ESTYMACJA
Szacowanie wartości parametrów w populacji na podstawie próby jest zadaniem estymacji parametrycznej.
Estymacja przedziałowa
Przedziałem ufności nazywamy taki przedział, który z zadanym z góry prawdopodobieństwem (1-α), zwanym poziomem ufności (lub współczynnikiem ufności), pokrywa nieznaną wartość szacowanego parametru Q.
Z reguły przyjmuje się poziom ufności bliski jedności, tzn. (1-α)=0,9; 0,95; 0,99.
-------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
Przedziały ufności dla średniej.
Zakładamy, że cecha X ma w populacji rozkład normalny N(m,σ). Niech
m - średnia arytmetyczna w populacji
σ - odchylenie standardowe w populacji
![]()
- średnia arytmetyczna z próby
S - odchylenie standardowe z próby
n - liczebność próby
-------------------------------------------------------------------------------------------------
(1) Przedział ufności dla średniej w przypadku, gdy σ - znane, dowolna liczebność próby
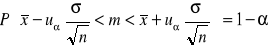
gdzie uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
-------------------------------------------------------------------------------------------------
(2) Przedział ufności dla średniej w przypadku, gdy σ - nieznane, liczebność próby n < 30
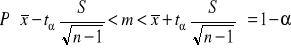
gdzie tα odczytujemy z tablic rozkładu t-Studenta dla danego α i (n-1) stopni swobody.
-------------------------------------------------------------------------------------------------
(3) Przedział ufności dla średniej w przypadku, gdy σ - nieznane, liczebność próby n ≥ 30, rozkład X w populacji nie musi być normalny
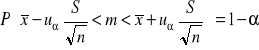
gdzie uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
-------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
Przedział ufności dla wskaźnika struktury.
Niech
p - wskaźnik struktury ( procent wyróżnionych elementów) w populacji,
k - liczba elementów wyróżnionych w próbie
n - liczebność próby
Zakładamy, że n>100, k/n >0,05. Wówczas
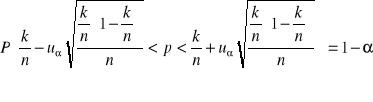
-------------------------------------------------------------------------------------------------
Przy ostrożnym szacunku
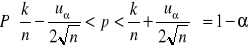
gdzie uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α
-----------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------
Przedział ufności dla wariancji.
Zakładamy, że cecha X ma w populacji rozkład normalny N(m,σ). Niech
σ2 - wariancja w populacji
S2 - wariancja w próbie
n - liczebność próby
-------------------------------------------------------------------------------------------------
(1) Dla n < 30
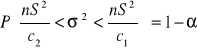
gdzie c1 - odczytujemy z tablic rozkładu χ2 dla (1- α/2) i (n-1) stopni swobody,
c2 - odczytujemy z tablic rozkładu χ2 dla ( α/2) i (n-1) stopni swobody.
(2) Dla n≥30
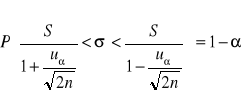
gdzie uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
-------------------------------------------------------------------------------------------------
Minimalna liczebność próby przy szacowaniu średniej m w populacji (losowanie proste)
Zakładamy, że cecha X ma w populacji rozkład normalny N(m,σ). Niech
m - średnia arytmetyczna w populacji
σ - odchylenie standardowe w populacji
![]()
- średnia arytmetyczna z próby
S - odchylenie standardowe z próby
n - niezbędna liczebność próby
n0 - liczebność próby wstępnej
d - dopuszczalny błąd szacunku
-------------------------------------------------------------------------------------------------
(1) σ - znane, dowolna liczebność próby, cecha X ma w populacji rozkład normalny N(m,σ)
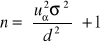
gdzie uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
[ ] - oznacza całość z liczby
-------------------------------------------------------------------------------------------------
(2) σ - nieznane, liczebność próby n < 30, cecha X ma w populacji rozkład normalny N(m,σ)
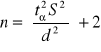
gdzie tα odczytujemy z tablic rozkładu t-Studenta dla danego α i (n-1) stopni swobody.
-------------------------------------------------------------------------------------------------
(3) σ - nieznane, liczebność próby n ≥ 30, rozkład X w populacji nie musi być normalny
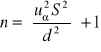
gdzie uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
Jeżeli n > n0 to należy dolosować n-n0 elementów.
Minimalna liczebność próby przy szacowaniu wskaźnika struktury w populacji (losowanie proste)
p - wskaźnik struktury ( procent wyróżnionych elementów) w populacji,
k - liczba elementów wyróżnionych w próbie
n - niezbędna liczebność próby
n0 - liczebność próby wstępnej
d - dopuszczalny błąd szacunku
-------------------------------------------------------------------------------------------------
Zakładamy, że n>100, k/n >0,05, znamy wskaźnik struktury p w populacji
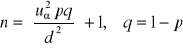
gdzie uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
Zakładamy, że n>100, k/n >0,05, nie znamy wskaźnika struktury p w populacji
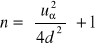
gdzie uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
PARAMETRYCZNE TESTY ISTOTNOŚCI
-------------------------------------------------------------------------------------------------
Test dla wartości średniej
------------------------------------------------------------------------------------------------
m - średnia arytmetyczna w populacji, m0- hipotetyczna wartość średniej arytmetycznej w populacji, ![]()
- średnia arytmetyczna z próby, σ - odchylenie standardowe w populacji, S - odchylenie standardowe w próbie, n - liczebność próby
-------------------------------------------------------------------------------------------------
(1) Zakładamy, że rozkład cechy w populacji jest normalny N(m,σ) lub zbliżony do normalnego, odchylenie standardowe σ w populacji jest znane.
H0 : m = m0
H1 : m ≠ m0 (obustronny obszar odrzucenia)
m < m0 ( lewostronny obszar odrzucenia)
m > m0 (prawostronny obszar odrzucenia)
Postać statystyki testowej:
![]()
Dla obszaru obustronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
Dla obszaru jednostronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- α.
Hipotezę zerową odrzucamy gdy: ![]()
dla obszaru obustronnego, ![]()
dla obszaru lewostronnego, ![]()
dla obszaru prawostronnego. W przeciwnym przypadku brak jest podstaw do odrzucenia H0.
-------------------------------------------------------------------------------------------------
(2) Zakładamy, że rozkład cechy w populacji jest normalny N(m,σ) lub zbliżony do normalnego, odchylenie standardowe σ w populacji jest nieznane oraz n ≤ 30
H0 : m = m0
H1 : m ≠ m0 , m < m0 , m > m0
Postać statystyki testowej:
![]()
Dla obszaru obustronnego tα odczytujemy z tablic rozkładu t-Studenta dla α i (n-1) stopni swobody.
Dla obszaru jednostronnego tα odczytujemy z tablic rozkładu t-Studenta dla 2α i (n-1) stopni swobody.
Hipotezę zerową odrzucamy gdy: ![]()
dla obszaru obustronnego, ![]()
dla obszaru lewostronnego, ![]()
dla obszaru prawostronnego. W przeciwnym przypadku brak jest podstaw do odrzucenia H0.
------------------------------------------------------------------------------------------------- (3) Zakładamy, że rozkład cechy w populacji jest normalny N(m,σ) lub dowolny, odchylenie standardowe σ w populacji jest nieznane oraz n > 30.
H0 : m = m0
H1 : m ≠ m0 , m < m0 , m > m0
Postać statystyki testowej:
![]()
Dla obszaru obustronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
Dla obszaru jednostronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- α.
Hipotezę zerową odrzucamy gdy: ![]()
dla obszaru obustronnego, ![]()
dla obszaru lewostronnego, ![]()
dla obszaru prawostronnego.W przeciwnym przypadku brak jest podstaw do odrzucenia H0.
-------------------------------------------------------------------------------------------------
Test dla wariancji
------------------------------------------------------------------------------------------------
m - średnia arytmetyczna w populacji, ![]()
- średnia arytmetyczna z próby
σ - odchylenie standardowe w populacji, σ0- hipotetyczna wartość odchylenia standardowego w populacji, S - odchylenie standardowe w próbie, n - liczebność próby
---------------------------------------------------------------------------------------------
Zakładamy, że rozkład cechy w populacji jest normalny N(m,σ), odchylenie standardowe σ w populacji jest nieznane.
H0 : σ2 = σ20
H1 : σ2 > σ20
Postać statystyki testowej:
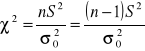
Dla obszaru obustronnego ![]()
odczytujemy z tablic rozkładu normalnego dla α i (n-1) stopni swobody. Hipotezę zerową odrzucamy gdy: ![]()
. W przeciwnym przypadku brak jest podstaw do odrzucenia H0. Pamiętając, że
![]()
-------------------------------------------------------------------------------------------------
Test dla wskaźnika struktury.
-------------------------------------------------------------------------------------------------
p - wskaźnik struktury ( procent wyróżnionych elementów) w populacji,, p0- hipotetyczna wartość wskaźnika struktury w populacji, k - liczba elementów wyróżnionych w próbie
n - liczebność próby
Zakładamy, że rozkład cechy w populacji dwupunktowy z parametrem p oraz n>100.
H0 : p = p0
H1 : p ≠ p0 , p < p0 , p > p0
Postać statystyki testowej:
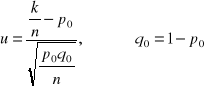
Dla obszaru obustronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
Dla obszaru jednostronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- α.
Hipotezę zerową odrzucamy gdy: ![]()
dla obszaru obustronnego, ![]()
dla obszaru lewostronnego, ![]()
dla obszaru prawostronnego. W przeciwnym przypadku brak jest podstaw do odrzucenia H0.
-------------------------------------------------------------------------------------------------
Test dla dwóch średnich.
-------------------------------------------------------------------------------------------------
m1 - średnia arytmetyczna w populacji I, m2- średnia arytmetyczna w populacji II
![]()
- średnia arytmetyczna z próby I, ![]()
- średnia arytmetyczna z próby II
σ1 - odchylenie standardowe w populacji I, σ2 - odchylenie standardowe w populacji II
S1 - odchylenie standardowe w próbie I, S2 - odchylenie standardowe w próbie II
n1 - liczebność próby I, n2 - liczebność próby II,
-------------------------------------------------------------------------------------------------
(1) Zakładamy, że rozkład cechy w populacjach jest normalny N(m1,σ1) i N(m2,σ2) lub zbliżony do normalnego, odchylenia standardowe σ1 i σ2 w populacjach są znane.
H0 : m1 = m2
H1 : m1 ≠ m2 (obustronny obszar odrzucenia)
m1 < m2 ( lewostronny obszar odrzucenia)
m1 > m2 (prawostronny obszar odrzucenia)
Postać statystyki testowej:
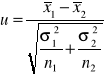
Dla obszaru obustronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
Dla obszaru jednostronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- α.
Hipotezę zerową odrzucamy gdy: ![]()
dla obszaru obustronnego, ![]()
dla obszaru lewostronnego, ![]()
dla obszaru prawostronnego. W przeciwnym przypadku brak jest podstaw do odrzucenia H0.
-----------------------------------------------------------------------------------------------------------------
(2) Zakładamy, że rozkład cechy w populacjach jest normalny N(m1,σ1) i N(m2,σ2) lub zbliżony do normalnego, n1≤ 30 i n2≤ 30, odchylenia standardowe σ1 i σ2 w populacjach są nieznane oraz zachodzi równość:![]()
. Normalność weryfikujemy testem Shapiro-Wilka, równość wariancji w populacjach weryfikujemy testem dla dwóch wariancji
H0 : m1 = m2
H1 : m1 ≠ m2 ,m1 < m2 ,m1 > m2
Postać statystyki testowej:
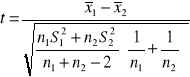
Dla obszaru obustronnego tα odczytujemy z tablic rozkładu t-Studenta dla α i (n1+n2-2) stopni swobody.
Dla obszaru jednostronnego tα odczytujemy z tablic rozkładu t-Studenta dla 2α i (n1+n2-2) stopni swobody.
Hipotezę zerową odrzucamy gdy: ![]()
dla obszaru obustronnego, ![]()
dla obszaru lewostronnego, ![]()
dla obszaru prawostronnego. W przeciwnym przypadku brak jest podstaw do odrzucenia H0.
-----------------------------------------------------------------------------------------------------------------
(3) Zakładamy, że n1> 30 i n2>30 oraz odchylenia standardowe σ1 i σ2 w populacjach są nieznane.
H0 : m1 = m2
H1 : m1 ≠ m2 ,m1 < m2 ,m1 > m2
Postać statystyki testowej:
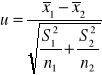
Dla obszaru obustronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
Dla obszaru jednostronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- α.
Hipotezę zerową odrzucamy gdy: ![]()
dla obszaru obustronnego, ![]()
dla obszaru lewostronnego, ![]()
dla obszaru prawostronnego.W przeciwnym przypadku brak jest podstaw do odrzucenia H0.
-------------------------------------------------------------------------------------------------
Test dla dwóch wariancji.
------------------------------------------------------------------------------------------------
Zakładamy, że rozkład cechy w populacjach jest normalny N(m1,σ1) i N(m2,σ2) lub zbliżony do normalnego, odchylenia standardowe σ1 i σ2 w populacjach są nieznane.
H0 : ![]()
H1 : ![]()
Postać statystyki testowej:
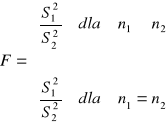
Fα odczytujemy z tablic F-Snedecora dla (n1 -1) i (n2 -1) stopni swobody.
Hipotezę zerową odrzucamy gdy: ![]()
. W przeciwnym przypadku brak jest podstaw do odrzucenia H0.
------------------------------------------------------------------------------------------------
Test dla dwóch wskaźników struktury.
-------------------------------------------------------------------------------------------------
Zakładamy, że populacje mają rozkłady dwupunktowe z parametrami p1 i p2 oraz n1> 100 i n2>100 .
H0 : p1 = p2
H1 : p1 ≠ p2 ,p1 < p2 ,p1 > p2
Postać statystyki testowej:
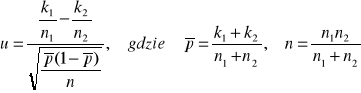
Dla obszaru obustronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- ½ α.
Dla obszaru jednostronnego uα odczytujemy z tablic rozkładu normalnego dla F(uα)= 1- α.
Hipotezę zerową odrzucamy gdy: ![]()
dla obszaru obustronnego, ![]()
dla obszaru lewostronnego, ![]()
dla obszaru prawostronnego.W przeciwnym przypadku brak jest podstaw do odrzucenia H0.
TESTY NIEPARAMETRYCZNE
Test normalności Shapiro-Wilka
![]()
, gdzie ![]()
jest dystrybuantą rozkładu normalnego
![]()
![]()
próba prosta n-elementowa, pobrana z populacji o ciągłej dystrybuancie ![]()
![]()
poziom istotności
Postać statystyki testowej
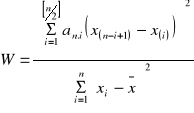
![]()
tablicowane współczynniki
![]()
uporządkowana próba według wartości rosnących
![]()
odczytujemy z tablic wartości krytycznych dla testu Shapiro-Wilka
Obszar odrzucenia ![]()
- zatem hipotezę H0 odrzucamy gdy ![]()
-lewostronny obszar odrzucenia.
Test zgodności ![]()
![]()
, gdzie ![]()
jest zbiorem rozkładów o określonym typie postaci funkcyjnej dystrybuanty
![]()
n- elementowa próba (n>100, dane przedstawione są w postaci szeregu rozdzielczego o r przedziałach klasowych o liczebnościach ![]()
(i=1,…,r)
![]()
poziom istotności
Postać statystyki testowej
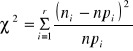
Statystyka ta przy założeniu prawdziwości ![]()
ma rozkład ![]()
o ![]()
stopniach swobody.
k - liczba szacowanych parametrów, które należy wstępnie wyznaczyć na podstawie próby
r - liczba przedziałów klasowych
![]()
- prawdopodobieństwo, że zmienna X przyjmuje wartość należącą do i-tego przedziału klasowego, gdy rozkład jest zgodny z ![]()
![]()
- liczba jednostek, które powinny się znaleźć w i-tym przedziale, przy założeniu, że zmienna ma rozkład zgodny z hipotetycznym
Obszar odrzucenia ![]()
(prawostronny), Wartość ![]()
odczytujemy z tablic dla (r-k-1) stopni swobody i danego![]()
Test serii losowości próby (test medianowy)
![]()
próba jest losowa
![]()
próba n-elementowa
![]()
poziom istotności
Wyznaczamy Me z próby (w tym celu porządkujemy próbę niemalejąco).
Każdemu wynikowi z próby (według kolejności losowania elementów) przypisujemy symbol:
a gdy ![]()
,
b gdy ![]()
,
![]()
odrzucamy.
Zliczamy:
k - liczba serii
n1- liczba symboli a
n2 - liczba symboli b
Obszar odrzucenia dwustronny odczytujemy z tablic rozkładu liczby serii
![]()
, ![]()
Tablice ![]()
; ![]()
Test serii dla sprawdzenia hipotezy, że dwie próby pochodzą z jednej populacji
![]()
![]()
dane:
dwie próby o liczebnościach:![]()
![]()
poziom istotności
Wyniki obu prób ustawiamy w jeden niemalejący ciąg. Elementy I próby oznaczamy symbolem a, próby II symbolem b. Zliczamy liczbę serii k
Obszar odrzucenia ![]()
odczytujemy z tablic rozkładu liczby serii dla danych ![]()
tak, aby ![]()
(lewostronny obszar odrzucenia hipotezy zerowej).
Test niezależności chi-kwadrat
W teście niezależności chi-kwadrat hipotezy zerowa i alternatywana mają postać
H0: cechy X i Y są niezależne (![]()
)
H1: cechy X i Y są zależne
Z populacji generalnej losuje się co najmniej 100 elementową próbę losową, a jej wyniki grupuje w tablicę o r-wierszach i s-kolumnach, nazywaną tablicą kontyngencji:
X |
Y |
|
|
|
|
|
|
|
|
|
|
|
|
n |
1 |
|
|
1 |
|
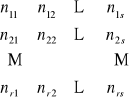
Wnętrze tablicy kontyngencji (korelacyjnej) stanowią liczebności empiryczne ![]()
takie, że ![]()
. Przez ![]()
,![]()
oznaczamy liczebności brzegowe, natomiast ![]()
oraz ![]()
są prawdopodobieństwami brzegowymi.
Postać statystyki testowej testu niezależności chi-kwadrat
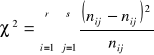
gdzie ![]()
są prawdopodobieństwami teoretycznymi.
Statystyka ta ma przy założeniu prawdziwości hipotezy H0 asymptotyczny rozkład ![]()
z (r-1)(s-1) stopniami swobody.
Test ma prawostronny obszar odrzucenia, tzn. że na poziomie istotności α hipotezę H0 odrzucamy na korzyść hipotezy alternatywnej, gdy ![]()
. W przeciwnym przypadku: na poziomie istotności α brak jest podstaw do odrzucenia H0.
10
Wyszukiwarka
Podobne podstrony:
wniosek o wydanie odpisu aktu urodzenia, Wzory dokumentow
lm ksiegowa, Wzory dokumentów, Listy motywacyjne
umowa kupna sprzedazy-1, Wzory dokumetów
zaswiadczenie o ukonczeniu szkolenia bhp, Wzory dokumentow
Sprawozdanie z przeprowadzenia zadania audytowegowzor, wzory dokumentów AUDYT
Prośba o uchyl decyzji, BHP, wzory dokument
Podanie o wydzierzawienie obwodow, Wzory dokumentów lowieckich
Umowa z klauzulą wyłączności, Studia, 7 semestr, ZiON, sprawozdanie 2, wzory dokumentów
Wniosek o przywrocenie terminu, wzory dokumentów
Konspekt zajęć opiekuńczo - wychowawczych, Polonistyka, Wzory dokumentów - polonistyka i pedagogika
cv murarz tynkarz v3, Wzory dokumentów, CV
lm pracownik biurowy, Wzory dokumentów, Listy motywacyjne
umowa uzyczenia samochodu, wzory dokumentów
UMOWA O PRACE, wzory dokumentów
Protokol Z prac wykonanych przez Koło Łowieckie, Wzory dokumentów lowieckich
Prośba o odrocz terminu decyzji, BHP, wzory dokument
Regulamin polowań, Wzory dokumentów lowieckich
wzor-zyciorys, wzory dokumentów
Protokol inwentaryzacji, Wzory dokumentów lowieckich
więcej podobnych podstron