MATERIAŁY DO ĆWICZEŃ ZE
STATYSTYKI Z DEMOGRAFIĄ
(część I)
POJĘCIA WSTĘPNE
STATYSTYKA - nauka traktująca o metodach ilościowych badania prawidłowości zjawisk (procesów) masowych.
DEMOGRAFIA - nauka o prawidłowościach rozwoju ludności w konkretnych warunkach gospodarczych
i społecznych badanego regionu, opis procesu zmian stanu i struktury ludności uwarunkowania tych zmian
i ich konsekwencje.
BADANIE STATYSTYCZNE - ogół prac mających na celu poznanie struktury określonej zbiorowości statystycznej.
ZBIOROWOŚĆ (POPULACJA) STATYSTYCZNA - zbiór dowolnych elementów (osób, przedmiotów, faktów) podobnych pod względem określonych cech (ale nie identycznych) poddanych badaniu statystycznemu.
JEDNOSTKA STATYSTYCZNA - składowe (elementy) zbiorowości (obiekty badania), które podlegają bezpośredniej obserwacji lub pomiarowi.
N - oznaczenie liczby jednostek statystycznych w populacji
ZBIOROWOŚĆ (POPULACJA) GENERALNA - wszystkie elementy będące przedmiotem badania, co do których chcemy formułować wnioski ogólne.
ZBIOROWOŚĆ PRÓBNA (PRÓBA) - podzbiór populacji generalnej; wyniki badań próby są uogólniane na zbiorowość generalną. Próba musi być reprezentatywna. Reprezentatywność zależy od: sposobu wyboru jednostek (celowy, losowy) oraz liczebności próby.
N > 30 - duża próba
N ≤ 30 - mała próba
RODZAJE BADANIA STATYSTYCZNEGO
1. całkowite (wyczerpujące)
2. częściowe (reprezentacyjne, ankietowe, itp.)
CECHA STATYSTYCZNA - podlegająca badaniu właściwość jednostki statystycznej.
Cechę oznaczamy dużą literą (np. X, Y, Z, ...).
Wartość cechy dla konkretnej jednostki (np. jednostki o numerze i) oznaczamy mała literą z indeksem dolnym
(np. xi , yi , zi , ...).
Cechy statystyczne dzielimy na:
cechy mierzalne (ilościowe). Cechy te dzielimy dalej na: ciągłe i skokowe ,
cechy niemierzalne (jakościowe)
Cechy mierzalne są to cechy,
których warianty wyrażane są przy pomocy liczb i jednostek miary, a cechy niemierzalne to te, których warianty wyrażane są przy pomocy słów.
Cechy mierzalne skokowe są to cechy, których warianty przyjmują tylko niektóre wartości z przedziału liczbowego (najczęściej są to liczby całkowite), a cechy mierzalne ciągłe są to cechy, których warianty mogą przyjmować wszystkie wartości z przedziału liczbowego.
Cechy mierzalne skokowe, które mogą przyjmować bardzo dużo wartości (np. zarobki pracowników wyrażane
w groszach) są to cechy quasi (prawie, niby) ciągłe.
Cechy te będziemy traktować tak, jak gdyby to były cechy ciągłe.
Zatem np. wszystkie te cechy, których wartości są wyrażane
w pieniądzach, będziemy uznawać za cechy ciągłe.
GRUPOWANIE materiału statystycznego
SZEREGI STATYSTYCZNE - odpowiednio usystematyzowany i uporządkowany surowy materiał statystyczny.
Szeregi statystyczne dzielimy na szeregi:
szczegółowe
rozdzielcze (punktowe, przedziałowe, jakościowe)
czasowe (momentów, okresów)
PRZYKŁAD 1 (szereg szczegółowy i szereg rozdzielczy)
Przedmiotem badania jest wadliwość produkcji
na III zmianie w firmie DINO. Liczba wyprodukowanych wyrobów wynosi 50 (N=50). Cecha badana (X) oznacza liczbę usterek w wyrobie.
Surowy materiał statystyczny to ciąg 50 liczb oznaczający liczbę braków stwierdzonych w kolejnym wyrobie. Ma on postać:
3, 0, 1, 0, 0, 0, 0, 1, 0, 0, 4, 2, 0, 0, 1, 1, 0, 3, 0, 2,
0, 1, 0, 0, 1, 0, 2, 0, 0, 0, 3, 0, 0, 4, 0, 2, 0, 0, 1, 0,
0, 1, 3, 0, 2, 0, 0, 0, 0, 2
SZEREG SZCZEGÓŁOWY otrzymamy sortując te liczby rosnąco (najczęściej) lub malejąco (rzadziej). Liczby braków posortowane rosnąco dają następujący ciąg {xi} 50 liczb:
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 3, 3, 3, 3, 4, 4
Liczby te spełniają warunek definicji szeregu szczegółowego:
x1 ≤ x2 ≤ x3 ≤ . . . ≤ x50
SZEREG ROZDZIELCZY PUNKTOWY
liczba xi |
liczba ni |
0 1 2 3 4 |
30 8 6 4 2 |
razem |
5555500 |
liczba xi |
liczebność ni sk |
0 0-1 0-2 0-3 0-4 |
30 38 44 48 50 |
razem |
× |
WSKAŹNIK STRUKTURY (wi)
Wskaźnik struktury (inaczej częstość) nazywany jest też:
liczebnością względną, frakcją, odsetkiem. Wylicza się go następująco:
![]()
dla i = 1, 2, ...,k
liczba xi |
liczba ni |
wskaźnik wi |
0 1 2 3 4 |
30 8 6 4 2 |
0,60 0,16 0,12 0,08 0,04 |
razem |
50 |
1,100 |
Kolumna liczb { wi } nazywana jest
rozkładem empirycznym (liczby usterek).
SKUMULOWANY WSKAŹNIK STRUKTURY (wi sk)
Skumulowany wskaźnik struktury (inaczej: częstość skumulowana). Wylicza się go następująco:
![]()
dla i = 1, 2, ...,k
liczba xi |
liczebność ni sk |
skumulowany wi sk |
0 1 2 3 4 |
30 38 44 48 50 |
0,60 0,76 0,88 0,96 1,00 |
razem |
× |
× |
Kolumna liczb { wi sk } nazywana jest
dystrybuantą empiryczną (liczby usterek).
WSKAŹNIK PODOBIEŃSTWA STRUKTUR
Wskaźnik podobieństwa struktur (wp) jest najprostszą miarą
statystyczną pozwalającą ocenić podobieństwo kształtowania się
badanej cechy w dwóch różnych zbiorowościach.
Wyliczamy go następująco:
![]()
czas dojazdu xi |
częstość DINO w1i |
częstość ZAUR w2i |
obliczenia wskaźnika wp |
5 - 15 15 - 25 25 - 35 35 - 45 45 - 55 55 - 65 |
0,05 0,55 0,20 0,10 0,05 0,05 |
0,05 0,10 0,15 0,25 0,40 0,05 |
0,05 0,10 0,15 0,10 0,05 0,05 |
razem |
1,00 |
1,00 |
0,50 |
INTERPRETOWANIE BEZWZGLĘDNEGO WSKAŹNIKA PODOBIEŃSTWA STRUKTUR Wp:
Wartość Wp |
Badane struktury są: |
Wp = 0 |
zupełnie różne |
0 < Wp ≤ 0,2 |
prawie zupełnie różne |
0,2 < Wp ≤ 0,3 |
bardzo mało podobne |
0,3 < Wp ≤ 0,5 |
mało podobne |
0,5 < Wp ≤ 0,7 |
prawie podobne |
0,7 < Wp ≤ 0,9 |
podobne |
0,9 < Wp < 1 |
bardzo podobne |
W = 1 |
identyczne |
WSKAŹNIK NATĘŻENIA (wn)
Wskaźnik natężenia wylicza się następująco:
![]()
gdzie:
NI ![]()
liczebność pierwszej zbiorowości,
NII ![]()
liczebność drugiej zbiorowości.
ZALECENIA przy grupowaniu
w szereg rozdzielczy przedziałowy
R - obszar zmienności (rozstęp)
![]()
k - liczba klas
a. k ≤ 5 lg N,
b. k ≈ 1 + 3,322 lg N,
c. ![]()
, dla N ≤ 100,
![]()
, dla N > 100
c - rozpiętość przedziału
![]()
PRZYKŁAD 2 (szereg rozdzielczy przedziałowy)
Przedmiotem badania jest czas dojazdu do pracy w dwóch firmach: DINO i ZAUR.
Czas dojazdu pracowników firmy DINO [w minutach]
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
00 |
17 |
28 |
22 |
20 |
53 |
36 |
37 |
21 |
19 |
21 |
10 |
22 |
17 |
32 |
33 |
22 |
31 |
9 |
30 |
19 |
24 |
20 |
16 |
22 |
20 |
34 |
19 |
15 |
21 |
17 |
17 |
27 |
30 |
36 |
51 |
23 |
24 |
16 |
38 |
21 |
13 |
42 |
19 |
40 |
17 |
25 |
19 |
16 |
19 |
29 |
31 |
24 |
39 |
28 |
50 |
65 |
18 |
19 |
20 |
48 |
23 |
60 |
21 |
24 |
37 |
60 |
19 |
22 |
30 |
22 |
21 |
19 |
27 |
31 |
18 |
43 |
70 |
24 |
23 |
58 |
30 |
47 |
19 |
32 |
20 |
18 |
20 |
80 |
20 |
35 |
17 |
5 |
24 |
27 |
31 |
51 |
32 |
39 |
90 |
60 |
58 |
39 |
19 |
24 |
21 |
29 |
14 |
18 |
16 |
Czas dojazdu pracowników firmy ZAUR [w minutach]
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
00 |
42 |
49 |
36 |
46 |
21 |
47 |
38 |
15 |
64 |
51 |
10 |
52 |
41 |
25 |
36 |
24 |
33 |
39 |
36 |
47 |
53 |
20 |
49 |
8 |
43 |
54 |
44 |
7 |
51 |
55 |
43 |
8 |
30 |
40 |
47 |
40 |
25 |
49 |
19 |
55 |
56 |
29 |
40 |
40 |
28 |
19 |
33 |
46 |
29 |
35 |
47 |
34 |
41 |
40 |
50 |
32 |
53 |
53 |
54 |
59 |
18 |
34 |
52 |
49 |
17 |
60 |
38 |
36 |
49 |
43 |
49 |
44 |
38 |
17 |
54 |
30 |
70 |
51 |
41 |
50 |
21 |
19 |
49 |
49 |
22 |
44 |
54 |
80 |
25 |
60 |
39 |
34 |
37 |
54 |
17 |
52 |
11 |
12 |
90 |
32 |
31 |
17 |
11 |
32 |
43 |
62 |
39 |
22 |
40 |
100 |
49 |
31 |
46 |
50 |
50 |
33 |
47 |
12 |
64 |
53 |
110 |
55 |
43 |
28 |
55 |
63 |
49 |
28 |
38 |
51 |
46 |
120 |
48 |
40 |
55 |
5 |
38 |
37 |
50 |
49 |
46 |
51 |
130 |
33 |
53 |
47 |
26 |
65 |
46 |
26 |
47 |
28 |
50 |
140 |
24 |
65 |
45 |
46 |
40 |
42 |
38 |
21 |
39 |
52 |
150 |
42 |
49 |
19 |
46 |
49 |
51 |
39 |
31 |
38 |
48 |
160 |
50 |
52 |
47 |
33 |
37 |
24 |
54 |
47 |
44 |
53 |
170 |
31 |
41 |
43 |
49 |
53 |
32 |
48 |
41 |
53 |
35 |
180 |
41 |
28 |
34 |
50 |
37 |
46 |
41 |
49 |
54 |
50 |
190 |
39 |
48 |
28 |
10 |
53 |
63 |
47 |
55 |
45 |
50 |
Pogrupuj dane w szeregi rozdzielcze następującej postaci :
DINO ZAUR
czas dojazdu |
liczba pracowników |
|
|
czas dojazdu |
liczba pracowników |
5 - 15 15 - 25 25 - 35 35 - 45 45 - 55 55 - 65 |
|
|
|
5 - 15 15 - 25 25 - 35 35 - 45 45 - 55 55 - 65 |
|
razem |
|
|
|
razem |
|
PREZENTACJA GRAFICZNA
SZEREGÓW STATYSTYCZNYCH
HISTOGRAM - wykres słupkowy
DIAGRAM - wykres liniowy
Oba typy wykresów mogą być sporządzane w wariantach dla:
liczebności
liczebności skumulowanej
Przykłady histogramów i diagramów dla ZAUR.
Histogram i diagram częstości
dla czasu dojazdu pracowników firmy ZAUR
Histogram i diagram częstości skumulowanej
dla czasu dojazdu pracowników firmy ZAUR
CHARAKTERYSTYKI LICZBOWE
STRUKTURY ZBIOROWOŚCI
(Parametry statystyczne)
PARAMETRY STATYSTYCZNE - liczby służące do syntetycznego opisu struktury zbiorowości statystycznej.
PARAMETRY DZIELIMY NA 4 GRUPY:
miary położenia
miary zmienności (dyspersji, rozproszenia)
miary asymetrii (skośności)
miary koncentracji
MIARY TENDENCJI CENTRALNEJ
(ŚREDNIE)
Miary tendencji centralnej charakteryzują średni lub typowy poziom wartości cechy.
Miary tendencji centralnej dzielą się na miary klasyczne
i miary pozycyjne.
Podział miar klasycznych jest następujący:
średnia arytmetyczna, średnia harmoniczna, średnia geometryczna.
Miary pozycyjne dzielą się na:
modalną i kwantyle.
Wśród kwantyli najczęściej mówi się o:
kwartylach (pierwszym, drugim zwanym medianą, trzecim) - podział zbiorowości na 4 części,
decylach - podział zbiorowości na 10 części,
centylach (percentylach) - podział zbiorowości na 100 części.
ŚREDNIA arytmetyczna
Średnią arytmetyczną definiuje się jako sumę wartości cechy mierzalnej przez liczebność populacji. Średnia jest wielkością mianowaną tak samo jak badana cecha.
Dla szeregów szczegółowych
Tutaj wyliczamy tzw. średnią arytmetyczną prostą (nieważoną), która ma postać:
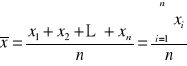
PRZYKŁAD 1
Weźmy dane z przykładu o liczbie braków:
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 3, 3, 3, 3, 4, 4
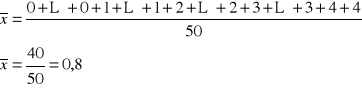
Średnio każdy pracownik produkował ok. 1 brak.
Dla szeregów rozdzielczych punktowych
Tutaj wyliczamy tzw. średnią arytmetyczną ważoną,
która ma postać:
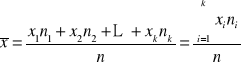
lub
![]()
W przykładzie z liczbą braków obliczenia według pierwszego wzoru (z liczebnościami ni) przedstawia poniższa tabela.
liczba xi |
liczba ni |
obliczenia xi ni |
0 1 2 3 4 |
30 8 6 4 2 |
0 8 12 12 8 |
razem |
50 |
40 |
![]()
Obliczenia średniej liczby braków z wykorzystaniem drugiego wzoru (ze wskaźnikami struktury wi)) pokazuje kolejna tabela.
liczba xi |
wskaźnik wi |
obliczenia xi wi |
0 1 2 3 4 |
0,60 0,16 0,12 0,08 0,04 |
0,00 0,16 0,24 0,24 0,16 |
razem |
1,00 |
0,80 |
![]()
Dla szeregów rozdzielczych przedziałowych
Tutaj wyliczamy tzw. średnią arytmetyczną ważoną,
która ma postać:
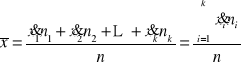
lub
![]()
gdzie ![]()
jest środkiem przedziału klasowego wyliczanym następująco: ![]()
Należy pamiętać, że przy pogrupowaniu danych źródłowych w szereg rozdzielczy przedziałowy następuje pewna utrata informacji. Jeżeli policzymy średnią dla szeregu szczegółowego lub szeregu rozdzielczego punktowego, to wynik będzie dokładny i taki sam. Dla danych w postaci szeregu rozdzielczego przedziałowego średnia będzie już tylko przybliżeniem. Tym większym, im szersze są przedziały klasowe, im jest ich mniej, itd.
Np. dla danych źródłowych o czasach dojazdu pracowników firmy ZAUR otrzymamy: ![]()
minuty.
PRZYKŁAD 2
Obliczenia dla średniej w przykładzie z czasem dojazdu w firmie ZAUR według pierwszego wzoru (z liczebnościami ni) przedstawia poniższa tabela.
czas (w min.) xi |
środek
|
liczba ni |
obliczenia
|
5 - 15 15 - 25 25 - 35 35 - 45 45 - 55 55 - 65 |
10 20 30 40 50 60 |
10 20 30 50 80 10 |
100 400 900 2000 4000 600 |
razem |
× |
200 |
8000 |
![]()
Obliczenia dla średniej według drugiego wzoru (ze wskaźnikami struktury wi) przedstawia kolejna tabela.
czas (w min.) xi |
środek
|
wskaźnik wi |
obliczenia
|
5 - 15 15 - 25 25 - 35 35 - 45 45 - 55 55 - 65 |
10 20 30 40 50 60 |
0,05 0,10 0,15 0,25 0,40 0,05 |
0,5 2,0 4,5 10,0 20,0 3,0 |
razem |
× |
1,00 |
40,0 |
![]()
Ważniejsze własności
ŚREDNIEJ arytmetycznej
Suma wartości cechy jest równa iloczynowi średniej arytmetycznej i liczebności populacji, tj.
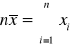
lub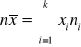
Średnia arytmetyczna nie może być mniejsza od najmniejszej wartości cechy ani też większa od największej jej wartości
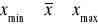
Suma odchyleń poszczególnych wartości cechy od średniej jest równa zero
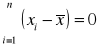
lub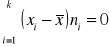
Suma kwadratów odchyleń poszczególnych wartości cechy od średniej jest minimalna
![]()
lub ![]()
Średnią arytmetyczną oblicza się w zasadzie dla szeregów o zamkniętych klasach przedziałowych. Można klasy sztucznie domknąć (i policzyć średnią) tylko wtedy, gdy odsetek jednostek w tych klasach jest niewielki (do 5%). Gdy ten odsetek jest duży należy stosować miary pozycyjne zamiast średniej.
Średnia arytmetyczna jest czuła na skrajne wartości cechy. Są to wartości cechy dla jednostek nietypowych w badanej zbiorowości
i przypadkowo (niepoprawnie) włączonych do badanej populacji.
ŚREDNIA harmoniczna
Średnią harmoniczną stosujemy wtedy, gdy wartości cechy są podane w przeliczeniu na stałą jednostkę innej cechy, czyli w postaci tzw. wskaźników natężenia (na przykład: prędkość pojazdu [km/godz.], cena jednostkowa [zł/szt.], spożycie [kg/osoba], itp.)
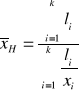
xi - wartość i-tego wariantu badanej cechy
li - wartość i-tego wariantu licznika badanej cechy
PRZYKŁAD 3
Kierowca przejechał trasę ze zmienną prędkością. Odcinek A o długości 30 km przejechał z prędkością 50 km/godz. Odcinek B o długości 81 km przejechał z prędkością 90 km/godz. Z jaką średnią prędkością pokonał trasę kierowca?
Badaną cechą X jest prędkość wyrażona w [km/godz.].
i |
trasa [km] li |
prędkość xi |
czas mi =li /xi |
1 2 |
30 81 |
50 90 |
0,6 0,9 |
Razem |
111 |
× |
1,5 |
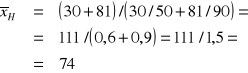
PRZYKŁAD 4
Producent przetworów owocowych sprzedawał słoje z przetworami na targowisku.
W godzinach 6-10 sprzedawał słoje po 7 zł/słój i utargował 840 zł.
W godzinach 10-12 sprzedawał słoje po 6 zł/słój i utargował 360 zł.
W godzinach 12-16 sprzedawał słoje po 5 zł/słój i utargował 100 zł.
Jaka była średnia cena słoja sprzedanego w tym dniu?
Badaną cechą X jest cena słoja wyrażona w [zł/słój].
i |
utarg [zł] li |
cena xi |
ilość mi =li /xi |
1 2 3 |
840 360 100 |
7 6 5 |
120 60 20 |
Razem |
1300 |
× |
200 |
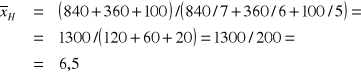
ŚREDNIA geometryczna
Średnią geometryczną określa się wzorem:
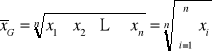
Średnia ta znajduje szczególne zastosowania w analizie dynamiki zjawisk.
Dominanta (Modalna)
Dominanta (D) zwana też modalną (Mo) jest to wartość cechy, która występuje najczęściej w badanej zbiorowości.
ZALECENIA przy wyznaczaniu dominanty
Dominantę wyznaczamy i sensownie interpretujemy tylko wtedy, gdy dane są pogrupowane w szereg rozdzielczy (punktowy lub przedziałowy).
Liczebność populacji powinna być dostatecznie duża.
Diagram lub histogram liczebności (częstości) ma wyraźnie zaznaczone jedno maksimum (rozkład jednomodalny).
Dla danych pogrupowanych w szereg rozdzielczy przedziałowy dominanta nie występuje w skrajnych przedziałach (pierwszym lub ostatnim) - przypadek skrajnej asymetrii. Nie da się w takim przypadku analitycznie wyznaczyć dominanty.
Dla danych pogrupowanych w szereg rozdzielczy przedziałowy przedział dominanty oraz dwa sąsiednie przedziały (poprzedzający i następujący po przedziale dominanty) powinny mieć taką samą rozpiętość.
Dominanta dla szeregów rozdzielczych punktowych
PRZYKŁAD 5
Badano czas obróbki detalu [w min.] przez pracowników firmy ZAUR. Otrzymane dane pogrupowano w szereg rozdzielczy punktowy.
czas xi |
liczba ni |
wskaźnik wi |
10 11 12 13 14 15 |
10 30 80 50 20 10 |
0,05 0,15 0,40 0,25 0,10 0,05 |
razem |
200 |
1,00 |
Łatwo zauważyć, że największa liczba pracowników (a zarazem największa częstość) znajduje się w klasie 3 (m=3). Zatem dominanta wynosi:
![]()
WNIOSEK: najczęściej występujący czas obróbki detalu wśród pracowników firmy ZAUR to 12 minut.
Dominanta dla szeregów rozdzielczych przedziałowych
Dominantę wyliczamy tutaj wg następującego wzoru:
![]()
m - numer klasy (przedziału) z dominantą
x0m - dolny kraniec przedziału dominanty
hm - rozpiętość przedziału dominanty (hm=x1m-x0m)
nm - liczebność przedziału dominanty
nm-1 (nm+1) - liczebność dla przedziałów sąsiadujących z przedziałem dominanty
PRZYKŁAD 6
Wykorzystamy badanie czasu dojazdu w firmie ZAUR:
czas (w min.) xi |
liczba ni |
5 - 15 15 - 25 25 - 35 35 - 45 45 - 55 55 - 65 |
10 20 30 50 80 10 |
razem |
200 |
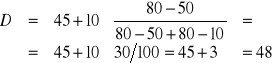
WNIOSEK: najczęściej występującym czasem dojazdu wśród pracowników firmy ZAUR jest 48 minut.
Z wykorzystaniem częstości (wskaźniki struktury) wzór na dominantę jest następujący:
![]()
wm - częstość (wskaźnik struktury) przedziału dominanty
wm-1 (wm+1) - częstość dla przedziałów sąsiadujących z przedziałem dominanty
ZAUR
czas (w min.) xi |
wskaźnik wi |
5 - 15 15 - 25 25 - 35 35 - 45 45 - 55 55 - 65 |
0,05 0,10 0,15 0,25 0,40 0,05 |
razem |
1,00 |
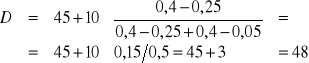
Dominantę możemy wyznaczyć graficznie tak jak to pokazano na rysunku.
KWARTYLE
Kwartyle to takie wartości cechy X, które dzielą zbiorowość na cztery równe części pod względem liczebności (lub częstości). Części te pozostają w okreśonych proporcjach do siebie.
Aby dokonywać takiego podziału zbiorowość musi być uporządkowana według rosnących wartości cechy X.
Każdy kwartyl dzieli zbiorowość na dwie części, które pozostają do siebie w następujących proporcjach. I tak:
kwartyl 1 (QI) - 25% z lewej i 75% populacji z prawej strony kwartyla,
kwartyl 2 (QII) - 50% z lewej i 50% populacji z prawej strony kwartyla,
kwartyl 3 (QIII) - 75% z lewej i 25% populacji z prawej strony kwartyla.
Mediana
Mediana (Me) - wartość środkowa, inaczej: kwartyl 2 (QII).
Jest to taka wartość cechy X, która dzieli zbiorowość na dwie równe części, tj. połowa zbiorowości charakteryzuje się wartością cechy X mniejszą lub równą medianie, a druga połowa większą lub równą.
Mediana dla szeregu szczegółowego
Szereg musi być posortowany rosnąco !!!
Wartość mediany wyznacza się inaczej gdy liczebność populacji (n) jest nieparzysta, a inaczej gdy jest parzysta.
Dla n nieparzystego: ![]()
Dla n parzystego: 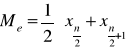
PRZYKŁAD 7
Zmierzono czas wykonania detali [minuta/ szt.] przez wybranego pracownika firmy ALFA i otrzymano następujący szereg szczegółowy:
10, 10, 10, 12, 12, 12, 12, 13, 13, 13,
13, 13, 14, 14, 15, 15, 15
Liczebność populacji jest nieparzysta: n=17
![]()
WNIOSEK:
Dla połowy detali czas wykonania jednego detalu przez pracownika firmy ALFA był nie dłuższy niż (≤) 13 minut, a drugiej połowy detali był nie krótszy (≥) niż 13 minut.
PRZYKŁAD 8
Zmierzono czas wykonania detali [minuta/ szt.] przez wybranego pracownika firmy BETA i otrzymano następujący szereg szczegółowy:
10, 10, 11, 12, 12, 12, 12, 12, 12, 13,
13, 13, 14, 14, 15, 15, 15, 16
Liczebność populacji jest parzysta: n=18
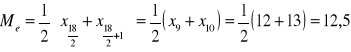
WNIOSEK:
Dla połowy detali czas wykonania jednego detalu przez pracownika firmy BETA był nie dłuższy niż (≤) 12,5 minuty, a dla drugiej połowy detali był nie krótszy (≥) niż 12,5 minuty.
Mediana dla szeregu rozdzielczego punktowego
Ustalamy na początek tzw. numer mediany (NMe). Jest to połowa liczebności populacji:
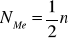
(albo ułamek ½ dla częstości).Kumulujemy liczebności (albo częstości).
Znajdujemy klasę, w której po raz pierwszy przekroczony został numer mediany. Klasa ta ma numer m.
Wartość cechy X w klasie m jest medianą, t.j.
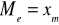
.
PRZYKŁAD 9
Dane z przykładu 5 o czasie obróbki detalu [w min.] przez pracowników firmy ZAUR.
czas xi |
liczba ni |
skumulowana ni sk |
skumulowana wi sk |
10 11 12 13 14 15 |
10 30 80 50 20 10 |
10 40 120 170 190 200 |
0,05 0,20 0,60 0,85 0,95 1,00 |
razem |
200 |
× |
× |
Liczebność populacji: n=200
Numer mediany:
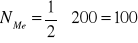
(dla liczebności) albo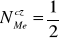
(dla częstości)
Numer klasy z medianą: m=3
Mediana: ![]()
WNIOSEK: Połowa pracowników firmy ZAUR obrabia detal nie dłużej niż (≤) 12 minut, a druga połowa nie krócej (≥) niż 12 minut.
Mediana dla szeregu rozdzielczego przedziałowego
Wzór na medianę (przy wykorzystaniu liczebności):
![]()
PRZYKŁAD 10
Dane z przykładu 6 (badanie czasu dojazdu w firmie ZAUR).
czas (w min.) xi |
liczba ni |
skumul. ni sk |
5 - 15 15 - 25 25 - 35 35 - 45 45 - 55 55 - 65 |
10 20 30 50 80 10 |
10 30 60 110 190 200 |
razem |
200 |
× |
Liczebność populacji: n=200
Numer mediany: ![]()
Numer klasy z medianą: m=4
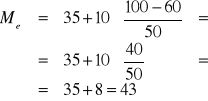
WNIOSEK: Połowa pracowników firmy ZAUR dojeżdża do pracy w czasie nie dłuższym (≤) niż 43 minuty, a druga połowa w czasie nie krótszym (≥) niż 43 minuty.
Wzór na medianę (przy wykorzystaniu częstości):
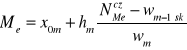
PRZYKŁAD 10 (c.d.)
czas w (min.) xi |
wskaźnik wi |
skumul. wi sk |
5 - 15 15 - 25 25 - 35 35 - 45 45 - 55 55 - 65 |
0,05 0,10 0,15 0,25 0,40 0,05 |
0,05 0,15 0,30 0,55 0,95 1,00 |
razem |
1,00 |
× |
Numer mediany: ![]()
Numer klasy z medianą: m=4
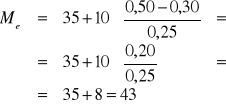
D=48 ==
Wyszukiwarka