
Property - rzeczy do wynajęcia
Owner - właściciel
Renter - wynajmujący
Lease - dzierżawca
DBMS - rzeczy do wynajęcia + właściciel + wynajmujący + dzierżawca + struktura plików
W bazach danych jedną z charakterystycznych cech jest oddzielenie opisów struktury danych od konkretnej aplikacji tym samym opis struktury danych staje się informacją przechowywaną niezależnie od programu i informacja ta może być przechowywana wraz z danymi.
Systemy baz danych stanowią odpowiedz na konieczność kontroli dostępu do danych, ich zawartości wykraczającą poza kontrolę którą mogły zapewnić dedykowane aplikacje.
Def.: Baza danych jest zbiorem logicznie uporządkowanych danych oraz ich opisów. Stałym elementem baz danych jest katalog systemu w którym znajdują się opisy struktur danych. W poprawnie zaprojektowanym systemie baz danych możliwe jest modyfikowanie struktury danych bez naruszenia zawartości danych.
Def.: ENCJA - to każdy przedmiot, zjawiskom, stan lub pojęcie - każdy obiekt który potrafimy (chcemy) odróżnić od innych obiektów. Encją jest zatem każdy stół, samochód itp.. Encją jest niedźwiedź, jako element składowy życia na ziemi. Encja to każdy obiekt dający się zidentyfikować na podstawie swoich atrybutów.
Def.: ATRYBUT - cechy encji które dają się wyrażać przez przydanie im pewnych wartości - są to cechy encji wynikające z ich natury, dające się wyrazić liczbami bądź prostymi określeniami słownymi. Stół ma np.: liczbę nóg, samochód - marka i pojemność silnika.
Wywołanie atrybutów wymaga także określenia dziedziny wartości tych atrybutów, np.: w przypadku dat urodzenia studentów w systemie dziekanat należało by założyć jakiś minimalny wiek studenta powiedzmy 15 lat w celu uniknięcia błędów przy wprowadzaniu danych, lub należało by kontrolować długość nazwiska, itp..
W systemach baz danych takie zbiory ograniczeń mogą być przechowywane niezależnie od danych, nie muszą też stanowić części aplikacji operującej na danych.
W systemach baz danych występują dwa typy języków:
język DDL (język do definiowania struktury danych; język ten pozwala na określenie typu danych, ich struktury i dziedziny danych)
język DML (język do manipulowania na danych, język tworzenia zapytań)
Bazy danych zapewniają następujące usługi:
system zabezpieczeń - daje on dostęp do danych i informacji tylko określonym użytkownikom na określonym poziomie szczegółowości
kontrola integralności danych (ich kompletność i ich poprawność)
kontrola jednoczesnego dostępu do danych przez wielu użytkowników (w taką procedurę może być wbudowana hierarchia użytkowników, np.: niektórzy mogą wprowadzać nowe dane i usuwać stare, inni mogą je tylko przeglądać
odtwarzanie stanu systemu sprzed awarii
Mechanizmy perspektyw.
Użytkownik bazy danych ma zawsze dostęp do informacji zawartych w bazie. Informacje zaś są pozyskiwane drogą zapytań z danych zapisanych w bazie tym samym informacja taka jest np.: średnia ze studiów nie musi być nigdzie zapisana w bazie danych jako dana jest po prostu wyznaczana na podstawie istniejących wpisów w bazie danych. W ogólnym przypadku użytkownik może w ogóle nie operować na surowych danych znajdujących się w bazie danych.
Perspektywy to sposób udostępniania użytkownikowi informacji w postaci i zakresie określonym w czasie projektowania bazy danych. Perspektywy uwzględniają zakres uprawnień konkretnego użytkownika do korzystania z danych.
Informacje dostępne w ramach danej perspektywy mogą być uzyskane z danych zebranych i przetworzonych z wielu różnych plików bazy danych, które mogą być ponadto rozmieszczone w różnych systemach komputerowych.
Kontrola redundacji danych.
Redundacja to jest występowanie wielu zapisów tych samych danych. Kontrola redundacji w bazach danych zaczyna się już na etapie projektowania bazy danych. W przypadku relacyjnych baz danych proces który zapewnia uporządkowanie danych w poszczególnych zbiorach zwany jest normalizacją. Bazy danych zapewniają większą wydajność pracy programistów.
Role użytkowników systemów baz danych:
administrator bazy danych (projektuje on strukturę baz danych, przydziela uprawnienia poszczególnym użytkownikom, określa perspektywy użytkownika, oraz prowadzi systematyczne kopiowanie zawartości bazy danych dla umożliwienia odtworzenia stanu bazy danych sprzed awarii, w niektórych systemach można wyróżnić dwie funkcje: administrator danych, administrator bazy danych)
programiści aplikacji(budują oni procedury pozwalające na pozyskiwanie informacji z danych, a procedury te budowane są w języku DML)
,, użytkownicy naiwni „ (są to wszyscy użytkownicy bazy danych którzy dostęp do danych i informacji uzyskują za pośrednictwem mechanizmu perspektyw)
Aplikacje dedykowane budowane do operowania na ściśle określonych strukturach danych mają również zalety do nich należy:
możliwość bardzo szybkiego dostępu do danych znacznie przekraczająca parametry bazy danych
Wady baz danych:
złożoność (korzystanie z bazy danych powoduje że każdorazowo taki system ma dostęp do szeregu usług nawet takich które w danym zastosowaniu nie są potrzebne)
rozmiar
dodatkowe koszty sprzętu (mogą one wynikać z podwyższonej złożoności oprogramowania bazy danych, konieczności zabezpieczenia fizycznego danych, np.: dodatkowe dyski)
koszt konwersji danych (mogą obejmować konieczność przetworzenia istniejących zapisów do nowego formatu, koszt zamiany struktury istniejących danych oraz kontroli integralności uzyskanych danych)
szybkość działania systemu baz danych z wyjątkiem wybranych funkcji tj. indeksowanie jest z reguły niższa niż systemów dedykacyjnych
Wykład 2.
Architektura ASCI-SPARC jako podstawa budowy systemu zarządzania danymi.
Cele architektury ASCI-SPARC:
wszyscy użytkownicy powinni mieć dostęp do tych samych danych
perspektywa konkretnego użytkownika nie powinna odzwierciedlać zmian wnoszonych do perspektyw innych użytkowników
użytkownik nie musi znać szczegółów technicznych zapisu danych w bazie
administrator bazy danych może zmieniać strukturę zapisu danych w systemie bez naruszania perspektyw poszczególnych użytkowników
wewnętrzna struktura bazy danych jest niezależna od sposobu jej zapisania w systemie komputerowym
administrator bazy danych może modyfikować strukturę pojęciową bazy danych bez odzwierciedlania tego w perspektywach użytkowników
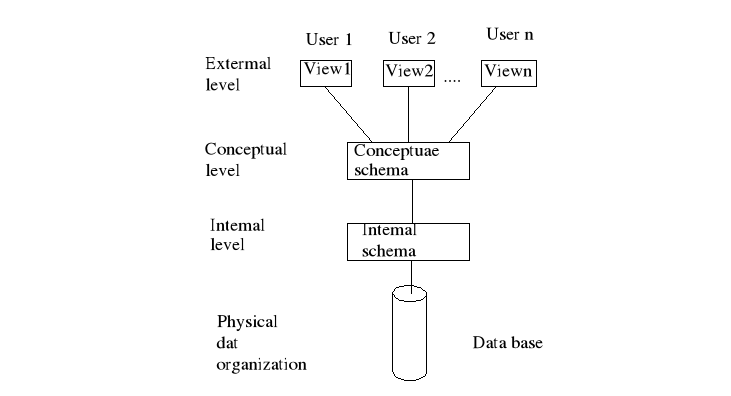
Powyższy schemat składa się z trzech poziomów, a mianowicie z:
poziomu zewnętrznego - perspektywy użytkownika, użytkownicy ,,naiwni”
poziom pojęciowy - schemat logiczny
poziom wewnętrzny - zapisać w efektywny sposób dane zgodnie z modelem na którym będą działać założone wcześniej perspektywy
Języki czwartego poziomu (4GL):
wbudowane języki zapytań - standardowym językiem zapytań jest SQL - a w Accessie mamy dodatkowo QBE
wbudowane generatory formularzy
wbudowane generatory raportów
wbudowane generatory grafiki (wykresów)
wbudowane generatory aplikacji
Model danych jest to reprezentacja danych sporządzona w pewien usystematyzowany sposób. Modele danych dzielą się na:
obiektowe
oparte na strukturze rekordowej
Wśród modeli opartych na zapisie rekordowym wyróżnia się:
modele hierarchiczne
modele sieciowe
modele relacyjne
Elementy składowe systemu zarządzania bazy danych.
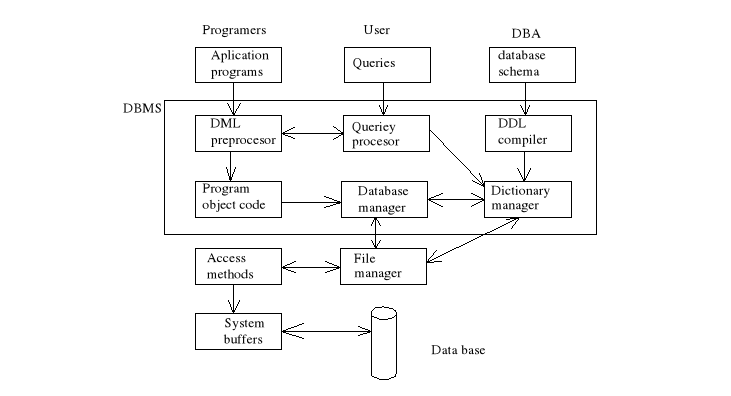
Podstawowe elementy systemu zarządzania bazą danych:
procesor zapytań
program zarządzający bazą danych
program zarządzający plikami
program procesor języka DML
kompilator języka DDL
program zarządzający katalogiem systemu
Elementy programu zarządzającego bazą danych:
system kontroli dostępu
procesor zapytań
system kontroli poprawności poleceń
optymalizator zapytań
program zarządzający transakcjami
system do harmonogramowania zadań
system usprawniający odtwarzanie systemu z przed awarii
Architektura systemu zarządzania bazą danych z wielodostępem:
zdalne przetwarzanie - jest to rozwiązanie wychodzące z użycia charakteryzujące się tym że system zarządzania bazą danych, dane oraz oprogramowanie aplikacji realizujących poszczególne perspektywy wszystko to jest zapisane na centralnym komputerze dołączone są terminale za pośrednictwem których użytkownicy dostają dostęp do danych
architektura serwera plików - dane z których mogą korzystać użytkownicy za pośrednictwem swoich stacji roboczych. Baza danych zapisana jest na serwerze plików na poszczególnych stacjach roboczych zainstalowane są systemy zarządzana bazą danych jako odrębne kopie oraz programy realizujące poszczególne perspektywy. Wszystkie stacje robocze są połączone z serwerem plików za pośrednictwem sieci komputerowej
Wady (serwera plików):
znaczne natężenie ruchu w sieci
konieczne jest instalowanie kopii systemu zarządzania bazą danych na każdej stacji roboczej
takie rozwiązanie utrudnia współdzielenie danych, kontrole ich poprawności, odtwarzanie stanu systemu sprzed awarii
architektura klient - serwer (serwer aplikacji)
Zalety:
ułatwiony dostęp do istniejącej bazy danych
usprawniony dostęp do danych - lepsze wykorzystanie przepustowości sieci
możliwie oszczędności na sprzęcie komputerowym
ułatwione administrowanie bazą danych
Katalog systemowy (słownik) - jest to zbiór informacji opisujących dane zapisane w bazie (metodane). Jego typowa zawartość to spis uprawnionych użytkowników bazy danych dla nazwy encji (obiektów bazy danych), ograniczenia związane z każdym elementem występującym w bazie danych (np.: ograniczenie wartość atrybutów), określenie zakresów danych dostępnych dla konkretnego użytkownika i sposobu dostępu.
Wykład 3.
Ochrona informacji i polityka bezpieczeństwa
najczęściej 90% decyzji podejmuje 5% kadry
sprzątaczka (20%) ma dostęp do prawie takiej samej ilości informacji jak zarząd 35%
administrator systemu (75%) może wiedzieć jeśli zechce prawie tyle samo co kierownik działu (85%)
kierownik działu (85%) nie zna wszystkich informacji w dziale
Konieczne jest w każdym przypadku opracowanie i przestrzeganie właściwych metod:
kontrolowania
klasyfikacji
opracowanie informacji
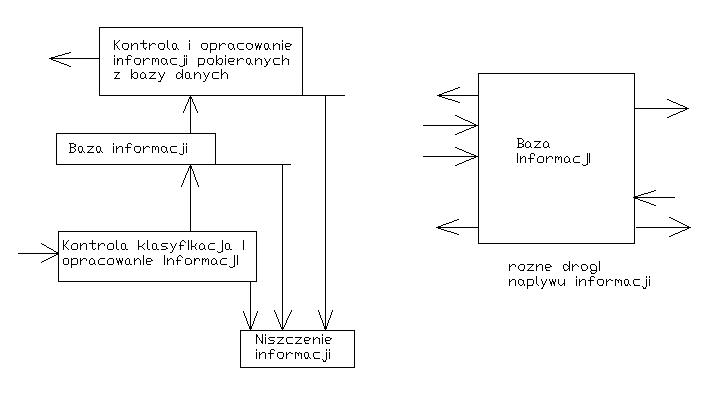
Miejsce przechowywania informacji (2 typy zagrożeń)
zagrożenia w obrębie przedsiębiorstwa 1) wewnętrzne
zagrożenia poza obrębem przedsiębiorstwa 2) zewnętrzne
sprzęt komputerowy, bazy danych, dokumenty elektroniczne, dokumenty papierowe, umysły pracowników (zabezpieczenia sprzętu, zabezpieczenie e-mailów)
bank, kurierzy, telekomunikacja (kluczowe informacje zawsze trafiają do banku, bank żąda konkretnych informacji - mają one najwyższy stopień poufności)
Procedura tworzenia i optymalizacji systemu bezpieczeństwa.
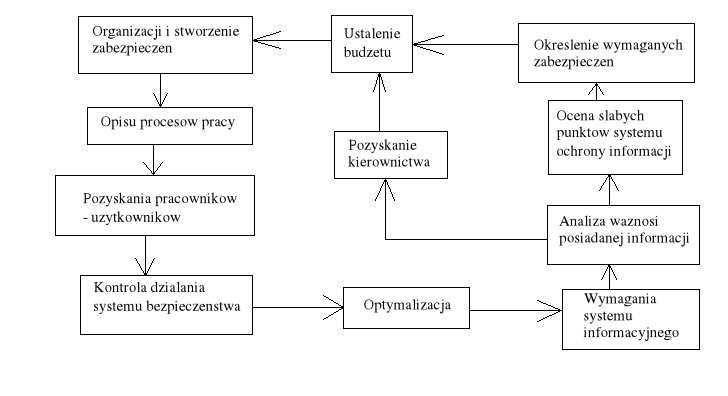
Grupy informacji:
informacje stanowiące o istnieniu przedsiębiorstwa (dokumentacja wewnętrzna, dane personalne, opis zdarzeń gospodarczych itp.)
informacje stanowiące o konkurencyjności na rynku (np. dane o technologiach, konstrukcji itp.)
informacje dotyczące kontroli dostępu do informacji (np. klucze kryptologiczne, zbiory haseł, konfiguracja systemu komputerowego
Informacja powinna zawierać:
czas tworzenia
czas odbioru
temat
treść
dane nadawcy
Opis procesów pracy.
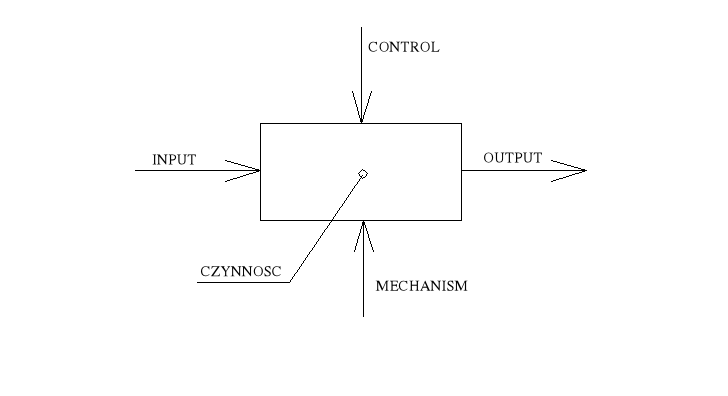
Do opisów procesów pracy stosuje się m.in. dwie odmiany systemów: IDEFO i DFD. System IDEFO i DFD powstały w latach 70-tych na potrzeby sił powietrznych USA. W systemach IDEFO występują następujące elementy opisu procesu:
czynność (określona zawsze przy pomocy czasownika)
wejście (może być informacja lub obiekt materialny, jak np. część do transportu czy obróbki) INPUT
wyjście (może być informacja lub obiekt fizyczny) OUTPUT
sterowanie (to informacja służąca do przetworzenia wejścia w wyjście) CONTROL
mechanizm (jest zawsze elementem fizycznym który umożliwia realizację działania) MECHANIK. W systemach IDERO mechanizm może ale nie musi być precyzowany.
W systemach IDERO opis procesów pracy jest realizowany na szeregu płaszczyznach. Poczynając od szczebla najwyższego jakim jest dana instytucja. Poszczególne warstwy opisują coraz niższe szczebla hierarchii dochodząc do poziomu konkretnych stanowisk roboczych.
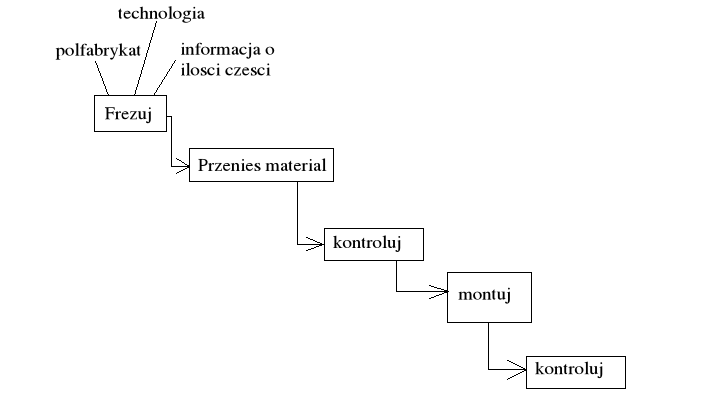
Czynności:
Plany (projekt, technologie)
Oszacuj stopień wykorzystania zasobów
Kieruj pracą wydziału
Wykonaj zadania danej obrabiarki (stacji roboczej)
Transportuj materiał
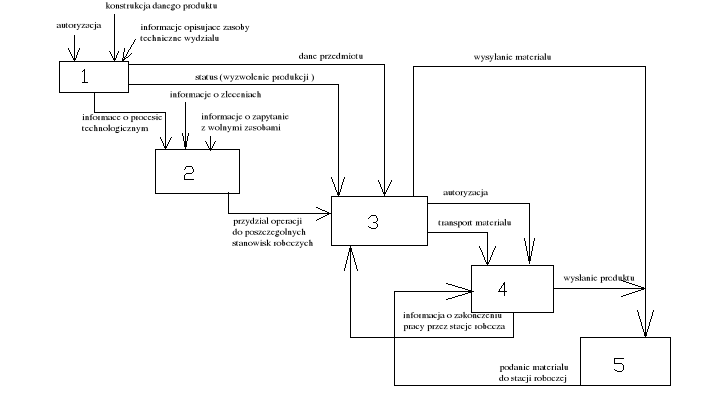
Schemat na poziomie wydziału.
Systemy operujące informacjami (bazy danych) na poziomie wydziału produkcyjnego muszą być w stanie udzielać informacji (odpowiedzi) na takie pytania jak:
skąd wiemy jakie produkty mamy montować i z jakich części ?
skąd wiemy gdzie aktualnie są te części ?
skąd wiemy kiedy należy przystąpić do obróbki lub do montażu ?
skąd wiemy jakie jest obciążenie (zlecenia) danego wydziału, jaka jest kolejność realizacji poszczególnych prac ?
jak należy zmodyfikować plan pracy wydziału w przypadku awarii któregoś z urządzeń
skąd wiadomo gdzie aktualnie jest część i materiał który został wyekspediowany z danego stanowiska roboczego ?
Modele DFD opisują wyłącznie część informacyjną procesów pracy. Zapis tych modeli składa się z następujących elementów:
obiekty wewnętrzne
składnice danych
procesy
strumienie danych
Obiekty wewnętrzne wyznaczają otoczenie modelowego procesy pracy. Budowa modeli DFD wymaga stosowania się do pewnych reguł takich jak:
strumienie danych muszą kończyć się lub zaczynać albo kończyć i zaczynać procesem
strumienie danych opatrzone dwoma strzałkami oznaczają przesyłanie w obu kierunkach informacji o ściśle takim samym formacie, jeżeli formaty są różne to w modelu umieszcza się symbole dwóch różnych strumieni informacji
Modele DFD budowane są również na różnych poziomach. Uogólnienia tym górnym tylko obiekty na najniższym poziomie takiej struktury mają swoje odzwierciedlenie rzeczywiście przesyłanych w strumieniach informacji, procesach pracy czy obiektach zewnętrznych. Na każdym poziomie szczegółowości modelu istnieją ograniczenia co do ilości procesów które mogą być w niej przedstawiane. Takich procesów powinno być nie mniej niż 4 i nie więcej niż 8. jeżeli w modelu konieczne jest odwołanie się do elementów fizycznych to mogą one wystąpić w postaci przypisów w dołączonych konkretnych procesów, wyjątkowo w postaci obiektów zewnętrznych. Każdy proces musi mieć zarówno wejście jaki wyjście przy czym nie mogą występować procesy tylko 1 we i 1 wy.
Wykład 4.
Wprowadzanie danych do baz danych.
Wśród systemów oprogramowania realizujących operacje na strumieniach danych określonych w opisach procesów pracy należą następujące typy narzędzi programowych:
to takie które operują na wspólnej sieci komputerowej i pozwalają one na prowadzenie telekonferencji i przesyłanie poczty elektronicznej wraz z załącznikami.
to systemu gromadzenia danych wspólnych dla konkretnego projektu umożliwiają one zarządzanie projektem, koordynację pracy członków zespołu oraz udostępniania fragmentów projektu i gromadzenie opinii na ich temat
oprogramowanie do pracy grupowej i pozwala na pracę zespołu z wykorzystaniem tych samych dokumentów i możliwe jest definiowanie drogi obiegu dokumentu
oprogramowanie pozwalające na dostęp do dokumentów wybranym użytkownikom systemu w tym samym czasie. Najczęściej takie oprogramowanie będzie służyło do udostępniania obrazów (prezentacji) wyświetlanych na monitorze prowadzącego dne spotkanie
oprogramowanie którego cechą jest operowanie na dokumentach tworzonych i edytowanych w danym momencie, w danym miejscu. Do tego rodzaju oprogramowania należy zaliczyć oprogramowanie wspomagające prowadzenie spotkań w postaci burzy mózgów, systemy wspomagania podejmowania decyzji oraz zapisu przebiegu spotkań i narad
Wprowadzanie danych do baz danych może odbywać się z wykorzystaniem szeregu technik
1. skanowanie - proces konwersji danych od formatu stosowanego w tworzonej bazie danych może obejmować przeniesienie danych z nośnika papierowego do postaci elektronicznej. Należy wyróżnić 2 przypadki:
seryjne skanowanie dokumentów o zunifikowanej strukturze (dane z biletów lotniczych)
skanowanie dokumentów o niejednorodnym formacie
SKANOWANIE SERYJNE.
Proces OCR jest zawsze obciążony błędem w związku z tym trzeba się liczyć, z błędnie odczytanymi znakami ok. 3% OCR korzystają ze słowników dla podniesienia poprawności odczytu.
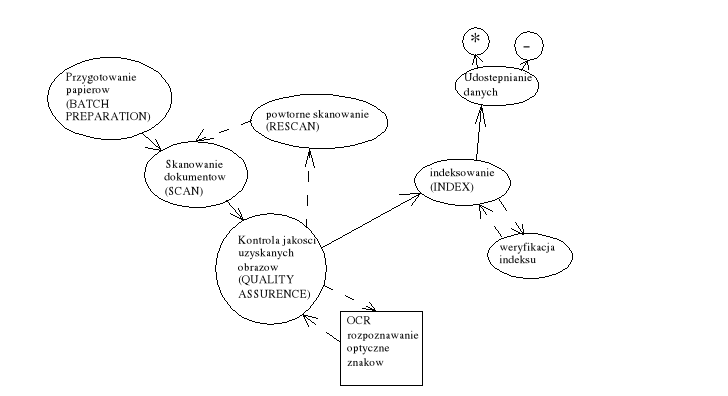
2. Indeksowanie jest procesem opatrzenia dokumentu lub dodania do jego zawartości unifikalnego znaku, jest to klucz do relacji zawierających dane dokumenty
* - mapy bitowe np. TIFF
- - SQL indices - przez udostępnianie klucza do dokumentu
PREPARE
przygotowanie dokumentu - określanie typu dokumentów oraz pola indeksowania
przygotowanie dokumentów - przygotowanie fizyczne
określanie stref które będą poddawane analizie OCR
SCAN
wczytywanie danych
powtórne skanowanie
analiza zawartości odczytanych danych
PRZETWARZANIE OBRAZÓW - image processing
korekta kątowego usytuowania skanowanego obrazu
rozpoznawanie kodów paskowych - kody paskowe są standardowym sposobem oznaczania typów dokumentów przewidzianych do masowego (seryjnego) skanowania. Rozpoznanie kodu paskowego decyduje o sposobie przetwarzania skanowanego dokumentu. [ Dokumenty mogą składać się z wielu obrazów skanowanych. Analiza zawartości dokumentu może więc wymagać połączenia wielu obrazów składowych w dokument wynikowy. Przykładem może być skanowanie dokumentów wielostronicowych ]
rozpoznawanie znaków OCR - odczyt zawartości dokumentu
Proces wprowadzania danych do bazy danych.
projektowanie formularzy - do projektu formularza w celu usprawnienia późniejszego seryjnego skanowania. stosuje się szereg narzędzi programowych w każdym przypadku narzędzia takie muszą umożliwiać następujące zadania: projekt, formularz, (znacznik dokumentu , kod dokumentu)
odczyt zawartości dokumentów - udostępnianie danych może mieć miejsce za pośrednictwem druku czy przy pomocy faksu. Wiele z tych przypadków udostępniania druku przy pomocy faksu zostały zastąpione przez formularze wypełniane i przesyłane przez pocztę elektroniczną.
pamięci EE PROM - zapis danych w tych pamięciach jest szeroko stosowany np. do znakowania narzędzi. Stosuje się również do znakowania pojazdów. Pojemność takiej pamięci to kilka kb a poszczególne pamięci mają swoje unikalne kody. Kody te wraz z datą i godziną odczytu mogą stanowić indeks do oznaczenia odczytywanej informacji. Odczyt z takiej pamięci może odbywać się za pomocą wiązań dotykowych i bezdotykowych (fale radiowe)
biometria - w ich ramach stosowane są następujące metody identyfikacji użytkowej systemów komputerowych:
identyfikacja wkładek, żył w dłoni
pomiar geometrii dłoni
identyfikacja odcisków palców
identyfikacja głosu
identyfikacja na podstawie obrazu tęczówki i siatkówki
Wprowadzanie danych w systemach produkcyjnych.
Poprawne zarządzanie pracą produkcyjną np. w walcowniach wymaga aktualizacji informacji o przebiegu produkcji co ok. 15min (wg danych hut z obszaru Beneluksu)
Często zamiast nanoszenia czytelnego opisu w formie znaków numerycznych nanoszone są oznaczenia kodów w formie szeregu nawierconych otworów (nadrukowane numery są czytelne jeżeli są świeże, gorzej jak wyschną, np. najpierw na przedmiot nanosimy białe tło a następnie na tło numeryczny opis). Oznakowania nanoszone na poszczególne produkty mają mieć gwarantowaną żywotność sięgająca kilkudziesięciu lat w innych przypadkach wymaga się ich odporności na wysokie temperatury lub dopuszczenia kontaktu z żywnością. Często informacje o produktach nanosi się na odpowiednio zaprojektowane formularz lub gromadzi przy pomocy specjalistycznych tabletów graficznych
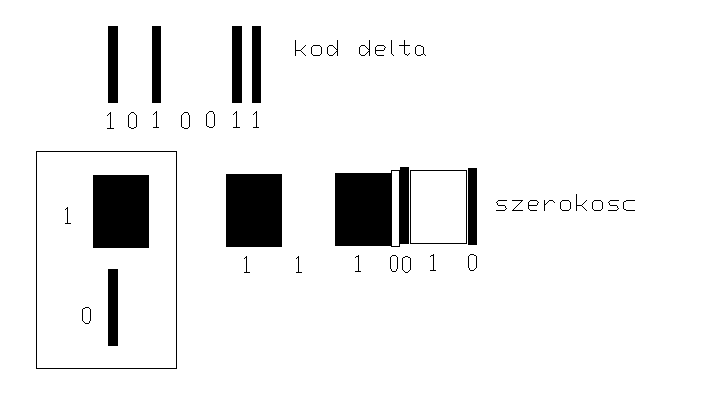
KODY paskowe są efektywnym i szeroko stosowanym nośnikiem danych przydatnym do automatyzacji procesów wprowadzania danych. W 1949r w USA opatentowano kody. Kody paskowe mogą być nanoszone bezpośrednio na produkt, mogą być wypalane lub grawerowane na produkcie lub drukowane na nalepkach umieszczanych na projektach. W przypadku prób wprowadzania nalepkami produktów hutniczych problemem jest wybór niezawodnego kleju do nanoszenia tego typu oznakowań. Kody paskowe to ciąg następujących po sobie pasków jasnych i ciemnych.
Wykład 5.
Modelowanie.
Złożenie modelu logicznego stanowiącego podstawę projektu bazy danych wymaga założenia zbioru encji wraz z ich atrybutami a następnie określeniu ich powiązania.
Należy rozróżnić dwa pojęcia.
Przechodząc do definicji związku pomiędzy encjami należy wyróżnić dwa typy encji:
to encje mocne, których istnienie encji nie wymaga istnienia odpowiednich elementów innych encji
słabe - których istnienie jest uzależnione od występowania powiązanych z nimi encji mocnych
Nie istnieje żadna reguła pozwalająca na stwierdzenie czy dana encja jest mocna czy słaba. Decyzję podejmuje się w trakcie analizy danego modelu.
Tworzenie wykresów związku encji ułatwia stworzenie poprawnego modelu logicznego świata, którego obrazem ma być tworzona baza danych. Model taki składa się z encji oraz powiązań między nimi. Poszczególne encje są na takich wykresach charakteryzowane przez nazwę oraz przez podanie dla nich atrybutów kluczowych.
Fakt istnienia powiązań pomiędzy poszczególnymi encjami jest dodatkową informacją pozwalającą na budowę poprawnej bazy danych.
Poszczególne encje w ramach danego modelu mają szereg atrybutów, które można podzielić na proste i złożone.
Atrybuty proste.
Atrybuty złożone - to takie które składają się z szeregu niezależnych elementów.
Atrybuty mają być pojedyncze i złożone.
Atrybuty pojedyncze - dla danej encji może mieć tylko pojedynczą wartość w przeciwnym przypadku mamy możliwość zapisania wielu atrybutów, wartości dla danej encji (kropka).
Atrybuty pochodne - to takie, których wartości wyznaczane są na podstawie innych atrybutów w tym na podstawie atrybutów innej encji.
Tworzenie modelu graficznego w tym graficznej reprezentacji poszczególnych encji umożliwia już na wczesnym etapie budowy bazy danych uzgodnienia z użytkownikiem bazy danych poprawnego widzenia świata.
Powiązania wstępne pomiędzy encjami mogą również mieć atrybuty. W ogólnym przypadku należy dążyć do unikania tworzenia modeli, których powiązania mają swoje atrybuty, takie modele poddają się trudniej reprezentacji w postaci modeli reprezentacyjnych.
Pod pojęciem klucza rozumiemy pewien zbiór identyfikujący relacje. Taki zbiór pozwala na jednoznaczne identyfikowaniu poszczególnych elementów danej relacji który ma być używany jako klucz być jednocześnie minimalnych zbiorem.
Minimalnym to znaczy takim którego żaden podzbiór nie jest zbiorem identyfikującym relacje. Dana relacja może mieć jednocześnie wiele różnych zbiorów identyfikujących. Zbiory takie nazywamy kluczami kandydującymi. Z pośród nich wybiera się jeden klucz noszący nazwę klucza relacji. Wybór klucza relacji podyktowany jest względami związanych z usprawnieniem operowania na danych i jego przydatności.
Związki.
Związek określa fakt istnienia pewnego rodzaju połączenia pomiędzy elementami różnych typów encji. Związek określany jest przez jego stopień. Stopniem związku nazywamy powiązania różnych typów encji, których elementy można w danym związku jednocześnie wystąpić.
Każde powiązanie musi nosić indywidualną nazwę.
Reprezentacja powiązań przy pomocy sieci schematycznych.
Ponieważ poszczególne elementy różnych obrazów encji mogą pozostawać z sobą w związkach to fakty takie należy zapisać. Zapis ten wymaga rozważania cech danego powiązania właściwych dla danego modelu świata.
Tworzenie sieci schematycznej i przedyskutowanie jej struktury z użytkownikiem pozwala na wykrycie szeregu reguł, które w następnym etapie projektu mogły nie być w sposób czytelny sformułowane.
W powiązaniach pomiędzy encjami mogą występować powiązania rekursyjne (nleży ich unikać ponieważ baza danych może dawać nie jednoznaczne wyniki dla takich samych zapytań).
Przy powiązaniach pomiędzy encjami należy określić typ powiązań. Pod pojęciem typu powiązań będziemy rozumieć 1 z 3 przypadków:
1 : N (człowiek wiele adresów)
1 : 1
N : N (wiele języków programowania i wiele jeżyków danych)
Tworząc modele baz danych należy unikać tworzenia modeli których występują powiązania 1:1. W przypadku N:N najczęściej konieczne będzie tworzenie wiele typów encji.
16
Wyszukiwarka