rozdział WSTĘP
zero
Informatyka jest dyscypliną próbującą stworzyć podstawy naukowa takich zagadnień, jak budowa komputerów, ich programowanie, przetwarzanie informacji, rozwiązywanie problemów za pomocą algorytmów oraz same algorytmy. W konsekwencji zapewnia podstawy do dzisiejszych i przyszłych zastosowań komputerów. Nie można zapoznać się z istotą informatyki, studiując jedynie kilka jej gałęzi w oderwaniu od innych, ani ucząc się jedynie obsługi dostępnych współcześnie komputerów i ich oprogramowania. Aby zrozumieć informatykę, trzeba ogarnąć duży zakres zagadnień i zrozumieć istniejące w.nich trendy rozwojowe.
Książka ta została napisana z myślą ułatwienia czytelnikowi tego zadania. Przedstawiono w niej informatykę, wprowadzając czytelnika w zagadnienia, które składają się na typowe uniwersyteckie studia informatyczne. Książka może zatBm służyć za podręcznik dla początkujących studentów informatyki albo być żródfem wiedzy dla innych studentów chcących zapoznać się z nauką stojącą za działaniami współczesnego społeczeństwa komputerowego.
0.1. Algorytmika - nauka o algorytmach
0.2. Początki maszyn liczących
0.3. Rozwój informatyki 0.4. Rola abstrakcji
0.5. Reperkusje etyczne, społeczne i prawne
\
xvi SPIS TREŚCI
Zachowanie integralności bazy danych 439
Społeczne skutki wprowadzenia baz danych 444
Pytania do rozdziału dziewiątego 447
Zagadnienia społeczne 451
Lektura uzupełniająca 452
CZĘŚĆ CZWARTA. MOŻLIWOŚCI MASZYN ALGORYTMICZNYCH 453
Rozdział 10. Sztuczna inteligencja 455
Inteligencja i komputery 456
Rozpoznawanie obrazów 460
Wnioskowanie 463
Sztuczne sieci neuronowe 478
Algorytmy genetyczne 487
Zastosowania sztucznej inteligencji 492
Rozważania na temat konsekwencji 501
Pytania do rozdziału dziesiątego 504
Zagadnienia społeczne 508
Lektura uzupełniająca 509
Rozdział 11. Teoria obliczeń 511
Język programowania Bare Bones 512
Maszyny Turinga 518
Funkcje obliczalne 523
Przykład funkcji nieobliczalne] 528
Złożoność problemów 534
Kryptografia z kluczem publicznym 544
Pytania do rozdziału jedenastego 553
Zagadnienia społeczne 556
Lektura uzupełniająca 557
Dodatki 559
A. KodASCn 561
B. Układy manipulujące wartościami reprezentowanymi
w notacji uzupełnieniowej do dwóch 563
C. Typowy język maszynowy 567
D. Przykłady programów 571
E. Równoważność struktur iteracyjnych
i rekurencyjnych 581
F. Odpowiedzi na pytania i rozwiązania ćwiczeń 585
Skorowidz 627
Efekt: Sztukmistrz wyjmuje kilka kart z normalnej talii do gry, umieszcza je figurami do dołu na stole, a następnie tasuje je i rozkłada na stole. Następnie zgodnie z życzeniem widowni odsłania karty czerwone lub czarne.
Tajemnica:
Krok 1.' Wybierz z talii dziesięć kart czarnych i dziesięć kart czerwonych. Ułóż te karty figurami do góry w dwóch kupkach zgodnie z kolorem.
Krok 2. Ogłoś, że wybrałeś pewne karty czerwone i czarne.
Krok 3. Zbierz karty czerwone. Pod pozorem ich wyrównania chwyć je figurami do dołu w lewej ręce, a kciukiem i palcem wskazującym prawej ręki ściśnij kortce tali! tak, aby karty wygięły się lekko do tylu. Następnie połóż czerwone karty na stole figurami do dołu, mówiąc: „Oto kupka kart czerwonych".
Krok 4. Zbierz karty czarne. W podobny sposób jak w kroku 3 wygnij te karty lekko w drugą stronę do przodu. Połóż je następnie na stole, mówiąc: „Oto kupka kart czarnych'.
Krok 5. Natychmiast po położeniu kart czarnych na stofa przetasuj karty czerwone I czarne obiema rękami (trzymając ciągle figurami do dołu) i rozłóż na stole. Wyjaśnij, że dokładnie tasujesz karty.
Krok 6. Dopóki są jeszcze karty na stole, powtarzaj następujące kroki:
Poproś widownię o wybranie koloru karty.
Jeśli został zgłoszony kolor czerwony i jest na stole karta wklęsła, odwróć tę kartę, mówiąc
„To jest karta czerwona".Jeśli został zgłoszony kolor czarny i jest na stole karta wypukła, odwróć tę kartę, mówiąc
„To jest karta czarna'.W przeciwnym wypadku ogłoś, że nie ma więcej kart wskazanego koloru i odwróć
pozostałe, aby udowodnić swoje twierdzenie.
Algorytm magicznej sztuczki
Jedno z głównych zadań informatyki to poszukiwanie algorytmów. Z tego powodu dużą część informatyki poświęcono zagadnieniom związanym z tym zadaniem. Rozpatrując niektóre z nich, możemy zrozumieć, jak szeroką gałęzią nauki jest informatyka. Jedno z zagadnień wiąże się z pytaniem, jak tworzyć algorytmy? Pytanie to jest ściśle związane w ogólności z rozwiązywaniem problemów. Znalezienie algorytmu do rozwiązywania danego problemu jest w istocie odkryciem rozwiązania tego problemu. Wynika z tego, że studia w tej gałęzi informatyki są ściśle związane z takimi obszarami wiedzy jak psychologia rozwiązywania problemów i teoria nauczania. Niektóre z nich omówimy w rozdziale 4.
0.1. ALGORrFMIKA - NAUKA O ALGORYTMACH
0.1. Algorytmika-nauka o algorytmach
Rozpoczniemy od najważniejszego pojęcia informatyki: od algorytmu. Nieformalnie algorytm (ang. algoriihm) to zestaw kroków, które należy wykonać, aby zrealizować pewne zadanie1. Przykładami algorytmów są opis sposobu złożenia modelu samolotu (wyrażony w postaci wydrukowanej instrukcji), instrukcja obsługi pralki (zazwyczaj umieszczona na wewnętrznej stronie pokrywy), opis sposobu wykonania utworu muzycznego (wyrażony w postaci zapisu nutowego) czy wykonania sztuczki magicznej (rys. 0.1).
Aby komputer mógł wykonać jakieś zadanie, należy najpierw opracować algorytm opisujący sposób wykonania tego zadania i przedstawić go w postaci zrozumiałej dla komputera. Ta zrozumiała dla komputera reprezentacja algorytmu nazywa się programem. Programy oraz algorytmy, które one reprezentują, nazywa się oprogramowaniem (ang. software). Oprogramowanie uruchamia się na sprzęcie (ang. hardware).
Ąlgorytmika była początkowo gałęzią" matematyki. Poszukiwanie algorytmów było ważną działalnością matematyków jeszcze na długo przed powstaniem dzisiejszych komputerów. Głównym celem tych poszukiwań było sformułowanie uniwersalnego zestawu wskazówek, za pomocą którego można by było opisać sposób rozwiązywania wszystkich problemów danego typu. Najbardziej znanym wynikiem tych wczesnych poszukiwań jest algorytm znajdowania ilorazu dwóch liczb wielocyfrowych. Inny znany przykład to algorytm znajdowania największego wspólnego dzielnika dwóch liczb naturalnych, odkryty w starożytności przez greckiego matematyka Euklidesa, i na jego cześć nazwany algorytmem Euklidesa (rys. 0.2).
Gdy jest znany algorytm wykonywania pewnej czynności, jej realizacja nie wymaga już rozumienia zasad, na których opiera się -ten algorytm.
Wykonanie tej czynności sprowadza się jedynie do ścisłego przestrzegania
instrukcji. Algorytm dzielenia przez liczbę wielocyfrową albo algorytm Euklidesa można wykonywać, nie rozumiejąc, dlaczego on działa. W pewnym
sensie, umiejętności potrzebne do wykonania zadania są już zaszyte w algorytm.
To właśnie dzięki tej możliwości „wyposażania" algorytmów w inteligencję można tworzyć maszyny, które stwarzają pozory inteligentnego zachowania. Poziom inteligencji przejawianej przez komputery jest zatem ograniczony poziomem inteligencji, którą możemy przedstawić w postaci algorytmów. Maszynę, realizującą konkretne zadanie, można skonstruować jedynie wtedy, kiedy odkryjemy algorytm, który opisuje sposób wykonania tego zadania. Na odwrót, jeśli nie istnieje algorytm, za pomocą którego można rozwiązać pewne zadanie, to jego rozwiązanie leży poza zasięgiem komputerów.
1 Dokładniej, algorytm (est uporządkowanym zbiorem jednoznacznych, wykonywalnych kroków, które określają czynność skończoną. Mówimy o tym w rozdziale 4.
ROZDZIAŁ ZERO WSTĘP
| RYSUNEK 0.2
Opis: Algorytm zakłada, że na wejściu pojawiają się dwie liczby całkowite dodatnie. Wynikiem jego działania jest największy wspólny dzielnik tych dwóch wartości.
Procedura:
Krok 1. Przypisz zmiennym M i N odpowiednio większą i mniejszą wartość wejściową.
Krok 2. Podziel M przez N, a resztę z dzielenia nazwij R.
Krok 3. Jeśli R nie jest zerem, to przypisz zmiennej M wartość N, zmiennej N wartość R i powróć do kroku 2; w przeciwnym razie największy wspólny dzielnik to wartość aktualnie przypisana zmiennej N.
Algorytm Euklidesa znajdowania największego wspólnego dzielnika dwóch liczb całkowitych dodatnich
Następnym krokiem po wymyśleniu algorytmu jest jego reprezentacja w takiej postaci, która jest zrozumiała dla komputera lub dla innych ludzi. Oznacza to, że algorytm pojęciowy trzeba opisać za pomocą dobrze określonego zbioru instrukcji i przedstawić te instrukcje w jednoznaczny sposób. Studia nad tą problematyką mają swoje źródła w nauce o językach i gramatykach i doprowadziły do powstania wielu schematów reprezentacji algorytmów, zwanych językami programowania. Oparto je na różnorodnych podejściach do procesu programowania, zwanych paradygmatami programowania. Niektóre z języków i paradygmaty, na których je oparto, opisano w rozdziale 5.
Projektowanie dużych systemów oprogramowania to coś więcej niż tylko konstruowanie pojedynczych algorytmów wykonujących określone czynności. Trzeba także zaprojektować sposób, w jaki poszczególne elementy systemu będą się ze sobą komunikować. Zatem problemy, które występują w trakcie tworzenia dużych systemów oprogramowania, są znacząco trudniejsze niż te, które trzeba rozwiązać, pisząc krótkie programy. W nadziei na znalezienie narzędzi i metod radzenia sobie z takimi problemami, informatycy sięgnęli do dobrze już rozwiniętej dziedziny: inżynierii. W ten sposób powstała gałąź informatyki zwana inżynierią oprogramowania, która dzisiaj czerpie wiedzę z tak różnych dyscyplin jak inżyniera, zarządzanie projektami, zarządzanie zasobami ludzkimi i projektowanie języków programowania. Ponieważ nasze społeczeństwo jest coraz bardziej zależne od dużych systemów oprogramowania, wciąż wzrasta i nadal będzie wzrastać potrzeba poprawy jakości narzędzi i metodyki tworzenia oprogramowania. Z tego powodu inżynieria oprogramowania jest współcześnie ważnym
ROZDZIAŁ ZERO WSTĘP
tematem badań naukowych. Inżynierię oprogramowania omawiamy w rozdziale 6. •
Inna ważna gałąź informatyki dotyczy projektowania i budowy komputerów. Zagadnienia z tym związane rozważamy w rozdziałach 1 i 2. Chociaż w przedstawieniu zagadnień dotyczących architektury komputerów znalazło się omówienie niektórych problemów natury technologicznej, to jednak nie jest naszym celem przedstawienie szczegółów Implementacji architektur sprzętowych za pomocą układów elektronicznych. Prowadziłoby to zbyt głęboko w dziedzinę elektroniki. Poza tym współczesne technologie elektroniczne mogą zostać w przyszłości zastąpione innymi technologiami -dobrym kandydatem wydaje się być optyka. W podobny sposób dawne mechaniczne maszyny liczące zostały zastąpione urządzeniami elektronicznymi. Naszym celem jest więc jedynie przybliżenie czytelnikowi współczesnej technologii w stopniu pozwalającym na dostrzeżenie jej wpływu na rozwój informatyki.
Ideałem byłoby, gdyby o architekturze komputerów decydowała jedynie nasza wiedza o procesach algorytmicznych i abyśmy nie musieli ograniczać się możliwościami technologicznymi. Zamiast dostosowywać sposób konstrukcji komputerów, a zatem także metody reprezentacji algorytmów do stanu obecnej technologii, wolelibyśmy, aby to aktualny stan wiedzy na temat algorytmów był siłą napędową rozwoju nowoczesnych architektur komputerowych. Dzięki postępowi technicznemu staje się to coraz bardziej realne. Współcześnie można już konstruować maszyny liczące, w których algorytmy reprezentuje się w postaci wielu, jednocześnie wykonywanych ciągów instrukcji lub jako sieć połączeń między wieloma jednostkami centralnymi. Przypomina to sposób reprezentacji informacji w mózgu - jako sieci połączeń między komórkami nerwowymi (rozdział 10).
Architekturę komputerów rozpatruje się także w kontekście przechowywania i uzyskiwania dostępu do danych. Pod tym względem wewnętrzne cechy komputera uwidaczniają się często w postaci jego zewnętrznej, zauważalnej dla użytkownika charakterystyki. Te cechy oraz sposoby unikania ich niepożądanych efektów rozważamy w rozdziałach 1, 7, 8 i 9.
Zagadnieniem blisko związanym z budową maszyn liczących jest sposób porozumiewania się komputera ze światem zewnętrznym. W jaki sposób, na przykład, wprowadzać algorytmy do komputera, w jaki sposób nakazać mu wykonanie konkretnego algorytmu? Rozwiązanie takich problemów w środowisku, w którym komputer realizuje różne usługi, wymaga rozwiązania wielu problemów dotyczących koordynacji wykonania różnych czynności i przydziału zasobów. Niektóre z rozwiązań takich problemów omawiamy przy okazji przedstawienia systemów operacyjnych w rozdziale 3.
Komputery wykonują zadania wymagające coraz większej inteligencji. Z tego powodu informatycy zainteresowali się wynikami badań nad inteligencją człowieka. Jest nadzieja, że zrozumienie procesów rozumowania i percepcji zachodzących w ludzkich umysłach umożliwi konstrukcję algorytmów, które naśladują te procesy i dzięki temu będzie można obdarzyć komputery umiejętnością wnioskowania. W ten sposób rozwinęła
0.1. ALGORYTMIKA - NAUKA O ALGORYTMACH
W czasach bardziej współczesnych, do konstrukcji maszyn liczących wykorzystano koła zębate. Wśród wynalazców takich maszyn liczących byli: Blaise Pascal (1623-1662) z Francji, Gottfried Wilhelm Leibniz (1646-1716) z Niemiec i Charles Babbage (1792-1871) z Anglii. W tych maszynach dane reprezentowano za pomocą pozycji kół zębatych, a wprowadzano je mechanicznie, ustawiając koła w odpowiedni sposób. W maszynach liczących Pascala i Leibniza wyniki odczytywano, analizując końcowe ustawienie kół, tak jak obecnie odczytuje się wartości w samochodowym liczniku przebiegu. Babbage wymarzył sobie maszynę, która drukowałaby wyniki, tak aby zmniejszyć możliwość błędu odczytu.
Można zaobserwować znaczny postęp w możliwościach wykonywania przez maszyny liczące wskazanych algorytmów. Maszynę Pascala zbudowano do realizacji algorytmu dodawania. Właściwy zestaw kroków był zatem wbudowany w strukturę samej maszyny. Maszyna Leibniza miała algorytm także ściśle zaszyty w swojej budowie, chociaż można było wykonywać na niej różne operacje arytmetyczne, które wybierał operator. Maszynę Bab-bage'a zaprojektowano z kolei tak, aby ciąg wykonywanych przez nią kroków można było definiować w postaci otworów na kartach papierowych. Zatem maszynę Babbage'a można było programować, a asystentka Babbage'a, Augusta Ada Byron, często bywa dziś uznawana pierwszym programistą na świecie.
Babbage nie był pierwszym, który wpadł na pomysł wprowadzania algorytmu do maszyny liczącej za pomocą otworów w papierze. W 1801 roku Joseph Jacuard zastosował we Francji podobną technikę do sterowania warsztatem tkackim (rys. 0.3). Opracował on maszynę tkacką, w której poszczególne kroki wykonywane w trakcie tkania definiowano za pomocą wzoru złożonego z otworów w karcie papierowej. Dzięki temu algorytm wykonywany przez maszynę można było łatwo zmieniać i uzyskiwać w ten sposób jóżne wzory. , , ■ . ,, - , ,v, ,■'..■■. .- , ,•■•■
Później, Herman Hollerith (1860-1929) zastosował pomysł reprezentowania informacji w postaci kart perforowanych do przyspieszenia powszechnego spisu ludności przeprowadzonego w 1890 roku w Stanach Zjednoczonych. To właśnie usprawnienie autorstwa Holleritha doprowadziło do powstania firmy IBM.
Ówczesna technologia nie dysponowała wystarczającą precyzją, aby spopularyzować złożone mechaniczne kalkulatory Pascala, Leibniza i Bab-bage'a. Technologia nie nadążała za odkryciami teoretycznymi na polu raczkującej informatyki aż do chwili uzupełnienia urządzeń mechanicznych układami elektronicznymi. Przykładami takich rozwiązań są: maszyna elektromechaniczna George'a Stibitza, zbudowana w 1940 roku w Bell Laboratories, oraz maszyna Mark I skonstruowana w 1944 roku w Harvard University przez Howarda Aikena i grupę inżynierów z IBM (rys. 0.4). W tych maszynach wykorzystano sterowane elektronicznie przekaźniki mechaniczne. Maszyny te stary się przestarzałe prawie natychmiast po skonstruowaniu, ponieważ inni naukowcy odkryli technologię lamp próżniowych i skonstruowali pierwsze całkowicie elektroniczne komputery. Pierwszą z tych maszyn była
0.2. POCZĄTKI MASZYN LICZĄCYCH
Maszyna tkacka Jacquarda (Zdjęcie zamieszczone dzięki uprzejmości International Business Machines Corporation. Wszelkie prawa zastrzeżone)
z pewnością maszyna Atanasoffa-Berry'ego, budowana w latach 1937-1941 w Iowa State College (obecnie Iowa State University) przez Johna Atana-soffa i jego asystenta Clifforda Berry'ego. Inna maszyna tego typu to CO-LOSSUS, zbudowany pod koniec drugiej wojny światowej w Anglii i przeznaczony do odszyfrowywania niemieckich depesz. Wkrótce powstały także inne, bardziej uniwersalne maszyny, takie jak ENIAC (ang. electronic nume-rical integrator and calculator) opracowany przez Johna Mauchly'ego i J. Pre-spera Eckerta w Moore School of Electrical Engineering, University of Pen-sylvania.
Począwszy od tego czasu, historia maszyn liczących łączy się ściśle z postępem technologicznym: odkryciem tranzystorów i układów scalonych, stworzeniem systemu komunikacji satelitarnej i postępami w technice
ROZDZIAŁ ZERO WSTĘP
..■.,■ aiOatmmiwmmt
optycznej. Współczesne komputery biurkowe (oraz ich mniejsi, przenośni kuzyni - laptopy) mają większą moc obliczeniową niż maszyny z 1940 roku, które zajmowały całe pokoje, i mogą szybko wymieniać dane za pomocą globalnych sieci komunikacyjnych.
Początki małych komputerów wiążą się z hobbystami, którzy zaraz po odkryciu dużych maszyn w 1940 roku rozpoczęli eksperymenty z komputerami zrobionymi domowymi sposobami. Steve Jobs i Stephen Wozniak zbudowali dostępny następnie komercyjnie komputer i w 1976 roku utworzyli firmę Apple Computer Inc, która zajęła się produkcją i wprowadzeniem na rynek ich produktów. Chociaż komputery Apple były popularne, nie zdobyły akceptacji w środowiskach biznesowych, w których w większości posługiwano się produktami dobrze już wtedy rozwiniętej firmy IBM.
W 1981 roku IBM wprowadził na rynek pierwszy komputer biurkowy, zwany komputerem osobistym albo krótko PC. Podstawowe oprogramowanie dla niego opracowała młoda firma Microsoft. Komputer PC stał się natychmiast sukcesem i spowodował, że komputery biurkowe uznano
0.2. POCZĄTKI MASZYN LICZĄCYCH
w środowisku biznesowym za godny uwagi i sprawdzony produkt. Współcześnie terminu PC używa się jako wspólnej nazwy wszystkich komputerów (różnych producentów), których architektura wywodzi się od pierwszego komputera biurkowego firmy IBM. Większość z nich w dalszym ciągu jest sprzedawana z oprogramowaniem firmy Microsoft. Czasem jednak skrót PC jest używany zamiennie z ogólnym terminem biurkowy.
Dostępność komputerów biurkowych spowodowała, że technika komputerowa stała się ważnym elementem we współczesnym społeczeństwie. Technologia komputerowa jest tak rozpowszechniona, że umiejętność posługiwania się nią jest podstawowym warunkiem bycia członkiem nowoczesnego społeczeństwa. To właśnie dzięki niej miliony indywidualnych użytkowników komputerów mają dostęp do globalnej sieci Internet, która z pewnością ma duży wpływ na sektory prywatne i komercyjne. Jednakże umiejętność posługiwania się współczesnymi produktami to nie to samo, co rozumienie naukowych podstaw ich działania. Celem autora jest przedstawienie zakresu badań stosunkowo młodej nauki, jaką jest informatyka.
0.3. Rozwój informatyki
Czynniki takie jak ograniczone możliwości gromadzenia danych i szczegółowe, czasochłonne procedury programowania ograniczały złożoność algorytmów, które mogły wykonywać wczesne maszyny liczące. W miarę usuwania tych ograniczeń komputery zaczęto wykorzystywać do coraz bardziej złożonych i większych zadań. Opisywanie metody wykonywania tych zadań w sposób algorytmiczny stanowiło wyzwanie dla umysłu ludzkiego. Coraz większe wysiłki wkładano w studia nad procesem konstrukcji algorytmów i programowania.
W tym właśnie kontekście zaczęły owocować teoretyczne wyniki prac matematyków, którzy już po odkryciu przez Godła niezupełności arytmetyki badali te problemy dotyczące procesu konstrukcji algorytmów, które niosła ze sobą nowoczesna technologia. Przygotowało to grunt pod nową dyscyplinę nauki zwaną informatyką.
Współcześnie ta nowa dyscyplina ustanowiła się jako nauka o algorytmach. Jak już to zauważyliśmy, jej zakres jest szeroki i obejmuje tak odległe od siebie zagadnienia jak matematyka, inżynieria, psychologia, biologia, zarządzanie czy lingwistyka. W kolejnych rozdziałach omówimy wiele z tych tematów. W każdym omówieniu naszym celem będzie przedstawienie podstawowych pojęć związanych z tematyką, aktualnych problemów badawczych i niektórych technik stosowanych w celu rozwijania wiedzy w danym obszarze. Pisząc o programowaniu, skoncentrujemy się na przedstawieniu zasad, na których opierają się współczesne narzędzia programistyczne, na procesie ich ewolucji do współczesnej postaci i problemach, nad którymi
10
ROZDZIAŁ ZERO WSTĘP
obecnie pracują naukowcy. Nie jest jednak naszym celem wyrobienie u czytelnika umiejętności programowania.
Przechodząc od jednego zagadnienia do następnego, jest łatwo stracić ogólny obraz. Zbierzmy zatem przemyślenia, stawiając pytania, które definiują informatykę i stanowią główny przedmiot badań informatyków.
K Jakie problemy można rozwiązać algorytmicznie?
E Jak ułatwić opracowywanie algorytmów?
B Jak ulepszyć metody reprezentowania algorytmów?
B Jak wykorzystać technologię i wiedzę o algorytmach do konstruowania
lepszych komputerów? K Jak analizować i porównywać właściwości różnych algorytmów?
Zwróćmy uwagę, że tematem wspólnym dla wszystkich tych pytań jest algorytmika (rys. 0.5).
0.4. Rola abstrakcji
Współczesne systemy komputerowe są nadzwyczaj złożone i nie sposób ogarnąć wszystkich szczegółów ich budowy. Częstą praktyką jest zatem analiza takich systemów na różnych poziomach szczegółowości. Na każdym poziomie system traktuje się jako zbiór elementów, których wewnętrzną charakterystykę ignoruje się. Dzięki temu można skupić się na sposobie współpracy poszczególnych elementów z tego samego poziomu i sposobie ich łączenia w elementy wyższego poziomu.
0.4. ROLA ABSTRAKCJI
11
1.1. Przechowywanie informacji w postaci bitów
Współczesne komputery przechowują informacje w postaci ciągów bitów. Bit (skrót angielskiej nazwy binary digit, oznaczającej cyfrę dwójkową lub binarną) to cyfra 0 albo 1. Na razie bity będą stanowić dla nas jedynie symbole bez żadnego numerycznego znaczenia. Wkrótce przekonamy się o tym, że bit w różnych kontekstach może mieć bardzo różne znaczenie. Zapamiętanie bitu przez maszynę liczącą wymaga istnienia w niej urządzenia zdolnego do przyjmowania jednego z dwóch możliwych stanów. Dobrze znanymi przykładami takich urządzeń są przełącznik elektryczny (który może być w stanie „włączony" lub „wyłączony"), przekaźnik („otwarty" albo „zamknięty"), a także flaga (wciągnięta na maszt lub opuszczona). Jeden z tych dwóch stanów reprezentuje wartość 0, a drugi - wartość 1. Przyjrzyjmy się sposobom zapamiętywania bitów stosowanym we współczesnych komputerach.
Bramki i przerzutniki
Omówienie rozpoczniemy od wprowadzenia operacji: AND (I), OR (LUB) oraz XOR (skrót od ang. exclusive or). Ich działanie przedstawiono na rysunku 1.1. Argumentami tych operacji, podobnie jak przy arytmetycznych działaniach mnożenia i dodawania, jest para wartości, które będziemy nazywać wartościami wejściowymi lub krótko wejściem. Ich wynikiem jest trzecia wartość zwana wartością wyjściową lub krótko wyjściem. Różnica między prezentowanymi operacjami a operacjami arytmetycznymi polega na tym, że jedynymi wartościami, na których działają AND, OR i XOR są 0 i 1. W ich kontekście cyfrę 0 interpretuje się jako reprezentację wartości logicznej fałsz (ang./afee), a cyfrę 1 -jako reprezentację wartości logicznej prawda (ang. true). Operacje, które manipulują wartościami prawda/fałsz nazywa się operacjami logicznymi lub operacjami boole'owskimi na cześć matematyka Geo-rge'a Boole'a (1815-1864). Operacja logiczna AND ma w zamyśle odzwierciedlać wartość logiczną zdania złożonego, zbudowanego z prostszych zdań połączonych spójnikiem I (ang. AND). Takie zdania mają ogólną postać
PANDQ
przy czym P reprezentuje jedno zdanie, a Q drugie; na przykład: Kermit jest żabą I Piggy jest aktorką.
Argumenty operacji AND reprezentują wartość logiczną (prawdziwość lub nieprawdziwość) poszczególnych składowych zdania złożonego. Wynik reprezentuje wartość logiczną całego zdania. Ponieważ zdanie postaci P AND Q jest prawdziwe wtedy i tylko wtedy, gdy oba zdania składowe są prawdziwe, więc 1 AND 1 musi mieć wartość 1. Dla wszystkich pozostałych par
20 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
wartości argumentów, wynikiem operacji AND jest 0. Jest to zgodne z tabelką przedstawioną na rysunku 1.1.
Operacja OR (LUB), tak jak operacja AND, jest operacją łączącą dwa prostsze zdania w jedno złożone zdanie postaci
PORQ
Tak jak poprzednio P reprezentuje jedno zdanie, a Q drugie. Tego typu zdania są prawdziwe, gdy co najmniej jedno z występujących w nim zdań składowych jest prawdziwe. Ta Interpretacja jest zgodna z operacją OR przedstawioną na rysunku 1.1.
W języku polskim znaczenie trzeciej z omawianych operacji może najlepiej (choć nie w pełni) oddaje spójnik ALBO. Wartością operacji XOR jest 1 (prawda), jeśli jeden z jej argumentów jest równy 1 (prawda), a drugi - 0 (fałsz). Zdanie P XOR Q oznacza zatem „albo P, albo Q jest prawdziwe, ale nie oba naraz".
Jest jeszcze jedna operacja logiczna - operacja NOT (NIE). W odróżnieniu od AND, OR oraz XOR jest ona jednoargumentowa. Jej wynikiem jest wartość przeciwna do wartości argumentu: jeśli na wejściu pojawia się wartość prawda, to wynikiem operacji NOT jest fałsz i na odwrót. Jeśli zatem argument operacji NOT reprezentuje wartość logiczną zdania
Fozzie jest misiem.
RYSUNEK 1.1 | |
|
|
|
|
|
(a) Operacja AND 0 ANDO |
0 AND1 |
BbbhHHH i ANDO |
1 AND 1 |
|
0 (b) Operacja OR 0 OR 0 |
0 Cl OR 1 |
0 1 OR 0 |
1 1 OR 1 |
|
0 (c) Operacja XOR 0 XOR0 |
1 0 XOR1 |
1 1 XOR0 |
1 1 XOR1 |
|
0 11 Operacje logiczne AND, OR, XOR |
0 |
||
1.1. PRZECHOWYWANIE INFORMACJI W POSTACI BITÓW
21
to jej wynik reprezentuje wartość logiczną zdania Fozzie nie jest misiem.
Urządzenie, które na podstawie wartości wejściowych tworzy wartość wyjściową zgodnie z pewną operacją logiczną nazywa się bramką logiczną (ang. gate). Bramki można konstruować, stosując różne techniki: koła zębate, przekaźniki, urządzenia optyczne. We współczesnych komputerach bramki są zazwyczaj małymi układami elektronicznymi, w których cyfry 0 i 1 reprezentuje się w postaci różnych poziomów napięcia. Nie ma jednak potrzeby, abyśmy wchodzili w takie szczegóły. W dalszym ciągu zadowolimy się reprezentacją bramek za pomocą symboli graficznych przedstawionych na rysunku 1.2. Zwróćmy uwagę, że bramki AND, OR, XOR oraz NOT przedstawia się za pomocą diagramów o odmiennych kształtach. Wejścia znajdują się po jednej stronie diagramu, a wyjście po drugiej.
AND |
|
OR |
|
Wejścia j \ Wyjście |
Wejścia T~^>- Wyjście |
||
Wejścia |
Wyjście |
Wejścia |
Wyjście |
0 0 0 1 1 0 1 1 |
0 0 0 1 |
0 0 0 1 1 0 1 1 |
0 . 1 1 1 |
XOR |
NOT |
||
Wejścia jj ~\- Wyjście |
Wejścia -f/O- Wyjście |
||
Wejścia |
Wyjście |
Wejścia |
Wyjście |
0 0 0 1 1 0 1 1 |
0 1 1 0 |
0 1 |
1 0 |
Graficzna reprezentacja bramek AND, OR, XOR, NOT wraz z ich wartościami wejściowymi i wyjściowymi |
|||
22
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Takie właśnie bramki są podstawowymi elementami, z których konstruuje się komputery. Ważnym etapem pośrednim jest układ przedstawiony na rysunku 1.3. Jest to szczególny przykład licznej rodziny układów zwanych przerzutnikami. Na wyjściu przerzutnika (ang. flip-flop) występuje wartość 0 lub 1. Wartość ta nie zmienia się, aż do chwili pojawienia się na wejściu krótkiego impulsu spowodowanego przez inny układ. Taki impuls powoduje zmianę wartości na wyjściu przerzutnika. Innymi słowy wartość wyjściowa zmienia się na skutek zewnętrznego bodźca. Tak długo, jak długo wartości na obu wejściach układu z rysunku 1.3 są równe 0, wartość na wyjściu (albo 0 albo 1) nie zmienia się. Jednakże pojawienie się na krótko wartości 1 na górnym wejściu wymusi ustawienie wartości wyjściowej na 1. Podobnie, krótki impuls (wartość 1) na dolnym wejściu spowoduje, że na wyjściu będzie wartość 0. Przeanalizujmy dokładniej działanie układu. Załóżmy, że nie znamy aktualnej wartości na wyjściu układu z rysunku 1.3 i że w pewnej chwili wartość na górnym wejściu zmienia się na 1, a wartość na dolnym wejściu pozostaje równa 0 (rys. 1.4a). Na wyjściu bramki OR pojawi się zatem wartość 1, niezależnie od stanu drugiego wejścia tej bramki. Z kolei oba wejścia bramki AND będą teraz równe 1, gdyż na jej drugim wejściu jest już 1 (otrzymana przez przejście sygnału 0 z dolnego wejścia przerzutnika przez bramkę NOT). Na wyjściu bramki AND pojawi się zatem 1, co oznacza, że drugie wejście bramki OR będzie teraz równe 1 (rys. 1.4b). To z kolei zapewnia, że na wyjściu bramki OR pozostanie wartość 1, nawet jeśli sygnał na górnym wejściu przerzutnika zmieni się znów na 0 (rys. 1.4c). W efekcie, na wyjściu przerzutnika pojawiła się wartość 1 i wartość ta nie zmieni się po powrocie górnego wejścia do stanu 0. W podobny sposób chwilowe pojawienie się wartości 1 na dolnym wejściu wymusi zmianę wartości na wyjściu przerzutnika na 0. Wartość ta nie zmieni się po ponownym pojawieniu się wartości 0 na wejściu przerzutnika.
1.1. PRZECHOWYWANIE INFORMACJI W POSTACI BITÓW
23
(a) 1 pojawia się na górnym wejściu.
RYSUNEK 1.4
(b) Powoduje to pojawienie się 1 na wyjściu bramki OR i w efekcie pojawienie się 1 na wyjściu bramki AND.
(c) 1 na wyjściu bramki AND nie pozwala na zmianę wartości
na wyjściu bramki OR po zmianie wartości na górnym wejściu na 0.
Ustawienie wyjścia przerzutnika na 1
24 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Przerzutnik jest ważnym układem, gdyż idealnie nadaje się do zapamiętania jednego bitu. Pamiętana w nim wartość to wartość znajdująca się na wyjściu. Inne układy mogą łatwo zmieniać pamiętaną w przerzutniku wartość, przesyłając impulsy na jego odpowiednie wejścia. Podobnie inne układy mogą wykorzystywać wyjście przerzutnika jako swoje wejście i w ten sposób odczytywać zapamiętaną w nim wartość.
Przerzutniki można także konstruować w inny sposób. Jedną z możliwości przedstawiono na rysunku 1.5. Po bliższym przyjrzeniu się temu układowi stwierdzimy, że chociaż ma on zupełnie inną strukturę wewnętrzną, to jednak jego właściwości dające się zaobserwować z zewnątrz, są takie same jak układu z rysunku 1.3. Jest to pierwszy w tej książce przykład roli, jaką grają narzędzia abstrakcyjne. Projektując przerzutnik, trzeba rozważyć różne możliwości zbudowania go z bramek logicznych. Jednak po jego zaprojektowaniu oraz zaprojektowaniu innych podstawowych układów, stosuje się je jako budulec innych bardziej złożonych układów. W efekcie, projektowanie komputera jawi się jako proces hierarchiczny: do zbudowania układów na każdym poziomie wykorzystuje się pewne narzędzia abstrakcyjne, którymi są elementy poziomu niższego.
Inne techniki przechowywania informacji
W latach sześćdziesiątych do zapamiętywania bitów w komputerach stosowano małe pierścienie materiału magnetycznego w kształcie obwarzanków, zwane rdzeniami (ang. core), na które nawijano przewody. Przesyłając prąd przez te przewody, można było namagnesować każdy rdzeń w jednym z dwóch możliwych kierunków. Następnie, kierunek namagnetyzowania
1.1. PRZECHOWYWANIE INFORMACJI W POSTACI BITÓW
25
rdzenia można było wykryć, obserwując jego wpływ na prąd elektryczny przepływający przez środek rdzenia. Rdzeń dawał zatem możliwość przechowania jednego bitu: wartość 1 reprezentowano za pomocą pola magnetycznego w jednym kierunku, a wartość 0 w przeciwnym. Takie systemy są już przestarzałe ze względu na ich rozmiar i duże zużycie energii.
Bardziej współczesną metodą przechowywania bitu jest kondensator, który składa się z dwóch małych metalowych płytek umieszczonych równolegle, w niewielkiej odległości od siebie. Po podłączeniu źródła napięcia do płytek - biegun ujemny do jednej, a dodatni do drugiej - ładunki ze źródła napięcia rozpraszają się na płytkach. Po odłączeniu napięcia ładunki pozostają na płytkach. Po ich późniejszym zwarciu popłynie prąd i kondensator rozładuje się. Zatem kondensator zawsze znajduje się w jednym z dwóch możliwych stanów: jest naładowany lub rozładowany. Jednego z nich można użyć do reprezentowania wartości 0, drugiego do reprezentowania wartości 1. Współczesna technika daje możliwość umieszczenia milionów maleńkich kondensatorów wraz z połączeniami między nimi na pojedynczej płytce (zwanej kością - ang. chip). Dzięki temu kondensator stał się techniką powszechnie stosowaną w maszynach liczących do zapamiętywania bitów.
Przerzutniki, rdzenie i kondensatory są przykładami układów przechowujących dane. Układy te charakteryzują się różnymi poziomami ulotności zapamiętanych danych. Rdzeń zachowuje swoje właściwości magnetyczne nawet po wyłączeniu komputera. Dane zapamiętane w przerzutniku są tracone natychmiast po odłączeniu zasilania. Ładunki zgromadzone w maleńkich kondensatorach są tak małe, że mają skłonności do samoistnego zanikania, nawet podczas pracy komputera. Z tego powodu ładunki zgromadzone w kondensatorach odświeża się w regularnych odstępach czasu za pomocą specjalnego układu odświeżającego. Pamięć komputera (pod-rozdz. 1.2) skonstruowana z użyciem takiej właśnie techniki jest często nazywana pamięcią dynamiczną.
Notacja szesnastkowa
Mówiąc o czynnościach wykonywanych przez komputer, często musimy posługiwać się ciągami bitów. Niektóre z takich ciągów są długie. Niestety, umysł ludzki nie jest przystosowany do pracy na takim poziomie szczegółowości. Odczytywanie ciągu bitów na przykład 101101010011 jest niewygodne i podatne na błędy. W celu uproszczenia reprezentacji ciągów bitów stosuje się zazwyczaj skrótową notację zwaną notacją szesnastkowa (ang. hexadecimal notation). Korzysta się w niej z faktu, że ciągi bitów pojawiające się w komputerze często mają długości będące wielokrotnościami czterech. W notaq'i szesnastkowej zastosowano zatem pojedynczy symbol do reprezentowania czterobitowych ciągów. Oznacza to, że ciąg dwunastu bitów można zapisać za pomocą jedynie trzech symboli szesnastkowych.
Na rysunku 1.6 przedstawiono system szesnastkowy. W lewej kolumnie zapisano wszystkie możliwe ciągi czterobitowe. W prawej kolumnie
26 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
umieszczono odpowiadające im symbole stosowane w notacji szesnastkowej. W takim systemie ciąg bitów 10110101 zapisuje się jako B5. Aby uzyskać kod szesnastkowy dla ciągu bitów, trzeba najpierw podzielić go na czterobitowe podciągi, a następnie zapisać każdy z nich za pomocą jego szesnastkowego odpowiednika: 1011 reprezentuje się jako B, a 0101 jako 5. Postępując w ten sam sposób, 16-bitowy ciąg 1010010011001000 można przedstawić w wygodniejszej, szesnastkowej postaci jako A4C8.
Notację szesnastkowa będziemy często stosować w następnym rozdziale. Wtedy w pełni docenimy jej efektywność.
PYTANIA I ĆWICZENIA
1. Jakie wartości muszą pojawić się na wejściach poniższego układu, aby na jego wyjściu była wartość 1?
1.1. PRZECHOWYWANIE INFORMACJI W POSTACI BITÓW
27
Stwierdziliśmy w tekście, że wartość 1 na dolnym wejściu przerzut-
nika z rysunku 1.3 (przy wartości na górnym wejściu równej 0) spo
woduje pojawienie się wartości 0 na jego wyjściu. Przedstaw ciąg
zdarzeń zachodzących w przerzutniku, które do tego doprowadzą.Przy założeniu, że oba wejścia przerzutnika z rysunku 1.5 są równe 0,
przedstaw ciąg zdarzeń, które zajdą, gdy na górnym wejściu pojawi
się 1.Często jest niezbędne skoordynowanie działania różnych składowych
układu. Realizuje się to, przyłączając do tych części układu, które
wymagają skoordynowania speqalny pulsujący sygnał (zwany zegarem
- ang. clock). Gdy zegar zmienia wartości między 0 a 1, aktywuje
różne składowe układu.
Poniżej jest przykład pewnego fragmentu układu, który zawiera prze-rzutnik z rysunku 1.3. Dla jakich wartości zegara wartość pojawiająca się na wyjściu przerzutnika nie zależy od wartości wejściowych układu? Dla jakich wartości zegara przerzumik będzie reagował na wartości z wejścia układu?
5. Podaj szesnastkową reprezentację następujących ciągów bitów:
(a) 0110101011110010 (b) 111010000101010100010111
(c) 01001000
6. Jakie ciągi bitów odpowiadają następującym ciągom szesnastkowym?
(a) 5FD97 (b) 610A (c) ABCD (d) 0100
1.2. Pamięć główna
Do gromadzenia danych w komputerze stosuje się zestaw wielu układów, z których każdy jest zdolny do zapamiętania jednego bitu. Taki magazyn bitów nosi nazwę pamięci głównej lub pamięci operacyjnej (ang. main memory) komputera. Układy przechowujące dane w komputerze są zorganizowane w jednostki zwane komórkami (ang. cells) lub słowami (ang. words). Zazwyczaj w jednej komórce mieści się 8 bitów. Ośmiobitowe ciągi stały
28
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
się tak powszechne, że zarezerwowano dla nich specjalny termin bajt (ang. h/U).
Małe komputery stosowane w urządzeniach gospodarstwa domowego, na przykład w kuchenkach mikrofalowych, są wyposażone w pamięci o wielkościach rzędu zaledwie kilkuset komórek. Duże komputery stosowane do gromadzenia olbrzymich ilości danych i operowania nimi mogą mieć nawet miliardy komórek pamięci głównej. Rozmiar pamięci głównej często wyraża się w jednostkach równych 1 048 576 komórkom. (Wartość 1 048 576 jest potęgą dwójki, 220; jest przez to bardziej naturalnym wyborem jako jednostka miary rozmiarów obiektów występujących w komputerze niż okrągły 1 000 000). Do nazywania omawianej jednostki miary używa się przedrostka tnega. Powszechnie stosuje się skrót MB do oznaczania megabajtu. Pamięć
0 wielkości 4 MB zawiera zatem 4 194 304 (4x1 048 576) komórki. W każdej
z nich mieści się jeden bajt. Inne jednostki, którymi wyraża się wielkość
pamięci, to kilobajty (oznaczane skrótem KB), na które składa się 1024 (210)
bajtów oraz gigabajty (skrót GB). Gigabajt jest równy 1024 MB, czyli 230
bajtom.
Każda komórka w pamięci komputera ma przypisaną unikatową nazwę zwaną jej adresem. Technika identyfikacji komórek pamięci jest analogiczna do techniki identyfikacji domów znajdujących się w mieście. Stosuje się przy tym taką samą terminologię. Adresy komórek pamięci są jednak po prostu wartościami liczbowymi. Mówiąc bardziej precyzyjnie, możemy wyobrazić sobie, że wszystkie komórki są zgromadzone w jednym rzędzie
1 numerowane kolejnymi liczbami począwszy od zera. Komórki znajdujące
się w komputerze z pamięcią rozmiaru 4 MB są zatem adresowane warto
ściami 0, 1, 2, ... , 4 194 303. Zwróćmy uwagę, że taki system adresowania
nie tylko daje nam możliwość jednoznacznej identyfikacji każdej komórki
pamięci, ale także ustawia je w pewnej kolejności (rys. 1.7). Zdefiniowanie
takiego porządku nadaje sens wyrażeniom „następna komórka" i „poprzed
nia komórka".
Uzupełnijmy teraz przedstawiony obraz pamięci głównej. Układy przeznaczone do przechowywania bitów są połączone z układami niezbędnymi do tego, aby pozostałe układy komputera mogły odczytywać dane z pamięci i zapisywać je do niej. Dzięki temu pozostałe układy mogą pobierać dane z pamięci, elektronicznie prosząc o zawartość wskazanego adresu (taką operaq'ę nazywa się operacją odczytu - ang. read). Mogą także zapisać informacje w pamięci, zlecając umieszczenie wskazanego ciągu bitów w komórce o podanym adresie (jest to operacja zapisu — ang. write).
Ważną konsekwencją organizacji pamięci głównej w małe, adresowalne komórki jest to, że dostęp do każdej komórki może odbywać się niezależnie od dostępu do pozostałych. Oznacza to, że dane zgromadzone w pamięci głównej można przetwarzać w dowolnej kolejności. Dlatego też pamięć główną nazywa się często pamięcią RAM (ang. random access tnemory - pamięć o dostępie swobodnym). Ta swoboda w dostępie do małych porcji danych jaskrawo kontrastuje z systemami pamięci masowej, które omówimy w następnym punkcie. W systemach pamięci masowej operuje się całymi
1.2. PAMIĘĆ GŁÓWNA 29
';..: >■,::- ■■■■Vv;::.::;:'>:.-
blokami, na które składają się długie ciągi bitów. Jeśli pamięć RAM wytworzono w technologii pamięci dynamicznych, to nazywa się ją często pamięcią DRAM (ang. Dynamie RAM).
Bity w pojedynczej komórce pamięci traktuje się, jakby były ustawione w szeregu. Jeden koniec takiego szeregu nazywamy najbardziej znaczącym (ang. high-order end), a drugi - najmniej znaczącym (ang. low-order end). Chociaż w komputerze nie ma pojęcia lewej i prawej strony, to jednak często bity ustawia się w szereg od lewej do prawej strony, przy czym najbardziej znaczący koniec znajduje się po lewej stronie. Bit umieszczony na tym końcu często nazywa się najbardziej znaczącym bitem (ang. most significant bit), a bit na drugim końcu - najmniej znaczącym (ang. least significant bit). Zawartość jednobajtowej komórki można zatem przedstawić jak na rysunku 1.8.
Ważną konsekwencją uporządkowania zarówno komórek w pamięci, jak i bitów w pojedynczej komórce jest to, że cały zbiór bitów w pamięci stanowi właściwie jeden długi szereg. Poszczególne fragmenty tego szeregu mogą posłużyć do zapamiętania ciągów bitów nie mieszczących się w jednej komórce. W szczególności, jeśli pamięć składa się z komórek jednobajtowych, to jednak nadal można przechowywać w niej ciągi 16-bitowe, wykorzystując w tym celu dwie sąsiednie komórki pamięci.
30
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
PYTANIA I ĆWICZENIA
Przypuśćmy, że w komórce pamięci o adresie 5 znajduje się wartość 8.
Czym różni się zapisanie do komórki o adresie 6 wartości 5 od zapisa
nia do komórki o numerze 6 zawartości komórki o numerze 5?Przypuśćmy, że chcemy zamienić miejscami wartości zapamiętane
w komórkach pamięci o numerach 2 i 3. Wskaż błąd w poniższym
sposobie postępowania:
Krok 1. Przenieś zawartość komórki o numerze 2 do komórki
o numerze 3.
Krok 2. Przenieś zawartość komórki o numerze 3 do komórki
o numerze 2.
Zaproponuj sposób poprawnej zamiany zawartości wskazanych
komórek.
3. Ile bitów znajduje się w pamięci o rozmiarze 4 KB?
1.3. Pamięć masowa
Ze względu na ograniczony rozmiar pamięci głównych (operacyjnych) i ulotność danych przechowywanych w nich, większość komputerów wyposaża się w dodatkowe nośniki do gromadzenia danych. Są to systemy pamięci masowej (ang. mass storage systemś). Pamięć masową realizuje się za pomocą dysków magnetycznych, płyt CD i taśm magnetycznych. Zaletą pamięci masowej w porównaniu z pamięcią główną jest mniejszy poziom ulotności zapisywanych w niej danych, możliwość zapamiętania większych danych i w wielu wypadkach także możliwość wyjęcia nośnika informacji z komputera i zarchiwizowania go.
1.3. PAMIĘĆ MASOWA 31
Urządzenia mogą być w danej chwili dostępne dla komputera albo niedostępne. Termin on-line (bezpośrednio) oznacza, że urządzenie lub informacje są przyłączone i dostępne dla komputera bez konieczności ingerencji człowieka. Termin off-line (odłączone, rozłączone) oznacza, że zanim informacja lub urządzenie staną się osiągalne dla komputera, człowiek musi wykonać pewne czynności wstępne: na przykład włączyć urządzenie lub włożyć do niego nośnik informacji.
Główną wadą systemów pamięci masowej jest to, że dostęp do przechowywanych w nich informacji wymaga zazwyczaj mechanicznego przemieszczenia pewnych elementów. Jest to czasochłonne. Z tego powodu czas reakqi takich urządzeń na polecenia jest dłuższy niż czas dostępu do pamięci głównej, w której wszystkie operacje realizuje się elektronicznie.
Dyski magnetyczne
Jedną z najpowszechniejszych współczesnych postaci pamięci masowej są dyski magnetyczne. Dane przechowuje się na cienkim, wirującym dysku powleczonym materiałem magnetycznym. Nad i/lub pod dyskiem znajdują się głowice zapisująco-odczytujące. Na skutek ruchu obrotowego dysku każda głowica zakreśla nad/pod dyskiem okrąg zwany ścieżką (ang. track). Przemieszczając głowice zapisująco-odczytujące wzdłuż promienia, można uzyskać dostęp do różnych ścieżek. Często, jeden system dyskowy składa się z kilku dysków zamontowanych na wspólnej osi jeden nad drugim. Między nimi znajduje się miejsce na głowice. W takim wypadku wszystkie głowice poruszają się razem. Przemieszczając je, uzyskuje się dostęp do zbioru ścieżek składających się na cylinder.
Ponieważ zazwyczaj operuje się mniejszymi porcjami danych niż zapisane na całej ścieżce, więc każda ścieżka jest podzielona na łuki zwane sektorami. Informacja w sektorze jest zapisywana w postaci spójnego ciągu bitów (rys. 1.9). Każda ścieżka w systemie dyskowym zawiera taką samą liczbę sektorów, a w każdym sektorze przechowuje się taką samą liczbę bitów. (Oznacza to, że bity w sektorach położonych blisko środka dysku są upakowane gęściej niż w sektorach brzegowych).
Zatem dyskowy system przechowywania danych składa się z wielu sektorów. Dostęp do każdego z nich jest niezależny i polega na zapisie lub odczycie całego ciągu bitów. Liczba ścieżek przypadających na jeden dysk oraz liczba sektorów na ścieżce są bardzo różne w zależności od konkretnego systemu dyskowego. Rozmiary sektorów nie przekraczają zazwyczaj kilku KB, powszechne są sektory o rozmiarach 512 lub 1024 bajtów.
Rozmieszczenie ścieżek i sektorów nie jest trwałą cechą fizycznej struktury dysku. Ich położenie wyznacza się przez odpowiednie namagnesowanie dysku podczas czynności zwanej formatowaniem (lub inicjowaniem) dysku. Czynność tę wykonuje zazwyczaj producent dysku. Mamy wtedy do czynienia z dyskami sformatowanymi wstępnie. Większość systemów komputerowych także jest zdolnych do wykonania zadania formatowania dysku.
32
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Jeśli zatem informacja o sposobie sformatowania dysku zostanie zniszczona, dysk można ponownie sformatować. Taka operacja powoduje jednak utratę wszystkich danych zapisanych uprzednio na dysku.
Pojemność systemu dyskowego zależy od zastosowanej w nim liczby dysków i gęstości rozmieszczenia w nich ścieżek i sektorów. Systemy o malej pojemności składają się z jednego plastikowego dysku zwanego dyskietką (ang. diskette) lub dyskiem elastycznym (ang. floppy disk) w przypadku giętkich dysków. (Obecnie stosowane dyskietki o średnicy 3,5 cala są zamykane w plastikowych obudowach i dzięki temu nie są tak giętkie jak ich starsze kuzynki: dyskietki o średnicy 5,25 cala, które były zaszywane w kopertach papierowych). Dyskietki wkłada się do odpowiednich urządzeń odczytu-jąco-zapisujących, łatwo się je przechowuje. Są one zatem często stosowane do przechowywania informacji off-line. Na typowej dyskietce 3,5-calowej mieści się 1,44 MB danych, ale dyskietki mogą mieć dużo większe pojemności. Przykładem jest system dyskowy Zip firmy Iomega Corporation, który oferuje możliwość zapisania do kilkuset MB na pojedynczej dyskietce.
Systemy dyskowe o dużej pojemności, zdolne pomieścić kilka gigabaj-tów, składają się z 5 do 10 sztywnych dysków zamocowanych na wspólnej osi. Ponieważ stosowane dyski są sztywne, takie systemy dyskowe nazwano dyskami twardymi (ang. hard disk) w odróżnieniu od ich giętkich odpowiedników. Aby umożliwić uzyskanie większych prędkości obrotowych, głowice w takich systemach nie dotykają dysków, lecz „unoszą się" tuż nad ich powierzchnią. Odległości są jednak tak niewielkie, że nawet jedna cząsteczka kurzu mogłaby utknąć między głowicą a powierzchnią dysku, uszkadzając oba elementy (zjawisko to nazywa się awarią głowicy - ang. head crash). Dyski twarde umieszcza się zatem w obudowach plombowanych w fabryce.
1.3. PAMIĘĆ MASOWA
33
Oceniając wydajność dysku, uwzględnia się różne parametry: (1) czas wyszukiwania (ang. seek time - czas przemieszczenia głowic dysku z jednej ścieżki na drugą); (2) opóźnienie obrotowe (ang. rotation delay; latency time) -połowa czasu potrzebnego na pełen obrót dysku; jest to zarazem średni czas oczekiwania na to, aby potrzebne dane znalazły się pod głowicą dysku po jej uprzednim ustawieniu na właściwą ścieżkę; (3) czas dostępu (ang. access time - suma czasu wyszukiwania i opóźnienia obrotowego); (4) szybkość przesyłania (ang. transfer ratę) - szybkość transmisji danych z dysku lub do niego.
Dyski twarde mają w ogólności znacznie lepsze charakterystyki niż dyskietki elastyczne. Ponieważ głowice zapisująco-odczytujące nie dotykają powierzchni dysków twardych, dyski można obracać z prędkością obrotową rzędu 3000 do 4000 obrotów na minutę, podczas gdy dyskietki wirują z prędkością rzędu 300 obrotów na minutę. W związku z tym szybkość przesyłania danych w dyskach twardych zazwyczaj mierzy się w megabajtach na sekundę. Jest to znacznie więcej niż w przypadku dyskietek, gdzie osiąga się wielkości mierzone w kilobajtach na sekundę.
Ponieważ systemy dyskowe zawierają ruchome elementy mechaniczne, które poruszają się przy uzyskiwaniu dostępu do danych, zarówno dyski twarde, jak i dyski elastyczne są wyraźnie wolniejsze niż układy elektroniczne. Opóźnienia w układach elektronicznych mierzy się w nanosekun-dach (bilionowych częściach sekundy), a nawet w jednostkach mniejszych, podczas gdy czas wyszukiwania, opóźnienie obrotowe i czas dostępu w systemach dyskowych osiągają wielkości rzędu milisekund (tysięcznych części sekundy). Czas potrzebny na pobranie informacji z dysku może wydawać się zatem wiecznością oczekującemu na nią układowi elektronicznemu.
Płyty kompaktowe
Inną popularną techniką przechowywania danych są płyty kompaktowe (CD). Takie płyty mają średnicę 12 cm (około 5 cali) i są wykonane z materiału odbijającego światło pokrytego przezroczystą warstwą ochronną. Informacje zapisuje się w postaci rowków wyżłobionych w powierzchni odblaskowej. Można je odczytać za pomocą promienia lasera, który wykrywa nieregularności na powierzchni odblaskowej płyty w trakcie jej obrotu.
Technologii CD używano początkowo do nagrań dźwiękowych. Stosowano przy tym format zapisu o nazwie CD-DA (compact disk-digital audio). Płyty CD stosowane współcześnie do zapisu danych komputerowych są podobne do ich dźwiękowych poprzedników, ale stosuje się w nich format zapisu o nazwie CD-ROM (compact disk-read-ońly memory). Różnica między CD-DA a CD-ROM polega na sposobie interpretacji pól z danymi. Przykładowo w formacie CD-DA pewne pola rezerwuje się do przechowywania informacji o czasie trwania poszczególnych utworów, a w formacie CD-ROM przestrzeń tę wykorzystuje się do innych celów.
34 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
W odróżnieniu od systemów dyskowych, w których informacje przechowuje się w oddzielnych współśrodkowych ścieżkach, informacje na CD gromadzi się w postaci jednej, spiralnej ścieżki, która przypomina rowek w starych płytach gramofonowych (na CD spirala rozpoczyna się jednak w środku płyty i kończy na jej brzegu). Ta ścieżka jest podzielona na jednostki zwane sektorami. Każdy sektor zawiera tę samą ilość danych i każdy jest jednoznacznie oznakowany. Sektor w formacie CR-ROM mieści 2 KB danych. W podobnej przestrzeni płyty zapisanej w formacie CD-DA mieści się 775 sekundy muzyki.
Zwróćmy uwagę, że wykonanie pełnego obrotu powoduje przebycie większej odległości na spiralnej ścieżce przy brzegu płyty niż w jej wewnętrznym fragmencie. W celu zwiększenia pojemności płyty, informacje zapisuje się jednak z taką samą gęstością na całej długości ścieżki. To oznacza, że w pętli znajdującej się w zewnętrznej części pryty znajduje się więcej informacji niż w pętli znajdującej się blisko środka. Zatem w trakcie jednego obrotu płyty zostanie odczytanych więcej sektorów, gdy promień lasera analizuje zewnętrzny fragment ścieżki niż podczas odczytu jej wewnętrznej części dysku. Aby uzyskać jednolitą szybkość transmisji danych, odtwarzacze płyt projektuje się tak, aby mogły modyfikować prędkość obrotową w zależności od położenia promienia lasera.
Konsekwencją takich decyzji projektowych jest to, że systemy CD wykazują najlepszą wydajność, gdy operują długimi, spójnymi ciągami danych. Tak właśnie dzieje się podczas odtwarzania muzyki. Gdy program potrzebuje swobodnego dostępu do danych (jak w systemach rezerwacji miejsc), rozwiązania zastosowane w dyskowych systemach pamięci masowej (pojedyncze, współśrodkowe ścieżki ze stałą liczbą sektorów) umożliwiają uzyskanie znacznie lepszej wydajności niż wariant z jedną spiralną ścieżką.
Płyty CD formatu CD-ROM mają pojemność nieco ponad 600 MB. Jednakże pojawiają się ciągle nowe formaty, takie jak DVD (Digital Versatile Disk) oferujące pojemność rzędu 10 GB. Na tego rodzaju płytach mieszczą się swobodnie prezentacje multimedialne, w których wykorzystuje się dane wizualne i dźwiękowe. Stwarza to możliwości prezentowania informacji w sposób ciekawszy i bardziej informacyjny niż tylko za pomocą tekstu. Tak naprawdę standard DVD stosuje się głównie do zapisu filmów, które dzięki temu mieszczą się na jednej płycie kompaktowej.
Innym wariantem technologii CD jest format CD-WORM (compact disk--write once, rmd many), który umożliwia nagranie danych na płycie już po jej wyprodukowaniu, a nie w trakcie produkcji. Tego typu możliwości są przydatne do archiwizowania danych i do produkcji płyt CD na małą skalę.
Taśmy magnetyczne
W pamięciach masowych starszego typu stosowano taśmy magnetyczne (rys. 1.10). Informacja była zapisywana na pokrytej magnetyczną substancją cienkiej taśmie plastikowej, która z kolei była nawinięta na szpulę. Aby
1.3. PAMIĘĆ MASOWA 35
uzyskać dostęp do danych, trzeba było zamontować taśmę na urządzeniu zwanym napędem taśmowym, które potrafiło pod nadzorem komputera odczytywać, zapisywać i przewijać taśmę. Napędy taśmowe miały bardzo różne rozmiary: od niewielkich urządzeń kasetowych zwanych strimerami, w których taśma była używana w podobny sposób jak w magnetofonach, do olbrzymich urządzeń szpulowych. Chociaż pojemność urządzeń taśmowych zależy od zastosowanego formatu zapisu, to jednak większość z nich mogła zmieścić kilka gigabajtów informacji.
Nowoczesne strimery dzielą taśmę na segmenty, z których każdy jest oznaczany (magnetycznie) podczas formatowania przypominającego czynność wykonywaną w urządzeniach dyskowych. Każdy z tych segmentów zawiera kilka ścieżek, które biegną równolegle do siebie wzdłuż całej taśmy. Dostęp do ścieżek jest niezależny, co oznacza, że taśmę, podobnie jak sektory na dysku, można traktować jako kilka ciągów bitów.
Główną wadą urządzeń taśmowych jest to, że przemieszczenie się między dwiema pozycjami na taśmie może trwać bardzo długo, gdy trzeba przewinąć duży fragment taśmy. Z tego powodu systemy taśmowe charakteryzują się znacznie dłuższym czasem dostępu niż systemy dyskowe, w których dostęp do różnych sektorów uzyskuje się za pomocą niewielkich ruchów głowicy zapisująco-odczytującej. W efekcie urządzenia taśmowe nie są powszechnie stosowane do przechowywania danych on-line. Gdy jednak celem jest gromadzenie danych off-line w celu ich archiwizowania, to wysoka niezawodność, duża pojemność i relatywnie niewielki koszt takich urządzeń sprawia, że są one najlepszym wyborem spośród współczesnych systemów przechowywania danych.
36
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Przechowywanie informacji w plikach
Informacja w pamięci masowej jest przechowywana w dużych jednostkach zwanych plikami (ang. fileś). Plik może stanowić pełny dokument tekstowy, zdjęcie, program lub zbiór danych o pracownikach pewnej firmy. Ze względu na fizyczne właściwości urządzeń obsługujących pamięć masową, pliki są zapamiętywane i odczytywane w postaci wielobajtowych jednostek. W przypadku dysku magnetycznego, na przykład, każdy sektor traktuje się jako jeden spójny ciąg bitów. Blok danych zgodny z fizyczną charakterystyką urządzenia nosi nazwę rekordu fizycznego (ang. physical record). Plik przechowywany w pamięci masowej zazwyczaj składa się z wielu rekordów fizycznych.
Niezależnie od opisanego podziału na rekordy fizyczne, pliki często w sposób naturalny dzieli się na fragmenty w zależności od informaq'i, która jest w nich zawarta. Na przykład plik przechowujący informacje o pracownikach pewnej firmy może składać się z wielu części, z których każda zawiera informacje o jednym pracowniku. Takie naturalnie wyodrębniane bloki danych nazywa się rekordami logicznymi (ang. logical record).
1.3. PAMIĘĆ MASOWA 37
Rozmiar rekordu logicznego rzadko jest równy rozmiarowi rekordu fizycznego, narzuconemu przez urządzenie. W rezultacie w jednym rekordzie fizycznym można umieścić wiele rekordów logicznych. Może się także zdarzyć, że jeden rekord logiczny jest umieszczony w wielu rekordach fizycznych (rys. 1.11). Odczytanie informacji z pamięci masowej wymaga zatem wykonania pewnych dodatkowych czynności związanych z przegrupowaniem danych. Zadanie to realizuje się zazwyczaj, rezerwując w pamięci
głównej obszar, w którym może zmieścić się kilka rekordów fizycznych. Obszar ten wykorzystuje się do wykonania niezbędnego przegrupowania danych. Między pamięcią masową a wyróżnionym obszarem w pamięci głównej przesyła się bloki danych o rozmiarze zgodnym z rozmiarem rekordu fizycznego. Po przesłaniu dane, znajdujące się w pamięci głównej, można traktować już tak, jakby składały się z rekordów logicznych. Obszar pamięci używany w powyższy sposób nosi nazwę bufora (ang. buffer).
Bufor ilustruje rolę, jaką względem siebie odgrywają pamięć główna i pamięć masowa. Pamięć główną stosuje się do przechowywania danych w celu ich przetwarzania, a pamięć masową do gromadzenia danych. Zatem uaktualnienie danych zapisanych w pamięci masowej wymaga przesłania danych do pamięci głównej, uaktualnienia ich, a następnie zapisania uaktualnionych danych znów w pamięci masowej.
Największą swobodę dostępu do danych daje pamięć główna. Dyski magnetyczne, płyty kompaktowe i taśma magnetyczna coraz bardziej ograniczają swobodny dostęp. Sposób adresowania stosowany w pamięci głównej umożliwia błyskawiczny swobodny dostęp do poszczególnych bajtów danych. Dyski magnetyczne umożliwiają swobodny dostęp jedynie do całych sektorów danych. Odczytanie sektora wydłuża się o czas przeszukiwania i o opóźnienie obrotowe dysku. Płyty kompaktowe także dają możliwość swobodnego dostępu do poszczególnych sektorów, ale opóźnienia są większe niż w wypadku dysków na skutek dodatkowego czasu wymaganego do odnalezienia właściwego miejsca na ścieżce spiralnej i dostosowania prędkości obrotowej płyty. Na koniec, taśmy magnetyczne oferują bardzo niewiele swobody w dostępie do danych. Nowoczesne systemy taśmowe znakują pozycje na taśmie, tak aby można było odwoływać się do poszczególnych segmentów taśmy. Fizyczna struktura taśmy powoduje jednak to, że czas potrzebny do odczytania segmentów znajdujących się na taśmie w dużej odległości od siebie będzie znaczny.
PYTANIA I ĆWICZENIA
Co zyskuje się dzięki temu, że dyski dysku twardego wirują szybciej
niż dyskietka?Jaka strategia zapisu danych w pamięci masowej złożonej z wielu
dysków jest lepsza: zapełnianie całej powierzchni dysku danymi przed
rozpoczęciem pisania na drugiej powierzchni lub też wypełnianie
całego cylindra i przejście do następnego?Dlaczego dane w systemie rezerwacji miejsc, które podlegają ciągłym
zmianom, powinno się przechowywać na dysku, a nie na taśmie?Przypuśćmy, że chcemy zapisać na dysku rekordy logiczne o rozmia
rze 450 bajtów każdy, podczas gdy rekordy fizyczne mają rozmiar
512 bajtów. Dlaczego w rekordzie fizycznym lepiej jest pamiętać tylko
jeden rekord logiczny, chociaż powoduje to zmarnowanie 62 bajtów
w każdym sektorze?
38 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
1.4. Reprezentowanie informacji w postaci ciągów bitów
Zastanowimy się teraz nad sposobem reprezentacji informacji w komputerze w postaci ciągów bitów. Skupimy się w szczególności na popularnych metodach kodowania tekstu, danych liczbowych i obrazów. Zastosowanie każdego z przedstawionych systemów kodowania ma pewne skutki zauważalne dla zwykłego użytkownika komputera. Naszym celem jest przybliżenie technik kodowania w stopniu wystarczającym do zrozumienia tych konsekwencji.
Reprezentacja tekstu
Informację tekstową zazwyczaj reprezentuje się, stosując pewien kod, który z każdym symbolem mogącym pojawić się w tekście (litery alfabetu, znaki przestankowe) związuje unikatowy ciąg bitów. Tekst reprezentuje się jako długi ciąg bitów, którego kolejne fragmenty reprezentują kolejne symbole pierwotnego tekstu.
AMERYKAŃSKI NARODOWY INSTYTUT
STANDARYZACJI (THE AMERICAN NATIONAL STANDARDS INSTITUTE)
The American National Standards Institute (ANSI) został założony w 1918 roku przez małe konsorcjum stowarzyszeń inżynieryjnych i agencji rządowych. Miał on tworzyć nie przynoszącą zysków federację koordynującą samorzutne opracowywanie standardów w sektorze prywatnym. Współcześnie członkami ANSI jest ponad 1300 przedsiębiorstw, organizacji zawodowych, stowarzyszeń handlowych i agencji rządowych. Siedzibą władz ANSI jest Nowy Jork. ANSI reprezentuje Stany Zjednoczone jako członek ISO. Witryna internetowa ANSI znajduje się pod adresem http://www.ansi.org
Podobne organizacje w innych krajach to: Standards Australia (Australia), Standards Council of Canada (Kanada), China State Bureau of Quality and Technical Supervision (Chiny), Deutsches Institut fur Normung (Niemcy), Japanese Industrial Standards Committee (Japonia), Dirección General de Normas (Meksyk), State Committee of the Russian Federation for Standardization and Metrology (Rosja), Swiss Association for Standardization (Szwajcaria) i British Standards Institution (Wielka Brytania).
We wczesnych latach rozwoju komputerów zaprojektowano wiele różnych kodów. Stosowano je w połączeniu z różnymi elementami osprzętu, co spowodowało wiele problemów komunikacyjnych. Aby opanować tę sytuację, Amerykański Narodowy Instytut Normalizacji (American National Standards Institute; ANSI) wprowadził kod ASCII - American Standard Code for Information Interchange (wym. aski), który zdobył niezwykłą popularność. W tym kodzie do reprezentacji małych i wielkich liter alfabetu angielskiego, znaków przestankowych, cyfr od 0 do 9, a także pewnych informacji sterujących, takich jak znak nowego wiersza, znak powrotu karetki i tabulacji, stosuje się ciągi siedmiobitowe. Współcześnie kod ASCII często rozszerza się do 8 bitów na symbole wprowadzając 0 na najbardziej znaczącej pozycji każdego ciągu 7-bitowego. Dzięki temu
1.4. REPREZENTOWANIE INFORMACJI W POSTACI CIĄGÓW BITÓW
39
I RYSUNEK 1.12 |
01010111 01101001 oinoioo onooooi 01101010 ooiomo \./ \/ \/ \/\/ \/
W i I a j
Komunikat „Witaj." w ASCII
uzyskuje się kod, który można wygodnie zapamiętać w typowej jednobaj-towej komórce pamięci, a ponadto jest w nim miejsce na zakodowanie 128 dodatkowych ciągów bitów (z dodatkowym bitem równym 1). Te dodatkowe kody można wykorzystać do reprezentowania symboli spoza oryginalnego kodu ASCII. Niestety, różni producenci w różny sposób interpretują te dodatkowe kody, więc dane zawierające je nie dają się łatwo przenosić między aplikacjami różnych producentów.
W dodatku A przedstawiono fragment kodu ASCII w formacie 8-bi-towym, a na rysunku 1.12 pokazano, że w tym systemie ciąg bitów:
01010111 01101001 01110100 01100001 01101010 00101110
MIĘDZYNARODOWA ORGANIZACJA
NORMALIZACYJNA
(THE INTERNATIONAL ORGANIZATION FOR STANDARDIZATION)
reprezentuje napis „Witaj.".
The International Organization for Standardization (ISO) utworzono w 1947 roku jako ogólnoświatową federację instytucji ustanawiających standardy, po jednej z każdego kraju. Obecnie siedzibą ISO jest Genewa w Szwajcarii. Organizacja liczy ponad 100 organizacji członkowskich oraz wielu członków korespondentów. (Członkiem korespondentem jest zazwyczaj instytucja ds. standardów z kraju, który nie ma instytucji ds. standardów o zasięgu ogólnokrajowym. Tacy członkowie nie mogą uczestniczyć bezpośrednio w opracowywaniu standardów, ale są informowani o działaniach ISO). ISO utrzymuje stronę internetową pod adresem http://www.iso.ch
Chociaż ASCII jest obecnie najbardziej rozpowszechnionym kodem, powoli zyskują popularność także inne, w których jest możliwe reprezentowanie dokumentów zapisanych w wielu różnych językach. Jednym z takich kodów jest Unikod opracowany dzięki współpracy wiodących wytwórców sprzętu i oprogramowania. W tym kodzie do reprezentacji każdego symbolu stosuje się unikatowy ciąg 16-bi-towy. W rezultacie, w Unikodzie występuje 65 536 różnych ciągów bitów, co wystarcza do reprezentacji najpowszechniejszych symboli chińskich
40
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
i japońskich. Kod, który prawdopodobnie będzie rywalizować z Unikodem, opracowała Międzynarodowa Organizacja Normalizacyjna (International Organization for Standardization, znana także pod nazwą ISO, która kojarzy się z greckim słowem isos - równy). Dzięki zastosowaniu 32 bitów do reprezentacji symboli, w tym kodzie można reprezentować ponad 17 milionów różnych symboli. Czas pokaże, który z tych kodów uzyska większą popularność.
Reprezentacja wartości liczbowych
Chociaż metoda przechowywania informacji jako zakodowanych znaków jest użyteczna, to okazuje się ona bardzo nieefektywna do reprezentowania informacji liczbowych. Przypuśćmy, że chcemy zapisać liczbę 25. Do przedstawienia jej w postaci ciągu znaków zakodowanych w ASCII przy zastosowaniu jednego bajtu do reprezentacji każdego symbolu, potrzeba 16 bitów. Co więcej, największą liczbą, którą możemy w taki sposób zapisać na 16 bitach, jest 99. Lepszym sposobem jest przedstawienie liczb w pozycyjnym układzie liczenia o podstawie dwa, czyli w układzie binarnym (dwójkowym).
Notacja binarna (dwójkowa) jest metodą reprezentacji wartości tylko za pomocą cyfr 0 i 1, a nie jak w tradycyjnym systemie dziesiątkowym -za pomocą cyfr 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Przypomnijmy, że w systemie dziesiątkowym z każdą pozycją jest związana jej waga. W reprezentacji 375 cyfra 5 znajduje się na pozycji z wagą 1, cyfra 7 na pozycji z wagą dziesięć, a 3 na pozycji z wagą 100 (rys. 1.13). Każda kolejna waga jest dziesięć razy większa niż waga związana z pozycją po jej prawej stronie.
1.4. REPREZENTOWANIE INFORMACJI W POSTACI CIĄGÓW BITÓW
41
Wartość, którą reprezentuję wyrażenie, wylicza się, mnożąc wartość każdej cyfry przez wagę związaną z pozycją, na której występuje ta cyfra, i sumując tak otrzymane iloczyny. Napis 375 reprezentuje zatem wartość (3 X sto) + (7 X dziesięć) + (5 X jeden).
Z pozycją każdej cyfry w układzie binarnym także związuje się wagę. Waga związana z każdą pozycją jest jednak dwa razy większa niż waga pozycji z prawej strony. Dokładniej, prawa skrajna cyfra w reprezentacji binarnej ma wagę jeden (2°), następna pozycja na lewo ma wagę dwa (21), następna cztery (22), następna osiem (23) i tak dalej. Na przykład w reprezentacji binarnej 1011 prawa skrajna jedynka jest na pozycji z wagą jeden, kolejna 1 jest na pozycji z wagą dwa, 0 na pozycji z wagą cztery, a skrajna lewa jedynka na pozycji z wagą osiem (rys. 1.13b).
Aby obliczyć wartość reprezentowaną przez napis w układzie binarnym postępujemy tak jak w systemie dziesiątkowym: mnożymy wartość każdej cyfry przez wagę związaną z pozycją tej cyfry i dodajemy otrzymane iloczyny. Na przykład wartość reprezentowana przez napis 100101 to 37, zgodnie z rysunkiem 1.14. Zauważmy, że ponieważ w reprezentacji binarnej wykorzystuje się tylko cyfry 0 i 1, cały proces mnożenia i dodawania sprowadza się właściwie do zsumowania wag związanych z pozycjami, na których występują jedynki. Zatem sekwencja 1011 reprezentuje wartość jedenaście, ponieważ jedynki znajdują się na pozycjach z wagami jeden, dwa i osiem.
42
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Zauważmy, że ciąg binarnych reprezentacji liczb od O do 8 jest na
stępujący: j ,
10 11
100 101 110
111
1000
ALTERNATYWY DLA SYSTEMU BINARNEGO
We wczesnych komputerach nie korzystano z notacji binarnej. Sposób reprezentacji wartości liczbowych w sprzęcie obliczeniowym byl przedmiotem burzliwej dyskusji u schyłku lat trzydziestych i w latach czterdziestych. Jednym z kandydatów byl system dwupiątkowy, w którym każdą cyfrę reprezentacji dziesiątkowej liczby zastępowano dwoma cyframi: jedną o wartości 0, 1, 2, 3 lub 4, drugą o wartości 0 lub 5, tak aby suma tych dwóch cyfr dawała pierwotną cyfrę reprezentacji dziesiątkowej. Taki system zastosowano w komputerze ENIAC. Innym kandydatem był system ósemkowy. W pracy „Binary Calculus", która ukazała się w Journal of the Institute of Actuaries w 1936 roku, E.W. Phillips pisał: „Ostatecznym celem jest przekonanie całego cywilizowanego świata do porzucenia systemu dziesiątkowego i stosowania w jego miejsce notacji ósemkowej; przekonanie do zaprzestania liczenia dziesiątkami i liczenia ósemkami."
Jest wiele sposobów wygenerowania ciągu reprezentacji binarnych kolejnych liczb naturalnych. Mając taki ciąg możemy, choć nie jest to elegancki sposób, szybko znajdować reprezentacje binarne małych liczb. W jednym ze sposobów korzysta się z analogii do samochodowego licznika przebiegu. Wyobraźmy sobie taki licznik, na którego kółkach znajdują się tylko cyfry 0 i 1. Licznik rozpoczyna pomiar od 0. W miarę przebywania przez samochód odległości, licznik obraca się i pokazuje 1. Przejście tej 1 na 0, powoduje pojawienie się 1 na kółku po lewej stronie (co razem daje ciąg 10). Prawe kółko obraca się na 1, otrzymujemy w ten sposób 11. Teraz prawa skrajna 1 obraca się, dając znów 0 i powodując obrót kółka po lewej stronie i zmianę pokazywanej na nim wartości na 0. To z kolei powoduje pojawienie się 1 w trzeciej kolumnie, powstaje w ten sposób ciąg 100.
W celu znalezienia reprezentacji binarnych dużych liczb, lepiej zastosować bardziej systematyczne podejście przedstawione w postaci algorytmu na rysunku 1.15. Zastosujmy ten algorytm do przekształcenia wartości trzynaście (rys. 1.16). Najpierw
dzielimy 13 przez dwa, otrzymując w wyniku sześć i resztę jeden. Ponieważ iloraz nie jest zerem, w kroku 2 dzielimy iloraz przez dwa, otrzymując nowy iloraz równy trzy i resztę zero. Ten nowy iloraz jest nadal różny od zera,
1.4. REPREZENTOWANIE INFORMACJI W POSTACI CIĄGÓW BITÓW
43
Krok 1. Podziel wartość przez dwa i zapamiętaj resztę.
Krok 2. Dopóki otrzymany iloraz nie jest zerem, powtarzaj dzielenie najnowszego ilorazu przez dwa i zapamiętuj resztę.
Krok 3. Teraz po otrzymaniu ilorazu zerowego, reprezentacja binarna pierwotnej wartości
składa się z reszt umieszczonych od prawej do lewej w kolejności ich pojawiania się.
Algorytm znajdowania binarnej reprezentacji liczby całkowitej dodatniej
więc dzielimy go przez dwa, co daje iloraz 1 i resztę 1. I jeszcze raz iloraz (jeden) dzielimy przez dwa, otrzymując tym razem w wyniku zero i resztę jeden. Ponieważ uzyskaliśmy tym razem iloraz równy 0, przechodzimy do kroku 3. W ten sposób dowiadujemy się, że reprezentacją binarną wartości (trzynaście) jest 1101.
| RYSUNEK 1.16 I
6 Reszta 1 2/13
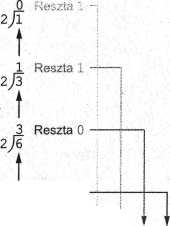
♦ ' ł
! 0 1 Reprezentacja binarna
Zastosowanie algorytmu z rys. 1.15 do obliczenia reprezentacji binarnej wartości trzynaście
44 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Przypomnijmy sobie teraz problem przechowywania danych numerycznych. Za pomocą notaqi binarnej w jednym bajcie można zapamiętać dowolną liczbę całkowitą z zakresu od 0 do 255 (od 00000000 do 11111111). Dysponując dwoma bajtami, można zapamiętać wartości całkowite z zakresu od 0 do 65535. Jest to wielkie ulepszenie w porównaniu z kodowaniem cyfr jedna po drugiej za pomocą kodu ASCII, które dawało możliwość zapamiętania w dwóch bajtach liczb całkowitych z zakresu od 0 do 99.
Z tego powodu, a także z wielu innych, upowszechnił się sposób zapamiętywania informacji liczbowych w pewnej odmianie notacji binarnej, a nie za pomocą kodowania poszczególnych symboli. Użyto sformułowania „w pewnej odmianie notacji binarnej", ponieważ prosty system binarny opisany wcześniej stanowi tylko podstawę dla wielu technik zapisywania w komputerze wartości liczbowych. Niektóre ze stosowanych wariantów systemu binarnego omawiamy w dalszej części rozdziału. Na razie tylko wspomnimy, że najczęstszą formą zapamiętywania liczb całkowitych jest system zwany notacją uzupełnieniową do dwóch. Daje on wygodny sposób reprezentacji liczb ujemnych oraz dodatnich. Do reprezentacji liczb z częścią ułamkową, takich jak 4]/2 lub 3A, stosuje się jeszcze inną technikę zwaną notacją zmiennopozycyjną. Widać zatem, że dowolną wartość (na przykład 25) można reprezentować w postaci wielu różnych ciągów bitów (kodując po kolei poszczególne znaki, stosując notację uzupełnieniową do dwóch lub traktując wartość jako 25% i kodując ją w notacji zmiennopozycyjnej). Podobnie konkretny ciąg bitów można interpretować na wiele sposobów.
Jest to właściwe miejsce, aby wspomnieć o ważnym problemie dotyczącym systemów przechowywania wartości liczbowych, który szczegółowo omówimy nieco później. Niezależnie od długości ciągu bitów, który przeznacza się w komputerze do reprezentowania wartości liczbowej, zawsze będą wielkości zbyt duże lub ułamki zbyt małe, aby dały się one zapamiętać w przeznaczonej do tego celu przestrzeni. W efekcie istnieje ciągłe ryzyko wystąpienia błędów takich jak: przepełnienie (wartości za duże) lub niedomiar (ułamki za małe). Z błędami tymi trzeba się uporać, w przeciwnym razie niczego niepodejrzewający użytkownik wkrótce stanie w obliczu mnóstwa błędnych danych.
Reprezentacja obrazów
Współczesne komputery znajdują znacznie szersze zastosowania niż tylko przetwarzanie tekstu i danych liczbowych. Z komputerów korzysta się także do przetwarzania zdjęć, filmów i dźwięków. W porównaniu z systemami kodowania informaq'i o znakach i liczbach, techniki reprezentacji danych wchodzących w skład takich złożonych obiektów są jeszcze w powijakach, a co za tym idzie, nie wykształciły się jeszcze powszechnie przyjęte standardy.
Popularne techniki reprezentacji obrazu można podzielić na dwie kategorie: techniki wykorzystujące mapę bitową (ang. bit map techniąue) oraz
1.4. REPREZENTOWANIE INFORMACJI W POSTACI CIĄGÓW BITÓW 45
techniki wektorowe (ang. vector technique). W technikach wykorzystujących mapy bitowe obraz traktuje się jako zbiór punktów, zwanych pikslami (pixeh skrót od angielskiego terminu picture element - element obrazu). W najprostszej formie obraz reprezentuje się jako długi ciąg bitów reprezentujących poszczególne wiersze piksli w obrazie, przy czym każdy bit jest 1 lub 0 w zależności od tego, czy odpowiadający mu piksel jest czarny, czy biały. Obrazy kolorowe są tylko nieco bardziej złożone, ponieważ każdy piksel reprezentuje się wtedy za pomocą ciągu bitów oznaczającego kolor tego piksla.
Wiele współczesnych urządzeń peryferyjnych, takich jak faksy, kamery wideo, skanery, przekształcają kolorowe obrazy do postaci mapy bitowej. Urządzenia te rejestrują kolor każdego piksla w postaci trzech składowych: czerwonej, zielonej i niebieskiej, które są trzema podstawowymi kolorami. Zazwyczaj do reprezentacji nasycenia każdej z tych składowych stosuje się jeden bajt. Zatem do zapamiętania jednego piksla obrazu są potrzebne trzy bajty.
Takie rozwiązanie polegające na związaniu z każdym pikslem wartości trzech składowych koloru odpowiada także sposobowi wyświetlania obrazu na współczesnych monitorach. Urządzenia te wyświetlają mnóstwo piksli, z których każdy składa się z trzech składowych: czerwonej, zielonej i niebieskiej. Można to łatwo zauważyć, przyglądając się z bliska obrazowi na monitorze (lepiej użyć szkła powiększającego).
Format trzech bajtów na piksel oznacza, że do zapamiętania obrazu złożonego z 1280 wierszy po 1024 piksle (typowe zdjęcie) potrzeba kilku megabajtów pamięci, a to przekracza pojemność typowej dyskietki. W podrozdziale 1.8 omówimy dwie popularne techniki (GIF i JPEG) kompresji takich obrazów do bardziej rozsądnych rozmiarów.
Wadą technik wykorzystujących mapy bitowe jest to, że zapamiętanych obrazów nie daje się łatwo skalować do dowolnych rozmiarów. W zasadzie jedynym sposobem powiększenia obrazu jest zwiększenie rozmiaru piksli. Prowadzi to do tego, że obraz wygląda jakby był złożony z dużych ziaren. Podobne zjawisko występuje przy powiększaniu zdjęć wykonanych na błonie fotograficznej. Sposobem rozwiązania problemu skalowania obrazów jest technika wektorowa. W tego typu systemach obraz reprezentuje się w postaci zbioru linii i krzywych. Szczegóły związane z metodą rysowania linii i krzywych pozostawia się urządzeniu, które kiedyś zostanie użyte do wyprodukowania obrazu. To podejście różni się zatem bardzo od wymuszania, żeby urządzenie reprodukowało konkretny ciąg piksli. Wiele czcionek dostępnych we współczesnych drukarkach i monitorach reprezentuje się zazwyczaj wektorowo. Dzięki temu uzyskuje się czcionki skalowalne (ang. scalable fonts), które wykazują dużą elastyczność pod względem rozmiaru znaków. Przykładowo TrueType (opracowany przez Microsoft i Apple Computer) jest systemem, w którym opisuje się sposób rysowania symboli tekstowych. Podobnie PostScript (opracowany przez Adobe Systems) jest sposobem opisu znaków oraz bardziej ogólnych danych obrazowych. Reprezentacja wektorowa jest także powszechnie stosowana w systemach projek-
46 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
towania wspomaganego komputerowo (CAD), które umożliwiają tworzenie i wyświetlanie na ekranie komputera obiektów trójwymiarowych złożonych z wielu linii oraz manipulowanie nimi. Za pomocą technik wektorowych nie można jednak uzyskać obrazów o jakości fotografii, co jest możliwe dzięki zastosowaniu map bitowych. Dlatego we współczesnych cyfrowych aparatach fotograficznych stosuje się techniki wykorzystujące mapy bitowe.
PYTANIA I ĆWICZENIA
1. Oto komunikat zakodowany w ASCII za pomocą ośmiu bitów na
symbol. Jaka jest jego treść?
01001001 01101110 01100110 01101111 01110010 01101101 01100001 01110100 01111001 01101011 01100001
Jaki jest związek między kodem wielkiej litery a kodem tej samej
małej litery w kodzie ASCII?Zapisz w kodzie ASCII następujące zdania:
Gdzie on jest?
„Jak?" pyta Jan.
2 + 3 = 5.
4. Opisz znane Ci z codziennego życia urządzenie, które zawsze znaj
duje się w jednym z dwóch stanów (tak jak flaga, która jest albo
wciągnięta na maszt, albo opuszczona). Przypisz symbol 1 do jednego
z tych stanów, a symbol 0 do innego i pokaż, jak wyglądałaby repre
zentacja w kodzie ASCII litery b, gdyby poszczególne bity kodować
w zaproponowany przez Ciebie sposób.
5. Przekształć każdą z poniższych reprezentacji binarnych do odpowia
dającej jej postaci dziesiątkowej:
(a) 0101 (b) 1001 (c) 1011 (d) 0110 (e) 10000 (f) 10010
6. Przekształć poniższe reprezentacje liczb w systemie dziesiątkowym do
równoważnej postaci binarnej:
(a) 6 (b) 13 (c) 11 (d) 18
(e) 27 (f) 4
Jaką największą wartość liczbową można zapisać za pomocą trzech
bajtów, jeśli każdą cyfrę koduje się za pomocą jej kodu ASCII pamięta
nego w jednym bajcie? Jak zmieni się odpowiedz, jeśli wykorzystamy
notację binarną?Oprócz notacji szesnastkowej, do reprezentacji ciągów bitów stosuje
się kropkową notację dziesiątkową, w której każdy bajt ciągu jest re
prezentowany przez jego odpowiednik w systemie dziesiątkowym.
Reprezentacje poszczególnych bajtów oddziela się od siebie krop
kami. Na przykład 12.5 jest reprezentacją ciągu 0000110000000101 (bajt
00001100 reprezentujemy jako 12, a bajt 00000101 jako 5), natomiast
1.4. REPREZENTOWANIE INFORMACJI W POSTACI CIĄGÓW BITÓW 47
ciąg 10001000001000000000111 jest reprezentowany jako 136.16.7.
Przedstaw następujące ciągi bitów w kropkowej notacji dziesiątkowej:
(a) 0000111100001111 (b) 001100110000000010000000
(c) 0000101010100000
1.5. System binarny
Przed dalszym omówieniem sposobów przechowywania wartości liczbowych stosowanych we współczesnych komputerach, należy przedstawić bardziej szczegółowo niektóre elementy systemu reprezentacji binarnej (dwójkowej).
Dodawanie binarne
Aby dodać dwie wartości reprezentowane w notacji binarnej, postępuje się tak jak przy pisemnym dodawaniu liczb w systemie dziesiątkowym. Najpierw trzeba opracować tabelę wartości uzyskiwanych w wyniku dodania dwóch cyfr binarnych (rys. 1.17). Z tej tabeli korzysta się w celu dodania dwóch ciągów cyfr binarnych. Najpierw dodajemy do siebie cyfry w prawej skrajnej kolumnie, zapisujemy mniej znaczącą cyfrę tej sumy pod kreską w tej samej kolumnie, a bardziej znaczącą cyfrę (o ile jest) przenosimy na lewo do następnej kolumny. Następnie wykonujemy dodawanie cyfr w kolejnej kolumnie. Aby zatem obliczyć sumę:
00111010 + 00011011
rozpoczynamy od dodania cyfr 0 i 1 po prawej stronie. Otrzymujemy w wyniku 1, którą zapisujemy pod kreską w ostatniej kolumnie. Teraz dodajemy 1 i 1 z następnej kolumny, otrzymując w wyniku 10. Zapisujemy zatem mniej znaczącą cyfrę 0 tego wyniku pod kreską w kolumnie, a 1 przenosimy do następnej kolumny, zapisując ją na górze. W tym momencie sytuacja wygląda tak:
1
00111010
+ 00011011
01
Dodajemy teraz 1,0 i 0 z kolejnej kolumny, otrzymując 1, którą zapisujemy na dole kolumny. Cyfry 1 i 1 z następnej kolumny dają w sumie 10; zapisujemy więc 0 na dole kolumny i przenosimy 1 do następnej. Teraz sytuacja wygląda tak:
48 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
0 |
1 |
0 |
I-l |
+0 |
+0 |
+1 |
+1 |
0 |
1 |
1 |
10 |
Tabela wyników dodawania cyfr binarnych
00111010
+ 00011011 .
0101
Cyfry 1, 1 i 1 w następnej kolumnie sumują się do 11. Zapisujemy zatem mniej znaczącą 1 pod kreską na dole kolumny, a drugą 1 przenosimy na górę kolejnej kolumny. Dodajemy tę 1 do 1 i 0 znajdujących się już w tej kolumnie i otrzymujemy 10. Znów zapisujemy mniej znaczące 0 pod kreską, a 1 przenosimy kolumnę dalej. Mamy teraz:
1
00111010
+ 00011011
010101
Dodajemy następnie 1, 0 i 0 z przedostatniej kolumny, otrzymując 1, którą zapisujemy na dole kolumny. Nie ma przeniesienia do następnej kolumny, więc dodajemy 0 i 0 z ostatniej kolumny, co daje 0, które zapisujemy na dole ostatniej kolumny. Wynik końcowy jest następujący:
00111010
+ 00011011
01010101
Ułamki w zapisie binarnym
Rozszerzymy teraz notację binarną tak, aby można było zapisywać w niej wartości ułamkowe. W tym celu wprowadzamy kropkę pozycyjną (ang. ra-dix pointy, która pełni tę samą rolę, co przecinek w notacji dziesiątkowej.
W informatyce przyjęła się konwencja wywodząca się z angielskiej notacji matematycznej oddzielania części całkowitej od ułamkowej kropką, a nie przecinkiem (przyp. tłum.).
1.5. SYSTEM BINARNY
49
Cyfry na lewo od kropki reprezentują część całkowitą liczby i są interpretowane tak jak w systemie binarnym omówionym w poprzednim punkcie. Cyfry po prawej stronie kropki reprezentują część ułamkową liczby i interpretuje się je tak jak pozostałe bity z tą różnicą, że ich pozycjom przypisuje się wagi ułamkowe. Pierwsza pozycja po kropce ma wagę ł/fc druga - wagę Vi, następna - Vs i tak dalej. Zwróćmy uwagę, że jest to w zasadzie naturalne rozszerzenie konwencji stosowanej poprzednio: każdej pozycji przypisuje się wagę dwa razy większą niż waga pozycji z jej prawej strony. Przy takim przypisaniu wag do pozycji, dekodowanie liczby zapisanej w reprezentacji binarnej z kropką pozycyjną polega na wykonaniu tej samej procedury, którą wykonywaliśmy przy notacji binarnej bez kropki pozycyjnej. Mnoży się zatem wartość każdego bitu przez wagę związaną z pozycją tego bitu w reprezentacji liczby. Przykładowo, reprezentacja binarna 101.101 oznacza 55/s/ jak zilustrowano to na rysunku 1.18.
Wykonując dodawanie, stosuje się te same techniki co przy dodawaniu liczb w systemie dziesiątkowym. Aby dodać do siebie dwie liczby zapisane w reprezentacji binarnej z kropką pozycyjną, zapisujemy je jedna pod drugą tak, aby kropki znalazły się w tej samej kolumnie, a następnie stosujemy ten sam algorytm dodawania co poprzednio. Na przykład 10.011 dodane do 100.11 daje 111.001, jak widać poniżej:
10.011 + 100.11 111.001
50
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
PYTANIA I ĆWICZENIA
1. Przekształć poniższe liczby zapisane w reprezentacji binarnej na
odpowiadającą im postać dziesiątkową:
(a) 101010 (b) 100001 (c) 10111 (d) 0110 (e) mu
2. Przekształć poniższe liczby zapisane w reprezentacji dziesiątkowej na
odpowiadające im postaci w reprezentacji binarnej:
(a) 32 (b) 64 (c) 96 (d) 15 (e) 27
3. Przekształć poniższe liczby zapisane w reprezentacji binarnej na
odpowiadającą im postać dziesiątkową:
(a) 11.01 (b) 101.111 (c) 10.1 (d) 110.011 (e) 0.101
4. Wyraź następujące wartości w notacji binarnej:
(a) 4V2 (b) 23/4 (c) ll/» (d) Vi6 (e) 5Vs
5. Wykonaj następujące dodawania w notacji binarnej:
(a) 11011 (b) 1010.001 (c) lllll (d) 111.11
+ 1100 + 1.101 + 1 + .01
1.6. Reprezentacja liczb całkowitych
Matematycy od dawna zajmowali się systemami zapisu liczb. Okazało się, że wiele z ich pomysłów nadaje się do zastosowania w układach cyfrowych. W tym podrozdziale omówimy dwa systemy notacyjne: notację uzupełnieniową do dwóch i notację z nadmiarem. Systemy te stosuje się do reprezentacji liczb całkowitych w maszynach liczących. Wywodzą się one z systemu binarnego przedstawionego w podrozdziale 1.5 i charakteryzują się dodatkowymi właściwościami, które sprawiają, że lepiej uwzględniają specyficzne cechy architektury komputera. Mimo tych zalet mają one jednak także swoje wady. W tym rozdziale przedstawimy właściwości systemów reprezentacji liczb całkowitych i ich konsekwencje zauważalne przy typowym korzystaniu z komputera.
Notacja uzupełnieniowa do dwóch
Najpopularniejszym obecnie systemem reprezentacji liczb całkowitych jest notacja uzupełnieniowa do dwóch (ang. two's complement notatioń). Do reprezentacji każdej wartości w tym systemie wykorzystuje się tę samą, ustaloną liczbę bitów. We współczesnym sprzęcie powszechnie stosuje się 32-bitową notację uzupełnieniową do dwóch. W tak dużym systemie można
1.6. REPREZENTACJA LICZB CAŁKOWITYCH 51
| RYSUNEK 1.19 | |
|
|
|
(a) Ciągi długości trzy |
(b) Ciągi długości cztery |
||
Ciąg |
Reprezentowana |
Ciąg |
Reprezentowana |
bitów |
wartość |
bitów |
wartość |
011 |
3 |
■ . om |
7 |
010 |
2 |
0110 |
6 |
001 |
1 |
0101 |
5 |
000 |
0 |
0100 |
4 |
111 |
-1 |
0011 |
3 |
110 |
-2 |
0010 |
2 |
101 |
-3 |
0001 |
1 |
100 |
-4 |
0000 |
0 |
% . . ■ |
|
1111 |
-1 |
■'■■■■ |
|
1110 |
-2 |
8 ■■ ■■.■•'■ |
|
1101 |
-3 |
B ': ■ |
|
1100 |
-4 |
B |
|
1011 |
-5 |
1 ■ ■ ■ ■ |
|
1010 |
-6 |
■■■■,■ . |
|
1001 |
-7 |
1 • |
|
1000 |
-8 |
|
Systemy notacji uzupełnieniowej do dwóch |
||
zapisać wartości z dużego zakresu, ale jest on niewygodny do celów demonstracyjnych. Z tego powodu przedstawiając właściwości systemów uzupełnieniowych do dwóch, będziemy analizować mniejsze systemy.
Na rysunku 1.19 pokazano dwa pełne systemy uzupełnieniowe do dwóch: jeden 3-bitowy, drugi 4-bitowy. Wartości w systemie konstruuje się począwszy od ciągu zer odpowiedniej długości, a następnie dodając binarnie jedynkę aż do uzyskania ciągu rozpoczynającego się od 0, po którym występują same 1. Tak otrzymane ciągi reprezentują wartości 0, 1, 2, 3, .... Ciągi reprezentujące wartości ujemne uzyskuje się począwszy od ciągu jedynek odpowiedniej długości, od którego odejmuje się binarnie jeden aż do uzyskania ciągu zaczynającego się od 1, po której następują same 0. Tak otrzymane ciągi reprezentują wartości -1, -2, -3, .... (Jeśli odliczanie binarne w tył jest dla Ciebie zbyt trudne, można rozpocząć od dołu tabeli; trzeba wtedy napisać ciąg rozpoczynający się od 1, po której następują same 0, a następnie dodawać do niego jedynkę aż do uzyskania ciągu złożonego z samych 1).
52
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Zwróćmy uwagę, że w systemie uzupełnieniowym do dwóch, wartość lewego skrajnego bitu decyduje o znaku reprezentowanej wartości. Z tego powodu ten bit bywa często nazywany bitem znaku (ang. sign bit). W systemie uzupełnieniowym do dwóch wartości ujemne reprezentuje się za pomocą ciągów bitów z bitem znaku równym 1, a wartości nieujemne - ciągami bitów z bitem znaku równym 0.
W systemie uzupełnieniowym do dwóch istnieje wygodna zależność między ciągami reprezentującymi wartości dodatnie i ujemne o tej samej wartości bezwzględnej. Są one identyczne, gdy czytamy je od prawej do lewej aż do pozycji pierwszej jedynki (która także występuje w obu ciągach). Od tego miejsca ciągi są swoimi wzajemnymi uzupełnieniami. (Uzupełnienie (ang. compkment) ciągu bitów to ciąg otrzymany przez zamianę wszystkich zer na jedynki i jedynek na zera; ciągi 0110 i 1001 są swoimi uzupełnieniami). W systemie czterobitowym z rysunku 1.19 ciągi reprezentujące wartości 2 i -2 kończą się na 10. Ciąg reprezentujący 2 rozpoczyna się od 00, a ciąg reprezentujący -2 od 11. To spostrzeżenie umożliwia opracowanie algorytmu przekształcającego ciąg bitów reprezentujący pewną wartość na ciąg bitów reprezentujący wartość przeciwną. Polega on na skopiowaniu ciągu bitów od prawej do lewej aż do napotkania pierwszej jedynki (tę jedynkę także kopiujemy), a następnie na zamianie pozostałych bitów na bity przeciwne (rys. 1.20).
1.6. REPREZENTACJA LICZB CAŁKOWITYCH
53
Zrozumienie podstawowych właściwości systemów uzupełnieniowych do dwóch umożliwia także opracowanie algorytmu odczytywania wartości reprezentowanych zadanym kodem uzupełnieniowym do dwóch. Jeśli ciąg bitów rozpoczyna się od bitu znaku o wartości 0, to odczytanie wartości reprezentowanej przez ten kod polega na zinterpretowaniu ciągu tak, jakby był naturalną reprezentacją binarną liczby. Na przykład 0110 reprezentuje wartość 6, ponieważ 110 jest binarną reprezentacją wartości 6. Jeśli odczytywany ciąg ma bit znaku równy 1, to wiemy, że reprezentowana przez niego wartość jest ujemna. Wystarczy teraz znaleźć wartość bezwzględną zakodowanej liczby. Obliczamy ją, kopiując ciąg bitów od strony prawej aż do skopiowania pierwszej 1, a następnie zmieniając pozostałe bity. Tak otrzymany ciąg traktujemy w ten sposób, jakby był naturalną reprezentacją binarną.
Na przykład, aby odczytać wartość reprezentowaną przez ciąg bitów 1010, określamy najpierw znak liczby. Ponieważ bit znaku jest równy 1, mamy do czynienia z wartością ujemną. Przekształcamy zatem ciąg bitów na 0110, stwierdzamy, że jest to reprezentacja 6 i w ten sposób ustalamy, że początkowy ciąg bitów reprezentuje wartość -6.
Dodawanie w notacji uzupełnieniowej do dwóch
54 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
W celu dodania wartości reprezentowanych w kodzie uzupełnieniowym do dwóch stosuje się ten sam algorytm, którego używano przy dodawaniu wartości reprezentowanych w kodzie binarnym z tą różnicą, że wszystkie ciągi bitów, w tym także wynik, muszą mieć tę samą długość. Oznacza to, że przy
dodawaniu w systemie uzupełnieniowym do dwóch należy odrzucić ewentualny dodatkowy bit wyniku, powstały na skutek przeniesienia ze skrajnej lewej pozycji. Zatem „dodanie" 0101 i 0010 daje w wyniku 0111, a „dodanie" 0111 i 1011 wynik 0010 (0111 + 1011 = 10010, więc po odrzuceniu nadmiarowego lewego bitu otrzymujemy 0010).
Pamiętając o tym, przeanalizujmy trzy dodawania z rysunku 1.21. W każdym z nich wartości przekształcono do kodu uzupełnieniowego do dwóch (czterobitowego), wykonano opisany powyżej algorytm dodawania i deko-dowano wynik do zwykłej notacji dziesiątkowej.
Zwróćmy uwagę, że gdyby stosować tradycyjne techniki, których uczy się w szkole podstawowej, to ostatni przykład wymagałby zupełnie innego sposobu postępowania (odejmowania) niż dwa pierwsze przykłady. Dzięki przekształceniu wartości do kodu uzupełnieniowego do dwóch, możemy jednak obliczyć wynik we wszystkich przedstawionych przykładach, stosując ten sam algorytm - algorytm dodawania. Jest to podstawowa zaleta notacji uzupełnieniowej do dwóch: dodawanie dowolnej kombinacji liczb ze znakiem można wykonać za pomocą tego samego algorytmu.
W odróżnieniu od uczniów szkoły podstawowej, którzy najpierw uczą się dodawać, a potem dopiero odejmować, komputer stosujący notację uzupełnieniową do dwóch musi jedynie umieć dodawać i zamieniać liczbę na przeciwną. Odjęcie 5 od 7 jest tym samym co dodanie -5 do 7. Jeśli komputer ma odjąć 5 (reprezentowane jako 0101) od 7 (reprezentowanego jako 0111), to najpierw wykonuje zamianę 5 na -5 (reprezentowane jako 1011) a następnie - dodawanie 0111 + 1011. W wyniku powstaje ciąg 0010, który reprezentuje wartość 2:
7 0111 0111 - 5 -» - 0101 -> + 1011
0010 -» 2
Widzimy zatem, że dzięki zastosowaniu do reprezentacji wartości liczbowych kodu uzupełnieniowego do dwóch, dodawanie i odejmowanie może realizować ten sam układ cyfrowy złożony z układu dodającego oraz z układu obliczającego wartości przeciwne (takie układy przedstawiono i omówiono w dodatku B).
Problem przepełnienia
W każdym omawianym systemie liczbowym istnieje ograniczenie rozmiaru wartości, które można w nim reprezentować. W czterobitowym systemie uzupełnieniowym do dwóch nie istnieje ciąg bitów reprezentujący liczbę 9. Oznacza to, że nie możemy otrzymać poprawnego wyniku dodawania 5 + 4. Tak naprawdę w wyniku takiego działania otrzymalibyśmy wartość -7. Błąd tego rodzaju nosi nazwę przepełnienia (ang. overflow) i pojawia się wtedy, kiedy wartość, którą chcemy zakodować, nie mieści się w zakresie repre-zentowalnych w kodzie wartości. W notacji uzupełnieniowej do dwóch błąd przepełnienia może wystąpić przy dodawaniu dwóch wartości dodatnich lub dwóch wartości ujemnych. W obu sytuacjach błąd przepełnienia można
1.6. REPREZENTACJA LICZB CAŁKOWITYCH 55
wykryć, sprawdzając bit znaku sumy. Przepełnienie występuje wtedy, kiedy wynikiem dodawania dwóch wartości dodatnich jest ciąg bitów reprezentujący wartość ujemną lub kiedy suma dwóch wartości ujemnych okazuje się dodatnia.
Oczywiście większość komputerów operuje dłuższymi ciągami bitów niż te, których użyliśmy w przykładach. Można zatem wykonywać działania na większych wartościach, nie powodując przy tym przepełnienia. Obecnie do zapamiętywania wartości w kodzie uzupełnieniowym do dwóch powszechnie stosuje się 32-bitowe ciągi. Umożliwia to zapamiętywanie bez błędu przepełnienia wartości dodatnich aż do 2 147 483 647. Jeśli są potrzebne jeszcze większe wartości, to trzeba użyć dłuższych ciągów bitów lub zmienić jednostki miary, w których wyraża się wartości danych. Może się na przykład okazać, że wyrażenie wyniku w kilometrach zamiast w centymetrach jest wciąż wystarczająco dokładne, a przy tym można użyć mniej-. szych liczb.
Jest ważne, aby uświadamiać sobie, że komputery mogą popełniać błędy. Osoby korzystające z komputerów muszą zdawać sobie sprawę z ewentualnego niebezpieczeństwa. Problem polega jednak na tym, że programiści i użytkownicy popadają w samozadowolenie i ignorują fakt, że dodawanie do siebie wielu małych wartości da w wyniku dużą liczbę. Na przykład do reprezentacji wartości w notacji uzupełnieniowej do dwóch dawniej powszechnie stosowano ciągi 16-bitowe. Przepełnienie nie występowało zatem jedynie do wartości 215 = 32 768. 19 września 1989 r., po latach niezawodnej pracy, system komputerowy w pewnym szpitalu nagle przestał działać. Po bliższym przeanalizowaniu przyczyn okazało się, że dzień ten był 32 768 dniem po 1 stycznia 1900 r. Jak myślisz, co okazało się przyczyną problemu?
Notacja z nadmiarem
Inną metodą reprezentacji wartości całkowitych jest notacja z nadmiarem
(ang. excess notation). W notacji z nadmiarem każdą wartość reprezentuje się w postaci ciągu bitów o ustalonej długości. Definiując system z nadmiarem, najpierw wybiera się długość reprezentacji, a następnie zapisuje wszystkie możliwe ciągi bitów tej długości w kolejności, w jakiej pojawiałyby się przy binarnym dodawaniu jedynki. Można zauważyć, że pierwszy ciąg z jedynką na najbardziej znaczącym bicie występuje mniej więcej w połowie takiej listy. Ten ciąg wybieramy jako reprezentację zera. Ciągi występujące po tym wyróżnionym ciągu reprezentują kolejne wartości dodatnie 1, 2, 3, ... , a ciągi poprzedzające go reprezentują wartości ujemne -1, -2, -3, .... Pełny czte-robitowy kod z nadmiarem przedstawiono na rysunku 1.22. Widzimy, że wartość 5 jest reprezentowana za pomocą ciągu 1101, a wartość -5 za pomocą ciągu 0011 (zwróćmy uwagę, że różnica między systemem z nadmiarem a systemem uzupełnieniowym do dwóch polega na odwróceniu bitu znaku).
56 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Ciąg |
Reprezentowana |
bitów |
wartość |
1111 ■ |
7 |
1110 |
6 |
1101 |
5 |
1100 |
4 |
1011 |
3 |
1010 |
2 |
1001 |
1 |
1000 |
0 |
0111 |
-1 |
0110 |
-2 |
0101 |
-3 |
0100 |
-4 |
0011 |
-5 |
0010 |
-6 |
0001 |
-7 |
0000 |
-8 |
Tabela konwersji do notacji z nadmiarem osiem
System przedstawiony na rysunku 1.22 jest znany pod nazwą notacji z nadmiarem osiem. Aby zrozumieć, skąd wzięła się ta nazwa, zinterpretujmy każdy ciąg bitów, stosując tradycyjny system binarny, i porównajmy te wyniki z wartościami reprezentowanymi przez nie w kodzie z nadmiarem. W każdym przypadku stwierdzamy, że interpretacja binarna jest o 8 większa niż interpretacja w kodzie z nadmiarem. Na przykład ciąg 1100 w zwykłym kodzie binarnym przedstawia wartość 12, a w naszym systemie z nadmiarem reprezentuje 4. Ciąg 0000 normalnie reprezentuje wartość 0, a w systemie z nadmiarem reprezentuje -8. Z tego samego powodu system z nadmiarem zbudowany na bazie ciągów 5-bitowych nazwalibyśmy notacją z nadmiarem 16. Ciąg bitów 10000 reprezentuje w tej notacji wartość 0, podczas gdy w zwykłej notacji binarnej jest to wartość 16. W podobny sposób można przekonać się, że 3-bitowy system z nadmiarem można nazwać notacją z nadmiarem cztery (rys. 1.23).
1.6. REPREZENTACJA LICZB CAŁKOWITYCH
57
Ciąg |
Reprezentowana |
bitów |
wartość |
111 |
3 |
110 |
2 |
101 |
1 |
ioo |
0 |
011 |
-1 |
010 |
-2 |
001 |
-3 |
000 |
-4 |
Notacja z nadmiarem z ciągami trzybitowymi
PYTANIA I ĆWICZENIA
1. Przekształć poniższe reprezentacje w kodzie uzupełnieniowym do
dwóch na odpowiadającą im postać dziesiątkową:
(a) 00011 (b) 01111 (c) 11100 (d) 11010 (e) 00000 (f) 10000
2. Przekształć poniższe reprezentacje dziesiątkowe na odpowiadające im
ośmiobitowe kody w kodzie uzupełnieniowym do dwóch:
(a) 6 (b) -6 (c) -17 (d) 13 (e) -1 (f) 0
3. Przypuśćmy, że następujące ciągi bitów reprezentują wartości zako
dowane w kodzie uzupełnieniowym do dwóch. Znajdź reprezentację
wartości przeciwnych w tym kodzie:
(a) 00000001 (b) 01010101 (c) 11111100 (d) 11111110 (e) 00000000 (f) 01111111
4. Przypuśćmy, że komputer przechowuje wartości w notacji uzupeł
nieniowej do dwóch. Jaką największą i najmniejszą wartość można
zapamiętać przy użyciu ciągów o następujących długościach?
(a) cztery (b) sześć (c) osiem
5. W następujących zadaniach każdy ciąg bitów reprezentuje wartość
przechowywaną w notacji uzupełnieniowej do dwóch. Podaj rozwiąza
nie każdego zadania w notaq'i uzupełnieniowej do dwóch, wykonując
dodawanie w sposób opisany w książce. Sprawdź wynik, przekształ
cając dane i wyniki do postaci dziesiątkowej.
(a) 0101 (b) 0011 (c) 0101 (d) 1110 (e) 1010
+ 0010 + 0001 + 1010 + 0011 + 1110
58 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
6. Wykonaj poniższe działania w notacji uzupełnieniowej do dwóch.
Tym razem uważaj na przepełnienia. Zaznacz te odpowiedzi, które są
niepoprawne ze względu na wystąpienie błędu przepełnienia.
(a) 0100 (b) 0101 (c) 1010 (d) 1010 (e) 0111 + 0011 +.0110 + 1010 + 0111 + 0001
7. Przekształć poniższe działania z notacji dziesiątkowej na czterobitową
notację uzupełnieniową do dwóch. Następnie zapisz je w postaci
odpowiedniego dodawania (tak jak zrobiłby to komputer) i wykonaj
go. Sprawdź wyniki, przekształcając je do notacji dziesiątkowej:
(a) 6 (b) 3 (c) 4 (d) 2 (e) 1
+1 -2 -6 +4 +5
Czy w kodzie uzupełnieniowym do dwóch może wystąpić nadmiar
przy dodawaniu wartości dodatniej do ujemnej? Uzasadnij odpo
wiedź.Przekształć poniższe reprezentacje w kodzie z nadmiarem osiem na
odpowiadającą im postać dziesiątkową:
(a)' 1110 (b) 0111 (c) 1000 (d) 0010 (e) 0000 (f) 1001
10. Przekształć poniższe reprezentacje dziesiątkowe na odpowiadające im
reprezentacje w kodzie z nadmiarem osiem:
(a) 5 (b) -5 (c) 3
(d) 0 (e) 7 (f) -8
11. Czy wartość 9 da się zapisać w notacji z nadmiarem 8? A wartość 6
w notacji z nadmiarem 4? Uzasadnij odpowiedzi.
1.7. Reprezentacja wartości ułamkowych
Reprezentacja liczb z częścią ułamkową wymaga nie tylko zapamiętania ciągów 0 i 1, reprezentujących część całkowitą i ułamkową liczby jak w reprezentacji liczb całkowitych, ale także pozycji kropki pozycyjnej. Popularnym sposobem realizacji tego zadania jest sposób wywodzący się z notacji naukowej, zwany notacją zmiennopozycyjną.
Notacja zmiennopozycyjną
Notację zmiennopozycyjną wyjaśnimy, posługując się przykładami, w których do zapamiętania liczby stosuje się tylko jeden bajt. Chociaż w komputerach używa się zazwyczaj znacznie dłuższych ciągów, to jednak ośmio-bitowy format jest reprezentatywny dla rzeczywistych systemów. Na jego
1.7. REPREZENTACJA WARTOŚCI UŁAMKOWYCH 59
przykładzie można zilustrować wszystkie ważne pojęcia bez konieczności posługiwania się długimi ciągami bitów.
Przede wszystkim najbardziej znaczący bit bajtu przeznacza się na bit znaku. I znów, 0 w bicie znaku oznacza wartość nieujemną, a 1 oznacza wartość ujemną. Pozostałe 7 bitów bajtu dzieli się na dwie grupy, zwane polami: pole wykładnika (ang. exponent field) i pole części ułamkowej (ang. mantissa field). Przeznaczmy pierwsze trzy bity po bicie znaku na pole wykładnika, a pozostałe 4 bity na pole części ułamkowej. Na rysunku 1.24 przedstawiono sposób podziału bajtu.
Znaczenie poszczególnych pól wyjaśnimy na przykładzie. Przypuśćmy, że bajt zawiera ciąg bitów 01101011. Odczytując ten bajt zgodnie z opisanym powyżej formatem, stwierdzamy, że bit znaku ma wartość 0, wykładnik to 110, a część ułamkowa to 1011. W celu odczytania wartości reprezentowanej przez bajt, umieszczamy kropkę pozycyjną po lewej stronie części ułamkowej, otrzymując
.1011
Następnie odczytujemy zawartość pola wykładnika (110) i interpretujemy ją jak liczbę całkowitą zapisaną w trzybitowej notacji z nadmiarem (rys. 1.23). Zatem w omawianym przykładzie ciąg bitów w polu wykładnika reprezentuje wartość 2. Oznacza to, że należy przesunąć kropkę o 2 pozycje w prawo (wartość ujemna oznaczałaby przesunięcie kropki w lewo). W efekcie otrzymujemy
10.11
60 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Jest to binarna reprezentacja liczby 23/4. Następnie stwierdzamy, że bit znaku w rozważanym przykładzie jest równy 0, więc reprezentowana wartość jest nieujemną. Zatem bajt 01101011 reprezentuje wartość 23/4.
Przeanalizujmy inny przykład: bajt 10111100. Po wyodrębnieniu części ułamkowej otrzymujemy
.1100
Przesuwamy kropkę o jedną pozycję w lewo, gdyż pole wykładnika (011) reprezentuje wartość -1. Otrzymujemy zatem
.01100
Jest to reprezentacja liczby 3/s- Ponieważ bit znaku w ciągu bitów jest równy 1, więc wartość jest ujemna. Wnioskujemy stąd, że ciąg 10111100 reprezentuje -%.
Aby zapisać liczbę w notacji zmiennopozycyjnej odwracamy poprzednie czynności. Aby zakodować wartość lVs, najpierw wyrażamy ją w notacji binarnej, otrzymując 1.001. Następnie kopiujemy ciąg bitów od lewej do prawej do pola części ułamkowej, rozpoczynając od skrajnie lewej 1. W tym momencie konstruowany bajt wygląda następująco:
1001
Musimy teraz wypełnić pole wykładnika. W tym celu wyobraźmy sobie zawartość pola części ułamkowej z kropką umieszczoną po jego lewej strome i określmy, o ile bitów i w którą stronę należy przesunąć kropkę, aby uzyskać wartość 1.001. Wykładnik powinien mieć wartość 1, więc umieszczamy 101 (co oznacza +1 w notacji z nadmiarem cztery) w polu wykładnika. Wreszcie wypełniamy bit znaku zerem, gdyż wartość jest nieujemna. Pełny bajt wygląda zatem następująco:
01011001
Jest pewna subtelność związana z określaniem zawartości pola części ułamkowej, którą łatwo przeoczyć. Metoda postępowania polega na skopiowaniu od lewej do prawej ciągu bitów występującego w reprezentacji binarnej liczby, począwszy od skrajnie lewej 1. Rozważmy proces kodowania liczby Vs, którą w notacji binarnej zapisuje się za pomocą ciągu .011. Część ułamkowa będzie zatem równa
110 0
0 110
Jest to spowodowane tym, że wypełnianie pola części ułamkowej rozpoczyna się od skrajnej lewej 1, występującej w reprezentacji binarnej. Taka metoda postępowania eliminuje możliwość reprezentacji tej samej wartości na wiele sposobów. Oznacza również, że w reprezentacji wszystkich nieze-rowych wartości pole części ułamkowej rozpoczyna się od 1. Taką postać
1.7. REPREZENTACJA WARTOŚCI UŁAMKOWYCH 61
reprezentacji nazywa się postacią znormalizowaną (ang. normalized form). Zwróćmy uwagę, że wartość 0 trzeba potraktować w szczególny sposób. Reprezentacja zera w notacji zmiennopozycyjnej jest ciągiem złożonym z samych zer.
Błędy zaokrąglenia
Rozważmy teraz irytujący problem, który pojawi się przy próbie przedstawienia wartości 25/s w omawianym jednobajtowym systemie zmienno-pozycyjnym. Zapiszmy najpierw wartość 25/s binarnie. Otrzymamy 10.101. W polu części ułamkowej zabraknie zatem miejsca i prawa skrajna 1 (która reprezentuje ostatnie Vs) zostaje zgubiona (rys. 1.25). Zignorujmy chwilowo ten problem i wypełniajmy dalej pole wykładnika oraz bit znaku. Otrzymujemy ciąg bitów 01101010, który reprezentuje 21/2/ a nie 25/s. Zjawisko, które zaobserwowaliśmy, nazywa się błędem zaokrąglenia (ang. truncation error, roundoff error), co oznacza, że część wartości, którą chcemy zapisać, zostaje zagubiona, gdyż pole części ułamkowej nie jest wystarczająco duże.
Rozmiar takich błędów można zmniejszyć, stosując dłuższe pole części ułamkowej. Powszechnie w notacji zmiennopozycyjnej używa się co najmniej 32 bitów, a nie ośmiu, jak w powyższym przykładzie. Stosuje się zarazem większe pole wykładnika. Nawet jednak przy użyciu takich dłuższych formatów zdarzają się sytuacje, w których jest wymagana jeszcze większa dokładność.
62
ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
WHKMBMNMUKB
SYSTEMY ANALOGOWE A SYSTEMY CYFROWE
We wczesnych latach życia komputerów dyskutowano, czy urządzenia komputerowe należy rozwijać, stosując technikę analogową czy cyfrową. W systemach cyfrowych liczby reprezentuje się za pomocą skończonego zbioru różnych cyfr (na przykład 0 i 1). W systemach analogowych każdą wartość zapamiętuje się w osobnym urządzeniu zdolnym do przechowania dowolnej wartości z pewnego ciągłego zakresu.
Porównajmy oba podejścia na przykładzie wiader z wodą. Aby zasymulować system cyfrowy możemy umówić się, że puste wiadro reprezentuje cyfrę 0, a pełne cyfrę 1. Można zatem reprezentować wartość liczbową zapisaną w notacji zmiennopozycyjnej za pomocą wiader ustawionych w rzędzie. System analogowy można by dla odmiany zasymulować za pomocą jednego wiadra, wypełniając go częściowo wodą tak, aby jej poziom był zgodny z reprezentowaną wartością. Na pierwszy rzut oka system analogowy wydaje się bardziej dokładny, gdyż nie ma w nim błędów zaokrągleń charakterystycznych dla systemu cyfrowego. Jednak każde poruszenie wiadra w systemie analogowym może spowodować błąd w określeniu poziomu wody. W systemie cyfrowym musiałby wystąpić bardzo silny wstrząs, aby spowodować zatarcie różnicy między wiadrem pustym a pełnym. Zatem system cyfrowy jest mniej czuły na błędy niż system analogowy. Ta odporność jest podstawową przyczyną tego, że wiele zastosowań opartych początkowo na technologii analogowej (komunikacja telefoniczna, nagrania dźwiękowe, telewizja) przenosi się na platformę cyfrową.
Innym źródłem błędów zaokrągleń jest zjawisko, które znamy także z systemu dziesiątkowego: problem nieskończonego rozwinięcia ułamka dziesiętnego, który występuje na przykład przy próbie zapisu 1/3 w postaci ułamka dziesiętnego. Niektórych wartości po prostu nie daje się dokładnie wyrazić niezależnie od tego, jak wiele cyfr użyjemy.
Różnica między zwykłym systemem dziesiątkowym a notacją binarną powoduje, że więcej wartości ma nieskończona reprezentacja w notacji binarnej niż w dziesiętnej. Na przykład wartość jedna dziesiąta ma rozwinięcie nieskończone w notacji binarnej. Wyobraźmy sobie, jakie mogą wystąpić problemy, gdy nieświadomy tego zjawiska człowiek stosuje notację zmiennopozycyjną do przechowywania informacji finansowych i manipulowania nimi. W szczególności, jeśli jako jednostki miary użyje się złotówki, to wartości dziesięciu groszy nie da się reprezentować w sposób dokładny. Aby uporać się z tym problemem, w tym akurat przykładzie można jako jednostkę wybrać grosze. W ten sposób wszystkie wartości są całkowite i mogą być reprezentowane dokładnie w notacji takiej jak notacja uzupełnieniowa do dwóch.
Błędy zaokrągleń i związane z nimi problemy są codziennym zmartwieniem ludzi zajmujących się analizą numeryczną. Ta gałąź matematyki bada problemy powstające podczas obliczeń, które często są bardzo intensywne i wymagają dużej dokładności.
A oto przykład, który z pewnością uradowałby serce numeryka. Przypuśćmy, że mamy dodać do siebie następujące trzy wartości zapisane w jed-nobajtowej notacji zmiennopozycyjnej
Jeśli będziemy dodawać te wartości od lewej do prawej, to najpierw wykonamy działanie 2% + 78, otrzymując w wyniku 25/8/ którego reprezentacją binarną jest 10.101. Niestety, ponieważ tej wartości nie można zapisać
1.7. REPREZENTACJA WARTOŚCI UŁAMKOWYCH
63
dokładnie (jak pokazaliśmy to w poprzednim akapicie), więc wynik pierwszego dodawania zostanie zapamiętany jako 2 Vi (jest to dokładnie jedna z dodawanych wartości). Kolejnym krokiem jest dodanie tego wyniku do drugiej wartości Vs- Znów pojawia się błąd zaokrąglenia i końcowym wynikiem jest niepoprawna wartość 21/2.
Wykonajmy teraz dodawanie w odwrotnej kolejności. Dodajmy najpierw 1/s do 1/g. Binarnie będzie to .01, więc wynik pierwszego dodawania zostanie zapamiętany jako 00111000; jest to reprezentacja dokładna. Dodajmy teraz tak otrzymane 1A do kolejnej wartości: 1xli. W wyniku otrzymujemy 23A, które można reprezentować dokładnie jako 01101011. Tym razem otrzymaliśmy poprawny wynik.
Podsumowując, w operacji dodawania kolejność wykonywania działań może okazać się istotna. Problemy powstają przy dodawaniu do bardzo dużej liczby wartości bardzo małej; dochodzi wtedy do obcięcia małej wartości. Zatem ogólną regułą przy wykonywaniu dodawania jest zsumowanie najpierw wartości małych w nadziei, że dadzą w sumie wartość wystarczająco dużą, aby nie została obcięta przy dodawaniu jej do wartości większych. To właśnie zjawisko obserwowaliśmy w poprzednim przykładzie.
Twórcy współczesnych komercyjnych pakietów oprogramowania starają się skutecznie bronić niedoświadczonego użytkownika przed tego typu problemami. W typowym arkuszu kalkulacyjnym można uzyskać poprawne wyniki, o ile dodawane wartości nie różnią się więcej niż 10lć razy. Jeśli zatem stwierdzimy, że konieczne jest dodanie 1 do wartości
10 000 000 000 000 000 możemy otrzymać w wyniku
10 000 000 000 000 000 a nie
10 000 000 000 000 001
Takie problemy mają dużo większe znaczenie w aplikacjach takich jak systemy nawigacyjne. Niewielkie błędy występujące przy kolejnych obliczeniach mogą zsumować się i w końcu doprowadzić do poważnych konsekwencji.
PYTANIA I ĆWICZENIA
1. Odczytaj wartości zapisane za pomocą poniższych ciągów bitów
w notacji zmiennopozycyjnej omówionej w tekście:
(a) 01001010 (b) 01101101 (c) 00111001 (d) 11011100 (e) 10101011
2. Zapisz następujące wartości w notacji zmiennopozycyjnej omówionej
w tekście. Wskaż występujące błędy zaokrągleń:
(a) 23/4 (b) 51/4 (c) V4 (d) -31/2 (e) -43/8
64 ROZDZIAŁ PIERWSZY PRZECHOWYWANIE DANYCH
Który z ciągów bitów 01001001 czy 00111101 reprezentuje większą
wartość w notacji zmiennopozycyjnej z tekstu? Zaproponuj prosty
sposób sprawdzania, który z dwóch ciągów bitów reprezentuje więk
szą wartość.Jaka jest największa wartość, którą można zapisać w notacji przedsta
wionej w tekście? Jaka jest najmniejsza dodatnia wartość, którą można
w niej zapisać?
1.8. Kompresja danych
Do przechowywania danych i ich przesyłania często jest przydatne (a czasem nawet niezbędne) zmniejszenie rozmiaru danych. Technika realizacji takiego zmniejszenia rozmiaru danych to kompresja danych. W tym punkcie omówimy najpierw pewne ogólne metody kompresji danych, a następnie przyjrzymy się bliżej metodom zaprojektowanym specjalnie do kompresji obrazów.
Techniki kompresji danych ogólnego przeznaczenia
Opracowano wiele technik kompresji danych. Dla każdej z nich można wskazać dane, przy których działa ona najgorzej i dane, przy których działa najlepiej. Metoda zwana kodowaniem grupowym lub kodowaniem długości serii (ang. run-length encoding) daje najlepsze wyniki, gdy kompresowane dane składają się z długich ciągów tej samej wartości. Kodowanie grupowe polega na zastąpieniu takich ciągów kodem złożonym z powtarzającej się wartości i z liczby wystąpień tej wartości w ciągu. Do zapamiętania informacji, że ciąg bitów składa się z 253 jedynek, po których występuje 118 zer i znów 87 jedynek, potrzeba zdecydowanie mniej miejsca niż do zapamiętania całego ciągu 458 bitów.
Niekiedy informacja składa się z bloków danych, z których każdy różni się nieznacznie od poprzedniego. Typowym przykładem jest zbiór ramek filmu. W takich sytuacjach dobrze sprawdza się technika kodowania względnego (ang. relatwe encoding). W tej metodzie zapamiętuje się różnice między kolejnymi blokami danych, a nie całe bloki. Oznacza to, że kodowane są różnice między następującymi po sobie blokami.
Inną metodą zmniejszania rozmiaru danych są kody zależne od częstości wystąpień (ang. frequency-dependent encoding). W takich kodach długość ciągu bitów używanego do reprezentacji danego elementu danych jest uzależniona od częstości wystąpień tego elementu: im częstsze wystąpienia, tym krótszy kod. Tego typu kody są przykładami kodów o zmiennej długości, co oznacza, że różne elementy danych reprezentuje się kodami
1.8. KOMPRESJA DANYCH 65
2.1. Jednostka centralna
Zazwyczaj układ elektroniczny, odpowiedzialny za wykonywanie poszczególnych operacji w komputerze, nie jest bezpośrednio połączony z komórkami w pamięci głównej. Jest on wydzielony w postaci części komputera zwanej jednostką centralną lub w skrócie CPU. Jednostka centralna składa się z dwóch części: jednostki arytmetyczno-logicznej (ang. arithmetic/logic unlt), która zawiera układy odpowiedzialne za operowanie danymi, oraz jednostki sterującej (ang. control unit) zawierającej układy koordynujące czynności wykonywane przez komputer.
Rejestry
Jednostka centralna zawiera komórki przypominające komórki pamięci i zwane rejestrami (ang. registers). Są one przeznaczone do tymczasowego przechowywania informacji. Rejestry dzielą się na rejestry ogólnego przeznaczenia (ang. generał purpose registers) i rejestry specjalnego przeznaczenia (ang. special-purpose registers). Z niektórymi rejestrami specjalnego przeznaczenia zapoznamy się w podrozdziale 2.3. Na razie przeanalizujmy funkcje rejestrów ogólnego przeznaczenia.
POPULARNE JEDNOSTKI CENTRALNE
Chyba najlepiej znanymi procesorami na rynku są obecnie procesory z serii Pentium opracowane przez Intel oraz procesory PowerPC produkowane przez Motorolę i IBM. Procesory Pentium są popularne w serii biurkowych komputerów „PC", a PowerPC ostatnio wybrany przez Apple Computer Corporation. Omawiane jednostki centralne mają kształt małych, płaskich kwadratów wyposażonych w złącza pasujące do gniazd we współczesnych płytach głównych. W celu zwiększenia wydajności są one w stanie pobierać wiele bajtów z pamięci w pojedynczym kroku. W szczególności z zasady pobierają one jednocześnie kilka rozkazów : pamięci i w większości wypadków potrafią wykonywać wiele rozkazów jednocześnie.
Jak zobaczymy w podrozdziale 2.6, Pentium i PowerPC są reprezentantami dwóch różnych architektur: Pentium jest przy-ładem procesora o architekturze CISC, a PowerPC procesora architekturą RISC.
Rejestry ogólnego przeznaczenia służą do tymczasowego przechowywania danych, którymi manipuluje jednostka centralna. Przechowują one dane wejściowe dla układu arytmetyczno-logicznego i stanowią miejsce, w którym układ arytmetyczno-logiczny zapisuje wyniki wykonanych operacji. Aby wykonać operację na danych przechowywanych w pamięci głównej, jednostka sterująca przesyła je z pamięci głównej do rejestrów ogólnego przeznaczenia, informuje jednostkę arytmetyczno-lo-giczną o tym, w których rejestrach zapamiętano dane, uaktywnia odpowiednie układy w jednostce arytmetyczno-logicznej i informuje ją, w którym rejestrze ma zostać umieszczony wynik.
Warto przyjrzeć się roli rejestrów w kontekście wszystkich tych układów komputera, których zadaniem jest przechowywanie danych. Rejestry
ROZDZIAŁ DRUGI OPEROWANIE DANYMI
Krok 1. Pobierz pierwszą z dodawanych wartości z pamięci i umieść ją w rejestrze.
Krok 2. Pobierz drugą z dodawanych wartości z pamięci i umieść ją w innym rejestrze.
Krok 3. Uaktywnij układ sumujący, podając mu jako wejście rejestry z poprzednich kroków i przeznaczając inny rejestr do zapamiętania wyniku.
Krok 4. Zapamiętaj wynik w pamięci. Krok 5. Stop.
Dodanie wartości składowanych w pamięci
czynności. Realizacja operacji dodawania wymaga współpracy jednostki sterującej, która koordynuje przesyłanie informacji między rejestrami a pamięcią główną z jednostką arytmetyczno-logiczną, która wykona operację dodania dwóch wartości wtedy, kiedy nakaże jej to jednostka sterująca. Cały proces dodania dwóch wartości przechowywanych w pamięci można zatem podzielić na 5 etapów przedstawionych na rysunku 2.2.
Rozkazy maszynowe
Kroki z rysunku 2.2 są przykładami rozkazów, które musi umieć wykonać typowa jednostka centralna. Takie rozkazy noszą nazwę rozkazów maszynowych (ang. machine instructions). Dużym zaskoczeniem dla wielu może być to, że lista rozkazów maszynowych jest niedługa. Jednym z fascynujących aspektów informatyki jest fakt, że jeśli tylko komputer jest w stanie wykonać pewne elementarne, dobrze wybrane rozkazy, to dodanie nowych nie zwiększa teoretycznych możliwości maszyny. Innymi słowy dokładanie nowych możliwości od pewnego momentu poprawia jedynie wygodę użytkowania i szybkość komputera i nie zwiększa podstawowych umiejętności maszyny. Tego typu zagadnienia omawiamy szerzej w rozdziale 11.
Rozkazy znajdujące się w repertuarze komputera jest wygodnie podzielić na trzy kategorie: (1) grupa rozkazów przesyłania danych, (2) grupa rozkazów arytmetyczno-logicznych oraz (3) grupa rozkazów sterujących.
Rozkazy do przesyłania danych
W skład pierwszej grupy wchodzą rozkazy, które powodują przenoszenie danych z jednego miejsca w inne. Do tej kategorii rozkazów należą kroki 1/ 2 i 4 z rysunku 2.2. Tak jak było to w wypadku pamięci głównej, dane
ROZDZIAŁ DRUGI OPEROWANIE DANYMI
przesyłane z jednego miejsca w inne zazwyczaj nie są usuwane ze swojego pierwotnego położenia. Proces przesyłania danych przypomina zatem bardziej kopiowanie danych niż ich przenoszenie. Wobec powyższego określenia przeniesienie danych (ang. move) czy przesyłanie danych (ang. transfer) są mylące. Znacznie lepiej istotę procesu oddają terminy kopiowanie danych ang. copy) lub klonowanie danych (ang. clone). Przy okazji zagadnień terminologicznych warto wspomnieć, że przeniesienie danych między jednostką centralną a pamięcią główną ma specjalną, odrębną nazwę. Żądanie wpisania do rejestru ogólnego przeznaczenia zawartości komórki pamięci powszechnie nazywa się rozkazem załadowania (ang. LOAD). Żądanie zapisu zawartości rejestru we wskazanej komórce pamięci nosi nazwę rozkazu zapamiętania (ang. STORE). Kroki 1 i 2 z rysunku 2.2 są rozkazami załadowania, i krok 4 jest rozkazem zapamiętania.
Ważną podgrupą w grupie rozkazów przesyłania danych są rozkazy przeznaczone do komunikacji jednostki centralnej z urządzeniami innymi niż pamięć główna. Ponieważ takie rozkazy realizują operacje wejścia-wyjścia komputera, nazywa się je rozkazami wejścia-wyjścia (ang. l/O instructions). Czasami wyróżnia się je w postaci odrębnej kategorii rozkazów. Z drugiej jednak strony, jak stwierdzimy w podrozdziale 2.6, operacje wejścia-wyjścia realizuje się często za pomocą tych samych rozkazów, które zlecają przesyłanie danych między pamięcią główną a jednostką centralną. Wobec tego uczynienie z nich osobnej kategorii byłoby trochę mylące.
Rozkazy arytmetyczno-logiczne
Grupa arytmetyczno-logiczna składa się z rozkazów, które informują jednostkę sterującą o konieczności zlecenia jednostce arytmetyczno-logicznej wykonania pewnych czynności. Krok 3 z rysunku 2.2 zalicza się do tej właśnie grupy. Jak to sugeruje nazwa, jednostka arytmetyczno-logiczna potrafi realizować nie tylko podstawowe działania arytmetyczne, ale także wiele innych operacji. Przykładami tych dodatkowych operacji są operacje logiczne: AND, OR oraz XOR, które wprowadzono w rozdziale 1. Omówimy je dokładniej w dalszej części tego rozdziału. Te dodatkowe możliwości wykorzystuje się często do manipulowania pojedynczymi bitami (bez zmiany pozostałych bitów) w rejestrze ogólnego przeznaczenia. Inny zestaw operacji udostępnianych przez większość jednostek arytmetyczno-logicznych umożliwia przesuwanie zawartości rejestru o określoną liczbę bitów w prawo lub w lewo. W zależności od tego, czy bity, które w wyniku przesunięcia znajdą się poza rejestrem, są po prostu gubione, czy też wypełnia się nimi zwolnione miejsce po drugiej stronie rejestru, operacje te nazywa się odpowiednio przesunięciem (ang. SHIFT) lub rotacją (ang. ROTATE).
Rozkazy sterujące
Do grupy sterującej należą te rozkazy, które sterują wykonaniem programu. Nie mają one nic wspólnego z manipulacją danymi. Do tej kategorii można zaliczyć krok 5 z rysunku 2.2 - jest to jednak bardzo prosty przykład.
2.1. JEDNOSTKA CENTRALNA 89
Krok 1. Załaduj do rejestru wartość z pamięci.
Krok 2. Załaduj do innego rejestru drugą wartość z pamięci.
Krok 3. Jeśli druga zawartość jest równa zeru, skocz do kroku 6.
Krok 4. Podziel zawartość pierwszego rejestru przez wartość drugiego rejestru i pozostaw wynik w trzecim rejestrze.
Krok 5. Zapamiętaj zawartość trzeciego rejestru w pamięci. Krok 6. Stop.
Dzielenie wartości składowanych w pamięci
W repertuarze komputera znajduje się wiele ciekawych rozkazów z tej grupy, jak na przykład cała rodzina rozkazów skoku (rozkazy JUMP lub BRANCH). Skoki informują jednostkę sterującą o tym, że następnym do wykonania jest wskazany rozkaz, a nie rozkaz następujący po właśnie wykonywanym. Są dwa warianty rozkazów skoku: skoki bezwarunkowe oraz skoki warunkowe. Przykładem skoku bezwarunkowego jest rozkaz: „przeskocz do kroku 5", a przykładem skoku warunkowego: „jeśli otrzymana wartość jest równa 0, to przeskocz do kroku 5". Różnica polega na tym, że skok warunkowy powoduje „zmianę planów" tylko wtedy, kiedy jest spełniony pewien warunek. Ciąg rozkazów z rysunku 2.3 realizuje algorytm dzielenia dwóch wartości. Krok 3 jest tutaj skokiem warunkowym, który chroni przed wykonaniem dzielenia przez zero.
PYTANIA I ĆWICZENIA
Jaki ciąg zdarzeń jest wykonywany w komputerze przy przenoszeniu
zawartości jednej komórki pamięci do drugiej?Jaką informację jednostka centralna musi przekazać pamięci głównej
w celu wpisania pewnej wartości do komórki pamięci?Dlaczego termin przeniesienie (ang. move) nie jest właściwą nazwą ope
racji przeniesienia danych z jednego miejsca w komputerze w inne?W omówionych w tym podrozdziale rozkazach skoku (JUMP), miejsce
do którego odbywa się skok, podano jawnie w rozkazie, używając
jego nazwy, czyli numeru kroku (na przykład: „skocz do kroku 6").
ROZDZIAŁ DRUGI OFEROWANIE DANYMI
Wadą tej metody jest to, że jeśli nazwa rozkazu (czyli jego numer) ulegnie zmianie, należy odnaleźć wszystkie skoki do tego rozkazu i odpowiednio zmienić nazwę miejsca przeznaczenia. Zaproponuj inną metodę wyrażania rozkazu skoku, tak aby nie występowała w nim jawnie nazwa miejsca przeznaczenia.
5. Czy rozkaz „Jeśli 0 równa się 0, skocz do kroku 7" jest skokiem warunkowym czy bezwarunkowym? Uzasadnij odpowiedź.
2.2. Koncepcja programu składowanego w pamięci
Wczesne maszyny obliczeniowe nie charakteryzowały się elastycznością. Program wykonywany przez urządzenie był wbudowany w jednostkę sterującą i stanowił integralną część maszyny. Taki system przypominał katarynkę, która zawsze gra tę samą melodię. Potrzebna jest tymczasem elastyczność zmieniacza płyt kompaktowych. Jedną z metod uzyskania żądanej elastyczności we wczesnych elektronicznych komputerach było takie zaprojektowanie jednostki sterującej, aby można było łatwo zmieniać w niej połączenia elektryczne. Zazwyczaj była to konsola z otworami i sworzniami podobna do central telefonicznych starego typu. Wkładając końce przewodów w odpowiednie otwory można było zmieniać sposób połączeń.
Rozkazy jako ciągi bitów
Przełomem (przypisywanym, niekoniecznie słusznie, Johnowi von Neuman-nowi)1 było spostrzeżenie, że program podobnie jak dane można zakodować i przechowywać w pamięci głównej. Projektując jednostkę sterującą tak, aby mogła pobierać program z pamięci głównej, odkodowywać rozkazy i wykonywać je, można zmieniać wykonywany przez nią program za pomocą zmiany zawartości pamięci komputera. Nie trzeba przy tym koniecznie dokonywać zmian w układzie elektrycznym jednostki sterującej. Taka koncepcja programu składowanego w pamięci (ang. stored-program concept) stała się standardowym podejściem stosowanym współcześnie. Komputer sterowany programem przechowywanym w pamięci należy zaprojektować tak, aby był w stanie rozpoznawać pewne ciągi bitów jako reprezentacje rozkazów. Zestaw rozkazów razem z ich kodami nazywa się językiem maszynowym
Wielu twierdzi, że pomysł składowania programu w pamięci komputera pochodzi od J.P. Eckerta juniora, z Moore School, a John von Neumann dowiedział się o tym podczas swoich wizyt w Moore School.
2.2. KONCEPCJA PROGRAMU SKŁADOWANEGO W PAMIĘCI 91
(ang. machine-language), gdyż definiuje sposób, w jaki możemy wprowadzać do komputera algorytmy.
Zakodowany rozkaz maszynowy zazwyczaj składa się z dwóch części: pola kodu operacji - opkodu (skrót od angielskiej nazwy operation code) oraz pola argumentu (ang. operand field). Ciąg bitów umieszczony w polu kodu operacji określa, którą z podstawowych operacji takich jak STORE, SHIFT, XOR czy JUMP jest dany rozkaz. Ciąg bitów umieszczony w polu argumentu precyzuje informacje o operacji określonej za pomocą kodu operacji. W wypadku operacji STORE informacja w polu argumentu określa, który rejestr zawiera dane do zapamiętania w pamięci oraz w której komórce pamięci należy je zapamiętać.
Koncepcja programu składowanego w pamięci nie jest skomplikowana. Początkowo taki model sprawiał trudności ze względu na to, że wszyscy traktowali dane i programy jak zupełnie różne obiekty. Dane składowano w pamięci, a programy były częścią jednostki sterującej. W efekcie nie zauważono prostszego rozwiązania. Historia informatyki pokazuje, że łatwo można trafić w taki ślepy zaułek - możliwe, że niczego nieświadomi przebywamy wciąż w wielu z nich. Piękno nauki polega między innymi na tym, że dzięki nowemu spojrzeniu na problem wciąż powstają nowe teorie i ich zastosowania.
Typowy język maszynowy
Przyjrzyjmy się teraz sposobowi kodowania rozkazów typowego komputera. Maszynę liczącą, której używamy w charakterze przykładu w poniższym omówieniu, opisano w dodatku C i krótko scharakteryzowano na rysunku 2.4. Ma ona 16 rejestrów ogólnego przeznaczenia i 256 komórek pamięci głównej. W każdej komórce mieści się 8 bitów. Rejestry są ponumerowane liczbami od 0 do 15, a komórki pamięci liczbami od 0 do 255. Liczby te zapisuje się w kodzie binarnym, a powstające w ten sposób ciągi bitów koduje w notacji szesnastkowej. Rejestry będą zatem oznaczane od 0 do F, a komórki pamięci będą miały adresy od 00 do FF.
Kody operacji
Po dokładniejszej analizie języka maszynowego z dodatku C można zauważyć, że każdy rozkaz koduje się za pomocą 16 bitów. Taki kod można zatem zapisać za pomocą 4 cyfr szesnastkowych (rys. 2.5). Kod operacji każdego rozkazu stanowią pierwsze cztery bity, czyli pierwsza cyfra szesnastkowa. Pełna lista rozkazów zawiera tylko 12 rozkazów podstawowych, których opkody reprezentuje się za pomocą cyfr szesnastkowych z zakresu od 1 do C. Każdy kod rozkazu rozpoczynający się cyfrą szesnastkowa 3 (ciąg bitów 0011) oznacza zatem rozkaz STORĘ, a każdy kod rozpoczynający się cyfrą szesnastkowa A oznacza rozkaz ROTATE.
Maszyna ma dwa rodzaje rozkazu ADD: pierwszy służy do dodawania liczb w reprezentacji uzupełnieniowej do dwóch, a drugi do dodawania
ROZDZIAŁ DRUGI OPEROWANIE DANYMI
|
|
Jednostka centralna |
|
Pamięć główna |
|
|
i i |
Jednostka sterująca |
|
Adres Komórka |
|
c N U OJ O "7 O I |
i i i i ! | |
5±ltry Licznik rozkazów —] □ m |
Magistrala |
00: [2 | |
|
co |
L 1 |
Rejestr rozkazu |
|
03: | | |
|
i Jednostk. |
1 1 | |
: |
1 |
|
• • • • |
|
|
|
|
|
|
Architektura komputera opisanego w dodatku C
2.2. KONCEPCJA PROGRAMU SKŁADOWANEGO W PAMIĘCI
93
liczb w reprezentacji zmiennopozycyjnej. To odróżnienie jest spowodowane tym, że jednostka arytmetyczno-logiczna wykonuje inne czynności przy dodawaniu ciągów bitów reprezentujących wartości w notacji binarnej niż przy dodawaniu liczb zapisanych w notacji zmiennopozycyjnej.
Argumenty
Przyjrzyjmy się teraz polu argumentu. Składa się ono z trzech cyfr szes-nastkowych (12 bitów) i w wypadku każdego rozkazu (z wyjątkiem HALT, który nie wymaga dalszego precyzowania) definuje szczegółowe znaczenie rozkazu określonego kodem operacji. Przykładowo, jeśli pierwszą cyfrą szesnastkową rozkazu jest 1 (kod operacji oznaczający pobranie danych z pamięci), to następna cyfra szesnastkową określa, do którego rejestru zostanie załadowana odczytana wartość, a następne dwie - z której komórki pamięci należy odczytać dane. Zatem rozkaz 1347 (szesnastkowo) można odczytać tak: „Załaduj do rejestru 3 zawartość komórki pamięci o adresie 47". W wypadku kodu operacji 7, który oznacza operację OR na dwóch rejestrach, druga cyfra szesnastkową oznacza rejestr, w którym ma zostać umieszczony wynik, a cyfry trzecia i czwarta pola argumentu określają rejestry, na których należy wykonać operację. Zatem rozkaz 70C5 oznacza polecenie: „Wykonaj operację logiczną OR, używając jako argumentów zawartości rejestru C i rejestru 5, a wynik umieść w rejestrze 0".
Jest subtelna różnica między dwoma rodzajami rozkazu LOAD dostępnymi w omawianej maszynie. Kod operacji 1 oznacza rozkaz załadowania do rejestru zawartości wskazanej komórki pamięci, a kod operacji 2 oznacza rozkaz wpisania do rejestru podanej wartości. Różnica polega na tym, że pole argumentu w rozkazie pierwszego rodzaju zawiera adres, a w rozkazie drugiego rodzaju ciąg bitów, który należy umieścić w rejestrze.
Do ciekawej sytuacji dochodzi w wypadku rozkazu JUMP (kod operacji równy szesnastkowo B). Pierwsza cyfra szesnastkową pola argumentu określa rejestr, którego zawartość należy porównać z rejestrem 0. Jeśli w podanym rejestrze znajduje się ta sama wartość co w rejestrze 0, to komputer wykona skok do rozkazu znajdującego się pod adresem określanym przez dwie ostatnie cyfry szesnastkowe argumentu. W przeciwnym razie wykonanie programu przebiega dalej w zwykły sposób. Rozkaz JUMP daje zatem możliwość wykonywania skoków warunkowych. Jeśli jednak pierwszą cyfrą szesnastkową argumentu jest 0, rozkaz spowoduje porównanie wartości rejestru 0 z wartością rejestru 0. Ponieważ wartości znajdujące się w tym samym rejestrze są równe, więc skok zostanie zawsze wykonywany. W efekcie każdy rozkaz, którego kod rozpoczyna się od cyfr szesnastkowych BO, jest rozkazem skoku bezwarunkowego.
Przykładowy program
Podrozdział kończymy, podając rozkazy z rysunku 2.2 w postaci zakodowanej. Zakładamy, że dodawane wartości są zapisane w pamięci pod adresami
ROZDZIAŁ DRUGI OPEROWANIE DANYMI
6C i 6D w notacji uzupełnieniowej do dwóch, a suma ma zostać umieszczona w pamięci pod adresem 6E:
Krok 1. 156C Krok 2. 166D Krok 3. 5056 Krok 4. 306E Krok 5. C000
PYTANIA I ĆWICZENIA
Zapisz przykładowy program z końca rozdziału, używając ciągów
bitów.Zapisz w języku polskim znaczenie następujących rozkazów z języka
maszynowego opisanego w dodatku C:
(a) 368A (b) BADE (c) 803C (d) 40F4
Na czym polega różnica między rozkazami 15AB i 25AB języka ma
szynowego opisanego w dodatku C.Oto pewne instrukcje zapisane po polsku. Zapisz każdą z nich w ję
zyku maszynowym opisanym w dodatku C.
Załaduj do rejestru 3 wartość szesnastkową 56.
Wykonaj rotację rejestru numer 5 trzy bity w prawo.
Wykonaj skok do rozkazu pod adresem F3, jeśli zawartość rejestru
numer 7 jest równa zawartości rejestru numer 0.Wykonaj operację AND na wartościach znajdujących się w reje
strach A oraz 5 i umieść wynik w rejestrze 0.
2.3. Wykonanie programu
Komputer wykonuje program zapamiętany w pamięci, kopiując w miarę potrzeb rozkazy z pamięci głównej do jednostki sterującej. Po sprowadzeniu rozkazu do jednostki sterującej jest on dekodowany i posłusznie wykonywany. Kolejność pobierania rozkazów z pamięci jest zgodna z kolejnością ich zapisania w pamięci, chyba że wystąpi rozkaz skoku. Aby zrozumieć pełny proces wykonywania rozkazu, jest niezbędna dokładniejsza analiza elementów jednostki sterującej. Jednostka ta ma dwa rejestry specjalnego przeznaczenia: licznik rozkazów (ang. program counter) oraz rejestr rozkazu (ang. instruction register; zobacz rysunek 2.4). Licznik rozkazów przechowuje adres następnego rozkazu przeznaczonego do wykonania. W ten sposób komputer pamięta, w którym miejscu wykonywanego programu aktualnie się znajduje. Rejestr rozkazu służy do przechowywania aktualnie wykonywanego rozkazu.
2.3. WYKONANIE PROGRAMU 95
Jednostka sterująca realizuje swoje zadanie, wykonując cyklicznie pewien algorytm zwany cyklem maszynowym (ang. machinę cycle). Składa się on z trzech kroków: pobrania rozkazu, dekodowania rozkazu oraz wykonania rozkazu (rys. 2.6). W fazie pobierania rozkazu jednostka sterująca wydaje pamięci głównej zlecenie dostarczenia jej kolejnego rozkazu do wykonania. Jednostka sterująca wie, w którym miejscu pamięci znajduje się potrzebny rozkaz, gdyż jego adres jest zapamiętany w liczniku rozkazów. Jednostka sterująca umieszcza pobrany rozkaz w rejestrze rozkazu, a następnie zwiększa licznik rozkazów, tak aby znalazł się w nim adres kolejnego rozkazu do wykonania.
Rozkaz przeznaczony do wykonania znajduje się teraz w rejestrze rozkazu, jednostka sterująca może go więc dekodować. To zadanie wymaga podzielenia pola argumentu na odpowiednie składowe, których znaczenie zależy od kodu operacji rozkazu.
Następnie jednostka sterująca wykonuje rozkaz, uaktywniając odpowiednie układy elektroniczne, które realizują żądane czynności. Jeśli rozkaz jest rozkazem pobrania wartości z pamięci, to jednostka sterująca inicjuje operację pobrania z pamięci. Jeśli rozkaz wymaga wykonania pewnych operacji arytmetycznych, to jednostka sterująca uaktywnia odpowiednie układy elektroniczne w jednostce arytmetyczno-logicznej, przekazując informacje o rejestrach przechowujących dane wejściowe.
2. Dekoduj ciąg bitów znajdujący się w rejestrze rozkazu.
1. Pobierz z pamięci kolejny rozkaz do wykonania (zgodnie z wartością licznika rozkazów) i zwiększ licznik rozkazów.
3. Wykonaj działanie wymagane do zrealizowania rozkazu znajdującego się w rejestrze rozkazu.
Cykl maszynowy
96
ROZDZIAŁ DRUGI OPEROWANIE DANYMI
Po zakończeniu wykonania rozkazu jednostka sterująca ponownie rozpoczyna cykl maszynowy, wykonując kolejną fazę pobrania. Ponieważ pod koniec poprzedniej fazy pobrania licznik rozkazów został zwiększony, jego wartość jest teraz adresem kolejnego rozkazu przeznaczonego do wykonania.
Nieco inaczej przebiega wykonanie rozkazu skoku (JUMP). Rozważmy dla przykładu rozkaz B258, który oznacza: „wykonaj skok do rozkazu pod adresem 58, jeśli wartość w rejestrze 2 jest równa wartości w rejestrze 0". W takim wypadku faza wykonania w cyklu maszynowym rozpoczyna się od porównania zawartości rejestrów 2 i 0. Jeśli są one różne, to faza wykonania kończy się i rozpoczyna się kolejny cykl maszynowy. Jeżeli jednak zawartości tych rejestrów są sobie równe, to komputer umieszcza wartość 58 w liczniku rozkazów. Następna faza pobrania zastanie zatem w liczniku rozkazów wartość 58 i w efekcie kolejnym wykonywanym rozkazem będzie rozkaz znajdujący się pod tym adresem w pamięci.
PORÓWNYWANIE MOCY OBLICZENIOWYCH KOMPUTERÓW
Kupując komputer osobisty, możesz stwierdzić, że porównując komputery często zwraca się uwagę na częstotliwość zegara. Zegar komputera to obwód oscylacyjny, którego sygnał w postaci impulsów stosuje się do koordynacji czynności wykonywanych przez maszynę: im szybciej ten układ generuje impulsy, tym szybciej komputer wykonuje swoje zadania. Częstotliwości zegara wyraża się w hercach (skrót: Hz), przy czym jeden Hz to jeden cykl (lub impuls) na sekundę. Zazwyczaj szybkości zegarów w komputerach biurkowych wynoszą około kilkuset megaherców (MHz), przy czym jeden MHz to milion Hz.
Niestety, w zależności od budowy procesory często wykonują różną ilość pracy w czasie jednego cyklu. Z tego powodu częstotliwość zegara nie stanowi miarodajnego sposobu porównywania komputerów o różnej architekturze jednostki centralnej. Porównanie komputera opartego na procesorze PowerPC z opartym na procesorze Pentium będzie bardziej wiarygodne, gdy użyjemy w tym celu testu porównawczego (ang. benchmarking). Polega on na porównaniu wydajności różnych komputerów przez wykonanie tego samego programu - testu porównawczego. Wybierając test reprezentatywny dla określonego typu aplikacji, można uzyskać porównanie wiarygodne dla określonego segmentu rynkowego. Często jest prawdą, że najlepszy komputer dla pewnej klasy zastosowań nie jest wcale najlepszy dla innych.
W celu skoordynowania czynności wykonywanych w poszczególnych fazach cyklu maszynowego, należy zsynchronizować działanie wielu układów. W tym celu układy wymagające synchronizacji łączy się z układem generującym sygnał pulsujący, zwanym zegarem. Zegar oscyluje, stale zmieniając wartości między 0 a 1. Układy elektroniczne buduje się w ten sposób, aby ich akcje były wyzwalane za pomocą różnych faz cyklu zegara. Szybkość zegara determinuje z kolei szybkość, z jaką procesor wykonuje swój cykl maszynowy.
Przykład wykonania programu
Przeanalizujmy cykl maszynowy przy wykonaniu programu, który zakodowaliśmy pod koniec podrozdziału 2.2. Najpierw program należy umieścić w pewnym miejscu pamięci. Przypuśćmy na potrzeby dalszego omówienia, że program znajduje się w kolejnych komórkach pamięci począwszy od adresu A0 (szesnastkowo). Tabela z rysunku 2.7 przedstawia zawartość tego obszaru pamięci. Wstawiając do licznika rozkazów wartość A0, czyli adres pierwszego rozkazu do wykonania, można spowodować, że komputer rozpocznie wykonanie zapamiętanego programu.
2.3. WYKONANIE PROGRAMU
97
Adres |
Zawartość |
AO |
15 |
Al |
6C |
A2 |
16 |
A3 |
6D |
A4 |
50 |
A5 |
56 |
A6 |
30 |
A7 |
6E |
A8 |
CO |
A9 |
00 |
Przykładowy program „dodawania" składowany w pamięci od adresu AO
Jednostka sterująca rozpoczyna cykl maszynowy od fazy pobrania, sprowadzając rozkaz spod adresu AO (rozkaz 156C) do rejestru rozkazu. Zwróćmy uwagę, że w omawianej maszynie liczącej rozkazy mają długość 16 bitów (2 bajtów). Zatem pobierany rozkaz znajduje się w dwóch komórkach pamięci o adresach AO oraz Al. Jednostka sterująca jest tak zaprojektowana, aby pobrać zawartość obu komórek i umieścić pobrane dane w 16-bi-towym rejestrze rozkazu. Jednostka sterująca dodaje następnie 2 do licznika rozkazów, aby znalazł się w nim adres kolejnego rozkazu przeznaczonego do wykonania. Pod koniec fazy pobrania w pierwszym cyklu maszynowym licznik rozkazów i rejestr rozkazu zawierają następujące dane:
Licznik rozkazów: A2 Rejestr rozkazu: 156C.
Następnie jednostka sterująca analizuje rozkaz znajdujący się w rejestrze rozkazu. Stwierdza, że jest to rozkaz przesłania do rejestru 5 zawartości komórki pamięci spod adresu 6C. Czynność ta jest realizowana w fazie wykonania w cyklu maszynowym, po czym jednostka sterująca rozpoczyna następny cykl.
Kolejny cykl rozpoczyna się pobraniem rozkazu 166D z dwóch komórek pamięci, począwszy od adresu A2. Jednostka sterująca umieszcza rozkaz w swoim rejestrze rozkazu i zwiększa licznik rozkazów do wartości A4. Wartości licznika rozkazów i rejestru rozkazu przedstawiają się następująco:
Licznik rozkazów A4 . Rejestr rozkazu: 166D.
ROZDZIAŁ DRUGI OPEROWANIE DANYMI
Jednostka sterująca dekoduje teraz rozkaz 166D i stwierdza, że jest to rozkaz załadowania do rejestru 6 zawartości komórki pamięci 6D. Wykonuje więc rozkaz, w wyniku którego dochodzi do umieszczenia w rejestrze 6 żądanej wartości.
Ponieważ wartością licznika rozkazów jest teraz A4, jednostka sterująca pobierze następny rozkaz spod tego właśnie adresu. Jego efektem jest umieszczenie wartości 5056 w rejestrze rozkazu i zwiększenie licznika rozkazów do wartości A6. Jednostka sterująca dekoduje zawartość rejestru rozkazów i wykonuje rozkaz, uaktywniając układ realizujący dodawanie liczb w notacji uzupełnieniowej do dwóch z wartościami wejściowymi znajdującymi się w rejestrach 5 i 6.
W fazie wykonania jednostka arytmetyczno-logiczna realizuje żądane dodawanie, umieszcza wynik w rejestrze 0 (jak nakazała jednostka sterująca) i informuje jednostkę sterującą o zakończeniu obliczeń. Jednostka sterująca rozpoczyna kolejny cykl maszynowy. Ponownie posługując się licznikiem rozkazów, pobiera kolejny rozkaz (o kodzie 306E) z dwóch komórek pamięci, począwszy od adresu A6, i zwiększa licznik rozkazów na A8. Rozkaz zostaje dekodowany i wykonany - suma zostaje umieszczona w pamięci pod adresem 6E.
Kolejny rozkaz pobiera się spod adresu A8. Licznik rozkazów zostaje zwiększony do wartości AA. Zawartość rejestru rozkazu (C000) oznacza rozkaz zatrzymania. W efekcie komputer zatrzymuje się w fazie wykonania w cyklu maszynowym i tym samym kończy wykonanie programu.
Reasumując, widzimy, że wykonanie programu składowanego w pamięci przypomina proces kolejnego wykonywania czynności zapisanych na liście spraw do załatwienia. Większość z nas po załatwieniu kolejnej sprawy odhacza ją na liście, pamiętając w ten sposób, w którym miejscu listy się znajduje. Komputer zapamiętuje miejsce za pomocą licznika rozkazów. Po odnalezieniu kolejnej sprawy do załatwienia na liście, ludzie odczytują opis i jego znaczenie. Na koniec wykonują zadanie i sprawdzają na liście, co jeszcze jest do załatwienia. W podobny sposób komputer odczytuje rozkaz zapamiętany w rejestrze rozkazu, wykonuje go i rozpoczyna kolejną fazę pobrania.
Programy a dane
W pamięci głównej komputera można na raz zapamiętać wiele programów, o ile tylko zostaną umieszczone w rozłącznych obszarach pamięci. To, który program zostanie wykonany po uruchomieniu komputera, zależy jedynie od wartości wstawionej do licznika rozkazów.
Dane są przechowywane w pamięci także w postaci ciągów zer i jedynek. Komputer nie jest w stanie odróżnić danych od programu. Jeśli do licznika rozkazów wpiszemy adres obszaru danych zamiast adresu programu, to komputer zacznie pobierać dane, interpretować je tak, jakby to były rozkazy i wykonywać je. Końcowy rezultat takiego procesu jest zależny od wartości danych.
2.3. WYKONANIE PROGRAMU 99
Nie należy jednak sądzić, że składowanie zarówno danych, jak i programów w pamięci komputera jest złą praktyką. Tak naprawdę okazało się to użyteczne, gdyż dzięki temu program może manipulować innymi programami (lub nawet sam sobą), tak jak manipulowałby danymi. Wyobraźmy sobie na przykład program, który na skutek interakcji z otoczeniem sam siebie modyfikuje, przejawiając w ten sposób zdolność uczenia się, albo program, który tworzy i wykonuje programy rozwiązujące zadawane mu problemy.
PYTANIA I ĆWICZENIA
1. Przypuśćmy, że komórki pamięci od adresu 00 do 05 w komputerze
opisanym w dodatku C zawierają następujące (szesnastkowe) wartości:
Adres Zawartość
14
02
34
17
CO
00
Jaki ciąg bitów znajdzie się w komórce pamięci pod adresem (szes-nastkowo) 17 po zatrzymaniu komputera/jeśli uruchomimy go z licznikiem rozkazów zawierającym wartość 0?
2. Przypuśćmy, że komórki pamięci od adresu BO do B8 w komputerze
opisanym w dodatku C zawierają następujące (szesnastkowe) wartości:
Adres |
Zawartość |
BO |
13 |
Bl |
B8 |
B2 |
A3 |
B3 |
02 |
B4 |
33 |
B5 |
B8 |
B6 |
CO |
B7 |
00 |
B8 |
0F |
Jaki ciąg bitów znajdzie się w komórce pamięci pod adresem
(szesnastkowo) 3 po zatrzymaniu komputera, jeśli uruchomimy go
z licznikiem rozkazów zawierającym wartość BO?Jaka będzie zawartość komórki pamięci B8 w chwili wykonania
rozkazu zatrzymania?
100 ROZDZIAŁ DRUGI OPEROWANIE DANYMI
3. Przypuśćmy, że komórki pamięci od adresu A4 do Bl w komputerze opisanym w dodatku C zawierają następujące (szesnastkowe) wartości:
Adres |
Zawartość |
A4 |
20 |
A5 |
00 |
A6 |
21 |
A7 |
03 |
A8 |
22 |
A9 |
01 |
AA |
Bl |
AB |
BO |
AC |
50 |
AD |
02 |
AE |
BO |
AF |
AA |
BO |
CO |
Bl |
00 |
Odpowiadając na poniższe pytania, załóż, że komputer uruchamiamy z licznikiem programu zawierającym A4.
Co znajduje się w rejestrze 0 przy pierwszym wykonaniu rozkazu
spod adresu AA?Co znajduje się w rejestrze 0, gdy rozkaz spod adresu AA jest
wykonany po raz drugi?Ile razy zostanie wykonany rozkaz spod adresu AA?
4. Przypuśćmy, że komórki pamięci od adresu F0 do F9 w komputerze opisanym w dodatku C zawierają następujące (szesnastkowe) wartości:
Adres |
Zawartość |
F0 |
20 |
Fl |
CO |
F2 |
30 |
F3 |
F8 |
F4 |
20 |
F5 |
00 |
F6 |
30 |
F7 |
F9 |
F8 |
FF |
F9 |
FF |
Co zrobi komputer, gdy dojdzie do rozkazu pod adresem F8, jeśli uruchomimy go z licznikiem rozkazów zawierającym wartość F0?
2.3. WYKONANIE PROGRAMU 101
Często jest wygodniej używać operacji logicznych zamiast arytmetycz
nych. Wynik operacji AND na dwóch bitach jest na przykład taki sam
jak wynik ich przemnożenia. Która z operacji logicznych działa prawie
tak samo jak dodawanie dwóch bitów? Na czym polegają różnice?Jaką operację logiczną i jaką maskę należy zastosować, aby zmienić
kody ASCII małych liter na kody odpowiadających im wielkich liter?
Jak zmienić wielkie litery na małe?Jaki jest wynik wykonania cyklicznego przesunięcia o 3 bity w prawo
następujących ciągów bitów:
(a) 01101010 (b) 00001111 (c) 01111111 7. Jaki jest wynik wykonania cyklicznego przesunięcia o 1 bit w lewo
następujących bajtów zapisanych szesnastkowo? Odpowiedzi zapisz
w notacji szesnastkowej:
(a) AB (b) 5C (c) B7 (d) 35
9. O ile bitów w lewo trzeba cyklicznie przesunąć ośmiobitowy ciąg, aby
było to równoważne cyklicznemu przesunięciu o 3 bity w prawo?
Ciągi 01101010 i 11001100 reprezentują wartości zapisane w notacji
uzupełnieniowej do dwóch. Jaki ciąg bitów reprezentuje sumę tych
wartości? Jak zmieni się odpowiedź, jeśli założymy, że ciągi repre
zentują wartości zapisane w notacji zmiennopozycyjnej omówionej
w rozdziale 1?Używając języka maszynowego z dodatku C, napisz program, który
umieści 1 w najbardziej znaczącym bicie komórki pamięci o adresie
A7, bez zmiany wartości pozostałych bitów.Używając języka maszynowego z dodatku C, napisz program, który
skopiuje cztery środkowe bity z komórki pamięci o adresie E0 do
czterech mniej znaczących bitów komórki pamięci El, zerując przy
tym jej cztery bardziej znaczące bity.
2.5. Komunikacja z innymi urządzeniami
Pamięć główna i jednostka centralna stanowią trzon komputera. W tym podrozdziale przeanalizujemy, w jaki sposób ten trzon porozumiewa się z urządzeniami peryferyjnymi, takimi jak dyski, drukarki czy inne komputery.
Komunikacja za pośrednictwem sterowników
Komunikację między komputerem a innymi urządzeniami obsługują zazwyczaj urządzenie pomocnicze zwane sterownikiem (ang. controller). W komputerach osobistych sterownik jest płytą z układami scalonymi (kartą), którą umieszcza się w gniazdach na płycie głównej komputera. Sterownik jest pc
106 ROZDZIAŁ DRUGI OPEROWANIE DANYMI
łączony za pomocą przewodów z urządzeniami peryferyjnymi wewnątrz komputera lub ze złączem z tyłu komputera, do którego można przyłączać urządzenia zewnętrzne.
Każdy sterownik obsługuje komunikację z konkretnym typem urządzenia. Zadaniem pewnych sterowników jest obsługa komunikacji z monitorem, inne obsługują komunikację z napędami dysków, jeszcze inne z napędem CD-ROM. Z tego powodu sterowniki często kupuje się razem z urządzeniami peryferyjnymi. Sterownik przekształca komunikaty i dane z postaci zgodnej z wewnętrzną architekturą komputera na postać zrozumiałą dla urządzenia peryferyjnego, do którego jest przyłączony, i na odwrót. Sterowniki są często same małymi komputerami, z których każdy ma własną pamięć i procesor wykonujący program nadzorujący pracę sterownika.
Umieszczając sterownik w jednym z gniazd płyty głównej, przyłącza się go elektronicznie do tej samej magistrali, która łączy jednostkę centralną komputera z pamięcią (rys. 2.8). Każdy sterownik monitoruje sygnały wysyłane z jednostki centralnej i reaguje, gdy wykryje sygnał przeznaczony dla siebie. Dzięki podłączeniu do magistrali komputera, kontroler może wysyłać sygnały zapisu i odczytu przeznaczone bezpośrednio do pamięci głównej w czasie, gdy jednostka centralna nie korzysta z magistrali.
Możliwość uzyskiwania przez sterownik dostępu do pamięci głównej nazwano bezpośrednim dostępem do pamięci (ang. direct memory access; DMA). Ma ona bardzo duży wpływ na wydajność komputera. Jeśli sterownik dysku zainstalowany w komputerze ma bezpośredni dostęp do pamięci,
2.5. KOMUNIKACJA Z INNYMI URZĄDZENIAMI
107
to jednostka centralna może wysyłać do niego zlecenia odczytu wskazanej sektora z dysku i umieszczenia danych w określonym bloku komórek pamięci. Zlecenia te są zakodowane w postaci ciągów bitów. Blok pamięci, c którego wczytuje się dane z dysku, nazywa się często buforem (ang. Buffer) W ogólności bufor jest miejscem, w którym jeden system umieszcza dane odczytywane później przez inny system. W czasie gdy sterownik wykonuje operację odczytu, jednostka centralna może wykonywać inne zadania. Dwie czynności wykonują się zatem w tym samym czasie: jednostka centralna wykonuje program, a sterownik nadzoruje przesyłanie danych między dyskietką a pamięcią główną. Dzięki temu nie marnuje się czasu procesora podczas relatywnie wolnej operacji przesyłu danych.
Efektem ubocznym stosowania techniki DMA jest zwiększenie liczby komunikatów obsługiwanych przez magistralę komputera. Przesyłane są przez nią ciągi bitów między jednostką centralną a pamięcią główną, między jednostką centralną a każdym sterownikiem oraz między każdym sterownikiem a pamięcią główną. Koordynacja tych wszystkich czynności magistrali jest podstawowym problemem technicznym. Nawet doskonale zaprojektowana magistrala główna może stać się przeszkodą zwaną wąskim gardłem von Neumanna (ang. von Neumann bottleneck), gdyż jednostka centralna i sterowniki stale rywalizują o dostęp do niej.
Komunikację między jednostką centralną komputera a sterownikiem obsługuje się prawie tak samo jak komunikację między jednostką centralną a pamięcią główną. W celu wysłania ciągu bitów do sterownika najpierw konstruuje się go w jednym z rejestrów ogólnego przeznaczenia. Następnie jest wykonywany rozkaz przypominający rozkaz wpisania do pamięci (STORE), który powoduje „umieszczenie" ciągu bitów w sterowniku. Jedyną różnicą między wpisaniem ciągu bitów do pamięci a przesłaniem go do sterownika jest miejsce przeznaczenia przesyłanego ciągu. Tak naprawdę w wielu komputerach w obu sytuacjach stosuje się ten sam rozkaz maszynowy. W takim wypadku układy pamięci głównej trzeba tak zaprojektować aby ignorowały odwołania do pewnych komórek pamięci - to sterownik powinien reagować na odwołania do tych miejsc. Gdy jednostka centralna wyśle po magistrali komunikat zlecający zapamiętanie danych w takim miejscu pamięci, to dane otrzyma sterownik, a nie pamięć główna. Podobnie jeśli jednostka centralna próbuje odczytać dane z takiego miejsca w pamięci głównej (jak przy realizacji rozkazu LOAD), to pobierze ciąg bitów ze sterownika, a nie z pamięci głównej. Taki system komunikacji nazywa się systemem z wejściem-wyjściem odwzorowywanym w pamięci (ang. metnon -mapped l/O), ponieważ urządzenia wejścia-wyjścia wydają się być podpięte do pewnych miejsc w pamięci. Adresy „pamięci" przypisane sterowników w ten właśnie sposób nazywa się portami (ang. port), gdyż reprezentuj one „miejsca", przez które informacja opuszcza komputer i do niego napływa.
Transfer danych między dwoma elementami systemu komputerowego rzadko jest jednokierunkowy. Chociaż drukarkę traktuje się jak urządzeni odbierające dane, to jednak tak naprawdę ona także wysyła pewne informacje
108 ROZDZIAŁ DRUGI OPEROWANIE DANYMI
Sterownik Urządzenie peryferyjne
Reprezentacja pojęciowa wejścia-wyjścia odwzorowanego w pamięci
do komputera. Komputer generuje znaki i wysyła je do drukarki znacznie szybciej niż jest ona w stanie je drukować. Gdyby komputer wysyłał dane „na oślep", drukarka szybko przestałaby za nimi nadążać, co powodowałoby zgubienie pewnych informacji. Zatem proces drukowania dokumentu wymaga stałego dialogu, w trakcie którego komputer i urządzenie peryferyjne wymieniają informacje o stanie urządzenia.
Taki dialog często wymaga użycia słowa stanu (ang. status word) - ciągu bitów, który jest generowany przez urządzenie peryferyjne i wysyłany do sterownika. Bity w słowie stanu odzwierciedlają stan urządzenia. W wypadku drukarki wartość najmniej znaczącego bitu w słowie stanu może oznaczać, że drukarka jest gotowa na przyjęcie kolejnych danych. W zależności od konkretnego systemu sterownik może reagować sam na informacje o stanie lub udostępniać je jednostce centralnej. W obu wypadkach albo program realizowany przez sterownik, albo program wykonywany przez jednostkę centralną muszą być tak napisane, aby opóźniać wysyłanie danych do drukarki aż do chwili pojawienia się odpowiedniej informacji o stanie.
Szybkość komunikacji
Szybkość przesyłania bitów z jednego urządzenia do drugiego mierzy się w bitach na sekundę (ang. bits per second - bps). Powszechnie stosuje się jednostki: Kbps (kilobps, równe 1000 bps), Mbps (megabps, równe milionowi bps) oraz Gbps (gigabps, równe bilionowi bps). Maksymalna szybkość osiągalna w konkretnej sytuacji zależy od rodzaju komunikacji i techniki stosowanej do jej implementacji.
Są dwa rodzaje komunikacji: komunikacja równoległa i komunikacja szeregowa. Nazwy te odnoszą się do sposobu, w jaki są przesyłane względem siebie ciągi bitów. Przy komunikacji równoległej (ang. parallel
2.5. KOMUNIKACJA Z INNYMI URZĄDZENIAMI
109
BUDOWA MAGISTRALI
Budowa magistrali komputera od dawna jest delikatną sprawą. Przewody w źle zaprojektowanej magistrali mogą na przykład działać jak małe anteny: odbierając transmitowane sygnały (radio, telewizję itd.) i zakłócając komunikację między procesorem, pamięcią główną a urządzeniami peryferyjnymi. Ponadto długość magistrali (około 6 cali w komputerze domowym) jest dużo większa niż długość „przewodów* w samej jednostce centralnej (około kilku mikronów). Zatem czas przejścia sygnałów przez magistralę jest znacznie większy niż czas transmisji sygnałów wewnątrz jednostki centralnej. W efekcie technologia produkcji magistrali jest w ciągłej pogoni, aby dotrzymać kroku technologii produkcji procesorów. We współczesnych komputerach osobistych można odnaleźć wiele rożnych architektur magistrali, które różnią się od siebie takimi właściwościami jak ilość danych, którą można przesyłać jednocześnie, szybkość zmiany sygnału w magistrali, fizyczne właściwości połączenia między magistralą a kartami sterowników. Najpopularniejsze standardy to ISA (Industrial Standard Architecture), EISA (Extended Indu-strial Standard Architecture) i PCI (Perypheral Component Inter-connect).
communication) jednocześnie przesyła się kilka bitów, każdy osobną nią. Taka technika umożliwia szybkie przesyłanie danych, ale wymaga relatywnie złożonej ścieżki komunikacyjnej. Komunikację równoległą stosuje się między innymi w wewnętrznej magistrali komputera or; przy komunikacji między komputerem a urządzeniami peryferyjnyn takimi jak systemy pamięci masowej i drukarki. W takich wypadkach powszechne szybkości rzędu Mb] lub nawet więcej.
W przeciwieństwie do komunikacji równoległej, przy komunikat szeregowej (ang. serial communication) transmituje się tylko jeden bit na raz. Ta technika jest wolniejsza, ale wymaga prostszej ścieżki danych, gdyż wszystkie bity transmituje się po jednej linii, jeden po drugim. Komunikację szeregową wykorzystuje się zazwyczaj przy komunikacji między
różnymi komputerami, gdzie prostsza ścieżka danych okazuje się być bardziej ekonomiczna.
Do realizacji komunikacji między komputerami wykorzystywało się i przykład i nadal wykorzystuje linie telefoniczne. Z natury są to typowe łącza szeregowe, gdyż transmituje się po nich jeden ton po drugim. Komunikację za pomocą linii telefonicznych realizuje się przez przekształcenie ciągów bitów na słyszalne dźwięki za pomocą modemu (skrót od ang. modulator-demodulator), transmisji tych dźwięków szeregowo za pomocą łączy telefonicznych, a następnie przekształceniu dźwięków znów na bity w modem po przeciwnej stronie.
W rzeczywistości prosta reprezentacja ciągów bitów jako dźwięków o różnych częstotliwościach (znana jako modulowanie kluczem z przesuwem częstotliwości - ang. frequency-shift keying), jest stosowana tylko do realizacji łączy komunikacyjnych o niedużej szybkości - nie więcej niż 1200 bps. W celu uzyskania szybkości transmisji 2400 bps, 9600 bps i więcej modem stosują modulację częstotliwości dźwięku, zmiany amplitudy (głośność oraz fazy (stopnia opóźnienia transmisji dźwięku). Aby uzyskać jeszcze większe szybkości, stosuje się często techniki kompresji danych, co pozwą uzyskać szybkości transmisji do 57,6 Kbps.
Te szybkości wydają się szczytem tego, co można uzyskać za pomocą tradycyjnych linii telefonicznych. Mimo to są one dalekie od szybkości, jak
110
ROZDZIAŁ DRUGI OPEROWANIE DANYMI
są współcześnie potrzebne. Przy szybkości 57,6 Kbps czas transferu typowego zdjęcia (o rozmiarze co najmniej megabajta) sięga kilku minut, a oglądanie filmu w trakcie jego transmisji jest niemożliwe. Są zatem rozwijane ciągle nowe technologie realizacji komunikacji między komputerami. Rozważane są światłowody, które dają szybkość przesyłania rzędu setek Mbps i potencjalne możliwości uzyskania szybkości rzędu Gbps.
PYTANIA I ĆWICZENIA
1. Przypuśćmy, że w komputerze opisanym w dodatku C stosuje się wej-
ście-wyjście odwzorowywane w pamięci i że pod adresem B5 znajduje
się port drukarki, do którego należy zapisywać dane przeznaczone
dla drukarki.
Jakiego rozkazu maszynowego należy użyć do wydrukowania
litery A na drukarce, jeśli rejestr 7 zawiera jej kod ASCII?Ile razy w ciągu sekundy można wysłać ten znak do drukarki,
przy założeniu, że komputer wykonuje milion rozkazów na se
kundę?Przypuśćmy, że drukarka jest w stanie wydrukować pięć stan
dardowych stron tekstu na minutę. Czy będzie mogła dotrzymać
kroku procesowi wysyłania znaków z punktu (b)?
Przypuśćmy, że dysk twardy w komputerze osobistym wykonuje 3000
obrotów na minutę i że każda ścieżka zawiera 16 sektorów, a każdy
sektor zawiera 1024 bajty. Jaka w przybliżeniu powinna być szybkość
komunikacji między napędem dysku a sterownikiem dysku, jeśli
sterownik ma otrzymywać bity z napędu dyskowego w miarę ich
odczytywania z wirującego dysku?Jak długo trwałoby przesłanie 300-stronicowej powieści zakodowanej
w ASCII przy szybkości transmisji 57 600 bps?
2.6. Inne architektury
W celu rozszerzenia naszych horyzontów rozważmy pewne architektury komputerowe różne od tych z poprzednich punktów.
Architektury CISC oraz RISC
Zaprojektowanie języka maszynowego wymaga podjęcia wielu decyzji. Jedną z nich jest decyzja, czy budować złożoną maszynę, która potrafi dekodować i wykonać wiele różnych rozkazów, czy też maszynę prostą
2.6. INNE ARCHITEKTURY 111
z niedużym zbiorem rozkazów. W pierwszym wypadku mamy do czynienia z komputerem o złożonym zbiorze rozkazów (ang. complex instructiot set computer; CISC), w drugim z komputerem o zredukowanym zbiorze rozkazów (ang. reduced instrudion set computer; RISC). Bardziej złożoną ma szynę obliczeniową łatwiej jest programować, ponieważ do realizacji za je pomocą zadania, które w prostszej maszynie wymaga wielu rozkazów, wystarcza jeden rozkaz. Złożone maszyny obliczeniowe jest jednak trudniej zbudować, są one droższe w budowie i eksploatacji. Ponadto większość złożonych rozkazów ma bardzo ograniczone zastosowania i w wyniku jedynie zwiększają koszt.
W celu zmniejszenia liczby układów scalonych, procesory CISC konstruuje się dwuwarstwowo. Każdy rozkaz maszynowy jest realizowany jako ciąg prostszych rozkazów. W takich architekturach jednostka centralna ma specjalny blok komórek pamięci, zwany mikropamięcią (ang. micromemory) gdzie przechowuje się program nazywany mikroprogramem (ang. micropro gram). To mikroprogram nadzoruje wykonanie złożonego rozkazu maszynowego. W szczególności znaczenie rozkazów języka maszynowego można zmieniać przez zmianę mikroprogramu. Dzięki temu, oprócz zysku płynącego z możliwości uzyskania architektury CISC bez konieczności stosowania złożonych układów scalonych, które byłyby potrzebne do realizowania bogatego repertuaru rozkazów, podejście oparte na mikroprogramach umożliwia dostosowanie przez zmianę mikrokodu architektury konkretnej jednostki centralnej, tak aby wspierała ona specjalne rozkazy maszynowe.
Zwolennicy architektury RISC twierdzą jednak, że zyski nie równoważą narzutu związanego z mikroprogramem. Ich zdaniem lepszym podejściem jest zaprojektowanie prostej maszyny z małym dobrze przemyślanym zbiorem rozkazów. Dzięki takiemu rozwiązaniu unika się złożonej architektura związanej z występowaniem mikropamięci, co prowadzi do prostszej budowy jednostki centralnej. Z drugiej strony oznacza to, że programy zapisane w języku maszynowym są dłuższe niż ich odpowiedniki w procesorach CISC, gdyż do wykonania złożonych operacji reprezentowanych w architekturze CISC pojedynczym rozkazem, potrzeba większej liczby rozkazów.
Zarówno procesory CISC, jak i RISC są dostępne komercyjnie. Procesor Pentium opracowane przez firmę Intel są przykładami architektury CISC procesory serii PowerPC opracowane przez Apple Computer, IBM i Motorole są przykładami architektur RISC.
Potoki
Impulsy elektryczne są przenoszone z szybkością nie większą niż prędkość światła. Ponieważ światło przemierza w przybliżeniu 1 stopę na nosekundę (jedną bilionową sekundy), potrzeba co najmniej 2 nanosekund aby jednostka sterująca w procesorze pobrała rozkaz z komórki w pamięci
112 ROZDZIAŁ DRUGI OPEROWANIE DANYMI
która jest odległa od niej o stopę (żądanie odczytu trzeba przesłać do pamięci, co wymaga co najmniej 1 nanosekundy, a rozkaz trzeba wysłać do jednostki sterującej, co wymaga jeszcze jednej nanosekundy). W efekcie pobranie i wykonanie rozkazu w takim komputerze trwa kilka nanosekund. Problem zwiększenia szybkości wykonywania rozkazów redukuje się tak naprawdę ^lo problemu uzyskania większej miniaturyzacji. Chociaż postęp w tej dziedzinie jest fantastyczny, są jednak granice jego możliwości.
Aby rozwiązać ten dylemat, inżynierowie zastąpili pojęcie szybkości wykonania pojęciem przepustowości (ang. throughput). Jest to łączna ilość pracy, jaką komputer jest w stanie wykonać w danym czasie (a nie, jak poprzednio, czas wykonania pojedynczego zadania).
Jednym ze sposobów zwiększenia przepustowości bez konieczności skrócenia czasu wykonania jest przetwarzanie potokowe (ang. pipining), które polega na nałożeniu na siebie poszczególnych faz cyklu maszynowego. W szczególności w czasie wykonywania jednego rozkazu można już rozpocząć pobieranie kolejnego. Oznacza to, że w potoku (lub strumieniu) może przebywać na raz kilka rozkazów, przy czym każdy z nich znajduje się w innej fazie przetwarzania. Powoduje to zwiększenie łącznej przepustowości maszyny, chociaż czas wymagany do pobrania i wykonania każdego rozkazu pozostaje taki sam. Oczywiście pojawienie się w potoku rozkazu skoku niweluje zyski uzyskane dzięki wcześniejszemu pobraniu kolejnego rozkazu do wykonania. Rozkazy w potoku nie są już bowiem tymi rozkazami, które są aktualnie potrzebne.
W nowoczesnych architekturach komputerowych przetwarzanie potokowe wykracza poza omówiony przez nas prosty przykład. Często jest w nich możliwe pobieranie i wykonanie wielu rozkazów na raz, o ile tylko wykonywacie jednocześnie rozkazy nie są ze sobą powiązane.
Komputery wieloprocesorowe
Przetwarzanie potokowe można traktować jako pierwszy krok w kierunku przetwarzania równoległego (ang. parallel processing), które polega na wykonywaniu wielu czynności w tym samym czasie. Przetwarzanie równoległe wymaga jednak wykorzystania wielu jednostek centralnych, co doprowadziło do powstania komputerów wieloprocesorowych.
Jednym z argumentów przemawiających za stosowaniem komputerów wieloprocesorowych jest analiza sposobu działania umysłu człowieka i potraktowanie go jako modelu komputera. Współczesna technologia zbliża się do możliwości konstruowania układów elektronicznych o liczbie układów przełączających równej z grubsza liczbie neuronów w mózgu człowieka (uważa się że neurony są naturalnymi układami przełączającymi). Możliwości współczesnych maszyn liczących są jednak dalekie od możliwości
Jedna stopą = 0,3048 m (przyp. red.).
2.6. INNE ARCHITEKTURY
113
ludzkiego umysłu. Twierdzi się, że jest to spowodowane nieefektywnym korzystaniem poszczególnych składowych komputera wymuszonym jego architekturą. Jeśli komputer ma dużą liczbą układów pamięciowych, ale tylko jedną jednostkę centralną, to większość układów przez większość czasu zostaje niewykorzystana. Tymczasem znaczna część ludzkiego umysłu zostaje aktywna przez cały czas. Z tego powodu zwolennicy przetwarzania równoległego optują za stosowaniem komputerów z wieloma jednostkami centralnymi. Prowadzi to, jak twierdzą, do konfiguracji z możliwością i uzyskania dużo wyższego współczynnika wykorzystania.
Wiele współczesnych maszyn konstruuje się zgodnie z tą koncepcją. Jedna ze strategii polega na przyłączeniu kilku procesorów, z których każdy przypomina jednostkę centralną komputera jednoprocesorowego, do te samej pamięci głównej. W takiej konfiguracji procesory mogą działać niezależnie od siebie, koordynując swoje czynności za pomocą komunikatów umieszczanych we wspólnych komórkach pamięci. Gdy któryś z procesorów otrzyma na przykład duże zadanie do wykonania, może zapamiętać program do realizacji jego części we wspólnej pamięci i zażądać, aby : procesor rozpoczął jego wykonanie. Otrzymuje się w ten sposób komputer w którym różne ciągi rozkazów wykonuje się na różnych zbiorach danych. Taki model obliczeń nazywa się MIMD (skrót od multiple-instruction str multiple-dała stream - wiele strumieni rozkazów, wiele strumieni dan w odróżnieniu od tradycyjnej architektury SISD (skrót od single-instru, streatn, single-data stream - jeden strumień rozkazów, jeden strumień dan;
i Innym wariantem architektury wieloprocesorowej jest połączenie
procesorów w taki sposób, aby wykonywały ten sam ciąg rozkazów, każdy na innym zestawie danych. Powstaje w ten sposób architektura SIMD (skrć
1 single-instruction stream, multipk-data stream - jeden strumień rozkazów, v
i i strumieni danych). Tego rodzaju maszyny przydają się w zastosowań
w których to samo zadanie trzeba wykonać na każdym zbiorze podob: elementów wewnątrz dużego bloku z danymi.
Inne podejście do przetwarzania równoległego polega na konstrukcj żych maszyn jako konglomeratów mniejszych maszyn, z których każd; własną pamięć i jednostkę centralną. W takiej architekturze każdy z m szych komputerów jest połączony ze swoimi sąsiadami, tak że zad zlecane całemu systemowi mogą być rozdzielane na pojedyncze mass Jeśli zatem zadanie przypisane pewnej wewnętrznej maszynie daje się dzielić na niezależne podzadania, komputer może poprosić swoich sąsia o współbieżne wykonanie tych podzadań. Całe zadanie można w ten sp zrealizować w czasie krótszym niż na komputerze jednoprocesorowyrr
Aktualna problematyka związana z projektowaniem i używaniem 1
puterów wieloprocesorowych wiąże się z kwestią równoważenia obci
(ang. load balancing), czyli dynamicznego przypisywania zadań do róż
procesów tak, aby wszystkie procesory były wykorzystywane efekty\
Problemem ściśle z tym związanym jest skalowanie (ang. scaling), czyli i
lenie zadania na pewną liczbę podzadań zgodnie z liczbą dostępnych procesorów. Inny problem dotyczy zapanowania nad złożonością rozproszenia
114 ROZDZIAŁ DRUGI OPEROWANIE DANYMI
przydziału zadań. W miarę wzrostu liczby zadań praca wymagana do wykonania przydziału podzadań i koordynacji interakcji między poszczególnymi zadaniami wzrasta wykładniczo. Jeśli są cztery zadania, to jest sześć potencjalnych par zadań, które mogą wymagać komunikacji ze sobą. Jeśli jest pięć zadań, liczba potencjalnych ścieżek komunikacyjnych wzrasta do dziesięciu, w wypadku sześciu zadań liczba ta wzrasta do piętnastu.
W rozdziale 10 przeanalizujemy sieci neuronowe, których budowę oparto na obecnym stanie wiedzy na temat mózgu ludzkiego. Te maszyny reprezentują inną postać architektury wieloprocesorowej. Składają się one z wielu procesorów podstawowych. Wartość na wyjściu każdego z nich pojawia się na skutek prostej reakcji na sygnały wejściowe. Takie proste procesory łączy się w sieć, w której wyjścia jednych procesorów stanowią wejścia dla innych. Tak otrzymaną maszynę programuje się, dobierając stopień, w jakim wyjście każdego procesora ma wpływać na procesory, z którymi jest ono połączone. Sądzi się, że w ten właśnie sposób uczymy się i sieci neuronowe są symulacją tego procesu. Oczywiście biologiczne sieci neuronowe uczą się reagować w konkretny sposób na zadane bodźce przez dostosowanie składu chemicznego połączeń (synaps) między neuronami, co z kolei decyduje o tym, jak duży jest wpływ neuronu na akcje innych neuronów.
PYTANIA I ĆWICZENIA
Dlaczego w jednostce centralnej komputera z mikroprogramami są
dwa liczniki rozkazów i dwa rejestry rozkazów?Wróćmy do pytania 3 z podrozdziału 2.3. Przypuśćmy, że w kom
puterze zastosowano przetwarzanie potokowe opisane w tekście. Co
znajdzie się w potoku, gdy wykonuje się rozkaz spod adresu AA?
Jaki warunek musi być spełniony, aby przetwarzanie potokowe nie
przyniosło żadnych zysków przy wykonaniu tego fragmentu przykła
dowego programu?Jakie konflikty trzeba rozstrzygnąć, uruchamiając program z pytania 4
z podrozdziału 2.3 w komputerze z przetwarzaniem potokowym?Przypuśćmy, że dwie jednostki „centralne" są przyłączone do tej
samej pamięci i wykonują różne programy. Załóżmy ponadto, że
jeden z tych procesorów chce dodać jeden do zawartości pewnej
komórki pamięci i mniej więcej w tym samym czasie, drugi chce odjąć
jeden od tej samej komórki. (Zatem w efekcie zawartość komórki
powinna zostać niezmieniona).
Podaj scenariusz, w którym zawartość komórki pamięci, po wy
konaniu obu operacji, będzie o jeden mniejsza niż była na po
czątku.Podaj scenariusz, w którym zawartość komórki pamięci, po wy
konaniu obu operacji, będzie o jeden większa niż była na po
czątku.
2.6. INNE ARCHITEKTURY 115
rozdział SYSTEMY OPERACYJNE I SIECI
trzeci
We współczesnych zastosowaniach komputery wykonują zazwyczaj wiele czynności, które często współzawodniczą ze sobą o dostęp do zasobów komputera. Typowy przykład to komputer, do którego przyłączono wiele terminali lub stacji roboczych, skąd różni użytkownicy mogą jednocześnie zlecać wykonanie pewnych zadań. Nawet jeśli jednoczesny dostęp do komputera ma tylko jeden użytkownik, może on zażądać wykonania czynności takich jak drukowanie dokumentu, modyfikacja innego, utworzenie grafiki, która będzie umieszczona w dokumencie. Wykonanie tych żądań wymaga wysokiego stopnia ich koordynacji, aby zapewnić, że niezwiązane ze sobą czynności nie będą sobie nawzajem przeszkadzać i że komunikacja między powiązanymi ze sobą zadaniami jest efektywna i niezawodna. Za taką koordynację odpowiada pakiet oprogramowania, zwanego systemem operacyjnym.
Podobne problemy komunikacyjne i koordynacyjne powstają, gdy rozważa się wiele komputerów połączonych w sieć. Metody rozwiązywania tych problemów są naturalnym rozszerzeniem rozwiązań stosowanych w systemach operacyjnych. W tym rozdziale omówimy podstawowe pojęcia dotyczące systemów operacyjnych i sieci.
3.1. Ewolucja systemów
operacyjnych
Systemy jednoprocesorowe Systemy wieloprocesorowe
3.2. Architektura systemów
operacyjnych
Przegląd oprogramowania Elementy systemu
operacyjnego Uruchamianie systemu
3.3. Koordynacja czynności
komputera
Pojęcie procesu Administrowanie procesami Model klient-serwer
*3.4. Rywalizacja między
procesami
Semafory
Zakleszczenie
3.5. Sieci Klasyfikacja sieci Internet
*3.6. Protokoły sieciowe Sterowanie uprawnieniami
do transmisji Warstwowa budowa
oprogramowania
internetowego Pakiet protokołów TCP/IP
3.7. Bezpieczeństwo
* Gwiazdki oznaczają sugestie co do opcjonalności podrozdziałów
3.1. Ewolucja systemów operacyjnych
Nasze rozważania o systemach operacyjnych rozpoczniemy od przedstawienia rysu historycznego, od wczesnych systemów jednoprocesorowych do współczesnych systemów wieloprocesorowych.
Systemy jednoprocesorowe
Jednoprocesorowe maszyny obliczeniowe z lat czterdziestych i pięćdziesiątych nie były ani elastyczne, ani efektywne. Wykonanie programu poprzedzało długie przygotowanie sprzętu: zamontowanie taśm magnetycznych, umieszczenie kart perforowanych w czytniku, ustawienie przełączników itp. Wykonanie każdego programu, nazywanego zadaniem (ang. job), było traktowane jako osobna czynność. Użytkownicy korzystający ze wspólnego komputera musieli wypełniać specjalne formularze, aby zarezerwować dla siebie czas komputera. W zarezerwowanym czasie komputer był całkowicie pod kontrolą jednego użytkownika. Każda sesja rozpoczynała się zazwyczaj od przygotowania programu do wykonania, a następnie krótkich okresów, w których program rzeczywiście wykonywał się na komputerze. Często sesja kończyła się pośpiesznymi próbami wykonania jeszcze jednej czynności („To zajmie tylko minutkę"), podczas gdy kolejny użytkownik niecierpliwie rozpoczynał przygotowania.
W takich właśnie realiach rozpoczęły działanie systemy operacyjne. Były to początkowo systemy, których zadaniem było uproszczenie procesu przygotowywania programów do wykonania i czynności związanych ze zmianą realizowanego zadania. Jednym z wczesnych pomysłów było oddzielenie użytkowników od sprzętu, co wyeliminowało fizyczną wymianę ludzi w sali komputerowej. Zatrudniono operatora, który obsługiwał maszynę liczącą. Każdy, kto chciał wykonać program, musiał dostarczyć go operatorowi razem z danymi wejściowymi i specjalnymi informacjami o wymaganiach programu. Później zgłaszał się po wyniki. Operator umieszczał dostarczony mu materiał w pamięci masowej komputera, gdzie miał do niego dostęp system operacyjny, który mógł rozpocząć wykonanie programu. Taka metoda postępowania dała początek przetwarzaniu wsadowemu (ang. batch processing), które polega na zebraniu zadań w postaci pojedynczego „wsadu" i wykonaniu go bez dalszej interakcji z użytkownikiem. Zadania umieszczone w pamięci masowej oczekiwały na wykonanie w kolejce zadań (ang. job queue; zobacz rysunek 3.1).
Kolejka (ang. ąueue) polega na takim sposobie przechowywania informacji, aby obiekty (w omawianym przykładzie - zadania) były uporządkowane w sposób zgodny z kolejnością ich przychodzenia, czyli zgodnie z zasadą „pierwszy na wejściu, pierwszy na wyjściu" (ang. first-in, first-out; FIFO). Oznacza to, że obiekty wyjmuje się z kolejki w kolejności ich pojawiania się. W rzeczywistości w większości kolejek zadań nie przestrzega
128 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
się rygorystycznie tej zasady. W większości systemów operacyjnych można przypisywać zadaniom priorytety. Powoduje to możliwość przesunięcia niektórych zadań do tyłu kolejki przez zadanie wysokopriorytetowe.
We wczesnych systemach wsadowych z każdym zadaniem dostarczano zbiór instrukcji opisujących kroki, które należy wykonać w celu przygotowania komputera do realizacji tego zadania. Instrukcje te zapisywano w specjalnym języku sterowania zadaniami (ang. job control language; JCL) i umieszczano je razem z zadaniem w kolejce zadań. Po wybraniu zadania do wykonania system operacyjny drukował te instrukcje na drukarce, dzięki czemu mógł je przeczytać i wykonać operator. Instrukcje, które wymagały podjęcia pewnych czynności od operatora, dotyczyły głównie sprzętu pomocniczego. Ponieważ takie działania są współcześnie minimalne, języki sterowania zadaniami stały się raczej metodą komunikacji z systemem operacyjnym, a nie z operatorem. Samo stanowisko operatora stało się także przestarzałe. Obecnie zatrudnia się administratorów systemu, których zadaniem jest pielęgnacja systemu komputerowego: pozyskiwanie nowego sprzętu i oprogramowania i nadzorowanie jego instalacji, ustalanie lokalnych zasad korzystania ze sprzętu, jak na przykład zasady zakładania nowych kont czy limity miejsca na dyskach dla różnych użytkowników, oraz koordynacja działań mających na celu rozwiązywanie problemów występujących w systemie. Nie obsługują oni już komputera w sposób bezpośredni.
Główną wadą tradycyjnego przetwarzania wsadowego jest to, że użytkownik nie ma możliwości interakcji z programem po dostarczeniu go do kolejki zadań. Takie rozwiązanie jest akceptowalne w wypadku niektórych zastosowań, takich jak przetwarzanie listy płac, w których dane i decyzje dotyczące przetwarzania są ustalone z góry. Metody nie daje się jednak
3.1. EWOLUCJA SYSTEMÓW OPERACYJNYCH
129
stosować, jeśli użytkownik musi porozumiewać się z programem w czasie jego wykonania. Przykładami tego typu systemów są systemy rezerwacji miejsc, które muszą podawać na bieżąco informacje o dokonywanych i odwoływanych rezerwacjach w miarę ich pojawiania się, systemy przetwarzania tekstu, które umożliwiają tworzenie dokumentów i ich poprawianie w sposób dynamiczny, oraz gry komputerowe, które w zasadzie opierają się na interakcji użytkownika z komputerem.
W celu zaspokojenia tego typu potrzeb opracowano nowe systemy operacyjne, które umożliwiały uruchamianie programów i ich dialog z użytkownikiem za pośrednictwem zdalnych terminali lub stacji roboczych. Ta zdolność systemów operacyjnych jest znana pod nazwą przetwarzania interakcyjnego lub konwersacyjnego (ang. interactive processing); zobacz rysunek 3.2. Systemy interakcyjne wymagają koordynacji czynności podejmowanych przez maszynę z czynnościami wykonywanymi w środowisku, w którym znajduje się maszyna. Koordynacja między maszyną a jej środowiskiem pracy nazywa się przetwarzaniem w czasie rzeczywistym (ang. real-time processing).
Jeśli z systemu interakcyjnego korzystałby na raz tylko jeden użytkownik, to przetwarzanie w czasie rzeczywistym nie stanowiłoby problemu. Jednak komputery były drogie, musiały więc obsługiwać wielu użytkowników. Z kolei użytkownicy często chcieli pracować w sposób interakcyjny, więc przetwarzanie w czasie rzeczywistym stwarzało problemy. Gdyby system operacyjny działający w takim środowisku z wieloma użytkownikami wykonywał tylko jedno zadanie na raz, to tylko jeden użytkownik zostałby obsłużony w satysfakcjonujący go sposób w czasie rzeczywistym.
Problem ten rozwiązano, opracowując system operacyjny, który na przemian wykonywał krótkie fragmenty poszczególnych zadań. Taką technikę
130
ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
nazwano podziałem czasu (ang. time-sharing). Polega ona na tym, że czas dzieli się na przedziały zwane kwantami czasu, a następnie wykonuje się każde zadanie tylko przez jeden kwant czasu. Po upływie tego kwantu, bieżące zadanie odkłada się na bok i zezwala na wykonanie drugiego przez następny kwant czasu. Stosując szybkie tasowanie zadań w opisany powyżej sposób, stwarza się złudzenie jednoczesnego wykonywania wielu zadań. W zależności od charakterystyki wykonywanych zadań wczesne systemy z podziałem czasu mogły obsługiwać w czasie rzeczywistym do 30 użytkowników na raz.
KORZYSTNA JEDNORODNOŚĆ CZY SZKODLIWY MONOPOL
Obecnie podział czasu stosuje się zarówno w systemach z jednym użytkownikiem, jak i w systemach z wieloma użytkownikami. Systemy z jednym użytkownikiem zazwyczaj nazywa się systemami wielozadaniowymi (ang. multitasking), jako że stwarzają one wrażenie jednoczesnego wykonywania wielu zadań. Stwierdzono, że niezależnie od tego czy środowisko jest z jednym, czy z wieloma użytkownikami, podział czasu poprawia całościowe wykorzystanie maszyny. To stwierdzenie może dziwić, zwłaszcza że proces przełączania między wykonywanymi zadaniami stanowi spory narzut czasowy. Czas realizacji przełączania zadań jest przecież bezproduktywny. Jednak w systemie komputerowym bez podziału czasu marnuje się większość czasu w oczekiwaniu, aż urządzenia peryferyjne zakończą wykonanie pewnych czynności lub użytkownik wyda kolejne polecenie. W chwili gdy jedno zadanie musi poczekać, można jednak wykonywać inne. To z kolei powoduje, że wykonanie zbioru zadań w środowisku z podziałem czasu trwa często krócej niż wykonanie tego samego zbioru w sposób sekwencyjny.
Systemy wieloprocesorowe
W ostatnich latach wystąpiło zapotrzebowanie na współdzielenie informacji i zasobów między różne komputery. Aby umożliwić wymianę informacji, zaczęto zatem łączyć komputery ze sobą. Dużą popularność zyskały systemy komputerowe połączone w sieć (ang. network). Koncepcja wielkiego centralnego komputera obsługującego wielu użytkowników zdecydowanie ustąpiła współcześnie koncepcji wielu małych komputerów połączonych ze sobą siecią, dzięki
Ponieważ to system operacyjny komputera ustala sposób komunikacji z komputerem, wydaje się, że stosowanie standardowego systemu operacyjnego w całej gamie różnorodnych komputerów byłoby bardzo dobrą rzeczą. Wprowadzenie takiego standardu oznaczałoby, że umiejętności nabyte na jednym komputerze można by wykorzystywać, pracując na innych. Ponadto producenci oprogramowania nie musieliby dbać o zgodność swoich produktów z wieloma systemami operacyjnymi. Taka argumentacja pomija jednak wiele realiów współczesnego społeczeństwa. Producent uniwersalnego systemu operacyjnego miałby olbrzymie 'znaczenie na rynku. Niewłaściwe wykorzystanie takiej pozycji może przynieść użytkownikom komputerów więcej szkody niż pożytku. Wiele z takich problemów udokumentowano w trakcie postępowania antymonopolowego wszczętego przez rząd Stanów Zjednoczonych przeciwko firmie Microsoft, rozpoczętego w 1998 r. Więcej o tym i podobnych sprawach można dowiedzieć się ze znakomitych archiwów wiadomości w sieci WWW.
Pożyteczne adresy to http://newsweek.com; http://www.npr.org; http://www.nytimes.com oraz http://washingtonpost.com.
3.1. EWOLUCJA SYSTEMÓW OPERACYJNYCH
131
której użytkownicy współdzielą zasoby takie jak: oprogramowanie, drukarki, urządzenia do przechowywania danych i informacji, które mogą być rozrzucone po całym systemie. Najlepszym przykładem jest Internet, sieć sieci, który obecnie łączy miliony komputerów na całym świecie. Internet omówimy dokładniej w podrozdziałach 3.5 i 3.6.
Wiele problemów związanych z koordynacją różnych czynności w architekturach sieciowych przypomina lub wręcz jest taka sama jak problemy, z którymi muszą radzić sobie systemy operacyjne. Tak naprawdę oprogramowanie kontrolujące sieć można uważać za sieciowy system operacyjny. W tym świetle zagadnienie tworzenia oprogramowania sieciowego jawi się jako naturalne rozszerzenie tematyki związanej z systemami operacyjnymi. Wczesne sieci konstruowano w postaci połączonych ze sobą pojedynczych maszyn z odrębnym systemem operacyjnym na każdej. Współczesne badania w dziedzinie sieci prowadzą raczej w kierunku systemów operacyjnych o zasięgu ogólnosieciowym, w których zasoby sieciowe są współdzielone w równym stopniu między zadaniami znajdującymi się w sieci. Te zasoby są z kolei przypisywane zadaniom zgodnie z zapotrzebowaniem, niezależnie od ich fizycznego położenia. Przykładem takiego rozwiązania jest system serwerów nazw stosowany w Internecie, który omówimy w podrozdziale 3.5. System umożliwia komputerom rozrzuconym po całym świecie współpracę przy tłumaczeniu adresów internetowych z ich mnemonicznej wygodnej dla człowieka postaci na postać numeryczną zrozumiałą dla sieci
Sieci to tylko jeden przykład architektur wieloprocesorowych, które stanowią inspirację dla twórców współczesnych systemów operacyjnych. Siei to system wieloprocesorowy, powstały przez połączenie wielu komputerów z których każdy być może zawiera tylko jedną jednostkę centralną. Powstają jednak także systemy wieloprocesorowe, pomyślane jako pojedyncza komputery zawierające kilka procesorów. System operacyjny przeznaczony dla takich maszyn musi nie tylko koordynować współzawodnictwo miedzy różnymi wykonywanymi jednocześnie czynnościami, ale także nadzorować przydział czynności do poszczególnych procesorów. Występują przy tym problemy takie jak równoważenie obciążenia (ang. load balancing), czyli zapewnienie, że procesory są wykorzystywane efektywnie, oraz skalowanie czyli problem podziału zadań na podzadania zgodnie z liczbą procesorów w komputerze.
Powstanie systemów wieloprocesorowych dodało nowy wymiar zadaniom systemu operacyjnego. Dziedzina ta na pewno będzie polem aktywnych badań przez najbliższe lata.
PYTANIA I ĆWICZENIA
Podaj przykłady różnych kolejek. W każdym z nich określ sytuacje,
które powodują naruszenie struktury FIFO.Które z poniższych czynności wymagają przetwarzania w czasie
rzeczywistym:
132 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
Drukowanie etykiet na koperty
Gra komputerowa
Wyświetlanie liter na ekranie monitora w trakcie ich wprowadza
nia z klawiaturyWykonanie programu, który prognozuje sytuację ekonomiczną na
następny rok
Na czym polega różnica między przetwarzaniem w czasie rzeczywi
stym a przetwarzaniem interakcyjnym?Na czym polega różnica między podziałem czasu a wielozada-
niowością?
3.2. Architektura systemów operacyjnych
Aby zrozumieć architekturę typowego systemu operacyjnego, jest pomocne przeanalizowanie różnych rodzajów oprogramowania dostępnego w typowym systemie komputerowym. Rozpocznijmy zatem od przeglądu oprogramowania, w którym przedstawimy pewien schemat jego klasyfikacji. Każda próba klasyfikacji oprogramowania w sposób nieunikniony powoduje umieszczenie podobnych do siebie programów w różnych klasach. W podobny zresztą sposób strefy czasowe powodują, że w niektórych miejscach położonych blisko siebie różnica czasu wynosi godzinę, chociaż nie występują duże różnice między czasem wschodu i zachodu słońca. Klasyfikację oprogramowania utrudnia ponadto sprzeczna terminologia spowodowana dynamicznym rozwojem tej dziedziny. Użytkownicy systemu Windows 98 firmy Microsoft mają do dyspozycji grupę programów o nazwie akcesoria. Grupa ta zawiera oprogramowanie, które w proponowanej poniżej klasyfikacji przydzielimy do klasy aplikacji, jak i oprogramowanie, które zaliczymy do klasy programów narzędziowych. Proponowaną klasyfikację należy zatem traktować jako pewną próbę przedstawienia ogólnego zarysu obszernej dziedziny, a nie jako stwierdzenie ogólnie przyjętego stanu rzeczy.
Przegląd oprogramowania
Programy komputerowe podzielimy na dwie duże kategorie: aplikacyjne (ang. application software) oraz systemowe (ang. system software). Do kategorii aplikacyjnej zaliczymy programy wykonujące pewne użyteczne czynności, czyli wykorzystujące możliwości maszyny. Komputer przeznaczony do inwentaryzacji pewnej spółki produkcyjnej będzie zawierać inne programy aplikacyjne niż komputer używany przez inżyniera elektryka. Przykładami aplikacyjnymi są arkusze kalkulacyjne, systemy baz danych, systemy składu tekstu, pakiety do tworzenia programów oraz gry.
3.2. ARCHITEKTURA SYSTEMÓW OPERACYJNYCH 133
Oprogramowanie systemowe, w odróżnieniu od aplikacji, realizuje te zadania, które są wspólne dla wszystkich systemów komputerowych. W pewnym sensie oprogramowanie systemowe dostarcza środowisko, w którym wykonują się aplikacje. W podobny sposób infrastruktura narodu stwarza podstawy, na których obywatele opierają się, tworząc własny styl życia.
W obrębie klasy oprogramowania systemowego wyróżnimy dwie kategorie, z których jedną jest sam system operacyjny, a w skład drugiej wchodzą różne programy zwane oprogramowaniem narzędziowym (ang. utility software). Większość z zainstalowanego oprogramowania narzędziowego składa się z programów do wykonywania pewnych czynności kluczowych dla instalacji komputerowej, które nie stanowią części systemu operacyjnego. Można powiedzieć, że w pewnym sensie oprogramowanie narzędziowe składa się z pakietów, które rozszerzają możliwości systemu operacyjnego. Narzędzia do formatowania dysku lub kopiowania pliku częste nie są implementowane jako integralna część systemu operacyjnego, ale właśnie jako oddzielne programy narzędziowe. Inne przykłady programów narzędziowych to oprogramowanie do obsługi komunikacji za pośrednictwem modemu, programy do komunikacji przez sieć, oprogramowanie do kompresji i dekompresji danych.
Zaimplementowanie pewnych czynności w postaci osobnych programów narzędziowych upraszcza sam system operacyjny. Jest on dzięki temu mniej złożony niż system, który dostarczałby odpowiednie usługi. Ponadto, udogodnienia implementowane jako osobne programy narzędziowe można łatwiej dostosowywać do potrzeb konkretnej instalacji. W rzeczywistości bardzo często zdarza się, że firmy lub nawet indywidualni użytkownicy
134
ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
modyfikują lub rozbudowują oprogramowanie narzędziowe, dostarczane pierwotnie razem z systemem operacyjnym.
Różnica między oprogramowaniem narzędziowym a oprogramowaniem aplikacyjnym jest dość płynna. Pod względem przedstawionej tu klasyfikacji kluczowe jest to, czy pakiet stanowi część infrastruktury oprogramowania. Nowy program aplikacyjny może zatem przekształcić się w program narzędziowy, jeśli stanie się elementarnym narzędziem. Różnica między oprogramowaniem narzędziowym a systemem operacyjnym jest równie płynna. W niektórych systemach oprogramowanie realizujące pewne podstawowe usługi, jak na przykład listowanie plików znajdujących się w pamięci masowej, jest dostarczane w postaci programów narzędziowych, w innych stanowi integralną część systemu operacyjnego.
Elementy systemu operacyjnego
Ten fragment systemu operacyjnego, który definuje interfejs między systemem operacyjnym a jego użytkownikami, jest często nazywany interpreterem poleceń albo powłoką systemu operacyjnego (ang. shell). Zadaniem interpretera poleceń jest umożliwienie komunikacji między użytkownikiem (lub użytkownikami) a maszyną. Nowoczesne interpretery realizują to zadanie za pomocą graficznego interfejsu użytkownika (ang. graphical user interface; GUI). Obiekty, którymi manipuluje użytkownik, takie jak pliki czy programy, są reprezentowane na ekranie graficznie jako ikony. W takich systemach użytkownicy mogą wydawać polecenia, wskazując i wybierając za pomocą urządzenia zwanego myszką odpowiednie ikonki na ekranie monitora. Starsze interpretery poleceń komunikują się z użytkownikami za pomocą komunikatów tekstowych, wprowadzanych z klawiatury i wyświetlanych na monitorze.
Chociaż interpreter poleceń systemu operacyjnego odgrywa ważną rolę w ustanowieniu funkcjonalności maszyny, jest on jednak jedynie interfejsem między użytkownikiem a sercem systemu operacyjnego (rys. 3.4). To odróżnienie interpretera od wewnętrznych warstw systemu operacyjnego jest bardzo widoczne w niektórych systemach operacyjnych, w których użytkownicy mogą wybrać jeden z wielu dostępnych interpreterów. W ten sposób każdy użytkownik może posługiwać się tym interpreterem, który jest dla niego najwygodniejszy. Użytkownicy systemu UNIX mogą na przykład wybierać między różnymi interpreterami, m.in. interpreterem Borne'a, interpreterem C i interpreterem Korna. Wczesne wersje systemu Microsoft Windows były w zasadzie zamiennymi interpreterami dla systemu MS-DOS. System operacyjny pozostawał ten sam, zmieniał się tylko sposób komunikacji z użytkownikiem.
Głównym elementem współczesnych interpreterów graficznych jest zarządca okien (ang. window manager). Przydziela on na ekranie bloki zwane oknami i przechowuje informacje o tym, która aplikacja jest związana z każdym z nich. Gdy aplikacja chce wyświetlić komunikat na ekranie, zawiadamia
3.2. ARCHITEKTURA SYSTEMÓW OPERACYJNYCH 135
LINUX
Entuzjaści komputerowi, którzy chcą poeksperymentować z wewnętrznymi elementami systemu operacyjnego, mogą to zrobić na przykładzie systemu Linux. Linux jest systemem operacyjnym zaprojektowanym przez Linusa Torvaldsa, gdy byt on studentem na Uniwersytecie Helsinskim. Jest to produkt nie-komercyjny, a zatem jest dostępny za darmo razem z kodem źródłowym (rozdział 5) i dokumentacją. Ponieważ jest dostępny w postaci źródłowej, stał się popularny wśród hobbystów, studentów zajmujących się systemami operacyjnymi i programistów. Stał się także popularny jako substytut komercyjnych systemów operacyjnych dostępnych na rynku. Zainstalowanie Linuksa wymaga jednak zazwyczaj większego doświadczenia niż instalacja produktów komercyjnych, takich jak Microsoft Windows, który zazwyczaj jest wstępnie instalowany na komputerach osobistych. Więcej o Linuksie dowiesz się ze strony internetowej http://www.linux.org.
zarządcę okien, który wyświetla go w oknie związanym z daną aplikacją. Gdy użytkownik naciśnie klawisz myszki, zarządca okien sprawdza położenie wskaźnika myszki na ekranie i zawiadamia odpowiednią aplikację o aktywności myszki.
W odróżnieniu od interpretera systemu operacyjnego, część wewnętrzna systemu operacyjnego jest często nazywana jądrem (ang. kernel). Jądro systemu operacyjnego zawiera oprogramowanie, które zapewnia elementarną funkcjonalność wymaganą w konkretnej instalacji. Jeden z modułów systemu operacyjnego, zarządca plików (ang. file manager), koordynuje wykorzystanie pamięci masowej komputera. Dokładniej, zarządca plików utrzymuje informacje o wszystkich
136
ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
plikach znajdujących się w pamięci masowej. Informacja ta zawiera dane o położeniu plików, o tym, którzy użytkownicy mają prawo dostępu do poszczególnych plików, oraz o tym, które fragmenty pamięci masowej są jeszcze dostępne i mogą być użyte w nowych plikach lub wykorzystane do powiększenia plików już istniejących.
Dla wygody użytkowników większość zarządców plików umożliwia gromadzenie plików w pakiety zwane katalogami (ang. directory) lub folderami (ang. folder). Dzięki temu użytkownicy mogą organizować strukturę plików zgodnie z potrzebami, umieszczając związane ze sobą pliki w tym samym katalogu. Ponieważ katalogi mogą zawierać inne katalogi, zwane podkatalogami, pliki można przechowywać hierarchicznie. Użytkownik może na przykład utworzyć katalog o nazwie Dane, który zawiera pod-katalogi o nazwach DaneFinansowe, DaneMedyczne i DaneDomowe. Wewnątrz każdego z tych katalogów mogą znajdować się pliki, które należą do konkretnej kategorii. Łańcuch katalogów wewnątrz katalogów jest nazywany ścieżką (ang. path) katalogów.
Gdy pewien program chce wykonać operację na pliku, zarządca plików nadzoruje jej wykonanie. Procedura rozpoczyna się od nakazania zarządcy udostępnienia pliku. Ta operacja nazywa się otwieraniem pliku. Jeśli zarządca pliku zezwoli na dostęp do pliku, przekazuje informacje potrzebne do odnalezienia pliku i manipulacji nim. Te informacje przechowuje się w pamięci głównej w obszarze zwanym deskryptorem pliku (ang. file descriptor). Poszczególne operacje na pliku realizuje się na podstawie informacji zapisanych w deskryptorze pliku.
Inny element jądra składa się z zestawu programów obsługi urządzeń (ang. device driver). Program obsługi urządzenia komunikuje się ze sterownikami urządzenia (lub czasami bezpośrednio z urządzeniem), gdy zachodzi potrzeba wykonania pewnych operacji w urządzeniach peryferyjnych maszyny. Każdy program obsługi urządzenia jest zaprojektowany specjalnie dla określonego typu urządzenia (drukarki, napędu dysku, urządzenia taśmowego czy monitora) i tłumaczy ogólne polecenia na ciąg szczegółowych kroków, które musi wykonać urządzenie sterowane tym programem obsługi. W ten sposób można uniezależnić budowę innych modułów programistycznych od szczegółów technicznych, specyficznych dla konkretnego urządzenia. W efekcie otrzymuje się system operacyjny, który można dopasowywać do konkretnych urządzeń peryferyjnych, instalując jedynie odpowiednie programy obsługi.
Jeszcze innym elementem jądra systemu operacyjnego jest zarządca pamięci (ang. memory manager). Jego zadaniem jest koordynacja wykorzystania pamięci głównej komputera. Obowiązki z tym związane są minimalne w środowiskach, w których komputer realizuje na raz tylko jedno zadanie. Program realizujący to zadanie jest wtedy wprowadzany do pamięci głównej, wykonywany, a następnie zastępowany programem realizującym kolejne zadanie. Jednak w środowiskach z wieloma użytkownikami lub w systemach wielozadaniowych, w których komputer wykonuje wiele programów na raz, zarządca pamięci ma wiele do zrobienia. W pamięci głównej musi
3.2. ARCHITEKTURA SYSTEMÓW OPERACYJNYCH 137
przebywać jednocześnie wiele programów i wiele bloków danych, każdy w obszarze przyznanym mu przez zarządcę pamięci. W miarę przybywania kolejnych zadań i ich realizowania, zarządca pamięci musi wyszukiwać w pamięci obszary wystarczająco duże do zaspokojenia wymagań pamięciowych tych zadań. Zarządca musi także przechowywać informacje o tym, które obszary pamięci nie są już przez nikogo zajmowane.
Zadanie zarządcy pamięci komplikuje się jeszcze bardziej, jeśli łączna ilość wymaganego miejsca w pamięci głównej przekracza ilość pamięci dostępną w komputerze. W takiej sytuacji zarządca pamięci może stworzyć iluzję dodatkowego miejsca w pamięci, przesyłając programy i dane z pamięci głównej do pamięci masowej i na odwrót. Taka iluzoryczna przestrzeń pamięci nazywa się pamięcią wirtualną (ang. virtual memory). Przypuśćmy, że jest potrzebna pamięć główna o rozmiarze 64 megabajtów, ale są dostępne tylko 32 megabajty. Aby stworzyć wrażenie większej ilości miejsca w pamięci, zarządca pamięci dzieli potrzebną przestrzeń na kawałki zwane stronami (ang. pages) i przechowuje zawartość tych stron w pamięci masowej. Zazwyczaj rozmiar strony nie przekracza 4 kilobajtów. Gdy nowe strony muszą znaleźć się w pamięci głównej, zarządca pamięci wymienia je ze stronami, które już nie są tam dłużej potrzebne. W ten sposób moduły programistyczne mogą być wykonywane, tak jakby w komputerze było naprawdę 64 megabajtów pamięci.
W skład jądra systemu operacyjnego wchodzą także moduł szeregujący lub planista (ang. scheduler) oraz moduł ekspediujący lub dyspozytor (ang. dispatcher), które omówimy w następnym podrozdziale. Na razie powiemy tylko, że w systemie z podziałem czasu moduł szeregujący decyduje o tym, które zadania wybrać do wykonania, a moduł ekspediujący steruje przydzielaniem kwantów czasu poszczególnym zadaniom.
Uruchamianie systemu
Przeanalizowaliśmy sposób porozumiewania się systemu operacyjnego z użytkownikami komputera i sposób, w jaki poszczególne elementy systemu współpracują ze sobą, koordynując wykonanie różnych czynności w komputerze. Nie zastanawialiśmy się jednak jeszcze nad tym, jak uruchamia się system operacyjny. Wykonuje się to za pomocą procedury ładowania początkowego lub rozruchowej (ang. boot strapping), którą komputer realizuje zawsze bezpośrednio po włączeniu. Aby zrozumieć tę procedurę, trzeba uświadomić sobie, dlaczego jest ona w ogóle potrzebna.
Jednostkę centralną konstruuje się w ten sposób, że zawsze bezpośrednio po jej włączeniu, do licznika rozkazów ładuje się pewną z góry określoną wartość. Wartość ta to adres, pod którym jednostka centralna spodziewa się zastać pierwszy rozkaz do wykonania. Aby zapewnić, że pożądany program zawsze jest obecny, porcja pamięci rozpoczynająca się od tego adresu jest zazwyczaj konstruowana w ten sposób, że jej zawartość jest wpisana na stałe. Taka pamięć nazywa się pamięcią ROM (ang. read-only memory). Po umieszczeniu ciągów bitów w pamięci ROM w drodze specjalnego procesu,
138 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
pozostaje on w niej niezależnie od tego, czy komputer jest włączony czy wyłączony.
W małych komputerach, używanych jako urządzenia sterujące w kuchenkach mikrofalowych, samochodowych układach zapłonowych bądź w odbiornikach stereofonicznych, przeznacza się większą część pamięci głównej na pamięć ROM. Program, który takie urządzenie wykonuje po włączeniu, jest zawsze taki sam i nie jest tu potrzebna elastyczność. Inaczej jest jednak w komputerach ogólnego przeznaczenia; poświęcenie dużego fragmentu ich pamięci głównej na z góry ustalone programy nie jest praktyczne. Zawartość pamięci w tego typu komputerach musi dać się zmieniać. W rzeczywistości większa część pamięci komputerów ogólnego przeznaczenia jest konstruowana w taki sposób, że jej zawartość można zmieniać, ale zawartość ta jest tracona po każdym wyłączeniu komputera. Mówi się, że taka pamięć jest pamięcią ulotną.
Procedura rozruchu komputera ogólnego przeznaczenia wymaga, aby jedynie mała część pamięci była pamięcią ROM. Składa się ona z tych komórek pamięci, w których jednostka centralna po każdym włączeniu spodziewa się znaleźć program. Mały program, który jest zapisany na stałe w tym obszarze, nazywa się programem ładującym lub rozruchowym (ang. bootstrap). Jest to program, który wykonuje się automatycznie po włączeniu komputera. Powoduje on, że jednostka centralna przenosi dane z określonego wcześniej miejsca w pamięci masowej do ulotnego obszaru w pamięci głównej (rys. 3.5). Najczęściej przenoszone dane to system operacyjny. Po umieszczeniu systemu operacyjnego w pamięci głównej, program rozruchowy wykonuje rozkaz skoku do tego obszaru pamięci. Wtedy kontrolę przejmuje system operacyjny, który od tej chwili nadzoruje wszystkie czynności maszyny.
W większości współczesnych komputerów osobistych program rozruchowy zaprojektowano tak, aby w pierwszej kolejności próbował odczytać system operacyjny z dyskietki. Jeśli dyskietki nie ma w napędzie, to program rozruchowy automatycznie próbuje wczytać system operacyjny z dysku twardego. Jeśli jednak w napędzie dyskietek jest dyskietka, która nie zawiera kopii systemu operacyjnego, to program rozruchowy wstrzymuje swoje działanie i wyświetla komunikat o błędzie. Prawdopodobnie Czytelnik doświadczył tego zjawiska, włączając komputer z dyskietką z danymi w napędzie.
PYTANIA I ĆWICZENIA
Wymień elementy typowego systemu operacyjnego i opisz jednym
zdaniem zadania każdego z nich.Na czym polega różnica między programami aplikacyjnymi a progra
mami narzędziowymi?Co to jest pamięć wirtualna?
Opisz krótko procedurę rozruchową.
3.2. ARCHITEKTURA SYSTEMÓW OPERACYJNYCH 139
3.3. Koordynacja czynności komputera
W tym podrozdziale rozważymy, w jaki sposób system operacyjny koordynuje wykonanie programów aplikacyjnych, programów narzędziowych i modułów systemu operacyjnego. Rozpoczniemy od wprowadzenia pojęcia procesu.
140
ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
pojęcie procesu
Jedną z najbardziej podstawowych cech nowoczesnych systemów operacyjnych jest odróżnienie pojęciowe programu od czynności polegającej na wykonywaniu programu. Program jest po prostu statycznym zbiorem rozkazów. Wykonanie programu jest czynnością dynamiczną, której właściwości zmieniają się w miarę upływu czasu. Ta czynność nosi nazwę procesu (ang. process). Proces zawiera informacje o bieżącym stanie wykonania, zwane stanem procesu (ang. process state). W stanie są przechowywane informacje o bieżącej pozycji w wykonywanym programie (wartość licznika rozkazów) oraz wartości pozostałych rejestrów jednostki centralnej, a także zawartość związanych z procesem komórek pamięci. Z grubsza mówiąc, stan procesu jest migawką stanu komputera w danej chwili. W różnych momentach wykonania programu (w różnych chwilach w procesie) obserwuje się różne migawki (różne stany procesu).
Aby jeszcze bardziej uwypuklić różnicę między procesem a programem, zwróćmy uwagę, że jeden program może być jednocześnie związany z wieloma procesami. W systemie z podziałem czasu i wieloma użytkownikami, dwóch użytkowników może w tym samym czasie edytować dwa różne dokumenty. Można w tym celu wykorzystać ten sam program edytora, ale każda z czynności jest osobnym procesem z innym zestawem danych i każda z tych czynności może być w innym stopniu zaawansowana. System operacyjny może zatem utrzymywać w pamięci głównej tylko jedną kopię programu edytora, z której korzystają różne procesy w trakcie przydzielonego im kwantu czasu.
W typowej instalacji komputerowej z podziałem czasu o kwanty rywalizuje zazwyczaj wiele procesów. Wśród nich są procesy wykonujące programy aplikacyjne, procesy wykonujące programy narzędziowe oraz procesy realizujące fragmenty systemu operacyjnego. Koordynacja działania tych procesów jest zadaniem systemu operacyjnego. Polega ona na zapewnieniu, że każdy proces otrzyma potrzebne mu zasoby (urządzenia peryferyjne, miejsce w pamięci głównej, dostęp do danych i jednostki centralnej), na zagwarantowaniu, że niezależne od siebie procesy nie będą sobie nawzajem przeszkadzać i że procesy, które muszą wymieniać się informacjami, będą mogły to robić. Komunikacja między procesami nosi nazwę komunikacji międzyprocesowej (ang. interprocess communication).
Administrowanie procesami
Zadania związane z koordynacją działania procesów są wykonywane przez wewnętrzne moduły jądra systemu operacyjnego: przez moduł szeregujący (planista) i moduł ekspediujący (dyspozytor). Moduł szeregujący przechowuje informacje o procesach znajdujących się w systemie, wprowadza nowe procesy do systemu oraz usuwa z niego zakończone procesy. Moduł szeregujący przechowuje w pamięci głównej blok danych zwany tablicą procesów
3.3. KOORDYNACJA CZYNNOŚCI KOMPUTERA 141
(ang. process table), który przechowuje informacje o wszystkich procesach. Po pojawieniu się nowego zadania do wykonania, moduł szeregujący zawsze tworzy dla niego nowy proces i przydziela mu nową pozycję w tablicy procesów. W pozycji znajdują się informacje, takie jak położenie obszaru pamięci przydzielonej temu procesowi (informację tę uzyskuje się od zarządcy pamięci), priorytet procesu oraz informacje o tym, czy proces jest gotowy, czy oczekujący. Proces jest gotowy (ang. ready), jeśli znajduje się w stanie, w którym możliwe jest jego dalsze wykonywanie. Proces jest oczekujący (ang. waiting), jeśli jego wykonanie odłożono na później, aż nastąpi jakieś zewnętrzne zdarzenie, na przykład zakończenie operacji dostępu do dysku lub nadejście komunikatu od innego procesu.
Dyspozytor jest częścią jądra systemu operacyjnego, która dba o to, aby wybrane do wykonania procesy faktycznie się wykonywały. W systemie z podziałem czasu wykonanie procesów realizuje się, dzieląc czas na krótkie przedziały zwane kwantami (ang. ąuantum lub time slice) (zazwyczaj około 50 milisekund), a następnie przydzielając jednostkę centralną procesom na zmianę, tak aby każdy z nich wykonywał się na raz nie dłużej niż jeden kwant (rys. 3.6). Procedura zmiany aktualnie wykonywanego procesu to przełączenie procesów (ang. process switch).
Zawsze gdy proces rozpoczyna swój kwant, dyspozytor inicjuje układ, który mierzy czas, jaki pozostał do końca kwantu. Po zakończeniu kwantu układ generuje sygnał zwany przerwaniem (ang. interrupt). Jednostka centralna reaguje na ten sygnał, tak jak ludzie reagują na polecenie przerwania wykonywania pewnej czynności - przerywają to, co w danej chwili robili, zapamiętując, w jakim punkcie realizacji czynności się znajdowali, i zajmują się realizacją zadania, które spowodowało przerwanie. Gdy procesor otrzymuje przerwanie, kończy bieżący cykl maszynowy, zapamiętuje pozycję w procesie bieżącym (powrócimy do tego kroku za chwilę) i rozpoczyna wykonanie programu zwanego programem obsługi przerwania (ang. interrupt handler), który znajduje się pod z góry określonym adresem w pamięci głównej.
W systemie z podziałem czasu program obsługi przerwania jest częścią modułu ekspediującego (dyspozytora). Efektem nadejścia przerwania jest zatem wywłaszczenie procesu bieżącego i przekazanie sterowania do dyspozytora. W tym momencie dyspozytor zezwala modułowi szeregującemu na uaktualnienie tablicy procesów (na przykład może okazać się konieczne zmniejszenie priorytetu procesu, który właśnie wykorzystał swój kwant, i zwiększenie priorytetu innych procesów). Dyspozytor wybiera następnie z tablicy procesów proces, który ma najwyższy priorytet spośród procesów gotowych, uruchamia ponownie układ odmierzający czas i zezwala wybranemu procesowi na rozpoczęcie jego kwantu.
Aby system z podziałem czasu mógł poprawnie działać, jest potrzebna możliwość zatrzymania i późniejszego wznowienia procesu. Gdy ktoś przerwie Ci czytanie książki, będziesz mógł powrócić do lektury później, jeśli potrafisz zapamiętać, w którym miejscu książki byłeś, oraz informacje, które zgromadziłeś do tej pory. W skrócie, musisz odtworzyć środowisko,
142 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
w którym znajdowałeś się tuż przed przerwaniem. W wypadku procesu takim środowiskiem jest stan procesu. Przypomnijmy, że stan zawiera wartość licznika rozkazów, zawartość rejestrów oraz istotnych dla procesu komórek pamięci. Komputery projektowane pod kątem systemów z podziałem czasu realizują czynności związane z zapamiętaniem tych informacji jako element reakcji jednostki centralnej na sygnał przerwania. W języku maszynowym takich komputerów znajdują się także rozkazy do odtworzenia uprzednio zapamiętanego stanu. Opisane możliwości komputera upraszczają dyspozytorowi zadanie przełączania procesu i stanowią przykład ilustrujący wpływ współczesnych systemów operacyjnych na architekturę nowoczesnych maszyn liczących.
Czasem proces nie wykorzystuje całego kwantu. Jeśli proces żądał wejścia-wyjścia, na przykład odczytania danych z dysku, to czas przydzielony temu procesowi kończy się natychmiast. W przeciwnym razie proces po prostu zmarnowałby pozostałą część kwantu, czekając aż sterownik urządzenia zrealizuje żądanie. W takim wypadku moduł szeregujący uaktualnia tablicę procesów, uwzględniając w niej to, że proces jest oczekujący, a dyspozytor przydziela nowy kwant procesowi, który jest gotowy. Później (być może za kilkaset milisekund), gdy sterownik powiadomi o zakończeniu realizacji żądania wejścia-wyjścia, moduł szeregujący ponownie zaklasyfikuje proces jako gotowy, dzięki czemu będzie on znów rywalizować o kwant czasu.
3.3. KOORDYNACJA CZYNNOŚCI KOMPUTERA 143
Model klient-serwer
Moduły systemu operacyjnego zazwyczaj wykonują się jako oddzielne procesy, które w systemie z podziałem czasu rywalizują pod nadzorem dyspozytora o kwanty czasu. W celu koordynacji ich działań, procesy te muszą się ze sobą porozumiewać. Przykładowo, aby wybrać do wykonania nowy proces, moduł szeregujący musi najpierw uzyskać dla niego miejsce w pamięci od zarządcy pamięci, a w celu uzyskania dostępu do pliku w pamięci masowej proces musi najpierw uzyskać odpowiednie informacje od zarządcy plików.
W celu uproszczenia komunikacji międzyprocesowej elementy systemu operacyjnego często projektuje się zgodnie z modelem klient-serwer (rys. 3.7). W tym modelu każdy z komunikujących się procesów gra rolę klienta albo rolę serwera. Klient wysyła żądania do innych modułów, a serwer obsługuje żądania klientów. Zarządca plików może na przykład przyjąć na siebie rolę serwera, który udostępnia pliki zgodnie z żądaniami klientów. W takim modelu komunikacja międzyprocesowa wewnątrz systemu operacyjnego polega na przekazywaniu żądań od procesów pełniących funkcję klientów do serwerów i przekazywaniu odpowiedzi od procesów pełniących funkcje serwerów do klientów.
144 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE 1 SIECI
Model klient-serwer w procesie projektowania oprogramowania prowadzi do powstania modułów z jasno określonymi rolami. Klient po prostu wysyła żądania do serwerów i oczekuje na odpowiedzi. Serwer realizuje odebrane żądania i wysyła klientom odpowiedzi. Działanie serwera nie zmienia się niezależnie od tego, czy obsługiwany klient znajduje się w tym samym komputerze, czy w odległym węźle sieci. Różnica między tymi przypadkami jest ukryta w oprogramowaniu realizującym komunikację, a nie w kodzie serwera ani klienta. Z kolei, jeśli elementy systemu projektuje się zgodnie z architekturą klient-serwer, to mogą one realizować swoje zadania niezależnie od tego, czy znajdują się na tym samym komputerze, czy na różnych komputerach nawet znacznie od siebie odległych (rys. 3.8). Zatem, jeśli tylko
istnieje oprogramowanie realizujące usługi wysyłania żądań i odpowiedzi, to zestaw klientów i serwerów może być rozproszony między różne komputery w dowolnej, wygodnej ze względu na sieć konfiguracji.
Ustanowienie jednorodnego systemu przekazywania komunikatów, który mógłby wspierać takie rozproszone systemy w sieciach komputerowych, jest podstawowym celem zbioru standardów i specyfikacji, znanych pod nazwą CORBA (od angielskiej nazwy Common Object Request Broker Architecture). W skrócie CORBA jest standardem komunikacji sieciowej między modułami programistycznymi, zwanymi obiektami (np.: klienci i serwery). CORBA została opracowana przez Object Management Group, która jest konsorcjum złożonym z producentów sprzętu i oprogramowania oraz użytkowników zainteresowanych promowaniem i rozszerzaniem metod obiektowych. Metody obiektowe wprowadzimy w rozdziale 5 i będziemy do nich stale powracać w kolejnych rozdziałach.
PYTANIA I ĆWICZENIA
Podsumuj różnice między procesem a programem.
Opisz krótko kroki podejmowane przez jednostkę centralną w chwili
pojawienia się przerwania.W jaki sposób można zapewnić szybsze wykonanie procesów wysoko-
priorytetowych w systemie z podziałem czasu?
3.3. KOORDYNACJA CZYNNOŚCI KOMPUTERA 145
Klasyfikacja sieci
Każdą sieć komputerową zalicza się do jednej z dwóch dużych kategorii: kategorii sieci lokalnych (ang. local area network; LAN) lub kategorii sieci rozległych (ang. wide area network; WAN). Sieć LAN zazwyczaj składa się ze zbioru komputerów znajdujących się w jednym budynku lub kompleksie budynków. Przykładami sieci LAN są komputery użytkowane w kampusie uniwersyteckim czy w zakładzie produkcyjnym. Sieci WAN łączą komputery, które mogą znajdować się na przeciwnych krańcach miasta lub nawet świata. Główna różnica między sieciami LAN i WAN polega na technice stosowanej do ustalenia ścieżek komunikacyjnych. (Łącza satelitarne dobrze nadają się dla sieci WAN, ale nie dla sieci LAN). Oprogramowanie, które musi uwzględniać te różnice, zazwyczaj wyodrębnia się z całego pakietu oprogramowania sieciowego w postaci małych modułów. Oznacza to, że dla oprogramowania, różnica między sieciami LAN i WAN staje się coraz mniej ważna.
Inny sposób podziału sieci na dwie grupy opiera się na prawie własności do wewnętrznej techniki realizacji sieci. Może ona być publiczna lub być w posiadaniu pewnej korporacji. Sieć pierwszego typu nazywa się siecią otwartą, a sieć drugiego typu siecią zamkniętą lub siecią prawnie zastrzeżoną. Internet jest systemem otwartym. Komunikację przez Internet realizuje się za pomocą otwartego zestawu standardów znanych jako pakiet protokołów TCP/IP, który omówimy w następnym punkcie. Dla odmiany, Novell Inc. jest głównym dostawcą oprogramowania sieciowego, które sam opracowuje, zastrzegając sobie do niego prawa. Zatem systemy instalowane i utrzymywane przez firmę Novell są systemami zamkniętymi.
Jeszcze inna klasyfikacja sieci jest oparta na konfiguracji połączeń sieciowych, czyli na sposobie połączenia poszczególnych komputerów ze sobą. Na rysunku 3.10 przedstawiono cztery popularne konfiguracje: (1) pierścień, w którym komputery są połączone w okrąg, (2) magistrala, gdzie komputery są przyłączone do wspólnej linii komunikacyjnej, zwanej magistralą, (3) gwiazda, w której jeden komputer pełni rolę węzła centralnego (huba), do którego są przyłączone wszystkie pozostałe maszyny i (4) połączenie nieregularne, kiedy nie stosuje się żadnego systematycznego sposobu łączenia komputerów. Konfiguracje nieregularne są powszechne w sieciach WAN, a konfiguracje pierścienia i gwiazdy spotyka się zazwyczaj w środowiskach lokalnych; za architekturę sieci w takich środowiskach często odpowiada tylko jeden nadzorca.
Internet
Jeśli połączymy wiele istniejących sieci, otrzymamy sieć sieci, zwaną inter-siecią (ang. internet). Najważniejszym przykładem takiej sieci jest Internet (zwracamy uwagę na pisownię przez wielkie I), którego początkiem był program naukowy rozpoczęty w 1973 roku przez agencję DARPA. Program
152 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
miał na celu opracowanie sposobu łączenia ze sobą różnorodnych sieci komputerowych, tak aby mogły one działać jak jedna niezawodna sieć. Obecnie Internet jest kombinacją o światowym zasięgu sieci WAN i LAN, w której znajdują się miliony komputerów. Każda sieć w Internecie jest połączona z inną siecią za pomocą komputera zwanego ruterem. Oznacza to, że ruter jest komputerem należącym do dwóch sieci, który umożliwia przekazywanie komunikatów z jednej sieci do drugiej1.
1 Oprócz terminu ruta w użyciu jest termin brama (ang. gateway). Tego drugiego terminu używa się jednak zazwyczaj w odniesieniu do połączeń bardziej złożonych niż te realizowane za pomocą rutera. Brama to często komputer łączący dwie intersieci, w których stosuje się różne protokoły. Komputer łączący Internet z siecią zamkniętą nazwalibyśmy zatem właśnie bramą.
3.5. SIECI
153
Adresy w Internecie
Na Internet można patrzeć jak na pewien zestaw skupisk sieci. Każde takie skupisko nazywa się domeną (ang. domain); zobacz rysunek 3.11. Zazwyczaj składa się ona z tych sieci, które działają w obrębie jednej instytucji, na przykład w obrębie uniwersytetu, firmy czy instytucji rządowej. Każda domena jest systemem autonomicznym, który konfiguruje się zgodnie z wymaganiami lokalnych władz. Może to być nawet globalny zbiór sieci WAN. Adres każdego komputera w Internecie jest 32-bitowym ciągiem złożonym z dwóch części: części identyfikującej domenę, w której znajduje się komputer, i części identyfikującej konkretny komputer w obrębie tej domeny. Część adresu określająca domenę, czyli identyfikator sieci (ang. ne-twork identifier) jest przydzielana i rejestrowana przez InterNIC (Internet Network Information Center) w chwili tworzenia domeny. Rejestracja
Domena
Sieci lokalne zgrupowane w domeny
■MS
154 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
InterNIC założono w 1993 roku, gdy National Science Foundation ustaliła z trzema firmami (AT&T, General Atomics oraz Network Solutions) przejęcie odpowiedzialności za czynności związane z Internetem, takie jak obsługa rejestracji domen i zarządzanie bazami danych potrzebnymi do identyfikacji domenowych serwerów nazw w Internecie. Uprzednio rejestracją domen zajmowało się Defense Information Systems Agency Network Information Center (DISA NIC). Te pierwotne kontrakty już się zakończyły i przyszłe struktury „ciała zarządzającego" Internetem są przedmiotem rozmów. Podstawowy argument to to, że Internet nie jest już związany z badaniami naukowymi i nie powinien już pozostawać pod auspicjami National Science Foundation. National Science Foundation finansuje obecnie rozwój systemu Internet 2, przeznaczonego dla społeczności naukowej. Rejestrację domen internetowych w dalszym ciągu obsługuje Network Solutions. Więcej na temat procesu rejestracji można znaleźć na stronie WWW http://internic.net
I
INTERNIC
zapewnia, że każda domena w Internecie ma unikatowy identyfikator sieci. Część adresu, która określa konkretną maszynę w obrębie domeny jest nazywana adresem hosta (termin host, oznaczający w języku angielskim gospodarza, stosuje się powszechnie w odniesieniu do komputera znajdującego się w sieci. W ten sposób podkreśla się jego rolę gospodarza dla zleceń nadchodzących od innych maszyn). Tę część adresu określają władze lokalne domeny; zazwyczaj jest to osoba, która pełni funkcję administratora sieci lub administratora systemu. Identyfikator sieciowy spółki wydawniczej Addison Wesley Long-man to na przykład 192.207.177 (tradycyjnie identyfikatory sieciowe zapisuje się w notacji dziesiętnej z kropkami; por. ćwiczenie 8 w podrozdziale 1.4). Z kolei pewien komputer w tej domenie może mieć adres 192.207.177.133, przy czym ostatni bajt jest adresem hosta.
Adresy zapisywane w postaci ciągów bitów są mało czytelne dla człowieka. Z tego powodu InterNIC przydziela także każdej domenie unikatowy adres mnemoniczny, nazywany nazwą domeny (ang. domain name). Władze lokalne domeny mogą swobodnie rozszerzać tę nazwę, tworząc nazwy dla poszczególnych komputerów znajdujących się w domenie. Przykładowo nazwą domeny dla wydawnictwa Addison Wesley Longman jest awl. com. Komputer w obrębie tej domeny może mieć na przykład nazwę ssenterprise.awl.com.
Notacja kropkowa stosowana w adresach mnemonicznych nie ma żadnego związku z notacją kropkową używaną do reprezentacji adresów w postaci ciągów bitów. Poszczególne części w notacji mnemonicznej określają położenie komputera w hierarchicznym systemie klasyfikacji. W szczególności adres ssenterprise.awl.com określa komputer o nazwie ssenterprise znajdujący się w instytucji awl, która jest organizacją komercyjną com. (Oprócz klasy com jest wiele klasyfikatorów domen, w tym: edu dla instytucji edukacyjnych, gov dla instytucji rządowych, org dla ogólnie pojętych organizacji). Władze lokalne wielkich domen mogą podjąć decyzję o ich podziale na poddomeny. Wtedy adres mnemoniczny komputera w domenie jest dłuższy. Przypuśćmy, że Uniwersytet Znikąd ma przydzieloną nazwę uz.edu i że zdecydowano się podzielić tę domenę na poddomeny. Wtedy komputer na tym uniwersytecie może mieć adres r2d2 . compsc. uz . edu, który oznacza,
3.5. SIECI
155
że komputer r2d2 znajduje się w poddomenie compsc domeny uz w obrębie klasy edu domen organizacji edukacyjnych.
Aby umożliwić przesyłanie komunikatów między indywidualnymi użytkownikami Internetu (za pomocą systemu o nazwie e-mail, skrót od electronic mail - poczta elektroniczna), władze lokalne przyznają każdemu uprawnionemu użytkownikowi adres elektroniczny w domenie. Taki adres składa się z ciągu znaków identyfikującego użytkownika, po którym umieszcza się symbol @ oraz nazwę komputera przeznaczonego do wykonywania czynności związanych z obsługą poczty elektronicznej w tej domenie. Zatem przykładowy adres elektroniczny użytkownika w Addison Wesley Longman może wyglądać tak: wshakespeare@mailroom.awl.com. Innymi słowy komputer mailroom w domenie awl.com zajmuje się obsługą poczty użytkownika wshakespeare.
Władze lokalne domeny odpowiadają za utrzymywanie spisu adresów mnemonicznych i odpowiadających im numerycznych adresów interneto-wych komputerów w domenie. Taki spis implementuje się na wyznaczonym do tego celu komputerze-serwerze, zwanym serwerem nazw (ang. name server). Komputer ten obsługuje zlecenia dotyczące udzielenia informacji o adresach. Wszystkie serwery nazw w całym Internecie tworzą razem system adresowy tłumaczący nazwy mnemoniczne na ich numeryczne odpowiedniki. W szczególności, gdy ktoś zleci wysłanie komunikatu pod adres podany w postaci mnemonicznej, to powyższy system serwerów nazw przekształci ten adres mnemoniczny do odpowiedniej postaci bitowej, zrozumiałej dla oprogramowania Internetu. Zazwyczaj zadanie to realizuje się w ułamku sekundy.
Gdy pewna organizacja podejmie decyzję o przyłączeniu do Internetu, może stać się albo częścią istniejącej domeny, albo poszukać miejsca w Internecie, w którym może umieścić ruter i ustanowić własną domenę. Zaletą ustanowienia własnej domeny jest to, że organizacja sama zarządza swoimi zasobami i nie podlega nadzorowi innej organizacji. Aby ustanowić nową domenę, należy dokonać rejestracji w InterNIC i uzyskać identyfikator sieciowy i nazwę domeny.
Indywidualni użytkownicy uzyskują zazwyczaj dostęp do Internetu, stając się członkami pewnej organizacji z własną domeną. Firmy, zwane dostawcami Internetu (ang. Internet access providers), oferują dostęp do Internetu na zasadach komercyjnych. Takie spółki, po ustanowieniu swoich domen w Internecie, umieszczają na swoich komputerach oprogramowanie, które umożliwia klientom uzyskanie połączenia telefonicznego. Za pomocą takiego połączenia klient uzyskuje dostęp do tych usług internetowych, które zamówił. Wielu dostawców Internetu oferuje także przyłącza do Internetu tym organizacjom, które chcą ustanowić własne dziedziny.
WWW - World Wide Web
Internet nie tylko daje możliwość komunikacji za pomocą poczty elektronicznej, ale także staje się metodą rozpowszechniania dokumentów multi-
156 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
medialnych złożonych z hipertekstu (ang. hypertext). Hipertekst jest tekstem zawierającym słowa, zdania lub obrazy, które są dowiązane do innych dokumentów. Czytelnik dokumentu hipertekstowego, jeśli sobie tego życzy, może uzyskać dostęp do dowiązanych dokumentów, zazwyczaj za pomocą myszy lub klawiatury. Przypuśćmy na przykład, że zdanie „Wykonanie Bolera Maurice'a Ravela było wspaniałe" pojawia się w dokumencie hipertekstowy m i że nazwisko Maurice Ravel jest dowiązane do innego dokumentu zawierającego informacje o kompozytorze. Czytelnik może obejrzeć ten dodatkowy materiał, klikając myszką na tekst Maurice Ravel. Jeśli tylko ustanowiono odpowiednie dowiązania, Czytelnik może także posłuchać nagrania, wybierając słowo Bolero.
WYSZUKIWARKI
W ten sposób, czytając dokument hipertekstowy, można przeglądać związane z nim dokumenty lub przechodzić od jednego dokumentu do drugiego. W efekcie związywania ze sobą fragmentów wielu dokumentów tworzy się pajęczyna przeplecionych, związanych ze sobą informacji. Dokumenty wchodzące w skład takiej pajęczyny mogą znajdować się na różnych komputerach połączonych siecią. W ten sposób powstaje pajęczyna o zasięgu ogólnosieciowym. Pajęczyna, która powstała w Internecie, ma zasięg ogólnoświatowy i nazywa się World Wide Web.
Aby ułatwić zadanie wyszukiwania informacji w sieci WWW, niektóre organizacje założyły witryny WWW zwane „wyszuki-warkami" (ang. search engines). Użytkownicy Internetu mogą przeszukiwać tam wielkie bazy danych, zawierające dowiązania do stron w Internecie. Dokumenty klasyfikuje się w tych bazach danych na podstawie słów kluczowych. Aby zatem odnaleźć informacje o modelu T marki Ford, użytkownik może poprosić wyszukiwarkę o przeszukanie bazy danych w celu odnalezienia wystąpień stów kluczowych: „Ford", „model T", „samochody zabytkowe", „kolekcjonerzy samochodów" itp.
Informacje w bazach danych są gromadzone na dwa sposoby: za pomocą programów, zwanych czasem pająkami; (ang. spiders), które po prostu pełzają po sieci Web, przechodząc po dowiązaniach z jednej strony na drugą i przekazując informacje
odnalezionych stronach. Inny sposób polega na bezpośrednim
zawiadamianiu. Autor strony WWW może powiadomić zarządcę
wyszukiwarki i poprosić o zamieszczenie go w bazie danych.
Popularne wyszukiwarki to (choć nie tylko) AltaVista pod adre
sem http://www.altavista.com, Infoseek pod http:/infoseek.go.comWebcrawler pod adresem http://www.webcrawler.com.
Pakiety oprogramowania, które asystują czytelnikom hipertekstu w wędrówce po łączach hipertekstowych, można podzielić na dwie kategorie: programy, które pełnią funkcję klientów, i programy, które pełnią funkcję serwerów. Program-klient znajduje się na komputerze czytelnika. Jego zadaniem jest uzyskanie materiałów, których zażąda użytkownik oraz przedstawienie ich w pewien uporządkowany sposób. Klient definiuje interfejs użytkownika, który pozwala użytkownikowi przeglądać sieć. Z tego powodu programy te często nazywa się przeglądarkami lub przeglądarkami stron WWW (ang. brow-sers). Serwer hipertekstu znajduje się w komputerze zawierającym odczytywane dokumenty. Jego zadaniem jest udostępnianie dokumentów z komputera zgodnie z żądaniami klienta. Krótko mówiąc, użytkownik uzyskuje dostęp do dokumentów hipertekstowych, komunikując się z przeglądarką znajdującą się na jego komputerze. Przeglądarka z kolei realizuje żądania
3.5. SIECI
157
użytkownika, prosząc o ich realizację serwery hipertekstowe rozrzucone po całym Internecie.
Wśród dostępnych współcześnie przeglądarek są produkty rywalizujących ze sobą firm. Przeglądarki potrafią obsługiwać dokumenty dźwiękowe, zdjęcia i filmy. Tego typu dokumenty określa się czasem mianem hiperme-diów w celu odróżnienia ich od tradycyjnego hipertekstu.
Aby utworzyć dokument hipertekstowy, jest potrzebna możliwość ustanawiania dowiązań między dokumentami. Każdy dokument ma zatem unikatowy adres - jednorodny Iokalizator zasobu (ang. uniform resource locator; URL). Informacja zawarta w URL pozwala przeglądarce na skontaktowanie się z właściwym serwerem i zamówienie potrzebnego dokumentu. Typowy URL przedstawiono na rysunku 3.12. Czasem URL może nie określać dokumentu jawnie. Może zawierać jedynie nazwę protokołu i mnemoniczną nazwę komputera. W takich wypadkach serwer, znajdujący się na wskazanym komputerze, przekazuje z góry określony dokument, zwany często stroną domową (ang. home page). Najczęściej znajduje się w niej opis informacji dostępnych na komputerze. Takie skrótowe URL stanowią standardowy sposób kontaktowania się z organizacjami. Na przykład URL http://www.awl.com spowoduje połączenie ze stroną domową Addison Wesley Longman, Inc, która zawiera dowiązania do wielu innych dokumentów związanych z firmą i jej produktami.
158 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
Dokument hipertekstowy przypomina tradycyjny dokument tekstowy, gdyż tekst jest kodowany znak po znaku za pomocą kodów takich jak ASCII
lub Unikod. Różnica polega na tym, że dokument hipertekstowy zawiera także specjalne znaczniki, które opisują sposób wyświetlania dokumentu na ekranie monitora i zawierają informację o tym, które elementy dokumentu są dowiązywane do innych dokumentów. System znaczników nosi nazwę języka HTML (ang. Hypertext Markup Language). Autor strony WWW opisuje w języku HTML wszystkie informacje, jakie potrzebuje przeglądarka do wykonania swoich zadań.
PYTANIA I ĆWICZENIA
Co to jest sieć otwarta?
Co to jest ruter?
Jakie są elementy pełnego adresu internetowego komputera?
Co to jest URL i przeglądarka?
Jakie są wady przekazywania komunikatów tylko w jednym kierunku
w sieci LAN o konfiguracji pierścienia?
3.6. Protokoły sieciowe
Reguły, według których odbywa się komunikacja między różnymi składowymi systemu komputerowego, są nazywane protokołami. Termin ten podkreśla analogię z protokołami, które określają obowiązujące w społeczeństwie zasady kontaktów międzyludzkich. Protokoły stosowane w sieciach komputerowych definiują szczegóły wykonania każdej czynności, w tym sposób adresowania komunikatów, sposób przekazywania praw do transmisji komunikatów i sposób obsługi czynności związanych z upakowywaniem komunikatów przeznaczonych do transmisji i rozpakowywaniem otrzymanych komunikatów. Niniejsze rozważania zaczniemy od omówienia protokołów sterowania prawami maszyny do transmisji własnych komunikatów do sieci.
Sterowanie uprawnieniami do transmisji
Jeden ze sposobów koordynacji prawa do transmisji komunikatów to protokół token ring stosowany w sieciach o konfiguracji pierścienia. Zgodnie z tym protokołem, każdy komputer przekazuje komunikaty tylko w „prawo", a odbiera je tylko z „lewej strony", tak jak to przedstawiono na rysunku 3.13. Komunikat z jednego komputera do drugiego jest zatem przekazywany po sieci przeciwnie do ruchu wskazówek zegara aż do chwili, gdy dotrze do miejsca przeznaczenia. Gdy komunikat dochodzi do celu, komputer odbierający kopiuje go, zatrzymuje kopię dla siebie, a drugi egzemplarz przekazuje
3.6. PROTOKOŁY SIECIOWE 159
Pakiet protokołów TCP/IP jest zbiorem protokołów definiującym czte-ropoziomową hierarchię stosowaną w Internecie. Właściwie TCP (Transmis-sion Control Protocol) i IP (Internet Protocol) są nazwami jedynie dwóch protokołów z tego zestawu. Nazwanie całego zbioru pakietem TCP/IP jest zatem nieco mylące. Protokół TCP definiuje pewną wersję warstwy transportowej. Używamy słowa wersja, gdyż TCP/IP udostępnia dwa sposoby implementacji warstwy transportowej. Ten drugi sposób jest definiowany przez protokół UDP (User Datagram Protocol). Używając poprzedniej analogii, możemy powiedzieć, że przy wysyłaniu części dla klienta, mamy wybór między różnymi firmami spedycyjnymi, z których każda oferuje te same usługi podstawowe, ale z innymi specyficznymi dla danej firmy charakterystykami. Zatem w zależności od wymaganej jakości usługi, oprogramowanie z warstwy aplikacji może decydować, której warstwy transportowej użyje do przesłania danych: TCP czy UDP.
Są dwie podstawowe różnice między TCP a UDP. Pierwsza polega na tym, że warstwa transportowa, oparta na TCP, przed przesłaniem danych wysyła do warstwy transportowej w miejscu przeznaczenia komunikat informujący o zamiarze przesłania danych i identyfikujący oprogramowanie z warstwy aplikacji, które ma dane odebrać. Następnie oczekuje na potwierdzenie tego komunikatu i dopiero wówczas rozpoczyna przesyłanie segmentów komunikatu. Mówi się, że warstwa transportowa TCP przed wysłaniem danych ustanawia połączenie. Warstwa transportowa oparta na UDP nie ustanawia takiego połączenia. Wysyła ona po prostu dane pod podany adres i więcej się nimi nie zajmuje. Może się nawet okazać, że komputer, dla którego są przeznaczone dane, w danej chwili nie działa. Z tego powodu UDP nazywa się protokołem bezpołączeniowym.
Druga ważna różnica między TCP a UDP polega na tym, że warstwy transportowe TCP w miejscu nadania i przeznaczenia komunikatu ściśle ze sobą współpracują za pomocą potwierdzeń i retransmisji segmentów w celu uzyskania pewności, że wszystkie segmenty komunikatu szczęśliwie dotarty do miejsca przeznaczenia. Protokół TCP nazywa się zatem protokołem niezawodnym, podczas gdy UDP, który nie oferuje takiej usługi retransmisji, jest protokołem zawodnym. Nie oznacza to jednak, że UDP jest złym wyborem. Warstwa transportowa oparta na UDP jest bardziej potokowa niż warstwa transportowa TCP, zatem jeśli tylko aplikacja jest przygotowana na obsługę potencjalnych konsekwencji stosowania UDP, jest on lepszym wyborem.
Protokół IP jest standardem internetowym dla warstwy sieciowej. Gdy warstwa sieciowa IP przygotowuje pakiet do doręczenia do warstwy kanałowej, dołącza do niego wartość zwaną liczbą hopów (ang. hop counter) lub czasem przeżycia pakietu. Wartość ta jest ograniczeniem nałożonym na liczbę pośrednich przekazań pakietu w trakcie jego wędrówki przez Internet. Gdy warstwa sieciowa IP przekazuje pakiet dalej, zmniejsza o 1 wartość licznika. Dysponując taką dodatkową informacją, warstwa sieciowa może chronić Internet przed pakietami krążącymi w systemie bez końca. Chociaż dzień w dzień Internet się powiększa, licznik hopów o wartości 64 wystarczałaby pakiet odnalazł właściwą drogę przez labirynt sieci LAN, WAN i ruterów.
168 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
1
PYTANIA I ĆWICZENIA
Które warstwy w hierarchii oprogramowania Internetu wykorzystuje
się do przekazywania nadchodzących komunikatów dalej do innego
komputera?Na czym polega różnica między warstwą transportową opartą na
protokole TCP a warstwą transportową opartą na protokole UDP?W jaki sposób oprogramowanie zapewnia, że komunikaty nie krążą
w nieskończoność po Internecie?Dlaczego komputer w Internecie nie przechowuje kopii wszystkich
przepływających przez niego komunikatów?
3.7. Bezpieczeństwo
CERT - THE COMPUTER EMERGENCY RESPONSE TEAM
W listopadzie 1988 roku robak wprowadzony do Internetu spowodował znaczące szkody. W efekcie Agencja DARPA (Defense Advanced Research Projects Agency - Agencja ds. Badań Perspektywicznych Obrony) utworzyła grupę CERT (Computer Emer-gency Response Team - Grupa Reagowania w Nagłych Wypadkach Komputerowych), której siedzibą jest CERT Coordina-tion Center w Carnegie-Mellon University. CERT jest interneto-wym „strażnikiem" bezpieczeństwa. Do jego obowiązków należy analiza problemów związanych z bezpieczeństwem, wydawanie ostrzeżeń związanych z bezpieczeństwem i prowadzenie kampanii uświadamiających w celu zwiększenia bezpieczeństwa Internetu. CERT Ćoordination Center utrzymuje witrynę WWW pod adresem httpV/www.cert.org, na której umieszcza informacje o swoich działaniach.
Komputer przyłączony do Internetu staje się dostępny dla wielu potencjalnych użytkowników. Wiążą się z tym problemy, które można podzielić na dwie grupy; pierwsza dotyczy nieuprawnionego dostępu do informacji, druga wandalizmu. Jednym ze sposobów rozwiązywania problemu nieuprawnionego dostępu do informacji jest stosowanie haseł albo w celu kontroli dostępu do komputera, albo w celu kontroli dostępu do określonych danych. Niestety hasła można przechwycić na wiele sposobów. Niektórzy użytkownicy po prostu przekazują swoje hasła przyjaciołom; jest to praktyka o wątpliwej etyce. Poza tym czasem dochodzi do kradzieży haseł. Jeden ze sposobów kradzieży polega na wykorzystaniu luk w systemie operacyjnym i uzyskaniu zapisanych w nim informacji o hasłach. Inny sposób polega na napisaniu programu, który symuluje proces rejestrujący na komputerze lokalnym. Użytkownicy sądząc, że porozumiewają się z systemem operacyjnym, wprowadzają swoje hasła, które program skwapliwie zapamiętuje. Jeszcze inna metoda zdobycia hasła polega na podaniu jakiegoś narzucającego się hasła i sprawdzeniu, czy zadziała. Użytkownicy, którzy boją się,
3.7. BEZPIECZEŃSTWO
169
że zapomną swoje hasło, stosują często swoje imiona lub nazwiska jako hasło. Popularne są także daty, na przykład data urodzenia.
W celu udaremnienia wysiłków tych, którzy bawią się w taką zgadywankę, systemy operacyjne projektuje się tak, aby informowały o próbach rejestracji w systemie za pomocą niepoprawnego hasła. Wiele systemów operacyjnych podaje także po rozpoczęciu nowej sesji informacje, kiedy ostatnio korzystano z konta. Dzięki temu użytkownicy mogą wykrywać nieuprawnione użycie ich konta. Bardziej wyrafinowany sposób obrony przed poławiaczami haseł polega na tym, że w razie podania niepoprawnego hasła system operacyjny udaje, że rejestracja się powiodła (nazywa się to bocznym wejściem, ang. tmpdoor) i kontynuuje działanie, próbując namierzyć włamywacza.
Innym sposobem ochrony danych przed nieuprawnionym dostępem jest szyfrowanie danych - wtedy nawet w wypadku zdobycia danych przez włamywacza, są one bezpieczne. Opracowano wiele różnych technik szyfrowania. Jednym z popularnych sposobów szyfrowania komunikatów przesyłanych w sieci jest szyfrowanie z kluczem publicznym (ang. public-key en-cryption). Umożliwia on wielu nadawcom bezpieczne wysyłanie komunikatów do centralnego odbiorcy. Szyfrowanie z kluczem publicznym wymaga użycia dwóch wartości zwanych kluczami. Jeden klucz, zwany kluczem publicznym, stosuje się do kodowania wiadomości. Jest on znany wszystkim uprawnionym do tworzenia komunikatów. Drugi klucz, zwany kluczem prywatnym, jest potrzebny do odszyfrowania komunikatu. Jest on znany tylko osobie, która ma odebrać komunikat. Do odszyfrowania komunikatów nie wystarcza znajomość klucza publicznego. Nie ma zatem problemu, gdy dostanie się on w niepowołane ręce. Niepowołana osoba będzie mogła wprawdzie tworzyć komunikaty, ale nie będzie w stanie odszyfrować przejętych komunikatów. Znajomość klucza prywatnego daje oczywiście większe możliwości, ale jest on z definicji lepiej zabezpieczony, gdyż zna go tylko jedna osoba. Pewnym konkretnym systemem z kluczem publicznym zajmiemy się w rozdziale 11.
Jest także wiele prawnych problemów związanych z nieuprawnionym dostępem do informacji. Niektóre z nich dotyczą ustalenia, kto jest stroną uprawnioną, a kto nieuprawnioną. Na przykład, czy pracodawca jest uprawniony do monitorowania komunikacji między pracownikami? W jakim stopniu dostawca Internetu jest uprawniony do dostępu do informacji przesyłanych przez jego klientów? W jakim stopniu dostawca Internetu jest odpowiedzialny za treść komunikatów wysyłanych przez swoich klientów? Tego rodzaju pytania stanowią wyzwanie dla środowisk prawniczych.
W Stanach Zjednoczonych wiele z tych problemów rozwiązano w dokumencie o nazwie Electronic Communication Privacy Act (ECPA - Ustawa o ochronie komunikacji elektronicznej) z 1986 roku. Ma on swoje źródła w procesie legislacyjnym dotyczącym kontroli podsłuchu. Chociaż ustawa jest długa, jej zakres został ujęty w kilku krótkich akapitach. W szczególności głosi ona, że:
170 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
Jeśli nie określono tego inaczej w niniejszym rozdziale, każdy, kto celowo przechwytuje, usiłuje przechwycić lub zmusza inne osoby do przechwycenia lub usiłowania przechwycenia jakichkolwiek treści słownych, elektronicznych lub telegraficznych podlega karze określonej w podrozdziale (4) lub postępowaniu sądowemu określonemu w podrozdziale (5).
oraz
. ..osobie lub jednostce oferującej publiczne usługi w zakresie komunikacji elektronicznej nie wolno celowo wyjawiać treści komunikatów ... przekazywanych w tej usłudze nikomu oprócz adresata komunikatu lub zamierzonemu jego odbiorcy, lub też przedstawicielowi adresata bądź odbiorcy...
W skrócie, ECPA potwierdza prawo jednostki do prywatności komunikacji: podsłuchiwanie komunikatów przez osoby nieuprawnione oraz przekazywanie przez dostawcę sieci informacji o komunikatach jego klientów jest nielegalne. Cytowany akt mówi jednak także:
Nie jest jednak bezprawnym ... przechwycenie komunikatu telegraficznego lub elektronicznego oraz słownego, transmitowanego radiowo, a także ujawnienie i wykorzystanie uzyskanej w ten sposób informacji przez oficera, urzędnika lub przedstawiciela zatrudnionego przez Federal Communications Commission (Federalna Komisja Komunikacji), wykonującego obowiązki służbowe zgodnie z rozdziałem 5, ustęp 47 United States Code.
Zatem ECPA daje Federal Communications Commission (FCC) prawo do monitorowania komunikacji z pewnymi jednak ograniczeniami. Prowadzi to do skomplikowanych problemów. Przede wszystkim, aby FCC mogło wyegzekwować prawa wynikające z ECPA, system komunikacyjny musi zostać tak skonstruowany i zaprogramowany, aby można było nadzorować komunikację. Udostępnienie tych możliwości było celem CALEA (Communications Assistance Law Enforcement Act). Wymagał on od firm telekomunikacyjnych takiego zmodyfikowania sprzętu, aby podsłuch wymuszany przez prawo był możliwy. Jednakże wprowadzenie tego aktu w życie okazało się skomplikowane i drogie, co spowodowało przedłużenie czasu jego wprowadzania w życie.
Bardziej kontrowersyjny problem dotyczy sprzeczności między prawem FCC do nadzoru komunikacji a prawem do szyfrowania komunikatów. Jeśli komunikat jest dobrze zaszyfrowany, to jego przechwycenie przez uprawnione organy jest bez wartości. Z tego powodu rząd Stanów Zjednoczonych próbuje utworzyć system rejestracji, który wymuszałby rejestrację kluczy (albo kluczy do kluczy). Żyjemy jednak w świecie, w którym wywiad gospodarczy stał się tak ważny jak wywiad wojskowy. Zrozumiałe jest zatem,
3.7. BEZPIECZEŃSTWO
171
że wymóg rejestracji kluczy wywoła niezadowolenie wielu praworządnych obywateli. Czy taki rejestr będzie odpowiednio zabezpieczony? Pytania tego rodzaju powstają nie tylko w Stanach Zjednoczonych. Wprowadzenie podobnych systemów rejestracji rozważa się także w Kanadzie i Europie.
Problem wandalizmu widać na przykładzie wirusów komputerowych i robaków sieciowych. W ogólności wirus jest segmentem programu, który dokleja się do innych programów w systemie. Wirus może na przykład przyczepić się na początek programu znajdującego się już w systemie i wykonywać się za każdym razem, gdy system realizuje ten program. Wirus może wykonywać złośliwe działania, które są łatwo zauważalne lub po prostu szukać innych programów, do których dołącza kopie samego siebie. Gdy zarażony program zostanie przeniesiony na inny komputer albo za pomocą sieci, albo za pomocą dyskietki, wirus zaczyna zarażać programy znajdujące się na tym komputerze zaraz po wykonaniu na nim zarażonego programu. W ten sposób wirusy przenoszą się między komputerami. Czasem wirusy rozpowszechniają się na inne programy, a gdy wystąpi pewien konkretny warunek (na przykład konkretna data) dokonują aktów wandalizmu. Taka metoda zwiększa prawdopodobieństwo rozpowszechnienia się wirusa na wiele komputerów, zanim zostanie wykryty.
Termin robak (ang. worm) oznacza niezależny program, który rozpowszechnia się w sieci, zadomawiając się w komputerze i transmitując własne kopie po sieci. Tak jak w przypadku wirusów, robaki po prostu powielają się lub dokonują aktów wandalizmu.
W miarę wzrostu popularności sieci niebezpieczeństwo zniszczeń wynikających z nieuprawnionego dostępu do informacji i wandalizmu rośnie. Prowadzi to do powstania wielu pytań dotyczących umieszczania kluczowych informacji w komputerze podpiętym do sieci, odpowiedzialności związanej z umieszczeniem w niej niedostatecznie zabezpieczonych informacji i odpowiedzialności za wandalizm. Z kolei pytania natury etycznej i prawnej związane z tą problematyką zdają się prowadzić do intensywnych debat w przyszłości.
PYTANIA I ĆWICZENIA
Technicznie termin dane oznacza reprezentację informacji, a informacja
to treści znaczeniowe. Czy stosowanie haseł chroni dane czy informa
cje? Czy szyfrowanie chroni dane czy informacje?Jakie są najważniejsze postanowienia ECPA?
CALEA pokazuje, że wydanie aktu prawnego wymuszającego wpro
wadzenie pewnych zmian nie zawsze załatwia sprawę. Wyjaśnij dla
czego.
172 ROZDZIAŁ TRZECI SYSTEMY OPERACYJNE I SIECI
PYTANIA DO ROZDZIAŁU TRZECIEGO
(Zadania oznaczone gwiazdką dotyczą rozdziałów opcjonalnych)
Wymień cztery zadania typowego sys
temu operacyjnego.Opisz krótko różnice między przetwa
rzaniem wsadowym a interakcyjnym.Na czym polega różnica między prze
twarzaniem interakcyjnym a przetwa
rzaniem w czasie rzeczywistym?Co to jest wielozadaniowy system ope
racyjny?Jaka informacja znajduje się w tablicy
procesów przechowywanej przez sys
tem operacyjny?Czym różni się proces gotowy od pro
cesu oczekującego?Na czym polega różnica między pamię
cią wirtualną a pamięcią główną?Jakie problemy mogą powstać w syste
mie z podziałem czasu, jeśli dwa pro
cesy żądają dostępu do tego samego
pliku w tym samym czasie? W jakich
okolicznościach zarządca plików powi
nien pozwalać na taki dostęp, a w ja
kich powinien odmawiać?Zdefiniuj pojęcia równoważenia obcią
żeń i skalowania w kontekście architek
tury wieloprocesorowej.
Opisz proces ładowania początkowego.
Przypuśćmy, że kwanty w systemie
z podziałem czasu trwają 50 milise
kund. Jaką część kwantu spędzałby
proces, oczekując na wykonanie ope
racji wejścia z dysku przy założeniu, że
ustawienie głowicy nad żądaną ścieżką
trwa 8 milisekund, a czas oczekiwania,
aż żądane dane znajdą się pod głowicą,
trwa dodatkowe 17 milisekund. Ile rozkazów można by wykonać w tym czasie, przy założeniu, że komputer wykonuje jeden rozkaz na mikrose-kundę? (Z tego właśnie powodu w systemach z podziałem czasu zazwyczaj pozwala się wykonywać innemu procesowi w czasie, gdy aktualnie wykonywany proces musi poczekać na usługi urządzenia peryferyjnego).
Wymień pięć zasobów, do których do
stęp musi być koordynowany przez
system wielozadaniowy.Mówi się, że proces jest związany wej-
śdem-wyjściem (I/O-bound), jeśli wy
konuje dużo operacji wejścia-wyjścia.
Proces, który wykonuje głównie obli
czenia, to proces związany obliczeniami
(compute-bound). Przypuśćmy, że za
równo proces związany wejściem-wyj-
ściem, jak i proces związany oblicze
niami oczekują na kwant czasu. Który
z nich powinien mieć priorytet? Dlaczego?
Kiedy uzyskamy większą przepusto
wość w systemie z podziałem czasu,
w którym wykonują się dwa procesy;
czy jeśli oba procesy są związane wej-
ściem-wyjściem (por. poprzednie zada
nie), czy jeśli jeden z nich jest związany
wejściem-wyjściem, a drugi oblicze
niami? Dlaczego?Opracuj zestaw instrukcji dla dyspo
zytora (modułu ekspediującego), który
pokieruje jego pracą po zakończeniu
kwantu przeznaczonego dla procesu.Określ elementy stanu procesu.
PYTANIA DO ROZDZIAŁU TRZECIEGO
173
konwencje dotyczące graficznej organizacji programu na stronie za pomocą wcięć, konwencje nazewnicze, które umożliwiają odróżnienie nazw zmiennych, starych, obiektów, klas itp. oraz zasady sporządzania dokumentacji, które zapewniają, że wszystkie programy są wystarczająco udokumento^ wane. Przyjęcie takich konwencji prowadzi do jednorodności w całym oprogramowaniu produkowanym przez firmę, co w efekcie upraszcza proces jego pielęgnaqi.
Innym elementem dokumentacji systemu jest pakiet dokumentów projektowych, opisujących specyfikację systemu i sposób zapewnienia tej specyfikacji. Tworzenie tej dokumentacji jest procesem, który rozpoczyna się na etapie analizy systemu i trwa przez cały czas tworzenia oprogramowania. Tu właśnie ujawnia się konflikt między zadaniami inżynierii oprogramowania a naturą ludzką. Jest bardzo prawdopodobne, że wstępna specyfikacja i wstępny projekt systemu zmienią się w trakcie procesu tworzenia programu. Pojawia się zatem pokusa, aby wprowadzać te zmiany bez uaktualniania wcześniejszych dokumentów projektowych. Efektem takiego działania jest wysokie prawdopodobieństwo tego, że dokumentaqa będzie nieprawidłowa i jej wykorzystanie jako dokumentacji końcowej będzie prowadzić do nieporozumień.
To właśnie jest kolejnym argumentem do stosowania narzędzi CASE. Dzięki nim zadanie ponownego narysowania diagramów i uaktualnienia słownika danych jest dużo łatwiejsze niż za pomocą starszych, ręcznych metod. W rezultacie łatwiej dokonywać uaktualnień, co zwiększa prawdopodobieństwo uzyskania dokładniejszej dokumentacji końcowej.
Na zakończenie chcemy podkreślić, że przykład z uaktualnianiem dokumentacji jest tylko jednym z wielu w sytuacjach, w których inżynieria oprogramowania musi borykać się z ludzką naturą. Inne dotyczą nieuniknionych konfliktów personalnych, zazdrości i konfliktów na tle osobowości, które powstają przy pracy zespołowej. Z tego powodu, jak już wspomnieliśmy, inżynieria oprogramowania obejmuje dużo więcej zagadnień niż te, które są bezpośrednio związane z informatyką.
PYTANIA I ĆWICZENIA
W jakiej postaci można dokumentować oprogramowanie?
W jakiej fazie (fazach) życia oprogramowania tworzy się jego doku
mentację?Co jest ważniejsze; program czy jego dokumentacja?
6.7. Prawo własności do oprogramowania i odpowiedzialność
Na ogół firma lub osoba fizyczna powinna mieć prawo do wynagrodzenia i czerpania korzyści z inwestycji poczynionych w wyprodukowanie oprogramowania wysokiej jakości. Bez środków ochrony tego prawa, tylko niewielu podjęłoby się zadania produkcji oprogramowania, na które jest zapotrzebowanie. Jednak pytania dotyczące własności oprogramowania i prawa własności często wymykają się dobrze ustanowionym prawom autorskim i patentowym. Te ustalenia prawne opracowano w celu umożliwienia producentom jakiegoś „produktu" jego publicznego udostępnienia przy ochronie ich praw własności. Charakterystyka oprogramowania wielokrotnie jednak stanowiła wyzwanie dla sądów, które do oprogramowania próbują stosować postanowienia prawa autorskiego i patentowego.
Prawo autorskie ustanowiono początkowo w celu ochrony praw autora do dzieła literackiego. W tym wypadku wartość produktu polega raczej na sposobie wyrażenia pewnych myśli, niż na wartości samych myśli. Wartość wiersza to jego rytm, styl i format, a nie przedmiot. Wartość powieści polega na sposobie, w jakim autor ją przedstawia, a nie na wartości samej opowieści. Zatem inwestycję poety lub powieściopisarza można chronić, uznając jego prawo do takiego sposobu wyrażenia myśli, a nie do samych myśli. Ktoś inny może wyrażać te same idee tak długo, jak długo sposób wyrażenia nie będzie wykazywał „istotnego podobieństwa" do oryginału.
W odróżnieniu od wiersza bądź powieści wartość oprogramowania nie leży zazwyczaj w konkretnym sposobie zapisu programu. Jest nią wyrażany tym programem algorytm (myśl). Zatem bezpośrednie stosowanie prawa autorskiego do oprogramowania nie gwarantuje jego twórcy ochrony inwestycji. Prawo autorskie zezwala na to, żeby algorytm, tworzony przez jego autora jako wynik dużych inwestycji, został wykorzystywany przez konkurentów, tak długo, jak długo jego reprezentacja nie jest zasadniczo podobna do oryginału.
Krótko mówiąc, prawo autorskie pomyślano tak, aby chronić formę, a nie funkcjonalność, ale wartość programu często polega na jego funkcjonalności, a nie na formie. W rezultacie prawo autorskie nadaje się lepiej do ochrony programów, które implementują dobrze znane, nieoryginalne algorytmy, niż do ochrony nowych algorytmów. Jeśli algorytm jest powszechnie znany, to jedyna wartość programu polega na jego wyrażeniu. Gdy jednak algorytm wyrażony programem jest nowy i twórczy, wówczas główną wartością programu jest algorytm, którego jednak nie chroni prawo autorskie. Jest to nieco paradoksalne: im więcej twórczego wysiłku wkłada się w produkcję programu, tym mniej prawo autorskie go chroni.
Próbując stosować prawo autorskie do oprogramowania, niektórzy wykorzystują pojęcie wyglądu i dotyku systemu oprogramowania. Chociaż sformułowania wygląd i dotyk nie stosowano do 1985 roku, korzenie tego
'
326 ROZDZIAŁ SZÓSTY INŻYNIERIA OPROGRAMOWANIA
6.7. PRAWO WŁASNOŚCI DO OPROGRAMOWANIA I ODPOWIEDZIALNOŚĆ
327
pojęcia sięgają do lat sześćdziesiątych, kiedy IBM wprowadził komputery z serii System/360. Seria ta składała się z różnych maszyn od zaprojektowanych dla małych przedsiębiorstw do dużych komputerów dla przedsiębiorstw o wielkich potrzebach. Wszystkie te komputery miały system operacyjny, który porozumiewał się z otoczeniem w mniej więcej ten sam sposób. Zatem cała seria komputerów miała ten sam standardowy interfejs z użytkownikiem. Dzięki temu przedsiębiorstwo, powiększając się, mogło przejść na większe maszyny z serii 360 bez wysiłku związanego z koniecznością wprowadzenia nowego oprogramowania i ponownym szkoleniem personelu. Istotnie, wygląd (oznaczający sposób postrzegania oprogamowa-nia systemowego) oraz dotyk (oznaczający sposób interakcji użytkownika z systemem) były takie same dla wszystkich maszyn serii 360.
Zalety standardowych interfejsów są współcześnie dobrze znane i można je odnaleźć w szerokim spektrum oprogramowania. Gdy jakiś interfejs zaprojektowany przez pewną firmę staje się popularny, rywalizującym firmom opłaca się tak projektować systemy, aby wyglądały i zachowywały się jak ten dobrze znany. To podobieństwo ułatwia użytkownikom dobrze znanego systemu przenieść się na systemy konkurencyjne, nawet jeśli wewnętrzna budowa tych systemów jest zupełnie inna. Firmy, które stanęły w obliczu takich praktyk, szukały sposobu ochrony swoich praw, domagając się praw autorskich do wyglądu i dotyku oryginalnych systemów. Te pojęcia przypominają właściwości chronione prawem autorskim.
Pierwszym sprawdzianem argumentacji opartej na wyglądzie i dotyku był proces wytoczony w 1987 roku firmie Mosaic Software przez Lotus De-velopment Corporation, która twierdziła, że pozwana firma wykorzystała wygląd i dotyk arkusza kalkulacyjnego Lotus 1-2-3. Proces zakończył się powodzeniem. We współczesnych przypadkach argumenty oparte na wyglądzie i dotyku przynoszą różne efekty.
Próby stosowania prawa patentowego do ochrony prawa własności do oprogramowania także napotykają problemy. Jedną z przeszkód jest stara zasada, że nikt nie może być właścicielem bytu naturalnego, takiego jak prawa fizyki, formuły matematyczne i myśli. Sądy z reguły stwierdzają, że algorytmy należą do tej kategorii. Zatem tak jak prawo autorskie, prawo patentowe zdaje się nie chronić głównego elementu stanowiącego o wartości programu: algorytmu. Ponadto, uzyskanie patentu jest procesem długotrwałym i kosztownym, często wymagającym wielu lat. W tym czasie oprogramowanie może stać się przestarzałe i, aż do chwili przyznania patentu, starający się o niego ma niewielkie środki ochrony przed przywłaszczeniem sobie przez innych jego produktu. Były jednak przypadki przyznania patentów algorytmom. Przykładem jest algorytm szyfrowania zwany RSA, który bardzo często wykorzystuje się w wielu współczesnych systemach szyfrowania z kluczem publicznym.
Prawo autorskie i prawo patentowe stworzono, aby umożliwić, a nawet zachęcać do rozpowszechniania inwencji, i aby wspierać wolną wymianę myśli dla dobra społeczeństwa. Kryło się za tym rozumowanie, że gdy prawo własności będzie chronione, to twórcy i wynalazcy chętniej będą publicznie
ujawniali swoje osiągnięcia. Odwrotnie, prawo o tajemnicy handlowej stanowi sposób ograniczenia rozpowszechniania idei. Powstało w celu zapewnienia etycznego postępowania rywalizujących firm. Prawo to chroni przed wyjawianiem lub bezpodstawnym przywłaszczaniem sobie wewnętrznych osiągnięć firmy. Firmy często próbują chronić swoje tajemnice handlowe za pomocą pisemnych umów, zgodnie z którymi pracownicy mający dostęp do tajemnic firmy nie mogą przekazywać swojej wiedzy innym. Sądy na ogół uznają moc prawną takich umów.
Aby uchronić się przed odpowiedzialnością, producenci oprogramowania często dołączają do swoich produktów klauzulę, w której ograniczają swoją odpowiedzialność. Stwierdzenia postaci: „Firma X nie ponosi odpowiedzialności za skutki użycia tego oprogramowania" są powszechne. Sądy jednak rzadko uznają takie klauzule, jeśli powód wykaże niedbałość pozwanego. Tego rodzaju postępowania koncentrują się na tym, czy pozwany wykazał dbałość na poziomie właściwym dla produkowanego produktu. Poziom dbałości, który może zostać uznany za właściwy w przypadku systemu przetwarzania tekstów, może zostać uznany za zaniedbanie w przypadku oprogramowania sterującego reaktorem atomowym. Zatem najlepszą obroną przeciwko oskarżeniom związanym z odpowiedzialnością jest właściwe podejście do procesu wytwórstwa oprogramowania.
PYTANIA I ĆWICZENIA
Jak można sprawdzić, czy jeden program wykazuje istotne podobień
stwo do drugiego?W jaki sposób społeczeństwo korzysta z prawa autorskiego, patento
wego i o tajemnicy handlowej?W jakim stopniu klauzule o nieponoszeniu odpowiedzialności nie są
uznawane przez sądy?
PYTANIA DO ROZDZIAŁU SZÓSTEGO
oprogramowania ma wpływ na inżynierię oprogramowania.
Czym różni się inżynieria oprogramo
wania od Innych tradycyjnych dziedzin
inżynierskich?(a) Podaj wady tradycyjnego modelu
kaskadowego procesu tworzenia oprogramowania.
(b) Podaj zalety tradycyjnego modelu kaskadowego procesu tworzenia oprogramowania.
Podaj przykład ilustrujący fakt, że wy
siłek włożony w tworzenie oprogramo
wania może opłacić się w późniejszej
fazie pielęgnacji programu.Co to jest prototypowanie ewolucyjne?
W jaki sposób wykorzystanie narzędzi
CASE zmieniło proces produkcji opro
gramowania?Wyjaśnij, w jaki sposób brak metody
pomiaru pewnych właściwości
328
ROZDZIAŁ SZÓSTY INŻYNIERIA OPROGRAMOWANIA
PYTANIA DO ROZDZIAŁU SZÓSTEGO
329
materiały w postaci magnetycznej? Czy Twoja odpowiedź zmieniłaby się, gdyby ta osoba była pracownikiem uniwersyteckim, informacje zaś danymi o studentach? Czy Twoja odpowiedź zmieniłaby się, gdyby pracownik uzyskiwał dostęp do danych za pomocą łączy telefonicznych?
Przypuśćmy, że programista zrobił so
bie dowcip i dodał do każdego rekordu
w pliku z pracownikami dodatkowe
pole i umieścił w nim żartobliwe ko
mentarze. Czy stanie się jakaś szkoda,
jeśli tylko programista wie, jak odczytać
dodatkowe informacje?Gdy plik jest usuwany z dysku, zazwy
czaj nie jest on kasowany, ale po prostu
oznaczony jako skasowany. Informacja
LEKTURA UZUPEŁNIAJĄCA
Folk M.J., Zoellick B., Riccardi G.: File Structures -
An Object-Oriented Approach in C++, 3rd ed.
Reading, MA: Addison-Wesley, 1998. Kay D.C., Levine J.R.: Graphic File Formats, 2nd ed.
New York: McGraw-Hill, 1995. Mc Fredies P: Windows 98 Unleashed. Indianapolis,
IN: Sams, 1998.
może pozostawać na dysku jeszcze jakiś czas, zanim ta część dysku zostanie ponownie wykorzystana. Czy rekonstrukcja usuniętych plików, z których uprzednio korzystali inni, jest etyczna?
5. Jakie problemy etyczne powstałyby, gdyby główny producent oprogramowania zaprojektował oprogramowanie w taki sposób, aby w tajemnicy oznaczał każdy utworzony plik informacją o twórcy pliku? Na przykład producent oprogramowania na komputery osobiste może tak napisać program, aby nazwisko właściciela komputera dołączało się w tajemnicy do każdego pliku utworzonego na tym komputerze. W ten sposób taka informacja może podróżować razem z plikiem po Internecie.
Miller N.E., Petersen C.G.: File Structures with Ada.
Redwood City, Ca: Benjamin/Cummings,
1990. Shaffer C.A.: A Practical Introduction to Data
Structures and Algorithm Analysis. Upper
Saddle River, NJ: Prentice-Hall, 1998.
rozdział
BAZY DANYCH
dziewiąty
Dziedzina baz danych stanowi syntezę zagadnień związanych ze strukturami danych oraz strukturami plikowymi. W nowoczesnych bazach danych korzysta się z technik stosowanych w obu tych dyscyplinach informatyki. Bazy danych są więc systemami gromadzenia danych w pamięci masowej, które w zależności od potrzeb i zastosowań mogą przedstawiać te dane na wiele różnych sposobów. Takie struktury zapewniają systemy danych dla różnych zastosowań, bez konieczności powielenia danych występujących w podejściu opartym na plikach. W tym rozdziale zbadamy budowę systemów baz danych i kierunki obecnych badań.
Zagadnienia ogólne
Warstwowa
implementacja baz danychModel relacyjny
Projektowanie relacyjne
Operacje na relacjach
SQL
*9.4. Obiektowe bazy danych
*9.5. Zachowanie integralności bazy danych Protokół Commit/Rollback
(zatwierdzania
i wycofywania) Blokady
9.6. Społeczne skutki wprowadzenia baz danych
* Gwiazdki oznaczają sugestie co do opcjonalności podrozdziałów
414 ROZDZIAŁ ÓSMY STRUKTURY PLIKOWE
9.1. Zagadnienia ogólne
W odniesieniu do tradycyjnego systemu plików stosuje się czasem termin plik piaski w celu odróżnienia go od bazy danych. Plik płaski jest jednowymiarowym systemem przechowywania danych, gdyż przedstawia on informację z jednego punktu widzenia. Termin baza danych natomiast odnosi się do wielowymiarowej kolekcji danych. Ta wielowymiarowość polega na tym, że w bazie danych jest wiele wewnętrznych powiązań między elementami, tak że przechowywaną informację można prezentować z różnych perspektyw. O ile plik płaski zawierający informację o kompozytorach i ich dziełach stanowi jedynie listę dzieł uporządkowaną według ich kompozytorów, o tyle baza danych umożliwia odnalezienie wszystkich dzieł danego kompozytora, wszystkich kompozytorów, którzy tworzyli określony gatunek muzyki, a nawet kompozytorów, którzy tworzyli wariacje na temat dzieł innych kompozytorów.
Historycznie bazy danych powstały jako sposób zintegrowania systemów przechowywania danych. W miarę rozszerzania się zastosowań sprzętu komputerowego w dziedzinie zarządzania informacją, każdą aplikację implementowano jako oddzielny system z własnym zestawem danych. Zazwyczaj oprogramowanie procesu przygotowywania listy płac powodowało utworzenie pliku sekwencyjnego. Gdy później zaistniała potrzeba interakcyjnego odczytywania danych, powstawał zupełnie inny system, w którym stosowano plik indeksowy. Chociaż każdy z tych systemów stanowił ulepszenie poprzednio stosowanych metod ręcznych, jednak zestaw takich pojedynczych zautomatyzowanych systemów wykorzystywał zasoby w sposób bardzo ograniczony i nieefektywny w porównaniu z możliwościami zintegrowanego systemu bazodanowego. Różne działy tej samej firmy nie mogły na przykład współdzielić potrzebnych im informacji, więc większość informacji powielano w pamięci masowej. W efekcie, zmiana adresu zamieszkania pracownika powodowała konieczność modyfikacji danych w różnych oddziałach firmy. Pracownik, zmieniając adres, musiał wędrować po różnych działach firmy i wypełniać formularze zmiany adresu. Literówki, źle ulokowane formularze i apatia urzędników powodowały błędy i niezgodności w danych znajdujących się w różnych systemach. Zdarzało się, że po przeniesieniu pracownika przesyłano mu biuletyny na nowy adres, ale z nieprawidłowym nazwiskiem, a paski z wypłatami zawierały w dalszym ciągu stary adres. W takich właśnie okolicznościach wykształciły się systemy bazodanowe jako sposób integracji informacji przechowywanej i zarządzanej przez określoną organizację (rys. 9.1). W takim zintegrowanym systemie zarówno wypłaty, jak i przesyłanie biuletynów można było wykonywać, opierając się na danych pochodzących z jednego źródła.
Inną zaletą zintegrowanych systemów danych jest możliwość kontroli dostępu do posiadanych informacji umieszczonych we wspólnym miejscu. Dopóki każdy dział przedsiębiorstwa dysponował niezależnymi danymi,
wykorzystywano je w interesie konkretnego działu, a nie całego przedsiębiorstwa. Po wprowadzeniu zintegrowanej bazy danych w dużej firmie, kontrolę nad informacją ma administrator bazy danych. Stanowisko to może być piastowane przez jedną bądź kilka osób. Administrator wie, jakie dane są dostępne w firmie oraz zna potrzeby poszczególnych oddziałów. Można zatem podejmować decyzje dotyczące organizacji danych i kontrolować dostęp do nich, mając na uwadze strukturę całego przedsiębiorstwa.
Integracja danych oprócz zalet ma także wady. Jednym z problemów jest zapewnienie kontroli dostępu do ważnych danych. Na przykład osoba
416
ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.1. ZAGADNIENIA OGÓLNE
417
pracująca nad biuletynem firmy potrzebuje dostępu do nazwisk i adresów pracowników, ale nie powinna ona mieć dostępu do danych finansowych. Podobnie pracownik przygotowujący listę plac nie powinien mieć dostępu do innych danych finansowych korporacji. Możliwość kontroli dostępu do informacji zgromadzonych w bazie danych jest często tak samo ważna jak możliwość ich współdzielenia.
W celu zróżnicowania uprawnień dostępu do informacji w systemach baz danych często stosuje się schematy i podschematy. Schemat jest opisem całej struktury bazy danych, która jest wykorzystywana przez oprogramowanie zarządzające bazą. Podschemat jest opisem tego fragmentu bazy danych, który jest istotny z punktu widzenia konkretnego użytkownika. Dla przykładu przeanalizujmy schemat uniwersyteckiej bazy danych, w której każdy rekord opisujący studenta zawiera takie informacje jak aktualny adres, numer telefonu oraz informacje o postępach w nauce. W schemacie uwzględnia się także fakt, że każdy rekord opisujący studenta jest dowiązany do rekordu z informacjami o jego opiekunie naukowym. Z kolei rekord opisujący pracownika zawiera dane o jego adresie, historię zatrudnienia itd. Taki schemat oznacza istnienie systemu wskaźników, które związują informacje
0 studencie z historią zatrudnienia pewnego pracownika.
Aby sekcja rejestrująca studentów nie korzystała z istniejących w bazie powiązań i nie uzyskiwała zastrzeżonych informacji o pracownikach, jej dostęp do bazy danych musi zostać ograniczony do podschematu. Opis pracownika w tym podschemacie nie zawiera informacji o historii jego zatrudnienia. Użytkownik korzystający z takiego podschematu może stwierdzić, kto jest opiekunem danego studenta, ale nie ma dostępu do dodatkowych informacji o tym pracowniku. Dla odmiany, podschemat przeznaczony dla sekcji finansowej dostarcza informacji o historii zatrudnienia każdego pracownika, ale nie zawiera informacji o powiązaniach między studentami a ich opiekunami. Sekcja finansowa może zatem modyfikować informacje o wynagrodzeniu pracownika, ale nie może uzyskać informacji o studentach, którymi się on opiekuje.
Rozwój technik baz danych niesie ze sobą także inne niedogodności oprócz tych bezpośrednio związanych z bezpieczeństwem. Rozmiary
1 zakres baz danych zwiększają się szybko. Niewielkim wysiłkiem można
obecnie zebrać i analizować olbrzymie kolekcje danych rozproszonych na
wielkich obszarach geograficznych. Wzrost ilości informacji powoduje także
większą dezinformację i możliwość wykorzystywania Informacji do niewła
ściwych celów. Często dochodzi do niesprawiedliwości spowodowanej nie
poprawnymi informacjami kredytowymi, złymi informacjami w rejestrach
kryminalnych, a także do dyskryminacji na skutek nieetycznego lub nie
uprawnionego dostępu do informacji personalnych.
W innych sytuacjach pojawiają się problemy dotyczące praw do gromadzenia i przechowywania informacji. Jaki rodzaj informacji o swoich klientach może gromadzić firma ubezpieczeniowa? Czy rząd ma prawo przechowywać informacje o głosach oddawanych przez poszczególnych obywateli? Czy firma wydająca karty kredytowe ma prawo sprzedawać firmom mar-
ketingowym dane o strukturze zakupów dokonywanych przez klientów? Te pytania stanowią tylko niektóre z problemów, z którymi społeczeństwo musi się uporać w obliczu rozwoju technik baz danych.
PYTANIA I ĆWICZENIA
Podaj przykład dwóch działów zakładu produkcyjnego, które wyko
rzystują te same lub podobne informacje inwentarzowe do różnych
celów.Określ różne kolekcje danych występujące w środowisku uniwersytec
kim, które mogłyby znaleźć się w zintegrowanej bazie danych.Opisz, czym mogłyby się różnić podschematy dla działów zakładu
produkcyjnego z pytania 1.
9.2. Warstwowa implementacja baz danych
W celu ukrycia złożoności implementacji bazy danych system bazy danych konstruuje się za pomocą warstw o różnych poziomach abstrakcji (rys. 9.2). Obraz danych udostępniany osobie korzystającej z bazy danych jest tworzony przez warstwę aplikacji, która porozumiewa się z użytkownikiem w sposób interakcyjny, opierając się na konkretnym zastosowaniu. W dużej spółce oprogramowanie takie mogą pisać zatrudnieni w niej programiści. W mniejszych środowiskach oprogramowanie tej warstwy zazwyczaj się
418
ROZDZ1AL DZIRWIĄTY BAZY DANYCH
9.2. WARSTWOWA IMPLEMENTACJA BAZ DANYC11
419
ROZPROSZONE BAZY DANYCH
Jak wskazano w tekście, bazy danych były pierwotnie pomyślane jako sposób konsolidacji lub scentralizowania informacji. Bardziej nowoczesny punkt widzenia to traktowanie baz danych jako sposobu na zintegrowanie informacji, którą można przechowywać na różnych komputerach w sieci lub Internecie. Międzynarodowa korporacja może przechowywać dane o pracownikach lokalnych w lokalnych siedzibach albo połączyć te informacje za pośrednictwem sieci, tworząc rozproszoną bazę danych - jedną, dużą zintegrowaną bazę danych, która składa się z danych umieszczonych na różnych komputerach.
Rozproszona baza danych może zawierać podzielone na fragmenty i/lub powielone dane. Przykładem pierwszej możliwości jest wspomniana wyżej baza danych o pracownikach, w której różne fragmenty bazy znajdują się w różnych miejscach. W wypadku drugim kopie tych samych elementów bazy danych umieszcza się w różnych miejscach. Takie powielanie może służyć skróceniu czasu dostępu do danych. W obu wypadkach występują problemy, których nie ma w tradycyjnych systemach scentralizowanych - na przykład, jak ukryć rozproszoną naturę bazy danych, tak żeby działała jak jeden spójny system, albo jak zapewnić, że powielone fragmenty bazy danych staną się dalej swoimi dokładnymi kopiami po wykonaniu uaktualnienia. Rozproszone bazy danych są aktualnym tematem badań.
kupuje. Jest to pakiet oprogramowania czwartej generacji, które można dostosowywać do potrzeb użytkownika. Budowa tego oprogramowania nadaje charakter całemu systemowi. Może ono na przykład komunikować się z użytkownikiem za pomocą dialogu pytanie-i-odpowiedź lub formularzy wypełnianych na ekranie. Niezależnie od ostatecznie zastosowanego interfejsu użytkownika, oprogramowanie warstwy aplikacji porozumiewa się z użytkownikiem, dowiadując się, jakie informacje są mu potrzebne i później, po zdobyciu tych informacji, prezentuje je użytkownikowi w wygodnej dla niego postaci.
Zwróćmy uwagę na to, że nigdzie nie stwierdziliśmy, że warstwa aplikacji manipuluje informacjami w bazie danych. Właściwe operacje na danych wykonuje inna warstwa oprogramowania zwana systemem zarządzania bazą
danych (ang. databasc management sys
tem; DBMS). Taka dwudzielność ma
wiele zalet. Jedną z nich jest to, że roz
dzielenie obowiązków upraszcza pro
ces projektowania. Gdyby użytkow
nik stosujący aplikację do rozwiąza
nia pewnego problemu musiał roz
ważać kwestie związane z pojęciami
komputerowymi, wówczas jego zada
nie byłoby bardzo skomplikowane. Po
dobnie zadanie programisty kompli
kowałoby się, gdyby musiał on zaj
mować się także problemami związa
nymi z manipulacją danymi. Jest to
szczególnie widoczne w przypadku
rozproszonych baz danych (baz da
nych rozproszonych na wiele kompu
terów w sieci). Bez usług systemu za
rządzania bazą danych w programie
aplikacji musiałyby znaleźć się proce
dury do określania miejsca przecho
wywania różnych danych w bazie da
nych. Dysponując dobrze zaprojekto
wanym systemem zarządzania bazą
danych, aplikacje można pisać tak,
jakby baza danych znajdowała się na
jednym komputerze.
■^■^■HNMIIMBHnnnaMRBH Drugą zaletą oddzielenia opro-
gramowania aplikacji od systemu zarządzania bazą danych jest to, że taka
organizacja umożliwia kontrolę dostępu do bazy danych. Ponieważ każde odwołanie do bazy danych jest realizowane przez jeden system zarządzający, więc może on wymuszać ograniczenia narzucane przez różne podschematy. W szczególności system zarządzania bazą danych może korzystać z całego
schematu bazy danych, realizując swoje wewnętrzne zadania, ale pilnuje, aby każdy użytkownik pozostawał w granicach opisywanych przez pod-schemat dla tego użytkownika.
Jeszcze inną przyczyną oddzielenia interfejsu użytkownika od manipulacji danymi w postaci dwóch modułów programu jest uzyskanie niezależności danych. Polega ona na możliwości zmiany organizacji samej bazy danych bez konieczności wprowadzania zmian do aplikacji. Dział kadr może dodać do rekordu każdego pracownika dodatkowe pole, które określa, czy dany pracownik bierze udział w nowym programie ubezpieczeń zdrowotnych prowadzonym w firmie. Jeśli aplikacje odwoływałyby się bezpośrednio do bazy danych, to taka zmiana w formacie danych wymagałaby zmian we wszystkich korzystających z nich aplikacjach. W efekcie, zmiana wprowadzona w dziale kadr powodowałaby konieczność zmian w programie przygotowującym listę płac oraz w programie drukującym adresy na kopertach.
Oddzielenie aplikacji od systemu zarządzania bazą danych usuwa konieczność wykonywania takich zmian. Jeśli jakiś użytkownik wprowadza zmiany, to trzeba jedynie zmienić ogólny schemat i podschematy tych użytkowników, których zmiana dotyczy. Wszystkie pozostałe podschematy pozostają bez zmian, więc odpowiednie aplikacje wykonują się, tak jakby nic się nie zmieniło.
Ostatnią zaletą oddzielenia aplikaqi od systemu zarządzania bazą danych jest to, że dzięki temu można pisać aplikację, posługując się uproszczonym, koncepcyjnym spojrzeniem na bazę danych, bez wchodzenia w szczegóły rzeczywistej, złożonej struktury bazy i uwzględniania ścieżek dyskowych, wskaźników i przestrzeni zapasowych. Przypomnijmy, że omawiając struktury danych pokazaliśmy, jak za pomocą odpowiednich podprogramów przekształcać żądania (takie jak umieszczenie elementu na stosie i zdjęcie go z niego) wyrażane w terminach koncepcyjnej struktury (stosu) na odpowiednie czynności wykonywane na rzeczywistej organizacji danych w pamięci. System zarządzania bazą danych także zawiera podprogramy, które można wykorzystać w aplikacji jako narzędzia abstrakcyjne, przekształcające polecenia wyrażane w terminach pojęciowego spojrzenia na bazę danych, zwanego modelem bazy danych, na terminy związane z rzeczywistą organizacją bazy danych.
Aplikacje często pisze się w języku programowania ogólnego przeznaczenia, takim jak omówione w rozdziale 5. Język udostępnia podstawowe składniki do zapisu algorytmu, ale brak w nim operacji, które ułatwiają manipulowanie danymi. Podprogramy udostępniane przez system zarządzania bazą danych rozszerzają możliwości używanego języka (jak zobaczymy to w następnym punkcie) w sposób, który stwarza koncepcyjny obraz modelu bazy danych. Metoda polegająca na wykorzystaniu języka programowania ogólnego przeznaczenia jako podstawowego aparatu, do którego wprowadza się możliwości systemu zarządzającego bazą danych powoduje, że oryginalny język programowania nazwano językiem bazowym. (Wiele komercyjnych pakietów z systemami zarządzania bazami danych jest współcześnie połączeniem tradycyjnych systemów zarządzania bazami danych z pewnym
420
ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.2. WARSTWOWA IMPLEMENTACJA BAZ DANYCH
421
językiem bazowym. W efekcie oba te elementy zaczyna się traktować jako jedną całość, choć stanowią one różne pojęcia).
W celu opracowania aplikacji wykorzystującej pewną instalację bazy danych, programista musi zrozumieć narzędzia abstrakcyjne dostarczane przez używany przez niego system zarządzania bazą danych. W następnym podrozdziale postaramy się spojrzeć na relacyjny model bazy danych oczami programisty aplikacji. Jest to model udostępniany przez większość współczesnych systemów zarządzania bazami danych. Pozwala on na pisanie aplikacji, tak jakby dane w bazie danych były przechowywane w postaci tabel z wierszami i kolumnami.
Ciągle poszukuje się lepszych modeli baz danych. Celem jest opracowanie takich modeli, które umożliwią łatwe ogarnięcie pojęciowe złożonych systemów, będą oferować zwarty sposób wyrażenia żądań dotyczących informacji i umożliwią tworzenie efektywnych systemów zarządzania bazami danych.
PYTANIA I ĆWICZENIA
Czy użycie wspólnego pliku indeksowego zarówno do przygoto
wywania listy płac, jak i do interakcyjnego pobierania danych daje
niezależność danych?Narysuj diagram przypominający diagram z rysunku 9.2 przedsta
wiający język maszynowy, język wysokiego poziomu i sposób, w jaki
programista postrzega komputer.Opisz krótko rolę, jaką w procesie uzyskiwania informacji z bazy
danych pełnią warstwa aplikacji, system zarządzania bazą danych
i podprogramy do manipulowania danymi.
9.3. Model relacyjny
W tym podrozdziale wprowadzimy relacyjny model bazy danych, który jest współcześnie najbardziej popularny. Jego popularność wynika z prostoty jego struktury. Dane traktuje się tak, jakby były przechowywane w prostokątnych tabelach zwanych relacjami, których format przypomina tabele stosowane w arkuszach kalkulacyjnych do prezentacji informacji. W modelu relacyjnym informacje o pracownikach firmy można przedstawić w postaci relacji pokazanej na rysunku 9.3.
Pojedynczy wiersz w relacji nazywa się krotką. W relacji z rysunku 9.3 poszczególne krotki zawierają informacje o konkretnym pracowniku. Kolumny w relacji noszą nazwę atrybutów, ponieważ każda pozycja w kolumnie opisuje pewną właściwość, czyli atrybut obiektu reprezentowanego za pomocą odpowiedniej krotki.
Projektowanie relacyjne
Projektowanie relacyjnej bazy danych koncentruje się na zaprojektowaniu relacji tworzących bazę danych. Chociaż wygląda to na proste zadanie, jest w nim wiele subtelności i pułapek czyhających na niedoświadczonego projektanta.
Przypuśćmy, że do informacji przedstawionych w relacji z rysunku 9.3 chcemy dodać informację o stanowiskach zajmowanych przez poszczególnych pracowników. Z każdym pracownikiem chcemy związać informację o stanowiskach, które zajmował w czasie swojego zatrudnienia, składającą się z takich atrybutów jak nazwa stanowiska (sekretarka, kierownik, kierownik piętra), kod identyfikujący stanowisko (unikatowy dla każdego stanowiska), kod umiejętności wymagany na każdym stanowisku, dział, w którym jest dane stanowisko, i okresy, w których pracownik zajmował to stanowisko w postaci daty początkowej i końcowej. (Będziemy stosować gwiazdkę jako datę końcową, jeśli pracownik aktualnie znajduje się na tym stanowisku).
Jedno z rozwiązań tego problemu polega na rozszerzeniu relacji z rysunku 9.3 i dołączeniu do niej powyższych atrybutów jako dodatkowych kolumn w tablicy. Otrzymamy w ten sposób tablicę przedstawioną na rysunku 9.4. Bliższe przyjrzenie się rezultatom pozwala odkryć wiele problemów. Jednym z nich jest nieefektywność. Relacja nie zawiera teraz jednej krotki dla każdego pracownika, lecz jedną krotkę dla każdego okresu zatrudnienia pracownika na danym stanowisku. Jeśli pracownik awansował w firmie stopniowo, zajmując coraz wyższe stanowiska, to w nowej relacji znajdzie się wiele krotek poświęconych temu samemu pracownikowi. Problem polega na tym, że w każdej z nich trzeba powtórzyć informacje
422
ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.3. MODEL RELACYJNY 423
426
w firmie (identyfikator stanowiska, nazwa stanowiska, dział, kod umiejętności) oraz informacje dotyczące związków między pracownikami a stanowiskami (data rozpoczęcia i zakończenia zatrudnienia na danym stanowisku). Na podstawie tych obserwacji opisane problemy można próbować rozwiązać, przeprojektowując system z wykorzystaniem trzech relacji - po jednej dla każdej z powyższych rodzajów informacji. Pierwotną relację zachowujemy bez zmian (nazwiemy ją teraz PRACOWNICY), a dodatkowe informacje umieścimy w dwóch nowych relacjach o nazwach STANOWISKA oraz ZATRUDNIENIE. Powstaje w ten sposób baza danych z rysunku 9.5.
Baza danych składająca się z takich trzech relacji zawiera istotne informacje o pracownikach w relacji PRACOWNICY, o dostępnych stanowiskach w relacji STANOWISKA, a o historii zatrudnienia w relacji ZATRUDNIENIE. Dodatkowa informacja jest dostępna niejawnie dzięki połączeniu informacji z różnych relacji. Na przykład można odnaleźć działy, w których dany pracownik pracował, wyszukując najpierw wszystkie stanowiska, które zajmował, za pomocą relacji ZATRUDNIENIE, a następnie odnajdując działy związane z tymi stanowiskami za pomocą relacji STANOWISKA. Za pomocą takich procesów można z trzech mniejszych relacji uzyskać dowolną informację, którą można było uzyskać z jednej dużej relacji, unikając przy tym przedstawionych wcześniej kłopotów.
Niestety podział informacji na poszczególne relacje nie zawsze jest taki bezproblemowy jak w poprzednim przykładzie. Przeanalizujmy relacje z rysunku 9.6 z atrybutami IdPrac, Stanowisko, Dział z jej dekompozycją na dwie relacje przedstawione na rysunku 9.7.
Na pierwszy rzut oka wydaje się, że system z dwiema relacjami zawiera te same informacje co system z jedną relacją. Tak jednak nie jest. Rozważmy problem wyszukania działu, w którym pracuje dany pracownik. Można to łatwo zrobić w systemie z jedną relacją, sprawdzając krotkę zawierającą numer identyfikacyjny danego pracownika i odczytując odpowiedni dział. W systemie z dwiema relacjami żądana informacja może jednak nie być dostępna. Można odnaleźć stanowisko wskazanego pracownika
ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
i dział z takim stanowiskiem, nie oznacza to jednak, że pracownik pracuje w tym konkretnym dziale. Te same stanowiska mogą występować w kilku działach.
W niektórych wypadkach relację można rozbić na mniejsze relacje bez utraty informacji (jest to podział bez utraty informacji), w innych wypadkach informacja jest tracona. Badania właściwości relacji były i nadal są ważną gałęzią informatyki. Doprowadziły one do określenia hierarchii klas relacji zwanych pierwszą postacią normalną, drugą postacią normalną, trzecią postacią normalną itd. o takiej właściwości, że relacje w każdej kolejnej klasie lepiej nadają się do zastosowania w bazach danych niż relacje z poprzedzających klas.
Operacje na relacjach
Po wyjaśnieniu struktury modelu relacyjnego nadszedł czas na pokazanie, jak można korzystać z takiej organizacji danych z punktu widzenia programisty. Rozpoczniemy od przyjrzenia się operacjom, które będziemy wykonywać na relacjach.
Czasami chcemy wydobyć z relacji pewne krotki. Aby uzyskać informacje o pewnym pracowniku, trzeba wybrać krotkę o odpowiedniej wartości atrybutu identyfikatora z relacji PRACOWNICY. W celu uzyskania listy stanowisk w danym dziale, trzeba wybrać te krotki z relacji STANOWISKA, które mają atrybut dział taki jak wskazany dział. Dokonując takiego wyboru, tworzymy nową relację (nową tabelę) złożoną z krotek wybranych z pierwotnej relacji. Wynikiem wybrania informacji o konkretnym pracowniku jest relacja zawierającą tylko jedną krotkę z relacji PRACOWNICY. Wynikiem wybrania krotek związanych z danym działem jest kilka krotek pochodzących z relacji STANOWISKA,
9.3. MODEL RELACYJNY
427
Zatem jedną z operacji, którą chcemy wykonywać na relacji, jest wybieranie z niej krotek mających pewne właściwości i umieszczenie tych krotek w nowej relacji. Do wyrażenia takiej operacji zastosujemy składnię
NOWA <- SELECT from PRACOWNICY where IdPrac = "34Y70"
Wynikiem tej instrukcji jest utworzenie nowej relacji o nazwie NOWA zawierającej te krotki (w omawianym przykładzie powinna to być tylko jedna krotka) z relacji PRACOWNICY, których atrybut IdPrac wynosi 34Y70 (rys. 9.8). W odróżnieniu od operacji SELECT, która wybiera pewne wiersze z relacji, operacja PROJECT wybiera kolumny. Przypuśćmy, że szukając stanowisk w danym dziale, wykonaliśmy już operację SELECT, wybierając z relacji STANOWISKA te krotki, które są związane z danym działem, i że umieściliśmy te krotki w nowej relacji o nazwie NOWA1. Lista, której poszukujemy, to kolumna Stanowisko w tej nowej relacji. Operacja PROJECT umożliwia wybranie tej kolumny (lub kolumn) i umieszczenie wyniku w nowej relacji. Taką operację będziemy zapisywać w postaci
N0WA2 <- PROJECT Stanowisko from NOWA1
Jej wynikiem jest utworzenie nowej relaqi (o nazwie NOWA2), która zawiera jedną kolumnę wartości pochodzących z kolumny Stanowisko w relacji NOWA1.
A oto inny przykład operacji PROJECT. Instrukcję
POCZTA «- PROJECT Nazwisko, Adres from PRACOWNICY
można wykorzystać do utworzenia listy nazwisk i adresów wszystkich pracowników. Lista ta znajdzie się w nowo utworzonej (dwukolumnowej) relacji o nazwie POCZTA (rys. 9.9).
Trzecią operacją, którą wprowadzimy, jest operacja JOIN. Stosuje się ją do łączenia różnych relacji w jedną. Operacja JOIN na dwóch relacjach daje w wyniku nową relację, której atrybuty są atrybutami pierwotych relacji (rys. 9.10). Nazwy tych atrybutów są takie jak w relacjach pierwotnych,
428
ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.3. MODEL RELACYJNY
429
z tym, że każda jest poprzedzana nazwą relacji, z której pochodzi (jeśli relacja A zawierająca atrybuty V i W zostanie połączona z relacją B zawierającą atrybuty X, Y, Z, to wynik ma pięć atrybutów: A.V, A.W, B.X, B.Y, B.Z). Taka konwencja nazewnicza zapewnia, że nazwy atrybutów w nowej relacji są unikatowe, nawet jeśli pierwotne relacje miały atrybuty o tych samych nazwach.
Krotki (wiersze) nowej relacji tworzy się, konkatenując krotki pierwotnych relacji (zobacz rys. 9.10). To, które krotki są łączone w nowe krotki nowej relacji, zależy od warunku użytego w operacji JOIN. Jedną z możliwości jest złączenie tych krotek, w których wskazane atrybuty mają tę samą wartość. Taką właśnie operację przedstawiono na rysunku 9.10, na którym pokazano wynik wykonania instrukcji
C <- JOIN A and B where A.W m B.X
W tym przykładzie krotka z relacji A jest łączona z krotką z relacji B wtedy i tylko wtedy, gdy atrybuty W oraz X obu krotek są równe. Zatem konkate-nacja krotki (r, 2) z relacji A z krotką (2, m, q) z relacji B jest elementem relacji wynikowej, ponieważ wartość atrybutu W w pierwszej z nich jest równa wartości atrybutu X w drugiej. Wynik złączenia krotki (r, 2) z relacji A z krotką (5/ S' P) z relacji B me jest elementem końcowej relacji, bo krotki te nie mają tych samych wartości w atrybutach W oraz X.
Rozważmy inny przykład. Na rysunku 9.11 przedstawiono wynik wykonania instrukcji
C «- JOIN A and B where A.W < B.X
Zauważmy, że krotki, które są elementami wyniku, to dokładnie te krotki, w których atrybut W w relacji A jest mniejszy niż atrybut X w relacji B.
430 ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.3. MODEL RELACYJNY
431
SYSTEMY BAZ DANYCH NA PC
Komputery osobiste wykorzystuje się do wielu różrych celów od bardzo prostych do skomplikowanych. W prostej aplikacji „bazo-danowej", polegającej na przechowywaniu listy kartek bożonarodzeniowych lub utrzymującej wyniki ligi kręglarskiej, korzysta się często z arkuszy kalkulacyjnych zamiast bazy danych, gdyż zadaniem takiej aplikacji jest głównie gromadzenie, drukowanie i sortowanie danych. Są jednak także dość złożon* systemy baz danych przeznaczone dla komputerów osobistych, których przykładem jest Microsoft Access. Jest to pełny system relacyjnej bazy danych ze wszystkimi możliwościami omówionymi w podrozdziale 9.3 oraz z oprogramowaniem do tworzenia diagramów i raportów. Główna różnica z punktu widzenia użytkownika polega na tym, że Access wykorzystuje graficzny interfejs użytkownika, który umożliwia tworzenie zapytań w postaci graficznej, a nie w składni SQL przedstawionej w tekście. Dodatkowo nowsze wersje Accessa udostępniają udogodnienia internetowe, które na przykład umożliwiają przechowywanie w krotce adresu URL, dzięki czemu związana z nim strona staje się łatwa dostępna z bazy danych. .
Zobaczmy teraz, jak można wykorzystać operację JOIN w bazie danych z rysunku 9.5 w celu uzyskania listy wszystkich numerów identyfikacyjnych pracowników wraz z nazwą działu, w którym pracują. Zauważmy najpierw, że potrzebne dane znajdują się w kilku relacjach, a zatem zadanie uzyskania potrzebnej informacji musi wykorzystywać coś więcej niż operacje SELECT i PROJECT. Oto broń, której potrzebujemy, w postaci instrukcji
N0WA1
JOIN ZATRUDNIENIE and STANOWISKA
where ZATRUDNIENIE.IdStan=STANOWISKA.IdStan
która tworzy relację N0WA1 przedstawioną na rysunku 9.12. Teraz można rozwiązać problem, wybierając najpierw te krotki, w których ZATRUDNIE-NIE.DataZak jest równe „*", a następnie wykonując operację PROJECT z atry-
butami ZATRUDNIENIE.IdPrac oraz STANOWISKA.Dział. Zatem potrzebną informa-cję można uzyskać z bazy danych z rysunku 9.5, wykonując instrukcje:
NOWA1 <- JOIN ZATRUDNIENIE and STANOWISKA
where ZATRUDNIENIE.IdStan=STANOWISKA.IdStan N0WA2 <- SELECT from NOWA1 where ZATRUDNIENIE.DataZak = "*" LISTA <- PROJECT ZATRUDNIENIE.IdPrac.STANOWISKO.Dział from NOWA2
Po wprowadzeniu podstawowych operacji na relacjach możemy ponownie rozważyć całościową strukturę systemu bazy danej. Pamiętajmy, że dane w bazie danych są tak naprawdę przechowywane w pewnym systemie pamięci masowej. Aby uwolnić programistów od konieczności zajmowania się problemami obsługi tej pamięci, wprowadza się system zarządzania bazą danych, który umożliwia pisanie aplikacji w modelu bazy danych, takim jak omówiony system relacyjny. Zadaniem zarządcy bazy danych jest przyjmowanie zleceń wyrażonych za pomocą modelu relacyjnego i przekształcanie ich na akcje odpowiednie dla rzeczywistej struktury danych w pamięci masowej. Uzyskuje się to przez udostępnienie zestawu podprogramów, których aplikacja używa jako narzędzi abstrakcyjnych. Zatem system zarządzania bazą danych oparty na modelu relacyjnym udostępnia podprogramy do wykonywania operacji wyboru (SELECT), rzutowania (PROJECT) i złączenia QOIN), które można wywoływać z poziomu aplikacji za pomocą struktur syntak-tycznych zgodnych ze składnią języka bazowego. W ten sposób można pisać i^^^^m^^^^^^^^^^^^^^^mm aplikacje, tak jakby dane były przechowywane w prostej postaci tabelarycznej z modelu relacyjnego.
Pouczające jest przeanalizowanie, w jaki sposób system zarządzania bazą danych przechowuje dane w bazie danych i jaki wpływ ma sposób ich przechowywania na działanie systemu. Najprostszym sposobem implementacji relacji w systemie zarządzania bazą danych jest zapamiętanie jej w postaci pliku sekwencyjnego, w którym każda krotka jest rekordem logicznym. Taka strategia oznaczałaby jednak konieczność sekwencyjnego przeszukiwania pliku przy wykonaniu operacji SELECT; jest to proces, który przy dużych relacjach może być zbyt czasochłonny. Zarządca bazy danych przechowuje zatem relację raczej w postaci pliku indeksowego. Jeśli relację PRACOWNICY
432 ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.3. MODEL RELACYJNY
433
z rysunku 9.5 indeksowano by po numerach identyfikacyjnych pracowników, to informację o konkretnym pracowniku można by wybrać dość szybko za pomocą operacji SELECT.
Na koniec zauważmy, że współczesne systemy zarządzania bazami danych nie udostępniają operacji SELECT, PROJECT i JOIN w ich czystej postaci, lecz wspierają operacje, które są połączeniem tych podstawowych kroków. Przykładem jest język SQL.
tworzy listę złożoną z nazwisk i adresów wszystkich pracowników znajdujących się w relacji PRACOWNICY. Zauważmy, że jest to po prostu operacja PROJECT. Instrukcja
select IdPrac, Nazwisko, Adres, PESEL
from PRACOWNICY
where Nazwisko • 'Cheryl H. Clark'
SQL
Język o nazwie SQL (Structured Query Language) stosuje się szeroko w przetwarzaniu danych do manipulowania relacyjnymi bazami danych. Jedną z przyczyn jego popularności jest to, że American National Standards In-stitute opracował jego standard. Innym powodem popularności SQL jest to, że został on opracowany i wprowadzony na rynek przez firmę IBM i przez to znalazł się w wyeksponowanym miejscu. W tym punkcie wyjaśnimy, jak zapytania dla relacyjnej bazy danych wyraża się w języku SQL.
Zauważmy najpierw, że zapytanie składające się z ciągu operacji SELECT, PROJECT i JOIN można wyrazić w SQL za pomocą jednej instrukcji. Ważniejsze jednak jest to, że instrukcje SQL nie określają żadnej konkretnej kolejności operacji. Chociaż zapytanie wyrażone w języku SQL brzmi impe-ratywnie, to tak naprawdę jest to instrukcja deklaratywna. Znaczenie tego faktu polega na tym, że SQL zwalnia użytkowników bazy danych od konieczności opracowywania konkretnego ciągu kroków potrzebnych do uzyskiwania potrzebnej informacji. Mogą oni po prostu opisać, jaką operację potrzebują. Przykładowo, ostatnie zapytanie z poprzedniego punktu, w którym opracowaliśmy procedurę złożoną z trzech kroków, uzyskującą wszystkie numery identyfikacyjne pracowników wraz z nazwami działów, w których pracują, można wyrazić w języku SQL za pomocą jednej instrukcji
select IdPrac, Dział frora ZATRUDNIENIE, STANOWISKA
where ZATRUDNIENIE.IdStan = STANOWISKA.IdStan and ZATRUDNIENIE.DataZak ■.,'*'
Jak pokazuje powyższy przykład, każda instrukcja w SQL może zawierać trzy klauzule: klauzulę select, klauzulę f rom i klauzulę where. Z grubsza, taka instrukcja jest zleceniem wykonania operacji JOIN na wszystkich relacjach wymienionych w klauzuli f rom, wybrania z niej tych krotek, które spełniają warunek klauzuli where, a następnie zrzutowania tych krotek, zgodnie z klauzulą select (zwróćmy uwagę, że terminologia jest tu nieco odwrócona: klauzula select w SQL określa atrybuty wykorzystywane przy rzutowaniu). Przyjrzyjmy się kilku przykładom.
Instrukcja:
select Nazwisko, Adres from PRACOWNICY
daje wszystkie informacje z krotki związanej z pracownikiem Cheryl H. Clark z relacji PRACOWNICY. Jest to w zasadzie operacja SELECT. Instrukcja
select Nazwisko, Adres
from PRACOWNICY
where nazwisko = 'Cheryl H. Clark'
daje w wyniku nazwisko i adres Cheryl H. Clark w postaci takiej jak w relacji PRACOWNICY. Jest to kombinacja operacji SELECT oraz PROJECT. Instrukcja
select PRACOWNICY.Nazwisko, ZATRUDNIENIE.DataPocz
from PRACOWNICY, ZATRUDNIENIE
where PRACOWNICY.IdPrac = ZATRUDNIENIE.IdPrac
daje w wyniku listę nazwisk wszystkich pracowników wraz z datami początku ich zatrudnienia. Zauważmy, że jest to wynik wykonania operacji JOIN na relacjach PRACOWNICY i ZATRUDNIENIE, a następnie operacji SELECT oraz PROJECT na odpowiednich krotkach i atrybutach zgodnie z klauzulami where i select.
Zakończmy te rozważania uwagą, że SQL zawiera także instrukcje do definiowania struktury relacji, tworzenia relacji i modyfikacji zawartości relacji oraz instrukcje do tworzenia zapytań. Poniższe przykłady ilustrują użycie instrukcji insert into, delete frora oraz update.
Instrukcja
insert into PRACOWNICY
values ('42Z12', 'Sue A. Burt', ''33 Fair St.',
'444661111')
dodaje krotkę zawierającą podane dane do relacji PRACOWNICY. Instrukcja
delete from PRACOWNICY
where nazwisko = 'G. Jerry Smith'
usuwa krotkę opisującą pracownika G. Jerry Smith z relacji PRACOWNICY. Instrukcja
update PRACOWNICY
set Address = '1812 Napoleon Ave.'
where nazwisko = 'Joe E. Baker'
zmienia adres w krotce związanej z Joe E. Bakerem w relacji PRACOWNICY.
434
ROZDZIAŁ DZIEWIĄTY BAZY DANYCII
9.3. MODEL RELACYJNY
435
PYTANIA I ĆWICZENIA
1. Odpowiedz na następujące pytania na podstawie częściowej infor
macji podanej W relacjach PRACOWNICY, STANOWISKA, ZATRUDNIENIE
z rysunku 9.5.
Kto jest sekretarką w dziale księgowości z doświadczeniem naby
tym w dziale kadr?Kto jest kierownikiem piętra w dziale sprzedaży?
Jakie stanowisko zajmuje aktualnie G. Jerry Smith?
Na podstawie relacji PRACOWNICY, STANOWISKA, ZATRUDNIENIE z ry
sunku 9.5 napisz ciąg operacji na relacjach umożliwiający uzyskanie
listy wszystkich stanowisk w dziale kadr.
Na podstawie relacji PRACOWNICY, STANOWISKA, ZATRUDNIENIE
z rysunku 9.5 napisz ciąg operacji na relacjach umożliwiający uzyskanie listy nazwisk pracowników wraz z działami, w których są zatrudnieni.
Zapisz odpowiedzi na pytania 2 i 3 w języku SQL.
W jaki sposób model relacyjny zapewnia niezależność danych?
W jaki sposób związuje się ze sobą różne relacje w relacyjnej bazie
danych?
potrzebnej informacji. Wystarczy po prostu zażądać od obiektu reprezentującego odpowiedniego pracownika wypisania jego historii zatrudnienia.
Pojęciową reprezentację takiej bazy danych przedstawiono na rysunku 9.13. Związki między różnymi obiektami przedstawiono za pomocą linii łączących związane ze sobą obiekty. Obiekt klasy PRACOWNICY jest na przykład związany ze zbiorem obiektów typu ZATRUDNIENIE, reprezentujących okresy zatrudnienia tego pracownika na różnych stanowiskach. Z kolei każdy z obiektów typu ZATRUDNIENIE jest powiązany z obiektem typu STANOWISKA reprezentującym stanowisko, którego dotyczy to zatrudnienie. Wszystkie stanowiska, jakie zajmował pracownik, można odnaleźć, analizując powiązania obiektu reprezentującego tego pracownika. Podobnie wszystkich pracowników, którzy byli na określonym stanowisku, można odnaleźć, analizując połączenia obiektu reprezentującego to stanowisko.
Połączenia między obiektami w obiektowej bazie danych utrzymuje zazwyczaj DBMS, a zatem szczegóły implementacji tych połączeń nie interesują programisty piszącego aplikację. Gdy do bazy danych wstawia się nowy obiekt, aplikacja po prostu określa, z jakimi innymi obiektami ma on zostać związany, a DBMS tworzy odpowiedni system wskaźników, za pomocą którego te związki są zapamiętywane. W szczególności DBMS może łączyć
Pracowni
9.4. Obiektowe bazy danych
Jednym z nowszych obszarów badań w dziedzinie baz danych jest zastosowanie paradygmatu obiektowego do konstuowania baz danych. Obiektowe bazy danych składają się z obiektów, które są powiązane ze sobą w sposób oddający zależności zachodzące między nimi. Obiektowa implementacja bazy danych pracowników z poprzedniego podrozdziału składałaby się z trzech klas (typów obiektów): PRACOWNICY, STANOWISKA, ZATRUDNIENIE. Obiekt klasy PRACOWNICY zawierałby elementy takie jak IdPrac, Nazwisko, Adres i PESEL, a obiekt klasy STANOWISKA zawierałby elementy takie jak: IdStan, Stanowisko, KodUmiejętności oraz Dziat. Każdy obiekt klasy ZATRUDNIENIE miałby pola DataPocz, DataKon.
Każdy z powyższych obiektów zawierałby także metody definiujące sposób reakcji obiektu na komunikaty dotyczące jego zawartości i związków z innymi obiektami. Każdy obiekt klasy PRACOWNICY zawierałby na przykład metody służące do wypisywania i uaktualniania informacji w obiekcie oraz metodę tworzenia raportu o historii zatrudnienia pracownika, a może także metodę zmiany stanowiska pracownika. Podobnie, każdy obiekt klasy STANOWISKA zawierałby metodę wypisującą informacje o tym stanowisku oraz metodę informującą o tych pracownikach, którzy byli zatrudnieni na tym stanowisku. W celu uzyskania historii zatrudnienia pracownika nie trzeba zatem pisać zewnętrznej procedury definiującej sposób uzyskania
Stanowisko Związki między obiektami w obiektowej bazie danych
436
ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.4. OBIEKTOWE BAZY DANYCH
437
ze sobą obiekty reprezentujące zatrudnienie danego pracownika w sposób podobny do listy z dowiązaniami.
Innym zadaniem obiektowego DBMS jest dostarczenie trwałej pamięci dla powierzonych mu obiektów. Wymaganie to może wydawać się oczywiste, ale jego natura jest zupełnie inna od sposobu obsługi zwykłych obiektów. Zazwyczaj obiekty tworzone podczas wykonania programu obiektowego są niszczone po jego zakończeniu. Obiekty są zatem w pewnym sensie tymczasowe. Obiekty, które się tworzy i dodaje do bazy danych, muszą być jednak trwałe - muszą zostać zachowane po zakończeniu programu, który je utworzył. Dostarczenie trwałej pamięci dla obiektów jest zatem istotnym odstępstwem od normy.
Ważną zaletą obiektowych baz danych jest to, że umożliwiają one projektowanie całego systemu zgodnie z tym samym paradygmatem. Aplikację, która korzysta z bazy danych, i samą bazę danych można projektować obiektowo. Różni się to od powszechnej praktyki tworzenia programu współpracującego z relacyjną bazą danych w języku imperatywnym. W takim rozwiązaniu występują naturalne konflikty między paradygmatem imperatywnym a relacyjnym. Na przestrzeni lat okazało się, że te różnice były przyczyną wielu błędów w programach. Możliwość uniknięcia różnic wynikających z odmiennych paradygmatów jest główną zaletą, na którą wskazują zwolennicy obiektowych baz danych.
Aby docenić inną zaletę obiektowych baz danych w porównaniu z ich relacyjnymi odpowiednikami, rozważmy problem przechowywania imion i nazwisk pracowników w relacyjnej bazie danych. Jeśli imię i nazwisko przechowujemy w postaci jednego atrybutu, to zapytania dotyczące tylko nazwiska są trudne do sformułowania. Jeśli jednak dane osobowe przechowujemy w postaci trzech oddzielnych atrybutów: imienia, drugiego imienia i nazwiska, to wtedy trudno jest poprawnie obsługiwać osoby, których dane osobowe nie są zgodne ze schematem imię, drugie imię, nazwisko. W obiektowej bazie danych te dane można ukryć w obiekcie, który przechowuje dane osobowe pracownika. Można je zapamiętać w sprytnym obiekcie, który potrafi przedstawiać je w różnych formatach. Zatem na zewnątrz obiektów jest tak samo łatwo operować tylko na nazwiskach, jak i na całych danych osobowych, nazwiskach panieńskich czy pseudonimach. Szczegóły związane z każdym z tych sposobów traktowania danych są kapsułkowane wewnątrz obiektów.
Możliwość kapsułkowania szczegółów technicznych związanych z różnymi formatami danych jest zaletą także w innych sytuacjach. W relacyjnej bazie danych atrybuty relacji są częścią całego projektu bazy danych, a zatem typy związane z atrybutami przenikają cały system zarządzania bazą danych. Taka budowa jest sensowna, gdy dotyczy danych złożonych z napisów i wartości liczbowych. Ale rozszerzanie relacyjnej bazy danych przez dodanie nowych relacji zawierających atrybuty typu audio lub wideo może stwarzać poważne problemy. Może zaistnieć wtedy konieczność rozbudowania wielu procedur znajdujących się w różnych fragmentach bazy danych, tak aby prawidłowo obsługiwały te nowe typy danych. W obiektowych bazach
danych ta sama procedura, którą stosuje się do uzyskania obiektu reprezentującego dane osobowe pracownika, może być użyta do uzyskania obiektu reprezentującego film. Różnice w typach można bowiem ukryć w obiektach. Podejście obiektowe lepiej nadaje się zatem do tworzenia multimedialnych baz danych. Ta właściwość już okazała się wielką zaletą.
PYTANIA I ĆWICZENIA
Jakie metody umieściłbyś w obiekcie klasy ZATRUDNIENIE w bazie
danych pracowników omówionym w tym punkcie?Określ klasy, które można by stosować w obiektowej bazie danych
przechowującej informację o magazynie sklepu. Podaj wewnętrzną
charakterystykę tych klas.Określ zalety obiektowej bazy danych w porównaniu z zaletami rela
cyjnej bazy danych.
9.5. Zachowanie integralności bazy danych
Niedrogie systemy zarządzania bazami danych przeznaczone do osobistego użytku są względnie prostymi systemami. Zdają się one mieć jeden cel -oddzielić użytkownika od technicznych szczegółów implementacji bazy danych. Bazy danych utrzymywane przez takie systemy są względnie małe i przechowują informacje, których utrata byłaby raczej niedogodnością niż katastrofą. W razie wystąpienia problemów użytkownik może zazwyczaj bezpośrednio poprawić te dane, które są błędne, lub odtworzyć bazę danych z kopii zapasowej i ręcznie dokonać poprawek koniecznych do uaktualnienia kopii. Proces ten jest uciążliwy, ale koszt uniknięcia takich niedogodności jest wyższy niż sama uciążliwość. W każdej sytuacji niedogodności dotyczą grona kilku zaledwie osób, a straty finansowe są na ogół niewielkie.
W wypadku wielkich komercyjnych systemów baz danych z wieloma użytkownikami zabezpieczenia muszą być jednak znacznie większe. Koszty błędów w danych lub ich utraty mogą być olbrzymie i mogą mieć poważne konsekwencje. W takich środowiskach głównym zadaniem systemu zarządzania bazą danych jest utrzymanie integralności bazy danych przez ochronę przed problemami takimi jak operacje, które z pewnych przyczyn wykonano jedynie częściowo, lub inne operacje, które mogą mieć na siebie niepożądany wpływ, powodując wprowadzenie do bazy niepoprawnych informacji. Tą właśnie rolą systemu zarządzania bazą danych zajmiemy się w tym podrozdziale.
438
ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.5. ZACHOWANIE INTEGRALNOŚCI BAZY DANYCH
439
J-
CZASOWE (TEMPORALNE) BAZY DANYCH
Tradycyjne bazy danych są przeznaczone do przechowywania aktualnych danych. W tradycyjnej magazynowej bazie danych przechowuje się na przykład dane o aktualnym stanie magazynu w celu utrzymania odpowiedniego poziomu zapasów. W takich wypadkach dane o dawnym stanie magazynu są dostępne często jedynie za pośrednictwem archiwalnych kopii bazy danych lub dzięki uwzględnieniu dat jako części danych. W wielu zastosowaniach przydaje się jednak wygodny dostęp do starszych danych przy jednoczesnej możliwości przechowywania nowych. Tak jest w wypadku uniwersyteckiego rejestru zajęć, w którym ustala się oferty zajęć, utrzymuje się stany poszczególnych grup, przydział sal i nauczycieli itp. nie tylko dla bieżącego semestru, ale także dla ubiegłych i przyszłych semestrów. Czasowe bazy danych to bazy danych przeznaczone do takich zastosowań. Po dodaniu nowych elementów do czasowych baz danych nie usuwa się z nich starych informacji. Nowe elementy stają się po prostu najnowszymi elementami rekordu historycznego, którego dowolny fragment jest łatwo dostępny.
Czasowe bazy danych to obszar aktywnych badań, których celem jest znalezienie efektywnych sposobów przechowywania i utrzymywania przeszłych, obecnych i przyszłych informacji, opracowanie technik wyszukiwania informacji w takich rekordach i opracowanie języków do wyrażania zapytań dotyczących informacji czasowych.
Protokół Commit/Rollback (zatwierdzania i wycofywania)
Pojedyncza transakcja, taka jak transfer funduszy z jednego konta bankowego na inne, odwołanie rezerwacji biletu lotniczego bądź rejestracja studenta na wykład, może składać się z wielu kroków na poziomie bazy danych. Przelew pieniędzy między kontami w banku wymaga na przykład zmniejszenia salda jednego konta i zwiększenia salda drugiego. Po wykonaniu pierwszego kroku, ale przed wykonaniem drugiego, informacja w bazie danych jest niespójna. Przez krótki czas po zmniejszeniu stanu pierwszego konta, ale przed zwiększeniem drugiego, suma funduszy się nie zgadza. Podobnie, przy zmianie rezerwacji miejsca w samolocie jest chwila, w której pasażer nie ma przydzielonego miejsca, lub chwila, w której lista pasażerów ma o jednego pasażera za dużo.
W wypadku dużych baz danych, w których często wykonuje się takie transakcje, jest duże prawdopodobieństwo, że w losowo wybranej chwili baza danych znajduje się w trakcie realizacji pewnej transakqi. Zlecenie wykonania nowej transakcji lub awaria sprzętu z dużym prawdopodobieństwem pojawi się zatem w chwili, gdy baza danych jest w niespójnym stanie.
Przeanalizujmy najpierw problem awarii. Zadaniem systemu zarządzania bazą danych jest zapewnienie, że takie zdarzenia nie pozostawią bazy danych w niespójnym stanie. Zadanie to realizuje się często, utrzymując w nieulotnej pamięci, na przykład na dysku, dziennik (log) zawierający informacje o czynnościach wykonanych przez każdą transakcję. Zanim
zezwoli się transakq'i na zmianę stanu bazy danych, najpierw zapisuje się informacje o mającej nastąpić zmianie w dzienniku. Dziennik zawiera zatem trwały zapis akcji każdej transakcji.
Punkt, w którym wszystkie kroki transakcji zapisano w dzienniku, jest nazywany punktem zatwierdzenia. W tym właśnie czasie system zarządzania bazą danych ma informację potrzebną do samodzielnego odtworzenia transakqi, jeśli okaże się to niezbędne. W tym punkcie system zarządzania bazą danych zatwierdza transakcję w takim sensie, że przyjmuje na siebie odpowiedzialność za
zapewnienie tego, że czynności wykonane przez transakcję znajdują odzwierciedlenie w bazie danych. W razie awarii sprzętu system zarządzania bazą danych może wykorzystać informacje z dziennika do rekonstrukcji tych transakcji, które zostały zakończone (zatwierdzone) od ostatnio wykonanej kopii zapasowej.
Jeśli problemy wystąpiły, zanim transakcja osiągnęła swój punkt zatwierdzenia, to system zarządzania bazą danych może znaleźć się w stanie częściowo wykonanej transakcji, której nie można ukończyć. W takich wypadkach można korzystać z dziennika do wycofania czynności już wykonanych przez niedokończoną transakcję. W razie awarii system zarządzania bazą danych może odtworzyć swój stan, wycofując te transakcje, które nie zostały zakończone (zatwierdzone) w chwili wystąpienia awarii.
Operacja wycofywania transakcji nie ogranicza się jednak tylko do procesu usuwania skutków awarii. Jest ona często jedną ze zwykłych czynności systemu zarządzania bazą danych. Transakcję można na przykład przerwać przed zakończeniem wszystkich jej kroków na skutek próby uzyskania dostępu do zastrzeżonej informacji. Może się także zdarzyć zakleszczenie, kiedy to rywalizujące ze sobą transakcje oczekują na dostępność danych używanych przez drugą transakcję. W takich sytuacjach system zarządzania bazą danych może wykorzystać dziennik do wycofania transakcji i uniknięcia błędów w bazie danych powstających na skutek częściowego wykonania transakcji.
W celu podkreślenia delikatnej natury budowy systemu zarządzania bazą danych, zauważmy, że są pewne subtelne problemy ukrywające się w procesie wycofywania transakcji. Wycofanie jednej transakcji może mieć wpływ na te elementy bazy danych, z których korzystały inne transakcje. Na przykład wycofywana transakcja mogła uaktualnić saldo rachunku bankowego, a inna transakcja mogła do swych dalszych działań wykorzystać tę uaktualnioną wartość. Oznacza to, że wycofując jedną transakcję, należy także wycofać inne transakcje, co z kolei może mieć wpływ na inne transakcje. Powstaje w ten sposób problem nazywany wycofywaniem kaskadowym.
Blokady
Rozważmy teraz problem wykonania transakcji, w czasie gdy baza danych wykonuje inną transakcję. Taka sytuacja może doprowadzić do niepoprawnych interakcji między transakcjami i prowadzić do uzyskania błędnych wyników. Przykładem jest problem niepoprawnego sumowania, który pojawia się wtedy, kiedy jedna transakcja jest w trakcie realizacji przelewu z jednego konta na drugie, gdy druga transakcja oblicza łączną kwotę zdeponowaną w banku. Prowadzi to do wyniku, który jest albo za mały, albo za duży w zależności od kolejności przeplatania się kroków poszczególnych transakcji. Inny przykład to problem utraconej modyfikacji, który pojawia
440
ROZDZIAŁ DZIEWIĄTY BAZY DANYCI1
9.5. ZACHOWANIE INTEGRALNOŚCI BAZY DANYCH
441
się, gdy dwie transakcje wykonują potrącenie z tego samego konta. Jeśli jedna transakcja odczyta saldo konta w chwili, gdy druga odczytała już to saldo, ale jeszcze nie obliczyła nowego salda, to obie transakcje dokonają potrąceń na podstawie tego samego salda początkowego. W rezultacie efekt wykonania jednego potrącenia nie zostanie uwzględniony w bazie danych.
Aby rozwiązać takie problemy, system zarządzania bazą danych może wymuszać całkowite wykonanie pewnej transakcji przed rozpoczęciem realizacji kolejnych, przechowując nowe transakcje w kolejce aż do chwili zakończenia wykonania ich poprzedników. Transakcje czekają jednak długo na wykonanie dyskowych operacji wejścia-wyjścia. Przeplatając wykonanie transakcji, można wykorzystać czas oczekiwania jednej transakcji na wykonanie przetwarzania już odczytanych danych w drugiej transakcji. Większość dużych systemów zarządzania bazami danych zawiera zatem program szeregujący, który koordynuje podział czasu między poszczególnymi transakcjami w taki sam sposób, jak robi to system operacyjny, przeplatając wykonanie różnych procesów.
Ochrona przed anomaliami, takimi jak problem niepoprawnego sumowania bądź problem utraconej modyfikacji, jest zapewniona przez program szeregujący zawierający protokół blokowania. W tym protokole są zaznaczone te dane w bazie danych, które są aktualnie wykorzystywane przez inne transakcje. Takie zaznaczanie nazywa się blokowaniem. Mówi się, że tak zaznaczone dane są zablokowane. Powszechnie są stosowane dwa typy blokad: blokady wspólne (dzielone) oraz blokady wyłączne. Odpowiadają one dwóm typom dostępu transakcji do danych - dostępowi współdzielonemu i dostępowi wyłącznemu. Jeśli transakcja nie będzie zmieniać wartości danych, to jest potrzebny dostęp współbieżny, co oznacza, że inne transakcje mogą w tym samym czasie odczytywać te dane. Jeśli jednak transakcja modyfikuje dane, to musi mieć do nich dostęp wyłączny, co oznacza, że musi być jedyną transakcją mającą do nich dostęp.
W protokole blokowania transakcja żądająca dostępu do danych musi za każdym razem informować system zarządzania bazą danych o typie żądanego dostępu. Jeśli transakcja domaga się dostępu współbieżnego do danych, które nie są zablokowane albo są zablokowane w sposób wspólny, to jest udzielane zezwolenie na dostęp do tych danych i są one blokowane w sposób wspólny. Jeśli jednak na dane nałożono blokadę wyłączną, to nie zezwala się na dostęp do nich. Jeśli transakcja domaga się wyłącznego dostępu do danych, to zgody na to udziela się tylko wtedy, kiedy na danych nie ma nałożonej blokady. W ten sposób transakcja, która modyfikuje dane, chroni je przed innymi transakcjami, uzyskując do nich wyłączny dostęp. Z tych samych danych może jednocześnie korzystać wiele transakcji, jeśli tylko żadna z nich ich nie zmienia. Oczywiście, gdy tylko dane przestają być transakcji potrzebne, zawiadamia ona o tym system zarządzania bazą danych, który zdejmuje nałożoną blokadę.
Do obsługi sytuacji, w których transakcji odmawia się dostępu do danych, stosuje się różne algorytmy. Jeden z nich polega po prostu na tym, że transakqa oczekuje na dostęp do danych. Takie rozwiązanie może jednak prowadzić do zakleszczeń, ponieważ dwie transakcje, które potrzebują wyłącznego dostępu do tych samych dwóch fragmentów danych mogą wzajemnie się zablokować. Stanie się tak, jeśli każda z nich uzyska wyłączny dostęp do jednego fragmentu danych i zacznie oczekiwać w nieskończoność na drugi. W celu uniknięcia takich zakleszczeń, niektóre systemy zarządzania bazami danych nadają priorytet starszym transakcjom. Jeśli starsza transakcja żąda dostępu do pewnego fragmentu danych, na który nałożyła blokadę młodsza transakqa, to młodsza transakcja musi zwolnić blokadę wszystkich używanych danych, a jej działania zostają wycofane (na podstawie dziennika). Następnie starsza transakcja dostaje dostęp do potrzebnych jej danych, a młodsza musi rozpocząć się od nowa. Jeśli młodsza transakcja jest ciągle wycofywana, to stopniowo starzeje się i w końcu staje się jedną ze starszych transakcji w systemie. Ten protokół, znany jako protokół ranienia i czekania (stare transakcje zadają rany młodszym, młode transakcje czekają na zakończenie starszych), zapewnia, że każda transakcja dostanie w końcu możliwość zakończenia swojego działania.
PYTANIA I ĆWICZENIA
Na czym polega różnica między transakcją, która doszła do punktu
zatwierdzenia, a transakcją, która nie osiągnęła tego punktu?W jaki sposób system zarządzania bazami danych może unikać czę
stego wycofywania kaskadowego?Pokaż, w jaki sposób niekontrolowany przeplot dwóch transakcji,
z których pierwsza zmniejsza stan konta o 100 PLN, a druga zmniejsza stan tego samego konta o 200 PLN, może spowodować powstanie końcowego salda wysokości 100 PLN, 200 PLN lub 300 PLN przy założeniu, że początkowo stan konta wynosił 400 PLN.
4. (a) Jakie są możliwe zachowania transakcji żądającej wspólnego do-
stępu do danych w bazie danych?
(b) Jakie są możliwe zachowania transakcji żądającej wyłącznego dostępu do danych w bazie danych?
Opisz ciąg zdarzeń, który prowadzi do zakleszczenia transakcji działa
jących w systemie bazy danych.Opisz, jak można przerwać zakleszczenie opisane w odpowiedzi na
poprzednie pytanie. Czy proponowane rozwiązanie wymaga użycia
dziennika prowadzonego przez system zarządzania bazą danych?
Uzasadnij odpowiedź.
442 ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.5. ZACHOWANIE INTEGRALNOŚCI BAZY DANYCH
443
9.6. Społeczne skutki wprowadzenia baz danych
W przeszłości kolekcje danych traktowano jak uśpione, pasywne byty. Każdą z nich tworzono i wykorzystywano w konkretnym celu. Biblioteka lokalna utrzymywała fizyczną listę złożoną z nazwisk i adresów swoich czytelników. W każdej książce znajdowała się wymienna karta z tytułem książki. Przy wypożyczaniu książki wyjmowano z niej kartę i zapisywano na niej nazwisko osoby wypożyczającej książkę. Kartę umieszczano w pliku kart w bibliotece. Przy zwrocie książki jej kartę umieszczano w niej z powrotem. Jeśli książki nie zwrócono w terminie, to bibliotekarz kontaktował się z osobą przetrzymującą książkę, korzystając z listy czytelników.
W takim ręcznym systemie można było uzyskać listę wszystkich książek wypożyczonych w przeszłości przez konkretną osobę. Wymagało to jednak przeszukania wszystkich książek w bibliotece i sprawdzenia, czy na kartach znajdujących się w nich widnieje dane nazwisko. Koszt takiego wyszukiwania powodował, że takie przedsięwzięcie było niewykonalne pod względem praktycznym. Chociaż dane biblioteki zawierały subtelne informacje o klientach, które można byłoby wykorzystać w celach niezwiązanych z obsługą biblioteki, jednak czytelnicy mogli mieć pewność, że takie wykorzystanie tych danych nie będzie miało miejsca. Współczesne biblioteki są jednak w większości zautomatyzowane, a profile gustów poszczególnych czytelników są w zasięgu ręki. Biblioteki mogą teraz z łatwością udostępnić takie informacje firmom marketingowym, organom ścigania, partiom politycznym, pracodawcom i osobom prywatnym. Możliwości są liczne.
Przykład biblioteki pokazuje możliwości, które dotyczą także szerokiego zakresu zastosowań baz danych. Technika ułatwiła gromadzenie informacji oraz łączenie i porównywanie różnych kolekcji danych w celu odsłaniania powiązań, które pozostawały ukryte.
Zbieranie danych odbywa się współcześnie na dużą skalę. W niektórych przypadkach proces jest jawny, w innych bardziej subtelny. Informacje zbiera się jawnie, prosząc wprost o jej udzielenie. Może to być czynność dobrowolna, jak w wypadku ankiet bądź formularzy rejestracyjnych na zawody, albo obowiązkowa, jak w przypadku czynności ustanawianych przez rząd. Czasami to, czy udzielenie informacji odbywa się dobrowolnie, czy nie, zależy od punktu widzenia. Czy przekazywanie danych osobowych przy występowaniu o kredyt jest dobrowolne, czy nie? Różnica zależy od stopnia, w jakim potrzebuje się kredytu. Używanie karty kredytowej w niektórych sklepach wymaga teraz udzielenia zgody na zapisanie podpisu w postaci cyfrowej. Ocena, czy takie wymaganie jest żądaniem bądź prośbą, zależy od wewnętrznej potrzeby dokonania zakupu.
Bardziej subtelne formy zbierania informacji unikają bezpośredniego kontaktu z zainteresowanym. Przykładami są wystawcy kart kredytowych, którzy zbierają informacje o zakupach dokonywanych przez posiadaczy tych
kart, strony WWW, które zapamiętują dane osób odwiedzających te strony. W takich wypadkach zainteresowany może nie być świadomy tego, że taka informacja jest zbierana, i nic nie wie o istnieniu baz danych przechowujących informacje związane z poszczególnymi osobami. Sklep spożywczy może oferować zniżki dla stałych klientów, którzy zarejestrują się przedtem w sklepie. Proces rejestracji może polegać na wydaniu kart identyfikacyjnych, które trzeba przedstawić przy zakupie, aby uzyskać zniżkę. W efekcie sklep ma informacje o zakupach dokonywanych przez klienta - informacje dużo cenniejsze niż wartość udzielonych zniżek.
Oczywiście siłą napędową tego dążenia do zbierania informacji jest wartość danych wynikająca głównie z rozwoju technik baz danych, które pozwalają na łączenie danych, tak że umożliwia to odkrywanie informacji dotąd ukrytych. Powstają w ten sposób połączone kolekcje danych, które zawierają więcej informacji niż zawarte łącznie we wszystkich ich składowych. Informacje o dobrach nabywanych przez właścicieli kart kredytowych można uporządkować i powiązać ze sobą, uzyskując profil klienta stanowiący olbrzymią wartość marketingową. Można na przykład wysyłać formularze subskrypcyjne na czasopisma kulturystyczne tym, którzy kupowali ostatnio przyrządy gimnastyczne, a tym, którzy kupili ostatnio pożywienie dla psów, można wysłać podobne formularze na czasopisma kynologiczne. Inne sposoby łączenia informacji wymagają czasem dużej wyobraźni. Można porównywać dane z opieki społecznej z kartoteką kryminalną w celu odnalezienia i zatrzymania więźniów zwolnionych warunkowo, a w 1984 roku the Selective Servis w Stanach Zjednoczonych wykorzystał listę z datami urodzeń, uzyskaną od popularnego sklepu z lodami, do znalezienia obywateli, którzy nie stawili się na spis przedpoborowy. W tym ostatnim przypadku listę zwrócono sprzedawcy, gdy ten oświadczył, że sprzedaż listy była błędem, ale do tego momentu informacja została już wykorzystana. Niestety, do takiego nieuprawnionego wykorzystania danych dochodzi ciągle. Przykłady pojawiają się stale. Są wśród nich pracownicy firm lub urzędnicy agenq'i rządowych, którzy wykorzystują informacje umieszczone w bazach danych ich pracodawców.
Sprzedaż listy z datami urodzin wywołuje także pytania dotyczące własności informacji. Czy ktoś, kto zbiera informacje, automatycznie staje się ich właścicielem? W jakim stopniu jesteśmy właścicielami informacji osobistych o sobie? Do jakiego stopnia ktoś inny może być właścicielem informacji o nas?
Jest wiele sposobów obrony społeczeństwa przed niewłaściwym wykorzystywaniem baz danych. Jednym z nich jest stosowanie odpowiednich ustaleń prawnych. Niestety, ustanowienie prawa przeciwdziałającego jakiejś działalności nie przerywa jej, a jedynie czyni ją nielegalną. Podstawowym przykładem w Stanach Zjednoczonych jest ustawa dotycząca ochrony prywatności z 1974 roku, której celem była ochrona obywateli przed niewłaściwym wykorzystaniem rządowych baz danych. Jednym z postanowień tego aktu prawnego było wymaganie, aby agencje rządowe publikowały istnienie swoich baz danych w Rejestrze Federalnym, tak aby obywatele mogli
444
ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
9.6. SPOŁECZNE SKUTKI WPROWADZENIA BAZ DANYCH
445
m
wskutek rozpowszechnienia tej informacji? A jeśli byłbyś w złej sytuacji finansowej?
4. Jaką rolę odgrywa wolna prasa w kontroli nadużyć związanych z dostępem do danych (Na przykład w jakim stopniu prasa kształtuje opinię publiczną?)
PYTANIA DO ROZDZIAŁU DZIEWIĄTEGO
(Zadania oznaczone gwiazdką dotyczą rozdziałów opcjonalnych)
uzyskać dostęp do danych o sobie i skorygować je. Jednak agencje rządowe wolno dostosowywały się do tego postanowienia. Nie musiało to koniecznie oznaczać złych intencji z ich strony. W wielu sytuacjach problem stanowiła biurokracja. Ale fakt, że biurokracja może powodować tworzenie baz danych o osobach i że istnienie tych baz nie daje się stwierdzić, nie jest budującą sytuacją.
Innym, być może lepszym sposobem ochrony przed nadużyciem baz danych, jest opinia publiczna. Bazy danych nie będą niewłaściwie używane, jeśli konsekwencje przewyższą zyski, a konsekwencją, której wiele firm boi się najbardziej, jest nieprzychylna opinia publiczna. Na początku lat dziewięćdziesiątych to właśnie opinia publiczna powstrzymała ważne biuro kredytowe przed sprzedażą swojej listy adresowej w celach marketingowych. Niedawno America Online (główny dostawca Internetu) ugięła się pod presją opinii publicznej, przeciwnej stosowanej przez nią polityce sprzedaży telemarketerom informacji dotyczących klientów. Nawet agencje rządowe liczą się z opinią publiczną. W 1997 roku Social Security Administration w Stanach Zjednoczonych zmieniła plany udostępnienia informacji o ubezpieczeniach społecznych w Internecie, gdy opinia publiczna zakwestionowała bezpieczeństwo tych informacji. Rezultaty w powyższych przypadkach uzyskano w ciągu kilku dni - silnie kontrastuje to z długim czasem związanym z procesami prawnymi.
Oczywiście w wielu sytuacjach, stosując bazy danych, zyskuje zarówno ich właściciel, jak i podmiot danych, ale we wszystkich przypadkach dochodzi do utraty prywatności, której nie należy lekceważyć. Problemy z ochroną prywatności są poważne, gdy informacja jest poprawna a stają się olbrzymie, gdy informacja jest błędna. Wyobraźmy sobie nasze uczucie beznadziejności, gdybyśmy dowiedzieli się, że zaufanie do nas zmalało na skutek błędnej informacji. Wyobraźmy sobie skalę problemu, jeśli informaq'a ta zostałaby rozpowszechniona.
Problemy związane z ochroną prywatności są i będą głównym efektem ubocznym postępu technicznego w ogólności, a technik bazodanowych w szczególności. Ich rozwiązanie wymaga wykształconych, czujnych i aktywnych obywateli.
PYTANIA I ĆWICZENIA
Czy organy ścigania powinny mieć dostęp do baz danych w celu
wychwycenia jednostek o skłonnościach przestępczych, nawet jeśli
osoby te jeszcze nie popełniły żadnego przestępstwa?Czy firmy ubezpieczeniowe powinny mieć dostęp do danych w celu
wychwycenia osób z potencjalnymi problemami zdrowotnymi, nawet
jeśli osoby te nie mają żadnych symptomów choroby?Załóżmy, że jesteś zamożny. Co mógłbyś zyskać, gdyby taką informa
cją dysponowały różne instytucje? W jaki sposób mógłbyś ucierpieć
Podsumuj różnice między plikiem pła
skim a bazą danych.Co rozumie się przez pojęcie niezależ
ności danych?Jaka jest rola systemu zarządzania bazą
danych w warstwowej implementacji
bazy danych?Czym różni się schemat od podsche-
matu?Podaj dwie zalety oddzielenia aplikacji
od systemu zarządzania bazą danych.Na którym poziomie systemu bazy da
nych (użytkownik, programista apli
kacji, projektant oprogramowania do
zarządzania bazą danych) rozważa się
następujące pytania:
(a) Jak przechowywać dane na dysku,
aby uzyskać jak najlepszą efektyw
ność?
(b) Czy są wolne miejsca na lot 243?
(c),Czy relację można przechowywać
jako plik sekwencyjny?
Ile razy użytkownik może podać
niepoprawne hasło przed zakończe
niem dialogu?Jak można zaimplementować ope
rację PROJECT?
7. Opisz, w jaki sposób można przedsta
wić w relacyjnej bazie danych nastę
pujące informaqe o liniach lotniczych,
lotach (w konkretnym dniu) i pasaże
rach.
Linie lotnicze: Clear Sky, Long Hop i Tree Top
Loty linii Clear Sky: CS205, CS37 i CS102
Loty linii Long Hop: LH67 i LH89 Loty linii Tree Top: TT331 i TT809
Smith ma rezerwację na lot CS205 (miejsce 12B), CS37 (miejsce 18C) i LH 89 (miejsce 14A).
Baker ma rezerwacje na lot CS37 (miejsce 18B) i LH89 (miejsce 14B).
Clark ma rezerwację na lot LH67 (miejsce 5A) i TT331 (miejsce 4B).
8. Jak wygląda relacja WYNIKI po wykonaniu każdej z poniższych operacji na relacjach przedstawionych poniżej:
Relacja X |
|
Relacja Y |
|||
U V W R |
S |
||||
A |
Z |
5 |
|
3 |
J |
B |
D |
3 |
|
4 |
K |
C |
Q |
5 |
|
|
|
WYNIKI <- PROJECT W from X
WYNIKI «- SELECT from X
where W = 5
WYNIKI «- PROJECT S from Y
WYNIKI «- JOIN X and Y
where X.W ^ Y.R
446 ROZDZIAŁ DZIEWIĄTY BAZY DANYCH
PYTANIA DO ROZDZIAŁU DZIEWIĄTEGO
447
rozdział SZTUCZNA INTELIGENCJA
dziesiąty
Ważnym celem dla informatyków jest opracowanie maszyn, które komunikują się ze swoim otoczeniem tradycyjnymi ludzkimi metodami i zachowują się inteligentnie bez potrzeby interwencji człowieka. Takie zadanie wymaga często tego, aby komputer „rozumiał" lub uświadamiał sobie znaczenie otrzymywanych danych wejściowych i był w stanie wyciągać wnioski na drodze pewnego procesu wnioskowania.
Zarówno percepcja, jak i wnioskowanie należą do kategorii procesów myślowych, które chociaż są naturalne dla ludzkiego umysłu, jednak są wyraźnie bardzo trudne dla maszyn. W efekcie obszar badań związany z tymi zagadnieniami, nazywany sztuczną inteligencją, jest ciągle w powijakach, zwłaszcza gdy porównamy go z wyznaczonymi celami i oczekiwaniami.
Inteligencja
i komputeryRozpoznawanie
obrazówWnioskowanie
Systemy produkcji
Drzewa wyszukiwania
Heury stykiSztuczne sieci
neuronowe
Podstawowe właściwości Konkretne zastosowanie
Algorytmy genetyczne
Zastosowania
sztucznej inteligencji
Przetwarzanie języka
naturalnego Robotyka
Systemy baz danych Systemy eksperckie
10.7. Rozważania na temat
konsekwencji
POCZĄTKI SZTUCZNEJ INTELIGENCJI
Próby zbudowania maszyn, które naśladują zachowanie ludzi, mają długą historię. Wielu zgodzi się jednak z tym, że nowoczesna dziedzina sztucznej inteligencji została zapoczątkowana w latach pięćdziesiątych publikacją pracy Alana Turinga Compu-ting Machinery and Intelligence. W niej właśnie Turing wysunął wniosek, że maszyny można tak zaprogramować, aby wykazywały inteligentne zachowanie. Nazwa dyscypliny - sztuczna inteligencja - pojawiła się kilka lat później w legendarnej dziś propozycji Johna McCarthy'ego, który zaproponował „przeprowadzenie badań nad sztuczną inteligencją latem 1956 roku w Dart-mouth College" w celu zastanowienia się nad „stwierdzeniem, że każdy aspekt uczenia się bądź inny objaw inteligencji można w zasadzie opisać tak precyzyjnie, aby można było skonstruować maszynę, która będzie go symulować."
10.1. inteligencja i komputery
Chociaż często personifikuje się komputer, to jednak jest istotna różnica między jego właściwościami a właściwościami umysłu ludzkiego. Współczesne komputery są w stanie szybko i dokładnie wykonywać ściśle zdefiniowane zadania. Nie są one jednak obdarzone zdrowym rozsądkiem. Gdy znajdą się w sytuacji nieprzewidzianej przez programistę, ich możliwości działania najpewniej szybko się pogorszą. Ludzki umysł z kolei często grzęźnie przy złożonych obliczeniach, ale jest za to w stanie wnioskować i uczyć się. W konsekwencji komputery przewyższają człowieka w rozwiązywaniu obliczeniowych problemów fizyki jądrowej, ale to człowiek jest w stanie zrozumieć wyniki i określić, jaki ma być kolejny krok w obliczeniach.
Jeśli mamy kiedykolwiek zbudować maszyny, które będą w stanie podejmować rozsądne czynności w sytuacjach nieprzewidzianych z góry bez konieczności interwencji człowieka, to muszą one stać się bardziej podobne do człowieka w tym sensie, że muszą posiąść (lub przynajmniej symulować) zdolność rozumowania. Gdy informatycy zdali sobie sprawę z tego wymogu, zwrócili się o pomoc do psychologów i ich modeli ludzkiego umysłu w nadziei znalezienia zasad, które można by zastosować przy konstruowaniu bardziej elastycznych maszyn i programów. W efekcie, czasem jest trudno odróżnić badania psychologiczne od badań informatycznych. Różnica tkwi nie w tym, w jaki sposób prowadzi się takie badania, ale w tym, jaki jest ich cel. Psycholog chce dowiedzieć się więcej o umyśle ludzkim i procesie myślenia. Informatyk próbuje skonstruować bardziej przydatne komputery. Podobne związki istnieją między pracą informatyka a badaczami w jeszcze innych dyscyplinach wiedzy. Lingwista jest zainteresowany poznaniem procesu przetwarzania języka przez człowieka, informatyk zaś zaprojektowaniem komputera, który będzie przetwarzał język. Zatem badania w dziedzinie sztucznej inteligencji obejmują wiele dyscyplin.
Konsekwencją tej rozległości dziedziny jest to, że sztuczna inteligencja zdaje się rozwijać zgodnie z dwoma różnymi paradygmatami. Przypuśćmy, że informatyk i psycholog pracują niezależnie od siebie nad programem grającym w pokera. Informatyk dąży do opracowania takiego programu na
podstawie zasad rachunku prawdopodobieństwa i statystyki. W rezultacie powstaje program, który gra na największą szansę, blefuje losowo, nie wykazuje żadnych emocji i konsekwentnie dąży do zwiększania szansy wygrania. Z kolei psycholog próbuje opracować program na podstawie teorii procesu myślowego człowieka i jego zachowań. Projekt może się nawet zakończyć powstaniem kilku różnych programów. Jeden z nich może grać agresywnie, a inny trochę bojaźliwie. W odróżnieniu od programu informatyka, program psychologa może stać się „zaangażowany emocjonalnie" w grę i zgrać się do cna.
Podsumowując, dążeniem informatyka przy opracowywaniu programu jest uzyskanie końcowego produktu. Mówi się, że jest to podejście nastawione na wynik (ang. performance oriented). W odróżnieniu psycholog jest bardziej zainteresowany zrozumieniem procesu naturalnej inteligencji, zatem traktuje zadanie jako okazję do przetestowania teorii za pomocą stworzenia ich komputerowego modelu. Z tego punktu widzenia opracowanie „inteligentnego programu" jest w zasadzie efektem ubocznym innej działalności - dążenia do zrozumienia procesów myślowych i zachowań człowieka. Takie podejście to podejście nastawione na symulację (ang. simulation oriented).
Oba podejścia mają swój sens i wnoszą ważny wkład do rozwoju sztucznej inteligencji. Powstają jednak nieuchwytne pytania filozoficzne dotyczące tej dziedziny. Wyobraźmy sobie na przykład dyskusję, którą mogłoby wywołać pytanie o to, czy programy opracowane przez informatyka i psychologa cechują się inteligencją, a jeśli tak, to który z nich jest bardziej inteligentny? Czy inteligencję mierzy się zdolnością wygrywania, czy zdolnością naśladowania człowieka?
Tę drugą interpretację przyjął w 1950 roku Alan Turing, proponując test (współcześnie zwany testem Turinga), którego zadaniem jest ocena, w jakim stopniu zachowanie komputera cechuje się inteligencją. Propozycja Turinga polegała na tym, że człowiek, którego nazwiemy ankieterem, komunikował się z badanym obiektem za pomocą klawiatury. Nie wiedział przy tym, czy badanym obiektem jest człowiek, czy maszyna. Zachowanie maszyny uważano za inteligentne, jeśli ankieter nie był w stanie stwierdzić, czy rozmawia z człowiekiem, czy z maszyną. Test Turinga sprawdza zatem zdolność maszyny do naśladowania człowieka. Turing postawił tezę, że prawdopodobieństwo pozytywnego przejścia maszyny przez test Turinga przed rokiem 2000 wyniesie 30 procent. Okazało się, że było to zaskakująco trafne przewidywanie.
Dobrze znanym przykładem testu Turinga jest sesja z programem DOCTOR (wersji bardziej ogólnego systemu ELIZA) opracowanego przez Josepha Weizenbauma w połowie lat sześćdziesiątych. Ten program in-terakcyjny próbuje naśladować psychoanalityka przeprowadzającego wywiad z pacjentem. Komputer odgrywa rolę analityka, a użytkownik rolę pacjenta. Tak naprawdę działanie programu polegało jedynie na zmianie struktury zdań wypowiadanych przez pacjenta. Transformacje odbywały się zgodnie z zestawem określonych z góry reguł, a odpowiedzi systemu były
456
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.1. INTELIGENCJA I KOMPUTERY
457
wypisywane na ekranie terminalu. Na stwierdzenie „Jestem dzisiaj zmęczony", DOCTOR mógł na przykład odpowiedzieć „Jak myślisz, dlaczego jesteś dzisiaj zmęczony?". Jeśli DOCTOR nie był w stanie rozpoznać struktury zdania, to po prostu odpowiadał ogólnikiem typu „Mów dalej" lub „To bardzo ciekawe".
Celem, który przyświecał Weizenbaumowi przy opracowywaniu DOCTORA, było studium nad sposobami komunikacji w języku naturalnym. Psychoterapia tworzyła jedynie środowisko (dostarczając tematu do dyskusji), w którym program działał. Konsternację Wiezefibauma wywołał fakt, że niektórzy psycholodzy proponowali wykorzystać program w psychoterapii. (Zgodnie z tezą Carla Rogersa to pacjent, a nie analityk, powinien kierunkować rozmowę podczas sesji terapeutycznej - zatem komputer może uczestniczyć w rozmowie z takim samym skutkiem jak terapeuta). Poza tym DOCTOR stwarzał tak silne wrażenie pojmowania, że wielu jego „rozmówców" powierzało mu intymne zwierzenia i skrywane uczucia. W pewnym sensie DOCTOR przeszedł pozytywnie test Turinga, powodując tym samym pojawienie się wielu pytań etycznych i technicznych.
Czy fakt, że maszyna przeszła test Turinga oznacza, że jest obdarzona inteligencją? Główna trudność w stwierdzeniu, czy maszyna jest inteligentna, wynika z kłopotów w odróżnianiu przejawów inteligencji od niej samej. Inteligencja jest cechą wewnętrzną, której istnienie uwidacznia się na zewnątrz jedynie pośrednio na drodze dialogu bodziec-reakcja. Ale czy inteligentne reakcje świadczą o faktycznym istnieniu inteligencji?
Takie filozoficzne pytania towarzyszą już samym podstawom, na których opiera się sztuczna inteligencja. Nie dziwi zatem, że dziedzinę tę otacza aura tajemniczości, wykorzystywana często zarówno przez media, jak i autorów powieści fantastycznych. Celem, który stawiamy sobie w tym rozdziale, jest na szczęście zbadanie, jak komputery można programować, aby sprawiały wrażenie inteligentnych, a nie odpowiedź na powyższe pytania. Zadanie to zrealizujemy, analizując budowę maszyny przejawiającej pewne inteligentne zachowania.
Omawiana maszyna ma postać metalowej skrzynki wyposażonej w chwytak, kamerę i palec z gumową końcówką, która powoduje, że palec nie ślizga się po przesuwanych przez siebie elementach (rys. 10.1). Wyobraźmy sobie, że taką maszyna znajduje się na stole, na którym położono ośmioelementową układankę. Jest to układanka składająca się z ośmiu kwadratowych elementów ponumerowanych od 1 do 8, umieszczonych w ramce, w której może się mieścić dziewięć takich elementów w trzech wierszach i trzech kolumnach. Między elementami jest jedno wolne miejsce, na które można przesunąć dowolny z sąsiednich elementów. Elementy są ułożone tak, jak pokazuje rysunek 10.2.
Załóżmy, że zaczynamy od ułożenia elementów i następnie przemieszczamy je, wykonując kilka losowych ruchów i przesuwając dowolne elementy w wolne miejsce. Następnie włączamy maszynę, której chwytak otwiera się i zamyka, jakby prosił o układankę. Umieszczamy ją zatem w zacisku, który zamyka się na niej. Po krótkiej chwili palec maszyny opuszcza
458
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.1. INTELIGENCJA I KOMPUTERY 459
się i zaczyna przesuwać elementy układanki w ramce (w pewien uporządkowany sposób) aż do chwili, gdy znajdą się one znów w pierwotnym porządku. W tym momencie maszyna wypuszcza układankę i wyłącza się. Takie zachowanie maszyny wskazuje na umiejętność postrzegania i rozumowania; na jej przykładzie przedstawimy zatem tematykę dwóch kolejnych punktów.
PYTANIA I ĆWICZENIA
Roślina umieszczona w ciemnym pokoju z pojedynczym źródłem
światła rośnie w stronę światła. Czy jest to inteligentna reakcja na
bodziec? Czy roślina jest inteligentna?Przypuśćmy, że automat sprzedający zaprojektowano tak, aby wyda
wał różne towary w zależności od wciśniętego przycisku. Czy uwa
żasz, że automat ma „świadomość" tego, który przycisk wciśnięto?Przypuśćmy, że pewna maszyna przeszła test Turinga. Czy zgodzisz
się z twierdzeniem, że jest ona inteligentna? Jeśli nie, to czy uważasz,
że stwarza wrażenie inteligentnej?
10.2. Rozpoznawanie obrazów
Otwieranie i zamykanie chwytaka w maszynie przedstawionej w poprzednim podrozdziale nie przedstawia poważniejszych problemów, a zdolność wykrycia obecności układanki w chwytaku jest łatwa do uzyskania, ponieważ w naszym zastosowaniu wymaga niewielkiej precyzji. (Automaty otwierające bramy garażowe są w stanie wykryć obecność przeszkody w otworze drzwiowym podczas ich zamykania i odpowiednio zareagować). Problem ustawienia właściwej ostrości obrazu układanki w kamerze można także łatwo rozwiązać, projektując tak chwytak, aby ustawiał układankę zawsze w konkretnej, z góry określonej pozycji. Zatem pierwsze inteligentne zachowanie maszyny do układania puzzli to wydobycie potrzebnych jej informacji z obserwowanego obrazu.
Należy zdawać sobie sprawę z tego, że problem, przed którym stoi maszyna, nie polega po prostu na wytworzeniu i zapamiętaniu obrazu. Jest to technicznie możliwe od lat, jak w przypadku tradycyjnej fotografii lub systemów telewizyjnych. Problemem jest interpretacja i zrozumienie obrazu, aby można było ustalić bieżący stan układanki (a później nadzorować przesuwanie jej elementów). Jest to proces zupełnie inny niż zasada działania odbiornika telewizyjnego, który po prostu przekształca obraz z jednego środka przekazu na inny, bez próby zrozumienia tego, co ten obraz przedstawia, krótko mówiąc, nasza maszyna musi przejawiać zdolność postrzegania.
To, co może obserwować maszyna do układania puzzli jest raczej ograniczone. Można założyć, że jest to zawsze obraz układanki zawierającej cyfry od 1 do 8, ustawione w ściśle zorganizowany sposób. Problem polega po prostu na odczytaniu ułożenia tych cyfr. Wyobraźmy sobie, że obraz układanki zakodowano w postaci bitów w pamięci komputera, przy czym każdy bit reprezentuje poziom jasności konkretnego fragmentu obrazu, zwanego pikslem. Zakładając, że rozmiar obrazu jest ustalony (maszyna trzyma układankę w określonym położeniu względem kamery), maszyna może wykryć, który element znajduje się na której pozycji, porównując różne fragmenty obrazu ze wstępnie przygotowanymi i zapamiętanymi wzorami, złożonymi z ciągów bitów reprezentujących obrazy pojedynczych cyfr występujących w układance. Stan układanki odczytuje się zatem, dopasowując fragmenty oglądanej układanki do wzorów poszczególnych cyfr.
Taka technika rozpoznawania obrazu jest jedną z metod stosowanych w optycznych czytnikach pisma. Ma ona jednak istotną wadę, gdyż wymaga dużego stopnia jednorodności stylu, rozmiaru i orientacji odczytywanych symboli. W szczególności mapy bitowe, tworzone z dużych znaków, nie pasują do wzorów mniejszych wersji tego samego znaku, nawet jeśli kształt tych znaków jest taki sam. Łatwo można sobie także wyobrazić, jak bardzo złożone jest to zadanie przy próbie przetwarzania materiału pisanego odręcznie.
Inna metoda rozpoznawania znaków polega na porównywaniu charakterystycznych właściwości geometrycznych symboli, a nie ich dokładnej postaci. Cyfrę 1 można na przykład scharakteryzować jako jedną prostą linię pionową, cyfrę 2 jako otwartą krzywą połączoną z prostą linią poziomą u dołu itd. Taka metoda rozpoznawania symboli składa się z dwóch faz: najpierw należy wyodrębnić analizowane właściwości z przetwarzanego obrazu, a następnie porównać te właściwości z cechami znanych symboli. Tak jak metoda porównywania ze wzorcem, ten sposób postępowania nie jest odporny na błędy. Niewielkie nawet niedokładności obrazu mogą powodować błędne odczytanie właściwości geometrycznych symboli. Dzieje się tak na przykład przy próbie odróżnienia liter O i C lub w omawianej układance przy próbie odróżnienia 3 i 8.
Na szczęście w rozważanym przykładzie nie trzeba analizować obrazów w przestrzeni trójwymiarowej. Zauważmy, ile zyskujemy dzięki zapewnieniu, że kształty, które trzeba rozpoznać (cyfry od 1 do 8), są oddzielone od siebie i znajdują się w różnych fragmentach obrazu, a nie nakładają się na siebie, jak często zdarza się przy bardziej ogólnych założeniach. Przy analizie zdjęcia, o którym nie przyjmuje się żadnych założeń, problem stwarza fakt, że rozpoznawany obiekt może być widoczny pod różnymi kątami, a w dodatku może być częściowo zasłonięty przez inne obiekty.
W ogólności zadanie rozpoznawania obrazów rozwiązuje się zazwyczaj w dwóch etapach: (1) przetwarzania obrazu, który polega na rozpoznaniu ogólnej charakterystyki obrazu i (2) analizy obrazu, który polega na zrozumieniu, co ta charakterystyka oznacza. Taki sam podział występował przy rozpoznawaniu symboli na podstawie ich właściwości geometrycznych.
160 ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.2. ROZPOZNAWANIE OBRAZÓW 461
Przetwarzanie obrazu polegało wtedy na określeniu właściwości geometrycznych obrazu, a analiza obrazu była procesem określenia znaczenia tych właściwości.
Proces przetwarzania obrazu obejmuje liczne zagadnienia. Jednym z nich jest wydobycie krawędzi, które polega na zastosowaniu technik matematycznych do wyodrębnienia granic między poszczególnymi składowymi obrazu. W pewnym sensie wydobycie krawędzi to próba przekształcenia zdjęcia na rysunek. Inną czynnością wykonywaną przy przetwarzaniu obrazu jest wyszukiwanie obszarów. Jest to proces wyodrębnienia tych obszarów obrazu, które mają takie same właściwości (jasność, kolor, wypełnienie). Taki obszar z dużym prawdopodobieństwem stanowi fragment tego samego obiektu. Zdolność rozpoznawania obszarów umożliwiła komputerowe dodanie kolorów do kreskówek lub do starych filmów czarno-białych. Jeszcze inną czynnością, mieszczącą się w zakresie rozpoznawania obrazów, jest wygładzanie, które jest procesem usuwania wad obrazu. Dzięki wygładzaniu ewentualne wady obrazu nie wprowadzają zamieszania w innych fazach przetwarzania obrazu. Zbyt duże wygładzenie może jednak powodować utratę ważnych informacji.
Wygładzanie, wydobywanie krawędzi i wyszukiwanie obszarów są krokami w kierunku rozpoznania różnych składowych obrazu. Analiza obrazu jest procesem prowadzącym do zrozumienia, co te składowe przedstawiają, a zatem w efekcie do zrozumienia tego, co przedstawia obraz. W tej fazie pojawiają się problemy związane z rozpoznawaniem obiektów częściowo zasłoniętych i obserwowanych pod różnymi względami. Jedna z metod analizy obrazu polega na przyjęciu pewnego początkowego założenia o tym, co może się na nim znajdować, i próbie przypisania elementów obrazu do obiektów, których występowanie założono. Wydaje się, że taką właśnie metodę stosują ludzie. Czasem na nieostrym zdjęciu nie potrafimy rozpoznać obiektu, którego wystąpienia w danych okolicznościach się nie spodziewamy. Jeśli jednak mamy jakąś przesłankę, czym może być dany obiekt, potrafimy go rozpoznać z łatwością.
Problemy związane z analizą obrazów w ogólności są bardzo trudne i pozostało jeszcze wiele do zrobienia w tej dziedzinie. Zadania, które umysł ludzki wykonuje szybko i z łatwością, w dalszym ciągu leżą poza możliwościami maszyn. Jednakże są pewne przesłanki świadczące o tym, że zastosowanie alternatywnych architektur komputerów może pewnego dnia doprowadzić do rozwiązania problemów, które współcześnie nas przerastają (zobacz podrozdział 10.4).
PYTANIA I ĆWICZENIA
1. Na czym polega różnica w wymaganiach stawianych systemowi wideo zamontowanemu w robocie w zależności od tego, czy ma on przekazywać obraz człowiekowi, który steruje pracą robota, czy robotowi do samodzielnego sterowania jego działaniem?
2. Co sprawia, że poniższy obraz jest niescnsowny? Jak tę intuicję zaprogramować na komputerze?
3. Ile bloków jest w wieży przedstawionej poniżej? Ja zaprogramować komputer, żeby dobrze odpowiadał na pytania tego typu?
10.3. Wnioskowanie
Gdy maszyna do układania puzzli odczyta już położenie poszczególnych elementów obrazu, jej zadaniem jest odnalezienie ruchów potrzebnych do ułożenia układanki. Jednym z rozwiązań tego problemu, które przychodzi do głowy, jest wstępne wprowadzenie do maszyny rozwiązań dla wszystkich możliwych początkowych położeń elementów. Wtedy zadaniem maszyny byłoby po prostu wybranie właściwego programu i jego wykonanie. Ośmioełementowa układanka ma jednak 181 440 różnych konfiguracji, więc pomysł przygotowania osobnego rozwiązania dla każdej z nich nie jest zachęcający, a po uwzględnieniu ograniczeń czasowych i pamięciowych zapewne nie jest nawet możliwy do zrealizowania.
Trzeba zatem zaprogramować maszynę tak, żeby potrafiła sama skonstruować rozwiązanie układanki. Oznacza to takie jej zaprogramowanie, aby potrafiła samodzielnie podejmować decyzję, wyciągać wnioski, czyli, krótko mówiąc, wykonywać elementarne działania występujące w procesie wnioskowania.
462 . ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.3. WNIOSKOWANIE
463
Systemy produkcji
Wytworzenie zdolności rozumowania w komputerze jest przedmiotem badań od wielu lat. Jednym z wyników tych badań jest spostrzeżenie, że duża klasa problemów ma wiele wspólnych cech. Te wspólne właściwości wyodrębniono w postaci systemu produkcji (ang. production system), który składa się z trzech głównych elementów:
Zbioru stanów. Każdy stan reprezentuje sytuację, do której może dojść
w środowisku aplikacji. Stan, od którego rozpoczyna się wykonanie, to
stan startowy lub początkowy. Stan (lub stany), który chcemy osiąg
nąć to stan docelowy. (W omawianym przykładzie stan reprezentuje
konfigurację układanki. Stan początkowy jest konfiguracją układanki
w chwili dostarczenia jej maszynie. Stan docelowy to konfiguracja re
prezentująca ułożoną układankę z rysunku 10.2).Zbioru produkcji (reguł lub ruchów). Produkcja jest operacją, która jest wy
konywana w środowisku aplikacji, aby przejść z jednego stanu w inny.
Z każdą produkcją są związane pewne warunki wstępne. Oznacza to,
że można nałożyć pewne warunki, które muszą być spełnione w środo
wisku, aby można było zastosować konkretną produkcję. (Produkcjami
w omawianym przykładzie są przemieszczenia elementów układanki.
Każdy ruch ma warunek wstępny, który jest spełniony tylko wówczas,
gdy obok przesuwanego elementu jest puste miejsce).Systemu sterującego. System sterujący to element logiczny systemu od
powiadający za proces przejścia ze stanu początkowego do docelowego.
Na każdym etapie tego procesu system sterujący musi podjąć decyzję,
którą z produkcji o spełnionych warunkach wstępnych zastosować w na
stępnej kolejności. (W każdym stanie przykładowej układanki z wolnym
polem sąsiaduje kilka elementów, zatem można wykonać kilka produk
cji. System sterujący musi podjąć decyzję, który element przesuwać).
Jak zatem widać, system sterujący jest programem maszyny. Program ten sprawdza bieżący stan systemu, określa ciąg produkcji, który prowadzi do stanu docelowego, i wykonuje ten ciąg.
W rozważaniach dotyczących systemu sterującego ważną rolę odgrywa pojęcie grafu stanów. Jest to wygodny sposób reprezentacji lub przynajmniej wyobrażenia sobie wszystkich stanów, produkcji i warunków wstępnych systemu produkcji. Pojęcie graf ma tutaj znaczenie matematyczne -jest to zbiór wierzchołków połączonych strzałkami, czyli krawędziami. Graf stanów składa się ze zbioru wierzchołków reprezentujących stany systemu połączonych krawędziami reprezentującymi produkcje zmieniające stan systemu. Dwa wierzchołki są połączone krawędzią w grafie stanów wtedy i tylko wtedy, gdy jest produkcja w systemie produkcji, która przekształca stan początkowy krawędzi (stan, z którego wychodzi strzałka) w stan wskazywany przez strzałkę krawędzi. Warunki wstępne są niejawnie reprezentowane przez brak krawędzi między pewnymi wierzchołkami.
Podkreślmy, że w przykładowym problemie układanki liczba stanów uniemożliwia jawną reprezentację całego grafu stanów - z tego samego powodu okazało się niemożliwe przygotowanie rozwiązania dla każdego stanu początkowego. Graf stanów jest zatem sposobem pojęciowego przedstawienia problemu, a nie czymś, co chcielibyśmy wyrażać w całości. Mimo to warto przeanalizować (a być może rozszerzyć) fragment grafu stanów dla układanki przedstawiony na rysunku 10.3.
W kontekście grafu stanów zadanie systemu sterującego polega na znalezieniu ciągu krawędzi, które prowadzą od stanu początkowego do stanu docelowego. Taki ciąg krawędzi reprezentuje ciąg produkcji, których wykonanie prowadzi do rozwiązania postawionego zadania. Niezależnie zatem od konkretnego przykładu, zadanie systemu sterującego można traktować jak zadanie znalezienia ścieżki w grafie stanów. Rozpatrując problem wnioskowania w kategoriach systemów produkcji, zyskujemy więc uniwersalny
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.3. WNIOSKOWANIE 465
punkt widzenia na system sterujący. Podkreślmy znaczenie tego osiągnięcia, wyrażając inne problemy w postaci systemów produkcji, to jest w postaci systemów sterujących, których zadaniem jest znalezienie ścieżki w grafach stanów.
Jednym z klasycznych przedmiotów zainteresowania sztucznej inteligencji są gry takie jak szachy. Takie gry cechują się średnią złożonością i tworzą dobrze zdefiniowany kontekst, dzięki temu stanowią idealne środowisko do testowania teorii. W szachach stanami systemu produkcji są wszystkie możliwe konfiguracje szachownicy, produkcjami są ruchy pionków i figur, a system sterujący jest zaszyty w graczy (na przykład ludzi). Wierzchołek początkowy grafu stanów reprezentuje szachownicę z początkowym rozstawieniem figur. Z tego wierzchołka wychodzą krawędzie prowadzące do tych konfiguracji szachownicy, które można uzyskać po pierwszym ruchu
gry. Z każdego z tych węzłów można przejść po krawędziach do konfiguracji osiągalnych po następnym ruchu itd. Formułując problem w ten sposób, na grę w szachy można patrzeć jak na dwóch graczy próbujących znaleźć ścieżkę w olbrzymim grafie stanów do wybranego przez siebie stanu docelowego.
Być może mniej oczywistym przykładem zastosowania systemu produkcji jest problem wyciągania konkluzji z podanego zbioru faktów. Produkcjami w takim kontekście są reguły logiki, które umożliwiają formułowanie ze zbioru już istniejących stwierdzeń nowych wniosków. Na przykład ze stwierdzeń „Wszyscy studenci ciężko pracują" i „Jan jest studentem" można wywnioskować, że „Jan ciężko pracuje". Zdanie „Marysia i Jurek są zdolni" można sformułować jako „Ani Marysia, ani Jurek nie są niezdolni". Stanami takiego systemu są zbiory tych stwierdzeń, których prawdziwość stwierdzono na danym etapie procesu dedukcyjnego. Stan początkowy jest zbiorem stwierdzeń podstawowych (zwanych często aksjomatami), z których są wyciągane wnioski, a stanem docelowym jest dpwolny zbiór stwierdzeń zawierający postulowaną konkluzję.
Na rysunku 10.4 przedstawiono fragment grafu stanów, którym można zilustrować proces wyprowadzenia stwierdzenia „Sokrates jest śmiertelny" ze zbioru zdań „Sokrates jest mężczyzną", „Wszyscy mężczyźni są ludźmi", „Wszyscy ludzie są śmiertelni". Widać, jak wraz z przechodzeniem od stanu do stanu, w miarę postępu procesu dedukcji zmienia się wiedza, którą dysponuje system. Sam proces dedukcji polega na zastosowaniu odpowiednich produkcji w celu utworzenia nowych stwierdzeń.
Drzewa wyszukiwania
Stwierdziliśmy, że zadaniem systemu sterującego jest przeszukiwanie grafu stanów w celu znalezienia ścieżki z wierzchołka początkowego do docelowego. Prosta metoda wykonania tego zadania polega na przejściu po każdej krawędzi wiodącej od stanu początkowego i zapamiętaniu stanu, do którego ta krawędź prowadzi. Następnie należy przejść po krawędziach wychodzących z tych nowych stanów i ponownie zapamiętać stany docelowe itd. Wyszukiwanie rozprzestrzenia się zatem na coraz więcej stanów począwszy od stanu początkowego, tak jak kropla barwnika stopniowo rozprzestrzenia się w wodzie. Proces przechodzenia do nowych stanów powtarza się aż do chwili, gdy któryś z nowych stanów okaże się stanem docelowym. Oznacza to, że zostało znalezione rozwiązanie, a system sterujący musi po prostu stosować po kolei produkcje znajdujące się na znalezionej ścieżce, począwszy od stanu początkowego do końcowego.
W wyniku zastosowania takiej strategii powstaje drzewo wyszukiwania, które składa się z tej części grafu stanów, która została przeanalizowana przez system sterujący. Korzeniem drzewa wyszukiwania jest stan początkowy, a dziećmi każdego węzła są stany osiągalne z rodzica przez zastosowanie pojedynczej produkcji. Każda krawędź między węzłami w drzewie
466 ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.3. WNIOSKOWANIE
467
7. Popraw opisaną metodę obliczania przewidywanego kosztu, aby algorytm wyszukujący z rysunku 10.9 nie wykonał złego wyboru, jak stało się to w przykładzie omówionym w tym podrozdziale. Czy potrafisz znaleźć przykład stanu początkowego, który wprowadzi na złą ścieżkę opracowany przez Ciebie algorytm?
10.4. Sztuczne sieci neuronowe
Mimo postępu poczynionego na polu sztucznej inteligenci, rozwiązanie wielu problemów z tej dziedziny dalej przekracza możliwości współczesnych, tradycyjnych komputerów. Jednostki centralne, które wykonują pojedyncze ciągi rozkazów, nie wydają się być zdolne do postrzegania i wnioskowania na poziomie porównywalnym z wieloprocesorowym umysłem ludzkim. Z tego powodu wielu badaczy zwraca się w stronę maszyn z architekturą wieloprocesorową. Jedną z takich architektur są sztuczne sieci neuronowe.
Podstawowe właściwości
Sztuczne sieci neuronowe, zgodnie z tym, co stwierdziliśmy w rozdziale 2, konstruuje się z wielu pojedynczych procesorów, które będziemy nazywać jednostkami sterującymi (lub krótko jednostkami), połączonych w sposób naśladujący sieci neuronów w żywych systemach biologicznych. Neuron biologiczny jest pojedynczą komórką z wypustkami wejściowymi, zwanymi dendrytami, i wypustkami wyjściowymi, zwanymi aksonami (rys. 10.14). Sygnały przesyłane przez aksony komórki odzwierciedlają to, czy komórka jest w stanie spoczynku, czy w stanie wzbudzenia. Stan ten jest wyznaczany na podstawie kombinacji sygnałów odbieranych przez dendryty komórki. Dendryty odbierają sygnały od aksonów innych komórek za pomocą małych szczelin zwanych synapsami. Naukowcy podejrzewają, że to, czy sygnał przepłynie przez synapsę, zależy od jej składu chemicznego. Zatem to, czy konkretny sygnał wejściowy spowoduje wzbudzenie neuronu, czy jego przejście w stan spoczynku zależy od składu chemicznego synapsy. Panuje pogląd, że biologiczna sieć neuronowa uczy się, dostosowując odpowiednio skład tych chemicznych łączy między neuronami.
Jednostka przetwarzająca (krótko: jednostka) w sztucznej sieci neuronowej to proste urządzenie, które naśladuje podstawowe zachowanie neuronu biologicznego. Wytwarza ono na wyjściu 0 lub 1 w zależności od tego, czy jego efektywna wartość wejściowa przekracza zadaną wartość graniczną. Ta efektywna wartość wejściowa jest sumą ważoną bieżących wartości wejściowych, jak przedstawiono to na rysunku 10.15. Na rysunku wyjścia trzech jednostek (oznaczane V\, Vz, U3) wykorzystuje się w charakterze wejścia dla
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.4. SZTUCZNE SIECI NEURONOWE 479
480 ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.4. SZTUCZNE SIECI NEURONOWE 481
innej jednostki. Z poszczególnymi wejściami tej czwartej jednostki są związane wartości nazywane wagami (oznaczone W\, "Wi, 103). Jednostka odbierająca mnoży każdą z wartości wejściowych przez wagę związaną z danym wejściem, a następnie dodaje iloczyny, obliczając w ten sposób efektywną wartość wejściową (v\w^ + viwi + 03^3). Jeśli suma przekroczy wartość graniczną jednostki, to wytwarza ona na wyjściu wartość jeden, w przeciwnym razie na wyjściu pojawia się wartość 0.
Zgodnie z rysunkiem 10.15 stosujemy konwencję przedstawiania jednostek jako prostokątów. Na brzegu jednostki umieszczamy wejścia w postaci mniejszych prostokątów. W każdym takim prostokącie wpisujemy związaną z wejściem wagę. Wartość graniczną zapisujemy wewnątrz dużego prostokąta. Na rysunku 10.16 przedstawiono jednostkę z trzema wejściami i wartością graniczną równą 1,5. Wagą pierwszego wejścia jest wartość —2, drugie wejście ma wagę 3, a trzecie -ł. Jeśli więc jednostka otrzyma na wejściach wartości 1, 1, 0, to efektywna wartość wejściowa będzie wynosić 1 • (-2) + 1 ■ 3 + 0 • (-1) = 1, a na wyjściu pojawi się 0. Jeśli jednak na wejściu pojawią się wartości 0, 1, 1, to efektywna wartość wejściowa wyniesie 0 • (-2) + 1 ■ 3 + 1 ■ (-1) = 2, co przekracza wartość graniczną. Na wyjściu jednostki pojawi się zatem wartość 1.
Fakt, że waga może być dodatnia lub ujemna, oznacza, że odpowiednie wejścia mogą mieć na odbierającą jednostkę albo efekt pobudzający, albo hamujący. (Jeśli waga wejścia jest ujemna, to wartość 1 na tym wejściu zmniejszy sumę ważoną, dążąc tym samym do utrzymania efektywnej wartości wejściowej poniżej wartości granicznej. Dla odmiany, waga dodatnia powoduje, że związane z nią wejście ma wpływ na zwiększenie sumy ważonej, a zatem zwiększa się szansa przekroczenia przez tę sumę wartości granicznej). Wartości wag kontrolują stopień wzbudzania lub hamowania jednostki przez to wejście. Dobierając wagi w całej sztucznej sieci neuronowej, możemy tak ją programować, aby reagowała na różne wejścia w z góry określony sposób.
Prostą sieć z rysunku 10.17(a) tak zaprogramowano na przykład, aby dawała na wyjściu wartość 1, jeśli wartości na jej wejściach są różne, a zero w przeciwnym razie. Jeśli jednak zmienimy wagi na wartości przedstawione na rysunku 10.17(b), to otrzymamy sieć, która odpowiada wartością 1, jeśli oba wejścia są równe 1, a wartością 0 w przeciwnym razie.
Zauważmy, że sieć z rysunku 10.17 jest dużo prostsza niż rzeczywiste sieci biologiczne. Mózg człowieka zawiera około 1011 neuronów, każdy z około 104 synapsami na neuron. Dendryty neuronu biologicznego są tak liczne, że przypominają włóknistą siatkę, nie zaś pojedyncze nitki przedstawiane na poprzednich rysunkach.
Konkretne zastosowanie
Aby docenić możliwości sztucznych sieci neuronowych, rozważmy konkretny problem odróżniania wielkich liter C i T przedstawionych na rysunku 10.18. Problem polega na rozpoznaniu litery, gdy zostanie ona umieszczona w polu widzenia, niezależnie od jej orientacji. Wszystkie wzorce z rysunku 10.19(a) powinny zostać rozpoznane jako C, a wszystkie wzorce z rysunku 10.19(b) jako litery T.
Załóżmy, że pole widzenia składa się z kwadratowych piksli. Rozmiar każdego z nich jest taki sam jak rozmiar kwadratów, z których składają się litery. Do każdego piksla jest przyłączony czujnik, który wytwarza wartość 1, jeśli piksel jest zakryty przez oglądaną literę, a w przeciwnym razie wytwarza sygnał 0. Wyjścia tych czujników wykorzystamy jako wejścia projektowanej sztucznej sieci neuronowej.
Sieć składa się z dwóch poziomów jednostek. Pierwszy poziom zawiera wiele jednostek - po jednej dla każdego bloku o rozmiarze trzy na trzy pik-sle w polu widzenia (zobacz rys. 10.20). Każda z tych jednostek ma dziewięć wejść, do których są przyłączone czujniki związane z blokiem nadzorowanym przez tę jednostkę. (Zwróćmy uwagę, że bloki związane z jednostkami pierwszego poziomu nakładają się na siebie. Zatem każdy czujnik przekazuje sygnał do dziewięciu jednostek z pierwszego poziomu).
Drugi poziom sieci składa się z jednej jednostki, która ma oddzielne wejście dla każdej jednostki z pierwszego poziomu. Jednostka z drugiego poziomu ma wartość graniczną równą 0.5, a z każdym jej wejściem jest związana waga 1. Jednostka ta wytworzy zatem wartość wyjściową 1 wtedy i tylko wtedy, gdy przynajmniej jedno jej wejście będzie miało wartość 1.
Każda jednostka na pierwszym poziomie ma wartość graniczną 0.5. Każde wejście ma wagę -1, z wyjątkiem wejścia związanego z centralnym pikslem bloku kontrolowanego przez tę jednostkę, które ma wagę 2. Każda
z tych jednostek może zatem wytworzyć na wyjściu wartość 1 tylko wtedy, gdy otrzyma 1 od czujnika związanego z centralnym pikslem bloku.
Jeśli teraz położymy literę C w polu widzenia (rys. 10.21), to na wyjściu wszystkich jednostek z pierwszego poziomu pojawi się 0. Stanie się tak, bo jedynymi jednostkami, które mają przykryty centralny piksel są jednostki, które mają przykryte także co najmniej dwa inne piksle z tego samego bloku, więc sygnały odebrane z tych czujników zniwelują efekt wzbudzenia centralnego czujnika. Jeśli zatem w polu widzenia pojawi się C, to wszystkie wejścia jednostki z drugiego poziomu będą miały wartość 0, co oznacza, że na wyjściu z całej sieci pojawi się 0.
Załóżmy teraz, że w polu widzenia znajduje się litera T. Rozważmy blok o rozmiarze trzy na trzy, którego środkiem jest kwadrat zakryty przez dolny piksel nóżki litery T (rys. 10.22). Jednostka przypisana temu polu otrzyma efektywną wartość wejściową wynoszącą 1 (2 z piksla centralnego oraz -Iz drugiego piksla przykrytego przez nóżkę). Przekracza ona wartość graniczną jednostki, więc przekaże ona wartość wyjściową 1 do jednostki z wyższego poziomu. To z kolei spowoduje, że jednostka ta wytworzy na wyjściu wartość 1.
Skonstruowaliśmy zatem sztuczną sieć neuronową, która rozróżnia litery C i T niezależnie od położenia litery w polu widzenia. Jeśli literą jest C, to na wyjściu sieci pojawia się 0, jeśli jest to T, to na wyjściu będzie 1.
482 ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.4. SZTUCZNE SIECI NEURONOWE
483
Oczywiście zdolność odróżniania tylko dwóch liter jest kroplą w morzu w porównaniu z możliwościami przetwarzania obrazu przez umysł ludzki. Elegancja rozwiązań takich jak przedstawione powyżej uzasadnia jednak celowość dalszych badań w tej dziedzinie.
W rezultacie sztuczne sieci neuronowe są przedmiotem aktywnych badań. Główne problemy wiążą się z projektowaniem i programowaniem takich sieci. Typowe cele badań nad sieciami neuronowymi to ustalenie, ile jednostek potrzeba do rozwiązania pewnych problemów oraz ile poziomów mają one tworzyć. Ważnym zadaniem jest też określenie wzorców łączenia jednostek w sposób jak najbardziej produktywny.
Co się tyczy programowania sieci, widzieliśmy już, że programowanie sztucznych sieci neuronowych polega na przypisaniu właściwych wag
wejściom poszczególnych jednostek sterujących w systemie. Najpopularniejszym sposobem osiągnięcia tego jest obecnie przeprowadzenie procesu treningu sieci, w którym wprowadza się do sieci przykładowe wartości wejściowe i koryguje się nieznacznie wagi, tak aby na wyjściu sieci pojawiła się wartość możliwie bliska oczekiwanej.
Po wielokrotnym powtórzeniu tego procesu na różnych przykładowych danych wejściowych będą potrzebne coraz mniejsze korekty wag, aż wreszcie sieć zacznie zachowywać się poprawnie dla wszystkich danych przykładowych. Jest zatem potrzebna strategia korygowania wag, aby każda nowa zmiana prowadziła do celu, a nie niweczyła postępów dokonanych na poprzednich przykładach.
484
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.4. SZTUCZNE SIECI NEURONOWE
485
PYTANIA I ĆWICZENIA
1. Jaka będzie wartość na wyjściu następującej jednostki, gdy oba wejścia są równe jeden? Jak zmieni się odpowiedź, jeśli na wejściu pojawią się pary wartości: 0,0; 0,1 i 1,0?
3. Zaprojektuj sztuczną sieć neuronową, która potrafi wykryć, który z następujących wzorców znajduje się w jej polu widzenia.
2. Dobierz wagi i wartość graniczną następującej jednostki, aby na wyjściu pojawiała się 1 wtedy i tylko wtedy, gdy co najmniej dwa wejścia są równe jedności.
4. Zaprojektuj sztuczną sieć neuronową, która potrafi wykryć, który z następujących wzorców znajduje się w jej polu widzenia.
10.5. Algorytmy genetyczne
Algorytmy genetyczne to obszar badań, w którym do rozwiązywania zadań próbuje się wykorzystać wiedzę o procesie ewolucji naturalnej. Metoda ta polega na skrzyżowaniu tych rozwiązań ze zbioru proponowanych rozwiązań, które dają najlepsze rezultaty. Otrzymuje się w ten sposób kolejne pokolenie rozwiązań, które stanowi ulepszenie pierwotnego zbioru. Powtarzając ten proces wielokrotnie, próbuje się zasymulować proces ewolucji i w końcu uzyskać rozsądne rozwiązania zadanego problemu.
Przypuśćmy na przykład, że w każdą środę wieczorem gramy w pokera z tą samą grupą przyjaciół i chcemy opracować strategię, która zmak-symalizuje wygraną. Podejście ewolucyjne do tego zagadnienia polega na określeniu różnych sytuacji, które mogą pojawić się w trakcie gry w pokera i możliwych reakcji na nie. Jest to oczywiście duże przedsięwzięcie, bo trzeba rozważyć wiele sytuacji. Po wykonaniu takiej analizy można
486 ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.5. ALGORYTMY GENETYCZNE
487
10.6. Zastosowania sztucznej inteligencji
Rozważywszy niektóre z technik stosowane w sztucznej inteligencji, możemy omówić teraz dziedziny, w których techniki te znalazły lub znajdują zastosowanie.
Przetwarzanie języka naturalnego
Zacznijmy od problemu automatycznego tłumaczenia zdań z jednego języka na drugi. Wykorzystuje się w tym celu zarówno tradycyjne systemy, jak i systemy oparte na technikach sztucznej inteligencji, w zależności od tego, o jaki język chodzi. Różnica tkwi w tym, czy do przetłumaczenia zdania trzeba znać jego znaczenie. Tradycyjne języki programowania tak zaprojektowano, że można je przetłumaczyć bezproblemowo, po prostu wyszukując oryginalną instrukcję (lub jej część) w tablicy, w której znajduje się także jej przetłumaczony odpowiednik. Komputer nie musi zatem rozumieć znaczenia tłumaczonych instrukcji. Rozpoznaje po prostu ich składnię, odnajduje je w tablicy i odczytuje z niej przetłumaczoną postać. Takie zastosowania leżą więc w zasięgu możliwości tradycyjnych programów komputerowych. Zupełnie inaczej wygląda problem tłumaczenia z języków naturalnych, takich jak angielski, niemiecki lub łacina. Aby dokonać poprawnego tłumaczenia, często trzeba zrozumieć sens zdania. Na przykład, aby dobrze przetłumaczyć z języka angielskiego poniższe zdania, trzeba je zrozumieć, nie wystarczy po prostu przetłumaczyć poszczególnych słów.
Norman Rockwell painted people .
Cinderella had a ball-t.
Opracowanie komputerów, które potrafią rozumieć język naturalny, stało się jednym z głównych zadań badawczych sztucznej inteligencji. Jest to zarazem problem, który pokazuje, jak wyzywające mogą być badania na polu sztucznej inteligencji.
Jeden z problemów, powstających podczas przetwarzania języka naturalnego, polega na tym, że ludzie wypowiadają się nie zawsze zgodnie z obowiązującymi regułami. Czasem nawet wypowiadają zdania, które nie wyrażają dokładnie tego, co mają na myśli. Pytanie
Wiesz, która jest godzina?
^Dosłownie: Norman Rockwell malował ludzi. Oczywiście chodzi o postaci ludzi malowane przez amerykańskiego malarza Normana Rockwella (przyp. tłum.). ^Kopciuszek miał dobry bal lub Kopciuszek miał piłkę (przyp. tłum.).
często oznacza „Powiedz proszę, która jest godzina". Jeśli jednak pytanie to usłyszymy, przychodząc spóźnieni na jakieś spotkanie, to może ono także oznaczać „Bardzo się spóźniłeś".
Zrozumienie znaczenia zdania wypowiedzianego w języku naturalnym wymaga zatem zastosowania wielopoziomowej analizy. Pierwszy poziom to analiza składniowa, której głównym elementem jest rozbiór gramatyczny zdania. To właśnie na drodze analizy składniowej rozpoznaje się, że podmiotem zdania
Marysia dała Jankowi kartkę urodzinową, jest Marysia, a podmiotem zdania
Janek dostał od Marysi kartkę z życzeniami.
jest Janek.
Następnym poziomem analizy jest analiza semantyczna. W odróżnieniu od procesu rozbioru, który po prostu określa gramatyczną funkcję każdego słowa, zadaniem analizy semantycznej jest określenie znaczeniowej roli każdego wyrazu w zdaniu. Na drodze analizy semantycznej próbuje się określić, które elementy zdania opisują akcję, obiekt wykonujący tę akcję (nie musi on być podmiotem zdania) i przedmiot akcji. To właśnie analiza semantyczna umożliwia stwierdzenie, że zdania „Marysia dała Jankowi kartkę urodzinową" oraz „Janek dostał od Marysi kartkę urodzinową" wyrażają
to samo.
Trzeci poziom analizy to analiza kontekstowa. Na tym poziomie do ustalenia znaczenia zdania wykorzystuje się kontekst jego wystąpienia. Określenie funkcji gramatycznej każdego wyrazu w poniższym zdaniu jest łatwe.
Piłka wyślizgnęła mu się z ręki.
Można nawet dokonać analizy semantycznej, identyfikując akcję wyślizgiwanie się, obiekt wykonujący tę akcję pitka itd. Ale dopóki nie uwzględnimy kontekstu, w którym pojawia się to zdanie, dopóty jego znaczenie nie będzie do końca jasne. Oznacza ono bowiem różne rzeczy w zależności od tego, czy wypowiedziano go, mówiąc o sportowcu, czy na przykład o stolarzu przycinającym listwy. Na etapie analizy kontekstowej odkrywa się także prawdziwy sens pytań w rodzaju „Czy wiesz, która jest godzina?".
Zauważmy, że poszczególne poziomy analizy: składniowej, semantycznej i kontekstowej nie są od siebie niezależne. Podmiotem następującego zdania w języku angielskim:
Stampeding cattle can be dangerous.
może być albo rzeczownik cattle - bydło opisany przymiotnikiem stampeding - spłoszone, pędzące w popłochu, rozpuszczone, jeśli myślimy o pędzącym stadzie bydła. Podmiotem może być jednak także słowo stampending - płoszenie (w gramatyce języka angielskiego taką część mowy nazywa się gerund) z dopełnieniem bydła, jeśli wyobrazimy sobie wichrzyciela zabawiającego się wzniecaniem paniki wśród bydła.
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.6. ZASTOSOWANIA SZTUCZNEJ INTELIGENCJI 493
Ar
REKURSJA W JĘZYKU NATURALNYM
;tury rekurencyjne polegające na występowaniu zdania aniu są bardzo częste w języku angielskim (także w innych ach). Zdanie zagnieżdżone w zdaniu to zdanie podrzędne, niki radzenia sobie z takimi zdaniami byty jednym z pierw-i tematów badań w dziedzinie komputerowego przetwarzania a naturalnego. Czasami takie struktury wykorzystują wiele imów rekursji, przez co ginie sens zdania, chociaż jego ca-jwa struktura jest gramatycznie poprawna. Rozważmy na ład zdanie
Mężczyźnie, którego zrzucił koń, który przegra} wyścig, nic się nie stało .
wyższym zdaniu występują trzy struktury zdaniowe jedna igiej. Zewnętrzne zdanie to
Mężczyźnie nic się nie stało.
la struktura wewnętrzna określa mężczyznę jako tego, io zrzuci! koń. W tej strukturze znajduje się kolejna struk-tfóra informuje, że chodzi o tego konia, który przegra) wy-Oto inne przykłady z nieco odmiennymi strukturami reku-nymi
Dbraz, który powiesił mężczyzna, którego latrudniła kobieta, która mieszka obok, spadł.
\Iowy kucharz, którego zatrudnił szef, który ciągle :rzyczy, a który nie potrafił przysmażać potraw, :ostał zwolniony.
jzyku angielskim to zdanie jest jeszcze bardziej niezrozu-ze względu na brak interpunkcji, przypadków i pominięcie ych zaimków: The man the horse that lost the race threw ot hurt. (przyp. tłum.).
Główne kierunki badań nad rozumieniem języka naturalnego dotyczą nie tylko problemów związanych z tłumaczeniem tekstów, ale także problematyki wyszukiwania i wydzielania informacji z tekstu. Wyszukiwanie informacji odnosi się do identyfikacji dokumentów, które są związane z określonym tematem. Zadanie to dobrze ilustruje przykład prawnika, który poszukuje informacji o wszystkich procesach, które mają związek z toczącym się postępowaniem. Powrócimy do tego przykładu niebawem w kontekście wyszukiwania informacji w bazach danych. Wydzielanie informacji polega na wydobyciu potrzebnej informacji z dokumentów i przedstawienie jej w postaci dogodnej do dalszego przetwarzania. Wydzielanie informacji może zatem oznaczać znalezienie odpowiedzi na zadane pytanie lub zapisanie informacji w postaci, która umożliwi późniejsze odpowiedzenie na pytania. Jedna z takich postaci to szablon. Jest to po prostu kwestionariusz, w którym zapisuje się szczegółowe informacje. Rozważmy system, którego zadaniem jest przygotowanie wyboru artykułów prasowych. W takim systemie może być wiele różnych szablonów - po jednym dla każdego rodzaju artykułu, który może pojawić się w prasie. Jeśli analizowany artykuł okazuje się być raportem o włamaniu, to próbuje się wypełnić poszczególne rubryki w szablonie dotyczącym włamań. Taki sza-
, m, u j ii rnwTTTTwnrnmTnmwtrfr*" błon zawiera zapewne takie elementy
jak: adres włamania, czas i data włamania, skradzione dobra itd. Z kolei,
jeśli system stwierdzi, że analizowany artykuł opowiada o klęsce żywiołowej, to szablon dotyczący klęsk żywiołowych zawiera zapewne informacje określające rodzaj klęski, wielkość zniszczeń itd.
Inną formą przechowywania informaq'i w trakcie jej wydzielania są sieci semantyczne. Jest to duża dowiązaniowa struktura danych, w której do
opisania związków między poszczególnymi elementami danych stosuje się wskaźniki. Na rysunku 10.25 przedstawiono fragment sieci semantycznej, w której zaznaczono informacje uzyskane ze zdania
Marysia uderzyła Janka.
Robotyka
Sztuczna inteligencja znajduje także zastosowania w robotyce, a dokładniej w procesie sterowania maszynami. Tradycyjne techniki można stosować, jeśli maszyna realizuje swoje zadanie w środowisku, nad którym mamy
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.6. ZASTOSOWANIA SZTUCZNEJ INTELIGENCJI 495
kontrolę. Tak jest na przykład w sterowanych komputerowo liniach produkcyjnych. W takim środowisku maszyna najczęściej powtarza wykonywane ciągle w ten sam sposób czynności. Przypuśćmy, że maszyna ma zbierać w regularnych odstępach elementy z taśmy przenośnika i umieszczać je w opakowaniach. Pełne opakowania są stale zastępowane nowymi, które umieszcza się zawsze w tym samym miejscu. Tutaj maszyna tak naprawdę nie zbiera elementów, lecz po prostu zamyka swój chwytak w określonej chwili, w określonym miejscu, i przemieszcza swoje ramię w inne miejsce, gdzie po prostu otwiera chwytak. Zgodzimy się chyba, że w takim sposobie działania nie widać inteligencji.
Sytuacja jednak zmienia się diametralnie, jeśli maszyna musi realizować swoje zadanie w niekontrolowanym środowisku. Dzieje się tak na przykład w obszarach niezamieszkanych i nieznanych, z którymi stykamy się w takich zastosowaniach jak eksploracja przestrzeni kosmicznej. Także opisany powyżej przykład taśmy produkcyjnej zmodyfikowany tylko w niewielkim stopniu może wymusić wymaganie, aby maszyna cechowała się inteligencją. Przypuśćmy, że elementy nie są odizolowane od innych części na taśmie przenośnika, ale że dostarcza się je w opakowaniach zawierających także inne części. Zadaniem maszyny jest teraz rozpoznanie właściwych elementów, usunięcie innych części, żeby nie przeszkadzały w pracy, i wybranie z opakowania właściwych elementów. Jeśli elementy w opakowaniu są dowolnie przemieszane, to wybranie każdego z nich wymaga wykonania innego ciągu kroków, który maszyna musi opracować sama. Poza tym, maszyna musi stale monitorować aktualną sytuację, gdyż części w opakowaniu mogą się przemieszczać. Rozwiązywanie takich problemów to kolejne zadanie badawcze sztucznej inteligencji.
Systemy baz danych
Systemy przetwarzające języki naturalne są stosowane przede wszystkim w systemach do przechowywania informacji i ich wyszukiwania, które teraz omówimy. Chodzi przy tym o to, aby człowiek używający takiego systemu nie musiał stosować specjalnego, nieco technicznego języka zapytań, ale by mógł uzyskiwać informację, posługując się językiem naturalnym.
Dobrze byłoby także, aby odpowiedzi systemu na stawiane mu pytania były inteligentne. Tradycyjne systemy przechowywania i wyszukiwania informacji potrafią jedynie podawać te informacje, których jawnie zażądano. W odróżnieniu od nich systemy ze sztuczną inteligencją mają pobierać informacje związane z zapytaniem, ale niekoniecznie te, które zapytanie bezpośrednio specyfikuje. Potrzebę udostępnienia takich możliwości dobrze widać w bazach danych z informacjami prawniczymi. Prawnik może chcieć uzyskać informacje o wszystkich postępowaniach związanych tematycznie z obecnie prowadzoną sprawą. Jednak stwierdzenie, czy dwa postępowania mają ze sobą jakiś związek, wymaga przeprowadzenia ich wstępnej analizy. Dobrze byłoby, gdyby prawnik otrzymał system informacyjny obdarzony
inteligencją, który potrafiłby odnaleźć materiał powiązany z szukaną informacją, a nie tylko przekazujący informację, której jawnie od niego zażądano. Tradycyjne sposoby wyszukiwania informacji polegają na tym, że prawnik określa słowa kluczowe i frazy, które występują w interesujących go sprawach. System przeszukuje następnie bazę danych i wyświetla te sprawy, które zawierają podane wyrazy lub frazy. Taki system działa po prostu jak sito pozwalające zmniejszyć liczbę postępowań, które trzeba przeanalizować. Niestety jest także możliwe przeoczenie ważnej informacji, chociażby z tego powodu, że w jej opisie pojawia się słowo „niepełnoletni", a nie „młodociani". Prawdziwie inteligentny system dostarczyłby bardziej wiarygodnych
informacji.
Oto inny przykład. Załóżmy, że mamy bazę danych zawierającą informację o zajęciach akademickich i prowadzących je nauczycielach oraz oceny, które wystawili oni poszczególnym studentom. Rozważmy następujący scenariusz. Pytamy o liczbę piątek wystawionych przez profesora Kowalskiego w ostatnim semestrze. Dostajemy odpowiedź „zero". Myślimy sobie, że profesor Kowalski jest wymagający i pytamy o liczbę dwójek. Baza danych znów daje odpowiedź „zero". Wyciągamy zatem wniosek, że profesor Kowalski uważa, że wszyscy studenci prezentują średni poziom, być może z nielicznymi wyjątkami, pytamy więc o liczbę ocen dostatecznych. I znów otrzymujemy odpowiedź „zero". W tym momencie nabieramy podejrzeń i pytamy, czy profesor Kowalski prowadził jakieś zajęcia w ostatnim semestrze. Baza danych odpowiada, że nie. Że też nie mogła od razu tak odpowiedzieć!
Inny problem związany z tradycyjnymi metodami przechowywania danych i systemami wyszukiwania informacji polega na tym, że podają one jedynie te informacje, które są w nich zapisane. Tymczasem chciałoby się, żeby takie systemy mogły wyciągać wnioski z posiadanych informacji i podawać także informacje, które wynikają z danych znajdujących się w bazie. Przyjrzymy się na przykład bazie danych z informacjami o prezydentach Stanów Zjednoczonych. Tradycyjne bazy danych nie potrafią odpowiedzieć na pytanie, czy któryś prezydent miał wzrost 10 stóp (1 stopa = 30,48 cm), chyba że wzrost każdego prezydenta jest zapamiętany w takiej bazie. Z drugiej strony inteligentny system potrafiłby odpowiedzieć poprawnie na to pytanie bez znajomości wzrostu każdego z prezydentów. Tok rozumowania byłby następujący: Gdyby był jakiś prezydent o wzroście 10 stóp, byłoby to bardzo niecodzienne i na pewno taką informację umieszczono by w bazie danych. Ponieważ nie odnotowano przy żadnym prezydencie informacji o tym, że ma 10 stóp wzrostu, to takich prezydentów nie było.
Wniosek o tym, że nie było prezydentów mierzących 10 stóp, wiąże się z ważnym pojęciem dotyczącym baz danych. Wśród baz danych wyróżnia się bazy danych zakładające domkniętość świata i bazy danych z otwartym światem. Mówiąc nieformalnie, baza danych z domkniętym światem to taka baza, o której zakłada się, że zawiera wszystkie prawdziwe fakty dotyczące pewnego zagadnienia. W bazach z otwartym światem nie przyjmuje się takiego założenia. Odrzucenie hipotezy istnienia 10-stopowego prezydenta
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.6, ZASTOSOWANIA SZTUCZNE] INTELIGENCJI 497
w poprzednim przykładzie oparto na założeniu domkniętości świata, czyli założeniu, że jeśli jakiś fakt nie jest zapamiętany w bazie, to musi być nieprawdziwy.
Chociaż bazy z domkniętym światem wyglądają z pozoru niewinnie, to jednak mogą prowadzić do subtelnych problemów. Przypuśćmy, że w bazie znajduje się informacja
Jest nadmiar towaru A lub jest nadmiar towaru B.
Z tego jednego zdania nie można wywnioskować, że jest nadmiar towaru A. Zatem założenie o domkniętości świata zmusza do wyciągnięcia wniosku:
Nie ma nadmiaru towaru A.
W podobny sposób wywnioskujemy, że przy założeniu domkniętości świata Nie ma nadmiaru towaru B.
Widać zatem, że założenie domkniętości świata prowadzi do sprzeczności. Mimo że mamy nadmiar towaru A albo B, jednak nie ma nadmiaru żadnego z nich. Zrozumienie ograniczeń tej z pozoru niewinnej techniki jest zadaniem współczesnych badań w dziedzinie sztucznej inteligencji.
Jeszcze innym celem badań sztucznej inteligencji na polu baz danych jest rozwiązanie problemu stwierdzania, co tak naprawdę użytkownik systemu chce wiedzieć i jakiej udzielić mu odpowiedzi zamiast dosłownej odpowiedzi na postawione pytanie.
Systemy eksperckie
Ważnym rozszerzeniem koncepcji inteligentnej bazy danych są systemy eksperckie - pakiety oprogramowania zaprojektowane do wspomagania człowieka w sytuacjach wymagających wiedzy eksperta w określonej dziedzinie. Takie systemy projektuje się, żeby symulowały wnioskowanie przyczynowo--skutkowe, które dokonywałby ekspert w takiej samej sytuacji. Medyczny system ekspercki zaproponowałby zatem ten sam sposób leczenia, jaki obrałby ekspert w dziedzinie medycyny, który wie, że na przykład w wypadku stwierdzenia zmian niezgodnych z normą i wykrycia na zdjęciu rentgenowskim obecności guzka, należy wykonać biopsję.
Z powyższego przykładu wynika, że głównym zadaniem przy konstruowaniu systemu eksperckiego jest zdobycie potrzebnej wiedzy od eksperta. Ważnym przedmiotem badań stało się opracowanie sposobu dokonania tego. Problem jest dwojakiego rodzaju. Po pierwsze, należy zapewnić sobie współpracę eksperta. Jest to niełatwe przedsięwzięcie, gdyż niezbędny proces wypytywania eksperta jest z reguły długi i nużący. Ekspert może poza tym nie chcieć przekazać swojej wiedzy systemowi, który kiedyś w przyszłości może zająć jego miejsce. Inna komplikacja wiąże się z tym, że większość ekspertów nigdy nie zastanawia się nad procesem swojego rozumowania,
który doprowadza do postawienia diagnozy. Na pytanie „Jak Pan do tego doszedł?", często odpowiadają „Nie wiem".
Po uporaniu się z problemami ze zdobyciem wiedzy od eksperta, trzeba ją uporządkować i zorganizować w postaci zrozumiałej dla systemu komputerowego. Często informacje zapisuje się w postaci zbioru regui, z których każda jest instrukcją warunkową if-then. Regułę nakazującą zdiagnozowanie za pomocą biopsji zmian potwierdzonych prześwietleniem można wyrazić następująco:
(zauważono zmiany (wykonaj biopsję)
prześwietlenie wykazało obecność guzka)
(Czytelnicy, którzy przeczytali opcjonalny rozdział o programowaniu deklaratywnym w rozdziale 5, dostrzegą podobieństwo struktury systemu eksperckiego i programu w Prologu. Podobieństwo to jest główną przyczyną popularności Prologu w dziedzinie sztucznej inteligencji; nadaje się on doskonale do opracowania systemów eksperckich).
Zauważmy podobieństwo między regułami systemu eksperckiego i produkcjami systemu produkcji. Pierwsza część reguły wyraża po prostu warunki wstępne, które muszą być spełnione, aby wykonać lub wywnioskować stwierdzenie stanowiące drugą część reguły. Wiele systemów eksperckich tak naprawdę jest systemami produkcji. Produkcjami w nich są reguły uzyskane od eksperta, a system sterujący nadzoruje proces rozumowania oparty na tych regułach. W takim kontekście zbiór produkcji nazywa się często bazą wiedzy systemu, a system sterujący mechanizmem wnioskowania.
Nie dajmy się jednak wprowadzić w błąd i nie traktujmy systemów eksperckich jak bardziej złożoną wersję maszyny rozwiązującej układankę omówionej poprzednio. Niektóre systemy eksperckie są zbiorami systemów produkcji, które wspólnymi siłami usiłują rozwiązywać problemy. Przykładami są systemy eksperckie, które oparto na modelu szkolnej tablicy. Model polega na tym, że wiele systemów rozwiązujących problem (zwanych źródłami wiedzy) dzieli wspólną przestrzeń zwaną tablicą. Na tablicy zapisuje się bieżący stan rozwiązywanego problemu, a ponieważ jest ona współdzielona przez wszystkie źródła wiedzy, za jej pomocą mogą one wnosić swój wkład w rozwiązanie problemu. W celu koordynacji działań źródeł wiedzy wprowadza się dodatkowy moduł sterujący, którego zadaniem jest uaktywnienie odpowiedniego źródła wiedzy w dogodnej chwili. Przy stosowaniu modelu tablicowego można powiedzieć, że moduł sterujący decyduje, na czym system ma skupić swoją uwagę.
Inna różnica między systemem eksperckim a prostym systemem produkcji polega na tym, że system ekspercki nie musi wcale osiągnąć pewnego z góry określonego celu. Jego zadaniem jest wygenerowanie rozsądnej porady. Przypuśćmy, że system ekspercki ma zdiagnozować chorobę. Idealnie byłoby, gdyby system dał odpowiedź postaci „Jest to choroba X", przy czym w miejscu litery X znajduje się właściwa nazwa choroby. Niestety takie definitywne stwierdzenia nie zawsze są możliwe. Czasem najlepszą odpowiedzią jest „Ta choroba to najprawdopodobniej X" lub „Choroba to X
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.6. ZASTOSOWANIA SZTUCZNEJ INTELIGENCJI 499
SILNA SZTUCZNA INTELIGENCJA A SŁABA SZTUCZNA INTELIGENCJA
Przypuszczenie, że maszyny można tak zaprogramować, aby okazywały inteligentne zachowanie jest znane jako słaba sztuczna Inteligencja. Jest to przypuszczenie szeroko choć w różnym stopniu akceptowane współcześnie. Przypuszczenie, że można tak zaprogramować maszyny, aby posiadły inteligencję i co za tym idzie świadomość, to silna sztuczna inteligencja. Dyskutuje się nad nią szeroko. Przeciwnicy silnej sztucznej inteligencji twierdzą, że maszyna jest ze swej natury zupełnie inna niż człowiek i, z tego powodu, nigdy się nie zakocha, nie odróżni dobrego od złego i nie będzie myśleć o sobie w ten sam sposób, w jaki robią to ludzie. Zwolennicy silnej sztucznej inteligencji twierdzą jednak, że mózg człowieka jest zbudowany z małych elementów, które z osobna nie tworzą człowieka ani jego świadomości, ale które dają taki efekt po połączeniu. Dlaczego to samo zjawisko miałoby być niemożliwe w przypadku maszyn?
Problem w rozstrzygnięciu dyskusji o silnej sztucznej inteligencji polega na tym, że jak zauważono w tekście, takie pojęcia jak inteligencja i świadomość są cechami wewnętrznymi, których istnienia nie można wykryć bezpośrednio. Jak wskazał Alan Turing, obdarzamy innych ludzi inteligencją, ponieważ zachowują się oni inteligentnie - chociaż nie jesteśmy w stanie obserwować stanu ich ducha. Czy jesteśmy zatem przygotowani do takiego samego postępowania z maszyną, która okaże zewnętrzne przejawy świadomości? Dlaczego?
lub Y. Proszę wykonać następujące badania w celu uzyskania pełniejszej diagnozy". Ze względu na brak Jednoznaczności system sterujący w systemie eksperckim może wybrać różne ścieżki w grafie stanów i wypisać wyniki uzyskane dla każdej z nich. Jeśli w jakimś stanie zostanie zastosowana produkcja
(obecny czynnik reumatyczny i pacjent odczuwa ból w stawach) (z prawdopodobieństwem 80% jest to artretyzm)
to dalsze wnioskowanie oparte na założeniu, że pacjent cierpi na artretyzm, może okazać się nieodpowiednie.
Tak jak w wypadku innych obszarów badań, pierwsze zastosowania systemów eksperckich były bardzo ograniczone. Współcześnie systemy eksperckie znajdują zastosowanie w licznych dziedzinach. Katalizatorem tej ekspansji było uświadomienie sobie, że w systemie eksperckim można wydzielić dwa elementy: moduł wnioskowania i moduł wiedzy. Usuwając moduł wiedzy z pewnego istniejącego systemu eksperckiego, otrzymuje się system procedur wnioskowania, który prawdopodobnie można wykorzystać także w innych sytuacjach. Nowe systemy eksperckie dla innych dziedzin można zatem tworzyć, dołączając nowe bazy wiedzy do już istniejących systemów wnioskowania. To spostrzeżenie oznacza, że system sterujący, który stworzyliśmy uprzednio do ułożenia układanki, można wykorzystać także do innych celów, zastępując produkcje dotyczące układanki produkqami reprezentującymi inne problemy.
(TANIA I ĆWICZENIA
. Porównaj wyniki rozbioru gramatycznego następujących dwóch zdań. Wyjaśnij na czym polega ich różnica znaczeniowa. Gospodarz postawił ogrodzenie w polu. Gospodarz postawił ogrodzenie w zimie.
. Na podstawie sieci semantycznej z rysunku 10.25 określ, jakie więzy rodzinne łączą Marysię i Janka.
. Baza danych z informacjami o abonentach zazwyczaj zawiera listę abonentów każdego czasopisma, ale nie zawiera listy osób, które nie są nimi. Jak w takiej bazie danych określić, że dana osoba nie prenumeruje danego czasopisma?
Na czym polega różnica między tradycyjną bazą danych a bazą wiedzy systemu eksperckiego?
10.7. Rozważania na temat konsekwencji
Bez wątpienia postęp w dziedzinie sztucznej inteligencji przynosi ludzkości wiele dobrego, ale łatwo można wpaść w pułapkę zachwytu nad tymi potencjalnymi dobrodziejstwami. Są również potencjalne niebezpieczeństwa, które czyhają w przyszłości, i mogą się równie dobrze okazać przekleństwem, jak i dobrodziejstwem. Różnica w ocenie ich skutków polega często jedynie na punkcie widzenia lub pozycji społecznej. To, co dla jednego jest dobrodziejstwem, dla innego może być przekleństwem. Warto zatem przyjrzeć się postępowi technicznemu z różnych perspektyw.
Niektórzy uważają, że postęp techniczny jest podarunkiem dla ludzkości - sposobem uwolnienia ludzi od wykonywania żmudnych czynności i wrotami do bardziej beztroskiego stylu życia. Inni traktują ten postęp jako przekleństwo, które pozbawia ludzi pracy i kieruje dobra do tych ludzi, którzy mają władzę. Takie było przesłanie zagorzałego filantropa Mahatmy Gan-dhiego, który przyczynił się znacznie do wyzwolenia Indii od Brytyjczyków. Uparcie powtarzał on, że Indie byłyby lepszym krajem, gdyby zastąpić wielkie zakłady tekstylne kołowrotkami w domach mieszkańców. Twierdził on, że w ten sposób scentralizowana produkcja masowa, która daje miejsca pracy jedynie nielicznym, zostałaby zastąpiona rozproszonym systemem produkcyjnym, z którego skorzystałoby wielu.
Historia pokazuje, że u źródeł wielu rewolucji stał nieproporcjonalny podział dóbr i przywilejów. Jeśli pozwoli się, aby współczesna technika prowadziła do takich rozbieżności, to skutki mogą być katastrofalne.
Konsekwencje tworzenia coraz bardziej inteligentnych maszyn są dużo subtelniejsze i bardziej elementarne niż problemy związane z podziałem władzy między różne warstwy społeczne. Powstające problemy burzą obraz ludzkości, który sobie stworzyliśmy. W dziewiętnastym wieku społeczeństwo przeraziła teoria
ROZDZIAŁ DZIESIĄTY SZTUCZNA INTELIGENCJA
10.7. ROZWAŻANIA NA TEMAT KONSEKWENCJI
501
POCZĄTKI MASZYN TURINGA
Alan Turing wymyślił maszynę Turinga w latach trzydziestych, na długo przed tym, jak konstrukcja komputerów, które znamy dzisiaj, stała się technologicznie możliwa. Turing wzorował się tak naprawdę na człowieku wykonującym obliczenia za pomocą kartki i otówka. Celem Turinga byto zbudowanie modelu, za pomocą którego można by zbadać ograniczenia „procesów obliczeniowych". Było to krótko po opublikowaniu w 1931 roku słynnej pracy Gódla wykazującej ograniczenia systemów obliczeniowych i główny wysiłek badawczy skierowano na zrozumienie tych ograniczeń. W tym samym roku, w którym Turing przedstawił swój model (1936 r.), Emil Post zaprezentował inny model (zwany obecnie systemem produkcji Posta), który, jak udowodniono, ma takie same możliwości jak maszyny Turinga. Modele opracowane przez tych naukowców wciąż służą w informatyce jako cenne narzędzia do badań w dziedzinie informatyki.
11.2. Maszyny Turinga
W podrozdziale 11.1 twierdziliśmy, że Bare Bones jest uniwersalnym językiem programowania, co oznacza, że można w nim zapisać rozwiązanie każdego problemu, który daje się rozwiązać za pomocą komputera. Twierdzenie to omówimy dokładniej w podrozdziale 11.3, ale najpierw musimy lepiej zrozumieć, co potrafią komputery.
Podstawy maszyn Turinga
Rozważmy teraz klasę maszyn obliczeniowych, zwanych maszynami Turinga. Maszyny te wprowadził Alan M. Turing w 1936 roku jako narzędzie do analizy siły wyrazu procesów algorytmicznych. Wciąż używa się ich w tym celu. Pamiętajmy, że Turing „wynalazł" te maszyny, zanim ich wykonanie stało się technologicznie możliwe. Zatem maszyna Turinga jest urządzeniem pojęciowym, a nie rzeczywistą maszyną.
Maszyna Turinga składa się z jednostki sterującej, która potrafi odczytywać i zapisywać symbole na taśmie za pomocą głowicy zapisująco-odczytu-jącej (rys. 11.3). Taśma jest nieograniczona w obie strony i jest podzielona na komórki. W każdej z nich można zapisać dowolny symbol ze skończonego zbioru. Ten zbiór nazywa się alfabetem maszyny.
W dowolnej chwili, podczas obliczeń wykonywanych przez maszynę Turinga, musi ona znajdować się w pewnym stanie wybranym ze skończonej liczby stanów. Obliczenie rozpoczyna się w specjalnym stanie zwanym stanem początkowym, a kończy się, gdy maszyna osiągnie inny wyróżniony stan, zwany stanem końcowym.
Obliczenie maszyny Turinga składa się z ciągu kroków, które wykonuje jednostka sterująca maszyny. Każdy krok polega na sprawdzeniu, jaki symbol znajduje się w aktualnej komórce na taśmie (w komórce znajdującej się pod głowicą), zapisaniu pewnego symbolu w tej komórce i ewentualnego przemieszczenia głowicy o jedną komórkę w lewo lub w prawo, a następnie zmianie stanu. Akcja, którą podejmuje maszyna, jest określona przez program, który w zależności od stanu maszyny i zawartości bieżącej komórki taśmy decyduje, co ma zrobić jednostka sterująca.
Chociaż w swojej naturze maszyna Turinga jest urządzeniem pojęciowym, to jednak można ją implementować na różne sposoby. Współczesne komputery ogólnego przeznaczenia są w zasadzie maszynami Turinga (z tą różnicą, że ich pamięci są skończone, podczas gdy abstrakcyjna maszyna Turinga ma nieskończoną taśmę). Procesor jest jednostką sterującą, której stany wyznaczają ciągi bitów znajdujące się w rejestrach. Pamięć ■■■^■^■■■^^■■■■■■^■M komputera gra rolę taśmy, a alfabet składa się z symboli 0 i 1.
To podobieństwo między maszynami Turinga a współczesnymi komputerami nie jest przypadkowe. Celem Turinga było zaprojektowanie maszyny abstrakcyjnej, w której uchwycono by istotę procesu obliczeniowego. Współczesne komputery pasują zatem do podstawowego schematu podanego przez Turinga.
Znaczenie maszyn Turinga w informatyce teoretycznej wynika z twierdzenia (zgodnie z tezą Churcha-Turinga, którą omówimy później), że moc obliczeniowa maszyn Turinga jest taka sama jak moc obliczeniowa dowolnego systemu algorytmicznego. Jeśli zatem jakiegoś problemu nie da się rozwiązać na maszynie Turinga, to nie da się go w ogóle rozwiązać algo-rytmicznie. Maszyny Turinga, choć proste w swojej budowie, reprezentują teoretyczne ograniczenie możliwości rzeczywistych maszyn. Z tego powodu są one użyteczne jako narzędzia badania ograniczeń komputerów oraz procesów algorytmicznych.
il8 ROZDZIAŁ JEDENASTY TEORIA OBLICZEŃ
11.2. MASZYNY TURIMJA
519
Przykładowa maszyna Turinga
Rozważmy przykład konkretnej maszyny Turinga. Przyjmijmy, że taśmę maszyny rysujemy jako poziomą wstęgę podzieloną na komórki, w których można zapisywać symbole alfabetu maszyny. Bieżącą pozycję maszyny na taśmie będziemy oznaczać, umieszczając strzałkę pod bieżącą komórką. Przyjmijmy, że alfabet przykładowej maszyny składa się z symboli 0,1 oraz *. Taśma maszyny może zatem wyglądać następująco:
Pozycja bieżąca
Interpretując ciąg symboli na taśmie jako ciąg reprezentujący liczby binarne oddzielone gwiazdkami, stwierdzimy, że na powyższej taśmie zapisano wartość 5. Maszynę Turinga tak zaprojektujemy, aby zwiększała wartość zapisaną na taśmie o 1. Ściślej, zakładamy, że pozycją początkową jest
pozycja gwiazdki oznaczającej prawy koniec ciągu zer i jedynek, a zadaniem maszyny jest zmiana ciągu bitów znajdujących się na lewo od pozycji początkowej, tak aby reprezentował on kolejną liczbę całkowitą.
Stany naszej maszyny to: START, DODAWANIE, PRZENIESIENIE, BEZ PRZENIESIENIA, NADMIAR, POWRÓT, STOP. Akcje związane z każdym z tych stanów i zawartością bieżącej komórki przedstawiono w tabeli na rysunku 11.4. Zakładamy, że maszyna zawsze rozpoczyna pracę w stanie START.
Prześledźmy działanie zaprojektowanej maszyny dla przedstawionej powyżej zawartości taśmy reprezentującej wartość 5. Zauważmy, że będąc w stanie START z bieżącą komórką zawierającą * (jak w tym wypadku), zgodnie z tabelą powinniśmy wpisać do komórki ponownie *, przesunąć pozycję o jedną komórkę w lewo i przejść do stanu DODAWANIE. Po zrobieniu tego aktualną sytuację można przedstawić następująco:
Idźmy dalej. Sprawdzamy w tabeli, co trzeba zrobić w stanie DODAWANIE, przy zawartości bieżącej komórki równej 1. Zgodnie z tabelą trzeba zastąpić 1 w bieżącej komórce przez 0, przesunąć się do komórki po lewej stronie i przejść do stanu PRZENIESIENIE. Otrzymaną sytuację można zatem przedstawić następująco:
Pozycja bieżąca
Znów sprawdzamy w tabeli, co robić dalej, i stwierdzamy, że w stanie PRZENIESIENIE z bieżącą komórką zawierającą 0, trzeba zastąpić 0 przez 1, przesunąć się do następnej komórki po lewej stronie i przejść do stanu BEZ PRZENIESIENIA. Sytuacja wygląda zatem następująco:
20 ROZDZIAŁ JEDENASTY TEORIA OBLICZEŃ
11.2. MASZYNY TURINGA
521
lii
W tej konfiguracji zgodnie z tabelą należy zastąpić jedynkę w bieżącej komórce inną jedynką, przesunąć się w lewo, pozostając w stanie BEZ PRZENIESIENIA. W efekcie maszyna jest w stanie
PYTANIA I ĆWICZENIA
1. Zasymuluj działanie maszyny Turinga opisanej w tym punkcie, rozpoczynając od następującego stanu początkowego:
Teraz zgodnie z tabelą zapisujemy ponownie gwiazdkę w bieżącej komórce i przechodzimy do stanu POWRÓT. Postępując w podobny sposób, pozostajemy w stanie POWRÓT, przesuwając się komórka po komórce w prawo, aż dotrzemy do sytuacji
Zaprojektuj maszynę Turinga, która zastępuje ciąg zer i jedynek poje
dynczym zerem.Zaprojektuj maszynę Turinga, która zmniejszy o jeden wartość zapi
saną na taśmie, jeśli jest ona większa od zera i nie zmieni jej, jeśli jest
ona równa zeru.Podaj przykłady z życia codziennego, w których dochodzi do wyko
nania pewnych obliczeń. Jakie są podobieństwa Twojego przykładu do
maszyny Turinga?
W tym momencie zgodnie z tabelą trzeba ponownie zapisać gwiazdkę w bieżącej komórce i przejść do stanu STOP. Maszyna zatrzymuje się zatem w następującej konfiguracji (symbole na taśmie reprezentują teraz wartość 6, tak jak tego chcieliśmy).
Na zakończenie zauważmy, że powyższy przykład pokazuje, jak wykonać za pomocą maszyny Turinga czynność opisywaną w języku Bare Bones z podrozdziału 11.1 przez instrukcję
incr X;
11.3. Funkcje obliczalne
Nasze zadanie polega na wykorzystaniu maszyn Turinga do zbadania siły języka programowania Bare Bones. Aby tego dokonać, jest potrzebna metoda pomiaru mocy obliczeniowej. Taką metodę można uzyskać dzięki pojęciu funkcji obliczalnych.
Funkcje i ich obliczanie
Rozważmy, jakie akcje na podstawowym poziomie wykonuje komputer. Jeśli zapamiętalibyśmy stany pamięci komputera przed i po wykonaniu programu, to zapisalibyśmy jeden zestaw wartości bitowych przed wykonaniem programu, a inny po jego wykonaniu. Program tak naprawdę wykonuje więc tylko jedną czynność: steruje przekształcaniem początkowego zestawu bitów, który nazwiemy wejściem, na inny zestaw bitów zwany wyjściem. To powiązanie między danymi wejściowymi a wyjściowymi jest nazywane funkcją. Wiele funkcji występuje tak powszechnie, że nadano im nazwy, takie jak dodawanie, które z każdą parą wartości wejściowych związuje wartość wyjściową równą sumie wartości wejściowych, mnożenie, które podobnie pobiera parę wartości wejściowych i w wyniku daje iloczyn tych wartości, oraz funkcja następnika, która z wartością wejściową związuje wartość wyjściową o jeden od niej większą.
522'
ROZDZIAŁ JEDENASTY TEORIA OBLICZEŃ
11.3. FUNKCJE OBLICZALNE
523
Proces określania wartości wyjściowej funkqi na podstawie jej wartości wejściowych to obliczenie funkcji. Działania podejmowane przez komputer podczas wykonywania programu można zatem interpretować jako obliczenie funkcji. Taki punkt widzenia stwarza możliwość zmierzenia mocy obliczeniowej komputera lub dowolnego systemu obliczeniowego. Trzeba po prostu określić funkcje, które system potrafi obliczyć, i użyć tego zbioru jako miary mocy obliczeniowej. Jeśli jeden komputer lub system algorytmiczny jest zdolny obliczyć więcej funkcji niż inny, to jest on mocniejszy.
Rozważmy system, w którym wartości wyjściowe funkcji określono z góry i zapisano w tablicy razem z odpowiadającymi im wartościami wejściowymi. Gdy jest potrzebna wartość wyjściowa funkcji, po prostu wyszukuje się odpowiednią wartość wejściową w tablicy i przekazuje związany z nią wynik. Proces obliczania funkcji sprowadza się w takim systemie do procesu przeszukiwania tablicy. Takie systemy są wygodne, ale ich zastosowania są bardzo ograniczone, gdyż wielu funkcji nie daje się przedstawić w postaci tabelarycznej. Przykład znajduje się na rysunku 11.5, na którym próbowano przedstawić funkcję następnika. Ponieważ długość listy zawierającej pary wejście-wyjście nie jest niczym ograniczona, to tablica nigdy nie będzie kompletna. Funkcja dodawania podziela los funkcji następnika -w żadnej tablicy nie można przedstawić wszystkich możliwych par wartości wejściowych i wyjściowych w celu dodawania.
Inną metodą określenia wartości wyjściowych funkcji jest podanie sposobu obliczenia wyniku, a nie próba przedstawiania wszystkich możliwych kombinacji wejścia-wyjścia w tablicy. Do opisu związków między wejściem a wyjściem wielu funkcji można wykorzystać formuły algebraiczne. Aby obliczyć wartość funkcji, której wynikiem jest wartość początkowej lokaty P złotych oprocentowanej r% w skali roku i zamrożonej na n lat, można użyć wzoru
V = P(l + r)n
który opisuje sposób wykonania obliczeń, zamiast przedstawiać wyniki w postaci tabelarycznej. W podobny sposób funkcję następnika można opisać za pomocą wzoru
Wyjście = Wejście + 1
Jednak moc formuł algebraicznych jest także ograniczona. Są funkcje, w których związek między wejściem a wyjściem jest zbyt złożony, aby dało się go opisać za pomocą operacji algebraicznych wykonywanych na wartościach wejściowych funkcji. Przykładami są funkcje trygonometryczne, takie jak sinus lub cosinus. Jeśli trzeba obliczyć sinus 38 stopni, to można narysować odpowiedni trójkąt, zmierzyć jego boki i policzyć odpowiedni iloraz. Proces ten nie daje się jednak wyrazić za pomocą działań algebraicznych na liczbie 38. Kieszonkowy kalkulator także z trudem wykonuje zadanie obliczenia sinusa 38 stopni. W rzeczywistości wykorzystuje on dość skomplikowane operacje matematyczne, obliczając dobre przybliżenia wartości sinusa 38 stopni, które wyświetla w odpowiedzi.
Widzimy zatem, że w wypadku funkcji, w których relacja między wartościami wejściowymi a wyjściowymi staje się coraz bardziej złożona, trzeba stosować coraz to bardziej złożone algorytmy obliczające te związki, a co za tym idzie są potrzebne coraz mocniejsze techniki opisywania tych algorytmów.
Zadziwiającym wynikiem matematycznym jest pokazanie istnienia funkcji, w których związek między wartościami wejściowymi a wynikiem jest tak złożony, że dobrze zdefiniowany, krokowy sposób określenia wyniku funkcji na podstawie jej wartości wejściowej nie istnieje. Są zatem funkcje, w których związku między wartością wejściową a wynikiem nie daje się wyznaczyć algorytmicznie. Mówi się, że takie funkcje są nieobliczalne, a funkcje, których wyniki można określić algorytmicznie na podstawie wartości wejściowych, są obliczalne.
Ponieważ nie ma algorytmicznej metody znalezienia wartości wyjściowych funkcji nieobliczalnych, funkcje te są poza zasięgiem możliwości współczesnych oraz przyszłych komputerów. Pamiętajmy, że aby coś policzyć na komputerze, trzeba najpierw znaleźć algorytm wykonujący niezbędne obliczenia. Zatem poznanie granicy między funkcjami obliczalnymi i nieobliczalnymi jest równoważne poznaniu granic możliwości komputerów. Teza Churcha-Turinga stanowi ważny krok w kierunku określenia tych granic.
24
ROZDZIAŁ JEDENASTY TEORIA OBLICZEŃ
11.3. FUNKCJE OBLICZALNE
525
funkcji, po prostu wykonuje się program, rozpoczynając od stanu, w którym zmienne wejściowe mają odpowiednie wartości, i odczytując wartości zmiennych wyjściowych, gdy program się zakończy. Zgodnie z takimi założeniami program
incr X;
jest przepisem na obliczenie tej samej funkcji (funkcji następnika), którą oblicza maszyna Turinga z przykładu z podrozdziału 11.2. Faktycznie, powoduje on zwiększenie wartości związanej z X o jeden. Jeśli potraktujemy zmienne X i Y jako wartości wejściowe, a zmienną Z jako wartość wyjściową, to program
move Y to Z; while X not 0 do;
incr Z;
decr X; end;
jest przepisem na obliczenie funkcji dodawania.
Widzimy zatem, że język Bare Bones można stosować do opisu relacji między wejściem a wyjściem funkcji. Udowodniono, że w języku programowania Bare Bones można opisać dokładnie te relacje między wejściem a wyjściem, które można obliczyć za pomocą maszyny Turinga.
Powyższa równoważność jest brakującym ogniwem potrzebnym do dokończenia rozwiązania problemu postawionego w podrozdziale 11.1, który polegał na opracowaniu prostego a jednocześnie dostatecznie mocnego języka programowania. Ponieważ dowolna funkcja obliczalna w sensie Turinga da się obliczyć za pomocą programu w języku Bare Bones, to (zgodnie z tezą Churcha-Turinga) dowolną funkcję obliczalną można obliczyć za pomocą programu w tym języku.
Zatem Bare Bones jest uniwersalnym językiem programowania, co oznacza, że jeśli istnieje algorytm rozwiązania danego problemu, to można ten problem rozwiązać za pomocą programu w języku Bare Bones. To z kolei oznacza, że teoretycznie Bare Bones może służyć jako język programowania
ogólnego przeznaczenia.
Użyliśmy powyżej stwierdzenia teoretycznie, ponieważ taki język ewidentnie nie jest tak wygodny jak języki wysokiego poziomu przedstawione w rozdziale 5. Każdy z nich zawiera jednak jako swoje jądro wszystkie konstrukcje z języka Bare Bones. To właśnie to jądro zapewnia uniwersalność każdego z tych języków. Pozostałe udogodnienia służą jedynie wygodzie programistów.
11.3. FUNKCJE OBLICZALNE 527
Wyszukiwarka