MODELOWANIE I SYMULACJA
Tematy wykładów
Pojęcia podstawowe. Modele. Modelowanie. Identyfikacja. Estymacja parametrów.
Niektóre dziedziny zastosowań. Przykłady zastosowań modelowania w zadaniach sterowania, diagnostyki, podejmowania decyzji, rozpoznawania obrazów.
Sygnały deterministyczne. Klasy sygnałów. Funkcje ortogonalne. Transformaty sygnałów
Sygnały losowe. Metody opisu sygnałów losowych.
Generowanie sygnałów losowych i pseudolosowych. Generatory fizyczne. Generatory liczb losowych. Generatory pseudolosowych sekwencji binarnych.
Generowanie sygnałów pseudolosowych o dowolnych rozkładach.
Testy statystyczne dla generatorów liczb losowych.
Podstawowe pojęcia teorii estymacji. Estymacja metodą najmniejszych kwadratów. Estymacja metodą Markowa. Estymacja metodą największej wiarygodności. Estymacja metodą najmniejszego ryzyka.
Modele procesów. Modele liniowe, zmienno-liniowe i nieliniowe. Szeregi Volterry. Modele typu GMDH.
Modele wejściowo-wyjściowe. Liniowe modele w przestrzeni stanów. Postacie kanoniczne modeli w przestrzeni stanów.
Podstawowe własności modeli. Sterowalność. Obserwowalność. Identyfikowalność.
Modele ciągłe w czasie. Symulacja modeli ciągłych. Metody całkowania numerycznego.
Modele dyskretne w czasie. Rodzaje modeli. Przykłady modeli dyskretnych. Wybór okresu próbkowania. Symulacja modeli dyskretnych.
Modele ciągów czasowych. Modele AR, MA i ARMA. Model obiektu dynamicznego z uwzględnieniem toru zakłóceń.
Modele neuronowe. Modele neuronowe bez sprzężeń zwrotnych. Neuronowe modele rekurencyjne.
Zastosowanie metod teorii zbiorów rozmytych dynamiki. Regulatory rozmyte.
Sprawdzanie poprawności modelu. Wybór rzędu modelu.
Pakiety oprogramowania do modelowania i symulacji. Środowisko matematyczno-symulacyjne MATLAB - SIMULINK.
POJĘCIA PODSTAWOWE
Modelowanie i symulacja - zestaw działań związanych z konstruowaniem modeli systemów rzeczywistych i symulowaniem ich na komputerze.
Rys. 1. Podstawowe elementy i relacje modelowania i symulacji
Modelowanie dotyczy głównie zależności pomiędzy systemami rzeczywistymi i ich modelami.
Symulacja jest związana głównie z zależnościami pomiędzy komputerami i modelami.
System rzeczywisty jest źródłem danych (wyników pomiarów, obserwacji).
Rys. 2. Ilustracja zachowania systemu. X(t) - np. temperatura w pokoju,
produkt narodowy brutto, itp.
Model jest reprezentowany w komputerze przez zbiór (sekwencję) instrukcji służących do wygenerowania danych opisujących zachowanie systemu rzeczywistego.
Zasadność modelu mówi, jak dobrze model reprezentuje system rzeczywisty. Zasadność modelu jest mierzona stopniem zgodności między danymi otrzymanymi z systemu rzeczywistego i modelu. Wyróżnić można trzy stopnie zasadności modelu:
Zasadność replikatywna: Model jest zasadny replikatywnie, jeżeli generowane przez niego dane odpowiadają danym otrzymanym poprzednio z systemu rzeczywistego.
Zasadność predykcyjna: Model jest zasadny predykcyjnie, jeżeli można zapewnić zgodność danych otrzymanych z modelu z danymi z systemu rzeczywistego, które nie były poprzednio stosowane do budowy modelu.
Zasadność strukturalna: Model jest zasadny strukturalnie, jeżeli nie tylko odtwarza zaobserwowane zachowanie systemu, lecz także odzwierciedla sposób, w jaki system ten działa.
Cele modelowania i symulacji:
Zrozumienie sposobu w jaki działa system rzeczywisty.
Optymalizacja parametryczna działania systemu rzeczywistego. Np., MS może być wykorzystywana podczas projektowania urządzeń lub systemów.
Eksperymentowanie z systemem rzeczywistym może być kosztowne i czasochłonne lub nawet niemożliwe.
Eksperymenty symulacyjne są całkowicie powtarzalne i niedestrukcyjne.
Dane otrzymane z symulacji komputerowej można często łatwiej interpretować i poddawać obróbce statystycznej lub graficznej dzięki udogodnieniom dostarczanym przez programy i języki symulacyjne.
Weryfikacja modelu - porównanie zachowania systemu rzeczywistego z zachowaniem jego modelu.
Rodzaje modeli:
koncepcyjny: Np., ptolemeuszowski model ruchów cykloidalnych zadawalająco wyjaśniał obserwowane ruchy planet.
fizyczny: Np., model w skali zredukowanej statku, samolotu, itp.
matematyczny: Np., model kopernikowski, który traktował obserwacje jako wynik ruchu zarówno Ziemi jak i planet.
Modele występują w wielu dziedzinach wiedzy ludzkiej: fizyka, biologia, astronomia, ekonomia, socjologia, psychologia, technika.
Cele i sposoby wykorzystywania modeli w technice:
Interpretacja pewnej wiedzy lub pomiarów.
Projektowanie systemów, urządzeń.
Sterowanie.
Diagnostyki stanu systemu.
Wykrywania uszkodzeń.
Predykcji zachowania systemu.
Modelowanie składa się z następujących kroków:
wybór struktury modelu na podstawie wiedzy fizycznej,
dopasowanie wartości parametrów (estymacja),
weryfikacja i testowanie modelu,
zastosowanie modelu.
Identyfikacja
Identyfikacją nazywa się proces budowy modelu matematycznego systemu rzeczywistego.
Definicja według Zadeha:
Identyfikacja jest to określenie na podstawie wejścia i wyjścia przynależności do określonej klasy układów, względem której badany układ jest równoważny.
Równoważność określa się za pomocą pewnego kryterium, nazywanego funkcją błędów lub strat, która jest funkcjonałem
, (1.1)
gdzie: y - wyjście systemu, - wyjście modelu.
Dwa modele są równoważne, jeżeli mają jednakowe wartości funkcji strat.
Rozwiązując zadanie identyfikacji należy dokonać wyboru:
klasy modeli,
klasy sygnałów wejściowych,
kryterium równoważności.
Model reprezentuje następujące trzy rodzaje wiedzy:
o strukturze, w postaci tożsamości matematycznych, schematów blokowych, schematów przepływowych lub grafów, macierzy połączeń,
o wartościach parametrów,
o wartościach zmiennych wewnętrznych modelu (zmiennych stanu).
1.2. Estymacja
W zastosowaniach technicznych dysponujemy często pewną wiedzą o systemie, np. o jego strukturze. Zadanie ogranicza się wtedy do zdobycia wiedzy o wartościach liczbowych pewnych parametrów (współczynników równań określających zachowanie systemu, wartości liczbowych zmiennych stanu, inaczej estymacji parametrów lub stanu systemu.
Estymacja parametrów - doświadczalne wyznaczanie wartości parametrów rządzących dynamiką i / lub nieliniowym zachowaniem się systemu przy założonej strukturze modelu systemu.
Niekiedy wymagana jest bardziej szczegółowa wiedza o systemie, np. ciągła znajomość jego stanu. Zadanie wyznaczania stanu systemu jest nazywane estymacją stanu.
Stan procesu jest to pewna zmienna (wektor), który razem z sygnałem wejściowym jednoznacznie określa zachowanie systemu.
Jeżeli oprócz stanu systemu należy wyznaczyć pewną liczbę jego parametrów, to zadanie takie nazywa się łączną estymacją parametrów i stanu.
Kryterium - często wyraża się w postaci funkcjonału określonego na błędzie , np. kryterium minimum sumy kwadratów błędów. Dla układu ciągłego otrzymuje się wtedy
, (1.2)
gdzie , (1.3)
dla układu dyskretnego
, (1.4)
gdzie . (1.5)
Definicje błędu identyfikacji
Błąd zdefiniowany za pomocą zależności (3) i (4) jako różnica sygnałów wyjściowych systemu i modelu jest nazywany błędem wyjściowym. Definicja ta jest naturalna, gdy zakłócenia są szumem białym występującym przy pomiarze sygnału wyjściowego * rys. 4.
Rys. 4. Definicja błędu wyjściowego
Jeżeli istnieje model odwrotny systemu, to błąd estymacji można definiować jako błąd wejściowy (rys. 5)
. (1.6)
Rys. 5. Definicja błędu wejściowego
Najbardziej ogólną postacią błędu jest błąd uogólniony definiowany przez zależność
. (1.7)
Rys. 6. Definicja błędu uogólnionego
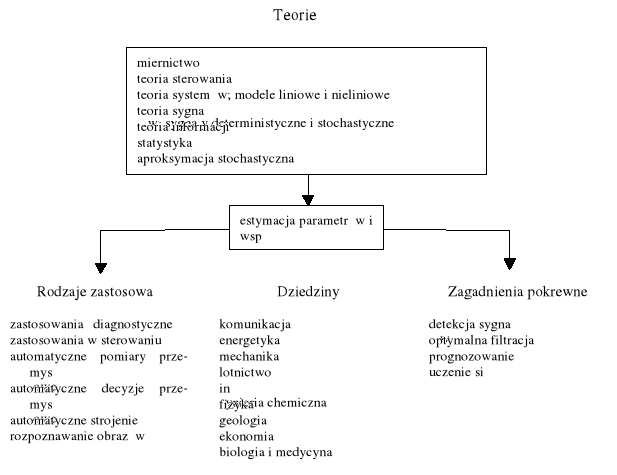
Teorie związane z estymacją parametrów i niektóre dziedziny zastosowań
Rys. 7. Zastosowania estymacji parametrów i stanu
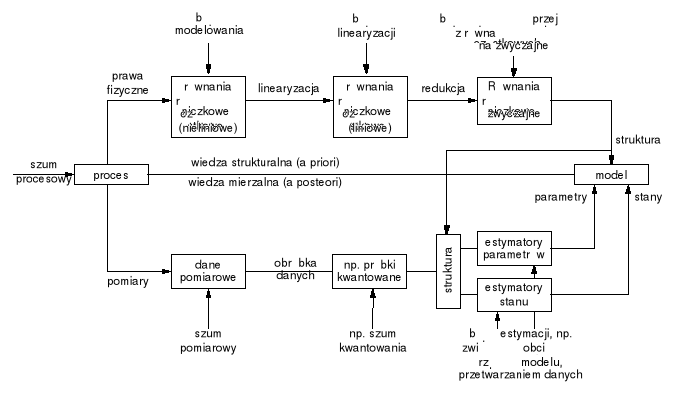
Rys. 8. Konstruowanie modelu na podstawie wiedzy strukturalnej i pomiarów
3. Sygnały deterministyczne. Klasy sygnałów
Podstawą identyfikacji i estymacji jest opis matematyczny (model) zależności między pewnymi sygnałami wejściowymi a wyjściowymi.
Klasy sygnałów:
ciągłe i próbkowane,
analogowe, kwantowane (binarnie i wielopoziomowo).
Aproksymacja funkcji za pomocą wielomianów
Załóżmy, że f(t) jest funkcją ciągłą określoną na przedziale [a,b]. Weierstrass (1885) wykazał, że dla dowolnej liczby ε > 0 istnieje wielomian
, (3.1)
stopnia n, gdzie są współczynnikami wielomianu P(t), który
spełnia warunek
. (3.2)
Funkcje ortogonalne
Funkcje o ogólnej naturze można zapisywać w postaci ich rozwinięć w szeregi funkcji ortogonalnych {gi(t)}. Dowolną funkcję można w przybliżeniu przedstawiać za pomocą skończonej liczby współczynników.
Dyskretny zbiór funkcji ortogonalnych g1(t), g2(t), ... określonych na przedziale (a,b) spełnia warunki:
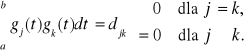
(3.3)
Jeżeli djk = δjk ( delta Kroneckera), δjk = 1 dla j = k i δjk = 0 dla j ≠ k, to zbiór funkcji nazywa się zbiorem ortonormalnym.
Jeżeli nie można znaleźć takiej niezerowej funkcji y(t), że
(3.4)
to zbiór nazywa się zbiorem zupełnym.
Za pomocą zbioru zupełnego i ortonormalnego można wyrazić funkcję czasu x(t)
, (3.5)
gdzie (3.6)
Przykładem zbiorów dyskretnych funkcji ortogonalnych są szeregi Fouriera, wielomiany Legendre'a, wielomiany Czebyszewa, wielomiany i funkcje Laguerre'a i Hermite'a.
Sygnały ciągłe
3.3.1. Sygnał skokowy
(3.7)
Sygnał skokowy spełniający warunek A = 1 jest nazywany skokiem jednostkowym.
(3.8)
Sygnały wykładnicze
Sygnały wykładnicze stanowią rozwiązania liniowego równania różniczkowego
(3.9)
W zależności od wartości jakie przyjmują pierwiastki wielomianu charakterystycznego równania (13) funkcja x(t) będąca jego rozwiązaniem może mieć postać
, (3.10)
gdzie αi oznacza i-ty pierwiastek (rzeczywisty lub zespolony), ni krotność i-tego pierwiastka.
Wielomian charakterystyczny
. (3.11)
3.3.3. Impuls jednostkowy Diraca
(3.12)
. (3.13)
Związek między funkcją skoku jednostkowego i funkcją impulsu Diraca.
, (3.14)
. (3.15)
3.3.4. Sygnał opóźniony o odcinek czasu τ
(3.16)
(3.17)
3.3.5. Rozwinięcie w szereg Fouriera
Zakładamy, że xT(t) jest sygnałem okresowym. Jeżeli funkcja xT(t) spełnia warunki Dirichleta -
jest skończona, to można ją rozwinąć w szereg Fouriera
, (3.18)
gdzie
, (3.19)
, (3.20)
. (3.21)
Rozwinięcie w szereg Fouriera można zapisać w postaci wykładniczej
, (3.22)
gdzie
. (3.23)
Zespolone współczynniki cn określają widmo sygnału okresowego (moduły i przesunięcia fazowe składników rozwinięcia).
3.3.6. Przekształcenie Fouriera
. (3.24)
Przekształcenie odwrotne
. (3.25)
Przekształcenie Laplace'a
Zakłada się, że jest zbieżna.
. (3.26)
Przekształcenie odwrotne
. (3.27)
4. Sygnały Losowe. Metody Opisu sygnałów losowych
4.1. Podstawowe pojęcia
Proces stochastyczny - funkcja przypadkowa X(t) czasu t.
Procesem stochastycznym jest funkcja losowa czasu, która dla każdej chwili czasu jest zmienną losową.
Zmienna losowa - wielkość przyjmująca wartości przypadkowe.
Dystrybuantą zmiennej losowej X nazywa się prawdopodobieństwo zdarzenia, że zmienna X przyjmie wartość mniejszą od x.
. (4.1)
Funkcją gęstości (rozkładu prawdopodobieństwa) zmiennej losowej ciągłej X nazywa się pochodną względem x dystrybuanty FX (x) tej zmiennej losowej.
. (4.2)
Moment k-tego rzędu
. (4.3)
Wariancja - moment centralny drugiego rzędu
, (4.4)
gdzie mx oznacza wartość oczekiwaną.
Odchylenie średnie (standardowe) lub dyspersja
. (4.5)
4. 2. Rozkład równomierny
. (4.6)
. (4.7)
. (4.8)
. (4.9)
4. 3. Rozkład normalny
. (4.10)
4. 4. Momenty procesu stochastycznego
Moment k-tego rzędu
. (4.11)
gdzie - k wymiarowa funkcja gęstości procesu X(t)
Wartość oczekiwana
. (4.12)
Funkcja korelacyjna - moment centralny drugiego rzędu procesu X(t)
. (4.13)
Wzajemna funkcja korelacyjna procesów X(t) i Y(t)
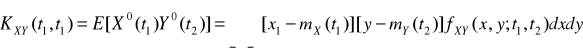
. (4.14)
Stacjonarność procesu stochastycznego
Proces stochastyczny X(t) nazywamy stacjonarnym w wąskim sensie jeżeli funkcja gęstości wektora losowego o składowych X(t1), X(t2),..., X(tn) jest równa funkcji gęstości wektora losowego o składowych X(t1+τ), X(t2+τ),..., X(tn+τ).
Jednowymiarowa funkcja gęstości procesu stochastycznego X(t) stacjonarnego w wąskim sensie nie zależy od czasu t, a dwuwymiarowa funkcja gęstości zależy tylko od τ = t2 - t1.
Wartość oczekiwana procesu stacjonarnego w wąskim sensie jest stała i nie zależy od czasu t.
Funkcja korelacyjna jest zależna tylko od τ = t2 - t1.
Proces stochastyczny X(t) nazywamy stacjonarnym w szerokim sensie, jeżeli wartość oczekiwana procesu stacjonarnego nie zależy od czasu, a funkcja korelacyjna jest zależna tylko od τ = t2 - t1
Procesy stochastyczne, które nie są stacjonarnym w wąskim lub szerokim sensie nazywa się niestacjonarnymi.
Ergodyczność procesu stochastycznego
Proces stochastyczny stacjonarny (w szerokim sensie) jest nazywany ergodycznym, jeżeli jest spełniony następujący warunek
. (4.15)
Proces stacjonarny X(t), którego funkcja korelacyjna KX(τ) jest ograniczona dla τ = 0 i maleje do zera dla τ → ∞ jest procesem ergodycznym.
Wartość oczekiwaną i funkcję korelacji procesu stacjonarnego i ergodycznego można obliczyć uśredniając (całkując) po czasie jedną realizację procesu:
, (4.16)
(4.17)5. GENEROWANIE SYGNAŁÓW LOSOWYCH I SYGNAŁÓW PSEUDOLOSOWYCH
Generatory fizyczne losowe
moneta, urna, kostka do gry, ruletka, generator wykorzystujący zjawisko promieniotwórczości, itp.
Generatory liczb pseudolosowych
Generatory pseudolosowych sekwencji binarnych
Generatory liczb pseudolosowych
5.1.1. Szum biały (dyskretny) - ciąg losowy, którego funkcja korelacyjna spełnia zależność
, (5.1)
gdzie: (5.2)
oznacza deltę Kroneckera.
Szum biały jest ciągiem czasowym o nieskończenie szerokim i stałym widmie mocy, tzn. przenoszącym moc za pośrednictwem składowych sinusoidalnych o wszystkich częstotliwościach z zakresu 0 ≤ ωTp ≤ π.
Podstawową rolę podczas generowania liczb pseudolosowych za pomocą programów komputerowych odgrywają generatory liczb losowych o rozkładzie równomiernym na przedziale (0,1).
5.1.2. Zmienna losowa o rozkładzie równomiernym na przedziale (0,1) - zmienna losowa ciągła R, dla której
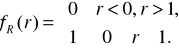
, (5.3)
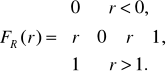
(5.4)
Zmiennej takiej nie można wygenerować na żadnym komputerze, ponieważ wykorzystując rejestr o długości k-bitów można zapisać 2k różnych liczb.
Generator liczb pseudolosowych - program do generowania liczb o właściwościach odpowiadających liczbom losowym. Ciągi liczb pseudolosowych mają deterministyczny charakter ale ich właściwości badane za pomocą testów statystycznych są takie same jak prawdziwych liczb losowych.
5.1.3. Generator kwadratowy (J. von Neumann)
. (5.5)
Przykład: x0 = 17, M = 1000;
x1 = 289,
x2 = 521,
x3 = 441,
x4 = 481,
x5 = 361,
x6 = 321,
x7 = 41,
x8 = 681,
x9 = 761,
...
5.1.4. Generatory liniowe
, (5.6)
gdzie ai, b, xi są liczbami całkowitymi z przedziału [0, M).
Generatory multiplikatywne
, (5.7)
Generatory mieszane
, (5.8)
Generatory addytywne (Fibonacciego)
. (5.9)
Liczby o rozkładzie równomiernym na przedziale (0,1)
. (5.10)
W ciągu {rn}, n = 1, 2,... może wystąpić co najwyżej M różnych liczb.
Własności arytmetyczne generatorów liczb pseudolosowych
Generatory multiplikatywne
. (5.11)
gdzie a, xi są liczbami całkowitymi z przedziału [0, M). Generator został zaproponowany przez D. H. Lehmera (1951).
Generator multiplikatywny jest generatorem okresowym.
|
M |
a |
x0 |
Okres N |
1 |
2m, m ≥ 3 |
1 (mod 8) 3(mod 8) 5 (mod 8) |
5,7,13,15 (mod 16) 1,3,9,11 (mod 16) 1,3 (mod 4) |
2m-2 |
2 |
10m, m > 3 |
λ (mod 200) |
1,3,7,9 (mod 10) |
5×10m-2 |
3 |
Liczba pierwsza |
Pierwiastek pierwotny M |
|
M |
Tabela 1. Zależność okresu N generatora multiplikatywnego od wyboru M, a i x0
gdzie λ = 3, 13, 27, 37, 53, 67, 77, 83, 117, 123, 133, 147, 163, 187, 197.
Przykład: a = 11, m = 5, M = 32, x0 = 1.
xn = 1, 11, 25, 19, 17, 27, 9, 3, 1, ...
. (5.12)
. (5.13)
. (5.14)
Generatory multiplikatywne mają na ogół dobre właściwości statystyczne. Analiza statystyczna za pomocą różnych testów prowadzi zwykle do akceptacji generatora.
Generatory mieszane
, (5.15)
gdzie a, b, xi są liczbami całkowitymi z przedziału [0, M).
Generator został zaproponowany przez A. Rotenberga (1960). Podobnie jak generator multiplikatywny, generator mieszany jest generatorem okresowym. Dokonując odpowiedniego wyboru stałych a i b można otrzymać generator o pełnym okresie N.
Generator (60) ma okres N, jeżeli:
b jest liczbą pierwszą względem N,
a ≡ 1 (mod p) dla każdego czynnika pierwszego p liczby M,
a ≡ 1 (mod 4), jeżeli 4 jest dzielnikiem liczby M.
Dla generatorów o stałej M = 2m otrzymuje się pełny okres 2m, jeżeli b jest liczbą nieparzystą i a ≡ 1 (mod 4).
Generatory mieszane mają na ogół gorsze właściwości statystyczne niż generatory multiplikatywne.
Generatory addytywne
. (5.16)
Fibonacci (Liber abaci, 1202) badał ciągi liczb dla i = 1. Generator (5.16 jest okresowy, a jego okres N = 3×2m-1, niezależnie od wyboru stałych początkowych x0 i x1.
Badania generatora Fibonacciego wykazały, że generator ten spełnia testy równomierności rozkładu (częstości i zgodności momentów), ale nie spełnia testów niezależności (serii). Ciągi utworzone z wyrazów o numerach parzystych lub nieparzystych mają lepsze właściwości statystyczne, ale gorsze od wyników uzyskiwanych dla generatorów multiplikatywnych:
zadawalające wyniki udaje się uzyskać jedynie w niektórych szczególnych przypadkach,
umożliwiają bardzo szybkie generowanie liczb pseudolosowych, dzięki eliminacji mnożenia.
Przykład: Uogólniony generator Fibonacciego
. (5.17)
Okres generatora N ≤ βk×2m-1, gdzie βk = 3, 7, 15, 21, 63, 127, 63, 73, 889, 2047, 3255, 2905, 11811, 32767, 255, odpowiednio, dla i = 2, 3,..., 16. Okres zależy od stałych początkowych. Generator spełniał wszystkie testy dla i = 16.
Testy statystyczne generatorów liczb pseudolosowych
Rodzaje testów statystycznych
Statystyczną ocenę właściwości liczb pseudolosowych przeprowadza się traktując kolejną liczbę xi wytworzoną przez generator jako zmienną losową. Weryfikacji poddawana jest hipoteza, że ciąg x1, x2,...,xN może być traktowany jak N - elementowa próbka z populacji o określonym rozkładzie prawdopodobieństwa. W celu zbadania właściwości liczb otrzymanych z generatora formułuje się różnorodne testy statystyczne. Pomyślne wyniki testowania pozwalają zaakceptować generator jako źródło liczb pseudolosowych w oparciu o zaufanie, że generator przejdzie również pomyślnie inne testy.
Testy służące do weryfikacji generatorów dzieli się na dwie grupy:
testy zgodności rozkładu,
testy niezależności.
Testy zgodności rozkładu umożliwiają weryfikację hipotezy, że próbka x1, x2,...,xN pochodzi z populacji o określonym rozkładzie. Drugi rodzaj testów umożliwia weryfikację losowości próbki.
Przykładami testów zgodności rozkładu są:
test wartości średniej,
test wariancji,
test zgodności rozkładu chi-kwadrat,
test zgodności rozkładu par.
Do testów losowości zalicza się natomiast:
test autokorelacji,
test przejść,
test serii poniżej stałej,
test serii powyżej stałej,
test pokerowy,
test kolekcjonera,
test permutacji.
Test wartości średniej
Statystyka - zmienna losowa będąca funkcją obserwowanej zmiennej losowej wielowymiarowej , której realizacją jest próba .
Statystyka (wartość oczekiwana z próby)
(5.18)
zgodnie z centralnym twierdzeniem granicznym (Lindeberga-Levy'ego) ma rozkład graniczny normalny N(mx, σx/).
, (5.19)
, (5.20)
, (5.21)
gdzie: mx - wartość oczekiwana zmiennej losowej zmiennej losowej Xn,
σn - dyspersja zmiennej losowej Xn.
Zmienna losowa unormowana
, (5.22)
ma rozkład normalny N(0, 1).
Przedział ufności zmiennej jest określony przez nierówność
, (5.23)
, (5.24)
spełnia warunek
, (5.25)
gdzie 1 − α jest nazywane poziomem ufności. Znając rozkład (70) można zapisać w postaci
, (5.26)
Rys. 8. Funkcja gęstości rozkładu normalnego i stała
Wartości określa się korzystając z tablic dystrybuanty unormowanego rozkładu normalnego.
. (5.27)
gdzie oznacza dystrybuantę unormowanego rozkładu normalnego.
|
1- α |
0.95 |
0.99 |
|
|
1.96 |
2.58 |
Tab. 2. Poziom ufności i stała dla rozkładu normalnego
Test wariancji
Estymatorem nieobciążonym i najefektywniejszym wariancji jest statystyka
, (5.28)
, (5.29)
, (5.30)
. (5.31)
Statystyka (71) ma rozkład graniczny normalny N(,).
Przedział ufności określa nierówność
, (5.32)
Test zgodności rozkładu (test częstości)
Test służy do weryfikowania nieparametrycznej hipotezy określającej postać funkcyjną dystrybuanty.
Statystykę Pearsona definiuje się następująco:
Zbiór wartości S zmiennej X dzieli się na k rozłącznych podzbiorów Si. Niech Pi oznacza prawdopodobieństwo, że zmienna losowa X przyjmuje wartość należącą do podzbioru Si. Dokonajmy N niezależnych obserwacji zmiennej losowej X i niech Ni oznacza liczbę obserwacji należących do i-tego podzbioru.
Statystyka
, (5.33)
ma rozkład graniczny chi-kwadrat o k - 1 stopniach swobody. Test chi-kwadrat jest oparty na twierdzeniu granicznym, dlatego liczebności Ni nie mogą być małe. Zaleca się, by przeciętna liczba obserwacji w podzbiorze była nie mniejsza od 5 lub 10.
Algorytm testowania generatora.
Podzielić przedział wartości zmiennej losowej na k przedziałów tak, aby prawdopodobieństwo zdarzenia że zmienna losowa przyjmie wartość z danego przedziału dla hipotetycznego rozkładu było jednakowe dla wszystkich przedziałów
Wyznaczyć liczby Ni zliczając ilość liczb należących do poszczególnych przedziałów.
Obliczyć wartość statystyki ze wzoru (78)
Zakładając poziom ufności 1− α odczytać z tablicy rozkładu chi-kwadrat wartość krytyczną dla k − 1 stopni swobody.
Jeżeli wartość statystyki jest mniejsza od wartości krytycznej akceptujemy generator.
Uogólniony test chi-kwadrat jest wykorzystywany do testowania rozkładów wielowymiarowych.
Test autokorelacji
Współczynniki autokorelacji ciągu liczb losowych określa wzór
, (5.34)
Ponieważ
, (5.35)
, (5.36)
. (5.37)
Z twierdzenia Hoeffidinga-Robbinsa wynika, że współczynniki korelacji dla rozkładu równomiernego mają rozkład graniczny N(0,).
Test przejść
Przejście definiuje się jako ilość liczb między dwoma kolejnymi punktami ekstremalnymi ciągu zwiększoną o dwa.
Rys. 9. Definicja przejścia
Punktami ekstremalnymi są punkty: 2, 4, 5, 6, 7, 8. Przejście o długości 3 występuje między punktami 2 i 4, między pozostałymi punktami ekstremalnymi występują przejścia o długości 2.
Wartość oczekiwaną liczby przejść Lk o długości k lub większej wyraża wzór
. (5.38)
Prawdopodobieństwo Pk wystąpienia przejścia o długości k określa wzór
. (5.39)
Zgodność rozkładu empirycznego z rozkładem teoretycznym weryfikuje się za pomocą testu chi-kwadrat.
Test serii
Ciąg liczb losowych dzieli się na dwa rozłączne podzbiory A i B. definiuje się nową zmienną losową Y o wartościach a i b
(5.40)
przekształcając wyrazy ciągu otrzymuje się ciąg typu aababbbabaaa.... Przekształcenia (84) dokonuje się, na przykład, przyjmując za wartości a liczby większe od pewnej stałej α a za wartości b liczby mniejsze lub równe od tej stałej lub na odwrót.
Odcinkiem elementarnym ciągu nazywa się odcinek złożony z elementów tego samego rodzaju. Serią jest odcinek o maksymalnej długości.
Wartość oczekiwaną i wariancję liczby serii określają wzory
, (5.41)
, (5.41)
gdzie , R oznacza liczbę serii. Rozkład graniczny statystyki ilości serii jest normalny N((2N-1)/3,(16N-29)/90). Rozkład weryfikuje się za pomocą testu chi-kwadrat.
Generatory liczb losowych o dowolnych rozkładach
Metoda odwracania dystrybuanty
Niech R będzie zmienną losową o rozkładzie równomiernym na przedziale (0.1) i niech F będzie pewną ciągłą i ściśle rosnącą funkcją taką, że
(5.42)
Zmienna losowa
(5.43)
ma rozkład o dystrybuancie F, ponieważ
(5.43)
Jeżeli { rn }, n = 1, 2, ..., jest ciągiem liczb losowych o rozkładzie równomiernym na przedziale (0,1), to ciąg { xn }, n = 1, 2, ..., dla jest ciągiem o rozkładzie z dystrybuantą F.
Przykład. Aby wygenerować liczby o rozkładzie wykładniczym
(5.44)
należy:
wygenerować liczby rn o rozkładzie równomiernym na przedziale (0,1),
obliczyć liczby .
Ponieważ 1 − rn ma również rozkład równomierny, to liczby rn można obliczać ze wzoru
Metoda odwracania dystrybuanty wymaga zwykle znacznego nakładu obliczeń, dlatego często stosowane są metody przybliżone. Na przykład, liczby losowe o rozkładzie ”w przybliżeniu” normalnym N(0,1), ograniczonym do wartości dodatnich, można otrzymać stosując przekształcenie
. (5.45)
Metoda eliminacji
Metoda zaproponowana została przez J. von Neumanna (1951):
Załóżmy, że zmienna losowa X ma rozkład f(x) na pewnym przedziale (a,b). Niech f(x) ≤ c, dla pewnej stałej c < +∞.
Procedura generowania:
wygenerować punkt (R1, R2). R1 jest zmienną losową o rozkładzie równomiernym na przedziale (a,b), R2 jest zmienną losową o rozkładzie równomiernym na przedziale (0,c) i zmienne losowe R1 i R2 są niezależne. Zmienną losową o rozkładzie równomiernym na przedziale (a,b) otrzymuje się stosując przekształcenie (b − a)R + a, gdzie R oznacza zmienną losową o rozkładzie równomiernym na przedziale (0,1),
jeżeli R2 ≤ f(R1), to przyjmuje się X = R1, w przeciwnym przypadku parę (R1, R2) eliminuje się i generuje się nowy punkt.
Generowanie liczb losowych o rozkładzie normalnym przy zastosowaniu centralnego twierdzenia granicznego
Zgodnie z centralnym twierdzeniem granicznym (Lindeberga−Levego) zmienną losową o rozkładzie normalnym N(0,1) otrzymuje się w wyniku następującego przekształcenia ciągu {Ri} niezależnych zmiennych losowych o rozkładzie równomiernym na przedziale (0,1):
. (5.46)
Często, dla uproszczenia obliczeń, przyjmuje się n = 12.
Generatory pseudolosowych sekwencji binarnych
Ciągi pseudolosowe o maksymalnej długości (m-ciągi) można wytwarzać w rejestrach przesuwnych ze sprzężeniem zwrotnym (rys. 10).
Rys. 10. Generator pseudolosowych sekwencji binarnych
Ciągi te są okresowe. Wybierając odpowiednio sprzężenie zwrotne można otrzymać ciąg o maksymalnej długości równej, gdzie Δ oznacza okres sygnału zegarowego.
n |
2 |
3 |
4 |
5 |
6 |
7 |
9 |
10 |
11 |
15 |
17 |
18 |
20 |
23 |
28 |
33 |
m |
1 |
2 |
3 |
2 |
1 |
3 |
4 |
3 |
2 |
1 |
8 |
7 |
3 |
5 |
8 |
13 |
Tab. 3. Sprzężenia zapewniające maksymalny okres
Funkcja korelacji m-ciągu dobrze aproksymuje funkcję Diraca dla odpowiednio dużego n − rys. 11.
Rys. 11. Funkcja korelacji pseudolosowego ciągu binarnego
Podstawowe pojęcia teorii estymacji. Estymacja metodą najmniejszych kwadratów. Estymacja metodą Markowa. Estymacja metodą największej wiarygodności. Estymacja metodą najmniejszego ryzyka
Identyfikacja modeli systemów statycznych metodą najmniejszej sumy kwadratów
Metoda najmniejszych kwadratów (A. M. Legendre - 1806, K. F. Gauss - 1809) jest najczęściej stosowaną metodą estymacji parametrów modeli liniowych względem parametrów. Zadanie identyfikacji formułuje się w następujący sposób:
Zakłada się, że identyfikowany system nieliniowy może być opisany za pomocą rozwinięcia wielomianowego r zmiennych wejściowych uj
(6.1)
gdzie y oznacza sygnał wyjściowy, ε jest zakłóceniem reprezentującym wszystkie inne zmienne wejściowe nie uwzględnione w modelu, a βj, βjk,βjkl,... są nieznanymi parametrami modelu. Ponieważ zależność (92) jest liniowa względem parametrów, to wprowadzając wtórne zmienne wejściowe
i oznaczając odpowiednie parametry przez βr+1, βr+2, βr+3,...,βs-1, βs można ją zapisać w postaci
, (6.2)
gdzie:
,.
Wykorzystując wyniki N obserwacji w postaci wartości y1, y2,..., yN otrzymanych dla N różnych zbiorów wartości wejściowych u1i, u2i,..., usi (i = 1,2,...,N) należy wyznaczyć określone przez wektor parametry modelu (funkcji regresji)
, (6.3)
minimalizując sumę kwadratów błędów,
. (6.4)
Uwzględniając wyniki N obserwacji na podstawie zależność (92) można zapisać w postaci
, (6.5)
gdzie:
jest wektorem wartości wyjściowych modelu odpowiadających kolejnym zbiorom wartości zmiennych wejściowych,
macierzą obserwacji zmiennych wejściowych.
Wektor błędów identyfikacji określa wyrażenie
, (6.6)
gdzie jest wektorem obserwacji zmiennej wyjściowej. Stąd sumę kwadratów błędów identyfikacji (93) można zapisać w postaci
. (6.7)
Rys. 12. Definicja błędu identyfikacji
Różniczkując (97) względem b otrzymuje się warunek konieczny istnienia minimum
. (6.8)
Zakładając, że macierz UTU jest nieosobliwa otrzymuje się następujące rozwiązanie zadania identyfikacji systemu statycznego
. (6.9)
Podstawowe własności estymatorów najmniejszej sumy kwadratów
Załóżmy, że zakłócenia ε są wektorem zmiennych losowych stochastycznie niezależnych spełniającym następujące zależności:
, (6.10)
(6.11)
Wartość oczekiwana wielkości wyjściowej obiektu y
. (6.12)
Macierz kowariancji wielkości wyjściowej y
(6.13)
Wartość oczekiwana estymatora parametrów b
. (6.14)
Wektor b jest nieobciążonym estymatorem wektora parametrów systemu β.
Różnica między estymatorem b a wektorem parametrów β
. (6.15)
Macierz kowariancji estymatora parametrów b
. (6.16)
Macierz (UTU)-1 jest nazywana macierzą kowariancyjną. Elementy diagonalne tej macierzy charakteryzują wariancje poszczególnych parametrów wektora b, pozostałe elementy kowariancje odpowiednich parametrów.
Nieobciążony estymator wariancji zakłóceń ε
![]()
. (6.17)
Algorytm rekurencyjny metody najmniejszych kwadratów
Obliczenie wektora parametrów b ze wzoru (99) jest możliwe po wcześniejszym zgromadzeniu N wyników obserwacji (pomiarów) wielkości wejściowych i wielkości wyjściowej. W wielu zastosowaniach celowe jest stosowanie procedury rekurencyjnej, która umożliwiałaby przetwarzanie napływających kolejno danych metodą on-line a nie dopiero po zgromadzeniu wszystkich N wyników obserwacji. W procedurze tej wartości macierzy i wektora określone w chwili i-tej oblicza się korzystając z następujących zależności rekurencyjnych:
, (6.18)
, (6.19)
gdzie: .
Pomijając szczegóły wyprowadzenia [10], [12], wektor ocen parametrów systemu bi oblicza się zgodnie z następującymi zależnościami rekurencyjnymi:
, (6.20)
, (6.21)
gdzie: . Stosowanie procedury rekurencyjnej opisanej wzorami (6.20) i (6.21) wymaga założenia początkowych wartości macierzy i wektora bi. Zwykle przyjmuje się .
Zadanie identyfikacji parametrów dyskretnego systemu dynamicznego
Metoda najmniejszych kwadratów może być również stosowana do identyfikacji nieliniowych systemów dynamicznych. Problem ten omówimy dokładniej dla modeli typu ARX (ang. AutoRegressive with eXogenous input)
, (6.22)
gdzie - parametry modelu.
Wprowadzając wielomiany i zmiennej z-1 (operatora opóźnienia o okres próbkowania) zależność (6.22) można zapisać w postaci
, (6.23)
przy czym:
,
.
Zakłada się, że znane są stopnie n i m wielomianów i oraz, że n ≥ m. Zależność (6.23) można inaczej zapisać w postaci
.
Błąd uogólniony dla modelu (6.23) definiuje zależność
, (6.24)
gdzie oznacza sygnał wyjściowy identyfikowanego systemu w k-tej chwili próbkowania. Błąd ![]()
można także zapisać w postaci
![]()
,
![]()
.
gdzie ![]()
oznacza wektor pomiarowy
![]()
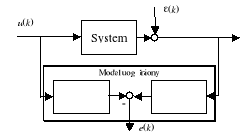
Rys. 13. Definicja błędu uogólnionego dla zadania identyfikacji modelu ARX
Błąd identyfikacji jest liniową funkcją parametrów modelu (6.23).
Zakładamy, że zostały zebrane wyniki N pomiarów sygnałów wejściowego i wyjściowego ,(). Wyniki te można zapisać w postaci macierzowej
, (6.25)
gdzie:
,
,
,
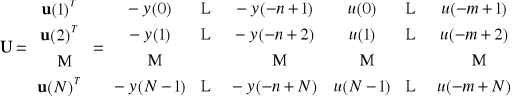
Podobnie jak w przypadku zadania identyfikacji obiektu statycznego, wektor parametrów modelu należy wyznaczyć tak, aby suma kwadratów błędów
(6.26)
osiągnęła wartość minimalną. Rozwiązując zadanie minimalizacji otrzymuje się
. (6.27)
Nieobciążone oceny parametrów można otrzymać, jeżeli:
Błędy ![]()
są statystycznie niezależne i mają wartość oczekiwaną równą zero,
Błędy i wartości są statystycznie niezależne,
Sygnały wejściowy i wyjściowy są znane z nieskończenie dużą dokładnością.
Spełnienie warunku I wymaga aby:
- identyfikowany system dynamiczny (rys. 14) był opisany następującym równaniem
![]()
, (6.28)
gdzie:
![]()
,
![]()
,
są parametrami systemu,
![]()
(6.29)
- zakłócenia były sekwencją niezależnych zmiennych losowych o wartości oczekiwanej
i funkcji korelacji
Rys. 14. Identyfikacja systemu ARX
Identyfikacja obiektów o wolnozmiennych parametrach
Ponieważ w algorytmie (6.20) − (6.21) elementy macierzy kowariancyjnej zmniejszają się stopniowo ze wzrostem liczby iteracji, maleją także korekty wektora b. W celu umożliwienia śledzenia wolnych w czasie zmian parametrów identyfikowanego obiektu stosowana jest modyfikacja tego algorytmu polegająca na wprowadzeniu tzw. współczynnika zapominania:
, (6.30)
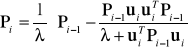
, (6.31)
gdzie
![]()
(6.32)
Zwykle przyjmuje się ![]()
.
Wprowadzenie współczynnika zapominania jest równoważne minimalizacji wskaźnika
![]()
(6.33)
Rozszerzona metoda najmniejszych kwadratów (metoda macierzy rozszerzonej)
W metodzie tej zakłada się, że obiekt jest opisany następującym równaniem:
![]()
, (6.34)
gdzie:
![]()
.
Błąd identyfikacji
![]()
, (6.35)
Stąd
![]()
. (6.36)
Zależność (6.36) można przedstawić w postaci
![]()
. (6.37)
Wektor ocen parametrów definiuje się w następujący sposób:
![]()
.
Wprowadzając wektor pomiarowy:
![]()
błąd ![]()
można zapisać w postaci ![]()
, a oceny parametrów obliczać tak jak w metodzie najmniejszych kwadratów.
Minimalnowartościowa predykacja ciągów czasowych
Zakłócenia można uważać za sumę składowej deterministycznej i składowej losowej o zerowej wartości oczekiwanej.
Jeżeli znany jest model matematyczny zakłóceń, to można przewidywać przyszłe wartości ciągu.
Predykcja ciągu czasowego − przewidywanie przyszłych wartości ciągu.
Model źródła zakłóceń − zakłócenia można przedstawiać jako wynik filtracji dyskretnego szumu białego.
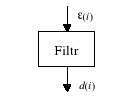
Rys. 15. Zakłócenia jako efekt filtracji szumu białego
Szum biały:
![]()
, (6.38)
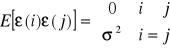
. (6.39)
Liniowy model źródła zakłóceń:
![]()
, (6.40)
![]()
![]()
![]()
![]()
− model stabilny,
![]()
![]()
− model minimalnofazowy.
K. J. Åström wykazał, że:
Optymalna predykcja zakłócenia ![]()
na k kroków naprzód wyznaczona w chwili i jest dana wyrażeniem:
![]()
, (6.41)
Minimalna wariancja predykcji zakłócenia ![]()
jest dana wyrażeniem
![]()
, (6.42)
Błąd predykcji minimalnowariancyjnej
![]()
, (6.43)
Wielomiany ![]()
i ![]()
są rozwiązaniami równania wielomianowego
![]()
. (6.44)
gdzie:
![]()
,
![]()
.
Przykład. Dla modelu podanego wyznaczyć wielomiany ![]()
i ![]()
dla predyktora 2-krokowego ![]()
.
![]()
.
![]()
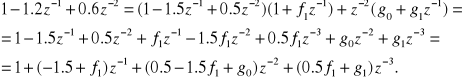
(6.45)
Porównując prawą i lewą stronę (6.45) otrzymuje się
![]()
![]()
![]()
Optymalny predyktor 2-krokowy ma postać
![]()
. (6.46)
Predykcja szumu białego
![]()
,
Dla szumu białego
![]()
, (6.47)
![]()
. (6.48)
Z równanie (6.44) otrzymuje się
![]()
. (6.49)
Stąd uwzględniając (6.47)
![]()
. (6.50)
Z zależności (6.50) wynika, że
![]()
(6.51)
![]()
(6.52)
a z (6.52) otrzymuje się ![]()
Optymalna k-krokowa predykcja d(i)
![]()
. (6.53)
Predykcja białego szumu jest zawsze równa zero, czyli wartości oczekiwanej szumu.
Wynika z tego, że nie można przewidywać przyszłych wartości białego szumu, ponieważ brak jest korelacji między wartościami szumu w chwili i i ![]()
Przedziały ufności dla błędów predykcji
Jeżeli ![]()
ma rozkład normalny, to błędy predykcji mają również rozkład normalny. Błędy
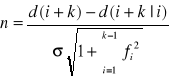
, (6.54)
mają rozkład N(0,1). Przedział ufności dla poziomu ufności ![]()
![]()
. (6.55)
7. MODELE PROCESÓW. MODELE LINIOWE, ZMIENNO-LINIOWE I NIELINIOWE. SZEREGI VOLTERRY MODELE TYPU GMDH
Klasy modeli procesów. Modele liniowe i nieliniowe, modele stacjonarne i niestacjonarne
Właściwości procesów dynamicznych opisuje się za pomocą równań różniczkowych. Np., liniowy ciągły proces można opisać za pomocą modelu wejściowo-wyjściowego
, (7.1)
z warunkami początkowymi .
Jeżeli współczynniki równania (7.1) nie zależą od czasu, to model nazywa się stacjonarnym. Modele o współczynnikach zależnych od czasu nazywa się niestacjonarnymi lub zmienno- liniowymi.
Procesy nieliniowe, w przeciwieństwie do procesów liniowych, nie spełniają zasady superpozycji.
Odpowiedź y(t) układu liniowego ciągłego na wymuszenie u(t) określa następujący funkcjonał (zależność splotowa):
, (7.2)
Właściwości dynamiczne procesu powodują, że y(t) jest zależne od poprzednich wartości u(t).
Modele procesów dynamicznych można podzielić na nieparametryczne:
odpowiedzi impulsowe (skokowe),
funkcje korelacyjne,
gęstości widmowe,
szeregi Volterry,
lub parametryczne:
równania różniczkowe,
transmitancje operatorowe,
modele w przestrzeni stanów.
Opis w przestrzeni stanów
Liniowy układ dynamiczny o r wejściach i p wyjściach
, (7.3)
gdzie: A − macierz układu (n×n),
B − macierz wejścia (n×r),
C − macierz wyjścia (p×n),
D − macierz transmisyjna (p×r).
Rys. 12. Schemat blokowy układu opisanego równaniami (94)
Rozwiązanie równania stanu w dziedzinie czasu:
(7.4)
(7.5)
Całkując (7.5) w przedziale (0,t) otrzymuje się
(7.6)
(7.7)
Wykładnik macierzowy definiuje się następująco:
(7.8)
Równanie stanu jednorodne (system autonomiczny)
(7.9)
ma rozwiązanie
(7.10)
Wartościami własnymi λ1, λ2,..., λn macierzy A nazywa się pierwiastki równania
. (7.11)
Modele nieliniowe
Ciągły nieliniowy system dynamiczny można opisać za pomocą nieliniowego równania różniczkowego
. (7.12)
Odpowiedź y(t) układu nieliniowego ciągłego na wymuszenie u(t) określa rozwinięcie w szereg Volterry:
, (7.13)
gdzie są odpowiedziami impulsowymi (jądrami). Opis za pomocą szeregów Volterry jest uogólnieniem opisu układów liniowych za pomocą całki splotu (7.2). Szereg Volterry jest nazywany szeregiem potęgowym funkcjonałów. W szczególnym przypadku, dla układów nie wykazujących dynamiki (statycznych), szereg Volterry przyjmuje postać szeregu potęgowego
, (7.14)
lub nieliniowych równań stanu i wyjścia
. (7.15)
Modele dyskretne
Opis wejście-wyjście
, (7.16)
z warunkami początkowymi ,
gdzie i a Tp oznacza okres próbkowania.
Zależność splotowa przyjmuje postać sumy
, (7.17)
gdzie g(k) oznacza dyskretną odpowiedź impulsową.
Wprowadzając operator przesunięcia o okres próbkowania z
zy(k) = y(k +1)
oraz definiując przekształcenie Z
, (7.18)
dla układów o zerowych warunkach początkowych otrzymuje się transmitancję dyskretną
. (7.19)
Opis w przestrzeni stanów:
. (7.20)
Rozwiązanie równania stanu można otrzymać obliczając wartości wektora stanu dla kolejnych chwil czasu k = 1,2,3,...
. (7.21)
Transmitancja dyskretnego układu sterowania
Rys. 13. Wyznaczanie transmitancji dyskretnej ciągłego obiektu sterowania
. (7.22)
Opis dyskretnych układów nieliniowych za pomocą szeregu Volterry
Opis obiektów nieliniowych za pomocą szeregów Volterry jest uogólnieniem opisu obiektów liniowych za pomocą zależności splotowej. Zakładając, że ![]()
dla ![]()
oraz ![]()
dla ![]()
, odpowiedź obiektu nieliniowego na wymuszenie ![]()
można przedstawić za pomocą następującego szeregu
![]()
![]()
(7.23)
Funkcje ![]()
są nazywane odpowiedziami impulsowymi stopnia odpowiednio 1,2 i n. Dla układów nie wykazujących dynamiki
![]()
![]()
![]()
szereg Volterry przyjmuje postać szeregu potęgowego
![]()
W ogólnym przypadku szereg Volterry ma nieskończoną liczbę wyrazów. Zakładając zbieżność szeregu można przyjąć jako przybliżoną postać opisu obiektu szereg skończony , ograniczony do n początkowych wyrazów.
Modele typu GMDH
Konstruowanie modeli parametrycznych obiektów nieliniowych utrudnia konieczność uwzględniania dużej liczby parametrów niezbędnej do odtwarzania z zadaną dokładnością złożonych zależności nieliniowych, co z kolei wymaga przetwarzania dużych zbiorów danych pomiarowch w celu wyznaczenia tych parametrów. Metoda zaproponowana przez Iwachnienkę nazwana metodą grupowej obróbki danych (ang. GMDH - Group Method of Data Handling) umożliwia wyznaczanie modelu parametrycznego zapewniając jednocześnie pewne ograniczenie liczby parametrów i ilości danych pomiarowych [4]. Idea metody polega na zastąpieniu w procesie estymacji jednego całościowego modelu obiektu strukturą hierarchiczną składającą się z modeli częściowych i wiążących je zasad wyboru zmiennych, co ilustruje rys. 14.
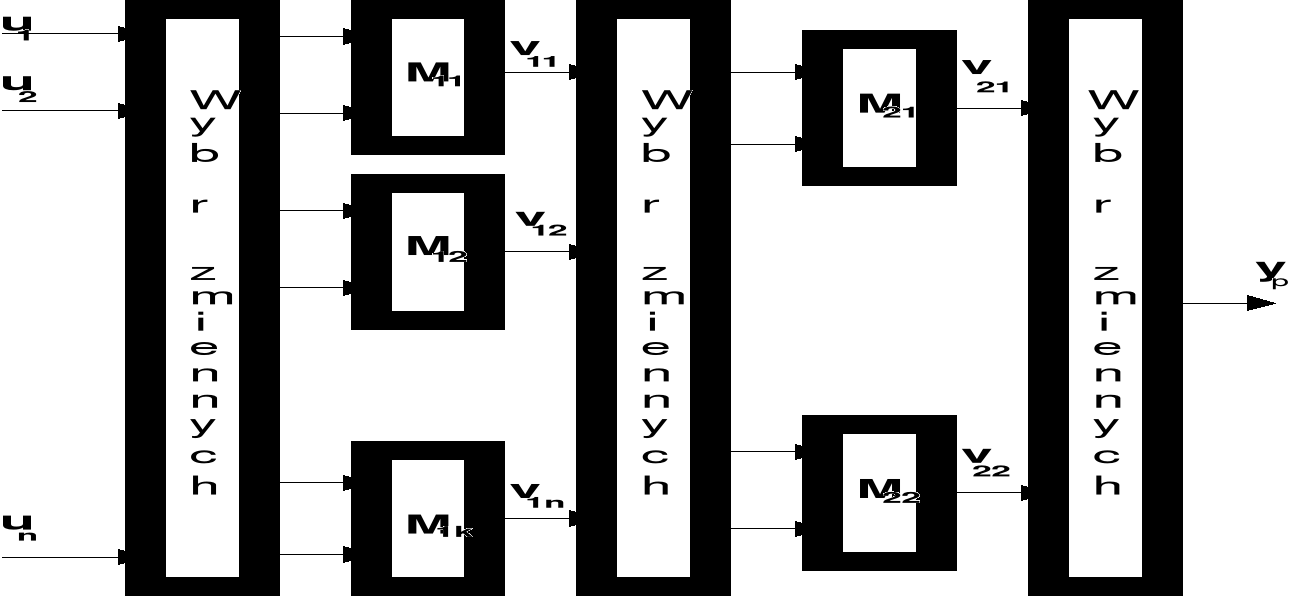
Rys. 14. Struktura modelu typu GMDH z trzema warstwami wyboru zmiennych i dwoma
warstwami modeli częściowych
Modele częściowe mają niewielką liczbę parametrów, które są dobierane w taki sposób, aby ich zmienne wyjściowe były najlepszymi przybliżeniami zmiennej wyjściowej obiektu. Wyboru zmiennych wejściowych dla modeli częściowych dokonuje się uwzględniając dokładność przybliżenia i zróżnicowanie zbioru zmiennych wejściowych dla danej warstwy. Odpowiednie zróżnicowanie zbioru zmiennych jest szczególnie ważne, gdyż pominięcie niektórych zmiennych na podstawie oceny dokładności modeli częściowych może mieć znaczący wpływ na błąd modelu całościowego.
Modele typu GMDH mogą być tworzone zarówno dla nielinowych obiektów statycznych jak i dynamicznych. W tym ostatnim przypadku jako zmienne wejściowe modelu wykorzystuje się także opóźnione wartości sygnałów wejściowego i wyjściowego obiektu.
Modele Wienera i Hammersteina
Cechą wspólną modeli Wienera i Hammersteina jest ich kaskadowa struktura złożona z liniowego układu dynamicznego i nieliniowego elementu statycznego. W modelu Wienera układ liniowy poprzedza element nieliniowy (rys. 15)

Rys. 15. Model Wienera
gdzie f(.) oznacza charakterystykę statyczną elementu nieliniowego, a G(z-1) jest transmitancją dyskretną układu liniowego
![]()
. (7.24)
Sygnał wyjściowy modelu ![]()
można zapisać jako funkcję opóźnionych wartości sygnałow ![]()
i ![]()
![]()
. (7.25)
Jeżeli funkcja ![]()
jest odwracalna, tzn. ![]()
, otrzymujemy następujące równanie różnicowe określające odpowiedź modelu na wymuszenie ![]()
:
![]()
. (7.26)
W modelu Hammersteina kolejność połączeń jest odwrotna i element nieliniowy poprzedza układ liniowy - rys. 16.
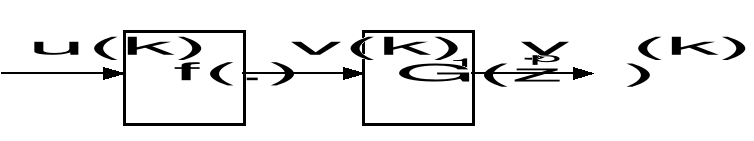
Rys. 16. Model Hammersteina
Model Wienera-Hammersteina będący kombinacją przedstawionych poprzednio modeli składa się z liniowego układu dynamicznego i dwóch statycznych elementów nieliniowych dołączonych do jego wejścia i wyjścia.
Zaletą modeli Wienera i Hammersteina jest ich prosta struktura. Zakładając, że funkcja f jest odwracalna, można dokonać linearyzacji obiektu poprzez szeregowe dołączenie do wejścia lub wyjścia odpowiedniego elementu korekcyjnego.
Nieliniowe równania różnicowe - modele ciągów czasowych
Ogólna postać modelu wejściowo-wyjściowego nieliniowego obiektu dynamicznego została nazwana NARMAX (ang.-Nonlinear Autoregressive Moving Avearge with eXogenous input). Sygnał wyjściowy modelu NARMAX określa pewna nieliniowa funkcja f, której argumentami są opóźnione wartości wejść i wyjść obiektu oraz zakłóceń
![]()
. (7.27)
Zakłada się także, że znane są całkowite współczynniki ![]()
i ![]()
określające maksymalne opóźnienia y, u i ![]()
. Zależność (7.27) ma ogólny charakter i obejmuje również modele znane jako NAR, NMA, NARX i NARMA:
![]()
, (7.28)
![]()
, (7.29)
![]()
, (7.30)
![]()
. (7.31)
Modele opisane równaniami (7.27) − (7.31) są nieliniowymi odpowiednikami znanych modeli liniowych o nazwach ARMAX, AR, MA, ARX i ARMA. W niektórych publikacjach przedmiotem zainteresowania są pewne szczególne modele będące podzbiorami ogólnych klas definiowanych przez powyższsze równania. Model typu NARX o liniowej zależności wyjścia od opóźnionych wartości wyjść, który stosowali Narendra i McDonnell opisuje równanie
![]()
. (7.32)
W modelu tym dla zapewnienia stabilności konieczne jest przyjęcie założenia, że pierwiastki równania charakterystycznego ![]()
znajdują się wewnątrz koła jednostkowego na płaszczyźnie zespolonej.
Zwróćmy uwagę, że struktura (7.32) jako bardziej ogólna obejmuje także model Hammersteina. W modelu o liniowej zależności sygnału wyjściowego od opóźnionych wartości sygnału wejściowego
![]()
, (7.33)
podobne założenie dotyczące składnika liniowego jest warunkiem koniecznym minimalnofazowości. W ostatnim z tych szczególnych modeli zakłada się, że nieliniowa zależność sygnału wyjściowego od opóźnionych wartości wejść i wyjść jest rozłączna
![]()
. (7.34)
Stosowanie do identyfikacji modeli (7.32) − (7.34) wymaga spełnienia pewnych szczegółowych założeń dotyczących identyfikowanego obiektu.
Model w przestrzeni stanów
Nieliniowy dyskretny system dynamiczny o jednym wejściu ![]()
i jednym wyjściu ![]()
można opisać za pomocą następującego układu równań stanu i wyjścia:
![]()
, (7.35)
![]()
, (7.36)
gdzie: ![]()
oznacza stan, a ![]()
stan początkowy systemu. Uwzględniając zakłocenia oddziałujące na stan ![]()
i wyjście ![]()
otrzymuje się model stochastyczny
![]()
, (7.37)
![]()
. (7.38)
Modele równoległy i szeregowo-równoległy
Sygnał wyjściowy nieliniowego modelu obiektu dynamicznego określa pewna funkcja nieliniowa, której argumentami mogą być, w ogólnym przypadku, opóźnione wartości sygnału wejściowego i sygnału wyjściowego obiektu lub jego modelu. Model, w którym na wejście oprócz opóźnionych wartości sygnału wejściowego są podawane opóźnione wartości sygnału wyjściowego modelu jest nazywany modelem równoległym.
![]()
. (7.39)
Stosowanie modelu równoległego (7.39) utrudnia to, że nawet przy założeniu stabilności identyfikowanego obiektu nie można zapewnić stabilności modelu otrzymanego w wyniku identyfikacji. Inaczej mówiąc, pomimo ograniczonych co do wartości sygnałów u(k) i ![]()
błąd identyfikacji ![]()
może nie być zbieżny do zera. Złożoność problemu identyfikacji modelu nieliniowego przy zastosowaniu modelu równoległego podkreśla to, że nawet dla modelu liniowego nie są dotychczas znane warunki zbieżności parametrów. Powyższe przyczyny sprawiają, że znacznie częściej jest stosowany model nazywany szeregowo-równoległym (rys. 17), w którym na wejście są podawane opóźnione wartości sygnałów obiektu - wejściowego ![]()
i wyjściowego ![]()
.
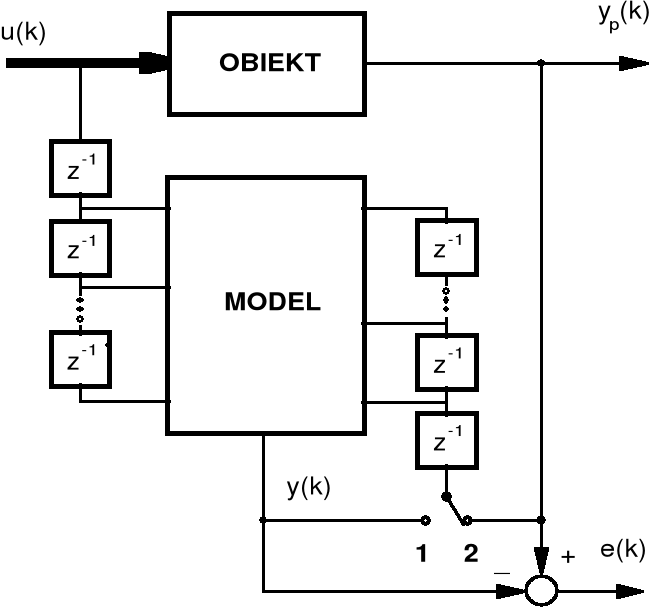
Rys. 17. Identyfikacja modelu równoległego (1)
i szeregowo-równoległego (2)
Równanie modelu szeregowo-równoległego
![]()
(7.40)
określa pewna nieliniowa, nierekurencyjna funkcja f, której argumenty ze względu na założoną stabilność obiektu są ograniczone co do wartości. Identyfikacji modelu można dlatego dokonać przy zastosowaniu statycznych sieci neuronowych, w których nie występują sprzężenia zwrotne.
Zauważmy ponadto, że modele szeregowo-równoległy i równoległy stają się tożsame w przypadku spełnienia warunku ![]()
. Wynika stąd możliwość stosowania modelu równoległego w końcowym etapie dwuetapowego algorytmu identyfikacji, w którym w pierwszym etapie stosuje się model szeregowo-równoległy, a w etapie drugim po spełnieniu warunku ![]()
model równoległy.
Nierekurencyjna postać modelu w przestrzeni stanów
Jeżeli oprócz wejścia i wyjścia obiektu także wszystkie zmienne stanu obiektu ![]()
są pomiarowo dostępne, to równanie stanu modelu i równanie wyjścia modelu można wyrazić jako funkcję stanu obiektu i sygnału wejściowego.
![]()
, (7.41)
![]()
. (7.42)
Model opisany równaniami (2.19) i (2.20) jest odpowiednikiem wejściowo-wyjściowego modelu szeregowo-równoległego. Identyfikację funkcji ![]()
(.) i g(.) można przeprowadzić rozdzielnie minimalizując dwa niezależne od siebie wskaźniki jakości dopasowania. Schemat blokowy obiektu i identyfikowanego modelu przedstawiono na rys. 18.
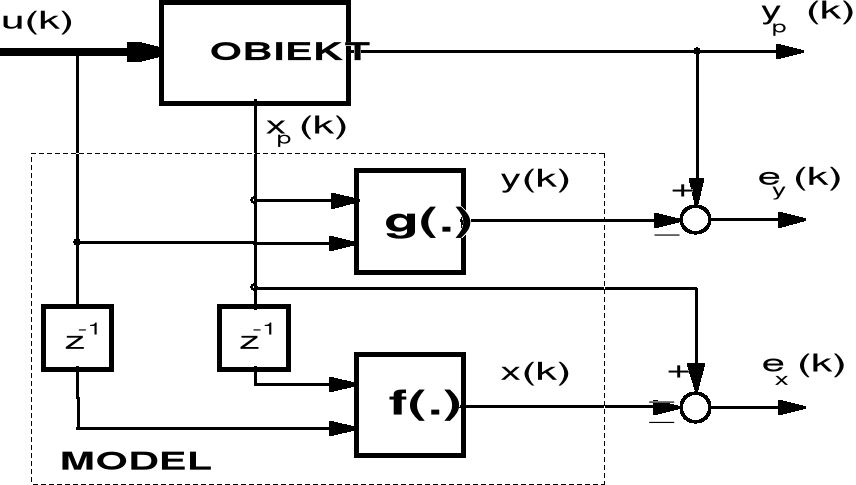
Rys. 18. Nierekurencyjna postać modelu w przestrzeni stanów
Rekurencyjna postać modelu w przestrzeni stanów
Przyjęcie założenia, że jedynie sygnał wejściowy u(k) i sygnał wyjściowy ![]()
są pomiarowo dostępne, a stan identyfikowanego obiektu ![]()
jest nieznany prowadzi do modelu typu równoległego, w którym równanie stanu modelu ma postać rekurencyjną
![]()
, (7.43)
![]()
. (7.44)
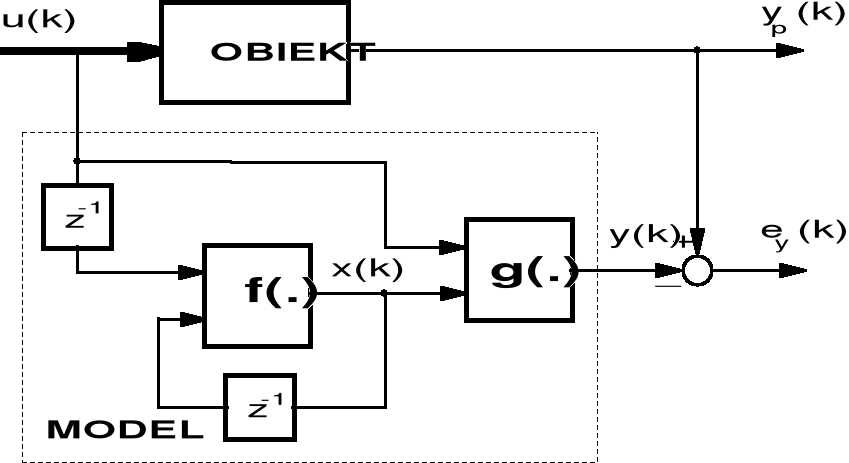
Rys. 19. Identyfikacja modelu rekurencyjnego
Schemat blokowy obiektu i identyfikowanego modelu przedstawia rys. 19. Model (7.43), (7.44) odpowiada wejściowo-wyjściowemu modelowi równoległemu.
Ponieważ w modelu rekurencyjnym występuje sprzężenie zwrotne, identyfikacja tego modelu jest możliwa jedynie przy zastosowaniu sieci neuronowej ze sprzężeniami zwrotnymi.
Sieci neuronowe w zadaniach modelowania obiektów sterowania
Modele matematyczne obiektów (systemów) dynamicznych znajdują zastosowania w wielu dziedzinach wiedzy, między innymi, w fizyce, biologii, ekonometrii, socjologii i technice. Zakres zastosowań w technice jest bardzo szeroki i obejmuje takie zadania jak: projektowanie urządzeń i systemów, sterowanie, symulację, monitorowanie działania obiektów.
Budowanie modelu matematycznego obiektu na podstawie danych eksperymentalnych i przy uwzględnieniu dostępnej wiedzy o badanym obiekcie ma na celu określenie struktury i parametrów modelu. Według definicji Zadeha [14], identyfikacją nazywa się określenie na podstawie wejścia i wyjścia przynależności do określonej klasy układów, względem których badany układ jest równoważny.
W kilku ostatnich dekadach nastąpił gwałtowny rozwój teorii, metod i algorytmów identyfikacji, zwiększyła się także liczba wykonywanych eksperymentów identyfikacyjnych i aplikacji. Pomimo tego, że znanych jest obecnie wiele różnych metod i algorytmów identyfikacji dla obiektów liniowych a także dla obiektów nieliniowych o znanej strukturze, wciąż brak jest ogólnych i efektywnych metod identyfikacji dla obiektów nieliniowych o nieznanej strukturze. Problem ten jest szczególnie istotny podczas rozwiązywania zadań sterowania, gdyż modele dynamiki obiektu są wykorzystywane w najbardziej skutecznych metodach sterowania adaptacyjnego obiektów o nieznanych właściwościach takich, jak sterowanie z modelem odniesienia (ang. MRAC - Model Reference Adaptive Control) i regulacja samonastrajająca (ang. STR - Self-Tuning Regulator) [21],[30].
Ogromny rozwój teorii i wiedzy eksperymentalnej dotyczących sztucznych sieci neuronowych, który nastąpił w ciągu kilku ostatnich lat, umożliwił również opracowanie nowych technik identyfikacji i modelowania systemów dynamicznych, w tym zwłaszcza systemów nieliniowych [19],[30]. O atrakcyjności sieci neuronowych jako narzędzi do rozwiazywania zadań identyfikacji decydują ich podstawowe właściwości, do których zalicza się [19], [22], [42]:
możliwość równomiernej aproksymacji dowolnych ciągłych zależności nieliniowych,
możliwość adaptacji, czyli dopasowywania wartości parametrów do zmian charakterystyk obiektu i zakłóceń,
równoległy sposób przetwarzania informacji,
możliwość implementacji hardware'owej przy zastosowaniu układów VLSI,
odporność na błędy działania, w tym także uszkodzenia, podstawowych elementów przetwarzających (neuronów),
duża szybkość działania, dzięki równoległemu przetwarzaniu informacji i efektywności stosowanych algorytmów,
możliwość generalizacji (uogólniania), czyli generowania właściwych odpowiedzi na pobudzenia nie zawarte w zbiorze danych stosowanych w procesie uczenia,
łatwość modelowania systemów wielowymiarowych.
Kierunek przepływu sygnałów (informacji) stanowi kryterium podziału sieci neuronowych na dwie klasy - wielowarstwowe sieci statyczne i sieci rekurencyjne. W sieciach typu statycznego, w przeciwieństwie do sieci rekurencyjnych, nie występują sprzężenia zwrotne i wszystkie sygnały mogą przepływać jedynie w kierunku od wejść do wyjść sieci. Sprzężenia zwrotne w sieciach rekurencyjnych powodują, że oprócz przepływu sygnałów w kierunku od wejść do wyjść występuje także wsteczny przepływ z wyjść neuronów lub sieci do wejść neuronów tej samej warstwy lub warstw ją poprzedzających. Sieci rekurencyjne są więc złożonymi nieliniowymi systemami dynamicznymi.
Architekturą sieci neuronowych najczęściej spotykaną w zastosowaniach w automatyce, w tym także do identyfikacji, jest nieliniowa statyczna sieć wielowarstwowa nazywana również perceptronem wielowarstwowym [18],[59]. Ważnymi zaletami perceptronu wielowarstwowego są: możliwość stosowania w procesie uczenia efektywnej obliczeniowo metody wstecznej propagacji błędów, eksperymentalnie potwierdzone właściwości aproksymacyjne, możliwość uczenia zarówno metodą off-line, jak i on-line [13],[33],[46],[52],[59],[60]. W strukturze perceptronu wielowarstwowego nie uwzględnia się dynamicznych zależności między sygnałami wejściowymi i wyjściowymi charakterystycznych dla modelowanych obiektów. Problem modelowania za pomocą sieci statycznej, jaką jest perceptron wielowarstwowy, nieliniowych systemów dynamicznych rozwiązuje się przez wprowadzenie do sieci neuronowej dodatkowych wejść, na które są podawane opóźnione wartości sygnałów. Rozwiązanie to jest równoważne wprowadzeniu na wejście sieci linii opóźniających sygnały i wymaga znajomości maksymalnych wartości opóźnień [5],[30].
Sieci rekurencyjne dzięki wbudowanym w ich strukturę sprzężeniom zwrotnym i dynamicznej naturze są uważane za szczególnie odpowiednie do modelowania nieliniowych systemów dynamicznych. Modelowanie nieliniowego systemu dynamicznego za pomocą innego systemu dynamicznego, jakim jest rekurencyjna sieć neuronowa, umożliwia zmniejszenie rozmiarów sieci w porównaniu z rozmiarami stosowanych do tego celu sieci statycznych [41],[48]. Pewnym utrudnieniem jest jednak wtedy konieczność stosowania innych metod uczenia, które są znacznie bardziej złożone obliczeniowo niż metoda wstecznej propagacji błędów.
3.1. Sieci bez sprzężeń zwrotnych
Pomimo pojawienia się wielu różnorodnych struktur sieci neuronowych [15],[19],[20],[22],[37] najczęściej stosowanymi w automatyce są sieci bez sprzężeń zwrotnych (ang. FFN - FeedForward neural Networks). Sieci tego typu modelują zależności statyczne wiążące zmienne wyjściowe ze zmiennymi wejściowymi. Uzasadnienie teoretyczne stosowania sieci bez sprzężeń zwrotnych wynika z pracy Cybenki i sformułowanego przez niego twierdzenia, że każda funkcja ciągła może być równomiernie aproksymowana z dowolnie dużą dokładnością za pomocą statycznej sieci neuronowej zawierającej jedną warstwę ukrytą zbudowaną z elementów o ustalonej ciągłej nieliniowości [7],[61].
W zadaniu identyfikacji nieliniowego obiektu dynamicznego sygnałami wejściowymi sieci neuronowej są opóźnione sygnały obiektu (wejściowy i wyjściowy) − rys. 20, a także poprzednie wartości błędu identyfikacji, jeżeli w estymowanym modelu jest uwzględniany model zakłóceń.
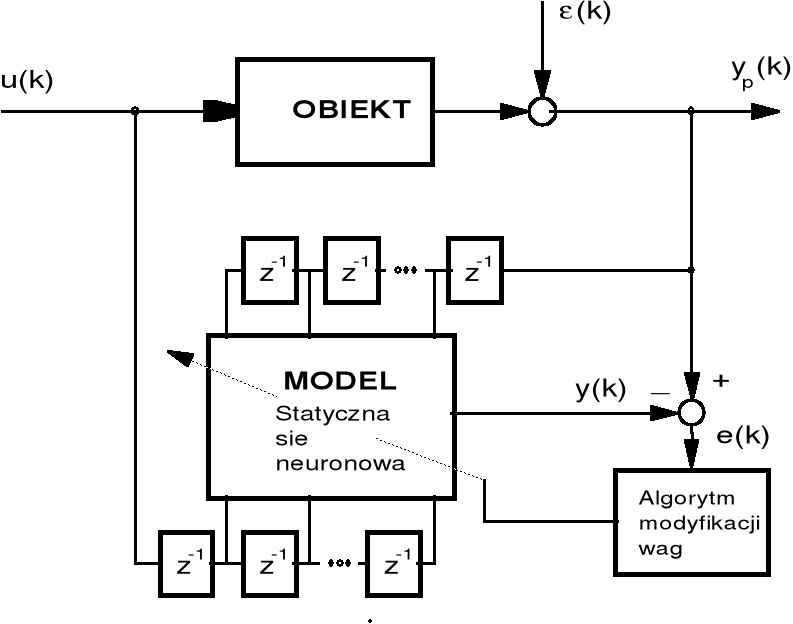
Rys. 20. Identyfikacja nieliniowego dyskretnego obiektu dynamicznego
przy zastosowaniu statycznej sieci neuronowej,
u(k) - sygnał wejściowy, ![]()
- sygnał wyjściowy,
(k) - zakłócenie, y(k) - sygnał wyjściowy modelu, e(k) - błąd
identyfikacji
Graficzne odzwierciedlenie statycznej wielowarstwowej sieci neuronowej lub inaczej mówiąc wielowarstwowego perceptronu przedstawiono na rys. 3.2. Sieć ta ma ![]()
wejść, na które podawane są opóźnione wartości sygnałów wejściowego i wyjściowego obiektu, ![]()
neuronów w pierwszej warstwie ukrytej, ![]()
neuronów w drugiej warstwie ukrytej i jeden neuron w warstwie wyjściowej. Współczynniki wagowe połączeń między i-tym wejściem i j-tym neuronem pierwszej warstwy oznaczono przez ![]()
, współczynniki wagowe połączeń między j-tym neuronem pierwszej warstwy a k-tym neuronem drugiej warstwy oznaczono przez ![]()
, natomiast współczynniki wagowe połączeń między k-tym neuronem drugiej warstwy a neuronem wyjściowym oznaczono przez ![]()
.
Transformacje sygnałów są realizowane przez nieliniowe neurony, które zgodnie z modelem McCullocha-Pitta można opisać następującą zależnością [54]
![]()
, (8.1)
gdzie ![]()
oznacza wyjście j-tego neuronu M-tej warstwy, ![]()
funkcję aktywacji neuronu, ![]()
współczynnik wagowy połączenia między wyjściem i-tego neuronu warstwy ![]()
a j-tym neuronem warstwy M-tej, a ![]()
wartość progową j-tego neuronu.
Nieliniową transformację realizowaną przez całą sieć pokazaną na rys. 21 można zapisać za pomocą zależności
, (8.2)
gdzie ![]()
oznaczają nieliniowe operatory macierzowe definiujące transformacje sygnałów dokonywane przez pierwszą i drugą warstwę ukrytą, ![]()
macierze współczynników wagowych warstw I, II i III o wymiarach odpowiednio ![]()
, ![]()
i ![]()
, ![]()
jest wektorem sygnałów wejściowych sieci. Uwzględniając wartości progowe całkowita liczba współczynników wagowych sieci jest równa ![]()
.
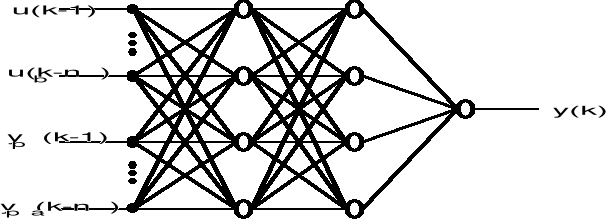
Rys. 21. Statyczna sieć neuronowa o ![]()
wejściach, dwóch warstwach ukrytych i jednym
wyjściu
Współczynniki te są parametrami nieliniowego odwzorowania i podlegają modyfikacji w trakcie procesu uczenia sieci. Celem uczenia jest wyznaczenie wartości współczynników wagowych dla danych wartości sygnałów wejściowych sieci ![]()
i sygnału wyjściowego obiektu ![]()
w taki sposób, aby sygnał wyjściowy sieci y(k) najlepiej przybliżał sygnał wyjściowy obiektu. Rozwiązanie tego zadania sprowadza się do minimalizacji pewnej funkcji błędu odwzorowania zdefiniowanego jako różnica między wyjściem obiektu i wyjściem sieci
![]()
(8.3)
W przedstawionej powyżej strukturze sieci przyjęto założenie, że znane są maksymalne opóźnienia ![]()
sygnałów ![]()
podawanych na wejście sieci. Wymagany jest więc pewien stopień znajomości a-priori struktury identyfikowanego obiektu. Efektem niewłaściwego przyporządkowania opóźnionych wejśc i wyjść obiektu do wejść sieci byłoby zmniejszenie dokładności dopasowania modelu wynikające z nieuwzględnienia pełnej dynamiki obiektu [7].
3.2. Algorytmy uczenia statycznych sieci neuronowych
Algorytm uczenia określa adaptacyjny sposób dostrajania współczynników wagowych połączeń między neuronami sieci na podstawie danego zbioru danych uczących. W algorytmach uczenia dla sieci neuronowych stosowanych w zadaniach identyfikacji wykorzystuje się metodę uczenia nadzorowanego (ang. supervised learning), w której zbiór uczący składa się z danych wejściowych podawanych na wejścia sieci i zbioru zadanych wartości wyjść sieci. Współczynniki wagowe sieci są obliczane w taki sposób, aby zminimalizować pewną funkcję błędu identyfikacji e(k), z reguły definiowaną jako suma kwadratów błędów.
Zakładając, że dany jest zbiór wyników pomiarów ![]()
![]()
, dla k = 1,2,..., N, zdefiniujmy następującą funkcję błędu
![]()
. (8.4)
Minimalizacji funkcji (8.4) można dokonać wykorzystując znane iteracyjne metody optymalizacji. Najczęściej stosowaną jest metoda gradientowa największego spadku, której ważną zaletą jest prosty algorytm obliczeń, nie wymagający obliczania drugich pochodnych funkcji błędu. W metodzie tej współczynniki wagowe są obliczane zgodnie z następującym wzorem:
![]()
![]()
, (8.5)
gdzie w oznacza wektor współczynników wagowych sieci, ![]()
gradient funkcji błędu względem w w punkcie w = w(i), a 0 jest stałym współczynnikiem określającym prędkość uczenia. Wzór (8.5) określa algorytm typu iteracyjnego, który można zrealizować po zebraniu pełnego zbioru danych pomiarowych (ang. batch learning). W zastosowaniach w automatyce szczególne znaczenie mają algorytmy typy rekurencyjnego, tzn. takie w których nowe zmodyfikowane oceny parametrów modelu oblicza się nie po zebraniu pełnego zbioru danych pomiarowych, ale każdorazowo po wykonaniu kolejnego pomiaru. Funkcja błędu dla algorytmu rekurencyjnego przyjmuje postać
![]()
. (8.6)
W wyniku minimalizacji funkcji (8.6) otrzymuje się algorytm, w którym skorygowany wektor wpółczynnków wagowych po uwzględnieniu k-tego pomiaru oblicza się zgodnie z następującym wzorem
![]()
![]()
. (8.7)
Symbol w(k) oznacza, że wektor współczynnków wagowych jest w tym przypadku funkcją dyskretnego czasu k określającego chwilę pomiaru, a nie numeru iteracji jak w metodzie gradientowej największego spadku. Oba omówione powyżej algorytmy należą do technik optymalizacyjnych typu gradientowego. Zasadnicza róznica między nimi polega na różnych definicjach funkcji błędu. Wynika stąd znany efekt polegający na tym, że obliczając za pomocą każdego z tych algorytmów współczynniki wagowe sieci dla tego samego zbioru danych pomiarowych i jednakowych warunków początkowych otrzymuje się nieco inne wyniki. Jednakże, jak wykazali Qin, Su i McAvoy w pracy [47], algorytm rekurencyjny można uważać za aproksymację metody gradientowej największego spadku pod warunkiem, że współczynnik jest dostatecznie mały. Różnicę między wektorem w(k) obliczonym metodą rekurencyjną, a wektorem w będącym iteracyjnym rozwiązaniem zadania optymalizacji metodą gradientową największego spadku można wtedy oszacować za pomocą zależności
![]()
. (8.8)
Rozważania teoretyczne Qin, Su i McAvoy zilustrowali przedstawiając wyniki identyfikacji symulowanego obiektu nieliniowego opisanego równaniem
![]()
,
w którym wymuszenie u(k) było generowane jako ciąg losowy o rozkładzie równomiernym. Sieć neuronowa zawierała dwie warstwy ukryte i została poddana procesowi uczenia poprzez wielokrotne podawanie na wejście zbioru danych pomiarowych składającego się z 100 wartości ![]()
. Współczynnki wagowe połączeń były obliczane za pomocą algorytmów rekurencyjnego i nierekurencyjnego największego spadku dla tych samych danych i identycznych warunków inicjalizacji, przy czym liczbę prezentacji zbioru danych pomiarowych zwiększano od 1 do 600. Wyniki identyfikacji w syntetyczny sposób obrazują wykresy zależności błędu identyfikacji od liczby prezentacji danych pomiarowych przy różnych wartościach współczynnika . Interesujące jest występowanie zjawiska gwałtownego wzrostu błędu identyfikacji dla metody nierekurencyjnej największego spadku, gdy współczynnik jest większy od 0.14. Dla metody rekurencyjnej wstecznej propagacji błędów zjawisko to nie występowało, a wraz ze wzrostem w zakresie od 0.15 do 1 szybkość uczenia zwiększała się. Interpretując te wyniki nie należy ich jednak uogólniać, ponieważ dotyczą one zaledwie jednego szczególnego obiektu i jednego zbioru danych.
Istotnym problemem podczas stosowania obu metod może być występowanie minimów lokalnych funkcji błędu wynikające ze złożonej nieliniowej postaci zależności (8.2) określającej wyjście sieci y(k). W wyniku tego wektory współczynników wagowych obliczone nawet dla tych samych danych pomiarowych ale przy różnych warunkach początkowych mogą się znacznie różnić.
Wadą metod gradientowych jest niestety często niewielka szybkość zbieżności. Znanych jest wiele różnych modyfikacji podstawowej wersji metody gradientowej najmniejszego spadku mających na celu zwiększenie szybkości uczenia [39]. Jeden ze sposobów przeciwdziałania temu zjawisku polega na wprowadzeniu do równań (3.5) i (3.7) dodatkowego składnika (tzw. momentum) proporcjonalnego do różnicy pierwszego rzędu w(k). Jednym z najszybszych algorytmów typu nierekurencyjnego jest algorytm QuickProp [39], w którym wykorzystano ideę dopasowywania paraboli do powierzchni funkcji błędu i przyjmowania jej minimum jako minimum funkcji błędów. Często stosowane są także algorytmy z adaptacyjnymi zmianami współczynnika szybkości uczenia. Jeszcze inne rozwiązanie polega na uzależnieniu członu korekcyjnego równania od drugiej pochodnej funkcji błędu, co zwiększa jednak znacznie złożoność obliczeniową [5],[7] i utrudnia dekompozycję algorytmu na postać równoległą, to znaczy taką, w której obliczenia współczynników wag połączeń pomiędzy poszczególnymi neuronami mogą być obliczane jednocześnie i niezależnie od siebie.
Literatura
Ackerman J.: Regulacja impulsowa. WNT. 1976.
Box G. E. P., Jenkins G. M.: Analiza szeregów czasowych. Prognozowanie i sterowanie. PWN. Warszawa. 1983.
De Larminat P., Thomas Y.: Automatyka układy liniowe. t. 2, t. 3. WNT, Warszawa. 1983.
Eykhoff P.: Identyfikacja w układach dynamicznych. PWN. Warszawa. 1980.
Hertz J., Krogh A., Palmer R. G.: Wstęp do teorii obliczeń neuronowych. WNT. Warszawa. 1993, 1995.
Janczak A., Pieczyński A., Sandecki R.: Laboratorium układów automatyki i sterowania. Skrypt. WSI. Zielona Góra, 1989.
Jermakow S. M.: Metoda Monte Carlo i zagadnienia pokrewne. PWN. Warszawa. 1976.
Korbicz J., Obuchowicz A., Uciński D.: Sztuczne sieci neuronowe. Podstawy i zastosowania. Akad. Ofic. Wyd. Warszawa. 1994.
Korbicz J., Mazurkiewicz Z., Janczak A.: Wybrane zagadnienia z teorii identyfikacji i estymacji. Skrypt. WSI. Zielona Góra. 1987.
Mańczak K., Nahorski Z.: Komputerowa identyfikacja obiektów dynamicznych. PWN. Warszawa. 1983.
Morrison F.: Sztuka modelowania układów dynamicznych deterministycznych, chaotycznych, stochastycznych. WNT, Warszawa, 1996.
Niederliński A.: Systemy komputerowe automatyki przemysłowej. t. 2 . Zastosowania. WNT. Warszawa. 1985.
Niederliński A., Kasprzyk J., Figwer J.: EDIP - Ekspert dla identyfikacji procesów. Podręcznik użytkownika. Skrypt Pol. Śląskiej. Gliwice. 1993.
Steiglitz K.: Wstęp do systemów dyskretnych. WNT. Warszawa. 1977.
Yager R. R., Filev D. P.: Podstawy modelowania i sterowania rozmytego. WNT. Warszawa. 1995.
Zeigler B. P.: Teoria modelowania i symulacji. PWN. Warszawa. 1984.
Zieliński R.: Generatory liczb losowych. WNT. Warszawa. 1979.
Żurada J., Barski M., Jędruch W.: Sztuczne sieci neuronowe. PWN. Warszawa. 1996.
1
52